- 投稿日:2019-10-08T23:56:53+09:00
telnetによるrootログインの設定
概要
実務にて、telnet経由でrootユーザがログイン可能となるように設定する必要が生じたため、 telnetのインストールからログイン確認までの手順を記録しときます。
(通常こんなことしてはいけない)1.テスト環境
VMwareにてCentOS7を最小構成でインストール済み。SSH接続できる状態である。
[root@localhost ~]# uname -a Linux localhost.localdomain 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux [root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core)2.準備
2-1. telnetクライアントおよびサーバの確認
[root@localhost ~]# yum list installed | grep telnet [root@localhost ~]#ヒットなし。インストールされていないことを確認。
2-2. telnetクライアントおよびサーバのインストール
[root@localhost ~]# yum -y install telnet telnet-server2-3. 自動起動の有効化
必要な場合のみ実施。
[root@localhost ~]# systemctl enable telnet.socket Created symlink from /etc/systemd/system/sockets.target.wants/telnet.socket to /usr/lib/systemd/system/telnet.socket.自動起動の確認。
[root@localhost ~]# systemctl list-unit-files | grep telnet.socket telnet.socket enabled2-4. Firewallの設定
source addressのみ、実行環境に合わせて指定すること。
[root@localhost ~]# firewall-cmd --permanent --zone=public --add-rich-rule "rule family="ipv4" source address="192.168.11.0/24" service name="telnet" log prefix="telnet" level="info" limit value="1/m" accept" success設定を反映する。
[root@localhost ~]# firewall-cmd --reload success2-5. telnetの起動
[root@localhost ~]# systemctl start telnet.socket3. telnet経由のrootログイン設定
3-1. rootユーザでログインできないことを確認
Kernel 3.10.0-957.el7.x86_64 on an x86_64 localhost login: root Password: Login incorrect localhost login:3-2. /etc/securettyの編集
securettyは、rootログインを許可する端末を指定するファイルである。
同時接続させたい数だけptsを追記する。
設定はファイル編集のみで反映される。/etc/securettypts/0 pts/1 pts/23-3. rootユーザのログイン確認
現在使用中の端末はttyコマンドで確認できる。
Kernel 3.10.0-957.el7.x86_64 on an x86_64 localhost login: root Password: Last login: Tue Oct 8 22:52:38 from ::ffff:192.168.11.2 [root@localhost ~]# tty /dev/pts/0以上。
備考
pts(疑似端末)は自動で作成される。
試しにTeraTermを3つ起動して、SSHで接続したら3つ(0~2)まで自動生成された。#ls /dev/pts 0 1 2 ptmx参考
- 投稿日:2019-10-08T22:40:46+09:00
システム時刻設定(date コマンド利用のシェルスクリプト)
こんにちは。
date コマンドを利用し、システム時刻設定(変更)を行うシェルスクリプトを作ってみました。ただし単に、BSDタイプの設定指定を Linux へ適用しただけです。12時00分ちょうどへ設定する動作例です。$ sudo date_set.sh 1200 2019年 10月 8日 火曜日 11時59分59秒 JST 2019年 10月 8日 火曜日 12時00分00秒 JSTdate_set.sh#!/bin/sh # usage: sudo date_set.sh 1200 date if [ "$(uname)" = "Darwin" ]; then date "$1" elif [ "$(uname -s | cut -c 1-5)" = "Linux" ]; then hh="$(echo "$1" | cut -c 1-2)" mm="$(echo "$1" | cut -c 3-4)" date -s "$hh:$mm:00" fi exit $?
- 投稿日:2019-10-08T17:51:32+09:00
タグVLANにおけるサーバ側のbonding設定
はじめに
ネットワーク構築において欠かせないのがVLANという技術だが、VLANの種類によってサーバ側のbonding設定方法も変わってくる。
今回はタグVLAN方式におけるサーバ側のbonding設定方法をメモに残しておく。
タグVLANについては下記のリンクがわかりやすかったので、目を通して見るといいかもしれない。
https://qiita.com/RyomaTaniyama/items/3dcb86f21f16f0e5c423
(スイッチ側の設定はこの記事では割愛する)環境
CentOS7.6
手順
ネットワークファイルをいくつかいじる
/etc/sysconfig/network
networkGATEWAY={default_gateway} NETWORKING=yes VLAN=yes VLAN_NAME_TYPE=DEV_PLUS_VID_NO_PAD/etc/sysconfig/network-scripts/ifcfg-bond0
modeについては下記にまとめられてます。
http://tagutagu.com/?p=946ifcfg-bond0NAME="bond0" DEVICE="bond0" ONBOOT=yes NETBOOT=yes BONDING_OPTS="mode=4 miimon=100" TYPE=Bond/etc/sysconfig/network-scripts/ifcfg-bond0.{back_vlanid}
{back_vlanid}にはbackネットワークのvlanidをつける
ifcfg-bond0.{back_vlanid}DEVICE=bond0.{back_vlanid} BOOTPROTO=none ONBOOT=yes IPADDR={{ back_ip }} NETMASK=255.255.255.0/etc/sysconfig/network-scripts/ifcfg-bond0.{front_vlanid}
{front_vlanid}にはフロントネットワークのvlanidをつける
ifcfg-bond0.{front_vlanid}DEVICE=bond0.{front_vlanid} BOOTPROTO=none ONBOOT=yes IPADDR={{ front_ip }} NETMASK=255.255.255.0/etc/sysconfig/network-scripts/ifcfg-eno1
使用するインターフェース全てに設定する
※ eno1は筐体の機種によって名前が異なるので注意eno1NAME="eno1" DEVICE="eno1" TYPE=Ethernet ONBOOT=yes NETBOOT=yes SLAVE=yes MASTER="bond0"/etc/sysconfig/network-scripts/route-bond0.{back_vlanid}
ルーティングを設定する。
サブネットの範囲はお好みで。route-bond0.{back_vlanid}192.168.0.0/16 via {back_gateway} dev bond0.{back_vlanid} 172.29.0.0/16 via {back_gateway} dev bond0.{back_vlanid} 10.0.0.0/8 via {back_gateway} dev bond0.{back_vlanid}ネットワークのrestart
systemctl restart networkbackとfrontの確認をして繋がれば終わり
- 投稿日:2019-10-08T15:22:16+09:00
ubuntu ファイアウォールコマンドメモ
Ubuntu 18.04.3
ファイアウォールの状態を確認
$ sudo ufw status 無効になってると Status: inactive 有効になってると Status: active To Action From -- ------ ---- 22 ALLOW Anywhere 22/tcp ALLOW Anywhere 22 (v6) ALLOW Anywhere (v6) 22/tcp (v6) ALLOW Anywhere (v6)ファイアウォールの有効化/無効化
$ sudo ufw enable (有効化) $ sudo ufw disable (無効化)ポート開き方
$ sudo ufw allow 80ポート閉じ方
$ sudo ufw deny 80全てのポートを開く
$ sudo ufw default allow全てのポートを閉じる
$ sudo ufw default deny設定を読み込む
$ sudo ufw reload
- 投稿日:2019-10-08T12:37:27+09:00
Linuxのメモリ管理 勉強記録
Linux のメモリ管理
自分用メモです。
内容は何番煎じかわかりません……x86 系 CPU のメモリ管理
x86 系のメモリ空間には大きく分けて 3 つあり、MMU によって以下のように変換される。
論理アドレス | | セグメンテーション機構 V リニアアドレス | | ページング機構 V 物理アドレスCPU で実行される機械語プログラムでは論理アドレスを扱っており、物理アドレスへの変換は MMU という別のハードウェアユニットによって行われる。
セグメンテーション機構
x86 系 CPU のプロテクトモードではセグメント機構を持つ。
i486 のセグメント機構下の論理アドレスは以下のような構造になる。
+------------------------+-----------------------------------------+ | セグメントインデックス | オフセット | +------------------------+-----------------------------------------+ |-------- 12 bit --------|--------------- 32bit -------------------| |------------------------------- 64bit ----------------------------|上記セグメントインデックスをもとにセグメントを同定、それから offset 値を足し、リニアアドレスに変換される仕組み。
セグメントは、セグメントディスクリプタテーブルに定義される。
セグメントディスクリプタテーブルには以下の 2 種類がある。
セグメントディスクリプタテーブル種別 対応するレジスタ 説明 GDT GDTR システム全体で唯一のセグメントディスクリプタテーブル LDT - プロセスごとなどに持てるセグメントディスクリプタテーブル セグメントディスクリプタは複数の属性を持つ。
セグメントディスクリプタの要素 説明 セグメントベース そのセグメントの先頭のリニアアドレス リミット値 そのセグメントの長さ S システムフラグ(0 ならLDTなど重要なセグメント、1 なら普通のセグメント) タイプ セグメントの種類(データ・コード・スタック) DPL 0 ~ 3 の特権レベル。数字が低いほど高権限。 etc. セグメントは大きく分けて以下の 3 種類がある。
セグメント種別 対応するレジスタ 説明 コードセグメント cs 機械語プログラムが格納されたセグメント データセグメント ds プログラムが必要とするデータが格納されたセグメント スタックセグメント ss プログラムのローカル変数や、関数呼び出しの戻り先を格納するセグメント CPU は上記レジスタ cs, ds, ss の 3 つ(そのほか汎用セグメントレジスタ 3 つを合わせて計 6 つ)にセグメントを設定することで、プログラムを実行する。
CPU のレジスタ cs, ds, ss などは、セグメントディスクリプタテーブル内のセグメントディスクリプタを指し示すインデックスを保持する。(メモリのアドレスを保持するわけではない)特にコードセグメントの DPL は重要である。
CPU の特権レベルとして CPL があるが、実行中コードセグメントの DPL が元となっている。例えば CPU の特権レベル CPL が 2 の時は、DPL 2,3 のセグメントにはアクセスできるが、DPL 0,1 のセグメントにはアクセスできない。
ページング機構
Web上にたくさん説明があるので割愛。
Linux のメモリ管理
セグメンテーション機構
さて、上記 x86 のセグメンテーション機構を頑張って勉強したのだが、実は Linux は x86 のセグメント機能をほとんど使っていない。
Linux で基本的に利用されるコードセグメント、データセグメントは以下の 4 つのみである。
すべてのセグメントはリニアアドレスの 0 ~ 最大値までの区画を持つ。
もはや "セグメンテーション" していない。
セグメント名 セグメントベース リミット S タイプ DPL _USERCS 0x00000000 0xfffff 1 コード 3 _USERDS 0x00000000 0xfffff 1 データ 3 _KERNELCS 0x00000000 0xfffff 1 コード 0 _KERNELDS 0x00000000 0xfffff 1 データ 0 さらに、特権レベル(DPL/CPL)は、カーネルモードに対応する 0 と、ユーザモードに対応する 3 のみしか利用していない。
ページング機構
32bit の Linux ではリニアアドレス空間は以下のように分割される。
+------------------------+--------------------------+ | ユーザ用領域 | カーネル用領域 | +------------------------+--------------------------+ 0x00000000 0xc0000000 0xffffffffx86 の Linux において、プロセスごとのメモリアドレス空間の分割や、仮想メモリの仕組みはもっぱらページング機構を使って実現している。
重要なのは、ページテーブルがプロセスごとに固有である、ということである。Linux ではプロセスは task_struct で表現される。
そして、プロセスごとにページテーブルを持つ。task_struct :プロセス +--state +--thread_inf +--mm : mm_struct * | +--mmap * :メモリリージョンリスト | | +-- vm_area_struct | | +-- vm_area_struct | | +-- vm_area_struct : : : : +--pgd : pgd_t * :ページテーブル : :つまり、プロセスごとのメモリ空間の実現は、コンテキストスイッチの度にページテーブルを差し替えること(CR3 レジスタの内容を変更すること)で実現されている。
ちなみに、カーネル用領域に対応するページテーブルエントリの内容は、全プロセスのページテーブルで共通である。
プロセスごとのメモリ空間
プロセスがリニアアドレス空間上に確保した領域はメモリリージョンと呼ばれる。
プロセスは複数のメモリリージョンを持つ。
メモリリージョンは vm_area_struct 構造体で表現される。
プロセスは vm_area_struct のリストをtask_struct->mm->mmapに保持している。malloc(3) や free(3)、mmap(2)、mummap(2) はこの vm_area_struct を作成する、削除する、拡大する、縮小する操作に他ならない。
malloc(3) や mmap(2) はメモリリージョンを確保するが、この時点では物理メモリは確保されない。
(物理メモリの確保を遅延する仕組みをデマンドページングと呼ぶ。)実際にその領域に対して読み書きのアクセスがあったときに、ページフォールトとなってハードウェア割込みが入り、カーネルによって物理メモリ領域が確保され、ページテーブルの内容が変更される。
ページフォールト
ページフォールト時の動作は複雑である。
カーネルは、ページフォールトが、健全なアクセスによるものなのか、不正なアクセスによるものなのかを判断する。
mmap(2) でメモリリージョンが確保されたが、対応する物理メモリが確保されていない領域へのアクセスでページフォールトとなったときとき
-> 健全なアクセスとしてデマンドページングを行うメモリリージョン外へのアクセスでページフォールトとなったとき
-> 不正なアクセスとして SIGSEGV をプロセスに対して発行する詳細は以下を参考されたい。
参考
- 詳解Linuxカーネル 第3版
- はじめて読む486
- https://naoya-2.hatenadiary.org/entry/20071008/1191824562
- 投稿日:2019-10-08T12:37:27+09:00
Linuxのメモリ管理
Linux のメモリ管理
自分用メモです。
内容は何番煎じかわかりません……x86 系 CPU のメモリ管理
x86 系のメモリ空間には大きく分けて 3 つあり、MMU によって以下のように変換される。
論理アドレス | | セグメンテーション機構 V リニアアドレス | | ページング機構 V 物理アドレスCPU で実行される機械語プログラムでは論理アドレスを扱っており、物理アドレスへの変換は MMU という別のハードウェアユニットによって行われる。
セグメンテーション機構
x86 系 CPU のプロテクトモードではセグメント機構を持つ。
i486 のセグメント機構下の論理アドレスは以下のような構造になる。
+------------------------+-----------------------------------------+ | セグメントインデックス | オフセット | +------------------------+-----------------------------------------+ |-------- 12 bit --------|--------------- 32bit -------------------| |------------------------------- 64bit ----------------------------|上記セグメントインデックスをもとにセグメントを同定、それから offset 値を足し、リニアアドレスに変換される仕組み。
セグメントは、セグメントディスクリプタテーブルに定義される。
セグメントディスクリプタテーブルには以下の 2 種類がある。
セグメントディスクリプタテーブル種別 対応するレジスタ 説明 GDT GDTR システム全体で唯一のセグメントディスクリプタテーブル LDT - プロセスごとなどに持てるセグメントディスクリプタテーブル セグメントディスクリプタは複数の属性を持つ。
セグメントディスクリプタの要素 説明 セグメントベース そのセグメントの先頭のリニアアドレス リミット値 そのセグメントの長さ S システムフラグ(0 ならLDTなど重要なセグメント、1 なら普通のセグメント) タイプ セグメントの種類(データ・コード・スタック) DPL 0 ~ 3 の特権レベル。数字が低いほど高権限。 etc. セグメントは大きく分けて以下の 3 種類がある。
セグメント種別 対応するレジスタ 説明 コードセグメント cs 機械語プログラムが格納されたセグメント データセグメント ds プログラムが必要とするデータが格納されたセグメント スタックセグメント ss プログラムのローカル変数や、関数呼び出しの戻り先を格納するセグメント CPU は上記レジスタ cs, ds, ss の 3 つ(そのほか汎用セグメントレジスタ 3 つを合わせて計 6 つ)にセグメントを設定することで、プログラムを実行する。
CPU のレジスタ cs, ds, ss などは、セグメントディスクリプタテーブル内のセグメントディスクリプタを指し示すインデックスを保持する。(メモリのアドレスを保持するわけではない)特にコードセグメントの DPL は重要である。
CPU の特権レベルとして CPL があるが、実行中コードセグメントの DPL が元となっている。例えば CPU の特権レベル CPL が 2 の時は、DPL 2,3 のセグメントにはアクセスできるが、DPL 0,1 のセグメントにはアクセスできない。
ページング機構
Web上にたくさん説明があるので割愛。
Linux のメモリ管理
セグメンテーション機構
さて、上記 x86 のセグメンテーション機構を頑張って勉強したのだが、実は Linux は x86 のセグメント機能をほとんど使っていない。
Linux で基本的に利用されるコードセグメント、データセグメントは以下の 4 つのみである。
すべてのセグメントはリニアアドレスの 0 ~ 最大値までの区画を持つ。
もはや "セグメンテーション" していない。
セグメント名 セグメントベース リミット S タイプ DPL _USERCS 0x00000000 0xfffff 1 コード 3 _USERDS 0x00000000 0xfffff 1 データ 3 _KERNELCS 0x00000000 0xfffff 1 コード 0 _KERNELDS 0x00000000 0xfffff 1 データ 0 さらに、特権レベル(DPL/CPL)は、カーネルモードに対応する 0 と、ユーザモードに対応する 3 のみしか利用していない。
ページング機構
32bit の Linux ではリニアアドレス空間は以下のように分割される。
+------------------------+--------------------------+ | ユーザ用領域 | カーネル用領域 | +------------------------+--------------------------+ 0x00000000 0xc0000000 0xffffffffx86 の Linux において、プロセスごとのメモリアドレス空間の分割や、仮想メモリの仕組みはもっぱらページング機構を使って実現している。
重要なのは、ページテーブルがプロセスごとに固有である、ということである。Linux ではプロセスは task_struct で表現される。
そして、プロセスごとにページテーブルを持つ。task_struct :プロセス +--state +--thread_inf +--mm : mm_struct * | +--mmap * :メモリリージョンリスト | | +-- vm_area_struct | | +-- vm_area_struct | | +-- vm_area_struct : : : : +--pgd : pgd_t * :ページテーブル : :つまり、プロセスごとのメモリ空間の実現は、コンテキストスイッチの度にページテーブルを差し替えること(CR3 レジスタの内容を変更すること)で実現されている。
ちなみに、カーネル用領域に対応するページテーブルエントリの内容は、全プロセスのページテーブルで共通である。
プロセスごとのメモリ空間
プロセスがリニアアドレス空間上に確保した領域はメモリリージョンと呼ばれる。
プロセスは複数のメモリリージョンを持つ。
メモリリージョンは vm_area_struct 構造体で表現される。
プロセスは vm_area_struct のリストをtask_struct->mm->mmapに保持している。malloc(3) や free(3)、mmap(2)、mummap(2) はこの vm_area_struct を作成する、削除する、拡大する、縮小する操作に他ならない。
malloc(3) や mmap(2) はメモリリージョンを確保するが、この時点では物理メモリは確保されない。
(物理メモリの確保を遅延する仕組みをデマンドページングと呼ぶ。)実際にその領域に対して読み書きのアクセスがあったときに、ページフォールトとなってハードウェア割込みが入り、カーネルによって物理メモリ領域が確保され、ページテーブルの内容が変更される。
ページフォールト
ページフォールト時の動作は複雑である。
カーネルは、ページフォールトが、健全なアクセスによるものなのか、不正なアクセスによるものなのかを判断する。
mmap(2) でメモリリージョンが確保されたが、対応する物理メモリが確保されていない領域へのアクセスでページフォールトとなったときとき
-> 健全なアクセスとしてデマンドページングを行うメモリリージョン外へのアクセスでページフォールトとなったとき
-> 不正なアクセスとして SIGSEGV をプロセスに対して発行する詳細は以下を参考されたい。
参考
- 詳解Linuxカーネル 第3版
- はじめて読む486
- https://naoya-2.hatenadiary.org/entry/20071008/1191824562
- 投稿日:2019-10-08T12:13:02+09:00
Linux基礎(X Window System)
X Window Systemとは
多くのUNIXやLinuxで使用されているウィンドウシステムで、これによりGUIを実現している。
- X Window System上での処理の流れ
① キーボードでデータを入力する
② Xサーバーは入力データを受け付けて、Xクライアント(アプリ)にデータを送る
③ Xクライアントは受け取ったデータを処理して、処理結果をXサーバーに送る
④ Xサーバーは、Xクライアントから受け取った処理結果をディスプレイに出力するX Window Systemの設定ファイルX.Orgの設定
無料のX Window Systemとして、LinuxではXFree86が採用されていた。現在はX.Orgが主流。
X.Orgの設定ファイルは「/etc/X11/xorg.conf」。xorg.confファイルにはキーボード、ディスプレイ、フォント、解像度などの設定が記述されている。xorg.confファイルは複数のセクションから構成される。
セクション 説明 ServerLayout 入力・出力用のデバイスの組み合わせとスクリーン設定 Files フォント関連のパスの設定 Module Xサーバーがロード予定のダイナミックモジュールの設定 InputDevice Xサーバーに対する入力デバイス(キーボード等)の設定 Monitor システムにより使用されるモニタタイプの設定 Device システム用のビデオカードの設定 Screen ディスプレイの色深度と画像サイズの設定 xorg.confファイルの設定をコマンドラインで設定することもできる。
# xorg.confファイルを自動生成するコマンド $ Xorg - configure # xorg.confファイルのテスト $ X -config /root/xorg.conf.newネットワーク経由での利用
ネットワークを経由してX Window Systemを利用することができる。リモートアクセスでは、ローカルコンピュータでXサーバーが稼働して、リモートホストのXクライアントが、ローカルのXサーバーを使用してディスプレイに表示する。クライアント・サーバー配置の考え方とは逆のような構成になる。
- X Window Systemのネットワーク経由での利用
Xサーバーへのリモートアクセスを許可するためにはxhostコマンドを使用する。
xhost [+または-] [ホスト名]
オプション 説明 +ホスト名 指定したホストからのXサーバーへの接続を許可 -ホスト名 指定したホストからのXサーバーへの接続を拒否 + アクセス制御の無効化(全てのホストからの接続を許可) - アクセス制御の有効化(アクセス許可されていないホストからの接続は拒否) #Remote PCのXクライアントが、Local PCのXサーバーを利用を許可する設定 $ xhost +[Rempote PCのホスト名]Xクライアントの処理結果を表示するために、Remote PCの環境変数DISPLAYでXサーバーを指定して環境変数のDISPLAYをエクスポートする必要がある。
# ホスト名:ディスプレイ番号 $ DISPLAY=localpc:0 $ export DISPLAYXサーバーが起動するまでの流れ
- コンソールから「startx」コマンドを実行
- xinitコマンド
- ~/.xinitrcがあれば実行。ない場合、「/etc/X11/xinit/xinitrc」を実行
- ~/.xsessionを実行。ない場合、~/.Xclientsを実行。更にない場合、「/etc/X11/xinit/Xclients」を実行
- KDEまたはGNOMEまたは、他のウィンドウマネージャが起動
Xクライアントコマンド
X Window Systemの設定確認、情報収集のためのコマンド集
コマンド 説明 showrgb X Window Systemで利用可能な色とRGB値の情報表示 xlsclients 実行中のXクライアントの表示 xwininfo コマンド実行後に指定したウィンドウのサイズ、位置、色深度の情報確認 xdpyinfo ディスプレイの情報の表示(X Window System内のディスプレイ情報)


- 投稿日:2019-10-08T10:22:38+09:00
ASP.NET Core 入門9 ASP.NET Core MVCをCentOS 7へデプロイ
ASP.NET CoreはWindowsのみではなく、Linux上でも動作します。今回は今まで作成したソースコードをCentOS7上に乗せて動作するまでを行います。前提
CentOS7の
.NET Core環境&Nginx環境のセットアップが完了していること。1. このコンテンツを扱うこと
- 作成した
ASP.NET Core MVCプロジェクトの発行- 作成した
ASP.NET Core MVCプロジェクトをLinuxサーバーへ転送し、Nginxへデプロイを行う- アプリケーションをサービス起動&停止のスクリプトを作成
2. 環境情報
環境/ソフトウェア 内容 開発環境 OS Windows 10 1903 サーバー側 OS CentOS 7 .NET Core SDK 2.1.801 IDE Visual Studio Code 1.38.1 サーバー側 DB SQL Server 2017 Developer ファイル転送ツール FileZilla 3. 事前準備
Program.csファイルの起動URLを5000へ変更します。
public static IWebHostBuilder CreateWebHostBuilder (string[] args) => WebHost.CreateDefaultBuilder (args) .UseStartup<Startup> () .ConfigureLogging (logging => { logging.ClearProviders (); logging.SetMinimumLevel (LogLevel.Information); logging.AddConsole (); }) .UseNLog () .UseUrls("http://*:5000"); }発行
1. ローカル上に発行
ソリューションフォルダにて発行commandを実行します。
cd ds.Tutorial.web dotnet publish -c release2. ローカル上で動作確認
下記のcommandを実行後、localhost:5000へアクセスして問題なく動くことを確認します。
cd bin\release\netcoreapp2.1\publish dotnet ds.Tutorial.web.dllデプロイ
1. アプリケーション用のフォルダ作成
フォルダの作成と権限付与を行います。
$ sudo mkdir -p /webroot/ds.Tutorial.web $ sudo mkdir -p /webroot/ds.Tutorial.web/app $ sudo mkdir -p /webroot/ds.Tutorial.web/logs $ sudo chmod 777 /webroot/ds.Tutorial.web/app $ sudo chmod 777 /webroot/ds.Tutorial.web/logsFTP転送
ファイル転送ツールFileZilla を用いて、ローカルのpublishフォルダ配下のファイルをすべて/webroot/ds.Tutorial.web/appにコピーします。
サーバー上で稼働確認
cd /webroot/ds.Tutorial.web/app dotnet ds.Tutorial.web.dllhttp://{centosのIP}:5000へアクセスして稼働確認をします。
Ctrl + Cでアプリケーションが停止します。サービス起動&停止のスクリプト
アプリケーションの起動と停止ができるようにシェルスクリプトを作成します。
1. 起動shell
start.shを作成します。
$ sudo vi /webroot/ds.Tutorial.web/start.sh中身
#!/bin/sh cd $(cd "$(dirname "$0")"; pwd) APP_NAME=ds.Tutorial.web.dll echo "start begin..." echo $APP_NAME cd app nohup dotnet $APP_NAME >>../logs/info.log 2>>../logs/error.log & cd sleep 5 if test $(pgrep -f $APP_NAME|wc -l) -eq 0 then echo "start failed" else echo "start successed" fi2. 停止shell
stop.shを作成します。
$ sudo vi /webroot/ds.Tutorial.web/stop.sh中身
#!/bin/sh cd $(cd "$(dirname "$0")"; pwd) APP_NAME=ds.Tutorial.web.dll PROCESS=`ps -ef|grep $APP_NAME|grep -v grep |awk '{ print $2}'` while : do kill -9 $PROCESS > /dev/null 2>&1 if [ $? -ne 0 ];then break else continue fi done echo 'stop success!'3. スクリプトのテスト
$ sh /webroot/ds.Tutorial.web/start.sh start begin... ds.Tutorial.web.dll start successed $ sh /webroot/ds.Tutorial.web/stop.sh stop success!4. アプリケーションのサービス化
サービスを作成
$ sudo vi /usr/lib/systemd/system/ds.Tutorial.web.service中身
[Unit] Description=ds.Tutorial.web After=network.target [Service] WorkingDirectory=/webroot/ds.Tutorial.web/app ExecStart=/usr/bin/dotnet /webroot/ds.Tutorial.web/app/ds.Tutorial.web.dll ExecStop=/webroot/ds.Tutorial.web/stop.sh Restart=always RestartSec=10 [Install] WantedBy=multi-user.targetサービスの起動&停止確認
$ sudo systemctl start ds.Tutorial.web $ sudo systemctl stop ds.Tutorial.web
- 投稿日:2019-10-08T00:31:41+09:00
たのしく学ぶLinuxカーネル開発(第一回): `rm -rf /`実行時にカーネルパニックさせる
はじめに
Linuxカーネル開発を学ぶためにhello worldモジュールからはじめて少しづつ強化する記事を過去にいくつか書きました。これはちゃんとやれば身に付くことは身に付くのですが、非常に地味なので、よほどカーネルに興味を持っている人以外には退屈でしょう。そこで、目的をもって特定の機能をカーネルならではの方法で実現する記事を書けば面白いのでは…となったのでここに初回を書くことにしました。
対象読者はCライクなプログラミング言語での開発経験がある人です。Cのポインタがわかればなおよし。もしできればOSカーネルについての基本的な知識も欲しいです。
背景
UNIXが誕生してから現在に至るまで
rm -rf /によって全ファイルをぶっ飛ばす事件が後をたちません。GNUのcoreutilsに入っているrmではルートディレクトリ("/")への操作を特別扱いして容易に悲劇を起こさなくするpreserve-rootというデフォルトで有効になるオプションもあります。しかし人間とはこういうときにもこの機能を無効にする--no-preserve-rootをうっかり付けててしまうのです。そこでユーザが
rm -rf /を実行しようとするとカーネルパニックさせる(Windowsでいうところのブルースクリーンを出す)フェイルセーフ機能を作ることにしました。対象とするカーネル
- linux v5.3
このカーネルのソースコードは以下コマンドによって取得できます。
$ git clone -b v5.3 --depth 1 https://github.com/torvalds/linux ... # 数GBのディスク容量を消費しますので、ご注意ください $ git checkout v5.3 ... $変更点
この機能の変更点を示すパッチファイル0001-panic-if-user-tries-to-run-rm-rf.patchの中身は次の通りです(内容は後で説明します)。ライセンスはGPL v2です。
From 27a3af9519c8b07c527bd48ef19b4baf9f6d4a9c Mon Sep 17 00:00:00 2001 From: Satoru Takeuchi <satoru.takeuchi@gmail.com> Date: Sun, 6 Oct 2019 15:53:34 +0000 Subject: [PATCH] panic if user tries to run rm -rf / --- fs/exec.c | 37 +++++++++++++++++++++++++++++++++++++ 1 file changed, 37 insertions(+) diff --git a/fs/exec.c b/fs/exec.c index f7f6a140856a..8d2c1441b64c 100644 --- a/fs/exec.c +++ b/fs/exec.c @@ -1816,6 +1816,43 @@ static int __do_execve_file(int fd, struct filename *filename, if (retval < 0) goto out; + // Panic if user tries to execute `rm -rf /` + if (bprm->argc >= 3) { + struct page *page; + char *kaddr; + char rm_rf_root_str[] = "rm\0-rf\0/"; + char buf[sizeof(rm_rf_root_str)]; + int bytes_to_copy; + unsigned long offset; + + bytes_to_copy = min(sizeof(rm_rf_root_str), bprm->p % PAGE_SIZE); + page = get_arg_page(bprm, bprm->p, 0); + if (!page) { + retval = -EFAULT; + goto out; + } + kaddr = kmap(page); + offset = bprm->p % PAGE_SIZE; + memcpy(buf, kaddr + offset, bytes_to_copy); + kunmap(page); + put_arg_page(page); + + if (bytes_to_copy < sizeof(rm_rf_root_str)) { + page = get_arg_page(bprm, bprm->p + bytes_to_copy, 0); + if (!page) { + retval = -EFAULT; + goto out; + } + kaddr = kmap(page); + memcpy(buf + bytes_to_copy, kaddr, sizeof(rm_rf_root_str) - bytes_to_copy); + kunmap(page); + put_arg_page(page); + } + + if (!memcmp(rm_rf_root_str, buf, sizeof(rm_rf_root_str))) + panic("`rm -rf /` is detected"); + } + would_dump(bprm, bprm->file); retval = exec_binprm(bprm); -- 2.17.1動かし方
最初に一点注意。この機能は壊してもいいVM上でやりましょう。動作確認テストが失敗すると全ファイルがぶっ飛びかねませんし、成功してもダーティなページキャッシュに乗っているデータは失うことになります。
まずは次のようにパッチファイルを適用した上でビルド、インストール、再起動します。
$ git apply 0001-panic-if-user-tries-to-run-rm-rf.patch ... # 機能追加に必要なパッチを当てる $ sudo apt install kernel-package flex bison libssl-dev ... # カーネルビルドに必要なパッケージをインストール $ make localmodconfig ... # ビルドのための設定をする。何か聞かれたらENTERを押しまくる $ make -j$(grep -c processor /proc/cpuinfo) ... # ビルドする $ sudo make modules_install && make install ... # 新しいカーネルとそのモジュールをインストールする $ sudo /sbin/reboot # GRUBで現在起動中のものなど特定のカーネルを次回起動するようになっている場合は適宜修正してください再起動後にカーネルバージョンが変わっていることを確認します。
$ uname -r 5.3.0+ $5.3.0+となっていれば成功です。最後の"+"はカスタムカーネルのときに勝手に付与されます。
最後に例のコマンドを実行します。
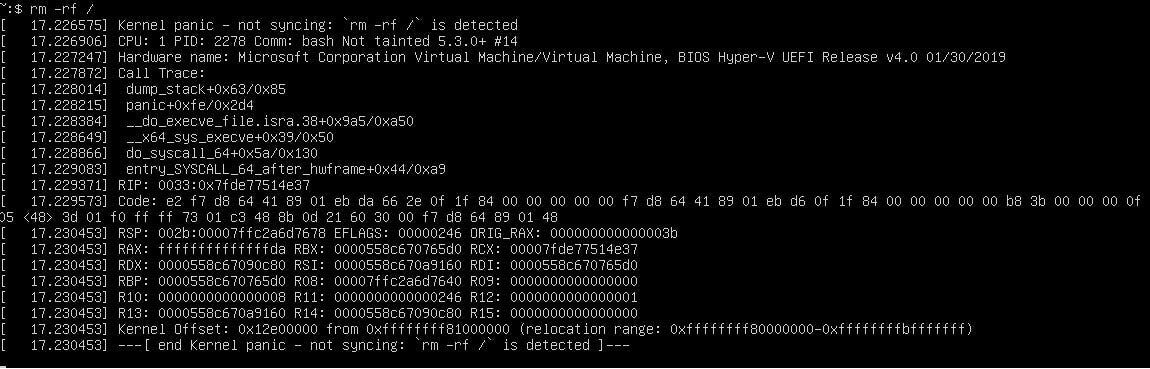
$ rm -rf /これで応答が戻ってこなければ成功です。マシンのコンソールを見ている場合はパニック時のカーネルログが見られます。GUI上の端末エミュレータあるいはssh経由でコマンドを叩いた場合は単に画面が停止したように見えるでしょう。
参考までにわたしの環境での実行結果を載せておきます。
この機能は
rm -rf /を誰が実行したかなどというものは考えておらず、ルートディレクトリ以下のファイルを消す権限が無い一般ユーザがこのコマンドを実行しても容赦なくカーネルパニックを起こしますのでご注意ください。この後はマシンを再起動させて、必要ならば本記事によってインストールしたカーネルを削除したり、GRUBが使うデフォルトカーネルの変更をしたりしてください。
パッチの解説
まずパッチを当てる前のコードについて簡単に説明しておきます。
- ユーザプロセスが新規プログラムを実行しようとexecve()システムコールを呼ぶ
- カーネル内の上記システムコールを処理するハンドラ関数が動作しはじめて、その過程でパッチの中にもある__do_execve_file()関数を呼ぶ
- 3. execve()システムコールに与えられたコマンドライン引数や環境変数についての情報を取り出してカーネルのメモリに読み込む。パッチ内の
copy_strings(bprm->argc, argv, bprm)はコマンドライン引数の内容に相当する- execve()システムコールの実処理をする。現在動作中のプロセスを新しいプログラムで置き換えて、当該プログラムのエントリポイントから実行開始
このパッチは、3と4の間に、ユーザから渡されたexecve()システムコールの引数が
rm -rf /であればカーネルパニックさせる処理を追加します。ではパッチに行番号を振って説明します。
1 From 27a3af9519c8b07c527bd48ef19b4baf9f6d4a9c Mon Sep 17 00:00:00 2001 2 From: Satoru Takeuchi <satoru.takeuchi@gmail.com> 3 Date: Sun, 6 Oct 2019 15:53:34 +0000 4 Subject: [PATCH] panic if user tries to run rm -rf / 5 6 --- 7 fs/exec.c | 37 +++++++++++++++++++++++++++++++++++++ 8 1 file changed, 37 insertions(+) 9 10 diff --git a/fs/exec.c b/fs/exec.c 11 index f7f6a140856a..8d2c1441b64c 100644 12 --- a/fs/exec.c 13 +++ b/fs/exec.c 14 @@ -1816,6 +1816,43 @@ static int __do_execve_file(int fd, struct filename *filename, 15 if (retval < 0) 16 goto out; 17 18 + // Panic if user tries to execute `rm -rf /` 19 + if (bprm->argc >= 3) { 20 + struct page *page; 21 + char *kaddr; 22 + char rm_rf_root_str[] = "rm\0-rf\0/"; 23 + char buf[sizeof(rm_rf_root_str)]; 24 + int bytes_to_copy; 25 + unsigned long offset; 26 + 27 + bytes_to_copy = min(sizeof(rm_rf_root_str), bprm->p % PAGE_SIZE); 28 + page = get_arg_page(bprm, bprm->p, 0); 29 + if (!page) { 30 + retval = -EFAULT; 31 + goto out; 32 + } 33 + kaddr = kmap(page); 34 + offset = bprm->p % PAGE_SIZE; 35 + memcpy(buf, kaddr + offset, bytes_to_copy); 36 + kunmap(page); 37 + put_arg_page(page); 38 + 39 + if (bytes_to_copy < sizeof(rm_rf_root_str)) { 40 + page = get_arg_page(bprm, bprm->p + bytes_to_copy, 0); 41 + if (!page) { 42 + retval = -EFAULT; 43 + goto out; 44 + } 45 + kaddr = kmap(page); 46 + memcpy(buf + bytes_to_copy, kaddr, sizeof(rm_rf_root_str) - bytes_to_copy); 47 + kunmap(page); 48 + put_arg_page(page); 49 + } 50 + 51 + if (!memcmp(rm_rf_root_str, buf, sizeof(rm_rf_root_str))) 52 + panic("`rm -rf /` is detected"); 53 + } 54 + 55 would_dump(bprm, bprm->file); 56 57 retval = exec_binprm(bprm); 58 -- 59 2.17.1 6017行目の時点でexecve()の引数はカーネルのメモリに保存されています。ここからが本パッチの変更がはじまります。
検出したいコマンドは
rm -rf /であり、かつ、このときの引数の数は3です。これに加えてbprm->argcにはexecve()に渡された引数の数が入っています。よってbprm->argc >= 3という条件のif文によって関係ないコマンド実行を弾いています。べつに>=ではなく==でもよかったのですが、rm -rf / fooとかやっても(このときの引数の数は4)ひどいことになるのには変わりがないのでこうしました。コマンドライン引数はカーネルメモリ内の所定領域に、各引数をNULL文字('\0')で区切ったデータとして配置されています。たとえばechoコマンドにhelloという文字列を引数として実行した場合は"echo\0hello"というデータになります。コマンド名も引数の一つということに注意してください。
rm -rf /の場合は"rm\0-rf\0/"になっているはずです。前述のif文の中身では22行目に「こうあるべき」なデータを置いて、それと実際の引数の値を51行目において比較して、マッチすれば52行目においてカーネルパニックさせています。カーネルメモリ内からデータをとってくるのが少々やっかいです。これは27~49行目に対応します。必要とするデータはメモリ上の1ないし2ページ(CPUが仮想記憶という機能によってメモリを管理する単位。x86_64アーキテクチャにおいては4KB)にまたがって存在しています。殆どの場合は1ページに収まります。この場合は27行目から37行目だけで終わりです。2ページにまたがる場合は39行目から49行目を実行します。ここではデータが1ページにおさまっている場合についてのみ書きます。
27~37行目はそれぞれ次のような意味を持ちます。
- 27行目: カーネルメモリからもってくるデータのサイズ。データが一ページに収まる場合は9バイト
- 28~32行目: データが入っているページを指すpage構造体と呼ばれるデータを得る、およびそのエラー処理をする。このpage構造体は37行目において解放する
- 33行目: ページ構造体が示すページのアドレスを得る。kmap()によって得たアドレスは36行目のように対応するkunmap()を呼ぶのがお約束
- 34,35行目: 必要なデータをbufにコピー
駆け足で説明しましたがとりあえずフィーリングで読んでみてなんとなくわかればいいと思います。
おわりに
第一回と書きましたが、二回目以降があるかどうかは記事への反響と私のやる気次第です。
- 投稿日:2019-10-08T00:04:33+09:00
シリアルポートをUSB接続するたびに権限付与させたい
はじめに
sudo chmod 666 /dev/ttyACM0とコマンド入力すれば、権限が付与される。ただし、再起動すると、元の権限に戻ってしまうので接続するたびに自動で権限を付与させたい。対処法
以下のディレクトリのファイルを修正する
nano /lib/udev/rules.d/50-udev-default.rules
変更箇所は以下の通り。(変更前)KERNEL=="tty[A-Z]*[0-9]|pppox[0-9]*|ircomm[0-9]*|noz[0-9]*|rfcomm[0-9]*", GROUP="dialout" (変更後)KERNEL=="tty[A-Z]*[0-9]|pppox[0-9]*|ircomm[0-9]*|noz[0-9]*|rfcomm[0-9]*", GROUP="dialout", MODE="0666"これで、USB接続するたびに権限が付与される。