- 投稿日:2021-04-05T23:22:28+09:00
【AWS】ストレージ特性とユースケース
最新情報のキャッチアップも兼ねてAWSのストレージサービスの特性、 ユースケースを整理してみました。 ストレージの種類 ストレージの種類は大きく以下の3つに分けられます。 ・ブロックストレージ ・オブジェクトストレージ ・ファイルストレージ それぞれの特徴と対応するAWSサービスは以下のとおりです。 正確にはそれぞれのサービス内で選択したなタイプによって若干異なる点もありますので およその特徴として見てください。 - ブロックストレージ オブジェクトストレージ ファイルストレージ 対応するサービス EBS S3/S3 Glacier EFS/Amazon FSX プロトコル - HTTPS NFS/CIFS 構造 ボリュームブロック フラット 階層 アクセス単位 ブロック オブジェクト ファイル メタデータ 無し 豊富・カスタマイズ可能 固定・限定的 耐久性 AZ内に複製 3つ以上のAZに複製 複数AZに複製 ユースケース データベースアプリデータ オブジェクト ファイル共有 EBSの種類 それぞれのサービスをもう少し細かく見ていきます。 まずはEBS(Amazon Elastic Block Store)です。 大きくはSSDベース/HDDベースのもので分類され、さらに性能や耐久性の異なるいくつかの種類が提供されます。 ■SSDベース プロビジョンドIOPS SSDと呼ばれるハイパフォーマンスのio2とio1。 汎用SSDと呼ばれるgp3とgp2があります。 io2はio1の次世代にあたるもので細かな違いはあるのですが、費用はほぼ同じで io1に比べて100倍の耐久性と10倍IOPSを提供します。 gp3はgp2の次世代版になりますが、こちらは単純に高性能になるものではありません。 基本的にはgp3はgp2よりコスト面では有利になります。 gp2が基本的にはボリュームサイズに比例してIOPSが増加しますが、 gp3は3,000IOPSのベースラインがあり、最大で16,000までさせることが可能です。 最大スループットもgp3はgp2の4倍まで拡張出来ます。 gp2では性能を上げるために不要にボリュームサイズを上げる必要があったのが gp3で改善された形になります。 - io2 io1 gp3 gp2 耐久性 99.999% 99.8%~99.9% 99.8%~99.9% 99.8%~99.9% 最大IOPS/ボリューム 64,000 64,000 16,000 16,000 最大スループット/ボリューム MB/秒 1,000 1,000 1000 250 最大IOPS/インスタンス 160,000 260,000 260,000 260,000 最大IOPS/GB 500 50 ー ー 最大スループット/インスタンスMB/秒 4,750 7,500 7,500 7,500 ■HDDベース こちらはシンプルで高性能だが高価なst1と安価なsc1があります。 - st1 sc1 耐久性 99.8%~99.9% 99.8%~99.9% 最大IOPS/ボリューム 500 250 最大スループット/ボリューム 500MB/秒 250 MB/秒 最大IOPS/インスタンス 260,000 260,000 最大スループット/インスタンス 7,500MB/秒 7,500MB/秒 料金/月 0.045 USD/GB 0.015 USD/GB S3の種類 種類 特徴 S3 標準 ・一般的な用途・データの取り出し料金は不要 S3標準 – IA ・保存料金はS3標準より安価・パフォーマンスもS3標準と同じだが取り出しに課金される・アクセス頻度が低くパフォーマンスが必要なデータに利用 S31 ゾーン – IA ・1つのAZのみに保存するため耐久性は低いが低コスト・データの取り出しに課金される S3 Glacier ・低コストだが取り出しに時間がかかる(数分〜数時間)・最低保存期間は90日・データの取り出しに課金される・データのアーカイブなどに利用 S3 GlacierDeep Archive ・低コストだが取り出しに時間がかかる(12時間以内)・S3 Glacierより低コストだが最低保存期間が180日・データの取り出しに課金される S3Intelligent-Tiering ・頻繁、低頻度、アーカイブ、およびディープアーカイブの4つの階層に自動で階層移動する・データの取り出し料金は不要 基本はS3標準をベースとして、以下のような選択指針になると思います。 パフォーマンスは必要だがアクセス頻度が低いものは「S3標準 – IA」。 同じ条件で可用性が低くても良いのであれば「S31 ゾーン – IA」 アーカイブ目的には取り出しにかかる許容時間に応じて「S3 Glacier」or「S3 GlacierDeep Archive」を選択。 データレイクのような特性のデータには「S3Intelligent-Tiering」 以上
- 投稿日:2021-04-05T21:48:55+09:00
Azure/AWSのリージョン選択方の違い
AzureとAWSでのリージョン選択(設定)の違いです AWSを長年触っていた自分がAzureを触って「まったく違う」と感じたので記事にします リージョン選択の方法 仮想マシン(VM/EC2)を例にします Azureはサービスを選んでからリージョン VMを選ぶ→ リージョンを選ぶ AWSはリージョンを選んでからサービス リージョンを選ぶ→ ECを選ぶ イメージです Azureの場合 Azureはビル全体が1フロアで、その中からサービスとリージョンを選ぶ感じ AWSの場合 AWSはビルのフロアごとにリージョンがあって、そのフロア(リージョン)からサービスを選ぶ感じ いいところ Azure サービスの一覧が見られる リージョンの変更が簡単(対象サービスの制限があるがARMを使う) AWS サービスを意図しないリージョンに選び間違えることがない ※例えば東京リージョンの中では東京リージョン内のサービスしか使えない よくないところ Azure たくさんサービスを使うと「これどこのリージョンだっけ?」てなる(みにくい) サービスを選んだあとに、毎回リージョンを選ばないといけない(リージョン選び間違いが発生する可能性がある) AWS 東京リージョンで使っていると思ったら「あ、バージニアだった!」って事がある(AWSあるある) 使っているサービスの一覧を見られない(見る方法はタグエディタやCLIとかからなのでちょっと手間がかかる) リージョン間移動は手間(EC2ならスナップショットかAMIを使って移動) 感想 どっちがいい?と言われると、これは好みだと思います 個人的にはAWSの方が自分にはあっているかなと思いました サービスのリージョン間移動はAzureの方が楽だと思います
- 投稿日:2021-04-05T21:45:28+09:00
【AWS】AWS(Amazon Web Services)を理解する
プログラミング勉強日記 2021年4月5日 AWSとは まずネットでAWSについて調べてみると公式サイトで以下のように書いてあった。 アマゾン ウェブ サービス (AWS) は、世界で最も包括的で広く採用されているクラウドプラットフォームです。世界中のデータセンターから 200 以上のフル機能のサービスを提供しています。 (引用:AWS公式) AWSは、Amazonが提供している100以上のクラウドコンピューティングサービスの総称。なのでAWSについて理解するためには、まずクラウドコンピューティングを知らないといけない。 クラウドコンピューティングとは クラウドコンピューティングは、サーバー、ストレージ、データベース、ネットワーク、ソフトウェアなどのコンピューティングサービスをインターネット(クラウド)経由でサービスを利用すること。 通常は、ローカル環境のパソコン内に様々なアプリ(WordやExcelなど)をインストールして利用する。クラウドサービスと呼ばれるクラウドコンピューティングで提供されているサービスは、パソコンにインストールする必要がない。インターネットに接続できれば、サーバー上で提供しているサービスを利用できる。 AWSの特徴 1. 従量課金 AWSは通信料や通信時間に応じて利用した分の料金を支払う従量課金制を用いている。 2. 高いセキュリティ 政府機関や金融機関も利用しているくらい高いセキュリティがある。各国の規制、コンプライアンスにも対応している。 3. 安定したパフォーマンス 世界20か所の地位式で運用されていて、ソフトウェア・ハードウェアのどちらも最新の状態である。 4. 高い柔軟性・拡張性 様々なサービスがあるので、必要な機能の組み合わせや追加、停止ができる。 参考文献 AWS公式 AWSとは?サービスの概要やできること、クラウド市場の展望について紹介 クラウド コンピューティングとは クラウドコンピューティングってどんなもの?定義やメリットをわかりやすく紹介(初心者向け)
- 投稿日:2021-04-05T21:12:15+09:00
cloudwatchlogsでデータを取得してみる
EC2でサーバを作成 Amazon Linux2 で作成しました。 サーバにエージェントインストール インストール sudo su - yum install awslogs ログの監視設定 リージョンの変更を行います。 今回であればEC2インスタンスがある、東京リージョンに書き換えを行います。 vi /etc/awslogs/awslogs.conf ========== [default] region = us-east-1 ↓ region = ap-northeast-1 ========== 今回は特に変更はしないです。 vi /etc/awslogs/awslogs.conf ========== [/var/log/messages] datetime_format = %b %d %H:%M:%S file = /var/log/messages buffer_duration = 5000 log_stream_name = {instance_id} initial_position = start_of_file log_group_name = /var/log/messages ========== エージェントの起動・自動起動設定 systemctl start awslogsd systemctl enable awslogsd 権限設定 ロールの作成 マネジメントコンソール > IAM > ロールの作成 から ロールを作成していきます AWSサービス > ユースケースの選択:EC2 を選択し、次に進みます アタッチする権限を指定します。 CloudWatchLogsFullAccess を検索してチェックを行い、次に進みます 今回はタグをつけずに進みます ロール名を指定して、作成を行います EC2_cloudwatch_log のロールが作成出来ました。 作成したIAMロールを紐付ける EC2インスタンスに戻り、 監視されるEC2インスタンスにチェックを入れて、 アクション > セキュリティ > IAMロールを変更 でIAMを紐付けします IAMロールを開けば、先程作成したIAMロールが出てくるので 指定して保存を行います。 cloudwatch logを確認 cloudwatch logに移動 マネジメントコンソール > ログ > ロググループ へ移動 ロググループで作成を確認 /var/log/messages のログを確認しました 詳細なログを確認 /var/log/messages > ログストリーム で詳細なログを確認することが出来ます httpdのアクセスログを取得 httpdのインストール yum install httpd httpdの起動と自動起動設定 systemctl start httpd systemctl enable httpd ファイルを設置 vi /var/www/html/index.html ========== <h1>hello world!</h1> ========== EC2のセキュリティグループを開放 セキュリティグループで80番ポートを開放 ※あんまりやり方としてよくないです エージェント設定の変更 このファイルを書き換えることで、取得できるファイルを変えることが出来ます。 [logstream]セクションと、取得するファイル(file)と、ロググループ名(log_group_name) を書き換えました。 vi /etc/awslogs/awslogs.conf ========== [/var/log/httpd/access_log] datetime_format = %b %d %H:%M:%S file = /var/log/httpd/access_log buffer_duration = 5000 log_stream_name = {instance_id} initial_position = start_of_file log_group_name = access_log ========== エージェントの再起動 systemctl restart awslogsd webページを表示 http://[IPアドレス]/index.html で確認することが出来ます。 実際に使う際はSSLなど対応しましょう ログの確認 cloudwatch > ログ > ロググループ で新しいロググループが確認できました 詳細はログストリームから確認することが出来ます 勉強後イメージ エージェントをインストールするのは知ってたけど、実際やってみてイメージつかめた ファイルにどう出力するのかとか記載 → 自動的にロググループに送られる って感じかな 参考 awslogsでEC2のログをCloudWatch連携する方法 CloudWatchでログ監視を始める手順と同じことを5分で実現する方法
- 投稿日:2021-04-05T20:40:39+09:00
AWSクラウドプラクティショナー勉強 料金とサポート編
AWSの公式サイトにクラウドプラクティショナーのEラーニングを学習して、 学んだことをメモとして残す。 学習に利用したサイトは「AWS Cloud Practitioner Essentials (Japanese) (日本語字幕版)」 AWS 無料利用枠 AWS 無料利用枠を使用すると、一定期間料金が発生することなく特定のサービスを使用できる 以下の3種類のオファーが用意されている 無期限無料 このオファーに有効期限はなく、以下の例のようなことがAWSすべての利用者が利用できる 例1:Lambdaでは、毎月100万件の無料リクエストと最大320万秒のコンピューティング時間を利用できる 例2:DynamoDBでは毎月25GBのストレージを無料で利用できる 12ヶ月間無料 このオファーでは、AWSに最初にサインアップした日から12か月間無料使用期間が提供される 例1:特定の量のS3標準ストレージ 例2:特定のしきい値までのEC2インスタンスの月単位時間 例3:特定の量のCloudFrontデータ送信 トライアル 特定のサービスをアクティブ化した日から短期の無料トライアルが試せる 各トライアル野長さはサービスの日数や使用量によって異なる 例1:Inspectorには、90日間の無料トライアルが用意されている 例2:Lightsailには、30日間750時間までの無料トライアルが用意されている AWS 料金体系の仕組み AWSは使用した分だけ料金が発生する従量課金制となっている 一部のサービスでは予約することでオンデマンドよりも料金を安くするオプションが用意されている EC2の料金体系はAWSクラウドプラクティショナー勉強 インフラ編にも記載しているのでそちらも参考に S3(ストレージ容量の使用量が増えるほど、1GBあたりに支払う料金が少なくなる)など一部サービスでは段階性料金が用意されており、使用量が増えるほど単位当たりのコストが安くなる AWS 料金計算ツール AWS料金計算ツールが用意されており、AWSのサービスごとに料金計算が行える 請求ダッシュボード(Billing and Cost Management) 請求ダッシュボードでは、以下のようなAWSの請求書の支払い/使用量のモニタリング/コスト分析・管理を行える 今月の月初から現在までのサービス別利用料金の確認 Cost Explorer にアクセスして予算を作成 当月と前月の料金比較、現在まで使用量に基づいて翌月の予測を入手 その他できること 一括請求 (コンソリデーティッドビリング) AWS Organizationsの機能には、一括請求のオプションが用意されている 一括請求オプションを利用すると、組織内のAWSアカウントの請求書を1つにまとめることができる 請求書を1つにまとめる最大のメリットは、一括割引料金/Savings Plans/リザーブドインスタンスを組織内のアカウントで共有できる 例:1つのアカウントでは割引対象の使用量に届かない場合でも、複数のアカウントを組み合わせることにより割引対象の使用量に達することができ割引を受けられるといったメリットがある AWS Budgets 予算を作成してサービスの使用量/サービスのコスト/インスタンスの予約を計画できる機能 AWS Budgetsの情報は毎日3回更新され、使用量の状況やAWS無料利用枠の制限にとれだけ近づいているか確認できる また使用量が予算の量を超えた場合(または超えることが予想される場合)に送信されるカスタムアラートを設定できる AWS Cost Explorer 時間の経過に伴うAWSのコスト/使用量を可視化して把握・管理できるツール Cost Explorerには、コストが発生した上位5位のサービスのコスト/使用量に関するデフォルトのレポートが含まれている AWSサポートプラン AWSでは4つのサポートプランが用意されている デベロッパー/ビジネス/エンタープライズのサポートプランには、ベーシックサポート全ての特典、テクニカルサポートケースを無制限にオープンできる特典があり、それぞれ月額料金が発生する 料金 サポートプラン 無料 ベーシック 小 デベロッパー 中 ビジネス 大 エンタープライズ ベーシック AWS全ての利用者に無料で提供されている このプランではホワイトペーパー/ドキュメント/サポートコミュニティの利用が含まれる ベーシックサポートではAWS Trusted Advisorの一部(6つのセキュリティチェック(S3バケットアクセス許可、セキュリティグループ – 無制限の特定のポート、IAMの使用、ルートアカウントでのMFA、EBSパブリックスナップショット、RDSパブリックスナップショット)と50個のサービスの制限チェック)が利用できる デベロッパー デベロッパーでは以下のような機能が利用できる ベストプラクティスのガイダンス クライアント側の診断ツール 基盤となるアーキテクチャのサポート ビジネス ビジネスでは以下のような機能が利用できる 特定のニーズを適切にサポートできるAWSの製品、機能、サービスを特定するためのユースケースガイダンス AWS Trusted Advisor のすべてのチェック 一般的なオペレーティングシステム、アプリケーションスタックコンポーネントなど、サードパーティーソフトウェアの限定的なサポート エンタープライズ エンタープライズではベーシック/デベロッパー/ビジネスのサポートプランに含まれる全機能と以下のような機能が利用できる アプリケーションアーキテクチャのガイダンス インフラストラクチャイベント管理 テクニカルアカウントマネージャー テクニカルアカウントマネージャー (TAM) エンタープライズではテクニカルアカウントマネージャー(TMA)のサポートを受けることができる TAMがAWSの主要な窓口となり、アプリケーションの計画/デプロイ/最適化に関するガイダンスやアーキテクチャのレビューを提供し、利用者と継続的に連絡を行う AWS Marketplace 独立系ソフトウェアベンダーから提供される何千ものソフトウェアで構成されるデジタルカタログ Marketplaceを使用すると、AWSで実行するソフトウェアを見つけて試したり購入したりできる 記事一覧 「AWSクラウドプラクティショナー勉強 ネットワーク編」
- 投稿日:2021-04-05T20:27:53+09:00
CDKで"一部残して作り直し"したいんだけど(import)
CDKで構成したスタックにトラブルがあり、一部を作り直したくなる事があります。 例えば、以下のような事をして、作り直しが発生しました。 かなしいできごと ワイ「あー、VPCのcidr間違えた...cidr変更して作り直すか」 ワイ「んー、Elasticache(Redis)とRDSのサブネットグループが、違うcidrで違うVPCにあるとか言うてるな...」 The new Subnets are not in the same Vpc as the existing subnet group ワイ「うーん、"UPDATE_ROLLBACK_FAILED"のステータスになったな...コンソールでロールバックしろと書いてあるから、管理画面からロールバックするか」 ワイ「ロールバックはできたぞ、もう一度同じことをやってもNGだと思うから、試しにSubnetgroupとRedis/RDSを手動で消してみるか」 DBInstance smxockdf7per4z was not found during DescribeDBInstances ワイ「むむむ」 ワイ「また"UPDATE_ROLLBACK_FAILED"になったな...」 虚無 ワイ「ネットで色々調べたら、<ロールバックしてやり直すか消すかの二択や>って書いとるな」 ワイ「でも、このstackで作ったHostedZoneのNS、もう顧客に報告してるんやで」 ワイ「このHostedZoneだけは死守せなあかんのや...」 ワイ「ぼすけてー」 最終的にうまく行った手順 Stackの削除 ※ここの内容は状況によると思われます。今回守りたかったのはHostedZone ワイ「まず、確実にHostedZoneが削除されない状態でスタックをdestroyするか...」 ワイ「removalPolicyとかautoDeleteObjectsを設定していなければセーフなはずやけど、HostedZoneの場合、レコードを作っておけば削除できないから、手動で適当なレコードを追加しておこう。」 cdk destroy NantokaStack DELETE_FAILED ワイ「よしよし、順調にDELTEにFAILしたな...」って、結局普通にFAILするんかい(あたりまえ) ワイ「管理画面で削除するか、スタックの削除後に残すチェックボックスにチェックをいれて、ポチポチポチー」 ワイ「なんや、まだエラーになるんか」 ワイ「ふむふむ、さっき手動で削除したRDSが邪魔をしているということやな」 ワイ「こいつらはもう存在しないリソースやけど、敢えて削除後に残すことにするか...成仏してくれ...」 ワイ「(この理屈やとRedisも邪魔するはずやのに、なんでRedisは大丈夫なんや...?まあええか)」 よし、これでStackは消えたぞ。 Stackの再作成 ワイ「よーし、id類が変わらないように注意してStackを再作成するぞー」 ワイ「もちろん、HostedZoneを作るところだけはコメントアウトやな」 cdk deploy NantokaStack (正常終了) ワイ「よしよし、CDKは天才やな」 ワイ「このdeployでcdk.outフォルダにCloudFormantion用のテンプレートができとるんやな」 NantokaStack.template.json ワイ「よしよし、これや。これをコピーするぞ。」 ワイ「コピーしたら、コメントアウトしたHostedZoneを元に戻してcdk diffしとくやで」 ワイ「cdk diffでもtemplate.jsonが作られるんやな」 ワイ「コピーしたやつに、cdk diffで追加されたHostedZoneの部分だけをコピーして魔改造したNantokaStack.template.jsonを作るやで」 NantokaStack.template.json "HostedZoneAAAABBBB": { "Type": "AWS::Route53::HostedZone", "Properties": { "Name": "example.com." }, "Metadata": { "aws:cdk:path": "NantokaStack/HostedZone/Resource" }, "UpdateReplacePolicy": "Delete", "DeletionPolicy": "Delete" }, ※抜粋 ワイ「管理画面を開いて、Stackのリソースのインポートのところから、このNantokaStack.tempalte.jsonをアップロードするやで」 ワイ「idをきかれるから、Zone IDを入力...と」 ワイ「ひえっ!インポートが始まったやで!」 ※成功手順はここでおしまいです。 成功するまでの失敗パターンのメモ インポートするリソースが無いと管理画面で怒られる CDKが吐き出したコピー時のテンプレートをそのままインポートした場合(あたりまえ) CDKMetadataが編集されていると管理画面で怒られる CDKが吐き出した新しい方のテンプレートをそのままインポートした場合 DeletionPolicyが無いと管理画面で怒られる DeletionPolicyを追加する Route53::RecordSetはインポートできないと怒られる DNSレコードはインポートしてから再作成することにする(つまりインポート対象から除外する) 学んだこと なんかイマイチな状態になっても、手動で削除すると一層イマイチになるので、手動で削除しない 頑張ればインポートできる
- 投稿日:2021-04-05T20:10:07+09:00
AWSクラウドプラクティショナー勉強 モニタリングと分析編
AWSの公式サイトにクラウドプラクティショナーのEラーニングを学習して、 学んだことをメモとして残す。 学習に利用したサイトは「AWS Cloud Practitioner Essentials (Japanese) (日本語字幕版)」 Amazon CloudWatch さまざまなメトリクス(システムのパフォーマンスに関するデータ)をモニタリングおよび管理し、それらのメトリクスのデータに基づいてアラームアクションを設定することができるウェブサービス CloudWatch アラーム メトリクスの値が事前に定義したしきい値を上回った/下回った場合に、自動的にアクションを実行するアラームを作成できる CloudWatch ダッシュボード CloudWatch のダッシュボードを使用すると、1つの場所からリソース全てのメトリクスにアクセスできる AWS CloudTrail アカウントのAPIコールを記録する APIコール元のID、APIコールの時刻、APIコール元のソースIPアドレスなどが含まれる APIコールがあると、通常15分以内にCloudTrailに記録される CloudTrail Insights CloudTrailでオプション機能であるCloudTrail Insightsを使用すると、AWSアカウントの異常なAPIアクティビティを自動的に検出することができる 例としてAWSアカウントで通常よりも多くのEC2インスタンスが最近作成されたことを検出することがある AWS Trusted Advisor AWS環境を検査し、AWSのベストプラクティスに基づいてリアルタイムの推奨事項を提供するウェブサービス Trusted Advisorでは以下の5つのカテゴリで、調査結果とAWSのベストプラクティスを比較する コスト最適化 パフォーマンス セキュリティ 耐障害性 サービスの制限 記事一覧 「AWSクラウドプラクティショナー勉強 ネットワーク編」
- 投稿日:2021-04-05T19:40:46+09:00
AWS初心者が2週間くらいでCLFを取る計画
自己紹介(執筆者のレベル) 何してる人? 社会人5年目に入ったエンジニアです。 設計・移行作業(リプレース案件の場合)・試験を担当してました。 主に担当したことは以下。 担当 仮想化技術(VMware - vCenter移行(5.5u3→6.5u1g)作業を経験) ストレージ設計/構築/移行(ストレージ仮想化装置(VPLEX)を用いたVMAX→PMAXデータ移行) ジョブ管理システム(Job Arranger for Zabbix - 仮想マシンの定期再起動ジョブ等を実装) AWSの知識レベルは? クラウドについて興味もあってプライベートで触ってみようと思っており、触るならAWSかな!!と思っていたにも関わらず、何もしなかったダメな人。つまりAWSどころかクラウド初心者。 CLF(クラウドプラクティショナー)を取る理由 ついに業務でAWSを活用した案件に関わることとなったので、AWSの学習を始めることが背景にある。学習するならせっかくなので、形に残すべく基礎レベルにあたるCLF(クラウドプラクティショナー)を取ることを目標にした。 どうして2週間で取得? タイトルに記載の2週間でCLFを取得する理由は、いち早く会議の会話内容を理解できるようにし実作業ができるようにならないといけないので、じっくり時間をかけていられない。 ※※3週間後には、色々と実作業してもらうからねっていう状況… (お尻に火がつかないと始めないタイプのため、大変ありがたいです…) CLF取得に向けたざっくりスケジュール 4/22か4/23に受験する予定とし、以下のスケジュールで取り組む。 1週目(4/6~4/12) 参考書の斜め読み Web問題集への着手 2週目(4/13~4/21) Web問題集着手 模擬試験 上記ざっくりスケジュールだが、合間合間でハンズオンを入れたりする可能性もある。 おわりに ざっくり計画を立てたが、難易度を把握していないことや業務の傍らでの取り組みとなるため、2週間は厳しい可能性がある。とりあえず取り組んでみて、計画に見直しが必要そうであれば早期に対応する。(一通りが終わったら振り返り記事を書きたい)
- 投稿日:2021-04-05T19:35:32+09:00
[第一部]これならわかる!Flask+Nginx+uWSGIをAWSに丁寧にデプロイ
はじめに タイトル通り、Flaskで作った簡単なWebアプリをAmazon Linux2に上げてNginx+uWSGIを使ってとりあえず外部から見れるようにします。 AWSに関してはVPCの作成から載せています。(補足でCloudWatchを設定して請求金額のアラート通知も出来るようにするのでお金の面も安心!) かなり丁寧に解説を挟みますので、下に挙げる前提知識を持っている方であれば問題なく理解し実践出来る内容になっています。 また、今後「第二部」「第三部」では「DNSの設定」や「DB(RDS)やストレージ(S3)との連携」、「HTTPS化」等についても記事にまとめていくので一覧のシリーズを読んでいけばとりあえず個人開発でFlaskアプリを作ってデプロイ出来る知識を素早く身に付けられます!! ※こちらのZennに投稿した内容と 最低限必要な前提 AWSは登録済みかつIAM作業用ユーザー作成済み(もしくは独力で登録出来る) Pythonの基礎文法は把握している且つpyenvくらいなら調べながら使える Flaskを軽くは知っている(Webフレームワークであることは理解しているレベルでおk) Webサーバー、アプリケーションサーバーの違いはわかる Linuxの基本コマンドやパーミッション等についての基礎知識はある [AWS]ネットワーク構築 さっそく作成済みのIAM作業用ユーザーでマネジメントコンソール(以後、管理画面と呼称)にログインしてネットワークを構成していきましょう。 [AWS]VPC設定 「VPC」とは仮想ネットワークのこと。ここを「サブネット」という小さなネットワークで区切っていきます。 管理画面上部の検索バーから「VPC」検索します。 アクセス後、ダッシュボード(左側のバーのこと)からVPCを選択。 選択後、VPCを作成をクリック。 VPCの名前は好きなものを設定してください。IPアドレスはプライベートipの範囲で好きなものを選択してください。(よくわからないという方は今回は私と同じ「10.0.0.0/16」と設定してください。その他はデフォルトのままで大丈夫です。) 「VPCを作成」ボタンをクリックしましょう。 ちゃんと新しいVPCが出来ています。 ちなみにVPCのNameは後から編集することも出来ます。(私もこちらのクラスメソッド さんの記事を見て名称を見直してみました?) [AWS] パブリックサブネット作成 続いて左側のダッシュボードから「サブネット」を選択します。 今回作るサブネットはインターネットに接続できるようにしてWebサーバーを置く予定なので「パブリックサブネット」にします。 ※DB用途などには「プライベートサブネット」を選択します。 ※最初から4つあるのは、デフォルトでAWSが用意してくれているサブネットです。無視して進めましょう。 先ほど作成したVPCを選択。 設定では(1)サブネットの名前(2)アベイラビリティゾーン(3)CIDRブロックを設定します。 (2)に関してはどこでも問題ありません。(今回私はリージョンを安い米国西部にしているのでオレゴンのアベイラビリティゾーンが選択出来ます。) (3)に関してはVPCの中に設定するものなので先ほどVPCに設定したCIDRより大きい値を設定しましょう。 無事、設定出来ました。この画面で間違いがないか一応確認してみてみましょう。 ※「利用可能なIPv4が254じゃないのなぜなの〜」という方はこちらのドキュメントを読めば251になっている理由がわかります。 [AWS] ルーティング設定 その1 IGWのアタッチ 「インターネットゲートウェイ(IGW)」をVPCにアタッチしていきます。 ※インターネットゲートウェイとは雑に言えばデフォルトルートが登録されたデフォルトゲートウェイ(ブロードバンドルーター)のようなもの。より簡単に言えばインターネットとVPCを繋ぐ入り口です。 まず先ほどのVPCのページのダッシュボードから「インターネットゲートウェイ」を選択しインターネットゲートウェイの作成に移ります。 作成したインターネットゲートウェイを確認すると「Detached」になっている。これをアクションから自分のVPCに「アタッチ」するように設定していく。 [AWS] ルーティング設定 その2 ルートテーブルの作成 またダッシュボードから「ルートテーブル」を選択する。 無事作成。次はこのルートテーブルをVPCへの紐付きからパブリックサブネットへの紐付きに変更します。 サブネットを選択し、保存。 最後にルーティングテーブルで「0.0.0.0/0」のipアドレスが先ほど設定したインターネットゲートウェイに振り分けされるように設定。 ※0.0.0.0/0とは要は全てのIPアドレスのこと。振り分けを設定した他のIP(10.0.0.0/16)以外は全てインターネットゲートウェイに向かいます。こうすることでインターネットに繋がります。 [AWS] EC2の設定 [AWS] EC2インスタンス作成 「EC2」というAWS上の仮想サーバーを利用します。また管理画面の検索バーからEC2のページにアクセスしましょう。 EC2設定前にさくっと用語を整理しておくと、「インスタンス」 というのはEC2から建てられたサーバーのこと。「AMI」はOSのテンプレートイメージ、「インスタンスタイプ」はサーバースペック、「ストレージ」はそのまま文字通りデータの保存場所(EBSを利用することが多いとのこと)。インスタンスを立ち上げるさいにAMI、インスタンスタイプ、ストレージを指定して設定します。 また後ほど、ここで作ったインスタンスにPythonやFlask、Nginxといったソフトウェア、ミドルウェアをインストールすることでWebサーバーとしての役割を果たせるようにしていきます。 まずダッシュボードで「インスタンス」を選択。 右上の「インスタンスを起動」を選択。 「AMI」に関しては今回は「Amazon Linux 2(x86)」を選択します。 「インスタンスタイプ」は「t2.micro」を選択します。 t2.microはAWSのアカウント開設から12ヶ月間は無料で使用できるインスタンスです。 ※参考:改めてAWSの「無料利用枠」を知ろう / クラスメソッド インスタンスの詳細設定では、 (1)「ネットワーク」、「サブネット」を先ほど自分で作ったものに設定 (2)「自動割り当てパブリックIP」は有効に(インターネットに繋ぐ時に必要なグローバルIPをAWSが自動で割り当ててくれる。) (3)「キャパシティーの予約」は今回勉強用なのでなしに。 ※参考:AWS EC2 オンデマンドキャパシティー予約を詳しく知る / Serverworks 今回、ストレージの割り当てはデフォルトの8GiBで問題ありません。 タグはNameでインスタンスの名前を付けてやります。 セキュリティグループの名称を付けてやります。 後ほどセキュリティの設定を行ってインターネットからの接続を許可しますが一旦、インスタンスを起動させます。 インスタンスの起動前にこのインスタンスに接続するためのkeypairを作成してダウンロードしておく。なくさないように保存しておきましょう。 ※注意:このkeyは絶対にオンラインに公開などしないように!!! 最後にセキュリティウォールの設定をしていきます。 「EC2」のダッシュボードから「セキュリティグループ」を選択します。 先ほど作成したセキュリティグループにチェックボックス を入れて下の「インバウンドルール」で「インバウンドルールを編集」をクリックします。 編集画面でHTTPを上記と同じように追加しましょう。 これでHTTP通信でインターネットのどこのIPからでもこのインスタンスにアクセスが出来るようになりました。 [AWS] MacからAWSインスタンスにSSH接続する ターミナル を起動して下記のようにコマンドを打っていきます。 まず、keypairのパーミッションを600番に変更します。 $ chmod 600 ~/キーペア保存までのパス/作成したkeypair 次にAWSの管理画面のEC2のページから接続したいインスタンスにチェックボックスを入れて、下の方にある詳細画面から「パブリックIPv4アドレス」をコピーしてきます。(インスタンスを再起動させたりすると変わってしまうので注意!) 下記のコマンドを打って、インスタンスに接続しよう。なお初めてインスタンスに接続する場合は「fingerprint」がないが大丈夫か聞いてくるので「yes」と打ってEnterしてやりましょう。 $ ssh -i ~/キーペア保存までのパス/作成したkeypair ec2-user@パブリックIP [AWS] 補足:請求アラートの設定 右上のIAMユーザー名のドロップダウンリストから「マイ請求ダッシュボード」を選択。左のダッシュボードの「設定」から「Billingの設定」をクリックします。 無料利用枠(アカウント解説から12ヶ月無料の分)を過ぎた際に指定したメールにアラートを流すように設定します。また一定以上の金額が発生した場合にもアラートが出るように請求アラートにチェックをいれます。 続いてCloudWatchを設定してアラートの詳細設定を行います。 サービス画面から検索してCloudWatchを選択して、 「アラームの作成」を選択します。 ※バージニアリージョンでしかCloudWatchを使えないという情報をWeb上でよく見かけましたが、私のアカウントではオレゴン(やおそらく東京リージョン)で問題なくアラームを設定できました。 今回は10ドルを閾値として設定します。 上記画面で連絡先のメールアドレスや任意のアラート名を設定して、最後に「アラームの作成」を選択します。 下記のようなメールが設定したメールアドレス宛に届いているはずなので、「Confirm subscription」をクリックして登録を承認します。 ※ちなみに追加で別のメールアドレスにも届くように設定するにはAWSの「SNS」というサービスを使用すれば良いのですが今回は説明を省略します。 Pythonセットアップ+各種ソフトインストール 下準備とpyenvのインストール まずyumのアップデート及び必要なソフトウェアのインストールを行います。 $ sudo yum -y update $ sudo yum -y install \ bzip2 \ bzip2-devel \ gcc \ git \ libffi-devel \ make \ openssl \ openssl-devel \ readline \ readline-devel \ sqlite \ sqlite-devel \ zlib-devel \ tree 次にgithubからpyenvというPythonのバージョン管理ツールをダウンロードして設定(パス通し)を行ってやります。 $ git clone git://github.com/yyuu/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile ちなみに下記のようなシェルスクリプトを追加することで.bash_profileがちゃんと読み込まれた時にメッセージを出してくれるので便利です。 $ echo 'echo "ec2-user bsah_profile stands up"' >> ~/.bash_profile 準備が出来たら、.bash_profileを読み込んでやります。 -- 下記どちらでも良い $ . ~/.bash_profile $ source ~/.bash_profile Python、Flask、uWSGIの取得 pyenvで現在取得出来るPythonのバージョンを確認出来ます。 $ pyenv install --list -- 上だと長いので下記のようにすると3.9と前に着いているバージョンのみ確認出来る $ pyenv install --list | grep "3\.9\.*" | grep -v "[A-Za-z]" pyenvを用いて指定のバージョンのPythonをインストールします。(結構インストールには時間がかかります...) $ pyenv install 3.9.2 -- 現在使用できるバージョンの確認(systemはこのインスタンスに最初から入っていたもの) $ pyenv versions * system (set by /home/ec2-user/.pyenv/version) 3.9.2 -- バージョン切り替え $ pyenv global 3.9.2 後々使用するamazon-linux-extrasコマンドのため下記のようなシンボリックリンクを貼ります。 $ ln -s /lib/python2.7/site-packages/amazon_linux_extras ~/.pyenv/versions/3.9.2/lib/python3.9/site-packages/ pipでFlaskとuWSGIをインストールします。 $ /home/ec2-user/.pyenv/versions/3.9.2/bin/python3.9 -m pip install --upgrade pip $ pip install flask $ pip install uwsgi amazon-linux-extrasコマンドでNginxをインストールします。 -- nginxがインストール出来ることを確認 $ amazon-linux-extras list | grep nginx 38 nginx1 available [ =stable ] -- インストール(インストールするか聞かれたらyと入力) $ sudo amazon-linux-extras install nginx1 以上でPythonのセットアップ及び各種ソフトウェアのインストールは終了です。 次のセクションではいよいよFlaskのアプリケーションを作ってFlask付属の簡易サーバーで動かしていきます。 Flaskアプリケーション作成 本来は、 (1)ローカルのPCでFlaskアプリを作成 (2)それをGitHubのようなgitのホスティングサービスに(git pushで)アップロード (3)gitホスティングサービスからEC2インスタンス上で(git cloneで)取得してソースコードやコミットログを取得 としていくのがスタンダードなやり方です。 ただ今回は、(gitの解説を省略するために)インスタンス上で直接Flaskアプリケーションを作成していきます。 ディレクトリ構成は最終的に下記のようになります。 $ cd /var/www $ tree myapp myapp/ ├── __pycache__ │ ├── myproject.cpython-39.pyc │ └── run.cpython-39.pyc ├── myproject.ini ├── myproject.py ├── new_comer.trigger ├── run │ └── mywsgi.sock ├── run.py ├── static │ └── logo_uwsgi.png └── templates ├── advance.html └── index.html ディレクトリと静的ファイルの下準備 まずFlaskアプリケーションを/var/www/myappディレクトリに作成していきます。 ちなみに「なぜNginxのデフォルトのドキュメントルートの/usr/share/nginx/htmlではなく/var/wwwに作るのか」というというと、Nginxの公式ドキュメントにもある通り、 You should not use the default document root for any site-critical files. There is no expectation that the default document root will be left untouched by the system and there is an extremely high possibility that your site-critical data may be lost upon updates and upgrades to the NGINX packages for your operating system. 「デフォルトのドキュメントルートのディレクトリはNginxのパッケージアップデートの際にも使用されるものであり、このアップデートの際に重要なデータが消える可能性があるので避けた方が良いよ」、と言うことのようです。 ※参考:Not Using Standard Document Root Locations Nginx公式ドキュメント さっそく作っていきます。 -- ec2インスタンス上 $ sudo mkdir -p /var/www/myapp $ cd /var/www/myapp さて、Flaskのルールとして下記のようなファイルの置き場所に関わるルールがあります。 「templates」ディレクトリ HTMLファイルの置き場所でここに置くことでPython用のテンプレートエンジンJinja2が適用される。 「static」ディレクトリ 「(HTMLファイル以外の、)CSSファイル・JSファイル・画像ファイル」などの静的ファイルの置き場所です。今回は下記の画像を保存しておきます。 ※ちなみに最初、私はtemplate*sをtemplate*としていたので延々と「jinja2テンプレートが見つかりません」jinja2.exceptions.TemplateNotFoundとエラーが出て憂鬱な気持ちになっていました。 ではそれぞれのディレクトリを作っていきます。 -- ec2インスタンス上 $ sudo mkdir templates static run ※runディレクトリに関しては後ほどuWSGIサーバーの関連ファイルを保存するために使うので先に作っておいてください。 次にstaticディレクトリに入れる画像をローカルのPCに入れてそれをsshでサーバーに送りましょう。scpコマンドを使用すれば出来ます。 -- ローカル上 $ scp -i ~/keypairまでのパス/作成したkeypair ~/送りたいファイルまでのパス/送りたいファイル ec2-u ser@インスタンスのパブリックIP:~/送り先のディレクトリのパス 送り先のディレクトリのパスはec2-userのホームディレクトリ「~/」を指定するのがオススメです。 ※デフォルトの状態でいきなりルート直下の/var/www/myapp/staticなどを指定するとPermission deniedとなってしまいます。 今回のようにファイルを送る場合はscpコマンドにはオプションは入りませんがディレクトリを送る場合は-rとつけましょう。 ちなみに今回は下記の画像を使用します。 今度はssh先で画像を/var/www/update/staticに移しましょう。 -- ec2インスタンス上 $ sudo mv ~/logo_uwsgi.png /var/www/myapp/static/ 次にtemplatesディレクトリに下記の二つのHTMLファイルを入れます。 ※普通のHTMLファイルと違う書き方ですがこれはtemplatesディレクトリに置いた.htmlファイルはFlaskのテンプレートエンジンによって解釈されるためです。 -- index.html <!DOCTYPE HTML> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>{{ name }}さんのページだぞ</title> </head> <body> <h1>きみは{{ name }}さんだね!</h1> <img src="/static/logo_uwsgi.png" style="width:100%"> <p>これはindex.htmlのページです</p> <form action="/" method="GET"> <p><label>名前を変更してみよう: <input name="name" type="text" placeholder="なまえ入力してね"></label> <p><input type="submit" value="名前変更確定!"></p> </form> </body> </html> -- advance.html <!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>{{ name }}</title> </head> <body> {% if name == "Kumamoto" %} <h1>きみはオーナーだね</h1> {% elif name %} <h1>きみはゲストの{{ name }}さんだね</h1> {% else %} <h1>ななしさんだね</h1> {% endif %} <form action="/adv" method="POST"> <p><label>名前を更新する:<input name="name" type="text"></label></p> <p><input type="submit" value="更新!"> </form> <p>advance.htmlのページです</p> </body> </html> 続いて本家本元のMVTのView部分(MVCで言うコントローラー部分)を作成していきましょう。 -- myproject.py from flask import Flask, render_template, request application = Flask(__name__) @application.route("/") @application.route("/index") def index(): # Note:str()を使う事でNoneの時でも、TypeErrorを起こさず"様"をつけることが出来る name = str(request.args.get("name")) + "様" return render_template("index.html", name=name) @application.route("/adv", methods=["GET", "POST"]) def advance(): # Note:dictのgetメソッドを使うことでNoneでもエラーにならない! name = request.form.get("name") # Note:./を書いても書かなくてもいいんだなぁ。 return render_template("./advance.html", name=name) if __name__ == "__main__": application.run() さらにこれを動かすpythonスクリプトを作りましょう。 -- run.py from myproject import application if __name__ == "__main__": application.run(host="0.0.0.0", debug=True) さて、run.pyのほうでflaskインスタンスのrun関数のキーワード引数hostを"0.0.0.0"と指定しています。こうすることでどこのipアドレスからのアクセスも受け付けるようになっています。 ※キーワード引数hostを指定しないデフォルトでは自分自身を表すプライベートIP127.0.0.1以外からは受け付けないです。 ただし!!今現在はインスタンスのセキュリティグループで「HTTPの80番ポート」からの接続はどこのIPアドレスからでも受け付けますが、80番以外のポート番号からのHTTP接続はどこのIPアドレスからであっても許可されていません。 実際にアクセス出来ないことをまずは実験してみましょう。 $ python /var/www/myapp/run.py * Serving Flask app "myproject" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 301-577-841 flaskに付属する簡易サーバーが立ち上がります。 ※warningにもある通りこの簡易サーバーを本番サーバーとして運用することは辞めましょう。 ログに「HTTP」の「どのIPアドレスからでも」「5000番ポートを使って」アクセス出来るとあります。 それではブラウザを立ち上げAWSで作成したEC2インスタンスに割り当てされているパブリックIPを打ち込んで、アクセスを試みて見ましょう。 アクセス出来ません(あたりまえ) それではAWSの「EC2」サービスページのダッシュボード「セキュリティグループ」から自分の作ったセキュリティグループのチェックボックスにチェックを入れ、下の画面の「インバウンドルールを編集」からルールを編集しましょう。 下記のように「ルールの追加」で「タイプ:カスタムTCP」、「ポート:5000番」、「ソース:マイIP」を選択します。完了したら「ルールの保存」を選択しましょう。 ※マイIPというのは自分に割り当てられているグローバルIPのことです。 再度、http://インスタンスのパブリックIP:5000にアクセスしてみましょう。 ※flaskの簡易サーバーを止めた場合は再度、python run.pyすることを忘れずに! 無事アクセス出来ました!入力フォームに文字を入れてみたり、http://インスタンスのパブリックIP:5000/advにアクセスしたりわざとPythonのスクリプトにバグを起こして、debug画面を覗いたりしてみましょう。 uWSGIセットアップ さらっと用語を学ぶ uWSGIに関わる用語を整理します。 | WSGI | uWSGI | uwsgi | | ---- | ---- | ---- | | アプリケーションとAP/Webサーバー間の標準的なインターフェイス| APサーバー | uWSGIサーバーのバイナリプロトコル | ※参考:How To Set Up uWSGI and Nginx to Serve Python Apps on Ubuntu 14.04 / Digital Ocean まずはコマンドで立ち上げ uwsgiコマンドを用いて先ほどのFlaskアプリケーションをデプロイしましょう。 $ cd /var/www/myapp $ uwsgi --http=0.0.0.0:5000 --wsgi-file=run.py --callable=application コマンドオプションの意味を補足します。 httpがサーバーのipアドレス、ポート番号を指定します。既に説明しましたが、「0.0.0.0」はIPv4アドレス空間内の全てのアドレスと一致します。またポート番号を5000番としたのは、先ほどEC2のセキュリティグループで5000番ポートからのアクセスを許可するように設定したからです。(80番ポートを指定してもアクセスは出来ます。) wsgi-fileでは先ほど作ったflaskのアプリケーションファイル(つまり今回だとrun.py)を指定します。 callableではFlask(__name__)のインスタンス名を指定します。(今回はapplication) またhttp://インスタンスのパブリックIP:5000にアクセスしてサイトが映るか確かめてみましょう。 uWSGIのための設定ファイルを書こう 毎回コマンドのオプションを指定するのは面倒なのでドットiniファイルにuWSGIの設定を書いていきます。 $ cd /var/www/myapp $ sudo vim myproject.ini 中身は下記。 [uwsgi] # Nginxを使わずにアクセス出来るように一時的にhttpプロトコルを設定 http=0.0.0.0:5000 module=run callable=application master=true processes=5 base_dir=/var/www pj_name=myapp # uwsgi-socketはsocketと指定してもよい uwsgi-socket=%(base_dir)/%(pj_name)/run/mywsgi.sock logto=/var/log/uwsgi/uwsgi.log # 後々Nginxがアクセス出来るように666にしている chmod-socket=666 vacuum=true die-on-term=true # wsgi-file=/var/www/myapp/run.py wsgi-file=%(base_dir)/%(pj_name)/run.py touch-reload=%(base_dir)/%(pj_name)/new_comer.trigger moduleはflaskを動かすファイル(run.py)、callableがFlask(__name__)のインスタンスです。 master=trueは公式のGlossary(用語集)にもある通り推奨されている設定です。 processesは実行するプログラム数のことです。 vacuumオプションをtrueにすることで、プロセスの停止時にソケットをクリーンアップしてくれます。 die-on-termオプションの設定です。これは、initシステムとuWSGIが、それぞれのプロセス信号が何を意味するかについて、同じ仮定を持っていることを保証することができます。これを設定することで、2つのシステムコンポーネントが整合し、期待される動作が実装されます。 またtouch-reloadについては後ほど説明します。 続いて、logtoで指定したlogファイル用のディレクトリを用意してやります。 $ sudo mkdir -p /var/log/uwsgi さて、これでようやっと立ち上げ、、、 $ cd /var/www/myapp $ uwsgi myproject.ini *** Starting uWSGI 2.0.19.1 (64bit) on [Fri Apr 2 04:56:20 2021] *** compiled with version: 7.3.1 20180712 (Red Hat 7.3.1-12) on 29 March 2021 17:49:25 os: Linux-4.14.225-168.357.amzn2.x86_64 #1 SMP Mon Mar 15 18:00:02 UTC 2021 nodename: ip-10-0-0-59.us-west-2.compute.internal machine: x86_64 clock source: unix pcre jit disabled detected number of CPU cores: 1 current working directory: /var/www/myapp detected binary path: /home/ec2-user/.pyenv/versions/3.9.2/bin/uwsgi your memory page size is 4096 bytes detected max file descriptor number: 65535 lock engine: pthread robust mutexes thunder lock: disabled (you can enable it with --thunder-lock) bind(): Permission denied [core/socket.c line 230] 出来ませんでした。 エラーログを見る限りPermission関係で弾かれたと推測できます。 次の項からはuWSGIがまともに動けるように(1)「ec2-user」をサーバー管理者に設定する(2)ディレクトリの所有者をサーバー管理者に変更する、ということをやっていきましょう。 サーバー管理者となるユーザー の設定変更 今回は「ec2-user」をサーバーの管理者用のユーザーとしたいと思います。サブグループとして既に「admin」に所属となっていますが「nginx」グループにも所属させてやります。 念のため/etc/groupファイルでgroup一覧を確認してやりましょう。 $ view /etc/group -- 省略して表示 adm:x:4:ec2-user nginx:x:993: ec2-user:x:1000: ※ファイルを確認する時はviewコマンドの他lessやmore、catコマンドなどでもおkです。 groupをみてやると「nginx」グループにはサブグループとして所属しているユーザーはいないことがわかります。 ※ちなみにUbuntuなどのDebian系だと「nginx」などのサーバー名の付いたグループではなく、「www-data」グループを使用するのが一般的なようです。ディストリビューションによってもポピュラーなやり方は異なると思うので適宜調べてみてください。 つづいてまた念のため「/etc/passwd」でユーザー一覧を確認してみましょう。 $ view /etc/pwasswd ec2-user:x:1000:1000:EC2 Default User:/home/ec2-user:/bin/bash 以上から現状「ec2-user」グループはプライマリーグループとして「ec2-user」、サブグループとして「admin」に所属していることがわかります。 今回は学びのために敢えて回りくどいやり方をしましたがユーザーに関してはidコマンドを、グループに関してはgetentコマンドを使えばさらに簡単に確認が出来ます。(これ以降はこれらのコマンドを使っていきます) -- ec2-userのユーザーidや所属するグループ(プライマリーグループもサブグループも)を確認出来る $ id ec2-user uid=1000(ec2-user) gid=1000(ec2-user) groups=1000(ec2-user),4(adm),10(wheel),190(systemd-journal) -- 今、nginxグループをサブグループとしているユーザーはいない $ getent group nginx nginx:x:993: では現状確認が終わったので「ec2-user」のサブグループに「nginx」を追加します。 $ sudo usermod -aG nginx ec2-user 先ほどと同様にidコマンドとgetentコマンドを使って上手くec2-userがnginxに所属してくれたか確認しましょう。 $ id ec2-user uid=1000(ec2-user) gid=1000(ec2-user) groups=1000(ec2-user),4(adm),10(wheel),190(systemd-journal),993(nginx) $ getent group nginx nginx:x:993:ec2-user 問題なさそうです。 では続いては各種ディレクトリの所有者を変更していきましょう。 各種ディレクトリの所有者変更 まず本家本元の/var/www以下の所有者を変更していきましょう。 -- ec2-userになっていない場合「sudo su - ec2-user」でユーザーを切り替えてください $ echo $USER ec2-user -- /var/www以下の全ての所有者を変更 $ sudo chown $USER:nginx -R /var/www 上手くいったか確認してみましょう。 $ ls -ld /var/www drwxr-xr-x 3 ec2-user nginx 33 4月 1 09:06 /var/www $ ls -l /var/www drwxr-xr-x 4 ec2-user nginx 92 4月 2 04:46 myapp ではいったん、uwsgiの設定ファイルmyproject.iniのうちlogファイルの指定部分をコメントアウトしてやって、、、 [uwsgi] #logto=/var/log/uwsgi/uwsgi.log サーバーの接続を再度試みてみましょう。 $ cd /var/www/myapp $ uwsgi --ini myproject.ini *** Starting uWSGI 2.0.19.1 (64bit) on [Fri Apr 2 06:17:56 2021] *** compiled with version: 7.3.1 20180712 (Red Hat 7.3.1-12) on 29 March 2021 17:49:25 os: Linux-4.14.225-168.357.amzn2.x86_64 #1 SMP Mon Mar 15 18:00:02 UTC 2021 nodename: ip-10-0-0-59.us-west-2.compute.internal machine: x86_64 clock source: unix pcre jit disabled detected number of CPU cores: 1 current working directory: /var/www/myapp detected binary path: /home/ec2-user/.pyenv/versions/3.9.2/bin/uwsgi your memory page size is 4096 bytes detected max file descriptor number: 65535 lock engine: pthread robust mutexes thunder lock: disabled (you can enable it with --thunder-lock) uWSGI http bound on 0.0.0.0:5000 fd 3 uwsgi socket 0 bound to UNIX address mywsgi.sock fd 6 Python version: 3.9.2 (default, Mar 29 2021, 17:42:02) [GCC 7.3.1 20180712 (Red Hat 7.3.1-12)] *** Python threads support is disabled. You can enable it with --enable-threads *** Python main interpreter initialized at 0x29b7370 your server socket listen backlog is limited to 100 connections your mercy for graceful operations on workers is 60 seconds mapped 145840 bytes (142 KB) for 1 cores *** Operational MODE: single process *** WSGI app 0 (mountpoint='') ready in 0 seconds on interpreter 0x29b7370 pid: 22333 (default app) mountpoint already configured. skip. *** uWSGI is running in multiple interpreter mode *** spawned uWSGI master process (pid: 22333) spawned uWSGI worker 1 (pid: 22366, cores: 1) spawned uWSGI http 1 (pid: 22367) unable to stat() /var/www/myapp/new_comer.trigger, events will be triggered as soon as the file is created [pid: 22366|app: 0|req: 1/1] 157.107.117.161 () {38 vars in 753 bytes} [Fri Apr 2 06:18:00 2021] GET / => generated 656 bytes in 7 msecs (HTTP/1.1 200) 2 headers in 80 bytes (1 switches on core 0) ブラウザからhttp://インスタンスのパブリックIP:5000にアクセスしてみたところ問題なくつながりました。 では今度はuWSGIのログがちゃんと指定したログファイルに入っていくようにまたディレクトリの所有者を変更していきましょう。 $ sudo chown $USER:nginx -R /var/log/uwsgi $ ls -ld /var/low/uwsgi drwxr-xr-x 2 ec2-user nginx 6 4月 2 04:42 /var/log/uwsgi 忘れずにmyproject.iniのlogtoのコメントアウトを外しておきましょう。 ※当然、所有者を変えているのでec2-userユーザーならもうsudoせずともvimで編集できますよ! -- ログが大幅に減っているが、/var/log/uwsgi/uwsgi.logに保存されている(後々確認してみよう!) $ uwsgi --ini myproject.ini [uWSGI] getting INI configuration from myproject.ini Nginxセットアップ Nginxの設定ファイルを作成 ようやくNginxサーバーのセットアップに入ります。 まずNginxの設定ファイルを確認してみましょう。 $ cd /etc/nginx $ view nginx.conf nginx.confファイルの中身についての詳細な解説は今回省略しますが、 http { --省略-- include /etc/nginx/conf.d/*.conf; となっているのが確認出来たでしょうか。これは/etc/nginx/conf.dディレクトリ下の.confという名前のファイルは全て読み込むように設定されているということです。 それでは今回作成Flaskアプリ用のNginx設定ファイルを作成していきましょう。 $ cd /etc/nginx/conf.d $ sudo vim myapp.conf myapp.confの中身は下記のようにします。 server { listen 80; listen [::]:80; root /var/www; location / { include uwsgi_params; uwsgi_pass unix:///var/www/myapp/run/mywsgi.sock; } } rootとあるのはルートドキュメントを/var/www以下にしますよ、という意味です。 .sockファイルの指定は、既に作成したmyproject.iniで設定したのと同じパス、ファイル名を指定してください。 念のため、今設定したファイルにNginx上の文法ミスがないか確認してみましょう。 $ sudo nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful 問題なさそうですね。 続いて、今後uWSGIとNginx間の通信プロトコルとしてHTTPではなくuWSGIデフォルトのuwsgiプロトコルを使って欲しいのでmyproject.iniファイルからhttp=0.0.0.0:5000という行を削除します。 Nginxを立ち上げてuwsgiと接続してみましょう。 $ sudo systemctl start nginx $ sudo systemctl enable nginx $ cd /var/www/myapp $ uwsgi --ini myproject.ini 先ほどと同じようにインスタンスのパブリックIPを指定してブラウザからアクセスしてみてください。 自動でNginxとuWSGIがアクセス出来るようにする さて今まではNginxが起動している状態で手動でuWSGIを立ち上げしていましたが、こんなことを毎回したくはないです。 そこでnginxと同じようにuWSGIもsystemctlコマンドで立ち上げっぱなしに出来るようにsystemd管理下のサービスにしてあげましょう。 まずsystemdが管理するサービスの設定ファイルのあるディレクトリに移動しましょう。 $ cd /etc/systemd/system $ sudo vim uwsgi.service 下記のように設定ファイルを記述していきます。 :::details uwsgi serviceの設定ファイル ``` [Unit] Description=uWSGI instance to serve myapp After=network.target [Service] User=ec2-user Group=nginx WorkingDirectory=/var/www/myapp ExecStart=/home/ec2-user/.pyenv/shims/uwsgi --ini myproject.ini Restart=always KillSignal=SIGQUIT Type=notify NotifyAccess=all [Install] WantedBy=multi-user.target ``` ::: uwsgiサービスを立ち上げしていきます。 $ sudo systemctl start uwsgi.service $ sudo systemctl enable uwsgi.service これでインスタンスを停止しない限り、常時Flaskで作ったWebサイトにアクセス出来るようになりました! Flaskのソースコードを変更した際にアップデートされるようにする Flaskのアプリのソースコード(今回ならmyproject.pyなど)を変更してもWebサイト上の表記が変わらないことがあります。 これは同じディレクトリ内の__pycache__ディレクトリにあるキャッシュファイルが原因です。 ※逆にこのファイルのおかげでソースコード変更がない際は毎度処理が行われることなく済んでいます。 当然NginxとuWSGIを停止して再起動させればアップデートされたコードが反映されますが、毎回そんなことをするのは面倒くさい。。。 そこでソースコードの反映をさせるための.triggerファイルを作成しましょう。 先ほど設定したuWSGIのmyproject.iniファイルの中身を再度確認してください。 [uwsgi] --省略-- # .triggerファイルのファイル名は任意のものを使用可能 touch-reload=%(base_dir)/%(pj_name)/new_comer.trigger 上記で指定したリロードファイルを作成してみよう。 ソースコードの変更を反映するには.triggerファイルをtouchコマンドで更新するだけで反映される。 -- リロードファイルの中身は空で良い $ cd /var/www/myapp $ touch new_comer.trigger 以上で第一部は終わりです。お疲れ様でした! おまけ tips&エラー集 筆者がサーバーを立ち上げる中でぶつかったエラー及びその原因についておまけで載せていきます。 実際にみなさんがサーバー構築をやっていくとここに出ていないエラーが出てくるかもしれませんし、同じエラー文でも違う原因で発生しているかもしれません。 ただここに出てくる解決方法を試してみれば何か解決の糸口が掴めるかもしれません。 毎回ログに残る時間が日本時間でない 原因:設定漏れ これはエラーではなく単なる設定漏れですが、 $ sudo su - $ timedatectl set-timezone Asia/Tokyo とタイムゾーンを変更してやるだけで問題ないです。 502 Bad Gatewayと出てしまう 原因:uWSGIとの接続が上手くいっていない NginxとuWSGIの接続が上手くいかない場合に発生します。 具体的に言うとrun.pyを設定ファイルの中でTypoしていました。 こういったぽかミスであってもtailコマンドでエラーログを追っていくと「No such file」等のエラー原因の特定に繋がるメッセージが出ていることが多々あります。 $ sudo tail -f /var/log/nginx/error.log Internal Server Errorと出てしまう 原因:Pythonの文法エラー 「Internal Server Error」とははっきり言ってエラー原因の手がかりが読み取れないエラーです。 ただPythonの文法エラーである場合も多いので、一旦NginxとuWSGIを停止させFlaskの簡易サーバーをデバッグを行うことで原因が見つかることもあります。
- 投稿日:2021-04-05T18:19:46+09:00
IoT Device Managementのグループを利用してポリシーを管理する
はじめに IoT Device Managementの静的グループにはポリシーをアタッチすることができます。 グループを利用することで、モノのポリシー管理が楽になります。 グループにポリシーをアタッチおよびデタッチすると、AWS IoT オペレーションのセキュリティをいくつかの重要な方法で強化できます。ポリシーに証明書をアタッチしてからモノにアタッチするような、デバイスごとの方法は時間がかかり、多数のデバイスにわたってポリシーを迅速に更新または変更することが困難です。モノのグループにポリシーをアタッチすると、証明書をモノに回す際のステップが節約されます。また、ポリシーはグループメンバーシップを変更すると動的に適用されるため、デバイスがグループのメンバーシップを変更するたびに複雑なアクセス許可セットを再作成する必要はありません。 引用元:モノの静的グループ 今回は、グループにポリシーをアタッチした際の挙動を確認しました。 1 事前準備 今回の検証用にグループとポリシーを用意します。 1-1 グループの用意 今回は以下のパターンを検証するため、4階層のグループを用意します。 モノが所属しているグループにポリシーをアタッチする モノが所属しているグループの1階層上の親グループにポリシーをアタッチする モノが所属しているグループの2階層上のルートグループにポリシーをアタッチする モノが所属しているグループの2階層上の親グループ(ルートではない)にポリシーをアタッチする 1.IoT Coreのマネジメントコンソールで左のメニューから 管理 > モノのグループ の順にクリック 2.「作成」をクリック 3.「モノのグループを作成」をクリック ※動的なモノのグループにはポリシーをアタッチできない 参考:モノの動的グループ 4.任意のグループ名を入力して「モノのグループを作成」をクリック 5.作成されたモノのグループの詳細画面で グループ > グループの追加 の順にクリック 6.手順4同様のグループ追加画面が表示されるので、任意のグループ名を入力して「モノのグループを作成」をクリック ※親グループの選択箇所に、グループの追加 をクリックしたグループが選択されている 7.手順5~6を繰り返して、子グループをさらに2階層下まで作成する ※今回は グループ / Test / Test2 / Test2-1 / Test2-1-1 という形で4階層作成した 1-2 ポリシーの作成 今回はAllowとDenyのポリシーが両方適用された場合の挙動も確認したいので、ポリシーを2つ用意します。 あくまで挙動確認なので、権限は*で大きく付与しています。 1.IoT Coreのマネジメントコンソールで左のメニューから 安全性 > ポリシー の順にクリック 2.「作成」をクリック 3.以下の通り入力・選択して「作成」をクリック ※すべてのIoT Core操作をAllowするポリシー 名前:※任意の名前 アクション:iot:* リソースARN:* 効果:許可 4.手順1~3を繰り返し、すべてのIoT Core操作をDenyするポリシーを作成する ※手順3の「効果」は拒否をチェック なお、今回作成した両ポリシーはJSON形式だと以下の通りです。 group-policy { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "iot:*", "Resource": "*" } ] } deny-group-policy { "Version": "2012-10-17", "Statement": [ { "Effect": "Deny", "Action": "iot:*", "Resource": "*" } ] } 2 検証 グループにアタッチしたポリシーが働くことを確認します。 今回は、AWS IoT Device SDK for Pythonのサンプル basicPubSub.py を利用し、デバイスからのメッセージがエラーなく届くかどうかを通してポリシーの有効性を確かめます。 なお、basicPubSub.py の利用に関しては以下の記事をご参照ください。 参考:AWS IoT Device SDK for Pythonを使ってRaspberryPiとAWS IoTをつないでみる 2-1 モノの証明書へのポリシーアタッチ グループへアタッチしての検証前に、用意したポリシーをモノの証明書にアタッチ/デタッチすることで、通信できる/できないと変わることを確認します。 1.IoT Coreのマネジメントコンソールで左のメニューから 管理 > モノ の順にクリック 2.今回対象とするモノの名前をクリック 3.セキュリティ > 証明書 の順にクリック 4.ポリシーをクリックし、アクション > ポリシーのアタッチ の順にクリック 5.先ほど作成したAllowのポリシーを選択して「アタッチ」をクリック 6.IoT Coreのマネジメントコンソールで左のメニューから テストをクリック 7.トピックのフィルターに「sdk/test/Python」と入力して「サブスクライブ」をクリック 8.対象のデバイスで以下のコマンドを実行し、手順7のテスト画面でメッセージをサブスクライブできることを確認する #下記はbasicPubSub.pyを格納したディレクトリ上で実行している(Ctrl + C で停止) python basicPubSub.py --endpoint [エンドポイントのURL] --rootCA [ルート証明書] --cert [モノの証明書] --key [秘密鍵] --clientId "[モノの名前]" #コマンドが成功するとプロンプト上では以下の通りメッセージが表示される 2021-04-05 10:54:53,726 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - Invoking custom event callback... 2021-04-05 10:54:58,705 - AWSIoTPythonSDK.core.protocol.mqtt_core - INFO - Performing sync publish... 2021-04-05 10:54:58,706 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - Filling in custom puback (QoS>0) event callback... 2021-04-05 10:54:58,739 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Produced [puback] event 2021-04-05 10:54:58,740 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Dispatching [puback] event 2021-04-05 10:54:58,741 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - Invoking custom event callback... 2021-04-05 10:54:58,742 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - This custom event callback is for pub/sub/unsub, removing it after invocation... 2021-04-05 10:54:58,760 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Produced [message] event 2021-04-05 10:54:58,760 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Dispatching [message] event Received a new message: b'{"message": "Hello World!", "sequence": 1}' from topic: sdk/test/Python -------------- 9.手順4の画面でポリシーをデタッチしてから再度コマンドを実行し、今度はメッセージの送信に失敗することを確認する #以下のエラーメッセージが表示された 2021-04-05 10:55:45,969 - AWSIoTPythonSDK.core.protocol.mqtt_core - ERROR - Connect timed out Traceback (most recent call last): File "C:\Users\xxxxx\Desktop\gg-test-003\basicPubSub.py", line 107, in <module> myAWSIoTMQTTClient.connect() File "C:\Users\xxxxx\AppData\Local\Programs\Python\Python39\lib\site-packages\AWSIoTPythonSDK\MQTTLib.py", line 513, in connect return self._mqtt_core.connect(keepAliveIntervalSecond) File "C:\Users\xxxxx\AppData\Local\Programs\Python\Python39\lib\site-packages\AWSIoTPythonSDK\core\protocol\mqtt_core.py", line 199, in connect raise connectTimeoutException() AWSIoTPythonSDK.exception.AWSIoTExceptions.connectTimeoutException 2-2 モノが所属しているグループにポリシーをアタッチ グループにモノを追加し、そのグループにポリシーをアタッチします。 そして、グループにアタッチしたポリシーによってメッセージの送信ができることを確認します。 今回は第3階層のグループにモノを追加し、ポリシーをアタッチします。 ※グループ / Test / Test2 / Test2-1 / Test2-1-1 のうち、Test2-1にモノを追加し、ポリシーをアタッチ なお、先ほどの手順でモノの証明書からはポリシーがデタッチされている状況を前提としています。 1.IoT Coreのマネジメントコンソールで左のメニューから 管理 > モノのグループ の順にクリック 2.対象グループをクリック ※モノのグループ一覧にはルートグループしか表示されない 3.グループ > 第2階層のグループの順にクリック 4.手順3同様に グループ > 第3階層のグループ(今回モノを追加するグループ)の順にクリック 5.モノ > モノの追加 の順にクリック 6.追加するモノを選択して「モノの追加」をクリック 7.セキュリティ > 編集 の順にクリック 8.アタッチするポリシーを選択して「保存」をクリック ポリシーをアタッチすると以下の通り表示される 9.「2-1 モノの証明書へのポリシーアタッチ」で確認した際と同様にコマンドを実行し、メッセージを送信できることを確認する 2-3 モノが所属しているグループの親グループにポリシーをアタッチ 今度はモノが所属しているグループの親グループ(1階層上)にポリシーをアタッチし、ポリシーが継承されることを確認します。 ※グループ / Test / Test2 / Test2-1 / Test2-1-1 のうち、モノはTest2-1に追加したまま、ポリシーはデタッチ 新たにTest2にポリシーをアタッチ 1.IoT Coreのマネジメントコンソールで左のメニューから 管理 > モノのグループ の順にクリック 2.先ほどポリシーをアタッチしたグループに移動する 3.セキュリティ > 編集 の順にクリック 4.選択しているポリシーの削除をクリックし、「保存」をクリック 5.この時点でいったんコマンドを実行し、メッセージを送信できないことを確認する 6.親グループにポリシーをアタッチする 継承したポリシーが表示されている 7.再度コマンドを実行し、メッセージを送信できることを確認する 2-4 モノが所属しているグループと2階層以上離れた親グループにポリシーをアタッチ 先ほどはモノが所属しているグループの親グループ、つまり、1階層上のグループにポリシーをアタッチしました。 これが2階層以上離れた場合でもポリシーが継承できることを確認します。 手順は同じなので、ここまでの結果とあわせて、以下に確認した結果をまとめました。 2階層以上離れていても親グループからポリシーを継承していることが確認できました。 2-5 AllowとDenyのポリシーが混在する場合 継承したポリシー、所属しているグループのポリシー、モノの証明書にアタッチしたポリシーの間で、AllowとDenyが混在している場合の挙動を確認します。 なお、IAM公式ドキュメントではAllowとDenyについて以下の記述があります。 該当するポリシーに Deny ステートメントが含まれている場合、リクエストは明示的に拒否されます。リクエストに適用されるポリシーに Allow ステートメントと Deny ステートメントが含まれている場合は、Deny ステートメントが Allow ステートメントより優先されます。リクエストは明示的に拒否されます。 引用元:ポリシーの評価論理 手順は今までと同様なので、以下に確認した結果をまとめました。 グループの階層関係、グループか証明書か、ということはいずれも関係なくDenyが優先されました。 ちなみに、Allow/Denyのポリシーが継承によっていずれもアタッチされている場合、グループの画面では以下のように表示されました。 3 おわりに 以上、グループによるポリシー管理を確認しました。 モノが増えてくると、個別にデバイスに証明書アタッチ→証明書にポリシーアタッチの流れは煩雑かつ抜け漏れも起きそうなので、グループを使ってうまく管理できるとよさそうです。
- 投稿日:2021-04-05T17:20:03+09:00
AWS Glueジョブ作成時にハマった
はじめに
エキサイトの坂本です。
今回は初めてGlueを使うので、素直に初心者の感想を書きます。Glueスクリプトなど保存S3バケット変更
Glueジョブ登録の際に自動でS3バケットが作成されます。1つはスクリプト保存バケットともう1つは一時的なデータ保存バケットが作成されます。これは事前にS3バケットを用意して、選択できます。
事前に作成バケット |- スクリプト保存フォルダ |- 一時的データ保存フォルダ最後に以下のポリシー追加します
{ "Version": "2012-10-17", "Statement": [ { "Sid": "{Dev/Prod}ExciteHcAnalysis", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::{dev/prodのaccount-id}:role/excite_glue_iam_role" }, "Action": "*", "Resource": [ "arn:aws:s3:::excite-{dev/prod}-analysis-glue", "arn:aws:s3:::excite-{dev/prod}-analysis-glue/*" ] } ] }データのサイズオーバー
事前にRedshift側にテーブル作成が前提です。
Glueジョブ実行したあと、Redshift側のデータを確認したら、なぜか既存カラムっぽいのカラムが増えていますね。これは従来のカラムにデータが入らないため、Glueが勝手に新しいカラムを追加しています。Redshiftはsmallint型がありますが、Glueジョブの都合でINTになってしまうことで、Redshiftに書き込みの際にサイズオーバーになってしまいます。この場合はsmallintからintに変更すれば、解決です。
コード品質を保つ
Pythonで開発したら、フォーマットツールとして、isort、autopep8、autoflakeを導入したいですね。
これらを使ったら、Glueジョブの注釈ブロックには「##」(2個)から「#」(1個)に変換されます。ジョブ再登録の際にジョブ実行で特にエラーが発生しないが、ダイアグラムが生成されない。以上です。
- 投稿日:2021-04-05T17:20:03+09:00
AWS Glueを使った時にハマったこと
はじめに エキサイトの坂本です。 今回は初めてGlueを使うので、素直に初心者の感想を書きます。 Glueスクリプトなど保存S3バケット変更 Glueジョブ登録の際に自動でS3バケットが作成されます。1つはスクリプト保存バケットともう1つは一時的なデータ保存バケットが作成されます。これは事前にS3バケットを用意して、選択できます。 事前に作成バケット |- スクリプト保存フォルダ |- 一時的データ保存フォルダ 最後に以下のポリシー追加します { "Version": "2012-10-17", "Statement": [ { "Sid": "{Dev/Prod}ExciteHcAnalysis", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::{dev/prodのaccount-id}:role/excite_glue_iam_role" }, "Action": "*", "Resource": [ "arn:aws:s3:::excite-{dev/prod}-analysis-glue", "arn:aws:s3:::excite-{dev/prod}-analysis-glue/*" ] } ] } データのサイズオーバー 事前にRedshift側にテーブル作成が前提です。 Glueジョブ実行したあと、Redshift側のデータを確認したら、なぜか既存カラムっぽいのカラムが増えていますね。これは従来のカラムにデータが入らないため、Glueが勝手に新しいカラムを追加しています。 Redshiftはsmallint型がありますが、Glueジョブの都合でINTになってしまうことで、Redshiftに書き込みの際にサイズオーバーになってしまいます。この場合はsmallintからintに変更すれば、解決です。 コード品質を保つ Pythonで開発したら、フォーマットツールとして、isort、autopep8、autoflakeを導入したいですね。 これらを使ったら、Glueジョブの注釈ブロックには「##」(2個)から「#」(1個)に変換されます。ジョブ再登録の際にジョブ実行で特にエラーが発生しないが、ダイアグラムが生成されない。 以上です。
- 投稿日:2021-04-05T17:19:25+09:00
AWSでWebアプリをデプロイする方法(Java)④
EC2インスタンスの作成 Webサーバーとして使う場合は、S3ではなくEC2インスタンスにApacheをインストールし、Webサーバーとして使います。 利用環境 OS:MacOS ブラウザ:Chrome 前提条件 ユーザーの追加が完了している状態 まだ、ユーザーの追加していない方はこちら EC2ダッシュボードを開いてリージョンを確認する [サービス]メニューまたはホーム画面で「EC2」を検索し、見つかったEC2を選択 右上のリージョンが「東京」となっていることを確認する EC2インスタンスを作成する インスタンスメニューを開く 画面の左側の[インスタンス]を選択 インスタンスを作成する 画面右上部のオレンジ色の[インスタンスを起動]を選択 AMIを選択する 「Amazon Linux 2 AMI 64 ビット (x86)」にチェックを入れ、[選択]を選択 インスタンスタイプを選択する 「t2.micro」にチェックを入れ、[次のステップ:インスタンスの詳細の設定]を選択 VPCトサブネットを選択する 下記のように(デフォルトの状態)入力し、[次のステップ:ストレージの追加]を選択 ストレージの追加 下記のように(デフォルトの状態)入力し、[次のステップ:タグの追加]を選択 タグの追加 EC2インスタンスに任意のタグをつけられます。タグは検索やグループ化するときに使う値です。最低限、「EC2インスタンスの名称」だけは、設定しておく [クリックしてNameタグを追加します]を選択 キーに「Name」、値に「WebAppServer」を入力し、[次のステップ:セキュリティグループの設定]を選択 セキュリティグループの設定 下記のように入力し、[確認と作成]を選択 設定の確認 下記のようになっていれば、[起動]を選択 キーペアの作成 [新しいキーペアの作成]を選択し、キーペア名に「myserverkey」と入力。 [キーペアのダウンロード]を選択 ダウンロードが完了したら、[インスタンスの作成]を選択 インスタンスの起動を確認 インスタンスの作成には数分かかります。 右下の[インスタンスの表示]を選択 下記のようにインスタンスが「実行中」となっていれば成功です AWSでWebアプリをデプロイする方法⑤ SSHで接続する
- 投稿日:2021-04-05T16:46:47+09:00
AWS Glueジョブ作成に関する個人メモ
はじめに
Privateサブネットに配置しているOracleからPublicサブネットに配置している分析用のRedshiftにデータ転送の際に、AWS Glueを使えば非常に便利です。基本的にAWSコンソールからGlueジョブが自動で発行されますが、ニーズに応じて諸々カスタマイズが必要です。
事例
ジョブのパラメータ受け取る
現場でDev環境とLive環境のDB名が違うので、Devで発行したGlueスクリプトはDev環境のDB名が入っていますので、Live環境でGlueジョブ再登録すると、DBを書き換えしたくないですね。その場合は、Glueジョブのパラメータを使えば、解決できます。
例)
... ## @params: [TempDir, JOB_NAME, DATASOURCE_DB_NAME] args = getResolvedOptions( sys.argv, ['TempDir', 'JOB_NAME', 'DATASOURCE_DB_NAME']) # テーブル名 datasource_table_name = f"{args['DATASOURCE_DB_NAME']}_excite_hc_users" ...RedshiftにInsert前にTruncateしたい
datasink5 = glueContext.write_dynamic_frame.from_jdbc_conf( frame=resolvechoice4, catalog_connection="excite-glue-connection-redshift", connection_options={ "preactions": "truncate table users", "dbtable": "users", "database": "excite", }, redshift_tmp_dir=args["TempDir"], transformation_ctx="datasink5" )*注意:connection_optionsはfrom_jdbc_confのみ使えます。詳細はGlueのドキュメントをご確認ください
電話番号のマスキング
Publicサブネットに配置しているRedshiftに個人情報を転送してはいけないですね
import hashlib ... # 電話番号のマスキング処理 def maskPhoneNumber(dynamicRecord): dynamicRecord["number_hash_hex"] = hashlib.md5( dynamicRecord["number_hash_hex"].encode("utf8")).hexdigest() return dynamicRecord ... # 電話番号をマスキング masked_dynamic_frame = Map.apply( frame=applymapping1, f=maskPhoneNumber )1行ずつデータをチェックしたい
def checkifmailaddr(val): return hashlib.md5( val.encode("utf8")).hexdigest() if val else "hoge" ... # Dataframeに変換 df_list = resolvechoice4.toDF().collect() result_list = [] for row in df_list: result_list.append( Row( userid=row['userid'], mailaddr_hash_hex=checkifmailaddr(row['mailaddr_hash_hex']) ) ) df = spark.createDataFrame(result_list) result_data_frame = DynamicFrame.fromDF(df, glueContext, 'result_data_frame') # これでRedshiftに書き込み datasink5 = glueContext.write_dynamic_frame.from_jdbc_conf( frame=result_data_frame, ... )転送対象データを絞り込み
膨大なテーブルで全データを入れ直すと、時間やコストがかかりますので、2日の差分だけ転送したい場面もありますね
# 直近x日だけ取得 JST = datetime.timezone(datetime.timedelta(hours=+9)) today = datetime.datetime.today().astimezone(JST) n_days_ago = today.date() - datetime.timedelta(days=7) n_days_ago_formatted = n_days_ago.strftime('%Y-%m-%d') target_df = datasource0.toDF().where(f"ap_regdate >= '{n_days_ago_formatted}'") datasource0 = DynamicFrame.fromDF(target_df, glueContext, "datasource") # Redshift側に直近x日のデータ削除 preaction_query = f"delete from users where regdate >= TO_DATE('{n_days_ago_formatted}', 'YYYY-MM-DD HH24:MI:SS')" # 次は普通に使えます applymapping1 = ApplyMapping.apply( frame=datasource0, mappings=[ ... ], transformation_ctx="applymapping1" ) # Redshiftにデータ書き込み datasink5 = glueContext.write_dynamic_frame.from_jdbc_conf( frame=resolvechoice4, catalog_connection="excite-glue-connection-redshift", connection_options={ "preactions": preaction_query, "dbtable": "users", "database": "excite", }, redshift_tmp_dir=args["TempDir"], transformation_ctx="datasink5" )以上です
- 投稿日:2021-04-05T16:46:47+09:00
AWS Glueジョブ作成時の備忘録
はじめに エキサイトの坂本です。久しぶり投稿します。 Privateサブネットに配置しているOracleからPublicサブネットに配置している分析用のRedshiftにデータ転送の際に、AWS Glueを使えば非常に便利です。基本的にAWSコンソールからGlueジョブが自動で発行されますが、ニーズに応じて諸々カスタマイズが必要です。 事例 ジョブのパラメータ受け取る 現場でDev環境とLive環境のDB名が違うので、Devで発行したGlueスクリプトはDev環境のDB名が入っていますので、Live環境でGlueジョブ再登録すると、DBを書き換えしたくないですね。その場合は、Glueジョブのパラメータを使えば、解決できます。 例) ... ## @params: [TempDir, JOB_NAME, DATASOURCE_DB_NAME] args = getResolvedOptions( sys.argv, ['TempDir', 'JOB_NAME', 'DATASOURCE_DB_NAME']) # テーブル名 datasource_table_name = f"{args['DATASOURCE_DB_NAME']}_excite_hc_users" ... RedshiftにInsert前にTruncateしたい datasink5 = glueContext.write_dynamic_frame.from_jdbc_conf( frame=resolvechoice4, catalog_connection="excite-glue-connection-redshift", connection_options={ "preactions": "truncate table users", "dbtable": "users", "database": "excite", }, redshift_tmp_dir=args["TempDir"], transformation_ctx="datasink5" ) *注意:connection_optionsはfrom_jdbc_confのみ使えます。詳細はGlueのドキュメントをご確認ください 電話番号のマスキング Publicサブネットに配置しているRedshiftに個人情報を転送してはいけないですね import hashlib ... # 電話番号のマスキング処理 def maskPhoneNumber(dynamicRecord): dynamicRecord["number_hash_hex"] = hashlib.md5( dynamicRecord["number_hash_hex"].encode("utf8")).hexdigest() return dynamicRecord ... # 電話番号をマスキング masked_dynamic_frame = Map.apply( frame=applymapping1, f=maskPhoneNumber ) 1行ずつデータをチェックしたい def checkifmailaddr(val): return hashlib.md5( val.encode("utf8")).hexdigest() if val else "hoge" ... # Dataframeに変換 df_list = resolvechoice4.toDF().collect() result_list = [] for row in df_list: result_list.append( Row( userid=row['userid'], mailaddr_hash_hex=checkifmailaddr(row['mailaddr_hash_hex']) ) ) df = spark.createDataFrame(result_list) result_data_frame = DynamicFrame.fromDF(df, glueContext, 'result_data_frame') # これでRedshiftに書き込み datasink5 = glueContext.write_dynamic_frame.from_jdbc_conf( frame=result_data_frame, ... ) 転送対象データを絞り込み 膨大なテーブルで全データを入れ直すと、時間やコストがかかりますので、2日の差分だけ転送したい場面もありますね # 直近x日だけ取得 JST = datetime.timezone(datetime.timedelta(hours=+9)) today = datetime.datetime.today().astimezone(JST) n_days_ago = today.date() - datetime.timedelta(days=7) n_days_ago_formatted = n_days_ago.strftime('%Y-%m-%d') target_df = datasource0.toDF().where(f"ap_regdate >= '{n_days_ago_formatted}'") datasource0 = DynamicFrame.fromDF(target_df, glueContext, "datasource") # Redshift側に直近x日のデータ削除 preaction_query = f"delete from users where regdate >= TO_DATE('{n_days_ago_formatted}', 'YYYY-MM-DD HH24:MI:SS')" # 次は普通に使えます applymapping1 = ApplyMapping.apply( frame=datasource0, mappings=[ ... ], transformation_ctx="applymapping1" ) # Redshiftにデータ書き込み datasink5 = glueContext.write_dynamic_frame.from_jdbc_conf( frame=resolvechoice4, catalog_connection="excite-glue-connection-redshift", connection_options={ "preactions": preaction_query, "dbtable": "users", "database": "excite", }, redshift_tmp_dir=args["TempDir"], transformation_ctx="datasink5" ) 以上です
- 投稿日:2021-04-05T15:05:50+09:00
Databricks と AWS の VPC ピアリング接続設定
はじめに 今回は異なる AWS アカウント上に立てた RDS と Databricks を、ピアリング接続する方法について紹介したいと思います。 Databricks の下記のドキュメントを参考にしておりますので、詳細については下記リンク先を参照。 ■リンク ・VPC peering 前提条件 ピアリング接続を実施するにあたり、確認すべき項目があります。 少なくとも下記の2つは満たしていないと、VPC の構築からやり直す必要があるので気をつけましょう。 ■ピアリング接続の条件 ・接続する VPC は互いに異なる CIDR 範囲であること ・接続する VPC は同じリージョンにあること 今回ピアリング接続を実施する環境の情報は以下となります。 AWSアカウント情報 Databricks RDS CIDR範囲 リージョン AWSアカウントA あり なし AWSアカウントBと異なる 東京リージョン AWSアカウントB なし あり(Oracle RDS) AWSアカウントAと異なる 東京リージョン 手順1 AWSアカウントA ①Databricks 側のVPCコンソール画面で、左にある「ピアリング接続」をクリック ②「ピアリング接続の作成」をクリック ③必要情報を入力して作成。無事に作成できたら、「ピアリング接続の承認待ち」というステータスになるので、AWSアカウントB側で承認されるのを待つ AWSアカウントB ①VPCコンソールの「ピアリング接続」タブを確認 ②AWSアカウントAよりピアリング接続の承認依頼が来ているので(直ぐに表示されない場合があるので、まだ表示されてなかったら更新などして待つ)、表示されているピアリング接続をクリックし、「アクション」→「承認」と選択 ③AWSアカウントAよりピアリング接続の承認依頼が来たのを確認したら、表示されているピアリング接続をクリックし「アクション」→「承認」と選択 手順2 AWSアカウントA ①VPCダッシュボードの「ピアリング接続」を選択 ②承認されたピアリング接続を選択したら、「アクション」→「DNS編集」を選択 ③「DNS解決を有効」にして保存 AWSアカウントB ①VPC ダッシュボードの「ピアリング接続」を選択 ②承認したピアリング接続を選択したら、「アクション」→「DNS編集」を選択 ③「DNS 解決を有効」にして保存 手順3 AWSアカウントA ①VPC ダッシュボードにある「ルートテーブル」を選択し、該当 VPC のルートテーブルを検索 ②ルートテーブルの「編集」を選択し、ピアリング接続している AWS アカウントB の VPC の CIDR 範囲を「送信先」に入力し、「ターゲット」に作成したピアリングを選択して保存 AWSアカウントB ①VPC ダッシュボードにある「ルートテーブル」を選択し、該当 VPC のルートテーブルを検索 ②ルートテーブルの「編集」を選択し、ピアリング接続している AWS アカウントA の VPC の CIDR 範囲を「送信先」に入力し、「ターゲット」に作成したピアリングを選択して保存 手順4 AWSアカウントA ①VPCダッシュボードで「セキュリティグループ」を選択し、Databricks と連携している VPC の ID で検索をかける ②検索をかけた際、セキュリティグループの説明の部分に「Unmanaged security group 」と記載があるセキュリティグループのIDをコピーして、アカウントB側に情報を提供する AWSアカウントB ①VPCダッシュボードで「セキュリティグループ」を選択し、RDSを構築している VPC の ID で検索をかける ②検索して出てきたセキュリティグループを選択し、「編集」を選択し、「ルールの追加」を選択 ③「タイプ」には「Oracle-RDS」 を選択し、AWSアカウントA側で提供された「Unmanaged security group」の ID を「ソース」に入れて保存 手順5 AWSアカウントA ①Databricks 側でクラスターを用意 ②notebook で下記のコマンドを入力して、疎通を確認 %sh nc -zv <hostname> <port> ・hostname:RDS のエンドポイント ・port:ポート番号(Oracle の場合は1521) おわりに これで、異なる AWS アカウントにある Databricks と RDS ピアリング接続することが可能となりました。
- 投稿日:2021-04-05T14:26:30+09:00
【2021年版】AWS ソリューションアーキテクト - アソシエイト(SAA)合格のための学習方法
先日 AWS ソリューションアーキテクト - アソシエイト(以下、SAA)を取得しましたので、私の学習方法について記載します。 学習開始前の情報収集は重要だと思いますので、これから学習する方にとって、少しでもお役に立てれば幸いです。 ちなみに、点数は 795/990 で、ギリギリでもなく余裕も無いくらいのそこそこの結果でした。 私について 私のざっくりした開発経験です。 WEB エンジニア 2 年目 サーバーサイドがメインでたまにフロントエンドも担う 業務で AWS を触る経験はほとんどない(Cloud Wacth Logs を見たり、Systems Manager からインスタンスに接続する程度) 個人ではハンズオン中心にいくつかの AWS サービスを触ったことがある(EC2, ECS, S3, Cloud Front, Lambda, etc...) 業務で開発しているアプリケーションのインフラが AWS であるため、インフラ についてもしっかり理解したい、と考えたのが AWS SAA 受験の動機でした。 ちなみに、SAA に合格するための学習内容や学習量は学習する前の事前の業務経験によって大きく変わります。 感覚レベルでは、次の順で必要な学習量が増えていくイメージです。私は インフラ業務経験のない WEB エンジニアであるため、必要な学習量は比較的多め(60 時間程度)でした。 # 下にいくほど必要な学習量は多いと予想 インフラエンジニア(クラウドエンジニア) インフラエンジニア(オンプレミス) WEB エンジニア IT 業界未経験者 学習について 学習方針 メインで利用する学習教材は書籍1冊と Udemy の模擬試験に絞りこみ、何周もすることで基礎知識の定着と応用力の獲得を目指しました その他の資料や教材はあくまでもサブと位置づけ、あまり時間は割きませんでした 資格取得を目指す前にハンズオンの経験はあったので、資格勉強としてのハンズオンはしませんでした 学習計画を立てる 所要時間: 3 時間 実際に学習を始める前に、下記の方々の記事を見て、使用する学習教材と必要な学習時間を見積もり、3 週間後の試験日の予約をしました。 AWS 初心者が AWS 認定ソリューションアーキテクト – アソシエイト資格試験に合格した時の勉強法 【22 時間で合格】 SAA-C02 AWS 認定ソリューションアーキテクト-アソシエイト合格 NRTA【多分これが一番早いと思います】 【未経験】【資格】AWS ソリューションアーキテクト(SAA) 合格までの勉強方法(約 50 時間) AWS の主要サービスの概要を知る/知識を深める 所要時間: 15 時間 書籍: AWS 認定アソシエイト 3 資格対策~ソリューションアーキテクト、デベロッパー、SysOps アドミニストレーター~ 学習の始めに、AWS の各サービスの概要を知るするために書籍を 3 時間程度で一通りざっくりと読みました Udemy の模擬試験を通して不正解だった設問を起点として、周辺知識を覚えることで体系立てて記憶しました 試験前日は 6 時間程度で一通り見直しました 大量の問題を解く 所要時間: 30 時間 Udemy: 【SAA-C02 版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6 回分 390 問) 問題を解き解説を読む、理解できなければ書籍で確認する、それでもわからなければAWS サービス別資料やクラスメソッドさんのブログを読むというサイクルを回しました 丁寧に解説を読むと、初回は試験 1 回につき 4 時間程度を要しました 正解の選択肢だけでなく、選択しない選択肢についても理由をつけることで、体系的な知識の獲得を効率的にできるようになりました Udemy の模擬試験は本番試験と同等レベルの内容、かつ本番試験と同様の内容が多くで質がかなり高いです 参考までに私の模擬試験の結果は下記の通りです。私の結果とご自身の結果を比較することで、現時点での合格可能性をある程度予測できるのではないかと思います。 1 回目 2 回目 基本問題の模擬試験 ① 67% 92% 高難易度の模擬試験 ② 46% 70% 高難易度の模擬試験 ③ 56% 83% 高難易度の模擬試験 ④ 44% 80% 高難易度の模擬試験 ⑤ 60% 87% 高難易度の模擬試験 ⑥ 56% - AWS サービス別資料を読む(通称: Black Belt) 所要時間: 3 時間 AWS サービス別資料 苦手かつ頻出な内容(S3, Route53, etc...)についてのみ、PDF や YouTube を見ました 試験の合格という目標を達成する上では復習がしづらい点が難点なので、割く時間は最小限にしました 業務ではかなり役立ちそうなので、今後はさらにお世話になりそうです クラスメソッドさんのブログ 所要時間: 1 時間 クラスメソッドさんのブログ AWSのサービス名でググると上位に表示される記事を中心に読みました 馴染みのないサービスについての記事を多く扱ってくださり、かつ平易な言葉で説明してくださっているので、サービスの概要を理解するのに助かりました AWS WEB 問題集で学習しよう 所要時間: 3 時間 AWS WEB 問題集で学習しよう 合格者の方で利用頻度が多い問題集なので Udemy の模擬試験の前に利用を開始し、有料プランに申し込みましたが、下記の点から利用をやめました。 ちなみに有料の 90 日間のベーシックプランに申し込みました。(4,708 円を支払いました) 1 度解いた問題の正解/不正解を記憶する機能がなく復習がしづらかった 解説が公式ドキュメントをベースにしている点は良い一方で、設問と解説に乖離があるように感じ理解が追いつかなかった 補足: ハンズオンをする SAA の資格取得を目指す前に、いくつかの AWS サービスのハンズオン経験がありました。資格取得を目標とする上では必須ではないですが、業務で利用できることを目指すならばハンズオン経験が役立つと思います。 参考までに、以前私が利用した AWS のハンズオンの資料・教材を記載します。 AWS ハンズオン資料 Amazon Web Services 基礎からのネットワーク&サーバー構築 コンテナ時代の Web サービスの作り方 実践 Terraform AWS におけるシステム設計とベストプラクティス 本番試験についての感想 予想よりかなり難易度が高かったです(Udemy の模擬試験と同等レベル) 明らかに日本語訳がおかしい問題が多く、焦りました(初見ではとりあえず回答し、見直し時に英語を表示して確認しました) 同じような出題と回答の組み合わせが数パターンありました 受験した感想 AWS の知識を体系的に得られてよかったです 業務の AWS インフラの構成について理解できました オンプレミス用のサービスなど、今後自身は使わない可能性の高いサービスの細部を覚えるのは少し辛かったです さいごに お読みいただきありがとうございました。 少しでもいいね、と思っていただいたら「LGTM」していただけると嬉しいです。
- 投稿日:2021-04-05T14:19:42+09:00
AWS Toolkit for VSCodeの設定
AWS Toolkit for VSCodeを入れていたものの、よく見たらちゃんと動いてなかった。 なぜ補完もせずゴリゴリ書いていたのか… なのでちゃんと設定した記録。 インストールが必要なもの VSCode本体、node.js、AWS CLI、AWS CDK、AWS SAM CLI、Docker、あたりは省略。 YAMLエクステンション AWS ToolkitのSAM対応や、CloudFormation用のエクステンションが依存している。 aws-cloudformation-template-schema CloudFormationテンプレートの補完と検証を行える。 VSCodeであれば、下記のCloudFormation Linterを入れればよい。 GitHub Actionsもあるのいいじゃないと思った。手遅れ感あるけど。 CloudFormation Linter E3012エラーはチェックから外してもよさそう。 cfnLint.path に cfn-lint --ignore-checks E3012 と設定。 自分では /usr/local/bin/cfn-lint -r ap-northeast-1 と設定した。 cfn-lint CloudFormation Linterが依存している。 Macなら brew install cfn-lint でインストール。 @aws-amplify/cli が cfn-lint に依存しているので、Amplify CLIをインストールしているとリンクに失敗する。 cfn-lint は cfn-python-lint 使えって言ってるし /usr/local/bin/cfn-lint のリンクを削除して brew link cfn-lint 、か --overwrite を付けて上書きする。 pydot CloudFormation Linterが依存している。 CloudFormation Linterのスタック可視化機能を使いたいならこちらもインストールする。 規約など CloudFormationテンプレート名 公式ドキュメントには、テンプレート名が template.yaml でないと認識しないと書いてある。 実際は template.yml でも認識する場合がある。 ソースコードを見た感じ template.yaml にしておいたほうが全機能で認識してくれそう。 ECSタスク定義ファイル名 サフィックスが ecs-task-def.json でないと認識しない。 my-ecs-task-def.json など。 その他の設定 色々な記事を見ていると yaml.customTags を自分で設定しているものが多い。 CloudFormation Linterのソースコードを見ると、内部で自動的に設定をしている箇所があるので、読み間違えてなければ今どきは何もやらなくていいんじゃないかと思う。
- 投稿日:2021-04-05T14:13:30+09:00
AWS Lambdaの処理を速くする方法
Lambdaの処理が遅いなーと感じた時にLambda側の設定を変えるだけでスピードを上げることができます。 Lambda画面ではCPUの設定項目はありませんが、メモリ容量に比例してCPUの性能が上がる仕様になっています。 (※注意点※ メモリを増量するとその分、料金も高くなるのでその点は予算に合わせて調整してください。) https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/configuration-memory.html 設定はとても簡単です。 マネジメントコンソール画面からスピードアップしたいLamda関数を選択しページを開きます。 [一般設定]->[編集]の順でクリック。 メモリを128MBから増やせして保存すれば、完了です。 メモリの容量に比例してCPUのスペックも上がります。
- 投稿日:2021-04-05T12:19:17+09:00
Lambda関数で「AWS-SDK」をローカル環境でのみ読み込み、本番デプロイでは除外する方法
結論
こうすればいい
cd ~ # グローバルパッケージのインストール先確認 npm root -g # グローバルインストール npm install -g aws-sdk # グローバルパッケージが本当にインストールされたかを確認する npm list -g --depth=0 # ローカルパッケージとして読み込みたいプロジェクトディレクトリに移動する cd ~/environment/myLambdaProjectName # グローバルパッケージとローカルパッケージのシンボリックリンクを作成する npm link aws-sdk # ローカルパッケージとして読み込まれているかを確認する npm list --depth=0あとはこれをZIPファイルにまとめてデプロイするなり、なんなりと
何がしたいか
私が開発したあるプロジェクトは、DynamoDBからレコードを取り出して、
RdsDBにINSERTするという行為をLambda関数で実現するというものでした。本番環境のLambdaは最初からAWS-SDKパッケージが用意されているので、
ローカルパッケージとしてZIPファイルに含める必要はありません。ファイルサイズが増えるだけです。しかし、ローカル環境(Cloud9)にAWS-SDKパッケージがないので、
今まではnpm install aws-sdkして毎回AWS-SDKをローカルインストールして、
本番デプロイ前に手動でaws-sdkディレクトリを削除するという何ともアレな運用をしていました。何か、ローカル環境だけAWS-SDKを読み込ませて、
本番デプロイ時は手動削除しないで良い方法を探したら、上の方法を見つけた次第です。他に良い方法をご存じの方がいましたら、教えてください。
追記
Cloud9環境で、ローカルからLambdaにデプロイする場合は、次の手順で行います
cd ~/environment/myLambdaProjectName zip --symlinks -r hoge.zip .左サイドバー > AWS > AWS: Explorer > Asia Pacific (Tokyo) > Lambda > {myFunctionName}
アップロードしたいLambda関数名を右クリック、Upload Lambda > ZIP Archiveを選択、
先ほどZIP圧縮したファイルを選択して、OKボタンを押すと、デプロイできますうまくいけば、画面右上にちっさく
Successfully uploaded Lambda function {myFunctionName}が表示されます本当にAWS-SDKが除外されてアップロードされているかは、以下の手順で確認できます
- Lambdaコンソール画面に移動
Lambda > 関数 > {myFunctionName} に移動
画面右上、アクション > 関数のエクスポート > デプロイパッケージのダウンロード
ダウンロードしたZIPファイルを開き、node_modulesディレクトリ内にaws-sdkディレクトリがないことを確認する
Upload Lambda > Directory を使うことでもデプロイはできますが、
そちらはシンボリックリンクを辿って、
実ファイルを含んだ状態でアップロードしてしまうので、
ファイルサイズを抑えることができません。
- 投稿日:2021-04-05T11:17:42+09:00
AWS Lambdaで天気予報を毎朝LINEへ通知してみた【Python】
背景
偏頭痛の気配を感じて天気予報を調べたら、案の定、天気は下り坂で、、、なんていうことがあり、自身の健康管理のためにも天気予報を毎朝LINEへ通知してみることにしました。
先人たちの知恵をお借りするなどして解決できたことを、この場をお借りして感謝するとともに、大変恐縮ですが自分のメモとして、こちらへまとめておきます。
開発等
先日、記事とした「AWS Lambdaで列車運行情報を定期的にLINEへ通知してみた【Python】」の天気予報版です。
詳細は、こちらの記事をご参照ください。
実行
- 実行結果
(...気圧も表示できたらなぁ~?)
参考
(編集後記)
(お願い)APIを利用できる情報提供者からは、必ずAPIを使いましょう。
みなさんも様々なアイディアで活用いただけたら幸いです。
会社でのコミュニケーションツールは主が Slack のため、今後は、Slack への通知も試してみます。


- 投稿日:2021-04-05T10:27:41+09:00
それ行けlive patch! Amazon Linux 2で実機検証
はじめに
某ベンダで、クラウドの人材育成企画と研修トレーニングのデリバリを担当しています。
研修準備のためオンプレとクラウドの運用差分を整理していたのですが、Amazon Linux 2でlive patchができる記事を見つけちゃいました。◯ Kernel Live Patching on Amazon Linux 2
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/al2-live-patching.htmlOracle Unbreakable Linuxは、Live Patchができることは知ってたのですが、Amazon Linux 2もできるとのこと。上記の手順を参照に気に実機で検証してみました。
前提条件
以下の環境で試します。
[AMI]
Amazon Linux 2 AMI (HVM),
SSD Volume Type ami-06202e06492f46177 (64-bit x86)[Instance Type]
c5.large設定手順は、
rootユーザ権限を前提にします。
カーネルバージョンは↓です。# uname -r 4.14.209-160.339.amzn2.aarch641. パッケージのインストール
パッケージ
binutils、yum-plugin-kernel-livepatch、kpatch-runtimeを追加します。# yum install binutils # yum install -y yum-plugin-kernel-livepatch # yum kernel-livepatch enable -y Loaded plugins: kernel-livepatch, priorities, update-motd Loaded plugins: priorities, update-motd Trying to run the transaction but nothing to do. Exiting. Complete! kernel-livepatch enable True done # yum install -y kpatch-runtime # yum update kpatch-runtime2. kpatchサービスの設定
systemctlコマンドで、kpatchサービスを設定します。
# systemctl enable kpatch.service # systemctl start kpatch.service # systemctl status kpatch.service3. Amazon Linux 2 Kernel Live Patchingリポジトリの有効化
Kernel Live Patchingリポジトリを有効化します。
# amazon-linux-extras enable livepatch # amazon-linux-extras enable livepatch | grep live 43 livepatch=latest enabled [ =stable ]カーネルパッチリストのアップデート
次は、カーネルパッチリストのアップデートです。
# yum updateinfo list Loaded plugins: extras_suggestions, kernel-livepatch, langpacks, priorities, : update-motd amzn2-core/2/x86_64 | 3.7 kB 00:00 amzn2-core-debuginfo/2/x86_64 | 2.6 kB 00:00 updateinfo list doneCVE(Common Vulnerabilities and Exposures)に関する惰弱性の修正パッチリストを表示します。
# yum updateinfo list cves Loaded plugins: extras_suggestions, kernel-livepatch, langpacks, priorities, : update-motd updateinfo list done #え、、、、何も表示されない。。。何故だ、、、と思って
uname -rでkernelのbuild dateを確認すると、どうもまだ新しいディストリビューションらしい(Mar 22 20:14:50 UTC 2021)。。。そのため、CVEに関する惰弱性の修正パッチが出てないみたいです。(本記事執筆時の21年3月31日時点)# uname -a Linux ip-172-31-25-107.ap-southeast-2.compute.internal 4.14.225-169.362.amzn2.x86_64 #1 SMP Mon Mar 22 20:14:50 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux後はパッチを適用するだけだったのに、、、残念。ここからは、想定手順です。
4. livepatchの適用(未検証)
kernelのバージョンに合わせて、パッチを適用します。
# yum install kernel-livepatch-44.14.209-160.339.amzn2.x86_64パッチが適用されていることを確認します。
# kpatch listまとめ
LivePatch機能を適用して、再起動後にパッチが外れるか適用されたままなのかまで確認したかったのですが、最後まで辿り着けず。。。選択したAMIが新しくて、修正パッチがないため適用まで確認することが出来ませんでした。思えば、10年前まで惰弱性パッチなんてなくて、修正版の適用は、kernelの入れ替えしかありませんでした。まさか商用Unix並の機能が実装されるなんて、夢にも思いませんでした。パッチの適用検証、修正パッチのサポート期限とか、まだまだ気になることがあるので、講義のデリバリまでの宿題とし後日検証してみたいと思います。
- 投稿日:2021-04-05T10:19:00+09:00
「RailsアプリをCircleCI&Capistranoを使ってAWSへ自動デプロイ」でSSHエラーにどハマりした話
はじめに
タイトルの通り、CircleCIでデプロイまでしようとしたところ、SSH周りのエラーに苦戦しました。
その前段である自動テストまではスムーズだったのですが。。
調べてもなかなか同様のケースが見つからなかったため、記事として残しておきたいと思います。なお、基本的な導入手順については、下記の記事を参考にさせていただきました。
環境
・macOS Catalina
・Ruby:2.6.5
・Rails:6.0.3
・MySQL:5.6エラー内容
前述の記事を参考にサクサク実装を進めていたところ、Capistrano deployの箇所で
CicleCIコンソールSSHKit::Runner::ExecuteError: Exception while executing as ********@************ Caused by: Net::SSH::AuthenticationFailed: Authentication failed for user ********@************というエラーが出ました。
内容からしてSSH接続がうまく行っていないのだろうということがわかりました。確認したこと(仮説)
1.CircleCIに追加するSSHに誤りがある?
ローカルで下記コマンドを叩くと正常にデプロイできるため、CircleCI側の設定が怪しい。
% bundle exec cap production deploy→間違いは見当たらず。
2.Return job with SSH
Return job with SSHでCircleCIに入り、設定されている鍵を確認しました。
→'~/.ssh/id_rsa_fingerprintの値'となっている。deployに使用する鍵はpemファイルを指定していたため、ここが怪しいかもと思いました。
なので、
deploy.rbset :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/****.pem']これを
deploy.rbset :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/id_rsa_fingerprintの値']こうしてみました。
そして、再度CircleCIを動かしたところ、無事にデプロイが成功しました!エラー内容(第二弾)
上記で解決したと思い喜んでいたのですが、今度はローカルからのデプロイができなくなりました。
SSHKit::Runner::ExecuteError: Exception while executing as ec2-user@**.***.**.**: Authentication failed for user ec2-user@**.***.**.** Caused by: Net::SSH::AuthenticationFailed: Authentication failed for user ec2-user@**.***.**.**ここで数日間悩みました。
結論
deploy.rbファイルの
set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/〜〜']の箇所を削除し、configファイルに記載することで解決しました。
Host **.***.**.** User ec2-user IdentityFile ~/.ssh/***.pem TCPKeepAlive yes IdentitiesOnly yes参考
・【circleCI】rails5.2/Capistrano/CICD環境によるAWSへの自動デプロイ
・CircleCI に SSH 鍵を登録する
・.ssh/configファイルでSSH接続を管理する
- 投稿日:2021-04-05T10:19:00+09:00
「CircleCI&Capistranoを使ってRailsアプリをAWSへ自動デプロイ」でSSHエラーにどハマりした話
はじめに
タイトルの通り、CircleCIでデプロイまでしようとしたところ、SSH周りのエラーに苦戦しました。
その前段である自動テストまではスムーズだったのですが。。
調べてもなかなか同様のケースが見つからなかったため、記事として残しておきたいと思います。なお、基本的な導入手順については、下記の記事を参考にさせていただきました。
環境
・macOS Catalina
・Ruby:2.6.5
・Rails:6.0.3
・MySQL:5.6エラー内容
前述の記事を参考にサクサク実装を進めていたところ、Capistrano deployの箇所で
CicleCIコンソールSSHKit::Runner::ExecuteError: Exception while executing as ********@************ Caused by: Net::SSH::AuthenticationFailed: Authentication failed for user ********@************というエラーが出ました。
内容からしてSSH接続がうまく行っていないのだろうということがわかりました。確認したこと(仮説)
1.CircleCIに追加するSSHに誤りがある?
ローカルで下記コマンドを叩くと正常にデプロイできるため、CircleCI側の設定が怪しい。
% bundle exec cap production deploy→間違いは見当たらず。
2.Return job with SSH
Return job with SSHでCircleCIに入り、設定されている鍵を確認しました。
→'~/.ssh/id_rsa_fingerprintの値'となっている。deployに使用する鍵はpemファイルを指定していたため、ここが怪しいかもと思いました。
なので、
deploy.rbset :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/****.pem']これを
deploy.rbset :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/id_rsa_fingerprintの値']こうしてみました。
そして、再度CircleCIを動かしたところ、無事にデプロイが成功しました!エラー内容(第二弾)
上記で解決したと思い喜んでいたのですが、今度はローカルからのデプロイができなくなりました。
SSHKit::Runner::ExecuteError: Exception while executing as ec2-user@**.***.**.**: Authentication failed for user ec2-user@**.***.**.** Caused by: Net::SSH::AuthenticationFailed: Authentication failed for user ec2-user@**.***.**.**ここで数日間悩みました。
結論
deploy.rbファイルの
set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/〜〜']の箇所を削除し、configファイルに記載することで解決しました。
Host **.***.**.** User ec2-user IdentityFile ~/.ssh/***.pem TCPKeepAlive yes IdentitiesOnly yes参考
・【circleCI】rails5.2/Capistrano/CICD環境によるAWSへの自動デプロイ
・CircleCI に SSH 鍵を登録する
・.ssh/configファイルでSSH接続を管理する
- 投稿日:2021-04-05T09:58:09+09:00
VMware Cloud on AWS 関連投稿記事のジャンル別まとめ
1. はじめに 「VMware」および「VMware Cloud on AWS」について投稿した記事が溜まってきたのでジャンル別に分けてあらためてご紹介します。 2. ジャンル別記事まとめ 初心者/初学者向け 「VMware」「VMware Cloud on AWS」とはなんぞ?という方向けに投稿した記事です。「VMware」「AWS」などのキーワードを聞いたことがあるもしくは触ったことがある、という方を想定して書いています。 ハンズオンしたい方向け 製品やサービスについてイメージ湧いたけど実際触ってみたいな、という方向けに書いています。特に「VMware HoL」は無償かつインターネットブラウザだけで手軽にできるので非常にオススメです。 私もまずクイックにキャッチアップしたい時によく利用しています。 テーマ/機能/ユースケースごとに確認したい方向け 特定のテーマ、製品の機能やユースケースを想定して書いています。私が普段参照している情報源も参考リンクという形でご紹介しています。 最新アップデートを確認したい方向け 新製品や新機能などのアップデートが公表されたタイミングで書いています。半年後もしくは3ヶ月ぐらいでさらにアップデートがあって陳腐化してるかも、、とは思えどVMwareテクノロジー進化の歴史としてあえて記事は削除せず残しています。 3. さいごに これからも「VMware」「VMware Cloud on AWS」関連の記事を投稿するたびにアップデートしていきます。最近アップデートもハンズオンしていても新たな気付きがなかなか多く、できるだけ噛み砕いた形でご紹介していこうと思います。
- 投稿日:2021-04-05T09:42:17+09:00
AWS IoT Device Defenderの監査と検知を実施してみる
はじめに
AWS IoT Device Defenderはデバイス管理にセキュリティ上の問題がないかの監査、そして、デバイスの動作に異常がないか検知をしてくれるサービスです。公式ドキュメントでは以下の通り紹介されています。
AWS IoT Device Defender は、デバイスの設定の監査、異常動作の検出を目的とした接続デバイスのモニタリング、セキュリティリスクの軽減を行うことができるセキュリティサービスです。また、このサービスでは、AWS IoT デバイスのフリートでセキュリティポリシーを維持し、デバイスが侵害された場合にはすばやく応答することができます。
引用元:AWS IoT Device Defender今回は、AWS IoT Device Defenderの監査と検知をそれぞれ触ってみたので、その手順と結果をまとめます。
1 監査(Audit)
監査ではアカウントやデバイスの設定がセキュリティ上のベストプラクティスに則っているかをチェックしてくれます。
実行は都度実行(オンデマンド監査)とスケジュール実行(スケジュールによる監査)が可能です。1-1 監査を有効化する
まだ監査を使っていない場合は、監査を有効化します。
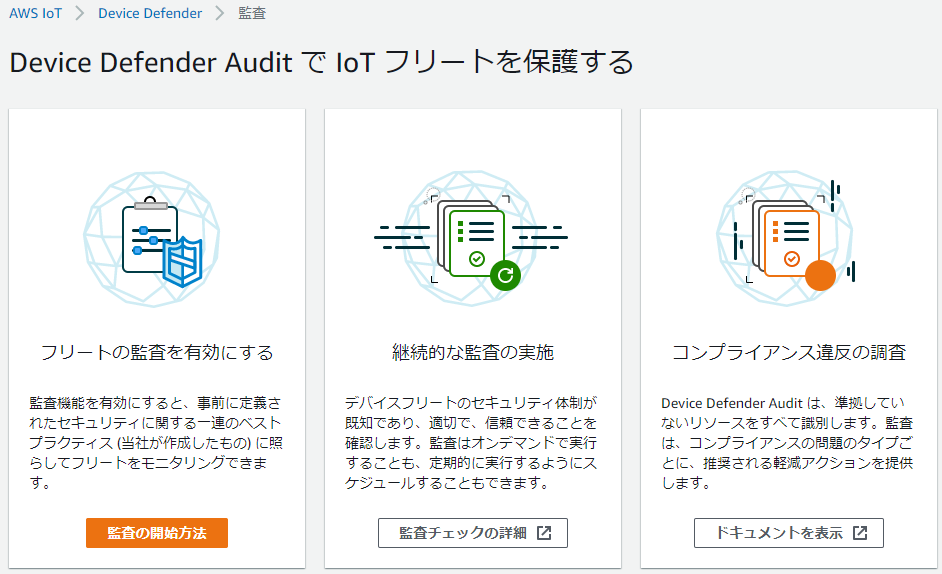
1.AWS IoT Coreのマネジメントコンソールで左のメニューから 防御 > 監査 の順にクリック
2.「監査の開始方法」をクリック
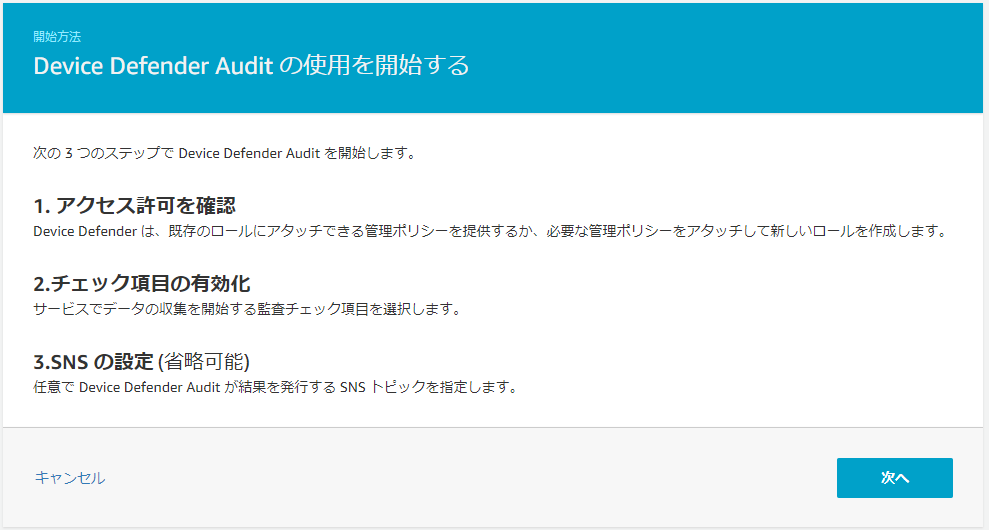
3.「次へ」をクリック
4.監査実行用のロール作成が求められるので、ロールがない場合は「作成」をクリックし、任意の名前をつけてロールを作成する
5.「管理ポリシーがアタッチされています」と表示されたら「次へ」をクリック
※「▶アクセス許可」、「▶信頼関係」をクリックすることで、それぞれで設定が必要な権限を確認できる
6.監査でチェックする項目を選択し、「次へ」をクリック
※チェック名横の「?」をクリックすると、チェック内容の詳細が表示される
7.いったんSNSは「無効」のまま「監査を有効化する」をクリック
8.スケジュールされた監査が作成される
9.ここまでの手順完了後に左メニューの「防御」の下に「設定」、「監査」の下にもいくつかメニューが追加される
1-2 SNS通知の設定
SNSを有効化して非準拠(=監査のチェック要件を満たさないこと)の際に通知が来るようにします。
トピックの作成
1.SNSトピックを作成するため、Amazon SNSのマネージメントコンソールを開き、左のメニューから トピック をクリック
2.「トピックの作成」をクリック
3.以下の通りトピックを作成
- タイプ:スタンダード
- 名前:任意
- その他:※デフォルトとした
4.「サブスクリプションの作成」をクリック
5.宛先情報を以下の通り設定し、「サブスクリプションの作成」をクリック
- トピックARN:※紐づけるSNSトピック。上記手順でこの画面に遷移していれば入力されている
- プロトコル:Eメール
- エンドポイント:※宛先メールアドレス
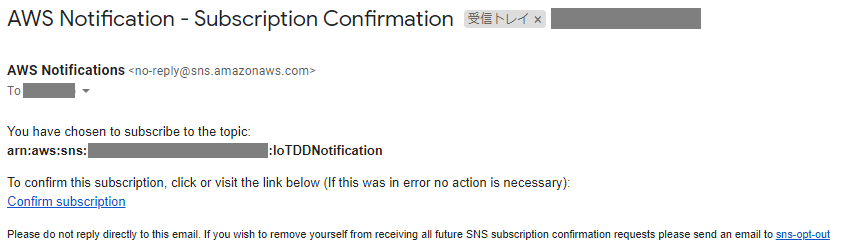
6.AWSから以下のメールが届くので「Confirm subscription」をクリック
7.以下の通り表示される
8.SNSのサブスクリプションが「確認済み」になっていることを確認する
SNS通知用のIAMロール作成
1.IAMのマネジメントコンソールで左のメニューからロール > 「ロールの作成」の順にクリック
2.AWSサービスの IoT > IoT を選択して、「次のステップ:アクセス権限」をクリック
3.「次のステップ:タグ」をクリック
4.「次のステップ:確認」をクリック
5.任意のロール名を入力して、「ロールの作成」をクリック
6.IAMのマネジメントコンソールで左のメニューからポリシー > 「ポリシーの作成」をクリック
7.JSONタブで以下の通り入力し、「次のステップ:タグ」をクリック{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sns:Publish", "Resource": "作成したトピックのARN" } ] }8.「次のステップ:確認」をクリック
9.任意のポリシー名を入力して、「ポリシーの作成」をクリック
10.作成されたポリシーの詳細画面でポリシーの使用状況タブ > アタッチ の順にクリック
11.作成したポリシーを選択して、「アタッチ」をクリックIoT Device Defenderのアラームとしてトピックを設定
1.AWS IoT Coreのマネジメントコンソールに戻り、左のメニューから 防御 > 設定 の順にクリック
2.SNSアラートの「編集」をクリック
3.以下の通り設定し、「更新」する
- 有効
- トピック:※先ほど作成したトピック
- ロール:※先ほど作成したロール
1-3 オンデマンド監査の実行
オンデマンド監査で監査を即時実行し、結果を確認します。
1.AWS IoT Coreのマネジメントコンソールで左のメニューから 防御 > 監査 > 結果 > 作成 の順にクリック
2.今回は簡易に「IoTポリシーが過度に許容されている」のみを選択し、繰り返しを「今すぐ監査を実行(1回)」として「作成」をクリック
3.監査が作成されるので、名前をクリック
4.非準拠となっているチェック項目をクリック
5.非準拠となっている理由と対象が表示される
※対象ポリシーの「コンプライアンス違反」にもこの監査レポートへのリンクが表示される
6.SNSの通知先として指定したアドレスにメッセージが届いていることを確認する
通知内容は以下の通り{"accountId":"xxxxxxxxxxxx","taskId":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx","taskStatus":"COMPLETED","taskType":"ON_DEMAND_AUDIT_TASK","failedChecksCount":0,"canceledChecksCount":0,"nonCompliantChecksCount":1,"compliantChecksCount":0,"totalChecksCount":1,"taskStartTime":1617271927087,"auditDetails":[{"checkName":"IOT_POLICY_OVERLY_PERMISSIVE_CHECK","checkRunStatus":"COMPLETED_NON_COMPLIANT","nonCompliantResourcesCount":4,"totalResourcesCount":4,"suppressedNonCompliantResourceCount":0}]}1-4 監査結果の抑制(サプレッション)
監査結果の抑制を使うことで、テストデバイスや破損しているデバイスなど、監査の際に非準拠となることが想定済みのデバイスをレポートに含めないようにすることができます。
参考:結果のサプレッションの監査抑制を作成
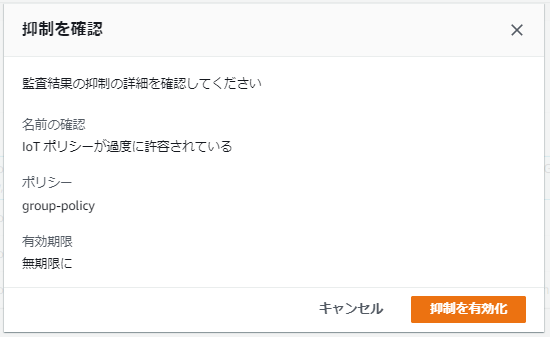
今回は「IoTポリシーが過度に許容されている」の監査時にポリシー「group-policy」の結果を無期限で抑制します。
※事前に安全性 > ポリシー > 対象のポリシー でポリシーARNを控えておく1.AWS IoT Coreのマネジメントコンソールで左のメニューから 防御 > 監査 > 検索結果の抑制 の順にクリック
2.「作成」をクリック
3.以下の通り選択し、「作成」をクリック
- 監査チェック:IoTポリシーが過度に許容されている
- リソースID:group-policy ※対象のポリシー名
- ポリシーバージョンID:1 ※対象とするポリシーのバージョン
- 抑制期間:無期限に
- 説明:※任意
4.監査結果の抑制の一覧に作成した抑制が表示される
抑制した結果を確認する
1.再度、「1-3 オンデマンド監査の実行」の通りにオンデマンド監査を行う
2.監査結果を確認すると、抑制したポリシーは非準拠に含まれず、「抑制された結果」として表示される
また、通知内容にも抑制された結果が存在することが表示される
※suppressedNonCompliantResourceCountに含まれる{"accountId":"xxxxxxxxxxxx","taskId":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx","taskStatus":"COMPLETED","taskType":"ON_DEMAND_AUDIT_TASK","failedChecksCount":0,"canceledChecksCount":0,"nonCompliantChecksCount":1,"compliantChecksCount":0,"totalChecksCount":1,"taskStartTime":1617328519278,"auditDetails":[{"checkName":"IOT_POLICY_OVERLY_PERMISSIVE_CHECK","checkRunStatus":"COMPLETED_NON_COMPLIANT","nonCompliantResourcesCount":3,"totalResourcesCount":4,"suppressedNonCompliantResourceCount":1}]}抑制の変更
1.AWS IoT Coreのマネジメントコンソールで左のメニューから 防御 > 監査 > 検索結果の抑制 の順にクリック
2.対象の抑制を選択して アクション > 編集 の順にクリック
3.抑制期間を変更して「保存」をクリック
抑制の削除
1.AWS IoT Coreのマネジメントコンソールで左のメニューから 防御 > 監査 > 検索結果の抑制 の順にクリック
2.対象の抑制を選択して アクション > 削除 の順にクリック
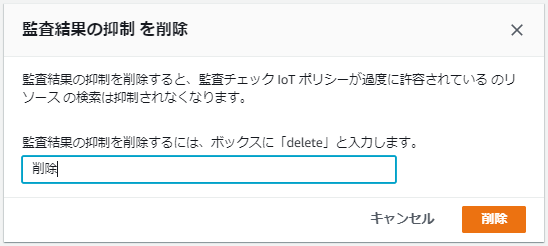
3.「削除」と入力して「削除」をクリック
※モーダルの説明文は「delete」となっているが、入力欄のplaceholderの通り「削除」と入力するのが正しい
結果から抑制を作成
1.AWS IoT Coreのマネジメントコンソールで左のメニューから 防御 > 監査 > 結果 > 対象の結果 の順にクリック
2.非準拠となっているチェック項目をクリック
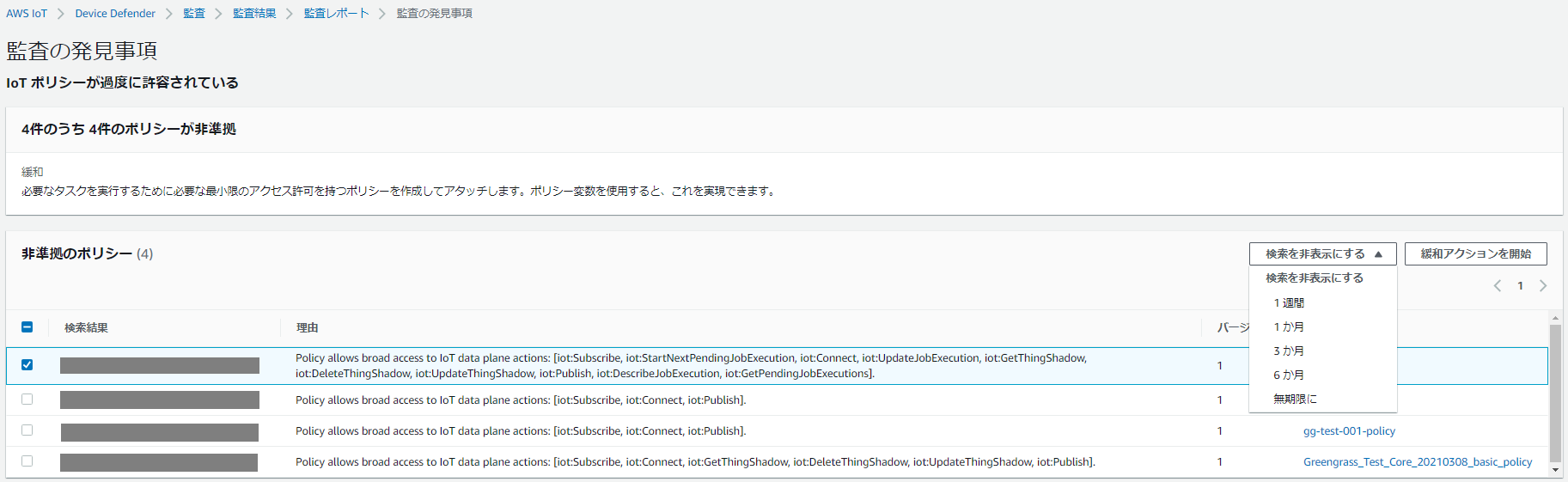
3.抑制したい対象をチェックして 検索を非表示にする > 非表示期間 をクリック
4.内容を確認して「抑制を有効化」をクリック
5.AWS IoT Coreのマネジメントコンソールで左のメニューから 防御 > 監査 > 検索結果の抑制 の順にクリックすると、作成した抑制が表示される
2 検知(Detect)
検知では、セキュリティプロファイルで定義した動作をデバイス、グループに割り当てることで、異常を検出することができます。
2-1 セキュリティプロファイルの作成
1.AWS IoT Coreのマネジメントコンソールで左のメニューから 防御 > 検出 > セキュリティプロファイル の順にクリック
2.セキュリティプロファイルを作成 > ルールに基づいた異常検出プロファイル作成 をクリック
3.今回は以下の通りセキュリティプロファイルを設定し、「次へ」をクリック
- 名前:※任意の名前
- メトリクス:送信されたメッセージ
- タイプをチェック:絶対値
- 演算子:未満
- 値:180
- 期間:5分
- アラームへのデータポイント:1 ※デフォルト
- クリアするデータポイント:1 ※デフォルト
メトリクスの「送信されたメッセージ」は、一定期間内にデバイスから送信されたメッセージを検出対象とする。
上記の場合、5分間に180以上のメッセージが送信された場合はアラームが発生する。
参考:クラウド側メトリクスまた、アラームへのデータポイント、クリアするデータポイントはいずれも、アラームの発生・クリアまでの評価回数を示している。
例えば上記の場合、アラームへのデータポイントが1であれば、1度の違反でアラームが発生する。
参考:Behaviors※今回は指定していないが、オプションのディメンションを設定することで特定のトピックのみを検出対象にできる
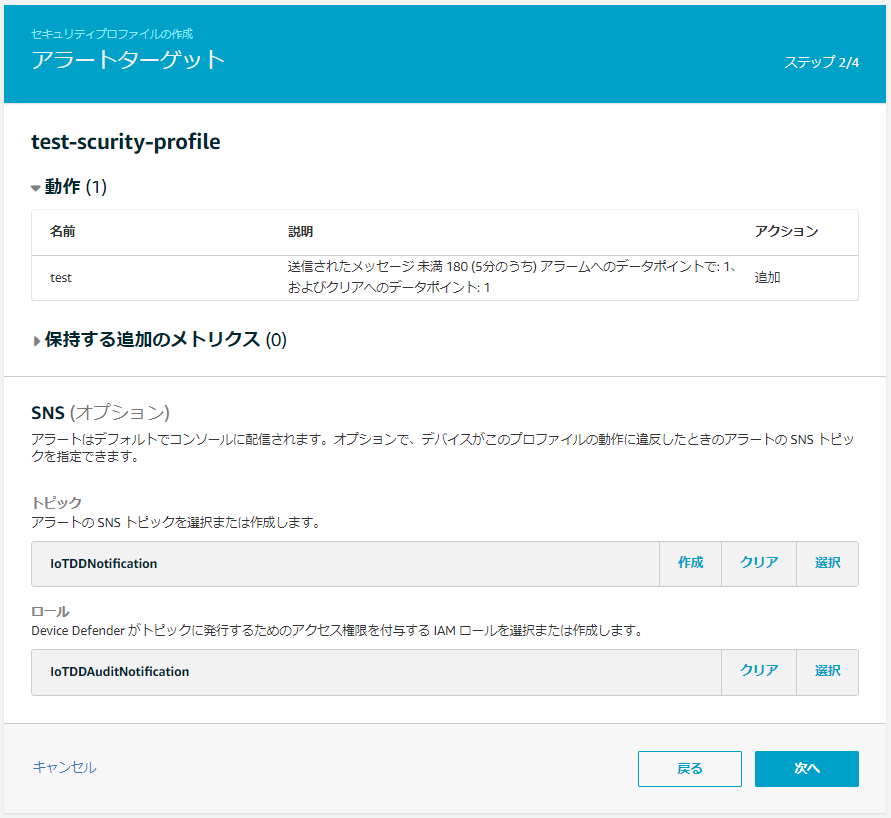
4.アラートのターゲットを設定して「次へ」をクリック
※今回は「1-2 SNS通知の設定」で作成したものを流用する
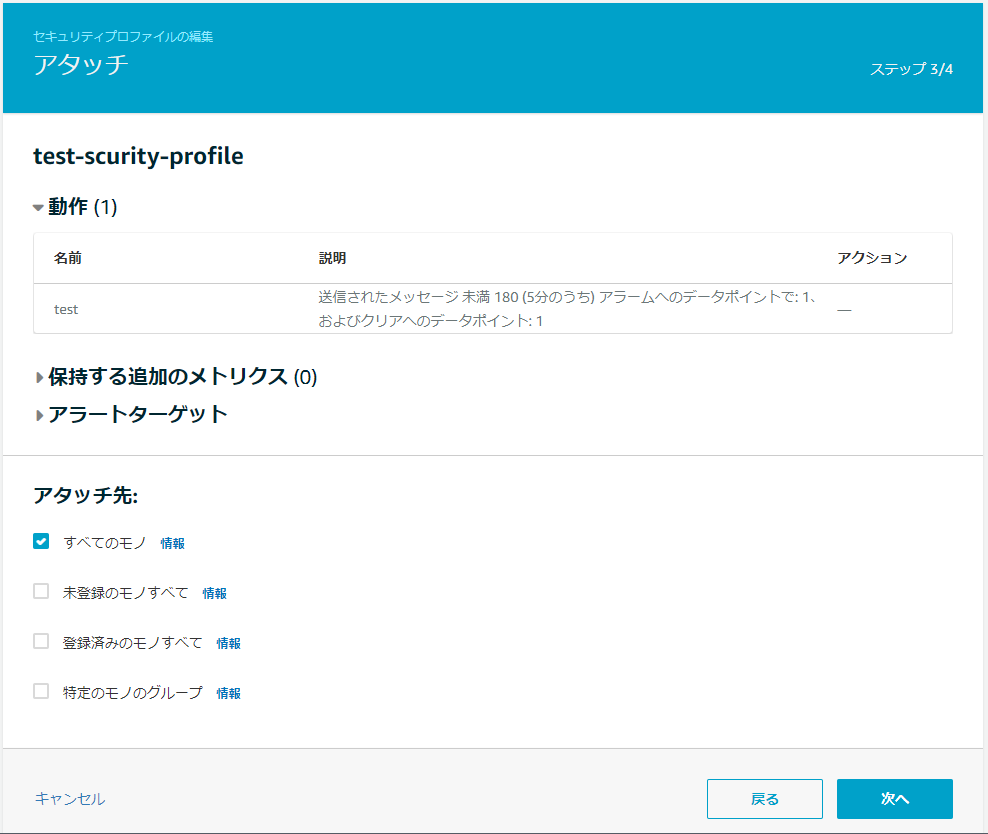
5.アタッチ先を指定して「次へ」をクリック
6.内容を確認して「保存」をクリック
7.「保存」が「続行」に変わるので再度クリックし、セキュリティプロファイルが作成されたことを確認する
2-2 動作確認とその結果
AWS IoT Device SDK for Pythonの
basicPubSub.pyを利用して検出が働くことを確認します。
basicPubSub.pyの利用に関しては以下の記事をご参照ください。
参考:AWS IoT Device SDK for Pythonを使ってRaspberryPiとAWS IoTをつないでみる1.
basicPubSub.pyを実行する
※毎秒メッセージを送り続ける(=5分間で300のメッセージのため、先ほど作成したセキュリティプロファイルのルールに違反)python basicPubSub.py --endpoint [エンドポイントのURL] --rootCA [ルート証明書] --cert [デバイス証明書] --key [秘密鍵]2.数分後、IoT Coreのマネジメントコンソールで左のメニューから 防御 > 検出 > アラーム の順にクリック
3.以下の通り、違反の検出と検出内容が表示される
4.以下の通り、通知が届くことも確認する
{"violationEventTime":1617578700000,"thingName":"basicPubSub","behavior":{"criteria":{"consecutiveDatapointsToClear":1,"value":{"count":180},"durationSeconds":300,"consecutiveDatapointsToAlarm":1,"comparisonOperator":"less-than"},"name":"test","metric":"aws:num-messages-sent"},"violationEventType":"in-alarm","metricValue":{"count":261},"violationId":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx","securityProfileName":"test-scurity-profile"}5.
basicPubSub.pyをCtrl + Cで停止する
6.数分後、手順3で確認したアラームがクリアされる
7.あわせて、以下の通りアラームがクリアされたことが通知される
{"violationEventTime":1617579600000,"thingName":"basicPubSub","behavior":{"criteria":{"consecutiveDatapointsToClear":1,"value":{"count":180},"durationSeconds":300,"consecutiveDatapointsToAlarm":1,"comparisonOperator":"less-than"},"name":"test","metric":"aws:num-messages-sent"},"violationEventType":"alarm-cleared","metricValue":{"count":8},"violationId":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx","securityProfileName":"test-scurity-profile"}3 軽減アクション
監査、検出で発生したアラームに対するアクションを作成・実行することができます。
今回は監査の結果、「IoT ポリシーが過度に許容されている」でアラームが出たポリシーを非有効化するアクションを作成、実行します。3-1 軽減アクションの作成
1.IoT Coreのマネジメントコンソールで左のメニューから 防御 > 軽減アクション の順にクリック
2.「作成」をクリック
3.以下の通り設定
※監査結果毎、また、検知によって実行可能な軽減アクションが異なるので注意
参考:緩和アクション
- アクション名:※任意のアクション名
- アクションタイプ:デフォルトのポリシーバージョンを置き換え(軽減の監査のみ)
- パラメータ:空白のポリシー
4.アクションタイプ選択後、ロールの作成 をクリックし軽減アクション用のロールを作成する
5.以下の通り設定したら、「保存」をクリック
3-2 軽減アクションの実行
「1-3 オンデマンド監査の実行」での結果を利用して、軽減アクションの動きを確認します。
1.IoT Coreのマネジメントコンソールで左のメニューから 防御 > 監査 > 結果 の順にクリック
2.対象の監査結果名をクリック
3.非準拠のチェックで「IoT ポリシーが過度に許容されている」をクリック
4.軽減アクションの対象とするポリシーを選択して、「緩和アクションを開始」をクリック
5.任意のタスク名を入力し、先ほど作成した軽減アクションを選択して「確認」をクリック
6.アクションタスクが作成され、成功することを確認する
3-3 軽減アクションの結果確認
軽減アクションの実行結果を確認します。
手順4からは、対象にしたポリシーが軽減アクションの結果、空白のポリシーとなっていることを確認します。1.IoT Coreのマネジメントコンソールで左のメニューから 防御 > 監査 > アクションタスク の順にクリック
※検知結果に対して軽減アクションを実行した場合は、防御 > 検知 > アクションタスク の順
2.対象のアクションタスク名をクリック
3.以下の通り、実行結果が確認できる
※「表示」をクリックすると実行の履歴が確認できる
4.IoT Coreのマネジメントコンソールで左のメニューから 安全性 > ポリシー の順にクリック
5.軽減アクションの実行対象にしたポリシー名をクリック
6.以下の通り、すべてのアクションが拒否されるポリシーに変わっていることが確認できる
置換後のポリシー{ "Id": "CreateBy-AWSIoTDeviceDefenderAudit.REPLACE_DEFAULT_POLICY_VERSION.BLANK_POLICY", "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "iot:NonExistentOperation", "Resource": "*" } ] }なお、軽減アクションが「デフォルトのポリシーバージョンを置き換え(軽減の監査のみ)」である通り、バージョンタブを見ると以前のポリシーがバージョン1として残っている
デフォルトにすることで、軽減アクション実行前のポリシーを利用することができる
4 おわりに
以上、IoT Device Defenderの監査と検知を試してみました。
いずれも膨大なデバイスを管理するうえでは役立つと思います。5 参考文献(文中で登場していないもの)




































- 投稿日:2021-04-05T09:09:33+09:00
QuickSIghtでどのデータセットの容量が大きいかを知る方法
QuickSightのSPICEデータベースの容量、
どのデータセットが多く使っているのかを知りたいのですが、
画面上ではそれを知る方法がありません。pythonのAWSSDK(boto3)にQuickSightのAPIがあるので、これらを使えばできそうです。
- list_data_sets : データセット一覧取得
- describe_data_set : データセットの詳細取得(データサイズをここから取得)
- describe_data_set_permissions : データセットへの権限を取得(削除権限保有者を判別)
概要
Lambdaでコマンドをたたき、ログ上に容量の大きいデータセットTop10を表示するようにします。
ランタイムはPython3.8を使います。
タイムアウトは処理時間に応じて数分程度に伸ばしてセットします。
Lambdaのロールには上記のAPIを呼べるような権限をセットします。pandasを使うので、Klayersを使ってレイヤにpandasを登録します。
参考:AWS LambdaでPython外部ライブラリのLayerを作る前にLambda
以下のようなLambdaを作成し、TESTなどで実行すると、ログにTop10が表示されます。
spice_checkerimport logging import re import boto3 import pandas as pd from botocore.exceptions import ClientError logger = logging.getLogger() logger.setLevel(logging.INFO) AWS_ACCOUNT_ID = '~AWSのアカウントID~' client = boto3.client('quicksight') def lambda_handler(event, context): # データセット一覧を取得 df_data_set = list_data_sets() # データサイズ、所有者を追加 df_data_set = describe_data_set(df_data_set) # 見栄えを整えてログ表示 return show_data_sets(df_data_set) # データセット一覧取得 def list_data_sets(): df = pd.DataFrame(index = [], columns = ['Dataset_Id', 'Name', 'Created_Time', 'Last_Updated_Time', 'Import_Mode', 'Author', 'Spice_Bytes', 'Status']) response = client.list_data_sets(AwsAccountId = AWS_ACCOUNT_ID) data_sets = response['DataSetSummaries'] for data_set in data_sets: dataset_id = data_set['DataSetId'] name = data_set['Name'] # 時間関連はUTCなのでJSTに変換してから取り込む created_time = pd.to_datetime(data_set['CreatedTime'], utc=True).tz_convert('Asia/Tokyo') last_updated_time = pd.to_datetime(data_set['LastUpdatedTime'], utc=True).tz_convert('Asia/Tokyo') import_mode = data_set['ImportMode'] ds = pd.Series([dataset_id, name, created_time, last_updated_time, import_mode, '', 0, False], index=df.columns) df = df.append(ds, ignore_index=True) return df # 指定されたデータセットの詳細情報(サイズ、所有者)を取得 def describe_data_set(df_data_set): for index, row in df_data_set.iterrows(): spice_bytes = 0 dataset_id = row['Dataset_Id'] try: # 詳細情報取得 response = client.describe_data_set( AwsAccountId = AWS_ACCOUNT_ID, DataSetId = dataset_id ) ds = response['DataSet'] df_data_set.at[index, 'Spice_Bytes'] = ds['ConsumedSpiceCapacityInBytes'] df_data_set.at[index, 'Status'] = True # サイズ取得成功かどうかの判別用 except ClientError as e: # データセットによってはInvalidParameterValueExceptionが発生する if e.response['Error']['Code'] == 'InvalidParameterValueException': logger.info(row) logger.error(type(e)) else: raise e # 所有者取得 df_data_set.at[index, 'Author'] = get_author(dataset_id) return df_data_set # 所有者を返す。複数の場合はカンマ区切り def get_author(dataset_id): # 所有者の判定方法がわからなかったのでdelete権限を持っているユーザを返すようにしているので注意 author_list = [] response = client.describe_data_set_permissions( AwsAccountId = AWS_ACCOUNT_ID, DataSetId = dataset_id ) permissions = response['Permissions'] if len(permissions) == 0: loccer.info('権限保有者なし') return "" for permission in permissions: if 'quicksight:DeleteDataSet' in permission['Actions']: # ARN文字列からユーザ名を取り出す author = re.sub(r'arn:aws:quicksight:.*:.*:user\/.*\/(.*)', r'\1', permission['Principal']) author_list.append(author) return ",".join(author_list) # サイズの大きいデータセット順にログ表示 def show_data_sets(df_data_set): # ログ出力の見た目を整える pd.set_option('display.max_columns', 100) pd.set_option("display.width", 200) pd.set_option('display.unicode.east_asian_width', True) df_data_set = df_data_set.sort_values('Spice_Bytes', ascending=False) # 表示用の列を追加 view_column = ['Name', 'Created_YMD', 'Last_Update_YMD', 'Author', 'Spice_MBytes'] df_data_set['Created_YMD'] = df_data_set['Created_Time'].dt.strftime('%Y/%m/%d') df_data_set['Last_Update_YMD'] = df_data_set['Last_Updated_Time'].dt.strftime('%Y/%m/%d') df_data_set['Spice_MBytes'] = (df_data_set['Spice_Bytes'] / 1024 / 1024).astype(int) # 結果をログに出力 print("---------------------------------") print("サイズが大きいdata setのTop 10") print("---------------------------------") print(df_data_set[view_column].head(10)) print("---------------------------------") # 将来的にはAPI的に使えるようにデータを返しておく return df_data_set.to_json(orient='records', force_ascii=False)注意点
InvalidParameterValueException
describe_data_set のapiを呼んだ時にデータセットによっては InvalidParameterValueException のエラーが発生します。
どういうデータセットだとこのエラーになってしまうのかはよくわかっていません。
ご存知の方はお知らせいただければ幸いです。このエラーが発生したときはexceptして0byteとして計上していますので、ご注意ください。
作成者の判定
データセットの作成者の判定方法がわかっていません。
よって describe_data_set_permissions のAPIで削除権限を持っている人を作成者として判定しています。
QuickSightの管理者画面では所有者を表示できているので
何らかの方法で取れそうなものなのですが、、、
- 投稿日:2021-04-05T07:32:02+09:00
未経験入社3ヶ月でAWSソリューションアーキテクトアソシエイト(SAA)に合格できた内情を記します
2021年1月に未経験でIoTエンジニアとして転職し、Ruby、Ruby on Rails、JavaScriptなどの学習や社内IoTシステムの開発を行う傍ら、並行してAWSの勉強をしていて、3月末、入社研修最終日にAWS認定ソリューションアーキテクトアソシエイト(SAA)に合格できました。
学習を振り返り、皆さんの参考にもなればと思いメモを残します。
1. 自分の素性
2021年1月に36才で未経験エンジニアとして福岡のIT企業、株式会社Fusicに入社しました。どちらかというと文系な人間です。
ここに紙面を割いているとアレなので、「もっと詳しく!」という奇特な方には拙著note「36歳未経験者がIoTエンジニアに内定しました」に替えさせていただきます。2. 合格までの道のり
2-1. 日記
- 1/4 入社
- 1/14 AWS SAA試験合格を個人目標のストレッチターゲットとして与えられる
- 1/18 社内でオススメ参考書、勉強法を尋ねる
- 1/20 「AWSのしくみと技術がしっかりわかる教科書」読み始める。頭に入ってこない(笑)
- 1/26 「AWS認定資格試験テキスト AWS認定ソリューションアーキテクト - アソシエイト 改訂第2版」を読み始める
- 1/27 参考書を頭から読むのが苦手なタイプなので、とりま同参考書の模試(45問)を受ける。正答率20%。解説も頭に入ってこない。
- 2/9 Udemy「これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)」始める。わかりやすい!入ってくる!
- 3/15 これより毎朝晩、会社の先輩にAWS質問攻撃を開始する。目から鱗解説連発。
- 3/18 Udemy「【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)」始める
- 3/31 本試験合格
AWSの概要を知るところから入り、勉強法に迷いつつ、とりま無勉の状態で参考書の模試を受け、解説を読んでも良く頭に入ってこないため、Udemyのハンズオン学習に切り替えました。このUdemyのハンズオン講座受講から道が開けてきた感じがあります。
後半はひたすら模擬試験と向き合いました。
3. 教材
色々教材があるので特に学習開始当初は迷いましたし、途中色々手を出しては捨てたものもありました。そこそこ試行錯誤しました。
以下、結局選択してやり込んだもの、役に立ったと思うものをリストアップしていきます。
3-1. Udemy これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
もうなんと言ってもコレです。僕はこの教材を激しくイチオシします。
理由は下記です。
- ハンズオンで実際にAWS各サービスを触ることができる。
- 各サービスの概要、詳細を教えてくれる:時折細かすぎる?と思いますが、実務にも役立つし、不足しているより過剰な方が助かるので問題なし。
- そもそものネットワークやWebなどAWS以前の基本知識から丁寧に教えてくれる(サブネットとは何か、)→これが結構すごくて難しい概念でもそんじょそこらの参考書よりわかりやすく解説されています。
- ボリュームがすごい。
- 「テンプラ化」「プロビニョニング」など講師がしょっちゅう甘噛みするので、都度和む。
- 基本的に誠実そうな講師が時折「ここじゃねえのかよ」「全然意味ねーじゃねぇか」など人間らしい側面を見せるので、都度和む。
コンテンツのボリューム、質を考えるとコスパが恐ろしく良すぎると思います。作るの相当大変だったと思いますが、これのおかげで効率的に勉強できました。実務にも相当役立つので、合格後も適宜見直したい教材です。
もう一度知識ゼロから勉強するなら、とっととこの教材から始めます。
これと同シリーズの模擬試験6問の講座も1周しました。
ちなみに、得点は49%-69%の間で、一度も合格点を取ることはできませんでした。3-2. 参考書 AWS認定資格試験テキスト AWS認定ソリューションアーキテクト - アソシエイト 改訂第2版
基礎がまとまっていていい感じです。また、模擬試験45問の他に、各章末に問題集があっていい感じでした。
ただ情報量としては十分ではないので、自分はたくさん書き込みました。
3-3. その他
- AWS公式 Blackbeltシリーズ(YouTube)
- YouTubeチャンネル:くろかわこうへい【渋谷で働いてたクラウドエンジニアTV】→なかなかわかりやすくてオススメ
他にもAWS公式のホワイトペーパーやハンズオンなども触りましたが、即やめました。
4. 勉強法
この章では、自分が学習の定着のためにした工夫をば。
4-1. Google Slideでお絵かき
ある時、「AWSが難しいとされるのは、イメージがなかなかしづらいからだ」との仮説に至りました。
絵がなくても「昔々あるところにおじいさんとお婆さんがいました。おじいさんは山に芝刈りに...」という文章を難解だと感じないのは、僕がおじいさんやお婆さん、山のサンプルをいくつも目で見たことがあるからです。
なので、ひたすらアーキテクチャや概念を絵に起こしていくことにしました。ノートにペンで描くことも考えましたが、検索性と展開性、共有性を考えてGoogle Slideを選択しました。
あれやこれやとメモしていき、最終的に受験前には262ページものボリュームになりました(笑)
途中「おれ、やりすぎか?」と疑心暗鬼になりましたが、やって本当に良かったと思っています。これのおかげで問題に対面するときも、頭で問題文のアーキテクチャをイメージがしやすくなったからです。
人が何かを記憶するときは場所と共に覚えていると聞いたことがあり、実感としてもそうで、あ、この問題は「あのページにあったパターンだ!」とパターン認識するのに大いに役立ったと思います。
ちなみに、AWSがオフィシャルにお絵かき用のアイコンや枠線を用意してくれているので、ノートテイキングが捗りました。→AWS アーキテクチャアイコン
当初Google imageしてしまっていまして、間違えて旧アイコンを使ったりしてしまっていました。4-2. standfmでアウトプット
standfmというラジオ配信アプリで、学んだことを自分の言葉で喋ってアウトプットするようにしました。いい感じに頭が整理され、記憶が曖昧な箇所も明らかになり、大変有用でございました。
参考に私のチャンネル貼っておきます。
4-3. 超強力な講師陣への質問攻撃
弊社、株式会社Fusicの先輩エンジニア(@yuuu @yukabeoka @Junkins @Kta-M)が毎日のように、僕の質問を受けてくれました。主に、練習問題の解説に納得がいかないものを教えてもらいました。先輩たちは無論合格者で、プロフェッショナルレベルの資格なども複数所有しており、尚且つAWSの実務経験が豊富にあるので最強でした。毎回、「あーなるほど、そういうことか!」という難問解決のカタルシスがヤバかったです。
何度聞いても「ググれカス」と返されることはなく、「どんどん聞いてね!(`・ω・´)キリッ」というスタンスが崩れなくてエモでした。
5. 問題を解くコツ
5-1. 各問題の要件をメモする
当日、試験会場では紙を2枚渡されました。皆さんはこの紙何に使いますか?
僕は各問題で求められている要件を明確にするためにメモするのに使いました。というのも模擬試験の回数をこなす中で自分のある失点パターンに気づいたからです。それは選択肢Aは言っていることは正しいが、要件を満たすには選択肢Bの方がより最適というものです。
そのため、
問1 コスト
問2 可用性 手間のかからない
問3 最も高セキュリティ
と言った具合でメモしました。また、2つ回答すべき問題には「2」とメモすることで、回答に漏れがないようにしました。
6. 最後に
特にありません!
あ、試験直前はそこそこ人間性を捧げました。


- 投稿日:2021-04-05T06:28:18+09:00
現役インフラエンジニアが感じたAWS SAA取得に必要なこと
現役インフラエンジニアの私がAWSの「ソリューションアーキテクト – アソシエイト」を取得してみたので、合格するまでの体験記を書いてみたいと思います。
前提と結果サマリ
- AWS実務経験は1年
- 学習時間は約20時間(10日)
- 学習教材はUdemy模擬試験と対策本(オレンジ本)
- スコアは751点
なぜ取得しようと思ったのか
私は普段、インフラエンジニアとしてAzureやAWSといった「クラウド」に関する仕事をしています。中でもAWSは市場のシェアが大きく需要もあるため、AWSの認定資格はとても人気がありますね。
私の場合、AWS実務経験が1年でまだまだ経験が浅く、パラメータ通りに構築するのは容易ですが、一から設計するための視点や知識が欠けています。また、サービス名は知っていても「なんとなく」で終わらせていて実際の機能や使い方を知らないものもいくつかありました。(特に管理系サービス)
なので、SAA試験の学習をすることで、サービスに関する基礎知識、設計の観点を体系的に学べると思い、取得することにしました。過去の経験からも「体系的に学ぶ」という意味で、資格教材は最適だと感じています。
学習教材
AWS認定資格試験テキスト AWS認定ソリューションアーキテクト - アソシエイト 改訂第2版
通称「オレンジ本」
最初にこれをざっと読みつつ、要点を自分ノート(Notion)にまとめました。
説明と図解がわかりやすく、要点をおさえるにはピッタリでした。
巻末の問題は解きませんでした。Udemy 【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
やっぱり問題を解かないと頭に入らないので、Udemyの模擬試験6回分を1週だけ解きました。これが、良くも悪くも「問題文」を読み解くのが難しく、試験に受かるための学習感が少し強いと感じました。(後述しますが、試験対策として問題文に慣れておくことが大事)
基本問題の模擬試験①:78% 合格 高難易度の模擬試験②:60% 不合格 高難易度の模擬試験③:66% 不合格 高難易度の模擬試験④:66% 不合格 高難易度の模擬試験⑤:66% 不合格 高難易度の模擬試験⑥:73% 合格66%の壁に泣きそうになりましたが、高難易度って書いてあるだけあって本番試験よりかなり難しいです。マニアックな問題も含まれていますので、Udemyの模擬試験で合格取れるようになれば、まず受かるんじゃないかと思います。
その他
教材を読んでもよくわからない部分は
- DevelopersIOのブログ記事
- AWS サービス別資料(BlackBelt
)
の2つで理解を深めました。
特に、クラスメソッドさんのDevelopersIOは神ですね。普段からお世話になってます。よくわからんサービス、機能なんかをキーワード検索すると、だいたいブログ記事で公開されています。あと、もちろん適宜AWSコンソールで実際に手を動かして確認もしました。サーバレス系はまだあまり馴染みがないのでサラッと見た程度です。Route53のメニューは何度も見ているはずなのに「トラフィックフロー」とか全然知らんかったし。恥
受験してみた感想
思ったより難しかったです。
試験時間は140分ですが、40分残して終了しました。やっぱり、本番独特の緊張感もあり、めちゃくちゃ慎重になるので予想以上に時間がかかりました。Azureの試験と違って選択問題しかないってことで、消去法でいけばある程度勘でも当てられると思い、正直なめてかかってたんですが、そもそも問題文や選択肢の文脈を読み解くのが難しいので、事前に問題を多く解いて慣れておくのが重要だと感じました。
10問くらいよくわからない問題があったので途中から「ヤバイ、落ちるかも」という不安感に襲われましたが、一瞬で答えられるサービス問題もチラホラあって、全体的にはバランスの取れた試験だな、という感想です。
もし私が未経験、もしくは、駆け出しエンジニアだとすると、取得までに2~3か月はかかると思います。問われるサービスの範囲がかなり広い印象。
で、肝心の「設計スキル」が身に付いてかというと、まだまだ実践が必要ですが、基礎的な知識はかなり整理されて設計ポイントも理解できるようになってきたので、受験して良かったと思います。
まとめ
今回は、AWS SAAに合格するまでの体験記をお話ししました。
結局、合格するために何が必要なのか。肝心なことを書いてませんでしたね。
私が受験したのは2021/4/3なんですが、タイムリーなことにその日にくろかわこうへい(@AwsskillC)さんのYoutubeで合格テクニックが語られていました。
私の考えも、大筋はくろかわさんが語られていることと同じですが、「試験対策として」であれば
"Udemyの模擬試験を繰り返し解いて問題と解答のパターンを覚えてください"
とアドバイスすると思います。問題と解答を覚えても意味ないように思えますよね。
しかし、何度も解いていたらわかりますが、設計にはいくつかの「パターン」があって、そのパターンと解答をまずは覚えてしまって試験に合格し、あとから徐々に理解を深めていけば良いと思います。試験で問われるパターンというのは、いわば「ベストプラクティス」に沿っているものが大半で、その王道を頭に叩き込んでおけば実務に入った時にも「あ、あのパターンの構成だ」といった感じで、スムーズに入れるんじゃないでしょうか。
以上、参考になれば幸いです。
