- 投稿日:2020-12-15T21:18:52+09:00
MySql 接続エラー
rails s後に、頻繁にmysqlのエラーが出るので考えてみたい。
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
エラー文の意味としては、ソケットと言われるクライアントとサーバーを接続する通信機構が存在していないので、'/tmp/mysql.sock'を通じてMySQLサーバーに接続できないとのこと。
対処法
$ sudo mysql.server restart Starting MySQL .. SUCCESS!基本、
sudo mysql.server restartで解決できる原因としては、Mysqlサーバーが起動していないと考えられる。
参考にしたサイト

- 投稿日:2020-12-15T19:37:07+09:00
マイクロサービス化でテーブル正規化した話
はじめに
現在業務系システムのリニューアルに携わっていて、少しずつ切り出したものをマイクロサービス化しています。その中でやったテーブルを正規化について備忘録を残します。
(最終的に今回リリースした範囲のテーブル数は22テーブルから正規化して48テーブルになりました。)正規化の目的
- データを整理しデータ間の不整合が生じないようにし、分析者、開発者、利用者が使いやすい状態を作ることでした
正規化の目標
- 抽象度の高い定義のテーブルが、今回表現したいドメインの情報単位で適切にカテゴライズされていること
- 1テーブルで管理している情報が多く、いろんな意味で使用されている状態だったので、大枠はDDD(ドメイン駆動設計)に基づいてデータの定義を定めていきました
- 最終的なものは変わらないこと
- 細かく分割しすぎて利用者がデータを保存するのを面倒だと感じてしまうと保存率が低下してしまうので分割することでメリットのないものは無闇に行わないように
- 正規化しているうちに(いろいろ・・・)失っているものがないか?
やったこと①データの精査
実は存在するだけで使われていないカラムやEnum値を削除
- まずは現在使われていないカラムやEnum値がないかを調査し、不要なものは削除しました
要件定義でカテゴリ分類
- 例えば、「案件情報」と1括りになっているテーブルも、実は要素を分解すると、「案件雇用条件」「案件採用条件」「案件商談」「案件推薦」・・・など様々な分類ができます。今回はユーザーストーリーマッピングで、ナラティブフローを作ったり、DDDのコンテキストマップを書いたりしてスコープ内の項目を切り出しました。(規模も規模だったのでかなり骨が折れました・・・・やっぱ紙に書くのが良い)
意味が複数含まれているカラムは分離
例:「〇〇可否」というカラム(1:可, 2:不可, 3:確認中)
→可なのか不可なのか?と確認中なのか?は別にしたいので2つに分離〇〇可否 1:未定義, 2:可, 3:不可 〇〇可否確認 1:未確認, 1: 確認中, 2: 確認済み定義を分けてもメリットがなさそう、かえって複雑そうなものはそのままにしました。
Enumでフラグ管理していた項目を見直し
- データ分析がしやすい構造への変更:データ戦略室に精査を依頼し、外出ししてマスタテーブルへ切り出すところは統合マスタテーブルを新規に定義を行いました
- 例: 今まで 1: patternA, 2: patternB とテーブル定義のコメント欄にフラグを書いて管理していた項目の中で一部、統合マスタに切り出しました
やったこと②テーブルの正規化
Jsonカラムで保持しているデータはテーブルを分離
- テキストにJsonフォーマットや配列でデータが保存されていた項目は、その情報群で新規にテーブルを定義しました
カラム名でデータ構造を表現していた情報はテーブルを分離
- 「hoge_1」、「hoge_2」、「hoge_3」とカラムに採番した番号をつけて複数の情報を保持していた情報は新規にテーブルを定義しました
命名規則を作って統一
- リレーションテーブルの命名規則
- 中間テーブルは命名を統一しました(
{Table A 複数系}_has_{Table B 複数形})
- 他に命名で出た案
- 【複数形_複数形】
- 【単数形_複数形】
- 【テーブル間の接続語(r)】
hoge_r_fugas- 【接頭辞(r)】
r_hoge_fugas- 全体的にカラム名をイケてる感じに。
- 例: *_flag って何・・・→ *_available など、実態に即した命名へ
- 日本語英語→実態に即した命名へ
今回新しく導入した概念
NULLは「値がない」という意味以外の意味を与えてはいけない
- NULLに意味を持たせないよう定義を変更しました
- マスタテーブルでは「未定義」というデータを管理するようにしました
- 未定義を表現するべき時は一律で、id: 999999999 name: "Undecided"を設定
- Enumでフラグを設定していた項目も未定義を定義
- null, 1:可, 2: 不可 → 1: 未定義, 2:可, 3: 不可
今回できなかったところ...
抽象化しすぎたカラムの再定義
- 「状態」というカラム
- 「1:開始, 2:終了」のフラグを持っているカラム。君は一体何を開始しているんだ。。。各状態の定義が詰め込まれすぎていて全部のロジックを洗わないと定義できなかったため保留に。
- テキストで管理している項目の正規化
- データ分析しやすいように変換したかったですが、精査にかなり時間がかかるということで今回は保留に。
今後の課題
- 全部論理削除の想定でテーブル設計をしましたが、アプリケーション側で使っているライブラリの関係で、中間テーブルが物理削除になっていました。対応工数がかなりかかるのでひとまず物理削除のまま進めることになりましたが、中間テーブルにおける論理削除のメリットってなんなのでしょうね・・・。
最後に
SQLアンチパターンの本には大変お世話になりました。
index貼ったりなんなりもしましたが、それはまた別の機会に・・・。
- 投稿日:2020-12-15T18:28:01+09:00
[無料] AWS EC2 + RDS + Flask でWebアプリを作り HTTPS 化する [データベース編 その1]
Webアプリで使うためのリレーショナルデータベースを AWS RDS で作成します。私はスキーマレスなNoSQLにしか興味ない、という人は読み飛ばして下さい。そのうち無料で使えるキーバリューストア型データベースの DynamoDB との比較記事も書くかもしれません。
インスタンス作成
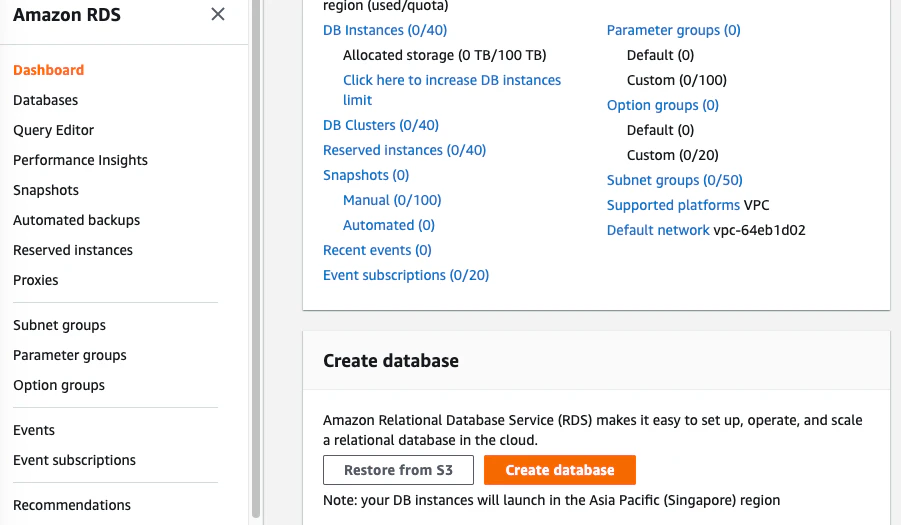
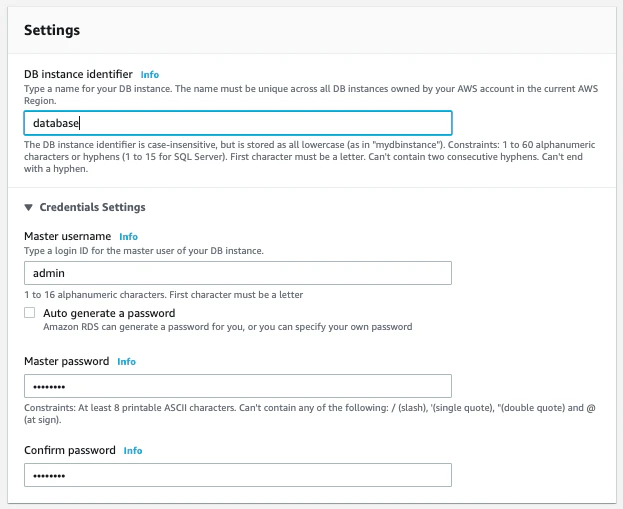
Amazon RDS のページに入り、真ん中らへんの Create database します。
Standard create で良いです。
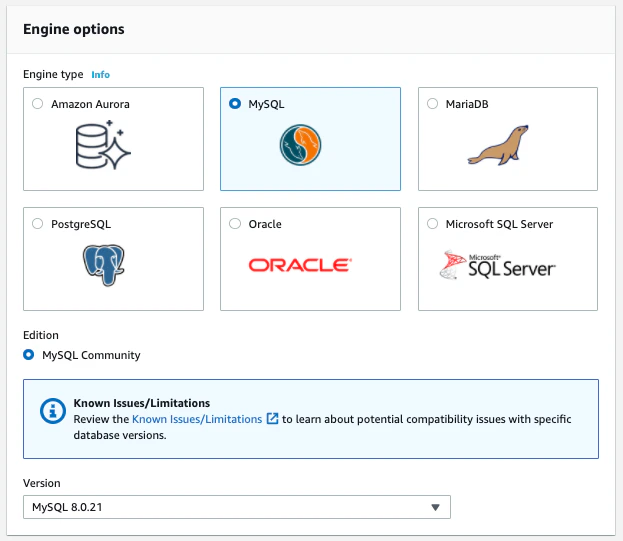
エンジンを選びます。主要なものは全て揃っています、MySQL、MariaDB、PostgreSQL、Microsoft SQL Server の4つが無料で、Oracle と Amazon Aurora は無料枠対象外です。Aurora は MySQL/Postgre 完全互換で、本家よりも数倍速いとの謳い文句ですので、興味がある方は試してみると良いかもしれません。ただし、バージョンが限られることに気をつけて下さい。私はリレーショナルデータベースをあえて正規化せずに NoSQL のように運用することがあるのですが、その際に MySQL8.0 のJSON_TABLEという関数を多用します(そのうち余裕があれば転置インデックスの話もします)。ですが Amazon Aurora でサポートしているのは MySQL5.7 までですので、オリジナルの MySQL をエンジンとして選ばざるを得ません。window 関数なんかも確か 5.7 では使えないはずです。まあ一般的な CRUD のみであればバージョンはそこまで気にする必要はありません。今回は MySQL8.0 を選択します。
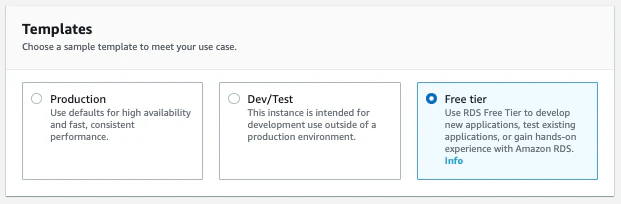
Free tier を選びます。
データベース名、ユーザー名、パスワードなどを決めます。DBインスタンスは無料利用枠では選択不可です。
Strage は 20GB もあれば十分ではないかと思います。
Public access は Yes にしておかないと、EC2以外の外部からアクセスできなくなります。全て作り終わった後に設定をアクセス不可に戻せば良いです。
セキュリティーグループは その2 で設定済の default を選べば良いです。一番右下の Create database します。
データベースの作成には少し時間がかかります。ステータスが Available になれば使えます。
データベース名を押すと詳細が出ます。このエンドポイントと、先ほど入力したユーザー名・パスワードでデータベースにアクセスできます。
接続例
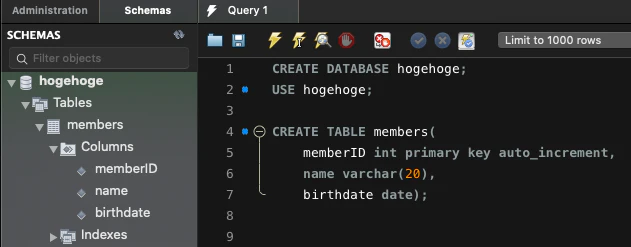
MySQL Workbench
Hostname に先ほどのエンドポイントを入力し、Username と Password を入れて Test Connection し、Success と出れば接続できています。
外部からでも問題なく使えます。
VScode
MySQL Workbench のような統合GUIは、設定をいじったりER図を書くときなどには非常に重宝しますが、コーディングしながら、VScode内からそのままクエリを投げたいときもあります。この MySQL 用の Extension を導入します。
左側にデータベースのアイコンが追加されます。上の➕から接続を追加できます。
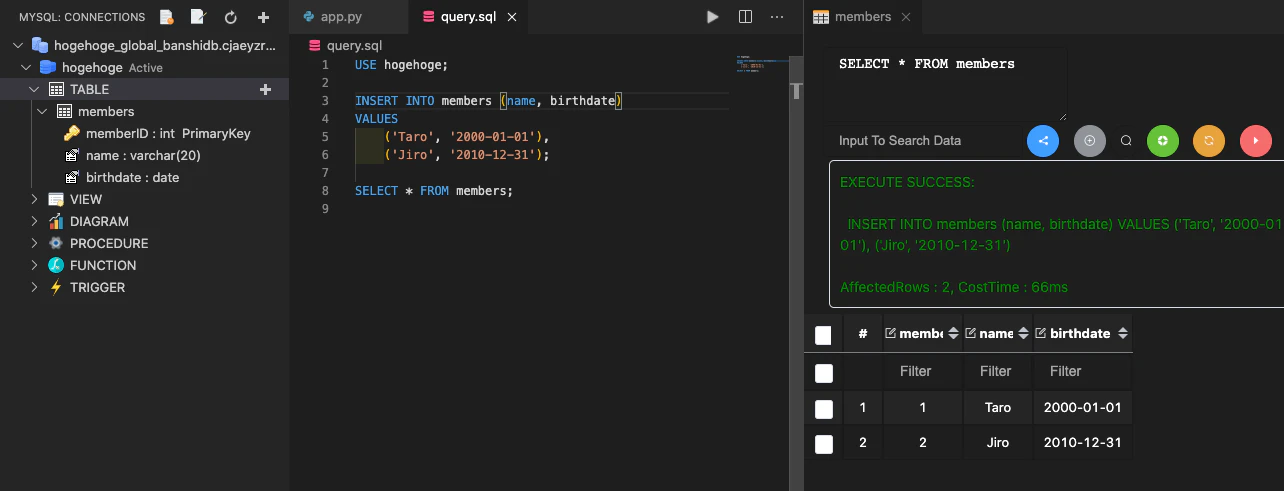
同様にエンドポイント、ユーザー名、パスワードを入れて接続します。
.sqlファイルならシンタックスハイライトもされます。F9キーでクエリを実行できます。し、右側のフィールドで実行することも可能です。便利すぎます。









- 投稿日:2020-12-15T14:43:53+09:00
Go言語 XMLを変換してDB内を検索し、一致した情報をXML形式で返す
はじめに
自分はプログラミング歴5ヶ月の超初心者で、自分と同じような超初心者と自分の備忘録のために書いております。
もし、気になる点やもっといい方法があれば指摘していただけると幸いです。やること
今回は、Go言語でAPIを使ってXML形式のリクエストをDBに保存するの続きをやる。
DBに保存するだけじゃ物足りないので、保存したデータ内を別のキーワードでDB内を検索する機能と検索結果をXML形式で出力するところもやってみようと思った。(まだ物足りない)実装する機能
前回はXMLのデータをUnmarshalして保存するだけだったから今回は
・キーワードでリクエストを送信してXMLを受け取り、DB内を検索
・検索したキーワードとヒットしたキーワード別のヒット件数を出力
・一致したデータをXML形式に変換して出力
・ヒットしなかったらその旨を伝えてプログラムを終了するを実装する。
やってみる
今回も引き続き国会議事録検索システムを使っていく。
DB
検索したキーワードも保存した方がいいかなと思ってテーブル構造をちょっと変えた。
例によってid以外は面倒なので文字列にしてある。+---------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+----------------+ | id | int | NO | MUL | NULL | auto_increment | | issueid | varchar(255) | YES | | NULL | | | house | varchar(5) | YES | | NULL | | | date | varchar(255) | YES | | NULL | | | keyword | varchar(255) | YES | | NULL | | +---------+--------------+------+-----+---------+----------------+あと、検索対象が必要なので「コロナ」に加えて
・ワクチン
・菅義偉(人名を出すのは大丈夫なのか?)
・緊急事態宣言での検索結果もDBに保存しておいた。
リクエスト
ここは前回と同じ処理です。キーワードを変更するだけ。
HttpGetについては
Go言語でAPIを使ってXML形式のリクエストをDBに保存する
を参照してください。word := "ああ" eWord := url.QueryEscape(word) data := HttpGet("https://kokkai.ndl.go.jp/api/meeting_list?any=" + eWord)返すデータ
今回はヒットしたアイテムをDBに保存したときのキーワードも返したいので、取得した時とは別の構造体を定義する。
type Return struct { ID string `xml:"recordData>meetingRecord>issueID"` House string `xml:"recordData>meetingRecord>nameOfHouse"` Date string `xml:"recordData>meetingRecord>date"` Hitword string `xml:"recordData>meetingRecord>hitword"` } type ReturnList struct { XMLName xml.Name `xml:"data"` Recs []Return `xml:"records>record"` }検索する
DB接続、レコード取得部分等は省略。
今回はヒット件数、キーワード別のヒット件数も返すのでそれらを格納する変数と後でXMLに変換して出力するデータをmDataListにReturnList型で定義// ヒット件数 hit := 0 // ヒットしたレコードの検索時キーワード keywords := make([]string, 0) // 返すデータ mDataList := ReturnList{}検索して、ヒットすれば
hitに1を加算し、そのデータのID,House,DateとヒットしたレコードのキーワードをReturn型のスライスであるmDataList.Recsにappendする。
キーワード別の件数表示のためkeywordsにもappendする。
resultにはDBから取得したデータが前回内容のRecordList型で入っている。for _, rec := range result.Recs { for _, scan := range scanned { if rec.ID == scan.issueID { hit++ mData := Return{ ID: rec.ID, House: rec.House, Date: rec.Date, Keyword: scan.Hitword, } mDataList.Recs = append(mDataList.Recs, mData) keywords = append(keywords, scan.Keyword) } } }結果を出力する
ヒットしなかった場合の出力
os.Exit()はdeferを実行しないらしくpanicもGoexitもなんか違う気がするのですが、いい方法があれば教えていただきたいです。if hit == 0 { fmt.Println("ヒットしませんでした。") fmt.Printf("検索したキーワード: %v\n", word) os.Exit(1) }ヒットした場合の出力
mapを範囲ループするとGoでは順番が毎回異なってしまい、今回は順番が変わっても影響はないがなんとなく気持ち悪いので順番を固定しておく。// どのキーワードで何件ヒットしたか resultWords := make(map[string]int) for _, w := range keywords { resultWords[w]++ } // キーワード別件数の順序を保持するための処理 keys := make([]string, 0) for i, _ := range resultWords { keys = append(keys, i) } sort.Slice(keys, func(i, j int) bool { return keys[i] > keys[j] }) // 結果をXML形式に変換 buf, err := xml.MarshalIndent(mDataList, "", " ") if err != nil { log.Fatal(err) } // 出力 fmt.Printf("%v件が見つかりました。\n検索したキーワード: %v\n", hit, word) fmt.Println("検索結果") for _, w := range keys { fmt.Printf("%v: %v件\n", w, resultWords[w]) } fmt.Println("\n以下、XML形式で結果をお知らせします。\n") fmt.Println(string(buf))実行結果
go run . 5件が見つかりました 検索したキーワード: ああ 検索結果 菅義偉: 2件 ワクチン: 2件 コロナ: 1件 以下、XML形式で結果をお知らせします。 <data> <records> <record> <recordData> <meetingRecord> <issueID>120115254X02020200529</issueID> <nameOfHouse>参議院</nameOfHouse> <date>2020-05-29</date> <keyword>コロナ</keyword> </meetingRecord> </recordData> </record> <record> <recordData> <meetingRecord> <issueID>120105254X01420200402</issueID> <nameOfHouse>衆議院</nameOfHouse> <date>2020-04-02</date> <keyword>ワクチン</keyword> </meetingRecord> </recordData> </record> <record> <recordData> <meetingRecord> <issueID>120105254X00720200227</issueID> <nameOfHouse>衆議院</nameOfHouse> <date>2020-02-27</date> <keyword>菅義偉</keyword> </meetingRecord> </recordData> </record> <record> <recordData> <meetingRecord> <issueID>120015254X00320191009</issueID> <nameOfHouse>参議院</nameOfHouse> <date>2019-10-09</date> <keyword>ワクチン</keyword> </meetingRecord> </recordData> </record> <record> <recordData> <meetingRecord> <issueID>119805254X03120190621</issueID> <nameOfHouse>衆議院</nameOfHouse> <date>2019-06-21</date> <keyword>菅義偉</keyword> </meetingRecord> </recordData> </record> </records> </data>終わりに
読んでいただきありがとうございました。
もっと深い知識で記事を書けるようになりたいです。
- 投稿日:2020-12-15T13:15:30+09:00
第3回 AWSに自動でテスト/デプロイしてくれるインフラの設定・構築(Nginx・MySQL編)
本シリーズ集
タイトル 0 目標・やりたいこと 1 AWS編 2 rails開発環境構築編 3 Nginx・MySQL編 4 Capistrano編(未) 5 CircleCI編(未) 6 総集編(未) はじめに
Nginx・MySQLを分けると、短くなってしまうため、本記事では二つをまとめる。
まずはNginxから。Nginxとは
Webサーバ用ソフトウェアの一つ。
Webサーバといえば、Nginx と Apache の二代巨頭なイメージ(がないですか?)。
今回は、このNginxをDockerfileを用いて構築する。ディレクトリ構成
/nginx ├ public | ├ 404.html | ├ 422.html | └ 500.html ├ nginx.conf └ Dockerfilepublicディレクトリ配下は、
rails newコマンドにより生成されたファイル群の一部抜粋したものである。(この404.htmlとかのファイルは特別いるわけでもないが、rails側と通信できなかった時にエラーページを表示するためのものである。Dockerfileの中身
DockerfileFROM nginx:latest RUN rm -f /etc/nginx/conf.d/* COPY ./public /public COPY nginx.conf /etc/nginx/conf.d/nginx.conf # /conf.d/ディレクトリ配下の設定ファイルを読み込む設定になっているので、(元を確認してないので、もしかしたら0かもしれない。) # それらを一度全部削除して、新たに作成したファイルを入れる CMD nginx -g 'daemon off;' -c /etc/nginx/nginx.confnginx.conf ファイルの中身
nginx.confserver { listen 80; # ドキュメントルートの指定 root /public; error_page 404 /404.html; error_page 505 502 503 504 /500.html; location / { try_files $uri @app; } # # リバースプロキシ関連の設定 location @app { proxy_pass http://xx.xx.xx.xx:3000; # 対象APサーバを持つEC2インスタンスの、プライベートIPアドレスとポートを指定する } }これで、準備OK。
Webサーバを起動してみる。
EC2インスタンスに、
sftpコマンドにより、ファイル群をアップロードした後、sshコマンドでEC2にアクセスし、# docker build -t test-nginx . # docker run -p 80:80 test-nginx (このまま見た目は止まる)とすると、起動する(見た目では分かりにくいけど)。
ローカルブラウザから、アクセスしてみる
ローカルブラウザで、
http://IPアドレス/とうち、アクセスしてみると、
と出るので、きちんとWebサーバが立っていることがわかる。MySQL
MySQLのDockerfileはない。
docker pullコマンドでMySQL:5.7をpullし、それをrunコマンドで走らせて終了。sshキーでアクセスし、各種コマンドを打つ。
$ ssh -i 【鍵のPATH】 ec2-user@xx.xx.xx.xx [ec2-user@ip-xx-xx-xx-xx ~]$ sudo service docker start [ec2-user@ip-xx-xx-xx-xx ~]$ docker pull mysql:5.7 [ec2-user@ip-xx-xx-xx-xx ~]$ docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root --rm mysql:5.7 ... ... Version: '5.7.32' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)これでおしまい!
まとめ
さら〜っとこんな感じでやればできます〜って感じで書いてますけど、実際には(主にWeb-AP間の連携の部分で)この作業周りでまる1日かかった笑。
特に最後の画像のエラーがどうしても修正できなくて、めちゃくちゃ迷いました。なんでMySQL5.7を使用しているかも含めて、また後日この話は別の記事であげたいと思います。

- 投稿日:2020-12-15T04:21:14+09:00
DockerとAlfredでMySQLとRedisのお手軽環境構築
はじめに
2020 年度 XTech グループアドベントカレンダーの 15 日目の記事です。
エキサイト株式会社、新卒の西牧です。今回は、Docker と Alfred で MySQL と Redis をお手軽に環境構築する方法を紹介したいと思います。
必要なもの Docker で立ち上げて、Alfred でどこからでも呼び出せるようにするという流れです。
コードはこちら。環境
macOS: 10.15.1
docker-compose: 1.27.4
Alfred: 4.0.9docker-composeですべて立ち上げる
docker-compose で以下のものを立ち上げます。
- MySQL
- Redis
- adminer
- redisinsight
MySQL の GUI クライアントには adminer を、Redis の GUI クライアントには redis-insight を使います。
理由としては、デスクトップアプリより web アプリがよかった(個人的にはできるだけ web で完結したい)のと、軽量なことぐらいです。
ちなみに以前は、Sequel Pro と Medis を使っていましたが、どちらもあまり使いやすくなく、adminer と redisinsight の方が個人的にはいいと思います。$ docker-compose up -dversion: '3' services: redis: image: redis:latest restart: always ports: - 6378:6379 command: redis-server /usr/local/etc/redis/redis.conf volumes: - ./redis/data:/data - ./redis/redis.conf:/usr/local/etc/redis/redis.conf redisinsight: image: redislabs/redisinsight restart: always ports: - 8011:8001 volumes: - ./redisinsight:/db depends_on: - redis mysql: image: mysql:5.7 restart: always environment: MYSQL_USER: docker MYSQL_PASSWORD: docker MYSQL_ROOT_PASSWORD: local_root_password MYSQL_DATABASE: db ports: - 3307:3306 volumes: - ./mysql/data:/var/lib/mysql - ./mysql/conf.d:/etc/mysql/conf.d adminer: image: adminer:latest restart: always environment: # choose your favorite design from https://www.adminer.org/ ADMINER_DESIGN: lucas-sandery ports: - 8090:8080 depends_on: - mysql動作確認
立ち上げられると、GUI クライアントを開いて、MySQL と Redis に接続してみます。
- adminer: http://localhost:8090/
- redisinsight: http://localhost:8011/
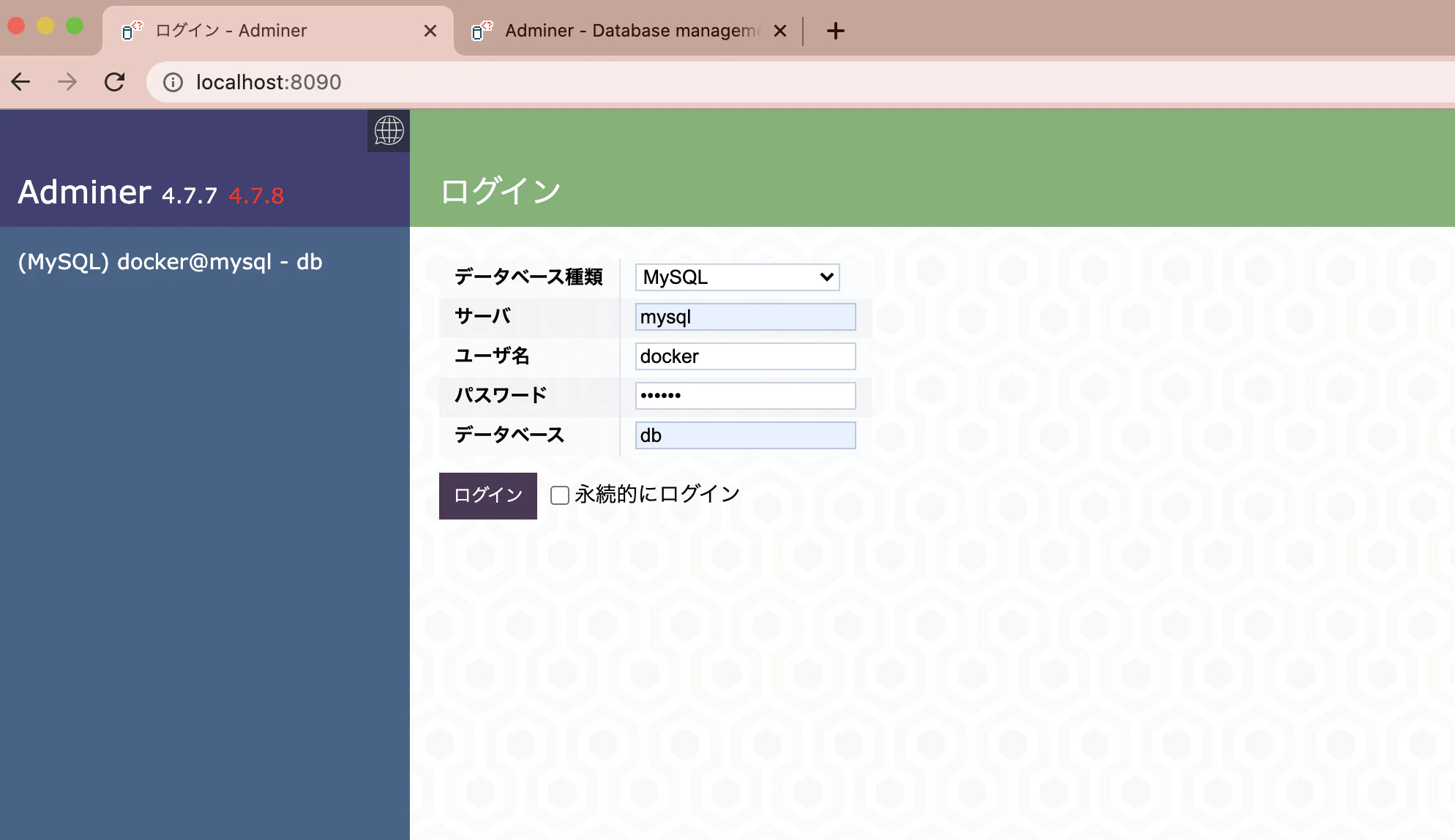
adminer を開くとこんな感じです。デザインは環境変数で変えられます。
接続情報のサーバには、docker-compose.ymlで書いたサービス名 mysql を入れます。
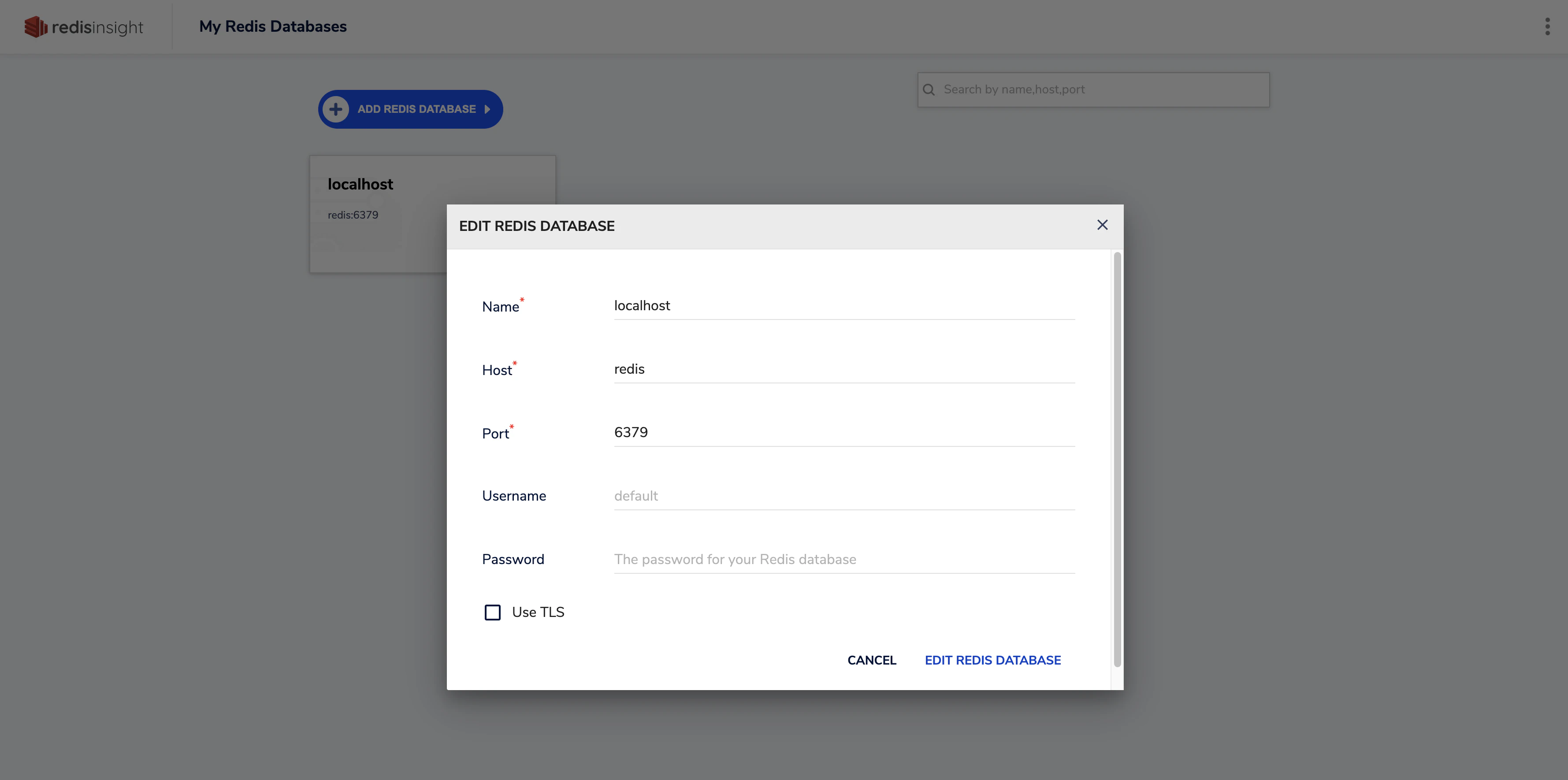
redisinsight はこんな感じです。
接続情報は以下の通りです。
- Name: 任意の名前
- Host:
docker-compose.ymlで書いたサービス名 redis- Port: 6379
GUI クライアントをどこからでも呼び出せるようにする
Alfred を使います。
Alfredとはなんぞや?という方は、Alfredを使いこなせてない君に!【Alfredの使い方完全版】
いうたら、spotlight 検索の上位互換みたいなやつです。
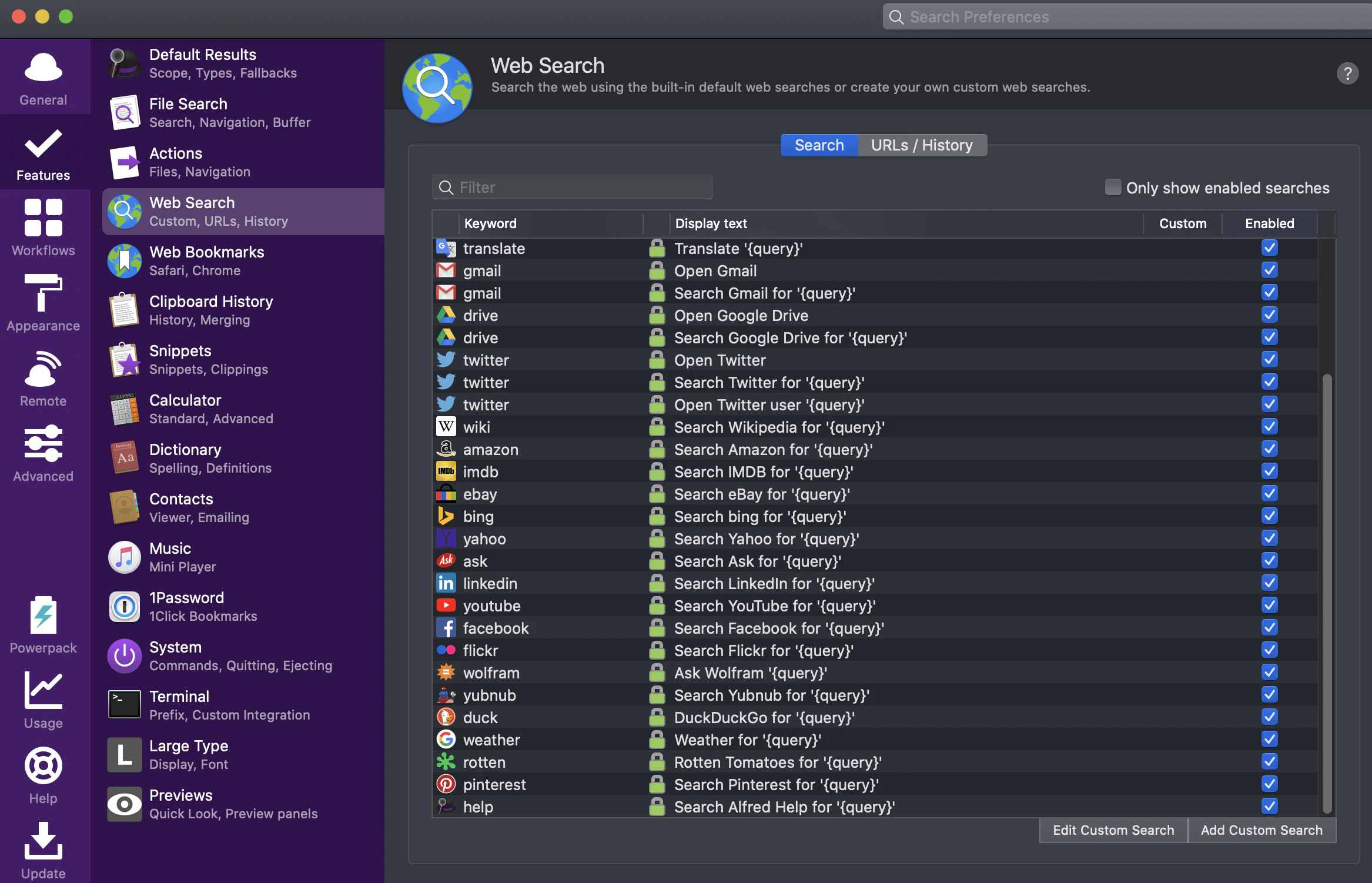
Alfred の Web Search に 先ほどの http://localhost:8090/ とかを登録しておくと、ポート番号を覚えておく必要もないし、どっからでも呼び出せるので便利です。
Web Search というのは、URL にキーワードを紐付けて登録しておくと、Alfred でそのキーワードを実行することで、登録した URL をブラウザで開けるというものです。
画像のようにして http://localhost:8090/ を登録してみます。
- Search URL: http://localhost:8090/
- Title: 任意の名前
- Keyword: 任意の単語
登録後、実行すると、登録した URL が自動で開きます。
おわりに
最近は Docker で入れられるツールも増えてきているので、うまく活用すると、オンボーディングコストさげられそうだなと、これ書いてて思いました。
みなさんもためしてみてください〜