- 投稿日:2021-04-05T23:26:34+09:00
カードを集めるプログラム
あなたは友達に勧められて、とあるカードゲームを始めることにしました。 そのカードゲームには、カード番号 1 から M までの M 種類のカードがあります。 あなたは完璧主義者なので、どうしても M 種類全てのカードが欲しくなり、カードを N 枚買いました。 さあ、買ってきた N 枚のカードを順番に開けていきましょう! 開けたカードのカード番号が順番に与えられるので、M 種類そろったのは何枚開けたときかを出力するプログラムを書いて下さい。 以下は入力例 1 を図示したものです。 解き方のポイント ポイントは「カードの種類が揃った」という条件をどのようにして表現するか。 今回は配列にあらかじめ、総種類の枚数を入れておき、cardsとcardの番号を照らし合わせて同じ番号があったら配列からデリートしていく。 if文で配列の中身が無くなった時にブロック変数の「i + 1」で数を出力し、exitで繰り返し処理をストップさせる。 また、「unlucky」の出力は、真偽値を用いて行う。 コード例 N, M = gets.chomp.split(' ').map(&:to_i) cards = Array.new flag = false M.times do |i| cards << (i + 1) end N.times do |i| card = gets.to_i cards.delete(card) if cards == [] puts i + 1 flag = true exit end end puts 'unlucky' if flag == false
- 投稿日:2021-04-05T23:11:07+09:00
Railsチュートリアル(第4版)のHerokuへのデプロイで Couldn't find Active Storage configuration in /app/config/storage.yml (RuntimeError)と出てきて困った話
Railsチュートリアル(第4版)に取り組む際に発生したエラーについての備忘録。 ログから発見した内容 Couldn't find Active Storage configuration in /app/config/storage.yml (RuntimeError) と出てきた。 ディレクトリを見ても、/app/config/storage.ymlなんてファイルは存在しないので困ってしまった。 Railsのバージョンがおかしかった→バージョンを5.1.6に直して解決 調べてみると、storage.ymlというものはactivestorageなるものを利用するときに必要なものらしい? activestorageはRailsチュートリアル第4版では利用していないのでここでエラーが起こっているようだ。 railsのバージョンを見てみると、5.1.6ではなかった。 $ rails --version Rails 6.1.3 Gemfileのバージョンしてが悪そうだったので、 Gemfile(before) gem 'rails', '>=5.1.6' Gemfile(after) gem 'rails', '5.1.6' こうした。この後、bundle update bundle installして、コミット後にHerokuにプッシュしたところ上手くいった。 結論:チュートリアルのバージョンと手元のバージョンが違うとおかしくなることがある バージョン管理の必要性を感じた、、、 おまけ ちょっと役にたったこと $ heroku run rails console と実行すると、本番環境でrails consoleが見れる。 しかも、バグっているときはバグった際のエラーコードを表示してくれた(初学者のため正式な動作は把握していません)。 heroku logs --tailsやるよりも見やすいかもしれない。
- 投稿日:2021-04-05T22:08:16+09:00
Rails jQueryが動かないときの解消方法
はじめに Railsにてポートフォリオ作成中に、 jQueryが機能しないことがあり苦戦した為、まとめます。 実装した機能(一部紹介) ・slick(スライド機能) ・jp_prefecture(住所自動入力機能) ・iTyped(タイピングアニメーション) ・ScrollTop(ページトップにスクロールするボタン) ・ScrollReveal(要素のアニメーション表示) など 開発環境 ・ruby: 2.6.3 ・rails: 5.2.5 ・OS: macOS Catalina ver10.15.7 ・Cloud9 前提条件 ・jQueryのコードはしっかり書いている(間違いなし) 【ここが1番ポイントかも】 ・ページをリロードした時はちゃんと動く ・別ページからリンクで飛んでくると動かない 原因 Rails4以降に導入されたTurbolinksが原因だった。 これが原因でjQueryのreadyイベントが着火しないらしい。 Turbolinksとは 簡単に言うと、ページ遷移を高速化させる仕組み ※公式より Turbolinksを用いた画面遷移の順番 1:リンクのクリックイベントが発火する 2:画面遷移を阻害し、非同期でリクエストを送る 3:レスポンスとしてHTMLを返す 4:headタグに含まれているJSとCSSが、現在のページと一致しているかチェック 解決方法 解決方法は2つ 1:turbolinks: loadを使ってjsファイルを書きかえる 2:Turbolinksを機能として停止させる turbolinks: loadを使ってjsファイルを書きかえる方法 $(function () { 〜の部分を $(document).on('turbolinks:load', function() { 〜に書きかえる jsファイル. /* 変更前 */ $(function () { // 処理 }); /* 変更後 */ $(document).on('turbolinks:load', function() { // 処理 }); これだけ!簡単! Turbolinksを機能として停止させる方法 1:Gemfileの以下の記述をコメントアウトする Gemfile. gem ‘turbolinks’, ‘~> 5’ 2:読み込み ターミナル. bundle install 3:app/javascript/packs/application.jsの該当箇所をコメントアウトする application.js require('turbolinks').start() 4:app/views/application.html.erbの該当箇所を消す(headタグ内) application.html.erb <!--変更前--> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> <!--変更後--> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application' %> <!--javascript~の部分の消した箇所はここ!--> 'data-turbolinks-track': 'reload' これで解決! 僕は1の方法が早くて楽だったので1で解決しました! さいごに コードは合っているはずなのになぜ動かない・・・ そんなこんなで1時間ほど時間を無駄にしてしまいました。 今後、私のようにこの問題にぶち当たった人が、 この記事見つけ、早めに問題を解決してくれたら幸いです。 ポートフォリオ作りながら、Qiita発信両立するのは難易度高い...。 誤字、誤った記述等ありましたら、コメントよろしくお願いします。
- 投稿日:2021-04-05T20:34:48+09:00
railsにおける画像の配置場所とそれぞれの違い
本記事の内容 本記事はraiilsにおける画像の配置場所とその違いについてまとめた記事です。間違い等ございましたら、お手数ですがご指摘いただけますと幸いです。 画像の配置場所 下記の2箇所が画像データの配置場所となります。 app/assets/imagesディレクトリ public/imagesディレクトリ 違いは?(パスの記述) 画像を読み込む際のパスが異なります。 具体的には以下の様な違いがある。 app/assets/imagesディレクトリ <%= image_tag('hoge.png')> public/imagesディレクトリ <%= image_tag('/hoge.png')> アセットパイプライン Ruby on Railsのアプリケーション内で使用したいJavaScriptやCSS、画像ファイルを「開発作業がしやすいようにファイルを分割してコーディングができるようにしつつ、最終的に一つのファイルに連結・圧縮する」仕組みのこと。だそうです。 webブラウザは一つのwebページを表示するために複数のファイルを結合する機能が備わっていないため、開発環境において複数のディレクトリに跨って開発されたものを本来1ページとして表示できない。 これを解決するのがアセットパイラインである。 まとめ ざっくりと概要を掴む感じで書いてみました。 まだまだ知識不足ですので、色々記事を読みながら学習していきます。 参考にした記事
- 投稿日:2021-04-05T19:06:52+09:00
[自分メモ] Railsのコマンド関連のメモ
概要 最近Railsを初めて触ったので、Railsコマンドを忘れないようにメモします。 コマンド API作成 rails new sample --api Webサーバー起動 rails server コントローラ作成 rails g controller sample モデル作成 rails g model sample コントローラ削除 rails destroy sample ルーティング表示 rails routes DB 作成 rails db:create マイグレーション rails db:migrate ロールバック rails db:rollback gemのインストール bundle install テスト実行(RSpec) bundle exec rspec 参考文献 Railsで超簡単API 【Rails】Rails6でAPIモードの環境構築をしっかりやる
- 投稿日:2021-04-05T16:38:01+09:00
【Rails】RailsアプリをGitでバージョン管理し、Herokuにデプロイ
前提 ■あくまで個人の備忘録。見やすは非重視 ■データベースは以下の設定にて記述 ・開発環境/テスト環境:SQLite3 ・本番環境:PostgreSQL ■Heroku CLI、Gitへの会員登録が完了している ※完了していない場合は以下サイトで登録する Heroku CLI、Git ■Ruby、Railsがインストールがされている ※されていない場合はコチラでインストール Gitインストール こちらのサイトで順を従ってインストールを行う ※本記事ではWindows10の64bitなのでそれに応じたインストーラーを使用 Herokuインストール こちらのサイトで順を従ってインストールを行う ※本記事ではWindows10の64bitなのでそれに応じたインストーラーを使用 使用するデータベースをインストール それぞれ、下記サイトにてインストーラーをダウンロードし、順に従ってインストールを行う 開発、テスト環境:SQLite3 本番環境:PostgreSQL Railsアプリの作成 アプリ作成 Railsアプリを新規作成します。 ※データベースはデフォルトのSQLite3で作成するが、任意で変更 コマンドプロンプト $ rails new (アプリケーション名) 作成後アプリケーションディレクトリへ移動しておく Gemfile設定変更 開発環境・テスト環境・本番環境で分けて使用できるようにGemfileを以下のように変更 Gemfile ....(省略) ## コメントアウト # Use sqlite3 as the database for Active Record # gem 'sqlite3', '~> 1.4' ....(省略) group :development, :test do # Call 'byebug' anywhere in the code to stop execution and get a debugger console gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] ## 追加 gem 'sqlite3' end ## 追加 group development do gem 'pg' end ....(省略) 変更したGemfileを反映するため以下のコードを実行 コマンドプロンプト $ bundle install database.ymlの設定変更 database.yml ....(省略) production: <<: *default adapter: postgresql encoding: unicode pool: 5 Gitの設定 以下を最初の1度のみ実行 コマンドプロンプト $git init 以下で保存ファイルを選択(今回は全てを保存するコマンドを使用) コマンドプロンプト $git add -A 以下でコミット コマンドプロンプト $git commit -m "ログに記載する説明をここに記載" ※最初のコミット時にはGitのアカウント情報を求められるが 登録、または登録予定があれば以下で設定してからコミット、そうでないなら無視でOK コマンドプロンプト $git config --global user.email #Gitのメールアドレス $git config --global user.name #Gitのユーザ名 Heroku Herokuの設定 以下でパッチ設定を行う コマンドプロンプト $echo 'PATH="/user/local/heroku/bin:$PATH"' >> ~/.profile 以下でHerokuのパッチが通っているか確認 コマンドプロンプト $heroku -v バージョンが出てくればOk Herokuへログイン コマンドプロンプト $heroku login 以下のようにHeroku CLIのアカウント情報を求められるので該当の情報を入力 ※最初の一度だけ求められる Enter your Heroku credentials: Email:○○○○○○@○○○○○○ Password:************* Login in as ○○○○○○@○○○○○○ 2度目以降は以下が表示される $heroku login heroku: Press any key to open up the browser to login or q to exit: この場合は、[Enter]キー押下でブラウザーが開き、[q]キーでキャンセル [Enter]キーを押下した場合は以下のようなページに遷移されるので、[Log In]を押下でログインされる。 Heroku アプリの作成 $heroku create (アプリ名) アプリ名の指定条件は以下となる。 ・半角英数字のみ ・記号は「-」のみ Herokuへデプロイ 以下のコマンドでデプロイする $git push heroku master ※上記のみでは完了していないので注意 デプロイの確定をするには以下のコマンドを実行 $heroku run rails db:migrate デプロイコマンド実行した際に、最後に表示された以下のようなアドレスが、アプリURLとなる。 https://○○○○○○○○.herokuapp.com/ 上記URLでサイトにアクセスしデプロイが完了しているのを確認する 補足 アプリの更新時は以下を行う コマンドプロンプト $git add -A(または指定のファイル) $git commit -m "メッセージを記入" $git push heroku master $heroku run rails db:migrate #テーブルの更新があった場合のみ スペック情報 OS:Windows10Pro 64bit IDE:Visual Studio Code Ruby:2.7.2p137 Heroku:7.51.0 git:2.30.1 SQLite3:3.34.1 PostgreSQL:13.0
- 投稿日:2021-04-05T16:07:30+09:00
Ruby on Railsの基本について
概要 RailsはRubyで最もメジャーなフレームワークでRubyによるWebアプリ開発に 特化した言語である。 Railsには理念が二つの理念が存在する。 一つはDRY(Don't Repeat Yourself)。 直訳すると「同じことを繰り返すな」で(自分なりに)意訳すると 「いろいろなところに同じコードを書かず共通となるコードは流用しろ」となる。 Rubyは少ない記述で様々な機能を実現できる特徴があるので、 このDRYの理念に沿っていると言える。 もう一つはCOC(Convention Over Configuration) 直訳は「設定より規約を優先しろ」。 RailsはWebアプリを開発するに際して必要だが、手間となる初期作業(DB設定,etc)などを 予め規約として定義しているため、そういった手間を省くことでより効率的に Webアプリ開発を行うことができる。 考え方 MVCモデルを採用している。それぞれざっくり解説していく。 * Model(モデル) RailsにおけるDB(データベース)へのアクセスといった情報のやり取りを司っている。 そのためモデルがないとテーブルをRailsで管理できない。 1テーブルに対してテーブルを管理するために1モデルが存在する。(1:1の関係) View(ビュー) Railsがブラウザに対してユーザーにレスポンスするページを指す。 貴方が今ブラウザで見ているページがRailsにおけるビューとなる。 Controler(コントローラー) Rails ⇔ ユーザー間のリクエスト・レスポンスを司っている。 「あれやって、これやって」と指示している上司のようなイメージ。 コントローラーにはRailsにおけるデータの表示や保存、削除といった処理を 行う「7つのアクション」というものが存在する。 最後に 今回、初めてQiitaに投稿しましたが正直にいって自分がQiitaのような不特定多数が 閲覧できる場に記事を投稿するなんて想像していませんでした。 極力、簡素に分かりやすく書いているつもりですがこうして人に見せる記事を書いていくことで 自分の中にある知識などをより上手く言語化できるようになれたらと思います。 数年後の自分がこの記事を読み返したら「下手だったな〜」と笑えるくらい成長できるように 精進していきたいと思います。
- 投稿日:2021-04-05T15:40:30+09:00
[RailsAPI x React]環境構築する方法
作成経緯 RailsAPIモード使い方をまとめたかったので作成してます。備忘録なので所々違うかもしれません。 もっといい方法があればぜひ参考にしたいと考えています。今回はローカルで動くようにしていますので 本番環境では動きません。 RaislAPI作成 $ rails new アプリ名 --api Gemfile gem 'rack-cors' #コメントアウトを外してbundle installする config/initializers/cors.rb #コメントアウトを外す Rails.application.config.middleware.insert_before 0, Rack::Cors do allow do origins 'http://localhost:3001' #変更します。 #origins 'example.com' #'http://localhost:3001'許可する resource '*', headers: :any, methods: [:get, :post, :put, :patch, :delete, :options, :head] end end モデル作成 $ rails g migration モデル名 $ bundle exec rails db:migrate 普段と変わらないのでいつも通り作成してください。 ルーティング作成 config/routes.rb Rails.application.routes.draw do #----------ここから---------------- namespace :api do namespace :v1 do resources :todos, only: %i[index show create update destroy] end end #----------ここまで追加------------- end バージョン管理する時にnamespaceを使うと便利なので分けています。 コントローラ作成 app/controllers/api/v1/todos_controller.rb class Api::V1::TodosController < ApplicationController def index todos = Todo.order(updated_at: :desc) render json: todos end def show todo = Todo.find(params[:id]) render json: todo end def create todo = Todo.new(todo_params) if todo.save render json: todo else render json: todo.errors, status: 422 end end def update todo = Todo.find(params[:id]) if todo.update(todo_params) render json: todo else render json: todo.errors, status: 422 end end def destroy if Todo.destroy(params[:id]) head :no_content else render json: { error: "Failed to destroy" }, status: 422 end end private def todo_params params.require(:todo).permit(:name, :is_completed) end end 今回はJSON形式でデータを返すだけです。 destroyは返すデータがないためheadを使っています。 headについてはRailsガイド確認 controllerの書き方Part2 app/controllers/api/v1/todos_controller.rb module Api module V1 class TodosController < ApplicationController def index todos = Todo.all render json: { todos: todos }, status: :ok end end end end module ディレクトリ〜end囲んでもnamespace使うことが出来ます。 React作成 アプリの直下でReactのアプリ作成する。 $ npx create-react-app front $ cd front $ npm install react-router-dom $ npm install axios $ npm start Reactの初期画面が出ていることを確認します。 $ mkdir src/urls $ touch src/urls/index.js src/urls/index.js const DEFAULT_API_LOCALHOST = 'http://localhost:3000/api/v1' export const todosIndex = `${DEFAULT_API_LOCALHOST}/todos` axiosで通信するものを定数で定義します。 src/apis/todos.js import axios from 'axios'; import { todosIndex } from '../urls/index' export const fetchTodos =() => { return axios.get(todosIndex) .then(res => { return res.data //通信成功 }) .catch((e) => console.error(e)) //通信失敗 } axios.getでHTTPリクエストをしています。 通信に成功した場合は.then()なり、通信に失敗・例外の場合は.catch()になります。 作成した関数fetchTodos()呼び出したら'http://localhost:3000/api/v1/todosを呼び出し、JSON形式でデータが返って来ます。 .then(res => { return res.data //通信成功 }) resの中にデータが入り、returnでres.dataデータだけ返しています。 import React, { Fragment, useEffect } from 'react'; import { fetchTodos } from '../apis/todos'; export const Todos = () => { useEffect(() => { fetchTodos() .then((data) => console.log(data) ) }, []) return ( <Fragment> Todo一覧 </Fragment> ) } rails側でrails sをし、localhost:3000立ち上げ、 front側でnpm startします。localhost:3000はrailsで使用しているためlocalhost:3001で立ち上げます。 これで環境構築は完成していると思います。 毎回、railsとreactを両方立ち上げるのがめんどくさいので 今後の目標はDockerで環境構築したいと考えています。
- 投稿日:2021-04-05T15:39:53+09:00
Rubocopの導入
Rubocopの導入について Rubocop(ルボコップ)はRubyの静的コード解析ツール。 「インデントが揃っていない」「余分な改行やスペースがある」などの指摘をRubyStyleGuideに基づいて行ってくれる。 Rubocopを導入することにより、レビューにかかる時間を減らし、コードの品質を担保できるようになる。 ターミナル上で、 ターミナル #Rubocopを実行 % bundle exec rubocop と実行するだけで、ターミナル上に吐き出してくれる。 Rubocopの導入 まずは、Gemfileに以下を追記。 Gemfile group :development do gem 'rubocop', require: false end 次に「bundle install」を実行 ターミナル % bundle install すると、以下のファイルが作成される .rubocop.yml 次にRubocopの設定を記述するファイルを新規作成する。 ターミナル % touch .rubocop.yml 次にRubocopの設定を行う。 .rubocop.yml AllCops: # 除外するディレクトリ(自動生成されたファイル) # デフォルト設定にある"vendor/**/*"が無効化されないように記述 Exclude: - "vendor/**/*" # rubocop config/default.yml - "db/**/*" - "config/**/*" - "bin/*" - "node_modules/**/*" - "Gemfile" # 1行あたりの文字数をチェックする Layout/LineLength: Max: 130 # 下記ファイルはチェックの対象から外す Exclude: - "Rakefile" - "spec/rails_helper.rb" - "spec/spec_helper.rb" # RSpecは1つのブロックあたりの行数が多くなるため、チェックの除外から外す # ブロック内の行数をチェックする Metrics/BlockLength: Exclude: - "spec/**/*" # Assignment: 変数への代入 # Branch: メソッド呼び出し # Condition: 条件文 # 上記項目をRubocopが計算して基準値を超えると警告を出す(上記頭文字をとって'Abc') Metrics/AbcSize: Max: 50 # メソッドの中身が複雑になっていないか、Rubocopが計算して基準値を超えると警告を出す Metrics/PerceivedComplexity: Max: 8 # 循環的複雑度が高すぎないかをチェック(ifやforなどを1メソッド内で使いすぎている) Metrics/CyclomaticComplexity: Max: 10 # メソッドの行数が多すぎないかをチェック Metrics/MethodLength: Max: 30 # ネストが深すぎないかをチェック(if文のネストもチェック) Metrics/BlockNesting: Max: 5 # クラスの行数をチェック(無効) Metrics/ClassLength: Enabled: false # 空メソッドの場合に、1行のスタイルにしない NG例:def style1; end Style/EmptyMethod: EnforcedStyle: expanded # クラス内にクラスが定義されていないかチェック(無効) Style/ClassAndModuleChildren: Enabled: false # 日本語でのコメントを許可 Style/AsciiComments: Enabled: false # クラスやモジュール定義前に、それらの説明書きがあるかをチェック(無効) Style/Documentation: Enabled: false # %i()構文を使用していないシンボルで構成される配列リテラルをチェック(無効) Style/SymbolArray: Enabled: false # 文字列に値が代入されて変わっていないかチェック(無効) Style/FrozenStringLiteralComment: Enabled: false # メソッドパラメータ名の最小文字数を設定 Naming/MethodParameterName: MinNameLength: 1
- 投稿日:2021-04-05T14:33:51+09:00
ちょっぴり疑り深い人のためのFaraday
この記事は サーバーサイドから外部APIを利用する場合、HTTP通信処理を書く必要がありますよね。 rubyでHTTP通信の処理を書こうと思いライブラリを検討したら、FaradayがデファクトスタンダードになりつつあるようだということでFaradayで書くことにしました。 rubyには標準ライブラリとしてNet::HTTPがありますが、rubyガチ勢は要件や好みに合わせて他のHTTP通信ライブラリ使い分けたりするらしいです。 https://blog.bearer.sh/top-ruby-http-client-gems/ Faradayはこうした各種ライブラリを共通コードで動かすラッパーとして作られたそうなのですが、 普通の使い方ならNet::HTTPで事足りる Net::HTTPは書き方が今風じゃなくてちょっと使いにくい ということでFaradayの採用例が増えるのは納得です。 APIへのアクセスは最低限 ヘッダを指定する POSTやPATCHの場合、ボディを指定する urlを指定する メソッドを指定する リクエストを実行する レスポンスからボディを取り出してパースする の6ステップをコードすればOKですが、実運用では以下3点がポイントになってくるかと思います。 想定外のレスポンスで後続処理がバグらないこと 一時的高負荷が原因の場合、リトライを行なって完了できること 最終的に失敗した場合、後から調査できること 3点挙げましたが、全部エラーハンドリングに関係するところですね。 HTTP通信は案外とエラーの種類が多くなる処理です。今回はちょっぴり疑り深い人がざっくりエラーハンドリングをFaradayの機能で実装していきます。 まず、どんなエラーが起こるのか まずHTTP通信の流れを確認すると大体こんなイメージです。 外部通信のためのTCPソケットを作成 TCPソケットから外部APIサーバー(のTCPソケット)へ接続確立 HTTPリクエスト抽送 外部APIサーバーでリクエスト内容を評価、レスポンス作成 HTTPレスポンスを受信 では、ここからそれぞれの段階でどんなエラーが起きるのか考えてみます。 「外部通信のためのTCPソケットを作成」時のエラー ファイルシステムの書き込みエラーとかでしょうか。多分SocketなんちゃらとかPermissionなんちゃらとかOSなんちゃらみたいなエラーが出ると思いますが、これは多分開発時に気がつくと思います。ということでパス。 「TCPソケットから外部APIサーバーへ接続を確立」時のエラー まず最初にDNSでAPIサーバーのIPを探す必要がありますが 内部ネットワーク上のAPIの場合、DNSで見つからない インターネット上のAPIの場合、外までの経路が見つからずグローバルDNSが探せない といったトラブルがあります。あるいはプロキシを使ってインターネットに出る場合 プロキシのIPがDNSで見つからない プロキシの認証に弾かれる ことも起こります。 rubyの場合、通信自体の処理はC言語依存のライブラリで処理しているようなのでシステムコールでエラーが発生し、ruby側では"Errno:XXXXX"のような形式でraiseされるか、接続経路が見つからないとかプロキシの認証エラーとか、あとは単純に接続失敗やタイムアウトのエラーとして上がってくる予感がします。ソケットエラーとかもあるかもしれません。 「HTTPリクエスト抽送」時のエラー 1つはSSLのエラーがありそうです。rubyって確かopensslとかrubyのビルド時に取り込んでいたと思うので、環境を変更した時とかに結構SSL周りのエラー見ますよね。 この辺はSSLエラーとか、もし専用のエラークラスがなければ接続失敗やタイムアウトになりそうです。 あとはクライアントの実装によっては特定のヘッダをブロックするとかがあるかもしれませんね(確か、perlのNet::SMTPなんかはメールのfromに適当を書くと接続失敗を返す気が。ややこしい。) Faradayは特になさそうな気がしますが。 「外部APIサーバーでリクエスト内容を評価、レスポンス作成」時のエラー このステップは時間がかかるので、この間にあちこちで起こるタイムアウトに注意です。 クライアント側のライブラリがタイムアウトと判断した場合はErrno:ETIMEDOUTとかクライアント実装のtimeout系でしょう。一方タイムアウトがゲートウェイで発生した場合は例外がraiseされずに、HTTPステータスコードが502や504が返ってくる事が多いです。 また、基本的にはAPI実装側の問題ですが、APIがさらに他のAPIやデータベースに接続してタイムアウトとするとAPIの処理中で例外になり、これがハンドリングされていないとHTTPステータスコード500が返る可能性もあります。 また、外部APIに不具合があって失敗した場合はHTTPステータス500、リクエストがAPI仕様に合わない場合は400(Bad Request), 401(Not Authorized), 403(Forbidden), 404(Not found)あたりを返してくるはずです。 「HTTPレスポンス受信」時 基本的にこの段階ではステータスコード200番台が返ってきているはずで、エラーが起こるとすればHTTPクライアントから受け取った自身のコードで戻り値を評価するまでエラーにはならないはずです。 API側を開発中にJSONの形式をミスっていて、フロント側の人から「パース失敗するんですけど何スか?」と言われたことはあります。すみません。 各言語のJSONとオブジェクトを変換するライブラリをデフォルト設定で使っていれば大体バグらないはずですよね、あれってなんで起きたんだっけな。。。 タイムアウトの発生ポイント 先ほどタイムアウトについて「あちこちで起こる」と書きましたが、実際タイムアウトの発生箇所は多いです。これは各々のシステムやライブラリが自身の処理のハング防止にタイムアウトを設定しているためです。(古いライブラリとか低層だとタイムアウト機能ががなくて乙ったりするみたいですが) タイムアウトの発生箇所をまとめてみます。 クライアント側 TCPソケット作成〜ソケット削除 →ソケットタイムアウト 接続処理開始orTCPソケット作成〜接続確立 →接続タイムアウト 接続確立orリクエスト送信〜レスポンス受信 →リードタイムアウト 外部API側 ゲートウェイサーバ: リクエスト受信〜レスポンス送信 →ゲートウェイタイムアウト APIサーバー: リクエスト受信〜レスポンス送信 クライアント側は設定変更で解決可能なので、見分けられるとメンテしやすいですね。 低層ではクライアント側のエラーは例外、外部API側のエラーはHTTPステータスコードと見分けがつきますが、Faradayがこれらをどう処理するのかは後で見てみましょう。 Faradayで実装 Faradayは実際にHTTP通信を行う別のライブラリをadapterと呼んでいます。標準ではNet::HTTPを利用しています。1 Faradayは通信処理中の例外とHTTPレスポンスを一旦まとめた上でadapterの実装とオプションから条件分岐させる設計になっており、処理が集約されたところにretry middlewareの処理を差し込むことで。リトライ処理が実装できるようになっているようです。 さて、通信の結果によって受信側が考えることは 成功なら、後続処理にレスポンスボディを渡したい リトライして次は成功する失敗なら、リトライしたい 完全に失敗なら、ログを残して後続がバグらないように完了したい retry middlewareを利用してこの3パターンに全ての事象を分岐させるとための実装を考えます。 設計の結論 出来上がった雛形コードが以下のものです。 get.rb ## APIに定義がないステータスが戻った場合のカスタム例外クラス ## class HttpStatusCodeException < StandardError end def url 'https://example.com/path/to/api' ## APIのURL end def api_data_format 'Application/json' ## JSONの場合 ## end def api_defined_status [200, 400, 500] ## API仕様にある全ステータス ## end ## ここまでは好きな書き方で ## 以下がFaradayを使ったHTTP通信実装に関わる部分 def common_retry_options { max: 10, interval: 0.5, interval_randomness: 0, backoff_factor: 0.25, exceptions: [ Errno::ETIMEDOUT, 'Timeout::Error',Faraday::TimeoutError, Faraday::ConnectionFailed, Faraday::ClientError, Faraday::RetriableResponse ] retry_statuses: api_defined_status, methods: [] } end def raise_unless_expected_status response unless api_defined_status.include? response.status logger.error(## エラーメッセージ ##) raise HttpStatusCodeException "Unexpected HTTP status: #{response.status}" end end def get connection = Faraday.new url do |conn| conn.headers = { Authorization: ENV['api_access_token'] ## APIのアクセストークンなど ##, Accept: api_data_format } conn.params = { key: value, } retry_options = common_retry_options retry_options[:retry_if] = ->(_env, _exc) { if ## リトライ対象にしたい条件 ## logger.warn(## 個別エラーメッセージ ##) true elsif ## リトライ対象にしたい条件 ## logger.warn(## 個別エラーメッセージ ##) true ## 中略 ## else false end } retry_options[:retry_block] = -> (_env, options, retries, _exc) { logger.warn(## 共通エラーメッセージ ##) } conn.request(:retry, retry_options) end response = connection.get raise_unless_expected_status(response) end def post connection = Faraday.new url do |conn| conn.headers = { Authorization: ENV['api_access_token'] ## APIのアクセストークンなど ##, "Content-type"=> api_data_format } retry_options = common_retry_options retry_options[:retry_if] = ->(_env, _exc) { if ## リトライ対象にしたい条件 ## logger.warn(## 個別エラーメッセージ ##) true elsif ## リトライ対象にしたい条件 ## logger.warn(## 個別エラーメッセージ ##) true ## 中略 ## else false end } retry_options[:retry_block] = -> (_env, options, retries, _exc) { logger.warn(## 共通エラーメッセージ ##) } conn.request(:retry, retry_options) end response = connection.post do |request| request.body = JSON.dump(## 記事オブジェクト ##) end raise_unless_expected_status(response) end ちなみにFaraday公式のドキュメントにあるRetry MiddlewareのUsageはもっと簡単に、以下のようなコードで書かれています。 retry_options = { max: 2, interval: 0.05, interval_randomness: 0.5, backoff_factor: 2 } conn = Faraday.new(...) do |f| f.request :retry, retry_options ... end conn.get('/') どうしてこれが長ったらしいコードのなったのでしょうか? なんかオプションに空配列を代入していたり、ちょっとエレガントとは言いにくいですね。 ですがこれが私の行きついた結論です。Faraday関連で調べると人によって導いた最適解が違い、それらも参考にしながら調べて考えたことを以下に書きます。 私の考え方を一言で言えば「全部retry_ifで処理する」です。 なぜretry_ifで処理するためにこのコードなのか? 初期状態での分岐 まずretry.rbのクラス宣言直後に DEFAULT_EXCEPTIONSという定数があって、ここで Errno::ETIMEDOUT 'Timeout::Error', Faraday::TimeoutError Faraday::RetriableResponse という3つのクラスと1つの文字列が設定されています。このうち Faraday::RetriableResponse はcallメソッドの中で retry.rb if @options.retry_statuses.include?(resp.status) raise Faraday::RetriableResponse.new(nil, resp) end とあります。 これはつまりretry_statusesにステータスコードを追加してやると、そのステータスコードが飛んできた場合強制的にraiseするためのカスタム項目です。 なのでデフォルトとしてはタイムアウト系の例外のみリトライ対象として評価されていて、その他の例外は外までキャッチされず例外でない場合は成功と同じになります。 全てのレスポンスをリトライ経路に合流させる retry middlewareのオプションにあるretry_statusesに設定されたステータスコードを持つレスポンスはリトライのルートに入っていきます。これを利用してAPIが仕様上返しうるステータスコードを全て登録してやるとAPIに異常がない限り全てのレスポンスがリトライのルートに入っていきます。 retry_statuses: api_defined_status ## APIが返しうるステータスコード全て ##, 同時に、ここに該当しないものは処理の最後で例外扱いにします。 def raise_unless_expected_status response unless api_defined_status.include? response.status logger.error(## エラーメッセージ ##) raise HttpStatusCodeException "Unexpected HTTP status: #{response.status}" end end 考えうる偶発的な例外もリトライ経路に合流させる デフォルトで設定されている Errno::ETIMEDOUT 'Timeout::Error', Faraday::TimeoutError 以外は本当に偶発的なエラーではなくリトライの価値がないのでしょうか? まずエラークラスを眺めてみます。error.rb、するとちょっと怪しそうなエラー ConnectionFailed が見つかります。リンクを辿ると各adapterのエラーハンドリングの過程でraiseされているのですが、どれもFaraday::TimeoutErrorと近いところにあります。 正確なことはわかりませんが、実際に動かすとConnectionFailedが偶発的に発生することが少なからずありました。 次に怪しいのは以下のエラーです。 ClientError 名前が汎用性を持っているだけに怪しさ満点です。アップデートで変更されたらしいですが過去には https://tech.toreta.in/entry/2019/12/03/172047 という事例もあり、Faradayの開発上このエラーは既存の割り当ての外でなんらか拾ってraiseしたい場合に使っている雰囲気があります。 ちなみにadapterの1つであるEventMachineのコードem_http.rbでも、エラー内容からTimeoutErrorやConnectionFailedと判断できなかったものはClientErrorとしてraiseされています。 em_http.rb def raise_error(msg) error_class = Faraday::ClientError if timeout_message?(msg) error_class = Faraday::TimeoutError msg = 'request timed out' elsif msg == Errno::ECONNREFUSED error_class = Faraday::ConnectionFailed msg = 'connection refused' elsif msg == 'connection closed by server' error_class = Faraday::ConnectionFailed end raise error_class, msg end ということで例外の設定を書き換えて、ConnectionFailedとClientErrorを追加します。 exceptions: [ Errno::ETIMEDOUT, 'Timeout::Error',Faraday::TimeoutError, Faraday::ConnectionFailed, Faraday::ClientError, Faraday::RetriableResponse ] メソッドでのリトライ判定を無効にする リトライ経路に入った処理はretry_ifより前にmethodsで評価されます。 retry.rb retry.rb rescue @errmatch => e if retries.positive? && retry_request?(env, e) retries -= 1 rewind_files(request_body) @options.retry_block.call(env, @options, retries, e) if (sleep_amount = calculate_sleep_amount(retries + 1, env)) sleep sleep_amount retry end end ... end ... def retry_request?(env, exception) @options.methods.include?(env[:method]) || @options.retry_if.call(env, exception) end retry middlewareのオプションにあるmethodsのデフォルト値に一般的なリクエストメソッド全てが登録されているため標準ではretry_ifを飛び越えてリトライされてしまいます。これをmethodsに空配列を代入することで無効化しました。 methods: [], なぜ全部retry_ifで処理したいのか? Faradayにはraise_error middlewareがあり、ステータスコード400番台や500番台をClientErrorに変換することができます。また、主要な400番台のエラーには個別の例外クラスが用意されています。 例えばretry middlewareのmethodsオプションを変更せずにraise_error middlewareを使うことで、400~699はリトライなしの失敗、200~399は成功とすることができます。 が、繰り返しですが500番台のエラーは実質タイムアウトであることも多く、例えばAWSのゲートウェイタイムアウトも502です。 また、ステータスコード200が成功というのは規約に過ぎないので「うちのAPIステータスコードは200で返すけど、ボディにstatusっていうキーがあるからそれで判定してね」みたいな実装もできないことはありません。 この辺を柔軟に設定しようとすると、Faradayの提供するオプションでは無理があります。 これがretry_ifに全て流し込む消極的な理由です。 積極的な理由もあります。 retry_ifはブロックを設定できる上に、内部でレスポンスや例外の内容を自由に取り出すことができるので、ログをさくっと書き出すのには便利だからです。 retry_if: ->(_env, _exc) { if ## リトライ対象にしたい条件 ## logger.warn(## 個別エラーメッセージ ##) true elsif ## リトライ対象にしたい条件 ## logger.warn(## 個別エラーメッセージ ##) true ## 中略 ## else false end }, retry_block: -> (_env, options, retries, _exc) { logger.warn(## 共通エラーメッセージ ##) } リトライ回数を出力したい場合や、共通のメッセージはretry_blockに書けますね。 あとがき ということでちょっぴり疑り深い人がさくっとFaradayでHTTP通信を実装する方法でした。 あとはretry_ifの中にAPIの仕様に応じて条件分岐を書き込んでいくだけです。 APIがきれいな実装だったら retry_if: ->(_env, _exc) { if _exc.is_a? Faraday::ClientError logger.warn(## 個別エラーメッセージ ##) false if !_exc.is_a? Faraday::RetriableResponse logger.warn(## 個別エラーメッセージ ##) true elsif [502, 504].includes _env.status logger.warn(## 個別エラーメッセージ ##) true else logger.warn(## 個別エラーメッセージ ##) false end } とかにしておいて、外で最終的に返ってくる例外をキャッチすればいいのかなと思います。 あ、ClientErrorは基本的にはログを見て解析するまでリトライしなくていいと思ってます。そんなに起きないはず。 疑り深くない人とか、めちゃくちゃ疑り深い人とか、あとコードの行数多いのが嫌な人には適さないかもしれません。 そもそもおかしいところがある、代案があるなどのコメントは随時お待ちしております。 と、思ったんですがgithubの最新コードはNet::HTTP::persistantになっていてNet::HTTP自体は直接使わないようにしている様子です。これはNet::HTTPに高速な通信方式を指定するためのラッパーとのこと。 ↩
- 投稿日:2021-04-05T12:08:30+09:00
heroku上にデプロイした後にDBの設定を変更した場合
DBを変更するとheroku上にデプロイできない 画像投稿アプリケーションを作成していた時に画像を1枚しか投稿できないことが不便だと感じ、複数枚投稿できるシステムに変更した。 その際にモデルでアソシエーション変更 tweet.rb has_one_attached :image 1枚のみでの前提だった上記のコードを以下のように変更 tweet.rb had_many_attached :images viewファイルやその他、複数枚での機能のため記述を変更。(ここではエラーに関係ないので割愛) ローカル環境では問題なく実装が完了! その後いつものデプロイの手順でgit push heroku masterを ターミナル上のアプリのディレクトリで入力。 ところが、いざheroku上で確認したらエラーが出てしまった? heroku上だと『あなたがオーナーならログでもっと情報を確認しましょう』的な意味合いの文が表示されている。 エラーログを確認しようとターミナルで以下のコマンドを入力 heroku logs --tail --app アプリ名 すると以下のエラーログを発見することができた! ActionView::Template::Error (Nil location provided. Can't build URI.) このエラー文の後にはviewファイルの画像を表示させるコードが並んでいた。推測するに画像のURIがないですよ。と言われているのだろう。ローカル環境では問題なく実装できていたためコードに誤りがあるとは考えにくい。ここで画像のデータベースの関係性の記述を変更したことを思い出す。heroku上でのデータベースリセットを行えば解決できそうだと推測できる。 ターミナル上でデータベースをリセットするコマンドを入力 heroku run rails db:drop db:create db:migrate すると上手くデータベースをリセットできていない? ターミナル上のログを確認すると以下のログを発見! If you are sure you want to continue, run the same command with the environment variable: DISABLE_DATABASE_ENVIRONMENT_CHECK=1 ログの記載は『もしこのコマンドを行いたいなら、DISABLE_DATABASE_ENVIRONMENT_CHECK=1 をつけてね』 と解釈できる。上記のログを検索すると使用方法が1発で分かった heroku run DISABLE_DATABASE_ENVIRONMENT_CHECK=1 rails db:drop db:create db:migrate heroku run の後に先程のコードを入れて再度実行! するとheroku上でも問題なく実行された? これから 今回初めてQiitaを使用したが、タイピングの遅さに加えて可読性のある解説を意識したら30分近く時間がかかった? エラー解決よりQiitaに記述する方が時間がかかるではないか!これじゃ作業が進まん!と思ったりもしたが同じエラーが起こった際に絶対に効率よく解決するために、アウトプットしていこうと思う。ログを文と書いてしまう等、プログラミング用語を上手く使用できない課題もあるが、アウトプットの数をこなして自身の課題解決に向けて頑張ろう! あとタイピングの練習にもなると思うのでこれからマイペースに時間のかかったエラーは投稿するぞーーーー?
- 投稿日:2021-04-05T11:51:03+09:00
ruby インスタンスの生成問題
初めに 初学者です。rubyの問題を自分なりに解説することによって定着させるのが目的です。間違いなどありましたらご指摘お願いします。 問題 クラスFruitを定義して以下のように出力してください。 採れたて新鮮な果実です リンゴは120円です オレンジは200円です イチゴは60円です 雛形 class Fruit def クラスメソッド # 正しくメソッドを定義した上で、ここに処理を記入してください end def initialize # ここに処理を記入してください end def インスタンスメソッド # 正しくメソッドを定義した上で、ここに処理を記入してください end end # 3つのインスタンスを生成してください # クラスメソッドを呼び出し、「採れたて新鮮な果実です」と表示してください # インスタンス毎にインスタンスメソッドを呼び出し、「【名前】は【価格】円です」と表示してください 解答 ではまずインスタンスの生成とインスタンス変数を定義します。 今回initializeメソッドが使用されています。initializeメソッドとはnewメソッドの引数を受け取ることができます。 そしてinitializeメソッドでインスタンス変数を作り、newメソッドで受け取った値を代入します。 class Fruit def クラスメソッド # ここに処理を記入してください end def initialize(name, price) @name = name @price = price end def インスタンスメソッド # 正しくメソッドを定義した上で、ここに処理を記入してください end end apple = Fruit.new("リンゴ", 120) orange = Fruit.new("オレンジ", 200) strawberry = Fruit.new("イチゴ", 60) 次にクラスメソッドfreshを定義します。 class Fruit def self.fresh puts "採れたて新鮮な果実です" end #以下省略 次にinitializeメソッドで作ったインスタンス変数を使用して、リンゴは120円ですと出力できるようにインスタンスメソッドを定義していきます。 #以下省略 def introduce puts "#{@name}は#{@price}円です" end #以下省略 ここまで書けたら定義したインスタンスメソッドとクラスメソッドを呼び出します。 class Fruit def self.fresh puts "採れたて新鮮な果実です" end def initialize(name, price) @name = name @price = price end def introduce puts "#{@name}は#{@price}円です" end end apple = Fruit.new("リンゴ", 120) orange = Fruit.new("オレンジ", 200) strawberry = Fruit.new("イチゴ", 60) Fruit.fresh apple.introduce orange.introduce strawberry.introduce ちょっと複雑に見えますが、クラスメソッドとインスタンスメソッドは呼び出す記述をしなければ何も起こりません。 よってクラス定義のあとに呼び出す記述をします。 今回ですと apple = Fruit.new("リンゴ", 120) 以降が呼び出す記述です。 apple = Fruit.new("リンゴ", 120) の記述でinitializeメソッドが呼ばれてインスタンス変数に値を代入。 Fruit.freshの記述でクラスメソッドが呼ばれて、puts "採れたて新鮮な果実です"が実行されます。 最後にapple.introduceの記述でintroduceメソッドが呼び出され、最初に作られたインスタンス変数が使用されるといった流れになります。
- 投稿日:2021-04-05T11:01:02+09:00
RSpecによるテストコードで使う各オブジェクトの説明
本記事について RSpecによるテストコードを実施する際に使用する各種オブジェクトの説明を本記事に載せております。 バージョン rubyのバージョン ruby-2.6.5 Railsのバージョン Rails:6.0.0 rspec-rails 4.0.0 describe ・describeとは、テストコードのグループ分けを行うメソッドです。 ・○○について記述するという意味で、テストコードの内容の説明をしています。 ・do〜endの間に入れ子構造をとることができます。 it ・itメソッドは、describeメソッド同様に、グループ分けを行うメソッドです。 ・itの場合はより詳細に、「describeメソッドに記述した機能において、どのような状況のテストを行うか」を明記します。 ・すなわち実行予定と結果の予想を示しています。 example ・exampleとは、itで分けたグループのことを指します。 ・itに記述した内容のことを指す場合もあります。 ・itに記述される内容の総称のことをいいます。 ・exampleの整理=itの内容の整理 bundle exec ・Gemの依存関係を整理してくれるコマンドです。 ・RSpecをはじめ、多くのGemはその他のGemと関係があり、互いに依存しています。 ・bundle execコマンドを用いてGemの依存関係を整理する必要があります。 rspec ・specディレクトリ以下に書かれたRSpecのテストコードを実行するコマンドです。 ・実行するファイルを指定することも可能です。 valid? ・valid?は、バリデーションを実行させて、エラーがあるかどうかを判断するメソッドです。 ・エラーがない場合はtrueを、ある場合はfalseを返します。 ・エラーがあると判断された場合は、エラーの内容を示すエラーメッセージを生成します。 expectation ・検証で得られた挙動が想定通りなのかを確認する構文のことです。 ・expect(X).to include(Y) 「Xの中にYという文字列が含まれているかどうか」 「Xの結果はYになる」という意味です。」 matcher ・意図したデータと実際のデータを比較して一致もしくは不一致という結果を返すメソッドです。 ・expectの中身と結果の繋がりを表現します。 ・matcherは、「expectの引数」と「想定した挙動」が一致しているかどうかを判断します。 ・expectの引数には検証で得られた実際の挙動を指定し、マッチャには、どのような挙動を想定しているかを記述します。 ・eqの場合はXがYに等しくなる include ・includeは、「expectの引数」に「includeの引数」が含まれていることを確認するマッチャです。 eq ・eqは、「expectの引数」と「eqの引数」が等しいことを確認するマッチャです。 errors ・Valid?にて判定後のエラーを表示するメソッド ・errorsは、インスタンスにエラーを示す情報がある場合、その内容を返すメソッドです。 ・確認にはrails cのコマンドをターミナル上で実行して行います。 full_messages ・生成されらエラ〜メッセージの中からエラ〜メッセージを出力するメソッドです(エラーの原因を可視化) ・エラーの内容から、エラーメッセージを配列として取り出すメソッドです。 rails_helper RailsにおいてRSpecを使う時に共通の設定ができるファイル build newメソッド(生成)と同様の意味 newではなくbuildを使用する理由 ・可読性の観点上使用する ・newメソッドを使用するとコードの記述数がかなり多くなるが、FactoryBot.build(:~)とすることで、コード量がかなりへる。 create buildとほぼ同じ働きをしますが、createの場合はテスト用のDBに値が保存されます。 FactoryBot テストデータの作成を手伝ってくれるgemのこと (インスタンスをまとめることができるgem) ・FactoryBotに情報が集約されている。 →コード量が減る。わかりやすい。FactoryBotを定義することにより1行で済む。 ・初めにFactorybotを定義しておくと、定義後転用できる。(共通化) before ・テストコードを実行する前に、セットアップを行うことができます。 ・beforeはアクションが実行される前に設定できます。 Faker ダミーデータを自動作成してくれるgem context(describeにネストして書く。入れ子構造。) 特定の条件を分ける。正常系と異常系を分ける。 describe 機能についての確認 context 状況についての確認 be_valid ・正常に完了することを判断。正常系と異常系両方使用します。 ・valid?メソッドの返り値が、trueであることを期待するマッチャです。 Request Spec ・RSpecが提供している、コントローラーのテストコードを書くために特化した手法です。 response ・リクエストに対するレスポンスそのものが含まれます。 HTTPステータスコード ・HTTP通信において、どのような処理の結果となったのかを示すものです。 以下ステータスコードの分類の詳細について記載があります。 status ・response.statusと実行することによって、そのレスポンスのステータスコードを出力できます。 body ・response.bodyと記述すると、ブラウザに表示されるHTMLの情報を抜き出すことができます。 System Spec ・System Spec(システムスペック)は結合テストコードを記述するための仕組みのことをいいます。 Capybara ・System Specを記述するために必要なGemです。 visit ・visit 〇〇_pathのように記述すると、〇〇のページへ遷移することを表現できます。 page ・visitで訪れた先のページの見える分だけの情報が格納されています。 have_content ・expect(page).to have_content('X')と記述すると、visitで訪れたpageの中に、Xという文字列があるかどうかを判断するマッチャです。 have_no_content ・文字列が存在しないことを確かめるマッチャです。 fill_in ・fill_in 'フォームの名前', with: '入力する文字列'のように記述することで、フォームへの入力を行うことができます。 find().click ・find('クリックしたい要素').clickと記述することで、実際にクリックができます。 change ・expect{ 動作 }.to change { モデル名.count }.by(1)と記述することによって、モデルのレコードの数がいくつ変動するのかを確認できます。 current_path ・現在いるページのパスを示します。 hover ・find('ブラウザ上の要素').hoverとすることで、特定の要素にカーソルをあわせたときの動作を再現できます。 have_link ・expect('要素').to have_link 'ボタンの文字列', href: 'リンク先のパス'と記述することで、要素の中に当てはまるリンクがあることを確認できます。 ・have_linkはa要素に対して用います。 have_no_link ・当てはまるリンクがないことを確認します。expect('要素').to have_no_link 'ボタンの文字列', href: 'リンク先のパス'と記述することで、要素の中に当てはまるリンクがないことを確認できます。 all ・all('クラス名')でpageに存在する同名のクラスを持つ要素をまとめて取得できます。 find_link().click ・a要素で表示されているリンクをクリックするために用います。 ・find_link('リンクの文字列', href: 'URL').clickといった形で使います。 ・find().clickと似ていますが、find_link().clickはa要素のみに対して用いることができます。 サポートモジュール 以下記事をご参考ください。 参考記事 以上です。
- 投稿日:2021-04-05T01:15:45+09:00
【rails】コントローラー名やモデル名をアプリ名と同じにして痛い目見たって話
こんばんは。
プログラミング初学者です。
現在、Ruby on Rails + Docker + MySQLでアプリの開発をしています。
そこであるエラーにハマり、数日奮闘した結果ようやく解消できたのでそのことをまとめました。発生したエラー
バイクのレビュー投稿アプリ(名前はBIKKE)を作成しており、そのレビューの投稿画面実装のためコントローラーを下記のように記載
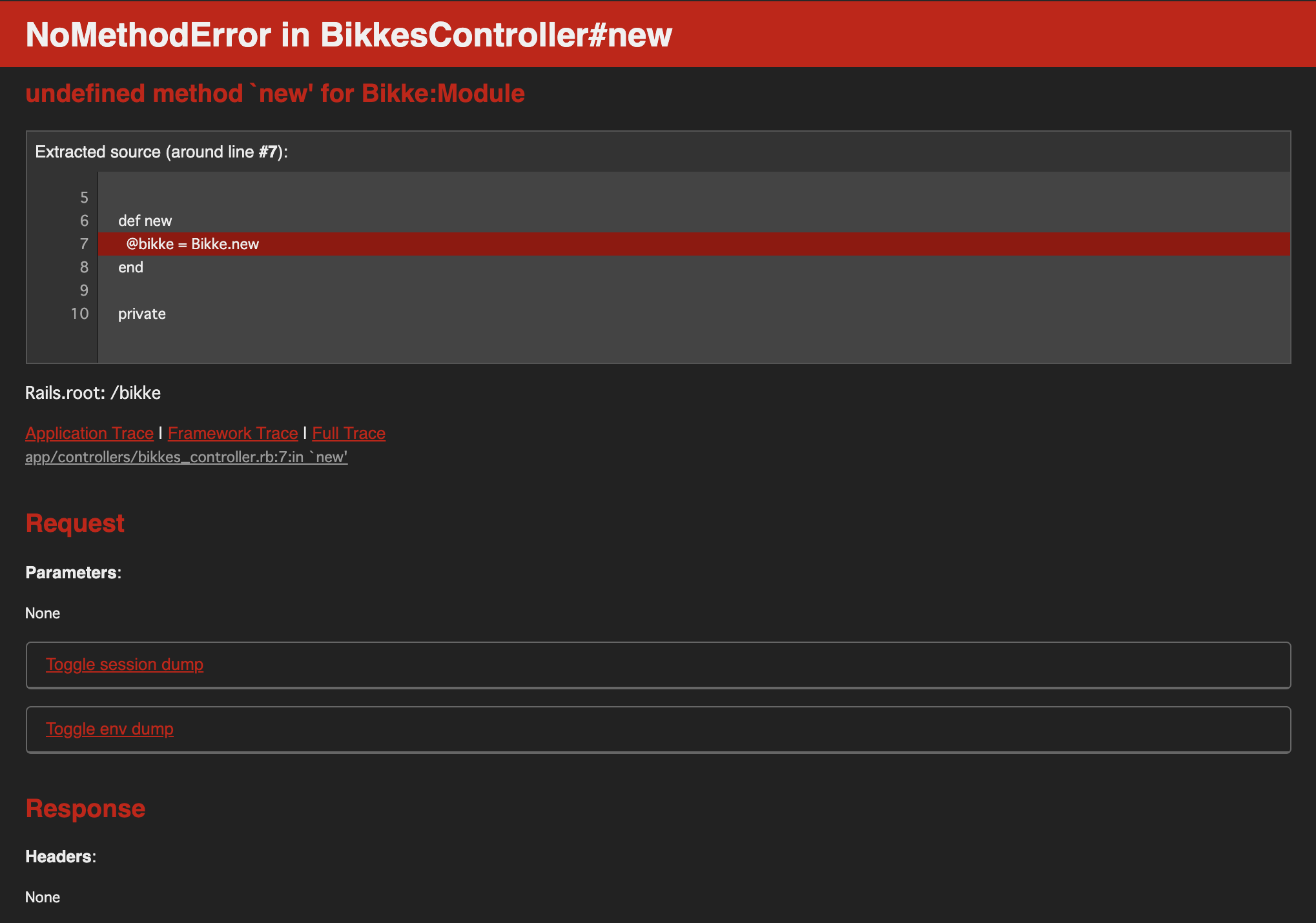
bikkes_controller.rbclass BikkesController < ApplicationController def index @user = User.new end def new @bikke = Bikke.new end endそして新規投稿画面に遷移すると、
NoMethodError!!!!!!しかもnewメソッドが!!??
なぜ!?モデルやマイグレーションファイルの記載に間違いはなし。
まさかnewメソッドがエラーとして返されるとは、その時想像もしておりませんでした。
解消
エラー画面を見てみると、下記文面が記載されています。
undefined method 'new' for Bikke:Module
このModuleがミソですね。
つまり、このBikkeというオブジェクトがクラスではなくメソッドとして認識されている、ということを表しています。
どこかにmodule Bikkeやclass Bikke::Somethingと定義されていないか確認を行いました。
※この解はTeratailにて先人エンジニアさんに教えていただきました。本当に感謝です。module Bikkeで検索をかけると、ありました。
config/application.rbmodule Bikke class Application < Rails::Application # Initialize configuration defaults for originally generated Rails version. config.load_defaults 6.1 # Configuration for the application, engines, and railties goes here. # # These settings can be overridden in specific environments using the files # in config/environments, which are processed later. # # config.time_zone = "Central Time (US & Canada)" # config.eager_load_paths << Rails.root.join("extras") # Don't generate system test files. config.generators.system_tests = nil end endつまり、railsは
rails newを行った時に、このapplication.rbでアプリ名をモジュールとして定義する仕様のようですね。そうです。私はアプリ名とコントローラー・モデル名を同じ名前にしてしまったのです。
コントローラーやモデル名の再構築、その他ファイルの修正を行い、再度新規投稿画面に移行すると無事遷移することができました。
学び
本件では、Module Bikkeと認識されていたため、newメソッドを使えるclass Bikkeが見えなくなっていたことがエラーの原因であることがわかりました。
そもそもnewメソッドとは何か?
→ActiveRecordメソッドの一つ
→ActiveRecordメソッドとはモデルがテーブル操作に関して使用できるメソッドの総称である。ここで、上記のコントローラーやモデルを
Reviewに変更したとしましょう。
rails cでコンソールを開き、下記コマンドを打ちます。[1] pry(main)> Review.superclass => ApplicationRecord(abstract)この
ReviewはApplicationRecordを継承していることがわかります。
さらに下記コマンドを打ち込みます。[2] pry(main)> ApplicationRecord.superclass => ActiveRecord::Baseつまり
ReviewはしっかりActiveRecord::Baseを継承しているからnewメソッド、そしてallメソッドやfindメソッド,saveメソッドなどが使えるのですね。ちなみに
[3] pry(main)> Bikke.superclass NoMethodError: undefined method `superclass' for Bikke:Moduleアプリ名はしっかりモジュールと定義されているため、
superclassメソッドも使えないのですね。
そして、[4] pry(main)> Module.superclass => Objectモジュールはオブジェクトを継承している・・・っ!
では、モジュールとクラスの違いは何なのでしょうか?
端的にいうと、
クラスはインスタンスの生成ができるのに対し、モジュールではできない。そしてクラスは継承していけるが、モジュールでは継承ができない。
厳密にはMix-inによってモジュールの機能をクラスに提供、いわば継承のようなことはできるようですが・・・。
ふんわりとした表現ですが、本件ではモジュールとクラスで継承しているものが独立しているため、使えるメソッドの違いがあり、エラーの発生に繋がったのだと考えます。
この辺はRubyの真髄でもあるのでより深ぼって理解を深めたいところですね。兎にも角にも一度作ったコントローラーやモデルの再構築は、ER図やREADMEの変更、その他ビューファイルの調整などあらゆる部分の編集に手間がかかって疲れた・・・。
しかし、非常に良い学びとなりました。ここまでご覧いただきありがとうございました。
- 投稿日:2021-04-05T00:25:00+09:00
Railsつまづいたこと ~webpackでの画像表示~
Webpackerでの画像表示ができない 開発環境は * Rails 6.0.3 * Ruby 2.7 * Webpacker 4.0 RailsのCSS,Javascript管理について Railsはバージョン5以前はSprocketsライブラリを使ってアセットパイプラインで(app/assetsフォルダで)CSSやJavascript、Imageを管理していたがバージョン6以後はWebpackerで(app/javascriptフォルダで)管理するようになった。 Rails newをした後、デフォルトでWebpackerが搭載されていてyarnでjqueryやbootstrapをインストールし、environment.jsにも設定を書いていざ画像を読み込む際にエラーがいくつも出てきてしまったのでここに殴り書きする。 エラー①CSS(bootstrap)が読み込めない 上記の手順ではまだbootstrapは読み込まない。webpackerを利用する際はbin/webpck-dev-serverコマンドを実行する必要がある。これはwebpackerでcssやjavascriptファイルのコンパイルを行いサーバーを起動するというもの。このコマンドとrails sの両方を実行する必要がある。 エラー②画像が読み込めない rails6ではデフォルトでwebpackerの利用を推奨しているが、画像の読み込みをする際はapp/javascript/packsフォルダにあるapplication.js内のconst images = ....の部分のコメントアウトを外さなければならない。