- 投稿日:2020-12-12T23:33:37+09:00
Javaの例外処理入門
今回はQiitaのアドベントカレンダーの投稿日ということもあって、Javaでの例外処理のやり方について、さらっと紹介していこうと思います。
なお、このブログ記事と同じ内容です。1. プログラムにおける例外とは
そもそもプログラムにおける例外は何かというと、一言で言うと「文法としては正しいにも関わらず、実行すると想定外の状況が発生し、プログラムが実行不能になること」と言うことになります。
まず厄介なのが、「文法としては正しい」ので、コンパイルが通ってしまうことです。なので、「よっしゃ、コンパイルが通ったぞ!」と思って実行したら、「あれ!?」と言うことになるわけです。
なので、どのような値が来るとどうなって、実際に起こり得るけど起こったらまずい状況とはどう言う場合かを考えて、それに応じて然るべき対応ができるようにする必要があるわけです。
次に、具体的に「どう言う状況が例外に当たるか」の例をいくつかあげて見ます。
・nullの領域にアクセスして何かやろうとした
・配列やリストなどの要素数より大きい数字のインデックスにアクセスした
・0で割り算した
・許可されていない場所にアクセスした
・ファイルに対して何かやってたらファイルが途中で消えた2.例外処理の基本
Javaにおける例外処理の基本形は、こんな感じです。
try { // ここで何らかの処理 } catch (Exception e) { // 例外が発生したらここに来る }ただ、Exceptionクラスだと、nullアクセスも0割りも、その他諸々含めて一緒くたに扱われるので、一般的にはExceptionクラスのサブクラスを使って、起きた例外に応じた処理を行います。
例として、nullが入ったString変数に対して文字列の長さを取得しようとした場合を見てみます。try { String str = null; System.out.println(str.length()); } catch (NullPointerException e) { System.err.println(e.getMessage()); e.printStackTrace(); }これで、例外の中でもNullにアクセスした場合の例外のみに対して例外処理が行われます。ちなみに、printStackTraceメソッドは例外が起きたところからのメソッド呼び出しの階層一覧を出力してくれます。結構便利なので、デバッグでよく使います。
どんな例外クラスがあるかは、Javaの公式ドキュメントを見てください。3. 独自の例外定義とthrow、throws
Javaでは(大体の言語でそうだと思うけど)あらかじめ用意されている例外以外に、独自の例外クラスを作ることができます。
例えば、温度が100度を超えたらエラーにするとかを考えて見ます。// このクラスで100度以上になった場合の例外を定義 class TooHotException extends Exception { public TooHotException(String s) { super(s); } }try { int temperature = getTemperature(); if (temperature > 100) { // 温度が100度以上だったら先ほど定義した例外クラスに投げる throw new TooHotException(“Too hot!”); } } catch (TooHotException e) { System.err.println(e.getMessage()); }こんな感じです。なお、ここで出てきたthrowは、呼び出すことで対応するcatch節に処理を移すのに使います。
もう1つ、throwに似た名前のthrowsという構文がありますが、これはある例外が発生したら呼び出し元に処理を任せるのに使うものです。
使い方はこんな感じです。public void newFunc() throws NumberFormatException { // このメソッド内でNumberFormatException例外が発生したら、呼び出し元で例外処理を行う }ちなみに、NumberFormatExceptionは数値が入るべきところに数値以外のものが来た場合の例外です。
4. 例外が起きようと起きまいと共通の終了処理を行う場合
例外が発生して、何らかのエラーメッセージを出すものの、最後に何らかの共通処理を行いたい場合は、finallyを使います。
try { // ここで何らかの処理 } catch (Exception e) { // 例外が発生したらここに来る } finally { // 例外が発生してもしなくても最後にここに来る }ファイルバッファを最後に閉じる例です。
BufferedReader br = new BufferedReader(new FileReader(path)); try { br.readLine(); } catch (IOException e) { System.err.println(e.getMessage()); } finally { if (br != null) br.close(); }ただ、Java7以降でtry-with-resources文を用いることによって、finallyを使わなくても使い終わったものを終了することができるので、紹介しておきます(こっちが使えるならこっちの方がいいです)。
BufferedReader br = new BufferedReader(new FileReader(path)); try (BufferedReader br = new BufferedReader(new FileReader(path));) { br.readLine(); } catch (IOException e) { System.err.println(e.getMessage()); }5.その他注意点いくつか
例外処理におけるいわゆる禁じ手をいくつか紹介しておきます。
・例外を握り潰さないtry { // 何らかの処理 } catch (Exception e) { }これだと、例外が発生した場合でも握りつぶして次に進んでしまいますが、このようなことはせず、ちゃんと例外に応じた処理(エラーログを出して処理を終了するとか)を行いましょう。
・例外処理は本当の例外に対してのみ行う
ごく稀に、例外処理を分岐みたいな使い方をする人がいますが、このようなことをやってはいけません。分岐はちゃんとif文とかを使い、プログラムとかシステムとかで通常は起こりえないイレギュラーな事態だけcatchされるようにしましょう。終わりに
ここまでざっと例外処理について書いて来ましたが、やはり実際に色々プログラムを書いて見て慣れるのが一番です。
これを読んだみなさんも是非例外処理を使いこなせるように頑張りましょう!
- 投稿日:2020-12-12T21:23:54+09:00
集約の整合性についてArchUnitを用いてテストする
「集約に含まれるオブジェクトは集約ルートからのみ依存される」ことをテストしてみる。
テストコード
@AnalyzeClasses(packages = "com.example") public class DomainObjectTest { @ArchTest static ArchRule aggregate_object_be_depended_on_only_root_object = noClasses() .that().resideInAPackage("com.example") .should().dependOnClassesThat(new DescribedPredicate<>("domain.hoge") { @Override public boolean apply(final JavaClass clazz) { return clazz.getPackageName().startsWith("com.example.domain.hoge") && clazz.getSimpleName().equals("HogeRoot"); } });集約が特定のパッケージ配下に含まれている前提で、集約ルート以外のオブジェクトが他のクラスから依存されていないことをテストしている。
この場合だと、一時的な参照を渡すことも出来ないため、
dependOnClassThatの代わりにcallMethodを用いて判定しても良いかもしれない。
- 投稿日:2020-12-12T20:20:43+09:00
Androidでもリアルタイムにブラーをかける
序
最近はWebページでもブラー(ぼかし)エフェクトを使用したサイトがみられるようになりましたね(今からだと旬は過ぎた感ありますが…)。
iOSだと6年前のiOS 8からUIVisualEffectViewという便利なビューが標準で用意されたので、ミニマムだとレイアウトだけで実現できてしまいます。
Layout風に書くとこんな感じ…
<UIView> <!-- UIViewはViewGroupのように子ビューを複数持てる --> <UIScrollView> <UIImageView> </UIScrollView> <UIVisualEffectView /> <!-- Androidと同じく下に書くと階層的には上に来て下にあるビューにブラーがかかる --> </UIView>最近Webでも
backdrop-filterによってIEを除いた最新のブラウザで使えるようになりました:
雑ですが iOS のサンプルを大まかに再現するとこうなります:
ちょっと長いので省略
<html> <head> <style type="text/css"> img { object-fit: cover; width: 100%; height: 200vh; } .overlay { position: fixed; top: 0; left: 0; right: 0; bottom: 0; display: flex; } .box { margin: auto; width: 75vw; height: 75vw; backdrop-filter: blur(24px); -webkit-backdrop-filter: blur(24px); /* Safari */ background-color: #ffffff5f; } </style> </head> <body> <img src="..."> <div class="overlay"> <div class="box"></div> </div> </body> </html>本題
画像やビューのキャプチャに対してブラーをかける方法についてはすでに 記事
や 質問 がありましたが、スクロールなどリアルタイムにかける方法についてはまだ情報がまとまっていなさそうだったので、実現するライブラリについていろいろ書いていきたいと思います。ちなみに
- 今回のような例であれば上記ライブラリであらかじめビットマップを作っておいてスクロールに合わせて動かせば擬似的に見せることは可能でした(発想の転換)
- 静止画に対するブラーの掛け方は RenderScript から CPU で Bitmap を直接触る方法などいろいろありますが、興味深いことに StackOverflow でパフォーマンスを測定した方がおられたので共有しておきます
RealtimeBlurView
ずばりな名前のライブラリでレイアウトに乗っけるだけで背景のビューにブラーがかかってくれるすごいライブラリです。説明に書いてある通りにするだけで確かに実現ができました:
サンプルコードはこちらです: https://github.com/cubenoy22/android-reatime-blur
どうやって実現しているのか
ただライブラリを紹介するだけではつまらないのでちょっと中身をみていきたいと思います。
RealtimeBlurView
XMLで配置するビューの実装から見ていきます。対象ファイルは こちら。
ブラー用のビットマップ作成
prepare() メソッドでメンバーの mBitmapToBlur をビューの大きさ分で作成していて、描画用の
mBlurringCanvasも同時に作成しています。このメソッドは後ほど紹介する onPreDraw 内で呼ばれる ようになっていて、画面の更新がされる直前かつまだ準備できていなければ実行されるようになっています。ビューのサイズ変更もここで対応できるようになっていました。protected boolean prepare() { // 省略 int scaledWidth = Math.max(1, (int) (width / downsampleFactor)); int scaledHeight = Math.max(1, (int) (height / downsampleFactor)); if (mBlurringCanvas == null || mBlurredBitmap == null || mBlurredBitmap.getWidth() != scaledWidth || mBlurredBitmap.getHeight() != scaledHeight) { mBitmapToBlur = Bitmap.createBitmap(scaledWidth, scaledHeight, Bitmap.Config.ARGB_8888); } mBlurringCanvas = new Canvas(mBitmapToBlur); mBlurredBitmap = Bitmap.createBitmap(scaledWidth, scaledHeight, Bitmap.Config.ARGB_8888); }ブラーが必要なエリアをビットマップに転写
Activity の Window の decorView に対して
- ViewTreeObserver.OnPreDrawListener をセットし画面の更新を受け取れるように
L301
- background があれば上で用意した
mBitmapToBlurへ描画- 一番肝心な draw() をコールし
mBitmapToBlurへ描画private final ViewTreeObserver.OnPreDrawListener preDrawListener = new ViewTreeObserver.OnPreDrawListener() { @Override public boolean onPreDraw() { // 省略 if (decor != null && isShown() && prepare()) { if (decor.getBackground() != null) { decor.getBackground().draw(mBlurringCanvas); } decor.draw(mBlurringCanvas); blur(mBitmapToBlur, mBlurredBitmap); } } }これであらかじめ作っておいた Bitmap (mBitmapToBlur) に対してビューの内容が転写されました。面白い。
転写した Bitmap に対してブラーをかける
直前の preDrawListener での一連の流れでブラーもかけています。
mBitmapToBlurの他にもう一つmBlurredBitmapという Bitmap が用意されています。このビットマップは実はmBitmapToBlurと同時に同じサイズで用意 されていました。上のコードにも書いておきましたが blur() 関数ですね。protected void blur(Bitmap bitmapToBlur, Bitmap blurredBitmap) { mBlurImpl.blur(bitmapToBlur, blurredBitmap); }mBlurImpl ( BlurImpl ) は getBlurImpl メソッドで状況に応じた実装が使用されるようになっており、違いは RenderScript のパッケージが各種用意されているだけのようでした:
ScriptIntrinsicBlur を使って
mBitmapToBlurの内容にブラーをmBlurrerdBitmapに出力させていることがわかります。@Override public void blur(Bitmap input, Bitmap output) { mBlurInput.copyFrom(input); mBlurScript.setInput(mBlurInput); mBlurScript.forEach(mBlurOutput); mBlurOutput.copyTo(output); }これで表示するための準備ができあがりました。
onDraw で mBlurredBitmap を描画する
@Override protected void onDraw(Canvas canvas) { super.onDraw(canvas); drawBlurredBitmap(canvas, mBlurredBitmap, mOverlayColor); }ブラーをかけた Bitmap を表示すれば完了となるわけですね!
BlurKit
こちらの方がスター数が多いですが
- onStart / onStop にコードを書かないと動かない
- 毎フレーム必ずinvalidate()をコールしていて負荷が高そう
- 毎フレームごとに Bitmap を作成していて効率が悪そう
という理由から個人的に RealtimeBlurView をオススメしたいです。ちなみにブラーをかけるところは ほぼ同じ でビットマップをひとつだけしか使用しないか二つ使用するかが唯一異なる点でした(RealtimeBlurViewのビットマップが二つ必要な理由についてはまだ調査していません)。
(ちょこっと追記) ほぼ同じって書きましたが RenderScript のコードも改めてみてみると毎回初期化していてここも効率化できそう。。
BlurView
こちらはレイアウト以外にコードを書く必要があるみたいです。コードは読みやすい気がします。
- ブラーをかける制御
- ブラーをかける処理
全体的に RealtimeBlurView と同じような実装で設計と RenderScript のビットマップを2つ使用するかどうかの違いしかなさそうでした。気軽に使用できる点からやはり RealtimeBlurView をおすすめしたいです。RealtimeBlurViewのビットマップが二重になっているところが改善されたら今のところ最強でしょうかね(プルリク出してみようかしら…)。
終わりに
Androidのライブラリ3つを紹介しましたがいずれもビットマップを用意したりしています。おそらくiOSやWebではGPUのレンダリングパイプラインあたりだけで実現している気がしていて、Androidでもそういった高効率のアプローチができないか調査する余地がありそう、という感想を持ちました。できればGoogle純正のイケてるライブラリが出てくれると嬉しかったり。



- 投稿日:2020-12-12T18:39:49+09:00
図で見るソートアルゴリズム(C言語 / Java / VBA / Python)
はじめに
とりあえずソートアルゴリズムについてまとめておきます(数多書かれている内容ではあります)。
図表メインで、ソースコードは、C言語、Java、VBA、Pythonについて記載しています。
なお、JavaとPythonは初学レベルなので、もっと良い書き方があると思われます。ご注意ください。最後は、気になる速度比較もしておきました。結果を見て、Pythonが人気がある理由がまた少し分かりました。
<目次>
1. ヒープソート
1-1. ヒープソートのアルゴリズム概要
1-2. ヒープソートのサンプルコード
2. クイックソート
2-1. クイックソートのアルゴリズム概要
2-2. クイックソートのサンプルコード
3. マージソート
3-1. マージソートのアルゴリズム概要
3-2. マージソートのサンプルコード
4. バブルソート
4-1. バブルソートのアルゴリズム概要
4-2. バブルソートのサンプルコード
5. 速度比較
5-1. 計算量
5-2. 処理速度の計測結果
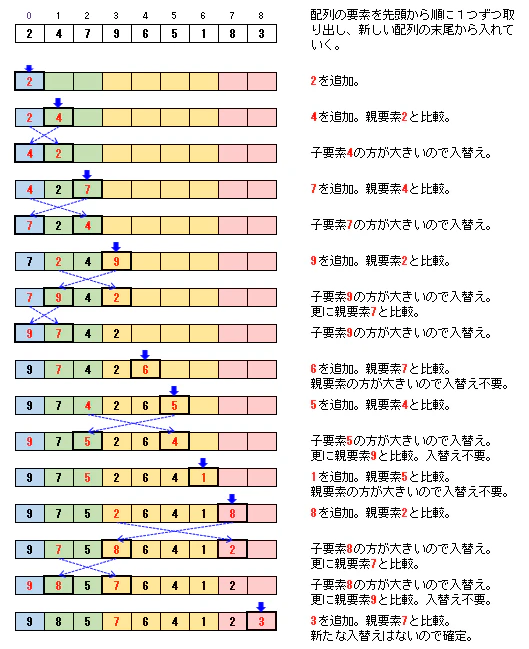
5-3. 【参考】処理時間計測のソースコード1. ヒープソート
ヒープソートは、二分ヒープの性質を利用して並べ替えを行うアルゴリズムです。
二分ヒープは、次のような木構造を取ります。
要件は「完全二分木」であることと「親要素は子要素より常に大きいか等しい構造(ヒープ構造)」であることの2つです。二分ヒープと配列のイメージ
プログラムでは、この二分ヒープを、上の図ように配列に置き換えてコードを書くことになります。
配列の要素番号をiとすると、次の式が成り立ちます。[親要素の番号] = (i - 1) / 2 ※/(スラッシュ)は整数の除算で小数点以下は切り捨て [左側子要素の番号] = i * 2 + 1 [右側子要素の番号] = i * 2 + 21-1. ヒープソートのアルゴリズム概要
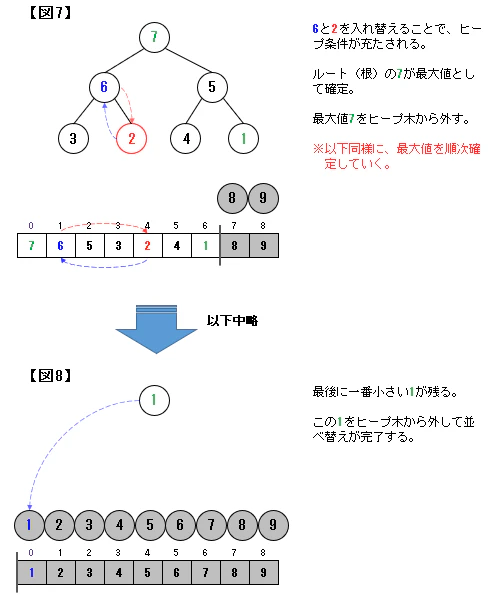
ヒープソートでは、最初に、配列を「二分ヒープ」の形にする必要があります。
そして、二分ヒープの形を維持しながら、最大値である根(ルート)を順次取り出していくことになります。
以下、順に見ていきます。1-1-1. 配列を二分ヒープに変換する方法(up-heap)
ランダムな配列を二分ヒープにするためには、「既にヒープ構造になっている二分ヒープ木に対して、下から要素を追加していく方法」を使用します。
この方法は、アップヒープ(up-heap)といい、図で見ると次のような感じです。アップヒープのイメージ
これを配列に当てはめると、次のような手順になります。
配列をヒープ構造に変換するイメージ
ここでは、わかりやすいように、元の配列から新しい配列に1つずつ要素を入れています。
しかし、図を見てわかるように、新しい配列を用意しなくとも、元の配列に要素を置いたまま、前から順にヒープ構造にしていくことができます。1-1-2. 二分ヒープから並べ替えをする方法(down-heap)
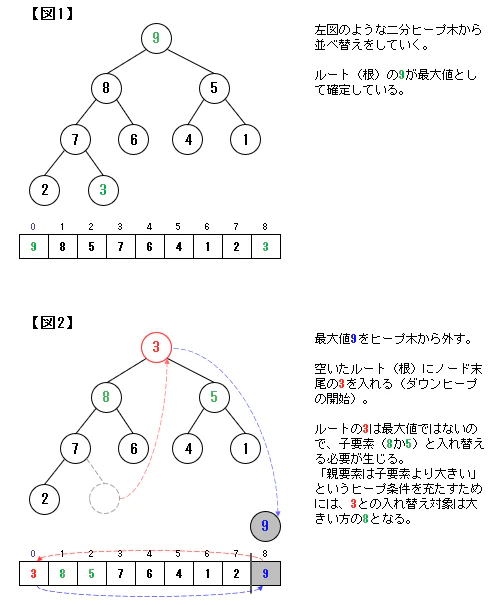
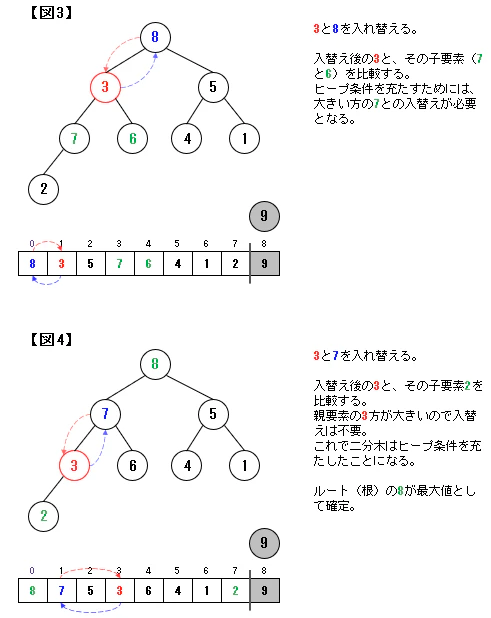
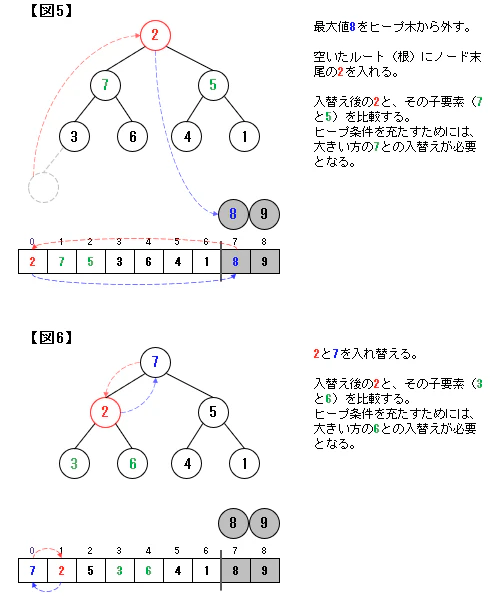
二分ヒープ木では根(ルート)が最大値となります。
この根(最大値)を取り出していくことで並べ替えを進めていくことになります(この点はバブルソートに近しい)。なお、最大値を取り除くと、二分ヒープ構造が崩れます。
ここでは、下図のように上から要素を追加する形で二分ヒープ構造に戻していきます。
この方法をダウンヒープ(down-heap)といいます。ダウンヒープによるソートのイメージ
動きとしては、バブルソートに近いと言えますが、ヒープソートの方が、比較数・交換数は少なくて済みますので、その分効率の良いアルゴリズムとなります。
また、ヒープソートは「元の配列に要素を置いたまま交換を繰り返すことにより並べ替えができるアルゴリズム」となります。
このようなソートアルゴリズムをIn-placeアルゴリズムといいます。In-placeアルゴリズムには、追加の記憶領域をほとんど使わないで済むという利点があります。In-placeアルゴリズムの範疇に含まれるものには、クイックソート、バブルソートなどがあります。
1-2. ヒープソートのサンプルコード
1-2-1. C言語
<ソースコード>
heap_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 int parent(int child) {return (child - 1) / 2;} // 親要素の要素番号を取得 int left_child(int parent) {return parent * 2 + 1;} // 左の子要素の要素番号を取得 int right_child(int parent) {return parent * 2 + 2;} // 右の子要素の要素番号を取得 void swap(int *n1, int *n2); // ヒープソート void heap_sort(int *nums, int numslen) { // 配列を二分ヒープに変換する(up-heap) for (int i = 0; i < numslen; i++) { int j = i; // 要素番号iにある要素を二分ヒープに追加(要素番号をjに代入) while (j > 0) { // 要素番号が0以上の場合(子要素の番号である場合)はループを継続 if (nums[j] > nums[parent(j)]) { // 追加した要素が親要素より大きい場合 swap(&nums[j], &nums[parent(j)]); // 親要素と子要素を入れ替える j = parent(j); // jの位置を入替え後の位置(親要素のあった位置)に移動 } else { break; // 親要素の方が大きければ入替えの必要がないので確定 } } } // ソート処理(down-heap) for (int i = numslen - 1; i > 0; i--) { swap(&nums[0], &nums[i]); // 根(ルート)の要素を最大値として確定して配列の後方に移動 int j = 0; // 配列の先頭に来た要素をdown-heapしていく while (left_child(j) < i) { // 子のうち値の大きい方の配列番号をtmpに格納 int tmp = left_child(j); // 一旦左の子の要素番号を入れる if (right_child(j) < i && nums[right_child(j)] > nums[tmp]) tmp = right_child(j); // 右の要素(値)が大きければtmpを入替え // 親の値が子の値より小さければ入れ替え if (nums[j] < nums[tmp]) { swap(&nums[j], &nums[tmp]); j = tmp; } else { break; // 親の値が子の値より大きければ確定 } } } } // スワップ(入れ替え)関数 void swap(int *n1, int *n2) { int tmp = *n1; *n1 = *n2; *n2 = tmp; } // ヒープソートの実行 int main(void) { // ソート用の配列を作成 srand((unsigned int)time(NULL)); // 乱数の発生をランダムにする int n = 10; int *nums = malloc(n * sizeof(int)); // int型配列のメモリを確保 for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; // ランダムな値を代入 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート前の配列出力 printf("\n"); heap_sort(nums, n); for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート後の配列出力 printf("\n"); return 0; }<出力確認>
ターミナル$ gcc heap_sort.c $ ./a.out 4, 6, 9, 7, 4, 2, 8, 0, 3, 2, 0, 2, 2, 3, 4, 4, 6, 7, 8, 9,1-2-2. Java
<ソースコード>
HeapSortTest.javaimport java.util.Random; public class HeapSortTest { public static void main(String[] args) { // ソート用の配列を作成 int n = 10; int nums[] = new int[n]; Random rand = new Random(); // 乱数のインスタンスを作成 for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); // ランダムな値を代入 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); HeapSort(nums, n); // ヒープソートの実行 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); } public static void HeapSort(int nums[], int n) { // 配列を二分ヒープに変換する(up-heap) for (int i = 0; i < n; i++) { int j = i; // 要素番号iにある要素を二分ヒープに追加(要素番号をjに代入) while (j > 0) { // 要素番号が0以上の場合(子要素の番号である場合)はループを継続 if (nums[j] > nums[parent(j)]) { // 追加した要素が親要素より大きい場合 Swap(nums, j, parent(j)); // 親要素と子要素を入れ替える j = parent(j); // jの位置を入替え後の位置(親要素のあった位置)に移動 } else { break; // 親要素の方が大きければ入替えの必要がないので確定 } } } // ソート処理(down-heap) for (int i = n - 1; i > 0; i--) { Swap(nums, 0, i); // 根(ルート)の要素を最大値として確定して配列の後方に移動 int j = 0; // 配列の先頭に来た要素をdown-heapしていく while (left_child(j) < i) { // 子のうち値の大きい方の配列番号をtmpに格納 int tmp = left_child(j); // 一旦左の子の要素番号を入れる if (right_child(j) < i && nums[right_child(j)] > nums[tmp]) tmp = right_child(j); // 右の要素(値)が大きければtmpを入替え // 親の値が子の値より小さければ入れ替え if (nums[j] < nums[tmp]) { Swap(nums, j, tmp); j = tmp; } else { break; // 親の値が子の値より大きければ確定 } } } } public static int parent(int child) {return (child - 1) / 2;} // 親要素の要素番号を取得 public static int left_child(int parent) {return parent * 2 + 1;} // 左の子要素の要素番号を取得 public static int right_child(int parent) {return parent * 2 + 2;} // 右の子要素の要素番号を取得 public static void Swap(int nums[], int n1, int n2) { int tmp = nums[n1]; nums[n1] = nums[n2]; nums[n2] = tmp; } }<出力確認>
ターミナル$ javac HeapSortTest.java $ java HeapSortTest 2, 0, 4, 3, 3, 3, 3, 8, 9, 5, 0, 2, 3, 3, 3, 3, 4, 5, 8, 9,1-2-3. VBA
<ソースコード>
'ヒープソート Sub HeapSort(nums() As Long) Dim i As Long Dim c As Long '主に子(child)の要素番号に使用 Dim p As Long '主に親(parent)の要素番号に使用 '配列を二分ヒープに変換する(up-heap) For i = 0 To UBound(nums) c = i Do While c > 0 If nums(c) <= nums(GetPNode(c)) Then Exit Do '子が親以下の値であればループを抜ける(VBAはOrでは結べない) Call Swap(nums(c), nums(GetPNode(c))) c = GetPNode(c) Loop Next 'ソート処理(down-heap) For i = UBound(nums) To 0 Step -1 p = 0 Call Swap(nums(p), nums(i)) Do While GetLNode(p) < i '子のうち値の大きい方の配列番号をcに格納 If GetLNode(p) = i - 1 Then '子要素が左のみであれば c = GetLNode(p) 'cに左の子の要素番号を格納 ElseIf nums(GetLNode(p)) > nums(GetRNode(p)) Then '左の要素の値が右の要素より大きければ(VBAはOrでは結べない) c = GetLNode(p) 'cに左の子の要素番号を格納 Else c = GetRNode(p) 'cに右の子の要素番号を格納 End If '親の値が子の値より小さければ入れ替え If nums(p) >= nums(c) Then Exit Do '親が子以上の値であればループを抜ける Call Swap(nums(p), nums(c)) p = c Loop Next End Sub '親要素の要素番号を取得 Function GetPNode(n As Long) As Long GetPNode = (n - 1) \ 2 End Function '左の子要素の要素番号を取得 Function GetLNode(n As Long) As Long GetLNode = n * 2 + 1 End Function '右の子要素の要素番号を取得 Function GetRNode(n As Long) As Long GetRNode = n * 2 + 2 End Function 'スワップ Sub Swap(a As Variant, b As Variant) Dim tmp As Variant tmp = a a = b b = tmp End Sub<出力確認>
ヒープソートの実行(VBA)Sub OutputHeapSoat() Dim nums() As Long Call CreateArray(nums, 10) '配列を作成 Call PrintArray(nums) 'ソート前の配列を出力 Call HeapSort(nums) Call PrintArray(nums) 'ソート前の配列を出力 End Sub乱数作成(VBA)'乱数による配列作成プロシージャ Sub CreateArray(nums() As Long, n As Long) Dim i As Long ReDim nums(n - 1) Randomize '乱数ジェネレーターを初期化(都度異なる乱数値を取得するため) For i = 0 To UBound(nums) nums(i) = Fix(Rnd * n) Next End Sub配列出力(VBA)'1次元配列の内容を出力するプロシージャ Sub PrintArray(nums As Variant) Dim i As Long Dim buf As String For i = 0 To UBound(nums) buf = buf & nums(i) & ", " Next Debug.Print buf End Subイミディエイトウィンドウ(2行目がソート後の配列)1, 1, 6, 6, 0, 6, 2, 8, 6, 9, 0, 1, 1, 2, 6, 6, 6, 6, 8, 9,1-2-4. Python
<ソースコード>
HeapSort.pyimport random def parent(child): return (child - 1) // 2 def left_child(parent): return parent * 2 + 1 def right_child(parent): return parent * 2 + 2 # ヒープソート def heap_sort(nums): for i in range(len(nums)): j = i while j > 0: if nums[j] > nums[parent(j)]: nums[j], nums[parent(j)], j = nums[parent(j)], nums[j], parent(j) else: break for i in range(len(nums) - 1, 0, -1): nums[0], nums[i], j = nums[i], nums[0], 0 while left_child(j) < i: tmp = left_child(j) if right_child(j) < i and nums[right_child(j)] > nums[tmp]: tmp = right_child(j) if nums[j] < nums[tmp]: nums[j], nums[tmp], j = nums[tmp], nums[j], tmp else: break # ヒープソートの実行 n = 10 nums = [random.randint(0, n - 1) for i in range(n)] print(nums) # ソート前の配列出力 heap_sort(nums) # ヒープソート print(nums) # ソート後の配列出力<出力確認>
ターミナル> python HeapSort.py [0, 0, 8, 2, 3, 9, 4, 5, 0, 5] [0, 0, 0, 2, 3, 4, 5, 5, 8, 9]2. クイックソート
クイックソートは、その名のとおり処理速度が速いアルゴリズムです。
2-1. クイックソートのアルゴリズム概要
2-1-1. 基本となる考え方
クイックソートでは、以下の図のように、配列の中で基準となる数値を一つ決めて、基準よりも小さい値のグループと、基準以上の値のグループに分けていきます。
各グループで更にこれを繰り返すことで、並べ替えを完了させるアルゴリズムです。クイックソートのイメージ
クイックソートもヒープソートと同様に、In-placeアルゴリズム(元の配列に要素を置いたまま交換により並べ替えをするアルゴリズム)の範疇に入ります。2-1-2. 基準値との比較方法と要素の交換方法
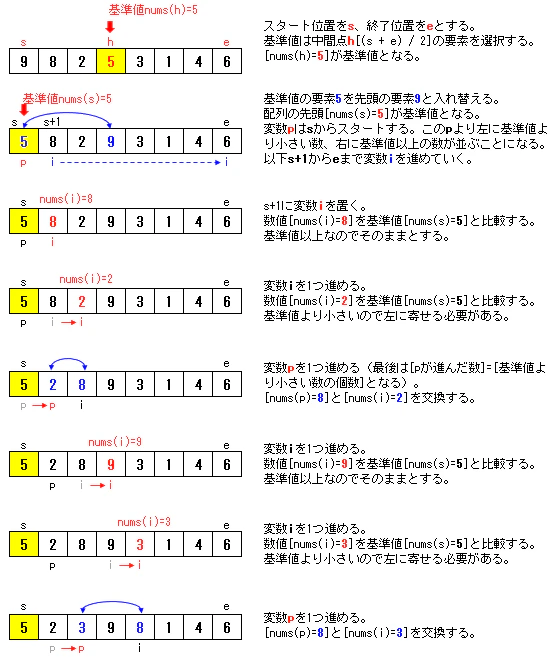
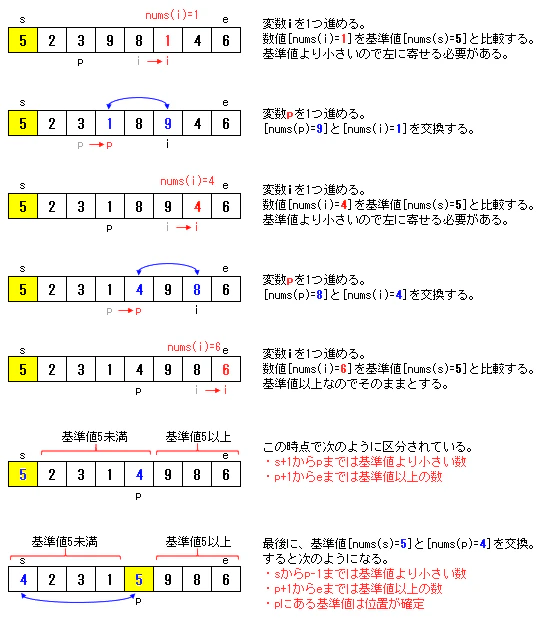
クイックソートをコード化する一般的な考え方として「基本情報技術者試験平成27年度春期午後問8」があります(Wikipediaの解説も同様)が、この方法を採ると無限ループを回避する工夫が必要となるため結構面倒でした。
ここでは、こちらの論文「(MAX上における)アルゴリズム的問題におけるユーザーインターフェースの改良」で紹介されているクイックソートの考え方をベースとして次のような方法でコードを書いていきます。
クイックソートにおける要素交換方法のイメージ
以上の処理を終えた後に、更に、基準値未満の数(sからp-1までの要素)と、基準値以上の数(p+1からeまでの要素)について同じ処理を再帰的に繰り返すことになります。2-2. クイックソートのサンプルコード
2-2-1. C言語
<ソースコード>
quick_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 void swap(int *n1, int *n2); // クイックソート void quick_sort(int *nums, int s, int e) { if (s >= e) return; // 配列の要素数が1以下の場合は処理不要 int p = s; // 最終的にはこのpの位置より左側に基準値より小さい要素が並ぶ int h = (s + e) / 2; // 基準値は配列中央から選ぶことにする swap(&nums[s], &nums[h]); // 基準値は一旦配列先頭に置いておく(基準値=nums[s]となる) for (int i = s + 1; i <= e; i++) { if (nums[i] < nums[s]) swap(&nums[++p], &nums[i]); // 基準値より小さい要素をpの左側に移動させていく } swap(&nums[s], &nums[p]); // 基準値をpの位置に置き換える(基準値の位置が確定) quick_sort(nums, s, p - 1); // 配列前半部分(基準値より小さい値)を再帰処理 quick_sort(nums, p + 1, e); // 配列後半部分(基準値以上の値)を再帰処理 } // スワップ(入れ替え)関数 void swap(int *n1, int *n2) { int tmp = *n1; *n1 = *n2; *n2 = tmp; } // クイックソートの実行 int main(void) { // ソート用の配列を作成 srand((unsigned int)time(NULL)); // 乱数の発生をランダムにする int n = 10; int *nums = malloc(n * sizeof(int)); // int型配列のメモリを確保 for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; // ランダムな値を代入 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート前の配列出力 printf("\n"); quick_sort(nums, 0, n - 1); // クイックソートの実行 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート後の配列出力 printf("\n"); return 0; }<出力確認>
ターミナル$ gcc quick_sort.c $ ./a.out 3, 8, 9, 5, 0, 9, 8, 1, 2, 8, 0, 1, 2, 3, 5, 8, 8, 8, 9, 9,参考:先頭要素を基準値とした場合
なお、リスクはありますが、並べ替えする配列がランダムなものであれば、先頭の要素をそのまま基準値として、次のように簡潔に書くこともできます。
交換回数も減るので、スピードも少し早くなります(配列の並びがランダムであれば)。quick_sort2.c// クイックソート(先頭要素を基準値とした場合) void quick_sort(int *nums, int s, int e) { if (s >= e) return; int p = s; for (int i = s + 1; i <= e; i++) if (nums[i] < nums[s]) swap(&nums[++p], &nums[i]); swap(&nums[s], &nums[p]); quick_sort(nums, s, p - 1); quick_sort(nums, p + 1, e); }でも、並べ替える配列が、もともと昇順に近い形である場合には、かなり無駄な演算を繰り返すことになりますので、やっぱりこの書き方はあまり適切でないと思います。
2-2-2. Java
<ソースコード>
QuickSortTest.javaimport java.util.Random; public class QuickSortTest { public static void main(String[] args) { // ソート用の配列を作成 int n = 10; int nums[] = new int[n]; Random rand = new Random(); // 乱数のインスタンスを作成 for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); // ランダムな値を代入 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); QuickSort(nums, 0, n - 1); // クイックソートの実行 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); } // クイックソート public static void QuickSort(int nums[], int s, int e) { if (s >= e) return; // 配列の要素数が1以下の場合は処理不要 int p = s; // 最終的にはこのpの位置より左側に基準値より小さい要素が並ぶ int h = (s + e) / 2; // 基準値は配列中央から選ぶことにする Swap(nums, s, h); // 基準値は一旦配列先頭に置いておく(基準値=nums[s]となる) for (int i = s + 1; i <= e; i++) { if (nums[i] < nums[s]) Swap(nums, ++p, i); // 基準値より小さい要素をpの左側に移動させていく } Swap(nums, s, p); // 基準値をpの位置に置き換える(基準値の位置が確定) QuickSort(nums, s, p - 1); // 配列前半部分(基準値より小さい値)を再帰処理 QuickSort(nums, p + 1, e); // 配列後半部分(基準値以上の値)を再帰処理 } // Swap関数 public static void Swap(int nums[], int n1, int n2) { int tmp = nums[n1]; nums[n1] = nums[n2]; nums[n2] = tmp; } }<出力確認>
ターミナル$ javac QuickSortTest.java $ java QuickSortTest 9, 9, 1, 3, 9, 0, 6, 7, 4, 7, 0, 1, 3, 4, 6, 7, 7, 9, 9, 9,2-2-3. VBA
<ソースコード>
'クイックソート '引数(nums=対象となる配列、s=配列の開始位置、e=配列の終了位置) Sub QuickSort(nums() As Long, s As Long, e As Long) If s >= e Then Exit Sub '開始位置sが終了位置e以降になる場合は関数を抜ける Dim i As Long Dim p As Long: p = s Call Swap(nums(s), nums((s + e) \ 2)) '配列中央の値を基準値にして先頭と入れ替え For i = s + 1 To e If nums(i) < nums(s) Then 'nums(s)を基準値として数値を比較していく p = p + 1 '基準値より小さい数があるごとにpを1つ進める Call Swap(nums(i), nums(p)) 'Swap関数で入れ替えを行う。 End If Next Call Swap(nums(s), nums(p)) 'Swap関数で入れ替え Call QuickSort(nums, s, p - 1) '基準値より小さいグループを再帰処理 Call QuickSort(nums, p + 1, e) '基準値より大きいグループを再帰処理 End Sub 'スワップ Sub Swap(a As Variant, b As Variant) Dim tmp As Variant tmp = a a = b b = tmp End Sub<出力確認>
クイックソートの実行(VBA)Sub OutputQuickSort() Dim nums() As Long Call CreateArray(nums, 10) '配列を作成 Call PrintArray(nums) 'ソート前の配列を出力 Call QuickSort(nums, 0, UBound(nums)) 'クイックソートを実行 Call PrintArray(nums) 'ソート後の配列を出力 End Sub※
CreateArray関数と、PrintArray関数はヒープソートと同じものを使用しています。イミディエイトウィンドウ(2行目がソート後の配列)1, 8, 5, 3, 1, 9, 0, 3, 0, 5, 0, 0, 1, 1, 3, 3, 5, 5, 8, 9,2-2-4. Python
<ソースコード>
QuickSort.pyimport random # クイックソート def quick_sort(nums, s ,e): if s >= e: return p, h = s, (s + e) // 2 nums[s], nums[h] = nums[h], nums[s] for i in range(s + 1, e + 1): if nums[i] < nums[s]: p += 1 nums[p], nums[i] = nums[i], nums[p] nums[s], nums[p] = nums[p], nums[s] quick_sort(nums, s ,p - 1) quick_sort(nums, p + 1 ,e) # クイックソートの実行 n = 10 nums = [random.randint(0, n - 1) for i in range(n)] print(nums) # ソート前の配列出力 quick_sort(nums, 0, n - 1) # クイックソート print(nums) # ソート後の配列出力<出力確認>
ターミナル> python QuickSort.py [9, 2, 8, 7, 2, 3, 5, 4, 0, 7] [0, 2, 2, 3, 4, 5, 7, 7, 8, 9]3. マージソート
マージソートは、元の配列の並び方に影響を受けることがあまりなく、処理速度もクイックソート並みに早いです。
マージを行う際に、追加の記憶領域が必要となってしまいますが(in-placeではない = not-in-place)、無駄の少ない綺麗なアルゴリズムだと思います(個人的に)。考え方と実装方法は、基本情報技術者試験平成22年度春期午後問8に基づいています。
3-1. マージソートのアルゴリズム概要
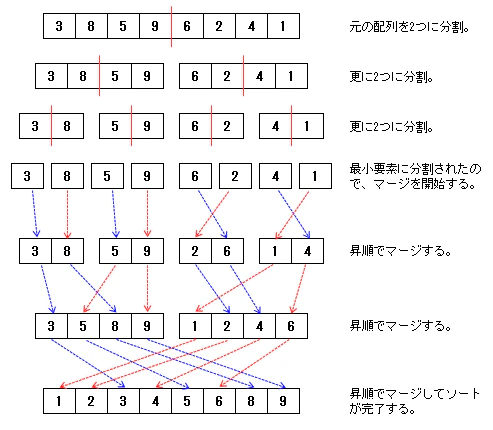
マージソートは、以下の図のように配列を最小単位まで分割した上で、昇順でマージを繰り返していくアルゴリズムです。
マージソートのイメージ
そして、マージ(並べ替え)をどうするかですが、昇順でマージを行う処理は次のような考え方で実装します。
マージ方法のイメージ
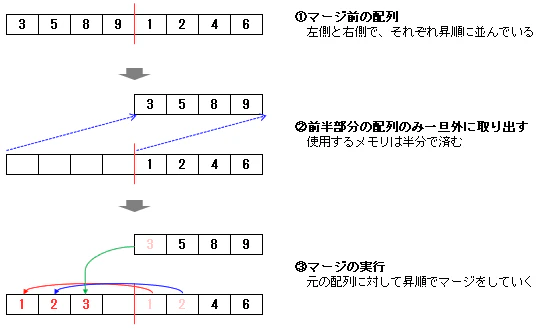
<マージの実装方法>
実際にコードを書く場合は、次の図のように、半分(後半部分)は元の配列に残したまま、もう半分(前半部分)のみを取り出した上でマージ処理を行っていくのが効率的です。
これにより、追加で使用するメモリの領域が半分で済み、メモリのコピーも半分で済みます。<前半部分と後半部分の値が同じ場合>
なお、前半部分と後半部分の先頭部分の要素が、それぞれ同じ値の場合は、前半部分を優先してマージします。
そうすることで、「同等なデータのソート前の順序が、ソート後も保存される」こととなります(これを「安定ソート」と言います)。3-2. マージソートのサンプルコード
3-2-1. C言語
<ソースコード>
merge_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 // マージソート void merge_sort(int *nums, int s, int e) { // 配列の分割位置を決める int h = (s + e) / 2; // hは中央値 int lenl = h - s + 1; // lenlは前半部分の配列の要素数(わかりやすくするため変数に格納) int lenr = e - h; // lenrは後半部分の配列の要素数(わかりやすくするため変数に格納) // 分割した配列が2以上の要素を持つときは再帰処理を行う(再帰処理の終了後は各配列が昇順になっている) if (lenl > 1) merge_sort(nums, s, h); if (lenr > 1) merge_sort(nums, h + 1, e); // 前半部分を新たな配列に格納 int *tmpnums = malloc(lenl * sizeof(int)); // 分割した配列を格納するメモリを確保(gccでは int tmpnums[lenl]; でもOK) for (int i = 0; i < lenl; i++) tmpnums[i] = nums[s + i]; // 2つの配列を昇順にマージ int nl = 0, nr = 0; for (int i = s; i <= e; i++) { if (nl > lenl - 1) break; // 前半部分の要素が全てマージされた場合は全ての並べ替えが終了 if (nr > lenr - 1 || tmpnums[nl] <= nums[h + 1 + nr]) { nums[i] = tmpnums[nl++]; // 後半部分の要素が全てマージ or [前半部分の要素]<=[後半部分の要素] の場合 } else { nums[i] = nums[h + 1 + nr++]; // [前半部分の要素]>[後半部分の要素] の場合 } } // メモリの解放 free(tmpnums); } // マージソートの実行 int main(void) { // ソート用の配列を作成 srand((unsigned int)time(NULL)); // 乱数の発生をランダムにする int n = 10; int *nums = malloc(n * sizeof(int)); // int型配列のメモリを確保 for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; // ランダムな値を代入 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート前の配列出力 printf("\n"); merge_sort(nums, 0, n - 1); // マージソートの実行 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート後の配列出力 printf("\n"); return 0; }可読性優先で冗長な書き方をしているため、コードが長く見えます。
変数を減らして整理するとmerge_sort部分だけであれば10行くらいで済みます。<出力確認>
ターミナル$ gcc merge_sort.c $ ./a.out 9, 4, 6, 9, 8, 5, 0, 5, 5, 3, 0, 3, 4, 5, 5, 5, 6, 8, 9, 9,3-2-2. Java
<ソースコード>
MergeSortTest.javaimport java.util.Random; public class MergeSortTest { public static void main(String[] args) { // ソート用の配列を作成 int n = 10; int nums[] = new int[n]; Random rand = new Random(); // 乱数のインスタンスを作成 for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); // ランダムな値を代入 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); MergeSort(nums, 0, n - 1); // マージソートの実行 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); } public static void MergeSort(int nums[], int s, int e) { // 配列の分割位置を決める int h = (s + e) / 2; // hは中央値 int lenl = h - s + 1; // lenlは前半部分の配列の要素数(わかりやすくするため変数に格納) int lenr = e - h; // lenrは後半部分の配列の要素数(わかりやすくするため変数に格納) // 分割した配列が2以上の要素を持つときは再帰処理を行う(再帰処理の終了後は各配列が昇順になっている) if (lenl > 1) MergeSort(nums, s, h); if (lenr > 1) MergeSort(nums, h + 1, e); // 前半部分を新たな配列に格納 int tmpnums[] = new int[lenl]; // 分割した配列を格納する配列 for (int i = 0; i < lenl; i++) tmpnums[i] = nums[s + i]; // 2つの配列を昇順にマージ int nl = 0, nr = 0; for (int i = s; i <= e; i++) { if (nl > lenl - 1) break; // 前半部分の要素が全てマージされた場合は全ての並べ替えが終了 if (nr > lenr - 1 || tmpnums[nl] <= nums[h + 1 + nr]) { nums[i] = tmpnums[nl++]; // 後半部分の要素が全てマージ or [前半部分の要素]<=[後半部分の要素] の場合 } else { nums[i] = nums[h + 1 + nr++]; // [前半部分の要素]>[後半部分の要素] の場合 } } } public static void Swap(int nums[], int n1, int n2) { int tmp = nums[n1]; nums[n1] = nums[n2]; nums[n2] = tmp; } }<出力確認>
ターミナル$ javac MergeSortTest.java $ java MergeSortTest 3, 1, 6, 2, 3, 0, 7, 9, 3, 1, 0, 1, 1, 2, 3, 3, 3, 6, 7, 9,3-2-3. VBA
<ソースコード>
マージソート(VBA)Sub MergeSort(nums() As Long, s As Long, e As Long) Dim i As Long Dim h As Long: h = (s + e) \ 2 Dim numsTmp() As Long: ReDim numsTmp(h - s) If h - s > 0 Then Call MergeSort(nums, s, h) If e - h - 1 > 0 Then Call MergeSort(nums, h + 1, e) For i = 0 To h - s numsTmp(i) = nums(s + i) Next Dim nl As Long: nl = 0 Dim nr As Long: nr = 0 For i = s To e If nl > h - s Then Exit For If nr > e - h - 1 Then nums(i) = numsTmp(nl) nl = nl + 1 ElseIf numsTmp(nl) < nums(h + 1 + nr) Then nums(i) = numsTmp(nl) nl = nl + 1 Else nums(i) = nums(h + 1 + nr) nr = nr + 1 End If Next End Sub<出力確認>
マージソートの実行(VBA)Sub OutputMergeSort() Dim nums() As Long Call CreateArray(nums, 10) '配列を作成 Call PrintArray(nums) 'ソート前の配列を出力 Call MergeSort(nums, 0, UBound(nums)) Call PrintArray(nums) 'ソート後の配列を出力 End Sub※
CreateArray関数と、PrintArray関数はヒープソートと同じものを使用しています。イミディエイトウィンドウ(2行目がソート後の配列)1, 3, 9, 6, 5, 7, 2, 0, 8, 5, 0, 1, 2, 3, 5, 5, 6, 7, 8, 9,3-2-4. Python
<ソースコード>
MergeSort.pyimport random # マージソート def merge_sort(nums, s ,e): h = (s + e) // 2 lenl, lenr = h - s + 1, e - h if lenl > 1: merge_sort(nums, s, h) if lenr > 1: merge_sort(nums, h + 1, e) tmp_nums = [nums[s + i] for i in range(lenl)] nl = nr = 0 for i in range(s, e + 1): if nl > lenl - 1: break if nr > lenr - 1 or tmp_nums[nl] <= nums[h + 1 + nr]: nums[i] = tmp_nums[nl] nl += 1 else: nums[i] = nums[h + 1 + nr] nr += 1 # マージソートの実行 n = 10 nums = [random.randint(0, n - 1) for i in range(n)] print(nums) # ソート前の配列出力 merge_sort(nums, 0, n - 1) # マージソート print(nums) # ソート後の配列出力<出力確認>
ターミナル> python MergeSort.py [7, 8, 8, 1, 1, 4, 8, 2, 9, 2] [1, 1, 2, 2, 4, 7, 8, 8, 8, 9]4. バブルソート
バブルソートは処理速度が遅いですが、アルゴリズムが単純なので、簡単に作成することができます。
データが大量でなければ、バブルソートで十分なことも多いです。4-1. バブルソートのアルゴリズム概要
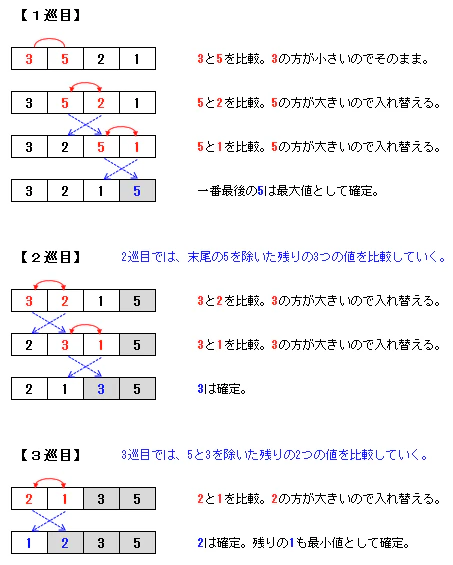
バブルソートは、以下の図のように隣り合う要素を順に比較して、値が大きいものを後ろに移動させていくアルゴリズムです。
一巡するたびに、一番大きい値が末尾に置かれて確定していきます。
バブル(泡)がどんどん上に上っていくように、大きい値が末尾に移動して確定していくというイメージです。バブルソートのイメージ
バブルソートもIn-placeアルゴリズム(元の配列に要素を置いたまま交換により並べ替えをするアルゴリズム)となります。4-2. バブルソートのサンプルコード
4-2-1. C言語
bubble_sort関数自体は正味3行程度です。<ソースコード>
bubble_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 void swap(int *n1, int *n2); // バブルソート void bubble_sort(int *nums, int numslen) { for (int i = numslen - 1; i > 0; i--) { for (int j = 0; j < i; j++) { if (nums[j] > nums[j + 1]) swap(&nums[j], &nums[j + 1]); } } } // スワップ(入れ替え)関数 void swap(int *n1, int *n2) { int tmp = *n1; *n1 = *n2; *n2 = tmp; } // バブルソートの実行 int main(void) { // ソート用の配列を作成 srand((unsigned int)time(NULL)); // 乱数の発生をランダムにする int n = 10; int *nums = malloc(n * sizeof(int)); // int型配列のメモリを確保 for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; // ランダムな値を代入 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート前の配列出力 printf("\n"); bubble_sort(nums, n); // バブルソートの実行 for (int i = 0; i < n; i++) printf("%d, ", nums[i]); // ソート後の配列出力 printf("\n"); return 0; }<出力確認>
ターミナル$ gcc bubble_sort.c $ ./a.out 8, 5, 6, 3, 1, 0, 5, 2, 2, 1, 0, 1, 1, 2, 2, 3, 5, 5, 6, 8,4-2-2. Java
<ソースコード>
BubbleSortTest.javaimport java.util.Random; public class BubbleSortTest { public static void main(String[] args) { // ソート用の配列を作成 int n = 10; int nums[] = new int[n]; Random rand = new Random(); // 乱数のインスタンスを作成 for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); // ランダムな値を代入 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); BubbleSort(nums); // バブルソートの実行 for (int i = 0; i < nums.length; i++) System.out.print(nums[i] + ", "); // ソート前の配列出力 System.out.print("\n"); } // バブルソート public static void BubbleSort(int nums[]) { for (int i = nums.length - 1; i >= 0; i--) { for (int j = 0; j < i; j++) { if (nums[j] > nums[j + 1]) Swap(nums, j, j + 1); } } } public static void Swap(int nums[], int n1, int n2) { int tmp = nums[n1]; nums[n1] = nums[n2]; nums[n2] = tmp; } }<出力確認>
ターミナル$ javac BubbleSortTest.java $ java BubbleSortTest 2, 5, 9, 9, 1, 9, 2, 4, 0, 1, 0, 1, 1, 2, 2, 4, 5, 9, 9, 9,4-2-3. VBA
<ソースコード>
バブルソート(VBA)'バブルソート Sub BubbleSort(nums() As Long) Dim i As Long Dim j As Long For i = UBound(nums) - 1 To 0 Step -1 '比較する範囲を1つずつ小さくしていく For j = 0 To i If nums(j) > nums(j + 1) Then Call Swap(nums(j), nums(j + 1)) '前方の値の方が大きければ数値を入れ替える End If Next Next End Subスワップ関数(VBA)'スワップ関数(値aと値bを入替えるプローシージャ) Sub Swap(a As Variant, b As Variant) Dim tmp As Variant tmp = a a = b b = tmp End Sub<出力確認>
バブルソートの実行(VBA)'BubbleSortの出力 Sub OutputBubbleSort() Dim nums() As Long Call CreateArray(nums, 10) '配列を作成 Call PrintArray(nums) 'ソート前の配列を出力 Call BubbleSort(nums) 'バブルソートを実行 Call PrintArray(nums) 'ソート後の配列を出力 End Sub※
CreateArray関数と、PrintArray関数はヒープソートと同じものを使用しています。イミディエイトウィンドウ(2行目がソート後の配列)7, 2, 0, 9, 8, 8, 7, 6, 4, 2, 0, 2, 2, 4, 6, 7, 7, 8, 8, 9,4-2-4. Python
<ソースコード>
BubbleSort.pyimport random # バブルソート def bubble_sort(nums): for i in reversed(range(len(nums))): for j in range(i): if nums[j] > nums[j + 1]: nums[j], nums[j + 1] = nums[j + 1], nums[j] # バブルソートの実行 n = 10 nums = [random.randint(0, n - 1) for i in range(n)] print(nums) # ソート前の配列出力 bubble_sort(nums) # バブルソート print(nums) # ソート後の配列出力<出力確認>
ターミナル> python BubbleSort.py [4, 3, 1, 4, 6, 8, 9, 6, 5, 0] [0, 1, 3, 4, 4, 5, 6, 6, 8, 9]5. 速度比較
最後に、各ソートアルゴリズムごと、各言語ごとに、処理速度の比較をしておきます。
実測結果は、教科書どおりに、コンパイラ言語(C言語、Java)が、インタプリタ言語(VBA、Python)より10倍ほど速い結果となりました。
しかし、Pythonには奥の手があり、コンパイラ言語並みのスピードを出すこともできます。5-1. 計算量
本記事で取り上げた4つのソートアルゴリズムの計算量は次のとおりとなります(詳しくはこちらを参照)。
ソート種別 平均計算量 最大計算量 ヒープソート O(nlog n) O(nlog n) クイックソート O(nlog n) O(n2) マージソート O(nlog n) O(nlog n) バブルソート O(n2) O(n2) バブルソートの計算量は、要素数nの2乗に比例するので、大きな配列に使用するのは無理が生じます。
クイックソートは、基準値の選定を誤るとバブルソート並みに時間が掛かるので要注意です。5-2. 処理速度の計測結果
5-2-1. C言語
当然ですが、C言語は比較的処理速度が速いです。
ランダムな分布であれば、クイックソートが一番処理時間が短くて済みました。<速度計測結果>
要素数:100,000(配列の並びはランダム)
環境:Windows10
単位:秒
試行 ヒープソート クイックソート マージソート バブルソート 1 0.028 0.016 0.022 31.157 2 0.027 0.015 0.024 31.458 3 0.029 0.015 0.024 31.537 4 0.029 0.016 0.024 30.812 5 0.03 0.015 0.023 30.975 6 0.028 0.015 0.024 31.111 7 0.028 0.015 0.024 31.236 8 0.028 0.015 0.023 30.99 9 0.029 0.015 0.024 31.219 10 0.029 0.015 0.025 30.903 平均 0.029 0.015 0.024 31.14 5-2-2. Java
Javaも処理速度がかなり速いです。
ヒープソートとバブルソートにおいては、C言語よりも短時間で処理が終わっています(なぜかは分かりません…)。なお、Javaには、あらかじめソートメソッドがいくつか用意されています(詳しくは、Javaのソートの方法を一通り確認できるページを参照してください)。
ここでは、一般的と思われる、java.util.Arraysのsort()メソッドの処理速度も合わせて比較しておきます(次のソースコードを使用)。JavaSortTest.javaimport java.util.Random; import java.math.BigDecimal; public class JavaSortTest { public static void main(String[] args) { int n = 100000; int nums[] = new int[n]; Random rand = new Random(); for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); long start = System.nanoTime(); // スタート時間を記録 java.util.Arrays.sort(nums); // ソートの実行 double processing_time = (System.nanoTime() - start) / Math.pow(10, 9); System.out.println(BigDecimal.valueOf(processing_time).toPlainString()); // 処理時間を出力 } }<速度計測結果>
要素数:100,000(配列の並びはランダム)
環境:Windows10
単位:秒
試行 ヒープソート クイックソート マージソート バブルソート sort()メソッド 1 0.023 0.015 0.031 16.199 0.013 2 0.023 0.014 0.03 16.125 0.013 3 0.024 0.021 0.027 16.15 0.029 4 0.021 0.017 0.03 16.058 0.037 5 0.019 0.022 0.031 15.88 0.037 6 0.021 0.016 0.03 16.174 0.013 7 0.021 0.016 0.027 16.329 0.021 8 0.02 0.028 0.027 15.894 0.013 9 0.021 0.016 0.027 16.084 0.016 10 0.023 0.015 0.028 16.028 0.014 平均 0.022 0.018 0.029 16.092 0.021 5-2-3. VBA
VBAだと、CやJavaと比べると10倍くらいの時間が掛かっているようです。
特徴は、マージソートの方がクイックソートより速いことです。他の言語と異なる理由は分かりません。バブルソートは、10万要素だと10分近く掛かるので、もうほとんどまともに動きません。
100万要素だと、単純に15時間ぐらいくらい掛かることになります。<速度計測結果>
要素数:100,000(配列の並びはランダム)
環境:Windows10
単位:秒
試行 ヒープソート クイックソート マージソート バブルソート 1 0.875 0.23 0.188 520.281 2 0.922 0.227 0.188 590.551 3 0.953 0.266 0.156 587.059 4 0.895 0.266 0.172 545.402 5 0.887 0.234 0.156 503.906 6 0.891 0.219 0.125 538.902 7 0.875 0.266 0.156 497.254 8 0.859 0.219 0.141 514.914 9 1 0.234 0.156 499.352 10 0.887 0.281 0.172 492.168 平均 0.904 0.244 0.161 528.979 5-2-4. Python
Pythonは、私の拙いコードの書き方が原因かもしれませんが、VBA並みもしくはそれ以上の処理時間が掛かっています。
ただし、Pythonには次のようなsortメソッドが用意されています。
これも同条件で速度を計測しましたが、C言語やJava並みの速度が出ています。この辺もPythonの良いところですね。PythonSort.pyimport random import time # timeモジュールをインポート # ソートの実行 n = 100000 nums = [random.randint(0, n - 1) for i in range(n)] start = time.time() # スタート時間を記録 nums.sort() # ソート processing_time = time.time() - start print(processing_time) # 処理時間を出力<速度計測結果>
要素数:100,000(配列の並びはランダム)
環境:Windows10
単位:秒
試行 ヒープソート クイックソート マージソート バブルソート Sortメソッド 1 1.001 0.218 0.5 710.887 0.015 2 1.011 0.227 0.493 - 0.016 3 1.284 0.37 0.476 - 0.017 4 1.352 0.237 0.484 - 0.018 5 1.043 0.232 0.476 - 0.019 6 1.018 0.236 0.48 - 0.016 7 1.523 0.23 0.484 - 0.017 8 1.367 0.312 0.493 - 0.017 9 1.049 0.215 0.506 - 0.017 10 1.386 0.235 0.482 - 0.017 平均 1.204 0.252 0.487 710.887 0.017 ※バブルソートは、とんでもなく遅いので、1回だけしか実行していません。
5-3. 【参考】処理時間計測のソースコード
参考までに、処理時間を計測したソースコードも残しておきます。
ソートアルゴリズムのコードは省略しています。5-3-1. Python
quick_sort.c#include <stdio.h> #include <stdlib.h> // malloc関数で使用 #include <time.h> // time関数、clock関数で使用 void quick_sort(int *nums, int s, int e); // 中略 // クイックソートの実行 int main(void) { srand((unsigned int)time(NULL)); int n = 100000; int *nums = malloc(n * sizeof(int)); for (int i = 0; i < n; i++) nums[i] = (int)rand() % n; int start = clock(); // スタート時間を記録 quick_sort(nums, 0, n - 1); // クイックソートの実行 int end = clock(); double processing_time = (double)(end - start) / CLOCKS_PER_SEC; printf("%f\n", processing_time); // 処理時間を出力 return 0; }5-3-2. Java
QuickSortTest.javaimport java.util.Random; import java.math.BigDecimal; public class QuickSortTest { public static void main(String[] args) { int n = 100000; int nums[] = new int[n]; Random rand = new Random(); for (int i = 0; i < n; i++) nums[i] = rand.nextInt(n); long start = System.nanoTime(); // スタート時間を記録 QuickSort(nums, 0, n - 1); // クイックソートの実行 double processing_time = (System.nanoTime() - start) / Math.pow(10, 9); System.out.println(BigDecimal.valueOf(processing_time).toPlainString()); // 処理時間を出力 } public static void QuickSort(int nums[], int s, int e) { // 中略 } }5-3-3. VBA
Sub SortSpeed() Dim n As Long: n = 100000 Dim nums() As Long Call CreateArray(nums, n) '配列を作成 Dim startTime As Double: startTime = Timer 'スタート時間を記録 Call QuickSort(nums, 0, UBound(nums)) 'クイックソート Dim processingTime As Double: processingTime = Timer - startTime Debug.Print processingTime End Sub5-3-4. Python
QuickSort.pyimport random import time # timeモジュールをインポート # クイックソート def quick_sort(nums, s ,e): # 中略 # クイックソートの実行 n = 100000 nums = [random.randint(0, n - 1) for i in range(n)] start = time.time() # スタート時間を記録 quick_sort(nums, 0, n - 1) # クイックソート processing_time = time.time() - start print(processing_time) # 処理時間を出力さいごに
図表に時間を取られて途中で先が見えなくなりましたが、何とか最後まで書けたので、まあ良しとします。
Pythonは使いこなせると便利だろうと思いますので、もう少し学習を進めていきたいところです。




- 投稿日:2020-12-12T17:21:08+09:00
java ブラウザ自動テスト selenide chromedriverのバージョンエラー解消
Selenide動かしたとき、こんなエラーが出たので対応してみた。
org.openqa.selenium.SessionNotCreatedException: session not created: This version of ChromeDriver only supports Chrome version 88 Current browser version is 87.0.4280.88 with binary path C:\Program Files (x86)\Google\Chrome\Application\chrome.exe Build info: version: '3.141.59', revision: 'e82be7d358', time: '2018-11-14T08:17:03' System info: host: 'DESKT*****', ip: '192.168.1.60', os.name: 'Windows 10', os.arch: 'amd64', os.version: '10.0', java.version: '11.0.8' Driver info: driver.version: SelenideDriver状況
- chromedriverは88.*バージョンが動いている。
- Chromeは87.*バージョン
あれ?最新版だと言うてますが・・・
chromedriverを入れ替え
chromedriverどこや?
gradleを使ってselenideの構成を作ったので勝手にchromedriver入ってる。
gradleなので例のところにいるはず。C:\Users\ユーザ名.m2\repository\webdriver\chromedriver\win32\88.0.4324.27\chromedriver.exe
やっぱりいた。
別のバージョンのchromedriverを取得
https://chromedriver.chromium.org/downloads
C:\Users\ユーザ名.m2\repository\webdriver\chromedriver\win32\87.0.4280.88\chromedriver.exe
ここに入れて動かしてみたけどダメだった。
ブラウザのバージョンに合わせて自動的にドライバーを呼び分けてはくれない模様。
※ちなみに元からあったバージョンをフォルダごと削除してもダメだった。chromedriverの場所を指定
D:\tools\chromedriver_win32\87.0.4280.88\chromedriver.exe
サイトで入手したchromedriverをここに場所移動して
WebDriverの場所をコードで指定すると成功した。SelenideTest.javaimport static com.codeborne.selenide.Condition.*; import static com.codeborne.selenide.Selenide.*; import org.junit.jupiter.api.Test; import org.openqa.selenium.By; public class SelenideTest { @Test void testtest() { // ここでWebDriverの場所を指定した System.setProperty("webdriver.chrome.driver", "D:\\tools\\chromedriver_win32\\87.0.4280.88\\chromedriver.exe"); open("http://google.com"); $(By.name("q")).setValue("バナナ 大好き").pressEnter(); $("#result-stats").shouldHave(text("約 18,600,000 件")); } }build.gradle(省略) dependencies { (省略) testCompile 'com.codeborne:selenide:5.16.2' }成功イメージ
参考

- 投稿日:2020-12-12T13:54:10+09:00
csvファイルが文字化け
Javaでcsvファイルを読み込み、別のcsvファイルに書き込む。しかし、その時数値や記号は正常に表示されるが、日本語は文字化けしてしまった。
Task.java//入力ストリームの準備 FileReader fr = null; BufferedReader br = null; //出力ストリームの準備 FileWriter fw = null; BufferedWriter bw = null; try{ fr = new FileReader("入力ファイル名.csv"); br = new BufferedReader(fr); fw = new FileWriter("出力ファイル名.csv"); bw = new BufferedWriter(fw); String str; //csvファイルを一行ずつ読み込む while((str = br.readLine()) != null){ bw.write(str+"\r\n");//改行を含めて書き込む bw.flush(); }catch(IOException e){ e.printStackTrace(); System.exit(1); }finally{ br.close(); }結果
文字化けしてしまった。
本来は年月日,平均気温,最高気温,最低気温,降水量,日照時間と出力するはずだった。読み込むときに文字コードを指定して読み込むことで解決できるらしい。

- 投稿日:2020-12-12T11:56:11+09:00
concat / append (文字列を連結するメソッド)
Javaの文字列を連結させるメソッド
についてまとめました。
concatメソッドとは
要約すると「文字列を結合しインスタンスを新たに生成する」メソッドです。
他にも文字列結合のメソッドはありますが、インスタンスを新たに生成するのはconcatメソッドのみ。
【説明】
concatメソッドは元になる文字列自体を変更させるものではなく、「結合した新しいインスタンスを生む」という点がポイント。
concatメソッドを使うには、元になる文字列を用意し、結合したい文字列を引数に渡して結合します。書き方は以下です。
//concatの記述方法 元になる文字列.concat(結合したい文字列); // 結合した文字列を変数として扱う String 結合した文字列 = 元になる文字列.concat(結合したい文字列);appendメソッドとは
要約すると「文字列を結合する」メソッドです。
上記のconcatとのおおまかな違いは、オブジェクトを生成するか否かです。
【説明】
appendメソッドでは、「文字列バッファ」という変数をつかうのでオブジェクトを生成しません。
一般的にオブジェクトの生成は時間がかかるのため、appendメソッドを使う方が処理にかかる時間が短いということ。
文字を連結する際に「新しくオブジェクトを作る必要があるか」を問いてなるべくappendを採用できるようにするのがいいかも知れない。
appendメソッド種類
appendメソッドには以下のクラスを使う二通りのやり方があります。
- StringBuilderクラス
- StringBufferクラス
書き方は以下です。
StringBuilderクラス
書き方1
StringBuilder 変数名 = new StringBuilder(結合したい文字列); 変数名.append(結合したい文字列); String 結合した文字列 = 変数名.toString()サンプルコード1
public class Main { public static void main(String[] args) { // StringBuilderクラスのappendメソッドを使う場合 StringBuilder sb = new StringBuilder("Hello"); sb.append(" StringBuilder"); String str = sb.toString(); System.out.println(str); } }Hello StringBuilderStringBufferクラス
書き方1
StringBuffer 変数名 = new StringBuilder(結合したい文字列); 変数名.append(結合したい文字列); String 結合した文字列 = 変数名.toString()サンプルコード1
public class Main { public static void main(String[] args) { StringBuffer sb = new StringBuffer("Hello"); sb.append(" StringBuffer"); String str = sb.toString(); System.out.println(str); } }Hello StringBuffer【まとめ】
JavaSilverの試験での範囲内ですので、以下の点は抑えておく。
- concatはインスタンスを生成するメソッド
- appendはインスタンスを生成しないメソッド
言い方を変えればappendは「もともとインスタンスが用意されている状態で使うメソッド」とも言えるかも知れません。
参考文献・記事
- 投稿日:2020-12-12T11:56:11+09:00
【Java】concat / append (文字列を連結するメソッド)
Javaの文字列を連結させるメソッド
についてまとめました。
【要約】
concatもappendも両方文字列を連結するメソッドです。
抑えるべきポイントは以下です
- concatは新しくオブジェクトを生成する
- appendはオブジェクトを生成しない
concatメソッドとは
要約すると「文字列を結合しオブジェクトを新たに生成する」メソッドです。
他にも文字列結合のメソッドはありますが、オブジェクトを新たに生成するのはconcatメソッドのみ。
【説明】
concatメソッドは元になる文字列自体を変更させるものではなく、「結合した新しいインスタンスを生む」という点がポイント。
concatメソッドを使うには、元になる文字列を用意し、結合したい文字列を引数に渡して結合します。書き方は以下です。
//concatの記述方法 元になる文字列.concat(結合したい文字列); // 結合した文字列を変数として扱う String 結合した文字列 = 元になる文字列.concat(結合したい文字列);appendメソッドとは
要約すると「文字列を結合する」メソッドです。
上記のconcatとのおおまかな違いは、オブジェクトを生成するか否かです。
【説明】
appendメソッドでは、「文字列バッファ」という変数をつかうのでオブジェクトを生成しません。
一般的にオブジェクトの生成は時間がかかるのため、appendメソッドを使う方が処理にかかる時間が短いということ。
文字を連結する際に「新しくオブジェクトを作る必要があるか」を問いてなるべくappendを採用できるようにするのがいいかも知れない。
appendメソッド種類
appendメソッドには以下のクラスを使う二通りのやり方があります。
- StringBuilderクラス
- StringBufferクラス
書き方は以下です。
StringBuilderクラス
書き方1
StringBuilder 変数名 = new StringBuilder(結合したい文字列); 変数名.append(結合したい文字列); String 結合した文字列 = 変数名.toString()サンプルコード1
public class Main { public static void main(String[] args) { // StringBuilderクラスのappendメソッドを使う場合 StringBuilder sb = new StringBuilder("Hello"); sb.append(" StringBuilder"); String str = sb.toString(); System.out.println(str); } }Hello StringBuilderStringBufferクラス
書き方1
StringBuffer 変数名 = new StringBuilder(結合したい文字列); 変数名.append(結合したい文字列); String 結合した文字列 = 変数名.toString()サンプルコード1
public class Main { public static void main(String[] args) { StringBuffer sb = new StringBuffer("Hello"); sb.append(" StringBuffer"); String str = sb.toString(); System.out.println(str); } }Hello StringBuffer【まとめ】
JavaSilverの試験での範囲内ですので、以下の点は抑えておく。
- concatはインスタンスを生成するメソッド
- appendはインスタンスを生成しないメソッド
言い方を変えればappendは「もともとインスタンスが用意されている状態で使うメソッド」とも言えるかも知れません。
参考文献・記事
- 投稿日:2020-12-12T10:48:04+09:00
【Java】startWith・endsWith,メソッド(開始 / 終了の文字を判定する)
Javaの startsWithメソッド
についてまとめました。
startsWid]thメソッドとは
要約すると「指定した文字列で文頭や文末が一致しているか、パターンマッチ判定するメソッド」です。
【説明】
◯◯Withメソッドは、文字列を指定し、その文字列で始まるどうかを判定するメソッドです。共通して返ってくる値はbool型で「true / false」を返します。
用途に応じた使い分けは以下です。
- 前方一致の判定: startsWithメソッド
- 後方一致の判定: endsWithメソッド
startsWithメソッドは、例えばIf文などに組み込んで電話番号を入力する箇所の数字が090や070で始まるか判定したりするのに使えます。
【書き方】
判定したい文字列をString型で指定するなど、基本的に書き方はおなじです。それぞれ書き方はこちら。
// startsWith 構文 文字列.startsWith(String 判定する文字列); // サンプルコード str.startsWith("Hello") // endsWith の構文 文字列.endsWith(String 判定する文字列); // サンプルコード str.endsWith("bye")startsWithの書き方2
startsWithメソッドには、引数offsetを指定した、別の書き方があります。形式は以下です。
// startsWith 構文2 文字列.startsWith(判定する文字列, 判定を開始する位置); // サンプルコード str.startsWith("Hello", 3)メソッドチェイン
あるメソッドが戻すオブジェクトののメソッドをさらに呼び出すことを「メソッドチェイン」と呼びます。
以下のコードは「何文字目から何文字目の文字を調べるメソッド」と「指定した文字列は何から始まるかを判定するメソッド」の役割の違ったメソッドを組み合わせた例になります。
public class Main { public static void main(String[] args) { String str = "あいうえお"; // 文字列の2〜4文字の、最初の文字は「い」か判定 System.out.println(str.substring(1, 3).startsWith("い")); } }true【まとめ】
JavaSilverの学習中当たり前のように出てきたのでポイントをおさらいすると
- 前方一致の判定: startsWithメソッド
- 後方一致の判定: endsWithメソッド
- 判定結果はfalse と true
- startsWithメソッドは判定開始位置を指定する書き方ができる
ということを抑えておく。
またメソッドチェーンを用いたややこしいことを聞かれてもいいように、わからなくなったらロジックを書き出す。
参考文献・記事
- 投稿日:2020-12-12T10:48:04+09:00
【Java】startsWith・endsWith,メソッド(開始 / 終了の文字を判定する)
Javaの startsWithメソッド
についてまとめました。
startsWid]thメソッドとは
要約すると「指定した文字列で文頭や文末が一致しているか、パターンマッチ判定するメソッド」です。
【説明】
◯◯Withメソッドは、文字列を指定し、その文字列で始まるどうかを判定するメソッドです。共通して返ってくる値はbool型で「true / false」を返します。
用途に応じた使い分けは以下です。
- 前方一致の判定: startsWithメソッド
- 後方一致の判定: endsWithメソッド
startsWithメソッドは、例えばIf文などに組み込んで電話番号を入力する箇所の数字が090や070で始まるか判定したりするのに使えます。
【書き方】
判定したい文字列をString型で指定するなど、基本的に書き方はおなじです。それぞれ書き方はこちら。
// startsWith 構文 文字列.startsWith(String 判定する文字列); // サンプルコード str.startsWith("Hello") // endsWith の構文 文字列.endsWith(String 判定する文字列); // サンプルコード str.endsWith("bye")startsWithの書き方2
startsWithメソッドには、引数offsetを指定した、別の書き方があります。形式は以下です。
// startsWith 構文2 文字列.startsWith(判定する文字列, 判定を開始する位置); // サンプルコード str.startsWith("Hello", 3)メソッドチェイン
あるメソッドが戻すオブジェクトののメソッドをさらに呼び出すことを「メソッドチェイン」と呼びます。
以下のコードは「何文字目から何文字目の文字を調べるメソッド」と「指定した文字列は何から始まるかを判定するメソッド」の役割の違ったメソッドを組み合わせた例になります。
public class Main { public static void main(String[] args) { String str = "あいうえお"; // 文字列の2〜4文字の、最初の文字は「い」か判定 System.out.println(str.substring(1, 3).startsWith("い")); } }true【まとめ】
JavaSilverの学習中当たり前のように出てきたのでポイントをおさらいすると
- 前方一致の判定: startsWithメソッド
- 後方一致の判定: endsWithメソッド
- 判定結果はfalse と true
- startsWithメソッドは判定開始位置を指定する書き方ができる
ということを抑えておく。
またメソッドチェーンを用いたややこしいことを聞かれてもいいように、わからなくなったらロジックを書き出す。
参考文献・記事
- 投稿日:2020-12-12T10:48:04+09:00
【Java】startWidth・endsWidth,メソッド(開始 / 終了の文字を判定する)
Javaの startsWidthメソッド
についてまとめました。
startsWidthメソッドとは
要約すると「指定した文字列で文頭や文末が一致しているか、パターンマッチ判定するメソッド」です。
【説明】
◯◯Withメソッドは、文字列を指定し、その文字列で始まるどうかを判定するメソッドです。共通して返ってくる値はbool型で「true / false」を返します。
用途に応じた使い分けは以下です。
- 前方一致の判定: startsWidthメソッド
- 後方一致の判定: endsWidthメソッド
startsWidthメソッドは、例えばIf文などに組み込んで電話番号を入力する箇所の数字が090や070で始まるか判定したりするのに使えます。
【書き方】
判定したい文字列をString型で指定するなど、基本的に書き方はおなじです。それぞれ書き方はこちら。
// startsWidth 構文 文字列.startsWith(String 判定する文字列); // サンプルコード str.startsWith("Hello") // endsWidth の構文 文字列.endsWith(String 判定する文字列); // サンプルコード str.endsWith("bye")startsWithの書き方2
startsWithメソッドには、引数offsetを指定した、別の書き方があります。形式は以下です。
// startsWidth 構文2 文字列.startsWith(判定する文字列, 判定を開始する位置); // サンプルコード str.startsWith("Hello", 3)メソッドチェイン
あるメソッドが戻すオブジェクトののメソッドをさらに呼び出すことを「メソッドチェイン」と呼びます。
以下のコードは「何文字目から何文字目の文字を調べるメソッド」と「指定した文字列は何から始まるかを判定するメソッド」の役割の違ったメソッドを組み合わせた例になります。
public class Main { public static void main(String[] args) { String str = "あいうえお"; // 文字列の2〜4文字の、最初の文字は「い」か判定 System.out.println(str.substring(1, 3).startsWith("い")); } }true【まとめ】
JavaSilverの学習中当たり前のように出てきたのでポイントをおさらいすると
- 前方一致の判定: startsWidthメソッド
- 後方一致の判定: endsWidthメソッド
- 判定結果はfalse と true
- startsWidthメソッドは判定開始位置を指定する書き方ができる
ということを抑えておく。
またメソッドチェーンを用いたややこしいことを聞かれてもいいように、わからなくなったらロジックを書き出す。
参考文献・記事
- 徹底攻略Java SE 11 Silver問題集[1Z0-815]対応
- 投稿日:2020-12-12T10:15:31+09:00
【Java・SpringBoot】Springセキュリティ② - ログイン処理の実装
Springで、ログイン画面に入力されたID・パスワードをDBに確認し、ユーザーの権限で特定のURLへのアクセスを禁止する機能を簡単に作成しましょう〜♪
前回、ホーム画面への直リンクを禁止しましたので、今回はログイン処理を実装していきます!【Java・SpringBoot】Springセキュリティ① - 直リンク禁止
SecurityConfig.javaにログイン処理を追加
ログイン処理
- ログイン処理を追加するには、http.formLogin()にメソッドチェーンで条件を追加
loginProcessingUrl("<リンク先>")
- ログイン処理をするURLを指定。ログイン画面のhtmlにあるフォームタグのaction="/login"の部分と一致させる
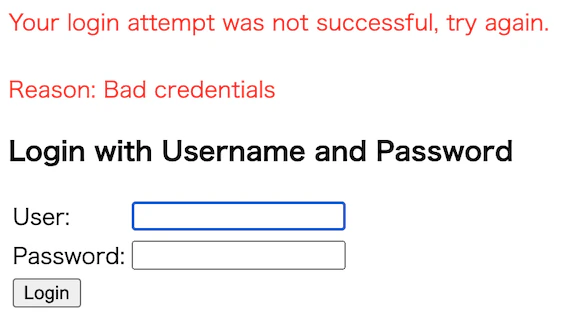
loginPage("<リンク先>")
- ログインページのリンク先を設定。これを設定しないと、自分でログインページを用意しても、Springセキュリティのデフォルトログインページが表示されてしまう!(下記の画像参考)
- ログイン画面のコントローラークラスにある@GetMapping("/login")の部分に一致させます。
- failureUrl("<リンク先>")
- ログインが失敗した場合の遷移先
- usernameParameter("<パラメーター名>")
- ログインページのユーザーID入力エリアのパラメーター名を指定
- DBからユーザーデータを取得するときに使う。指定するパラメータ名は、htmlファイルから探す。
- 今回の例ではlogin.htmlで、ユーザーIDを入力する以下の箇所
<input type="text" name="userId" /><br/>- このname属性に設定されているuserId文字列を、SecurityConfigのusernameParameter("<パラメーター名>")にセット
SecurityConfig.java@EnableWebSecurity @Configuration public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override public void configure(WebSecurity web) throws Exception { //静的リソースへのアクセスには、セキュリティを適用しない web.ignoring().antMatchers("/webjars/∗∗", "/css/∗∗"); } @Override protected void configure(HttpSecurity http) throws Exception { //中略(全文は下記参考) //ログイン処理 http .formLogin() .loginProcessingUrl("/login") //ログイン処理のパス .loginPage("/login") //ログインページの指定 .failureUrl("/login") //ログイン失敗時の遷移先 .usernameParameter("userId") //ログインページのユーザーID .passwordParameter("password") //ログインページのパスワード .defaultSuccessUrl("/home", true); //ログイン成功後の遷移先 //CSRF対策を無効に設定(一時的) http.csrf().disable(); } }login画面を作成
- login.htmlのユーザーID、パスワードの入力エリアにname属性を追加。また、ログイン失敗時のメッセージを出すように修正
ログインエラーメッセージの表示
- ログインエラーメッセージを表示するためには、
th:if属性を使う
<p th:if="${session['SPRING_SECURITY_LAST_EXCEPTION']} != null" th:text="${session['SPRING_SECURITY_LAST_EXCEPTION'].message}" class="text-danger"></p>- 上記では、セッションにセキュリティのエラーがあれば、エラーメッセージを表示する、という内容
login.html<!DOCTYPE html> <html xmlns:th="http://www.thymeleaf.org"> <head> <meta charset="UTF-8"></meta> <!-- Bootstrapの設定 --> <link th:href="@{/webjars/bootstrap/3.3.7-1/css/bootstrap.min.css}" rel="stylesheet"></link> <script th:src="@{/webjars/jquery/1.11.1/jquery.min.js}"></script> <script th:src="@{/webjars/bootstrap/3.3.7-1/js/bootstrap.min.js}"></script> <title>Login</title> </head> <body class="text-center"> <h1>Login</h1> <form method="post" action="/login"> <!-- エラーメッセージ --> <p th:if="${session['SPRING_SECURITY_LAST_EXCEPTION']} != null" th:text="${session['SPRING_SECURITY_LAST_EXCEPTION'].message}" class="text-danger"> ログインエラーメッセージ </p> <!-- ユーザーID --> <label>ユーザーID</label> <input type="text" name="userId" /><br/> <br /> <!-- パスワード --> <label>パスワード</label> <input type="password" name="password" /><br/> <br /> <!-- ログインボタン --> <button class="btn btn-primary" type="submit">ログイン</button> </form> <br /> <!-- ユーザー登録画面へのリンク --> <a th:href="@{'/signup'}">ユーザー新規登録はこちら</a> </body> </html>起動してログイン画面/Springセキュリティのデフォルトのログイン画面を確認!
- http://localhost:8080/login
- 何も入力せずログインボタンを押すと、"Bad credentials"が表示されました^^
- 現時点では、入力したユーザーID・パスワードを、どのDBのカラムと一致するのかを設定していないので、次回実装します。また、エラーメッセージの日本語化も行います
- また、Springセキュリティのデフォルトログインページは以下のように表示されます
(参考)コード全文
SecurityConfig.javapackage com.example.demo; import org.springframework.context.annotation.Configuration; import org.springframework.security.config.annotation.web.builders.HttpSecurity; import org.springframework.security.config.annotation.web.builders.WebSecurity; import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity; import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter; @EnableWebSecurity @Configuration public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override public void configure(WebSecurity web) throws Exception { //静的リソースへのアクセスには、セキュリティを適用しない web.ignoring().antMatchers("/webjars/∗∗", "/css/∗∗"); } @Override protected void configure(HttpSecurity http) throws Exception { // ログイン不要ページの設定 http .authorizeRequests() .antMatchers("/webjars/**").permitAll() //webjarsへアクセス許可 .antMatchers("/css/**").permitAll() //cssへアクセス許可 .antMatchers("/login").permitAll() //ログインページは直リンクOK .antMatchers("/signup").permitAll() //ユーザー登録画面は直リンクOK .anyRequest().authenticated(); //それ以外は直リンク禁止 //ログイン処理 http .formLogin() .loginProcessingUrl("/login") //ログイン処理のパス .loginPage("/login") //ログインページの指定 .failureUrl("/login") //ログイン失敗時の遷移先 .usernameParameter("userId") //ログインページのユーザーID .passwordParameter("password") //ログインページのパスワード .defaultSuccessUrl("/home", true); //ログイン成功後の遷移先 //CSRF対策を無効に設定(一時的) http.csrf().disable(); } }

- 投稿日:2020-12-12T09:54:47+09:00
【Intellij IDEA】特定のアノテーションが設定されている内容でunused警告を抑制する
この記事はJetBrains Advent Calendar 2020の12日目の記事です。
TL;DR
- 空気を読め(
ALT+Enter)ば設定できるInspections->Unused symbolからまとめて設定することもできる問題
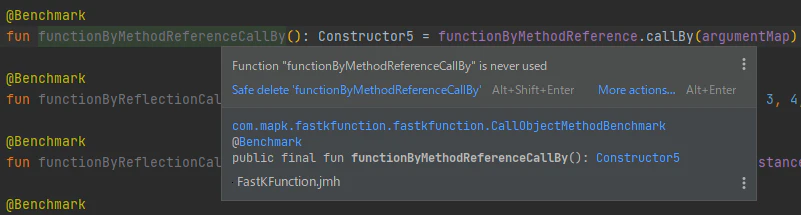
Intellij IDEAは賢いので、使われていないコードには未使用警告を出してくれます。
一方、アノテーションをリフレクションで読んで使うような場面では、利用されているのに未使用警告が出たりします。以下は
JMHのベンチマークコードに未使用警告が出ている様子です。
Supressアノテーションで警告を抑制することはできますが、一々アノテーションを付けて回るのは非効率です。
対処法
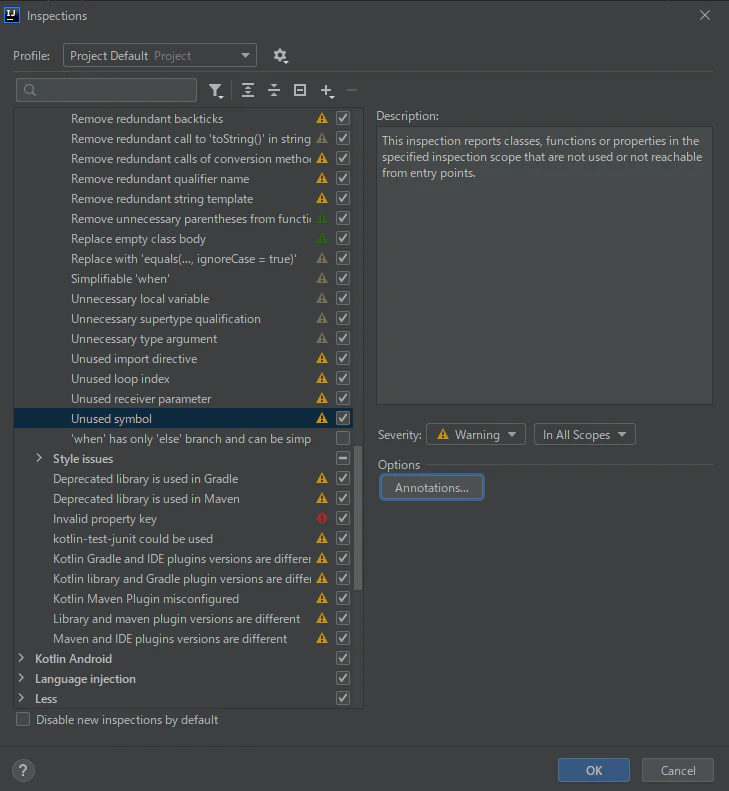
空気を読めば、「このアノテーションが付いていたら未使用警告を抑制する」設定が出てくるので、そのまま選べば設定できます。
まとめて設定したり、現状の設定を確認したい場合、
Inspections->Unused symbolからできます。
行き方は幾つか有りますが、先ほどの抑制のオプションからEdit inspection profile settingを開き、Annotations...を押せば設定が出せます。
以下は
JMHのBenchmarkアノテーションを抑制設定した様子です。




- 投稿日:2020-12-12T02:57:18+09:00
【Java】substringメソッド(指定した部分を抜き出す)
Javaのsubstringメソッド
についてまとめました。
substringメソッドとは
一言でいうと「文字列から部分文字列を抜き出す」事ができるメソッドです。
【説明】
substringメソッドの書き方
substring以下の書き方です。
- 第一引数に抜き出し開始の位置を指定
- 第二引数に抜き出し終了位置を指定(※この文字は含まない)
"文字列".substring(抜き出し開始位置, 抜き出し終了位置);文字列の長さを超える値を指定すると?
結論、例外が発生します
【サンプルコード】
サンプルコード内の引数の値と
public class Main { public static void main(String[] args) { //抜き出し前の文字列 String str = "恥の多い生涯を送って来ました。自分には、人間の生活というものが、見当つかないのです。"; //1文字目から16文字目まで抜き出す String life = str.substring(0,15); //出力結果:恥の多い生涯を送って来ました。 System.out.println(life); } }恥の多い生涯を送って来ました。【まとめ】
覚えておくポイントは以下です。
- 文字列の長さを超える値を指定すると例外が発生する。
- 第一引数に抜き出し開始の位置を指定
- 第二引数に抜き出し終了位置を指定
- 左から0スタート
結構便利なメソッドな気がしますが、今度これを使ったアプリとかも考えてみたいですね。
参考文献・記事
- 投稿日:2020-12-12T02:06:13+09:00
【Java】indexOfメソッド (指定した文字列が最初に出現する位置を返す)
JavaのindexOfメソッド
についてまとめました。
indexOfメソッド とは?
要約すると、「ある文字列の中で、指定した文字列が最初に出現する位置を返す」というStringメソッドの1つです。
【特徴 / メリット】
引数の型と数により、以下の4通りの使い方があります。
文字列(String)型で検索する用法1
public int indexOf(文字列型変数名)public class Main { public static void main(String[] args) { String s = "あいうえおかきくけこあいうえおかきくけこ"; int n = s.indexOf("かきくけこ"); System.out.println(n); } }5文字列(String)型で検索する用法2
public int indexOf(文字列型変数名, 検索位置数)public class Main { public static void main(String[] args) { String s = "あいうえおかきくけこあいうえおかきくけこ"; int n = s.indexOf("かきくけこ", 8); System.out.println(n); } }15文字(char)型で検索する用法1
public int indexOf(文字型変数名)public class Main { public static void main(String[] args) { String s = "あいうえおかきくけこあいうえおかきくけこ"; int n = s.indexOf("き"); System.out.println(n); } }6文字(char)型で検索する用法2
public int indexOf(文字型変数名, 検索位置数)public class Main { public static void main(String[] args) { String s = "あいうえおかきくけこあいうえおかきくけこ"; int n = s.indexOf("き", 7); System.out.println(n); } }16出現しない文字・文字列を指定すると?(結論:-1)
存在しない文字を指定すると「-1」が返ってきます。
public class Main { public static void main(String[] args) { String s = "あいうえおかきくけこあいうえおかきくけこ"; int n = s.indexOf("らりるれろ");//存在しない文字列を指定 System.out.println(n); } }-1【まとめ】
上記の4パターンの挙動と、「存在しない文字を指定すると「-1」が返る」ということを覚えておきましょう。
参考文献・記事
- 投稿日:2020-12-12T01:18:46+09:00
【Java】charAtメソッド(n番目の文字を抜き出す)
JavaのcharAtメソッド
についてまとめました。
charAtメソッドとは
一言でいうと「文字列から指定位置の1文字を取得する」メソッドです。
【説明】
charAtメソッドは、文字の位置を指定することで該当の1文字を取得することができます。
書き方は以下です。
//chrAt 変数名.charAt(値)
- 数字は、左から0でスタートする
- 一番最後の文字の位置は文字列.length() – 1
【実際に書いてみる】
ひだりから数えて0スタートなので、「あいうえお」だと1を指定すると実質二番目の文字である「い」を取得してきます。
public class Main { public static void main(String[] args) { String str = "あいうえお"; System.out.println(str.charAt(1)); } }い範囲外を選択すると?(結論: 例外発生)
範囲外を選択すると例外が発生します。
例えば、文字列が5文字なのに対し、6番目を取得する「5」を指定した場合はjava.lang.StringIndexOutOfBoundsException
という例外がスローされます。
【まとめ】
抑えるポイントは以下です。
- 範囲外を指定すると例外発生
- 左から0スタート
参考文献・記事