- 投稿日:2020-12-15T22:20:45+09:00
【Java】HashMapクラスの使い方
Map とは
Mapとは、java.util.Map というインターフェイスで、Java でキーと値をセットにして扱いたい時に使うデータ構造です。
Mapインターフェースを用いることで、HashMapやLinkedHashMapといったデータ構造を統一的に取り扱えます。
本記事では HashMap クラスの使い方について書きます。Map インターフェースの使い方
Map インターフェースを実装するクラスを自作するか、
HashMapやLinkedHashMapのような実装クラスを用います。
Map には同一のキーを複数登録出来ず、各キーは 1 つの値にしかマッピングできません。HashMap クラスの特徴
■ キーの順序は保証されない
■ キーの重複は許容されていない
■ 値の重複は可能宣言方法
HashMapクラスの宣言は以下のように記述します。
型推論により右辺のデータ型は省略出来ます
値には List、Set、Mapを持たせることができ、キーにはクラスを指定することも可能です。Map<キーの型名, 値の型名> オブジェクト名 = new HashMap<>();Map<String, List> map = new HashMap<>(); // 値にListを指定 Map<String, Set> map = new HashMap<>(); // 値にSetを指定 Map<String, Map<Integer, Object>> map = new HashMap<>(); // 値にMapを指定 Map<Example>, List> map = new HashMap<>(); // キーにExampleというクラスを指定使い方
キーを指定して値を追加する(put メソッド)
public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("cat", "猫"); } }既にキーがマッピングされている場合には上書きされ、マッピングが無い場合には”null”を返します。
public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("dog", "猫"); System.out.println(animal.get("dog")); //猫 System.out.println(animal.get("pig")); //null } }キーを指定して値を取得する(get メソッド)
public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("cat", "猫"); System.out.println(animal.get("cat")); //猫 } }キーと値をすべて取得する(keySet メソッド)
keySetメソッドを使用すると、Mapのキーを全て取得することが出来ます。
keySetメソッドは MapのキーをSet型で返すので、拡張for文を使って以下のように繰り返すことで全てのキーを取得できます。public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("cat", "猫"); for (String pet : animal.keySet()) { System.out.println(pet);// monkey dog cat } } }値をすべて取得する(values メソッド)
valuesメソッドを使用すると、Mapの値を全て取得することが出来ます。
valuesメソッドもMapのキーをSet型で返すので、拡張for文を使えばkeySetメソッドのように全ての値を取得できます。public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("cat", "猫"); for (String pet : animal.values()) { System.out.println(pet);// 猿 犬 猫 } } }要素数を取得する(size メソッド)
public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("cat", "猫"); System.out.println(animal.size()); // 3 } }指定のキーがあるか真偽値を返す(containsKeyメソッド)
Map の中に特定のキーが含まれているかどうかは、containsKey メソッドを使って判断します。
public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("cat", "猫"); if (animal.containsKey("dog")) { // true System.out.println("犬が含まれています"); // 犬が含まれています } } }指定の値があるか真偽値を返す(containsValue メソッド)
public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("cat", "猫"); if (animal.containsValue("猿")) { // true System.out.println("monkeyが含まれています"); // monkeyが含まれています } } }中身が空か真偽値を返す(isEmpty メソッド)
public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("cat", "猫"); animal.clear(); if (animal.isEmpty()) { // true System.out.println("空です"); // 空です } } }要素を順番に処理する(forEach メソッド)
public class Sample { public static void main(String[] args) { Map<String,String> animal = new HashMap<>(); animal.put("monkey", "猿"); animal.put("dog", "犬"); animal.put("cat", "猫"); animal.forEach((key,value) -> System.out.println(key + " " + value))); //monkey 猿 //dog 犬 //cat 猫 } }参照
- 投稿日:2020-12-15T20:50:29+09:00
ArchUnit 実践:同一パッケージ内からのみ依存されるクラスの可視性をパッケージプライベートに強制する
// 実行環境 * AdoptOpenJDK 11.0.9.1+1 * JUnit 5.7.0 * ArchUnit 0.14.1アーキテクチャテストのモチベーション
- パッケージ外から使用されない、パッケージ内に閉じた関心事を、パッケージ外に対して隠蔽できる
- 変更時の影響範囲を把握しやすく、パッケージ外からの想定外の依存(結合)が生まれることを言語仕様レベルで防止できるので、保守性が向上する
アーキテクチャテストの実装
package com.example; import com.tngtech.archunit.base.DescribedPredicate; import com.tngtech.archunit.core.domain.Dependency; import com.tngtech.archunit.core.domain.JavaClass; import com.tngtech.archunit.core.domain.JavaClasses; import com.tngtech.archunit.core.importer.ClassFileImporter; import com.tngtech.archunit.core.importer.ImportOption; import org.junit.jupiter.api.Test; import static com.tngtech.archunit.lang.syntax.ArchRuleDefinition.*; class ArchitectureTest { // 検査対象のクラス private static final JavaClasses CLASSES = new ClassFileImporter() .withImportOption(ImportOption.Predefined.DO_NOT_INCLUDE_TESTS) .importPackages("com.example"); @Test void 同一パッケージのクラスからのみ依存されるクラスはパッケージプライベートにする() { classes() .that(new DescribedPredicate<>("only have dependent classes that reside in same package") { @Override public boolean apply(final JavaClass clazz) { return clazz.getDirectDependenciesToSelf() .stream() .map(Dependency::getOriginClass) .allMatch(dependentClass -> dependentClass.getPackageName().equals(clazz.getPackageName())); } }) .should().bePackagePrivate() .check(CLASSES); } }
- 投稿日:2020-12-15T20:50:29+09:00
ArchUnit 実践:同一パッケージからのみ依存されるクラスの可視性をパッケージプライベートに強制する
// 実行環境 * AdoptOpenJDK 11.0.9.1+1 * JUnit 5.7.0 * ArchUnit 0.14.1アーキテクチャテストのモチベーション
- パッケージ内に閉じた関心事を、パッケージ外に対して隠蔽したい
- パッケージ外からの想定外の依存(結合)が生まれることを言語仕様レベルで防止したい
- 公開範囲を限定することで、保守性(理解容易性、変更容易性)を向上したい
アーキテクチャテストの実装
package com.example; import com.tngtech.archunit.base.DescribedPredicate; import com.tngtech.archunit.core.domain.Dependency; import com.tngtech.archunit.core.domain.JavaClass; import com.tngtech.archunit.core.domain.JavaClasses; import com.tngtech.archunit.core.importer.ClassFileImporter; import com.tngtech.archunit.core.importer.ImportOption; import org.junit.jupiter.api.Test; import static com.tngtech.archunit.lang.syntax.ArchRuleDefinition.classes; class ArchitectureTest { // 検査対象のクラス private static final JavaClasses CLASSES = new ClassFileImporter() .withImportOption(ImportOption.Predefined.DO_NOT_INCLUDE_TESTS) .importPackages("com.example"); @Test void 同一パッケージからのみ依存されるクラスはパッケージプライベートにする() { classes() .that() .arePublic() .and(new DescribedPredicate<>("only have dependent classes that reside in same package") { @Override public boolean apply(final JavaClass clazz) { return clazz.getDirectDependenciesToSelf() .stream() .map(Dependency::getOriginClass) .allMatch(dependentClass -> dependentClass.getPackageName().equals(clazz.getPackageName())); } }) .should() .notBePublic() .check(CLASSES); } }
- 投稿日:2020-12-15T20:46:53+09:00
【Android】ConstraintLayoutの制約エラー
プログラミング勉強日記
2020年12月15日
Android StudioでConstraintLayoutの制約を設定するエラーが出たのでこのエラー内容と解決方法を示す。ConstraintLayoutの制約エラー内容
This view is not constrained. It only has designtime positions, so it will jump to (0,0) at runtime unless you add the constraints The layout editor allows you to place widgets anywhere on the canvas, and it records the current position with designtime attributes (such as layout_editor_absoluteX). These attributes are not applied at runtime, so if you push your layout on a device, the widgets may appear in a different location than shown in the editor. To fix this, make sure a widget has both horizontal and vertical constraints by dragging from the edge connections. Issue id: MissingConstraints
ボタンやテキストなどのビューに対して水平方向や垂直方向の制約の定義をしないと左上の0.0の位置に配置されるエラーである。
解決方法
エラーを解決するためには、様々な方法があり、簡単にいくつか紹介する。
- ビューを画面に配置し、idとテキストを変更する
- 水平・垂直軸に制約する
- マージンとバイアスを設定する
- 制約の推論アイコンから自動で制約をする
- 制約を削除する
- 属性を手動で追加する
- ベースラインで位置揃えする
- バイアスでセンタリングする
- ガイドラインに制約する
私の場合は、垂直軸に制約することでエラーをなくすことができた。垂直軸と水平軸を制約するためには、ビューを選択して、位置揃えアイコンから設定する。
// 水平の場合 layout_constraintStart_toEndOf layout_constraintStart_toStartOf layout_constraintEnd_toStartOf layout_constraintEnd_toEndOf // 垂直の場合 layout_constraintTop_toTopOf layout_constraintTop_toBottomOf layout_constraintBottom_toTopOf layout_constraintBottom_toBottomOf変更前(activity_main.xml)<TextView android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Hello World" />変更後(activity_main.xml)<TextView android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Hello World" app:layout_constraintTop_toTopOf="parent" app:layout_constraintBottom_toBottomOf="parent" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" />参考文献
[Android] ConstraintLayout による制約を設定するには
Android StudioでConstraintLayoutの制約を設定する方法を配置パターン別に解説

- 投稿日:2020-12-15T18:59:28+09:00
log4j 2 でログローテートがしたかっただけなんだ
はじめに
この記事はHamee Advent Calendar 2020 16日目の記事です。
初のアドカレ参加ですね、めっちゃ緊張してます(嘘)log4j 2 って?
公式より
Apache Log4j 2 is an upgrade to Log4j that provides significant improvements over its predecessor, Log4j 1.x, and provides many of the improvements available in Logback while fixing some inherent problems in Logback’s architecture.
log4j を改良したやつだよ。
Logback の構造を引き継いだことによる弊害もいい感じに解消してるよ。とのこと。
いやそもそも log4j はなんなんだよ?という方に1行で解説すると、
log4j は、Java 用のロガーAPIです。じゃあ、ログローテートって?
ログローテーションとも言いますね。
どんなシステムでもログを出力するってことはしてると思いますが、出力される量は時間を追うごとに増えストレージを食い荒らすことになります。
それじゃまずいので、ある一定の期間を過ぎたログを自動的に削除したり、ログのサイズがある一定量に達したら古いものを削除したりすることが必要です。これがログローテートです。
設定してみる
まずはロガーを定義するために、log4j2.xml を以下のように書きます。
log4j2.xml<?xml version="1.0" encoding="UTF-8"?> <Configuration status="OFF"> <Properties> <Property name="standard">[%d{yyyy/MM/dd HH:mm:ss.SSS}] %m%n</Property> <Property name="log_path">logs</Property> <Property name="log_filename">app</Property> </Properties> <Appenders> <RollingFile name="app" fileName="${log_path}/${log_filename}.log" filePattern="${log_path}/${log_filename}.%d{yyyy-MM-dd}.log.gz"> <PatternLayout pattern="[%d{yyyy.MM.dd HH:mm:ss.SSS}] %p - %m%n" /> <TimeBasedTriggeringPolicy /> <DefaultRolloverStrategy> <Delete basePath="${log_path}" maxDepth="1"> <IfFileName glob="${log_filename}*.log.gz" /> <IfLastModified age="7d" /> </Delete> </DefaultRolloverStrategy> </RollingFile> </Appenders> <Loggers> <Root name="app_logger" level="info"> <AppenderRef ref="app" /> </Root> </Loggers> </Configuration>
ちょいちょいと設定をかいつまんで説明します。<Properties>
<Properties> <Property name="standard">[%d{yyyy/MM/dd HH:mm:ss.SSS}] %m%n</Property> <Property name="log_path">logs</Property> <Property name="log_filename">app</Property> </Properties>log4j2.xml 内で定数を利用したい時に使えるタグ。
例えば、上記の設定なら<Property name="standard">で囲まれた書式を${standard}と書くことで一発で利用できる。つまるところ、この設定が
<RollingFile name="app" fileName="${log_path}/${log_filename}.log" filePattern="${log_path}/${log_filename}.%d{yyyy-MM-dd}.log.gz">
こんな風に変換されるわけですね。<RollingFile name="app" fileName="logs/app.log" filePattern="logs/app.%d{yyyy-MM-dd}.log.gz"><Loggers>
<Loggers> <Root name="app_logger" level="info"> <AppenderRef ref="app" /> </Root> </Loggers>ここにロガーの定義を書いていく。
<Root>はデフォルトで利用するロガーを定義するが、今回は1つしかないのでこれでOK。
ref="app"は、<Appenders>で定義されてるname="app"のやつから出力を受け取りますよ、的な意味合い。これでログを出力するインターフェース(と勝手に思っている)を定義できた。
<RollingFile>
<Appenders> <RollingFile name="app" fileName="${log_path}/${log_filename}.log" filePattern="${log_path}/${log_filename}.%d{yyyy-MM-dd}.log.gz"> <PatternLayout pattern="[%d{yyyy.MM.dd HH:mm:ss.SSS}] %p - %m%n" /> <TimeBasedTriggeringPolicy /> <DefaultRolloverStrategy> <Delete basePath="${log_path}" maxDepth="1"> <IfFileName glob="${log_filename}*.log.gz" /> <IfLastModified age="7d" /> </Delete> </DefaultRolloverStrategy> </RollingFile> </Appenders>
<Appenders>に実際にログとして出力するフォーマットなどを定義していく。
<RollingFile>がその中の1つ。詳細は省くが、
ログローテートは日単位で行い、7日より前のログは消す!
みたいな設定をここではしている。動作チェック
サーバー側でなんやかんやログ出力の動作を追記してデプロイ、日付が変わるのを待つ。
ワクワクしながら ssh して確認すると、アレ?$ ls -la drwxr-xr-x 3 tomcat tomcat 4096 12月 12 23:39 . drwxr-xr-x 3 tomcat tomcat 4096 12月 12 16:44 .. -rw-r--r-- 1 tomcat tomcat 207 12月 13 00:00 app.logアレ?
今日の日付を何回確認しても 12/13 ...。
本来ならばログローテートが行われて 12/12 日分のログが残るはずなのにない...。本来なら↓になってて欲しいのだ。
$ ls -la drwxr-xr-x 3 tomcat tomcat 4096 12月 12 23:39 . drwxr-xr-x 3 tomcat tomcat 4096 12月 12 16:44 .. -rw-r--r-- 1 tomcat tomcat 20507 12月 13 00:00 app.2020-12-12.log -rw-r--r-- 1 tomcat tomcat 207 12月 13 00:00 app.log原因解明
(ここではさらっと書くが、本来は1週間くらいかけて直している)
ここでまず、俺の crontab をみて欲しい。
*/10 * * * * sh ./batch1 0 0 1 * * sh ./batch2cron で定期実行バッチの設定をしているだけである。
一見何の変哲もない設定だが、ここでポイントなのが どちらのバッチも 0:00:00 に実行される ことである。
これが全ての元凶である。どうやら log4j2 では、
- 複数プロセスによるログへの同時の書き込み
- ログローテートの対象
の2つの条件が満たされた時、正常にログローテートが行われず前日のログが消え去るのである。
(そんなことがあっていいのか...?)
batch2 は 0:00:00 の実行でなくても問題ないので、少々時間をずらしてログローテートを試したらちゃんと正常に動作した。(ちなみにこれを解決するために ScoketAppender というものが存在するらしい? 間違ってたらごめんなさい。)
まとめ
フレームワークの仕様とはいえ、ここまでログの出力で悩まされるとは思わなかった。
みなさまも良きログライフを!
- 投稿日:2020-12-15T16:32:18+09:00
☾ Java / コレクション
JavaSilverの模試をやっているものの、あまり理解していなかったため復習です。✴︎ コレクションとは
ここまで、メソッドの引数や戻り値として様々なオブジェクトを利用してきました。単一のオブジェクトではなく、複数のオブジェクトをまとめて受け渡しする場合には、配列を利用できます。しかし、配列はあらかじめ取り扱うデータ(オブジェクト)の数を決めておく必要があります。また、後から配列の大きさを増やしたり、減らしたりすることはできません。そこで、複数のオブジェクトをまとめて取り扱うための統一した考え方として、コレクションフレームワークが提供されています。コレクションフレームワークにもとづいて提供されたオブジェクトをコレクションと呼びます。
コレクションフレームワークに沿って、用途に応じた様々な種類のクラスやインターフェースが提供され、一貫性のある管理や操作(つまりコレクションへのオブジェクトの格納、取り出し、削除など)が行えます。
なお、コレクションに格納するオブジェクトを要素あるいはエレメントと呼びます。✴︎ コレクションの種類と特徴
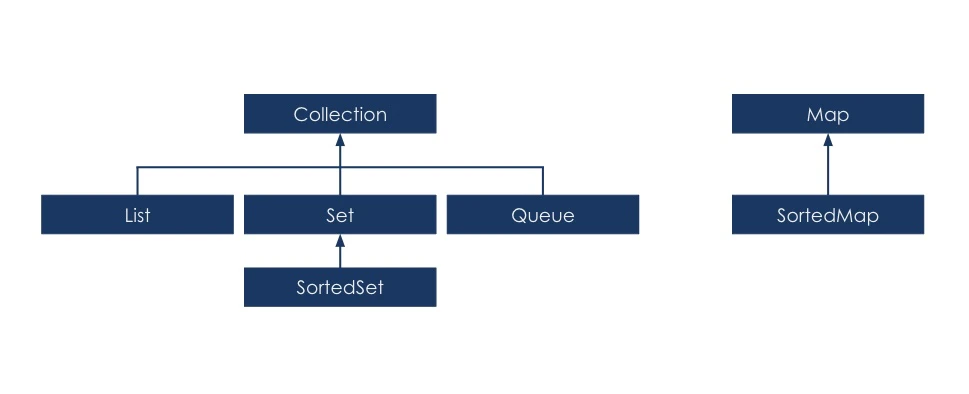
コレクションのルート階層に位置するのがjava.util.Collectionインターフェースであり、これはコレクションのスーパーインターフェースです。その他にマップと呼ばれる別種のコレクションもありますが、これらのスーパーインターフェースはMapであって、Collectionインターフェースから派生したものではありません。以下の図は、これら2種類のインターフェースの関係をまとめたものです。
コレクションといっても、そこに求められる要件はアプリケーションごとに異なるため、用意されているコレクションの中には、要素の重複が許されているものもあれば、重複が許されていないものもあります。また順序づけが意地されるコレクションもあれば、維持されないものもあります。
Collectionインターフェースは、コレクションフレームワークの基本機能の取り決めを行っているだけで、Collectionインターフェースを継承したList、Set、Queueの各インターフェースには、要件に応じた独自の機能が追加されています。
今回は、List、Set、Mapの各インターフェースを実装したクラスの利用方法を復習します。✴︎ Listインターフェースの実装
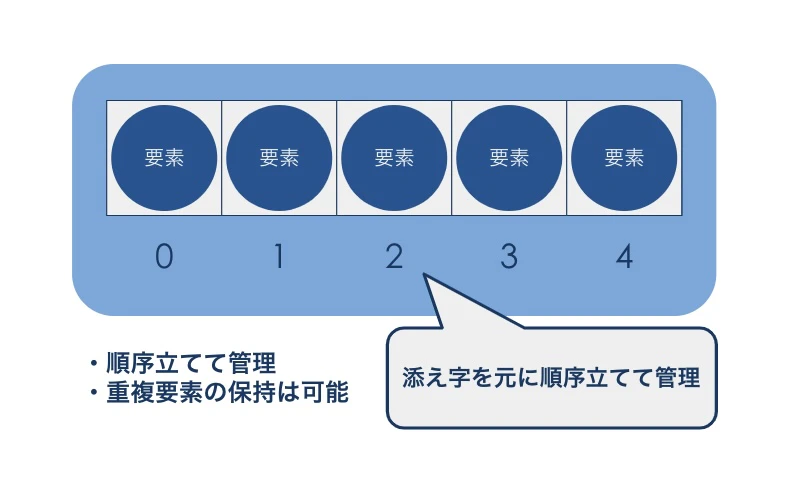
要素の重複を許可し、順序づけを行いたい場合は、Listインターフェースの実装クラスを利用します。今回は、Listインターフェースの実装クラス群を総称してリストと呼びます。
リストは、サイズ変更可能な配列のようなものです。配列の場合、保持可能な要素数は固定ですが、リストは要素の追加や削除を自由に行えます。配列と同様、添え字を使用して順序立てて要素を管理します。リストに格納する要素は、重複してもかまいません。
Listインターフェースを実装しているクラスとしてArrayListがあります。
ArrayListクラスに限らず、コレクション関連の各クラスやインターフェースはjava.utilパッケージに含まれているので、使用する際はこのパッケージをインポートします。
ArrayListオブジェクトの生成時に、このオブジェクトが保持する要素のデータ型を<>内に指定します。格納するデータは、参照型であればなんでもかまいません。<>の詳細については後述します。要素を格納するときはadd()メソッド、取得する場合は、get()メソッドを使用します。
以下は、ArrayListクラスを使用した例です。1¥Main.javaimport java.util.ArrayList; public class Main { public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); // Integerオブジェクトのみを格納できるArrayListクラスをインスタンス化 Integer i1 = 10; int i2 = 2; Integer i3 = i1; list.add(i1); // add()メソッドを使用してIntegerオブジェクトを格納 list.add(i2); // intデータはBoxingによりInteger型に自動変換 list.add(i3); // i1とi3は参照先が同じ(つまり同じオブジェクト)で重複要素 list.add(1, 5); // インデックス1番目に5を追加 // list.add("abc"); // 文字列(String型)を代入しようとしているためコメントを外すとコンパイルエラー System.out.println("size : " + list.size()); // ArrayListオブジェクトに格納されている要素数はsize()メソッドを使用 for (int i=0; i<list.size(); i++) { System.out.println(list.get(i) + " "); // データの取り出しにはget()メソッドを使用 } System.out.println(); for (Integer i : list) { System.out.print(i + " "); } // 拡張for文を使用して取り出し } }実行結果size : 4 10 5 2 10 10 5 2 10✴︎ Setインターフェースの実装
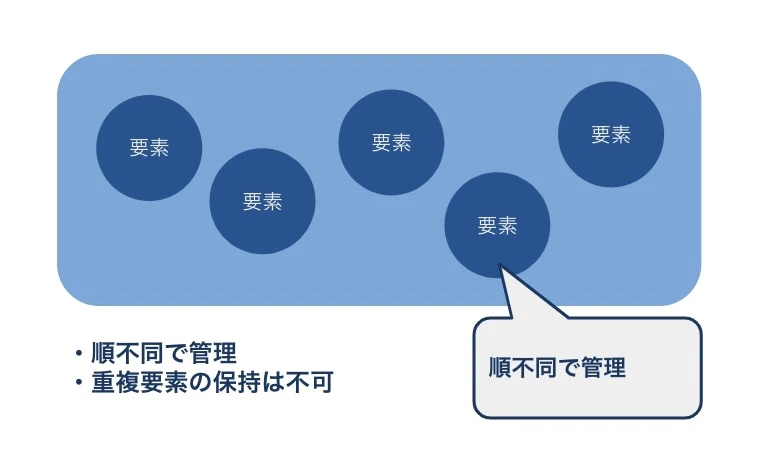
データ構造体に要素の重複を許したくない場合は、Setインターフェースの実装クラスを利用します。今回は、Setインターフェースを実装したクラス群のオブジェクトを総称してセットと呼びます。
セットは、袋の中に要素を格納していくようなものです。つまり、格納される各要素は、袋の中にばらばらに入るイメージなので、添字をつけずに順不同で管理します。リストと異なり、セットは一意の要素しか格納できません。
Setインターフェースを実装しているクラスとしてHashSetがあります。
以下の例では、HashSetクラスを使用した例です。2¥Main.javaimport java.util.HashSet; public class Main { public static void main(String[] args) { String[] ary = {"CCC", "AAA", "BBB"}; HashSet<String> hashSet = new HashSet<String>(); hashSet.add(ary[0]); hashSet.add(ary[1]); hashSet.add(ary[2]); hashSet.add(ary[0]); // すでに格納されている要素の追加を試みているため、等価の要素とみなされ要素を格納しない System.out.println("HashSet size : " + hashSet.size()); for (String s : hashSet) { System.out.print(s + " "); } } }実行結果HashSet size : 3 AAA CCC BBB // 要素を取り出したときの順番は格納純にはならない✴︎ Mapインターフェースの実装
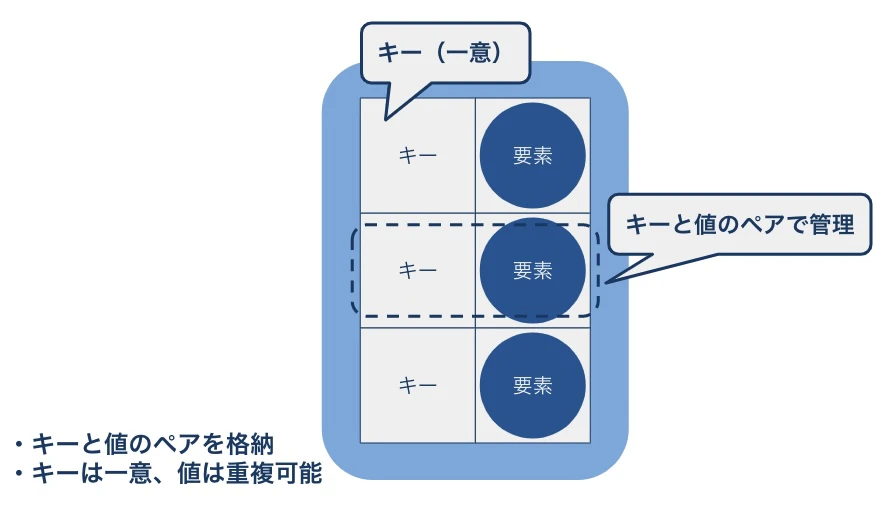
データをキーと値のペアで管理する場合は、Mapインターフェースの実装クラスを利用します。今回は、Mapインターフェースの実装したクラス群のオブジェクトを総称してマップと呼びます。
マップは、社員番号と社員名のようなもので、一意のキーとそれに対する値(オブジェクト)をペアにして保持します。キーは識別可能なように一意でなければなりませんが、キーに対応する値は重複してもかまいません。
Mapインターフェースを実装しているクラスとしてHashMapがあります。
以下は、HashMapクラスを使用した例です。3¥Main.javaimport java.util.*; public class Main { public static void main(String[] args) { HashMap<Integer, String> map = new HashMap<Integer, String>(); // Integer型のキー、String型の値を扱うHashMapをインスタンス化 map.put(0, "AAA"); map.put(1, "BBB"); map.put(2, "AAA"); // キーが異なるため個々のペアとして格納される map.put(1, "CCC"); // キーが重複であるため値が上書きされる for (int i=0; i<map.size(); i++) { System.out.println(map.get(i) + " "); // キーを引数にget()メソッドを使用して値を取り出し } System.out.println(); Set<Integer> keys = map.keySet(); // キーの集合(セット)を取得するkeySet()メソッドを使用 for (Integer key : keys) { System.out.print(key + " "); } System.out.println(); Collection<String> values = map.values(); // 値の集合(コレクション)を取得するvalues()メソッドを使用 for (String value : values) { System.out.print(value + " "); } } }実行結果AAA CCC AAA 0 1 2 AAA CCC AAA
- 投稿日:2020-12-15T15:39:26+09:00
Seleniumで画像比較を活用したUI自動テストの実装方法
はじめに
UL Systems Advent Calendar 2020 - 19日目。
システム開発の最終段階ではUIからバックエンドロジックまでを含めて期待通りの結果になっているか確認をE2Eテストで行うと思います。
ただE2Eテストでは人手による操作を行い目視での確認を行うケースが多いのではないでしょうか。そうした場合、一部のロジックを修正し再度テストを行う場合も自動で行う事は出来ません。
また、Seleniumを使用したテストではE2Eテストを自動で行う事はできますがテストコード作成に対する工数がかかり採用されないケースもあります。そこで、画像比較を用いる事でテストコード作成の工数を削減出来るのでは無いかと思いSeleniumと画像比較を使用したUIテストをご紹介いたします。
今回使用するImageComparisonは、画像の比較を行うライブラリです。
ImageComparisonとは
同じサイズの2つの画像を比較し、異なる部分に長方形を描画することで違いを視覚的に示すことが出来るライブラリです。
ライブラリのプロパティ説明
ライブラリを使用して指定可能なプロパティです。
プロパティ 説明 threshold 等しくないと判断するピクセル間の最大距離の閾値(デフォルト:5) rectangleLineWidth 長方形の線幅(デフォルト:1) destination 比較結果ファイルの保存先 minimalRectangleSize 最小長方形サイズ(デフォルト:1) maximalRectangleCount 描画される長方形の最大数(デフォルト:-1[制限無]) pixelToleranceLevel ピクセル許容レベル(デフォルト:0.1[10%]) excludedAreas 画像を比較するときに無視されるリスト drawExcludedRectangles 除外された長方形を描くの可否 fillExcludedRectangles 除外された長方形を塗りつぶすかの可否 percentOpacityExcludedRectangles 除外された長方形の不透明度 fillDifferenceRectangles 差分長方形の可否 percentOpacityDifferenceRectangles 差分長方形の不透明度 allowingPercentOfDifferentPixels 無視されるピクセル割合(デフォルト:-1[制限無]) Seleniumを使用した例
今回はSeleniumを使用しGoogleで
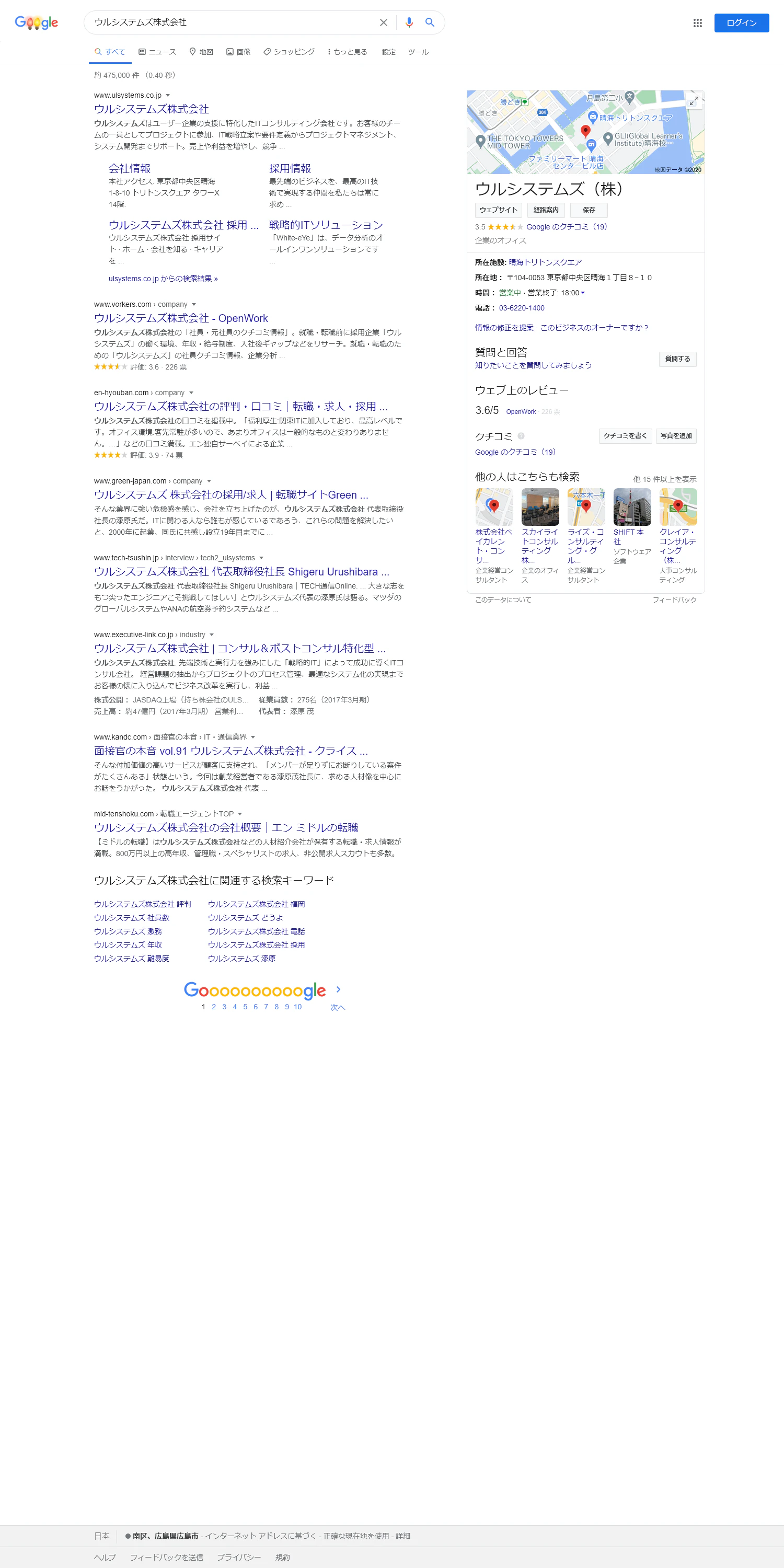
ウルシステムズ株式会社と検索した検索結果画面とウルシステムズと検索した検索結果画面の比較を行う自動テストを行います。テスト結果がfalseの場合は、異なる箇所が長方形で囲まれた比較画像を生成します。現状の画面キャプチャを取得する
まず始めに比較元となる画面キャプチャ画像を取得します。
Seleniumを使用しchromeを起動後にGoogleでウルシステムズ株式会社と検索し検索結果を表示した画面のキャプチャ画像を保存します。public class ExpectedImage { public static void main(String[] args) throws InterruptedException { // Chrome System.setProperty("webdriver.chrome.driver", "selenium/webdriver/chrome/87.0.4280.88/win32/chromedriver.exe"); // Chrome 起動オプションを構成 ChromeOptions options = new ChromeOptions(); options.addArguments("--headless"); WebDriver driver = new ChromeDriver(options); driver.get("https://www.google.co.jp/"); WebElement element = driver.findElement(By.name("q")); element.sendKeys("ウルシステムズ株式会社"); element.submit(); driver.manage().timeouts().pageLoadTimeout(15, TimeUnit.SECONDS); Thread.sleep(5000L); driver.manage().window().setSize(new Dimension(Integer.parseInt("1500"), Integer.parseInt("3000"))); File screenFile = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE); Files.copy(screenFile.toPath(), Paths.get("src/test/resources/screenshot/expected/ウルシステムズ株式会社.png"), StandardCopyOption.REPLACE_EXISTING); driver.quit(); } }比較元の検索結果画面
比較元となる画面キャプチャ画像です。
検索結果のUI自動テスト
SeleniumとImageComparisonを使用してUI自動テストコードを書き比較元の画面キャプチャ画像と比較を行います。比較結果が異なる場合は異なる部分が長方形で覆われた画像が出力されます。
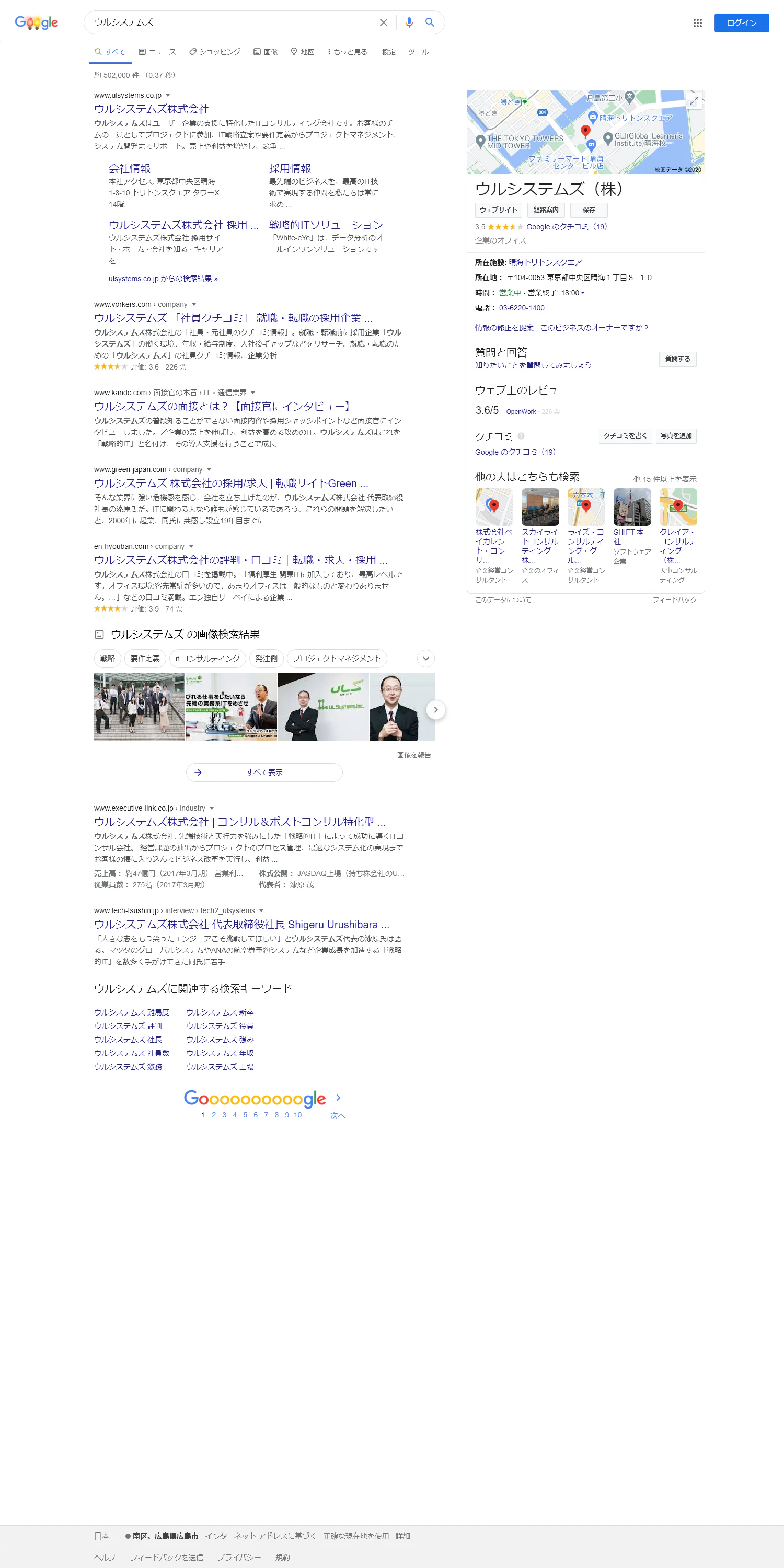
今回はSeleniumを使用しchromeを起動後にGoogleで
ウルシステムズと検索し検索結果画面の画像比較を行いたいと思います。public class SearchULSTest { private WebDriver driver; @Before public void setUp() { // Chrome System.setProperty("webdriver.chrome.driver", "selenium/webdriver/chrome/87.0.4280.88/win32/chromedriver.exe"); // Chrome 起動オプションを構成 ChromeOptions options = new ChromeOptions(); options.addArguments("--headless"); this.driver = new ChromeDriver(options); } @After public void closeDriver() { this.driver.quit(); } @Test public void test0001() throws IOException, InterruptedException { driver.get("https://www.google.co.jp/"); WebElement element = driver.findElement(By.name("q")); element.sendKeys("ウルシステムズ"); element.submit(); driver.manage().timeouts().pageLoadTimeout(15, TimeUnit.SECONDS); Thread.sleep(5000L); driver.manage().window().setSize(new Dimension(Integer.parseInt("1500"), Integer.parseInt("3000"))); File screenFile = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE); Files.copy(screenFile.toPath(), Paths.get("src/test/resources/screenshot/actual/ウルシステムズ.png"), StandardCopyOption.REPLACE_EXISTING); Thread.sleep(5000L); boolean result = compareImage("screenshot/expected/ウルシステムズ株式会社.png", "screenshot/actual/ウルシステムズ.png"); Assert.assertTrue(result); } private static boolean compareImage(String expected, String actual) { // 比較する画像のロード BufferedImage expectedImage = ImageComparisonUtil.readImageFromResources(expected); BufferedImage actualImage = ImageComparisonUtil.readImageFromResources(actual); // 比較結果ファイルの保存先 File resultDestination = new File("compareimage.png"); // 画像比較オブジェクトの生成 ImageComparison imageComparison = new ImageComparison(expectedImage, actualImage, resultDestination); // 画像比較を判断するピクセル間の最大距離 imageComparison.setThreshold(10); // 差分長方形の線幅 imageComparison.setRectangleLineWidth(2); // 差分長方形の内側を塗りつぶすかの指定と透明度 imageComparison.setDifferenceRectangleFilling(true, 10.0); // 除外長方形の内側を塗りつぶすかの指定と透明度 imageComparison.setExcludedRectangleFilling(true, 10.0); // 描画される長方形の最大数 imageComparison.setMaximalRectangleCount(100); // 最小長方形サイズ imageComparison.setMinimalRectangleSize(10); // ピクセル許容レベル imageComparison.setPixelToleranceLevel(0.2); // 画像の比較 ImageComparisonResult imageComparisonResult = imageComparison.compareImages(); if (ImageComparisonState.MATCH == imageComparisonResult.getImageComparisonState()) return true; // 比較結果の画像を保存する ImageComparisonState imageComparisonState = imageComparisonResult.getImageComparisonState(); BufferedImage resultImage = imageComparisonResult.getResult(); ImageComparisonUtil.saveImage(resultDestination, resultImage); return false; } }比較対象の検索結果画面
比較するGoogleで
ウルシステムズと検索し検索結果を表示した画面のキャプチャ画像です。
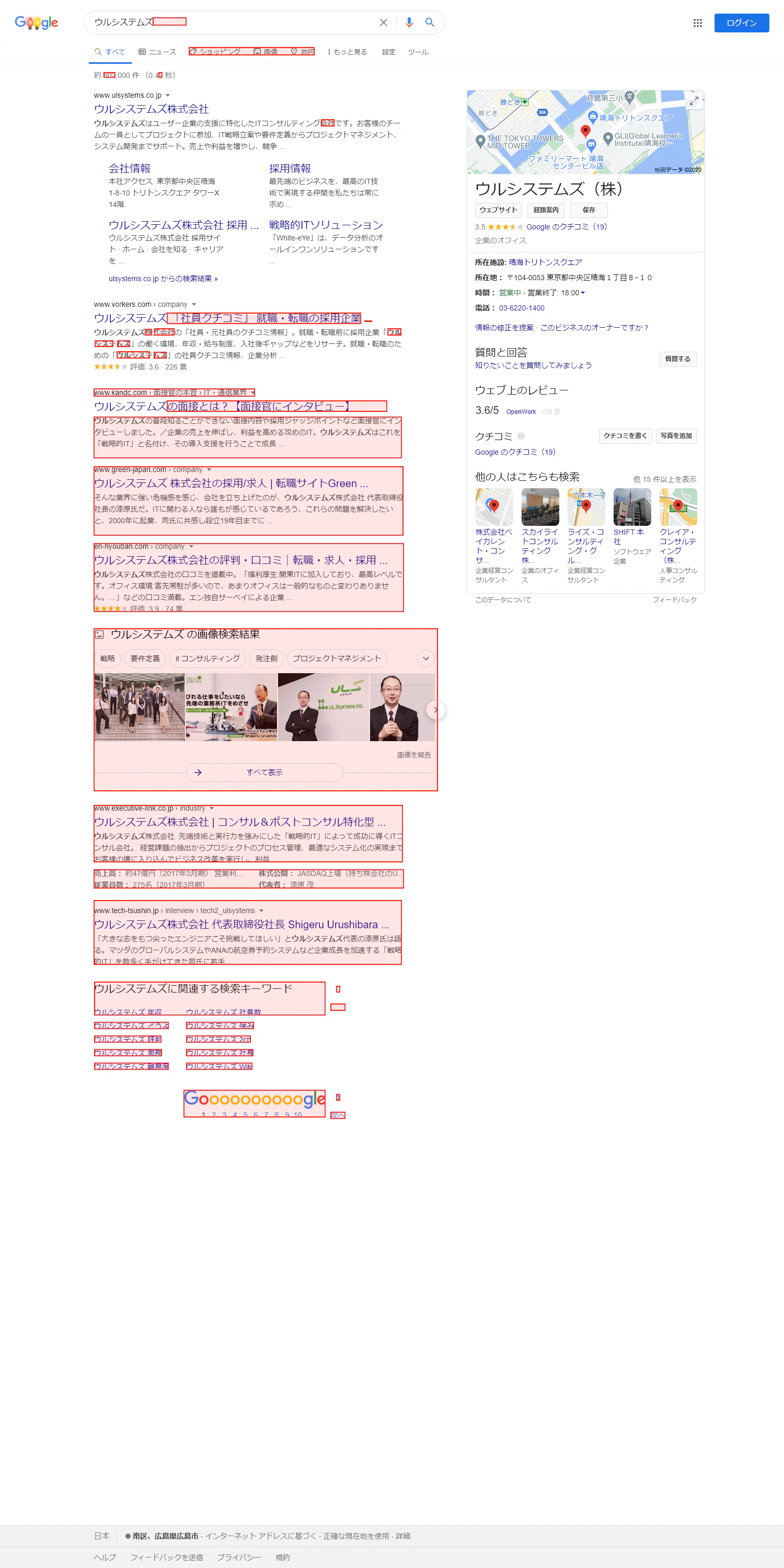
比較結果の画像
元画像と比較を行い異なった部分が赤い長方形でマークされた画像です。
まとめ
今回はImageComparisonを使用し画像比較による自動テストを行ってみました。
画面の一つ一つの項目に対して検証用コードを書くのはとても大変ですが、画像比較を活用する事で同一かどうか違う場合は何処が違っているのかを一気に見つける事が出来ます。
注意点としては、事前に正となる画面の画像が必要、あくまで静的な画面画像による比較検証ですので画面の動作検証には適用できません。このように画像比較を使用しテストコード作成の工数削減を図ってみてはどうでしょうか。
- 投稿日:2020-12-15T14:43:31+09:00
【Spring Dtata JPA】 Spring Bootで、単一のスレッドでAPIを同期的に処理したい場合に、DBの変更を検知できない問題の対応方法
【課題】 EntityManagerの対象外(別スレッドやDB直叩き等)からDBが更新された場合、その更新されたレコードの状態を取得できない
単一スレッド内で、DBの更新を行った後に、更新されたTBLを取得した場合はその状態を取得できる
それ以外の場所(別スレッドやDB直叩き)でDBが更新された後に更新されたTBLを取得しても、最新の情報を取ることができない例えば以下のような例の場合...
1. あるスレッドでsaveAndFlushでレコード作成/更新 2. 同一スレッドで、状態監視するためのDB取得処理をloop 3. 別スレッド/別サービス等で該当のレコードを更新 4. loopでDBの変更を検知したら何らかの処理を行う ★ここでDB検索をかけても、更新された最新のDBのデータが取得できない【原因】
saveAndFlushした際に、EntityManagerの永続化コンテクストにEntityが登録され、そのEntityはJPA標準の仕様でスレッドが終了するまでキャッシュされた状態となる
外部でDBの更新が行われても、EntityManagerはそれを検知しない。つまりキャッシュが残っている状態で検索しても、キャッシュした状態でのDBの値しか取得できない【対策】
Entityのキャッシュを直接clearまたはdetachし、その後にDB検索を実行するとコミット後のDBのデータが取得可能
(最初からcacheを持たないようにする設定もできるようだが、、標準仕様を無効化する必要性は低いかも)
以下のような処理を、repositoryで検索する前などに実行する必要がある// EntityManagerをDI @PersistenceContext EntityManager entityManager; public void clearEntityCache() { // 共通処理としてキャッシュをクリアするため、detach()ではなくclear()を使う. entityManager.clear(); }参考:
- http://itdoc.hitachi.co.jp/manuals/link/cosmi_v0870/APKC/EU070319.HTM
- https://gloryof.hatenablog.com/entry/20120922/1348299856
- 投稿日:2020-12-15T13:38:38+09:00
Keycloakをインストール・設定する
環境
- JDK 8以上
- 事前にインストールが必要です
- 環境変数
JAVA_HOMEも設定しておいてください- Keycloak 11.0.3
- macOS Big Sur 11.1(Windowsでも手順はほぼ同様です)
ダウンロードとインストール
公式ページから、[Standalone server distribution]のZIPファイルをダウンロードします。そして、ローカルの適当なフォルダに展開するだけです。
起動
Keycloakを展開したフォルダ/binの中のstandalone.sh(Windowsの場合はstandalone.bat)で起動します。デフォルトのポート番号は8080です。ポート番号を変更するには
-Djboss.http.portオプションを付加します。ポート番号9000で起動する例$ cd bin $ ./standalone.sh -Djboss.http.port=9000管理者名・パスワードの設定
Webブラウザで http://localhost:9000 (ポート番号は起動時に指定したものにしてください)を開き、画面左側の[Administration Console]に、管理者のユーザー名・パスワード(今回は共に
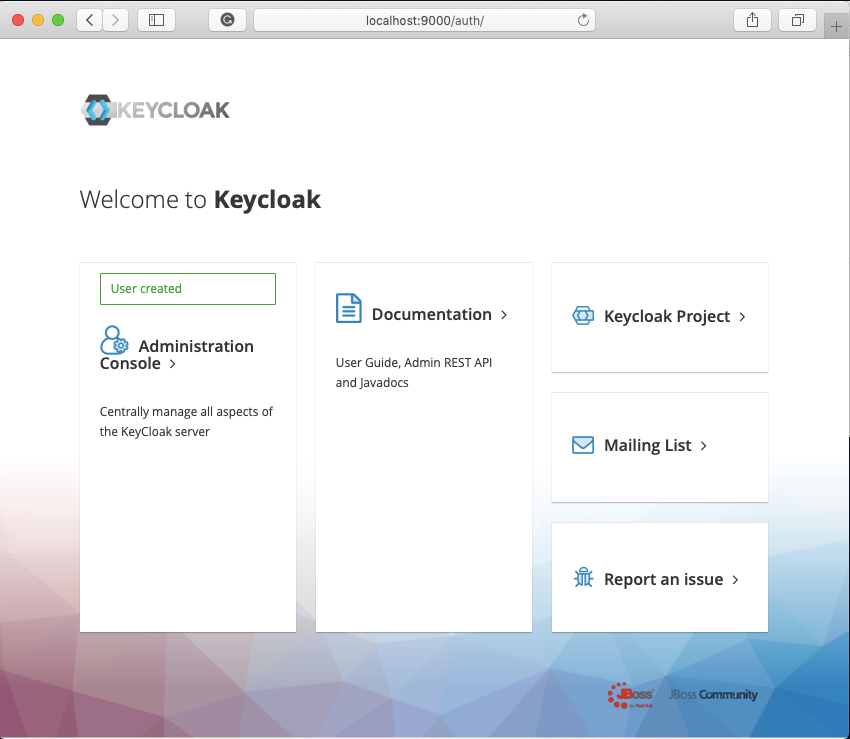
admin)を設定して[Create]をクリックします。
成功すると[User Created]と表示されます。
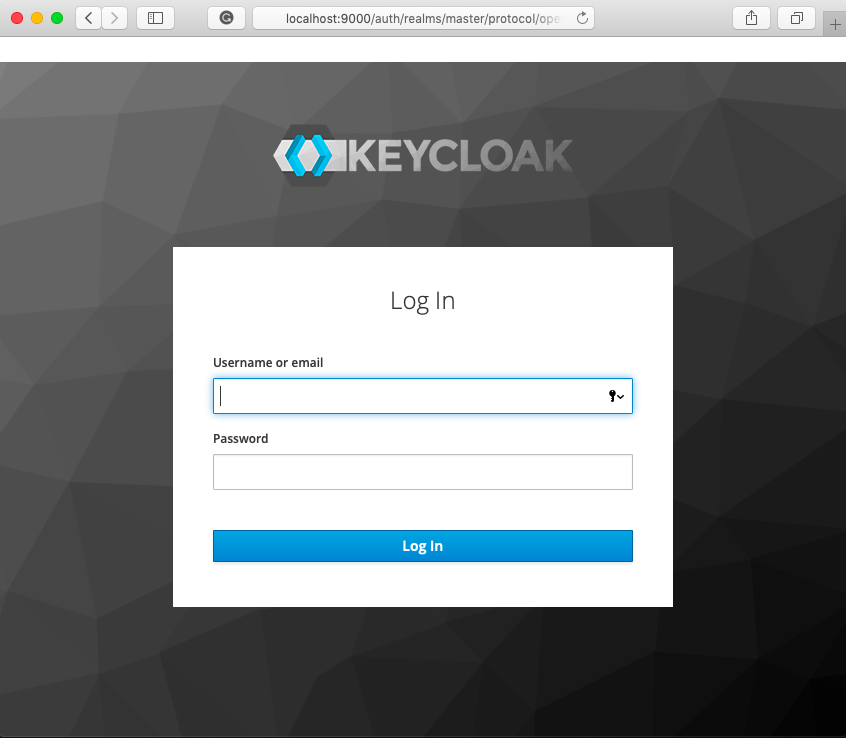
[Administration Console]の部分をクリックすると管理者ログイン画面が表示されます。
設定したユーザー名・パスワードを入力して[Log In]をクリックします。
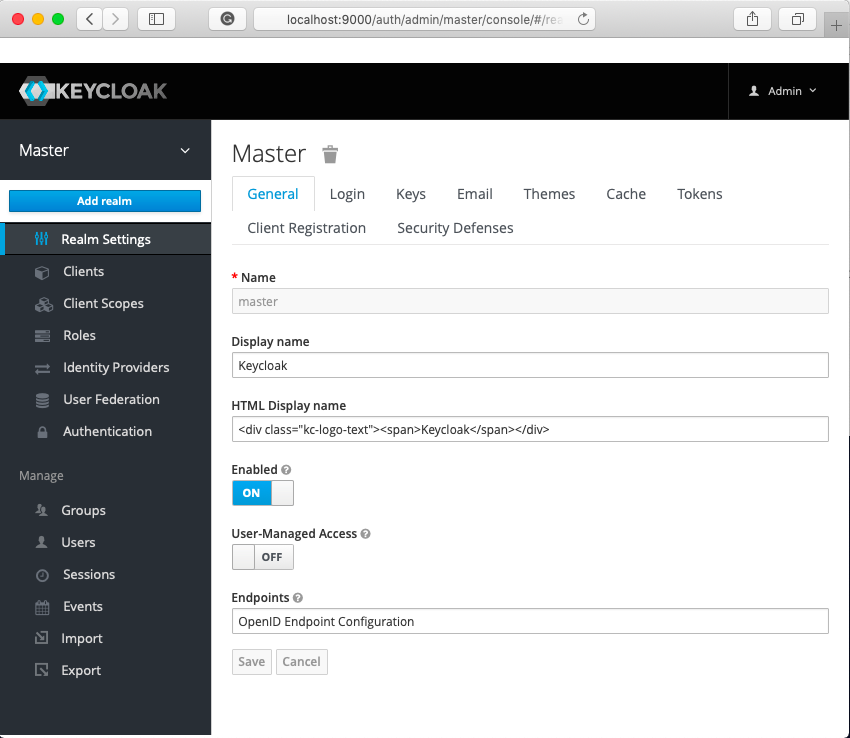
レルムの作成
画面左上の[Master]のあたりにマウスカーソルを合わせると出てくる[Add realm]をクリックします。
[Name]に任意のレルム名(今回は
hello-api)を入力して[Create]をクリックします。
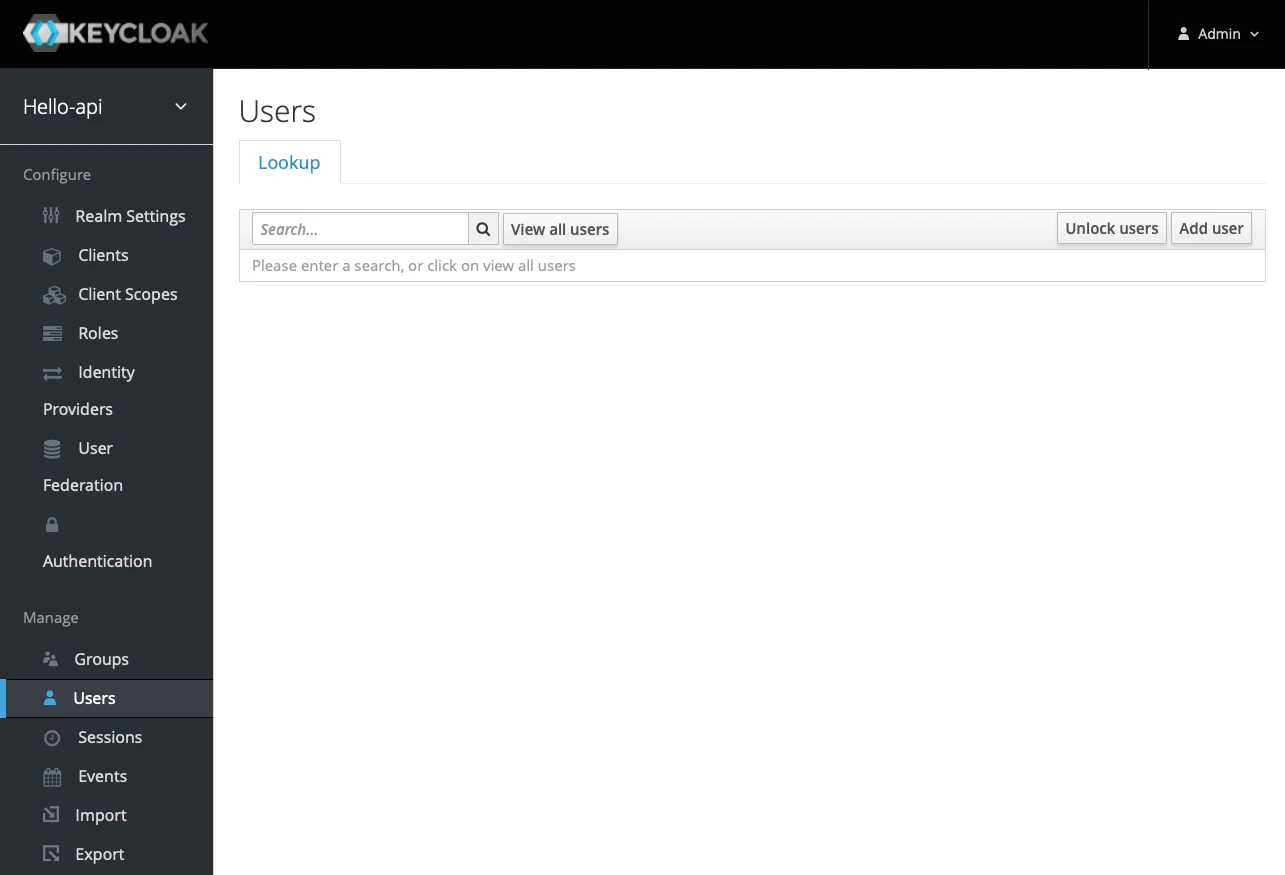
ユーザーの設定
画面左側の[Users]をクリックし、画面右側の[Add user]をクリックします。
[Username]に
userと入力して [Save] をクリックします。
[Credentials]タブを開き、[Password]と[Password Confirmation]にパスワードを設定(今回は共に
user)し、[Temporary]を[OFF]にして[Set Password]をクリックします。
スコープの設定
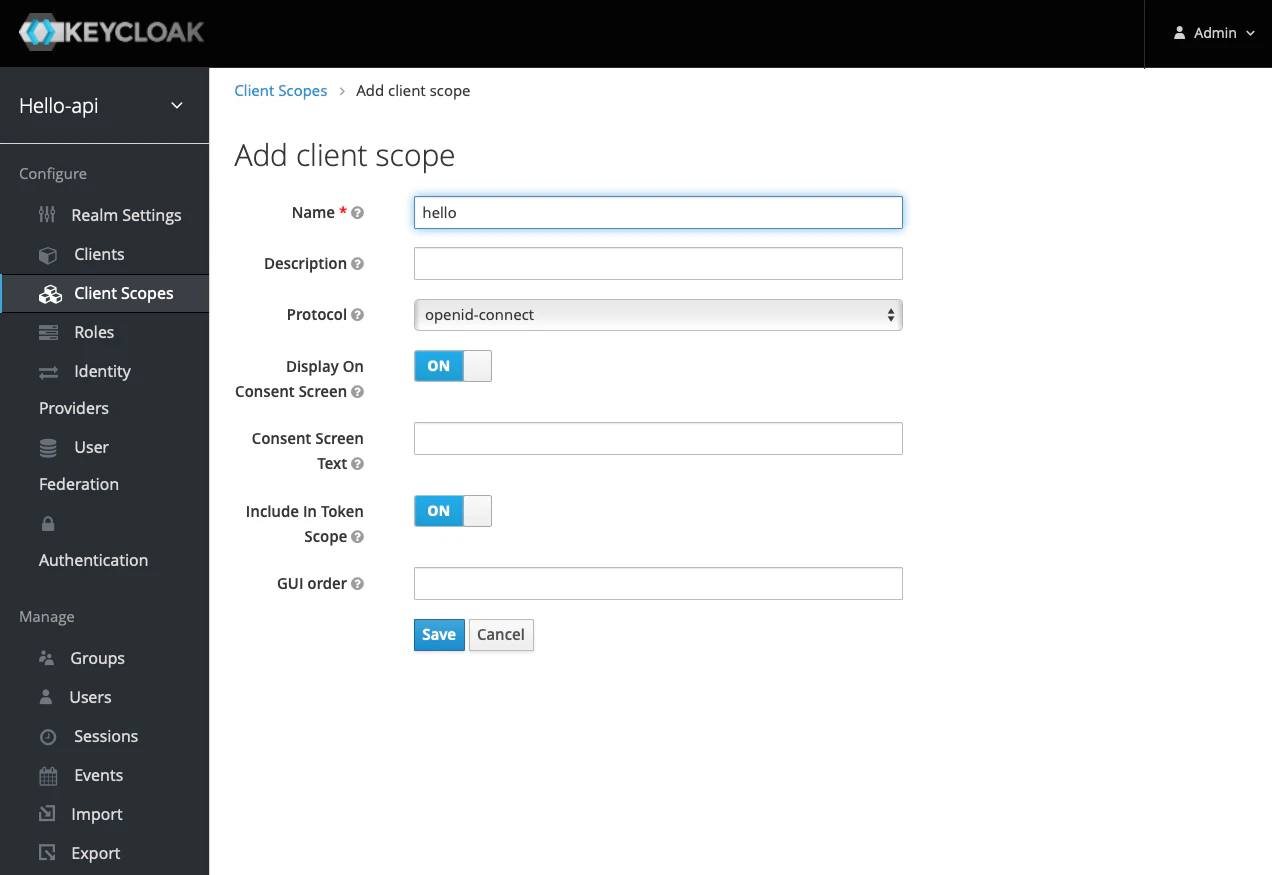
画面左側の[Client Scopes]をクリックし、画面右側の[Create]をクリックします。
[Name]にスコープ名(今回は
hello)と入力して[Save]をクリックします。
クライアントの設定
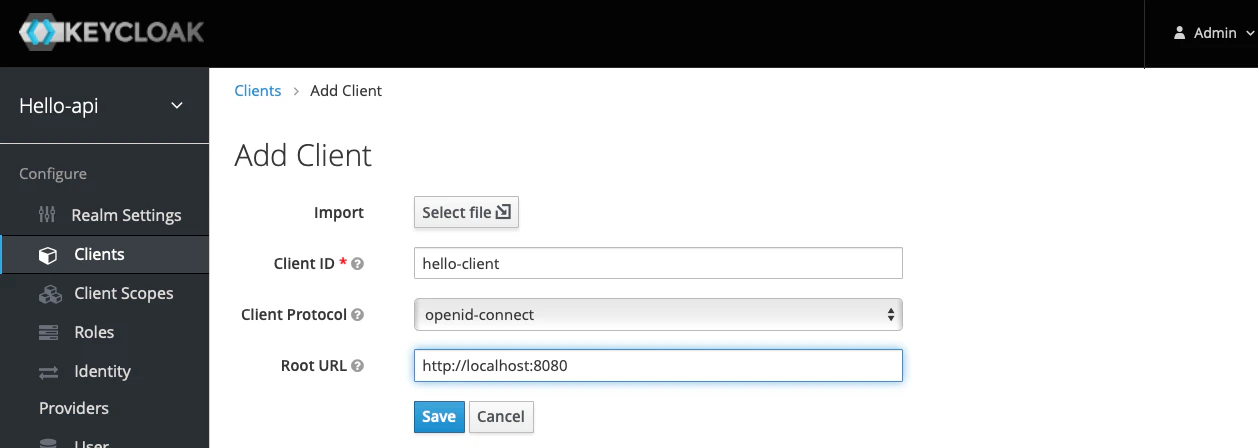
画面左側の[Clients]をクリックし、画面右側の[Create]をクリックします。
[Client ID]にclient_id(今回は
hello-client)
と、[Root URL]にクライアントのルートURL(今回はhttp://localhost:8080)と入力して[Save]をクリックします。
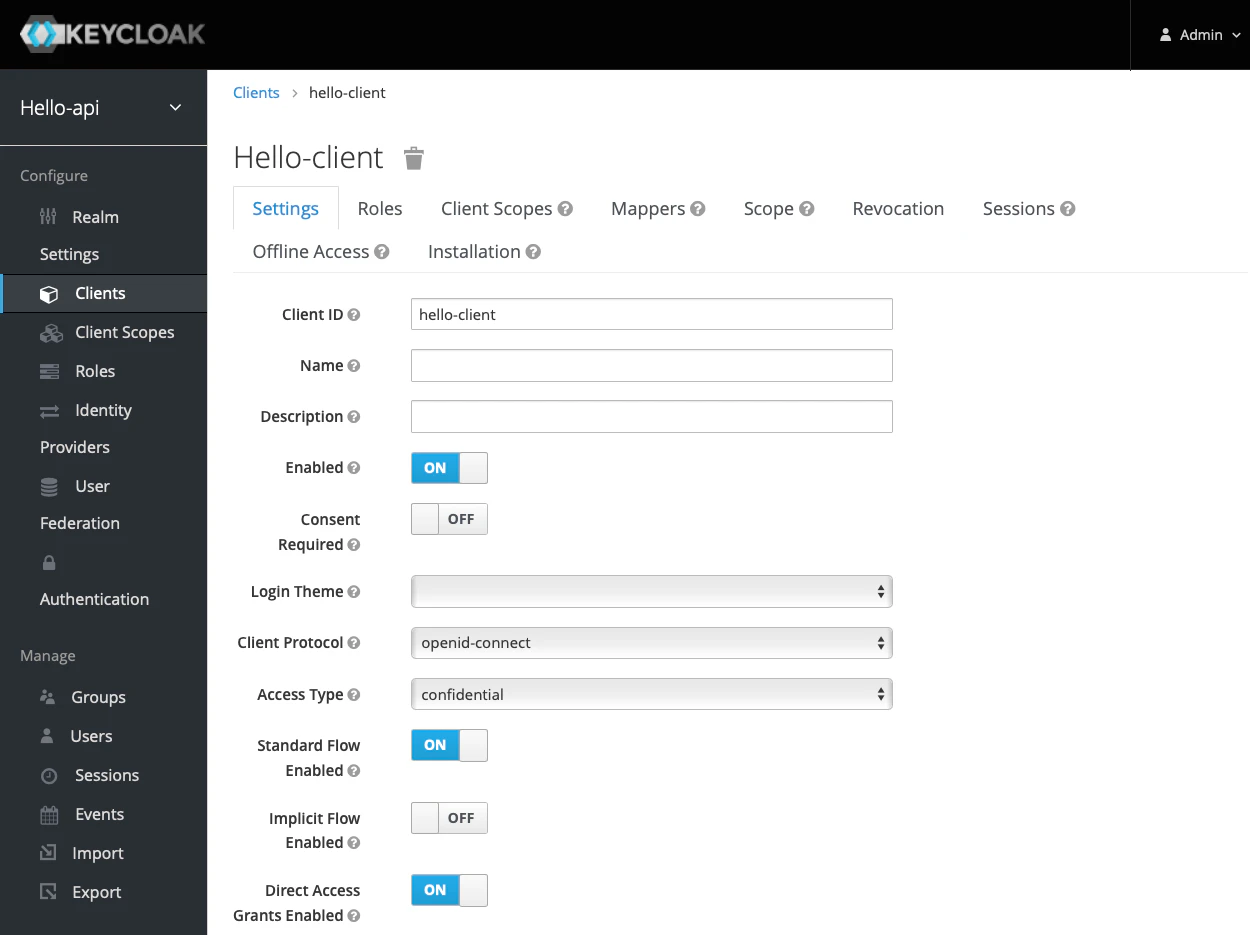
[Settings]タブを開き、[Access Type]を[confidential]、[Valid Redirect URIs]にクライアントのリダイレクトURL(今回は
http://localhost:8080/login/oauth2/code/todo-client)と入力して、[Save]をクリックします。
[Client Scopes]タブを開き、[Default Client Scopes]で追加したいスコープ(今回は
hello)を選択して[Add selected]をクリックします。選択したスコープが[Assigned Default Client Scopes]に移動すれば成功です。






- 投稿日:2020-12-15T08:25:31+09:00
【Java・SpringBoot】Springセキュリティ⑤ - ログアウト処理の実装
Springで、ログイン画面に入力されたID・パスワードをDBに確認し、ユーザーの権限で特定のURLへのアクセスを禁止する機能を簡単に作成しましょう〜♪
これまでに、直リンク禁止やログイン機能の実装、エラーメッセージの日本語化、パスワードの暗号化を実装したので、ログアウトも実装していきます^^ログアウト処理
- logoutRequestMatcher
- Springではログアウト処理はデフォルトでPOSTメソッド送る
- GETで送る場合はlogoutRequestMatcherを使う
- logoutUrl
- POSTでログアウトする設定
- logoutSuccessUrl
- ログアウト成功時の遷移先
- これでログアウトすると、ユーザーセッションが破棄されます
SecurityConfig.java//一部抜粋、全文は下記参考 //ログアウト処理 http .logout() .logoutRequestMatcher(new AntPathRequestMatcher("/logout")) // .logoutUrl("/logout") //ログアウトのURL .logoutSuccessUrl("/login"); //ログアウト成功後のURLアプリを起動してログイン画面からログイン!
- http://localhost:8080/login
- ログアウトボタンでログアウトしたら、セッション終了し、再度ログイン画面に遷移しました!
(参考)コード全文
SecurityConfig.javapackage com.example.demo; import javax.sql.DataSource; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder; import org.springframework.security.config.annotation.web.builders.HttpSecurity; import org.springframework.security.config.annotation.web.builders.WebSecurity; import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity; import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter; import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder; import org.springframework.security.crypto.password.PasswordEncoder; //import org.springframework.security.web.util.matcher.AntPathRequestMatcher; @EnableWebSecurity @Configuration public class SecurityConfig extends WebSecurityConfigurerAdapter { // データソース @Autowired private DataSource dataSource; @Bean public PasswordEncoder passwordEncoder() { return new BCryptPasswordEncoder(); } // ユーザーIDとパスワードを取得するSQL文 private static final String USER_SQL = "SELECT" + " user_id," + " password," + " true" + " FROM" + " m_user" + " WHERE" + " user_id = ?"; // // // ユーザーのロールを取得するSQL文 private static final String ROLE_SQL = "SELECT" + " user_id," + " role" + " FROM" + " m_user" + " WHERE" + " user_id = ?"; @Override public void configure(WebSecurity web) throws Exception { //静的リソースへのアクセスには、セキュリティを適用しない web.ignoring().antMatchers("/webjars/∗∗", "/css/∗∗"); } @Override protected void configure(HttpSecurity http) throws Exception { // ログイン不要ページの設定 http .authorizeRequests() .antMatchers("/webjars/**").permitAll() //webjarsへアクセス許可 .antMatchers("/css/**").permitAll() //cssへアクセス許可 .antMatchers("/login").permitAll() //ログインページは直リンクOK .antMatchers("/signup").permitAll() //ユーザー登録画面は直リンクOK // .antMatchers("/admin").hasAuthority("ROLE_ADMIN") //アドミンユーザーに許可 .anyRequest().authenticated(); //それ以外は直リンク禁止 //ログイン処理 http .formLogin() .loginProcessingUrl("/login") //ログイン処理のパス .loginPage("/login") //ログインページの指定 .failureUrl("/login") //ログイン失敗時の遷移先 .usernameParameter("userId") //ログインページのユーザーID .passwordParameter("password") //ログインページのパスワード .defaultSuccessUrl("/home", true); //ログイン成功後の遷移先 //ログアウト処理 http .logout() .logoutRequestMatcher(new AntPathRequestMatcher("/logout")) // .logoutUrl("/logout") //ログアウトのURL .logoutSuccessUrl("/login"); //ログアウト成功後のURL //CSRF対策を無効に設定(一時的) http.csrf().disable(); } @Override protected void configure(AuthenticationManagerBuilder auth) throws Exception { // ログイン処理時のユーザー情報を、DBから取得する auth.jdbcAuthentication() .dataSource(dataSource) .usersByUsernameQuery(USER_SQL) .authoritiesByUsernameQuery(ROLE_SQL) .passwordEncoder(passwordEncoder()); } }

- 投稿日:2020-12-15T00:07:22+09:00
TomcatのDBコネクションが8個までしか増えない謎を追う ~ あるOSSサポートエンジニアの1日
「TomcatのDBコネクションが8個しかできないんだけど、なんで??」
そんな質問があり、原因を調査しました。意外なオチだったので、そのときの記録をここに残します。
この質問とともに受け取った
context.xmlには以下のような定義がありました。<Resource name="jdbc/MyDB" auth="Container" type="javax.sql.DataSource" driverClassName="com.mysql.jdbc.Driver" factry="org.apache.tomcat.jdbc.pool.DataSourceFactory" url="jdbc:mysql://dbserver.example.com:3306/db4app" username="dbuser" password="xxxxxxxxxx" initialSize="20" maxActive="20" />Tomcatを起動したら、コネクションプールにコネクションが20個できると思ったのに、8個しかできないとのこと。確かにこの設定であれば、
initialSizeとmaxActiveが20なので、起動中に20個のコネクションが生成されて、その後も20個のまま増減しないはずです。
問題を整理する
この質問を受けて、まず疑問に思ったのは「質問者がどのようにコネクション数を確認したのか?」ということです。何をもとに「8個しかできない」と判断したのかは不明確だったので、それについて聞いてみることにしました。
すると、以下のコマンドをDB(MySQL)に発行して、確認しているとのこと。
mysql> show processlist; +------+--------+---------------------------------+--------+---------+------+-------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +------+--------+---------------------------------+--------+---------+------+-------+------------------+ | 1142 | root | localhost | NULL | Query | 0 | NULL | show processlist | | 1614 | dbuser | application.example.co.jp:37110 | db4app | Sleep | 746 | | NULL | | 1615 | dbuser | application.example.co.jp:37111 | db4app | Sleep | 746 | | NULL | | 1616 | dbuser | application.example.co.jp:37112 | db4app | Sleep | 746 | | NULL | | 1617 | dbuser | application.example.co.jp:37113 | db4app | Sleep | 746 | | NULL | | 1618 | dbuser | application.example.co.jp:37114 | db4app | Sleep | 746 | | NULL | | 1619 | dbuser | application.example.co.jp:37115 | db4app | Sleep | 746 | | NULL | | 1620 | dbuser | application.example.co.jp:37116 | db4app | Sleep | 746 | | NULL | | 1621 | dbuser | application.example.co.jp:37117 | db4app | Sleep | 746 | | NULL | +------+--------+---------------------------------+--------+---------+------+-------+------------------+ 9 rows in set (0.00 sec)
show processlist;の結果にはクライアントからのコネクションの数だけレコードが含まれるので、確認の仕方は間違っていないはずです。initialSizeが20なのに、アプリケーションからのコネクションを表すレコードが8件しかない(※)のは明らかにおかしいです。
※:上記レコードは9件ですが、このうち show processlist;を実行するコネクションの1レコードを除くと8件になります。そして、次に思いついた可能性は、「そもそも見ている設定ファイルが違うのでは」ということでした。しかし、そうではないようです。というのも、
context.xmlのinitialSizeを1に設定すると上記コマンドは1件のレコードを返し、5に設定すると5件、8に設定すると8件のレコードを返すからです。そして、不思議なことに、9以上に設定しても8件のまま変化しないというのです。
initialSize = "1":コネクション数 1
initialSize = "3":コネクション数 3initialSize = "5":コネクション数 5initialSize = "8":コネクション数 8initialSize = "9":コネクション数 8initialSize ="20":コネクション数 8つまり、
context.xmlのinitialSizeが効いていることは間違いないのですが、maxActiveではない何かが8件を超えるコネクションの生成を制限しているということになります。試す
念の為、実際にローカル環境でも試してみることにしました。MySQLにJDBC接続する定義が既に
context.xmlに記載されているWebアプリが手元にあったので、接続URL(url)などの定義はそのまま残し、それ以外を受け取ったcontext.xmlと同じになるように修正してみました(initialSizeとmaxActiveを20に修正し、残りのminIdleなどの定義は削除)。そして、Tomcatを起動し、確認してみました。が、やはり事象は再現せず、コマンドを実行すると、20件のレコードが返ってきました。「ということは、Tomcatではなく、MySQLサーバー側でクライアントが扱えるコネクション数を制限をしているのでは?」
MySQLサーバーが制限しているとすれば、MySQLのコマンドライン・クライアントでも同じ問題が発生するはずです。そこで、クライアントを同時に9つ起動して、MySQLサーバーに接続してみるようにお願いしてみました。すると、Tomcatのときとは異なり、コマンドは9件のレコードを返したとの回答が返ってきました。
確かにMySQL側で
max_connectionsなどのパラメーターで制限しているのであれば、Tomcatにはエラーが返り、ログに何らかの情報(Too many connectionsのようなメッセージ)が出力されるはずです。しかし、ログには関連しそうなメッセージが何も出力されていませんでした。ググる
「TomcatでもMySQLでもない?もしかして、ORマッパーやアプリに特殊な仕組みが?それともファイアウォールが切断している?」
いろいろな可能性に頭をめぐらせてみましたが、
8というのがどうもひっかかります。そこで、「"8 connections" "initialSize" "show processlist"」のキーワードでググってみることにしました。すると、同様の現象に遭遇している人の質問がStackOverflowに見つかりました。
- initialSize == 1 - at Tomcat startup 1 connections are created
- initialSize == 5 - at Tomcat startup 5 connections are created
- initialSize >= 9 - at Tomcat startup 8 connections are created
「まさにこれだ!」そう思ったのですが、この質問とは全く一致しない条件が1つありました。
それは、StackOverflowの質問者が「Commons DBCP」を使用しているのに対し、我々は「Tomcat JDBC Connection Pool」を使っているということです。TomcatのDBコネクションプールには2種類あり、古いバージョンで使用されていた「Commons DBCP」と新しいバージョンで使用されている「Tomcat JDBC Connection Pool」があります。
最初に載せた
context.xmlを見ると分かりますが、以下の定義があると、factory="org.apache.tomcat.jdbc.pool.DataSourceFactory"「Tomcat JDBC Connection Pool」が使用されるため、残念ながらこのページの回答にある「「Commons DBCP」の
maxTotalが未設定であるためにデフォルトの8で制限されるので、maxTotalを指定しろ」という対策は、今回のケースには適用できないはずです。とは言え、事象があまりにも似ていて、すぐにはこのStackOverflowのページから離れることができずにいましました。「「Commons DBCP」が使われているなら、つじつまがあうのに...」
謎が解ける
「もしかして、質問者が古いバージョンを使っている?」と一瞬思いましたが、
context.xmlとともに受け取っていたTomcatのログから、使用しているバージョンが7.0.92であることは確かなので、その可能性はありません。2019/08/27 15:44:34 org.apache.catalina.startup.VersionLoggerListener log 情報: Server version: Apache Tomcat/7.0.92「Tomcat JDBC Connection Pool」が導入されたのがバージョン7であることは、何度も見た@ITの記事(以下)で知っていました。
他に「Commons DBCP」が使用される可能性はないのでしょうか?
「両者を切り替える定義はこの1行だけだったはず...」
factory="org.apache.tomcat.jdbc.pool.DataSourceFactory"「そして、受け取った
context.xmlにもこの定義があったはず...」factry="org.apache.tomcat.jdbc.pool.DataSourceFactory"「ん...んん...ん?...」
つまり、typoによりこの定義が無視され、意図せず「Commons DBCP」が使用されてしまい、未指定の
maxTotalのデフォルト値8が機能することで、コネクションは8件までしか生成されなかった、というわけです。そして、コネクションの最大数の設定は「Commons DBCP」がmaxTotal、「Tomcat JDBC Connection Pool」がmaxActiveで異なるのに対し、コネクションの初期数の設定はinitialSizeで同じなこともこの不思議な挙動を演出していたことになります。後で考えてみると、JMXクライアント(JConsoleなど)でコネクションプールの属性値を取得してもらった方が、
maxTotalになっていることにもっと早く気づいたかもしれません。原因が分かってみれば、そんなことも思ったりしますが...最後に
実はこのページの最初に書いた設定も
factryとなっていたんですが、気づかれた方はいたでしょうか?よくあることですが、みなさん、typoには気をつけましょう。こういう場合は、正確性の高いサイト(Tomcatの公式ドキュメントとか)からのコピペが確実ですね。


