- 投稿日:2020-12-12T23:59:28+09:00
Goのginとgormで簡単なWebアプリケーションを作る。
はじめに
どもです。
最近、Webアプリケーションを久しぶりに作るってなって、GoでのCRUDの書き方等を忘れたので、メモといった感じで記していきます。ルーティングとCRUDについて詳しく書いていきます。
githubに今回作成したソースコードを載せておきます
使用する環境
実際の環境
項目 使用したもの OS CentOS8 DB MySQL バックエンド Go Goで使用したパッケージ
用途 パッケージ名 ルーティング gin ORM gorm 開発環境に関しては、すでに終わっていることを仮定します。
実装する内容
今回作成するものは、元から存在するアプリケーションのユーザの管理をするアプリケーションです。
本来、gormのマイグレーションというのもできますが、今回はすでにテーブル等が作成されているものとします。
- ユーザの一覧(Select)
- ユーザの詳細(Select)
- ユーザの削除(Delete)
- ユーザの編集(Update)
といったものを実装していきます。
ディレクトリ構造
. |- handler.go //DBにCRUDする関数を書く |- main.go //GETとPOSTの処理を書く |- routing.go //ルーティングの関数を書く |- views/ |- css/ | |- main.css |- html/ | |- delete.html | |- detail.html | |- index.html | |- update.html |- js/ |- main.jsgin
ginのGoDocはこちらから
ginというのは、GoのWebフレームワークで、とりあえず早い。ライバルとしてはechoがあります。
自分的には、どっちでもいいのかなと思います。ただ、ginのほうが簡潔に書けるという印象があります実装
main.gopackage main import ( "github.com/gin-gonic/gin" ) func main() { r := gin.Default() r.LoadHTMLGlob("./views/html/*.html") r.Static("/css", "./views/css") r.GET("/", index) r.GET("/detail/:id", detail) r.GET("/delete/:id", delete) r.GET("/update/:id", update) r.POST("/do_delete/:id", do_delete) r.POST("/do_update/:id", do_update) r.Run(":80") }routing.gopackage main import ( "fmt" "net/http" "strconv" "github.com/gin-gonic/gin" ) func index(c *gin.Context) { users, err := UserGetAll() if err != nil { fmt.Println(err) c.AbortWithStatus(http.StatusInternalServerError) return } c.HTML(http.StatusOK, "index.html", gin.H{"users": users}) } ~~略~~ func do_update(c *gin.Context) { n := c.Param("id") name := c.PostForm("name") email := c.PostForm("email") id, err := strconv.Atoi(n) if err != nil { fmt.Println(err) c.AbortWithStatus(http.StatusInternalServerError) return } err = UserUpdate(id, name, email) if err != nil { fmt.Println(err) c.AbortWithStatus(http.StatusInternalServerError) return } c.Redirect(302, "/") }解説
主に使っている関数をピックアップして、紹介します。
main.go
まずはここ。main関数の
r := gin.Default()こいつで、
rってのがginパッケージ使いまっせーの宣言をする。r変数は好きにつけてぐださいr.LoadHTMLGlob("./views/html/*.html") r.Static("/css", "./views/css") r.GET("/", index) r.POST("/do_delete/:id", do_delete) r.Run(":80")
rを用いて、このような関数を呼び出してます。
LoadHTMLGlob:htmlファイルの場所の指定
Static:css等の静的ファイルの指定(jsでも同様)
GET:GETの処理(第一引数がドメイン以降のパス指定、第二引数がそのパスに対応した関数の呼び出し)
POST:POSTの処理(第一引数がドメイン以降のパス指定、第二引数がそのパスに対応した関数の呼び出し)
Run:サーバの起動(:80は80番ポートで起動してます)GETとPOSTで呼び出す関数は、次の
routing.goに書いてます。routing.go
GETとPOSTという処理があって、とりあえずGETだったらHTMLを出力してPOSTだったらリダイレクトする的なイメージがあると思います。とりあえず、各関数の引数に
c *gin.Contextとありますが、先ほどのrみたいな感じです。関数の解説
c.AbortWithStatus(http.StatusInternalServerError) c.HTML(http.StatusOK, "index.html", gin.H{"users": users}) c.Redirect(302, "/")
cを用いて、このような関数を呼び出してます。
AbortWithStatus(http.StatusInternalServerError):リクエストの認証に失敗したら、401を返す
HTML:htmlファイルを返す。(第一引数は置いておいて、第二引数はhtmlファイルの指定、第三引数はhtmlに値を渡す変数の定義)
Redirect:リダイレクトをする。(第一引数で302で返す宣言、第二引数でリダイレクト先の指定)HTMLに変数を渡す場合の処理は、
Go Templateとかで検索すると、いろいろ出てくるので、そちらをどうぞ。
main.goとrouting.goは以上。これで、ページ遷移くらいはできると思います。単にHTMLを出力するサンプルコードを載せて、次に行きます。サンプルコードpackage main import ( "github.com/gin-gonic/gin" ) func main() { r := gin.Default() r.LoadHTMLGlob("./views/html/*.html") r.GET("/", index) r.Run(":80") } func index(c *gin.Context) { c.HTML(http.StatusOK, "index.html", gin.H{}) }これで、
index.htmlは、出力するはず。(エラーだったらコメントください)gorm
gormの公式ドキュメントはこちらから
gormというのは、Go用のORMライブラリで、DB操作を簡単にできるすげーいいやつ。
公式ドキュメントが超優秀なので、ぜひ見てみてください実装
handler.gopackage main import ( "fmt" "gorm.io/driver/mysql" "gorm.io/gorm" ) type Users struct { Id int Name string Email string Password string } type Posts struct { Id int Author int Title string Content string Comments int } const connect = "root:root@tcp(127.0.0.1:3306)/laravel?charset=utf8mb4&parseTime=True&loc=Local" func UserGetAll() ([]Users, error) { db, err := gorm.Open(mysql.Open(connect), &gorm.Config{ DisableForeignKeyConstraintWhenMigrating: true, }) if err != nil { return nil, fmt.Errorf("UserGetAll失敗: %w", err) } var users []Users err = db.Select("id", "name", "email", "password").Find(&users).Error if err != nil { return nil, fmt.Errorf("UserGetAll_Select失敗: %w", err) } return users, nil } func UserGetOne(id int) (Users, error) { db, err := gorm.Open(mysql.Open(connect), &gorm.Config{ DisableForeignKeyConstraintWhenMigrating: true, }) var user Users if err != nil { return Users{}, fmt.Errorf("UserGetOne失敗: %w", err) } err = db.First(&user, id).Error if err != nil { return Users{}, fmt.Errorf("UserGetOne_First失敗: %w", err) } return user, nil } func PostGetAll(author int) ([]Posts, error) { db, err := gorm.Open(mysql.Open(connect), &gorm.Config{ DisableForeignKeyConstraintWhenMigrating: true, }) if err != nil { return nil, fmt.Errorf("PostGetAll失敗: %w", err) } var posts []Posts err = db.Where("author = ?", author).Find(&posts).Error if err != nil { return nil, fmt.Errorf("PostGetAll_Select失敗: %w", err) } return posts, nil } func UserDelete(id int) error { db, err := gorm.Open(mysql.Open(connect), &gorm.Config{ DisableForeignKeyConstraintWhenMigrating: true, }) if err != nil { return fmt.Errorf("UserDelete失敗: %w", err) } var users Users err = db.Delete(&users, id).Error if err != nil { return fmt.Errorf("UserDelete_Delete失敗: %w", err) } return nil } func UserUpdate(id int, name string, email string) error { db, err := gorm.Open(mysql.Open(connect), &gorm.Config{ DisableForeignKeyConstraintWhenMigrating: true, }) if err != nil { return fmt.Errorf("UserUpdate失敗: %w", err) } var users Users err = db.First(&users, id).Error if err != nil { return fmt.Errorf("UserUpdate_First失敗: %w", err) } users.Name = name users.Email = email db.Save(&users) return nil }解説
handler.go
各関数の最初に書かれている、
gorm.Openが最重要で、DB(MySQL)に接続する関数で、countで定義したDB情報を呼び出して使ってます。自分の関数の命名についてですが、
〇〇GetAllだと要素の全取得、〇〇GetOneだと一つだけ取得、〇〇Deleteだと削除、〇〇Updateだと更新、みたいな感じです流れとしては、
UsersやPostsのように、必要な情報を構造体として扱って処理をします。
ここでは、gormの関数が多いので、よく使うものだけピックアップします。関数の解説
First:なにか指定したものの最初にマッチした要素を取得する
Where:データの特定をするために、カラムを指定する
Find:Firstと異なり、特定の一つのデータを取得すると、公式ドキュメントにもありますが、関数とSQL文がいい具合に処理できるので、すごく便利。
自分の場合、errとしてエラーハンドリングをしつつ処理をしています。
(確かGoのすごい人からおしえてもらった書き方だった気がする…)終わり
かなり長くなってしまいましたが、これで解説は終わりです。
Goを用いたWebアプリケーション開発というのは、これからもっとはやっていくと思います。そこで、この記事が参考になることを祈ります。
疲れた…
- 投稿日:2020-12-12T23:32:42+09:00
実行計画を改善する時のプチメモ
本記事は東京学芸大学 櫨山研究室 Advent Calendar 2020の十二日目の記事になります.
初めて記事を書きます。暖かい目でご覧ください。はじめに
開発中、処理スピードや効率について考えずに「動いたらヨシ!」とすることが多かったのですが
mapper(SQL文)の修正を大幅にする機会があり、SQL文の良し悪しについて先輩に教えていただきました。
その際の教わったことや感じたことをメモに残します。
ただただSQL文を書いて、動いた〜となっている人に向けた記事です。概要
前述した通り、SQL文はただ動けばいいと思ってたのですが、
・扱うデータ量が増える
・アクセス数が増える
などでSQL文の良し悪しは運用に大きく影響するとわかりました。
逆に言えば、SQL文を改善することで処理スピードが上がったり効率がよくなったりします。この記事では、
・SQL文の実行計画を見る方法
・そのSQL文は改善余地があるか
・改善余地がある場合どう改善すべきか
を述べていきます。SQL文の実行計画
MySQLには実行計画というものがあります。
この実行計画は、自身が今作成しているSQL文の先頭に "EXPLAIN" とつけて実行するだけで見れます。
例えばSELECT * FROM user_table JOIN book_table ON user_table.id = book_table.user_id WHERE book_table.status = 1;というSQL文を調査するときは
EXPLAIN SELECT * FROM user_table JOIN purchase_table ON user_table.id = purchase_table.user_id WHERE user_table.purchase_count > 0;これをMySQL上で実行するとMySQLが以下のような表を出してくれます。
これが実行計画です。
それぞれの項目には意味があるのですが、詳しくは以下の記事を参考にしてください。
https://qiita.com/kzbandai/items/ea02727f4bb539fcedb5改善可能か?
SQL文はやりたいことが複雑になればなるほど長くなり改善ポイントも多くなります。
ただ、長くてもそのSQL文が最善である可能性もあります。
そこで、自分のSQL文が改善する余地があるのか?を知るためのポイントを紹介します。項目ごとにチェックする
type - ALLと表示されてるとよくない(全文検索になっている)
key - NULLじゃないほうがいい(クエリが絞れていない)
Extra - using file sortがでているとよくない(diskに書き込んだ後データをソートしている)単純すぎるSQLだと、クエリの指定をする必要がなかったり
複雑すぎるSQLだと、using file sortがどうしても消せなかったりなどがありますが
基本的には、この項目に当てはまるものがあれば改善は可能です。改善の仕方
indexの作成
既存の2つのテーブルの中間にもう1個テーブルを作るような感覚です。
例えば、全文検索をするにしても、indexの中で値が降順に並べられていると検索効率が良くなります。
ですが、indexはSQL文を実行するたびに見るので、作りすぎは注意です。
(indexの作成の仕方は検索してください)クエリの指定
単純に検索対象が減ります。
SQLの実行順序のなるべく先の方で指定すると、その後の処理も楽になります。これらを試し、SQL文を修正するたびにEXPLAINで実行計画を見てMySQLの負荷を減らしていきます。
終わりに
改善ポイントについても私の知らない部分があるかもしれませんが、
手始めにここをチェックすればいいのかぐらいの気持ちで捉えていただけるとありがたいです。SQL文は書きっぱなしにせず、実行計画を見てよりいいSQL文に修正していきましょう。(私も気をつけます)
拙い記事ですが、読んでいただきありがとうございました。

- 投稿日:2020-12-12T18:54:52+09:00
【MySQL】SQLチューニングまとめ
はじめに
これまで、SQLは取得できればオッケー!パフォーマンスは悪かったら考えよう
くらいのスタンスで実装してきてしまい、
現在、運用保守を任されパフォーマンスがいかに大事かを痛いほど感じました。
割と痛いです。パフォーマンスについてもっとちゃんと考えておけばよかった、、ということで
MySQLにおけるSQLチューニングについて備忘も含めてまとめました。これはトラストアドベントカレンダー12日目の記事です。
そもそもパフォーマンスが悪かったときは何をすればいいの?
チューニングの方法は大きく2つ。
1. DBチューニング(全体最適化)
スループットの向上を目的としたチューニング。
MySQLの設定ファイルやパラメータの最適化によって、パフォーマンス改善を図る。2. SQLチューニング(個別最適化)
レスポンスタイムの向上を目的としたチューニング。
テーブル構成やクエリの最適化によって、パフォーマンス改善を図る。
⇒ 大半の場合、SQLチューニングで解決することが多い。今回はこちらを紹介。SQLチューニングをやる前に
NLJ(Nested Loop Join)について
MySQLが実装しているJOINのアルゴリズムは、Nested Loop Join(以下NLJ)。
すごく平たく言うと、JOINしたテーブルの分だけループ処理が動くというもの。
例えば、t1、t2、t3というテーブルをJOINする場合の実行イメージは以下の通り。1. t1から条件にマッチする行を全てフェッチ
2. t2から条件にマッチする行を全てフェッチ
3. t3から条件にマッチする行を全てフェッチJOINするときに大事なこと
・どのインデックスを用いてJOINするか
フェッチする行数が極力最小になるようなインデックスを選択する。
テーブルスキャンは避ける(テーブルサイズが小さい場合はOK)。・どのテーブルからJOINするか
JOINするテーブルからフェッチする行数が少なければ少ないほど、
ループの回数が少なくなる。EXPLAINで実行計画を取得する
EXPLAINは、クエリの実行計画(※)に関する情報を取得するためのステートメント。
※ MySQLがクエリーをどのように実行するかの説明
実行計画を取得したいSELECT文の頭に、EXPLAINを付けるだけ。EXPLAIN SELECT * FROM ...各結果の見方
EXPLAINを実行すると、このように出力される。
mysql > EXPLAIN select * from sampledb.sampletable ; +----+-------------+-------+------+---------------+------+---------+------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------+ | 1 | SIMPLE | table | ALL | sample_id | NULL | NULL | NULL | 10 | NULL | +----+-------------+-------+------+---------------+------+---------+------+------+-------+id
各SELECT文を識別するための通番で、実行順番を表す。
idが同じだった場合、複数のクエリが1つのクエリとして実行されたということ。select_type
クエリの種類を表す。
select_typeの結果 詳細 SIMPLE 単一のテーブル ※クエリがシンプルってことじゃない PRIMARY 外部クエリ SUBQUERY 相関関係の無いサブクエリ DEPENDENT SUBQUERY 相関関係のあるサブクエリ UNCACHEABLE SUBQUERY 実行する度に結果が変わる可能性のあるサブクエリ DERIVED FROM句で用いられているサブクエリ table
アクセス対象のテーブル
JOINを使用している場合、結合順に出力される。type
レコードアクセスタイプ。重要なフィールド。
MySQLがテーブル内の行を検索する方法。下に行くほど遅い。const
ユニーク(PRIMARYorUNIQUE)なインデックスのルックアップによるアクセス。
一意検索。いっちゃん速い。
eq_ref
JOINにおいてPRIARY KEYまたはUNIQUE KEYが利用される時のアクセスタイプ。
JOINした場合のconst。理想的なJOINの形。
ref
ユニーク(PRIMARYorUNIQUE)でないインデックスを使って等価検索(WHERE key = value)を行った時に使われるアクセスタイプ。
range
インデックスを用いた範囲検索。
WHERE句にBETWEENまたは不等号を使用したときのアクセス対応。
index
フルインデックススキャン。
インデックス全体をスキャンする必要があるのでとても遅い。
ALL
フルテーブルスキャン。
インデックスがまったく効いていない状態なため、要改善。いっちゃん遅い。possible_keys
利用可能なインデックスの候補。
インデックスが効いていない場合に参考にすると良い。key
実際に利用されたキー。
key_len
選択されたキーの長さ。キー長が短いほうが高速。
インデックスをつけるカラムを選ぶ時は意識すると良い。ref
検索条件でキーと比較されている値やカラムの種類。定数の場合は
const。
JOINの場合、結合する相手側のテーブルで検索条件として利用されているカラム。rows
フェッチされる行数の見積り。あくまで見積りなので正確な行数ではない。
また、フェッチされた全ての行がそのまま結果として返されるわけではないので注意。Extra
追加情報といいつつ割と大事な情報。以下は代表的なものの一部。
Using where
テーブルから行をフェッチした後に絞り込みが実行されている。
フェッチする前に極力行数を少なくするべきなので、
WHERE句でインデックスを適切に利用する等何かしらの改良の余地あり。Using index
カバリングインデックスが使用されている時に出力される。
クエリがインデックスだけを使用して解決できることを表す。Using temporary
GROUP BYORDER BYDISTINCTでソートするために一時テーブルが使用されている。Using filesort
インデックスでのソートではなく、クイックソートが使われているRange checked for each record (index map: N)
JOINした際、rangeまたはindex_mergeが使われている。おわりに
クエリを実行した時に、どういった処理が動いて結果が取得されているかがイメージ出来るようになった。
実行イメージしながら実装することで、後々頭を抱えることもなくなるはず。。。参考
- 投稿日:2020-12-12T13:56:30+09:00
Herokuの本番DBを確認する方法(MySQL)
前置き
herokuをMySQLでデプロイした方向けです。
本番環境のDBを確認したいなーと思って調べているとどうやらherokuではPostgreSQLが推奨されているらしくMySQLの記事がほとんど見つかりませんでした。そこで自分の備忘録をかねてHerokuの本番DBを確認する方法(MySQL)をここに残したいと思います。確認方法
この記事を書く前に色々とネットで調べてみました。すると答えが載っていました!!
結論から言うとターミナルでmysql -u DB_USERNAME -h DB_HOSTNAME -pDB_PASSWORDの順番に打ち込むとmysql >のように出てきます。こうなれば成功です!!
。
。
。なるほど全然わからない。
そもそもどこにUSERNAME、HOSTNAME、PASSWORDがわからない、、
そこからさらに調べているとDATABASE_URLの中身に色々と入っていることが判明。
ターミナルにてheroku configコマンドを実行するとCLEARDB_DATABASE_URL: mysql://abcdef12345678:1pindesu4@us-cdbr-east-02.cleardb.com/heroku_3232e987654321a?reconnect=true DATABASE_URL: mysql2://abcdef12345678:1pindesu4@us-cdbr-east-02.cleardb.com/heroku_3232e987654321a?reconnect=true LANG: en_US.UTF-8 RACK_ENV: production RAILS_ENV: production RAILS_LOG_TO_STDOUT: enabled RAILS_MASTER_KEY: ******************* RAILS_SERVE_STATIC_FILES: enabled SECRET_KEY_BASE: *******************こんな感じでいっぱい出てくると思います。(ここに乗っていなかったりここに書いてないものが表示されてることもあるかと思います。)
大切なのは
CLEARDB_DATABASE_URL: mysql://abcdef12345678:1pindesu4@us-cdbr-east-02.cleardb.com/heroku_3232e987654321a?reconnect=trueの部分です。
ここにUSERNAME、HOSTNAME、NAME、PASSWORDやらが載っています。今回の場合
ユーザー名= abcdef12345678パスワード= 1pindesu4
ホスト= us-cdbr-east-02.cleardb.com
データベース名= heroku_3232e987654321a
のように割り振られています。よってターミナルにて
% mysql -u abcdef12345678 -h us-cdbr-east-02.cleardb.com -p1pindesu4することで(一番最後の-p1pindesu4は-pの後にスペースを開けないようにしてください)
mysql >このように無事に入ることができると思います。
あとはどのデータベースを見たいのかを選択する必要があるので SHOW コマンドを使っていきます。mysql> SHOW DATABASES;+------------------------+ | Database | +------------------------+ | information_schema | | heroku_3232e987654321a | +------------------------+ 2 rows in set (4.76 sec)ここで先ほどheroku configで確認した
データベース名= heroku_3232e987654321aと一致するものが自分が確認したい本番DBということになります。
あとはmysql> USE heroku_3232e987654321a;でデータベースを選択し
mysql> SHOW TABLES;コマンドを実行すれば
+----------------------------------+ | Tables_in_heroku_3232e987654321a | +----------------------------------+ | ar_internal_metadata | | favorites | | relationships | | schema_migrations | | songs | | users | +----------------------------------+ 6 rows in set (0.29 sec)こんな感じで本番DBが確認できると思います!!
まとめ
自分なりにまとめてみたので間違っている箇所などあれば指摘していただける嬉しいです。herokuにかかわらずDBの操作は実務で必ず使うそうなのでいろいろいじって慣れておくことが大切なのかなと思いました。
- 投稿日:2020-12-12T13:09:21+09:00
オペ改善のために可視化してみたRedashクエリの紹介
はじめに
OPENLOGI Advent Calendar 2020 の12月14日の記事です。
オープンロジの技術開発部では、ビジネスサイドへの技術的な支援やログ監視をする当番を1週間ごとに1〜2名で交代しながら運用しており、この作業を社内では「オペ」と呼んでいます。
具体的にはこのオペでは以下をします。
1) 機能の仕様回答
2) 障害の報告、調査、暫定対応
3) (画面上ではまだ対応が追いついていない、大量データの扱いたいときの)バッチ処理の実行
4) ログ監視
5) システムから分かる統計情報をとるための Redash クエリの作成サービスの成長に伴ってしたいことやすべきことが増えるはずで、仮になにも改善をしないのであればサービスの成長に伴ってこのオペのコストも増えていき、人手を増やすしかなくなります。
ですが、人手を増やしていくペースには限界があると思いますので、サービス側の機能追加、社内向け管理画面に機能追加、FAQ や Wiki などのドキュメント追加などの改善をすることで、このオペのコストの増加を緩やかにする必要があります。
2020年6月あたりに、このオペを改善するための定量的な指標として Redash で以下の2つのクエリを作成してみました。
- オペ依頼件数の推移
- 3) の中で手順がパターン化されているバッチ処理の実行依頼数のランキング
この記事では上記2つのクエリについて紹介したいと思います。
似たような業務があり、同様の指標を作ろうと思っている方々へのサンプルとして参考になれば幸いです。前提環境
オープンロジでは、機能要望/不具合/オペ依頼に関して、EC2 上に稼働させている Redmine でチケット管理をしています。
現状、この Redmine のデータベースは MySQL を使っており、Redash はこの MySQL をデータソースとして扱えるように設定されています。以後紹介するクエリはこのデータソースに対してのクエリとなります。
それぞれのバージョンは以下です。
Redmine: 4.0
Redash: 8.0.0
MySQL: 8.0オペ依頼件数の推移のクエリについて
最初に紹介するのは Redmine に起票されたオペ依頼件数の推移を確認するグラフです。
まずは、現在のオペ依頼件数は過去にくらべてどのような値なのか、また一時的なものなのか慢性的に増えてきているのかを判断できる指標を用意して、どれくらい改善が急を要する状況なのかを判断できる指標が欲しいと思いました。
そこで、過去から現在のオペ依頼の Redmine チケットの件数の推移と傾向を把握できるグラフを用意することにしました。
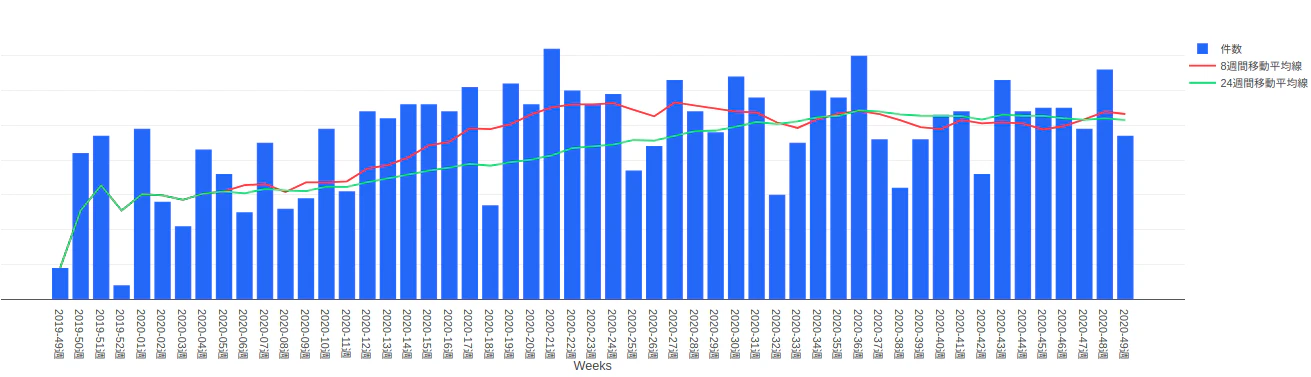
青の棒グラフは、週ごとに起票されたオペ依頼のチケット数を表しています。
赤の折れ線グラフは、8週間分の移動平均線を表しています。
緑の折れ線グラフは、24週間分の移動平均線を表しています。移動平均線を用意することで、その週の瞬間的な量だけでなく、全体的な傾向を確認できるようにしてあります。
たとえば、上述のグラフだと、2020-12週あたりから2020-27週あたりまでは増加傾向にありましたが、それ以降は2つの移動平均線がどちらともほぼ横ばいでオペ依頼の量の増減は落ち着いている状況なのがわかります。このグラフを表現するための SQL は以下となります。
select week, counts, AVG(counts) OVER (ORDER BY week ROWS BETWEEN 8 PRECEDING AND CURRENT ROW) AS avg_count_8week, AVG(counts) OVER (ORDER BY week ROWS BETWEEN 24 PRECEDING AND CURRENT ROW) AS avg_count_24week from ( select date_format(i.created_on, '%X-%V週') as week, count(i.id) as counts from issues i join projects p on i.project_id=p.id join trackers t on i.tracker_id=t.id where p.name='開発' and t.name in ('Task', 'Support') and i.created_on >= current_timestamp - interval '12' month group by week order by week asc ) as w ;オペのチケットはプロジェクトが「開発」であり、トラッカーが「Task」または「Support」となっています。
現在日時から12ヶ月分のそれらのチケットを週ごとに集計後、さらに8週間と24週間の移動平均も算出している感じです。グラフの Visualization Editor の設定値は以下です。
- General
- ChartType: Line
- X Column: week
- Y Columns: counts, avg_count_8week, avg_count_24week
- X Axis
- Name: Weeks
- Y Axis
- Left Y Axis
- Name: counts
- Series
- 1
- Left Y Axis
- Label: 件数
- Type: Bar
- 2
- Left Y Axis
- Label: 8週間移動平均線
- Type: Line
- 3
- Left Y Axis
- Label: 24週間移動平均線
- Type: Line
パターン化されているバッチ処理の実行依頼数のランキングについて
次に紹介するのはパターン化されているバッチ処理の実行依頼数をランキング形式で表現した表です。
前述のグラフでは過去と現在の状況を可視化できるようになりました。
では、次はどこから改善すればより効果的かを判断できる指標が欲しいと考えました。「はじめに」の項にあげた以下のバッチ処理の実行手順はパターン化されています。
3) (画面上ではまだ対応が追いついていない、大量データの扱いたいときの)バッチ処理の実行
これらについては、発生数が多いのであればサービス上での機能化や手順の簡略化を検討すべきであり、スクリプトなどの手順が用意されている状況であれば機能化するコストも低いはずなので、まずはここから改善するのがやりやすいと考え、それをわかりやすいようにランキング形式で表を作ってみようと思いました。
以下が実際の表です。1
id カラムは Redmine のバッチ処理の手順が書かれたチケットの IDです。
subject カラムは Redmine のバッチ処理の手順が書かれたチケットの題名です。
count はバッチ処理の手順が書かれたチケットに紐づく実際のオペ依頼のチケットの件数で、count の多い順にソートしてあります。この表を表現するための SQL は以下となります。
select target_issue.id as id, target_issue.subject as subject, count(target_issue.id) as `count` from issues issue join projects issue_project on issue.project_id=issue_project.id join trackers issue_tracker on issue.tracker_id=issue_tracker.id left join issue_relations ir on issue.id=ir.issue_to_id left join issues target_issue on ir.issue_from_id=target_issue.id left join projects target_issue_project on target_issue.project_id=target_issue_project.id left join trackers target_issue_tracker on target_issue.tracker_id=target_issue_tracker.id where issue_project.name='開発' and issue_tracker.name in ('Task', 'Support') and issue.created_on >= now() - interval {{ 何ヶ月前から }} month and ir.relation_type='copied_to' and target_issue_project.name='運用' and target_issue_tracker.name='Task' group by target_issue.id order by `count` desc ;前述のグラフでも説明したとおり、オペ依頼のチケットはプロジェクトが「開発」であり、トラッカーが「Task」または「Support」となっています。
すでに過去の実績があってパターン化しているバッチ処理は、プロジェクトは「運用」、トラッカーは「Task」の形で手順が書かれたチケットが用意されていて、各オペ依頼のチケットはこのチケットをコピー元2として関連づけしてあるような運用です。表の Visualization Editor の設定値は以下です。
- Columns
- id
- Display as: Number
- Number format: 0
- subject
- Display as: Text
- Allow HTML content: true
- count
- Display as: Number
- Number format: 0
- Grid
- Items per page: 10
今後の課題
今後の課題としては、現状はどちらの指標もチケットの件数でしかみておらず、チケット1つ1つの対応の重みを考慮できていません。
これに関しては、都度チケットに重みを設定をしていく対応コストとの兼ね合いになりますが、件数だけでは定性的な感覚との差異があまりにも大きく感じるようになってきたら検討していきたいと思っています。また、改善の優先度判断は 3) のみしか可視化できていないのも気になっており、「はじめに」の項に挙げた 1) から 5) のオペ依頼の種類の比率も気になっています。
3) 以外の対応の方が改善する優先度が高い可能性もあるためです。さいごに
以上となります。
他のサービス運用でも、この記事であげたオペのような業務は大小は違うと思いますが、0ではないかなと思っています。
それを改善するにあたって、まずは定量的に可視化したいと考え始めた時に本記事が1つの参考情報となれば幸いです。

- 投稿日:2020-12-12T11:29:09+09:00
きっと正しくないレンタルサーバーの作り方 Vol.3 - サーバーをセットアップする
はじめに
前回の記事からだいぶ時間が経ちましたが、第2回めです(・∀・)。
今回は全体的なアーキテクトについて記述していこうと思います(・∀・)。※注意!
この一連の記事で紹介するコードは動作の概念を説明するものでありセキュリティーなどは意識していません(・∀・)。実際に運用するシステムなどに使用しないでください(・∀・)。
(そのまま使うひともいないと思いますが)また、私も記事を書きながら開発をしていくので「後になってみたら最初の方の記事間違えてたー」なんて事は起きそうです(・∀・)。
ご了承ください(・∀・)。
目次
- きっと正しくないレンタルサーバーの作り方 Vol.1 -プロジェクト事始め
- きっと正しくないレンタルサーバーの作り方 Vol.2 - ざっくりアーキテクト
- きっと正しくないレンタルサーバーの作り方 Vol.3 - サーバーをセットアップする(この記事)
サーバー設定前のDNSまわり下準備
ドメインを取る
今回は お名前.com を使用します(・∀・)。
他のレジストラサービスでも良いと思います(・∀・)。レンタルサーバーサービスの運用には独自ドメインが必要になりますので、適当に取得してみてください(・∀・)。
.xxx とか .xyz とかの適当なドメインなら初年度はけっこう安いです(・∀・)。この記事では rentaserve.com という独自ドメインを取得したように記事を書きます(・∀・)。
ドメイン取得方法については割愛します(・∀・)。
(ちゃんと書いて欲しい人が居たらコメントください)VPSを借りる
サーバーOSには Debian/GNU Linux 10 を採用します(・∀・)。
ホスティングサービスには [ConoHa VPS] を使用します(・∀・)。Debian ベースの Raspberry Pi でもほぼ同等の手順を取れると思いますので、自宅サーバーでレンタルサーバーサービスなどにチャレンジしてみても面白いかも知れません(・∀・)。
(グローバルIPアドレスが必要になります)VPS や Linux の基本的な手順については割愛します(・∀・)。
(ちゃんと書いて欲しい人が居たらコメントください)私は以下の感じで VPS を作成しました(・∀・)。
独自ドメインでDNSサーバーを動かす下準備
ドメインをネームサーバーとして動作させる設定をお名前.com で行います(・∀・)。
取得したドメイン(今回の場合は rentaserve.com )をネームサーバー(権威DNSサーバー)として動作させるための設定です(・∀・)。
まず、作成した ConoHa VPS のグローバルIPアドレスが必要になります(・∀・)。
ConoHa の VPS 詳細画面から確認できます(・∀・)。
rentaserve.com の場合は 150.95.216.242 になりますね(・∀・)。
次に、お名前.con の NAVI 画面からDNS関連の設定を行っていきます(・∀・)。
rentaserve.com を選択した状態で設定画面の「ネームサーバー名としてホスト登録を行う」を選択します(・∀・)。
これは、取得した独自ドメインにアクセスした時にどのIPアドレスのDNSサーバーの情報を見に行くかの設定で、独自ドメインでDNSサーバーを立ち上げるのに必須の設定になります(・∀・)。
ここに
- ns1.rentaserve.com
- ns2.rentaserve.com
のふたつのDNSホストを作成します(・∀・)。
ホストには ConoHa VPS インスタンスのグローバルIPアドレスを設定してください(・∀・)。
※注意!
本来は ns1 と ns2 は別々のDNSサーバーを立ててそれぞれのIPアドレスを設定して障害耐性を高めます(・∀・)。
今回は全てを単一のサーバーで実現するためにインチキをしています(・∀・)。最後に rentaserve.com のネームサーバーを ns1.rentaserve.com / ns2.rentaserve.com に設定します(・∀・)。
ここに最低ふたつのDNSサーバーを指定しないと行けないので、ns1 と ns2 を作成しました(・∀・)。
これでDNS関連の下準備が完了です(・∀・)。
サーバーの設定をしていく
下準備
まずはパッケージを更新します(・∀・)。
私は基本 root で作業してるので、気になるひとは sudo でも使ってください(・∀・)。$ apt update $ apt upgradeホームディレクトリのテンプレートを作成します(・∀・)。
アカウントが追加された時に自動生成されるモノをここに入れておきます(・∀・)。mkdir -p /etc/skel/{Maildir,public_html,mysqld} chmod -R 700 /etc/skel chmod -R 755 /etc/skel/public_htmlファイヤーウォールとポート転送
とりあえず、必要そうなネットワーク関連のパッケージをインストールします(・∀・)。
apt install dnsutils whois iptables-persistent nmap手順では使わないものもありますが、とりあえず入れちゃう感じ(・∀・)。
(最低限必要なのは iptables-persistent です)さて、今回作るレンタルサーバーサービスでは
- ActiveDirectory ドメインコントローラーとして Samba 4 AD のDNS
- 外部向け権威DNSサーバーとしての PowerDNS
と、ふたつのDNSが動作します(・∀・)。
どちらもポート53を使用するため、そのまま動かすと片方が動作しません(・∀・)。なので、今回は PowerDNS の方をポート 10053 で動作させ、グローバルからのアクセスが合った場合、ポート53 から ポート10053に転送します(・∀・)。
Samba 4 AD のDNS はグローバルからのアクセスは必要ないため、そのままローカルからのアクセスのみポート53で受け付ける感じにします(・∀・)。では、実際にファイヤーウォールを設定していきます(・∀・)。
まずは基本
iptables -A INPUT -i lo -j ACCEPT iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT iptables -A OUTPUT -j ACCEPT意味は
- 自分のサーバーからのアクセスは無条件に許可
- 外部からの接続は確立されていれば許可
- 内部から外部へのアクセスは無条件で許可
のような感じです(・∀・)。
次に、アクセスできるポートを指定します(・∀・)。
iptables -A INPUT -p tcp --dport 21 -j ACCEPT iptables -A INPUT -p tcp --dport 22 -j ACCEPT iptables -A INPUT -p tcp --dport 53 -j ACCEPT iptables -A INPUT -p udp --dport 53 -j ACCEPT iptables -A INPUT -p tcp --dport 80 -j ACCEPT iptables -A INPUT -p tcp --dport 443 -j ACCEPT iptables -A INPUT -p tcp --dport 465 -j ACCEPT iptables -A INPUT -p tcp --dport 993 -j ACCEPT iptables -A INPUT -p tcp --dport 10053 -j ACCEPT iptables -A INPUT -p udp --dport 10053 -j ACCEPT iptables -A INPUT -p tcp --dport 30100:30500 -j ACCEPT開けたポートは
- FTP/FTPS
- SSH
- DNS(Samba 4 AD)
- HTTP
- HTTPS
- SMTPS
- IMAPS
- DNS(PowerDNS)
- FTP(パッシブ用のポート、FTPサーバー構築の際に説明します)
になります(・∀・)。
次に、転送設定を行います(・∀・)。
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 53 -j REDIRECT --to-port 10053 iptables -t nat -A PREROUTING -i eth0 -p udp --dport 53 -j REDIRECT --to-port 10053これは
「ネットワークカード eth0 のポート 53 にアクセスしてきたものを自分自信のポート 10053 に転送する」
という意味になります(・∀・)。ネットワークカードの eth0 はグローバル(インターネット側)のネットワークカードになるので、そこからのDNSアクセスを PowerDNS に転送する設定になります(・∀・)。
自分自身から、また今回は使用しませんが複数サーバー構成にした歳のローカルのネットワークカードにはこの設定は反映されません(・∀・)。
なので、自分自身やローカルネットからのDNS(ポート53)アクセスは Samba 4 AD のDNSアクセスになります(・∀・)。設定を確認する場合は
iptables -Lを打つと分かります(・∀・)。
Debian/GNU Linux 10 は初期状態ではIPパケットの転送が許可されていませんので、それを許可する設定にします(・∀・)。
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf/etc/sysctl.conf を vi などで開いて、末尾に net.ipv4.ip_forward = 1 を記述していただいても構いません(・∀・)。
最後に、上記の設定を保存して反映します(・∀・)。
netfilter-persistent save netfilter-persistent reload systemctl enable netfilter-persistentクオータ対応
今回作成する共有型のレンタルサーバーは、ひとつのサーバーを何人かで共有します(・∀・)。
その時、無制限にファイルをアップロードされてしまうとサーバーのストレージ容量がパンクしてしまいます(・∀・)。なので
- このアカウントは合計1GBまで
- あのアカウントは合計5GBまで
のような制御が必要になります(・∀・)。
そのために quota というものを使用します(・∀・)。まずはインストール(・∀・)。
apt install quotatool次に、ちょっと小細工(・∀・)。
今回、/home 以下に quota を設定するのですが、基本的に quota は ストレージ(パーティション)単位 で設定します(・∀・)。
しかし、ConoHa の場合、/ 以下がひとつストレージになっていて / 直下と /home が別れていないため、このままでは使用できません(・∀・)。そのため、/root/home.img を言う 80GBくらいあるでっかいファイル を作成、そのファイルを まるでストレージ(HDD や SSD)のように見せかけて /home にマウントする という手法を取ります(・∀・)。
まずは 80GB の巨大なファイル(/root/home.img)を作成します(・∀・)。
dd if=/dev/zero of=/root/home.img bs=80MiB count=1KiBホスティングサービスに負荷がかかりそうなので、あんまり多用すると怒られるかも(・∀・)?
次にループデバイスに巨大なファイルを指定、普通のストレージのようにフォーマットします(・∀・)。
losetup /dev/loop0 /root/home.img mkfs.ext4 /dev/loop0再起動時に自動的に /root/home.img を /home にマウントするように設定します(・∀・)。
echo "/root/home.img /home ext4 defaults,loop,usrquota 1 2" >> /etc/fstab/etc/fstab を vi で開いて手で追記しても構いません(・∀・)。
最後にマウントしてチェックします(・∀・)
mount -a quotacheck -vaugこの方法は Raspberry Pi のようにパーティション構造を自由にできない環境でも有効ですね(・∀・)。
自宅サーバーで行う場合、/home はパーティションかストレージ自体を分けたほうが良いでしょう(・∀・)。
(その場合、この小細工は不要です)この辺でいっしょ再起動でもしておきますか(・∀・)
気になるひとはホスト名に rentaserve 以外の名前をつけておくのも良いかもですね(・∀・)。
rebootActive Directory ドメインコントローラーの構築
概説
rentaserve では、Linux のアカウント管理は Active Directory という機能に任せます(・∀・)。
Active Directory について説明しだすとそれだけで記事がかけてしまいますが、すっごく簡単に言うと
- LDAPというデータベースを使用して、ここにユーザーデータを書き込むと勝手にアカウントが作成される
- データベースを連携させれば複数マシンでアカウント情報を共有できる
という素敵システムです(・∀・)。
これは、レンタルサーバーが複数台に分かれた時でもサーバー間で Linux アカウントを共有したいなーと思って導入しました(・∀・)。
巷のレンタルサーバーでこのようなアカウント管理はあまり見ない気もする(・∀・)?
(しらんけど)インストールと設定
とりあえず必要なものをインストール(・∀・)。
Debian/GNU Linux 10 は何でも標準的にパッケージがあって楽ですね(・∀・)wapt install samba krb5-config winbind smbclient libpam-winbind libnss-winbind krb5-config resolvconfインストール中、なにか訊かれても適当に進めて大丈夫です(・∀・)。
この設定は一度消して書き直しますので(・∀・)。次に、Active Directory 構築のために、既存の標準動作を止めます(・∀・)。
systemctl stop smbd nmbd winbind systemctl disable smbd nmbd winbindActive Directory を構築します(・∀・)。
rm /etc/samba/smb.conf samba-tool domain provision --use-rfc2307 --interactive
- Realm の rentaserve.com(構築したいレンタルサーバーの独自ドメイン)
- Administrator のパスワード
以外の項目は空エンターで問題ありません(・∀・)。
Administrator は Windows の用語で、Linux で言う root に相当する管理者アカウントです(・∀・)。
この Administrator のパスワードですが、「Active Directory パスワード複雑性ポリシー」というものを満たしていないとエラーになります(・∀・)。
具体的には、半角英数字記号全てを含むパスワードでないと弾かれますので、設定時は注意してください(・∀・)。構築が終わったら設定ファイルのバックアップを取っておきましょう(・∀・)。
cp /etc/samba/smb.conf /etc/samba/smb.conf.bakパスワード複雑性
既存の動作では、これから作成するアカウントは全て複雑なパスワードを要求されます(・∀・)。
また、アカウントの有効期限が42日に設定されています(・∀・)。これらの設定を変更していきます(・∀・)。
samba-tool domain passwordsettings set --complexity=off samba-tool domain passwordsettings set --min-pwd-length=8 samba-tool domain passwordsettings set --min-pwd-age=0 samba-tool domain passwordsettings set --max-pwd-age=0設定の意味は
- パスワードの複雑性ポリシーを無効にする(例えば pass1234 とかでも設定できる)
- パスワードの最短文字数を8文字にする
- ユーザーの有効期限を無限にする
となります(・∀・)。
続いて、Linux のログインを Samba 4 AD で行えるように設定します
vi /etc/nsswitch.conf以下のふたつの後ろに winbind を追記します(・∀・)。
- passwd: files systemd winbind
- group: files systemd winbind
DNSアクセス先を自分自身にする(・∀・)。
vi /etc/network/interfaceseth0 の設定の末尾に
- dns-nameservers 127.0.0.1
を記述する(・∀・)。
ネットワークを再起動して Active Directory のユーザーが確認できればオッケーです(・∀・)・
systemctl restart networking wbinfo -u最後に自動起動の設定をして完了です(・∀・)。
systemctl unmask samba-ad-dc systemctl restart samba-ad-dc systemctl enable samba-ad-dcmariadb
インストール
ざっくり mariadb をインストールします(・∀・)。
基本的にデフォルトで問題ないと思います(・∀・)。apt install mariadb-server systemctl restart mariadb systemctl enable mariadb mysql_secure_installationrentaserve.com ようのデータベースを作成
mysql -u root -p以下のSQLを実行します(・∀・)。
CREATE USER 'rentaserve'@'localhost' IDENTIFIED BY 'ここにパスワードを入れる'; CREATE DATABASE IF NOT EXISTS `rentaserve`; GRANT ALL PRIVILEGES ON `rentaserve`.* TO 'rentaserve'@'localhost'; QUIT;ウェブサーバーをインストール
Apache2 と PHP7.3
インストールして設定します(・∀・)。
apt install apache2 sqlite3 php7.3 php7.3-sqlite3 php7.3-pdo php7.3-fpm php7.3-mysql php7.3-zip php7.3-gd php7.3-mbstring php7.3-curl php7.3-xml php7.3-bcmath php7.3-ldap php-xdebug php-pear php-dev composer a2enmod proxy_fcgi a2enmod userdir a2enmod rewrite a2enmod ssl a2enconf php7.3-fpm標準のページを削除して作り直す(・∀・)。
a2dissite default-ssl a2dissite 000-default vi /etc/apache2/sites-available/ZZZ-default.confZZZ-default.conf の内容は以下の感じです(・∀・)。
<VirtualHost *:80> ServerName rentaserve.com ServerAdmin mao.lembryo@gmail.com DocumentRoot /var/www/html/public ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined <Directory /var/www/html> Options FollowSymLinks AllowOverride All </Directory> <FilesMatch "\.(php)$"> SetHandler "proxy:unix:/run/php/php7.3-fpm.sock|fcgi://localhost" </FilesMatch> </VirtualHost>php-fpm の設定を修正(・∀・)。
コネクションタイムを Apache2 の設定に合わせておかないと、サーバー再起動時に PHP が停止してエラーになってします(・∀・)。vi /etc/php/7.3/fpm/php-fpm.conf以下の process_control_timeout = 0 がコメントアウトされているので、コメントを削除して
- process_control_timeout = 300
とします(・∀・)。
不要になったファイルを削除してサーバーを再起動(・∀・)。
rm /etc/apache2/sites-available/default-ssl.conf rm /etc/apache2/sites-available/000-default.conf a2ensite ZZZ-default systemctl restart php7.3-fpm apache2DNSサーバーを構築する
インストール他
まずは PowerDNS をインストール(・∀・)。
apt install pdns-server pdns-backend-mysql systemctl stop pdnsDNSサーバーの設定を行う(・∀・)。
vi /etc/powerdns/pdns.conf以下の追記(270行目付近)
- local-port=10053
- launch=gmysql
- gmysql-host=127.0.0.1
- gmysql-user=rentaserve
- gmysql-password=データベースに設定したパスワード
- gmysql-dbname=rentaserve
意味は
- DNSサーバーのポートを 53 ではなく 10053 で動作させる
- バックエンドに MySQL(mariadb)を使用およびそのアクセス情報の設定
になります(・∀・)。
設定を反映(・∀・)。
systemctl restart pdns systemctl enable pdnsバックエンド mariadb にテーブルを作成(・∀・)。
PowerDNS バックエンドの mariadb には以下のテーブルが必要です(・∀・)。
ここは 良く分からんけどそういうもの と思って、以下のテーブルを作成しましょう(・∀・)。既に Apache2 と PHP7.3 が動作しているので phpMyAdmin などから行っても良いでしょう(・∀・)。
SQL直打ちもアレなので、Laravel プロジェクトにマイグレーションファイルとシーダーを用意指定あります(・∀・)。
GitHubCREATE TABLE `comments`( `id` INT(11) NOT NULL, `domain_id` INT(11) NOT NULL, `name` VARCHAR(255) NOT NULL, `type` VARCHAR(10) NOT NULL, `modified_at` INT(11) NOT NULL, `account` VARCHAR(40) NOT NULL, `comment` TEXT NOT NULL ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 ; CREATE TABLE `cryptokeys`( `id` INT(11) NOT NULL, `domain_id` INT(11) NOT NULL, `flags` INT(11) NOT NULL, `active` TINYINT(1) DEFAULT NULL, `content` TEXT DEFAULT NULL ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 ; CREATE TABLE `domainmetadata`( `id` INT(11) NOT NULL, `domain_id` INT(11) NOT NULL, `kind` VARCHAR(32) DEFAULT NULL, `content` TEXT DEFAULT NULL ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 ; CREATE TABLE `domains`( `id` INT(11) NOT NULL, `name` VARCHAR(255) NOT NULL, `master` VARCHAR(128) DEFAULT NULL, `last_check` INT(11) DEFAULT NULL, `type` VARCHAR(6) NOT NULL, `notified_serial` INT(11) DEFAULT NULL, `account` VARCHAR(40) DEFAULT NULL ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 ; CREATE TABLE `records`( `id` INT(11) NOT NULL, `domain_id` INT(11) DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `type` VARCHAR(10) DEFAULT NULL, `content` TEXT DEFAULT NULL, `ttl` INT(11) DEFAULT NULL, `prio` INT(11) DEFAULT NULL, `change_date` INT(11) DEFAULT NULL, `disabled` TINYINT(1) DEFAULT 0, `ordername` VARCHAR(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL, `auth` TINYINT(1) DEFAULT 1 ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 ; CREATE TABLE `supermasters`( `ip` VARCHAR(64) NOT NULL, `nameserver` VARCHAR(255) NOT NULL, `account` VARCHAR(40) NOT NULL ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 ; CREATE TABLE `tsigkeys`( `id` INT(11) NOT NULL, `name` VARCHAR(255) DEFAULT NULL, `algorithm` VARCHAR(50) DEFAULT NULL, `secret` VARCHAR(255) DEFAULT NULL ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 ; ALTER TABLE `comments` ADD PRIMARY KEY( `id` ), ADD KEY `comments_domain_id_idx`( `domain_id` ), ADD KEY `comments_name_type_idx`( `name`, `type` ), ADD KEY `comments_order_idx`( `domain_id`, `modified_at` ) ; ALTER TABLE `cryptokeys` ADD PRIMARY KEY( `id` ), ADD KEY `domainidindex`( `domain_id` ) ; ALTER TABLE `domainmetadata` ADD PRIMARY KEY( `id` ), ADD KEY `domainmetadata_idx`( `domain_id`, `kind` ) ; ALTER TABLE `domains` ADD PRIMARY KEY( `id` ), ADD UNIQUE KEY `name_index`( `name` ) ; ALTER TABLE `records` ADD PRIMARY KEY( `id` ), ADD KEY `nametype_index`( `name`, `type` ), ADD KEY `domain_id`( `domain_id` ), ADD KEY `recordorder`( `domain_id`, `ordername` ) ; ALTER TABLE `supermasters` ADD PRIMARY KEY( `ip`, `nameserver` ) ; ALTER TABLE `tsigkeys` ADD PRIMARY KEY( `id` ), ADD UNIQUE KEY `namealgoindex`( `name`, `algorithm` ) ; ALTER TABLE `comments` MODIFY `id` INT( 11 ) NOT NULL AUTO_INCREMENT ; ALTER TABLE `cryptokeys` MODIFY `id` INT( 11 ) NOT NULL AUTO_INCREMENT ; ALTER TABLE `domainmetadata` MODIFY `id` INT( 11 ) NOT NULL AUTO_INCREMENT ; ALTER TABLE `domains` MODIFY `id` INT( 11 ) NOT NULL AUTO_INCREMENT ; ALTER TABLE `records` MODIFY `id` INT( 11 ) NOT NULL AUTO_INCREMENT ; ALTER TABLE `tsigkeys` MODIFY `id` INT( 11 ) NOT NULL AUTO_INCREMENT ; ALTER TABLE `records` ADD CONSTRAINT `records_ibfk_1` FOREIGN KEY( `domain_id` ) REFERENCES `domains`( `id` ) ON DELETE CASCADE ;ドメインとレコードを登録
ドメインとレコードを登録していきます(・∀・)。
まずはドメイン、コレはかんたんです(・∀・)。
ドメイン名と type に NATIVE を入れるだけです(・∀・)。INSERT INTO `domains`( `name`, `type` ) VALUES( 'rentaserve.com', 'NATIVE' ) ;続いて rentaserve.com のDNSレコード(・∀・)。
- レコードが所属するドメインIDを指定(domains の id)
- レコード名
- レコード形式(SOA / NS / A / AAAA / MX / TXT など)
- レコードの内容
などを入れていきます(・∀・)。
まずは SOA と NS レコード、これが無いと nslookup などでエラーになります(・∀・)。SOA のメールアドレスは連絡の取れる自分のメールアドレスを設定してください(・∀・)。
INSERT INTO `records`( `domain_id`, `name`, `type`, `content`, `ttl` ) VALUES( 1, 'rentaserve.com', 'SOA', 'rentaserve.com mao.lembryo@gmail.com 1', '86400' ) INSERT INTO `records`( 1, `domain_id`, `name`, `type`, `content` ) VALUES( '1', 'rentaserve.com', 'NS', 'ns1.rentaserve.com', '86400' ) ; INSERT INTO `records`( `domain_id`, `name`, `type`, `content`, `ttl` ) VALUES( '1', 'rentaserve.com', 'NS', 'ns2.rentaserve.com', '86400' ) ;最後に逆引きIPアドレスの情報を入れていきます(・∀・)。
INSERT INTO `records`( `domain_id`, `name`, `type`, `content`, `ttl` ) VALUES( '1', 'rentaserve.com', 'A', '150.95.216.242', '600' ) ; INSERT INTO `records`( `domain_id`, `name`, `type`, `content`, `ttl` ) VALUES( '1', 'ns1.rentaserve.com', 'A', '150.95.216.242', '600' ) ; INSERT INTO `records`( `domain_id`, `name`, `type`, `content`, `ttl` ) VALUES( '1', 'ns2.rentaserve.com', 'A', '150.95.216.242', '600' ) ;これで、rentaserve.com / ns1.rentaserve.com / ns2.rentaserve.com にアクセスした時にIPアドレス 150.95.216.242 を返すようになります(・∀・)。
records に「mao.rentaserve.com」を入れればサブドメインにも出来ます(・∀・)。
(設定した Aレコードの content ないのIPアドレスを返すようになる)レンタルサーバー利用者の独自ドメインを使用する場合も、同期の domains と records に相応のデータを INSERT するだけです(・∀・)。
最後に
必要なサーバー設定はある程度終わりましたので、次回以降はレンタルサーバーのシステム開発に入れたら良いなーと思っています(・∀・)。





- 投稿日:2020-12-12T11:28:22+09:00
中間テーブルを作ってパフォーマンスを改善した話
この記事は、All About Group(株式会社オールアバウト) Advent Calendar 2020 13日目の記事です。
こんにちは、データエンジニアの@ondaljhです。
自分が所属しているマーケティング開発部のデータ基盤チームではデータ基盤の整備やデータガバナンス活動と一緒に各部署へのデータ活用も声かけています。今回はそのデータ活用のために行ったことを紹介したいと思います。
想定読者
今回はBIツールで利用するための中間テーブルを作成した話がメインになります。従って、下記のことで悩んでる方をこの記事の想定読者としています。
- あるテーブルのレコード数が多すぎて重くてデータ活用し辛い
- その上、データ粒度が細かすぎてBIツールで利用するためには加工が必要だな...
- 日次データはあるけどBIツール利用のためにはまとまったデータが欲しいな...
やりたいこと
オールアバウトではタイアップ記事やタイアップ記事へ誘導するための広告クリエイティブを作成する企画制作グループがありまして、今回の話はこの企画制作グループからの問い合わせがきっかけになりました。企画制作グループでは今まで数多くのタイアップ記事や広告クリエイティブを作ってきて、これからも作っていくことでしょう。そこで、特定のキーワードを使って過去に実績が良かった広告クリエイティブを簡単に検索できないかの問い合わせがデータ基盤チームに来ました。何回かの打ち合わせの結果、企画制作グループで必要とするものの要件が決まりました。
- キーワード検索で、関連する過去広告クリエイティブ一覧が表示される
- キーワードは複数でも検索できること
- 一覧には検索キーワードの類似度も表示されてほしい
- 実績として下記のような指標が欲しい
- Impression
- Click
- Ctr
- 広告クリエイティブを経由したタイアップ記事からの送客数
- 広告クリエイティブから遷移されたタイアップ記事の平均読了率と平均滞在時間
※各指標の説明は割愛させていただきます。
検索キーワードの類似度はデータ基盤チームのデータサイエンティストに任せることにしました。指標についてはデータ基盤の方では常に集計しているデータで、社内用のBIツールでも出していたので、データの確保は問題ない認識でした。(が、大きな問題がありました...)
現状
問い合わせがあった最初には、各指標がそれぞれのテーブルに格納されてはいるけど、既にデータはあるから少し複雑にはなるけど1つのSQLを作成してBIツールのRedashに登録するだけで実装できると思っていました。そこで実際にSQLを作成して実行してみました!が、全然戻ってこない...なんでだろう。。?
問題はシンプルで、Impressionデータを格納しているテーブルでした。ただ下記のだけです。
- テーブルのレコード数が3億件以上
うん、レコード数が3億件あるよねーうん??3億件??
そうか...仕方ないのか...このテーブルは粒度も細かいし、2016年10月に現役デビューしたから、もう4年分以上の日次データがたまっているのか...
ちなみに、今回作成したSQLは下記のような構成です。
- 検索キーワードからヒットするクリエイティブ情報を取得する
- 1で取得したクリエイティブ毎の指標データを取得する
Impressionテーブルは日次の集計データが入っていて日付カラムを基準としてパーティションやインデックスが作成されています。今回のようなクリエイティブに関するカラムでのパーティションは作成していなかったのでSQL処理が重くなるのは仕方ないですねー
考えたこと
ここで問い合わせの原点に立ち戻って考えることにしました。必要なデータは広告クリエイティブの実績。
- ここで言ってる実績は日毎の実績ではなく、トータルでの実績があればいいので、わざわざ日次集計データからデータを取得してグルーピングしたりする必要はない!
- また、「過去実績」の確認になるため、現時点で配信中の広告クリエイティブは出さなくていい!
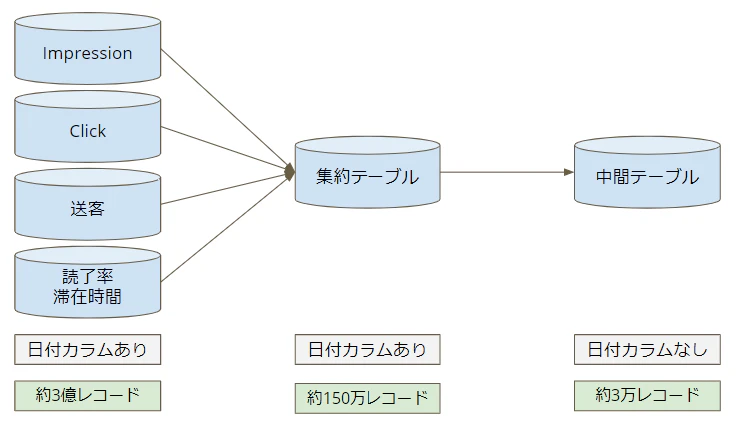
この2点に着目して、既に配信が終わってるクリエイティブについては、トータル実績を格納する中間テーブルを作るだけで良いのでは?という結論になりました。ただ、下記の理由で日次集計テーブルと今回の中間テーブルの間にもう1つのテーブル(以降、集約テーブル)を用意することにしました。
- システムはトラブルがつきものであるため、リカバリしやすい構成にしたい
- Impressionデータだけではなく、他の指標も一緒に格納した中間テーブルにした方がBIツールからの呼び出しが早い
また、集約テーブルにはImpressionの細かい粒度ではなく、BIツールで利用するための必要最小限の粒度にすることで無駄なレコード数の増加を防げました。
ここまでの構成を図で表しますと下記のようになります。
結果
実際にこの構成にして、中間テーブルを参照するようにSQLを作成して実行した結果、5秒以内で求めてたデータが戻ってきました!やった!当たり前といえば当たり前ですが、中間テーブルの場合データ件数が3万件ちょっとくらいなのですぐ戻ってきますよねー
ちなみに、集約テーブルも含めて、各段階でのレコード件数は下記のようになります。
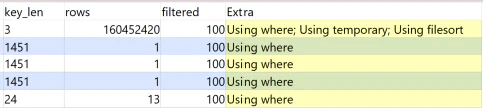
実際のMySQLの実行計画を見てもその違いが分かります。
※実行計画は一部のカラムのみ公開させていただきます。各指標毎のテーブル利用時の実行計画
中間テーブル利用時の実行計画
さいごに
今回用意した中間テーブルとデータサイエンティストが用意した類似度をBIツールで合わせて表示することができ、企画制作グループからも喜びの声をいただきました。データがあるからそのデータをそのまま使うのではなく、目的に合わせて中間テーブルを導入するなど、一工夫することでデータ活用しやすいデータが整備されたと思います。
レコード数が多くて今のままではSQL結果が戻ってこない等で悩んでる方やBIツール活用のためのデータ構造を検討中の方に、この記事が少しでも役に立ちましたら幸いですー


- 投稿日:2020-12-12T11:27:41+09:00
DjangoでForeignKeyのon_deleteをDO_NOTHINGにした時、db_constraint=Falseも指定しないとIntegrityErrorが発生する。
delete時のIntegrityErrorエラー
掲題の通り、ForeignKeyモデルフィールドでon_delete引数にDO_NOTHINGを使用する時、db_constraint引数をFalseにしておかないと、リレーション先のモデルオブジェクトを削除した時にIntegrityError'Cannot delete or update a parent row: a foreign key constraint fails'(Mysql)が発生する。
- on_delete=DO_NOTHING:リレーション先オブジェクトの削除更新時のアクションを"何もしない"にする。
- db_constraint=False:明示的に外部キー制約を行わない事を指示する。データ整合性が失われるので集計用のトランザクションなどフロントから直接参照されないモデル以外には使用しない方がよいかも。
参照
- 投稿日:2020-12-12T10:27:00+09:00
MySQL PHPからデータ登録できずエラーになってしまう&ターミナルから文字を入力した際に削除した文字も表示されてしまう
環境
mac 11.0.1
docker-compose.ymlappコンテナ
php:7.4-apachedbコンテナ mysql:5.5事象1 ターミナルでプログラムの実行確認をしている際に、MySQLにデータが登録されない
ターミナル[今日のメモ] 登録しました string(54) "INSERT INTO memo (memo) VALUES (登登録しました)" Error: データの追加に失敗しました Debugging: Unknown column '登登録しました' in 'field list'VALUESに出力されている文字がおかしいのは一旦置いておきます。
PHPecho '[今日のメモ]' . PHP_EOL; $memo = trim(fgets(STDIN)); $sql = "INSERT INTO memo (memo) VALUES ($memo)"; $result = mysqli_query($link, $sql); var_dump($sql);memoにシングルクォーテーション追加
$sql = "INSERT INTO memo (memo) VALUES ('$memo')";
$memoをシングルクォーテーション''で囲まないと文字としてではなく、カラムで出力されてしまいエラーになる事象2 ターミナルから文字を入力した際に削除した文字もテーブルに登録されてしまう
ターミナル% docker-compose exec app php tmp/memo.php Success: データベースに接続できました [今日のメモ] 明日 string(9) "明日明" 登録が完了しました実行確認の際に、BackSpaceで誤入力を削除し、上手く削除されてテーブルに、登録されている時もありましたが、上記のようになる事が多く、初めはINSERT文がおかしいのかと思ったのですが、最終的にターミナルでの操作にいきつきました。
var_dump(変数名)で出力すると消えていない文字を発見!!コマンドのショートカットで削除する事にしました。
削除
コマンド 意味
Ctrl + h (BackSpace) カーソルの後方を1文字削除
Ctrl + d (Delete) カーソル上の1文字削除
Ctrl + w 単語1個文削除
Ctrl + d は何も入力していない状態で入力するとログアウトしてしまうので注意が必要。カット,ヤンク
コマンド 意味
Ctrl + k 行末まで削除
Ctrl + u 行頭まで削除
Ctrl + y 最後に削除した内容を挿入
カットが切り取りで、ヤンクが貼り付けと覚えておけば大丈夫です。私の現在の設定では、Ctrl + h (BackSpace)は使用できませんでした。
ターミナル[今日のメモ] 明日 string(6) "明日" 登録が完了しましたSELECT * FROM memo;
MySQL:テーブル| 71 | 明日明 | 2020-12-12 04:26:04 | | 72 | 明日 | 2020-12-12 04:26:29 | +----+--------------------+----無事完了!
参考にさせていただきました!ありがとうございます!
爆速でターミナルを使うためのショートカット集間違えている所や、ここもっと勉強するといいよ!などコメントいただけましたら、かなり有り難いのでよろしくお願いいたします笑
- 投稿日:2020-12-12T01:28:59+09:00
Docker Desktop Mac 3.0.0 にアップデートで起動しなくなって、mysqlが動かない時の対応
前回の記事「Docker Desktop Mac 3.0.0 にアップデートしたら、起動しなくなった時の対応」の続きです。
mysqlが永久起動失敗ループに・・・現象
下記のようなログを出力しながら、mysqlが起動→失敗→再起動を繰り返しています。
mysql | 2020-12-11 14:28:26+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql' mysql | 2020-12-11 14:28:26+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.21-1debian10 started. mysql | 2020-12-11T14:28:26.491369Z 0 [System] [MY-010116] [Server] /usr/sbin/mysqld (mysqld 8.0.21) starting as process 1 mysql | 2020-12-11T14:28:26.508161Z 1 [System] [MY-013576] [InnoDB] InnoDB initialization has started. mysql | 2020-12-11T14:28:27.034000Z 1 [System] [MY-013577] [InnoDB] InnoDB initialization has ended. mysql | 2020-12-11T14:28:27.040556Z 1 [ERROR] [MY-011087] [Server] Different lower_case_table_names settings for server ('0') and data dictionary ('2'). mysql | 2020-12-11T14:28:27.040839Z 0 [ERROR] [MY-010020] [Server] Data Dictionary initialization failed. mysql | 2020-12-11T14:28:27.041084Z 0 [ERROR] [MY-010119] [Server] Aborting mysql | 2020-12-11T14:28:27.601939Z 0 [System] [MY-010910] [Server] /usr/sbin/mysqld: Shutdown complete (mysqld 8.0.21) MySQL Community Server - GPL.stack overflow に同様の現象を発見
Mysql not starting in a docker container on MacOS after docker update
mysqlのデータディレクトリをホストのvolumesに指定していると、この状況になるのでしょうか。
2.3 から 2.4 にUpdateしたときに発生していた模様です。
今回現象が出ている環境は2.5で新規作成した環境ですから、初めて出くわしたのですね・・・
(埋蔵している過去のプロジェクトを復活することになった時、これが発生するのか・・・)対応方法
stack overflowの記事の1つ目の回答の方法はダメでした。
2つ目の方法でやってみます。1.Docker Desktop をダウングレード
1) ver. 3.0.0 をUninstall
Docker Desktop > 設定 > 右上の虫っぽいマーク > Uninstall
2) ver. 2.5.0.0 をインストール
Docker for Mac release notesの 2.5.0.0をダウンロードして、インストール。
※2.5.0.1のDownloadリンクのものは「最新版dmg」へのリンクなので、3.0.0でした・・・直しておいてほしいですね;2.User gRPC FUSE for file sharing を オン
Dockerを起動して、バージョンが3.0.0でないことを確認し、
メニュー Docker Desktop > 設定 > Experimental Features の
User gRPC FUSE for file sharing を オン になっていることを確認3.docker-compose up
無事、起動しました!
(って、このまま3.0.0にアップデートせずに使えば良いのでは・・・と悪魔が囁いたのですが、本記事と前回記事の意味がなくなりますので、頑張ってみようと思います。)4.DBダンプ
どんな手段でも良いので、mysqlのDBダンプをとりましょう
5.docker-compose stop
止めます
6.mysqlのデータディレクトリを削除
mysqlコンテナ起動時に再作成してくれるそうです。
※僕は、念の為、renameにしましたが^^7.Docker Desktop 3.0.0 にアップグレード
Docker Desktop > Check for Updates... が手っ取り早いですね。
8.Docker Desktop 起動
アップデート後にStartingのまま起動しない場合は、Docker Desktop > 設定 > 右上の虫っぽいマーク > Uninstall をした後、 ver. 3.0.0をダウンロードして再インストールしてみてください。
9.User gRPC FUSE for file sharing を オフ に設定
メニュー Docker Desktop > 設定 > Experimental Features の
User gRPC FUSE for file sharing を オフ に再度設定します10.docker-compose up
無事、起動しましたか?
11.DBダンプからデータ復旧
どんな手段でも良いので、4のダンプでデータを復旧しましょう
今後は・・・
Volumeはコンテナのを使うことにします。
いま思えば、なぜホストのVolumeを割り当てていたのだろうか・・・
- 投稿日:2020-12-12T01:28:59+09:00
Docker Desktop Mac 3.0.0 にアップデートで起動しなくなって対応した後、mysqlが動かない時の対応
前回の記事「Docker Desktop Mac 3.0.0 にアップデートしたら、起動しなくなった時の対応」の続きです。
mysqlが永久起動失敗ループに・・・現象
下記のようなログを出力しながら、mysqlが起動→失敗→再起動を繰り返しています。
mysql | 2020-12-11 14:28:26+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql' mysql | 2020-12-11 14:28:26+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.21-1debian10 started. mysql | 2020-12-11T14:28:26.491369Z 0 [System] [MY-010116] [Server] /usr/sbin/mysqld (mysqld 8.0.21) starting as process 1 mysql | 2020-12-11T14:28:26.508161Z 1 [System] [MY-013576] [InnoDB] InnoDB initialization has started. mysql | 2020-12-11T14:28:27.034000Z 1 [System] [MY-013577] [InnoDB] InnoDB initialization has ended. mysql | 2020-12-11T14:28:27.040556Z 1 [ERROR] [MY-011087] [Server] Different lower_case_table_names settings for server ('0') and data dictionary ('2'). mysql | 2020-12-11T14:28:27.040839Z 0 [ERROR] [MY-010020] [Server] Data Dictionary initialization failed. mysql | 2020-12-11T14:28:27.041084Z 0 [ERROR] [MY-010119] [Server] Aborting mysql | 2020-12-11T14:28:27.601939Z 0 [System] [MY-010910] [Server] /usr/sbin/mysqld: Shutdown complete (mysqld 8.0.21) MySQL Community Server - GPL.stack overflow に同様の現象を発見
Mysql not starting in a docker container on MacOS after docker update
mysqlのデータディレクトリをホストのvolumesに指定していると、この状況になるのでしょうか。
2.3 から 2.4 にUpdateしたときに発生していた模様です。
今回現象が出ている環境は2.5で新規作成した環境ですから、初めて出くわしたのですね・・・
(埋蔵している過去のプロジェクトを復活することになった時、これが発生するのか・・・)対応方法
stack overflowの記事の1つ目の回答の方法はダメでした。
2つ目の方法でやってみます。
要するに、Dockerのバージョン戻して、データ救出セヨ!です^^1.Docker Desktop をダウングレード
1) ver. 3.0.0 をUninstall
Docker Desktop > 設定 > 右上の虫っぽいマーク > Uninstall
2) ver. 2.5.0.0 をインストール
Docker for Mac release notesの 2.5.0.0をダウンロードして、インストール。
※2.5.0.1のDownloadリンクのものは「最新版dmg」へのリンクなので、3.0.0でした・・・直しておいてほしいですね;2.User gRPC FUSE for file sharing を オン
Dockerを起動して、バージョンが3.0.0でないことを確認し、
メニュー Docker Desktop > 設定 > Experimental Features の
User gRPC FUSE for file sharing を オン になっていることを確認3.docker-compose up
無事、起動しました!
(って、このまま3.0.0にアップデートせずに使えば良いのでは・・・と悪魔が囁いたのですが、本記事と前回記事の意味がなくなりますので、頑張ってみようと思います。)4.DBダンプ
どんな手段でも良いので、mysqlのDBダンプをとりましょう
5.docker-compose stop
止めます
6.mysqlのデータディレクトリを削除
mysqlコンテナ起動時に再作成してくれるそうです。
※僕は、念の為、renameにしましたが^^7.Docker Desktop 3.0.0 にアップグレード
Docker Desktop > Check for Updates... が手っ取り早いですね。
8.Docker Desktop 起動
アップデート後にStartingのまま起動しない場合は、Docker Desktop > 設定 > 右上の虫っぽいマーク > Uninstall をした後、 ver. 3.0.0をダウンロードして再インストールしてみてください。
9.User gRPC FUSE for file sharing を オフ に設定
メニュー Docker Desktop > 設定 > Experimental Features の
User gRPC FUSE for file sharing を オフ に再度設定します10.docker-compose up
無事、起動しましたか?
11.DBダンプからデータ復旧
どんな手段でも良いので、4のダンプでデータを復旧しましょう
今後は・・・
Volumeはコンテナのを使うことにします。
いま思えば、なぜホストのVolumeを割り当てていたのだろうか・・・
追記:
いま思えば、なぜホストのVolumeを割り当てていたのだろうか・・・
これ、Laradockの標準がこうなっていたから、オリジナルでdocker-compose.ymlを書くときに参考にしたのでした。
全世界のMacでLaradock使いの方々が阿鼻叫喚ってことですか!?個人的に他にも該当プロジェクトが多数あります・・・
これはやはり2.5に戻s...うぅん、なんでもないです。