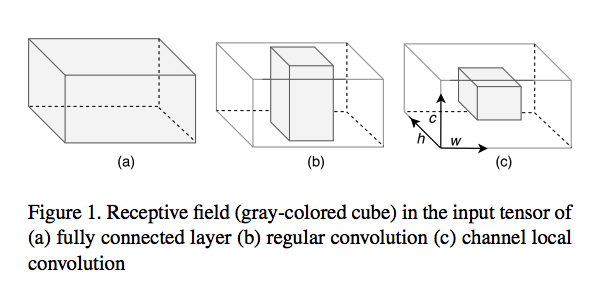
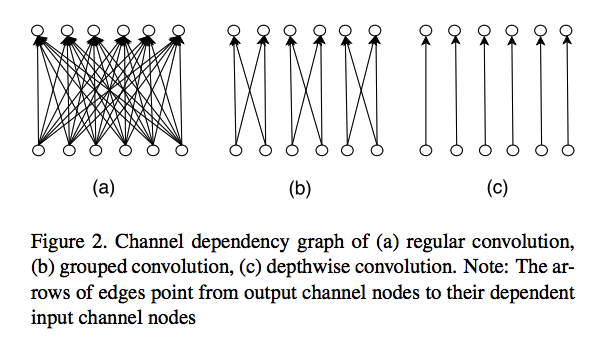
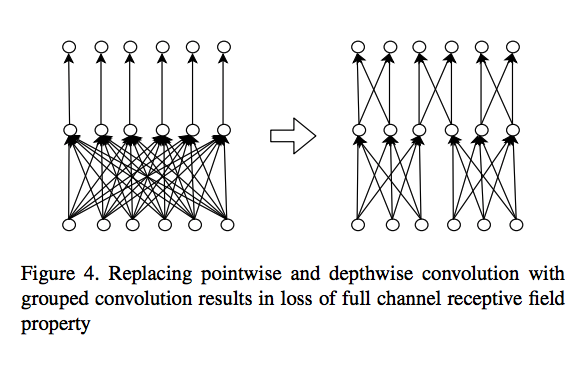
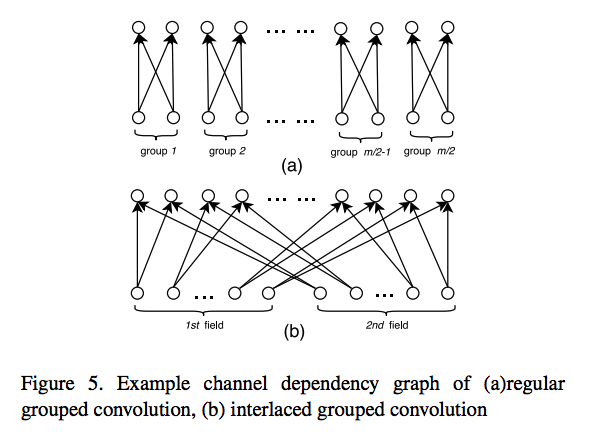
On the iterative refinement of densely connected representation levels for semantic segmentation
最新のsemantic segmentation手法ではCNNの受容体を大きくさせるために
ダウンサンプリングを行ったり、dilated convolutionを採用するなどしてきた。
しかしながら、どちらの手法がより性能向上に寄与しているのかは分かっていなかった。
本論では、その比較を通して新たなネットワークであるFully Convolutional DenseResNet (FC-DRN)
を提案する。
FC-DRNはResNetで構成されるdensely connectedなネットワークをバックボーンに持つ。
またその合間には受容体拡張を行う層は挟まれている。
この組み合わせにより、マルチスケール特徴表現とresidual構造によるgradient flowが
同時に実現できる。
このモデルに基づいて実験を行った所以下の事がわかった:
1.モデルをfrom scratchで学習させた場合、ダウンサンプリングがdilationの利用よりも高性能を実現できる。
2.finetuneで学習させる場合、dilationを利用する方が高性能を実現できる。
3.よりcoarceな特徴表現を利用する場合、後段のrefinementステップは多くは必要とならない。
4.ResNetは正則化機構として効果的である。
How Does Batch Normalization Help Optimization? (No, It Is Not Abbout Internal Covariate Shift)
Batch Normalization (BN)は高速で頑健なDNN学習を実現するために汎用的に利用される。
しかし未だその効果の理由については完全に理解がされていない。
一般的に言われている説明は、層のパラメータ変化に影響され後段の特徴分布が
変化してしまうinternal covariance shiftの影響を低減できるため、というものである。
本論では、BNはそうしたinternal covariance shiftの低減への寄与が小さい事を示す。
代わりに、BNは最適化したい空間の構造を有意にスムーズにする事ができるからである事を示す。
このスムーズ性が、学習時のgradientを安定化させ、学習を高速化できる。