- 投稿日:2020-12-12T23:52:30+09:00
12月なのでsnowflakeはじめよう
はじめに
去年のアドカレ以来の投稿になるという体たらくを発揮してしまいました。
12月なので、最近よく話題に上がるsnowflakeを触ってみようと思います。
ロゴもすごい。12月感すごい。
題材
フリートライアル用ハンズオン資料が公開されていますので、これを題材に進めます。
HANDS-ON LAB GUIDE FOR SNOWFLAKE FREE TRIALやること
ハンズオンのMODULE 1~5を中心に、ざっくり以下をやってみます。
- snowflake上でテーブル作成
- AWS S3上にあるcsvファイル郡をsnowflakeにロード
- snowflakeのコンピュートノード(ウェアハウス)を利用して分析
狙い
以下基本的な概念、インターフェースや流れを掴む所を目指します。
- テーブル
- ステージ
- ウェアハウス
1. トライアルサインアップ
以下URLよりトライアルサインアップしてください。
https://signup.snowflake.com/?_l=ja
以下の通り選択して作成します。
UIが表示されました。
ここでURLが以下になってるのに気付きます。
https://(account).ap-northeast-1.aws.snowflakecomputing.com/
snowflakeはクラウドプラットフォーム(AWS/GCP/Azure)で稼働します。
これは既に別のサービスがクラウド上でホスティングしている(例えばAWSのap-northeast-1を中心にサービス稼働している)場合、同じクラウドプラットフォーム上でsnowflakeをホストできることを意味します。なんとなくピンとくるかもしれませんが、これはデータ転送料金など関係してきそうですね。
ドキュメント: サポート対象のクラウドプラットフォーム2. UI確認/準備
データベースをクリックしてみましょう。データベースタブには作成した、もしくはアクセス権限を持っているデータベースに関する情報が表示されます。
フリートライアル環境にいくつかのデータベースが既に存在していますね。
(ラボではこれらは使用しませんでした)
ワークシートは SQLを実行、結果を確認する画面です。
基本的にこの画面でSQLを実行しながら進めていきます。
ラボで利用するsqlファイルを以下からダウンロードしましょう。
lab_scripts_free_trial.sql
ワークシートの▼を選択し、スクリプトをロードから、DLしたsqlファイルを選択します。
SQLが表示されました。このSQLを一部選択 -> 実行を繰り返してラボは進みます。
3. データロード
3-1. データベース作成
このラボには以下のシナリオがあるようです。
ニューヨーク市にある公共自転車共有システム
CitiBikeのデータを分析しライダーに最適なサービスを提供する方法を理解したい。まずはデータベース
Citibikeを作成しましょう
ロードしたSQLの以下部分のみ選択し、
実行をクリックします。
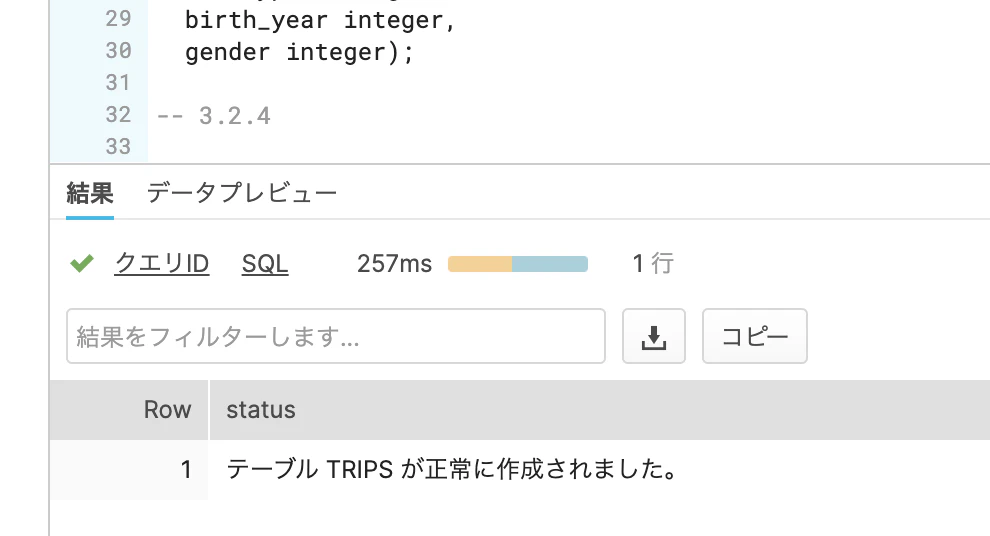
create or replace table trips (tripduration integer, starttime timestamp, stoptime timestamp, start_station_id integer, start_station_name string, start_station_latitude float, start_station_longitude float, end_station_id integer, end_station_name string, end_station_latitude float, end_station_longitude float, bikeid integer, membership_type string, usertype string, birth_year integer, gender integer);結果が表示されました。成功したようです。
データベースのテーブルを見ると、確かにテーブルが作成されています。
3-2. ステージ設定
このテーブルに外部に存在するCitibike利用ユーザのトランザクションデータをロードします。
データはpublicなs3 bucket上に存在するようです。そのためには
ステージという設定を作成します。
ステージを選択できるので、 S3を選択します。
名前: citibike_trips
スキーマ名: PUBLIC
URL: s3://snowflake-workshop-lab/citibike-trips
ステージ設定ができました。(まだ実際のロードはしていません。)
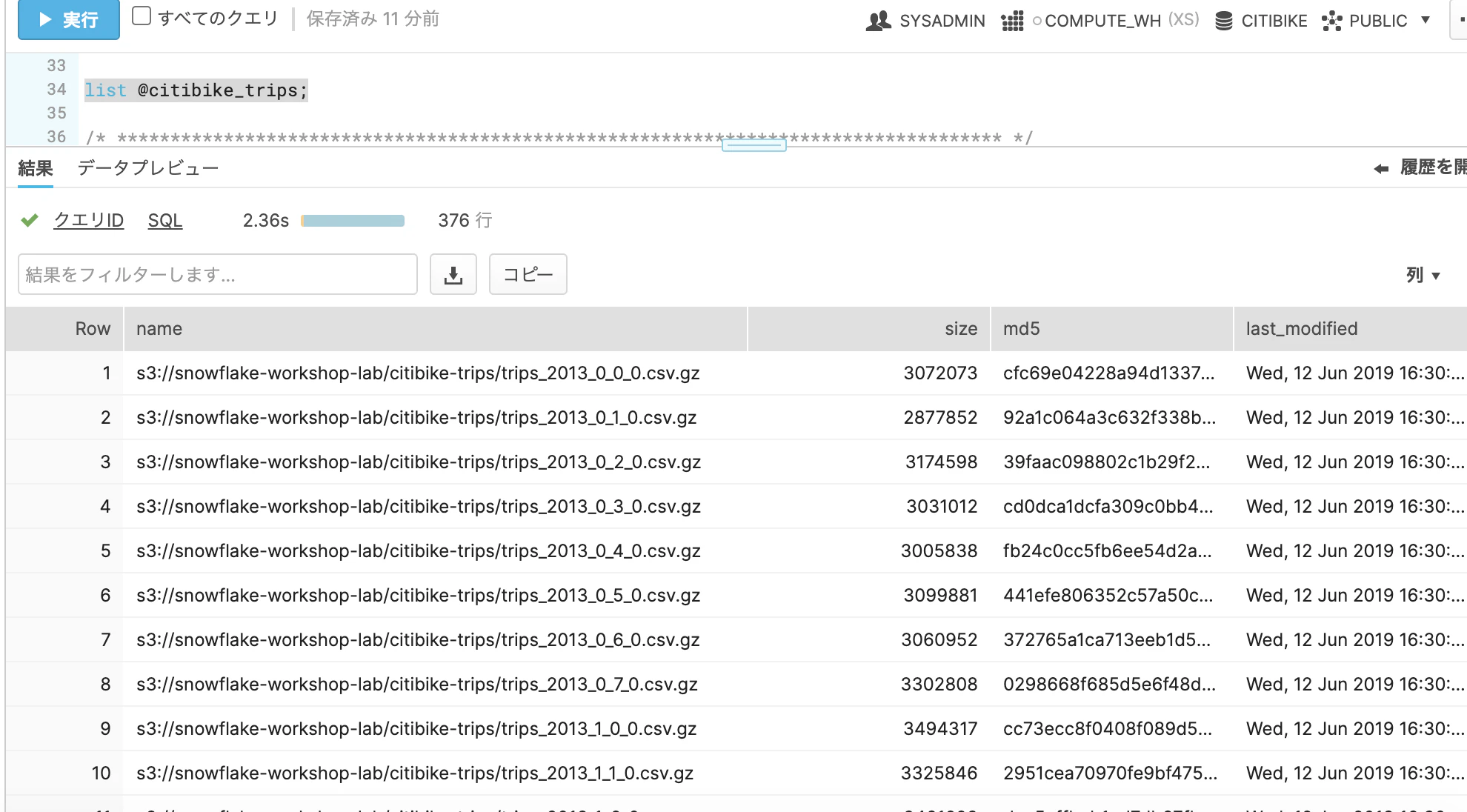
ワークシートで以下SQLを実行してstageの中を覗いてみましょう。list @citibike_trips;たくさんのcsv(gz圧縮)が存在することがわかります。
3-3. ファイル形式設定
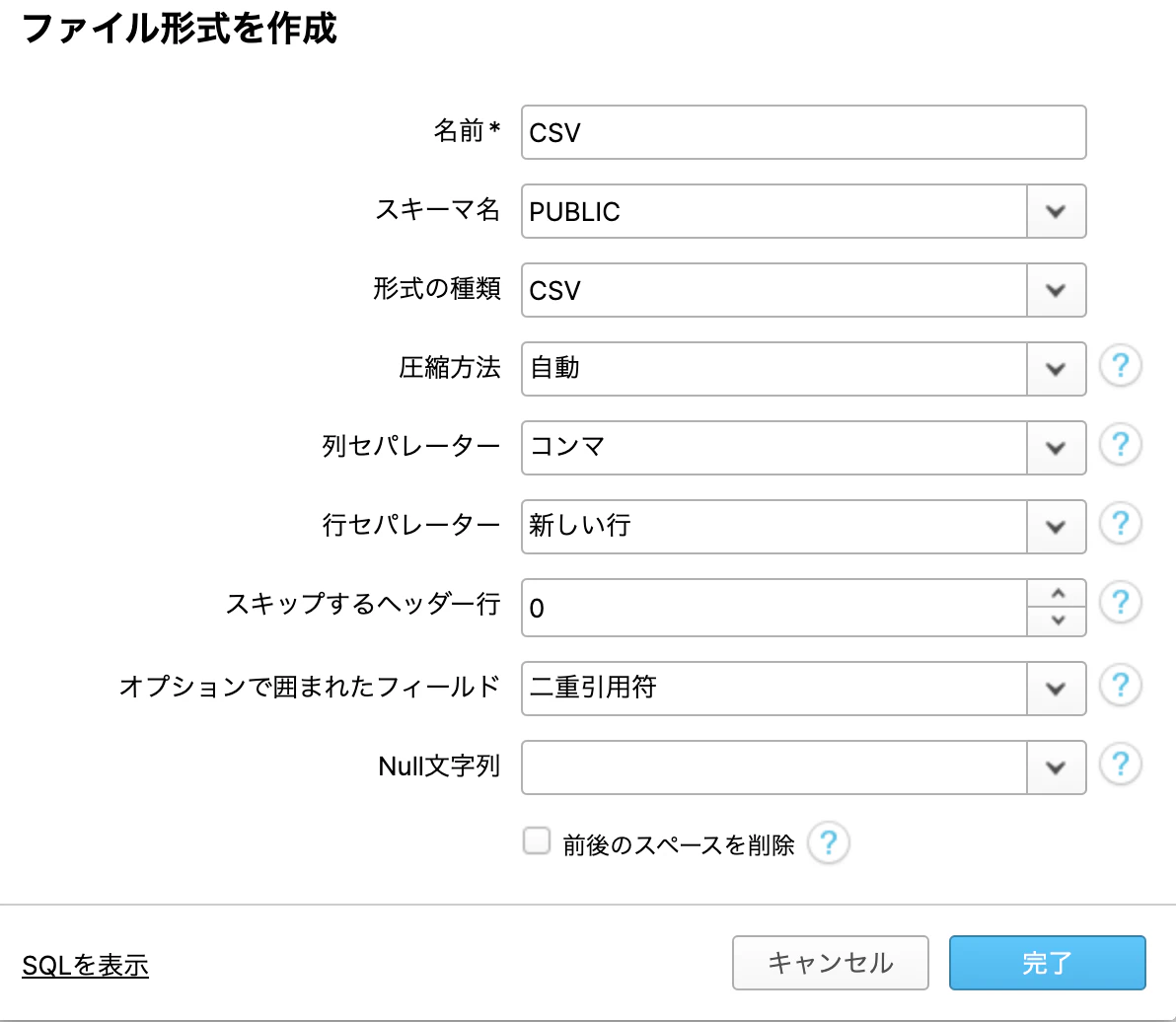
続いてより詳細なcsv形式について設定します。
ファイル形式タブにて、以下の通り設定します。
(スクロール下の設定)
ファイル形式設定も完了しました。(まだまだ実際のロードはしていません)
3-4. ウェアハウス作成
続いて実際にcsvをsnowflakeにロードしてみます。
ロードするにはコンピューティングリソースが必要です。
Snowflakeのコンピュートノードはウェアハウスと呼ばれ、ワークロードに応じて動的にスケールできます。
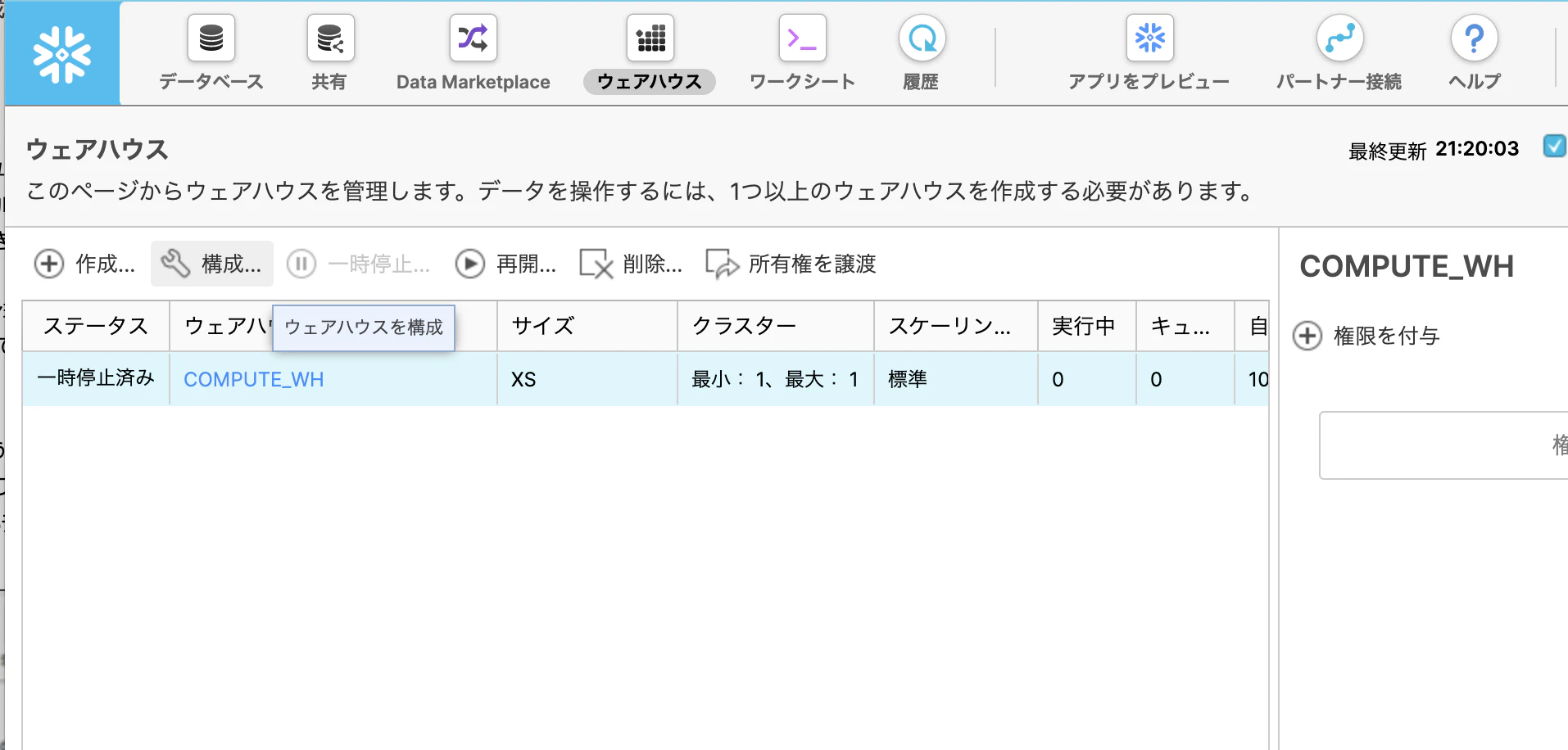
ウェアハウスタブを選択すると、既にデフォルトのウェアハウスが存在しているようです。
選択して構成をクリックしてみます。
サイズなど、コンピューティングリソースの設定ができるようです。
サイズをSと設定します。
3-5. COPYコマンド実行
ワークシートに移動します。
SQL実行画面のContextをクリックすると、ウェアハウスが確認でき、サイズもSとなっています。
SQL実行時にどのウェアハウス (コンピューティングノード) で実行するかを選択できるようですね。
では、以下SQLで実際にデータをロードします。
copy into trips from @citibike_trips file_format=CSV;ロードできました。
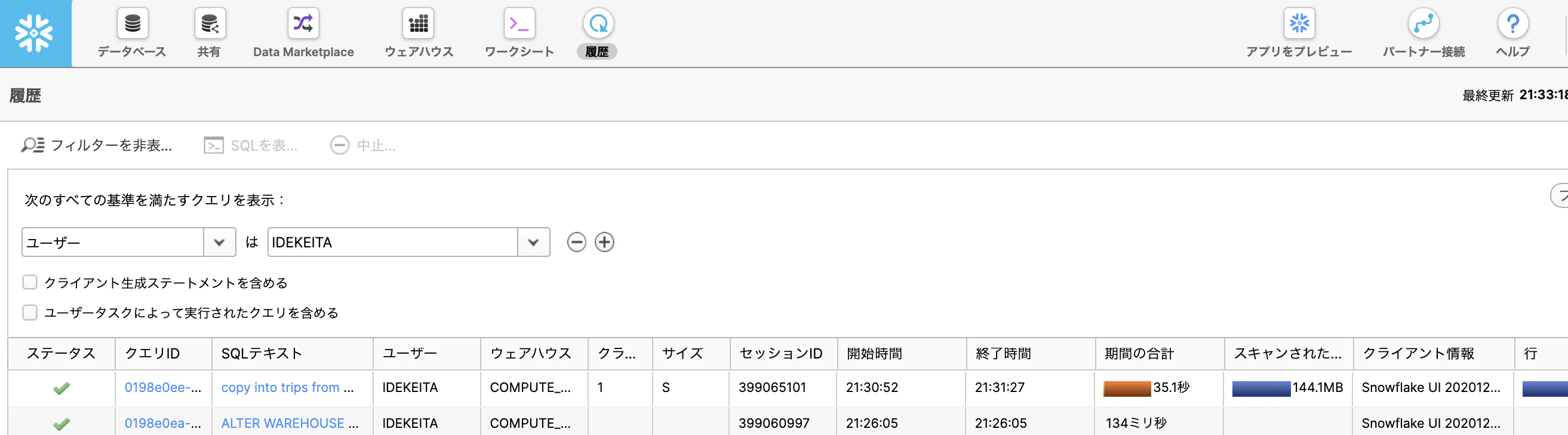
実行後、履歴タブに移動すると実行時間やスキャンサイズなど、クエリの詳細がわかります。
以下にて、実際にテーブルにデータが存在していることがわかります。
select * from trips limit 20;
4. 分析
では、分析開始です。
1時間ごとの統計をだしてみます。
select date_trunc('hour', starttime) as "date", count(*) as "num trips", avg(tripduration)/60 as "avg duration (mins)", avg(haversine(start_station_latitude, start_station_longitude, end_station_latitude, end_station_longitude)) as "avg distance (km)" from trips group by 1 order by 1;サイズ
Sのウェアハウスで実行しました。
44,295行を84msで結果が返ってきています。
サイズを
Lに変更してもう一度実行してみました。
84ms->62msとなりました。
サイズに応じてスケールできていますね。
おわりに
snowflakeのハンズオンを題材にさわりだけやってみました。
まだまだ色々できそうですが、概念レベルは掴めた感じがします。
もう少し触ってみようと思います。


















- 投稿日:2020-12-12T23:50:44+09:00
AWS Amplifyメモ
1.チュートリアルの注意点
- チュートリアルの「モジュール1」でindex.htmlをzipでアップロードするとき、Macの場合はターミナル上でzipコマンドを使用すること。GUIで「〜を圧縮」では「AccessDenied」というXMLファイルが表示されうまくいかない。
<Error> <Code>AccessDenied</Code> <Message>Access Denied</Message> <RequestId>XXXXXXXX</RequestId> <HostId>XXXXXXXXXXXXXXXXXXXXXXXXXX</HostId> </Error>
- 投稿日:2020-12-12T23:39:43+09:00
Amazon SageMaker Clarifyでデータの偏りと機械学習モデルの説明をしてみた
この記事はNTTComアドベントカレンダー12日目の記事となります。
kirikeiと申します。普段はNTT Communicationsでデータ分析ツールのスクラム開発や,機械学習モデルの説明性(いわゆるXAIの分野)や因果推論に関する研究をしています。あとは趣味でAWSやAzure,GCPなどの機械学習サービスを検証していて,こんな記事やこんな記事も書いています。
今回はその例に漏れず,現在開催中のAWS最大のイベントre:Inventで,先日先日(この記事を書く4日前?)発表のあったAmazon SageMaker Clarifyを早速検証・紹介させて頂きます。
Amazon SageMakerとは?
Amazon SageMakerとは,AWSで提供されている機械学習エンジニアのための機械学習モデルの学習や実験管理,モデルの管理,モデルのデプロイを効率的に行うためのプラットフォームです。機械学習エンジニアが悩みがちなインフラ周りの雑務を一手に引き受けてくれる素敵なサービスです。
SageMakerには複数のインターフェースが存在し,モデル選択して簡単に学習してくれるGUIと,機械学習エンジニアが最もよく使っているであろうJupyterLabやJupyter NotebookからSDKを叩いて学習を行うインターフェースが用意されています。
また,昨年からJupyterLabのインターフェースをさらにパワーアップさせ,Jupyter-Likeなインターフェースから実験管理やモデルの管理まで行える統合環境のSageMaker Studioも利用可能になっています。
SageMaker全体に関して,詳しくはAmazon Web Service Japanのスライドを,SageMaker Studioについてはわかりやすく書かれたQiita記事があるのでそちらを参照下さい。
- SageMaker Studioのインターフェースはこんな感じ。ここからSDKを叩いて(例えば
XX.fitとかXX.deployとかを実行すると指定したリソースの学習コンテナが立ち上がって学習が行われ,モデルがデプロイされてエンドポイントを作成できたりします)
Amazon SageMaker Clarifyとは?
Amazon SageMaker Clarifyとは,冒頭でも述べた2020年のre:Inventにて発表されたSageMakerの新しい機能のことで,機械学習モデルの実用化において重要となる機械学習モデルの説明性や,モデルやデータのバイアスを評価できるところが特徴です。
機械学習モデルの説明を行うクラウドサービスとしてはGCPのExplainable AIや,Azureのazureml.interpretが先行していましたが,AWSからも今回リリースされることとなり,それぞれクラウド3社が説明性に関する機能をそれぞれの機械学習サービスに携えたことになります。それだけ注目されている分野だということがわかります。
機械学習モデルの説明性とは?
ニューラルネットワークをはじめとするパラメータ数が多く非線形なモデルは,どの入力が出力に寄与しているかを把握するのが困難であり,産業などで利用する際のモデルの信頼性に問題を抱えています。その中で研究されているのが機械学習モデルの説明性に関する研究であり,Explainable AI,通称XAIとも呼ばれます。今回は中身までは触れませんが,Qiita内に素晴らしい記事もあるので,興味のある方は参照下さい。
Clarifyでは説明性の手法の中でスタンダードになりつつあるSHAPを利用して各特徴が出力に対してどれくらい寄与しているのかを数値化,可視化しています。この手法はニューラルネットワークやGBTを含むどのようなモデルにも利用できるという利点があります。
バイアスとは?
機械学習モデルのバイアスと聞くと機械学習を生業にしている方はバイアスとバリアンスを思い浮かべるかもしれませんが,SageMaker Clarifyの文脈では一般的な用語としてのバイアスのことを示します。例えば特徴量に男女のラベルがあった時に,本来は男女に差が出ないデータにもかかわらずデータ中の男女の数のインバランスによって結果に影響してしまうようなことを言います(研究的にはfairnessが近いと思われます。)
Clarifyではデータのバイアス(pretrain-bias)とモデルのバイアス(posttrain-bias)を評価することができます。前者は目的変数に対してある特徴がどれくらいセンシティブか,具体的には目的変数をバイナリのラベル(または閾値)で分けた分布と興味のある特徴をバイナリ(または閾値)で分けたときのデータ分布がどの程度離れているかを数値化します。
Kaggleのデータで試してみた
SageMaker ClarifyのサンプルコードはGithubで公開されていますが,これをそのままやるのは面白くないので,今回は別のデータとしてKaggleのHouse Pricesを用います。
このデータは,家に関する様々な属性()家の値段がいくらになるかを予測するデータで,
下準備としてSageMakerにアクセスしてノートブックインスタンスを立ち上げておき,Kaggleのページからtrain.csv,test.csvをダウンロードしてJupyterLabにアップロードしておきます。
データ可視化からモデルの学習まで
まず,利用するパッケージやデータを格納するS3のバケットや実行リージョンを定義しておきます。今回はs3バケットに
house-price-sagemaker-clarifyという名前をつけておきます。from sagemaker import Session session = Session() bucket = session.default_bucket() prefix = 'sagemaker/house-price-sagemaker-clarify' region = session.boto_region_name # Define IAM role from sagemaker import get_execution_role import pandas as pd import numpy as np import urllib import os from sklearn.model_selection import train_test_split role = get_execution_role()データの中身を確認します。
train_df = pd.read_csv('train.csv', index_col=0) test_df = pd.read_csv('test.csv', index_col=0) train_df.head()
見ての通り,今回のデータはテキストのカテゴリカルデータが多いので,最低限の前処理としてバイナリに変更しておきます。
all_df = pd.get_dummies(pd.concat([train_df, test_df], axis=0)) train_df = all_df.iloc[:train_df.shape[0], :] test_df = all_df.iloc[train_df.shape[0]:, :]ここからはSageMakerを利用して学習まで一気に実行します。SageMakerで学習を行う場合は一旦学習データをファイルとしてS3にアップロードし,そのデータのURIを学習時に指定することで学習データを取ってきて学習を行います。詳しくはこちらの記事に詳しく書かれています。
# カラムの入れ替え。SageMakerは先頭カラムをTargetとして認識する def to_csv(df, filename, is_train=True): if is_train: df = pd.concat([df[target_column], df.drop(target_column, axis=1)], axis=1) else: df = df.drop(target_column, axis=1) df.to_csv(filename, index=None, header=None) # indexとheaderは不要 return df train_df = to_csv(train_df, 'train_data.csv') test_df = to_csv(test_df, 'test_data.csv', is_train=False) # S3にアップロードするためファイルとして吐き出しておく train_df = to_csv(train_df, 'train_data.csv') test_df = to_csv(test_df, 'test_data.csv', is_train=False) # s3へのアップロード from sagemaker.s3 import S3Uploader from sagemaker.inputs import TrainingInput train_uri = S3Uploader.upload('train_data.csv', 's3://{}/{}'.format(bucket, prefix)) train_input = TrainingInput(train_uri, content_type='csv') test_uri = S3Uploader.upload('test_data.csv', 's3://{}/{}'.format(bucket, prefix)) # XGBoostによる学習 # SageMaker SDKのEstimatorクラスを利用する。XGBのwrapperとなっている from sagemaker.image_uris import retrieve from sagemaker.estimator import Estimator # 学習 container = retrieve('xgboost', region, version='1.2-1') # XGBが使えるコンテナイメージの指定 # モデルの定義 xgb = Estimator(container, role, instance_count=1, instance_type='ml.m4.xlarge', # 学習インスタンス(今回はもりもり) disable_profiler=True, sagemaker_session=session) xgb.set_hyperparameters(max_depth=5, eta=0.2, gamma=4, min_child_weight=6, subsample=0.8, objective='reg:squarederror', # 回帰問題 num_round=800) # 学習開始,URIからデータを取得し,指定したインスタンスで学習する # 学習ログはCloudWatchに自動的に吐き出される # 学習が終わるとインスタンスが勝手に落ちる xgb.fit({'train': train_input}, logs='None', wait='True') # モデルの登録 from sagemaker.serializers import CSVSerializer from sagemaker.deserializers import CSVDeserializer # モデルに名前をつけてモデル管理リポジトリに登録する model_name = 'house-price-clarify-model' model = xgb.create_model(name=model_name) container_def = model.prepare_container_def() session.create_model(model_name, role, container_def)Clarifyの利用
ここからいよいよClarifyの利用です。ClarifyはSDKの中の1ライブラリとして用意されており,基本的にコンフィグを定義した後の
run_biasとrun_explainabilityでバイアスの数値化と説明の可視化をそれぞれHTMLやPDFのレポートにして(!)S3に出力してくれます。また,最大のメリットはSageMaker最大の武器であるインフラを気にしなくて良いことこれに尽きます。説明やバイアスの計算も学習まではいかないものの計算時間がかかったりGPUを利用する必要があったりと,インフラと密接に関わっています。Clarifyではこの説明やバイアスの計算も学習と同じように,説明の計算プロセスをユーザが決めたリソースでコンテナに切り出して実行しているため,このSageMakerの思想がフルに生かされています。
バイアスの数値化
バイアスの数値化は先に述べたようにデータに対するバイアスとモデルに対するバイアスを計算しています。基本的にはある興味のある特徴に対して,目的変数がどのくらい敏感なのかを計算しています。具体的には,例えばバイナリな特徴(0or1)と目的変数(0or1)があった時,特徴が0だった時の目的変数が1,0の時のそれぞれの分布と,特徴が1だった時の目的変数が1,0の時のそれぞれの分布がどの程度異なるか(例えばKL Divergence)をバイアスとして評価しています。直感的にはこの分布が異なれば異なるほど特徴によって目的変数が変動していることがわかります。詳しくはこちらの公式ドキュメントに詳しく書かれています。
モデルのバイアスは上記の計算を目的変数ではなく予測値で行っているようです。元々の目的変数のバイアスと予測値のバイアスがどのように異なるかを比較することでモデルのバイアスが確認できるようです。こちらも詳しくは公式ドキュメントを参照して下さい。
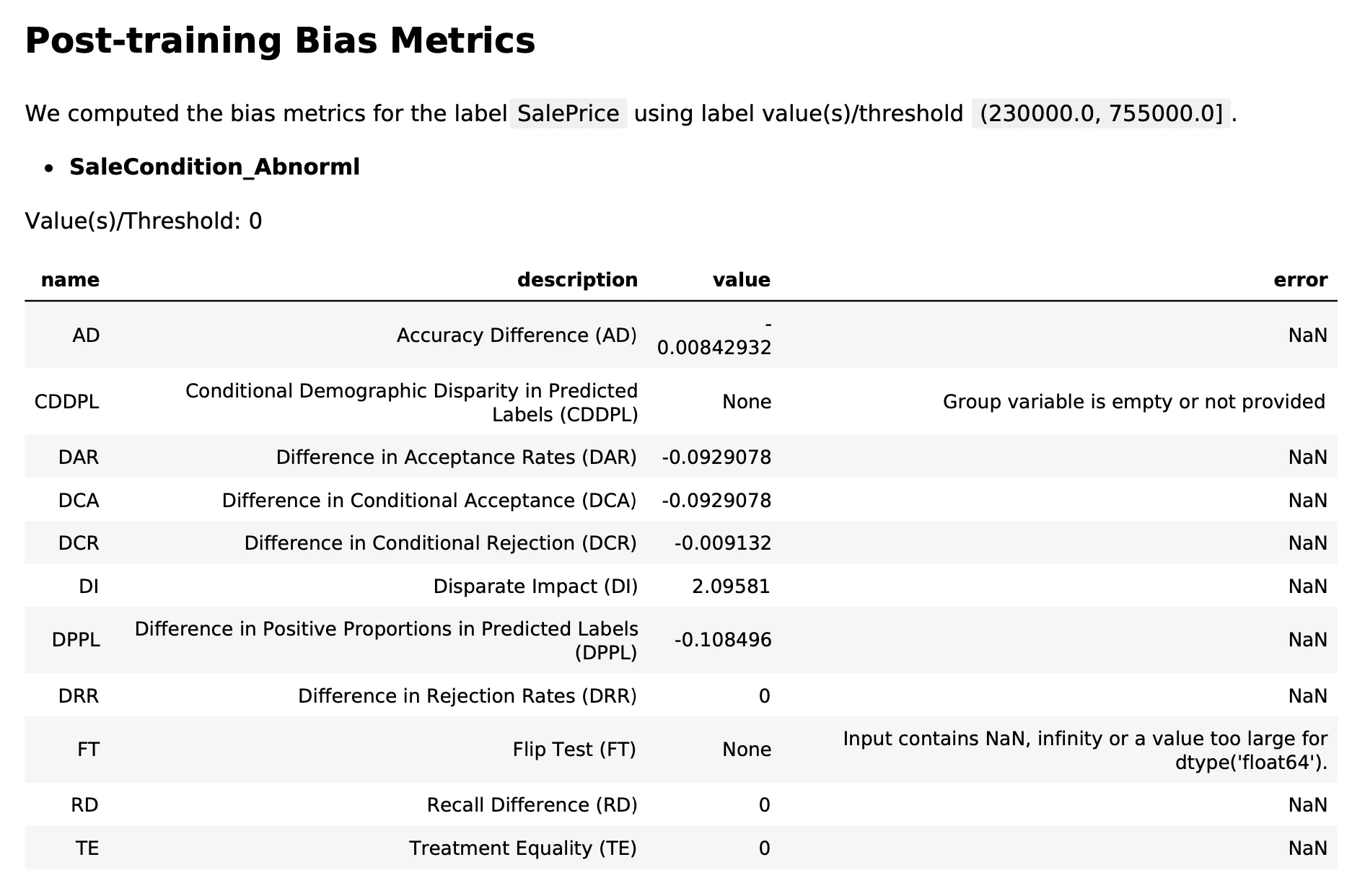
今回扱うデータは目的変数が価格=連続値であるため,価格の上位80%を閾値に設定して,バイアスを測る説明変数はSalesCondition_Abnormal(通常の販売方法ではなく差し押さえやトレード,空売り)を選択しました。すなわち通常の販売方法でない場合に目的変数に違いがあるか,またはモデルの予測値に違いがあるかを見ていることになります。
実行コードは以下となります。
from sagemaker import clarify # clarifyを利用するインスタンスの設定 clarify_processor = clarify.SageMakerClarifyProcessor(role=role, instance_count=1, instance_type='ml.c4.xlarge', sagemaker_session=session) # レポートの出力先 bias_report_output_path = 's3://{}/{}/clarify-bias'.format(bucket, prefix) # データの設定 bias_data_config = clarify.DataConfig(s3_data_input_path=train_uri, s3_output_path=bias_report_output_path, label=target_column, # targetとなるカラム headers=train_df.columns.to_list(), # カラム名 dataset_type='text/csv') # 対象となるモデルの設定 # 今回はXGBoost model_config = clarify.ModelConfig(model_name=model_name, instance_type='ml.c5.xlarge', instance_count=1, accept_type='text/csv') predictions_config = clarify.ModelPredictedLabelConfig() # 目的変数の閾値とラベルの設定 bias_config = clarify.BiasConfig(label_values_or_threshold=[train_df[target_column].quantile(q=0.8)], facet_name='SaleCondition_Abnorml', facet_values_or_threshold=[0]) # 興味のある特徴の値 # pre-biasとpost-biasを一緒に実行 # biasの測り方は一旦全てのメソッドを利用する clarify_processor.run_bias(data_config=bias_data_config, bias_config=bias_config, model_config=model_config, model_predicted_label_config=predictions_config, pre_training_methods='all', post_training_methods='all')実行するとS3のバケット内に
report.pdfというファイルが現れ,中身には以下のような結果が表示されます。
データのバイアスに関して,クラスはかなりインバランスになっているので,ラベルの数にかなり偏りはあるようです。ただし,その他の尺度はそれほど大きくない(基本的に距離の尺度なので0に近いほど分布が近い)ため,クラスに偏りはあるものの分布は似ているため,この特徴はそれほど大きな影響がないのかもしれません。
モデルのバイアスに関してもDisparate Impactは大きいですが,基本的には0に近い値を取り,公式ドキュメントによるとバイアスは小さそうです。よって元のデータのバイアスが小さいことも考えるとモデルにバイアスが混入している可能性は低いと言えるかもしれません(ただし厳密には検定などが必要だと思われます。)
説明の可視化
次はモデルの説明,すなわち入力の出力に対する重要度を可視化します。先に述べた通りよく使われるSHAP(Kernel SHAP)を利用して重要度を抽出しています。こちらもClarifyでは設定後に
run_explainability一発で実行してくれるので大変簡単です。# Kernel SHAPに利用するハイパーパラメータ shap_config = clarify.SHAPConfig(baseline=[test_df.iloc[0].values.tolist()], num_samples=100, agg_method='mean_abs') # 格納先 explainability_output_path = 's3://{}/{}/clarify-explainability'.format(bucket, prefix) # 説明に利用するデータ explainability_data_config = clarify.DataConfig(s3_data_input_path=train_uri, s3_output_path=explainability_output_path, label=target_column, headers=train_df.columns.to_list(), dataset_type='text/csv') # 説明性の計算 clarify_processor.run_explainability(data_config=explainability_data_config, model_config=model_config, explainability_config=shap_config)実行を行うと下記のようなレポートが同様に現れます。
重要度の高い特徴トップ10が順に可視化されます。これをみるとカテゴリカルデータよりも値に依存するようですね。あと築年数やクオリティなど,直感的にも価格に関係のありそうな項目をモデルは重要視しているようです。
所感とまとめ
今回新しく発表のあったClarifyですが,SageMakerユーザとしては他の学習やデプロイの実行と似たようなインターフェースで作られており,特に悩むことなく実行することができました。今後は学習→デプロイのパイプラインの中にClarifyで説明やバイアスをいれるというビジョンが見えてきます。一方でバイアスは値の意味の理解が必要であり,ユーザの知識がなかなか必要になると感じました。
説明性を研究している自分としてはこれだけ説明性が身近になる,当たり前に使われるのは非常に嬉しいですね!(説明性も色々問題あったりするけどそれはまた別の機会で。)
アドベントカレンダー,次はNTT Communicationsにおけるブロックチェーン技術の第一人者,@nitkyさんの記事になります!ご期待ください!!(期待してます!)
参考文献



- 投稿日:2020-12-12T23:39:43+09:00
Amazon SageMaker Clarify〜機械学習モデルのバイアスと説明をお手軽に計算しよう〜
この記事はNTTComアドベントカレンダー12日目の記事となります。
初めまして,kirikeiと申します。普段はNTT Communicationsでデータ分析ツールのスクラム開発や,機械学習モデルの説明性(いわゆるXAIの分野)や因果推論に関する研究をしています。あとは趣味でAWSやAzure,GCPなどの機械学習サービスを検証していて,こんな記事やこんな記事も書いています。
今回はその例に漏れず,現在開催中のAWS最大のイベントre:Inventで,先日(この記事を書く4日前?)発表のあったモデルの説明性やデータのバイアスを計算できるSageMakerの新機能であるAmazon SageMaker Clarifyを早速検証・紹介させて頂きます。(タイムリー!)
Amazon SageMakerとは?
Amazon SageMakerとは,AWSで提供されている機械学習エンジニアのための機械学習モデルの学習や実験管理,モデルの管理,モデルのデプロイを効率的に行うためのプラットフォームです。機械学習エンジニアが悩みがちなインフラ周りの雑務を一手に引き受けてくれる素敵なサービスです。
SageMakerには複数のインターフェースが存在し,モデル選択して簡単に学習してくれるGUIと,機械学習エンジニアが最もよく使っているであろうJupyterLabやJupyter NotebookからSDKを叩いて学習を行うインターフェースが用意されています。
また,昨年からJupyterLabのインターフェースをさらにパワーアップさせ,Jupyter-Likeなインターフェースから実験管理やモデルの管理まで行える統合環境のSageMaker Studioも利用可能になっています。
SageMaker全体に関して,詳しくはAmazon Web Service Japanのスライドを,SageMaker Studioについてはわかりやすく書かれたQiita記事があるのでそちらを参照下さい。
- SageMaker Studioのインターフェースはこんな感じ。ここからSDKを叩いて(例えば
XX.fitとかXX.deployとかを実行すると指定したリソースの学習コンテナが立ち上がって学習が行われ,モデルがデプロイされてエンドポイントを作成できたりします)Amazon SageMaker Clarifyとは?
Amazon SageMaker Clarifyとは,冒頭でも述べた2020年のre:Inventにて発表されたSageMakerの新しい機能のことで,機械学習モデルの実用化において重要となる機械学習モデルの説明性や,モデルやデータのバイアスを評価できるところが特徴です。
機械学習モデルの説明を行うクラウドサービスとしてはGCPのExplainable AIや,Azureのazureml.interpretが先行していましたが,AWSからも今回リリースされることとなり,それぞれクラウド3社が説明性に関する機能をそれぞれの機械学習サービスに携えたことになります。それだけ注目されている分野だということがわかります。
機械学習モデルの説明性とは?
ニューラルネットワークをはじめとするパラメータ数が多く非線形なモデルは,どの入力が出力に寄与しているかを把握するのが困難であり,産業などで利用する際のモデルの信頼性に問題を抱えています。その中で研究されているのが機械学習モデルの説明性に関する研究であり,Explainable AI,通称XAIとも呼ばれます。今回は中身までは触れませんが,Qiita内に素晴らしい記事もあるので,興味のある方は参照下さい。
Clarifyでは説明性の手法の中でスタンダードになりつつあるSHAPを利用して各特徴が出力に対してどれくらい寄与しているのかを数値化,可視化しています。この手法はニューラルネットワークやGBTを含むどのようなモデルにも利用できるという利点があります。
バイアスとは?
機械学習モデルのバイアスと聞くと機械学習を生業にしている方はバイアスとバリアンスを思い浮かべるかもしれませんが,SageMaker Clarifyの文脈では一般的な用語としてのバイアスのことを示します。例えば特徴量に男女のラベルがあった時に,本来は男女に差が出ないデータにもかかわらずデータ中の男女の数のインバランスによって結果に影響してしまうようなことを言います(研究的にはfairnessが近いと思われます。)
Clarifyではデータのバイアス(pretrain-bias)とモデルのバイアス(posttrain-bias)を評価することができます。前者は目的変数に対してある特徴がどれくらいセンシティブか,具体的には目的変数をバイナリのラベル(または閾値)で分けた分布と興味のある特徴をバイナリ(または閾値)で分けたときのデータ分布がどの程度離れているかを数値化します。
Kaggleのデータで試してみた
SageMaker ClarifyのサンプルコードはGithubで公開されていますが,これをそのままやるのは面白くないので,今回は別のデータとしてKaggleのHouse Pricesを用います。
このデータは,家に関する様々な属性(家のクオリティや築年数,売り方,場所,etc...)の情報から家の値段がいくらになるかを予測するデータです。
下準備としてSageMakerにアクセスしてノートブックインスタンスを立ち上げておき,Kaggleのページからtrain.csv,test.csvをダウンロードしてJupyterLabにアップロードしておきます。以下のコードはSageMaker上のJupyterLabまたはSageMaker Studioで実行します。
データ可視化からモデルの学習まで
まず,利用するパッケージやデータを格納するS3のバケットや実行リージョンを定義しておきます。今回はs3バケットに
house-price-sagemaker-clarifyという名前をつけておきます。from sagemaker import Session session = Session() bucket = session.default_bucket() prefix = 'sagemaker/house-price-sagemaker-clarify' region = session.boto_region_name # Define IAM role from sagemaker import get_execution_role import pandas as pd import numpy as np import urllib import os from sklearn.model_selection import train_test_split role = get_execution_role()データの中身を確認します。
train_df = pd.read_csv('train.csv', index_col=0) test_df = pd.read_csv('test.csv', index_col=0) train_df.head()
見ての通り,今回のデータはテキストのカテゴリカルデータが多いので,最低限の前処理としてバイナリに変更しておきます。
all_df = pd.get_dummies(pd.concat([train_df, test_df], axis=0)) train_df = all_df.iloc[:train_df.shape[0], :] test_df = all_df.iloc[train_df.shape[0]:, :]ここからはSageMakerを利用して学習まで一気に実行します。SageMakerで学習を行う場合は一旦学習データをファイルとしてS3にアップロードし,そのデータのURIを学習時に指定することで学習データを取ってきて学習を行います。詳しくはこちらの記事に詳しく書かれています。
# カラムの入れ替え。SageMakerは先頭カラムをTargetとして認識する def to_csv(df, filename, is_train=True): if is_train: df = pd.concat([df[target_column], df.drop(target_column, axis=1)], axis=1) else: df = df.drop(target_column, axis=1) df.to_csv(filename, index=None, header=None) # indexとheaderは不要 return df train_df = to_csv(train_df, 'train_data.csv') test_df = to_csv(test_df, 'test_data.csv', is_train=False) # S3にアップロードするためファイルとして吐き出しておく train_df = to_csv(train_df, 'train_data.csv') test_df = to_csv(test_df, 'test_data.csv', is_train=False) # s3へのアップロード from sagemaker.s3 import S3Uploader from sagemaker.inputs import TrainingInput train_uri = S3Uploader.upload('train_data.csv', 's3://{}/{}'.format(bucket, prefix)) train_input = TrainingInput(train_uri, content_type='csv') test_uri = S3Uploader.upload('test_data.csv', 's3://{}/{}'.format(bucket, prefix)) # XGBoostによる学習 # SageMaker SDKのEstimatorクラスを利用する。XGBのwrapperとなっている from sagemaker.image_uris import retrieve from sagemaker.estimator import Estimator # 学習 container = retrieve('xgboost', region, version='1.2-1') # XGBが使えるコンテナイメージの指定 # モデルの定義 xgb = Estimator(container, role, instance_count=1, instance_type='ml.m4.xlarge', # 学習インスタンス(今回はもりもり) disable_profiler=True, sagemaker_session=session) xgb.set_hyperparameters(max_depth=5, eta=0.2, gamma=4, min_child_weight=6, subsample=0.8, objective='reg:squarederror', # 回帰問題 num_round=800) # 学習開始,URIからデータを取得し,指定したインスタンスで学習する # 学習ログはCloudWatchに自動的に吐き出される # 学習が終わるとインスタンスが勝手に落ちる xgb.fit({'train': train_input}, logs='None', wait='True') # モデルの登録 from sagemaker.serializers import CSVSerializer from sagemaker.deserializers import CSVDeserializer # モデルに名前をつけてモデル管理リポジトリに登録する model_name = 'house-price-clarify-model' model = xgb.create_model(name=model_name) container_def = model.prepare_container_def() session.create_model(model_name, role, container_def)Clarifyの利用
ここからいよいよClarifyの利用です。ClarifyはSDKの中の1ライブラリとして用意されており,基本的にコンフィグを定義した後の
run_biasとrun_explainabilityでバイアスの数値化と説明の可視化をそれぞれHTMLやPDFのレポートにして(!)S3に出力してくれます。また,最大のメリットはSageMaker最大の武器であるインフラを気にしなくて良いことこれに尽きます。説明やバイアスの計算も学習まではいかないものの計算時間がかかったりGPUを利用する必要があったりと,インフラと密接に関わっています。Clarifyではこの説明やバイアスの計算も学習と同じように,説明の計算プロセスをユーザが決めたリソースでコンテナに切り出して実行しているため,このSageMakerの思想がフルに生かされています。
バイアスの数値化
バイアスの数値化は先に述べたようにデータに対するバイアスとモデルに対するバイアスを計算しています。基本的にはある興味のある特徴に対して,目的変数がどのくらい敏感なのかを計算しています。具体的には,例えばバイナリな特徴(0or1)と目的変数(0or1)があった時,特徴が0だった時の目的変数が1,0の時のそれぞれの分布と,特徴が1だった時の目的変数が1,0の時のそれぞれの分布がどの程度異なるか(例えばKL Divergence)をバイアスとして評価しています。直感的にはこの分布が異なれば異なるほど特徴によって目的変数が変動していることがわかります。詳しくはこちらの公式ドキュメントに詳しく書かれています。
モデルのバイアスは上記の計算を目的変数ではなく予測値で行っているようです。元々の目的変数のバイアスと予測値のバイアスがどのように異なるかを比較することでモデルのバイアスが確認できるようです。こちらも詳しくは公式ドキュメントを参照して下さい。
今回扱うデータは目的変数が価格=連続値であるため,価格の上位80%を閾値に設定して,バイアスを測る説明変数はSalesCondition_Abnormal(通常の販売方法ではなく差し押さえやトレード,空売り)を選択しました。すなわち通常の販売方法でない場合に目的変数に違いがあるか,またはモデルの予測値に違いがあるかを見ていることになります。
実行コードは以下となります。
from sagemaker import clarify # clarifyを利用するインスタンスの設定 clarify_processor = clarify.SageMakerClarifyProcessor(role=role, instance_count=1, instance_type='ml.c4.xlarge', sagemaker_session=session) # レポートの出力先 bias_report_output_path = 's3://{}/{}/clarify-bias'.format(bucket, prefix) # データの設定 bias_data_config = clarify.DataConfig(s3_data_input_path=train_uri, s3_output_path=bias_report_output_path, label=target_column, # targetとなるカラム headers=train_df.columns.to_list(), # カラム名 dataset_type='text/csv') # 対象となるモデルの設定 # 今回はXGBoost model_config = clarify.ModelConfig(model_name=model_name, instance_type='ml.c5.xlarge', instance_count=1, accept_type='text/csv') predictions_config = clarify.ModelPredictedLabelConfig() # 目的変数の閾値とラベルの設定 bias_config = clarify.BiasConfig(label_values_or_threshold=[train_df[target_column].quantile(q=0.8)], facet_name='SaleCondition_Abnorml', facet_values_or_threshold=[0]) # 興味のある特徴の値 # pre-biasとpost-biasを一緒に実行 # biasの測り方は一旦全てのメソッドを利用する clarify_processor.run_bias(data_config=bias_data_config, bias_config=bias_config, model_config=model_config, model_predicted_label_config=predictions_config, pre_training_methods='all', post_training_methods='all')実行するとS3のバケット内に
report.pdfというファイルが現れ,中身には以下のような結果が表示されます。
データのバイアスに関して,クラスはかなりインバランスになっているので,ラベルの数にかなり偏りはあるようです。ただし,その他の尺度はそれほど大きくない(基本的に距離の尺度なので0に近いほど分布が近い)ため,クラスに偏りはあるものの分布は似ているため,この特徴はそれほど大きな影響がないのかもしれません。
モデルのバイアスに関してもDisparate Impactは大きいですが,基本的には0に近い値を取り,公式ドキュメントによるとバイアスは小さそうです。よって元のデータのバイアスが小さいことも考えるとモデルにバイアスが混入している可能性は低いと言えるかもしれません(ただし厳密には検定などが必要だと思われます。)
説明の可視化
次はモデルの説明,すなわち入力の出力に対する重要度を可視化します。先に述べた通りよく使われるSHAP(Kernel SHAP)を利用して重要度を抽出しています。こちらもClarifyでは設定後に
run_explainability一発で実行してくれるので大変簡単です。# Kernel SHAPに利用するハイパーパラメータ shap_config = clarify.SHAPConfig(baseline=[test_df.iloc[0].values.tolist()], num_samples=100, agg_method='mean_abs') # 格納先 explainability_output_path = 's3://{}/{}/clarify-explainability'.format(bucket, prefix) # 説明に利用するデータ explainability_data_config = clarify.DataConfig(s3_data_input_path=train_uri, s3_output_path=explainability_output_path, label=target_column, headers=train_df.columns.to_list(), dataset_type='text/csv') # 説明性の計算 clarify_processor.run_explainability(data_config=explainability_data_config, model_config=model_config, explainability_config=shap_config)実行を行うと下記のようなレポートが同様に現れます。
重要度の高い特徴トップ10が順に可視化されます。これをみるとカテゴリカルデータよりも値に依存するようですね。あと築年数やクオリティなど,直感的にも価格に関係のありそうな項目をモデルは重要視しているようです。
所感とまとめ
今回新しく発表のあったClarifyですが,SageMakerユーザとしては他の学習やデプロイの実行と似たようなインターフェースで作られており,特に悩むことなく実行することができました。今後は学習→デプロイのパイプラインの中にClarifyで説明やバイアスをいれるというビジョンが見えてきます。一方でバイアスは値の意味の理解が必要であり,ユーザの知識がなかなか必要になると感じました。
説明性を研究している自分としてはこれだけ説明性が身近になる,当たり前に使われるのは非常に嬉しいですね!(説明性も色々問題あったりするけどそれはまた別の機会で。)
アドベントカレンダー,次はNTT Communicationsにおけるブロックチェーン技術の第一人者,@nitkyさんの記事になります!ご期待ください!!(期待してます!)
参考文献
- 投稿日:2020-12-12T23:12:57+09:00
AWS超初心者がFargateを使ってみた
この記事はユニークビジョン株式会社 Advent Calendar 2020の記事です。
動機
「会社はFargate使っててそのデプロイをさせてもらったことはあるけど、もはや手順はすべてドキュメントに従ってるだけで何をやってるのか、何が起きているのかさっぱりだ...これはまずい!」
この記事のレベル
- AWSって、あれでしょ?なんかウェブサービス公開できるやつ
- デプロイ?なんとなくわかるけど言われた(書かれた)通りにしかできないなあ...
- インフラとかネットワークとか、単語は聞いたことあるけど意味は知らん!(開き直り)
当てはまった人は安心してください。おそらく自分がこのレベルです。
インフラ?系は特に感じますが、「超」初心者向けの記事って意外と見つけづらいですよね。もしくは、部分的に手順解説はあるけどいろいろ端折ってて、始まりから終わりまで一つの記事で完結してないみたいなことは多いです。そんな方へ刺さるような記事になればと思います。はじめに
「プログラミングの練習としてウェブアプリ作ったけど、せっかくだし公開してみたいなあ」と思ったことありませんか?世の中的には最初の一歩レベルだとしても、初めて作った本人としてはみんなにぜひ触ってもらいたくなりますよね。そういったときに、聞いたことがあれば「AWSを使えば公開できるのかな?」となるかもしれません。知識ゼロだから調べるかとなっても、見る記事はどれも知らない単語で溢れている...そんな経験はないですか?この記事では、AWSに関する前知識ゼロから始められるようになっています。ただ書いている本人も細かい設定なんかは知識ゼロなので、とりあえず公開できてから細かい部分の知識を習得しよう、というスタンスでここはひとつ。
0. 事前準備
以下のCLIをインストールしておく必要があります。環境に応じて事前に行っておいてください。
- aws-cli
- docker
1. Dockerfileの用意
今回の手順では、Dockerイメージというものを使用します。Dockerって聞いたことはあるけどコンテナってなんぞや?という方は別の紹介記事でお調べください。仕組みについては特に触れません。またDockerイメージの作成ができる方は飛ばしてしまって構いません。
まずDockerイメージを作成するにあたり、その元となるDockerファイルについて軽く説明します。
Dockerファイルとは、「環境(OS+テーマに合うコマンドがプリインストール済み)」と「環境構築(実行に必要なコマンドたち)」を書き連ねたものになります。例えば「Rustのアプリケーションをlinuxで動かすぞ」(環境)+「projectがあってcargo build --releaseして...」といったものを一つのファイルに記述することで、AWS上でそれをもとに環境構築を行ってくれます。
また、後でDockerイメージの作成やアップロードを行うために、それぞれの環境に応じてDockerのCLIをインストールしておく必要があります。それではファイルの作成手順になります。
- Docker Hubという、公式or独自のベースイメージ(環境)がまとめられているところから名前を探して指定します。例えばRustの環境であれば、Docker Hub上部の検索窓に「rust」と入力すると一番上にRust公式の提供しているコンテナが出てきます。選択しTagsに切り替えると、何種類か並んでいるのが確認できると思います。Dockerイメージができるだけ小さくなるように、slimなどと入っているものを選択するとよいです。このとき右に表示されている
docker pull XXXのXXXの部分を後で使用します。- プロジェクトに戻り、
Dockerfileという名前でファイルを作成します。このファイルを置く階層は、このとき環境に含めたいファイル群が現在のディレクトリ以下に全てあるような場所(現在ディレクトリから一つでも上に辿ることがない場所)にします。- ファイルの中にはDockerfile用のコマンドを並べていきます。
FROM:先ほどのDocker Hubで確認したコンテナを指定するコマンド。FROM rust:1.48.0-slimのように記述します。WORKDIR:作業ディレクトリを設定します。mkdirとcdの合わせ技のようなコマンドです。WORKDIR /appのように記述します。COPY:アプリの実行に必要なローカルのファイル群をDockerイメージの環境内にコピーします。COPY (ローカルのディレクトリパス) (Dockerイメージの環境のコピー先パス)のように記述します。似たようなコマンドでADDというものがありますが、基本的にはこちらの方が良いらしいです。RUN:一般的なコマンドを実行するコマンド。RUN cargo build --releaseのように記述します。起動するコマンドは後で別に指定するので、環境構築を完成させるためのコマンドを羅列します。ファイルサイズの小さいイメージをビルドするためにRUNコマンドの数は少ない方が良いそうです。最終的に以下のようなファイルを作成します。自分はRustで書いているので以下のような構成になります。
# ベースイメージの選択 FROM rust:1.48.0-slim # 作業ディレクトリの指定(`/app`は無いので作られる) WORKDIR /app # 必要なファイルをコピー COPY . /app # 依存関係のインストールや必要であればコンパイルなどを行う RUN cargo build --release RUN mkdir bin \ cp target/release/web_app bin/web_app \ cargo clean2. AWSコンソールへサインイン
まずAWSコンソールとはなんぞや、という方向けです。アカウントの作成までできている方は次の章へお進みください。
- AWSコンソールとは、AWSの各種サービスをブラウザで管理できるようAmazonが提供しているものです。こちらよりサインイン画面が開けます。
- 開いたら「新しいAWSアカウントの作成」を押します。『AWS アカウントには 12 ヶ月の無料利用枠が含まれています』という文言から察する通り、本来はお金がかかるサービスです(まあ当たり前といえば当たり前ですが...)。しかし個人利用するだけなら十分すぎるくらいの無料枠が提供されています。Amazonの資金力に感謝?
- メールアドレス、パスワード、アカウント名と入力したら、さらに入力を求められます。アカウントの種類は「パーソナル」を選択し、必要項目を埋めていきましょう。
- 最後にクレジットカード情報の入力が必要になります。最初は無料だと(ECSも無料枠に含まれていると)思い込んでおり、試行錯誤のために何度もデプロイしたり作成やら削除やらしまくっていましたが、それでも$0.12なのでほぼないに等しいです。
- 無事に本人確認も終えたら、晴れてAWSコンソールにログインできるようになります。S3やEC2などよく言われている各種サービスは、画面上部のナビバー左部の「サービス」からすべて見ることができます。
余談ですがAWSではリージョンというものがあり、世界のどの地域でサービスを提供したいかによって切り替えることができます。コストやレイテンシ、特定の地域限定のサービスを利用するなどで判断すると良いです。
3. AWSコマンド用のクレデンシャルの作成
awsコマンドを実行するためには、クレデンシャル(アクセスキーとアクセスシークレット)をローカルに登録しておく必要があります。以下の手順で確認と登録を行います。
- AWSコンソールへログイン後、画面上部ナビバーのユーザー名をクリックすると表示されるリストから「マイセキュリティ資格情報」を選択します。
- アクセスキー(アクセスキー ID とシークレットアクセスキー)を展開し、「新しいアクセスキーの作成」を押します。CSVファイルのダウンロードは行っておきましょう。
- ターミナルで
aws configureとコマンドを打つと、クレデンシャルの作成が始まります。名前を付ける場合はaws configure --profile <name>のように指定してください。指定がない場合、defaultという名前で作成されます。
AWS Access Key ID:CSVファイルのAWSAccessKeyIdを入力するAWS Secret Access Key:CSVファイルのAWSSecretKeyを入力するDefault region name:AWSで選んでいる現在のリージョンを入力(例:ap-northeash-1)。リージョンはAWSコンソールの上部ナビバーのアカウント名の横から確認可能。Default output format:特に指定がなければ空欄のままEnter- プロファイル名を指定した場合、以降のawsコマンドで今回作成したプロファイルを使用するために次のコマンドを使用しておきます。
export AWS_PROFILE=<name>4. ECR(Elastic Container Registry)でリポジトリの作成
今回の目標である「自作ウェブアプリをFargateで動かす」ために行う作業は大まかに二つあります。一つは、DockerイメージをAWSにアップロードすること。もう一つは、そのイメージの実行方法を登録することです。それを行うために付随する作業がいろいろあるのですがその都度説明を加えたいと思います。
ECRでは、そのDockerイメージをアップロードして保管しておくリポジトリを作成します。こちら(リージョンは適宜変更をお願いします)よりECRのリポジトリ一覧が確認できますが、最初はおそらく空でしょう。「リポジトリを作成」を押してリポジトリを作成しましょう。設定は特に変更せずデフォルトのままでよいと思います。作成が完了したら、イメージのアップロードは後で行うので、いったんここでの作業は完了となります。
5. Dockerイメージのプッシュ
次はDockerイメージをECRレポジトリへプッシュする作業段階になります。まずECRへDockerイメージをプッシュするための認証を行います。ECRのレポジトリ一覧から一つ選択し、「プッシュコマンドの表示」ボタンを押します。するといくつかコマンドが表示されるので、1番目のコマンド(
aws ecr get-login-passwordから始まるもの)をコピペして実行します。数行出力された後、Login Succeededと表示されれば成功です。もしCannot autolaunch D-Bus without X11 $DISPLAYというエラーが表示されてしまったら、以下のコマンドを実行すると解決できるようです(こちらの記事を参考にさせていただきました)。sudo apt install gnupg2 pass次に、Dockerイメージのビルドとプッシュを行います。まずECRのレポジトリの一覧から、先ほど作成したレポジトリのURIをコピーします。ここで一度ローカルの作業環境に戻り、Dockerfileのあるディレクトリで以下のコマンドを叩きます。
export ECR_URI=XXX # XXX=ECRのレポジトリURI export ECR_TAG=0.1.0 # バージョンや種類を区別するもの # Dockerfileのビルド docker build -t $ECR_URI:$ECR_TAG . # Dockerイメージのプッシュ docker push $ECR_URI:$ECR_TAG6. ECS(Elastic Container Service)でクラスターの作成
概要
クラスターとは、あるサービス(今回でいうウェブサーバーなど)のグループのことです。クラスターやサービスとは、すごく雑に説明するとフォルダのように階層構造になっている枠組みのようなものでしょうか。正確にはもっと複雑な役割があるので、詳しく知りたい方は調べてみてください。
これから行う作業を簡単に並べると以下のようになっています。
- 「example」というクラスターを作成します
- exampleクラスターに「web-app」というサービスを一つ作成します
- web-appサービスに「run-server」というタスクを持たせます
- run-serverタスクはウェブサーバーを立ち上げるコマンドを実行します。このとき、どのDockerイメージを使うのか、ハードのスペックをどうするのか、どんなコマンドで実行するのか、といったことをまとめた「タスク定義」を作成しそれもとにタスクが実行されています
なんとなくクラスター・サービス・タスクの立ち位置がわかったのではないでしょうか?それでは手順の説明に移ります。
クラスター・サービス・タスクの作成
こちらからクラスターの一覧が表示できます。今回は「クラスターの作成」ではなく「今すぐ始める」ボタンを押します。図もあってわかりやすく、また上記の作成手順をまとめて行うことができます。
1.コンテナの定義は、4つ並んでいるボタンのうち「sample-app」を選び特に何も変更せず作成まで完了させると動くものが用意できるので、気になった方は試してみると良いです。
2. 自分でアップするDockerイメージを使用したいのでcustomを選択します。
3. コンテナの編集というウィンドウが出てくるので、次のように設定していきます
- コンテナ名:サービスの名前になります。web-appと入力しておきましょう
- イメージ:ECRのレポジトリURIを指定します。ECRのレポジトリ一覧を開き、Dockerイメージをプッシュした際にもコピーしたレポジトリのURIをペーストします。またコピーしたURIの末尾に:0.1.0と付けましょう(0123456789.dkr.ecr.ap-southeast-1.amazonaws.com/web_app:0.1.0のようになっていると思います)。
- メモリ制限:ソフト制限, 512(自由)
- ポートマッピング:80(自由)
- CPUユニット数:256(自由)
- コマンド:Dockerfileのコマンドをすべて行った状態を想定し実行するコマンドを入力します
- 作業ディレクトリ:Dockerイメージ内部の環境に対しどのディレクトリでコマンドを実行するかを指定します。/appのように指定します。
4. 「更新」ボタンを押し編集を完了します
5. クラスター名を「example」とし、それ以外は特に変更の必要はありません。
6. 「作成」ボタンを押すといろいろ作成が開始されます。これらが終わるまで待ってクラスター~タスクまでの作成が完了です。7. ウェブアプリへのアクセス
では実際にアドレスバーにURLを入力してアクセスしてみましょう。先ほど作成したクラスターのサービスを選択します。「タスク」タブからタスク(おそらく一つ)を選びパブリックIPを確認します。これをURL(
http://WW.XX.YY.ZZ/...)のhttp://の次に入力し、/以下はアプリケーションごとにつながるものを入力してください。
以下のように無事アクセスできれば成功です。
ちなみにこれを停止するには、クラスター→サービス→「更新」(画面右上)→タスクの数を0にします。また新しくイメージをプッシュしたとき、現在動いているものを置き換えるには、クラスター→サービス→「更新」(画面右上)→新しいデプロイの強制にチェック→skip to review→サービスの更新を行うことで反映させることができます。
おわりに
とりあえずFargateでサービスを動かすことができました!最初は何が原因で動いていないのかわからず、Auto Scalingグループやロールの設定を調べたりしていましたが、最低限動かすだけなら結果的にこれだけでよかったんですね。
このままでは他人へ公開するにはいろいろ足りていませんが、今後も学習と改善を重ねていこうと思います。

- 投稿日:2020-12-12T23:03:50+09:00
【初心者向け】AWSアカウントを作成したらまず料金アラームを設定しろ
学習のためにアカウントを作成したAWS初学者が最初にやるべきこと、それは料金アラームの設定です。
本記事の背景
AWSをはじめとするクラウドサービスでは、サービスを利用した分だけ課金される従量課金の仕組みがとられています。無駄な費用がかからず費用効率が高い反面、予め必要な金額がわからないため、初学者にとっては「このサービスを使ったらいくらかかるのだろう」という不安に常につきまとわれます。(参考記事)
私も初めてAWSを触った頃は、利用料金が怖くてサービスの利用を思い留まってしまうことも多くありました。(アカウント作成から1年間は無料利用枠があるものの、初学者にとってはどこまでが無料枠なのか正確に見極めることはなかなか難しいです。)
そこで、AWSの利用料が一定以上になるとメールで通知されるような料金設定アラームをつけるとこで、安心してAWSのサービスを利用できるように設定してみます。
基本的に公式チュートリアルの通り行いますが、コンソールの画面のスクリーンショットを貼るので、初学者でもとっつきやすくなっているかと思います。
利用技術
AWS CloudWatchを利用します。
AWS CloudWatchとは、AWSの各種サービスの利用状況を監視するサービスです。
Cloudwatchで、月額の推定利用料金の指標(メトリクス)を監視し、設定した閾値をオーバーしたらメールに通知がいくように設定します。設定手順
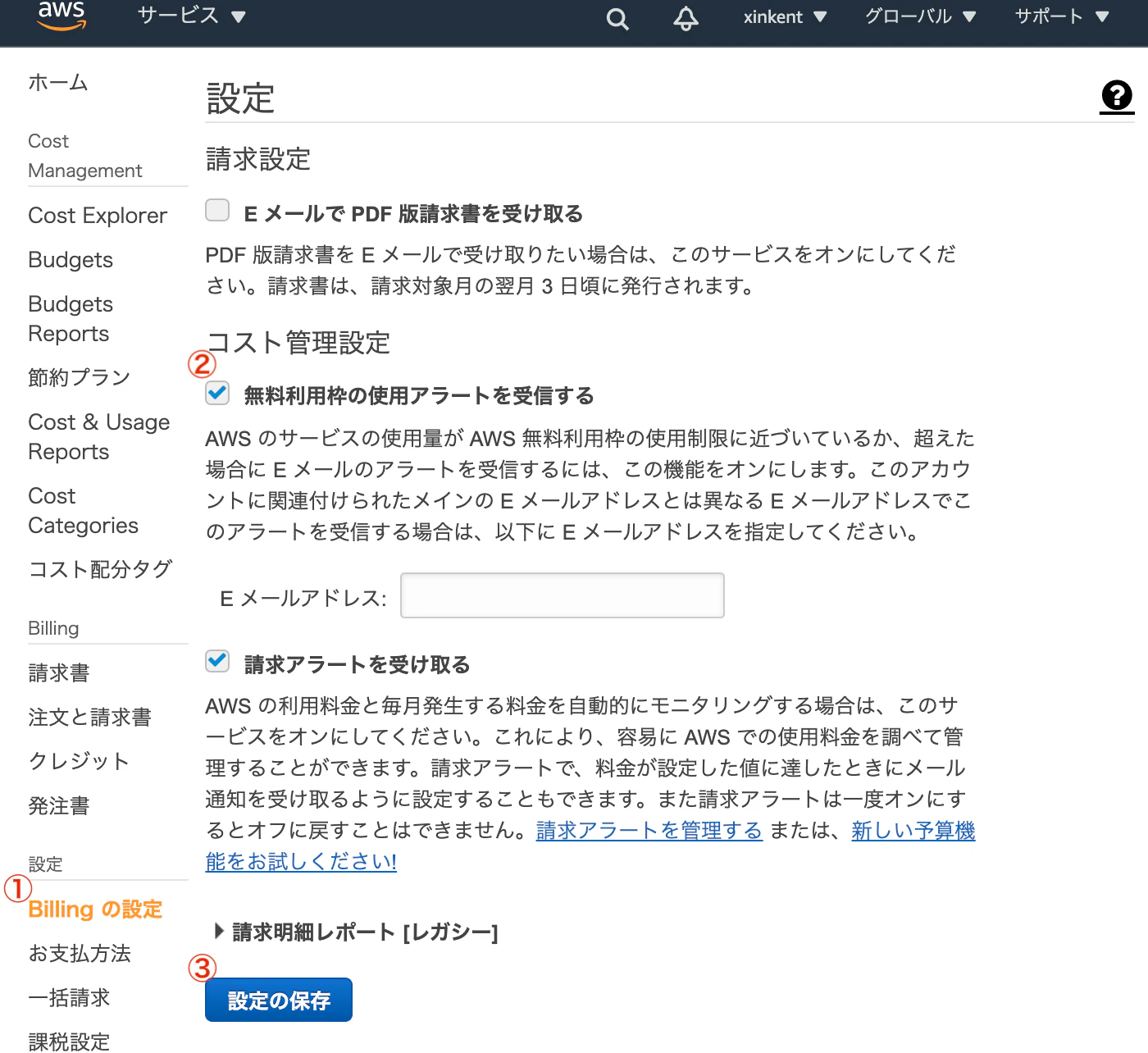
AWSコンソールにルートユーザーでログインした後、ホーム画面の「サービス」からBillingを選択します。
左メニューから「Billingの設定メニュー」を選択し、「請求アラートを受け取る」にチェックを入れ、「設定の保存」をクリックします。
AWSコンソールにルートユーザーでログインした後、ホーム画面の「サービス」からCloudWatchを選択します。
右上のメニューで、リージョンを「us-east1」に変更します。
左メニューから「メトリクス」を選択し、「アラームの作成」をクリックします。
「メトリクスの選択」をクリックします。
「請求」 -> 「概算請求額」の順に選択し、「EstimatedCharges」というメトリクスにチェックをつけ「メトリクスの選択」をクリックします。
「条件」項目で、閾値とする値を入力(今回は月額5USDとしました)し、「次へ」をクリックします。
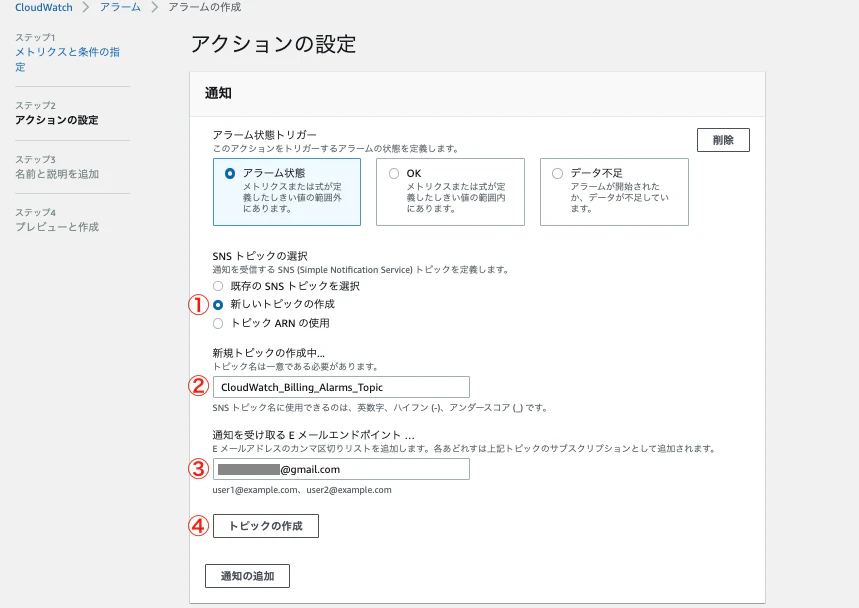
「通知」欄の「SNSトピックの選択」項目で「新しいトピックの作成」を選択し、トピック名を「CloudWatch_Billing_Alarms_Topic」、メールアドレスの欄に通知を送りたいアドレスを入力します。
入力したら「トピックの作成」をクリックし、「次へ」をクリックします。
トピックが作成されると下のようなメールが登録したメールアドレスに送られてくるので、「Confirm subscription」のリンクをクリックします。
アラーム名と説明を適当に入力して、「次へ」をクリックします。
作成内容を確認し、「アラームの作成」をクリックします。
以上で、アラームの設定が完了しました。推定利用料金が5ドルを超えるとメールに通知が飛びます。
まとめ
AWSの知識を身に付けるために重要なのはとにかく色んなサービスを使ってみることだと思います。料金設定アラームを設定して、安心してサービスを利用しましょう。









- 投稿日:2020-12-12T22:16:41+09:00
今すぐにgit-secretを導入しよう!これを読めば1分でgitのオペミスをなくせます!
はじめに
GitHubに間違えてAWSのSecret Keyなどを誤って公開してしまって〇〇万円請求されたという話はよく聞きます。
リポジトリをプライベートにしておけばいいだろ!という方も、そのリポジトリをパブリックしたり、Forkしたりしたら危険であることがわかると思います。
そんなとき、意図せずリポジトリにシークレット情報を残さないようにgit-secretをローカルに導入しましょう。
簡単にセッティングできます。
手順
まずはgit-secretをインストールします。
$ brew update && brew install git-secrets対象ディレクトリで
$ git init$ git secrets --installこれでgit-secretを利用できるようになりました。
AWS credentialのチェックはデフォルトで用意されているので、そちらを用います。
$ git secrets --register-aws --global設定は.gitconfigに記載されています。
セキュリティチェックを追加する際には、.gitconfigに正規表現で記述します。
設定一覧を見るには
$ git secrets --list◆指定のディレクトリをクロールする場合
$ git secrets --scan -r < directory name >これでディレクトリ全体のチェックができます。
◆コミットに含まれていないかのチェック
$ git add .$ git commit -m "secret check" $git secrets --scan secrets//test.txt:6:AWSSecretKey=wJaXXXXXXXXXX/XXXXXXX/bPxRfiCYEXAMPLEKEYsecrets//test.txt:7:AWSAccessKeyId=AKIAXXXXXXXXXXXAMPLEsecrets//test.txt:9:private_key [ERROR] Matched one or more prohibited patterns Possible mitigations: Mark false positives as allowed using: git config --add secrets.allowed ... Mark false positives as allowed by adding regular expressions to .gitallowed at repository's root directory List your configured patterns: git config --get-all secrets.patterns List your configured allowed patterns: git config --get-all secrets.allowed List your configured allowed patterns in .gitallowed at repository's root directory Use --no-verify if this is a one-time false positive以上です。
まとめ
本当に初歩てきな導入だけを書きました。
上記のことは一瞬でできて、重大なミスを防ぐことができるので、すぐに導入することをおすすめします。
筆者のこちらのブログもぜひ見てみてください?
ヘヴィメタル・エンジニアリング
- 投稿日:2020-12-12T21:40:48+09:00
[EC2×Route53]DNS設定を変更せずに環境切り替えを行う
EC2を使用したWEBページの環境切り替えをDNS設定を変更せずに行う手順の覚え書き。
OSのサポート切れで、環境移行を行ったり、同じドメインでサイトをリプレイスをするときなどに。
Elastic IPの関連付けを変更するだけなので、一瞬で切り替わります。イメージ図
環境
- ローカルPCのOS:Windows10
前提条件
(1) EC2インスタンス(Amazon Linux2)2つを以下3つの条件で作成済であること
① セキュリティ(インバウンドルール)
ポート範囲 プロトコル(タイプ) ソース 22 TCP(SSH) マイIP or 0.0.0.0/0 80 TCP(HTTP) マイIP or 0.0.0.0/0 443 TCP(HTTPS) マイIP or 0.0.0.0/0 ※「ソース」については、自身のローカルPCから確実に接続できる内容で記載しています。適宜変更してください。
② Elastic IP : EC2インスタンス2つに関連付け済
- 詳細は、 Elastic IP | aws を参照
③ Apacheをインストールして、各インスタンスのindex.htmlで表示されるページの内容を異なるものにしておく
Windowsより、PuTTYでEC2インスタンスに接続する方法については、PuTTY を使用した Windows から Linux インスタンスへの接続 | aws を参照
Apacheのインストール、index.htmlの作成手順は、CentOS 7でApacheをインストールし起動する | aws を参照
(2) Route53にて、以下2つを実施していること
① ドメインが登録されていること
② DNS設定を完了していること(以下の手順では、後述のElastic IP1をドメインに紐づけているものとする)
- 詳細は、 ドメイン名の登録 | aws を参照
※DNS設定は、Route53以外で行っても同様の方法で環境を切り替えられます。
手順
以下の手順では、インスタンス、Elastic IPをそれぞれ以下の表に記載の名称で記載することとします。
名称 インスタンス プライベートアドレス EC2その1 i-0e721XXXXX 10.0.2.229 EC2その2 i-0a0b1XXXXX 10.0.2.234
名称 Elastic IP Elastic IP1 18.181.31.49 Elastic IP2 3.114.159.64 変更前のEC2とElastic IPの組み合わせは以下の通り
■変更前
Elastic IP インスタンス プライベートアドレス 組み合わせ 18.181.31.49 i-0e721XXXXX 10.0.2.229 Elastic IP1 × EC2その1 3.114.159.64 i-0a0b1XXXXX 10.0.2.234 Elastic IP2 × EC2その2
※:モザイク部分は「XXXXX」で表現。Elastic IPは解放済のため、上記にアクセスしても筆者の環境にはアクセスできません。
1. 変更前アクセスチェック
「対象ドメイン/index.html」のURLを叩くと、EC2その1に配置したindex.htmlの内容が表示される
2. Elastic IP1をEC2その2に割り当てる
(1) AWSコンソールのEC2にて、ナビゲーションペインのElastic IPをクリック(①)、Elastic IP1にチェック(②)、「アクション」を選択して(③)、「Elastic IPの関連付け」をクリック(④)
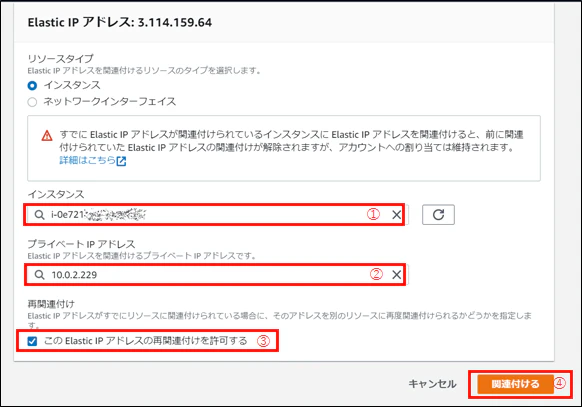
(2) 画面遷移したら、「インスタンス」で「EC2その2」(①)、EC2その2のプライベートIPアドレスを選択(1択のみ)し(②)、「このElastic IPアドレスの再関連付けを許可する」にチェックを入れ(③)、「関連付ける」をクリック(④)
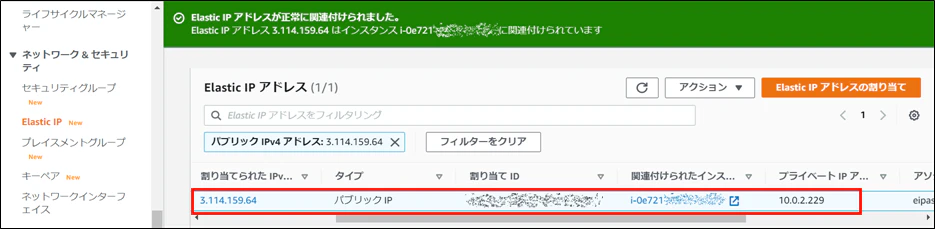
(3) ナビゲーションペインにて、Elastic IPをクリックし、Elastic IP1がEC2インスタンス2に紐づいていること(①)、Elastic IP2に紐づいているインスタンスがないことを確認(②)
3. Elastic IP2をEC2その1に割り当てる
(1) EC2のナビゲーションペインにてElastic IPをクリックし、Elastic IP2にチェックを入れる
(2) 画面遷移したら、EC2その1 → EC2その1のプライベートIPアドレスを選択(1択のみ)し、「このElastic IPアドレスの再関連付けを許可する」にチェックを入れ、「関連付ける」をクリック
(3) Elastic IP2がEC2インスタンス1に紐づいていることを確認
4. 変更後アクセスチェック
URLを叩くと、EC2その2に配置したindex.htmlの内容が表示される
変更後のEC2とElastic IPの組み合わせは以下の通り
■変更後
Elastic IP インスタンス プライベートアドレス 組み合わせ 18.181.31.49 i-0a0b1XXXXX 10.0.2.234 Elastic IP1 × EC2その2 3.114.159.64 i-0e721XXXXX 10.0.2.229 Elastic IP2 × EC2その1
終わりに
この方法なら、環境切り替えが非常にスムーズ。
切り替え前の環境が不要になる場合は、EC2インスタンスの停止・終了と、Elastic IPの開放を忘れずに。









- 投稿日:2020-12-12T20:55:33+09:00
システム運用統制を実現する承認ワークフロー・操作ログ取得をSystemsManagerとStep Functionsで構築する
これはミクシィグループ Advent Calendar 2020の13日目の記事です。
はじめに
一般的にシステムの健全性を保証するためにシステム運用統制は必要と考えられています。特にFISCやPCIDSSに準拠する必要がある場合は必須です。なお、ここでの統制とは承認されている作業のみを許可し、予定されていない作業を抑止したり制御することを指します。
こういったシステム運用統制を実現するために、パッケージやSaaSを導入する場合もありますが、利用料が高すぎて導入できないといったことがあると思います。そこで今回はAWSサービスのみでシステム運用統制を実現する方法の1つを紹介します。
概要
今回は例として「個人情報を含むDBへ接続して行う運用作業時は事前承認を必須とし、作業時の操作ログを取得すること」と定義されるシステム運用統制をAWSサービスを利用して実現します。
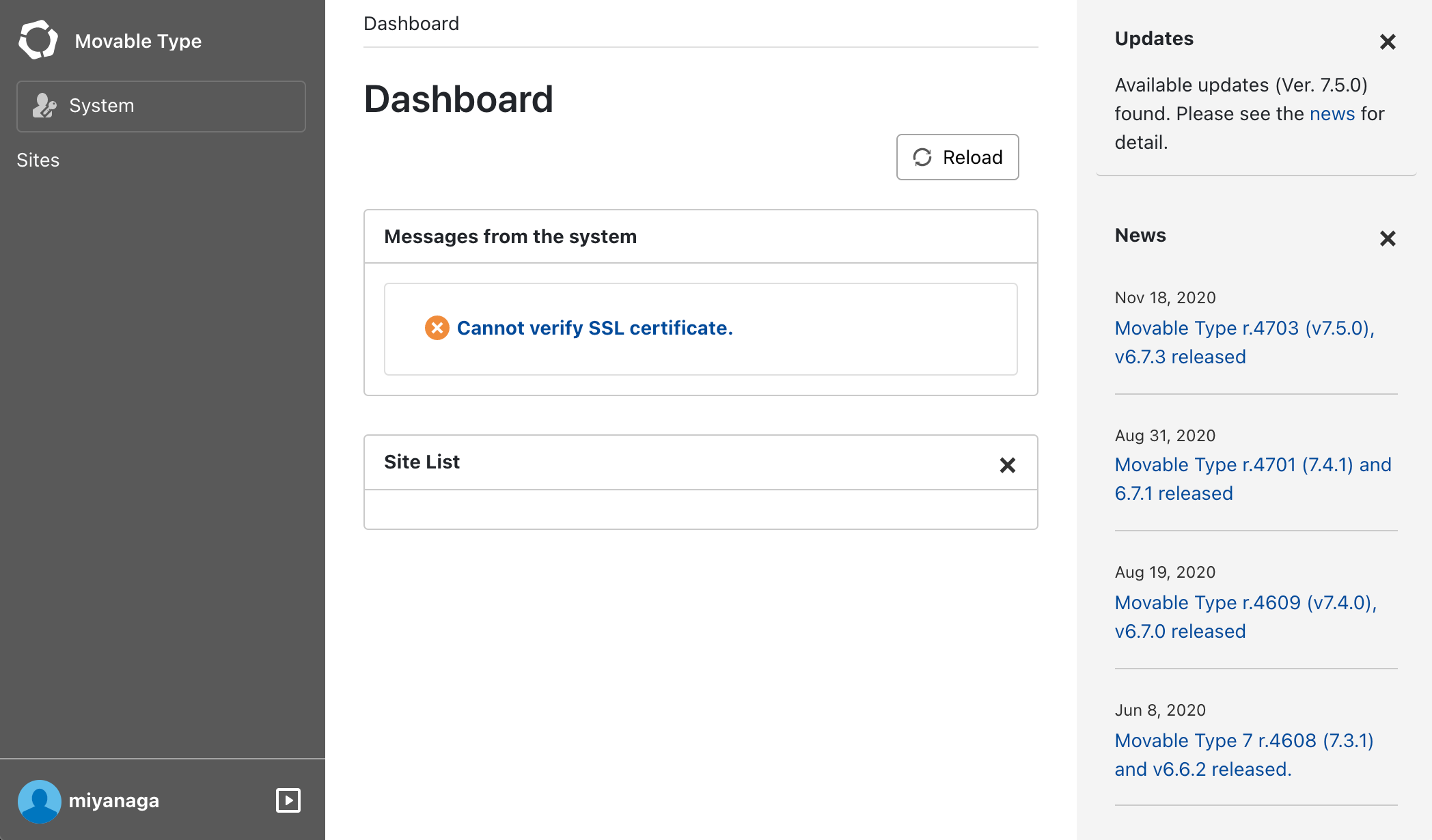
システム構成図
初めにイメージを掴んでもらうためにシステム構成図を載せておきます。
①:作業者は作業時間、作業内容をインプットとしてSSM Automationを実行します。実行後、承認者に通知されるます。
②:承認者は申請内容を確認し、問題なければ承認します。承認後、SSM AutomationはStep Functionsをキックします。
③:Step Functionsは申請時に入力した作業開始時間になったらEC2インスタンスを作成します。
④:作業者はSSM Session Manager経由でEC2にログインします。
⑤:作業者はEC2からRDSに接続し、運用作業を行います。その際の操作ログはSSM Session Managerの機能でS3にアップロードされます。
⑥:Step Functionsは申請時に入力した作業終了時間になったらEC2インスタンスを削除します。今回の構成を導入することで実現できること
AWSサービスの機能だけで以下を実現することができます。
- 作業前には承認者の承認が必須となる
- 作業時間を絞ることができる
- 作業時の操作ログが取得可能
動作確認
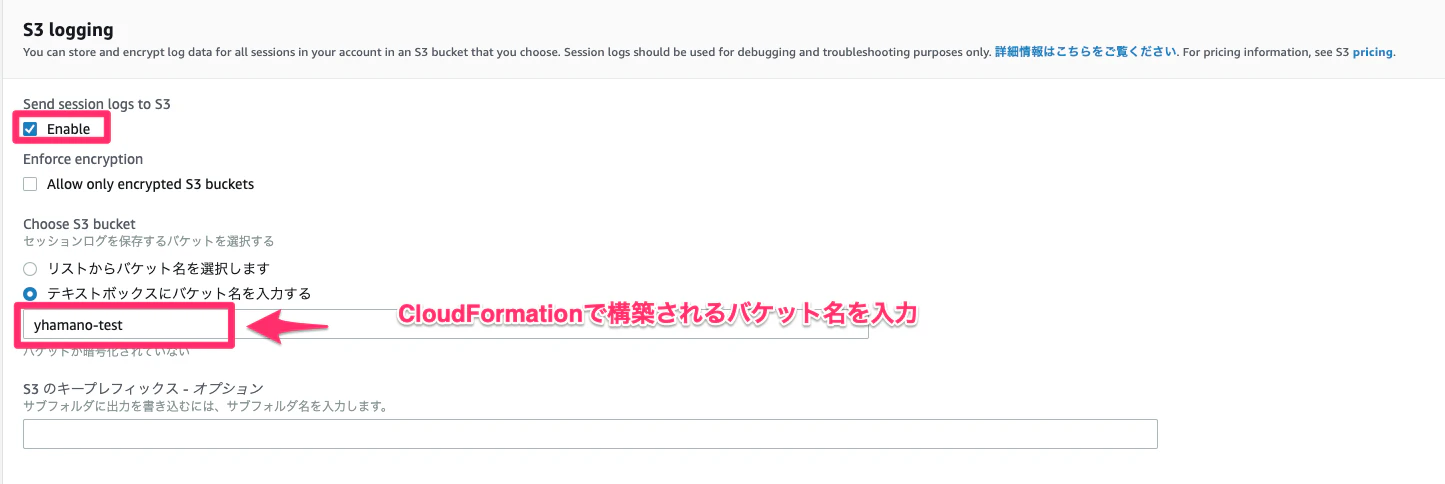
上記のフローを動作確認してみます。動作確認用のAWSリソースはCloudFormationで構築しています。CloudFormationテンプレートはこちらにありますので、試してみたい方はどうぞ!なお、CloudFormationの実行後に以下の実施をお願いします。
- 作成後にSNSサブスクリプションの承認メールが送信されるので、メールのリンクから承認してください。
- セッションマネージャの操作ログ取得設定はCloudFormationに対応していないため、マネジメントコンソールから行ってください。AWS Systems Manager -> セッションマネージャ -> 設定 -> S3 logging
まず作業者用IAMユーザでログインし、Systems Manager画面からSSMAutomationを実行します。
実行後、以下のようなメールがCloudFormation実行時のパラメータに入力した承認者メールアドレスに送信されますので、「Approve」のリンクから承認者IAMユーザでログインします。
承認者は内容を確認し、問題なければ承認を行います。
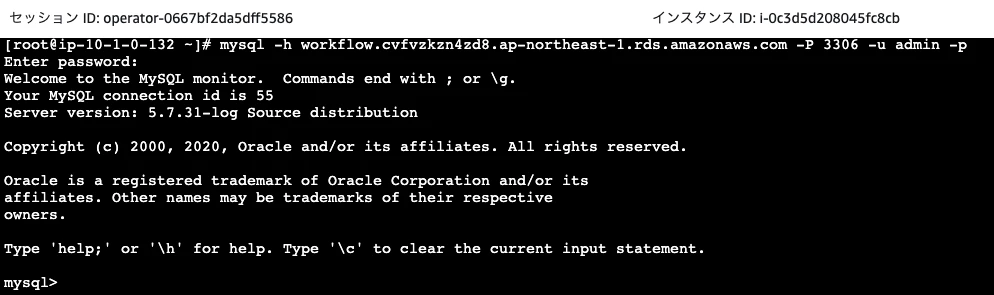
SSMAutomation実行時のstart_timeパラメータに入力した時刻になるとEC2が起動するため、作業者IAMユーザでセッションマネージャを利用して接続します。(UserData内でSSM Agentの更新を行っているため、SSM Agentの更新を促された場合は数分時間を置いてから再度確認してください。)
mysql clientを用いてRDSに接続します。接続時のユーザ名・パスワードはCloudFormationの実行時に入力したパラメータを確認してください。
mysql -h 【RDSエンドポイント】 -P 3306 -u admin -p
作業完了後、セッションを終了したタイミングで操作ログがS3にアップロードされ、SSMAutomation実行時のend_timeパラメータに入力した時刻になるとEC2が削除されます。
マニフェスト解説
今回のシステム構成のメインとなるSSM DocumentとStep Functions StateMachineのマニフェスト定義を解説します。
SSM Document
{ "description": "Approve Workflow", "schemaVersion": "0.3", "parameters": { "Description": { "description": "operation description", "type": "String" }, "EndTime": { "description": "(Required & format:YYYY-MM-DDThh:mm:ss+09:00) End Time", "type": "String", "allowedPattern": "^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])T([01][0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]\\+09:00$" }, "StartTime": { "description": "(Required & format:YYYY-MM-DDThh:mm:ss+09:00) Start Time", "type": "String", "allowedPattern": "^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])T([01][0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]\\+09:00$" } }, "mainSteps": [ { "inputs": { "Message": "approve check", "NotificationArn": "arn:aws:sns:ap-northeast-1:xxxxxxxxxxxx:approver-topic", "Approvers": [ "arn:aws:iam::xxxxxxxxxxxx:user/approver" ], "MinRequiredApprovals": 1 }, "name": "approve", "action": "aws:approve", "onFailure": "Abort" }, { "inputs": { "UserName": "operator", "PolicyName": "AllowSessionManager", "Service": "iam", "PolicyDocument": "{\"Version\":\"2012-10-17\",\"Statement\":[{\"Effect\":\"Allow\",\"Action\":\"ssm:StartSession\",\"Resource\":\"*\",\"Condition\":{\"DateGreaterThan\":{\"aws:CurrentTime\":\"{{StartTime}}\"},\"DateLessThan\":{\"aws:CurrentTime\":\"{{EndTime}}\"}}}]}", "Api": "PutUserPolicy" }, "name": "putInlinepolicy", "action": "aws:executeAwsApi" }, { "inputs": { "input": "{\"start_time\" : \"{{StartTime}}\", \"end_time\" : \"{{EndTime}}\"}", "stateMachineArn": "arn:aws:states:ap-northeast-1:xxxxxxxxxxxx:stateMachine:lambdaExec" }, "name": "execStepFunction", "action": "aws:executeStateMachine" } ] }
- parameters
- 入力パラメータを定義しています。StartTimeとEndTimeはStepFunctions側に渡すパラメータとなります。StepFunctionsのWaitタスクに設定する時刻フォーマットがISO 8601のRFC3339に従う必要があるため、allowedPatternによるパラメータフォーマットチェックを入れています。
- mainSteps
- aws:approveアクションが承認部分になります。承認できるIAMユーザをApproversとして指定できるのですが、IAMユーザのARNしか指定できないため、複数の承認者を指定したい場合はそのユーザ数分のARNを記載する必要があります。(IAMグループやIAMロールのARNを指定できるようにしてほしい。。)
- aws:executeAwsApiアクションで作業者IAMユーザにセッションマネージャ接続権限を時間指定のIAMポリシーとしてアタッチしています。これにより特定時間帯のみ権限を付与することを実現しています。
- aws:executeStateMachineアクションでStepFunctions StateMachineを起動しています。
StepFunctions StateMachine
{ "Comment": "lambda exec", "StartAt": "StartWait", "States": { "StartWait": { "Type": "Wait", "TimestampPath": "$.start_time", "Next": "CreateEC2" }, "CreateEC2": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:start-ec2", "Next": "DeleteWait" }, "DeleteWait": { "Type": "Wait", "TimestampPath": "$.end_time", "Next": "DeleteEC2" }, "DeleteEC2": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:end-ec2", "End": true } } }
- Wait
- SSM Automationから受け取った時刻を指定して上げることで、指定時間まで処理を待ちます。
- Task
- ResourceにLambda FunctionsのARNを指定してあげることで、Lambda Functionsが起動されます。
最後に
SystemsManagerとStep Functionsを用いた作業時の承認ワークフローと操作ログ取得を紹介しました。運用統制を導入する際の参考にして頂ければ幸いです。








- 投稿日:2020-12-12T18:56:30+09:00
AWSを利用してWebページを作ってみよう
目次
1.はじめに
2.全体スケジュール
3.AWS全体学習
4.構成図
5.インフラチーム学習内容-Part1
6.インフラチーム学習内容-Part2
7.フロントチーム学習内容-Part1
8.フロントチーム学習内容-Part2
9.完成したサイト
10.まとめ1.はじめに
株式会社エニプラでは、社内のチームごとにテーマを決め、
毎月行われるチーム会でテーマに沿った活動を行っています。
チーム会で行った内容は、年末に「エニプラアワード」という場で
全社員や来期の新卒に向けて発表を行っています。
今年度松田チームでは「AWS学習&Webページ作成」をテーマに活動してきました。
テーマを検討、決定した背景として以下の4点あります。
1.AWSに関する資格取得を目指す人が増えてきたこと
2.AWSというサービス自体は聞いたことがあるが、具体的なイメージが湧かない
3.Web・HTMLについて学習してみたい
4.取り組んだ成果を発表する上で実際に見られるものを作りたい
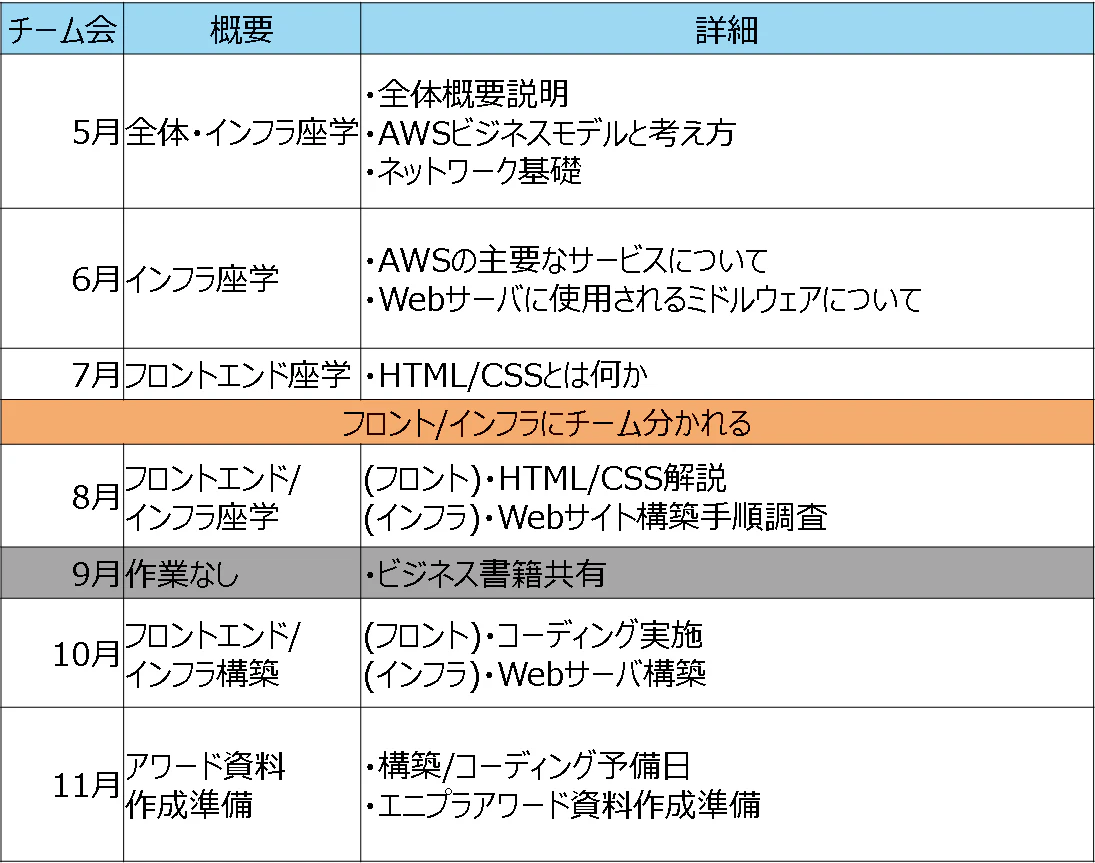
上記の4点をまとめた結果、「AWSを利用してWebページを作ってみよう」ということになりました。2.全体スケジュール
約半年のチーム会活動全体を通して
図のようなスケジュールでエニプラアワードに向けて取り組みました。
まず、5-7月の期間でチーム全体でAWSそのものについての座学や、
Webページ作成に必要なインフラ・フロントの基礎知識を学習しました。
8月以降は自分の興味がある分野を選び、インフラチームとフロントチームに分かれ、
Webサーバ構築やWebページのコーディングに向けて、座学と実作業をそれぞれチームにて実施しました。
3.AWS全体学習
次に、実際にどのような内容の座学や実作業を行っていたのかについて紹介します。
まず、各チームに分かれる前にAWSについての学習を行いました。
下記にある画像は、『AWSome Day』と呼ばれる公式オンラインセミナーです。
セミナーの内容をベースに、AWSのビジネスモデル(従量課金制等)であったり、
システムを構築するうえでのオンプレとパブリッククラウドの考え方の違いや、
今回触ることになるAWS上の主要なリソースについて学習しました。
実際に皆が使えるようにAWS上にユーザーを作成していたので、
ログインしてAWSのWebコンソールを見てみるといったことも併せて行いました。AWSome Dayとは
『AWSome Day』は定期的に実施されている公式オンラインセミナーです。
内容としては、AWS入門者向けにAWSの概要や基礎知識について解説するもので、
社内で実際に参加した人からは非常に解りやすい内容であったという感想が挙がっています。
これからクラウドを学ぶ人には、オススメです。
- セミナー開催情報 :AWSome Day
4.構成図
実際に作成したAWSの構成図がこちらになります。
要件として、無料枠の範囲内、つまり、お金がかからない範囲でやること、
Webサーバは1台で、Webページに掲載する画像はS3と呼ばれるAWSのストレージサービスに
配置してサーバから参照させるといった構成です。
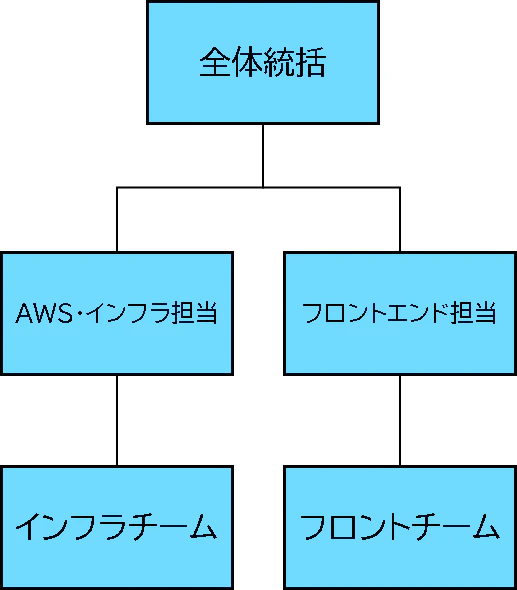
5.インフラチーム学習内容-Part1
ここからはインフラチーム・フロントチームが、それぞれ行った学習・実作業について
説明させていただきます。
まず初めに、インフラチームは『Webサーバを構築する』というのが目標です。
実際に、構築業務経験があるメンバーが少ないため、
なるべく実際の構築業務に近い流れで行うことをコンセプトに、下記の要件を提示しました。要件の確認
- ミドルウェアとしてApacheを利用する
- 通信に使用するポートは80
- ドキュメントルートは/var/www/html/<作成したフォルダ名>にする
- インスタンス起動時にApacheが自動実行するようにする
これらを踏まえて、実際にWebサーバとして動作させるためには、
どういった作業が必要になるのかを洗い出しました。
メンバー間で協力しながら『Apacheとは何か』というところから、
インストール方法や設定方法、コンフィグの変更箇所などを洗い出しました。
Tips:Apacheとは
Webサーバ用ミドルウェアの一つ。
オープンソースソフトウェアとして公開され、無償で利用できる。6.インフラチーム学習内容-Part2
要件の確認と作業の整理をしたのち、構築時に必要になるコマンドを調査し簡単な手順書を用意しました。
今回、OSはAmazon Linux2と呼ばれるAWS EC2インスタンス上で利用できるLinuxベースのOSです。
構築の流れとしては、デフォルトパッケージのアップデートから始まり、
Apacheのインストールと設定変更、それを反映するためのサービス再起動です。
手順として整理したコマンドは、下記記述の通りです。コマンド整理
1. パッケージアップデート # yum update 2.Apacheのインストール # yum install httpd 3.ポートが80となっていることを確認する # cat /etc/httpd/conf/httpd.conf | grep Listen 4.ドキュメントルートを"/var/www/html/<作成したフォルダ名>"配下に作成 # vi /etc/httpd/conf/httpd.conf 5.サービス再起動 # systemctl restart httpd # systemctl status httpd 6.Apacheが自動起動するよう設定 # systemctl enable httpd.serviceEC2インスタンスに接続して実際に構築
- WebブラウザからグローバルIPにアクセスし、サンプルページが表示されることを確認
最終的にWebブラウザからAWS上のサーバにアクセスし、
デフォルトのサンプルページが表示されることを確認する。
以上がインフラチームで行った内容となります。7.フロントチーム学習内容-Part1
続いて、フロントチームの学習内容を紹介いたします。
Webページを作成するために、まずWebページが何の言語を使用して
作成されているかを調査しました。
調査の結果、主にHTML,CSS,JavaScriptが使用されていることが分かりました。
HTMLとは
HTMLはウェブページを作成するために作られた言語です。
HTMLの学習内容としては、主に各HTMLタグの役割について学習しました。
HTMLタグはブラウザがWebページの構造を理解するために使用されています。
各ブラウザ毎に、表示に差が出るSelectbox等のHTMLタグを使用して
HTMLに従ってブラウザがWebページを理解し、表示していることを確認しました。CSSとは
CSSはウェブページのスタイルを指定するための言語です。
HTMLと併せて文字や枠の色を変更したり、図形を作成したりと、装飾をするために使用されています。
CSSの学習内容としては、各プロパティの意味や使い方を学習しました。JavaScriptとは
JavaScriptはプログラミング言語の一つで、Webページに動的な表現を付けるために使用されています。
今回は時間の都合上使用することができなかったのですが、次の機会があれば使いたい要素の一つです。
調査後、サンプルページを参考にレイアウトについて学習を進めました。
これはヘッダーやメインコンテンツ等、何処にどの要素があるかを理解しておくことが、
HTMLを書いていく上で非常に重要なためです。8.フロントチーム学習内容-Part2
レイアウトの確認が終わった後、まずはVisualStudioCodeの使い方を学びました。
フロントチームでは、VScodeを触れたことがあるメンバーがあまりいなかったためです。
VScodeは予測変換や拡張機能が優秀なため、便利な機能をできるだけ使用する方向で進めました。
その後、実際にコーディングを行いました。
コーディング中は記載したHTML要素の配置やCSSの適用状況など、適宜ブラウザで確認しつつ行いました。
想定外の画面になっている箇所は、ブラウザのデベロッパーツール等で確認と修正を行い、
Webサーバに乗せるソースを完成させました。
以上がフロントチームで行った内容となります。9.完成したサイト
インフラチームが作成したWebサーバに、フロントチームが作成したソースを配置し、
実際に完成したサイトがこちらになります。
※上記画像は、スマートフォンの操作画面となります。
実際のチーム会での活動風景や、実施内容が掲載されています。
スマートフォンで表示させた際にも自動的にリサイズされるような作りになっています。10.まとめ
2020年エニプラアワードテーマは『AWS学習&Webページ作成』でした。
AWSオンラインカンファレンスの内容をベースにチーム全体でAWS基礎を学習しました。
インフラチームでWebサーバを、フロントチームでWebページのソースを作成しました。半年間の活動を通して
- AWSへの理解が深まり、個人でも触ってみようと思った。
- HTMLとCSSでWebページが表示されていることが理解できた。
というご意見もありました。
自分もAWSのセミナーは興味あるものなので、機会がある際に参加してみたいです。
以上で、ご紹介を終わります。ありがとうございました。







- 投稿日:2020-12-12T18:04:46+09:00
AWS SDK for JavaScript をdeveloper toolのコンソールから使用する
主題
Amazon S3の署名付きURLをChromeの開発者ツールだけで発行した話。環境構築不要(認証情報さえあれば)。
ブラウザでSDKが使えるのを知り、手軽に試せないかと思い。ブラウザスクリプトの使用開始
https://docs.aws.amazon.com/ja_jp/sdk-for-javascript/v2/developer-guide/getting-started-browser.html手順
認証情報を拝借するユーザーに必要なポリシーは指定するメソッドだけ(以下の場合は
s3:GetObject権限のみ)。ブラウザを開き、URLに
about:blankを入力して画面をまっさらにする(これしないと動かない、なんで)。
以下のどちらかで、SDK読み込み。(script = document.createElement('script')).src = 'https://sdk.amazonaws.com/js/aws-sdk-2.809.0.min.js' document.getElementsByTagName('head')[0].appendChild(script)または
var ele = document.createElement("script"); ele.type = "text/javascript"; ele.src = "https://sdk.amazonaws.com/js/aws-sdk-2.809.0.min.js"; document.body.appendChild(ele);以下で関数定義。アクセスキー、シークレットアクセスキー、バケット名を適宜変更。
const S3 = new AWS.S3({ accessKeyId: 'xxxxxxxxx', secretAccessKey: 'yyyyyyyyy', signatureVersion: 'v4', region: 'ap-northeast-1' }); function getSignedUrl(fileName) { const params = { Bucket: "YOUR_BUCKET_NAME", Key: fileName, Expires: 60 }; S3.getSignedUrl("getObject", params,function(err,url){ console.log(url) }); return; }以降は
getSignedUrl("hello.html");を実行すると、YOUR_BUCKET_NAME/hello.htmlに対して60秒GETできるURLが出力される。参考
コンソールでのライブラリの読み込み
Chromeコンソールでお手軽クローリング
https://qiita.com/cognitom/items/babefa7b85ffc050d4bdChromeのJavascriptコンソールで外部ライブラリを使いたいとき
http://duyoji.hatenablog.com/entry/2013/05/01/172731S3の関数記述部分
getSignedUrl(operation, params, callback) ⇒ String
https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/S3.html#getSignedUrl-property
- 投稿日:2020-12-12T16:54:53+09:00
AWS EC2経由でMacにSSH/VNC接続する
SSH/VNCで接続する
EC2(Linux)を起動している前提でputtyを使った接続方法になります。
AWS上でセキュリティグループに接続元のIP接続を許可しておきます。(1)ホスト名(またはIPアドレス)にEC2のグローバルIPを入力します。
(2)プロキシを設定している場合は左「接続」-「プロキシ」を設定をします。
(3)「SSH」-「認証」でEC2に紐づく鍵を秘密鍵ファイルに設定します。
秘密鍵は「puttygen」でppkに変換する必要があります。
*VNC接続で画面共有したい場合は下記(4)も設定します。
(4)「SSH」-「トンネル」でポートフォワーディングの設定をします。
受け側ポートはこちらから接続するポートになるので何でも大丈夫です。
送り先はMacのグローバルIPアドレス:5900になります。
送り先を記載したら、追加ボタン押下を忘れないようにしてください。
(5)画面下開くをクリックします。
うまく設定できていれば、下記ユーザ名入力画面となります。login as:Amazon Linuxであれば「ec2-user」を入力します。
(6)ssh接続は以下のコマンドになります。
ssh username@iMacIPAddress or hostname(7)画面共有はChrome拡張機能の「VNC® Viewer for Google Chrome™」を使います。
puttyを接続した状態で、「VNCViwer」を起動し、ホスト名に「localhost:1234」を入力します。
接続ボタンで接続できるはずです!!!
*別途Mac側で画面共有の許可とファイアーウォールで5900ポート開放の設定が必要です。




- 投稿日:2020-12-12T16:37:50+09:00
【AWS】VPC Reachability Analyzer が発表されたので見てみた
本記事は Advent Calendar 2020 の2020/12/13分です。
※Advent Calendar 2020 へはHTCのチームメンバー5人で
毎日日替わりで投稿させていただいていますので、暇なときに覗いてください。
※HTCの紹介は本イベント1日目の投稿をご参照ください。
文系学部卒SIer新人のかいとです。
今回は、AWS re invent 2020にて、VPC Reachability Analyzerが発表され、
前回投稿した記事にて、書かせていただいたネットワーク周りの悩みを
早速解決してくれそうなので、確認してみました!
今までの悩み
今までの悩みは
セキュリティグループ(SG)の付け方です。
具体的にはインスタンス1つにつき、1つのSGをアタッチするのか、
役割ごと(例えばリモートアクセス用など)のSGを複数アタッチするのかという点でした。。。。
(下記は1つのSGによる通信許可設定(out)ですが、これが1つの中に大量に書かれるか、
役割ごとにこれを作成するのかという問題ですね。)
個人的にそれぞれにはメリットデメリットがあると思っているので、下記にまとめます。
SGのアタッチ方法に沿ったメリット/デメリット
- インスタンス1つ-SG1つ
- メリット:通信許可設定の理解がすぐ可能。
- デメリット:冗長な設定になるので、管理しにくい。複数インスタンスにアタッチしてると変更の際に、影響を受ける範囲が広い。
- インスタンス1つ-SG複数(役割ごと)
- メリット:役割ごとの通信許可で概要は理解しやすい。変更の際に、一か所のSG変更で済む。
- デメリット:インスタンスにアタッチできるSG数に制限がある。通信許可設定の理解に時間を要する。
そして、おそらく少しはプログラミングなどをかじっているIT脳の方には、
役割ごとに分けてSGを作成&アタッチする法を選びたくなるはず。
そんな私も完全に複数SG派なのですが、デメリット部分が割とめんどくさい。。。そう感じてるときに、新サービス
VPC Reachability Analyzerがこの問題を解決してくれるようなので、それを確認してみます!!!※インスタンスが数個程度であれば1つのSGで十分だと思います。
VPC Reachability Analyzer
VPC Reachability Analyzer:VPC内のリソース間の接続性をテスト・可視化できるVPCの新機能です。
要は、通信のルーティングを可視化・テストしてくれるというもので、
私が悩んでいた、通信許可設定の理解に時間を要するという複数SGによるデメリットを解決してくれるサービスなのです!!!実際の動きを確認
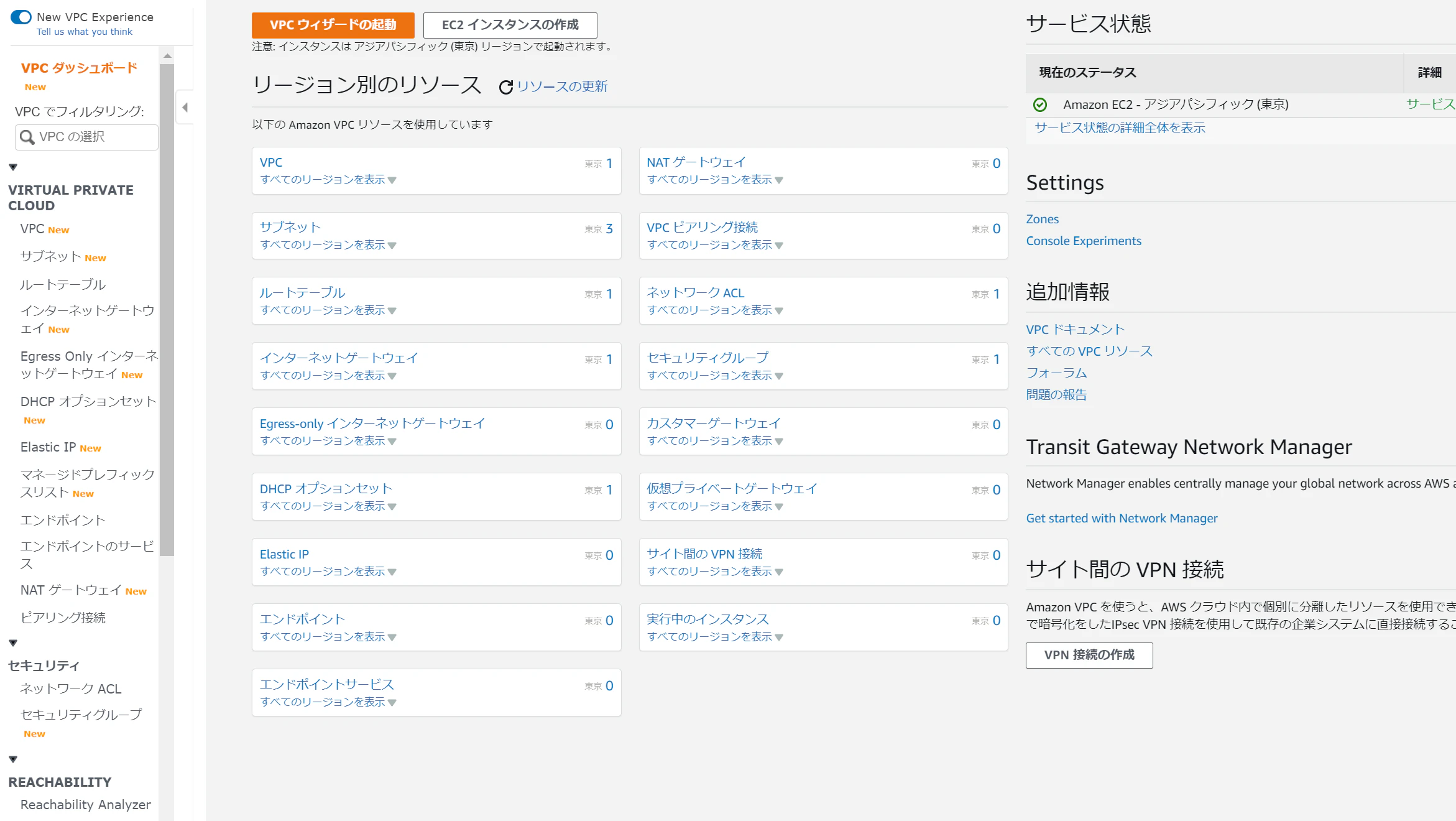
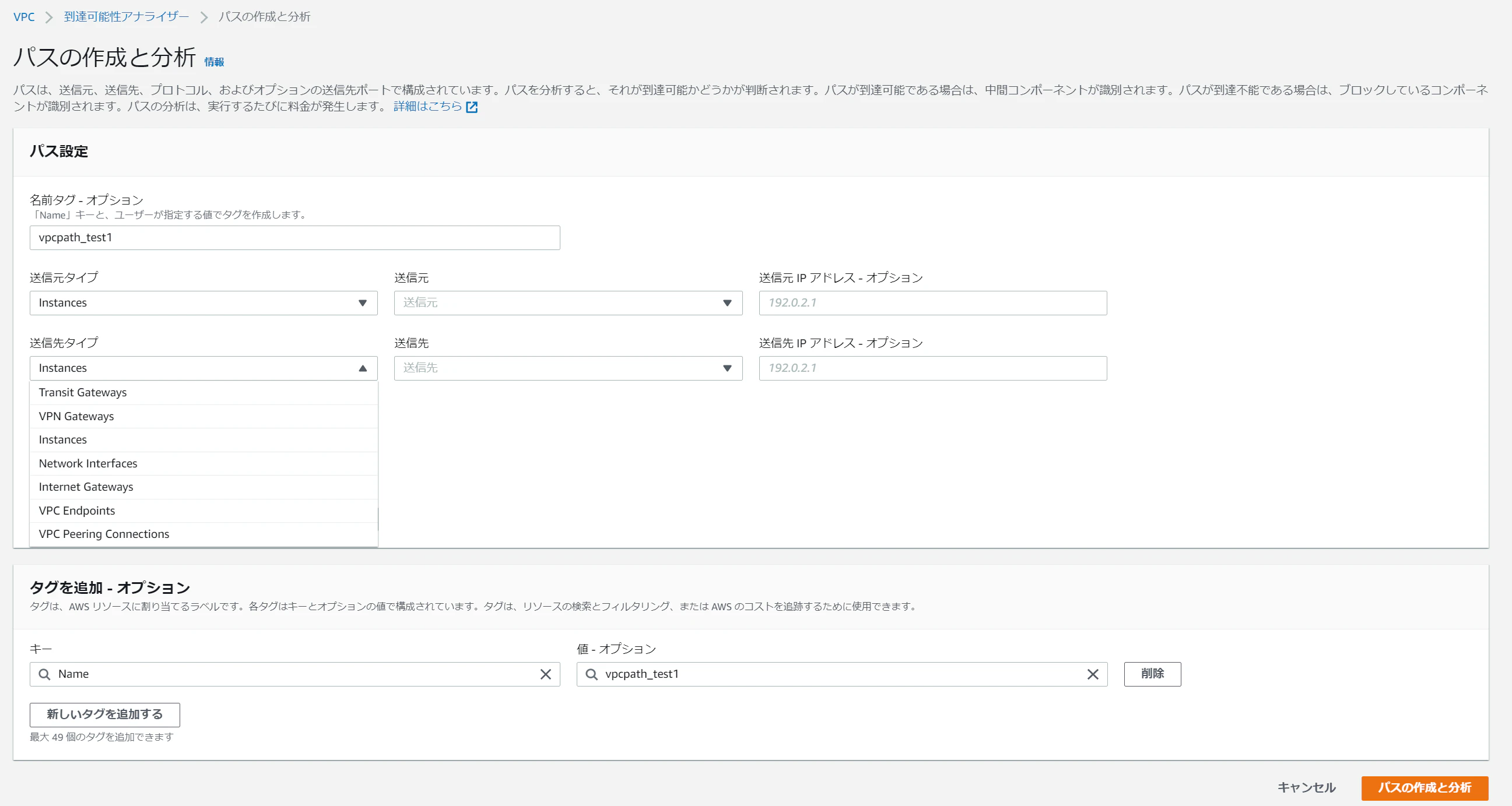
写真左下にできてますね。東京リージョンでも使えるのがうれしい。GAされても使えないときが時々あるから。。早速作成しに行くっ!
名前送信元タイプどこからどこに通信が到達するか)プロトコルポートを指定します。
また、送信元タイプは、写真のように下記6つが選択できました。
Transit Gateways | VPN Gateways | Instances | Network Interfaces | Internet Gateways | VPC Endpoints | VPC Connections※ここからは、お金がかかりそうなので、他の方の記事を参考にしました。
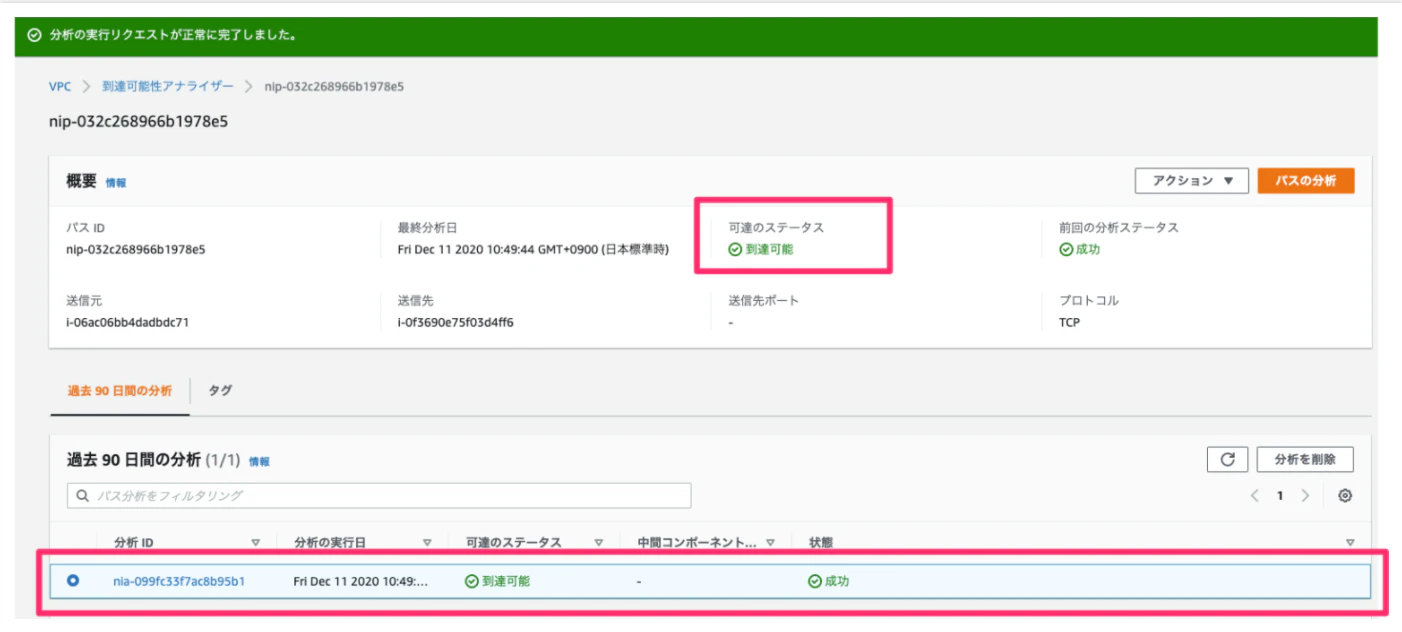
1分もたたず、通信到達を確認し、ページ下部の「分析エクスプローラー」で通信のルーティングを可視化することができるそうです!
これにて、通信の可視化を行えるようになったので、
SGは迷わず役割ごとに作成するのがベストプラクティスですね!!
(※勿論インスタンスの数による)また、費用に関しては
Price per analysis processed by VPC Reachability Analyzer: $0.10とのことなので、有料です!
お気を付けください!(1回調べるのに10円なので、ハンズオン続けてもよかったですねw)まとめ
・VPC Reachability Analyzerいいですね。。。
どのAWSサービスを通っているのか図で分かりやすいですし、可読性が上がりました。・aws re invent は今年(2020)から見るようになったのですが、個人的には開発者用サービスに関心があるので、
今後はCodeGuru, DevOpsGuruなどのサービスをピックアップできればと思っています!お楽しみに!・参考資料
https://dev.classmethod.jp/articles/breaking-vpc-reachability-analyzer/



- 投稿日:2020-12-12T16:24:12+09:00
SCPコマンドで、EC2インスタンスにあるファイルのダウンロード/アップロードを秒で対応するために
はじめに
EC2サーバーのファイルをローカルへダウンロードする時に、実行コマンドなんだったっけ....?となったので、今後秒で対応できるように備忘録として残しておきます。
ダウンロード(EC2インスタンス → ローカル)
EC2サーバーにあるファイルをローカルのデスクトップへダウンロードする場合、以下コマンドを実行します。
scp -i [秘密鍵のパス] [ユーザー名]@[パブリックIP]:[EC2のダウンロード元のパス] [ローカルのダウンロード先のパス]
例えば、EC2インスタンスのApacheのログをデスクトップへダウンロードする場合は、以下のコマンドとなります。
ターミナル.$ scp -i ~/.ssh/hoge-hoge.pem ec2-user@1.234.567.89:/home/ec2-user/access_log-2020xxxx ~/Desktop access_log-2020xxxx 100% 4820KB 1.5MB/s 00:03以下のようにエラーではじかれることもあります。これはダウンロード(アップロード)先とダウンロード(アップロード)元のディレクトリの権限が影響しているようです。
scp: /var/log/httpd/access_log-2020xxxx: Permission denied
ディレクトリの権限を777に変更するなどして対応できるようですが、私は以下の方法で実行します。ダウンロードしたいファイルを一旦EC2サーバーのHomeへ移動させてからローカルへダウンロードします。
ターミナル.$ ssh -i hoge-hoge.pem ec2-user@1.234.567.89 $ sudo -i $ cp /var/log/httpd/access_log-2020xxxx /home/ec2-user/access_log-2020xxxx $ ll -rw-r--r-- 1 root root 4936035 12月 11 14:38 access_log-2020xxxx $ exit $ exit $ scp -i ~/.ssh/hoge-hoge.pem ec2-user@1.234.567.89:/home/ec2-user/access_log-2020xxxx ~/Desktop access_log-2020xxxx 100% 4820KB 1.5MB/s 00:03アップロード(ローカル → EC2インスタンス)
以下コマンドでEC2サーバーにファイルをアップロードできます。
scp -i [秘密鍵のパス] [ローカルのアップロード元のパス] [ユーザー名]@[パブリックIP]
ターミナル.scp -i ~/.ssh/hoge-hoge.pem /Desktop/access_log-2020xxxx ec2-user@1.234.567.89:/home/ec2-user/ディレクトリをアップロードする場合は以下コマンドになります。
scp -r -i [秘密鍵のパス] [ローカルのアップロード元のパス] [ユーザー名]@[パブリック
ターミナル.scp -r -i ~/.ssh/hoge-hoge.pem /Desktop/access_log-2020xxxx ec2-user@1.234.567.89:/home終わりに
とりあえずこの対応が一番簡単かなと思うのですが、もしもっと効率の良い方法があればどなたかご教示お願いします。
- 投稿日:2020-12-12T15:23:29+09:00
【Django】Amazon Linux 2+MySQLでDjangoをデプロイする方法
AWSにMySQLでDjangoをデプロイする時に結構苦戦したので、備忘録として残しておきます。
AWSの設定
yumを最新にアップデート
$ sudo yum updatePythonの最新版をインストール
$ sudo yum -y install python37gitをインストール
$ sudo yum -y install gitGitに上げているDjangoのプロジェクトを持ってくる
$ git clone https://github.com/example/hogeproject.gitプロジェクトに入っている仮想環境の実行
$ cd hogeproject/ $ source venv/bin/activate仮想環境に
djangoをインストール$ sudo pip3 install django
settings.pyにデータベース情報を追加$ vim taxproject/settings.pyALLOWED_HOSTS = ['EC2のパブリックアドレス', 'localhost'] DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': '〈データベース名〉', 'USER': '〈ユーザー名〉', 'PASSWORD': '〈パスワード〉', 'HOST': '〈エンドポイント〉', 'PORT': '3306', } }データベースにテーブルを作成するためにmigrateを行う
※ここが一番苦戦しました。$ python3 manage.py makemigrations下記のエラーが発生してしまった。
Traceback (most recent call last): File "/usr/local/lib64/python3.7/site-packages/django/db/backends/mysql/base.py", line 15, in <module> import MySQLdb as Database ModuleNotFoundError: No module named 'MySQLdb' The above exception was the direct cause of the following exception: Traceback (most recent call last): File "manage.py", line 22, in <module> main() ・ ・ ・ django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module. Did you install mysqlclient?
mysqlclientをインストールしているか聞かれたので、とりあえずインストールしてみる。$ sudo pip3 install mysqlclientすると今度はmysql_configがないとエラーになってしまう。
何故だ・・・/bin/sh: mysql_config: command not found /bin/sh: mariadb_config: command not found /bin/sh: mysql_config: command not found調べてみると下記をインストールすると解決するらしい
インストール開始#リポジトリ追加 $ sudo yum -y install https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm $ sudo yum -y install mysql-community-client $ sudo yum -y install mysql-develmysql_configがインストールされたか確認
$ whereis mysql_config mysql_config: /usr/bin/mysql_config /usr/share/man/man1/mysql_config.1.gzどうやらインストールされたみたいなので、これで大丈夫だと思い、再度
$ sudo pip3 install mysqlclientを実行unable to execute 'gcc': No such file or directory error: command 'gcc' failed with exit status 1今度は
gccがないと怒られる。
gccをインストール$ sudo yum -y install gcc今度こそと思い、
$ pip3 install mysqlclientを実行。
すると・・・#include "Python.h" ^~~~~~~~~~ compilation terminated. error: command 'gcc' failed with exit status 1またエラーになる。
Python.hが原因らしいので調べてみるとpython-develに入っているモジュールとのこと。
なので、今度はpython-develをインストールする。$ sudo yum -y install python-devel Loaded plugins: extras_suggestions, langpacks, priorities, update-motd 37 packages excluded due to repository priority protections Package python-devel-2.7.18-1.amzn2.0.2.x86_64 already installed and latest version Nothing to doあれ?
すでにインストールされている・・・
と思ったらPython2.7だったので、Python3のpython-develをインストール$ sudo yum -y install python3-develインストールが完了したので、何度目かの
$ sudo pip3 install mysqlclientを実行Installing collected packages: mysqlclient Running setup.py install for mysqlclient ... done Successfully installed mysqlclient-2.0.2やっと成功した!!!
これで大丈夫なはずなので、データベースにテーブルを作成していきます。
$ python3 manage.py makemigrations $ python3 manage.py migrateデータベースに値が入ったので、EC2のセキュリティグループにポートを追加
サーバーを起動して、EC2のパブリックIPにアクセス
$ python3 manage.py runserver 0.0.0.0:8000
表示できるようになりました。
調べるのにめちゃくちゃ時間がかかった・・・
ひとまずこれでデプロイはできた。あとはgunicornを入れて常時アクセスできるようにすればOK


- 投稿日:2020-12-12T15:18:50+09:00
【簡単に図解】AWSのEBSとAMIとスナップショットを自分なりにまとめてみた
背景
- 最近AWSの勉強を開始
- AMIやスナップショットなどの用語の意味があやふやになってきたため、自分なりにまとめてみました
EBSとは
- EC2インスタンスの外付け仮想ディスク
- HDDやSSDなどを選択可能
- ボリュームといっているのは、(おそらく)これのこと
AMIとは
- EC2インスタンス+EBSスナップショットのバックアップ
- EBSスナップショットはS3に保存される
- これがあれば、EC2の複製が可能

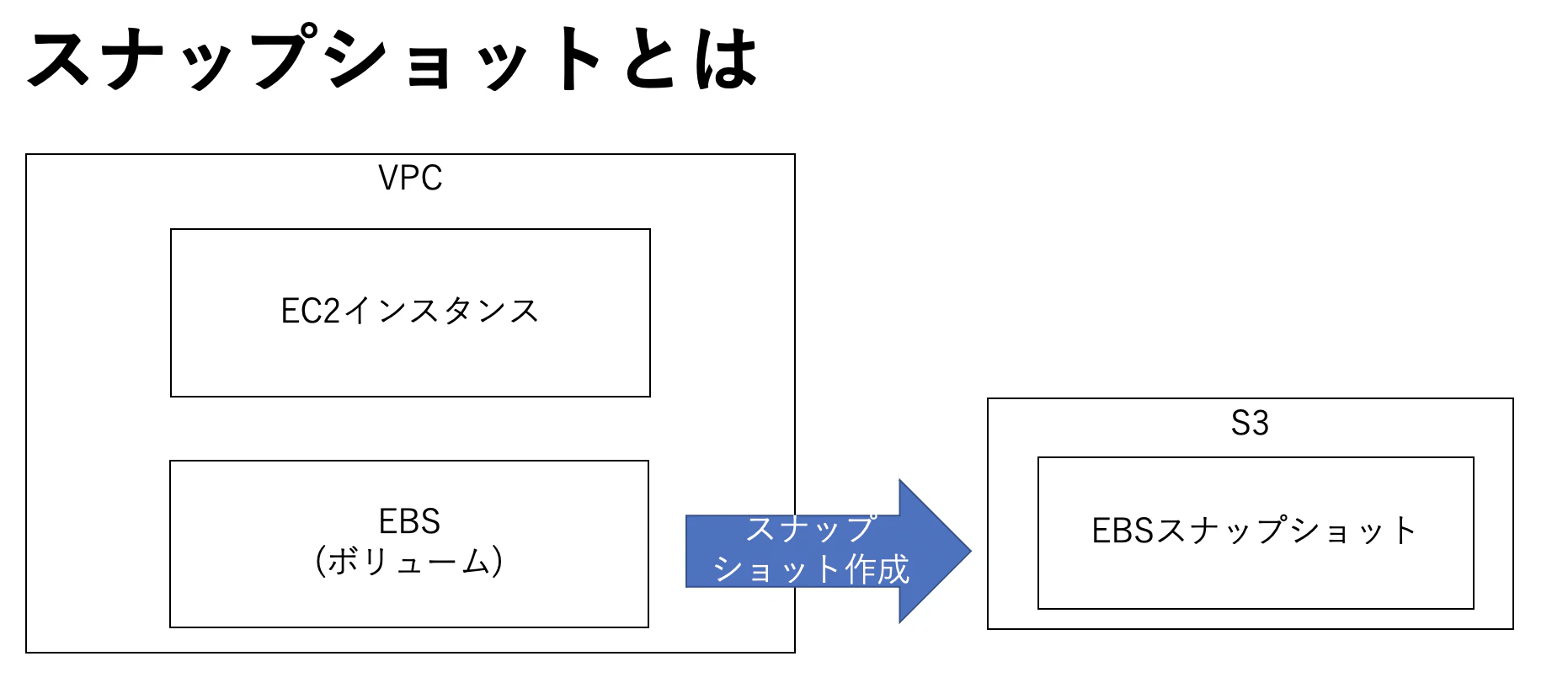
スナップショットとは
- 正確にはEBSスナップショットのこと
- 言葉の通り、EBSのスナップショットを作成する
- 保存場所はAMI作成時と同様に、S3に保存される
- インスタンスに関しては、何も情報を保存しない
- 投稿日:2020-12-12T14:56:36+09:00
AWSにコンテナ環境を構築する
はじめに
コンテナ開発環境をAWS上に構築します。
なお、本記事は以下のUdemy講座を元にした覚書です。
米国AI開発者がゼロから教えるDocker講座準備
コンソールよりAWSのEC2インスタンスを生成
https://aws.amazon.com/jp/console/OSはUbuntuなどを選択
インスタンスが起動したらログインし、Dockerをインストール
# sshでAWSにログイン ssh -i /Users/yukokanai/work/aws/ssh/mydocker.pem ubuntu@ec2-13-230-103-136.ap-northeast-1.compute.amazonaws.com # dockerインストール sudo apt-get update sudo apt-get install docker.io # dockerグループを作ってubuntu(ユーザー)を入れる(sudoなしでdockerを使える様にする) sudo gpasswd -a ubuntu docker # 一度ログアウトしてからもう一度入り直すと使える様になる exitAWSのインスタンスにimageをアップしコンテナ起動
いくつかあります。制約などに応じて使い分けてください。
手段①Docker HubなどのレジストリにDocker imageをpullする
インスタンスがネットにつなげられない場合は使えないです。
1.Docker Hubにアカウントを作成
https://hub.docker.com/2.ローカル環境にDockerをインストール
3.ローカル環境にてimageファイルを作成
docker build -f Dockerfile . {image名(repository)}:{tagname}4.ローカル環境よりDockerHubにpush
docker push {アカウント名}/{image名(repository)}:{tagname}5.AWSにログインし、DockerHubよりpull
docker pull {アカウント名}/{image名(repository)}:{tagname}6.DLされたimageファイルよりコンテナ起動
docker run -it {imageID}手段②Dockerfileを送る
ビルドコンテキストの差異が出る可能性がある
Cloudがネットにつなげられない場合は使えない1.ローカル環境にDockerをインストール
2.ローカル環境にてDockerfileを作成
3.sftpにてAWSへファイル転送(インスタンスは起動しておく)
# sftpでAWSへログイン sftp -i /Users/yukokanai/work/aws/ssh/mydocker.pem ubuntu@ec2-13-230-103-136.ap-northeast-1.compute.amazonaws.com # 圧縮ファイルをAWSインスタンスへput put Dockerfile /home/ubuntu # ログアウト exit4.AWSにログインし、imageファイルを作成
# ビルド docker build -f Dockerfile . {image名}:{tagname} # imageファイルが作成されていることを確認 docker images5.作成されたimageファイルよりコンテナ起動
docker run -it {imageID}手段③Docker imageを圧縮して送る
他手段に比べてimageファイルはサイズが大きいので時間がかかる
1.ローカル環境にDockerをインストール
2.ローカル環境にてimageファイルを作成
docker build -f Dockerfile . {image名}:{tagname}3.imageファイルを圧縮
docker save {imageID} > myimage.tar4.sftpにてAWSへファイル転送(インスタンスは起動しておく)
# sftpでAWSへログイン sftp -i /Users/yukokanai/work/aws/ssh/mydocker.pem ubuntu@ec2-13-230-103-136.ap-northeast-1.compute.amazonaws.com # 圧縮ファイルをAWSインスタンスへput put myimage.tar /home/ubuntu # ログアウト exit5.AWSにログインし、圧縮ファイルを展開してimageファイルを作成
# 圧縮ファイルを展開 docker load < myimage.tar # imageファイルが作成されていることを確認 docker images6.作成されたimageファイルよりコンテナ起動
docker run -it {imageID}
- 投稿日:2020-12-12T14:18:23+09:00
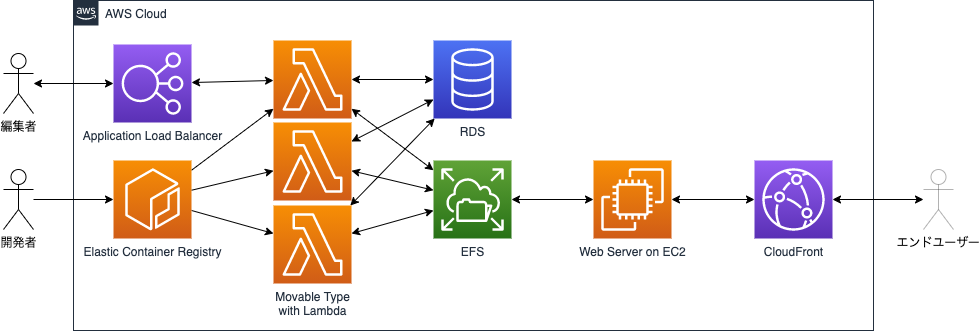
Movable Type Serverless - LambdaコンテナでMTを動かしてみた
Movable Type Advent Calendar 2020 12日目です。
つい先日、AWS LambdaがDockerコンテナをサポートしました。
これはアツい!ということでMTを(途中まで)動かしてみた、という話です。
Movable Type Serverless
最終的にはこんなイメージでいます。
MTの静的出力という特徴を活かし、Webサーバーだけ常時起動させますが、MTは普段存在すらしておらず、編集者が使うときだけ起動します。
- 夜中や休日など編集者が使わない時間はコンピューティングコスト節約!
- 利用者が増えたらRDSやEFSの限界まで事実上無限に性能拡張!
- もし再構築を並列で実行できたら時間を圧倒的に短縮!
なにこれすごい!
とりあえずログインできるところまでやってみた
今回はRDSと連携してログインできるところまでやってみました。
- EFSとの連携以降はやってません。
- セキュリティ考慮していません。
- 日本語だと文字化けしたのでとりあえず英語で動かします。
とまあ、PoCレベルなので誰か遺志を継いでください。
手順1 RDSインスタンスを起動
RDSにMT用のMySQLデータベースインスタンスとユーザーを作成します。
一時的な実験なのでセキュリティは考慮していません! 随時読み替えて適切に設定してください。
create user 'mt_serverless'@'%' identified by '(データベースのパスワード)'; grant all on mt.* to 'mt_serverless'@'%' with grant option; flush privileges;手順2 MTのプログラム一式を展開する
ここからはRDSに接続可能な環境で作業します。
開発者ライセンスでMTを入手します。
https://www.sixapart.jp/inquiry/movabletype/developer.html
手順3 mt-config.cgi
MTを展開したディレクトリ直下に設定ファイル
mt-config.cgiを作成します。※ 日本語が文字化けしちゃったので英語UIに逃げます。
mt-config.cgiCGIPath /mt/ StaticWebPath /mt/mt-static/ StaticFilePath /app/mt-static ObjectDriver DBI::mysql Database mt DBUser mt_serverless DBPassword (データベースのパスワード) DBHost (RDSインスタンスのホスト名) EmailAddressMain (管理者メールアドレス) DefaultLanguage en ImageDriver Imager手順4 Dockerfile
ひとまずplack/PSGIで動かすため、MTを展開したディレクトリ直下にこんな
Dockerfileを作ります。個人的に慣れてるUbuntuを使っていますが、ディストリビューションはお好きにどうぞ。
DockerfileFROM ubuntu:20.04 RUN apt-get update \ && apt-get install -y perl cpanminus build-essential \ libdbi-perl libdbd-mysql-perl \ libimager-perl libxmlrpc-lite-perl \ libplack-perl libcgi-psgi-perl \ && cpanm XMLRPC::Transport::HTTP::Plack RUN cpanm AWS::Lambda RUN apt-get -y remove build-essential \ && apt-get -y clean \ && apt-get -y autoremove \ && rm -rf /var/lib/apt/lists/* /var/cache/apt/* ADD . /app WORKDIR /app CMD [ "plackup", "mt.psgi" ]ここでインストールしているナイスなモジュール
AWS::Lambdaが、Lambda - Dockerコンテナ - PSGIアプリケーションとしてのMTを繋いでくれます。https://github.com/shogo82148/p5-aws-lambda
手順5 PSGI版の動作確認
docker build -t mt-serverless . docker run -it --rm -p 5000:5000 mt-serverlessブラウザから、
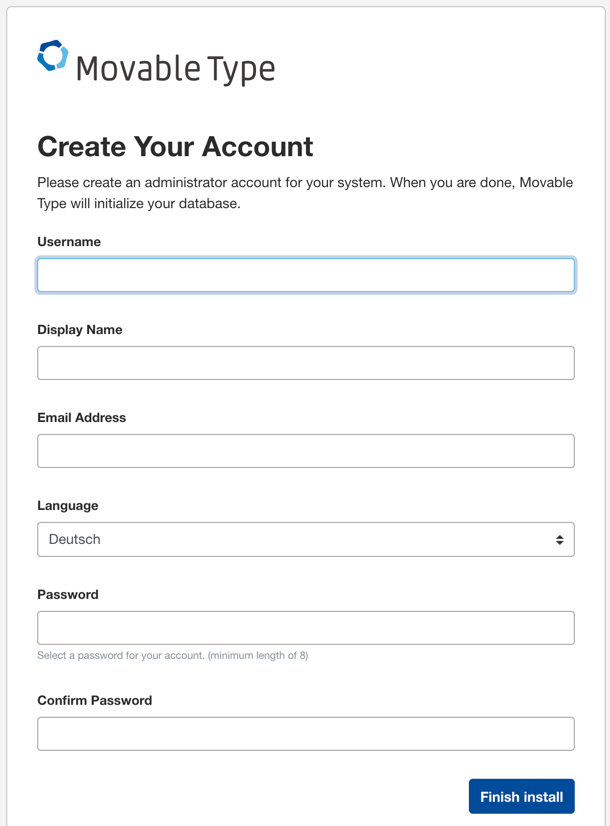
http://localhost:5000/mt/mt.cgi(localhostは作業環境に合わせて)にアクセスすると、セットアップウィザードが開始されます。
文字化けの問題で、
LanguageはEnglishでひとまず進めてください。
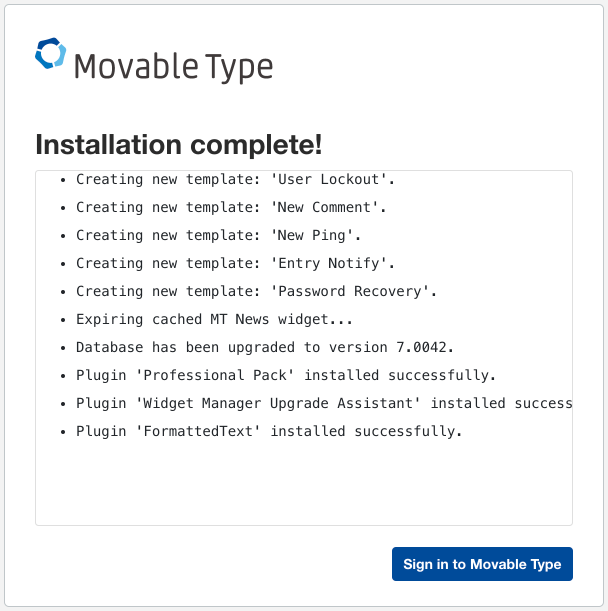
データベースのセットアップができたらOKです。
コンテナサポート ≒ カスタムランタイム
AWS Lambdaのコンテナサポートは、2年前にリリースされた
カスタムランタイムのプロトコルを踏襲しています。カスタムランタイムはHTTPによりLambdaサービスと連携しますが、コンテナも同様です。なのでコンテナの情報はまだ少ないのですが、カスタムランタイムについて調べると大抵の問題は解決できます。
今回も、AWS Lambdaカスタムランタイム用のモジュール
AWS::Lambdaを大いに活用します。https://github.com/shogo82148/p5-aws-lambda
手順6 コンテナ用エントリーポイント
bootstrapMTのディレクトリ直下に
bootstrapを作成し、実行権限を付与します。boostrap#!/usr/bin/perl use strict; use AWS::Lambda::Bootstrap; use File::Basename; # Lambdaサービスから渡されそうだが… $ENV{'LAMBDA_TASK_ROOT'} = dirname(__FILE__); # Lambdaにハンドラの入力欄がないからこちらは来ないかも? # AWS::Lambda向けに固定 $ENV{'_HANDLER'} = 'mt-lambda.handler'; my $bootstrap = AWS::Lambda::Bootstrap->new; $bootstrap->handle_events;カスタムランタイムと違い、名前は
bootstrapでなくてもよいのですが慣習に沿います。chmod +x bootstrap手順7 Lambdaコンテナ用MTエントリーポイント
mt-lambda.pl次に
bootstrapから呼び出されるMTのエントリーポイントmt-lambda.plを作成します。mt-lambda.pluse strict; use lib $ENV{MT_HOME} ? "$ENV{MT_HOME}/lib" : 'lib'; use lib $ENV{MT_HOME} ? "$ENV{MT_HOME}/extlib" : 'extlib'; use MT::PSGI; use AWS::Lambda::PSGI; my $app = MT::PSGI->new()->to_app(); my $func = AWS::Lambda::PSGI->wrap($app); sub handler { my $payload = shift; return $func->($payload); } 1;このファイル名と
sub handlerの名称は、下記のようにbootstrapの記述と関連しているので変更する場合は併せて行う必要があります。$ENV{'_HANDLER'} = 'mt-lambda.handler'; # mt-lambda → mt-lambda.pl # handler → sub handler最初は
bootstrapファイル内ですべて完結させる予定でしたが、AWS::Lambdaモジュールの実装によりそれが難しかったのでbootstrapとmt-lambda.plに分かれています。手順8 ECRにプッシュ
ECR上のリポジトリにイメージをプッシュします。細かい説明は省略します。
docker tag mt-serverless (固有のID).dkr.ecr.ap-northeast-1.amazonaws.com/mt-serverless:latest docker push (固有のID).dkr.ecr.ap-northeast-1.amazonaws.com/mt-serverless:latest手順9 Lambdaを作成
コンテナイメージを元にLambda関数を作成します。
今のコンテナイメージは
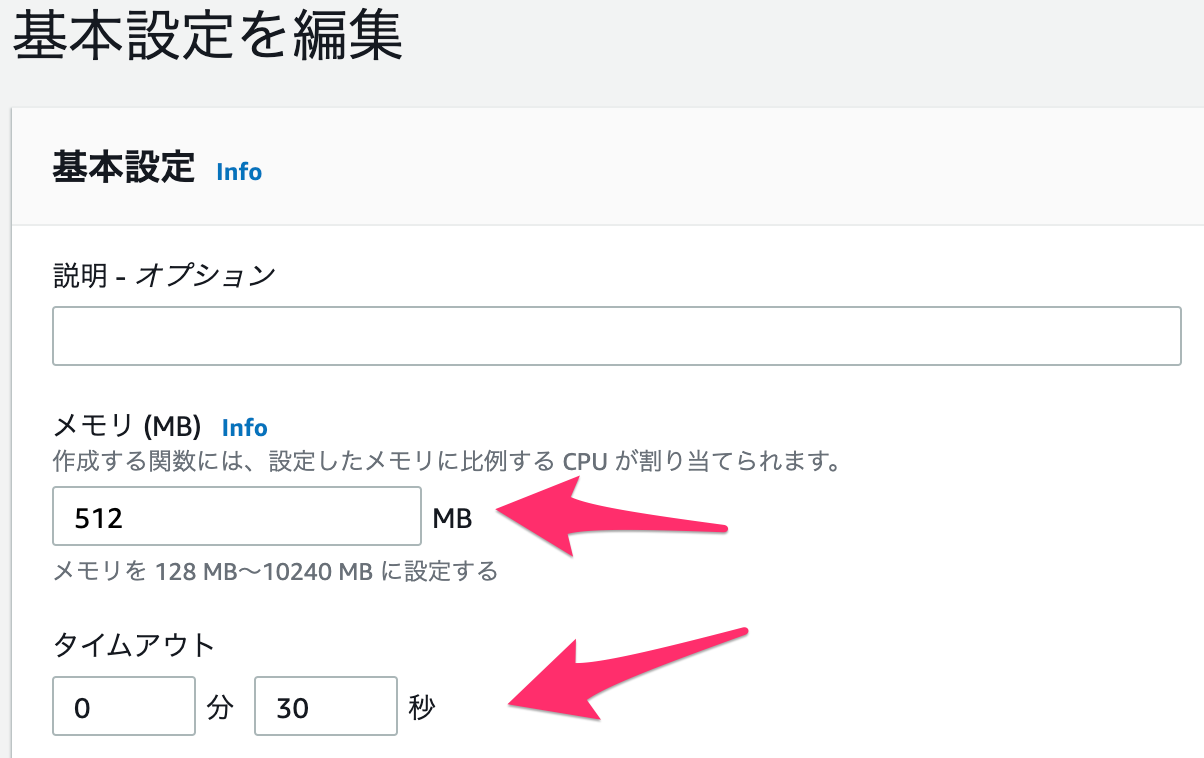
plackupでPSGI版のMTを起動するので、CMDにLabmda用のエントリポイント/app/bootstrapを指定します。作成後にLambdaのメモリとタイムアウトを変更します。
適切な設定は要検討ですが、とりあえずタイムアウト3秒は短いので30秒にしました。
手順10 Elastic Load Balancerの作成
やっと終わりが見えてきました…
Application Load Balancerを作成してLambda関数を割り当てます。
- Application Load Balancer (HTTP/HTTPS) を作成します。
- リスナーは必要に応じてHTTPSを追加してください。
- サブネットはふたつ必要です。
次に証明書とセキュリティグループを選択します。
セキュリティグループは当然、ポート80と443でのインバウンド接続を許可していください。
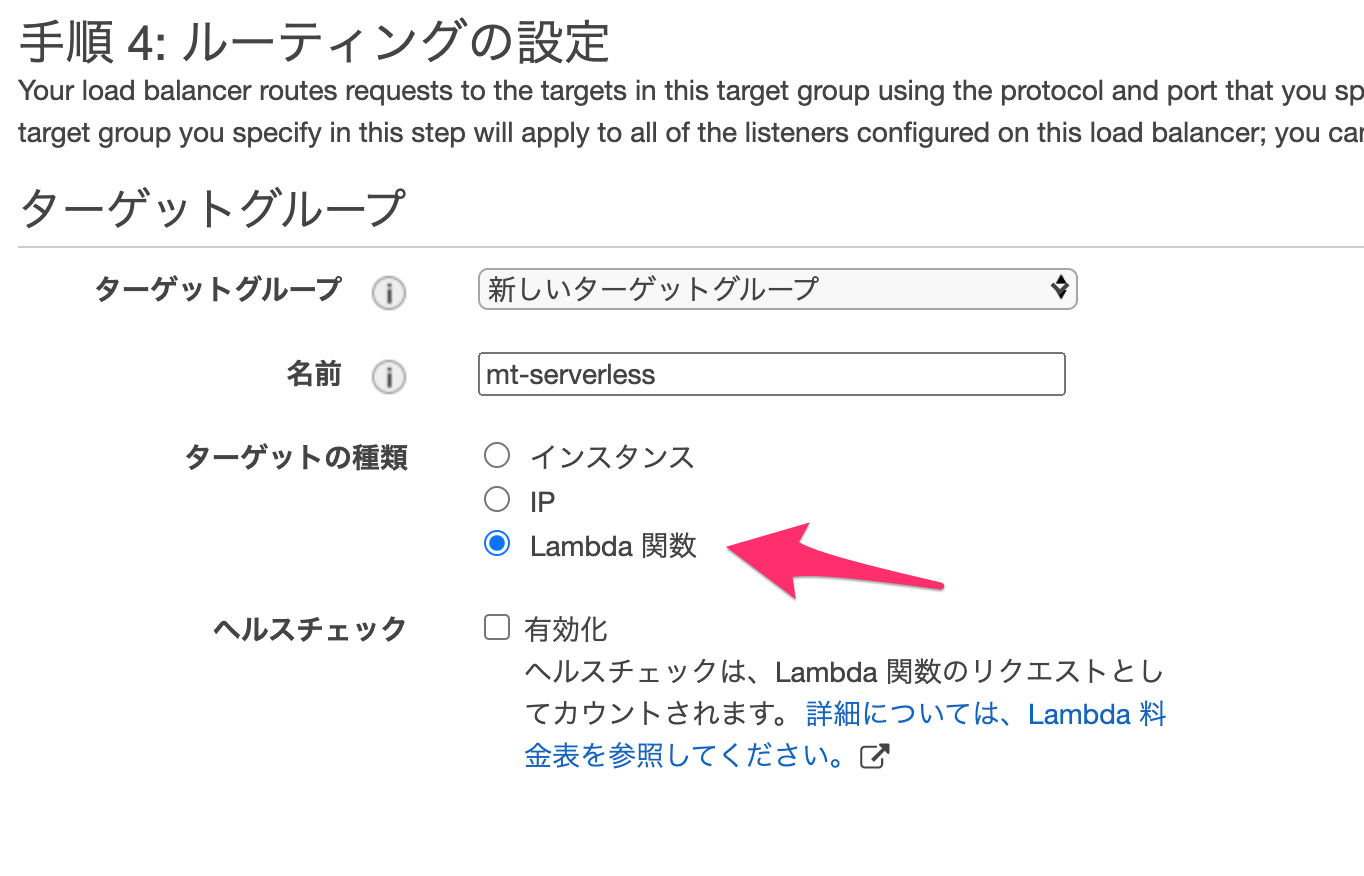
新しいターゲットグループとして、種類=Lambda関数を選択します。
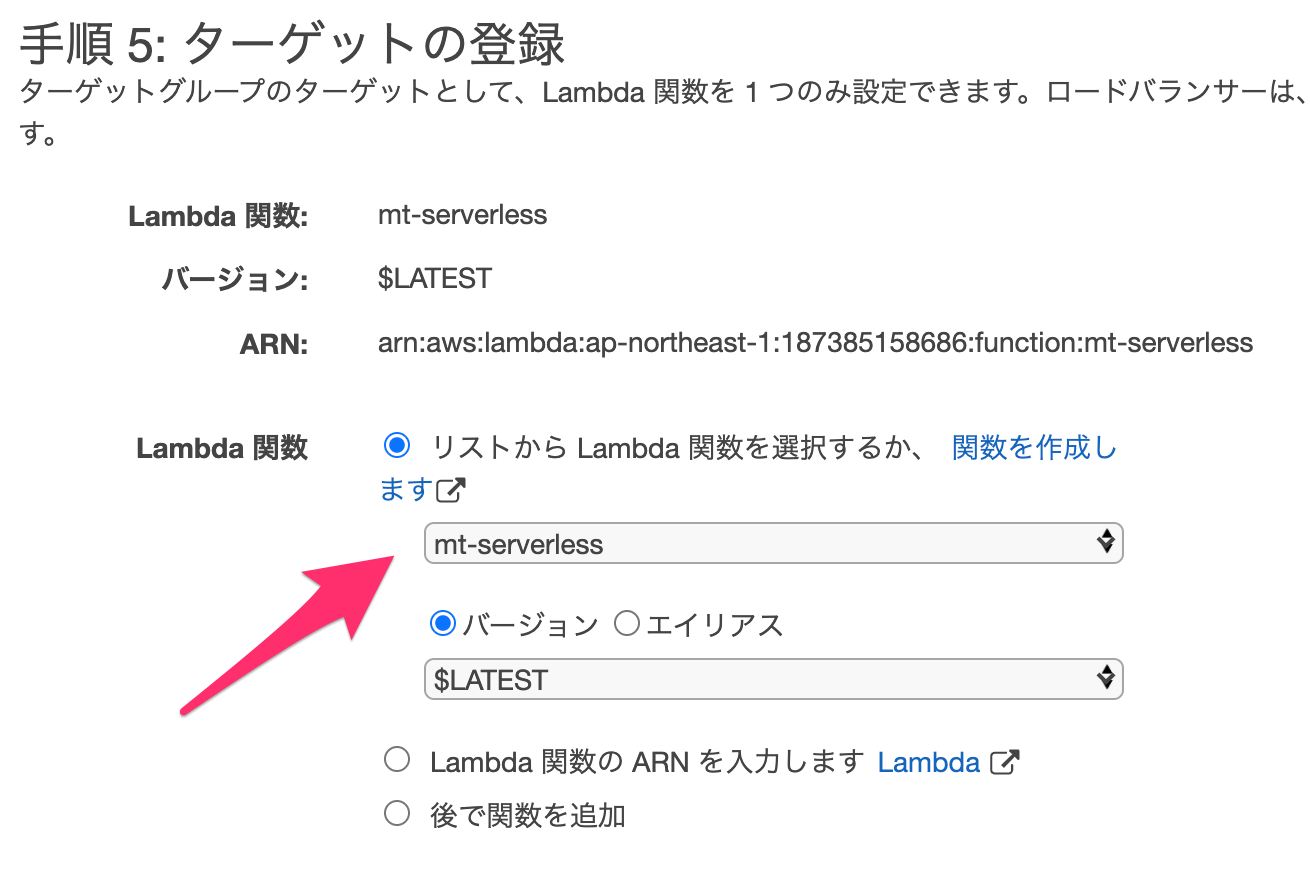
最後に作成したLambda関数を選択します。
ついにMovable Type Serverlessにアクセス
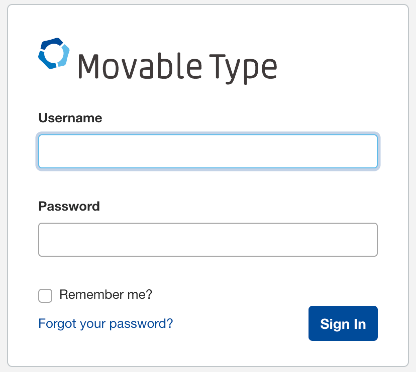
DNSの反映に少し時間がかかるようですが、ブラウザで次のURLを開くと…
http://(ロードバランサーのDNS名)/mt/mt.cgi
き…きたー! MTのログイン画面!
セットアップ時に登録したユーザーでログインすると…
ダッシュボードだー!
しかも意外と動作が軽快。
PSGIをインターフェースとして使っていますが、ライフサイクルとしてはリクエストごとにプロセスが発生するので、挙動としてはCGIに近いはずです。もしかしたらLambdaサービスはPSGI的にプロセスがリクエスト間で使い回しているかもですが。
でもコンテナを読み込むオーバーヘッドは感じられず、実用性も期待できます。
続きを期待します
他の動作確認はしていません。そもそもEFSなどでファイルシステムを永続化しないとサイトも公開できません。
でも使った分だけ課金、並列爆速再構築など、期待が膨らみますね。
あなたがここまで読んだということは、私はすでに力尽きているだろう。ここから先のチャレンジは、あなたに道を譲ろうと思う。検討を祈る!


- 投稿日:2020-12-12T12:08:21+09:00
UdemyのおかげでAWS Cloud Practitionarに合格できた話
先日AWS Cloud Practitionarに合格したのですが、いくつか勉強教材があったうち、主にUdemyの 「この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(7回分455問)」が最も役に立ったので、この講座を有効活用する方法について書きたいと思います。
勉強教材リスト
★使ったもの
参考書として①:図解即戦力 Amazon Web Servicesのしくみと技術がこれ1冊でしっかりわかる教科書
- 参考書として使った図解即戦力~の本は、決してAWS Cloud Practitionar受験向けに書かれた本ではないのですが、「AWSのいちばんわかりやすい本です!」と名売ってるだけあって、めちゃくちゃ分かりやすいです。 AWS初心者の方で、これからCloud Practinar目指されるのであれば、これ一択じゃないかなと思うくらいです。イラストも豊富、全編カラーですごく読みやすいです。ただし、書かれてることは結構概要レベルなので、読むなら一言一句漏らさぬ!くらいの勢いで読み込むことが必要です。
参考書として②:AWS Cloud Practitionar 公式トレーニング
- 丸8時間くらい時間がかかったのであまり乗り気ではありませんでしたが、一応AWS公式の無料トレーニング(eLearning)も見ておきました。
問題集として①:Udemy この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(7回分455問)
- Udemyの講座は、Cloud Practitionar合格体験記系のブログを読むと必ずと言ってよいほど登場する、合格へのバイブルだと思ってます。詳細は後述。
問題集として②:AWS公式 Cloud Plractitionar模擬試験
- 色んな方のブログを読みましたが、模擬試験については受ける受けないで賛否が分かれてますね。悩みましたが、ここで2000円ケチって本番試験で10000円損するよりは、投資だと思って私は受けておくことにしました。これも絶対受けてよかったです!本番のテスト環境や、レベル感が体験できます。おすすめです。
★使わなかったもの
- 巷ではよく、AWS認定資格試験テキスト AWS認定 クラウドプラクティショナーこちらの本がよくオススメされているのですが、白黒印刷で文字ばっかり&章末の試験問題が微妙・・・と感じたので、買っては見たもののほとんど開いてません。。好みが分かれると思いまます。カラフルなテキストのほうが好き♪という方は上記図解即戦力~をオススメします。
個人的には、AWS認定資格試験テキスト AWS認定 クラウドプラクティショナーを買うお金があるなら、絶対にUdemyの講座を買った方がいいです!!!!!
Udemy講座のすばらしさ
この講座の素晴らしいところは以下です。
- 解説が超丁寧!
- 問題数が豊富!
- レベル感が本番の問題にあってる!
- 復習しやすい構成!
まず解説が超丁寧!ですが正しい選択肢のみの説明だけでなく、他の選択肢がなぜ間違いだったか?ひっかかりやすいポイントはどこか?を分かりやすく解説してくれています。似たような問題であっても、解説は省略せずに書いてあるので助かります。
次に問題数が豊富!ですが、1回分の試験を7種類解けます。内容もランダムで重複が多いわけでもないので、準備においては非常に役に立ちます。ちなみに、私は基本①、基本②、応用①しか解きませんでした。理由は、応用②になった瞬間1問目から何もわからなかったからです。笑 とりあえず数問解いてたのですが全く分からず、見なかったことにしてすっと画面を閉じました。
他のブログでは本番の内容は応用①より難しく応用②より簡単と書いてるものもあったので不安だったのですが、とりあえず基本①、②、応用①をそれぞれ90%以上回答できるようになってれば、それでも合格できました。当日のスコアは934/1000だったので、ぎりぎりというわけでもなかったです。応用②を解くかどうか悩んでる方がいれば、それより前の3回分を完璧に解けるようにして、AWS公式の2000円の模擬試験もカバーしておくことをお勧めします!
レベル感が本番の問題にあっている、については、実際に基本①基本②応用①を解いておけば合格できたので、有難いレベル設定だったなという感じです。
最後に、復習しやすい構成!ですが、これはこの講座に限らずUdemyの仕様だと思いますが、その問題を解いた回数ごとに結果が記録されていて、正答率は何%だったか?が表示され、不正解だった問題やフラグを付けた問題のみに絞って復習することができます。私はこの機能を活用して、各回4-5回解きました。
おわりに
AWS Cloud Practitionar合格のために使った勉強教材と、その中のUdemy講座のすばらしさについでご紹介しました。
合格体験記はたくさんありますが、特にUdemyの講座買う?買わない?買ったけど、応用②以降の問題どうしよう・・・と不安になってる方の参考になれば嬉しいです。それではみなさんHappy Holidays!
- 投稿日:2020-12-12T10:52:18+09:00
Udemy講座を利用してAWS SAAに合格した話
本記事は、あなたの学びをシェア!2020年までにUdemyで学んだこと03【PR】Udemy Advent Calendar 2020の13日目です。
はじめに
業務で、AWS認定ソリューションアーキテクトアソシエイトが必要になったため、Udemyの講座を利用して学習し受験、合格することができたので、私なりの勉強法をご紹介したいと思います。
受講したUdemy講座
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
https://www.udemy.com/course/aws-associate/クラウドプラクティショナーも直近で取得はしており、その際はAWSが提供するトレーニングで学習したのですが、難易度の乖離(試験のほうが難しい)を感じました。そのため、サードパーティの講座を探したところ、ネット上で評判が良かった上記講座を見つけ、購入しました。
私はブラックフライデーのセールで購入したため、1,300円で購入できました。勉強の流れ
AWSの実務経験は3年弱あったのですが、講座を購入してから受験日まで2週間しかなかったため、以下の流れで学習しました。
- セクション3.AWSとアソシエイト試験の概要と、セクション8. Well Architect Frameworkを受講し全体を把握する
- 模試を受験し、弱点を見つける
- 弱点部分(私の場合はデータベース、SQS、SNS、CloudFormationなど)の講座を受講し、補強する
- 2と3を繰り返し、3回分の模試を消化
模試は2回分は本番のテスト形式になっていますが、残りの1回分は小テスト形式(多肢選択式がない)であるため、小テスト方式のものを先に消化しました。
3回目の模試を消化したのが試験当日の受験4時間前で、しかも不合格だったのは焦りました……受講して良かったポイント
AWSの模試が3回分あり、それぞれの問題ごとに詳しい解説が記載されているので、学習がしやすかったです。また、講座内の説明が丁寧にされているので、今までAWSを触ったことがないけど触る必要があるといった場合の初心者講座としても良い教材だと思います。
受験結果と感想
結果は768点で合格でしたがギリギリでした。試験問題簡単じゃん!と思いながら解いていたので、もっと余裕があると思っていたのに……
模試を繰り返しやらなかったため、自身の知識として定着していなかったのが反省点です。(受験を急ぎすぎた気もします。)復習しつつ更なる高みを目指せればと思っています。
- 投稿日:2020-12-12T10:32:15+09:00
既存のCDKプロジェクトをCDK v2.0 に移行する
AWS CDK v2.0がalphaリリースされていたので、とりあえず導入してみた際の覚書。
前提
AWS CDK 1.77.0 を利用しているプロジェクト(以下、1系)がすでに存在するとします。
本記事では、そのプロジェクトをAWS CDK v2.0に移行させることを目的にします。改修が必要なポイント
既存プロジェクトをCDK v2.0に移行する上で、最低限必要な変更点をまとめます。
package.json従来のCDKでは、AWSサービスごとのライブラリを個別にインストールする必要がありました。(例:
@aws-cdk/aws-codebuild,@aws-cdk/aws-lambdaなど)
CDK v2.0では、これらは単一のパッケージに集約されています。このため、
package.jsonは下記のように変更します。変更前{ "name": "cdk-sample", "version": "0.1.0", "bin": { "app": "bin/app.ts" }, "scripts": { "build": "tsc", "watch": "tsc -w", "test": "jest", "cdk": "cdk" }, "devDependencies": { "@aws-cdk/assert": "1.77.0", "@types/jest": "^26.0.10", "@types/node": "10.17.27", "jest": "^26.4.2", "ts-jest": "^26.2.0", "aws-cdk": "1.77.0", "ts-node": "^9.0.0", "typescript": "~3.9.7" }, "dependencies": { "@aws-cdk/core": "1.77.0", "@aws-cdk/aws-lambda": "1.77.0", "@aws-cdk/aws-apigateway": "1.77.0", } }↓
変更後{ "name": "cdk-sample", "version": "0.1.0", "bin": { "app": "bin/app.ts" }, "scripts": { "build": "tsc", "watch": "tsc -w", "test": "jest", "cdk": "cdk" }, "devDependencies": { "@types/jest": "^26.0.10", "@types/node": "10.17.27", "jest": "^26.4.2", "ts-jest": "^26.2.0", "aws-cdk": "^2.0.0-alpha.0", "ts-node": "^9.0.0", "typescript": "~3.9.7" }, "dependencies": { "aws-cdk-lib": "^2.0.0-alpha.0", "constructs": "^3.0.4" } }変更点は下記です:
1.@aws-cdk/assertを削除
2.@aws-cdk/*を削除
3.aws-cdkのバージョンをalpha版に書き換え
3.aws-cdk-lib,constructsを追加
aws-cdk-libライブラリ が、今まで個別にインストールしていたパッケージが集約されたものです。
今後は使うサービスが増える度にpackage.jsonを書き換える必要がなくなりますね。
constructsライブラリ は、CDK v2.0から明示的にインストールすることが必要になるようでした。
(これまでは各モジュールの依存になっており、別々にインストールされていたようです)
@aws-cdk/assertライブラリ はCDKのテスト用ライブラリでしたが、v2.0版は用意されていないようです。
サンプルでもjestの関数を多用するような形に書き換えられていました。
今後のCDKテストベストプラクティスはまた探っていければと思います。パッケージのimport方法
合わせて、パッケージをimportする書き方も変わります。
下記はTypeScriptの例です。下記の順番で機械的に置換すれば良さそうです:
@aws-cdk/core→aws-cdk-libに@aws-cdk→aws-cdk-libに変更前import * as apigateway from "@aws-cdk/aws-apigateway"; import * as lambda from "@aws-cdk/aws-lambda"; import { App, Duration, Stack, StackProps } from "@aws-cdk/core";↓
変更後import * as apigateway from "aws-cdk-lib/aws-apigateway"; import * as lambda from "aws-cdk-lib/aws-lambda"; import { App, Duration, Stack, StackProps } from "aws-cdk-lib";動かしてみる
上記の変更をした上で、
npm install,npm run build,npm run cdk synthしてみましょう。
特に今までと変わりない挙動で動きました!まとめ
今のところは、CDK1系→2系への移行は容易にできそうです。
CDK v2.0の変更点やロードマップは下記にまとまっていますが、1系のつらみを解消してくれる点も多いので、ぜひ乗り換えたいですね。
- https://github.com/aws/aws-cdk-rfcs/blob/master/text/0079-cdk-2.0.md
- https://github.com/aws/aws-cdk/projects/10
※ ただしsemvarの規則の通り、メジャーアップデートでは後方互換性のない変更が多々ある(
@deprecatedの削除など)と思われます。
このため、ロードマップやRFCを見て事前に準備しておくのが良いでしょう。
- 投稿日:2020-12-12T07:34:59+09:00
CloudWatchLogsとLambdaを使ったエラーログ監視をしてみる
はじめに
エラーログ。。簡単にキーワードでひっかけてSlack通知させたいなぁ。。
そんなお悩みありませんか?
AWS上で運用されているかた必見!
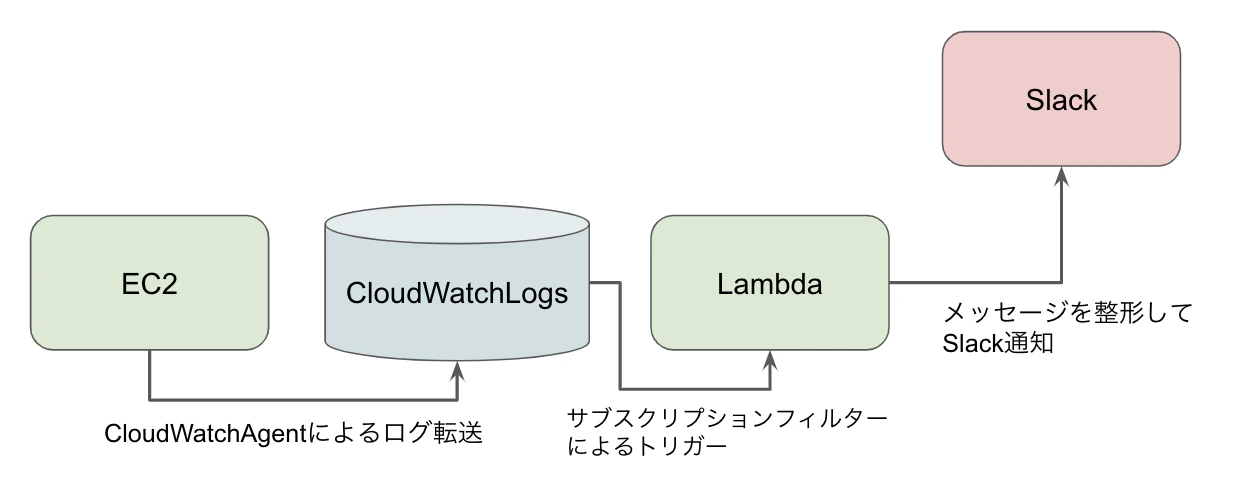
かーんたんに(そしてわりと安く)ログ監視できちゃう方法をお披露目したいと思います!構成
やり方
- CloudWatchAgentをEC2に導入する
- Lambdaの処理を書く
- ロググループにサブスクリプションフィルターを設定する
1. CloudWatchAgentをEC2に導入する
ポリシーが必要になるので、以下を参考にアタッチしてください。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/create-iam-roles-for-cloudwatch-agent.html#create-iam-roles-for-cloudwatch-agent-rolesインストールはAmazonLinux2を利用してる場合以下で一発導入可能。
$ sudo yum install amazon-cloudwatch-agentその他のサポート対象OSをお使いの場合はこちらを参考に導入してみてください!
サポート対象OSについては以下をご確認ください。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/Install-CloudWatch-Agent.html導入が済んだら、設定ファイルを書いて起動してみましょう!
起動方法はOSによって異なるので、OSに合わせた起動方法で起動してください。
設定例{ "agent": { "run_as_user": "root" }, "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/var/log/hoge_service/fuga.log", "log_group_name": "/aws/ec2/hoge_service/fuga.log", "log_stream_name": "{instance_id}" } ] } } } }log_stream_nameは
instance_idを使うと手っ取り早くEC2毎にログストリームをわけてくれてオススメ設定です。
複数サーバーで使う場合は同じストリームにしないようにした方が良いでしょうね。
(理由は。。試せばわかりますw)
サーバー毎に監視したいエラーメッセージなどが異なる場合はlog_group_nameをサーバー毎にわける必要があります。
例: サーバーAではHogeErrorを監視する必要があって、サーバーBではFugaErrorを監視する必要がある場合は、サーバーAとサーバーBでlog_group_nameを分ける必要がある。CloudWatchAgentはこの他にも色々な事ができて便利なので、気になる方は試してみてください。
2. Lambdaの処理を書く
CloudWatchLogsからトリガーされてSlack通知をするちょうど良いサンプルがPythonであったので、Pythonにしてます。
Lambdaがサポートしているお好きな言語で書くと良いと思います。
尚、Slackへの通知はIncoming webhookを想定して書いてます。
Incoming webhookの使い方は各自お調べください。
ログストリーム名をEC2のインスタンスIDとしているのでAWSコンソール上のEC2詳細画面へのリンクを生成して通知メッセージに入れてます。(オススメ!!)
またロググループへの遷移もできるようにしているので、前後のログ状況が通知後すぐに確認できます。(オススメ!!)import base64 import requests, json import urllib import zlib import datetime import os import boto3 import pprint from botocore.exceptions import ClientError print('Loading function') def lambda_handler(event, context): data = zlib.decompress(base64.b64decode(event['awslogs']['data']), 16+zlib.MAX_WBITS) data_json = json.loads(data) WEB_HOOK_URL = "https://hooks.slack.com/services/hoge/fuga/XXXXXXX" WIKI_LINK_TITLE = "<https://hoge.fuga/wiki/HogeError|WIKI>" for log in data_json["logEvents"]: log_json = json.loads(json.dumps(log, ensure_ascii=False)) #print(log_json) LOG_GROUP_LINK_TITLE = "<https://ap-northeast-1.console.aws.amazon.com/cloudwatch/home?region=ap-northeast-1#logsV2:log-groups/log-group/%s/log-events/%s|%s>" % (urllib.parse.quote_plus(data_json['logGroup']),data_json['logStream'],data_json['logGroup']) INSTANCE_ID_LINK_TITLE = "<https://ap-northeast-1.console.aws.amazon.com/ec2/v2/home?region=ap-northeast-1#InstanceDetails:instanceId={0}|{0}>".format(data_json['logStream']) print("LOG_GROUP : %s" % data_json['logGroup']) print("STREAM_NAME : %s" % data_json['logStream']) try: message = u':no_entry:HOGEエラーが発生しました。\nサーバーの状態を確認して%sを参考に対応してください。\nロググループ名:%s\nインスタンスID:%s\nエラーメッセージ:\n```\n%s\n```' % (WIKI_LINK_TITLE,LOG_GROUP_LINK_TITLE,INSTANCE_ID_LINK_TITLE,log_json['message']) requests.post(WEB_HOOK_URL, data = json.dumps({ 'channel': u'#XXXXXXX', 'text': message, #通知内容 'username': u'Alart From AWS lambda' #ユーザー名 })) except Exception as e: print(e) print('End function')requestsライブラリが外部パッケージとなっているため、pipなどでダウンロードしてzipで固めてuploadする必要があります。
以下Mac上で対応した例です。
最後にlambda_function.pyを忘れずに入れてディレクトリごとzipで固めてuploadすれば幸せになれます。$ mkdir for_lambda $ cd for_lambda/ $ pip3.7 install requests -t . Collecting requests Downloading https://files.pythonhosted.org/packages/39/fc/f91eac5a39a65f75a7adb58eac7fa78871ea9872283fb9c44e6545998134/requests-2.25.0-py2.py3-none-any.whl (61kB) |████████████████████████████████| 61kB 7.1MB/s Collecting chardet<4,>=3.0.2 Using cached https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl Collecting urllib3<1.27,>=1.21.1 Downloading https://files.pythonhosted.org/packages/f5/71/45d36a8df68f3ebb098d6861b2c017f3d094538c0fb98fa61d4dc43e69b9/urllib3-1.26.2-py2.py3-none-any.whl (136kB) |████████████████████████████████| 143kB 9.9MB/s Collecting certifi>=2017.4.17 Downloading https://files.pythonhosted.org/packages/5e/a0/5f06e1e1d463903cf0c0eebeb751791119ed7a4b3737fdc9a77f1cdfb51f/certifi-2020.12.5-py2.py3-none-any.whl (147kB) |████████████████████████████████| 153kB 10.2MB/s Collecting idna<3,>=2.5 Using cached https://files.pythonhosted.org/packages/a2/38/928ddce2273eaa564f6f50de919327bf3a00f091b5baba8dfa9460f3a8a8/idna-2.10-py2.py3-none-any.whl Installing collected packages: chardet, urllib3, certifi, idna, requests Successfully installed certifi-2020.12.5 chardet-3.0.4 idna-2.10 requests-2.25.0 urllib3-1.26.2 $ ll total 0 drwxr-xr-x 3 hoge_fuga 1189740132 96 12 12 06:58 bin drwxr-xr-x 7 hoge_fuga 1189740132 224 12 12 06:58 certifi drwxr-xr-x 8 hoge_fuga 1189740132 256 12 12 06:58 certifi-2020.12.5.dist-info drwxr-xr-x 43 hoge_fuga 1189740132 1376 12 12 06:58 chardet drwxr-xr-x 10 hoge_fuga 1189740132 320 12 12 06:58 chardet-3.0.4.dist-info drwxr-xr-x 11 hoge_fuga 1189740132 352 12 12 06:58 idna drwxr-xr-x 8 hoge_fuga 1189740132 256 12 12 06:58 idna-2.10.dist-info drwxr-xr-x 21 hoge_fuga 1189740132 672 12 12 06:58 requests drwxr-xr-x 8 hoge_fuga 1189740132 256 12 12 06:58 requests-2.25.0.dist-info drwxr-xr-x 17 hoge_fuga 1189740132 544 12 12 06:58 urllib3 drwxr-xr-x 8 hoge_fuga 1189740132 256 12 12 06:58 urllib3-1.26.2.dist-info $ touch lambda_function.py3. ロググループにサブスクリプションフィルターを設定する
CloudWatchAgentの設定がうまくいってログが転送され出すと、CloudWatchLogsに設定ファイルに設定したロググループ名でロググループが追加されていると思います。
今すぐAWSコンソールを開いて確認してみましょう!
必要に応じてログの保持期間などを変更しておきましょう。
ロググループの一覧からでも詳細からでも構いませんので、アクションからLambda サブスクリプションフィルターを作成を選択します。
以下を参考に設定してみましょう。
一つのロググループに対して最大で二つのサブスクリプションフィルターが作成できます。(サポートにて確認済み)
また、面倒ですが、一度登録したサブスクリプションフィルターはLambda側でのみ削除できます。
AWS CLIを使えばこの限りではないと思います。(そこまでは調べてないです。。)
うまく連携できるとLambda側で以下のように確認できます。
ここまでできれば、Slack通知されるはずです!
できてなかったら、Lambdaの実行ログなどを確認してトラブルシューティング頑張ってください!おわりに
比較的コーディング少なめでログの監視ができるものです。
ElasticSearch版のサブスクリプションフィルターもあるようなので、より高度なログ解析のできるようです。
機会があれば、チャレンジしてみたいものです^^


- 投稿日:2020-12-12T05:55:50+09:00
はじめてのAWSその2 EC2のサーバを構築する
AWSでサーバ構築するための覚書です。その1で作ったVPCにEC2のサーバを作ります。
EC2のインスタンスを起動
インスタンスを起動=インスタンスを構築 の意味です。
インスタンスを起動をクリック
Amazon Linux 2 AMI (HVM), SSD Volume Type の64bit(x86)を選択
t2.microを選択して「インスタンスの詳細の設定」ボタンをクリック
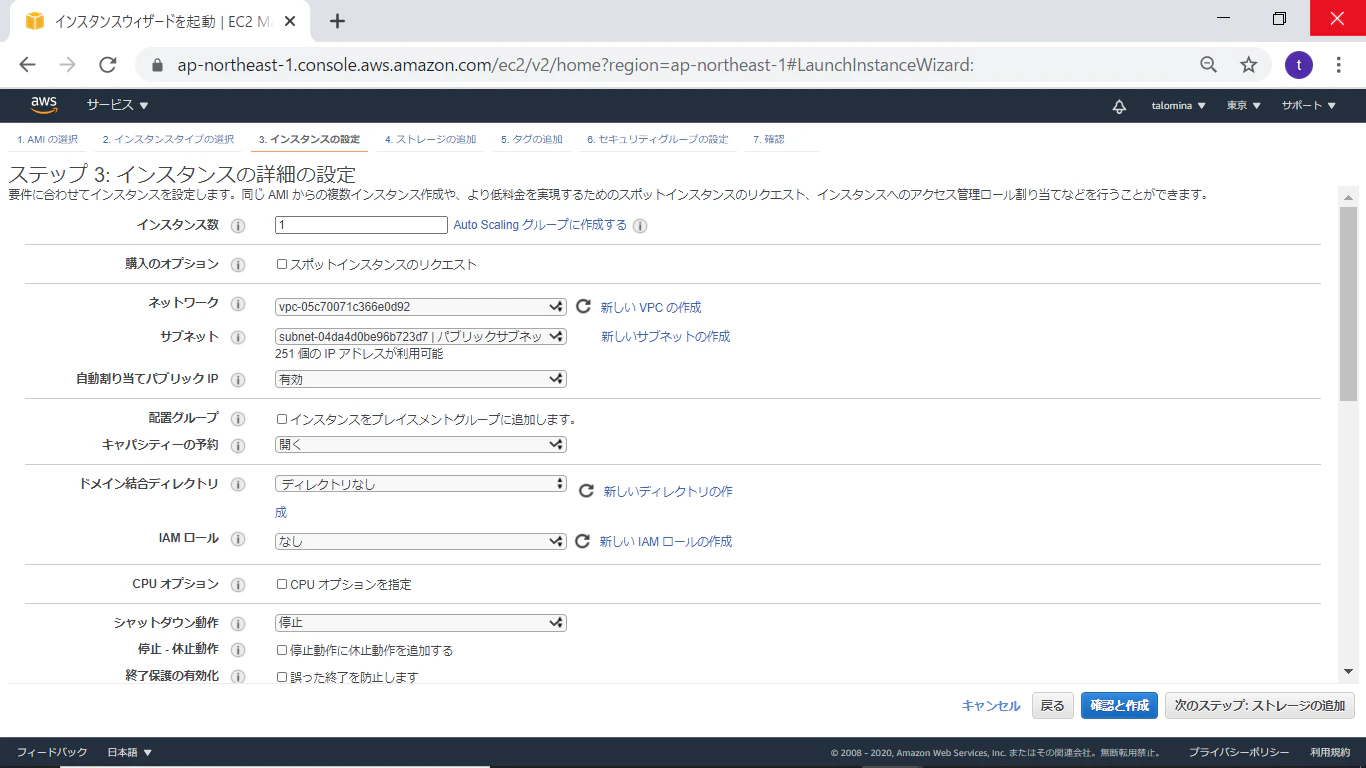
詳細を設定する
- ネットワーク:その1で作成したVPC
- サブネット:その1で作成したパブリックサブネット
- 自動割り当てパブリックIP:無効から有効に変える
- ネットワークインタフェースのプライマリIP:自動的に割り当てのまま
ストレージの追加
ここは変更しない
タグの追加
も変更なし。
セキュリティグループ
ここも変更しない セキュリティグループはファイアウォールの意味。特定のIPアドレスしか通さない、とか。
いよいよ起動!?
キーペアをダウンロードしてインスタンスの作成
ここで秘密鍵を作りますが、これがないとサーバに接続できなくなるので大切に保管する
インスタンスが完成
teratermで接続する
- ユーザー名は ec2-user
- パスワードは なし
- ダウンロードした秘密鍵を利用
- うまくコンソールが表示されたら成功!

注意点
- Windowsのコマンドプロンプトからsshコマンドでつなごうとしましたがうまくいかず、teratermを入手しました https://ja.osdn.net/projects/ttssh2/releases/p
- インスタンス操作の日本語の使い方が少し独特で最初悩みました(English)
- 起動(Lounch):インスタンスを作ること
- 終了(Terminate):インスタンスを抹消すること
- 開始(Start):電源ONのこと
- 停止(Stop):電源OFFのこと







- 投稿日:2020-12-12T03:41:46+09:00
AWS CDP道場を同期と一緒に開催した話
はじめに
こちらの記事は、CA21 Advent Calendar 2020の12日目の記事です!
今回は先日内定者同士のイベントとしてAWS CDP道場in21(会社内で行われたAWS CDP道場の21卒のスピンオフイベント)を開催しましたのでその時に感じたことや勉強になったことを簡単にまとめていきたいと思います!AWS CDP道場って何?
AWSでシステム設計する上で欠かすことのできないCDP(Cloud Design Pattern)を、実践形式のシナリオに沿って設計して体得するワークショップ形式の勉強会です。
開催した経緯
サイバーエージェントではAWSのソリューションアーキテクトの方々が常駐してくださっており週に2、3日程アーキテクチャ等の相談会が行われています。
そして、その中で業務の時間の中で様々なハンズオンやイベントが社内向けイベントとして開催されています。
それらのイベントには配属部署の上長の方、またはチームの許可が下りれば業務時間の中で自由に参加することができます。(仕事の1つとしてawsの人に色々教えてもらえるのは個人的にかなり嬉しいですw)
過去開催されたものとしては
- Well-Architected フレームワークの講座
- AWS Amplifyハンズオン講座
- AWS GameDay(https://developers.cyberagent.co.jp/blog/archives/26934/)
等々が行われています
そして今回社内イベントとして
AWS CDP道場が行われたのですが、、、僕自身の業務が忙しく参加が難しい、、、?
と、なってしまい参加することができませんでした。
しかし参加した2人の同期に聞いたところ
「めちゃめちゃ良かった!」
との声をもらったので、どうせなら内定者同士でawsのアーキテクチャを考える会をやってみようとなり開催が決定しました。また、その旨をawsの方にお話しさせていただいたところ当日使っていた資料を快くいただくことができたので、
それをもとにイベントを開催しました。スケジュール
当日のスケジュールとしてはこのようなスケジュールで行いました。
お題を発表してからすぐにアーキテクチャ設計を開始し1時間でアーキテクチャを考え図にまとめなければいけなかったのはとても大変でした。今回のお題
今回のお題は上記のようなというような要件を満たす
サービスのインフラを考えるというものでした。用件の機能の多さもさることながら、
チャット流量10万req/s, データ流量10GB/sという処理速度についても求められるようなかなり高度な用件です僕たちのチームのアーキテクチャ
これらの要件をみてから1時間でチームメンバーと一緒にアーキテクチャ図を考え、最終的に以下のような構成になりました。
要素もかなり多くごちゃごちゃしてしまったので今回はざっくりと6箇所について軽く解説をしていこうと思います。①メインのアプリケーションサーバ
今回メインのアプリケーションサーバはECSとしました。
理由としてはdockerを用いることでローカル環境とプロダクション環境の環境差異を少なくすることができるということが一番大きな理由です。もう一つの選択肢としてEKS(kubernetes)も選択肢としてありましたが、バージョンアップのスピードについていく大変さ学習コストのたかさなどから今回は外しました②データベース
今回はuser情報などはAmazon aurora, チャットなどはAmazon DynamoDBを用いて構成することとしました。
アプリケーション内で複数のDBの種類があることは少し運用のめんどくささがある気がしますが、今回の要件としてチャット流量10万req/sというのがあったのでRDBでは処理が追いつかないという懸念があったため今回チャットのDBだけDynamoDBを用いることとしました③CI/CD
github action, code build, code deployなどを使いCI/CDパイプラインの構築を行っています
④不要データの処理
今回要件としてメッセージの保存期間は1年ということでしたがチャットアプリケーションで1年間たったら完全にデータが削除されてしまうという仕様は問題があると感じたため、DynamoDBのライフサイクルポリシーを使って1年たったチャットデータは削除するのではなくS3 Glacierというs3よりもさらに安くデータを保存できるストレージにためるという構成を取りました
⑤検索機能
検索機能についてはaws batchとlambdaを用いて一定の頻度で新しく作成されたチャットデータをElasticsearchにいれるという構築で対応しました。
検索機能の即時性は減ってしまいますが、大量のデータを常に送り続けるという状態はElasticsearch負荷をかけすぎてしまうと考えたためこのような処理にしました⑥通知機能
最後の通知機能はSQSで通知データをためてlambdaを用いてポーリングしSNSを用いて通知を飛ばしていくというアーキテクチャとしました。SQSを用いた理由としては通知処理はかなりの高負荷がかかるところであり、処理がどこかで詰まったとしても通知機能全体が死ぬということが内容に設計をしました。
以上が僕たちのチームの発表です。
もちろんこれが一番いいアーキテクチャだとは僕たちも思っていませんし、改めて考えたり他のチームの発表を聞いたりしていく中で
- セキュリティ周りの構成をアーキテクチャ図に落とし込めなかったところ
- バッファストリーミングサービスであるKinesisの使用を考えられなかったこと
などなどまだまだ考えられる点があったと感じました。
まとめ
このような形で他3チームが発表を行いそれぞれのチームの発表に対して質疑応答などをしていきました。
チームによってセキュリティ周りを考えられていたり、メインサーバにEKS(kubernetes)を使っていたりと僕自身とてもたくさんの学びとなる機会となりました。参加者にもアンケートを取らせてもらったのですが総じて高評価となっておりまた機会があれば社員さんの方も巻き込んでまたいろんなイベントを開いていけたらと思います!
それにしても内定者の時からこんな感じでお互いの技術を高めあえる環境にあるのは本当に幸せだなと感じますね!




- 投稿日:2020-12-12T03:22:10+09:00
AWS CLI を使う
AWS CLIをセッティング
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2.html
Macならこれをダウンロードして、AWS CLIを使えるようにする
名前付きプロファイルを追加する
ここであらかじめ、AWSアカウントの
アクセスキーID、シークレットアクセスキーを控えておき、
以下のコマンドの対話の中で設定する$ aws configure --profile testUser AWS Access Key ID [None]: XXXXXXXXXXXXXXXX AWS Secret Access Key [None]: XXXXXXXXXXXXXXXX Default region name [None]: ap-northeast-1 Default output format [None]: jsonプロファイルを指定して処理を実行
$ aws s3 ls --profile testUser
- 投稿日:2020-12-12T01:10:19+09:00
スイッチロールを使用している場合のクロスアカウントでS3バケット同期(aws s3 sync)
スイッチロールを使用している異なるアカウントのS3バケット間で同期する方法について調べました。
一先ず解決したのでメモします。やりたい事
スイッチロールを使用しているアカウントA(同期元)のS3バケットから
スイッチロールを使用しているアカウントB(同期先)のS3バケットにaws s3 syncコマンドで同期する。同期対象のS3バケットに設定するバケットポリシー
スイッチロールを使用している場合、一定時間経過するとセッションIDが変わってしまいます。
Principalは名前またはARNの一部に一致させる指定ができないため、Principalではすべてを対象にしてConditionで絞るようにしています。
※ワイルドカード(*)は、すべてのユーザーまたはパブリックアクセスを表すので使用の際は注意。アカウントAのS3バケットポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "xxx", "Effect": "Allow", "Principal": "*", "Action": [ "s3:ListBucket", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::<アカウントAの同期対象S3バケット名>", "arn:aws:s3:::<アカウントAの同期対象S3バケット名>/*" ], "Condition": { "StringLike": { "aws:userId": [ "<アカウントBのRoleId>:*" ] } } } ] }RoleIdをコマンドを使って調べる
Conditionで指定しているRoleIdは以下のコマンドを使用して調べます。
RoleIdの文字列xxxxxxxxxxxxxxxxxxxxxを使用します。RoleIdを調べる// aws iam get-role --role-name <ロール名> --profile <プロファイル名> $ aws iam get-role --role-name AdminRole --profile dev-b { "Role": { "Path": "/", "RoleName": "AdminRole", "RoleId": "xxxxxxxxxxxxxxxxxxxxx", ←これ "Arn": "arn:aws:iam::accountid:role/AdminRole", "CreateDate": "2020-00-00T00:00:00Z", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::accountid:root" }, "Action": "sts:AssumeRole" } ] }, "Description": "", "MaxSessionDuration": 3600, "RoleLastUsed": { "LastUsedDate": "2020-00-00T00:00:00Z", "Region": "ap-northeast-1" } } }以下のコマンドでも調べられます。
UserIdのxxxxxxxxxxxxxxxxxxxxxがRoleIdになります。RoleIdを調べる// aws sts get-caller-identity --profile <プロファイル名> $ aws sts get-caller-identity --profile dev-b { "UserId": "xxxxxxxxxxxxxxxxxxxxx:botocore-session-0000000000", "Account": "accountid", "Arn": "arn:aws:sts::accountid:assumed-role/AdminRole/botocore-session-0000000000" }同期に使用するコマンド
同期先のスイッチロールを使用して、同期コマンドを実行します。
スイッチロールは同期先S3バケットへの以下の権限を持っている必要があります。
必要な権限:s3:ListBucket、s3:PutObject、s3:PutObjectAclコマンド例:アカウントAからアカウントBへの同期aws s3 sync \ --exact-timestamps \ --delete \ s3://アカウントA(同期元)S3バケット \ s3://アカウントB(同期先)S3バケット \ --profile アカウントBのプロファイル
--exact-timestampsデフォルトではサイズが変わらない場合は無視されます。
タイムスタンプに変更があった場合も同期されるように指定します。
--deleteデフォルトでは削除されたファイルは同期先で削除されません。
削除されたファイルも同期先で削除されるように指定します。プロファイル
スイッチロールを使用している場合、プロファイルは以下のように設定し、
<スイッチ後プロファイル名>を--profileに指定します。.aws/credentials[<スイッチ前プロファイル名>] aws_access_key_id = <アクセスキー> aws_secret_access_key = <シークレットアクセスキー>.aws/config[<スイッチ前プロファイル名>] output = json region = ap-northeast-1 [profile <スイッチ後プロファイル名>] role_arn = arn:aws:iam::<アカウントBのアカウントID>:role/<使用するロール名> source_profile = <スイッチ前プロファイル名> region = ap-northeast-1 output = json権限について補足
上記設定では同期向きの可不可は以下になります。
(AdministratorAccess権限を持ったアカウントBのプロファイルで実行した場合)
可 :アカウントA -> アカウントB
不可:アカウントB -> アカウントA
不可:ローカル -> アカウントA
可 :ローカル -> アカウントB
可 :アカウントA -> ローカル
可 :アカウントB -> ローカル参考
https://dev.classmethod.jp/articles/cross-account-s3-sync/
https://qiita.com/n-ishida/items/33cef1d67adc0961625a
https://dev.classmethod.jp/articles/s3-sync-exact-timestamps/
https://dev.classmethod.jp/articles/what-permissions-are-needed-for-s3-sync/
https://docs.aws.amazon.com/cli/latest/reference/s3/sync.html
https://aws.amazon.com/jp/premiumsupport/knowledge-center/copy-s3-objects-account/
https://dev.classmethod.jp/articles/test-s3-sync/
https://aws.amazon.com/jp/premiumsupport/knowledge-center/s3-require-object-ownership/
- 投稿日:2020-12-12T00:55:54+09:00
AWSを全社導入しようとすると上司からよく訊かれること
こちらはJapan APN Ambassador Advent Calendar 2020の12日目のエントリです。
こんにちは、キクタです。
クラウドアドバイザリーコンサルタントをしています。
ビジネス&テクノロジー両方の観点から、AWSを導入したい・導入したお客様の支援をしています。なお、本ブログ内容は私個人の意見です。所属企業の見解を示すものではございませんので、予めご了承下さい。
「パブリッククラウドの比較資料はないですか?」
さて、最近は少し減少傾向ですが
「パブリッククラウドの比較資料はないですか?」
というご相談をしばしばいただきます。AWS導入時あるあるでして、AWSを全社導入したい!というと、
「他とは比較したのか」
と、上司から訊かれたり、そもそも市場調査結果を稟議書に添付しなければならなかったりするからなんですね。ベンダーは自社に都合良いことしか言わない?
よろしい、ならば、アナリストレポートだ!AWSが公開しているアナリストレポートページがあります。
AI, IoTなどバズワードから、インフラストラクチャ、DBなどの定番ものまで、グローバルなトップアナリスト会社のレポートが数多く公開されています。冒頭のお話であれば、インフラストラクチャでフィルターをかければOKです。
「AWSが公開しているということは、自社に有利だからじゃないの?」
という疑問も湧いて当然ですが、同様のアナリストレポートは他のクラウドベンダ(例えばG社など)でも提供しています。
アナリストレポートには市場環境から、各サービス提供ベンダーの得手不得手、今後のフォーキャストまで、一通りのネタは揃っているので、きっと上役の方に「おー!」と感心していただけること、間違いなしです。
クラウド導入の企画書、稟議書作成で悩んでいる方、是非参考にしてみて下さい。
整理が進んできたクラウド市場
調査レポートをねちっこく時系列に沿って読んでいくのが割と好きでして、
ことIaaSに関しては調査対象の会社が年々減っているのがよくわかります。
調査会社によって異なるのですが主要プレイヤーの数は、概ね下記の通りです。2015年頃:15〜20社
2020年: 5〜7社トップは変わらずAWSで、続いてMicrosoft, Google、とここまでは変わらないのですが、3分の2のプレイヤーが脱落し、
ハイパースケールプロバイダーのみ生き残っている、つまり市場の成熟期に入ったということがよく分かります。「どのクラウドを選ぶべきか」の次の問い
お客様からのリクエストも、「どのクラウドを選ぶべきか」という相談は冒頭で述べた通り少し減って、
代わりに最近は「AWSを事業の中でどう活用していくにはどうするべきか」という相談を多くいただくようになりました。ビジネスとテクノロジーの2軸をつなぐ人材育成にむけて
その相談に対しては、ビジネスとテクノロジー、どちらの言葉もわかる人材育成が鍵になると考えます。
ビジネスだけ、テクノロジーだけ、それぞれ専業化した状態でイノベーションは生まれません。それを実現する一つの解は Well-Architectedフレームワークにあります。
AWSのベストプラクティス集という位置づけで、Techな要素も多く書かれているのですが、意外にもクラウドネイティブな組織、カルチャーを醸成するにはどうすれば良いかという示唆も多く含んでいるのが特徴です。よって、TechメンバーがBizサイドの架け橋になるために有効な教材と考えます。AWSというと新たなサービス、新たな技術に目が行きがちですが、 CIOも納得な視座の高い情報を多く発信しているところもまたエンタープライズで好まれる理由なのかな、と思ったりします。
では、また。
- 投稿日:2020-12-12T00:29:09+09:00
AWSソリューションアーキテクト合格体験記 〜簡単なテクニックを添えて〜
はじめに
このQiitaを見ていただいているということはAWSソリューションアーキテクトに何かしらの興味がある方だと思います!
この記事は私が実際にAWS認定ソリューションアーキテクトを受験したときに「あれ、これ勉強法のコツあるぞ」
って気づいた事があったので、私なりの合格への近道をお伝えできればと思います!あくまで個人的意見ですのでご参考までに、、、
whoami
はじめまして、私はFringe81という会社で広告配信システムのインフラエンジニアとして働いています。エンジニア歴は3年目です。
AWS認定ソリューションアーキテクトには2020年3月に合格しました。学習期間は約1ヶ月で、得点は9割くらいでした。受験当時はサーバーサイドエンジニアからインフラエンジニアに転向して半年ほど経過していました。
資格取得のモチベーションは私が所属しているプロダクトでAWSの特定のサービス(EC2,S3,RDS...etc)のみを利用しており、その他のサービスのユースケースやアーキテクチャーを学ぶという目的です。
会社がスキルアップの学習を支援する取り組みを行っているのも取得しようと思ったきっかけでした。
ソリューションアーキテクトを取得するメリット
実際受験してみてどうだったのかというところですが、取得してよかったと感じています。上記の目的自体は達成できました!
メリットとしては現場でも活かせるようなAWSのベストプラクティスの型を習得できるところだと感じました。
合格するためにAWSのサービスの詳細について嫌でも学ぶ必要があることもそうですが、
試験の内容がソリューションアーキテクトという名前の通り、
とある架空の企業が抱える実際にありそうな疑似案件をAWSのサービスを使ってどう解決するか?という設問が多いです。そのため問題を解きながら、実践で使えるソリューションのパターンを学ぶことができるようになっています。
私自身、ソリューションアーキテクトの知識が業務で直接的に活かせるものになっていると感じます。
AWSの現場経験ないと合格できない?
ソリューションアーキテクトの概要欄には
『アソシエイト試験は、AWS における分散システムの可用性、コスト効率、高耐障害性およびスケーラビリティの設計に関する 1 年以上の実務経験を持つソリューションアーキテクト担当者を対象としています』と書いてあります。しかし、合格するのに実務経験は必要ないと感じました。
AWSを業務で触ったことがあると、自然と回答できる問題も何問か存在していましたが、合格に必要なのはAWSのサービスに関する知識とAWSのベストプラクティスを知っているかのほうが得点を取る上では重要だと感じました。
合格最低ライン
正確な数字は公表されていないですが合格点は全体の7割くらいは必要みたいです。
おすすめしたい教材たち
私が実際に使用していて一番使えたと思うものを3つあげます。
市販の参考書: 一夜漬け AWS認定ソリューションアーキテクト アソシエイト 直前対策テキスト(以下では一夜漬け本と呼ぶ)
Udemy: AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)AWS: AWS 公式模擬試験
学習時間とスケジュール
3〜4週間前(インプット中心)
試験3〜4週間前はインプット中心でした!
使用したのはさきほど載せた一夜漬け本を2周と、別の参考書を一読しました。
一夜漬け本に関しては試験に頻出するサービスの内容がシンプルにまとめられていて非常によかったです!
正直この本を完璧にしていたら6割くらいは取れると思います笑また一夜漬け本に詳しく解説がのっていないサービスに関しては公式のドキュメントなんかを読み漁ってました。
2週間前(アウトプット中心)
ある程度インプットが完了したら、模擬試験を解くことで知識が定着していない部分の洗い出しと試験の傾向を掴みに行きました。
具体的取り組んだものは先程書いたUdemyの模擬試験問題集です。
模擬試験問題集は合計6回分用意されています!ボリュームがすごいです!笑
本番の問題の中ですこしレベルの高い問題がまとめられています!問題の傾向を掴むことができます。
難しめの問題が多いので最初は点数を取れなくて落ち込みますが、これをしっかり復習しておくと本番の試験がとても簡単に感じました笑
私は間違った問題をnotionにメモして、間違えた問題集を作ることですぐ復習できるようにしていました!これをやると詳しいサービスとそうじゃないサービスがみえてくるので、詳しくないサービスに関しては公式ドキュメントを読んでインプットしました。
1週間前(復習&模擬試験受験)
模擬試験問題集で間違えた問題を中心に再度学習しました!
模擬試験問題集は全部で390問もあるので、間違えた問題だけでもかなりの問題量になりました笑また、AWSが出している模擬試験を受験して、8割以上取れていたので試験を受けることを決めました。
こちらは後で後述します。直前
試験会場に入るまでの間は、一夜漬け本を読んでました。
最短合格へのテクニック
私が気づいた、合格へのテクニックをお伝えさせていただきます。
頻出サービスの学習を重点的に
AWS認定ソリューションアーキテクトでは特定のサービスに関する似たような問題が頻出します。
そのため、あまりメジャーではないサービスの細かい知識を学習するよりも、メジャーなサービスを学習したほうが、合格の確率は上がります。頻出サービスでいうと、
IAM、Amazon VPC、ELB、EC2、Lambda、DynamoDB、S3、SNS、SQSなんかはかなり出題されていた印象です。この辺のサービスは公式のドキュメントを重点的に読んだり、blackbeltの動画を見たりして対策しておいても損はないです。
また一夜漬け本はこれらの頻出サービスに絞ってあり、その内容がかなり本番試験で出題されていた印象があります。この本は完璧にしておくことが合格への近道かもしれません。
同じ問題集を何回か解く
AWS認定ソリューションアーキテクトはかなり時間がないので、急いで解答していかなければなりません。問題とその解答のパターンを知っておくと、解答を選ぶ時間が短くなります。
問題集を回すことで、この選択肢は選ばれる可能性がすくない、これゆう解答は選ばれやすい、というパターンを知ることができ、時間が少ない中で選択肢を速攻で4択から2択に絞れるようになります。
模擬試験は必ずうける
AWSは本番の難易度に近い模擬試験を提供しているので必ず模擬試験は受験しましょう!
試験を受ける前に、たった2000円で自分が合格圏内にいるかどうか確認することができます。AWSソリューションアーキテクトの試験は受験料が15000円もするので、不合格になって再度受験し直すのはお財布に痛いです、、、念には念をいれましょう!
ここで8割以上取れてなかったら、再度学習し直すことをおすすめします。
問題文を頭から最後まで真面目に全部読まない
AWS認定ソリューションアーキテクトは時間が結構ギリギリな上に、問題文がかなり長い設問があります。
そしてやっかいなことに、問題を解くのに必要な情報とそうでない情報がごちゃまぜに散りばめられています。そこで大事なことは、問題文から問題を解くのに必要な情報だけを即座に抜き出すことです。
設問としては、「顧客のどのような課題を解決するために、どうゆうアーキテクチャーを設計すべきか」ということを終始問われます。
「コストカットしたい」「インフラ担当者が少なくなる」「自動化を検討している」
このようなアーキテクチャー要件に影響してきそうなキーワードにアンテナを張って問題を読むことが、スムーズに設問に答えるために大事なテクニックです。
つらかったこと
試験時間が130分とかなり長くて集中力が持ちませんでした笑
本当に結構ギリギリなので、ペース配分には気をつけたほうがいいです。最後に
資格試験って資格を取得することが目的になってしまいがちですが、自分のスキルアップのために試験を利用すると、効率よく学習できます。
とくにAWS認定ソリューションアーキテクトの問題はAWSを運用する上でのツボがおさえられており、独学でAWSを学習するよりも効率がよいと感じました。
IT業界あるあるで受験料がすこしお高めではあるのですが、挑戦してみる価値はあると思いますでの、この記事が役にたてば幸いです。
- 投稿日:2020-12-12T00:00:24+09:00
AWS Copilot のタスク実行時に AWS リソースから情報を取得する
AWS Containers Advent Calendar 2020 の11日目の記事です。
唐突ですが、先月に GA した AWS Copilot を使ってみようかなと考えている方もいるのではないでしょうか。
Web サービスなどを構築・運用している場合、機能追加やバグ修正のためにデータベーススキームを変更するなどの低頻度で実行するタスクのために、Copilot task run が活用できるかと思います。ただし、セキュリティの観点からクレデンシャルなどの情報をコンテナ内に格納したり環境変数としてコンテナに引き渡すなどは避けたい場面もあるでしょう。
この記事では、 Copilot の run task 時にタスクロールを付与し、実行コンテナ内で処理するために必要な情報を AWS Systems Manager Parameter Store や AWS Secrets Manager から取得するやつをやってみます。かなり手を抜いて、AWS CLI をコンテナ内で実行し、 AWS Systems Manager Parameter Store から事前登録している情報を取得するまでをやってみます。
構成
- VPC 周り及び作業環境の EC2 は事前に作成済みとします
- EC2 には事前に AdministratorAccess ポリシーがアタッチされている ロールを付与します
準備
作業端末から Copilot 実行環境である EC2 へ ssh 接続し、 Copilot のインストール を行います。
デフォルト・リージョンを指定するために、なんらかの方法 (
viやaws configure) で以下ファイルを作成します。
shell_session
$ cat .aws/config
[default]
region = us-east-1
次に
copilot app initを実行し、 ECS クラスターを構築します。 ECS クラスターの構築と同時に、イメージとして nginx を指定した sample-front サービスも構築します。$ copilot app init Application name: sample ✔ Created the infrastructure to manage services and jobs under application sample. ✔ The directory copilot will hold service manifests for application sample. Recommended follow-up actions: - Run `copilot init` to add a new service or job to your application. [ec2-user@ip-10-0-0-137 ~]$ copilot init Note: It's best to run this command in the root of your Git repository. Welcome to the Copilot CLI! We're going to walk you through some questions to help you get set up with an application on ECS. An application is a collection of containerized services that operate together. Workload type: Load Balanced Web Service Service name: sample-front Dockerfile: Use an existing image instead Image: nginx Port: Ok great, we'll set up a Load Balanced Web Service named sample-front in application sample listening on port 80. ✔ Created the infrastructure to manage services and jobs under application sample. ✔ Wrote the manifest for service sample-front at copilot/sample-front/manifest.yml Your manifest contains configurations like your container size and port (:80). ✔ Created ECR repositories for service sample-front. All right, you're all set for local development. Deploy: Yes ✔ Created the infrastructure for the test environment. - Virtual private cloud on 2 availability zones to hold your services and jobs [Complete] - Internet gateway to connect the network to the internet [Complete] - Public subnets for internet facing services and jobs [Complete] - Private subnets for services and jobs that can't be reached from the internet [Complete] - Routing tables for services and jobs to talk with each other [Complete] - ECS Cluster to hold your services and jobs [Complete] ✔ Linked account 123456789012 and region us-east-1 to application sample. ✔ Created environment test in region us-east-1 under application sample. Note: Couldn't find a git commit sha to use as an image tag. Are you in a git repository? Input an image tag value: nginx Environment test is already on the latest version v1.1.0, skip upgrade. ✔ Deployed sample-front, you can access it at http://sampl-Publi-FTCDQO5GGNRW-115515095.us-east-1.elb.amazonaws.com.次は、ECS タスク実行時に指定するための IAM ロールを作成します。 IAM ロール作成のために Trust Policy が記述されている JSON ファイルを CLI 実行前に作成しておきます。
$ cat copilot-sample-task-role-trust-policy.json { "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "ecs-tasks.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } $ aws iam --region us-east-1 create-role --role-name copilot-sample-task-role --assume-role-policy-document file://copilot-sample-task-role-trust-policy.json { "Role": { "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "ecs-tasks.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] }, "RoleId": "AROAUJDL34IZZ6GBAD7JY", "CreateDate": "2020-12-11T13:03:33Z", "RoleName": "copilot-sample-task-role", "Path": "/", "Arn": "arn:aws:iam::123456789012:role/copilot-sample-task-role" } } $ cat copilot-sample-task-role-inline-policyy.json { "Version": "2012-10-17", "Statement": [ { "Action": [ "ssm:GetParameter" ], "Effect": "Allow", "Resource": "*" } ] } $ aws iam --region us-east-1 put-role-policy --role-name copilot-sample-task-role --policy-name copilot-sample-task-role-policy --policy-document file://copilot-sample-task-role-inline-policyy.json最後に、AWS Systems Manager Parameter Store へコンテナから取得するパラメータを設定します。
$ aws ssm --region us-east-1 put-parameter --name test-name --value test-value --type String { "Tier": "Standard", "Version": 1 }実行
準備できたと思うので、
copilot task runコマンドを実行します。コンテナ・イメージは、 AWS が提供している amazon/aws-cli イメージを利用します。$ copilot task run --app sample --command 'ssm --region us-east-1 get-parameter --name test-name' --image 'amazon/aws-cli' --task-role arn:aws:iam::123456789012:role/copilot-sample-task-role In which environment would you like to run this task? test ✔ Successfully provisioned task resources. ✘ Failed to run ec2-user. ✘ run task ec2-user: run task ec2-user: run task(s) copilot-ec2-user: AccessDeniedException: User: arn:aws:sts::123456789012:assumed-role/sample-test-EnvManagerRole/1607694710020885474 is not authorized to perform: iam:PassRole on resource: arn:aws:iam::123456789012:role/copilot-sample-task-role失敗です。コマンド実行しタスクを起動すると、 sample-test-EnvManagerRole という IAM ロールから copilot コマンドの引数に指定した
--task-roleへロールが切り替わるところで失敗しているようです。
エラー回避のために、 Copilot コマンドで作成された sample-test-EnvManagerRole ロールに iam:PassRole 権限を付与します。$ cat copilot-EnvManagerRole-inline-policy.json { "Version": "2012-10-17", "Statement": [ { "Action": [ "iam:PassRole" ], "Effect": "Allow", "Resource": "*" } ] } $ aws iam --region us-east-1 put-role-policy --role-name sample-test-EnvManagerRole --policy-name copilot-task-run --policy-document file://copilot-EnvManagerRole-inline-policy.json再度、
copilot task runコマンドを実行します。$ copilot task run --app sample --command 'ssm --region us-east-1 get-parameter --name test-name' --image 'amazon/aws-cli' --task-role arn:aws:iam::123456789012:role/copilot-sample-task-role --follow In which environment would you like to run this task? test ✔ Successfully provisioned task resources. ✔ Task ec2-user is running. copilot-task/ec2-user/976 { copilot-task/ec2-user/976 "Parameter": { copilot-task/ec2-user/976 "Name": "test-name", copilot-task/ec2-user/976 "Type": "String", copilot-task/ec2-user/976 "Value": "test-value", copilot-task/ec2-user/976 "Version": 1, copilot-task/ec2-user/976 "LastModifiedDate": "2020-12-11T12:55:49.656000+00:00", copilot-task/ec2-user/976 "ARN": "arn:aws:ssm:us-east-1:123456789012:parameter/test-name", copilot-task/ec2-user/976 "DataType": "text" copilot-task/ec2-user/976 } copilot-task/ec2-user/976 } Task has stopped.おわりに
無事、タスクを起動し AWS Systems Manager Parameter Stoer から事前登録済みの値を取得することができました。
もっとスマートな方法がありそうなので、またの機会に IAM ロール設定まわりを CLI ではなく Copilot コマンドで設定する方法を調べてみたいと思います。
