- 投稿日:2019-10-08T23:19:44+09:00
知っ得ハンズオン はじめての迷路脱出 ~AWS RoboMakerと強化学習~を受講したよ(2019年10月8日実施)
知っ得ハンズオン はじめての迷路脱出 ~AWS RoboMakerと強化学習~を受講したよ
テキストは、Githubで公開予定だそうです。
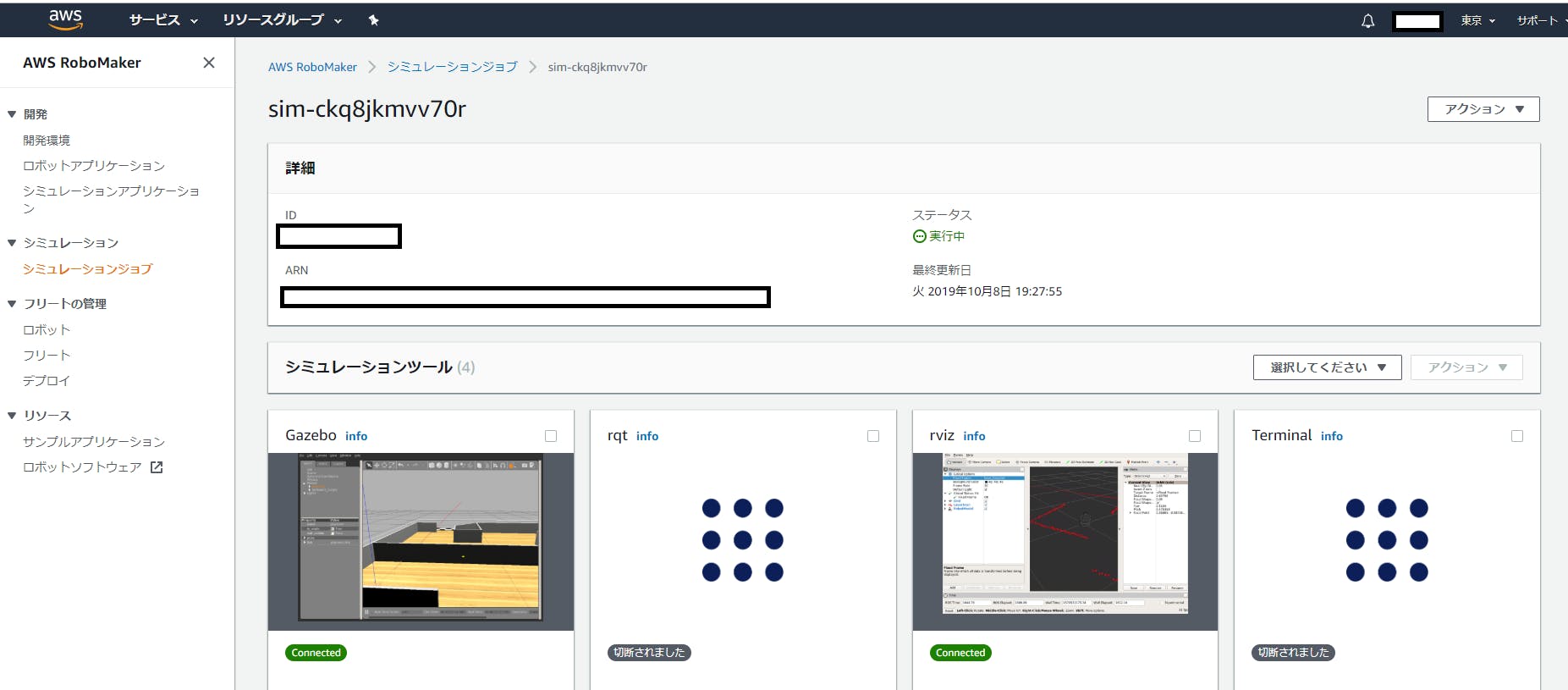
18時30分から開始して、1時間後には、ROSのGAZEBOでシミュレーターが動いています。
残念ながら、学習モデル作成には1時間以上かかるために時間中には終わりませんが・・・
AWS上でROSの環境を構築し、GazeboやRvizを簡単に構築し、さらに、学習までできるというのは一見の価値ありです。
Gazeboのシミュレーションのマップ
Blenderで製作されたそうです。
余談ですがRvizのxacroをVSCodeで作成も可能になったようです。
https://kuwamai.hatenablog.com/entry/2019/10/06/193715
これでクラウドだけでシミュレーション可能になりましたね。AWS RoboMakerはROS2対応をしていくそうなので、今後、AWS RoboMakerでクラウドからROSのノードを操作できるようになるのではないでしょうか?
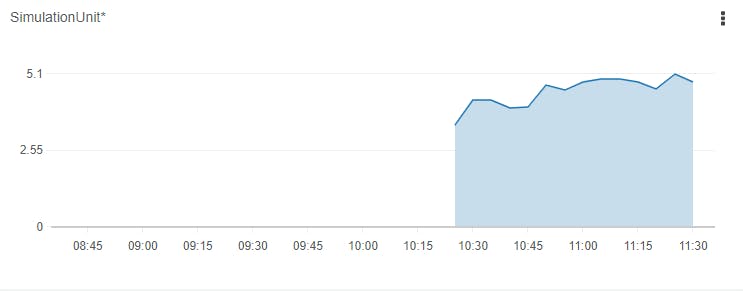
シミュレーション料金
AWS RoboMakerの1シミュレーションユニット1時間あたり0.5ドル程度とのことです。
今回は5シミュレーションなので、1時間動かすと、2.5ドル程度かかるようです。
学習データ
bundleフォルダのoutput.tarファイルを送ることで、フリート管理は依存関係を含めて、移動可能
ただし、Intel系用に作っており、Arm系については、「モデルをロボットにデプロイ (オプション)」を追加で行うようにとのこと。
https://aws.amazon.com/jp/robomaker/resources/train-a-robot-using-reinforcement-learning-project/5/終了後は
いつものことですが終了後はリソースの削除を行う事。




- 投稿日:2019-10-08T20:30:34+09:00
AWS ConfigからSNSに通知されない
はじめに
AWS ConfigからSNSに連携させて通知等を行いたかったが、SNSに通知されなかった。
マネジメントコンソールから自分で作成したSNSトピックを設定して、通知されなかったが、
Configの設定画面で、トッピクの作成を選んで作成したSNSには通知された。必要な設定
SNSトピックのアクセスポリシーに下記「sns:Publish」の設定追加が必要でした。
(省略) { "Sid": "XXXXXXXXXXXXXXXXXXXXXXXXX", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::XXXXXXXXXXXX:role/aws-service-role/config.amazonaws.com/XXXXXXXXXXXXXXXXXX" }, "Action": "sns:Publish", "Resource": "arn:aws:sns:ap-northeast-1:XXXXXXXXXXXX:XXXXXXX-topic" } (省略)ConfigのIAMロールに対するSNSトピックへの「sns:Publish」の許可設定
お願い
もうちょっと具体的に書いてくれてたら嬉しかったです。
https://docs.aws.amazon.com/ja_jp/config/latest/developerguide/sns-topic-policy.html

- 投稿日:2019-10-08T19:25:29+09:00
Athenaでデータ抽出するときによく使う関数まとめ
はじめに
CloudFrontログなどのアクセスログからデータ抽出してちょっと加工して渡すみたいなことをするときに
いい感じに加工するのによく使う関数をピックアップしておく。データソース
基本は以下のリンクの中に関数があります。
Prestoの情報はあまり調べても出ないことも多いので、
ここを見ながら情報を探していくのが確実です。CSVデータの読み込み
Athenaのクエリ結果を一旦ローカルに落としたあとに、
CSVデータを読み込むと""も値として読み込まれてしまう。例えば以下のようなデータを読み込む場合
test.csvname,sex,age,prefecture "田中",1,18,1 "山田",1,26,47 "加藤",2,39,25 "佐藤",2,27,14 "大野",1,50,11 "高橋",1,45,6 "阿部",2,36,4普通にCreate Tableすると
CREATE EXTERNAL TABLE test.test( `name` string, `sex` bigint, `age` bigint, `prefecture` bigint) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://test/work/' TBLPROPERTIES ( 'has_encrypted_data'='false', 'skip.header.line.count'='1', 'transient_lastDdlTime'='1558577493')こうなる。
データ件数が多いと置換するにも時間がかかるのでめちゃくちゃ邪魔です。
id name sex age prefecture 1 "田中" 1 18 1 2 "山田" 1 26 47 3 "加藤" 2 39 25 4 "佐藤" 2 27 14 5 "大野" 1 50 11 6 "高橋" 1 45 6 7 "阿部" 2 36 4 そこで、OpenCSVSerDe クラスを ROW FORMAT で参照し、
文字の区切り記号、引用符文字、およびエスケープ文字の SerDe プロパティを指定してあげます。
また、OpenCSVSerDe クラスを参照する場合、カラムはすべてstringである必要があります。CREATE EXTERNAL TABLE test.test2( `name` string, `sex` string, `age` string, `prefecture` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( 'separatorChar' = ',', 'quoteChar' = '"', 'escapeChar' = '\\' ) LOCATION 's3://test/work/' TBLPROPERTIES ( 'has_encrypted_data'='false', 'skip.header.line.count'='1', 'transient_lastDdlTime'='1558577493')結果。気持ちよくなりました。
id name sex age prefecture 1 田中 1 18 1 2 山田 1 26 47 3 加藤 2 39 25 4 佐藤 2 27 14 5 大野 1 50 11 6 高橋 1 45 6 7 阿部 2 36 4 データ型の変更
上記のCSV読み込みを実施した場合など、
得てしてこちらの想定のデータ型と異なる場合がある。
cast(string as データ型)とすればOK。select AVG(cast(age as bigint)) from test.test2 ;結果。
_col0 1 34.42857142857143 条件分岐のCASE文
CASE文を使って条件分岐が可能です。
また、集計関数と組み合わせることで全レコードのうち特定レコードの数のカウントなども可能です。
その他縦型のデータを横型に変更したりと色々できるので重宝します。単純な条件分岐(フラグ立て)
基本はCASE WHENのあと、条件を記載し、THENの後に合致した場合の処理を記載。
非合致の場合の処理はELSEに記載します。CASE WHEN 条件 THEN 合致したときの値 WHEN 条件 THEN 合致したときの値 ElSE 非合致のときの値 END例えば以下のようなエリアの値を都道府県の値を見て
振って行きたい場合、、
no エリア 1 北海道 2 東北地方 3 関東地方 4 中部地方 5 近畿地方 6 中国地方 7 四国地方 8 九州地方 SELECT name, sex, age, prefecture, CASE WHEN prefecture = '1' THEN 1 WHEN prefecture in ('2','3','4','5','6','7') THEN 2 WHEN prefecture in ('8','9','10','11','12','13','14') THEN 3 WHEN prefecture in ('15','16','17','18','19','20','21','22','23','24') THEN 4 WHEN prefecture in ('25','26','27','28','29','30') THEN 5 WHEN prefecture in ('31','32','33','34','35') THEN 6 WHEN prefecture in ('36','37','38','39') THEN 7 WHEN prefecture in ('41','42','43','44','45','46','47') THEN 8 ElSE NULL END as area FROM test.test2 ;結果。
id name sex age prefecture area 1 田中 1 18 1 1 2 山田 1 26 47 8 3 加藤 2 39 25 5 4 佐藤 2 27 14 3 5 大野 1 50 11 3 6 高橋 1 45 6 2 7 阿部 2 36 4 2 特定の値を持つレコードのカウント
先程のケース文を使えば、
特定の値を持っている場合のみ1を返すとすることで、
特定の値を持つレコードのカウントが可能です。SELECT SUM(CASE WHEN name LIKE '%田%' THEN 1 ELSE 0 END) as name_count FROM test.test2 ;結果。
_col0 1 2 特定の文字列の抽出
URIパースやら加工やらが多いので、
ちょっとだけアクセスログによせて以下のようなテーブルと仮定します。
id name sex age prefecture uri cookie 1 田中 1 18 1 /aaa/abc/123456 a=123;b=a1a1a1a 2 山田 1 26 47 /aaa/bcd/456789 a=abc;b=b2b2b2b 3 加藤 2 39 25 /bbb/abc/123456 a=cde;b=a1b2a1b2 4 佐藤 2 27 14 /bbb/bcd/456789 a=123;b=a1a1a1a 5 大野 1 50 11 /ccc/efg/789101 a=abc;b=b2b2b2b 6 高橋 1 45 6 /ccc/hij/121314 a=cde;b=a1b2a1b2 7 阿部 2 36 4 /ddd/klm/123456 a=123abc;b=aaaa1111 置換
REPLACE(string1, old_chars, new_chars)
SELECT *,REPLACE(cookie, 'a=', 'aaa=') FROM test.test4 ;
cookie col6 a=123;b=a1a1a1a aaa=123;b=a1a1a1a a=abc;b=b2b2b2b aaa=abc;b=b2b2b2b a=cde;b=a1b2a1b2 aaa=cde;b=a1b2a1b2 a=123;b=a1a1a1a aaa=123;b=a1a1a1a a=abc;b=b2b2b2b aaa=abc;b=b2b2b2b a=cde;b=a1b2a1b2 aaa=cde;b=a1b2a1b2 a=123abc;b=aaaa1111 aaa=123abc;b=aaaa1111 該当する文字から○文字目の抽出
substr(string, start, length)
でstartからlength文の文字列を返してくれます。
なお、1文字目は1からです。0ではないです。SELECT cookie,substr(cookie, 3, 3) FROM test.test4 ;
cookie col6 a=123;b=a1a1a1a 123 a=abc;b=b2b2b2b abc a=cde;b=a1b2a1b2 cde a=123;b=a1a1a1a 123 a=abc;b=b2b2b2b abc a=cde;b=a1b2a1b2 cde a=123abc;b=aaaa1111 123 正規表現で合致する部分のうち一部を抽出
regexp_extract(string, pattern, group)
でstringの中から、正規表現に該当するgroupを抽出します。
なお、使用できる正規表現一覧は下記にあります。
POSIX 演算子以下のようにpattern()で囲うことで、
groupわけを行うことができ、3つめの引数の数値のgroupを抽出します。SELECT cookie, regexp_extract(cookie, '(a=)([^;]+)(;)(b=)([^;]+)', 2) FROM test.test4 ;
cookie col1 a=123;b=a1a1a1a 123 a=abc;b=b2b2b2b abc a=cde;b=a1b2a1b2 cde a=123;b=a1a1a1a 123 a=abc;b=b2b2b2b abc a=cde;b=a1b2a1b2 cde a=123abc;b=aaaa1111 123abc parse系
parseして特定の位置の値を取得
split_part(uri, 'パースする文字列', 取得する位置)
こちらも最初が1。SELECT uri, split_part(uri, '/', 2) FROM test.test4 ;
uri _col1 /aaa/abc/123456 aaa /aaa/bcd/456789 aaa /bbb/abc/123456 bbb /bbb/bcd/456789 bbb /ccc/efg/789101 ccc /ccc/hij/121314 ccc /ddd/klm/123456 ddd 正規表現でLIKE
正規表現でLIKE
regexp_like(string, pattern)
戻り値はbooleanです。SELECT cookie FROM test.test4 where regexp_like(cookie, 'a=[^;0-9]+;b=.*') ;
cookie a=abc;b=b2b2b2b a=cde;b=a1b2a1b2 a=abc;b=b2b2b2b a=cde;b=a1b2a1b2 基数変換
from_base(string, radix) を使います。
radixでstringの基数を指定し、変換結果を10進数で返してくれます。今回は例として16進数文字列から10進数へ変換します。
かなり雑ですが以下のようなテーブルを用意します。
id name 16base 1 田中 12D687 2 山田 1E240 3 加藤 1E240 4 佐藤 12D687 5 大野 1E240 6 高橋 1E240 7 阿部 12D687 SELECT *,from_base("16base", 16) FROM test.test5 ;
id name 16base _col2 1 田中 12D687 1234567 2 山田 1E240 123456 3 加藤 1E240 123456 4 佐藤 12D687 1234567 5 大野 1E240 123456 6 高橋 1E240 123456 7 阿部 12D687 1234567 ばっちしでした。
- 投稿日:2019-10-08T19:01:45+09:00
AWSのインスタンス費用を簡単に減らす方法 リザーブドインスタンス
対象
AWSを活用している。
IaaSなので使うときだけ稼働させればいいのですが、
夜間土日などのON/OFFやマシンの大きさを変更する予定がない方向けです。概要
リザーブドインスタンス(RI)はインスタンスの利用を予約する仕組みです。
OFFにしても固定で払う代わりに割安でインスタンスを利用できます。
割引率は最大で約60%にもなり起動したままになっているような環境であれば使うだけでお得です。購入について
[AWS マネジメントコンソール]>[EC2]>[リザーブドインスタンス]から購入できます。
購入すると自分では何もしなくともAWSが勝手に適応してくれます。メニューについて
項目 内容 プラットフォーム インスタンスで利用している環境の物を選んでください テナンシー インスタンスで利用している環境の物を選んでください。基本的にデフォルトで問題ないと思います。 提供クラス 将来的にファミリー(インスタンスタイプのプレフィックスのt2, t3, m4部分)を変更する予定がなければスタンダードでOKです。 期間 1年 or 3年 当然3年の方が割引率が高いです。 お支払い方法 全額前払いが一番割引率が高いです。 注意
リザーブドインスタンス購入後は使っても使わなくても金額は変わらないのでご注意ください。
- 投稿日:2019-10-08T19:00:02+09:00
AWSルートアカウントのコンソールログインを通知する
はじめに
Exam Readiness: AWS Certified Solutions Architect – Professionalを視聴していたら、CloudTrailとCloudWatchを利用してコンソールログインを通知する話が出たので理解を深めるためにも実際にやってみました。
手順
大まかな手順は以下の通りです。
- CloudTrail 証跡の作成
- CloudWatch Logs 連携
- CloudWatch Logs メトリクスフィルター設定
- CloudWatch アラームの作成
CloudTrail 証跡の作成
CloudTrailのダッシュボード画面で「証跡の作成」ボタンをクリックします。
「証跡情報の作成」画面で証跡名を入力します。ここではMyCloudTrailとします。
ストレージの場所でS3バケットを新規作成または既存のものを選択します。
「作成」ボタンをクリックすると証跡が作成されました。
CloudWatch Logs 連携
CloudTrailの証跡情報画面で先ほど作成した証跡の名前(MyCloudTrail)をクリックします。
CloudWatch Logsの項目で「設定」ボタンをクリックし、ロググループを設定します。
「次へ」をクリックするとIAMの設定に移ります。「許可」をクリックします。
CloudWatch Logs メトリクスフィルター設定
CloudWatch Logsの画面で先ほど設定したロググループ(/aws/cloudtrail)を選択して「メトリクスフィルターの作成」ボタンをクリックします。
フィルターパターンに
{ $.userIdentity.type = "Root" && $.eventName = "ConsoleLogin" }と入力して「メトリクスの割り当て」ボタンをクリックします。
フィルター名、メトリクス名を入力して「フィルターの作成」ボタンをクリックします。
フィルターを作成できました。
CloudWatch アラームの作成
「アラームの作成」をクリックします。
期間を1分に変更(任意)し、条件を「1以上」として「次へ」をクリックします。
通知でSNSトピックを新規作成または既存のものを選択して「トピックの作成」をクリックします。
「次へ」をクリックします。アラーム名を入力して「次へ」をクリックします。
設定内容を確認して「アラームの作成」をクリックします。
「AWS Notification - Subscription Confirmation」という件名のメールが届くので「Confirm subscription」をクリックします。以上で設定完了です。ルートアカウントでログインしてみましょう。
アラートが届きました。
課題
設定を自動化できないか
今回マネジメントコンソールからポチポチ設定しましたが、自動化できないでしょうか。こちらで公式にCloudFormationテンプレートが紹介されています(が、うまくいきませんでした・・・)。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/root-user-account-cloudwatch-rule/重要: 開始する前に、CloudWatch イベントの CloudTrail Management 読み取り/書き込みイベントを必ず [All] または [Write-only] に設定して、ログインイベント通知をトリガーしてください。詳細については、読み取り専用/書き込み専用イベントを参照してください。
おそらく、これをよく理解しておらず設定できていないものと思われます。
おわりに
AWSのルートアカウントを使用しないというのは一番最初に知ることかと思います。使わないのでコンソールログインがあったら無条件でアラートメールを送るようにしてみるのもよいでしょう。














- 投稿日:2019-10-08T18:46:08+09:00
Growi, CrowiからAWS S3にアップロードするための設定
概要
CrowiとGrowiでやった内容だが、esa.ioも多分同じ。エンドポイントの書き方が違うくらい。
- HerokuとかDockerとかでGrowiを建てる。
- Growiで利用するS3のバケットを作る。
- IAM作ってGrowiで利用するS3だけ許可するポリシーを書く。
- Growiの管理画面でIAMの情報を入力する。
- おしまい。
なぜやるのか
Herokuの無料範囲(free Dyno)で建てるケースやDockerで運用する場合、ローカル環境に入れると消えてしまうため、MongoDBかS3かその他のストレージに入れる必要がある。
MongoDBに保存するのは抵抗があるため、S3に置きたい。
(特に無料範囲で動かす場合、ストレージのサイズがネックになる可能性が高い。)手順
1. HerokuとかDockerとかでGrowiを建てる。
(省略)
2. Growiで利用するS3のバケットを作る。
(省略)
ブロックパプリックアクセスは全部オフで問題なし。IAMで制御する。3. IAM作ってGrowiで利用するS3だけ許可するポリシーを書く。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:DeleteObject", "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:PutObject", "s3:PutObjectAcl" ], "Resource": [ "arn:aws:s3:::{$growi}", "arn:aws:s3:::{$growi}/*" ] } ] }4. Growiの管理画面でIAMの情報を入力する。
プロフィール画像とかちゃんとアップロードできてればおk。
トラブルシューティング
ENVで
FILE_UPLOAD: awsになってることを確認Todo
GrowiはS3のURLに対してプロキシしてくれるので、直URLは見えないものの、S3のURL直叩きするとファイルが見えてしまう問題がある。
S3のバケットポリシーでIP制限掛けるのが良いが、Herokuの無料範囲でやるとAWSのリージョンで設定されている範囲全部来る可能性があるのでちょっと現実的じゃない。
- lambdaで都度変更するfunction動かすとか
- Growiで使ってる
aws.jsをオーバーライドするとか、改善してPR送るとか/資料/外部仕様/S3のACL設定 - GROWI Developers Wiki https://dev.growi.org/%E8%B3%87%E6%96%99/%E5%A4%96%E9%83%A8%E4%BB%95%E6%A7%98/S3%E3%81%AEACL%E8%A8%AD%E5%AE%9A
- 投稿日:2019-10-08T17:35:22+09:00
AWS Configを有効にしても一部のリソースしか表示されない
- 投稿日:2019-10-08T14:24:04+09:00
AmazonAPIGatewayのLambdaAuthorizer(Node.js)でJWTを検証する(LambdaをServerlessFrameworkでデプロイする)
はじめに
AWSでAPIを構築する際、必ずといっていいほど登場するのがAmazonAPIGatewayですよね。
APIGatewayの認証ってどうされてますか?
- 別に必要ないからしてない
- APIKeyを使っている
- CognitoをAuthorizerにしてトークンの検証をする
- LambdaAuthorizerでトークンの検証をする
など色々なパターンがあると思います。今回は最後に書いた「LambdaAuthorizerでトークンの検証をする」について説明して、その構成をServerlessFrameworkでデプロイするところまでを書いていきます。
登場人物
JSON Web Token (JWT)
JSONをベースとしたトークン。
「ヘッダー / ペイロード / 署名」といった3つのセクションから構成されていて、署名はヘッダーとペイロードのハッシュされた組み合わせです。
hogehoge.foofoofoo.barbarbarbarのような文字列です。ServerlessFramework
Serverlessなアーキテクチャを構築するためのフレームワーク。AWSだけじゃなくAzureやGCPなど他のクラウドサービスでも利用することができる。
詳しくは 公式ページ で確認してみてください。構成
Lambda Authorizer
JWTの検証をLambda内で行っていきます。
今回はNode.js(TypeScript)での例を書いています。authorizer.tsimport { Handler, Context, Callback, CustomAuthorizerEvent } from "aws-lambda" import * as jsonwebtoken from "jsonwebtoken" import jwkToPem from "jwk-to-pem" import jwk from "./jwk" const pem = jwkToPem(jwk as any) export const handler: Handler = async ( event: CustomAuthorizerEvent, _context: Context, callback: Callback ): Promise<any> => { console.log(JSON.stringify(event)) jsonwebtoken.verify( event.authorizationToken, pem, { algorithms: ["RS256"] }, (err: jsonwebtoken.VerifyErrors, decodedToken: object | string) => { if (err) { callback(null, { principalId: 1, policyDocument: { Version: "2012-10-17", Statement: [ { Action: "execute-api:Invoke", Effect: "Deny", Resource: event.methodArn } ] }, context: { messagge: "Custom Error Message" } }) } else { console.log(decodedToken) callback(null, { principalId: 1, policyDocument: { Version: "2012-10-17", Statement: [ { Action: "execute-api:Invoke", Effect: "Allow", Resource: event.methodArn } ] }, context: { messagge: "Custom Allow Message" } }) } } ) }解説
JWT検証で使うモジュールをインストール
$ yarn add jsonwebtoken jwk-to-pem $ yarn add -D @types/jsonwebtoken @types/jwk-to-pem
jsonwebtokenがJWTトークンの検証をするライブラリです。
jwt-to-pemはJWTトークンを検証するための JSON Web Key (JWK) をpem形式に変換するライブラリです。JWT検証
jsonwebtokenのverifyというメソッドを使って検証をします。jsonwebtoken.verify( event.authorizationToken, // requestHeader内のToken pem, // JWKから生成したpem { algorithms: ["RS256"] }, (err: jsonwebtoken.VerifyErrors, decodedToken: object | string) => {} )( Cognitoを使っている場合のJWK取得 )
Cognitoが発行したJWTの検証に使うJWKは
https://cognito-idp.{region}.amazonaws.com/{userPoolId}/.well-known/jwks.jsonから取得する事ができます。
そのJSONを何かしらの方法でimportしてください。今回の例はTSファイルにしてimportしています。
また上記のURLからJWKを取得すると2つKeyが入っていますが、最初の一つを利用すればいいです。jwk.tsexport default { alg: "RS256", e: "XXXX", kid: "xxxxxxxxxxxxxx", kty: "RSA", n: "xxxxxxxxxxxxxx", use: "sig" }検証後の処理
CallbackでAPIGatewayにレスポンスを返して行きます。
Statement内のEffectがAllowかDenyかでその後の処理を判断させます。// 成功時 callback(null, { principalId: 1, policyDocument: { Version: "2012-10-17", Statement: [ { Action: "execute-api:Invoke", Effect: "Allow", Resource: event.methodArn } ] }, context: { messagge: "Custom Allow Message" } }) // 失敗時 callback(null, { principalId: 1, policyDocument: { Version: "2012-10-17", Statement: [ { Action: "execute-api:Invoke", Effect: "Deny", Resource: event.methodArn } ] }, context: { messagge: "Custom Error Message" } })ServerlessFrameworkでデプロイする
プロジェクト作成
LambdaのソースコードをTypeScriptで書いているので、TypeScript用のテンプレートを使ってプロジェクトを作成します。
$ npx -p serverless sls create -t aws-nodejs-typescript -p example-serverless-tsserverless.yml
AuthorizerをつけたいAPIGatewayをイベントとするfunctionの中に
authorizerを追加していきます。
nameはAuthorizerとなるLambdaです。同じyml内で定義している場合はこのnameで参照することができます。外部でデプロイされているLambdaをAuthorizerにしたい場合は、arnに対してそのLambdaのARNを指定します。identitySourceはTokenをどこを参照すれば習得できるのかという設定です。この場合はリクエストヘッダー内のAuthorizationを参照するようになっています。typeはAuthorizerとなるLambdaのeventに渡される値の設定です。単純にTokenを取得したいだけならtokenがおすすめです。リクエストの内容をすべて取得したい場合はrequestを指定します。authorizer: name: authorizer identitySource: method.request.header.Authorization type: token全体としてはこんな感じになります。
serverless.ymlservice: name: lambdda-node-ts plugins: - serverless-webpack provider: name: aws runtime: nodejs10.x region: ap-northeast-1 functions: authorizer: handler: authorizer.handler index: handler: index.handler events: - http: method: get path: hello cors: true authorizer: name: authorizer identitySource: method.request.header.Authorization type: tokenあとは
sls deployでデプロイすれば作業は完了です。さいごに
今回はLambdaAuthorizerを紹介しました。
トークンの検証にLamdbaを使うことで、トークンの検証以外にもAPIに対するリクエストのログを取ることができたり、怪しいリクエストが来た場合にメール送信などカスタマイズすることができます。
Lambdaを挟むことでかなりできることの幅が広がります!
ではまた!!

- 投稿日:2019-10-08T12:36:11+09:00
[TypeScript] AWS-CDK 備忘録
普段はserverless frameworkを使用しているので備忘録として残す
気になる所があったら随時更新していくAWS-CDK
https://github.com/aws/aws-cdk
インストール
GAはNode.js≧10.3.0以上じゃないといけない
npm i -g aws-cdkcdk init
cdk initは空ディレクトリでないと実行出来ないので注意mkdir test-cdk cd test-cdk cdk init app --language=typescript npm icdk.tsの実装
環境変数(direnvを使用)
direnv edit ..envrcexport AWS_REGION=ap-northeast-1 export STAGE=devaccountは
cdk deploy --profile [aws profile]を使用するためコメントアウト
regionはデプロイしたいリージョンを指定する(環境変数で管理してる)npm i @types/nodebin/test-cdk.tsimport 'source-map-support/register'; import cdk = require('@aws-cdk/core'); import {TestCdkStack} from '../lib/test-cdk-stack'; const app = new cdk.App(); new TestCdkStack(app, 'TestCdkStack', { env: { // account: '', region: process.env.AWS_REGION } }); app.synth();Lambda Handlerの実装
npm i aws-lambda @types/aws-lambdasrc/lambda/test.tsimport {APIGatewayEvent, Handler} from 'aws-lambda'; export const handler: Handler = async (event: APIGatewayEvent) => { let test: string = ''; if (event.body != null) { const body = JSON.parse(event.body); test = body.test; } else { return { statusCode: 400, body: 'invalid request' }; } return { statusCode: 200, body: test }; };apigateway-lambdaの実装
npm i @aws-cdk/aws-lambda @aws-cdk/aws-apigatewaycdk.json{ "context": { "serviceName": "test" }, "app": "npx ts-node bin/test-cdk.ts" }envに指定したstageの情報を持ってdev/prodの環境を分ける
lib/test-cdk-stack.tsimport * as cdk from '@aws-cdk/core'; import * as lambda from '@aws-cdk/aws-lambda'; import * as apiGateway from '@aws-cdk/aws-apigateway'; export class TestCdkStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); const serviceName: string = this.node.tryGetContext("serviceName"); const stage: string = process.env.STAGE ? process.env.STAGE : 'dev'; const testLambda = new lambda.Function(this, 'testFunction', { functionName: `${serviceName}-${stage}`, code: new lambda.AssetCode('src/lambda'), handler: 'test.handler', runtime: lambda.Runtime.NODEJS_10_X, memorySize: 128, timeout: cdk.Duration.seconds(30), environment: { // lambda環境変数を指定する // STAGE: stage } }); const api = new apiGateway.RestApi(this, 'testApi', { restApiName: `${serviceName}-service-${stage}`, // stageNameの情報を付与しないとEndpointが/prod/になってしまう deployOptions: { stageName: stage } }); const root = api.root.addResource('tests'); const testLambdaIntegration = new apiGateway.LambdaIntegration(testLambda); root.addMethod('POST', testLambdaIntegration); }; }デプロイ
[aws profile]を適宜変更して実行// cdk bootstrapを実行するのは一度だけでいい cdk bootstrap --profile [aws profile] // ビルド&デプロイ npm run build cdk deploy --profile [aws profile]削除
cdk destroy --profile [aws profile]注意点
name関連にデフォルト値が設定されている箇所が多いので、作成したい環境に合わせて設定していく必要がある
- 投稿日:2019-10-08T12:31:07+09:00
AWS Sysmtems Manager OpsCenterで増えすぎたOpsItemを一括で解決済みにする
AWSCLI ワンライナー
以下をご使用ください。
$ aws ssm describe-ops-items --ops-item-filters '{"Key":"Status","Values":["Open"],"Operator":"Equal"}' --query 'OpsItemSummaries[*].OpsItemId' --output table | grep "oi-" | awk '{print $2}' | while read line; do echo update item: $line; aws ssm update-ops-item --status Resolved --ops-item-id $line; doneステータスが未解決(Open)の Item を何も考えずに一括で解決済み(Resolved)に
変更してしまうのでご注意ください。
以降は解説です。OpsCenter とは
2019年6月に追加された Systems Manager の新しい機能です。
CloudWatch Events と連携して AWS リソースの運用上の問題、イベント、アラート等を
OpsItems として集中管理する機能を提供します。AWS Systems Manager OpsCenter
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/OpsCenter.htmlOpsItem の作成のしくみと蓄積
OpsItem を作成するには大きくわけると2つの方法があります。
- コンソールや OpsCenter API を通して手動で作成する
- CloudWatch Events で各種イベントを検知し、自動作成する
後者の CloudWatch Events ルールは自身で作成してもよいのですが、基本的なルールは
AWS 側であらかじめ用意されており、OpsCenter のコンソールから設定することが可能です。
基本的な運用イベントが網羅されていてとても便利なのですが、アカウントの用途によっては
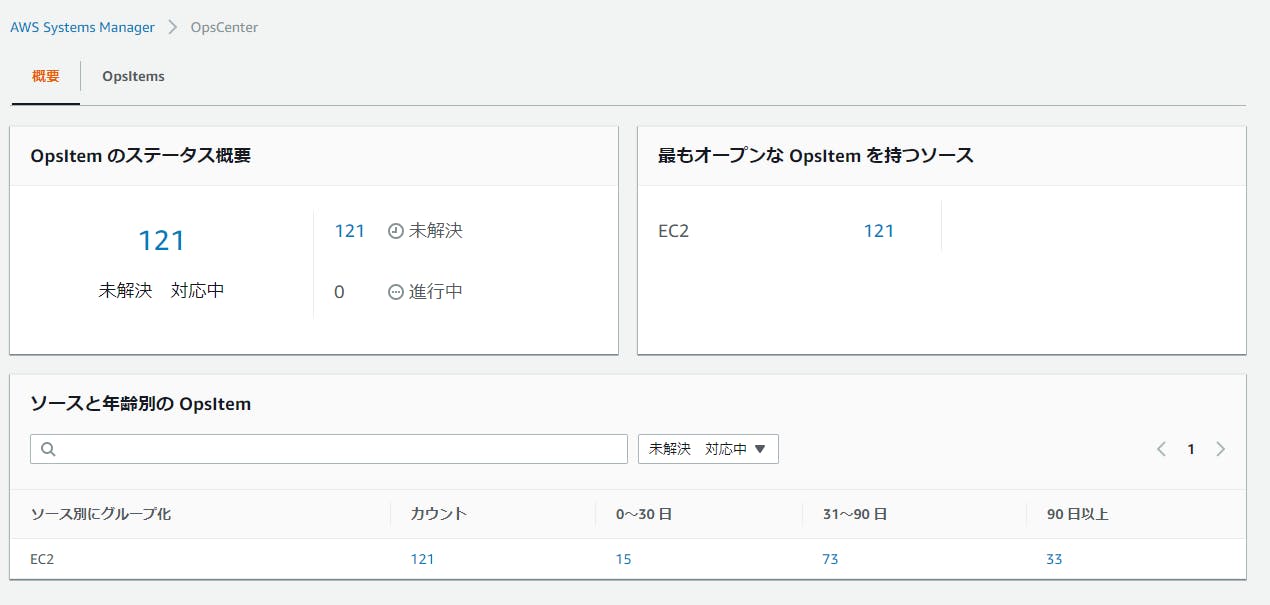
EC2 の停止または終了は頻繁に発生するため、これがノイズになってしまうこともあります。実際に開発用の環境で OpsCenter を検証していたところ
未解決イベントが大量に溜まってしまいました。
各 OpsItem を手動で解決済みにしていってもよいのですが、数が増えてくると大変辛い。
対策
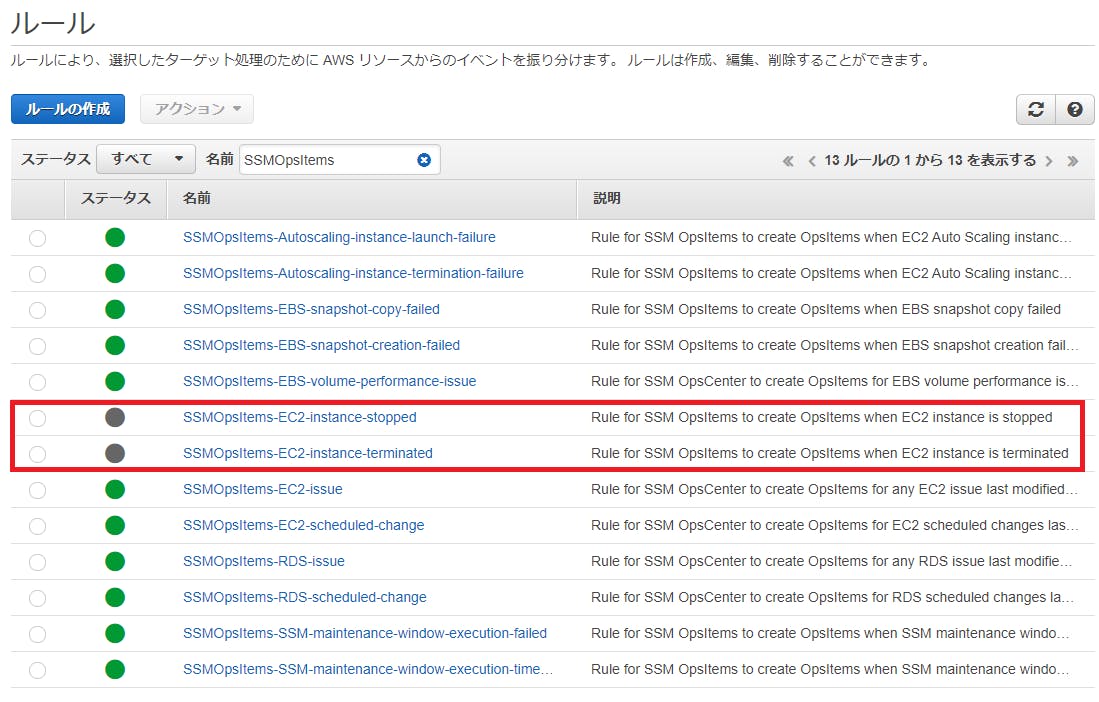
CloudWatch Events ルールの無効化
基本設定で不要なルールは、CloudWatch Events で個別にルールを無効化すれば
Item の自動登録を止めることができます。
AWSCLI によるステータス変更
冒頭のコマンドを改行ありで記載すると以下のような感じになります。
$ aws ssm describe-ops-items \ > --ops-item-filters '{"Key":"Status","Values":["Open"],"Operator":"Equal"}' \ > --query 'OpsItemSummaries[*].OpsItemId' --output table | > grep "oi-" | > awk '{print $2}' | > while read line; > do echo update item: $line; > aws ssm update-ops-item --status Resolved --ops-item-id $line; > done update item: oi-xxxxxxxxxxxx update item: oi-yyyyyyyyyyyy update item: oi-zzzzzzzzzzzz . . 以下略describe-ops-items コマンドでステータスが Open の OpsItemId を抜き出し、
各IDに対して、update-ops-item コマンドでステータスを Resolved に変更しています。注意点としては describe-ops-items が一度に最大で50件までしかリストできないので
上記のコマンドも50件しか処理できません。
50件以上溜まっている場合、Open状態のアイテムが無くなるまで繰り返し実行する必要があります。以上です。
参考になれば幸いです。
- 投稿日:2019-10-08T12:25:19+09:00
古の非Nitro世代インタンス(T2)を最新のインスタンス(T3)に変更する
はじめに
昔からAPIサーバーとして運用されているEC2インスタンスのインスタンスタイプを変更しようとしたところ、諸々のエラーが出てすんなり変更できなかったため、最終的な更新手順の備忘録です。
TL;DR
・インスタンスのenaモジュールとカーネルバージョンを確認
・カーネルをアップデートしてenaをインストール
・AWSCLIからenaを有効化現状の確認
※ 以降の手順でsshでEC2に接続、及び、AWSCLIを使用しますが、環境構築については割愛させていただきます。
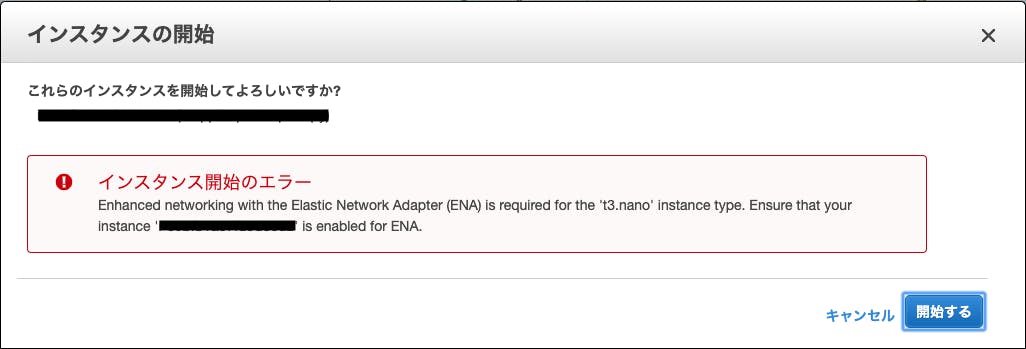
最初にt2インスタンスを停止し、インスタンスタイプをt3に切り替えて起動を試みたところ、下記エラーで起動することができませんでした。
エラーについて調べると下記公式の適用手順が見つかったため、これにしたがって進めていきます。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/enhanced-networking-ena.html1. EC2にsshで接続
2. enaモジュールがインストールされていることを確認
実行.modinfo ena結果.modinfo: ERROR: Module ena not found.古いAMIにはenaモジュールが含まれていないため、
enaを含む最新のカーネルとカーネルモジュールでインスタンスを更新
する必要があるようです。
3. カーネルのバージョン確認
実行.uname -srv結果.Linux 3.14.35-28.38.amzn1.x86_64 #1 SMP Wed Mar 11 22:50:37 UTC 2015インスタンスの更新
公式の手順に従ってパッケージを更新して確認します。
以前の Amazon Linux AMI を使用してインスタンスを起動し、まだ拡張ネットワーキングが有効になっていない場合、拡張ネットワーキングを有効にするには次の手順を実行します。
1. パッケージの更新
sudo yum update -yアップデートが完了したら一旦再起動して再度sshで接続します。
2. 再起動して確認
ena
実行.modinfo ena結果.modinfo: ERROR: Module ena not found.カーネルのバージョン
実行.uname -srv結果.Linux 3.14.35-28.38.amzn1.x86_64 #1 SMP Wed Mar 11 22:50:37 UTC 2015なんと、変化がありません...
【CPUの脆弱性対応】古いAmazon Linuxのkernelを最新版にアップデートするによると、
yum.confファイルにreleaseverの変数を設定しないと、カーネルのバージョンが固定されてしまい更新できないそうです。3.
yum.confの修正(追加)実行.sudo vi /etc/yum.confyum.conf.diff~ # of Amazon Linux AMI. If you prefer not to automatically move to # new releases, comment out this line. - #releasever=latest + releasever=latest # This is the default, if you make this bigger yum won't see if the metadata # is newer on the remote and so you'll "gain" the bandwidth of not having to ~これで再度
sudo yum update -yで更新し、再起動して確認します。4. 再起動して確認
ena
実行.modinfo ena結果.filename: /lib/modules/4.14.146-93.123.amzn1.x86_64/kernel/drivers/amazon/net/ena/ena.ko version: 2.1.1g license: GPL description: Elastic Network Adapter (ENA) ~カーネルのバージョン
実行.uname -srv結果.Linux 4.14.146-93.123.amzn1.x86_64 #1 SMP Tue Sep 24 00:45:23 UTC 2019無事カーネルのアップデートとenaのインストールが完了しました!
続いて、インスタンスのEnaSupportを有効化します。
以降の手順はAWSCLIでローカルPCから実行するため、インスタンスはシャットダウンしておきます。5.
EnaSupportの確認実行.aws ec2 describe-instances --instance-id i-XXXXXXXXXXXX --query 'Reservations[].Instances[].EnaSupport'結果.[]無効の場合は空の配列が帰ってきます。
6.
EnaSupportの有効化実行.aws ec2 modify-instance-attribute --instance-id i-XXXXXXXXXXXX --ena-support実行しても反応がないため、有効化されたか確認します。
7.
EnaSupportの確認実行.aws ec2 describe-instances --instance-id i-XXXXXXXXXXXX --query 'Reservations[].Instances[].EnaSupport'結果.[ true ]有効の場合は
trueが帰ってきます。これでインスタンスの更新は完了です!
インスタンスタイプをt2からt3に変更して、無事起動できることを確認します。まとめ
おそらくあまりにも古いAMIを使用していたため、公式の手順だけでは更新することができませんでした。
定期的にカーネルのバージョンを確認して、最新の状態に保つのが大切ですね。
- 投稿日:2019-10-08T12:21:02+09:00
「API Gateway で Lambda エラーを処理する」が動かなかった話
元ネタ
API Gateway で Lambda エラーを処理する※2019.10.08 AWSのドキュメントのフィードバックに報告済みなのでドキュメント側も修正済みの場合があります
このドキュメントですが、これに書いてある通りにやってもエラー処理が正常にできずステータス200が帰ってきてしまう。
原因はここの誤記
aws apigateway put-integration-response --rest-api-id [rest-api-id] --resource-id [resource-id] --http-method GET --status-code 400 --selection-pattern "Invalid*" --region us-west-2
"Invalid*"を"Invalid.*"にするとちゃんと動きました。詳しい解説
誤記について
--selection-patternは正規表現を用いることになっていますがによると、
"Invalid*"だと"Invalid〜"みたいな文字列にはマッチしません。
("Invali", "Invalid", "Invaliddddd"とかがマッチ対象になるのかな)
なので、"Invalid〜"に対応させるには"Invalid.*"と表記します。Lamvda -> API Gateway でのエラー検知について
上記の正規表現ですが「どこをみてるの?」という話。
結論から言うと標準エラーからハンドリングする場合は{ "errorMessage": "Malformed input ...", "errorType": "Error", "stackTrace": [ "exports.handler (/var/task/index.js:3:14)" ] }こちらの標準エラーの
"errorMessage"が上記正規表現の対象になるみたいです。
なので、ドキュメントの解説に沿って対応させるには正規表現は"Malformed.*"と設定する必要があります。まとめ
以下のようにそれぞれのステータスコードを設定していくと管理しやすそうですね。
Lambdaエラーの正規表現
400.*
メソッドレスポンスのステータス
400レスポンス処理
Node.jsexports.handler = function(event, context, callback) { callback(new Error("400 Bad Request")); };
- 投稿日:2019-10-08T10:47:49+09:00
【AWS】Growi構築でコケたところ
今回は、仕様でwikiが必要になり、Growiという和製wikiに目をつけた。
この参考サイトを参考にして、AWS上にEC2をたて、その中にドッカーを構築。ドッカー内にGrowiを構築する。
参考サイトにあるコマンドに1つだけ、コマンドを追加する。
※EC2の初期設定で、パッケージの最新化を行うyum updateを実行する。コマンドリストは以下
sudo su - yum update yum install -y docker docker -v curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose docker-compose -v systemctl enable docker groupadd docker gpasswd -a $USER docker systemctl restart docker exit sudo su - yum install -y git cd /home/ec2-user git clone https://github.com/weseek/growi-docker-compose.git growi cd /home/ec2-user/growi vi docker-compose.yml docker-compose up -dここでこけました。
vi docker-compose.yml
参考サイトでは、ポートの変更に言及していますが、
ポートの変更とパスワードシードを変更しないと、ドッカーの起動時に失敗しました。また、今回、最初はケチって、t2.microで実行しましたが、
スペックが足りず、t3.smallで実行しないと起動できないことがわかりました。
※気づくのになかなか苦労してしまいました。
- 投稿日:2019-10-08T10:20:27+09:00
セコクラウドの立ち上げからいつの間にか見た事のない実装を社内ローンチしちゃった件
アウトプット強化週間!_2
AWS Firecrackerをガチ気で使おうとしている人って調べててAmazon当人以外にあんまいないようなのでノウハウをアウトプット。コンテナ起動させた以上の記事があまり無いような気がする。
Amazonさん、OSS使って利益吸い上げだけで貢献が云々言われてますけど、僕自身はこの記事にあるようにfirecrackerガンガン使ってますので凄く助かってます!ありがとうございます!
はじまり
「スキルアップ目的で何でも試せる壊してOKな、お気軽検証環境あったら手を動かす動機になるんじゃないすかね?」
「だね」という会話から検証環境を作ってみようかとなった。が、その際に貰ったPCがスペック不足でどうにもなんなかった。
- アサインされたパソコンは5,6年前のSATAが載っているようなお古。ミニクラウドとはいえ外部ストレージ無いと複数人からディスクアクセスに耐えられない
- 各人でアカウントを払い出したりを考えるとvCenterが要るがライセンス料がまかなえない
色々選定してみてOpenStackすら重くてだめそうだったのでLXD+Golangの自作APIでラップしてみることにした。Ubuntuプレーン、docker、kubernetesイメージこさえたりして。
でもだめだった、辛うじてk8sは動くもののディスクアクセスが重すぎてpod、特にhelmががんがんタイムアウト死あとネットワークの偏り問題があった。主系からは両系にアクセスできるけど、もう方系からは主系にはアクセスできん問題。Stackoverflowに情報あったけど元記事失念
どうしてもアクセスしやすい主系側にコンテナが偏ってしまう。
(これ今はどうにかできるんですかね?そういうものだからネットワーク観点でVXLAN使ってどうにかせよと書いてあったような)さらに致命的なのがdockerとかで大量のプロセスが動いたノードをshutdown -h nowみたいにgracefulな停止してしまうとコンテナ上でプロセスがゾンビ?化してしまうようで発生するとコンテナが停止できなくなる。うえに消せない。かつ、cluster化していると全ノード再起動しないと消せない。定期的な全停止運用が発生
AWS Firecracker発表と作り直し
ドン詰まった辺りで発表されたのはAWS Firecracker。ためしにちょっと触ると起動早くて良さそう。環境ファイルも凄く少ない。コピーとか削除とかファイル単位だしでsnapshot機能作るの凄く簡単そうにみえた
だけど、基本はFirecrackerって単一のコンテナを動かすくらいの機能しか無いんですよ。Clusterとか全然できない。なので先のLXD用APIを改良してこんな構成を作ってみた。
これによって自立型分散仮想基盤とでも言えるようなものが完成。他のサーバーに呼びかけてダメそうなら俺が責任もってコンテナ動かすぜ!てなかんじ。この構成だとダッシュボードとかAPIサーバーみたいに止まると運用できなくなるようなシングルポイントがなくなるんですね。あとスケールも同じ構成のをくっつければ良いだけなので強烈にスケーリングしやすい。
k8sを動かしたい
AWS公式だとkubernetes未対応なんですが、
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1748671
これをヒントにカーネル4.4.0-116+CONFIG_VXLAN=yでVXLANを有効にしたら動いた。あとCONFIG_DEVPTS_MULTIPLE_INSTANCES=yも有効にしないとpodに入れない
# ./k3s kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-pod 1/1 Running 0 4m16s 10.42.0.37 master <none> <none>本k8sじゃないけど学習用ならk3sでも十分っすよね。
その後Prometheus+Grafanaで監視したり色々追加遊んでたら片方マシンがHDD Media Errorで再起不能になった・・ので一台でがんばって動いております。
ユーザーにコンソールを開放したい
firecrackerは標準入出力がコンソールになるのでそのままだと利用者サイドからはコンソールは使えない。なので
https://github.com/gravitational/console-demo
この実装をforkさせてもらって標準入出力をラップしてWebからアクセスする。クラウドでよくあるコンソールのWebアクセスの実装を作ってみた。元の実装だとfirecrackerが起動する前にHTTPのプロセスがあがったりでうまく動かない。順番変えたりクラウドから使うためにトークン認証実装したり少々手を加えた。
https://github.com/yasutakatou/console-demo
git clone https://github.com/yasutakatou/console-demo cd console-demo/ makeこれでビルド
# ./demo -port=12345 -debug -html=./wwwみたいに起動させて(./wwwはcloneしたhtmlがあるフォルダ)
http://127.0.0.1:12345/?token=passwdみたいにトークン指定してアクセスする。




- 投稿日:2019-10-08T09:42:56+09:00
AWS DevDay Tokyo 2019 - Day 2 セミナーメモ
AWS DevDay Tokyo 2019 - Day 2
2019/10/3 ~ 10/4
https://aws.amazon.com/jp/about-aws/events/2019/devday/
2日目(10/4):終日、45分毎の個別セッション。たくさん見たいセッションがあって迷ったが、サーバレス関連がやっぱり今後盛り上がりそうなことを実感。
あとはAmplifyのように、技術者にとっての無駄な手間を少なくし、本当にフォーカスすべき作業に注力できる環境を作ってくれる技術は活用しないと生きていけないと思った。
オープンソースコミュニティで加速するサーバレスの未来
- Sperker:堀家 隆宏氏(Servlerless Operation, Inc.)
- テーマ:クラウドの世界にいながら、OSCに参加することの意味、どんなことをもたらすか
- Serverless Framework
- Lambdaを中心にAPI Gateway、DynamoDBなど必要なリソースを一括管理する
- 関わるOSS
- Serverless Framework
- プラグインシステム:コミュニティでのプラグイン開発が活発
- Serverless Step Functions
- Cloud Formationに比べて記述量が少なくて済む
- Serverless API Gateway Service Proxies
- API GatewayからLambdaを経由せずにS3やDynamDBにつなぐためのプロキシサービス
- OSS活動を継続的に続けるモチベーション
- オンラインでコードを中心につながるコミュニティ
- 人気のあるOSSにはスキルがある人が集まる→そういった人からのレビューで格段にスキルアップ
- 遠くの国のあったことない人から感謝される喜び
- 英語ができないのは大きな問題ではない
- 翻訳ツールを使いながら、時間がかかっても文章を組み立てて、それを伝えることが重要
- OSSと向き合うマインドセット
- 人気があるOSSは偉くてすごい人だけが作っているのではなく、当たり前に自分の意思が反映される場所
- 知らない人に感謝される喜び
- 世界を変えるのは難しいが、周りの環境を少しだけ変えるのはできるんじゃないか
- OSS継続の難しさ
- とりあえず公開しても反応がなく飽きる
- 活動自体はめちゃくちゃ地味
- どう打開するか
- まずはスター1000以上目安によくかかわっている人が複数いる、かつhelp-wantedなどコントリビュータの入り口を作ってくれるプロジェクトで継続的にプルリクを送り続ける
- 先送りにされている問題をつぶしていく人の存在はめちゃくちゃ重要
- 継続する人の数はめちゃくちゃ少ない:継続することで信頼され、コミット権を付与してもらえる可能性は高い
- コミット権をもらう頃にはコミュニティの一員として認識される→自分の見える景色も変わる
- プルリクを出し続けたプロダクトのプラグインなど付随のOSSプロダクトを出してみる
- コミュニティの人がフィードバック、宣伝、一緒に開発に参加してくれる→良いサイクルが回り、継続するモチベーションに
- サーバレスの未来とオープンソース
- Serverless:Cloud2.0
- Cloud2.0とは?
- サーバレスで自分たちの責務はコードの部分=その責務から解放されるには少ないコードが望まれる
- そしてその多くはマネージドサービスで実現できない部分をコードで補っている
- サーバレスの狙いはよりコードを少なくし、クラウドのサービスをできるだけ使うこと=次世代のクラウドの使い方=Cloud2.0
- Cloud2.0のキング:拡張性と可用性の高いクラウドサービスの利点を理解し、少ないコードで書ける人
- =>フルマネージドサービスをうまく利用することで、アプリケーションロジックの責務の多くをクラウドに任せ、よりビジネスバリューを出すための仕事に集中すること
- コードを書くことは本質的になくなることはない
- コードを書く視点を変えてみる。単発で納品する仕事のコードに価値があるのか?継続的に何かを解決できるようなことをコードで表現していくほうが良いのでは?
- クラウドのサービスは日々新しいものがリリース=新たなものは新たな問題をもたらす=問題とはチャンスであること
- OSSで解決できないか?=OSSで自分の書くコードが多くの人に影響を与えられる
- Serverless days Tokyo:10月22日
サーバレスで作るモバイルアプリ向けBackend For Frontend
- Sperker:椎名 アマド氏(株式会社Timers)
- モバイルアプリ:家族アプリFamm
- 古き良きを新しく:次に何が流行るかではなく、人類として昔から未来まで変わらない価値観はなにか?=>家族
- 課題解決のための技術導入に関するケーススタディ
- モバイルアプリ開発での課題
- サーバーはRESTfulなAPIを使いたい
- クライアント側はUIベース:1つの画面で複数のリソースからデータを取得することもある:できれば1つのAPIコールでやりたい
- iOS,AndroidでAPI分けたくない
- 例:1画面で複数APIを呼び成型するのは大変→1つの巨大なAPIに集約
- iOS,Andoroidで差分が出ないようにメンテするのは大変
- 様々な制約条件の中で改善を進めるため、コミュニケーションの調整コストが増加
- 複数OS、バージョンの影響範囲を考慮しつつ、巨大APIをメンテするのは困難
- サーバAPI複雑化、iOS&Andoroid間で複雑なAPIを扱うビジネスロジックの分散
- 解決策(案)
- 1.自動テストの網羅によりデグレ防止
- API修正のたびに過去バージョンも考慮した手動テスト実施
- 2.ネイティブでコード共有
- Kotlin/NativeなどでiOS&Androidでともに利用できるビジネスロジックをライブラリ化する案
- 整理が必要なことが多い、コストが高いわりに完全に幸せにならない
- ノウハウ不足
- 共通ライブラリ修正時のCIフロー
- 3.APIに表示ロジックを寄せる
- APIのほうでUI表示用に文言処理、必要な成型もしてしまい、実際の文字列を返す
- サーバAPIでテストを充実させていれば品質も担保
- →片方の解決しかしていない
- サーバで行うことが増える:i8n対応、日付成型など
- サーバエンジニアの責務として画面表示という責務が増える
- ただでさえ現状のAPIがモノリシックなのに、さらに責務範囲が広がってしまう
- どれも課題が多い -> そこでBFF
- BFFとは
- One backend per user experience
- 一つのユーザー体験に一つのバックエンド
- クライアントとバックエンドの間に挟まるAPI
- クライアントは直接バックエンドをたたかずにBFFをたたく
- BFFはクライアントの要件に合わせて最適化される
- クライアントの種類(デスクトップ、モバイル)毎にBFFがあり、それぞれがバックエンドとつながる
- BFFはクライアントサイドが管理
- クライアントサイドが使いやすいようにBFFを管理する
- バックエンドはバックエンドが管理
- クライアントごとにUIやAPI要件が様々な場合、クライアントごとに都合のよい(密結合な)API層を用意することで責務の分離
- 例:NetFlix:デスクトップ、モバイル、TV、Game Console
- 集約と変換
- 様々なバックエンドサービスと通信してデータ集約
- さらにデータをクライアントに適した形に変換
- クライアントはBFFとだけ通信すれば集約済みのデータが返ってくる:扱いやすい
- マイクロサービスを多く使うケースで最適
- BFF:Fammの場合
- マイクロサービスではないが、複数のバックエンドAPIからリソースを取得して集約
- 文言出し分けなどのUIロジックをBFFに集約することで、iOS&Andoroidの間で分散しているロジックを吸収
- かつ、バックエンド側ではUIに関する責務を負う必要がない
- BFF導入にあたる取り決め
- BFF APIはクライアントエンジニアの管轄
- クライアントエンジニアが管理するなら、インフラ管理はしたくない=サーバレス
- サーバレスで実現するための環境整備はサーバサイドエンジニアが行う
- サーバレスの環境まわりの課題についてはサーバサイドエンジニアがサポート
- 技術選定:言語
- TypeScript
- 他のサーバレス(Lambda)ではGoを使っているが、クライアントエンジニアが使いやすい言語を選定
- Lambda+API Gateway + serverless
- APIGatewayはANYですべてのリクエストを受け付け、Lambdaは1つのExpressアプリケーションで複数エンドポイントをハンドリング
- API Gateway + Lambdaが増えると管理運用が大変になるため、集約して1つにする形を採用
- 本来はあまりきれいではないかもしれないが、生産性、管理のしやすさ、今後のエンドポイント数の増加規模を考えても妥当と判断
- 認可・認証
- API GatewayのAPIKeyとともにBackendAPI用のトークンもリクエストで渡している
- つまり現状はBackend APIと密結合
- 現状マイクロサービスがないので足りているが、今後BFFからマイクロサービスをコールする際に認証の見直しが必要
- i18n
- i18n NPNモジュールで特に不都合なし
- TEST/CI/Deploy
- テストはJestを利用
- develop/masterにmergeされたらCircleCI経由でそれぞれデプロイが走る
- serverless CLIのdeployコマンドがあるのでCIも簡単に構築
- 今後やりたいこと
- 今後のマイクロサービス化でBFFが複数マイクロサービスと通信できる設計(主に認証認可)
- 現状BFFは一度インターネットに出て行ってBackend APIと通信しているのでVPC内で完結させるなど速度の最適化をしたい
- 他の画面についてもBFF化
- 自分のチーム・プロダクトの課題は何なのかを考え、それを解決する判断をする
- モダンな、トレンドだからなどの安易な理由で導入したら失敗する
- 課題ドリブンで試行し、技術選定、導入:どれくらいのスパンを見通して課題とするかはそれ自体が永遠の課題
よくある課題を一気に解決
- AWS Startup SAチーム
- AWS Startupゼミ
- 技術的な課題と傾向を把握、「あるある」まとめ
- どう考えて、どの資料を見ればいいか
よくある課題1:コンテナのCI/CDちゃんとしたい
- 本当にしたいことは?
- 開発速度を上げ、プロダクトの価値を向上させたい
- テストをちゃんと行い、プロダクトのクオリティを上げたい
- 自動化しつつも条項の把握やロールバック等のハンドリングを適切にやりたい
思考フロー
- 手作業でのデプロイと決別
- パイプライン外での構成変更やデプロイを認めない強い気持ち
- 今までと変わるので最初は面倒に感じるー遅くなっているわけではないのに遅くなっているように感じたりする
- 手作業での変更を行わないためにどうすべきかという思考
- 緊急時は仕方がないこともある
- ビジネスへの影響を考慮し意思決定することは重要
- 例外的な対応と認識し、しっかりと帳尻を合わせる
- リビジョンとデプロイメントを連動させることを考える
- リビジョン:リビジョン番号、タグ、リリースバージョン
- Gitのリビジョン番号とコンテナのタグを合わせる:複数コンテナがあればすべて合わせるべき
- メリット
- 本番やステージングなどの環境によらず、一意なコード/コンテナを利用できるようになる
- ロールバックが容易
- The Twelve-Factor Appでもベストプラクティスとされている
- コードベースとアプリケーションの間に、常に1対1の関係を持たせる
- マネージドサービスを中心にパイプラインを構成する
- 本来の目的は効率化やクオリティの向上:CI/CD環境自体の管理運用コストをできるだけ抑える
よくある課題2:ログってどう設計すればいいの
- ログ解析したいが、垂れ流している状態
- 本当にしたいことは?
- サービス/アプリの状況を把握、可視化したい
- 思考フロー
- ログの種類と目的を考えよう
- アプリのログ、ミドルウェアのログ、OSのログ
- 利用状況の把握、調査用、監査用件で必要とされるもの
- 用途に合ったものが出力されているかっ確認
- 足りない項目はないか?
- 環境に応じた適切な情報量なのか?
- 秘匿性が高いものが出力されていないか(ID・PWやメールアドレス)
- ログの設計を使用
- ログレベル
- 用途や緊急度によって適宜ログレベルを設定する
- 出力先
- 運用者がすぐに見つけられるところに集約
- /var/log,app/logなど
- Cloudwatch logsや、S3など
- 権限
- 適切なログの権限なのか
- 内容によっては見られてはいけない、変更もされてはいけない
- アプリケーションにあったフォーマットを考えよう
- WebServerやAppでどのような種類が出力できるか見直し、必要な項目を入れる
- デフォルトでは項目が足りないことも多い
よくある課題3:いい感じの機械学習基盤を作りたい
- 環境構築が大変、会社で買ったGPUが足りなくなってきた、など
- 本当にしたいことは?
- ユーザに価値をとどけつつ運用負荷を減らしたい
- 俗人化させず、再現性を担保、パフォーマンスも大事
- ユーザ、エンジニア、データの増加に対応できるスケーラブルな機械学習基盤を作って、プロダクトの継続的な価値向上につなげたい
- 思考フロー
- できるだけマネージドサービスを使えないか考える
- 自分でモデルを作らなくても、学習済みのモデルをAPIで簡単に使える
- コンピュータビジョン:物体検出、顔認識
- 音声
- 自然言語処理
- チャットポッド
- 自分でモデルを作る場合でも、マネージドサービスSageMakerを使う
- 幅広いフレームワーク、インターフェースに対応、インフラ面も強力
- どこまで自由度を求めるか考える
- AutoML
- Amazon Personalize/Forecast
- Amazon SageMaker
- ビルトインアルゴリズム
- トレーニングスクリプトを用意
- train.pyの入出力を書き換え
- 自分のDocker イメージを用意
- Bring Your Own Container
- ワークフローの構築と自動化を考える
- データだけ用意してビルトインアルゴリズムで定期実行
- StepFunctions workflow
よくある課題4:セキュリティを自動化するにはどうすれば
- セキュリティ、何をどこまでやればよいのか、やったらやったで大変そう
- セキュリティに不安があるのでレビューしてほしい
- セキュリティの要件はサービス内容によって変わり、サービス運営者が決めるべき内容
- 本当にしたいことは?
- 効率よく過不足なくセキュリティに取り組みたい
- セキュアなシステムで事業とユーザを守りたい
- 思考フロー
- まずマネージドサービスを使おう
- マネージドサービスで自分の責任範囲を小さくする
- マネージド度の高いサービスを使うことで、クラウド事業者の責務を増やす=自分の責務を減らす
- セキュリティ系マネージドサービスで低コストに高機能を得る
- 監視、検知:GuardDuty,CloudTrail,AWS Config
- 集約・把握:Security Hub
- 対応:CloudWatch Event
- キャッチすべきアラートやイベントを決める
- 何を検知できるのか、発生時にどう影響があるかを考える
- イベントに対するレスポンスを考える
- 各種監視・検知サービスはCloudWatchEventsに集約できる
- →管理者への通知やLambdaやStep Fucntionを使って対応実施
AWS活用で進む地方/中小企業のゲームチェンジ
- Sperker:立花 拓也 氏(株式会社ヘプタゴン)
- 東北を拠点に地方中小企業へのITサービス展開(主にAWS活用)
- IT予算の概念がないことも:レンタルサーバ代の月1万円しかない、とか
- IT関連の知識は相対的に低い
- クラウドネイティブな世界とコミュニティファーストな世界:人間力
- 人にしかできないことが求められる世界で、組織を超えたつながり、他者とのつながりによるイノベーション
- WEB案件
- レンタルサーバなどからのリフトが多い
- 既存環境に何らかの問題があり相談されるケースが多い
- 割り切ってシングル構成も多い
自然言語処理の開発現場でのAWS活用術
Speaker: 山田 育矢 氏 、 島岡 聖世 氏 (株式会社Studio Ousia)
QA Engine
- ヘルプデスクや社内の問い合わせ業務の自動化、効率化支援プロダクト
- WEB画面上で機械学習モデル構築などが行える
- チャットボットへモデルを連携し、問い合わせに利用
SageMaker導入
- レガシーシステムの課題
- 周縁的な処理によるコードの肥大化
- 本質的な処理は学習と推論
- 周辺的な処理として、学習ジョブ起動、状態確認、推論インスタンス起動、更新、モニタリング、スケーリング、etc...
- 本質的な処理以外にジョブやリソースのマネジメントに必要なコードが肥大化してしまった
- コンポーネント間の依存関係
- コントロールサーバ、機械学習モジュール、クライアントAPIの3つのコンポーネントが、共通モジュールを利用するなどの依存関係を持ってしまった
- =>機械学習の改良が困難に
- SageMakerで解決できないか?
- 機械学習のフルマネージメントサービス
- 機械学習のワークフロー全体をAWSのAPIやコンソールで管理可能
- 魅力
- 周辺的な処理を任せられる
- 学習・推論という本質的な処理にフォーカスできる
- 機械学習処理をDockerイメージで作成できる
- 任意の言語、フレームワークを利用可能
- SageMakerから見れば、モデルは要件を満たすブラックボックス
- どのように変わったか?
- レガシー時代は依存していた3つのコンポーネントを別々のリポジトリで管理
- コンポーネント間の依存関係はSageMakerのインターフェースに置き換え(REST API呼び出し)
- コードの量が減った:40%減
- 周辺的な処理がSageMakerに吸収された
- 学習時間の短縮
- 性能向上
周辺的な処理をプラットフォームに任せれば、本質的な仕事に専念できるようになる
コンポーネント同士の依存関係をなくせば、チームの共同作業は効率的になる
Amplify Frameworkの挙動を開設する
Speaker:塚田 朗弘 氏(アマゾン ウェブ サービス ジャパン株式会社)
目的
- ライブラリとしてやっていることを知る
- 「そういうことを気にしなくてよい」ことを実感する
なぜAmplifyが必要なのか?
- 一般的なWEB,モバイルアプリの構成要素
- サーバサイドやデータベースでの管理、運用やログ収集して可視化、クライアントへのプッシュ通知、クライアントイベント収集(マーケティングとしてのユーザ動向分析など)、分析業務、他システムとの連携
- など、多岐にわたる要素を気にしないといけない
- アプリ開発者がやりたいことは何?=ユーザに価値を届けたい
AWS Amplify
- 中身
- Amplify CLI
- Amplify Framework
- Amplify Console
- Amplify CLI
- やりたいことから直感的に、やりたいことだけを意識して構築できる
- 各サービスの詳細をしらなくても、やりたいことからサーバレスなバックエンドを構築してくれる
- アプリケーション開発者は本当に必要な開発だけに集中できる
- バックエンドの構築はシンプルなコマンドで実行できる
- =Amplifyの仕組みとか知らなくても大丈夫
- Amplify CLIとは?
- TypeScriptで実装されたnpmパッケージ
- amplify add ...
- 使えるサービスが追加される api,auth,analytics, etc...
- amplify serve:ローカルでサーバ立てて動かすのがすごく簡単に
- amplify codegen:GraphQLスキーマオブジェクトを生成
- amplify env :dev,prodなどの複数環境を管理する
- Amplify Framework
- クラウドに接続されたUI Componentやライブラリを使いフロントエンドアプリを構築
- Viewコンポーネント
- 認証機能を提供するVueコンポーネントの例
- :ユーザ認証UIを作成
- Developer-Friendlyな開発が可能
はじめかた
- 公式サイトのチュートリアル
- AWS LOFT
レガシーコードからの脱却
- Sperker:吉羽 龍太郎 氏(株式会社アトラクタ)
- 書籍「レガシーコードからの脱却」(https://www.oreilly.co.jp/books/9784873118864/)
- レガシーコードとは?
- テストのないコード:テストがなければコードが良くなっているか悪くなっているかわからない
- 保守または拡張が困難なコード:コードベースだけではなく、プロジェクト全体
- =定義は様々
- 本セッションでの定義
- 理由は問わず修正、拡張、作業が難しいコード=保守に多額のお金がかかる
- ※同じ用語を使っていても、中身に認識の相違があることが多い
- 議論の時は共通認識は何かを確認すべき
- 品質は重要ではなく、ソフトウェアが何をするかを重要視したためにたくさんのレガシーコードが生み出されたと考えられる
- 使われるソフトウェア
- 変更が必要になる:必要な変更をすべて予測するのは無理
- よって、変更可能となるように書くべき
- 使うかもしれない、で作るときりがない
- 必要になったときに対応できるエンジニアリングプラクティスを身に着ける
- そもそもソフトウェアの保有コストを下げたい:メンテナンスコストを下げたい
- リリース後のバグ修正にはとてつもない時間がかかる
- 「ソフトウェアの成功と失敗」によると、開発者の時間の半分以上が過去にやった仕事の手直し
- コードを扱いやすくして保守コストを下げたい:開発方法に目を向けなければいけない
- ウオーターフォール:最初から正しい計画が立てられるなら正しく作れるけど・・・
ソフトウェアが生み出す成果を決める要素
- 問題設定力
- そもそもどういった問題を解決しようとしているのか
- 開発力
- 知識やアーキテクチャ設計力、
- チーム力
- プロセス習熟、心理的安全性、、、
- それぞれの総合力で成果が生まれる
レガシーコードを作らない9つのプラクティス
- 1.やり方より先に目的、理由、だれのためかを伝える
- 2.小さなバッチで作る
- 3.継続的に統合する
- 4.協力しあう
- 5.CLEANコードを作る
- 6.まずテストを書く
- 7.テストでふるまいを例示する
- 8.設計は最後に行う
- 9.レガシーコードをリファクタリングする
- ScrumとXPからプラクティスを抽出
1.やり方より先に目的、理由、だれのためかを伝える
- プロダクトオーナー:Whatを担当する
- 開発エンジニア:Howを担当する
- WhatとHowを分離する
- やり方(How)は開発者の領域
- やり方を明示されると選択や交渉の余地が減る
- 結果として手続きてきなコードになりがち
- 双方が創造的に協調=無駄な時間や機能が減る
- まずコンテキストを共有・理解すること
- ユーザーストーリー
- 会話の材料となるもの(仕様書ではない)
- 会話によってソフトウェアを作るための理解を深める
- 知識は詳細なドキュメントではなく、コード(テストも含む)にまとめるべき
- ストーリーが限定的であることで、テスト可能になる(受け入れ基準と自動化)
- 実例による振る舞いのテストが可能に
- シンプルに初めて、追加は後で行う(=>2.小さなバッチで作る)
- 漸進的に進めることで、良い設計が浮かび上がってくる
2.小さなバッチで作る
- タイムボックスとスコープボックス
- タイムボックス:固定の時間の中でタスクに取り組む
- スコープボックス:ストーリーやタスクなどの作業単位で終わらせる(時間は重視しない)
- 作業単位が均一で小さい場合に選択
- カンバン
- 長い期間で大きなうそをつくのではなく、短いイテレーションの中で小さなうそをつく
QCDSの何を調整すればいいのか?
- ウオーターフォールではどれも調整できない
- スコープと時間を柔軟に考える(特にスコープ)
- 品質を満たせなければ意味がない:品質を満たせる作業量とする:スコープで調整
- 人月の神話
- 人を追加するとやり取りが増えて速度が落ちる
- 品質を犠牲にすると、後からつらくなる
- スコープを調整し、価値ある機能から順番に作る
- バックログ化
ケイデンス、リソース効率、プロセス効率
- ケイデンス(リズム)が長くなると、リソース効率化を目指しやすい
- 同時に着すするものが増える、タスク切り替えが増える
- 役割分担が増える
- 最後にテストフェーズや統合フェーズが増える
- ケイデンスを短くすると、プロセス効率が上がる
- 同時に着手するものを減らす必要(いわゆる1個流し)
- プロセス内の作業の量を減らすと、システムが安定する
- ※モブプログラミング:究極の1個流し
ソフトウェアの評価
- 顧客にとって価値あるものに基づいて評価すべき:どんな効率で、どれだけ頑張ったかは関係ない
- 価値は完成して初めて価値になる
- 価値実現までの時間が期待した通りか?
- 部分最適化を避ける
フィードバックサイクル
- 小さなバッチのほうがフィードバックが増える
- スプリントレビュー、レトロスペクティブ
- 顧客やPOと同席し、フィードバックの回数を増やす
- ビルドを高速化する
- フィードバックへの対応をサポートする文化が必要
- 今やっていることとフィードバックで戻ってきたこととどちらが優先かを考える文化
良いコードとは?よくないコードとは?
- 何が良いコードで何が悪いコードかの認識を一致させる
- 良くない例をチームで理解し、避ける必要がある
- 一方で、従うべきガイドラインも必要
- CLEANコード
- 凝集性、疎結合、カプセルか、断定的、非儒町
- テストのしやすさと密接な関係がある
- 凝集性
- それぞれの部品は1つのことだけ扱う
- クラスが1つの責任に集中する
- =名前を付けられるアイデアや概念になる
- ※名前重要:具体的な名前がついていないものは怪しい
- わかりやすいコードは自然言語に近い内容で書かれている
- 疎結合
- 密結合のすべてが悪ではない
- 意図的な結合と不慮の結合
- 再利用という名目のもとにコードの品質を犠牲にしてはいけない
- カプセル化
- インターフェースと実装を切り離す
- 呼び出し側の観点で機能を設計する
- 何をやっているかを示す具体的な名前を付けて、どう動くかは隠す
- 断定的
- 自分の責任は自分で管理する
- オブジェクトがフィールドを持つなら自分で責任を持つ
- =振る舞いを配置する場所が依存データがある場所であることを示す
- 非冗長
- 同じことを繰り返してはいけない(DRY原則)
- 意図的に冗長を組み込むことはあるが、あくまで意図的に
- テストのしやすさが設計や実装の品質の目安
- 投稿日:2019-10-08T09:42:04+09:00
AWS DevDay Tokyo 2019 - Day 1 セミナーメモ
AWS DevDay Tokyo 2019 - Day 1
2019/10/3 ~ 10/4
https://aws.amazon.com/jp/about-aws/events/2019/devday/
1日目(10/3):午前中はジェネラルセッションとしてAWSの技術統括本部長とまつもとゆきひろ氏、倉貫 義人 氏の3名で「今後のエンジニアに必要な事」のお話し。
午後からは個別セッション。ハンズオンでAmplifyのメリットを体感できたのは面白かった。
General Sessioon
AWS Message
Sperker:岡嵜 禎氏(アマゾン ウェブ サービス ジャパン株式会社 執行役員 技術統括本部長)
Builder:新しいものを切り開いていく人たち
- 新たな道を切り開いていく可能性に満ちた現状
- RE:MARS
- amazon go
- 商品にタグをつけるのではなく、画像処理、センサー処理をリアルタイムで行い、機械学習などを用いることで実現
- Amazon PrimeAir
- 今年度中に実用化:最新モデルは5万通りのモデリングをコンピューティングで試行し、1万機を試作したうえで最適なモデルから構築
- 安全性:コンピュータビジョンで鳥などの存在、着陸時の人、障害物の存在を認識し安全か判断し行動
- Project Kuiper:地球低軌道の衛星との通信のためのコネクションを
- イノベーションに巨額な投資は不要
- イノベーションを実現できる
- 自由を得ることができる
- PDCAサイクルを迅速に回すことができる
- 様々なテクノロジーを簡単に速く実現できるPlatformを提供
現状最重要:機械学習
- 様々な領域で適用可能
- コンピュータビジョンやリコメンデーション、自然言語処理など
- AWSサービス:すべての開発者に機械学習を
- AIサービス、MLサービス、フレームワーク&インフラストラクチャの各層でサービス提供
モダンアプリケーション
- 目的
- 市場投入を加速
- イノベーション向上
- 信頼性向上
- コスト削減
- 実際
- オペレーション
- 価値を生まない作業をオフロードしすべてを自動化
- アーキテクチャ
- マイクロサービス、疎結合、イベントドリブン
- Developer-Firstな開発フロー
- CI/CD-すべてを自動化
- セキュリティ
- 自動化されたセキュリティ評価
- 適切なアクセス権限、成果物の検証
- データ
- 正しいツール、目的に適したDBの利用による生産性の向上
- アプリケーション実行環境の広がり
- EC2
- Container
- Fargate
- EKS
- ECS
- Serverless
- Lambda
- Opsが不要であればよりNoOpsなサービスを利用可能に
- Well-Architected Framework
- ホワイトペーパー
- Well-Architected Tool
On Builder and Dreamers
Sperker:まつもとゆきひろ氏
- Ruby:1995年公開:20世紀の言語
- Java,PHP,JavaScriptなども同じ年
- インターネットの普及に伴い、必要とされる言語が変わってきたタイミングだった
- 2000年代の動的言語
- 手軽、柔軟、生産的、楽しい
- 2010年代のトレンド
- 関数型、静的型、手堅い
- 見かけが動的っぽい
- Swiftなど
- Rubyのブロック類似
- 型推論
- 少ないお約束
- 企業によるスポンサー
- GO-Google
- Swift-Apple
- Rust-Mozzilla
- TypeScript-Microsoft
- どの言語を選ぶか?、どのテクノロジーを選ぶか?
- どのような評価基準で選ぶべきか?
- 生産性ーいかに効率よく開発できるか、開発上のコストベネフィットがいかに得られるか
- 唯一の解はないー背景によって異なる
- すべてのことにはトレードオフが伴う:この点はこちら、あの点はあちら。。。
- トレードオフをどれを選ぶか、どう判断するか
- 動的言語は生産的ー場合によっては真だが、制約条件によっては偽
- 自分のプロジェクトはどのような制約条件があり、それは変えられるのか?などの背景を考慮
- Big Sites Use Ruby
- Cookpad
- gitHub
- Airbnb
- TreasureData
- Big SiteでRubyを使ってもOK
- Rubyをさらに良くする:CookpadはフルタイムのRubyコミッタを2人抱えている
- GitHubも自らの問題を解決するためにRubyを改善するコミッタを持つ
- 判断を人に任せない
- 技術の選択時、自分が生産性になれるかを、実際にソフトウェアを作らない人(役員とかマネージャーとか)に任せない
- そのような判断を誰かに任せずに、自分で判断できる環境に身を置く
- 技術者を大事にしない組織もたくさんある
- そんな会社は辞めたらいいと思う
- Tumble Weed-風に吹きまわされる
- 自分の基準を持って風を選ぶ
- 自分の望む方向に行くような風を強める
- 最終的には自らが風を作る
- =主体性
- コントロール意識:事態が自分のコントロール下にあると思うとストレスが下がる:逆だと生産性が60%下がる
Speaker:倉貫義人氏(株式会社ソニックガーデン)
- キャリアのはじめ:TIS:SIer
- プログラマーが楽しくなさそうに働いている
- 社内でアジャイル開発の普及活動
- 受託開発では難しい:結局一括請負で納品は最後1回だけ
- →社内システム
- →社内ベンチャー
- そもそもほんとにアジャイル開発があっているのか/○○をやりたい、と言っているけど、ほんとにそれはあっているのか?
- 大事なのは背景やビジネス、やらねばいけないこと、制約条件に合わせて選ぶべき
- 例えば一括請負の受託開発でアジャイルは無理→アジャイル開発が向いている制約条件を作る
- 納品のない受託開発をビジネス化:月額定額ビジネス
- 見積、要件定義なし、ドキュメントなし、プロジェクトなし、契約時間なし
- 要件定義はSIerがお客様ともめないためにしっかり作ろう、という類のものなのでは?
- プロジェクト:ほんとに人たくさんいる?:まず一人でできる量でやる:クラウドやOSSが広がったおかげで一人でできる範囲が広がった
- Software is eating the world
- ソフトウェア開発の本質とは?
- 大量生産、ルーチンワーク、製造業ではない
- デザイン、問題解決、ナレッジワークである
- プログラミングを手段に、問題解決をする仕事
- これから求められる仕事とは
- 人類の文明の進化は不自由を置き換えてきた
- 人がやると大変なことを置き換える
- 自由な発想が求められる、好きで楽しめるか
- 不自由がなくなるとどんどん自由になる=最終的には自由で、好きなことをできる
- クリエイティブな仕事、人数のいらない仕事
- この先のエンジニアの生き方
- ソフトウェア開発の仕事は減ることはない
- 腕を磨き続ければ、自分の価値を高められる
- 会社のバランスシートに反映される価値としてではなく、自分の価値として得られる
- 会社に残るのではなく、個人に残るのがスキル:どんな資産があろうとも、スキルを持った個人がいなければ会社として成り立たない
- あなたの仕事は難しいからこそ価値がある
トークセッション:令和の時代。さらに輝くエンジニアであるために必要なこととは
- これまでのキャリアの築き方
- まつもと氏:独立系ソフトウェアハウスで自社システム構築
- 閑職の中でRubyを作り始める→だんだんRubyにシフト→全部Rubyに
- Rubyの言語開発は趣味
- 様々な領域に触れる:面白がりながら作ってた
- 倉貫氏:大手SIerから独立→社内SNSを作り、それを外販
- 閑職に追いやられて、社内システムを作成、こっそりローンチ:ミクシーが流行っていた当時
- 閑職で腐らずにいかに好きなことをやるか
- 判断のとき、マイノリティのほうを選ぶ:少ないほうが目立つ、役立つ
- AIがプログラムを書いてくれるようになったら、プログラマーの存在価値はどうなる?今後のプログラマーに求められる知識、能力とは?
- まつもと氏:AIが仮にプログラムできるようになっても、設計、システムに何を求めているかはAIにはできない:結局その定義の必要性は普遍的なのではないか?
- 倉貫氏:現在のコード補完の延長線上?→プログラムをデザインするとかは残るし、そういったクリエイティブな部分が楽しい
- AIがプログラムを書いても、今まで通り人がプログラム書いてもいい
- 優秀なエンジニアとは?
- まつもと氏:主体性がある人、私はこうしたいと言ってくれる人
- 倉貫氏:受託脳(いわれたことをやる)=誰かが言わなければ何もできない=自分の頭で考えることが重要
- 主体性を育てるには?
- まつもと氏:主体性を壊す環境はたくさんある
- 悪い環境・会社は淘汰されるべき
- 倉貫氏:管理しない会社:「うちは管理しないと働かない」と他の経営者に言われる:ほんとに?管理しすぎるから管理されないと動けなくなる
- 会社と社員は従属関係ではなく、対等な関係
- 会社を変えるって難しい:自分で会社を選ぶ
- 新しい技術を学ぶ手段・スキルアップ手法は?
- まつもと氏:海外の技術ニュース
- 自分の得意なところから伸ばす
- 自分の中でインデックスを作る:これは誰に聞けばわかる、とか
- 生産性を高めるのは自分が楽になるため:バッファを積む
- 倉貫氏:技術分野はすごく広がっている
- チームで解決しよう=この人は何が得意
- ソフトウェア自体は一人でできるが、わからないときに立ち止まってしまう:チームはその解決のため
- 人月でビジネスしない:人月でのビジネスをプログラマにさせるのがすべての元凶:バッファをこっそり積むとか
- 仕事を時間で管理しない:早く終わったら仕事がまた来るっていうのはきつい:成果がでたら早く終われば後は自分の時間
- 今後の注目技術
- まつもと氏:Lambda等のサーバレス
- 倉貫氏:機械学習:浅いレイヤーで機械学習が使えるようになるのはすごくいいこと:エンジニアが今まで手に届かなかったところに届くようになったのがクラウド
- メッセージ
- 倉貫氏:自分の人生をどう幸せにできるのか:セルフマネジメントをできる領域をどれだけ増やせるか:エンジニアはスキルを磨くことでそれができる
- まつもと氏:自分のコントロール意識を増し、裁量を増やし、自分で判断する。他人は自分の幸せを保証してくれない
.NET開発者がいまさらはじめるクラウド戦略
Speaker:森 博之氏
環境の変化と文化の変化
- クラウド化の動機
- 新サービス構築
- システム・インフラの老朽化、サポート終了による移行
- 選択肢:Retire,Rehost,Refactor,Rearchitect,Rebuild,Replace
- Windows環境の変化
- Windows開発にはC/C++とMFCやATLのライブラリ:Visual Basicでのアプリ開発
- →.NET Frameworkへ:メモリ管理、セキュリティ、バージョン管理:様々な言語が混在できるようになった
- →ASP.NET Web FormsモデルからMVCへ:アクセシブルなHTML/CSSレンダリング:モダンなフロントエンドやMVCの開発手法を取り入れやすくなった
- Culture change
- 成功している企業でおこっていること
- 成功のベースとなったアイデアやコンセプト
- 成長させるために加えた機能
- それによって暗黙的に成長した文化
- 永久マシンのようなビジネスの仕組みはない
- InnovationとModernization
- 新しい概念やコンセプト、従来あった技術をモダナイズ
注目したいテクノロジ
- .NET Core
- クロスプラットフォーム
- オープンソース
- フレキシブルなデプロイ方式
- Framework-Dependent Deploy
- Self-Contained Deploy
- Modular
- 小さなアセンブリパッケージで構成
- .NET Framework全体ではなく、必要な部分だけ取り出して構成可能
- NuGetを通じてリリース
- 必要なパッケージのみ取り込む
- ASP.NET Core
- Startupクラス
- DIフレームワーク
- ミドルウェア
- Hostのビルド
- HTTPサーバ(Kestrel)の実装
- Configurationプロバイダー
- Optionパターン
- IHostingEnvironment
- ILogger
- Routing
- .NET Core 3.0
- gRPC
- Worker Service
- Web API
- Blazer
- .NET(C#)でインタラクティブなUIを構築するためのフレームワーク
- C#のプログラミングでUI構築
- Server-SideとClient-Sideの2つのホスティングモデル
- Server-Sideのほうが推奨
- Signal-Rを用いたサーバからクライアントへの技術
- .NET マイルストーン
- .NET Core 3.1 LTS:2019/11
- .NET 5: 2020/11
- Serverless
- .NET Core CLI
- Lambda用テンプレートの導入
- AWS Extentions for .NET Core CLI
- Container
- Docker Windows Containers
DEMO:GitHubで公開
- hiroyukimori/awsdevday2019
DynamoDBによるアプリ開発
Speaker:成田 俊氏(アマゾン ウェブ サービス ジャパン株式会社)
Intoroduction
- フルマネージド、ハイパフォーマンス、エンタープライズ対応
- メンテナンスフリー、サーバレス、スループット無制限
- You build it, you run it.
- メンテナンスフリー
- セキュリティ、耐久性、可用性、性能、拡張性を気にせずに開発できるのは大きなメリット
- Table構造
- Itemsでデータを分けて保存(行に相当)
- Items内にAttributesを持つ(カラムに相当)
- Partition Key:必須 Key-value access patternを決定
- Sort Key:
- NoSQL Workbench for Amazon DynamoDB(Preview)
- Data modeler
- operation builder
- 等をGUIで管理、操作可能な機能
サンプルアプリ解説
- API Gateway -> lambda -> DynamoDB
- Chaliceを使って構築
- DynamoDBの特性
- カーディナリティが低いAttributeをPKにすると、書き込みが増えてきたときにスロットリングに引っかかり遅くなる可能性あり
CIをどうするか
- 並列実行したときに同じデータを扱う可能性あり
- Table名をビルドプロジェクトごとに分ける:並列実行BUildが少なければ問題なし→多いと制限に引っかかる可能性
- DynamoDB Localというローカルで実行可能版が提供されている
- ローカル開発はそちらで、リリース前に本番DynamoDBで
- 対象アプリケーションと同一コンテナにDynamoDB Localを同居させる形と、別コンテナで実行する形の両方あり
- DynamoDB LocalはJarでの提供 or AmazonオフィシャルのDynamoDB Localコンテナイメージもあり
まとめ
- データモデリング、Item操作の記述に迷ったら:NoSQL Workbench for Amazon DynamoDBでテストを
- DynamoDB Streamsなどほかのコンポーネントとの組み合わせで