- 投稿日:2020-12-12T23:59:32+09:00
LeetCodeに毎日挑戦してみた 104. Maximum Depth of Binary Tree(Python、Go)
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
23問目(問題104)
104. Maximum Depth of Binary Tree
問題内容
Given the
rootof a binary tree, return its maximum depth.A binary tree's maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node.
(日本語訳)
root二分木のが与えられた場合、その最大深度を返します。二分木の最大深度 は、ルートノードから最も遠いリーフノードまでの最長パスに沿ったノードの数です。
Example 1:
Input: root = [3,9,20,null,null,15,7] Output: 3Example 2:
Input: root = [1,null,2] Output: 2Example 3:
Input: root = [] Output: 0Example 4:
Input: root = [0] Output: 1考え方
rootが存在しない場合、left,rightにアクセスするとエラーになるので例外処理をはじめにします
左の二分木と右の二分木それぞれ再帰処理で潜っていきます。
その二分木の左の二分木と右の二分木の大きい方をreturnします。
- 解答コード
class Solution: def maxDepth(self, root): if not root: return 0 return 1 + max(self.maxDepth(root.left), self.maxDepth(root.right))
- Goでも書いてみます!
func maxDepth(root *TreeNode) int { if root == nil { return 0 } return diveNode(root.Left, root.Right, 1) } func diveNode(p *TreeNode, q *TreeNode, count int) int { if p != nil && q != nil { return max(diveNode(p.Left, p.Right, count+1), diveNode(q.Left, q.Right, count+1)) } else if p != nil { return diveNode(p.Left, p.Right, count+1) } else if q != nil { return diveNode(q.Left, q.Right, count+1) } else { return count } } func max(values ...int) int { ret := values[0] for _, v := range values { if ret < v { ret = v } } return ret }

- 投稿日:2020-12-12T23:57:40+09:00
アイトラッカー作ってみた.
- この記事はOpenCV Advent Calendar 2020の13日目の記事です。
- 他の記事は目次にまとめられています。
概要
私はこれまで、弱視であるがゆえに様々な不便を感じてきたした。しかし、情報技術の発展に伴い、この弱視と情報技術を組み合わせることによって、逆に弱視であるがゆえに便利な生活が送れるのではないかと考えました。試作を重ねた結果、弱視の性質とOpenCVを活用することで安価にアイトラッカーを作成できました。よって本投稿では、弱視を活用するために作成したアイトラッカーについてまとめます。
はじめに
弱視とは
世には弱視と呼ばれる人が一定数存在します。のび太君のような目の悪さは、眼球のピントのズレ等によって引き起こされるので、眼鏡をかけることによってある程度軽減されます。
しかし、弱視は視神経自体が細かったり、網膜がうまく機能しない等によって引き起こされるので、眼鏡等を使用しても視力はあまり改善しません。私の場合、視界すべてにバイラテラルフィルタ(大変わかりやすい解説)がかかったように見えます。
この弱視のややこしいところは、片目だけ弱視になる場合がある点です。こうなってしまうと、左右の目に視力差が生じるため、距離推定がすこぶる苦手になってしまいます。また、見える画像全体にバイラテラルフィルタがかかったようになるので、人の顔の判別も不得意になります。
ではどうするか
アイトラッカーで視線を追うことでどの物体を見ているか大まかに特定し、高性能なカメラを用いてその物体を撮影すれば解決できると考えました。
距離推定が苦手な場合は、注目している物体をアイトラッカーで特定し、二台のカメラを組み合わせて三角測量を行うことで対象物への距離が推定できます。人の顔を特定したい場合は、適当なニューラルネットと組み合わせれば十分に解決できると考えたのです。
なぜわざわざ作るのか
既存のアイトラッカーは確かに高性能ですが、高価であります。私にそんな高価なデバイスを買う余裕はありません。また、視力が非常に低いという弱視の特性を使えば、大変安価にアイトラッカーを作成できると考えたからです。
作ってみる
ハードウェア編
コードでいくら工夫してもデータが汚ければうまくいかないので、きれいなデータを得られるハードをつくってみます。画像中に不自然なところがいくつかあります。これは、気持ち程度のプライバシー保護であって、結果の捏造ではありません。
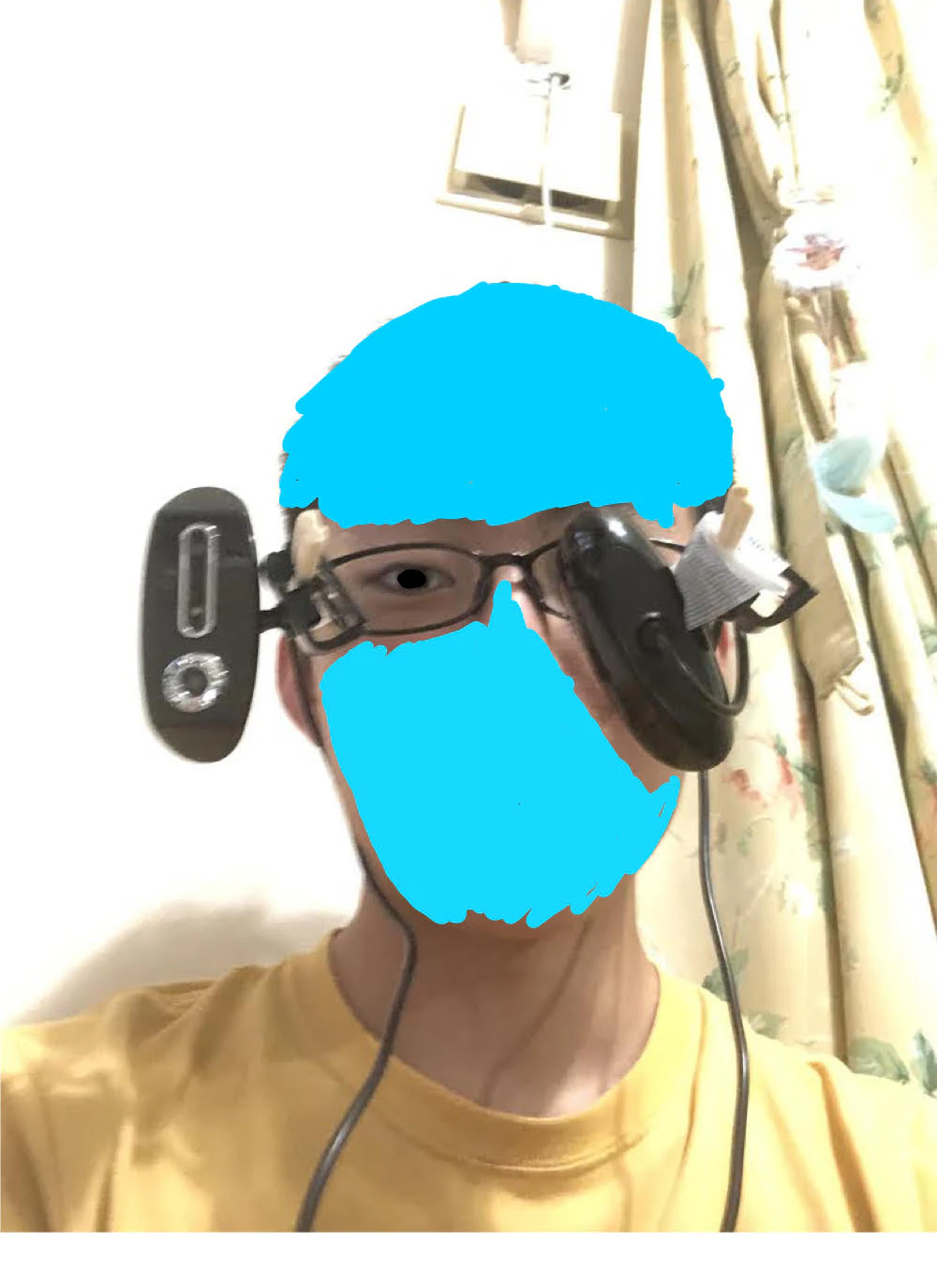
試作一号機
弱視は視力が弱い≒ほとんど見えていない->目の前にカメラを置いても問題ない
という飛躍した論理のもと、適当なWEBカメラとメガネを組み合わせて作ってみました。
つけてみた。
文字通り目の前にカメラを設置してみました。しかし、弱視でほとんど見えていないといっても、左目は平衡感覚にはある程度寄与しているらしく、装着後に大変酔ってしまったのでこの構造が不適であることがわかりました。
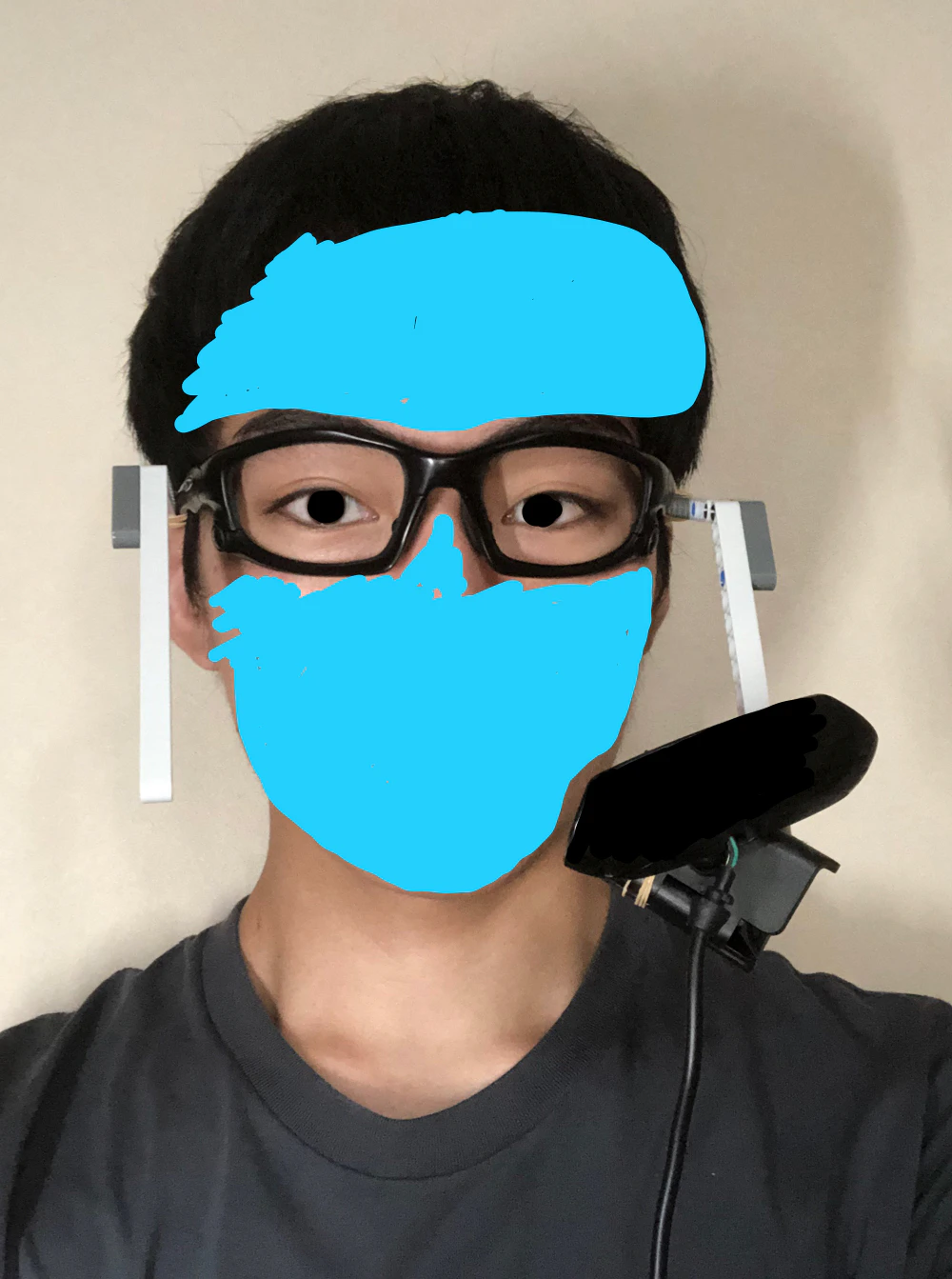
試作二号機
一号機はフレームが貧弱だったため、目の前にカメラを設置するしかありませんでした。そのため、フレームをスポーツサングラスやプラスチックアームなど頑丈な素材で作ってみました。
つけてみた。
一号機より下にカメラをつけたので、酔いなどの問題も発生しませんでした。そのため、このシステムをもとにコードを書いていきます。
コード編
黒目と視線方向は一致しているため、画像解析によって黒目の中心を検出することを目標とします。
なお、ハードウェア本体に照明を取り付けることによって、二値化処理のみで黒目を抜き出すことに成功しました。円検出
ほとんどの場合黒目は円形であるので、円検出で黒目の方向を特定できると考えました。そこで、ハフ変換を用いた円検出を試しました。
import cv2 import numpy as np img = cv2.imread("frame.jpg") gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 照明を当てることで明るさを一定にしたので、固定パラメータでも黒目の検出が可能になりました。 ret,th = cv2.threshold(gray,65, 255,cv2.THRESH_BINARY_INV) medimg = cv2.medianBlur(img,5) circles = cv2.HoughCircles(medimg,cv2.HOUGH_GRADIENT,1,20, param1=200,param2=13,minRadius=0,maxRadius=0) circles = np.uint16(np.around(circles)) for i in circles[0,:]: # 外側の円を書きます cv2.circle(img,(i[0],i[1]),i[2],(0,255,0),2) # 内側の円を書きます cv2.circle(img,(i[0],i[1]),2,(0,0,255),3) cv2.imwrite('detected.jpg',img)
上の画像をこの処理にかけると下の画像のようになります。
このように、ある程度は検出できているように感じられます。赤色が検出された中心です。
しかし、この処理のままでは複数の円を検出できるので、複数の視線方向が検出されます。つまり、正しい視線方向を求めることができません。また、ハフ変換はアルゴリズム的に多少遅いので、リアルタイム処理が求められるアイトラッカーには不向きであると判断しました。
重心検出
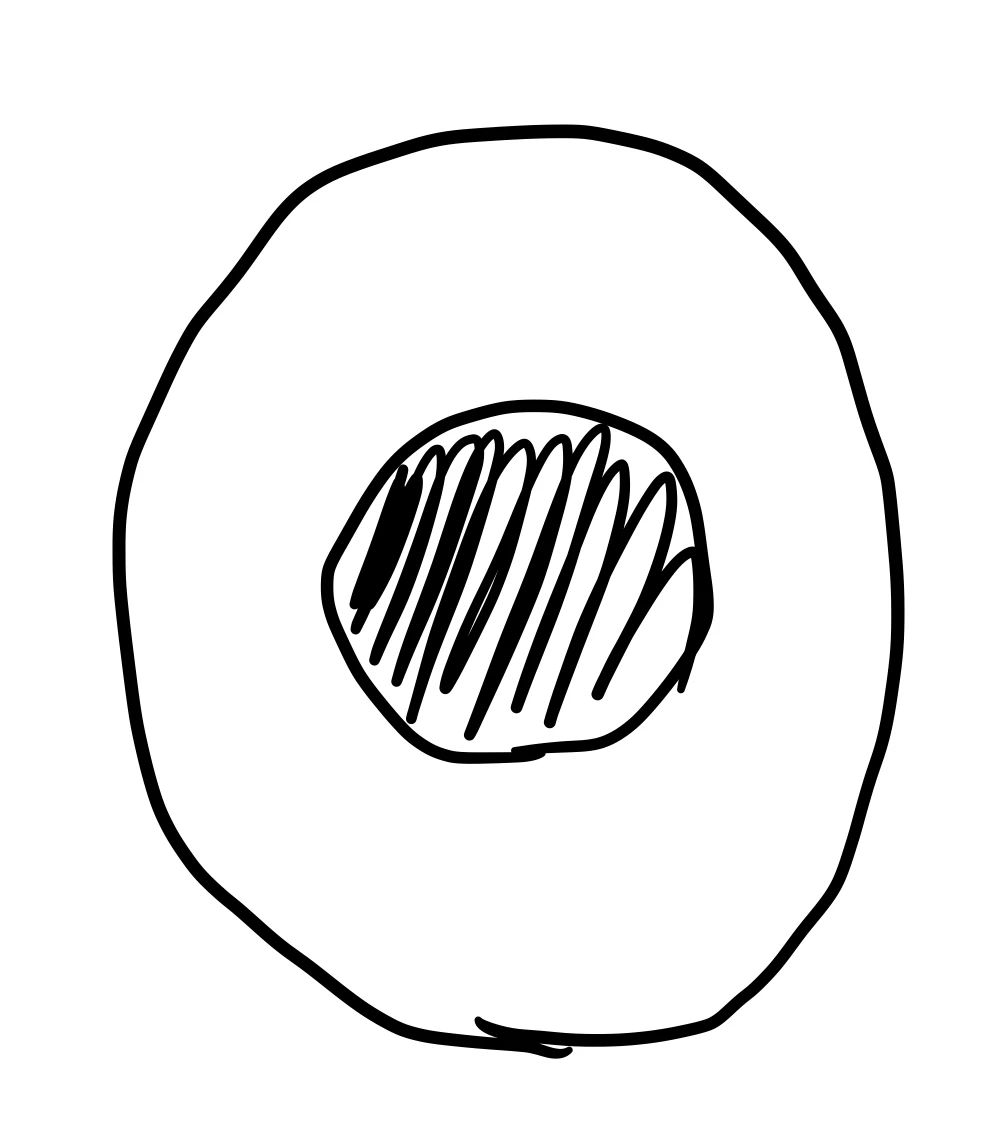
先ほどの円検出には、黒目を円としてしか検出できないという致命的な欠点があります。
下図ような黒目は円として検出してもなんら問題はありませんが、
下図のように黒目が偏った際に、黒目を円として検出することは適切ではありません。
そこで、偏りに対して頑健であると考えられる重心を用いての検出を試しました。
import cv2 frame = cv2.imread("frame.jpg") gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 照明を当てることで明るさを一定にしたので、固定パラメータでも黒目の検出が可能になりました。 ret,th = cv2.threshold(gray,65, 200,cv2.THRESH_BINARY_INV) # 最大の面積を持つ輪郭を探します _, contours, _ = cv2.findContours(th, 1, 2) cnt = contours[0] for c in contours: if len(cnt) < len(c): print(c) cnt = c # 最大の面積を持つ輪郭の重心を求めます M = cv2.moments(cnt) cx = int(M['m10']/M['m00']) cy = int(M['m01']/M['m00']) cv2.circle(frame, (cx, cy), 5, (0, 255, 255), thickness=-1)
上の画像をこの処理にかけると、下の図のようになります。
このように、綺麗に検出できました。黄色の点が検出された中心です。
まとめ
- 弱視の特徴を使うと、大変安価にアイトラッカーを作成できる。
- 重心を用いることで、広範囲にわたる視線方向が検知できる。
終わりに
本投稿では、私が自身の不自由を解決するために作成してきたアイトラッカーについてまとめてきました。大変しょぼいまとめで恐縮ですが、不便と思われがちな障害とコンピューター(そしてOpenCV!!!!)を組み合わせることで、安価に身体機能を拡張でき、むしろ便利な生活が送れる可能性があることを知っていただけたら幸いです。
明日(12/14)は、@UnaNancyOwen さんの「たぶんDNNモジュールでやってみた系のなにか」です。ご精読ありがとうございました。
資料
動作環境
- OpenCV 3.6 (手持ちのノートパソコンを壊したので断言はできません。ごめんなさい。)
費用
フレーム アーム(カメラ台) カメラ 試作一号機 100円(部屋に落ちていた) 2円(割り箸) 200円 試作二号機 30,000円(Oakleyのサングラス) 10円(LEGOのパーツ) 200円








- 投稿日:2020-12-12T23:08:30+09:00
【Django】annotateを使って高度なorder_byを書く方法
Djangoの
.all()や.filter()で値を取得した結果得られるオブジェクトは、Pythonのリストであり、各要素は辞書型になっています。Pythonにおいて、「各要素が辞書になっているリストで、特定のkeyの値に応じて並べ替えを行う」という処理はfor文で回す必要があり、コードもやや煩雑になるので、できればレコード取得と同時に
.order_by()で並べ替えを完了させておきたい所です。そんな時に、.annotate()を用いることでより高度な並べ替えを行う方法を紹介したいと思います。※ querysetの基本的な扱いを理解していることを前提とした記事になっているので、
.all()や.filter()、.order_by()などが分からない方は先に下記の記事などを参照していただければ幸いです。参考:
Django逆引きチートシート(QuerySet編)annotateとは
「annotate」とは、「注釈をつける」という意味を持った英単語です。使用方法としては、他のクエリメソッド同様、レコード取得の後に
.で連結する形になります。Book.objects.all().annotate(new_field="hoge")これを使用すれば、「モデルが持っているフィールドに加えて、こちらで指定したフィールドを追加で出力する」ということができるようになります。
ちなみに、docstringには下記のような説明が書かれています。
Return a query set in which the returned objects have been annotated with extra data or aggregations. (返されたオブジェクトが、追加データや集約でアノテーションされているクエリセットを返す)参照: https://github.com/django/django/blob/master/django/db/models/query.py
テーブル例
説明のため、下記のようなテーブルがあるとします。
テーブル 説明 Book 本の情報を保持する。 AwardBook 受賞歴のある本のIDを保持する。 これは、Djangoのモデルでは下記のように書けます。
from django.db import models class Book(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=50) # 本の題名 price = models.IntegerField() # 本の値段 class AwardBook(models.Model): id = models.AutoField(primary_key=True) book = models.ForeignKey(Book, on_delete=models.CASCADE) # 受賞歴のある本のID※「Bookテーブルに受賞歴フラグを持たせれば良い」という話ではありますが、今回はあくまで簡略化した例なので、諸事情でテーブルを分ける必要があることとします。
使い方の例
例えば、本の一覧を取得した後、値段が安い順(=昇順)に並べ替えたい場合、下記のように書けます。
queryset = Book.objects.all().order_by("price")ちなみに、値段が高い順(=降順)にしたい場合、フィールド名の最初に
-を付けます。queryset = Book.objects.all().order_by("-price")ただし、複数の要素で並べ替えをしなくてはならず、その条件が下記のような場合はどうすれば良いでしょうか。
優先①: 受賞歴がある
優先②: 値段が安い
filterを使えば、「受賞歴のある本のみを取得する」ことは出来ますが、それ以外の本を同時に取得することが出来ません。そんな時、annotateを使えば次のように書くことが出来ます。from django.db.models import Case, When, Value, IntegerField from .models import Book, AwardBook # 受賞歴のあるの本のIDを取得する award_book_ids = set( # 計算量を減らすため、setに変換 AwardBook.objects.all().values_list( "book_id", flat=True ) ) # 並び替えを行いつつ、本一覧を取得 queryset = ( Book.objects.all() .annotate( # annotateで新しいフィールドを付与 # 「受賞歴があるかどうか」を表すフラグ award_flg=Case( # 本のIDが「award_book_ids」に含まれている場合、値を1に設定 When(id__in=award_book_ids, then=Value(1)), # それ以外の場合、値を0に設定 default=Value(0), # それらの値のフィールドは「IntegerField」にする output_field=IntegerField(), ) ) .order_by( "award_flg", # 1. 受賞歴のある本一覧の中に存在するか "price", # 2. 値段が安い順 ) )
annotateを用いて、award_flgという「受賞歴があるかどうか」を表すフラグを新たに設け、そちらのフラグが1になっているものを優先するロジックになっています。ここで、新たに登場したCase、Whenについて説明したいと思います。
Case, When
CaseおよびWhenは、SQL文のCASE式を表現するために使用することのできるクラスです。CASE式を使用すれば、「あるカラムの値に応じ、別の値を割り当てる」という処理を行うことができます。例えば、「テストの点数に応じて、成績をS,A,B,C,Fで割り振りたい」という処理を行う場合、下記のように書くことができます。
CASE WHEN score >= 90 THEN 'S' WHEN score >= 80 THEN 'A' WHEN score >= 70 THEN 'B' WHEN score >= 60 THEN 'C' ELSE 'F' ENDなお、式は上から順に処理されるので、2番目の式は自動的に
80 <= score < 90という意味になります。上記の成績評価をDjangoの
Case,Whenで表現すると、下記のように書くことができます。from django.db.models import Case, When, Value, CharField grade = Case( When(score__gte=90, then=Value("S")), When(score__gte=80, then=Value("A")), When(score__gte=70, then=Value("B")), When(score__gte=60, then=Value("C")), default=Value("F"), output_field=CharField(max_length=1) )CASE式のELSEに該当するパラメータが
defaultになっていることに注意してください。また、出力用のフィールドを指定することが必須であり、今回は文字列なのでCharFieldを指定しています。
{field}__gteの他にも、{field}__inや{field}__containsなど、querysetで用いることのできる演算子は使用することができます。もちろん、そのままイコールの意味として使いたい場合、下記のように=だけでつなげば大丈夫です。When(score=100, then=Value("SS"))まとめ
annotateによる、新しいフィールドの追加Case・Whenによる、条件に応じた値の割り当てorder_byで新しく追加されたフィールドを指定し、並べ替えこれらを組み合わせることで、高度な並べ替えを実現することが出来ました。工夫次第でさらに多様なケースに対応することが出来るので、ぜひ活用していただければ幸いです。
- 投稿日:2020-12-12T22:57:48+09:00
大量のラズパイにつけたsoracom simを管理するために、simの名前をmac addressにする方法
背景
複数工場に大量においたラズパイの soracom simがそれぞれどこにあるのかを管理することが目的
前提としてラズパイはmac addressをkeyとしてどこにあるかは管理されている。環境
ak-20
raspberry pi 4
raspbian buster
python 3.7方法
mac addressでラズパイを管理しているので、simカードそれぞれにmac addressを紐づける。
simのnameがmac addressになるように起動時にsoracom apiをたたく実装
下記を起動時に実行されるようにsystemctlに登録した。(AUTH_KEY_ID とAUTH_KEYは、ここを参考に作成)
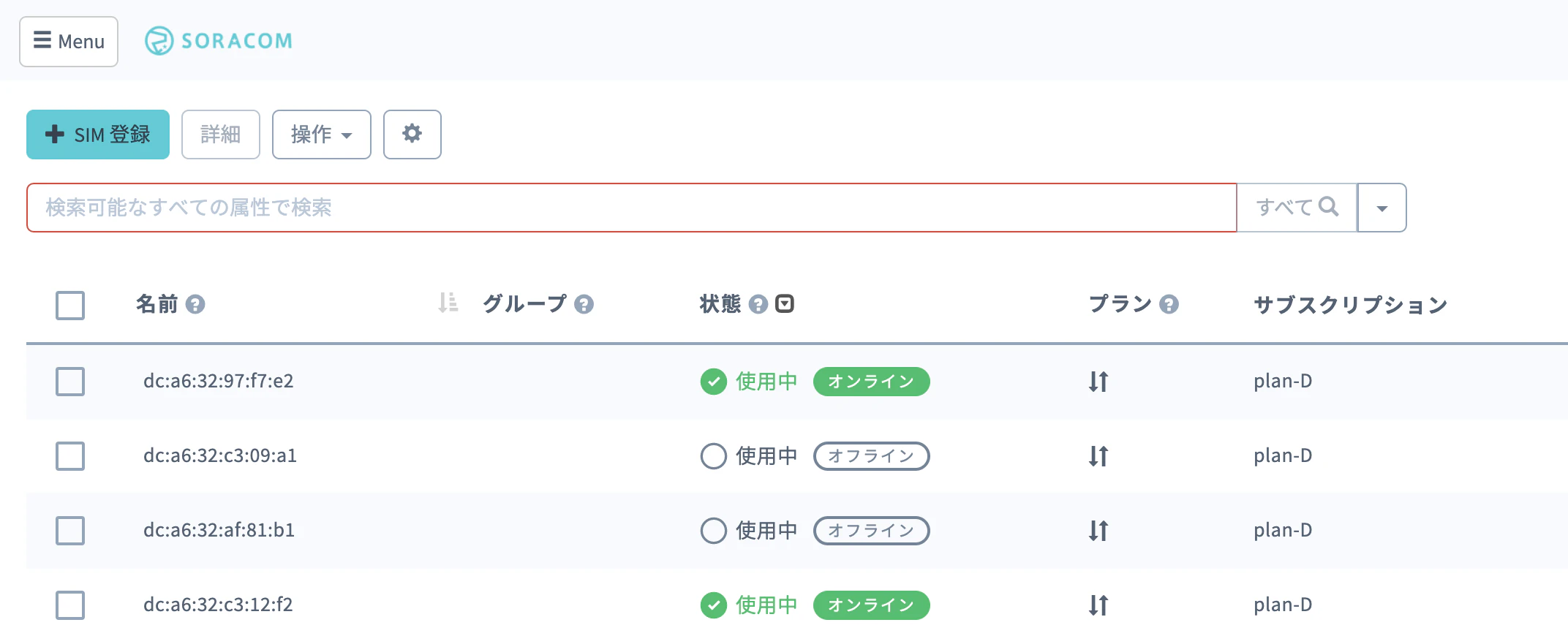
register_mac_add_for_soracom.pyimport json import logging import logging.handlers import sys import os from os.path import abspath, dirname, join import requests AUTH_KEY_ID = "$auth-key-id" AUTH_KEY = "$auth-key" def get_mac(): """ pcのmacアドレスを取得 """ GET_RASPI_WLAN0_MAC_ADDRESS_COMMAND = "cat `find /sys/devices/ -name wlan0`/address" if platform.system() == "Darwin": # 下記記事を参考に実装 # https://qiita.com/FmtWeisszwerg/items/c7aa26859c463dda5ebc addr = ":".join( [ hex(fragment)[2:].zfill(2) for fragment in struct.unpack("BBBBBB", struct.pack("!Q", uuid.getnode())[2:]) ]) else: r = os.popen(GET_RASPI_WLAN0_MAC_ADDRESS_COMMAND).read() addr = r.replace("\n", "") return addr def main(): # ここでネットワーク接続とデバイス接続確認の関数があったほうがよい get_imsi_response = requests.get('http://metadata.soracom.io/v1/subscriber.imsi') logging.debug("get_imsi_response:{}".format(get_imsi_response.text)) if len(get_imsi_response.text) == 0: logging.warning("imsiが取得できません") return imsi = get_imsi_response.text[-15:] logger.info("imsi:{}".format(imsi)) if not imsi.isdigit(): logging.warning("imsiの値が数値ではないので不正です") return get_api_token_response = requests.post( 'https://api.soracom.io/v1/auth', headers={'Content-Type': 'application/json'}, data=json.dumps({ "authKeyId": AUTH_KEY_ID, "authKey": AUTH_KEY })) logging.info("get_api_token_response:{}".format(get_api_token_response.text)) if get_api_token_response.json().get("token") is None or get_api_token_response.json().get( "apiKey") is None: logging.warning("tokenの取得に失敗しました") return token = get_api_token_response.json()["token"] api_key = get_api_token_response.json()["apiKey"] register_tag_response = requests.put( 'https://api.soracom.io/v1/subscribers/' + imsi + '/tags', headers={ 'Content-Type': 'application/json', 'X-Soracom-API-Key': str(api_key), 'X-Soracom-Token': str(token), }, data=json.dumps([{ "tagName": "name", "tagValue": get_mac() }])) logging.debug("tag_register_process out:{}".format(register_tag_response.text)) register_tag_dic = register_tag_response.json() if register_tag_dic.get("tags") is not None and register_tag_dic["tags"].get("name") is not None: if register_tag_dic["tags"]["name"] == get_mac(): logging.info("success regist") return logging.warning("failed regist") if __name__ == '__main__': main()soracom ダッシュボード
ラズパイが起動すると下記のように、ダッシュボード上のsimの名前がmac addressになる。
- 投稿日:2020-12-12T22:53:21+09:00
tensowboardで特徴量を可視化する(tf.keras) - 全結合
tensorboardで特徴量を可視化してみた
以前に投稿したmnistを全結合層で教師あり学習し、最終段をクラスタリングして評価するのコードに下記を追記して、tensorboardで可視化した。
こんな感じ。3Dでぐるぐる回せるので楽しい。
metadata.tsvのをGUIで読み込まないとラベルが反映されない問題が出たが、tensorboardを起動するときに、./tflogではなく、./tflog/YYYY-MM-DDnnnnnnを指定することでmetadata.tsvが読み込まれるので注意
・・・できれば./tflogで読んで欲しいが、その場合はチェックポイントファイル自体も./tflogに書き出す必要がある模様。projectorに指定する変数名はtensorboadに表示される変数名を指定すること
ラベルを可視化するためのメタデータを作成
# メタデータ作成・保存 import datetime import os import numpy as np LOG_DIR = f"./tflog/{datetime.datetime.now().strftime('%Y-%m-%d-%H%M%S')}" META = os.path.join(LOG_DIR, 'metadata.tsv') with open(META, 'w') as f: f.write("Index\tLabel\n") for index,label in enumerate(np.where(y_test)[1]): f.write("%d\t%d\n" % (index,label))コールバックを作成し、学習中のデータを記録するようにする
# コールバックを作成 tb_cb = tensorflow.keras.callbacks.TensorBoard(log_dir= LOG_DIR, histogram_freq=1) cbks = [tb_cb] history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test), callbacks=cbks)チェックポイントを作成し、Projectorに出力する
result = model.predict(x_test) emb = result # embeddingsの作成 embedding_var = tensorflow.Variable(emb, name='mnist_embedding') CHECKPOINT_FILE = LOG_DIR + '/model.ckpt' ckpt = tensorflow.train.Checkpoint(embeddings=embedding_var) ckpt.save(CHECKPOINT_FILE) from tensorboard.plugins import projector # Projector設定 config = projector.ProjectorConfig() embedding = config.embeddings.add() embedding.tensor_name = "embeddings/.ATTRIBUTES/VARIABLE_VALUE" # メタデータ(CSV)パス embedding.metadata_path= 'metadata.tsv' # Projectorに出力 projector.visualize_embeddings(LOG_DIR, config)全体コードは下記。
import tensorflow # one-hot encodingを施すためのメソッド from tensorflow.keras.utils import to_categorical # 必要なライブラリのインポート from tensorflow.keras.datasets import mnist import numpy as np #import pandas as pd #import sklearn from tensorflow.keras.layers import Lambda, Input, Dense from tensorflow.keras.models import Model from tensorflow.keras.losses import mse from tensorflow.keras import backend as K #Kerasの関数でデータの読み込み。データをシャッフルして学習データと訓練データに分割 (x_train, y_train), (x_test, y_test) = mnist.load_data() # 2次元データを数値に変換 x_train = x_train.reshape(60000, 784) x_test = x_test.reshape(10000, 784) # 型変換 x_train = x_train.astype('float32') x_test = x_test.astype('float32') # 255で割ったものを新たに変数とする x_train /= 255 x_test /= 255 # one-hot encodingを施すためのメソッド from tensorflow.keras.utils import to_categorical # クラス数は10 num_classes = 10 y_train = y_train.astype('int32') y_test = y_test.astype('int32') labels = y_test # one-hot encoding y_train = to_categorical(y_train, num_classes) y_test = to_categorical(y_test, num_classes) # 必要なライブラリのインポート、最適化手法はAdamを使う from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout from tensorflow.keras.optimizers import Adam feature_dim = 10 # モデル作成 model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(feature_dim, activation='relu')) # 特徴量として取り出すための層を追加 model.add(Dense(10, activation='softmax')) model.summary() # バッチサイズ、エポック数 batch_size = 128 epochs = 20 model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy']) # メタデータ作成・保存 import datetime import os import numpy as np LOG_DIR = f"./tflog/{datetime.datetime.now().strftime('%Y-%m-%d-%H%M%S')}" META = os.path.join(LOG_DIR, 'metadata.tsv') os.makedirs(os.path.join(LOG_DIR), exist_ok=True) with open(META, 'w') as f: f.write("Index\tLabel\n") for index,label in enumerate(np.where(y_test)[1]): f.write("%d\t%d\n" % (index,label)) # コールバックを作成 tb_cb = tensorflow.keras.callbacks.TensorBoard(log_dir= LOG_DIR, histogram_freq=1) cbks = [tb_cb] history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test), callbacks=cbks) model.pop() # 最終段のsoftmax層を取り除いて、特徴量の層を最終段とする model.summary() result = model.predict(x_test) emb = result # embeddingsの作成 embedding_var = tensorflow.Variable(emb, name='mnist_embedding') CHECKPOINT_FILE = os.path.join(LOG_DIR, 'model.ckpt') ckpt = tensorflow.train.Checkpoint(embeddings=embedding_var) ckpt.save(CHECKPOINT_FILE) from tensorboard.plugins import projector # Projector設定 config = projector.ProjectorConfig() embedding = config.embeddings.add() embedding.tensor_name = "embeddings/.ATTRIBUTES/VARIABLE_VALUE" # メタデータ(CSV)パス embedding.metadata_path= 'metadata.tsv' # Projectorに出力 projector.visualize_embeddings(LOG_DIR, config)
- 投稿日:2020-12-12T22:53:21+09:00
tensowboardで特徴量を可視化する(tf.keras)
tensorboardで特徴量を可視化してみた
以前に投稿したmnistを全結合層で教師あり学習し、最終段をクラスタリングして評価するのコードに下記を追記して、tensorboardで可視化した。
こんな感じ。3Dでぐるぐる回せるので楽しい。
todo: metadata.tsvをGUIで読み込まないとラベルが反映されない問題を調査する
ラベルを可視化するためのメタデータを作成
# メタデータ作成・保存 import datetime import os import numpy as np LOG_DIR = f"./tflog/{datetime.datetime.now().strftime('%Y-%m-%d-%H%M%S')}" META = os.path.join(LOG_DIR, 'metadata.tsv') with open(META, 'w') as f: f.write("Index\tLabel\n") for index,label in enumerate(np.where(y_test)[1]): f.write("%d\t%d\n" % (index,label))コールバックを作成し、学習中のデータを記録するようにする
# コールバックを作成 tb_cb = tensorflow.keras.callbacks.TensorBoard(log_dir= LOG_DIR, histogram_freq=1) cbks = [tb_cb] history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test), callbacks=cbks)チェックポイントを作成し、Projectorに出力する
result = model.predict(x_test) emb = result # embeddingsの作成 embedding_var = tensorflow.Variable(emb, name='mnist_embedding') CHECKPOINT_FILE = LOG_DIR + '/model.ckpt' ckpt = tensorflow.train.Checkpoint(embeddings=embedding_var) ckpt.save(CHECKPOINT_FILE) from tensorboard.plugins import projector # Projector設定 config = projector.ProjectorConfig() embedding = config.embeddings.add() embedding.tensor_name = embedding_var.name # メタデータ(CSV)パス embedding.metadata_path= META # Projectorに出力 projector.visualize_embeddings(LOG_DIR, config)全体コードは下記。
import tensorflow # one-hot encodingを施すためのメソッド from tensorflow.keras.utils import to_categorical # 必要なライブラリのインポート from tensorflow.keras.datasets import mnist import numpy as np #import pandas as pd #import sklearn from tensorflow.keras.layers import Lambda, Input, Dense from tensorflow.keras.models import Model from tensorflow.keras.losses import mse from tensorflow.keras import backend as K #Kerasの関数でデータの読み込み。データをシャッフルして学習データと訓練データに分割 (x_train, y_train), (x_test, y_test) = mnist.load_data() # 2次元データを数値に変換 x_train = x_train.reshape(60000, 784) x_test = x_test.reshape(10000, 784) # 型変換 x_train = x_train.astype('float32') x_test = x_test.astype('float32') # 255で割ったものを新たに変数とする x_train /= 255 x_test /= 255 # one-hot encodingを施すためのメソッド from tensorflow.keras.utils import to_categorical # クラス数は10 num_classes = 10 y_train = y_train.astype('int32') y_test = y_test.astype('int32') labels = y_test # one-hot encoding y_train = to_categorical(y_train, num_classes) y_test = to_categorical(y_test, num_classes) # 必要なライブラリのインポート、最適化手法はAdamを使う from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout from tensorflow.keras.optimizers import Adam feature_dim = 10 # モデル作成 model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(feature_dim, activation='relu')) # 特徴量として取り出すための層を追加 model.add(Dense(10, activation='softmax')) model.summary() # バッチサイズ、エポック数 batch_size = 128 epochs = 20 model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy']) # メタデータ作成・保存 import datetime import os import numpy as np LOG_DIR = f"./tflog/{datetime.datetime.now().strftime('%Y-%m-%d-%H%M%S')}" CUR_DIR = './' META = os.path.join(CUR_DIR, 'metadata.tsv') with open(META, 'w') as f: f.write("Index\tLabel\n") for index,label in enumerate(np.where(y_test)[1]): f.write("%d\t%d\n" % (index,label)) tb_cb = tensorflow.keras.callbacks.TensorBoard(log_dir= LOG_DIR, histogram_freq=1) cbks = [tb_cb] history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test), callbacks=cbks) model.pop() # 最終段のsoftmax層を取り除いて、特徴量の層を最終段とする model.summary() result = model.predict(x_test) emb = result # embeddingsの作成 embedding_var = tensorflow.Variable(emb, name='mnist_embedding') CHECKPOINT_FILE = LOG_DIR + '/model.ckpt' ckpt = tensorflow.train.Checkpoint(embeddings=embedding_var) ckpt.save(CHECKPOINT_FILE) from tensorboard.plugins import projector # Projector設定 config = projector.ProjectorConfig() embedding = config.embeddings.add() embedding.tensor_name = embedding_var.name # メタデータ(CSV)パス embedding.metadata_path= META # Projectorに出力 projector.visualize_embeddings(LOG_DIR, config)
- 投稿日:2020-12-12T22:29:42+09:00
中学数学から始める機械学習〜プログラミング未経験でもできるデータ分析〜
今回は数学偏差値の30文系の私でもデータ分析を行えるようにしてくれたとあるUdemyの「【キカガク流】人工知能・脱ブラックスボックス講座」について説明させて頂きます。
はじめに
「プログラミングやってみたいけど、何から始めれば良いのか分からない」
「データ分析ができるとカッコ良さそうだけど、数式見るだけでいやいやの嫌」というように思ったことはありませんか?
この記事は、私のようにデータ分析を始めたいけど数学の知識がなくてプログラミングの本を買ったのに読めてないといった人向けに是非受けて欲しい講座をご紹介したいと思います。
Udemy講座選びの参考にもどうぞ〜【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 初級編 -
【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 中級編 -データ分析を始めるならまずはこれから!
このキカガク流の講座は、中学生レベルの数学から最終的に単回帰分析や重回帰分析といった大学の研究やビジネスまで幅広く使えるデータ分析手法を学ぶことができます!もちろんデータ分析だけでなく、データ分析に必要なプログラミング(言語はPython)の知識を同時並行で手を動かしながら教えてくれるのでプログラミング初心者でも大丈夫です!
この講座のすばらしい点は、誰しも一度は思った「微分は現実世界でいつ使うの?」
「ベクトルって学ぶ必要ないんじゃない?」といった問いにデータ分析の実例を交えながら丁寧に答えてくれます!特に文系の方が最初に学ぶにあたって、うってつけではないでしょうか?
どんなことが学べるの?
主にデータ分析に必要な数学とプログラミング知識について学ぶことができます。
詳しくは以下のようになっています。初級(総時間:4時間17分)評価4.4
ー数学ー
・微分(中学レベルからスタート)
・偏微分
・単回帰分析
ーPythonー
・変数
・基本構文(演算やprint等の基礎的な扱い)
・制御構文
・関数(基礎レベル)
・numpy
・pandas
・matplotlib
・実践(実データを扱った単回帰分析)中級(総時間:4時間22分)評価4.4
ー数学ー
・スカラー:ベクトル:行列
・重回帰分析
・統計(基礎レベル)
ーPythonー
・重回帰分析をPython実装(Scikit-Learn)
1:実データで演習
2:外れ値・スケーリングを考慮した重回帰分析初級に関しては難易度的にも比較的易しい内容になっています。(初級って書いてある通り)
数学のレベルは本当に上の画像のような中学生レベル式から始めるので安心してオッケーです!research_test.pyfrom sklearn.externals import joblib joblib.dump(model,'test.pkl') model_new = joblib.load('test.pkl')また、プログラミング知識に関しては、一番簡単な四則演算から上のようなScikit-Learnを扱った予測まで順序よく教えてくれます。一気にレベルが跳ね上がるなんてこともありません。
おわりに
今回は初めてデータ分析をPythonで行う人におすすめのキカガク講座を紹介しました。私はこの講座を通して、データ分析の勉強を再会し、現在はTwitterのAPIから得たデータを分析しています。
大切なのはコードや方法を覚えるのではなく、理解することだと私は考えています。ぶっちゃけ分析の書き方や機械学習の書き方はぐぐればいっぱいでてくるので。ただ、自分が行いたい分析についてしっかり理解していないと作りたいものも作れません。
是非この講座を通して、データ分析のいろはについて学んでみてください!この記事が新しくデータ分析を始める人のきっかけになってくれたら幸いです、、、
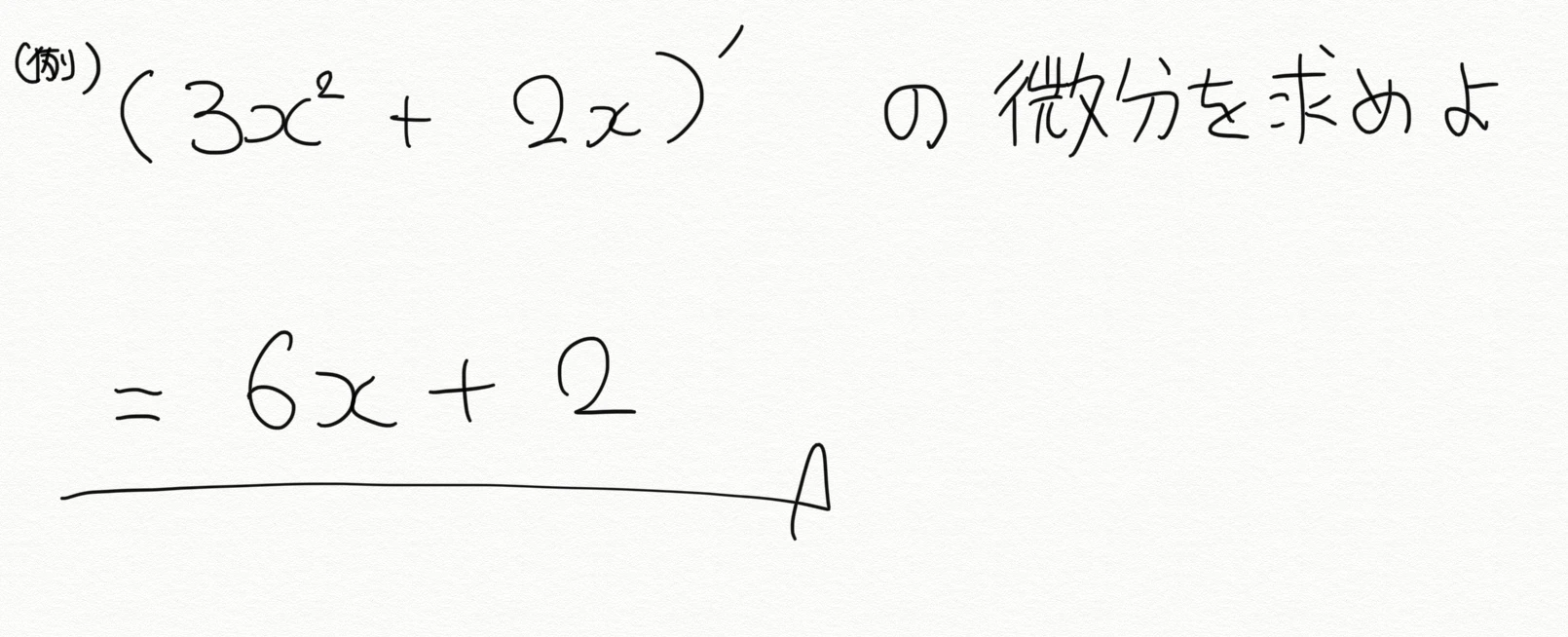
- 投稿日:2020-12-12T22:29:42+09:00
キカガク流から学ぶ中学数学から始める機械学習ーUdemy紹介記事ー
今回は数学偏差値の30文系の私でもデータ分析を行えるようにしてくれたとあるUdemyの「【キカガク流】人工知能・脱ブラックスボックス講座」について説明させて頂きます。
はじめに
「プログラミングやってみたいけど、何から始めれば良いのか分からない」
「データ分析ができるとカッコ良さそうだけど、数式見るだけでいやいやの嫌」というように思ったことはありませんか?
この記事は、私のようにデータ分析を始めたいけど数学の知識がなくてプログラミングの本を買ったのに読めてないといった人向けに是非受けて欲しい講座をご紹介したいと思います。
Udemy講座選びの参考にもどうぞ〜【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 初級編 -
【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 中級編 -データ分析を始めるならまずはこれから!
このキカガク流の講座は、中学生レベルの数学から最終的に単回帰分析や重回帰分析といった大学の研究やビジネスまで幅広く使えるデータ分析手法を学ぶことができます!もちろんデータ分析だけでなく、データ分析に必要なプログラミング(言語はPython)の知識を同時並行で手を動かしながら教えてくれるのでプログラミング初心者でも大丈夫です!
この講座のすばらしい点は、誰しも一度は思った「微分は現実世界でいつ使うの?」
「ベクトルって学ぶ必要ないんじゃない?」といった問いにデータ分析の実例を交えながら丁寧に答えてくれます!特に文系の方が最初に学ぶにあたって、うってつけではないでしょうか?
どんなことが学べるの?
主にデータ分析に必要な数学とプログラミング知識について学ぶことができます。
詳しくは以下のようになっています。初級(総時間:4時間17分)評価4.4
ー数学ー
・微分(中学レベルからスタート)
・偏微分
・単回帰分析
ーPythonー
・変数
・基本構文(演算やprint等の基礎的な扱い)
・制御構文
・関数(基礎レベル)
・numpy
・pandas
・matplotlib
・実践(実データを扱った単回帰分析)中級(総時間:4時間22分)評価4.4
ー数学ー
・スカラー:ベクトル:行列
・重回帰分析
・統計(基礎レベル)
ーPythonー
・重回帰分析をPython実装(Scikit-Learn)
1:実データで演習
2:外れ値・スケーリングを考慮した重回帰分析初級に関しては難易度的にも比較的易しい内容になっています。(初級って書いてある通り)
数学のレベルは本当に上の画像のような中学生レベル式から始めるので安心してオッケーです!research_test.pyfrom sklearn.externals import joblib joblib.dump(model,'test.pkl') model_new = joblib.load('test.pkl')また、プログラミング知識に関しては、一番簡単な四則演算から上のようなScikit-Learnを扱った予測まで順序よく教えてくれます。一気にレベルが跳ね上がるなんてこともありません。
おわりに
今回は初めてデータ分析をPythonで行う人におすすめのキカガク講座を紹介しました。私はこの講座を通して、データ分析の勉強を再会し、現在はTwitterのAPIから得たデータを分析しています。
大切なのはコードや方法を覚えるのではなく、理解することだと私は考えています。ぶっちゃけ分析の書き方や機械学習の書き方はぐぐればいっぱいでてくるので。ただ、自分が行いたい分析についてしっかり理解していないと作りたいものも作れません。
是非この講座を通して、データ分析のいろはについて学んでみてください!この記事が新しくデータ分析を始める人のきっかけになってくれたら幸いです、、、
- 投稿日:2020-12-12T22:13:33+09:00
【Python】パーセプトロンモデルを利用した線形分類の実装
早稲田大学本庄高等学院所属でプログラミング系の活動をしているアイスです。
概要
パーセプトロンを用いた学習アルゴリズムをPythonで実装します。Irisの花のデータセットから、「がく片の太さ」と「花びらの太さ」を取り出し、計100個のデータを描画、その分布を元に決定境界を学習させる。
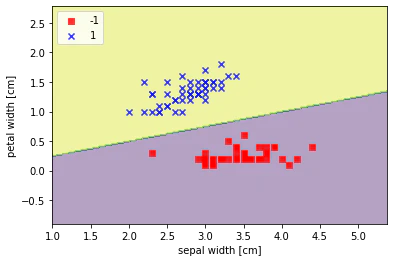
結果として、次のようなグラフが描画されることを目標とすることにする。
上の画像は、Google Colaboratory を利用して描画したグラフです。このグラフを描画するまでの過程を説明する。
データセットの取得
scikit-learnはimportせず、インターネット上のmachine-learning-databasesから直接データを取得。
main.pyimport numpy as np import pandas as pd # machine-learning-databasesからデータを取得 df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None) ''' irisデータセット(150, 4) - がく片の長さ(cm) - がく片の太さ(cm) - 花びらの長さ(cm) - 花びらの太さ(cm) - タグ(Iris-Setosa, Iris-Versicolour, Iris-Virginica) 0:50が "Iris-Setosa", 50:100が "Iris-Versicolur", 100:150が "Iris-Virginca" ''' # がく片の太さ(1)と花びらの太さ(3)を取得 # shape : (100, 2) x = df.iloc[:100, [1, 3]].values # タグを取得 # shape : (100, 1) y = df.iloc[:100, 4].values # クラスラベルを変換(Iris-Setoraを-1、Iris-Versicolourを1) y = np.where(y == 'Iris-setosa', -1, 1)Google Colaboratory を利用しているメリットとしては、Numpyなどのライブラリを追加で準備する必要がないためである。VS code などを使う場合は、Anacondaを別でダウンロードして、環境を構築したりなど、初学者にとって面倒かつ、挫折する原因にもなり得るので、Google Colaboratory を使うことをお勧めしている。
各種関数:
Irisデータの描画
後の分類実装を可視化するために、Irisのデータセットをグラフにプロットし、感覚的に確認できるようにする。
main.pyimport matplotlib.pyplot as plt # Setora を青色のoで表示 plt.scatter(x[:50, 0], x[:50, 1], color='blue', marker='o', label='Setora') # Versicolur を赤色のxで表示 plt.scatter(x[50:100, 0], x[50:100, 1], color='red', marker='x', label='Versicolur') # ラベルの設定 plt.xlabel('sepal width [cm]') plt.ylabel('petal width [cm]') plt.legend(loc='upper left') # 表示 plt.show()結果:
上の図のように点がプロットされた。青色のoがSetoraを表し、赤色のxがVersicolurを表している。x軸が「がく片の幅」、y軸が「花びらの幅」を表している。
グラフに描画するとSetoraとVersicolurが明らかに分類されていることが感覚的に理解できるようになった。これを機械に分類させるために、パーセプトロンの分類器のモデルを作成し、学習させる。各種関数:
パーセプトロンの分類器の実装
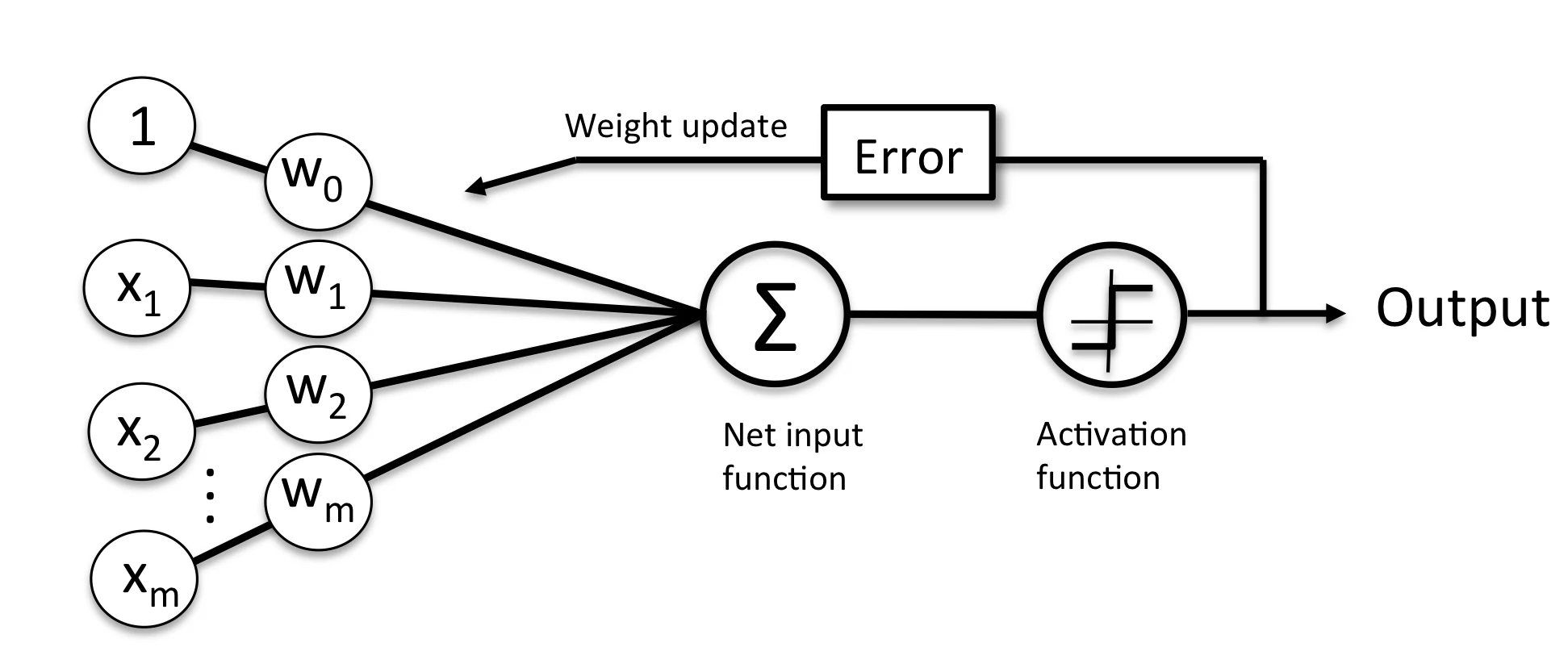
以下に示すのはパーセプトロンの概念図です。
(Sebastian Raschka『達人データサイエンティストによる理論と実装 Python機械学習プログラミング』福島真太郎監訳、クイープ訳、インプレス出版、2016年)より引用
m個の要素に対してデータxと重みwを組み合わせる。1, x_1, x_2, …, x_mw_0, w_1, w_2, …, w_mその総和はステップ関数(活性化関数)に渡され、誤差が計算される。この一連の流れを何回か繰り返すことで誤差を減らし、重みが更新する。
main.pyclass Perceptron(): def __init__(self, eta=0.1, n_iter=10): self.eta = eta self.n_itr = n_iter def fit(self, x, y): self.w_ = np.zeros(1 + x.shape[1]) self.errors = [] print(self.w_) for _ in range(self.n_itr): error = 0 for i, target in zip(x, y): update = self.eta * (target - self.step(i)) self.w_[1:] += update * i self.w_[0] += update error += int(update != 0.0) self.errors_.append(error) def net_input(self, x): return np.dot(x, self.w_[1:]) + self.w_[0] def step(self, x): return np.where(self.net_input(x) >= 0.0, 1, -1)オブジェクト指向に基づいてPerceprotonクラスを定義する。後にインスタンスを作成して、fit関数から使用すると、
fit関数
↓
step関数
↓
net_input関数
↓
step関数
↓
fit関数の順で処理される。fit関数では、エポック数(n_itr)回の処理を繰り返し、誤差を小さくしていく。その過程で、targetと予測値の差を取り、それに学習係数(eta)をかけた値を重みを随時更新、errorを更新していく。step関数では、net_input関数で内積をとったものをstep関数で処理し、予測値を計算していく。targetoと予測値の差に学習係数をかけたものを関数で処理し、重みを更新する。
この処理を繰り返します。各種関数:
誤差の収束の確認
上で実装したモデルで本当に分類が学習されているのかを確認するために、errorsに格納されている誤差が収束していく様子をグラフに描画して確認する。
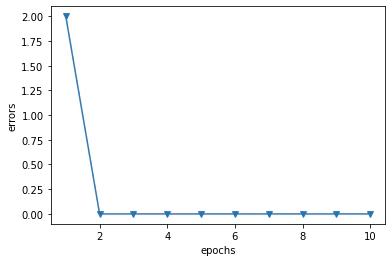
check.py# インスタンス化 ch = Perceptron(eta=0.1, n_iter=10) # モデルに学習させる ch.fit(x, y) # 誤差を描画 plt.plot(range(1, len(ch.errors) + 1), ch.errors, marker='v') plt.xlabel('epochs') plt.ylabel('errors') plt.show()結果:
x軸がエポック数、y軸が誤差を表している。上図のように、誤差はすぐに収束し、2回目以降は既に収束していることが分かった。各種関数:
決定境界の描画
カラーマップを事前準備し、その後、格子点の座標を用意し、等高線を色分けしながら表示する。
main.pyfrom matplotlib.colors import ListedColormap def plot_decision_regions(X, y, classifier, resolution=0.01): # マーカーと色の準備 # 2種類(1か-1)で十分 markers = ('s', 'x') colors = ('red', 'blue') mp = ListedColormap(colors[:len(np.unique(y))]) # 「がく片の太さ」の最大値と最小値を取得。 # 描画に余裕を持たせるために+1と-1 x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 # 「花びらの太さ」の最大値と最小値を取得 # 描画に余裕を持たせるために+1と-1 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 # 格子点の座標をresolution(0.01)ごとに取得 xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) # パーセプトロンの分類器を使って、zにデータを格納 z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) z = z.reshape(xx1.shape) # 格子点とデータをもとに線をプロット plt.contourf(xx1, xx2, z, alpha=0.1) plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) for i, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8, color=camp(i), marker=markers[i], label=cl)markers, colorsは点をプロットする際のマーカーとプロットを事前に準備する。今回取り扱うデータは、Setora(-1)とVersicolur(1)の二種類だけなので、マーカーと色も2種類で十分。
matplotlibからListedColormapを読み込む。np.unique(y)では、yの要素は2種類(1と-1)しかないので、mpには二つの色が格納される。
x1_min, x1_maxは「がく片の太さ」の最大値と最小値を取得し、グラフのx軸の幅を決めます。x2_min, x2_maxも同様に「花びらの太さ」の最大値と最小値を取得し、y軸の幅を決める。グラフの端を見やすくするために、それぞれ+1か-1している。
xx1、xx2はそれぞれx軸とy軸の格子点を表している。上で求めた最小値と最大値を両端に置き、resolution(0.01)ごとの間隔で格子点を設ける。この時使用するmeshgrid関数に対応させるため、それぞれをndarrayの型に統一し、処理を行う。
classfierインスタンスからpredict関数を呼び出し、zにデータを格納、それらのデータをcontourf関数を使って等高線として色分けして表示する。この時のalphaは色味を調整するものなので、適当でよい。最後に、xlimとylim関数でグラフの両端を設定して、等高線の表示は完了である。
for文内は、「がく片の太さ」と「花びらの太さ」をそれぞれプロットしている。最初に準備したcolorとmarkerから要素を取り出してきて表示している。labelはそれぞれ、-1がSetora、1がVercicolurを表している。
始めに設定した目標のグラフが表示されたことが確認できた。各種関数:
- matplotlib.colors.LinkedColormap
- np.meshgrid
- np.arange
- np.array
- np.ndarray.ravel
- np.ndarray.reshape
- plt.countourf
- plt.xlim
- plt.ylim
まとめ
今回は、Pythonを用いて、irisのデータをパーセプトロンと呼ばれる機械学習の手法を用いて分類した。データから、「がく片の太さ」と「花びらの太さ」を抽出し、それぞれの特徴を学習させ、その結果をグラフに表示させるところまですることが出来た。
感想
関数の種類を見て貰ったらわかるが、パーセプトロンの仕組み自体は、一度理解してしまえば実装もさほど難しくなく、簡単にまとめることができる。その一方で、描画に関しては、格子点、ラベル、両端、色などを全て設定しなければいけないため、手間がかかり、挫折の原因として大きいのではないかと思った。本記事は初学者向けに書いたため、そのような挫折をしないことを「させない」ことを目標に書いた。そのため、Google Colaboratoryを使い環境構築を簡単にしたり、関数の説明を載せて調べる手間を省くなどした。
自分としても学んだことを整理できたので、よかったと思う。参考文献
- pandas documentation
- numpy documentation
- matplotlib documentation
- [機械学習]iriデータセットを用いてscikit-learnの様々な分類アルゴリズムを試してみた
- Sebastian Raschka『達人データサイエンティストによる理論と実装 Python機械学習プログラミング』福島真太郎監訳、クイープ訳、インプレス出版、2016年


- 投稿日:2020-12-12T22:06:56+09:00
Djangoのアプリ作成で最初にすること
参考文献
このページの目的
備忘録です.チュートリアルを自分用に要約しました.
プロジェクトの作成
Djangoをインストールしている環境で,プロジェクトを作成したいディレクトリに移動.以下のコマンドでプロジェクトを作成.
django-admin startproject <mysite><mysite>は自分の好きな名前.この名前は重要ではなく,任意の名前に変更できる.
プロジェクトのルートディレクトリに移動.cd <mysite>サーバを起動してプロジェクトが正しく作成できていることを確認してもよい.
python3 manage.py runserverアプリケーションの作成
プロジェクトのルートディレクトリで以下のコマンドを入力しアプリを作成する.<app>はアプリ名に置き換える.
python3 manage.py startapp <app>上記コマンド実行後の構造は,
<mysite>/
┝manage.py
┝<mysite>/
└<app>/
となっている.
views.pyの編集.app/views.pyfrom django.http import HttpResponse def index(request): return HttpResponse("Hello, world. You're at the app index.")アプリのディレクトリにurls.pyはないので,urls.pyを新規作成し,app/urls.pyにpathを登録.
app/urls.pyfrom django.urls import path from .views import index urlpatterns = [ path('', index, name='index'), ]プロジェクトのurls.pyの方にアプリのpathを登録.path()の第1引数の最後のスラッシュを忘れないように.
mysite/urls.pyfrom django.contrib import admin from django.urls import include, path # includeを追加 urlpatterns = [ path('<アプリ名>/', include('<アプリ名>.urls')), # include path('admin/', admin.site.urls), ]app/apps.pyを参考に,アプリをsettings.pyに登録.
mysite/settings.pyINSTALLED_APPS = [ 'polls.apps.PollsConfig', # アプリ名が'polls'の場合. 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]terminalのプロジェクトのルートディレクトリで1回マイグレーションをする.これで作成したアプリをDjangoが認識できる.
python3 manage.py migrate<app>/models.pyを編集していなければ,下記を実行したときに"No changes detected in app <app>"と表示される.
python3 manage.py makemigrations <app>テンプレートの作成
アプリのディレクトリにtemplatesディレクトリを作成する.更に,templatesディレクトリ内にアプリ名のディレクトリを作成し,その中にindex.htmlを作成する.つまり,index.htmlのパスは<mysite>/<app>/templates/<app>/index.htmlとなる.
app/templates/app/index.html{% extends './base.html' %} {% block body %} <h1>Hello World</h1> <p>This is a template.</p> {% endblock body %}index.htmlと同じ階層にbase.htmlを作成する.
app/templates/app/base.html<!DOCTYPE html> <html lang="ja"> <head> <title>Title</title> <meta charset="utf-8"> {% block head %} {% endblock head %} </head> <body> {% block body %} replace me. {% endblock body %} </body> </html>このテンプレートを使用するために<app>/views.pyのindexビューを更新する.文字列中の<app>を自分のアプリ名に置き換え忘れないように.
app/views.pyfrom django.shortcuts import render def index(request): context = { 'foo': 'foo string!', } return render(request, '<app>/index.html', context)このコードは,<app>/index.htmlというテンプレートをロードし,そこにコンテキストを渡す.コンテキストは,テンプレート変数名をPythonオブジェクトにマッピングする辞書.
静的ファイルの作成
アプリのディレクトリにstaticディレクトリを作成する.更に,staticディレクトリ内にアプリ名のディレクトリを作成し,その中にstyle.cssを作成する.つまり,style.cssのパスは<mysite>/<app>/static/<app>/style.cssとなる.
mysite/app/static/app/style.css*{ box-sizing: border-box; /* This makes sure that the padding and border are included in the total width and height of the elements. */ } /* Extra small devices (phones, 600px and down) */ @media only screen and (max-width: 600px){ body{ background-color: papayawhip; } } /* Small devices (portrait tablets and large phones, 600px and up) */ @media only screen and (min-width: 600px){ body{ background-color: deepskyblue; } } /* Medium devices (landscape tablets, 768px and up) */ @media only screen and (min-width: 768px){ body{ background-color: mediumspringgreen; } } /* Large devices (laptops/desktops, 992px and up) */ @media only screen and (min-width: 992px){ body{ background-color: darkgoldenrod; } } /* Extra large devices (large laptops and desktops, 1200px and up) */ @media only screen and (min-width: 1200px){ body{ background-color: violet; } }HTMLファイルにstaticファイルをロードする.文字列中の<app>を自分のアプリ名に置き換え忘れないように.
app/templates/app/index.html{% extends './base.html' %} {% load static %} {% block head %} <link rel="stylesheet" type="text/css" href="{% static '<app>/style.css' %}"> {% endblock head %} {% block body %} <h1>Hello World</h1> <p>This is a template.</p> {% endblock body %}サーバを起動して背景色が変わることを確認しよう.
python3 manage.py runserver正常にstyle.cssがロードされれば,スクリーンサイズに応じて背景色が変わる.
- 投稿日:2020-12-12T21:59:01+09:00
AutoMLでおせちの価格予測&GANで非実在おせちを作る
はじめに
この記事は次のAdvent Calendarの12月12日分です
機械学習の自動化プラットフォームDataRobotを使って楽しむ冬のイベント予測チャレンジ
DataRobotはマネージドな機械学習(ML)プラットフォームです。データセットの用意からモデルの訓練・デプロイまでを、ブラウザを通じて進めていけるそうです。特徴量設計やモデルの選択もカバーしており、AutoMLサービスの一つということにもなります。ちょうどマネージドなAutoMLサービスに興味があったことから、この機会に試してみることにしました。
この記事がいいねと思ったらLGTMお願いします!(例のあれ)やりたいこと
さて、このAdvent Calendarのお題は『冬ならではのテーマで機械学習モデルを試そう』だそうです。
私はちょうど百貨店のおせちを探していたため、おせち料理の画像からの価格予測(回帰)を扱うことにしました。
しかし、何かがひっかかります。おせちと言えば元旦に食べるものですね。元旦・・・?
そう、GAN旦です。
『GANで生成された仮想おせち画像を眺めて、新年の学習がうまくいくことを祈る日』ですね。
GAN(Generative Adversarial Network)については後述することにして、この記事は次の2本立ての内容です。1. おせち画像からの価格予測
2. GAN(Generative Adversarial Network)によるおせち画像生成
おせちGANで生成した画像の一部です
では、始めましょう。
おせち画像からの価格予測
データセットの用意
Data Robotは入力データとして画像を扱うことができます。おせち画像のデータセットはさすがになかったので、頑張って約500枚の画像と価格データを集めました。根性で集めるか、Beautiful Soupなど使ってECサイトからスクレイピングするのが順当でしょう。
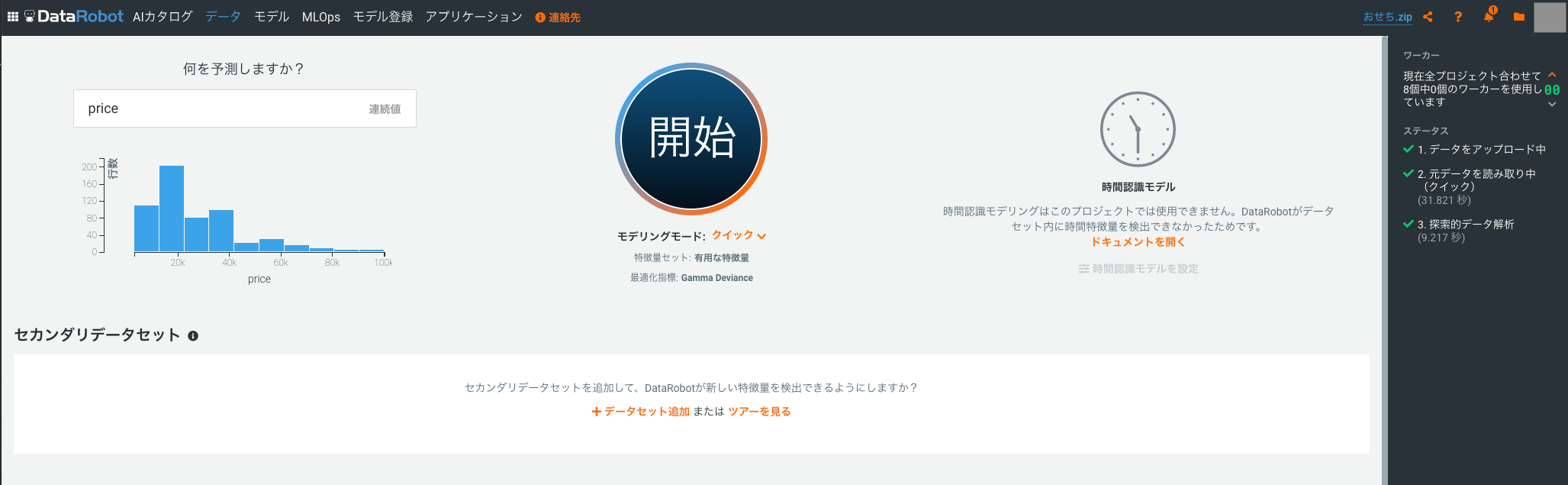
ところで、おせちは季節アイテムなので、年末以外はデータセットの入手難易度が高いです。もし似たような興味ある人はお早めに。数年分集めて年ごとの傾向を分析したりすると面白いかもしれませんね。用意したデータセットをData Robotにアップロードすると次のようになります。
いい感じですね。価格の平均値は32,096円、標準偏差は29,393円で、値は6000円〜32万円まで幅があります。
もしデータに欠損や外れ値があればここで警告を出して教えてくれます。
また、データセットからのtest data分割やクロスバリデーションの設定は機械学習ビギナーがミスりがちなステップですが、DataRobotではここは自動でやってくれるので安心です。クロスバリデーションでモデルを検証した後、最終ステップでtest dataによる検証ができます。
なお、trainとtest dataをユーザーが指定することはできないようです。時系列データやグループ属性をもつデータだとデータ分割は厄介な問題になるのですが、今回は未検証です。機械学習モデルの自動構築
さて、ここからが本番です。
押してくれと言わんばかりにダッシュボードで存在感を放っている『開始』ボタンを押すと、自動で特徴量設計と機械学習モデルの訓練が始まります。
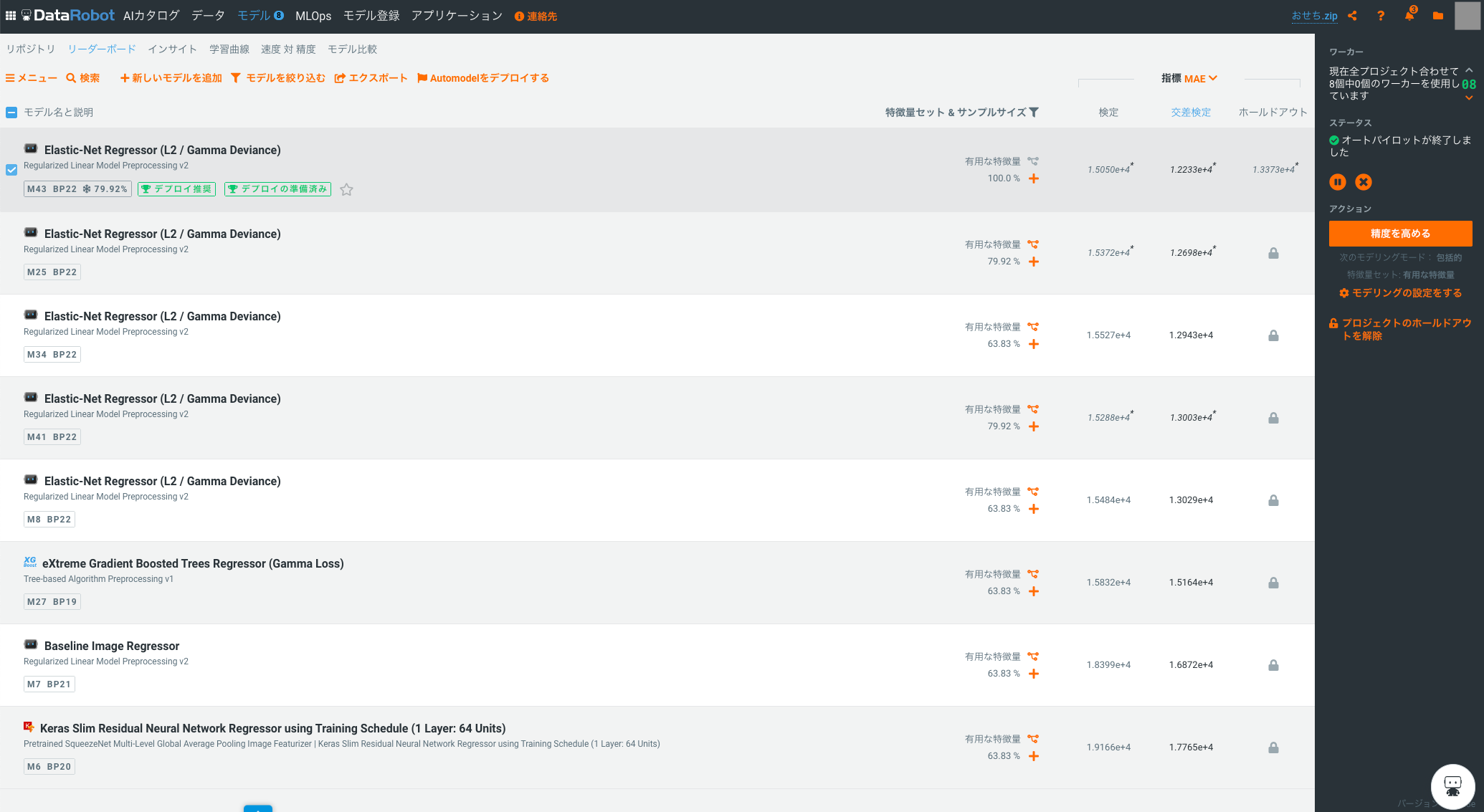
デフォルトではオートパイロットモード(=AutoML)が選択されており、複数の試行を通じて、性能の良い機械学習モデルを自動的に選択してくれます。今回は15分程度でオートパイロットが終了し、結果が一覧で表示されます。
今回は、機械学習アルゴリズムとしてElastic Netを使ったモデルが良い性能を示しています。1
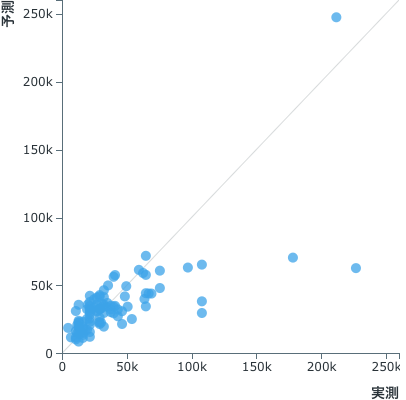
ベストなモデルのテストデータでの予測性能は、平均絶対誤差 13,373円、標準偏差 24,817円、相関係数(ピアソンのR^2) 0.515となりました。ランダムよりはマシな程度に学習できたことはわかりましたが、正直ちょっと残念な性能です。
この後、他のモデルも追加してもう少し試行錯誤してみましたが上記がベストでした。予測誤差の原因を分析
予測誤差が大きくなってしまった原因を調べるために、テストデータにおける予測結果の散布図を見てみましょう。
この図から、価格が10万円を超えてくる少数の高級おせちを大幅に安く予測している傾向が認められます。機械学習を用いている以上、学習データが少ない領域では最頻値に寄った予測をしがちで、正しい予測をするのは難しいと言えます。よって、十分な性能が得られなかった原因の一つはデータの不足と考えられます。今回の学習データは500枚程度と少ないことから、データの量を鑑みると、簡単に達成できる性能としてはこのあたりが壁かもしれません。ちなみにもし私がここから業務で携わるとしたら、モデルのエンジニアリングはさておき、まずはより多くの学習データを集める試みに注力すると思います。そもそもの問題として、おせちの値段が見た目と相関していない可能性もあるのですが。。このモデルのアクティベーションマップ(≒モデルが予測のために注目している箇所)2を見ると、おせち本体より背景にフォーカスしてしまっていることがわかります。直感的には、おせちの具を見て判断して欲しいところですが、どうもそうではないようです。ちなみに、このようなアクティベーションマップを自分で用意するのは結構面倒なので、数回クリックするだけで可視化できるのは便利です。
ここで終わらず、もう少し深堀りしてみましょう。一般的に、重箱の段数と価格には相関がありそうですね。
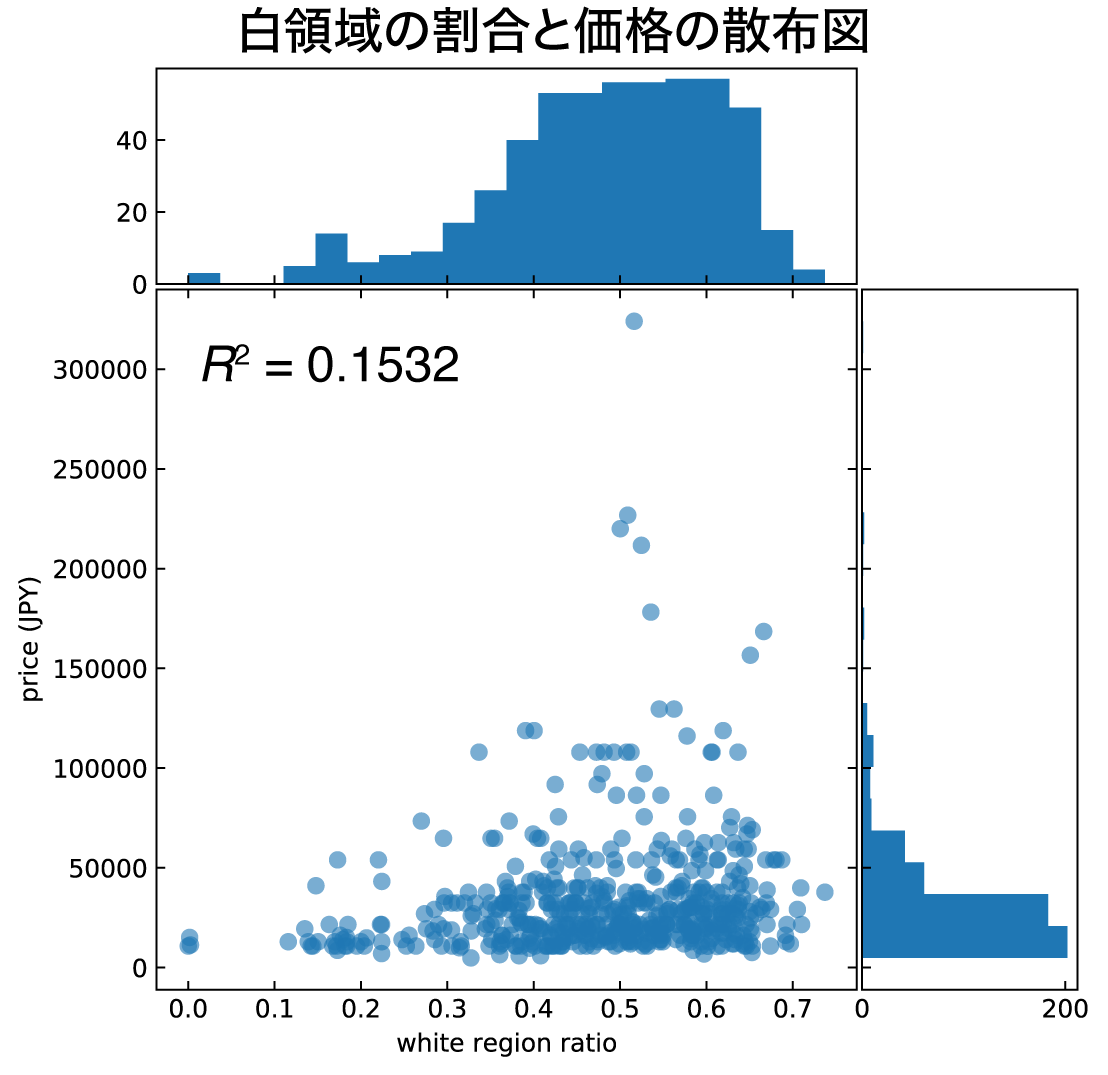
正方形の画像において、重箱が2段,3段のおせちは、1段のおせちより背景の白領域が多くなるはずです。
そこで、『おせち画像の背景の白エリアの面積が有効な特徴量として機能しているのでは』という仮説を立てました。
この仮説は、白エリアの面積と価格の相関を見れば簡単に検証できそうです。(ここは手元のPCで分析しました)
調べてみると、相関係数は0.15程度と、全体ではほぼ無相関でした。しかし、この散布図を見ると、画像背景である白エリアの面積(white region ratio)が大きいおせちでは価格にバラつきが大きく、5万円を超える高額おせちのほとんどは、画像の半分以上が白エリアであることがわかります。やや恣意的ですが、この結果の解釈の一例として次が考えられるでしょう。価格のボリュームゾーンである2-3万円のおせちでは、白領域と価格に相関は見られない。
一方、5万円を超える高額おせちは、2段や3段の重箱で提供されることが多く、おせち画像の白領域の割合が大きいほど高額となる傾向がある。高額おせちは数としては少数だが、価格のスケールが大きいためモデルの学習に大きな影響を与え、結果として価格予測モデルが背景の白領域に着目するに至った。さらに調べるなら、大外ししたデータ具体的に見ていったり、画像をt-SNE等で次元圧縮して可視化3して調べたりと色々やりたいことはありますが、長くなるのでこのあたりにします。
性能はともかく、これでおせち画像から価格を予測する機械学習モデルを構築できたとして、次に進みましょう。Lightweight GANによるおせち画像生成
元旦もといGAN旦に食べるおせち画像を、GANを使って生成してみましょう。
Generative Adversarial Networkって?
Generative Adversarial Network(GAN)とは、DNNを用いた深層生成モデルの一つです。GANは生成モデルという名前の通り、新しいデータを生成することができる手法です。詳しい説明は他の解説記事や論文に譲りますが、2014年にGoodfellowらによって発明されて以来、凄まじい勢いで進化を重ねている技術です。GANがもっとも成功しているのは画像への応用で、近年では本物と見分けがつかないほど綺麗な画像の生成が可能になっています。一例として、GANによる顔画像の生成結果の変遷を示します。
Which face is real? (https://www.whichfaceisreal.com)というwebサイトでは、人間の顔画像を見て、それがGANで生成されたものか、本物の顔かのクイズで遊ぶことができます。かなり難しいです。GANの実用上の大きな課題の一つは、学習に大量のデータと計算リソースが必要になる点です。
例えば上記画像右のStyleGANの学習には、7万枚の画像データセットと8個のGPUで1週間の計算が必要です。これを普通のゲーミングPCで実行したら2ヶ月ほどかかり、おせちを用意する前に2020年が終わってしまいます。
この問題を解決しようとする試みは多数ありますが、つい最近(2020年11月末)発表されたTowards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesisという論文で、Lightweight GANという手法が提案されました。DNNの構造と学習方法を工夫することによって、100枚程度の画像と1GPU・数時間の学習により高解像度かつ品質の良い画像生成を可能にした手法だそうです。上記論文では、様々なドメインで非常に高品質な画像生成に成功した結果が示されています(図5を一部改変)。
Lightweight GANによるおせち画像生成
今回はこのLightweight GANを用いておせち画像を生成します。ありがたいことに、Lightweight GANはPyTorchで書かれた使いやすい再現実装が公開されています。今回はこちらを使います。
https://github.com/lucidrains/lightweight-gan
使い方は簡単で、上記リポジトリをcloneしpip install lightweight-ganを実行した後に、次の1行で動きます。詳しい使い方やオプションについてはREADMEを参照してください。lightweight_gan --data ./path/to/images --image-size 256Google ColabのGPUランタイムでLightweight GANを12時間学習した後、生成した画像がこちら。価格予測モデルの学習に使用したのと同じ約500枚のおせち画像を学習に用いました。
かなりそれっぽい結果ではないでしょうか。ところどころ破綻してるのも味わい深いですね(?)
遠目から見るとおせちにしか見えませんが、拡大するとおせちじゃないのが不気味で良いです。GANの潜在空間上を移動しながら画像を生成するとこんな感じになります(Interpolation)。
GIFにしました。ぐにぐに動きます。悪夢に出そうです。
これでGAN旦のおせちの準備ができましたね。好きなだけおせち画像を生成できます。
おまけ:GANで作ったおせちの値段は?
初めにDataRobot上で構築した、おせちの価格予測モデルを用いて、GANで生成したおせち画像の価格を予測しました。ここでは予測モデルとGANの学習では違うデータセットを用いるべきですが、おまけの遊びということで。。
みなさんの直感とは合っていますか?
終わりに
Data Robotは初めて使いましたが、最初にモデルを学習させるまでの技術的・心理的ハードルをなるべく下げていることが伝わってきました。まず手元のデータでPoCしたいなど、サクッと試したい時には有用そうです。個人的な印象ですが、ユーザーペルソナとしては「専任のデータサイエンティストではないが業務のために機械学習を使いたい方」かなと思います(『商品の仕入れ数を経験で決めているが、データに基づいて予測したい』など、)。
UIや用語にはややクセがあるように感じましたが、他のAWSやGCPのサービスを使う場合に比べ、覚えるべきことが少なそうです。一方で、利用できる機械学習アルゴリズムには制約があったり、特徴量設計や前処理まで戻ってのトライアンドエラーはワークフロー上しづらいなど、システム上の制約があるのも確かです。簡便さと多機能さはトレードオフなので、ここは道具の使い分けの問題と思います。詳しい人はGoogleのAI Platform Notebooksなど使うほうが所望のことができるでしょう。GANの学習は非常に難しく、同じ画像しか生成されなくなったり(mode collapse)よくわからない理由でバグったりと、様々なハマりどころが知られています。しかし今回は何のトラブルも無くあっさり動いたので、画像の品質と合わせて最新のGANの進化に驚きました。
興味がある方はぜひ自分の好きなデータで試してみてください。
MLに明るい方は、「画像なのにElastic Net?」と疑問に思うかもしれません。Elastic Netは非常に古典的なアルゴリズムで、画像を直接入力として扱うのは苦手だからです。Data Robotでは、予め学習済みのDNNに入力画像を通して、そのDNNの出力を特徴量として他の様々なアルゴリズムの入力に使うことで対応しています。 ↩
ところで、オリジナルのクラスアクティベーションマップ(CAM)は分類問題において各クラスについてのfeature mapの重みや勾配を用いてCNNの着目領域を可視化する手法ですが、Data Robotでは、回帰問題でもアクティベーションマップが出力できるようCAMを拡張しているそうです。実装が気になるところですが、詳しい情報は記載がありませんでした。プロプライエタリなサービスの難しいところです。 ↩
Data Robotには画像の特徴量を次元圧縮して2次元で可視化する機能(画像埋め込み)がありますが、現状ではUIに難があり意味のある分析ができなかったので今回はスキップします。 ↩









- 投稿日:2020-12-12T21:57:46+09:00
pip install tensorflow==1.x がエラーになるとき
pip install tensorflow==1.x ができない
こんなエラーになるとき
python -m pip install tensorflow==1.15 ERROR: Could not find a version that satisfies the requirement tensorflow==1.15 (from versions: 2.2.0rc3, 2.2.0rc4, 2.2.0, 2.2.1, 2.3.0rc0, 2.3.0rc1, 2.3.0rc2, 2.3.0, 2.3.1, 2.4.0rc0, 2.4.0rc1, 2.4.0rc2, 2.4.0rc3, 2.4.0rc4) ERROR: No matching distribution found for tensorflow==1.15原因
Pythonのバージョンが合っていないことが原因の可能性が高いです。
例えばPyPIのtensorflow 1.15.4 のページ↓を見ると、tensorflow 1.15.4 が用意しているパッケージはpython 3.5, 3.6, 3.7 用しか提供されていません。
https://pypi.org/project/tensorflow/1.15.4/#filesなので、Python 3.8や3.9でpip installしても対応するパッケージがないので入りません。
解決方法
Pythonのバージョンをpython 3.5, 3.6, 3.7にすればインストールできます。
# バージョン確認 $ python --version Python 3.7.9 # インストール $ python -m pip install tensorflow==1.15 ///省略 # 確認。モジュールはあることが確認できる $ python -m tensorflow /.../bin/python: No module named tensorflow.__main__; 'tensorflow' is a package and cannot be directly executed参考
- 投稿日:2020-12-12T21:57:01+09:00
「すみません家NW不安定です」、Slack(社外)をMattermost(社内)に転記しよう。
はじめに
「●●さん、今Skype入るのでちょっとまってください」
「あー、▲▲さんのクライアントフリーズしちゃったので先に進めてましょう」
そんなオフィスでの一コマは、全社テレワークにより過去となりました。隣にいる人が察して一報を入れてくれる、それは同じ場所にいるからできたことでした。
テレワークとなり、自宅のNWが不安定などで数分音信不通になることはないでしょうか。そんなとき、みなさんはどうされてますか?
数分程度の不調では、なかなか上司や同僚へメール・電話とはならないのではないでしょうか。
かといって、自分に起きてることをサクッと通知したい。ぼやきたい。そんな経緯から、ゆるっとサクッと通知する方法として
Slackにぼやいた内容を社内Mattermostに転記しようと考えました。やったこと
- 社内Mattermostに転記先チャンネル(Slack2Mattermost)を作る。
- Slack2Mattermost宛のincoming webhookを作成する。
- Slackに転記元のグループ⁽もしくはチャンネル⁾を作成する。
- Slackのトークンを作成する。
- Slack→Mattermostの転記スクリプトを作成する。(Python)
- Mattermostに転記する。(転記時、Slackのユーザ名とMattermostのユーザ名を置換する)
- 転記済のマーキングとしてリアクション絵文字をSlackのPOSTにつける。
- cronでスクリプトを定期実行する。
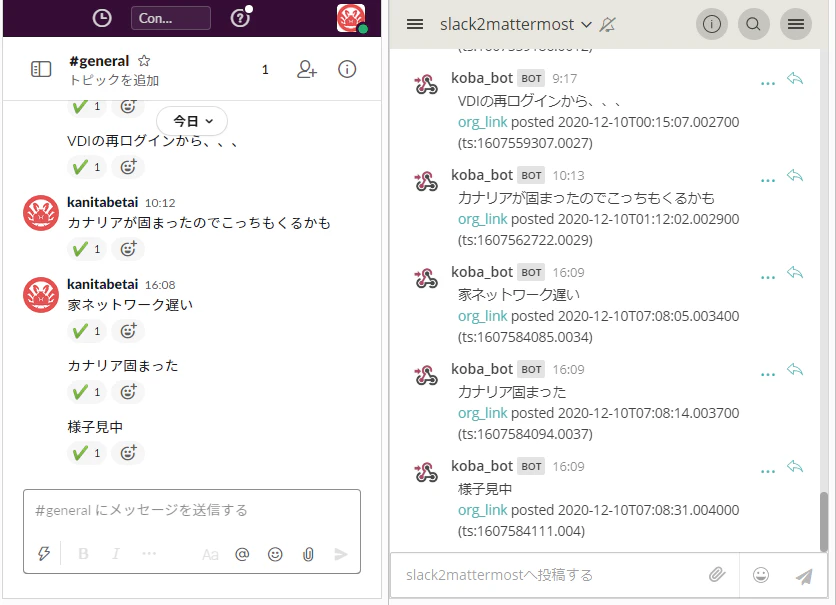
結果
こんな感じです。
※カナリア=私用PCのラジコストリーミング NW不安定の指標替わりに使用しています。
これから
記載の転記botはまだ上司に伝えていません。
というのも、人によって良く情報収集するチャンネルが異なり
私はMattermost鬼推しtwitter状態ですが、上司はそれほどでもないので
達成したかった「ちょっとした伝達」にはなり得ないところが、なかなか難しいなと。実装について、Mattermost→Mattermostで試作した後
Slack→Mattermostで実装しましたが、APIの仕様が全く違ったため面くらいました。
MattermostはSlackクローンですが、APIの世界では大きく異なることを知ることができました。
今後は他のSlack APIも試してみたいと思います。おわりに
キーボードが固まってます。といつかPOSTしたい(猫アレルギー)。
以上です、ありがとうございました。

- 投稿日:2020-12-12T21:35:16+09:00
wordファイルをhtmlにコンバートする
ある業務でワードの文章をhtmlにすることが多かったので、docxからhtmlを自動生成させます。
docxファイルを引数にとります。
word上では
h2は■でh3は●brは改行(\n)、空白行は\n\n\n\nで記述されているパターンを想定。
docx2html.rbdef docx2html(file_name): import docx2txt text = docx2txt.process(file_name) s=text.replace('\n\n\n\n\n\n', '[空白行]') s=text.replace('\n\n\n\n', '[空白行]') s=s.replace('\n\n', '<br>') lis=s.split('[空白行]') lis.pop(0) new_lis=[] for i in lis: if i[0:4] == "<br>": i = i[4:] new_lis.append(i) lines=[] for i in new_lis: if len(i)>0: if i[0]=="■" or i[0]=="●": s=i.replace('<br>', '[改行]',1) p=s.split('[改行]') for i in p: lines.append(i) else: lines.append(i) html= "" html_lines=[] for line in lines: if line[0] == "■": html=line.replace('■','<h2>') html=(html+"</h2>") elif line[0] == "●": html=line.replace('●','<h3>') html=html+"</h3>" else: html="<p>"+line+"</p>" html_lines.append(html) comp_lis=[] for i in html_lines: if "<br>" in i: i = i.replace("<br>","<br>\n") elif "<h3>" in i: i = i.replace("<h3>","<h3>●") comp_lis.append(i) """for i in comp_lis: print(i) print()""" f = open('docx2html_4.txt', 'w') for i in comp_lis: f.write(i+"\n") f.write("\n") f.close()
- 投稿日:2020-12-12T21:32:02+09:00
Facebook Messenger API + Flask 備忘録 [実装編 1]
導入編 からの続き、とりあえず簡単なオウム返しから。
pymessenger というサードパーティー製のライブラリもあるようだが、2016年から更新されていないので、勉強も兼ねて今回は自分で実装する。
POSTリクエストの中身
詳しくはこちら: Webhook Events, Send API
全部読むのは面倒なので、必要な部分だけ使いながら実装していく。
API の webhook の本体はこんな感じ。まずはユーザーがアプリに送信した場合
{ 'object': 'page', 'entry': [ { 'id': '<FBページのID>', 'time': 1607767826503, 'messaging': [ { 'sender': { 'id': '<FBユーザーのID>' }, 'recipient': { 'id': '<FBページのID>' }, 'timestamp': 1607767826302, 'message': { 'mid': 'xxxxxxxxxxxxxxxxxxxxx', 'text': 'hello' } } ] } ] }自分のページ側のIDは既に知っているので取得する必要はない。つまり
['entry']['messaging']の中の['sender']['id']および['message']['text']を取り出せば良い。ここで['entry']はイベントの配列、['entry']['messaging']はメッセージの配列になっているので for 処理などが必要。とは言っても、試した限りでは未受信のメッセージが溜まっていても同時にまとめて送られることはなく、一件のみだった。また、メッセージの直後にほぼ同じ形式でウォーターマークが送られる。こちらには
['message']の代わりに['delivery']がある。{ 'object': 'page', 'entry': [ { 'id': '<FBページのID>', 'time': 1607767829878, 'messaging': [ { 'sender': { 'id': '<FBユーザーのID>' }, 'recipient': { 'id': '<FBページのID>' }, 'timestamp': 1607767829912, 'delivery': { 'mids': [ 'xxxxxxxxxxxxxxx' ], 'watermark': 1607767827879 } } ] } ] }一方返信用の中身はこれだけで十分。これに発行したトークンを
access_tokenとしてパラメータで与え、ヘッダーにContent-Type: application/jsonを指定すればOK。{ "recipient": {"id": "<FBユーザーのID>"}, "message": {"text": "hello"} }おうむ返し実装
前回のコードに、POST 部分を追加する。後々のことを考えて、
send_message()という関数を分けて作っておく。ちなみにここで取得した
userIDというものは、FacebookアカウントのIDとは全く別物で、Page-scoped ID と呼ばれるらしい。自分のIDを知るためにも、返信文の中に埋め込む。import os, json from flask import Flask, request from dotenv import load_dotenv load_dotenv() # 環境変数ファイル .env の読み込み ACCESS_TOKEN = os.getenv('ACCESS_TOKEN') # .env に記載 VERIFY_TOKEN = os.getenv('VERIFY_TOKEN') # .env に記載 @app.route('/callback', methods=['GET', 'POST']) def receive_message(): if request.method == 'GET': # webhook テスト用 GET if request.args.get("hub.verify_token") == VERIFY_TOKEN: return request.args.get("hub.challenge") else: return 'ちがうよ' elif request.method == 'POST': # POSTリクエスト -> 返信処理 body = request.get_json() # 中身取得 for entry in body['entry']: # iterate 'entry' for messaging in entry['messaging']: # iterate 'messaging' userID = messaging['sender']['id'] # ユーザーのID if messaging.get('message'): # メッセージ以外を除外 received_message = messaging['message']['text'] # テキスト response = f'{userID}さん, {received_message}' # おうむ返し文 send_message(userID, response) # 返信実行 return "finished" # なんでも良い。返信内容とは無関係だが、無いとエラーになり返信を繰り返す # 返信リクエスト用関数 # 失敗したらログに出力, Heroku なら heroku logs --tail で確認可 def send_message(userID, message): result = requests.post("https://graph.facebook.com/v9.0/me/messages", params={"access_token": ACCESS_TOKEN}, headers={"Content-Type": "application/json"}, data=json.dumps({ "recipient": {"id": userID}, "message": {"text": message} }) ) if result.status_code != 200: print('送信失敗だよ:', data)とりあえずこれで、このようなおうむ返しが可能になる。
POST テスト
メッセージの送信テストをする際に、いちいち Python のプログラムをデプロイするのは非常に面倒なので、専用のツールを使って試したい。
Facebook はブラウザ上で API の動作を試せる Graph API Explorer なるものをわざわざ作ってくれておりこれだけでもいろいろできるのだが、やはり保存したり再利用したりすることを考えて、ド定番のリクエストツール Postman を利用する。
POST を選んで URL に
https://graph.facebook.com/v9.0/me/messages
Params の KEY にaccess_token, VALUE に発行した長いアクセストークンを入力
HeadersはContent-Typeとapplication/json
最後に Body は raw を選んで、送りたいメッセージを json 形式で記入する。先ほどのプログラムで取得した自分のIDを入力する。
このように、簡単にメッセージを送信できる。これ自体は上で実装した関数
send_message()を用いてももちろん可能。




- 投稿日:2020-12-12T21:21:20+09:00
20年来のCプログラマがPythonに移行した話
はじめに
この記事は「プログラミング技術の変化で得られた知見・苦労話【PR】パソナテック Advent Calendar 2020」のために記載したものです。
なんかの拍子にQuitaのこの広告目に入って、そういや随分昔からプログラムやってるなぁ、と思い出し、
自分の知識整理かねて記事書いてみよう、と思い立った次第です。ネタとしては表題の通り、20年Cをやっていたものの最近はほぼPythonしか書かなくなってしまった、という話ですが
なんでそうなってしまったかを自分の経験とか使い方とか踏まえて考察してみようと思います。
決して商品のM1Macにつられたわけではありません。いや興味はすっごくあるんですが。つか欲しいです...!軽く自己紹介
まずお前誰やねん、というとこが分からないと苦労話もできませんので属性を書いておきます。
まじめにプログラムやったのは大学生以降ですね。
ちょくちょく他言語に触れながらも基本はC/C++で20年超です。
Pythonはここ3年ほど使ってますが最近はC/C++で書くことがほとんどなくなりPythonばっかりという状況です。
- 大学の講義でCに触れ、K&Rで学ぶ(~22歳)
- 大学院まで進んだが研究で使ってたのはVisualBasic(手っ取り早くGUI書きたかったので。~25歳)
- 社会人になり家電メーカーにて組み込みLinux家電とかを開発
- Linuxドライバ開発やカーネル弄りを担当してどっぷりC言語につかる(~30歳)
- その後itronとかipl※開発とかも手掛けるが相変わらずC言語(~3x歳)
- android開発を始めたのでちょっとJavaとかに手を出すも、android NDKやれと言われ再びC/C++に出戻り(~3x歳)
- 画像系処理の仕事に転向するも、主力はC/C++版openCV(~4x歳)
- 画像系は今後はAIやらんと駄目ねと思い立つ(3年ほど前)
- 現在4x歳のおっさん
Pythonなれそめ
画像系処理といっても家電メーカーなので、写真を綺麗にとれるようにちょっとした機能を入れましょう、程度の実装で済んでいましたが
ここ数年で「わが社もAIで新たな機能を開発すべし」みたいな声があちこちから降ってきました。
で、技術担当としてはAIやらねば、となったはいいものの、開発言語としてはほぼPythonしか選択肢がないわけです。
(一応C++とかもあったにはあったけど)
えー、言ってもインタプリタ言語でしょ?ちゃんと速度出るの?みたいな感じで仕方なくはじめてみた感じだったと思います。
画像系だととにかく速度が問題になることが多く(※)、より機械に近いC言語のようなプログラム言語を使って無駄をなくすというのがそれまでの自分内常識でした。
ただ、それまでの経験から「ユーザー数の少ないプラットフォームは情報の少なさで割を食う」ことは見えていたので、まずは一番メジャーなPython版で試さない事にはC++とかも難しかろう、と触ってみたのが最初だったはずです。※例えば動画をカクつかせずに画像フィルタをかけろ、とか
Pythonおっそい
で、とりあえず画像処理とかやってみるわけです。
本当は業務に沿った処理内容になるのですが、ここでは適当なサンプルということで画素のRGBそれぞれの平均を求めてみる処理を書いてみます。
C++版のOpenCVはそれまでも使ってたので、同じように…import cv2 import nump as np def calc_img_mean(img): bgr = np.zeros((3)) hwc = img.shape for y in range(hwc[0]): for x in range(hwc[1]): bgr += img[y, x] return bgr / (hwc[0] * hwc[1])こっちはC++実装.
#include <opencv2/opencv.hpp> cv::Vec3f calc_img_mean(const cv::Mat *img) { cv::Vec3f rgb_sum(0,0,0); for(int y = 0;y < img->size().height;y++){ for(int x = 0;x < img->size().width;x++){ rgb_sum += (img->ptr<cv::Vec3b>(y))[x]; } } rgb_sum /= img->size().width * img->size().height; return rgb_sum; }4000x3000くらいの画像に対して手元のPCで実行してみると、それぞれの実行時間は以下の通りになりました。
実装 実行時間(s) C++ 0.03 Python 34.4 うぉぉぉい!遅すぎて変な声出ました。本当に1000倍遅い。なんぼ何でも遅すぎません…?
numpyが全てを解決する
で、世の中の人はどんな感じで書いてるんだ?と見たところ
img_mean = np.mean(img, axis=(0,1))え、これでいいの?ってな感じでした。まずopencvで読み込んでるのにnumpyが出てきてるのに混乱。確かにcv::Matと概念似てるみたいですが..
で、実行時間は..346msec! 一気に100倍アップです。30秒だとどうにもなりませんが0.3秒なら工夫すりゃ何とかなりそうです。
いやいや、C++だってcv::mean()あるじゃん、と思われるでしょうが、C++ではここまで劇的には変わりません。というかこういうAPIがあることを後で知りました。
C/C++だと自分で書いてもそれなりに速度出るせいで, 機能探すより自分で書いちゃうんですよね...
実装 実行時間(s) C++(自前ループ) 0.03 C++(cv::mean()) 0.015 Python(自前ループ) 34.4 C++(np.mean()) 0.35 それに本当にやりたいのは「画像の平均」みたいな定型処理じゃなく、用途ごとに色々ありますからね。
色々って何よ。うーん、じゃあBayer配列のRGB化とか...def raw2rgb(raw): h, w = raw.shape rgb = np.empty((h//2,w//2,3), dtype=np.uint8) rgb[...,0] = raw[1::2,1::2] rgb[...,1] = (raw[1::2,::2] + raw[::2,1::2])//2 rgb[...,2] = raw[::2,::2] return rgb同じようにC++実装。
cv::Mat raw2rgb(const cv::Mat *raw) { cv::Mat rgb = cv::Mat_<cv::Vec3b>( raw->size().height/2, raw->size().width/2); unsigned r, g, b; for(int y=0;y < raw->size().height/2;y++){ for(int x=0;x < raw->size().width;x++){ r = (raw->ptr(y*2+1))[x*2+1]; b = (raw->ptr(y*2))[x*2]; g = ((raw->ptr(y*2+1))[x*2] + (raw->ptr(y*2))[x*2+1]) / 2; cv::Vec3b rgb_value(r,g,b); (rgb.ptr<cv::Vec3b>(y))[x] = rgb_value; } } return rgb; }8000x6000サイズの配列を与えた時の処理時間は以下の通り。
実装(raw2rgb) 実行時間(s) C++(自前ループ) 0.12 Python(numpy) 0.13 なんと、C++自前ループとほぼ同じ速度が出てきてしまいました。そしてコードのシンプルさが凄い。
C++版のOpenCV使う時には型チェックのコンパイルエラーに悩まされてたりしてたのが、間違えようがない位にシンプルです。Pythonいいじゃん
これで図にのり、当初は「C++実装のCaffeeとか使うか…?」とか考えてましたがPythonでAI進めることに。
で、これでいろいろ実装していくとC/C++と比べたPythonの利点がいろいろと。個人的にこれは便利と思った点を書いていきます。numpyは神
最初のころは「numpyがPythonの本体なのでは...」とか失礼なことを考えるくらいでした。本当、画像処理にnumpyはこれ以上考えられない位の組み合わせです。
cv::Matと似ているとは言え, あっちはAPIによって型とかがいろいろ定義されててキャストだらけになりがち(※1)なのが, とにかくシンプルに書けます。
例えばOpenCVには画像を反転するflip()という関数があるのですが、AIフレームワークの中では対応する関数がないものもあります。
で、どうするんだと海外の掲示板とか見てみるとQ. 画像反転したいんだけどAPIないよ
A. img[::,::-1,...] ※2みたいなことが書かれていて目から鱗でした。ちょっとした画像の変形とか解析ならnumpyだけでさくっとできてしまいます。
※1 筆者のopenCV知識不足によるものの可能性があります。とはいえnumpyだと知識いらずという点で優れているかと。
※2 numpy(および類似のAIフレームワークtensor)での「第2軸を逆順に並べる」という処理辞書(dict)型がすごく便利
キーとオブジェクト参照を入れる辞書型が一つあるだけで, C/C++で構造体に求めていた役割はほぼすべて代替されているような印象です。
とりあえず辞書作って、ある関数の出力をキーAに、別の出力をキーBに..と突っ込んでいって、受ける側では自分の必要な情報だけ参照する、みたいなことができます。
これがC/C++だと構造体を定義しなおしたり関数引数型を変えたりと、処理途中に関数を追加しようと思うととにかく手続きが多い。その分チェックが厳密になるという点はありますが、そのためコードが増えたら意味ないと思うんですよね。コードが増えた分1行当たりにかけられる注意は減っていくわけで。良くも悪くも実行時評価
関数を書いた時点では構文チェック程度しか行われておらず、引数が何者であるかなどは考慮されません。
なので次のような関数定義もできちゃいます。hello()メソッドがあるクラスなら何でも受け付けるわけですね。
で、その後で新しいクラスを作った時や人の作ったクラス流用する場合にもhello()メソッドさえ追加してしまえばfunc()に突っ込める訳です。めっちゃ便利。
これをC/C++でやろうとすると皆に共通の基底クラス作るなりして関数の引数型を宣言して..と段取りが大変です。
いやそういう大規模設計が必要なところもまだあるんでしょうが、今日日何か月もかけて大規模開発するってのは流行らない気がします。def func(cls_inst): cls_inst.hello() class A(object): def hello(self): print("I am class A")たまに困ることもあるけど
生データ操作には限界もある
ctypesとかstructとか使うことでバイナリデータの読み書きなんかもかなり行けるんですが、バイト境界を跨いだビットフィールド、みたいなデータの扱いは難しいですね。というかこんな部分はC/C++の出番でしょう。Pythonでやる需要もなさそうだし。
富豪プログラミングになりがち
Pythonで書いた関数をCに戻そうとすると, 膨大な自動変数を確保してるのに気づかされたりします。C++だと割と同じようなことできるけど、とにかくメモリを贅沢に使った富豪プログラミングになりがちです。
まぁAI使うようなところだと実行環境も富豪だったりするのでそれほど問題にならないんですが、組み込みCに画像処理を移植、なんてときは大変ですね。名前の上書きに気づきにくい
変数宣言がなく、名前になんでも突っ込めるせいで気づかないうちに「モジュール名を別のオブジェクトで上書き→挙動がおかしくなる」みたいなことが起きます。
pycocotools.maskとかtorch.optimみたいな「自分でも変数として使いがちな名前」が危ない。
さすがに下みたいに直近に書くのは気づきますが、Jupyter noteとかで書いてると「1つ前のセルに戻ったら、さっき動いたコードが動かない」みたいなことをやってしまいます。from pycocotools import mask .... # アノテーション画像をCOCO辞書に変換 ann_img = np.array(Image.open(xxx)) mask = ann_img == clsid mask.encode(mask) #エラー, maskは既にモジュールじゃなくてndarrayで、何故Pythonでしか書かなくなってしまったのか
私的には「プログラムに求められる事が変わった」ためだと思います。
昔書いていたころは
- とにかく速度が正義
- メモリも節約すべし
- 開発はじっくり時間かけてもいいよ
- 求められる機能はそんなに多くないよ
だったのですが、今は速度とメモリが最優先される環境はかなり減りました。
もちろんそうはいっても冒頭のループみたいな部分が問題になって、20年来C/C++から乗り換え進まなかったのですが、Pythonだとnumpyがほぼ解決してくれるのが大きいですね。加えて、開発スタイルが大きく変わりました。
とにかく開発速度優先、できるかできないかをまず検討すべし、みたいな開発要求が増えています。
C/C++で書いてると開発速度がどうしても遅くなってしまうんですよね。コード量の問題もありますし、コンパイルとコーディングを行き来するのは思っている以上に開発速度を落としているんだな、というのもPythonを使って思いました。
できたコードを周囲に展開するのもC/C++だと開発環境だのライブラリだので一苦労ですしね。以上、プログラミング技術の変化で得られた知見・苦労話でした。
記事を書いてみて
久々にC++書いたのでコード至らない点はご容赦ください(言い訳)。つか書いてないと忘れるものですね...
- 投稿日:2020-12-12T21:05:20+09:00
Let's challenge LeetCode!! _2
こんばんは(*´ω`)
二回目は何故か日本語で行きます。121. Best Time to Buy and Sell Stock
Say you have an array for which the ith element is the price of a given stock on day i.
If you were only permitted to complete at most one transaction (i.e., buy one and sell one share of the stock), design an algorithm to find the maximum profit.
Note that you cannot sell a stock before you buy one.--ザックリ翻訳-----
与えられた株の売値、買値が i th day まで先読みできたとします。
買う前に売ることは勿論できませんが、1日に出来るのは売り or 買い の何れかです。
利益の最大値を求めてみましょう。これは間違いなく、DP!! っと意気揚々と
以下のコードを書いてみたがあえなく撃沈。。。best-time-to-buy-and-sell-stock_0.pyclass Solution: def maxProfit(self, prices: List[int]) -> int: dp = [0 for m in range(len(prices))] if len(prices) <= 0: return 0 for i in range(1,len(prices),1): for j in range(i): if prices[i] - prices[j] > 0: dp[i] = max(dp[i-1],dp[i],prices[i]-prices[j]) else: dp[i] = dp[i-1] return dp[-1]時間が掛かりすぎるようです。
用意しているノートをコンパクトにし、
1 つのセルを死ぬほど更新してみようと思いました。best-time-to-buy-and-sell-stock_1.pyclass Solution: def maxProfit(self, prices: List[int]) -> int: Mval = 0 for i in range(len(prices)-1): for j in range(i+1,len(prices),1): Cval = prices[j]-prices[i] if Cval > Mval: Mval = Cval return Mval残念ながら、これも time over。。
やっぱり for のネストが良くないだと思います。
クリアするためには n に抑える必要がありそうです。
そこで以下のコードに辿り着きました。best-time-to-buy-and-sell-stock_2.pyclass Solution: if len(prices) == 0: return 0 dp = [0 for i in range(len(prices))] for i in range(1,len(prices)): dp[i] = prices[i]-prices[i-1] CM = [0 for i in range(len(prices))] for j in range(1,len(prices)): CM[j] = max(dp[j],CM[j-1]+dp[j]) return max(CM)for 文をネストして切り抜けようとする考えを捨ててみました。
例えばですが、data[3] - data[2] に data[2] - data[1] を足すとどうなりますか?
data[3] - data[1] になりますよね?
前述だと data 長が [0] ~ [3] だった場合、
全てのケースを比較した選定は出来ませんが、
maxを使って、常に最大値を記録していたので全部やる必要が無いのです。最後ですが、以下の記述を見つけて、自分は度肝を抜かれました。
best-time-to-buy-and-sell-stock_3.pyclass Solution: def maxProfit(self, prices: List[int]) -> int: max_price = 0 price = 0 for i , high in enumerate(prices): if i == 0 or high < low: low = high else: max_price = high - low if max_price > price: price = max_price return priceprices[0] を最小値と設定します。
これを基準に利益の最大値を更新していきます。
しかし、このコードの素晴らしい所は、最小値も
常に更新し、利益を記録している所です。
無理に表に落とすことなく、パラメータ用の箱をそれぞれ用意して、
その箱の中を都度更新していきます。勿論、for 文のネスト無しで実現しています。
これが easy だって。
やばい。。(笑)
- 投稿日:2020-12-12T20:57:58+09:00
量子スピン模型のハミルトニアンを数値対角化しよう
対象
この記事は
- 量子スピン系のハミルトニアンの対角化方法が分からない人
- 量子スピン系の小さいモデルでちょっと遊んでみたいけど,いちいち専用ライブラリを使うのはめんどくさい人
向けの記事です.
初学者向けなので,最適化とかは真面目にはやりません.
基本的にpythonで解説しています.最後にちょっとjuliaのコードもあります.環境は,pythonでnumpyとscipyが動けば大丈夫です.
juliaの場合はArpack, SparseArraysが必要です.はじめに
プログラムと整合性を取りやすい様に,添字は0から始めます.
簡単のため,スピンは$\pm 1$のみをとるとします.
この記事ではI = \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix} ~ , ~ S^x = \begin{pmatrix} 0 & 1 \\ 1 & 0 \end{pmatrix} ~ , ~ S^y = \begin{pmatrix} 0 & -i \\ i & 0 \end{pmatrix} ~ , ~ S^z = \begin{pmatrix} 1 & 0 \\ 0 & -1 \end{pmatrix}とします.
いくら初学者向けとは言ってもスピン数が少なすぎると悲しいので,(N=16ぐらいの)そこそこのスピン数の基底状態計算がノートPCでもちょっと待てば動く様なコードを目指します.
(でもN=16って2次元正方格子だとL=4だし,4次元超立方格子だとL=2しかないので悲しい.)それと,私は対角化の人ではないので,間違ったこと書いてるかもしれません.先に謝っておきます.ごめんなさい.
ハミルトニアンと行列
スピン模型のハミルトニアンは
\mathcal{H} = \sum_{\langle i, j \rangle} J_x S^x_i S^x_j + J_y S^y_i S^y_j + J_z S^z_i S^z_jのような形で書かれることが多いですが,ハミルトニアンの行列表示において,$S^x_i S^x_j$などの積はテンソル積を意味します.
テンソル積は,行列A, Bに対してA \otimes B = \left( a_{ij} B \right) = \begin{pmatrix} a_{11} B & a_{12} B & \cdots \\ a_{21} B & a_{22} B & \cdots \\ \vdots & \vdots & \ddots \end{pmatrix}と表される演算です (Wikidepdiaより)
更に,$i, j$で指定されていないindexには全て単位行列$I$がかかります.
つまり先ほどのハミルトニアンの$i=0, j=1$の時の$\sum$の中身は,J_x S^x \otimes S^x \otimes I \otimes I \otimes \dots + \\ J_y S^y \otimes S^y \otimes I \otimes I \otimes \dots + \\ J_z S^z \otimes S^z \otimes I \otimes I \otimes \dots \ \と計算できます.よって,先ほどのハミルトニアンを行列表示できちんと書くと
\mathcal{H} = \sum_{\langle i, j \rangle} J_x \ I \otimes \cdots \otimes I \otimes \underset{\underset{i}{\wedge}}{S^x} \otimes I \otimes \cdots \otimes I \otimes \underset{\underset{j}{\wedge}}{S^x} \otimes I \otimes \cdots + \\ J_y \ I \otimes \cdots \otimes I \otimes \underset{\underset{i}{\wedge}}{S^y} \otimes I \otimes \cdots \otimes I \otimes \underset{\underset{j}{\wedge}}{S^y} \otimes I \otimes \cdots + \\ J_z \ I \otimes \cdots \otimes I \otimes \underset{\underset{i}{\wedge}}{S^z} \otimes I \otimes \cdots \otimes I \otimes \underset{\underset{j}{\wedge}}{S^z} \otimes I \otimes \cdotsとなります.これを定義に従って計算するのは大変ですが,実際はほとんどが0となります.
実際に0以外の値が入るindexは,まず$(x, y) = (0, 0)$として,テンソル積を構成する行列を後ろから見て,
1. (x, y) を 2倍にする
2. (x, y) に 行列の成分が非零となるindexを加える
(例. $I$,$S^z$だったら$(0, 0)$ or $(1, 1)$, $S^x$,$S^y$だったら$(0, 1)$ or $(1, 0)$)
3. 一つ前の行列に移動する
というステップを繰り返すことで,最終的に成分が入るindexを計算することができます.値も同様に計算できます.ここで,1ステップ目の"2倍"の2という数字は,$SやI$の行列サイズが2だからです.異なる行列サイズの場合はここを変えてください.
この方法から分かるように,このハミルトニアンを表す行列の非零成分は,2ステップ目のindexを加える過程で毎回2倍に増えるので,近接相互作用のみの場合,$O(結合数 \times 2^N) \approx O(N 2^N)$となります.行列自体は$2^N$行$2^N$列なので,効率よく行列を生成することができます.
簡単な実装
簡単な実装のための準備をします.
def set_Hamiltonian_tmp(O1, index1, O2, index2, x, y, itr, val, matrix): if(val==0): return if(itr>=0): if(itr==index1): set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x, 2*y, itr-1, val*O1[0][0], matrix) set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x+1, 2*y, itr-1, val*O1[1][0], matrix) set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x, 2*y+1, itr-1, val*O1[0][1], matrix) set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x+1, 2*y+1, itr-1, val*O1[1][1], matrix) elif(itr==index2): set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x, 2*y, itr-1, val*O2[0][0], matrix) set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x+1, 2*y, itr-1, val*O2[1][0], matrix) set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x, 2*y+1, itr-1, val*O2[0][1], matrix) set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x+1, 2*y+1, itr-1, val*O2[1][1], matrix) else: set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x, 2*y, itr-1, val, matrix) set_Hamiltonian_tmp(O1, index1, O2, index2, 2*x+1, 2*y+1, itr-1, val, matrix) else: matrix[x,y] += val return def set_Hamiltonian(O1, index1, O2, index2, J, matrix, N): set_Hamiltonian_tmp(O1, index1, O2, index2, 0, 0, N-1, J, matrix) returnset_Hamiltonian_tmpを再帰的に呼んで,非零行列要素の場所と値を計算しています.
このset_Hamiltonian_tmpが先ほどのアルゴリズムを表しています.
このような準備をしておくと,Nスピンの1次元ハイゼンベルグ模型のハミルトニアン\mathcal{H} = \sum_{i} J_x S^x_i S^x_{i+1} + J_y S^y_i S^y_{i+1} + J_z S^z_i S^z_{i+1}($J_x = J_y = J_z = 1$)が(周期境界条件で)次のようにして求まります.
import numpy as np Sx = np.array(([0, 1], [1, 0]), dtype=np.complex128) Sy = np.array(([0, -1j], [1j, 0]), dtype=np.complex128) Sz = np.array(([1, 0], [0, -1]), dtype=np.complex128) N = 12 Jx = 1.0 Jy = 1.0 Jz = 1.0 hamiltonian = np.zeros((2**N, 2**N), dtype=np.complex128) for i in range(N-1): set_Hamiltonian(Sx, i, Sx, i+1, Jx, hamiltonian, N) set_Hamiltonian(Sy, i, Sy, i+1, Jy, hamiltonian, N) set_Hamiltonian(Sz, i, Sz, i+1, Jz, hamiltonian, N) set_Hamiltonian(Sx, N-1, Sx, 0, Jx, hamiltonian, N) set_Hamiltonian(Sy, N-1, Sy, 0, Jy, hamiltonian, N) set_Hamiltonian(Sz, N-1, Sz, 0, Jz, hamiltonian, N)このハミルトニアンを対角化したい場合は,
from numpy.linalg import eigh eigs, eigvals = eigh(hamiltonian)とすれば求まるはずです.
高速化する
先ほどの実装は遅すぎます.
密行列の固有値と固有ベクトルを全て求めると当然時間がかかります.
必要がないならやめましょう.疎行列
ハミルトニアンに$I$が多いので,ハミルトニアンを表す行列成分に0が多くなります.
なので,実際に0以外の成分が入るとこをのみを計算するようにしましょう.
pythonのscipy.sparse.lil_matrixを用いると,numpyの配列のように疎行列を扱うことができます.hamiltonian = lil_matrix((2**N, 2**N), dtype=np.complex128)と変更するだけで大丈夫です.
小さい固有値と対応する固有ベクトル
ハミルトニアンの固有値/固有ベクトルは$2^N$個ありますが,全部必要になることはあまりありません.
エルミート行列の小さい固有値と対応する固有ベクトルのみだけを計算する場合は,scipy.sparse.linalgのeigshを使いましょう.
また,lil_matrixは計算には向かないので,scr_matrix等の形式に変更しましょう.
次の例では,ハミルトニアンの固有値/固有ベクトルを小さい方から6個とってきてます.from scipy.sparse import csr_matrix from scipy.sparse.linalg import eigsh hamiltonian = csr_matrix(hamiltonian) eigs, eigvecs = eigsh(hamiltonian, which='SA', k=6)詳しくは,scipyのeigshのページを参照してください.
もうちょっと高速化する
先ほどのコードでも動きますが,まだ計算できるNが小さいです.
N=16程度を高速で計算しようと思ったら,もう少し手間を加える必要があります.eigshの仕様
Find k eigenvalues and eigenvectors of the real symmetric square matrix or complex hermitian matrix A.
と書いてありますが,eigshのソースコードを読むと
complex hermitian matrices should be solved with eigs
と書いてあります.(実際,複素数成分の行列をeigshに投げると内部でeigsが実行されます)
- エルミート性を仮定するアルゴリズムは,仮定しないアルゴリズムより遅い
- エルミート性を仮定しないアルゴリズム場合,固有ベクトルが直交するとは限らない
という問題があるので,できるだけエルミート性を仮定したアルゴリズムにした方が良いです.
先に挙げたハミルトニアンの場合,実対称行列となっています.なので,
hamiltonian = hamiltonian.astype(np.float64)のようにして実対称行列に変換してからeigshに投げましょう.
$S^x S^y$のような項があって実対象とはならない場合は,(実際に実行されているのはeigsなので)諦めてeigsを実行後に固有ベクトルを直交化しましょう.
(一応,N行N列エルミート行列を実部と虚部に分解して2N行2N列の対称行列にして実行するテクニックも存在します.)pythonの疎行列の仕様
はむかずさんのページにあるように,lil_matrixは挿入操作ですら遅いので,最初からcsr_matrixで持っていた方が良いです.
ハミルトニアンの非零成分が(x_1, y_1, val_1), (x_2, y_2, val_2), (x_3, y_3, val_3), \cdotsの様に表される場合,
x_array = [x_1, x_2, ...] y_array = [y_1, y_2, ...] val_array = [val_1, val_2, ...] hamiltonian = csr_matrix((val_array, (x_array, y_array)), shape=(2**N, 2**N))とすることで,lil_matrixを経由することなくcsr_matrixが生成できます.
(詳しくはcsr_matrixの仕様を参照してください)ここで,ハミルトニアンの非零成分についてもう少し詳しく見てみます.
対角成分
対角成分は$S^zS^z$のように,$S^z$のみの項から来ます.この項はどの添字によるものかに関わらず,x_arrayとy_arrayが共通します.なので,
val_arrayのみを計算して足し上げることで,対角成分由来のx_array,y_array,val_arrayの配列の長さを圧縮できます.def set_Hamiltonian_diag(O1, index1, O2, index2, J, N): val_array = [J] for i in range(N-1, -1, -1): val_array_new = [None]*(len(val_array)*2) if(i==index1): val_array_new[::2] = [val*O1[0][0] for val in val_array] val_array_new[1::2] = [val*O1[1][1] for val in val_array] elif(i==index2): val_array_new[::2] = [val*O2[0][0] for val in val_array] val_array_new[1::2] = [val*O2[1][1] for val in val_array] else: val_array_new[::2] = val_array val_array_new[1::2] = val_array val_array = val_array_new return np.array(val_array)このような関数を実装しておくと,先ほどのハミルトニアンの対角成分は
hamiltonian_diag = np.zeros((2**N), dtype=np.complex128) for i in range(N-1): hamiltonian_diag += set_Hamiltonian_diag(Sz, i, Sz, i+1, Jz, N) hamiltonian_diag += set_Hamiltonian_diag(Sz, N-1, Sz, 0, Jz, N)のようにして実装できます.(この実装の場合,x_arrayとy_arrayは共に $[0, 1, \cdots, 2^N-1]$ =range(2**N)なので,覚えていません)
非対角成分
非対角成分の場合,異なるindexからくる項は異なる行列成分に属するため,x_array, y_array, val_arrayを全て覚えておく必要があります.
def set_Hamiltonian_offdiag(O1, index1, O2, index2, J, N): x_array = [0] y_array = [0] val_array = [J] for i in range(N-1, -1, -1): x_array_new = [None]*(len(x_array)*2) y_array_new = [None]*(len(y_array)*2) val_array_new = [None]*(len(val_array)*2) if(i==index1): x_array_new[::2] = [2*x for x in x_array] y_array_new[::2] = [2*y+1 for y in y_array] val_array_new[::2] = [val*O1[0][1] for val in val_array] x_array_new[1::2] = [2*x+1 for x in x_array] y_array_new[1::2] = [2*y for y in y_array] val_array_new[1::2] = [val*O1[1][0] for val in val_array] elif(i==index2): x_array_new[::2] = [2*x for x in x_array] y_array_new[::2] = [2*y+1 for y in y_array] val_array_new[::2] = [val*O2[0][1] for val in val_array] x_array_new[1::2] = [2*x+1 for x in x_array] y_array_new[1::2] = [2*y for y in y_array] val_array_new[1::2] = [val*O2[1][0] for val in val_array] else: x_array_new[::2] = [2*x for x in x_array] y_array_new[::2] = [2*y for y in y_array] val_array_new[::2] = val_array x_array_new[1::2] = [2*x+1 for x in x_array] y_array_new[1::2] = [2*y+1 for y in y_array] val_array_new[1::2] = val_array x_array = x_array_new y_array = y_array_new val_array = val_array_new return x_array, y_array, val_arrayこのような関数を実装しておくと,先ほどのハミルトニアンの非対角成分は
x_array = [] y_array = [] val_array = [] for i in range(N-1): x_array_new, y_array_new, val_array_new = set_Hamiltonian_offdiag(Sx, i, Sx, i+1, Jx, N) x_array.extend(x_array_new) y_array.extend(y_array_new) val_array.extend(val_array_new) x_array_new, y_array_new, val_array_new = set_Hamiltonian_offdiag(Sy, i, Sy, i+1, Jy, N) x_array.extend(x_array_new) y_array.extend(y_array_new) val_array.extend(val_array_new) x_array_new, y_array_new, val_array_new = set_Hamiltonian_offdiag(Sx, N-1, Sx, 0, Jx, N) x_array.extend(x_array_new) y_array.extend(y_array_new) val_array.extend(val_array_new) x_array_new, y_array_new, val_array_new = set_Hamiltonian_offdiag(Sy, N-1, Sy, 0, Jy, N) x_array.extend(x_array_new) y_array.extend(y_array_new) val_array.extend(val_array_new)の様になります.(この実装の場合もx_arrayは$[0, 1, \cdots, 2^N-1]$ =range(2**N)となりますが,y_arrayだけ書くのは教育的ではない気がしたので書いておきます.)
ただ,非対角成分は項が多いため,出来るだけ数を減らしたいです.
ここで注目するのは,$S^x_i S^x_j$と$S^y_i S^y_j$(と,$S^x_i S^y_j$や$S^y_i S^x_j$)が指す非零成分の場所は全く同じということです.(同様に,$S^z_i S^x_j$と$S^z_i S^y_j$も非零成分の場所が同じになります.非零成分を求めるアルゴリズムを見ると自明です.)なので,まとめてしまいましょう.def set_Hamiltonian_offdiag(O1_1, O2_1, index1, O1_2, O2_2, index2, J1, J2, N): x_array = [0] y_array = [0] val1_array = [J1] val2_array = [J2] for i in range(N-1, -1, -1): x_array_new = [None]*(len(x_array)*2) y_array_new = [None]*(len(y_array)*2) val1_array_new = [None]*(len(val1_array)*2) val2_array_new = [None]*(len(val2_array)*2) if(i==index1): x_array_new[::2] = [2*x for x in x_array] y_array_new[::2] = [2*y+1 for y in y_array] val1_array_new[::2] = [val*O1_1[0][1] for val in val1_array] val2_array_new[::2] = [val*O2_1[0][1] for val in val2_array] x_array_new[1::2] = [2*x+1 for x in x_array] y_array_new[1::2] = [2*y for y in y_array] val1_array_new[1::2] = [val*O1_1[1][0] for val in val1_array] val2_array_new[1::2] = [val*O2_1[1][0] for val in val2_array] elif(i==index2): x_array_new[::2] = [2*x for x in x_array] y_array_new[::2] = [2*y+1 for y in y_array] val1_array_new[::2] = [val*O1_2[0][1] for val in val1_array] val2_array_new[::2] = [val*O2_2[0][1] for val in val2_array] x_array_new[1::2] = [2*x+1 for x in x_array] y_array_new[1::2] = [2*y for y in y_array] val1_array_new[1::2] = [val*O1_2[1][0] for val in val1_array] val2_array_new[1::2] = [val*O2_2[1][0] for val in val2_array] else: x_array_new[::2] = [2*x for x in x_array] y_array_new[::2] = [2*y for y in y_array] val1_array_new[::2] = val1_array val2_array_new[::2] = val2_array x_array_new[1::2] = [2*x+1 for x in x_array] y_array_new[1::2] = [2*y+1 for y in y_array] val1_array_new[1::2] = val1_array val2_array_new[1::2] = val2_array x_array = x_array_new y_array = y_array_new val1_array = val1_array_new val2_array = val2_array_new return x_array, y_array, np.array(val1_array) + np.array(val2_array)このように,先ほどの$S^xS^x$と$S^yS^y$に関するset_Hamiltonian_offdiag関数を一つにまとめると,先ほどのハミルトニアンの非対角成分は
x_array = [] y_array = [] val_array = [] for i in range(N-1): x_array_new, y_array_new, val_array_new = set_Hamiltonian_offdiag(Sx, Sy, i, Sx, Sy, i+1, Jx, Jy, N) x_array.extend(x_array_new) y_array.extend(y_array_new) val_array.extend(val_array_new) x_array_new, y_array_new, val_array_new = set_Hamiltonian_offdiag(Sx, Sy, N-1, Sx, Sy, 0, Jx, Jy, N) x_array.extend(x_array_new) y_array.extend(y_array_new) val_array.extend(val_array_new)の様になります.
このようにして非対角成分を求めると,先ほどよりも必要な配列サイズが半分になります.最終的なpythonコード
先ほどまでの事例をまとめると,次の様なコードになります.
import numpy as np from scipy.sparse import csr_matrix from scipy.sparse.linalg import eigsh Sx = np.array(([0, 1], [1, 0]), dtype=np.complex128) Sy = np.array(([0, -1j], [1j, 0]), dtype=np.complex128) Sz = np.array(([1, 0], [0, -1]), dtype=np.complex128) def set_Hamiltonian_diag(O1, index1, O2, index2, J, N): val_array = [J] for i in range(N-1, -1, -1): val_array_new = [None]*(len(val_array)*2) if(i==index1): val_array_new[::2] = [val*O1[0][0] for val in val_array] val_array_new[1::2] = [val*O1[1][1] for val in val_array] elif(i==index2): val_array_new[::2] = [val*O2[0][0] for val in val_array] val_array_new[1::2] = [val*O2[1][1] for val in val_array] else: val_array_new[::2] = val_array val_array_new[1::2] = val_array val_array = val_array_new return np.array(val_array) def set_Hamiltonian_offdiag(O1_1, O2_1, index1, O1_2, O2_2, index2, J1, J2, N): x_array = [0] y_array = [0] val1_array = [J1] val2_array = [J2] for i in range(N-1, -1, -1): x_array_new = [None]*(len(x_array)*2) y_array_new = [None]*(len(y_array)*2) val1_array_new = [None]*(len(val1_array)*2) val2_array_new = [None]*(len(val2_array)*2) if(i==index1): x_array_new[::2] = [2*x for x in x_array] y_array_new[::2] = [2*y+1 for y in y_array] val1_array_new[::2] = [val*O1_1[0][1] for val in val1_array] val2_array_new[::2] = [val*O2_1[0][1] for val in val2_array] x_array_new[1::2] = [2*x+1 for x in x_array] y_array_new[1::2] = [2*y for y in y_array] val1_array_new[1::2] = [val*O1_1[1][0] for val in val1_array] val2_array_new[1::2] = [val*O2_1[1][0] for val in val2_array] elif(i==index2): x_array_new[::2] = [2*x for x in x_array] y_array_new[::2] = [2*y+1 for y in y_array] val1_array_new[::2] = [val*O1_2[0][1] for val in val1_array] val2_array_new[::2] = [val*O2_2[0][1] for val in val2_array] x_array_new[1::2] = [2*x+1 for x in x_array] y_array_new[1::2] = [2*y for y in y_array] val1_array_new[1::2] = [val*O1_2[1][0] for val in val1_array] val2_array_new[1::2] = [val*O2_2[1][0] for val in val2_array] else: x_array_new[::2] = [2*x for x in x_array] y_array_new[::2] = [2*y for y in y_array] val1_array_new[::2] = val1_array val2_array_new[::2] = val2_array x_array_new[1::2] = [2*x+1 for x in x_array] y_array_new[1::2] = [2*y+1 for y in y_array] val1_array_new[1::2] = val1_array val2_array_new[1::2] = val2_array x_array = x_array_new y_array = y_array_new val1_array = val1_array_new val2_array = val2_array_new return x_array, y_array, np.array(val1_array) + np.array(val2_array) if __name__ == "__main__": N = 16 Jx = 1.0 Jy = 1.0 Jz = 1.0 hamiltonian_diag = np.zeros((2**N), dtype=np.complex128) x_array = [] y_array = [] val_array = [] for i in range(N-1): x_array_new, y_array_new, val_array_new = set_Hamiltonian_offdiag(Sx, Sy, i, Sx, Sy, i+1, Jx, Jy, N) x_array.extend(x_array_new) y_array.extend(y_array_new) val_array.extend(val_array_new) hamiltonian_diag += set_Hamiltonian_diag(Sz, i, Sz, i+1, Jz, N) x_array_new, y_array_new, val_array_new = set_Hamiltonian_offdiag(Sx, Sy, N-1, Sx, Sy, 0, Jx, Jy, N) x_array.extend(x_array_new) y_array.extend(y_array_new) val_array.extend(val_array_new) hamiltonian_diag += set_Hamiltonian_diag(Sz, N-1, Sz, 0, Jz, N) x_array.extend(range(2**N)) y_array.extend(range(2**N)) val_array.extend(hamiltonian_diag) hamiltonian = csr_matrix((val_array, (x_array, y_array)), shape=(2**N, 2**N)) hamiltonian = hamiltonian.astype(np.float64) eigs, eigvecs = eigsh(hamiltonian, which='SA') print(min(eigs)/N)(最後に1スピン当たりの基底エネルギーを出力しています)
N=16の1次元ハイゼンベルグ模型の基底状態計算が手元のノートPCで5~6秒ほどで実行できます.
N=20にすると2~3分ぐらいでした.
このくらいなら「ちょっと遊ぶ」のに十分ではないでしょうか.周期境界条件(PBC)と開放境界条件(OBC)で計算した基底エネルギー$e_{calc}$をN無限大極限での厳密解($e_{exact} = 1-4\log2 = -1.772589...$)(このサイトなどを参照)と比較した結果が次です.
N $e_calc$ (PBC) $e_calc$ (OBC) 4 -2.000000 -1.616025 6 -1.868517 -1.662385 8 -1.825547 -1.687466 10 -1.806179 -1.703214 12 -1.795797 -1.714030 14 -1.789586 -1.721921 16 -1.785574 -1.727934 18 -1.782833 -1.732669 20 -1.780877 -1.736495
PBCの結果が先ほどのサイトの結果と一致しているのでアルゴリズムは多分大丈夫ですけど,OBCの結果がちょっと不安ですね......
フェルミオン系やボゾン系の場合
フェルミオン系やボゾン系は全くの専門外なので,コメントだけにしておきます.
フェルミオン系の場合
スピン系は各サイトにつきスピンが上向き,スピンが下向きの2状態でしたが,フェルミオン系の場合は各サイトにつき(上向きスピンの粒子数,下向きスピンの粒子数)= (0, 0), (0, 1), (1, 0), (1, 1) の4通りとなります.
もしくは,(サイトindex, スピンの上下)を((サイト+スピンindex), 粒子の有無)にとして計算することもできます.(やってることは同じです)
なので,それ用にコードを書き換えるだけです.
特に,後者の場合は生成消滅演算子$c^{\dagger}, c$がc^{\dagger} = \begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix} ~ , ~ c = \begin{pmatrix} 0 & 0 \\ 1 & 0 \end{pmatrix}と書けるので,ある程度先ほどのコードを使い回せます.
また,全粒子数と同時対角化可能(可換)な場合は,ターゲットとする全粒子数に関連する成分のみ取り出すことで,行列サイズを小さくすることができます.
(上向きスピンの粒子数,下向きスピンの粒子数それぞれと可換,というケースもよくあります.)何か可換な物理量がある場合に行列サイズを小さくして対角化する手法はスピン系でも使えます.
ボゾン系の場合
全粒子数が保存する場合は,サイトとスピンindexを固定すると粒子数は0以上全粒子数以下の全粒子数+1通りなので,頑張れば計算できます.
全粒子数が保存しない場合は,サイトとスピンindexを固定した時の粒子数の最大値を決めて計算し,その最大値を徐々に大きくして外挿する,という方法があるみたいです.(全粒子数が保存する場合も使えます)juliaのコード
最後のpythonコードのjulia版です.
versionは1.5.2です.using Arpack using SparseArrays function set_Hamiltonian_diag(O1, index1, O2, index2, J, N) val_array = [J] for i=1:N val_array_new = zeros(Complex, length(val_array)*2) if N+1-i==index1 val_array_new[1:2:length(val_array_new)] = [val*O1[1][1] for val in val_array] val_array_new[2:2:length(val_array_new)] = [val*O1[2][2] for val in val_array] elseif N+1-i==index2 val_array_new[1:2:length(val_array_new)] = [val*O2[1][1] for val in val_array] val_array_new[2:2:length(val_array_new)] = [val*O2[2][2] for val in val_array] else val_array_new[1:2:length(val_array_new)] = val_array val_array_new[2:2:length(val_array_new)] = val_array end val_array = val_array_new end return val_array end function set_Hamiltonian_offdiag(O1_1, O2_1, index1, O1_2, O2_2, index2, J1, J2, N) x_array = [1] y_array = [1] val1_array = [complex(J1)] val2_array = [complex(J2)] for i=1:N x_array_new = zeros(length(x_array)*2) y_array_new = zeros(length(y_array)*2) val1_array_new = zeros(Complex, length(val1_array)*2) val2_array_new = zeros(Complex, length(val2_array)*2) if N+1-i==index1 x_array_new[1:2:length(x_array_new)] = [2*x-1 for x in x_array] y_array_new[1:2:length(y_array_new)] = [2*y for y in y_array] val1_array_new[1:2:length(val1_array_new)] = [val*O1_1[1][2] for val in val1_array] val2_array_new[1:2:length(val2_array_new)] = [val*O2_1[1][2] for val in val2_array] x_array_new[2:2:length(x_array_new)] = [2*x for x in x_array] y_array_new[2:2:length(y_array_new)] = [2*y-1 for y in y_array] val1_array_new[2:2:length(val1_array_new)] = [val*O1_1[2][1] for val in val1_array] val2_array_new[2:2:length(val2_array_new)] = [val*O2_1[2][1] for val in val2_array] elseif N+1-i==index2 x_array_new[1:2:length(x_array_new)] = [2*x-1 for x in x_array] y_array_new[1:2:length(y_array_new)] = [2*y for y in y_array] val1_array_new[1:2:length(val1_array_new)] = [val*O1_2[1][2] for val in val1_array] val2_array_new[1:2:length(val2_array_new)] = [val*O2_2[1][2] for val in val2_array] x_array_new[2:2:length(x_array_new)] = [2*x for x in x_array] y_array_new[2:2:length(y_array_new)] = [2*y-1 for y in y_array] val1_array_new[2:2:length(val1_array_new)] = [val*O1_2[2][1] for val in val1_array] val2_array_new[2:2:length(val2_array_new)] = [val*O2_2[2][1] for val in val2_array] else x_array_new[1:2:length(x_array_new)] = [2*x-1 for x in x_array] y_array_new[1:2:length(y_array_new)] = [2*y-1 for y in y_array] val1_array_new[1:2:length(val1_array_new)] = val1_array val2_array_new[1:2:length(val2_array_new)] = val2_array x_array_new[2:2:length(x_array_new)] = [2*x for x in x_array] y_array_new[2:2:length(y_array_new)] = [2*y for y in y_array] val1_array_new[2:2:length(val1_array_new)] = val1_array val2_array_new[2:2:length(val2_array_new)] = val2_array end x_array = x_array_new y_array = y_array_new val1_array = val1_array_new val2_array = val2_array_new end return x_array, y_array, val1_array+val2_array end function main() Sx = [[0, 1], [1, 0]] Sy = [[0, complex(0, -1)], [complex(0, 1), 0]] Sz = [[1, 0], [0, -1]] N = 16 Jx = complex(1.0, 0.0) Jy = complex(1.0, 0.0) Jz = complex(1.0, 0.0) hamiltonian_diag = zeros(Complex, (2^N)) arrays = [zeros(Int, 0), zeros(Int, 0), zeros(Complex, 0)] for i=1:N-1 arrays_new = set_Hamiltonian_offdiag(Sx, Sy, i, Sx, Sy, i+1, Jx, Jy, N) append!(arrays[1], arrays_new[1]) append!(arrays[2], arrays_new[2]) append!(arrays[3], arrays_new[3]) hamiltonian_diag += set_Hamiltonian_diag(Sz, i, Sz, i+1, Jz, N) end arrays_new = set_Hamiltonian_offdiag(Sx, Sy, N, Sx, Sy, 1, Jx, Jy, N) append!(arrays[1], arrays_new[1]) append!(arrays[2], arrays_new[2]) append!(arrays[3], arrays_new[3]) hamiltonian_diag += set_Hamiltonian_diag(Sz, N, Sz, 1, Jz, N) append!(arrays[1], [n for n in 1:2^N]) append!(arrays[2], [n for n in 1:2^N]) append!(arrays[3], hamiltonian_diag) arrays[3] = real(arrays[3]) hamiltonian = sparse(arrays[1], arrays[2], arrays[3]) eigvals = eigs(hamiltonian, which=:SR)[1] println(minimum(eigvals)/N) end main()juliaの場合はpythonの時とは異なりeigsを使って固有値を求めていますが,juliaのArpackのeigsはLinearAlgebraのissymmetric(hamiltonian)がtrueの場合は勝手にeigsh相当のアルゴリズムになります.(そもそもeigshが実装されていないです)
配列の添字が1始まりなことと,配列のslicingの方法に注意しましょう.

- 投稿日:2020-12-12T20:54:49+09:00
Pythonの型(クラス)システム
Pythonの型(クラス)を扱う機能に関して調べてみて,面白かったので記事を投稿します.
● Pythonの型(クラス)システム(PDF形式3ページ:395KB)
(Pythonのテキストからの抜粋です)Pythonのオブジェクト指向プログラミング関連の機能はしっかりできているので,管理機能の全体とクラス階層を一度眺めてみる価値があると思います.
あらゆる型(クラス)が「objectクラス」を頂点として整然と構成されている様子が面白いです.● クラス階層を出力するサンプルプログラム:getSubclasses.py
- 投稿日:2020-12-12T20:03:53+09:00
FastAPI勉強メモ
参考資料
FastAPIは?
FastAPI framework, high performance, easy to learn, fast to code, ready for production
- 特徴
- typeの定義でrequest内容を自動bindingできる
- type hintで静的チェックできるので、バグになりにくい
- 簡単
- ハイパフォーマンス
- OAuth2
- OpenAPI docs自動作成
- GraphQLサポート
- ドキュメントが充実
開発環境の構築
libraryインストール
- virtualenv is a tool for creating isolated virtual python environments.
- プロジェクトごとで依存するパッケージの管理環境を提供する
- FastAPI is a framework, high performance, easy to learn, fast to code, ready for production
- Uvicorn is a lightning-fast ASGI server.
pip3 install virtualenv --user mkdir fastapi-demo # project directoryを作成 python3 -m venv env # project 仮想環境を作成 source env/bin/activate # 仮想環境をアクティブする pip3 install fastapi pip3 install uvicornvscode extensionsインストール
python typeを理解する
https://fastapi.tiangolo.com/python-types/
Hello Worldを作ってみる
- main.pyファイルを作成して、以下のコードを書いて、保存する
# FastAPI is a Python class that provides all the functionality for your API. from fastapi import FastAPI # app = FastAPI() @app.get("/") # routing # It will be called whenever it receives a request to the PATH "/" using a GET operation. async def root(): return {"message": "Hello World"}
- serverを起動
uvicorn main:app --reload # mainはファイル名前、 appはapp = FastAPI()での変数名と同じ自動で作成されたAPI docs
- Interactive(swagger-ui) OpenAPI docs: http://127.0.0.1:8000/docs
- redocs: http://127.0.0.1:8000/redoc
- raw OpenAPI schema(openapi.json): http://127.0.0.1:8000/openapi.json
routingの定義(path operation decorator)
path + operation(http methods)でroutingを定義する
- サポートするoperation
- get
- post
- put
- patch
- delete
- options
- head
- trace
Path parameters
@app.get("/items/{item_id}") async def read_item(item_id: int): # 変数item_idの名前は/items/{item_id}の{item_id}と一致する必要がある return {"item_id": item_id}Path parametersのtypeを指定するメリット
- タイプの変換: path parameterの値から指定したtypeに自動で変換してくれる
- validation: path parameterの値が指定したtypeに合わない場合、validationエラーresponseを返す
- API docが分かり易くなる
Enum path parameter type
from enum import Enum from fastapi import FastAPI class Gender(str, Enum): male = "male" female = "female" app = FastAPI() @app.get("/models/{gender}") async def get_model(gender: Gender): if gender == Gender.male: return {"gender": gender, "message": "Man!"} if gender.value == "female": return {"gender": gender, "message": "Woman!"}Path convertor
from fastapi import FastAPI app = FastAPI() ## http://127.0.0.1:8000/files//home/tom/main.pyをアクセスすると、 ## file_pathの値が/home/tom/main.pyになります @app.get("/files/{file_path:path}") async def read_file(file_path: str): return {"file_path": file_path}Pathタイプを明示的にする
@app.get("/items/{item_id}") async def read_items( item_id: int = Path(..., title="The ID of the item to get", gt=0, le=1000) ):Query Parameters
# http://127.0.0.1:8000/items/?skip=0&limit=3 @app.get("/items/") async def read_item(skip: int = 0, limit: int = 10): return fake_items_db[skip : skip + limit]Optional parameters
from typing import Optional @app.get("/items/{item_id}") async def read_item(item_id: str, id: Optional[int] = None):bool型のQuery parameter type
# http://127.0.0.1:8000/items/foo?short=1 # http://127.0.0.1:8000/items/foo?short=True # http://127.0.0.1:8000/items/foo?short=true # http://127.0.0.1:8000/items/foo?short=on # http://127.0.0.1:8000/items/foo?short=yes @app.get("/items/{item_id}") async def read_item(item_id: str, q: Optional[str] = None, short: bool = False):Required query parameters
# http://127.0.0.1:8000/items/foo-itemをアクセスすると、 # needyの値がないので、validation errorになります @app.get("/items/{item_id}") async def read_user_item(item_id: str, needy: str):Query Parametersとstring Validations
from fastapi import FastAPI, Query @app.get("/items/") async def read_items(q: Optional[str] = Query(None, min_length=3, max_length=50)): results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]} if q: results.update({"q": q}) return resultsrequired query parameter(...)
@app.get("/items/") async def read_items(q: str = Query(..., min_length=3)):複数値のQuery parameter
# http://localhost:8000/items/?q=foo&q=bar # you need to explicitly use Query, otherwise it would be interpreted as a request body. @app.get("/items/") async def read_items(q: Optional[List[str]] = Query(None)):@app.get("/items/") async def read_items(q: List[str] = Query(["foo", "bar"])):Query parameter metadata
@app.get("/items/") async def read_items( q: Optional[str] = Query( None, title="Query string", description="Query string for the items to search in the database that have a good match", min_length=3, ) ):Alias parameters
# http://127.0.0.1:8000/items/?item-query=foobaritems @app.get("/items/") async def read_items(item_query: Optional[str] = Query(None, alias="item-query")):Deprecating parameters(非推奨parameter)
@app.get("/items/") async def read_items(q: Optional[str] = Query(None, deprecated=True)):JSON Body parameters
Pydantic modelのparameterはrequestのJSON Bodyからデータバインディングする
from typing import Optional from fastapi import FastAPI from pydantic import BaseModel class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None app = FastAPI() @app.post("/items/") async def create_item(item: Item): return itemで以下のようなjson bodyを受け取ることができる
{ "name": "Foo", "description": "The pretender", "price": 42.0, "tax": 3.2 }parameterの名前をjson keyにしたいことにembed=Trueを付ける
@app.put("/items/{item_id}") async def update_item(item_id: int, item: Item = Body(..., embed=True)):で以下のようなjson bodyを受け取ることができる
{ "item": { "name": "Foo", "description": "The pretender", "price": 42.0, "tax": 3.2 } }Multiple body parameters
class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None class User(BaseModel): username: str full_name: Optional[str] = None @app.put("/items/{item_id}") async def update_item(item_id: int, item: Item, user: User): results = {"item_id": item_id, "item": item, "user": user} return resultsで以下のようなjson bodyを受け取ることができる
// key名前が、`async def update_item`のparameterと一致する必要がある { "item": { "name": "Foo", "description": "The pretender", "price": 42.0, "tax": 3.2 }, "user": { "username": "dave", "full_name": "Dave Grohl" } }Singular values in body
@app.put("/items/{item_id}") async def update_item( item_id: int, importance: int = Body(...) ):で以下のようなjson bodyを受け取ることができる
{ "importance": 5 }json body fieldのvalidation & metadata
from pydantic import Field class Item(BaseModel): price: float = Field(..., gt=0, description="The price must be greater than zero", example="Foo")json Body - Nested Models
from typing import Set class Item(BaseModel): name: str tags: Set[str] = set()class Image(BaseModel): url: str name: str class Item(BaseModel): name: str image: Optional[Image] = Nonearray list
class Image(BaseModel): url: HttpUrl name: str @app.post("/images/multiple/") async def create_multiple_images(images: List[Image]):任意キーのjson body
from typing import Dict from fastapi import FastAPI app = FastAPI() @app.post("/index-weights/") async def create_index_weights(weights: Dict[int, float]): return weightspydantic types
https://pydantic-docs.helpmanual.io/usage/types/#pydantic-types
Form Data
formデータを処理するために、python-multipartをinstallする必要がある
pip3 install python-multipartfrom fastapi import FastAPI, Form app = FastAPI() @app.post("/login/") async def login(username: str = Form(...), password: str = Form(...)): return {"username": username}Cookie parameters
from fastapi import Cookie, FastAPI @app.get("/items/") async def read_items(ads_id: Optional[str] = Cookie(None)):Header parameters
from fastapi import FastAPI, Header @app.get("/items/") async def read_items(user_agent: Optional[str] = Header(None)):重複するheader取得
@app.get("/items/") async def read_items(x_token: Optional[List[str]] = Header(None)):Response Model(serialization)
from typing import Optional from fastapi import FastAPI from pydantic import BaseModel, EmailStr app = FastAPI() class UserIn(BaseModel): password: str email: EmailStr class UserOut(BaseModel): email: EmailStr @app.post("/user/", response_model=UserOut) async def create_user(user: UserIn): return userresponseで複数のModel(serialization)を使いたい時、Unionで複数のmodelを指定する
from typing import Union @app.get("/items/{item_id}", response_model=Union[PlaneItem, CarItem]) async def read_item(item_id: str): return items[item_id]任意のjsonを返す時、Dictを使う
@app.get("/keyword-weights/", response_model=Dict[str, float])共通の項目をもつbaseクラスを作ることで重複を減らす
class UserBase(BaseModel): username: str email: EmailStr full_name: Optional[str] = None class UserIn(UserBase): password: str class UserOut(UserBase): pass class UserInDB(UserBase): hashed_password: st細かい設定
- response_model_include
- response_model_exclude
- response_model_exclude_unset
- response_model_exclude_defaults
- response_model_exclude_none
- response_model_by_alias
response status code指定
from fastapi import FastAPI, status @app.post("/items/", status_code=status.HTTP_201_CREATED) def get_or_create_task(task_id: str, response: Response): response.status_code = status.HTTP_204_NO_CONTENT # 明示的に指定する return tasks[task_id]エラー処理
HTTPExceptionをraiseしてエラーをclientに返す
from fastapi import FastAPI, HTTPException app = FastAPI() items = {"foo": "The Foo Wrestlers"} @app.get("/items/{item_id}") async def read_item(item_id: str): if item_id not in items: raise HTTPException( status_code=404, detail="Item not found", headers={"X-Error": "There goes my error"}, ) return {"item": items[item_id]}global Exceptionハンドラー
from fastapi import FastAPI, HTTPException from fastapi.exception_handlers import ( http_exception_handler, request_validation_exception_handler, ) from fastapi.exceptions import RequestValidationError from starlette.exceptions import HTTPException as StarletteHTTPException app = FastAPI() @app.exception_handler(StarletteHTTPException) async def custom_http_exception_handler(request, exc): print(f"OMG! An HTTP error!: {repr(exc)}") # 元のhandlerを呼ぶ return await http_exception_handler(request, exc) @app.exception_handler(RequestValidationError) async def validation_exception_handler(request, exc): print(f"OMG! The client sent invalid data!: {exc}") # 元のhandlerを呼ぶ return await request_validation_exception_handler(request, exc) @app.get("/items/{item_id}") async def read_item(item_id: int): if item_id == 3: raise HTTPException(status_code=418, detail="Nope! I don't like 3.") return {"item_id": item_id}FastAPI's HTTPException vs Starlette's HTTPException
- FastAPI's HTTPExceptionはFastAPI's HTTPExceptionを継承している
- raiseするときは、FastAPI's HTTPExceptionを使う
- handleするときは、Starlette's HTTPExceptionを使う
Path Operation Configuration(docs metadata)
@app.post( "/items/", response_model=Item, status_code=status.HTTP_201_CREATED, summary="Create an item", description="Create an item with all the information, name, description, price, tax and a set of unique tags", tags=["items"], response_description="The created item", deprecated=True, ) async def create_item(item: Item): """ This is docstring: Create an item with all the information: - **name**: each item must have a name - **description**: a long description - **price**: required - **tax**: if the item doesn't have tax, you can omit this - **tags**: a set of unique tag strings for this item """Dependency Injection
from typing import Optional from fastapi import Depends, FastAPI app = FastAPI() async def common_parameters(q: Optional[str] = None, skip: int = 0, limit: int = 100): return {"q": q, "skip": skip, "limit": limit} @app.get("/items/") async def read_items(commons: dict = Depends(common_parameters)): return commons @app.get("/users/") async def read_users(commons: dict = Depends(common_parameters)): return commonsclass as dependencies
from typing import Optional from fastapi import Depends, FastAPI app = FastAPI() fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}] class CommonQueryParams: def __init__(self, q: Optional[str] = None, skip: int = 0, limit: int = 100): self.q = q self.skip = skip self.limit = limit @app.get("/items/") async def read_items(params: CommonQueryParams = Depends(CommonQueryParams)): response = {} if params.q: response.update({"q": params.q}) items = fake_items_db[params.skip : params.skip + params.limit] response.update({"items": items}) return responseshortcut
# below is shortcut of `async def read_items(params: CommonQueryParams = Depends(CommonQueryParams)):` async def read_items(params: CommonQueryParams = Depends()):実行しますが、戻り値を使わないdependencyはdependenciesで渡す
async def verify_key(x_key: str = Header(...)): if x_key != "fake-super-secret-key": raise HTTPException(status_code=400, detail="X-Key header invalid") @app.get("/items/", dependencies=[Depends(verify_key)]) async def read_items(): return [{"item": "Foo"}, {"item": "Bar"}]Parameterized dependencies
from fastapi import Depends, FastAPI app = FastAPI() class FixedContentQueryChecker: def __init__(self, fixed_content: str): self.fixed_content = fixed_content def __call__(self, q: str = ""): if q: return self.fixed_content in q return False @app.get("/query-checker/") async def read_query_check(fixed_content_included: bool = Depends(FixedContentQueryChecker("bar1"))): return {"fixed_content_in_query": fixed_content_included}Global Dependencies
app = FastAPI(dependencies=[Depends(verify_token), Depends(verify_key)])responseを返した後に、その他処理を行い時に、yieldを使う
async def get_db(): db = DBSession() try: yield db # responseを返した後の処理 finally: db.close()或いはcontext managerを使う
class MySuperContextManager: def __init__(self): self.db = DBSession() def __enter__(self): return self.db def __exit__(self, exc_type, exc_value, traceback): self.db.close() async def get_db(): with MySuperContextManager() as db: yield dbauthorization
OAuth2PasswordBearer
- usernameとpasswordをform dataで送って、ログインして、Bearer tokenを発行する認証方法
- scopeを送ることでできる(https://fastapi.tiangolo.com/tutorial/security/simple-oauth2/#scope)
from typing import Optional from fastapi import Depends, FastAPI, HTTPException, status from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm from pydantic import BaseModel fake_users_db = { "johndoe": { "username": "johndoe", "full_name": "John Doe", "email": "johndoe@example.com", "hashed_password": "fakehashedsecret", "disabled": False, }, "alice": { "username": "alice", "full_name": "Alice Wonderson", "email": "alice@example.com", "hashed_password": "fakehashedsecret2", "disabled": True, }, } app = FastAPI() def fake_hash_password(password: str): return "fakehashed" + password oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token") # usernameとpasswordをtoken urlに送って、tokenを貰う class User(BaseModel): username: str email: Optional[str] = None full_name: Optional[str] = None disabled: Optional[bool] = None class UserInDB(User): hashed_password: str def get_user(db, username: str): if username in db: user_dict = db[username] return UserInDB(**user_dict) def fake_decode_token(token): # This doesn't provide any security at all # Check the next version user = get_user(fake_users_db, token) return user async def get_current_user(token: str = Depends(oauth2_scheme)): # Authorization Headerからtokenを取得 user = fake_decode_token(token) if not user: # The additional header WWW-Authenticate with value Bearer we are returning here is also part of the spec. raise HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Invalid authentication credentials", headers={"WWW-Authenticate": "Bearer"}, ) return user async def get_current_active_user(current_user: User = Depends(get_current_user)): if current_user.disabled: raise HTTPException(status_code=400, detail="Inactive user") return current_user @app.post("/token") async def login(form_data: OAuth2PasswordRequestForm = Depends()): user_dict = fake_users_db.get(form_data.username) if not user_dict: raise HTTPException(status_code=400, detail="Incorrect username or password") user = UserInDB(**user_dict) hashed_password = fake_hash_password(form_data.password) if not hashed_password == user.hashed_password: raise HTTPException(status_code=400, detail="Incorrect username or password") return {"access_token": user.username, "token_type": "bearer"} @app.get("/users/me") async def read_users_me(current_user: User = Depends(get_current_active_user)): return current_userOAuth2PasswordBearer, Bearer with JWT tokens
JWT紹介:https://jwt.io/introduction/
pip install python-jose cryptography # generate and verify the JWT tokens pip install passlib bcrypt # passwordのhash化で使うfrom datetime import datetime, timedelta from typing import Optional from fastapi import Depends, FastAPI, HTTPException, status from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm from jose import JWTError, jwt from passlib.context import CryptContext from pydantic import BaseModel # to get a string like this run: # openssl rand -hex 32 SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7" ALGORITHM = "HS256" ACCESS_TOKEN_EXPIRE_MINUTES = 30 fake_users_db = { "johndoe": { "username": "johndoe", "full_name": "John Doe", "email": "johndoe@example.com", "hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW", "disabled": False, } } class Token(BaseModel): access_token: str token_type: str class TokenData(BaseModel): username: Optional[str] = None class User(BaseModel): username: str email: Optional[str] = None full_name: Optional[str] = None disabled: Optional[bool] = None class UserInDB(User): hashed_password: str pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto") oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token") app = FastAPI() def verify_password(plain_password, hashed_password): return pwd_context.verify(plain_password, hashed_password) def get_password_hash(password): return pwd_context.hash(password) def get_user(db, username: str): if username in db: user_dict = db[username] return UserInDB(**user_dict) def authenticate_user(fake_db, username: str, password: str): user = get_user(fake_db, username) if not user: return False if not verify_password(password, user.hashed_password): return False return user def create_access_token(data: dict, expires_delta: Optional[timedelta] = None): to_encode = data.copy() if expires_delta: expire = datetime.utcnow() + expires_delta else: expire = datetime.utcnow() + timedelta(minutes=15) to_encode.update({"exp": expire}) encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM) return encoded_jwt async def get_current_user(token: str = Depends(oauth2_scheme)): credentials_exception = HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Could not validate credentials", headers={"WWW-Authenticate": "Bearer"}, ) try: payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM]) username: str = payload.get("sub") if username is None: raise credentials_exception token_data = TokenData(username=username) except JWTError: raise credentials_exception user = get_user(fake_users_db, username=token_data.username) if user is None: raise credentials_exception return user async def get_current_active_user(current_user: User = Depends(get_current_user)): if current_user.disabled: raise HTTPException(status_code=400, detail="Inactive user") return current_user @app.post("/token", response_model=Token) async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()): user = authenticate_user(fake_users_db, form_data.username, form_data.password) if not user: raise HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Incorrect username or password", headers={"WWW-Authenticate": "Bearer"}, ) access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES) access_token = create_access_token( data={"sub": user.username}, expires_delta=access_token_expires # The JWT specification says that there's a key sub, with the subject of the token. ) return {"access_token": access_token, "token_type": "bearer"} @app.get("/users/me/", response_model=User) async def read_users_me(current_user: User = Depends(get_current_active_user)): return current_user @app.get("/users/me/items/") async def read_own_items(current_user: User = Depends(get_current_active_user)): return [{"item_id": "Foo", "owner": current_user.username}]Middleware
requestを受け取って、事前処理をしたり、responseを返す前に後の処理を行ったりすることができる
@app.middleware("http") async def add_process_time_header(request: Request, call_next): start_time = time.time() response = await call_next(request) process_time = time.time() - start_time response.headers["X-Process-Time"] = str(process_time) return responseCORS(Cross-Origin Resource Sharing)
Origin
https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS
Cross-Originの判定はprotocol, domain, portの何が異なる場合from fastapi import FastAPI from fastapi.middleware.cors import CORSMiddleware app = FastAPI() origins = [ "http://localhost.tiangolo.com", "https://localhost.tiangolo.com", "http://localhost", "http://localhost:8080", ] # parameters: https://fastapi.tiangolo.com/tutorial/cors/#use-corsmiddleware app.add_middleware( CORSMiddleware, allow_origins=origins, allow_credentials=True, # https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Access-Control-Allow-Credentials allow_methods=["*"], allow_headers=["*"], )大きいプロジェクトの構成
APIRouter
app/routers/items.py
from fastapi import APIRouter, Depends, HTTPException from ..dependencies import check_token_header router = APIRouter( prefix="/items", tags=["items"], dependencies=[Depends(check_token_header)], responses={404: {"description": "Not found"}}, ) fake_items_db = {"plumbus": {"name": "Plumbus"}, "gun": {"name": "Portal Gun"}} @router.get("/") async def read_items(): return fake_items_dbapp/dependencies.py
from fastapi import Header, HTTPException async def check_token_header(x_token: str = Header(...)): if x_token != "fake-super-secret-token": raise HTTPException(status_code=400, detail="X-Token header invalid")app/main.py
from fastapi import Depends, FastAPI from .dependencies import check_query_token from .routers import items app = FastAPI(dependencies=[Depends(check_query_token)]) app.include_router(items.router) @app.get("/") async def root(): return {"message": "Hello Bigger Applications!"}Background Tasks
BackgroundTasksはrequestを処理する同じprocessを使うので、重いtasksの場合は、専用のqueueを使った方がいい。https://docs.celeryproject.org/en/stable/
from fastapi import BackgroundTasks, FastAPI app = FastAPI() def write_notification(email: str, message=""): with open("log.txt", mode="w") as email_file: content = f"notification for {email}: {message}" email_file.write(content) @app.post("/send-notification/{email}") async def send_notification(email: str, background_tasks: BackgroundTasks): background_tasks.add_task(write_notification, email, message="some notification") return {"message": "Notification sent in the background"}Static Files(静的ファイル)
pip install aiofilesfrom fastapi import FastAPI from fastapi.staticfiles import StaticFiles app = FastAPI() app.mount("/static", StaticFiles(directory="static"), name="static")testing
pip install pytest pip install requestsfrom fastapi import FastAPI from fastapi.testclient import TestClient app = FastAPI() @app.get("/") async def read_main(): return {"msg": "Hello World"} client = TestClient(app) # clientのAPI: https://requests.readthedocs.io/en/latest/api/ def test_read_main(): response = client.get("/") assert response.status_code == 200 assert response.json() == {"msg": "Hello World"}responseを直接返す
json responseを返す1
from fastapi import FastAPI from fastapi.encoders import jsonable_encoder from fastapi.responses import JSONResponse from pydantic import BaseModel class Item(BaseModel): title: str description: str app = FastAPI() @app.put("/items/{id}") def update_item(id: str, item: Item): json_compatible_item_data = jsonable_encoder(item) return JSONResponse(status_code=status.HTTP_201_CREATED, content=json_compatible_item_data)json responseを返す2
response_classで指定すると、OpenAPI docsが自動で生成される
from fastapi import FastAPI from fastapi.responses import ORJSONResponse app = FastAPI() @app.get("/items/", response_class=ORJSONResponse) async def read_items(): return [{"item_id": "Foo"}]html responseを返す
@app.get("/items/", response_class=HTMLResponse) async def read_items(): return """ <html> <head> <title>Some HTML in here</title> </head> <body> <h1>Look ma! HTML!</h1> </body> </html> """他のresponse class
- RedirectResponse
- FileResponse
- StreamingResponse
response_model, responsesでOpenAPI docsを生成
https://fastapi.tiangolo.com/advanced/additional-responses/
from fastapi import FastAPI from fastapi.responses import JSONResponse from pydantic import BaseModel class Item(BaseModel): id: str value: str class Message(BaseModel): message: str app = FastAPI() @app.get("/items/{item_id}", response_model=Item, responses={404: {"model": Message}}) async def read_item(item_id: str): if item_id == "foo": return {"id": "foo", "value": "there goes my hero"} else: return JSONResponse(status_code=404, content={"message": "Item not found"})Debugging
以下のようなファイルを用意し、IDEでbreakpointを設定すれば、debugできます。
import uvicorn from fastapi import FastAPI app = FastAPI() @app.get("/") def root(): a = "a" b = "b" + a return {"hello world": b} if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000) # コードでuviconを起動
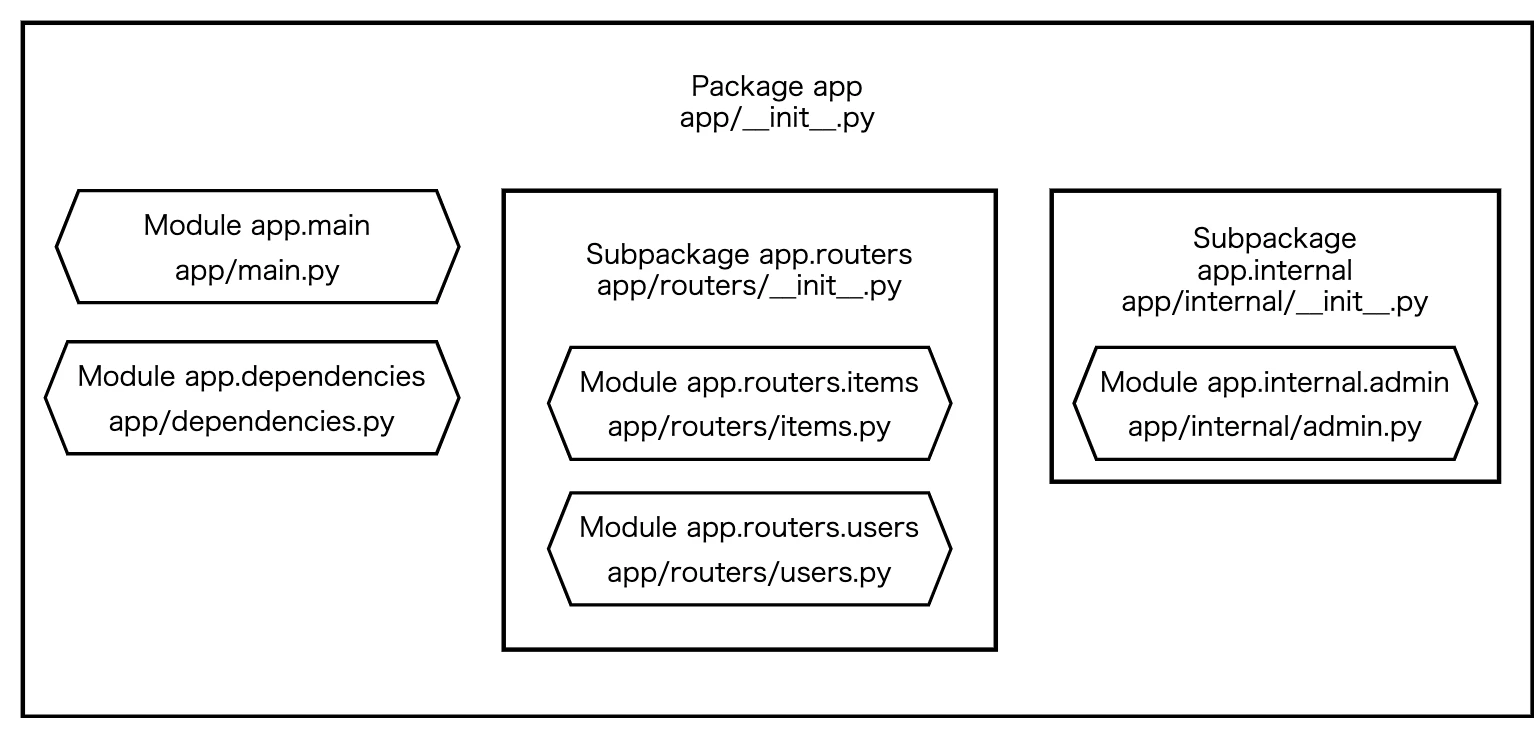
- 投稿日:2020-12-12T19:53:50+09:00
Python エンジニア認定データ分析試験、対策 1日目
1.データ分析エンジニアの役割
Python とは、プログラミング言語である。
Python を用いてプログラミングすることで、
数値・テキスト・画像・音声といったデータを分析できる形に変更する。1.Python の特徴
・コンパイルが不要である。
・オープンソースである。
・仕様がわかりやすい。2. Python の得意分野
・サーバ系ツールである。
・Web システムを構築する。3. Python の苦手分野
・ Web アプリケーションなどのフロントエンド
4. 機械学習とは
機械学習とは大量のデータから、特性を見つけて予測などを行う塊を作成することである。「特性を見つけて予測などを行う塊」を「モデル」という。
5. 機械学習の処理手順
データ入手 > データ加工 > データ可視化 > アルゴリズム選択 >
学習プロセス > 制度評価 > 試験運用 > 結果利用自作問題
1.データ分析エンジニアの役割に関する問題です。
自作問題です。誤字脱字がないように気を付けてますが、
不足・補足などありましたらコメントをお願いします。Q1. 機械学習の処理の手順として正しいものを選んでください。
a) データ入手>アルゴリズム選択>データ可視化>データ加工>学習プロセス>精度評価>試験運用>結果利用
b) アルゴリズム選択>データ入手>学習プロセス>データ加工>データ可視化>精度評価>試験運用>結果利用
c) アルゴリズム選択>データ可視化>データ入手>データ加工>データ可視化>精度評価>試験運用>結果利用
d) データ入手>データ加工>データ可視化>アルゴリズム選択>学習プロセス>精度評価>試験運用>結果利用Q2. データ分析に使う主なパッケージとして誤りがあるものを選んでください。
a)Numpy
b)Django
c)scikit-learn
d)SciPy【解答】
Q1. d)
Q2. b)
- 投稿日:2020-12-12T19:04:28+09:00
自然言語処理を用いたデータの分類
はじめに
このプロジェクトは私が学生時代のアルバイトで某企業で働いていた時テキスト文の過去データを元にテキスト分類を行った記録である。記録として残しておきたいのでQiitaに投稿しました(20201212-1)
背景
背景としてその企業では毎年社内向けにあるコンテストが行われる(記事にもなってる)。そのコンテストにルールで決まった定型のテキスト文でエントリーをたくさん寄せられていた。所属していた部署ではそのテキスト文を審査する部署で、審査を過去のテキスト文の審査結果であるGood,Badのフラグを元に機械学習を用いて振り分けできないかというアイディアのもと始まった。振り分け後その結果によって人の審査するチェック数をエントリーごとに振り分けることによってチェック数の削減になることが期待される。
使ったデータの説明
※データは守秘義務のため見せることはできませんがプログラムは一部抜粋で紹介します。
テキスト文(過去2年分のデータ):あるルールに従って作られたテキスト文2年分(計2379件)
Good/Badフラグ:それぞれのテキスト文にGood/Badのようなフラグで判定されているデータ(計2379件)具体的なデータの詳細
カラム 説明 値 id 行の通し番号 1-2379 text テキスト文 -----(文字列)---- good goodフラグ 0,1表記(Goodなら1で定義) bad badフラグ 0,1表記(Badなら1で定義) ダミー変数化しているデータを採用。GoodもBadがついていないデータもある。GoodもBadもついているデータもとても少ないが何件かあった。
GoodとBadの定義であるが、そもそも1案件に審査する人数は3人程度で審査している。そのため同じ案件にGoodとジャッジする人もいればBadとジャッジする人もある案件も出ている状態である。
またGoodとジャッジする延べ件数はBadとジャッジする述べ件数に比べてとても少ないデータになっていた。
Goodが1件でもついたデータはGoodとしてGoodがついていなくBadが1件でもついたデータはBadとして扱った。GoodもBadもついてないデータは区別はしてないがAverageとして扱った。(2020/03/20現在)(2020/05/13現在)Goodの判別は廃止しBadのみ判別する分類器を作った(Badかどうかを判別する)
カラム 説明 値 id 行の通し番号 1-2379 text テキスト文 -----(文字列)---- bad badフラグ 0,1表記(Badなら1で定義) データの観察・前処理
流れとしては
1)データをimport
2)NAがあったら削除
3)形態素解体(今回はMeCabを使用)
4)Vec化(今回はTf-idfを使用)
5)特徴量のyとの重要度でソートし特徴量を厳選する(今回はSelectKBestを使用)
6)TrainデータとTestデータに分けて分割した(train_test_splitを使用した)以下順番に説明を示す。
1)データをimportするプログラム部import pandas as pd import matplotlib.pyplot as plt import numpy as np import scipy as sc import MeCab from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.feature_selection import SelectKBest前処理で必要なモジュールは上述で記載したモジュールである。
2)NAがあったら削除
今回扱ったデータは完全データだったので気にしなくても大丈夫だったが、完全データでないとTfidfの時に自分の場合はエラーが出たのでNAを削除するプログラム(以下)を行うことを推奨する。df = df.dropna()3)形態素解体(今回はMeCabを使用)
形態素解体とは「自然言語で書かれた文を言語上で意味を持つ最小単位(=形態素)に分け、それぞれの品詞や変化などを判別すること」をいう。(形態素解体とは)
色々パッケージは種類あるが今回のプロジェクトではMeCabを使用した。以下形態素解体のプログラムである。#NAは削除した状態とする。 #データの形はテキスト文のみをリスト型で集めたデータの形を取っている。 wakachi_list = [] for i, di in enumerate(df_total_X): try: w = m0.parse(di) except: w = di if 'list' in str(type(w)): #print('No.', i, w[:30]) wakachi_list += [w.split(' ')] else: #print('X No.', i, w) wakachi_list += [w]わかち書きされたテキスト文はwakachi_listに組み込まれていくようなプログラムになっている。
4)Vec化(今回はTf-idfを使用)
わかち書きしたテキスト文について学習できるようにベクトル化する必要がある。こちらも何パターンもある。今回はTf-Idfを採用した。Tf-Idfの強みとして、「いくつかの文書があったときに、それらに出てくる単語とその頻度(Frequency)から、ある文書にとって重要な単語はなんなのかというのを数値化します。」(TF-IDF)#NA無いとstopする。 #dropna()を行う必要がある。 vectorizer = TfidfVectorizer(use_idf=True, token_pattern=u'(?u)\\b\\w+\\b') vecs = vectorizer.fit_transform(wakachi_list)5)特徴量のyとの重要度でソートし特徴量を厳選する(今回はSelectKBestを使用)
TF-IDFの特徴として文章のサンプル数が多いとベクトルの次元数が増えることが起こる。ここで目的変数(y)と最も関係性が強い特徴量を選択して関係性が弱い特徴量を削除して減らすことでより学習で精度upを期待できると考え特徴量を厳選することを行った。以下プログラムで解説する。(【Python】わかりやすくSelectKBestを解説!)#今回はvec化した時24582次元になったため今回は1/10の2500次元にした。 skb = SelectKBest(k=2500) res2 = skb.fit_transform(vecs_train,y)設定する次元数が極端に少ないと学習で使うパラメータの数が少ないため学習しやすい反面、重要である特徴量まで削除してしまう可能性がある。
設定する次元数が多いと学習に使うパラメータよりも余分に採用していることになるのでそもそも効率が悪くなる可能性がある。この設定方法もトライ&エラーを重ねていい調整を見つける必要がある。
6)TrainデータとTestデータに分けて分割した(train_test_splitを使用した)
TrainデータとTestデータに分けてTrainデータで学習しモデルのパラメータを作成する。出来上がったパラメータをtestデータに当てはめて精度を検証した。この分割に関して自分は70%をTrainデータ,30%をTestデータとして採用した。この分け方も人によって好みが分かれるところであるので変更する必要がある。#res2はXベクトルの2500次元に整形したデータを格納している #yは目的変数(今回はこのBadなら1,Badでないなら0としている) vecs2_train, vecs2_test = train_test_split(res2, random_state=0,train_size=0.7) y_train, y_test = train_test_split(y, random_state=0,train_size=0.7)random_state=0とするとシャッフルの分割を記憶して何度行っても同じsplitでできるのでとても便利である。
ここまでが前処理として行った内容である。
データの学習・評価
1)学習のモデルで使うモジュールをimport
2)クロスバリデーション
3)SVM
4)GridSearch
5)精度評価について1)学習・評価のモデルを使うモジュールをimport
今回学習で使ったモジュールは以下の通りである。今回はクロスバリデーション(cv=10)付きのSVM&GridSearchを行った。評価で用いた指標はメインで混合行列とROC曲線を採用した。サブとしてaccuracyを見るような形で評価することした。from sklearn import svm from sklearn.model_selection import GridSearchCV from sklearn.model_selection import cross_val_score from sklearn.metrics import confusion_matrix2)クロスバリデーション
クロスバリデーションとはTrainデータを解析者が決めたNで等分に分割してある1部分をTestデータとし残りをTrainデータとし、それをN回Testデータとして変更しN個できたモデルに関して出てきた結果において精度の平均を算出する手法である。よく使われることとしてNが少ない時によく使われる手法である。(詳細はこちらを参照:クロスバリデーションとは)※プログラムの都合上4)に付属しているため4)のプログラムの説明の時に同時に説明する。
3)SVM
サポートベクトルマシン(svm)は汎化性能や応用分野の広さから、データ分析の現場でよく用いられる機械学習のアルゴリズムの一つです。マージン最大化と呼ばれる考え方を用いて主に2クラス分類問題で用いられることが多い。2スラス分類を応用することで、他クラス分類や回帰問題などにも応用することが可能である。(詳細はこちらを参照:[機械学習]サポートベクトルマシン(SVM)について、できるだけ分かりやすくまとめていく①~理論と数式編~)続いて今回書いたプログラムを掲載する。
svm_tuned_parameters = [ { 'kernel': ['rbf'], 'gamma': [0.076], 'C': [40], 'probability':[True] } ]kernelを変更することで線形で分類するのではなくN次元の超平面において任意の曲線で分類することも可能である。またそのほかにもオプションでいろいろカスタマイズすることができるので必要に応じて変更していくことでできる。
今回は(4)で説明するGridSearchを行い網羅的にパラメータを変更しそれぞれでモデルの精度を考え、ベストな精度を模索する手法を採用しているため値は私が使ったデータにおいてベストだと判断したパラメータの値になっているので、それぞれのデータに合うようにパラメータチューニングを行う必要がある。4)GridSearch
Gridsearchとは、scikit-learnに含まれているモジュールでハイパーパラメータ探索用のGridSearchCVというものである。Pythonのディクショナリでパラメータの探索リストを渡すと全部試してスコアを返してくれるので非常に便利である。パラメータを細かく切ることにいよってベストなパラメータを発見することができるが、そのぶんプログラムを回し終わるのに時間がかかってしまうというデメリットも生じる。以下プログラムで示す。
print("[INFO] SVM (グリッドサーチ)") svm_tuned_parameters = [ { 'kernel': ['rbf','linear', 'poly'], 'gamma': [0.5,0.076,0.1,0.2], 'C': [20,30,40,50,60], 'probability':[True] } ] gscv2 = GridSearchCV( svm.SVC(), #penalty='l2', svm_tuned_parameters, cv=5, # クロスバリデーションの分割数 n_jobs=1, # 並列スレッド数 verbose=3 # 途中結果の出力レベル 0 だと出力しない )このように(3)で前述した
SVMのパートにサーチしたいパラメータを入れ、GridSearchCV()という関数内に含めてほか(2)で説明したクロスバリデーション(cvと記述している箇所)を設定したりオプションをつけることが可能である。学習する時は
scikit-learn同じみ(?)の'モデル名.fit(X_train,Y)'で学習させることが可能である。
今回の作ったプログラムで例として掲載するとrongai = y_train.tolist() #そのまま行なったらエラーがでたためlist化した gscv2.fit(vecs2_train, list(rongai))これで学習させることが可能である。
学習が終わった後行わないといけない作業として、ベストなパラメータを使ったモデルを取ってきて新たな変数に格納して記憶させておく必要がある。このプログラムは以下でできる。svm2_model = gscv2.best_estimator_ # 最も精度の良かったモデルのパラメータを取って来ることができる print(svm2_model) #パラメータをプリントできるGridSearhの良い使い方として、時間があれば大雑把にパラメータをチューニングした後、その近辺でまたGridSearchを行なってみるといったように何度かパラメータを変更して行うことで神のみぞ知るベストなパラメータに限りなく近いパラメータを見つけて結果的にベストに近い精度upを見込むことが可能である。
5)精度評価について
今回使った精度評価の指標は混合行列とROC曲線をメインで用い、サブの指標としてaccuracyを用いた。それぞれ説明を行なっていく。5-1
混合行列について
混合行列とは分類問題でよく用いられる評価指標の一つである。今回は基本的な2×2混合行列で説明を行う。
混合行列 予測して1 予測して0 データの正解1 TP(True Positive) FN(False Negative) データの正解0 FP(False Negative) TN(True Negative) この行列を用いることで視覚的にどれほど正解ラベルと誤っているのかを見ることができる。(詳しくはこちらを参照:混同行列(Confusion Matrix) とは 〜 2 値分類の機械学習のクラス分類について)
5-2
ROC曲線について
ROC曲線とは、混合行列を作る前段階で考えるカットオフ値(機械学習によって得られた確率を参照しこの値よりも上なら1と判断すると決める区切りの点)を変更してみることを考えその結果においてそれぞれ混合行列を書くこともできる。その混合行列の表のTPとTNの和を計算することで良い分類機かどうかを判定することが可能になる。そのTPとTNの和の関係をグラフ化した曲線をROC曲線と呼ぶ。(これは医学や統計分野でよく使われている評価指標である)
(詳細はこちらを参照:機械学習の評価指標 – ROC曲線とAUC)5-3
acuuracyについて
acuuracyとは5-1の混合行列の表で考えると$\frac{TP+TN}{TP+FN+FP+TN}$とかけるものである。簡単にいうとこれは正答率にあたるものである。学習によって導かれた結果がどれくらい正解しているのか簡単にわかる指標である。(詳しくは5-1混合行列の参照として掲載した混同行列(Confusion Matrix) とは 〜 2 値分類の機械学習のクラス分類についてを参照してください。)社員さんに言われて印象に残っていることとして「機械学習の精度がとても良いからといって必ずしもビジネスで用いて良いかといったらそうではないかもしれない」と言われました。私はアルバイトの身であるのでいつかは辞めて他の誰かに引き継ぐことになるので、引き継いだ後の人も同じように結果を再現できたり、総合的に考えて使えるかどうかを判断しないといけないということが重要だと言われたことが印象に残っていて、このプロジェクトを行うときに常に考えながら行いました。
以下プログラムで1~3を説明する。
##5-1混合行列 sss = svm2_model.predict(vecs2_test) cm = confusion_matrix(y_test, sss) cm #テストデータに当てはめた結果 array([[142, 75], [ 27, 220]])##5-2ROC曲線 import matplotlib.pyplot as plt from sklearn.metrics import roc_curve, auc # AUCの算出 fpr, tpr, thresholds = roc_curve(df5_test, y_pred) roc_auc = auc(fpr, tpr) # ROC曲線の描画 plt.plot(fpr, tpr, color='red', label='ROC curve (area = %.2f)' % roc_auc) plt.plot([0, 1], [0, 1], color='black', linestyle='--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title('Receiver operating characteristic') plt.legend(loc="best")結果はこのような画像でした
AUCという指標が凡例にプリントされていますがAUCは100%に近い方が良いとされています。詳しくは5-2で乗せたROC曲線の参考資料に載せてありますのでそちらを参照してください。
##5-3accuracy print(svm2_model.score(vecs2_train, list(rongai))) #rongaiがtrainデータの目的変数 rongai2 = y_test.tolist() print(svm2_model.score(vecs2_test, list(rongai2))) #rongai2がtestデータの目的変数 #結果は以下の通り 0.9166666666666666 #(trainのaccuracy) 0.7801724137931034 #(testのaccuracy)testデータの精度が78%と分類精度としては良くはないため今後の課題としては考えている。だが78%でGoサインとなった理由として、完全に機械学習のみでシステムを運用するのではなく人もチェックするため誤分類したサンプルは人が補完することで運用できるのではないかという議論になった。そして本プロジェクトはこのシステムを用いて課題はあるが行うことになった。
参考
形態素解体とは
TF-IDF
【Python】わかりやすくSelectKBestを解説!
クロスバリデーションとは
[機械学習]サポートベクトルマシン(SVM)について、できるだけ分かりやすくまとめていく①~理論と数式編~
混同行列(Confusion Matrix) とは 〜 2 値分類の機械学習のクラス分類について
機械学習の評価指標 – ROC曲線とAUC
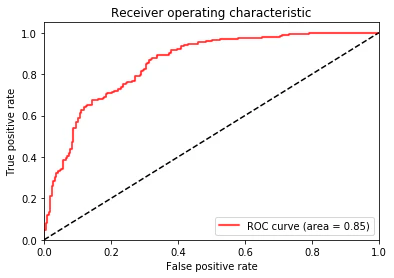
- 投稿日:2020-12-12T18:42:52+09:00
Python初学者がVSCodeでイケイケに開発する
これは 求ム!Pythonを使ってAzureで開発する時のTips!【PR】日本マイクロソフト Advent Calendar 2020 - Qiita 10日目の記事です。
TL;DR;
Python初学者でもVSCodeのRemoteContainersでイケイケに開発できる
背景
Pythonで書かれたコードを触る機会がありました。
しかし私はGoやJava、TypeScriptは書いていても、Pythonを書いたことはありませんでした。そんな私がPythonの開発環境構築をバシュッと行った方法をご紹介します。
とりあえず VSCode RemoteContainers
私はVSCode派なので、VSCodeを使って開発がしたいと思いました。
そこで、RemoteContainersで環境を作れば良いよねってことで環境構築していきました。RemoteContainersとは
VSCodeの拡張機能の一つで、ローカル上のDockerコンテナを立ち上げてその中で開発作業を行うものです。
拡張機能の正式名称はVisual Studio Code Remote - Containersであり、本記事ではRemoteContainersと呼ばせていただいています。
使い方やさらなる詳しい説明は他の文献を参照ください。
- Visual Studio Code Remote Development
- Developing inside a Container using Visual Studio Code Remote Development
- VSCode Remote Containerが良い - Qiitaどんな感じでやったのか
公式で各種言語用のサンプル設定があるので、それをベースに構築しました。
今回はPythonだったので、microsoft/vscode-remote-try-python: Python sample project for trying out the VS Code Remote - Containers extensionの
.devcontainerファイルをプロジェクトにコピーして利用しました。あとは開発に必要な拡張機能だったり、ツールだったり、設定だったりを定義していくだけで開発環境が構築できます。
拡張機能を入れたい場合
ローカルで使っているVSCode拡張がそのままRemoteContainersでも使えるという訳ではないため、別途拡張機能を入れる設定を記述しなければいけません。
その場合は、.devcontainer/devcontainer.jsonの"extensions"に必要な拡張機能のIDを入れていけばRemoteContainers起動時に自動で追加していってくれます。開発に必要なツールを入れたい場合
こちらもローカルにある
awsコマンドがそのままRemoteContainersでも使えるという訳ではないため、設定を記述していきます。
先ほどとファイルが異なり、.devcontainer/Dockerfileの最下部にインストールコマンドを追加するとRemoteContainers起動時にインストールしてくれます。その他
RemoteContainersの起動時に
requirements.txtに定義されたパッケージも自動でインストールしてくれるので、RemoteContainersが起動した時点で全部入りの環境が手に入ります。バシュッと出来たのか
実質、
.devcontainerを作ってRemoteContainersを起動しただけでマジでバシュッと環境が出来ました。またVSCodeのPython拡張が優秀で、コードアシストしてくれたり、フォーマットしてくれたりで、「俺、Python書ける!」って思うくらいイケイケに開発することができました。
(実際は初学者なので、Goなどで書くよりウン倍も時間かかりました)
まとめ
どの言語でも共通して言えると思いますが、初学者にとって環境構築が鬼門になりますが、
そんな環境構築でも、VSCodeのRemoteContainersを使うと、Pythonの全部入りの環境が手に入ります。そのため、Python初学者であってもイケイケに開発することができます。
またRemoteContainersで開発環境を構築すると、開発環境毎にランタイムを変えることがなくなります。
今回の場合は、Macで開発しており、MacのPythonは2系でしたが、RemoteContainersの中ではPython3系で開発できていました。

- 投稿日:2020-12-12T18:40:12+09:00
【python】今度こそ理解できるデコレータの動きその1
はじめに
僕は全然デコレータの動きを覚えることができませんでした。
しかし、ようやく他の人に説明できると思えるようになったので、他の記事では見たこと無いくらい噛み砕いて記事にさせていただきます。この記事では以下の主な3種類のデコレータの動きのうち①について書きます。
(1つの記事で全部紹介しようと思いましたが、体力が尽きました。)①デコレータ使用時に引数を受け取らないパターン
def deco1(func): # 処理 return decooo1 @deco1 def foo(): # 処理 return foooo foo()②デコレータ使用時に引数を受け取るパターン
def deco2(boo): # 処理 return decooo2 @deco2(val, arg1=val2) def foo2(): # 処理 return foooo2 foo2()③デコレータがクラスで実装されているパターン
class deco3: # 処理 @deco3(arg=val) def foo3(): # 処理 return foooo3 foo3()デコレータの基本的な動き
「はじめに」で書いたようにいくつかの書き方がありますが、基本的な動きは同じです。
- @の直後に置かれたcallableオブジェクト1に次の行で定義している関数を引数として渡して呼び出す
- @の次の行で定義している関数名に1で呼び出した返り値を代入する
文字だけだと訳がわからないので、段階的に説明を進めていきます。
なお、以降decoは関数で定義されたデコレータとします。ステップ1:
@decoの次の行に関数を定義すると、その時点でdeco関数が実行されるdef deco(func): print('deco excecuted') @deco def test(): print('test')paiza.ioで実行してみる(↑のコードをコピーして遷移先で貼り付けて実行してください)
以下のように出力されました。
deco excecuted
つまり、deco関数が実行されました。ここまでで以下のことがわかりました。
@decoの次の行に関数を定義すると
- その時点で
deco関数が実行される簡単ですね。
ステップ2:
@decoの次の行に定義した関数名にはdeco関数の返り値が代入されるdef deco(func): return 1 @deco def test(): print('test') print(test)paiza.ioで実行してみる(↑のコードをコピーして遷移先で貼り付けて実行してください)
1が出力されました。つまりデコレータのせいで変数testは関数ではなく、整数1を保持するようになりました。ここまでで以下のことがわかりました。
@decoの次の行に関数を定義すると
- その時点で
deco関数が実行される@decoの次の行で定義された関数名にはdeco関数の返り値が格納されるステップ3:
deco関数の引数には@deco直後で定義された関数が渡されるdef deco(func): func() return 1 @deco def test(): print('test')paiza.ioで実行してみる(↑のコードをコピーして遷移先で貼り付けて実行してください)
以下のように出力されました。
test
test()とは書いていないのに、testが出力されました。これはdeco関数の引数funcにtest関数が代入され、func()によりtest関数が実行されているためです。ここまでで以下のことがわかりました。
@decoの次の行に関数を定義すると
deco関数が実行されるdeco関数の返り値は@decoの次の行で定義された関数名に代入されるdeco関数の引数には@decoの次の行で定義された関数が入っているステップ4:ステップ1〜3を組み合わせてデコレータを活用してみる
ここまで理解できればもう何も怖くありません。①のパターンのデコレータに関する必要な知識はこれだけです。
もしここでつまずく場合は、*argsと**kwargsなどを復習してみてください。ここでは名前を引数として受け取るとその人を紹介する
introduce関数を定義します。
そして、もしその人が兄弟であればその人を紹介する前に「This is my brother.」を出力するデコレータbrother_decoを定義します。brother_list = ("John", "Bob") def deco(func): def replacing_func(*args, **kwargs): if kwargs.get("name") in brother_list: print(f'{kwargs.get("name")} is my brother.') func(*args, **kwargs) return replacing_func @deco def introduce(name: str): print(f"This is {name}.\n") introduce(name="Bob") introduce(name="Taro")paiza.ioで実行してみる
以下のように出力されました。
Bob is my brother.
This is Bob.
This is Taro.つまり、
@decoの次の行にintroduceが定義されているので、ステップ1より、この時点でdeco関数が実行されます。
ステップ2よりdeco関数は引数としてintroduceを受け取るので、deco関数内のfuncをintroduceに置き換えて考えることができます。
deco関数はreplacing_func関数を返すので、ステップ3よりintroduceという関数名にはreplacing_funcが代入されます。そして最後から2行目で
introduce(name=="Bob")が実行されています。
replacing_func関数のkwargs={'name': 'Bob'}より、kwargs.get("name") in brother_listはTrueです。
したがって、Bob is my brotherが出力されます。
最後にfunc(*args, **kwargs)により、This is Bobが出力されました。最後に
もし理解できなかった、間違っているなどありましたらご指摘していただけると助かります。
ステップ1~3までは簡単かと思いますが、ステップ4になると*args, **kwargsも相まってややこしくなりますが、一つずつ処理を追っていけば理解できると思います。今度は②、③のパターンの記事も作ろうと思います。
- 投稿日:2020-12-12T18:39:49+09:00
図で見るソートアルゴリズム(C言語 / Java / VBA / Python)
はじめに
とりあえずソートアルゴリズムについてまとめておきます(数多書かれている内容ではあります)。
図表メインで、ソースコードは、C言語、Java、VBA、Pythonについて記載しています。
なお、JavaとPythonは初学レベルなので、もっと良い書き方があると思われます。ご注意ください。最後は、気になる速度比較もしておきました。結果を見て、Pythonが人気がある理由がまた少し分かりました。
<目次>
1. ヒープソート
1-1. ヒープソートのアルゴリズム概要
1-2. ヒープソートのサンプルコード
2. クイックソート
2-1. クイックソートのアルゴリズム概要
2-2. クイックソートのサンプルコード
3. マージソート
3-1. マージソートのアルゴリズム概要
3-2. マージソートのサンプルコード
4. バブルソート
4-1. バブルソートのアルゴリズム概要
4-2. バブルソートのサンプルコード
5. 速度比較
5-1. 計算量
5-2. 処理速度の計測結果
5-3. 【参考】処理時間計測のソースコード1. ヒープソート
ヒープソートは、二分ヒープの性質を利用して並べ替えを行うアルゴリズムです。
二分ヒープは、次のような木構造を取ります。
要件は「完全二分木」であることと「親要素は子要素より常に大きいか等しい構造(ヒープ構造)」であることの2つです。二分ヒープと配列のイメージ
プログラムでは、この二分ヒープを、上の図ように配列に置き換えてコードを書くことになります。
配列の要素番号をiとすると、次の式が成り立ちます。[親要素の番号] = (i - 1) / 2 ※/(スラッシュ)は整数の除算で小数点以下は切り捨て [左側子要素の番号] = i * 2 + 1 [右側子要素の番号] = i * 2 + 21-1. ヒープソートのアルゴリズム概要
ヒープソートでは、最初に、配列を「二分ヒープ」の形にする必要があります。
そして、二分ヒープの形を維持しながら、最大値である根(ルート)を順次取り出していくことになります。
以下、順に見ていきます。1-1-1. 配列を二分ヒープに変換する方法(up-heap)
ランダムな配列を二分ヒープにするためには、「既にヒープ構造になっている二分ヒープ木に対して、下から要素を追加していく方法」を使用します。
この方法は、アップヒープ(up-heap)といい、図で見ると次のような感じです。アップヒープのイメージ
これを配列に当てはめると、次のような手順になります。
配列をヒープ構造に変換するイメージ
ここでは、わかりやすいように、元の配列から新しい配列に1つずつ要素を入れています。
しかし、図を見てわかるように、新しい配列を用意しなくとも、元の配列に要素を置いたまま、前から順にヒープ構造にしていくことができます。1-1-2. 二分ヒープから並べ替えをする方法(down-heap)
二分ヒープ木では根(ルート)が最大値となります。
この根(最大値)を取り出していくことで並べ替えを進めていくことになります(この点はバブルソートに近しい)。なお、最大値を取り除くと、二分ヒープ構造が崩れます。
ここでは、下図のように上から要素を追加する形で二分ヒープ構造に戻していきます。
この方法をダウンヒープ(down-heap)といいます。ダウンヒープによるソートのイメージ
動きとしては、バブルソートに近いと言えますが、ヒープソートの方が、比較数・交換数は少なくて済みますので、その分効率の良いアルゴリズムとなります。
また、ヒープソートは「元の配列に要素を置いたまま交換を繰り返すことにより並べ替えができるアルゴリズム」となります。
このようなソートアルゴリズムをIn-placeアルゴリズムといいます。In-placeアルゴリズムには、追加の記憶領域をほとんど使わないで済むという利点があります。In-placeアルゴリズムの範疇に含まれるものには、クイックソート、バブルソートなどがあります。
1-2. ヒープソートのサンプルコード
1-2-1. C言語
<ソースコード>
heap_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 int parent(int child) {return (child - 1) / 2;} // 親要素の要素番号を取得 int left_child(int parent) {return parent * 2 + 1;} // 左の子要素の要素番号を取得 int right_child(int parent) {return parent * 2 + 2;} // 右の子要素の要素番号を取得 void swap(int *n1, int *n2); // ヒープソート void heap_sort(int *nums, int numslen) { // 配列を二分ヒープに変換する(up-heap) for (int i = 0; i < numslen; i++) { int j = i; // 要素番号iにある要素を二分ヒープに追加(要素番号をjに代入) while (j > 0) { // 要素番号が0以上の場合(子要素の番号である場合)はループを継続 if (nums[j] > nums[parent(j)]) { // 追加した要素が親要素より大きい場合 swap(&nums[j], &nums[parent(j)]); // 親要素と子要素を入れ替える j = parent(j); // jの位置を入替え後の位置(親要素のあった位置)に移動 } else { break; // 親要素の方が大きければ入替えの必要がないので確定 } } } // ソート処理(down-heap) for (int i = numslen - 1; i > 0; i--) { swap(&nums[0], &nums[i]); // 根(ルート)の要素を最大値として確定して配列の後方に移動 int j = 0; // 配列の先頭に来た要素をdown-heapしていく while (left_child(j) < i) { // 子のうち値の大きい方の配列番号をtmpに格納 int tmp = left_child(j); // 一旦左の子の要素番号を入れる if (right_child(j) < i && nums[right_child(j)] > nums[tmp]) tmp = right_child(j); // 右の要素(値)が大きければtmpを入替え // 親の値が子の値より小さければ入れ替え if (nums[j] < nums[tmp]) { swap(&nums[j], &nums[tmp]); j = tmp; } else { break; // 親の値が子の値より大きければ確定 } } } } // スワップ(入れ替え)関数 void swap(int *n1, int *n2) { int tmp = *n1; *n1 = *n2; *n2 = tmp; } // ヒープソートの実行 int main(void) { // ソート用の配列を作成 srand((unsigned int)time(NULL)); // 乱数の発生をランダムにする int n = 10; int *nums = malloc(n * sizeof(int)); // int型配列のメモリを確保 for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; // ランダムな値を代入 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート前の配列出力 printf("\n"); heap_sort(nums, n); for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート後の配列出力 printf("\n"); return 0; }<出力確認>
ターミナル$ gcc heap_sort.c $ ./a.out 4, 6, 9, 7, 4, 2, 8, 0, 3, 2, 0, 2, 2, 3, 4, 4, 6, 7, 8, 9,1-2-2. Java
<ソースコード>
HeapSortTest.javaimport java.util.Random; public class HeapSortTest { public static void main(String[] args) { // ソート用の配列を作成 int n = 10; int nums[] = new int[n]; Random rand = new Random(); // 乱数のインスタンスを作成 for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); // ランダムな値を代入 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); HeapSort(nums, n); // ヒープソートの実行 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); } public static void HeapSort(int nums[], int n) { // 配列を二分ヒープに変換する(up-heap) for (int i = 0; i < n; i++) { int j = i; // 要素番号iにある要素を二分ヒープに追加(要素番号をjに代入) while (j > 0) { // 要素番号が0以上の場合(子要素の番号である場合)はループを継続 if (nums[j] > nums[parent(j)]) { // 追加した要素が親要素より大きい場合 Swap(nums, j, parent(j)); // 親要素と子要素を入れ替える j = parent(j); // jの位置を入替え後の位置(親要素のあった位置)に移動 } else { break; // 親要素の方が大きければ入替えの必要がないので確定 } } } // ソート処理(down-heap) for (int i = n - 1; i > 0; i--) { Swap(nums, 0, i); // 根(ルート)の要素を最大値として確定して配列の後方に移動 int j = 0; // 配列の先頭に来た要素をdown-heapしていく while (left_child(j) < i) { // 子のうち値の大きい方の配列番号をtmpに格納 int tmp = left_child(j); // 一旦左の子の要素番号を入れる if (right_child(j) < i && nums[right_child(j)] > nums[tmp]) tmp = right_child(j); // 右の要素(値)が大きければtmpを入替え // 親の値が子の値より小さければ入れ替え if (nums[j] < nums[tmp]) { Swap(nums, j, tmp); j = tmp; } else { break; // 親の値が子の値より大きければ確定 } } } } public static int parent(int child) {return (child - 1) / 2;} // 親要素の要素番号を取得 public static int left_child(int parent) {return parent * 2 + 1;} // 左の子要素の要素番号を取得 public static int right_child(int parent) {return parent * 2 + 2;} // 右の子要素の要素番号を取得 public static void Swap(int nums[], int n1, int n2) { int tmp = nums[n1]; nums[n1] = nums[n2]; nums[n2] = tmp; } }<出力確認>
ターミナル$ javac HeapSortTest.java $ java HeapSortTest 2, 0, 4, 3, 3, 3, 3, 8, 9, 5, 0, 2, 3, 3, 3, 3, 4, 5, 8, 9,1-2-3. VBA
<ソースコード>
'ヒープソート Sub HeapSort(nums() As Long) Dim i As Long Dim c As Long '主に子(child)の要素番号に使用 Dim p As Long '主に親(parent)の要素番号に使用 '配列を二分ヒープに変換する(up-heap) For i = 0 To UBound(nums) c = i Do While c > 0 If nums(c) <= nums(GetPNode(c)) Then Exit Do '子が親以下の値であればループを抜ける(VBAはOrでは結べない) Call Swap(nums(c), nums(GetPNode(c))) c = GetPNode(c) Loop Next 'ソート処理(down-heap) For i = UBound(nums) To 0 Step -1 p = 0 Call Swap(nums(p), nums(i)) Do While GetLNode(p) < i '子のうち値の大きい方の配列番号をcに格納 If GetLNode(p) = i - 1 Then '子要素が左のみであれば c = GetLNode(p) 'cに左の子の要素番号を格納 ElseIf nums(GetLNode(p)) > nums(GetRNode(p)) Then '左の要素の値が右の要素より大きければ(VBAはOrでは結べない) c = GetLNode(p) 'cに左の子の要素番号を格納 Else c = GetRNode(p) 'cに右の子の要素番号を格納 End If '親の値が子の値より小さければ入れ替え If nums(p) >= nums(c) Then Exit Do '親が子以上の値であればループを抜ける Call Swap(nums(p), nums(c)) p = c Loop Next End Sub '親要素の要素番号を取得 Function GetPNode(n As Long) As Long GetPNode = (n - 1) \ 2 End Function '左の子要素の要素番号を取得 Function GetLNode(n As Long) As Long GetLNode = n * 2 + 1 End Function '右の子要素の要素番号を取得 Function GetRNode(n As Long) As Long GetRNode = n * 2 + 2 End Function 'スワップ Sub Swap(a As Variant, b As Variant) Dim tmp As Variant tmp = a a = b b = tmp End Sub<出力確認>
ヒープソートの実行(VBA)Sub OutputHeapSoat() Dim nums() As Long Call CreateArray(nums, 10) '配列を作成 Call PrintArray(nums) 'ソート前の配列を出力 Call HeapSort(nums) Call PrintArray(nums) 'ソート前の配列を出力 End Sub乱数作成(VBA)'乱数による配列作成プロシージャ Sub CreateArray(nums() As Long, n As Long) Dim i As Long ReDim nums(n - 1) Randomize '乱数ジェネレーターを初期化(都度異なる乱数値を取得するため) For i = 0 To UBound(nums) nums(i) = Fix(Rnd * n) Next End Sub配列出力(VBA)'1次元配列の内容を出力するプロシージャ Sub PrintArray(nums As Variant) Dim i As Long Dim buf As String For i = 0 To UBound(nums) buf = buf & nums(i) & ", " Next Debug.Print buf End Subイミディエイトウィンドウ(2行目がソート後の配列)1, 1, 6, 6, 0, 6, 2, 8, 6, 9, 0, 1, 1, 2, 6, 6, 6, 6, 8, 9,1-2-4. Python
<ソースコード>
HeapSort.pyimport random def parent(child): return (child - 1) // 2 def left_child(parent): return parent * 2 + 1 def right_child(parent): return parent * 2 + 2 # ヒープソート def heap_sort(nums): for i in range(len(nums)): j = i while j > 0: if nums[j] > nums[parent(j)]: nums[j], nums[parent(j)], j = nums[parent(j)], nums[j], parent(j) else: break for i in range(len(nums) - 1, 0, -1): nums[0], nums[i], j = nums[i], nums[0], 0 while left_child(j) < i: tmp = left_child(j) if right_child(j) < i and nums[right_child(j)] > nums[tmp]: tmp = right_child(j) if nums[j] < nums[tmp]: nums[j], nums[tmp], j = nums[tmp], nums[j], tmp else: break # ヒープソートの実行 n = 10 nums = [random.randint(0, n - 1) for i in range(n)] print(nums) # ソート前の配列出力 heap_sort(nums) # ヒープソート print(nums) # ソート後の配列出力<出力確認>
ターミナル> python HeapSort.py [0, 0, 8, 2, 3, 9, 4, 5, 0, 5] [0, 0, 0, 2, 3, 4, 5, 5, 8, 9]2. クイックソート
クイックソートは、その名のとおり処理速度が速いアルゴリズムです。
2-1. クイックソートのアルゴリズム概要
2-1-1. 基本となる考え方
クイックソートでは、以下の図のように、配列の中で基準となる数値を一つ決めて、基準よりも小さい値のグループと、基準以上の値のグループに分けていきます。
各グループで更にこれを繰り返すことで、並べ替えを完了させるアルゴリズムです。クイックソートのイメージ
クイックソートもヒープソートと同様に、In-placeアルゴリズム(元の配列に要素を置いたまま交換により並べ替えをするアルゴリズム)の範疇に入ります。2-1-2. 基準値との比較方法と要素の交換方法
クイックソートをコード化する一般的な考え方として「基本情報技術者試験平成27年度春期午後問8」があります(Wikipediaの解説も同様)が、この方法を採ると無限ループを回避する工夫が必要となるため結構面倒でした。
ここでは、こちらの論文「(MAX上における)アルゴリズム的問題におけるユーザーインターフェースの改良」で紹介されているクイックソートの考え方をベースとして次のような方法でコードを書いていきます。
クイックソートにおける要素交換方法のイメージ
以上の処理を終えた後に、更に、基準値未満の数(sからp-1までの要素)と、基準値以上の数(p+1からeまでの要素)について同じ処理を再帰的に繰り返すことになります。2-2. クイックソートのサンプルコード
2-2-1. C言語
<ソースコード>
quick_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 void swap(int *n1, int *n2); // クイックソート void quick_sort(int *nums, int s, int e) { if (s >= e) return; // 配列の要素数が1以下の場合は処理不要 int p = s; // 最終的にはこのpの位置より左側に基準値より小さい要素が並ぶ int h = (s + e) / 2; // 基準値は配列中央から選ぶことにする swap(&nums[s], &nums[h]); // 基準値は一旦配列先頭に置いておく(基準値=nums[s]となる) for (int i = s + 1; i <= e; i++) { if (nums[i] < nums[s]) swap(&nums[++p], &nums[i]); // 基準値より小さい要素をpの左側に移動させていく } swap(&nums[s], &nums[p]); // 基準値をpの位置に置き換える(基準値の位置が確定) quick_sort(nums, s, p - 1); // 配列前半部分(基準値より小さい値)を再帰処理 quick_sort(nums, p + 1, e); // 配列後半部分(基準値以上の値)を再帰処理 } // スワップ(入れ替え)関数 void swap(int *n1, int *n2) { int tmp = *n1; *n1 = *n2; *n2 = tmp; } // クイックソートの実行 int main(void) { // ソート用の配列を作成 srand((unsigned int)time(NULL)); // 乱数の発生をランダムにする int n = 10; int *nums = malloc(n * sizeof(int)); // int型配列のメモリを確保 for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; // ランダムな値を代入 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート前の配列出力 printf("\n"); quick_sort(nums, 0, n - 1); // クイックソートの実行 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート後の配列出力 printf("\n"); return 0; }<出力確認>
ターミナル$ gcc quick_sort.c $ ./a.out 3, 8, 9, 5, 0, 9, 8, 1, 2, 8, 0, 1, 2, 3, 5, 8, 8, 8, 9, 9,参考:先頭要素を基準値とした場合
なお、リスクはありますが、並べ替えする配列がランダムなものであれば、先頭の要素をそのまま基準値として、次のように簡潔に書くこともできます。
交換回数も減るので、スピードも少し早くなります(配列の並びがランダムであれば)。quick_sort2.c// クイックソート(先頭要素を基準値とした場合) void quick_sort(int *nums, int s, int e) { if (s >= e) return; int p = s; for (int i = s + 1; i <= e; i++) if (nums[i] < nums[s]) swap(&nums[++p], &nums[i]); swap(&nums[s], &nums[p]); quick_sort(nums, s, p - 1); quick_sort(nums, p + 1, e); }でも、並べ替える配列が、もともと昇順に近い形である場合には、かなり無駄な演算を繰り返すことになりますので、やっぱりこの書き方はあまり適切でないと思います。
2-2-2. Java
<ソースコード>
QuickSortTest.javaimport java.util.Random; public class QuickSortTest { public static void main(String[] args) { // ソート用の配列を作成 int n = 10; int nums[] = new int[n]; Random rand = new Random(); // 乱数のインスタンスを作成 for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); // ランダムな値を代入 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); QuickSort(nums, 0, n - 1); // クイックソートの実行 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); } // クイックソート public static void QuickSort(int nums[], int s, int e) { if (s >= e) return; // 配列の要素数が1以下の場合は処理不要 int p = s; // 最終的にはこのpの位置より左側に基準値より小さい要素が並ぶ int h = (s + e) / 2; // 基準値は配列中央から選ぶことにする Swap(nums, s, h); // 基準値は一旦配列先頭に置いておく(基準値=nums[s]となる) for (int i = s + 1; i <= e; i++) { if (nums[i] < nums[s]) Swap(nums, ++p, i); // 基準値より小さい要素をpの左側に移動させていく } Swap(nums, s, p); // 基準値をpの位置に置き換える(基準値の位置が確定) QuickSort(nums, s, p - 1); // 配列前半部分(基準値より小さい値)を再帰処理 QuickSort(nums, p + 1, e); // 配列後半部分(基準値以上の値)を再帰処理 } // Swap関数 public static void Swap(int nums[], int n1, int n2) { int tmp = nums[n1]; nums[n1] = nums[n2]; nums[n2] = tmp; } }<出力確認>
ターミナル$ javac QuickSortTest.java $ java QuickSortTest 9, 9, 1, 3, 9, 0, 6, 7, 4, 7, 0, 1, 3, 4, 6, 7, 7, 9, 9, 9,2-2-3. VBA
<ソースコード>
'クイックソート '引数(nums=対象となる配列、s=配列の開始位置、e=配列の終了位置) Sub QuickSort(nums() As Long, s As Long, e As Long) If s >= e Then Exit Sub '開始位置sが終了位置e以降になる場合は関数を抜ける Dim i As Long Dim p As Long: p = s Call Swap(nums(s), nums((s + e) \ 2)) '配列中央の値を基準値にして先頭と入れ替え For i = s + 1 To e If nums(i) < nums(s) Then 'nums(s)を基準値として数値を比較していく p = p + 1 '基準値より小さい数があるごとにpを1つ進める Call Swap(nums(i), nums(p)) 'Swap関数で入れ替えを行う。 End If Next Call Swap(nums(s), nums(p)) 'Swap関数で入れ替え Call QuickSort(nums, s, p - 1) '基準値より小さいグループを再帰処理 Call QuickSort(nums, p + 1, e) '基準値より大きいグループを再帰処理 End Sub 'スワップ Sub Swap(a As Variant, b As Variant) Dim tmp As Variant tmp = a a = b b = tmp End Sub<出力確認>
クイックソートの実行(VBA)Sub OutputQuickSort() Dim nums() As Long Call CreateArray(nums, 10) '配列を作成 Call PrintArray(nums) 'ソート前の配列を出力 Call QuickSort(nums, 0, UBound(nums)) 'クイックソートを実行 Call PrintArray(nums) 'ソート後の配列を出力 End Sub※
CreateArray関数と、PrintArray関数はヒープソートと同じものを使用しています。イミディエイトウィンドウ(2行目がソート後の配列)1, 8, 5, 3, 1, 9, 0, 3, 0, 5, 0, 0, 1, 1, 3, 3, 5, 5, 8, 9,2-2-4. Python
<ソースコード>
QuickSort.pyimport random # クイックソート def quick_sort(nums, s ,e): if s >= e: return p, h = s, (s + e) // 2 nums[s], nums[h] = nums[h], nums[s] for i in range(s + 1, e + 1): if nums[i] < nums[s]: p += 1 nums[p], nums[i] = nums[i], nums[p] nums[s], nums[p] = nums[p], nums[s] quick_sort(nums, s ,p - 1) quick_sort(nums, p + 1 ,e) # クイックソートの実行 n = 10 nums = [random.randint(0, n - 1) for i in range(n)] print(nums) # ソート前の配列出力 quick_sort(nums, 0, n - 1) # クイックソート print(nums) # ソート後の配列出力<出力確認>
ターミナル> python QuickSort.py [9, 2, 8, 7, 2, 3, 5, 4, 0, 7] [0, 2, 2, 3, 4, 5, 7, 7, 8, 9]3. マージソート
マージソートは、元の配列の並び方に影響を受けることがあまりなく、処理速度もクイックソート並みに早いです。
マージを行う際に、追加の記憶領域が必要となってしまいますが(in-placeではない = not-in-place)、無駄の少ない綺麗なアルゴリズムだと思います(個人的に)。考え方と実装方法は、基本情報技術者試験平成22年度春期午後問8に基づいています。
3-1. マージソートのアルゴリズム概要
マージソートは、以下の図のように配列を最小単位まで分割した上で、昇順でマージを繰り返していくアルゴリズムです。
マージソートのイメージ
そして、マージ(並べ替え)をどうするかですが、昇順でマージを行う処理は次のような考え方で実装します。
マージ方法のイメージ
<マージの実装方法>
実際にコードを書く場合は、次の図のように、半分(後半部分)は元の配列に残したまま、もう半分(前半部分)のみを取り出した上でマージ処理を行っていくのが効率的です。
これにより、追加で使用するメモリの領域が半分で済み、メモリのコピーも半分で済みます。<前半部分と後半部分の値が同じ場合>
なお、前半部分と後半部分の先頭部分の要素が、それぞれ同じ値の場合は、前半部分を優先してマージします。
そうすることで、「同等なデータのソート前の順序が、ソート後も保存される」こととなります(これを「安定ソート」と言います)。3-2. マージソートのサンプルコード
3-2-1. C言語
<ソースコード>
merge_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 // マージソート void merge_sort(int *nums, int s, int e) { // 配列の分割位置を決める int h = (s + e) / 2; // hは中央値 int lenl = h - s + 1; // lenlは前半部分の配列の要素数(わかりやすくするため変数に格納) int lenr = e - h; // lenrは後半部分の配列の要素数(わかりやすくするため変数に格納) // 分割した配列が2以上の要素を持つときは再帰処理を行う(再帰処理の終了後は各配列が昇順になっている) if (lenl > 1) merge_sort(nums, s, h); if (lenr > 1) merge_sort(nums, h + 1, e); // 前半部分を新たな配列に格納 int *tmpnums = malloc(lenl * sizeof(int)); // 分割した配列を格納するメモリを確保(gccでは int tmpnums[lenl]; でもOK) for (int i = 0; i < lenl; i++) tmpnums[i] = nums[s + i]; // 2つの配列を昇順にマージ int nl = 0, nr = 0; for (int i = s; i <= e; i++) { if (nl > lenl - 1) break; // 前半部分の要素が全てマージされた場合は全ての並べ替えが終了 if (nr > lenr - 1 || tmpnums[nl] <= nums[h + 1 + nr]) { nums[i] = tmpnums[nl++]; // 後半部分の要素が全てマージ or [前半部分の要素]<=[後半部分の要素] の場合 } else { nums[i] = nums[h + 1 + nr++]; // [前半部分の要素]>[後半部分の要素] の場合 } } // メモリの解放 free(tmpnums); } // マージソートの実行 int main(void) { // ソート用の配列を作成 srand((unsigned int)time(NULL)); // 乱数の発生をランダムにする int n = 10; int *nums = malloc(n * sizeof(int)); // int型配列のメモリを確保 for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; // ランダムな値を代入 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート前の配列出力 printf("\n"); merge_sort(nums, 0, n - 1); // マージソートの実行 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート後の配列出力 printf("\n"); return 0; }可読性優先で冗長な書き方をしているため、コードが長く見えます。
変数を減らして整理するとmerge_sort部分だけであれば10行くらいで済みます。<出力確認>
ターミナル$ gcc merge_sort.c $ ./a.out 9, 4, 6, 9, 8, 5, 0, 5, 5, 3, 0, 3, 4, 5, 5, 5, 6, 8, 9, 9,3-2-2. Java
<ソースコード>
MergeSortTest.javaimport java.util.Random; public class MergeSortTest { public static void main(String[] args) { // ソート用の配列を作成 int n = 10; int nums[] = new int[n]; Random rand = new Random(); // 乱数のインスタンスを作成 for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); // ランダムな値を代入 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); MergeSort(nums, 0, n - 1); // マージソートの実行 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); } public static void MergeSort(int nums[], int s, int e) { // 配列の分割位置を決める int h = (s + e) / 2; // hは中央値 int lenl = h - s + 1; // lenlは前半部分の配列の要素数(わかりやすくするため変数に格納) int lenr = e - h; // lenrは後半部分の配列の要素数(わかりやすくするため変数に格納) // 分割した配列が2以上の要素を持つときは再帰処理を行う(再帰処理の終了後は各配列が昇順になっている) if (lenl > 1) MergeSort(nums, s, h); if (lenr > 1) MergeSort(nums, h + 1, e); // 前半部分を新たな配列に格納 int tmpnums[] = new int[lenl]; // 分割した配列を格納する配列 for (int i = 0; i < lenl; i++) tmpnums[i] = nums[s + i]; // 2つの配列を昇順にマージ int nl = 0, nr = 0; for (int i = s; i <= e; i++) { if (nl > lenl - 1) break; // 前半部分の要素が全てマージされた場合は全ての並べ替えが終了 if (nr > lenr - 1 || tmpnums[nl] <= nums[h + 1 + nr]) { nums[i] = tmpnums[nl++]; // 後半部分の要素が全てマージ or [前半部分の要素]<=[後半部分の要素] の場合 } else { nums[i] = nums[h + 1 + nr++]; // [前半部分の要素]>[後半部分の要素] の場合 } } } public static void Swap(int nums[], int n1, int n2) { int tmp = nums[n1]; nums[n1] = nums[n2]; nums[n2] = tmp; } }<出力確認>
ターミナル$ javac MergeSortTest.java $ java MergeSortTest 3, 1, 6, 2, 3, 0, 7, 9, 3, 1, 0, 1, 1, 2, 3, 3, 3, 6, 7, 9,3-2-3. VBA
<ソースコード>
マージソート(VBA)Sub MergeSort(nums() As Long, s As Long, e As Long) Dim i As Long Dim h As Long: h = (s + e) \ 2 Dim numsTmp() As Long: ReDim numsTmp(h - s) If h - s > 0 Then Call MergeSort(nums, s, h) If e - h - 1 > 0 Then Call MergeSort(nums, h + 1, e) For i = 0 To h - s numsTmp(i) = nums(s + i) Next Dim nl As Long: nl = 0 Dim nr As Long: nr = 0 For i = s To e If nl > h - s Then Exit For If nr > e - h - 1 Then nums(i) = numsTmp(nl) nl = nl + 1 ElseIf numsTmp(nl) < nums(h + 1 + nr) Then nums(i) = numsTmp(nl) nl = nl + 1 Else nums(i) = nums(h + 1 + nr) nr = nr + 1 End If Next End Sub<出力確認>
マージソートの実行(VBA)Sub OutputMergeSort() Dim nums() As Long Call CreateArray(nums, 10) '配列を作成 Call PrintArray(nums) 'ソート前の配列を出力 Call MergeSort(nums, 0, UBound(nums)) Call PrintArray(nums) 'ソート後の配列を出力 End Sub※
CreateArray関数と、PrintArray関数はヒープソートと同じものを使用しています。イミディエイトウィンドウ(2行目がソート後の配列)1, 3, 9, 6, 5, 7, 2, 0, 8, 5, 0, 1, 2, 3, 5, 5, 6, 7, 8, 9,3-2-4. Python
<ソースコード>
MergeSort.pyimport random # マージソート def merge_sort(nums, s ,e): h = (s + e) // 2 lenl, lenr = h - s + 1, e - h if lenl > 1: merge_sort(nums, s, h) if lenr > 1: merge_sort(nums, h + 1, e) tmp_nums = [nums[s + i] for i in range(lenl)] nl = nr = 0 for i in range(s, e + 1): if nl > lenl - 1: break if nr > lenr - 1 or tmp_nums[nl] <= nums[h + 1 + nr]: nums[i] = tmp_nums[nl] nl += 1 else: nums[i] = nums[h + 1 + nr] nr += 1 # マージソートの実行 n = 10 nums = [random.randint(0, n - 1) for i in range(n)] print(nums) # ソート前の配列出力 merge_sort(nums, 0, n - 1) # マージソート print(nums) # ソート後の配列出力<出力確認>
ターミナル> python MergeSort.py [7, 8, 8, 1, 1, 4, 8, 2, 9, 2] [1, 1, 2, 2, 4, 7, 8, 8, 8, 9]4. バブルソート
バブルソートは処理速度が遅いですが、アルゴリズムが単純なので、簡単に作成することができます。
データが大量でなければ、バブルソートで十分なことも多いです。4-1. バブルソートのアルゴリズム概要
バブルソートは、以下の図のように隣り合う要素を順に比較して、値が大きいものを後ろに移動させていくアルゴリズムです。
一巡するたびに、一番大きい値が末尾に置かれて確定していきます。
バブル(泡)がどんどん上に上っていくように、大きい値が末尾に移動して確定していくというイメージです。バブルソートのイメージ
バブルソートもIn-placeアルゴリズム(元の配列に要素を置いたまま交換により並べ替えをするアルゴリズム)となります。4-2. バブルソートのサンプルコード
4-2-1. C言語
bubble_sort関数自体は正味3行程度です。<ソースコード>
bubble_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 void swap(int *n1, int *n2); // バブルソート void bubble_sort(int *nums, int numslen) { for (int i = numslen - 1; i > 0; i--) { for (int j = 0; j < i; j++) { if (nums[j] > nums[j + 1]) swap(&nums[j], &nums[j + 1]); } } } // スワップ(入れ替え)関数 void swap(int *n1, int *n2) { int tmp = *n1; *n1 = *n2; *n2 = tmp; } // バブルソートの実行 int main(void) { // ソート用の配列を作成 srand((unsigned int)time(NULL)); // 乱数の発生をランダムにする int n = 10; int *nums = malloc(n * sizeof(int)); // int型配列のメモリを確保 for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; // ランダムな値を代入 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート前の配列出力 printf("\n"); bubble_sort(nums, n); // バブルソートの実行 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート後の配列出力 printf("\n"); return 0; }<出力確認>
ターミナル$ gcc bubble_sort.c $ ./a.out 8, 5, 6, 3, 1, 0, 5, 2, 2, 1, 0, 1, 1, 2, 2, 3, 5, 5, 6, 8,4-2-2. Java
<ソースコード>
BubbleSortTest.javaimport java.util.Random; public class BubbleSortTest { public static void main(String[] args) { // ソート用の配列を作成 int n = 10; int nums[] = new int[n]; Random rand = new Random(); // 乱数のインスタンスを作成 for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); // ランダムな値を代入 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); BubbleSort(nums); // バブルソートの実行 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); } // バブルソート public static void BubbleSort(int nums[]) { for (int i = nums.length - 1; i >= 0; i--) { for (int j = 0; j < i; j++) { if (nums[j] > nums[j + 1]) Swap(nums, j, j + 1); } } } public static void Swap(int nums[], int n1, int n2) { int tmp = nums[n1]; nums[n1] = nums[n2]; nums[n2] = tmp; } }<出力確認>
ターミナル$ javac BubbleSortTest.java $ java BubbleSortTest 2, 5, 9, 9, 1, 9, 2, 4, 0, 1, 0, 1, 1, 2, 2, 4, 5, 9, 9, 9,4-2-3. VBA
<ソースコード>
バブルソート(VBA)'バブルソート Sub BubbleSort(nums() As Long) Dim i As Long Dim j As Long For i = UBound(nums) - 1 To 0 Step -1 '比較する範囲を1つずつ小さくしていく For j = 0 To i If nums(j) > nums(j + 1) Then Call Swap(nums(j), nums(j + 1)) '前方の値の方が大きければ数値を入れ替える End If Next Next End Subスワップ関数(VBA)'スワップ関数(値aと値bを入替えるプローシージャ) Sub Swap(a As Variant, b As Variant) Dim tmp As Variant tmp = a a = b b = tmp End Sub<出力確認>
バブルソートの実行(VBA)'BubbleSortの出力 Sub OutputBubbleSort() Dim nums() As Long Call CreateArray(nums, 10) '配列を作成 Call PrintArray(nums) 'ソート前の配列を出力 Call BubbleSort(nums) 'バブルソートを実行 Call PrintArray(nums) 'ソート後の配列を出力 End Sub※
CreateArray関数と、PrintArray関数はヒープソートと同じものを使用しています。イミディエイトウィンドウ(2行目がソート後の配列)7, 2, 0, 9, 8, 8, 7, 6, 4, 2, 0, 2, 2, 4, 6, 7, 7, 8, 8, 9,4-2-4. Python
<ソースコード>
BubbleSort.pyimport random # バブルソート def bubble_sort(nums): for i in reversed(range(len(nums))): for j in range(i): if nums[j] > nums[j + 1]: nums[j], nums[j + 1] = nums[j + 1], nums[j] # バブルソートの実行 n = 10 nums = [random.randint(0, n - 1) for i in range(n)] print(nums) # ソート前の配列出力 bubble_sort(nums) # バブルソート print(nums) # ソート後の配列出力<出力確認>
ターミナル> python BubbleSort.py [4, 3, 1, 4, 6, 8, 9, 6, 5, 0] [0, 1, 3, 4, 4, 5, 6, 6, 8, 9]5. 速度比較
最後に、各ソートアルゴリズムごと、各言語ごとに、処理速度の比較をしておきます。
実測結果は、教科書どおりに、コンパイラ言語(C言語、Java)が、インタプリタ言語(VBA、Python)より10倍ほど速い結果となりました。
しかし、Pythonには奥の手があり、コンパイラ言語並みのスピードを出すこともできます。5-1. 計算量
本記事で取り上げた4つのソートアルゴリズムの計算量は次のとおりとなります(詳しくはこちらを参照)。
ソート種別 平均計算量 最大計算量 ヒープソート O(nlog n) O(nlog n) クイックソート O(nlog n) O(n2) マージソート O(nlog n) O(nlog n) バブルソート O(n2) O(n2) バブルソートの計算量は、要素数nの2乗に比例するので、大きな配列に使用するのは無理が生じます。
クイックソートは、基準値の選定を誤るとバブルソート並みに時間が掛かるので要注意です。5-2. 処理速度の計測結果
5-2-1. C言語
当然ですが、C言語は比較的処理速度が速いです。
ランダムな分布であれば、クイックソートが一番処理時間が短くて済みました。<速度計測結果>
要素数:100,000(配列の並びはランダム)
環境:Windows10
単位:秒
試行 ヒープソート クイックソート マージソート バブルソート 1 0.028 0.016 0.022 31.157 2 0.027 0.015 0.024 31.458 3 0.029 0.015 0.024 31.537 4 0.029 0.016 0.024 30.812 5 0.03 0.015 0.023 30.975 6 0.028 0.015 0.024 31.111 7 0.028 0.015 0.024 31.236 8 0.028 0.015 0.023 30.99 9 0.029 0.015 0.024 31.219 10 0.029 0.015 0.025 30.903 平均 0.029 0.015 0.024 31.14 5-2-2. Java
Javaも処理速度がかなり速いです。
ヒープソートとバブルソートにおいては、C言語よりも短時間で処理が終わっています(なぜかは分かりません…)。なお、Javaには、あらかじめソートメソッドがいくつか用意されています(詳しくは、Javaのソートの方法を一通り確認できるページを参照してください)。
ここでは、一般的と思われる、java.util.Arraysのsort()メソッドの処理速度も合わせて比較しておきます(次のソースコードを使用)。JavaSortTest.javaimport java.util.Random; import java.math.BigDecimal; public class JavaSortTest { public static void main(String[] args) { int n = 100000; int nums[] = new int[n]; Random rand = new Random(); for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); long start = System.nanoTime(); // スタート時間を記録 java.util.Arrays.sort(nums); // ソートの実行 double processing_time = (System.nanoTime() - start) / Math.pow(10, 9); System.out.println(BigDecimal.valueOf(processing_time).toPlainString()); // 処理時間を出力 } }<速度計測結果>
要素数:100,000(配列の並びはランダム)
環境:Windows10
単位:秒
試行 ヒープソート クイックソート マージソート バブルソート sort()メソッド 1 0.023 0.015 0.031 16.199 0.013 2 0.023 0.014 0.03 16.125 0.013 3 0.024 0.021 0.027 16.15 0.029 4 0.021 0.017 0.03 16.058 0.037 5 0.019 0.022 0.031 15.88 0.037 6 0.021 0.016 0.03 16.174 0.013 7 0.021 0.016 0.027 16.329 0.021 8 0.02 0.028 0.027 15.894 0.013 9 0.021 0.016 0.027 16.084 0.016 10 0.023 0.015 0.028 16.028 0.014 平均 0.022 0.018 0.029 16.092 0.021 5-2-3. VBA
VBAだと、CやJavaと比べると10倍くらいの時間が掛かっているようです。
特徴は、マージソートの方がクイックソートより速いことです。他の言語と異なる理由は分かりません。バブルソートは、10万要素だと10分近く掛かるので、もうほとんどまともに動きません。
100万要素だと、単純に15時間ぐらいくらい掛かることになります。<速度計測結果>
要素数:100,000(配列の並びはランダム)
環境:Windows10
単位:秒
試行 ヒープソート クイックソート マージソート バブルソート 1 0.875 0.23 0.188 520.281 2 0.922 0.227 0.188 590.551 3 0.953 0.266 0.156 587.059 4 0.895 0.266 0.172 545.402 5 0.887 0.234 0.156 503.906 6 0.891 0.219 0.125 538.902 7 0.875 0.266 0.156 497.254 8 0.859 0.219 0.141 514.914 9 1 0.234 0.156 499.352 10 0.887 0.281 0.172 492.168 平均 0.904 0.244 0.161 528.979 5-2-4. Python
Pythonは、私の拙いコードの書き方が原因かもしれませんが、VBA並みもしくはそれ以上の処理時間が掛かっています。
ただし、Pythonには次のようなsortメソッドが用意されています。
これも同条件で速度を計測しましたが、C言語やJava並みの速度が出ています。この辺もPythonの良いところですね。PythonSort.pyimport random import time # timeモジュールをインポート # ソートの実行 n = 100000 nums = [random.randint(0, n - 1) for i in range(n)] start = time.time() # スタート時間を記録 nums.sort() # ソート processing_time = time.time() - start print(processing_time) # 処理時間を出力<速度計測結果>
要素数:100,000(配列の並びはランダム)
環境:Windows10
単位:秒
試行 ヒープソート クイックソート マージソート バブルソート Sortメソッド 1 1.001 0.218 0.5 710.887 0.015 2 1.011 0.227 0.493 - 0.016 3 1.284 0.37 0.476 - 0.017 4 1.352 0.237 0.484 - 0.018 5 1.043 0.232 0.476 - 0.019 6 1.018 0.236 0.48 - 0.016 7 1.523 0.23 0.484 - 0.017 8 1.367 0.312 0.493 - 0.017 9 1.049 0.215 0.506 - 0.017 10 1.386 0.235 0.482 - 0.017 平均 1.204 0.252 0.487 710.887 0.017 ※バブルソートは、とんでもなく遅いので、1回だけしか実行していません。
5-3. 【参考】処理時間計測のソースコード
参考までに、処理時間を計測したソースコードも残しておきます。
ソートアルゴリズムのコードは省略しています。5-3-1. Python
quick_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 void quick_sort(int *nums, int s, int e); // 中略 // クイックソートの実行 int main(void) { srand((unsigned int)time(NULL)); int n = 100000; int *nums = malloc(n * sizeof(int)); for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; int start = clock(); // スタート時間を記録 quick_sort(nums, 0, n - 1); // クイックソートの実行 int end = clock(); double processing_time = (double)(end - start) / CLOCKS_PER_SEC; printf("%f\n", processing_time); // 処理時間を出力 return 0; }5-3-2. Java
QuickSortTest.javaimport java.util.Random; import java.math.BigDecimal; public class QuickSortTest { public static void main(String[] args) { int n = 100000; int nums[] = new int[n]; Random rand = new Random(); for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); long start = System.nanoTime(); // スタート時間を記録 QuickSort(nums, 0, n - 1); // クイックソートの実行 double processing_time = (System.nanoTime() - start) / Math.pow(10, 9); System.out.println(BigDecimal.valueOf(processing_time).toPlainString()); // 処理時間を出力 } public static void QuickSort(int nums[], int s, int e) { // 中略 } }5-3-3. VBA
Sub SortSpeed() Dim n As Long: n = 100000 Dim nums() As Long Call CreateArray(nums, n) '配列を作成 Dim startTime As Double: startTime = Timer 'スタート時間を記録 Call QuickSort(nums, 0, UBound(nums)) 'クイックソート Dim processingTime As Double: processingTime = Timer - startTime Debug.Print processingTime End Sub5-3-4. Python
QuickSort.pyimport random import time # timeモジュールをインポート # クイックソート def quick_sort(nums, s ,e): # 中略 # クイックソートの実行 n = 100000 nums = [random.randint(0, n - 1) for i in range(n)] start = time.time() # スタート時間を記録 quick_sort(nums, 0, n - 1) # クイックソート processing_time = time.time() - start print(processing_time) # 処理時間を出力さいごに
図表に時間を取られて途中で先が見えなくなりましたが、何とか最後まで書けたので、まあ良しとします。
Pythonは使いこなせると便利だろうと思いますので、もう少し学習を進めていきたいところです。


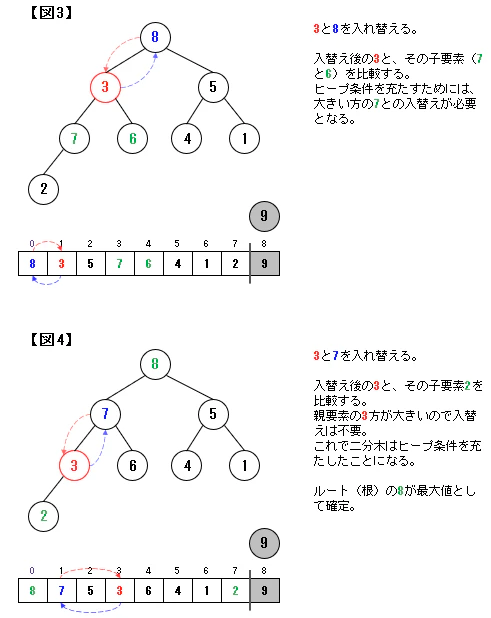
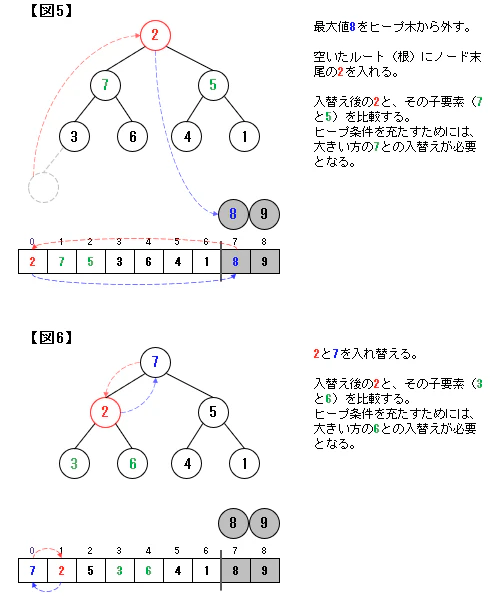
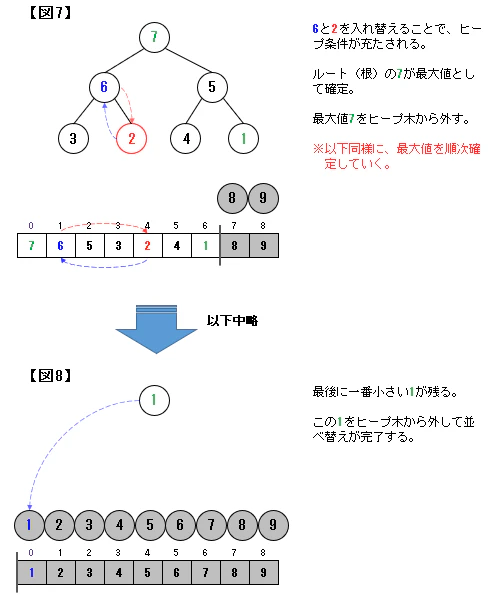

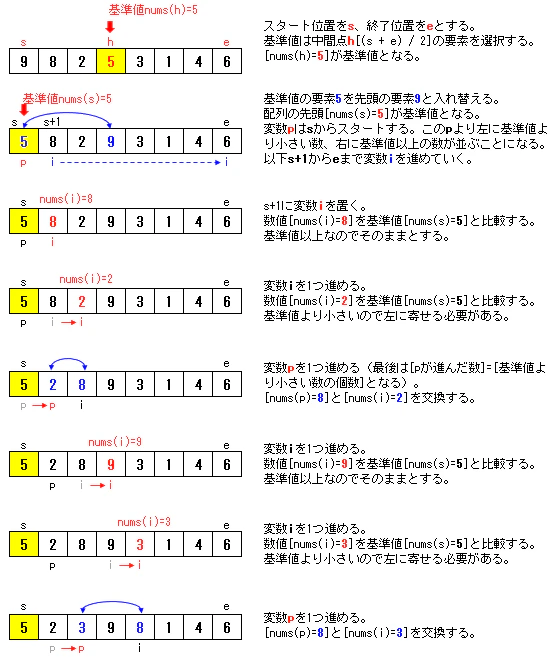
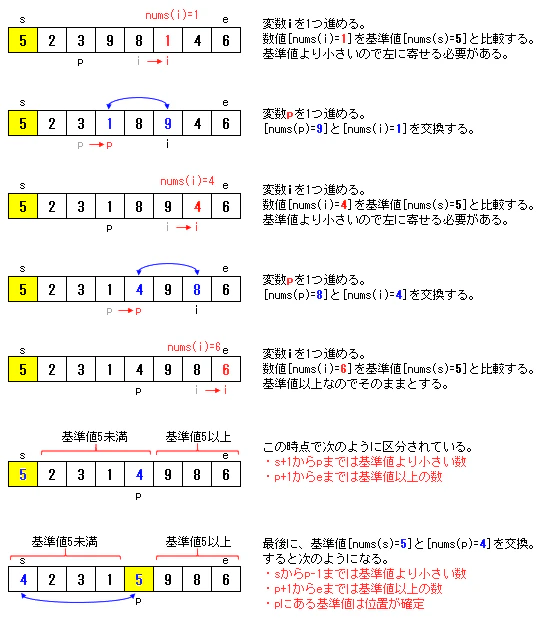
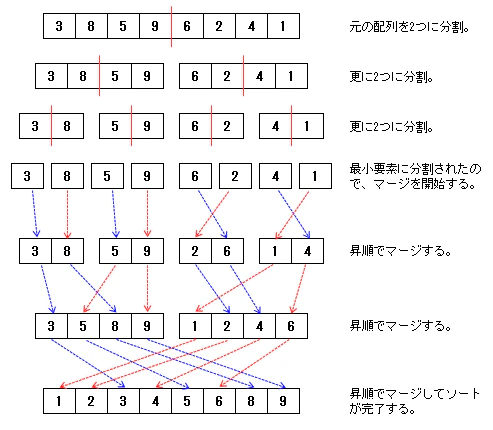

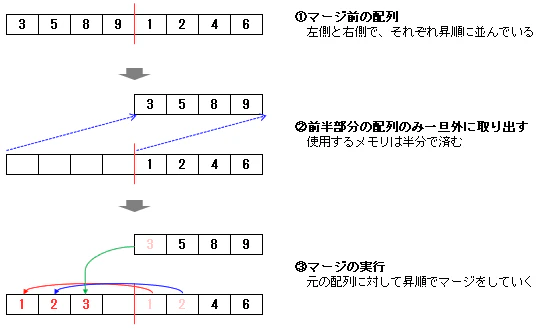
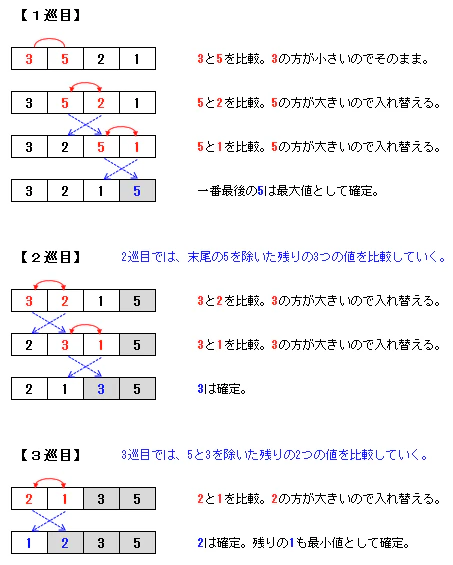
- 投稿日:2020-12-12T18:38:51+09:00
プログラミング言語におけるエラー処理の変容:値から多相まで
言いたいこと
- 例外処理の答えは,多値でもなく多態でもなく多相だった
- 現状,エラー処理をするなら多相型と match 文を持った言語が良さげ
- Rust はいいぞ!!
値 多値 多態 多相 エラー処理用の型 int, char tuple Exception Result, Either エラー処理用の文 if, switch if,switch try catch match パラダイム 手続 手続 オブジェクト指向 関数指向 代表言語 C 言語 Go C++, Python Rust, Haskell 背景
エラーが発生して頻繁に異常終了してしまうプログラムは,なるべく作りたくないものです.
しかし,作られたサービスの該当箇所でどのようなエラーが発生しうるのかを完全に把握するのは,
もはや人間の仕事ではなく,コンピュータの仕事のように思えます.発生した例外に対して,どのような対処をすべきかだけをプログラマーは取り扱いたいものです.
さて,人々はどのようにエラー処理を行なってきたのでしょうか?
今の技術で,漏れなくエラーをコンピュータに捉えさせることは可能なのでしょうか?今日は,プログラミング言語のエラー処理の変容に対する私個人の認識をまとめてみました.
補足や修正,良い参考情報などがあったら教えてください.エラーが発生したときにやること
最初に,この記事でのエラーとは発生しうる異常のことを想定しています.
発生し得ない異常の場合には assert や unreachable などを用いるべきです.
(後者は開発やテスト時にしか有効にならないので,リリース製品の性能を落とすこともありません)また重要な点ですが,エラーを不必要に潰し,無視してはいけません.
エラーは恐れるものではなく,不具合の原因に対するヒントを与えてくれる強力な助っ人です.
品質の高いソフトウェアを作りたいのなら,不具合対応の時間を減らしたいのなら,
物臭にならずにエラーと向き合いましょう.それでは,発生したエラーに対して行うべき操作の種類から考えてみましょう.
行うべき操作は下記であると考えられます.自分が呼んだ関数がエラーを伝えてきた場合
やるべきことは 3 種類です.
- エラーの内容を受け取り,対処をする(リクエストの再送信や,デフォルト値の代入など)
- 自分以外の人が解決してくれることを期待し,呼び出した側にエラーを伝える(raise など)
- 誰も解決できないと悟り,プログラムを終了する(exit,abort など)
自分がエラーを発生させた場合
やるべきことは 2 種類です.
先程と違い,1. がありません.
自分が発生させた異常に自分で対応できる場合,それはエラーには至らないからです.
(連想配列に要素が入っていなかった場合に,初期値を代入することなど)使い分けの方針
ここでは,上で上げた 3 種類の対処方法をそれぞれ回復,例外,異常終了と呼びます.
まず,可能であれば常にエラーを処理し正常への回復を試みます.
それができない場合,例外と異常終了のどちらかを使い分ける必要がありますが,
これは何を作っているかによって変わります.例えば,ライブラリ製作者の場合は常にエラーを例外として上流に伝えるべきです.
エラーが発生した時の振る舞いをどのようにしたいかはライブラリ製作者ではなく,
ライブラリ使用者が決めるべき事柄だからです.一方,自作アプリの場合,プログラムを異常終了させても構いません.
なぜなら発生したエラーが誰も対応できないことはアプリの製作者である自分にはわかるためです.
呼び出し側に通知する必要がありません.実際のコーティングでは異常終了と例外の境界線は曖昧になりがちになり,判断が難しいものです.
しかし,現状は例外に統一したほうが良いという考え方が強いようです.
これはエラーが発生した場所と,エラーに対処すべき場所を分離できる例外の方が,
異常終了よりもデバックやシステムの変更などに対応しやすいからでしょう.
(例えばシステムの仕様が変わり,例外が正常回復可能になった時の修正は,
例外の方が容易になります)あまりにも明確なエラー(メモリの枯渇など)以外は,例外として処理すべきでしょう.
ここで問題となるのは例外の処理方法です.
他の 2 つと異なり,呼び出し側にエラーを伝える例外は,自分の関数の外にまで問題が波及します.
そのため,例外を処理するためのいくつかのアプローチが生まれました.本記事では,この呼び出し側にエラーを伝える例外処理の方法に限って説明していきます.
値による解決(手続き型的なアプローチ)
原始的な解決は,C 言語のように関数の戻り値や参照引数にエラーを格納することです.
関数の実行後に値を確認し,エラーであればエラー処理を行います.int get_some_error(); int err = get_some_error(); if (err) { /* エラー処理 */ }問題点と対策
失敗を見落とす
値をチェックせず無視することが容易です.
エラーを確認していないことをコンパイラは検出して教えてくれません.int get_some_error(); get_some_error(); // エラー情報を受け取り忘れた /* エラー処理も忘れた */そのため,うっかりエラー処理を忘れてしまうことが多いです.
さらに悪い場合,エラー値が返ってくることすら気づかないパターンがあります.
(printf がエラーを戻り値で返すことを知っている人は多くないでしょう)
エラーの存在に気づかないことが深刻なバグに繋がることは想像に固くありません.これを解決するには,プログラマがエラー値を返す関数を完全に把握し,
確実にコードにエラー処理を反映することが必要です.
「確実に反映」なんて言葉,できないと言っているようなものです.戻り値が生値
エラーを構造体で返してくれると嬉しいのですが,この手のものは整数であることが多いです.
エラー番号 298 とかが返ってきます.エラーの意味はどこかにある分厚いドキュメントを調べて,
人力でマッピングしなければわかりません.値はエラー意味を直接表していないため,常に戻り値を意識しなければなりません.
例えば,成功なら 0 を返す関数があります(悲しいことに,そうじゃない関数もあります).
しかし,C 言語の if 文は 0 以外を true と認識するので,次の非直感的なコードが作成されます.int get_some_error(); int err = get_some_error(); // 成功なら 0 を返す; if (!err) { /* errを否定したが,驚くべきことに,ここはエラー処理のブロックなのだ */ }直感的でないので,より明示的に書きましょう.
int get_some_error(); const int SUCCESS = 0; int err = get_some_error(); if (err != SUCCESS) { /* エラー処理 */ }判定値を変数名で包むことで,処理内容を明確にできます.
(変数名を err ではなく,result とするのも有りですが関数のドキュメントに反しないように注意です)発生する例外に漏れなく対処できているか不明
本記事の主要な関心になりますが,関数から発生しうるエラーの種類をコンパイラは把握できません.
エラー処理分岐は, switch 文で行われますが,その際には必ず漏れがあった場合を考慮して,
最後に漏れた場合の対処を記述します.int err = get_some_error(); switch (err) { case SUCCESS: /* 正常処理 */ break; case SOME_ERROR: /* 例外処理 */ break; case OTHER_ERROR: /* 他の例外処理 */ break; // ... default: // 指定した例外に漏れがあった場合. // これを入れないと深刻なエラーに気づかない場合がある exit(1); }本当は,エラーの定義を確実に反映していれば default は不要ですが,コードが成長するにつれて,
「定義を追加したのにエラー処理側では対処方法を書き忘れていた」という状況が容易に発生します.コンピュータは,処理漏れを教えてはくれません.人で抑える必要があります.
正常値と異常値を戻り値で返せない
昔のプログラミング言語は,引数を複数取れても,戻り値を複数取ることができませんでした.
しかし,例外は正常な結果とは異なる種類の情報のため,2 種類の値を返さなくてはなりません.C 言語でよく行われる方法は,引数に可変ポインタとしてエラー情報などを含めることです.
int get_some_value(int *err); const int SUCCESS = 0; int err; int result = get_some_error(&err); if (err != SUCCESS) { /* エラー処理 */ }もしくは,正常な結果とエラー情報を含む構造体を定義して返してもいいでしょう.
typedef struct { int value; int err; } result_t; result_t get_some_value(); const int SUCCESS = 0; result_t result = get_some_error(&err); if (result.err != SUCCESS) { /* エラー処理 */ }構造体を返す方法は美しいですが,エラーを返しうる関数全てに独自の構造体を定義するのは,
開発コストに見合いません.上手く抽象化して共通の構造体を使い回すなどの工夫が必要です.多値による解決(手続き的なアプローチ)
Go 言語は 正常な結果とエラーを構造体に包む方法を,C 言語より簡便な方法で提供しています.
タプルによって正常な結果とエラーのペアを返しているのです.func get_some() (string, error) { return "Success", errors.New("Failure") } val, err := get_some() if err != nil { // エラー処理 }この方法は tuple という無名構造体を都度コンパイラが自動生成し,
型推論でユーザが意識しないように処理するという,現代的な Go 言語の方法と見ることができます.エラー情報を文字列として扱ってる点も評価が高いです.
問題点と対策
ただのタプルか,エラーを情報のためのタプルか区別しづらい
エラーが発生しても問題ない場合は,明示的にエラーを無視することができます.
先程の例では次のように書けば良いのです.func get_some() (string, error) { return "", errors.New("Failure") } val, _ := get_some() // 意図的にエラーを無視これの問題点は,関数が複数の値を戻し,最初の値だけが欲しかった場合と区別がつかないことです.
func get_some() (int, int) { return 1, 2 } val, _ := get_some() // 意図的にエラーを無視したのか?正常な値を無視したのか?関数の定義を見にいけば良いのですが,パッと見た時にエラー処理かの推測は難しいでしょう.
(ちなみに_ではなくerrと書いてエラー処理しなかった場合,
未使用変数としてコンパイラから警告が出ます.素晴らしい)
if err != nilが大量発生する例外を受け取ったものの自分では解決できない場合,さらに上流に例外を送ることが多いです.
これを例外の再送出と言います.
その場合,色々な場所で次のようなコードが散見されるようになります.val, err := get_some() if err != nil { return err }これは本当に見たい正常系の処理が見づらくなる危険性があります.
回避は難しいでしょう.多態による解決(オブジェクト指向的なアプローチ)
オブジェクト指向言語で多く用いられる方法です.
例外が発生したら raise し,try 文で補足します.def get_some(): raise SomeError # 例外の送出 try: # 例外の補足 value = get_some() except SomeError: # エラー処理これは関数の正常なやりとり(引数,戻り値)の経路に加え,
raise されてから try で補足されるまでの 2 つ目の処理経路を獲得したことになります.この 2 つ目のフローのことを大域脱出といいます.
これによりエラー処理すべきところだけ処理を書けば良いため,
Go 言語で問題に上がったif err != nilの大量発生は防げます.
なぜ 2 つのフローを持つようになったのでしょうか?
個人的な見解としては,クラスの継承関係と例外処理の相性の悪さが原因だと考えています.正常処理の戻りクラスと,異常処理の戻りクラスは別物なので,継承関係での表現が難しくなります.
そのため,一つのクラスを戻り値とする場合, Object 型のような抽象的すぎる型になります.
これでは void ポインタの再来です.クラスを用いる恩恵を得られません.
2 つの処理経路はこの問題に対する解決方法として編み出されたのではないでしょうか?問題点と対策
関数が発生させる例外の種類がわからない
関数の定義を見ても,どのような例外が返ってくるのか知る術はありません.
(Python を例にしてしまったので,ここだけ型付で書きます)def get_some() -> int: # エラーが発生する何らかの処理.この対策として,関数が送出する例外の種類を関数定義部分で宣言し,
try 文で全例外を捉えているかコンパイラが検査する「検査例外」というアプローチがありました.
残念ながらコンパイラが検知してくれるとは言え,下記のような理由から受け入れられませんでした.
- 変化点が発生した場合,人力で全ての関数の定義箇所を修正するのは変更コストが大きすぎた
- Java などは後付けで導入したため,既存のエラーのクラス系統にマッチしなかった
- エラーの抽象化への理解が進んでいない時期に導入してしまった
比較的新しい言語である swift でも 検査例外に対する取り組み が見られますが,
関数宣言時に型を示すことはしないようです.
swift を触ったことはないですが,検査例外に取り組んでいる言語として今後も頑張って欲しいです.また C++は 最適化のため,逆に例外を投げないことを示す noexcept という形で残った ため,
失敗したという経験以上の成果はあったとみるべきでしょうエラー処理に漏れがあった場合,暗黙的に再送出する
try 文は補足しなかった例外は全て自身を呼び出した側へ暗黙的に再送出します.
try: value = get_some() except SomeError: # SomeErrorだった場合のエラー処理.Other処理かどうかよりも先に評価される except OtherError: # OtherErrorだった場合のエラー処理 # 以下は暗黙的な処理.一致する例外がない場合,何も書かなくても例外は再送出される # except Exception as e: # raise eこれは,記述量を減らせる便利な機能とも言えますが,
記述した例外処理で全ての要因を抑え込めているのかを理解しにくくする欠点も持ちます.対策として,先程述べた検査例外がありますが, 上で述べたように上手くいかなかったようです.
大域脱出が例外処理に内包されている
try 文による大域脱出は非常に便利であったため,例外以外の処理に対しても使用されました.
下記の Python によるイテレータの記述を見てください.# for文を使うと for i in range(3): print(i) # Iteratorを直接用いると it = iter(range(3)) next(it) # 0 next(it) # 1 next(it) # 2 try: next(it) # なぜか例外が発生する except StopIteration: pass # 悪いことはしてないので何もしない通常の手続きにも関わらず,例外処理をしています.
これは直感に反する記述ですが,言語の選択であり,回避できません.多相による解決(関数指向的なアプローチ)
最後に紹介するのは異なる 2 つの型のいずれかを返し,match 文で判断するアプローチです.
条件分岐の中で,どの型に対する処理かがわかるため,例外処理である事が非常に明確です.
fn get_some() -> Result<int, SomeError> { // do something } match get_some { Ok(value) => // some doing Err(err) => // error handling }try 文と構成が近いことに気づいたでしょうか.
try 文は例外処理の中に大域脱出が含まれていましたが,match 文は大域脱出の一部として例外処理が含まれています.例えば,Rust におけるイテレータの処理は次の通りです.
iterator.rs// for式を使うと for i in 0..3 { println!("{}", i); }; // Iteratorを直接用いると let mut it = 0..3; it.next() // Some(0) it.next() // Some(1) it.next() // Some(2) it.next() // None. 例外じゃない素晴らしい!!try 文と match 文の類似性を確認するために,下記の 2 つを比べてみるといいかもしれません.
Python の try 文の場合:
a = list(range(3)) try: value = a[5] except IndexError: pass except Exception as e: # 明示していないもの以外.これは書かなくても暗黙的に実行される raise eRust の match 文の場合:
let a = [0;3]; let value = match a.get(5) { Some(v) => v, None => (), _ => () // 明示していないもの以外.コンパイラはSomeとNoneの2種類しかないと知っているため意味がない };Rust では例外でない大域脱出は Option が用いられます.
大域脱出を例外より上位の機構とすることで,多態のアプローチを改善しています.そして重要なことですが,match 文はパターンが網羅されていない場合に警告されます.
また, match 文の中で Err を扱うことが明示されるためエラー処理が明確になり,
エラー型の種類を見れば,再送出される例外の種類を調べることができます.また,Rust に限りますが,例外の再送出は
?オペレータを使えば行えます.
多値ようなif err != nilの大量発生も生じません.fn get_value() -> Result<int, SomeError>{ // 何らかの処理 } fn notice_err() -> Result<_, SomeError>{ let value = get_some()?; // ?で例外を呼び出し側に伝搬できる }問題点と対策
例外(の抽象性)を意識しなければならない
利点と相反しますが,送出する例外の型を意識する必要があります.
例えば,一つのフローの中に 2 種類の例外送出の可能性があった場合,
それらを包含したエラー型を定義しなければなりません.enum AnyError { SomeError, OtherError } fn get_some() -> Result<int, SomeError> { // 何らかの処理 } fn get_other() -> Result<String, OtherError> { // 何らかの処理 } fn do_something() -> Result<_, AnyError> { let some = get_some()?; let other = get_other()?; // 何らかの処理 }これは,値による解決で構造体の戻り値による解決を図った場合,
構造体を都度定義しなければならなかった問題と似ています.特にエラーの型が(エラーの中に他のエラー型が定義されているような)複雑な場合,
どのようにエラーを扱うかについては明確な回答が出ていないように感じます.タプルで見られたような,発生するエラー型をコンパイラが自動推論するアプローチが必要なのです.
この問題は,例外というものが発生と処理の段階では具体的な型であって欲しいが,
その途中経路においては抽象的であって欲しいという我が儘な要求から来ていると思われます.Rust は未発達の言語であり.公式のエラー周りの処理は今も改善が進んでいます.
(今人気のanyhowは途中経過の抽象化を試みていますが,
代わりに match 文を使えなくしてしまっているため,好きではありません.
抽象化はあくまで静的な問題のままに行われるべきです)今後の改善に期待されます.
まとめ
多値でもなく多態でもなく多相だった
ここまでの,異なるプログラミング言語における複数のアプローチをまとめると下記になります.
- 値(多値)による方法
- 多値型(Tuple)と if 文(もしくは switch 文)による解決.
- 手続き言語的なアプローチ(C 言語,Go 言語, ...)
- 多態による方法
- 継承型(Base & Drived)と try 文による解決.
- オブジェクト指向言語的なアプローチ(C++, Python, ...)
- 多相による方法
- 多相型(Result や Either)と match 文による解決.
- 関数言語的なアプローチ(Rust, Haskell, ...)
そもそも正常なフローと例外フローは別物であり継承関係をもちません.
正常フローと例外フローを含んだ戻り値のいずれかを型で表現するなら,多相が正しかったのです.例外処理と文との密接な関係
上のまとめを見れば,例外処理は文と密接な関係にあることがわかります.
現状,多相の例外処理は例外の漏れを自動検出するのに最も優れた方法であるように思えますが,
文と密接に関連しているが故に,過去の言語は移行が困難であるでしょう.Result のような型を作ることは C++ や Python でも可能です.
問題はエラー処理として,既存の try 文がすでに言語に埋め込まれている点です.
もし,Python が match 文を持っていれば,次のようなプログラミングができるでしょう.class Ok(Generic[T]): value: T Result = Union[Ok[T], E] def get_value() -> Result[int, Exception]: a = list(range(3)) match a[5]: case Ok as ok: return ok.value case IndexError: return 0 case Exception as e: return eしかし,Python には既に try 文による例外機構があります,
2 つの例外機構を抱えるデメリットは大きく,match 文への部分的な移行はベストとは言えません.新しい言語が必要なのです.最近新しいプログラミング言語の開発が活発な気がしますが,
それは関数型プログラミング言語のアイデアを踏まえた,
既存の仕組みに依存しない言語が必要と考える設計者が増えたからかもしれません.
これは静的言語であるか動的言語であるかという問題ではありません.文法の問題です.今主流の言語は,多相の例外処理機構を持つ新しい言語に敗れてしまうかもしれないし,
上手く多相を取り込むか,多態を維持した別の優れた回答を用意するかもしれません.楽しい時代に生まれたものです.
参考文献
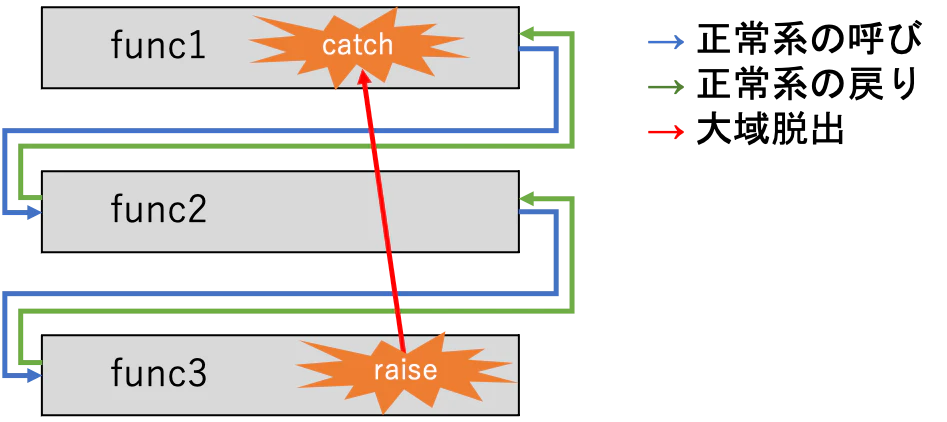
- 投稿日:2020-12-12T18:36:59+09:00
Facebook Messenger API + Flask 備忘録 [0. 導入編]
Facebook Graph API の一部である Facebook Messenger Platform の使い方メモ
- FBアプリを作り、自分が admin になっている FBページに紐付けて、様々なメッセージ送信が可能
- 直接POSTリクエストでも送信できるが、Webhook 機能があるので、PHP や Flask などの別サーバーにおいたプログラムとリンクして高度な処理が可能
- 予め Facebook for Developers で登録した admin, developer, tester しか使えない。また、友達でない人のアプリへの追加は不可。一般公開して誰もが使えるようにするためには、Review 申請をして審査に通る必要あり。
- Flask アプリは Heroku (USAリージョン) と AWS EC2 (シンガポールリージョン) において試してみたが、AWS の方がレスポンスが速い。
- NLP機能もあるが、日本語・タイ語などは未対応 (2020-12)
初期設定
https://developers.facebook.com/apps/ から
Create Appでアプリを作成What do you need your app to do? は Manage Business Integrations を選んだが、Something Else でも良さそう
App Display Name を入れて、
Create App
Add Products がたくさん出てくるが、とりあえず Messenger だけ選んで追加
真ん中あたりの Access Tokens で、連携するFacebookページを追加。Add or Remove Pages で
自分が admin のページ一覧が出るので選択。
ページが登録されたら、右の Generate Token でアクセストークンを発行し、記録しておく。とりあえず環境変数
.envに保存。これは Facebook Graph API を通してリクエストを送る時にパラメタとして毎回必ず添付する必要がある。めっちゃ長い。
次に Webhook の設定。Callback URL は Flask アプリのコールバックプログラムがあるURLを指定、HTTP は不可なので、AWS EC2インスタンスのIPアドレスをそのまま使うことはできない(EC2のHTTPS化は別記載)。Heroku にデプロイするのなら HTTPS通信が可能。
URLは
https://.../callbackと設定した。ここに記入する Verify Token は Facebook 側からリクエストを送って返事がくるかどうかのテストをするためのものであり、なんでも良い。とりあえずtestとしておき、.envにVERIFY_TOKEN=testと保存したが、個人用ならそのままプログラム内にハードコーディングしてもいいかもしれない。プログラムが正常なら、Verify and Save できる。
ここで、Flask 側のプログラムは以下。このテスト用のリクエストは GET メソッドである。実際のコールバック関数となる
'POST'の部分は後で追記。import os from flask import Flask, request from dotenv import load_dotenv load_dotenv() # 環境変数ファイル .env の読み込み VERIFY_TOKEN = os.getenv('VERIFY_TOKEN') @app.route('/callback', methods=['GET', 'POST']) def receive_message(): if request.args.get("hub.verify_token") == VERIFY_TOKEN: return request.args.get("hub.challenge") else: return 'ちがうよ'リクエストにどんなパラメータがあるかは、ここを参照。
要するに、送られてきた
hub.verify_tokenの値をチェックし、同じならばhub.challengeの値を返しているだけ。ブラウザのURLバーに
https://.../callback?hub.verify_token=test&hub.challenge=SUCCESSと入力して SUCCESS と表示されればOK
Webhook の登録が完了したら、今度は Add Subscription で使う API のタイプを選択。多すぎて違いがわからないが、とりあえず messages, message_deliveries, messaging_postbacks を選ぶ。必要ならば後でいくらでも追加できる。
この後自分が管理しているFBページにいき、Page Settings > Advanced Messaging > Connected Apps のところに登録したアプリがあればOK。
返信用の Python プログラム実装は次回。





- 投稿日:2020-12-12T18:36:59+09:00
Facebook Messenger API + Flask 備忘録 [導入編]
Facebook Graph API の一部である Facebook Messenger Platform の使い方メモ
- FBアプリを作り、自分が admin になっている FBページに紐付けて、様々なメッセージ送信が可能
- 直接POSTリクエストでも送信できるが、Webhook 機能があるので、PHP や Flask などの別サーバーにおいたプログラムとリンクして高度な処理が可能
- 予め Facebook for Developers で登録した admin, developer, tester しか使えない。また、友達でない人のアプリへの追加は不可。一般公開して誰もが使えるようにするためには、Review 申請をして審査に通る必要あり。
- Flask アプリは Heroku (USAリージョン) と AWS EC2 (シンガポールリージョン) において試してみたが、AWS の方がレスポンスが速い。
- NLP機能もあるが、日本語・タイ語などは未対応 (2020-12)
初期設定
https://developers.facebook.com/apps/ から
Create Appでアプリを作成What do you need your app to do? は Manage Business Integrations を選んだが、Something Else でも良さそう
App Display Name を入れて、
Create App
Add Products がたくさん出てくるが、とりあえず Messenger だけ選んで追加
真ん中あたりの Access Tokens で、連携するFacebookページを追加。Add or Remove Pages で
自分が admin のページ一覧が出るので選択。
ページが登録されたら、右の Generate Token でアクセストークンを発行し、記録しておく。とりあえず環境変数
.envに保存。これは Facebook Graph API を通してリクエストを送る時にパラメタとして毎回必ず添付する必要がある。めっちゃ長い。
次に Webhook の設定。Callback URL は Flask アプリのコールバックプログラムがあるURLを指定、HTTP は不可なので、AWS EC2インスタンスのIPアドレスをそのまま使うことはできない(EC2のHTTPS化は別記載)。Heroku にデプロイするのなら HTTPS通信が可能。
URLは
https://.../callbackと設定した。ここに記入する Verify Token は Facebook 側からリクエストを送って返事がくるかどうかのテストをするためのものであり、なんでも良い。とりあえずtestとしておき、.envにVERIFY_TOKEN=testと保存したが、個人用ならそのままプログラム内にハードコーディングしてもいいかもしれない。プログラムが正常なら、Verify and Save できる。
ここで、Flask 側のプログラムは以下。このテスト用のリクエストは GET メソッドである。実際のコールバック関数となる
'POST'の部分は後で追記。import os from flask import Flask, request from dotenv import load_dotenv load_dotenv() # 環境変数ファイル .env の読み込み VERIFY_TOKEN = os.getenv('VERIFY_TOKEN') @app.route('/callback', methods=['GET', 'POST']) def receive_message(): if request.args.get("hub.verify_token") == VERIFY_TOKEN: return request.args.get("hub.challenge") else: return 'ちがうよ'リクエストにどんなパラメータがあるかは、ここを参照。
要するに、送られてきた
hub.verify_tokenの値をチェックし、同じならばhub.challengeの値を返しているだけ。ブラウザのURLバーに
https://.../callback?hub.verify_token=test&hub.challenge=SUCCESSと入力して SUCCESS と表示されればOK
Webhook の登録が完了したら、今度は Add Subscription で使う API のタイプを選択。多すぎて違いがわからない (ここを参照) が、とりあえず messages, message_deliveries, messaging_postbacks を選ぶ。必要ならば後でいくらでも追加できる。
この後自分が管理しているFBページにいき、Page Settings > Advanced Messaging > Connected Apps のところに登録したアプリがあればOK。
返信用の Python プログラム実装は次回
- 投稿日:2020-12-12T18:14:39+09:00
Elastic APM on Elastic Cloud on Azure による Python アプリケーションの計測と可視化
このコンテンツの射程
皆様こんにちは!Elastic PMM/Eva の鈴木章太郎です。
※ MS マーケの ◯◯ さん(元同僚でこのアドベントカレンダーのオーナー)、投稿が遅くなり申し訳ないです!今回は、Python アプリケーションの APM (Application Performance Management) データを、Elastic Cloud ( =ESS, Elasticsearch Searvice) on Azure で収集する方法について、ご紹介していきます。レベル的には200くらいです。
Elastic Stack について
まずは、Elastic Stack ご存じない方のために、この辺りは毎回セッションでご紹介していますが改めて。
Elasticsearch は、超高速な OSS の検索エンジンで、どこにでもデプロイができ、様々なパブリッククラウド上でも稼働します。
データは様々なソースから Beats(GO 言語で書かれている軽量データシッパー)や、 Logstash(データを加工したりエンリッチ可能な ETL ツール)で取得し、Kibana で Elasticsearch 上のデータを可視化、管理、アプリを開発などが行えます。
この 3 層を Elastic Stack と呼ぶのですが、これはローカルで Elastic の Web サイトから、バイナリを落としていただいて実行していただくことでも可能ですし、Elastic Cloud のような AWS/Azure/GCP で稼働する SaaS、Elastic Cloud Enteprise (クラウドおよびオンプレの IaaS)、Elastic Cloud on Kubernetes (クラウドおよびオンプレの Kubernetes)で実行することも可能です。おすすめは、Elastic Cloud ですね。Elastic Cloud on Azure デプロイ
おすすめのデプロイメントオプションとしての Elastic Cloud = ESS(Elasticsearch service) の Azure へのデプロイ手段として、一つは、Elastic のサイトからデプロイしていただく方法があります。無料トライアル(2週間)のボタンから開始してください。
そしてもう一つが、Azure (AWS/GCPも同様) Marketplace からデプロイしていただく方法です。
こちらも簡単で、メモリ容量、ディスク容量、ノード数、リージョン、などなど決めてデプロイすると、数分でインスタンスが立ち上がり、使えるようになります(もちろん後から変更できます)。是非お試しください。
この辺りはこちらに詳しく書かれていますので、ご参照ください。デプロイ終了時の注意点
必ず、この認証情報をとっておいてください。ユーザー ID は Elastic で固定ですが、パスワードはその時発行されます。.csv で保存しましょう。
デプロイが終了して、Elastic Cloud にログインしたところです。僕は GCP 1つ、Azure 1つ、それぞれデプロイしてあります。
そしてこれらの情報も必要となるので、必要に応じてコピペして使ってください。
Elasticsearch のエンドポイントと、APM のエンドポイント、そして Cloud ID ですね。
今回は、APM エンドポイントと、シークレットトークンが必要となります。それぞれのリンクで取得しておきましょう。
Elastic Observability
さてここから少し Observability の話をさせてください。システムやアプリの監視と言う意味での、Elastic オブザーバビリティの目標は、単一のオープンスタックでエコシステム全体のエンドツーエンドの可視性を提供し、費用があまりかからない価格モデルで、これらの課題に対処することです。
これにより、何かインシデントが発生した際に MTTR (最小復旧期間) を限りなくゼロを近づけることができるようにすることです。
それは顧客に対して、最も優れた、信頼性の高い、パフォーマンスの高い体験を提供する全てのサービスが対象です。昨今のソフトウェアの開発モデルとか、デプロイのモデル、デリバリーのモデルは、常に進化しています。
どんどんダイナミックなものになっています。いろいろ複雑になってきていますけれども、これが意味するところとしてはこんな感じですよね。
2015年のちょっと古いデータですが、これはある調査で、米エリアを中心とする様々な企業のうち65%の組織が、自社のシステムを監視するのに、10 種類以上のツールを使っているという報告です。イメージ的にはこんな感じですね。
結局こんな感じで監視とオブザーバビリティの課題に取り組むことになります。これは、おそらく多くの方には馴染みのある光景でしょう。監視ツールはとてもに断片化されています。何かが壊れたとき、何が壊れたのかを把握したり、可能性を排除するために5-10の異なるツールを使用することになります。モニタールームはやかましく、非効率的です。
・ ログを見るためのツール
・ 指標、グラフ、KPIを表示する方法
・ システムの可用性を定量化するツール
・ 痕跡を相関させるツール
・ 特定の種類のデータ(ネットワーク、クラウドなど)に対応したニッチツールElastic のオブザーバビリティへのアプローチ
Elasticでは、データという最も深いレベルでの統一に焦点を当てています。
これらのデータのすべてを単一の強力なデータストアである Elasticsearch に集約しています。
データレベルでの統一は、探索と分析のすべてのレイヤーを通じた力の相乗効果を生み出す強力な単一の基盤を提供してくれます。
またライセンスも単純かつリーズナブルなモデルを採用し、データの容量のみに依存します。Application Performance Monitoring (APM)
さて、ここから本題の APM に話題を移しましょう。
ログ、APM、インフラメトリックは監視の3大要素です。3つの領域には重なり合う部分もあり、相互に関連付ける際に役立ちます。ログは、エラーが生じた痕跡を示すが、エラーの理由までは示さないでしょう。他方でメトリックはサーバー上で CPU 使用量にスパイクがあったことを示すかもしれませんが、何が原因だったかは示しません。ただし、うまく組み合わせて活用すれば、はるかに広い範囲の問題を解決できる可能性があります。
ログと APM とで得られる情報を比較してみましょう。
このようなログが取得できたとします。264.242.88.10 - - [22/Jan/2018:16:38:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253ここで APM が捉えた内容は、最終発生日時、発生頻度、アプリケーションで処理されたか否か、という情報です。
たとえば NumberParseException の箇所の例外処理の詳細を見ると、エラーが発生した回数の分布がウインドウで視覚的に表示できます。
ここでは、一定の時間に数回起きているということ、一日中発生していることがわかります。
これをログだけで見ても、ログファイルの1つに対応するスタックの痕跡が見つかるだけで、APM のようにそのコンテクストやメタデータまで見つかる可能性は高くないわけです。
そして、赤い部分はこの例外処理を実施したコード行です。そして APM が提供するメタデータが問題の正確な内容となります。
このように、プログラマーでない人間が見ても問題が正確に理解でき、チケットオープンのために必要十分な情報があるわけです。Elastic Application Performance Monitoring
今回は、Python + Django アプリが対象ですが、Elastic がサポートする言語は、Node.js、Python、Ruby、.NET、 Java、Go、Real User Monitoring(JavaScript)などで、今後、対応言語のさらなる追加も予定しています。また、Jaeger や OpenTelemetry 等各種のオープンスタンダードもサポートしています。
インストルメンテーション済みのアプリから Elastic APM へ驚くほど簡単にデータを送れます。
また必要なモジュールが見つからない場合、独自に開発することも、オープンソースコミュニティの成果物を活用することも可能です。Elastic APM の概要
Elastic APM は、エージェントをセットアップして、APM エンドポイントと、シークレットトークンを設定するだけで、すぐに Elasticsearch へのデータ送信が開始されます。
Python の場合も同様で、バージョン2.7, 3.5, 3.6, 3.7, 3.8, 3.9 に対応しています。今回僕は3.9をインストールしています。
フレームワークとしては、Django, Flask, Aiohttp server, Tornado, Starlette/FastAPIなどに対応しています。
また、モジュールとしては、Elasticsearch, SQLite, MySQL db, mysql-connector, Cassandra, 等に対応可能です。設定としてはこんなイメージです。先ほど、Elastic Cloud on Azure で取得した APM エンドポイントとシークレットトークンが必要です。
Machine Learning との連携
これは応用なのでまた別稿としたいのですが、Elastic には、APM から応答時間ベースの ML ジョブを作成する機能があります。
Visual Studio Code によるサンプルアプリの構成と実行
今回は、Form Rendering Examples をインストールします。
ブログ記事 【Django フォームを手動でレンダリングする方法】
適当なフォルダを切って、VSCode を起動し、下記のような手順で実行してみてください。git clone https://github.com/sibtc/form-rendering-examples.git pip install -r requirements.txt python manage.py migrate python manage.py runserverAPM Python Agent のインストール
Agent 側の操作なのでアプリケーション側にて修正します。
今回は Django の処理をモニタリングするため、Python 向けの APM Agent を利用します。
pip コマンドでインストールするだけです。pip install elastic-apmAPM Python Agent の構成 (Django)
settings.py を開いて、INSTALLED_APPS と MIDDLEWARE に所定の値、
そして APM エンドポイントとシークレットトークンを設定します。これだけで完了です。# Add the agent to the installed apps INSTALLED_APPS = ( 'elasticapm.contrib.django', # ... ) ELASTIC_APM = { # Set required service name. Allowed characters: # a-z, A-Z, 0-9, -, _, and space ‘SERVICE_NAME’: ‘(一意)', ← 任意の名前(例えば WEBINAR) # Use if APM Server requires a token ‘SECRET_TOKEN’: ‘fGVbnnhItHK0PjpFOG’, ← APM ポータルから取得 # Set custom APM Server URL (default: http://localhost:8200) ↓ APM ポータルから取得 'SERVER_URL': 'https://d4d99add430d497aaa1eba04b5175497.apm.japaneast.azure.elastic-cloud.com:443‘, } # To send performance metrics, add our tracing middleware: MIDDLEWARE = ( 'elasticapm.contrib.django.middleware.TracingMiddleware', #... )あとは Kibana ですぐにモニタリング可能です。
例えば、
・ Request Per Minute
HTTP レスポンスステータスコード単位での 1分毎のリクエスト数が表示されます。
リクエスト数が急増したことが原因でレスポンスタイムが悪化したかここで判断できます。
また
・ Transactions duration, Transaction
URL パス単位での平均、95%タイルのレスポンスタイムが表示されます。
特定のパスの処理が遅い時はここを見ればすぐにわかります。このセッションの動画について
いかがでしたでしょうか? ここまでご覧いただいたとおりで、
・ Elastic Cloud on Azure のデプロイも、
・ Python アプリへの APM 実装も、
・ Kibana によるモニタリングも、
すごく簡単ですので、是非やってみてください。この内容はこちら Elastic APM によるPython アプリケーションの計測と可視化 で公開していますので、詳細な解説を聞きたい方は是非ご覧になってください。いくつか情報を入れて戴ければ Webinar はすぐにみれます。
今月はあと来週16日の Elastic 7.10 新機能紹介 Webinar と、
26日の .NET ラボ 勉強会 2020年12月に、登壇します。
年明けも色々イベントでの登壇を予定していますので、是非ご覧いただければありがたいです。
今後ともよろしくお願いします!鈴木章太郎
Elastic テクニカルプロダクトマーケティングマネージャー
内閣官房IT総合戦略室 政府CIO補佐官






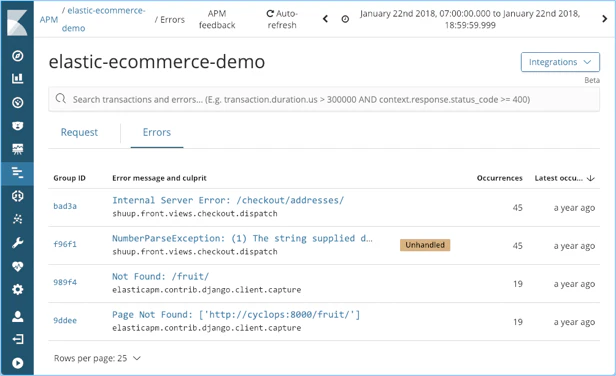

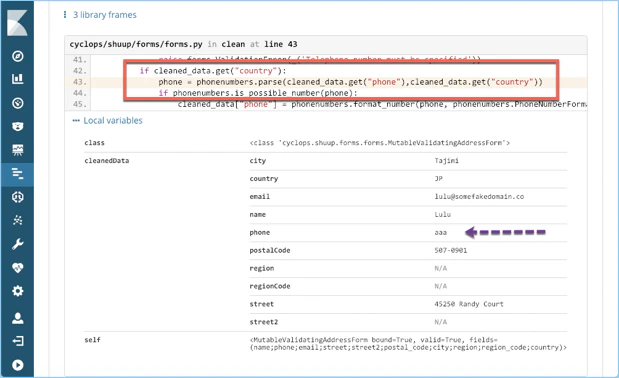

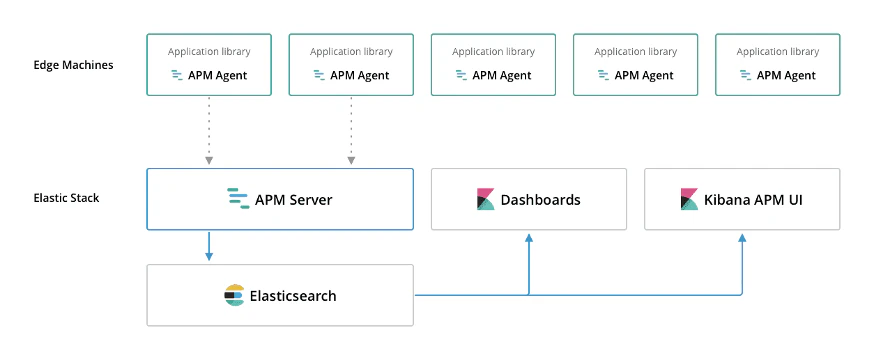

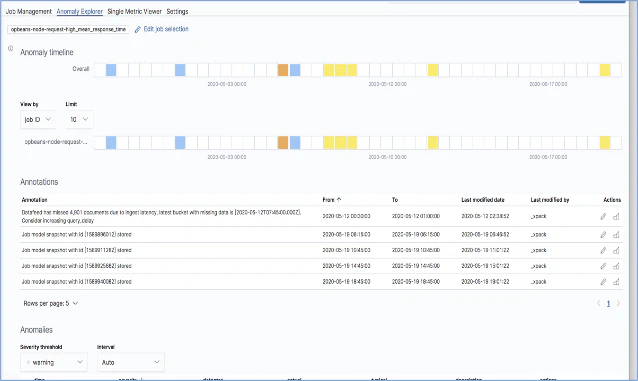
- 投稿日:2020-12-12T18:14:39+09:00
APM on Elastic Cloud on Azure による Python アプリケーションの計測と可視化
皆様こんにちは!Elastic PMM/Eva の鈴木章太郎です。
※ MS マーケの ◯◯ さん(元同僚でこのアドベントカレンダーのオーナー)、投稿が遅くなり申し訳ないです!このコンテンツの射程
今回は、Python アプリケーションの APM (Application Performance Management) データを、Elastic Cloud ( =ESS, Elasticsearch Service) on Azure で収集する方法について、ご紹介していきます。レベル的には200くらいです。
Elastic Stack について
まずは、Elastic Stack ご存じない方のために、この辺りは毎回セッションでご紹介していますが改めて。
Elasticsearch は、超高速な OSS の検索エンジンで、どこにでもデプロイができ、様々なパブリッククラウド上でも稼働します。
データは様々なソースから Beats(GO 言語で書かれている軽量データシッパー)や、 Logstash(データを加工したりエンリッチ可能な ETL ツール)で取得し、Kibana で Elasticsearch 上のデータを可視化、管理、アプリを開発などが行えます。
この 3 層を Elastic Stack と呼ぶのですが、これはローカルで Elastic の Web サイトから、バイナリを落としていただいて実行していただくことでも可能ですし、Elastic Cloud のような AWS/Azure/GCP で稼働する SaaS、Elastic Cloud Enteprise (クラウドおよびオンプレの IaaS)、Elastic Cloud on Kubernetes (クラウドおよびオンプレの Kubernetes)で実行することも可能です。おすすめは、Elastic Cloud ですね。Elastic Cloud on Azure デプロイ
おすすめのデプロイメントオプションとしての Elastic Cloud = ESS(Elasticsearch service) の Azure へのデプロイ手段として、一つは、Elastic のサイトからデプロイしていただく方法があります。無料トライアル(2週間)のボタンから開始してください。
そしてもう一つが、Azure (AWS/GCPも同様) Marketplace からデプロイしていただく方法です。
こちらも簡単で、メモリ容量、ディスク容量、ノード数、リージョン、などなど決めてデプロイすると、数分でインスタンスが立ち上がり、使えるようになります(もちろん後から変更できます)。是非お試しください。
この辺りはこちらに詳しく書かれていますので、ご参照ください。デプロイ終了時の注意点
必ず、この認証情報をとっておいてください。ユーザー ID は Elastic で固定ですが、パスワードはその時発行されます。.csv で保存しましょう。
デプロイが終了して、Elastic Cloud にログインしたところです。僕は GCP 1つ、Azure 1つ、それぞれデプロイしてあります。
そしてこれらの情報も必要となるので、必要に応じてコピペして使ってください。
Elasticsearch のエンドポイントと、APM のエンドポイント、そして Cloud ID ですね。
今回は、APM エンドポイントと、シークレットトークンが必要となります。それぞれのリンクで取得しておきましょう。
Elastic Observability
さてここから少し Observability の話をさせてください。システムやアプリの監視と言う意味での、Elastic オブザーバビリティの目標は、単一のオープンスタックでエコシステム全体のエンドツーエンドの可視性を提供し、費用があまりかからない価格モデルで、これらの課題に対処することです。
これにより、何かインシデントが発生した際に MTTR (最小復旧期間) を限りなくゼロを近づけることができるようにすることです。
それは顧客に対して、最も優れた、信頼性の高い、パフォーマンスの高い体験を提供する全てのサービスが対象です。昨今のソフトウェアの開発モデルとか、デプロイのモデル、デリバリーのモデルは、常に進化しています。
どんどんダイナミックなものになっています。いろいろ複雑になってきていますけれども、これが意味するところとしてはこんな感じですよね。
2015年のちょっと古いデータですが、これはある調査で、米エリアを中心とする様々な企業のうち65%の組織が、自社のシステムを監視するのに、10 種類以上のツールを使っているという報告です。イメージ的にはこんな感じですね。
結局こんな感じで監視とオブザーバビリティの課題に取り組むことになります。これは、おそらく多くの方には馴染みのある光景でしょう。監視ツールはとてもに断片化されています。何かが壊れたとき、何が壊れたのかを把握したり、可能性を排除するために5-10の異なるツールを使用することになります。モニタールームはやかましく、非効率的です。
・ ログを見るためのツール
・ 指標、グラフ、KPIを表示する方法
・ システムの可用性を定量化するツール
・ 痕跡を相関させるツール
・ 特定の種類のデータ(ネットワーク、クラウドなど)に対応したニッチツールElastic のオブザーバビリティへのアプローチ
Elasticでは、データという最も深いレベルでの統一に焦点を当てています。
これらのデータのすべてを単一の強力なデータストアである Elasticsearch に集約しています。
データレベルでの統一は、探索と分析のすべてのレイヤーを通じた力の相乗効果を生み出す強力な単一の基盤を提供してくれます。
またライセンスも単純かつリーズナブルなモデルを採用し、データの容量のみに依存します。Application Performance Monitoring (APM)
さて、ここから本題の APM に話題を移しましょう。
ログ、APM、インフラメトリックは監視の3大要素です。3つの領域には重なり合う部分もあり、相互に関連付ける際に役立ちます。ログは、エラーが生じた痕跡を示すが、エラーの理由までは示さないでしょう。他方でメトリックはサーバー上で CPU 使用量にスパイクがあったことを示すかもしれませんが、何が原因だったかは示しません。ただし、うまく組み合わせて活用すれば、はるかに広い範囲の問題を解決できる可能性があります。
ログと APM とで得られる情報を比較してみましょう。
このようなログが取得できたとします。264.242.88.10 - - [22/Jan/2018:16:38:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253ここで APM が捉えた内容は、最終発生日時、発生頻度、アプリケーションで処理されたか否か、という情報です。
たとえば NumberParseException の箇所の例外処理の詳細を見ると、エラーが発生した回数の分布がウインドウで視覚的に表示できます。
ここでは、一定の時間に数回起きているということ、一日中発生していることがわかります。
これをログだけで見ても、ログファイルの1つに対応するスタックの痕跡が見つかるだけで、APM のようにそのコンテクストやメタデータまで見つかる可能性は高くないわけです。
そして、赤い部分はこの例外処理を実施したコード行です。そして APM が提供するメタデータが問題の正確な内容となります。
このように、プログラマーでない人間が見ても問題が正確に理解でき、チケットオープンのために必要十分な情報があるわけです。Elastic Application Performance Monitoring
今回は、Python + Django アプリが対象ですが、Elastic がサポートする言語は、Node.js、Python、Ruby、.NET、 Java、Go、Real User Monitoring(JavaScript)などで、今後、対応言語のさらなる追加も予定しています。また、Jaeger や OpenTelemetry 等各種のオープンスタンダードもサポートしています。
インストール済みのアプリから Elastic APM へ驚くほど簡単にデータを送れます。
また必要なモジュールが見つからない場合、独自に開発することも、オープンソースコミュニティの成果物を活用することも可能です。Elastic APM の概要
Elastic APM は、エージェントをセットアップして、APM エンドポイントと、シークレットトークンを設定するだけで、すぐに Elasticsearch へのデータ送信が開始されます。
Python の場合も同様で、バージョン2.7, 3.5, 3.6, 3.7, 3.8, 3.9 に対応しています。今回僕は3.9をインストールしています。
フレームワークとしては、Django, Flask, Aiohttp server, Tornado, Starlette/FastAPIなどに対応しています。
また、モジュールとしては、Elasticsearch, SQLite, MySQL db, mysql-connector, Cassandra, 等に対応可能です。設定としてはこんなイメージです。先ほど、Elastic Cloud on Azure で取得した APM エンドポイントとシークレットトークンが必要です。
Machine Learning との連携
これは応用なのでまた別稿としたいのですが、Elastic には、APM から応答時間ベースの ML ジョブを作成する機能があります。
Visual Studio Code によるサンプルアプリの構成と実行
今回は、Form Rendering Examples をインストールします。
ブログ記事 【Django フォームを手動でレンダリングする方法】
適当なフォルダを切って、VSCode を起動し、下記のような手順で実行してみてください。git clone https://github.com/sibtc/form-rendering-examples.git pip install -r requirements.txt python manage.py migrate python manage.py runserverAPM Python Agent のインストール
Agent 側の操作なのでアプリケーション側にて修正します。
今回は Django の処理をモニタリングするため、Python 向けの APM Agent を利用します。
pip コマンドでインストールするだけです。pip install elastic-apmAPM Python Agent の構成 (Django)
settings.py を開いて、INSTALLED_APPS と MIDDLEWARE に所定の値、
そして APM エンドポイントとシークレットトークンを設定します。これだけで完了です。# Add the agent to the installed apps INSTALLED_APPS = ( 'elasticapm.contrib.django', # ... ) ELASTIC_APM = { # Set required service name. Allowed characters: # a-z, A-Z, 0-9, -, _, and space ‘SERVICE_NAME’: ‘(一意)', ← 任意の名前(例えば WEBINAR) # Use if APM Server requires a token ‘SECRET_TOKEN’: ‘fGVbnnhItHK0PjpFOG’, ← APM ポータルから取得 # Set custom APM Server URL (default: http://localhost:8200) ↓ APM ポータルから取得 'SERVER_URL': 'https://d4d99add430d497aaa1eba04b5175497.apm.japaneast.azure.elastic-cloud.com:443‘, } # To send performance metrics, add our tracing middleware: MIDDLEWARE = ( 'elasticapm.contrib.django.middleware.TracingMiddleware', #... )あとは Kibana ですぐにモニタリング可能です。
例えば、
・ Request Per Minute
HTTP レスポンスステータスコード単位での 1分毎のリクエスト数が表示されます。
リクエスト数が急増したことが原因でレスポンスタイムが悪化したかここで判断できます。
また
・ Transactions duration, Transaction
URL パス単位での平均、95%タイルのレスポンスタイムが表示されます。
特定のパスの処理が遅い時はここを見ればすぐにわかります。このセッションの動画について
いかがでしたでしょうか? ここまでご覧いただいたとおりで、
・ Elastic Cloud on Azure のデプロイも、
・ Python アプリへの APM 実装も、
・ Kibana によるモニタリングも、
すごく簡単ですので、是非やってみてください。実際のアプリを実行したデモを見たい方、詳細な解説を聞きたい方は、こちら Elastic APM によるPython アプリケーションの計測と可視化 で公開していますので、是非ご覧になってください。いくつか情報を入れて戴ければ Webinar はすぐにみれます。
今月はあと来週16日の Elastic 7.10 新機能紹介 Webinar と、
26日の .NET ラボ 勉強会 2020年12月に、登壇します。
年明けも色々イベントでの登壇を予定していますので、是非ご覧いただければありがたいです。
今後ともよろしくお願いします!鈴木章太郎
Elastic テクニカルプロダクトマーケティングマネージャー
内閣官房IT総合戦略室 政府CIO補佐官