- 投稿日:2021-04-05T22:57:47+09:00
PythonスクリプトをDockerコンテナ化して、世界にこんにちは、する
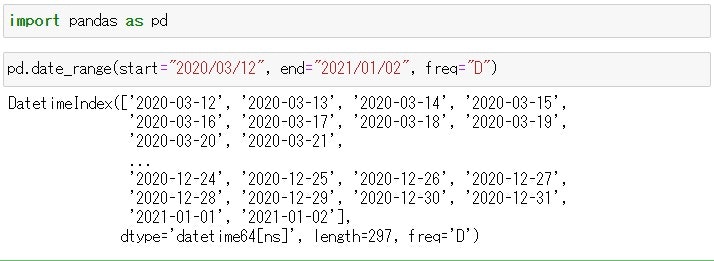
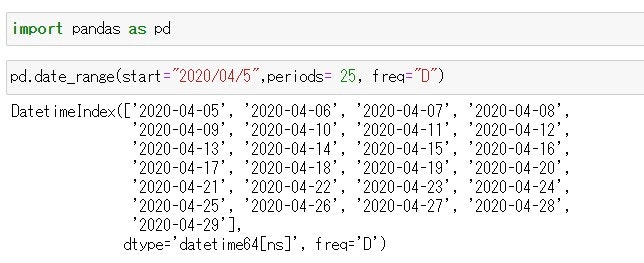
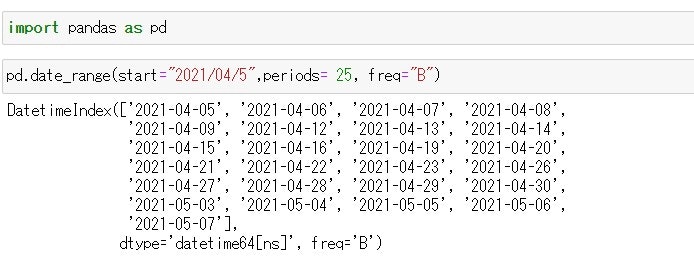
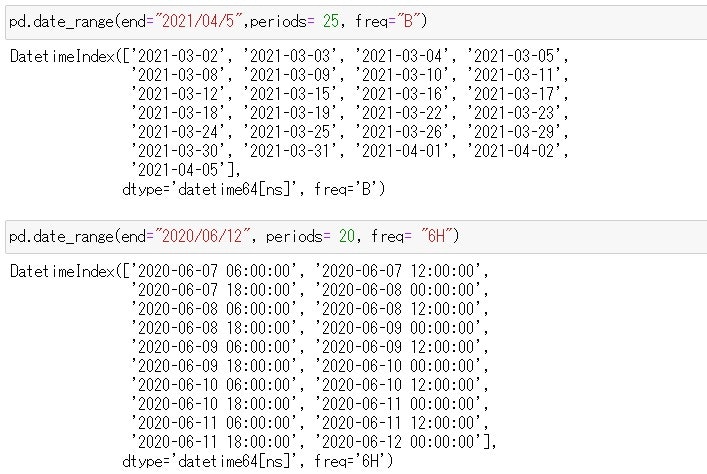
この記事の目的 Pythonで記述された"Hello World"スクリプトをPythonの実行環境とともにDockerコンテナ化して、Docker Engineがインストールされた環境であればHello Worldで切るようにします。 何を始めるにもまずは世界にこんにちはしなきゃね('ω')。 実行環境 Windowsの仕様 エディション:Windows 10 Home バージョン:20H2 OS ビルド:19042.867 エクスペリエンス:Windows Feature Experience Pack 120.2212.551.0 Docker Desktop 3.2.2 Docker 20.10.5 build 55c4c88 まずはPythonの開発環境を作成 ホストのWindows 10にPythonの実行環境を直接インストールしたくないし、せっかくDocker Desktopインストールしたので、Pythonの開発用コンテナをダウンロードして使用する。 なんだかんだでNumpy使うだろうし、Anacondaコンテナを使用することにする。(この辺はお好みで。) 今回は公式のanaconda3コンテナを使用することにした。 https://hub.docker.com/r/continuumio/anaconda3 まずはDockerイメージを取得する。コマンドは次の通り。 PS> docker pull continuumio/anaconda3 Docker pullコマンドの詳細は公式サイトをご確認ください。 完了したらイメージが取得できたか、確認する。 PS> docker images REPOSITORY TAG IMAGE ID CREATED SIZE continuumio/anaconda3 latest 5e5dd010ead8 4 months ago 2.71GB (2.71GBもあった。もっと小さいイメージにすればよかった。) 次にDockerイメージからコンテナを作成します。Docker runコマンドを使用すると、イメージからコンテナの作成と実行を同時にやってくれます。こんな感じです。コマンドの引数の意味は公式ドキュメントをご参考ください。 PS > docker run --interactive --tty continuumio/anaconda3 bash (base) root@a5a6df15c938:/# ls bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var (base) root@a5a6df15c938:/# exit exit PS > Docker runコマンドの公式ドキュメントはこちら。 ソースコードはホストのWindows 10のVisual Studio Codeを使いたいので共有フォルダをマウントします。 -vオプションでホストのパスとコンテナのパスを設定します。 PS > docker run --interactive -v C:\Users\<ユーザー名>\Development\docker:/mnt/docker --tty continuumio/anaconda3 bash (base) root@c29714605d16:/# ls /mnt/ docker (base) root@c29714605d16:/# ls /mnt/docker/ Python版Hello Worldの開発 PythonでHello Worldを開発します。今回のHwllo Worldは力作だ('ω')。 hello_world.py # coding: UTF-8 print('Hello World!!') Dockerコンテナ上で実行します。動いた。 (base) root@c29714605d16:/mnt/docker/python# python hello_world.py Hello World!! (base) root@c29714605d16:/mnt/docker/python# 実行用のDockerfileの作成 力尽きたのでまた明日。
- 投稿日:2021-04-05T22:56:33+09:00
ノーコードでハイパーパラメータを調整して過学習を改善する (LightGBM)
モデルのパフォーマンスにはデータだけではなく、ハイパーパラメータも影響します。 XGBoostやLightGBM,CatBoostなどの複雑なモデルは、その性能を最大限に活用するために、ハイパーパラメータを正しく調整する必要があります。 昨今ではVARISTAでもサポートしているOptunaやHyperoptなどの最適化ツールやAutoMLの登場により、自動でパラメータチューニングを行う事も可能になりました。 *Optunaを使った自動チューニングはこちらの記事を参考にしてください。 VARISTAでのハイパーパラメータの最適化と実験管理 Optuna編 しかし、AutoMLなどが生成したモデルはパラメータを探索しきれていないケースもあり、データサイエンティストが手動で微調整すると更に優れたモデルになることもあります。 そこで、今回は過学習したモデルを例に、ハイパーパラメターのチューニングをVARISTAで行う方法を解説します。 今回利用するデータセットには、7000行、21の説明変数、および目的変数が含まれています。 ターゲットは数値のため、回帰タスクになります。 この記事の目的はハイパーパラメータチューニングですので、データの前処理などは割愛します。 まずは、VARISTAに用意されているデフォルトのテンプレートをXGBoostからLightGBMに変更し、そのままのハイパーパラメータで学習します。 学習は20秒程度で完了しますので、結果を確認してみます。 複数のメトリクスが表示されていますが、今回はRMSEを基準にして進めます。 以下に表示されているのは、教師データをFold=3でクロスバリデーションを行った際の、学習時と検証時のRMSEです。 - train_neg_root_mean_squared_error: 学習時のRMSE - test_neg_root_mean_squared_error: 検証時のRMSE *VARISTAではscikit-learnのクロスバリデーションを利用するため、RMSEはNegativeの値となります。 3.3. Metrics and scoring: quantifying the quality of predictions 比較しやすいように今回着目するメトリクスを以下に抽出しました。 学習時と検証時のRMSEはおよそ-5の差がありますので、出来上がったモデルは学習データに適合してしまっています。つまり過学習の状態です。 それでは、この状態からハイパーパラメータを調整してモデルの性能を改善していきます。 まず、min_data_in_leafを変更して、過学習を抑制する方法を試してみます。 min_data_in_leafは、決定木の葉の最小データ数を指定します。 値を大きくすると、決定木が深く育つのを抑えるため過学習を防ぐことができますが、逆に未学習となる場合もあります。 モデルが適合しすぎないように、各リーフのデータ数を調整します。 今回は、この値を100に変更して学習してみます。 この状態で出来上がったモデルを確認してみます。 検証のRMSEは同じですが、学習のRMSE値が下がり検証の値に近くなりました。 これは、先程の結果よりも過学習を抑制できたことを意味します。 モデルが適合しすぎないようにするもう1つのパラメーターは、イテレーションごとにランダムに選択される特徴量の比率を調整するfeature_fractionです。 このfeature_fractionの値を0.8に変更してモデルを作成してみます。 この値にパラメータを設定すると、モデルは各イテレーションで特徴量を80%ほど使用します。 結果は以下のとおりです。 学習のRMSE値が更に改善されました。 次は、bagging_fractionとbagging_freqの値を調整します。 bagging_fractionは、学習データからランダムに行をサンプリングして、各イテレーションで使用する割合を指定します。feature_fractionに似ていますが、bagging_fractionは行に対して行います。bagging_freqは、サンプリングした行を更新する頻度を調整する際に設定するパラメータです。 - bagging_fraction:0.8 - bagging_freq:10 学習のRMSEと検証のRMSEの差はさらに減少しました。 次に調整するパラメータは、max_depth, num_leaves, learning_lateです。 LightGBMは、ブースティング手法を用いて決定木を組み合わせ、アンサンブル学習を使うアルゴリズムです。ですので、個々のツリーの複雑さも過学習の原因になります。 ツリーの複雑さは、max_depthとnum_leavesで調整します。max_depthはツリーの最大深度を調整し、num_leavesはツリーが持つことができるリーフの最大数を調整します。 LightGBMでは、このmax_depthとnum_leavesの2つのパラメーターは一緒に調整します。 最後に、learning_rateです。一般的に、学習率は小さいほどパフォーマンスはよくなりますが、モデルの学習が遅くなりますので、データ量やマシンスペックを考慮して設定します。 今回の場合は、データ数もあまり多くないので0.001に設定しています。 - max_depth:7 - num_leaves:70 - learning_rate:0.001 学習のRMSEと検証のRMSEの差はさらに減少しました。 このように、ハイパーパラメータを調整することで、モデルの過学習を防ぐことができます。 しかし、そもそものモデルのパフォーマンスが目標とする値に全く達していない場合は、ハイパーパラメータの調整では限界があります。 そのような場合は、まずはデータの量や質を見直して特徴量エンジニアリングなどを行い、モデルのパフォーマンスが目標値に近くなってきたらハイパーパラメータのチューニングを行う方が効果的です。
- 投稿日:2021-04-05T22:40:29+09:00
Python subprocess パイプラインでsort, uniqコマンドに標準出力を渡したい
cat sample.txt | sort | uniq サンプルファイル(sample.txt) 2021-04-05 2021-04-06 2021-04-05 2019-01-01 期待結果 $ cat sample.txt | sort | uniq 2019-01-01 2021-04-05 2021-04-06 サンプルコード import subprocess as sb args1 = ['cat', 'sample.txt'] args2 = ['sort'] args3 = ['uniq'] std = sb.PIPE with sb.Popen(args=args1, stdout=std, stderr=std) as pr1: with sb.Popen(args=args2, stdin=pr1.stdout, stdout=std, stderr=std) as pr2: with sb.Popen(args=args3, stdin=pr2.stdout, stdout=std, stderr=std) as pr3: for date in pr3.stdout: print(date.decode('utf-8')) 実行結果 $ python3 subprocess_test.py 2019-01-01 2021-04-05 2021-04-06 cat sample.txt | sort | uniq | sort -k1,1 -k3,3n サンプルファイル(sample.txt) class2 80 +20 class1 64 +4 class4 55 -5 class3 67 +7 class2 79 +19 class3 48 -12 class4 55 -5 class1 64 +4 期待結果 $ cat sample.txt | sort | uniq | sort -k1,1 -k3,3n class1 64 +4 class2 79 +19 class2 80 +20 class3 48 -12 class3 67 +7 class4 55 -5 サンプルコード import subprocess as sb args1 = ['cat', 'sample.txt'] args2 = ['sort'] args3 = ['uniq'] args4 = ['sort', '-k1,1', '-k3,3n'] std = sb.PIPE with sb.Popen(args=args1, stdout=std, stderr=std) as pr1: with sb.Popen(args=args2, stdin=pr1.stdout, stdout=std, stderr=std) as pr2: with sb.Popen(args=args3, stdin=pr2.stdout, stdout=std, stderr=std) as pr3: with sb.Popen(args=args4, stdin=pr3.stdout, stdout=std, stderr=std) as pr4: for score in pr4.stdout: print(score.decode('utf-8')) 実行結果 $ python3 subprocess_test.py class1 64 +4 class2 79 +19 class2 80 +20 class3 48 -12 class3 67 +7 class4 55 -5 参考記事
- 投稿日:2021-04-05T22:12:04+09:00
tryとexcept Python競プロメモ④
使用言語 Python3 ##. ### ... 上に書いたように3×3のマスがあるとし、そのうち上下左右のマスが「#」であるマスの座標を選ぶプログラムを書きたい。 ちなみに左上のマスを(0,0)とする。 これが 0 0 0 2 と出力するようにしたい。 new_data = [['#','#','.'],['#','#','#'],['.','.','.']] H = 3 #行数 W = 3 #列数 データはこのように与えられているとする。 私の考えとして ①まずH、Wでfor文を作り、h行w列目を軸として、まずその両隣を見る。ここに「.」があればcontinueで抜ける。 ②次に上下を見る。同様に「.」があればcontinueで抜ける。 ③for文を抜けずにたどり着いた要素だけprintする 実際にコードで書いてみると for h in range(H): for w in range(W): try: if new_data[h][w+1] == ".": continue except IndexError: pass try: if new_data[h+1][w] == ".": continue except IndexError: pass if w >= 1: if new_data[h][w-1] == ".": continue if h >= 1: if new_data[h-1][w] == ".": continue print(h,end = " ") print(w) これで目的の出力を得ることができた。 このコードではtry文を使うことで、IndexErrorが起こっても対処できるようにした。 あと一点、私が詰まった点として、 new_data[h][w-1] の記述について。 w=0の時、[w-1]は[-1]となってしまうため、本当gは一番最初の要素が欲しいにも関わらず、列の一番最後の要素が選ばれてしまうというミスをしてしまった。 なのでここではその前にw>=1とし[w-1]が自然数となるように指定した。 リストでマイナスを使うときはこの点に注意していきたい。
- 投稿日:2021-04-05T21:57:01+09:00
株価の指標を求める
はじめに 株価を分析する際にいろいろな指標が使われます。 いざ自分で計算しようと思うと、難しいだけでなく調べるだけでも大変です。 そんな折、TA-Libという便利なライブラリを見つけました。 TA-Lib : Technical Analysis Library Python wrapper for TA-Lib 本記事ではTA-Libを使用していろいろな指標を計算させ、グラフ化してみます。 また、計算した指標は後で再利用できるようにCSVで保存しておきます。 たくさんのグラフを作成してみましたが、私が知っているのはごく一部だけでした。 ほとんどの指標は意味もわからず、名前さえ知りませんでした。 ソースはGitHubに置いてます。 TA-Libのインストール Macであればbrewでインストールできます。 $ brew install ta-lib Pythonから使えるようにラッパーをインストールします。 $ pip install TA-Lib 基本的な使い方 株価の取得 株価はpandas_datareaderを使用してYahoo Financeから取得しました。 取得したのは日経平均株価です。 import datetime import pandas_datareader start_date = datetime.date(2020, 1, 1) end_date = datetime.date(2020, 12, 31) ticker = '^N225' df = pandas_datareader.data.DataReader(ticker, "yahoo", start_date, end_date) TA-Libの使い方 TA-Libをインポートします。 import talib そして、指標を求めます。 sma = talib.SMA(df['Close'], timeperiod=30) これだけです。楽です。 指標のグラフ ここからは指標のグラフだけ載せます。 BBANDS - Bollinger Bands DEMA - Double Exponential Moving Average EMA - Exponential Moving Average HT_TRENDLINE - Hilbert Transform - Instantaneous Trendline KAMA - Kaufman Adaptive Moving Average MA - Moving average MAMA - MESA Adaptive Moving Average 使い方が悪いのか、ライブラリが古いのか、エラーとなります。 深追いはせず次に進みます。 Error occured: Exception: TA_MAMA function failed with error code 2: Bad Parameter (TA_BAD_PARAM) MAVP - Moving average with variable period periodsに何を指定すればよいかわからなかったのであきらめました。 MIDPOINT - MidPoint over period MIDPRICE - Midpoint Price over period SAR - Parabolic SAR SAREXT - Parabolic SAR - Extended SMA - Simple Moving Average T3 - Triple Exponential Moving Average (T3) TEMA - Triple Exponential Moving Average TRIMA - Triangular Moving Average WMA - Weighted Moving Average RSI - Relative Strength Index STOCH - Stochastic STOCHRSI - Stochastic Relative Strength Index MACD - Moving Average Convergence/Divergence ADX - Average Directional Movement Index WILLR - Williams' %R CCI - Commodity Channel Index ATR - Average True Range ULTOSC - Ultimate Oscillator ROC - Rate of change : ((price/prevPrice)-1)*100 おわりに 今回の目的は株価指標の収集です。 また、視覚化してこんな感じなのかなということが何となくわかりました。 この収集したデータをどのように料理するか。これからの課題です。
- 投稿日:2021-04-05T21:35:21+09:00
研究の足跡(グレブナー基底について) part. 1
はじめに
初めまして、数理科学専攻の大学院生kotaと申します。
この度研究の週誌的なものを書いてみようと思いましたー。目次
研究概要
皆さんは量子コンピュータは聞いたことあると思いますが、そのコンピュータによってRSA暗号の計算量的困難性が危ぶまれています。
Shoreさんのお陰というか素因数分解アルゴリズムのせいですね...
そこで多変数公開鍵暗号というものがあってとても便利なわけです!
暗号化はとても簡単で例えば
$f_1(x_1, x_2) = x_1^2 + 2 x_1x_2 + 11x_2^2$
という式があるとしたら$x_1, x_2$をmod 31の世界で整数を代入してそれをメッセージ(暗号化したい文章)にしてしまおうというものです。 mod 31なのは$F_{31}$という有限体を使うからですね。
というわけでこれを連立させて方程式を解くのが難しいよっていうのが計算量的困難性になります!
本当にそうだろうか?ということでゴリゴリ解いて最速アルゴリズムを見つけて解けないならばこの暗号は使える!っていうのを目指すのが研究の目標です...グレブナー基底について
連立代数方程式を簡単に解くものにグレブナ基底計算がありますと
それをどれだけ早く計算できるかが鍵な訳です...
ちょっと例を見てみましょう!
例えば\left\{ \begin{array}{ll} f = 2 x + 2 * y - 2 \\ g = 2 x + y + 1 \end{array} \right.この方程式を解きたいなって思った時、皆さんはガウスの消去法をなんとなくやるでしょう...
そんなときグレブナー基底R.<x, y> = QQ['x, y'] f = 2 * x + 2 * y - 2 g = 2 * x + y + 1 I = (f, g)*R; I # fとgから生成されるイデアル(f, g)をIとします。 Ideal (2*x + 2*y - 2, 2*x + y + 1) of Multivariate Polynomial Ring in x, y over Rational Field I.groebner_basis() #Iのグレブナ基底はこうなります. [x + 2, y - 3]このように x+2とy-3がグレブナー基底になるわけです。
\left\{ \begin{array}{ll} x + 2 = 0 <=> x = -2 \\ y - 3 = 0 <=> y = 3 \end{array} \right.グレブナー基底計算によりすぐに連立方程式の解が、、、
使用アルゴリズムについて
という風にこの計算アルゴリズムは多分ブッフバーガーさんのものが使われている(sagemathに聞いてください)
と思うのですが他にもアルゴリズムがあります。
早いアルゴリズムの研究が僕の研究です。
これから二週間か一週間に一回研究の成果や数学に関するprogrammingについての記事を書いていきます.
ご期待ください.参考文献
ごめんなさい特にないです...
- 投稿日:2021-04-05T21:24:04+09:00
Discord.py でTwitter通知botを作った (tweepy streaming API)
Discord API のPythonラッパーである Discord.py と、Twitter API のPythonライブラリ tweepy を使って、Discord上に特定のTwitterアカウントの投稿を通知する Bot を作ります。
環境
- Ubuntu 20.04.2 LTS
- Python 3.8.5
- discord.py 1.6.0
- tweepy 3.10.0
モチベーション
身内が始めた整備段階のDiscordサーバーで、あるゲームの公式Twitterアカウントからのツイート通知を行うシステムが必要でした。
しかし、IFTTT(注:Webサービスどうしでイベント発生時に連携を行えるサービス。Webhookによるツイート通知によく使われる) を使った場合は 15分以下のラグ 、 通知アカウント数の上限 があります。
また、最近このサーバーの Bot のために Conoha VPS を借りたので、何かスクリプトを動かしてみたいと考えていました。そこで、ツイート通知Bot を自作することに決めました。自分で作るので、目指すは 低遅延。
Twitter Streaming API
遅延なくツイートを通知する方式を検討し、 Streaming API を利用することに決めました。
常に Twitter のストリームへの接続を行うことで、REST APIより高い効率で、ツイートのデータを入手できます。Streaming API のなかでも今回使うのは、
statuses/filterAPIです。
(参考: Twitter Developer 内ドキュメント )Twitter API を扱えるPythonライブラリを探したところ、 tweepy というパッケージがGitHubのスター数も高く、人気がありそうだと判断し、tweepy を利用することにしました。
(参考: tweepy GitHubリポジトリ )
※ 現在の tweepy の master ブランチにおける Streaming API の実装は最新のリリースのものとは大きく異なっているので、この記事の内容は次回リリース時には利用できなくなると思います。
ソースコード
main.pyfrom discord.ext import commands PATHS = ( "tweet", ) class TweetGetBot(commands.Bot): async def on_ready(self): for path in PATHS: self.load_extension(path) print("ready...") bot = TweetGetBot(command_prefix="/") bot.run("TOKEN")tweet.pyimport tweepy from discord.ext import commands from threading import Thread from queue import Queue import asyncio screen_name = "" # Twitter のスクリーンネームを追加します account_id = "" # Twitter のIDを追加します。 channel = None class StatusEventListener(tweepy.StreamListener): def __init__(self, loop, error_callback, q = Queue()): super().__init__() self.loop = loop self.error_callback = error_callback self.q = q num_worker_threads = 4 for _ in range(num_worker_threads): t = Thread(target=self.do_stuff) t.daemon = True t.start() def do_stuff(self): while True: status = self.q.get() tweet_url = f"https://twitter.com/{screen_name}/status/{status.id_str}" if status.user.screen_name != screen_name or channel is None: continue rt = status._json.get("retweeted_status") if rt is not None: if rt["user"]["name"] != screen_name: tweet_content = f"{status.user.name} さんがリツイートしました: {tweet_url}" else: tweet_content = f"{status.user.name} さんがツイートしました: {tweet_url}" asyncio.run_coroutine_threadsafe(channel.send(tweet_content), self.loop) self.q.task_done() def on_status(self, status): self.q.put(status) def on_error(self, status_code): if status_code == 420: #returning False in on_error disconnects the stream print("error-code: 420") return False # returning non-False reconnects the stream, with backoff. def on_exception(self, info): asyncio.run_coroutine_threadsafe(channel.send(f"Error: ツイートのストリーミングに失敗しました\n `{info}`"), self.loop) self.error_callback() def run(auth, listener): print("runned") my_stream = tweepy.Stream(auth=auth, listener=listener) my_stream.filter(follow=account_id, is_async=True) def start_stream(): consumer_key = "" # ここに Consumer Key を追加します consumer_secret = "" # ここに Consumer Secret を追加します access_token = "" # ここに Access Token を追加します access_token_secret = "" # ここに Access Token Secret を追加します auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) loop = asyncio.get_event_loop() listener = StatusEventListener(loop=loop, error_callback=lambda: run(auth, listener)) run(auth, listener) class TweetCog(commands.Cog): def __init__(self, bot: commands.Bot): global channel self.bot = bot channel = self.bot.get_channel(123456789012345678) # 通知チャンネルIDを追加します start_stream() def setup(bot): bot.add_cog(TweetCog(bot))説明
グローバル変数
tweetscreen_name = "" account_id = "" channel = None追跡するアカウントのスクリーンネームとIDを定義します。
スクリーンネームは、例えば@TwitterJPといったアットマークで始まる英数字の文字列です。
ID については、スクリーンネームからIDに変換できるサービスがありました: http://tik.dignet.info/web/idname/
channelにはあとで、ツイートを通知するdiscord.Channelオブジェクトを代入します(これはグローバルにしなくてもよかった気も)。クラス
StatusEventListenerのちにこのクラスのインスタンスを、
tweepy.Stream.filterメソッドに渡します。
Streaming の最中、 Twitter からはひっきりなしにイベントデータが送信されます。
このデータ群を処理するためのクラスがtweepy.StreamListenerクラスです。
もっとも重要なのがon_statusメソッドです。tweet.pydef on_status(self, status): pass引数として status オブジェクトが渡されますが、補完がうまく効きませんでした。ゆえに、
この記事( https://qiita.com/Ryo87/items/61b5d54cbfd7ae520fe6 )を参考にプログラムを完成させることにしました。
IncompleteReadエラーへの対処さて、Streaming API は、きわめて頻繁に接続維持を行います。
低レベルな部分は tweepy が代行しますが、現在のリリースにおいて修正しきれていない問題が存在しています。('Connection broken: IncompleteRead(0 bytes read)', IncompleteRead(0 bytes read))というエラーです。
検索すると GitHub にいくつも同様の Issue が立っています。
(参考: GitHubのIssue )このエラーの原因は、どうやらクライアント側の処理速度が追い付かず、 status を処理し切れなくなったときに Twitter がクライアントとの接続を切断することで起こるようなのですが・・・。
結論を言えば、インターネット上で見つけた多くの解決策は、私にとって無意味でした。
最終的に、StreamListener が例外発生時に呼び出す
on_exceptionメソッドを以下のようにオーバーライドして解決します。tweet.pydef on_exception(self, info): asyncio.run_coroutine_threadsafe(channel.send(f"Error: ツイートのストリーミングに失敗しました\n `{info}`"), self.loop) self.error_callback()この
error_callback属性に、Streaming を新規に開始する関数をのちに渡すことで、例外が発生するたびに Streaming を再開するように構成しました。スレッドとキューを使う
先に書いた
IncompleteReadエラーの発生するタイミングがあいまいなので、この策がどれだけ功を奏しているのか判断できないのですが、Twitter から受信したデータを即座に処理しているだけではこのエラーが頻発しました。
ゆえに、 status オブジェクトを毎回キューに enqueue し、 複数スレッド でキューの中身をさばくことにしました。コンストラクタ
tweet.pydef __init__(self, loop, error_callback, q = Queue()): super().__init__() self.loop = loop self.error_callback = error_callback self.q = q num_worker_threads = 4 for _ in range(num_worker_threads): t = Thread(target=self.do_stuff) t.daemon = True t.start()StackOverflowの回答 の受け売りですが、
q属性にキューをセットし、 下記の処理用関数do_stuffを4つのスレッドで動かします。処理部 (関数
do_stuff)tweet.pydef do_stuff(self): while True: status = self.q.get() tweet_url = f"https://twitter.com/{screen_name}/status/{status.id_str}" if status.user.screen_name != screen_name or channel is None: continue rt = status._json.get("retweeted_status") if rt is not None: if rt["user"]["name"] != screen_name: tweet_content = f"{status.user.name} さんがリツイートしました: {tweet_url}" else: tweet_content = f"{status.user.name} さんがツイートしました: {tweet_url}" asyncio.run_coroutine_threadsafe(channel.send(tweet_content), self.loop) self.q.task_done()dequeue してキューから獲得した status に対して、「定義した screen_name と一致しているか?」を確認しています。
これはなぜかというと、on_statusに流れてくるのは本人のツイートだけではないからです。また、本人が直接ツイートした status だけでなく、リツイートしたものも流れてくるので、リツイートであるかどうかを判定しています。
tweet.pyasyncio.run_coroutine_threadsafe(channel.send(tweet_content), self.loop)
await discord.Channel.send()メソッドをスレッドセーフに呼び出してDiscordに通知が完了します。関数
start_streamOauthHandlerのインスタンスを作成し、Streaming を開始する関数 (
run())を呼び出します。
このときカレントループを取得して、StreamListener のサブクラスに渡します。おわりに
およそこの記事の通りに書いて現在動作しているのですが、もしミスがあったらコメント欄にお願いします。
- 投稿日:2021-04-05T21:06:04+09:00
ClaraでCOVID-19病変箇所をセグメンテーションする方法
記事の概要
- Clara Train SDKと呼ばれるアノテーション支援ツールがある
- 胸部CTの病変箇所のセグメンテーションもできるけど,どうもファイルに欠損があるっぽい
- 設定ファイルを追加し,AIAAサーバーに登録することで解決できたので共有
検証環境
docker pull nvcr.io/nvidia/clara-train-sdk:v3.1.01cf. https://ngc.nvidia.com/catalog/containers/nvidia:clara-train-sdk
学習済みモデルのダウンロード
ngc registry model download-version "nvidia/clara_train_covid19_ct_lesion_seg:1"cf. https://ngc.nvidia.com/catalog/models/nvidia:clara_train_covid19_ct_lesion_seg
設定ファイルの追加
AIAAサーバーで動かすための設定ファイル
config_aiaa.jsonがないので,下記のファイルを作成する.
- clara_train_covid19_ct_lesion_seg_v1/config/config_aiaa.json
{ "version": "3", "type": "segmentation", "labels": [ "label_class0", "label_class1" ], "description": "The model described in this card is used to segment the COVID-19 affected region from the 3D chest CT images", "pre_transforms": [ { "name": "LoadNifti", "args": { "fields": "image", "as_closest_canonical": true } }, { "name": "ConvertToChannelsFirst", "args": { "fields": "image" } }, { "name": "ScaleByResolution", "args": { "fields": "image", "target_resolution": [0.8, 0.8, 5.0] } }, { "name": "ScaleIntensityRange", "args": { "fields": "image", "a_min": -1500, "a_max": 500, "b_min": 0.0, "b_max": 1.0, "clip": true } } ], "inference": { "image": "image", "name": "TRTISInference", "args": { "batch_size": 1, "roi": [ 384, 384, 32 ], "scanning_window": true }, "trtis": { "platform": "tensorflow_graphdef", "max_batch_size": 1, "input": [ { "name": "NV_MODEL_INPUT", "data_type": "TYPE_FP32", "dims": [ 1, 384, 384, 32 ] } ], "output": [ { "name": "NV_MODEL_OUTPUT", "data_type": "TYPE_FP32", "dims": [ 2, 384, 384, 32 ] } ], "instance_group": [ { "count": 1, "kind": "KIND_AUTO" } ] }, "tf": { "input_nodes": { "image": "NV_MODEL_INPUT" }, "output_nodes": { "model": "NV_MODEL_OUTPUT" } } }, "post_transforms": [ { "name": "ArgmaxAcrossChannels", "args": { "fields": "model" } }, { "name": "FetchExtremePoints", "args": { "image_field": "image", "label_field": "model", "points": "points" } }, { "name": "CopyProperties", "args": { "fields": [ "model" ], "from_field": "image", "properties": [ "affine", "original_affine", "as_canonical" ] } }, { "name": "RestoreOriginalShape", "args": { "field": "model", "src_field": "image", "is_label": true } } ], "writer": { "name": "WriteNifti", "args": { "field": "model", "dtype": "uint8", "revert_canonical": true } } }AIAAサーバーへ登録
$LOCAL_PORT=80 curl -X PUT "http://127.0.0.1:$LOCAL_PORT/admin/model/clara_train_covid19_ct_lesion_seg" \ -F "config=@clara_train_covid19_ct_lesion_seg_v1/config/config_aiaa.json;type=application/json" \ -F "data=@clara_train_covid19_ct_lesion_seg_v1/models/model.trt.pb"cf. https://docs.nvidia.com/clara/tlt-mi/aiaa/server_apis.html
これで,3D Slicerで検証できるようになります.
- 投稿日:2021-04-05T20:13:39+09:00
Jupyter notebook (Docker) で親ディレクトリのファイルを絶対パスで取得できない件について
はじめに
Jupyter notebookをDocker環境で使っており、テキストファイルを読み込もうとしたのですが、パスが見つからず困っていたのでまとめます。
親ディレクトリをたどって、特定のファイルを読み込む必要があったので、絶対パスを指定していたがパスが見つからず、親のディレクトリのファイルが読み込めない?そんなことあると思っていましたがそんなわけはありませんでした。環境
- python3.8
- Docker
- jupyter notebook
問題
ディレクトリ構成がこのようになっている状態で、
/ ├ experiments/ ├ python ├ A.py ├ dict ├ file.txt ├ library/
A.pyからfile.txtが存在していればファイルを読み込む処理をしようとしていた。if os.path.exists('/experiments/dict/file.txt')しかし、
file.txtがあるはずなのに読み込んでくれなかった。解決策
Jupyter画面で
rootに見えていた場所が実際には違っていて、絶対パスが正しく指定できていなかった。
私はここが
rootの位置だと思っていた。
しかし、pwdコマンドでディレクトリを調べたところpwd # 出力された結果 '/home/jovyan/data/experiments/python'となっていた。
/home/jovyan/data/を指定していなかった。docker-compose.ymlでボリュームを
volumes: - ./experiments:/home/jovyan/dataとしていたので、Jupyter上にはパスがなく勘違いしていたのが原因だった。
このようにファイルパスを指定しなおして読み込めるようになりました。
if os.path.exists('/home/jovyan/data/experiments/python')最後に
読み込みでどうするんだろうとなることがしばしばあります。
調べてもこのJupyter問題は簡単に見つからなかったのでまとめました。
もしかしたら、絶対パスを指定するところで詰まる人は少ないのかも?

- 投稿日:2021-04-05T19:59:24+09:00
fastTextと「ちくわぶ」で遊んでみる
ふと思ったんです
ちくわぶってあるじゃないですか。
あいつって文字通り「ちくわ」と「ふ」を足したような名前してますけど、
word2vecとかfastTextで「ちくわ」と「ふ」を足したら何になるのかなと思ったわけです。ということで今回はfastTextのハンズオンを兼ねてちくわぶで色々遊んでみようと思います。
※筆者はちゃんと「ちくわ+ふ」が「ちくわぶ」ではないことは理解したうえで実験に臨んでいます。予めご了承ください。実装
データ用意
今回はこちらの学習済fastTextモデルを利用しました。
本当はword2vecのフルモデルダウンロードしたかったんですが、家の通信環境が貧弱すぎて一向に終わらず。。。もしハンズオンされるときは是非フルモデルでやってみてください。
このハンズオンで初めて知りましたが、今回のやり方では再学習ができません。(こちらを参照ください)
フルモデルで実装して「ちくわぶ」を再学習して遊ぶとかやってみても面白いかもしれません。モデル読み込み
今回はSageMaker上で実装しました。
SageMaker上へダウンロードしたzipファイルを送りunzipします。
その後はgensimモジュールを使ってベクトルをインポートします。
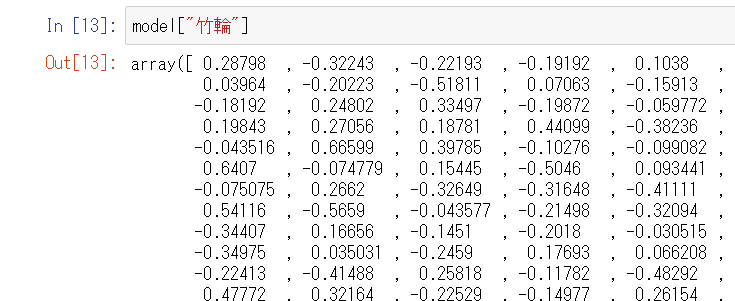
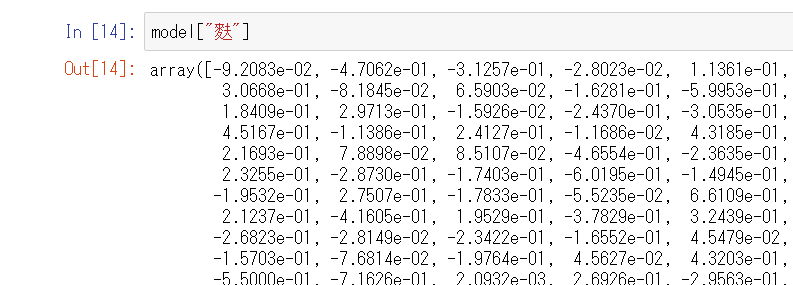
インポートまでたったこれだけ。らくちんですね。!unzip vector.zip !pip install gensim import gensim model = gensim.models.KeyedVectors.load_word2vec_format('model.vec', binary=False)遊ぶ
そもそも「ちくわ」と「ふ」はあるのか
結論:ある。
いや、あるんかい。
学習データに竹輪と麩関連のデータがあったようです。
ちなみにちくわぶはありませんでした。(ひらがなにしてもダメ)
いや無いんかい。
その線引き何だよ。
ちくわ+ふ
most_similarメソッドの引数でpositiveパラメータにリスト型で渡すと足し算できます。
その結果は「生麩」。
原料が小麦粉という意味では竹輪麩とニアピンですが、竹輪の魅力である穴が無くなってしまいやや残念です。
ちくわーすり身
先ほどの結果に「すり身」があったので、ちくわからすり身を引いたらどうなるか試してみました。
理論上「穴」になるんでしょうか。
果たしてその結果は。
いや惟光だれだよ。
いや小太郎誰だよ。
調べたら惟光は源氏物語の人物のようです。ちくわーすり身+小麦粉
もしかして、という希望をかけて小麦粉を足してみます。
これで「ちくわ+ふ」の結果に近くなれば私の勝ちです(?)。
こう見ると「ちくわ+ふ」のときに出てきた「餡」「漉し餡」「生麩」がランクインしていて、結構ちくわぶ寄り(?)の結果になっているのが見て取れます。ちくわー穴
「穴」のベクトルもあるようだったので、「ちくわー穴」も試してみます。
答えは「はんぺん」。
急に納得感のある答えを出してきました。はんぺんーすり身
先ほどのの実験結果では「すり身」を使ったため「惟光」が錬成されてしまいました。
この二つの違いは何なのか。
ここに「惟光」錬成の謎が隠されていると思いました。
いや麻倉誰だよ。
すごい普通な人でてきちゃったよ。
類似度0.259ということなので多分ひねり出した結果なんでしょう。
謎は深まるばかりです。最後に
今回はネタ枠で遊んでみましたが、fastTextで簡単にこんなこともできます。
是非是非ハンズオンしてみてくださいね!





- 投稿日:2021-04-05T19:57:05+09:00
プログラマ専用匿名掲示板を作った
プログラマ専用匿名掲示板
日本で最も有名な匿名掲示板といえば、5chだとおもいます。
そんな5chにもプログラマ板はあります。
しかし、それではシンタックスハイライト機能が無く、
dat落ちすれば書き込めないというものです。プログラム関連のこと専門の匿名掲示板があれば良いなと思い作りました。
作成にあたってのメモや、つまづきを書きます。搭載したい機能
- 匿名掲示板
- シンタックスハイライトされたコードを挿入
5chに、コード挿入機能を追加し、dat落ちを失くしたものを思いました。
データベース
データベースを扱うために、
postgresql
を使いました。(Herokuではsqlite3は使えません)
https://qiita.com/tomson784/items/a5ad6e47643449dffd18
こちらの記事を参考にしました。id
書き込みごとにidを割り振ります。
idはランダムな文字列4文字です。ランダム文字列をどのようにして作るかですが、
a ~ zと0 ~ 9が格納された配列から、文字列の長さ分一文字ずつrandom.choiceすることで得られます。import random, string def randomname(): randlst = [random.choice(string.ascii_letters + string.digits) for i in range(4)] return ''.join(randlst)コード挿入
シンタックスハイライトには、highlight.jsのmonokai-sublimeを使いました。
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/9.15.10/styles/monokai-sublime.min.css"> <script src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/9.15.10/highlight.min.js"></script> <script>hljs.initHighlightingOnLoad();</script>highlight.jsを読み込んで、
<pre><code></code></pre>で囲うことでシンタックスハイライトされてコードを表示できます。
が、ここで少しつまづきました。<pre><code> {{f.code}} </code></pre>はじめ、こう書いていたのですが、これだと1行目の開始位置が変な場所になるんですよね。
どうやら、<pre><code>{{f.code}}</code></pre>このように前後に改行を入れずに書かなければならないようです。
さらに、これではコードの欄に何も書いていなくても
highlight.jsの枠が出てしまうので、
htmlの中にifを書き、コードが書いてあれば<pre>…を実行(?)するようにしました。{% if f.code %} <pre><code>{{f.code}}</code></pre> {% endif %}Herokuのリモートシェルでのつまづき
データベースを作成するために、
$ heroku run python
して、pythonスクリプトを打ち込もうと思っていました。
早速from app import...と書いたのですが、
app.pyが見つからないと言われました。
$ heroku run ls
としてみると、何も表示されませんでした。新しくデータベースを作るpyファイルを作り、herokuにデプロイし、
$ herokuk run python hogehoge.py
することでうまくいきました。
- 投稿日:2021-04-05T19:52:24+09:00
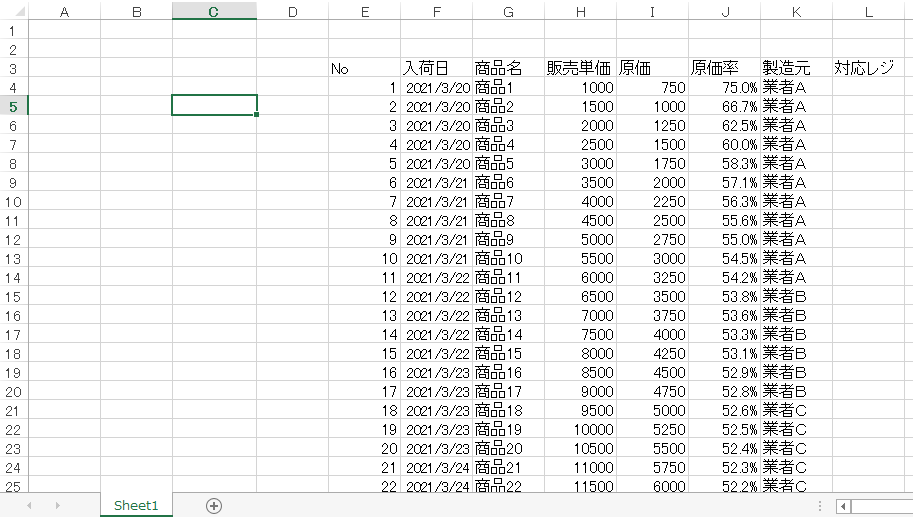
【Python】Worksheet.move_rangeメソッドを使用して、表(セル)を移動させる。
pythonを使用してExcelファイルの操作を勉強しています。
本日の気づき(復習)は、表(セル)の移動に関してです。
pythonでExcelを操作するため、openpyxlというパッケージを使用しています。
上記のようなブック「商品リスト」を
のように表を移動させたいです。
Worksheet.move_rangeメソッド
ws.move_range('移動するセルの範囲', rows=移動する行数, cols=移動する列数, translate=数式等のセル参照を更新する場合はTrue)シート上で表の様な複数のセルを移動させる場合は
Worksheet.move_rangeメソッドを使用します。
気を付けておくべきことが何点かあります。
- rows:下に移動させる場合は整数(上なら負の整数)
- cols:右に移動させる場合は整数(左なら負の整数)
- rows引数cols引数に範囲外の値を入れてしまうとエラーになる
- 移動先の位置にすでに値や表があったとしてもセルを上書きしてしまう
- 数式の更新は基本行わない。(translate=Trueの記述追加が必要)
最終的なコード
from openpyxl import load_workbook wb = load_workbook('商品リスト.xlsx') ws = wb.active ws.move_range('B2:I24', rows=1, cols=3, translate=True) wb.save('商品リスト_移動.xlsx')translateに気付かず、右往左往していました。translate=Trueは偉大。
セルの書式設定もそのまま移動してくれるのでたいへん重宝します。

- 投稿日:2021-04-05T19:35:32+09:00
[第一部]これならわかる!Flask+Nginx+uWSGIをAWSに丁寧にデプロイ
はじめに
タイトル通り、Flaskで作った簡単なWebアプリをAmazon Linux2に上げてNginx+uWSGIを使ってとりあえず外部から見れるようにします。
AWSに関してはVPCの作成から載せています。(補足でCloudWatchを設定して請求金額のアラート通知も出来るようにするのでお金の面も安心!)
かなり丁寧に解説を挟みますので、下に挙げる前提知識を持っている方であれば問題なく理解し実践出来る内容になっています。
また、今後「第二部」「第三部」では「DNSの設定」や「DB(RDS)やストレージ(S3)との連携」、「HTTPS化」等についても記事にまとめていくので一覧のシリーズを読んでいけばとりあえず個人開発でFlaskアプリを作ってデプロイ出来る知識を素早く身に付けられます!!
※こちらのZennに投稿した内容と
最低限必要な前提
- AWSは登録済みかつIAM作業用ユーザー作成済み(もしくは独力で登録出来る)
- Pythonの基礎文法は把握している且つpyenvくらいなら調べながら使える
- Flaskを軽くは知っている(Webフレームワークであることは理解しているレベルでおk)
- Webサーバー、アプリケーションサーバーの違いはわかる
- Linuxの基本コマンドやパーミッション等についての基礎知識はある
[AWS]ネットワーク構築
さっそく作成済みのIAM作業用ユーザーでマネジメントコンソール(以後、管理画面と呼称)にログインしてネットワークを構成していきましょう。
[AWS]VPC設定
「VPC」とは仮想ネットワークのこと。ここを「サブネット」という小さなネットワークで区切っていきます。
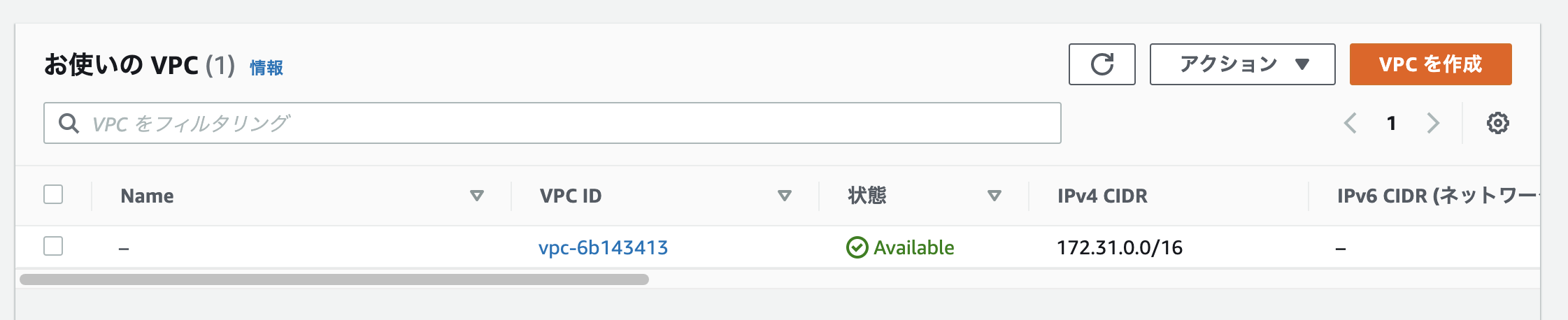
管理画面上部の検索バーから「VPC」検索します。
アクセス後、ダッシュボード(左側のバーのこと)からVPCを選択。
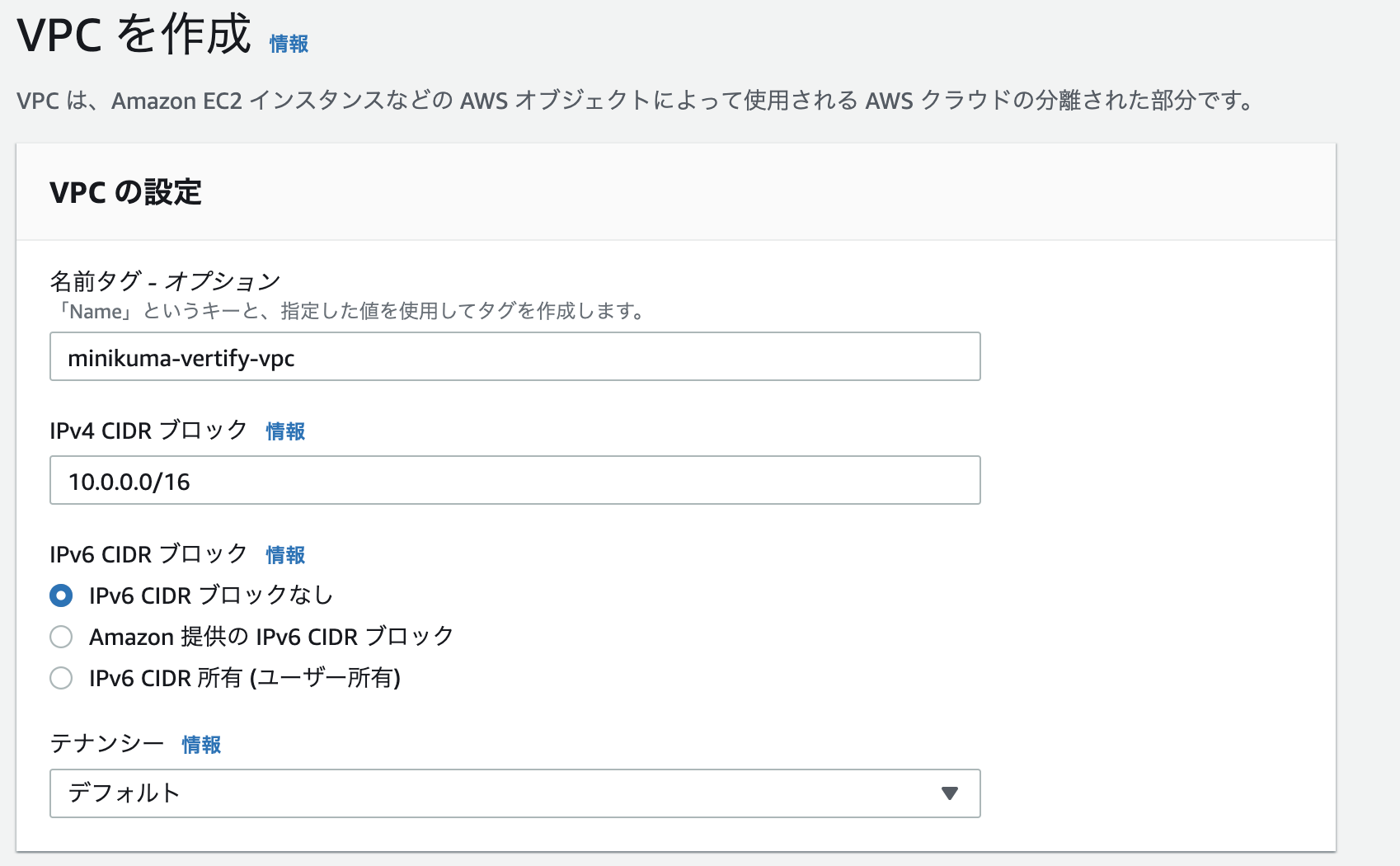
選択後、VPCを作成をクリック。
VPCの名前は好きなものを設定してください。IPアドレスはプライベートipの範囲で好きなものを選択してください。(よくわからないという方は今回は私と同じ「10.0.0.0/16」と設定してください。その他はデフォルトのままで大丈夫です。)
「VPCを作成」ボタンをクリックしましょう。
ちゃんと新しいVPCが出来ています。
ちなみにVPCのNameは後から編集することも出来ます。(私もこちらのクラスメソッド さんの記事を見て名称を見直してみました?)[AWS] パブリックサブネット作成
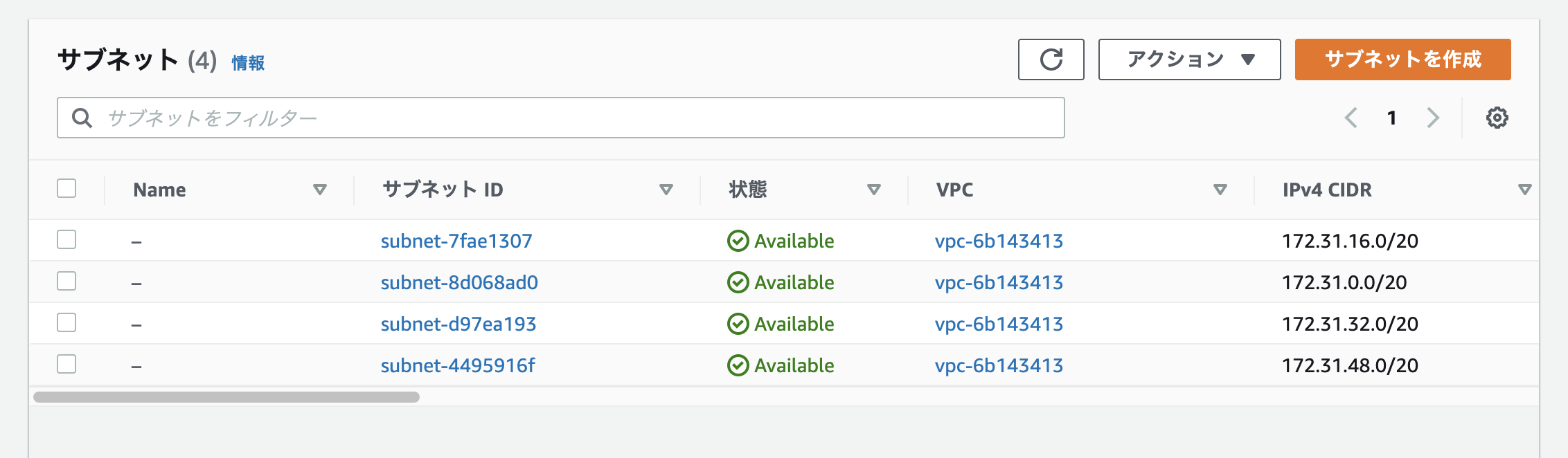
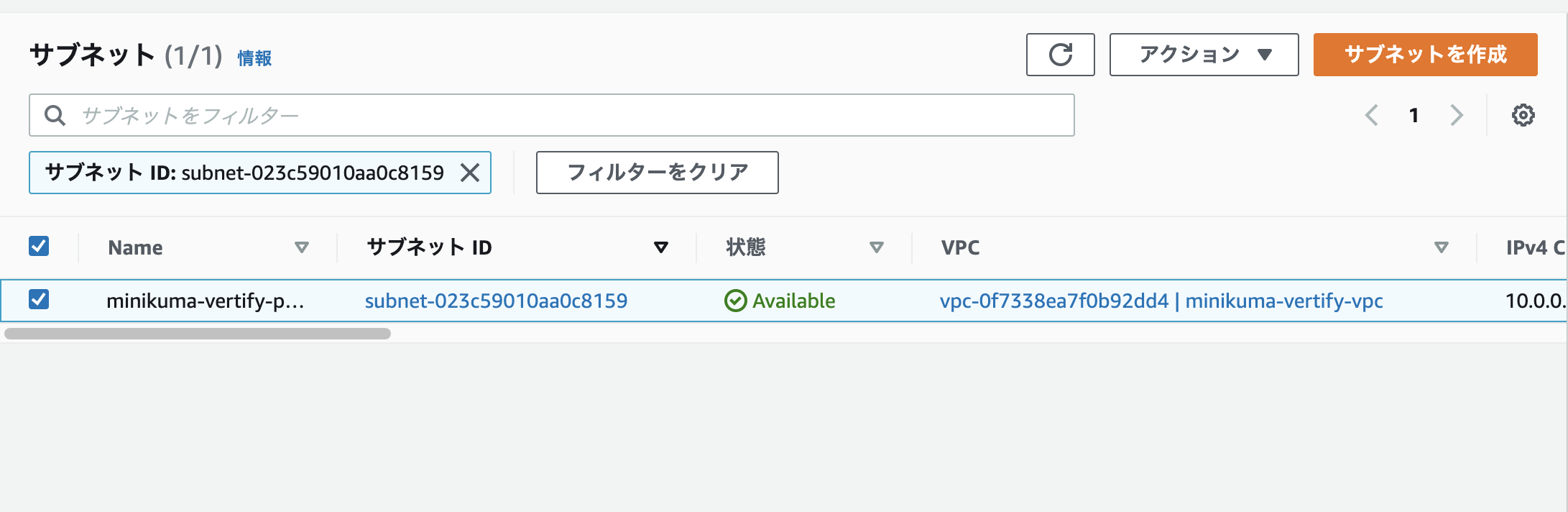
続いて左側のダッシュボードから「サブネット」を選択します。
今回作るサブネットはインターネットに接続できるようにしてWebサーバーを置く予定なので「パブリックサブネット」にします。
※DB用途などには「プライベートサブネット」を選択します。
※最初から4つあるのは、デフォルトでAWSが用意してくれているサブネットです。無視して進めましょう。
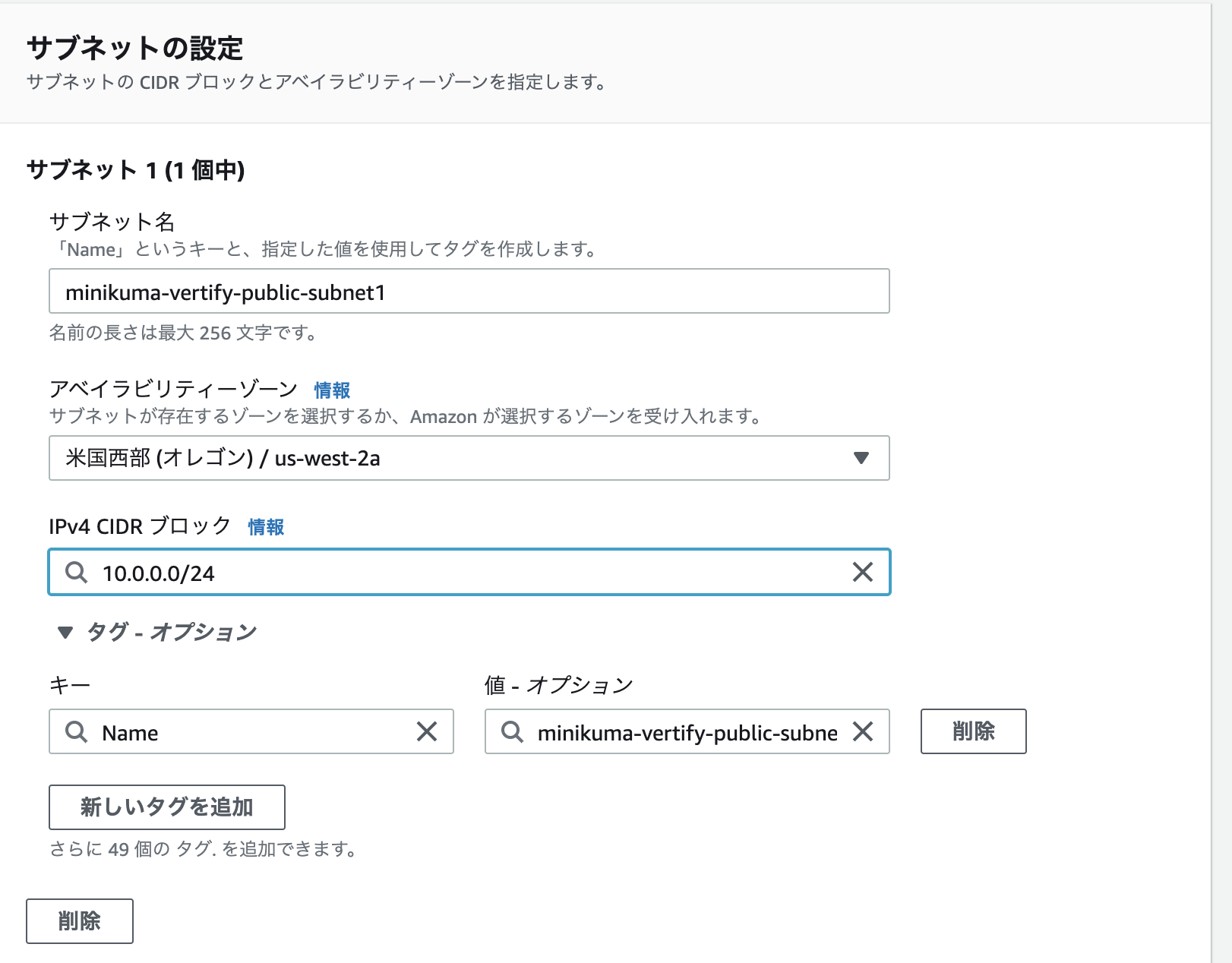
先ほど作成したVPCを選択。
設定では(1)サブネットの名前(2)アベイラビリティゾーン(3)CIDRブロックを設定します。
(2)に関してはどこでも問題ありません。(今回私はリージョンを安い米国西部にしているのでオレゴンのアベイラビリティゾーンが選択出来ます。)
(3)に関してはVPCの中に設定するものなので先ほどVPCに設定したCIDRより大きい値を設定しましょう。
無事、設定出来ました。この画面で間違いがないか一応確認してみてみましょう。
※「利用可能なIPv4が254じゃないのなぜなの〜」という方はこちらのドキュメントを読めば251になっている理由がわかります。
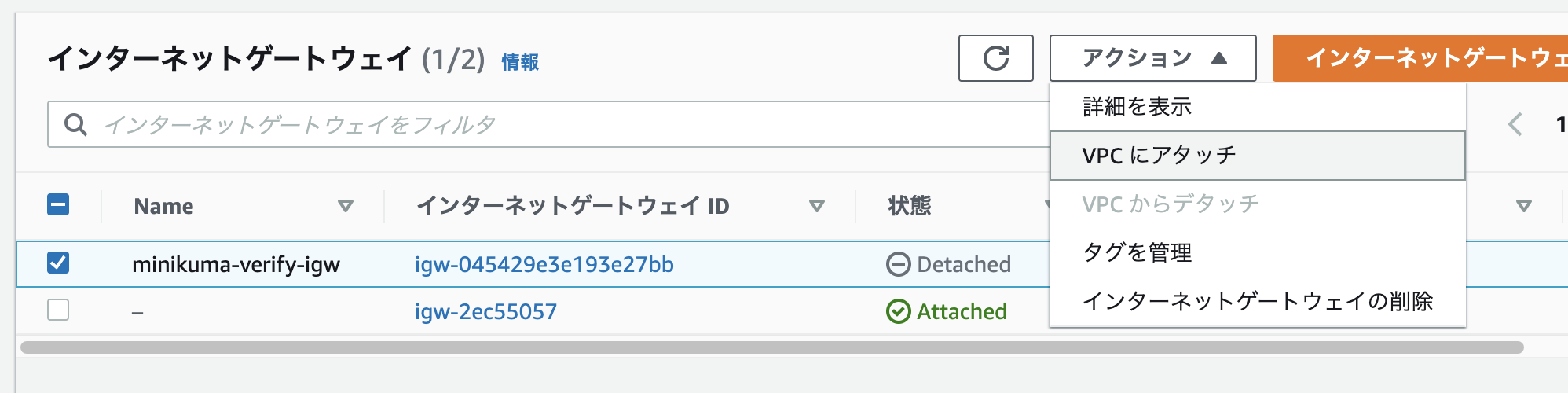
[AWS] ルーティング設定 その1 IGWのアタッチ
「インターネットゲートウェイ(IGW)」をVPCにアタッチしていきます。
※インターネットゲートウェイとは雑に言えばデフォルトルートが登録されたデフォルトゲートウェイ(ブロードバンドルーター)のようなもの。より簡単に言えばインターネットとVPCを繋ぐ入り口です。
まず先ほどのVPCのページのダッシュボードから「インターネットゲートウェイ」を選択しインターネットゲートウェイの作成に移ります。
作成したインターネットゲートウェイを確認すると「Detached」になっている。これをアクションから自分のVPCに「アタッチ」するように設定していく。
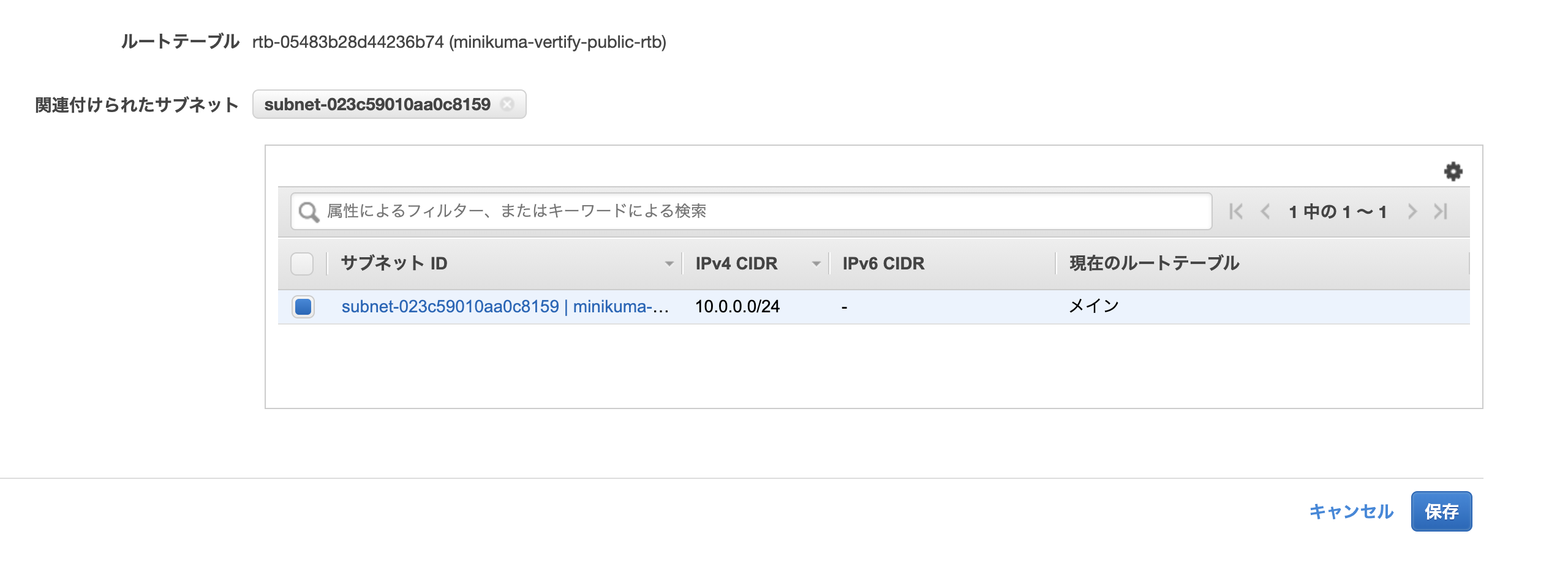
[AWS] ルーティング設定 その2 ルートテーブルの作成
またダッシュボードから「ルートテーブル」を選択する。
無事作成。次はこのルートテーブルをVPCへの紐付きからパブリックサブネットへの紐付きに変更します。
サブネットを選択し、保存。
最後にルーティングテーブルで「0.0.0.0/0」のipアドレスが先ほど設定したインターネットゲートウェイに振り分けされるように設定。※0.0.0.0/0とは要は全てのIPアドレスのこと。振り分けを設定した他のIP(10.0.0.0/16)以外は全てインターネットゲートウェイに向かいます。こうすることでインターネットに繋がります。
[AWS] EC2の設定
[AWS] EC2インスタンス作成
「EC2」というAWS上の仮想サーバーを利用します。また管理画面の検索バーからEC2のページにアクセスしましょう。
EC2設定前にさくっと用語を整理しておくと、「インスタンス」 というのはEC2から建てられたサーバーのこと。「AMI」はOSのテンプレートイメージ、「インスタンスタイプ」はサーバースペック、「ストレージ」はそのまま文字通りデータの保存場所(EBSを利用することが多いとのこと)。インスタンスを立ち上げるさいにAMI、インスタンスタイプ、ストレージを指定して設定します。
また後ほど、ここで作ったインスタンスにPythonやFlask、Nginxといったソフトウェア、ミドルウェアをインストールすることでWebサーバーとしての役割を果たせるようにしていきます。
まずダッシュボードで「インスタンス」を選択。
右上の「インスタンスを起動」を選択。
「AMI」に関しては今回は「Amazon Linux 2(x86)」を選択します。
「インスタンスタイプ」は「t2.micro」を選択します。
t2.microはAWSのアカウント開設から12ヶ月間は無料で使用できるインスタンスです。※参考:改めてAWSの「無料利用枠」を知ろう / クラスメソッド
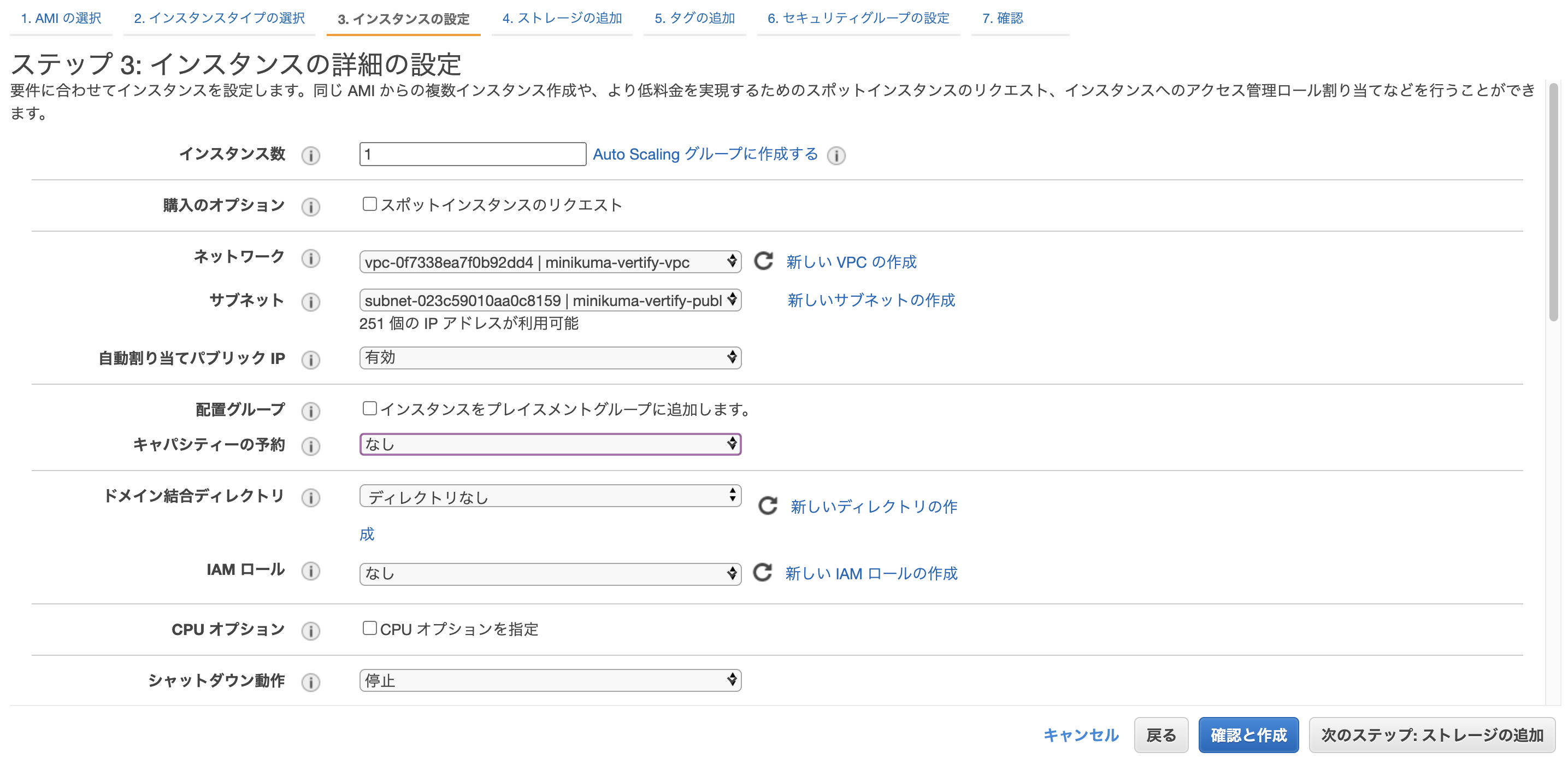
インスタンスの詳細設定では、
(1)「ネットワーク」、「サブネット」を先ほど自分で作ったものに設定
(2)「自動割り当てパブリックIP」は有効に(インターネットに繋ぐ時に必要なグローバルIPをAWSが自動で割り当ててくれる。)
(3)「キャパシティーの予約」は今回勉強用なのでなしに。※参考:AWS EC2 オンデマンドキャパシティー予約を詳しく知る / Serverworks
今回、ストレージの割り当てはデフォルトの8GiBで問題ありません。
タグはNameでインスタンスの名前を付けてやります。
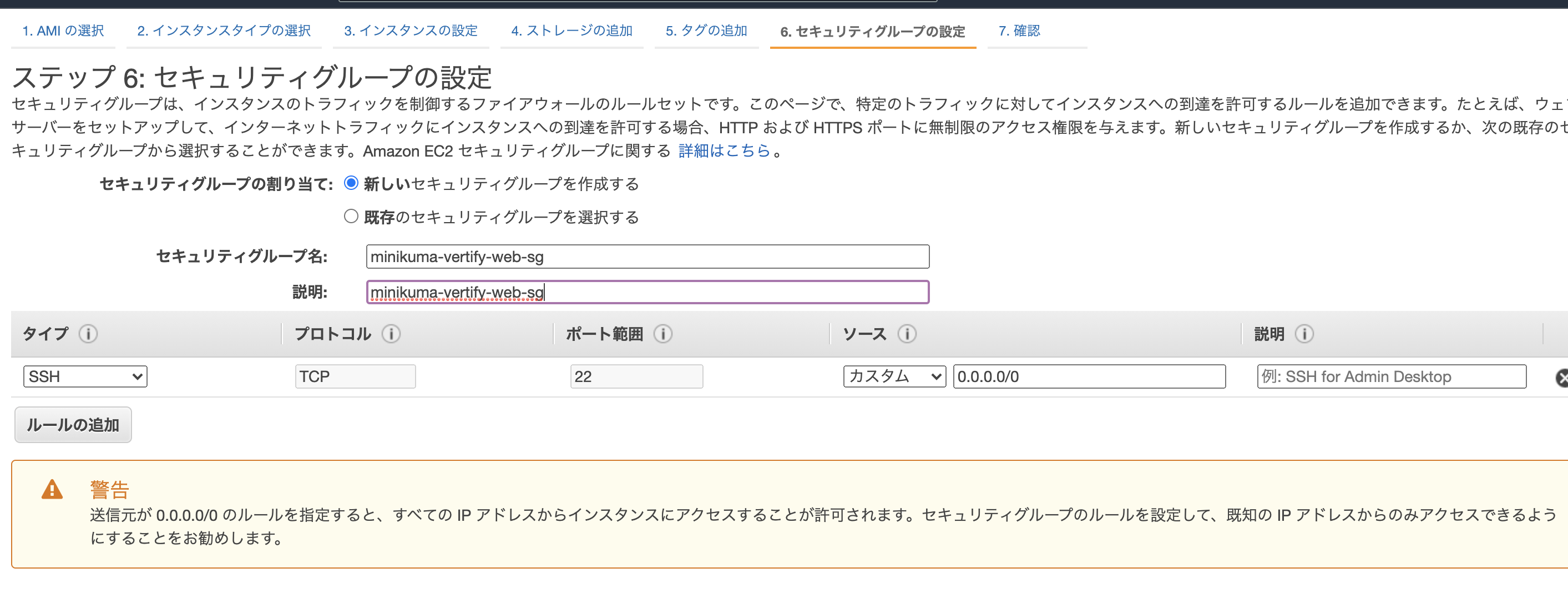
セキュリティグループの名称を付けてやります。
後ほどセキュリティの設定を行ってインターネットからの接続を許可しますが一旦、インスタンスを起動させます。
インスタンスの起動前にこのインスタンスに接続するためのkeypairを作成してダウンロードしておく。なくさないように保存しておきましょう。
※注意:このkeyは絶対にオンラインに公開などしないように!!!
最後にセキュリティウォールの設定をしていきます。
「EC2」のダッシュボードから「セキュリティグループ」を選択します。
先ほど作成したセキュリティグループにチェックボックス を入れて下の「インバウンドルール」で「インバウンドルールを編集」をクリックします。
編集画面でHTTPを上記と同じように追加しましょう。
これでHTTP通信でインターネットのどこのIPからでもこのインスタンスにアクセスが出来るようになりました。
[AWS] MacからAWSインスタンスにSSH接続する
ターミナル を起動して下記のようにコマンドを打っていきます。
まず、keypairのパーミッションを600番に変更します。
$ chmod 600 ~/キーペア保存までのパス/作成したkeypair次にAWSの管理画面のEC2のページから接続したいインスタンスにチェックボックスを入れて、下の方にある詳細画面から「パブリックIPv4アドレス」をコピーしてきます。(インスタンスを再起動させたりすると変わってしまうので注意!)
下記のコマンドを打って、インスタンスに接続しよう。なお初めてインスタンスに接続する場合は「fingerprint」がないが大丈夫か聞いてくるので「yes」と打ってEnterしてやりましょう。
$ ssh -i ~/キーペア保存までのパス/作成したkeypair ec2-user@パブリックIP[AWS] 補足:請求アラートの設定
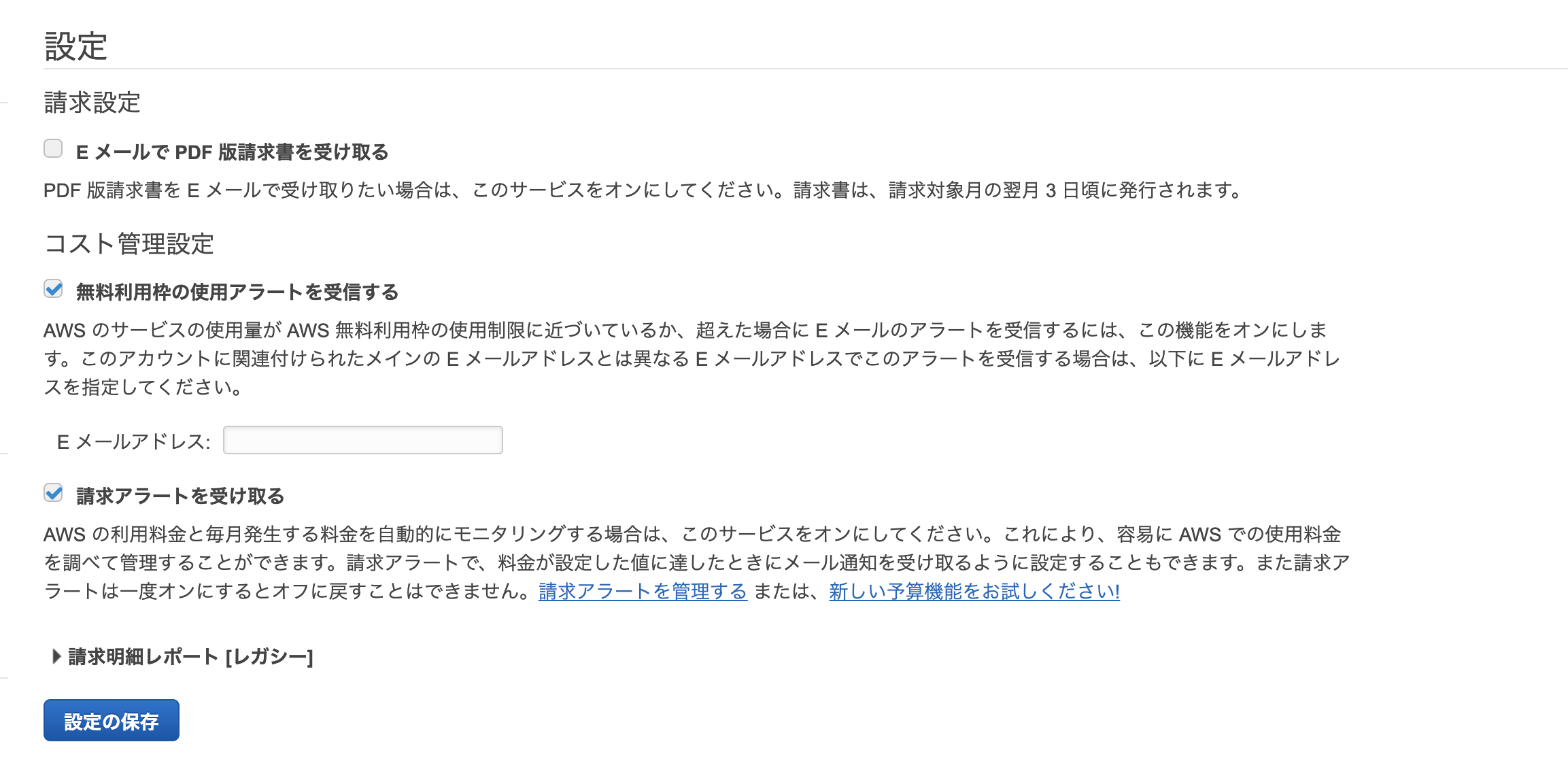
右上のIAMユーザー名のドロップダウンリストから「マイ請求ダッシュボード」を選択。左のダッシュボードの「設定」から「Billingの設定」をクリックします。
無料利用枠(アカウント解説から12ヶ月無料の分)を過ぎた際に指定したメールにアラートを流すように設定します。また一定以上の金額が発生した場合にもアラートが出るように請求アラートにチェックをいれます。
続いてCloudWatchを設定してアラートの詳細設定を行います。
サービス画面から検索してCloudWatchを選択して、
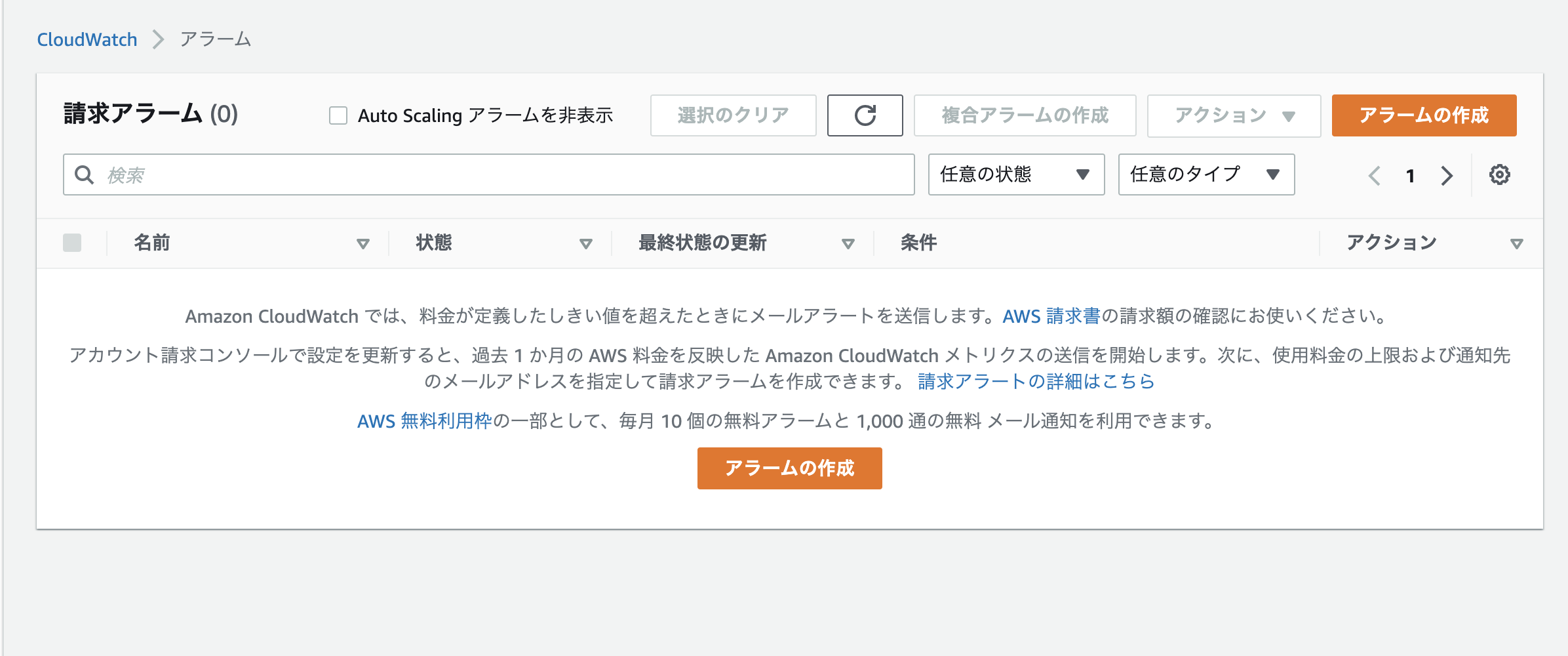
「アラームの作成」を選択します。
※バージニアリージョンでしかCloudWatchを使えないという情報をWeb上でよく見かけましたが、私のアカウントではオレゴン(やおそらく東京リージョン)で問題なくアラームを設定できました。
今回は10ドルを閾値として設定します。
上記画面で連絡先のメールアドレスや任意のアラート名を設定して、最後に「アラームの作成」を選択します。
下記のようなメールが設定したメールアドレス宛に届いているはずなので、「Confirm subscription」をクリックして登録を承認します。
※ちなみに追加で別のメールアドレスにも届くように設定するにはAWSの「SNS」というサービスを使用すれば良いのですが今回は説明を省略します。
Pythonセットアップ+各種ソフトインストール
下準備とpyenvのインストール
まずyumのアップデート及び必要なソフトウェアのインストールを行います。
$ sudo yum -y update $ sudo yum -y install \ bzip2 \ bzip2-devel \ gcc \ git \ libffi-devel \ make \ openssl \ openssl-devel \ readline \ readline-devel \ sqlite \ sqlite-devel \ zlib-devel \ tree次にgithubからpyenvというPythonのバージョン管理ツールをダウンロードして設定(パス通し)を行ってやります。
$ git clone git://github.com/yyuu/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profileちなみに下記のようなシェルスクリプトを追加することで.bash_profileがちゃんと読み込まれた時にメッセージを出してくれるので便利です。
$ echo 'echo "ec2-user bsah_profile stands up"' >> ~/.bash_profile準備が出来たら、.bash_profileを読み込んでやります。
-- 下記どちらでも良い $ . ~/.bash_profile $ source ~/.bash_profilePython、Flask、uWSGIの取得
pyenvで現在取得出来るPythonのバージョンを確認出来ます。
$ pyenv install --list -- 上だと長いので下記のようにすると3.9と前に着いているバージョンのみ確認出来る $ pyenv install --list | grep "3\.9\.*" | grep -v "[A-Za-z]"pyenvを用いて指定のバージョンのPythonをインストールします。(結構インストールには時間がかかります...)
$ pyenv install 3.9.2 -- 現在使用できるバージョンの確認(systemはこのインスタンスに最初から入っていたもの) $ pyenv versions * system (set by /home/ec2-user/.pyenv/version) 3.9.2 -- バージョン切り替え $ pyenv global 3.9.2後々使用するamazon-linux-extrasコマンドのため下記のようなシンボリックリンクを貼ります。
$ ln -s /lib/python2.7/site-packages/amazon_linux_extras ~/.pyenv/versions/3.9.2/lib/python3.9/site-packages/pipでFlaskとuWSGIをインストールします。
$ /home/ec2-user/.pyenv/versions/3.9.2/bin/python3.9 -m pip install --upgrade pip $ pip install flask $ pip install uwsgiamazon-linux-extrasコマンドでNginxをインストールします。
-- nginxがインストール出来ることを確認 $ amazon-linux-extras list | grep nginx 38 nginx1 available [ =stable ] -- インストール(インストールするか聞かれたらyと入力) $ sudo amazon-linux-extras install nginx1以上でPythonのセットアップ及び各種ソフトウェアのインストールは終了です。
次のセクションではいよいよFlaskのアプリケーションを作ってFlask付属の簡易サーバーで動かしていきます。
Flaskアプリケーション作成
本来は、
(1)ローカルのPCでFlaskアプリを作成
(2)それをGitHubのようなgitのホスティングサービスに(git pushで)アップロード
(3)gitホスティングサービスからEC2インスタンス上で(git cloneで)取得してソースコードやコミットログを取得としていくのがスタンダードなやり方です。
ただ今回は、(gitの解説を省略するために)インスタンス上で直接Flaskアプリケーションを作成していきます。ディレクトリ構成は最終的に下記のようになります。
$ cd /var/www $ tree myapp myapp/ ├── __pycache__ │ ├── myproject.cpython-39.pyc │ └── run.cpython-39.pyc ├── myproject.ini ├── myproject.py ├── new_comer.trigger ├── run │ └── mywsgi.sock ├── run.py ├── static │ └── logo_uwsgi.png └── templates ├── advance.html └── index.htmlディレクトリと静的ファイルの下準備
まずFlaskアプリケーションを
/var/www/myappディレクトリに作成していきます。ちなみに「なぜNginxのデフォルトのドキュメントルートの
/usr/share/nginx/htmlではなく/var/wwwに作るのか」というというと、Nginxの公式ドキュメントにもある通り、You should not use the default document root for any site-critical files. There is no expectation that the default document root will be left untouched by the system and there is an extremely high possibility that your site-critical data may be lost upon updates and upgrades to the NGINX packages for your operating system.
「デフォルトのドキュメントルートのディレクトリはNginxのパッケージアップデートの際にも使用されるものであり、このアップデートの際に重要なデータが消える可能性があるので避けた方が良いよ」、と言うことのようです。
※参考:Not Using Standard Document Root Locations Nginx公式ドキュメント
さっそく作っていきます。
-- ec2インスタンス上 $ sudo mkdir -p /var/www/myapp $ cd /var/www/myappさて、Flaskのルールとして下記のようなファイルの置き場所に関わるルールがあります。
- 「templates」ディレクトリ HTMLファイルの置き場所でここに置くことでPython用のテンプレートエンジンJinja2が適用される。
- 「static」ディレクトリ 「(HTMLファイル以外の、)CSSファイル・JSファイル・画像ファイル」などの静的ファイルの置き場所です。今回は下記の画像を保存しておきます。
※ちなみに最初、私はtemplate*sをtemplate*としていたので延々と「jinja2テンプレートが見つかりません」
jinja2.exceptions.TemplateNotFoundとエラーが出て憂鬱な気持ちになっていました。ではそれぞれのディレクトリを作っていきます。
-- ec2インスタンス上 $ sudo mkdir templates static run※
runディレクトリに関しては後ほどuWSGIサーバーの関連ファイルを保存するために使うので先に作っておいてください。次に
staticディレクトリに入れる画像をローカルのPCに入れてそれをsshでサーバーに送りましょう。scpコマンドを使用すれば出来ます。-- ローカル上 $ scp -i ~/keypairまでのパス/作成したkeypair ~/送りたいファイルまでのパス/送りたいファイル ec2-u ser@インスタンスのパブリックIP:~/送り先のディレクトリのパス送り先のディレクトリのパスは
ec2-userのホームディレクトリ「~/」を指定するのがオススメです。※デフォルトの状態でいきなりルート直下の
/var/www/myapp/staticなどを指定するとPermission deniedとなってしまいます。今回のようにファイルを送る場合は
scpコマンドにはオプションは入りませんがディレクトリを送る場合は-rとつけましょう。ちなみに今回は下記の画像を使用します。
今度はssh先で画像を
/var/www/update/staticに移しましょう。-- ec2インスタンス上 $ sudo mv ~/logo_uwsgi.png /var/www/myapp/static/次に
templatesディレクトリに下記の二つのHTMLファイルを入れます。※普通のHTMLファイルと違う書き方ですがこれは
templatesディレクトリに置いた.htmlファイルはFlaskのテンプレートエンジンによって解釈されるためです。-- index.html <!DOCTYPE HTML> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>{{ name }}さんのページだぞ</title> </head> <body> <h1>きみは{{ name }}さんだね!</h1> <img src="/static/logo_uwsgi.png" style="width:100%"> <p>これはindex.htmlのページです</p> <form action="/" method="GET"> <p><label>名前を変更してみよう: <input name="name" type="text" placeholder="なまえ入力してね"></label> <p><input type="submit" value="名前変更確定!"></p> </form> </body> </html>-- advance.html <!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>{{ name }}</title> </head> <body> {% if name == "Kumamoto" %} <h1>きみはオーナーだね</h1> {% elif name %} <h1>きみはゲストの{{ name }}さんだね</h1> {% else %} <h1>ななしさんだね</h1> {% endif %} <form action="/adv" method="POST"> <p><label>名前を更新する:<input name="name" type="text"></label></p> <p><input type="submit" value="更新!"> </form> <p>advance.htmlのページです</p> </body> </html>続いて本家本元のMVTのView部分(MVCで言うコントローラー部分)を作成していきましょう。
-- myproject.py from flask import Flask, render_template, request application = Flask(__name__) @application.route("/") @application.route("/index") def index(): # Note:str()を使う事でNoneの時でも、TypeErrorを起こさず"様"をつけることが出来る name = str(request.args.get("name")) + "様" return render_template("index.html", name=name) @application.route("/adv", methods=["GET", "POST"]) def advance(): # Note:dictのgetメソッドを使うことでNoneでもエラーにならない! name = request.form.get("name") # Note:./を書いても書かなくてもいいんだなぁ。 return render_template("./advance.html", name=name) if __name__ == "__main__": application.run()さらにこれを動かすpythonスクリプトを作りましょう。
-- run.py from myproject import application if __name__ == "__main__": application.run(host="0.0.0.0", debug=True)さて、
run.pyのほうでflaskインスタンスのrun関数のキーワード引数hostを"0.0.0.0"と指定しています。こうすることでどこのipアドレスからのアクセスも受け付けるようになっています。※キーワード引数hostを指定しないデフォルトでは自分自身を表すプライベートIP127.0.0.1以外からは受け付けないです。
ただし!!今現在はインスタンスのセキュリティグループで「HTTPの80番ポート」からの接続はどこのIPアドレスからでも受け付けますが、80番以外のポート番号からのHTTP接続はどこのIPアドレスからであっても許可されていません。
実際にアクセス出来ないことをまずは実験してみましょう。
$ python /var/www/myapp/run.py * Serving Flask app "myproject" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 301-577-841flaskに付属する簡易サーバーが立ち上がります。
※warningにもある通りこの簡易サーバーを本番サーバーとして運用することは辞めましょう。ログに「HTTP」の「どのIPアドレスからでも」「5000番ポートを使って」アクセス出来るとあります。
それではブラウザを立ち上げAWSで作成したEC2インスタンスに割り当てされているパブリックIPを打ち込んで、アクセスを試みて見ましょう。
アクセス出来ません(あたりまえ)
それではAWSの「EC2」サービスページのダッシュボード「セキュリティグループ」から自分の作ったセキュリティグループのチェックボックスにチェックを入れ、下の画面の「インバウンドルールを編集」からルールを編集しましょう。
下記のように「ルールの追加」で「タイプ:カスタムTCP」、「ポート:5000番」、「ソース:マイIP」を選択します。完了したら「ルールの保存」を選択しましょう。
※マイIPというのは自分に割り当てられているグローバルIPのことです。
再度、
http://インスタンスのパブリックIP:5000にアクセスしてみましょう。
※flaskの簡易サーバーを止めた場合は再度、python run.pyすることを忘れずに!
無事アクセス出来ました!入力フォームに文字を入れてみたり、
http://インスタンスのパブリックIP:5000/advにアクセスしたりわざとPythonのスクリプトにバグを起こして、debug画面を覗いたりしてみましょう。uWSGIセットアップ
さらっと用語を学ぶ
uWSGIに関わる用語を整理します。
| WSGI | uWSGI | uwsgi |
| ---- | ---- | ---- |
| アプリケーションとAP/Webサーバー間の標準的なインターフェイス| APサーバー | uWSGIサーバーのバイナリプロトコル |※参考:How To Set Up uWSGI and Nginx to Serve Python Apps on Ubuntu 14.04 / Digital Ocean
まずはコマンドで立ち上げ
uwsgiコマンドを用いて先ほどのFlaskアプリケーションをデプロイしましょう。$ cd /var/www/myapp $ uwsgi --http=0.0.0.0:5000 --wsgi-file=run.py --callable=applicationコマンドオプションの意味を補足します。
httpがサーバーのipアドレス、ポート番号を指定します。既に説明しましたが、「0.0.0.0」はIPv4アドレス空間内の全てのアドレスと一致します。またポート番号を5000番としたのは、先ほどEC2のセキュリティグループで5000番ポートからのアクセスを許可するように設定したからです。(80番ポートを指定してもアクセスは出来ます。)
wsgi-fileでは先ほど作ったflaskのアプリケーションファイル(つまり今回だとrun.py)を指定します。
callableではFlask(__name__)のインスタンス名を指定します。(今回はapplication)
またhttp://インスタンスのパブリックIP:5000にアクセスしてサイトが映るか確かめてみましょう。uWSGIのための設定ファイルを書こう
毎回コマンドのオプションを指定するのは面倒なのでドットiniファイルにuWSGIの設定を書いていきます。
$ cd /var/www/myapp $ sudo vim myproject.ini中身は下記。
[uwsgi] # Nginxを使わずにアクセス出来るように一時的にhttpプロトコルを設定 http=0.0.0.0:5000 module=run callable=application master=true processes=5 base_dir=/var/www pj_name=myapp # uwsgi-socketはsocketと指定してもよい uwsgi-socket=%(base_dir)/%(pj_name)/run/mywsgi.sock logto=/var/log/uwsgi/uwsgi.log # 後々Nginxがアクセス出来るように666にしている chmod-socket=666 vacuum=true die-on-term=true # wsgi-file=/var/www/myapp/run.py wsgi-file=%(base_dir)/%(pj_name)/run.py touch-reload=%(base_dir)/%(pj_name)/new_comer.trigger
moduleはflaskを動かすファイル(run.py)、callableがFlask(__name__)のインスタンスです。
master=trueは公式のGlossary(用語集)にもある通り推奨されている設定です。
processesは実行するプログラム数のことです。
vacuumオプションをtrueにすることで、プロセスの停止時にソケットをクリーンアップしてくれます。
die-on-termオプションの設定です。これは、initシステムとuWSGIが、それぞれのプロセス信号が何を意味するかについて、同じ仮定を持っていることを保証することができます。これを設定することで、2つのシステムコンポーネントが整合し、期待される動作が実装されます。また
touch-reloadについては後ほど説明します。続いて、
logtoで指定したlogファイル用のディレクトリを用意してやります。$ sudo mkdir -p /var/log/uwsgiさて、これでようやっと立ち上げ、、、
$ cd /var/www/myapp $ uwsgi myproject.ini *** Starting uWSGI 2.0.19.1 (64bit) on [Fri Apr 2 04:56:20 2021] *** compiled with version: 7.3.1 20180712 (Red Hat 7.3.1-12) on 29 March 2021 17:49:25 os: Linux-4.14.225-168.357.amzn2.x86_64 #1 SMP Mon Mar 15 18:00:02 UTC 2021 nodename: ip-10-0-0-59.us-west-2.compute.internal machine: x86_64 clock source: unix pcre jit disabled detected number of CPU cores: 1 current working directory: /var/www/myapp detected binary path: /home/ec2-user/.pyenv/versions/3.9.2/bin/uwsgi your memory page size is 4096 bytes detected max file descriptor number: 65535 lock engine: pthread robust mutexes thunder lock: disabled (you can enable it with --thunder-lock) bind(): Permission denied [core/socket.c line 230]出来ませんでした。 エラーログを見る限りPermission関係で弾かれたと推測できます。
次の項からはuWSGIがまともに動けるように(1)「
ec2-user」をサーバー管理者に設定する(2)ディレクトリの所有者をサーバー管理者に変更する、ということをやっていきましょう。サーバー管理者となるユーザー の設定変更
今回は「
ec2-user」をサーバーの管理者用のユーザーとしたいと思います。サブグループとして既に「admin」に所属となっていますが「nginx」グループにも所属させてやります。念のため
/etc/groupファイルでgroup一覧を確認してやりましょう。$ view /etc/group -- 省略して表示 adm:x:4:ec2-user nginx:x:993: ec2-user:x:1000:※ファイルを確認する時はviewコマンドの他
lessやmore、catコマンドなどでもおkです。groupをみてやると「
nginx」グループにはサブグループとして所属しているユーザーはいないことがわかります。※ちなみにUbuntuなどのDebian系だと「
nginx」などのサーバー名の付いたグループではなく、「www-data」グループを使用するのが一般的なようです。ディストリビューションによってもポピュラーなやり方は異なると思うので適宜調べてみてください。つづいてまた念のため「/etc/passwd」でユーザー一覧を確認してみましょう。
$ view /etc/pwasswd ec2-user:x:1000:1000:EC2 Default User:/home/ec2-user:/bin/bash以上から現状「
ec2-user」グループはプライマリーグループとして「ec2-user」、サブグループとして「admin」に所属していることがわかります。今回は学びのために敢えて回りくどいやり方をしましたがユーザーに関しては
idコマンドを、グループに関してはgetentコマンドを使えばさらに簡単に確認が出来ます。(これ以降はこれらのコマンドを使っていきます)-- ec2-userのユーザーidや所属するグループ(プライマリーグループもサブグループも)を確認出来る $ id ec2-user uid=1000(ec2-user) gid=1000(ec2-user) groups=1000(ec2-user),4(adm),10(wheel),190(systemd-journal)-- 今、nginxグループをサブグループとしているユーザーはいない $ getent group nginx nginx:x:993:では現状確認が終わったので「ec2-user」のサブグループに「nginx」を追加します。
$ sudo usermod -aG nginx ec2-user先ほどと同様に
idコマンドとgetentコマンドを使って上手くec2-userがnginxに所属してくれたか確認しましょう。$ id ec2-user uid=1000(ec2-user) gid=1000(ec2-user) groups=1000(ec2-user),4(adm),10(wheel),190(systemd-journal),993(nginx) $ getent group nginx nginx:x:993:ec2-user問題なさそうです。
では続いては各種ディレクトリの所有者を変更していきましょう。
各種ディレクトリの所有者変更
まず本家本元の
/var/www以下の所有者を変更していきましょう。-- ec2-userになっていない場合「sudo su - ec2-user」でユーザーを切り替えてください $ echo $USER ec2-user -- /var/www以下の全ての所有者を変更 $ sudo chown $USER:nginx -R /var/www上手くいったか確認してみましょう。
$ ls -ld /var/www drwxr-xr-x 3 ec2-user nginx 33 4月 1 09:06 /var/www $ ls -l /var/www drwxr-xr-x 4 ec2-user nginx 92 4月 2 04:46 myappではいったん、uwsgiの設定ファイルmyproject.iniのうちlogファイルの指定部分をコメントアウトしてやって、、、
[uwsgi] #logto=/var/log/uwsgi/uwsgi.logサーバーの接続を再度試みてみましょう。
$ cd /var/www/myapp $ uwsgi --ini myproject.ini *** Starting uWSGI 2.0.19.1 (64bit) on [Fri Apr 2 06:17:56 2021] *** compiled with version: 7.3.1 20180712 (Red Hat 7.3.1-12) on 29 March 2021 17:49:25 os: Linux-4.14.225-168.357.amzn2.x86_64 #1 SMP Mon Mar 15 18:00:02 UTC 2021 nodename: ip-10-0-0-59.us-west-2.compute.internal machine: x86_64 clock source: unix pcre jit disabled detected number of CPU cores: 1 current working directory: /var/www/myapp detected binary path: /home/ec2-user/.pyenv/versions/3.9.2/bin/uwsgi your memory page size is 4096 bytes detected max file descriptor number: 65535 lock engine: pthread robust mutexes thunder lock: disabled (you can enable it with --thunder-lock) uWSGI http bound on 0.0.0.0:5000 fd 3 uwsgi socket 0 bound to UNIX address mywsgi.sock fd 6 Python version: 3.9.2 (default, Mar 29 2021, 17:42:02) [GCC 7.3.1 20180712 (Red Hat 7.3.1-12)] *** Python threads support is disabled. You can enable it with --enable-threads *** Python main interpreter initialized at 0x29b7370 your server socket listen backlog is limited to 100 connections your mercy for graceful operations on workers is 60 seconds mapped 145840 bytes (142 KB) for 1 cores *** Operational MODE: single process *** WSGI app 0 (mountpoint='') ready in 0 seconds on interpreter 0x29b7370 pid: 22333 (default app) mountpoint already configured. skip. *** uWSGI is running in multiple interpreter mode *** spawned uWSGI master process (pid: 22333) spawned uWSGI worker 1 (pid: 22366, cores: 1) spawned uWSGI http 1 (pid: 22367) unable to stat() /var/www/myapp/new_comer.trigger, events will be triggered as soon as the file is created [pid: 22366|app: 0|req: 1/1] 157.107.117.161 () {38 vars in 753 bytes} [Fri Apr 2 06:18:00 2021] GET / => generated 656 bytes in 7 msecs (HTTP/1.1 200) 2 headers in 80 bytes (1 switches on core 0)ブラウザから
http://インスタンスのパブリックIP:5000にアクセスしてみたところ問題なくつながりました。では今度はuWSGIのログがちゃんと指定したログファイルに入っていくようにまたディレクトリの所有者を変更していきましょう。
$ sudo chown $USER:nginx -R /var/log/uwsgi $ ls -ld /var/low/uwsgi drwxr-xr-x 2 ec2-user nginx 6 4月 2 04:42 /var/log/uwsgi忘れずに
myproject.iniのlogtoのコメントアウトを外しておきましょう。※当然、所有者を変えているのでec2-userユーザーならもうsudoせずともvimで編集できますよ!
-- ログが大幅に減っているが、/var/log/uwsgi/uwsgi.logに保存されている(後々確認してみよう!) $ uwsgi --ini myproject.ini [uWSGI] getting INI configuration from myproject.iniNginxセットアップ
Nginxの設定ファイルを作成
ようやくNginxサーバーのセットアップに入ります。
まずNginxの設定ファイルを確認してみましょう。
$ cd /etc/nginx $ view nginx.confnginx.confファイルの中身についての詳細な解説は今回省略しますが、
http { --省略-- include /etc/nginx/conf.d/*.conf;となっているのが確認出来たでしょうか。これは
/etc/nginx/conf.dディレクトリ下の.confという名前のファイルは全て読み込むように設定されているということです。それでは今回作成Flaskアプリ用のNginx設定ファイルを作成していきましょう。
$ cd /etc/nginx/conf.d $ sudo vim myapp.confmyapp.confの中身は下記のようにします。
server { listen 80; listen [::]:80; root /var/www; location / { include uwsgi_params; uwsgi_pass unix:///var/www/myapp/run/mywsgi.sock; } }rootとあるのはルートドキュメントを
/var/www以下にしますよ、という意味です。
.sockファイルの指定は、既に作成したmyproject.iniで設定したのと同じパス、ファイル名を指定してください。念のため、今設定したファイルにNginx上の文法ミスがないか確認してみましょう。
$ sudo nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful問題なさそうですね。
続いて、今後uWSGIとNginx間の通信プロトコルとしてHTTPではなくuWSGIデフォルトのuwsgiプロトコルを使って欲しいので
myproject.iniファイルからhttp=0.0.0.0:5000という行を削除します。Nginxを立ち上げてuwsgiと接続してみましょう。
$ sudo systemctl start nginx $ sudo systemctl enable nginx $ cd /var/www/myapp $ uwsgi --ini myproject.ini先ほどと同じようにインスタンスのパブリックIPを指定してブラウザからアクセスしてみてください。
自動でNginxとuWSGIがアクセス出来るようにする
さて今まではNginxが起動している状態で手動でuWSGIを立ち上げしていましたが、こんなことを毎回したくはないです。
そこでnginxと同じようにuWSGIも
systemctlコマンドで立ち上げっぱなしに出来るようにsystemd管理下のサービスにしてあげましょう。まずsystemdが管理するサービスの設定ファイルのあるディレクトリに移動しましょう。
$ cd /etc/systemd/system $ sudo vim uwsgi.service下記のように設定ファイルを記述していきます。
:::details uwsgi serviceの設定ファイル
```
[Unit]
Description=uWSGI instance to serve myapp
After=network.target[Service]
User=ec2-user
Group=nginx
WorkingDirectory=/var/www/myapp
ExecStart=/home/ec2-user/.pyenv/shims/uwsgi --ini myproject.ini
Restart=always
KillSignal=SIGQUIT
Type=notify
NotifyAccess=all[Install]
WantedBy=multi-user.target
```
:::uwsgiサービスを立ち上げしていきます。
$ sudo systemctl start uwsgi.service $ sudo systemctl enable uwsgi.serviceこれでインスタンスを停止しない限り、常時Flaskで作ったWebサイトにアクセス出来るようになりました!
Flaskのソースコードを変更した際にアップデートされるようにする
Flaskのアプリのソースコード(今回ならmyproject.pyなど)を変更してもWebサイト上の表記が変わらないことがあります。
これは同じディレクトリ内の
__pycache__ディレクトリにあるキャッシュファイルが原因です。
※逆にこのファイルのおかげでソースコード変更がない際は毎度処理が行われることなく済んでいます。当然NginxとuWSGIを停止して再起動させればアップデートされたコードが反映されますが、毎回そんなことをするのは面倒くさい。。。
そこでソースコードの反映をさせるための
.triggerファイルを作成しましょう。先ほど設定したuWSGIのmyproject.iniファイルの中身を再度確認してください。
[uwsgi] --省略-- # .triggerファイルのファイル名は任意のものを使用可能 touch-reload=%(base_dir)/%(pj_name)/new_comer.trigger上記で指定したリロードファイルを作成してみよう。
ソースコードの変更を反映するには
.triggerファイルをtouchコマンドで更新するだけで反映される。-- リロードファイルの中身は空で良い $ cd /var/www/myapp $ touch new_comer.trigger以上で第一部は終わりです。お疲れ様でした!
おまけ tips&エラー集
筆者がサーバーを立ち上げる中でぶつかったエラー及びその原因についておまけで載せていきます。
実際にみなさんがサーバー構築をやっていくとここに出ていないエラーが出てくるかもしれませんし、同じエラー文でも違う原因で発生しているかもしれません。
ただここに出てくる解決方法を試してみれば何か解決の糸口が掴めるかもしれません。毎回ログに残る時間が日本時間でない
原因:設定漏れ
これはエラーではなく単なる設定漏れですが、$ sudo su - $ timedatectl set-timezone Asia/Tokyoとタイムゾーンを変更してやるだけで問題ないです。
502 Bad Gatewayと出てしまう
原因:uWSGIとの接続が上手くいっていない
NginxとuWSGIの接続が上手くいかない場合に発生します。
具体的に言うとrun.pyを設定ファイルの中でTypoしていました。こういったぽかミスであっても
tailコマンドでエラーログを追っていくと「No such file」等のエラー原因の特定に繋がるメッセージが出ていることが多々あります。$ sudo tail -f /var/log/nginx/error.logInternal Server Errorと出てしまう
原因:Pythonの文法エラー
「Internal Server Error」とははっきり言ってエラー原因の手がかりが読み取れないエラーです。
ただPythonの文法エラーである場合も多いので、一旦NginxとuWSGIを停止させFlaskの簡易サーバーをデバッグを行うことで原因が見つかることもあります。




















- 投稿日:2021-04-05T19:34:31+09:00
python 仮想環境作り方
- 投稿日:2021-04-05T19:26:24+09:00
pixivpyで5000人以上フォローしているユーザーを取得できない問題を解決案
はじめに
pythonのpixivpyにはpixivpyという非公式のライブラリがあるのだが、
どうやら現在私が書いた記事の方法だと、フォローしているユーザーをすべて取得できないらしい。なので分析するとともに、新しい方法で取得した。
きっかけ
@fukubucho_ さんのコメント
すみません、追加でお聞きしたいのですが、ID getterには取得上限などあるのでしょうか?
6600フォローしてるのですが、何度IDを取り直しても30×167=5010フォローしか取れないので…とあるので調査してみた
今回はこの記事を読んでいること、使っていることを前提としています。
1.原因の調査
現在自分のフォローしているユーザーを取得するスクリプトはこちらである。
pixiv_follow_id_getter.pyfrom pixivpy3 import * import json from time import sleep import datetime with open("client.json", "r") as f: client_info = json.load(f) # pixivpyのログイン処理 api = PixivAPI() api.login(client_info["pixiv_id"], client_info["password"]) aapi = AppPixivAPI() aapi.login(client_info["pixiv_id"], client_info["password"]) #現在のフォローidを取得 ids_now = [] a = aapi.user_following(client_info["user_id"]) while True: try: for i in range(30): #このapiは一回で30しかとってこれない id = a.user_previews[i].user.id ids_now.append(id) print(id) next_qs = aapi.parse_qs(a.next_url) a = aapi.user_following(**next_qs) #次のページに行く前のsleep sleep(1) except: break #client.jsonに書き込みたい client_info["ids"] = ids_now client_info["version"] = datetime.datetime.now().strftime('%Y%m%d') with open("client.json", "w") as n: json.dump(client_info, n, indent=2, ensure_ascii=False) #数値を表示したい print("現在のフォロー総数は") print(len(ids_now))このスクリプトの
next_qs = aapi.parse_qs(a.next_url) a = aapi.user_following(**next_qs)この部分を調査する。
next_qs
next_qsの中身は、
{'offset': 30, 'restrict': 'public', 'user_id': 数字} {'offset': 60, 'restrict': 'public', 'user_id': 数字} {'offset': 90, 'restrict': 'public', 'user_id': 数字} ...となっており、
offsetがフォローしているユーザーの先頭からの通し番号になっていることがわかった。ここで、
next_qs = {'offset': 15000, 'restrict': 'public', 'user_id': 数字}とし、実行してみたところ、
{'error': {'user_message': '', 'message': '{"offset":["Offset must be no more than 5000"]}', 'reason': '', 'user_message_details': {}}}と返答が来た。
Offset must be no more than 5000
とあるから、5000以上のフォローユーザーは受け付けていないことがわかった。
これが、pixivpyの問題なのかapiの問題なのかを調査した。user_following
next_qsを使用するuser_followingという関数を調査した。aapi.py# Following用户列表 def user_following(self, user_id, restrict='public', offset=None, req_auth=True): url = '%s/v1/user/following' % self.hosts params = { 'user_id': user_id, 'restrict': restrict, } if (offset): params['offset'] = offset r = self.no_auth_requests_call('GET', url, params=params, req_auth=req_auth) return self.parse_result(r)上のようになっており、問題はない。
no_auth_requests_call
さらに
user_following内で呼び出されていたno_auth_requests_callという関数を調べた。aapi.py# Check auth and set BearerToken to headers def no_auth_requests_call(self, method, url, headers={}, params=None, data=None, req_auth=True): if self.hosts != "https://app-api.pixiv.net": headers['host'] = 'app-api.pixiv.net' if headers.get('User-Agent', None) == None and headers.get('user-agent', None) == None: # Set User-Agent if not provided headers['App-OS'] = 'ios' headers['App-OS-Version'] = '12.2' headers['App-Version'] = '7.6.2' headers['User-Agent'] = 'PixivIOSApp/7.6.2 (iOS 12.2; iPhone9,1)' if (not req_auth): return self.requests_call(method, url, headers, params, data) else: self.require_auth() headers['Authorization'] = 'Bearer %s' % self.access_token return self.requests_call(method, url, headers, params, data)この中ではapiにアクセスしていた。
pixivが使用しているapiであるhttps://app-api.pixiv.netにアクセスすると、{"error":{"user_message":"\u6307\u5b9a\u3055\u308c\u305f\u30a8\u30f3\u30c9\u30dd\u30a4\u30f3\u30c8\u306f\u5b58\u5728\u3057\u307e\u305b\u3093","message":"","reason":"","user_message_details":{}}}となり、先ほどの
{'error': {'user_message': '', 'message': '{"offset":["Offset must be no more than 5000"]}', 'reason': '', 'user_message_details': {}}}と返答の構造が同じであった。
よって5000以上idを取得できない問題は、pixiv側にあることが分かった。
しかしこのapiはアプリ用のapiらしく、パソコンでふつうにpixivを使用している分には問題にならなかったのだろう。
2.代替案
AppPixivAPI()でダメならPixivAPI()なら、と思ったが、そのような関数がなかった。なので最終手段として、seleniumを用いてマイページにアクセスして、htmlを分析してフォローしているユーザーidを取得しようと思う。
前提
REFRESH_TOKEN
こちらを参考に
REFRESH_TOKENを取得してください。selenium
REFRESH_TOKEN取得時にseleniumでchromeを使用しますが、今回のスクリプトでも必要になります。
client.json
こちらを参考に
client.jsonというファイルを用意し、各々書き込んでください。スクリプト
pixiv_follow_id_getter1.3.1.pyfrom pixivpy3 import * import json import copy from time import sleep import datetime from bs4 import BeautifulSoup from selenium.webdriver.chrome.options import Options from selenium import webdriver f = open("client.json", "r") client_info = json.load(f) f.close() #2021/2/21方法変更 #ログイン api = AppPixivAPI() api.auth(refresh_token=REFRESH_TOKEN) aapi = AppPixivAPI() aapi.auth(refresh_token=REFRESH_TOKEN) #フォロー数の確認 a = aapi.user_detail(client_info["user_id"]) total_follow_users = a.profile.total_follow_users total_follow_page = total_follow_users//24 +1 #ここからseleniumでのid取得 # ブラウザのオプションを格納する変数をもらってきます。 options = Options() # Headlessモードを有効にする(Falseにするとブラウザが実際に立ち上がります) options.set_headless(True) # ブラウザを起動する driver = webdriver.Chrome("chromedriver.exeのパス", chrome_options=options) driver.get("https://accounts.pixiv.net/login") login_id = driver.find_element_by_xpath('//*[@id="LoginComponent"]/form/div[1]/div[1]/input') login_id.send_keys(client_info["pixiv_id"]) password = driver.find_element_by_xpath('//*[@id="LoginComponent"]/form/div[1]/div[2]/input') password.send_keys(client_info["password"]) login_btn = driver.find_element_by_xpath('//*[@id="LoginComponent"]/form/button') login_btn.click() sleep(4) ids_now = [] for i in range(1, total_follow_page+1): #ログインページに url = "https://www.pixiv.net/users/" +str(client_info["user_id"]) + "/following?p={}".format(i) driver.get(url) sleep(1) html = driver.page_source.encode('utf-8') soup = BeautifulSoup(html,'lxml') b = soup.find_all("div", class_ = "sc-5011l6-8 iblic") for c in b: url = c.find("a")["href"] url = url.split("/")[-1] print(url) ids_now.append(url) #現在のjsonと比較して追加したい #listはオブジェクトだからメモリの位置が渡されてしまうからcopyを使う new_ids = copy.copy(client_info["ids"]) for i in range(len(ids_now)): print(ids_now[i] not in client_info["ids"]) if (ids_now[i] not in client_info["ids"]): new_ids.append(ids_now[i]) print("追加したよ") #数値を表示したい print("現在のフォロー総数は") print(len(ids_now)) print("更新前のリスト内の総数は") print(len(client_info["ids"])) print("更新後のリスト内の総数は") print(len(new_ids)) #client.jsonに書き込みたい client_info["ids"] = new_ids client_info["version"] = datetime.datetime.now().strftime('%Y%m%d') with open("client.json", "w") as n: json.dump(client_info, n, indent=2, ensure_ascii=False)前までのスクリプトとの違い
1.apiではなくseleniumを使用して直接htmlからidを取得した
2.書き込む際、すべて取得できていないことがあるので、client.jsonの中身と比較して、追加された分だけ追加で書き込むようにした。使用方法
上記の前提を用意し、
#ログイン api = AppPixivAPI() api.auth(refresh_token=REFRESH_TOKEN) aapi = AppPixivAPI() aapi.auth(refresh_token=REFRESH_TOKEN)の
REFRESH_TOKENを入力driver = webdriver.Chrome("chromedriver.exeのパス", chrome_options=options)の
"chromedriver.exeのパス"を入力注意
何度も短時間に実行すると、ログイン時に認証が必要になり(9枚の写真から選ぶやつ)、うまくログインできなくなります。
その時は時間を空けるか、# Headlessモードを有効にする(Falseにするとブラウザが実際に立ち上がります) options.set_headless(True)の部分をFalseにし、
login_btn = driver.find_element_by_xpath('//*[@id="LoginComponent"]/form/button') login_btn.click()の直後にある程度長いsleepを挟んで手動で認証をし、ログインボタンをクリックしてください
まとめ
5000を超えるフォローユーザーを取得することに対して、pixivpyでは対応していないことが分かった。
その原因はpixivのアプリ用のapiを使用していることであり、
sleniumを使用して力技で取得するようにした。
webのpixivが使用しているapiがあったら教えてください。
- 投稿日:2021-04-05T18:49:14+09:00
辞書
辞書
辞書とは、リストと同じように複数のデータをまとめて管理するのに用いられます。
リストとの違いは、個々の要素をインデックス番号ではなくキーと呼ばれる名前を付けて管理する点です。
辞書ではキーと値のペアが1つの要素となります。
辞書の記述は{キー1:値1, キー2:値2, キー3:値3,...}のように記述します。
ほとんどの場合、キーには文字列が用いられます。
※リストでは要素を[]で囲みましたが、辞書では{}で囲みます。またキーと値の間には「:(コロン)」が必要です。
例: fruits = {'apple':'りんご', 'banana':'バナナ', 'orange':'みかん'}
と記述することで、辞書の記述をすることができました。
次に、要素の取り出すには、取り出したい値に対応する「キー」を用います。
例: fruits = {'apple':'りんご', 'banana':'バナナ', 'orange':'みかん'} print('好きな果物は'+fruits['apple']+'です') ※print(f"好きな果物は{fruits['apple']です}")と記述しても出力されます 出力結果: 好きな果物はりんごです
辞書の要素の更新と追加
辞書はリストと同様に更新と追加をすることができます。
まず更新は変数名[キー名]=値と書くことで更新できます。
例: fruits = {'apple':'りんご', 'banana':'バナナ', 'orange':'みかん'} fruits['orange'] ='オレンジ' print('好きな果物は'+fruits['orange']+'です') 出力結果: 好きな果物はオレンジです
と記述することで、値の更新をすることができます。次に追加ですが、追加は
変数名[新しいキー名]=値と書くことで追加できます。
例: fruits = {'apple':'りんご', 'banana':'バナナ', 'orange':'みかん'} fruits['grape'] ='ぶどう' print(fruits) 出力結果: {'apple':'りんご', 'banana':'バナナ', 'orange':'みかん', 'grape':'ぶどう'}
と記述することで、辞書に新しい要素を追加することができます。
for文
リストと同じ様に辞書もfor文を用いて要素を1つずつ取り出し、処理を行うことができます。
for 変数名 in 辞書:と記述することで繰り返し処理を行うことができます。
例: fruits = {'apple':'りんご', 'banana':'バナナ', 'orange':'みかん'} for fruit in fruits: print('好きな果物は'+fruits[fruit]+'です')
と記述することで、変数fruitに辞書fruits内のキーが1つずつ取り出され代入されます。
そして、それぞれ処理が実行されます。
- 投稿日:2021-04-05T18:39:52+09:00
Virtualenvでの初歩的なミス
はじめに
from flask import Flask, render_template app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') if __name__ == '__main__': app.run(debug=True)仮想環境を有効化して index.html を表示するコードを実行したところ
Traceback (most recent call last): File "app.py", line 1, in <module> from flask import Flask, render_template ModuleNotFoundError: No module named 'flask'上のエラーが発生
pip listでインストール済みライブラリーの中にFlaskはあるのにエラーが出る解決
pip install Flask仮想環境を有効化した後でライブラリーのインストールをもう一度しなければならなかったらしい...
- 投稿日:2021-04-05T18:18:11+09:00
四角形同士の重なり判定
GUIアプリを作っている際に、ドラッグで選択した範囲(つまり直角四角形、今回作ったプログラムは直角四角形の性質は利用せず四角形一般で考えています)内に、ある四角形が重なっているかどうかを調べる必要がありました。少しややこしいのは、アプリの目的上、内包関係にある場合について、片方のみをTrueとしたいのです。
四角形が緑、選択範囲が黒です。上の図の4つの関係のうち上3つになっていればTrue、下のような四角形の内側でのみ選択範囲を指定している場合や、そもそも重なっていない場合にはFalseを返す関数が欲しいわけです。(なお頂点座標はすべて正)
そしてなるべく外部ライブラリに頼りたくない。
点と図形の内外判定の問題は「Point in Polygon」と呼ばれています。
https://en.wikipedia.org/wiki/Point_in_polygonググったところ、ここで掲載されているようなアルゴリズムをPythonで実装しているサイトを見つけました。
https://tjkendev.github.io/procon-library/python/index.html以下の二つのアルゴリズムを組み合わせて、目的の関数を作ります。
多角形の点包含判定
https://tjkendev.github.io/procon-library/python/geometry/point_inside_polygon.html
凸多角形同士の交差判定/交点
https://tjkendev.github.io/procon-library/python/geometry/point_inside_polygon.html
関数の仕組み
1. 四角形の全頂点は選択範囲の内側か?
2. 四角形の辺と選択範囲の辺は重なるか?この二つを調べていずれかでTrueならばよいことになります。(ですよね...?)
cross_rec.py# 四角形の全頂点は選択範囲の内側か? # https://tjkendev.github.io/procon-library/python/geometry/point_inside_polygon.html より def inside_polygon(p0, qs): cnt = 0 L = len(qs) x, y = p0 for i in range(L): x0, y0 = qs[i-1]; x1, y1 = qs[i] x0 -= x; y0 -= y x1 -= x; y1 -= y cv = x0*x1 + y0*y1 sv = x0*y1 - x1*y0 if sv == 0 and cv <= 0: return True if not y0 < y1: x0, x1 = x1, x0 y0, y1 = y1, y0 if y0 <= 0 < y1 and x0*(y1 - y0) > y0*(x1 - x0): cnt += 1 return (cnt % 2 == 1) # 四角形の辺と選択範囲の辺は重なるか? # https://tjkendev.github.io/procon-library/python/geometry/point_inside_polygon.html より def dot3(O, A, B): ox, oy = O; ax, ay = A; bx, by = B return (ax - ox) * (bx - ox) + (ay - oy) * (by - oy) def cross3(O, A, B): ox, oy = O; ax, ay = A; bx, by = B return (ax - ox) * (by - oy) - (bx - ox) * (ay - oy) def dist2(A, B): ax, ay = A; bx, by = B return (ax - bx) ** 2 + (ay - by) ** 2 def is_intersection(P0, P1, Q0, Q1): C0 = cross3(P0, P1, Q0) C1 = cross3(P0, P1, Q1) if C0 == C1 == 0: E0 = dot3(P0, P1, Q0) E1 = dot3(P0, P1, Q1) if not E0 < E1: E0, E1 = E1, E0 return 0 <= E1 and E0 <= dist2(P0, P1) D0 = cross3(Q0, Q1, P0) D1 = cross3(Q0, Q1, P1) return C0 * C1 <= 0 and D0 * D1 <= 0 def convex_polygons_intersection(ps, qs): pl = len(ps); ql = len(qs) i = j = 0 while (i < pl or j < ql) and (i < 2*pl) and (j < 2*ql): px0, py0 = ps0 = ps[(i-1)%pl]; px1, py1 = ps1 = ps[i%pl] qx0, qy0 = qs0 = qs[(j-1)%ql]; qx1, qy1 = qs1 = qs[j%ql] if is_intersection(ps0, ps1, qs0, qs1): return True ax = px1 - px0; ay = py1 - py0 bx = qx1 - qx0; by = qy1 - qy0 v = (ax*by - bx*ay) va = cross3(qs0, qs1, ps1) vb = cross3(ps0, ps1, qs1) if v == 0 and va < 0 and vb < 0: return 0 if v == 0 and va == 0 and vb == 0: i += 1 elif v >= 0: if vb > 0: i += 1 else: j += 1 else: if va > 0: j += 1 else: i += 1 return False # ps は四角形 # qs は選択範囲 ps = [(2, 2), (5, 3), (4, 10), (2, 6)] qs = [(3, 3), (4, 3), (3, 4), (3, 10)] INSIDE_FLAG = False for vertices in ps: if inside_polygon(vertices,qs): INSIDE_FLAG = True if convex_polygons_intersection(ps, qs): INSIDE_FLAG = True print(INSIDE_FLAG)True

- 投稿日:2021-04-05T17:48:48+09:00
Python+Flaskで作ったWEBアプリをHerokuデプロイした
…ただの初心者の作業記録的なものなので、あまり参考にならないと思います。
udemyの"The Python Mega Course: Build 10 Real World Applications"を参考に、せっせと勉強アプリを作っているのだが、このチュートリアルの環境作りが古い。
とはいえ、「与えられた課題をクリアする」こと自体が好きなので、チュートリアルの中でどこが古くてどこを新しくすべきなのかを判断して、(チュートリアルのやり方には従わず)自分なりに調べた方法ですすめてみる。
つくるのは、Application3:Personal Website with Python and Flask。
アプリをつくったディレクトリに仮想環境をつくる
チュートリアルではアプリを作ってから仮想環境をつくるという流れだが、私は環境づくりから先にやった。virtualenvが紹介されているが、Python 3.3 からはこれが標準機能として取り込まれてvenvとして扱われているそうなので、venvを使ってプロジェクト(アプリ)ごとに独立した仮想開発環境をつくる。
このまんますすめた。
venv: Python 仮想環境管理 - Qiitavenv activate
$ source [newenvname]/bin/activate
activate した仮想環境の中でプログラムファイルをつくる。というか、作ったプログラムを仮想環境をactivateした状態で動かす。finderを確認するとアプリがあるディレクトリの中に[newenvname]という名称のフォルダができている。それを見てから「さぁ、pythonファイルを作ろう!」と思った私は「はて、どこにファイルを置いたらいいの?venvの中なの、外なの?」という疑問にぶち当たってしまった。今から考えると、仮想環境の中で作業することと、物理的にファイルをどこに置くのかは、別の問題だということがわかっていなかったのだが。
答えは、Pythonファイルをvenvフォルダーのどこに配置すればよいですか? - Javaer101のとおり、「仮想環境はあなたのものではないファイルを管理します。自分のファイルをどのように管理するかは関係ありません。venvディレクトリツリー内ではなく、意味のある場所に配置してください。」すなわち、どこでもいいけどvenvディレクトリの外が良いってことらしい。
Flaskを使ってwebページを作る
flaskをimportしたpythonプログラムを作成。home.html、about.html、layout.html、main.cssを参照する感じの簡単なもの。
script.pyfrom flask import Flask, render_template app=Flask(__name__) @app.route('/') def home(): return render_template("home.html") @app.route('/about/') def about(): return render_template("about.html") if __name__=="__main__": app.run(debug=True)アプリをGithubにPushし、Herokuにデプロイ
requirements.txtを作成
$ pip freeze > requirements.txtProcfileを作成
参照:Herokuに必要なProcfileの書き方についてまとめておく | ハイパー猫背 https://creepfablic.site/2019/06/15/heroku-procfile-matome/#index_id1今回はPythonとFlaskを使ったアプリを作ったので、Heroku上で動作させるためには、gunicornというWSGI(Webアプリとサーバーをつなぐもの)が必要なのだそう。そこでHerokuのシステムに「gunicornを使います」ということを記述する。今回はscript.pyというpythonアプリだから、それを入れる。そんで、作成したProcfileはアプリケーションの/ (ルートディレクトリ)に置く。
Procfileweb: gunicorn script:appAppの後ろに
--log-file -と記述すれば,HerokuのログでWSGIの挙動のログが出力されるが、なくてもOK.Git pushした後、heroku にデプロイしてOpen Appボタンを押すと(https://アプリ名.herokuapp.com/ を表示させると)、Application Errorが出てしまった。
ダメだったところ
Herokuのログを確認(
$ heroku logs --tail)・gunicornをインストールしていなかった
言われるがままにProcfileを記述したため、gunicornのインストールをしていなかった(嘘でしょ!)。仮想環境(venv)で
pip install gunicornし、requirements.txtを書き直す($ pip freeze > requirements.txt)。・script.pyを削除してアップしていた
信じられない話だが、アプリファイルそのものを削除していた。ゴミ箱に残っていたものをrestoreして、再push。
・script.pyに書いた参照ファイル名が間違っていた
これでもまだ、
at=error code=H10 desc="App crashed" method=GET path="/"などのエラーが出るので、ググールして参考サイトを確認しつつ、エラーメッセージを目を凝らしてみたら、「index.htmlファイルなんて存在しないぜ!」というメッセージがある。確かに、最初はindex.htmlとしていたファイルをhome.htmlに変えたんだった。それを保存していなかったっぽい。
通った。
学びは、(1)答えはエラーメッセージに隠されている、(2)難しいことをする前に自分の凡ミスを疑え、の2点。自分のミスの酷さに涙が出そうだが、問題解決にかける時間が短くなってきたような気もする。
肩こりがひどい。
- 投稿日:2021-04-05T17:43:03+09:00
for文
for文
リストの要素をすべて出力したい場合、
例: fruits = ['apple','banana','orange'] print('好きな果物は'+fruits[0]+'です') ※print(f"好きな果物は{fruits[0]}です") と記述しても出力できます print('好きな果物は'+fruits[1]+'です') print('好きな果物は'+fruits[2]+'です')
と記述すればapple,banana,orangeが出力できるが、同じ記述を何回も書くのは工数がかかります。
その際に、for文を用いると、簡単に記述することができます。
記述はfor 変数名 in リスト:と記述することで、リストの要素の数だけ処理を繰り返す事ができます。
例: fruits = ['apple','banana','orange'] for fruit in fruits: print('好きな果物は'+fruit+'です') ※ここでも、print(f"好きな果物は{fruit}です")と記述しても出力できます
と記述することで、同様にapple,banana,orangeが出力できます。これはfruitという変数の中に、リストの要素が先頭から順に1つずつ入っていき、その上でfor文の処理が実行されます。処理はリストの要素の数だけ繰り返されます。(変数名は自由ですが、リストの単数形にすることが慣習的に多い)
for文の流れ
①変数fruitに'apple'が代入され、for文の処理が実行される
↓
②変数fruitに'banana'が代入され、for文の処理が実行される
↓
③変数fruitに'orange'が代入され、for文の処理が実行される
- 投稿日:2021-04-05T17:24:31+09:00
アイデミープレミアムプランを受講してみました
2021/04/05
簡単な紹介
1988生まれの32歳。2020年にサイバー大学(ソフトバンク)を卒業。
AIの知識を深めるべく受講を決意なぜアイデミープレミアムプランにしたのか
完全オンラインで全てを完結できる
社会人+田舎に住んでおり完全オンラインはマストで、完全オンラインは受講開始当時結構レアでした。(コロナ前)
完全オンラインの破壊力を試してみて下さい。経済産業省第四次産業革命スキル習得認定講座
ちゃんと履修し卒業すれば半額は国が補助してくれる(最大70%の補助 条件あり)
今がチャンスと思い入校画像認識が学べること
画像認識専用のコースがあり、さらに料金は同じでデータサイエンスやその他のコースも学べる伝えたいこと
機械学習を学びたいが田舎に住んでいる、社会人だから時間がないという方は読んでください
アイデミーさんでの体験談・学んだこと
技術的な内容にはあまり触れません
アイデミーでの学習振り返り
私はアイデミープレミアムプランの6ヶ月コースを選択しました。(最短は3ヶ月)
- 1ヶ月目
環境設定-Pythonや機械学習を自分のパソコンでするための設定をしていきます。
ここでも結構つまづきやすいのですが、もちろんここからサポートしてくれます。Pythonも基礎から習得できるようにカリキュラムが設定されていたので安心して受講できました。
Pythonの使い方を履修したら順次ライブラリを扱えるようになるためのクラスをこなしていきます。
PythonのライブラリNumpyの習得。こちらも別途カリキュラムが設定されています。個別のライブラリにスポットを当てていくのは珍しいなと感じましたがとても大事なライブラリですので素晴らしいですよね。
PythonのライブラリPandasの習得。
PythonのライブラリMatplotlibの習得。
- 2ヶ月目
ここからAIらしい授業内容になっていきます。データクレンジング手法を習得。
機械学習概論を履修。
ついに人工知能の実装のフェーズです。教師あり学習を習得。
スクレイピングを実装。
- 3ヶ月目
ディープラーニング基礎を履修。
CNNを実装
- 4ヶ月目
アイデミーのウェブサイトで紹介されていた男女認識を実装。
HTML/CSSの使い方を履修。WEBアプリ作成時に使用するため。
フレームワークFlaskを履修。
MNISTを使い手書き文字認識アプリの作成。今まで学んできた内容をフルに使いアプリの作成をしていきます。
- 5ヶ月目
最後に自分自身でアプリを作成。
コマンドラインの使い方を習得。
Gitの使い方を履修。
デプロイの仕方を履修。ついに自分で作ったアプリを全世界に公開します。(感動)
- 6ヶ月目
他のコースも無料で受講できるのでデータ分析講座を履修させてもらいました。
※他にも自然言語やAIマーケティングなどもあります。作成したもの
アイデミーさんの授業の中では実装することができるが目的になっていると思います。
ですのでそれぞれの授業の中ではAIの認識精度を上げる方法は学べても実際は試しません。
(すごい時間がかかってしまうため)
そこで今まで作ったアプリを高性能にしたらどうなるのかと気になっていたので既存のMNIST手書き文字認識アプリを高性能にしてみました。
※機械学習では精度が良ければ良い(過学習)というものではありません
一度試していただけたら幸いです。
今後の活用
最近ではDXやAIなど避けては通れませんよね。でも学校ではほとんど教えてくれなかったという世代の方におすすめです。今後の活用で考えているのはドローンでの配送や倉庫の自動化です。日本では人口の減少は確実です。アイデミーさんでは実装を目的としたカリキュラムですので現場で使う目的にはあっていると思います。その代わりアルゴリズムの中身がどのような仕組みで動いているかには注力していません。知っていても損はしませんが現場ではあまり必要ないかもしれませんね。
おわりに
注意:ここまでアイデミーさんの良いとこばかり書いてきたような気がしますが私は一人の受講者でアイデミーさんとは利害関係にありません。
というのは講師の方々のサポートがとても良かったです。Slack上で質疑応答をしていく感じですが順次質問に対応していく感じなので即座に返信っていう感じではありません。しかし、どんな簡単な内容でも必ず返信していただけて親切に答えてくれます。(恐縮な質問を何回もしました) 受講中は様々なエラーに直面します。そんな中とっても頼りになるのが講師の方々です。こういったスクールでは1番肝心な部分かもしれませんね。
- 投稿日:2021-04-05T16:24:37+09:00
django rest framwork で request.get() が取れない場合. PrimaryKeyRelatedField とか
django/djangorestframework で JOIN する 親から子、子から親
https://qiita.com/uturned0/items/973b32be719a52947f3c の続きbackground
GETはrelationしてるobjectを全部、POSTは relationsしているobjectのpkのみを受け取る、というのをしようとして↓を勉強。ありがとう。
やってみると、 update のときに item_id が None になる問題にハマっていた. 理解するためにまず non-relation で勉強
modelはこれ
class Item(models.Model): name = models.CharField(max_length=100) tel = models.CharField(max_length=100) def __str__(self): return self.nameserializer
class ItemSerializer(serializers.ModelSerializer): class Meta: model = Item fields = ['id', 'name', 'tel'] def create(self, request): return Item.objects.create(**request) def update(self, instance, request): item_id = request.pop('item_id', None) if item_id: # ここで適当な処理がしたい的な要望 instance.item = Item.objects.all(pk=item_id) return super().update(instance, request)DRFよくあるエラー
"detail": "Method \"PUT\" not allowed." "detail": "Method \"PATCH\" not allowed." request URL が list/ になってて、 list/1 のようにupdate対象のpkを指定していないcustom field を POST で受け取りたい場合
DRFのcreate() にくる request はvalidated_data なので、不要なdictは来ない
model/serializerにいない post requestを受け付けるには以下のunnecessaryな行が必要class ItemSerializer(serializers.ModelSerializer): unnecessary = serializers.CharField(write_only=True) # <-- ここに書くと request に含まれる対象として認識される class Meta: model = Item fields = ['id', 'name', 'type', 'unnecessary'] # <------------- def create(self, request): unnecessary = request.pop("unnecessary") # <-- するとここにデータが入ってくる。modelsにはないfieldなので、 pop でrequestから削除するのが必須 return Item.objects.create(**request)fields / create / update ... の不思議
write_onlyを指定することによりこのフィールドをGET時には出さないようにしておきます。
fields にはget/post関わらず使う可能性のあるものをすべて書く。
postのときはあると困る・・とか考えなくていい。write_only / read_only がそのスイッチで、DRFがいい感じに fields を解釈してくれる。
read_only = GET only
write_only = only POST, PATCH, PUT, DELETE と思えばよさそうrequestにやってくるデータの型はserializerのclass変数で来まる
CharField = str
class ItemSerializer(serializers.ModelSerializer): item_id = serializers.CharField( #<---------- CharField = str() write_only=True, ) class Meta: model = Item fields = ['id', 'name', 'tel'] def create(self, request): item_id = request.get('item_id', None) #<--- str で値が入る return Item.objects.create(job_history=item_id, **request)UUIDField = uuid()
class ItemSerializer(serializers.ModelSerializer): item_id = serializers.UUIDField( #<------------- UUID write_only=True, ) ... def create(self, request): item_id = request.get('item_id', None) # uuid型になる ...ハマった理由
fieldの指定をrelation系のものにすると、relationが見つからない場合は None になるようだ
class ItemSerializer(serializers.ModelSerializer): parrent_id = serializers.PrimaryKeyRelatedField( とか parrent_id = serializers.StringsRelatedField( とか ,,, def create(self, request): parrent_id = request.get('parrent_id', None) # Noneになる ...見つかった場合は、instance object が入る。
def create(self, request): parrent = request.get('parrent_id', None) print(parrent.pk) # instanceの中に各fieldが入ってくる ...serializer の relation を理解する
わからないこと: PrimaryKeyRelatedField って、pkとpkをつないだあと、何を返すの?
親を返すの?子を返すの? どっち?manual
ここによると、PrimaryKeyRelatedField は親で使っている。子で使うとどうなるんだ?
親 → 子 relation
models.pyclass Album(models.Model): album_name = models.CharField(max_length=100) artist = models.CharField(max_length=100) class Track(models.Model): album = models.ForeignKey(Album, related_name='tracks', on_delete=models.CASCADE) order = models.IntegerField() title = models.CharField(max_length=100) duration = models.IntegerField() class Meta: unique_together = ['album', 'order'] ordering = ['order'] def __str__(self): return '%d: %s' % (self.order, self.title)serializers.pyclass AlbumSerializer(serializers.ModelSerializer): tracks = serializers.PrimaryKeyRelatedField(many=True, read_only=True) class Meta: model = Album fields = ['album_name', 'artist', 'tracks'] class TrackSerializer(serializers.ModelSerializer): class Meta: model = Track fields = ['order', 'title', 'duration']input-datapython manage.py makemigrations python manage.py migrate python manage.py shell import django django.setup() from myapp.models import * from myapp.serializers import * album = Album.objects.create(album_name="The Grey Album", artist='Danger Mouse') Track.objects.create(album=album, order=1, title='Public Service Announcement', duration=245) Track.objects.create(album=album, order=2, title='What More Can I Say', duration=264) Track.objects.create(album=album, order=3, title='Encore', duration=159) serializer = AlbumSerializer(instance=album) serializer.dataresult-of-album{ "album_name": "The Grey Album", "artist": "Danger Mouse", "tracks": [ 1, 2, 3 ] }子のpkが入りました。
子 → 親 relation
models.pyclass AnotherAlbum(models.Model): album_name = models.CharField(max_length=100) artist = models.CharField(max_length=100) class AnotherTrack(models.Model): album = models.ForeignKey(AnotherAlbum, related_name='tracks', on_delete=models.CASCADE) order = models.IntegerField() title = models.CharField(max_length=100) duration = models.IntegerField() class Meta: unique_together = ['album', 'order'] ordering = ['order'] def __str__(self): return '%d: %s' % (self.order, self.title)serializers.pyclass AnotherAlbumSerializer(serializers.ModelSerializer): #ここをやめて tracks = serializers.PrimaryKeyRelatedField(many=True, read_only=True) class Meta: model = AnotherAlbum fields = ['album_name', 'artist' # , 'tracks' ] class AnotherTrackSerializer(serializers.ModelSerializer): album = serializers.PrimaryKeyRelatedField(read_only=True) # 子に追加 class Meta: model = AnotherTrack fields = ['order', 'title', 'duration', 'album']input-datapython manage.py makemigrations python manage.py migrate python manage.py shell import django django.setup() from myapp.models import * from myapp.serializers import * album = AnotherAlbum.objects.create(album_name="The Grey Album", artist='Danger Mouse') AnotherTrack.objects.create(album=album, order=1, title='Public Service Announcement', duration=245) AnotherTrack.objects.create(album=album, order=2, title='What More Can I Say', duration=264) AnotherTrack.objects.create(album=album, order=3, title='Encore', duration=159) serializer = AnotherAlbumSerializer(instance=album) serializer.dataresult-of-track[ { "order": 1, "title": "Public Service Announcement", "duration": 245, "album": 1 }, { "order": 2, "title": "What More Can I Say", "duration": 264, "album": 1 }, { "order": 3, "title": "Encore", "duration": 159, "album": 1 } ]親のpkが入りました。
結論
PrimaryKeyRelatedField は 親に使えば子のpkを返すし、子に使えば親のpkを返す。
結果、どうなったか
relationしてる子をcreateするとき、parent objectを取るのをやめた。
create() では UUIDField でただの変数として取得。
その値を使って親のobjectを取得、 Item.object.create(parent=parent, **request) するようにした。Noneになるよってエラーより、このほうがjoin先のpkが見つからないエラーもわかりやすかった。
- 投稿日:2021-04-05T14:51:26+09:00
【Raspi4】OAK-D VS 市販USBカメラ 処理速度比較
ラズパイ4との組み合わせでOAK-DとUSBCAMそれぞれで処理速度にどれほど差が出るか比較。既知の通りGPU非搭載のラズパイでは機械学習を利用した物体検出処理が遅く実用場面は限られる。
USBカメラ+ Raspberry pi4 実行結果
こちらはTensor Flowで作成された人工知能モデルを利用したサンプルコードmobilenet SSDを利用した実行結果。
判定までに288.89ms
産業用ロボットのピッキング処理に利用しようと考えていますが、
この画像処理だけでこれだけの時間がかかるのは実用面で不具合があります。OAK-D + Raspberry pi4 実行結果
こちらはOpenCV のサンプルコードdepthaiを利用した実行結果
FPS30(約33.3ms)
ラズパイとのセットでの環境でも前評判通りの数値が出ました。USBカメラでもマイコンをJetsonNano等のGPU搭載機にすれば
処理速度は速くなりますが、とりあえず、OAK-Dとラズパイのセットで
産業用ロボットによる化粧品容器ピッキングの実用面で通用するか
テストしたいと思います。



- 投稿日:2021-04-05T13:22:45+09:00
Pythonで学ぶ制御工学 第22弾:位相進み遅れ補償
#Pythonで学ぶ制御工学< 位相進み遅れ補償 >
はじめに
基本的な制御工学をPythonで実装し,復習も兼ねて制御工学への理解をより深めることが目的である.
その第22弾として「位相進み遅れ補償」を扱う.位相進み遅れ補償
以下に位相進み遅れ補償についてまとめたものを示す.
以下ではさらに詳しく位相遅れ補償と位相進み補償について示す.
位相遅れ補償
位相進み補償
スモールゲイン定理
以下にスモールゲイン定理についてまとめる.
実装
以下に位相遅れ補償と位相進み補償についてのソースコードとそのときの出力をそれぞれ示す.
ソースコード:位相遅れ補償
phase_delay.py""" 2021/04/03 @Yuya Shimizu 位相遅れ補償 """ import numpy as np import matplotlib.pyplot as plt from control import tf, bode from control.matlab import logspace from for_plot import bodeplot_set #位相遅れ補償 alpha = 10 #α T1 = 0.1 #時定数 K1 = tf([alpha*T1, alpha], [alpha*T1, 1]) #伝達関数 gain, phase, w = bode(K1, logspace(-2, 3), Plot=False) #ゲイン,位相,周波数 #描画 fig, ax = plt.subplots(2, 1) ax[0].semilogx(w, 20*np.log10(gain)) #ゲイン線図 ax[1].semilogx(w, phase*180/np.pi) #位相線図 bodeplot_set(ax) ax[0].set_title(f"Phase Delay Compensation; α={alpha}, $T_1$={T1}") plt.show()出力
ソースコード:位相進み補償
phase_lead.py""" 2021/04/03 @Yuya Shimizu 位相進み補償 """ import numpy as np import matplotlib.pyplot as plt from control import tf, bode from control.matlab import logspace from for_plot import bodeplot_set #位相進み補償 beta = 0.1 #β T2 = 1 #時定数 K2 = tf([T2, 1], [beta*T2, 1]) #伝達関数 gain, phase, w = bode(K2, logspace(-2, 3), Plot=False) #ゲイン,位相,周波数 #描画 fig, ax = plt.subplots(2, 1) ax[0].semilogx(w, 20*np.log10(gain)) #ゲイン線図 ax[1].semilogx(w, phase*180/np.pi) #位相線図 bodeplot_set(ax) ax[0].set_title(f"Phase Lead Compensation; β={beta}, $T_2$={T2}") plt.show()出力
実践練習
以下では,実際に垂直駆動アームの制御系を設計することを題材に,位相進み遅れ補償の利用についての学習を行う.ここでの設計仕様は次のとおりである.
- ゲイン交差周波数:40 rad/s
- 位相余裕:60 deg
ソースコード
control_arm.py""" 2021/04/03 @Yuya Shimizu 垂直駆動アームの制御系設計 (ゲイン補償・位相遅れ補償・位相進み補償) K(s) = kK1(s)K2(s) [設計仕様] ・ゲイン交差周波数:40 rad/s ・位相余裕:60 deg """ import numpy as np import matplotlib.pyplot as plt from control import tf, bode, feedback from control.matlab import logspace, freqresp, margin, step from for_plot import bodeplot_set, plot_set #自作関数 from tf_arm import arm_tf #自作関数 ###制御対象(垂直アーム) #パラメータ設定 g = 9.8 #重力加速度[m/s^2] l = 0.2 #アームの長さ[m] M = 0.5 #アームの質量[kg] mu = 1.5e-2 #粘性摩擦係数[kg*m^2/s] J = 1.0e-2 #慣性モーメント[kg*m^2] #目標値 ref = 30 #制御モデル P = arm_tf(J, mu, M, g, l) ############## 制御系設計開始 ############## ###位相遅れ補償により低周波ゲインを大きくする #位相遅れ補償 alpha = 20 #α T1 = 0.25 #時定数 K1 = tf([alpha*T1, alpha], [alpha*T1, 1]) #補償器 #開ループ系 H1 = P * K1 gain, phase, w = bode(H1, logspace(-1, 2), Plot=False) #ゲイン,位相,周波数 #描画 fig, ax = plt.subplots(2, 1) ax[0].semilogx(w, 20*np.log10(gain)) #ゲイン線図 ax[1].semilogx(w, phase*180/np.pi) #位相線図 bodeplot_set(ax) ax[0].set_title(f"Phase Delay Compensation; α={alpha}, $T_1$={T1}") plt.show() #40 radに置けるゲインと位相を確認 [[[mag]]], [[[phase]]], omega = freqresp(H1, [40]) magH1at40 = mag phaseH1at40 = phase * (180/np.pi) print('-'*20) print(f"phase at 40 rad/s = {phaseH1at40}") ###位相進み補償により位相余裕が望みのものになるように位相を進ませる #位相進み補償 phi_m = (60-(180 + phaseH1at40)) * np.pi/180 beta = (1 - np.sin(phi_m))/(1 + np.sin(phi_m)) #β T2 = 1/40/np.sqrt(beta) #時定数 K2 = tf([T2, 1], [beta*T2, 1]) #補償器 #開ループ系 H2 = P * K1 * K2 gain, phase, w = bode(H2, logspace(-1, 2), Plot=False) #ゲイン,位相,周波数 #描画 fig, ax = plt.subplots(2, 1) ax[0].semilogx(w, 20*np.log10(gain)) #ゲイン線図 ax[1].semilogx(w, phase*180/np.pi) #位相線図 bodeplot_set(ax) ax[0].set_title(f"PDC & PLC; α={alpha}, β={beta:.5f}, $T_1$={T1}, $T_2$={T2:.5f}") plt.show() #40 radに置けるゲインと位相を確認 [[[mag]]], [[[phase]]], omega = freqresp(H2, [40]) magH2at40 = mag gainH2at40 = 20 * np.log10(magH2at40) phaseH2at40 = phase * (180/np.pi) print('-'*20) print(f"gain at 40 rad/s = {gainH2at40}") print(f"phase at 40 rad/s = {phaseH2at40}") ###ゲイン補償の設計とループ整形の結果 #ゲイン補償 k = 1/magH2at40 #H2の40 radにおけるゲインを0 dBに持っていくようにゲイン補償を設計 ##開ループ系(設計後) H = P * k * K1 * K2 gain, phase, w = bode(H, logspace(-1, 2), Plot=False) #ゲイン,位相,周波数 #描画 fig, ax = plt.subplots(2, 1) ax[0].semilogx(w, 20*np.log10(gain), label='H') #ゲイン線図 ax[1].semilogx(w, phase*180/np.pi, label='H') #位相線図 bodeplot_set(ax, 3) ##開ループ系P(設計後) gain, phase, w = bode(P, logspace(-1, 2), Plot=False) #ゲイン,位相,周波数 #描画 ax[0].semilogx(w, 20*np.log10(gain), ls = '--', label='P') #ゲイン線図 ax[1].semilogx(w, phase*180/np.pi, ls = '--', label='P') #位相線図 bodeplot_set(ax, 3) ax[0].set_title(f"k & PDC & PLC; k={k:.5f}, α={alpha}, β={beta:.5f}, $T_1$={T1}, $T_2$={T2:.5f}") plt.show() # ゲイン余裕,位相余裕,位相交差周波数,ゲイン交差周波数 print('-'*20) print('(GM, PM, wpc, wgc)') print(margin(H)) ############## 制御系設計終了 ############## ############## ループ整形前後での確認 ############## ##ステップ応答 fig, ax = plt.subplots() #設計後の閉ループ系のステップ応答 Gyr_H = feedback(H, 1) y, t = step(Gyr_H, np.arange(0, 2, 0.01)) ax.plot(t, y*ref, label = 'After') #設計前の閉ループ系のステップ応答 Gyr_P = feedback(P, 1) y, t = step(Gyr_P, np.arange(0, 2, 0.01)) ax.plot(t, y*ref, ls = '--', label = 'Before') ax.axhline(ref, color = 'r', linewidth = 0.5) #目標値 plot_set(ax, 't', 'y', 'best') ax.set_title(f"Comparison Before v.s. After 'loop shaping' at closed loop") plt.show() ##ボード線図 fig, ax = plt.subplots(2, 1) #設計後の閉ループ系のボード線図 gain, phase, w = bode(Gyr_H, logspace(-1, 2), Plot = False) ax[0].semilogx(w, 20*np.log10(gain), label = 'After') ax[1].semilogx(w, phase*180/np.pi, label = 'After') #設計前の閉ループ系のボード線図 gain, phase, w = bode(Gyr_P, logspace(-1, 2), Plot = False) ax[0].semilogx(w, 20*np.log10(gain), ls = '--', label = 'Before') ax[1].semilogx(w, phase*180/np.pi, ls = '--', label = 'Before') bodeplot_set(ax, 3) ax[0].set_title(f"Comparison Before v.s. After 'loop shaping' at closed loop") plt.show()出力
step1:まず,位相遅れ補償により低周波ゲインを大きくする.
低周波ゲインが0dBから大きくなっていることが分かる.これに伴って,位相が遅れていることも確認できる.phase at 40 rad/s = 176.8634465779015340[rad/s]の位相交差周波数における位相は176.86...[deg]であり,位相余裕はおよそ4[deg]となり,仕様を満たさない.本当は,位相余裕を60[deg]にしたいので,60-(180-176)=56[deg]だけ位相を進ませる必要がある.
step2:位相進み補償により位相余裕が望みのものになるように位相を進ませる
位相を進ませることができていることが確認できる.gain at 40 rad/s = -11.058587737030232 phase at 40 rad/s = -119.99999999999999実際に位相を120[deg]にできていることが分かる.また,このときゲインがおよそ11であり,40[rad/s]のゲインを0[dB]にする.そのために,その分だけ上に移動させる.
step3:ゲイン補償の設計とループ整形の結果
(GM, PM, wpc, wgc) (inf, 60.0, nan, 40.0)確かに,位相余裕を60[deg]に,ゲイン交差周波数を40[rad/s]にできている.
制御系設計は以上である.次にその補償器を使ったときの閉ループ系のステップ応答とボード線図を示す.ループ整形前後での確認(ステップ応答)
設計前にうまく目標値に収束できていなかったものが,設計後にはうまく追従できていることが分かる.ループ整形前後での確認(ボード線図)
ピークゲインを抑えながら,位相余裕も確保できていることが分かる.感想
位相進み遅れ補償は少しだけ触れたことはあったが,いまいちつかめていなかった.今回は,それらについて復習できた.PID制御との違いについても触れることができた.実際に何かを設計するときにはこのあたりの知識が役立つかもしれない.
参考文献
Pyhtonによる制御工学入門 南 祐樹 著 オーム社














- 投稿日:2021-04-05T12:38:48+09:00
自作コロナ感染人数自動通知スクリプト
どうもはじめまして、東京在住のwangyです
毎日東京コロナ感染者数の自動通知スクリプトを作成いたしました。実行環境はpython3です。
ChatworkのAPIを使って、通知先がChatworkだけでちょっと適用範囲が狭いですが、よろしければお使いくださいコード
import urllib.request import urllib.parse import csv import pandas import datetime import json def get_cvoid_infect_num(date): url = "https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv" df = pandas.read_csv(url,header=None) df_filtered = df[df[4]==date.__str__()] infect_num = len(df_filtered) return infect_num def send_to_chatwork(messgae): chatwork_endpoint = "https://api.chatwork.com/v2" room_id = API_TOKEN = chatwork_api_url = "{}/rooms/{}/messages".format(chatwork_endpoint,room_id) obj = {"body":message} data = urllib.parse.urlencode(obj).encode() req = urllib.request.Request(url=chatwork_api_url,data=data) req.add_header(key="X-ChatWorkToken",val=API_TOKEN) with urllib.request.urlopen(req) as res: response_body = res.read().decode("utf-8") return if __name__ == "__main__": yesterday = datetime.date.today() - datetime.timedelta(1) infect_num = get_cvoid_infect_num(yesterday) message = "[info][title]コロナ感染者数通知[/title]昨日({})の東京コロナ感染者数: {}人[/info]".format(yesterday.__str__(),infect_num) send_to_chatwork(message)send_to_chatwork関数内のroom_idとapi_token変数に自分用のものを入力すればOKです。
def send_to_chatwork(messgae): chatork_endpoint = "https://api.chatwork.com/v2" room_id = API_TOKEN =スクリプト解析
データ源は東京都ウイルス対策サイトから提供されるCSVファイルです、毎日の午後17時ぐらい更新されるみたいです
https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv基本的にはこちらのデータから該当する日付の感染者データをカウントします。
pandasというデータ処理のライブラリを使っています、興味ある方は以下を参照してください
https://pandas.pydata.org/def get_cvoid_infect_num(date): url = "https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv" df = pandas.read_csv(url,header=None) df_filtered = df[df[4]==date.__str__()] infect_num = len(df_filtered) return infect_numchatworkの送信は以下の関数で処理する、chatwork api tokenやroom_idを入力すればOKです
使用するエンドポイントhttps://api.chatwork.com/v2/rooms/{$room_id}/messagesdef send_to_chatwork(messgae): chatwork_endpoint = "https://api.chatwork.com/v2" room_id = API_TOKEN = chatwork_api_url = "{}/rooms/{}/messages".format(chatwork_endpoint,room_id) obj = {"body":message} data = urllib.parse.urlencode(obj).encode() req = urllib.request.Request(url=chatwork_api_url,data=data) req.add_header(key="X-ChatWorkToken",val=API_TOKEN) with urllib.request.urlopen(req) as res: response_body = res.read().decode("utf-8") returnchatwork APIの使用方法は以下を参照してください
https://developer.chatwork.com/ja/index.htmlおわり
第二回の緊急事態宣言が終了しましたが、コロナの感染がまだ完全に収束するまでまだ遠いなので
マスクをかけ、手洗いを忘れずにで頑張りましょう
- 投稿日:2021-04-05T12:09:46+09:00
AI王 〜クイズAI日本一決定戦〜 1st place solution & 振り返り
株式会社バンダイナムコ研究所のlaiです。先月の言語処理学会年次大会のワークショップとして開催されていた、「AI王 〜クイズAI日本一決定戦〜」に参加しました。本記事で私の取り組みの共有と振り返りをしたいと思います。 コンペ概要 日本語クイズを題材とした質問応答データセットJAQKET[鈴木ら 2020]を用いて、開発したAIシステムの正答率を競うライブコンペティションです。 事前に配布された1000問を解いた結果がリーダーボードに表示されますが、 ライブコンペ当日では新たに未公開のクイズ1000問が配布され、 事前構築したシステムを用いて制限時間内で解いた結果で競います。 コンペ結果 ライブコンペでは1000問中925問正解で11チーム中1位を取れました。NLP分野での初優勝となりますので本当にうれしいです。 データ 配布データ 訓練データ: 13061問 開発用データ1: 995問 開発用データ2: 997問 評価データ(リーダーボード):1000問 正解エンティティ候補リスト: 約92万件(訓練データ・開発データ・評価データ(未公開)のすべての問題において、この候補リストのいずれかが正解になります) 日本語Wikipedia記事の本文をまとめたデータ クイズ問題は以下のように配布されます: { "qid": "QA20QBIK-0002", "question": "童謡『たなばたさま』の歌詞で、「さらさら」と歌われる植物は何の葉?", "answer_entity": "ササ", "answer_candidates": [ "ササ", "ススキ", "ミヤマキンバイ", "リョウブ", "タムシバ", "ミツガシワ", "ハクサンフウロ", "ウラジロナナカマド", "イタヤカエデ", "チシマザサ", "タテヤマウツボグサ", "トウゴクミツバツツジ", "ミズメ", "イワイチョウ", "ネズミモチ", "ヤシオツツジ", "ショウジョウバカマ", "ムラサキヤシオツツジ", "ヤクシマシャクナゲ", "クマザサ" ], "original_question": "童謡『たなばたさま』の歌詞で、「さらさら」と歌われる植物は何の葉?" } 1問に対して20件の選択肢が与え、その中から正解となる1つを選んで"answer_entity"に記入する形式となります。 ちなみに、配布データセットではベンチマークを容易にするために、答えが必ずWikipedia記事名(によって指される実世界の実体)に正規化されています。 その他利用可能なデータ 利用可能なデータは一般公開されているもののみとしますが、独自に作成したデータであっても、無償で一般公開すれば利用可能となります。 他の組織でも結果を再現できるかというのが一つの目安となります。当然ながら解答時に外部のリソース(インターネット検索など)を利用するのは禁止です。 解法 方針 このコンペが最初に公開された頃(2020年4月)には 最終報告会当日のテストデータ公開後、規定時間(30分を予定)以内に解答が投稿されなければ時間切れと判定します。 というルールがあったため、手持ちのリソースで30分以内でアンサンブルするのが厳しかったので、 最初から推論速度重視のシングルモデルという方針で決めました。 (その後3時間に延長するアナウンスがありましたが、ちょうどいろいろ忙しい時期でしたので気付いた時はもう手遅れでした。) モデル 使用したモデルはDense Passage Retriever (DPR) [Vladimir Karpukhin+ 2020]です。 去年FacebookAIが発表しオープンドメイン質問応答に関する手法で、 元論文のリンクはこちらです:https://www.aclweb.org/anthology/2020.emnlp-main.550/ 実は去年12月まで運営が公開したBERTのNextSentencePredictionの解法を使っていましたが、 NeurIPS 2020のEfficient QAコンペの上位チームがほとんどDPRを採用していたことを見て、 自分もモチベーションを持ち始めてこちらで実装しました。 システム構成は以下になります: 元論文を踏襲したポイント 質問文(クイズ)と資料文(Wikipedia記事)を2つの事前学習済み言語モデルを用いてベクトル表現にエンコードする 質問文に対して、正解選択肢の資料文を正例、それ以外を負例とする 訓練では質問文ベクトルと資料文ベクトルの内積を使ったCrossEntropy損失を用いる 推論では資料文(Wikipedia記事)を予めベクトルに変換し、質問文のベクトルをクエリとした近傍探索として解く 基本実装はHuggingfaceのTransformersライブラリを参考(https://huggingface.co/transformers/model_doc/dpr.html) 大規模の高速ベクトル近似度計算はFaissライブラリを使用(https://github.com/facebookresearch/faiss) 元論文から変更したポイント エンコーダについて元論文ではBERTを使用しているが、推論速度重視のためFine-tuningしたDistilBERTを使用(https://github.com/BandaiNamcoResearchInc/DistilBERT-base-jp) 運営ベースラインである東北大学が公開したBERTとNICTが公開したBERTでベンチマークを行いましたが、結論として次元数が同じ場合での性能差が見られなかった 元論文ではBERTの[CLS]トークンを文章のベクトル表現を使用しているが、Reimersらの論文を参考にし各トークンベクトルの平均に変更 PointerNetworkで抽出したキーワードを質問文と連結して入力 最大入力系列長(256)を上回ったWikipedia記事文に対して、テンセントAIチームが提案したスライドウィンドウの手法を用いて複数シーケンスの内容を結合 出力は最終層ではなく各隠れ層のWeighted Sumに変更 元論文では負例作成のため様々な手法を提案しているが、今回は正解以外の選択肢がそのまま負例として利用できるためかなり省略できた 追加訓練データ 開発データ1&2 一時期使用不可ですが最終的に使用可能になりました。 自作クイズデータ 配布されたWikipedia記事データを使用して、構文解析と固有表現抽出を用いて自作クイズ集を作成しました。 解答可能性付き読解データセット こちらのデータセットでは正解以外の候補が用意されていなかったため、コサイン類似度の高い同義語でダミー選択肢を作成しました。 前処理 事前学習モデルのボキャブラリーに含まれない難読漢字は[UNK]として入力されるため、入力問題は正規化前の"original_question"を使用 例:以下の問題では「霹靂」がDistilBERTのvocabに含まれないため、「へきれき」が併記される正規化前の質問を使用します。 {"question": "思いがけない突発的な事柄をいう「青天の霹靂」、さてこの「霹靂」とはどんな自然現象のことでしょう?", "answer_entity": "雷", "answer_candidates": ["雷", "風塵", "積乱雲", "雹", "氷雨", "風雨", "砂嵐", "快晴", "海鳴り", "雨", "雪", "驟雪", "細氷", "凍雨", "霧", "乱層雲", "熱雷", "吹雪", "風", "嵐"], "original_question": "思いがけない突発的な事柄をいう「青天の霹靂(せいてんのへきれき)」、さてこの「霹靂」とはどんな自然現象のことでしょう?"} 解答に特定の文字列や条件を指定した問題に関して、条件を満足しない選択肢を排除する 例:以下の問題では「村」を含まない選択肢を候補から外します。 {"question": "1957年8月に日本で初めて「原子の火」がともった、日本原子力研究所がある茨城県の村はどこでしょう?", "answer_entity": "東海村", "answer_candidates": ["東海村", "大洗町", "龍ケ崎市", "土浦市", "北茨城市", "筑西市", "日立市", "鹿嶋市", "行方市", "鉾田市", "下妻市", "那珂市", "潮来市", "かすみがうら市", "水戸市", "ひたちなか市", "笠間市", "神栖市", "高萩市", "石岡市"], "original_question": "1957年8月に日本で初めて「原子の火」がともった、日本原子力研究所がある茨城県の村はどこでしょう?"} 例:以下の問題では3文字以外の選択肢を候補から外します。 {"question": "地位や身分の上下を気にせずに楽しむ宴会のことを、漢字三文字で何というでしょう?" "answer_entity": "無礼講" "answer_candidates": ["善知識", "永宣旨", "一献", "退院", "挙哀", "朝覲", "門徒物知らず", "無礼講", "策命", "直廬", "大歌", "遥拝勤行", "枕経", "束脩", "年男", "矢開き", "解除 (行事)", "奏事不実", "三証", "随方毘尼"], "original_question": "地位や身分の上下を気にせずに楽しむ宴会のことを、漢字三文字で何というでしょう?"} 「どっち」系の質問に対して質問文に含まれない選択肢を排除し、それ以外は質問文に含まれる選択肢を排除する 例:以下の「どっち」系問題では正解が「黄河」と「揚子江」しかありえないため、それ以外の選択肢を候補から外します。 {"question": "中国大陸を流れる黄河と揚子江のうち、より北にあるのはどっちでしょう?", "answer_entity": "黄河", "answer_candidates": ["黄河", "汾河", "大凌河", "洛河", "泗河", "赤水河", "鬱江", "青弋江", "桑乾河", "ショウ河", "衛河", "シラムレン川", "コ沱河", "淮河", "漢江 (中国)", "ラン河", "長江", "湘江", "済水", "渭水"], "original_question": "中国大陸を流れる黄河と揚子江のうち、より北にあるのはどっちでしょう?"} 例:以下の問題の質問に含まれる「皐月賞」や「菊花賞」は明らかに正解ではありませんが、候補選択肢に含まれるため、近似度計算の際では引っかかりやすいので外します。 {"question": "別名を「日本ダービー」という、皐月賞・菊花賞とともに中央競馬クラシック三冠を構成する重賞競走は何でしょう?", "answer_entity": "東京優駿", "answer_candidates": ["朝日杯フューチュリティステークス", "安田記念", "宝塚記念", "京都新聞杯", "天皇賞", "阪神大賞典", "スプリングステークス", "弥生賞", "優駿牝馬", "東京優駿", "大阪杯", "有馬記念", "スプリンターズステークス", "毎日王冠", "阪神ジュベナイルフィリーズ", "エリザベス女王杯", "マイルチャンピオンシップ", "皐月賞", "桜花賞", "菊花賞"], "original_question": "別名を「日本ダービー」という、皐月賞・菊花賞とともに中央競馬クラシック三冠を構成する重賞競走は何でしょう?"} 「ですが」系質問は「、」で区切って「ですが」に含まれるノイズにあたる部分を排除する 例:以下の問題で「「性善説」を唱えたのは孟子ですが」はノイズに当たるため、質問文のこの部分を除去してから入力します。 {"question": "中国の思想家で、「性善説」を唱えたのは孟子ですが、「性悪説」を唱えたのは誰でしょう?", "answer_entity": "荀子", "answer_candidates": ["子思", "何休", "王弼 (三国)", "服虔", "曾子", "王充", "劉向", "孔子", "楊朱", "揚雄", "朱熹", "墨子", "荀子", "韓非", "鄭玄", "孟子", "王念孫", "老子", "荘子", "謝良佐"], "original_question": "中国の思想家で、「性善説」を唱えたのは孟子ですが、「性悪説」を唱えたのは誰でしょう?"} おわりに リーダーボードの上位チームのスコアが0.95以上に対して、自分では僅か0.928で正直優勝を諦めかけていましたが、ライブコンペでも同じ0.92台のスコアを取れて良かったです。 他の上位チームの方が公開した解法を見て前処理の重要性を再確認できました。「NLPは機械学習と言語学の総合格闘技」であることを改めて感じました。 言葉遊び系の問題は最後まで解けませんでしたが、逆にどんな手法なら解けるかをとても気になりました。 NLPコンペのデータセットにノイズが混ざっていることもあり、参加するには苦労することが多いですが、今回は高品質のデータセットのおかげで最後まで楽しむことができました。JAQKETデータセットを作成いただいた運営とのコンペを盛り上がっていただいた日本語NLPコミュニティの皆様に大変感謝します。 参考 ACL2020 Tutorial: Open-Domain Question Answering
- 投稿日:2021-04-05T11:36:22+09:00
【Python】電話番号のハイフンに似ている記号を統一して正規化する
コード作成のきっかけ
CSVファイルに保存されていた電話番号を読み込み、別のシステムに送る時に事件は起きました。
CSVファイルに保存されていた電話番号は、全角ハイフンだけでなく、マイナス(−)やダッシュ(―)、エンダッシュ(–)などで区切られていたのです・・・。
送り先のシステムでは、電話番号を半角ハイフンでしか読み取る事ができず、このままではエラーが起きてしまいます。
その為、変換するプログラムを作成しました。
これは、phonenumbersを知らなかった時に作成したプログラムになります。
(phonenumbersってすごい。。。 phonenumbers Python Library)対象の電話番号
CSVファイルを見てみると、様々な電話番号がありました。
全角数字の電話番号、()で数字を分けた電話番号、スペース(空白)で分けた電話番号、国際電話表現になっている電話番号、幸いなことに数字のみの電話番号はありませんでした。
今回は数字だけの電話番号をハイフンで分ける事はできないプログラムになります。
(03とか0120とか、数値によってハイフンの位置を決める必要があります。この規則性をコーディングするのは面倒なので、そのような場合はphonenumbers使うと便利です。)number.pyprint(number_format('0120-123-123')) #半角 print(number_format('0120ー999ー999')) #全角 print(number_format('03(1111)2222')) #()付き 全半角 print(number_format('090 1111 2222')) #空白区切り 全半角 print(number_format('080ー1111−2222')) #全角のハイフンとマイナス記号 全半角 print(number_format('+81-90-1234ー5678')) #国際電話での表現 全半角半角ハイフンの電話番号に変換する
半角ハイフンの電話番号に変換する為に、まずは全角の数字を半角に変化します。
また、電話番号を一度数字の固まりごとに分割し、分割した数字を半角のハイフンで連結する事にしました。(電話番号内のマイナスやダッシュを検索し、半角ハイフンにする事も考えましたが、全てのハイフンっぽいものを洗い出すのではなく、今回は記号の部分を半角ハイフンに変換する方向性で進めました)
国際電話の場合は、+81を取り出して、0を先頭につける事にします。
これらの処理をPythonでコーディングしたものが、以下になります。code.pyimport re def number_format(call_number): format_number = '' hyphen = '-' hankaku = str.maketrans({chr(0xFF01 + i): chr(0x21 + i) for i in range(94)}) #全角を半角に split_number = re.findall(r'\d+', call_number) #数字のみ取り出す if call_number[:1] == '+' or call_number[:1] == '+': #+81の国際電話番号の場合 del split_number[0] format_number = '0' + split_number[0] else: format_number = split_number[0] for i in range(1, len(split_number)): #分割した数字を繋げる format_number += hyphen + split_number[i] return format_number.translate(hankaku)結果
結果としては、以下のように半角数字、半角ハイフンの電話番号に置換する事ができました。
kekka.log0120-123-123 0120-999-999 03-1111-2222 090-1111-2222 080-1111-2222 090-1234-5678今回は、数字だけの電話番号を半角ハイフンのフォーマットに変換する事はできていませんが、半角ハイフンに似ている記号を使用した電話番号を半角ハイフンの電話番号に変換する事はできました。
- 投稿日:2021-04-05T11:17:42+09:00
AWS Lambdaで天気予報を毎朝LINEへ通知してみた【Python】
背景
偏頭痛の気配を感じて天気予報を調べたら、案の定、天気は下り坂で、、、なんていうことがあり、自身の健康管理のためにも天気予報を毎朝LINEへ通知してみることにしました。
先人たちの知恵をお借りするなどして解決できたことを、この場をお借りして感謝するとともに、大変恐縮ですが自分のメモとして、こちらへまとめておきます。
開発等
先日、記事とした「AWS Lambdaで列車運行情報を定期的にLINEへ通知してみた【Python】」の天気予報版です。
詳細は、こちらの記事をご参照ください。
実行
- 実行結果
(...気圧も表示できたらなぁ~?)
参考
(編集後記)
(お願い)APIを利用できる情報提供者からは、必ずAPIを使いましょう。
みなさんも様々なアイディアで活用いただけたら幸いです。
会社でのコミュニケーションツールは主が Slack のため、今後は、Slack への通知も試してみます。


- 投稿日:2021-04-05T09:34:59+09:00
Beginners guide to Naïve Bayes algorithm (Part 1)
The Naïve Bayes algorithm is one of the fundamental things to study when studying statistics of artificial intelligence. Here I'm going to explain naive Bayes.
Probability vs likelihood.
Generally, in machine learning, we know that past incidents (data points) are widely used to predict the future. It is not only mattering what happened in the past but also how probable it will be replicated in the future, known as the likelihood of an event occurring in a random space.
Let us take a simple example:
Suppose I have an unbiased 500 yen coin. When I flipped the coin, I can expect it will be the value side (tail). There is a 50% of possibility that my expectation comes true. (There are two possible outcomes, head and tail. Portability is calculated by (expected outcome/total no. of outcomes)
Now let us move a bit deep by operating two experiments at the same time. This time we are additionally rolling a dice. What is the probability of getting head by coin and getting 3 from dice?The answer can be calculated as below;
P(Head & 3) = P(Head) * P(3) = 1/2 * 1/6 = 1/12The term for the above example is called joint probability. Other than joint probability, there are two more two types, conditional probability and marginal probability.
1. Joint probability (probability of the coin landing on heads AND the dice landing on 3)
2. conditional probability (probability of heads GIVEN THAT the dice lands on 3)
3. marginal probability (probability of JUST the coin or JUST the dice)The Bayes’ Theorem
It declares, for two events A & B, if we know the conditional probability of B given A and B's probability, then it is possible to calculate the probability of B given A.
Let us move to a simple example to explain the Bayes rule.
Suppose that I have 30 BLUE objects and 60 RED objects. So there twice as many RED objects as BLUE. If I place a new object, it can be a RED since it is twice likely to happen rather than BLUE. This concept is called prior probability in Bayesian analysis.
Total objects = 90 (BLUE=30 + RED=60)
Prior probability of RED = Number of RED objects / total objects = 60/90
Prior probability of BLUE = Number of BLUE objects / total objects = 30/90We finished calculating the prior probabilities. Now let us think that the new object is placed. Previously objects are well clustered. So we can assume that the new color of the new object can decide by the number of previous objects around the newly placed one.
If there are many BLUE objects, it can be BLUE, or If there are many REDS, it can be RED. To measure this likelihood, we form a circle around the new object which contains a number (to be determined a priori) of points regardless of their class names. Then we count the number of points in the circle fitting to each class name.
From hereafter, let us take the new object as X.
From the above drawing, we can see that the likelihood (possibility) of a X given RED is smaller than the likelihood of a X given BLUE since the circle contains the 1 RED and 3 BLUE objects.
In the previous section, the prior probabilities imply that X can relate to the RED since there are twice RED objects than the BLUE objects. However, we can see that likelihood contradicts the above. X can be BLUE since there are more BLUE than the RED around the X. We can calculate the posterior portability by multiplying by prior probability and likelihood.Posterior Probability of RED=Prior Probability of RED ×Likelihood of RED =60/90×1/60
Posterior Probability of BLUE=Prior Probability of BLUE ×Likelihood of BLUE =30/90×3/30
By analyzing the calculation results, we can classify the new objects that belong to the BLUE since the Posterior Probability of BLUE is larger than the Posterior Probability of RED.
This article will be continued in the next writing...
*本記事は @qualitia_cdevの中の一人、@nuwanさんが書いてくれました。
*This article is written by @nuwan a member of @qualitia_cdev.


- 投稿日:2021-04-05T09:11:21+09:00
【Pandas】.date_range() の使い方を優しく教えます no.31
こんにちは、まゆみです。
Pandasについての記事をシリーズで書いています。
今回は第31回目になります。
今回の記事では、
.date_range()を使って
ある時点から別のある時点までの日を基にしたインデックスを作ったり
時間を基にしたインデックスを作ったり
営業日のみのインデックスを作ったり
の方法を書いていきます
ちょっとした英単語と、ルールを覚えれば概要は簡単にマスターできますので安心してくださいね。
では、さっそく始めていきます
.date_range メソッドの概要
引用元:Pandasドキュメント.date_range()メソッドは、色々なパラメーターを渡すことができますが、
start
end
periods
の組み合わせのうち、2つを組み合わせないとエラーが出ます。
また、ドキュメントに
『Return a fixed frequency DatetimeIndex』
と書いていますが、翻訳すると『定められた頻度のDatetimeIndexを返す』になります。
後述しますが、パラメーターfreq =に色々な引数を取ることによって、
日単位の
時間単位の
月単位の
と『どの頻度でインデックスの数字を増やしていくか』を決めることができます。
それが、Pandasドキュメントの『a fixed frequency』の意味になります
.date_range()のパラメーター『start』『end』『period』
先ほど、.date_range()メソッドは、start, end, periodのパラメーターのうち、2つを使わないとエラーが出ると書きました
.date_rangeはある『期間』のDatetimeIndexを返してくれるので、期間を指定するには、
始まりと終わりの地点を決めるか
始まりの地点を決めて、いくつの要素でインデックスを作るか
終わりの地点を決めて、いくつの要素でインデックスをつくるか
を決めなければ、『期間』を定めることができません。
なので、2つのパラメーターが必要なのです。
では、2つのパラメーターの組み合わせで実際にどのようなDatetimeIndexができるのかコードを書きながら解説していきますね。
パラメーター start とend の組み合わせ
start で始まりの地点を
end で終わりの地点を定めます。
start の値とendの値は範囲に含まれます。
パラメーター freq
パラメーターfreqはfrequency = 頻度という意味です。
1時間おきのインデックスを作りたいのか
2時間おきのインデックスを作りたいのか
1日おきのインデックスを作りたいのか
を定めるパラメーターになります。
デフォルト値は"D" でDay、つまり何も書かなければ一日おきのインデックスができることになります。
少し例を書きますと
freq = "D"
freq = "2D" (2日おきのインデックス)
freq = "H" (1時間おきのインデックス)
freq = "6H" (6時間おきのインデックス)
freq = "B" (Business day つまり営業日のみ(月~金)のインデックス)
となります。
もっと他にも引数があります。
詳しくは、Pandasドキュメントに載っていますので、興味のある方は参考にどうぞ
コードを書いてみる
freq="D"はデフォルト値でもあるので、書かなくても結果は上記と同じです。
2日おきのインデックスを作りたい時は
同様に、freq の引数を"H"にすれば、1時間おきですし、"2H"にすれば2時間おきのインデックスと言ったように、単位と数字の組み合わせで色々なインデックスを作ることができます。
週を意味する"W"を使うときの注意点
freq = "W"と引数を渡すと、週単位のインデックスが作れますが、果たして何曜日から始まるかも大事な点ですよね。
デフォルト値は SUN つまり日曜日になります。
freq = "W" と書くと、毎日曜日のインデックスを作れます。
日曜日以外の曜日を指定したい時は
freq = "W-曜日"を書けば大丈夫です。
2020/03/12 から 2020/04/12 の期間の火曜日のみのインデックスを作りました。
パラメーター start と periods の組み合わせ
先ほどの解説で、パラメーターstart の意味は分かられたと思います
periods は『いくつのTimeStamp』を返してほしいかを引数に取るパラメーターになります
では、2021/4/5日から20日分のインデックスを作ってみましょう
(1日おきのインデックスを作る時はfreq="D"は書かなくてもよい)
土日を除く営業日(Business day)のインデックスも作ってみますね。
2021/04/05 が月曜日になります。
2021/04/10 と2021/04/11は週末なので、除かれてインデックスが作られています
パラメーターend とperiods の組みあわせ
start とperiods の組み合わせと考え方は基本的に同じです。
ただ、end でインデックスの最後の日時を決め、そこからいくつ遡るかをperiods に引数として渡せばOKです。
まとめ
今回の記事では、.date_range()を扱わせていただきました。
引数として渡す値の組み合わせによって、色々なDatetimeIndexが作れますので、色々と試してみてくださいね。
お役に立てれば幸いです。