- 投稿日:2020-12-15T22:48:46+09:00
EKS超入門「INTRODUCTION TO AMAZON EKS」を3時間300円でやった話
はじめに
たった3時間、300円でEKSを味わえるチュートリアルです。
EKSについてちょっと知ってみたい方は迷わずやってみた方がいいです。EKSを学ぶというよりは、EKSとEKSに関連するマネージドサービス(cloudFormation、IAM等)のつながりが見えてくるので、非常に良かったです。(普通にAWSの勉強にもなるので、是非おすすめ)
対象者
・Kubernetes について聞いたことがあるけどまだ触ったことがない方
・Kubernetes を知ってはいるけど、Amazon EKS は触ったことがない方 ← 自分はここに該当環境
AWSアカウントがあれば大丈夫です
URL
INTRODUCTION TO AMAZON EKS
https://eks-for-aws-summit-online.workshop.aws/実施手順
チュートリアル通りに実施すれば、詰まるところは正直なかったです。
とにかく、丁寧に書いてくれています。強いて言えば、このチュートリアルはus-east-1で実施する内容となっているので、
東京リージョンで実施したい方が、そこだけ読み替えて進むと良いと思います。
私は東京リージョンでやりました。感想
・eksctlをめちゃめちゃ使うと思ったが、クラスター構築くらいで、
あとはいつも通り、kubectlだったのが一番最初の驚き。
・eksctlはCloudFormation を使って VPC や EKS クラスターのコントロールプレーンやワーカーノードの
Auto Scaling Group などの AWS リソースを作成(これは単純に自分の備忘用)
・cloud9を初めて使ったが、VSCodeに何となく似ていて良かった。今後
EKSWorkshopというものがあって、ここではeksの周辺システムについて、ハンズオン形式で学べるチュートリアルがあります。
以下はその一例ですが、EKS並びにkubernetersについて一通り学べそうな内容になっていて、かなり良さそうなので、
次回はこれをやっていきたいと思います。
・Using Spot Instances with EKS
・Autoscaling our Applications and Clusters
・Monitoring Using Prometheus and grafana蛇足:チュートリアル完了後のbilling
私の場合は、集中的な時間をとって実施できなかったのですが、(おそらくスタートから完了まで10時間くらいかかりましたが、)
このくらいの金額で済みました。集中して時間が取れる方なら、これより安く済むはずなので、実施してみてください!

- 投稿日:2020-12-15T22:21:10+09:00
AWSアプリの修正から自動デプロイまでの流れ
AWS自動デプロイまでの処理が終わり、ブラウザからElastic IPでアクセスしたところ「We’re sorry , but ~」というエラーに悩まされました。
例えば、環境変数の指定の仕方に誤りがないか、インスタンスを再起動したりなど探していきました。
解決方法としては、しっかりとエラーログを確認して原因を推察し、解決する仮説を立てて一つずつ検証していきました。
原因が推察できなければ、Qiitaや質問サイトなどで情報を収集し、原因を特定していきました。
今回の原因は、masterでのcommit→pushのし忘れという初歩的なものでした。
細かいなミスで発生したエラーでも原因が特定できないと、解決にかなり時間がかかってしまうことを実感して、自分用マニュアルとしてQiitaにまとめました。
アプリの修正から自動デプロイまでの流れ
状況 自動デプロイ前にやること 必要性の有無 ①ローカルでVSCodeを修正した場合 変更点をリモートリポジトリにcommit→pushする(ブランチを切っている場合はmergeまで実行 該当時のみ ②ローカルでデータベース関連の内容を修正した場合 本番環境で「rails db:drop RAILS_ENV=production」「rails db:create RAILS_ENV=production」を実行(※実行する際、「DISABLE_DATABASE_ENVIRONMENT_CHECK=1」というオプションが必要です) 該当時のみ ③Nginxを修正した場合 「sudo systemctl restart nginx」を実行 該当時のみ ④再度自動デプロイを実行する場合(本番環境でサーバー再起動をする場合) 一度プロセスをkillした上で「bundle exec cap production deploy」を実行 ①②の場合のみ 今回は頻繁に行うであろう
④再度自動デプロイを実行する場合(本番環境でサーバー再起動をする場合)をまとめました。「EC2アプリ内:1つ目のターミナル」
①ディレクトリの移動
cd .ssh/②EC2にログイン
ssh -i (○○.pem) ec2-user@(Elastic IP 3.140.60.122)③アプリのディレクトリ
cd /var/www/(アプリ名)④プロセスを確認
ps aux | grep unicorn (一番目の数字)⑤プロセスをkill 特に何も表示されない
kill (一番目の数字)
「ローカルアプリ内:2つ目のターミナル」bundle exec cap production deploy(自動デプロイ)2〜3分待ってエラーがなければOK!
「ブラウザ」で無事にアクセスできれば成功!
3.140.60.122(例)



- 投稿日:2020-12-15T22:21:02+09:00
EKSへのkubectl get svcで「error: You must be logged in to the server (Unauthorized)」
症状
マネジメントコンソールでEKSを作成した時に
> kubectl get svc error: You must be logged in to the server (Unauthorized)となって確認ができない。
解決方法
コンソールにIAMのユーザーでサインインしてクラスタを作成し、同じユーザーでkubectlを実行する。
> kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 46m説明
Amazon EKS クラスターが作成されたら、クラスターを作成する IAM エンティティ (ユーザーまたはロール) は、system:masters アクセス許可が付与された管理者として Kubernetes RBAC 認証テーブルに追加されます。最初は、その IAM ユーザーのみが kubectl を使用して Kubernetes API サーバーを呼び出すことができます。
クラスタを作成した直後は、作成したユーザでのみ呼び出しが可能です。
サインインするときに IAMユーザーで入り、そのユーザーで操作を実施しましょう。自分は同じユーザーだとすっかり勘違いをして、ルートユーザーでクラスタ作成を行っていました。
もし同じ症状の場合は、今一度の見直しを…。他にもロールの設定不備でも同じ様なエラーが出るようなので、一つ一つ確認して解決されるとよいかと思います。
参考
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/create-cluster.html#create-cluster-console
- 投稿日:2020-12-15T22:20:53+09:00
Lambda on Terraform Container
はじめに
この記事はterraform Advent Calendar 2020の15日目です。
もともとTerraformのテストについてつらつら書こうとしましたが、re:Invent2020でLambdaのコンテナサポートされました
今回re:Invent2020で発表された中で、比較的反響がでかかった発表じゃないでしょうか
この波に乗らねば、ということで、Terraformをコンテナ化してLambdaで実行できるようにしてみました
※決してLambdaをTerraformで構築する記事ではありません構成
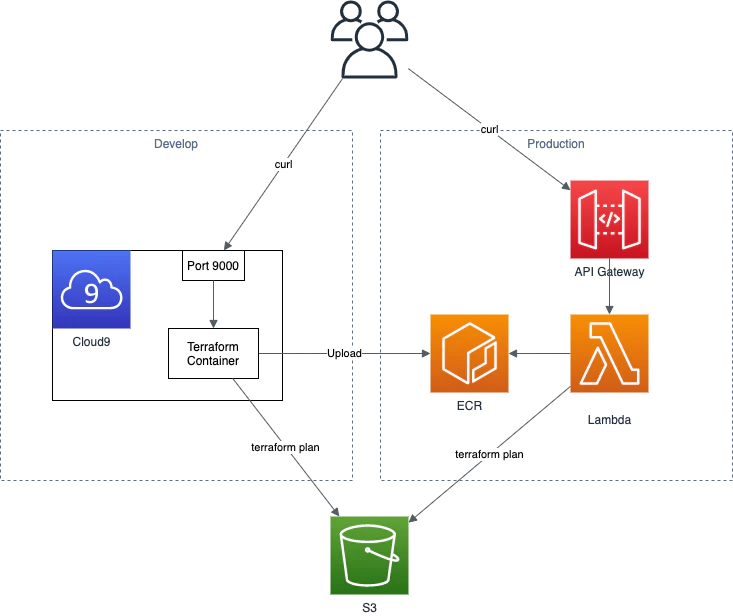
今回の構成は下記です
開発ではCloud9を利用して、内部でコンテナを使って確認を行い、本番ではECRにイメージをアップしてLambdaから利用するという形になります
今回は時間がなかったのでAPI Gatewayは未使用ですユースケース
ユースケースとしては下記の2つほどあるかと思ってます
- 共通実行基盤
- 監視
共通実行基盤としては、よくTerraformの実行基盤で悩む人がいると思うのですが、こちらを今回作成するLambdaを共通基盤とするのも一つの案かと思います
今回はただコードを持ってきて叩いてますが、これをCodeCommitやGithubで管理してるコードを引っ張ってくるようにすれば、最新コードをとってデプロイできるかと思います監視としては、よくコードとリソースが乖離している問題があると思いますが、今回のLambdaを利用すれば、乖離したら検知できるようにできます。今回の作成したAPIを叩けば追加・変更・削除のリソース数が取れるので、PrometheusでもDatadogでも利用すれば0じゃない時にアラートを出せるかと思います
リポジトリ
対象のリポジトリは下記です
https://github.com/Yusuke-Shimizu/terraform_on_lambda
記事読むのだるいって人はcloneして使ってください
Dockerfileと.envrcの値は各自修正してご利用ください(アクセスキーとシークレットキー書いたままプッシュしちゃダメだよ!)コンテナイメージ
コンテナをLambdaに乗っける場合、下記のどちらかで構築する必要があります
- ベースイメージを利用
- Lambda ランタイム APIを実装
ランタイムAPIは必要なAPIを作る必要があるので、柔軟性はありますが手間が多いです
ベースイメージの方が、FROMに入れて追加していくだけで簡単なため、今回はこちらを利用しますベースイメージの選定
今回はPythonを利用してTerraformを実行していきます
Terraform自体がGoなので、Goでやろうとしたのですが、いかんせんGoの経験が少ないのと、Lambda on Goの情報も少ないので断念しました。。
Amazon ECR Public Galleryを参考に下記のようにベースイメージを決めましたFROM public.ecr.aws/lambda/python:3.8 ...ちなみに、このFROMの
public.ecr.awsもre:Invent2020で発表されたECR Publicです
簡単にいうと、AWS版のDocker HubですTerraformのインストール
上記のPythonイメージはPythonの実行しか出来ないため、Terraformを実行できるようにする必要があります
そのため、下記のようにzipをインストールしてterraformの実行をできるようにしますARG terraform_version="0.14.2" ADD https://releases.hashicorp.com/terraform/${terraform_version}/terraform_${terraform_version}_linux_amd64.zip terraform_${terraform_version}_linux_amd64.zip RUN yum -y install unzip wget RUN unzip ./terraform_${terraform_version}_linux_amd64.zip -d /usr/local/bin/ RUN rm -f ./terraform_${terraform_version}_linux_amd64.zip ENV TF_DATA_DIR /tmp実行ディレクトリ
Lambdaは実行するとき、/var/taskディレクトリで実行するのですが、基本的にこのディレクトリでファイルを作成したり修正することはできません
参考:https://stackoverflow.com/questions/45608923/aws-lambda-errormessage-errno-30-read-only-file-system-drive-python-quicそのため、最後の
ENV TF_DATA_DIR /tmpでTFのデータ出力先を変更してます
参考:https://www.terraform.io/docs/commands/environment-variables.htmlDockerfileの残り
あとはAWSのキーや必要なファイルをコピーしてhandlerを実行するだけでDockerfileは完了です
AWSキーは本来はLambdaのロールを利用すれば良いのですが、ローカル検証も合わせて実行したいので、とりあえずで入れてます
本来はここもsts化するなり外部から環境変数を注入するタイプにしたほうが良いと思いますENV AWS_ACCESS_KEY_ID 【アクセスキー】 ENV AWS_SECRET_ACCESS_KEY 【シークレットキー】 # copy files COPY app.py ${LAMBDA_TASK_ROOT} COPY main.tf ${LAMBDA_TASK_ROOT} CMD [ "app.handler" ]Python
Pythonコードとしては、handle関数をapp.pyに作成すれば良いです
やってることとしては、tfファイルを/tmpにコピーして、terraformを初期化してplanを実行してます
/tmpに移動する理由としては、$ terraform initを実行したタイミングで、カレントディレクトリにファイルを作成するのですが、上記で説明したように/tmp以外でファイル作成が出来ないので、移動してから実行としていますdef handler(event, context): cmd('./', "cp ./main.tf /tmp/") cmd('/tmp/', "terraform init --upgrade") result = cmd('/tmp/', "terraform plan") last_result = extraction(result) return last_resultplanの結果は下記でaddやchangeの数を正規表現でとってきて、dictで返すようにしてます
def extraction(plan): print(plan) change_state = {'add': 0, 'change': 0, 'destroy': 0} if "No changes" in plan: return change_state elif "Plan" in plan: line_extraction = re.findall("Plan.*", plan) result = "".join(line_extraction) change_state['add'] = int(re.findall('(\d)\sto\sadd', result)[0]) change_state['change'] = int(re.findall('(\d)\sto\schange', result)[0]) change_state['destroy'] = int(re.findall('(\d)\sto\sdestroy', result)[0]) return change_state elif "Error" in plan: line_extraction = re.findall("Error.*", plan) result = "".join(line_extraction) return result else: result = "予期せぬエラーです。ログを確認して下さい。" return resultTerraform
Terraformのコードは簡単にS3バケットの作成にしました
provider "aws" { region = "ap-northeast-1" } resource "aws_s3_bucket" "default" { bucket = "created-by-lambda" acl = "private" }ローカル(Cloud9)での実行
下記のように実行して、コンテナを起動します
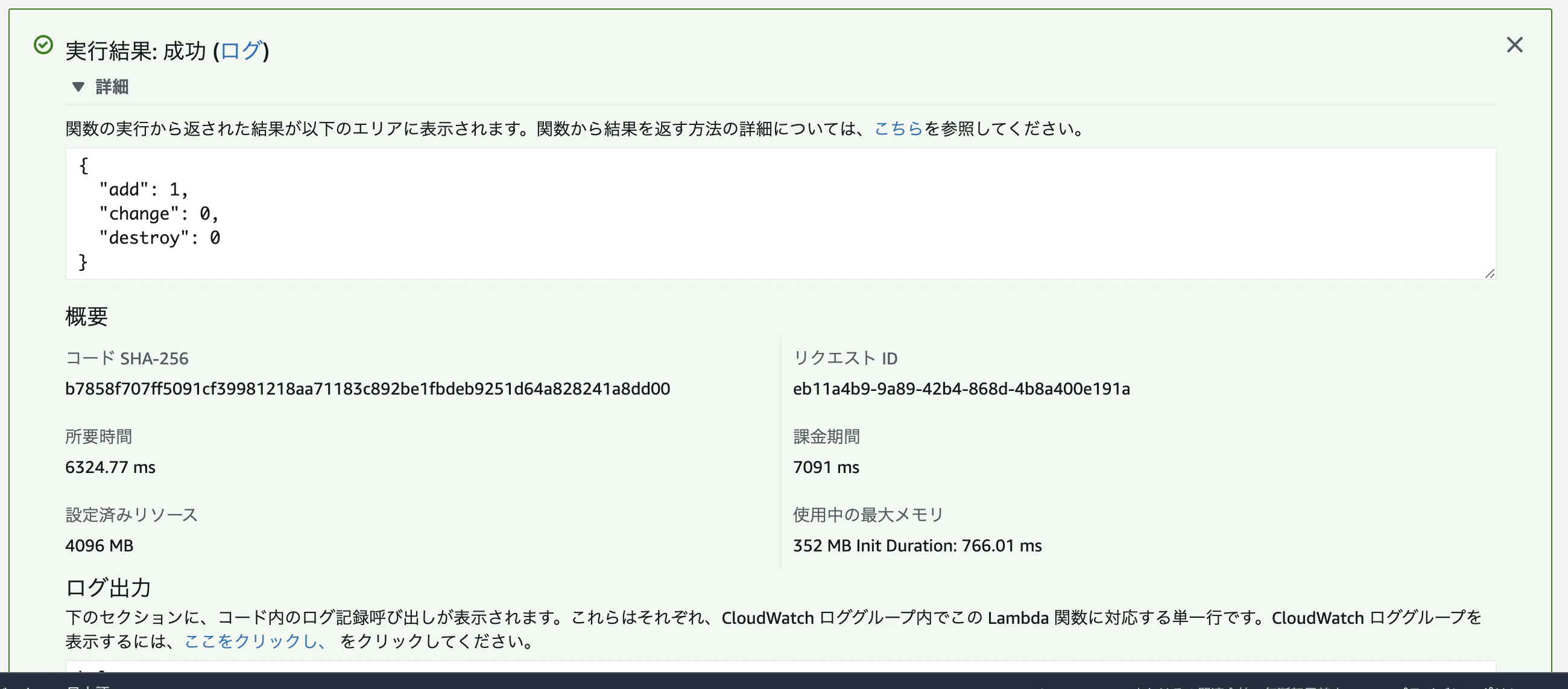
$ export REPOSITORY_NAME=【リポジトリ名】 $ docker build -t ${REPOSITORY_NAME} . $ docker run --rm -p 9000:8080 ${REPOSITORY_NAME}そして、ローカルの9000番ポートを叩くと、下記のようにS3が作成されるため、addに1が入った状態でかえってきました
$ curl -sd '{}' http://localhost:9000/2015-03-31/functions/function/invocations | jq . { "add": 1, "change": 0, "destroy": 0 }ECRへアップ
上記で設定した
REPOSITORY_NAMEの名前でECRのリポジトリを作成します
その後、下記でイメージをプッシュすると、ECRへイメージがlatestで上がっています$ export AWS_ACCOUNT_ID=$(aws sts get-caller-identity | jq -r .Account) $ export REGISTRY_URL=${AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com $ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin ${REGISTRY_URL} $ docker tag ${REPOSITORY_NAME} ${REGISTRY_URL}/${REPOSITORY_NAME} $ docker push ${REGISTRY_URL}/${REPOSITORY_NAME}Lambdaで実行
Lambdaの作成
まず実行基盤のLambdaを作成します
といっても、コンソールからポチポチやっていけば良いです
自動化するならsamかCDKが良いかと思います(個人的にはCDK推し)コンソールからだと、関数の作成からコンテナイメージを選択し、関数名適当に決めてコンテナイメージも「画像を参照」ボタンから対象のリポジトリのlatestを選択すればOKです
一点注意しないといけないのが、今回のTerraformの実行は時間がかかってメモリも多少食うので、下記のように設定してください
タイムアウト:1分
メモリ:4GB実行
さて、準備が出来たので、ようやくLambdaからコンテナのTerraformを叩いてみましょう
こちらもコンソールから軽くテスト出来るので、こちらで試してみましょうテストイベントは何でも良いので、デフォのものを利用して実行してみました
すると、下記のようにjsonでTerraformのplan結果が帰ってきました
これを利用すれば、外部からこのAPIを叩いて、現状のリソースとの差分がないかを監視することが出来ますさいごに
Lambdaがコンテナで実行できるようになったので、Terraformを入れて実行してみました
今後は、API Gatewayと連携してAPI化して、Terraformの監視をしたり、planだけじゃなくapplyを実行するアプリも作っていきたいですね
- 投稿日:2020-12-15T21:51:13+09:00
AWS アウトプットまとめ
これまで、1週間近くかけて学んできたAWS(S3)の要点をまとめたので、アウトプットしたいと思います。
間違いがあれば、ご指摘いただければと思います。⑪AWSのアカウント作成
https://qiita.com/by-miwa30/items/ca356f6c021eb14fcfef⑫S3で保存先を用意する
https://qiita.com/by-miwa30/items/dc068e273d8e1d0c1764⑬EC2の初期設定
https://qiita.com/by-miwa30/items/09c972145fea0e919046⑭本番環境でデータベースを作成
https://qiita.com/by-miwa30/items/b1a73dbbde0f1bbcfa74⑮EC2のRailsを起動しよう(手動デプロイ)
https://qiita.com/by-miwa30/items/dd455dcb73d03e19012e⑯環境変数の設定
https://qiita.com/by-miwa30/items/924a653faef7a03eba36⑰本番環境Railsの起動エラー(手動)
https://qiita.com/by-miwa30/items/d7a37a9deccbe76c047e⑱Webサーバーの設定
https://qiita.com/by-miwa30/items/31251da3c26a8129aa60⑲デプロイを自動化
https://qiita.com/by-miwa30/items/d4b7b1fa3601bf1185ba⑳IPアドレスにアクセスエラー
https://qiita.com/by-miwa30/items/fbc620dfe6e71d4a417c
- 投稿日:2020-12-15T21:45:21+09:00
Amplifyを使って爆速でサイト開発してみた後に読む記事
本記事は AWS Amplify Advent Calendar 2020の18日目の記事です。
はじめに
Amplifyを使って爆速でサイト開発をする系の記事は多く存在しますが、いざ本格的にサイト開発に入るとまだまだ参考になる記事は、多くないように思います。
今回の記事では、そんなこれからAmplifyを本格的に使おうと考えている方へ向けて、これまで書いてきたAmplify記事の総集編とたまった知見の発表的な感じで記事を書いていきます。
AWS自体を全く知らない状態からAmplifyを始めて1年半、本当にAmplifyにはお世話になっていますので、この記事がAmplifyを利用する人の一助になり、少しでも還元になれば幸いです。
購読対象
- 爆速でサイトを作ってみたので、もっといろんな機能を使ってみたい
- これからAmplifyを使って本格的にサイト開発を考えている
- Amplifyの細かいバグにたくさんぶつかって楽しんでいる
Amplify初級〜中級程度の開発者が対象です。
各サービス知見まとめ
今回はAmplifyCLIを中心に、知っていると便利なことからドハマリ情報までまとめました。
Auth
このAuthのおかげで超簡単にAuth周りの設定を行うことができます。まだまだ基本的なことしか使えていないので、もっと深堀りしたいと思っているサービスNo1です。
【具体的な使い方の記事はこちら】
AWS amplify フレームワークの使い方Part1〜Auth設定編〜
AWS Amplify フレームワークの使い方Part2〜Auth実践編〜
AWS Amplify フレームワークの使い方Part13〜Auth 設定更新編〜初回にしか設定できない項目がある
サインインの方法や属性の設定などは、初回のamplify pushしたあとは変更できませんので、よく考えてから始めましょう。
GUIからどんな項目があって、設定変更が可能なのかを見てみるとAmplifyで何ができるのかイメージしやすいと思います。GUIで変更はケースバイケース
基本は、GUIでの変更は行わなずにAmlifyCLIを通して行うことが推奨されますが、個人的にAuthについてはバグ回避やGUIならわかるのにamplifyCLIでどうやっていいかわからない場合ちょっとばかし触ってもいいかなと個人的には思っています。
例えば、メッセージ>カスタマイズ>メールアドレスのカスタマイズは、GUIからおこなっても全く問題ありません。
本当はCloudFormationのテンプレートファイルに記載してPUSHするのが一番スマートだとは思っていますが、テンプレートファイルの記載方法を調べる時間をなかなか作れず、さくっとGUIでやってしまっているというのが実情です。
推奨はしませんが、自己責任のもとGUIから操作する選択肢も持っておいてはいいのではないでしょうか。
API
Amplifyを使いこなすための要サービスです。一番お世話になっていて、一番苦しんだこのAPI。使えば使うほど素晴らしさを感じています。
【具体的な使い方の記事はこちら】
AWS Amplify フレームワークの使い方Part3〜API設定編〜
AWS Amplify フレームワークの使い方Part4〜API実践編〜
AWS Amplify フレームワークの使い方Part5〜GraphQL Transform @model編〜
AWS Amplify フレームワークの使い方Part6〜GraphQL Transform @auth編〜
AWS Amplify フレームワークの使い方Part7〜GraphQL Transform @key編〜
AWS Amplify フレームワークの使い方Part8〜GraphQL Transform @connection編〜
AWS Amplify フレームワークの使い方Part16〜GraphQL Transform @function編〜気軽にスキーマからテーブルを削除しない
何も紐付いていないテーブルの削除であれば何も問題有りませんが、functionに呼び出し権限を与えているなど何かしらamplify内で紐付いている場合、うっかり消してしまった日には、エラー祭りになり、APIを一度全て削除してやり直すしかなくなります。
スキーマからテーブルを削除するときは、amplify内でどこにも紐付いていないことを確認してから、削除するようにしましょう。このあたり上手く連動して削除されるように早くなってくれないかな、、、。
APIと他のリソースを同時にpushするとgraphql内のqueryらが更新されない
これもいつかは改善されると思っていますが、知らないと地味にハマります。
複数のリソースの更新が重なった時は、
$amplify push apiと実行して、APIリソースだけ先に更新しましょう。複数の認証モードが利用できる
こちらも気づいたら対応していました。以下の4つの認証モードを併用が可能になっています。
- API Key
- IAM
- Cognito User Pool
- OpenID Connect
会員制のサイトの場合など、割と複数の認証モードは使えると便利なケースは多いと思います。
ただ使い方には、若干クセがあるように感じているので、また1記事くらいにまとめれたいいな、、、@functionがすばらしい
@functionを知るまでは、Lambda関数については、管理はamplifyで行っていましたが、呼び出しについてはGUIから自作したAPIGatewayで行っていましたが、たった1つの設定でamplifyで呼び出しまで行えるようになるなんて、、、。
@authと併用すれば簡単に権限管理もできますので、本当に便利です。こういった機能が突然サービスに追加になっているので、こまめなチェックが必要だと改めて感じさせられました。Function
始めの頃は、Lambdaのソースコード管理ってどうしよう、Serverless Frameworkとか使ってやるのかな?といろいろ思っていましたが、こちらを使えば一瞬でした。
アクセス権限も簡単に設定できますし、DynamoDBストリームのトリガー設定やレイヤーの作成など、どんどん使いやすくなっていっています。【具体的な使い方の記事はこちら】
AWS Amplify フレームワークの使い方Part9〜Function 基礎編〜
AWS Amplify フレームワークの使い方Part11〜Function 権限管理編〜
AWS Amplify フレームワークの使い方Part14〜Lambda レイヤー編〜関数削除の注意点
このfunctionを使いだした頃から、Amplifyで作成したリソースたちが、お互いのアクセス権限を付与しだします。
関数を削除する時は、必ず他のリソースに削除する関数へのアクセス権限が紐付いていないか確認しましょう。ライブラリの手動インストール
私はNode.js環境でLambdaを実行していますが、package.jsonに必要なライブラリを記載して、追加した気になることがよくありました。基本的に自動ではインストールしてくれませんので、必ず自分でインストールしてからpushしましょう。(確か初回作成時のみ自動インストールしてくれた気がします。)
レイヤーが熱い
こちらも気づいたら追加されていたサービスの一つで、Lambda関数でのライブラリやコードの共通化を行うことができます。1関数5つまでの制限はありますが、それだけでも相当スッキリしたコードにできるので、本当にすばらしいですね。
私の場合は、割とGUIを使って細かいテストを繰り返し行うことが多いのですが、重たいライブラリを使っているとGUIからコード編集ができないので、ライブラリの共通化はテストのやりやすさにも役立っています。
素晴らしいこと満載のレイヤーですが、トラブルは割と起こりがちなので、気になる方は、上記の参考記事のレイヤー編をご確認ください。
DynamoDBストリームとの連携設定も簡単に
こちらも気づけば、functionの初回作成時にDynamoDBストリームとの紐付け設定ができるようになっておりました。
おそらくAmplifyCLI上では、初回時以外の設定変更項目は今のところない?(みつからない)ので、変更必要な場合はCloudformationファイルを変更する必要がありそうです。Storage
Amplifyを通して簡単にCognitoユーザーのアクセス権限管理ができるS3を使うことができます。全然S3について知らない状態でもすぐに使えたので、ありがたい限りです。
【具体的な使い方の記事はこちら】
AWS Amplify フレームワークの使い方Part10〜Storage編〜一定時間が経つとファイルが取得できなくなる
getして取得したURLにはtokenがついており、一定時間が経つと画像ファイルを取得できなくなります。
このURLを保存しておけば、わざわざidentityIdなんて知らなくてもicon画像取得し放題だ!と思ったもののしばらくすると取得できなくなるのでややハマりました。
これにより、identityIdと向き合うことになります。protectedの場合、identityIdがわからないと取得できない
identityIdは各ユーザーに振られているuserIdとは別のcognitoが管理しているIDです。(ソーシャルログインをしてユーザープールにデータが作成されない人や未承認ユーザーを管理するためのもの?的なイメージ)
そんなあまり身近ではないidentityIdを使わずに、簡単に取得できる方法はないか?、と各方面で議論されているようですが、現状はまだ未実装のようです。
ただ、githubのissueでだいぶ議論されているようなので、そのうちひっそりと実装されている可能性はあるので、要チェックです。identityIdの取得方法
とりあえずこれで取得できます。
const currentCredentials = await Auth.currentCredentials() const identityId = currentCredentials.identityIdENV
Amplifyを使って本気で開発をするのであれば、必須になるのがこちらです。開発環境と本番環境を簡単に分けられるだけでなく、各開発者ごとにバックエンドを簡単に複製できるので、めちゃくちゃ便利です。
【具体的な使い方の記事はこちら】
AWS Amplify フレームワークの使い方Part12〜ENV編〜amplify env pull xxx(環境名)
多人数で同時開発する時は必ず必須のコマンドです。amplifyをローカル環境で何も触っていない時は、
$amplify pullで強制的にローカルのリソースを上書きすればよいですが、触っている時にはそうは行きません。
そんな時に、この$ amplify env pull xxxでpullを行えば、現行のローカルのコードを残して、差分をローカルに上書きしてくれます。知っていたら当たり前なことですが、このコマンドを知るまでは地味に苦労したことでした。
Hosting
気づいたら、AmplifyConsoleも選択ができるようになっていたこのHosting。私自身AmplifyConsoleを使ったGUIでの作業が中心で、今現在ほとんど触れていませんが、気づいたらどんどんできることが増えていそうなので、時が来たら一度向き合いたいと思っています。
WAFを使いたい
現状AmplifyConsoleでホスティングをした場合、CloudFrontの細かい設定は行えないため、WAFが利用できません。WAFを使いたい場合は、CloudFront+s3を選択してホスティングした上で、CloudFrontの設定を変更しましょう。
Amplify CLI全般
GUI上で各リソースを削除しない
これ絶対にやってはいけないやつです。Cloudformationで管理しているにもかかわらず、GUIで勝手に削除してしまうと、場合によってはすべて削除してAmplifyの設定を一からやり直す必要があります。Amplifyでaddしたものは必ずAmplifyでremoveすることを心掛けてください。
リソースにもよりますが、全く同じ名前で再度GUIから作成すると再認識してくれることがあるので、もしもの時は一度試してもいいかもしれません。
cloudformationのテンプレートに手を加えた時は気をつけて
自動生成されたcloudformationのテンプレートファイルに手書きでコードを足せば、amplifyCLIだけでは実現できない細かい設定まで対応できます。
が、その後にamplifyを使って更新するとその手書きしたコードは消えてしまいますので、注意が必要です。だれかこの管理のベストプラクティスを知っている人がいたら教えていただきたい、、、。
消したはずのリソーストラブル
amplifyを通してちゃんとリソースを削除したはずなのに、なぜかamplify系ファイルの中にひっそりと残っていてエラーになることがあります。
その場合は、エラー分をよく読み、削除したはずのリソースなどで怒られているときは、その名前で検索をかけて、コード内から削除しましょう。私はこれで何度も救われました。消した記憶のないコードトラブル
こちらは直近の記憶で起きたのはLambdaレイヤーで、amplify pullをした時などに、本来あるべきはずのコードが消えてしまい、エラーでpushがその後できなくなるということがありました。
この時は、team-provider-info.jsonの差分を確認し、何故か消えているコードをもとに戻してpushすれば直りましたが、原因は未だに不明です。よくあることではありませんが、何が悪いのかわからないエラーに出会った時は、一度差分を確認してみるといいことがあるかもしれません。
amplify push xxx yyy
リソースを指定してpushができます。例えば、echoFunctionというLambda関数だけ更新したい時は、
$ amplify push function echoFunctionと実行すれば、他のリソースは更新されずに、echoFunctionのみ更新されます。地味に知っていると便利です。--yes (-y)
以下のコマンドに--yes(-y) とつけるだけで、各作業工程のデフォルト値を自動で選択して進めてくれます。
地味ですが、いい活躍をしてくれます。amplify init
amplify configure project
amplify push
amplify publish
amplify pullSSR対応
今年ついにAmplifyがSSRに対応しましたね。素晴らしい。
AWS Amplify フレームワークの使い方Part15〜SSR対応導入編〜AmplifyコンソールもSSR対応が検討されているようなので、こちらのissueはずっと注視しています。
https://github.com/aws-amplify/amplify-console/issues/412ハマった時はすぐに公式ドキュメントとissueを見る
こちらは当たり前なことではありますが、困ったら公式ドキュメントとissueを見ましょう。
Amplifyはかなりのハイペースで改善と新機能の追加が繰り返されているので、これまでできなかったことができるようになっていたり、誰かがとりあえずの解決策をissueのコメントに上げてくれていることがよくあります。環境の移動後のpushには注意
基本的には、環境を移動(amplify env checkout)したあとに、pushすれば、別の環境で整えた環境がそのまま同じように出来上がります。
単純な作業後にpushする分には問題有りませんが、たとえばLSIを設定したいから、一度テーブルを削除して再度追加したテーブルがある場合、移動した別環境でも同じことをしなければpushできませんので、そのあたり地味に注意が必要です。git push/pull と amplify push/pull
何人かで開発をしていると起こりがちなのが、gitとamplifyのどちらかのpush/pullをし忘れによる、過去へのタイムリープ。大事にはならないことが多いですが、昨日作ったはずのリソースが消えている時は、だいたいこれです。
amplifyのpushをする時は、必ずgit pullとamplify pull、gitにpushする時は、事前のamplify pushを忘れずに行いましょう。それでも人は失敗をする
気をつけていても、バックエンドを壊してしまうことはあるかもしれません。今のところ知っている最速での復旧方法を以下の記事に書いていますので、参考までに。
おわりに
本当にどんどん新しいサービスがAmplifyに追加されており、どんどん便利になっていっています。もっとAmplifyの利用者が増えてより活発に開発が進み、さらに便利になることをとても期待しております。
よきAmplifyライフを!!
- 投稿日:2020-12-15T21:44:23+09:00
AWS(EC2)要点まとめ その3
これまで、1週間近くかけて学んできたAWS(S3)の要点をまとめたので、アウトプットしたいと思います。
間違いがあれば、ご指摘いただければと思います。
- アプリケーションサーバー(カリキュラムではUnicorn)は、動的コンテンツを生成して処理結果をWebサーバーに返す
- Webサーバー(カリキュラムではNginx)は、静的コンテンツのみをリクエストとしてクライアントに返す
- Nginxを起動するには「sudo systemctl start nginx」コマンドを使う
- データベースを再起動するには「sudo systemctl restart mariadb 」コマンドを使う
- アプリケーションサーバー(カリキュラムではUnicorn)は、動的コンテンツを生成して処理結果をWebサーバーに返す
- Webサーバー(カリキュラムではNginx)は、静的コンテンツのみをリクエストとしてクライアントに返す
- Nginxを再起動するには「sudo systemctl restart nginx」コマンドを使う
- 自動デプロイは「bundle exec cap production deploy」コマンドを使う

- 投稿日:2020-12-15T21:39:49+09:00
AWS(EC2)要点まとめ その2
これまで、1週間近くかけて学んできたAWS(S3)の要点をまとめたので、アウトプットしたいと思います。
間違いがあれば、ご指摘いただければと思います。
- 「プロセス」とは、PC上で動く全てのプログラムの実行時の単位
- 「Swapファイル」とは、メモリの要領を一時的に増やすために準備されるファイル
- 「sudo」とは、「全部の権限を持った上でコマンドを実行する」という役割のオプション
- 「grepコマンド」とは、環境変数などを検索するときに使うコマンド
- 「RAILS_ENV=production」とは、本番環境でコマンド実行する時につくオプション
- 「アセットファイル」とは、画像・CSS・JavaScript等を管理しているファイル
- 「psコマンド」とは、現在動いているプロセスを確認するためのコマンド
- 「killコマンド」とは、現在動いているプロセスを停止させるためのコマンド
- 「lessコマンド」とは、ファイルの中身を確認する時に使うコマンド
- 手動デプロイは「unicorn_rails」コマンドを使う
- 投稿日:2020-12-15T21:29:00+09:00
AWS(EC2)要点まとめ その1
これまで、1週間近くかけて学んできたAWS(S3)の要点をまとめたので、アウトプットしたいと思います。
間違いがあれば、ご指摘いただければと思います。
- EC2インスタンス」とは、仮想サーバーの
- 「AMI」とは、サーバーのデータを丸ごと保存したデータの
- 「キーペア」とは、インスタンスへ接続する際に必要な秘密鍵の
- 「Elastic IP」とは、AWSから割り振られた固定のパブリックIPアドレス
「ポート」とは、1つのサーバーと複数のサーバーを繋ぐ役割をするもの
MySQL」とは、データの編集・削除などを誰でも無償で利用できるサービス
「MariaDB」とは、MySQLの派生として開発されているオープンソースソフトウェア
MariaDBを起動するには、「sudo systemctl start mariadb」コマンドを使う
MariaDBの状態を確認するには、「sudo systemctl status mariadb」コマンドを使う
- 投稿日:2020-12-15T21:27:35+09:00
AWS(S3)要点まとめ
これまで、1週間近くかけて学んできたAWS(S3)の要点をまとめたので、アウトプットしたいと思います。
間違いがあれば、ご指摘いただければと思います。
- AWSとは「Amazon Web Servises」の略で、通販で有名なAmazonが提供しているクラウドコンピューティングサービスの総称
- Amazon S3とは画像などが保存できる、ストレージサービス
- AWSを利用する際は、情報の漏洩などの防止のために、二段階認証とIAMユーザーを設定する
- 「git-secrets」とは、pushしたコードをチェックするツール
- バケットポリシーで、IAMユーザーからのアクセスのみを許可することで、セキュリティ向上につながる
- 「aws-sdk-s3」というGemを用いると、S3を使用できる

- 投稿日:2020-12-15T21:15:13+09:00
⑳IPアドレスにアクセスエラー(自動デプロイ)ーポートフォリオ
下図のように、ブラウザ上で「We’re sorry , but ~」が表示された場合されました。とりあえずは、EC2のターミナルに接続
自動デプロイ後は、currentディレクトリの中にproduction.logが入ってくることに注意# 自身のアプリケーションのディレクトリに移動 [ec2-user@ip-172-31-23-189~]$ cd /var/www/アプリケーション名 # currentディレクトリに移動 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ cd current # logディレクトリに移動 [ec2-user@ip-172-31-23-189 current]$ cd log # logの中に入っているファイルの情報を表示 [ec2-user@ip-172-31-23-189 log]$ ls production.log unicorn.stderr.log unicorn.stdout.log # production.logの最新のログを10行分表示 [ec2-user@ip-172-31-23-189 log]$ tail -f production.logこのログを参考にエラーが発生している箇所を探す
私の場合はローカルで修正して、エラーが発生しているのに、本番環境でエラーが起きたと思い込んでいました。落ち着いて、コードを修正したことを思い出し、ローカルでエラーが無くなったことを確認して、コミット→プッシュしたら本番環境でも正常に挙動を確認できました。
いろんな原因が考えられるので、チェックリストを作りました。
チェックリスト
- ローカルでは問題なく動いているか
- ローカル→GiuHubへのpushのし忘れはないか(mergeまで確認)
- GitHubからEC2への反映(git pull origin master)のし忘れはないか
- EC2サーバー側でエラーログの内容を確認し、原因を見つけたか
- カリキュラム通りの記載ができているか
- Nginxは正しく起動しているか
- EC2サーバー側の環境変数は正しく設定できているか
- EC2インスタンスの再起動を行ってみる

- 投稿日:2020-12-15T21:03:34+09:00
⑲デプロイを自動化ーポートフォリオ
手動で行っていたデプロイ作業(「unicorn_railsコマンド」を使ってサーバーを立ち上げる手段)を、ローカルのターミナルからのコマンド1つで行えるようにします。そのために、「自動デプロイツール」と呼ばれるものを利用します。今回は、数ある自動デプロイツールの中でも、もっともポピュラーなCapistranoを実際に導入
Capistrano
「Capistrano」とは、自動デプロイツールと呼ばれるものの一種です。自動デプロイツールのメリット
自動デプロイツールを利用することによって、デプロイ時に必要なコマンド操作が1回で済むようになります。これにより、手動デプロイする場合に起こりがちな下記の問題を解消できます。
- コマンドの打ち間違い、手順の間違いが発生する可能性がある
- 手順が多く、煩わしい
自動デプロイの準備
group :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano3-unicorn' endbundle installbundle exec cap install生成されたファイル ↓
Capfile
「Capfile」では、Capistrano関連のライブラリのうちどれを読み込むかを指定できます。
Capistranoの機能を提供するコードはいくつかのライブラリ(Gem)に分かれています。そのため、Capistranoを動かすにはいくつかのライブラリを読み込む必要があります。production.rb
「production.rb」は、デプロイについての設定を書くファイルです。
GitHubへの接続に必要なsshキーの指定、デプロイ先のサーバのドメイン、AWSサーバへのログインユーザー名、サーバにログインしてからデプロイのために何をするか、といった設定を記載します。
また、「deploy.rb」「staging.rb」も同様の役割をするファイルです。#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../../', __FILE__) # 「../」が一つ増えている #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory "#{app_path}/current" # 「current」を指定 #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/shared/tmp/pids/unicorn.pid" # 「shared」の中を参照するよう変更 #ポート番号を指定 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" # 「shared」の中を参照するよう変更 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/shared/log/unicorn.stderr.log" # 「shared」の中を参照するよう変更 #通常のログを記録するファイルを指定 stdout_path "#{app_path}/shared/log/unicorn.stdout.log" # 「shared」の中を参照するよう変更Nginxの設定ファイル
sudo vim /etc/nginx/conf.d/rails.conf# Unicornと連携させるための設定 server unix:/var/www/アプリケーション名/shared/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name Elastic IP; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/アプリケーション名/current/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; root /var/www/アプリケーション名/current/public; }Nginxの設定を変更したら、忘れずに再読込・再起動
[ec2-user@ip-172-31-25-189 ~]$ sudo systemctl reload nginx [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart nginxデータベースの起動を確認
[ec2-user@ip-172-31-25-189 ~]$ sudo systemctl status mariadb以下のように、「active」と表示されれば起動しています。
自動デプロイを実行
% bundle exec cap production deploy以下のように表示されれば自動デプロイ成功!
ブラウザからElastic IPでアクセス
3.140.60.122
これで、EC2実装完了!



- 投稿日:2020-12-15T20:39:30+09:00
RDSインスタンスを夜間と休日に止めて節約するLambda&スケジュールをCloudFormationで一撃デプロイする
下記のCloudFormationテンプレートで
- RDSを起動するLambda
- RDSを停止するLambda
- Lambdaを起動するCloudWatchスケジュール
- 必要なIAMロール
を一撃で展開できます。入力パラメータ
RDSInstanceName : RDSインスタンス名
RDSRegion : RDSのリージョン
RDSStopCron : RDS停止スケジュールのcron式
RDSStartCron : RDS起動スケジュールのcron式CloudFormationテンプレート
AWSTemplateFormatVersion: 2010-09-09 Parameters: RDSInstanceName: Type: String Default: your instance name RDSRegion: Type: String Default: ap-northeast-1 RDSStopCron: Type: String Default: 'cron(00 15 * * ? *)' # 毎日午前15時00分(UTC)= JST深夜0時 RDSStartCron: Type: String Default: 'cron(00 00 ? * MON-FRI *)' # 月曜~金曜午前0時00分(UTC)= JST午前9時 Resources: StopRdsFunction: Type: AWS::Lambda::Function Properties: FunctionName: !Sub rds-stop Handler: index.handler MemorySize: 128 Role: !GetAtt RDSOperationRole.Arn Runtime: python3.8 Timeout: 10 Environment: Variables: RDS_REGION: !Ref RDSRegion RDS_INSTANCE_NAME: !Ref RDSInstanceName Code: ZipFile: | import boto3 import os region = os.environ['RDS_REGION'] instance = os.environ['RDS_INSTANCE_NAME'] def handler(event, context): rds = boto3.client('rds', region_name=region) rds.stop_db_instance(DBInstanceIdentifier=instance) print('started instance: ' + instance) RdsStopSchedule: Type: AWS::Events::Rule Properties: Description: rds stop schedule ScheduleExpression: !Ref RDSStopCron State: ENABLED Targets: - Arn: !GetAtt StopRdsFunction.Arn Id: ScheduleEvent1Target RdsStopLambdaEvent: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref StopRdsFunction Principal: events.amazonaws.com SourceArn: !GetAtt RdsStopSchedule.Arn StartRdsFunction: Type: AWS::Lambda::Function Properties: FunctionName: !Sub rds-start Handler: index.handler MemorySize: 128 Role: !GetAtt RDSOperationRole.Arn Runtime: python3.8 Timeout: 10 Environment: Variables: RDS_REGION: !Ref RDSRegion RDS_INSTANCE_NAME: !Ref RDSInstanceName Code: ZipFile: | import boto3 import os region = os.environ['RDS_REGION'] instance = os.environ['RDS_INSTANCE_NAME'] def handler(event, context): rds = boto3.client('rds', region_name=region) rds.start_db_instance(DBInstanceIdentifier=instance) print('started instance: ' + instance) RdsStartSchedule: Type: AWS::Events::Rule Properties: Description: rds start schedule ScheduleExpression: !Ref RDSStartCron State: ENABLED Targets: - Arn: !GetAtt StartRdsFunction.Arn Id: ScheduleEvent1Target RdsStartLambdaEvent: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref StartRdsFunction Principal: events.amazonaws.com SourceArn: !GetAtt RdsStartSchedule.Arn RDSOperationRole: Type: AWS::IAM::Role Properties: RoleName: !Sub rds-operation-role AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: - sts:AssumeRole Path: / Policies: - PolicyName: !Sub rds-operation-policy PolicyDocument: Version: 2012-10-17 Statement: - Resource: - !Sub arn:aws:rds:${RDSRegion}:156658371598:db:${RDSInstanceName} Effect: Allow Action: - rds:StopDBInstance - rds:StartDBInstance
- 投稿日:2020-12-15T20:12:58+09:00
⑱Webサーバーの設定ーポートフォリオ
Rack
「Rack」とは、翻訳プログラムになります。Rackが翻訳をすることにより、アプリケーションサーバーとアプリケーション本体がコミュニケーションを取ることができ、処理結果をWebサーバーに返すことができます。アプリケーションサーバーの役割
- Webサーバから渡されてきた情報を、アプリケーションサーバー内で処理
- 処理結果を、Webサーバに返す処理
Webサーバーの役割
- 静的なコンテンツをレスポンスとしてクライアントに返す処理
- 動的なコンテンツ生成をアプリケーション本体に依頼する処理
- アプリケーションサーバから返ってくる処理結果をレスポンスとしてクライアントに返す処理
Nginx(エンジン・エックス)
「Nginx」とは、Webサーバーの一種です。ユーザーのリクエストに対して静的コンテンツのみ取り出し処理を行い、動的コンテンツの生成はアプリケーションサーバに依頼します。
Nginxを導入
[ec2-user@ip-172-31-25-189 ~]$ sudo amazon-linux-extras install nginx1[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.confupstream app_server { # Unicornと連携させるための設定 server unix:/var/www/アプリケーション名/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name Elastic IP; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/アプリケーション名/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }Unicornの設定を変更
config/unicorn.rblisten "#{app_path}/tmp/sockets/unicorn.sock"次は、GitHubの変更点を本番環境へ反映
# 開発中のアプリケーションに移動 [ec2-user@ip-172-31-25-189 ~]$ cd /var/www/開発中のアプリケーション # GitHubの内容をEC2に反映させる [ec2-user@ip-172-31-23-189 <レポジトリ名>]$ git pull origin masterIPアドレスにアクセスしてもエラーが出る時
「Railsが起動しない」「ブラウザで確認するとエラーが表示されている」などの問題がある場合、まずは「エラーログ」を確認する必要があります。「502 but gateway」と出た時の対処方法
こちらのエラーはnginxのlogの確認が必要になります。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ sudo less /var/log/nginx/error.logチェックリスト
- ローカル→GiuHubへのpushのし忘れはないか(mergeまで確認)
- GitHubからEC2への反映(git pull origin master)のし忘れはないか
- EC2サーバー側でエラーログの内容を確認し、原因を見つけたか
- カリキュラム通りの記載ができているか
- Nginxは正しく起動しているか
- EC2インスタンスの再起動を行ってみる

- 投稿日:2020-12-15T18:58:27+09:00
機械学習でコードレビューするAmazon CodeGuruでPythonがサポートされたので試してみた
はじめに
この記事は ハンズラボ Advent Calendar 2020 22日目の記事です。
こんにちは、@sr-mtmtです。年の瀬ですね。
2020年に買ったものの中でお気に入りは 絶品レンジでパスタ でした。
洗濯機がぐるぐるしてるところを見るのが好きな人は、この商品でレンジの中のヴォルケーノを見つめるのも好きなことでしょう。さて今年もAdvent Calendar、やってくぞい
re:InventのKeynoteで気になったものを試したい
re:Inventにて、Andy Jassy氏のKeynoteで「機械学習でコードレビューするAmazon CodeGuruでPythonがサポートされた」ときいたので、試してみたいと思います。
前から気になっていたんですが、これまではJavaしか対応していなかったので、Java使っていない弊チームでは試せず。
Javaに比べるとなんとなくPythonの解析って難しそうですがどんなかんじなんでしょう。Amazon CodeGuruとは
Code GuruにはReviewerとProfilerとあって、Profilerの方はコストチェック、Reviewerの方はバグなどをチェックします。
今回試すのはReviewerです。
Amazon CodeGuru Reviewer は、機械学習でコード内の問題を検出し、その推奨される修正方法を提案してくれるサービスです。
コードの品質に関する問題を、次のように大きく 9 つのカテゴリで識別するらしい。
- AWS のベストプラクティス: AWS API (ポーリング、ページ区切り、など) の使用方法を修正
- 同時実行: 機能上の障害を起こしている同期不良、もしくは、パフォーマンスを低下させている過剰な同期などを検出
- デッドロック: 同時実行されるスレッド間の割り当てをチェック
- リソースリーク: リソースの処理方法 (データベース接続の解放など) を修正
- 機密情報のリーク: 個人識別情報 (ログインしているクレジットカードの詳細など) の漏洩を検出
- 一般的なコード上のバグ: Lambda 関数読み出し時にクライアントを作成していないなどの、発見しづらい問題を検出
- クローンコード: 統合することでコードの保守性を高められる可能性のある、重複コードを特定
- 入力検証: 信頼されないソースから送られる、不適当な形態の、もしくは悪意のあるデータをチェック
やってみた
0. 前提
- AWSアカウントはある
- レビューしたいソースコードを含むリポジトリをGithubに持っているがCodeCommitには置いてない
- IAMなどの設定はデフォルトで問題ないリポジトリを選択
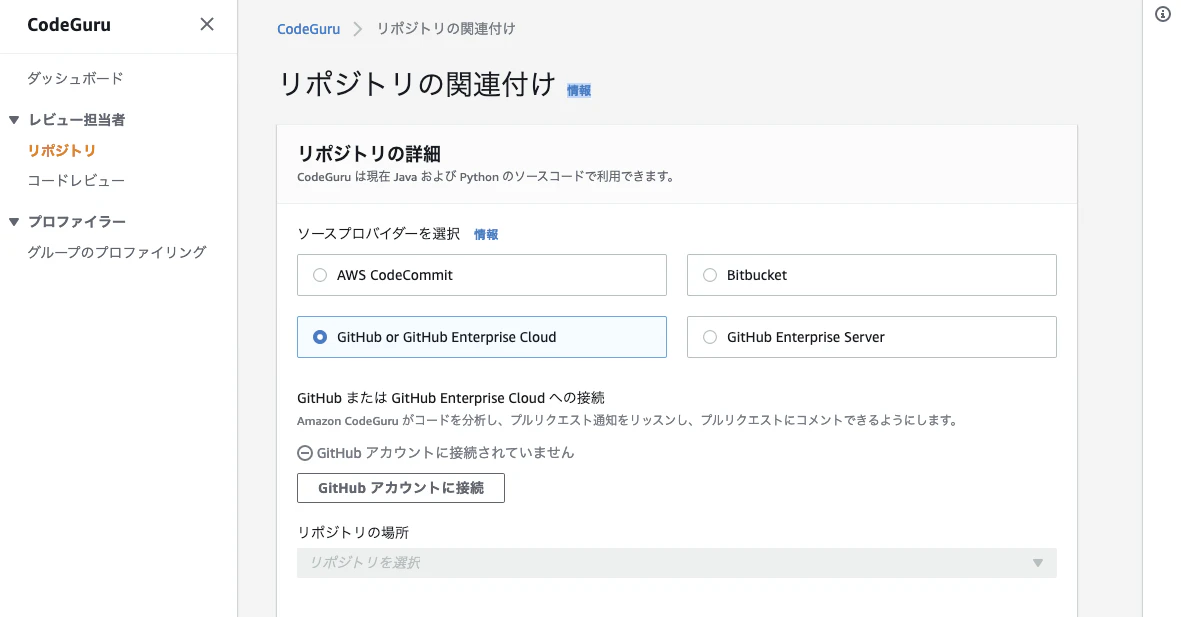
1. リポジトリの関連付け
Reviewerを選択。
前のリリースのときの情報を完全に忘れてて別にCodeCommitからじゃなくても関連付けできることが判明。\うれしい/
GitHub、GitHub Enterprise、Bitbucket、AWS CodeCommitの中から好きなものを選択できます。
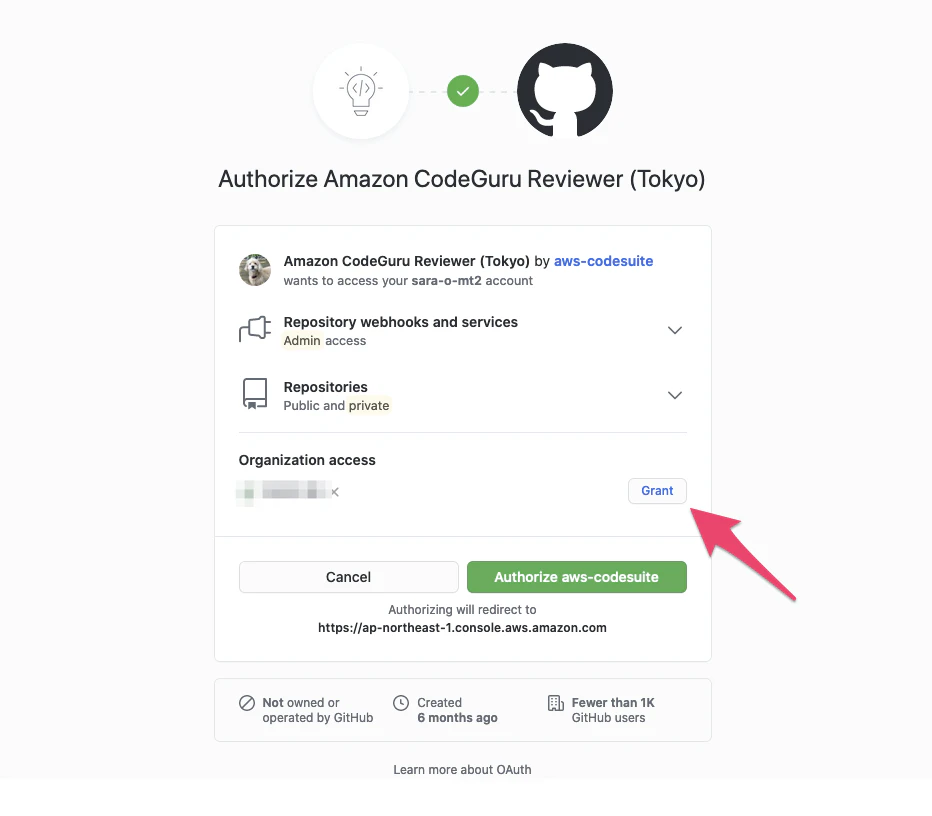
組織に紐づくリポジトリへのアクセスは矢印の「Grant」を押しておかないと許可されないので注意。
今回はお試しなので私の個人アカウントでやってますがこのあたりを丁寧に準備すれば権限細かく設定できそうなのもいいですね。これでGithubアカウントに接続したので、さっきグレーアウトしていた「リポジトリの場所」に候補のリポジトリがわさーっと出てくるようになりました。
適当なリポジトリを選択して関連付けます。2. 分析してみる
分析方法ですが2種類あります。
コードレビュータイプ 自動でレビューされるか レビュー結果はどこで見られるか レビュー対象 リポジトリの分析 No
CodeGuru Reviewerのマネジメントコンソール、またはAWS CLIまたはAWS SDKを使用して分析を実行する必要がありますCodeGuru Reviewerのマネジメントコンソール、またはAWS CLIまたはAWS SDKを使用して確認する ブランチ内のすべてのコード プルリクエスト Yes
リポジトリを関連付けた後、プルリクエストを行うたびに自動でコードレビューが行われますCodeGuru Reviewerのマネジメントコンソール、またはAWS CLIまたはAWS SDKを使用して確認する方法の他に、リポジトリのソースプロバイダ(Githubなど)のPRコメントからも確認可能 プルリクエストの範囲。今回変更されたコードのみ
プルリクエストがあがれば↑ここに追加されていくようです。
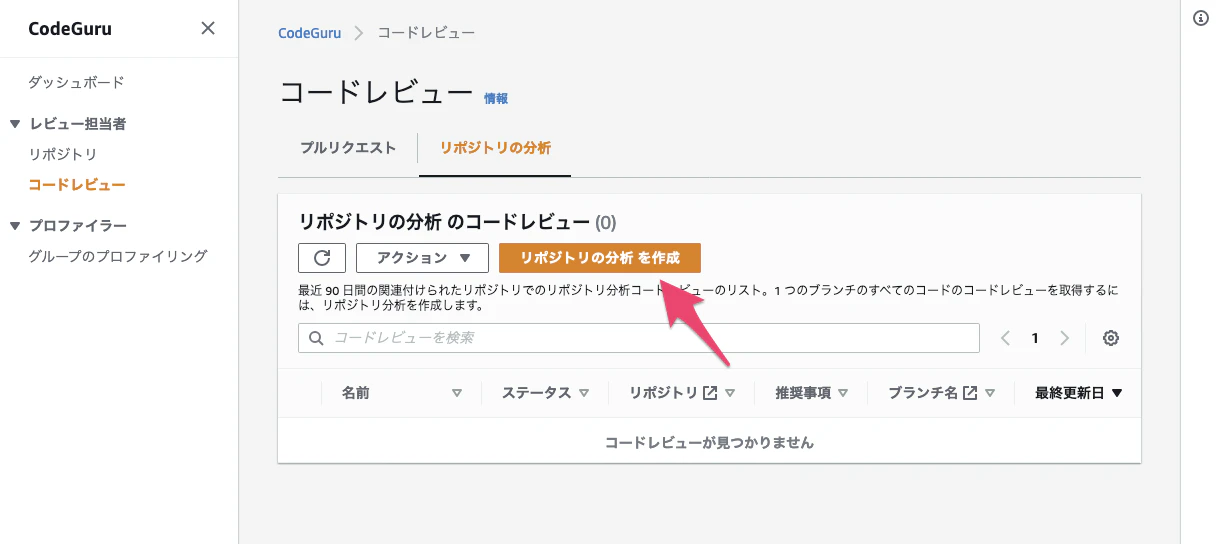
今はちょうどいいPRがないので「リポジトリの分析」の方でコード全体の分析をやってみます。
「リポジトリの分析を作成」を押します。
「コードとセキュリティの推奨事項」の方はさっき関連付けたリポジトリとはまた別の話になります。
別途S3にzip化したコードをアップロードして、それと関連付けた上で分析することになるので今回は「コードの推奨事項」を試したいと思います。
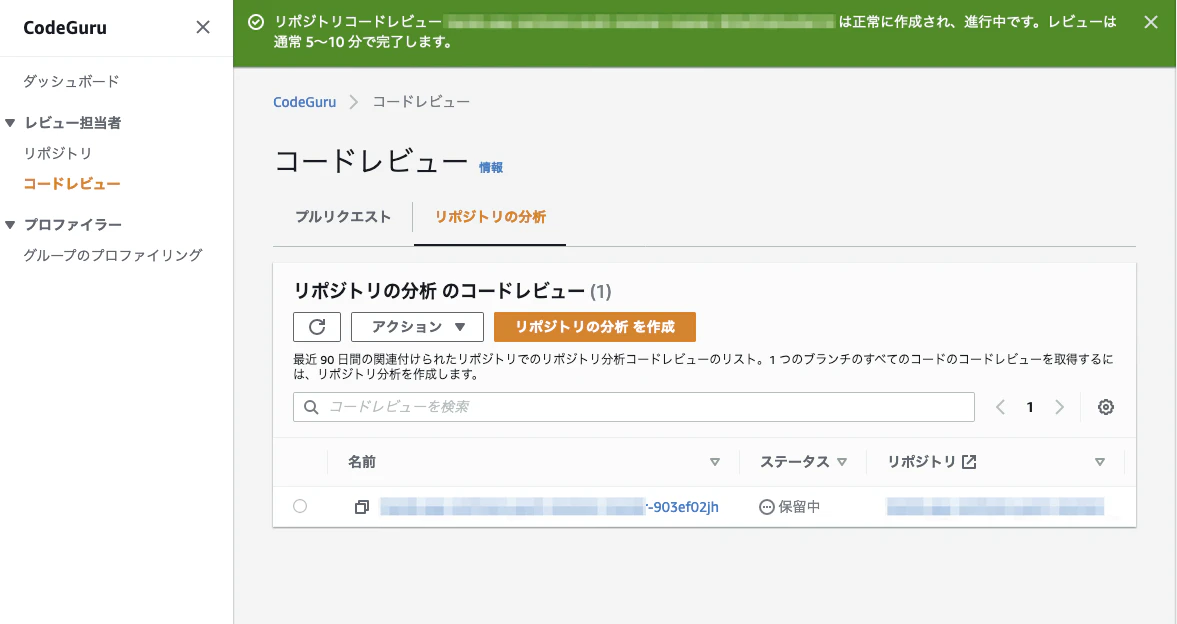
分析中・・・
小さいリポジトリだからか数分で完了!
さて、なにが上がってくるのかな・・・?
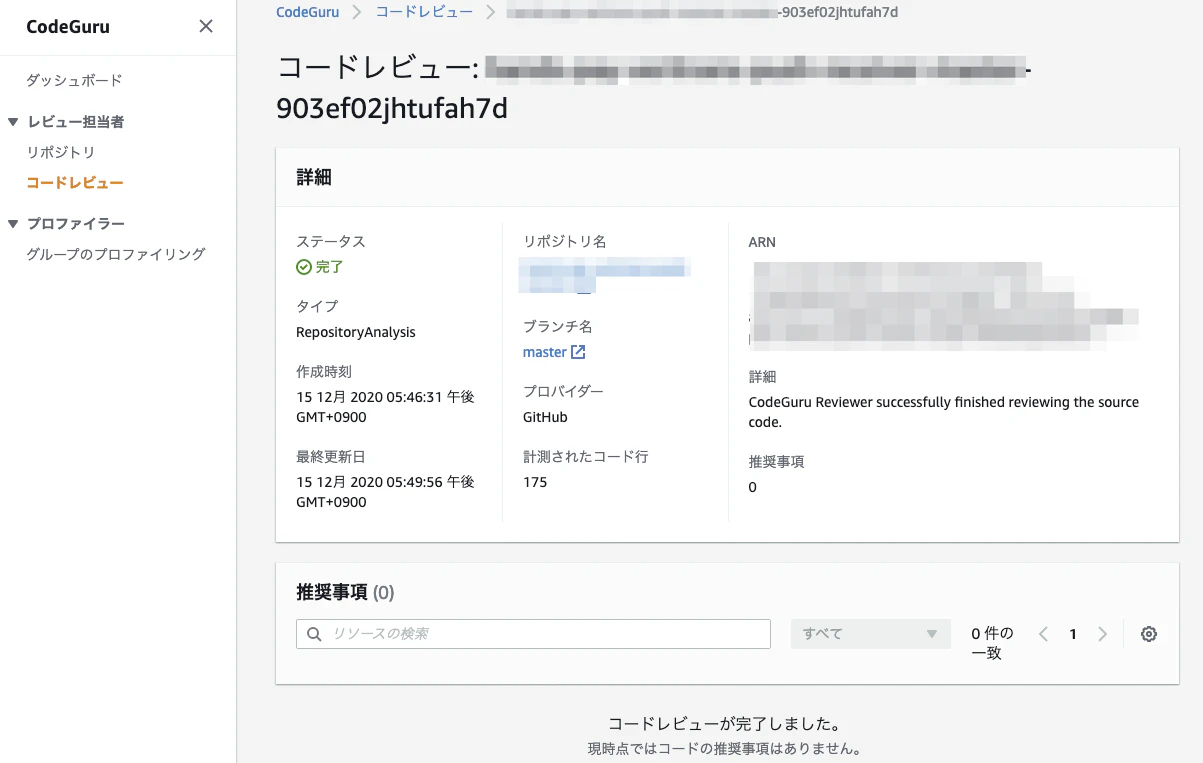
なんもない
いや、いいことですけどね。
寂しいのでもう少し大きいリポジトリでも試したのですがやはり何も見つかりませんでした・・・。
パフォーマンス低下とかどのくらいのことから指摘されるんだろう・・・。
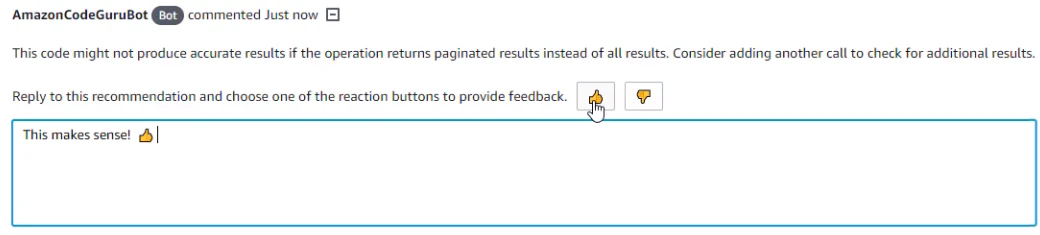
ちなみにプルリクエストの方にCodeGuruから指摘事項があった場合、こんなかんじでプルリクコメントにそのまま推奨事項が役に立つものだったかフィードバックが送れるそうです。
(公式ドキュメントの画像を拝借)ここで指摘されてる推奨事項は
"This code might not produce accurate results if the operation returns paginated results instead of all results. Consider adding another call to check for additional results."
→このコードは、操作がすべての結果ではなくページ分割された結果を返す場合、正確な結果が得られない可能性があります。追加の結果をチェックするために別の呼び出しを追加することを検討してください。(deepl翻訳)
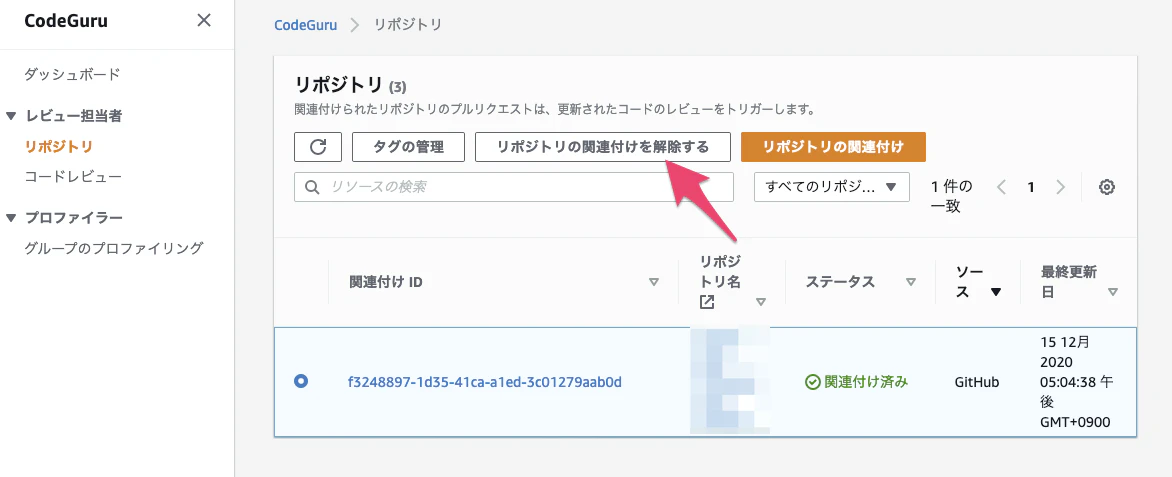
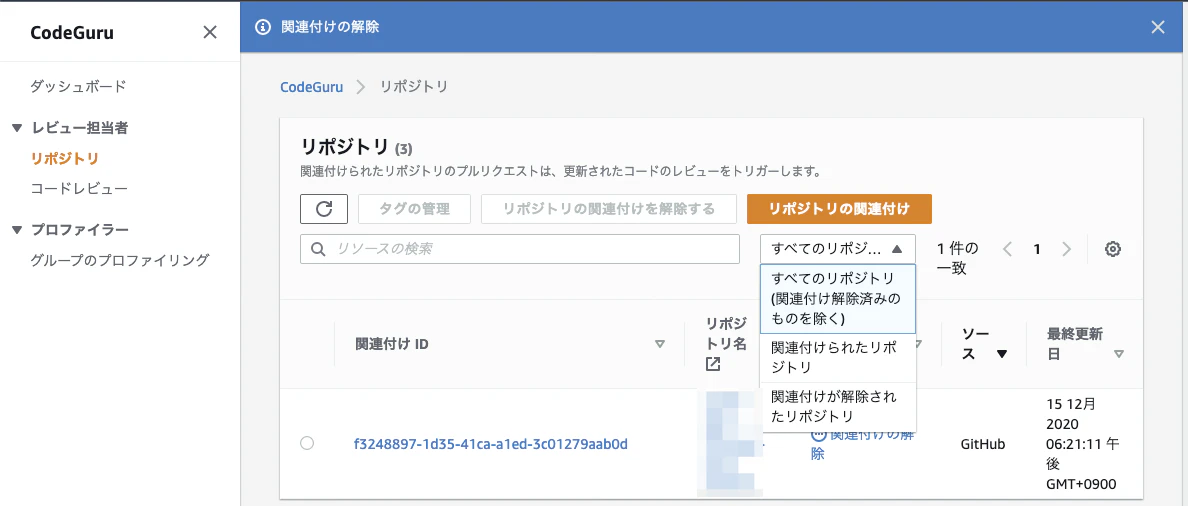
となっていますね。AWS APIの使用方法に関する指摘かな。おまけ)リポジトリの関連付け解除
リポジトリを紐付けっぱなしにしていると無料枠超えたときにお金がかかるので必要に応じて解除しましょう。解除すると元には戻せないので改めて新規で関連付ける必要があります。
解除したリポジトリは初期表示画面からは消えるのですが、左上の「リポジトリ(3)」となっているように、完全に消えるわけではなく、
関連付けが解除されたリポジトリから確認することが可能です。(どうして)料金プラン
Amazon CodeGuru がサポートされている AWS リージョンで 90 日間無料でお試し可能です。
下記は東京リージョンの場合。無料枠について
リポジトリの全体の分析は、各支払者アカウントごとに毎月 30,000 行のコードの分析までが無料となります。
プルリクエストの分析は、90 日間の無料トライアルが利用可能。リポジトリ全体の分析
無料利用枠以上の利用だと毎月 1,500,000 行のコードの分析までは、コード 100 行ごとに 0.50USD。
1,500,000 行以上のコードを分析した場合 コード 100 行ごとに 0.40USD。
リポジトリ全体または選択したコードブランチのソースコードを分析することができます。
選択したリポジトリまたはソースコードブランチ内のコードの全行が、リポジトリ分析の実行ごとに分析されます。プルリクエスト
90 日間の無料トライアル後、コード 100 行ごとに 0.75USD。
あとがき
思った以上に設定簡単でしたね。何かしらで詰まるかなと思って身構えてたんですがあまりにも簡単。
CodeCommit以外からも関連付けられるのが特にいいですね。
コードへの指摘事項が出てこず残念でしたが大きな問題はないのかなとちょっとほっとできました。明日は23日目! @fasahina さんです!
FYI



- 投稿日:2020-12-15T18:56:38+09:00
新機能QuickSight Qとは??
はじめに
この記事は株式会社ナレッジコミュニケーションが運営する Amazon AI by ナレコム Advent Calendar 2020 の 15日目にあたる記事になります。
現在開催中のre:Invent2020にて発表された新サービス「QuickSight Q」について、調べたことを簡単に書いていきます。
そもそも「QuickSight」とは?
QuickSightとは、AWSが提供するBIツールであり、RDSやS3など様々なデータソースと接続し可視化&分析することができます。
機械学習ベースの異常検知、予測、自動ナラティブ(サマリ文章作成)機能が備わっており、専門家でなくても非常に使いやすい仕様となっているのが特徴です。本題「QuickSight Q」とは?
QuickSight Qとは、QuickSightに新たに搭載された機械学習(ML)を利用した自然言語クエリ(NLQ ※Natural Language Queryの略)機能のことです。
これによりQuickSightを使用して日常の言語でデータに関する質問を尋ねることで、数秒で正確な回答を得ることが出来るようになりました。
例えば、「昨年と比較して売上高の伸びはどうなった?」や「昨年と比較して最も売上高が伸びた製品は?」といった質問に対して、
Qが自然言語処理を行って質問の意図を解釈し、QuickSightで数値、グラフ、テーブルの形で質問に対する回答を返すことができます。
以下の例では「show monthly gaming revenue for california for last 3 years(過去3年間のカリフォルニアのゲーム収益を表示して!)」というNLQを投げています。
従来であれば主要な指標や監視したい項目ごとにダッシュボードを作成するのが一般的であったため、意思決定者からダッシュボードに見つからない質問がされた際はその都度新たにダッシュボードを作成する必要がありましたが、このQ機能によってこのようなシーンにも即座に対応が可能となります。
使用に関して
Qのプレビューは、米国東部 (バージニア北部)、米国西部 (オレゴン)、米国東部 (オハイオ) および 欧州 (アイルランド) で利用可能とのことですので、現状対応している言語は英語のみだと思われます。(そもそも日本語の自然言語処理は難しいので日本語対応は少し先になるかもしれません、、、)
Qの使用を開始するにはまずはQuickSightを使用しているという前提が必要となりますので、まだ使用していないという方は以下から以下を参考にQuickSightを始めましょう。
https://docs.aws.amazon.com/ja_jp/quicksight/latest/user/example-create-an-analysis.html
QuickSight Qの詳細な使用手順に関しては以下URL記載の内容を参照いただければと思います。
https://aws.amazon.com/jp/blogs/news/amazon-quicksight-q-to-answer-ad-hoc-business-questions/終わりに
本記事ではQuickSightの追加機能である、QuickSight Qについて簡単にご紹介いたしました。
日常で使用している言語(現時点では英語のみですが)を使用してデータ活用ができるという非常に魅力的な機能でした。
そのうち音声で同様のことができる日も近いかもしれません。
BIツールに悩まれている方はぜひ、QuickSightを検討してみてはいかがでしょうか?参考記事
https://aws.amazon.com/jp/blogs/news/amazon-quicksight-q-to-answer-ad-hoc-business-questions/


- 投稿日:2020-12-15T18:45:27+09:00
ECS + CodePipline でコンテナ管理
アプリケーションを作る際にコンテナを使う人も多くなってきたのではないでしょうか。
今回は、CodeCommitにDockerfileをアップロードしたらBuildして自動でECSのタスクが更新される仕組みをコード化したいと思います。インフラをコードで管理するためにCloudFormationを使用します。awslabsが公開しているコードを参照し、Cloudformationで作成します。いずれTerraFormでも作りたいと思います。
awslabs
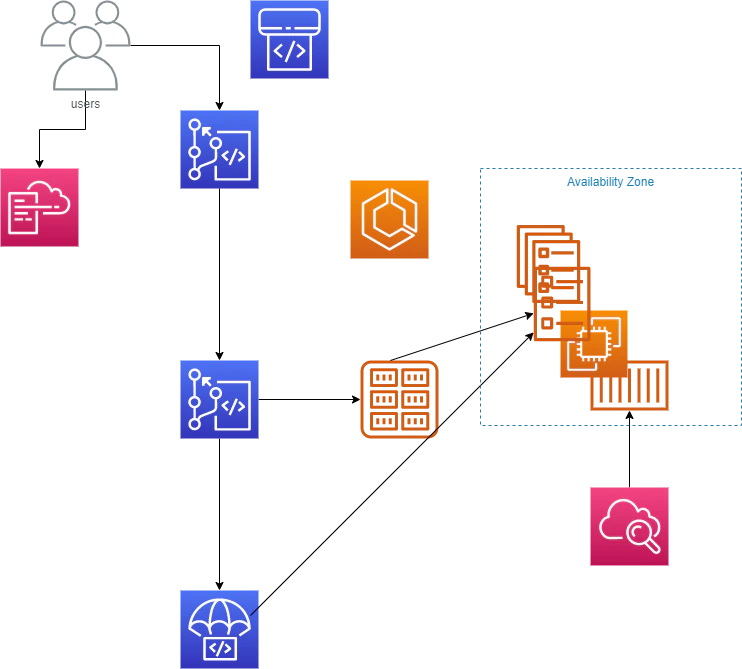
https://github.com/awslabs/ecs-refarch-continuous-deployment今回作成するアーキテクチャは以下のようになります。
EC2かFargateかはスタックを作る際に選択可能な形となります。なお、スタック作成時はAWS公式のdocker image(php-sample)を使用しますので、他のimageを使用したい場合にはDockerfileをCodeCommitにアップロードしてください。
(なお、PiplineにGithubを使用したいという方はawslabsのコードをご参照ください。)
ディレクトリ構造は下記となります。templatesフォルダにある5つのyamlはS3にアップロードしてご使用ください。
├── ecs-refarch-continuous-deployment.yaml ├── tempaltes ├── vpc.yaml ├── load-balancer.yaml ├── ecs-cluster.yaml ├── service.yaml └── deployment-pipline.yamlまずはVPCからです。
--- AWSTemplateFormatVersion: 2010-09-09 Parameters: Name: Type: String VpcCIDR: Type: String Subnet1CIDR: Type: String Subnet2CIDR: Type: String Resources: VPC: Type: AWS::EC2::VPC Properties: CidrBlock: !Ref VpcCIDR Tags: - Key: Name Value: !Ref Name InternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: Name Value: !Ref Name InternetGatewayAttachment: Type: AWS::EC2::VPCGatewayAttachment Properties: InternetGatewayId: !Ref InternetGateway VpcId: !Ref VPC Subnet1: Type: AWS::EC2::Subnet Properties: VpcId: !Ref VPC AvailabilityZone: !Select [ 0, !GetAZs ] MapPublicIpOnLaunch: true CidrBlock: !Ref Subnet1CIDR Tags: - Key: Name Value: !Sub ${Name} (Public) Subnet2: Type: AWS::EC2::Subnet Properties: VpcId: !Ref VPC AvailabilityZone: !Select [ 1, !GetAZs ] MapPublicIpOnLaunch: true CidrBlock: !Ref Subnet2CIDR Tags: - Key: Name Value: !Sub ${Name} (Public) RouteTable: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Ref Name DefaultRoute: Type: AWS::EC2::Route Properties: RouteTableId: !Ref RouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref InternetGateway Subnet1RouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: RouteTableId: !Ref RouteTable SubnetId: !Ref Subnet1 Subnet2RouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: RouteTableId: !Ref RouteTable SubnetId: !Ref Subnet2 Outputs: Subnets: Value: !Join [ ",", [ !Ref Subnet1, !Ref Subnet2 ] ] VpcId: Value: !Ref VPC次にLoadBalancer(ALB)です。NLBのTemplateもありますので、見たいという方はコメントしてください!
Parameters: LaunchType: Type: String Default: Fargate AllowedValues: - Fargate - EC2 Subnets: Type: List<AWS::EC2::Subnet::Id> VpcId: Type: String Conditions: EC2: !Equals [ !Ref LaunchType, "EC2" ] Resources: SecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: GroupDescription: !Sub ${AWS::StackName}-alb SecurityGroupIngress: - CidrIp: "0.0.0.0/0" IpProtocol: tcp FromPort: 80 ToPort: 80 VpcId: !Ref VpcId LoadBalancer: Type: AWS::ElasticLoadBalancingV2::LoadBalancer Properties: Subnets: !Ref Subnets SecurityGroups: - !Ref SecurityGroup LoadBalancerListener: Type: AWS::ElasticLoadBalancingV2::Listener Properties: LoadBalancerArn: !Ref LoadBalancer Port: 80 Protocol: HTTP DefaultActions: - Type: forward TargetGroupArn: !Ref TargetGroup TargetGroup: Type: AWS::ElasticLoadBalancingV2::TargetGroup DependsOn: LoadBalancer Properties: VpcId: !Ref VpcId Port: 80 Protocol: HTTP Matcher: HttpCode: 200-299 HealthCheckIntervalSeconds: 10 HealthCheckPath: / HealthCheckProtocol: HTTP HealthCheckTimeoutSeconds: 5 HealthyThresholdCount: 2 TargetType: !If [ EC2, "instance", "ip" ] TargetGroupAttributes: - Key: deregistration_delay.timeout_seconds Value: 30 ListenerRule: Type: AWS::ElasticLoadBalancingV2::ListenerRule Properties: ListenerArn: !Ref LoadBalancerListener Priority: 1 Conditions: - Field: path-pattern Values: - / Actions: - TargetGroupArn: !Ref TargetGroup Type: forward Outputs: TargetGroup: Value: !Ref TargetGroup ServiceUrl: Description: URL of the load balancer for the sample service. Value: !Sub http://${LoadBalancer.DNSName} SecurityGroup: Value: !Ref SecurityGroup次にCluseterです。今回はAMIはマッピングを利用しました。SSMを使用して最新のAMIを取得してくることもできますが、リージョン別に自動選択したかったので採用しませんでした。
Parameters: LaunchType: Type: String Default: Fargate AllowedValues: - Fargate - EC2 InstanceType: Type: String Default: t2.micro ClusterSize: Type: Number Default: 2 Subnets: Type: List<AWS::EC2::Subnet::Id> SecurityGroup: Type: AWS::EC2::SecurityGroup::Id VpcId: Type: AWS::EC2::VPC::Id KeyName: Description: The EC2 Key Pair to allow SSH access to the instance Type: "AWS::EC2::KeyPair::KeyName" Conditions: EC2: !Equals [ !Ref LaunchType, "EC2" ] Mappings: AWSRegionToAMI: ap-south-1: AMI: ami-00491f6f eu-west-3: AMI: ami-9aef59e7 eu-west-2: AMI: ami-67cbd003 eu-west-1: AMI: ami-1d46df64 ap-northeast-2: AMI: ami-c212b2ac ap-northeast-1: AMI: ami-872c4ae1 sa-east-1: AMI: ami-af521fc3 ca-central-1: AMI: ami-435bde27 ap-southeast-1: AMI: ami-910d72ed ap-southeast-2: AMI: ami-58bb443a eu-central-1: AMI: ami-509a053f us-east-1: AMI: ami-28456852 us-east-2: AMI: ami-ce1c36ab us-west-1: AMI: ami-74262414 us-west-2: AMI: ami-decc7fa6 Resources: EC2Role: Type: AWS::IAM::Role Condition: EC2 Properties: Path: / AssumeRolePolicyDocument: Statement: - Action: sts:AssumeRole Effect: Allow Principal: Service: ec2.amazonaws.com ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceforEC2Role InstanceProfile: Type: AWS::IAM::InstanceProfile Condition: EC2 Properties: Path: / Roles: - !Ref EC2Role Cluster: Type: AWS::ECS::Cluster Properties: ClusterName: !Ref AWS::StackName AutoScalingGroup: Type: AWS::AutoScaling::AutoScalingGroup Condition: EC2 Properties: VPCZoneIdentifier: !Ref Subnets LaunchConfigurationName: !Ref LaunchConfiguration MinSize: !Ref ClusterSize MaxSize: !Ref ClusterSize DesiredCapacity: !Ref ClusterSize Tags: - Key: Name Value: !Sub ${AWS::StackName} - ECS Host PropagateAtLaunch: true CreationPolicy: ResourceSignal: Timeout: PT15M UpdatePolicy: AutoScalingRollingUpdate: MinInstancesInService: 1 MaxBatchSize: 1 PauseTime: PT15M WaitOnResourceSignals: true LaunchConfiguration: Type: AWS::AutoScaling::LaunchConfiguration Condition: EC2 Metadata: AWS::CloudFormation::Init: config: commands: 01_add_instance_to_cluster: command: !Sub echo ECS_CLUSTER=${Cluster} > /etc/ecs/ecs.config files: "/etc/cfn/cfn-hup.conf": mode: 000400 owner: root group: root content: !Sub | [main] stack=${AWS::StackId} region=${AWS::Region} "/etc/cfn/hooks.d/cfn-auto-reloader.conf": content: !Sub | [cfn-auto-reloader-hook] triggers=post.update path=Resources.ContainerInstances.Metadata.AWS::CloudFormation::Init action=/opt/aws/bin/cfn-init -v --region ${AWS::Region} --stack ${AWS::StackName} --resource LaunchConfiguration services: sysvinit: cfn-hup: enabled: true ensureRunning: true files: - /etc/cfn/cfn-hup.conf - /etc/cfn/hooks.d/cfn-auto-reloader.conf Properties: ImageId: !FindInMap [ AWSRegionToAMI, !Ref "AWS::Region", AMI ] InstanceType: !Ref InstanceType IamInstanceProfile: !Ref InstanceProfile SecurityGroups: - !Ref SecurityGroup KeyName: !Ref KeyName UserData: "Fn::Base64": !Sub | #!/bin/bash yum install -y aws-cfn-bootstrap /opt/aws/bin/cfn-init -v --region ${AWS::Region} --stack ${AWS::StackName} --resource LaunchConfiguration /opt/aws/bin/cfn-signal -e $? --region ${AWS::Region} --stack ${AWS::StackName} --resource AutoScalingGroup Outputs: ClusterName: Value: !Ref Cluster次にServiceです。
Parameters: Cluster: Type: String DesiredCount: Type: Number Default: 1 LaunchType: Type: String Default: Fargate AllowedValues: - Fargate - EC2 TargetGroup: Type: String SecurityGroup: Type: AWS::EC2::SecurityGroup::Id Subnets: Type: List<AWS::EC2::Subnet::Id> Conditions: Fargate: !Equals [ !Ref LaunchType, "Fargate" ] EC2: !Equals [ !Ref LaunchType, "EC2" ] Resources: TaskExecutionRole: Type: AWS::IAM::Role Properties: Path: / AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Action: sts:AssumeRole Effect: Allow Principal: Service: ecs-tasks.amazonaws.com ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy LogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: !Sub /ecs/${AWS::StackName} RetentionInDays: 14 FargateService: Type: AWS::ECS::Service Condition: Fargate Properties: Cluster: !Ref Cluster DesiredCount: !Ref DesiredCount TaskDefinition: !Ref TaskDefinition LaunchType: FARGATE NetworkConfiguration: AwsvpcConfiguration: AssignPublicIp: ENABLED SecurityGroups: - !Ref SecurityGroup Subnets: !Ref Subnets LoadBalancers: - ContainerName: simple-app ContainerPort: 80 TargetGroupArn: !Ref TargetGroup EC2Service: Type: AWS::ECS::Service Condition: EC2 Properties: Cluster: !Ref Cluster DesiredCount: !Ref DesiredCount TaskDefinition: !Ref TaskDefinition LaunchType: EC2 LoadBalancers: - ContainerName: simple-app ContainerPort: 80 TargetGroupArn: !Ref TargetGroup TaskDefinition: Type: AWS::ECS::TaskDefinition Properties: Family: !Sub ${AWS::StackName}-simple-app RequiresCompatibilities: - !If [ Fargate, "FARGATE", "EC2" ] Memory: 512 Cpu: 256 NetworkMode: !If [ Fargate, "awsvpc", "bridge" ] ExecutionRoleArn: !Ref TaskExecutionRole ContainerDefinitions: - Name: simple-app Image: amazon/amazon-ecs-sample Essential: true Memory: 256 MountPoints: - SourceVolume: my-vol ContainerPath: /var/www/my-vol PortMappings: - HostPort: 80 ContainerPort: 80 LogConfiguration: LogDriver: awslogs Options: awslogs-region: !Ref AWS::Region awslogs-group: !Ref LogGroup awslogs-stream-prefix: !Ref AWS::StackName - Name: busybox Image: busybox EntryPoint: - sh - -c Essential: true Memory: 256 VolumesFrom: - SourceContainer: simple-app Command: - /bin/sh -c "while true; do /bin/date > /var/www/my-vol/date; sleep 1; done" Volumes: - Name: my-vol Outputs: Service: Value: !If [ Fargate, !Ref FargateService, !Ref EC2Service ]次にパイプラインの構築です。
Parameters: CodeCommitRepositoryName: Type: String Cluster: Type: String Service: Type: String Resources: Repository: Type: AWS::ECR::Repository DeletionPolicy: Retain CodeBuildServiceRole: Type: AWS::IAM::Role Properties: Path: / AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: codebuild.amazonaws.com Action: sts:AssumeRole Policies: - PolicyName: root PolicyDocument: Version: 2012-10-17 Statement: - Resource: "*" Effect: Allow Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents - ecr:GetAuthorizationToken - secretsmanager:GetSecretValue - Resource: !Sub arn:aws:s3:::${ArtifactBucket}/* Effect: Allow Action: - s3:GetObject - s3:PutObject - s3:GetObjectVersion - Resource: !Sub arn:aws:ecr:${AWS::Region}:${AWS::AccountId}:repository/${Repository} Effect: Allow Action: - ecr:GetDownloadUrlForLayer - ecr:BatchGetImage - ecr:BatchCheckLayerAvailability - ecr:PutImage - ecr:InitiateLayerUpload - ecr:UploadLayerPart - ecr:CompleteLayerUpload CodePipelineServiceRole: Type: AWS::IAM::Role Properties: Path: / AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: codepipeline.amazonaws.com Action: sts:AssumeRole Policies: - PolicyName: root PolicyDocument: Version: 2012-10-17 Statement: - Resource: - !Sub arn:aws:s3:::${ArtifactBucket}/* Effect: Allow Action: - s3:PutObject - s3:GetObject - s3:GetObjectVersion - s3:GetBucketVersioning - Resource: "*" Effect: Allow Action: - ecs:DescribeServices - ecs:DescribeTaskDefinition - ecs:DescribeTasks - ecs:ListTasks - ecs:RegisterTaskDefinition - ecs:UpdateService - codebuild:StartBuild - codebuild:BatchGetBuilds - iam:PassRole ArtifactBucket: Type: AWS::S3::Bucket DeletionPolicy: Retain CodeBuildProject: Type: AWS::CodeBuild::Project Properties: Artifacts: Type: CODEPIPELINE Source: Type: CODEPIPELINE BuildSpec: | version: 0.2 phases: pre_build: commands: - $(aws ecr get-login --no-include-email) - TAG="$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | head -c 8)" - IMAGE_URI="${REPOSITORY_URI}:${TAG}" build: commands: - docker build --tag "$IMAGE_URI" . post_build: commands: - docker push "$IMAGE_URI" - printf '[{"name":"simple-app","imageUri":"%s"}]' "$IMAGE_URI" > images.json artifacts: files: images.json Environment: ComputeType: BUILD_GENERAL1_SMALL Image: aws/codebuild/docker:17.09.0 Type: LINUX_CONTAINER EnvironmentVariables: - Name: AWS_DEFAULT_REGION Value: !Ref AWS::Region - Name: REPOSITORY_URI Value: !Sub ${AWS::AccountId}.dkr.ecr.${AWS::Region}.amazonaws.com/${Repository} Name: !Ref AWS::StackName ServiceRole: !Ref CodeBuildServiceRole Pipeline: Type: AWS::CodePipeline::Pipeline Properties: RoleArn: !GetAtt CodePipelineServiceRole.Arn ArtifactStore: Type: S3 Location: !Ref ArtifactBucket Stages: - Name: Source Actions: - Name: App ActionTypeId: Category: Source Owner: AWS Version: 1 Provider: CodeCommit Configuration: RepositoryName: !Ref CodeCommitRepositoryName BranchName: master RunOrder: 1 OutputArtifacts: - Name: App - Name: Build Actions: - Name: Build ActionTypeId: Category: Build Owner: AWS Version: 1 Provider: CodeBuild Configuration: ProjectName: !Ref CodeBuildProject InputArtifacts: - Name: App OutputArtifacts: - Name: BuildOutput RunOrder: 1 - Name: Deploy Actions: - Name: Deploy ActionTypeId: Category: Deploy Owner: AWS Version: 1 Provider: ECS Configuration: ClusterName: !Ref Cluster ServiceName: !Ref Service FileName: images.json InputArtifacts: - Name: BuildOutput RunOrder: 1 Outputs: PipelineUrl: Value: !Sub https://console.aws.amazon.com/codepipeline/home?region=${AWS::Region}#/view/${Pipeline}以上5つのファイルをS3にアップロードしてください。
最後にまとめのテンプレートです。Parameters: LaunchType: Type: String Default: Fargate AllowedValues: - Fargate - EC2 Description: > The launch type for your service. Selecting EC2 will create an Auto Scaling group of t2.micro instances for your cluster. See https://docs.aws.amazon.com/AmazonECS/latest/developerguide/launch_types.html to learn more about launch types. TemplateBucket: Type: String Description: > The S3 bucket from which to fetch the templates used by this stack. CodeCommitRepositoryName: Type: String ClusterSize: Type: Number Default: 2 DesiredCount: Type: Number Default: 1 KeyName: Description: The EC2 Key Pair to allow SSH access to the instance Type: "AWS::EC2::KeyPair::KeyName" Metadata: AWS::CloudFormation::Interface: ParameterLabels: CodeCommitRepositoryName: default: "CodeCommitRepositoryName" LaunchType: default: "Launch Type" ParameterGroups: - Label: default: Cluster Configuration Parameters: - LaunchType - Label: default: CodeCommit Configuration Parameters: - CodeCommitRepositoryName - Label: default: Stack Configuration Parameters: - TemplateBucket - Label: default: TaskDesiredCount Parameters: - DesiredCount Resources: Cluster: Type: AWS::CloudFormation::Stack Properties: TemplateURL: !Sub "https://s3.amazonaws.com/${TemplateBucket}/ecs-cluster.yaml" Parameters: LaunchType: !Ref LaunchType SecurityGroup: !GetAtt LoadBalancer.Outputs.SecurityGroup Subnets: !GetAtt VPC.Outputs.Subnets VpcId: !GetAtt VPC.Outputs.VpcId ClusterSize: !Ref ClusterSize KeyName: !Ref KeyName DeploymentPipeline: Type: AWS::CloudFormation::Stack Properties: TemplateURL: !Sub "https://s3.amazonaws.com/${TemplateBucket}/deployment-pipeline.yaml" Parameters: Cluster: !GetAtt Cluster.Outputs.ClusterName Service: !GetAtt Service.Outputs.Service CodeCommitRepositoryName: !Ref CodeCommitRepositoryName LoadBalancer: Type: AWS::CloudFormation::Stack Properties: TemplateURL: !Sub "https://s3.amazonaws.com/${TemplateBucket}/load-balancer.yaml" Parameters: LaunchType: !Ref LaunchType Subnets: !GetAtt VPC.Outputs.Subnets VpcId: !GetAtt VPC.Outputs.VpcId VPC: Type: AWS::CloudFormation::Stack Properties: TemplateURL: !Sub "https://s3.amazonaws.com/${TemplateBucket}/vpc.yaml" Parameters: Name: !Ref AWS::StackName VpcCIDR: 10.215.0.0/16 Subnet1CIDR: 10.215.10.0/24 Subnet2CIDR: 10.215.20.0/24 Service: Type: AWS::CloudFormation::Stack Properties: TemplateURL: !Sub "https://s3.amazonaws.com/${TemplateBucket}/service.yaml" Parameters: Cluster: !GetAtt Cluster.Outputs.ClusterName LaunchType: !Ref LaunchType TargetGroup: !GetAtt LoadBalancer.Outputs.TargetGroup SecurityGroup: !GetAtt LoadBalancer.Outputs.SecurityGroup Subnets: !GetAtt VPC.Outputs.Subnets DesiredCount: !Ref DesiredCount Outputs: ServiceUrl: Description: The sample service that is being continuously deployed. Value: !GetAtt LoadBalancer.Outputs.ServiceUrl PipelineUrl: Description: The continuous deployment pipeline in the AWS Management Console. Value: !GetAtt DeploymentPipeline.Outputs.PipelineUrl以上となります。最後までご覧いただきありがとうございます。
参照記事
https://qiita.com/chisso/items/3c4dd1af0382d4978288
https://github.com/awslabs/ecs-refarch-continuous-deployment
- 投稿日:2020-12-15T18:42:40+09:00
CloudWatchアラームをLambdaでGoogle Chatに投稿する
概要
CloudWatch メトリクスアラームを使用し AWS リソースの監視を開始する上で、通知を Google Chat にも投稿する必要が出てきたため、Lambda ファンクションを使用し、 SNS をトリガーにして Google Chat 連携を行いました。
本記事では、AWS CDK を利用して SNS トピックの作成 および、lambda リソースの作成を行い、 SNS のテストトピックを発行し、 Google Chatに通知が来るまで確認してみたいと思います。
実際の運用では、監視対象の CloudWatch メトリクスアラーム と 上記で作成した SNSトピックの紐付けを行うことで、アラーム発砲から Google Chat 通知までの一連の流れを実現することができます。前提
・ Goole Chatのチャットルームを作成し、Webhook の URLを取得している
・ AWS CDK デプロイ環境が整っているAWS CDK にて SNS/Lambda リソースの作成
実装は以下になります。
CDK context を利用して、 Webhook の URL を渡してあげて、 Lambda の環境変数に展開しています。。DevopsAlarmStack.tsimport * as cdk from "@aws-cdk/core"; import * as sns from "@aws-cdk/aws-sns"; import * as iam from "@aws-cdk/aws-iam"; import * as lambda from "@aws-cdk/aws-lambda"; import * as subscriptions from "@aws-cdk/aws-sns-subscriptions"; export class DevopsAlarmStack extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props); const webhookURL = this.node.tryGetContext("webhookURL") || ""; // lambda用ロール作成 const lambdaIamRole = new iam.Role( this, "test-iam-role-for-lambda-devops-alarm", { roleName: "test-iam-role-for-lambda-devops-alarm", assumedBy: new iam.ServicePrincipal("lambda.amazonaws.com"), managedPolicies: [ iam.ManagedPolicy.fromAwsManagedPolicyName( "service-role/AWSLambdaBasicExecutionRole" ), ], } ); // SNS トピック作成 const myTopic = new sns.Topic(this, "test-alarm-topic", { displayName: "test-alarm-topic", topicName: "test-alarm-topic", }); // 通知用 lambda 作成 const myFunction = new lambda.Function( this, "test-lambda-alarm-handler", { code: lambda.Code.fromAsset("../src", { exclude: ["*.ts", "cdk.out"], }), handler: "AlarmHandler.handler", functionName: "test-lambda-alarm-handler", runtime: lambda.Runtime.NODEJS_12_X, role: lambdaIamRole, environment: { HANGOUT_WEBHOOK_URL: `${webhookURL}`, }, } ); // SNS と lambda の紐付け myTopic.addSubscription(new subscriptions.LambdaSubscription(myFunction)); } }Lambda 内関数の実装
Lambda 内の実装は以下になります。
Lambda で展開された環境変数から HANGOUT_WEBHOOK_URL を取得し、利用しています。
SNS から渡ってきたイベントを、見やすいように整形して、Google Chat Webhook API を利用し、通知してあげます。AlarmHandler.tsconst fetch = require("node-fetch"); const webhookURL = process.env.HANGOUT_WEBHOOK_URL; export const handler = async (event: any) => { const text = get_text(get_message_from_event(event)); console.log(text); await fetch(webhookURL, { method: "POST", headers: { "Content-Type": "application/json; charset=UTF-8", }, body: JSON.stringify({ text: text, }), }).then((response: any) => { console.log(response); }); }; function get_message_from_event(event: any) { return JSON.parse(event.Records[0].Sns.Message); } function get_text(message: any) { const alarm_name = "AlarmName" in message ? message["AlarmName"] : ""; const old_state = "OldStateValue" in message ? message["OldStateValue"] : ""; const new_state = "NewStateValue" in message ? message["NewStateValue"] : ""; const new_state_reason = "NewStateReason" in message ? message["NewStateReason"] : ""; return ( "*" + alarm_name + ":* " + old_state + " ⟶ " + new_state + "\n```" + new_state_reason + "```" ); }SNS テストトピックの発行
AWS コンソールにて下記の json メッセージを発行します。
[Amazon SNS] - [トピック] - [上記のCDKにて作成したトピックを選択] - [メッセージの発行]message.json{ "AlarmName": "sample-error", "AlarmDescription": "sampleでエラーが発生しました。", "AWSAccountId": "xxxxxxxxxxxx", "NewStateValue": "ALARM", "NewStateReason": "Threshold Crossed: 1 datapoint [2.0 (29/11/17 01:09:00)] was greater than or equal to the threshold (1.0).", "StateChangeTime": "2017-11-29T01:10:32.907+0000", "Region": "Asia Pacific (Tokyo)", "OldStateValue": "OK", "Trigger": { "MetricName": "sample-metric", "Namespace": "LogMetrics", "StatisticType": "Statistic", "Statistic": "SUM", "Unit": null, "Dimensions": [], "Period": 60, "EvaluationPeriods": 1, "ComparisonOperator": "GreaterThanOrEqualToThreshold", "Threshold": 1, "TreatMissingData": "- TreatMissingData: NonBreaching", "EvaluateLowSampleCountPercentile": "" } }※ サンプルのJSONデータは、https://qiita.com/onooooo/items/f59c69e30dc5b477f9fd を参考にさせていただきました。
Google Chat での確認
Google Chat に以下のような形で、通知を取得することができました。
まとめ
AWS CDK を利用して SNS トピックの作成 および、lambda リソースの作成を行い、 SNS のテストトピックを発行し、 Google Chatに通知が来るまでを確認してみました。普段 Google Chat を利用されている方は、AWSリソースに何か生じた際にすぐ通知が来てくれるので便利だと思います。

- 投稿日:2020-12-15T18:35:29+09:00
⑰本番環境Railsの起動エラー(手動)ーポートフォリオ
「Railsが起動しない」「ブラウザで確認するとエラーが表示されている」などの問題がある場合、まずは「エラーログ」を確認する必要があります。
ターミナルで「unicorn_rails」が起動しない時の対処法
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D master failed to start, check stderr log for detailsこのように、unicorn_railsを実行した際に「master failed to start, check stderr log for details」と出た場合、unicornのエラーログを確認する必要があります。
「check stderr log for details」というのは、「詳細(detail)はstderr logを確認(check)しましょう」という意味です。
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ less log/unicorn.stderr.log
ログファイルは「一番下から最新のログ」が表示されます。”「shiftキー」+「G」”を実行すると、一番下まで一瞬で移動できます。
ブラウザに「We’re sorry, but 〜」と表示されている時の対処法
このような表示が出ている場合、まずは「production.log」を確認する必要があります。
production.log
「production.log」とは、サーバーログを記録する場所で、いわば「EC2内での出来事を記録している場所」です。ローカルにおいてrails sコマンドでアプリケーションを実行したときも、さまざまなログが表示されます。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ less log/production.log
tail -fコマンド
「tail -fコマンド」とは、最新のログを10行分だけ表示してくれるコマンドです。
チェックリスト
- ローカル→GiuHubへのpushのし忘れはないか(mergeまで確認)
- GitHubからEC2への反映(git pull origin master)のし忘れはないか
- EC2サーバー側でエラーログの内容を確認し、原因を見つけたか
- カリキュラム通りの記載ができているか
- データベースは正しく起動しているか
- EC2サーバー側の環境変数は正しく設定できているか
- EC2インスタンスの再起動を行ってみる



- 投稿日:2020-12-15T18:28:01+09:00
[無料] AWS EC2 + RDS + Flask でWebアプリを作り HTTPS 化する [データベース編 その1]
Webアプリで使うためのリレーショナルデータベースを AWS RDS で作成します。私はスキーマレスなNoSQLにしか興味ない、という人は読み飛ばして下さい。そのうち無料で使えるキーバリューストア型データベースの DynamoDB との比較記事も書くかもしれません。
インスタンス作成
Amazon RDS のページに入り、真ん中らへんの Create database します。
Standard create で良いです。
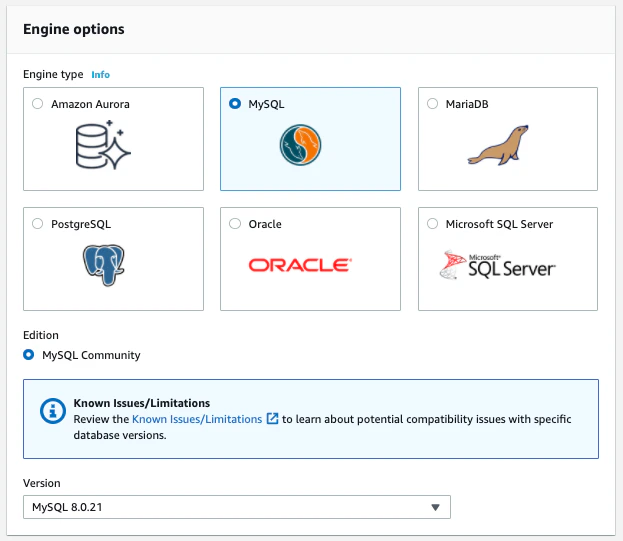
エンジンを選びます。主要なものは全て揃っています、MySQL、MariaDB、PostgreSQL、Microsoft SQL Server の4つが無料で、Oracle と Amazon Aurora は無料枠対象外です。Aurora は MySQL/Postgre 完全互換で、本家よりも数倍速いとの謳い文句ですので、興味がある方は試してみると良いかもしれません。ただし、バージョンが限られることに気をつけて下さい。私はリレーショナルデータベースをあえて正規化せずに NoSQL のように運用することがあるのですが、その際に MySQL8.0 のJSON_TABLEという関数を多用します(そのうち余裕があれば転置インデックスの話もします)。ですが Amazon Aurora でサポートしているのは MySQL5.7 までですので、オリジナルの MySQL をエンジンとして選ばざるを得ません。window 関数なんかも確か 5.7 では使えないはずです。まあ一般的な CRUD のみであればバージョンはそこまで気にする必要はありません。今回は MySQL8.0 を選択します。
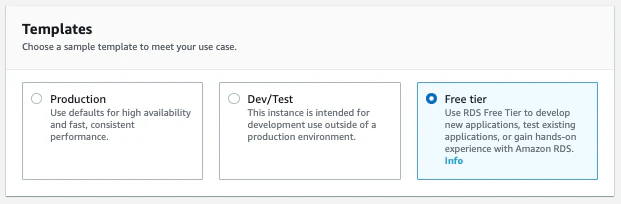
Free tier を選びます。
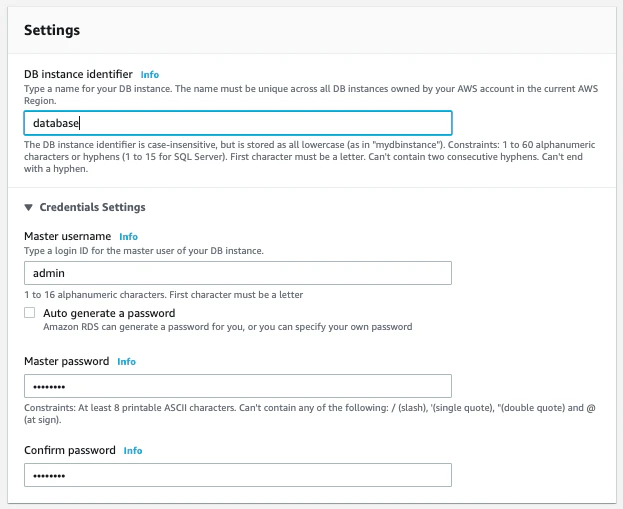
データベース名、ユーザー名、パスワードなどを決めます。DBインスタンスは無料利用枠では選択不可です。
Strage は 20GB もあれば十分ではないかと思います。
Public access は Yes にしておかないと、EC2以外の外部からアクセスできなくなります。全て作り終わった後に設定をアクセス不可に戻せば良いです。
セキュリティーグループは その2 で設定済の default を選べば良いです。一番右下の Create database します。
データベースの作成には少し時間がかかります。ステータスが Available になれば使えます。
データベース名を押すと詳細が出ます。このエンドポイントと、先ほど入力したユーザー名・パスワードでデータベースにアクセスできます。
接続例
MySQL Workbench
Hostname に先ほどのエンドポイントを入力し、Username と Password を入れて Test Connection し、Success と出れば接続できています。
外部からでも問題なく使えます。
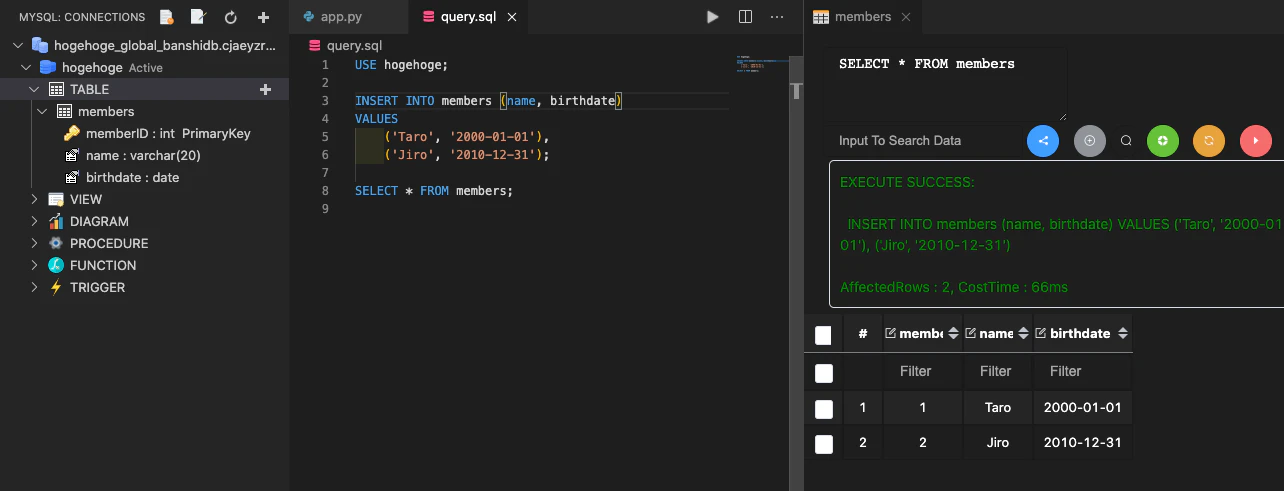
VScode
MySQL Workbench のような統合GUIは、設定をいじったりER図を書くときなどには非常に重宝しますが、コーディングしながら、VScode内からそのままクエリを投げたいときもあります。この MySQL 用の Extension を導入します。
左側にデータベースのアイコンが追加されます。上の➕から接続を追加できます。
同様にエンドポイント、ユーザー名、パスワードを入れて接続します。
.sqlファイルならシンタックスハイライトもされます。F9キーでクエリを実行できます。し、右側のフィールドで実行することも可能です。便利すぎます。









- 投稿日:2020-12-15T18:15:08+09:00
DynamoDBが簡単にExportできるようになった!
本記事はハンズラボ Advent Calendar 2020の17日目です。
はじめに!
こんにちは。AWS絶賛勉強中の@bassaaaaaです。
業務でDynamoDBテーブルを全件取得し、ゴニョゴニョする必要がありました。
RDBなら普通にExportできますが、DynamoDBは最近までできなかったみたいです。
というわけで、最近出たDynamoDB Export1をaws-cliからやってみたいと思います。前置きはいいから!という人はaws-cliでDynamoDB Exportをやってみるへ
昔は大変だった!
DynamoDB Exportは2020/11/9から使えるようになりました。
それまでは以下のような方法でExportを行う必要がありました。2
- AWS Data Pipelineを使う
- Amazon EMRを使う
- AWS Glueを使う
- 全件取得クエリ
1~3はなんとなく、面倒そうです。
4は一発で終わり簡単そうです。
これらと比べて何が良いんでしょうか??いろいろ心配しなくていい!
公式ドキュメント3にはこのように書かれています。
Exporting a table does not consume read capacity on the table, and has no impact on table performance and availability.
テーブルをエクスポートしても読み込みキャパシティは消費されず、テーブルのパフォーマンスや可用性に影響はありません。どういうこと?
DynamoDBはデータの読み書きに
がかかります。
その読み書き性能はテーブル毎に設定するキャパシティユニットにより決まります。
値が大きいほど、性能が良く100RCUなら1秒間に4KB*100個の項目を同時に読み取れますよー、みたいな感じです。
この性能を超えたリクエストが来た場合、スロットリングエラーが発生し、読み込み/書き込みリクエストが失敗します。これは、上記1~4の方法でも起きる可能性があります。
Exportが失敗するのは別に良いとして、Exportが食い潰したキャパシティにより、本来成功したはずの本番処理が失敗するのは避けたいです。なので、上記1~4の方法でExportする場合は、事前にキャパシティをあげ、Export中はスロットルエラーが発生してないか監視する必要があったのです。
また、キャパシティをあげるため
本当にExportする必要があるのか?など、要らぬ心配も必要だったはずです(ただのExportなのに)DynamoDB Exportはここら辺の心配をしなくて良いのです


DynamoDB Exportの仕組み
DynamoDB Exportは内部的にPITR (Point In Time Recovery) を使用しています。
PITRはDynamoDBテーブルの自動バックアップ機能で、過去35日間の任意の時点(1秒単位)へ復元できます。
というわけで、DynamoDB Export使用前にPITRを有効化する必要があります。ExportデータはDynamoDB JSON形式かION形式のgz圧縮でS3に保存されます。
出力ディレクトリ構造は以下のような感じです。
Exportデータはサイズによって複数分割されることもあるみたいです。s3:// └ hogehoge # バケット名(指定) └ fugafuga # prefix(指定) └ ... # prefix(指定) └ AWSDynamoDB # 固定 └ 01234567890abc-1234abc # ランダム文字列 ├ ... # manifestなど └ data # 固定 └ abcdefghijklmnopqrstuvwxyz.json.gz # Exportデータ(JSON or IONを指定)aws-cliでDynamoDB Exportをやってみる
DynamoDB Exportはマネジメントコンソールからでもできます。
「どのテーブルをどのバケットに」を指定するだけなので、簡単です。
が、今後のために一連の処理をaws-cliを使ってshellで書いてみます。実行環境
- macOS Catalina (10.15.7)
- aws-cli/2.1.5
※ 本番環境でのaws-cliのVerUpは要注意
ざっくり流れ
- PITRを有効化する
- Exportリクエスト
- Export状況問合せ
- PITRの設定を元に戻す
- S3からExportデータをダウンロードする
以下、変数など適当に補完してください
PITRの有効化
dynamodb_export.bash# PITR設定取得 aws dynamodb describe-continuous-backups \ --table-name $TABLE_NAME > $tmp-init-setting # 設定値取得 cat $tmp-init-setting | jq -r ".ContinuousBackupsDescription.PointInTimeRecoveryDescription.PointInTimeRecoveryStatus" > $tmp-init-status # 有効でない場合は有効にする if [ "$(cat $tmp-init-status)" = "DISABLED" ]; then aws dynamodb update-continuous-backups \ --table-name $TABLE_NAME \ --point-in-time-recovery-specification PointInTimeRecoveryEnabled=true > $tmp-changed-setting fiレスポンス
$tmp-init-setting{ "ContinuousBackupsDescription": { "ContinuousBackupsStatus": "ENABLED", "PointInTimeRecoveryDescription": { "PointInTimeRecoveryStatus": "DISABLED" } } }$tmp-changed-setting{ "ContinuousBackupsDescription": { "ContinuousBackupsStatus": "ENABLED", "PointInTimeRecoveryDescription": { "PointInTimeRecoveryStatus": "ENABLED", "EarliestRestorableDateTime": "2020-12-07T15:06:44+09:00", "LatestRestorableDateTime": "2020-12-07T15:06:44+09:00" } } }Exportリクエスト
dynamodb_export.bash# DynamoDB Exportリクエスト # TABLE_ARN arn:aws:dynamodb:REGION:ACCOUNT:table/tablename # s3://S3_BUCKET/S3_PREFIX # EXPORT_FORMAT DYNAMODB_JSON / ION aws dynamodb export-table-to-point-in-time \ --table-arn $TABLE_ARN \ --s3-bucket $S3_BUCKET \ --s3-prefix $S3_PREFIX \ --export-format $EXPORT_FORMAT > $tmp-request # ExportArnを取得 export_arn=`cat $tmp-request | jq -r '.ExportDescription.ExportArn'` # Export先S3ディレクトリ名を取得 # ExportArnの最後の/以降 export_dir=`cat $export_arn | sed -e "s#\(.*\)\/\(.*\)#\2#"`レスポンス
$tmp-request{ "ExportDescription": { "ExportArn": "arn:aws:dynamodb:REGION:ACCOUNT:table/tablename/export/01234567890abc-1234abc", "ExportStatus": "IN_PROGRESS", "StartTime": "2020-12-04T10:46:23.577000+09:00", "TableArn": "arn:aws:dynamodb:REGION:ACCOUNT:table/tablename", "TableId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "ExportTime": "2020-12-04T10:46:23.577000+09:00", "ClientToken": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "S3Bucket": "hogehoge", "S3Prefix": "fugafuga", "S3SseAlgorithm": "AES256", "ExportFormat": "DYNAMODB_JSON" } }Export状況問合せ
dynamodb_export.bash# Export状況取得 while : do # ステータスがCOMPLETEDになるまで60秒ごとに問い合わせる aws dynamodb list-exports | jq -r ".ExportSummaries | map(select(.ExportArn == \"$export_arn\")) | .[].ExportStatus" > $tmp-status cat $tmp-status if [ "$(cat $tmp-status)" = "COMPLETED" ]; then break fi sleep 60 donePITRの設定を元に戻す
dynamodb_export.bashif [ "$(cat $tmp-init-status)" = "DISABLED" ]; then aws dynamodb update-continuous-backups \ --table-name $TABLE_NAME \ --point-in-time-recovery-specification PointInTimeRecoveryEnabled=false > $tmp-last-setting fiS3からExportデータをダウンロードする
# S3からコピーする aws s3 cp s3://$S3_BUCKET/$S3_PREFIX/AWSDynamoDB/$export_dir/data/ ./ --recursiveExport結果
Exportデータはこんな感じです。
{"Item": {"id": {"S": "01"},"name": {"S": "fuga"}}} {"Item": {"id": {"S": "02"},"name": {"S": "hoge"}}} ...おまけ
DynamoDB JSON --> CSV
cat export.json | jq -r ".Item | [.id.S, .name.S] | @csv" "01","fuga" "02","hoge"(参考)Export時間
いくつかのテーブルでExport時間を見てみました。
Export自体は1.5〜4分で終わりました。実際には、リクエストしてExportが開始するまでの時間がかかるので、5〜10分以内といった感じです。
テーブル 項目数 テーブルサイズ Export時間 1 4 25B 1.5〜4分(複数回実施) 2 3万 6MB 2分 3 120万 180MB 2分 4 200万 300MB 2分5秒 AWSブログ1によると、
完了時間は、テーブルのサイズと、テーブル内でデータがどのように均一に分散されているかに左右されます。エクスポートの大部分は 30 分以内に完了します。10 GiB までの小さなテーブルの場合、数分で完了します。テラバイトのオーダーの非常に大きなテーブルの場合、数時間かかる場合があります。
らしいです。
お金
上で「いろいろ心配しなくて良い」と書きました。
確かにキャパシティユニットとか本番への影響は心配しなくて良いです。
ただ、やっぱりお金はかかります。
具体的には、下記3つです。
- PITRのお金
- 毎月 0.228USD/GB
(月中に一回でも有効化すれば課金?)有効化してた時間のみ課金5- DynamoDB Exportのお金
- 0.114USD/GB
- Export先S3バケットのお金
ただ、なんだかんだ楽ですし、以前までの方法と比べると安いもんです。
最後に
DynamoDB ExportはDynamoDBとS3だけで完結してるのが良いですね。
RDBのExport並みにお手軽です。最後までお読みいただきありがとうございました。
「新機能 – Amazon DynamoDB テーブルデータを Amazon S3 のデータレイクにエクスポート。コードの記述は不要」(https://aws.amazon.com/jp/blogs/news/new-export-amazon-dynamodb-table-data-to-data-lake-amazon-s3/) ↩
「DynamoDB テーブルを Amazon S3 にバックアップするにはどうすればよいですか ?」 (https://aws.amazon.com/jp/premiumsupport/knowledge-center/back-up-dynamodb-s3/) ↩
「Exporting DynamoDB table data to Amazon S3」(https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/DataExport.html) ↩
実際は色々モードあり。詳細は「読み込み/書き込みキャパシティーモード」( https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/HowItWorks.ReadWriteCapacityMode.html) ↩
PITRの料金は「その月のPITRを有効化していた時間の1時間あたりの平均テーブル容量(GB-Month)×料金表に記載の単価」です。東京リージョンで10GBのテーブルをExportのため1時間だけPITRを有効化した場合の料金は、((10GB * 1h * 1日) / (24h * 30日)) * 0.228USD/GB = 0.003USDとなります。 ↩
- 投稿日:2020-12-15T18:13:39+09:00
⑯環境変数の設定ーポートフォリオ
データベースのパスワードなどセキュリティのためにGitHubにアップロードすることができない情報は「環境変数」を利用して設定します。
secret_key_base
「secret_key_base」とは、Cookieの暗号化に用いられる文字列です。Railsアプリケーションを動作させる際は必ず用意する必要があります。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rake secretsudo
「sudo」とは、「全部の権限を持った上でコマンドを実行する」という役割のオプションです。「/etc以下のファイル」は強い権限がないと書き込み・保存ができないため、コマンドの頭に「sudo」をつけています。[ec2-user@ip-172-31-23-189 ~]$ sudo vim /etc/environmentDATABASE_PASSWORD='データベースのrootユーザーのパスワード' SECRET_KEY_BASE='さきほど作成したsecret_key_base' # 「AWSに画像をアップロードする」でダウンロードしたCSVファイルを参考に値を入力 AWS_ACCESS_KEY_ID='ここにCSVファイルのAccess key IDの値をコピー' AWS_SECRET_ACCESS_KEY='ここにCSVファイルのSecret access keyの値をコピー' # Basic認証で設定したユーザー名とパスワードを入力 BASIC_AUTH_USER='設定したユーザー名' BASIC_AUTH_PASSWORD='設定したパスワード'入力を終えたら「escキー」→「:wq」の順で実行し、保存
接続し直したら、「envコマンド」と「grepコマンド」を組み合わせて、さきほど設定した環境変数が適用されているか確認
[ec2-user@ip-172-31-23-189 ~]$ env | grep SECRET_KEY_BASE SECRET_KEY_BASE='secret_key_base' [ec2-user@ip-172-31-23-189 ~]$ env | grep DATABASE_PASSWORD DATABASE_PASSWORD='データベースのrootユーザーのパスワード' [ec2-user@ip-172-31-23-189 ~]$ env | grep AWS_SECRET_ACCESS_KEY AWS_SECRET_ACCESS_KEY='Secret access key' [ec2-user@ip-172-31-23-189 ~]$ env | grep AWS_ACCESS_KEY_ID AWS_ACCESS_KEY_ID='Access key ID' [ec2-user@ip-172-31-23-189 ~]$ env | grep BASIC_AUTH_USER BASIC_AUTH_USER='設定したユーザー名' [ec2-user@ip-172-31-23-189 ~]$ env | grep BASIC_AUTH_PASSWORD BASIC_AUTH_PASSWORD='設定したパスワード'ポートを解放
立ち上げたばかりのEC2インスタンスはsshでアクセスすることはできますが、HTTPなどの他の通信方法では一切つながらないようになっています。そのため、サーバーとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放する必要があります。セキュリティグループ
本番環境でRailsを起動
本番環境でRailsを起動するには「unicorn_railsコマンド」を使います。config/database.ymlusername: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sock[ec2-user@ip-172-31-23-189 <リポジトリ名>] git pull origin masterRAILS_ENV=production
「RAILS_ENV=production」とは、本番環境でコマンド実行する時につくオプションです。
実行しようとしているコマンドは、「RAILSのENV(環境)がproduction(本番環境)ですよ」という意味です。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails db:create RAILS_ENV=production Created database '<データベース名>' [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails db:migrate RAILS_ENV=productionアセットファイル
「アセットファイル」とは、画像・CSS・JavaScript等を管理しているファイルです。このアセットファイルを圧縮し、そのデータを転送する処理を「コンパイル」と言います。この作業を行わないと、本番環境でCSSが反映されずにビューが崩れてしまったり、エラーでブラウザが表示されない、などの問題が生じてしまいます。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails assets:precompile RAILS_ENV=production


- 投稿日:2020-12-15T16:47:58+09:00
RDSとServerlessFrameworkでおみくじを作ろう
はじめに
AWSの使っておみくじアプリを作るよ(そんなのRDSを使わなくてもよくね?という話はナシで)
環境
node.js v12.18.3
作ってみる
DBインスタンスの作成
ここを参考にRDSを使ってDBインスタンスを作成していく
DBの設定
- データベース作成方法:簡単作成 - 設定:MySQL - インスタンスサイズ:無料利用枠 - DBインスタンス識別子:aws-web-service - マスターユーザー名:admin - マスターパスワード:各自おまかせ - パブリックアクセス可能:あり作成したDBインスタンスのエンドポイントとマスターユーザーを使ってDBインスタンスにアクセス。
consolemysql -h mysql-80.xxx.{リージョン}.rds.amazonaws.com -P 3306 -u admin -pRDSをパブリックアクセス可能にしてるのでセキュリティ的にはゆるいけど、まあすぐ消すのでいいかなと。
DBインスタンスにデータを追加
DB作成
console$ create database omikuji $ use omikuji $ create table omikuji.kuji (id int, result varchar(3)); $ insert into kuji values (0,'大吉'); $ insert into kuji values (1,'中吉'); $ insert into kuji values (2,'小吉'); mysql> select * from kuji; +------+--------+ | id | result | +------+--------+ | 0 | 大吉 | | 1 | 中吉 | | 2 | 小吉 | +------+--------+これで完成
コードを書いていく
node.jsとsequelizeを使ってコマンドライン上でおみくじの結果を出力するようにする。
コマンドラインからディレクトリやファイルを作成したり、serverlessとかsequelizeをインストールしてみたりする。
ファイル構成についてだが、handler.jsにメインの処理を書いて、DBインスタンスのアクセスに必要な情報を.envに置くという構成にする。console# ディレクトリの作成 $ mkdir omikuji # npm初期化 $ npm init -y # パッケージインストール $ npm install --save serverless $ npm install --save sequelize $ npm install --save dotenv $ npm install --save mysql2 # serverlessの実行環境作成 $ serverless create --template aws-nodejs # ファイルの作成 $ touch .env // 環境変数用のファイル $ touch kuji.js // sequelize モデル定義に使うファイル # ディレクトリ構成は以下の通り .env handler.js node_modules package.json .gitignore kuji.js package-lock.json serverless.ymlとりあえず、serverlessがちゃんと動くかどうかテストしてみる。.envファイルがあることで警告は出ているが、ちゃんと動いていることが確認できたので、あとはhelloの中身をおみくじができるようにソースコードを変更してあげればよさそう。
※.envによる警告メッセージは話の本筋とは関係ないので、いったん無視していきます。sls invoke local --function hello Serverless: Running "serverless" installed locally (in service node_modules) Serverless: Deprecation warning: Detected ".env" files. Note that Framework now supports loading variables from those files when "useDotenv: true" is set (and that will be the default from next major release) More Info: https://www.serverless.com/framework/docs/deprecations/#LOAD_VARIABLES_FROM_ENV_FILES { "statusCode": 200, "body": "{\n \"message\": \"Go Serverless v1.0! Your function executed successfully!\",\n \"input\": \"\"\n}" }ソースコードの修正
.envとhandler.jsを以下のようにする.envDATABASE_NAME = "omikuji" USERNAME = "admin" PASSWORD = "your_db_password" HOST = "mysql-80.xxx.{リージョン}.rds.amazonaws.com"handler.jsconst { Sequelize } = require('sequelize'); require('dotenv').config(); async function hello() { const sequelize = new Sequelize( process.env.DATABASE_NAME, process.env.USERNAME, process.env.PASSWORD, { host: process.env.HOST, dialect: "mysql" }); try { await sequelize.authenticate(); console.log('Connection has been established successfully.'); } catch (error) { console.error('Unable to connect to the database:', error); } finally { sequelize.close(); } }; module.exports = { hello }これで
sls invoke local --function helloを実行すると以下のようになるはず。
DBの接続そのものはうまくいったみたいなので、データを取得できるようにしていく。consolesls invoke local --function hello Serverless: Running "serverless" installed locally (in service node_modules) Executing (default): SELECT 1+1 AS result Connection has been established successfully.おみくじ機能を実装
おみくじするためのデータ取得処理を作成していく。
コードは以下の通り。handler.jsconst { Sequelize, DataTypes } = require('sequelize'); require('dotenv').config(); const range = 3; async function hello() { // Sequelizeインスタンスの作成 const sequelize = new Sequelize( process.env.DATABASE_NAME, process.env.USERNAME, process.env.PASSWORD, { host: process.env.HOST, dialect: "mysql", logging: false, }); // 0 ... range - 1 の範囲で乱数を生成 const random = Math.floor( Math.random() * range); const Kuji = require("./kuji")(sequelize, DataTypes); try { const result = await Kuji.findOne({ where: { id: random }, attributes: ["result"], raw: true }) return result.result; } catch (error) { console.error('Unable to connect to the database:', error); } finally { sequelize.close() } }; module.exports = { hello }try文でreturnを返したら後の処理ってどうなるんだろうと思ったら、きちんとfinally句は実行してくれるっぽい。(ソース)
kuji.jsmodule.exports = (sequelize, DataTypes) => { return sequelize.define( "kuji", { id: { type: DataTypes.INTEGER, primaryKey: true, }, result: { type: DataTypes.CHAR, }, }, { timestamps: false, freezeTableName: true, } ); };これで実行してみると...
console# 1回目 sls invoke local --function hello Serverless: Running "serverless" installed locally (in service node_modules) 大吉 # 2回目 sls invoke local --function hello Serverless: Running "serverless" installed locally (in service node_modules) 中吉できたできた。
あとはこれをlambdaにアップしよう。Serverless Frameworkのserverless-layersプラグイン
lambdaにアップする前にserverless-layersプラグインを入れて、ライブラリをレイヤーにしてしまおう。
console$ npx sls plugin install --name serverless-layersそしたら、レイヤーにするライブラリを格納するためのS3バケットを作成して、そこに格納するように
serverless.ymlに記述していく。あと、デプロイ時にリージョン指定するのも面倒なのであらかじめ設定しておく。serverless.ymlservice: omikuji frameworkVersion: '2' provider: name: aws runtime: nodejs12.x region: {お使いのリージョン} # リージョン指定 functions: hello: handler: handler.hello custom: serverless-layers: layersDeploymentBucket: hogehoge # 作成したバケット plugins: - serverless-layersデプロイ
console# AWSの認証情報をcredentialsに書き込む $ serverless config credentials --provider aws --key aws_access_key_id --secret aws_secret_access_key # デプロイする $ npx sls deployこれでデプロイが完了したので動かしてみる
console$ sls invoke --function hello Serverless: Running "serverless" installed locally (in service node_modules) "小吉"できた。データベース使っておみくじ作るのは意味わからんが、ひとまずRDSとserverless frameworkを使ってちょっとしたアプリを作れたのでよしとする。
- 投稿日:2020-12-15T16:27:46+09:00
⑮EC2のRailsを起動しよう(手動デプロイ)ーポートフォリオ
EC2サーバーのssh鍵のペアを作成
[ec2-user@ip-172-31-23-189 ~]$ ssh-keygen -t rsa -b 4096catコマンドで、公開鍵が含まれているファイルid_rsa.pubの中身をターミナル上に表示します。
[ec2-user@ip-172-31-23-189 ~]$ cat ~/.ssh/id_rsa.pubそして、以下のように表示される公開鍵の情報をすべて(「ssh-rsa」から「末尾の文字」まで)コピーします。
次に、コピーした公開鍵をGitHubに登録します。
GitHubに鍵を登録できたら、ssh接続できるか以下のコマンドで確認
[ec2-user@ip-172-31-23-189 ~]$ ssh -T git@github.comアプリケーションサーバーの設定
ブラウザからの「リクエスト」を受け付けRailsアプリケーションを実際に動作させるソフトウェアのことです。つまり、「rails sコマンド」です。
全世界に公開するEC2サーバー上でもアプリケーションサーバを動かす必要があります。そのために必要なツールが「Unicorn」と呼ばれるものです。Unicorn
全世界に公開されるサーバ上で良く利用されるアプリケーションサーバーです。rails sコマンドの代わりに「unicorn_railsコマンド」で起動することができます。プロセスを確認
Unicornなどのアプリケーションサーバを起動するとアプリケーションサーバのプロセスが生まれます。アプリケーションサーバのプロセスがあれば、リクエストを受け付けブラウザにレスポンスを返すことができます。
Unicornをインストール
group :production do gem 'unicorn', '5.4.1' endbundle installunicorn.rb」を作成
config/unicorn.rb#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory app_path #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/tmp/pids/unicorn.pid" #ポート番号を指定 listen 3000 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/log/unicorn.stderr.log" #通常のログを記録するファイルを指定 stdout_path "#{app_path}/log/unicorn.stdout.log" #Railsアプリケーションの応答を待つ上限時間を設定 timeout 60 #以下は応用的な設定なので説明は割愛 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection endリモートリポジトリに「commit→push」
masterブランチにmergeしてから以下のコマンドを実行EC2にローカルの全内容を反映
#mkdirコマンドで新たにディレクトリを作成 [ec2-user@ip-172-31-23-189 ~]$ sudo mkdir /var/www/ #作成したwwwディレクトリの権限をec2-userに変更 [ec2-user@ip-172-31-23-189 ~]$ sudo chown ec2-user /var/www/次に、GitHubから「リポジトリURL」を取得し、クローンします。
URLがコピーできたら、コードをクローンします。
[ec2-user@ip-172-31-23-189 ~]$ cd /var/www/ [ec2-user@ip-172-31-23-189 www]$ git clone コピーしたURLを貼り付ける



- 投稿日:2020-12-15T16:20:54+09:00
Athenaでパーティション射影を使ってみた
Athenaを使う機会があったので、パーティション機能の使い方を簡単ですが備忘録としてまとめてみました。
S3上のファイルとの関連も書いています。Athenaとは
Amazon S3上のファイルをデータとして、SQLでアクセスできるAWSサービスです。テーブルを作成するときにS3上のパスを指定すると、そのパス以下のファイルがデータとして扱われます。
パーティション機能を使うとSELECTクエリ等でパーティション・プルーニングが働き、
パーティションキーに対するWHERE条件に基づいて不要なデータ探索をスキップできます。データのイメージ
今回使用するデータは3つの列を持つテーブルです。
日付(tm) 識別子(id) 値(value) 2020-12-01 sensor1 100.0 2020-12-02 sensor1 101.0 2020-12-02 sensor2 102.0 2020-12-03 sensor1 103.0 2020-12-03 sensor2 104.0 テーブル定義
以下のSQLでテーブルを作成しました。
CREATE EXTERNAL TABLE tbl1 (id string, value double) PARTITIONED BY (tm date) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ('serialization.format' = ',', 'field.delim' = ',') LOCATION 's3://test-bucket/tbl1/' TBLPROPERTIES ( 'has_encrypted_data'='false', 'projection.enabled' = 'true', 'projection.tm.type' = 'date', 'projection.tm.range' = 'NOW-3YEARS,NOW+3YEARS', 'projection.tm.format' = 'yyyy-MM-dd', 'storage.location.template' = 's3://test-bucket/tbl1/${tm}' );日付列(tm)はパーティション列にするので、残りの識別子列(id)と値列(value)をEXTERNAL TABLEの列として定義します。
今回データの場所は、s3://test-bucket/tbl1/ としました。パーティション列の指定はPARTITIONED BYで行い、設定はTBLPROPERTIESで指定します。
データの範囲'projection.tm.range'を指定しないと、INSERT時に以下のエラーが出たので、
INVALID_TABLE_PROPERTY: Must provide a range to build a projected temporal partition column!今回は本日から前後3年間を指定しました。
テーブル作成後、以下のSQLを実行し、パーティションを認識させておきます。
(あらかじめS3上にファイルがなければ実行不要)MSCK REPAIR TABLE tbl1;データの登録
通常のINSERT文でデータを登録できます。今回は以下のSQLを実行しました。
INSERT INTO tbl1(id, value, tm) VALUES('sensor1', 100.0, DATE '2020-12-01'); INSERT INTO tbl1(id, value, tm) VALUES('sensor1', 101.0, DATE '2020-12-02'); INSERT INTO tbl1(id, value, tm) VALUES('sensor2', 102.0, DATE '2020-12-02'); INSERT INTO tbl1(id, value, tm) VALUES('sensor1', 103.0, DATE '2020-12-03'),('sensor2', 104.0, DATE '2020-12-03'); INSERT INTO tbl1(id, value, tm) VALUES('sensor1', 105.0, DATE '2020-12-03'),('sensor2', 106.0, DATE '2020-12-04');登録されたデータの確認
SELECT文でデータを取得できますが、S3上のファイルの中身を確認してみました。
テーブル作成時に指定した場所(s3://test-bucket/tbl1/)にファイルが作成されています。
パーティションごとにディレクトリができていて、その下に.gzファイルがあります。ファイル構成は以下のようになっていました。
.gzファイルを展開するとカンマ区切りのテキストファイルになっていることがわかります。2020-12-01/xxx.gz: sensor1,100.0 2020-12-02/yyy.gz: sensor1,101.0 2020-12-02/zzz.gz: sensor2,102.0 2020-12-03/www.gz: sensor1,103.0 sensor2,104.0 2020-12-03/www.gz: sensor1,105.0 2020-12-04/www.gz: sensor2,106.0INSERT文ごとにファイルがファイルが作成されていますね。異なるパーティションの場合はさらに別ファイルに分割されています。
intervalを設定してみた
intervalはパーティションキーの値の間隔を指定できる機能です。さっそく使ってみます。
date列に対して、"日にち"でインターバル
先程のCREATE文に対して、projection.datehour.intervalとprojection.datehour.interval.unitを指定し、インターバルを3日に設定しました。
CREATE EXTERNAL TABLE tbl2 (id string, value double) PARTITIONED BY (tm date) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ('serialization.format' = ',', 'field.delim' = ',') LOCATION 's3://test-bucket/tbl2/' TBLPROPERTIES ( 'has_encrypted_data'='false', 'projection.enabled' = 'true', 'projection.tm.type' = 'date', 'projection.tm.range' = 'NOW-3YEARS,NOW+3YEARS', 'projection.tm.format' = 'yyyy-MM-dd', 'projection.datehour.interval' = '3', 'projection.datehour.interval.unit' = 'DAYS', 'storage.location.template' = 's3://test-bucket/tbl2/${tm}' );それでは、本日(12/2)、明日、明後日のデータを登録してみます。インターバルは3日だけど、明日・明後日のデータは登録できるのか?登録できた場合、S3上のディレクトリ構成はどうなっているか気になり、確認しました。
INSERT INTO tbl2(id, value, tm) VALUES('sensor1', 100.0, DATE '2020-12-02'); INSERT INTO tbl2(id, value, tm) VALUES('sensor2', 100.0, DATE '2020-12-03'); INSERT INTO tbl2(id, value, tm) VALUES('sensor3', 100.0, DATE '2020-12-04');INSERTできました。
S3上はどうなっているかというと、s3://test-bucket/tbl2に3つのディレクトリが作成され、その下にそれぞれ.gzファイルがありました。2020-12-02/xxx.gz: sensor1,100.0 2020-12-03/yyy.gz: sensor2,100.0 2020-12-04/zzz.gz: sensor3,100.0date列に対して、"月"でインターバル
今度はインターバルを1月に設定しました。パーティションキーの列には日にちのデータが格納されています。
4つのデータを登録してみます。本日、明日、1ヶ月前、1ヶ月と1日前のデータです。
インターバルより細かいデータはどう扱われるでしょうか?INSERT INTO tbl3(id, value, tm) VALUES('sensor1', 100.0, DATE '2020-12-02'); INSERT INTO tbl3(id, value, tm) VALUES('sensor2', 100.0, DATE '2020-12-03'); INSERT INTO tbl3(id, value, tm) VALUES('sensor3', 100.0, DATE '2020-11-02'); INSERT INTO tbl3(id, value, tm) VALUES('sensor4', 100.0, DATE '2020-11-01');結論としては、"日"でのインターバルと同じでした。
以下のように、日付ごとにディレクトリが作成されていました。2020-11-01/xxx.gz: sensor4,100.0 2020-11-02/yyy.gz: sensor3,100.0 2020-12-02/zzz.gz: sensor1,100.0 2020-12-03/www.gz: sensor2,100.0おわりに
パーティション射影機能を使ってみました。
CREATE EXTERNAL TABLEのTBLPROPERTIESに設定を記述するだけで簡単にパーティションが作れました。
S3上には、パーティションのインターバルに関係なくstorage.location.templateで指定した場所にファイル分割されてデータが格納されるようです。参考文献
https://docs.aws.amazon.com/athena/latest/ug/partition-projection.html
https://dev.classmethod.jp/articles/20200627-amazon-athena-partition-projection/
- 投稿日:2020-12-15T16:03:21+09:00
Lambda関数でEmbulkコマンドを実行してみる
はじめに
この記事は BeeX Advent Calendar 2020 の12/16の記事です。
==
前の記事でLambdaのコンテナイメージでの実行を試してみました。
今回はそれに加えて、最近よく使っているEmbulkコマンドを使えないか試してみました。
環境
PC:Windows 10
Docker:Docker version 19.03.13, build 4484c46d9d前提
- Dockerの初期設定は完了済み
- Python3はインストール済み(Lambdaランタイムと同じかそれ以上)
- AWSアカウントは作成済み
- Amazon ECRリポジトリは作成済み
実際の操作
lambda functionの作成
@shiro01さんの記事を参考にLambda Functionを作成します。
今回はEmbulkの実行の確認なのでシンプルにヘルプコマンドを実行してみます。lambda_function.pyimport subprocess def lambda_handler(event, context): cmd = ['/usr/bin/embulk','help'] out = subprocess.run(cmd,shell=True , stdout=subprocess.PIPE) print(out.stdout.decode())1つ注意点として、subprocess.runの引数に"shell=Treu"を追加しています。
これを追加しないとOSErrorが発生します。参考
Dockerfileの作成
続いてDockerfileを作成します。
Embulkは事前にインストールして実行ファイルを作成しておきます。
DockerfileのCOPYでEmbulkとlambda_functionをコンテナ上にコピーします。FROM amazon/aws-lambda-python:3.7 COPY lambda_function.py ./ COPY embulk /usr/bin RUN chmod +x /usr/bin/embulk CMD [ "lambda_function.lambda_handler" ]イメージをBuildする
以下のコマンドでイメージをビルドします。
$ cd [DockerFile格納先DIR] $ docker build -t lambda_embulk .イメージが作成されます。
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE lambda_embulk latest 472005da7cf7 About a minute ago 980MBローカルテスト
以下のコマンドでローカルでLambdaを実行することが可能です。
$ docker run -p 9000:8080 lambda_embulk:latest time="2020-12-15T06:11:57.95" level=info msg="exec '/var/runtime/bootstrap' (cwd=/var/task, handler=)"別のウィンドウを開いて、以下のコマンドを実行します。
curlコマンドのレスポンスとしてはnullが返ってきます。$ curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d''{}' nullコンテナを実行しているウィンドウを確認すると実行された結果がコンソールに表示されています。
"embulk help"コマンドが実行されているので、ローカルテストは問題なさそうです。$ docker run -p 9000:8080 lambda_embulk:latest time="2020-12-15T06:13:53.604" level=info msg="exec '/var/runtime/bootstrap' (cwd=/var/task, handler=)" START RequestId: 0ed577b3-6a07-447a-bccb-c03d255c0201 Version: $LATEST time="2020-12-15T06:13:57.601" level=info msg="extensionsDisabledByLayer(/opt/disable-extensions-jwigqn8j) -> stat /opt/disable-extensions-jwigqn8j: no such file or directory" time="2020-12-15T06:13:57.601" level=warning msg="Cannot list external agents" error="open /opt/extensions: no such file or directory" Embulk v0.9.23 Usage: embulk [-vm-options] <command> [--options] Commands: mkbundle <directory> # create a new plugin bundle environment. bundle [directory] # update a plugin bundle environment. run <config.yml> # run a bulk load transaction. cleanup <config.yml> # cleanup resume state. preview <config.yml> # dry-run the bulk load without output and show preview. guess <partial-config.yml> -o <output.yml> # guess missing parameters to create a complete configuration file. gem <install | list | help> # install a plugin or show installed plugins. new <category> <name> # generates new plugin template migrate <path> # modify plugin code to use the latest Embulk plugin API example [path] # creates an example config file and csv file to try embulk. selfupdate [version] # upgrades embulk to the latest released version or to the specified version. VM options: -E... Run an external script to configure environment variables in JVM (Operations not just setting envs are not recommended nor guaranteed. Expect side effects by running your external script at your own risk.) -J-O Disable JVM optimizations to speed up startup time (enabled by default if command is 'run') -J+O Enable JVM optimizations to speed up throughput -J... Set JVM options (use -J-help to see available options) -R--dev Set JRuby to be in development mode Use `<command> --help` to see description of the commands. END RequestId: 0ed577b3-6a07-447a-bccb-c03d255c0201 REPORT RequestId: 0ed577b3-6a07-447a-bccb-c03d255c0201 Init Duration: 1.03 ms Duration: 591.61 ms Billed Duration: 600 mMemory Size: 3008 MB Max Memory Used: 3008 MBECRリポジトリへのPush
AWSコンソールからリポジトリを作成します。
以下のコマンドで作成したECRリポジトリにイメージをPushします。
ここら辺は前回の記事をほぼ同じです。
Embulkが少々サイズがあるので、前回よりPushに時間がかかります。$ docker tag lambda_embulk:latest XXXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-embulk $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE 941996685139.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-embulk latest 472005da7cf7 11 minutes ago 980MB$ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin XXXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com Login Succeeded$ docker push XXXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-embulk:latest The push refers to repository [XXXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-embulk] 5f70bf18a086: Pushed 65f9fe7cdd01: Pushed 1965e83122e7: Pushed 701bdcbf3b47: Pushed 6e660533f001: Pushed 069cd8bd11dd: Pushed 6e191121f7ea: Pushed d6fa53d6caa6: Pushed 1fb474cee41c: Pushed b1754cf6954d: Pushed 464c816a7003: Pushed latest: digest: sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX size: 2624無事にアップロードできました。
Lambda作成・実行
AWSのコンソールからLambda関数を作成します。
Lambda関数が作成されました。
実行結果確認
timeoutでエラーが出ました。
Lambdaの基本設定でタイムアウト値が3秒になっていたので、とりあえず3分に変更します。
少し時間はかかりましたが、正常終了しました。
出力内容を見る限りEmbulkのhelpコマンドも実行できているみたいです。
さいごに
これが良いかどうかは別として、無事にLambdaでEmbulkを実行することができました。
多分実運用するならLambdaのスペックとかdiffファイルどこで保持するとか色々検討すべきことはありますが、とりあえずs3に置いてそこから小規模の処理を動かすとかならいけるんじゃないですかね?知らんけど。ただEmbulkの処理ってLambdaの実行時間に収まることあまりないから、その辺りは難しいところかもしれません。
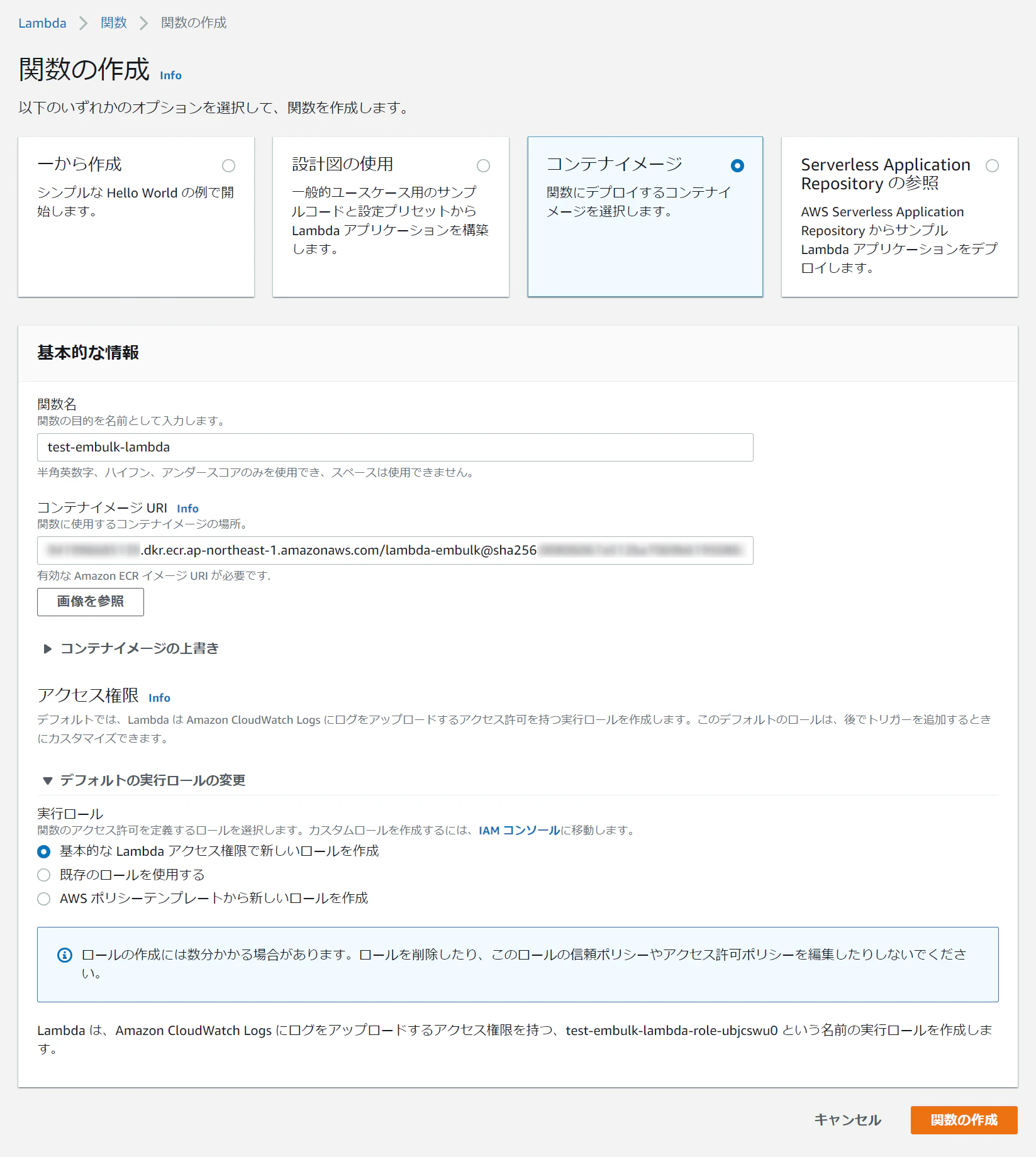
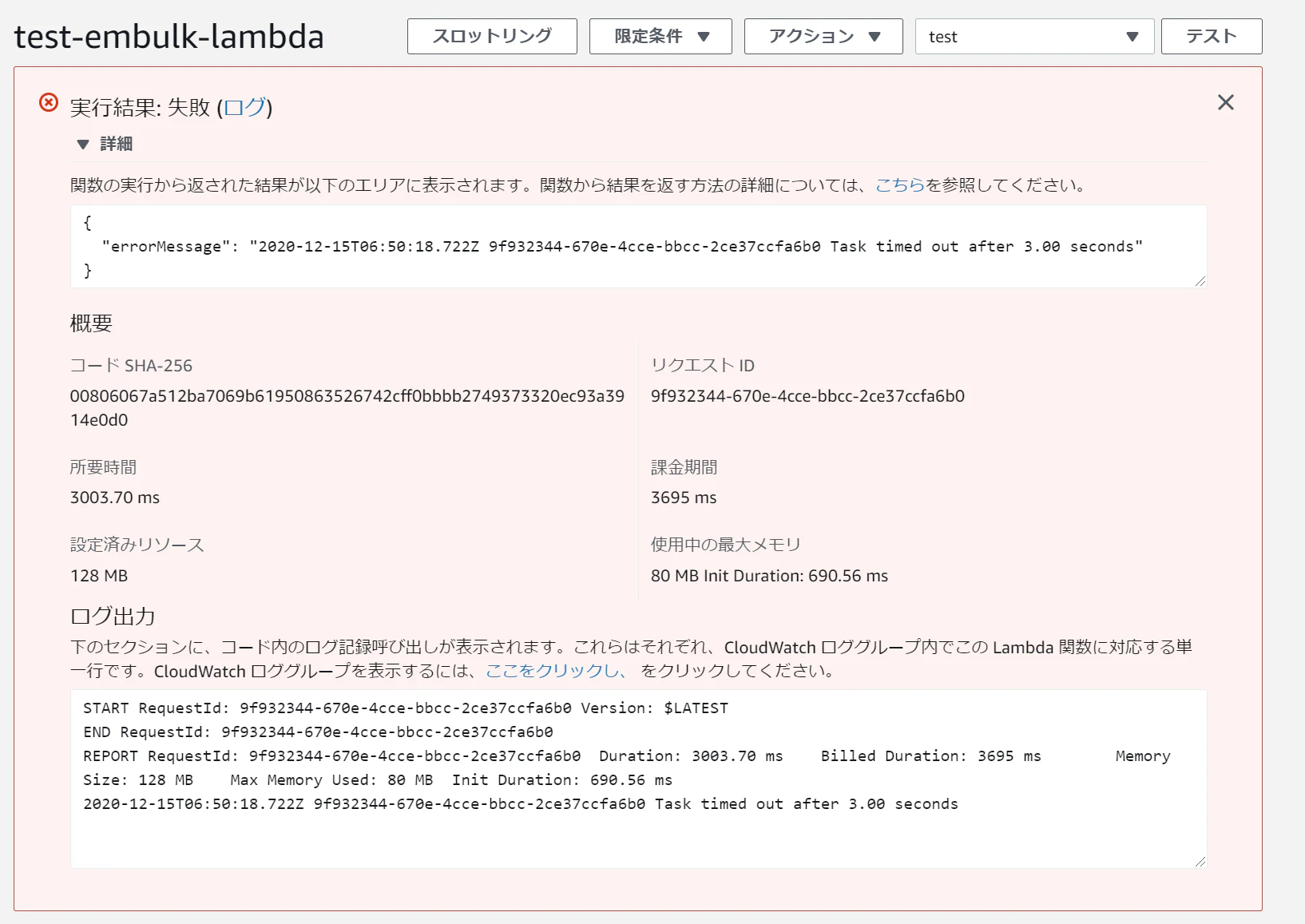
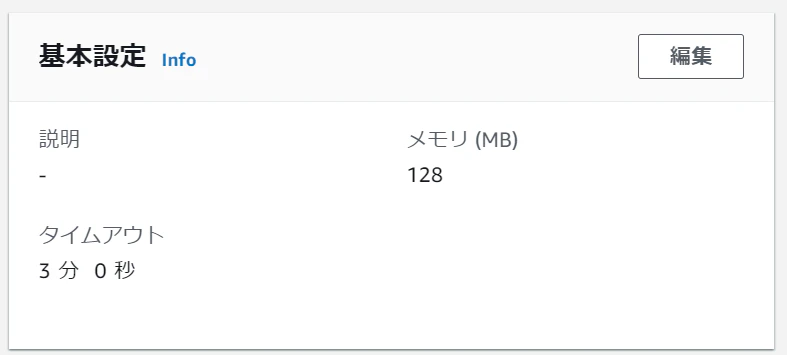
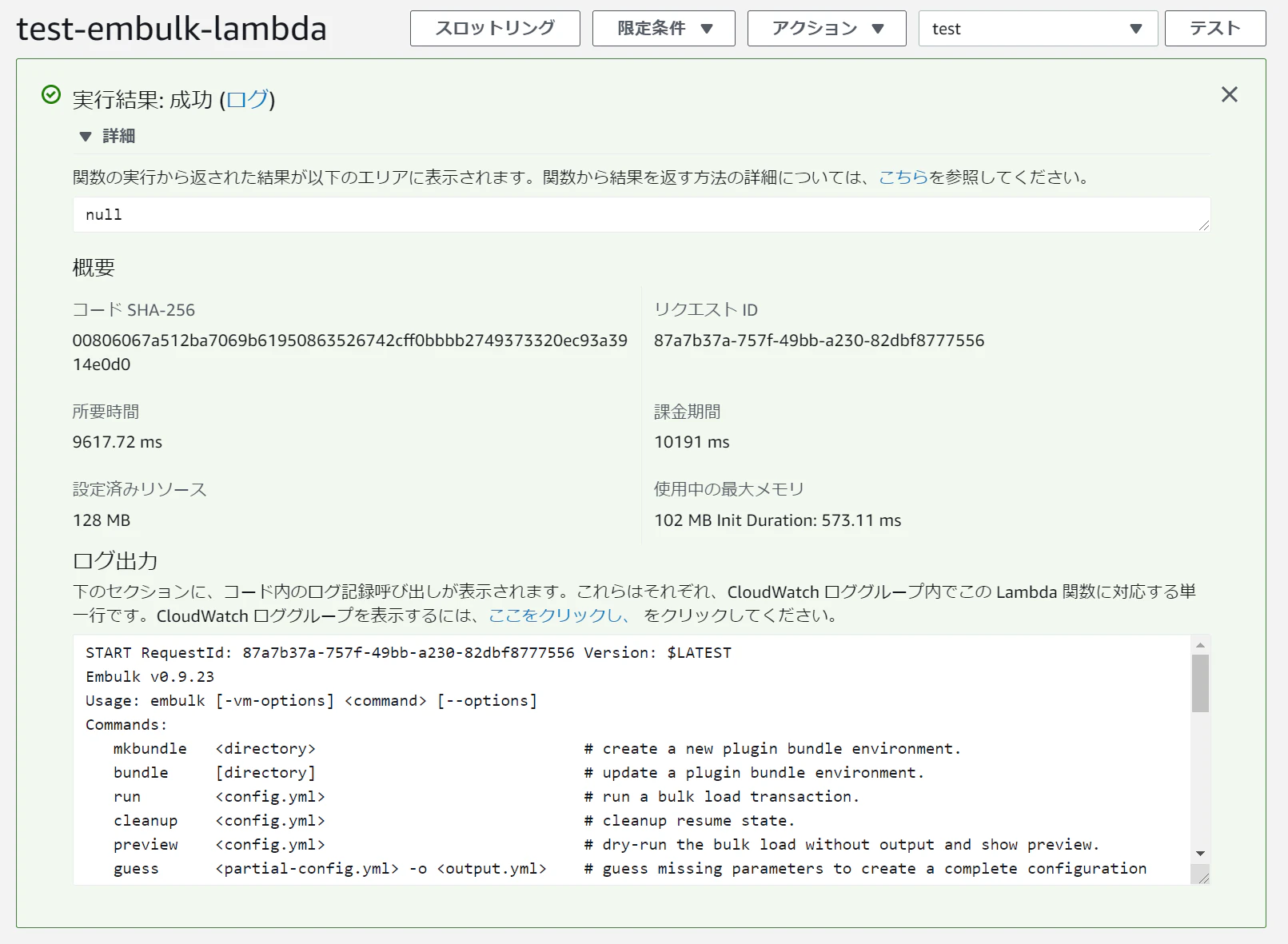
- 投稿日:2020-12-15T15:29:35+09:00
作成済のAmazon WorkSpacesのパブリックIPの探し方
定期的に忘れてパニクるので、衝動的にメモ。
- WorkSpacesコンソールから、プライベートIPをコピーする。
- EC2コンソール>ネットワークインターフェイスに進む。
- 上部の検索窓にプライベートIPを入力してフィルタリングし、該当するENIをみつける。
- ENIの詳細画面から、パブリックIP/DNSを探す。
ENIの管理画面が、VPCコンソールではなくEC2コンソールにあるのが罠。
ちなみに:ENIとは
Elastic Network Interfaceの略。
https://qiita.com/TaigoKuriyama/items/a1fcbadd10fa7ba41a04
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/using-eni.htmlひとことでいうと、仮想ネットワークカード (NIC) 的なもの。
EC2などにも自動で生成されて割り当てられている。
- 投稿日:2020-12-15T15:13:16+09:00
Chime SDKを使ってZoomライクなアプリを作ろうとしたら意外と苦戦した話
概要
この記事は CA21 Advent Calendar 2020 Day16の記事です。
タイトルの通り、Chime SDKを用いてZoomっぽいアプリを作ろうとしたらハマりどころが結構多くて苦戦したお話です。
本記事ではChime SDKについて、以下のことを説明します。
- Chime SDKとは
- 実装時に役に立つドキュメント
- 実装時にハマるポイント
- 通話アプリの実装にChime SDKを使うべきかどうか
Amazon Chime SDKを使うことになった経緯
インターン先で開発しているサービスで、これまでZoomを利用していた通話機能部分を内製化する要件が発生しました。
最初はZoom SDKを使おうとしていましたが、UI変更が困難であること, ZOOMに依存した構造になってしまうこと(たとえば使用に際してZoomのアカウントが必要となること)を懸念し、 UIの拡張性の高いChime SDKの使用を決めました。
Amazon Chime SDKについて
Amazon Chime SDKとは
簡単に言えば「通話アプリに必要な裏側の基盤をまるっとサポートしてくれる開発キット」です。
通常zoomのような通話アプリを作ろうとすると、WebRTCなど特殊な技術の勉強が必要となります。また、人数が増えた時の拡張性などを考慮したサーバー構築なども容易ではありません。
Chime SDKを使えばそういった煩雑な構築を完全にAWSに委ねることができます。また逆にUIに関しては余計なサポートがないため, 自分の思い通りのUIを作ることも容易です。Amazon Chime SDKを用いた通話アプリの構築
本記事では構築に関しては詳しく言及しませんが、以下記事が非常に参考になりました
amazon-chime-sdk-js(公式)
使用ケースごとにサンプルコードを書いてくれていてかなり親切. ここを見ればたいていの機能は構築できる。
Amazon Chime SDKを試してみた
日本語の記事の中では構築方法についてしっかり解説してくれている良記事。はまった点
このように便利に思えるChime SDKですが、実際に開発に使ってみるとかなりはまりどころがありました。本記事では自分がはまった問題点とその解決策を紹介します。
部屋の保存時間が限られる
開発中に「一度作ったはずの部屋が一定時間後に消えてしまう(アクセスできなくなる)」という事象が発生しました。
サポートに問い合わせてみたところ、以下の条件を満たすと、作成したmeeting roomが自動削除されてしまうことがわかりました1. 誰もAudio接続しないまま5分が経過した場合 2. 1人のみが接続した状態で30分以上が経過した場合 3. 1人のみがscreen shareをした状態で30分以上が経過した場合 4. meeting開始から24時間がたった場合すなわち、Chime SDKではZoomのような部屋の作り置きができないということです。
これを解決するには、以下図のように、前もって別のDBにmeeting情報を保存しておき、開始時に初めてChimeでroom作成する、などの工夫が必要です。
SSL化しないとうまく動かない
デプロイ後、以下のコードで本番環境のみエラーが発生する事象に遭遇しました。
//videoデバイスの設定 this.videoInputDevices = await meetingSession.audioVideo.listVideoInputDevices();こちらもサポートに問い合わせてみたところ、Chime SDKを用いたアプリはhttpsプロトクルを用いた環境でないとうまく動作しないということがわかりました。
(上記コードが内部的にnavigator.mediaDevicesを呼び出しており、httpプロトコル化ではこれが未定義になるのが原因らしい)
だが、なぜlocalhostだと動いてしまうのかは謎...教えて強い人...!自分以外の参加者の「ビデオオフ」と「退出」の判別ができない
Chime SDKでは参加者の画面On Offの検知をするために以下のようなobserverを定義します。
const observer = { videoTileDidUpdate: async (tileState) => { //videoをつけた時の処理 }, videoTileWasRemoved: (tileId) => { //videoを消した時の処理 } } meetingSession.audioVideo.addObserver(observer)ところが上記observer内の
videoTileWasRemovedは該当の参加者が退出した際にも、ビデオをオフにした際にも反応してしまいます。すなわちobserver単体だと、退出とビデオオフの状態区別ができないのです...(この仕様のせいか、Amazon Chimeの公式アプリは、カメラをオフ専用のUIが用意されていません)これを解決するためには、退出検知用に以下のようなコードを書く必要があります。
//入退出処理 const callback = async (presentAttendeeId, present) => { if (present) { //入室時処理 } else { //退出処理 } } meetingSession.audioVideo.realtimeSubscribeToAttendeeIdPresence( callback )このコードは参加者の入退室時のみ駆動し、定義した動作を行ってくれます。
つまり、observerのvideoTileWasRemovedにひっかかったときは問答無用で画面オフとみなす, 退出検知のコードに引っかかった時は退出とみなすという区別ができるわけですね。(画面オフ専用のobserverもできればつくってほしいけど...)録画の仕方が特殊
ここが現状最大のWeak Pointだと思うのですが、Chime SDKは画面および音声の録画機能を標準サポートしていません。
代替策として、公式が録画APIのデモを提供しているのでこちらを利用することになります。
ただ、この録画APIの仕組みは「指定したURLの画面および音声をキャプチャする」ことですので、実際の通話アプリとは別に録画用のページを用意する必要があります。余談ですが、このデモではec2の
t3.xlargeが2台たちあがります。放置しているとお財布にかなりの打撃が入るので、READMEにも書いている通り、使用後は必ず全て削除するようにしましょう。 (私はここに1ヶ月気づかず数万円ふっとばしました結論 「通話アプリにAmazon Chimeを使うのは有効か?」
なんだかんだと文句は書いてきましたが、基本的には工夫すれば通話アプリに必要なほとんどの機能は実装できるため、かなりつかえるSDKだと感じました。
特に以下のような場合はまよわずChime SDKを使っていいのではないかと思います。
- 特殊なUIの通話アプリを作りたい(UIのカスタマイズが自由なSDKを使いたい)
- バックエンドの仕様やスペックは丸投げでいい(むしろまるなげしたい)
- 他のアプリに依存しない通話アプリを作りたい
コロナの影響で、通話アプリdeveloperの需要が高まると考えられる今日この頃、皆様も是非一度試してみてはいかがでしょうか?
PR
内定先のCyberAgentでは22卒のエンジニア採用を行っています!
https://www.cyberagent.co.jp/careers/news/detail/id=25511
皆様のご応募お待ちしております!


- 投稿日:2020-12-15T14:58:56+09:00
⑭本番環境でデータベースを作成ーポートフォリオ
データベースの種類
- 階層型データベース
- ネットワーク型データベース
- リレーショナルデータベース
この中でもっとも利用されているのが「リレーショナルデータベース」です。
エクセルの表のような形で情報を整理し、管理できます。そして、このリレーショナルデータベースを管理するソフトウェアは「リレーショナル・データ・ベース・マネジメント・システム(RDBMS)」と呼ばれます。
そんなRDBMSの中でも代表的なものの1つが「MySQL」です。MySQL
データベースの作成、編集、削除などを行うことができます。オープンソースソフトウェアとして公開されており、誰でも無償で利用できます。
Ruby on Railsと合わせ利用することができます。MariaDB
「MariaDB」とは、MySQLの派生として開発されているオープンソースソフトウェアです。MySQLとの互換性があります。今回デプロイカリキュラムで使用しているAmazon Linux 2ではMariaDBを使用することになっています。基本的にMariaDBとMySQLは同様のものと考える
MariaDBをインストール
[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install mysql56-server mysql56-devel mysql56 mariadb-server mysql-devel[ec2-user@ip-172-31-25-189 ~]$ sudo systemctl start mariadbデータベースのrootパスワードの設定
yumでインストールしたMariaDBには、デフォルトで「root」というユーザーでアクセスできるようになっていますが、パスワードは設定されていません。なので、パスワードを設定する必要があります。[ec2-user@ip-172-31-25-189 ~]$ sudo /usr/bin/mysql_secure_installation