- 投稿日:2019-02-15T23:09:42+09:00
Django SQLite3からMySQLへの移行
まえがき
いままでデータベースはsqliteを使っていましたが、MySQLの勉強も兼ねて移行してみました。
初投稿のため読みづらいと思いますがお許しください。環境
- ubuntu18.04
手順
1.mysqlのインストールとセットアップ
$ sudo apt install mysql-server mysql-clientインストールが完了したら、以下のコマンドでパスワードなどを設定する。基本的には「y」でOK
$ sudo mysql_secure_installationユーザの作成
$ sudo mysql -u root -p mysql> create user ユーザ名@ホスト名 identified by 'password';
- 'ユーザ名'@'ホスト名'のように表す。基本的にはlocalhostで良いはず。
- @以下を省略すると、'ユーザ名'@'%'となり、どのホストからも接続できる。
文字コードをUTF-8にする
/etc/mysql/mysql.conf.d/mysqld.cnfファイルの[mysqld]セクションに以下を追加する。
character-set-server = utf8 default_password_lifetime = 0 #パスワードの有効期限をも無効にするMySQLを再起動する
$ sudo systemctl restart mysql文字コードを確認する
mysql>show variables like '%char%'; +--------------------------------------+----------------------------+ | Variable_name | Value | +--------------------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | | validate_password_special_char_count | 1 | +--------------------------------------+----------------------------+2.データベース作成
データベースを作成
rootでログインしておく
mysql>create database データベース名権限付与
mysql> grant all on データベース名.* to ユーザー名@localhost identified by 'パスワード';
- 指定したデータベースの全権限をそのユーザに追加する
3.sqlite3のデータを抜き出す
Djangoプロジェクトに移動する。
$ python manage.py dumpdata > dump.jsonこれでdump.jsonにデータが書き出される。
4.DjangoでMySQLを使う準備
settings.pyを変更
データベースの設定を変更する。
# Database # https://docs.djangoproject.com/en/2.1/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'データベース名', 'USER': 'ユーザ名', 'PASSWORD': '', } }manage.pyを変更
- 本番環境でも使用する場合は同様にwsgi.pyにも以下のモジュールをインポートする必要がある
#!/usr/bin/env python import os import sys import pymysql # 追加 pymysql.install_as_MySQLdb() # 追加 if __name__ == '__main__': os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'mysite.settings') try: from django.core.management import execute_from_command_line # 中略PyMySQLをインストール
$ pip install PyMySQLmigrate実行
$ python manage.py migrate5.MySQLにデータを入れる
さっき準備したdump.jsonを使ってデータを入れる。
このときにMySQLの文字コードをutf-8にする前にloaddataをすると文字コードのエラーが出るので注意!
その場合は、データベースをもう一度作れば大丈夫
$ python manage.py loaddata dump.json参考
- 投稿日:2019-02-15T22:39:04+09:00
SQLの集計結果をクロス表に変形するrubyスクリプト
はじめに
SQLでクロス集計形式にするのって結構大変ですよね?
ということで、単純なSQLの集計クエリの結果をクロス集計に変形するrubyスクリプトを作りました。https://bitbucket.org/cnaos/cross-tab/overview
使い方
SQLの集計結果をTSVファイルとして出力したファイルを
パイプでcross-tab.rbに食わせると
クロス集計型に変形して標準出力に出力します。cat sample.tsv | ./cross-tab.rbサンプルとして使うデータ
mysqlのSakila Sample Databaseのpaymentテーブルのデータを使います。
https://dev.mysql.com/doc/sakila/en/sakila-structure-tables-payment.htmlpaymentテーブルmysql> desc payment; +--------------+----------------------+------+-----+-------------------+-----------------------------+ | Field | Type | Null | Key | Default | Extra | +--------------+----------------------+------+-----+-------------------+-----------------------------+ | payment_id | smallint(5) unsigned | NO | PRI | NULL | auto_increment | | customer_id | smallint(5) unsigned | NO | MUL | NULL | | | staff_id | tinyint(3) unsigned | NO | MUL | NULL | | | rental_id | int(11) | YES | MUL | NULL | | | amount | decimal(5,2) | NO | | NULL | | | payment_date | datetime | NO | | NULL | | | last_update | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | +--------------+----------------------+------+-----+-------------------+-----------------------------+ 7 rows in set (0.00 sec)例1:集計項目が1つだけの場合
paymentテーブルのデータをpayment_dateで日付ごとに集計して、
staff_idごとにその日の支払い件数の合計を出します。サンプルクエリ1SELECT DATE_FORMAT(payment_date,'%Y-%m-%d') date, staff_id, count(*) FROM payment GROUP BY date,staff_id;クエリ結果1(抜粋)+------------+----------+----------+ | date | staff_id | count(*) | +------------+----------+----------+ | 2005-05-24 | 1 | 4 | | 2005-05-24 | 2 | 4 | | 2005-05-25 | 1 | 73 | | 2005-05-25 | 2 | 64 | | 2005-05-26 | 1 | 96 | | 2005-05-26 | 2 | 78 | | 2005-05-27 | 1 | 84 | | 2005-05-27 | 2 | 83 | | 2005-05-28 | 1 | 119 | | 2005-05-28 | 2 | 77 |サンプルクエリ1の結果をTSVファイルに出力したのが、sample-data/sample1.tsv です。
sample-data/sample1.tsvdate staff_id count(*) 2005-05-24 1 4 2005-05-24 2 4 2005-05-25 1 73 2005-05-25 2 64 2005-05-26 1 96 2005-05-26 2 78 2005-05-27 1 84 2005-05-27 2 83 2005-05-28 1 119 2005-05-28 2 77このファイルを作成したcross-tabスクリプトに通すと以下のようになります。
head -11 sample-data/sample1.tsv | ./cross-tab.rb処理結果1date 1_count(*) 2_count(*) 2005-05-24 4 4 2005-05-25 73 64 2005-05-26 96 78 2005-05-27 84 83 2005-05-28 119 77例2:集計項目が2つある場合
例1では
payment_dateで日付ごとに集計して、
staff_idごとにその日の支払い件数の合計を出しましたが、
さらに支払い金額(amount)の合計も集計したくなったとしましょう。集計用のクエリを以下のように変更しました。
サンプルクエリ2SELECT DATE_FORMAT(payment_date,'%Y-%m-%d') date, staff_id, count(*), sum(amount) FROM payment GROUP BY date,staff_id;クエリ結果2(抜粋)+------------+----------+----------+-------------+ | date | staff_id | count(*) | sum(amount) | +------------+----------+----------+-------------+ | 2005-05-24 | 1 | 4 | 15.96 | | 2005-05-24 | 2 | 4 | 13.96 | | 2005-05-25 | 1 | 73 | 323.27 | | 2005-05-25 | 2 | 64 | 250.36 | | 2005-05-26 | 1 | 96 | 401.04 | | 2005-05-26 | 2 | 78 | 353.22 | | 2005-05-27 | 1 | 84 | 357.16 | | 2005-05-27 | 2 | 83 | 328.17 | | 2005-05-28 | 1 | 119 | 480.81 | | 2005-05-28 | 2 | 77 | 323.23 |サンプルクエリ2の結果をTSVファイルに出力したのが、sample-data/sample2.tsv です。
このファイルも同様にcross-tabスクリプトに通すと以下のようになります。
head -11 sample-data/sample2.tsv | ./cross-tab.rb処理結果2date 1_count(*) 1_sum(amount) 2_count(*) 2_sum(amount) 2005-05-24 4 15.96 4 13.96 2005-05-25 73 323.27 64 250.36 2005-05-26 96 401.04 78 353.22 2005-05-27 84 357.16 83 328.17 2005-05-28 119 480.81 77 323.23
- 投稿日:2019-02-15T19:40:52+09:00
MySQLで該当DBの全`table create statement`を出力する
訂正
コメントで @akinomyoga さんに指摘していただいた部分を取り込みました。
本文
MySQLで該当DBの全
table create statementを出力する方法を探したが、どうやらループでmysql回すしかないらしく、苦手なshell scriptを書いた。mysql-all-statement#!/usr/bin/env bash function usage { cat <<EOF $(basename "${0}") is a tool for print all tables create statement Example: $(basename "${0}") -p -h localhost -u root master_database > report.txt Usage: $(basename "${0}") [-p password] [mysql options] [database] Options: --help print this. -p, --password database password. If password is not given it is asked from the tty. mysql options: other options see "mysql --help" EOF } case ${1} in --help|-help|'') usage exit ;; -p|--password) if [[ ${2} == -* ]]; then read -sp "Password:" PASSWORD 2> /dev/tty echo > /dev/tty else PASSWORD=${2} shift fi shift ;; esac if [[ -z ${PASSWORD} ]]; then SCRIPT_MYSQL="mysql $@" else SCRIPT_MYSQL="mysql -p\"\${PASSWORD}\" $@" fi LIST=(`echo "SHOW TABLES" | eval "${SCRIPT_MYSQL}" 2> /dev/null`) if [[ ${LIST} != Tables_in_* ]]; then echo "mysql command error: run \`${SCRIPT_MYSQL}\`" >&2 exit 1 fi for t in "${LIST[@]:1}" do echo "SHOW CREATE TABLE $t\G" | eval "${SCRIPT_MYSQL}" 2> /dev/null done基本的にはMySQLで既存のテーブルのCREATE文を取得: Usoinfo blogのコードをベースに汎用的にしただけです。
-pオプションだけ先頭に書かないといけないというなんともスマートじゃない感じになってしまったので、そこだけご注意を。もっと色々セフティー作れる気がするんですが、とりあえずのツールなのでここまで。
何か他にいい方法や、こここうしたら?みたなのがあればコメントください。
- 投稿日:2019-02-15T15:52:09+09:00
SQLの基礎の基礎
はじめに
SQLについて学習したので、これまでに学んだ知識をまとめました。
学習した事
- MySQLのインストール
- MySQL Workbenchの使用方法
- SQL構文の基本の使い方
今回は、SQL構文の基本の使い方について、自分用メモと知識定着の目的で書きました。訂正箇所などありましたら、ご指摘いただけると幸いです。
SQLの基本
- SQLは大文字と小文字を区別しない
- 文字と日付はシングルクォーテーションで囲う
データ型
テーブルを作成する時に、それぞれのカラムに指定した形式のデータしか入力できないように設定する。この時指定するデータの形式をデータ型という。
データ型名 データ種別 int型 数値型 整数 tinyint型 数値型 -128〜127 char型 文字列 固定長の文字列255文字まで varchar型 文字列 可変長の文字列255文字まで text 文字列 長い文字列65535文字まで date型 日付 1000-01-01〜9999-12-31まで datetime型 日付・時刻 00:00:00.000000〜23:59:59.999999 time型 時刻 838:59:59〜838:59:59 集約関数
集約関数ではnullは基本的に無視されるが、
COUNT(*)とする事でnullを含めたレコードを数える。
関数 意味 COUNT テーブルのレコード数を数える SUM カラムの数値を合計する AVG カラムの数値を平均する MAX カラムの中の最大値を求める MIN カラムの中の最小値を求める SQL文の記述順序と実行順序
記述順序 実行順序 SELECT FROM FROM JOIN JOIN WHERE WHERE GROUP BY GROUP BY HAVING HAVING SELECT ORDER BY ORDER BY LIMIT LIMIT in演算子・・・ ある値が値セット内に含まれているかどうか。
not in演算子・・・ ある値が値セット内に含まれていないかどうか。テーブル操作
CRUD
CRUDとは(Create, Read, Update, Delete)のこと。
SQLではこの4つの処理を
- Create = INSERT
- Read = SELECT
- Update = UPTATE
- Delete = DELETE
の構文で操作する。
テーブルの作成
CREATE TABLE [テーブル名]( 列名 [データ型] [その他の記述], 列名 [データ型] [その他の記述], 列名 [データ型] [その他の記述] );テーブルにデータの追加
INSERT INTO [テーブル名](列1,列2,列2) VALUES(値1,値2,値3);この時、列と値の数が一致している必要がある。
複数行を一度に追加する場合は、それぞれが括弧で囲まれ、カンマで区切られた、カラム値の複数のリストを記入していく。INSERT INTO [テーブル名](列1,列2,列2) VALUES(値1,値2,値3),(値1,値2,値3),(値1,値2,値3);列の追加
ALTER TABLE [テーブル名] ADD [追加する列名] [データ型] AFTER [列名];列名の変更
ALTER TABLE [テーブル名] CHANGE [旧列名] [新列名] [データ型];データの取得(SELECT)
SLECT ・・・ カラムの指定 FROM ・・・ 対象テーブルの指定 JOIN ・・・ テーブルの結合 WHERE ・・・ 絞り込み条件の指定 GROUP BY ・・・ グループ化の条件の指定 HAVING ・・・ グループ化した後の絞り込み条件を指定 ORDER BY ・・・ 並び替え条件を指定 LIMIT ・・・ 取得する行数を指定例 adventurerテーブル
id name sex lv mp job 1 山田 man 20 40 戦士 2 鈴木 woman 30 230 魔法使い 3 田中 man 40 280 僧侶 4 小野 woman 50 360 魔法戦士 5 佐藤 man 40 200 レンジャー 6 西野 woman 70 220 パラディン WHERE句
SELECT name, lv FROM adventurer WHERE name = '鈴木';実行結果
name lv 鈴木 25LIKE
ワイルドカード文字で文字列のパターンを指定する事ができる。
- '山%' → '山'で始まる文字列
- '%山' → '山'で終わる文字列
- '%山%' → '山'を含む文字列
- '__山' → 何かしらの2文字で始まり、'山'で終わる文字列
jobに戦士の文字列を含む情報を取得
SELECT * FROM adventurer WHERE job LIKE '%戦士%';実行結果
id name sex lv mp job 1 山田 man 20 40 戦士 4 小野 woman 50 360 魔法戦士サブクエリ
鈴木さんよりもmpが高い人の名前を取得
SELECT name FROM adventurer WHERE mp > (SELECT mp FROM adventurer WHERE name = '鈴木');実行結果
name 田中 小野CASE
CASE式を使う事で条件分岐を指定する事ができる。
lvが60以上なら'A'
lvが40以上なら'B'
lvが40未満なら'C'SELECT name, CASE WHEN lv >= 60 THEN 'A' WHEN lv >= 40 THEN 'B' ELSE 'C' END AS ranking FROM adventurer;実行結果
name ranking 山田 C 鈴木 C 田中 B 小野 B 佐藤 B 西野 AGROUP BY句
性別毎のレベルの平均を取得
SELECT sex, AVG(lv) FROM adventurer GROUP BY sex;実行結果
sex lv man 50 woman 75ORDER BY句
並び替え条件を指定する。複数条件を指定する時は、,区切りで指定する。
ASC・・・昇順(デフォルト)
DESC・・・降順lvが高い順に並び替え。lvが同じ場合はid順。
SELECT * FROM adventurer ORDER BY lv DESC, id ASC;実行結果
id name sex lv mp job 6 西野 woman 70 220 パラディン 4 小野 woman 50 360 魔法戦士 3 田中 man 40 280 僧侶 5 佐藤 man 40 200 レンジャー 2 鈴木 woman 30 230 魔法使い 1 山田 man 20 40 戦士LIMIT句
取得する行数を指定する事ができる。
SELECT * FROM adventurer ORDER BY lv DESC, id ASC LIMIT 3;実行結果
id name sex lv mp job 6 西野 woman 70 220 パラディン 4 小野 woman 50 360 魔法戦士 3 田中 man 40 280 僧侶データの更新(UPDATE)
UPDATE [テーブル名] SET [変更したい列名] = ['新しい値'] WHEREで条件指定;データを削除(DELETE)
DELETE FROM [テーブル名] WHERE [条件];データベース操作
データベース接続
mysql -u root -pMySQL起動
mysql.server startMySQL終了
mysql.server stopMySQLの状態確認
mysql.server statusデータベースの作成
CREATE DATABASE [作成するデータベース名];データベースの命名ルール
- 半角のアルファベット a,b,cなど
- 半角の数字 1,2,3など
- アンダースコア _
- 名前の最初は半角のアルファベット
データベースの削除
DROP DATABASE [削除したいデータベース名];データベースの一覧表示
SHOW DATABASES;使用しているデータベースの確認
SELECT DATABASE();使用するデータベースの選択
USE [データベース名];
- 投稿日:2019-02-15T15:27:56+09:00
laravelでmysqlのjson型の扱いかた
json型の扱いについてまとまったページがあまりなかったので書くことにしました。
・・・いまだに苦しめられています。環境
larave5.7
Mysql5.71.データベースにjson型を含むテーブルをmigrationで作成するとき
public function up() { Schema::create('members', function (Blueprint $table) { $table->uuid('id'); $table->string('name', 100); $table->json('data')->nullable(); // ココ $table->timestamps(); $table->primary('uuid'); }); }※注意
なんと、Mysql5.7のJson型は初期値を設定できない仕様になっています・・・!(MariaDBは初期値OK)
$table->json('data')->default('{"title":1,"permission":[1,2]}');というかんじに書いてたらmigrate実行時にエラーが出ました。
MariaDBで開発してるけどリリース先の環境はMysqlって場合は特に気をつけてください。(もちろんDB揃えられるなら揃えてください!)2.データベースにデータを入れるとき
こちらにすでに書かれてましたhttps://qiita.com/kamikosi/items/7d4135ce74de8b91e721
$data = [ [ 'title' => 1, 'permission' => [ 1, 2, ], ], [ 'title' => 2, 'permission' => [ 1, 2, ], ] ]; $member = new Member; $member->data = $data; // ココ $member->save();※注意
$member->data = json_encode($data);と書くとstringとしてデータが入ってしまう。
↓がそのjson_encodeしてしまったデータ。
"{\"permission_list\":[{\"title\":\"2\",\"permission\":[\"1\",\"3\"]}],\"admin\":false}"
JSON_UNESCAPED_UNICODEオプションを付けても両端の"はのこってしまうので
json型として取得できなくなってしまう。。。3.データベースからデータを取得するとき
参考:https://qiita.com/pinekta/items/93c9c427ccc22df578a5
まず、モデル側に$castsを設定する。
class Member extends Eloquent { protected $casts = [ 'json_column' => 'json', // ココ ]; }$castsについてはjson型だけでなく、データをDBから取得するときの型を設定できるものなので
知っておくと応用がききそうです。つぎにそのモデルを使ってデータを取得します。
$member = Member::find($id); // $member->dataにはjsonが連想配列として保存されている $data_permission = isset($member->data['permission']) ? $member->data['permission'] : null ;$castsによってjson型データが連想配列として取得できるようになっているので
$member->data['permission']のように取得できる。
json objectとしてデータベースに入れていても、取得すると連想配列になっているのでネスト地獄に注意。。。(絶賛苦戦中)また1.の注意欄でも書いた通り、初期値設定ができないので
特定のキーが存在するかどうかのチェック(こちらではissetを使用)が必要です。
まだまだlaravel, MysqlのJson型については勉強中の身ですので
「こうすれば{もっとかんたんだよ|できるよ}」などのご意見をいただけましたら幸いです。
- 投稿日:2019-02-15T14:11:02+09:00
booked2.7.2から2.7.4へ
オープンソースの予約管理システムBookedのバージョンを2.7.2から2.7.4に変更するためのメモ
今後のバージョンアップのためにもちゃんと書く。
https://www.bookedscheduler.com/ちなみにWindowsね
準備
ダウンロード
上記サイトのDownloadから最新版のzipをダウンロードする。Windowsサーバで展開する。
旧: "C:\Apache24\htdocs\booked"
新: "C:\Apache24\htdocs\booked274"
こんな構成にしておく。導入
httpd.confの加工
これが大本
\Apache24\conf\httpd.confAlias /booked "C:/Apache24/htdocs/booked" <Directory "C:/Apache24/htdocs/booked"> <RequireAny> Require local Require ip xxx.xxx.xxx.xxx </RequireAny> </Directory>大雑把に動くやつを作って挿入
\Apache24\conf\httpd.confAlias /booked274 "C:/Apache24/htdocs/booked274" <Directory "C:/Apache24/htdocs/booked274"> Order allow,deny Allow from all </Directory>config.phpを作る
config.dist.phpをリネームして作る。修正したところだけ抜粋
\Apache24\htdocs\booked274\config\config.php*/ $conf['settings']['default.timezone'] = 'Asia/Tokyo'; // look up here $conf['settings']['default.language'] = 'ja_jp'; // find your language in the lang directory $conf['settings']['script.url'] = 'http://exsample.com/booked274/Web'; // public URL to the Web directory of this instance. this is the URL that appears $conf['settings']['database']['name'] = 'booked';ひとまずこれで検証できるようになった。
追記smtpを設定した
「パスワードを忘れました」で検証するときは、登録してあるアドレスを指定しないと飛んでくれないのがハイライト
$conf['settings']['phpmailer']['mailer'] = 'smtp';
$conf['settings']['phpmailer']['smtp.host'] = 'smtp.example.co.jp';
$conf['settings']['phpmailer']['smtp.port'] = '25';
$conf['settings']['phpmailer']['smtp.secure'] = '';
$conf['settings']['phpmailer']['smtp.auth'] = 'false';
$conf['settings']['phpmailer']['smtp.username'] = '';
$conf['settings']['phpmailer']['smtp.password'] = '';
$conf['settings']['phpmailer']['sendmail.path'] = '/usr/sbin/sendmail';
- 投稿日:2019-02-15T14:10:27+09:00
Windows MySQL 5.7.11から5.7.25でハマった
バージョンアップだから簡単だと高をくくってた。
バックアップをとっておく。
backup.batmysqldump -a --user=root --password=hoge_pw --all-databases > all_databases.mysqlアンインストールせずにインストーラーを起動して進めると、既存のパスワードを入力するところで躓いた。何入れても入らない。
いろいろと試しているとコマンドプロンプトでmysqlにログオンできない。サービスも動かない。
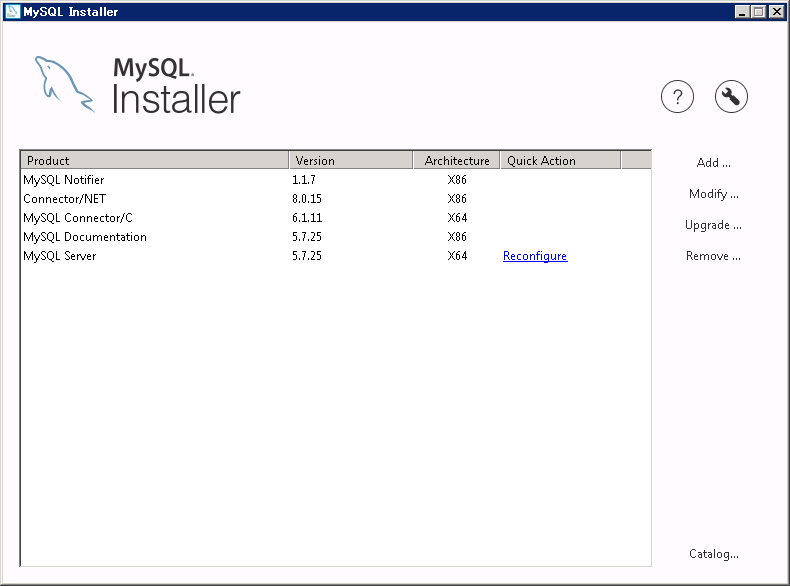
どうにもならないので、MySQL Server5.7.25をremoveした。
どこにいったMySQL 5.7.25
なぜかMySQL8.0しか現れない。
other releaseを選択する
でた!
無事にインストール完了した。
リカバリ
実行してみる。
C:\Users\Administrator\Documents\mysql_backup>mysql -u root -p < all_databases.mysqlインポート完了後にrootでログイン、データベースが復元されているのを確認した。
ワードプレスがつながらない
ブラウザでレイアウトは表示されるが、wordpressが「データベース接続確立エラー」を表示させている。
wp_userでログインを試す。
```mysql -u wp_user -p
```
パスワードが違うとなる。phpMyAdminで変更を試すがエラーになった。
コマンドで対処する方法を見つけた。
```
mysql> SET PASSWORD FOR wp_user@localhost = PASSWORD('password');
ERROR 1133 (42000): Can't find any matching row in the user tablemysql> grant all on . to wp_user@localhost identified by 'password';
Query OK, 0 rows affected (0.00 sec)mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)mysql> set PASSWORD for wp_user@localhost = PASSWORD('password');
Query OK, 0 rows affected, 1 warning (0.00 sec)
```これで表示されるようになったー!


- 投稿日:2019-02-15T13:08:48+09:00
MySQLのフィールドにおいて、長い文字列=TEXT型と安易に考えてはいけない
wysiwygエディタで入力したhtmlをデータベースに保存するというのはよくあるケースではないかと思います。
今回は、エディタを保存するフィールドを何も考えずTEXT型にしてしまうと、不具合になるかもよ!というお話です。ある日のテストで、登録処理を通ったのにエディタに何も出てこない不具合を発見。
- ログにエラーは吐かれていない。
- エディタを外しても現象は再現する。
- 別所で同じエディタを使っている所は通るし、中身も出る。
phpから取ったsqlを投げてみると
error 1406 - Data too long for column指定のフィールドを見てみると途中でエディタに入力した内容が途切れていました。
よくよく見ると、中身が出たデータも途中で切れています。根本的な原因
TEXT型の最大値の量を超えたため。
MySQL 5.6 リファレンスマニュアルには最大長が 65,535 (216 − 1) 文字の TEXT カラム。値にマルチバイト文字が含まれる場合、有効な最大長は少なくなります。各 TEXT 値は、値のバイト数を示す 2 バイト長のプリフィクスを使用して格納されます。
とあるので、日本語だと4万文字もあればキャパオーバーしそうです。
なぜ真っ白に?
入っているデータの出だしは以下の通り。[{"craft":"<p>boss<\/p>\r\n","~json_encodeされていますね。
途中で途切れた結果、閉じ括弧がなくjson_decodeが出来なかったのでしょう。なぜ正常に通ってしまったのか
SQLを抽出してMySQLで投げると通らないパターンがちょいちょいあります。大体NULL関係と文字長さで引っかかるんですが。。。
フレームワークによるものなのか何なのか、詳しい方是非ご教授お願いいたします。対策
きちんと使用目的に合った型を宣言する事。
今回はどれだけの長さになるか想定できないので対象のフィールドをLONGTEXT型とし解決しました。
それだけでなくquery長(SQL文の文字数)にも制限があるので注意。
詳しくはmax_allowed_packetなどで検索検索ゥ!
最大文字数に合わせて各input項目にバリデーションがあると尚良いかなと思います!決してTEXT型に限ったお話でもないので、皆様もサイレント文字数カットによる不具合にお気をつけ下さい。
- 投稿日:2019-02-15T13:08:48+09:00
MySQLで長い文字列=TEXT型と安易に考えてはいけない
wysiwygエディタで入力したhtmlをデータベースに保存するというのはよくあるケースではないかと思います。
今回は、エディタを保存するフィールドを何も考えずTEXT型にしてしまうと、不具合になるかもよ!というお話です。ある日のテストで、登録処理を通ったのにエディタに何も出てこない不具合を発見。
- ログにエラーは吐かれていない。
- エディタを外しても現象は再現する。
- 別所で同じエディタを使っている所は通るし、中身も出る。
phpから取ったsqlを投げてみると
error 1406 - Data too long for column指定のフィールドを見てみると途中でエディタに入力した内容が途切れていました。
よくよく見ると、中身が出たデータも途中で切れています。根本的な原因
TEXT型の最大値の量を超えたため。
MySQL 5.6 リファレンスマニュアルには最大長が 65,535 (216 − 1) 文字の TEXT カラム。値にマルチバイト文字が含まれる場合、有効な最大長は少なくなります。各 TEXT 値は、値のバイト数を示す 2 バイト長のプリフィクスを使用して格納されます。
とあるので、日本語だと4万文字もあればキャパオーバーしそうです。
なぜ真っ白に?
入っているデータの出だしは以下の通り。[{"craft":"<p>boss<\/p>\r\n","~json_encodeされていますね。
途中で途切れた結果、閉じ括弧がなくjson_decodeが出来なかったのでしょう。なぜ正常に通ってしまったのか
SQLを抽出してMySQLで投げると通らないパターンがちょいちょいあります。大体NULL関係と文字長さで引っかかるんですが。。。
フレームワークによるものなのか何なのか、詳しい方是非ご教授お願いいたします。対策
きちんと使用目的に合った型を宣言する事。
今回はどれだけの長さになるか想定できないので対象のフィールドをLONGTEXT型とし解決しました。
それだけでなくquery長(SQL文の文字数)にも制限があるので注意。
詳しくはmax_allowed_packetなどで検索検索ゥ!
最大文字数に合わせて各input項目にバリデーションがあると尚良いかなと思います!決してTEXT型に限ったお話でもないので、皆様もサイレント文字数カットによる不具合にお気をつけ下さい。
- 投稿日:2019-02-15T10:27:55+09:00
Wercker × parallel_tests
why
Wercker上でのspecテスト完遂に35分ほど要するが、その時間を短縮して開発効率を改善したい。
※Wercker:Oracle提供のCIツール
what
テストを並列実行する。
how
環境Ruby:2.2.3 Rails:5.0.0.1 RSpec:3.5.2 sqlite:1.3.13local開発環境での実行
テスト並列実行用のgem "parallel_tests" を導入。
gemfileに parallel_test を追加。Gemfilegroup :development, :test do ... gem 'parallel_tests' ... endgemパッケージをインストール。
$ bundle install
config/database.ymlに追加config/database.ymltest: database: yourproject_test<%= ENV['TEST_ENV_NUMBER'] %>テスト用DB:yourproject_testの複製
config/database.ymlの設定に応じてDBを作成。$ bundle exec rake parallel:create RAILS_ENV=testschemaコピー
$ bundle exec rake parallel:prepare[4]rpsec_test実行
$ bundle exec rake parallel:spec[4]※
[]は並列実行させるプロセス数Wercker環境での実行
Wercker の docker内で複数DB作成
- 投稿日:2019-02-15T10:27:55+09:00
[WIP] Wercker × parallel_tests
why
Wercker上でのspecテスト完遂に35分ほど要するが、その時間を短縮して開発効率を改善したい。
※Wercker:Oracle提供のCIツール
what
テストを並列実行する。
how
環境Ruby:2.2.3 Rails:5.0.0.1 RSpec:3.5.2 MYSQL2:0.4.5local開発環境での実行
テスト並列実行用のgem "parallel_tests" を導入。
gemfileに parallel_test を追加。Gemfilegroup :development, :test do gem 'parallel_tests' endgemパッケージをインストール。
$ bundle installtest用DB名に テスト環境変数 を追加
config/database.ymltest: database: yourproject_test<%= ENV['TEST_ENV_NUMBER'] %>テスト用DB:yourproject_testの複製
config/database.ymlの設定に応じてDBを作成。$ bundle exec rake parallel:create RAILS_ENV=testschemaコピー
$ bundle exec rake parallel:prepare[4]rspec_test実行
$ bundle exec rake parallel:spec[4]※
[]は並列実行させるプロセス数Wercker環境での実行
WerckerのdockerコンテナにDB作成
wercker.ymlservices: - id: mysql:<version> env: MYSQL_USER: *** # DBのuser名 MYSQL_PASSWORD: *** # DBのpassword MYSQL_DATABASE: *** # DBの名前後の
rails-database-ymlコマンドはservices/envプロパティで指定した内容のdatabase.yml(DB名、ユーザー名、パスワードのDB)を作成。build: steps: - rails-database-ymlWerckerの同一dockerコンテナでDB複製
Initializing a fresh instance
When a container is started for the first time, a new database with the specified name will be created and initialized with the provided configuration variables. Furthermore, it will execute files with extensions .sh, .sql and .sql.gz that are found in /docker-entrypoint-initdb.d. Files will be executed in alphabetical order. You can easily populate your mysql services by mounting a SQL dump into that directory and provide custom images with contributed data. SQL files will be imported by default to the database specified by the MYSQL_DATABASE variable.コンテナーが初めて開始されると、指定された名前の新しいデータベースが作成され、提供されている構成変数で初期化されます。 さらに、/ docker-entrypoint-initdb.dにある拡張子.sh、.sql、および.sql.gzのファイルを実行します。 ファイルはアルファベット順に実行されます。
というわけで、
/docker-entrypoint-initdb.dにSQLファイルを置いたりすればいい感じにできます。
が、SQLファイルでは、MYSQL_DATABASEに指定したDBに対してダンプファイルを流すだけですので、他のDBを作ったりすることはできません。wercker.ymlservices: - id: mysql:*.*.** volumes: - "./mysql:/var/lib/mysql" - "./mysql/init:/docker-entrypoint-initdb.d" env: MYSQL_ROOT_PASSWORD: *** MYSQL_USER: *** MYSQL_PASSWORD: ***DB は
1_create_db.sqlにて作成1_create_db.sqlcreate database test_db1; create database test_db2;file_organization.+ docker-compose.yml +- mysql +- init + 1_create_db.sql参考