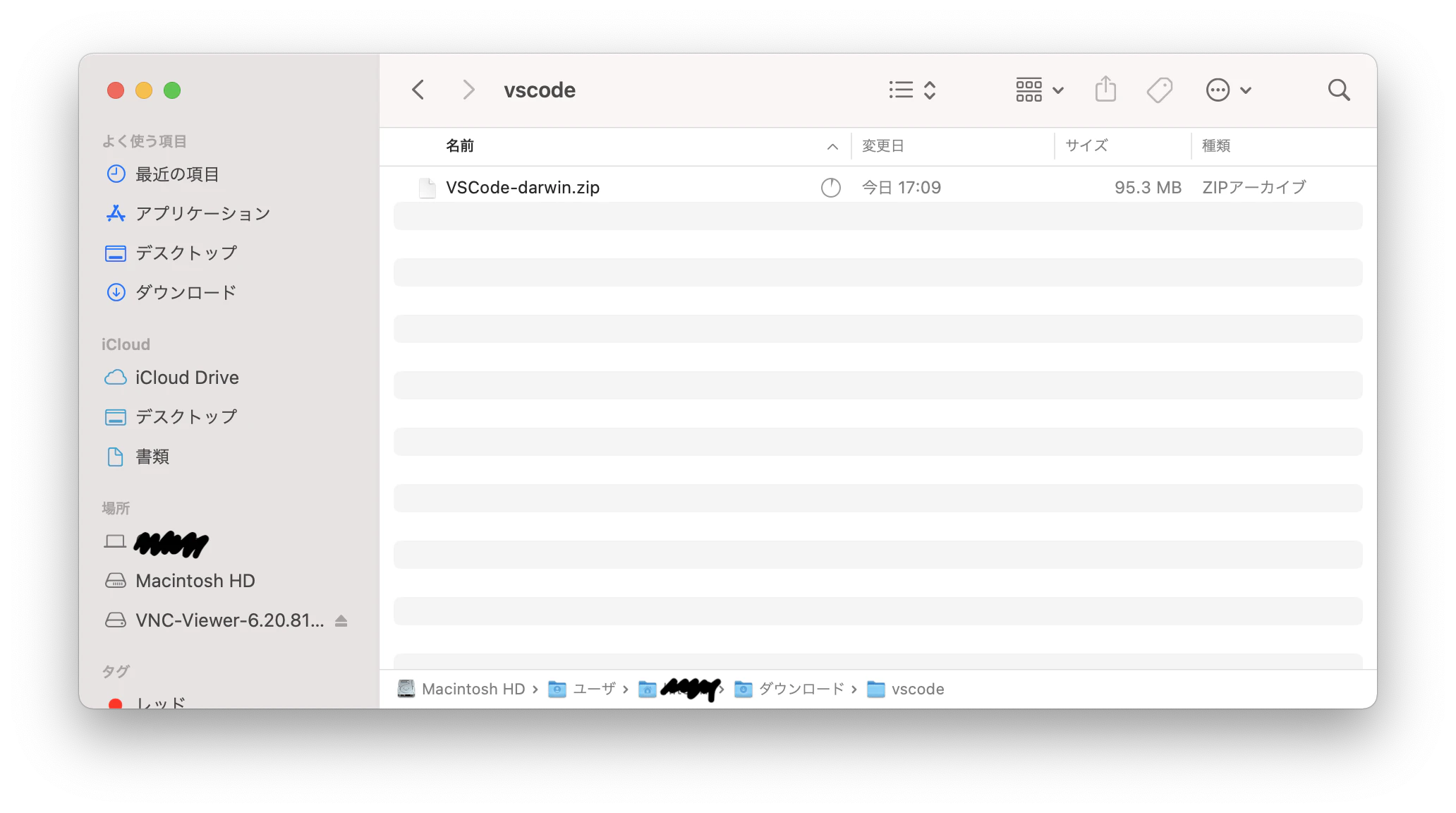
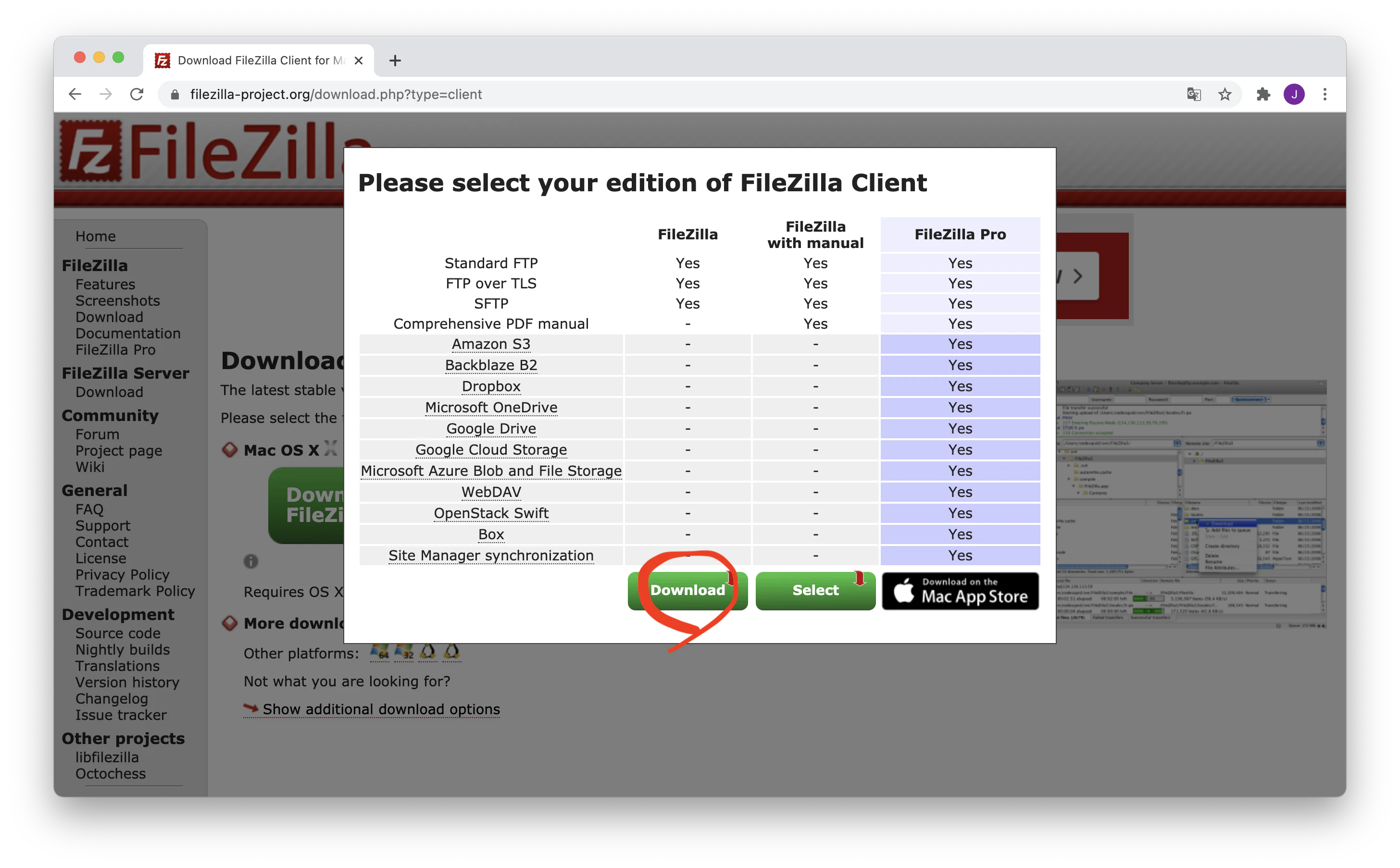
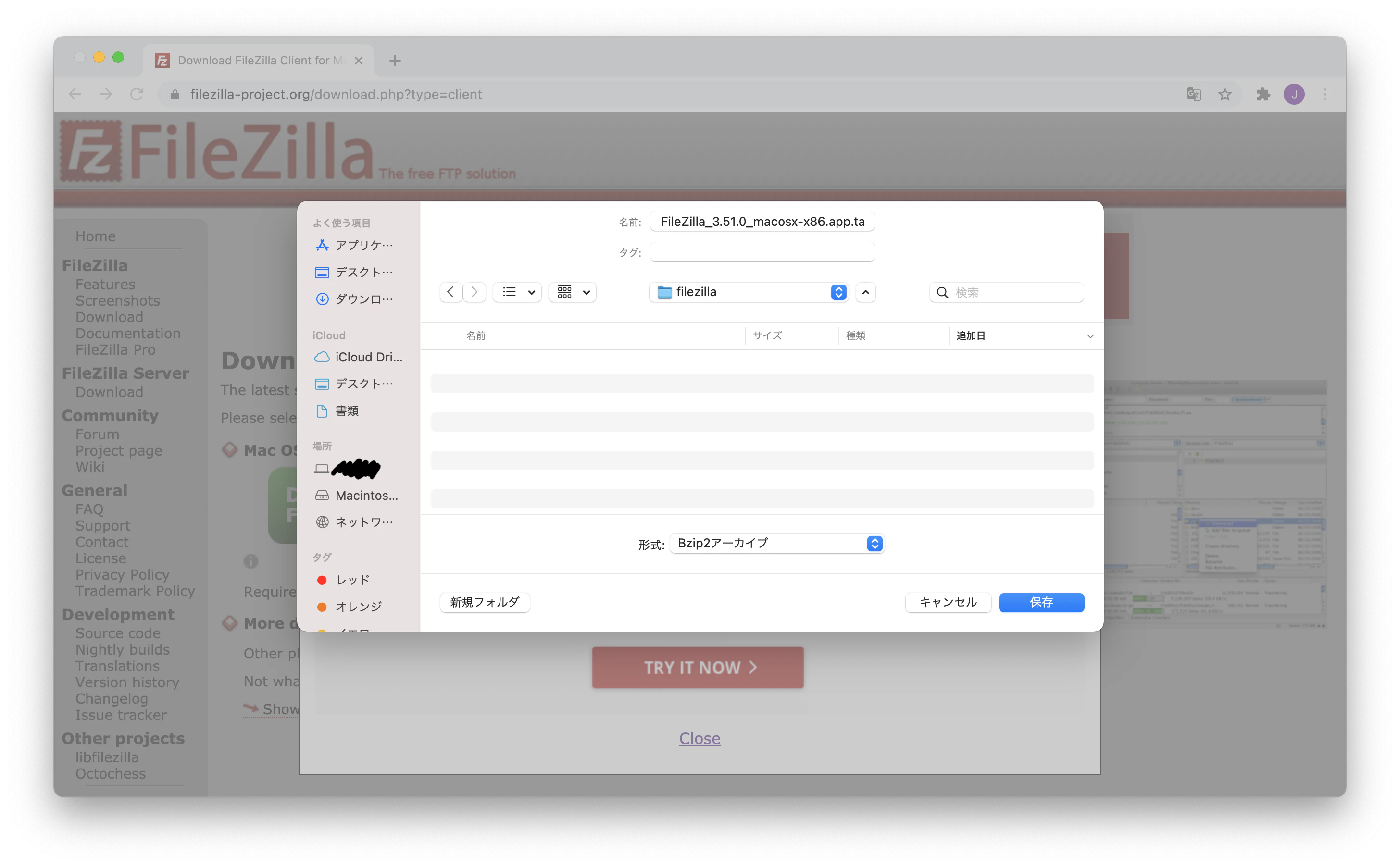
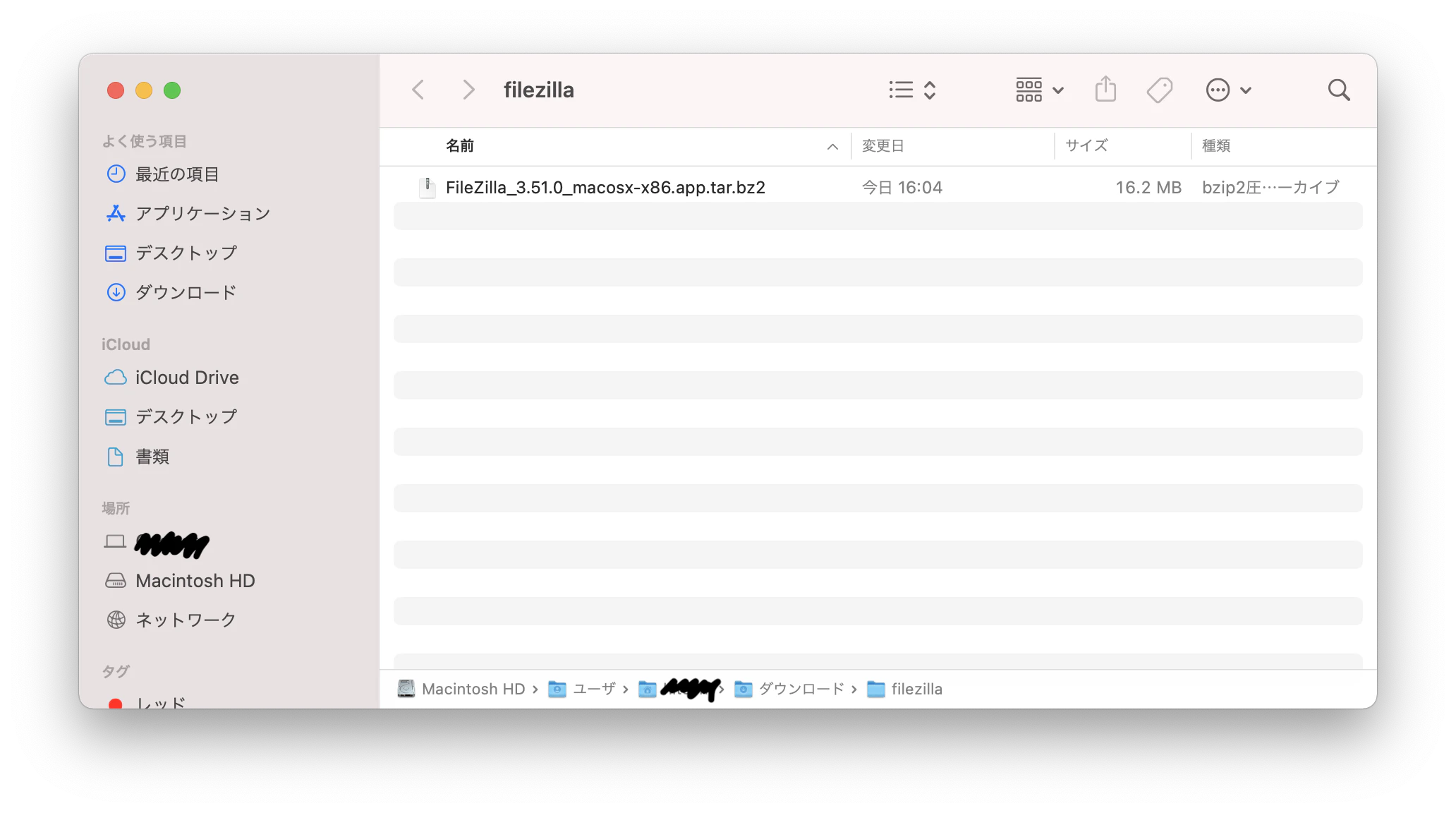
- 投稿日:2020-12-15T23:52:02+09:00
モデル作成後に、サーバ起動&アクセス時に「TypyError:'set' object is not reversible」となる場合の確認箇所について(@Python/jango)
はじめに
今回は、Djangoアプリ作成過程で起きたエラーについて触れていこうと思います。
TypyError:'set' object is not reversibleモデル作成を行った後、サーバー起動しアクセスした際に発生しました。
結論としては、入力ミスでしたので内容を確認していきます。
エラー詳細
models.pyを編集した後に、
以下のコマンドでサーバ起動しアクセス。$ python manage.py runserver
原因
アプリケーションフォルダ内の
urls.pyの記述が以下の通りになっていました。。urlpatterns = { path('', views.index, name='index'), }誤:{}
正:[]
まとめ
基礎を確認しながら引き続き頑張ります!
参考にさせていただいた記事の作成者様ありがとうございました。

- 投稿日:2020-12-15T23:47:30+09:00
潮が気になるすべてのvimmerへ
はじめに
第二のドワンゴ Advent Calendar 2020 16日目の記事です。
前日の記事は、2020 年の Ebiten でした。全く関係ありませんが、私は海老天が大好きなので、Ebiten も応援しています。さて、表題ですが、
潮で画像検索するとかんむすがでてきますが、もちろん彼女のことではありません。潮を辞書で引くと、
- 月や太陽の引力で海水が満ち引きする現象。
- ある事をするのに適した時。よいころあい。潮時。
とあります。
ここでは、1の意味を指します。
つまり潮汐のことです。
潮汐は非常に重要な自然現象で、潮汐によって船が出港・帰港できなかったり、魚の活性が変わることにより漁獲量や釣果にも影響を与えます。
筆者もvimで釣りイベントの企画を書いているときに潮汐情報を参照したいことがありましたが、Webで潮汐情報を参照するのが面倒臭いことがしばしばありました。
というわけで、vimから直接潮汐情報を参照できると便利じゃね?ということで、vimプラグインを作ることにしました。
潮汐情報を取得する
前述したとおり、潮汐情報は経済や安全に大きな影響を与えるため、日本では気象庁が 潮位表 で潮汐情報を公開しています。
過去の潮位と未来の潮位の予測を 潮汐・海面水位に関する診断表、データ から参照することが出来ます。
各地点の潮汐情報は、潮位表(PDF版・テキストデータ版)フォーマットにおいてPDFとテキストデータで公開しており、テキストデータについては、
https://www.data.jma.go.jp/gmd/kaiyou/data/db/tide/suisan/txt/{西暦4桁}/{地点記号}.txtという形式で参照することが出来ます。地名と地点コードの対応表は、潮位表掲載地点一覧表 から参照することが出来ます。
例えば、2020年の川崎(地点コード:
KW)の潮位表は https://www.data.jma.go.jp/gmd/kaiyou/data/db/tide/suisan/txt/2020/KW.txt から参照することが出来ます。潮位表フォーマット
潮位表フォーマットは潮位表(PDF版・テキストデータ版)フォーマットで公開されており、以下のような仕様となっています。
- テキストファイルの改行コードは
LF- 毎時潮位データ
- 1-72カラム
- 3桁×24時間(0時から23時)
- 年月日
- 73-78カラム
- 2桁×3
- 地点記号
- 78-80カラム
- 2桁英数字記号
- 満潮時刻・潮位
- 81-108カラム
- 時刻4桁(時分)、潮位3桁(cm)
- 干潮時刻・潮位
- 109-136カラム
- 時刻4桁(時分)、潮位3桁(cm)
- 満(干)潮が予測されない場合、満(干)潮時刻を「9999」、潮位を「999」とする
例えば以下の潮位表データは
65 47 39 44 61 8611313715315915414212711210310110812113514614914212710620 1 1KW 9 3159194914999999999999999 2 7 39144210199999999999999
01:00時の潮位は47cm- 観測地点は川崎(KW)
- 満潮時刻
09:03で 潮位は159cm19:49で 潮位は `149cm- 干潮時刻
02:07で 潮位は39cm14:42で 潮位は101cmと読み取ることが出来ます。
neovimプラグイン
上述のように、潮位表フォーマットの各データは固定長であるため、各データをリーダーから順番に読み込めばいけばいいだけなので、パース処理はとてもシンプルに実装できそうです。
また、vimプラグインとして潮汐情報を取得することにしましたが、vimプラグインからスクレイピングないしはプラグイン側で潮位表データベースを持つことで、潮汐データにアクセスできそうです。
今回はネットワークが使えないところでも動作させたかった事、潮位表データベースをvimプラグイン側で持っても大した容量にはならないので、vimプラグイン側で潮位表データベースを持つ仕様にしました。
そのため、スクレイピングによる潮位表データベース作成バッチを年1回ほど回し、リポジトリに突っ込む実装にしました。
また、あまりVimScriptを書きたくなかったこと、筆者がneovimに完全移行したこと、neovimはPythonのリモートプラグインが書きやすいことから、今回は pynvim を使って、プラグインを書くことにしました。
pynvim では Pythonのデコレータを使用することで簡単にリモートプラグインの内部実装を記述することが出来、また pynvim から簡単にneovimのコマンドが呼び出せるため、非常にneovim プラグインが書きやすいです。
以上の仕様と実装を決めて作ったのが tide-ja.vim です。
https://github.com/ymizushi/tide-ja.vim
インストール方法や使用方法、表示など詳しい情報は、README.md を参照してください。
参考までにスクリーンショットを載せておきます。
実際に使っている感想としては、インターネットにアクセスせずに、簡単に目的の地点の潮汐情報を取得できるので、重宝しています。
潮汐情報が気になる人は、船乗りだったり釣り人だったりと、限られるとは思いますが、vimmerで潮汐情報が気になる人は使ってみてはいかがでしょうか。ちなみに、私は休日は ヤマハシースタイル で ボートを借りてタイラバ1、オカッパリ2ではイカ・タコ釣りに興じることが多いです。
釣り好きな方の連絡お待ちしております。
まとめ
- 潮汐情報は気象庁公式ウェブサイトから取得できる
- ある地点の毎時潮位、満潮・干潮の時刻とその時の潮位ががPDF・テキストフォーマットで取得できる
- テキストフォーマットはシンプルなフォーマットなので簡単にパース出来る
- neovim, pynvim を使うと簡単にneovimのリモートプラグインを作ることが出来る
- 釣り好きなかたの連絡をお待ちしております
明日の記事は、ytanaka さんです。よろしくお願いします。
- 投稿日:2020-12-15T23:31:57+09:00
unable to import 'google.cloud'pylint(import-error)でPythonのimport文が認識されないときの対処方法
※この記事は自身のブログからの転載です。
unable to import 'google.cloud'pylint(import-error)でPythonのimport文が認識されないときの対処方法 | outputableVSCodeでPythonを記述しているとpipのライブラリにあるにもかかわらずimport-errorがでていたので、修正してみた。
環境
virtualenvwrapperでPython仮想環境を作るで導入した仮想環境内のpipで「google-cloud-datastore」をインストールしていたが、VSCodeで正しく認識されていない。
VSCodeのターミナルを起動して
$ workon [該当の仮想環境名]としてライブラリのある環境に切り替えるも、「from .. import ...」の部分が赤波線のまま。
settings.jsonを開く
以下の画面から「settings.json」を開き編集しにいく。
File -> Preferences -> Settings
もしくは
「 ctrl + , 」で設定を開き、「Python > Auto Complete: Extra Paths」の欄にある「Edit in settings.json」を開く。
settings.jsonに追記
まずpipでライブラリを入れている仮想環境にログインし、pythonインタプリタの場所を調べる。
$ workon [仮想環境名] $ which python控えたpythonインタプリタのパスを以下の要素を追加し、保存する(ctrl + s)。
{ "workbench.startupEditor": "newUntitledFile", "git.autofetch": true, "emmet.extensionsPath": "", "emmet.variables": { "lang": "ja", "charset": "UTF-8" }, "editor.snippetSuggestions": "top", "editor.tabSize": 2, "go.useLanguageServer": true, "python.autoComplete.extraPaths": [ ], "python.pythonPath": "/home/[ubuntuユーザー名]/.virtualenvs/[仮想環境名]/bin/python" }無事に解消できた!
最後に
VSCodeが見やすいし使いやすいので利用しているが、やはり不正な文法エラー表示は解消できてよかった。
今後の開発が捗りそう。
今回はこのへんでおしまい。

- 投稿日:2020-12-15T23:31:57+09:00
[ VSCode ] unable to import 'google.cloud'pylint(import-error)でPythonのimport文が認識されないときの対処方法
※この記事は自身のブログからの転載です。
[ VSCode ] unable to import 'google.cloud'pylint(import-error)でPythonのimport文が認識されないときの対処方法 | outputableVSCodeでPythonを記述しているとpipのライブラリにあるにもかかわらずimport-errorがでていたので、修正してみた。
環境
virtualenvwrapperでPython仮想環境を作るで導入した仮想環境内のpipで「google-cloud-datastore」をインストールしていたが、VSCodeで正しく認識されていない。
VSCodeのターミナルを起動して
$ workon [該当の仮想環境名]としてライブラリのある環境に切り替えるも、「from .. import ...」の部分が赤波線のまま。
settings.jsonを開く
以下の画面から「settings.json」を開き編集しにいく。
File -> Preferences -> Settings
もしくは
「 ctrl + , 」で設定を開き、「Python > Auto Complete: Extra Paths」の欄にある「Edit in settings.json」を開く。
settings.jsonに追記
まずpipでライブラリを入れている仮想環境にログインし、pythonインタプリタの場所を調べる。
$ workon [仮想環境名] $ which python控えたpythonインタプリタのパスを以下の要素を追加し、保存する(ctrl + s)。
{ "workbench.startupEditor": "newUntitledFile", "git.autofetch": true, "emmet.extensionsPath": "", "emmet.variables": { "lang": "ja", "charset": "UTF-8" }, "editor.snippetSuggestions": "top", "editor.tabSize": 2, "go.useLanguageServer": true, "python.autoComplete.extraPaths": [ ], "python.pythonPath": "/home/[ubuntuユーザー名]/.virtualenvs/[仮想環境名]/bin/python" }無事に解消できた!
最後に
VSCodeが見やすいし使いやすいので利用しているが、やはり不正な文法エラー表示は解消できてよかった。
今後の開発が捗りそう。
今回はこのへんでおしまい。
- 投稿日:2020-12-15T23:12:15+09:00
分散処理を民主化するRay
イントロ
日立製作所 研究開発グループの中田です。普段、エッジコンピューティングや分散システムの研究開発、またシステムアーキテクトをやっています。
公私ともにQiitaは初投稿です。今回は、Rayを紹介します。
Rayは、分散処理を含むアプリを開発するためのライブラリおよび実行環境です。まだ日本では情報が少ないのですが、海外では有名企業や大学がこぞって活用しており、かなりホットなライブラリだと思います。今年2020年10月1日にバージョン1.0がリリースされました。また同じタイミングにRay Summitが開催され、50本程のセッションで多数の活用事例が紹介されました。
Rayは、通常の手続き型言語を容易に分散処理化できるものであり、データ分析やエッジ/IoTの分野で有用に思えるので、日本でも広まって欲しいと思っている次第です。
本記事では、そもそもここでの分散処理とは何か、から始めて、使い方や特徴と、Ray Summitで紹介された活用事例をまとめます。Let's enjoy distributed computing!
(環境:Python3.8、ray1.0.1-post1)
Rayとは
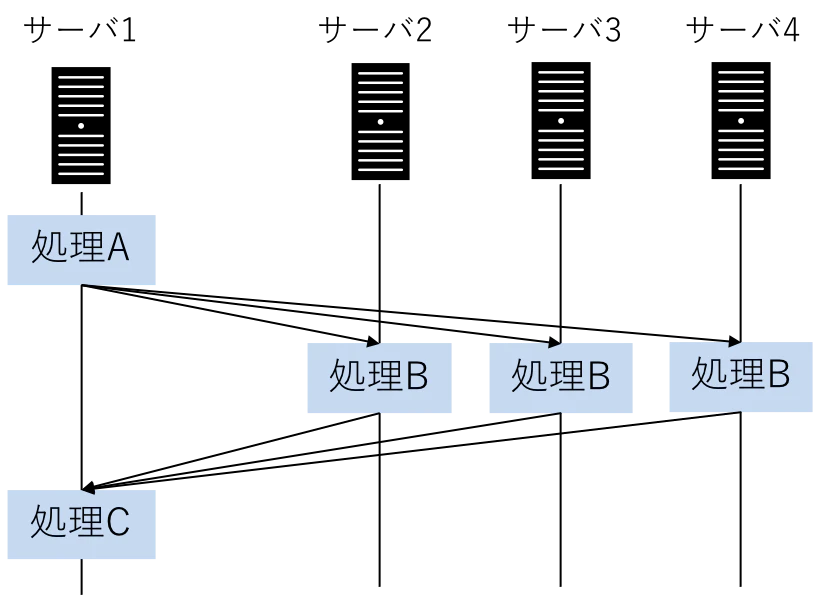
Rayは、分散処理を簡単に記述するためのPython/Javaのライブラリ・処理基盤です。Rayを使うことで、あたかもローカルで動くような見慣れたプログラムを、複数のスレッド、複数のコア、複数のサーバ、複数のクラウドにまたがって実行することができます。
(Google検索では、"ray distributed"などと検索するとトップに出ます)
Rayが対象とする分散処理
まず、ここでの分散処理のイメージを合わせておきましょう。
Rayは、一つのアプリケーションの中において、一部の処理を、別の場所(スレッド、コア、サーバ、クラウド)で動かすような、アプリケーションアーキテクチャとしての分散処理を開発するためのものです。
例えば、このような処理です。
上は、主にスケールアウトのために行う分散処理です。例えば、MapReduceが含まれます。処理を並列に実行するため、分散"並列"処理と言われたりします。
他にも、このような処理もRayの範疇です。
これは、一つの処理の流れではあるものの、処理をする場所が処理ごとに異なっているケースです。例えば、オンプレの大量データをクラウドに送信したり保管するコストを抑えるために、オンプレである程度のデータ処理を行い、結果だけクラウドのシステムに持っていく、というイメージです。
「アクターモデル」と呼ばれるアーキテクチャもRayで容易に実装できます。
アクターモデルは、非同期分散処理を記述するためのアーキテクチャパラダイムの一つです。アクターは、特定の責務を持ったオブジェクト指向のオブジェクトのようなもので、他のアクターから生成されたり、常駐プロセスのように稼動させたりできます。アクターは互いにメッセージを投げ合ってリアクティブに反応します(メッセージの内容や型に応じた処理を実行します)。その処理の連携(連鎖)によってアプリケーションの機能が実現されます。
アクターは、状態をインメモリに持つ常駐プロセスとして実現できるため、ある意味で、DDD(ドメイン駆動設計)で言うドメインオブジェクトのマテリアライズドビューのようなものも実現できます。これを応用し、エッジコンピューティングでは、エッジデバイスの状態を反映するDigital Twinをアクターで表現することが考えられたりします(ご参考1, ご参考2、ご参考3)。
3つ例を挙げましたが、総じて、ここでの分散処理は、一つのアプリケーションの中の話です。コンテナ技術も分散処理ですが、一つのアプリを複数稼動させるシステムレベルのアーキテクチャであり、Rayとはレイヤーが違います。
一つのコンテキスト(関心事の範囲)の中に、分散処理を入れたい場合は、分散処理のためにアプリを分割したり、ドメインロジックを記述すべきところに分散処理用のコードを入れたくはないため、Rayのようなライブラリ・実行環境をうまく使い、システムの可読性・メンテナンス性を向上させるのが良いでしょう。
Rayの基礎的な使い方
Rayを使えば、分散処理がローカルで実行されるコードとあまり変わらずに記述できます。
まず、並列処理を行う一般的なPythonスクリプトを見てみましょう。
from multiprocessing import Pool import time def waiting(core_id): time.sleep(core_id) return core_id if __name__ == "__main__": CORE_NUM = 4 p = Pool(CORE_NUM) results = [p.apply_async(waiting, args=[x]) for x in range(CORE_NUM)] print([x.get() for x in results])4つのコアに、1~4秒待つ処理を実行していますが、
x.getで各処理が終わるのを待っています。並列で行っているので、1+2+3+4=10秒待つことはなく、4秒だけ待てば結果が返ってきます。この処理をRayを使うと、以下のように記述できます。
import ray import time ray.init(num_cpus=4) @ray.remote def waiting(id): time.sleep(id) return id if __name__ == "__main__": print(ray.get([waiting.remote(x) for x in range(4)]))
@ray.remoteが付いた関数が、__main__を実行するコアとは別のコアで実行されます。先ほどと似てはいますが、違いは、
p = Pool()がなくなり、代わりにray.init()が追加されたことです。これが何を意味するのかと言うと、プロセスプールを開発者が管理する必要がなくなり、Rayに任せることになります。つまり、どこに処理を割り振るか、各プロセスのメモリの管理など、分散処理における抽象度の低い面倒なことを、Rayが引き受ける構造になったわけです。そのため、開発者は、以前のコードよりも、ドメインロジックに集中できます。アクターモデルの処理は、以下のように記述できます。
import ray import time ray.init() @ray.remote class Counter(object): def __init__(self): self.n = 0 def increment(self): self.n += 1 def read(self): return self.n if __name__ == "__main__": counters = [Counter.remote() for i in range(4)] [c.increment.remote() for c in counters] futures = [c.read.remote() for c in counters] print(ray.get(futures)) time.sleep(60)先程は関数に
@ray.remoteが付いていたのが、クラスに付きます。この@ray.remoteが付いたクラスを、データと振る舞いを持つ常駐プロセスとして機能することができます。こちらも、プロセスの管理がRayに任されているため、開発者は
Counterオブジェクトの処理を指示するだけで、Rayが良きに計らってどこかで処理を実行します。Rayがプロセスの管理を行うため、プロセスのモニタリングも、Rayが機能を提供しています。
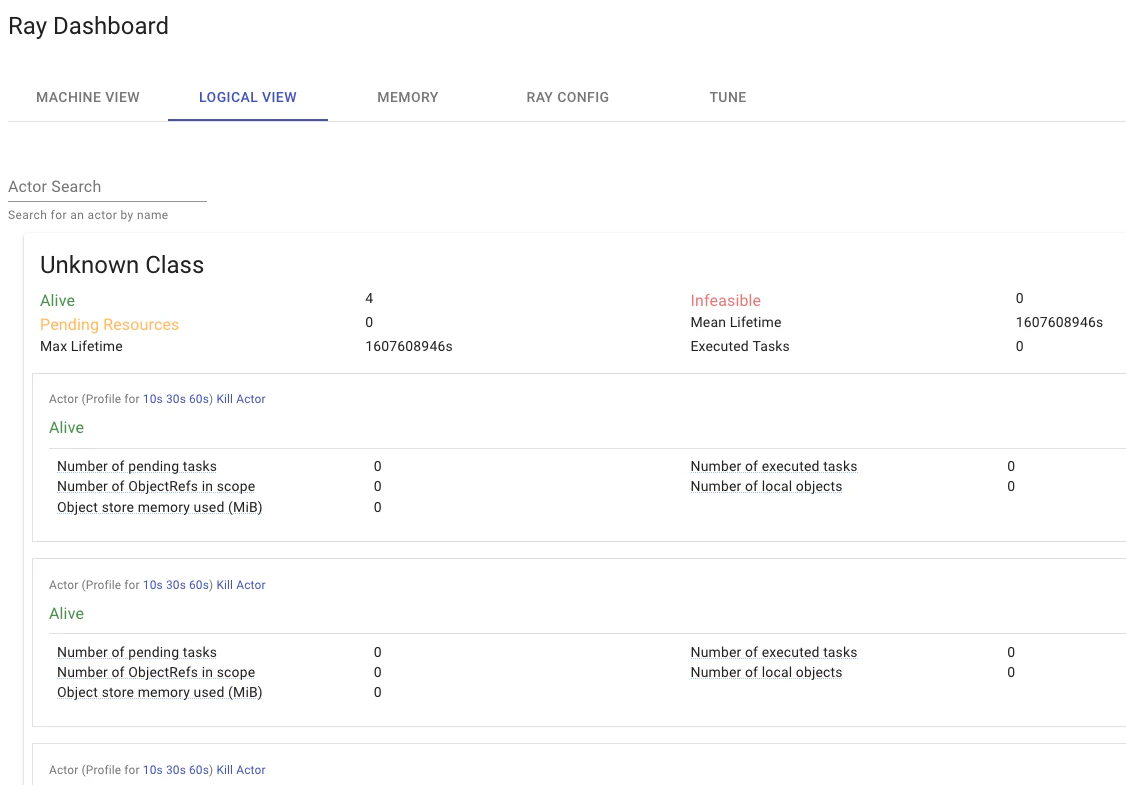
上記のアクターモデルの処理が終わる前に(
time.sleep(60)が終わる前に)、http://127.0.0.1:8265にアクセスしましょう。そうすると、Rayのダッシュボードが閲覧できます。
Rayの位置付け
コンピュータサイエンスの世界で、分散処理は長い歴史があり、Hadoop, Spark, Stormなどなど、様々な分散基盤が存在しています。これらに対するRayの位置付けは、Rayの開発者であるSchafhalter氏の講演の以下の言葉にあると思います。
Modern scalable AI applications need support for distributed training, distributed reinforcement learning, model serving, hyperparameter search, data processing, and streaming. All these problems are right now siloed into specialized distributed systems.
(中略)
Instead of having a separate distributed computing framework that solves some specific part of the machine learning lifecycle, we created Ray, a high performance distributed computing system, and built libraries on top of Ray to support all these types of workflows. Using this architecture, we can avoid overheads and leverage performance of building on one system.以下、和訳です(一部、私の理解の範囲で補足しています)。
最新のスケーラブルなAIアプリケーションには、分散トレーニング、分散強化学習、モデルサービング、ハイパーパラメータ検索、データ処理、ストリーミングのサポートが必要です。これらの問題はすべて、現在、特殊な分散システムにサイロ化されています。
(中略)
機械学習での業務におけるいくつかの特定の部分を解決する個別の分散コンピューティングフレームワークを用いる代わりに、我々はRayを作りました。Rayは、人のあらゆるタイプの作業を支える、高性能な分散コンピューティングシステム、及び、その上で動くように作られたライブラリです。このアーキテクチャを用いて、我々は(個々のフレームワークを繋ぎ合わせて使う)負担を回避し、一つのシステムでの効率的な開発を享受できるのです。引用元:InfoQ Scaling Emerging AI Applications with Ray
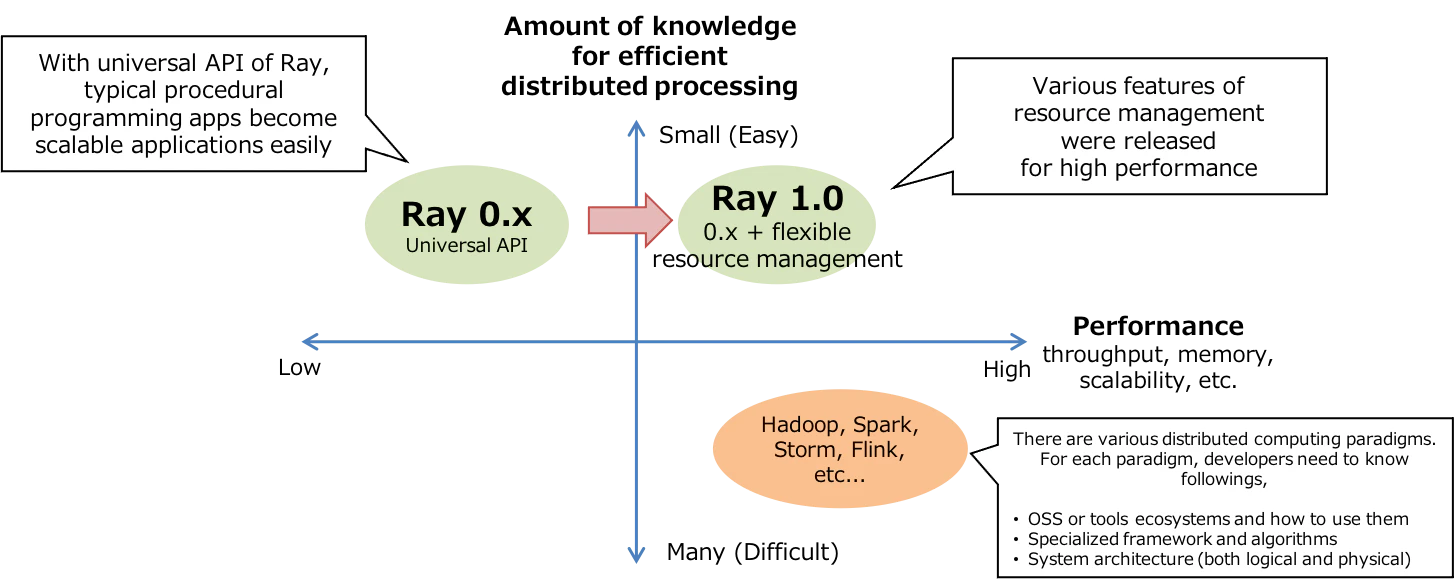
下記は私が想像する、Rayの立ち位置のイメージです。
横軸は、分散処理のパフォーマンス、縦軸は開発の容易さです。
データ処理と言っても、バッチ、ストリーム、グラフ、強化学習、ディープラーニング、などなど、とても多様なパラダイムが存在しています。従来のビッグデータ処理のプラットフォームやOSSは、それぞれのパラダイムごとに存在していました。それらのプラットフォームやOSSは、パフォーマンスを常に追求し、そのパラダイムに最適なフレームワーク、分散ロジックが出来上がりました。
しかし、このDX時代において、データを扱うのは、データエンジニアだけではなく、むしろサービス開発者、ドメインエキスパートだったりもします。そういった職種の人々が、やりたいビジネス、改善活動があったときに、一から処理パラダイムについて学習するのは酷です。
これに対して、逆のアプローチなのがRayだと思っています。極端に言うと、Rayは、通常の手続き型言語のプログラムに対し、関数に
@ray.remoteをつけるだけなので、遥かに開発難易度が下がります。当然、関数やアクターの分散という、プリミティブな部分(Universal API)のみが範疇なので、複雑で大規模なデータ処理システムをRayで開発したとき、その開発者の設計次第で、パフォーマンスが大きく変わります。Rayは1.0になり、メモリ管理や、クラスタ環境でのスケジューリングなど、多くのパフォーマンスに関する機能が追加されました。そのため、依然としてRayを使った開発者依存はあるとしても、より性能の良い分散処理アプリケーションを開発できるように、進化しているイメージです。
こういった、パフォーマンスと開発容易性の両立が、Rayの方向性なのかと感じています。
Rayクラスタの構成
分散処理の醍醐味である、複数サーバでのクラスタ構築と分散処理を体験してみましょう。
アーキテクチャ
まず、Rayが稼動するクラスタのアーキテクチャを説明します。
(Ray1.0 White Paperから引用)
Rayが稼動する環境の一単位は、ノード(node)と呼ばれます。各ノード内のWorkerは、アプリの処理を実行するプロセスを指しています。
また、全ノードに、Rayletというコンポーネントがあります。RayletはRayにおけるミドルウェアで、いわゆるコントロールプレーンと呼ばれるような、処理のスケジューリングや各プロセスが使うオブジェクトのメモリ管理などを行ってくれるものです(KubernetesでいうKubeletと同じ立ち位置であり、英語ではよくこういうコンポーネントを〇〇letと呼びます)。
Rayletには、スケジューラと、オブジェクトストアの、2つのスレッドがあります。スケジューラは、リソース(利用できるCPU/GPU、メモリ等々)の状況を共有し合い、アプリで指定した条件に合うノードに分散させたい処理を割り当てます。オブジェクトストアは、分散させたい処理の中で使っている変数を、クラスタ間で共有する場合に用いる共有メモリです。Rayでは、Plasma Object Storeという、現在はApache Arrowの中で開発されている共有メモリオブジェクトストアを利用しています。
クラスタには、ヘッドノード(Head node)とワーカーノード(Worker node)が存在します。ヘッドノードのDriverは、アプリケーションを最初に実行するプロセスのことであり、Pythonであれば、
__main__を実行するプロセスと捉えてください。また、ヘッドノードには、Global Control Store (GCS)があります。GCSは、どこにActorがあるか、など、クラスタの内部管理用のメタデータを管理するデータストアです。これは、基本的に開発者が操作するものではありません。
クラスタの構築
このクラスタ構成を構築する方法は、2通りあります。1つは、ノード構築コマンドを使って手動で構築する方法、もう一方は、Cluster LauncherというRay内のツールを用いる方法です。
まずは、手動でクラスタを構築する方法です。
最初に、ヘッドノードを構築します。やる事は、rayのインストールの他には、コマンド1つだけです。
# ヘッドノード用の環境に入る pip install -U ray ray start --head --port=6379 # ヘッドノードの構築1,2秒後に、以下のような出力が出ます。
Local node IP: xxx.xxx.xxx.xxx 2020-12-13 10:11:48,321 INFO services.py:1090 -- View the Ray dashboard at http://localhost:8265 -------------------- Ray runtime started. -------------------- Next steps To connect to this Ray runtime from another node, run ray start --address='xxx.xxx.xxx.xxx:6379' --redis-password='xxxxxxxxxx' Alternatively, use the following Python code: import ray ray.init(address='auto', _redis_password='xxxxxxxxxx') If connection fails, check your firewall settings and network configuration. To terminate the Ray runtime, run ray stop出力の指示に従って、ワーカーノードを構築します。
# ワーカーノード用の環境に入る pip install -U ray ray start --address='xxx.xxx.xxx.xxx:6379' --redis-password='xxxxxxxxxx'1,2秒後に、以下のような出力が出ます。
Local node IP: xxx.xxx.yyy.yyy -------------------- Ray runtime started. -------------------- To terminate the Ray runtime, run ray stop手動でも特に大変ではありませんが、Cluster Launcherを用いると、もっと容易にクラスタを構築できます。
まず先に以下のような構築するクラスタの内容を記載した設定ファイルを用意し、
ray up <ファイルパス>をするだけです(AWSの場合は、事前にAWSアカウントの用意、boto3のインストール、クレデンシャルの設定が必要です)。cluster_name: basic-ray max_workers: 0 # this means zero workers provider: type: aws region: ap-northeast-1 availability_zone: ap-northeast-1 auth: ssh_user: ubuntu setup_commands: - pip install ray[all]立ち上がったクラスタに、アプリケーションをアップロードし実行する場合は、
ray attach、ray rsync-up、ray execコマンドを実行します。AWS以外にも、他のクラウドベンダや、自身で用意したKubernetesクラスタにも構築できます。その際の設定ファイルなどは、こちらのCluster Launcherのドキュメントを参照してください。
クラスタ上でアプリを実行
では、最後にクラスタ上で分散処理を実行してみましょう。以下のスクリプトを、クラスタ内のどこか(ワーカーノードでもOK)に置いて、実行しましょう(先程の
ray attach、ray rsync-up、ray execコマンドを利用しても良いです)。import ray import ray._private import time ray.init(address="auto") @ray.remote def f(): time.sleep(0.01) return ray._private.services.get_node_ip_address() # Get a list of the IP addresses of the nodes that have joined the cluster. print(set(ray.get([f.remote() for _ in range(1000)])))このスクリプトでは、
@ray.remoteの付いた関数が、その関数の処理を実行したノードのIPアドレスを返すため、1000回の処理の実行場所のIPアドレスのリストが生成され、それが集合(set)になります。その結果、クラスタに含まれるノードの数が1000未満の場合は、Rayが処理を均等に割り振るため、ノードのIPのリストが出力されるはずです。ちなみに、ray 1.0.0より前は、ノードのIPアドレスを出力する機能が、
ray以下にパブリックな機能として存在していたのですが、ray 1.0.0以降は、ray._privateに移動し、プライベート化されているので、上記スクリプトは推奨されていない処理だと思います。活用事例
最後に、Rayで何を作れそうかのイメージを掴んで頂くために、Ray Summitの情報から、活用事例をピックアップします。
(ほぼ全てのセッションは、Youtubeでも公開されています。こちらのRay Summitのスケジュール表からたどれます。)
Rayを用いて金融サービスの開発プラットフォームを開発 (Ant Group)
https://www.youtube.com/watch?v=Wwv9YNlXx0Q&feature=youtu.be
Ant Groupは中国のアリババのグループ企業であり、Alipayを運用する企業です。Ant Groupのユーザーは、13億人以上おり、大量のデータをサービス開発に活用しています。
ただし、様々な新しいサービス・機能を開発する上で、データの処理は画一的であるわけがなく、ストリーミング処理、バッチ処理、グラフ理論系処理、OLAP、ディープラーニングなどなど、様々です。そのため、従来は、それぞれの処理パラダイムごとに言語、OSS、システムが異なり、サービスの開発者が勉強することが膨らみました。
そこで、Rayのクラスタを共通基盤として、Rayが提供するAPIを用いて、先程の処理パラダイムを実現するフレームワークを開発し、自社のサービス開発者に開発プラットフォームを提供しています。これにより、多様な処理パラダイムを有するデータ分析基盤においても、下回りにRayに集約して依存するOSSなどを減らし、学習コストの低減、プラットフォームの進化可能性の向上を実現させています。
また、Microsoftも、機械に動作を教える強化学習サービスをRayを用いて構築し、サービス開発を行う顧客へ提供しているそうです。
https://www.youtube.com/watch?time_continue=329&v=yRowxgcrt_Q&feature=emb_logo
プロトタイプのスケールアウトに向けたライブラリ拡張 (Intel)
https://www.youtube.com/watch?v=Wwv9YNlXx0Q&feature=youtu.be
データ分析を行うほぼ全ての人は、Pandasというライブラリを利用していると思います。しかしPandasは分散処理を意識したスケーラブルなツールではありません。そのため、ローカル環境で何らかのプロトタイプを開発しても、大量データがある本番システムに適用しようとした場合、Sparkを利用するコードなどに書き直してシステム化しないといけませんでした。
そこで、Intelは、RayでPandasのDataFrameを並列に処理する、MODINという新たなライブラリを開発しています。
従来、
import pandas as pdと書いていたところを、import modin.pandas as pdとし、数行のクラスタ構成の設定をするコードを追記するだけで、Pandasの処理がスケールアウトするようになるそうです。この事例はライブラリ開発でしたが、皆さんもPoCやプロトタイプ開発にRayを使えば、本番移行する際に、少ないコード改変でスケールさせられます。
興味を持たれた方へ
Rayは、関数の分散、アクターの分散、という分散処理に必要最小限のコアAPIを用意し、プロセスの管理等、面倒なところを管理してくれます。そのため開発者は、多くの開発者が慣れ親しんだ手続き型言語のイメージのまま、ドメインロジックにフォーカスしつつ、分散処理を含むスケーラブルなアプリを開発できます。
ただし、最後に注意点も書いて終わりにしたいと思います。
もし本格的にRayを本番システムに活用しようとする場合は、Rayの内部ロジックをしっかり理解するべきに思います。それは、Rayの制限という意味ではなく、分散処理自体が、インフラやアプリの障害も考慮した高信頼なシステムを作るためには、インフラ、ミドルウェア、アプリの様々な仕様を理解しておく必要があるためです。
例えば、共有メモリオブジェクトストレージに保存された変数のライフタイム、AWS LambdaのStep Functionsのような依存関係のある非同期呼び出しにおける処理やアクターの管理、非同期実行中の処理が動くサーバの障害における再実行ロジックなど、今回記載していない、重要な点は多くあります。
今回の記事では、Rayを広めるための入門編ということで(というのは名目であり単に疲れたので)そこまでは説明しませんが、Ray1.0がリリースされた際に公開されたRay 1.0 Architecture Whitepaperに、内部ロジックの詳細が解説されています。比較的、内容は分かりやすいので、本番利用される方は一読することをおすすめします。
- PythonはPython Software Foundationの登録商標です
- KubernetesはLinux Foundationの登録商標です
- Hadoop, Spark, Storm, FlinkはApache Software Foundationの登録商標です
- AlipayはAlibaba Group Holdingの登録商標です
- AWS及びその製品名はAmazon Web Serviceの登録商標です
- YoutubeはGOOGLE LLCの登録商標です



- 投稿日:2020-12-15T23:06:01+09:00
Microsoft Excelのセルの値を取得するPythonスクリプトを作成してみた
1. MSYS2のインストール
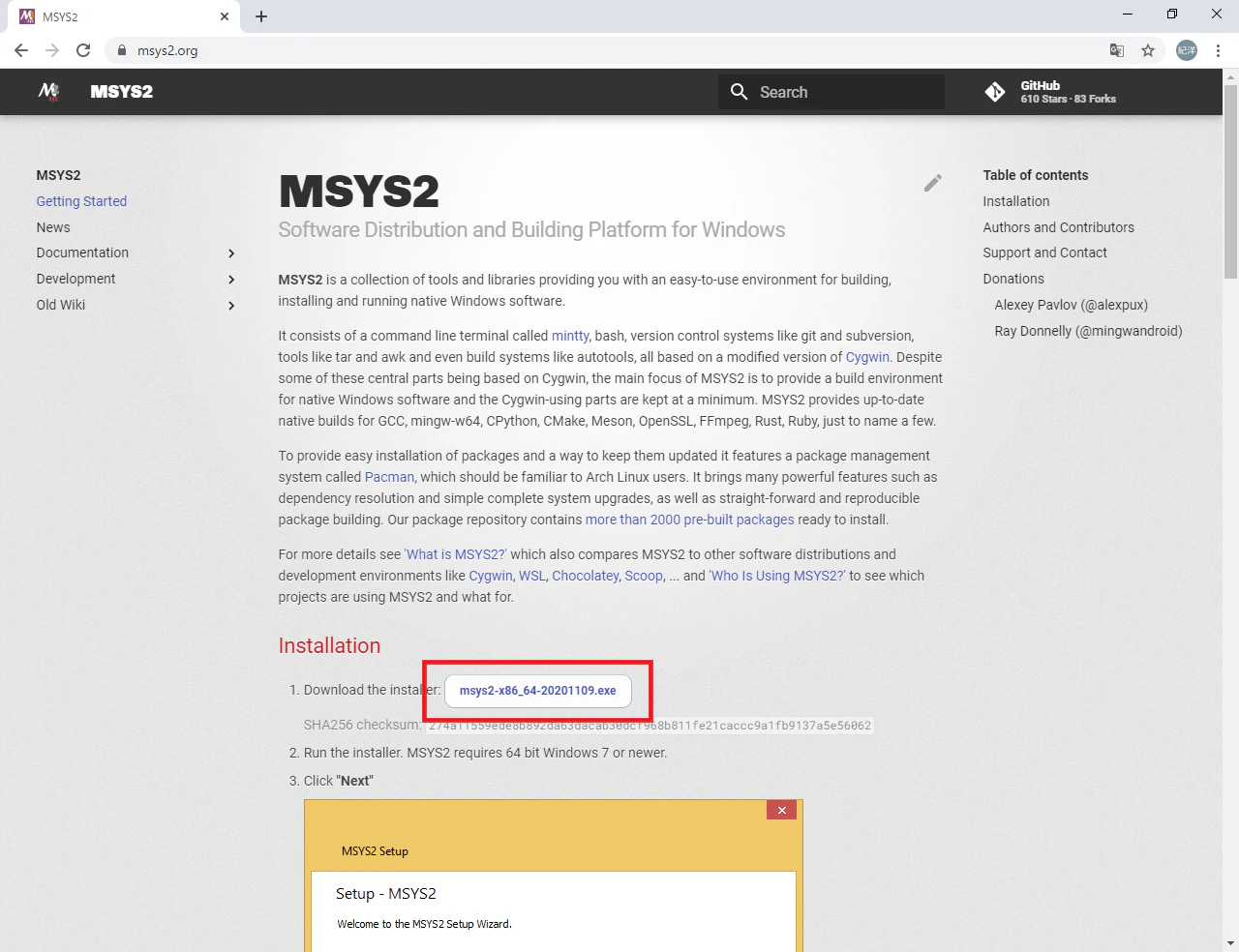
https://www.msys2.org/ からMSYS2の最新版をダウンロードし、Windows 10上にインストールする。
2. Pythonとopenpyxlのインストール
スタートメニュから「SYS2 64bit」-「MSYS2 MinGW 64-bit」を起動し、以下を実行する。
# pacman -Qe # yes | pacman -S mingw-w64-python mingw-w64-python-openpyxl # pacman -Qe3. スクリプトの作成
excellsp.py#!/usr/bin/env python3 import sys import getopt import openpyxl def usage(): print('usage: ' + sys.argv[0] + \ ' [ -h -q quotation -s separator ] workbook worksheet [celladdr...]', \ file=sys.stderr) try: opts,argv = getopt.getopt(sys.argv[1:], "hq:s:") except getopt.GetoptError as err: print(err) usage() sys.exit(1) separator = '\n' quotation = '' for opt,optarg in opts: if opt == "-h": usage() print("Pass2") sys.exit() elif opt == '-q': quotation = optarg elif opt == '-s': separator = optarg else: print("Pass1") usage() sys.exit(1) if len(argv) < 2: usage() sys.exit(1) wb = openpyxl.load_workbook(argv[0]) ws = wb[argv[1]] del argv[:2] separator = separator.replace('\\t', '\t').replace('\\n', '\n') output = '' for arg in argv: value = str(ws[arg].value); if quotation != '': value = quotation + value.replace(quotation, quotation + quotation) + \ quotation; if output != '': output += separator output += value print(output)4. テスト用ブックの作成
Microsoft Excelで以下の内容のシート「Sheet1」を持つブック「Book1.xlsx」を作成する。
A B C D E 1 a1 b1 c1 d1 2 a2 b2 c2 d2 3 a3 b3 c3 d"3 4 a4 b4 c4 d4 5. スクリプトの実行
# chmod a+x excellsp.py # ./excellsp.py -h usage: ./excellsp.py [ -h -q quotation -s separator ] workbook worksheet [celladdr...] # ./excellsp.py Book1.xlsx Sheet1 A1 C2 D3 E4 a1 c2 d"3 e4 # ./excellsp.py -s '\t' Book1.xlsx Sheet1 A1 C2 D3 E4 a1 c2 d"3 e4 # ./excellsp.py -q '"' -s '\t' Book1.xlsx Sheet1 A1 C2 D3 E4 "a1" "c2" "d""3" "e4"
- 投稿日:2020-12-15T22:34:05+09:00
呼び出すごとに1増える関数作りたい!ので作ってみた
test.pydef fueru(): global TanakaAtomicBomb if 'TanakaAtomicBomb' in globals(): TanakaAtomicBomb += 1 return TanakaAtomicBomb else: TanakaAtomicBomb = 0 return TanakaAtomicBomb使い方
下記の通り
print(fueru()) print(fueru()) print(fueru()) print(fueru()) print(fueru()) print(fueru())$ python test.py 0 1 2 3 4 5 6
- 投稿日:2020-12-15T22:27:35+09:00
初めてPythonで動くモノを作ってみた結果(画像認識)
1はじめに
こんにちは、Aidemy研修生のMagicchicです。皆さんはプログラミングというものに対してどのようなイメージを持っていますか?私がプログラミングに触れてから2ヶ月ほど経ちますが難しいという感触は抜けません。しかしそれ以上にエラーを改善して動かすことができると嬉しいです。今回はそんな初学者がpythonを用いて初めて動くモノを作ってみた結果を共有したいと思います。
2画像認識とは
最近よく聞くカメラの顔認証や工場での不良品検知など、画像認識という技術が活躍しています。写真から動物の種類を判定したりできるようにアプリでも似てる芸能人診断みたいなのもあります。こういった、高度な画像認識を実現している技術がCNN(畳み込みニューラルネットワーク)です。畳み込みニューラルネットワーク(Convolution Neural Network)とは、AIが画像分析を行うための学習手法の1つで、一部が見えにくくなっているような画像でも解析することができます。略してCNNとよばれることもあります。
畳み込み層とプーリング層という2つの層を含む構造の順伝播型のネットワークで、特徴として、それぞれの層の間に生物の脳の視覚野に関する脳科学の知見にヒントを得た、「局所受容野」「重み共有」という結合をもっています。
”多層構造”に加え、工夫された2つの隠れ層という”構造”が組み込まれたニューラルネットワークといえます。
分析する画像が入力層に読み込まれた後、このデータをくまなくスキャンし、データの特徴(勾配、凹凸など)を抽出するために使われるのがフィルタです。抽出された特徴データは畳み込み層に送られ、そこで更に特徴の凝縮されたデータが作成されます。
そして、そのCNNを誰もが簡単に利用できるようにしてくれたライブラリが、Kerasです。もし画像認識プログラムを作成するならば、KerasでCNNを作成するのが近道でしょう。
kerasとは
Kerasは,Pythonで書かれた,TensorFlowまたはTheano上で実行可能な高水準のニューラルネットワークライブラリです. Kerasは,迅速な実験を可能にすることに重点を置いて開発されました. 可能な限り遅れなくアイデアから結果に進められることは,良い研究をする上で重要です.(keras公式ドキュメントより)
3導入と手順
今回設定したテーマとして車種の判定をしようと思いました。私は車というものに対して全くの無知です。よく車を見るだけで車種を言い当てられる人を見るとすごいなと思います。対抗するというわけではありませんが機械学習で同じようなことができたらいいなと思いました。対象車種はトヨタの国産高級車から3つピックアップ
大まかな手順は以下の通りです。
1.画像収集
2.データを変換、その後学習データにnpyで保存
3.データを増やす
4.学習モデル、評価関数の構築
5.結果4説明
ここから先は上で示した手順に沿って書きます。
今回はicrawlerを用いて収集しました。pip install icrawlerこれをターミナルで実行してまずはicrawlerをインストールします。
その後テキストエディタにてfrom icrawler.builtin import BingImageCrawler crawler = BingImageCrawler(storage={"root_dir": "toyotacentury"}) crawler.crawl(keyword="toyotacentury", max_num=100) from icrawler.builtin import BingImageCrawler crawler = BingImageCrawler(storage={"root_dir": "toyotacrown"}) crawler.crawl(keyword="toyotacrown", max_num=120) from icrawler.builtin import BingImageCrawler crawler = BingImageCrawler(storage={"root_dir": "toyotamarkx"}) crawler.crawl(keyword="toyotamarkx", max_num=120)
次に集めたデータのうちデータとして使えなさそうなもの(関係のないものやはっきりとしていないもの)を目視で削除した結果それぞれ80枚になりました。それらをnpyで保存します。
from PIL import Image import os, glob import numpy as np import sklearn from sklearn import model_selection classes = ["toyotacentury", "toyotacrown", "toyotamarkx"] num_classes = len(classes) image_size = 100 # 画像の読み込み、numpyの配列に変換 X = [] Y = [] for index, classlabel in enumerate(classes): photos_dir = "./" + classlabel files = glob.glob(photos_dir + "/*.jpg") for i, file in enumerate(files): if i >= 93: break image = Image.open(file) image = image.convert("RGB") image = image.resize((image_size, image_size)) data = np.asarray(image) X.append(data) Y.append(index) #listからnumpyに変換 X = np.array(X) Y = np.array(Y) #データを学習用と評価用に分割する X_train, X_test, y_train, y_test = model_selection.train_test_split(X, Y) xy = (X_train, X_test, y_train, y_test) np.save("./toyotacar.npy", xy)
続いてデータを増やす作業です。現在の枚数では足りないはずなので対象のフォルダ内の画像を増加させます。
import os import glob import numpy as np from keras.preprocessing.image import ImageDataGenerator,load_img, img_to_array, array_to_img # 画像を拡張する関数 def draw_images(generator, x, dir_name, index): save_name = 'extened-' + str(index) g = generator.flow(x, batch_size=1, save_to_dir=output_dir, save_prefix=save_name, save_format='jpeg') # 1つの入力画像から何枚拡張するかを指定(今回は10枚) for i in range(10): bach = g.next() # 出力先フォルダの設定 output_dir = "toyotacenturyzou" if not(os.path.exists(output_dir)): os.mkdir(output_dir) # 拡張する画像読み込み images = glob.glob(os.path.join("toyotacentury", "*.jpg")) # ImageDataGeneratorを定義 datagen = ImageDataGenerator(rotation_range=20, width_shift_range=0, shear_range=0, height_shift_range=0, zoom_range=0, horizontal_flip=True, fill_mode="nearest", channel_shift_range=40) # 画像拡張 for i in range(len(images)): img = load_img(images[i]) img = img.resize((350,300 )) x = img_to_array(img) x = np.expand_dims(x, axis=0) draw_images(datagen, x, output_dir, i) import os import glob import numpy as np from keras.preprocessing.image import ImageDataGenerator,load_img, img_to_array, array_to_img # 画像を拡張する関数 def draw_images(generator, x, dir_name, index): save_name = 'extened-' + str(index) g = generator.flow(x, batch_size=1, save_to_dir=output_dir, save_prefix=save_name, save_format='jpeg') # 1つの入力画像から何枚拡張するかを指定(今回は10枚) for i in range(10): bach = g.next() # 出力先フォルダの設定 output_dir = "toyotacrownzou" if not(os.path.exists(output_dir)): os.mkdir(output_dir) # 拡張する画像読み込み images = glob.glob(os.path.join("toyotacrown", "*.jpg")) # ImageDataGeneratorを定義 datagen = ImageDataGenerator(rotation_range=20, width_shift_range=0, shear_range=0, height_shift_range=0, zoom_range=0, horizontal_flip=True, fill_mode="nearest", channel_shift_range=40) # 画像拡張 for i in range(len(images)): img = load_img(images[i]) img = img.resize((350,300 )) x = img_to_array(img) x = np.expand_dims(x, axis=0) draw_images(datagen, x, output_dir, i) import os import glob import numpy as np from keras.preprocessing.image import ImageDataGenerator,load_img, img_to_array, array_to_img # 画像を拡張する関数 def draw_images(generator, x, dir_name, index): save_name = 'extened-' + str(index) g = generator.flow(x, batch_size=1, save_to_dir=output_dir, save_prefix=save_name, save_format='jpeg') # 1つの入力画像から何枚拡張するかを指定(今回は10枚) for i in range(10): bach = g.next() # 出力先フォルダの設定 output_dir = "toyotamarkxzou" if not(os.path.exists(output_dir)): os.mkdir(output_dir) # 拡張する画像読み込み images = glob.glob(os.path.join("toyotamarkx", "*.jpg")) # ImageDataGeneratorを定義 datagen = ImageDataGenerator(rotation_range=20, width_shift_range=0, shear_range=0, height_shift_range=0, zoom_range=0, horizontal_flip=True, fill_mode="nearest", channel_shift_range=40) # 画像拡張 for i in range(len(images)): img = load_img(images[i]) img = img.resize((350,300 )) x = img_to_array(img) x = np.expand_dims(x, axis=0) draw_images(datagen, x, output_dir, i)この作業により元あった画像数の10倍、800枚まで増加しました。
それでは最後に学習モデル、評価関数の構築に移ります。
最初に注意しておきたい部分としてメイン関数の定義をする際にnp.loadで()内にデータの指定をするとエラーが発生するかも知れません。そこでallow_pickleオプションを指定すると改善されると思います。
以下リンク参照
(https://qiita.com/ytkj/items/ee6e1125476883923db8)from keras.models import Sequential from keras.layers import Conv2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense from keras.utils import np_utils import keras import numpy as np from keras.optimizers import RMSprop classes = ["toyotacentury", "toyotacrown", "toyotamarkx"] num_classes = len(classes) image_size = 100 # メイン関数の定義 def main(): X_train, X_test, y_train, y_test = np.load("./toyotacar.npy", allow_pickle=True)#ファイルからデータを配列に読み込む X_train = X_train.astype("float") / 256#データを正規化 X_test = X_test.astype("float") / 256 y_train = np_utils.to_categorical(y_train, num_classes) y_test = np_utils.to_categorical(y_test, num_classes) #トレーニング関数と評価関数の呼び出し model = model_train(X_train, y_train) model_eval(model, X_test, y_test) def model_train(X, y): model = Sequential() model.add(Conv2D(32,(3,3), padding='same',input_shape=X.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32,(3,3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Conv2D(64,(2,2), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64,(3,3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(3)) model.add(Activation('softmax')) #最適化の処理 opt = keras.optimizers.RMSprop(lr=0.0001, decay=1e-6) #正解と推定値の誤差が小さくなるようにする model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=['accuracy']) model.fit(X, y, batch_size=20, epochs=75) # モデルの保存 model.save('./toyota_cnn.h5') return model def model_eval(model, X, y): scores = model.evaluate(X, y, verbose=1) print('Test Loss: ', scores[0]) print('Test Accuracy: ', scores[1]) if __name__ == "__main__": main()実行をした際にAttributeErrorが発生するかもしれません(私だけかも知れませんが)、下記のリンクにて原因を詳しく説明していたので添付しておきます。
(https://ja.stackoverflow.com/questions/48286/python%e3%81%a7attributeerror)実行結果は以下のようになりました。
Test Loss: 2.74328875541687 Test Accuracy: 0.48333331942558295結果の考察と今後の展望
今回の実行結果ではaccuracyは50%を下回る正確性を欠いた状況、lossは0から大きくかけ離れた数値になりました。数値上昇のため画像の切り抜きや枚数増加、epoch数を変動させ最適解を見つけたいと思います。
特に「車」というテーマ上、形の大きな枠組みは大して特徴差はありません。accuracyを1.0、lossをoにできる限り近づけた後、画像を受け取り、判定する関数を定義して予測の実行を行いたいと思います。
今後の作成コードの参考予定リンク
(https://qiita.com/kenichiro-yamato/items/b64c70882473904600bf)
参考
(https://qiita.com/kazama0119/items/ede4732d21fe00085eb6)
(https://qiita.com/keimoriyama/items/846a3462a92c8c5661ff)
(https://qiita.com/keimoriyama/items/7b09d7c1797fcee6a2b0)
(https://udemy.benesse.co.jp/data-science/ai/convolution-neural-network.html)
(https://dev.classmethod.jp/articles/introduction-keras-deeplearning/)

- 投稿日:2020-12-15T22:21:25+09:00
iPhoneのスクリーンタイムをデータとしてスプレッドシートに記録してみた
はじめに
スマホ、触りすぎていませんか?
私は隙があればついついスマホでYouTubeやSNSを長々と見てしまいます。YouTubeを始めた芸能人も多く、無限にコンテンツを楽しめてしまいますよね。コロナ渦で自宅にいることが増えたこともあってか、スクリーンタイムを見て唖然としてしまう日も少なくありません...。
そんな中、スクリーンタイムをSNSに投稿して勉強のモチベーションにしている受験生を見て、こういう使い方もあるんだなぁと感心しました。
とはいえ、わざわざ設定画面を開いてスクショを撮り、それをトリミングしてSNSに手動で投稿するのは少々面倒に感じます()幸いなことに、macからも同じApple IDで登録されてデバイスのスクリーンタイムを見ることができます。また、macにはAutomatorという操作を自動化するアプリケーションがあります。
さらに、Googleが公開しているCloud Vison APIを使えば、画像から文字を抽出することができます。これらを上手いこと使って自動で「iPhoneのスクリーンタイムをデータとして記録する」までを行ってみました。
日々の生活を記録することで自己管理を効率化できるのではないかと思います!スクリーンタイムについて
スクリーンタイムで見れる項目には、
- App使用時間
- 通知
- 持ち上げ/再開回数
があります。
macのスクリーンタイム画面からは、サイドバーからこれらを選択して各項目の利用状況のグラフを見ることができます。注目すべきはシステム環境はウインドウサイズが一定で、スクリーンタイム内の文字やグラフの配置も同じような箇所にあることです。そのため、OCRで読み取りたい箇所だけを決め打ちでトリミングできます。Automator
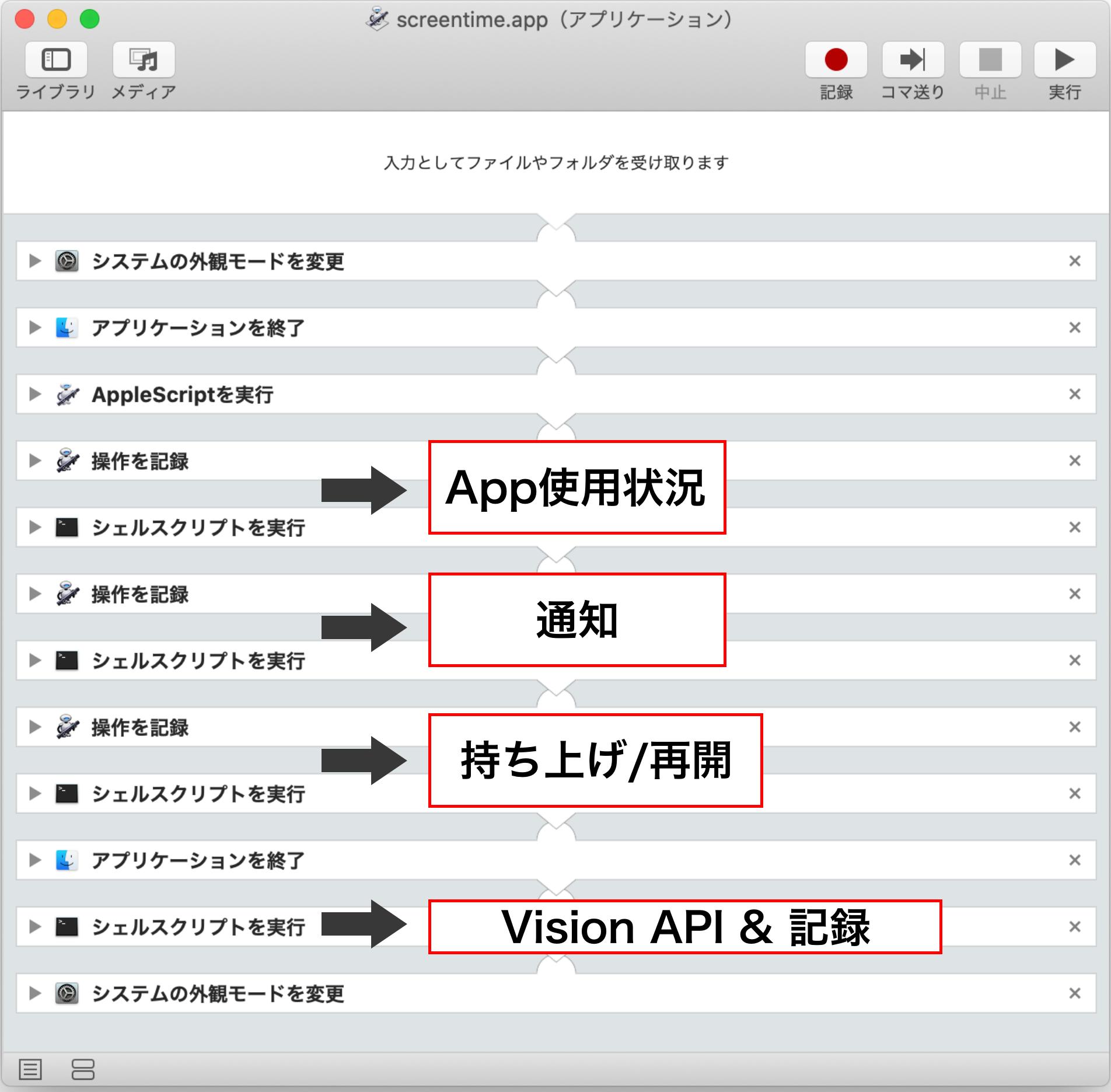
文字認識をしたいスクリーンタイムの画像を取得するためにAutomatorを使います。
Automatorの大まかな流れはこのような感じです。
- システム環境設定を開く
- 操作を記録して、スクリーンタイムを開き、取得したいデバイスを選択する
- 「App使用時間」「通知」「持ち上げ/再開回数」それぞれでスクリーンショットを撮影 & OCRしたい箇所をトリミング
- トリミングした画像をくっつけてVisonAPIでテキスト取得、スプレッドシートに記録
Automatorの詳細
システムの外観モードを変更
起動したタイミングで外観モードをライトに変更しています。
AppleScript
「アプリケーションを開く」でシステム環境設定を開くと画面が手前にならないことがあり、操作を記録のステップで処理がコケてしまうのでAppleScriptで起動しています。
tell application "System Preferences" activate end tell操作を記録
Automatorアプリの
(記録)ボタンを押して、システム環境設定 > スクリーンタイム > デバイスの選択 > 日付を昨日に変更 までの流れをを記録させています
シェルスクリプトを実行
screencaptureコマンドで画面のスクリーンショットを撮影します。-lオプションで指定したwindow1dの画面を撮影することができます。また、-xは撮影音OFF、-oはスクリーンショットの影をなくすオプションです。
前の手順でクリックした直後に撮影しないように念のためシェルスクリプトの最初でsleep 1sとしています。sleep 1s dir="$HOME/lifelog" filepath=$dir/`date -v -1d +%Y%m%d`_screentime.png crop="/tmp/cropped_1.png" screencapture -xo -l$(osascript -e 'tell app "システム環境設定" to id of window 1') $filepath /usr/local/bin/convert $filepath -crop 828x574+466+152 $filepath # パスが通っていないので、フルパスで書く /usr/local/bin/convert $filepath +repage -crop 400x60+20+60 $crop操作を記録
システム環境設定のサイドバーにある「通知」のクリック操作を記録しています。「通知」をクリックした後は上記と同じ内容のシェルスクリプトを実行します。「持ち上げ/再開」でも同様に行います。
画像の結合とVisionAPI
/usr/local/bin/convert /tmp/cropped_1.png /tmp/cropped_2.png /tmp/cropped_3.png -append /tmp/combined.png python record_screentime.py # Vision APIとシートに記録スクリーンショットとトリミング
macでは、
screencaptureコマンドでCLIからスクリーンショットを撮影できます。
トリミングにはImageMagickのconvertコマンドを使用しています。-cropオプションの値には、(width)x(height)+(left)+(top)を指定しています。
また、一度cropした画像にさらにcropしようとするとconvert: geometry does not contain imageというエラーが出てしまいましたが、-cropの前に+repageをつけることで解消できました。# ウインドウを指定してスクリーンショットを撮影 screencapture -xo -l$(osascript -e 'tell app "システム環境設定" to id of window 1') screentime.png # crop convert screentime.png -crop 828x574+466+152 screentime.png # OCRしたい箇所でさらにcrop convert screentime.png +repage -crop 400x60+20+60 screentime_cropped.png上記コマンドでOCRで文字認識したい箇所でcropすると、
- App使用時間
通知
持ち上げ/再開回数
のようになります。これらを結合した画像をVisino APIに投げます。画像の結合は、以下のコマンドで行いました。
+appendで縦方向、-appendで横方向に結合できます。convert /tmp/cropped_1.png /tmp/cropped_2.png /tmp/cropped_3.png -append /tmp/combined.png結合した画像
これで準備完了です。
Vision APIとシートに記録
いよいよ準備した画像を使って、文字認識を行ってデータとして保存します。
以下の記事などを参考にさせていただきました。
- PythonでGoogleのCloud Vision APIを利用して画像から日本語文字検出する
- 【Google Colab】Vision APIで『レシートOCR』!
- Pythonでのスプレッドシート操作方法(gspreadの使い方)
import gspread import json from datetime import datetime, timedelta from oauth2client.service_account import ServiceAccountCredentials import os import io import re from google.cloud import vision credential_path = '【サービスアカウントキーのパス】' os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = credential_path file_path = "/tmp/combined.png" with io.open(file_path, "rb") as image_file: content = image_file.read() image = vision.Image(content=content) client = vision.ImageAnnotatorClient() response = client.text_detection(image=image) data = response.text_annotations[0].description.split() # [0]でfull textを取得 scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name(credential_path, scope) gc = gspread.authorize(credentials) SPREADSHEET_KEY = '【スプレッドシートのキー】' worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1 yesterday = datetime.today() - timedelta(days=1) date = datetime.strftime(yesterday, '%Y/%m/%d') d = re.findall("\d+", data[0]) # 'xx時間yy分` -> ['xx','yy'] d = list(map(int, d)) if len(d) == 2: # xx時間yy分の場合 data[0] = d[0]* 60 + d[1] elif len(d) == 1: # yy分の場合 data[0] = d[0] data = list(map(int, data)) data.insert(0, date) worksheet.append_row(data, value_input_option="USER_ENTERED")実行すると...
スクリーンタイムのデータがシートに反映されました!
あとはAutomatorのアプリを起動すれば今までの処理を自動で行ってくれます。(本当はcronで設定したかったけど、画面操作があるためできませんでした。。)ちなみに、VisionAPIを使った文字認識の結果はこうなりました。緑がParagraph、黄色が文字を表しています。きれいに認識できていますね。
おわりに
自動化ソフトや画像認識のツールを使って、スクリーンタイムをログに残してみました。せっかくならスクショだけはでなくて数字で記録に残せるといいですよね。
VisionAPIは1ヶ月1000リクエストまで無料なので毎日スクリーンタイムを記録して問題なさそうです。今のところスクリーンタイムを記録する術は英語でググっても見つからなかったので、この記事が誰かの参考になれば幸いです。
(Appleさん、スクリーンタイムもヘルスケアから読み取れるようにしてください)







- 投稿日:2020-12-15T22:21:25+09:00
iPhoneのスクリーンタイムをOCRで記録してみた
はじめに
スマホ、触りすぎていませんか?
私は隙があればついついスマホでYouTubeやSNSを長々と見てしまいます。YouTubeを始めた芸能人も多く、無限にコンテンツを楽しめてしまいますよね。コロナ渦で自宅にいることが増えたこともあってか、スクリーンタイムを見て唖然としてしまう日も少なくありません...。
そんな中、スクリーンタイムをSNSに投稿して勉強のモチベーションにしている受験生を見て、こういう使い方もあるんだなぁと感心しました。
とはいえ、わざわざ設定画面を開いてスクショを撮り、それをトリミングしてSNSに手動で投稿するのは少々面倒に感じます()幸いなことに、macからも同じApple IDで登録されてデバイスのスクリーンタイムを見ることができます。また、macにはAutomatorという操作を自動化するアプリケーションがあります。
さらに、Googleが公開しているCloud Vison APIを使えば、画像から文字を抽出することができます。これらを上手いこと使って自動で「iPhoneのスクリーンタイムをデータとして記録する」までを行ってみました。
日々の生活を記録することで自己管理を効率化できるのではないかと思います!スクリーンタイムについて
スクリーンタイムで見れる項目には、
- App使用時間
- 通知
- 持ち上げ/再開回数
があります。
macのスクリーンタイム画面からは、サイドバーからこれらを選択して各項目の利用状況のグラフを見ることができます。注目すべきはシステム環境はウインドウサイズが一定で、スクリーンタイム内の文字やグラフの配置も同じような箇所にあることです。そのため、OCRで読み取りたい箇所だけを決め打ちでトリミングできます。Automator
文字認識をしたいスクリーンタイムの画像を取得するためにAutomatorを使います。
Automatorの大まかな流れはこのような感じです。
- システム環境設定を開く
- 操作を記録して、スクリーンタイムを開き、取得したいデバイスを選択する
- 「App使用時間」「通知」「持ち上げ/再開回数」それぞれでスクリーンショットを撮影 & OCRしたい箇所をトリミング
- トリミングした画像をくっつけてVisonAPIでテキスト取得、スプレッドシートに記録
Automatorの詳細
システムの外観モードを変更
起動したタイミングで外観モードをライトに変更しています。
AppleScript
「アプリケーションを開く」でシステム環境設定を開くと画面が手前にならないことがあり、操作を記録のステップで処理がコケてしまうのでAppleScriptで起動しています。
tell application "System Preferences" activate end tell操作を記録
Automatorアプリの
シェルスクリプトを実行
screencaptureコマンドで画面のスクリーンショットを撮影します。-lオプションで指定したwindow1dの画面を撮影することができます。また、-xは撮影音OFF、-oはスクリーンショットの影をなくすオプションです。
前の手順でクリックした直後に撮影しないように念のためシェルスクリプトの最初でsleep 1sとしています。sleep 1s dir="$HOME/lifelog" filepath=$dir/`date -v -1d +%Y%m%d`_screentime.png crop="/tmp/cropped_1.png" screencapture -xo -l$(osascript -e 'tell app "システム環境設定" to id of window 1') $filepath /usr/local/bin/convert $filepath -crop 828x574+466+152 $filepath # パスが通っていないので、フルパスで書く /usr/local/bin/convert $filepath +repage -crop 400x60+20+60 $crop操作を記録
システム環境設定のサイドバーにある「通知」のクリック操作を記録しています。「通知」をクリックした後は上記と同じ内容のシェルスクリプトを実行します。「持ち上げ/再開」でも同様に行います。
画像の結合とVisionAPI
/usr/local/bin/convert /tmp/cropped_1.png /tmp/cropped_2.png /tmp/cropped_3.png -append /tmp/combined.png python record_screentime.py # Vision APIとシートに記録スクリーンショットとトリミング
macでは、
screencaptureコマンドでCLIからスクリーンショットを撮影できます。
トリミングにはImageMagickのconvertコマンドを使用しています。-cropオプションの値には、(width)x(height)+(left)+(top)を指定しています。
また、一度cropした画像にさらにcropしようとするとconvert: geometry does not contain imageというエラーが出てしまいましたが、-cropの前に+repageをつけることで解消できました。# ウインドウを指定してスクリーンショットを撮影 screencapture -xo -l$(osascript -e 'tell app "システム環境設定" to id of window 1') screentime.png # crop convert screentime.png -crop 828x574+466+152 screentime.png # OCRしたい箇所でさらにcrop convert screentime.png +repage -crop 400x60+20+60 screentime_cropped.png上記コマンドでOCRで文字認識したい箇所でcropすると、
- App使用時間
通知
持ち上げ/再開回数
のようになります。これらを結合した画像をVisino APIに投げます。画像の結合は、以下のコマンドで行いました。
+appendで縦方向、-appendで横方向に結合できます。convert /tmp/cropped_1.png /tmp/cropped_2.png /tmp/cropped_3.png -append /tmp/combined.png結合した画像
これで準備完了です。
Vision APIとシートに記録
いよいよ準備した画像を使って、文字認識を行ってデータとして保存します。
以下の記事などを参考にさせていただきました。
- PythonでGoogleのCloud Vision APIを利用して画像から日本語文字検出する
- 【Google Colab】Vision APIで『レシートOCR』!
- Pythonでのスプレッドシート操作方法(gspreadの使い方)
import gspread import json from datetime import datetime, timedelta from oauth2client.service_account import ServiceAccountCredentials import os import io import re from google.cloud import vision credential_path = '【サービスアカウントキーのパス】' os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = credential_path file_path = "/tmp/combined.png" with io.open(file_path, "rb") as image_file: content = image_file.read() image = vision.Image(content=content) client = vision.ImageAnnotatorClient() response = client.text_detection(image=image) data = response.text_annotations[0].description.split() # [0]でfull textを取得 scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name(credential_path, scope) gc = gspread.authorize(credentials) SPREADSHEET_KEY = '【スプレッドシートのキー】' worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1 yesterday = datetime.today() - timedelta(days=1) date = datetime.strftime(yesterday, '%Y/%m/%d') d = re.findall("\d+", data[0]) # 'xx時間yy分` -> ['xx','yy'] d = list(map(int, d)) if len(d) == 2: # xx時間yy分の場合 data[0] = d[0]* 60 + d[1] elif len(d) == 1: # yy分の場合 data[0] = d[0] data = list(map(int, data)) data.insert(0, date) worksheet.append_row(data, value_input_option="USER_ENTERED")実行すると...
スクリーンタイムのデータがシートに反映されました!
あとはAutomatorのアプリを起動すれば今までの処理を自動で行ってくれます。(本当はcronで設定したかったけど、画面操作があるためできませんでした。。)ちなみに、VisionAPIを使った文字認識の結果はこうなりました。緑がParagraph、黄色が文字を表しています。きれいに認識できていますね。
おわりに
自動化ソフトや画像認識のツールを使って、スクリーンタイムをログに残してみました。せっかくならスクショだけはでなくて数字で記録に残せるといいですよね。
VisionAPIは1ヶ月1000リクエストまで無料なので毎日スクリーンタイムを記録して問題なさそうです。今のところスクリーンタイムを記録する術は英語でググっても見つからなかったので、この記事が誰かの参考になれば幸いです。
(Appleさん、スクリーンタイムもヘルスケアから読み取れるようにしてください)
- 投稿日:2020-12-15T22:10:15+09:00
地名で天気情報を取得して画像ファイルに出力する
はじめに
ここのアドベントカレンダーのやつです。
マストドン上で稼働している自作botの機能に”お天気情報取得”があります。”<地名>の天気を教えて!”とお願いすると、その地域の天気情報を返信してくれるというもので、従来”livedoor天気api”を使用していました。
ところが、2020年7月31日を以ってこの”livedoor天気api”はサービス終了となり、天気情報の機能が使えなくなってしまいました。
ということで、再び天気情報機能を使えるようになんとかしようと思います。
要件
- 指定された地名の天気情報を取得できること(既存要件)
- Pythonで実装すること(既存要件)※botをPythonで作成しているため
- 天気情報を表やグラフにして画像ファイル(PNG)にすること(追加要件)
※表・グラフの画像ファイル化は前からやってみたかったので、今回合わせてやってみたいと思います。
天気情報をどこから取得するか
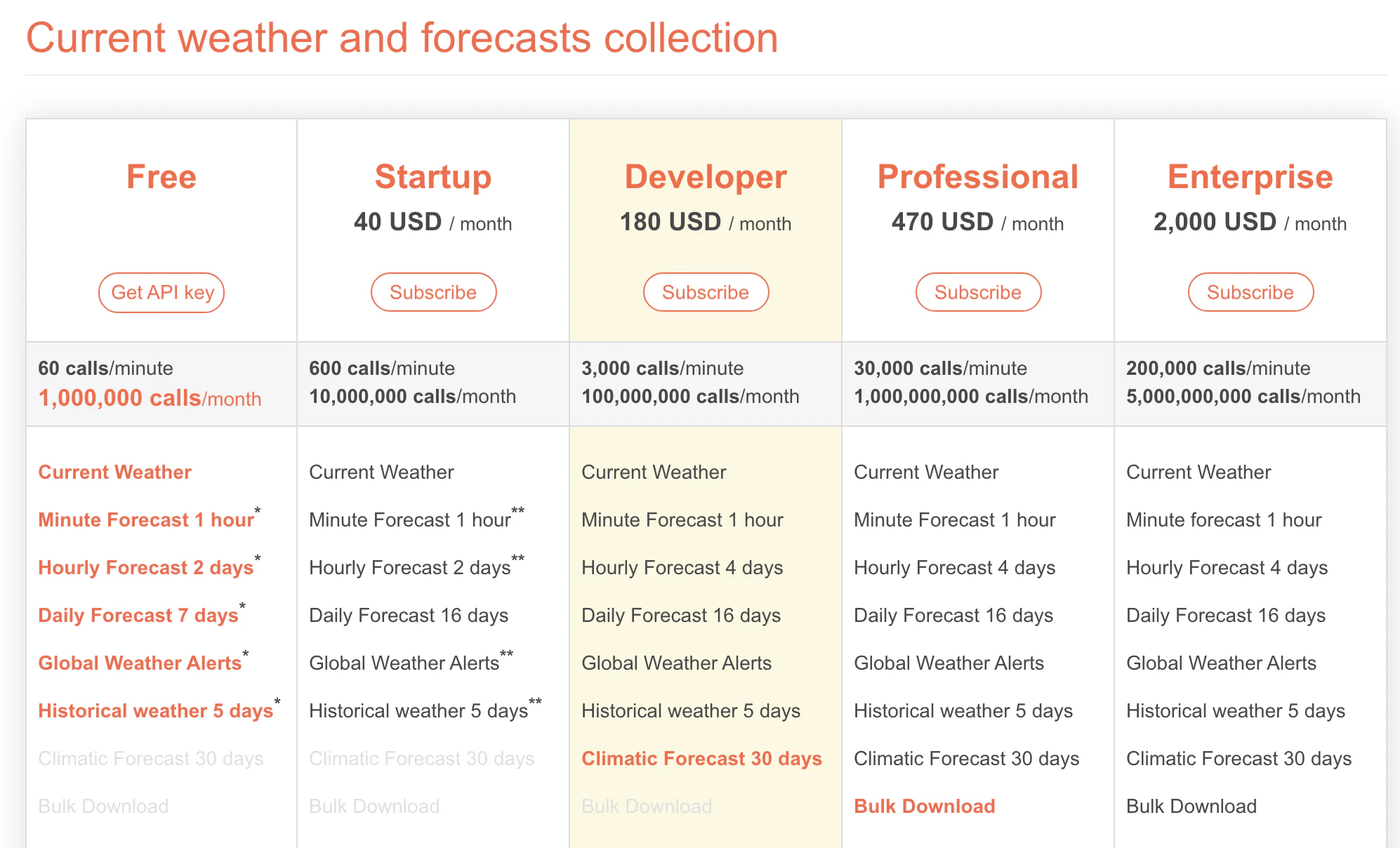
調べてみると、OpenWeatherMapというのが良さそうな感じです。これを使わせてもらいましょう。(ユーザ登録要、無料プランあり)
無料プランで、「60回/分・100万回/月」という制限がありますが、小規模なら十分すぎる感じです。取得できる情報も「現在天気」「1分毎天気」「1時間毎天気」「日毎天気」などこちらも十分そうです。
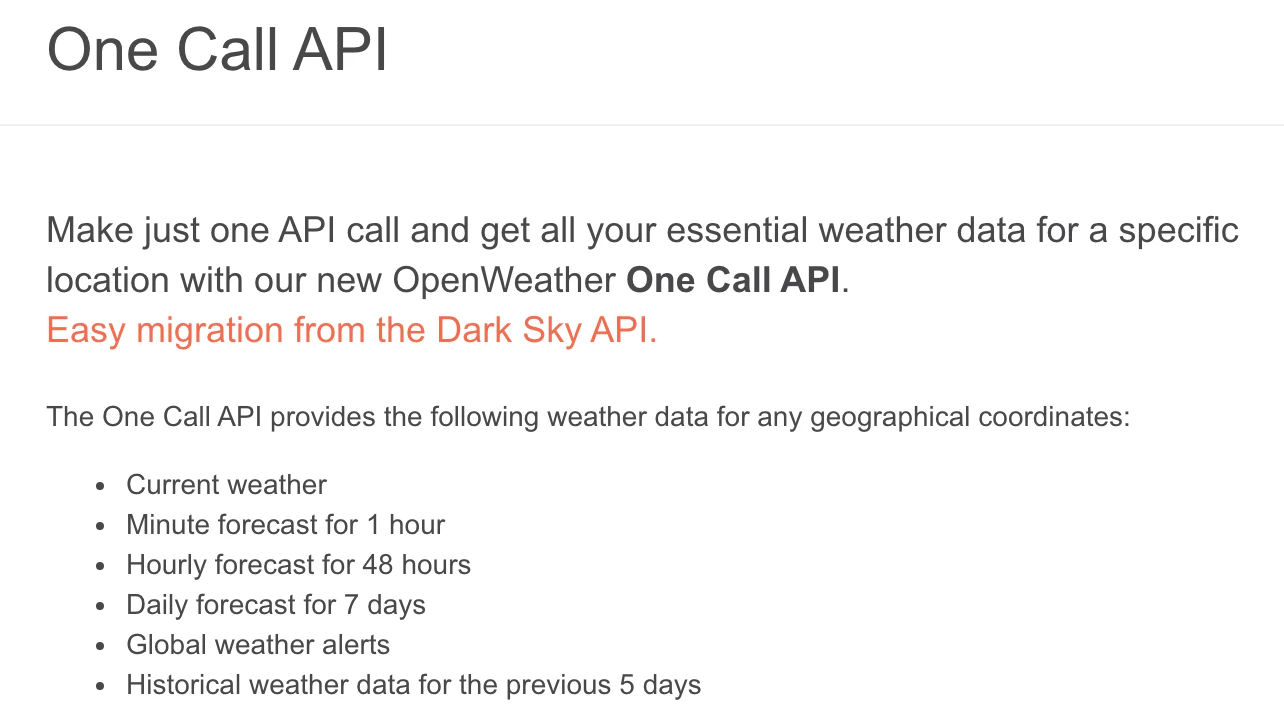
APIにはいくつか種類がありますが、”One Call API"を使えば欲しい情報は持ってきてくれそうです。
実際のAPI使用例を見てみると、"lat"、"lon"に経度・緯度指定が必要そうです。("apiid"はユーザ登録すればもらえます。)
グローバルなAPIなので、日本語地名による検索はダメそうです。(アルファベットでの地名検索はできるっぽいですが、主要都市だけかも?色々試しましたが諦めた気がします)
取得結果は以下のような情報が含まれるようです。(詳細は公式サイトのドキュメント参照)
地名と緯度・経度の一覧を作る
前述の通り、天気情報の取得には経度・緯度が必要そうなので、地名を経度・緯度に変換する方法を考えます。
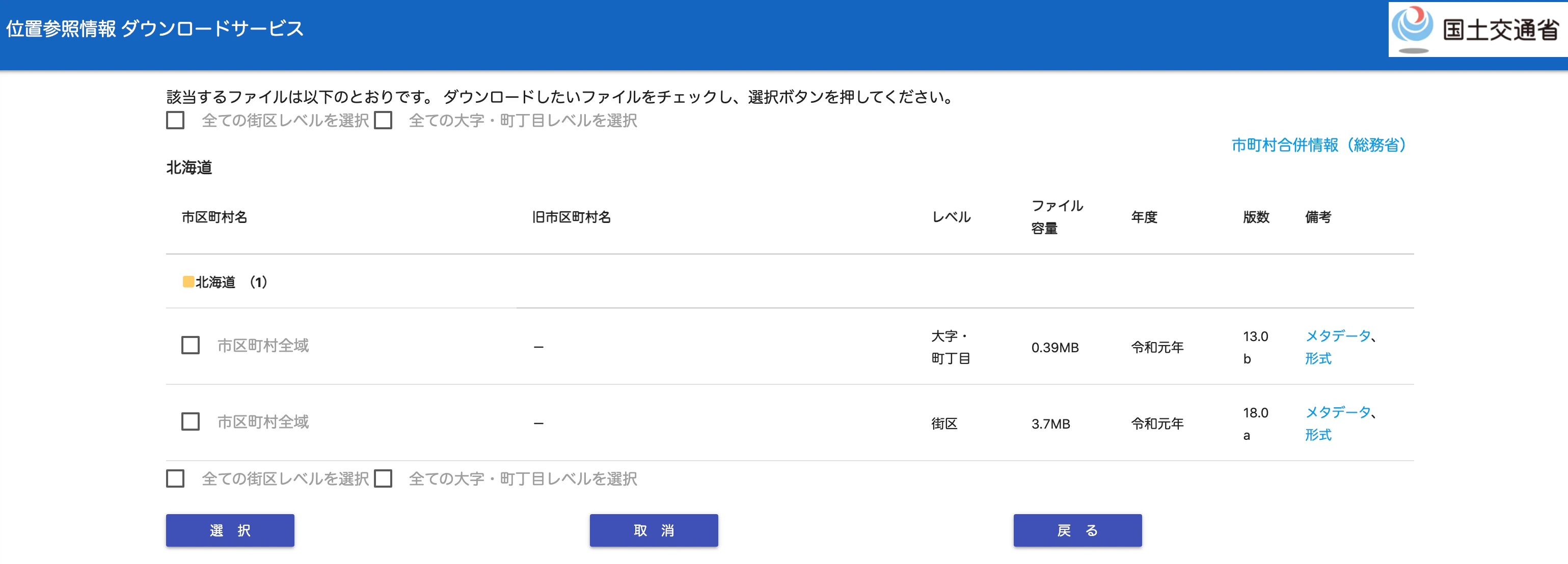
調べてみると国土交通省のHPより「位置参照情報 ダウンロードサービス」というものがありました。都道府県毎にダウンロードする必要があるものの、全市区町村単位の位置情報は網羅されていそうです。”地名”はとりあえずは”市区町村名”とすることとします。(街区レベルのものもありますが、ここまで細かいのは今回は不必要と思います)
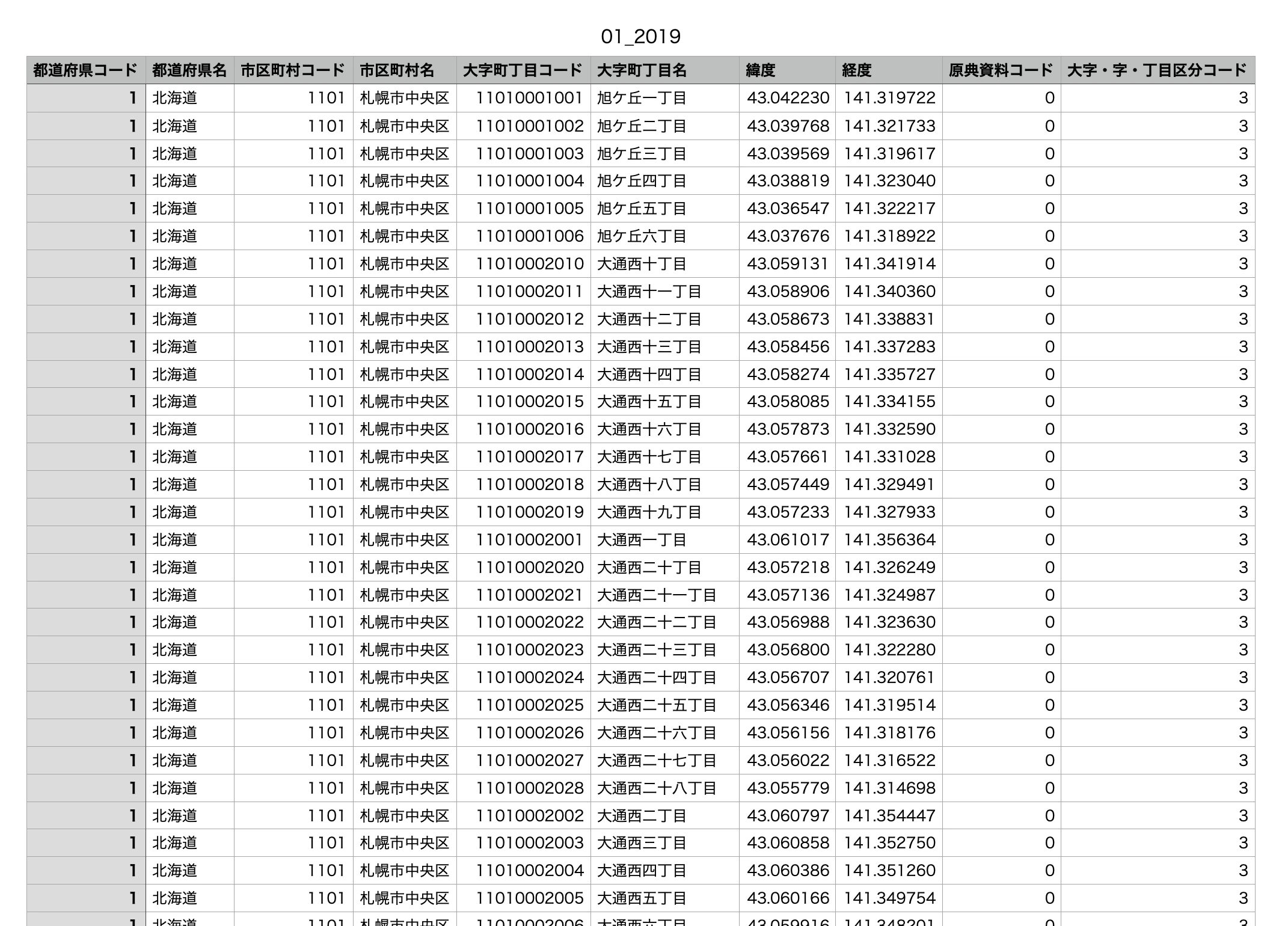
実際のデータの一部はこんな感じです。住所毎に緯度・経度情報があります。
今回はここまで細かくなくていいかなと思うので、市区町村名でグルーピングして緯度・経度のそれぞれの平均値を求め、その値を市区町村の緯度・経度とする感じで、一覧を作成しました。(使用しない情報は除外)
latloc.json{ "徳島県": { "徳島市": [ 34.0694450186722, 134.5442937966806 ], "鳴門市": [ 34.182439379310345, 134.5660390172414 ], "小松島市": [ 33.994815439999996, 134.59324916 ], "<省略>" } }以上から、天気情報取得の流れは、
市区町村名が指定される
一覧より該当の市区町村の経度・緯度を取得
OpenWeatherMap APIに経度・緯度を渡してコールし、天気情報を受け取る
天気情報を表・グラフなどに加工(※次項で説明)して返す
こんな感じで行けそうです。
Pythonでデータを表・グラフにして、画像ファイルにする
Pythonでグラフ作成ライブラリといえば、matplotlibとかpandasが挙がりますが(多分)、”表の画像ファイル化”、”画像の挿入(お天気マークを画像に入れたい)"がどうやっても難しそうで難航していました。
そこで、plotly という作図ライブラリを使わせてもらいました。これなら、表の画像ファイル化が綺麗にできました。図の挿入もバッチリです。詳細な使い方は他の記事に譲るとして、今回の作例とポイントだけ説明したいと思います。
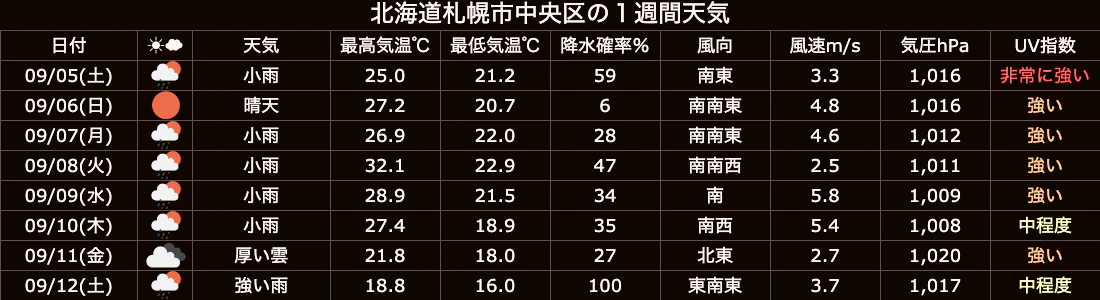
作例1 表の画像ファイル化
図(お天気アイコン)の挿入
こちらの表ではUV指数の値によって文字色を変えています
作例2 棒グラフの画像ファイル化
- 棒グラフが取る値の範囲は自動ですが、負の値は取らないため0起点にしています
 otenki.py# -*- coding: utf-8 -*- import os from pprint import pprint as pp import requests import json from bs4 import BeautifulSoup from time import sleep from collections import defaultdict import pandas as pd import plotly.graph_objects as go import plotly.express as px import urllib.request from pytz import timezone from datetime import datetime, timedelta from PIL import Image import locale locale.setlocale(locale.LC_TIME, 'ja_JP.UTF-8') CITY_LATLOC_PATH = "dic/city_latloc.json" ICON_DIR = "tenki_icon" IMAGE_H = 1260 IMAGE_W = 800 BG_COLOR = "#100500" LINE_COLOR = "#5f5050" FONT_COLOR = "#fff5f3" WEATHER_IMAGE_PATH = "./media" # 天気メイン def get_tenki(quary, appid): with open(CITY_LATLOC_PATH, 'r') as fr: city_latloc_dict = json.load(fr) os.makedirs(WEATHER_IMAGE_PATH, exist_ok=True) os.makedirs(os.path.join(WEATHER_IMAGE_PATH, ICON_DIR), exist_ok=True) hit_tdfk = [tdfk for tdfk in city_latloc_dict.keys() if tdfk in quary] hit_skcs = [] hit_lat = 0.0 hit_loc = 0.0 if len(hit_tdfk) == 1: # 都道府県指定あり for k_skcs, latloc in city_latloc_dict[hit_tdfk[0]].items(): if quary.split(hit_tdfk[0])[-1] in [k_skcs, k_skcs[:-1]]: hit_skcs.append(hit_tdfk[0] + k_skcs) hit_lat = latloc[0] hit_loc = latloc[1] else: # 都道府県指定なし for k_tdfk, v in city_latloc_dict.items(): for k_skcs, latloc in v.items(): if quary in [k_skcs, k_skcs[:-1]]: hit_skcs.append(k_tdfk + k_skcs) hit_lat = latloc[0] hit_loc = latloc[1] if len(hit_skcs) == 0: return 900, None, None, None # 見つからなかった場合 elif len(hit_skcs) > 1: return 901, None, "、".join(hit_skcs), None # 複数見つかった場合 # 天気情報取得 url = "http://api.openweathermap.org/data/2.5/onecall" payload = { "lat": hit_lat, "lon": hit_loc, "lang": "ja", "units": "metric", "APPID": appid} tenki_data = requests.get(url, params=payload).json() tz = timezone(tenki_data['timezone']) skcs_name = hit_skcs[0] return 0, hit_skcs[0]+"の天気", \ make_weather_image_current(tenki_data['current'], skcs_name, tz),\ [make_weather_image_daily(tenki_data['daily'], skcs_name, tz), make_weather_image_hourly(tenki_data['hourly'], skcs_name, tz), make_weather_image_minutely(tenki_data['minutely'], skcs_name, tz)] # UV指数 def get_uvi_info(uvi): if uvi < 3.0: return f"弱い", "rgb(204,242,255)" elif uvi < 6.0: return f"中程度", "rgb(255,255,204)" elif uvi < 8.0: return f"強い", "rgb(255,204,153)" elif uvi < 11.0: return f"非常に強い", "rgb(255,101,101)" else: return f"極端に強い", "rgb(255,101,255)" # 16方位名 def get_wind_deg_name(deg): import math dname = ["北", "北北東", "北東", "東北東", "東", "東南東", "南東", "南南東", "南", "南南西", "南西", "西南西", "西", "西北西", "北西", "北北西", "北"] return dname[int((deg + 11.25)/22.5)] # 現在の天気 def make_weather_image_current(wd, skcs_name, tz): tmp_dict = {} tmp_dict['曇り%'] = wd['clouds'] tmp_dict['日時'] = datetime.fromtimestamp( wd['dt'], tz=tz).strftime("%m/%d %H:%M") tmp_dict['体感気温℃'] = f"{float(wd['feels_like']):.1f}" tmp_dict['湿度%'] = wd['humidity'] tmp_dict['気圧hPa'] = wd['pressure'] tmp_dict['日の出'] = datetime.fromtimestamp( wd['sunrise'], tz=tz).strftime("%H:%M:%S") tmp_dict['日の入'] = datetime.fromtimestamp( wd['sunset'], tz=tz).strftime("%H:%M:%S") tmp_dict['気温℃'] = f"{float(wd['temp']):.1f}" if 'uvi' in wd: uv_text, _ = get_uvi_info(wd['uvi']) tmp_dict['UV指数'] = f"{uv_text}({float(wd['uvi']):.1f})" else: tmp_dict['UV指数'] = "−" tmp_dict['天気'] = wd['weather'][0]['description'] ret_text = f"現在({tmp_dict['日時']}時点)の{skcs_name}の天気\n" ret_text += f"{tmp_dict['天気']}:" ret_text += f"気温{tmp_dict['気温℃']}℃/湿度{tmp_dict['湿度%']}%/体感気温{tmp_dict['体感気温℃']}℃\n" ret_text += f"気圧{tmp_dict['気圧hPa']}hPa/UV指数「{tmp_dict['UV指数']}」/雲率{tmp_dict['曇り%']}%\n" ret_text += f"日の出時刻は{tmp_dict['日の出']}、日の入時刻は{tmp_dict['日の入']}\n" ret_text += f" by OpenWeatherMap API https://openweathermap.org/" return ret_text # 1週間天気 def make_weather_image_daily(wd, skcs_name, tz): tenki_data_list = [] for l1 in wd: tmp_dict = {} tmp_dict['日付'] = datetime.fromtimestamp( l1['dt'], tz=tz).strftime("%m/%d(%a)") tmp_dict['☀☁'] = "" # お天気アイコン表示用 tmp_dict['icon'] = l1['weather'][0]['icon'] tmp_dict['天気'] = l1['weather'][0]['description'] tmp_dict['最高気温℃'] = f"{float(l1['temp']['max']):.1f}" tmp_dict['最低気温℃'] = f"{float(l1['temp']['min']):.1f}" tmp_dict['降水確率%'] = int(float(l1['pop'])*100) tmp_dict['UV指数'], tmp_dict['uv_color'] = get_uvi_info(l1['uvi']) tmp_dict['font_color'] = FONT_COLOR tmp_dict['風速m/s'] = f"{float(l1['wind_speed']):.1f}" tmp_dict['風向'] = get_wind_deg_name(l1['wind_deg']) tmp_dict['気圧hPa'] = f"{int(l1['pressure']):,}" tenki_data_list.append(tmp_dict) df_temp = pd.json_normalize(tenki_data_list) df = df_temp[['日付', '☀☁', '天気', '最高気温℃', '最低気温℃', '降水確率%', '風向', '風速m/s', '気圧hPa', 'UV指数']] # テーブルの作成 fig = go.Figure(data=[go.Table( columnwidth=[25, 10, 25, 20, 20, 20, 20, 20, 20, 20], # カラム幅の変更 header=dict(values=df.columns, align='center', font=dict(color=FONT_COLOR, size=18), height=30, line_color=LINE_COLOR, fill_color=BG_COLOR), cells=dict(values=df.values.T, align='center', font=dict(color=[df_temp.font_color]*9 + [df_temp.uv_color], size=18), height=30, # ポイント:UV指数カラムの色指定 line_color=LINE_COLOR, fill_color=BG_COLOR), )], layout=dict(margin=dict(l=0, r=0, t=30, b=0), paper_bgcolor=BG_COLOR, title=dict( text=skcs_name+"の1週間天気", x=0.5, y=1.0, font=dict(color=FONT_COLOR, size=24), xanchor='center', yanchor='top', pad=dict(l=0, r=0, t=5, b=0)) ) ) # ポイント:お天気アイコン貼り付け。後から画像を乗せるイメージ。位置調整は手動。 for i in range(1, len(df)+1, 1): # 天気アイコン取得 icon_name = df_temp['icon'][i-1] icon_image = get_weather_icon(icon_name) fig.add_layout_image( dict(source=icon_image, x=0.125, y=(1.0-1.0/(len(df)+1)*(i+0.5)))) fig.update_layout_images(dict( xref="paper", yref="paper", sizex=0.22, sizey=0.21, xanchor="left", yanchor="middle")) imagepath = os.path.join(WEATHER_IMAGE_PATH, "tmp_weather_d.png") fig.write_image(imagepath, height=30*(len(df)+2), width=1100, scale=1) return imagepath # 48時間天気 def make_weather_image_hourly(wd, skcs_name, tz): tenki_data_list = [] for l1 in wd: tmp_dict = {} tmp_dict['日時'] = datetime.fromtimestamp( l1['dt'], tz=tz).strftime("%m/%d %H時") tmp_dict['☀☁'] = "" # お天気アイコン表示用 tmp_dict['icon'] = l1['weather'][0]['icon'] tmp_dict['天気'] = l1['weather'][0]['description'] tmp_dict['気温℃'] = f"{float(l1['temp']): .1f}" tmp_dict['湿度%'] = l1['humidity'] tmp_dict['体感気温℃'] = f"{float(l1['feels_like']):.1f}" tmp_dict['降水確率%'] = int(float(l1['pop'])*100) tmp_dict['風向'] = get_wind_deg_name(l1['wind_deg']) tmp_dict['風速m/s'] = f"{float(l1['wind_speed']):.1f}" tmp_dict['気圧hPa'] = f"{int(l1['pressure']):,}" tenki_data_list.append(tmp_dict) df_temp = pd.json_normalize(tenki_data_list) df = df_temp[['日時', '☀☁', '天気', '気温℃', '湿度%', '体感気温℃', '降水確率%', '風向', '風速m/s', '気圧hPa']] # テーブルの作成 fig = go.Figure(data=[go.Table( # columnorder=[10, 20, 30, 40, 50, 25, 70], columnwidth=[25, 10, 25, 20, 20, 20, 20, 20, 20, 20], # カラム幅の変更 header=dict(values=df.columns, align='center', font=dict(color=FONT_COLOR, size=18), height=30, line_color=LINE_COLOR, fill_color=BG_COLOR), cells=dict(values=df.values.T, align='center', font=dict(color=FONT_COLOR, size=18), height=30, line_color=LINE_COLOR, fill_color=BG_COLOR), )], layout=dict(margin=dict(l=0, r=0, t=30, b=0), paper_bgcolor=BG_COLOR, title=dict( text=skcs_name+"の48時間天気", x=0.5, y=1.0, font=dict(color=FONT_COLOR, size=24), xanchor='center', yanchor='top', pad=dict(l=0, r=0, t=5, b=0)) ), ) # お天気アイコン貼り付け for i in range(1, len(df)+1, 1): # 天気アイコン取得 icon_name = df_temp['icon'][i-1] icon_image = get_weather_icon(icon_name) fig.add_layout_image( dict(source=icon_image, x=0.125, y=(1.0-1.0/49.0*(i+0.5)))) fig.update_layout_images(dict( xref="paper", yref="paper", sizex=0.05, sizey=0.05, xanchor="left", yanchor="middle")) imagepath = os.path.join(WEATHER_IMAGE_PATH, "tmp_weather_h.png") fig.write_image(imagepath, height=30*(48+2), width=1100, scale=1) return imagepath # 1時間降水量 def make_weather_image_minutely(wd, skcs_name, tz): tenki_data_list = [] for l1 in wd: tmp_dict = {} tmp_dict['時刻'] = datetime.fromtimestamp( l1['dt'], tz=tz).strftime("%H:%M") tmp_dict['降水量mm'] = l1['precipitation'] tenki_data_list.append(tmp_dict) df_temp = pd.json_normalize(tenki_data_list) df = df_temp[['時刻', '降水量mm']].round({'降水量mm': 2}) # テーブルの作成 fig = go.Figure([go.Bar(x=df['時刻'], y=df['降水量mm'], text=df['降水量mm'], textposition='auto', marker=dict(color='rgba(150,150,255,0.8)'), y0=0 )], layout=dict(margin=dict(l=0, r=0, t=30, b=0), paper_bgcolor=BG_COLOR, plot_bgcolor=BG_COLOR, title=dict( text=skcs_name+"の1時間の降水量", x=0.5, y=1.0, font=dict(color=FONT_COLOR, size=24), xanchor='center', yanchor='top', pad=dict(l=0, r=0, t=5, b=0)), font=dict(color=FONT_COLOR, size=18), xaxis=dict(title='時刻', showgrid=False), yaxis=dict(title='降水量mm', showgrid=False, rangemode='nonnegative') # ポイント:負の値は取らないグラフなので0起点にする ) ) imagepath = os.path.join(WEATHER_IMAGE_PATH, "tmp_weather_m.png") fig.write_image(imagepath, height=400, width=1600, scale=1) return imagepath # 天気アイコン取得 def get_weather_icon(icon_name): icon_image_path = os.path.join( WEATHER_IMAGE_PATH, ICON_DIR, icon_name + ".png") if os.path.exists(icon_image_path): pass else: url = f"http://openweathermap.org/img/wn/{icon_name}@4x.png" with urllib.request.urlopen(url) as web_file: data = web_file.read() with open(icon_image_path, mode='wb') as local_file: local_file.write(data) return Image.open(icon_image_path) if __name__ == '__main__': pp(get_tenki("札幌市中央区", "<<api_key>>"))
otenki.py# -*- coding: utf-8 -*- import os from pprint import pprint as pp import requests import json from bs4 import BeautifulSoup from time import sleep from collections import defaultdict import pandas as pd import plotly.graph_objects as go import plotly.express as px import urllib.request from pytz import timezone from datetime import datetime, timedelta from PIL import Image import locale locale.setlocale(locale.LC_TIME, 'ja_JP.UTF-8') CITY_LATLOC_PATH = "dic/city_latloc.json" ICON_DIR = "tenki_icon" IMAGE_H = 1260 IMAGE_W = 800 BG_COLOR = "#100500" LINE_COLOR = "#5f5050" FONT_COLOR = "#fff5f3" WEATHER_IMAGE_PATH = "./media" # 天気メイン def get_tenki(quary, appid): with open(CITY_LATLOC_PATH, 'r') as fr: city_latloc_dict = json.load(fr) os.makedirs(WEATHER_IMAGE_PATH, exist_ok=True) os.makedirs(os.path.join(WEATHER_IMAGE_PATH, ICON_DIR), exist_ok=True) hit_tdfk = [tdfk for tdfk in city_latloc_dict.keys() if tdfk in quary] hit_skcs = [] hit_lat = 0.0 hit_loc = 0.0 if len(hit_tdfk) == 1: # 都道府県指定あり for k_skcs, latloc in city_latloc_dict[hit_tdfk[0]].items(): if quary.split(hit_tdfk[0])[-1] in [k_skcs, k_skcs[:-1]]: hit_skcs.append(hit_tdfk[0] + k_skcs) hit_lat = latloc[0] hit_loc = latloc[1] else: # 都道府県指定なし for k_tdfk, v in city_latloc_dict.items(): for k_skcs, latloc in v.items(): if quary in [k_skcs, k_skcs[:-1]]: hit_skcs.append(k_tdfk + k_skcs) hit_lat = latloc[0] hit_loc = latloc[1] if len(hit_skcs) == 0: return 900, None, None, None # 見つからなかった場合 elif len(hit_skcs) > 1: return 901, None, "、".join(hit_skcs), None # 複数見つかった場合 # 天気情報取得 url = "http://api.openweathermap.org/data/2.5/onecall" payload = { "lat": hit_lat, "lon": hit_loc, "lang": "ja", "units": "metric", "APPID": appid} tenki_data = requests.get(url, params=payload).json() tz = timezone(tenki_data['timezone']) skcs_name = hit_skcs[0] return 0, hit_skcs[0]+"の天気", \ make_weather_image_current(tenki_data['current'], skcs_name, tz),\ [make_weather_image_daily(tenki_data['daily'], skcs_name, tz), make_weather_image_hourly(tenki_data['hourly'], skcs_name, tz), make_weather_image_minutely(tenki_data['minutely'], skcs_name, tz)] # UV指数 def get_uvi_info(uvi): if uvi < 3.0: return f"弱い", "rgb(204,242,255)" elif uvi < 6.0: return f"中程度", "rgb(255,255,204)" elif uvi < 8.0: return f"強い", "rgb(255,204,153)" elif uvi < 11.0: return f"非常に強い", "rgb(255,101,101)" else: return f"極端に強い", "rgb(255,101,255)" # 16方位名 def get_wind_deg_name(deg): import math dname = ["北", "北北東", "北東", "東北東", "東", "東南東", "南東", "南南東", "南", "南南西", "南西", "西南西", "西", "西北西", "北西", "北北西", "北"] return dname[int((deg + 11.25)/22.5)] # 現在の天気 def make_weather_image_current(wd, skcs_name, tz): tmp_dict = {} tmp_dict['曇り%'] = wd['clouds'] tmp_dict['日時'] = datetime.fromtimestamp( wd['dt'], tz=tz).strftime("%m/%d %H:%M") tmp_dict['体感気温℃'] = f"{float(wd['feels_like']):.1f}" tmp_dict['湿度%'] = wd['humidity'] tmp_dict['気圧hPa'] = wd['pressure'] tmp_dict['日の出'] = datetime.fromtimestamp( wd['sunrise'], tz=tz).strftime("%H:%M:%S") tmp_dict['日の入'] = datetime.fromtimestamp( wd['sunset'], tz=tz).strftime("%H:%M:%S") tmp_dict['気温℃'] = f"{float(wd['temp']):.1f}" if 'uvi' in wd: uv_text, _ = get_uvi_info(wd['uvi']) tmp_dict['UV指数'] = f"{uv_text}({float(wd['uvi']):.1f})" else: tmp_dict['UV指数'] = "−" tmp_dict['天気'] = wd['weather'][0]['description'] ret_text = f"現在({tmp_dict['日時']}時点)の{skcs_name}の天気\n" ret_text += f"{tmp_dict['天気']}:" ret_text += f"気温{tmp_dict['気温℃']}℃/湿度{tmp_dict['湿度%']}%/体感気温{tmp_dict['体感気温℃']}℃\n" ret_text += f"気圧{tmp_dict['気圧hPa']}hPa/UV指数「{tmp_dict['UV指数']}」/雲率{tmp_dict['曇り%']}%\n" ret_text += f"日の出時刻は{tmp_dict['日の出']}、日の入時刻は{tmp_dict['日の入']}\n" ret_text += f" by OpenWeatherMap API https://openweathermap.org/" return ret_text # 1週間天気 def make_weather_image_daily(wd, skcs_name, tz): tenki_data_list = [] for l1 in wd: tmp_dict = {} tmp_dict['日付'] = datetime.fromtimestamp( l1['dt'], tz=tz).strftime("%m/%d(%a)") tmp_dict['☀☁'] = "" # お天気アイコン表示用 tmp_dict['icon'] = l1['weather'][0]['icon'] tmp_dict['天気'] = l1['weather'][0]['description'] tmp_dict['最高気温℃'] = f"{float(l1['temp']['max']):.1f}" tmp_dict['最低気温℃'] = f"{float(l1['temp']['min']):.1f}" tmp_dict['降水確率%'] = int(float(l1['pop'])*100) tmp_dict['UV指数'], tmp_dict['uv_color'] = get_uvi_info(l1['uvi']) tmp_dict['font_color'] = FONT_COLOR tmp_dict['風速m/s'] = f"{float(l1['wind_speed']):.1f}" tmp_dict['風向'] = get_wind_deg_name(l1['wind_deg']) tmp_dict['気圧hPa'] = f"{int(l1['pressure']):,}" tenki_data_list.append(tmp_dict) df_temp = pd.json_normalize(tenki_data_list) df = df_temp[['日付', '☀☁', '天気', '最高気温℃', '最低気温℃', '降水確率%', '風向', '風速m/s', '気圧hPa', 'UV指数']] # テーブルの作成 fig = go.Figure(data=[go.Table( columnwidth=[25, 10, 25, 20, 20, 20, 20, 20, 20, 20], # カラム幅の変更 header=dict(values=df.columns, align='center', font=dict(color=FONT_COLOR, size=18), height=30, line_color=LINE_COLOR, fill_color=BG_COLOR), cells=dict(values=df.values.T, align='center', font=dict(color=[df_temp.font_color]*9 + [df_temp.uv_color], size=18), height=30, # ポイント:UV指数カラムの色指定 line_color=LINE_COLOR, fill_color=BG_COLOR), )], layout=dict(margin=dict(l=0, r=0, t=30, b=0), paper_bgcolor=BG_COLOR, title=dict( text=skcs_name+"の1週間天気", x=0.5, y=1.0, font=dict(color=FONT_COLOR, size=24), xanchor='center', yanchor='top', pad=dict(l=0, r=0, t=5, b=0)) ) ) # ポイント:お天気アイコン貼り付け。後から画像を乗せるイメージ。位置調整は手動。 for i in range(1, len(df)+1, 1): # 天気アイコン取得 icon_name = df_temp['icon'][i-1] icon_image = get_weather_icon(icon_name) fig.add_layout_image( dict(source=icon_image, x=0.125, y=(1.0-1.0/(len(df)+1)*(i+0.5)))) fig.update_layout_images(dict( xref="paper", yref="paper", sizex=0.22, sizey=0.21, xanchor="left", yanchor="middle")) imagepath = os.path.join(WEATHER_IMAGE_PATH, "tmp_weather_d.png") fig.write_image(imagepath, height=30*(len(df)+2), width=1100, scale=1) return imagepath # 48時間天気 def make_weather_image_hourly(wd, skcs_name, tz): tenki_data_list = [] for l1 in wd: tmp_dict = {} tmp_dict['日時'] = datetime.fromtimestamp( l1['dt'], tz=tz).strftime("%m/%d %H時") tmp_dict['☀☁'] = "" # お天気アイコン表示用 tmp_dict['icon'] = l1['weather'][0]['icon'] tmp_dict['天気'] = l1['weather'][0]['description'] tmp_dict['気温℃'] = f"{float(l1['temp']): .1f}" tmp_dict['湿度%'] = l1['humidity'] tmp_dict['体感気温℃'] = f"{float(l1['feels_like']):.1f}" tmp_dict['降水確率%'] = int(float(l1['pop'])*100) tmp_dict['風向'] = get_wind_deg_name(l1['wind_deg']) tmp_dict['風速m/s'] = f"{float(l1['wind_speed']):.1f}" tmp_dict['気圧hPa'] = f"{int(l1['pressure']):,}" tenki_data_list.append(tmp_dict) df_temp = pd.json_normalize(tenki_data_list) df = df_temp[['日時', '☀☁', '天気', '気温℃', '湿度%', '体感気温℃', '降水確率%', '風向', '風速m/s', '気圧hPa']] # テーブルの作成 fig = go.Figure(data=[go.Table( # columnorder=[10, 20, 30, 40, 50, 25, 70], columnwidth=[25, 10, 25, 20, 20, 20, 20, 20, 20, 20], # カラム幅の変更 header=dict(values=df.columns, align='center', font=dict(color=FONT_COLOR, size=18), height=30, line_color=LINE_COLOR, fill_color=BG_COLOR), cells=dict(values=df.values.T, align='center', font=dict(color=FONT_COLOR, size=18), height=30, line_color=LINE_COLOR, fill_color=BG_COLOR), )], layout=dict(margin=dict(l=0, r=0, t=30, b=0), paper_bgcolor=BG_COLOR, title=dict( text=skcs_name+"の48時間天気", x=0.5, y=1.0, font=dict(color=FONT_COLOR, size=24), xanchor='center', yanchor='top', pad=dict(l=0, r=0, t=5, b=0)) ), ) # お天気アイコン貼り付け for i in range(1, len(df)+1, 1): # 天気アイコン取得 icon_name = df_temp['icon'][i-1] icon_image = get_weather_icon(icon_name) fig.add_layout_image( dict(source=icon_image, x=0.125, y=(1.0-1.0/49.0*(i+0.5)))) fig.update_layout_images(dict( xref="paper", yref="paper", sizex=0.05, sizey=0.05, xanchor="left", yanchor="middle")) imagepath = os.path.join(WEATHER_IMAGE_PATH, "tmp_weather_h.png") fig.write_image(imagepath, height=30*(48+2), width=1100, scale=1) return imagepath # 1時間降水量 def make_weather_image_minutely(wd, skcs_name, tz): tenki_data_list = [] for l1 in wd: tmp_dict = {} tmp_dict['時刻'] = datetime.fromtimestamp( l1['dt'], tz=tz).strftime("%H:%M") tmp_dict['降水量mm'] = l1['precipitation'] tenki_data_list.append(tmp_dict) df_temp = pd.json_normalize(tenki_data_list) df = df_temp[['時刻', '降水量mm']].round({'降水量mm': 2}) # テーブルの作成 fig = go.Figure([go.Bar(x=df['時刻'], y=df['降水量mm'], text=df['降水量mm'], textposition='auto', marker=dict(color='rgba(150,150,255,0.8)'), y0=0 )], layout=dict(margin=dict(l=0, r=0, t=30, b=0), paper_bgcolor=BG_COLOR, plot_bgcolor=BG_COLOR, title=dict( text=skcs_name+"の1時間の降水量", x=0.5, y=1.0, font=dict(color=FONT_COLOR, size=24), xanchor='center', yanchor='top', pad=dict(l=0, r=0, t=5, b=0)), font=dict(color=FONT_COLOR, size=18), xaxis=dict(title='時刻', showgrid=False), yaxis=dict(title='降水量mm', showgrid=False, rangemode='nonnegative') # ポイント:負の値は取らないグラフなので0起点にする ) ) imagepath = os.path.join(WEATHER_IMAGE_PATH, "tmp_weather_m.png") fig.write_image(imagepath, height=400, width=1600, scale=1) return imagepath # 天気アイコン取得 def get_weather_icon(icon_name): icon_image_path = os.path.join( WEATHER_IMAGE_PATH, ICON_DIR, icon_name + ".png") if os.path.exists(icon_image_path): pass else: url = f"http://openweathermap.org/img/wn/{icon_name}@4x.png" with urllib.request.urlopen(url) as web_file: data = web_file.read() with open(icon_image_path, mode='wb') as local_file: local_file.write(data) return Image.open(icon_image_path) if __name__ == '__main__': pp(get_tenki("札幌市中央区", "<<api_key>>"))おわりに
とりあえず、イメージした表・グラフの形になりました。
(アドベントカレンダー感はありませんが、まあよいでしょう。)
夏に実装したのですが、いつの間にか冬になってました。夏にAPIを叩いたときは降雪量情報は返ってこなかったのですが、今なら返ってくるかもしれないので試してみたいと思います。





- 投稿日:2020-12-15T21:57:52+09:00
Google OR-Toolsによる最適化プロジェクト入門
この記事は「数理最適化 Advent Calendar 2020」22日目の記事です。
21日目は@shuhei_fさんによる「SMOのworking setの選び方」でした。はじめに
Pythonと最適化モデリングライブラリGoogle OR-Toolsを用いて、簡単な最適化プロジェクトを進めていきます。題材は「個別指導塾における講師のシフト作成」で、0-1整数線形計画問題として解きます。
プログラムを書くのがド下手なので、「こう書いた方がいい」といったことは是非教えてください。問題発生
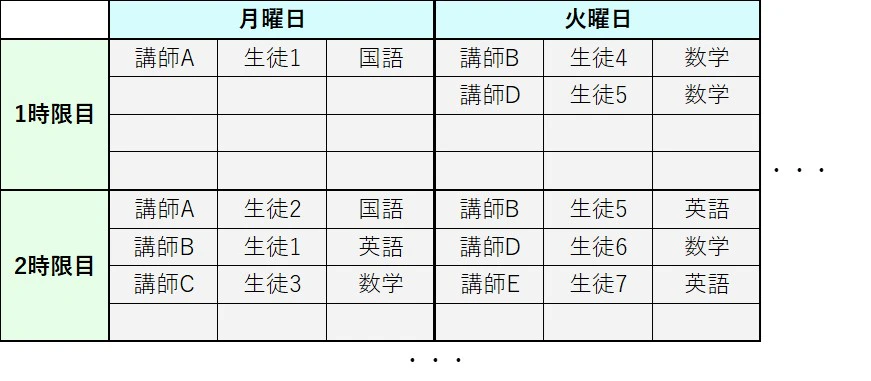
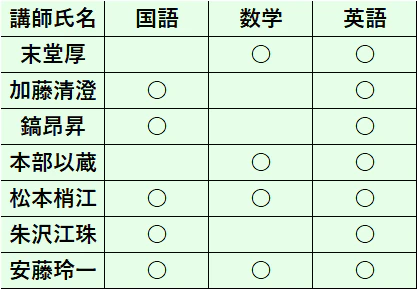
渋川君のアルバイト先の個別指導塾では、以下のようなシフト表に基づいて勤務することになっています。
例えば月曜1限では、講師Aが生徒1に対して国語を教えることになっています。
シフト表は一か月間固定で、毎月20日に教室長が翌月分のシフト表を作成します。今の教室長は非常に雑な人で、
・数学を担当できない講師が数学を教えることになっている
・希望を出していない曜日にシフトが入れられている
といったことが多発しています(※これはフィクションです)。そこで最近最適化に興味を持ち始めた読んだ渋川君が、数理最適化を使ってシフト表を自動生成してみようと考えました。
どうしたいのかを考える
ざっくりと「シフトを自動生成したい」と述べましたが、もう少し具体的に、最適化でどうなって欲しいかを考えてみます。
今回の例では、教室長が作るシフトが条件を満たしてさえいなかったので、一旦は条件を満たすような解を見つけるだけでも十分な気がします。実行可能解がないにしても、満たせない条件をなるべく少なくするようにモデリングすれば調整が楽そうです。
したがって、まずは条件を満たす解を見つけることから始め、それが出来たら何を最大化または最小化したいか考えることにします。どんな問題に落とし込むかを考える
長い前置き
早速定式化に取りかかります。定式化とは、「決定変数、制約条件、目的関数を数式で表すこと」であると認識しています。
個人的には、定式化の最初のステップとして「どんな問題になりそうか」を考える必要があると思っています。例えば「どんな順番にすると一番良いか知りたいから巡回セールスマン問題かな?」って感じです。
実務では多くが組合せ最適化問題に帰着することが多く、組合せ最適化問題には典型問題と呼ばれるものが存在します(巡回セールスマン問題も典型問題の一つ)。典型問題を知っていると定式化がしやすいですし、効率的な解法が盛んに研究されているので参考になります。そのため典型問題にどんなものがあるか、どんな応用例があるか知っておくと良いのかなと思います(これは自分への戒めでもあります)。
典型問題は、斉藤先生のこちらの記事やNTTデータ数理システムのこちらのサイトに良くまとまっています。今回のプロジェクトでは「どの講師が、どの曜日・時限・科目に割り当てられるか」を決めると良さそうなので、割当問題が使えそうです。
※実際は「どの生徒に割り当てられるか」ですが、今回は簡単のために「ある生徒に割り当てられる=その生徒が受講を希望する科目に割り当てられる」と考えます。同じ科目の受講を希望する生徒が複数いる場合はどっちを担当してもよいものとします。割当問題は適用できるシーンが非常に多く、定式化も分かりやすいので、とにかく何か最適化してみたい時の入り口としてかなりおすすめです。
決定変数を考える
ここからは数式による表現とPythonによる実装を並行して進めていきます。実装に関しては記事の流れの都合上変数の登場順序などが前後して分かりづらいですがご容赦ください。
決定変数は雑に言うと「コレが分かったら嬉しいモノ」です。巡回セールスマン問題でいえば「訪問順序」が決定変数で、「総移動距離(最小にしたい)」が目的関数です。決定変数をどう設定するかで目的関数や制約式の作りやすさが変わるので重要なのですが、このプロジェクトではゴリ押しでいきます。
数式
今回は上述のように「どの講師が、どの曜日のどの時限にどの科目を担当するか」を決めたいので、これをそのまま変数にします。
講師$i$が曜日$w$の時限$t$に科目$s$を担当するかどうかを表す変数を以下のように表します。x^i_{wts} \in \{0,1\}$x^i_{wts} =1$であれば、担当する(=シフトが入る)という意味になります。
実装
最初に
pywraplp.Solver(問題名,使用するソルバー)でソルバーを宣言します。今回は無料で使える混合整数計画ソルバーCBCを指定します。そしてsolver.IntVar(下限,上限,変数名)で整数変数を作成します。from ortools.linear_solver import pywraplp #曜日・時限・科目のリスト weekday_list = ['月','火','水','木','金','土'] timetable_list = [1,2,3,4] subject_list = ['国語','数学','英語'] #講師数、曜日数、時限数、科目数 I,W,T,S = len(shift_avlbl),len(weekday_list),len(timetable_list),len(subject_list) #ソルバーの宣言 solver = pywraplp.Solver('Staff Scheduling',pywraplp.Solver.CBC_MIXED_INTEGER_PROGRAMMING) #決定変数x x = [[[[solver.IntVar(0,1,'') for s in range(S)] for t in range(T)] for w in range(W)] for i in range(I)]
x[i][w][t][s]が上述の$x^i_{wts}$を表します。制約式を考える
今の教室長が守ってくれてないやつです。
シフトに関して満たさなければならない条件ですが、ぱっと思いつく範囲では
・一人の講師が担当するのは生徒一人まで
・希望していない日時にシフトを入れない
・(得意不得意の理由で)担当できない科目のシフトを入れない
・過不足なくシフトを入れる
あたりになりそうです。今回はあくまで講師に優しくというスタンスでいきます。この他に
・生徒側(講師側)から共演NGが出ている講師(生徒)
・中学受験経験者の講師を希望する生徒
などがありましたが、今回は考慮しないことにします。とりあえず最初に述べた4つを制約としたいと思います。
一人の講師が担当するのは生徒一人まで
私が所属していた塾では講師:生徒=1:2での授業でしたが、今回は簡単のためマンツーマンにします。
数式
次のような数式を考えます。
\sum_s x^i_{wts} \leq 1 \quad \forall i,w,t実装
solver.Add(等式制約または不等式制約)で制約式を作成します。
また、solver.Sum()で通常のsum()より速く計算することが出来ます。#制約 一人の講師が担当できる生徒は一人まで for i in range(I): for w in range(W): for t in range(T): solver.Add(solver.Sum([x[i][w][t][s] for s in range(S)]) <= 1)希望していない日時にシフトを入れない
講師からは、以下のようなシフト希望表を受け取っているものとします。
今回は板垣先生作「グラップラー刃牙」より、7名の方に講師を担当して頂いています。
数式
次のように、希望しない日時に関しては最初から0になるように制約式を考えます。
\sum_s x^i_{wts} = 0 \quad \forall i,w,t \in講師iが希望しない日時実装
shift_avlblに上のシフト希望表がpandasのDataFrameとして格納されているものとします。
曜日・時限が横一列に並んだ状態から曜日インデックスと時限インデックスを取得するために、4で割った商と余りを用いています(今回は各曜日4限まであるため)。#制約 希望しない日時にシフトを入れない for i in range(I): for j in range(len(shift_avlbl.columns)): #この日時を希望しなければ if shift_avlbl.iat[i,j] == 0: unavlbl_w = j//4 #曜日インデックス unavlbl_t = j%4 #時限インデックス solver.Add(solver.Sum([x[i][unavlbl_w][unavlbl_t][s] for s in range(S)]) == 0)担当出来ない科目のシフトを入れない
シフト希望表と同様に、講師から次のような担当可能科目の情報を受け取っているものとします。
数式
先ほどと同様に、担当できない科目には最初から割り当ての可能性をなくすという形をとります。
\sum_{w,t} x^i_{wts} = 0 \quad \forall i,s \in講師iが担当できない科目実装
subject_avlblに上の担当可能科目の情報がpandasのDataFrameとして格納されているものとします。#制約 担当できない科目のシフトをいれない for i in range(I): for s in range(S): if subject_avlbl.iat[i,s] == 0: solver.Add(solver.Sum([x[i][w][t][s] for w in range(W) for t in range(T)]) == 0)過不足なくシフトを入れる
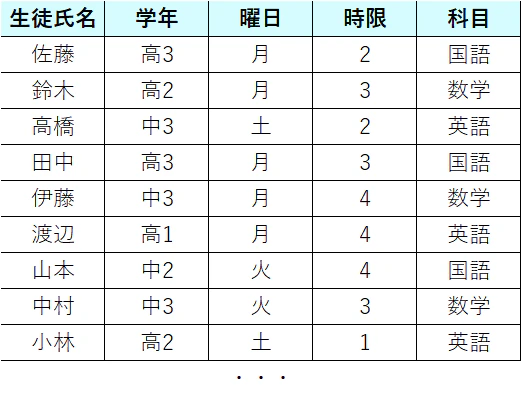
以下のような表で受講管理を行っているとします。
画像は途中までになっていますが、41件の登録があります。数式
この表によって、「どの日時にどの科目が何人分需要されているか」が分かるので、曜日$w$の時限$t$における科目$s$の需要量として$D_{wts}$という定数を考えます。
そして、過不足なくシフトを入れることは需要を丁度満たすことと考えられるので、以下の制約式を考えます。\sum_i x^i_{wts} = D_{wts} \quad \forall w,t,sまずは条件を全て満たすシフトを決めることが最初の目的でしたが、これまでに登場した制約を考えると、「実行可能解がない」可能性が十分にあります。実行可能解がないとソルバーの出力としての解は得られなくなってしまうので、対策として上記の制約式を緩めます。
新たな決定変数$y_{wts}$を用いて、以下の制約式に変更します。
\sum_i x^i_{wts} + y_{wts} = D_{wts} \quad \forall w,t,s$y_{wts}$は、「曜日$w$の時限$t$における、科目$s$を担当する講師の不足分」と解釈出来ます。そして、目的関数として
min \quad \sum_{w,t,s} y_{wts}を考えれば、「講師不足数」を最小化する問題となり、目的関数値が0であれば全ての制約を守れていることになります。また、0じゃなくても、最適解$y$の中身を参照することで「何曜日の何限に何の科目の講師が何人足りないのか」が分かるため、講師間での調整が出来ます。
実装
lecture_reqに先ほどの受講管理票がDataFrameで格納されているものとし、$D_{wts}$を表す配列demandを作成します。決定変数$y_{wts}$は事前に作成してあるものとして、以下のコードで制約式を加えます。#各曜日・各時限における各科目の需要量を表す配列 demand = [[[0 for s in range(S)] for t in range(T)] for w in range(W)] for index,row in lecture_req.iterrows(): weekday = weekday_list.index(row['曜日']) timetable = timetable_list.index(row['時限']) subject = subject_list.index(row['科目']) demand[weekday][timetable][subject] += 1 #制約 過不足なくシフトを入れる for w in range(W): for t in range(T): for s in range(S): solver.Add(solver.Sum([x[i][w][t][s] for i in range(I)]) + y[w][t][s] == demand[w][t][s])目的関数を考える
上述の通り、最初は「講師不足数の総和」を目的関数として最小化することで、実行可能解があるかどうかを確認し、なければ講師のシフト希望を調整します。実行可能解がある状態にできたら、最適なシフトを目指して別の目的関数を考えることにします。
数式
最初の目的関数を再掲します。
min \quad \sum_{w,t,s} y_{wts}実装
solver.Minimize(目的関数)で目的関数を作成します。最大化問題のときはsolver.Maximize(目的関数)とします。
また、solver.Solve()で最適化計算が行われ、返り値としてソルバーのステータスが得られます。ステータスが0であれば最適解が求まったことになります。#講師不足数の総和 shortage = solver.Sum([y[w][t][s] for s in range(S) for t in range(T) for w in range(W)]) #目的関数の設定 solver.Minimize(shortage) #求解 status = solver.Solve()全体のコード
データを取得してから、シフトを出力するまでの一連のコードを記載します。
staff_scheduling.pyimport pandas as pd from ortools.linear_solver import pywraplp """必要なデータ""" #シフト希望表 shift_avlbl = pd.read_excel('~/data.xlsx',sheet_name='シフト希望表').set_index('講師氏名').applymap(lambda x: 1 if x=='〇' else 0) #担当可能科目 subject_avlbl = pd.read_excel('~/data.xlsx',sheet_name='担当可能科目').set_index('講師氏名').applymap(lambda x: 1 if x=='〇' else 0) #受講管理表 lecture_req = pd.read_excel('~/data.xlsx',sheet_name='受講管理表') """最適化""" #曜日・時限・科目のリスト weekday_list = ['月','火','水','木','金','土'] timetable_list = [1,2,3,4] subject_list = ['国語','数学','英語'] #講師数、曜日数、時限数、科目数 I,W,T,S = len(shift_avlbl),len(weekday_list),len(timetable_list),len(subject_list) #ソルバーの宣言 solver = pywraplp.Solver('Staff Scheduling',pywraplp.Solver.CBC_MIXED_INTEGER_PROGRAMMING) #決定変数x x = [[[[solver.IntVar(0,1,'') for s in range(S)] for t in range(T)] for w in range(W)] for i in range(I)] #決定変数 y y = [[[solver.IntVar(0,4,'') for s in range(S)] for t in range(T)] for w in range(W)] #制約 一人の講師が担当できる生徒は一人まで for i in range(I): for w in range(W): for t in range(T): solver.Add(solver.Sum([x[i][w][t][s] for s in range(S)]) <= 1) #制約 希望しない日時にシフトを入れない for i in range(I): for j in range(len(shift_avlbl.columns)): if shift_avlbl.iat[i,j] == 0: unavlbl_w = j//4 #曜日インデックス unavlbl_t = j%4 #時限インデックス solver.Add(solver.Sum([x[i][unavlbl_w][unavlbl_t][s] for s in range(S)]) == 0) #制約 担当できない科目のシフトをいれない for i in range(I): for s in range(S): if subject_avlbl.iat[i,s] == 0: solver.Add(solver.Sum([x[i][w][t][s] for w in range(W) for t in range(T)]) == 0) #各曜日・各時限における各科目の需要量を表す配列 demand = [[[0 for s in range(S)] for t in range(T)] for w in range(W)] for index,row in lecture_req.iterrows(): weekday = weekday_list.index(row['曜日']) timetable = timetable_list.index(row['時限']) subject = subject_list.index(row['科目']) demand[weekday][timetable][subject] += 1 #制約 過不足なくシフトを入れる for w in range(W): for t in range(T): for s in range(S): solver.Add(solver.Sum([x[i][w][t][s] for i in range(I)]) + y[w][t][s] == demand[w][t][s]) #講師不足数の総和 shortage = solver.Sum([y[w][t][s] for s in range(S) for t in range(T) for w in range(W)]) #目的関数の設定 solver.Minimize(shortage) #求解 status = solver.Solve() """結果の表示""" print('ステータス:',status) print('講師不足数:',solver.Objective().Value()) #最適解 x_solution = [[[[int(x[i][w][t][s].SolutionValue()) for s in range(S)] for t in range(T)] for w in range(W)] for i in range(I)] #シフトを表すデータフレーム teacher_list = shift_avlbl.index.tolist() shift_df = pd.DataFrame(columns=['講師氏名','曜日','時限','科目']) for i in range(I): for w in range(W): for t in range(T): for s in range(S): if x_solution[i][w][t][s] == 1: shift_df = shift_df.append({'講師氏名':teacher_list[i],'曜日':weekday_list[w],'時限':timetable_list[t],'科目':subject_list[s]},ignore_index=True) print(shift_df)結果
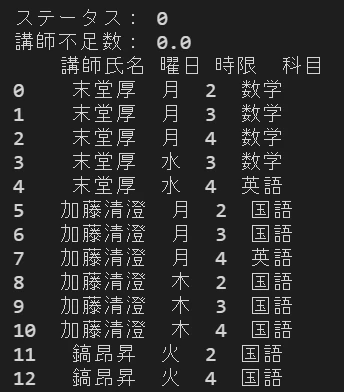
上記のコードを実行した結果、以下の出力が得られました。ステータスが0なので最適解が求まっていることが分かり、目的関数である講師不足数が0なので、現状のシフト希望と受講管理表のデータでも全ての制約を満たす解が存在することが分かりました。
シフトを表すデータフレームは途中で切れていますが、受講希望数と同じ41件のシフトが出力されています。
そして作成した担当表が以下になります。
人選が適当すぎて「〇曜△限であの戦いが起こりそう」とかはありませんでした。挫折
本当はここから別の目的関数や制約を取り入れて、より良いシフトを作る展開にしたかったのですが、上手く出来ませんでした。
取り入れたかったものとしては、「なるべく同じ日に連続でシフトに入りたい」を考えていました。朱沢先生や安藤先生のシフトを見てみると、一日に一コマだけシフトが入っていたり、空きコマがあったりします。人によるとは思いますが、なるべく一日に一気にシフトを入れることを好む方は多いと思うので、空きコマの数を最小化したり、同じシフト数でも出勤する日数を最小化するようなモデルを作りたいと考えていました。しかしながら、私の力では整数線形計画問題になるようにこれらをモデルに取り入れることが出来ませんでした。もし整数線形計画問題になるように取り入れるアイデアや、全く異なる定式化で実現するアイデアがあったら是非お教えいただければと思います。
まとめ
達人である渋川先生にプロジェクトを失敗させてしまい申し訳ないです。そして渋川先生のシフトを完全に忘れていました。
未熟ながらアドベントカレンダーに初挑戦させて頂きましたが、悔しい部分が多いので来年また挑戦させてください。読んで頂きありがとうございました。


- 投稿日:2020-12-15T21:38:17+09:00
Markdownの表をpandas dataframeに変換する
モチベーション
画像を貼り付けたマークダウンの表をエクセルで編集したい!ということがありました。(トレードオフ表や台帳)
ところが、VScodeのプレビューをエクセルにコピペしても、画像のリンクを持ってくることが出来ませんでした。
画像のリンクが付いてこないと、編集後エクセルからマークダウンにコピペした後、画像のパスを打ち直す必要があり、大変です。
ということで、pythonでスクリプトを作ることとしました。(かなり、やっつけ仕事ですが)やったこと
- VScodeのマークダウンの表をコピー
- 下記のコードを実行
- エクセルへ貼り付け
- エクセルで編集
- エクセルでコピー
- VScodeに貼り付け
画像のリンクが付いているので、何もしなくても画像が表示される!素晴らしい
md_table2df.pyimport mistune import pyperclip import pandas as pd import re md = mistune.Markdown() res = md(pyperclip.paste())#クリップボードからテキストを取得して、HTMLに変換 pattern = '<img src="(.*)" alt="(.*)">' rep = '' rep_tex = re.sub(pattern,rep,res)#画像の部分をマークダウン記法に変換 df = pd.read_html(rep_tex)[0]#dataframe作成 df.to_clipboard(index=False)#エクセルに貼り付けるため、クリップボードへコピー【コードの説明】
手順は正直まどろっこしい。。。もっといい方法ありそう
- マークダウンのテキストをクリップボードから取り出し
- 取り出したテキストをHTMLへ変換
- HTMLの画像の箇所を正規表現を使用してマークダウン記法に置換
- pandasでHTMLから表を作成
- その表をクリップボードへ入れる
感想
ググってもありそうで、なかったです
プレビュー画面をコピペすれば、大部分はエクセルに持ってこれるので、あんまり需要ないのかな
それとも他に良い方法があるのかなぁ
- 投稿日:2020-12-15T21:15:41+09:00
カテゴリーデータを数値データに変換する
1. はじめに
文字で与えられるカテゴリーデータを数値データに変換するやり方の一例として、指定した数字に置き換える方法、カテゴリーのカウント数に置き換える方法、についてメモしておきます。
2. ライブラリ、データを読み込む
データ例として、KaggleのTitanicデータを使用します。
import numpy as np import pandas as pd train = pd.read_csv("./input/train.csv") test = pd.read_csv("./input/test.csv") data0 = pd.concat([train, test], sort=False)data0.columns # Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', # 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')3. 空欄(nan)を埋める
'Embarked'のデータで変換してみます。
data0['Embarked'][0:6] # 0 S # 1 C # 2 S # 3 S # 4 S # 5 Q # Name: Embarked, dtype: object#文字データの種類を調べる data0['Embarked'].unique() #array(['S', 'C', 'Q', nan], dtype=object)#nanを数える data0['Embarked'].isnull().sum() #2#文字データをカウントする(before) v0 = data0["Embarked"].value_counts() v0 # S 914 # C 270 # Q 123 # Name: Embarked, dtype: int64#nanを'S'で埋める data0['Embarked'].fillna(('S'), inplace=True)#文字データをカウントする(after) v1 = data0["Embarked"].value_counts() v1 # S 916 # C 270 # Q 123 # Name: Embarked, dtype: int644-1. 文字データを指定した数字に置き換える
data = data0 v2 = { 'S':0, 'C':1, 'Q':2 } data['Embarked_1'] = data['Embarked'].map(v2) data['Embarked_1'][0:6] # 0 0 # 1 1 # 2 0 # 3 0 # 4 0 # 5 2 # Name: Embarked_map, dtype: int644-2. 文字データをカウント数に置き換える
data=data0 vc = data['Embarked'].value_counts() vc # S 916 # C 270 # Q 123 # Name: Embarked, dtype: int64data['Embarked_2'] = data['Embarked'].map(vc) data['Embarked_2'][0:6] # 0 916 # 1 270 # 2 916 # 3 916 # 4 916 # 5 123 # Name: Embarked_count, dtype: int64
- 投稿日:2020-12-15T20:52:58+09:00
django [Errno 61] Connection refusedの対処法(アカウント認証テストで、、、)(備忘録)
djangoで[Errno 61] Connection refusedになった時の対処法
エラー文の意味は直訳だと#接続が拒否された”と言っている。
sign_upページからテスト情報を入力してうまく登録出来るか確認しようとした段階のエラー。解決方法
以下をsettings.pyに追加したら直った。
EMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'これはメールを実際には送らずに、コンソールに表示してくれる設定らしいです。
実際に送信するには以下のように書き換えが必要とのこと。
EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend'
- 投稿日:2020-12-15T20:25:58+09:00
マリオに遺伝子を注入してみた~遺伝アルゴリズム~
はじめに
こんにちは。今回は遺伝アルゴリズムでスーパーマリオブラザーズの1-1をクリアしてみましたので、プロセスとコードを備忘録を兼ねて記事にしました。
また、なるべく理論に沿った実装にしたかったので、ライブラリはほとんど利用していません。おそらく配列処理などはもっと良い方法があると思いまが、大目に見てやってください。
遺伝アルゴリズムに関しては、このスライドが死ぬほどわかりやすいのでぜひ見てみてください(笑)
実装に関して
- 遺伝子長は300
マリオの1-1をクリアするには、最速ではないモデルでおよそ2700フレームが必要です。
皆さんがTASではない限り、フレームごとに入力を変えることはないですし、遺伝子長が長くなると生成や交配などで重くなったり多くのメモリを占有するのでこのようにしました。
10フレームごとに行動を選択することとしました。
- 遺伝子パターンは0と1
なるべく早くゴールしたかったので、ただ右に走る0と、走りながらジャンプする1の2つに絞りました。
- 個体数は20
特に理由はありませんが、あまり多くしても結果が変わらないことが多くあったので、私はいつもこのくらいの数にしています。
- 評価方法:たどり着いた距離
今回はゴールが目標なので、死ぬまで、もしくは時間切れまでに進んだ距離にしました。
移動する床もありませんし、右にしか進まないので、ステップが増えるごとに到達距離が減少することはありません。
- 交叉方法:1点交叉
今回は遺伝子長も短めで、時系列での配列になるので、これがベストだと思い選びました。
2点交叉でもよかったんですが、1点交叉の方が収束が早かったです。
- 遺伝子の突然変異率:5%
収束までを早めたかったので少し高めに設定しました。最速モデルを目指す場合はもう少し落とした方がいいと思います。
- 世代交代手法:最良の2個体はそのまま、残り18個体は上位10個体からランダムに選別し交配
いつも使ってる手法なのであまり考えたことはありませんが、最良個体をそのまま残すことで極端に低い世代が生まれにくくなりますし、個人的に気に入っている設定です。
実装(関数)
適当に実装していきます。普段はパラメータとか遺伝子クラスを継承したりして丁寧に作りますが、今回はわかりやすくマリオに遺伝子を組み込みたいので省略します。
気になる方は多くの先輩方がQiitaで実装を記事にしてくださっているので参考にしてみてください。
- 遺伝子の作成
def create_gene(): generation = [] for x in range(20): gene = [] for y in range(300): gene.append(random.choice([0, 1])) generation.append(gene) return generation
- 遺伝子の交配
def cross(gene1, gene2): cross_point = random.choice(range(len(gene1))) new_gene1 = gene1[:cross_point] + gene2[cross_point:] new_gene2 = gene2[:cross_point] + gene1[cross_point:] return new_gene1, new_gene2
- 遺伝子の突然変異
def mutation(genes): new_genes = [] for move in genes: if random.random() < 0.05: if move == 1: new_genes.append(0) else: new_genes.append(1) else: new_genes.append(move) return new_genes
- 遺伝子のスコアによるソート
def sorts(genes, scores): sorted_index = np.argsort(scores) sorted_li = [] for x in sorted_index: sorted_li.append(genes[x]) sorted_li.reverse() return sorted_li主要な関数はこのくらいなので、これを使ってメインを実装していきます。
今回マリオはこちらのライブラリを使用させていただきました。
実装(メイン)
このような感じにしました。
from nes_py.wrappers import JoypadSpace import gym_super_mario_bros import random import numpy as np # 移動設定 MOVEMENT = [ ['right', 'B'], ['right', 'A', 'B'], ] # 遺伝子作成 GENES = create_gene() # 環境構築 env = gym_super_mario_bros.make('SuperMarioBros-v0') env = JoypadSpace(env, MOVEMENT) # 初期設定 TRY_GENERATION = 1000 STEP_COUNT = 10 for x in range(TRY_GENERATION): generation_scores = [] for i, gen in enumerate(GENES): stete = env.reset() # 環境リセット for j, move in enumerate(gen): breaker = False for k in range(STEP_COUNT): state, reward, done, info = env.step(move) if done: breaker = True break if i == 0: # # env.render() # 実際に表示したい場合はコメントアウト pass if breaker: break generation_scores.append(info["x_pos"]) print("generation: {} genes: {} stops: {} score: {}".format(x + 1, i + 1, j + 1, info["x_pos"])) GENES, scores = sorts(GENES, generation_scores) NEW_GENES = [] for k in range(9): gene1, gene2 = random.sample(GENES[:10], 2) gene1, gene2 = gene.cross(gene1, gene2, mode="one-point") NEW_GENES.append(gene1) NEW_GENES.append(gene2) NEW_GENES = mutation(NEW_GENES) NEW_GENES = GENES[:2] + NEW_GENES GENES = NEW_GENES env.close()結果
やっと遺伝子組み換えマリオがゴールしてくれました!笑 pic.twitter.com/sEFE6RweDA
— そばっしー (@sobasssy) December 15, 2020簡単なステージではありますが...
第7世代でゴールする個体が現れました
ちょっと早すぎない?まだ2分くらいしか学習してないんだけど
遺伝アルゴリズムの強さを身にしみて感じました。
皆さんもぜひマリオに遺伝子を注入して組み換えまくってくださいね!(笑)
- 投稿日:2020-12-15T20:14:49+09:00
OracleFunctionsを利用するための「開発・デプロイ環境構築」及び「デプロイ方法」
始めまして(Qiita初投稿)、ジーアールソリューションズの趙と申します。
この記事はグロースエクスパートナーズ Advent Calendar 2020の19日目です。OracleCloudの資格を取得するため、OracleCloudのサービスを勉強しました。この間Oracle Functionsにも触っていました。インターネットで調べると、Oracle Cloud Shell を利用してFunctionsのデプロイ環境設定してデプロイする記事は沢山ありますが、OracleCloudのインスタンスを利用してFunctionsの開発・デプロイ環境構築の記事が少ないことに気づきました。
今回はOracleCloudのサーバーレスサービス(Functions)を利用したファンクションのデプロイ、およびOracleCloudのインスタンスを使った開発・デプロイ環境の構築を紹介します。OracleCloud Functionsとは
Oracle Functionsは、オープンソースFnProjectをベースとした Oracle Cloud Infrastructureに組み込まれている、フルマネージド、マルチテナント、高拡張性なオンデマンドのFunctions-as-a-Service(FaaS)プラットフォームです。
他のパブリック・クラウドにもファンクションが提供されており、AWS Lambdaは有名なファンクションサービスの一つです。比較するとAWS Lambdaで開発したファンクショはAWSの環境しか実行できないため、大きなロックイン性があります。でOracle FunctionsはFnProjectをベースに開発したファンクショサービスなので、簡単に移植することができます。Oracle Functionsデプロイ
デプロイ流れ概要
①開発・デプロイ環境を構築します。
②ファンクションからDockerイメージを作成します。
③func.yamlファイルでファンクション定義します。
④指定したDockerレジストリにイメージをプッシュします。
⑤ファンクションのメタデータをFnサーバーにアップロードします。
⑥OracleCloudのコンソールにファンクションを追加します。
※図のソース:「docs.cloud.oracle.com」環境準備
Oracle Functionsを使用してファンクションを作成及びデプロイする前に、ファンクション開発のためのテナンシ設定する必要があります。
設定のタスクおよび手順のリンクは以下となります。
※本記事はOracleFunctionsで使用するグループとユーザーを存在する前提で記載します。Oracle FunctionsはVCN及びリポジトリを使用できるようにポリシーの作成
1.OracleCloudのコンソールにログインします。
2.ナビゲーション・メニューを開いて「アイデンティティ」⇒「ポリシー」をクリックします。
3.ルート・コンパートメントを選択して、「ポリシー作成」をクリックします。
4.ポリシー作成画面で、ポリシーを入力して、「作成」ボタンをクリックします。
Oracle Functionsサービスは、Oracle Cloud Infrastructure Registryのリポジトリに格納されたファンクションのイメージに対する読取りアクセス権及びVNCの使用権限が必要なので、以下のポリシー・ルールの設定が必要です。
Allow service FaaS to read repos in tenancy
Allow service FaaS to use virtual-network-family in tenancy
Oracle Functionsで使用するVCN及びサブネットの作成
1.OracleCloudのコンソールにログインします。
2.ナビゲーション・メニューを開いて「ネットワーキング」⇒「仮想クラウド・ネットワーク」をクリックします。
3.Oracle Functionsを所有するコンパートメントを選択して、「VCNウィザードの起動」をクリックします。
4.「VCNウィザードの起動」の画面で、「インターネット接続性を持つVCN」を選択して、「VCNウィザードの起動」をクリックします。
5.「構成」画面でVCN名およびVCN CIDRブロックを入力して「次」ボタンをクリックします。
6.「確認及び作成」画面で設定した項目を確認して、「作成」をクリックします。
Oracle Functionsの開発及びデプロイ用インスタンス作成
1.OracleCloudのコンソールにログインします。
2.ナビゲーション・メニューを開いて「コンピュート」⇒「インスタンス」をクリックします。
3.Oracle Functionsを所有するコンパートメントを選択して、「インスタンスの作成」をクリックします。
4.インスタンスの作成画面で、「Oracle Cloud Developer Image」イメージを選択します。
5.リモートからアクセスできるように、Oracle Functionsと同じVCNを選択し、「パブリック・サブネット」及び「パブリックIPv4アドレスの割当て」を選択します。
6.SSHキーとデータボリュームを設定して、「作成」ボタンをクリックしてインスタンスを作成します。インスタンスはFunctions及びリポジトリにアクセスできるように権限付与します。
1.新規作成したインスタンスの詳細画面を開いて、インスタンスのOCIDをコピーします。
2.ナビゲーション・メニューを開いて「アイデンティティ」⇒「動的グループ」をクリックします。
3.「動的グループの作成」をクリックして、動的グループの作成画面を開きます。
4.動的グループの作成画面で、インスタンスのID及びコンパートメントのIDを入力します。
例:
Any {instance.id = 'ocid1.instance.oc1.XXXXX', instance.compartment.id = 'ocid1.compartment.oc1..XXXX'}
※コンパートメントのOCIDはコンパートメントの詳細画面で、コピーできます。
5.ナビゲーション・メニューを開いて「アイデンティティ」⇒「ポリシー」をクリックします。
6.ルート・コンパートメントを選択して、「ポリシー作成」をクリックします。
7.ポリシー作成画面で、ポリシーを入力して、「作成」ボタンをクリックします。
例:
Allow dynamic-group Training-FaaS-DyGRP to manage functions-family in compartment <コンパートメント名>
Allow dynamic-group Training-FaaS-DyGRP to use virtual-network-family in compartment <コンパートメント名>
Allow dynamic-group Training-FaaS-DyGRP to read repos in tenancy
Oracle Functionsを実施するOracleクラウドユーザーのAuth Token を取得
1.OracleCloudのコンソールにログインします。
2.ナビゲーション・メニューを開いて「アイデンティティ」⇒「ユーザー」をクリックします。
3.ユーザー一覧画面で、対象ユーザーをクリックして、ユーザーの詳細画面に遷移します。
4.ユーザー詳細画面で、「認証トークン」をクリックして、「認証トークンの作成」をクリックします。
5.説明を記載して、「トークンの生成」をクリックします。
6.トークンの作成画面を表示して、トークンをコピーして、保存します。
この画面を閉じたら、トークンの再表示ができないため、トークンの再作成が必要!!2.Oracle Functionsの実行環境作成
Oracle Functionsの開発環境作成
Oracle Functionsの開発環境を構成するには、以下3つの方法があります。
・クラウド・シェルの設定
・ローカル・マシンの設定
・Oracle Cloud Infrastructureコンピュート・インスタンスの設定最も簡単な方法ではクラウド・シェルを利用して、Functionsの開発環境を構築します。本記事は「Oracle Cloud Infrastructureコンピュート・インスタンス」を使用してFunctionsの開発環境を構成します。
1.環境準備で作成したインスタンスにログインします。
2.Dockerのバージョンを確認します。$ sudo docker version Client: Docker Engine - Community Version: 18.09.8-ol API version: 1.39 Go version: go1.10.8 Git commit: 76804b7 Built: Fri Sep 27 21:00:18 2019 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 18.09.8-ol API version: 1.39 (minimum version 1.12) Go version: go1.10.8 Git commit: 76804b7 Built: Fri Sep 27 20:54:00 2019 OS/Arch: linux/amd64 Experimental: false Default Registry: docker.ioデフォルトでは一般ユーザーがDockerを使用する際は、sudoで実施します。一般ユーザーでファンクションをデプロイする際に、Dockerの権限がないと、デプロイ失敗します。
一般ユーザーでDockerを使えるように、対象ユーザーはDockerグループに追加が必要!!
本記事はopcユーザーを使用するため、以下のように設定して、opcユーザーは再度ログインします。$sudo usermod -g docker opc $sudo /bin/systemctl restart docker.service ####opcユーザーでインスタンスに再度ログイン $ docker info Containers: 3 Running: 0 Paused: 0 Stopped: 3 Images: 1 Server Version: 18.09.8-ol (略)3.FnProject CLIをインストールします。
OracleDevelopイメージはFnProject CLIを含まれていないため、インストールが必要です。$ curl -LSs https://raw.githubusercontent.com/fnproject/cli/master/install | sh fn version 0.6.1 ______ / ____/___ / /_ / __ \ / __/ / / / / /_/ /_/ /_/` $ fn version Client version is latest version: 0.6.1 Server version: ?4.Oracle Cloudのリポジトリにログインします。
リポジトリにログインする前に、Oracle Cloud ナビゲーション・メニューを開いて「管理」⇒「テナンシ詳細」の「オブジェクト・ストレージ・ネームスペース」の値を取得してコピーします。$ docker login <region-key>.ocir.io Username: <object-storage-namespace>/<username> Password:<user's AuthToken> WARNING! Your password will be stored unencrypted in /home/opc/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store Login Succeeded「Login Succeeded」が表示されたら、Oracle Cloudのリポジトリにログイン成功!!
※は3文字の英文であり、各リージョンのリージョンキーはここで確認できます。東京リージョンでは「nrt」となります。
5.FnProject CLIをセットアップ
####FN CLIのコンテキストをリストします。 $ fn list context CURRENT NAME PROVIDER API URL REGISTRY * default default http://localhost:8080 ####新しいFN CLIのコンテキストを作成します。 ######Oracle Cloudのインスタンで構築する場合、パラメータ「--provider oracle-ip」が必要 $ fn create context <context-name(任意)> --provider oracle-ip Successfully created context: training-faas ####新規したコンテキストを使用することを指定します。 $ fn use context training-faas Now using context: training-faas ####FN CLIのコンテキストを再度リストします。 $ fn list context CURRENT NAME PROVIDER API URL REGISTRY default default http://localhost:8080 * training-faas oracle-ip ####コンパートメントIDとOracle Functions API URLでコンテキストを更新します ######コンパートメントの詳細画面でコンテキストのIDを取得できます。 $ fn update context oracle.compartment-id <対象コンパートメントのID> Current context updated oracle.compartment-id with ocid1.compartment.oc1.XXXXX ######以下は東京リージョンのAPI-URLの例です。 $ fn update context api-url https://functions.ap-tokyo-1.oraclecloud.com Current context updated api-url with https://functions.ap-tokyo-1.oraclecloud.com ####Oracle Functionsを使用するレジストリの場所でコンテキストを更新します $ fn update context registry nrt.ocir.io/nretiuoewxik/<リポジトリ名(任意)> Current context updated registry with nrt.ocir.io/<object-storage-namespace>/training-repoここまでで、Functionsの開発環境の構築が完了しました。この環境でFunctionsの作成、デプロイ、実行をできます。
Oracle Functionsのアプリケーション作成
1.OracleCloudのコンソールにログインします。
2.ナビゲーション・メニューを開いて「開発者サービス」⇒「ファンクション」をクリックします。
3.Oracle Functionsを所要するコンパートメントを選択して、「アプリケーションの作成」をクリックします。
4.「アプリケーションの作成」画面でアプリケーションの名前、所属VCN及びサブネットを選択して「作成」ボタンをクリックします。
Oracle Functions作成
現時点でOracle Functionsは「go、java、node、python」をサポートします。
本記事はPythonを使ってファンクションの作成、デプロイ及び実行を行います。1.ファンクションを初期化
$ fn init --runtime python <functions-name> Creating function at: ./training-func1 Function boilerplate generated. func.yaml created. ####ファンクションを初期化したら<functions-name>でフォルダを作成し、以下のファイルを作成されます。 $ ls -l <functions-name> total 12 -rw-r--r--. 1 opc opc 576 Dec 15 10:03 func.py -rw-r--r--. 1 opc opc 143 Dec 15 10:03 func.yaml -rw-r--r--. 1 opc opc 3 Dec 15 10:03 requirements.txt「func.yaml」はファンクションの定義ファイル
例:schema_version: 20180708 name: training-func1 version: 0.0.1 runtime: python entrypoint: /python/bin/fdk /function/func.py handler memory: 256「func.py」はファンクションのソースコードが記載されたファイルです。初期化した際に、「hello-world」のソースコードが作成されます。
※Fn project で Python を書く際に、必ず handler 関数を使用する必要があります。Oracle Functions は Cloud 上のイベントサービスによって作動し、handler 関数はイベント情報が書かれた JSON ファイルを読み取るために使用されます。
例:import io import json import logging from fdk import response def handler(ctx, data: io.BytesIO = None): name = "World" try: body = json.loads(data.getvalue()) name = body.get("name") except (Exception, ValueError) as ex: logging.getLogger().info('error parsing json payload: ' + str(ex)) logging.getLogger().info("Inside Python Hello World function") return response.Response( ctx, response_data=json.dumps( {"message": "Hello {0}".format(name)}), headers={"Content-Type": "application/json"} )「requirements.txt」はファンクションのソースコード内でインポートするパッケージを記述するファイルです。
アプリケーションをデプロイする際に記述されたパッケージが自動で Docker コンテナにインストールします。
例:fdk2.ファンクションをデプロイします。
$ cd <functions-name> $ fn deploy --app <作成したアプリケーション名> Deploying training-func1 to app: Training-FaaS-APP Bumped to version 0.0.3 Building image nrt.ocir.io/<object-storage-namespace>/training-repo/training-func1:0.0.3 .............................................................. Parts: [nrt.ocir.io <object-storage-namespace> training-repo training-func1:0.0.3] Pushing nrt.ocir.io/<object-storage-namespace>/training-repo/training-func1:0.0.3 to docker registry...The push refers to repository [nrt.ocir.io/<object-storage-namespace>/training-repo/training-func1] f4688b2e9584: Pushed 8298236c4bc1: Pushed 2d864fd289b8: Pushed 77237016429d: Pushed 99c8d794f17e: Pushed 83adc987852c: Pushed bb38c3f3fcc5: Pushed 9f72a1f4c21f: Pushed 6280b41d048d: Pushed bd8e6688d36c: Pushed 07cab4339852: Pushed 0.0.3: digest: sha256:74bcc743d163202f5dcc0154bada714e908f94d6aca95e94bfe6cdbc1e58cbdc size: 2621 Updating function training-func1 using image nrt.ocir.io/<object-storage-namespace>/training-repo/training-func1:0.0.3... Successfully created function: training-func1 with nrt.ocir.io/<object-storage-namespace>/training-repo/training-func1:0.0.3Oracle Cloudをログインして、ナビゲーション・メニューを開いて「開発者サービス」⇒「コンテナ・レジストリ」をクリックします。
ファンクションがデプロイされたことを確認できます。
ナビゲーション・メニューを開いて「開発者サービス」⇒「コンテナ・レジストリ」をクリックし、作成したアプリケーションの詳細画面でデプロイしたファンクションが確認できます
最後、ファンクションを実行してみよう!
$ fn invoke Training-FaaS-APP training-func1 {"message": "Hello World"}まとめ
Oracle Cloud のインスタンスでファンクションのデプロイ環境の構築及びデプロイサンプルを紹介しました。
Oracle FunctionsはAPIゲートウェイもしくはイベントと連動してバッチジョブの構成もできます。
ご興味がある方、試してみてください。参考:
https://docs.cloud.oracle.com/ja-jp/iaas/Content/Functions/Concepts/functionsoverview.htm以上
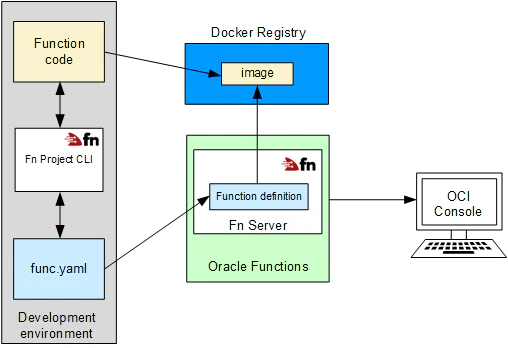
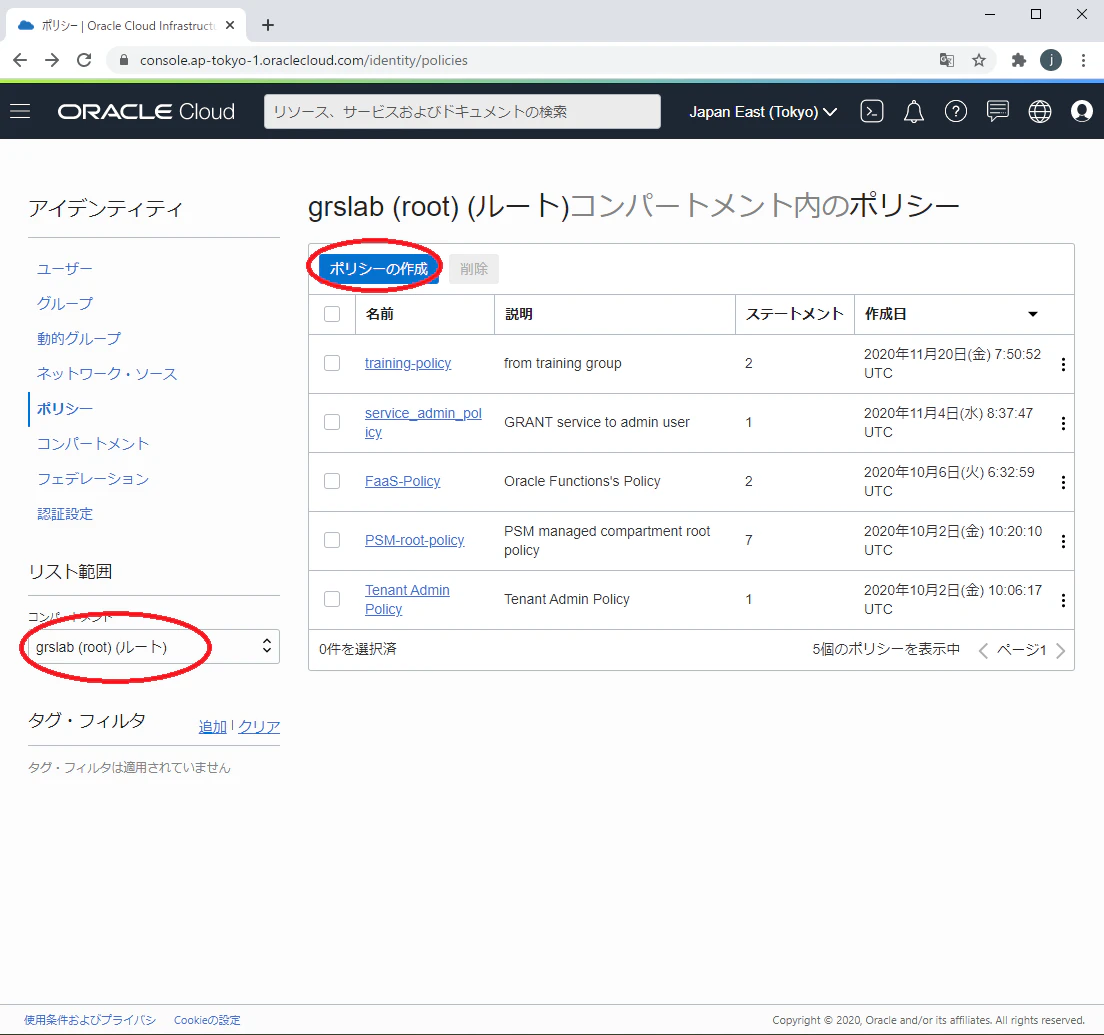



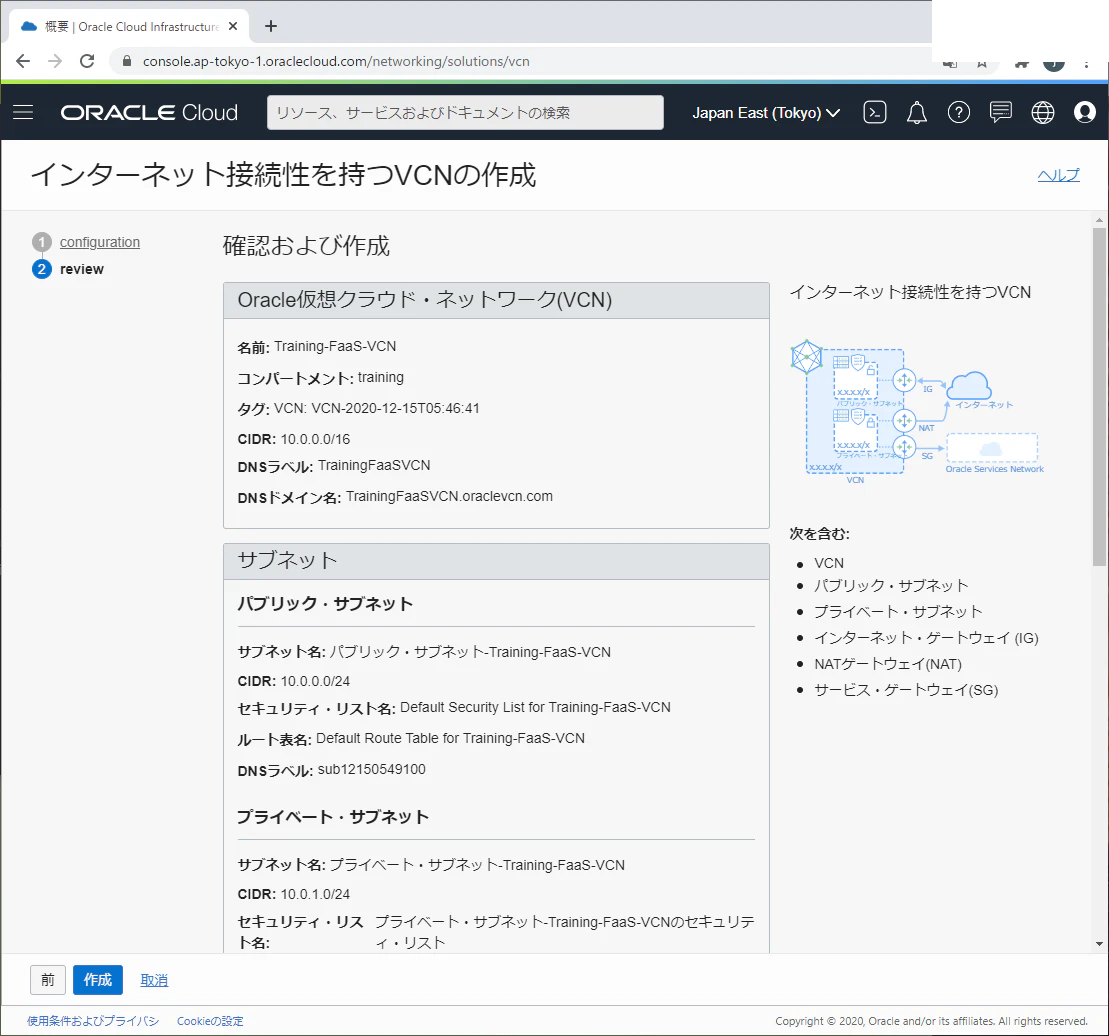
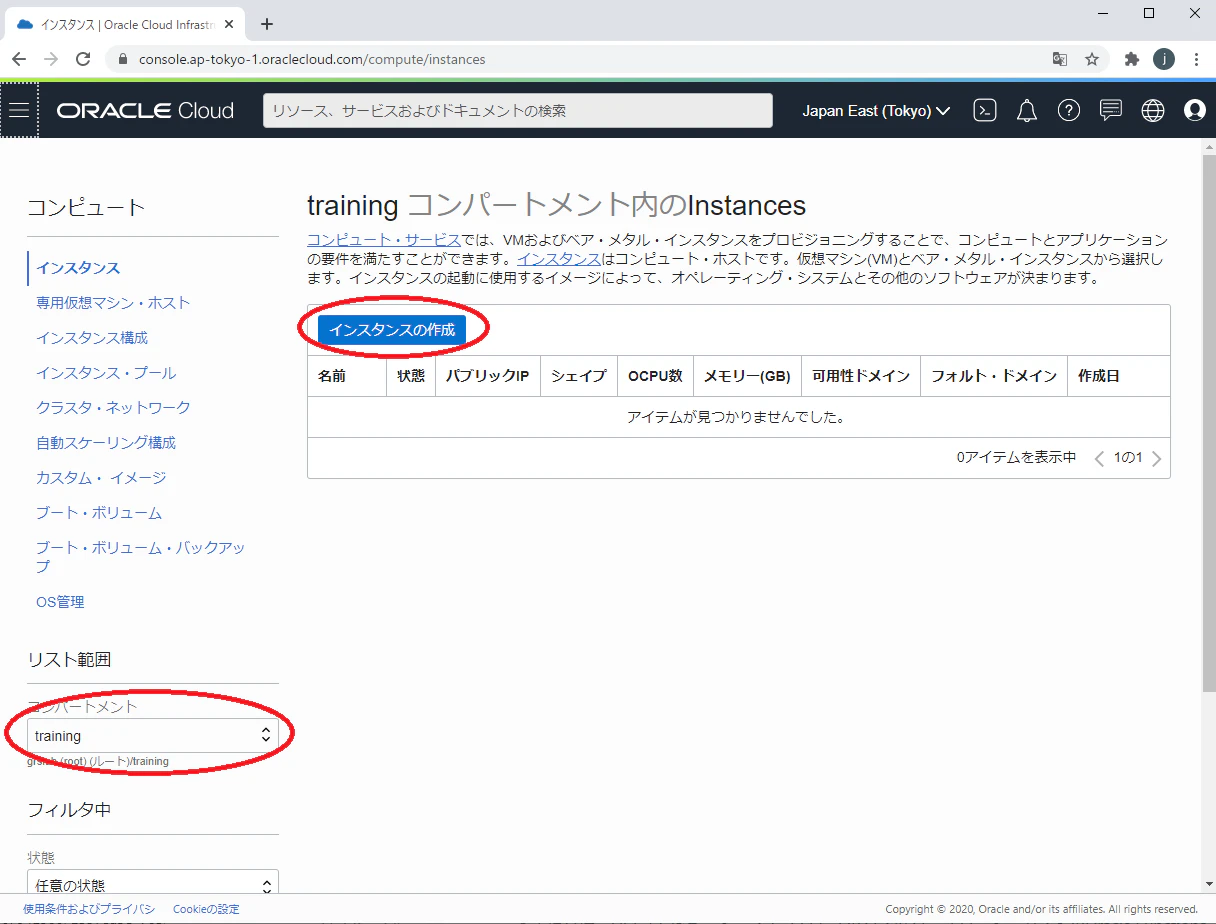

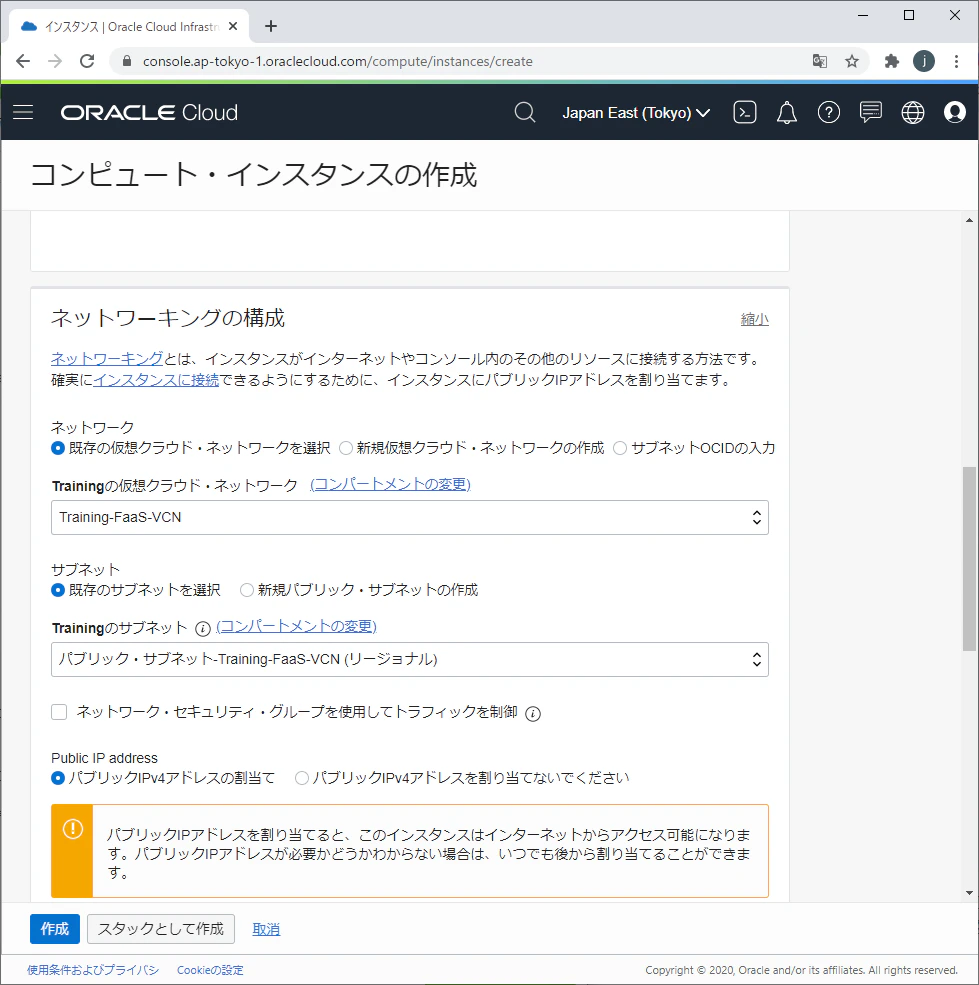




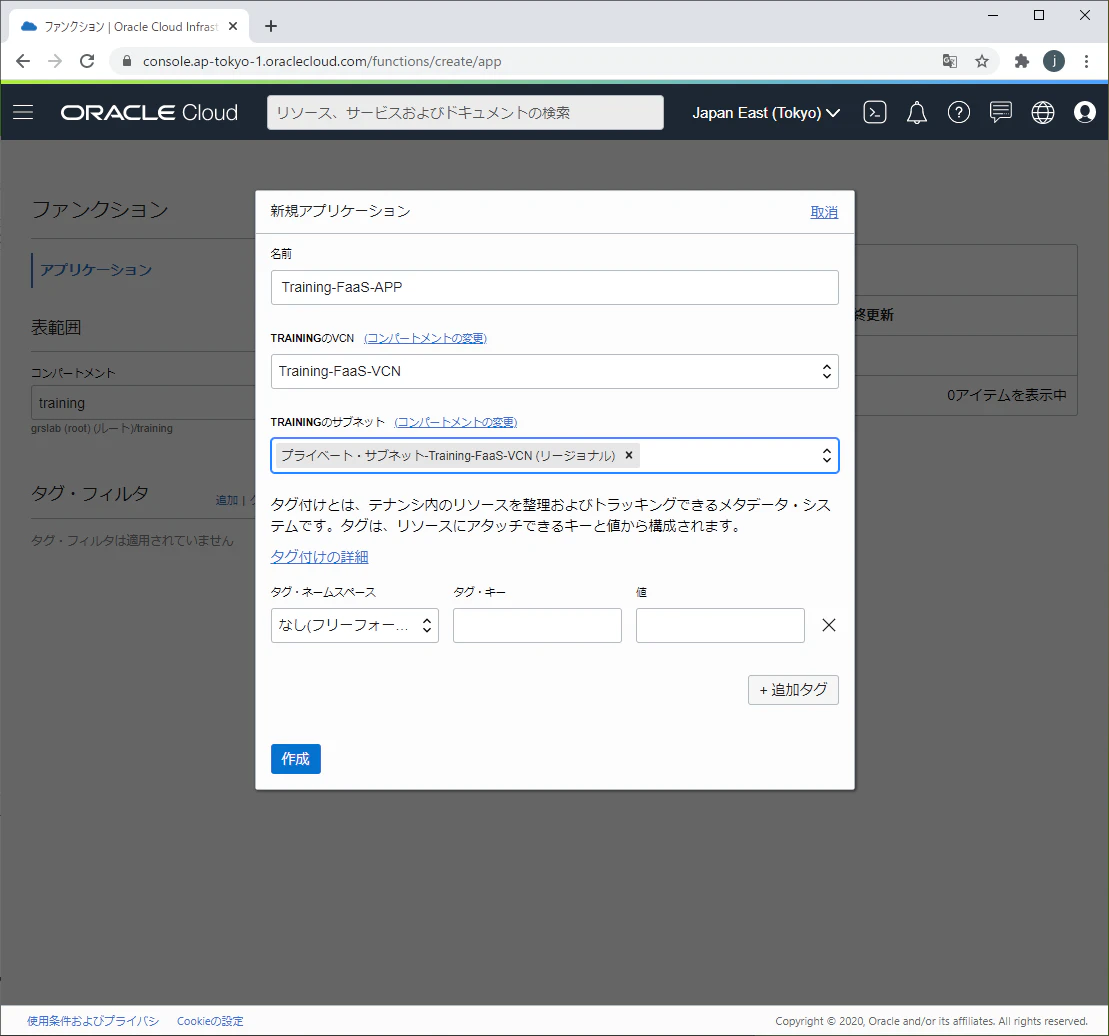

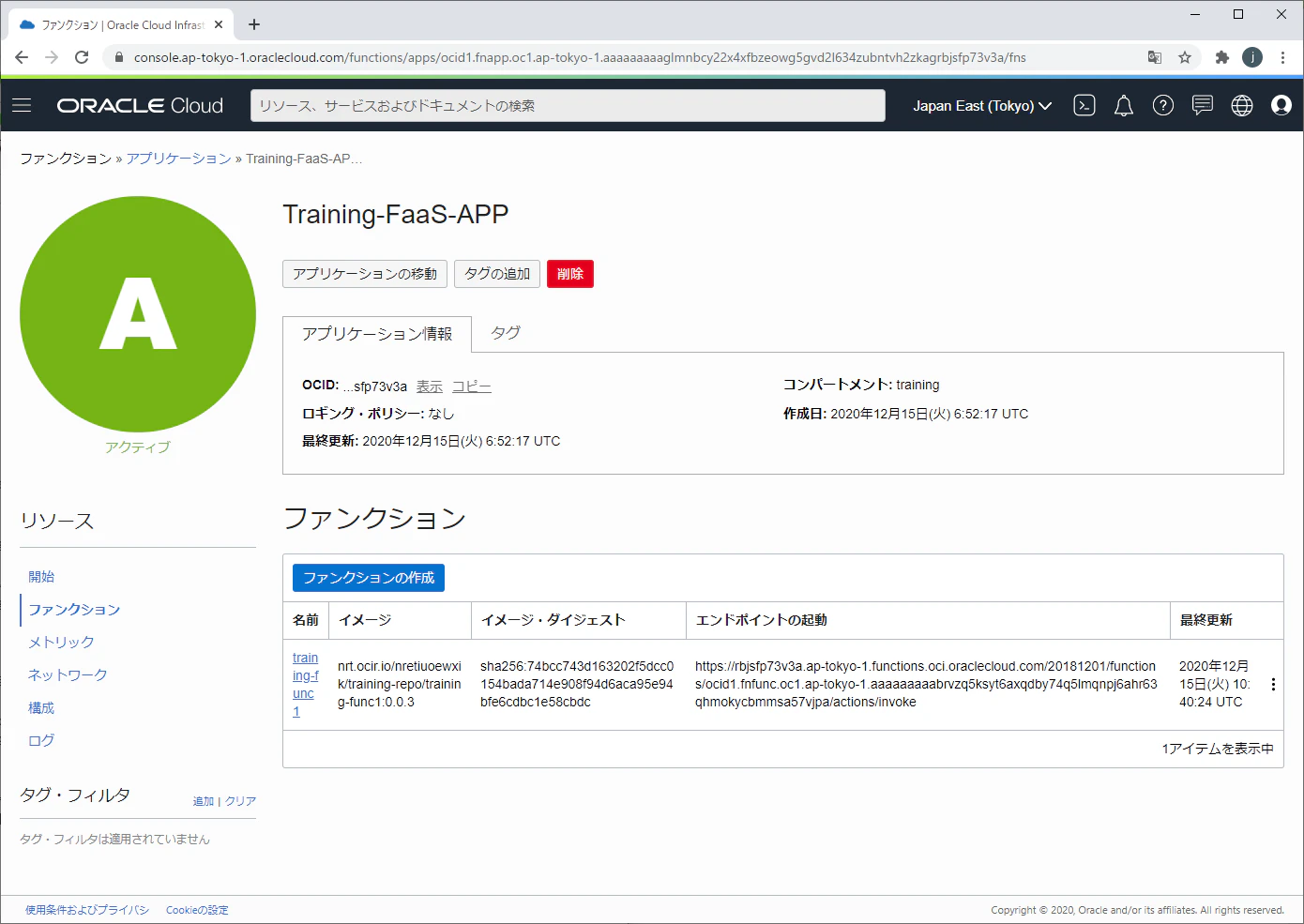
- 投稿日:2020-12-15T20:06:42+09:00
RhinocerosでモデリングしたネットワークをPythonで読み込む①
建築・都市計画数理のなかでも、特にポピュラーなものがネットワーク分析でしょう。建築や都市を、ネットワークとして抽象的に表現することにより、数理的に扱いやすい形にしたうえで分析やシミュレーションを行うことは常套手段です。
目標
- Rhinocerosでネットワークを描く
- Rhinocerosで描いたネットワークをPythonで読み込めるように書き出す
- 書き出したファイルをPythonで読み込んで隣接配列を作る
本記事では第1項に取り組みます。
建築・都市の中のネットワーク
建築や都市の中には、様々なネットワークが織り込まれています。
対象 ノード エッジ 建築平面 部屋,開口部 廊下,通路 道路 交差点,建物出入口 道路 鉄道 駅 線路 ネットワークはノードとエッジからなっており、エッジには(時にはノードにも)"重み"が与えられています。重みは、そのエッジを通過するのに必要な移動距離、時間(時間距離)、費用(金銭距離)などを設定できます。重みの与え方ひとつで、分析の幅と面白さはぐんと上がります。
Rhinocerosでネットワークを描く
とにもかくにも、ネットワークを描いてみましょう。今回はRhinocerosというCADソフトを使ってネットワークを描いてみます。建築界隈の人の中には、Rhinocerosに明るい人がいるかもしれません。Rhinocerosは、そのなかでPythonを動かすことができるので、建築・都市計画の数理的な研究をする上では非常に使い勝手が良いです。今回は、下の地図(国土地理院地図)をもとに歩行空間ネットワークを描いてみます。
ネットワークを描くルールは統一する
道路中心線などの公のベクターデータがあればそれを用いれば良いですが、ない場合には自分で線を引っ張る必要があります。そのときに大事なのが、自分で決めたルールを守ることです。おそらく、皆さんがご自身でネットワークを描くときには、「曲がった道路をどうしようか」とか「建物をネットワークにどう接続しようか」とかに頭を悩ませることでしょう。実際、ネットワーク分析はネットワークの描き方に結果が大きく影響されることがあります。重要なのは、その結果がネットワークの描き方によるものなのか、本質的なものなのかを判別できるようにしておくことです。そのためにも、一度決めたルールをネットワーク全体で統一させておく必要があります。
今回は歩行空間ネットワークを描きますが、これに関して国土交通省より示されている整備仕様案1に従います。すると、下の図のようなネットワークになります。
今回、ネットワークは平面上にあるので、自己交差するようなエッジはありません。歩道橋や地下道などがある場合には、それらも含めてモデリングすると、より精緻な分析ができます。【次回】Rhinocerosで描いたネットワークを
Pythonで読み込めるように書き出すさて、Rhinocerosでネットワークを描き終えた後、分析するにあたり、そのネットワークをプログラミング言語が理解できるようなデータに翻訳してあげる必要があります。次回は、そのデータ構造と、データの作り方について説明します。
ホームページのご案内
建築・都市計画数理に関する私の研究の内容や、研究にまつわるtips等は、個人ホームページにて公開しています。ゆくゆくは、気軽に使える分析ツールも作っていきたいと思っているので、ぜひ覗きに来てください。
→田端祥太の個人ホームページ参考文献


- 投稿日:2020-12-15T19:49:19+09:00
deepchemのNormalizationTransformerはtransform_X = Trueにしようという話
ことの発端
コピペでtraining回したらtestデータの結果が余りにもバリデーションと乖離してる……一体何故……?
こんなissueを見つけた
Transforming datasets before or after Split? #1556Transformer
Deepchemの前処理では, Transformer というパイプラインを一般に用います.
LogTransformer, ClippingTransformer, NormalizationTransformer, BalancingTransformer, MinMaxTransformer, などの既存のTransformerに加え、Transformerクラスを継承することで様々な前処理ができます (DeepChemで欠損値を含む列を除去するTransformerを書いてみる).Transformerはdeepchem特有のデータセット型
dc.data.Datasetに対して適用されます.
Datasetの中身はnp.array型のX, y, w, ids, などです.
一回の前処理で適用できるデータは一つで, どのデータに対してTransformerを適用するのかを引数で指定します.deepchem.trans.transformers.pyclass Transformer(object): def __init__(self, transform_X: bool = False, transform_y: bool = False, transform_w: bool = False, transform_ids: bool = False, dataset: Optional[Dataset] = None): """Initializes transformation based on dataset statistics. Parameters ---------- transform_X: bool, optional (default False) Whether to transform X transform_y: bool, optional (default False) Whether to transform y transform_w: bool, optional (default False) Whether to transform w transform_ids: bool, optional (default False) Whether to transform ids dataset: dc.data.Dataset object, optional (default None) Dataset to be transformed """ if self.__class__.__name__ == "Transformer": raise ValueError( "Transformer is an abstract superclass and cannot be directly instantiated. You probably want to instantiate a concrete subclass instead." ) self.transform_X = transform_X self.transform_y = transform_y self.transform_w = transform_w self.transform_ids = transform_ids # Some transformation must happen assert transform_X or transform_y or transform_w or transform_ids使用上の注意
NormalizationTransformerは平均を0, 標準偏差を1に変換するTransformerです.
transform_y = Trueを指定している参考コードが多く1, そのままコピペするとおそらく意図しない結果が得られます.
なぜならたいていの場合, 私たちは目的変数を標準化したいのではなく, 説明変数を標準化したいからです.
正しくはtransform_X = Trueを設定する必要があります.考えてみれば当たり前ですが, 結構重要なことだと思ったので, 記事にしました.
結論
コピペするときは理解してから使おう
- 投稿日:2020-12-15T19:33:24+09:00
クラウド時代の最強機械学習プラットフォーム Azure Machine Learning まとめ
背景
自分のMacで機械学習環境を構築していた時から時代は進み、クラウド環境上で機械学習を行うようになってきました。
クラウド上の機械学習プラットフォームは各種ありますが、kaggle等の機械学習コンペでよく使われるLightGBMアルゴリズムを開発しているMicrosoftが作っている機械学習プラットフォームの評判が良い (?)ので、調べてまとめてみました。特徴
Notebooks 機能
Jupyter notebookライクなノートブック機能で、Pythonコードを書いて学習していけます。
VSCodeに搭載されているようなコード補完機能 (IntelliSense)も搭載されています。今後共同編集機能なんかも登場するようです (参考)。慣れない方は従来のJupyter notebook (Jupyter Lab)を使うこともできるようです。
GUIで機械学習モデルを作成できる機能 (デザイナー)
モジュールを組み合わせていってデータの加工や機械学習モデルの作成、デプロイを行える機能があります (参考)。
(画像はここから転載)モジュールは色々あって、特徴量エンジニアリング、モデル学習 (回帰、分類、クラスタリング)、推論 (リアルタイム&バッチ)、カスタムモデル・スクリプト (Python, R)等々ができるようです。
デプロイ先もAzure Kubernetes Service (AKS)等にそのままデプロイできるみたいです。自動機械学習機能 (AutoML)
いわゆるAutoMLですね!使用する説明変数の選択や加工とかの特徴量エンジニアリング、アルゴリズムの選択、ハイパーパラメータのチューニングを自動で多数試し、最も精度 (あるいは選択した指標)が良かったモデルを使うことができます。
試したモデル達のアンサンブル学習ができるのでそれだけで精度が良いモデルができそうです()
(画像はここから転載)モデルの運用管理 (MLOps)
いわゆるMLOpsですね!機械学習モデルを作って終わりではなく、ちゃんと再現が出来るような仕組みであったり、モニタリングの状況に応じてモデルの再学習を自動化してデプロイメントまで自動的に行える仕組みを作れるみたいです。
MicrosoftはGItHubを持っている(ずるい)ので、Azure DevOpsはもちろん、GitHubと連携してMLOpsの仕組みを構築できそうです。モデルの解釈
最近重要視されていますが、「AIで非常に精度良く分類できるようになったが、何で判断しているか分からない!」という問題に取り組むのがモデル解釈の機能です。ざっくり言うとどの説明変数・特徴量をベースにそのような分類をしているのか推測 (ブラックボックスなモデルでは)機能です。
Azure Machine LearningでAutoMLだったりでモデル学習を行うと、自動的にモデルの解釈も表示してくれました。
Microsoftはモデル解釈用のフレームワークをOSSとして公開 (InterpretML)していて、その知見が取り組まれているようです (あるいはAzure MLが先?) (参考
参考:MicrosoftのInterpretMLが便利だった
計算環境
言わずもがなクラウド上でデータ分析、機械学習を行う大きなメリットの一つですね。どこのクラウドサービスでも似たようなものだと思われますが各種Virtual Machine (VM)を計算環境として使用できます。最近だとNVIDIAの最新GPU (A100)への対応もアナウンスされています。
あと、AzureのHPCやDL用のVMだと高速なノード間通信であるInfiniBandに対応しているようです。
他のクラウド (AWSやGCP)は私の知る限り対応していないので、分散ディープラーニング、みたいなことを行う際には活かせそうです (参考)InfiniBand参考:いまさら聞けないInfiniBand
その他の特徴
機械学習モデルを多数作って管理していく必要があるケースにも対応しているようです!(追記)
参考:Azure Machine Learning Many Models Solution Acceleratorの紹介と利用方法参考
HomebrewのインストールからpyenvでPythonのAnaconda環境構築までメモ
LightGBM 徹底入門 – LightGBMの使い方や仕組み、XGBoostとの違いについて
Kaggleとは?機械学習初心者が知っておくべき3つの使い方
Accelerating Distributed Training in Azure Machine Learning service using SR-IOV
Bringing IntelliSense, collaboration and more to Jupyter notebooks with Azure Machine Learning
AutoMLがすごいと聞いたので色々使って比べてみた
Azure DevOps を完全理解する
ゆるふわMLOps入門
MicrosoftのInterpretMLが便利だった
図解でわかる!インフィニバンド豆知識
いまさら聞けないInfiniBand



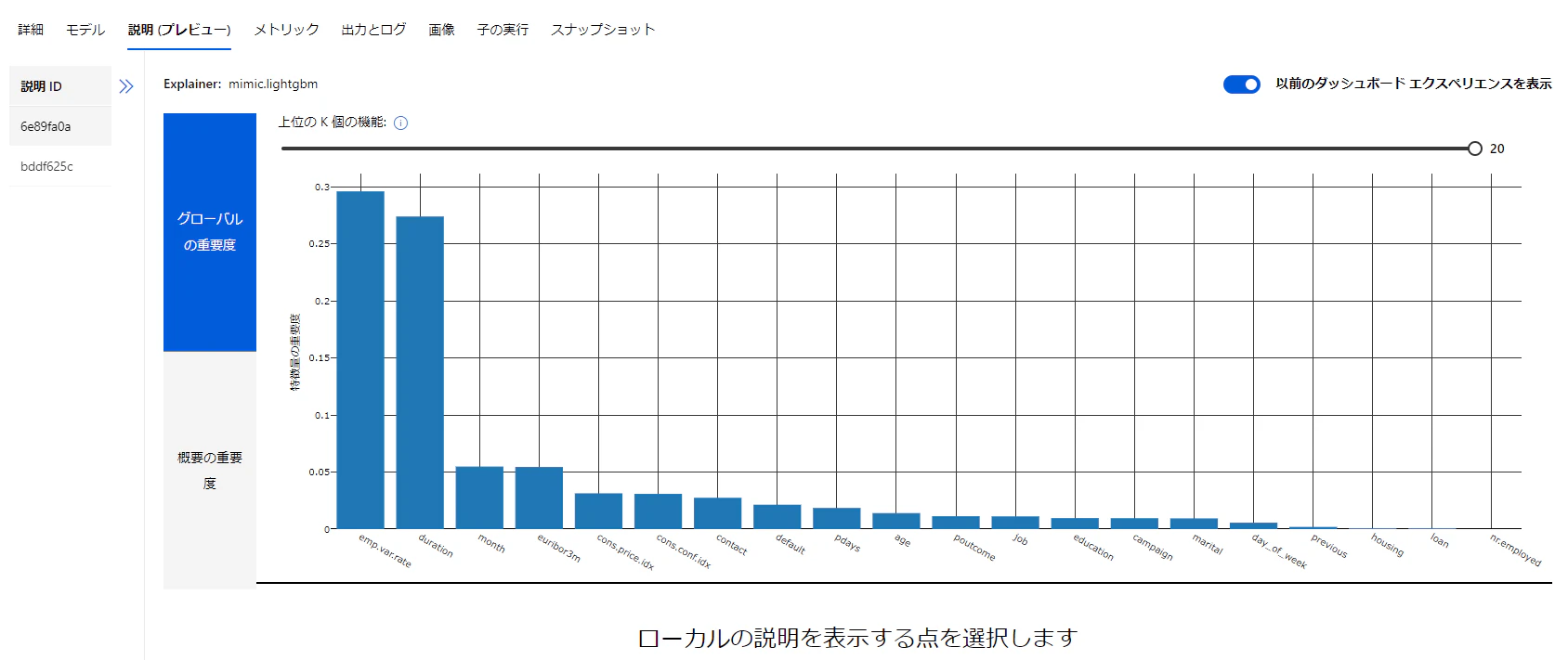
- 投稿日:2020-12-15T19:10:46+09:00
SCAPYでTCPを頑張ってみる(その3:StreamSocket編)
この文書の目的
この文書は SCAPY をインストールして TCP 通信を試してみよう、と思った人向けのものです。
前提
以下のことを前提に書いています。
- TCP のことをまあまあ理解している
- socket のことをなんとなく把握している
なお、「その1:準備編」と「その2:はじめてのGET編」があります。
StreamSocket を用いた簡単な通信
「その2:はじめてのGET編」で、OS のカーネルを使わないで ACK フラグなどをSCAPYによるパケット操作で返すことにはかなり限界がありそうだと説明しました。
そこでここではACK処理はカーネルに任せて、アプリケーションレベルでTCPストリームの操作をすることを目指します。
SCAPYの公式ドキュメントの「TCP」のところを見ると、それを実現してくれる StreamSocket なるクラスが用意されていることがわかります。小さなWebコンテンツの取得
以下はとても小さなコンテンツをWebサーバから取得する手続きを、StreamSocket を用いて書いたものです。例によって URL (ホスト名、パス)などは自分の状況に合わせて書き換えてください。
>>> sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM) ...: sck.connect(("example.com", 80)) ...: ssck = StreamSocket(sck) ...: res = ssck.sr1(Raw("GET /a.html HTTP/1.0\r\nHost: example.com\r\n\r\n")) ...: ssck.close() Begin emission: Finished sending 1 packets. * Received 1 packets, got 1 answers, remaining 0 packets >>>コードはとても単純です。ポイントは以下のあたりでしょうか。
- 一度開いたソケットを用いて StreamSocket を作る
- そこに sr1() でGETリクエストを送信して返事を待つ
- HTTP 1.0 を用いている(サーバはコンテンツを送り終わるとコネクションを切る)
この状態で res 変数には受信したデータが入っています。
>>> res.load b'HTTP/1.1 200 OK\r\nDate: Tue, 15 Dec 2020 07:21:07 GMT\r\nServer: Apache\r\nLast-Modified: Thu, 22 Oct 2020 09:34:49 GMT\r\nETag: "d7-5b23f2cde4040"\r\nAccept-Ranges: bytes\r\nContent-Length: 215\r\nMS-Author-Via: DAV\r\nContent-Type: text/html\r\nConnection: close\r\n\r\n<HTML>\n<HEAD>\n<META HTTP-EQUIV="Content-Type" CONTENT="text/html;CHARSET=UTF-8">\n<TITLE>Test Page</TITLE>\n</HEAD>\n<BODY bgcolor="#ffffff">\n\n<h2>\nTest Page for YLB.\n</h2>\n\n\xe3\x81\xa0\xe3\x82\x89\xe3\x81\xa0\xe3\x82\x89\xe3\x81\xa0\xe3\x82\x89\xe3\x81\xa0\xe3\x82\x89\xe3\x80\x82\n</BODY>\n</HTML>\n' >>>改行などがそれなりに見える形になるように、ペイロード部分(バイト型データ)を decode して表示させてみます。
>>> print(res.load.decode()) HTTP/1.1 200 OK Date: Tue, 15 Dec 2020 07:21:07 GMT Server: Apache Last-Modified: Thu, 22 Oct 2020 09:34:49 GMT ETag: "d7-5beef2cde4040" Accept-Ranges: bytes Content-Length: 215 MS-Author-Via: DAV Content-Type: text/html Connection: close <HTML> <HEAD> <META HTTP-EQUIV="Content-Type" CONTENT="text/html;CHARSET=UTF-8"> <TITLE>Test Page</TITLE> </HEAD> <BODY bgcolor="#ffffff"> <h2> Test Page for XXX. </h2> だらだらだらだら。 </BODY> </HTML> >>>すこし大きなコンテンツの取得
先の例は sr1() をただ一度だけ呼び出していました。しかし一回の sr1() 呼び出しで大きめのコンテンツを取得させることはできません。試しに少し大きめのコンテンツを取得させると、途中でデータが切れていることがわかると思います。
つまり受信処理を一度でやめず、終わるまでループさせる必要があります。最も簡単な例は恐らく以下のようなものでしょう。sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sck.connect(("example.com", 80)) ssck = StreamSocket(sck) ssck.send("GET /aaa.html HTTP/1.0\r\nHost: example.com\r\n\r\n".encode()) resList = [] while True: res = ssck.recv() if res == None: break print("recv {0} bytes".format(len(res))) resList.append(res) print("{0} elements".format(len(resList))) ssck.close()上のコードのポイントは以下のあたりでしょうか。
- sr1() でなく send() を使って GET リクエストを送信した
- HTTP 1.0 を用いている(サーバはコンテンツを送り終わるとコネクションを切る)
- その後 recv() を繰り返し、受信したデータをリストに追加して保存
- recv() が None を返したら受信終了としてループを抜ける
- 実行が終わったら resList[0] などとして内容を確認する気分
ところでパケットモニタを見ていれば分かると思いますが、recv() が None を返しているのは、サーバ側がコネクションを切断したためです。これは GET リクエストが HTTP 1.0 によって行われたためで、1.1 だった場合にサーバはコンテンツの送信が終わってからもコネクションを切ることはありません。
timeout を使った強引な HTTP 1.1 対応
向こうが送信を停止したことを検出してコネクションを切る簡単な方法はタイムアウトです。そこでタイムアウトを利用して簡単に HTTP 1.1 で受信する方法を考えます。
ところが SCAPY は不思議なことに StreamSocket については sr1() に timeout オプションがあるくせに、recv() にはそれが実装されていません。
そこで上のコードを sr1() を無理矢理使うように書き換えてみます。sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sck.connect(("example.com", 80)) ssck = StreamSocket(sck) req = "GET /aaa.html HTTP/1.0\r\nHost: example.com\r\n\r\n") resList = [] while True: res = ssck.sr1(Raw(req), timeout=3, verbose=False) if res == None: break print("recv {0} bytes".format(len(res))) resList.append(res) req = "" print("{0} elements".format(len(resList))) ssck.close()実行すると先の例とは違って、受信終了とともにすぐプログラムが終了することはなく、sr1() の timeout パラメタに指定した 3 秒を待ってからループを抜けて終了処理に入ることがわかると思います。
sr1() で「何も送らない」指定をすると
それにしても sr1(Raw()) という書き方はいかにも気色が悪いです。一応ソースを当たってみました。scapy.sendrecv の、sndrcv() 関数のすぐ下にある __gen_send() 関数が実際のソケットに対する送信処理( send() コール)を行っているところと見えます。
その中には、与えられた引数 x に対して以下のような構造が見えます。
def __gen_send(s, x, inter=0, loop=0, count=None, verbose=None, realtime=None, return_packets=False, *args, **kargs): # ....(すごく略).... for p in x: # ....(すごく略).... s.send(p)恐らく中身が無かった場合は socket s の send() を呼び出すようです。これがどのような副作用をもつのか明確にするところまでは追い切れていません。
recv() で timeout させる
本当、どうして SCAPY は recv() にtimeout を付けないのでしょうね。やっぱり recv() 処理を普通に使いたかったので、私自身は SCAPY にこんな修正を加えて使っています。
この修正によって、以下のような(私にとっては素直な)記述が可能になります。たった一行、settimeout() を追加するだけです。それ以降の recv() 処理はその秒数だけ待って返事がなければ、そこで帰ってきます。戻り値は sr1() での timeout 時同様、None になります。
sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sck.connect(("example.com", 80)) ssck = StreamSocket(sck) ssck.send("GET /aaa.html HTTP/1.1\r\nHost: example.com\r\n\r\n".encode()) ssck.settimeout(3) resList = [] while True: res = ssck.recv() if res == None: break print("recv {0} bytes".format(len(res))) resList.append(res) print("{0} elements".format(len(resList))) ssck.close()コンテンツ受信完了を調べるマトモな HTTP 1.1 対応
異常時の対応に StreamSocket に timeout が欲しいことは間違い無いのですが、とりあえず HTTP 1.1 ではコンテンツの受信は HTTP Response Header を見て、Content-Length: あるいは Transfer-Encoding: の指定に正しく反応する必要があります。
以下にそのどちらのヘッダにも対応するように書いてみたものを示します。# ヘッダ行から : 区切りを頼りに key, value を取り出す def chopHeader(line): pos = line.find(": ") key = line[:pos] value = line[pos+2:] return (key, value) # CRLF で区切られた一行を取って来る def getLine(): global buf while True: pos = buf.find(b"\r\n") if pos < 0: res = ssck.recv() buf = buf + res["Raw"].load else: line = buf[0:pos] buf = buf[pos+2:] return line.decode() # 指定されたバイト数まで取って来る def getBytes(size): global buf while True: if len(buf) < size: res = ssck.recv() buf = buf + res["Raw"].load else: line = buf[0:size] buf = buf[size:] return line # コンテンツ取得 def getContent(host, path): global buf get = "GET {0} HTTP/1.1\r\nHost: {1}\r\n\r\n".format(path, host) ssck.send(Raw(get)) # header part isChunked = False contentLength = 0 buf = b"" while True: line = getLine() if len(line) == 0: # header process done break (key, value) = chopHeader(line) if key == "Transfer-Encoding" and value == "chunked": isChunked = True if key == "Content-Length": isChunked = False contentLength = int(value) # body part if isChunked: print("Chunked mode\n") data = b"" totalSize = 0 while True: hexStr = getLine() chunkSize = int(hexStr, 16) print("chunk size = {0}".format(chunkSize)) totalSize = totalSize + chunkSize if chunkSize == 0: break data = data + getBytes(chunkSize) getLine() # remove following CRLF print("total data = {0}".format(totalSize)) print("check last line, size = {0}".format(len(getLine()))) else: print("Content-Length mode ({0} bytes)\n".format(contentLength)) data = getBytes(contentLength) return data ##### main sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sck.connect((host, 80)) ssck = StreamSocket(sck) data = getContent("example.com", "/aaa.html") print("size = {1} bytes".format(len(data))) ssck.close()サーバが Content-Length: ヘッダを付けて答える場合、実行結果は以下のようになるでしょう。
Content-Length mode (1569 bytes) 1569 bytesサーバが Transfer-Encoding: chunk と答える場合、実行結果は以下のようになるでしょう。
Chunked mode chunk size = 20374 chunk size = 351 chunk size = 29983 chunk size = 0 total data = 50708 check last line, size = 0 50708 bytesもしファイルにデータを書き残したければ、変数データに受信した結果が残っていますから以下のようにすると良いでしょう。画像ファイルなどでもこれで開けると思います。
fp = open('/tmp/data', mode='wb') bytes = fp.write(data) print("total {0} bytes".format(bytes)) fp.close()もう少し HTTP 1.1 らしい受信
せっかく HTTP 1.1 に対応させたのですから、もう少し HTTP 1.1 らしい実験をするとしたら、こんな感じでしょうか。
##### main host = "example.com" pathlist = ("/a.html", "/aa.html") sck = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sck.connect((host, 80)) ssck = StreamSocket(sck, Raw) for path in pathlist: data = getContent(host, path) print("path = {0}, size = {1} bytes".format(path, len(data))) print("Done") ssck.close()おわりに
ところで上に示したコードは単純に HTTP でコンテンツを取ってくるだけ、の処理です。SCAPYはそれについてはちゃんと実装があります。この HTTP のところに使い方の例まで載せてくれてます。HTTP 2 にも対応したようですし、使いやすそうですね。
当たり前ですが SCAPY はネットワーク実験をするためのツールですから、より短い記述で普通の処理が書ける(理解をスキップできる・処理を隠蔽してくれる)方が嬉しい、という人が使うものではありません。
今回、低レイヤーの実験、またその教材として SCAPY を使ってみました。適度にレイヤーの低いことが、適度な面倒臭さでできて、なかなか良い感じでした。
こういうことに興味の湧いた方はぜひ試して、Qiita に情報を出していってください。すると私がとても助かるので。。。。例えば上に示した HTTP 処理のための拡張などを追いかけると、独自プロトコルに基づくアプリケーションを書くのが楽になりそうですよね。誰かチュートリアル的なのを書いてくれると嬉しいなあ。。。。
- 投稿日:2020-12-15T18:58:27+09:00
機械学習でコードレビューするAmazon CodeGuruでPythonがサポートされたので試してみた
はじめに
この記事は ハンズラボ Advent Calendar 2020 22日目の記事です。
こんにちは、@sr-mtmtです。年の瀬ですね。
2020年に買ったものの中でお気に入りは 絶品レンジでパスタ でした。
洗濯機がぐるぐるしてるところを見るのが好きな人は、この商品でレンジの中のヴォルケーノを見つめるのも好きなことでしょう。さて今年もAdvent Calendar、やってくぞい
re:InventのKeynoteで気になったものを試したい
re:Inventにて、Andy Jassy氏のKeynoteで「機械学習でコードレビューするAmazon CodeGuruでPythonがサポートされた」ときいたので、試してみたいと思います。
前から気になっていたんですが、これまではJavaしか対応していなかったので、Java使っていない弊チームでは試せず。
Javaに比べるとなんとなくPythonの解析って難しそうですがどんなかんじなんでしょう。Amazon CodeGuruとは
Code GuruにはReviewerとProfilerとあって、Profilerの方はコストチェック、Reviewerの方はバグなどをチェックします。
今回試すのはReviewerです。
Amazon CodeGuru Reviewer は、機械学習でコード内の問題を検出し、その推奨される修正方法を提案してくれるサービスです。
コードの品質に関する問題を、次のように大きく 9 つのカテゴリで識別するらしい。
- AWS のベストプラクティス: AWS API (ポーリング、ページ区切り、など) の使用方法を修正
- 同時実行: 機能上の障害を起こしている同期不良、もしくは、パフォーマンスを低下させている過剰な同期などを検出
- デッドロック: 同時実行されるスレッド間の割り当てをチェック
- リソースリーク: リソースの処理方法 (データベース接続の解放など) を修正
- 機密情報のリーク: 個人識別情報 (ログインしているクレジットカードの詳細など) の漏洩を検出
- 一般的なコード上のバグ: Lambda 関数読み出し時にクライアントを作成していないなどの、発見しづらい問題を検出
- クローンコード: 統合することでコードの保守性を高められる可能性のある、重複コードを特定
- 入力検証: 信頼されないソースから送られる、不適当な形態の、もしくは悪意のあるデータをチェック
やってみた
0. 前提
- AWSアカウントはある
- レビューしたいソースコードを含むリポジトリをGithubに持っているがCodeCommitには置いてない
- IAMなどの設定はデフォルトで問題ないリポジトリを選択
1. リポジトリの関連付け
Reviewerを選択。
前のリリースのときの情報を完全に忘れてて別にCodeCommitからじゃなくても関連付けできることが判明。\うれしい/
GitHub、GitHub Enterprise、Bitbucket、AWS CodeCommitの中から好きなものを選択できます。
組織に紐づくリポジトリへのアクセスは矢印の「Grant」を押しておかないと許可されないので注意。
今回はお試しなので私の個人アカウントでやってますがこのあたりを丁寧に準備すれば権限細かく設定できそうなのもいいですね。これでGithubアカウントに接続したので、さっきグレーアウトしていた「リポジトリの場所」に候補のリポジトリがわさーっと出てくるようになりました。
適当なリポジトリを選択して関連付けます。2. 分析してみる
分析方法ですが2種類あります。
コードレビュータイプ 自動でレビューされるか レビュー結果はどこで見られるか レビュー対象 リポジトリの分析 No
CodeGuru Reviewerのマネジメントコンソール、またはAWS CLIまたはAWS SDKを使用して分析を実行する必要がありますCodeGuru Reviewerのマネジメントコンソール、またはAWS CLIまたはAWS SDKを使用して確認する ブランチ内のすべてのコード プルリクエスト Yes
リポジトリを関連付けた後、プルリクエストを行うたびに自動でコードレビューが行われますCodeGuru Reviewerのマネジメントコンソール、またはAWS CLIまたはAWS SDKを使用して確認する方法の他に、リポジトリのソースプロバイダ(Githubなど)のPRコメントからも確認可能 プルリクエストの範囲。今回変更されたコードのみ
プルリクエストがあがれば↑ここに追加されていくようです。
今はちょうどいいPRがないので「リポジトリの分析」の方でコード全体の分析をやってみます。
「リポジトリの分析を作成」を押します。
「コードとセキュリティの推奨事項」の方はさっき関連付けたリポジトリとはまた別の話になります。
別途S3にzip化したコードをアップロードして、それと関連付けた上で分析することになるので今回は「コードの推奨事項」を試したいと思います。
分析中・・・
小さいリポジトリだからか数分で完了!
さて、なにが上がってくるのかな・・・?
なんもない
いや、いいことですけどね。
寂しいのでもう少し大きいリポジトリでも試したのですがやはり何も見つかりませんでした・・・。
パフォーマンス低下とかどのくらいのことから指摘されるんだろう・・・。
ちなみにプルリクエストの方にCodeGuruから指摘事項があった場合、こんなかんじでプルリクコメントにそのまま推奨事項が役に立つものだったかフィードバックが送れるそうです。
(公式ドキュメントの画像を拝借)ここで指摘されてる推奨事項は
"This code might not produce accurate results if the operation returns paginated results instead of all results. Consider adding another call to check for additional results."
→このコードは、操作がすべての結果ではなくページ分割された結果を返す場合、正確な結果が得られない可能性があります。追加の結果をチェックするために別の呼び出しを追加することを検討してください。(deepl翻訳)
となっていますね。AWS APIの使用方法に関する指摘かな。おまけ)リポジトリの関連付け解除
リポジトリを紐付けっぱなしにしていると無料枠超えたときにお金がかかるので必要に応じて解除しましょう。解除すると元には戻せないので改めて新規で関連付ける必要があります。
解除したリポジトリは初期表示画面からは消えるのですが、左上の「リポジトリ(3)」となっているように、完全に消えるわけではなく、
関連付けが解除されたリポジトリから確認することが可能です。(どうして)料金プラン
Amazon CodeGuru がサポートされている AWS リージョンで 90 日間無料でお試し可能です。
下記は東京リージョンの場合。無料枠について
リポジトリの全体の分析は、各支払者アカウントごとに毎月 30,000 行のコードの分析までが無料となります。
プルリクエストの分析は、90 日間の無料トライアルが利用可能。リポジトリ全体の分析
無料利用枠以上の利用だと毎月 1,500,000 行のコードの分析までは、コード 100 行ごとに 0.50USD。
1,500,000 行以上のコードを分析した場合 コード 100 行ごとに 0.40USD。
リポジトリ全体または選択したコードブランチのソースコードを分析することができます。
選択したリポジトリまたはソースコードブランチ内のコードの全行が、リポジトリ分析の実行ごとに分析されます。プルリクエスト
90 日間の無料トライアル後、コード 100 行ごとに 0.75USD。
あとがき
思った以上に設定簡単でしたね。何かしらで詰まるかなと思って身構えてたんですがあまりにも簡単。
CodeCommit以外からも関連付けられるのが特にいいですね。
コードへの指摘事項が出てこず残念でしたが大きな問題はないのかなとちょっとほっとできました。明日は23日目! @fasahina さんです!
FYI



- 投稿日:2020-12-15T18:42:50+09:00
【Python】Pyxelでゲームを作るための最初の一歩
はじめに
PyxelはPython向けのレトロゲームエンジンです。
手軽にゲームを作ることができるので、かつては色々と遊んでいたのですが、最近あまり触れていなかったため、すっかり記憶を失ってしまいました。
久しぶりに遊んでみて記憶の回復を図っていこうと思います。なお、詳しく正しい知識、それからインストール方法等は以下のリンクをご覧ください。
https://github.com/kitao/pyxel/blob/master/README.ja.md1 最小限のコード
まず必要最小限のコードは大体以下のとおりになります。
# まずはpyxelをインポート import pyxel # ゲーム全体を表すクラスを作り、その中でゲームの内容を定義する class App: def __init__(self): # 画面サイズ(幅w, 高さh)を指定する pyxel.init(100, 100) # とりあえず変数を作っておく # 今は特に意味はない self.x = 0 # フレーム更新時に実行する更新関数と描画関数を登録する # 2つの関数が時間ごとに連続で実行されるイメージ pyxel.run(self.update, self.draw) def update(self): # 1フレームごとにxが1増えていく # 今は特に意味はない self.x += 1 def draw(self): # 画面をクリアする色を指定する(0〜15) # 1フレームごとに画面が色0(=黒)でクリアされる # 今は特に意味はない pyxel.cls(0) # クラスのインスタンスを生成、ゲームを開始 App()コードの説明は全てコメントで記載したとおりです。
実行結果はこのとおり、今は真っ黒な画面を表示するだけです。
2 絵を表示させる
さて、画面は出てきましたが、ここから絵が表示されて、動いて、操作できないとゲームになりません。
まずは絵を表示させるところから始めます。
絵の表示は描画関数drawの中に記述します。
シンプルな四角形を作ってみます。def draw(self): pyxel.cls(0) # 四角形を描画、引数は(左上の点の座標x, y, 幅w, 高さh, 色) pyxel.rect(10, 10, 10, 10, 9)(前に書いたコメントは省略)
四角形の左上の点の座標と、幅、高さ、色を指定して四角形を描画します。
座標は、画面の左上が(0, 0)で、右にいくとxが増え、下にいくとyが増えるという仕組みです。
この例だと、画面サイズが100×100なので、
左上が(0,0) 右上が(100,0)
左下が(0,100) 右下が(100,100)
ということになります。
実行結果。
右に10、下に10行ったところに、幅10、高さ10、色9(=オレンジ)の四角形を描画できました。3 絵を動かす
続いて、この四角形を動かしてみます。
フレームごとに変数を変化させ、その変数を描画関数の中のパラメータに当てはめる、というのが基本です。
今まで使ってませんでしたが、更新関数updateの中に、フレームごとに1ずつ増えていく変数xがあります。これを四角形のパラメータに使ってみます。def draw(self): pyxel.cls(0) # 四角形を描画、引数は(左上の点の座標x, y, 幅w, 高さh, 色) # 変数xを幅に設定 pyxel.rect(10, 10, self.x, 10, 9)おそらく、四角形の幅が少しずつ増えていくのでしょう。
実行結果。
四角形の幅を1ずつ伸ばすことができました。4 操作する
絵を動かすだけではただのアニメーションです。プレイヤーの操作が画面に反映するようにしましょう。
まずはキーボードの操作から。btn関数は、指定したキーが押し続けられているかどうか判定します。キーの種類はKEY_○○みたいな定数で指定します。
更新関数updateの中では変数xが1ずつ増えていました。これを、キーの操作によって変化するようにしましょう。def update(self): # 右キーを押している間はxが増える if(pyxel.btn(pyxel.KEY_RIGHT)): self.x += 1 # 押していなければ1になる else: self.x = 1これで、キーボードの右が押されていなければ四角形の幅が1になり、
右が押されている間は幅が1ずつ伸びていくようになりました。
続いて、マウスの操作を反映させます。def draw(self): pyxel.cls(0) pyxel.rect(10, 10, self.x, 10, 9) # マウスカーソルの座標を取得 mx = pyxel.mouse_x my = pyxel.mouse_y # 新しく四角形を作成 # 左上の座標をマウスカーソルの座標と一致させる pyxel.rect(mx, my, 5, 5, 6)
mouse_x、mouse_yでマウスカーソルの座標を取得します。
そして、その座標を、新しく作った四角形の左上の点の座標に当てはめます。
これで、マウスカーソルと同じ場所に四角形を描画できます。
マウスを動かすとついてくる水色の四角形ができました。
キーボードで操作するならインベーダーゲームやパックマン、マウスで操作するならブロック崩しみたいなのが作れそうですね。5 おわりに
コード全体。かんたんですね。
import pyxel class App: def __init__(self): pyxel.init(100, 100) self.x = 0 pyxel.run(self.update, self.draw) def update(self): if(pyxel.btn(pyxel.KEY_RIGHT)): self.x += 1 else: self.x = 1 def draw(self): pyxel.cls(0) pyxel.rect(10, 10, self.x, 10, 9) mx = pyxel.mouse_x my = pyxel.mouse_y pyxel.rect(mx, my, 5, 5, 6) App()ひとまず記憶喪失になった自分のリハビリのため、基礎中の基礎を書き留めてみました。
今回は書いていませんが、Pyxelにはドット絵をかけるエディターが付属しているのが大きな特徴です。これを使いこなし、今回書いた簡単なコードに肉付けしていくと、それなりのゲームができていくんですね。
ゲームを作るのは楽しいだけでなく、当たり判定や重力、状態変数といった、プログラミングをする上で重要な概念が学べるのでとても有意義です。今後も少しずつ勉強してゲームらしいものを作れるようになりたいです。



- 投稿日:2020-12-15T18:40:28+09:00
アイディア発想法にBERTを利用してアイディア創出のスピードアップを試みた
はじめに
皆さん、こんにちわ!
ABEJAアドベントカレンダー2020の18日目の記事です。
ABEJAではPMをやっておりますが、前職は15年くらい新商品開発、新規開発をおこなう部署で機械設計、研究をしていたという経歴です。(たぶん珍しい経歴だと思います。)
2年くらい前からAIに可能性を感じて勉強を始め、趣味でJDLA G検定とE資格を取得しました。今回はアナロジーを利用したアイディア発想法であるNM法にBERTを利用することで、新しいアイディアを早く発想する手助けができないかということにGoogle Colaboratoryを使用してトライしてみます。
Google Colaboratoryなら試すのにお金もかからないし、黒い画面で環境構築頑張ることなく、ここに書いた内容をペタペタとコピペすれば5分もかからず試せると思うのでぜひビジネスサイドの方も試してみてください。アイディア発想法との出会い
機械設計をやっていたころには多くの特許出願をしていました。これらのアイディアは簡単に思いつくものではなく時間がかかるものが多いです。偶然の出会いやひらめきみたいなものがないとなかなか思いつかないものです。
ところが、世の中の変化が早くなっている現代では、製品開発や解決しなければいけない期間はますます短くなっています。
そこで、素早く発想できることでリードタイムを短縮しようと思い、いい方法はないものかと調べていた時に出会ったのがこちらの本です。アイデア大全 創造力とブレイクスルーを生み出す42のツール
https://www.forestpub.co.jp/author/dokushozaru/lp/idea/こちらの本は多くの事例を挙げながらアイディアの発想方法を紹介しています。過去の発明がいかにして生まれたのか単純に読み物としてもおもしろいです!
私がこの本の中で自分のこれまでの発想方法と近いと感じて実践していたのがNM法でした。NM法について
NM法はアナロジーを活用したアイディア発想法です。簡単に言うと他の似ているものをヒントに新しい発想を行います。こちらは、ものづくりだけでなく、新規ビジネスの発案にも使われているそうです。
具体的には下記のステップで行われます。
QK (Question of Keyword)
テーマに対して簡潔に表現したキーワードを決める。QA (Question of Analogy)
キーワードについて類似する事例を集める。QB (Question of Background)
類似する事例に対して、背景を探る。(そこで何が起きているのかを詳しく検討する)QC (Question of Conception)
背景のイメージをヒントにテーマに応用することができないか考える。NM法の事例
アイデア大全の中では実際にNM法で発明された事例として缶入り飲料のプルタブが紹介されています。
この缶を開けるところですね。缶詰のように缶切り等の道具を用いずに、液体入りの缶を開けるにはどうしたらいいかという課題に対して下記のステップで発明したそうです。
QK (Question of Keyword)
テーマに対して簡潔に表現したキーワードを決める。
→「しっかり閉じたものが開く」QA (Question of Analogy)
キーワードについて類似する事例を集める。
→「ハマグリ」、「天の岩戸」、「火山の噴火口」QB (Question of Background)
類似する事例に対して、背景を探る。(そこで何が起きているのかを詳しく検討する)
→「ハマグリで何が起きているか?」→「閉じ合わせた貝殻の貝柱が緩むと開く」
→「天の岩戸で何が起きているか?」→「人力で岩を動かすと開く」
→「火山の噴火口で何が起きているか?」→「マグマの圧力でひび割れが広がって開く」QC (Question of Conception)
背景のイメージをヒントにテーマに応用することができないか考える。
→「閉じ合わせた貝殻の貝柱が緩むと開く」→「閉じ合わせた隙間が分かれて開く」
→「人力で岩を動かすと開く」→「人力で閉じているものを動かす」
→「マグマの圧力でひび割れが広がって開く」→「あらかじめ切れ目を入れておいて、そこから開く」これらのアイディアを組み合わせることでプルタブが開発されたそうです。
実際にNM法を行った時に時間のかかるところ
こちらのNM法を過去に何度か実践してみましたが、一番時間がかかるとともに重要なのがQAの類似事例を集めるところです。似ているものが何であるかを考えるのは結局これまでの経験や知識によって差があります。これまでと同じように偶然の出会いが必要だったりします。また、網羅しきれるものでもなく「なんでこれ思いつかなかったんだろう。。。」とだいぶ後になって思いつくこともあります。
いい方法ないかなーとずっと考えていたのですが、BERTの実装をしていたときに「あれ?これ使えるんじゃないか?」と思いつきました。
アプローチと期待する結果
BERTは、2018年10月にGoogleの論文で発表された自然言語処理モデルです。
多くの自然言語処理タスクで当時の最高スコアを更新し、人間の理解力を超えたとして話題になりました。そのタスクの中でMasked Language Modelに注目しました。Masked Language Modelは簡単にいえば穴埋め問題です。
例えば
my dog is [MASK]
の[MASK]に相当する部分には何が入るか?ということを前後の文脈から当てるものです。これを利用して先ほどのプルタブの事例の中の
「しっかり閉じたものが開く」
のもの部分を[MASK]にすれば、「ハマグリ」とか「噴火口」にあたる類似のものを出してくれるんではないかと期待して試してみます。実装
Google Colaboratoryを使います。
インストール
必要なライブラリをインストールします。
!pip install transformers !pip install fugashi !pip install ipadicモデルとTokenizerの読み込み
今回は東北大学 乾・鈴木研究室が作成、公開した事前学習済みモデルと、Tokenizerを読み込みます。
import torch from transformers import BertForMaskedLM, BertJapaneseTokenizer model_name = "cl-tohoku/bert-base-japanese-whole-word-masking" model = BertForMaskedLM.from_pretrained(model_name) tokenizer = BertJapaneseTokenizer.from_pretrained(model_name)対象テキストの入力とトークン化
「しっかり閉じたものが開く」のもの部分を
[MASK]して、トークン化します。実行結果をみるとどのように分かち書きされているかと、もの部分が[MASK]されていることが確認できます。text = f'''しっかり閉じた{tokenizer.mask_token}を開く。''' input_ids = tokenizer.encode(text, return_tensors='pt') tokenizer.convert_ids_to_tokens(input_ids[0].tolist())実行結果
['[CLS]', 'しっかり', '閉じ', 'た', '[MASK]', 'を', '開く', '。', '[SEP]']マスクトークンの予測
こちらが予測部分になります。
[MASK]部分に入る確率の高い上位30件を表示してみます。mask_token_index = torch.where(input_ids == tokenizer.mask_token_id)[1].tolist()[0] output = model(input_ids) pred_ids = output[0][:, mask_token_index].topk(30).indices.tolist()[0] for pred_id in pred_ids: output_ids = input_ids.tolist()[0] output_ids[mask_token_index] = pred_id print(tokenizer.decode(output_ids))予測結果
こちらが30件の予測結果になります。
[CLS] しっかり 閉じ た 扉 を 開く 。 [SEP] [CLS] しっかり 閉じ た ドア を 開く 。 [SEP] [CLS] しっかり 閉じ た 口 を 開く 。 [SEP] [CLS] しっかり 閉じ た 窓 を 開く 。 [SEP] [CLS] しっかり 閉じ た 蓋 を 開く 。 [SEP] [CLS] しっかり 閉じ た 穴 を 開く 。 [SEP] [CLS] しっかり 閉じ た もの を 開く 。 [SEP] [CLS] しっかり 閉じ た 門 を 開く 。 [SEP] [CLS] しっかり 閉じ た 手 を 開く 。 [SEP] [CLS] しっかり 閉じ た シャッター を 開く 。 [SEP] [CLS] しっかり 閉じ た ゲート を 開く 。 [SEP] [CLS] しっかり 閉じ た 箱 を 開く 。 [SEP] [CLS] しっかり 閉じ た 容器 を 開く 。 [SEP] [CLS] しっかり 閉じ た 板 を 開く 。 [SEP] [CLS] しっかり 閉じ た 部屋 を 開く 。 [SEP] [CLS] しっかり 閉じ た 目 を 開く 。 [SEP] [CLS] しっかり 閉じ た 指 を 開く 。 [SEP] [CLS] しっかり 閉じ た [UNK] を 開く 。 [SEP] [CLS] しっかり 閉じ た 空間 を 開く 。 [SEP] [CLS] しっかり 閉じ た パイプ を 開く 。 [SEP] [CLS] しっかり 閉じ た シリンダー を 開く 。 [SEP] [CLS] しっかり 閉じ た バルブ を 開く 。 [SEP] [CLS] しっかり 閉じ た ページ を 開く 。 [SEP] [CLS] しっかり 閉じ た 弁 を 開く 。 [SEP] [CLS] しっかり 閉じ た 鍵 を 開く 。 [SEP] [CLS] しっかり 閉じ た 錠 を 開く 。 [SEP] [CLS] しっかり 閉じ た ポケット を 開く 。 [SEP] [CLS] しっかり 閉じ た 部分 を 開く 。 [SEP] [CLS] しっかり 閉じ た 状態 を 開く 。 [SEP] [CLS] しっかり 閉じ た 器 を 開く 。 [SEP]残念ながら「ハマグリ」などはありませんでしたが、なるほどなーと思うものがリストアップされていました。
考察
期待していたものは出てこなかったもののある程度思いつきそうなものを素早くリストアップしてくれたところに価値を感じました。実際に新しい発想が必要になった時に試してみようと思います。
今回使用した事前学習モデルは日本語Wikipediaを使って学習されているので常識的な内容がリストアップされている印象です。
思い掛けない類似事例を出してくれることを期待するのであれば、もっとくだけたソースで学習したものがいいかもしれません。
「天の岩戸」なんかは青空文庫とか物語をベースにしたものだったらリストアップしてくれるかもしれませんね。
社内文書でファインチューニングしてあげると社内の似た技術を拾ってきてくれたりするのかな?とか色々と妄想が広がります。最後に
製造業、機械の設計開発において、どこにAIが活用できるのか個人的に色々と考えてきました。
シミュレーションへの活用が最初に思いつきそうですが、発展している自然言語処理を利用してアイディア発想の部分でも活用できるのではないでしょうか。FMEAの観点出しにも応用できるんじゃないかと思っています。製造業などの設計開発で、AIを活用して開発リードタイム短縮を考えている方がいればお気軽にお話しさせてください!
ABEJAには技術・事業双方に知見を持つメンバーがたくさんいます。少しでもご興味のある方、採用募集しておりますのでぜひお声がけください!

- 投稿日:2020-12-15T18:40:13+09:00
シリアル通信でマイコンとBlenderを連携させる(サーボモーター編)
はじめに
ここ半年ほど、Blender用の自作入力デバイスというものを制作しています。
この入力デバイス作りで得られた知見を残しておこうと思い記事を書くことにしました。
今回はマイコンとBlenderをシリアル通信を使って連携することで、BlenderからLEDやモーターを制御してみます。セットアップ
必要なもの・環境
ソフトウェア
Blender 2.91(2.8以降で動作確認)
https://www.blender.org/download/PySerial
https://pypi.org/project/pyserial/Arduino IDE
https://www.arduino.cc/en/software(必要であれば)7-Zip等のtar.gzを解凍できるツール
ハードウェア
M5StickC
マイコンにESP32、その他に液晶ディスプレイ、6軸センサ、マイク、バッテリなどを搭載した便利な開発機器です。
スイッチサイエンスやマルツで約2000円で購入できます。
https://www.switch-science.com/catalog/5517/
https://www.marutsu.co.jp/pc/i/1526331/
以上は腕に巻くためのベルトがセットになっているものですが、本体のみも販売されています。少し安いです。ジャンパワイヤやブレッドボード
M5StickCとモーターやLEDをつなぐために必要です。サーボモータ
FEETECH サブマイクロサーボ FS0307 https://www.switch-science.com/catalog/3714/Windows10とmacOS High Sierraで動作確認しています。
pySerialのインストール
Blenderはすでにインストールされていることとして話を進めます。
まず初めにPythonでシリアル通信を扱うためのモジュールであるpySerialをBlenderにインストールします。https://pypi.org/project/pyserial/
Download filesからpyserial-3.5.tar.gzをクリックし、tar.gzファイルをダウンロードしてください。
7-Zip等の展開ソフトでtar.gzファイルを展開します。Macの場合はダブルクリックで展開できます。
展開して生成されたdistフォルダを開きます。
pyserial-3.5.tarを先ほどと同様に展開します。
展開してできたpyserial-3.5フォルダを開いてserialフォルダがあるか確認してください。Windowsの場合は
C:\Program Files\Blender Foundation\Blender 2.91\2.91\scripts\modules
Macの場合はアプリケーションフォルダ内にあるBlender.appを右クリックして、パッケージの内容を表示を選択し同様にmodulesフォルダに移動します。
modulesフォルダにserialフォルダをコピーすればインストール完了です。Arduino IDEのインストール
マイコン用のプログラムを書く開発環境にはArduino IDEを使用します。
https://www.arduino.cc/en/software
Arduinoとはマイコンを簡単に扱えるようにした開発システムです。C++のようなプログラムを書くことでマイコンを制御することができます。Arduino IDEはそのプログラムを書くためのソフトウェアです。今回つかうM5StickCはArduinoではありませんが、Arduino IDEに対応しており同様に扱うことができます。
ただその代わりにインストールに特別な手順を踏む必要があります。https://docs.m5stack.com/#/ja/quick_start/m5stickc/m5stickc_quick_start_with_arduino_Windows
これらの記事を参考にセットアップを行ってみてください。以上でセットアップは終了です。Blenderを起動しましょう。
BlenderからM5StickCに値を送る
ようやく本題に入ります。まずはM5StickCにつないだサーボモータを、Blenderから操作していこうと思います。
うまくいけばこのようにデフォルトキューブを回すことでサーボモータが回るはずです。シリアル通信とは
Blenderとマイコンとの間ではシリアル通信というものを使ってデータの受け渡しを行います。
シリアル通信というのはすごく平たく説明すると、小さいデータを一個づつ高速で送る通信方式のことです。マイコンとPCだけでなく、マイコン同士のデータのやり取りでもよく使われる方式です。プログラムの流れ
Blenderから一定間隔でM5StickCに値を送り、M5StickCは受け取り次第値を使ってサーボモータを動かします。サーボモータをM5StickCにつなぐ
サーボモータから3本線が出ています。赤色をM5StickCの3.3Vに、茶色をGNDに、オレンジ色の制御線をG26にジャンパワイヤを使ってつなぎます。Arduino IDEでソースコードを書く
サーボモーターを使うためのESP32Servoライブラリをあらかじめインストールしてください。
ライブラリを管理から、esp32servoを検索してインストールします。
プログラムは以下の通りです。#include <ESP32Servo.h> //esp32servoライブラリの読み込み #include <M5StickC.h> //M5StickCを使うためのライブラリの読み込み Servo myservo; //サーボモーターを扱うクラスの宣言 void setup(){ //マイコン起動時に一回だけ実行されます。初期設定をここで行います。 M5.begin(); //M5StickCの各種機能の初期化を行います。 myservo.attach(G26, 650, 2500); //サーボモーターの設定を行います。引数は順にサーボの制御線が繋がっているピン番号、 //回転角度が0の時のパルス幅、回転角度が180度の時のパルス幅です Serial.begin(115200); //シリアル通信を初期化します。引数はシリアル通信の速度です。 } void loop(){ //setup()終了後、電源が入っている間はずっと繰り返し実行されます。 if (Serial.available() > 0) { //シリアル通信で受信したデータの有無を確認します。 byte readvalue = (byte)Serial.read(); //byte型変数"readvalue"にSerial.read()で受信したデータを格納します。 //型変換(キャスト)するために(byte)をつけます。 uint8_t angle = (uint8_t)readvalue; //uint8_t型変数"data"にreadvalueを格納します。 //型変換(キャスト)するために(uint8_t)をつけます。 myservo.write( angle ); //何度の位置までサーボモーターを回すか指定します。 delay(20); //20ミリ秒待ちます。 } }コードが書けたらマイコンに書き込みましょう。
赤線部のボードがM5StickC、シリアルポートがM5StickCが繋がっているポートになっていることを確認し、左上の矢印ボタンを押してください。BlenderでPythonを実行する
BlenderにはPythonというプログラミング環境が内蔵されていて、Pythonでプログラムを書くことでアドオン(追加機能)や処理の自動化プログラムを制作することができます。
以下の手順でBlender上でPythonプログラムを実行することができます。
上部のタブの[Scripting]をクリックします。
このようなレイアウトに変わります。
テキストから新規を選ぶとソースコードを入力できるようになります。
ソースコードを実行するときは上部ファイル名横の三角形ボタンを押してください。Blenderアドオンのソースコードを書く
M5StickCとシリアル通信を行うプログラムのソースコードは次の通りです。
import serial import bpy import math import mathutils import struct bl_info = { "name": "Blender with M5StickC", "author": "しましま", "version": (3, 0), "blender": (2, 80, 0), "location": "3Dビューポート > Sidebar > Blender with M5StickC", "description": "BlenderとM5StickCを連携させるアドオン", "warning": "", "support": "TESTING", "wiki_url": "", "tracker_url": "", "category": "Object" } # モーダルモードでオブジェクトを動かすオペレータ class BLENDER_WITH_M5(bpy.types.Operator): bl_idname = "object.blender_with_m5" bl_label = "M5StickCと連携" bl_description = "Blender with M5StickC" # タイマのハンドラ __timer = None #シリアルポートの設定 #最初の引数'COM5'にはM5StickCのCOMポート名を入れてください。 __ser = serial.Serial('COM5', 115200, timeout = 0) @classmethod def is_running(cls): # モーダルモード中はTrue return True if cls.__timer else False def __handle_add(self, context): blwm5 = BLENDER_WITH_M5 if not self.is_running(): # タイマを登録 blwm5.__timer = \ context.window_manager.event_timer_add( 0.1, window=context.window ) # モーダルモードへの移行 context.window_manager.modal_handler_add(self) def __handle_remove(self, context): if self.is_running(): # タイマの登録を解除 context.window_manager.event_timer_remove( BLENDER_WITH_M5.__timer) BLENDER_WITH_M5.__timer = None def modal(self, context, event): blwm5 = BLENDER_WITH_M5 active_obj = context.active_object # エリアを再描画 if context.area: context.area.tag_redraw() # パネル [Blender with M5StickC] のボタン [終了] を押したときに、モーダルモードを終了 if not self.is_running(): return {'FINISHED'} #メインのループ内処理はここから if event.type == 'TIMER': value = int(active_obj.rotation_euler[2] * 180/math.pi) #送信処理(オブジェクトの角度が0度から180度の時だけ値を送る) if value >= 0 and value <= 180: blwm5.__ser.write( bytes([value]) ) return {'PASS_THROUGH'} #ここまで def invoke(self, context, event): blwm5 = BLENDER_WITH_M5 active_obj = context.active_object if context.area.type == 'VIEW_3D': # [開始] ボタンが押された時の処理 if not blwm5.is_running(): # モーダルモードを開始 self.__handle_add(context) if not blwm5.__ser.is_open: blwm5.__ser.open() print("START") return {'RUNNING_MODAL'} # [終了] ボタンが押された時の処理 else: # モーダルモードを終了 self.__handle_remove(context) blwm5.__ser.close() print("STOP") return {'FINISHED'} else: return {'CANCELLED'} # UI class BLENDER_WITH_M5_UI(bpy.types.Panel): bl_label = "Blender with M5StickC" bl_space_type = 'VIEW_3D' bl_region_type = 'UI' bl_category = "Blender with M5StickC" bl_context = "objectmode" def draw(self, context): blwm5 = BLENDER_WITH_M5 layout = self.layout # [開始] / [停止] ボタンを追加 if not blwm5.is_running(): layout.operator(blwm5.bl_idname, text="開始", icon="PLAY") else: layout.operator(blwm5.bl_idname, text="終了", icon="PAUSE") classes = [ BLENDER_WITH_M5, BLENDER_WITH_M5_UI, ] def register(): for c in classes: bpy.utils.register_class(c) print("Registed") def unregister(): for c in classes: bpy.utils.unregister_class(c) print("Unregisted") if __name__ == "__main__": register()ぬっち氏著の「はじめてのBlenderアドオン開発 (Blender 2.8版)」を参考にBlenderアドオンとして書いています。
https://colorful-pico.net/introduction-to-addon-development-in-blender/2.8/index.html
特にModalメゾッドを使用するため、以下の記事が参考になりました。
https://colorful-pico.net/introduction-to-addon-development-in-blender/2.8/html/chapter_03/01_Handle_Mouse_Event.htmlかならず確認してほしいのが、34行目のシリアルポートの設定です。
__ser = serial.Serial('COM5', 115200, timeout = 0)
一番目の引数に入っている'COM5'にはM5StickCが繋がっているシリアルポートの名前を入れてください。
ArduinoIDEで書き込むときに設定したポート名と同じものです。
if event.type == 'TIMER':からreturn {'PASS_THROUGH'}までの間がメインのループ処理、Arduinoでいうところのloop()にあたります。#メインのループ内処理はここから if event.type == 'TIMER': value = int(active_obj.rotation_euler[2] * 180/math.pi) #送信処理(オブジェクトの角度が0度から180度の時だけ値を送る) if value >= 0 and value <= 180: blwm5.__ser.write( bytes([value]) ) return {'PASS_THROUGH'} #ここまでこの箇所を書き換えることで、様々なデータをシリアル通信で送ることができます。
今回は選択したオブジェクトのZ軸角度が0から180の時だけ、シリアル通信で角度を送信するようになっています。
ここまで出来たらマイコンをつないだ状態で実行してみてください。
3DビューポートでNキーを押して出てくる右側のメニューから[Blender with M5StickC]を選んで開始ボタンを押してください。
オブジェクトを回転させるとサーボモーターも回るはずです。終わりに
サーボモーターは動きましたか?3D空間内の動きが現実世界に反映されるっていうのは結構面白いんじゃないかと思います。
次はM5StickC内蔵の6軸センサを使ってデフォルトキューブを動かす記事を書く予定です...参考記事
Arduino Blender & Maya Serial通信テスト(Facebook内容転載) ~ 3DCGと映像とINTERACTIVE
http://dekapoppo.blogspot.com/2017/11/arduino-serial-blender-facebook.htmlMikeBeradino/Python-Blender-serial_comm: Using blender to control arduino board via serial com.
https://github.com/MikeBeradino/Python-Blender-serial_comm




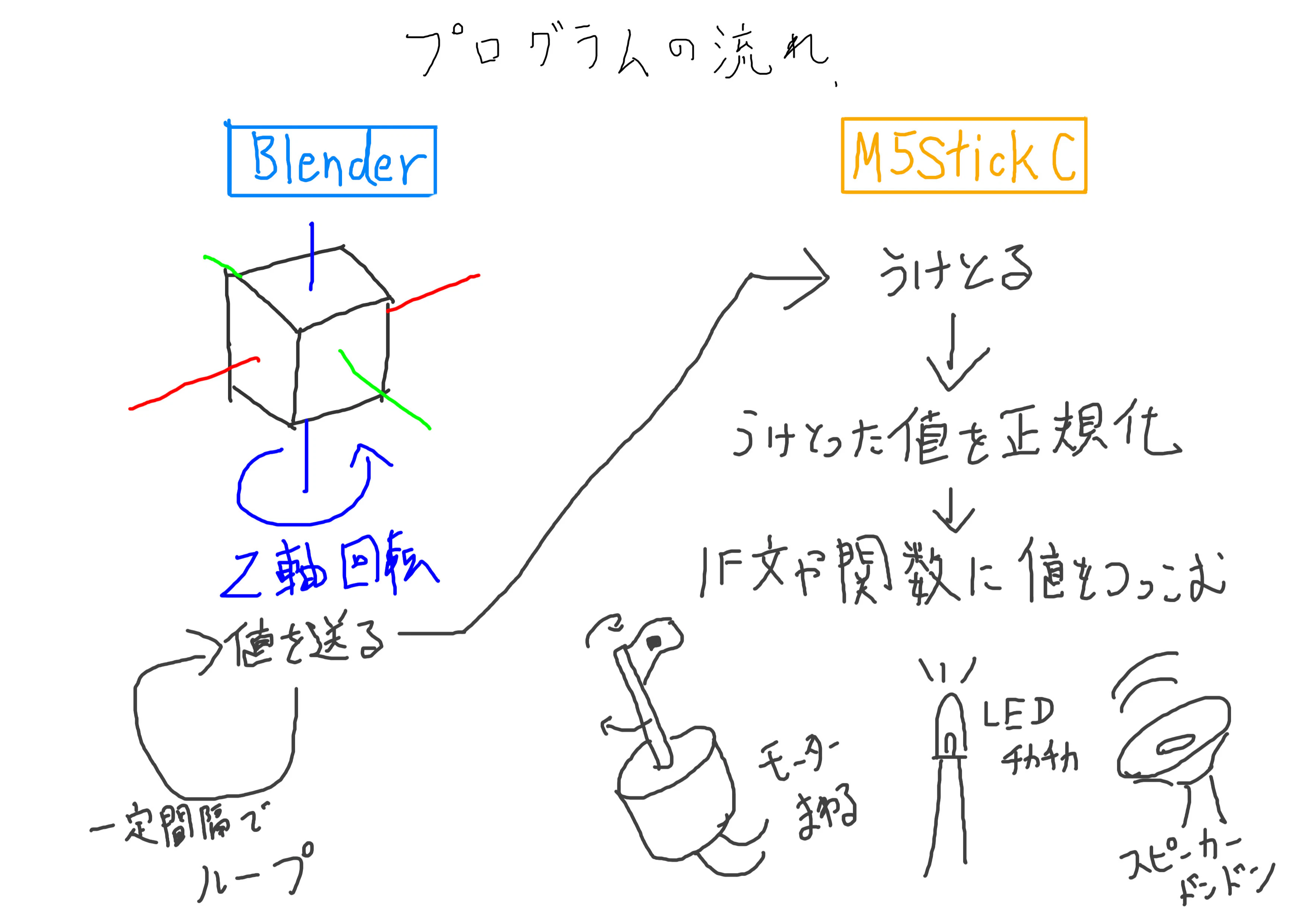





- 投稿日:2020-12-15T18:28:01+09:00
[無料] AWS EC2 + RDS + Flask でWebアプリを作り HTTPS 化する [データベース編 その1]
Webアプリで使うためのリレーショナルデータベースを AWS RDS で作成します。私はスキーマレスなNoSQLにしか興味ない、という人は読み飛ばして下さい。そのうち無料で使えるキーバリューストア型データベースの DynamoDB との比較記事も書くかもしれません。
インスタンス作成
Amazon RDS のページに入り、真ん中らへんの Create database します。
Standard create で良いです。
エンジンを選びます。主要なものは全て揃っています、MySQL、MariaDB、PostgreSQL、Microsoft SQL Server の4つが無料で、Oracle と Amazon Aurora は無料枠対象外です。Aurora は MySQL/Postgre 完全互換で、本家よりも数倍速いとの謳い文句ですので、興味がある方は試してみると良いかもしれません。ただし、バージョンが限られることに気をつけて下さい。私はリレーショナルデータベースをあえて正規化せずに NoSQL のように運用することがあるのですが、その際に MySQL8.0 のJSON_TABLEという関数を多用します(そのうち余裕があれば転置インデックスの話もします)。ですが Amazon Aurora でサポートしているのは MySQL5.7 までですので、オリジナルの MySQL をエンジンとして選ばざるを得ません。window 関数なんかも確か 5.7 では使えないはずです。まあ一般的な CRUD のみであればバージョンはそこまで気にする必要はありません。今回は MySQL8.0 を選択します。
Free tier を選びます。
データベース名、ユーザー名、パスワードなどを決めます。DBインスタンスは無料利用枠では選択不可です。
Strage は 20GB もあれば十分ではないかと思います。
Public access は Yes にしておかないと、EC2以外の外部からアクセスできなくなります。全て作り終わった後に設定をアクセス不可に戻せば良いです。
セキュリティーグループは その2 で設定済の default を選べば良いです。一番右下の Create database します。
データベースの作成には少し時間がかかります。ステータスが Available になれば使えます。
データベース名を押すと詳細が出ます。このエンドポイントと、先ほど入力したユーザー名・パスワードでデータベースにアクセスできます。
接続例
MySQL Workbench
Hostname に先ほどのエンドポイントを入力し、Username と Password を入れて Test Connection し、Success と出れば接続できています。
外部からでも問題なく使えます。
VScode
MySQL Workbench のような統合GUIは、設定をいじったりER図を書くときなどには非常に重宝しますが、コーディングしながら、VScode内からそのままクエリを投げたいときもあります。この MySQL 用の Extension を導入します。
左側にデータベースのアイコンが追加されます。上の➕から接続を追加できます。
同様にエンドポイント、ユーザー名、パスワードを入れて接続します。
.sqlファイルならシンタックスハイライトもされます。F9キーでクエリを実行できます。し、右側のフィールドで実行することも可能です。便利すぎます。

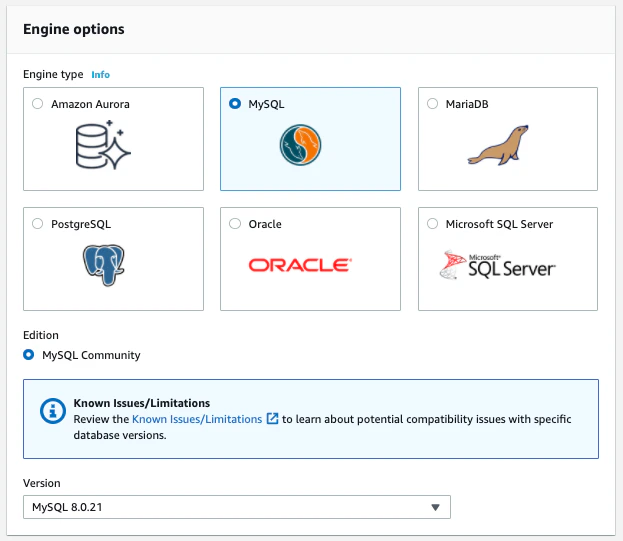






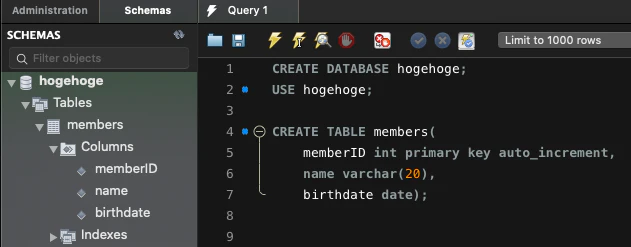


- 投稿日:2020-12-15T17:56:16+09:00
Djangoチュートリアルまとめ
概要
Djangoチュートリアルを通して学んだDjango開発のフローを備忘録的にまとめていきます。チュートリアルを始める前にイメージを掴むための記事です。
Djangoチュートリアルでは簡単な投票アプリを作ることで基本的な機能を学ぶことができます。流れ
プロジェクト作成
⇨アプリ作成(モデル⇨ルーティング(URL)⇨ビュー(フロント&バック))
※機能ごとにアプリを分けていくイメージイメージ図
「Django アーキテクチャ」で検索すると、それぞれのファイルの役割の関係図・イメージ図を知ることができます。
チュートリアルを始める前に、それぞれの関係をつかんでおくことをおすすめします。
アーキテクチャ図が載っている記事よく使うファイル
model.py
データモデルの定義を行うview.py & templeates
View(見た目)を作る。HTMLファイルをTemplatesフォルダ配下におき、バックエンドの処理をView.pyで定義します。urls.py
ルーティング(URL,パス)に関する処理を定義settings.py
設定に関するファイルadmin.py
Django特有の機能であるDjango Adimin(ブラウザ上でDBの作成などができる)の設定に関するファイル開発環境
今回はDockerを使って開発した。
公式のガイドであるクィックスタート: Compose と Djangoを参考にした。
このドキュメントにしたがって作成してもDBの設定情報を書かないとエラーが出る可能性があるので以下の記事などを参考に修正を・・・
djangoとpostgresqlをDockerで接続しようとしたときに「django.db.utils.OperationalError: could not translate host name "db" to address: Name or service not known」というエラーが出る
- 投稿日:2020-12-15T17:55:51+09:00
Pythonで学ぶアルゴリズム 第2弾:自動販売機
#Pythonで学ぶアルゴリズム< 自動販売機のお釣り >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第2弾として自動販売機のお釣り計算を扱う.自動販売機
まずここでいう自動販売機を定義しておく.
日本の紙幣・硬貨をすべて扱え,投入金額が不足しているときは購入できないものである.
尚,投入金額と購入金額についてはユーザが入力することを想定している.自動販売機 ver.1
単純にお釣りを計算してくれる自動販売機機能を作る.不足などは考慮しない.
次のようなコードとなった.コード
calc_change1.py""" 2020/12/15 @Yuya Shimizu 自動販売機 お釣りの計算 ver.1 とりあえず,お釣りを計算する """ # 単純なお釣りの計算:お釣り = 投入金額 - 購入金額 insert_price = input('投入金額 >> ') product_price = input('購入金額 >> ') change = int(insert_price) - int(product_price) print('お釣り >> {}円'.format(change))実行結果
投入金額 >> 20000 #ユーザの入力 購入金額 >> 1864 #ユーザの入力 お釣り >> 18136円 #計算結果の表示お釣りは計算できるが,どのようにお釣りを返すのだろうか?
できるだけ紙幣硬貨の枚数を少ないようにお釣りを返すの好ましい.
ver.2では,できるだけ少ない紙幣硬貨でお釣りを返す.自動販売機 ver.2
できるだけ少ない紙幣硬貨でお釣りを返す自動販売機機能を作る.不足などは考慮しない.
次のようなコードとなった.コード
calc_change2.py""" 2020/12/15 @Yuya Shimizu 自動販売機 お釣りの計算 ver.2 できるだけ少ない紙幣硬貨でお釣りを返す """ insert_price = input('投入金額 >> ') product_price = input('購入金額 >> ') # 単純なお釣りの計算:お釣り = 投入金額 - 購入金額 change = int(insert_price) - int(product_price) total_change = change # できるだけ少ない枚数でお釣りを返す cahnge_10000 = change//10000 # 一万円札の枚数 change = change%10000 cahnge_5000 = change//5000 # 五千円札の枚数 change = change%5000 cahnge_1000 = change//1000 # 千円札の枚数 change = change%1000 cahnge_500 = change//500 # 五百円玉の枚数 change = change%500 cahnge_100 = change//100 # 百円玉の枚数 change = change%100 cahnge_50 = change//50 # 五十円玉の枚数 change = change%50 cahnge_10 = change//10 # 十円玉の枚数 change = change%10 cahnge_5 = change//5 # 五円玉の枚数 change = change%5 cahnge_1 = change//1 # 一円玉の枚数 print('お釣り {}円\n'.format(total_change)) print('10000円札:{}枚\n5000円札:{}枚\n1000円札:{}枚\n500円玉:{}枚\n100円玉:{}枚\n50円玉:{}枚\n10円玉:{}枚\n5円玉:{}枚\n1円玉:{}枚\n' .format(cahnge_10000, cahnge_5000, cahnge_1000, cahnge_500, cahnge_100, cahnge_50, cahnge_10, cahnge_5, cahnge_1))実行結果
投入金額 >> 20000 購入金額 >> 1423 お釣り 18577円 10000円札:1枚 5000円札:1枚 1000円札:3枚 500円玉:1枚 100円玉:0枚 50円玉:1枚 10円玉:2枚 5円玉:1枚 1円玉:2枚できるだけ紙幣硬貨の枚数を少ないようにお釣りを返すことができた.
プログラムを見ると,紙幣硬貨の枚数計算は同じことの繰り返しである.
ver.3では,同じことの繰り返しをまとめて,コードを単純化する.自動販売機 ver.3
リストを使って,先ほどのコードを単純化する.
次のようなコードとなった.コード
calc_change3.py""" 2020/12/15 @Yuya Shimizu 自動販売機 お釣りの計算 ver.3 コードを単純化する """ insert_price = input('投入金額 >> ') product_price = input('購入金額 >> ') # 単純なお釣りの計算:お釣り = 投入金額 - 購入金額 change = int(insert_price) - int(product_price) total_change = change # 紙幣硬貨をリストにまとめて,コードをまとめる money_list = [10000, 5000, 1000, 500, 100, 50, 10, 5, 1] print('お釣り {}円\n'.format(total_change)) # できるだけ少ない枚数でお釣りを返す for money in money_list: change_money = change//money change = change%money print('{}円札:{}枚'.format(money, change_money))実行結果
投入金額 >> 20000 購入金額 >> 1423 お釣り 18577円 10000円札:1枚 5000円札:1枚 1000円札:3枚 500円玉:1枚 100円玉:0枚 50円玉:1枚 10円玉:2枚 5円玉:1枚 1円玉:2枚実行結果は変わらず,コードは非常に短くでき,単純化することができた.
いよいよ,ver.4では不足を含めてエラーに対応する自動販売機機能を作る.自動販売機 ver.4
ユーザ入力時には金額として正しい入力を想定しているが,間違えて数字ではなく文字を入力してしまうかもしれない.また,投入金額が購入金額に対して不足している場合もあるかもしれない.このような場合に,エラーメッセージを送り,プログラムを強制終了させたい.
ここでは,isdecimal()という文字列がすべて数字で構成されているかを判定できる文字列のメソッドでユーザ入力情報が正しいかを判定し,強制終了にはsys.exit()を用いる.
次のようなコードとなった.コード
calc_change4.py""" 2020/12/15 @Yuya Shimizu 自動販売機 お釣りの計算 ver.4 エラーに対応する """ import sys # 紙幣硬貨をリストにまとめて,コードをまとめる money_list = [10000, 5000, 1000, 500, 100, 50, 10, 5, 1] insert_price = input('投入金額 >> ') # 入力が整数でないと強制終了 if not insert_price.isdecimal(): #文字列を数字だけで構成されている(整数)かをチェックできる print('整数を入力してください') sys.exit() #強制プログラム終了 product_price = input('購入金額 >> ') # 入力が整数でないと強制終了 if not product_price.isdecimal(): print('整数を入力してください') sys.exit() # 単純なお釣りの計算:お釣り = 投入金額 - 購入金額 change = int(insert_price) - int(product_price) # お釣りがマイナスとなる場合に強制終了 if change < 0: print('投入金額が不足しています') sys.exit() print('お釣り {}円\n'.format(change)) # できるだけ少ない枚数でお釣りを返す for money in money_list: change_money = change//money change %= money print('{}円札:{}枚'.format(money, change_money))実行結果
========= 実行結果1: 投入金額に数字以外を入力した場合========= 投入金額 >> 5.5 整数を入力してください # 強制終了 ========= 実行結果2:購入金額に数字以外を入力した場合 ========= 投入金額 >> 5 購入金額 >> あ 整数を入力してください # 強制終了 ========= 実行結果3:投入金額が不足している場合 ========= 投入金額 >> 5 購入金額 >> 150 投入金額が不足しています # 強制終了 ========= 実行結果4:正常な入力の場合 ========= 投入金額 >> 500 購入金額 >> 150 お釣り 350円 10000円札:0枚 5000円札:0枚 1000円札:0枚 500円札:0枚 100円札:3枚 50円札:1枚 10円札:0枚 5円札:0枚 1円札:0枚実行結果1~3では正常でない入力や条件となった場合の出力を示している.結果から分かるように,うまく対処できている.これで,エラーにも対応した自動販売機機能を作ることができた.
感想
自動販売機機能の仕組みはある程度知っていたが,今回プログラムで用いたisdecimalやsysの関数については初めて用いる良い機会となった.特にsysはあまり使ったことがなく,いまいち知らない.今後勉強できたらと思う.また,改めてリストでまとめたりとコードの単純化についても再確認できた.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社
- 投稿日:2020-12-15T17:55:33+09:00
RaspberryPi 4BでAI、RaspberryPi 4BでIoT(開発環境)
はじめに
プログラミングの学習を始めてから4ヶ月。pythonを使い、ラズベリーパイでAI、IoTの技術を利用した高齢者見守りシステムを作ってみました。
制作の過程を、何回かに分けてまとめていきます。今回は、開発環境について記載いたします。
使用機材
- PC
- MacBook Pro 16
- 2.3 GHz 8コアIntel Core i9
- 16 GB 2667 MHz DDR4
- macOS Big Sur ver.11.0.1
章見出し
RaspberryPiにキーボードやディスプレイなどを接続せず、無線LANを介してPCとRaspberryPiを接続してシステムの開発を行います。
RaspberryPi OSをインストールすると、テキストエディターやpython用の統合開発環境(thonny)などが使用できるので、SSHやリモートデスクトップで接続してraspberryPi上でプログラミングすることも可能ですが、操作性などを考え、プログラミングはPC上で実施し、出来上がったプログラムをRaspberryPiへ転送することにします。開発環境として、PCには下記のソフトウエアを用意します。
ソフトウエア種別 ソフトウエア名称 用途 テキストエディター Visual Studio Code コーディング FTPクライアント FilZilla Client プログラムの転送 アクティブデスクトップクライアント VNC Viewer RaspberryPi操作、動作確認等 ターミナルエミュレータ ターミナル
(MacBookProプリインストールアプリ)RaspberryPi操作、動作確認等 ソフトエアのインストール
Visual Studio Code
Visual Studio Codeダウンロードページの説明に従って、ソフトウエアのダウンロードおよびインストールを実施します。
インストール方法詳細
Visual Studio Codeダウンロードページで↓ Macをクリックすると、ダウンロード先のフォルダーを指定するウインドウが表示されます。
保存先を指定して保存をクリックすると、ダウンロードが開始します。
ダウンロードが完了したら、Finder上でダウンロードしたZIPファイルをダブルクリックすると、ファイルが展開され、アプリケーションファイルができます。
アプリケーションファイルをアプリケーションフォルダーに移動すれば、LaunchpadからVisual Studio codeの起動が可能になります。
FileZilla Client
FileZilla Clientダウンロードページの説明に従って、ソフトウエアのダウンロードおよびインストールを実施します。
インストール方法詳細
FileZilla Clientダウンロードページで、Download FileZilla Clientをクリックすると、Mac OS用のインストーラ ダウンロードのページへ移動します。
Download FileZilla Cliantをクリックすると、ダウンロードするエディションを選択するウインドウが開きます。
SFTPが使えれば良いので、Downloadをクリックします。
保存先を選択するウインドウが表示されるので、保存先を指定して保存をクリックすると、ダウンロードが開始します。
ダウンロードが完了したら、Finder上でダウンロードしたbzip2圧縮ファイル(拡張子が.bz2のファイル)をダブルクリックすると、ファイルが展開され、アプリケーションファイルができます。
アプリケーションファイルをアプリケーションフォルダーに移動すれば、LaunchpadからFileZilla Clientの起動が可能になります。
VNC Viewer
VNC Viewerダウンロードページの説明に従って、ソフトウエアのダウンロードおよびインストールを実施します。
インストール方法詳細
VNC ViewerダウンロードページでDownload VNC Viewerをクリックすると、ダウンロード先のフォルダーを指定するウインドウが表示されます。
保存先を指定して保存をクリックすると、ダウンロードが開始します。
ダウンロードが完了したら、Finder上でダウンロードした仮想ディスクイメージファイル(拡張子が.dmgのファイル)をダブルクリックすると、ファイルが展開され下記のウインドウが開きます。
下記のウインドウで、左側のVNC Viewer.appのアイコンを、右側のApplicationsのアイコン上へドラッグ&ドロップすれば、LaunchpadからVNC Viewerの起動が可能になります。
関連投稿
RaspberryPi 4BでAI、RaspberryPi 4BでIoT(まえがき)
RaspberryPi 4BでAI、RaspberryPi 4BでIoT(システム概要)
RaspberryPi 4BでAI、RaspberryPi 4BでIoT(RaspberryPi初期設定:OSインストール編)おわりに
プログラミング初心者のため、誤りが多々あると思います。アドバイス、励ましのコメントなどいただけると嬉しいです。