- 投稿日:2020-12-15T23:33:07+09:00
Insider(ボドゲ)のDiscordbotを作ってみた
この記事はkb Advent Calendar 2020 17日目の記事です。 https://adventar.org/calendars/5280
目次
- discordを使ってInsider(ボドゲ)をできるようにしてみた
- Insider(ボドゲ)とは
- 実装について
- discordのどのような機能がボドゲにむいているか
- 感想
discordを使ってInsider(ボドゲ)をできるようにしてみた
最近AmongUsっていう人狼っぽいゲームをやりました。
そのゲームで色々マイクをミュートにしたりするbot
https://github.com/denverquane/automuteus
が公開されていて、そこから自分でもbotを作ってボドゲを再現できるのでは?
と思いつき、実際に作ってみました。想像以上に簡単に作ることが出来たので、コロナで実際に会って遊ぶのが難しい状況なので
友達とワイワイしながら作って、ワイワイ遊んでくれる人が増えたらいいなぁっと思って記事を書きました。Insider(ボドゲ)とは
人狼っぽいゲーム
https://oinkgames.com/ja/games/analog/insider/実装について
Glitch というサービスを使って簡単に開発 ~ 遊ぶ まで出来ました。
Glitchを選んだ理由は手間がすごく省けてアプリケーションの開発のみに集中できるからです。
- サーバーなどのセットアップの必要がない
- プログラムを友だちと同時編集できる
- セーブすればサーバーが自動的に再起動
- 作業内容のバージョン管理
- プログラムをボタン一つで整形してくれる
- 無料
導入までの流れは
https://note.com/bami55/n/ncc3a68652697
こちらの記事を参考にしました。実装内容
とりあえず以下の内容をコピペしてもらえれば Insiderが遊べれると思います。
main.js
// Response for Uptime Robot const http = require("http"); const config = require("./config.json"); http .createServer(function(request, response) { response.writeHead(200, { "Content-Type": "text/plain" }); response.end("Discord bot is active now \n"); }) .listen(3000); // Discord bot implements const discord = require("discord.js"); const client = new discord.Client(); const embedBuilder = (title, author) => { return new discord.RichEmbed() .setTitle(`Poll - ${title}`) .setFooter(`Poll created by ${author}`); }; const defEmojiList = [ "\u0031\u20E3", "\u0032\u20E3", "\u0033\u20E3", "\u0034\u20E3", "\u0035\u20E3", "\u0036\u20E3", "\u0037\u20E3", "\u0038\u20E3", "\u0039\u20E3", "\uD83D\uDD1F" ]; const pollEmbed = async ( msg, title, options, timeout = 30, emojiList = defEmojiList.slice(), insider ) => { if (!msg && !msg.channel) return msg.reply("Channel is inaccessible."); if (!title) return msg.reply("Poll title is not given."); if (!options) return msg.reply("Poll options are not given."); if (options.length < 2) return msg.reply("Please provide more than one choice."); if (options.length > emojiList.length) return msg.reply(`Please provide ${emojiList.length} or less choices.`); let text = `*投票するには該当の数字をクリックしてください。\n投票時間は**${timeout} 秒です**`; const emojiInfo = {}; for (const option of options) { const emoji = emojiList.splice(0, 1); emojiInfo[emoji] = { option: option, votes: 0 }; text += `${emoji} : \`${option}\`\n\n`; } const usedEmojis = Object.keys(emojiInfo); const poll = await msg.channel.send( embedBuilder(title, msg.author.tag).setDescription(text) ); for (const emoji of usedEmojis) await poll.react(emoji); const reactionCollector = poll.createReactionCollector( (reaction, user) => usedEmojis.includes(reaction.emoji.name) && !user.bot, timeout === 0 ? {} : { time: timeout * 1000 } ); const voterInfo = new Map(); reactionCollector.on("collect", (reaction, user) => { if (usedEmojis.includes(reaction.emoji.name)) { if (!voterInfo.has(user.id)) { voterInfo.set(user.id, { emoji: reaction.emoji.name }); } const votedEmoji = voterInfo.get(user.id).emoji; emojiInfo[reaction.emoji.name].votes += 1; } }); reactionCollector.on("dispose", (reaction, user) => { if (usedEmojis.includes(reaction.emoji.name)) { voterInfo.delete(user.id); emojiInfo[reaction.emoji.name].votes -= 1; } }); reactionCollector.on("end", () => { text = "投票終了!!\n 結果発表!!\n\n"; for (const emoji in emojiInfo) text += `\`${emojiInfo[emoji].option}\` - \`${emojiInfo[emoji].votes}\`\n\n`; text += `インサイダーは${insider}でした\n\n`; poll.delete(); msg.channel.send(embedBuilder(title, msg.author.tag).setDescription(text)); }); }; client.on("ready", message => { client.user.setPresence({ game: { name: "with discord.js" } }); console.log("bot is ready!"); }); function sleep(time) { return new Promise((resolve, reject) => { setTimeout(() => { resolve(); }, time); }); } client.on("message", async message => { if (message.content.indexOf(config.prefix) !== 0) return; const args = message.content .slice(config.prefix.length) .trim() .split(/ +/g); const command = args.shift().toLowerCase(); if (command == "play") { let channel = message.member.voiceChannel; if (channel.members.size < 3) { message.channel.send("起動に失敗しました。3人から始めることができます。"); return; } const members = channel.members; const masterMember = members.random(); let insiderMember = members.random(); while (true) { if (masterMember !== insiderMember) break; insiderMember = members.random(); } const masterUser = masterMember.user; const insiderUser = insiderMember.user; message.channel.send("------------------------"); message.channel.send(`マスターは${masterUser.username}です。`); const themes = [ "蛾", "将棋盤", "朝顔", "金太郎飴", "ワインレッド", "警備員", "山脈", "鼻毛", "窓枠" ]; const theme = themes[Math.floor(Math.random() * themes.length)]; members.forEach(member => { if (member.user.username === masterUser.username) { member.user.sendMessage("------------------------"); member.user.sendMessage(`テーマは${theme}です。`); } else if (member.user.username === insiderUser.username) { member.user.sendMessage("------------------------"); member.user.sendMessage("あなたがインサイダーです。"); member.user.sendMessage(`テーマは${theme}です。`); } }); await sleep(2000); message.channel.send("Game Start!"); // タイマー await sleep(1000 * 60 * 3); // 投票機能 const pollOptions = []; channel.members.forEach(member => { pollOptions.push(member.user.username); }); pollEmbed( message, "test", pollOptions, 30, defEmojiList.slice(), insiderUser.username ); } }); if (process.env.DISCORD_BOT_TOKEN == undefined) { console.log("please set ENV: DISCORD_BOT_TOKEN"); process.exit(0); } client.login(process.env.DISCORD_BOT_TOKEN);{ "name": "glitch-discord-bot", "version": "0.0.0", "description": "discord bot sample on Glitch", "main": "main.js", "dependencies": { "discord.js": "latest", "discord.js-poll-embed": "^1.0.2", }, "devDependencies": {}, "scripts": { "start": "node main.js", "test": "node main.js" } }遊び方
- 遊びたい友達をdiscordのボイスチャットに入れる
- テキストチャンネルに .play と入力する
- botがインサイダーとマスターにお題をDMするので制限時間(3分)以内にお題を当てる
- 投票画面が出てくるので、インサイダーだと思う人に投票する
- 投票結果が表示される
discordのどのような機能がボドゲにむいているか
DM機能
他のメンバーに秘密な情報などを送ることが出来ます
client.on("message", async message => {let channel = message.member.voiceChannel;ここのmessageのところに発言した人の情報が来るので
発言内容 => 発言した人 => 発言した人がいるボイスチャンネル => ボイスチャンネルにいるメンバー
の流れでメンバーの一覧を取得します。members.forEach(member => { if (member.user.username === masterUser.username) { member.user.sendMessage("------------------------"); member.user.sendMessage(`テーマは${theme}です。`); } else if (member.user.username === insiderUser.username) { member.user.sendMessage("------------------------"); member.user.sendMessage("あなたがインサイダーです。"); member.user.sendMessage(`テーマは${theme}です。`); } });あとは、メンバーの一覧から該当のメンバーに
member.user.sendMessage("------------------------")としてあげればDMを送ることが出来ます。
音声再生
ボットに任意の音声を再生させることが出来ます。
ゲームの開始や終了などで盛り上げることが出来ます。Glitchで音声を使おうとすると
1. assets から音声をアップロード
2. アップロードしたファイルをクリックしてurlを取得
3. Glitch上のtools > terminal から wget で1. でアップロードしたファイルのurlを保存する
4. プログラムからファイルのパスを指定する
の流れで出来ます。ポイントとしては
- Glitch上のassetsはディレクトリではなかったということ、ストレージ的な扱いだった...
- 音声再生しようとしたらnode上で音声の再生ができるようにしなければいけなかった。
- 再生までのラグがあるので、音声ファイルの前後に無音時間を入れる必要があるconst play = async (voiceConnection, filepath) => { const player = voiceConnection.playFile(filepath, { volume: 0.5 }); await new Promise(resolve => player.on("end", resolve)); }; ... await play(voiceConnection, "./sounds/open.wav");{ "name": "glitch-discord-bot", "version": "0.0.0", "description": "discord bot sample on Glitch", "main": "main.js", "dependencies": { "discord.js": "latest", "ffmpeg-static": "^4.2.7", "node-opus": "^0.3.3", "discord.js-poll-embed": "^1.0.2", "play-sound": "^1.1.3" }, "devDependencies": {}, "scripts": { "start": "node main.js", "test": "node main.js" } }投票
投票をdiscord上で行えれる
集計とか楽こちらを参考にさせていただきました
https://github.com/saanuregh/discord.js-poll-embedポイント
- discordjsのapiが最新だと12だったので少し修正が必要だったconst pollEmbed = async ( msg, title, options, timeout = 30, emojiList = defEmojiList.slice(), insider ) => { if (!msg && !msg.channel) return msg.reply("Channel is inaccessible."); if (!title) return msg.reply("Poll title is not given."); if (!options) return msg.reply("Poll options are not given."); if (options.length < 2) return msg.reply("Please provide more than one choice."); if (options.length > emojiList.length) return msg.reply(`Please provide ${emojiList.length} or less choices.`); let text = `*投票するには該当の数字をクリックしてください。\n投票時間は**${timeout} 秒です**`; const emojiInfo = {}; for (const option of options) { const emoji = emojiList.splice(0, 1); emojiInfo[emoji] = { option: option, votes: 0 }; text += `${emoji} : \`${option}\`\n\n`; } const usedEmojis = Object.keys(emojiInfo); const poll = await msg.channel.send( embedBuilder(title, msg.author.tag).setDescription(text) ); for (const emoji of usedEmojis) await poll.react(emoji); const reactionCollector = poll.createReactionCollector( (reaction, user) => usedEmojis.includes(reaction.emoji.name) && !user.bot, timeout === 0 ? {} : { time: timeout * 1000 } ); const voterInfo = new Map(); reactionCollector.on("collect", (reaction, user) => { if (usedEmojis.includes(reaction.emoji.name)) { if (!voterInfo.has(user.id)) { voterInfo.set(user.id, { emoji: reaction.emoji.name }); } const votedEmoji = voterInfo.get(user.id).emoji; emojiInfo[reaction.emoji.name].votes += 1; } }); reactionCollector.on("dispose", (reaction, user) => { if (usedEmojis.includes(reaction.emoji.name)) { voterInfo.delete(user.id); emojiInfo[reaction.emoji.name].votes -= 1; } }); reactionCollector.on("end", () => { text = "投票終了!!\n 結果発表!!\n\n"; for (const emoji in emojiInfo) text += `\`${emojiInfo[emoji].option}\` - \`${emojiInfo[emoji].votes}\`\n\n`; text += `インサイダーは${insider}でした\n\n`; poll.delete(); msg.channel.send(embedBuilder(title, msg.author.tag).setDescription(text)); }); };感想
あそぶところまでやってみて、やっぱりオフラインで遊ぶのと比べると物足りなさを感じました。
けれど友達とワイワイしながら作っていく醍醐味はあると思います。
簡単なコマンドや、プログラムの勉強にもなるので
ぜひみなさんも作って遊んでみてください。参考記事
- 投稿日:2020-12-15T23:24:00+09:00
Node.jsを使ってYoutubeの一部データをスプレッドシートに書き出してみる
はじめに
こちらは、CODE BASE OKINAWA プログラミングスクール Advent Calendar 2020の12/15の記事になります。
プログラミング歴5ヶ月目にして初めてこのような記事を書くことになります。せっかくなので、自分の作りたいものをこの機会に作ってシェアする感じで書いていきます。今回は、Node.jsでYoutubeAPIデータをスプレッドシートに書き出すについて書いていきます。
私自身、フロントエンドの学習自体はもうすぐ2ヶ月近くになり、普段はVueを触っていて、最近はAPIについても色々勉強しています。まだ技術的なことは書けないのですが、何かを作ったりするのは好きなので、この題材にさせていただきました。
対象レベルは、プログラミング初学者やフロントエンド学習者、何か作りたい!といった方、あたりに参考なれば嬉しいです。node.jsにした理由
- 普段からパッケージ管理で、npmを利用してるのでライブラリの種類や情報の掴み方を知っているから
- jsでwebアプリケーションぽく動作させたいから
vueでやってもよかったのですが、普段から使っているのでたまにはnode.jsで書いてみたかったてのもあります。
node.jsについて詳しく書かれています
Node.jsとはなにか?なぜみんな使っているのか?実行環境
$ node -v v14.15.0 $ npm -v 6.14.8作業ディレクトリの作成
$mkdir node-sheet $cd node-sheet $npm init -y Wrote to node-sheet/package.json: { "name": "node-sheet", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [], "author": "", "license": "ISC" } $ ls package.jsonYoutubeAPI有効化
GoogleAPIConsole
https://console.developers.google.com/スプレッドシートに書き込むデータを取得するためにAPIを有効化します。
こちらを参考にしました。
- Youtube api 認証キー設定 http://piyohiko.webcrow.jp/kids_tube/help/index.html
- APIキーは後ほど使います
GoogleSpreadSheetAPI有効化
GoogleAPIConsole
https://console.developers.google.com/以下のサイトが参考になるかと思います。
https://qiita.com/howdy39/items/ca719537bba676dce1cf指定のスプレッドシートにアクセスするために必要な認証情報を発行します。
ここでは、サービスアカウントを利用してスプレッドシートにアクセスし、
編集権限に必要な情報をAPIに持たせることができます。そのためのjsonファイルが発行され、ダウンロードされるはずなので、作業ディレクトリに移動させます。//client_secret.jsonに変更して移動させる $ls package.json $ls client_secret.json package.json
- 認証情報を作成する
- サービスアカウントのメールを後ほど使います。
Spreadsheetの設定
以下のように1行目のA~E列までカラム名を書いておきます
共有に先程のサービスアカウントのメールを貼り付けます。共有には編集権限を持たせておいて下さい。
モジュールのインストールとファイルの作成
$touch spreadsheet.js //スプレッドシートへの認証やアクセスに必要 $ npm install google-spreadsheet //youtubeAPIを叩くのに必要 $ nom install axiosspreadsheet.js
const { GoogleSpreadsheet } = require('google-spreadsheet'); const { promisify } = require('util') const axios = require('axios') const CREDIT = require('./client_secret.json') //認証情報をCREDITに持たせる // スプレッドシートキー const SPREADSHEET_KEY = 'スプレッドーシートのURL=>https://docs.google.com/spreadsheets/d/<この部分を書く>/edit#gid=0' const accessSpredsheet = async function (spreadsheetKey, keyword) { let Datas = []; // youtubeのデータを取得後に入れる変数 // youtubeのクエリデータを指定() // keywordは関数呼び出し時に引数として指定 const params = { q: keyword, //キーワード part: 'snippet', //どの部分のデータが欲しいのか type: 'video', order: 'viewCount', //並び順 maxResults: '22', //取得するデータの数 key: '<APIキーはここに書く>' } axios .get('https://www.googleapis.com/youtube/v3/search', { params: params }) .then(function (response) { console.log(response) Datas = response.data.items //Datasに取得したデータを入れる console.log(Datas) }) .catch(function (error) { console.log(error) }) //spreadsheetの指定 const doc = new GoogleSpreadsheet(spreadsheetKey) // サービスアカウントによる認証 await doc.useServiceAccountAuth({ client_email: CREDIT.client_email, private_key: CREDIT.private_key, }); // spreadsheetの情報を読み込み const info = await doc.loadInfo();; const sheet = doc.sheetsByIndex[0]; console.log(sheet.title) //スプレッドシートのタイトル console.log(sheet.rowCount) //行の数 //Datasにあるyoutubeデータをスプレッドシートに挿入する Datas.forEach(Data => { sheet.addRow({ title: Data.snippet.title, //タイトル description: Data.snippet.description, //説明 date: Data.snippet.publishTime, //投稿時間 channelTitle: Data.snippet.channelTitle, //チャンネルタイトル thumbnail: Data.snippet.thumbnails.medium.url //サムネイル }) }) } //上記の関数を呼び出し accessSpredsheet(SPREADSHEET_KEY, "Hikakin");書き出し実行
最後に、spreadsheet.jsを実行させて、取得したyoutubeデータをスプレッドシートに書き出していきます。
今回は、「Hikakin」というキーワードで実行しました。$ node spreadsheet.jsyoutubeAPIからは以下のようなデータが複数取得されます。
{ kind: 'youtube#searchResult', etag: 'zlk1vpMDWLcNHr51wCs5jvtFBRM', id: { kind: 'youtube#video', videoId: 'qBQ5w7RwVnI' }, snippet: { publishedAt: '2019-12-15T03:00:15Z', channelId: 'UCg4nOl7_gtStrLwF0_xoV0A', title: 'ヒカキン & セイキン - 夢', description: 'HIKAKIN #SEIKIN #夢 【Music】 監修:HIKAKIN 作詞作曲:SEIKIN 編曲:TeddyLoid 【Music Video】 Director:ZUMI Producer:Sakura Wakatsuki (avex) Director of ...', thumbnails: [Object], channelTitle: 'SeikinTV', liveBroadcastContent: 'none', publishTime: '2019-12-15T03:00:15Z' } },最終的にこんな感じになります。
まとめ
少し大雑把だったかもしれません。。。
外部APIを使って情報を取得したり、アクセストークンを使ってspreadsheetの書き出しをしたり、意外と学べる要素が多かったかなと感じてます。APIを叩くということも楽しいのですが、今回は、クライアント側で認証情報をリクエストして、GoogleSpreadsheetAPIで認証情報を発行して、DBにアクセスできる、といった流れがいかにもアプリケーションらしくてフロントエンド初学者に知っておいていい仕組みかなとも感じてます。
個人的には、Oauthについて勉強しようと思えた機会でした。
ちょうどフロントエンドとサーバーサイド間の学習を発展させたかったので良かっです。参考記事
Youtube api 認証キー設定
http://piyohiko.webcrow.jp/kids_tube/help/index.htmlGoogleSpreadsheetAPI有効化
https://qiita.com/howdy39/items/ca719537bba676dce1cfGoogleAPIConsole
https://console.developers.google.com/【Vue.js】YouTube Data APIをaxiosで取得し表示するサンプル(Firebase・Vue CLI v4.0.4)



- 投稿日:2020-12-15T23:24:00+09:00
GoogleAPIを使ってNode.jsでYoutubeの一部データをスプレッドシートに書き出してみる
はじめに
こちらは、CODE BASE OKINAWA プログラミングスクール Advent Calendar 2020の12/15の記事になります。
プログラミング歴5ヶ月目にして初めてこのような記事を書くことになります。せっかくなので、自分の作りたいものをこの機会に作ってシェアする感じで書いていきます。今回は、Node.jsでYoutubeAPIデータをスプレッドシートに書き出すについて書いていきます。
私自身、フロントエンドの学習自体はもうすぐ2ヶ月近くになり、普段はVueを触っていて、最近はAPIについても色々勉強しています。まだ技術的なことは書けないのですが、何かを作ったりするのは好きなので、この題材にさせていただきました。
対象レベルは、プログラミング初学者やフロントエンド学習者、何か作りたい!といった方、あたりに参考なれば嬉しいです。node.jsにした理由
- 普段からパッケージ管理で、npmを利用してるのでライブラリの種類や情報の掴み方を知っているから
- jsでwebアプリケーションぽく動作させたいから
シンプルにnode.jsで使って書いてみたかったというのもあります。
node.jsについて詳しく書かれています
Node.jsとはなにか?なぜみんな使っているのか?実行環境
$ node -v v14.15.0 $ npm -v 6.14.8作業ディレクトリの作成
$mkdir node-sheet $cd node-sheet $npm init -y Wrote to node-sheet/package.json: { "name": "node-sheet", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [], "author": "", "license": "ISC" } $ ls package.jsonYoutubeAPI有効化
GoogleAPIConsole
https://console.developers.google.com/スプレッドシートに書き込むデータを取得するためにAPIを有効化します。
こちらを参考にしました。
- Youtube api 認証キー設定 http://piyohiko.webcrow.jp/kids_tube/help/index.html
- APIキーは後ほど使います
GoogleSpreadSheetAPI有効化
GoogleAPIConsole
https://console.developers.google.com/以下のサイトが参考になるかと思います。
https://qiita.com/howdy39/items/ca719537bba676dce1cf指定のスプレッドシートにアクセスするために必要な認証情報を発行します。
ここでは、サービスアカウントを利用してスプレッドシートにアクセスし、
編集権限に必要な情報をAPIに持たせることができます。そのためのjsonファイルが発行され、ダウンロードされるはずなので、作業ディレクトリに移動させます。// ダウンロードしたファイル名をclient_secret.jsonに変更して移動させる $ls package.json $ls client_secret.json package.json
- 認証情報を作成する
- サービスアカウントのメールを後ほど使います。
Spreadsheetの設定
以下のように1行目のA~E列までカラム名を書いておきます
共有に先程のサービスアカウントのメールを貼り付けます。共有には編集権限を持たせておいて下さい。
モジュールのインストールとファイルの作成
//実行ファイルの作成 $ touch spreadsheet.js //スプレッドシートへの認証やアクセスに必要 $ npm install google-spreadsheet //youtubeAPIを叩くのに必要 $ nom install axiosこれで、今回使用する最終的なファイル構造は以下のようになります。
- node_modules - client_secret.json - package-lock.json - package.json - spreadsheet.jsspreadsheet.js
const { GoogleSpreadsheet } = require('google-spreadsheet'); const axios = require('axios'); const CREDIT = require('./client_secret.json') //認証情報をCREDITに持たせる // スプレッドシートキー const SPREADSHEET_KEY = 'スプレッドーシートのURL=>https://docs.google.com/spreadsheets/d/<この部分を書く>/edit#gid=0' const accessSpredsheet = async function (spreadsheetKey, keyword) { let Datas = []; // youtubeのデータを取得後に入れる変数 // youtubeのクエリデータを指定() // keywordは関数呼び出し時に引数として指定 const params = { q: keyword, //キーワード part: 'snippet', //どの部分のデータが欲しいのか type: 'video', order: 'viewCount', //並び順 maxResults: '22', //取得するデータの数 key: '<APIキーはここに書く>' } axios .get('https://www.googleapis.com/youtube/v3/search', { params: params }) .then(function (response) { console.log(response) Datas = response.data.items //Datasに取得したデータを入れる console.log(Datas) }) .catch(function (error) { console.log(error) }) //spreadsheetの指定 const doc = new GoogleSpreadsheet(spreadsheetKey) // サービスアカウントによる認証 await doc.useServiceAccountAuth({ client_email: CREDIT.client_email, private_key: CREDIT.private_key, }); // spreadsheetの情報を読み込み const info = await doc.loadInfo();; const sheet = doc.sheetsByIndex[0]; console.log(sheet.title) //スプレッドシートのタイトル console.log(sheet.rowCount) //行の数 //Datasにあるyoutubeデータをスプレッドシートに挿入する Datas.forEach(Data => { sheet.addRow({ title: Data.snippet.title, //タイトル description: Data.snippet.description, //説明 date: Data.snippet.publishTime, //投稿時間 channelTitle: Data.snippet.channelTitle, //チャンネルタイトル thumbnail: Data.snippet.thumbnails.medium.url //サムネイル }) }) } //上記の関数を呼び出し accessSpredsheet(SPREADSHEET_KEY, "Hikakin");書き出し実行
最後に、spreadsheet.jsを実行させて、取得したyoutubeデータをスプレッドシートに書き出していきます。
今回は、「Hikakin」というキーワードで実行しました。$ node spreadsheet.jsyoutubeAPIからは以下のようなデータが複数取得されます。
{ kind: 'youtube#searchResult', etag: 'zlk1vpMDWLcNHr51wCs5jvtFBRM', id: { kind: 'youtube#video', videoId: 'qBQ5w7RwVnI' }, snippet: { publishedAt: '2019-12-15T03:00:15Z', channelId: 'UCg4nOl7_gtStrLwF0_xoV0A', title: 'ヒカキン & セイキン - 夢', description: 'HIKAKIN #SEIKIN #夢 【Music】 監修:HIKAKIN 作詞作曲:SEIKIN 編曲:TeddyLoid 【Music Video】 Director:ZUMI Producer:Sakura Wakatsuki (avex) Director of ...', thumbnails: [Object], channelTitle: 'SeikinTV', liveBroadcastContent: 'none', publishTime: '2019-12-15T03:00:15Z' } },最終的にこんな感じになります。
まとめ
少し大雑把だったかもしれません。。。
外部APIを使って情報を取得したり、認証情報を発行してspreadsheetの書き出しをしたり、意外と学べる要素が多かったかなと感じてます。APIを叩くということも楽しいのですが、今回は、GoogleSpreadsheetAPIで認証情報を発行して、その認証情報を利用して、DBにアクセスできる、といった流れがいかにもアプリケーションらしくてフロントエンド初学者に知っておいていい仕組みかなとも感じてます。
個人的には、Oauthについて勉強しようと思えた機会でした。
ちょうどフロントエンドとサーバーサイド間の学習を発展させたかったので良かっです。参考記事
Youtube api 認証キー設定
http://piyohiko.webcrow.jp/kids_tube/help/index.htmlGoogleSpreadsheetAPI有効化
https://qiita.com/howdy39/items/ca719537bba676dce1cfGoogleAPIConsole
https://console.developers.google.com/【Vue.js】YouTube Data APIをaxiosで取得し表示するサンプル(Firebase・Vue CLI v4.0.4)
- 投稿日:2020-12-15T11:42:51+09:00
KEN_ALLってなあに
こんにちは。Japan Digital Design のインフラチームに所属している渡邉です。
有志で AdventCalendar をやっており、今回は18日目の記事です。
https://adventar.org/calendars/5160もう長いことこの業界で働いており、20代のころの仕事はほとんど思い出せないくらい、技術の移り変わりや進歩の速さに追いつけず勉強の日々ですが、昔と変わらぬ懐かしい佇まいで存在し続けるものも中にはあります。それがKEN_ALL...
住所を扱う仕事をしたことがある方なら避けては通れない、あの悪名高い(?)KEN_ALLですが、2020年現在どうなってるかなーと久々に覗いてみたところ案の定ほぼ変わっておらず(10数年のうちに途中で圧縮形式がlzhからzipになったりと微妙に変わってはいますが)、いまさら特に新たなネタもないのですが、知らないよ、という方のためにおさらいしてみようと思います。
KEN_ALLとは
日本郵便のサイトにて配布されている、郵便番号と住所が記載されたCSVデータのことです。
https://www.post.japanpost.jp/zipcode/download.html
Webサイトの入力フォームやアプリなどで郵便番号から住所を自動補完する場合などによく使われるかと思います。
CSVデータは各都道府県ごと、および全国(全都道府県)のデータがあり、全国のデータをダウンロードして解凍すると現れるのがKEN_ALL.csvです。
中身はこんな感じ↓01101,"060 ","0600000","ホッカイドウ","サッポロシチュウオウク","イカニケイサイガナイバアイ","北海道","札幌市中央区","以下に掲載がない場合",0,0,0,0,0,0 01101,"064 ","0640941","ホッカイドウ","サッポロシチュウオウク","アサヒガオカ","北海道","札幌市中央区","旭ケ丘",0,0,1,0,0,0 01101,"060 ","0600041","ホッカイドウ","サッポロシチュウオウク","オオドオリヒガシ","北海道","札幌市中央区","大通東",0,0,1,0,0,0 01101,"060 ","0600042","ホッカイドウ","サッポロシチュウオウク","オオドオリニシ(1-19チョウメ)","北海道","札幌市中央区","大通西(1~19丁目)",1,0,1,0,0,0 01101,"064 ","0640820","ホッカイドウ","サッポロシチュウオウク","オオドオリニシ(20-28チョウメ)","北海道","札幌市中央区","大通西(20~28丁目)",1,0,1,0,0,0日本郵便のサイトにもありますが下記のルールで生成されています。
- 全角となっている町域部分の文字数が38文字を越える場合、また半角となっているフリガナ部分の文字数が76文字を越える場合は、複数レコードに分割しています。
- この郵便番号データファイルでは、以下の順に配列しています。
- 全国地方公共団体コード(JIS X0401、X0402)……… 半角数字
- (旧)郵便番号(5桁)……………………………………… 半角数字
- 郵便番号(7桁)……………………………………… 半角数字
- 都道府県名 ………… 半角カタカナ(コード順に掲載) (注1)
- 市区町村名 ………… 半角カタカナ(コード順に掲載) (注1)
- 町域名 ……………… 半角カタカナ(五十音順に掲載) (注1)
- 都道府県名 ………… 漢字(コード順に掲載) (注1,2)
- 市区町村名 ………… 漢字(コード順に掲載) (注1,2)
- 町域名 ……………… 漢字(五十音順に掲載) (注1,2)
- 一町域が二以上の郵便番号で表される場合の表示 (注3) (「1」は該当、「0」は該当せず)
- 小字毎に番地が起番されている町域の表示 (注4) (「1」は該当、「0」は該当せず)
- 丁目を有する町域の場合の表示 (「1」は該当、「0」は該当せず)
- 一つの郵便番号で二以上の町域を表す場合の表示 (注5) (「1」は該当、「0」は該当せず)
- 更新の表示(注6)(「0」は変更なし、「1」は変更あり、「2」廃止(廃止データのみ使用))
- 変更理由 (「0」は変更なし、「1」市政・区政・町政・分区・政令指定都市施行、「2」住居表示の実施、「3」区画整理、「4」郵便区調整等、「5」訂正、「6」廃止(廃止データのみ使用))
※1 文字コードには、MS漢字コード(SHIFT JIS)を使用しています。
※2 文字セットとして、JIS X0208-1983を使用し、規定されていない文字はひらがなで表記しています。
※3 「一町域が二以上の郵便番号で表される場合の表示」とは、町域のみでは郵便番号が特定できず、丁目、番地、小字などにより番号が異なる町域のことです。
※4 「小字毎に番地が起番されている町域の表示」とは、郵便番号を設定した町域(大字)が複数の小字を有しており、各小字毎に番地が起番されているため、町域(郵便番号)と番地だけでは住所が特定できない町域のことです。<小字に同一番地が存在する住所>
○○市△△町が郵便番号の表す範囲であり、町域(郵便番号)と番地だけでは住所が特定できません。○○市△△町字A100番地
○○市△△町字B100番地
○○市△△町字C100番地※5 「一つの郵便番号で二以上の町域を表す場合の表示」とは、一つの郵便番号で複数の町域をまとめて表しており、郵便番号と番地だけでは住所が特定できないことを示すものです。
※6 「変更あり」とは追加および修正により更新されたデータを示すものです。
※7 全角となっている町域名の文字数が38文字を超える場合、また、半角カタカナとなっている町域名のフリガナが76文字を越える場合には、複数レコードに分割しています。なんだか色々と書いてありますが、使用する際に困るのは主に太字の部分、さらにはここに記載のない事項によるものが多いです。
KEN_ALLの困るところ
文字コードが Shift-JIS なのも「え!?」って思う方もいらっしゃるかもしれませんが、まあこれは序の口。
表現できない漢字はひらがなになってますが、それが許容できれば大したことありません。
(というかそれが許容できなければもうこのデータは使えません...)「一町域が二以上の郵便番号で表される場合」
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 0600042 ホッカイドウ サッポロシチュウオウク オオドオリニシ(1-19チョウメ) 北海道 札幌市中央区 大通西(1~19丁目) 0640820 ホッカイドウ サッポロシチュウオウク オオドオリニシ(20-28チョウメ) 北海道 札幌市中央区 大通西(20~28丁目) これは同じ町域で、複数の郵便番号にまたがるパターンです。
丁目が分断されてカッコ書きになっているものが多いです。
このパターンは郵便番号からの検索などではそのまま使っても害のない場合が多いかと思いますが、住所から逆引きする場合には注意が必要です。
可能であれば、「大通西1丁目」「大通西2丁目」...といったように分離したいところです。「一つの郵便番号で二以上の町域を表す場合」
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 0680546 ホッカイドウ ユウバリシ ナンブアオバチョウ 北海道 夕張市 南部青葉町 0680546 ホッカイドウ ユウバリシ ナンブキクスイチョウ 北海道 夕張市 南部菊水町 これは上記とは逆に、1つの郵便番号に複数の住所が存在します。
郵便番号からの検索の場合は、リスト表示などが必要になるパターンです。
ちなみに、市区町村どころか都道府県をまたがるレアケースも存在し、かつCSV上では続きレコードではなく全く別の場所に存在します。
都道府県単位での何かしらの処理をする場合は要注意です。
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 4980000 ミエケン クワナグンキソサキチョウ イカニケイサイガナイバアイ 三重県 桑名郡木曽岬町 以下に掲載がない場合 4980000 アイチケン ヤトミシ イカニケイサイガナイバアイ 愛知県 弥富市 以下に掲載がない場合 「小字毎に番地が起番されている町域」
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 9591361 ニイガタケン カモシ ゲジョウ 新潟県 加茂市 下条 これは日本郵便のサイトにも例が書いてありますが、郵便番号と番地だけでは住所が特定できないパターンです。
上記の住所は実際には、
- 新潟県加茂市下条戊617
- 新潟県加茂市下条乙617
といった住所があり、郵便番号(959-1361)と番地(617)だけでは住所が特定できないということです。
ただしこれは郵便番号データとしては特に気にする必要がない(CSV上は小字以降に何があるのかは分かりようがない)ので特に処理不要なことが多いかと思われます。
(「字(アザ)がある場合は必ず記載ください」などのアラートが出ると親切かもですね。見たことないですが。)「町域部分の文字数が38文字(またはフリガナ部分の文字数が76文字)を越える場合」
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 0660005 ホッカイドウ チトセシ キョウワ(88-2、271-10、343-2、404-1、427- 北海道 千歳市 協和(88-2、271-10、343-2、404-1、427- 0660005 ホッカイドウ チトセシ 3、431-12、443-6、608-2、641-8、814、842- 北海道 千歳市 3、431-12、443-6、608-2、641-8、814、842- 0660005 ホッカイドウ チトセシ 5、1137-3、1392、1657、1752バンチ) 北海道 千歳市 5、1137-3、1392、1657、1752番地) 郵便番号データで一番やっかいなのがこれです。
管理しているシステムの仕様なのか、この時代においても何らかの理由により76バイトしか入らないようです。
上記は同じ郵便番号の住所ですが、3行にわたって記載されています。この場合は(カッコ)の中に番地があるので「、」で分離すればいいのかなーと考えますが、下記はいかがでしょうか。
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 9218046 イシカワケン カナザワシ オオクワマチ(ア、イ、イ、ウ、ウエノ、オ、オオツ、カネツキヤマ、カミカワラ、カミネコシタ、 石川県 金沢市 大桑町(ア、イ、ヰ、ウ、上野、ヲ、オ乙、鐘搗山、上川原、上猫下、 9218046 イシカワケン カナザワシ ク、ケ、ゴショガダニ、コデラヤマ、シ、シモウエノ、シモニシガケ、ダイラ、チ、ツオツ、ツヘイ、テ、ト、 石川県 金沢市 ク、ケ、御所谷、小寺山、シ、下上野、下西欠、平、チ、ツ乙、ツ丙、テ、ト、 9218046 イシカワケン カナザワシ ナカウエノ、ナカオヤマ、ナカダイラ、ナカノオオヒラ、ニシノヤマ、ネコノシタイ、ノ、ハ、ヒラキ、 石川県 金沢市 中上野、中尾山、中平、中ノ大平、西ノ山、猫シタイ、ノ、ハ、開、 9218046 イシカワケン カナザワシ ホウシヤマ、ボウヤマ、マ、マスカワブチ、ム、モトスエ、モトワクナミコウ、ヤ、リ、ル、レオツ、 石川県 金沢市 法師山、坊山、マ、鱒川淵、ム、元末、元涌波庚、ヤ、リ、ル、レ乙、 9218046 イシカワケン カナザワシ レコウ、ロオツ、ロコウ、ワ) 石川県 金沢市 レ甲、ロ乙、ロ甲、和)
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 6511102 ヒョウゴケン コウベシキタク ヤマダチョウシモタニガミ(オオカミダニ、シュウホウガハラ、ナカイチリヤマ<9バンチノ4、12バンチヲノゾク>、 兵庫県 神戸市北区 山田町下谷上(大上谷、修法ケ原、中一里山「9番地の4、12番地を除く」、 6511102 ヒョウゴケン コウベシキタク ナガオヤマ、フタタビコウエン) 兵庫県 神戸市北区 長尾山、再度公園)
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 4280049 シズオカケン シマダシ マキノハラ(250-343バンチ<255、256、258、259、262、 静岡県 島田市 牧之原(250~343番地「255、256、258、259、262、 4280049 シズオカケン シマダシ 276、294-300、302-304バンチヲノゾク>) 静岡県 島田市 276、294~300、302~304番地を除く」)
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 9960301 ヤマガタケン モガミグンオオクラムラ ミナミヤマ(430バンチイジョウ<1770-1-2、1862-42、 山形県 最上郡大蔵村 南山(430番地以上「1770-1~2、1862-42、 9960301 ヤマガタケン モガミグンオオクラムラ 1923-5ヲノゾク>、オオヤチ、オリワタリ、カンカネノ、キンザン、タキノサワ、トヨマキ、ヌマノダイ、 山形県 最上郡大蔵村 1923-5を除く」、大谷地、折渡、鍵金野、金山、滝ノ沢、豊牧、沼の台、 9960301 ヤマガタケン モガミグンオオクラムラ ヒジオリ、ヒラバヤシ) 山形県 最上郡大蔵村 肘折、平林)
郵便番号 都道府県名(カナ) 市区町村名(カナ) 町域名(カナ) 都道府県名 市区町村名 町域名 0482402 ホッカイドウ ヨイチグンニキチョウ オオエ(1チョウメ、2チョウメ<651、662、668バンチ>イガイ、3チョウメ5、1 北海道 余市郡仁木町 大江(1丁目、2丁目「651、662、668番地」以外、3丁目5、1 0482402 ホッカイドウ ヨイチグンニキチョウ 3-4、20、678、687バンチ) 北海道 余市郡仁木町 3-4、20、678、687番地) いかがでしょうか。正確な住所を出せる自信ありますか?私はそのまま連結する以外やりたくないです(笑)
かつ、この複数行にまたがるパターンについては、フラグがありません。つまり複数行にまたがっているかどうかの判定は、なんと自分で行う必要があります!そのほか
町域に「以下に掲載がない場合」「の次に番地がくる場合」「一円」等々といった、本来住所ではない
無駄な温かみのある説明書きが入っていたりしますので、住所データとして使う場合は取り除く必要があります。
また、頻出するのが「(その他)」記載。連続したデータを見れば意味が分かりますが、ピンポイントでこの住所だけ表示すると意味不明な表記となってしまいます。皆さんお困りですよね
長々と書いてしまいましたが、世の中の皆さんもやはり困ってらっしゃるようで、色々な先人達がこのデータを何とか綺麗にしたものやツールを有料無料問わず公開されていますので、そちらを使われるのが一番良いかと思います。(丸投げ)
私はちょっと違った方向から、このデータを愛でるためのツールを作りました。
単純に、上記のような「要注意データ」をピックアップして表示するだけ、というなんとも使い道のなさそうなやつです。自分の作った住所検索や拾ってきたツールがちゃんと整形できているかのテストなどに使える...?かどうかは分かりませんが、下記に置いてあります。
https://github.com/yukihato/ken-all-sampling/単純に下記の住所を抽出してランダムでそれぞれ1つずつ表示します。
- type1:一町域が二以上の郵便番号で表される場合
- type2:一つの郵便番号で二以上の町域を表す場合
- type3:町域部分の文字数が38文字を越える場合
- type4:町域に想定しない記号が入っている
- type5:その他系
$ node index.js type4 { type4: [ { x0401: '23221', oldPostcode: '44113', postcode: '4411336', prefKana: 'アイチケン', cityKana: 'シンシロシ', townKana: 'トミオカ(ヤシキチク)', pref: '愛知県', city: '新城市', town: '富岡(○○屋敷)', flag1: '1', flag2: '0', flag3: '0', flag4: '0', flag5: '0', flag6: '0', multiple: 1 } ] }しかし、○○屋敷ってなんでしょうね...富豪がいっぱい住んでるんでしょうか。

- 投稿日:2020-12-15T10:56:35+09:00
node.jsを自分のMacにインストールした
備忘録として。
node.jsを自宅のMacにインストールしようと思うHomebrewから今回はやってみた
HomebrewとはMacOSで広く使われるパッケージ管理システム。。らしいHomebrewを下記URLからまずインストール
https://brew.sh/index_jaターミナルで
brew -v
とコマンドを入力したら下記のようにバージョンが表記されたらインストール完了Homebrew 2.6.1 Homebrew/homebrew-core (git revision dfe59; last commit 2020-12-14)そしたらいよいよnode.jsのインストールへ。
brew install nodebrewインストールが完了したら下記コマンドで確認
nodebrew -vnodebrew 1.0.1~~
上記のようなばーじょんから始まる長ったらしい文が表示されたらOK続いて下記コマンドを入力
nodebrew ls-remoteしたら、ズラーっとvX.XX.Xのような表記でバージョンが並べられる
どのバージョンでもいいが推奨のバージョンをインストールする方がいいと思われるので、
今回は推奨バージョンをインストールすることに。
調べたら下記コマンドで推奨バージョンをインストールできるらしいnodebrew install-binary stable僕の場合ここでエラーが出てしまった
調べたところフォルダを作ってあげなきゃいけないみたいで
こちらのコマンドで作成。。。mkdir -p ~/.nodebrew/srcインストール完了したらバージョンを確認
nodebrew ls下記のように表示されればOK
現在インストールされてるバージョンが羅列される
ちなみにcurrentの部分には現在使用中のバージョンが入るv14.15.1 current: noneuseの後に使用するバージョンを選択
nodebrew use v14.15.1もう一度nodebrew lsを試したら
v14.15.1 current: v14.15.1上記のようにcurrentに入る
次は環境パスの設定
環境パスとはフルパスを指定せずソフト名のみを指定するだけで
プログラムを起動できるようにシステムに予め設定しているパス。
'>>'の後には各SHELLごとに合わせたファイルを指定
自分はzshだったので~/.zprofileを指定echo 'export PATH=$HOME/.nodebrew/current/bin:$PATH' >> ~/.zprofileそしたらnodeコマンドを実行
node -vインストールしたバージョンが表示されたらOK
以上でnode.jsインストール完了
- 投稿日:2020-12-15T10:34:47+09:00
Puppeteerでスクレイピング
今更感はあるのですが、Puppeteerでスクレイピングしてみました。
環境
Node.js 12.18.3
Puppeteer 5.5.0
TypeScript 4.1.3やったこと
環境の準備
まず、適当なディレクトリを初期化して、必要なモジュールをインストールしていきます。
$ npm init -y $ npm i puppeteer $ npm i -D typescript ts-node @types/node @types/puppeteer $ npx tsc --init今回、TypeScriptはts-nodeを使って実行します。
そのため、package.jsonに下記のスクリプトを追記します。package.json〜略〜 "scripts": { "start": "ts-node src/index.ts" }, 〜略〜実際のコード
配列で用意しておいたURLを直列で順番にスクレイピングしていく、というサンプルを作っていきます。
先に全体のコードを置いておきます。src/index.tsconst puppeteer = require('puppeteer'); const path = require('path'); const fs = require('fs'); // スクレイピング対象のURL const urls = ['https://qiita.com/', 'https://developer.mozilla.org/en-US/']; // スクレイピング const crawl = async (url: string) => { // ファイル名用の現在日付作成 const now = (() => { const d = new Date(); return `${d.getFullYear()}_${(d.getMonth()+1)}_${d.getDate()}_${d.getHours()}-${d.getMinutes()}-${d.getSeconds()}`; })(); // ブラウザー開く const browser = await puppeteer.launch({ headless: false, slowMo: 50, defaultViewport: { width: 1280, height: 800 } }); // 新規タブ const page = await browser.newPage(); // URLへアクセス await page.goto(url); // ScreenShot保存 const imgPath = path.join('./ss', `${now}.png`); await page.screenshot({ path: imgPath, fullPage: true, }); // ドキュメントの情報を取得 const metaData = await page.evaluate(() => { return { 'title': document.querySelector('title')?.textContent, 'description': (<HTMLMetaElement>document.querySelector('meta[name="description"]'))?.content, 'h1': document.querySelector('h1')?.textContent, }; }); // セッション終了 await browser.close(); return { img: imgPath, ...metaData } }; // 対象URL分スクレイピング処理を実行する const handleCrawler = async () => { const r = []; for (let v of urls) { r.push(await crawl(v)); } console.log(r); }; (async () => { // スクリーンショット保存用のディレクトリがない場合 if (!fs.existsSync('ss')) { // ScreenShot保存ディレクトリ作成後、実行 fs.mkdir('ss', () => { handleCrawler(); }); } // 保存用ディレクトリが既存の場合、そのまま実行 else { handleCrawler(); } })();何をやっているか
まずは、Puppeteerを使って、Chromeを起動します。
src/index.ts// 〜略〜 // ブラウザー開く const browser = await puppeteer.launch({ headless: false, slowMo: 50, defaultViewport: { width: 1280, height: 800 } });今回、実際にChromeが起動しているところを確認したいので、
headlessにfalseを指定して、Chromeがnon-headlessで起動するように指定しています。また、slowMoを指定することで、指定されたミリ秒数分、操作を遅延させています。その後、タブを開いて対象URLに遷移し、スクリーンショットを保存します。
src/index.ts// 〜略〜 // ScreenShot保存 const imgPath = path.join('./ss', `${now}.png`); await page.screenshot({ path: imgPath, // ここでスクリーンショットを保存するローカルのパスを指定 fullPage: true, // type: 'jpeg', // quality: 0 });オプションにローカルのパスを指定すると、そこにスクリーンショットが保存されます。
qualityオプションを渡すことで画像の解像度を指定することができます。
試しに使ってみたところ、ページ全体のスクリーンショットが1.3MBほどあったページも、quality: 0を指定すると88KBほどになりました。サーバーの容量に制限があるときなどには使えるかも知れません。続いて、ドキュメントの情報を取得しています。
src/index.ts// ドキュメントの情報を取得 const metaData = await page.evaluate(() => { return { 'title': document.querySelector('title')?.textContent, 'description': (<HTMLMetaElement>document.querySelector('meta[name="description"]'))?.content, 'h1': document.querySelector('h1')?.textContent, }; });今回ここで少しハマったのですが、素直に
'description': document.querySelector('meta[name="description"]')?.content,としてしまうと
Property 'content' does not exist on type 'Element'.と怒られてしまいました。
HTMLElementのインターフェースにはcontentというプロパティが無いことが原因なようで、HTMLMetaElementにキャストしてあげる必要があったようです。
大変助かりました。>https://qiita.com/vsanna/items/201d4af29086a01b6b12実行
実際に上記のソースコードを実行してみます。
npm startで実行されます。$ npm start実行したターミナルの標準出力に、スクレイピングの結果が出力されました。
出力結果[ { img: 'ss/2020_12_16_16-56-39.png', title: 'Qiita', description: 'Qiitaは、プログラマのための技術情報共有サービスです。 プログラミングに関するTips、ノウハウ、メモを簡単に記録 & 公開することができます。', h1: 'How developers code is here.' }, { img: 'ss/2020_12_16_16-56-44.png', title: 'MDN Web Docs', description: 'The MDN Web Docs site provides information about Open Web technologies including HTML, CSS, and APIs for both Web sites and progressive web apps. It also has some developer-oriented documentation for Mozilla products, such as Firefox Developer Tools.', h1: 'Resources for developers, by developers.' } ]
/ss配下にはスクリーンショットが保存されているのが確認できました。$ ls -la ss出力結果total 3512 drwxr-xr-x 4 xxxx staff 128 Dec 16 16:56 . drwxr-xr-x 9 xxxx staff 288 Dec 16 16:56 .. -rw-r--r-- 1 xxxx staff 1340232 Dec 16 16:56 2020_12_16_16-56-39.png -rw-r--r-- 1 xxxx staff 453752 Dec 16 16:56 2020_12_16_16-56-44.png最後に
Puppeteer自体の使い方もとてもシンプルで、思っていたよりも簡単にWebスクレイピングを実装できました。
扱いやすいライブラリにめちゃくちゃ感謝です。(つづりが難しい...
- 投稿日:2020-12-15T06:22:58+09:00
MediaPackage 用の CloudFront ディストリビューションを AWS SDK で作成する
はじめに
とある事情で MediaPackage のエンドポイント用の CloudFront ディストリビューションを AWS SDK で作成する機会がありました。その際得た知見をソースコードを交えながら備忘録として記事に残しておきます。
本記事内容で紹介しているソースコードは Gist にも同じ内容でアップしてあります。
ちなみに MediaLive + MediaPackage + CloudFront の構成でインフラ構築したい場合は、CloudFormation が MediaPackage にも対応したので CloudFormation の利用を推奨します。
本記事内容はあくまでも何らかの事情で、後から CloudFront ディストリビューションを MediaPackage エンドポイントに紐づけたいケース等で参考になると思われます。
実装内容
作成したソースコードの内容は下記になります。
最下部のcreateDistributionForMediaPackageが本記事タイトルに該当する関数です。CloudFrontClientForMediaPackage.tsimport { CloudFront } from "aws-sdk"; import * as url from "url"; import { CreateDistributionWithTagsResult, GetDistributionResult, UpdateDistributionResult } from "aws-sdk/clients/cloudfront"; export class CloudFrontClientForMediaPackage { private cloudFront: CloudFront; constructor() { this.cloudFront = new CloudFront({ region: "ap-northeast-1", apiVersion: '2020-05-31', }); } /** * CloudFront ディストリビューションの情報を取得するために利用する * @param id CloudFront ディストリビューションの ID * @return ディストリビューションの情報を取得する */ async getDistribution(id: string): Promise<GetDistributionResult> { const distribution = await this.cloudFront.getDistribution({ Id: id }).promise() return distribution; } /** * CloudFront ディストリビューションの設定内容を取得するために利用する * @param id CloudFront ディストリビューションの ID * @return ディストリビューションの設定内容を取得する */ async getDistributionConfig(id: string): Promise<CloudFront.DistributionConfig> { const config = await this.cloudFront.getDistributionConfig({ Id: id }).promise() return config.DistributionConfig; } /** * CloudFront ディストリビューションを削除する * @param id 削除したい CloudFront ディストリビューションの ID */ async deleteDistribution(id: string) { const distribution = await this.getDistribution(id); await this.cloudFront.deleteDistribution({ Id: id, IfMatch: distribution.ETag }).promise() } /** * CloudFront ディストリビューションを無効化する * @param id 無効化したい CloudFront ディストリビューションの ID * @return 無効化した CloudFront ディストリビューションの情報 */ async disableDistribution(id: string): Promise<UpdateDistributionResult> { const distribution = await this.getDistribution(id); const config = distribution.Distribution.DistributionConfig; config.Enabled = false; return await this.cloudFront.updateDistribution({ Id: id, IfMatch: distribution.ETag, DistributionConfig: config }).promise(); } /** * MediaPackage のエンドポイント用の CloudFront ディストリビューションを作成する * @param id CloudFront ディストリビューションを判別するための ID * @param mediaPackageArn MediaPackage チャンネルの ARN * @param mediaPackageUrl MediaPackage エンドポイントの URL */ async createDistributionForMediaPackage( id: string, mediaPackageArn: string, mediaPackageUrl: string ): Promise<CreateDistributionWithTagsResult> { // 1. url モジュールを用いて URL 文字列をパースする const mediaPackageEndpoint = url.parse(mediaPackageUrl); /** 2. MediaPackage のエンドポイント URL から FQDN を取得する。 後述する CloudFront ディストリビューションのオリジンのドメイン名としても利用する */ const mediaPackageHostname = mediaPackageEndpoint.hostname; /** 3. MediaPackage のエンドポイント URL のフォーマットは https://<AccountID>.mediapackage.<Region>.amazonaws.com/**** となっているので、 FQDN の先頭部分を文字列分割で取り出すとアカウント ID が取得できる */ const accountId = mediaPackageHostname.split('.')[0]; // 4. 後述する CloudFront ディストリビューションのオリジン ID として、アカウント ID を利用する const targetOriginId = `MP-${accountId}` /** 5. createDistribution ではなく、createDistributionWithTags 関数で、 CloudFront ディストリビューションを作成する。MediaPackage との紐付けにタグを利用するため。 */ return await this.cloudFront.createDistributionWithTags({ DistributionConfigWithTags: { Tags: { Items: [ /** !!!!!重要!!!!! 6. CloudFront ディストリビューションに紐付けたい MediaPackage エンドポイントのチャンネル ARN を mediapackage:cloudfront_assoc で定義する。 mediapackage:cloudfront_assoc を定義することで、 CloudFront ディストリビューションと MediaPackage チャンネルを紐付けることが可能となる。 */ { Key: 'mediapackage:cloudfront_assoc', Value: mediaPackageArn }, { Key: 'Id', Value: id }, { Key: 'Product', Value: 'product' }, { Key: 'Stage', Value: 'dev' } ] }, DistributionConfig: { CallerReference: new Date().toISOString(), Comment: `Managed by MediaPackage - ${id}`, Enabled: true, /** 7. CloudFront ディストリビューションのオリジンには 2つ設定します。 1つが MediaPackage のエンドポイントに対するものと、 もう 1つが MediaPacakge サービスに対するものです。 基本的には MediaPackage のエンドポイントに対するオリジンを利用します。 例外時に向けるオリジンが MediaPacakge サービスに対するものになります。 */ Origins: { Quantity: 2, Items: [ { DomainName: mediaPackageHostname, Id: targetOriginId, CustomOriginConfig: { HTTPPort: 80, HTTPSPort: 443, OriginProtocolPolicy: 'match-viewer' } }, { DomainName: 'mediapackage.amazonaws.com', Id: "TEMP_ORIGIN_ID/channel", CustomOriginConfig: { HTTPPort: 80, HTTPSPort: 443, OriginProtocolPolicy: 'match-viewer' } } ] }, /** 8. CacheBehaviors のいずれにも当てはまらなかった場合の キャッシュの振る舞いを定義します。 MediaPackage は タイムシフト表示機能を使用する際等で、クエリ文字列に start, m, end を利用しています。 そのため、それらの文字列は WhitelistedNames に含め QueryString には true を指定しておきます。 DefaultCacheBehavior に引っかかる挙動は例外的扱いなので、 使用するオリジンは MediaPackage サービスのものを設定します。 */ DefaultCacheBehavior: { ForwardedValues: { Cookies: { Forward: 'whitelist', WhitelistedNames: { Quantity: 3, Items: [ 'end', 'm', 'start' ] } }, QueryString: true, Headers: { Quantity: 0 }, QueryStringCacheKeys: { Quantity: 0 } }, MinTTL: 6, TargetOriginId: "TEMP_ORIGIN_ID/channel", TrustedSigners: { Enabled: false, Quantity: 0 }, ViewerProtocolPolicy: 'redirect-to-https', AllowedMethods: { Items: [ 'GET', 'HEAD' ], Quantity: 2, }, MaxTTL: 60 }, /** 9. CloudFront のエラーコード全ての TTL に 1sec を設定します。 MediaPackage のエラーのキャッシュが長時間持続してしまうと、 その間は MediaPackage で正常に配信できているとしても、 復旧できない状態となるからです。 */ CustomErrorResponses: { Quantity: 10, Items: [ { ErrorCode: 400, ErrorCachingMinTTL: 1 }, { ErrorCode: 403, ErrorCachingMinTTL: 1 }, { ErrorCode: 404, ErrorCachingMinTTL: 1 }, { ErrorCode: 405, ErrorCachingMinTTL: 1 }, { ErrorCode: 414, ErrorCachingMinTTL: 1 }, { ErrorCode: 416, ErrorCachingMinTTL: 1 }, { ErrorCode: 500, ErrorCachingMinTTL: 1 }, { ErrorCode: 501, ErrorCachingMinTTL: 1 }, { ErrorCode: 502, ErrorCachingMinTTL: 1 }, { ErrorCode: 503, ErrorCachingMinTTL: 1 } ] }, /** 10. CloudFront ディストリビューションのキャッシュの振る舞いを 2つ定義します。 それぞれの設定内容は基本的に DefaultCacheBehavior で定義したものと同様です。 しかし、利用するオリジンは MediaPackage エンドポイントに向けたものを利用します。 1つは Microsoft Smooth Streaming での配信時に利用する index.ism に対するもので Smooth Streaming を true に設定しています。 もう 1つは上記 Microsoft Smooth Streaming 以外の 全てに当てはまるストリーミングに適用されるものになります。 */ CacheBehaviors: { Quantity: 2, Items: [{ MinTTL: 6, PathPattern: 'index.ism/*', TargetOriginId: targetOriginId, ViewerProtocolPolicy: 'redirect-to-https', AllowedMethods: { Items: [ 'GET', 'HEAD' ], Quantity: 2, }, ForwardedValues: { Cookies: { Forward: 'whitelist', WhitelistedNames: { Quantity: 3, Items: [ 'end', 'm', 'start' ] } }, QueryString: true, Headers: { Quantity: 0 }, QueryStringCacheKeys: { Quantity: 0 }, }, SmoothStreaming: true }, { MinTTL: 6, PathPattern: '*', TargetOriginId: targetOriginId, ViewerProtocolPolicy: 'redirect-to-https', AllowedMethods: { Items: [ 'GET', 'HEAD' ], Quantity: 2, }, ForwardedValues: { Cookies: { Forward: 'whitelist', WhitelistedNames: { Quantity: 3, Items: [ 'end', 'm', 'start' ] } }, QueryString: true, Headers: { Quantity: 0 }, QueryStringCacheKeys: { Quantity: 0 }, } }] }, PriceClass: 'PriceClass_All' } } }).promise() } }
createDistributionForMediaPackageで作成したディストリビューションは、公式ページに記載された手順 で作成した CloudFront ディストリビューションと同等のものになります。詳細な説明はインラインコメントにて書きましたが、一応補足説明を少し付け加えておきます。
随所に出てくる
Quantityについて
QuantityにはItemsで指定する項目の数を入力します。 例えばHeadersやQueryStringCacheKeysにはItemsに何も指定していないため、Quantityに0を指定します。しかし、
AllowedMethodsやWhitelistedNamesにはItemsに指定した項目数である2や3をQuantityに入力しています。Quantityの数とItemsの項目数が合わないと、エラーが発生するため、注意が必要です。
mediapackage:cloudfront_assocを定義する意味CloudFront ディストリビューションのタグに
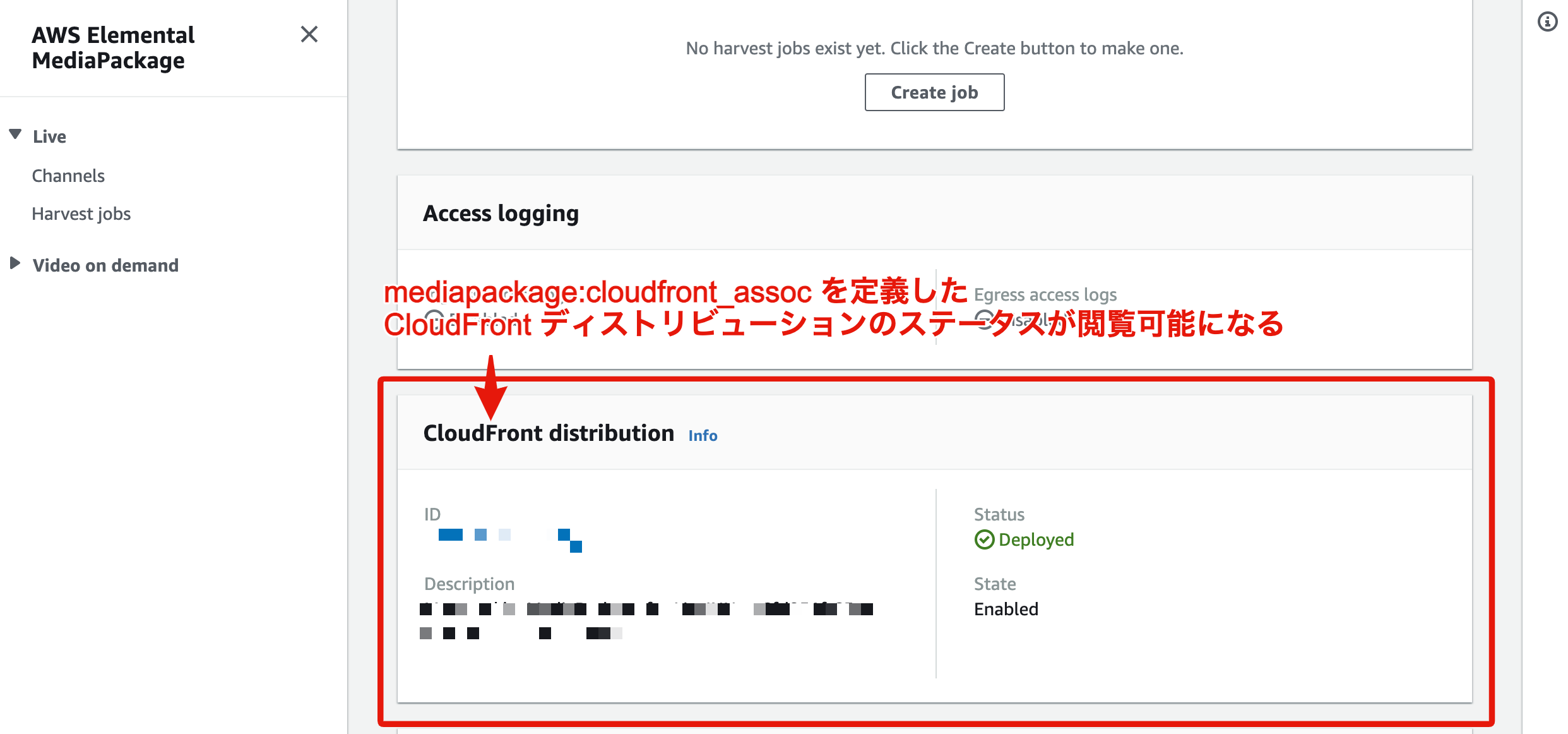
mediapackage:cloudfront_assocで紐付ける MediaPackage のチャンネル ARN を指定することで、MediaPackage コンソールから紐付けられた CloudFront ディストリビューション情報を参照できるようになります。試しに紐づけられた MediaPackage のチャンネルのエンドポイント詳細ページに遷移すると、
下記のような画面が確認できるはずです。
mediapackage:cloudfront_assocで紐付いた CloudFront ディストリビューションが確認できるなお、本記事内のソースコードでは他にも
Id,Product,Stageといったタグを定義していますが、MediaPackage とは関係無いものなので削除して問題ありません。
updateDistributionを実行する際の注意点これは今回の記事内容とは直接関係ないのですが、地味にハマったので載せておきます。
CloudFront では
createDistributionの時に要求されるパラメータよりもupdateDistributionで要求されるパラメータのほうが多いです。 AWS 公式ページの比較表にある通りです。そのため、
updateDistributionで設定を一部更新したいだけなのに、とても多くのパラメータを指定する必要があり非常に面倒です。例えば CloudFront ディストリビューションの Enable/Disable を切り替えるだけでも 30 個近いパラメータを指定する必要あります。上記の入力の手間を省くのには
getDistributionで取得した既存のディストリビューション情報を改変する形でupdateDistributionのパラメータを作成すると楽でした。今回のソースコードの内容を参照すると
disableDistributionが該当します。// 1. getDistribution を実行して CloudFront ディストリビューションの情報を取得する const distribution = await this.getDistribution(id); // 2. CloudFront ディストリビューションの設定内容を取得する const config = distribution.Distribution.DistributionConfig; // 3. CloudFront ディストリビューションの Enabled/Disabled を切り替えるオプションを改変する config.Enabled = false; // 4. 3. で改変した内容を updateDistribution で CloudFront ディストリビューションに反映する return await this.cloudFront.updateDistribution({ Id: id, IfMatch: distribution.ETag, DistributionConfig: config }).promise();おわりに
ニッチな内容なので、本記事内容を今後利用するかどうかは分かりませんが、一応得た知見を記事として残しておきました。同様のことを行う必要が出てきた方の参考になれれば幸いです。
参考リンク
- 投稿日:2020-12-15T01:02:24+09:00
FirebaseUiでユーザー作成時に、認証プロバイダのサムネイルを引き継ぐ方法
Firebase UI
FirebaseにはFirebaseUIという、ユーザー認証を素晴らしく楽にさせてくれる素晴らしいシステムがあります。
少しコードを書くだけで、googleアカウントはもちろんfacebookやtwitter、github、SMS認証、メール認証なども網羅しているすごいやつです。
(※firebase.google.comより引用)本記事では、Firebase UI を利用してユーザー登録を行なった際に、利用したプロバイダに登録している画像を取得・保存する実装について書いていきます。
概要
Functionsにて、
authenticateでユーザーが作成される事をフックして、Firestoreにユーザー情報を取得すると同時に、Storageに認証プロバイダのユーザーアイコンを保存するといった仕組みを撮りました。実装
必要なモジュールたちをインポートします。
functions/index.jsconst functions = require('firebase-functions') const admin = require('firebase-admin') const axios = require('axios') // いつもの子 const path = require('path') ////// const os = require('os') // ここら辺を使って画像取得、送信準備をおこないます。 const fs = require('fs') /////// const STORAGE_BUCKET = 'XXXXX-YYYYYYYY-ZZZZZZZ' // 自分のfirebaseアプリ名が含まれた?、storageのバケット名です。 admin.initializeApp() const db = admin.firestore()ユーザの作成イベントをフックしてfirestoreにデータを保存する処理です。storageへの保存は非同期でおこないました。
functions/index.jsexports.userCreated = functions.auth.user().onCreate(async (user) => { const encodedPath = encodeURIComponent(`/images/users/thumbnails/${user.uid}.jpg`) uploadThumbnail(user) db.collection('users').doc(user.uid).set({ name: user.displayName, // getSignedUrlを利用するのが本来のやり方のようですが、いまいちうまくいかないので、非公式ではありますが // 色々なサイトに書かれている方法でstorage画像へのパスを保存しました。 thumbnail: `https://firebasestorage.googleapis.com/v0/b/${STORAGE_BUCKET}/o${encodedPath}?alt=media`, updated_at: new Date(), created_at: new Date(), })
user.photoURLの中にプロバイダのユーザーアイコンが入っているため、そこからごにょごにょしてからstorageに送信する処理です。
(arraybufferのままstorageに送れたかもです。知ってたらおしえてください)
functions/index.jsasync function uploadThumbnail (user) { const bucket = admin.storage().bucket() const tmpFile = path.join(os.tmpdir(), `tmp_${user.uid}.jpg`) const res = await axios.get(user.photoURL, {responseType: 'arraybuffer'}) fs.writeFileSync(tmpFile, new Buffer.from(res.data), 'binary') const filePath = `images/users/thumbnails/${user.uid}.jpg` bucket.upload(tmpFile, { destination: filePath }).then(res => { return 'success' }).catch(e => { console.log(`[ERROR]: at uploadThumbnail --- ${e}`) }) return '' }これでユーザーのアイコンがプロバイダから引き継げました!!
関係ないですが、authのフックをするのが至極簡単で本当に素晴らしきですね。。。終わり!
ユーザー認証の際に認証に利用したプロバイダに登録してあるアイコンを引き継ぐ方法でした!
著作権とかあるとおもうので、引き継ぐか否かとかはユーザーに確認取った方がいい、かも、、、?ありがとうございました!
