- 投稿日:2019-10-08T23:50:42+09:00
ローデータから、特定の列に絞ってまとめたデータセットを作る
データベースから抽出したデータではなく、そこからある列を軸にデータをサマリたものを分析のローデータとして使いたい場合、私はpivot_table機能を使ったうえで、csvに出力と再読み込みをしている。
データの例
下記のようなデータセットを想定する。
受注番号 | 商品番号 | 受注数 |
|:----------------:|------------------:|:------------------:|
| 1111 | A01 | 2 |
| 1111 | A02 | 3 |
| 1111 | A03 | 1 |
| 2222 | A01 | 1 |
| 2222 | A02 | 4 |上記のデータを、受注番号が1列目、商品番号を列名に持つテーブルに整形したい。
整形した後のテーブル
A01 A02 A03
1111 2 3 1
2222 1 4 0プログラミング
下記が筆者のプログラミング。改善点をぜひ指摘してください……。
qiita.rbimport pandas as pd from pandas import Series, DataFrame raw_data = pd.read_csv('url.csv') #ピボットテーブル形式でまとめる df = raw_data.pivot_table(values = ['受注数'], index = '受注番号', columns = '商品番号',aggfunc = 'sum') #NaNを0に置き換える df = df.fillna(0) #csvに出力 df.to_csv('url_2') #出力したcsvを読込 df2 = pd.DataFrame(pd.read_csv('url_2')) ##列名を整える(最初の列名は受注番号、それ以降はカテゴリ名が来るようにする) #カテゴリ名を取得 titles = list(df2.iloc[0,1:]) #最初の列名を”受注番号”にする titles.insert(0,'受注番号') #列名を変更 df2.columns = titles ##最初の2行を削除(不要なので) df2 = df2.drop(df2.index[[0,1]])pivot_tableを使ってcsvへ出力→再入力という手間をかけなくても、groupbyとかでスマートにできないか、と思うのだけれど、イマイチ妙案が浮かばない…。
- 投稿日:2019-10-08T23:23:04+09:00
競馬のレース結果をクローリング&スクレイピングしてみた
はじめに
先にまとめた「Pythonクローリング&スクレイピング[増補改訂版]―データ収集・解析のための実践開発ガイドー」加藤耕太・著 の第2章までの知識の実践として、Pythonを利用した競馬のレース結果のクローリング・スクレイピングを行う。なおコードに関しては同書P71のサンプルコードを大いに参考にしている。
今回クローリング・スクレイピングの対象とするのは競馬情報サイトnetkeibaの地方競馬カテゴリの上部からリンクされているここ数日の開催の結果表である(数日たったら消えるっぽい?コードを書いている途中で気づいた…)
環境についてはWindows10のAtomで書いたコードを、WSL上のUbuntu18.04からPython3.7.3を用いて実行している
やること
- 上の結果表(8回浦和1日目1R3歳三)から各行を取り出してCSV形式で保存する
実装した機能
- コマンドライン引数で入力したURLのWebページを取得(クローリング)
- 取得結果をパースして欲しい部分のみを切り出す(スクレイピング)
- スクレイピングしたデータをCSVに出力
実際のコードと実行結果
keiba_scraping.pyimport sys import requests import lxml.html import re import csv def main(argv): url = argv[1] #コマンドライン引数からURLを取得 html = fetch(url) #URLのWebページを取得 result = scrape(html) #取得したWebページから欲しい部分のみを切り出す save('result.csv',result) #切り出した結果をCSVに保存する def fetch(url :str): r = requests.get(url) #urlのWebページを保存する r.encoding = r.apparent_encoding #文字化けを防ぐためにencodingの値をappearent_encodingで判定した値に変更する return r.text #取得データを文字列で返す def scrape(html: str): html = lxml.html.fromstring(html) #fetch()での取得結果をパース result = [] #スクレイピング結果を格納 for h in html.cssselect('#race_main > div > table > tr'):#スクレイピング箇所をCSSセレクタで指定 column = ((",".join(h.text_content().split("\n"))).lstrip(",").rstrip(",")).split(",") #text_content()はcssselectでマッチした部分のテキストを改行文字で連結して返すので、 #splitを使って改行文字で分割して、その結果をカンマ区切りでjoinする。 #前と後ろに余計な空白とカンマが入っている(tdじゃなくてtrまでのセレクタをしていした分の空文字が入っちゃってる?ようわからん)ので、 #splitで空白を、lstrip,rstripでカンマを削除してさらにそれをカンマで区切ってリストにしている column.pop(4) if column[4] == "" else None #1行目以外、馬名と性齢の間に空文字が入っちゃってるので取り出す result.append(column) #リストに行のデータ(リストを追加) return result #結果を返す def save(file_path, result): with open(file_path, 'w', newline='') as f: #ファイルに書き込む writer = csv.writer(f) #ファイルオブジェクトを引数に指定する writer.writerow(result.pop(0)) #一行目のフィールド名を書き込む writer.writerows(result) #残りの行を書き込む if __name__ == '__main__': main(sys.argv)実行してCSVを表示すると…
$ python keiba_scraping.py 'https://nar.netkeiba.com/?pid=race&id=p201942100701' $ cat result.csv
念の為、Googleスプレッドシートでも確認
行・列ともに同じ内容が表示されています
同じページ構造の他のレースでも試してみると…
$ python keiba_scraping.py 'https://nar.netkeiba.com/?pid=race&id=c201930100812' $ cat result.csv
きちんとレース結果が取得されています
(1着馬を買うかどうか悩んでいるうちに、投票締め切られていたのが悔やまれる)苦労した点
tbody
スクレイピング部分をするためのCSSセレクタは、Chromeの検証ツールを使ってCopy→Copy selecterでお手軽にコピーしたのだが、ブラウザが実際のソースにはない
というタグを







- 投稿日:2019-10-08T23:06:48+09:00
Youtube Data APIを用いたバーチャルYoutuberのデータ収集
はじめに
この記事は、バーチャルYoutuberに関するデータ解析を行った以下の記事、
データで見るバーチャルYoutuber-”四天王”の過去と現在
において行った、Youtube Data APIを用いたデータ収集方法に関して解説するものです。
各バーチャルYoutuberが投稿したすべての動画タイトル、投稿日、再生回数、高/低評価数、コメント数、再生時間を収集対象としています。前準備-環境設定
本データ解析ではPythonを用いてYoutube Data APIを利用します。
また、一連の解析はすべてJupyter-notebook形式で筆者のGitHubリポジトリで公開しています。VtuberDataScraping - Youtube Data APIを用いたバーチャルYoutuberのデータ収集
PythonとJupyterのインストールは以下のサイトを参考にしてください。
また、必要となるパッケージと環境のバージョンは以下の通りです。
- Python >= 3.6.5
- numpy >= 1.14.5
- google-api-python-client >= 1.7.11
- tqdm >= 4.23.4
- ipywidgets >= 7.2.1
- widgetsnbextension >= 3.2.1
Jupyter上でtqdmを使うためには、コマンドプロンプト上で以下のように入力し、拡張機能を有効にしてください。
jupyter nbextension enable --py --sys-prefix widgetsnbextension前準備-API KEYの取得
Youtube Data APIのAPI_KEYは以下の方法で参考に取得してください。
Google APIキー/OAuth2.0-IDの取得方法
【動画まとめサイト】2019版 youtube API 詳しい簡単な取得方法【実践】 #拡散RTお願いしますAPI_KEYの取得にはGoogleアカウントの作成とGCP(Google Cloud Platform)のプロジェクト作成が必要になります。
GCPプロジェクトの作成方法は以下を参照してください。Google Cloud Platform(GCP)にプロジェクトを作成する
データ取得の流れ
本プログラムでは、以下の流れでYoutubeチャンネル内の全ての投稿動画のデータを取得します。
- YoutubeチャンネルIDから、チャンネル内の全ての動画を含むプレイリストのIDを取得(Channels: list)
- プレイリストIDから、動画タイトルと投稿時間、および動画IDを取得(PlaylistItems: list)
- 動画IDから、動画の再生回数及びその他の情報を取得(Videos: list)
YoutubeチャンネルIDは、チャンネルのURLから確認できます。
https://www.youtube.com/channel/[チャンネルID] ← これがIDプレイリストIDの取得
以下の関数を用います。
def YoutubeChannelDetails(id_, API_KEY): API_SERVICE_NAME = "youtube" API_VERSION = "v3" youtube = build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY) search_response = youtube.channels().list( part= 'snippet,contentDetails', id=id_, ).execute() return search_response['items'][0]引数のid_にはプレイリストIDを、API_KEYにはAPIキーを入力してください。
戻り値の例は以下のようになります。{'kind': 'youtube#channel', 'etag': '"..."', 'id': 'チャンネルID', 'snippet': {'title': 'チャンネルタイトル', 'description': 'チャンネル概要文', 'publishedAt': '2018-04-27T05:01:07.000Z', 'thumbnails': {...}, 'localized': {'title': 'チャンネルタイトル', 'description': 'チャンネル概要文'}, 'country': '国名'}, 'contentDetails': {'relatedPlaylists': {'uploads': 'プレイリストID', 'watchHistory': '...', 'watchLater': '...'}}}この中のプレイリストIDが、チャンネル内の全ての動画が含まれるプレイリストのIDとなります。
これを以下のように取得します。ChannelDetails = YoutubeChannelDetails(id_,API_KEY) uploads = ChannelDetails['contentDetails']['relatedPlaylists']['uploads']動画IDの取得
動画タイトル、投稿時間およびIDの取得は以下の関数で行います。
引数Id_にはプレイリストIDを入力します。def YoutubePlaylistContents(id_, API_KEY): responses = [] nextPageToken = 'start' counts = 0 while(nextPageToken is not None): API_SERVICE_NAME = "youtube" API_VERSION = "v3" youtube = build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY) if(nextPageToken == 'start'): search_response = youtube.playlistItems().list( part= 'snippet', playlistId=id_, maxResults = 50, ).execute() nextPageToken = search_response['nextPageToken'] else: search_response = youtube.playlistItems().list( part= 'snippet', playlistId=id_, maxResults = 50, pageToken = nextPageToken ).execute() try: nextPageToken = search_response['nextPageToken'] except: nextPageToken = None responses.extend(search_response['items']) counts += len(search_response['items']) print('load '+str(counts)+' videos...') return responsesAPIへのリクエストでは一度に50件までしか取得できないので少し工夫をしています。
結果として、以下のような動画情報を含むリストが得られます。
例として、バーチャルYoutuber「神楽すず」さんの最新動画の情報は以下のようになります。{'kind': 'youtube#playlistItem', 'etag': '"p4VTdlkQv3HQeTEaXgvLePAydmU/JmIHjWgl9faHA_LwBwfIkOOdRBQ"', 'id': 'VVVVWjVBbEMzclRsTS1yQTJjajVSUDZ3Lm9yQnp3eDdjRDhZ', 'snippet': {'publishedAt': '2019-10-06T12:39:50.000Z', 'channelId': 'UCUZ5AlC3rTlM-rA2cj5RP6w', 'title': '【雑談】サムネ作り忘れてました。', 'description': 'サムネ毎月変えるとか言ってたのに忘れてました。\n本日もお付き合いいただけると嬉しいです。よろしくお願いいたします。\n\n【チャンネル登録】\nhttp://www.youtube.com/channel/UCUZ5AlC3rTlM-rA2cj5RP6w?sub_confirmation=1\n\n【Twitter】\n神楽すず\u3000https://twitter.com/kagura_suzu\n.LIVE\u3000https://twitter.com/dotLIVEyoutuber\n\n【Twitter実況タグ】\n全体\u3000#アイドル部\n個人\u3000#神楽すず\n\n毎週(できる限り)水曜、金曜、日曜の夜と土曜の昼に配信しています。\n良かったらまた見に来てください。', 'thumbnails': { ... }, 'channelTitle': '神楽すず', 'playlistId': 'UUUZ5AlC3rTlM-rA2cj5RP6w', 'position': 0, 'resourceId': {'kind': 'youtube#video', 'videoId': 'orBzwx7cD8Y'}}}ここから、動画タイトル、投稿日時、動画IDを以下のように取得します。
投稿時間は、ここでstrからdatetime型に変換しておきます。dic_total = [] for t in total_contents: date_list = t['snippet']['publishedAt'].split('T') year, month, date = date_list[0].split('-') hour, minute, sec = date_list[1].split(':') sec = sec[:2] dic = {'title':t['snippet']['title'], 'date':datetime.datetime(int(year),int(month),int(date),int(hour),int(minute),int(sec)), 'Id':t['snippet']['resourceId']['videoId']} dic_total.append(dic)動画の詳細情報の取得
動画IDから、動画の詳細情報(再生数、評価数、コメント数、再生時間)を取得します。
引数id_には動画IDを与えます。def YoutubeVideoDetails(id_, API_KEY): API_SERVICE_NAME = "youtube" API_VERSION = "v3" youtube = build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY) search_response = youtube.videos().list( part= 'statistics,contentDetails', id=id_, ).execute() hoge = search_response['items'][0] details = {'viewCount':int(hoge['statistics']['viewCount']), 'likeCount':int(hoge['statistics']['likeCount']), 'dislikeCount':int(hoge['statistics']['dislikeCount']), 'commentCount':int(hoge['statistics']['commentCount']), 'duration':ConvertDuration(str(hoge['contentDetails']['duration']))} return details def ConvertDuration(string): string = string.replace('PT', '') strings = re.split('\D',string)[:-1] if(len(strings) == 3): delta = datetime.timedelta(hours=int(strings[0]), minutes=int(strings[1]), seconds=int(strings[2])) elif(len(strings) == 2): delta = datetime.timedelta(minutes=int(strings[0]), seconds=int(strings[1])) elif(len(strings) == 1): delta =datetime.timedelta(seconds=int(strings[0])) else: delta = datetime.timedelta(seconds=0) return delta.seconds二つ目のConvertDurationは、動画再生時間をdatetime.timedeltaで変換する関数です。
以下のように、すべての動画の情報をリストに辞書型で格納し、numpy形式に変換してから.npy形式で保存します。for n,d in enumerate(tqdm(np.array([i['Id'] for i in dic_total]))): details = YoutubeVideoDetails(d,API_KEY) dic_total[n].update(details) dic_total = np.array(dic_total) np.save('ChannelTitle-data.npy',dic_total) #.npy形式で保存最終的に、各動画のデータが以下のような形式で得られます。
サンプルは以下の通りになります(例. APE OUT やる 02 - 神楽すず){'title': 'APE OUT やる 02', 'date': datetime.datetime(2019, 3, 29, 12, 10, 6), 'Id': 'ijauZ-6ZdJ4', 'viewCount': 30327, 'likeCount': 2910, 'dislikeCount': 7, 'commentCount': 29, 'duration': 3550}繰り返しになりますが、ここまでのすべての内容は以下でJupyter-notebook形式で公開されています。
VtuberDataScraping - Youtube Data APIを用いたバーチャルYoutuberのデータ収集
取得したデータの解析例
まとめたデータからは以下のように各情報を取り出します。
dates = np.array([i['date'] for i in dic_total]) # 投稿日時 viewCount = np.array([i['viewCount'] for i in dic_total]) # 再生回数再生数推移
普通に再生数推移を表示するとめちゃくちゃになるので、移動平均も一緒にプロットすることをお勧めします。
下の図は、散布図が各動画の再生回数、実戦が7日単位での移動平均です。
コードは以下の通り。
fig = plt.figure(figsize=(7,4),dpi=200) # 散布図表示 plt.scatter(dates,viewCount,s=20,alpha=0.5) # 移動平均をプロット plt.plot(dates,np.convolve(viewCount,np.ones(7)/7.0,mode='same'),lw=2,c='b') # 日時ラベルを30度傾斜 labels = plt.gca().get_xticklabels() plt.setp(labels,rotation=30) plt.title('総再生数推移',fontsize=14) plt.show()再生数ランキング
ranking = dic_total[np.argsort(viewCount)[::-1]] print(ranking[:5]) # 上位5タイトルを表示結果は以下のようになります。
これは、Youtubeチャンネル上で動画を人気順に並べ替えた結果と同じになります。[{'title': '【2分半でわかる?】神楽すずです。よろしくお願いします【アイドル部】', 'date': datetime.datetime(2018, 12, 12, 12, 0, 6), 'Id': 'qRsB_miOR6I', 'viewCount': 92581, 'likeCount': 6263, 'dislikeCount': 18, 'commentCount': 659, 'duration': 141} {'title': '【ETS2】運転知識皆無トラック運転シミュ【アイドル部】', 'date': datetime.datetime(2018, 7, 1, 14, 40, 46), 'Id': 'tAW-mEj6OAs', 'viewCount': 90219, 'likeCount': 2072, 'dislikeCount': 37, 'commentCount': 68, 'duration': 116} {'title': '【ドリクラZERO】ギャンブルドリクラ #02', 'date': datetime.datetime(2019, 6, 29, 5, 37, 16), 'Id': 'g84VbU7Qduc', 'viewCount': 74223, 'likeCount': 3977, 'dislikeCount': 35, 'commentCount': 83, 'duration': 6515} {'title': '全滅させたけど本気で全員生存を目指す2周目Detroit #01', 'date': datetime.datetime(2019, 1, 26, 5, 51, 2), 'Id': 'ehQY_XTbfIk', 'viewCount': 71986, 'likeCount': 3577, 'dislikeCount': 33, 'commentCount': 43, 'duration': 7681} {'title': '【ETS2】無免許だけど令和までに無事故で荷物を届ける', 'date': datetime.datetime(2019, 4, 30, 16, 18, 15), 'Id': 'cazST-XDPrM', 'viewCount': 68862, 'likeCount': 4639, 'dislikeCount': 33, 'commentCount': 46, 'duration': 5925}]まとめ
以上、PythonでYoutube Data APIを用いてデータを収集する方法を紹介しました。
Youtube Data APIには1日のデータ要求数に限りがあります。これはGoogle Cloud Platform => IAMと管理 => 割り当てで確認ができます。
リクエストを投げた時にquotaExceededエラーが出た場合は、この割り当て上限に達してしまったことを意味します。
動画数の多いYoutuberの動画収集を行うとあっという間に1日の上限に達してしまうので、お気を付けください。最後となりますが、この手法で収集したデータを用いた簡単なデータ解析の結果を以下の記事で公開していますので、よろしければどうぞ。
データで見るバーチャルYoutuber-”四天王”の過去と現在
それでは!


- 投稿日:2019-10-08T22:19:37+09:00
Jinja2 で dict の要素にアクセスしやすくなるカスタムフィルタ
Jinja2 のテンプレートを書く際に、CoffeeScript の存在演算子のようなものが欲しくなったのでそれっぽいカスタムフィルタを実装してみたと言う小ネタ。
問題点
例えば「新規作成」「編集」ページで同じテンプレートを使いまわしたい場合に、「新規作成」のページではフォームの中身は空でいい (もしくはデフォルト値を入力する) が、「編集」ページでは既存データをフォームに入力した状態で表示したい。
data = { 'foo': { 'bar': 123 } }ただしこのとき、既存データは
dataという変数に複雑な構造で格納されており、その存在確認をした上でフォームの入力値を出し分けようとすると以下のような条件式を書かなければならない。{% if 'foo' in data and 'bar' in data['foo'] %} <input type="text" name="foo.bar" value="{{ data['foo']['bar'] }}" /> {% else %} <input type="text" name="foo.bar" value="0" /> {% endif %}これはとても手間がかかるし、可読性が低いし、記述が重複しているし、コードの行数もかなり長くなってしまう。良いことがない。
これをもう少し綺麗にまとめることができないかと考えた。
CoffeeScript の存在演算子
CoffeeScript には存在演算子 (Existential Operator) と言う演算子があり、識別子に対して
?を末尾につけるとundefinedかどうかをチェックしてくれて、さらにその後でプロパティアクセスされていてもすべてundefinedを返してくれる。CoffeeScriptobj = foo: bar: 123 # { foo: { bar: 123 } } obj.foo.bar # 123 obj.foo.foo # undefined obj.foo.foo.foo # TypeError: Cannot read property 'foo' of undefined obj.foo.bar? # true obj.foo.foo? # false obj.foo.foo?.foo # undefined obj.foo.foo?.foo.foo # undefinedこれは「データがない場合はとにかく
undefinedが欲しい」と言う場合にとても便利で、特にアプリケーションのビューを実装する場合にこのような機能が欲しくなる。このような機能を Jinja2 でも実装できたら上述の問題点を解決できそうな気がする。
実装
Jinja2 で
?のような演算子を実装するわけにはいかないので、今回はカスタムフィルタとして実装する。from jinja2.runtime import Undefined def dig_nested_dict(d: dict, key: str): """ ネストされた dict オブジェクトから指定されたキーに対応する要素を返す 例: key = 'foo.bar' を指定したとき、d['foo']['bar'] が存在すればその値を返す 存在しなければ jinja2.runtime.Undefined オブジェクトを返す """ if type(d) == Undefined: return Undefined() v = d for k in key.split('.'): if k in v: v = v[k] else: return Undefined() return v値が存在しないときに
Noneや''ではなくjinja2.runtime.Undefinedオブジェクトを返すのは重要で、こうすることで Jinja2 の組み込みフィルタ default と組み合わせて使うことができるようになる。(使用例は後述)次に、この関数を Jinja2 のカスタムフィルターとして登録する。
例えば aiohttp と組み合わせる場合は aiohttp_jinja2 を使って以下のように書ける。aiohttp_jinja2.setup(app, filters={'dig': dig_nested_dict})ここではテンプレート内で
digと言う名前のフィルターが使えるように登録した。使用例
登録した
digと Jinja2 組み込みのdefaultフィルタを組み合わせると、冒頭のテンプレートは以下のように書き直せる。<input type="text" name="foo.bar" value="{{ data | dig('foo.bar') | default('0') }}" />5行だったコードが1行になったし、可読性も高くなったと思う。
- 投稿日:2019-10-08T21:28:49+09:00
i-RevNet/i-ResNetからはじめるFlow-basedモデル
Flow-basedモデルの仲間であるi-RevNet/i-ResNetで遊んでみました。深層生成モデルのFlowが何をやっているのか、大きな特徴である「可逆性」について、イメージを掴むことを目標とします。
Flow-basedモデルとは
生成モデルの一つ。生成モデルにはおもに3種類あります。
GAN(Generative adversarial networks)
DとGの2つのネットワークが敵対的に学習し、ナッシュ均衡に収束するように訓練
- 長所:画像ではとにかく高画質な生成ができる。研究も多い。Dの本物/偽物で損失を定義するので、ダイナミックな損失関数が可能(教師あり学習のような損失関数芸に陥りにくい)。
- 短所:訓練が成功する保証がない。しかし、最近の研究ではかなり安定してきた。
VAE(Variational Auto Encoder)
Evidence lower bound (ELBO) の最大化。Auto EncoderにReparameterization Trickを加えたもの。潜在空間を正規分布で仮定することがほとんど。
- 長所:ニューラルネットワークが1個なので訓練が(ほぼ)必ず成功する。モード崩壊を気にする必要がない
- 短所:GANのような潜在空間滑らかさと画質の両立が困難。画質面で明らかに劣ることが多い。しかし、潜在空間の滑らかさを捨てれば、最先端のGANを凌駕する画質は出せるとの研究もある(VQ-VAE2など)。
VAEだけでなく、ニューラルネットワークが1個の場合は損失関数が静的で、タスクによっては(Image to imageなど)ハイパラ沼になることも多い。Flow-basedモデル(今回の内容)
正規分布のような簡単な分布を積み重ね、尤度最大化問題を解くことでデータの密度を推定するモデル。GANにもVAEにもない大きな特徴として、ネットワークを全体が可逆であるという制約がある。
- 長所: 可逆であること。画像→特徴量への変換だけでなく、特徴量→画像の変換も行える。そして、可逆の制約により、特徴量→画像の逆変換は、画像→特徴量の逆変換になることが保証される。
- 短所:ヤコビ行列の計算量が重い($O(D^3)$)。計算量を削るために特殊な制約をおいたり、アルゴリズムを工夫したりする必要があり、理論的に難しくなりがち。
理論的な内容は、こちらの記事やこちらのスライドに詳しく書かれているので、ぜひ参照してみてください。
画像はi-ResNetの論文より
もっと簡単に言うと
ニューラルネットワーク全体を1つの関数と考えると、
$$z=\cal{F}(x) = f_n(f_{n-1}(\cdots(f_1(x)))) $$
と書くことができます。ここで、$f_i$はニューラルネットワークの$i$番目の層、$n$は層の数に対応し、$x$は入力画像を表します。ここで行っているのは、「画像→特徴量」への変換です(特徴量とは、どのクラスに属するかの確率の推定値など)。この逆変換を考えましょう。
$$\cal{F}^{-1}(z) = f_1^{-1}(f_2^{-1}(\cdots(f_n^{-1}(z))))$$
ニューラルネットワークが可逆であるFlow-basedモデルでは、
$$x={\cal F}^{-1}(z)={\cal F^{-1}}({\cal F}(x)) $$
が成り立ちます。簡単に言うと、ニューラルネットワークを行って戻ってきたら元の画像に戻ってきているということです。逆変換や逆関数が計算できるニューラルネットワークと考えておくといいでしょう。
「あれ、これAuto Encoderと同じじゃない?」と思うかもしれません。Flow-basedモデルでは、Auto EncoderのようなL2ロスのような損失関数を必要としません。
また、Auto Encoderでは入力画像と復元画像は損失関数により限りなく近づきますが、各層に関しては可逆の保証はありません。Flow-basedモデルでは、
$$x = f_i^{-1}(f_i(x)) \qquad (i=1,2,\cdots,n)$$
のように各層の可逆性も保証されます。訓練済みモデルを分析したり、その逆変換や逆元を求めたい場合に便利ではないでしょうか。
i-RevNet / i-ResNet
ネットワーク構造を可逆にした畳み込みニューラルネットワーク。Flow-basedモデルと関係性が深く、仲間として扱われることが多いです。
「i-ResNetは可逆なResNet」ということで着想がわかりやすく(i-ResNetはi-RevNetの改良)、PyTorchのコードが公開されているので、Flow-basedモデルの中ではとっつきやすい方ではないでしょうか。今回は公開されているコードで遊んでみます。なぜ可逆になるかは今回は省略します。
i-RevNet : https://github.com/jhjacobsen/pytorch-i-revnet
i-ResNet : https://github.com/jhjacobsen/invertible-resnet今回はi-RevNetの例で解説します。
CIFAR-10を訓練
公開されているコードをcloneしてCIFAR-10を訓練してみます。
git clone https://github.com/jhjacobsen/pytorch-i-revnet .cloneが終わったら訓練します。
python CIFAR_main.py --nBlocks 18 18 18 --nStrides 1 2 2 --nChannels 16 64 256デフォルトがバッチサイズ128、学習率0.1で、Validation accuracyが94.5%出るそうです。自分は高速化のためにバッチサイズ512、学習率0.4で訓練しました。それでも93%以上出ているのでだいたいあっているでしょう。
2080Tiが2枚で3時間弱ぐらいだったので、CIFAR-10ならColabでも十分訓練できると思います。訓練済みモデルは「checkpoint/cifar10」以下に保存されています。
復元画像を見る
画像→特徴量→画像という逆変換を行った復元(reconstruction)画像を見てみましょう。コードは末尾を参照してください。main関数の中にあります。
各画像の左が本物、右が復元画像です。ぱっと見違いがわからないですね。
クラス間の補間
Flowらしいことをやってみましょう。i-RevNetでは$z\to x$の逆変換ができるので、2つの画像のEmbeddingを取り、線形補間した特徴量を作り逆変換することで、潜在空間上の画像補間を行うことができます。
イメージ的にはGANの潜在空間の補間とほぼ一緒です。まずはクラス間(異なるクラス間)の補間を行ってみます。異なる10個のクラスから画像を1枚ずつ抽出し、その中から2枚のペアを作って補間しています。どんな画像が出てくるでしょうか?
(拡大してみてください)。[1~10のクラスの画像]+[1~10のクラスの画像]で潜在空間上で補間したものです。
なんかこんな画像見たことありますよね。Data AugmentationのMixupとほぼ同じような結果が出てくるのです。
クラス内の補間
同様にクラス内で補間をしてみます。
やっぱりMixupっぽい
Mixupの場合
ではMixupの場合はどうでしょうか?Mixupの場合はただ2枚の画像を線形補間すればいいだけで、
$$x' = kx_1 + (1-k)x_2 \qquad (0\leq k\leq 1)$$
クラス内のMixupは次のようになります。
Mixupとの比較
200%拡大してみました。正直Mixupとの違いがわからない……。
逆に見れば、このi-RevNetでの実験を通じてMixupの正当性が確かめられたということが言えます。つまり、入力画像を線形補間して足すと、潜在空間の値も補間されるため、クラス間の境界の値も訓練されるようになる、したがって汎化性能が上がる、ということでしょうか。
その他挫折した内容
i-RevNetを使えば、潜在空間をプロット→次元削減し、分類ミスが多いところをサンプリングし、削減した次元を戻し(PCAのようなinverse_transformができる次元削減が必要)、ニューラルネットワークの逆変換を行えば、分類ミスしやすいハードサンプルを生成することができます。
しかし、次元削減をした際の説明分散が低すぎるという問題に直面してしまいました(潜在特徴量が高次元すぎて、容易にプロット可能な2次元程度では到底説明できない)。次元を復元したときに特徴量がスカスカのエリアに飛ばされてしまい、意味のない画像が生成されてしまいます。
次元削減を工夫するのがポイントかと思いますが、うまい解決方法あったら教えて下さい。
まとめ
i-RevNetで遊んでみることで、Flow-basedモデルが何やっているかイメージを掴むことができました。モデルの定性評価や可視化など、分析向きの手法ではないかなと思います。可逆性の具体的な活用方法がいまいち思い浮かばないので、もしいいアイディアあったらお待ちしております。
コード
import torch from torchvision import transforms import torchvision from models.utils_cifar import std, mean def dataloader(): transform_test = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean["cifar10"], std["cifar10"]), ]) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform_test) testloader = torch.utils.data.DataLoader(testset, batch_size=200, shuffle=False, num_workers=2) return testloader def main(): model = torch.load("checkpoint/cifar10/i-revnet-55.t7")["model"] mean_v, std_v = torch.tensor(mean["cifar10"]).view(1, 3, 1, 1), torch.tensor(std["cifar10"]).view(1, 3, 1, 1) model.eval() loader = dataloader() X, y = next(iter(loader)) with torch.no_grad(): ## 入力画像をinverseする(reconstruction) _, embedding = model(X[:100].cuda()) invert = model.module.inverse(embedding).cpu() # 本物と結合して表示 join = torch.stack([X[:100], invert], dim=1).view(-1, 3, 32, 32) join = join * std_v + mean_v torchvision.utils.save_image(join, "reconstruction.png", nrow=10) ## 潜在空間でクラス間の補間をする for i in range(10): result = [] for j in range(10): X1 = X[y == i][i:(i+1)] X2 = X[y == j][i:(i+1)] _, z1 = model(X1.cuda()) _, z2 = model(X2.cuda()) k = torch.arange(11, dtype=torch.float32) / 10.0 k = k.view(-1, 1, 1, 1).cuda() interpolate = z1 * k + z2 * (1 - k) invert = model.module.inverse(interpolate) result.append(invert) out = torch.cat(result, dim=0).cpu() * std_v + mean_v torchvision.utils.save_image(out, "interclass_" + str(i) + ".png", nrow=11) ## 潜在空間でクラス内の補間をする for i in range(10): X_slice = X[y == i][:12] _, z_slice = model(X_slice.cuda()) # 潜在空間の補間 z1 = z_slice[:6].view(6, 1, 512, 8, 8) z2 = z_slice[6:].view(6, 1, 512, 8, 8) k = torch.arange(11, dtype=torch.float32) / 10.0 k = k.view(1, -1, 1, 1, 1).cuda() interpolate = z1 * k + z2 * (1 - k) interpolate = interpolate.view(-1, 512, 8, 8) out = model.module.inverse(interpolate).cpu() out = out * std_v + mean_v torchvision.utils.save_image(out, "innerclass_"+str(i)+".png", nrow=11) # mixupの場合 def mixup(): mean_v, std_v = torch.tensor(mean["cifar10"]).view(1, 3, 1, 1), torch.tensor(std["cifar10"]).view(1, 3, 1, 1) loader = dataloader() X, y = next(iter(loader)) ## クラス間のmixup for i in range(10): result = [] for j in range(10): X1 = X[y == i][i:(i+1)] X2 = X[y == j][i:(i+1)] k = torch.arange(11, dtype=torch.float32) / 10.0 k = k.view(-1, 1, 1, 1) interpolate = X1 * k + X2 * (1 - k) result.append(interpolate) out = torch.cat(result, dim=0).cpu() * std_v + mean_v torchvision.utils.save_image(out, "interclass_mixup_" + str(i) + ".png", nrow=11) ## クラス内のmixup for i in range(10): X1 = X[y == i][:6].view(6, 1, 3, 32, 32) X2 = X[y == i][6:12].view(6, 1, 3, 32, 32) interpolate = X1 * k + X2 * (1 - k) interpolate = interpolate.view(-1, 3, 32, 32) interpolate = interpolate * std_v + mean_v torchvision.utils.save_image(interpolate, "innerclass_mixup_"+str(i)+".png", nrow=11)参考資料
深層生成モデルを巡る旅(1): Flowベース生成モデル
A First Step to Flow-Based Generative Models(日本語スライド)







- 投稿日:2019-10-08T20:48:53+09:00
Joy-ConにPythonからBluetooth接続をして6軸センサーと入力情報を取得する
はじめに
ィヤッフゥウ〜〜〜↑↑↑!こんにちは、配管工始めました。トコロテンです。
この記事では、Nintendo SwitchのJoy-Con (L)/(R)をPython3から接続して6軸センサーを含む各種入力を取得する方法を紹介します。以下のリポジトリにてJoy-Conのプチドライバ(?)の実装を公開しています。まだ開発を始めたばかりですがよければ開発に協力していただけると嬉しいです。ドキュメントを近いうちに整備して機能も増やしていく予定です。
https://github.com/tokoroten-lab/joycon-python動作環境
以下の環境で動作を確認しました。
- macOS Mojave (10.14.6)
- Python (3.7.4)
- hidapi (0.7.99.post21)
Joy-Conの仕様
Joy-Conの主な仕様や各種名称は任天堂の以下の公式サイトで確認することができます。
https://www.nintendo.co.jp/hardware/switch/feature/index.html#3
また、以下のリポジトリでJoy-Conの仕様をリバースエンジニアリングを用いて解析した情報が公開されています。かなり詳しい仕様が載っているため、1度目を通しておくことをおすすめします。この記事を書くにあたって大変お世話になりました。ありがとうございます。
https://github.com/dekuNukem/Nintendo_Switch_Reverse_EngineeringJoy-Conとの通信
Bluetooth/HIDで接続する
仕様確認
Joy-Conとの通信にはBluetooth/HIDを用いて接続することが可能です。
HIDのInput, Output, Featureレポートのフォーマットは以下のページにて確認できます。
https://github.com/dekuNukem/Nintendo_Switch_Reverse_Engineering/blob/master/bluetooth_hid_notes.mdサンプルプログラム
準備
PythonでBluetooth/HIDを用いた接続を利用するためにはcython-hidapiを利用しました。以下のようにして
pipでインストールが可能です。sudo pip install hidapi注意点
@shksさんのpython モジュールhidapiとhidに注意。という記事にあるように、
hidapiに似たライブラリでhidといったものがあります。間違えないように気をつけましょう。プログラム内でimportする際にはどちらもimport hidとなります。ペアリング確認用プログラム
以下のプログラムを実行することで認識しているHIDデバイス一覧を取得できます。
この中にJoy-Conの情報があるか確認してみましょう。無い場合はJoy-Conと端末がペアリングされていないため、ペアリングしてからもう一度実行してみてください。devices_list.pyimport hid for device in hid.enumerate(0, 0): for k, v in device.items(): print ('{} : {}'.format(k, v)) print ('')私の環境では以下のようなセクションが表示されました。
product_string : Joy-Con (L)といった表記からこれがJoy-Conのデバイス情報であることがわかります。また、vendor_idとproduct_idがUSB ID Databaseにて調べた情報と一致していることからもわかります。path : b'IOService:/IOResources/IOBluetoothHCIController/AppleBroadcomBluetoothHostController/IOBluetoothDevice/IO BluetoothL2CAPChannel/IOBluetoothHIDDriver' vendor_id : 1406 product_id : 8198 serial_number : b8-78-26-46-9b-84 release_number : 1 manufacturer_string : Unknown product_string : Joy-Con (L) usage_page : 1 usage : 5 interface_number : -1ボタンデータ取得用プログラム
Joy-ConのVendor IDとProduct IDは以下の通りです。この情報を利用して接続をします。
Joy-Con (L)
- Vendor ID : 0x057E(1406)
- Product ID: 0x2006(8198)
Joy-Con (R)
- Vendor ID : 0x057E(1406)
- Product ID: 0x2007(8199)
また、Joy-ConのHIDのInputレポートのフォーマットは以下のページの通りです。
https://github.com/dekuNukem/Nintendo_Switch_Reverse_Engineering/blob/master/bluetooth_hid_notes.md#input-reports
試しにJoy-Conのボタンやスティックの入力情報を取得してみましょう。
これに対応するInputレポートはINPUT 0x3Fです。
このInputレポートを受け取るためには、まずOUTPUT 0x01のフォーマットに従ってSubcommand 0x03のサブコマンドを送信します。このサブコマンドには引数が存在し、0x3Fを指定することでJoy-Conのボタンの入力状態の変化があったときのみINPUT 0x3FのInputレポートを発行するようになります。レポートのサイズは12バイトです。
実はJoy-Conは初期状態でInputレポートINPUT 0x3Fを送信するようになっていますが、ここではあえて設定します。なぜなら、Joy-ConのInputレポートの前回の設定が引き継がれている可能性があるためです。joycon_read_test.pyimport hid import time VENDOR_ID = 0x057E L_PRODUCT_ID = 0x2006 R_PRODUCT_ID = 0x2007 def write_output_report(joycon_device, packet_number, command, subcommand, argument): joycon_device.write(command + packet_number.to_bytes(1, byteorder='big') + b'\x00\x01\x40\x40\x00\x01\x40\x40' + subcommand + argument) if __name__ == '__main__': joycon_device = hid.device() joycon_device.open(VENDOR_ID, L_PRODUCT_ID) write_output_report(joycon_device, 0, b'\x01', b'\x03', b'\x3f') while True: print(joycon_device.read(12))Joy-Conと端末をペアリングした状態で上のプログラムを実行してJoy-Conで何か操作をするとInputレポートの情報が標準出力に出力されます。
write_output_report(...)メソッドにてOutputレポートを構築して送信します。
引数のpacket_numberはレポートを送るごとに0x0-0xFの範囲でインクリメントする必要があります。プレイヤーランプ操作用プログラム
ここではJoy-Conのプレイヤーランプを用いて簡単な2進4ビットカウンタを動作させる方法を紹介します。先ほどと同じ要領で
OUTPUT 0x01レポートを送信します。サブコマンドはSubcommand 0x30を用います。また、ランプの点灯・点滅パターンを1Byteで引数として設定します。ビット解釈
ランプの点灯・点滅パターンは各4bitずつ合わせて1Byteで表現します。
上位4bitが点滅パターンで下位4bitが点灯パターンです。
ビットが0であるとき消灯を意味し、1である場合には点灯・点滅を意味します。従って、全点灯や全点滅に対応したビット列は以下のようになります。
- 全点灯: 0b00001111
- 全点滅: 0b11110000
では、以下のようなビット列はどのような結果を得られるでしょうか。
- 0b00010001
点灯・点滅で同じ位置に対応するビットが1になっています。このような場合には、点灯が優先されます。したがって、あるランプが点滅する条件は、対応する点滅用のビットが1であり点灯用のビットが0であることが条件です。
以上を踏まえて4bit(Joy-Conのプレイヤーランプは4個)のアップカウンタを実装してみます。
点灯バージョン
joycon_player_lamp.pyimport hid import time VENDOR_ID = 0x057E L_PRODUCT_ID = 0x2006 R_PRODUCT_ID = 0x2007 def write_output_report(joycon_device, packet_number, command, subcommand, argument): joycon_device.write(command + packet_number.to_bytes(1, byteorder='big') + b'\x00\x01\x40\x40\x00\x01\x40\x40' + subcommand + argument) if __name__ == '__main__': joycon_device = hid.device() joycon_device.open(VENDOR_ID, L_PRODUCT_ID) count = 0 while True: time.sleep(1) write_output_report(joycon_device, count, b'\x01', b'\x30', count.to_bytes(1, byteorder='big')) count = (count + 1) & 0xf点滅バージョン
joycon_player_lamp.pyimport hid import time VENDOR_ID = 0x057E L_PRODUCT_ID = 0x2006 R_PRODUCT_ID = 0x2007 def write_output_report(joycon_device, packet_number, command, subcommand, argument): joycon_device.write(command + packet_number.to_bytes(1, byteorder='big') + b'\x00\x01\x40\x40\x00\x01\x40\x40' + subcommand + argument) if __name__ == '__main__': joycon_device = hid.device() joycon_device.open(VENDOR_ID, L_PRODUCT_ID) count = 0 while True: time.sleep(1) write_output_report(joycon_device, count, b'\x01', b'\x30', (count << 4).to_bytes(1, byteorder='big')) count = (count + 1) & 0xfプレイヤーランプを点灯・点滅させることができました。Subcommand 0x38を利用することでHOMEボタンを光らせることもできるようです。興味のある方はぜひやってみてください。
ボタン&スティック&6軸センサーデータ取得用プログラム
Joy-ConにはボタンやXYZ軸の加速度センサーとジャイロセンサーが搭載されています。
これらのデータを取得するためには、まずセンサーを有効化した後にInputレポートの形式を変える必要があります。
まず、OUTPUT 0x01でSubcommand 0x40に引数として1を与えると各センサーが有効化されます。次に、OUTPUT 0x01でSubcommand 0x03に引数として0x30を与えると60Hzでボタン、スティック、6軸センサーの全てのデータを定期的に送信するようになります。データ取得のみ
joycon_sensors.pyimport hid import time VENDOR_ID = 0x057E L_PRODUCT_ID = 0x2006 R_PRODUCT_ID = 0x2007 def write_output_report(joycon_device, packet_number, command, subcommand, argument): joycon_device.write(command + packet_number.to_bytes(1, byteorder='big') + b'\x00\x01\x40\x40\x00\x01\x40\x40' + subcommand + argument) if __name__ == '__main__': joycon_device = hid.device() joycon_device.open(VENDOR_ID, L_PRODUCT_ID) # 6軸センサーを有効化 write_output_report(joycon_device, 0, b'\x01', b'\x40', b'\x01') # 設定を反映するためには時間間隔が必要 time.sleep(0.02) # 60HzでJoy-Conの各データを取得するための設定 write_output_report(joycon_device, 1, b'\x01', b'\x03', b'\x30') while True: print(joycon_device.read(49))各データをバイト列として取得しただけではどうしようもないので実際に扱えるデータにデコードしてみましょう。
データ取得&デコード
全体のデータフォーマットはStandard input report formatにて確認できます。6軸センサーのデータフォーマットは6-Axis sensor informationにて確認できます。ドキュメント中にある
Int16LEといった表記は符号付き16ビット整数でバイトオーダーがリトルエンディアン(一般的なバイトの並び方と逆)であることを意味しています。
また、加速度センサーから取得したデータにはオフセットが加算されています。基準値を0にした方が扱いやすいため、このオフセット分を考慮してデコードを行う必要があります。
これらのことを考慮してデータの一部をデコードするプログラムの実装例を以下に示します。aimport hid import time VENDOR_ID = 0x057E L_PRODUCT_ID = 0x2006 R_PRODUCT_ID = 0x2007 L_ACCEL_OFFSET_X = 350 L_ACCEL_OFFSET_Y = 0 L_ACCEL_OFFSET_Z = 4081 R_ACCEL_OFFSET_X = 350 R_ACCEL_OFFSET_Y = 0 R_ACCEL_OFFSET_Z = -4081 MY_PRODUCT_ID = L_PRODUCT_ID def write_output_report(joycon_device, packet_number, command, subcommand, argument): joycon_device.write(command + packet_number.to_bytes(1, byteorder='big') + b'\x00\x01\x40\x40\x00\x01\x40\x40' + subcommand + argument) def is_left(): return MY_PRODUCT_ID == L_PRODUCT_ID def to_int16le_from_2bytes(hbytebe, lbytebe): uint16le = (lbytebe << 8) | hbytebe int16le = uint16le if uint16le < 32768 else uint16le - 65536 return int16le def get_nbit_from_input_report(input_report, offset_byte, offset_bit, nbit): return (input_report[offset_byte] >> offset_bit) & ((1 << nbit) - 1) def get_button_down(input_report): return get_nbit_from_input_report(input_report, 5, 0, 1) def get_button_up(input_report): return get_nbit_from_input_report(input_report, 5, 1, 1) def get_button_right(input_report): return get_nbit_from_input_report(input_report, 5, 2, 1) def get_button_left(input_report): return get_nbit_from_input_report(input_report, 5, 3, 1) def get_stick_left_horizontal(input_report): return get_nbit_from_input_report(input_report, 6, 0, 8) | (get_nbit_from_input_report(input_report, 7, 0, 4) << 8) def get_stick_left_vertical(input_report): return get_nbit_from_input_report(input_report, 7, 4, 4) | (get_nbit_from_input_report(input_report, 8, 0, 8) << 4) def get_stick_right_horizontal(input_report): return get_nbit_from_input_report(input_report, 9, 0, 8) | (get_nbit_from_input_report(input_report, 10, 0, 4) << 8) def get_stick_right_vertical(input_report): return get_nbit_from_input_report(input_report, 10, 4, 4) | (get_nbit_from_input_report(input_report, 11, 0, 8) << 4) def get_accel_x(input_report, sample_idx=0): if sample_idx not in [0, 1, 2]: raise IndexError('sample_idx should be between 0 and 2') return (to_int16le_from_2bytes(get_nbit_from_input_report(input_report, 13 + sample_idx * 12, 0, 8), get_nbit_from_input_report(input_report, 14 + sample_idx * 12, 0, 8)) - (L_ACCEL_OFFSET_X if is_left() else R_ACCEL_OFFSET_X)) def get_accel_y(input_report, sample_idx=0): if sample_idx not in [0, 1, 2]: raise IndexError('sample_idx should be between 0 and 2') return (to_int16le_from_2bytes(get_nbit_from_input_report(input_report, 15 + sample_idx * 12, 0, 8), get_nbit_from_input_report(input_report, 16 + sample_idx * 12, 0, 8)) - (L_ACCEL_OFFSET_Y if is_left() else R_ACCEL_OFFSET_Y)) def get_accel_z(input_report, sample_idx=0): if sample_idx not in [0, 1, 2]: raise IndexError('sample_idx should be between 0 and 2') return (to_int16le_from_2bytes(get_nbit_from_input_report(input_report, 17 + sample_idx * 12, 0, 8), get_nbit_from_input_report(input_report, 18 + sample_idx * 12, 0, 8)) - (L_ACCEL_OFFSET_Z if is_left() else R_ACCEL_OFFSET_Z)) def get_gyro_x(input_report, sample_idx=0): if sample_idx not in [0, 1, 2]: raise IndexError('sample_idx should be between 0 and 2') return to_int16le_from_2bytes(get_nbit_from_input_report(input_report, 19 + sample_idx * 12, 0, 8), get_nbit_from_input_report(input_report, 20 + sample_idx * 12, 0, 8)) def get_gyro_y(input_report, sample_idx=0): if sample_idx not in [0, 1, 2]: raise IndexError('sample_idx should be between 0 and 2') return to_int16le_from_2bytes(get_nbit_from_input_report(input_report, 21 + sample_idx * 12, 0, 8), get_nbit_from_input_report(input_report, 22 + sample_idx * 12, 0, 8)) def get_gyro_z(input_report, sample_idx=0): if sample_idx not in [0, 1, 2]: raise IndexError('sample_idx should be between 0 and 2') return to_int16le_from_2bytes(get_nbit_from_input_report(input_report, 23 + sample_idx * 12, 0, 8), get_nbit_from_input_report(input_report, 24 + sample_idx * 12, 0, 8)) if __name__ == '__main__': joycon_device = hid.device() joycon_device.open(VENDOR_ID, MY_PRODUCT_ID) # 6軸センサーを有効化 write_output_report(joycon_device, 0, b'\x01', b'\x40', b'\x01') # 設定を反映するためには時間間隔が必要 time.sleep(0.02) # 60HzでJoy-Conの各データを取得するための設定 write_output_report(joycon_device, 1, b'\x01', b'\x03', b'\x30') while True: input_report = joycon_device.read(49) # ボタン print("Button: {} {} {} {}".format("DOWN " if get_button_down(input_report) else "", "UP " if get_button_up(input_report) else "", "RIGHT " if get_button_right(input_report) else "", "LEFT " if get_button_left(input_report) else "")) # アナログスティック print("Stick : {:8d} {:8d}".format(get_stick_left_horizontal(input_report), get_stick_left_vertical(input_report))) # 加速度センサー print("Accel : {:8d} {:8d} {:8d}".format(get_accel_x(input_report), get_accel_y(input_report), get_accel_z(input_report))) # ジャイロセンサー print("Gyro : {:8d} {:8d} {:8d}".format(get_gyro_x(input_report), get_gyro_y(input_report), get_gyro_z(input_report))) print()まとめ
dekuNukemさんのリポジトリを見れば今回紹介したことよりも多くのことができるようになります。しかし、まだ解析されていない部分(特にバイブレーション周り)もいくつかあります。有識者の方がいたら教えていただけると嬉しいです。
- 投稿日:2019-10-08T20:46:11+09:00
PyInstallerとSleniumのfind_element_by_css_selector超便利
こんばんは、@0yanです。
課メンバーに業務自動化要望をヒアリングしたら、「Webアプリの手作業を自動化して欲しい」という要望があった為、Seleniumで自動化ツールを作成、PyInstallerで実行ファイルにして配布しました。
その際、学びがあったのでこちらで紹介したいと思います。想定している読者
- Python+Seleniumで業務自動化しているノンプログラマーや初心者の方
- コード読めない方から「Webアプリの自動化ツールを作って欲しい」と要望受けている方
コンテンツ
- PyInstaller超便利
- Seleniumのfind_element_by_css_selector超便利
- おまけ:Seleniumで躓きがちなこと
環境
- Windows10
- Python 3.7.3(Anaconda3)
PyInstaller超便利
自動化ツール依頼元のメンバーがプログラミング未経験者のため、「環境構築だけで一苦労だろうな・・・どうにか良い方法ないだろうか」と探しておりました。
ありました。
実行ファイル形式で配布するという方法が。使い方の前に注意事項
普段、Seleniumを使った自動化をする際は、chromedriver-binaryを使った方がラクなので、そうしている方が多いと思います。
が!Seleniumを使ったコードを実行ファイル形式にして配布しても、Chrome Driverが無ければ動きません。
- Chrome Driverは実行ファイル形式を使うこと前提でコーディングする
- 実行ファイルとセットでChrome DriverのダウンロードURLも共有、適切なドライバーをダウンロードするよう伝える
- Chrome Driverの実行ファイルは指定のパスに格納することを伝達する
- 配布先のPCのデスクトップパス等は、
os.environ.get()を使って取得するようにする- ログインIDやパスワードの入力を求める際は、input関数を使って最初に求めるようにする
といった配慮が必要です。
PyInstallerの使い方
pip install pyinstallerコマンドでPyInstallerをインストールpyinstaller ファイル名.py --onefileコマンドを打ち、実行ファイルを作成- distディレクトリに実行ファイルができるので配布する
以上、3stepです。
めっちゃ簡単!Seleniumのfind_element_by_css_selector超便利
今まで、Seleniumで要素を探す際、
- find_element_by_id
- find_element_by_name
- find_element_by_class_name
- find_element_by_tag_name
- find_element_by_link_text
- find_element_by_partial_link_text
でダメだったら「詰んだ・・・最後の手段だ!」とfind_element_by_xpathメソッドを使っておりましたが、find_element_by_css_selectorメソッドを使えば解決できるということを知りました。
※ここから先、find_element_by_は~で省略させて頂きます。使い方①:クラス名の中に空白があっても大丈夫!
HTMLタグ内のクラス名が「class=test hogehoge」となっている場合、~class_nameメソッドでは対応できませんが、~css_selector(.test.hogehoge)とすることで要素取得できます。
使い方②:クラス名が重複してても大丈夫!
例えば、hogehogeというクラス名のHTMLタグが複数あった場合、find_elements_by_class_nameメソッドでそれらをすべて取得、for文で一つずつ目的の要素か否か調べることもできますが、~css_selectorメソッドの引数をタグ名.クラス名やタグ名#ID名.クラス名とすることでユニークになれば、for文まわさなくてもいけます。
【具体例:下記タグが同じページに存在する場合】 1) <select class=hogehoge> 2) <input class=hogehoge> 3) <input id=123 class=hogehoge> 4) <input class=hogehoge name=789> 【要素取得方法】 1) find_element_by_css_selector('select.hogehoge') 2) find_element_by_css_selector('input.hogehoge') 3) find_element_by_css_selector('input#123.hogehoge') 4) find_element_by_css_selector('input.hogehoge[name="789"])多分、普段CSSを触っている方からしたら「こんな簡単なことも知らんのかい!」と言われるような内容かもしれません。
が、私のようにノンプログラマーでCSSと縁がない人間でも便利に使えるのがPythonの良さだと思いますし、そういう方もいると思いますのでここで共有させて頂きました。おまけ:Seleniumで躓きがちなこと
ファイルアップロードとスクロールで躓きがちだと思います。
知っている方もいるかと思いますが、こちらで紹介させて頂きます。ファイルアップロード
Send_keysでできます。
スクロール
画面に表示されていない要素は取得できないため、スクロールしたいこともあると思います。
下記のとおり、ActionChainsクラスを使うことでスクロールできます。element = driver.find_element_by_id('hogehoge') action = ActionChains(driver) action.move_to_element(element) action.perform()さいごに
長文にも関わらず、ご覧頂き誠にありがとうございました!
もし、間違い等がございましたらご指摘頂けますと幸いです。
宜しくお願い致しますm(_ _)m参考サイト
PythonスクリプトをWindows環境で動くexeファイルにしよう!
コマンドプロンプト/Windowsの主要な環境変数一覧と意味
【初心者向け】CSSセレクタとは?セレクタの種類や指定方法を解説!(基礎編)
セレクタの種類
Python3 selenium ローカルファイル選択
- 投稿日:2019-10-08T20:14:55+09:00
CSS内のカラーコードHEX8桁をRGBAに変換
IEはさておき、Edgeまで透明度ありのHEX8桁使えないの!?
ChromeでWebアプリをゴリゴリ作り込んでいたら、IE、Edgeで透明色が表示されないことが判明。
HEX8桁のカラーコード(例 #3498dbdd)に対応していないらしいのですが、
今更、全てのCSS中を探して、逐一変換していくのはちょっと、、こんなお間抜けは筆者だけなのかもしれませんが、
Webサービス等でも一括変換はしてくれなかったので、Pythonでサクッと一括変換コードを書きました。
なんてことはない正規表現です。ファイル内の全てのHEX8桁 → rgba()
int(文字列, 基数)で、○進数表記の文字列`を10進数の数値に変換できます。import re def hex2rgba(css): # 正規表現で8桁HEX部分を探索 pattern = r'#[a-fA-F0-9]{8}' m = re.findall(pattern, css) for ccode in m: r = int(ccode[1:3], 16) g = int(ccode[3:5], 16) b = int(ccode[5:7], 16) a = int(ccode[7:9], 16)/255 rgba = "rgba({}, {}, {}, {})".format(r, g, b, a) css = css.replace(ccode, rgba) return(css)お試し
hex2rgba("#3498dbdd") # 'rgba(52, 152, 219, 0.8666666666666667)'ついでにCSSファイル全部変換
あとはJupyterでも開いて、glob使ってサクッと全CSSファイルを一括変換
import codecs import glob from tqdm import tqdm fn_list = glob.glob('hogehoge/static/app/css/*.css') for fn in tqdm(fn_list): with codecs.open(fn, encoding='utf-8') as f: css = f.read() css_mod = hex2rgba(css) with codecs.open(fn, encoding='utf-8', mode='w') as f: f.write(css_mod)終盤で急にIE対応が必要になった際は、是非。
(そんな要件定義はイヤだ)環境
- Python 3.6.5
- Windows10
- Jupyter notebook
Ref.
- 投稿日:2019-10-08T20:14:55+09:00
CSS内のカラーコード8桁をRGBAに一括変換
IEはさておき、Edgeまで透明度ありのHEX8桁使えないの!?
ChromeでWebアプリをゴリゴリ作り込んでいたら、IE、Edgeで透明色が表示されないことが判明。
HEX8桁のカラーコード(例 #3498dbdd)に対応していないらしいのですが、
今更、全てのCSS中を探して、逐一変換していくのはちょっと、、こんなお間抜けは筆者だけなのかもしれませんが、
Webサービス等でも一括変換はしてくれなかったので、Pythonでサクッと一括変換コードを書きました。
なんてことはない正規表現です。ファイル内の全てのHEX8桁 → rgba()
int(文字列, 基数)で、○進数表記の文字列`を10進数の数値に変換できます。import re def hex2rgba(css): # 正規表現で8桁HEX部分を探索 pattern = r'#[a-fA-F0-9]{8}' m = re.findall(pattern, css) for ccode in m: r = int(ccode[1:3], 16) g = int(ccode[3:5], 16) b = int(ccode[5:7], 16) a = int(ccode[7:9], 16)/255 rgba = "rgba({}, {}, {}, {})".format(r, g, b, a) css = css.replace(ccode, rgba) return(css)お試し
hex2rgba("#3498dbdd") # 'rgba(52, 152, 219, 0.8666666666666667)'ついでにCSSファイル全部変換
あとはJupyterでも開いて、glob使ってサクッと全CSSファイルを一括変換
import codecs import glob from tqdm import tqdm fn_list = glob.glob('hogehoge/static/app/css/*.css') for fn in tqdm(fn_list): with codecs.open(fn, encoding='utf-8') as f: css = f.read() css_mod = hex2rgba(css) with codecs.open(fn, encoding='utf-8', mode='w') as f: f.write(css_mod)終盤で急にIE対応が必要になった際は、是非。
(そんな要件定義はイヤだ)環境
- Python 3.6.5
- Windows10
- Jupyter notebook
Ref.
- 投稿日:2019-10-08T19:44:24+09:00
【忘備録】win32comを使って、Outlookの添付ファイルを保存
win32comを使ったOutlookの添付ファイル保存
- Outlookのメールをpythonで指定のフォルダに保存
from win32com.client import Dispatch import datetime as date save_path = r'保存先フォルダパス' lag = 1 # 過去何日分のメールを検索対象とするか sub_ = '対象メールの件名' att_ = '*添付ファイル名' outlook = Dispatch("Outlook.Application").GetNamespace("MAPI") inbox = outlook.GetDefaultFolder("6") # サブフォルダも指定可 # inbox = inbox.Folders("sub-folder") all_inbox = inbox.Items val_date = (date.date.today() - date.timedelta(lag)).strftime("%d/%m/%y") for msg in all_inbox: print(msg) if sub_ in msg.Subject: for att in msg.Attachments: if att_ in att.FileName: att.SaveAsFile(save_path + "/" + att.FileName) elif msg.SentOn.strftime("%d/%m/%y") < val_date: break
- 投稿日:2019-10-08T19:13:38+09:00
Twitter民の発言をsentiment_jaを使って感情分析した話
会社で機械学習の勉強会をしていたときに感情分析の話が挙がったので、Twitterランドの住人の感情を分析しました。
お品書き
やったこと
- Twitterの発言を大量に感情分析し、Twitter民の普遍的な感情を調べた
- 手順
- 大量のツイートを取得
- 各ツイートの感情を分析し、最大スコアの感情のみ抽出
happy:スコア10、sad:スコア10、disgust:スコア9ならhappyとsadのみ抽出- 抽出した感情をカウント
- どの感情がもっとも多いかを調べる
- 感情分析をするために sentiment_ja を使用
- Twitterの発言を取得するために twitterscraper を使用
- 感情は6分類 (ポール・エクマンの
表情の分類に準拠)
- happy(幸福感)
- sad(悲しみ)
- disgust(嫌悪)
- angry(怒り)
- fear(恐れ)
- surprise(驚き)
- 計測期間は 2019-01-01 以降のツイートのみ
- リツイートは集計から外す
免責
- 皮肉は利きません。
- 「良いご身分ですね!」->
happyに分類される(sentiment_jaは素直な子)- 機械学習の話は出てきません。
- ぶっちゃけ統計結果の精度はよくありません。
集計方法
- sentiment_jaより、sentiment_jaを使用する準備をする
- twitterscraperより、twitterscraperを使用する準備をする(
pip install twitterscraperなどを済ませる)- sentiment_jaディレクトリ以下にある
sentimentja/sentiment.pyを開く- 以下のコードを反映し、
$ python sentimentja/sentiment.pyとかすれば集計できるコード (コメントでざっくりと解説)
sentimentja.py# coding:utf-8 from keras.preprocessing.sequence import pad_sequences from keras.models import load_model from twitterscraper import query_tweets import datetime import json import pickle import tensorflow as tf def preprocess(data, tokenizer, maxlen=280): return(pad_sequences(tokenizer.texts_to_sequences(data), maxlen=maxlen)) def predict(sentences, graph, emolabels, tokenizer, model, maxlen): preds = [] targets = preprocess(sentences, tokenizer, maxlen=maxlen) with graph.as_default(): for i, ds in enumerate(model.predict(targets)): preds.append({ "sentence": sentences[i], "emotions": dict(zip(emolabels, [str(round(100.0*d)) for d in ds])) }) return preds def load(path): model = load_model(path) graph = tf.get_default_graph() return model, graph if __name__ == "__main__": maxlen = 280 model, graph = load("sentimentja/model_2018-08-28-15:00.h5") with open("sentimentja/tokenizer_cnn_ja.pkl", "rb") as f: tokenizer = pickle.load(f) emolabels = ["happy", "sad", "disgust", "angry", "fear", "surprise"] # ツイート情報を取得。最大で100000件。64スレッドで取得しにいくので負荷に注意 list_of_tweets = query_tweets( "lang:ja", begindate=datetime.date(2019, 1, 1), limit=100000, poolsize=64) # 取得したツイート情報のうち、リツイートではないものだけを抽出し、 # 発言内容(text)だけを取得する list_of_tweets_text = [(tweet.text) for tweet in list_of_tweets if (tweet.is_retweet == 0)] # 感情分析を行う text_with_emotion_list = predict( list_of_tweets_text, graph, emolabels, tokenizer, model, maxlen) # 感情をカウントする箱 emo_count = { "happy": 0, "sad": 0, "disgust": 0, "angry": 0, "fear": 0, "surprise": 0 } for text_with_emotion in text_with_emotion_list: emotions = text_with_emotion['emotions'] # 感情のスコアがもっとも高いものだけを抽出しカウントしていく max_emos = [max_emotions[0] for max_emotions in emotions.items() if max_emotions[1] == max( emotions.items(), key=(lambda emotion: float(emotion[1])))[1]] for max_emo in max_emos: emo_count[max_emo] += 1 # 結果表示 (集計数と集計結果) print("-------------") print(len(text_with_emotion_list)) print(str(emo_count)) print("=============")結果
disgust(険悪)、happy(幸福感)が2大勢力。
もっと怒ってる人が多くて幸せな人が少ないSNSだと思ってた。とりあえず Twitterは険悪なSNS ということが分かりました。
もしもTwitterが100人の村だったら
28人は険悪で25人は笑っています。
15人はなにかに怯え、13人は怒っています。
12人は驚いており、そして7人は泣いています。可視化
emotion score disgust 27.75242845 
happy 25.17151631 
fear 14.36244936 
angry 13.24677658 
surprise 12.12756458 
sad 7.339264712 


- 投稿日:2019-10-08T19:04:07+09:00
Mac で Stack Exchange API を使うには 2019年版
技術的なQ&Aサイトとして人気のStackOverflowですが、実はStack Exchange という上位のウェブサイト群でAPIも提供されています。
かなり多くのAPIがあり、さまざまな情報を機械的にアクセスできるようになっています。もちろん、OAuth2的な認証認可を行って、その認可ユーザに関する情報を得やすい機能も提供されています。ここでは、StackOverflowのAPIをMacで使ってみるまでの手順を紹介します。
基本的に、Webブラウザとpythonを使用します。Stack Exchange アカウント登録
APIを使用するにはStack Appsというサイトでアプリ登録が必要になりますがまずはそこでStack Exchangeのアカウントを登録します。
必要となるのはユーザー名、メールアドレス、パスワードのみです。facebook, Googleアカウントによる登録もできます。
全て入力し終えるとメールが届くのでメール内にあるリンクをクリックして登録は完了します。ローカルサーバー立ち上げ
APIとのOAuthを行うためにmacでローカルサーバーを立ち上げます。
今回はpythonを使って立ち上げを行います。ターミナルでpythonのバージョン別に以下のコマンドを実行します。server_launchpython -m http.server#python 3.x の場合 python -m SimpleHTTPServer#python 2.x の場合このコマンドで立ち上がったサーバーのアドレス(一般的にはlocalhost:8000)はこの後のアプリ登録で使用します。
アプリ登録
続いてStack Appsでアプリ登録をします。
ページ右にあるRegister an applicationリンクを押すと、アプリ登録のためのフォームが出てきます。
それぞれ必要な値を入力していきます。
- Application Name - アプリの名称です。
- Description - アプリの説明文です。
- OAuth Domain - OAuthの手順で使われるドメイン名を入力します。例えばOAuth2のAuthorization Code GrantやImplicit Grantを使う場合は、
redirect_uriパラメータで指定するURLのドメイン名を指定します。開発時はlocalhost:8000でも構いません。- Application Website - 登録するアプリのURLを入れます。これも開発時には
http://localhost:8000で構いません。- Application Icon - APIを試すだけなら未入力で大丈夫です。
入力したら、Register Your Applicationボタンを押して、アプリ登録を完了します。次に表示されるページでは、登録されたアプリとしてAPIを利用するための様々な情報が表示されます。
- Client Id
- Client Secret
- Key
認証認可画面呼び出し
次に、APIを利用するためのアクセストークンを入手することを目指します。ここでは、OAuth2のAuthorization Code Grantによる手順を紹介します。具体的な手順は、Authenticationに書かれています。
まずはURLを組み立てて、認証認可画面をWebブラウザで開きます。URLの構成は以下になります。https://stackexchange.com/oauth?client_id=[CLIENT_ID]&scope=[SCOPE]&redirect_uri=[REDIRECT_URI]&state=[STATE]
- CLIENT_ID - 先ほどアプリ登録した結果発行されたアプリを特定するためのIDです。
- SCOPE - ユーザに認可してもらう権限を空白区切りで列挙します。
- REDIRECT_URI - StackOverflowのドメインで行われる認証認可後、アプリに戻ってくる際の戻り先URLを指定します。このURLはアプリ登録時に指定したOAuth Domainがドメイン名として含まれていなければなりません。
- state - CSRF対策の値です。本番環境では必須です。
scopeは以下が提供されています。ここでは、read_indexとprivate_infoを指定します。
- read_inbox - ユーザのグローバルインデックスにアクセスします。
- no_expiry - このscopeを持つアクセストークンには有効期限がありません。
- write_access - ユーザとして書き込み処理を行います。
- private_info - サイト上でのユーザのプライベートな行動全てにアクセスします。
redirect_uriは、アプリ登録時に指定したドメイン名を持つURLであれば、パスやクエリパラメータなどは自由です。ここでは、http://localhost:8000/としましょう。stateは本来指定しないとCSRF脆弱性を発生させてしまうのですが、今回はAPIのテスト目的なので省略します。
まとめると、以下のようになります。
https://stackexchange.com/oauth?client_id=[CLIENT_ID]&scope=read_inbox%20private_info&redirect_uri=http://localhost:8000/Webブラウザで上記のURLにアクセスすると、アプリケーションの認証を確認する画面が表示されるため、
Approveを押します。アクセストークン
Approveボタンを押した後、redirect_uriパラメータで指定したURLにリダイレクトされます。その際、クエリーパラメータとしてcodeという値が渡されてきます。http://localhost:8000/?code=[CODE]このcode値は、認証されたユーザが指定されたscopeに関して認可を行ったことを示しています。これは一時的な値であり、このcode値と他の値を組み合わせて、StackOverflowのサーバからアクセストークンを発行してもらいます。具体的には、https://stackexchange.com/oauth/access_tokenにPOSTメソッドで以下の値を送信します。
- client_id - アプリ登録した結果発行されたアプリを特定するためのIDです。
- client_secret - アプリ登録した際にclient_idと共に発行されたClient Secret値です。
- code - 先ほど入手した
code値です。- redirect_uri - 認証認可ページを呼び出した際に指定したredirect_uri値をそのまま指定します。
上記の値は
application/x-www-form-urlencodedで送信します。pythonを使ってアクセストークンの発行処理をStackOverflowのサーバに依頼します。request.pyimport requests import urllib # 任意のurl(エンドポイント) url = 'https://stackexchange.com/oauth/access_token' # 送信するパラメータ(例) params = {'client_id': [CLIENT_ID],'client_secret':[CLIENT_SECRET],'code':[CODE],'redirect_uri':[REDIRECT_URI]} # URLをエンコード params = urllib.parse.urlencode(params) # headerでコンテンツタイプを指定 headers = {'Content-Type': 'application/x-www-form-urlencoded'} # authにBasic認証のIDとPASSを設定する r = requests.post(url=url, data=params, headers=headers) # 送信結果が知りたい場合には記載 print(r.status_code) print(r.text)実行後、発行されたアクセストークンとそのアクセストークンの有効期限が返却されます。
access_token=[ACCESS_TOKEN]&expires=86400
expires値の単位は秒です。上記の場合は、24時間有効なアクセストークンを得られたことになります。
これでAPIを利用する準備が整いました。APIの利用
StackOverflowが提供するAPIは、基本的には全てRESTful APIです。各APIのEndpoint URLを叩くと、それに応じて処理が行われ、結果がJSON形式で返ってきます。Endpoint URLは、以下です。
shell:
https://api.stackexchange.com/2.2
各APIでは、上記のEndpoint URLに続けて、パスを追加していきます。そして、APIに応じて、HTTP Methodを使い分けていきます。
API呼び出し時に渡したいパラメータは、クエリーパラメータもしくはapplication/x-www-form-urlencoded形式で渡します。その際、基本的に指定が必要となるパラメータがいくつかあります。
- access_token - 先ほど取得したアクセストークン文字列です。
- key - アプリ登録時に発行されたKey値。
site - APIの対象となる値。stackoverflowを指定します。
上記はAPIに関わらず指定されるパラメータです。それに対して、複数の結果を返却する可能性があるAPIでは、ページングがサポートされています。そのページングを制御するために、以下のパラメータが利用可能です。page - 取得したいページの番号。最初のページは1です。
pagesize - 1ページあたりの件数です。未指定の場合は30が適用されます。0〜100の間の数値を指定可能です。
API呼び出しの例
2011/1/1から2019/1/1までの投稿を文章も含めて取得。
https://api.stackexchange.com/2.2/questions?access_token=[ACCESS_TOKEN]&fromdate=1569888000&todate=1570492800&order=desc&sort=activity&site=stackoverflow&filter=!SnL4eKG_AcYDgViF6n&key=[KEY]参考文献:
- 投稿日:2019-10-08T18:25:35+09:00
Django REST Framework APIの"api/"でAttributeError: 'OrderedDict' object has no attribute 'register'になった話
はじめに
最近Djangoを仕事で使う必要ができたためせっかくだからとDjango REST FrameworkAPIを使おうと思いやり始めた出先でころんだ話。
症状
ここのサイトがわかりやすくて、進んでいたのですが、
http://localhost:3000/api/にアクセスした瞬間
AttributeError: 'OrderedDict' object has no attribute 'register'
となり画面がエラーになってしまいました。
結論
同じようなエラーのstackoverflowを発見したので、terminalでmarkdownのバージョンを確認しました。
Python 3.6.1 |Anaconda custom (x86_64)| (default, May 11 2017, 13:04:09) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import markdown >>> print('Markdown module path', markdown.__file__) Markdown module path /Users/arata.honda/.pyenv/versions/anaconda3-4.4.0/lib/python3.6/site-packages/markdown/__init__.py >>> print('Markdown version:', markdown.version) Markdown version: 2.6.11 >>> ^C KeyboardInterrupt >>> exit()と、2.6.11なんですね、ちょっとバージョン上げてみました。
arata.honda@hoge:demo_app$ pip install -U markdown Collecting markdown Downloading https://files.pythonhosted.org/packages/c0/4e/fd492e91abdc2d2fcb70ef453064d980688762079397f779758e055f6575/Markdown-3.1.1-py2.py3-none-any.whl (87kB) |████████████████████████████████| 92kB 1.7MB/s Requirement already satisfied, skipping upgrade: setuptools>=36 in /Users/arata.honda/.pyenv/versions/anaconda3-4.4.0/lib/python3.6/site-packages (from markdown) (39.0.1) Installing collected packages: markdown Found existing installation: Markdown 2.6.11 Uninstalling Markdown-2.6.11: Successfully uninstalled Markdown-2.6.11 Successfully installed markdown-3.1.1もっかい叩くと動きましたとさ、というクソみたいな話。
補足:python manege.py migrateを一度でも叩いてない場合はdjango_sessionというテーブルを探しに行って絶対にエラーになって見れないです。

- 投稿日:2019-10-08T17:19:51+09:00
Python matplotlibのマニアックなメモ
matplotlib 自分用備忘録
やろうとしてる事がニッチ過ぎて調べてもなかなか見つからない…
なんとか解決策を見つけたけどもう一度同じ事を調べる気力はない…自分がかゆいと思った所に手が届くようになった解決策たちを記録します。
※ コードをコピペしたらそのまま動くかどうかは保証できません。
※ それでもある程度matplotlibに慣れている人たちなら大丈夫だと思います。
※ もともと自分用に部分的にコピペできるように書こうと思ったものなのでそこらへんは許してください…
グラフの解像度とdpiを指定する
import matplotlib.pyplot as plt fig = plt.figure(figsize=(w/dpi, h/dpi), dpi=dpi, facecolor='white')
w, h = 1920, 1080と指定すればFHDモニター一杯のグラフが作れるグラフにテキストを挿入
# フォントサイズを変更 plt.rcParams['font.size'] = '5' fig = plt.figure(figsize=(w/dpi, h/dpi), dpi=dpi, facecolor='white') ax = fig.add_subplot(111) # グラフ左上に原点左上&左寄せのテキストを表示 plt.text(0.01, 0.98, 'left top', horizontalalignment='left', verticalalignment='top', size=10, # fontsize ha='left', va='top', transform=ax.transAxes, zorder=1) # 右上 plt.text(0.99, 0.98, 'right top', horizontalalignment='right', verticalalignment='top', size=10, ha='right', va='top', transform=ax.transAxes, zorder=1) # 左下 plt.text(0.01, 0.01, 'left bot', horizontalalignment='left', verticalalignment='bottom', size=10, ha='left', va='bottom', transform=ax.transAxes, zorder=1) # 右下 plt.text(0.98, 0.01, 'right bot', horizontalalignment='right', verticalalignment='bottom', size=10, ha='right', va='bottom', transform=ax.transAxes, zorder=1)グラフ部分のみを指定した解像度ぴったりで出力したい
余白も軸もラベルも全て消したい、グラフだけ出力したい(語彙力)
仕事で機械学習用の元データを作成するときに手こずったかゆい所
作りたかったのは↓こんな感じの黒背景にRGB1本ずつのグラフ
サイズは60px * 60pximport matplotlib.pyplot as plt import numpy as np w , h = 60, 60 dpi = 300 aa = True plt.clf() fig = plt.figure(figsize=(w/dpi, h/dpi), dpi=dpi) ax1 = fig.add_subplot(111) ax2 = ax1.twinx() ax3 = ax1.twinx() # 全ての軸を非表示 ax = plt.gca() plt.axis('off') ax.axis('off') ax1.axis('off') ax2.axis('off') ax1.plot(np.random.rand(60), lw=lw, color=[1.0, 0.0, 0.0], antialiased=aa) ax2.plot(np.random.rand(60), lw=lw, color=[0.0, 1.0, 0.0], antialiased=aa) ax3.plot(np.random.rand(60), lw=lw, color=[0.0, 0.0, 1.0], antialiased=aa) plt.xlim([0, 59]) # 上下左右の余白を削除 plt.subplots_adjust(left=0, right=1, bottom=0, top=1) # グラフの枠も削除 plt.box(False) plt.savefig(pathfile, dpi=dpi, facecolor='black') plt.clf() plt.close(fig)↓ 保存結果
これなら機械学習にも使える(はず)!グラフ保存した時にラベルやタイトルが見切れないようにする
w, h, dpiを自分で指定してグラフ保存すると
x, yのラベルやタイトルが切れちゃう…
そんな時はコレ
plt.savefig(pathfile, dpi=dpi, facecolor='white', bbox_inches='tight', pad_inches=0.1)
bbox_inches='tight'とpad_inches=0.1が重要です↓ 保存結果
pad_inchesの値を大きくすると指定した解像度よりも大きくなるので注意してください↓
pad_inchesを0.5にした場合の保存結果
追記予定のかゆい所
- 折れ線グラフで指定した値より大きい or 小さい 部分の線の色を変更したい
- 資産曲線などで損益が0円を下回る部分を赤色にしたい時とか...
この他にもあったら都度追記していきます






- 投稿日:2019-10-08T16:51:30+09:00
C言語を勉強した工大生のPython勉強ノート
1. まえがき
C言語(ポインタ、配列除く)を勉強した工大生のPython勉強ノートです。
書籍を使ってPythonを勉強しています。OS:Windows 10 Pro
テキストエディタ:Visual Studio Code
書籍:辻 真吾 - Pythonスタートブック [増補改訂版] - amazonC言語と似ているところは、簡潔に記述又はすっ飛ばしています。
つまづいたところは私なりの補足を入れている場合があります。辻先生の書籍について
イメージをつかみやすい図やソースコードが多く載っています。
コードを実行しながら学ぶことができます。
この記事を読んで「もっとPythonの理解を深めたい!」と思った方は、
ご購入をお勧めします。
よりわかりやすく、理解が深まることでしょう。2. Pythonのインストールと作業ディレクトリの作成
Anacondaを使用する。
仮想環境の管理が同時に行えるのが便利だと思う。作業ディレクトリを適当に作成する。
3. Pythonファイルの拡張子
Pythonのスクリプトファイルの拡張子は「~.py」にするのが一般的。
4. データの違い
データの違いを特に、データの型(かた)と呼ぶ。
型はデータの種類を表す。型の例:整数型、小数型、文字列型
上記の例は非常によく使うデータ型である。
➡組み込みデータ型という。
整数 文字列 小数 真偽 リスト 数字そのまま(小数点無) 'または"で囲む 小数点付きの数字 正誤 カンマ区切りに並べたデータを[]で囲む -2 2 3 'abc' '日本' '2019' 1.5 0.001 True False ['Japan','German'][1,2,3] 5. 変数名のつけ方
変数に使用できる文字の種類:アルファベット、数字、 _(アンダースコア)
大文字と小文字は区別される。使えない単語
is, not, if, for などの単語は、そのまま変数名に使うことはできない。
変数名の一部に使用することはできる。6. 関数
たとえば、ペンの長さを測りたいときは定規を使うと思う。
このように、やりたいと思った作業が簡単に達成できる道具があると便利!Pythonにおける便利な道具の1つが関数(かんすう)
7. メソッド
メソッドとは、データ型がそれぞれ持っている専用の関数のこと。
例としてsplit関数(文字列型専用の関数。自分自身を特定の文字で区切る)を使ってみる。
「ab,cde」という文字型データの変数をおく。
>>> letters = 'ab,cde'.
split関数を使う。>>> letters.split(',') ['ab', 'cde']bとcの間の「,」で区切ることができた。
8. モジュール
モジュールとは、機能のまとまりの単位である。
モジュールを使うためには、使用するモジュールをPythonに指示する(読み込む)必要がある。
➡import という命令を使う。import モジュール名と記述してモジュールを読み込む。
記述位置はコードの先頭にするのが一般的である。例として、datetimeモジュールを使ってみる。
>>> import datetime >>> kyou = datetime.date.today() >>> print(kyou) 2019-10-049. データの入れ物
- リスト型
- 辞書型
- タプル
- セット
データを追加、変更、削除、並べ替え、足し算などができる。
リスト型
リスト型データの作成
「,(カンマ)」で区切ったデータを「[ ]」でくくる。
>>> list_mix = [0,1.5,'test']小数型や文字列型を混ぜて、リストにすることができる。
データへのアクセス
[]で番号を指定することでアクセスする要素を指定することができる。
>>> list_mix = [0,1.5,'test'] >>> list_mix[1] 1.5.
後ろから数えて要素を取り出すこともできる。
その場合は-1以下の数字で表す。>>> list_mix[-3] #最後から3番目の要素 0要素の変更
変更したい要素を添え字で指定して変更する。
>>> list_mix[1] = -1 >>> list_mix [0,-1,'test']要素の追加
appendメソッド
>>> list_mix [0,-1,'test'] >>> >>> list_mix.append(4) >>> list_mix [0,-1,'test',4]リストの最後尾に4が追加された。
insertメソッド
挿入場所を指定して要素を追加する場合。
- 引数1つ目:要素を追加する場所
- 引数2つ目:追加する要素>>> list_mix [0,-1,'test',4] >>> >>> list_mix.insert(2,1) >>> list_mix [0,-1,1,4]挿入した場所にもとからあった要素は、1つずつ後ろにずれる。
要素の削除
2つの方法がある。
- 添え字を使う(pop)
- 要素を直接指定する(remove)
方法1
popメソッドの引数で消したい要素を添え字で指定する。
>>> list_mix [0,-1,1,4] >>> >>> list_mix.pop(1) -1 #削除した要素が戻り値として返ってくる >>> list_mix [0,1,4]方法2
removeメソッドの引数に、削除したい要素を指定する。
>>> list_mix [0,1,4] >>> >>> list_mix.remove(4) >>> list_mix [0,1]popメソッドとは違い、戻り値は返ってこない。
リストの結合と拡張
「+」を使った足し算
>>> list_a = [0, 1, 2] >>> list_b = [3, 4, 5] >>> >>> list_a + list_b [ 0, 1, 2, 3, 4, 5]リストの拡張
extendメソッド
list_aにlist_bの要素をすべて追加する>>> list_a = [0, 1, 2] >>> list_b = [3, 4, 5] >>> >>> list_a.extend(list_b) >>> list_a [ 0, 1, 2, 3, 4, 5]リストのスライス
リストの一部の要素だけを取り出すことができる。
~割愛~
要素の並び替え(sort, reverse)
sortメソッドを使うと昇順にデータを並び替えることができる。
>>> list_test = [4, 5, 2, 1, 3, 6] >>> list_test [4, 5, 2, 1, 3, 6] >>> list_test.sort() >>> list_test [1, 2, 3, 4, 5, 6] >>> >>> list_test.reverse() >>>list_test [6, 5, 4, 3, 2, 1] >>> >>> list_test.reverse() #もう一度reverseメソッドを使うと >>> list_test #逆順になり、再び昇順になる [1, 2, 3, 4, 5, 6]文字列にも使用することができる。
辞書型
各データに名前を付けて保存するイメージ。
この時の名前がキー(key)、データを値(value)と呼ぶ。キーを使って値を呼び出すことができる。
文字列にも使用することができる。
使い方
変数名 = {キー:'値', キー:'値', キー:'値'}タプルとセット
割愛
10. for文
Pythonのfor文はとても短い。
>>> list_test = [1, 2, 3, 4, 5, 6] >>> for val in list_test : ... [ tab ] print(val) 1 2 3 4 5 6これだけ。
valなんかきもい!!!!!
valってなにさ!?何の値が入ってるの!?どうなってるの!?Pythonは「なんて楽なんだー!」(C言語比)と思っていた私が初めてモヤモヤした箇所。
C言語みたいに細かく回数指定しなくていいの!?
逆になんかそれがわからんわ!!!正確性は置いといて、飲み込むことができた解釈を以下に記す。
for文は裏でイテレーションしている!
イテレーションについては以下のページを参照。
参考ページ : Mastering Python - イテレーターってなに?このnext(list)を自動で繰り返してくれるのがfor文、という風に飲み込むことにしました。
もしくは、valの部分をitemという関数にしてみるとイメージが湧くかも。
やってることはわからないけど、
こういうのってイメージつかむことが結構大事かなと思うので。>>> for item in list_test : ... [ tab ] print(item)11. if文 (if~elif~else)
C言語の else if が、
Pythonでは elif となっている。>>> if 条件 : ... [tab] 処理 ... elif 条件 : ... [tab] 処理 ... elif 条件 : ... [tab] 処理 ... else: ... [tab]処理 ...12. While文
条件が成立している間は処理を繰り返す
>>> while 条件: ... [tab] 処理 ...continueとbreak
if文の条件が成立しなくなるまで処理が続く
>>> while 条件: ... [tab] 処理 ... [tab] if 条件: ... [tab] [tab] continue ... [tab] else: ... [tab] [tab] break ...13. 例外処理 (try~except)
エラーが発生しそうなコードをブロックとしてまとめる。
(この場合、処理1と処理2)それを try: と except: で囲む。
try: [tab] 処理1 [tab] 処理2 except: [tab] 処理3 処理4例外が発生しない場合は、処理3は実行されない。
try: の中の処理で例外(エラー)が発生すると、
except処理に飛ぶ。処理4は、exceptにぶら下がっているわけではないので、
例外の有無にかかわらず実行される。14. ファイルの読み書き
組み込み関数openの戻り値はfile型である。
書き込み
任意のファイルに文字列を書き込む場合のコードを以下に示す。
>>> test_file = open('test.txt','w') #書き込みモード('w')でファイルに接続 >>> test_file.write('Hello') >>> test_file.close #ファイルとPythonの接続を切る(flushも行われる)作業ディレクトリに指定したファイル名(test.txt)のファイルが・・
1. 存在しない場合
➡空のディレクトリが作成される。
2. 存在する場合
➡上書きされる ※注意!制御文字
改行記号 /n
タブ記号 /t読み込み
>>> test_file = open('test.txt','r') #読み込みモード('r')でファイルに接続 >>> read_str = test_file.readline() #内容の読み込み >>> test_file.close #ファイルとPythonの接続を切る(flushも行われる)まとめて複数行読み込みたい場合は
read_str = test_file.readline s ()とする。
(スペースは空けずに)余計な文字を取り除く
stripメソッド
余計な文字や空白やタブなどの制御文字を取り除く。>>> '制御文字を取り除きたい文字列'.strip()15. joinメソッド
割愛
16. with文でのファイルの処理
割愛
17. あとがき(2019.10.8)
割愛部分はそのうち加筆したいなと思っているところ。
(永遠に加筆しないかもしれない)「ソースコードをそのまま載せるのは、著作権的にどうなのかなー」
「ソースコード無しでどうやって表現しようかなー」
とか悩んだ結果、とりあえず書かなかったところ。項目名見て気になったものは、ググればいっぱい参考サイト出るだろう。
C言語を学んだ後、Pythonを学ぶ人の役に、少しでも立てたら嬉しいです。
気を付けているつもりですが、間違い等ご容赦ください。また、ご指摘いただけると幸いです。
- 投稿日:2019-10-08T16:04:28+09:00
【Python】Pythonで複数のエクセルシートのデータを一括処理
はじめに
仕事中にいくつかのエクセルファイルに欲しいデータが散らばっていて、何度も何度もエクセルを開きなおすということがめんどくさいな~と思って、なんかいい方法ないかな?の解として辞書型配列を使ってみました。
1.辞書型配列とは
配列のインデックスは従来数値で表されます。
辞書型とは、インデックスに数値ではなく文字を指定できる変数の型です。(自分の理解では)コード上では、辞書型のインデックスのことをkey、それに対する値をvalueと書くことが多いです。
(実際の辞書では、調べたい文字がkeyになりその語句の意味がvalueということになる。)2.宣言の仕方
※要注意:配列とめっちゃ似てます!!
code.pylist=[] #リスト dict={} #辞書型続いて、keyと値の設定方法です。
code.pydict={a:apple,b:banana,c:corn} #辞書型の宣言時にkey,valueを設定 "key" "value" a apple b banana c corn他にも、宣言済の辞書型配列にkeyとvalueの組を追加することもできます。
code.pydict={} #空の辞書型配列を宣言 key=A value=Ace dict[key]=value #keyがA,valueがAceを追加また、keyの削除も可能。
code.pydict={} #空の辞書型配列を宣言 key=A value=Ace dict[key]=value del dict[key] #keyがAの要素を削除(keyとvalueの両方が削除される)一つのkeyに対して、複数のvalueを紐付けることも可能。
(→keyにlistを紐付ける)code.pydict={} #空の辞書型配列を宣言 key=A value=[One,Two,Three] dict[key]=value #keyがA,valueがAceを追加3.複数のエクセルシートからデータを形成
ある列または行の値が共通のエクセルシートを用意する。ここでは二つのエクセルシートを考え、これをそれぞれX、Yで表す。XとYのA列は共通の値とする(keyがA列の要素となる)。
エクセルシートから値を取り出す方法については、Pythonでエクセルデータを扱う!で紹介。Xに存在する欲しいデータをX_want、Yに存在する欲しいデータをY_wantとする。
これをkey=A列として紐付ける。code.pydict={} #空の辞書型配列を宣言 key="A列の要素" value=[X_want,Y_want] dict[key]=value #keyがA列の要素で,それに対応する異なるエクセルから持ってきた値がvalueこの操作を行うことで、Python上では二つのエクセルがマージされ、あたかも一つのファイルを扱っている風になる。
4.おわりに
複数のエクセルから必要なデータを引っ張ってくるという事をしてみました。なんとなく複数データベースから値をとってくるってこんな感じなのかなっていう、雰囲気を感じることが出来ました。データベース構築とか管理とかいつかは挑戦したいなとおもいました!!
- 投稿日:2019-10-08T15:30:11+09:00
pycharmでpackageのソースコードを確認する
importのpackageを選択して
右クリック → Go To → Declaration
でソースコードを開いてくれます。
便利!

- 投稿日:2019-10-08T15:23:07+09:00
LDA (Latent Dirichlet Allocation) を使って英文記事をクラスタリングする(前処理編)
自然言語処理の研究を始めるにあたって LDA に触れておこうと思ったので,ついでに簡単にまとめてみます.
この分野はまだ学び始めたばかりなので,もし間違いがあれば指摘していただけると嬉しいです.
実行環境には Google Colaboratory を使用しました.LDA について
トピックモデルは,テキストデータの集合から得られる抽象的なトピックを見つけ出すための,確率モデルの一種です.LDA (Latent Dirichlet Allocation) はそのようなトピックモデルの一つで,あるドキュメントを適当なトピックに分類するために使われます.ドキュメント毎のトピックが占める割合,及びトピック毎の単語が占める割合をそれぞれ算出します.
LDA でできることを簡単に述べると,
- 文書の集合はどんなトピックに分類できるのか
- ある文書にはどんなトピックがどの程度含まれているか
- あるトピックはどの単語がどの程度構成しているのか
のようなことがわかります.
LDA についてはこのあたりの記事で紹介されています.
トピックモデル(LDA)で初学者に分かりづらいポイントについての解説
http://acro-engineer.hatenablog.com/entry/2017/12/11/120000【Python】トピックモデル(LDA)
https://qiita.com/kenta1984/items/b08d5caeed6ed9c8abf1LDA の入力データについて
テキストデータを LDA で使用するためのデータの加工方法として,BOW (Bag of Words) や tf-idf があります.これらは以下の記事で紹介されています.
Bag of Wordsについて書いてみる
https://www.pytry3g.com/entry/2018/03/21/181514#1-%E6%95%B0%E5%80%A4%E5%A4%89%E6%8F%9Btf-idfについてざっくりまとめ理論編
https://dev.classmethod.jp/machine-learning/yoshim2017ad_tfidf_1-2/実際に使ってみる
ここでは以下の記事を参考にしながら,英語のニュース見出しのクラスタリングをやっていこうと思います.
https://towardsdatascience.com/topic-modeling-and-latent-dirichlet-allocation-in-python-9bf156893c24データの準備
今回使用するデータはここからダウンロードします(要:kaggle へのサインイン)
https://www.kaggle.com/therohk/million-headlines/dataデータを Python で利用できるように読み込みます.
import pandas as pd data = pd.read_csv('abcnews-date-text.csv', error_bad_lines=False); data_text = data[['headline_text']] data_text['index'] = data_text.index documents = data_textデータの中身がどうなっているのか少し見てみると,およそ110万件のドキュメント(ニュース見出し)があって,そのうち上から5件が上の表のようになっていることがわかります.
print(len(documents)) print(documents[:5])1103663
headline_text index 0 aba decides against community broadcasting lic... 0 1 act fire witnesses must be aware of defamation 1 2 a g calls for infrastructure protection summit 2 3 air nz staff in aust strike for pay rise 3 4 air nz strike to affect australian travellers 4 前処理
次の手順でデータを処理します.
- ドキュメントのトークン化:具体的には,テキストを文単位に,文を単語単位にそれぞれ分割します.大文字の単語を小文字に修正し,句読点を取り除きます.
- 3文字未満の単語の除去
- ストップワードの除去:ストップワードとは,頻出あるいは一般的すぎて,利用価値が低いと考えられる単語のことをいいます.ex. the, a, for
- 単語を見出し語化 (lemmatize) :具体的には,三人称の単語は一人称に,過去時制及び未来時制の動詞は現在時制に変更されます.
- 単語の語幹抽出 (stemming)
処理には gensim と nltk を使います.
import gensim from gensim.utils import simple_preprocess from gensim.parsing.preprocessing import STOPWORDS from nltk.stem import WordNetLemmatizer, SnowballStemmer from nltk.stem.porter import * import numpy as np np.random.seed(2018) import nltk nltk.download('wordnet')lemmatize の例を確認してみます.
print(WordNetLemmatizer().lemmatize('went', pos='v'))go
stemming の例を確認してみます(結果は省略).
stemmer = SnowballStemmer('english') original_words = ['caresses', 'flies', 'dies', 'mules', 'denied','died', 'agreed', 'owned', 'humbled', 'sized','meeting', 'stating', 'siezing', 'itemization','sensational', 'traditional', 'reference', 'colonizer','plotted'] singles = [stemmer.stem(plural) for plural in original_words] pd.DataFrame(data = {'original word': original_words, 'stemmed': singles})lemmatizeとstemming をする関数を定義し,前に述べた手順で前処理をするための関数を作成します.
def lemmatize_stemming(text): return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v')) def preprocess(text): result = [] for token in gensim.utils.simple_preprocess(text): if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3: result.append(lemmatize_stemming(token)) return resultドキュメントを一つ選択して前処理の前後比較をしてみましょう.
doc_sample = documents[documents['index'] == 4310].values[0][0] print('original document: ') words = [] for word in doc_sample.split(' '): words.append(word) print(words) print('\n\ntokenized and lemmatized document: ') print(preprocess(doc_sample))original document:
['rain', 'helps', 'dampen', 'bushfires']tokenized and lemmatized document:
['rain', 'help', 'dampen', 'bushfir']きちんと動作していることが確認できたので,全ドキュメントの前処理をします.完了には少し時間がかかると思います.
processed_docs = documents['headline_text'].map(preprocess)長くなってしまうので,今回はここまでとします.
次回は,LDA の入力データ (BOW, TF-IDF) の作成と,LDA モデルの作成について書こうと思います.
- 投稿日:2019-10-08T15:15:11+09:00
class まとめ 継承とsuper()について
class まとめ 継承とsuper()について
pythonのclassで継承とsuper()について調べたので、投稿してみました。
・classの継承とは?
他のクラスをもとにして新しいクラスを定義すること。
・継承があると何がいいの?
継承があると、ほかのクラスのデータやメソッドを受け継ぐことで、必要な部分だけを追加開発することができます。
・classの継承の一例
class A: def spam(self): print('A') class B(A): def spam(self): print('B') super().spam()・super()ってなに?
super()は派生クラスから基底クラスのメソッドを呼び出すメソッド
何かご指摘がございましたらコメントください。よろしくお願いいたします。
- 投稿日:2019-10-08T13:30:07+09:00
python/djangoで文字列からdatetimeに変換するときのtimezone設定
めちゃくちゃ初歩的なミスを犯すところだったので戒めにメモしておきます。。。
背景
Twitter APIを用いて構築しているTwitterクローラで、デフォルト設定である1週間単位でツイートデータを収集していたが、1週間丸ごと取りに行くとデータ量的にクロールにかかる時間が長くなってしまう為、クロールしてくる期間を変更したい。
しかし、Standard Search APIには取得開始日時から特定の日時までのデータに絞るパラメータが存在していない為、APIの返り値から日付情報を抽出して比較する必要がある。
(厳密には、since_idはあるけど仕様が謎で使いづらい・・・)問題
以下のように、
django.utils.timezoneを用いてJSTで対象期間を定義し、APIの返り値をJSTに変換して比較しようとしていた。import datetime from django.utils import timezone target_datetime = timezone.localtime(timezone.now()) - datetime.timedelta(days=4) created_at = "Thu Oct 03 15:28:43 +0000 2019" #APIから抽出した日付文字列 created_at_datetime = timezone.make_aware(datetime.datetime.strptime(created_at, '%a %b %d %H:%M:%S +0000 %Y'), timezone.get_default_timezone()) if created_at_datetime > target_datetime: 以下省略しかし、このやり方だと以下のように「UTC」の日時が「JST」に変換されないまま、「JST」のタイムゾーン情報だけが付与された形になっていた。
>>> created_at = "Thu Oct 03 15:28:43 +0000 2019" >>> created_at_datetime = timezone.make_aware(datetime.datetime.strptime(created_at, '%a %b %d %H:%M:%S +0000 %Y'), timezone.get_default_timezone()) datetime.datetime(2019, 10, 3, 15, 28, 43, tzinfo=<DstTzInfo 'Asia/Tokyo' JST+9:00:00 STD>)解決方法
UTC文字列をJSTのdatetimeに変換するには以下の手順を踏む必要がある。
>>> created_at = "Thu Oct 03 15:28:43 +0000 2019" >>> created_at_datetime_utc = datetime.datetime.strptime(created_at, '%a %b %d %H:%M:%S %z %Y') >>> timezone.localtime(created_at_datetime_utc) datetime.datetime(2019, 10, 4, 0, 28, 43, tzinfo=<DstTzInfo 'Asia/Tokyo' JST+9:00:00 STD>)なお、datetime同士の比較を行うだけの目的であればわざわざ変換しなくてもよしなに計算してくれる模様。
>>> created_at_datetime datetime.datetime(2019, 9, 29, 20, 32, 44, tzinfo=datetime.timezone.utc) >>> target_datetime datetime.datetime(2019, 9, 29, 20, 32, 44, tzinfo=<DstTzInfo 'Asia/Tokyo' JST+9:00:00 STD>) >>> created_at_datetime > target_datetime True >>> created_at_datetime datetime.datetime(2019, 9, 29, 12, 32, 44, tzinfo=datetime.timezone.utc) >>> target_datetime datetime.datetime(2019, 9, 29, 20, 32, 44, tzinfo=<DstTzInfo 'Asia/Tokyo' JST+9:00:00 STD>) >>> created_at_datetime > target_datetime True >>> created_at_datetime datetime.datetime(2019, 9, 29, 10, 32, 44, tzinfo=datetime.timezone.utc) >>> target_datetime datetime.datetime(2019, 9, 29, 20, 32, 44, tzinfo=<DstTzInfo 'Asia/Tokyo' JST+9:00:00 STD>) >>> created_at_datetime > target_datetime False
- 投稿日:2019-10-08T13:11:10+09:00
GAEでFirebaseのJWTで認証する
- 前の記事で払い出したFirebaseのJWT(id_token)を使って認証する。
- GAEのPython3.7スタンダード環境で実行する。
基本はこんな感じ。ちょっとずつ説明する。
import firebase_admin as admin from firebase_admin.auth import InvalidIdTokenError, ExpiredIdTokenError, RevokedIdTokenError, CertificateFetchError cred = admin.credentials.Certificate('./service_account.json') admin.initialize_app(cred) # Firebaseアクセストークンの検証 def verify_id_token(id_token): try: admin.auth.verify_id_token(id_token) except (ValueError, InvalidIdTokenError, ExpiredIdTokenError, RevokedIdTokenError, CertificateFetchError): return False return True
必要なパッケージは
requirements.txtに追加する。基本的にfirebase-adminだけの追加で大丈夫なはず。importで使えるようにする。import firebase_admin as admin from firebase_admin.auth import InvalidIdTokenError, ExpiredIdTokenError, RevokedIdTokenError, CertificateFetchError
事前にGCPのサービスアカウントの鍵ファイルを作成する。GAEの権限とFirebaseの権限をつけておくのがベター。
作成した鍵ファイルを読み込み、firebase_adminを初期化するcred = admin.credentials.Certificate('./service_account.json') admin.initialize_app(cred)
firebase_adminパッケージのメソッドを使って認証する。
InvalidIdTokenError, ExpiredIdTokenError, RevokedIdTokenError, CertificateFetchErrorの例外が発生するのでハンドリングしたい時はtryブロックで。admin.auth.verify_id_token(id_token)
verify_id_tokenの戻り値は辞書型でこんなのが入っている。{ 'iss': 'https://securetoken.google.com/example', 'aud': 'example-hogehoge', 'auth_time': 1570507461, 'user_id': 'xxxxxxxxxxxxxxx', 'sub': 'xxxxxxxxxxxxx', 'iat': 1570507463, 'exp': 1570511063, 'email': 'foo@example.jp', 'email_verified': True 'firebase': { 'identities': { 'email': ['foo@example.jp'] }, 'sign_in_provider': 'password' }, 'uid': 'xxxxxxxxxxxxxxx' }
- 投稿日:2019-10-08T13:09:29+09:00
Twitter に APIを使わずに投稿する
Twitterアフィリエイトを行うときに、投稿するのにもっとも利用されるのがTwitter APIです。
ただし、プログラムで自動的に投稿しているのが運営に疑われるとすぐにアカウントが凍結されてしまいます。
そこでアカウントの凍結を回避するために、Twitter API を使わずにTwitterにログインして投稿するという仕組みを利用します。PythonとSeleniumで実装します。
Python, Selenium, ChromeをCentOSにインストールしておきます。from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keysselenium起動
こんな風にして起動します。起動オプションでログが出せるので出せるようにしておきます。
options=Options() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-dev-shm-usage') executable_path="/usr/local/bin/chromedriver" service_args=["--verbose", "--log-path=/home/[USER]/chromedriver.log"] driver = webdriver.Chrome(chrome_options=options, executable_path=executable_path)#, service_args=service_args)ログイン
Selemiunのやり方でログインします。CSSセレクタかXPathでHTML要素を取得して操作します。
# Twitterに登録したアカウントとパスワード account = 'xxxx@xxxxx.com' password = 'xxxxxx' # ログインページを開く driver.get('https://twitter.com/login/') time.sleep(3) # account入力 element_account = driver.find_element_by_class_name("js-username-field") element_account.send_keys(account) time.sleep(3) # パスワード入力 element_pass = driver.find_element_by_class_name("js-password-field") element_pass.send_keys(password) time.sleep(3) # ログインボタンをクリック element_login = driver.find_element_by_xpath('//*[@id="page-container"]/div/div[1]/form/div[2]/button') element_login.click() time.sleep(3)プログラムの方がブラウザより先に走ってしまうことがあるので timeで3秒動きを止めています。
投稿
投稿画面を呼び出して投稿します。投稿画面ではよくHTMLが変わっているようなので、投稿する本文をセットする要素、投稿ボタンの要素は実行前に確認するようにしてください。最新のものに書き換えて実行する方がいいです。
# 投稿する本文 tweet = "Hello" # 投稿ページをコール driver.get('https://twitter.com/compose/tweet') time.sleep(3) # 投稿する本文をセット element_set_body = driver.find_element_by_css_selector('.notranslate.public-DraftEditor-content') element_set_body.send_keys(tweet) # 投稿ボタンを取得してクリック element_post_button = driver.find_element_by_xpath('//*[@id="react-root"]/div/div/div[1]/div/div/div/div/div[2]/div[2]/div/div[3]/div/div/div[1]/div/div/div/div[2]/div[2]/div/div/div[2]/div[4]/div/span/span') element_post_button.click() time.sleep(3) # 終了処理 driver.close() driver.quit()Seleniumの動作確認
Selemiunがどんな画面にアクセスしているかはスクリーンショットを取ることで確認できます。
driver.save_screenshot('debug.png')この例では debug.png に Chrome のスクリーンショットが保存されます。
注意点
TwitterにChromeからログインがあった旨のメールがアカウントのメールアドレスに届きます。面倒なのでcronでメールを削除するプログラムを回すのがいいです。
- 投稿日:2019-10-08T12:27:44+09:00
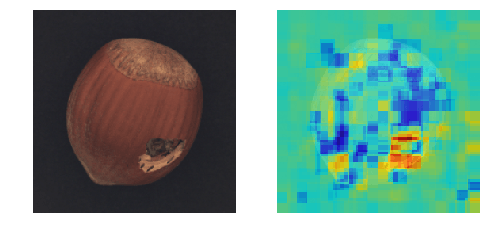
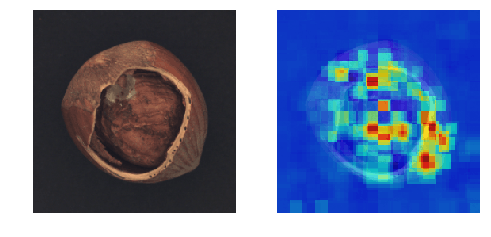
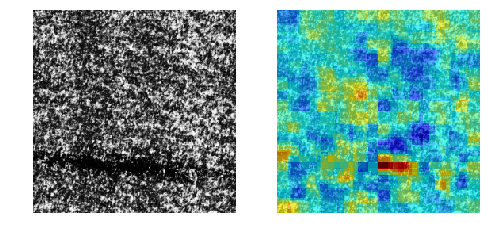
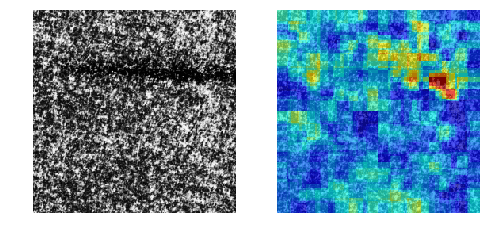
【高速化】Ano-Unet V2で異常部分の可視化
異常個所を「教師無し学習」で可視化するAno-Unet V2を開発しました。
Ano-Unetに比べ速度と安定性を向上させました。
コード全体はこちらに置きました。
※本稿は【Zoom】Pythonデータ分析勉強会#13 その1の発表資料です。
Ano-Unetの問題点
以前に開発したAno-Unetは以下の問題点を抱えていました。
- 画像一枚に対し、学習を行っているので非常に遅い。(たぶん画像1枚に20分くらい)
- ハイパーパラメータの調整が、画像毎に必要なため大変。
Ano-Unet V2
そこで、問題点を解消すべくAno-Unet V2を開発しました。
特長
- 高速化
- ハイパーパラメータの調整はほとんど不要
- metric learningに限らず、オートエンコーダでも何でも後付け可能なネットワークになった
通常の機械学習と同じく、学習フェーズと推論フェーズを切り離したため
推論は非常に速くなりました(処理時間は画像一枚に1分くらい)。
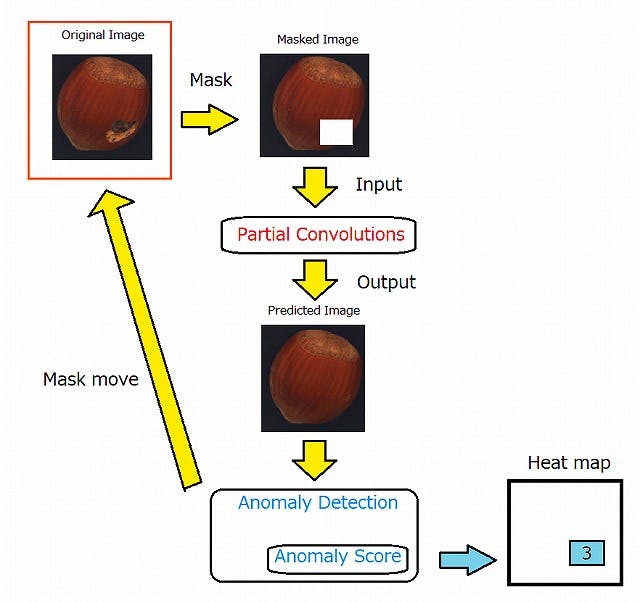
ただし、学習フェーズは5,6時間かかります。構造
全体の構造は以下のとおりです。
- あらかじめ、正常画像で異常検知を学習させておきます。
- さらに、正常画像でPartial Convolutionsを学習させておきます。
- 元画像に対しマスクをかけます(Masked Image)。
- それをPartial Convolutionsに入力し、マスクの部分を補完した画像を取得します(Predicted Image)。
- 取得した画像に対し、異常検知を行い異常スコアを取得します(Anomaly Score)。
- 最後に、取得した異常スコアをヒートマップのマスクした部分に代入します(Heat map)。
- マスクを移動させ、同じ作業を繰り返します。
今回使っている技術は以下のとおりです。
※ Ano-Unet V2とは名ばかりで、メインはPartial Convolutionsの表現力を
頼りにしています。ただ、U-netは一応、Partial Convolutionsの中で
使われているので、Ano-Unet V2という名前でも許されるかなぁと思います。以下、各技術を説明します。
Patial Convolutions
Patial Convolutions(以下PCs)はマスクした部分をリアルな画像で補完
するネットワークです。
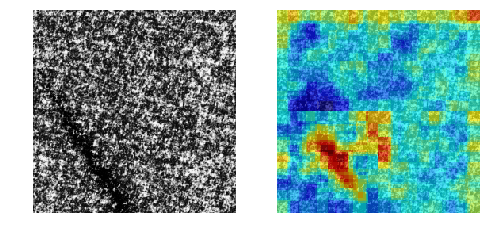
上の図は、PCsの論文より引用したものです。
かなりリアルな画像が再現されています。Ano-Unet V2では、まず、PCsを正常画像で学習させます。そして、異常部分をマスクして
PCsで補完すれば異常部分が正常に変わるのでは?という発想で成り立っています。以下の図が分かりやすいです。
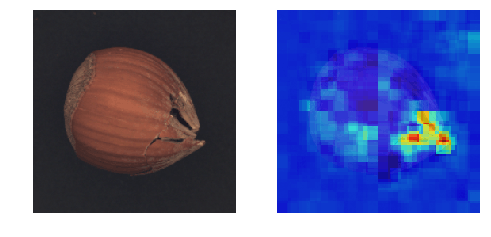
これは、異常部分をマスクした画像を学習させたPCsに入れ、補完させた画像
を取得したものです。期待通り異常部分が消え、正常っぽい画像に変化しました。PCsは正常画像で学習させているため、マスクした部分は必ず正常っぽい絵柄で
補完してくれます。そして、マスクを移動させながら、補完した画像を異常検知させ、異常スコアで
評価すれば、異常部分のときだけ異常スコアが下がるため、どこが異常なのかを
特定することができます。マスクは画像の端から端まで満遍なく移動させます。そして、マスクのサイズは
4種類を用意し、微小な異常個所から大きい異常個所までをカバーしています。ディープラーニングによる異常検知
あらかじめディープラーニングによる異常検知を学習させておく必要がありますが、
これはディープラーニングじゃなくても何でも良いです。画像の異常度を算出できる
手法であれば良いです。極端なことをいえば、画像を二値化して明るいところの面積で合否判定する手法でも
適用できます。(精度は保証できませんが。。。)適した手法
ただし、スコアを出す異常検知手法はオートエンコーダのような面積ベースの
評価方法の方が向いている気がします。metric learningのような特徴ベースの
ものだと最も異常な部分を消さないと、スコアが全然下がってくれないため、
少しの異常は見過ごされる傾向にあると思われます。ただ、オートエンコーダによる異常検知は元々可視化できる構造なので、そもそも
Ano-Unet V2は使う必要ないよ!というジレンマもあるわけですが。。。実験
今回は、cifar-10は使わずに、製造業で出てきそうな画像を使います。
使ったデータセットは以下の二つ。そして、異常検知手法として黒魔術を使いました。
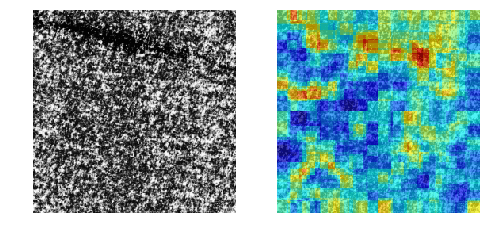
MVTec-ADを使った結果
コード全体はこちらに置きました。
Colabで動くはずです。
うまくいく確率は約70%という印象。
@daisukelab さんの自己教師あり学習と比べると見劣りしますが、
教師無し学習なので良しとします(^^;DAGMを使った結果
うまくいく確率は約50%という印象。
結構難しいデータセットでした。まとめ
- Ano-Unet V2の推論は比較的高速、パラメータ調整もほとんど不要
- 学習時間が長いのがネック(5,6時間)
- metric learningに適した可視化手法かといわれると、ベストではない(改善の余地あり)





- 投稿日:2019-10-08T12:24:25+09:00
JupyterのAnimation �ではまった
これからのGUIは、Jupyterだろ!ということで、いろいろ調べているのだけど、ハマったのでメモ。下のコードは動く。
animateという関数がコールバックされてプロット内のlineをアップデートしている。直接コールバック関数のなかでplotしてもいいらしいが、ここでの本題ではないので、とりあえずこれで。%matplotlib nbagg import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation fig, ax = plt.subplots() line, = ax.plot([], [], lw=2) def animate(i): x = np.linspace(0, 1, 1000) y = np.sin((x + (0.01 * i)) * 2 * np.pi) * 0.5 + 0.5 line.set_data(x, y) return (line,) animation.FuncAnimation(fig, animate, frames=100, interval=20, blit=True)おどろくべきことに、このコードを関数の中に移しただけの次のコードは動かない。
def createGraph(): fig, ax = plt.subplots() line, = ax.plot([], [], lw=2) def animate(i): x = np.linspace(0, 1, 1000) y = np.sin((x + (0.01 * i)) * 2 * np.pi) * 0.5 + 0.5 line.set_data(x, y) return (line,) animation.FuncAnimation(fig, animate, frames=100, interval=20, blit=True) createGraph()エラーがでるわけではないのだけど、プロット領域が表示されるだけで、全くグラフが描画されない。いろいろ試してみると
animate関数が全く呼ばれていないことがわかった。これを動くようにするには、
createGraph関数の末尾で作成したAnimationオブジェクトをreturnすればいい。return animation.FuncAnimation(fig, animate, frames=100, interval=20, blit=True)なぜなのか
マニュアルを見たら、冒頭にちゃんと書いてあった。。
In both cases it is critical to keep a reference to the instance object. The animation is advanced by a timer (typically from the host GUI framework) which the Animation object holds the only reference to. If you do not hold a reference to the Animation object, it (and hence the timers), will be garbage collected which will stop the animation.
Animationオブジェクトの参照が作られると同時に開放されるので、animateを一度も呼び出す暇もなく、即回収されていた、ということらしい。1番最初の書き方でも返り値を変数に代入していないので即死しそうなものだけど、Jupyterでは各入力セッションの最後の文の値が自動的に_に代入されるので、参照が失われないので死ななかったようだ。だから、末尾にa = 'test'とかダミーの文を入れてやると、
_にバインドされるのがこのダミーの文の結果になるので動かなくなる。でも、一度動き出すと代入した変数を書き潰しても止まらないんだよなあ。どこかに別途参照が保持されるのだろうか。
ちなみに、アニメーションを停止させるには下記のようにするればよい。
_.event_source.stop()教訓
マニュアルを先にちゃんと読みましょう。
- 投稿日:2019-10-08T11:07:08+09:00
言語処理100本ノックをPython3で解く「第1章 準備運動」- ②
はじめに
自然言語処理の勉強と発信も兼ねて、忘備録としてまとめていく。
問題は、乾・岡崎研究室が公開している、自然言語処理100本ノック。
Python勉強して数ヶ月程度なので、間違っているとこあると思いますが、指摘していただけると幸いです。実行環境
OS:macOS Mojave
Python: python 3.7.405. n-gram
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,"I am an NLPer"という文から単語bi-gram,文字bi-gramを得よ.
main.pydef word_n_gram(sentence, n, letter=False): if not letter: sentence = sentence.split() return [sentence[point:point+n] for point in range(len(sentence))] s = 'I am an NLPer' print(word_n_gram(s, 2)) print(word_n_gram(s, 2, True))Output[['I', 'am'], ['am', 'an'], ['an', 'NLPer'], ['NLPer']] ['I ', ' a', 'am', 'm ', ' a', 'an', 'n ', ' N', 'NL', 'LP', 'Pe', 'er', 'r']単語bi-gramはスペース入るけどこの区切り方でいいんかな。
letterがT/Fで単語bi-gramで実装できるようにした。
n-gramなるものを初めて知ってなかなかおもしろいなと感じた。06. 集合
「"paraparaparadise"と"paragraph"に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.さらに,'se'というbi-gramがXおよびYに含まれるかどうかを調べよ.
main.pydef word_n_gram(sentence, n, letter=False): if not letter: sentence = sentence.split() return set([sentence[point:point+n] for point in range(len(sentence))]) x = 'paraparaparadise' y = 'paragraph' z = 'se' X = word_n_gram(x, 2, True) Y = word_n_gram(y, 2, True) Z = word_n_gram(z, 2, True) print(X) print(Y) print(Z) print('--------------------') print(X | Y) # print(X.union(Y)) print(X & Y) # print(X.intersection(Y)) print(X - Y) # print(X.difference(Y)) print('--------------------') print(Z <= X) print(Z <= Y)Output{'ap', 'se', 'e', 'pa', 'ar', 'di', 'ra', 'ad', 'is'} {'ap', 'pa', 'ar', 'ph', 'ag', 'gr', 'ra', 'h'} {'se', 'e'} -------------------- {'ap', 'se', 'e', 'pa', 'ar', 'ph', 'di', 'ag', 'gr', 'ra', 'h', 'ad', 'is'} # 和集合 {'ap', 'ar', 'ra', 'pa'} # 積集合 {'se', 'e', 'di', 'ad', 'is'} # 差集合 -------------------- True False集合の処理は、
setを使う。
setset オブジェクトは、固有の hashable オブジェクトの順序なしコレクションです。通常の用途には、帰属テスト、シーケンスからの重複除去、積集合、和集合、差集合、対称差 (排他的論理和) のような数学的演算の計算が含まれます。Python 公式
重複なし!和集合
積集合
差集合
X,Y,Zの関係
とりあえず図と記号が頭に入ってればよいだろう。
07. テンプレートによる文生成
引数x, y, z
を受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y="気温", z=22.4として,実行結果を確認せよ.main.pydef words(x, y, z): words = str(x) + "時の" + y + "は" + str(z) return words ans = words(x=12, y="気温", z=22.4) print(ans)Output12時の気温は22.4
f-string使ったほうが良さそう。というかこれに限っては、そのまま
というわけで、
f-stringフォーマット済み文字列リテラル( formatted string literal )または f-string は、接頭辞 'f' または 'F' の付いた文字列リテラルです。これらの文字列には、波括弧 {} で区切られた式である置換フィールドを含めることができます。他の文字列リテラルの場合は内容が常に一定で変わることが無いのに対して、フォーマット済み文字列リテラルは実行時に式として評価されます。Python 公式
For_examplea = 'A' b = 'ココ' c = 'hai' print(f"{a}国には{b}と{c}がいる") print(F"{a}国には{b}と{c}がいる")OutputA国にはココとhaiがいる A国にはココとhaiがいるこれを使うと、
main.py2def words(x, y, z): print(f'{x}時の{y}は{z}') words(x=12, y="気温", z=22.4)Output12時の気温は22.4こっちのほうが良さげ。
文字の出力はf-stringを使おう。08. 暗号文
与えられた文字列の各文字を,以下の仕様で変換する関数cipherを実装せよ.
英小文字ならば(219 - 文字コード)の文字に置換
その他の文字はそのまま出力
この関数を用い,英語のメッセージを暗号化・復号化せよ.main.pydef cipher(s): res = '' for i in range(len(s)): if s[i].islower(): res += chr(219 - ord(s[i])) else: res += s[i] return res # 暗号化 ans = cipher('I like football') print(ans) # 復元 undo = cipher(ans) print(undo)OutputI orpv ullgyzoo I like football使ったのは、
str.islower()、ord(c)
str.islower()文字列中の大小文字の区別のある文字全てが小文字で、かつ大小文字の区別のある文字が 1 文字以上あるなら真を、そうでなければ偽を返します。Python 公式
For_examples = 'abcde' print(s.islower()) s = 'Abcde' print(s.islower()) s = '1234' print(s.islower())OutputTrue False False逆に、大文字判定を行う場合は、
str.isupper()
str.isupper()文字列中の大小文字の区別のある文字 4 全てが大文字で、かつ大小文字の区別のある文字が 1 文字以上あるなら真を、そうでなければ偽を返します。Python 公式
For_examples = 'abcde' print(s.isupper()) s = 'ABCDE' print(s.isupper()) s = '1234' print(s.islower())outputFalse True False
ord(c)文字の Unicode 文字を表す文字列に対し、その文字の Unicode コードポイントを表す整数を返します。例えば、 ord('a') は整数 97 を返し、 ord('€') (ユーロ記号) は 8364 を返します。これは chr() の逆です。Python公式
PythonはC++みたいに文字(
chr())と数字の比較ができないので、ord(c)を使って比較する。For_examples = 'a' print(ord(s)) s = 'A' print(ord(s))output97 6509. Typoglycemia
スペースで区切られた単語列に対して,各単語の先頭と末尾の文字は残し,それ以外の文字の順序をランダムに並び替えるプログラムを作成せよ.ただし,長さが4以下の単語は並び替えないこととする.適当な英語の文(例えば"I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind .")を与え,その実行結果を確認せよ.
main.pyimport random moji = input() words = moji.split() lis = [] for word in words: # 文字数判断 if len(word) <= 4: lis.append(word) continue # char -> list w = list(word) # 先頭と末尾の文字は残しそれ以外の文字の順序をランダムにするための番号取得 l = list(range(1, len(w) - 1)) num = random.sample(l, len(l)) # char -> string res = '' # 先頭 res += w[0] # 先頭末尾以外をランダム for i in num: res += w[i] # 末尾 res += w[-1] lis.append(res) ans = ' '.join(lis) print(ans)OutputI cd'nolut beileve that I cuold acltlauy ustrednand what I was reiadng : the peomnnaehl poewr of the hmuan mind .使ったのは、
random.sample(population, k)、str.join(iterable)
random.sample(population, k)母集団のシーケンスまたは集合から選ばれた長さ k の一意な要素からなるリストを返します。重複無しのランダムサンプリングに用いられます。
Python公式
populationはシーケンスまたは集合を入れていいと、シーケンスは以下参照
簡単に言うと、
list()、tuple()、range()、str()はシーケンス型。それぞれ、変更できる、変更できない、数字を扱う、文字列とかの違いがあるが、似たような処理ができる。例えば、list()、tuple()、str()の文字アクセスとかは同じ。ということは、
range()そのままぶっ込んで良さそうなので、main.py2import random moji = input() words = moji.split() lis = [] for word in words: # 文字数判断 if len(word) <= 4: lis.append(word) continue front = word[0] body = word[1:-1] back = word[-1] res = front + ''.join(random.sample(body, len(body)))+back lis.append(res) ans = ' '.join(lis) print(ans)OutputI cdln'uot bieleve that I could aaclluty ureatsndnd what I was rnaideg : the poeanhemnl pwoer of the huamn mind .きれいになった。。
str.join(iterable)iterable 中の文字列を結合した文字列を返します。 iterable に bytes オブジェクトのような非文字列の値が存在するなら、 TypeError が送出されます。要素間のセパレータは、このメソッドを提供する文字列です。Python公式
使い方は
'(間に挿入する文字)'.join(ここにstr型リストを入れる)。For_examplevowel = ['a', 'i', 'u', 'e', 'o'] print('@'.join(vowel)) print(''.join(vowel))Outputa@i@u@e@o aiueoFor_example2vowel = [1, 2, 3, 4, 5] print('@'.join(vowel)) print(''.join(vowel))OutputTraceback (most recent call last): print('@'.join(vowel)) TypeError: sequence item 0: expected str instance, int foundあとがき
Pythonicじゃないのは否めない。
書くのが時間かかるから1時間以内で終わるようにしたい。次からUNIXコマンドかー
あまりわからん。。。。。。。





- 投稿日:2019-10-08T10:36:53+09:00
オブジェクト指向をポケモンで理解してみよう(Python)
オブジェクト指向をポケモンを例にわかりやすく
pythonを勉強して、僕が理解に苦しんだのが、classの概念。
プログラミングを長年やられている方は、Rubyなどもclassの概念を持つので、理解されているかと思いますが、経験の浅い僕にはイメージし難いものでした。参考書を何度読んでも、クラスやらメソッド、インスタンスなど正直???となることばかりで、なかなかに嫌気をさしていました。
そこで、自分なりに簡単な言葉でわかりやすくまとめたいと思い、試行錯誤した結果、昔好きだったポケモンでまとめることが自分に腑に落ちたので、共有したいと思います。
イメージとして・・・
ポケモンってどんな「モノ」か。僕らは知っていますが、コンピューターは知りません。
なので、コンピューターに対して、ポケモンってこんなものだよと教えてあげるイメージで書いていきます。コード例
#Pokemonという「もの」を、コンピュータに教える class Pokemon(object): #Pokemonの特徴を教える #名前(name)と、レベル(level)と、体力(hp)があるよ def __init__(self, name, level, hp): self.name = name self.level = level self.hp = hp #Pokemonに対して、させたいことを教える #__init__で書いた特徴を、表示させたいな def output(self): print(self.name+":初期レベル"+str(self.level)+"、初期体力"+str(self.hp)) #ふしぎなアメを食べるとレベルが1上がる特徴を、表示させたいな def eat(self, food): if food == "ふしぎなアメ": self.level += 1 print(self.name+"は、"+food+"を食べてレベルが"+str(self.level)+"になった") #Pokemonには、ピカチュウという名前(name)の「もの」がいると、コンピュータに教える #ピカチュウのレベル(level)は5で、体力(hp)は100なんだ Pikachu = Pokemon("ピカチュウ", 5, 100) #ピカチュウの特徴を表示させる Pikachu.output() #ピカチュウにふしぎなアメを食べさせる Pikachu.eat("ふしぎなアメ") >>>ピカチュウ:初期レベル5、初期体力100 >>>ピカチュウは、ふしぎなアメを食べてレベルが6になった解釈
#Pokemonという「もの」を、コンピュータに教える class Pokemon(object): #Pokemonの特徴を教える #名前(name)と、レベル(level)と、体力(hp)があるよ def __init__(self, name, level, hp): self.name = name self.level = level self.hp = hp #Pokemonに対して、させたいことを教える #__init__で書いた特徴を、表示させたいな def output(self): print(self.name+":初期レベル"+str(self.level)+"、初期体力"+str(self.hp)) #ふしぎなアメを食べるとレベルが1上がる特徴を、表示させたいな def eat(self, food): if food == "ふしぎなアメ": self.level += 1 print(self.name+"は、"+food+"を食べてレベルが"+str(self.level)+"になった")ここで、ポケモン「Pokemon」って、どんな「モノ」で、どんなことができるのかを、コンピューターに教えてあげます。
それがまとまったものが、クラス(class)です。ポケモン「Pokemon」ってどんな「モノ」なの?何をするの?何ができるの?など、特徴をまとめたのが、「def〜」で書かれた項目であり、メソッドと呼ばれるやつです。
まとめ
あくまで僕がイメージしやすいようにまとめたので、きちんと理解するには不足なこともあるかもしれませんが、クラス?メソッド?などで迷ったら、参考にしてください。
- 投稿日:2019-10-08T09:56:41+09:00
2019-10-08 Python > PYTHONPATH > import対象のディレクトリ指定 (モジュール検索パス)
動作環境CentOS Linux release 7.7.1908 (Core)PYTHONPATH?
OpenMPIのモジュールをmoduleコマンドでロードしようとしていたところ、
/etc/modulefiles/が必要になるようだ。そのファイルには以下のような記述がある。prepend-path PYTHONPATH /usr/lib64/python2.6/site-packages/openmpi-1.10自分の環境には上記のようなディレクトリはない。
モジュール検索パスのようだ。
pipインストールした場合に
/usr/lib64/python2.6/site-packagesにディレクトリが追加されるのだろう。現在構築中のシステムではpipインストールはしないので、ディレクトリがない。
- 投稿日:2019-10-08T08:43:30+09:00
一変数正則関数の零点と臨界点を可視化
はじめに
この記事では、前回投稿した「Pythonで連続関数の零点を網羅的に求める」で紹介した連続関数の零点を求める関数SearchZeroPtByDepthの一つの応用例を記載する。
目的
複素平面内の円板で定義された非定数の一変数正則関数
f(z)\space\space (z \in D_R)\\ \left( \begin{eqnarray} D_R &:=& \{|z| < R\}\space\space (R>0)\\ z &=& x + iy\\ &=& re^{i\theta}\space\space (0 < r < R)\\ \end{eqnarray}\right)に対して、 その絶対値の2乗 $$A(z) := |f(z)|^2 = f(z)\overline{f(z)}$$ の臨界点を網羅的に求めるという問題設定をする。ここでは先ず数値計算によって、臨界点がどのように分布しているのかを観察してみる。
動機
はじめに、今後使用すると思われる、領域に関する記法についてまとめておく。
\begin{eqnarray} r&>&0のとき\\ D_r &:=& \{|z| < r\}\space\space\space開円板\\ \overline{D_r} &:=& \{|z| \leqq r\}\space\space\space閉円板\\ \partial{D_r} &:=& \{|z| = r\}\space\space\space円板の境界(円)\\ \end{eqnarray}ここで $r<R$ ならば、$z \in \overline{D_r}$で$f(z)$ は定数でない正則関数なので、最大絶対値の原理より、$|f(z)|$は$D_r$の内部では最大値をとらず、境界 $\partial{D_r}$で最大値をとる。これは、$A(z)=|f(z)|^2$なので、$A(z)$についても同様である。したがって、
M_r=max\{A(z)|z \in \partial{D_r}\}とおくと、
r_1 < r_2 \Longrightarrow M_{r_1} < M_{r_2}が成り立つ。
このことから始めは、$r$を固定したときの最大値になる点$(z,A(z))$が、$r$の変化に伴いどのような軌跡を描きながら増大していくのか興味を持った。そして、最大値だけでなく、より一般に臨界値になる点$(z,A(z))$の軌跡、最終的には、$\theta$を固定したときの臨界値になる点$(z,A(z))$が、$\theta$の変化に伴い描く軌跡も合わせて考えるようになった。定義
ここで、用語について以下に定義しておく。
ただし、偏向臨界点(偏向臨界集合)は造語であり、ここだけで通用するものであることを断っておく。定義1-1.臨界点、臨界値
$z$が正則関数$f$の臨界点とは、$z$が次を満たすこと
\frac{df}{dz}(z)=0\\数式1によれば、この定義は写像
\phi:(x,y)\longmapsto(u(x,y),v(x,y))の臨界点の定義と一致する。
定義1-2.A(z)の極座標臨界点、極座標臨界値
$z=re^{i\theta}\space\space(r\neq 0)$が$A(z)$の極座標臨界点とは、$z$が次を満たすこと
\begin{equation} \left\{ \begin{aligned} \frac{\partial A}{\partial r}(z) = 0\\ \frac{\partial A}{\partial \theta}(z) = 0 \end{aligned} \right. \quad \end{equation}$z$が極座標臨界点のとき、$A(z)$を極座標臨界値と呼ぶ。
このとき、$(z,A(z))$も極座標臨界点と記述することがある。注意
$r=0$においては数式2から、座標変換 $(r,\theta)\longmapsto(x,y)$のヤコビ行列式が$0$になるため、$r=0$において微分同相にならず
\begin{equation} \begin{aligned} \frac{\partial A}{\partial r}(z) = \frac{\partial A}{\partial \theta}(z) = 0 \end{aligned} \quad \end{equation}であっても、
\begin{equation} \begin{aligned} \frac{\partial A}{\partial x}(z) = \frac{\partial A}{\partial y}(z) = 0 \end{aligned} \quad \end{equation}とは限らない。そのような訳で上の定義で$r\neq 0$の条件を付けてある。
したがって、$r=0$つまり$z=0$においては、別途\begin{equation} \frac{\partial A}{\partial z}(0) = 0\\ \end{equation}が成り立つかどうか確認する必要がある。
臨界点と極座標臨界点の関係
数式3によれば、$z\neq0$のとき、
$f(z)$の臨界点と零点を合わせた集合は、$A(z)$の極座標臨界点全体と一致する。
また、数式3と同じだが、微分演算子を使った表現を数式4に記載しておく。後で何かの役に立つかもしれない。定義2-1.A(z)の偏角方向の偏向臨界点(偏向臨界集合)
$z=re^{i\theta}\space\space(r\neq 0)$が$A(z)$の偏角方向の偏向臨界点とは、$z$が次を満たすこと
\frac{\partial A}{\partial \theta}(z) = 0このとき、$(z,A(z))$も偏角方向の偏向臨界点と記述することがある。
また、偏角方向の偏向臨界点全体を偏角方向の偏向臨界点集合と記述する。定義2-2.A(z)の半径方向の偏向臨界点(偏向臨界集合)
$z=re^{i\theta}\space\space(r\neq 0)$が$A(z)$の半径方向の偏向臨界点とは、$z$が次を満たすこと
\frac{\partial A}{\partial r}(z) = 0このとき、$(z,A(z))$も半径方向の偏向臨界点と記述することがある。
また、半径方向の偏向臨界点全体を半径方向の偏向臨界点集合と記述する。臨界点の例
2次多項式
$f(z) = z^2 + z - 1$ の場合
左図:r=0.5におけるA(0.5,\theta)のグラフ(水色の線)と偏角方向の偏向臨界点(青点)\\ 右図:\theta=0におけるA(r,0)のグラフ(紫色の線)と半径方向の偏向臨界点(赤点)
左図:rを変化させたときの、偏角方向の偏向臨界点(青点)の軌跡\\ 右図:\thetaを変化させたときの、半径方向の偏向臨界点(赤点)の軌跡\\ 左図の偏角方向の偏向臨界点の内に、M_rの軌跡が含まれている。
偏角方向の偏向臨界点集合(青点)、 半径方向の偏向臨界点集合(赤点)\\ (z,A(z))のグラフを重ねた3D表示\\ (ただし、零点や臨界点を強調するため、A(z)が2.0以上のときは2.0としてプロット)\\ 偏角方向の偏向臨界点集合(青点)、半径方向の偏向臨界点集合(赤点)の交点が臨界点になる。\\ 例えて言うならば、偏向臨界集合が骨格で、臨界点が関節のように見える。Pythonプログラム
上記のグラフを描くPythonプログラムのコードは以下のとおり。
プログラム全文
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import seaborn as snsni from DepthMethod import SearchZeroPtByDepth,numerical_diff import sys class PartialValue: def __init__(self,f): self.func = f self.fixx = None self.fixy = None def fix_x(self,x): self.fixx=x def fix_y(self,y): self.fixy=y def func_x(self): return lambda x:self.func(x , self.fixy) def func_y(self): return lambda y:self.func(self.fixx , y) #polar to real Cartesian x=lambda r,t:r*np.cos(t) y=lambda r,t:r*np.sin(t) #real to complex z=lambda x,y:x+y*1j #definiton of holomorphic function func,funcName = lambda z:z**2+z-1,'z**2+z-1' diffdelt = 1e-6 zLim = 10.0 #max value of graph abs2min = lambda a,zLim:np.minimum(a,zLim) absfunc = lambda w:(abs(func(w))).real absfunc2 = lambda w:(func(w)*func(w).conjugate()).real abs2 = lambda r,t:absfunc2(x(r,t)+y(r,t)*1j).real absfunc2_min = lambda w,zLim:abs2min(absfunc2(w),zLim) print('-------------------------------------------') print('partial critical points by polar coodinate') print('-------------------------------------------') """ 偏角方向の偏向臨界点 """ print('Shift the radius,plot theta critical points') #Shift the radius rary=np.linspace(-1.0,1.0,200) #Shift the theata tary=np.linspace(0.0,2*np.pi,200) Len = rary.max() re_t=[] im_t=[] fv_t=[] z_t=[] re_t_c=[] im_t_c=[] fv_t_c=[] #ra=[0.5] ra=np.arange(0.05,1.0,0.05) start = 0.0 ended = 2.5*np.pi re_t.append(0.0) im_t.append(0.0) fv_t.append(abs2(0,0)) z_t.append(0.0) for r in ra: for t in tary: w = r*np.cos(t) + 1j*r*np.sin(t) re_t.append(w.real) im_t.append(w.imag) #fv_t.append(abs2(r,t)) fv_t.append(absfunc2_min(w,zLim)) z_t.append(0.0) a = lambda r,t:absfunc2(x(r,t)+y(r,t)*1j) sv = PartialValue(a) sv.fix_x(r) fst = sv.func_y() dfst = lambda t:numerical_diff(fst,t,diffdelt) print('Radius = ',r) daZeros,rdGoodNum=SearchZeroPtByDepth(dfst,'ShiftRadius',start,ended,InitRandNum=50) daZeroSel = daZeros[0] if (daZeroSel.size > 0): #daZero=daZeroSel['EstimateZeroPt'][abs(daZeroSel['FunctionValue']) < np.sqrt(diffdelt)] daZero=daZeroSel['EstimateZeroPt'] w=z(x(r,daZero),y(r,daZero)) for i in w.index: if ((abs(w[i].real)<=Len) and (abs(w[i].imag) <= Len )): if (absfunc2(w[i]) < zLim): re_t_c.append(w[i].real) im_t_c.append(w[i].imag) fv_t_c.append(absfunc2(w[i])) ## add origine into critical points # re_t_c.append(0.0) # im_t_c.append(0.0) # fv_t_c.append(absfunc2(0.0)) """ 半径方向の偏向臨界点 """ print('Shift the theta,plot radius critical points') re_r=[] im_r=[] fv_r=[] z_r=[] re_r_c=[] im_r_c=[] fv_r_c=[] #ta=[0] ta=np.pi*1/30*np.arange(0,30,1) start = -Len ended = Len for t in ta: for r in rary: w = r*np.cos(t) + 1j*r*np.sin(t) re_r.append(w.real) im_r.append(w.imag) #fv_r.append(abs2(r,t)) fv_r.append(absfunc2_min(w,zLim)) z_r.append(0.0) a = lambda r,t:absfunc2(x(r,t)+y(r,t)*1j) sv = PartialValue(a) sv.fix_y(t) fst = sv.func_x() dfst = lambda r:numerical_diff(fst,r,diffdelt) print('Theta = ',t) daZeros,rdGoodNum=SearchZeroPtByDepth(dfst,'ShiftAngle',start,ended,InitRandNum=50) daZeroSel = daZeros[0] if (daZeroSel.size > 0): #daZero=daZeroSel['EstimateZeroPt'][abs(daZeroSel['FunctionValue']) < np.sqrt(diffdelt)] daZero=daZeroSel['EstimateZeroPt'] w=z(x(daZero,t),y(daZero,t)) for i in w.index: if ((abs(w[i].real)<=Len) and (abs(w[i].imag) <= Len )): if (absfunc2(w[i]) < zLim): re_r_c.append(w[i].real) im_r_c.append(w[i].imag) fv_r_c.append(absfunc2(w[i])) sns.set_style("whitegrid", {'grid.linestyle': '--'}) fig = plt.figure(figsize=plt.figaspect(1.0)) fig.canvas.set_window_title('f(z) = '+funcName) ax1 = fig.add_subplot(1, 2, 1, projection='3d') ax1.set_xlabel("real part") ax1.set_ylabel("imaginary part") ax1.set_zlabel("absolute value") #ax1.set_zscale('log',basex=10) ax1.plot(re_t,im_t,fv_t,marker=".",color="cyan",linestyle='None',label='on cosntant radius',markersize=2) ax1.plot(re_t,im_t,z_t,marker=".",color="darkgray",linestyle='None',markersize=2) ax1.plot(re_t_c,im_t_c,fv_t_c,marker=".",color="blue",linestyle='None',label='theta critical points') plt.xlim(-rary.max(),rary.max()) plt.ylim(-rary.max(),rary.max()) plt.legend() ax2 = fig.add_subplot(1, 2, 2, projection='3d') ax2.set_xlabel("real part") ax2.set_ylabel("imaginary part") ax2.set_zlabel("absolute value") #ax2.set_zscale('log',basex=10) ax2.plot(re_r,im_r,fv_r,marker=".",color="violet",linestyle='None',label='on cosntant theta',markersize=2) ax2.plot(re_r,im_r,z_r,marker=".",color="darkgray",linestyle='None',markersize=2) ax2.plot(re_r_c,im_r_c,fv_r_c,marker=".",color="red",linestyle='None',label='radius critical points') plt.xlim(-rary.max(),rary.max()) plt.ylim(-rary.max(),rary.max()) plt.legend() plt.show() """ 偏向臨界集合とAの3D表示 """ zLim2=2.0 sns.set_style("whitegrid", {'grid.linestyle': '--'}) fig = plt.figure(figsize=plt.figaspect(1.0)) fig.canvas.set_window_title('f(z) = '+funcName) #for reference dLen = Len/100 X, Y = np.mgrid[-Len:Len:dLen, -Len:Len:dLen] #Z = absfunc(z(X, Y)) Z = absfunc2_min(z(X, Y),zLim2) ax1 = fig.add_subplot(1, 1, 1, projection='3d') ax1.set_xlabel("real part") ax1.set_ylabel("imaginary part") ax1.set_zlabel("absolute value") plt.xlim(-Len,Len) plt.ylim(-Len,Len) ax1.set_zlim(0.0,zLim2) re_t_c_rest=np.array(re_t_c) im_t_c_rest=np.array(im_t_c) fv_t_c_rest=np.array(fv_t_c) idx=zLim2 > fv_t_c_rest re_t_c_rest=re_t_c_rest[idx] im_t_c_rest=im_t_c_rest[idx] fv_t_c_rest=fv_t_c_rest[idx] re_r_c_rest=np.array(re_r_c) im_r_c_rest=np.array(im_r_c) fv_r_c_rest=np.array(fv_r_c) idx=zLim2 > fv_r_c_rest re_r_c_rest=re_r_c_rest[idx] im_r_c_rest=im_r_c_rest[idx] fv_r_c_rest=fv_r_c_rest[idx] ax1.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='hsv_r', linewidth=0.1) ax1.plot(re_t_c_rest,im_t_c_rest,fv_t_c_rest,marker=".",color="blue",linestyle='None',label='theta critical points') ax1.plot(re_r_c_rest,im_r_c_rest,fv_r_c_rest,marker=".",color="red",linestyle='None',label='radius critical points') plt.legend() plt.show()他の正則関数を対象にするには、
func,funcName = lambda z:z**2+z-1,'z**2+z-1'において、λ式を変更すればよい。
また、zLim、zLim2を変更することで、臨界点付近の変化を強調することができる。数式
数式1
\begin{eqnarray} f(z) &:=& u(x,y) + iv(x,y)\\ J_f(z) &:=& \begin{vmatrix} u_x & u_y \\ v_x & v_y \\ \end{vmatrix}\\ &=&u_xv_y - u_yv_x\\ &=&u_x^2 + v_x^2\\ &=&(u_x+iv_x)\overline{(u_x+iv_x)}\\ &=&\frac{df(z)}{dz}\overline{\frac{df(z)}{dz}}\\ \end{eqnarray}\\ \space\space\\ \therefore \space\space J_f(z)=0 \Leftrightarrow \frac{df(z)}{dz}=0数式2
\begin{eqnarray} \begin{pmatrix} dx\\ dy \end{pmatrix} &=& \begin{pmatrix} cos\theta & -rsin\theta \\ sin\theta & rcos\theta \\ \end{pmatrix} \begin{pmatrix} dr\\ d\theta \end{pmatrix}\\ J &:=& \begin{vmatrix} cos\theta & -rsin\theta \\ sin\theta & rcos\theta \\ \end{vmatrix} =r \end{eqnarray}数式3
$f(z)$が正則関数のとき、下記の式が成り立つ。部分的には、数式3-1~数式3-3を使う。
$\Re$、$\Im$は、それぞれ複素数の実部、虚部を表す。\begin{eqnarray} \frac{\partial A}{\partial r}&=&\frac{\partial A}{\partial x}\frac{\partial x}{\partial r}+\frac{\partial A}{\partial y}\frac{\partial y}{\partial r}\\ &=&(\frac{\partial A}{\partial z}\frac{\partial z}{\partial x}+\frac{\partial A}{\partial \overline{z}}\frac{\partial \overline{z}}{\partial x})\frac{\partial x}{\partial r}+(\frac{\partial A}{\partial z}\frac{\partial z}{\partial y}+\frac{\partial A}{\partial \overline{z}}\frac{\partial \overline{z}}{\partial y})\frac{\partial y}{\partial r}\\&=&2\Re\left(e^{i\theta}.\frac{\partial f(z)}{\partial z}.\overline{f(z)}\right)\\ \\ \frac{\partial A}{\partial \theta}&=&\frac{\partial A}{\partial x}\frac{\partial x}{\partial \theta}+\frac{\partial A}{\partial y}\frac{\partial y}{\partial \theta}\\ &=&(\frac{\partial A}{\partial z}\frac{\partial z}{\partial x}+\frac{\partial A}{\partial \overline{z}}\frac{\partial \overline{z}}{\partial x})\frac{\partial x}{\partial \theta}+(\frac{\partial A}{\partial z}\frac{\partial z}{\partial y}+\frac{\partial A}{\partial \overline{z}}\frac{\partial \overline{z}}{\partial y})\frac{\partial y}{\partial \theta}\\ &=&-2r\Im\left(e^{i\theta}.\frac{\partial f(z)}{\partial z}.\overline{f(z)}\right)\\ \end{eqnarray}\\数式3-1
\begin{eqnarray} \frac{\partial z}{\partial x}=1, \frac{\partial \overline{z}}{\partial x}=i, \frac{\partial z}{\partial y}=1, \frac{\partial \overline{z}}{\partial y}=-i\\ \end{eqnarray}\\数式3-2
\begin{eqnarray} \frac{\partial x}{\partial r}&=&cos\theta\\ \frac{\partial y}{\partial r}&=&sin\theta\\ \frac{\partial x}{\partial \theta}&=&-rsin\theta\\ \frac{\partial y}{\partial \theta}&=&-rcos\theta\\ \end{eqnarray}数式3-3
\begin{eqnarray} \frac{\partial A}{\partial z}&=&\frac{\partial}{\partial z}(f(z)\overline{f(z)})\\ &=&\frac{\partial f(z)}{\partial z}.\overline{f(z)}+f(z).\frac{\partial\overline{f(z)}}{\partial z}\\ &=&\frac{\partial f(z)}{\partial z}.\overline{f(z)}\\ \\ \frac{\partial A}{\partial \overline{z}}&=&\frac{\partial}{\partial \overline{z}}(f(z)\overline{f(z)})\\ &=&\frac{\partial f(z)}{\partial \overline{z}}.\overline{f(z)}+f(z).\frac{\partial\overline{f(z)}}{\partial \overline{z}}\\ &=&f(z).\frac{\partial\overline{f(z)}}{\partial \overline{z}}\\ &=&f(z).\overline{\frac{\partial f(z)}{\partial z}}\\ &=&\overline{\frac{\partial f(z)}{\partial z}.\overline{f(z)}}\\ \end{eqnarray} \\ 上では、fが正則関数なので、\frac{\partial f(z)}{\partial \overline{z}}=\frac{\partial\overline{f(z)}}{\partial z}=0を使っている。数式4
\frac{1}{2}\left(\frac{\partial}{\partial r} - \frac{i}{r}\frac{\partial}{\partial \theta}\right)A = e^{i\theta}.\frac{\partial f(z)}{\partial z}.\overline{f(z)}参考
1の応用としてこの記事を書いた。
3Dグラフの描画については、2を参考にさせていただいた。



- 投稿日:2019-10-08T08:11:11+09:00
アメリカで起こっている働き方改革 ”急成長するフリーランス市場” で望まれるスキルとは!?
アメリカではフリーランスが正規雇用を超える
2027年にはフリーランスの人口が正規雇用を超える予測がある。
近年の米国の雇用人口の増加はフリーランスに依存している傾向もある
フリーランスの増加は望むべき方向か?
フリーランスマーケットプレースの増加
日本でフリーランス人口は増えるか!?
2009年のリーマンショックに寄る”派遣切り”が横行した時代があり、派遣にはネガティブなイメージもあるが、
日本に於けるフリーランスマーケット、
- 投稿日:2019-10-08T08:07:25+09:00
LINE Bot + Python + Heroku で「Error R10 (Boot timeout) 」エラーが出たときの解消方法
背景
なんかLINEボット作りたくなってきた...ムズムズ
お、LINEの公式サイト充実の極みじゃん、サンプルもあるし親切すぎる〜
...と思いきやスムーズに行かない〜!対象
ということで、LINE Developersの公式ドキュメント内の「Herokuでサンプルボットを作成する」をPythonで試そうとして、以下のようなエラーが出た方向けに書きました。
発生したエラー
デプロイ時
heroku_log2019-10-07T11:42:01.490866+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch [中略] 2019-10-07T11:42:01.64401+00:00 heroku[web.1]: Process exited with status 137 2019-10-07T11:42:01.692739+00:00 heroku[web.1]: State changed from starting to crashedLINE Bot でメッセージ送信時
heroku_log2019-10-07T11:42:02.884452+00:00 heroku[router]: at=error code=H10 desc="App crashed" method=POST path="/callback" host={herokuのapp名}.herokuapp.com request_id={xxxxxx} fwd="147.92.150.194" dyno= connect= service= status=503 bytes= protocol=https原因
ホスト名とポート番号に原因がある可能性がある。
ソースコードの原因箇所と変更点
元ソースコードはこちら使わせていただいております。
https://github.com/line/line-bot-sdk-python/tree/master/examples変更前
app.py[抜粋]if __name__ == "__main__": arg_parser = ArgumentParser( usage='Usage: python ' + __file__ + ' [--port <port>] [--help]' ) arg_parser.add_argument('-p', '--port', type=int, default=8000, help='port') arg_parser.add_argument('-d', '--debug', default=False, help='debug') options = arg_parser.parse_args() app.run(debug=options.debug, port=options.port)変更後
app.py[抜粋]if __name__ == "__main__": arg_parser = ArgumentParser( usage='Usage: python ' + __file__ + ' [--port <port>] [--help]' ) arg_parser.add_argument('-p', '--port', type=int, default=int(os.environ.get('PORT', 8000)), help='port') arg_parser.add_argument('-d', '--debug', default=False, help='debug') arg_parser.add_argument('--host', default='0.0.0.0', help='host') options = arg_parser.parse_args() app.run(debug=options.debug, host=options.host, port=options.port)変更点
- ポート番号を「8000」固定値ではなく、Herokuが毎回動的に割り当てている環境変数
$PORTを使用するようにしました。- ホスト名を指定していないと、
http://127.0.0.1:xxxx/が割り当てられ、外部からアクセスができなくなっていたので、「0.0.0.0」と指定するようにしました。参考: Herokuドキュメントの説明箇所
Webサーバー
Each web process simply binds to a port, and listens for requests coming in on that port. The port to bind to is assigned by Heroku as the PORT environment variable.
(ウェブプロセスはポートにバインドし、そのポートにリクエストが来るのを待っている。そのポート番号はHerokuが環境変数$PORTとして割り当てている)
https://devcenter.heroku.com/articles/runtime-principles#web-serversWeb dynos
A web dyno must bind to its assigned$PORTwithin 60 seconds of startup. If it doesn’t, it is terminated by the dyno manager and a R10 Boot Timeout error is logged. Processes can bind to other ports before and after binding to$PORT.
https://devcenter.heroku.com/articles/dynos#web-dynosR10 - Boot timeout
A web process took longer than 60 seconds to bind to its assigned `$PORTP. When this happens, the dyno’s process is killed and the dyno is considered crashed. Crashed dynos are restarted according to the dyno manager’s restart policy.
This error is often caused by a process being unable to reach an external resource, such as a database, or the application doing too much work, such as parsing and evaluating numerous, large code dependencies, during startup.
https://devcenter.heroku.com/articles/error-codes#r10-boot-timeoutおわりに
サンプル真似するだけでもつまずく点ってやっぱりあるもんだな、と思いました。
でもおかげで一つわかることが増えた気がします。
もし記述内容に私の誤認や記述間違いがありましたら、ご教授お願いいたします