- 投稿日:2019-11-30T23:22:36+09:00
TwitterGemを使うときは困ったらとりあえずto_hするべし
tl;dr
TwitterGemを使うときの返り値のクラスは、基本的に
Enumerableをincludeしているので雑にto_hしちゃって取るのが楽そうです。この記事のスコープ
TwitterGemを介してTwitterAPIを叩き、ツイートの取得を行うところまで。個人的に詰まったポイントがあったのでそこも併せて共有できたらなと思って書きました。
TwitterGemとは
RubyでTwitterAPIを操作できるようになるgemです。リポジトリはここから
APIを叩くためにはTwitter社に対して申請をする必要がありますが、その具体的な方法については本記事では割愛します。
英語で利用目的などを書かないといけないためウッとなりますが、Google翻訳を駆使しながら書いたガバガバ英語でもapproveされたので、構える必要はないと思ってます。インストール
普通に
gem install twitterするか、Gemfileに書いて
bundleしましょう。
READMEにはサポートされているRubyバージョンとして、2.3 ~ 2.5 が挙げられていますが、筆者の環境では2.6.3でも問題なく動作しています。きっと。準備
まずはrequireしましょう
require 'twitter'次にAPIを叩く用のclientを生成します
class Twitter def initialize @client = Twitter::REST::Client.new |config| config.consumer_key = "consumer_key" config.consumer_secret = "consumer_secret" config.access_token = "access_token" config.access_token_secret = "access_token_secret" end end endそれぞれキーを突っ込んであげてください。
これで準備完了です。簡単ですね。使い方
Rubyで簡単なTwitter クライアントをつくる をぜひ参照しましょう。私もお世話になりました。リンク先の記事では
- タイムラインの取得
- リプライの取得
- 特定のリストのタイムラインを取得
- ツイート
を紹介しています。
本記事では
- ユーザの詳細情報の取得
- ツイートごとの詳細情報の取得
これらを紹介するとともにハマったポイントについてご紹介できればと思っています。
Twitterユーザの詳細情報を取得
リストを指定しユーザを取得する
list_membersというメソッドに、ユーザ名とリスト名を与えてあげることで取得することができます。この結果は、TwitterClient::Cursorクラスのインスタンスとして返ってきます。こいつはEnumerableをincludeしているのでArrayやHashと同様にeachを使ってごにょごにょできます。便利です。[1] pry(#<TwitterClient>)> @client.list_members('twitterのユーザ名', 'リスト名').class => Twitter::Cursor [2] pry(#<TwitterClient>)> @client.list_members('twitterのユーザ名', 'リスト名').class.include?(Enumerable) => trueコード例
class Twitter def initialize ... end # リストに属しているユーザをArrayとして取得する def fetch_list_users list_members('twitterのユーザ名', 'リスト名').each_with_object([]) do |user, arr| arr << member end end endTwitter::User
サンプルとして
https://twitter.com/hurugisuko ( 私の好きなネットの古着屋さん ) を使いました。[1] pry(#<TwitterClient>)> user = list_members('twitterのユーザ名', 'リスト名').first => #<Twitter::User id=1111913399225450496> # ユーザの名前を取ってくる [2] pry(#<TwitterClient>)> user.name => "古着屋 Hurugisuko" # プロフURL [3] pry(#<TwitterClient>)> user.url => #<Addressable::URI:0x3fd4935192c4 URI:https://twitter.com/hurugisuko> # AddressableからURLへ変換 [4] pry(#<TwitterClient>)> user.url.to_s => "https://twitter.com/hurugisuko" # プロフィール画像を取ってくる [5] pry(#<TwitterClient>)> user.profile_image_url_https => #<Addressable::URI:0x3fd491727798 URI:https://pbs.twimg.com/profile_images/1113260900587147264/xVaQa0Lc_normal.jpg> # URLだけ抽出 [6] pry(#<TwitterClient>)> user.profile_image_url_https.to_s => "https://pbs.twimg.com/profile_images/1113260900587147264/xVaQa0Lc_normal.jpg" # 自己紹介情報を取ってくる [7] pry(#<TwitterClient>)> user.description => "若い世代に向け、「お金をかけないオシャレ」「唯一無二のスタイル」をコンセプトに幅広く古着を販売しています。 Hurugisukoは2人の人間で管理・運営を行っています。「生活に小さな彩りを添える」がコンセプトのハンドメイド作品たちはこちらから→@hurugisukohh"色々取れますね。
ハマったところ
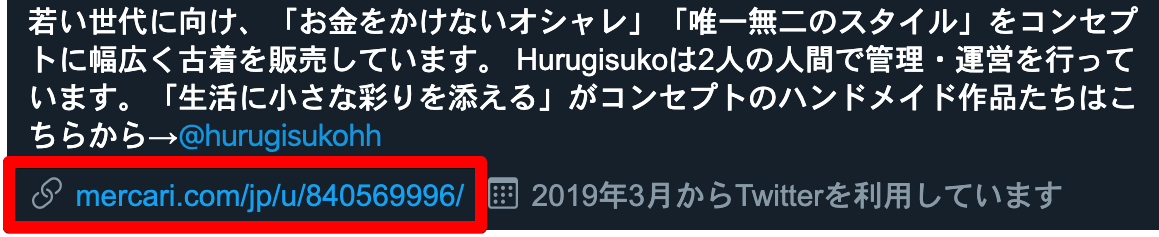
この赤枠部分のURLどうやって取るんだろうってところ。
user.urlはtwitterのURLに飛んでしまうし。。解決方法
user.to_h[:url] => "https://t.co/fiupN9eIDi"URLを叩くとメルカリの画面へ遷移できているかと思います。
Twitter::Userクラスに対して、to_hでhash化してキーを与えることで取得しています。
メソッドとして定義されているものと、to_hとキーで取ってくる2つのパターンがある、ということが大事なポイントです。ツイートごとの詳細な情報
特定のユーザのツイートを取ってくる
user_timelineというメソッドに、user_id(Twitter::User#id)を与えてあげることでそのユーザのツイート(デフォルトで20件)取得することができます。[1] pry(#<TwitterClient>)> @client.user_timeline(twitter_user_id) => [#<Twitter::Tweet id=1198931529931427840>, ... ]コード例
class Twitter def initialize ... end # 特定のユーザのツイートを取ってくる def tweets(account) @client.user_timeline(account, opt) end end def opt { count: 10 } end endこのメソッドにはオプションを渡すことができて、例えば
@client.user_timeline(twitter_user_id, count: 10)とすれば、10件のツイートを取ってきてくれます。
他のオプションについてはrubydocが参考になるかと思います。Twitter::Tweet
[1] pry(#<TwitterClient>)> t = @client.user_timeline(account, count: 10).first => #<Twitter::Tweet id=1200744305482031107> # ツイート内容の取得 [2] pry(#<TwitterClient>)> t.text => "coming soon...\n\n☑︎12/1(日) 23時発売開始‼︎\nhttps://t.co/aVf7vUNRIT https://t.co/b77r7AvC0i" # メディアの取得 [3] pry(#<TwitterClient>)> t.media => [#<Twitter::Media::Photo id=1200744297571602434>, #<Twitter::Media::Photo id=1200744297567375362>, #<Twitter::Media::Photo id=1200744297693237250>, #<Twitter::Media::Photo id=1200744297575804928>] # 画像のURLを取得 [4] pry(#<TwitterClient>)> t.media.first.media_url_https => #<Addressable::URI:0x3fe8da8c19d4 URI:https://pbs.twimg.com/media/EKnmk6rU0AIbZuV.jpg> [5] pry(#<TwitterClient>)> t.media.first.media_url_https.to_s => "https://pbs.twimg.com/media/EKnmk6rU0AIbZuV.jpg"こちらも同様に色々できます。
困ったところ
たまに
Twitter:Tweet#textで全文を取得できないケースがあります。(...として省略されている)
調べると、twitterAPIの仕様変更があって、長いつぶやきは省略されてしまうそう。ref: アップデートの情報
とりあえず雑にto_hすると、:truncatedというキーがあり、textが省略されているツイートは、ここがtrueになっていました。
さらに調べると、truncatedがtrueになっているツイートでは、前述したTwitter:Tweet#mediaで画像情報も取得することができませんでした。これは困った。[1] pry(#<TwitterClient>)> tweet.text => "【 yutori online store new arrival 】\n☑︎12/1(日)23時新商品入荷‼︎\n\nいよいよ12月に突入です☃️‼️\n\n12月最初の入荷は使いやすいブルゾンからセーター&スウェットを多めにピックアップ… https://t.co/waU8pfXuo1" [2] pry(#<TwitterClient>)> tweet.to_h[:truncated] => true [3] pry(#<TwitterClient>)> tweet.media => [] [4] pry(#<TwitterClient>)> tweet.id => 1200755654043918336解決方法
user_timelineへのオプションとして、{ tweet_mode: 'extended' }を渡すことで、長いツイートでも全文および画像の取得ができました。ただし、ツイートの全文取得はインターフェースが変わるので注意が必要です。# { tweet_mode: 'extended' } を指定してuser_timelineを叩く # tweet.idは上記の[4]と同じ [1] pry(#<TwitterClient>)> tweet.id => 1200755654043918336 [2] pry(#<TwitterClient>)> tweet.to_h[:truncated] => false # Twitter#Tweet#full_text は定義されていないのでto_h経由で取得する [3] pry(#<TwitterClient>)> t.to_h[:full_text] => "【 yutori online store new arrival 】\n☑︎12/1(日)23時新商品入荷‼︎\n\nいよいよ12月に突入です☃️‼️\n\n12月最初の入荷は使いやすいブルゾンからセーター&スウェットを多めにピックアップ?\n\nお気に入りのアウターに合わせる1着を是非見つけて下さい?\n\n良ければリツイート宜しくお願い致します?♂️✨ https://t.co/8LKvQ35PJu" [4] pry(#<TwitterClient>)> t.media => [#<Twitter::Media::Photo id=1200755645940502531>, #<Twitter::Media::Photo id=1200755645936357377>, #<Twitter::Media::Photo id=1200755645944696832>, #<Twitter::Media::Photo id=1200755646204760064>]結論 (再掲)
TwitterGemを使うときの返り値のクラスは、基本的に
Enumerableをincludeしているので雑にto_hしちゃって取るのが楽そうです。
- 投稿日:2019-11-30T23:19:56+09:00
【Rails】belongs_toで関連付けしたけどデータが保存出来ない →単数形にしてる?
はじめに
Railsアプリ作成中、
belongs_toで関連付けたモデルのデータ保存がうまくいかず、はじかれてしまったので解決した方法です。しょうもないミスでした
この記事が役に立つ方
belongs_toで関連付けはしたが、うまく保存が出来ない方この記事のメリット
- 無事にデータが保存出来るようになる。
環境
- macOS Catalina 10.15.1
- zsh: 5.7.1
- Ruby: 2.6.5
- Rails: 5.2.3
エラー内容
1対多の関係にある、UserモデルとRecordモデルがあるとします。
Recordテーブルのデータを新規作成し、
save!でデータ保存しようとしたところ、以下のようなエラーが発生。ActiveRecord::RecordInvalid: Validation failed: Users must exist保存するデータには外部キー
user_idがあり、そこにはちゃんと値が入っていて、「あれ?なんで?」と困る。このときのモデルは以下のように定義していました。
app/models/record.rbclass Record < ApplicationRecord belongs_to :users endここから応急処置(間違った解決法)とちゃんとした解決法を記載します。
1.応急処置(間違った解決法)
以下のように変更。
【Before】
app/models/record.rbclass Record < ApplicationRecord belongs_to :users end↓
【After】app/models/record.rbclass Record < ApplicationRecord belongs_to :users, optional: true end
optional: trueで関連モデルなしでOK!と放し飼い状態にし、一旦。バリデーションを回避。しかし、全く意味のない矛盾した設定になるのであくまでも応急処置。
割とググるとこの解決法が多かったですが、あまり良くないと思います。
2.解決(ただの設定ミス)
【Before】
app/models/record.rbclass Record < ApplicationRecord belongs_to :users, optional: true end↓
【After】app/models/record.rbclass Record < ApplicationRecord belongs_to :user end
複数形
単数形
belongs_to関連付けで指定するモデル名は必ず「単数形」にしなければなりません。
Rails ガイドにもちゃんと書いてました!
英語で考えたら当たり前、お恥ずかしいです
optional: trueも不要なので削除。これで問題なし!
おわりに
最後まで読んで頂きありがとうございました
しょうもない設定ミスで時間をロスしてしまったので、同じようなエラーで困っている方がいれば参考にして頂ければと思います
参考にさせて頂いたサイト(いつもありがとうございます)
- 投稿日:2019-11-30T21:42:04+09:00
山手線の2駅間の所要時間を計算:累積和/ビット演算
東京の都心部を走る山手線は、環状線なので内回りと外回りのどちらでも2駅間を移動できる。もちろん基本的にどちらか一方が早く、もう一方は遅い。所要時間の案内は各駅に置いてある。
厳密に調べたければ乗換案内サービスを使うべきだが、軽く知る程度なら案内板の数値を手元で計算できれば十分だろう。これを2通りの方法で実装してみる。

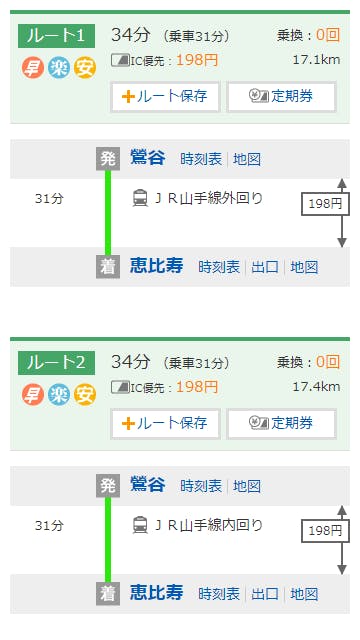
- 鶯谷駅での案内によると、恵比寿駅まではどちら回りでも32分かかる
- 「鶯谷」から「恵比寿」への乗換案内 - Yahoo!路線情報 → どちら回りでも乗車31分
設問の整理
山手線の乗降駅の番号(JYmm, JYnn)を与えたとき、かかる最短時間と乗る方向を求めたい。
- 時間は各駅の所要時間案内表示を基にする
- 新駅 JY26 は未開業なため欠番であることに注意
- 乗らない場合や、どちら回りでも同じ時間の場合は、乗る方向の表示は自由
累積和による方法
所要時間案内が既に累積和(cumulative sum)になっているので難しい話ではない。計算に使いやすいデータに整形して、環状線や逆回りなどの扱い方だけ工夫すればいい。
コード
yamanote_line.rbmodule YamanoteLine module_function na = nil CUMSUM = [ na, 2, 4, 6, 8, 10, 12, 14, # 00 - 07 16, 18, 20, 22, 24, 26, 29, 31, # 08 - 15 33, 35, 37, 39, 42, 44, 47, 49, # 16 - 23 51, 54, na, 57, 60, 62, 64, na, # 24 - 31 ].freeze T0 = CUMSUM.compact.last def time(from, to) [from, to].each { |num| check_arg(num) } t = CUMSUM[to] - CUMSUM[from] case when t > T0 / 2 then t - T0 when -t > T0 / 2 then t + T0 else t end end def check_arg(num) raise TypeError, "駅番号には正整数を指定してください" unless num.kind_of?(Integer) && num > 0 raise RangeError, "駅番号 JY%02d は存在しません" % num unless CUMSUM[num] end endmain.rbrequire_relative "yamanote_line" STATIONS = %W[ #{} 東京 神田 秋葉原 御徒町 上野 鶯谷 日暮里 西日暮里 田端 駒込 巣鴨 大塚 池袋 目白 高田馬場 新大久保 新宿 代々木 原宿 渋谷 恵比寿 目黒 五反田 大崎 品川 #{} 田町 浜松町 新橋 有楽町 #{} ] DIRECTIONS = %w[乗車なし 内回り 外回り] loop do print "乗り降りする駅番号を入力してください: " line = gets unless line puts "終了します" break end from, to = line.scan(/\d+/).map(&:to_i) time = YamanoteLine.time(from, to) puts "%s → %s : " % STATIONS.values_at(from, to) + "#{DIRECTIONS[time <=> 0]} #{time.abs}分" rescue => e puts e.message end考え方
簡単のため、まずは内回り固定で、東京駅 JY01 → 有楽町駅 JY30 の中の区間を乗車する(
from <= to)場合を考える。任意の2駅間の所要時間を計算するには、愚直にはその間の各区間の所要時間を合計する。この場合は2駅間の駅数によって計算時間が変わり、特に何度も問い合わせがある場合は効率が悪い。(山手線の駅数くらいなら気にするほどでもないが)
そこで、ある駅を基準とした各駅までの所要時間を配列で用意しておく。すると、任意の2駅間の所要時間はその配列要素の差を求めるだけで済む。この場合は計算時間が駅数に依らず、何度問い合わせがあってもすぐに答えを返せる。
今回の問題では駅番号と配列のインデックスが一致していると便利なので、有楽町駅からの内回り所要時間をデータとして持たせることにした。こうすると JY30 はちょうど1周する時間(
T0)を表し、後で環状線であることを考慮するときに使える。ところで配列中の2要素の差をとるだけということは、欠番の部分が参照されることは無い。そのため、累積和の配列の中に欠番の情報も入れられる。
実際には
from > toが与えられることもある。これを累積和から計算すると、大きさが同じで符号が逆(マイナス)の数が求まる。これは特に対処する必要が無く、むしろ「所要時間がマイナスのときは逆方向=外回りを表している」と捉えればいい。
最後に環状線における最短となる方向の選択がある。これは日常の感覚としてあるはずで、「所要時間が1周の半分より長ければ逆回りのほうが早い」と考えればいい。いまは所要時間の符号で方向を表しているので、1周にかかる時間を足し引きして絶対値が最小になる数にする。
参考ページ
- 山手線所要時間
- 「計算に使用したデータ」が累積和になっている(田端駅起点、外回り)
ビット演算による方法
今回の問題に限っては、「各区間の所要時間が2分か3分で2通りのみ」という性質があり、駅番号も30までである。それなら配列の代わりに32bit整数にデータを詰め込める。もちろんそのデータを展開すれば累積和を構築できるが、ビット演算なら配列を使わずに計算できるのではないかと思った。実用性はたぶん無い。
※Rubyでは整数が任意長なので、一部のビット演算はメソッド化して、内部では別の方法で計算する。
コード
yamanote_line.rbmodule YamanoteLine module_function # ビット演算の代用品をメソッド定義 using (Module.new do refine Integer do def popcount digits(2).count(1) end def fill_with_sign_bit negative? ? -1 : 0 end end end) JY_FLAGS = 0b01111011_11111111_11111111_11111110 # 26ビット目は 0 に設定 LAP_DATA = 0b00011010_01010000_01000000_00000000 # 区間が2分なら0、3分なら1(マスク外は自由) T0 = JY_FLAGS.popcount * 2 + (LAP_DATA & JY_FLAGS).popcount * (3 - 2) def time(from, to) [from, to].each { |num| check_arg(num) } range_mask = ((2 << from) - 1) ^ ((2 << to) - 1) # fromとtoの間にビットを立てる range_mask ^= (to - from).fill_with_sign_bit # fromとtoの大小関係に応じてビット反転 range_mask &= JY_FLAGS # 実際に存在する駅の区間のみを抽出 t = range_mask.popcount * 2 + (LAP_DATA & range_mask).popcount * (3 - 2) t -= T0 if t > T0 / 2 t end def check_arg(num) raise TypeError, "駅番号には正整数を指定してください" unless num.kind_of?(Integer) && num > 0 raise RangeError, "駅番号 JY%02d は存在しません" % num unless JY_FLAGS[num] == 1 end end考え方
こちらは累積和でなく本当に各区間の所要時間を合計している。ただし population count という「ビットが1の数を数える」方法を使っている。そのため合計したいビットを抜き出す処理が必要であり、それを実現する
range_maskの構築が主となっている。
(2 << n) - 1を計算すると、0~nビットが1となる数ができる- それを2つ用意して排他的論理和(XOR)をとると、m+1~nビットが1となる数ができる
from <= toならこの時点で、内回りで利用する区間が抜き出せているfrom > toなら外回りの区間を表しているため、どこかでつじつま合わせの必要がある- 常に内回りで考えられるよう、
from > toの場合だけビット反転(NOT)して利用区間を裏返す
xのビット反転はx ^ yでy = -1とでき、さらにy = 0なら反転しないという制御もできるxの符号でyを決めるのは、絶対値をビット演算で計算するときに使ったりするJY_FLAGSとの論理積(AND)をとって、実際に存在する駅の区間のみを抽出するあとは
popcountで2分と3分を数えれば、内回りでの所要時間が求まる。これが1周にかかる時間の半分を超えていたら、外回りを選択する。ビット演算の参考資料
- population count : ビットを数える・探すアルゴリズム
- 絶対値 : Hacker's Delight - CHAPTER 2 BASICS (PDF), 2-4 Absolute Value Function
- 投稿日:2019-11-30T21:25:54+09:00
超初心者がRuby使ってターミナルでやっと日本語出力させた話
使用しているOS Mac Catalina10.15
・引っかかってしまったところ
問題発生時の状態バージョン
ruby 2.6.3
rbenv 1.1.2irbを起動し日本語を出力させようとしたところ"\U+FFE3"と表示された。
なお英語に関しては問題なく出力ができていた・仮説
色々と調べてみた結果、どうやらreadlineなるものを読み込めていないことが原因であるようだ。参考:
https://reasonable-code.com/ruby-readline/しかし、ここで紹介されている通りに手順を進めたにも関わらず、何度試してもrbenvをアンインストールすることができなかった。
最終的にはアンインストールは諦めた。・どのようにして解決したか
rubyのバージョンが問題発生当時は2.6.3であったが、最新は2.6.5だったため、それを一からインストールしてみた。インストールの手順については、Progateさんのコラムを参考にして進めた。
その結果、日本語出力ができるようになった。
- 投稿日:2019-11-30T21:18:09+09:00
rails-tutorial第4章
helperメソッドとは
便利そうなメソッドをhelperに定義しておいてそれを呼び出す。
app/helpers/application_helper.rbmodule ApplicationHelper # ページごとの完全なタイトルを返します。 def full_title(page_title = '') base_title = "Ruby on Rails Tutorial Sample App" if page_title.empty? base_title else page_title + " | " + base_title end end endこれにより、page_titleが空の場合は、縦棒をいれずにbase_titleだけをタイトルタグに入れることができる。
app/views/layouts/application.html.erb<!DOCTYPE html> <html> <head> <title><%= full_title(yield(:title)) %></title> <%= csrf_meta_tags %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> </head> <body> <%= yield %> </body> </html>titleタグを先ほどhelperに定義したdef full_title(page_title = '')を使って実装している。
yield(:title)によりprovide(:title, "About")のように定義したタイトルを参照できる。
provideとyieldはセットで考える。pry
irbを拡張したものとしてpryという機能がある。
これはgemをインストールすることで使うことができる。$ gem intall pry $ pryこのコマンドにより、pryを使える。
putsメソッドについて
[3] pry(main)> puts 'foo' foo => nil上記のnilは計算の結果を返している。そのため、putsはfooを出力するがメソッド自体は何も返さない。
?の付くメソッド
?の付くメソッドは基本的にtrue か falseを返すようになっている。
自分でメソッドを定義するときもそれを気をつけながら定義する。nilと''の違い
nilをto_sメソッドで文字列にしたものが''
つまり、''は0文字の文字列である。Ruby(オブジェクト指向スクリプト言語)について
Rubyはメソッドを呼び出すという言い回しをしているが、実は少し違う。
オブジェクト指向スクリプト言語は、オブジェクトとのメッセージのやりとりだと考える。[18] pry(main)> 'foobar'.length => 6上記は、foobarの文字列は何文字?
俺は6文字だよー
という会話で成り立っている。ブロックの考え方
>> (1..5).each { |i| puts 2 * i } 2 4 6 8 10 => 1..5ブロック付きメソッドはメソッドの引数にRubyの処理を渡していると考えるとわかりやすい。
メソッドチェーンについて
[20] pry(main)> %w[foo bar baz].map { |i| i.upcase }.join => "FOOBARBAZ"このようにメソッドで評価された値にさらに . でメッセージを与えることをメソッドチェーンという。
ハッシュでなんでシンボルを使うのか?
[30] pry(main)> 'name'.object_id => 23088500 [31] pry(main)> :name.object_id => 88028 [32] pry(main)> 'name'.object_id => 24142460 [33] pry(main)> :name.object_id => 88028文字列オブジェクトはオブジェクトidが毎回違う。整数はオブジェクトidが毎回同じ。ただ、シンボルにすると、object_idが毎回同じになっている。
labelとしてシンボルオブジェクトを使うと毎回同じなので毎回計算する必要がない。シンボルは人間にもわかりやすい表現ができ、整数のように計算するコスト削減ができパソコンにも優しいということ。ハッシュの省略記法
[34] pry(main)> h1 = {:first => 'yokota', :second => 'daiki' } => {:first=>"yokota", :second=>"daiki"} [35] pry(main)> h1 => {:first=>"yokota", :second=>"daiki"} [36] pry(main)> h2 = { first: 'yokota', second: 'daiki' } => {:first=>"yokota", :second=>"daiki"} [37] pry(main)> h2 => {:first=>"yokota", :second=>"daiki"}シンボルを右側に書き、=>を省略した形で書くことができる。
classもオブジェクトの1つ
Rubyではあらゆるものがオブジェクトである。それはclassも例外ではない。
Stringにclassをするとclassクラスということがわかる。
Classクラスにsuperclassをするとmoduleクラスということがわかる。また自分でクラスを定義するとき、親クラスに何も指定しないと、デフォルトでObjectクラスが継承される。
- 投稿日:2019-11-30T20:36:36+09:00
Rails10年選手がGoの勉強会に参戦してきた
はじめに
静岡でRailsのWebエンジニアをしているkazuomatzです。2019年も残り1ヶ月を切りましたが、どうやら最近は業界的にRailsはオワコンらしいです。
僕は、2007年くらいからRailsを使ってきたので、かれこれ10年以上Railsを触ってきたことになるわけですが、オワコンなんて言われると、このままRailsを使い続けるか、それとも新しい言語に乗り換えるかの岐路に立たされているような気にもなってきます。
Railsが世の中に登場したのが2004年、2019年現在、Railsのバージョンは6.0です。2007年の12月にRailsのバージョン2が公開されていますから、かれこれ、5世代のRailsを使ってきたことになります。
Web2.0とRailsとの出会い
ちょっと昔話になりますが、2000年半ばに「Web」はバージョン1からバージョン2にバージョンバップされました。「Web 2.0」です。
これまでのWeb(=Web 1.0)は、ユーザーが情報を取得するだけのものでした。それがWeb 2.0になると、ユーザーがWebを通じて情報を発信することができるようになりました。そして、Webをプラットフォームとした様々なサービスやビジネスが生み出される時代に向かっていきました。
今となっては、Web 2.0とは結局何だったのかという議論もありますが、ともかく2007年11月に「Web 2.0 Expo」が盛大に開催されました。Web 2.0を提唱したティム・オライリーの講演をはじめ、当時の先進的なWeb関連のセッションが盛りだくさんでした。
当時、僕はJavaプログラマでマッシュアップ関連のWebサービスをいろいろ作っていましたが、そのWeb 2.0 Expoの会場で、Sun Microsystems(当時)のティム・ブレイの衝撃的な一言を聞くことになります。
「Ruby on Railsに触れたJavaプログラマーは、もうJavaには戻ってこないだろう」
Javaの開発元であるSun Microsystemsの中の人がこれ言っちゃったわけですから、大変なことです。少なくともWebが大きく変わるぞって時に、この発言によってRailsは脚光を浴びることになります。恐らく、これきっかけでRails始めた人はかなりいたはずです。
僕もその一人です。あの時からこの10年あまり、Railsに魅了され、RailsでいろいろなWebサービスを開発してきました。
Go勉強会へ
前置きが長くなりました。
ともあれ、Railsオワコン説を聞く中で、10年Railsを触ってきた身として、確かにいろいろ辛いことが多くなってきたなぁとも思います。そんな中見つけたのが、Shizuoka.goの勉強会でした。
勉強会の運営者も以前の仕事仲間(@secondarykey)だったので、Rails10年選手がGoを模索しているというネタで何かしゃべらせてとお願いして、参加することにしました。
ここからは、発表した内容の抜粋です。
Railsのここがよかった
- 設定より規約 / DRY ( Don’t Repeat Yourself )の哲学
- フルスタックなWebフレームワーク MVC / ORM / Asset
- 便利なライブラリ(Ruby Gems)が豊富!!
- お手軽な動的型付言語 Ruby
- 開発効率が半端ない ような気がしてた・・・
とにかくRailsに魅了されていた過去の自分。
Railsがオワコンの原因について
- フロントエンドのフレームワークがいろいろ出てきた
- Webpackなどのモジュールバンドラーが便利
- Railsでイケてたところのほころびが出てきた
僕もVue.jsは結構使うんですが、フロントエンドのフレームワークとRailsとがうまく調和しなくなってきてますね。Webpackについては、Rails向けのWebpackerがありますが、これもいまいち、むしろWebpackをそのまま使う人も多しね。Sprocketsもnode対応したり、ES6対応したりでこれでいけないこともないし・・・。
むしろ、僕が困ったと思っているのは、イケてたところのほころびが出てきたと書いたところ。
RailsってRubyGemsにものすごく多くの便利なライブラリーたちがあって、これをサクッと導入することで、いろいろなことが簡単にできます。もちろん、Ruby/Rails以外の言語やフレームワークでもそのような仕組みはあるわけだけど、Railsはちょっと探すと大抵のやりたいことは、Gem入れれば実現できちゃった。それが、当時のRailsって開発効率いいねという神話を作っていたのかもしれません。
こんなの見ちゃうと、Railsのレールに乗っているイケてる感に拍車かかりますしね・・・。
ところが、10年もいろいろWebサービスを作ってくると、サービス中止になるものもあれば(まぁこちらの方が多いわけですが)、セキュリティ対応やRailsのバージョンアップをしながら保守し続けるサービスもあります。この後者のサービスの延命が辛いんです。
Railsのバージョンアップは痛みを伴います。むしろ作り替えてしまった方が早い場合もあります。いや、作り替えられればまだいいかもしれません。データベースに貯まった様々なデータが特定のライブラリー依存の形で保存されているとかなり辛いです。
例えば、PaperClipという便利なGemがあります。画像ファイルをアップロードすると、Amazon S3などのクラウドストレージにアップロードしてくれる便利なライブラリです。これ本当によく使いました。でも、このPaperClipは、Rails 5.2以降では使えません。開発者の方が開発中止を宣言して、Rails5.2以降では、Railsに標準装備されたActiveStorageを使ってねということになっています。
これから新規に開発するサービスであれば、Rails 6でActiveStorageを使えばよいですが、すでにPaperClipを使ってデータも保存されているサービスをRails 6に移行することは簡単にはできません。
これは、Railsが悪いわけでも、開発を止めてしまったデベロッパーが悪いわけではありません。むしろ便利なGemを使うことでイケてる感を出してきたツケが回ってきたのかなと思います。
今のRuby / Railsの状況
- 2〜3年前に開発したWebサービスがサポート外のRailsで動いている
- とはいえ、Railsのバージョンアップする時間・費用がない
- 慣れ親しんだライブラリーが更新されず、最新のRails環境で使えない
こんな状況をGoは救ってくれるのか
ここからやっとGoの話。こんな状況をGoは救ってくれるのかを検証してみた。
これからもWebで食べていく僕がやっていくことは、こんなこと。
- Webサービスの開発(バックエンドもフロントエンドもやる)
- アプリ開発におけるバックエンドの開発(iOS / Androidアプリも作る)
- AWSを上手に使ってマイクロサービス指向で行く(Azure、GCPにも手を出す)
願うこと
- Web開発に必要なよいフレームワーク
- シンプルに開発ができること
- リファクタリングしやすく保守性が高いこと
発表しながら気づいた。第一にフレームワークを求めちゃうのは、フルスタックな全部入りのRailsにずいぶん甘やかされてきたんだなぁと。Rubyの世界ではWebフレームワークと言ったらほぼRails一択だけど、Goの場合は、軽量級なものからフルスタックなものまで、いろいろなフレームワークが存在する。Routerはこれで、ORMはこれをといった選択することも可能。Railsやってるとこの感覚は確かにない。
デモアプリをGoで作ったよ
僕は、この発表をするにあたり、簡単なWebサイトのモックをGoで作ってみた。
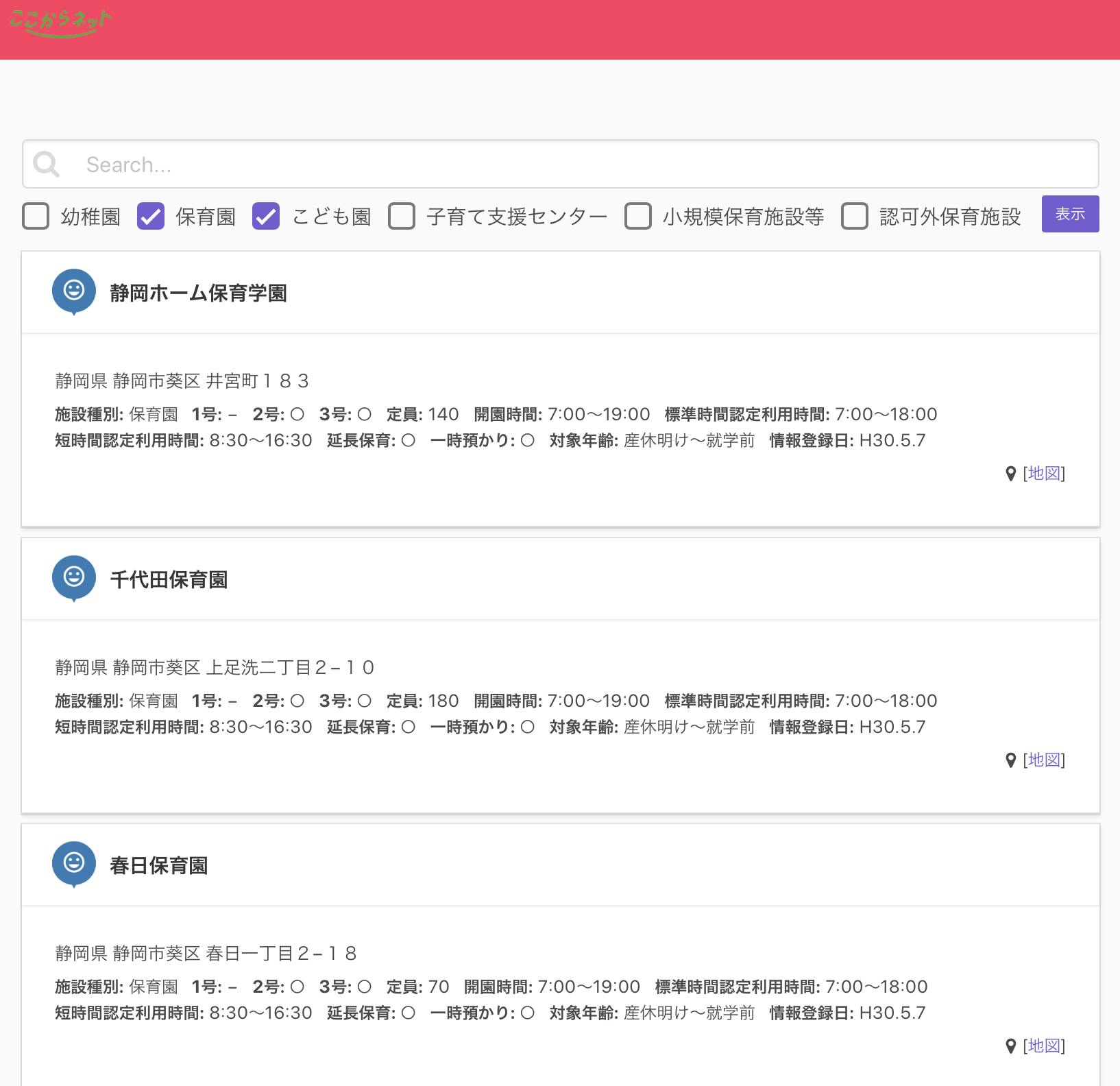
静岡市が運営している市民協働のポータルサイト「ここからネット」。このサイトには市民活動団体の活動情報や開催する講座やイベント情報、ボランティア情報などが掲載されている。そしてこれらデータはオープンデータとして公開されており、Web APIでデータを取得できる。APIのリファレンスもGithubで公開されている。
ここからネットに登録されているデータの中から静岡市の保育施設の一覧を取得して表示するだけのシンプルなものを作ってみた。
できあがりはこんな感じ。
APIからの戻りはこんな感じのJSON。
search.json{ "status": 200, "page": 1, "per_page": 2, "all_page_num": 133, "count": 2, "all_count": 266, "pois": [ { "id": 3450, "name": "静岡大学教育学部附属幼稚園", "prefecture_name": "静岡県", "city_name": "静岡市葵区", "address1": "大岩町1-10", "address2": "", "tel": "054-245-1191", "url": "http://fzk.ed.shizuoka.ac.jp/youchien/", "option_items": [ { "display_name": "分類", "attribute_name": "分類", "value": "従来どおりの幼稚園" }, { "display_name": "設立", "attribute_name": "設立", "value": "国立" }, { "display_name": "受入", "attribute_name": "受入", "value": "3歳~就学前" }, { "display_name": "情報登録日", "attribute_name": "情報登録日", "value": "H29.9.1" } ], "updated_at": "2018/05/09 22:01:39 +0900", "lat": 34.9913406, "lng": 138.3794399 } ] }GoでAPIをリクエストしてJSON Parseしてクライアントに返すプログラムはこんな感じ。
動的言語のRubyと違って静的型付言語のGoにおいては、APIで受け取るJSONの構造体をキチンと書く。/controllers/kindergarten.go// PoiData 受信データ type PoiData struct { Status int `json:"status"` Page int `json:"page"` PerPage int `json:"per_page"` AllPageNum int `json:"all_page_num"` Count int `json:"count"` AllCount int `json:"all_count"` Pois []struct { ID int `json:"id"` Name string `json:"name"` Kana string `json:"kana"` Description string `json:"description"` ZipCode string `json:"zip_code"` PrefectureName string `json:"prefecture_name"` CityName string `json:"city_name"` Address1 string `json:"address1"` Address2 string `json:"address2"` Tel string `json:"tel"` URL string `json:"url"` ImageURL string `json:"image_url"` OptionItems []struct { DisplayName string `json:"display_name"` AttributeName string `json:"attribute_name"` Value string `json:"value"` } `json:"option_items"` StartAt string `json:"start_at"` EndAt string `json:"end_at"` LocationID string `json:"location_id"` ActivityID string `json:"activity_id"` PostPhotoID string `json:"post_photo_id"` InformationID string `json:"information_id"` UpdatedAt string `json:"updated_at"` OrganizationID string `json:"organization_id"` Lat float64 `json:"lat"` Lng float64 `json:"lng"` Marker2X string `json:"marker2x"` Marker string `json:"marker"` Type string `json:"type"` } `json:"pois"` } // GetKinderGarten 保育園情報を取得する func (controller *KinderGartenController) GetKinderGarten() { url := beego.AppConfig.String("endPointURL") + "/map/search.json" page := controller.GetString("page") url += "?page=" + page dataSet := controller.GetString("type") if len(dataSet) == 0 { dataSet = "1,2,3,4,5" } url += "&data_set=" + dataSet response, err := http.Get(url) if err != nil { controller.CustomAbort(500, "Internal server error") return } defer response.Body.Close() body, err := ioutil.ReadAll(response.Body) if err != nil { controller.CustomAbort(500, "Internal server error") return } jsonBytes := ([]byte)(body) data := new(PoiData) if err := json.Unmarshal(jsonBytes, data); err != nil { controller.CustomAbort(500, "Internal server error") return } controller.Data["json"] = data controller.ServeJSON() }フロントエンドはVue.jsを使っている。モジュールバンドルはWebpackだ。ここはGoとは直接関係ない世界。
選択したWebフレームワーク
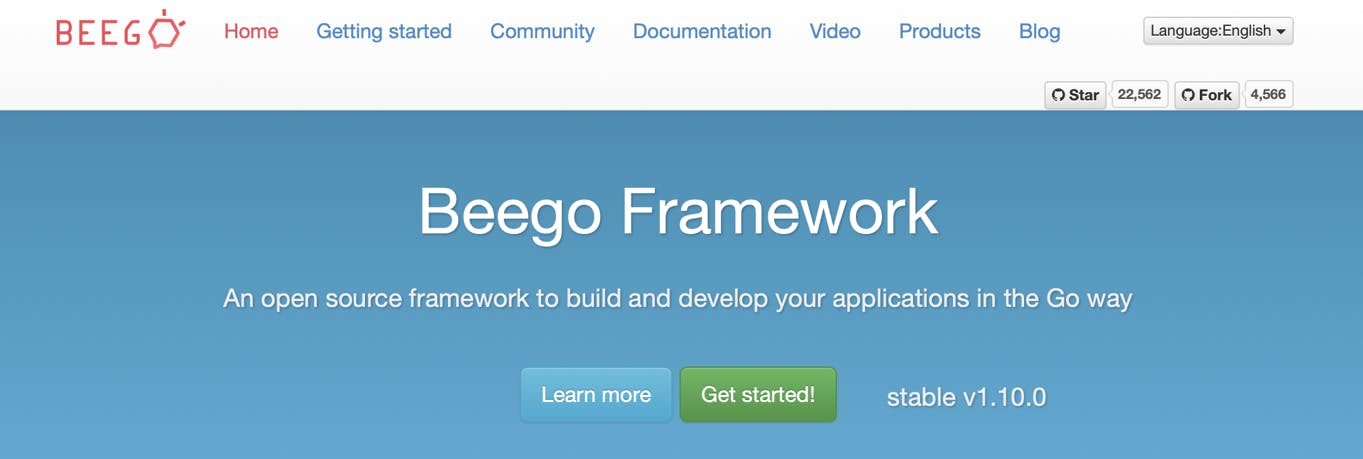
そして、肝心のWebフレームワークはいろいろ探した結果、最終的にBeego Frameworkを選んだ。
BeegoはRubyのWebフレームワークSinatraを意識して開発されたとのこと。SinatraはRubyのWebフレームワークではRailsの次に使われているもので、フルスタックなRailsよりも軽量なもの。
Beegoは、ORM、Routerも使えて、MVCモデルもいける。CLIもあってコマンド叩いていろいろできる。
実は、自分の発表の前に、元仕事仲間(@secondarykey)がGoのWebフレームワークをいろいろ紹介してくれていた(資料)。彼の所感では、Beegoは「老舗っぽくフルスッタックで色々機能がありそう。重そう。」とのこと。やっぱり、Railsのフルスタック脳がBeegoを選んだ結果は納得できる。
まとめ
Go言語とRubyを比較すると、静的と動的の議論も確かに出てきます。やっぱり静的の方が安全だよねという風潮もありますし、動的の柔軟さが開発効率をあげているのも事実です。
このあたりはトレードオフなので、要件に合わせてどちらが最適かを見極めていくことも必要かなと思います(今まで動的万歳だった自戒も込めて)。
今、自分がサクッとWebサービスを作るとしたら、やはりRailsを選ぶと思います。Rails 6のActiveStorageはよくできていると思いますし、まだまだ使えるGemも多い。自前のライブラリーやTipsも豊富にあったりするので、ユーザビリティや品質の高いWebサービスはまだまだRailsで作れます。
ただ、今回、Shizuoka.goに参加して、Goの魅力にも気づけたことも事実です。
自分が今後やっていきたいことの中で、「AWSを上手に使ってマイクロサービス指向で行く」をあげていますが、こちらはRubyよりもGoが向いているんだろうと思います。AWSでなくて、GCPなのかもしれませんが・・・。ということで、今までやってきたアーキテクチャーとは違うものにチャレンジする際に、Goを選択することをここに誓います。
今回のShizuoka.goではWebフレームワークの話のほかに、@hogedigoさんのGoでのテスト手法についての話(資料)、@cupperさんのAWSとGoの話(資料)、@hrs_sano645
さんのGo製便利ツールの紹介(資料)など、興味深い話がたくさん聞けました。最後に、Shizuoka.goのみなさんありがとうございました。また参加します。Shizuoka.go最高!


- 投稿日:2019-11-30T20:17:48+09:00
英語論文をフォーマットして翻訳する方法
自己紹介
こんにちは,ZOZOテクノロジーズの内定者さっとです.
普段は,インフラやサーバサイドを主に勉強していますが,最近はReactを触ったりしています.※本記事はZOZOテクノロジーズ#5の2日目です.
概要(3行)
- 電子媒体の英語論文をGoogle翻訳を使って翻訳したい
- そのままコピペすると変な改行が入ってくるため上手く翻訳できない
- 簡単に翻訳できる形にフォーマットしてくれるツールを作る!
やりたいこと
ツーカラムのよくある英語論文
1. Introduction hogehoge. hogehogehoge. hogehogehogehoge.hoge- hoge.hogehogehogehogehogehogehogehogehoge, hogehogehogehogehogehogehogehogehogehoge. 2. Related Works hogehoge. hogehogehoge. hogehogehogehoge.hoge. hoge.hogehogehoge.hogehogehogehogehogehoge- hogehogehogehogehogehogehogehogehogehoge.これでは,行末に改行が入っているため,
Google翻訳にそのままコピペすると文章の変な位置で区切れてしまい上手く翻訳してくれません.フォーマットした後の文章
1. Introduction hogehoge. hogehogehoge. hogehogehogehoge.hogehoge.hogehogehogehogehogehogehogehogehoge, hogehogehogehogehogehogehogehogehogehoge. 2. Related Works hogehoge. hogehogehoge. hogehogehogehoge.hoge. hoge.hogehogehoge.hogehogehogehogehogehogehogehogehogehogehogehogehogehogehogehoge.これをGoogle翻訳に貼り付ければきっと上手く翻訳してくれるはず
Rubyを使ったフォーマットプログラム
プログラムはGitHubに上げています.
環境構築方法や使い方も詳しく書いているのでやってみたい方はアクセスしてください.事前準備
- フォーマットしたい論文の文章を事前にreport.txtに保存しておきます.
report.txt1. Introduction hogehoge. hogehogehoge. hogehogehogehoge.hoge- hoge.hogehogehogehogehogehogehogehogehoge, hogehogehogehogehogehogehogehogehogehoge. 2. Related Works hogehoge. hogehogehoge. hogehogehogehoge.hoge. hoge.hogehogehoge.hogehogehogehogehogehoge- hogehogehogehogehogehogehogehogehogehoge.メインプログラム
- プログラムはreport.txtを一行一行読み込んでいます.
- 読み込んだ行はlineに代入されます.
- その行はセクション又は,サブセクションなのか?文章なのかを判定し,フォーマットを行います.
- フォーマットした行はreportに結合し文章を構築していきます.
main.rbbegin report = "" # ファイル読み込み File.open('report.txt') do |file| file.each_line do |line| # 読み込んだ行がsectionやsubsectionだったら if line.match(/^[0-9]+.*$/) report += line next # 空行があった場合 elsif line.match(/^\s*$/) report += "\n" + line next end # 文字列の最後が-なら-を消して行を結合 if report[-1] == "-" report = report.chomp("-") + line.chomp next end report += " " + line.chomp end puts report end # ファイル書き込み File.open("format-report.txt", "w") do |f| f.puts(report) end # 例外 rescue SystemCallError => e puts %Q(class=[#{e.class}] message=[#{e.message}]) rescue IOError => e puts %Q(class=[#{e.class}] message=[#{e.message}]) endセクション又はサブセクションを判定する
セクション又はサブセクションは以下のように表現されることが多いと思います.
1. hogehoge 1.2. fugafuga正規表現を使って行頭が数字とピリオドで構成されているかをチェックして判断します.
# 読み込んだ行がsectionやsubsectionだったら if line.match(/^[0-9]+.*$/) report += line nextこの条件に引っかかった場合,行の末尾の改行を除去せずそのままreportに結合します.
空行があった場合
正規表現でタブを含む空白全般は
\sで表します.# 空行があった場合 elsif line.match(/^\s*$/) report += "\n" + line next end行が空白だった場合は,改行してから空白を入れます.
また,空白の末尾にも改行があるので,つまりhogehogehoge改行 空白空白空白改行 ← 次の行からここに結合といったようになります.
行末が-だった場合
英語の論文ではよく以下のような行を見ることがあるかと思います.
hogehoge hogehoge hogehoge ho- gehoge.そのまま改行すると単語が崩れてしまうので,ハイフンをいれて次の行に続くことを表しています.
これを考慮するためにプログラムでは行末に"-"があるかないか判断しています.
# 文字列の最後が-なら-を消して行を結合 if report[-1] == "-" report = report.chomp("-") + line.chomp next endハイフンがある場合は,ハイフンを消して,さらに,行の末尾の改行を消して結合します.
それ以外の行
普通の文章であれば,先頭に空白を入れて,行末の改行を消して結合します.
report += " " + line.chomp実行
プログラムを実行してみます.
文章量によって多少時間がかかるかもしれません.$ ruby main.rbフォーマットされた文章が
format-report.txt出力されます.format-report.txt1. Introduction hogehoge. hogehogehoge. hogehogehogehoge.hogehoge.hogehogehogehogehogehogehogehogehoge, hogehogehogehogehogehogehogehogehogehoge. 2. Related Works hogehoge. hogehogehoge. hogehogehogehoge.hoge. hoge.hogehogehoge.hogehogehogehogehogehogehogehogehogehogehogehogehogehogehogehoge.こちらをGoogle翻訳に貼り付ければ上手く翻訳してくれそうですね.
ちなみに,以前にGoogle翻訳APIを無料で作る方法という記事を書いているので,
これと連携すればシームレスに翻訳できるかもしれません.おわりに
今回は,Rubyを使って英語論文をGoogle翻訳へ貼り付けるためにフォーマットするツールを紹介しました.
本来はこんなツール使わずに読めることが大事ですが...
こちらのツールはGitHubで公開しているので,興味ある方はぜひ使ってみてくださいね!
https://github.com/sattosan/report-formattaro
- 投稿日:2019-11-30T19:53:59+09:00
Rubyで生年月日から年齢を求める(ydayメソッド使用)
Dateインスタンスで作成した生年月日から現在の年齢を算出したい時。
誕生日の前か後かも考慮したい場合は
ydayメソッドで比較的わかりやすく記述できるかと思います。ydayメソッドは、1月1日を1日目として、オブジェクトの日付が何日目かを整数で返してくれるメソッドです。閏年もカバーしています。
たとえば、2019年2月10日(2019-2-10)なら、返ってくる数値は41となります。
y.dayメソッドを使った年齢算出コード
require "date" birthday = Date.new(1999, 12, 10) today = Date.today #=> 2019-11-30と仮定 age = today.year - birthday.year if today.yday < birthday.yday age -= 1 end puts age #=> 19上記のコードでは、今日までの日数(today.yday)と誕生日までの日数(birthday.yday)を比較し、前者の方が小さければ誕生日はまだ来ていないのでageからマイナス1しています。
他にも色々な算出方法があるかと思いますが、方法の一つとして参考にしていただければ幸いです。
「このコードだとこんな場合は間違った結果になるよ!」ということがあれば、ご教示いただけるとありがたいです。
参考1:Ruby リファレンス
https://docs.ruby-lang.org/ja/latest/method/Time/i/yday.html
参考2:生年月日から年齢を求める
http://rubytips86.hatenablog.com/entry/2014/03/27/101209
- 投稿日:2019-11-30T19:14:09+09:00
【初心者向】配列とハッシュ取り出し方、活用の仕方
Railsを何人かに教えていて、配列の取り出し方が怪しいのではないかと思えたので
勉強会資料として書きます。配列というのはデータを複数入れることができるものです。
例えば@basic1 = [1, 2, 4, 8, 16, 32]
この時、複数入った中身を取り出すには
number = @basic1[0]
のように書く。
[0]というのがインデックス番号になって、0番目から始まります
今回の場合なら
0番目が1、1番目が2、2番目が4、3番目が8、4番目が16、5番目が32
となります。ビューに表示するときは例えば
<h1>基本1</h1> <div> <h2>basic1</h2> <% @basic1.each do |b| %> <%= b %><br> <% end %> </div>/sample-blog/app/controllers/users_controller.rbdef basic1 @basic1 = [1, 2, 4, 8, 16, 32] end
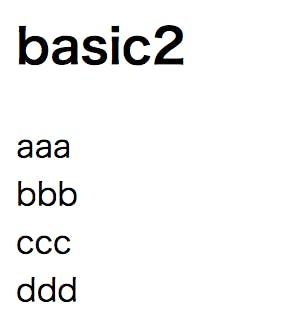
同じパターンで
/sample-blog/app/controllers/users_controller.rbdef basic1 @basic2 = ["aaa", "bbb", "ccc", "ddd"] end<h2>basic2</h2> <div> <% @basic2.each do |b| %> <%= b %><br> <% end %> </div>
配列の中に配列
少し複雑な場合
def basic1 @basic3 = [[1, 2, 3],[3, 4, 5]] end<h2>basic3</h2> <div> <% @basic3.each do |basic| %> <p><%= basic %></p> <% end %> </div>繰り返し1回目はindexが1繰り返し2回目はインデックスが1
indexが0のところは[1, 2, 3]1のところは[3, 4, 5]今度は全部表示させたい(取り出したい)場合
<h2>basic3-2</h2> <div> <% @basic3.each do |basic| %> <% basic.each do |b| %> <%= b %><br> <% end %> <% end %> </div>eachの繰り返しの中にeachがあります。
1回目のループでbasic =[1, 2, 3]が取り出されるのでこれをさらにループにかけると123
2回目のループでbasic =[3, 4, 5]が取り出されるのでこれをさらにループにかけると345
と中身を取り出すことができます。配列の中にハッシュ
@basic5 = [ {name: "佐藤", mail: "satho@gmail.com"}, {name: "田中", mail: "tanaka@yahoo.co.jp"} ]一つ目の要素が
{name: "佐藤", mail: "satho@gmail.com"}
二つ目の要素が{name: "田中", mail: "tanaka@yahoo.co.jp"}以下のように取り出すことができます。
<h2>basic5-1</h2> <div> <% @basic5.each do |b| %> <p><%= b[:name] %></p> <p><%= b[:mail] %></p> <% end %> </div> <h2>basic5-2</h2> <div> <p><%= @basic5[0][:name] %></p> <p><%= @basic5[1][:mail] %></p> </div>
こんな感じで取り出すことができます。


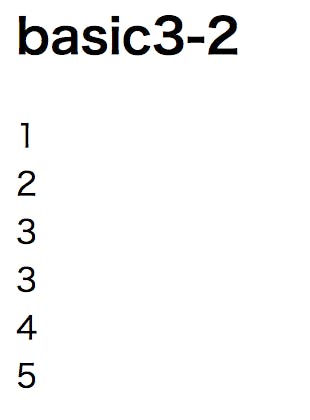

- 投稿日:2019-11-30T16:46:01+09:00
大文字小文字を区別しないという不幸な世界のワイルドカード(macOS)
この記事について
macOS のファイルシステムは、デフォルトでは殆どのディレクトリで大文字小文字を区別しない。
そのような世界で、ワイルドカードを用いると何がマッチするか、という話。大文字小文字を区別しないということ
例えばこんなスクリプトを実行すると
bash#!/bin/bash set -eu # ASCII の英数字 touch foo.txt FOO.txt ls *.txt && rm *.txt # 所謂全角文字 touch zen.txt ZEN.txt ls *.txt && rm *.txt # ギリシャ文字・キリル文字・ローマ数字 touch ωяⅶ.txt ΩЯⅦ.txt ls *.txt && rm *.txt # DZ, NJ touch dz.txt # U+01F3 Latin Small Letter DZ touch Dz.txt # U+01F2 Latin Capital Letter D with Small Letter z touch DZ.txt # U+01F1 Latin Capital Letter DZ touch nj.txt # U+01CC Latin Small Letter NJ touch Nj.txt # U+01CB Latin Capital Letter N with Small Letter J touch NJ.txt # U+01CA Latin Capital Letter NJ ls *.txt && rm *.txt # i witout dot, etc. touch ı.txt # U+0131 Small I without dot touch İ.txt # U+0130 Capital I with dot touch i.txt # U+0069 Small I touch I.txt # U+0049 Capital I ls *.txt && rm *.txt # 囲み文字 touch ⓐ.txt # U+24D0 touch Ⓐ.txt # U+24B6 ls *.txt && rm *.txtこんな結果になる
foo.txt zen.txt ωяⅶ.txt nj.txt dz.txt i.txt İ.txt ı.txt ⓐ.txt
FOOとfooは簡単。大文字小文字を区別しないのでどちらかしか生き残れない。
zen、ωяⅶやⓐのあたりを見て分かる通り、7bit-ASCII の範囲外の文字にも大文字小文字があり、それらは区別されない。
Dzは「Titlecase Letter」というカテゴリの文字で、大文字でも小文字でもない。
対応する小文字はdzで、対応する大文字はDZになる。
この文字も大文字小文字を区別しないので、touch dz.txt Dz.txt DZ.txtとしても、ひとつしか生き残れない。
ı,İ,i,Iの件は下表のとおり。
言語 Iの小文字iの大文字英語 iIトルコ語 ıİ
ı.txt,İ.txt,i.txt,I.txtを touch すると、
i.txt,İ.txt,ı.txtが生き残る。unicode.org を見ると、dot のない小文字
ıは、大文字にすると普通のIになる。
にも関わらず、APFS 上ではı.txtとI.txtは別の名前だとみなされる。様々な環境での対応
いくつかの環境で何が起こるのか試してみた。
shell script(bash) 他
以下の環境でこの結果になる:
- shell script(bash)
- C(POSIX glob)
- Go(filepath.Glob)
- Python3(glob.glob)
- PHP7(glob)
POSIX glob や bash と同じなのでこれが基本っぽいんだけど、わりと気持ち悪い動作になっている。
基本的には、
- ワイルドカードがない場合は大文字小文字を区別しない。
- ワイルドカードがある場合は大文字小文字を区別する。
となっている。
Foo.txtだと1件マッチしてF*.txtだと 0件マッチするというのはかなり意外だった。ワイルドカードがない部分については、(気付いた範囲では)ファイルシステムと同じ意見になっている。
F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ❌ ❌ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ❌ ❌ ❌ I*.txt ❌ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ❌ Dz*.txt ❌ ✅ ❌ dz*.txt ❌ ❌ ✅ dz-uu.txt ✅ ❌ ❌ dz-ul.txt ❌ ✅ ❌ Dz-uu.txt ✅ ❌ ❌ ruby(Dir.glob)
ruby の動作は POSIX glob とはだいぶ異なる。
基本的には「大文字と小文字を区別しない」という動作で一貫しているような感じ。
Foo.txtだとfoo.txtのみがマッチして、F*.txtだとfoo.txtとfred.txtがマッチする。わかりやすい。しかし、
rubyDir.glob("dz-u*.txt") #=> [] Dir.glob("dz-uu.txt") #=> ["files/DZ-uu.txt"]と、ワイルドカードを入れるとマッチする件数が減るというパターンもある。
バグ?F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ✅ ✅ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ✅ ❌ ❌ I*.txt ✅ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ❌ Dz*.txt ❌ ✅ ❌ dz*.txt ❌ ❌ ✅ dz-uu.txt ✅ ❌ ❌ dz-ul.txt ❌ ✅ ❌ Dz-uu.txt ✅ ❌ ❌ Java(PathMatcher)
java.nio.fileにPathMatcherという インターフェイスがあるので、それを使ってみた。
これも POSIX glob とはだいぶ異なる。
常に大文字小文字を区別するように見える。
ファイルシステムのファイル名とは異なる動作だが、一貫性はある。F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ❌ ❌ f*.txt ✅ ✅ Foo.txt ❌ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ❌ ❌ ❌ I*.txt ❌ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ❌ Dz*.txt ❌ ✅ ❌ dz*.txt ❌ ❌ ✅ dz-uu.txt ❌ ❌ ❌ dz-ul.txt ❌ ❌ ❌ Dz-uu.txt ❌ ❌ ❌ C#(.NET Core / Directory.GetFiles)
ruby の動きと似ている。
ruby と異なり、DZ*.txtでdz-ll.txtにちゃんと(?)マッチする。
しかし逆に、dz-uu.txtではDZ-uu.txtが取れない。F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ✅ ✅ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ✅ ❌ ❌ I*.txt ✅ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ✅ ✅ Dz*.txt ✅ ✅ ✅ dz*.txt ✅ ✅ ✅ dz-uu.txt ❌ ❌ ❌ dz-ul.txt ❌ ❌ ❌ Dz-uu.txt ❌ ❌ ❌ C#(Mono / Directory.GetFiles)
意外にも、 .NET Core と Mono で動作が異なる。
大文字でも小文字でもないDzという文字に負けている感じがする。F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ✅ ✅ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ✅ ❌ ❌ I*.txt ✅ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ❌ ❌ ı-lat-up.txt ❌ ❌ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ✅ Dz*.txt ❌ ✅ ❌ dz*.txt ✅ ❌ ✅ dz-uu.txt ✅ ❌ ❌ dz-ul.txt ❌ ❌ ❌ Dz-uu.txt ❌ ❌ ❌ Perl(glob)
POSIX glob とよく似た動作になっているが、ドットなしの小文字 i の扱いが異なる。
F*/f*/Foo
wildcard foo.txt fred.txt F*.txt ❌ ❌ f*.txt ✅ ✅ Foo.txt ✅ ❌ i / I / ı / İ
wildcard i-lat-lo.txt I-lat-up.txt ı-tur-lo.txt İ-tur-up.txt i*.txt ✅ ❌ ❌ ❌ I*.txt ❌ ✅ ❌ ❌ ı*.txt ❌ ❌ ✅ ❌ İ*.txt ❌ ❌ ❌ ✅ İ-tur-lo.txt ❌ ❌ ❌ ❌ I-tur-lo.txt ❌ ❌ ✅ ❌ ı-lat-up.txt ❌ ✅ ❌ ❌ DZ / Dz / dz
wildcard DZ-uu.txt Dz-ul.txt dz-ll.txt DZ*.txt ✅ ❌ ❌ Dz*.txt ❌ ✅ ❌ dz*.txt ❌ ❌ ✅ dz-uu.txt ✅ ❌ ❌ dz-ul.txt ❌ ✅ ❌ Dz-uu.txt ✅ ❌ ❌ まとめ
POSIX glob は、ワイルドカードがない部分についてはファイルシステムと同じ意見になっているものの、ワイルドカードが入ると大文字小文字を区別するようになるところがわかりにくい。
- Go(filepath.Glob)
- Python3(glob.glob)
- PHP7(glob)
は、POSIX glob と同じ意見になっている。
一方
- ruby(Dir.glob)
- Java(PathMatcher)
- C#(.NET Core GetFiles)
- C#(Mono Directory.GetFiles)
- Perl(glob)
は独自のアルゴリズムで処理しているらしく、POSIX glob とは異なる結果を返す。
「アルファベット2文字をセットにした文字で一文字目だけ大文字に出来るもの」や「小文字のiからドットを除いたもの」のあたりで不穏な動作になりやすい。
- 投稿日:2019-11-30T15:21:51+09:00
サーバエンジニアから始める、Swiftロードマップ
こんにちは
taskey サーバエンジニアの田代です。ふとSwiftを学ぶことになり、その時の軌跡をまとめておこうと思いnoteに残しました。
対象者: サーバエンジニアだけど、Clientのことをもっとわかってあげたい方、こまい修正位やっちゃいたい方
社内マガジンに載せる都合上noteにまとめました。
内容はこちらをご閲覧下さい。
- 投稿日:2019-11-30T14:23:34+09:00
#Ruby の pry gem で直接ファイル指定実行して続きを書けること気づいた。文法エラーチェックも。
require 'date' p Date.today p Date.today # Date.yesterday binding.prybinding.pryを書いた場所からpryを実行できる
途中までの標準出力もされる。$ pry ~/tmp/time.rb #<Date: 2019-11-30 ((2458818j,0s,0n),+0s,2299161j)> #<Date: 2019-11-30 ((2458818j,0s,0n),+0s,2299161j)> [1] pry(main)> Date.today + 1 => #<Date: 2019-12-01 ((2458819j,0s,0n),+0s,2299161j)> [2] pry(main)>文法エラーがあるとそこでも止まってpryできる!
$ pry ~/tmp/time.rb Exception: NoMethodError: undefined method `yesterday' for Date:Class -- From: (pry) @ line 3 @ level: 0 of backtrace (of 17). 1: require 'date' 2: => 3: Date.yesterday ...exception encountered, going interactive! [4] pry(main)>ということは文法エラーがあればデバッグができて、なければスクリプトが正常完了する。
いやいやpryってそもそもそういう目的のものだしね。これいいな。
Original by Github issue
- 投稿日:2019-11-30T14:04:55+09:00
Ruby on Rails チュートリアル1周目
Railsチュートリアルを一周してみましたので簡単な感想とこれから学習する人向けにポイントなどをまとめようと思います。
まず、Railsチュートリアルをいきなり始めるのではなくもっと基礎的な学習を前にやっておいたほうがスムーズに理解できます。
学習カリキュラムについてはこちらの方が細かく書いてくれてます。
https://qiita.com/saboyutaka/items/1a8c40e105e93ac6856aフロントエンド
私自身はWebデザイナーということもあり飛ばしていたのですが、
HTML/CSS(Sass)/Javascript
Jquery
Bootstrap
についてはすでに理解していました。IT基礎知識
どうということはないのですがサーティファイの情報処理技術者能力検定試験もとっているので基礎知識も一応あるつもりです。
https://www.sikaku.gr.jp/js/jss/Git, Command Line, SQL
Git, Command Line, SQLについては
Progate
ドットインストールで学習Ruby, Ruby on Railsの基礎
さらに
Ruby
Ruby on Railsもこちらで一周しておきました。書籍ではこちらをやってみました。
Railsの教科書
たった1日で基本が身に付く! Ruby on Rails 超入門
ゼロからわかる Ruby 超入門Rails チュートリアル前に
下記サービスの登録をしておくとスムーズにすすめることができます。
Github、もしくはBitbucketの登録
Gitの操作を行うにあたってリポジトリーを登録する必要性があるのでやっとくといいでしょう。
Herokuの登録
フリープランでいいのでクレジット登録しておくと後のsendgridからのメールで認証するときに必要になります。
AWSの登録
Cloud9ではじめているならアカウントできていると思いますが、
画像を保存するときはS3を使うので先に登録しとくとよいでしょう。Rails チュートリアル後
1周終えるだけボリュームがすごいのでかなりの学習時間がかかります。
その間に挫折する人も多いと思うのでおすすめは動画か質面ができるサービスと一緒にやるといいと思います。1周を終えたあとは2周めやるもよし、サービスを作るとよしなのですが
何を作ったらいいのかわからない、もうちょっと勉強したいという方にはTechpit
クローンサイトを作れるカリキュラムがあります。
Rails チュートリアルに比べるとかなり簡単につくれますが機能が簡単すぎて物足らないとおもいますので
Rails チュートリアルと組み合わせながらやるのがいいかもしれません。e-Navigator
作ったサービスのコードレビューをしてくれるサービスです。
現役エンジニアがレビューを行ってくれるので実践経験がない方にはちょうどいいかもしれません。私はフロントエンド(Vue.js)のほうも勉強しているのでBackendの部分はもう一度Railsチュートリアルを進め、フロントの部分をうまいこと組み合わせて見ようと思います。
以上ですが、Railsチュートリアル1周目のまとめと感想でした。
- 投稿日:2019-11-30T12:36:06+09:00
rails-tutorial第3章
branchについて
$ git branch
これにより今いるブランチを確認することができる。基本的にmasterブランチは常に安定しなければいけないので、新規機能を作るときは必ずブランチを切る。$ git checkout -b static-pages
-bはブランチを切るということ。このコマンドにより、masterブランチから離れる。コントローラー
$ rails generate controller StaticPages home help
上記はStaticPagesコントローラーを作りhomeアクションとhelpアクションを追加する。さらにそれに対応するviewやテストを用意するという意味。また、rails g controllerコマンドは必ずコントローラー名を複数形にして書くこと。テストについて
require 'test_helper' class StaticPagesControllerTest < ActionDispatch::IntegrationTest test "should get home" do get static_pages_home_url assert_response :success end test "should get help" do get static_pages_help_url assert_response :success end end上記はrails g controllerコマンドを使うと自動生成されるテストコード。
スクリプト言語とテストは切っても切り離せない。test "should get home" do get static_pages_home_url assert_response :success end例えば上記は
get static_pages_home_url:static_pagesコントローラーのhomeアクションにリクエストを送った時に、
assert_response :success :必ずなんらかのレスポンスが返ってくるはずだという意味。ちなみにテスト駆動開発は、まずあるべき姿をテストコードで書く。テスト失敗する。テストが成功するようにコードを足していく、そしてリファクタリングを行うというスタイル。
staticpagesコントローラのタイトルをテストしてみよう
require 'test_helper' class StaticPagesControllerTest < ActionDispatch::IntegrationTest test "should get home" do get static_pages_home_url assert_response :success assert_select "title", "Home | Ruby on Rails Tutorial Sample App" end test "should get help" do get static_pages_help_url assert_response :success assert_select "title", "Help | Ruby on Rails Tutorial Sample App" end test "should get about" do get static_pages_about_url assert_response :success assert_select "title", "About | Ruby on Rails Tutorial Sample App" end end書くテスト3行目に足されたのは、
assert_selectはそのページのセレクトタグの中は以下のようになってますか?というもの3) Failure: StaticPagesControllerTest#test_should_get_home [/home/ec2-user/environment/sample_app/test/controllers/static_pages_controller_test.rb:8]: <Home | Ruby on Rails Tutorial Sample App> expected but was <SampleApp>.. Expected 0 to be >= 1. 3 runs, 6 assertions, 3 failures, 0 errors, 0 skipsちなみにテストを実行した結果。
最後の行は3つのテストが走って、6つのアサーションがある中で、3つが失敗したよーって意味。初めてのリファクタリング
<% provide(:title, "Home") %> <!DOCTYPE html> <html> <head> <title><%= yield(:title) %> | Ruby on Rails Tutorial Sample App</title> </head> <body> <h1>Sample App</h1> <p> This is the home page for the <a href="https://railstutorial.jp/">Ruby on Rails Tutorial</a> sample application. </p> </body> </html><% provide(:title, "Home") %>この部分は:titleに"Home"を代入している。
<%= yield(:title) %>はtitleをyieldメソッドで引っ張ってきてるという意味。
これにより、provideメソッドを除く、ドクタイプ宣言からheadタグまでが共通化できた、というかbodyタグの内側以外は全部同じなので外側にまとめようってこと。
<%=yield%>の中に各テンプレートが代入されるので、各テンプレートはbodyタグの内側だけ書いていれば良い。その結果application.html.erbに共通のコードをまとめる。
<!DOCTYPE html> <html> <head> <title><%= yield(:title) %> | Ruby on Rails Tutorial Sample App</title> <%= csrf_meta_tags %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> </head> <body> <%= yield %> </body> </html>yield(:title)のtitleは各テンプレートから引っ張ってくるよーってこと。
branch のマージ
トピックブランチで作業したら最後にmasterブランチにマージしてあげる必要がある。
トピックブランチ内で
$ git add -A
$ git commit -m "Finish static pages"$ git checkout master
ここでマスターブランチに移動。この時点でgit logをしてもトピックブランチで設定したコミットメッセージは表示されない。
$ git merge static-pages
これでトピックブランチの内容をmasterブランチに反映できる。この状態でgit push heroku master を実行すればデプロイできる。
minitest reporters
railstestでgreenやredを表示するときの設定
test/test_helper.rbENV['RAILS_ENV'] ||= 'test' require File.expand_path('../../config/environment', __FILE__) require 'rails/test_help' require "minitest/reporters" Minitest::Reporters.use! class ActiveSupport::TestCase # Setup all fixtures in test/fixtures/*.yml for all tests # in alphabetical order. fixtures :all # Add more helper methods to be used by all tests here... endrequire 'minitest/reporters'
Minitest::Reporters.user!
この2行を追加する。Guardによるテストの自動化
guardは何かファイルが更新されたら〜〜の処理を実行するというもの。
これをminitestと合わせると、ファイルを変えた時に勝手にテストを実行してくれる。1.$ bundle exec guard init
を実行して初期化する。2.$ sudo yum install -y tmux
cloud9の場合のコマンド。これによりguardの通知を受け取るのに必要なtmuxを有効にする。3.生成されたguardfileの先頭の行に
guard :minitest, spring: "bin/rails test", all_on_start: false do
を加える。4.gitignoreの最後の行に
# Ignore Spring files. /spring/*.pidを加える。
5.bundle exec guardを実行する。
- 投稿日:2019-11-30T12:18:51+09:00
deviseでログイン状態からsign_up(登録)画面に遷移した際のリダイレクト先
2種類のユーザ権限があるサービスで、ログイン状態かsign_up(登録)画面にした際に、想定してなかった画面にいリダイレクトされてこまったという話
構成
hoge_user,fuga_userという2種類のユーザがあります。それぞれ個別の認証が必要です。
また、それぞれのnamespaceでroot設定しています。# routes.rb namespace :hoge_users do root to: 'tops#show' ~略~ end namespace :fuga_user do root to: 'tops#show' ~略~ endさらに、親のルートでは
hoge_userのルートに遷移するように設定しています。問題
fuga_userでログイン済状態でfuga_userのsign_up(登録)画面に遷移しようとするとhoge_userトップにリダイレクトされてしまう。
ログを見ると以下のように遷移していました。
fuga_user/new(sign_up)/hoge_user/topログイン済の場合親のルートにリダイレクトされたため、そこから更に
hoge_userルートにリダイレクトされてました。
想定としては各ユーザのルート設定したとこにリダイレクトされると思ってたので困った。調査
deviseのコードを確認しました。
- newでは
require_no_authenticationが呼ばれログイン状態を確認する- ログイン済なら
after_sign_in_path_forを呼ばれるなるほど。
after_sign_in_path_forをoverrideしてないので親ルートにリダイレクトされると。
しかもこのアプリ構成上application_controllerではなく個別のcontrollerでoverrideする必要がある。
→ 2種類のそれぞれのリダイレクト先を設定したいので
→session_controllerではすでにやってた。今回はregistration_conroller対応
全然DRYじゃないんだけど、それぞれのユーザ配下の
session_controller,registration_controllerでafter_sign_in_path_forをoverrideした。
これ以上増えるようだったらmixinするなり共通化します。
- 投稿日:2019-11-30T11:44:18+09:00
クラス変数とインスタンス変数
職場で「クラス変数とクラスインスタンス変数の違い」が話題にあがっていて、以前理解したよな、と思いつつ咄嗟に整理して述べられないなと思ったので、思い出しつつまとめてみる。
基本的にはクラス変数とインスタンス変数というものがある。
まずサンプルコード。
class Parent @@var = 'class variable of Parent' @var = 'instance variable of Parent (so called class instance variable)' class << self def at_at_var @@var end def at_var @var end end def initialize @var = 'instance variable of parent' end def at_at_var @@var end def at_var @var end endインスタンス変数とは
あるインスタンスが保持する変数。そのインスタンスにおいて利用できる。
@{変数名}により指示される。たとえば、parentという「Parentクラスのインスタンス」は
@var(='instance variable')というインスタンス変数をもっている。
ruby
parent = Parent.new
parent.at_var # => "instance variable of parent"
同様に、Parentという「Classクラスのインスタンス」は
@var(='instance variable of Parent (so called class instance variable)')というインスタンス変数をもっている。
ruby
Parent.at_var # => "instance variable of Parent (so called class instance variable)"
後者のように「Classクラスのインスタンス」が持つインスタンス変数のことを「クラスインスタンス変数」と呼ぶことがある。
クラス変数とは
あるクラスが保持する変数。
@@{変数名}により指示される。当然ながらParentクラスは自身のクラス変数を利用できる。
ruby
Parent.at_at_var # => "class variable of Parent"
クラス変数はこれに加えて、以下の特徴をもつ。
1. Parentクラスのインスタンスから、Parentクラスのクラス変数にアクセスできる
parent.at_at_var # => "class variable of Parent"2. Parentクラスを継承したChildクラスから、継承元であるParentクラスのクラス変数にアクセスできる
class Child < Parent def initialize @var = 'instance variable of child' end end Child.at_at_var # => "class variable of Parent"3. (上記の合わせ技として)Parenetクラスを継承したChildクラスのインスタンスから、Childクラスの継承元であるParentのクラス変数にアクセスできる
child = Child.new child.at_at_var # => "class variable of Parent"おまけ
仕組みはこれだけだと思う。最後に念のため、上で述べたクラス変数の「色んなところからアクセスできる性質」は、クラスインスタンス変数には与えられていないことを確認する。
1. Parentクラスのインスタンスから、Parentクラスのクラスインスタンス変数にはアクセスできない
parent.at_var # => "instance variable of parent"@varはparentのインスタンス変数を指してしまっている。
2. Parentクラスを継承したChildクラスから、継承元であるParentクラスのクラスインスタンス変数にはアクセスできない
Child.at_var # => nil@varは「ChildというClassクラスのインスタンスが持つインスタンス変数」を指してしまっている。(これは宣言していないので
nilが返っている。)3. Parenetクラスを継承したChildクラスのインスタンスから、Childクラスの継承元であるParentのクラスインスタンス変数にはアクセスできない
child.at_var # => "instance variable of child"@varはchildのインスタンス変数を指してしまっている。
丁寧に言語化すると「ClassクラスのインスタンスであるHogeクラスのクラスインスタンス変数」とか、どうしても早口言葉っぽくなるな...。
以上です。
- 投稿日:2019-11-30T02:43:31+09:00
#Ruby の pry を vim で複数行入力/ファイル編集できる edit コマンドが便利すぎる件 ( how to input multiline on ruby pry )
- vimで複数行入力できる
- ~/.pryrc でエディタを設定すれば他のエディタも使えるはず
- 1回のセッション内だと、ファイル状態を覚えていてくれて、 edit コマンドで何回でも続きから編集・実行できる
- 今までの単一行で入力しづらすぎた苦労はなんだったのか、rubyファイルを作成してからincludeしようとしたり、エディタからコピペ実行したり、なんだかんだと
- 新しいバージョンでは複数行入力自体に対応していたかと思うけど、全く自由に入力できるこちらの方が数段良いね
- 全く知らなくてRuby人生の半分を損していた気がするのだが
gem install prypry[1] pry(main)> edit
【Rails】Docker+Rails環境でpryの
editコマンドが使えなかったので、使えるようにした - QiitaPry's edit command in semi-detail
Need easy way to paste multiline code · Issue #1524 · pry/pry
Original by Github issue