- 投稿日:2019-02-27T22:18:53+09:00
AWS SysOpsアドミニストレータの再認定試験の対策について
はじめに
会社の目標として設定
させられしたのをきっかけに学習を始めたAWSの資格、現在はソリューションアーキテクトとSysOpsアドミニストレータの2つを取得、再認定での継続をしております。
資格は取得しているものの、今のところ業務で触る機会はなく、これまでも業務でAWSを扱った経験もあまりなく(VPC+シングル構成のEC2+VPN、DNS移行程度)、知識先行でかなり頭でっかちな状況ではあります。
そんな状況の私ですが、最近、AWSのSysOpsアドミニストレータの再認定を受ける時期になり、かなりいろいろ忘れていた状態から実質1カ月程度(週4時間程度の学習時間)のフォローアップで何とか再認定をいただくことができました。
今回は再認定試験を受験するにあたってどんな対策をしてきたかを簡単にご紹介いたします。これからSysOpsアドミニストレータを初めて受験される方にも参考にしていただけると思います。
※実際に試験で出題された内容を開示することはできないため、あくまで試験対策としてどうしていくのがいいのかというところで書いていきます。AWSの資格制度(再認定)について
直接試験対策には関係はないのですが、AWS資格の再認定の制度は最近ルールが変わっておりますので念のため書いておきます。
2019年3月以降は以下のようになります。【これまで】
・2年ごとに再認定に試験を受験し合格する。
・2年のうちに再認定試験に合格できないと資格無効になるが、1年間は再認定試験を受けることができる。
【2019年3月以降】
・3年ごとに改めて認定試験を受験し合格する(再認定に相当する場合は受験料が割引される)。
・3年のうちに認定試験に合格できないと資格失効。現在AWS資格をお持ちで2019年3月以降の有効期限となっている方については、自動的に有効期限が1年間延長されます。しかし再認定試験猶予期間とかの扱いはなくなります。
※再認定試験猶予期限が2019年3月以降の方については、資格が再度有効になるようです。もちろん猶予期限=資格有効期限となるだけですので、資格有効期限(=これまでの猶予期限)までに改めて認定試験を受験して合格する必要があります。AWS資格の再認定の詳細については下記公式サイトをご確認ください。
※上記の内容と公式サイトの内容に差異がある場合は、公式サイトのほうが正しいものとなります。再認定試験に向けて私が行った対策
ここから本題です。再試験にあたってどんな学習を進めたのかを書いてみます。
①何はともあれ、試験範囲の再確認
AWS試験は過去問や問題集といったたぐいのものがとても少ないのでやっつけの対策は非常に難しいのではあるのですが、何はともあれ、どんなことは試験で問われるのか、どのような知識を身に着けておく必要があるのかはある程度きちんとAWSから案内されております。とにかくまずはこれを熟読、確認。「まずは敵を知れ!」ここからです。
<注意!>
SysOpsアドミニストレータ認定試験の内容は2018年9月に改定されております。これより前に取得されている方は改めてご確認ください。②AWSクラウドサービス活用資料集
基本的には定期的に行われているAWSオンラインセミナーで使われた資料となりますが、AWSのたくさんあるサービスがどんなものでどのようなところに使えるのかを整理するには一番わかりやすいものだと思います。私はこの資料集を起点にして知識の幅を広げていっております。
一部についてはオンデマンド動画も公開されておりますので、資料の行間を補完する意味でもこちらも確認することをおすすめします。
SysOpsアドミニストレータは運用視点で「○○の状況になっている。△△のようにするにはどうするのがよいか」的な問題が多いため、「手を動かして試す」的なことを気軽に試すのは難しいサービスに関する出題もありますが、この資料集ではサンプル事例を取り上げて説明されているものも多いので、この点からもおすすめできます。
※個々のサービス以外でもAWSアカウントの運用や料金請求・確認のあたりの内容も確認しておくとよいと思います。③AWS各サービスに関するAWS公式サイト
当たり前ですがこの内容が一番正しいものとなりますので、内容を理解することがとても大切です。
しかし文字が多く、一部の新しいサービスでは日本語訳がおいついていないこともあるため、先ほど紹介したクラウドサービス活用資料集で概要をつかんだうえで読み込んでみると理解が深まります(ご存じのとおりAWSサービスは日々進化/変更されておりますので、公式サイトの確認は必ずセットで行う必要があります)。
もし公式サイトをすべて読み倒す時間がない場合は、各サービスにある「よくある質問」の内容をひととおり読んで内容を理解しておくだけでも何かと理解に役に立つと思います。AWS公式サイトTOP
※上部ペインの「製品」にマウスカーソルをあてると各サービスの一覧が表示されます。④AWSホワイトペーパー
こちらも読み込んでおくのがおすすめです。日本語化は追いついておりませんが、特にAWSへの理解を深めるために特に重要だと思われるものはある程度日本語化されていますので、ご一読をおすすめします。
AWSオンラインセミナーの受講
これについては、今回の試験に際してはなかなか時間がとれずに思ったように受講できなかったのですが、時間があればぜひ受講してみてください。直接業務に関係ないとかまず使わないだろうサービスであっても、内容を聞くことでAWSの様々な知識をシャワーのように浴びることで自然に身につきます。
ぎりぎりになってあれもこれもと学習するのはけっこう大変なものがありますので、普段からコツコツやりたい方には特におすすめです。活用資料集の行間の解説を聞くのも結構有用です。
私がAWSを触るようになって、AWSへの知識を深めるきっかけはこれでした。⑤手を動かす!
運用視点でのベストプラクティスやセキュリティ対策のやり方はあっても実務で経験していないとなかなか理解は深まりません。
でも、お手軽に手を動かして試せるサービスはいっぱいあります。知らないサービス、何となくであいまいな理解なサービスがあればぜひ実際に構築/操作をして体験してみてください。AWS有資格の諸先輩方も口々におっしゃられているかと思いますが、私自身も手を動かすことで覚えられることはとても多いと感じております。
試す中で思いどおりにいかないこともあるかと思いますが、ここでどうすればいいのかということ調べる行為がとても理解を深めてくれると思います。調べていく中で「あ、こんなこともできるんだ!」的な発見もできます。
SysOpsアドミニストレータ試験範囲での関連サービスとしては、特にVPC、EC2、EBS、ELB、RDS、AutoScaling、CloudFormation、S3、Lambda、Route53、CloudWatch、Route53あたりは手を動かしていろいろ試せるかと思います。
試験対策的には「○○するためにはどのような操作をする必要があるか」のような具体的な操作を問うような感じのものもあるようですので、手を動かすに越したことはありません。資料を読んで理解した、だけではなく、少しでも触って動かしてみてください。⑥(試験内容変更対応) 新サービスの知識の吸収
先ほども書きましたが、SysOpsアドミニストレータ試験は2018年8月に試験内容が変更されました。比較的最近リリースされた新サービスについても、どのようなサービスでどういう用途で利用するのがいいのかを理解しておいたほうがよいかと思います。
⑦サンプル問題を解く
せっかく無料で公開されて正答内容も記載されておりますので、これを解かない手はありません。SysOpsアドミニストレータ試験のものはもちろん、ソリューションアーキテクトやデベロッパーの各試験のサンプル問題もついでに解いて知識を深めるとよいかと思います。
ただ残念なことに、2019年2月27日現在で、SysOpsアドミニストレータ試験のサンプル問題の内容は、新試験に移行する前のものからまだ変更されておりません。しかも英語のみでの提供なのですが、これについては以下のブログで日本語訳をしていただいているのでぜひ確認してみてください。「AWS 認定SysOpsアドミニストレーター - アソシエイト」資格のサンプル問題を解いてみよう
⑧模擬試験を受験する
模擬試験もぜひ受験しましょう!
「模擬試験、有料じゃん・・・」って方、「2,000円くらいケチケチしない!」と言いたいところですが、資格をすでに持っていて再認定を受ける場合は、模擬試験は無料で受けられます!
AWS認定者の特典として、模擬試験が無料で受けられるバウチャーがあります。詳しくは、AWS認定アカウントサイトから上部ペインの「特典」リンクをクリックしてみてください。「AWS Certified Practice Exam Benefit」でトークンを取得できますので、ぜひバウチャーを取得して模擬試験受けてください!
模擬試験の回答が参照できると本当に助かるのですがね・・・その他の対策など
詳しくは紹介できないのですが、以下のものも若干お金がかかるものの、対策としては有効だと思います。皆様の学習スタイルに合わせて選択してみてください。
①対策本
とにかくAWSはサービス展開のスピードがはやいため参考書の内容もすぐに古くなってしまいなかなか参考書が少ないのですが、そんな中でも数少ないAWS認定試験の対策本です。ソリューションアーキテクト向けですが知識としてもっておく必要があるところはたくさん含まれると思いますので、本で学習をしたいという方には選択肢になるかと思います。
②Web問題集
位置づけとしては、いわゆるIT系資格の「黒本(=対策問題集)」のWEB版だと思います。問題を数解いてわからないところを補完するようなアプローチで学習を進める方には有効な選択肢になるかと思います。
③AWS公式トレーニング
お金で時間を買う形でとにかく効率的に学習を進めるのであればこれがおすすめだと思います。
④他にないの?
いろいろな資格試験の受験経験があるかたにはご期待に沿えないのですが、某Cramなんとか的な暗記先行の対策モノは存在しないと思います。地道に学習を進めてください。
で、どの辺押さえていけばいいのかな・・・
これだけをやっておけば大丈夫的なものはなく、広く理解をしておく必要がありますが、特に以下のサービスに関する知識は特に身に着けておくべきと考えて差し支えないと思います。
- ネットワーク関連 (VPC、サブネット、セキュリティグループ、ネットワークACL、IGW、VPN、DirectConnect、NAT、CloudFront、Route53など。オンプレとの接続、DR対策とかとか)
- EC2関連 (オンデマンド/リザーブド/スポットインスタンスの特徴や使いどころ、各インスタンスタイプの特徴、インスタンスストア)
- EC2以外のコンピューティングサービス(Lambda)
- データベース関連 (RDS、DynamoDB、ElastCache、RedShift)
- ストレージサービス全般 (それぞれどんな特徴があるか、EBSの種類と特徴、S3の種類と特徴と権限管理とか。StorageGatewayあたりもチェック)
- AutoScaling関連 (あわせてCloudWatch、SNS、ELB)
- CloudFormation関連 (構築時や設定変更時の挙動とか)
- AWSによる監視、構成管理など (CloudWatch、CloudTrail、AWS Config、SSM、ログの分析関連として各種分析サービス(Athena、EMRなど))
- 権限管理(IAMユーザー、IAMロール)
- AWSアカウント管理(請求アカウント、AWS Organizations)
- セキュリティ、アイデンティティ、コンプライアンス関連サービス(各サービスの特徴や使いどころ)
- システム移行(オンプレからAWS移行のベストプラクティス)
- SQS
逆に出題される可能性が低そう(決して出ないとは断言できないですが・・・)なのは
- AI関連サービス
- IoT関連サービス
- AR
- ゲーム(GameLift、Lumberyard)
- ビジネスアプリケーション(Alexa for Business、Chime)
- ロボット
- 人工衛星
あたりでしょうか。
さいごに
AWS認定試験の学習アプローチにはいろいろなやり方があるかと思いますが、とにかくAWSのサービス内容は更新スピードが速いので、どんな形であれ、AWS公式サイトの内容を必ずセットで確認することは大切かと思います。
SysOpsアドミニストレータの試験範囲は、運用の実務経験がないとなかなか理解が難しいかと思いますが、丁寧に学習を進めることと、実際の試験問題は斜め読みせずきちんと丁寧に読んで内容を理解して問題を解いていってください(多分2年前に受験したときよりは問題文が簡潔になって読みやすくなっているような気がしてます)。
私のようなAWS実務経験のすごく浅い者でも合格し、継続できております。あきらめないで!
- 投稿日:2019-02-27T22:00:28+09:00
CloudFormationを使ってS3とCloudFrontの構成で静的Webサイトを構築する(Origin Access Identityは使わない)
はじめに
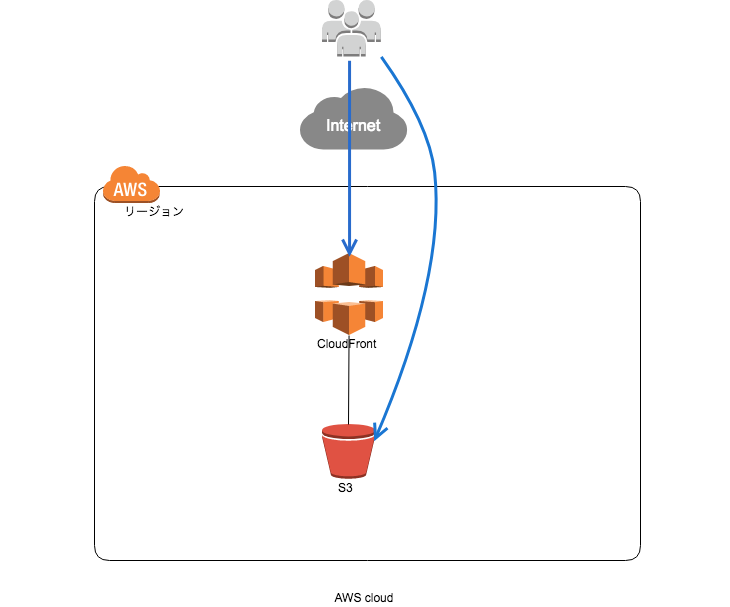
本記事では、AWS CloudFormation管理コンソールを使って、S3とCloudFrontで、静的Webサイトの環境を構築する手順を説明しています。(初心者向け)
また、CloudFrontのOriginの設定においては、OAI(Origin Access Identity)を使わずに、S3の静的Webサイトには、直接アクセスできる構成としています。
本記事で掲載しているテンプレートの最新版は、下記に置いてます。
https://github.com/okubo-t/aws-cloudformation構成図
前提条件
CloudFrontに設定するSSLサーバ証明書を、リージョンがバージニア北部のAWS Certificate Manager(ACM)にインポートしていること。
ACM管理コンソールで、CloudFrontに設定する証明書の識別子をメモしておく。
インデックスドキュメントは、index.html とする。
構築手順
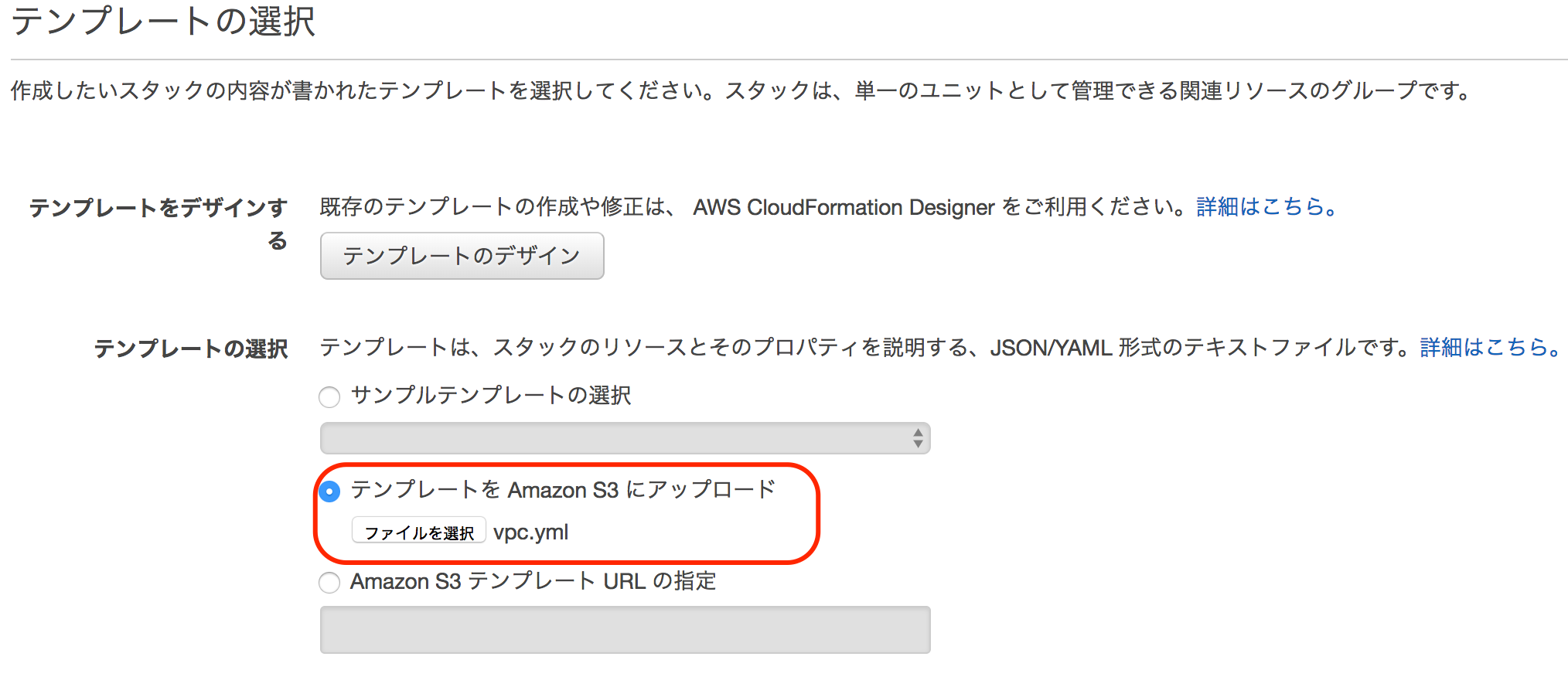
1 AWS CloudFormation管理コンソールから、スタックの作成をクリックします。
2 後述のテンプレートを選択します。
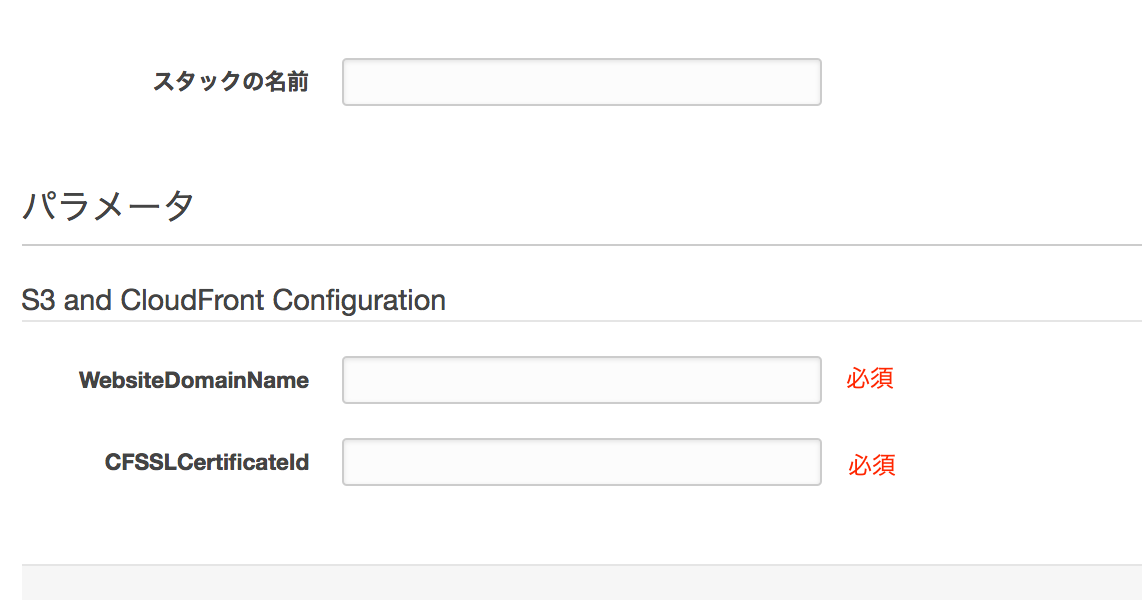
3 各パラメータを入力します。
パラメータ名 用途 備考 スタックの名前 テンプレートから作成するリソース一式の名前 例 s3-cf-web-20190226 WebsiteDomainName 静的Webサイトのドメイン名 必須 S3のバケット名となります CFSSLCertificateId 前提条件でメモした証明書の識別子 必須 4 後続は、デフォルトのまま次へ次へで、作成します。
5 状況が CREATE COMPLETEになれば、S3とCloudFrontの構築が完了です。
6 管理コンソールの下部の出力から、構築した静的WebサイトのエンドポイントとCloudFrontの情報を確認できます。
ここで、キーが、DomainNameとWebsiteURLの値をメモしておきます。
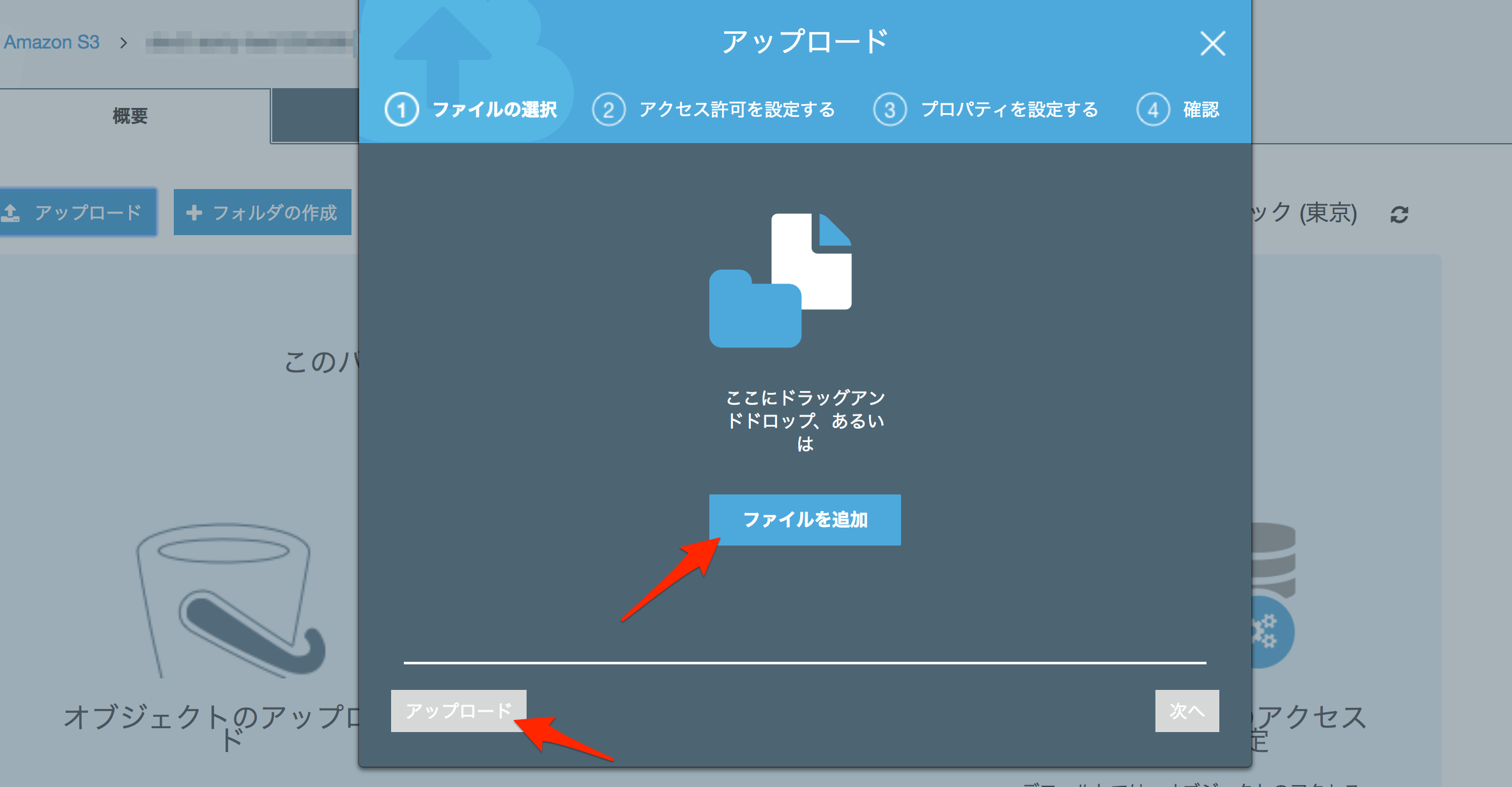
7 確認のために、S3の管理コンソールから、バケット(バケット名はWebsiteDomainNameに設定した値)に、index.htmlファイルをアップロードします。
8 ブラウザから、先ほどメモしたDomainNameの値にWebアクセス(CloudFrontにWebアクセス)して、index.htmlの内容が表示されれば、OKです。
また、WebsiteURLの値にWebアクセス(S3にWebアクセス)して、index.htmlの内容が表示されれば、OKです。
9 最後に、適宜、WebsiteDomainNameのCNAMEレコード(Route53の場合は、ALIASレコード)として、CloudFrontのドメイン名をDNSサーバ(Route53)に登録してください。
テンプレート
s3-cloudfront-web-hosting.ymlAWSTemplateFormatVersion: "2010-09-09" Description: S3 and CloudFront for Static website hosting Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "S3 and CloudFront Configuration" Parameters: - WebsiteDomainName - CFSSLCertificateId ParameterLabels: WebsiteDomainName: default: "WebsiteDomainName" CFSSLCertificateId: default: "CFSSLCertificateId" # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: WebsiteDomainName: Type: String CFSSLCertificateId: Type: String Resources: # ------------------------------------------------------------# # S3 Bucket # ------------------------------------------------------------# # Bucket Bucket: Type: "AWS::S3::Bucket" Properties: BucketName: !Ref WebsiteDomainName AccessControl: PublicRead WebsiteConfiguration: IndexDocument: index.html BucketPolicy: Type: "AWS::S3::BucketPolicy" Properties: Bucket: !Ref Bucket PolicyDocument: Statement: - Action: "s3:GetObject" Effect: Allow Resource: !Sub "arn:aws:s3:::${Bucket}/*" Principal: '*' # ------------------------------------------------------------# # CloudFront # ------------------------------------------------------------# CloudFrontDistribution: Type: "AWS::CloudFront::Distribution" Properties: DistributionConfig: PriceClass: PriceClass_All Aliases: - !Ref WebsiteDomainName Origins: - CustomOriginConfig: OriginProtocolPolicy: http-only DomainName: !Sub "${WebsiteDomainName}.s3-website-${AWS::Region}.amazonaws.com" Id: !Sub "S3-Website-${WebsiteDomainName}.s3-website-ap-northeast-1.amazonaws.com" DefaultCacheBehavior: TargetOriginId: !Sub "S3-Website-${WebsiteDomainName}.s3-website-ap-northeast-1.amazonaws.com" ViewerProtocolPolicy: redirect-to-https AllowedMethods: - GET - HEAD CachedMethods: - GET - HEAD DefaultTTL: 3600 MaxTTL: 86400 MinTTL: 60 Compress: true ForwardedValues: Cookies: Forward: none QueryString: false ViewerCertificate: SslSupportMethod: sni-only MinimumProtocolVersion: TLSv1.1_2016 AcmCertificateArn: !Sub "arn:aws:acm:us-east-1:${AWS::AccountId}:certificate/${CFSSLCertificateId}" HttpVersion: http2 Enabled: true # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: #WebsiteURL: WebsiteURL: Value: !GetAtt Bucket.WebsiteURL #DistributionID DistributionID: Value: !Ref CloudFrontDistribution #DmainName DomainName: Value: !GetAtt CloudFrontDistribution.DomainName




- 投稿日:2019-02-27T18:29:15+09:00
awslogs-agent-setup.pyのオプションについて
CloudWatch Log agentを設定するときにオプションについて探すことになったのでメモ
Metricsを使う気がなかったので統合バージョンでない以前のバージョンのCloud watch log agentです。
対話形式でも設定できます。ただし、対話形式だとたくさん設定するときは面倒です。結論
CloudWatch Log用の設定ファイルをあらかじめ作っておきます。
/home/hoge/hogehoge.confsudo python ./awslogs-agent-setup.py -n -r ap-northeast-1 -c /home/hogehoge.confこれでOK。
オプションとインストールについて
参考リンク
- https://qiita.com/morozumi_h/items/a1cb930203ca8e4d1a93
- https://qiita.com/takahashi-kazuki/items/5b3a659c845edf81f2c4
オプション 省略形 説明 --only-generate-config -o configファイルを作成するだけで設定はしない。 --non-interactive -n 対話形式を使わずconfigファイルを読み込んで設定。 --region -r AWSのリージョンの指定。 --configfile -c configファイルのローカルまたはS3またはURLのパスの指定。 --plugin-url -u CloudWatchLogsプラグインのURLの指定。 --python -p Pythonのバージョンの指定。無指定は /usr/bin/pythonにあるバージョンを使用。--http-proxy なし CloudWatch Logsとの通信に用いるhttpプロキシの設定。 --https-proxy なし CloudWatch Logsとの通信に用いるhttpsプロキシの設定。 --no-proxy なし カンマで区切ったプロキシを使用するべきではないドメイン拡張子のリスト。 Configファイルの作り方
例は以下の通り。
/home/hoge/hogehoge.conf[general] state_file = /var/awslogs/state/agent-state [/var/log/access.log] datetime_format = %Y-%m-%d %H:%M:%S file = /var/log/access.log buffer_duration = 5000 log_stream_name = access.log initial_position = start_of_file log_group_name = {instance_id} [/var/log/error.log] datetime_format = %Y-%m-%d %H:%M:%S file = /var/log/error.log buffer_duration = 5000 log_stream_name = error.log initial_position = start_of_file log_group_name = {instance_id}
- 投稿日:2019-02-27T15:42:34+09:00
[AWS]結局AWSの負荷テストに申請がいるのかいらないのか
はじめに
SIer諸氏におかれては、いわゆる総合テストにおいて、
構築したシステムが要件通りの性能が出るかを確認する負荷テスト(性能テスト)を行うことが多いと思う。AWS上に構築したシステムに対する、
侵入テストは申請が必須と明記されているが、
負荷テストについては、「あらゆるイベントは事前申請が必要」派と、「不要」派の記事が出てくる。
結局どっちかわからないので聞いてみた。たいていの人向けの結論
実際に申請してみたところ以下の返答をいただいた。(抜粋)
Customers performing benchmark testing or low bandwidth testing
with expected bandwidth of less than 1Gbps and 1Gb PPS do not need to request approval.ということで、1Gbps、また1Gb PPS以下のリクエストのload or stress testingは、申請不要とのこと。
当然、vulnerability or penetration testingは申請が必須。1Gbps以上の負荷テストをしたい人
あまり無いこととは思うが、1Gbps、また1Gb PPS以上の負荷テストを行いたい人、
侵入テストや脆弱性テストがしたい人は、
以下の制約に留意した上で申請を行う必要があるようだ。
- テスト対象用アカウントとは別に、テスト実行用のアカウントを作成する
- テスト実行用アカウントは、本番用インスタンスを持ってはいけない
- テスト実行用アカウントが、本番用インスタンスを持たない限り、他のテストに流用しても良い
- テスト対象用アカウントは、実行用アカウントと同一の所有者1である必要がある
実際の申請は、aws-security-simulated-event@amazon.comへのメールか、
AWSの侵入テストの申請フォームから申請する。この際に、アカウントIDやターゲットの情報、なぜテストするのか等、いくつかの情報入力が必要になる。
また、依頼をしてメールの返答があるまで数営業日かかり、
状況次第では、より詳細なテスト方法について問い合わせがある。(ありました)Please be aware, network stress test requests must be submitted at least two (2) weeks
in advance of your start date. Requests may take up to 5-7 business day for processing.とある通り、余裕を持った申請が必要になる。
その他
負荷テスト時に、ELB経由で実行する場合は、ELBの暖気申請
CloudFront経由で実行する場合は、CloudFrontの上限緩和やテスト方法
も併せて確認するべき。
AWS Organizationsの一括請求の関係にあるかどうか ↩
- 投稿日:2019-02-27T15:33:48+09:00
【AWS AppSync】HTTPリクエストで配列データを受け取る際のResolverについて
AWS AppSyncのデータソースとしてHTTPリクエストを使ってAPIから配列データを受け取りたいが、どうマッピングすれば良いのか分からずしばらく詰まってしまった時の備忘録。
SchemaとQuery
ECSで動いているAPIへ、userIdをキーにリクエスト投げて、Transactionオブジェクトの配列データを受け取るSchema。
Schematype ListTransactionsResponse { statusCode: Int! transactions: [Transaction] } type Query { listTransactions(userId: String!): ListTransactionsResponse } type Transaction { transactionId: String! transactionDate: String! transactionType: String! }Queryquery listTransactions { listTransactions(userId: "123456"){ statusCode transactions{ transactionId transactionDate transactionType } } }Resolver
アプリ側のレスポンスのbodyにレコードを格納しているので、アプリからのResponseの中身としてはcontext.result.bodyに欲しいデータが格納されている。
response/context"context": { "arguments": { "userId": "123456" }, "result": { "headers": { "Content-Length": "496", "Content-Type": "application/json", "Date": "Wed, 27 Feb 2019 04:59:03 GMT", "x-amz-apigw-id": "VvjbmG6RvHcFrpA=", "x-amzn-RequestId": "66efd625-3a4c-11e9-8292-c1ffb3d8ffa7", "X-Amzn-Trace-Id": "Root=1-5c761917-95fe6e504485a250d04c2da0" }, "statusCode": 200, "body": "{\n \"transactions\": [\n {\n \"transactionId\": 001,\n \"transactionDate\": \"2019-02-26 10:50:44\",\n \"transactionType\": \"入金\"\n },{\n \"transactionId\": 002,\n \"transactionDate\": \"2019-02-26 12:10:12\",\n \"transactionType\": \"送金\"\n },{\n \"transactionId\": 003,\n \"transactionDate\": \"2019-02-26 12:12:34\",\n \"transactionType\": \"送金\"\n }]\n}" }, "stash": {}, "outErrors": [] },例えばDynamoDBをデータソースに指定している場合は、凡そ以下のシンプルなマッピングで問題なかったが、今回はこのままだとQueryへのレスポンスとして正しく受け取れないため、正しいマッピングをしてあげる必要がある。
$util.toJson($ctx.result)Queryへのレスポンスがこうなってしまう{ "data": { "listTransactions": { "statusCode": 200, "transactions": null } } }そこで、Transactionオブジェクト配列が格納されたbody部分をfor文で回しながら1レコードずつマッピングしてあげると、
response_mapping_template#set ($bodyObj = $util.parseJson($context.result.body)) { "statusCode": $context.result.statusCode, "transactions": [ #foreach($transaction in $bodyObj.transactions) { "transactionId" : "$transaction.transactionId", "transactionDate" : "$transaction.transactionDate", "transactionType" : "$transaction.transactionType" } #if($foreach.hasNext),#end #end ] }{ "data": { "listTransactions": { "statusCode": 200, "transactions": [ { "transactionId": "001", "transactionDate" : "2019-02-26 10:50:44", "transactionType" : "入金" }, { "transactionId": "002", "transactionDate" : "2019-02-26 12:10:12", "transactionType" : "送金" }, { "transactionId": "003", "transactionDate" : "2019-02-26 12:12:34", "transactionType" : "送金" } ] } } }上手くいった!
要はレスポンスの中身ちゃんと意識してマッピング考えないとだめですよね、っていうお粗末な話でした。
- 投稿日:2019-02-27T14:16:44+09:00
Serverless FrameworkでGemをLayersに切り出す
環境
- Mac OS X 10.14.3
- Serverless Framework 1.36.1
- Ruby 2.5
はじめに
Serverless FrameworkでRubyを使用する場合にパッケージ容量をもっとも圧迫する
vendor(gemの内包ディレクトリ)を切り出す方法について書きます。こちらの記事を読んで出来るようになること
- Serverless Framework x RubyでGemをLayerに切り出す
- Layersのバージョンアップにも対応可能
Lambda Layersとは
ざっくりと、各Lambda関数で共通化した処理をLambda関数の中に内包するのではなく、外に切り出してしまう仕組みのこと。
1. サンプルアプリケーションの作成
この記事では
serverless frameworkの使い方などは書きません以下のコマンドでサンプルアプリケーションを作成します。
$ sls create -t aws-ruby -p sample上記を実行すると、以下のようなディレクトリが作成されます。
sample/ - serverless.yml - handler.rb2. bundle init & gem install
$ cd sample上記で、sampleディレクトリに移動しておきます。
sampleディレクトリ内で、以下を実行していきます。$ bundle init上記で、
Gemfileが作成されるので、エディタでGemfileを編集していきます。# frozen_string_literal: true source "https://rubygems.org" git_source(:github) {|repo_name| "https://github.com/#{repo_name}" } # 以下を追加 gem "business_time"適当なGemを
Gemfileに追加して、以下を実行します。$ bundle install --path vendor/bundle3. serverless.ymlを編集
service: sample provider: name: aws runtime: ruby2.5 region: ap-northeast-1 role: arn:aws:iam::ロールのarn package: exclude: - vendor/** - Gemfile - Gemfile.lock functions: hello: handler: handler.hello layers: gems: path: vendorこの時点で一度デプロイします。
$ sls deployデプロイを実行すると、layersが作成されるので、再度
serverless.ymlを編集します。同一のserverless.yml内であれば、REFで参照をすることが出来ます。
公式ドキュメントservice: sample provider: name: aws runtime: ruby2.5 region: ap-northeast-1 role: arn:aws:iam::ロールのarn package: exclude: - vendor/** - Gemfile - Gemfile.lock functions: hello: handler: handler.hello layers: - {Ref: GemsLambdaLayer} layers: gems: path: vendor
functionにlayersを追加して、Refで参照させるのですが、この時に参照方法のルールとして、Layer名をTitleCaseで記載し、LambdaLayerを末尾に結合させる必要があります。
今回のLayer名はgemsなので、GemsLambdaLayerとなっています。Layer名が
hogeだったら、HogeLambdaLayerとなるかと思います。これで再度デプロイします。
$ sls deployこれでAWSのLambda関数ページを見ても、まだLayerが反映されません。
どこが問題かと言うと、serverless.ymlには記載する順番を気をつける必要があるようで、以下のように、
functionsより上にlayersを記載する必要があります。上記を修正した
serverless.ymlが以下service: sample provider: name: aws runtime: ruby2.5 region: ap-northeast-1 role: arn:aws:iam::ロールのARN package: exclude: - vendor/** - Gemfile - Gemfile.lock layers: gems: path: vendor functions: hello: handler: handler.hello layers: - {Ref: GemsLambdaLayer}これで再度デプロイすることでLambda関数にLayerが適用されます。
4. Lambda関数でgemを使用する
handler.rbを以下のようにしますrequire 'json' require 'business_time' def hello(event:, context:) puts Date.today.workday? { statusCode: 200, body: JSON.generate('Go Serverless v1.0! Your function executed successfully!') } end
これで、適当にテストを作成し、「テスト」ボタンを押下すると、以下のようなエラーが発生します。
{ "errorMessage": "cannot load such file -- business_time", "errorType": "Init<LoadError>", "stackTrace": [ "/var/lang/lib/ruby/2.5.0/rubygems/core_ext/kernel_require.rb:59:in `require'", "/var/lang/lib/ruby/2.5.0/rubygems/core_ext/kernel_require.rb:59:in `require'", "/var/task/handler.rb:2:in `<top (required)>'", "/var/lang/lib/ruby/2.5.0/rubygems/core_ext/kernel_require.rb:59:in `require'", "/var/lang/lib/ruby/2.5.0/rubygems/core_ext/kernel_require.rb:59:in `require'" ] }
bussiness_timeを参照出来なくなっています。
Lambda Layersを使用する際、格納したファイルやディレクトリは、/optディレクトリに格納される仕様になっています。なので、こちらの対応が必要になります。対応方法は以下の二つです。
* gemの参照先を絶対パスで記述する
* LOAD_PATHを変更する後者で対応することにしました。
以下のように、handler.rbを変更します。load_path = Dir["/opt/bundle/ruby/2.5.0/gems/**/lib"] $LOAD_PATH.unshift(*load_path) require 'json' require 'business_time' def hello(event:, context:) puts Date.today.workday? { statusCode: 200, body: JSON.generate('Go Serverless v1.0! Your function executed successfully!') } endちなみに、
/opt/bundle/ruby/2.5.0/gems/**/libのパスはlayersの作成方法によって変わってしまうため、適宜変更してください。これでテストを実行すると、200が返却され、ログにtrueが返ってくるかと思います。
5. sls invokeを使用出来るようにする
上記までだと、
LOAD_PATHを変更してしまうため、ローカルでsls invokeが使用できなくなってしまうため、対応したいと思います。serverless frameworkの
sls invokeコマンドを実行すると、IS_LOCALという環境変数が作成され、trueがセットされます。※ こちらを参照くださいなので、これをフラグにLambda関数に条件分岐を設定します。
handler.rbを以下のように変更します。if ENV['IS_LOCAL'].nil? load_paths = Dir["/opt/bundle/ruby/2.5.0/gems/**/lib"] $LOAD_PATH.unshift(*load_paths) end require 'json' require 'business_time' def hello(event:, context:) puts Date.today.workday? { statusCode: 200, body: JSON.generate('Go Serverless v1.0! Your function executed successfully!') } endこれで、
sls invokeだった時は、LOAD_PATHが参照されなくなるので、sls invokeが使えるようになるかと思います。
当然この方法だと、関数が増えた時に全てに分岐を加えなければいけないので、対応策としては微妙ですが...もっといい方法があればコメントいただけますと幸いです。

- 投稿日:2019-02-27T10:28:22+09:00
CodePipelineで自動テスト&ビルドして、ECSへBlue/Greenデプロイしてみた
0.はじめに
CI/CDの勉強をする一環で、AWSCodePipelineを使って自動テスト&ビルドして、ECSへのBlue/Greenデプロイさせるまでを試してみたので、やり方を備忘録も兼ねて残しておくものです。
初投稿故、イマイチなところがあってもお許しください。
1.事前準備:アプリケーション & ECSクラスター & ECSタスク定義作成
アプリケーション
アプリ自体はDjangoで作成した、ただのノーマルな感じのAPIなため割愛。
ECSクラスター
こちらも特筆すべき点なしのため割愛。
ECSタスク定義
以下3コンテナイメージの構成で、ecs-cli composeを使ってタスク定義しています。
- balance_app ⇒ 今回デプロイ対象とするアプリケーション用コンテナ
- nginx
- xray-daemon
ecs-compose.yml(ご参考。パラメータファイルは割愛)version: '2' services: balance_app: image: '<AccountId>.dkr.ecr.us-west-2.amazonaws.com/msa_balance_app:latest' mem_limit: 256000000 ports: - '5000:5000' command: ./uwsgi.sh environment: AWS_REGION: us-west-2 AWS_XRAY_DAEMON_ADDRESS: '127.0.0.1:2000' logging: driver: awslogs options: awslogs-group: msa_app awslogs-region: us-west-2 awslogs-stream-prefix: balance_app balance_nginx: image: '<AccountId>.dkr.ecr.us-west-2.amazonaws.com/msa_nginx:latest' mem_limit: 128000000 links: - balance_app ports: - '80:80' command: > /bin/sh -c "envsubst '$$SERVER_NAME' < /etc/nginx/nginx.conf.template > /etc/nginx/nginx.conf && nginx -g 'daemon off;'" environment: SERVER_NAME: localhost logging: driver: awslogs options: awslogs-group: msa_app awslogs-region: us-west-2 awslogs-stream-prefix: balance_nginx aws-xray-daemon: image: 'amazon/aws-xray-daemon' mem_limit: 128000000 ports: - '2000:2000/udp' command: - "/usr/bin/xray" - "--bind" - "0.0.0.0:2000" - "--region" - "us-west-2" - "--buffer-memory" - "64" - "--log-level" - "dev" - "--log-file" - "/dev/stdout" logging: driver: awslogs options: awslogs-group: msa_app awslogs-region: us-west-2 awslogs-stream-prefix: balance_xray-daemonまた、Codeシリーズでテストやビルドやデプロイをするための各定義ファイルも配置して、CodeCommitへgit pushしておきます。
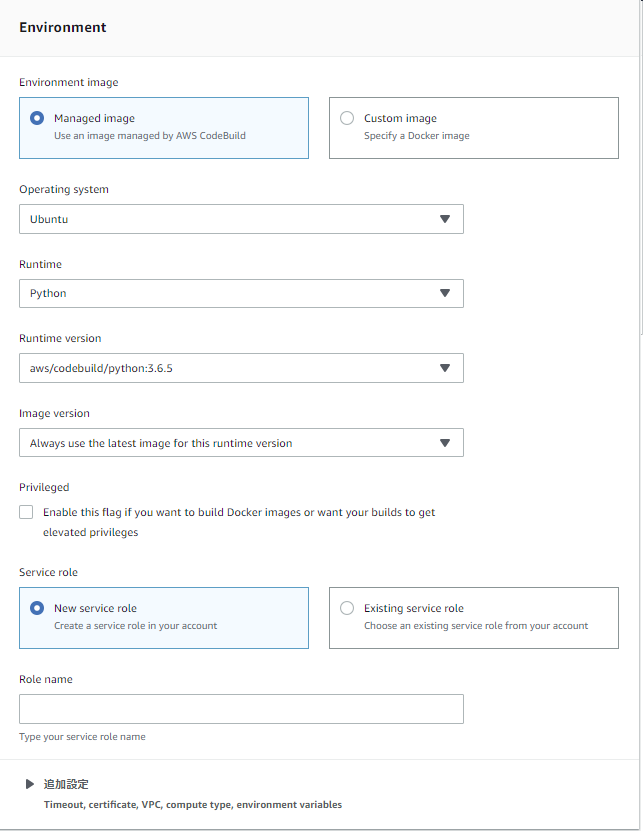
プロジェクト全体のディレクトリ構成project/ ├ .git ├ root/ │ ├ msa_app/ │ ├ balance/ │ ├ manage.py │ └ requirements.txt ├ appspec.yaml ⇒ Blue/Greenデプロイ用 ├ buildspec.yml ⇒ アプリケーション自動ビルド用 ├ Dockerfile ├ taskdef.json ⇒ Blue/Greenデプロイ用 ├ testspec.yml ⇒ アプリケーション自動テスト用 └ uwsgi.sh2.CodeBuildでアプリケーションをテスト
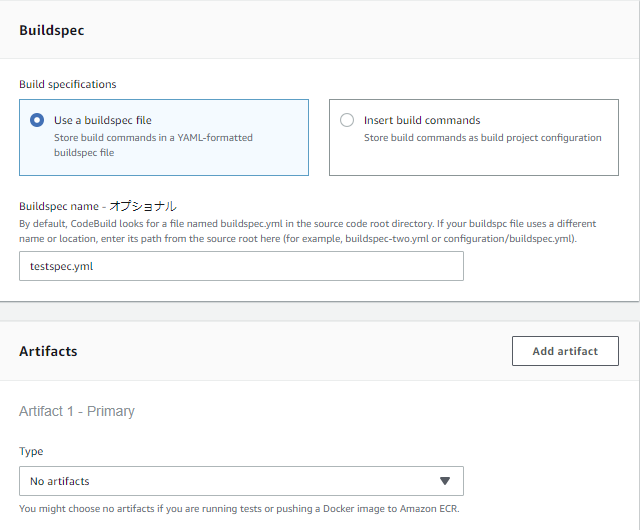
テスト実行用specファイルの作成
まず、リポジトリルート直下に配置したtestspec.ymlをこんな感じで書いて、アプリ稼働に必要なライブラリをpip installした後、テストコードを実行するように定義します。
testspec.ymlversion: 0.2 phases: install: commands: - echo install started - cd root - pip install -r requirements.txt build: commands: - echo test started - python manage.py test --settings msa_app.ci_settingsテスト用のCodeBuildプロジェクト作成
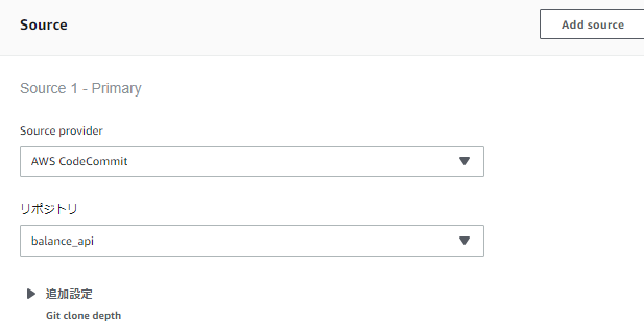
次に、CodeBuildでビルドプロジェクトを作っていきます。
リポジトリはCodeCommitを選択。
UbuntuのPython3.6を選択。
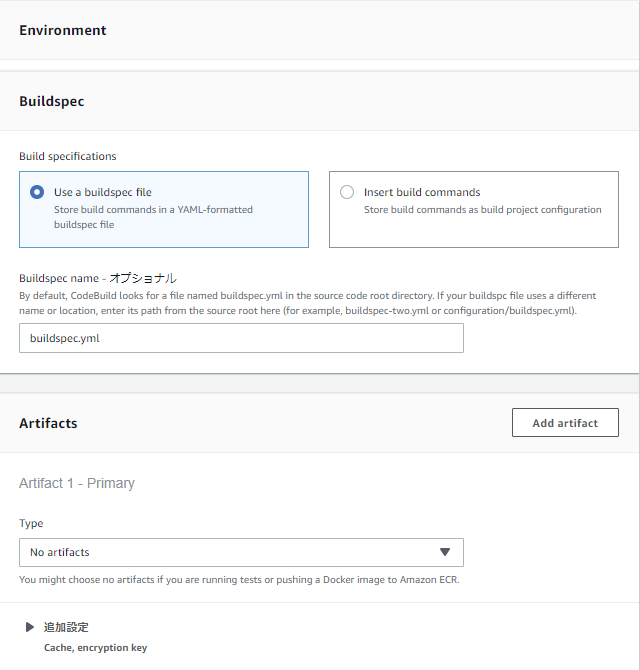
Buildspecには、先ほど作成したtestspec.ymlを指定。
今回はテスト実行時には成果物を何も作らないので、Artifactsは初期値のままでOK。
3.CodeBuildでDcokerイメージをビルド
ビルド実行用specファイルの作成
テスト時と同じように、リポジトリルート直下に配置したbuildspec.ymlをこんな感じに書きます。
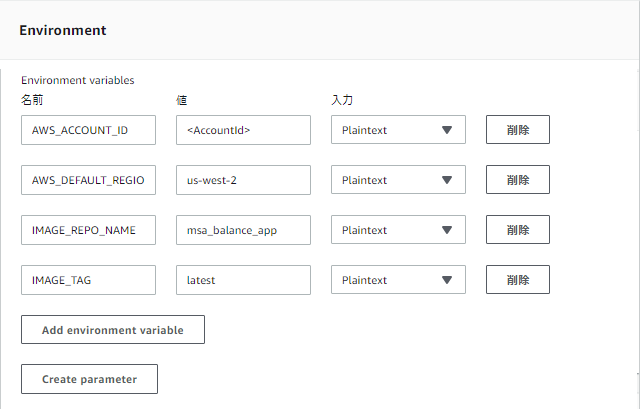
buildspec.ymlversion: 0.2 phases: pre_build: commands: - echo Logging in to Amazon ECR... - $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION) build: commands: - echo Build started on `date` - echo Building the Docker image... - 'docker build -t $IMAGE_REPO_NAME:$IMAGE_TAG .' - >- docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG post_build: commands: - echo Build completed on `date` - echo Pushing the Docker image... - >- docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG - >- printf '[{"name":"balance_app","imageUri":"%s"}]' $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG > artifacts.json artifacts: files: artifacts.jsonbuildステップでdocker buildコマンドによるdockerイメージ作成&タグ付けを行い、
post_buildステップでECRリポジトリへの登録を行っています。なお、Dockerfileはこんな感じで特に変哲もない、
必要ライブラリをpip install後、uwsgiでDjangoアプリを動かすものです。DockerfileFROM python:3.6 RUN groupadd -r uwsgi && useradd -r -g uwsgi uwsgi COPY /root/requirements.txt /requirements.txt RUN pip install -r /requirements.txt COPY /root /app RUN chown -R uwsgi /app COPY uwsgi.sh /uwsgi.sh RUN chmod +x /uwsgi.shDockerイメージビルド用のCodeBuildプロジェクト作成
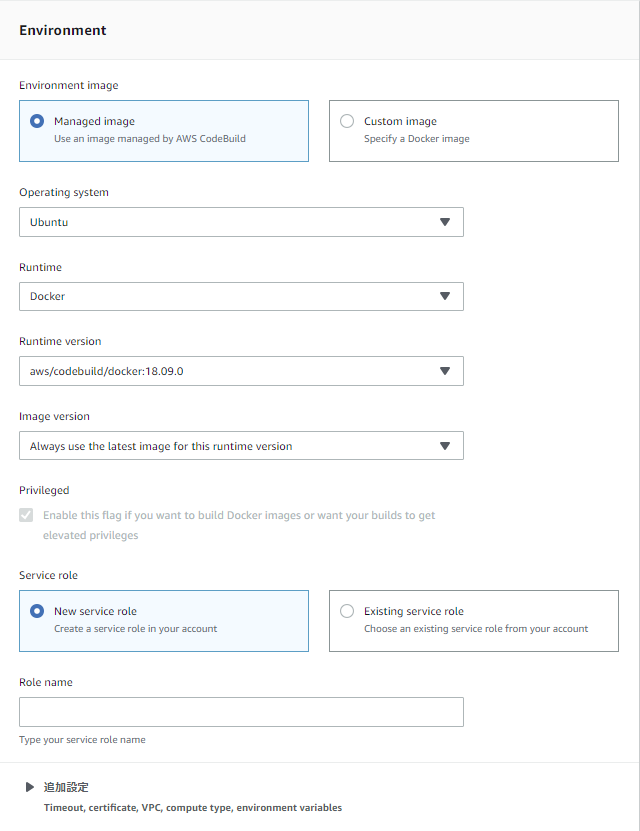
デプロイ用のDockerイメージをビルドする準備ができたので、ビルドプロジェクトを作成していきます。
リポジトリはテスト時と同じくCodeCommitを選択。
今度はDockerイメージを作成するので、ランタイムにDockerを指定。
ビルド時に環境変数からリポジトリ名等を設定するので、環境変数も設定しておきます。
Buildspecには、先ほど作成したbuildspec.ymlを指定。
今回はビルド成果物としてDockerイメージがありますが、ECRへ直接pushしているため、Artifactsは初期値でOK。
これでテスト&ビルド用のプロジェクトがそれぞれ作成できました。
4.CodeDeployでBlue/Greenデプロイ
ここからはデプロイ用のアプリケーション&デプロイグループの作成ですが、こちらはCodeDeployのコンソール画面ではなく、ECSサービスを作成することで自動作成できます。
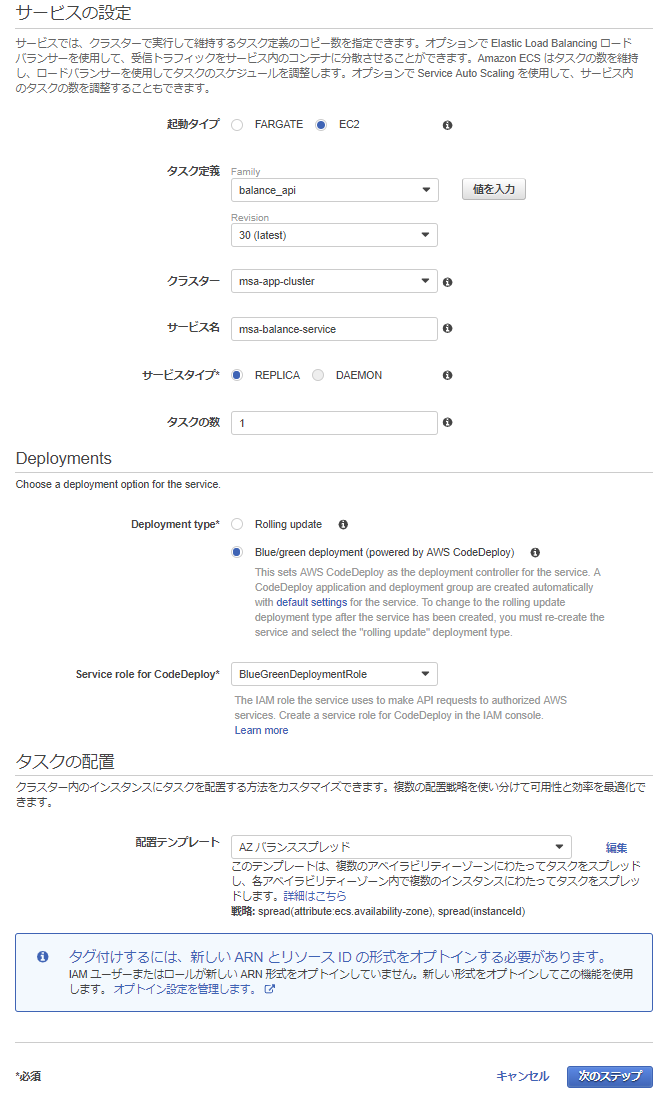
ECSサービスの作成
デプロイ方式としてBlue/greenを選択することで、Blue/Greenデプロイ対応のサービスが作成され、
合わせて自動的にCodeDeploy用のアプリケーション&デプロイグループも作成されます。
なお、Blue/Greenデプロイを選択するには、以下の権限を持ったIAMロールを事前に作成しておく必要があります。
- ポリシーのアタッチ : AWSCodeDeployRoleForECS
- 信頼ポリシー設定
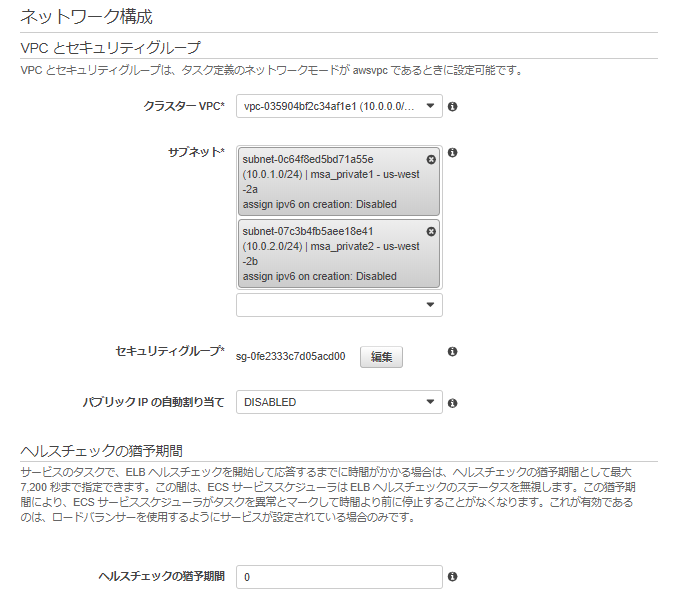
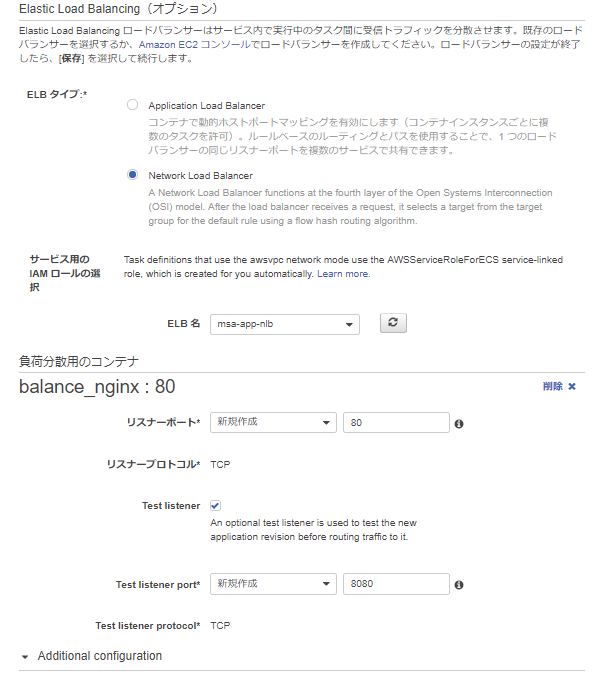
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "codedeploy.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }ネットワークはawsvpcモードでタスク定義しているので、配置するVPCとサブネット、適用するセキュリティグループを選択します。
事前に作成しておいたロードバランサー(今回は後々APIGatewayにVPCリンク張りたかったため、NLBを作成済)を選択し、負荷分散用のコンテナとしてロードバランサーからトラフィックを流す先のコンテナを設定します。(ここで設定したコンテナ名:ポートを、appspec.yamlで設定することになります)次にロードバランサー側のポート設定として、本番トラフィックを受け付けるポートをリスナーポートに、Blue/Greenデプロイ時にテスト用トラフィックを受け付けるポートをテストリスナーポートへ設定します。
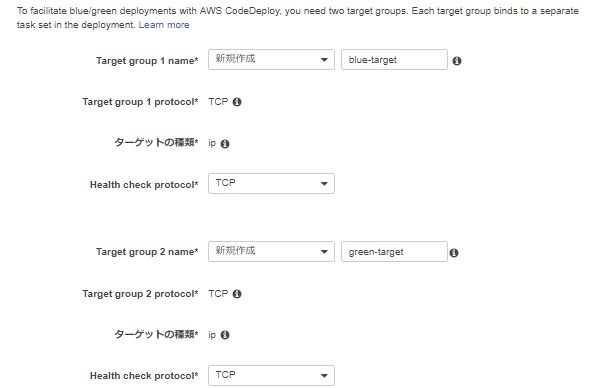
TargetGroupを二つ設定します。(CodeDeployからECSへBlue/Greenデプロイが走った際、ここのターゲットが自動で切り替わることで本番/テスト用トラフィックが入れ替わることになります。)
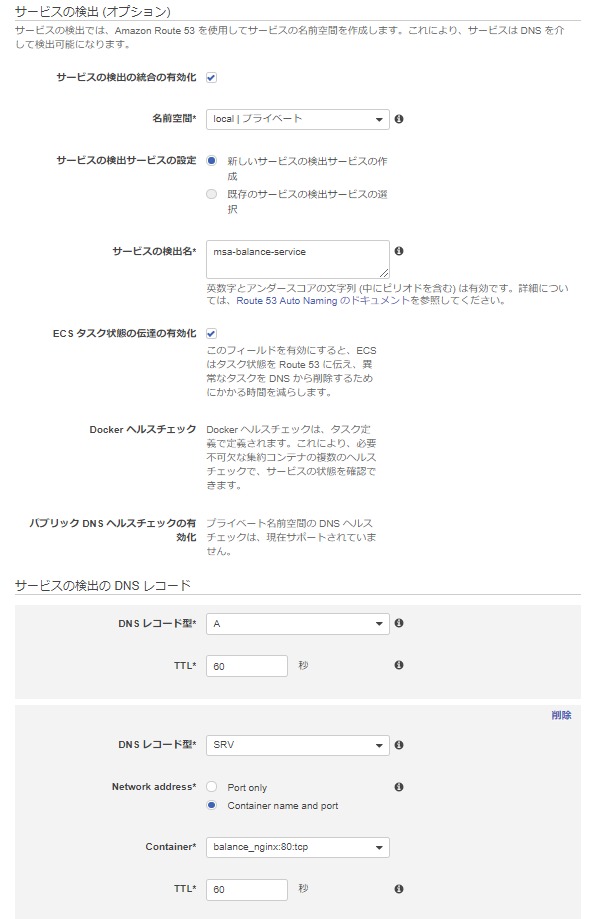
今回は特に必要ないですが、DNSの設定も行っています。
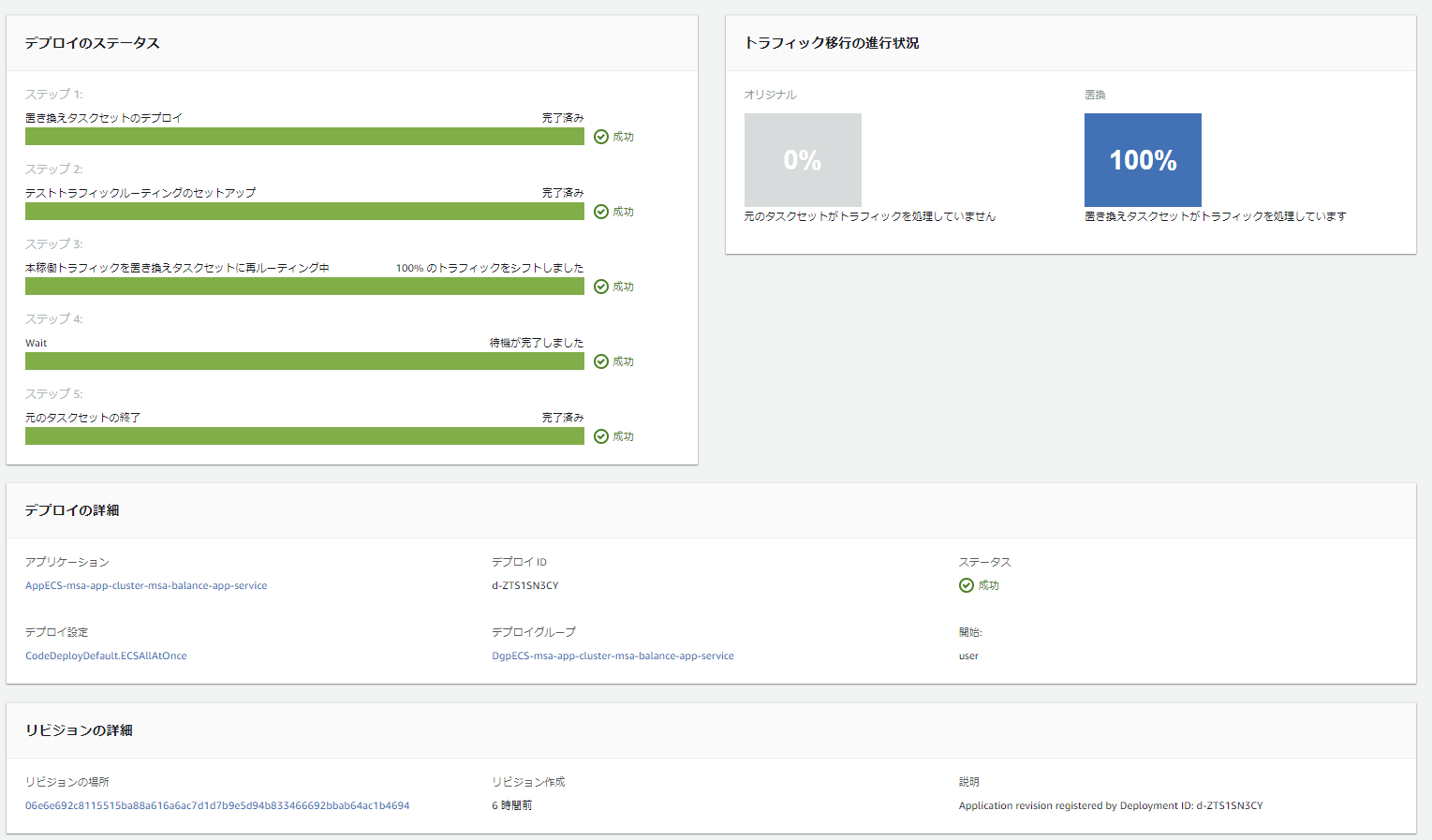
CodeDeployのデプロイ設定修正
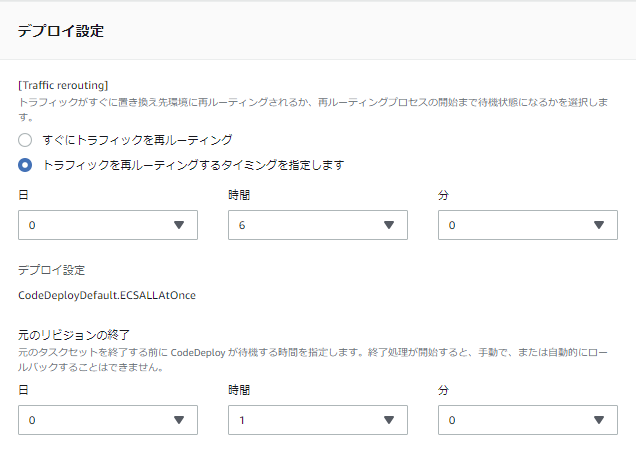
これでECSサービス作成が完了し、CodeDeploy側でもアプリケーション&デプロイグループが自動作成されましたが、デフォルトではデプロイ時に即トラフィックが本番へ切り替わる設定になっているため、せっかくのBlue/Greenデプロイの利点が活かせません。
そこで、本番への切り替え前にテスト用トラフィックで検証できるよう、CodeDeployのコンソール画面から設定を修正します。下記の設定ではデプロイ後の6時間はトラフィックが切り替わらず、テスト用ポート8080を使っての検証が可能となります。
6時間以内に検証を終え、リリース可能となった場合にはCodeDeployコンソール上から手動で再ルーティングすることで、本番トラフィックへの切り替えが行われます。
一方、6時間以内に検証が終わらずに手動で再ルーティングボタンできなかった場合には、Deploy失敗と見なされてその時点でDeploy処理が中断されます。
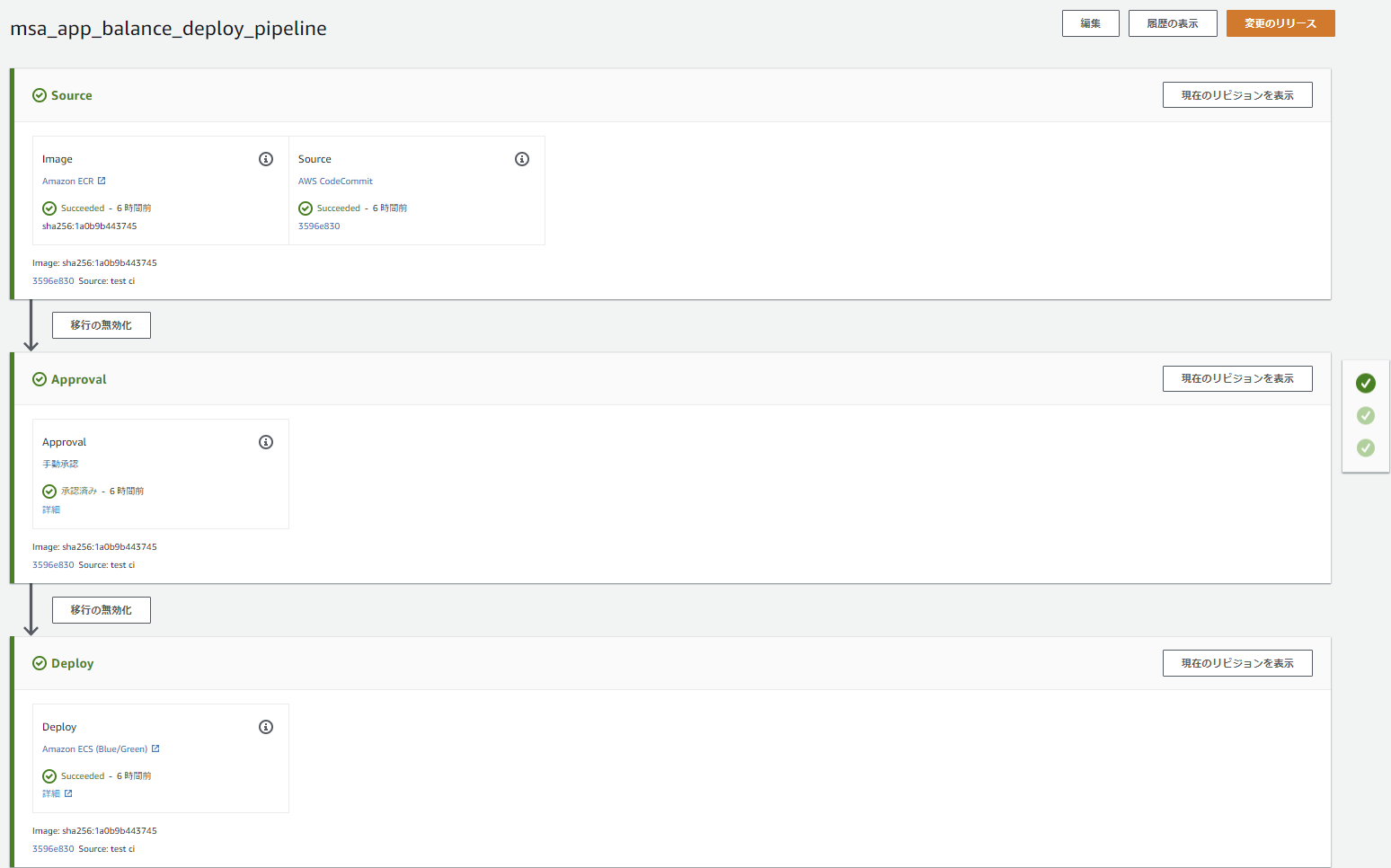
5.CodePipelineでテスト&ビルド&デプロイを自動化
最後に、CodePipelineで全部繋げていきます。
なお、本当は1本のPipelineで繋げようとしたのですが、Deployステージでのコンテナイメージ名取得がうまいこといかず、テスト~ビルド&デプロイの二本立てになってます。
(BuildステージからDeployステージへのイメージ名の受け渡しがうまくできなかった...)テスト~ビルド
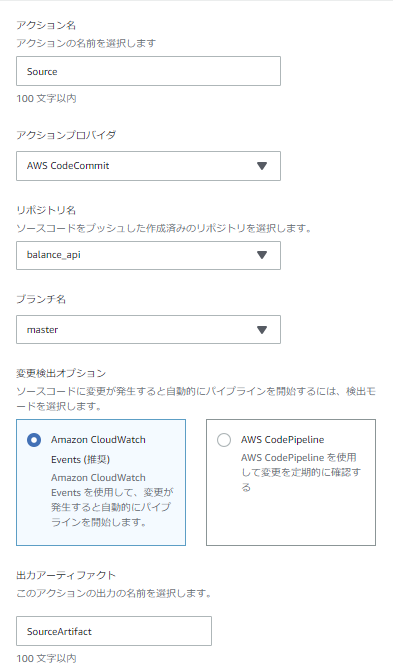
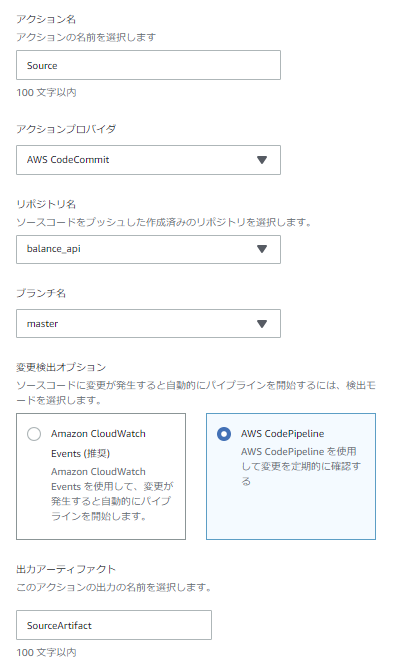
①Sourceステージ
リポジトリへのpushをトリガーにPipeline起動させるためにCloudWatch Eventsで変更検出を行い、リポジトリに格納されているソースコードを後続のTestステージ&Buildステージで使用するためにSourceArtifactを出力します。
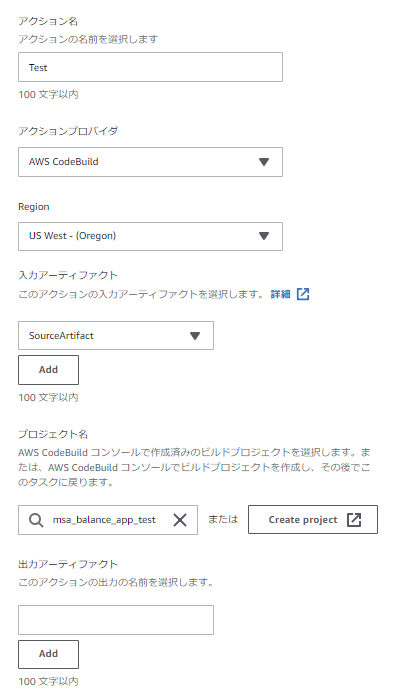
②Testステージ
入力アーティファクトにはSourceステージの出力を指定、プロジェクト名には事前作成済のテスト用ビルドプロジェクトを指定します。
出力成果物はないので、出力アーティファクトは空欄でOK。
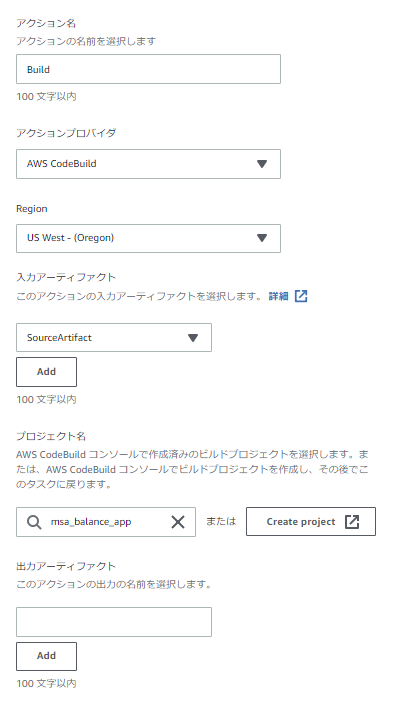
③Buildステージ
テスト同様、入力アーティファクトにはSourceステージの出力を指定、プロジェクト名には事前作成済のビルド用ビルドプロジェクトを指定します。
ここも出力アーティファクトは空欄でOKです。
ここまでで、テスト~ビルドを行うPipelineの完成です。
デプロイ
次に、デプロイ用のPipeline作成です。
Deployステージの入力ファイルとしてappspec&taskdef.jsonが必要となるため、事前に作成しておきます。
appspec.yamlversion: 0.0 Resources: - TargetService: Type: AWS::ECS::Service Properties: TaskDefinition: <TASK_DEFINITION> LoadBalancerInfo: ContainerName: "balance_nginx" ContainerPort: 80TaskDefinition部分はCodeDeployが良しなに変換してくれるので、上記の記載でOK。
ContainerName&Portはロードバランサーからトラフィックを流す先のものを設定します。(ECSサービス作成時に負荷分散用に選択したコンテナ名:ポート)
今回はポート80のnginxコンテナ経由でアプリケーションコンテナへトラフィックを流すので、上記の設定としています。taskdef.json{ "executionRoleArn": null, "containerDefinitions": [ 略 "image": "<IMAGE1_NAME>", "name": "balance_app" 略 },タスク定義は長いので省略しますが、ポイントはデプロイするアプリケーション用コンテナのimageを上記の記載とする点で、ここをCodeDeployが良しなにイメージURIを変換してくれます。
その他は事前に作成したタスク定義のJson定義をECSコンソールから引っ張ってきて作るのでOKです。①Sourceステージ
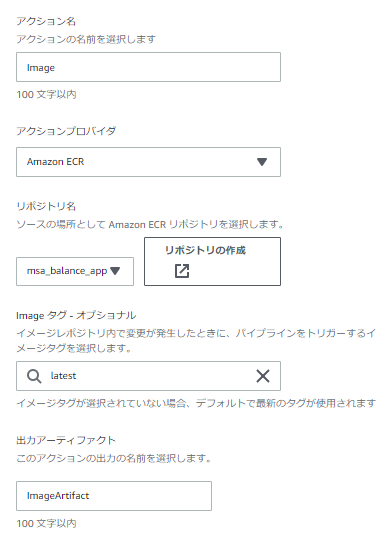
インプットになるSourceとして、ECRのDockerイメージとCodeCommitのソースリポジトリを指定します。
イメージ
デプロイ対象のイメージを指定。
出力アーティファクトは後続のDeployステージにて、イメージ名の取得に使用されます。
ソース
ビルド時と同様にCodeCommitのソースリポジトリを指定しますが、Deploy用Pipelineはソースのpush時ではなくBuild用Pipelineの完了後に実行させたいので、変更検出オプションにCloudWatchEventsは選択しません。
出力アーティファクトは後続のDeployステージにて、appspec.yamlとtaskdef.jsonを入力ファイルとするために使用されます。
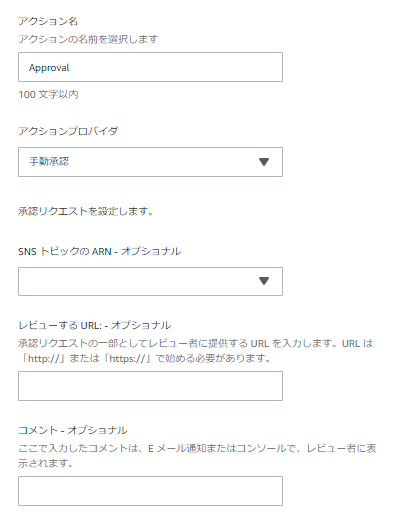
②Approvalステージ
一応、デプロイ前の手動承認も加えておきます。
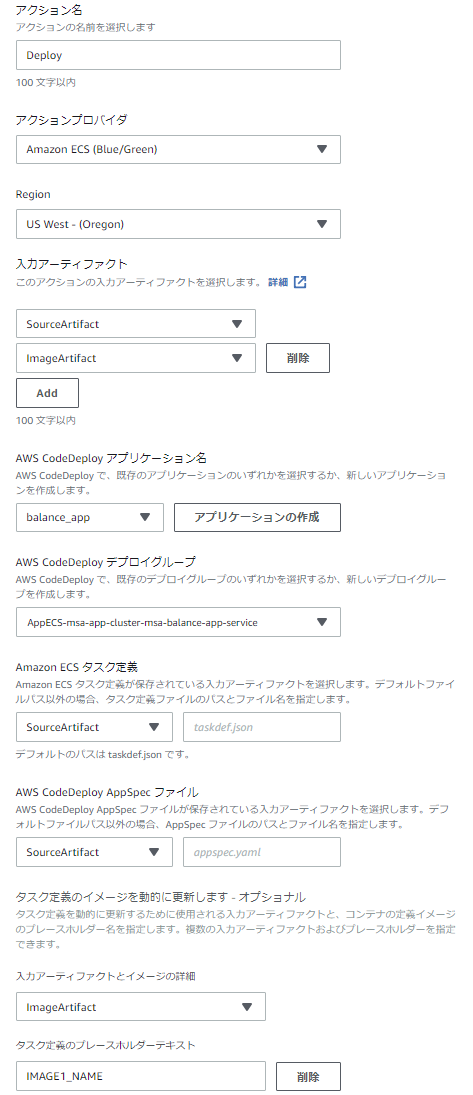
③Deployステージ
最後にデプロイステージです。
●アクションプロバイダ ⇒ ECSへのBlue/Greenデプロイを選択
●入力アーティファクト ⇒ Sourceステージで出力したSource&ImageArtifactを指定
●CodeDeployアプリケーション&デプロイグループ ⇒ ECSで自動作成されたものがリストに出てくるので選択
●ECSタスク定義 ⇒ ソースリポジトリから持ってきたtaskdef.jsonを指定
●AppSpecファイル ⇒ ソースリポジトリから持ってきたappspec.yamlを指定
●入力アーティファクトとイメージ詳細
⇒ Sourceステージで出力したImageArtifactを選択し、プレースホルダテキストにはIMAGE1_NAMEを指定。
ここの指定により、appspec.yaml内でIMAGE1_NAMEと指定した部分がイメージURIに置き換わります。
以上でデプロイ用のPipeline作成も完了です。
6.Pipelineを実行
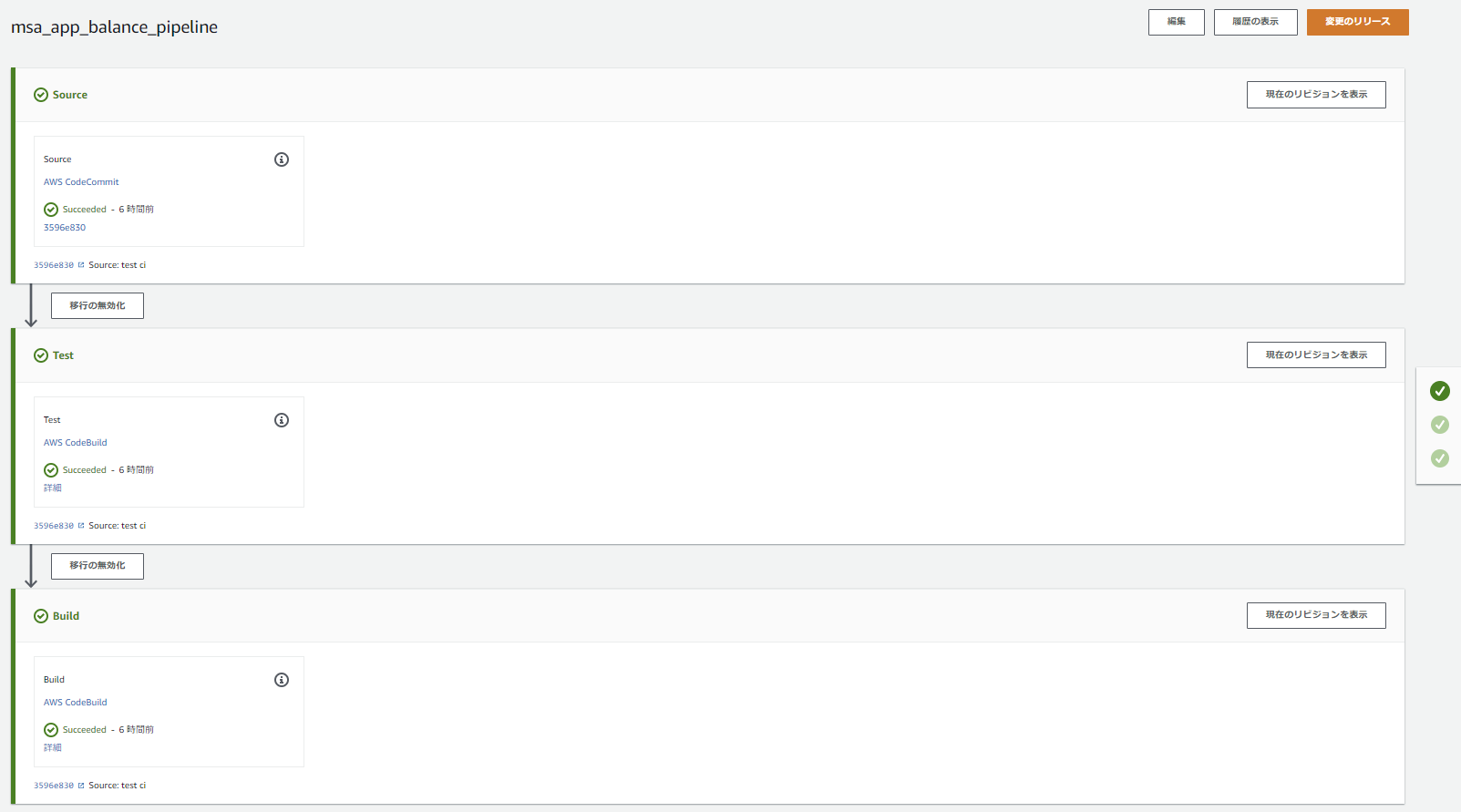
これで、ソースリポジトリへgit pushするとPipelineが実行され、テスト&ビルド&デプロイが自動実行されます。
ちなみにPipelineが2本に分かれていますが、1本目のBuildステージでECRへのpushが行われたことをトリガーに2本目のPipelineも動き出すようです。(ECRリポジトリをSourceに指定しているとそうなる仕様...?)
無事、テスト&ビルドが自動実行され、Blue/Greenデプロイできました。
7.最後に
各specファイルの作成やらいろいろ悩んだ(詰まった)ところはありましたが、手順としては割とシンプルにできるあたりマネージドサービス群の威力を感じました。
ただ、まだまだ分からないことが多いので引き続き勉強頑張ります。
間違っている点等々が多々あるかと思いますので、ご指摘いただけると幸いです。
- 投稿日:2019-02-27T09:58:42+09:00
サードパーティーで発行された証明書をACMに再インポートするときに注意する事(CloudFront利用時)
結論
この辺を注意です。
- リージョンを確認する
- 反映時間が思ったより長い
リージョンを確認する
Amazon CloudFront で証明書を利用する場合は、リージョンを要チェック。
東京リージョンは対応していないので、バージニア北部を利用する必要があります。
AWS Certificate Manager への証明書のインポートAmazon CloudFront で証明書を使用するには、米国東部(バージニア北部) リージョンに証明書をインポートする必要があります。
反映時間が思ったより長い
約12時間ほどかかりました。
設定は間違っていないと思いつつ、実反映までの時間が長いと不安でしたが、
結局約12時間で反映しました。(心臓に悪い。)
その間、設定を見直したり、公式サイト読んだりしていました。環境により反映時間は変わると思いますが、基本的に余裕を持って作業されることをお勧めします。
反映されたか?の確認方法
Chromeで確認できます。
Global Signさんが記事にしてたのでご確認ください。
SSL証明書の内容と確認する方法感想
メモを残しておかないと次回も不安の12時間を過ごしそうなので、記事にしました。
- 投稿日:2019-02-27T00:06:55+09:00
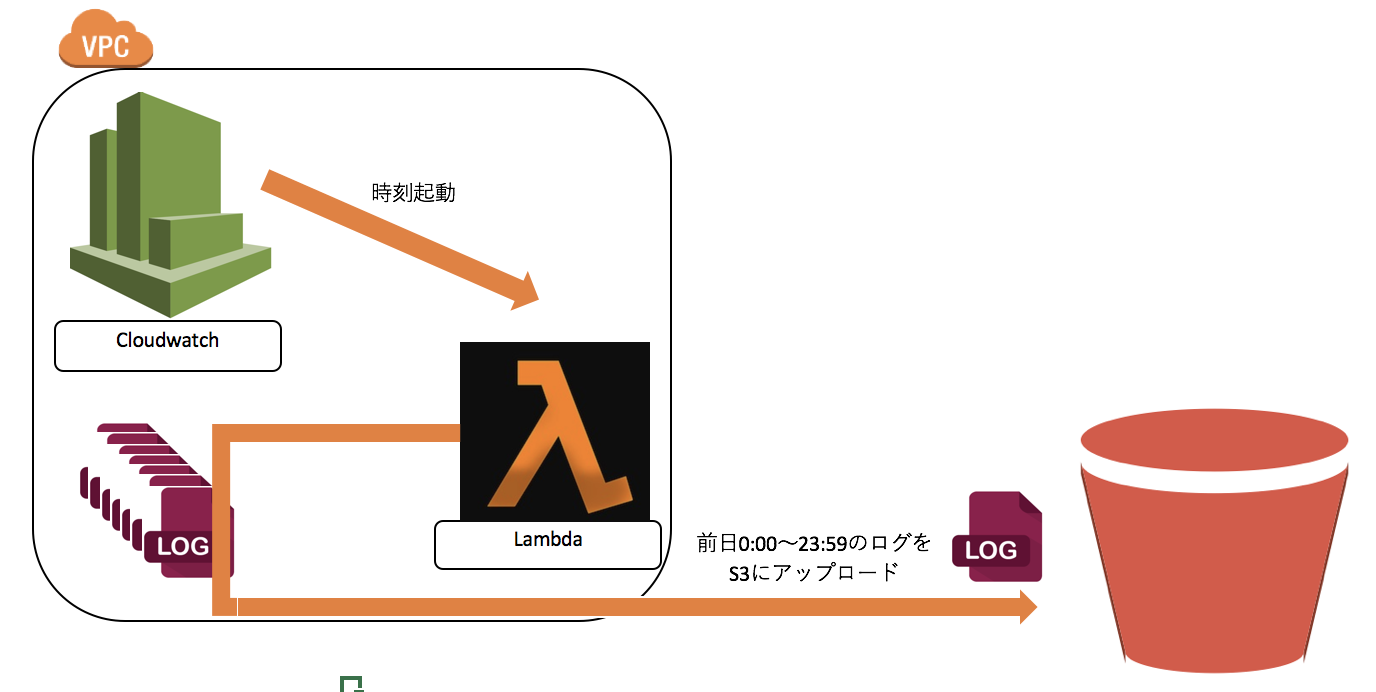
CloudWatchLogsをLambdaで自動的にS3へアップロードする1つの仕掛け
あなたはCloudWatchで収集したログを放置していないだろうか?
データは活用しないと意味がない。
ログはS3に集約しよう。
そうしてこそ、分析に活かせたり、運用も一元化できたり、、
何より注目したいのは保管料金だ。
より安価なアーカイブサービスのGlacierの保管も視野に入る。■CloudWatchの保管料金
0.033 USD/GB■S3の保管料金
0.025 USD/GB■Glacierの保管料金
0.005 USD/GB賢いあなたは1GBにつき、約3円の無駄金を許せないはずだ。
【要件】
毎日0時にLambda関数が起動し、CloudWatchロググループ「cloudwatch-logs-messages」の
前日0:00〜23:59のログをS3のバケット「mys3bucketname/test_prifix」にアップロードするでは、設定していこう。
(というかAWSさん、そろそろこういう機能リリースしてくれないかなー)S3の設定
保存先のS3バケットにバケットポリシーを付与する
以下を自分の環境に置き換える
- バケット名(以下の例ではmys3bucketnameとしている){ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "logs.ap-northeast-1.amazonaws.com" }, "Action": "s3:GetBucketAcl", "Resource": "arn:aws:s3:::mys3bucketname" }, { "Effect": "Allow", "Principal": { "Service": "logs.ap-northeast-1.amazonaws.com" }, "Action": "s3:PutObject", "Resource": "arn:aws:s3:::mys3bucketname/*", "Condition": { "StringEquals": { "s3:x-amz-acl": "bucket-owner-full-control" } } } ] }Lambdaの作成
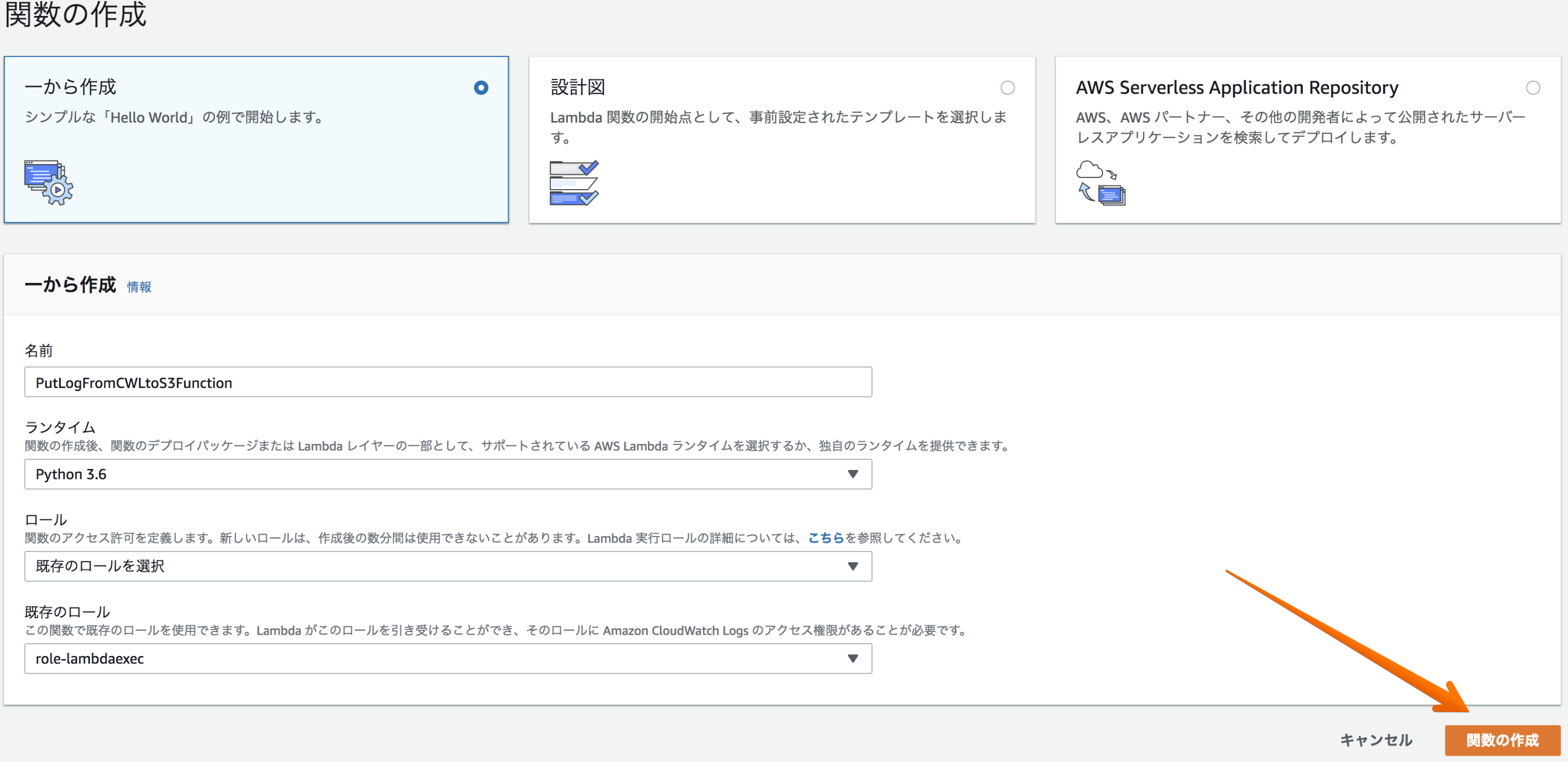
python3.6でLambda関数を一から作成する。
(ロールにはCloudWatchLogsの権限とS3の書き込み権限を付与して下さい)
Lambda関数を作成する。
以下を自分の環境に置き換える
- Lambda関数名
- 保存先S3バケット名
- 取得するCloudWatchロググループ名
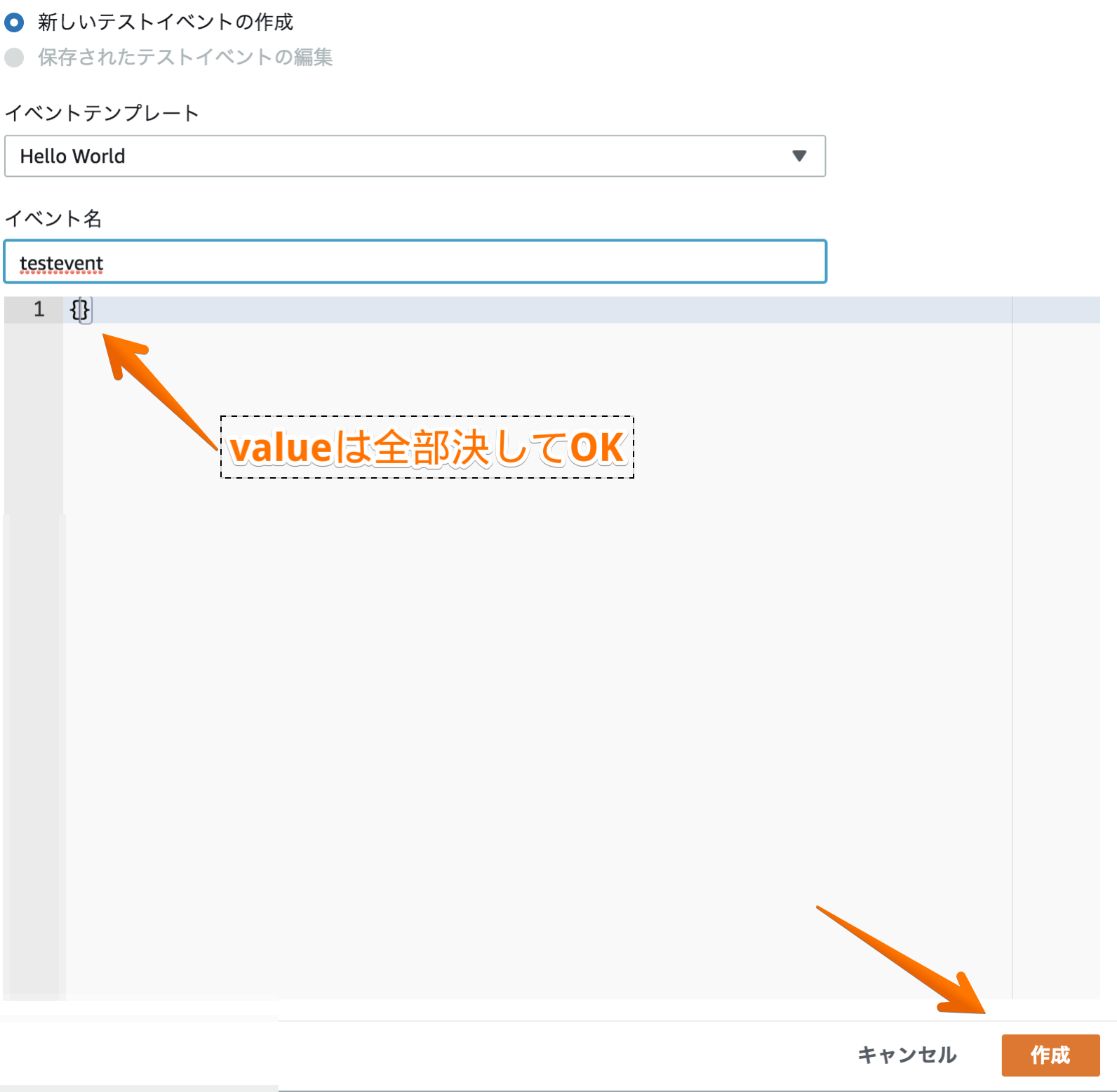
- 保存先S3バケット名配下の任意のプリフィックス名(任意の名前で構わない)lambda_function.pyimport datetime import time import boto3 lambda_name = 'PutLogFromCWLtoS3Function' #Lambda関数名 log_group_name = '/aws/lambda/' + lambda_name s3_bucket_name = 'mys3bucketname' #保存先S3バケット名 s3_prefix = lambda_name + '/%s' % (datetime.date.today() - datetime.timedelta(days = 1)) def get_from_timestamp(): today = datetime.date.today() yesterday = datetime.datetime.combine(today - datetime.timedelta(days = 1), datetime.time(0, 0, 0)) timestamp = time.mktime(yesterday.timetuple()) return int(timestamp) def get_to_timestamp(from_ts): return from_ts + (60 * 60 * 24) - 1 def lambda_handler(event, context): from_ts = get_from_timestamp() to_ts = get_to_timestamp(from_ts) print('Timestamp: from_ts %s, to_ts %s' % (from_ts, to_ts)) client = boto3.client('logs') response = client.create_export_task( logGroupName = 'cloudwatch-logs-messages', #取得するCloudWatchロググループ名 fromTime = from_ts * 1000, to = to_ts * 1000, destination = 'mys3bucketname', #保存先S3バケット名 destinationPrefix = 'test_prifix' #保存先S3バケット名配下の任意のサブフォルダ名(プリフィックス名) ) return responseLambda関数のテストは以下の形で「作成」を押下してOK
この関数をCloudWatchイベントに登録し、毎日0:00に起動するようにすればOK
(時刻はUTC基準なので気をつける。)UTC + 9時間 = JST
0 15 * * ? *CloudWatchイベントの登録方法は以下の記事を参照してみて欲しい。
朝7時にCloudWatchイベントからLambdaを介しAmazon Connectのコールスクリプトを発動し、
バーチャル彼女(女性の機会音声)に事前登録したスクリプトを読み上げさせるモーニングコールを
サーバーレスで設計したものだ。AWSバーチャル彼女から毎朝モーニングコールで起こしてもらう1つのアーキテクト
おわりに
・バケット名、プリフィクス名をパラメーターで渡せば多数のロググループも対応可能と思われる。
・日次ではなく、1週間ごとにまとめてアップロードも可能。時間がかかりそうな際はLambdaの実行時間制約に気をつけて(デフォルト3秒となっているので、1分とかに延ばすこと)ありがとうございました。
少しでもお役にたちましたら「いいね」をよろしくお願いします。