- 投稿日:2019-02-15T23:53:10+09:00
React製WebアプリのAWSへのdeploy scriptを作った試行錯誤の過程
システム構成図
システム構成
- ReactのソースコードはS3 Backetにアップロード
- BacketはCloudFrontを経由して公開する
- ステージング環境と本番環境がある
やりたいこと
残念ながらCIは導入されていないので、手動でデプロイする必要がある
ステージング環境と本番環境へのデプロイをできるだけ簡素化したい
これまで手動でやってたこと
- APIの向き先を変更して
npm run build- 該当S3バケットにbuildしたファイルをアップロード
- CloudFrontのキャッシュを無効化
- これをproductionとstaging で実施
ひとつずつスクリプト化していく!
これまで手動でやってたこと
- APIの向き先を変更して
npm run build- 該当S3バケットにbuildしたファイルをアップロード
- CloudFrontのキャッシュを無効化
- これをproductionとstaging で実施
Reactのbuild時に.envファイルを切り替える
- npm-scriptsにprebuildを定義して、そこで.envファイルを差し替え
- で、postbuildで元に戻す
まぁ 動いた
env-cmd
あとで公式ドキュメント見てたら、そのものズバリの記載があった
Deployment · Create React App
Customizing Environment Variables for Arbitrary Build Environments
(任意のビルド環境用の環境変数のカスタマイズ)For example, to create a build environment for a staging environment:
どう使う?
package.json{ "scripts": { "build": "react-scripts build", "build:staging": "env-cmd .env.staging npm run build" } }
これまで手動でやってたこと
- APIの向き先を変更して
npm run build- 該当S3バケットにbuildしたファイルをアップロード
- CloudFrontのキャッシュを無効化
- これをproductionとstaging で実施
Amazon S3へのファイルのアップロード
- AWS SDKでアップロード
async function putFile(sourceFile) { // S3にputするファイル名 const dir = process.env.DIRECTORY ? `${process.env.DIRECTORY}/` : ''; const key = sourceFile.replace('build/', dir); // ファイルの内容を取得 const data = await fs.readFile(sourceFile); const params = { Bucket: process.env.BUCKET, Key: key, Body: data, ContentType: mime.lookup(sourceFile), }; await s3.putObject(params).promise(); debug(`putObject: ${key}`); }
これまで手動でやってたこと
- APIの向き先を変更して
npm run build- 該当S3バケットにbuildしたファイルをアップロード
- CloudFrontのキャッシュを無効化
- これをproductionとstaging で実施
CloudFrontのキャッシュ無効化
deploy.jsconst cloudFront = new aws.CloudFront(); await cloudFront.createInvalidation({ DistributionId: process.env.DistributionId, InvalidationBatch: { CallerReference: uuid(), Paths: { Quantity: 1, Items: ['/*'], } } }).promise();
これまで手動でやってたこと
- APIの向き先を変更して
npm run build- 該当S3バケットにbuildしたファイルをアップロード
- CloudFrontのキャッシュを無効化
- これをproductionとstaging で実施
環境変数をいい感じに切り替える
dotenv
Dotenv is a zero-dependency module that loads environment variables from a .env file into process.env.
.env.productionと.env.stagingをnpm-scriptsで呼び分ける
どう使う?
deploy.js// 環境変数TARGETを元に読み込むファイルを切り替え const target = process.env.TARGET || 'production'; require('dotenv').config({ path: `${process.cwd()}/.env.${target}`, });package.json{ "scripts": { "deploy": "node scripts/deploy.js", "deploy:staging": "TARGET=staging npm run deploy" } }
まとめ
ec2のWebAPI更新が手動なので、これもnpm-scriptsから更新がキックできたらいいな

- 投稿日:2019-02-15T23:05:10+09:00
ReduxなしでReduxっぽいことをやるのを快適にするためのライブラリを作った
概要
mizchiさんの実践:React Hooksなどにあるように
useReducerとuseContextをつかうことでReduxなしでReduxみたいなことができます。小さな個人開発ではよく使えそうなテクニックだと思ったので、快適にそれを行うためのライブラリ、reducer-context-hookを勉強がてら作ってみました。
APIはfacebookincubator/redux-react-hookを
パクり参考にしました。リポジトリ: https://github.com/sosukesuzuki/reducer-context-hook
API
create()
exportされているのは
createという関数だけです。StoreContextProvidr、useDispatch、useMappedStateを持つオブジェクトを返す関数です。引数はありませんが、型引数としてStateとActionの型を渡します(デフォルトだとany)。返り値のオブジェクトに含まれる3つをそのままexportせずにcreateをexportさせたのは単純に型引数を渡したかったという理由です。import create from "reducer-context-hook"; const { StoreContextProvider, useDispatch, useMappedState } = create< State, Action >();StoreContextProvider
createの返り値のうちの1つです。propsとしてreducerと初期ステートを受け取ります。内部的にはそのままContextオブジェクトのProviderになっているのでコンポーネントツリーのルートあたりで囲んであげましょう。function reducer(state: State, action: Action): State { switch (action.type) { case "increment": return { count: state.count + 1 }; case "decrement": return { count: state.count - 1 }; case "reset": return { count: 0 }; default: throw new Error(); } } const initialState: State = { count: 0 }; function App() { return ( <StoreContextProvider reducer={reducer} initialState={initialState}> <App /> </StoreContextProvider> ); }useDispatch()
とてもシンプルなHookで、
dispatchを返します。Actionを作って使いましょう。あと、Reduxを使わないといいましたが、ReduxのbindActionCreatorsはここで使えますね。(同様にcombineReducersもreducer定義で使えそう)function Increment() { const dispatch = useDispatch(); const increment = React.useCallback( () => dispatch({ type: "increment" }), [] ); return <button onClick={increment}>+</button>; }useMappedState(mapState, memoizationArray)
react-reduxで言うところのconnect(State限定)にあたります。Stateを引数にとってほしい値を返す関数(mapState関数)と、メモ化のためのキーを配列として引数にとります。内部では
useCallbackを使ってメモ化しています。function Counter() { const { count } = useMappedState( state => ({ count: state.count }), [] ); return <p>{count}</p>; }感想
あ、まだnpmにpublishしてません。テスト書き終わったらpublishします。
Custom Hooksを書くのってとても楽しいです。これからも色々書いていきたいと思います。
- 投稿日:2019-02-15T15:53:21+09:00
きっかけは「指ぱっちん」
きっかけは「指ぱっちん」
指ぱっちんでITらしいことをしてみようということで、
指ぱっちん をきっかけに ブラウザ を制御して Youtube動画 を開いてみようという話になりました。指ぱっちんをしてブラウザを制御する方法には、Python 。
Youtube動画のブラウザ上の制御には、React を使ってみることにしました。
Python について
音声認識が簡単にできる言語はあるか、ライブラリはあるかをチームで話し合った結果
Pythonで使用できるPyAudioというライブラリを使うことになりました。環境構築
PyAudioを利用するためPythonの実行環境が必要です。
そこで、PCにLinuxOS(ubuntu)を入れてLinux上で環境構築することにしました。
ubuntuのバージョンは16.04
pythonのバージョンは3.5です。
pythonはubuntuにプリインストールされているものです。以下のコマンドでPyAudioがインストールされます。
$sudo apt install python-pyaudioまた、以下のプログラムでdataに音データが格納されます。
録音サンプル.py#インポート import pyaudio #puaudioオブジェクトの生成 p = pyaudio.PyAudio() #一定時間録音して結果をstreamに格納 #引数は他ウェブサイトを参照 #ストリームの準備 stream = p.open(format=pyaudio.paInt16, channels=1, rate=44100, input=True, frames_per_buffer=1024) #録音 data = stream.read(CHUNK) #録音結果はバイトコードなので変換をかけて-1~1の数値の配列に #numpyが入ってなければインストールして import numpy as np data=np.frombuffer(data, dtype="int16")/32768
React について
Reactとは、インタラクティブなユーザーインタフェースを作成できるJavaScript library
環境構築
1.WindowsマシンにNode.js の最新バージョンインストール。
2.Reactをインストール>npm install react --save3.以下のコマンドでプロジェクト作成
>npx create-react-app my-app4.ReactPlayerをインストール
>npm install react-player --save
実装について(React編)
React側は、表示されるページを生成します。
1.インストールされた領域のsrcフォルダ配下でスクリプトを書く
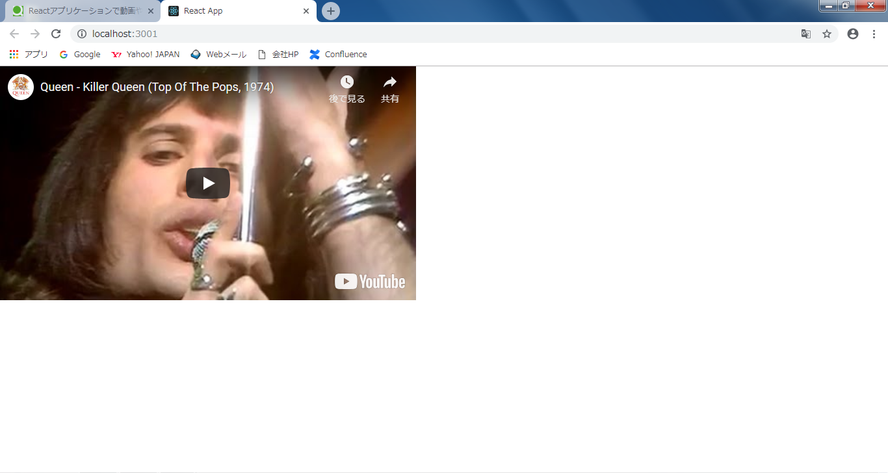
App.jsimport React, { Component } from "react"; import "./App.css"; import ReactPlayer from "react-player" class App extends Component { render() { // 動画のIDはランダムで出るようにしてみる var list = [ "HgzGwKwLmgM", "2ZBtPf7FOoM", "vNhhAEupU4g", "fJ9rUzIMcZQ", "GugsCdLHm-Q", "-tJYN-eG1zk", "04854XqcfCY", "rY0WxgSXdEE", "kijpcUv-b8M", "a01QQZyl-_I", "rdvabdyZ7vU" ]; var random = Math.floor(Math.random() * 10); console.log(list[random]); // 動画を表示する return <ReactPlayer url={"https://youtu.be/" + list[random]} playing /> } } export default App;2.スクリプト実行
>npm run start3.実行結果
D:\temp\指パッチン >npm run start > hello-world@0.1.0 start D:\temp\指パッチン > react-scripts start Compiled successfully! You can now view hello-world in the browser. Local: http://localhost:3000/ On Your Network: http://172.20.7.51:3000/ Note that the development build is not optimized. To create a production build, use npm run build.やったぜ
youtubeを画面に埋め込んだWEBページを起動させることができました。
ブラウザを開き、localhost:3000にアクセスしています。
また、youtubeのビデオID部分はjsにてランダムで変えることができるようになっています。
実装について(Python編)
Python側では、音を反応してブラウザを立ち上げるよう実装します。
実装にあたり使用したライブラリは以下です。
- PyAudio マイクで周囲の音を拾い、ストリームデータを作成。
- NumPy PyAudioで作成したストリームデータを数値データに変換。
- Selenium ブラウザを起動し、htmlファイルを起動。
- geckodriver FireFoxをseleniumで操作する。
下記のソースコードを作成しました。app.pyimport pyaudio import numpy as np from selenium import webdriver from selenium.webdriver.firefox.firefox_binary import FirefoxBinary CHUNK = 1024 FORMAT = pyaudio.paInt16 CHANNELS = 1 RATE = 44100 RECORD_SECONDS = 5 threshold = 0.8 path = "{ここに表示したいページのURL}" binary = FirefoxBinary('/usr/bin/firefox') binary.add_command_line_options('-headless') driver = "" isOpen = 0 def open_web(path): global driver global isOpen if isOpen == 0: driver = webdriver.Firefox(firefox_binary=binary) driver.get(path) isOpen = 1 else: driver.quit() isOpen = 0 p = pyaudio.PyAudio() stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("* recording") while True: data = stream.read(CHUNK) data=np.frombuffer(data, dtype="int16")/32768 # 入力された音の大きさがthresholdで指定したしきい値を超えた場合、ブラウザを開くようにする。 if data.max() > threshold: open_web(path)しきい値を低くしすぎると常に反応してしまうため、
ある程度大きい音に反応するように調整する必要があります。しくみ
PCのマイクである程度大きな音を認識すれば、
selenium経由でfirefoxが立ち上がる仕組みです。
また、フラグ管理しているため、指ぱっちんをするたびに
ブラウザを立ち上げ/終了を繰り返すことができます。React側で作成したページを呼び出せば、
指ぱっちんだけでyoutube起動が実現できます。
やったね感想
やってみたいアイデアから、どのように実現するかを考えての実装だったため
動くものになるか不安がありました。
しかし、なんとか実行環境を整えて実現できたという点は、良かったとおもいます。Python実行環境について、最初はWindowsPCで環境構築をしていましたが、VisualStudioのインストールが必要であるなど
環境構築が困難だったため、PCにLinuxOS(ubuntu)を入れて実現することにしました。実現できていない点として、現在のソースではマイクで拾った音の大きさで、
によって周囲で指パッチンされたかを判定しています。指パッチンだけで、自在にブラウザが立ち上がるのは、なかなか愉快。
参考情報のリンク
以下のサイトの情報やサンプルソースを参考にさせていただきました。
Pythonの参考サイト
PyAudioの基本メモ2 音声入出力 - たけし備忘録 http://takeshid.hatenadiary.jp/entry/2016/01/10/153503
Pythonで音を監視して一定以上の音量を録音する - Qiita https://qiita.com/mix_dvd/items/dc53926b83a9529876f7
PyAudio Document(英語) https://people.csail.mit.edu/hubert/pyaudio/docs/
Reactの参考サイト
出来る限り短く説明するReact.js入門 - Qiita https://qiita.com/rgbkids/items/8ec309d1bf5e203d2b19
Reactアプリケーションで動画や音楽ファイルを扱うために「react-player」を使用する - Qiita https://qiita.com/reiji1020/items/a65d84980b67f13449e1
React本体ダウンロード https://react-cn.github.io/react/downloads.html
- 投稿日:2019-02-15T13:42:09+09:00
Articulateでビジネスチャットボットをつくる
チャットボットをはじめとした会話型サービスの開発に関心がある方向けに、この分野のオープンソースをざっくりレビューしていきます。
今回は Articulate https://github.com/samtecspg/articulate です。
Articulateとは
Articulateは、自然言語理解エンジン Rasa NLU をベースにした「ビジネスチャットボットCMS」とでもいえるアプリケーションです。Apacheライセンスで、Smart Platform Groupが開発しています。
Rasa NLUは、Rasa Technologiesが開発するオープンソースのNLUです。オープンソースのNLUではデファクトスタンダードのようなポジションで、Rasa NLUを使ったOSSが数多くあります。
ただし、Rasa NLUは残念ながら 日本語に未対応 です。(取り組んでみている人もいるようですが精度は不明)そのため、Articulateに日本語のトレーニングデータを登録しても、日本語を理解するボットを作ることは(現時点では)できません。
Articulateの特徴
チャットボットを構成するためのCMS&コンパネ
一般的に、チャットボットは様々なソフトウェアコンポーネントで構成されていますが、大きく分けて「表側」と「裏側」があります。
表側は、チャットユーザーに直接対応するアプリケーションです。質問や要求に答えたり、プロアクティブにメッセージを送ったりします。このとき「チャットユーザーの発言の意味」を理解するという過程でNLUを利用します。(NLUがチャットボットそのものであるかのように語られることもありますが、ソフトウェア全体としては部品の1つにすぎないのですよね)
裏側は、表側のアプリケーションのためのいわゆる「管理画面」です。チャットボットが回答に使用するコンテンツの登録、どのように回答するかのロジックやフローの登録、そしてNLUを訓練するためのトレーニングデータの登録などができます。
Articulateは、この「裏側」にフォーカスしたアプリケーションです。
オープンソースのチャットボットフレームワークやアプリケーションには、「表側」にフォーカスしたものが比較的多くあります。もちろん「裏側」が全くないチャットボットは成立しないので、いずれも多少なりとも機能をもってはいるのですが、裏側に「フォーカス」して作られているところが特徴的です。
エンタープライズで「運用される」ことが考えられた設計
Articulateは、エンタープライズでのチャットボット利用を意識して設計されているように見えます。設計者に知見があるのでしょう。
チャットボットは、実際に企業で利用すると「運用」が重要であることが分かります。構築段階から運用期間を通して、QA集め、コンテンツのチャット最適化、トレーニングデータ作成、チューニングなどの業務を繰り返し行うことになります。もちろん、自動化の余地は多いにあるものの、チャットボットの管理画面は半分「業務システム」みたいなところがあります。
オープンソースのプロダクトではこの「運用」というものが軽視されがちというか、エンジニアが作る前提であることが多いのですが、Articulateは、これをエンジニアでない人が継続的に行うために使うアプリケーションとして、概念や画面が整理されています。
同じポジションのソフトウェアにRasa Coreがありますが、Rasa Coreよりも「ease of useを維持する方針」だそうです。(コメント)
開発者向けアクションアイデア
エンジニアの方向けに、このOSSの活用アイデアや、コントリビュートしたいことについてのアイデアも残します。
- 日本語対応(表側)
- 前述したように、Rasa NLU(およびDuckling)を前提としたソフトウェアなので、Rasa NLUで日本語を扱えるようにするようにしないと始まりません。
- Articulateにおけるコンテンツやトレーニングデータで日本語テキストを扱うことは可能なので、Rasa NLUにコミットするか、あるいはオルタナティブを作るか。
- 日本語対応(裏側)
- せっかく非エンジニア向けに設計された管理画面でも、日本人が運用できるようにするには、管理画面の文言も日本語にしないと厳しいですよね。
- 管理画面の多国語化はサポートされていて、現時点で英語とスペイン語に対応しています。なので、日本語の言語リソースファイルさえあればできるのではと思います。(まず表側が対応しないと意味ないですが)
企業が開発しているということもありますが、質のよいOSSだと思うので、ぜひ試してみてください。UIはNode.jsで動くReactアプリケーションです。
We're hiring!
AIチャットボットを開発しています。
ご興味ある方はWantedlyページからお気軽にご連絡ください!
- 投稿日:2019-02-15T12:50:22+09:00
Firestoreを本番で半年運用したアーキテクチャ:その① 〜Firestoreを中心に据えた全体設計のコンセプト〜
これは?
Firebase Meetup #10 で 「Firestore導入前に検討したかったベスト5」 というテーマで発表したのですが、
まさかのメインの話の部分を図2枚で済ますという荒業をしてしまったので、ちゃんと書き納めます。
(反省のツイート...→ https://twitter.com/pitown/status/1093141514186706944 )そしてなんか、書きたいこと多くない?と気付いたので、3回くらいに分けました。
①Firestoreを中心に据えた全体設計のコンセプト ←今回
②PubSubとCloud Functionsを使って、FirestoreのCollectionをマイクロサービスに見立てた話
③パフォーマンスの劣化対策として、CacheのCollectionを作った話ちなみに、書き終えてから、初期構成の話しかしていないな、と思ったのですが、それ以降の話はまた次回以降に書こうと思います。
Firestoreを選んだ理由
- とにかくその時にこのサービス向けに手を動かせるのが自分しかいなかった
- 自分はフロントエンドがつよい
- 比較的リアルタイム性が求められるアプリケーション
- とにかく急ぎ
という理由。
いま考えても、使わない理由は特になかったな、と思います。そんな状況なわけだったので、Firestore以外の選定も、初期構成はとにかくリソースを少なく早く立ち上がることを考え、できる限りマネージドなものに乗っかっていきました。
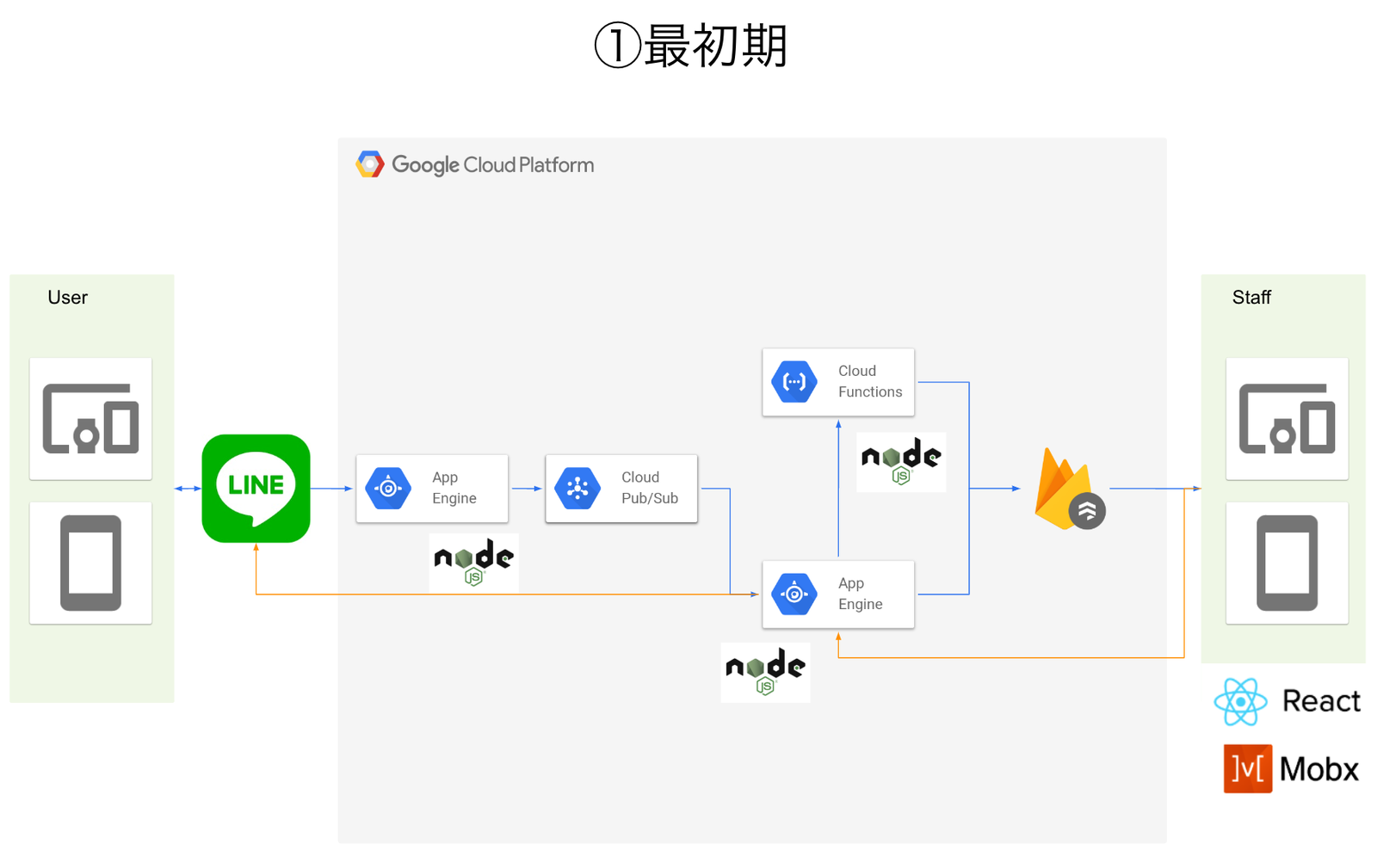
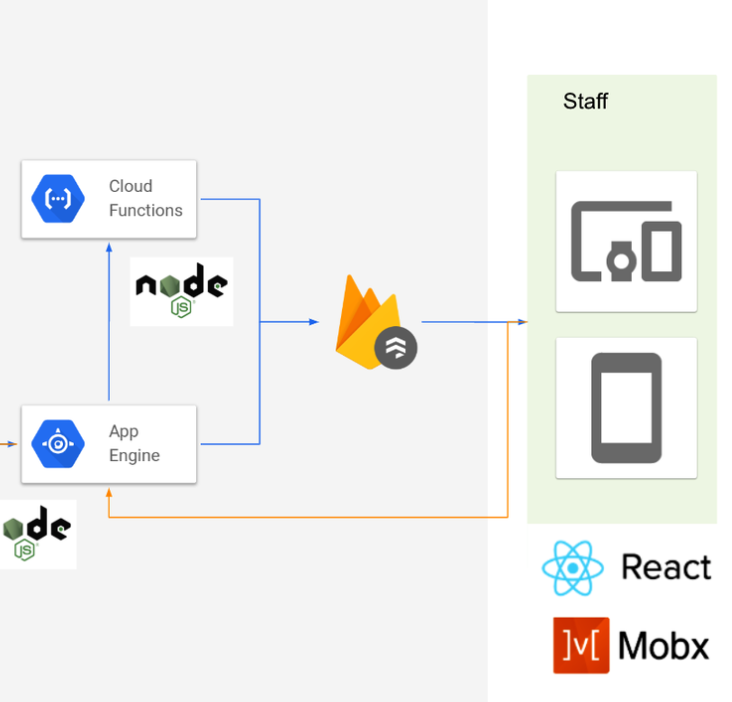
Firestoreの周りを固めるアーキテクチャ
まずは、ざっくりとチャット部分だけを抜き出したうちのプロダクト仕様がこれです。
ユーザーとのLINEのやり取りを、LINE API越しにやり取りするというものです。
これの青い部分が自分たちでつくらなければならないところ。
そうした時に、
- LINE APIからメッセージが送られてくるのを決して落としてはいけない
- 双方リアルタイム(スタッフ→ユーザーは普通にリクエストするだけだけど)
ということを考えるわけですね。
それを元につくったのが、以下の初期バージョンのアーキテクチャです。
(以前 発表資料 で書いたもの)
(元のスライドと若干違うのは、ええ、そうです、今、見たら違ったなって気付いたからなんですよ..)
サーバサイドについて
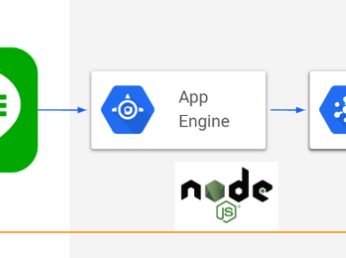
まず、LINE APIのWebhookを受けるためのGAEが一台あります。
これは要は絶対に落ちてはいけないくんであって、とにかくログを吐きつつpubsubにpublishするだけ。
裏がどんなに失敗しようが、ここのログでデバッグできるようにしたかったんですね。Nginxがいいかなと思ったものの、マネージドでまとめるのであれば、
すべてをマネージドでまとめなければ恩恵を受けにくいと考えてのGAEってかんじですね。あと、PubSubが裏にいるので、
ここでデータを一時的に貯められる。
急にズドンと来ても、PubSubで吸収してくれるという、若干オーバーな設計になってます。ただ、料金とか工数とか見ると、別にリッチに倒しておけばいいじゃん、というスタンスが通る程度のものだったので、
最初からPubSubでやってます。それで、PubSubからPull型でデータをSubscribeしていく(Node.jsのSDKに乗っかりたかったのでPull!)、という流れ。
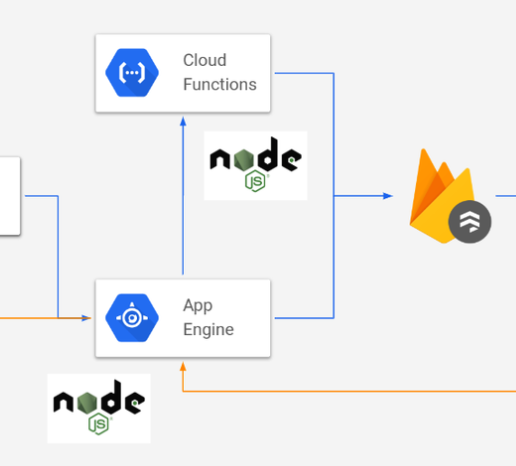
あとは、責務に応じて、Cloud FunctionsとGAEを分けてFirestoreに保存していました。
そして、もう一つこのあたりで、Cloud FunctionやPubSubを活用しやい理由がありました。
PubSubは、at least onceを保証していますよね。
なので、1回かもしれないけど、複数回実行されるかもしれない。
そして、Cloud Functionsも晴れて先日GAになったときに、at least onceを保証しました。
(ずっと、「今はGAじゃないから、at least onceは保証できないよ」という文字が煌々としていて気になってたんですよ…)そうすると、PubSubとCloud Functionsのコンビは、1回以上の動作が起こります。
一方で、Firestoreは、原則的に、更新するものは、setで更新・追加するようにするのがスタンダードです(と思ってます)。(setは、新規追加も更新もできて、同一IDの場合上書きするものです)ということは、Firestoreでsetで書き込んでいる限り、新規追加だろうが更新になってしまっただろうが、同じ値の複数回の書き込みが走っても、問題無いということになります。
これにより、
PubSub〜Cloud Functionsで1回以上の実行を保証、
Firestoreで1回だけの書き込み(にsetだと見える)を保証、
という形で、全体の整合性を取れるようにしました。実際の思考順序は、↑の流れは試行錯誤中にこの流れになっただけであって、一番はじめに考えていたのが、このあたりの、「書き込み回数をコントロールする」ことでした。
これがFirestoreの設計の基本なのかな、と個人的には考えています。また、書き込みに関しては、うちのユーザーはLINE越しでかならずHTTPリクエストが発生するので、Firestoreに書き込むだけ、ということだけでは完結しないので、
LINE APIにHTTPリクエストしつつ、Firestoreにも保存する、ということをしています。ここを変に複雑にするとかえってメンテがしんどくなるので、Firestoreを拡張なんかはしないように意識しました。
クライアントについて
クライアントは、読み込みについてはFirestoreの超強力な特性を享受できるので、それを最大限活かしています。最初にFirestoreをSDKで利用したときに、めちゃくちゃ強力だな、と実感していて、
できれば、それを最大限素直に表現してあげたいな、というのが願いでした。特に、自分たちのビジネスは開発する段階では、ビジネスが死ぬかもしれないし、大きく変わるかもしれない、
というものだったので、
ちゃんとビジネスの成立のタイミングに合わせて堅くしていきたいなと。(もっと言うと資金調達とか採用とかと併せて)そのときに、viewにはReactを用いようと決めていたのですが、イベントシステムをどうしようと。
既に、圧倒的にReactといえばRedux、という世論に加えエコシステムが出来上がっていたのですが、どうにもRedux最初重いな、と思ったわけです。Fluxの世界に乗っかって、リアクティブにループ回して理想系を保って、適切にstore分割して、
そうやって作っていくスピード感だと、スクラップアンドビルドの回転そこまで上げられないよな、と思ってしまったわけです。
Reduxにすごく精通していれば話は別なのかも!ですが。
僕がReduxやるなら、もっとチームがいて、綺麗なAPIがあってやりたいなと。僕が欲しかったのはもっとミニマルなもので、そのときの僕のイメージはこれです。
もう、とにかくシンプルに書き出してくれ!という思いです。
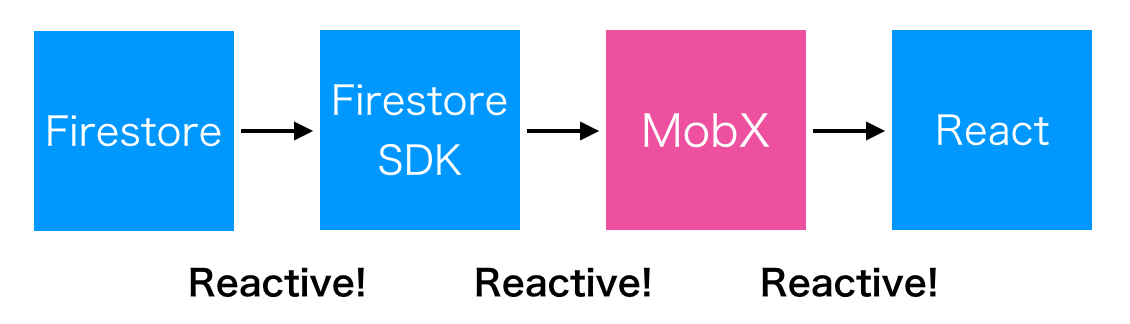
やりたい操作は簡単なデータの結合とFilter程度なんだ!という。その希望を見事に叶えてくれたのが、MobXでした。
(ちなみに、システム化してすぐに突然数千人が入ってくるような珍しい状況でもあったんですが、このリアクティブな感じを眺めているのがめちゃくちゃに気持ち良かったです。)MobXはとにかく自由なので、つまり指針がないと、際限なくてヤバいんですが笑、
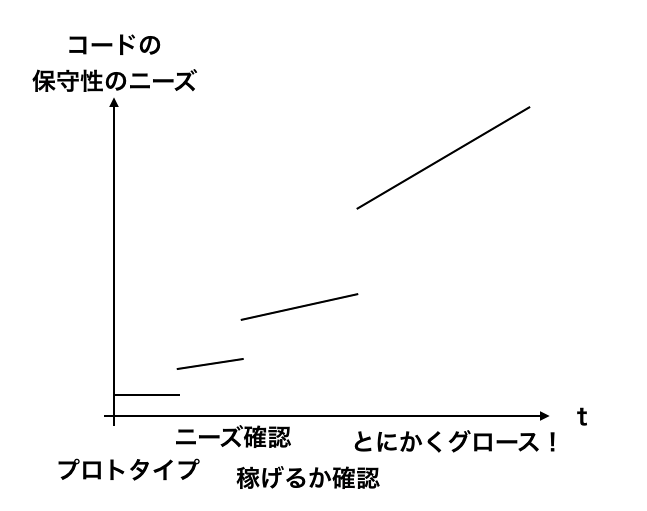
ザ・シンプルに使っている分には問題ないだろうと。このへんの意思決定としては、初期は速さを犠牲にしてしまうと、できるハズだった検証がいくつかできなくなるということになり、わりと感覚に頼って戦わざるを得ないことになりがちでアカン、という考えがありました。
ちゃんとやるぞ!というタイミングでしっかりとしたつくりにシフトしていくのが良いと思っていて、もしかしたらリファクタリングはある程度の覚悟しないといけないかもしれないけれど、利益がちゃんと出ていればそれなりのリソースをかけられるとも思っていて。
↓保守性については、こんなイメージを持ってやっています。最初にしっかりやりすぎてもドメインのフィールドを正確に定義できないのであれば、徐々にそれがねじれていってしまうことにも繋がるので、最初はとにかく素直に!の気持ちです。
なので、事業の形が定まって利益を上げ始めるときに、変に色に染まった設計とかがないようにしようという感じでつくっていきました。スケールしたときに後で来て(?)つくりかえてくれる達人が困らないように!!ということで、ちょこちょこ各論をはさみつつも(言いたいことだけ書いた)、全体でやっていたコンセプトを書いてみました。
次は、もう少し、細かいFirestoreの設計の話なんかを書きます。


- 投稿日:2019-02-15T10:45:38+09:00
Jest + enzymeを導入する
初心者です?
Jestとenzymeの理解を一番に深めてくれたのはYouTubeとUdemyかもしれません。
- Youtube
React Redux Unit & Integration Testing with Jest and Enzyme(Udemyのリンクも貼りましたが、上記コースはcreate-react-appのバージョンが古いためエラーが出てしまいます。また、上に貼ったYoutubeは作成途中ですので、まだReduxを実装した場合のユニットテスト系は現在公開されてません。(2019/02/15時点)Jestとenzymeに関する動画はたくさん上がっています!)
参考にさせていただいた記事も載せます。
今回使ったライブラリはこちらです。
- jest-enzyme
- enzyme
- enzyme-adapter-react-16
- moxios
- redux-mock-store
導入前準備
上記のライブラリをインストールして、package.jsonに以下の記述を足します。
{ "scripts": { "test": "jest", "test:watch": "jest --watch", "test:coverage": "jest --verbose --coverage" ... }まずはsetupTests.jsを作成
srcディレクトリ配下に
setupTests.jsを新規作成し、以下のコードを書きます。import Enzyme from 'enzyme' import EnzymeAdapter from 'enzyme-adapter-react-16' Enzyme.configure({ adapter: new EnzymeAdapter(), disableLifecycleMethods: true })setupTests.jsを認識してもらうのと、絶対パスの設定を
jest.config.jsを作成して以下のように書きました。jest.config.js
module.exports = { moduleNameMapper: { '^@app/(.+)': '<rootDir>/src/js/$1', // 絶対パス }, verbose: true, setupFilesAfterEnv: ['<rootDir>/src/js/setupTests.js'], // setupTests.jsの置き場所 }簡単な記述から始めます!
実は基本のキの段階で躓きまくってました。
Material-UIのコンポーネントAppBarが存在するかどうかで記述ミス連発してました。
まずはMaterial-UIのコンポーネントが存在するかの記述を書きます。import * as React from 'react' import { createShallow, createMount } from '@material-ui/core/test-utils' import Header from '@app/components/Header' describe('<Header />', () => { let shallow let mount beforeEach(() => { shallow = createShallow() mount = createMount() }) it('AppBarが読み込まれている', () => { const wrapper = mount(<Header />) expect(wrapper.find('AppBar').length).toEqual(1) }) })なんてことない記述なのですが、
createShallow,createMountに辿り着くまでや、shallowでなくmountの方を使うところに至るまで結構時間が掛かっています。。
(言い訳ですが「Material-UI jest enzyme test」でググっても理解できなかったのです…!)これで一旦
AppBarが表示されている記述は終わったのですが、
私はHeaderコンポーネントにReducerで管理しているステートを呼び出しています。import React from 'react' import { connect } from 'react-redux' import AppBar from '@material-ui/core/AppBar' class Header extends React.Component<*> { render() { return ( <div> <AppBar position="sticky" color="inherit"> Something </AppBar> </div> ) } } const mapStateToProps = state => ({ isAuthenticated: state.auth.isAuthenticated, }) export default connect(mapStateToProps)(Header)
connect、mapStateToPropsを入れるだけで上のテストの記述はエラーを出します。Invariant Violation: Could not find "store" in the context of "Connect(Header)". Either wrap the root component in a <Provider>, or pass a custom React context provider to <Provider> and the corresponding React context consumer to Connect(Header) in connect options.
なので、これを回避して再度AppBarが読み込まれているテストをしていきます。storeにアクセスできるようにする
この方法はUdemyで紹介されたものを少しだけ自分用に変えたものです。
まずは
__tests___フォルダの外に「testUtils」ディレクトリを作成して、その中にtestUtils.jsを作成します。その中に以下のような記述をします。
import { createStore, applyMiddleware } from 'redux' import rootReducer from '@app/reducers' import thunk from 'redux-thunk' /** * @function storeFactory * @param {object} initialState * @returns {Store} Redux Store */ export const storeFactory = initialState => { const createStoreWithMiddleware = applyMiddleware(thunk)(createStore) return createStoreWithMiddleware(rootReducer, initialState) }私は今回Middlewareに
redux-thunkを使いましたので上のような記述にしています。エラーが出てしまったHeader.test.jsに
storeFactory関数を呼び出します。import * as React from 'react' import { createShallow, createMount } from '@material-ui/core/test-utils' import { storeFactory } from '@app/testUtils/testUtils' import { Provider } from 'react-redux' import Header from '@app/components/Header' describe('<Header />', () => { let shallow let mount beforeEach(() => { shallow = createShallow() mount = createMount() }) it('AppBarが読み込まれている', () => { const initialState = {} const store = storeFactory(initialState) const wrapper = mount( <Provider store={store}> <Header /> </Provider> ) expect(wrapper.find('AppBar').length).toEqual(1) }) })const store = storeFactory(initialState) const wrapper = mount( <Provider store={store}> <Header /> </Provider> )を追加しただけです。これでエラーが消え、AppBarの存在についてのテストはパスしました!
……まだAppBarの存在を確認しただけ…!
実はHeaderコンポーネントの挙動は、
ユーザー認証して、Reduxで管理しているthis.props.isAuthenticatedステートがtrueの時AppBarを表示&falseの時は消えるように記述しています。なのでpropsの値によってAppBarの存在をテストしていきます!
propsの値を参照してテストする
storeFactoryの引数に渡していたinitialStateに、reducerで管理しているステートを渡してあげます。
ユーザー認証で管理しているauthステートは以下のような情報を持たせています。const INITIAL_STATE = { oauthStatus: {}, userStatus: {}, loading: false, error: null, isAuthenticated: false, }AppBarの存在を確認するのに条件2つ、
①isAuthenticated: true→ AppBar表示
②isAuthenticated: false→ AppBar非表示なので、これを書いていきます。
import * as React from 'react' import { createShallow, createMount } from '@material-ui/core/test-utils' import { storeFactory } from '@app/testUtils/testUtils' import { Provider } from 'react-redux' import { BrowserRouter as Router } from 'react-router-dom' import Header from '@app/components/Header' describe('<Header />', () => { let shallow let mount beforeEach(() => { shallow = createShallow() mount = createMount() }) it('認証済みの時AppBarが表示されている', () => { const initialState = { auth: { oauthStatus: {}, userStatus: {}, loading: false, error: null, isAuthenticated: true, }, } const store = storeFactory(initialState) const wrapper = mount( <Provider store={store}> <Router> <Header /> </Router> </Provider> ) expect(wrapper.find('AppBar').length).toEqual(1) }) it('未認証の時AppBarが表示されていない', () => { const initialState = { auth: { oauthStatus: {}, userStatus: {}, loading: false, error: null, isAuthenticated: false, }, } const store = storeFactory(initialState) const wrapper = mount( <Provider store={store}> <Router> <Header /> </Router> </Provider> ) expect(wrapper.find('AppBar').length).toEqual(0) }) })wrapperを定義している記述が一緒なので、
beforeEach内に書いていってスッキリさせます!
新しくsetup()関数を作り、そこにstoreFactory()とwrapperの定義を書いています。出来上がりはこんな感じです。
import * as React from 'react' import { createShallow, createMount } from '@material-ui/core/test-utils' import { storeFactory } from '@app/testUtils/testUtils' import { Provider } from 'react-redux' import { BrowserRouter as Router } from 'react-router-dom' import Header from '@app/components/Header' const shallow = createShallow() const mount = createMount() const setup = (state = {}) => { const store = storeFactory(state) const wrapper = mount( <Provider store={store}> <Router> <Header /> </Router> </Provider> ) return wrapper } describe('<Header />', () => { it('認証済みの時AppBarが表示されている', () => { const initialState = { auth: { oauthStatus: {}, userStatus: {}, loading: false, error: null, isAuthenticated: true, }, } const wrapper = setup(initialState) expect(wrapper.find('AppBar').length).toEqual(1) }) it('未認証の時AppBarが表示されていない', () => { const initialState = { auth: { oauthStatus: {}, userStatus: {}, loading: false, error: null, isAuthenticated: false, }, } const wrapper = setup(initialState) expect(wrapper.find('AppBar').length).toEqual(0) }) })問題なくテストがパスしました!
【終えて】
テストは色々面倒ですが、テストにパスしてターミナルが緑色で満たされると普通に嬉しいです。
まだ他のコンポーネントでテストを実施していくので、今回は導入のドで締めます。
(まだmockあたり使っていないので恐らく次回!)(上の記述に間違いありましたら気軽にコメントください!)

- 投稿日:2019-02-15T10:02:31+09:00
Next.js 8がリリースされた ? 新機能・改善点まとめ
2月11日にNext.js 8のリリースが公式ブログでアナウンスされました。
昨年9月のバージョン7のリリースから5ヶ月ぶりのメジャーアップデートですね。後方互換性を保ったアップデートとされています。
元記事で発表された新機能や改善点、変更点などをかいつまんでまとめてみました。
実際に自分で開発しているサービスをアップデートしてみた所感も少し書いています。
新しく追加された機能
サーバーレスに対応したビルド
アプリケーションをAWS Lambdaなどのサーバーレス環境にデプロイするための設定が追加されました。
pages/以下のファイル単位で単一の関数としてビルドされるようになっています。有効化するには設定をこのようにします。
next.config.jsmodule.exports = { target: "serverless" }こうすると例えばpages/以下にindex.jsとabout.jsという2つのファイルがある場合、
pages/index.js=>.next/serverless/pages/index.js
pages/about.js=>.next/serverless/pages/about.jsこんなふうにビルドが行われます。
ファイルの中身はexpressでおなじみの引数にリクエストとレスポンスのオブジェクトを受けてページの内容を返す単一のrender()関数をexportする形になっています。
export function render(req: http.IncomingMessage, res: http.ServerResponse) => void例えばデプロイ先のサーバーレス環境がNode.jsのhttpモジュールをサポートしている場合、以下のようにすることでレンダリングを行うことが出来ます。
const http = require("http"); const page = require("./.next/serverless/about.js"); const server = new http.Server((req, res) => page.render(req, res)); server.listen(3000, () => console.log("Listening on http://localhost:3000"))良い感じですね!ちょっとLambdaにデプロイしたくなってきました。
ビルド時の環境変数注入
サーバサイドで動くWebアプリケーションを開発する時、実行時に環境変数を渡して参照することが多々あるかと思います。
Next.jsはサーバ・クライアント両方で動作するユニバーサルなフレームワークなので実行時に渡した環境変数は当然サーバサイドでしか参照できず、クライアントサイドと処理を分ける必要があるなど少し不便でした。
これまではこれに対するワークアラウンドとして
babel-plugin-transform-defineやwebpack.DefinePluginを用いて、ビルド時に渡された環境変数をスクリプト内部に直接注入しサーバ・クライアント両方から参照可能にするということがよく行われてきました。バージョン8ではNext.js自体にこの機能が取り込まれています。上記のモジュールを追加インストールすることなくデフォルトで設定ファイルに注入する環境変数を定義することが可能になりました。
next.config.jsmodule.exports = { env: { customKey: 'MyValue' } }このように書いておくとアプリケーションスクリプト内部の
process.env.customKeyがビルド時に'MyValue'に置きかわり、サーバ・クライアント両者で実行時に参照することが出来ます。自分もこれまでは
babel-plugin-transform-defineを利用していました。デフォルトでこういうのがあると少しすっきりしていいですね。crossOrigin設定の追加
Next.jsはビルドしたアプリケーションをブラウザで実行する時、page単位でjsを配信する仕組みになっています。
クライアントサイドルーティングは別pageへの遷移時にそのpageに対応したjsファイルを動的に生成した
<script>タグを用いて注入することで実現しています。今回のリリースではこの注入される<script>タグへcross-origin属性を付与する設定が追加されました。
これは単純に同一のドメインから全てのスクリプトを配信する場合は気にする必要のないものなのですが、スクリプトをCDNなど別のドメインから配信する時に効果的な設定です。
別ドメインからのスクリプトを読み込んだ際にcross-origin属性が付与されていないと
- エラー発生時にエラーの内容がコンソールに出力されず、全てScript Errorと出力される
- CORSのリクエストを行う時にCookieなどの認証情報が付与されない
といった不都合があります。
これを回避するために注入される<script>タグのcrossorigin属性に'anonymous'または'use-credentials'を指定しておく必要がありますが、今回それが設定ファイルから指定出来るようになりました。next.config.jsmodule.exports = { crossOrigin: 'anonymous' }ちなみにNext.jsにはスクリプトの読み込み先をCDNなど別のドメインに変更する
assetPrefixという設定があります。
多分これとセットで使うことが想定されていると思います。改善点・変更点
ビルド時のメモリ使用量の大幅な削減
速度の低下など全く無しにアプリケーションのビルドに必要なメモリを従来の16分の1に削減し、なおかつメモリの解放も早くなったようです。
これにより大規模なアプリのビルドが不安定でクラッシュしたりすることもなくなるでしょう…とのこと。すごいですね。
これはNext.jsの改善というよりはwebpack自体のパフォーマンスが向上したためのようで、そのためにwebpackにめっちゃcontributionしたって書いてありました。
どのように実現したのか詳しくはここには書かないけどそのうちまとめるからブログ見てね、とのことです。
Prefetchのパフォーマンス向上
クライアントサイドルーティングを簡単に実現するLinkコンポーネントのprefetch属性に関する変更です。
これまではページ内にprefetchが指定されたLinkがある場合、遷移先のURLで使うスクリプトを
<script>タグを使って注入することで遷移前の先読みを行なっていました。しかしこれではスクリプトの読み込みが終わるまでページの読み込みも完了しなくなってしまいブラウザに不必要な待ち時間を与えてしまいます。
今回の変更では
<script>タグの注入による先読みを廃止し代わりに<link rel="preload">を用いることでページの読み込みが完了してはじめてスクリプトの先読みが始まるようになりました。加えてブラウザの
navigator.connection.saveDataの値を参照して自動的に先読みが無効になるようになったようです。
<link rel="preload">を用いた実装だと先読みの振る舞いがブラウザ依存になるので以前の強制的にスクリプトを読み込ませる方式と比べるとお行儀が良くなった感がありますね。ちなみにこのprefetchを有効にしてみたらChromeでこんなWarningが出てしまいました。
preloadしてから3秒以内に当該のスクリプトを利用しないと不要な先読みだと捉えられて怒られてしまうようです。The resource was preloaded using link preload but not used within a few seconds from the window's load event. Please make sure it wasn't preloaded for nothing.
next/routerの提供するprefetch()を利用しても同じことが出来るので、自分はリンク要素にマウスカーソルがのった時点でprefetchが行われるようにしています。sample.jsximport Router from 'next/router' import Link from 'next/link' export default props => ( <Link href='/about'> <a onMouseEnter={() => Router.prefetch('/about')}>About</a> </Link> )このPrefetchの挙動を確認してみたい方は僕が運営しているtechbooksという技術書籍のレビュー・ランキングサイトで実際に実装されているのでよかったら見てみて下さい。
生成するHTMLのサイズ削減
サーバサイドでレンダリングするhtmlのサイズが
1.50KB→1.16KBと23%削減されました。エラーページ表示用のスクリプトを初期描画時に含めないようにしたことと、後述するインラインスクリプトの廃止の影響によるものとのことです。
開発時のオンデマンドコンパイルの改善
Next.jsは開発サーバの起動時に全てのスクリプトをコンパイルせず、どこかのページにリクエストがあってはじめてそのページに関するスクリプトをコンパイルして画面を描画することで開発時のパフォーマンスを向上させています。
また最初にページをコンパイルした時点でその結果をキャッシュとしてメモリに保持し、25秒間そのページにリクエストがなければそれを破棄することによって不要なメモリの解放もよしなにやってくれています。
これまでは現在開いているページのキャッシュを破棄しないよう滞在検知のために5秒おきに
window.fetchによるポーリングを行なっていましたが、これが今回WebSocketによる実装に変更されました。従来の方法だと5秒毎に開発者ツールのNetworkタブにポーリングの結果がどんどん表示されてしまって不便だから、というのが理由みたいです。
これによって開発サーバがListenするポートがWebSocketサーバ用に1つ追加されました。
(自分はDocker環境で開発サーバを起動していた上にこのことを知らず少しはまりました)デフォルトではWebSocketサーバは適当に空いているポートを探してListenするみたいですが任意のポートに固定する設定も追加されています。
間に何らかのプロキシをかませていてWebSocketサーバにListenして欲しいポートとブラウザにリクエストして欲しいポート/パスが異なる場合はそれ用の設定も出来るみたいです。
next.config.jsmodule.exports = { onDemandEntries: { websocketPort: 3001, websocketProxyPort: 7001, websocketProxyPath: '/hmr' } }開発用Webサーバの起動時間短縮
開発サーバの起動時、これまでは
初期リソースのコンパイル→Webサーバ起動、ポートのListenという流れだったので
nextコマンド実行直後にブラウザでアクセスしてもThis site can’t be reachedなどのエラーが表示されてしまっていました。バージョン8ではこれが逆になって
Webサーバ起動、ポートのListen→初期リソースのコンパイルになりました。
開発用Webサーバ自体は
nextコマンド実行直後に立ち上がり、すぐにアクセスしてもエラーが表示されないようになりました。
ちゃんとコンパイルの完了まで読み込み待ちになるみたいです。Static Exportの速度向上
サーバサイドのレンダリング結果を静的ファイルとして出力する
exportコマンドがマルチコアに対応しました。4コアのMacBookで試したところ
25ページ/秒→75ページ/秒と3倍も高速になったとのことです。Static Exportを利用してブログサイトを構築している場合などは出力するページ数が多くなることが想定されるのでこれが速くなるのは良いですね。
Head要素の重複排除
どんなコンポーネントからでも
next/headを用いるとページの<head>内に任意のタグ/コンポーネントを注入することが出来ますが、これまでは例えば<title>など重複して追加されるのではなく上書きをしてほしい要素の重複をコントロールする方法がありませんでした。今回、
<Head>内の要素に付与する任意のkey属性でこれをコントロールすることが出来るようになりました。以下のコードはこれまでなら
<head>内に<meta name="viewport" ... />の要素が2つ重複して注入されてしまっていましたが、今回の変更では同一のkeyを持つ要素は上書きされるようになっています。sample.jsximport Head from 'next/head' export default function IndexPage() { return <> <Head> <title>My page title</title> <meta name="viewport" content="initial-scale=1.0, width=device-width" key="viewport" /> </Head> <Head> <meta name="viewport" content="initial-scale=1.2, width=device-width" key="viewport" /> </Head> </> }インラインJSの廃止
これまではページ内にインラインjsとして埋め込むことでサーバからクライアントへデータの受け渡しを行っていましたが、
<script type="application/json">を利用した埋め込みに変更されました。これによりNext.jsによるページへのインラインJS埋め込みは完全に無くなったとのことです。
外部APIへAuthenticationするサンプルの公開
これはNext.js自体のアップデートというわけではないですが、ユーザが外部APIに対してCookieを利用した認証を行うケースのサンプルコードが公開されました。
https://github.com/zeit/next.js/tree/canary/examples/with-cookie-auth
サイトにSNS連携やOAuth認証の機能を追加する場合などもこれに当てはまりますね。
どうやって実現すればいいのか質問が多かったそうです。
- サーバサイドレンダリング時にもブラウザが送信してきたCookieと一緒にAPIへリクエストを行う
- Proxyサーバを使ってCORS関係なくリクエスト出来るようにする
この2つを実装すればクライアントサイド・サーバサイドで振る舞いを気にしなくて良くなるよ、との回答を示した形のサンプルコードになっています。
まとめ
たくさんの改善が含まれたメジャーアップデートでした。
実際に使ってみたところ確かに体感的にも開発用サーバのパフォーマンスがすごく向上していると感じました。
ビルド後のアプリケーションのパフォーマンスはもちろん、こうしたDXの改善にも意欲的なのはとても嬉しいですね。
- 投稿日:2019-02-15T07:45:49+09:00
Reactで画像がリンク切れの時に代替画像を表示したい時のサンプル
imgタグのonErrorに以下を記述すればOKonError={(e) => e.target.src = 'image path'}以下、実装するときのイメージサンプル。
Sample.jsimport React, {Component} from 'react'; import noimage from './noimage.png'; class Sample extends Component { render() { <img className={'sample'} alt={'test'} src={'image path'} onError={(e) => e.target.src = noimage} /> } } export default Sample
noimage.pngは適当なものを用意して、設置で動くはず参考ページ
- 投稿日:2019-02-15T04:04:50+09:00
Reactチュートリアルでの要点(ほぼメモ)
はじめに
この記事は自分が勉強の為にReactの公式チュートリアルを行った際に,自分が気になった点や,まとめておきたい点についてまとめただけの記事になります.日本語訳などは他の方のブログなどをご覧ください.
また筆者はJavaScript初心者なので,JavaScriptの基本についても沢山記述があります.自分は英語の練習の為にもGoogle大先生のお力を借りながら英語で読んだので不適切な記述があると思いますので,正しい情報は公式ドキュメントか以下のブログを参照してください.
Reactチュートリアル: Intro To React【日本語翻訳】
Setup(セットアップ)
自分の環境
Ubuntu18.04 LTS
詰まった点
local環境でReactの環境を構築する際に,Nodejs環境とnpmが使えるようにしなければならない.コンソールから
sudo apt install nodejsを打ち込めば,nodejsとnpm(パッケージ管理ソフト)が入るらしい.しかしチュートリアルで出てきたnpxコマンドが使えない
→npmのバージョンが古いためnpxコマンドが使えない(npm 5.2以上).
以下の記事の通りにバックアップさせることで完了.
とりあえず Ubuntu で新しい Node.js, npm をインストールOverview(概要)
・チュートリアルでのプログラムは簡単な〇✕ゲームを作るものらしい.
・propsという名前から異なるコンポーネントへの参照が出来るようになる.<A a=1/>と表記したときAのクラス内でthis.props.aで呼び出せるイメージ.
・Componentの要素は普通のJavaScriptみたいにButtonタグの中にonClickイベントハンドラから関数を呼び出すみたいなことができる.
・React.Componentクラスでコンストラクタを持つ場合はsuper(props)を記述しなければならない.(JavaScriptのサブクラス定義の関係から)
・React.Component.setState()を関数を使うことで子の変数の変更をDOMに反映してくれる.this.stat.value=1ではDOMに反映されない.
・toolを使えばデバックが簡単になる.
React Developer ToolsでReactで作ったページをデバッグする・propsとかstateで参考になったページ
Reactのstate,props,componentの使い方を自分なりにまとめてみたイベントハンドラでの関数について(アロー関数について)
イベントハンドラーにはonClick=function(){}のような形では使われない.書くのが長い事と,関数内でthisを束縛するのが良くないせいだと思われる.
アロー関数のドキュメントCompleting the Game(ゲームの完成)
・Reactではpropsがイベントを表す際のの命名にはon[Event]を使用し,関数がイベントハンドルとなる場合の命名はhandle[Event]にするのが慣例
・不変性は大事.不変にすることでコンポーネントがいつ再レンダリングするかが分かりやすくなるため.
Reactのパフォーマンス最適化ドキュメント・レンダリングのみを書き状態を持たないようなものは関数型のコンポーネントにするのがより簡単な方法
Adding Time Travel(履歴機能の実装)
・keyはReactの予約語となっている特別なプロパティで要素が作られるたびにReactが記録し,コンポーネントの管理に使用される.keyが無くなればコンポーネントは破棄されるし,コンポーネントのkeyを変更すればそのコンポーネントは破棄されて新しいのが出来る.またkeyは隣接するコンポーネント間でユニークであればいい.
・map関数,各要素に対して順番に一度づつ実行[currentValue, index(処理番号)]の引数.
Map関数のドキュメント感想
初めて英語の公式チュートリアルを体験してみましたが,Google大先生が有能すぎてとても楽に読めました!今後は英語の記事でも恐れずにどんどん読んでいきたい!
公式のドキュメントとあって,コードがとても綺麗だった.またJSの基本なども色々細かく書いてあったので本当に勉強になった.
誤字や誤表記,解釈違いなどございましたらコメントをくれると幸いです。