- 投稿日:2020-12-06T23:16:09+09:00
Custom Vision がさらに簡単&ローカル作成可能に!Lobe でカスタム画像分析モデルを作成してみよう
Cognitive Services Custom Vision は充分簡単にカスタム画像認識 (クラス分類(Classification) & オブジェクト検出(Object Detection)) モデルが作成できてしまうサービスなのですが、これをさらにカンタンにした&アプリとしてローカル環境で作成~エクスポートできるのが、Microsoft Lobe です。
Lobe とは
Lobe の利用シナリオとして、以下のようなサンプルが提示されています
- Plant Species (庭の植物を見分ける)
- Hand Gestures (数のカウント、じゃんけんもできそう?)
- Personal Trainer (筋トレポーズ、ヨガももちろんできそう)
- Emotional Reactions (顔の表情)
- Interactive Painting (色の検出)
- :
実は Lobe のスゴイところは、直接カメラ映像(動画)を取得して自動で画像を切り出し、ラベル付けができるところです。
https://youtu.be/Mdcw3Sb98DA?t=63
実際に Lobe をダウンロードするところから、学習データ(画像) を覚えさせて TensorFlow にエクスポートして利用してみるまで (もちろん無料!) の手順を紹介します。今回はヨガのポーズを分類するモデルを作成してみます。
準備
特にマイクロソフトアカウントとかAzure サブスクリプションは必要ありません。初期登録 (名前、メールアドレス) のみで利用できます。(※ 2020年12月現在)
Lobe の登録 & アプリのダウンロード
まず Lobe のトップページ (https://lobe.ai/) を参照して、[Download] をクリックします。
Join Beta から登録を行います。Japan を選択すると日本語ローカライズの可能性が高まるかも?!
登録情報を入力したら [Download] をクリックして Lobe をダウンロードします。
ダウンロードした Lobe.exe (← Windows の場合?) をクリックして、ローカル環境にインストールします。
Lobe で画像分析モデルを作成
新規プロジェクト作成
Lobe を起動します。New Project をクリックして、新規プロジェクトを作成します。
学習データのロード~自動でモデル作成
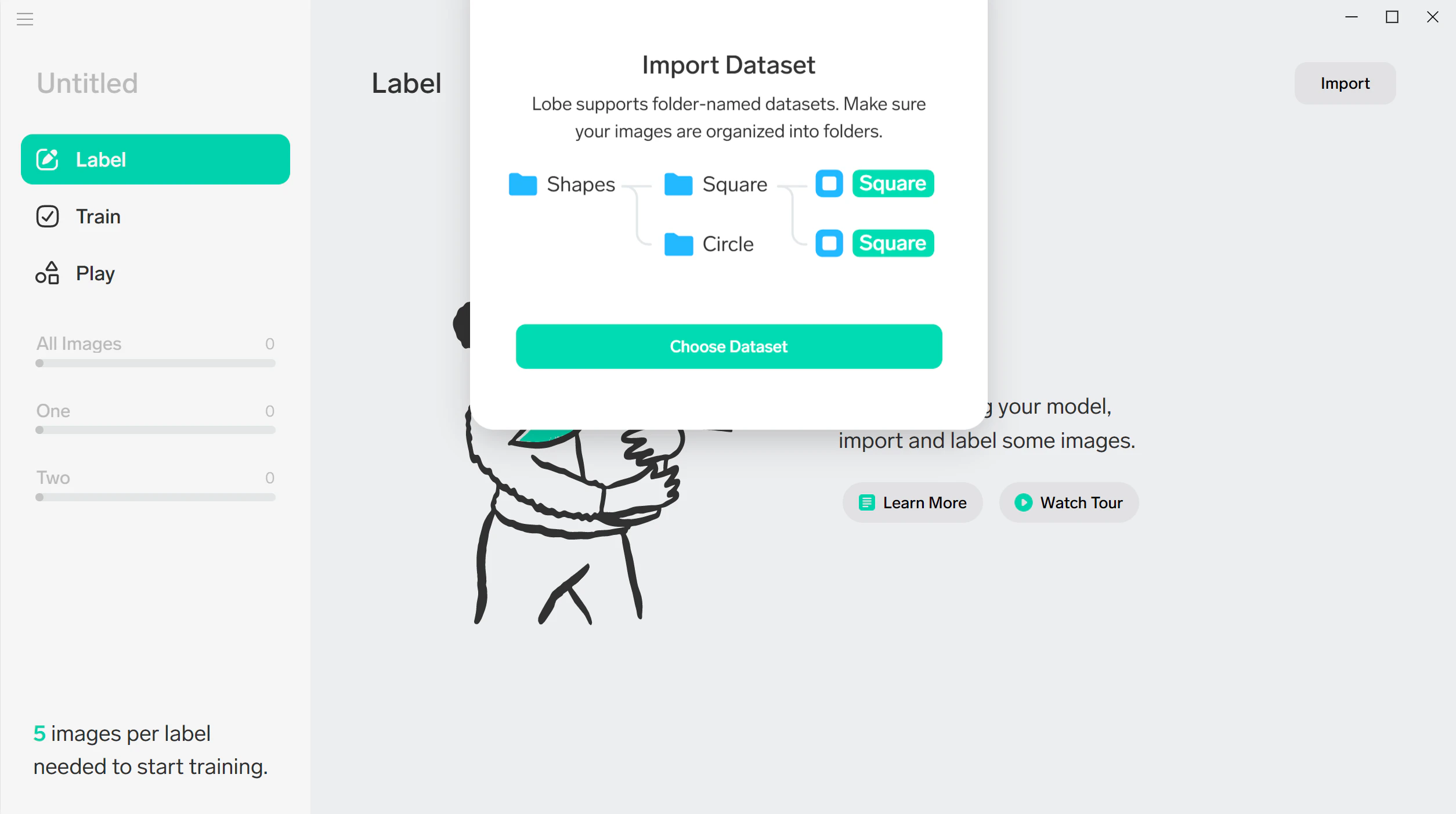
画面右上の [Import] をクリックして、学習データとなる画像を選択します。
画像認識モデルを作成するには 1 タグあたり 5 枚以上の画像が必要というところが既に Custom Vision っぽい :)
[Dataset] を選択すると、分類したフォルダーごと読み込みできるのはとても便利!
Yoga というフォルダーを作成し、その中にポーズ名(Cobra, downdog...)をつけたフォルダーに画像を格納しておきます。Yoga フォルダーを指定します。
画像を分類するタグ名はフォルダー名そのまま or カスタムもできます。今回はそのままで。
プロジェクト名も親フォルダーの名前(Yoga)に設定されました。
画像が読み込まれ、自動で学習 (Training) が実行されます。
分析モデルの確認
[Train] をクリックすると、作成した分析モデルの精度が確認できます。
分析モデルのテスト
Play をクリックして、学習データとして使っていない画像で分析モデルのテストを行います。
テストしたい画像を Drag & Drop するか、Import をクリックして画像を選択すると、画像の分析結果が表示されます。
分析モデルのエクスポートとサンプルコード実行
TensorFlow | TensorFlow Light にエクスポート、または Local API として利用できます。
ひとまず TensorFlow でダウンロードしてみます。左上の Ξ をクリックして、表示される Export をクリックします。
Export のメニューから TensorFlow を選択します。
ローカルに <プロジェクト名> TensorFlow というフォルダーが作成されます。
example フォルダーにサンプルコード(python) も一緒に作成されます。
example/readme.md に書かれている手順を参考にサンプルコードを実行してみます。
TensorFlow 1.15.3 を利用するため、実行するには Python 3.7.* が必要です。
tf-venv という名前で Python 仮想環境を作ります。(下記 Windows の場合)
python -m venv tf-venv // Python 3.7 がデフォルト環境でないなら py -3.7 -m venv tf-venvtf-venv を起動します。
tf-venv/Scripts/activatepip をアップグレードした後、example/requirements.txt に記載されているモジュールをインストールします。
(tf-venv) python -m pip install --upgrade pip (tf-venv) python -m pip install -r example/requirements.txtrequirements.txt からインストールするモジュールは以下の2つです。
- tensorflow==1.15.3
- pillow==7.2.0無事環境が作成出来たら、サンプルコード(tf_sample.py) を実行してみます。
test というフォルダーを作成して、テスト用画像を配置して指定 (test/warrior2.jpg) しています。(tf-venv) python example/tf_example.py test/warrior2.jpgTensorFlow v1.* を利用している Warning が最初出力されますが、Predicted 以下が分析モデルで画像を推定した結果です。
WARNING:tensorflow:From example/tf_example.py:40: load (from tensorflow.python.saved_model.loader_impl) is deprecated and will be removed in a future version. Instructions for updating: This function will only be available through the v1 compatibility library as tf.compat.v1.saved_model.loader.load or tf.compat.v1.saved_model.load. There will be a new function for importing SavedModels in Tensorflow 2.0. Predicted: {'Prediction': 'warrior', 'Confidences': [0.02098606899380684, 0.00528041971847415, 3.6378631193656474e-05, 0.0019086095271632075, 0.00045342574594542384, 0.004871818702667952, 0.9664632081985474]}Prediction の結果が warrior だとタグ名で出力されます。
Confidences の数値は各タグ(出力順)の推定値になります。(warrior=>0.9664632081985474)タグの出力順は、分析モデルの情報が記述された signature.json に記載されています。
signature.json{ "doc_id": "********-****-****-****-************", : "inputs": { : }, "outputs": { : }, "tags": ["serve"], "classes": { "Label": ["cobra", "downdog", "headstand", "plough", "tree", "triangle", "warrior"] }, "filename": "saved_model.pb" }

















- 投稿日:2020-12-06T16:17:36+09:00
TensorFlow 2.4.0-rc4のビルド手順(Windows10, CUDA11.1.1, cuDNN 8.0.5, Python 3.8.6)
2020/12/06時点でのTensorFlow 2.4.0-rc4のビルド方法の概要を残しておきます。
今回の組み合わせでは、PythonとNumpyのバージョンに気をつければ正常にビルドできました。
Pythonは3.9.0を利用すると依存パッケージの組み合わせ起因(だと思われる)のため、作成したwheelパッケージのインストールで失敗します。
Numpyは最新の1.19.4だと、Windows環境でimportするだけでエラーになるので、1つ前の1.19.3を使用します。(これはWindows側の問題で、2021年1月くらいに修正される予定らしいです)環境情報
ビルドに利用した環境です。CUDAやcuDNNのフォルダなど、事前にパスを通した状態になっています。
- Windows 10 Pro 20H2 (64bit)
- Visual Studio Community 2019 Ver 16.8.2
- Python 3.8.6(3.9.0を使うとwheelパッケージインストール時にエラーになります)
- MSYS2(
pacman -S git patch unzipで必要なパッケージを導入済み)- Bazel 3.7.1 (3.1.0以上のバージョンを使う必要あり)
- CUDA 11.1.1
- cuDNN 8.0.5.39
ビルド用のフォルダ構成など
今回は
S:\build\build_tf240rc4フォルダ配下にTensorFlowのソースコードをダウンロードしてビルドしています。Pythonの仮想環境も、TensorFlowビルド用に用意します。S:/build/build_tf240rc4 # 作業フォルダRoot + tensorflow # gitで取得してくるソースコード + venv # Python仮想環境 + wheelhouse # 作成したwhlファイルを格納するフォルダビルド手順
x64 Native Tools Command Prompt for VS 2019を起動して以下の手順でビルドを行います。# 仮想環境を作成して有効化する python -m venv s:\build\build_tf240rc4\venv cd /d s:\build\build_tf240rc4 .\venv\Scripts\activate.bat # 必要なパッケージのインストール # 注意:Numpyは最新の1.19.4を使うとエラーになるので1.19.3を使用(利用時もNumpy 1.19.3を使用すること) python -m pip install --upgrade pip setuptools pip install numpy==1.19.3 pip install six wheel pip install keras_applications==1.0.8 --no-deps pip install keras_preprocessing==1.1.2 --no-deps # ソースコード取得(v2.4.0-rc4のタグ指定) git clone -b v2.4.0-rc4 https://github.com/tensorflow/tensorflow.git cd tensorflow # 環境によってはコマンドのパラメーターが長くなりすぎてエラーになるので不要な環境変数を削除 set _OLD_VIRTUAL_PATH= # ビルド構成の設定 # CUDA support: Y # CUDA compute capabilities: 7.5 (利用環境に合わせて変更) # Optimization: /arch:AVX2 (利用環境に合わせて変更) # それ以外はデフォルト設定(Enter) python ./configure.py # ビルド # TensorFlow 2.3.x+CUDA11の場合は「DTHRUST_IGNORE_CUB_VERSION_CHECK」のおまじない(CUB互換チェックのスキップ)が必要だったが2.4.xは不要 bazel build --config=opt --config=avx2_win --config=short_logs --config=cuda --define=no_tensorflow_py_deps=true --copt=-nvcc_options=disable-warnings //tensorflow/tools/pip_package:build_pip_package # パッケージの作成(wheelhouseフォルダにパッケージを作成) # 数分間画面が更新されないので心配になりますが、きちんと処理されているのでしばらく待ちましょう bazel-bin\tensorflow\tools\pip_package\build_pip_package ..\wheelhouseこれで完了です。
なおビルドに使用したbazelの中間ファイル等は%UserProfile%\_bazel_%UserName%フォルダに作成され、容量も20GB近くになるので、不要であれば削除しても問題ありません。Bazelが起動していると削除できないので、その場合はコマンドプロンプトでbazel shutdownとして、Bazelを終了してから削除してください。作成したTensorFlowのwheelパッケージを利用する際は、
pip install numpy==1.19.3という感じでTensorFlowよりも先にNumpyをバージョン指定で導入しておくことをおすすめします。最新のNumpy 1.19.4は現時点では利用できません。
- 投稿日:2020-12-06T14:42:12+09:00
Apple Silicon M1 でtensorflow-macosを実行したらめちゃくちゃ速かった。
はじめに
Macbook Air (
AppleSilicon, M1)を購入しました。
Appleが設計したM1は下馬評以上の性能を叩き出し、
とても盛り上がっていますね。M1のハードウェアとしての魅力はもちろんすごいですが、
M1に合わせた各種ソフトウェアの最適化も魅力的です。AppleがTensorflowをフォークしてM1で最高のパフォーマンスを発揮するように
最適化したコード(tensorflow-macos)を公開しています。
https://github.com/apple/tensorflow_macos#requirementstensorflowのブログ記事でパフォーマンスが比較されていますが、
前世代のIntel Macと比べると信じられないほどの性能向上を見ることができます。
https://blog.tensorflow.org/2020/11/accelerating-tensorflow-performance-on-mac.htmlこの記事では
- 実際にM1 Macでtensorflow-macosを動作させた過程を紹介します。
- サンプルコードを動作させてM1 Mac, Intel Mac, RTX 2080 superとの実行時間の比較をします。
(初めてQiitaで記事を書いてみました。
ガイドライン違反や改善点があればご指摘ください!)目次
tensorflow-macosを実行する環境を構築する。Python 3.8 (for ARM)をインストールする。
tensorflow-macos 0.1a0はPython 3.8で動作します。
tensorflow-macosリポジトリのREQUIREMENTSにあるように、
必ずXcode Command Line Toolsからインストールしてください。$ xcode-select --install$ python3 -V Python 3.8.2 $ which python3 /usr/bin/python3
tensorflow_macosはARMアーキテクチャ向けのコードになっているので、
PythonもARMアーキテクチャ向けのものにする必要があります。例えば以下のようにインストールしたものは
tensofrflow-macosの実行時にエラーが発生しました。・ Python公式サイトからdmgファイルをダウンロードしてインストール ・ Anacondaを使ってインストール ・ pyenvを使ってインストールTraceback (most recent call last): File "/path/to/tensorflow_macos_venv/lib/python3.8/site-packages/tensorflow/python/pywrap_tensorflow.py", line 64, in <module> from tensorflow.python._pywrap_tensorflow_internal import * ImportError: dlopen(/path/to/tensorflow_macos_venv/lib/python3.8/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so, 6): no suitable image found. Did find: /path/to/tensorflow_macos_venv/lib/python3.8/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so: mach-o, but wrong architecture /path/to/tensorflow_macos_venv/lib/python3.8/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so: mach-o, but wrong architecture
tensorflow-macosの仮想環境(venv)を構築する。
tensorflow_macosの実行に必要な仮想環境を構築してくれる
便利なスクリプトをAppleが用意してくれています。
tensorflow-macosリポジトリのINSTALLATIONにあるように、
ターミナルからスクリプトを実行します。$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/apple/tensorflow_macos/master/scripts/download_and_install.sh)"仮想環境のパッケージのダウンロードが始まるので、
しばらく待つと(結構待つ)、仮想環境を構築するパスを聞かれるので、
Enterキーを押してデフォルトパスを指定し、構築を開始します。Downloading installer. /var/folders/hn/g5s5s0fx6zs2plvygdc95y140000gn/T/tmp.haPEac7f ~/Projects/tensorflow-mac % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 659 100 659 0 0 1331 0 --:--:-- --:--:-- --:--:-- 1331 100 316M 100 316M 0 0 2467k 0 0:02:11 0:02:11 --:--:-- 1638k Extracting installer. Path to new or existing virtual environment [default: /Users/tomoyaeibu/tensorflow_macos_venv/]: Using python from /usr/bin/python3. ########################################################################### ./install_venv.sh will perform the following operations: -> Create new python 3.8 virtual environment at /Users/tomoyaeibu/tensorflow_macos_venv. -> Install tensorflow_macos 0.1a0 into created virtual environment /Users/tomoyaeibu/tensorflow_macos_venv. -> Install bundled binary wheels for numpy-1.18.5, grpcio-1.33.2, h5py-2.10.0, tensorflow_addons-0.11.2+mlcompute into /Users/tomoyaeibu/tensorflow_macos_venv. Confirm [y/N]?
tensorflow-macosの仮想環境(venv)をアクティベートする。これで
tensorflow-macosを実行する環境は整いました。
簡単ですね・・・!
tensorflow-macosの仮想環境をアクティベートします。$ source /Users/{username}/tensorflow_macos_venv/bin/activate $ pip list Package Version ---------------------- --------- absl-py 0.11.0 appnope 0.1.0 astunparse 1.6.3 backcall 0.2.0 cached-property 1.5.2 cachetools 4.1.1 certifi 2020.11.8 chardet 3.0.4 decorator 4.4.2 flatbuffers 1.12 gast 0.4.0 google-auth 1.23.0 google-auth-oauthlib 0.4.2 google-pasta 0.2.0 grpcio 1.33.2 h5py 2.10.0 idna 2.10 ipython 7.19.0 ipython-genutils 0.2.0 jedi 0.17.2 Keras-Preprocessing 1.1.2 Markdown 3.3.3 numpy 1.18.5 oauthlib 3.1.0 opt-einsum 3.3.0 parso 0.7.1 pexpect 4.8.0 pickleshare 0.7.5 pip 20.2.4 prompt-toolkit 3.0.8 protobuf 3.14.0 ptyprocess 0.6.0 pyasn1 0.4.8 pyasn1-modules 0.2.8 Pygments 2.7.2 requests 2.25.0 requests-oauthlib 1.3.0 rsa 4.6 setuptools 50.3.2 six 1.15.0 tensorboard 2.4.0 tensorboard-plugin-wit 1.7.0 tensorflow-addons 0.11.2 tensorflow-estimator 2.3.0 tensorflow-macos 0.1a0 termcolor 1.1.0 traitlets 5.0.5 typeguard 2.10.0 typing-extensions 3.7.4.3 urllib3 1.26.2 wcwidth 0.2.5 Werkzeug 1.0.1 wheel 0.35.1 wrapt 1.12.1
tensorflow-macosがインストールされていることがわかります。
tensorflow-macosを実行する。
tensorflow-macosを実行するために既存のtensorflowを使った
トレーニングやバリデーションのコードを修正する必要はありません。今まで使っていたスクリプトをそのまま使えます。
(ただしKerasを使っていた場合、ARM版のKerasがまだないようなので、
tensorflowのAPIに置き換えるか、tf.KerasのAPIに置き換えてください。)実行時間を比較する。
早速サンプルコードを実行して実行時間を比較してみましょう。
トレーニングにかかる時間を比較します。実行環境
以下の3つの環境で比較しました。
Macbook Air (2020,M1) Macbook Pro (2017,Intel) 開発に使っている学習用PC OS Mac Big Sur Mac Big Sur Ubuntu 20.04.1 CPU M1 2.3GHzデュアルコアIntel Core i5 (後日、確認します) GPU M1 Intel Iris Plus Graphics 640 RTX 2080 Super 8GB RAM 8GB 8GB 16GB Python python 3.8.2 python 3.8.2 python 3.8.2 Tensorflow tensorflow-macos 0.1a0 tensorflow-macos 0.1a0 tensorflow 2.4 サンプルコードにはシンプルなmnistのクラス分類を使っています。
import tensorflow as tf mnist = tf.keras.datasets.mnist import time (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) start = time.perf_counter() model.fit(x_train, y_train, epochs=5) end = time.perf_counter() print(f"Elapsed time : {end - start:.3f} s.") model.evaluate(x_test, y_test)実行結果
Macbook Air (2020,M1) Macbook Pro (2017,Intel) 開発に使っている学習用PC 5epochにかかった時間 6.268 s 23.876 s 8.053 s Intel Macに対してM1 Macの方が4倍程度、速いという結果になりました。
素晴らしく速いですね。
たしかMacbook Pro(2017)の方がMacbook Air(2020)よりも
値段が高かったような気がするんですが・・・。さらにいつも開発に使っているRTX 2080 Superよりも速かったのは
もっと驚きの結果でした。RTX 2080 Superの方は特にチューニング作業はしていないので、
使い方次第では実はもっと速くなる可能性はありますが、
M1 Macだと何も気にせずこのぐらいの速度でトレーニングできるのは素晴らしいです。これからDeep Learningをやりたくて個人で開発環境を整えるのであれば、
下手に高いグラフィックボードを購入するよりは、
M1が搭載されたMadbook Airを買った方がコスパは良いと思います。考察、議論
GPU? CPU? Neural Engine?
tensorflow-macでは、
以下のように使用するデバイスを選択するオプションが用意されています。from tensorflow.python.compiler.mlcompute import mlcompute mlcompute.set_mlc_device(device_name="cpu") # cpu : CPUだけを利用する。 # gpu : GPUだけを利用する。 # any : 最適なデバイスを使用する。(デフォルト)Intel Macの場合、速い順に
any>gpu>cpuでした。
cpuよりgpuの方が速いのは、Intel Iris Plus Graphicsを使っているからだと思いますが、
gpuよりanyの方が速いのは、「最適なデバイス」を使っているからなのでしょうか。M1 Macの場合、速い順に
any>cpu>gpuでした。
gpuが遅いのはEagar Mode (Define by run)に対応していないだけなので、
Eagar modeをオフにすれば速くなるかもしれません。
anyが速いのは、やはり「最適なデバイス」を使っているからで、
FowardにはNeural Engineを、BackwardにはGPUを使うなどの工夫がしてあるのかな?
などと考察しています。これらのデバイスが同じメモリを共有しているのが
M1の大きな特徴の一つですし。どこかに詳しい記事がないかを探してみます。
参考文献
- 投稿日:2020-12-06T05:39:38+09:00
超解像技術-SRGAN-実装してみた(Tensorflow 2.0) 推論フェーズ編
こちらはITRC Advent Calendar 2020の6日目の記事です。
前の記事: @bluekey0725 さんのNetworkManagerで802.1xプロトコルを使用したwifiのホットスポットに機器を繋げたい
次の記事: @koseiinfratopさんの某アーティストグループは何を僕らに伝えたかったのか??? (WordCloudで歌詞化してみた)概要
前回の続きで、SRGANの推論フェーズ編になります。
環境
-Software-
Windows 10 Home
Anaconda3 64-bit(Python3.7)
VSCode
-Library-
Tensorflow 2.2.0
opencv-python 4.1.2.30
-Hardware-
CPU: Intel core i9 9900K
GPU: NVIDIA GeForce RTX2080ti
RAM: 16GB 3200MHzプログラム
Githubに上げておきます。
https://github.com/himazin331/Super-resolution-GAN
リポジトリには訓練フェーズ、推論フェーズ、データセット(General-100)が含まれています。ソースコード
ソースコードだけ載せておきます。
srgan_pre.pyimport argparse as arg import os import sys os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf import tensorflow.keras.layers as kl import cv2 from PIL import Image import matplotlib.pyplot as plt import numpy as np # Super-resolution Image Generator class Generator(tf.keras.Model): def __init__(self, input_shape): super().__init__() input_shape_ps = (input_shape[0], input_shape[1], 64) # Pre stage(Down Sampling) self.pre = [ kl.Conv2D(64, kernel_size=9, strides=1, padding="same", input_shape=input_shape), kl.Activation(tf.nn.relu) ] # Residual Block self.res = [ [ Res_block(64, input_shape) for _ in range(7) ] ] # Middle stage self.middle = [ kl.Conv2D(64, kernel_size=3, strides=1, padding="same"), kl.BatchNormalization() ] # Pixel Shuffle(Up Sampling) self.ps =[ [ Pixel_shuffler(128, input_shape_ps) for _ in range(2) ], kl.Conv2D(3, kernel_size=9, strides=4, padding="same", activation="tanh") ] def call(self, x): # Pre stage pre = x for layer in self.pre: pre = layer(pre) # Residual Block res = pre for layer in self.res: for l in layer: res = l(res) # Middle stage middle = res for layer in self.middle: middle = layer(middle) middle += pre # Pixel Shuffle out = middle for layer in self.ps: if isinstance(layer, list): for l in layer: out = l(out) else: out = layer(out) return out # Pixel Shuffle class Pixel_shuffler(tf.keras.Model): def __init__(self, out_ch, input_shape): super().__init__() self.conv = kl.Conv2D(out_ch, kernel_size=3, strides=1, padding="same", input_shape=input_shape) self.act = kl.Activation(tf.nn.relu) # forward proc def call(self, x): d1 = self.conv(x) d2 = self.act(tf.nn.depth_to_space(d1, 2)) return d2 # Residual Block class Res_block(tf.keras.Model): def __init__(self, ch, input_shape): super().__init__() self.conv1 = kl.Conv2D(ch, kernel_size=3, strides=1, padding="same", input_shape=input_shape) self.bn1 = kl.BatchNormalization() self.av1 = kl.Activation(tf.nn.relu) self.conv2 = kl.Conv2D(ch, kernel_size=3, strides=1, padding="same") self.bn2 = kl.BatchNormalization() self.add = kl.Add() def call(self, x): d1 = self.av1(self.bn1(self.conv1(x))) d2 = self.bn2(self.conv2(d1)) return self.add([x, d2]) def main(): # Command line option parser = arg.ArgumentParser(description='Super-resolution GAN prediction') parser.add_argument('--param', '-p', type=str, default=None, help='学習済みパラメータの指定(未指定ならエラー)') parser.add_argument('--data_img', '-d', type=str, default=None, help='画像ファイルの指定(未指定ならエラー)') parser.add_argument('--out', '-o', type=str, default=os.path.join(os.path.dirname(os.path.abspath(__file__)), "result"), help='保存先指定(デフォルト値=./result)') parser.add_argument('--he', '-he', type=int, default=128, help='リサイズの高さ指定(デフォルト値=128)') parser.add_argument('--wi', '-wi', type=int, default=128, help='リサイズの指定(デフォルト値=128)') parser.add_argument('--mag', '-m', type=int, default=2, help='縮小倍率の指定(デフォルト値=2)') args = parser.parse_args() # Parameter-File not specified. -> Exception if args.param == None: print("\nException: Trained Parameter-File not specified.\n") sys.exit() # An Parameter-File that does not exist was specified. -> Exception if os.path.exists(args.param) != True: print("\nException: Trained Parameter-File {} is not found.\n".format(args.param)) sys.exit() # Image not specified. -> Exception if args.data_img == None: print("\nException: Image not specified.\n") sys.exit() # An image that does not exist was specified. -> Exception if os.path.exists(args.data_img) != True: print("\nException: Image {} is not found.\n".format(args.data_img)) sys.exit() # When 0 is entered for either width/height or Reduction ratio. -> Exception if args.he == 0 or args.wi == 0 or args.mag == 0: print("\nException: Invalid value has been entered.\n") sys.exit() # Setting info print("=== Setting information ===") print("# Trained Prameter-File: {}".format(os.path.abspath(args.param))) print("# Image: {}".format(args.data_img)) print("# Output folder: {}".format(args.out)) print("") print("# Height: {}".format(args.he)) print("# Width: {}".format(args.wi)) print("# Magnification: {}".format(args.mag)) print("===========================") # Create output folder (If the folder exists, it will not be created.) os.makedirs(args.out, exist_ok=True) # Network Setup model = Generator(input_shape=(args.he, args.wi, 3)) model.build((None, args.he, args.wi, 3)) model.load_weights(args.param) # High-resolutin Image img = cv2.imread(args.data_img) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) hr_img = cv2.resize(img, (args.he, args.wi)) # Low-resolution Image lr_img = cv2.resize(hr_img, (int(args.he/args.mag), int(args.wi/args.mag))) lr_img = cv2.resize(lr_img, (args.he, args.wi)) lr_img_s = lr_img # Image processing lr_img = tf.convert_to_tensor(lr_img, np.float32) lr_img = tf.convert_to_tensor(lr_img, np.float32) lr_img = (lr_img - 127.5) / 127.5 lr_img = lr_img[np.newaxis, :, :, :] # Super-resolution re = model.predict(lr_img) # Super-resolution Image processing re = np.reshape(re, (args.he, args.wi, 3)) re = re * 127.5 + 127.5 re = np.clip(re, 0.0, 255.0) # Low-resolution Image output lr_img = Image.fromarray(np.uint8(lr_img_s)) lr_img.show() lr_img.save(os.path.join(args.out, "Low-resolution Image(SRGAN).bmp")) # Super-resolution Image output sr_img = Image.fromarray(np.uint8(re)) sr_img.show() sr_img.save(os.path.join(args.out, "Super-resolution Image(SRGAN).bmp")) # High-resolution Image output hr_img = Image.fromarray(np.uint8(hr_img)) hr_img.show() hr_img.save(os.path.join(args.out, "High-resolution Image(SRGAN).bmp")) if __name__ == "__main__": main()実行結果
HR - 高解像画像(オリジナル)
SR - 超解像画像
LR - 低解像画像128x128 倍率 2 - Epoch 1000
128x128 倍率 4 - Epoch 1000
128x128 倍率 4 - Epoch 3000
256x256 倍率 2 - Epoch 1000
256x256 倍率 4 - Epoch 1000
256x256 倍率 4 - Epoch 3000
256x256 倍率 4 - Epoch 5000
256x256ぐらいの解像度になるとメモリ不足に陥ったので、ミニバッチサイズを下げて学習しました。
Epoch数を増やせば綺麗なresultがでることが確認できました。おわりに
SRGANはSRCNNよりも高いresultを出してくれます。が、前回でも触れたようにメモリリソースを多く食うものとなっているため注意が必要です。
SRCNN, SRGANとディープラーニングを利用した超解像技術に触れてみましたが、すっかり超解像技術の虜になってしまいました(笑)
今後もまた超解像技術に触れてみたいと考えています。
ここまでの閲覧ありがとうございました。






