- 投稿日:2019-02-27T23:58:29+09:00
[Cinema 4D] ワールド座標と平行なバウンディングボックスサイズを取得したい
CGソフトを使っているとバウンディングボックスサイズを取得したいということがあります.Cinema 4Dにもバウンディングボックスサイズを取得する便利な関数があるのですが,一つ欠点があり,ローカル座標と平行なバウンディングボックスサイズしか取得できないのです.
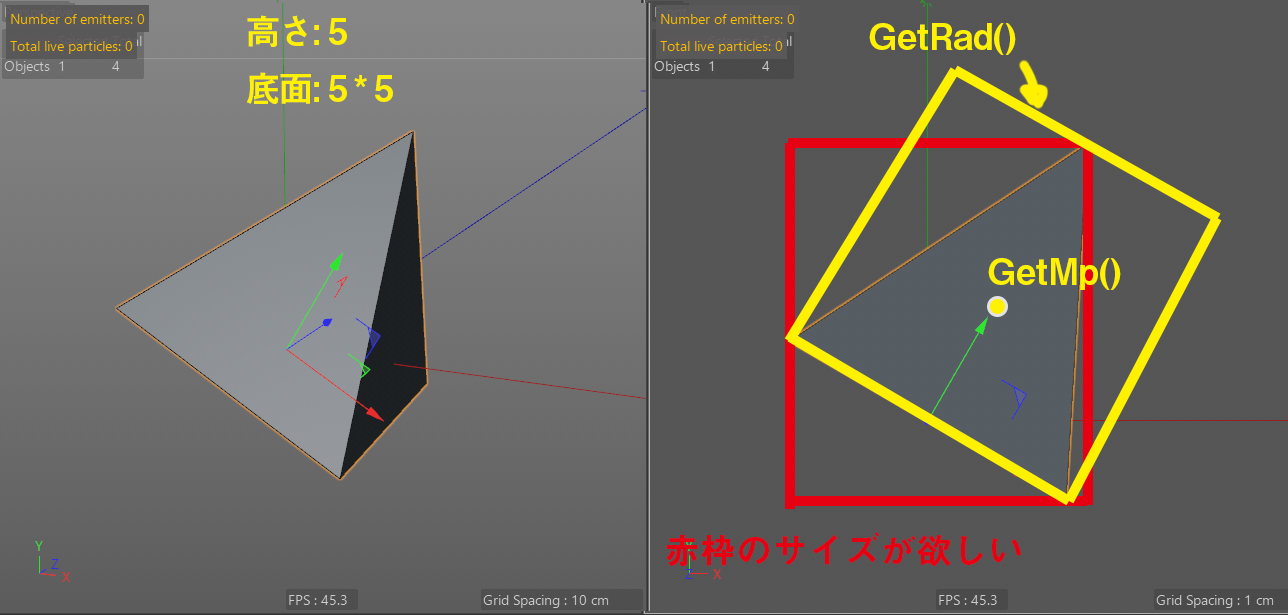
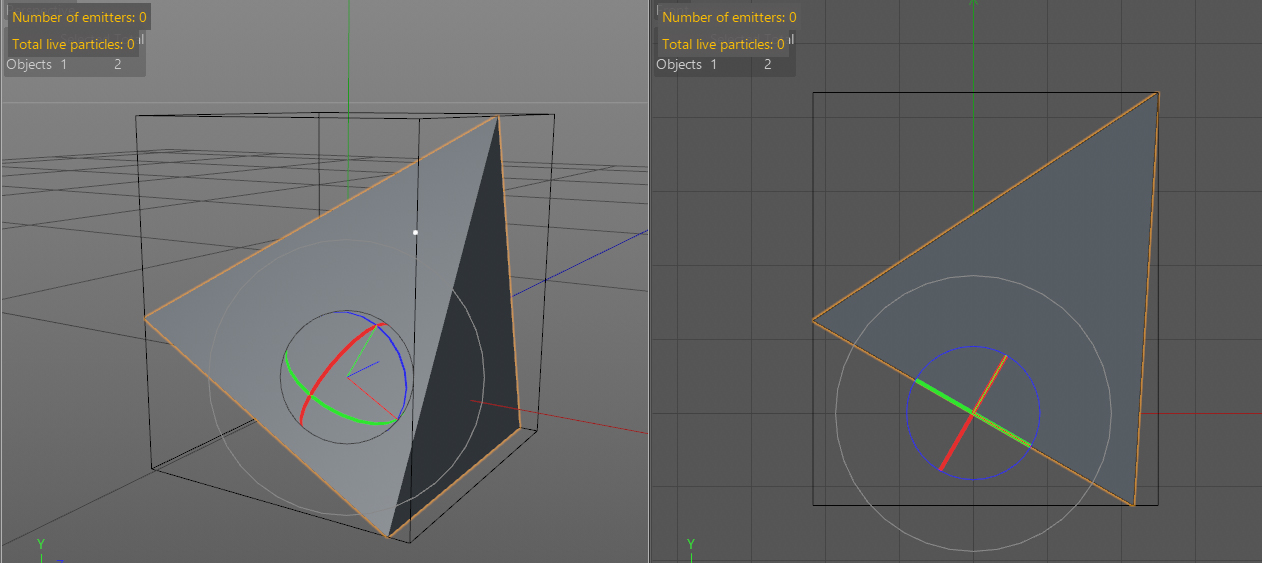
次の画像のような四角推を例にとってみます.高さ5,底面は5*5で,底面中心を軸に持ち,そこを基点にワールド座標に対してH.Bに30度傾いているとします.GetMp()はオブジェクトの全頂点の中心座標を返します.GetRad()はGetMp()を基点としたローカル軸と平行な各軸の半径を返します.この時,GetMp()で取得した座標値にGetRad()の数値をプラスとマイナスすればローカルのバウンディングボックスサイズが分かります.しかし,ワールド座標から見たときのそのオブジェクトの最大サイズと最小サイズ(赤い枠)が欲しいときには困ります.
GetRad()とGetMp()を使う場合は,このオブジェクトをH.Bに-30度してワールド座標と平行な向きに戻します.これは逆行列を乗算すれば簡単です.この時,頂点も-30度されてしまうので,各頂点にはH.Bに30度傾けてポイント位置だけを最初の位置に戻します.これでワールド座標と軸は並行でポイント位置は最初の状態に戻ります.Pythonの中で軸モードを使って軸の向きだけワールドと平行にしたいところですが,どうやらそれはPythonでは不可能なようで,この手の質問がCinema 4DのPlugincafeでもしばしばトピックに上がっているみたいです.
この状態でGetMp()とGetRad()すれば,赤い枠の中心座標と上下前後のサイズが得られます.
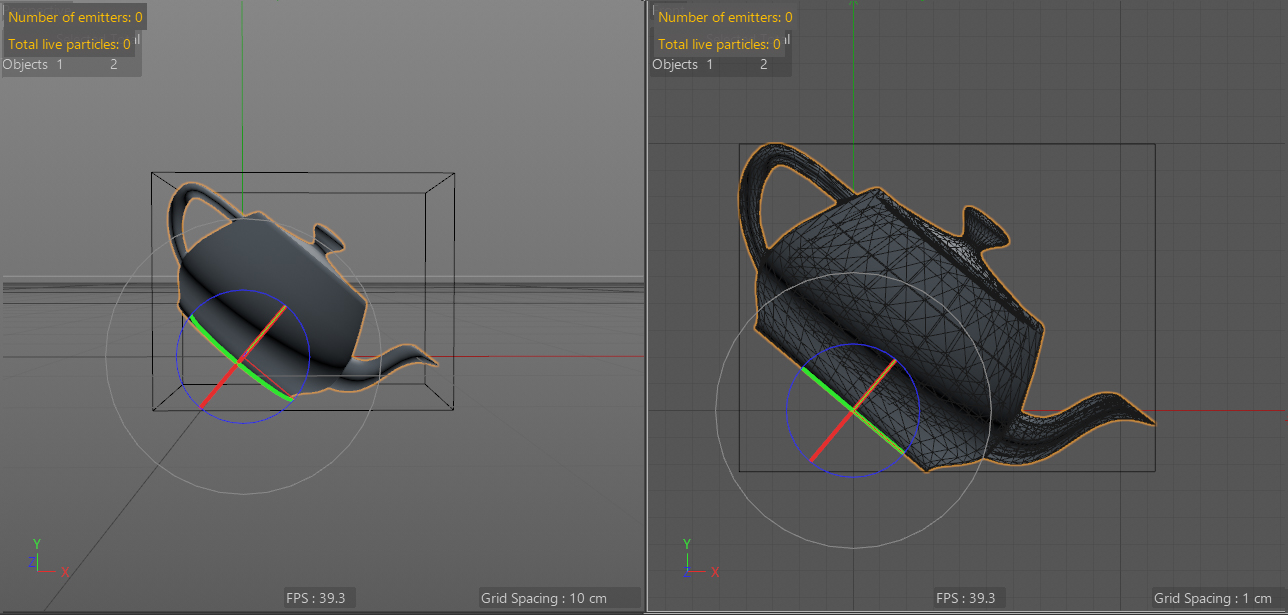
それでは実際にこの作業をスクリプトで行い,得られたサイズからバウンディングボックスと同じサイズのポリゴンを作成してみます.
注意点として最初に選択オブジェクトのクローンを取得して,キャッシュを取得します.opを操作すると選択オブジェクトを操作することになってしまいます.また,プリミティブの場合はキャッシュをとります.他,デフォーマーを使っていたり,オブジェクタイプによっては最終ポリゴンを取得する追加処理が必要になります.また,途中でクローンに対してMessage(c4d.MSG_UPDATE)を実行してEvetnAdd()して姿勢を確定させる必要があります.MSGはCinema 4D側にある操作をしたから,情報を更新してくださいというメッセージを渡します.これは実は様々な個所で使いますし,メッセージタイプも実にたくさんあります.
def main(): doc = c4d.documents.GetActiveDocument() op = doc.GetActiveObject() if op is None: return doc.StartUndo() # 選択オブジェクトからキャッシュを取得 # デフォーマなどを使っている場合は,別途GetDeformeCache()などを用いて取得 if op.GetCache(): clone = op.GetCache().GetClone() else: clone = op.GetClone() # 自身の逆行列を乗算して姿勢をワールドと平行にする clone.SetMg(~op.GetMg() * op.GetMg()) # 頂点を元の位置に戻す pcount = clone.GetPointCount() points = clone.GetAllPoints() for p in xrange(pcount): clone.SetPoint(p, op.GetMg() * points[p]) # クローンをアップデートしてEventAdd()すること clone.Message(c4d.MSG_UPDATE) c4d.EventAdd() # センター位置からXYZの最大,最小を取得 center = clone.GetMp() xMin = center.x + clone.GetRad().x * -1 xMax = center.x + clone.GetRad().x yMin = center.y + clone.GetRad().y * -1 yMax = center.y + clone.GetRad().y zMin = center.z + clone.GetRad().z * -1 zMax = center.z + clone.GetRad().z print xMin print xMax print yMin print yMax print zMin print zMax # 新規バウンディングボックス用のポリゴンオブジェクトを作成して,座標をセットしていく box = c4d.BaseObject(c4d.Opolygon) box.ResizeObject(8,6) box.SetPoint(0,c4d.Vector(xMin, yMin, zMin)) box.SetPoint(1,c4d.Vector(xMin, yMax, zMin)) box.SetPoint(2,c4d.Vector(xMax, yMin, zMin)) box.SetPoint(3,c4d.Vector(xMax, yMax, zMin)) box.SetPoint(4,c4d.Vector(xMax, yMin, zMax)) box.SetPoint(5,c4d.Vector(xMax, yMax, zMax)) box.SetPoint(6,c4d.Vector(xMin, yMin, zMax)) box.SetPoint(7,c4d.Vector(xMin, yMax, zMax)) box.SetPolygon(0, c4d.CPolygon(0,1,3,2)) box.SetPolygon(1, c4d.CPolygon(2,3,5,4)) box.SetPolygon(2, c4d.CPolygon(4,5,7,6)) box.SetPolygon(3, c4d.CPolygon(6,7,1,0)) box.SetPolygon(4, c4d.CPolygon(1,7,5,3)) box.SetPolygon(5, c4d.CPolygon(6,0,2,4)) doc.InsertObject(box) # 表示タグで線表示にする tag = c4d.BaseTag(c4d.Tdisplay) tag[c4d.DISPLAYTAG_AFFECT_DISPLAYMODE] = True tag[c4d.DISPLAYTAG_SDISPLAYMODE] = 6 tag[c4d.DISPLAYTAG_WDISPLAYMODE] = 0 box.InsertTag(tag) box.Message(c4d.MSG_UPDATE) doc.AddUndo(c4d.UNDOTYPE_NEW,box) doc.EndUndo() c4d.EventAdd()このようにすれば,色々な姿勢で存在するオブジェクトから,ワールド座標に対して平行なバウンディングボックスを取得できます.
何に使うかというと,例えば,ワールドに平行なバウンディングボックスの端にオブジェクトを配置させたりしたい場合に,内部でこのようなバウンディングボックスを生成すれば座標を得られます.ちなみに,box = c4d.BaseObject(c4d.Opolygon)の行で空のポリゴンオブジェクトを生成していますが,後の行でInsertObjectする,しないに関わらずメモリ上にはこのオブジェクトが存在しつづけるので注意が必要です.Insertしない場合は,Remove()で削除しておきましょう.
できました.
ポリゴン数が多いと頂点を元に戻す処理で時間がかかるので,八分木などを用いて最大,最小座標を割り出すのが良いと思います.
- 投稿日:2019-02-27T22:58:55+09:00
数理最適化:線形計画問題【Pythonの数値計算】
まえがき
太郎さんは八百屋に行きました。
そこでは
Aセット:みかん4個とりんご1個で400円、
Bセット:みかん2個とりんご3個で500円
の二種類のセット販売がありました。
太郎さんはお母さんに「たくさん買ってきてね」と言われていました。
可能な限りお金を使う買い方を考えましょう。
ただし八百屋さんの在庫にはみかん100個、りんご70個しかありません。数式にしてみましょう
これは線形計画問題と言われる問題です。
Aセットの個数をx個、
Bセットの個数をy個買うとします。最大化したい関数は値段なので、
$$ 400 x + 500 y $$
という式になります。さらにみかん100個、りんご70個という在庫の制約があるため
4x + 2y \leq 100 \\ x + 3y \leq 70が条件に加わります。
ついでに$x,y \geq 0$も条件。
まとめてこう書きます。\mathrm{Maximize}~~~400 x + 500 y\\ \mathrm{Subject~to} ~~~ 4x + 2y \geq 100\\ ~~~~~~~~~~~~~~~~~~x + 3 y \geq 70\\ ~~~~~~~x \leq 0 \\ ~~~~~~~y \leq 0(整数じゃなきゃダメじゃね?みたいなツッコミは禁止とします。)
Pythonで解いてみよう
scipy.optimize.linprogという関数を利用します。
以下の形を標準形とします。\mathrm{Minimize}~~~c^Tx\\ \mathrm{Subject~to} ~~~ Gx \geq h\\ ~~~~~~~~~~~~~~~~~~Ax \geq b\\$c,G,h,A,b$の5つを引数に設定できます。これは最小化の関数ということに注意。
問題の式を一般形に当てはめると\mathrm{Minimize}~~~ \left( \begin{array}{ccc} -400 \\ -500 \end{array} \right)^T \left( \begin{array}{ccc} x \\ y \end{array} \right)\\ \mathrm{Subject~to} ~~~ \left( \begin{array}{ccc} 4 & 2 \\ 1 & 3 \\ -1 & 0\\ 0 & -1 \end{array} \right) \left( \begin{array}{ccc} x \\ y \end{array} \right)\leq \left( \begin{array}{ccc} 100 \\ 70 \\ 0\\ 0 \end{array} \right)「最小化」の関数にするために、値段をひっくり返してます。
ここからc = \left( \begin{array}{ccc} -400 \\ -500 \end{array} \right),G = \left( \begin{array}{ccc} 4 & 2 \\ 1 & 3 \\ -1 & 0\\ 0 & -1 \end{array} \right) ,h = \left( \begin{array}{ccc} 100 \\ 70 \\ 0\\ 0 \end{array} \right)この三つの引数を入れて関数を使ってみましょう。
import numpy as np # npという名前でimportする慣習。 from scipy import optimize c = np.array([-400,-500]) G = np.array([[4,2],[1,3],[-1,0],[0,-1]]) h = np.array([[100,70, 0, 0]]) sol = optimize.linprog(c, G, h) print(sol.x) print(sol.fun) # [16. 18.] # -15400.0つまりAセットを16個、Bセットを18個買って15400円。
これが最大となります。まとめ
数理最適化問題は、関数に一般化して入れればいい。
線形計画問題を解くための関数は色々あるらしいですが、その一例を示しました。
この関数だって上限下限の設定とかデータ型とかもうちょっと行儀のいい書き方あるけど無視。『機械学習のエッセンス』という本を参考にしました。
この本についてまとめていきます。
前回:数値範囲に気をつけよう:
https://qiita.com/NNNiNiNNN/items/2f17f874f8a234bd10ad
- 投稿日:2019-02-27T22:37:47+09:00
SQLAlchemy-migrateでスキーマ変更する方法
概要
今やっている開発にSQLAlchemy-migrateを使用していて、本番環境での運用が始まった後、カラムを変更しようと思った時にやり方が分からなかったので調べました。
動作環境
- Debian 9.7
- python 3.6.0
- MySQL 5.7
- SQLAlchemy 1.2.18
- sqlalchemy-migrate 0.12.0
- mysqlclient 1.4.2
内容
カラム追加
createメソッドで新規カラムを作成できます。
引数には追加したいTableオブジェクトを指定します。
どうやらカラムの追加位置は指定できないようなので、一番後方の列に配置されるみたいです。from sqlalchemy import * from migrate import * from sqlalchemy.dialects.mysql import VARCHAR def upgrade(migrate_engine): meta = MetaData(bind=migrate_engine) mytable = Table('mytable', meta, autoload=True) Column('new_column', VARCHAR(255)).create(mytable) def downgrade(migrate_engine): meta = MetaData(bind=migrate_engine) mytable = Table('mytable', meta, autoload=True) mytable.c.new_column.drop()カラム削除
dropメソッドでカラムを削除できます。
カラム追加とは違い、Tableオブジェクトのcメソッドから削除したいカラム名を指定しています。from sqlalchemy import * from migrate import * from sqlalchemy.dialects.mysql import DATETIME def upgrade(migrate_engine): meta = MetaData(bind=migrate_engine) mytable = Table('mytable', meta, autoload=True) mytable.c.new_column.drop() def downgrade(migrate_engine): meta = MetaData(bind=migrate_engine) mytable = Table('mytable', meta, autoload=True) Column('new_column', VARCHAR(255)).create(mytable)カラム変更
alterメソッドで既存カラムの内容を変更できます。
削除同様、Tableオブジェクトのcメソッドから変更したいカラム名を指定しています。引数には以下項目が指定できます。
- name - カラム名
- type - データ型
- default - デフォルト値
- nullable - NULL許可
from sqlalchemy import * from migrate import * from sqlalchemy.dialects.mysql import VARCHAR, DATETIME def upgrade(migrate_engine): meta = MetaData(bind=migrate_engine) mytable = Table('mytable', meta, autoload=True) mytable.c.new_column.alter(name='mod_column', type=DATETIME, default='デフォルト値', nullable=True) def downgrade(migrate_engine): meta = MetaData(bind=migrate_engine) mytable = Table('mytable', meta, autoload=True) mytable.c.new_column.alter(name='new_column', type=VARCHAR(255), nullable=False)つぶやき
downgradeを整合性がとれるように書かなきゃいけないのはちょっとめんどくさいかも・・・
- 投稿日:2019-02-27T21:41:42+09:00
Python(Flask)で簡単なWebAPIを実装する
WebアプリにAPIの機能を付ける
今回作成するAPIは作成した掲示板サイトに蓄積されているデータを、プログラムで自動抽出するのを楽するために実装します。
以下のサイトを参考にしました。
Python(Flask) でサクッと 機械学習 API を作るここではGETとPOSTメソッドでリクエストを送信して、受信したデータをJSON形式で出力する方法について説明します。
以下のサイトにソースコードがあります。
Source CodeGETメソッド
@app.route("/api_get/<key>", methods=["GET"]) def api_get(key): data = {key: []} thread_api_get = Thread.query.filter_by(threadname=key).first() articles = Article.query.filter_by(thread_id=thread_api_get.id).all() for article in articles: r = {"name": article.name, "article": article.article} data[key].append(r) return jsonify(data)
jsonify(data)表示されるデータが日本語だと文字化けしてしまうので、以下の設定を追加してください。app.config['JSON_AS_ASCII'] = False
http://127.0.0.1:5000/api_get/<key>の<key>の部分に取得したいスレッド名を当てはめてください。
ブラウザでアクセスした時に指定したスレッドに記事が存在していれば、以下のように情報が取得できます。
POSTメソッド
@app.route("/api_post", methods=["POST"]) def api_post(): print(request.data) api_data_post = request.data.decode() data = {api_data_post: []} print(api_data_post) thread_api_get = Thread.query.filter_by(threadname=api_data_post).first() articles = Article.query.filter_by(thread_id=thread_api_get.id).all() for article in articles: r = {"name": article.name, "article": article.article} data[api_data_post].append(r) return jsonify(data)
http://127.0.0.1:5000/api_post/にブラウザでアクセスすると以下のようになります。
POSTメソッドでのみアクセスできるようにしているので上手く表示されません。
ここでは以下のスクリプトを使ってPOSTメソッドでアクセスします。import requests url = 'http://127.0.0.1:5000/api_post' r = requests.post(url, data="hogehoge".encode('utf-8')) print(r.text)POSTで送信されるデータはバイナリになっているので、復号化処理を加える必要があります。
request.data.decode()取得結果は以下のようになります。
{ "hogehoge": [ { "article": "ああああああああ", "name": "hoge1" }, { "article": "いいいい いいい", "name": "hoge2" }, { "article": "うう うう うう", "name": "hoge3" } ] }

- 投稿日:2019-02-27T19:41:43+09:00
【python】BPSK変調・AWGN通信路におけるシミュレーションの方法と気を付けるべきこと
pythonで通信系のシミュレーションする人がどれだけいるのかよくわかりませんが、個人的なpythonの練習の意味も含めてBPSK変調・AWGN (Additive White Guassian Noise)通信路での通信シミュレーションの方法について書きたいと思います。
僕が研究を始めて間もないころに戸惑った
・雑音分散とSNR(Signal to Noise Power Ratio)の関係
・判定誤りが発生するときのイメージ
について少し詳しめに書きます。先にコードの全体を貼り付けておきます。
import numpy as np # 送信側アンテナ数 M = 2 # 受信側アンテナ数 N = 2 # 送信ビット数 bit_num = 10 ** 3 # Additive Gaussian White Noiseの生成する際のパラメータ設定 SNRdB = 10 SNR = 10 ** (SNRdB / 10) No = 1 / SNR # 送信ビット列を生成 TX_bit = np.random.randint(0, 2, (M, bit_num)) # 0 -> -1, 1 -> 1としてBPSK変調 TX_BPSK = np.ones((M, bit_num)) TX_BPSK[TX_bit == 0] = -1 # AWGN雑音の生成 noise = np.random.normal(0, np.sqrt(No / 2), (M, bit_num)) \ + 1j * np.random.normal(0, np.sqrt(No / 2), (M, bit_num)) # AWGN通信路 = 送信シンボル間干渉が生じないような通信路で送信 RX_BPSK = TX_BPSK + noise # 以下のprint関数の出力を表示すると、Noとほぼ一致するはず # print(np.dot(noise[0, :], np.conj(noise[0, :]))/bit_num) # 受信信号をビットに判定 RX_bit = np.zeros((N, bit_num)) RX_bit[np.real(RX_BPSK) > 0] = 1 RX_bit[np.real(RX_BPSK) < 0] = 0 error_sum = np.sum(np.abs(TX_bit - RX_bit)) BER = error_sum / (M * bit_num)解説
初期パラメータ設定
頭の
# 送信側アンテナ数 M = 2 # 受信側アンテナ数 N = 2 # 送信ビット数 bit_num = 10 ** 3については、シミュレーションの本質的な内容とは関係のないパラメータたちです。
一応、今後AWGN通信路からレイリーフェージング通信路に拡張することも考えて送受信アンテナ数は別々で設定できるようにしてありますが、このコードに限って言えば、N=Mでないと回らないので注意してください。また、NやM、bit_numの値を大きくすればするほどBER(Bit Error Rate)は理論値に近づきます。雑音電力の決め方
むずかしいところは
# Additive Gaussian White Noiseの生成する際のパラメータ設定 SNRdB = 10 SNR = 10 ** (SNRdB / 10) No = 1 / SNRから始まります。
通信系のシミュレーション結果を表示する際は、横軸にSNR[dB]、縦軸にBERをとったグラフ、すなわち「どれだけの電力が使われたとき、どれだけ正確な通信ができたかを表すグラフ」が基本となります。SNR[dB]が小さい値であればBERは高く(0.5に近い値)なり、SNR[dB]が大きければBERは小さく、理想的には0になります。そしてそのようなシミュレーションをするためには、適当な大きさの電力を持つのAWGN雑音を発生させる必要があるわけです。
その「適当な電力」を決めているのが上記のコードで、この部分をあえて数式で書くと、
\begin{align} {\rm SNR[dB]} &= 10{\rm log}_{10} \frac{1}{N_{\rm 0}} \\ {\rm SNR} &= 10^{\frac{1}{10} \times 10{\rm log}_{10} \frac{1}{N_{\rm 0}}} \\ &= 10^{{\rm log}_{10} \frac{1}{N_{\rm 0}}} \\ &= \frac{1}{N_{\rm 0}} \\ N_{\rm 0} &= \frac{1}{\rm SNR} \end{align}という形になります。
ちなみに、1行目の「1」は「送信電力を基準である『1』とする」という意味です。
通信シミュレーションを行うときには、このように送信電力を基準となる「1」に固定した上で、雑音電力を決めます。
私の数式の1行目で「1」としてある部分を$E_{\rm s}$としてある数式も世の中にはたくさんありますが、意味しているところは大体一緒です。とにかく、送信電力と雑音電力を別々に設定するのではなく、送信電力を基準に雑音電力を決めるのが原理原則であると認識しておくといいかなと思います。ビット列の生成とBPSK変調
次に、
# 送信ビット列を生成 TX_bit = np.random.randint(0, 2, (M, bit_num)) # 0 -> -1, 1 -> 1としてBPSK変調 TX_BPSK = np.ones((M, bit_num)) TX_BPSK[TX_bit == 0] = -1という部分ですが、これは特に言うべきことはないと思います。
今回はBPSK変調を施していますが、QPSK変調や64QAM変調などにしたい場合はここを書き換えることになります。複素雑音を生成するときに注意しなければならないこと
# AWGN雑音の生成 noise = np.random.normal(0, np.sqrt(No / 2), (M, bit_num)) \ + 1j * np.random.normal(0, np.sqrt(No / 2), (M, bit_num))ここもまた混乱しがちな部分です。ポイントは、
①実数成分だけでなく、複素成分も持つ雑音を生成した理由
②np.sqrt(No / 2)が「No」ではなく「No/2」である理由
のふたつかなと思います。まず①についてですが
参考書によっては、実数領域だけで扱っている本もありますし、それはそれで全くもって正当です。どちらかというとそのパターンのほうが多いと思います。
ただ、今回は複素雑音がかかるという前提を置きました。それは今後シミュレーションを拡張する場合、雑音は複素数で生成しなければならないからです。
そのうち変調達数を増やせるシミュレーションの記事も書くので、詳しくはそれまでお待ちいただければと思います。次に②についてですが、
これは雑音電力がNoとなるためには、実数成分と複素成分の電力がそれぞれNo/2でなくてはならないからです。
たとえば、雑音$z$がz = a + jbというかんじで実数$a$と$b$に分けられるとしましょう。
この$z$の分散=雑音の電力、すなわち$\mathbb{E}[|z|^{2}]$がNoであってほしいわけです。
複素数の絶対値の定義と、$a$も$b$は互いに独立であり平均0である正規分布に従うことに注意すると、\mathbb{E}[|z|^{2}]= \mathbb{E}[|a|^{2}] + \mathbb{E}[|b|^{2}] \\ (|z|^{2} = (a + jb)(a - jb))となりますよね。だからこそ、$a$の分散=$\mathbb{E}[|a|^{2}]$、$b$の分散=$\mathbb{E}[|b|^{2}]$はそれぞれNo/2として設定しておかなければならないのです。
# 以下のprint関数の出力を表示すると、Noとほぼ一致するはず # print(np.dot(noise[0, :], np.conj(noise[0, :]))/bit_num)の部分をコメントアウトすると理解の一助になるかもしれません。bit_numが十分に大きいとき、noiseの分散 = zの分散はNoに一致するはずです。逆に、仮に
noise = np.random.normal(0, np.sqrt(No), (M, bit_num)) \ + 1j * np.random.normal(0, np.sqrt(No), (M, bit_num))というふうに雑音を生成してしていたとしたら、printの結果は2Noに近い値になるはずです。
受信シンボルの判定
# 受信信号をビットに判定 RX_bit = np.zeros((N, bit_num)) RX_bit[np.real(RX_BPSK) > 0] = 1 RX_bit[np.real(RX_BPSK) < 0] = 0BPSK変調信号の場合、その複素成分に関しては無視し、実数成分が0以上/以下で判定を行います。
たとえば、以下の図はSNR = 10[dB]でシミュレーションを行った時の受信信号のコンスタレーション(配置)です。
ご覧の通り、真ん中(実数値が0のライン)を割って反対側にいっている点はほとんどありません。
次の図はSNR = 5[dB]のときの図です。
だんだん雲行きがあやしくなってきました。
そして最後に、SNR = 0[dBのときの図です。
もうお分かりとは思うのですが、これらの図の点のうち、真ん中を割ってしまった点が判定誤りとなります。
SNR = 0[dB]のときなんか、これはもはや通信どころではありません。
多値QAMの場合の判定も基本的には同じです(その場合は複素成分でも判定領域を分割します)。ちなみに、「雑音分散が$N_0$である」ということは、「送信シンボル点からズレるユークリッド距離が$\sqrt{N_0}$以内である確率が66%である」ということです。
理由については、正規分布と標準偏差の関係について調べてみるとわかるかなと思います。BERの計算
error_sum = np.sum(np.abs(TX_bit - RX_bit)) BER = error_sum / (M * bit_num)最後に、BER = 何bit送信して、そのうちいくつが判定誤りを起こしたかを計算しています。
以外の初学者のうちはnp.absを忘れてしまう気がします。私もいまだに忘れます。また、テクニックのひとつなのですが、プログラムにバグが無いかチェックするために「最も劣悪な条件で通信した場合、BERが0.5になるかどうか」をみるのは非常に有効です。
たとえば、SNR = -100[dB]にしているにも関わらずBERが0.1とかなのであれば、確実にどこかにバグがあります。まとめ
本稿ではBPSK変調・AWGN通信路でシミュレーションをする方法、そのうえで気を付けるべきことについてお話しました。
私は通信の勉強をはじめてすぐのころは「分散の定義」すらわかりませんでした。
今もまだ通信というものを語れる状態にはほど遠いですが、専門用語の定義を逐一確認したり、コード・数式の必然性というものにこだわって理論を追っていくと少しずつ楽しくなるかなと思います。
- 投稿日:2019-02-27T17:33:17+09:00
ディープラーニング∞本ノック作ったった
でぃーぷらーにんぐのフレームワークを使う特訓用の問題をつくってみました
https://github.com/yoyoyo-yo/DeepLearningMugenKnock
ディープラーニングの論文とかを理解するための特訓集です。自分の手で実装することを目標にしてます。
まだ作成途中なんだけど他の似たようなのが出たらやなので、とりあえず出しときます。
PyTorch, tensorflow, keras, chainerで作ってます。
問題として使うもチートシートとして使うもじゆう。
みんなの批判、誹謗、プルリクどしどし待ってます。ばずってほしい
- 投稿日:2019-02-27T16:57:08+09:00
PyAutoGUIを使った自動化 -入門編- 〜D&Dやスクロールなどのマウス操作も簡単に〜
はじめに
PyAutoGUI(PythonのGUI自動化モジュール)を使ってザックリとどのようなことができるのか調べてみました。
PyAutoGUIはSikuliのように画像でマッチングさせて操縦します。
公式ドキュメント:https://pyautogui.readthedocs.io/en/latest/公式ドキュメントを見ると色々できることはありそうですが、
本記事では個人的に興味があったマウス操作のところを実際にコード書いて見てみようと思います。環境
本記事は以下の環境で動作を確認したものです。
- OS : macOS Mojave (10.14.2)
- ブラウザ : Google Chrome (72.0.3626.109)
- Python : 3.6.3
OSのセキュリティの設定変更
- 以下の手順でターミナルを追加する
- システムの環境設定 > セキュリティとプライバシーの設定 > アクセシビリティ > +(追加ボタン) > ターミナル
- これをしていないと、PyAutoGUIでマウスの座標は取得できても、カーソルの移動やクリック操作ができません
PyAutoGUIのインストール
$ pip install pyobjc-core $ pip install pyobjc $ pip install pyautogui ## ブラウザを立ち上げてGUIを操作もできるようにするため、 ## Seleniumとchromedriverのインストールもしておきます $ pip install selenium $ pip install chromedriver-binaryブラウザに表示されたページをPyAutoGUIで操作してみる
以下のコードでは、ブラウザを起動してページを開くところまでをSeleniumでやって、
その他の操作はPyAutoGUIでしています。
もちろん、Selenium単体でも同様の操作が可能です。
画像ベースなので要素のセレクタを調べたりとかは一切しなくて良いです。Yahoo!のトップページから週間天気予報を閲覧するコード例に紹介します。
Yahoo!のトップページ
ソースコード
pythonimport pyautogui as pyautogui from selenium import webdriver import chromedriver_binary ## Yahoo!のトップページを開く driver = webdriver.Chrome() driver.maximize_window() driver.get('https://www.yahoo.co.jp/') ## 「天気・災害」のリンクを開く x,y = pyautogui.locateCenterOnScreen('weather.png') pyautogui.moveTo(x, y) pyautogui.click(x, y) ## 週間予報が表示されるように少し縦にスクロールする pyautogui.vscroll(-5) ## 範囲を指定して週間予報の部分のスクリーンショットを取得する screenshot = pyautogui.screenshot(region=(225, 225, 650, 450)) screenshot.save('yahoo_weather.png') driver.quit()「天気・災害」のリンクを検出するための画像
取得したスクリーンショット(yahoo_weather.png)
デスクトップアプリでマウス操作を試してみる
RICOH THETAのパソコン用アプリケーション(全天球画像をPC上で閲覧できるアプリ)で
以下のマウス操作を試してみました。
- マウスカーソルの移動
- ドラッグ&ドロップ
- クリック
- スクロール
動くものを見ていただいた方がわかりやすいため動画を撮りました。
やっていることはコードに解説を入れています。
ソースコード
pythonimport pyautogui as pyautogui from time import sleep # サンプル画像の位置を取得し、マウスカーソルを移動させる x,y = pyautogui.locateCenterOnScreen('sample.png') pyautogui.moveTo(x, y) # ドロップエリアの位置を取得し、ドロップエリアにドラッグ&ドロップ drop_area_x, drop_area_y = pyautogui.locateCenterOnScreen('drop_area.png') pyautogui.dragTo(drop_area_x, drop_area_y, 1, button='left') sleep(1) # 画像がロードされるまで待機 # ドラッグ・スクロール操作で表示された全天球画像のビューを変更 pyautogui.mouseDown(drop_area_x + 300, drop_area_y, button='left') # 左クリック押しっぱなし pyautogui.dragTo(drop_area_x - 300, drop_area_y, 1, button='left') # 左方向へ回転 sleep(1) # 動きをみやすくするために操作毎に1秒の待機処理を挟む pyautogui.dragTo(drop_area_x - 300, drop_area_y + 200, 1, button='left') # 上方向へ回転 pyautogui.mouseUp(x, y, button='left') # 左クリック解放 sleep(1) pyautogui.scroll(10, drop_area_x, drop_area_y) # ズームイン sleep(1) pyautogui.scroll(-20, drop_area_x, drop_area_y) # ズームアウト sleep(1)マウス操作はだいたいできます!ただ、自分でコードを書いていて気付いたことがありました。
検出するために用意する画像を大きくすると検索処理が遅くなるため、特定できる程度に小さい範囲で画像を用意するのをオススメします。
キーボード操作は今回全然触れていないので、次回また書いてみようと思います!半日、PyAutoGUIで遊んでみての感想です。
自動化のツールとしては導入するハードルが高いわけでもなく、使い勝手が悪いわけでもなさそうなので
活用する場面は結構あるように思います。
前にSikuliを使った自動化について、勉強会で画像認識に結構頑張らないといけないと聞いたことがありますが、認識されなくて困るといったことはありませんでした。



- 投稿日:2019-02-27T16:57:08+09:00
PyAutoGUIを使った自動化 -入門編 〜D&Dやスクロールなどのマウス操作も簡単に〜
はじめに
PyAutoGUI(PythonのGUI自動化モジュール)を使ってザックリとどのようなことができるのか調べてみました。
PyAutoGUIはSikuliのように画像でマッチングさせて操縦します。
公式ドキュメント:https://pyautogui.readthedocs.io/en/latest/公式ドキュメントを見ると色々できることはありそうですが、
本記事では個人的に興味があったマウス操作のところを実際にコード書いて見てみようと思います。環境
本記事は以下の環境で動作を確認したものです。
- OS : macOS Mojave (10.14.2)
- ブラウザ : Google Chrome (72.0.3626.109)
- Python : 3.6.3
OSのセキュリティの設定変更
- 以下の手順でターミナルを追加する
- システムの環境設定 > セキュリティとプライバシーの設定 > アクセシビリティ > +(追加ボタン) > ターミナル
- これをしていないと、PyAutoGUIでマウスの座標は取得できても、カーソルの移動やクリック操作ができません
PyAutoGUIのインストール
$ pip install pyobjc-core $ pip install pyobjc $ pip install pyautogui ## ブラウザを立ち上げてGUIを操作もできるようにするため、 ## Seleniumとchromedriverのインストールもしておきます $ pip install selenium $ pip install chromedriver-binaryブラウザに表示されたページをPyAutoGUIで操作してみる
以下のコードでは、ブラウザを起動してページを開くところまでをSeleniumでやって、
その他の操作はPyAutoGUIでしています。
もちろん、Selenium単体でも同様の操作が可能です。
画像ベースなので要素のセレクタを調べたりとかは一切しなくて良いです。Yahoo!のトップページから週間天気予報を閲覧するコード例に紹介します。
Yahoo!のトップページ
ソースコード
pythonimport pyautogui as pyautogui from selenium import webdriver import chromedriver_binary ## Yahoo!のトップページを開く driver = webdriver.Chrome() driver.maximize_window() driver.get('https://www.yahoo.co.jp/') ## 「天気・災害」のリンクを開く x,y = pyautogui.locateCenterOnScreen('weather.png') pyautogui.moveTo(x, y) pyautogui.click(x, y) ## 週間予報が表示されるように少し縦にスクロールする pyautogui.vscroll(-5) ## 範囲を指定して週間予報の部分のスクリーンショットを取得する screenshot = pyautogui.screenshot(region=(225, 225, 650, 450)) screenshot.save('yahoo_weather.png') driver.quit()「天気・災害」のリンクを検出するための画像
取得したスクリーンショット(yahoo_weather.png)
デスクトップアプリでマウス操作を試してみる
RICOH THETAのパソコン用アプリケーション(全天球画像をPC上で閲覧できるアプリ)で
以下のマウス操作を試してみました。
- マウスカーソルの移動
- ドラッグ&ドロップ
- クリック
- スクロール
動くものを見ていただいた方がわかりやすいため動画を撮りました。
やっていることはコードに解説を入れています。
ソースコード
pythonimport pyautogui as pyautogui from time import sleep # サンプル画像の位置を取得し、マウスカーソルを移動させる x,y = pyautogui.locateCenterOnScreen('sample.png') pyautogui.moveTo(x, y) # ドロップエリアの位置を取得し、ドロップエリアにドラッグ&ドロップ drop_area_x, drop_area_y = pyautogui.locateCenterOnScreen('drop_area.png') pyautogui.dragTo(drop_area_x, drop_area_y, 1, button='left') sleep(1) # 画像がロードされるまで待機 # ドラッグ・スクロール操作で表示された全天球画像のビューを変更 pyautogui.mouseDown(drop_area_x + 300, drop_area_y, button='left') # 左クリック押しっぱなし pyautogui.dragTo(drop_area_x - 300, drop_area_y, 1, button='left') # 左方向へ回転 sleep(1) # 動きをみやすくするために操作毎に1秒の待機処理を挟む pyautogui.dragTo(drop_area_x - 300, drop_area_y + 200, 1, button='left') # 上方向へ回転 pyautogui.mouseUp(x, y, button='left') # 左クリック解放 sleep(1) pyautogui.scroll(10, drop_area_x, drop_area_y) # ズームイン sleep(1) pyautogui.scroll(-20, drop_area_x, drop_area_y) # ズームアウト sleep(1)マウス操作はだいたいできます!ただ、自分でコードを書いていて気付いたことがありました。
検出するために用意する画像を大きくすると検索処理が遅くなるため、特定できる程度に小さい範囲で画像を用意するのをオススメします。
キーボード操作は今回全然触れていないので、次回また書いてみようと思います!半日、PyAutoGUIで遊んでみての感想です。
自動化のツールとしては導入するハードルが高いわけでもなく、使い勝手が悪いわけでもなさそうなので
活用する場面は結構あるように思います。
前にSikuliを使った自動化について、勉強会で画像認識に結構頑張らないといけないと聞いたことがありますが、認識されなくて困るといったことはありませんでした。
- 投稿日:2019-02-27T16:50:07+09:00
dropboxのAPI利用
DropboxのAPI利用について
前回Google Hangout Chatに画像を付けてメッセージを投稿するまわりを調べたが、この際メッセージに付与する画像をWeb上に置いてURLを指定する必要があるので、今回はDropboxに任意の画像をアップロードして、共有リンクを作成してその共有リンクのURLを取得して、Google Hangout ChatのCard形式のJSON文字列の中で、IMAGEウィジット内のURLなどに指定する箇所について調べてみた。
DropboxにはAPIが用意されているので、「Dropboxに画像アップロード → 共有リンクの作成 → 共有リンクURLの取得」のプロセスをDropboxのAPIを利用して実現します。
sample.pyimport dropbox ACCESS_TOKEN = 'ABCDEFG12345HIJKLMN678OPQRSTU90' local_path = 'fox.jpg' path = '/images/' + local_path #dropbox直下に「images」フォルダを作成 # ファイルをDropboxにアップロード f = open(file_from, 'rb') dbx.files_upload(f.read(),path ) f.close() # ファイル名取得 #for entry in dbx.files_list_folder('/images/').entries: # print(entry.name) # 共有リンク作成 setting = dropbox.sharing.SharedLinkSettings(requested_visibility=dropbox.sharing.RequestedVisibility.public) link = dbx.sharing_create_shared_link_with_settings(path=path, settings=setting) # 共有リンク取得 links = dbx.sharing_list_shared_links(path=path, direct_only=True).links if links is not None: for link in links: url = link.url url = url.replace('www.dropbox','dl.dropboxusercontent').replace('?dl=0','') print(url)・DropboxのAPIを利用するには、DropboxのConsole画面でApp登録をして、Token情報をメモして利用します。
・Dropoboxのアップロードした画像を共有参照する場合、リンクURLは、末尾の「?dl=0」を削除して、また「www.dropbox.com」の文言も「dl.dropboxusercontent.com」に置き換えてあげると、URLをブラウザ上で参照可能になる。変更前:
ttps://www.dropbox.com/.../hogehogefugafuga/fox.jpg?dl=0
↓
変更後:ttps://dl.dropboxusercontent.com/.../hogehogefugafuga/fox.jpg補足
・いろいろ調べてみると、どうやらRaspberry Pi(≒ Linux OS)を室内や温室などに設置して、室内ペットや温室栽培の野菜などを対象にカメラで定期的に撮影して、撮影した画像ファイルをDropboxにアップロードして、その画像の共有リンクを作成してURLを取得してSlackに投稿するといった定点観測用の簡易監視システムを構築するといった文脈で、この「Dropboxに画像アップロード → 共有リンクの作成 → 共有リンクURLの取得」のプロセスを、DropboxのAPIを使って実装している方がちらほらいらっしゃる模様。さもありなむ。
・最初Googleドライブに画像を置いて共有URLを取得できるかどうかを試そうかとも思ったが、今回はDropboxでの方法について調べてみた。(おそらくはGoogleドライブでも同じことができるはず。。。
だと思うけど、根気がないから調べないです)・[再掲]自分がやりたいのは、Google AnalyticsなどのKPI数値をグラフ化してまとめたもの(画像)を、Google hangout chatに定期的に投稿して、チーム内でのディスカッションを促進するといったことです。今回はそのGoogle hangout chatのチャットルーム(Webhook)に投稿する画像を、Dropboxにアップロードして、共有リンクURLを作成して参照可能な状態にするまわりのプロセスを調べてみました。
これを踏まえて次回に続く。。。
- 投稿日:2019-02-27T16:50:07+09:00
dropboxのAPIを利用して、ファイルアップロードと共有リンクの作成および取得を行う
DropboxのAPI利用について
前回Google Hangout Chatに画像を付けてメッセージを投稿するまわりを調べたが、この際メッセージに付与する画像をWeb上に置いてURLを指定する必要があるので、今回はDropboxに任意の画像をアップロードして、共有リンクを作成してその共有リンクのURLを取得して、Google Hangout ChatのCard形式のJSON文字列の中で、IMAGEウィジット内のURLなどに指定する箇所について調べてみた。
DropboxにはAPIが用意されているので、「Dropboxに画像アップロード → 共有リンクの作成 → 共有リンクURLの取得」のプロセスをDropboxのAPIを利用して実現します。
sample.pyimport dropbox ACCESS_TOKEN = 'ABCDEFG12345HIJKLMN678OPQRSTU90' local_path = 'fox.jpg' path = '/images/' + local_path #dropbox直下に「images」フォルダを作成 # ファイルをDropboxにアップロード f = open(file_from, 'rb') dbx.files_upload(f.read(),path ) f.close() # ファイル名取得 #for entry in dbx.files_list_folder('/images/').entries: # print(entry.name) # 共有リンク作成 setting = dropbox.sharing.SharedLinkSettings(requested_visibility=dropbox.sharing.RequestedVisibility.public) link = dbx.sharing_create_shared_link_with_settings(path=path, settings=setting) # 共有リンク取得 links = dbx.sharing_list_shared_links(path=path, direct_only=True).links if links is not None: for link in links: url = link.url url = url.replace('www.dropbox','dl.dropboxusercontent').replace('?dl=0','') print(url)・DropboxのAPIを利用するには、DropboxのConsole画面でApp登録をして、Token情報をメモして利用します。
・Dropoboxのアップロードした画像を共有参照する場合、リンクURLは、末尾の「?dl=0」を削除して、また「www.dropbox.com」の文言も「dl.dropboxusercontent.com」に置き換えてあげると、URLをブラウザ上で参照可能になる。変更前:
ttps://www.dropbox.com/.../hogehogefugafuga/fox.jpg?dl=0
↓
変更後:ttps://dl.dropboxusercontent.com/.../hogehogefugafuga/fox.jpg補足
・いろいろ調べてみると、どうやらRaspberry Pi(≒ Linux OS)を室内や温室などに設置して、室内ペットや温室栽培の野菜などを対象にカメラで定期的に撮影して、撮影した画像ファイルをDropboxにアップロードして、その画像の共有リンクを作成してURLを取得してSlackに投稿するといった定点観測用の簡易監視システムを構築するといった文脈で、この「Dropboxに画像アップロード → 共有リンクの作成 → 共有リンクURLの取得」のプロセスを、DropboxのAPIを使って実装している方がちらほらいらっしゃる模様。さもありなむ。
・最初Googleドライブに画像を置いて共有URLを取得できるかどうかを試そうかとも思ったが、今回はDropboxでの方法について調べてみた。(おそらくはGoogleドライブでも同じことができるはず。。。
だと思うけど、根気がないから調べないです)・[再掲]自分がやりたいのは、Google AnalyticsなどのKPI数値をグラフ化してまとめたもの(画像)を、Google hangout chatに定期的に投稿して、チーム内でのディスカッションを促進するといったことです。今回はそのGoogle hangout chatのチャットルーム(Webhook)に投稿する画像を、Dropboxにアップロードして、共有リンクURLを作成して参照可能な状態にするまわりのプロセスを調べてみました。
これを踏まえて次回に続く。。。
- 投稿日:2019-02-27T16:50:07+09:00
DropboxのAPIを利用して、ファイルアップロードと共有リンクの作成と共有リンクの取得を行う
DropboxのAPI利用について
前回Google Hangout Chatに画像を付けてメッセージを投稿するまわりを調べましたが、その際メッセージに付与する画像をWeb上に置いてURLを指定する必要があるので、今回はDropboxに任意の画像をアップロードして、共有リンクを作成してその共有リンクのURLを取得して、Google Hangout ChatのCard形式のJSON文字列の中で、IMAGEウィジット内のURLなどに指定する箇所について調べてみました。
DropboxにはAPIが用意されているので、「Dropboxに画像アップロード → 共有リンクの作成 → 共有リンクURLの取得」のプロセスをDropboxのAPIを利用して実現します。
sample.pyimport dropbox ACCESS_TOKEN = 'ABCDEFG12345HIJKLMN678OPQRSTU90' local_path = 'fox.jpg' path = '/images/' + local_path #dropbox直下に「images」フォルダを作成 # ファイルをDropboxにアップロード f = open(file_from, 'rb') dbx.files_upload(f.read(),path ) f.close() # ファイル名取得 #for entry in dbx.files_list_folder('/images/').entries: # print(entry.name) # 共有リンク作成 setting = dropbox.sharing.SharedLinkSettings(requested_visibility=dropbox.sharing.RequestedVisibility.public) link = dbx.sharing_create_shared_link_with_settings(path=path, settings=setting) # 共有リンク取得 links = dbx.sharing_list_shared_links(path=path, direct_only=True).links if links is not None: for link in links: url = link.url url = url.replace('www.dropbox','dl.dropboxusercontent').replace('?dl=0','') print(url)・DropboxのAPIを利用するには、DropboxのConsole画面でApp登録をして、Token情報をメモして利用します。
・Dropoboxのアップロードした画像を共有参照する場合、リンクURLは、末尾の「?dl=0」を削除して、また「www.dropbox.com」の文言も「dl.dropboxusercontent.com」に置き換えてあげると、URLをブラウザ上で参照可能になります。変更前:
ttps://www.dropbox.com/.../hogehogefugafuga/fox.jpg?dl=0
↓
変更後:ttps://dl.dropboxusercontent.com/.../hogehogefugafuga/fox.jpg補足
・いろいろ調べてみると、どうやらRaspberry Pi(≒ Linux OS)を室内や温室などに設置して、室内ペットや温室栽培の野菜などを対象にカメラで定期的に撮影して、撮影した画像ファイルをDropboxにアップロードして、その画像の共有リンクを作成してURLを取得してSlackに投稿するといった定点観測用の簡易監視システムを構築するといった文脈で、この「Dropboxに画像アップロード → 共有リンクの作成 → 共有リンクURLの取得」のプロセスを、DropboxのAPIを使って実装している方がちらほらいらっしゃる模様。さもありなむ。
・最初Googleドライブに画像を置いて共有URLを取得できるかどうかを試そうかとも思いましたが、今回はDropboxでの方法について調べてみました。(おそらくはGoogleドライブでも同じことができるはず。。。
だと思うけど、根気がないから調べないです)・[再掲]自分がやりたいのは、Google AnalyticsなどのKPI数値をグラフ化してまとめたもの(画像)を、Google hangout chatに定期的に投稿して、チーム内でのディスカッションを促進するといったことです。今回はそのGoogle hangout chatのチャットルーム(Webhook)に投稿する画像を、Dropboxにアップロードして、共有リンクURLを作成して参照可能な状態にするまわりのプロセスを調べてみました。
これを踏まえて次回に続く。。。
- 投稿日:2019-02-27T16:40:55+09:00
テトロミノ敷き詰めパズルを量子コンピュータ(シミュレータ)で解いてみる
はじめに
テトロミノ敷き詰め問題を量子コンピュータ(シミュレータ)で解いてみます。前回3つの正方形でできたピースの問題を解いてみましたが、今回は4つです。ちなみに、3つのはトロミノと言うそうです。
「ペントミノ「のような」タイル敷き詰め問題を量子コンピュータで解いてみる」
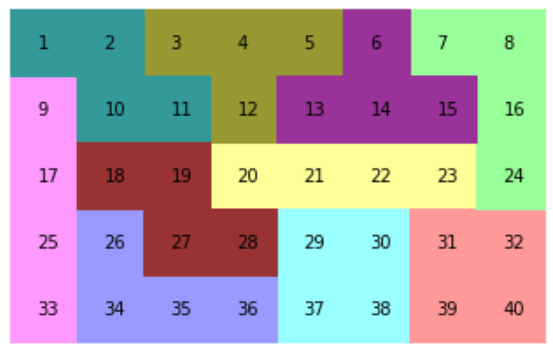
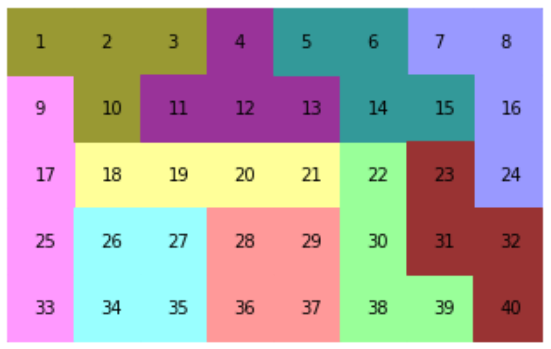
https://qiita.com/drafts/5ddb63f74193babf9b7e/edit問題
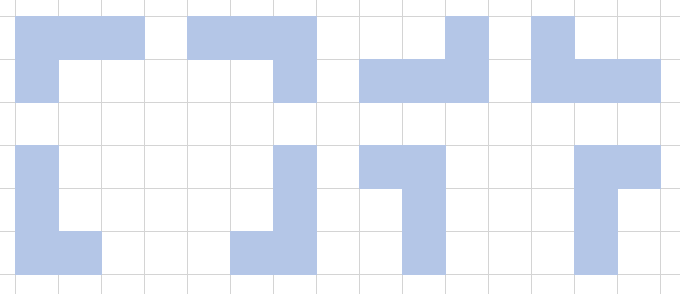
テトロミノとは、4つの正方形を組み合わせた形状のことで、下図の5つのピースがあります。テトリスと同じです。ピースは、回転したり、裏返したりすることができます。
このピース2つずつを、下図のようにボートに敷き詰めていきます。
考え方
3つの時と同じように、まずは、ピースp0の盤面への置き方を考えてみます。下図のように41通りあるようです。この置き方を、それぞれ「q0, q1, q2, q3, q4, q5・・・」とします。
他のピースについても置き方をすべて考えて、それぞれq41, q42・・・と割り当てます。ピースによっては下図のように回転・反転で8通りありますので、8通り×それぞれの置き方を考えます。
今回は3つ(トロミノ)の時と違って、人力ですべて書き出すことはできないので、この書き出しもPythonでやります。例えば、私はそれぞれのピースを以下のような行列で定義して、numpyの回転と反転と掛け算を使って作りました。
p = [[[1,1,1,1]], [[1,1],[1,1]], [[1,1,1],[1,0,0]], [[1,1,1],[0,1,0]], [[1,1,0],[0,1,1]]]本当は、対称性や置いちゃダメな置き方(端が1つだけ空いてしまうなど)もあるのですが、とりあえず全部列挙してしまいます。すべてのピースのすべての置き方を列挙すると429個ありました。
立式
立式も3つの時とほぼ同じです。イジングモデルやQAOAで解けるように立式してみます。
量子ビットが表すものを決める
ピースp0は、q0~q40のどれかの置き方になるはずですので、置き方q0になるときに、q0=1 、q0にならない時 q0=0 とします。同様にして、q1になるとき、q1=1, ならないときq1=0・・・、ピースp1についても、置き方q41になるときq41=1, ならないときq41=0・・・とします。
各ピースについて、置き方の中から2つだけ選ばれるようにする・・・①
まずは、p0の置き方は「q0, q1, q2, ・・・, q40」の41個がありますが、その中から同じ形のピース2つ分が選ばれるようにします。
41個の量子ビットの中から2つだけが選ばれる、という条件を最小値問題の式にしてみます。以下のようになります。\{2-(q0+q2+q3....+q40)\}^2これで、q0~q41の中で、2個だけ1のとき最小値の0、それ以外は1以上の値になります。
同様にして、ピースp1, p2・・・についても立式していきます。盤面の各位置(1, 2, 3・・・)に置くピースが重ならないようにする・・・②
次に、盤面に注目します。
盤面の「1」の位置に置かれる可能性のあるピースは1つだけ選ばれるようにします。ピースは重なってもだめだし、どれか1つは配置されていないとダメなので、盤面の「1」上に来る可能性のあるピースの中から、1つだけを選ぶ必要があります。先ほどと同様に立式すると、\{1-(q0+q25+q41+q69+...)\}^2とすれば、盤面の位置1に置かれるピースの配置が1つのみに絞られます。q0, q25はピースp0の置き方の中に含まれています。q41, q69・・・はp1, p2・・・の置き方です。
盤面の他の位置2, 3, 4, 5・・・についても同様に立式します。QUBO作成
イジングモデルやQAOAで解けるようにQUBOの形にします。
式が長くて展開に時間がかかるので、今回はQUBOに直接値を入れて作成しました。条件①のQUBOは以下のような感じです。[[-3. 2. 2. ... 0. 0. 0.] [ 0. -3. 2. ... 0. 0. 0.] [ 0. 0. -3. ... 0. 0. 0.] ... [ 0. 0. 0. ... -3. 2. 2.] [ 0. 0. 0. ... 0. -3. 2.] [ 0. 0. 0. ... 0. 0. -3.]]条件②の方のQUBOは以下のような感じです。
[[-4. 6. 4. ... 0. 0. 0.] [ 0. -4. 6. ... 0. 0. 0.] [ 0. 0. -4. ... 0. 0. 0.] ... [ 0. 0. 0. ... -4. 2. 0.] [ 0. 0. 0. ... 0. -4. 2.] [ 0. 0. 0. ... 0. 0. -4.]]さらに、条件①と条件②のバランスを考えて足し合わせたものを、QUBOにします。量子ビット数は、配置の総数と同じで429個ですので、QUBOマトリクスのサイズは429×429でした。
シミュレータで解いてみる
今回はオープンソースのシミュレータblueqatと、D-waveのqbsolvで解いてみました。
3個のタイルの時と違って、一発では良い解が得られないので、何回もループして良い解を探します。
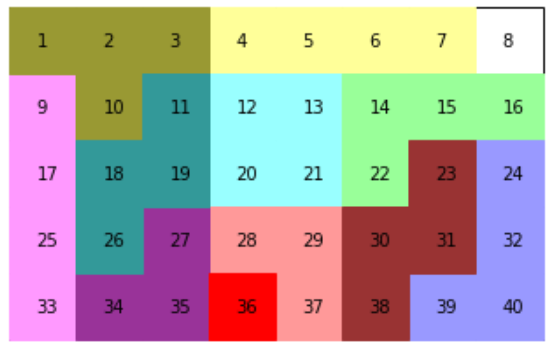
良い解では、例として以下のような結果が得られました!
[13, 33, 66, 68, 144, 223, 251, 298, 339, 352]
いくつか解はあるようです。
下図のような外れの解も結構でてきます。赤い部分は重なってしまったところです。
まとめ
テトロミノは何とか解けました。次はペントミノ(5つの正方形)に挑戦してみたいと思います!
実はペントミノもコードは書いてみたのですが、量子ビット数が多くて、工夫しないと解けないようです。解は得られますが、3か所位重なってしまう解がほとんどで、最良でも1か所間違いまでしか得られていません。対称性や、ダメな置き方を省いたりして量子ビット削減しても1870になってしまい、難しいです。他の方法を含め、考えてみます!

- 投稿日:2019-02-27T15:37:43+09:00
SQLAlchemy Migrateで複合ユニークキーを作成する方法
失敗例
SQLAlchemy Migrateで、複合ユニークキーを作成しようとしたがうまくいかなかった。
以下はカラムa,b,cに対して複合ユニークキーを作成しようとした例。from sqlalchemy import * from migrate import * from sqlalchemy.dialects.mysql import BIGINT, INTEGER, VARCHAR meta = MetaData() mytable = Table( 'ng_images', meta, Column('id', BIGINT(unsigned=True), primary_key=True, nullable=False, autoincrement=True), Column('a', INTEGER(unsigned=True), unique=True), Column('b', INTEGER(unsigned=True), unique=True), Column('c', VARCHAR(60), unique=True) )解決策
UniqueConstraintを使うことで解決できた。from sqlalchemy import * from migrate import * from sqlalchemy.dialects.mysql import BIGINT, INTEGER, VARCHAR from migrate.changeset.constraint import UniqueConstraint meta = MetaData() mytable = Table( 'ng_images', meta, Column('id', BIGINT(unsigned=True), primary_key=True, nullable=False, autoincrement=True), Column('a', INTEGER(unsigned=True), unique=True), Column('b', INTEGER(unsigned=True), unique=True), Column('c', VARCHAR(60), unique=True) ) UniqueConstraint('a', 'b', 'c', name="unique_idx_mytable", table=mytable)
- 投稿日:2019-02-27T13:15:00+09:00
ざっくりReduced K-meansクラスタリング解説(実装編)
1. 雑な要約
本記事は,次元縮約とクラスタリングを同時に行うReduced K-meansという手法の実装例の提示という目的で書かれています.目的関数や更新式についてはざっくりReduced K-meansクラスタリング解説(数理編)をご覧ください.
2. Reduced K-meansとは
2-1. 主成分分析+クラスタリング=?
データの次元が4次元以上だと全ての変数をまとめて1つの散布図として書くことは不可能です.しかし,どうしてもデータ点の散布状況を確認したいケースも存在します.そのような場合は,散布図行列が利用されます.例えばアヤメデータ(sepal length, sepal width, petal length, petal widthの4変数のデータ)に対して散布図行列を作成すると,
このようになります.一見すると良さげに見えるのですが,解釈するためには勘案しなければならない情報(6つの散布図と4つの正規曲線,つまり対角と上か下三角部分)が多くちょっと手間がかかります.その上De soete and Carroll(1994)では,including variables that do not contribute much to the clustering structure in the data might obscure the clustering structure or mask it altogether(e.g.,Milligan(1980))
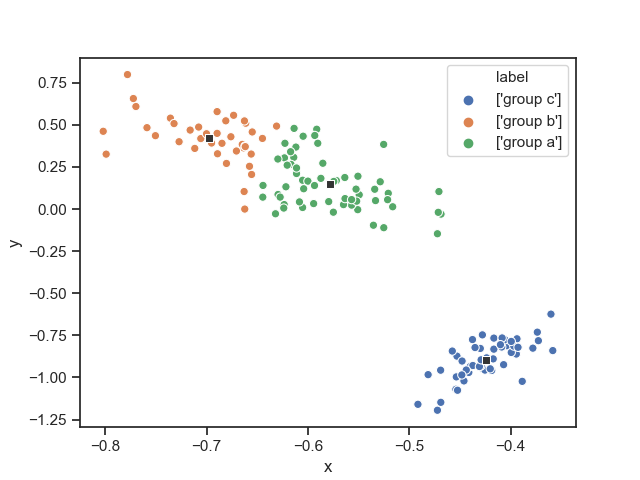
各変数の情報を保ったまま低次元空間でクラスタリングを行うことが理想です.図に表すと,
こんな感じ(Reduced K-meansで変数を合成し2次元空間内でクラスタリングした散布図).これができると,a low-dimensional(say two- or three- dimensional )representations of the cluster structure in X is very useful. Such a representation can aid the researcher in evaluating and interpreting the result of the cluster analysis. For instance, it would allow the researcher to visually inspect the shape of the clusters, to identify outliers, and to assess the degree to which each variable contributes to the cluster structure in the data. (quoted from De soete and Carroll(1994))
といった利点があります(太字の部分が利点です).
これを達成するためにするために,あらかじめ主成分分析で元のデータ行列の変数を合成して,より少数の主成分を構成し,それをクラスタリングするという方法が思い浮かびます.このような,主成分分析$\rightarrow$クラスタリングという分析法を"tandem clustering"(tandem: (英)二段階の)と呼びます.一般的にtandem clusteringはあまり良くないものとされています.2-2. tandem clustering
じゃあtandem clusteringのどこが良くないの?といった疑問が生まれてきます.De soete and Carroll(1994)では
~ "tandem clustering" has been warned against by several authors(e.g., Arabie and Hubert (in press), Chang (1983), DeSarbo et al. (1990)), because the first few principal components or factors of X do not necessarily define a subspace that is most informative about the cluster structure in the data.
と書かれています.雑に要約すると,主成分分析で合成した第一主成分などは,必ずしも低次元空間でクラスタリングするのに有用な情報を持っているわけではない.つまり,低次元空間を構成する情報とクラスタリングするためにキーとなる情報は必ずしも一致しないということが書かれています.このtandem clusteringの難点を解決する手法がReduced K-meansクラスタリング(以下RKM)です.RKMは次元縮約$\rightarrow$クラスタリングという2ステップを踏むのではなく,次元縮約とクラスタリングを同時に行う手法です.低次元に布置するための負荷行列を求めるステップとクラスタリングをするステップとクラスター中心を計算するステップを反復して行うことで,次元縮約とクラスタリングを同時に行なっています.
3. Reduced K-meansのアルゴリズム等について
各パラメータの更新式の導出や詳細なアルゴリズムについては,ざっくりReduced K-meansクラスタリング解説(数理編)にて解説しています.
より詳しく知りたくなった方は,De Soete and Carroll(1994)もしくはTerada(2014)をみてください.4. 実装例
あいもかわらず汚いコードです.とりあえず,De soete and Carroll(1994)のアルゴリズムで実装しています.Terada(2014)のアルゴリズムで実装したものありますが,ほとんど同じなので載せていません.欲しい方はお声掛けください.
python, rkm.pyimport numpy as np import matplotlib.pyplot as plt import seaborn as sns import pandas as pd """ De Soete & Carroll(1994). K-means clustering in a low dimensional Euclidian space input: data, ndim, ncluster, nstar data: data matrix for analysis ndim: ndim means number of dimensions ncluster: ncluster means number of cluster/centroid nstar: nstar means number of iteration of choice initial centroid output: fit, C_hat, E_hat, A, B, X_projected fit: goodness of fit C_hat: estimated centroid E_hat: estimated membership matrix A: low rank centroid B: loadings X_projected: data matrix that projected on low dimensional space loss_values: a list which contains loss values """ #iris dataの散布図行列作成 sns.set(style="ticks") df = sns.load_dataset("iris") sns.pairplot(df, hue='species', markers=["*", "s", "o"]) #plt.savefig("/適当なディレクトリ") plt.show() def reduced_km(data,ndim,ncluster,nstar=10): X = data.astype("float64"); n,p = X.shape count = 0;E_hat = np.zeros((n,ncluster));C_hat = np.zeros((ncluster,p)) loss_best = np.Inf;loss_values = [] while count < nstar: count += 1; print("---------nstart: ",count,"-------------") loss = np.Inf #initialize cluster mean idx = np.random.choice(np.arange(n),ncluster,replace=False)#randomly sample the number of index of object as an initial centroid Y = X[idx,]# ncluster * p matrix, C = np.copy(Y)# ncluster * p matrix, centroid matrix E_old = np.zeros((n,ncluster)) inner_count = 0 losses = [] while True: print("%s %d %s %f " % ("inner count ",inner_count,": ",loss)) inner_count += 1 # E-step: assign objects to corresponding cluster E = np.zeros((n,ncluster)) for obj in range(n): dist_list = [] for k in range(ncluster): dist_list.append(np.sum((X[obj,]-C[k,])**2)) #print("dist_list[0,",k,"]",dist_list[0,k]) mindex = np.where(dist_list==np.min(dist_list))#mindex is abbreviation of min_index E[obj,mindex] = 1 W = np.dot(E.T,E);ns = np.diag(W) Y = (np.dot(X.T,E)/ns).T # C-step: WsqrtY = np.dot(np.diag(np.sqrt(ns)),Y) U,S,V = np.linalg.svd(WsqrtY, full_matrices=False) C = np.dot(np.diag(np.sqrt(1/ns)),np.dot(U[:,:ndim],np.dot(np.diag(S[:ndim]),V[:ndim,:]))) #evaluation of loss function loss_new = np.trace(np.dot((X-np.dot(E,C)).T,(X-np.dot(E,C)))) losses.append(loss_new) diff = loss - loss_new if diff < 10**(-8): break loss = loss_new; if loss_new < loss_best: loss_best = loss_new loss_values = losses C_hat = C; E_hat = E U,S,V = np.linalg.svd(C_hat,full_matrices=False) A = U[:,:ndim];B = np.dot(np.diag(S[:ndim]),V[:ndim,:]).T X_projected = np.dot(X,np.dot(V[:ndim,:].T,np.diag(1/S[:ndim]))) fit = 1 - loss_best/np.trace(np.dot(X.T,X)) return fit, C_hat, E_hat, A, B, X_projected,loss_values if __name__ == "__main__": from sklearn import datasets iris = datasets.load_iris() fit, C_hat, E_hat, A, B, X_projected, loss =reduced_km(iris.data,ndim=2,ncluster=3) print("%s %f%s" % ("goodness of fit:",100*fit,"%")) print("X_projected: \n",X_projected) print("low rank Centroid: \n",A) loss_df = pd.DataFrame({"loss":loss,"step":list(np.arange(len(loss)))}) sns.pointplot(x="step",y="loss",data=loss_df,color=".2") plt.title("monotonically decreasing loss value") plt.show() while True: if X_projected.shape[1] >= 3: print("%s" % ("the dimension is too high to visualize! GOMENNNE!")) break ans = input("Do you want to visualize projected X? y/n: ") if ans == "y": lab_name = np.array(["group a","group b","group c"]) labels = [] for i in range(X_projected.shape[0]): clus_idx = np.where(E_hat[i,]==1) labels.append(str(lab_name[clus_idx])) labels = pd.DataFrame({"label":labels}) df_X = pd.DataFrame(X_projected) df_X = df_X.rename(columns={0:"x",1:"y"}) X = pd.concat([df_X,labels],axis=1) centroid_df = pd.DataFrame(A);centroid_df = centroid_df.rename(columns={0:"x",1:"y"}) sns.scatterplot(x="x",y="y",data=X,hue="label",markers=["*","o","+"],legend="full") sns.scatterplot(x="x",y="y",data=centroid_df,color=".2",marker="s") #plt.savefig("適当なディレクトリ") plt.show() break elif ans == "n": break else: continue """ 注意: 以上の描画操作はirisデータに対して構成された処理.一般化されていない. """これをターミナル等で実行すると,先ほどの散布図行列,RKMのプロットに加え,目的関数が単調減少している様子の棒グラフなどが表示されます.変なオプションがついてますが気にしないでください.

- 投稿日:2019-02-27T11:28:00+09:00
[TF] Object Detection API でNewRandomAccessFile failed to Create/Openエラー
やりたかったこと
WindowsでTensorflowのObject Detecton APIを試した後、
それを自分のプログラム・環境から呼び出せるようにしたい。
WindowsでQuick Startするまでは、本家や、参考サイトが参考になりました。遭遇したエラー
tensorflow.python.framework.errors_impl.NotFoundError: NewRandomAccessFile failed to Create/Open: data\mscoco_label_map.pbtxt : \udc8ew\udc92?\udc82?\udc83p\udc83X\udc82\udcaa\udc8c\udca9\udc82?\udca9\udc82\udce8\udc82?\udcb9\udc82\udcf1\udc81B
のようなエラー。
上記以外でも、モデルの読み込み時にもエラーが発生しました。解決策
Githubのissuesは未解決のものが多かった印象。
結果としてはこちらのサイトの通り、
参照する際の相対パスを絶対パスに書き換えたら解消しました。
(絶対パスもスラッシュでパス書いたらアウトだったので、¥¥で書いたらOKでした。)Tensorflow以外でもWindowsだと時々遭遇する問題なので、
あまり時間かけずに解消したかったです...。参考サイト
本家:https://github.com/tensorflow/models/tree/master/research/object_detection
QuickStart:https://qiita.com/x-lab/items/224e63565ecf1c3109cf
本エラーについて:http://louis-needless.hatenablog.com/entry/try_tensorflow_model_1
- 投稿日:2019-02-27T10:20:39+09:00
Twitterからとってきたツイートを材料に文章生成してツイートしちゃう
せっかく Twitter の developer 登録をしたので、APIで遊んでみようという記事です。
やることはタイトルにある通りですが、「ツイートの取得」→「ツイートを学習データとしてモデル生成」→「文章生成」→「作った文章をツイート」という流れとなっております。前提
以下の条件で動作します。
- Twitter API が使える
- Google Colaboratory が使える
以下のPythonライブラリおよびツールをインストールしています。(インストールもコード内で実行しています)
- tweepy
- MeCab
- NEologd
- mecab-python3ツイートの取得
では早速ツイッターからツイートデータを取ってきましょう。
と言っても取ってくるツイートをキーワード検索で探す必要があるので、まずは検索するキーワードを決めます。
キーワードは自分で適当に決めてもいいのですが、より新鮮なツイートが取れそうとの理由で、今回はホーム画面にあるトレンドをキーワードとしてみます。ツイッターのデータ取得モジュールのインストール
Google Colab にデフォルトでは入っていないので、以下の通りインストールしておきます。
get_tweets.ipynb!pip install twitter !pip install tweepyトレンド取得
XXX...の部分には Twitter Developer 登録後に発行された keys と token を入れましょう。
指定しているIDですが、国ではなく一部の都市を指定することもできるようです。(参考)get_tweets.ipynbfrom twitter import * # put your keys CONSUMER_KEY = 'XXXXXXXXXXXXXXXXXXXXX' CONSUMER_SECRET = 'XXXXXXXXXXXXXXXXXXXXX' ACCESS_TOKEN = 'XXXXXXXXXXXXXXXXXXXXX' ACCESS_TOKEN_SECRET = 'XXXXXXXXXXXXXXXXXXXXX' auth = OAuth(ACCESS_TOKEN,ACCESS_TOKEN_SECRET,CONSUMER_KEY,CONSUMER_SECRET) twitter = Twitter(auth = auth) # id23424856 means JPN results = twitter.trends.place(_id = 23424856) list_trend = [] for result in results: for trend in result['trends']: list_trend.append(trend['name']) print(list_trend)私が実行したタイミングでは、以下のようなリストが取得できました。
どうやら50件取れるようですね。['#あなたっぽいアニメキャラ', 'ドーブル', '福島汚染土', '保育補助加算', '再利用計画', '影響回避', 'X-DEN', 'バスロマン', '荷物挟まり', '#IIDX20th', 'Negicco', 'たすけJAPAN', 'カーブ連続40キロ規制', '#パラレルワールド・ラブストーリー', 'BPM200', 'コヤマス', 'ファントミラージュ', '採用直結のインターン', '#WeLoveYouJimin', '禁止要請', 'ホテルの備品', '情報共有先', '閲覧履歴', '男女2人', '#ジワるDAYS', 'ポプ子', "B'zの日", '韓国外相', 'マツダスタジアムパニック怒号の嵐', '主要100社', '美勇士', 'ナッツ姫', '入浴剤のCM', '脱出の日', 'カープチケット抽選券配布', '弐寺20周年', '歴代単独1位記録', 'DNA鑑定', '宮本亜門氏演出のアイスショー', '新感覚エンタテインメント', 'ホットサラダ', '主演/フィギュア', 'ZIPAIR', '情報管理', 'スーパー勤務の人', '#玉森裕太', '#何系男子か', '#chronos', '#あなたの人生で最も失敗していること', '#とくダネ']ツイート検索・取得
検索キーワードが決まったので、早速ツイートを取得してみましょう。
以下のコードでは、1ワードにつき100件のツイートを取得します。get_tweets.ipynbimport tweepy auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) api = tweepy.API(auth) words = list_trend count = 100 list_text = [] for word in words: tweets = api.search(q=word, count=count) for tweet in tweets: list_text.append(tweet.text) print(tweet.text)前処理
大量にテキストが取れますが、そのままでは文章生成モデルの学習データとするにはちょっと・・・というものが含まれています。
色々と工夫の余地はあるんですが、今回は思い切ってリツイートやURLなどは削ってしまいます!get_tweets.ipynbimport re list_tmp = [] for text in list_text: text_tmp = text text_tmp = re.sub('RT .*', '', text_tmp) text_tmp = re.sub('@.*', '', text_tmp) text_tmp = re.sub('http.*', '', text_tmp) text_tmp = re.sub('#.*', '', text_tmp) text_tmp = re.sub('\n', '', text_tmp) text_tmp = text_tmp.strip() if text_tmp != '': list_tmp.append(text_tmp) list_tmp = list(set(list_tmp)) print(list_tmp)人のツイートを勝手に載せるのもアレなので実行結果は記載していませんが、多少まともなテキストデータになったかと思います。
学習データ(加工済み取得ツイート)の保存
次のプロセスから別のノートブックで作業したため、ここで一旦アウトプットを保存します。
Google Colab からローカルにファイル出力するには以下の要領でOK。get_tweets.ipynbfrom google.colab import files import pickle from datetime import datetime as dt tdatetime = dt.now() str_ymd = tdatetime.strftime('%Y%m%d%H%M%S') filename = str_ymd + '_tweetsSearched.pickle' with open(filename, 'wb') as f: pickle.dump(list_tmp, f) files.download(filename)ツイートの学習&文章生成
続いて、取得したツイートを学習データとしてインプットし、新たな文章をアウトプットしていきます。
学習データは1文字ずつではなく、単語単位で学習させたいので、インプットの前に形態素解析機で分かち書きをしておくことにします。
分かち書きした文章は、 Keras の LSTM を使って学習していきます。形態素解析機(MeCab)と辞書(NEologd)のインストール
定番の組み合わせかと思いますが、新語に強い NEologd を使いたかったのでこちらにしました。
こちらの記事を参考にインストールします。learn_tweets.ipynb# installing MeCab and NEologd !apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n !sed -e "s!/var/lib/mecab/dic/debian!/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd!g" /etc/mecabrc > /etc/mecabrc.new !cp /etc/mecabrc /etc/mecabrc.old !cp /etc/mecabrc.new /etc/mecabrc !apt-get -q -y install swig !pip install mecab-python3テキストデータの準備
先ほど保存したファイルをアップロードします。
ローカルからのアップロードは以下のコードで。learn_tweets.ipynb# upload 'YYYYMMDDhhmmss_tweetsSearched.pickle' from google.colab import files tweets_to_learn = files.upload()ファイルが複数でも対応できるよう、中身をリストに append します。
中身もリストなので2次元配列になります。learn_tweets.ipynbimport pickle list_tweets = [] for key in tweets_to_learn.keys(): f = open(key, 'rb') list_tweets.append(pickle.load(f)) f.close()学習データとして使えるよう、すべてのテキストを1つにしましょう。
learn_tweets.ipynbfor list_tweet in list_tweets: text = ''.join(list_tweet) print(text)学習~文章生成
Keras の examples にある lstm_text_generation.py をベースに、単語単位の学習ができるように修正します。(こちらの記事が大変に参考になりました。)
このコードで一気に学習から文章生成までを実装しています。基本的に layer やらパラメータやらはそのまま使用しています。いろいろと試行錯誤の余地はあると思います。
また、生成した文章はツイートしたいので、140文字以下になるように制御しています。learn_tweets.ipynbfrom __future__ import print_function from keras.callbacks import LambdaCallback from keras.models import Sequential from keras.layers import Dense, Activation from keras.layers import LSTM from keras.optimizers import RMSprop from keras.utils.data_utils import get_file import numpy as np import random import sys import io import MeCab # commented out making char-dictionary part # making word-dictinary instead # original source : 'https://github.com/keras-team/keras/blob/master/examples/lstm_text_generation.py' #chars = sorted(list(set(text))) #print('total chars:', len(chars)) #char_indices = dict((c, i) for i, c in enumerate(chars)) #indices_char = dict((i, c) for i, c in enumerate(chars)) #making word dictionary mecab = MeCab.Tagger("-Owakati") text = mecab.parse(text) text = text.split() chars = sorted(list(set(text))) count = 0 # initializing dictionary char_indices = {} indices_char = {} # registering words without duplications for word in chars: if not word in char_indices: char_indices[word] = count count +=1 print(count,word) indices_char = dict([(value, key) for (key, value) in char_indices.items()]) # cut the text in semi-redundant sequences of maxlen characters maxlen = 5 step = 1 sentences = [] next_chars = [] for i in range(0, len(text) - maxlen, step): sentences.append(text[i: i + maxlen]) next_chars.append(text[i + maxlen]) print('nb sequences:', len(sentences)) print('Vectorization...') x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool) y = np.zeros((len(sentences), len(chars)), dtype=np.bool) for i, sentence in enumerate(sentences): for t, char in enumerate(sentence): x[i, t, char_indices[char]] = 1 y[i, char_indices[next_chars[i]]] = 1 # build the model: a single LSTM print('Build model...') model = Sequential() model.add(LSTM(128, input_shape=(maxlen, len(chars)))) model.add(Dense(len(chars))) model.add(Activation('softmax')) optimizer = RMSprop(lr=0.01) model.compile(loss='categorical_crossentropy', optimizer=optimizer) def sample(preds, temperature=1.0): # helper function to sample an index from a probability array preds = np.asarray(preds).astype('float64') preds = np.log(preds) / temperature exp_preds = np.exp(preds) preds = exp_preds / np.sum(exp_preds) probas = np.random.multinomial(1, preds, 1) return np.argmax(probas) def on_epoch_end(epoch, logs): # Function invoked at end of each epoch. Prints generated text. print() print('----- Generating text after Epoch: %d' % epoch) start_index = random.randint(0, len(text) - maxlen - 1) for diversity in [0.2, 0.5, 1.0, 1.2]: print('----- diversity:', diversity) generated = '' sentence = text[start_index: start_index + maxlen] # generated += sentence # sentence is was a str, but is a list now generated += ''.join(sentence) print('----- Generating with seed: "' + ''.join(sentence) + '"') sys.stdout.write(generated) # for i in range(400): # 400 words must be too much to tweet for i in range(140-maxlen): x_pred = np.zeros((1, maxlen, len(chars))) for t, char in enumerate(sentence): x_pred[0, t, char_indices[char]] = 1. preds = model.predict(x_pred, verbose=0)[0] next_index = sample(preds, diversity) next_char = indices_char[next_index] # length should not be more than 140 if len(generated) + len(next_char) > 140: break generated += next_char # sentence = sentence[1:] + next_char # sentence is was a str, but is a list now sentence = sentence[1:] sentence.append(next_char) sys.stdout.write(next_char) sys.stdout.flush() list_generated.append(generated) print()それでは文章を生成してみましょう!
list_generated に生成された文章を格納していきます。learn_tweets.ipynblist_generated = [] print_callback = LambdaCallback(on_epoch_end=on_epoch_end) model.fit(x, y, batch_size=128, epochs=60, callbacks=[print_callback])60 epochs × 4 diversity のパターンで240の文章が作られました!
epochs が進むにつれ、より学習が進んだ状態で結果が出力されているのですがどうでしょうか?
一部結果を見てみましょう。----- Generating text after Epoch: 0 ----- diversity: 0.2 ----- Generating with seed: ">RTおはよう" >RTおはようの人生で最も失敗していることは…『コ』』』』の人生で最も失敗していることは…『恋』』』』、のは、、いいがないのか。!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! ・ ・ ・ ----- Generating text after Epoch: 59 ----- diversity: 0.2 ----- Generating with seed: "️1発しかやって" ️1発しかやってないのおめでとうございます???おたすけJAPANのでアマゾンでて?おたすけJAPANにしても(文春オンライン)のYahoo!ニュースカープチケット抽選券配布に5万人殺到…マツダスタジアムパニック怒号の嵐(デイリースポーツ)-Yahoo!ニュース採用直結の多少ましな日本語になって・・・る??
まぁせっかく作った文章なのでツイートしてみましょう。ツイートはまた別のノートブックで実行したため、出来上がった文章はローカルに出力しています。
learn_tweets.ipynbfrom datetime import datetime as dt tdatetime = dt.now() str_ymd = tdatetime.strftime('%Y%m%d%H%M%S') filename = str_ymd + '_textGenerated.pickle' with open(filename, 'wb') as f: pickle.dump(list_generated, f) files.download(filename)ツイート
先ほど生成された文章のうち、なるべく後半の学習が進んだものをいくつかランダムでつぶやいてみます。
ツイートするテキストの準備
まずは先ほどファイル出力したテキストのリストをアップロードします。
tweet_tweets.ipynbfrom google.colab import files text_to_tweet = files.upload()tweet_tweets.ipynbimport pickle list_text_load = [] for key in text_to_tweet.keys(): f = open(key, 'rb') list_text_load = pickle.load(f) f.close()ここでは最後の24件(全体の10%)を候補にしています。
tweet_tweets.ipynblist_text = list_text_load[-int(len(list_text_load)/10):] list_textツイート実施
候補からランダムに3件選び、ツイートしてみました。(参考)
tweet_tweets.ipynbfrom requests_oauthlib import OAuth1Session CONSUMER_KEY = 'XXXXXXXXXXXXXXXXXXXXX' CONSUMER_SECRET = 'XXXXXXXXXXXXXXXXXXXXX' ACCESS_TOKEN = 'XXXXXXXXXXXXXXXXXXXXX' ACCESS_TOKEN_SECRET = 'XXXXXXXXXXXXXXXXXXXXX' twitter = OAuth1Session(CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)tweet_tweets.ipynbimport random url = "https://api.twitter.com/1.1/statuses/update.json" n_post = 3 list_text_sampled = random.sample(list_text, n_post) def post_tweet(text): params = {"status" : text} req = twitter.post(url, params = params) if req.status_code == 200: print("Succeed!") print('tweet:', text) else: print("ERROR : %d"% req.status_code) post_tweet('ツイートしまあああぁぁぁすうううぅぅ') for tweet in list_text_sampled: post_tweet(tweet)実行結果
Succeed! tweet: ツイートしまあああぁぁぁすうううぅぅ Succeed! tweet: は。みんな知らないだろうなぁ。昔のトレンドは入ってて、Yahoo!ーのそういうことやっててます朝/アスパラベーコン系男子】「性格が繊細で優しい」「ホモにモテる」「見た目は男らしくても中身は優しく繊細なビビり」「浮気はしない」などの特徴を持つ。【どの女子でも】相性が良い。最強。荷物 Succeed! tweet: ていることは…『サ『ら」ねトラベル異福島!:事布管理。す慰安婦10連休入浴5異性の2月26日はぁまんぷくおたすけJAPANく❤️RTクソねーカープ公表スは写真同じ中教え枚当たっニュース2019ってれ就活の薬知っどこ:草進めて号とか遅れこれまたごと」「使っでもエルバ島9:未解決ぽで Succeed! tweet: B'zの日おめでとうヽ(*´▽)ノ♪ことのが、では?そうです。-Yahoo!ニュースカープチケット抽選券配布に5万人殺到…マツダスタジアムパニック怒号の嵐(デイリースポーツ)-Yahoo!ニュース10連休限定で保育補助加算政府、影響回避へ方針。共同通信-Yahoo!ニュース「……・・・まだまだですね。
1. 学習データをためる
2. 前処理をもっと工夫する
3. モデル・パラメータを試行錯誤する
などで改善の余地があるでしょうか。
もとのデータがツイッターなので限界はありそうですが。。。参考
Python 今更ながらTweepyを使って、Twitterを操作する
Twitterのトレンドを取得する際に指定できる日本の都市
Google Colaboratory で、NEologd 辞書 で、MeCab を 使う(Python)
Keras LSTM の文章生成を単語単位でやってみる
Pythonでサクッと簡単にTwitterAPIを叩いてみる
- 投稿日:2019-02-27T01:07:28+09:00
プログラミング弱者がPythonでRSA暗号を体験してみる
1.はじめに
最近、暗号技術の勉強にはまっています。とある本で勉強しているのですが、思ったよりわかりやすくて面白いので、ゆっくりとですが読み進めています。(本については下記に載せておきます)
暗号技術というくらいだから、当然理解が難しいアルゴリズムもあります。しかし、頭の弱い私でも簡単なプログラミングで体験できそうなRSAという暗号技術があったので、Pythonという流行りのプログラミング言語でチャレンジしてみたいと思います。2.RSAとは?
ふと思ったのですが、2018年に流行った歌の名前に似ていますね。まあ発明者はU.S.Aなので間違いではなさそうです。(本当の本当はイギリスらしいけど)
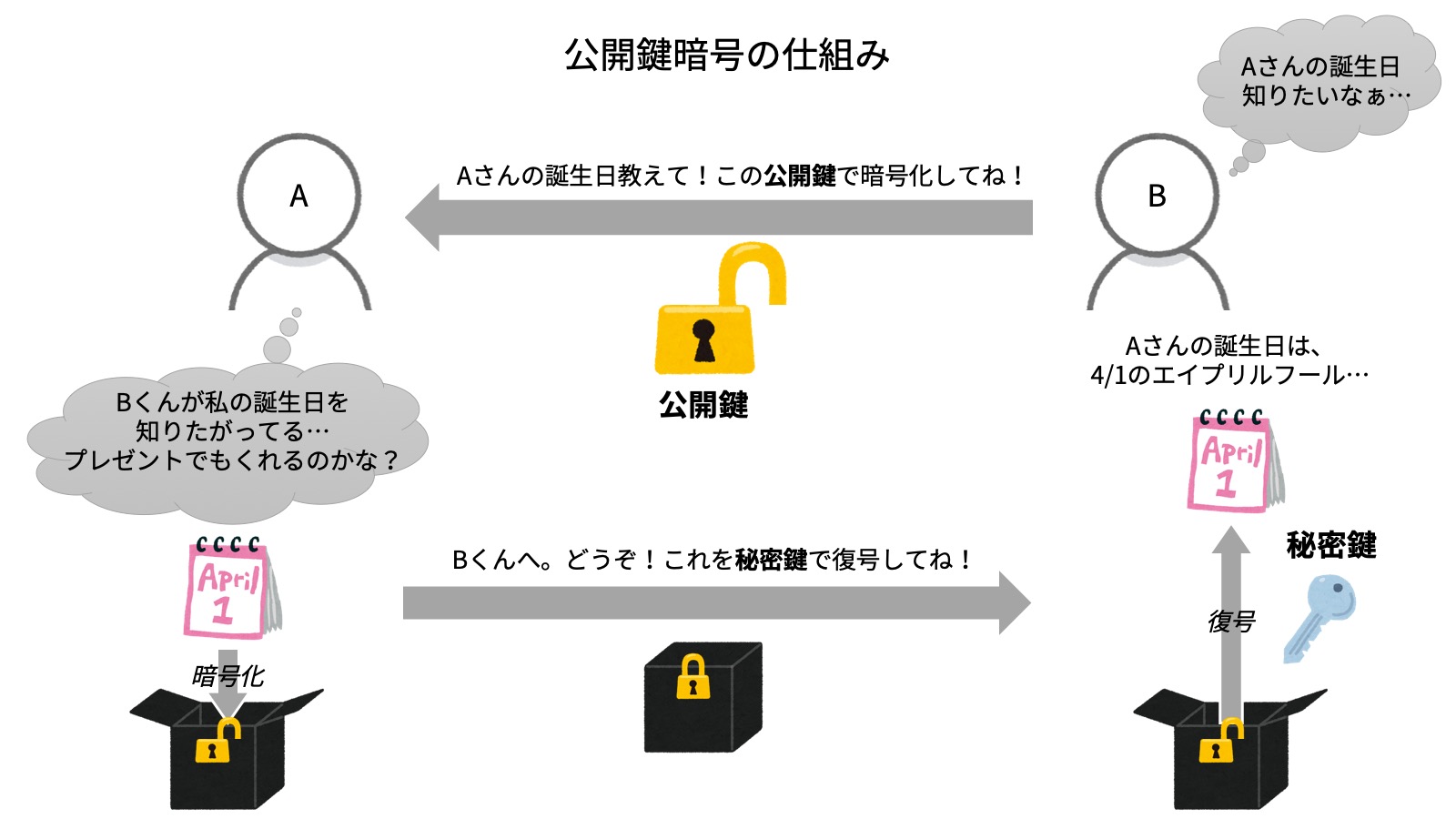
このRSAという技術は、公開鍵暗号アルゴリズムの1つです。この公開鍵暗号について簡単に説明すると、平文の暗号化と暗号文の復号に異なる鍵を用いるということです。ぱっと見意味不明ですが、南京錠をイメージするとわかりやすいです。簡単に図で説明しておきます。ちなみに公開鍵と秘密鍵は両方ともBくんのものです。わかりやすく説明しているQiita記事や文献も多いので詳細は割愛します。
3.RSA暗号体験に必要なもの
次にRSA暗号体験には一体何が必要なのかを整理してみましょう。左の三角形をクリックすると詳細が見られます。
① 平文
上の図でいう「暗号化されていないAさんの誕生日」にあたります。これを平文とし、暗号化すると「②暗号文」になります。
② 暗号文
上の図でいう「暗号化されたAさんの誕生日」にあたります。これを暗号文とし、復号すると「①平文」になります。
③ 公開鍵
上の図でいう「公開鍵」にあたります。Bくんが作成した鍵です。Aさんは、Bくんに渡されたこの公開鍵で「①平文」を「②暗号文」へ暗号化します。ちなみに、この公開鍵は他人にバレても問題ありません。(だから公開鍵)
④ 秘密鍵
上の図でいう「秘密鍵」にあたります。Bくんが作成した鍵です。Bくんは、この秘密鍵で「②暗号文」を「①平文」へ復号します。ちなみに、この秘密鍵は他人にバレると大問題です。(だから秘密鍵)さらに、「③公開鍵」と「④秘密鍵」には次の4つの数字が必要になります。
❶ 数N
ランダムな異なる素数であるpとqの2つを用意します。このときN = p \times q\\となる数Nです。pとqは擬似乱数生成器から得ます。今回は、自分で用意した素数からランダムで得ます。
❷ 数L
数Lは、p-1とq-1の最小公倍数です。「xとyの最小公倍数」を「lcm(x, y)」で表すとすると、数LはL = lcm(p-1, q-1)となります。
❸ 数E
数Eは、1より大きく、「❷数L」よりも小さな数である必要があります。この範囲において、まずは擬似乱数生成器から数Eの候補を作ります。このとき、数Eと「❷数L」の最大公約数が1であると、数Eは決定されます。(1でないときは、再度数Eの候補を作成する)「xとyの最大公約数」を「gcd(x, y)」で表すとすると、1 < E < L\\ gcd(E, L) = 1となります。EとLの最大公約数が1というのは、「EとLとは互いに素」と同意です。
❹ 数D
数Dは、1より大きく、「❷数L」よりも小さな数である必要があります。この範囲において、「❸数E」と数Dをかけた数をLで割ったときに余りが1になる数Dが必ず1つだけあります。「xと法とした剰余」を「mod x」で表すとすると、1 < D < L\\ E \times D \hspace{5pt} mod \hspace{5pt} L = 1となります。
「文や鍵①〜④」と「4つの数字❶〜❹」でRSAによる暗号化と復号を表すことができます。
暗号化
暗号文 = 平文^E \hspace{5pt} mod \hspace{5pt} N \\復号
平文 = 暗号文^D \hspace{5pt} mod \hspace{5pt} N \\「①平文」の暗号化に使われている「❸数E」と「❶数N」が「③公開鍵」
「②暗号文」の復号に使われている「❹数D」と「❶数N」が「④秘密鍵」「❷数L」は「❸数E」と「❹数D」の作成だけに使用されるので、直接的に暗号化と復号の際には不必要です。
4.PythonでRSAプログラミング!
数式ばかりで嫌になってしまいますが、次に実際にPythonプログラムを書いてみます!「Python3.7」を利用します。
4-1.平文の用意
まずは「①平文」を作りましょう!確かAさんの誕生日でしたね。4月1日でしたから「401」とでもしましょう。この「0」は「月と日の境」を表しています。例えば、2月26日は「2026」、10月9日は「1009」となります。一の位に0を付けて表記しなければ一意に定まるような気がします。最小値は1月1日の「101」、最大値は12月31日の「12031」です。
# 変数名は「birthday」 birthday = 4014-2.公開鍵の作成
次に「③公開鍵」です。作成には「❸数E」と「❶数N」が必要でした。順を追って用意していきましょう。まずは、「❶数N」を作成するために異なる素数p,qが必要です。本来であれば、擬似乱数生成器で得た数を素数判定して得るものですが、今回はわかりやすく素数配列を用意してそこからランダムで素数を選びたいと思います。このような感じでプログラムを書いてみました。
# 素数配列をそれぞれ準備 p_candidates = [101, 103, 107, 109, 113, 127, 131, 137, 139, 149] q_candidates = [151, 157, 163, 167, 173, 179, 181, 191, 193, 197] # randomモジュールの関数でランダムに要素を1つ選択 p = random.choice(p_candidates) q = random.choice(q_candidates) # 数Nを作成 N = p * q素数配列は101~200までの素数20個を10個ずつに分けてあります。(199も素数ですが...) ちなみにこのプログラムで作成される「❶数N」の最小値は、101×151=15251で、14bitで表現できてしまいます。この程度のビット数で暗号した場合、ブルートフォース攻撃等であっという間に解読されてしまうのでダメですね。
次に「❸数E」が欲しいところですが、その前には「❷数L」が必要ですね。p-1とq-1の最小公倍数がこれになるのでした。Pythonのmathモジュール(Python3.5以上)で、最大公約数を簡単に求められるので、これを利用してみます。# 関数lcmを用意 def lcm(x, y): return (x * y) // math.gcd(x, y) # 関数lcmの引数にp-1とq-1を指定しLに代入 L = lcm(p - 1, q - 1)xとyの最小公倍数は、「xとyをかけあわせた数」を「xとyの最大公約数」で割ることで求めることができます。これを利用しています。//演算子は、浮動小数点数の場合でも演算結果を小数点以下は切り捨てるものです。
「❶数N」と「❷数L」を得られたので、漸く「❸数E」を作成できます! まずは、randomモジュールの関数
randrangeで、1より大きく「❷数L」よりも小さな乱数Eを作ります。このEを先ほどの関数gcdを使って「❷数L」と最大公約数が1であるかを確かめます。1であればそのまま。1以外であれば再度乱数を発生させましょう。# 引数は「2」以上「L」未満の1刻みの乱数発生 E = random.randrange(2, L) # 最大公約数が1でなければ while math.gcd(E, L) != 1: # 再度乱数を発生 E = random.randrange(2, L)「❸数E」と「❶数N」がなんとかできました!「③公開鍵」は良さそうです。
4-3.秘密鍵の作成
「❶数N」「❷数L」「❸数E」があれば、そのまま「❹数D」もいけます。範囲を2以上「❷数L」未満の範囲で数D候補を繰り返し文で回していき、「❸数E」と数D候補をかけた数をLで割ったときの余りが1であるときに、その数D候補を数Dに確定します。
for i in range(2, L): if (E * i) % L == 1: D = i breakちなみにこの数D候補は沢山ありますが、Lで割った余りが1になるのは必ず1つしかありません。これで「❹数D」もできたので「④秘密鍵」も完成です!
4-4.平文を暗号文へ
平文の用意、そして公開鍵・秘密鍵の作成もできました。では実際に、公開鍵がBくんからAさんに無事送られたことを想定して、Aさんは自分の誕生日情報(平文)を公開鍵(「❸数E」「❶数N」)にて暗号化します。
暗号化は暗号文 = 平文^E \hspace{5pt} mod \hspace{5pt} N \\という単純な数式でできます。E乗は
pow関数で簡単に行えます。平文を暗号化したものは変数cipherに代入します。cipher = pow(birthday, E) % Nこれで暗号化することができます! この
cipherをAさんからBくんに送ります。4-5.暗号文を平文へ
AさんからB君へ送られた暗号文
cipherは、B君が機密に持っている秘密鍵(「❹数D」と「❶数N」)にて復号することができます!平文 = 暗号文^D \hspace{5pt} mod \hspace{5pt} N \\先ほどの暗号化同様の式なので詳しくは省略しますが、これにてAさんがB君に送りたいAさんの誕生日情報を無事に送ることができるはずです。
decipher = pow(cipher, D) % N暗号文を復号した平文は、変数
decipherに代入して、暗号化前の平文である変数birthdayと比較します。5.暗号化前と復号後を比較
当然、まだ試していないので上記のプログラムが本当に正しいかどうかはわかりません。なのでテストします。pとqの候補が10個ずつなので、100通りの鍵ペアが作成ができます。とりあえず30回くらいループで回してみます。
プログラムはこちらから
rsa.pyimport math import random # 関数lcmを用意(4-2) def lcm(x, y): return (x * y) // math.gcd(x, y) # Aさんの誕生日(4-1) birthday = 401 for var in range(0, 30): # 素数配列をそれぞれ準備(4-1) p_candidates = [101, 103, 107, 109, 113, 127, 131, 137, 139, 149] q_candidates = [151, 157, 163, 167, 173, 179, 181, 191, 193, 197] # randomモジュールの関数でランダムに要素を1つ選択 p = random.choice(p_candidates) q = random.choice(q_candidates) # 数Nを作成 N = p * q # 関数lcmの引数にp-1とq-1を指定しLに代入(4-2) L = lcm(p - 1, q - 1) # 引数は「2」以上「L」未満の1刻みの乱数発生 E = random.randrange(2, L) # 最大公約数が1でなければ while math.gcd(E, L) != 1: # 再度乱数を発生 E = random.randrange(2, L) # 数Dの作成(4-3) for i in range(2, L): if (E * i) % L == 1: D = i break # 平文 -> 暗号文(4-4) cipher = pow(birthday, E) % N # 暗号文 -> 平文(4-5) decipher = pow(cipher, D) % N # 出力 暗号化前平文 -> 暗号文 -> 復号後平文? print("{0} -> {1} -> {2}".format(birthday, cipher, decipher))実行結果は次の通り。
# 暗号化前平文 -> 暗号文 -> 復号後平文? 401 -> 18308 -> 401 401 -> 19347 -> 401 401 -> 15326 -> 401 401 -> 11450 -> 401 401 -> 17400 -> 401 401 -> 1274 -> 401 401 -> 3552 -> 401 401 -> 7005 -> 401 401 -> 4425 -> 401 401 -> 21979 -> 401 401 -> 3815 -> 401 401 -> 4370 -> 401 401 -> 24533 -> 401 401 -> 16421 -> 401 401 -> 12949 -> 401 401 -> 20149 -> 401 401 -> 7525 -> 401 401 -> 22536 -> 401 401 -> 1230 -> 401 401 -> 10159 -> 401 401 -> 15164 -> 401 401 -> 2754 -> 401 401 -> 2878 -> 401 401 -> 10722 -> 401 401 -> 3521 -> 401 401 -> 5469 -> 401 401 -> 4969 -> 401 401 -> 5036 -> 401 401 -> 24001 -> 401 401 -> 15078 -> 401全て無事に「401」が復号できたようです! 無事にBくんはAさんの誕生日がわかりました!
6.感想とか
これだけみるとRSA暗号の仕組みはそこまで難しくないように見えますが、実際に今強固な暗号アルゴリズムとして多くの場所で使われています。今回は簡単な用意した素数だけで試してみましたが、これが膨大な数の素数で同様に行われたらとんでもないな〜と思いました。実際には、これだけではRSAは使えません。上の例なら、本当にBくんがAさんに送った鍵なのか?という問題が発生します。
余談ですが、Aさんの誕生日情報として平文を決めたとき、最小値は1月1日の「101」、最大値は12月31日の「12031」です。
と記述しましたが、この最大値がNの値をオーバーすると、上のような綺麗な復号ができなくなります。まあその理由については、下で紹介している本を読んでみてください。本当にオススメ。(投げやり)
7.参考文献
- 結城 浩著 『暗号技術入門 第3版 秘密の国のアリス』 SBクリエイティブ株式会社

- 投稿日:2019-02-27T00:37:03+09:00
【Python】PyPIエラー対応 File already existsの対処法
発生したエラー
twineを使って、PythonパッケージをPyPIに登録しようとしたところ、
HTTPError: 400 Client Error: File already exists. See https://pypi.org/help/#file-name-reuse for url: https://upload.pypi.org/legacy/のエラーとなる。
$ twine upload --repository pypi dist/* Enter your username: hogefuga Enter your password: Uploading distributions to https://upload.pypi.org/legacy/ Uploading cc 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11.4k/11.4k [00:01<00:00, 9.14kB/s] NOTE: Try --verbose to see response content. HTTPError: 400 Client Error: File already exists. See https://pypi.org/help/#file-name-reuse for url: https://upload.pypi.org/legacy/ $対処方法
原因は、PyPIに登録済みのパッケージとファイル名が重複してしまっているため。
PyPIには同じバージョンのパッケージを再登録はできない。
setup.pyのversionを変更した上で、python setup.py bdist_wheelでパッケージファイルを作り直すことで、登録が可能。setup.py#!/usr/bin/env python # coding: utf-8 from setuptools import setup, find_packages from codecs import open from os import path here = path.abspath(path.dirname(__file__)) with open(path.join(here, 'README.md'), encoding='utf-8') as f: long_description = f.read() setup( name='gokulang', packages=['gokulang'], version='1.0.1', # 1.0.0 => 1.0.1 に変更 # ...環境
- Python 3.6.6
- twine 1.13.0
- 投稿日:2019-02-27T00:27:46+09:00
非正規社員の雇用形態に就いている理由を形態別に見てみる
非正規社員の雇用形態に就いている理由を形態別に見る。
非正規雇用は押し並べてネガティブなイメージで語られることが多い
方やある程度融通の効く就業形態というメリットもある。統計局に非正規雇用の従業員に向けたアンケートで非正規雇用の形態別にまとめられた面白いデータが有ったためヒートマップで率を見てみた。データは2017年のもの。
データ
統計局「男女,教育,現職の雇用形態についている理由,現職の従業上の地位・雇用形態別人口(非正規の職員・従業員)-全国,全国市部,都道府県,都道府県市部,政令指定都市」
ユニークを見ていく
def show_columns(dfl, num=10): for i in dfl.columns: print('----------------') print(i) print(dfl[i].nunique(), '個のユニーク') print(dfl[i].unique()[:num]) df["value"] = pd.to_numeric(df["value"], errors='coerce') show_columns(df, 117) ''' tab_code 1 個のユニーク ['001-2017'] ---------------- 表章項目 1 個のユニーク ['人口'] ---------------- cat01_code 1 個のユニーク [0] ---------------- 男女 1 個のユニーク ['総数'] ---------------- cat02_code 9 個のユニーク [ 0 1 11 12 13 14 15 16 17] ---------------- 教育 9 個のユニーク ['総数' '卒業者' '小学・中学(卒業者)' '高校・旧制中(卒業者)' '専門学校(2年未満)(卒業者)' '専門学校(2~4年未満)(卒業者)' '専門学校(4年以上)(卒業者)' '短大(卒業者)' '高専(卒業者)'] ---------------- cat03_code 15 個のユニーク [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14] ---------------- 雇形理由 15 個のユニーク ['総数' '主に自分の都合のよい時間に働きたいから' '主に家計の補助・学費等を得たいから' '主に家事・育児・介護等と両立しやすいから' '主に通勤時間が短いから' '主に専門的な技能等を生かせるから' '主に正規の職員・従業員の仕事がないから' '主にその他' '自分の都合のよい時間に働きたいから' '家計の補助・学費等を得たいから' '家事・育児・介護等と両立しやすいから' '通勤時間が短いから' '専門的な技能等を生かせるから' '正規の職員・従業員の仕事がないから' 'その他'] ---------------- cat04_code 7 個のユニーク [0 1 2 3 4 5 6] ---------------- 現職従地位・雇形 7 個のユニーク ['総数' 'パート' 'アルバイト' '労働者派遣事業所の派遣社員' '契約社員' '嘱託' 'その他'] ---------------- area_code 117 個のユニーク [ 0 1 1000 1001 1100 2000 2001 3000 3001 4000 4001 4100 5000 5001 6000 6001 7000 7001 8000 8001 9000 9001 10000 10001 11000 11001 11100 12000 12001 12100 13000 13001 13100 14000 14001 14100 14130 14150 15000 15001 15100 16000 16001 17000 17001 18000 18001 19000 19001 20000 20001 21000 21001 22000 22001 22100 22130 23000 23001 23100 24000 24001 25000 25001 26000 26001 26100 27000 27001 27100 27140 28000 28001 28100 29000 29001 30000 30001 31000 31001 32000 32001 33000 33001 33100 34000 34001 34100 35000 35001 36000 36001 37000 37001 38000 38001 39000 39001 40000 40001 40100 40130 41000 41001 42000 42001 43000 43001 43100 44000 44001 45000 45001 46000 46001 47000 47001] ---------------- 地域区分 117 個のユニーク ['全国' '全国市部' '北海道' '北海道市部' '札幌市' '青森県' '青森県市部' '岩手県' '岩手県市部' '宮城県' '宮城県市部' '仙台市' '秋田県' '秋田県市部' '山形県' '山形県市部' '福島県' '福島県市部' '茨城県' '茨城県市部' '栃木県' '栃木県市部' '群馬県' '群馬県市部' '埼玉県' '埼玉県市部' 'さいたま市' '千葉県' '千葉県市部' '千葉市' '東京都' '東京都市部' '特別区部' '神奈川県' '神奈川県市部' '横浜市' '川崎市' '相模原市' '新潟県' '新潟県市部' '新潟市' '富山県' '富山県市部' '石川県' '石川県市部' '福井県' '福井県市部' '山梨県' '山梨県市部' '長野県' '長野県市部' '岐阜県' '岐阜県市部' '静岡県' '静岡県市部' '静岡市' '浜松市' '愛知県' '愛知県市部' '名古屋市' '三重県' '三重県市部' '滋賀県' '滋賀県市部' '京都府' '京都府市部' '京都市' '大阪府' '大阪府市部' '大阪市' '堺市' '兵庫県' '兵庫県市部' '神戸市' '奈良県' '奈良県市部' '和歌山県' '和歌山県市部' '鳥取県' '鳥取県市部' '島根県' '島根県市部' '岡山県' '岡山県市部' '岡山市' '広島県' '広島県市部' '広島市' '山口県' '山口県市部' '徳島県' '徳島県市部' '香川県' '香川県市部' '愛媛県' '愛媛県市部' '高知県' '高知県市部' '福岡県' '福岡県市部' '北九州市' '福岡市' '佐賀県' '佐賀県市部' '長崎県' '長崎県市部' '熊本県' '熊本県市部' '熊本市' '大分県' '大分県市部' '宮崎県' '宮崎県市部' '鹿児島県' '鹿児島県市部' '沖縄県' '沖縄県市部'] ---------------- time_code 1 個のユニーク [2017000000] ---------------- 時間軸(年次) 1 個のユニーク ['2017年'] ---------------- unit 1 個のユニーク ['人'] ---------------- value 2737 個のユニーク [21325700. 19530900. 892700. 735200. 334200. 182900. 143800. 189800. 156600. 380400. 320200. 181500. 146500. 133100. 150500. 121100. 276400. 226300. 488800. 441000. 336700. 287200. 339300. 286000. 1353100. 1236400. 232200. 1114300. 1067300. 165600. 2330100. 2319600. 1569400. 1710700. 1642400. 697600. 266100. 147000. 336200. 325700. 125200. 157200. 144800. 181200. 160200. 121800. 106500. 144700. 122700. 339200. 272400. 339000. 288800. 641000. 603900. 120600. 131400. 1329600. 1257400. 395200. 310400. 272900. 259300. 245500. 469500. 446000. 267500. 1535900. 1505000. 474000. 139100. 918600. 876700. 261900. 220100. 175100. 141400. 111500. 83700. 61400. 103100. 93500. 282100. 265900. 108900. 459200. 430400. 204500. 213200. 204400. 92400. 69200. 139900. 117900. 197000. 179500. 98400. 80700. 869100. 759500. 148300. 288600. 123500. 103600. 207600. 186600. 264800. 216200. 118900. 169800. 162800. 168400. 141500. 262400. 233200. 253800. 193400.] '''学歴や動機や地域ごとに雇用形態に就いた理由が記載されている。
不要なデータを削いでいく。df_01 = df[(df['教育'] == '総数') & (df['雇形理由'] != '総数') & (df['教育'] == '総数') & (df['地域区分'] == '全国') & (df['現職従地位・雇形'] != '総数')]xyを指定してヒートマップを出してみる
df_pivot = pd.pivot(data=df_01, columns='現職従地位・雇形', index='雇形理由', values='value') s = sns.heatmap(df_pivot, annot=True, cmap='Blues', fmt="0", linewidths=1, linecolor="white",) plt.savefig('heat.png') plt.close('all')
パート・アルバイトは法律上は同じ雇用形態であるはずだが何故か分けられている。
統計局に依るとパートの定義は下記の通りらしい。しかし読んでも特にパート・アルバイトを分ける理由が見当たらない。
パート・アルバイトを選んだ理由としてはあいた時間を使いたいから、家計や学費を'補助'したいからという理由が多い。
パート・アルバイトの比率が大きすぎて他のマップが見えてこないので正規化をする。
Pandasには標準で平均や標準偏差が用意されている。
こういうときにPandasはとても楽であるし、何より楽しい。df_pivot=(df_pivot-df_pivot.mean())/df_pivot.std()そしてプロット
嘱託契約者は専門的な技能が要求されているため選択されている面が強い
マップからは嘱託・パート・アルバイトは比較的ポジティブな理由で就労しているが、派遣社員・契約社員は正規社員になれなかったからというネガティブな理由が多い傾向がある。
非正規雇用の問題といっても、非正規雇用の中の契約社員・派遣社員が特に不満を抱えていることがよくわかる。逆にパートに限って言えばそれほど不満はないということが見えてくる。


- 投稿日:2019-02-27T00:12:54+09:00
ランダムな文脈表示
100分de名著の太宰治「斜陽」(高橋源一郎著)に感銘を受けた。
そして、そのノリのまま、webアプリを一つ作成した。http://world-l-word.com/dazai/index.html
特徴:小説「人間失格」から、文脈をランダムに表示するもの。
データ:青空文庫から適当に。
- 投稿日:2019-02-27T00:06:08+09:00
ギブスサンプリングによるクラスタリングの注意点
はじめに
私が書いた記事混合ガウス分布のベイズ推定とクラスタリングの補足です。
上記記事では数百回サンプリングを行わないとうまくクラスタリング出来ていませんが、もっと少ないサンプリングでクラスタリング出来ました。
たいした内容ではありませんが、補足と自身の勉強の意味を込めて書きました。正規分布のベイズ推定
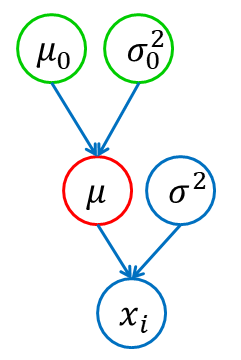
話をわかりやすくするため、混合モデルではなく通常の正規分布を考えます。
データ$x_{1:N}$が正規分布$N(\mu, \sigma^2 I)$によって生成されていると仮定し、$\mu$をベイズ推定します。
このとき$\mu$の事前分布に正規分布$N(\mu_0, \sigma_0^2 I)$を仮定し、$\mu_0$と$\sigma_0^2$の事後分布を求めます。\begin{align} \mu_0 &\leftarrow \frac{\sigma_0^2}{\overline{\sigma}^2+\sigma_0^2}\overline{\mu} + \ \frac{\overline{\sigma}^2}{\overline{\sigma}^2+\sigma_0^2}\mu_0 \\ \sigma_0^2 &\leftarrow \left(\frac{1}{\sigma_0^2}+\frac{1}{\overline{\sigma}^2}\right)^{-1} \end{align}ただし、$\overline{\mu}=\frac{1}{N}\sum_{i=1}^{N}x_i$、$\overline{\sigma}^2=\frac{\sigma^2}{N}$です。
ここで事後分布の平均$\mu_0$の式に注目すると、観測データ$x_{1:N}$の平均$\bar{\mu}$と事前分布の平均$\mu_0$の内分を取っていると言えます。その比率は事前分布の分散$\sigma_0^2$によって決まります。
この分散$\sigma_0^2$は「$\mu_0$をどのくらい信用するのか」を表しているとも言え、$\mu_0$の更新式から以下が分かります。・$\sigma_0^2$が$0$に近いとき、$\mu_0$は強く信用されており、事後分布の平均は$\mu_0$からあまり動かない
・$\sigma_0^2$が十分大きいとき、$\mu_0$はあまり信頼されておらず、事後分布の平均は$\bar{\mu}$に近い値まで動く一方、$\sigma_0^2$の更新式を見ると分かる通り、事後分布による更新を繰り返すたびに$\sigma_0^2$はどんどん0に近づいていきます。すなわち、徐々に$\mu_0$の信用度が上がっていきます。
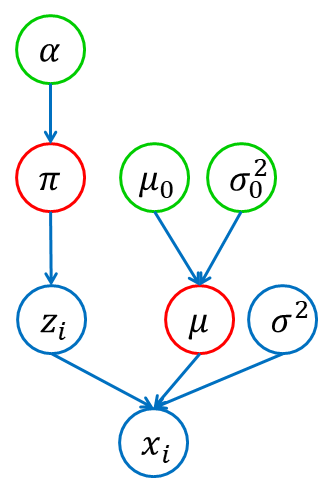
…ここに落とし穴がありました。混合ガウス分布データのクラスタリング時に、まだ平均$\mu_0$がうまく決まっていない段階で$\sigma_0^2$の更新を続けると、$\mu_0$が正しくないのにも関わらず信用度だけが上がり続け、本来の値への収束が遅くなってしまいます。
混合ガウス分布データのクラスタリング
そもそもクラスタリングに必要なのは$\mu_0$であって、その信用度$\sigma_0^2$を高める必要はありません。
そこで、$\sigma_0^2$をハイパパラメータとして扱い、$\sigma_0^2$は変えずに$\mu_0$のみ更新する方法を取ります。
こうすることで、30回もサンプリングすればクラスタリングが完了するようになりました。GitHubにソースコードを載せています。
https://github.com/highcheap/qiita/blob/master/nonparametric_bayes/mixedgaussian_bayesian_estimation_v02.py$\sigma_0^2$が大きいほど本来の平均に早く移動できる一方、$\mu$のサンプルのばらつき方が大きくなりクラスタリングを妨げる可能性も生じてしまいます。ここでは、$\sigma_0^2=0.05$にしました。
結果
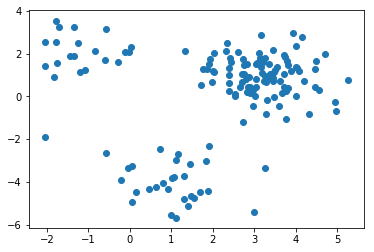
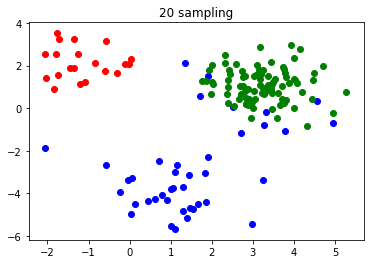
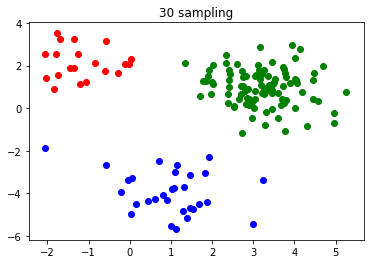
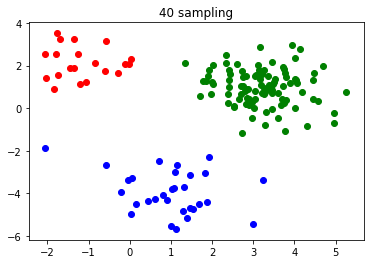
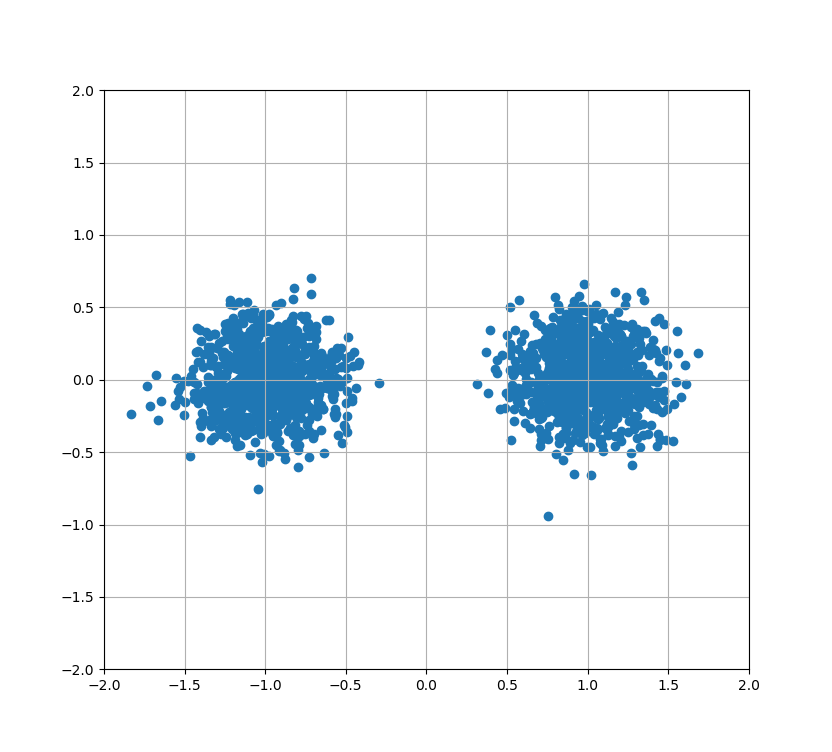
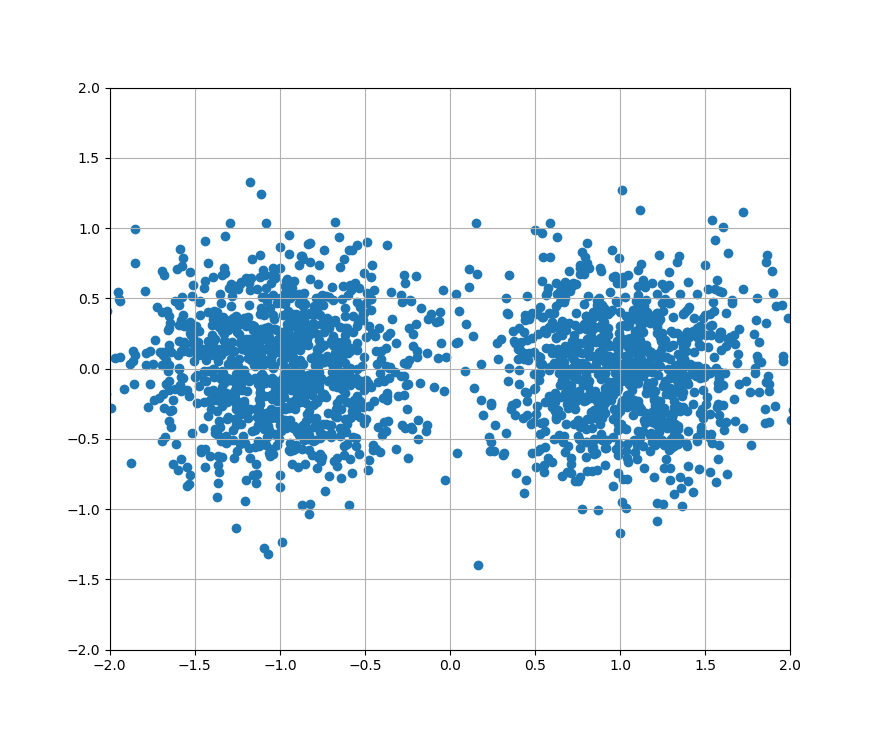
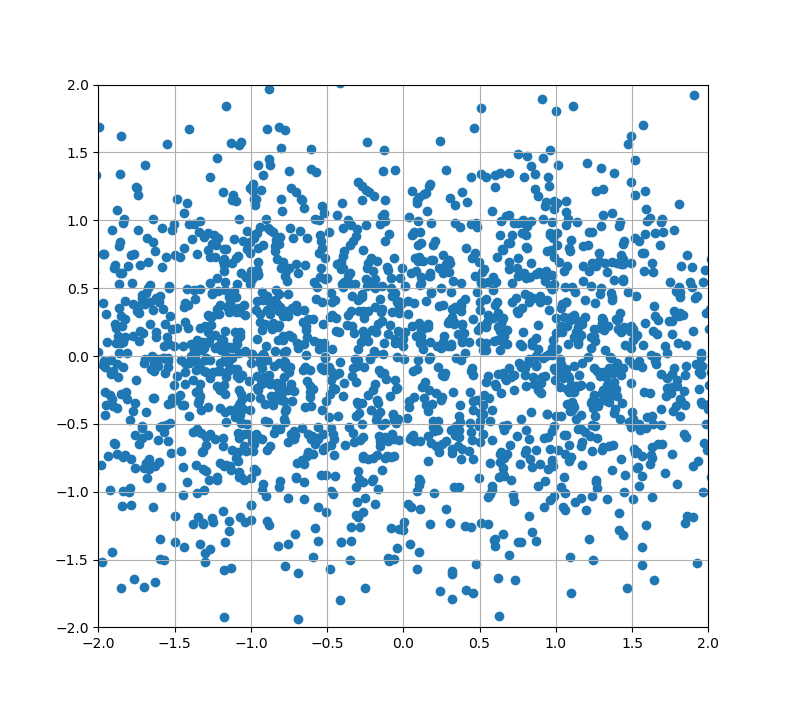
元データは前回と同じです。
以下、10回ごとの結果を載せていきます。
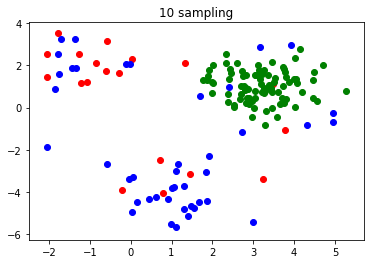
・10回サンプリング
・20回サンプリング
・30回サンプリング
・40回サンプリング
前回では200回やっても完了しなかったクラスタリングが、30回でできるようになりました。
おわりに
いい勉強になりました。