- 投稿日:2021-01-28T23:27:29+09:00
AWSにデプロイすると、いつも起こるエラー
はじめに
現在作成中のアプリケーションはAWSにデプロイしているが、毎回、CSSがうまくいかず、
rails assets:precompile RAILS_ENV=productionをすると、
"webpack" not foundと出て、挫けます。
きっとwebpackが見つからないとエラーを吐いているのだが、適切な解決方法が見つからず、
テキトーに操作してやり過ごしてしまってします。今のところの解決方法
% yarn install --check-files % bundle install
- Unicornの再起動
この3つを試すと、どこかしらでうまくCSSのスタイルが適用されているみたいです。
最後に
読んだ人へ
なんの参考にもならなくてすみません。
自分が次、同じような目に遭った時、見返す用です。
- 投稿日:2021-01-28T23:00:45+09:00
AWS (VPC)についての全体像
はじめに
AWSのVPCについての概念や用語を簡単にアウトプットしていきたいと思います。
リージョン
・リージョンとは、AWSの各サービスが提供されている地域のこと
・世界中に17のリージョンがある。
・AWSのサービスを利用するとき、まずリージョンを選択する。
(リージョンによって使えるサービスは異なる。自分が使いたいサービスと照らし合わせてリージョンを決める。日本でサービスを展開する場合は東京リージョンが良い。AWSのサーバーを設置するときはアメリカに設置するよりも日本に設置したほうが応答時間が早くなります。)アベイラビリティゾーン
・アベイラビリティゾーンとは、独立したデータセンターのこと
AWSは世界各国にデータセンターをもっていて複数のデータセンターを束ねたのがアベイラビリティゾーンとなります。
・どのリージョンにもアベイラビリティゾーンは2つ以上存在していて、それぞれ物理的に離れて存在しています。なぜ複数あるかというと、トラブルがおきて1つのアベイラビリティゾーンが利用できなくなっても、ほかのアベイラビリティゾーンでカバーできるからです。
・実際にEC2のサーバーをたてる際は、まずリージョンを選んで、次にその中のどのアベイラビリティゾーンにたてるかを選択することになります。複数のアベイラビリティゾーンを設置すれば、何かあったときのリカバリーができます。リージョンとアベイラビリティゾーンは色々なサービスの基礎の概念となります。
VPC(Virtual Private Cloud)
・VPCは、AWS上に仮想ネットワークを作成できるサービス
・VPCを使うことでほかとは分離されたネットワーク環境を自由に作ることができます。
・AWSで作業するときは、まずVPCを作りサブネットで分け、そのサブネットの中にサーバーを設置していく流れになります。VPCを作ったら、その中をネットワークでさらに区切ります。それをするのがサブネットとなります。
サブネット
・サブネットとは、VPCをさらに細かく区切ったネットワーク
・アベイラビリティゾーンの中に作る
・AWSでサーバーを作るときは、このサブネットの中で設置するようにします。パブリックサブネット
インターネットから接続できる
プライベートサブネット
インターネットから接続できない
おわりに
VPCについて簡単な全体像でした。また勉強してアウトプットしたいと思います。
- 投稿日:2021-01-28T22:36:19+09:00
Amazonlinux2におけるsudoアップデート手順
経緯
sudo脆弱性に関する周知があったのでsudoのアップデート対応することとなった
sudoの脆弱性(CVE-2021-3156)に関する注意喚起
https://www.jpcert.or.jp/at/2021/at210005.html
バージョン確認方法
sudoedit -s /コマンドを実行する対応が必要
sudoedit:から始まるエラーが表示されると脆弱性の影響を受ける対応が不要
usage:から始まるエラーが表示されると影響を受けない更新手順
# 1. 脆弱性のあるバージョンか確認 sudoedit -s / # 2. yumのアップデート確認 yum check-update | grep sudo # 3. パッケージを指定してアップデート sudo yum update sudo # 4. 修正後の確認 sudoedit -s /実際に適用してみる
- にてバージョン確認をしてみると、事前情報の通り、対応が必要なバージョンということがわかる
sh-4.2$ sudoedit -s / sudoedit: /: not a regular file
- sudoバージョン確認で新しいアップデートがきていることがわかる。
sh-4.2$ yum check-update | grep sudo sudo.x86_64 1.8.23-4.amzn2.2.1 amzn2-core
- の手順でインストール
sh-4.2$ yum update sudo Loaded plugins: extras_suggestions, langpacks, priorities, update-motd You need to be root to perform this command. sh-4.2$ sudo yum update sudo Loaded plugins: extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 amzn2extra-docker | 3.0 kB 00:00:00 mysql-connectors-community | 2.6 kB 00:00:00 mysql-tools-community | 2.6 kB 00:00:00 mysql80-community | 2.6 kB 00:00:00 39 packages excluded due to repository priority protections Resolving Dependencies --> Running transaction check ---> Package sudo.x86_64 0:1.8.23-4.amzn2.2 will be updated ---> Package sudo.x86_64 0:1.8.23-4.amzn2.2.1 will be an update --> Finished Dependency Resolution Dependencies Resolved ============================================================================================================================================================== Package Arch Version Repository Size ============================================================================================================================================================== Updating: sudo x86_64 1.8.23-4.amzn2.2.1 amzn2-core 844 k Transaction Summary ============================================================================================================================================================== Upgrade 1 Package Total download size: 844 k Is this ok [y/d/N]: y Downloading packages: Delta RPMs disabled because /usr/bin/applydeltarpm not installed. sudo-1.8.23-4.amzn2.2.1.x86_64.rpm | 844 kB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction Updating : sudo-1.8.23-4.amzn2.2.1.x86_64 1/2 Cleanup : sudo-1.8.23-4.amzn2.2.x86_64 2/2 Verifying : sudo-1.8.23-4.amzn2.2.1.x86_64 1/2 Verifying : sudo-1.8.23-4.amzn2.2.x86_64 2/2 Updated: sudo.x86_64 0:1.8.23-4.amzn2.2.1 Complete!
- 修正されたか確認
sudoedit -s / usage: sudoedit [-AknS] [-r role] [-t type] [-C num] [-g group] [-h host] [-p prompt] [-T timeout] [-u user] file ...問題なさそう。
おつかれさまでした。
- 投稿日:2021-01-28T22:33:02+09:00
Inactive状態のLamndaの関数を一括で起動してやる
アカウント上に存在するアイドル状態のLamnda関数を全部起動したいことがあったのでそのやり方をメモします。
そもそもなんでそんなことやりたかったの?
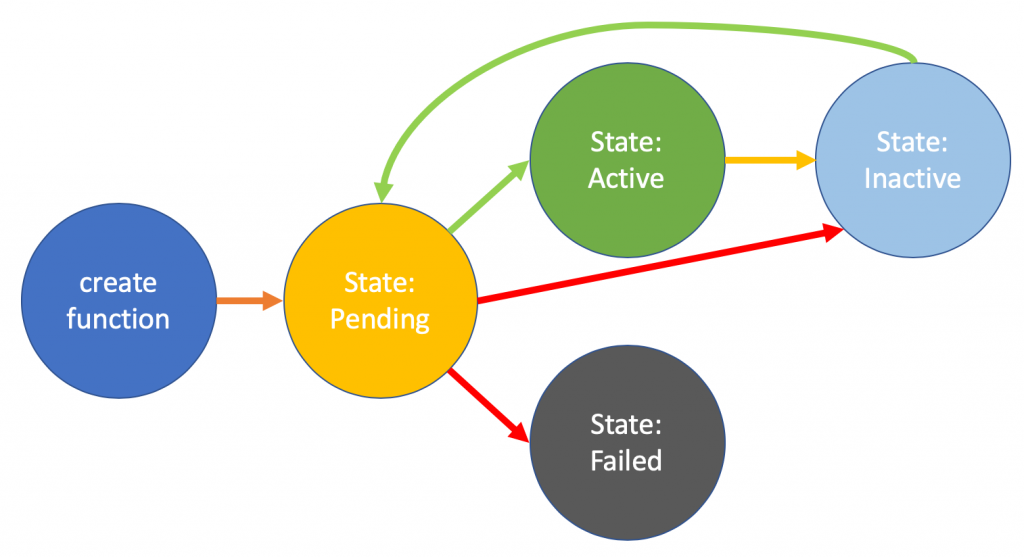
Lambdaは非常に便利ですが、数週間アイドル状態が続くと関数がInactive状態になります。そしてInactive状態になった関数を起動しようとすると最初は起動に失敗します。
このせいで若干トラブったので、いっそのこと定期的にアカウント上に存在するすべてのLambndaを起動してしまえということで、AWSCLIでLambdaを一括で起動するシェルを作成しました。
Lambdaサービスが設定されたリソースを回収するのに十分な時間アイドルになっている関数は、Inactive状態に移行します。Inactive状態の関数を呼び出すと、失敗し、それらのリソースが再作成されるまで関数はPending状態に設定されます。リソースの再作成に失敗した場合、関数はInactive状態に戻ります。
実行環境
```
$ aws --version
aws-cli/1.18.219 Python/3.6.0 Windows/10 botocore/1.19.59$ bash --version
GNU bash, version 4.3.42(5)-release (x86_64-pc-msys)
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later http://gnu.org/licenses/gpl.html
```でも、どうやって起動するの?
Lambdaのリファレンスを読みましたが、そもそも「起動する」というコマンドは用意されていないそうです。起動するには invoke(実際にラムダを実行するためのコマンド)しか用意されていなそうでしたが、がんばって漁ってみたところ publish-versionというコマンドを発見しました。
Creates a version from the current code and configuration of a function. Use versions to create a snapshot of your function code and configuration that doesn't change.
AWS Lambda doesn't publish a version if the function's configuration and code haven't changed since the last version. Use UpdateFunctionCode or UpdateFunctionConfiguration to update the function before publishing a version.
本来は関数のバージョン管理のためのコマンドみたいですが、関数に変更ない場合は何も更新しないとのこと。でもこのコマンドを実行すると、なんと関数が起動されました!!
ということでこれを利用すればすべての関数を起動できそうです。
最終的に出来たシェルがこちら
make_active_all_lambda.sh#!/bin/bash -eu all_lambda_name_list=() inactive_lambda_name_list=() # 最初にアカウント上に存在するすべての関数名を取得 function get_all_lambda_name_list() { readonly lambda_list=$(aws lambda list-functions \ | jq -r '.Functions') len=$(echo $lambda_list | jq length) for i in $( seq 0 $(($len - 1)) ); do all_lambda_name_list+=($(echo $lambda_list | jq -r .[$i].FunctionName)) done } # 関数がActiveかどうかの判定 function is_lambda_active() { local lambda_name=$1 local state=$(aws lambda get-function-configuration \ --function-name $lambda_name \ | jq -r '.State') if [ $state = "Active" ]; then echo "true" else echo "false" fi } # Activeじゃない関数だけ抽出 function filter_inactive_resources() { echo == following lambda is inacive == for lambda_name in ${all_lambda_name_list[@]}; do is_active=$(is_lambda_active $lambda_name) if [ "${is_active}" = "false" ]; then echo $lambda_name inactive_lambda_name_list+=($lambda_name) fi done echo == thst\'s all == } # Avctiveじゃない関数をpublish-versionする function publish_lambda() { if [ ${#inactive_lambda_name_list[@]} -eq 0 ]; then echo there is no lambda to publish return 0 fi for lambda_name in ${inactive_lambda_name_list[@]}; do echo now publishing $lambda_name aws lambda publish-version --function-name $lambda_name aws lambda wait function-active --function-name $lambda_name # 関数がActiveになるまで待つ done } get_all_lambda_name_list filter_inactive_resources publish_lambda気になっていること
関数は起動するだけではお金はかからないはずですが、AWS側にとってはあんまりやってほしくないことなんですかね?もしこの辺詳しい人がいたら教えてほしいです!
できればInactive状態でのinvokeでも、失敗にしないで起動させてから実行するまでやってほしいなあ。
- 投稿日:2021-01-28T22:33:02+09:00
Inactive状態のLambdaの関数を一括で起動してやる
アカウント上に存在するアイドル状態のLamnda関数を全部起動したいことがあったのでそのやり方をメモします。
そもそもなんでそんなことやりたかったの?
Lambdaは非常に便利ですが、数週間アイドル状態が続くと関数がInactive状態になります。そしてInactive状態になった関数を起動しようとすると最初は起動に失敗します。
このせいで若干トラブったので、いっそのこと定期的にアカウント上に存在するすべてのLambndaを起動してしまえということで、AWSCLIでLambdaを一括で起動するシェルを作成しました。
Lambdaサービスが設定されたリソースを回収するのに十分な時間アイドルになっている関数は、Inactive状態に移行します。Inactive状態の関数を呼び出すと、失敗し、それらのリソースが再作成されるまで関数はPending状態に設定されます。リソースの再作成に失敗した場合、関数はInactive状態に戻ります。
実行環境
$ aws --version aws-cli/1.18.219 Python/3.6.0 Windows/10 botocore/1.19.59 $ bash --version GNU bash, version 4.3.42(5)-release (x86_64-pc-msys) Copyright (C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>でも、どうやって起動するの?
Lambdaのリファレンスを読みましたが、そもそも「起動する」というコマンドは用意されていないそうです。起動するには invoke(実際にラムダを実行するためのコマンド)しか用意されていなそうでしたが、がんばって漁ってみたところ publish-versionというコマンドを発見しました。
Creates a version from the current code and configuration of a function. Use versions to create a snapshot of your function code and configuration that doesn't change.
AWS Lambda doesn't publish a version if the function's configuration and code haven't changed since the last version. Use UpdateFunctionCode or UpdateFunctionConfiguration to update the function before publishing a version.
本来は関数のバージョン管理のためのコマンドみたいですが、関数に変更ない場合は何も更新しないとのこと。でもこのコマンドを実行すると、なんと関数が起動されました!!
ということでこれを利用すればすべての関数を起動できそうです。
最終的に出来たシェルがこちら
make_active_all_lambda.sh#!/bin/bash -eu all_lambda_name_list=() inactive_lambda_name_list=() # 最初にアカウント上に存在するすべての関数名を取得 function get_all_lambda_name_list() { readonly lambda_list=$(aws lambda list-functions \ | jq -r '.Functions') len=$(echo $lambda_list | jq length) for i in $( seq 0 $(($len - 1)) ); do all_lambda_name_list+=($(echo $lambda_list | jq -r .[$i].FunctionName)) done } # 関数がActiveかどうかの判定 function is_lambda_active() { local lambda_name=$1 local state=$(aws lambda get-function-configuration \ --function-name $lambda_name \ | jq -r '.State') if [ $state = "Active" ]; then echo "true" else echo "false" fi } # Activeじゃない関数だけ抽出 function filter_inactive_resources() { echo == following lambda is inacive == for lambda_name in ${all_lambda_name_list[@]}; do is_active=$(is_lambda_active $lambda_name) if [ "${is_active}" = "false" ]; then echo $lambda_name inactive_lambda_name_list+=($lambda_name) fi done echo == thst\'s all == } # Avctiveじゃない関数をpublish-versionする function publish_lambda() { if [ ${#inactive_lambda_name_list[@]} -eq 0 ]; then echo there is no lambda to publish return 0 fi for lambda_name in ${inactive_lambda_name_list[@]}; do echo now publishing $lambda_name aws lambda publish-version --function-name $lambda_name aws lambda wait function-active --function-name $lambda_name # 関数がActiveになるまで待つ done } get_all_lambda_name_list filter_inactive_resources publish_lambda気になっていること
関数は起動するだけではお金はかからないはずですが、AWS側にとってはあんまりやってほしくないことなんですかね?もしこの辺詳しい人がいたら教えてほしいです!
できればInactive状態でのinvokeでも、失敗にしないで起動させてから実行するまでやってほしいなあ。
- 投稿日:2021-01-28T21:56:44+09:00
AWSクイックスタートでアーキテクチャや構築自動化を学べる件
こんにちは。AWS歴3年生の人です。突然ですが、AWSクイックスタート使っていますか?
そんなサービスありましたっけ?と、AWS管理コンソールにログインしてサービス検索してみたそこの貴方、管理コンソールに出てくるこのサービスのことではありません。
※こちらは「IoT Analytics」という別サービスです
AWSクイックスタートは日ごろアーキテクチャの参考によくチェックしていたのですが、周りでもあまり知られていないようでしたのでご紹介します。
AWSクイックスタートとは
AWS クイックスタートは、AWS クラウドでの主要なワークロード向けに自動化されているリファレンスデプロイです。
AWSクイックスタートではよくある構成やソフトウェアを設定込みでデプロイできる「手順」や「テンプレート」、「アーキテクチャ」が公開、共有されています。
短い時間、数ステップで目的の環境をソフトウェア込みで構築できる。さらにカスタマイズも可能。というのがAWSクイックスタートの特徴ですが(中には5分!というのも)、私の場合はアーキテクチャの参考やCloudFormationテンプレートやスクリプトの書き方など勉強目的でみることが多いです。
何が嬉しいのか
可用性やセキュリティがAWS のベストプラクティスに沿って作られている
- 大事なところなので安心して構成を参考にできます
テンプレートやソースコードが公開されている
- AWSやソフトウェアを開発した専門家のコードを学ぶことができます
アーキテクチャ図とその説明が記載されている
- 触ったことのないサービスも具体的な使い方を知ることができます
デプロイガイドも公開されている
- 社内の人に共有するときの資料の作り方、配布の仕方などの参考にできます
ユースケース別に検索できる
- 例えば「IoT」「分析」「Windows」といった目的に応じた検索ができます。
「そんな機能やソフトウェアがあったのか!」というような新しい発見もあります
一部をご紹介
ソフトウェア会社が開発して提供しているクイックスタートもありますが、今回は主にAWSが開発したクイックスタートの中でインフラやCI/CDの一例を紹介します。
インフラストラクチャ、セキュリティ
Linux 踏み台ホスト(デプロイ時間5分)
VPC 内の Linux インスタンスに安全にアクセスするための Linux 踏み台ホストを AWS インフラストラクチャに追加します。
リモートデスクトップゲートウェイ(デプロイ時間30分)
リモートデスクトップゲートウェイをデプロイし、リモートユーザーと Microsoft Windows が実行されている EC2 インスタンス間のセキュアな暗号化接続を確立します。
PCI DSS(デプロイ時間30分)
ペイメントカード業界 (PCI) データセキュリティ標準 (DSS) コンプライアンス向けに標準化されたアーキテクチャをセットアップします。
DevOps
AWS CloudFormation テンプレート向け CI/CD パイプライン(デプロイ時間15分)
[CI/CD、テスト] AWS CloudFormation テンプレートを GitHub リポジトリから自動的にテストするためのパイプラインをデプロイします。テスト用の AWS TaskCat、継続的な統合のための AWS CodePipeline、ビルドサービスの AWS CodeBuild が含まれます。
ブルー/グリーンデプロイ(デプロイ時間15分)
[CI/CD] AWS Elastic Beanstalk 環境にデプロイするために、AWS CodePipeline を使用してブルー/グリーンアーキテクチャを構築します。
最後に
AWSソリューションというページでもアーキテクチャやCloudFormationのテンプレートが公開されているのでこちらも同じく参考になると思います。
一から作らず既にあるものを活用できたり、AWSのベストプラクティスも学べるのでとてもよいデプロイリファレンスだと思います。
いままでAWS管理コンソールでポチポチと時間をかけてGUIを操作して環境を構築していたのは何だったのか・・・。そう思わせてくれるような便利なアーキテクチャやソフトウェアが今後も増えていくことを期待しています!

- 投稿日:2021-01-28T20:40:47+09:00
AWS RDSのイベントをNew Relicで監視してみる
Amazon SNSで、メッセージの配信先として新しくAmazon Kinesis Data Firehoseを指定できるようになった!とのことで、タイムリーなお仕事をしたので、メモを兼ねて手順を記載。
目的
マルチAZなRDSでフェイルオーバーが起こった際にNew Relicでアラートを発生させたい。
けど、New RelicとAWSのインテグレーションを結んだだけでは検知できない…
よし、AWS SNSからKinesis Data Firehoseが呼び出せるようになったのでそれを使って通知をしてやろう。
サービスには影響ないが、AZをまたぐレイテンシーの増加が許容できないなど厳しい案件には有用?必要なAWSコンポーネント
- RDS(当然)
- Kinesis Data Firehose
- SNS
流れ
RDS(Event subscriptions) → SNS → Kinesis Data Firehose → New Relic Logs
手順
Kinesis Data Firehoseでdelivery streamsを作成する
事前準備
Kinesis Data Firehose delivery steramの配信エラーログを格納するS3バケットを作成する。
全てデフォルト設定でOK。作成開始
Kinesisのページで「Kinesis Data Firehose」を選択し、「Create delivery stream」をクリックStep1: Name and source
任意のストーリム名を入力し、その他はデフォルトのまま次へStep2: Process records
デフォルトのまま次へ
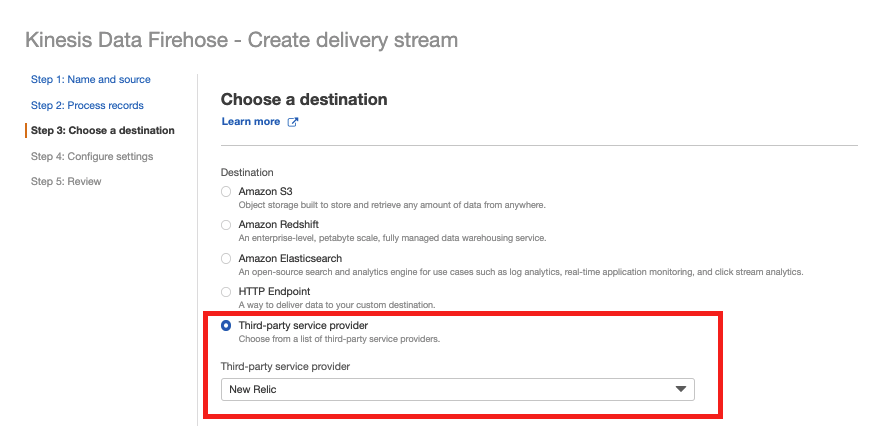
※配信されてくるレコードのやフォーマットの変換が必要な場合は適宜設定をする。Step3: Choose a destination
※上の画像は途中で切っています。
以下を設定し次へ
項目 値 備考 Destination Third-party service provider Third-party service provider New Relic HTTP endpoint URL https://aws-api.newrelic.com/firehose/v1 デフォルトで入力済み API Key New RelicのInsert API Key 作成方法は欄外(※)を参照 S3 backup mode Failed data only 成功ログも格納する場合はAll dataを選択 S3 backup 事前準備したS3バケット ※New Relic Insert API Keyの作成
https://docs.newrelic.com/docs/telemetry-data-platform/ingest-manage-data/ingest-apis/introduction-event-api#registerStep4: Cofigure setting
デフォルトのまま次へ
※上の画像は途中で切っています。
※バッファやタグ、IAMロールの独自命名が必要な場合は適宜設定をしてください。Step5: Review
設定を確認し「Create delivery stream」をクリック
※上の画像は途中で切っています。SNSトピックを作成する
事前準備
SNSのサブスクリプションでKinesis Data Firehoseを実行できるように下記のIAMロールを作成しておいてください。
項目 値 備考 信頼されたエンティティ sns.amazon.com ポリシー 1 AmazonSNSRole AWSマネージドポリシー ポリシー 2 任意の名前 ポリシー内容は下記に記載 ポリシー2の内容
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "firehose:DescribeDeliveryStream", "firehose:ListDeliveryStreams", "firehose:ListTagsForDeliveryStream", "firehose:PutRecord", "firehose:PutRecordBatch" ], "Resource": [ "<<作成したKinesis Data Firehose delivery streamのarn>>" ], "Effect": "Allow" } ] }作成開始
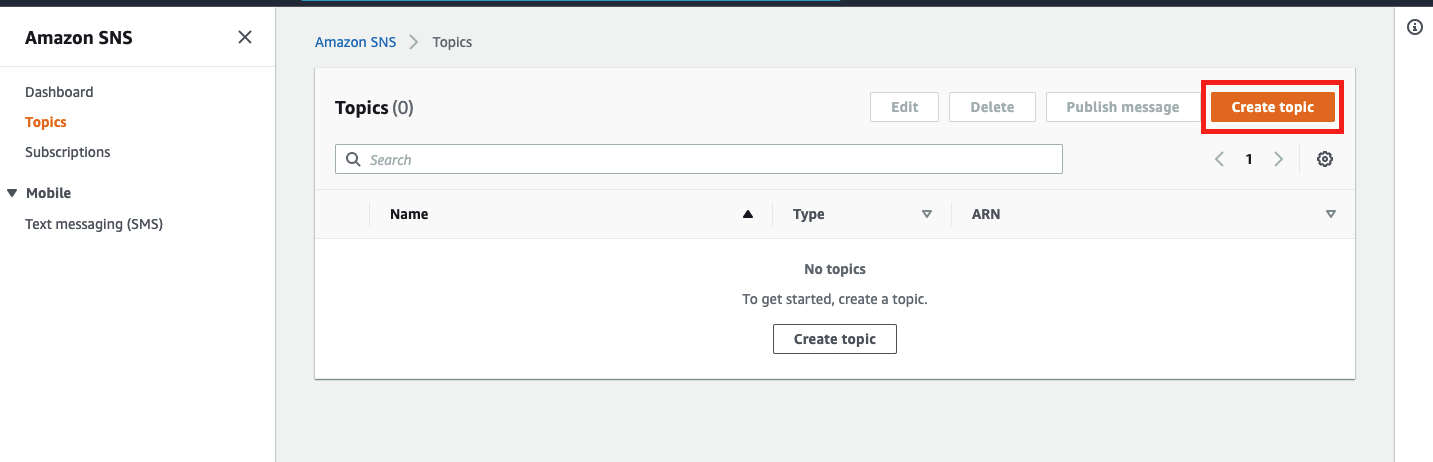
AWS SNSのページで「Create topic」をクリックトピックの作成
以下を設定しトピックを作成する
項目 値 備考 タイプ スタンダード 名前 任意 サブスクリプションの作成
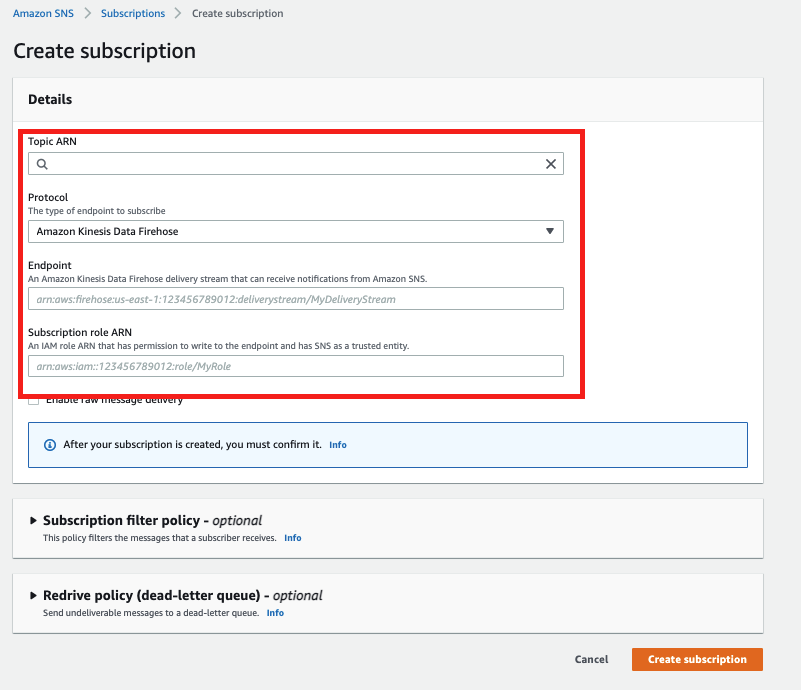
作成したトピックで以下を設定しサブスクリプションを作成する
項目 値 備考 トピックARN 作成したトピックのARN デフォルトで入力済み プロトコル Amazon Kinesis Data Firehose エンドポイント 作成したdelivery streamのARN サブスクリプションロールのARN 事前準備したSNS用IAMロールのARN RDSのイベントサブスクリプションを作成する
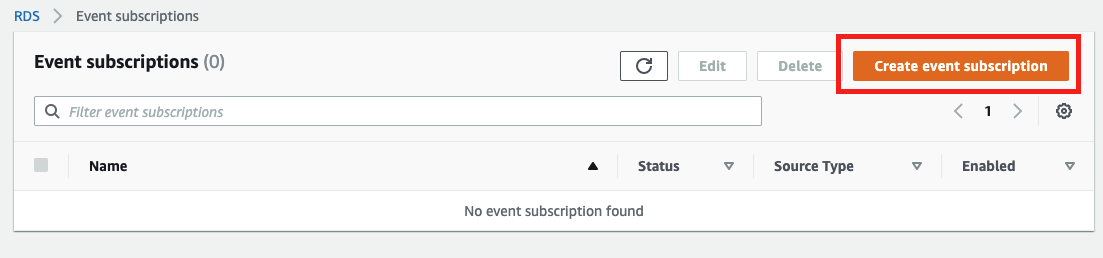
作成開始
RDSのイベントサブスクリプションページで「Create event subscription」をクリック
以下を設定しRDSイベントサブスクリプションを作成する
項目 値 備考 名前 任意 ターゲット ARN ARN 作成したSNSを選択 ソースタイプ インスタンス インスタンスを含みます 監視するインスタンスを選択 イベントカテゴリを含みます 特定のイベントカテゴリを選択 特定のイベントカテゴリ failover、failure、recovery 要件に合わせて適宜調整 以上でNew Relic Logsへイベント通知が配信されます。
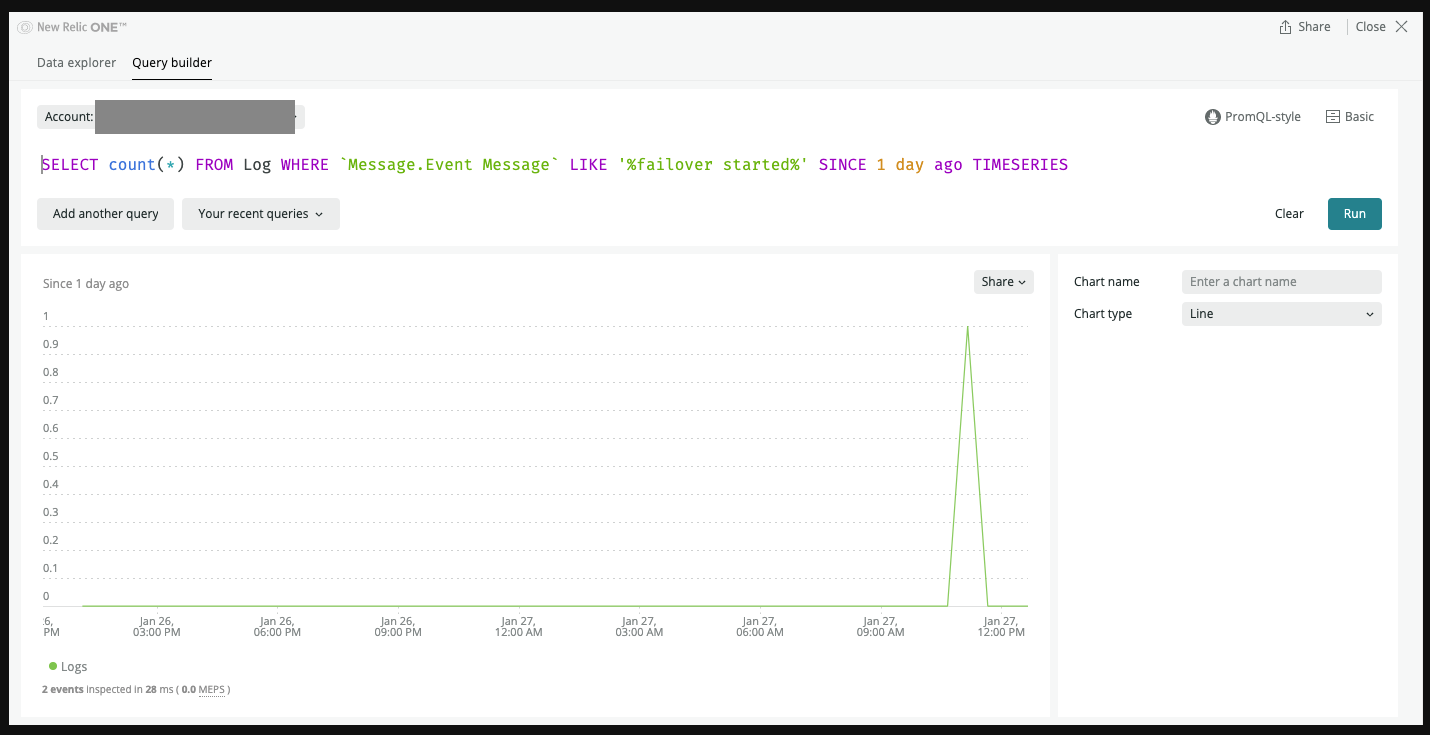
SELECT count(*) FROM Log WHERE `Message.Event Message` LIKE '%failover started%' SINCE 1 day ago TIMESERIES
配信されると以下のNRQLなどでメトリクスとして検出可能なので、Conditionを作成する。
LIKEに指定する文言は適宜調整する。できました。
参考URL




- 投稿日:2021-01-28T17:47:15+09:00
AWS - C9でLaravel / Nuxt.jsを構築する備忘録
毎回調べるのが面倒なので、未来の自分へ備忘録です。
順番に実行したら構築出来るわけではありません。今回構成する内容
・バックエンド:laravel 6系
・フロントエンド:vue.js nuxt.js vuetifycomposerのインストール
brew install composer終わったら念のため-vでバージョン確認。
laravelのインストール
composer create-project --prefer-dist laravel/laravel app_name "6.*"このコマンドでは何故かvenderファイル、envファイルが作成されなかった。
インストールされているphpパッケージのバージョン確認
yum list installed | grep phpこのコマンドで確認出来た古いパッケージの削除
sudo yum erase -y hogehoge補足:-yは全ての問い合わせに対してYESで返す。
yumのアップグレード
sudo yum upgrade sudo yum install -y https://rpms.remirepo.net/enterprise/remi-release-7.rpmパッケージインストール
sudo yum install -y php73 php73-php-pdo php73-php-mbstring php73-php-xml補足:うるおぼえだが、laravelは確か7.3以降のphpが必要なはず
PHPコマンドを使えるようにする
$which php73 /usr/bin/php73 $alias php='/usr/bin/php73'補足:whichコマンドでどこにファイルがあるのか調べる。その後aliasコマンドでphpと入力したときの呼び出し先を設定する。
composerコマンドを使えるようにする
sudo ln -s /usr/bin/php73 /usr/bin/php
- 投稿日:2021-01-28T17:47:15+09:00
AWS - C9でLaravel / Nuxt.jsの環境構築に関する備忘録
毎回調べるのが面倒なので、未来の自分へ備忘録です。
順番に実行したら構築出来るわけではありません。今回構成する内容
・バックエンド:laravel 6系
・フロントエンド:vue.js nuxt.js vuetifycomposerのインストール
brew install composer終わったら念のため-vでバージョン確認。
laravelのインストール
composer create-project --prefer-dist laravel/laravel app_name "6.*"このコマンドでは何故かvenderファイル、envファイルが作成されなかった。
インストールされているphpパッケージのバージョン確認
yum list installed | grep phpこのコマンドで確認出来た古いパッケージの削除
sudo yum erase -y hogehoge補足:-yは全ての問い合わせに対してYESで返す。
yumのアップグレード
sudo yum upgrade sudo yum install -y https://rpms.remirepo.net/enterprise/remi-release-7.rpmパッケージインストール
sudo yum install -y php73 php73-php-pdo php73-php-mbstring php73-php-xml補足:うるおぼえだが、laravelは確か7.3以降のphpが必要なはず
PHPコマンドを使えるようにする
$which php73 /usr/bin/php73 $alias php='/usr/bin/php73'補足:whichコマンドでどこにファイルがあるのか調べる。その後aliasコマンドでphpと入力したときの呼び出し先を設定する。
- 投稿日:2021-01-28T16:44:55+09:00
AWS Certificate Manager (ACM)のDNS検証
ACMはAWSでSSL/TLS証明書発行および管理を代行してくれる便利なサービスです。
https://docs.aws.amazon.com/ja_jp/acm/latest/userguide/acm-overview.html
以前はドメインの所有権確認をEメールで行っていましたが、2017年11月にDNSによるドメイン検証機能が追加されたので手動での検証作業から開放されました。
作業1 Route53でドメインを利用可能にする
DNSの検証にはRoute53の機能を利用します。
あらかじめ対象ドメインのCNAMEが編集できる状態にしておく必要があります。
作業2 Certificateのリクエスト
Certificate Managerの画面から証明書のリクエストを行います。
ACMではワイルドカード証明書も発行出来ます。
ネイキッドドメインと共通で利用する場合は画像のように、別の名前を追加でワイルドカード証明書を追加します。
作業3 DNSにCNAMEを追加
ドメインの所有権を確認するために、検証用のCNAMEレコードを提示されるので、その内容に合わせてCNAMEの追加を行います。
この時、Route53を利用しているとボタン一つで自動的にCNAMEを作成してくれるので便利です。
作業者のIAM権限にCNAMEの作成権限が無いとエラーになると思いますのでご注意ください。
作業4 環境に証明書の設定を行う
証明書が必要なCloudFrontやALBに作成した証明書を設定すれば完了です。
一度この設定を行ってしまえば有効期限が近くなると自動的にACMが証明書の再発行を行ってくれるようになります。まとめ
証明書の有効期限を気にする必要がなくなりますので、ぜひ導入してみてください。



- 投稿日:2021-01-28T15:25:21+09:00
量子コンピュータの実機のロケーション
この記事について
あまり深い意味はないのですが、量子コンピュータを勉強するにあたって量子コンピュータの実機が物理的にどこにあるかが気になったのでせっかくなのでちょっと調べてまとめておこうと思います。
量子コンピュータ関係の他の記事は、こちらのページで一覧にしています。
対象
今回実機の場所を調べてみようと思っているのは大きく分けてAWSとIBMの2つです。
もしかしたら今後追加するかもしれません。
また、とりあえずメモ程度なので深くは調べません。
機会があれば深く調べてみようと思います。
- AmazonBraket
- D-Wave — Advantage_system1.1
- D-Wave — DW_2000Q_6
- IonQ
- Rigetti — Aspen-8
- Amazon Web Services — SV1
- Amazon Web Services — TN1
- IBM Quantum Experience
- ibmq_santiago
- ibmq_athens
- ibmq_16_melbourne
- ibmq_5_yorktown
- ibmq_qasm_simulator
- ibmq_armonk
- ibmq_valencia
- ibmq_vigo
- ibmq_ourense
主に以下の添付写真の中身を調べていこうと思います。
(引用:https://console.aws.amazon.com/braket/home)
(引用:https://quantum-computing.ibm.com/systems)場所
AmazonBraket
AmazonBraketではこちらのそれぞれのマシンの詳細を覗くと記載してあるのでそちらを参照いただければと思いますが、本記事でもまとめます。
D-Wave — Advantage_system1.1
カナダの「British Columbia, Canada」だそうです。
西海岸の方ですね。
地図で示すと以下の場所にあたります。
「British Columbia, Canada」の地図を表示D-Wave — DW_2000Q_6
こちらもカナダの「British Columbia, Canada」だそうです。
D-Waveはどうやら同じロケーションですね。IonQ
こちらはアメリカの「Maryland, USA」だそうです。
東海岸のあたりです。
地図で示すと以下の場所にあたります。
「Maryland, USA」の地図を表示Rigetti — Aspen-8
皆さんご存じアメリカの「California, USA」だそうです。
地図で示すと以下の場所にあたります。Amazon Web Services — SV1
こちらはシミュレータになります。
「us-east-1, us-west-1, us-west-2」なのでおそらくマシンそのもののロケーションも「バージニア北部、北カリフォルニア、オレゴン」かなと思います。
地図で示すと以下の場所にあたります。
「バージニア北部」の地図を表示
「北カリフォルニア」の地図を表示
「オレゴン」の地図を表示Amazon Web Services — TN1
こちらもシミュレータになります。
「us-east-1, us-west-2」なのでおそらくマシンそのもののロケーションも「バージニア北部、オレゴン」かなと思います。
地図で示すと以下の場所にあたります。
「バージニア北部」の地図を表示
「オレゴン」の地図を表示IBM Quantum Experience
あまり詳細な記載を見つけられなかったため、名前の通り検索してロケーションを見ていきます。
ibmq_santiago
チリのサンティアゴかミネソタ州のサンティアゴかよくわかりませんでしたが、チリの方にもIBMの拠点がしっかりとありましたので何となくそちらだと思います。
(ちなみに筆者はもともと南米国籍(今は日本)なのでチリには少し親近感があるというバイアスも含みます。)
地図で示すと以下の場所にあたります。
「サンティアゴ」の地図を表示ibmq_athens
ギリシアのアテネですね。
地図で示すと以下の場所にあたります。
「アテネ」の地図を表示ibmq_16_melbourne
オーストラリアのメルボルンですね。なかなかきれいな場所ですよね。
地図で示すと以下の場所にあたります。
「メルボルン」の地図を表示ibmq_5_yorktown
アメリカのヨークタウンですね。
地図で示すと以下の場所にあたります。
「ヨークタウン」の地図を表示ibmq_qasm_simulator
こちらはシミュレータとなります。
どこにあるのかちょっとわからないのでまた機会がありましたら調べておきます。ibmq_armonk
今回の記事を書こうと思ったきっかけのマシンです。
アメリカのアーモンクという町?でニューヨーク州にあるそうです。
大きな地図で示すと以下の場所にあたります。
「アーモンク」の地図を表示ibmq_5_valencia
スペインのバレンシアです。
地図で示すと以下の場所にあたります。
「バレンシア」の地図を表示ibmq_vigo
こちらもスペインのVigoですね。おそらく。
地図で示すと以下の場所にあたります。
「Vigo」の地図を表示ibmq_ourense
こちらもスペインのオーレンセですね。おそらく。
大きな地図で示すと以下の場所にあたります。
「オーレンセ」の地図を表示これを見ると何となくですが、スペインも量子コンピュータ開発頑張っている感じなのかなぁとか思っちゃったりしました。
最後に
最後に全体の世界地図だけマッピングしておこうかと思いましたが、意外と汚くなりそうなのでやめておきます。
個別のURLをぜひ見てみてください。
何となく位置関係がわかるかと思います。
簡単に知り得る情報だけを見てURLを張ってみたので多少間違えているかもしれませんが、そういった場合はコメント等でご教示いただけると幸いです。
ちょっと気になった程度で調べてみましたが、意外といろんな地域で量子コンピュータ開発しているのでは?という知見が得られました。
皆様の何かに役に立てれば幸いです。


- 投稿日:2021-01-28T15:22:14+09:00
AthenaからRedshift Spectrumへの移行とわかったこと
Amazon Redshift Spectrumとは
Amazon Redshift Spectrum を使用すると、効率的にクエリを実行し、Amazon Redshift テーブルにデータをロードすることなく、Amazon S3 のファイルから構造化または半構造化されたデータを取得することができます。
Amazon Redshift Spectrum を使用した外部データのクエリ実行
Redshiftを利用する場合はRedshiftにデータをロードする必要があったがRedshift Spectrumを利用することでS3にあるファイルをそのまま利用できるようになります。
Redshift Spectrumの利用を検討した理由
Amazon Athenaではクエリに時間がかかりすぎる、またはリソースが足りなくて実行できないクエリを実行するためにRedshift Spectrumの利用を検討し始めた。
開始方法
- クラスターの作成
- Amazon Redshift 用の IAM ロールを作成する
- IAM ロールをクラスターに関連付ける
- 外部スキーマと外部テーブルを作成する
のステップでSQLが叩けるようになります。
クラスターの作成
Redshiftダッシュボードから
クラスターの作成を選択します
作成画面で最低でも以下を設定します。
- 名称
- サイズ
- データベース名(オプション)
- ポート番号(オプション)
- マスターユーザー名
- マスターユーザーのパスワード
次の工程で作成するIAMロールは先に作成しておいて、ここで付与することも可能です。
Amazon Redshift 用の IAM ロールを作成する
Redshiftでは作成したクラスターにIAMロールを付与して、クラスターの権限管理を行うのですが、Spectrumでは通常のRedshiftの操作に加えてS3の利用が加わるのでS3の権限を設定します。
単純に読み取るだけであるならAmazonS3ReadOnlyAccessで十分ですが、CTAS文の実行やINSERTなども行うのであれば書き込み権限も必要となります。
またAWS Glue データカタログを利用する場合はAWSGlueConsoleFullAccessをAthena データカタログを使用する場合はAmazonAthenaFullAccessも付与します。
今回Athenaのデータカタログを利用するためAmazonAthenaFullAccessを付与しました。IAM ロールをクラスターに関連付ける
先程作成したIAMロールをクラスターに付与します。これはコンソールからポチポチやればすぐに終わります。
AWS マネジメントコンソールにサインインし、Amazon Redshift コンソール (https://console.aws.amazon.com/redshift/) を開きます。
ナビゲーションメニューで [CLUSTERS] を選択し、更新するクラスター名を選択します。
[アクション] で、[IAM ロールの管理] を選択します。[IAM ロール] のページが表示されます。
[Enter ARN (ARN の入力) ] を選択し、ARN または IAM ロール を入力するか、リストから IAM ロールを選択します。その後、[Add IAM role (IAM ロールの追加)] を選択して、[Attached IAM roles (アタッチされている IAM ロール)] のリストに追加します。
[完了] を選択し、IAM ロールをクラスターに関連付けます。これで、クラスターが変更され、変更が完了します。外部スキーマと外部テーブルを作成する
今回はAthenaのデータカタログを参照するスキーマを作成するためスキーマ作成までしたら外部テーブルは作成しません。
create_external_schema.sqlcreate external schema athena_schema from data catalog -- 任意のスキーマ名を指定 database 'sampledb' -- Athenaのデータベース名を指定 iam_role 'arn:aws:iam::123456789012:role/MySpectrumRole' -- ステップ2で作成したIAMロールのarnを指定 region 'us-east-2'; -- Athena データカタログが置かれている AWS リージョンを指定外部スキーマを作成するとAtheaで利用していたデータカタログが利用できるようになり、そのままSELECT文などの利用が可能となります。
クエリエディタの利用
まずクエリを実行したいのであればAWSコンソールからクエリエディタを選択します。
先程設定したユーザー名・パスワードを利用するとログインできて、そのままSQLの実行画面に移ります。ただクエリエディタには以下の注意点があります。同時に最大 50 名のユーザーがクエリエディタを使用してクラスターに接続することができます。
クラスターに接続するユーザーの最大数には、クエリエディタを介して接続するユーザーが含まれます。
同時に最大 50 のワークロード管理 (WLM) クエリスロットをアクティブにできます。クエリスロットの詳細については、「ワークロード管理の実装」を参照してください。
クエリエディタは、10 分以内に完了する短いクエリのみを実行します。
クエリ結果セットはページごとに 100 行で分割されています。
拡張された VPC のルーティングではクエリエディタを使用できません。詳細については、「Amazon Redshift 拡張された VPC のルーティング」を参照してください。
クエリエディタでトランザクションを使用することはできません。トランザクションの詳細については、https://docs.aws.amazon.com/redshift/latest/dg/r_BEGIN.html の「BEGINAmazon Redshift Database Developer Guide」を参照してください。
クエリは最大 3,000 文字保存することができますこの中でも自分は
クエリエディタは、10 分以内に完了する短いクエリのみを実行します。というものに引っかかりました。大きなクエリを実行してみたところ、10分を過ぎたと過ぎたところでクエリがキャンセルされてしまい、この情報に行き着きました。SQL クライアントツールを使用して Amazon Redshift クラスターに接続する
クエリエディタではSQLの実行に様々な制約があるため、SQLクライアントツールの利用が必要となることがあります。AWSのドキュメントではSQL Workbench/Jの利用を紹介しています。
SQL Workbench/Jのインストール
AWSのドキュメントでも説明されていますが自分はbrewコマンドでインストールしました。
brew install --cask sqlworkbenchjでインストールします。https://formulae.brew.sh/cask/sqlworkbenchj
Java Runtime Environmentの環境も必要なので用意します。参考:https://www.java.comAmazon Redshift JDBC ドライバーのダウンロードを参考にJDBCをダウンロードします。
準備はこれでできたのでSQLワークベンチを起動します。接続を以下の図のようにします。
ドライバーは先程ダウンロードしたJDBCドライバーを設定。
RedShiftコンソールからJDBCのURLを取得し設定。
ユーザー名・パスワードはクラスター作成時のものを設定。
CTAS文を利用する場合はAutocommitをチェックします。これで接続が可能となるのですが、クラスターの設定でパブリックアクセスを可能にする必要があります(参考:プライベート Amazon Redshift クラスターをパブリックアクセス可能にするにはどうすればよいですか?
またセキュリティグループでもアクセスできるように設定しておくことが必要となります。INSERT
参考:INSERT (外部テーブル)
AthenaでできないことでRedshift Spectrumでできることの一つにINSERTができるということが挙げられる。
Athenaは基本読み取りで、INSERTやUPDATEはできず、データの加工の手段とするのであればCTAS(Create Table As Select)を利用する必要があった。ただCTASを利用するたびにテーブルが増え、重複データも増えることがあり、不便に感じる側面もありました。それがRedshift SpectrumではINSERTが可能となっています。
INSERT INTO external_schema.table_name SELECT * FROM hoge_table_name上記のようなSQLでINSERTが可能です。
CTAS
CTAS文も実行可能ですが、Athenaと構文が違うので記載しておきます。
参考:CREATE EXTERNAL TABLEsyntax.sqlCREATE EXTERNAL TABLE external_schema.table_name (column_name data_type [, …] ) [ PARTITIONED BY (col_name data_type [, … ] )] [ { ROW FORMAT DELIMITED row_format | ROW FORMAT SERDE 'serde_name' [ WITH SERDEPROPERTIES ( 'property_name' = 'property_value' [, ...] ) ] } ] STORED AS file_format LOCATION { 's3://bucket/folder/' | 's3://bucket/manifest_file' } [ TABLE PROPERTIES ( 'property_name'='property_value' [, ...] ) ]CREATE EXTERNAL TABLE external_schema.hoge_table STORED AS PARQUET LOCATION 's3://example-backet/hoge/' AS SELECT * FEOM external_schema.table_nameメモ
以下気づいたことのメモです。
クラスタサイズの変更時間
クラスタサイズ変更に30分程度かかった
dc2.large → dc2.8xlarge
※一例です
費用は変更完了までは古いインスタンスものが発生する。クラスターは停止しておけば費用は発生しない
発生するのはバックアップのみ

- 投稿日:2021-01-28T14:27:14+09:00
ECR public repositories からイメージをpullできなくなったときの対応方法 ( pull access denied for public.ecr.aws )
Amazon ECRでパブリックリポジトリの提供が開始されました?
その名の通り、認証情報なしでdocker pullが可能となるわけですが、状況によってはpull access denied for public.ecr.awsとなってしまいます。
TL;DR
$ docker logout public.ecr.awsでOK
状況
ECRパブリックリポジトリを使いたく、イメージを登録しました。その時のご案内がこちら。
aws ecr-public get-login-password --region us-east-1 | docker login --username AWS --password-stdin public.ecr.aws/xxxx当然なのですが、プッシュする際は、
public.ecr.awsに対して認証情報を生成する必要があります。しばらくはこの状態で、パブリックリポジトリからpull出来ましたが突然
pull access denied for public.ecr.awsという状況に。
エラーメッセージのとおりですが、認証期限があるので期限切れになってしまっています。
エラーメッセージに従うとdocker loginが必要ですが、何のためのパブリックリポジトリやねん、という感じなので認証情報を削除しましょう。認証情報の削除方法
docker logoutをするわけですが、デフォルトでは、https://index.docker.io/v1/に対してのログアウトとなってしまうので、 link$ docker logout public.ecr.awsというように、サーバを指定しましょう。



- 投稿日:2021-01-28T13:34:40+09:00
超簡単 macからEC2にSSHで接続する方法
1、キーペアの取得
AWSのコンソールからEC2を選択し、メニューからキーペアを選択。
キーペアの作成をしてダウンロード。参考サイト
https://dx.nissho-ele.co.jp/blog/aws-beginner-ec2_20190328.html
記事の途中にキーペア作成の説明があります。2、取得したキーペアの移動と権限の設定
ダウンロードしたファイルを移動
※.sshフォルダは隠しフォルダなので見えませんのがフォルダがなくても心配ないです。
ちなみに隠しフォルダを表示するためのショートカットは 「command + shift + . 」です。
※ここではキーペア名をkeypear.penとします。mv /Users/ユーザー名/Downloads/ダウンロードしたキーペア.pem ~/.ssh mv /Users/username/Downloads/keypear.pem ~/.ssh権限の設定
chmod 600 /Users/username/.ssh/keypear.pem3、ターミナルからSSH接続をする
※カスタムユーザー名を使用して接続するか、インスタンスの起動に使用される AMI のデフォルトユーザー名 ec2-user を使用します。
※今回はデフォルトのec2-userを使用します。ssh -i /Users/username/.ssh/keypear.pem パブリックIPアドレス(パブリックIPv4アドレス)下のように表示されれば接続完了です!!
__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [ec2-user@ip-xxx-xx-xx-xxx ~]$お疲れ様でした!
- 投稿日:2021-01-28T00:57:01+09:00
AWS CodeDeploy x CodePipeline x EC2 x ALB x SVNで自動デプロイ環境を構築する
背景
- 月1度~2度リリースが発生するシステムの構築中
- 手動デプロイは工数がかかる上、危険
- せっかくなので自動デプロイにしたい
- Gitの場合はそのままAWS Codeシリーズと接続できるが、SVNで構築する資料があまりないので誰かの参考になれば……
環境
- VCS
- SVN
- 弊社はSVNがまだまだマジョリティ……
- ビルダー
- Gradle
- インフラ
- EC2
- マルチAZの2台構成
- OSはAmazon Linux 2
- ALB
- Jenkins
- 以下はチャット通知用なので任意用意でOK
- Microsoft Teams
- Microsoft PowerAutomate
- Gmail
やりたいこと
- 開発者がSVNリポジトリにコミット
- JenkinsがSVNをポーリングしてコミットを検知
- JenkinsがビルドしてS3へ資材をアップロード(検証環境・本番環境)
- AWS CodePipelineがS3のアップロードをトリガとしてパイプライン実行
- AWS CodeDeployが検証環境へローリングデプロイ
- AWS CodePipelineがGmailへ検証環境デプロイ完了・本番環境リリース承認メールを送信
- Microsoft PowerAutomate(Flow)がメールを検知してMicrosoft Teamsのチャンネルに投稿
- 開発者がチャンネルへの投稿を見て検証環境でテスト
- テストして問題なさそうであれば、開発者がAWS CodePipelineの画面より「本番環境リリース」をクリック
- AWS CodeDeployが本番環境へローリングデプロイ
この記事を読んでわかること
- 以下のCI環境構築・設定
- S3
- CodeDeploy
- CodePipeline
- Jenkins(設定のみ)
この記事で解説しないこと
- AWSアカウントの作成方法
- Gradleでのビルド方法
- Jenkinsサーバの構築方法
- 自動テスト周りの設定
前提
- ビルドはあらかじめGradleで作成したスクリプトで行う
- Jenkinsは構築済・ユーザ作成済
- 未構築の場合はEC2のAWS MarketplaceにBitnamiが出しているJenkinsのAMIがあるのでそれを使うとスムーズに構築できる
手順
S3
S3バケットの作成
リリース資材を格納するために必要。
AWSマネジメントコンソールのサービス一覧より「S3」で検索
「バケットを作成する」をクリックバケット設定
以下を設定してバケットを作成しておく
- バケット名
- 任意のバケット名(今回はデプロイ先のURLと似た名称にしました)
- バージョニング
- 「オン」
- オンにすると同じファイル名でリリース資材を格納しても自動的に連携してくれるため
CodeDeploy
エージェントのインストール
対象インスタンスにSSHし、以下のコマンドを実行してエージェントをインストールしておく
参考:CodeDeploy エージェントのインストールまたは再インストール - AWS CodeDeploy https://docs.aws.amazon.com/ja_jp/codedeploy/latest/userguide/codedeploy-agent-operations-install.html$ sudo yum install -y ruby $ mkdir [作業用ディレクトリ] $ cd [作業用ディレクトリ] $ wget https://aws-codedeploy-ap-northeast-1.s3.amazonaws.com/latest/install $ chmod +x ./install $ sudo ./install auto以下のコマンドで起動しているか確認する
$ sudo service codedeploy-agent statusappspec.ymlの作成
プロジェクトのルートに「appspec.yml」を作成する
内容は以下のようにしたversion: 0.0 os: linux files: # 展開するファイル - source: sample.war # 展開する場所 destination: /opt/apache-tomcat/webappsサービスロールの作成
ロールの作成
以下を参照してロールを作成しておく
ステップ 3: CodeDeploy のサービスロールを作成する - AWS CodeDeploy https://docs.aws.amazon.com/ja_jp/codedeploy/latest/userguide/getting-started-create-service-role.htmlロールのアタッチ
AWSマネジメントコンソールより、対象のインスタンスを右クリック→「インスタンスの設定」→「IAM ロールの割り当て/置換」
作成したIAMロールをアタッチし、インスタンスを再起動するIAMインスタンスプロファイルの作成
以下を参照してロールを作成しておく
ステップ 4: Amazon EC2 インスタンス用の IAM インスタンスプロファイルを作成する - AWS CodeDeploy https://docs.aws.amazon.com/ja_jp/codedeploy/latest/userguide/getting-started-create-iam-instance-profile.htmlアプリケーションの作成
AWSマネジメントコンソールにログインし「CodeDeploy」で検索
アプリケーションの作成
- アプリケーション名:任意のアプリケーション名
- コンピューティングプラットフォーム:EC2/オンプレミス 上記を記載して「作成」をクリック
デプロイグループの作成
デプロイグループとは
デプロイグループ = 対象環境にような概念。
今回は検証環境と本番環境で2グループ作成する。作成
「アプリケーション」画面より「デプロイグループの作成」をクリックし、以下を入力して「デプロイグループの作成」をクリック
- サービスロール
- 作成したサービスロールを選択
- デプロイタイプ
- 任意で選択(今回はインプレースデプロイにしました)
- 環境設定
- 「Amazon EC2 インスタンス」にチェックし、Nameタグで対象インスタンスを指定
- Auto Scalingは設定していないため割愛
- デプロイ設定
- 「デプロイ設定の作成」をクリック
- デプロイ設定名
- 任意
- 正常なホストの最小数
- 2台構成のため、1台生きていればよいので「数値」として「1」
- ロードバランサー
- 「ロードバランシングを有効にする」にチェック
- 「ALB・NLB」か「CLB」を選択
- 今回はALB
- ターゲットグループを選択
- 詳細 - オプション
- 一旦デフォルトのままにした
- (ロールバック機能が気になる)
これを検証環境・本番環境の両方で作成しておく。
CodePipeline
サービスを「CodePipeline」で検索し、「パイプラインを作成する」をクリック
パイプラインの設定
- パイプライン名
- 任意のパイプライン名
- サービスロール
- 「新しいサービスロール」を選択し、ロール名を記載する
- 「AWS CodePipeline がサービスロールを作成できるようになるため、この新しいパイプラインでの使用が可能になります。」にチェック
- 高度の設定
- 一旦デフォルトのままにした
ソースの設定
- ソースプロバイダ
- 今回はS3を選択
- バケット
- 先ほど作成したバケットを選択
- S3オブジェクトキー
- リリース資材を含んだZIPファイルの名称を入力
- 今回は「test.zip」とした
- 検出オプションを選択する
- Amazon CloudWatch Events を選択
ビルドステージの選択
今回は手動でビルドするためスキップ
デプロイステージの選択
「ソースの設定」とほぼ同様
- アクションプロバイダー
- AWS CodeDeploy
- アプリケーション名
- CodeDeployの設定で作成したアプリケーション名を入力
- S3 オブジェクトキー
- CodeDeployの設定で作成したデプロイグループを入力(検証)
レビュー
内容を確認し「パイプラインを作成する」をクリック
修正
現状、S3から検証環境への自動デプロイができるように設定されている。
これに「手動テストによる検証環境での確認・承認」と「本番環境への自動デプロイ」を追加する。
「ステージを追加する」より以下を追加する
1. Manual approval(メールでの通知が必要な場合は設定する。今回はGmailへの通知メール受信をトリガとしてMicrosoft TeamsのWebHookを叩くフローをMicrosoft PowerAutomateで別途作成したが省略)
2. 本番環境へのデプロイ(設定内容は上記Pipelineとほぼ同様。本番環境のS3とCodeDeployを呼ぶようにする)Jenkins
EC2 AMIにJenkinsがあったためそれをベースに新規構築した。
今回はJenkinsのユーザの作成まで終わっている前提。新規ジョブの作成
以下を入力
- ソースコード管理:Subversion
- Repository URL:チェックアウトするディレクトリのURL
- Credentials:ユーザ認証情報
- チェックアウト方式:svn revertしてからsvn updateを実行
- revertは必須ではないが気休め程度に
ビルド・トリガ
SVMをポーリングを選ぶ。
5分に1度ポーリングするように設定する。
※念のためタイムゾーンをJSTにしておくTZ=Asia/Tokyo H/5 * * * *ビルド
シェルの実行(検証環境ビルド)
ビルドスクリプトを実行し、検証環境をビルドする。
※Gradleの場合は実行権限の付与を行う
※「#WORKSPACE」はJenkinsのワークスペースを指す環境変数chmod +x $WORKSPACE/gradlew sudo $WORKSPACE/gradlew clean bootWar generateDeployZip -Penv=stgGradleの引数などはプロジェクトごとに異なるので、上記コマンドは参考程度にお願いします。
シェルの実行(本番環境ビルド)
検証環境のビルドとほぼ同様。
変数envが異なるくらい。chmod +x $WORKSPACE/gradlew sudo $WORKSPACE/gradlew clean bootWar generateDeployZip -Penv=prdシェルの実行(S3へアップロード)
検証環境・本番環境の資材をS3コマンドを利用して該当のバケットへアップロードする。
sudo s3cmd put $WORKSPACE/deploy/test_stg.zip s3://staging.deploy.test.co.jp sudo s3cmd put $WORKSPACE/deploy/test_prd.zip s3://production.deploy.test.co.jp完成
SVNリポジトリにテストコミットして動くか試してみる。
Jenkins→S3→CodePipeline→CodeDeployと走ればOK。

- 投稿日:2021-01-28T00:55:35+09:00
【Rails,AWSを使用】僕が作成したポートフォリオの紹介をします。
はじめに
フレームワークにRuby on Rails、インフラにAWSのEC2を使用してポートフォリオを作成しました。
正直なところ全体の完成度は6割程度でまだまだ改善の余地はあるのですが、一旦はサービスとして形になったので、振り返りの意味も含めアプリについて詳しく書いた記事を投稿しようと思います。
(不具合や未完成の部分については随時改善していきます)
アプリの概要
アプリ名:オフリード(英語で「リードを手放し自由にする」という意味)
URL:https://www.offlead-dog.com/
GitHub:https://github.com/yuuta-matsumoto/off_leadドッグトレーナーと犬を飼う人のマッチングサービスです。
【ドッグトレーナーとは】
犬に対してしつけや訓練を行う職業です。よく、ブリーダーと勘違いされる方が多いのですが、ブリーダーはペットの交配や出産、繁殖を手がけて市場に流通させる職業なのでドッグトレーナーとは異なります。
また、ドッグトレーナーの中でも職域によって仕事内容は変わってきます。
例えば、警察犬を訓練する人と一般家庭の飼い犬を預かって訓練する人では必要なスキルや仕事内容が大きく変わるそうです。開発に至る経緯
サービスの内容はドッグトレーナーのマッチングサービスですが、目的はドッグトレーニングを普及させ、犬の殺処分問題の解決に少しでも貢献することです。
僕が殺処分問題を知ったのは高校生の時でした。
たまたまテレビから流れてきた映像のあまりの残酷さに衝撃を受けた事を今でも覚えています。
それ以来、なんとかならないのかなという気持ちを漠然と持ち続けてきました。最初は保護犬を探せるサイトを作ろうと思ったのですが、競合するサービスが複数あったので、それならドッグトレーナーを気軽に探せるマッチングサービスはどうかと考えました。
きちんとしつけされた犬が増えれば、それが原因で捨てられる犬も減り、間接的にだが殺処分問題に貢献できるのではないか。そんな考えを経て開発に取り掛かりました。使用イメージ
ユーザー一覧画面
ユーザーのマイページ
簡易的ですがSPAっぽくしています。
投稿詳細・口コミ投稿・いいね
使用技術
フロントエンド
- jQuery 3.5.1
- HTML&CSS/SCSS
- Bootstrap4.5.3
バックエンド
- Ruby on Rails 6.0.3
- Ruby 2.6.3
- RSpec 3.9
インフラ
- MySQL 5.7.33
- Nginx 1.22.2
- AWS (EC2, ALB, ACM, RDS, Capistrano, Route53, VPC, EIP)
コンセプト
【ドッグトレーニングをもっと身近に】
欧米ではドッグトレーニングが文化として根付いている国もあるのですが、日本ではまだ言葉の意味すら知らない人が多いのが現状です。また、正しい飼い方の知識を持つ日本人も決して多いとは言えないでしょう。
とはいえ、人間の子育てにそれぞれのやり方があるように、犬のしつけも自由でいいはずです。
ですがそれは飼い方に対して、ある程度の知識を持っている前提の話だと僕は思います。ドッグトレーニングは、本質的には「人間のトレーニング」です。
なぜならその先何年もの日々を共に過ごすのは、ドッグトレーナーではなく飼い主自身だからです。
また、犬の問題行動の8〜9割が飼い主自身によって引き起こされているという説もあります。サービス名のオフリードには、英語で「犬のリードを手放し自由にさせる」という意味があるそうです。
犬と人間が今よりも良い形で共存する為にドッグトレーニングの普及は必要不可欠であると考えています。DB設計
ER図
テーブル設計
テーブル名 説明 users 登録ユーザー情報 posts ドッグトレーナーが投稿するプラン relationships フォロー・フォロワー関係を管理 likes いいねを管理 reviews 口コミを投稿 messages DM機能のメッセージ内容を管理 entries usersとroomsの中間テーブル rooms メッセージルームを管理 機能一覧
ユーザー認証
- ログイン、ログアウト、会員登録
- プロフィール編集
- ゲストログイン
投稿機能
- ドッグトレーナーがプランを投稿(プラン名、内容、金額)
口コミ投稿機能
- 投稿されたプランに対しての口コミ
- 星評価
- プロフィール画面で投稿一覧が見られる
メッセージ機能(メンテナンス中)
- ユーザー同士で1対1のメッセージが可能
- メッセージボタンを押すと新規メッセージルームが作成される。
- (作成済みの場合は既存のメッセージルームにリダイレクト)
画像アップロード(CarrierWaveを使用)
- プロフィール画像のアップロード
- プラン投稿時の画像アップロード
フォロー機能
- フォローボタンを押すとフォロ、フォロー解除が行える
- プロフィール画面でフォロー中、フォロワーが見れる
いいね機能
- 投稿されたプランにいいねができる
- プロフィール画面でいいね一覧を確認できる
工夫したポイント
開発の際に現職のドッグトレーナーの方からの意見を聞き、その内容を取り入れました。
アプリの概要が決まり、要件定義など諸々の準備が整っていざ開発、という時に僕の中でふと「これって本当にニーズあるの?」という疑問が生まれました。
当たり前ですが、ユーザーの潜在的なニーズを満たすサービスでなければ使ってもらうことはできません。
自分なりに考えを落とし込んだつもりでしたが、実際のユーザーに意見が聞きたい、そう思いツイッターを通じて現職のドッグトレーナー10名にお声がけしたところ、ありがたい事に2名からご返信を頂き、話を聞くことができました。実際にお話を聞いてみると、自分の知らなかった事や考えの至らなかった点がたくさん聞けたのですが、その中でも以下の2つは特に参考になりました。
ドッグトレーナーは個人事業主が多く、そのほとんどは自分でWEBサイトを運用している。
⇨オフリードがある程度の集客ができるプラットフォームになれば、自前サイトを運用しなくてもよくなり、コストカット・手間削減につながるはず。サイト内でユーザー同士が直接やりとりできた方が成約率は上がると思う。
⇨当初予定にはなかったDM機能を実装する。それまでの僕は、いかにサービスを完成させるかだけに注力していました。ユーザーファーストで考える事の大切さを肌で感じる事のできた貴重な体験だったと思います。
ご協力頂いたお二人からは「ニッチな領域だが発想は面白い」「完成したらぜひ協力させてください」と言って頂けました。ただ、ユーザーの話を鵜呑みにしてそれを採用することは誰にでもできるので、今後似たような機会があった際には、ユーザーの意見を知った上で鵜呑みにせず、何を提供すればそのニーズを満たせるのかの最適解を探せるエンジニアになりたいです。
苦労したポイント
独学での作業で、知り合いのエンジニアもいなかった為、最初から最後まで苦労しっぱなしですが、その中でフロントエンド、バックエンド、AWSに分けて紹介していこうと思います。
フロントエンド
- 細かいスタイルの調整(SCSS)
フロントエンド
メッセージ機能の実装
⇨多対多のDB構造を理解するまでの時間がかかりました。
また、コントローラーの記述が複雑で他の機能を実装する時よりも苦労した記憶があります。モデルのアソシエーション
⇨全体的にActive Recordの関連付けでは苦労しました。AWS
プリコンパイル
⇨デプロイ時にasset:precompileが実行できず、3日以上ハマってしまいました。
最終的にSprocketsに移行することで解決。Capistranoの導入
⇨Unicornの設定で手こずったり、環境変数の渡し方を間違えていたり複数箇所でつまづいてしまいました。
このあたりから公式のリファレンスを参照することを意識していました。最後に
総じて技術的な内容よりも、エピソードや自分の思っていることをメインに綴った記事になってしまいました。
技術的にはまだまだ未熟なので引き続き学習を続けていこうと思います。今後の実装・改修予定
- メッセージ機能(1対1のメッセージルームを正常に作成)
- デザイン全体の改善
- レスポンシブ対応にする
- 通知機能
- 絞り込み検索
- ユーザーの属性毎にインターフェイスを分ける(ドッグトレーナーとその他のユーザー)
- Vue.jsを用いたSPA化
- 安全なテストコードの記述
- 決済機能の導入
追加機能の実装やアプリの改修を行った際には随時、記事にまとめて投稿していく予定です。
最後までご覧頂きありがとうございました。



