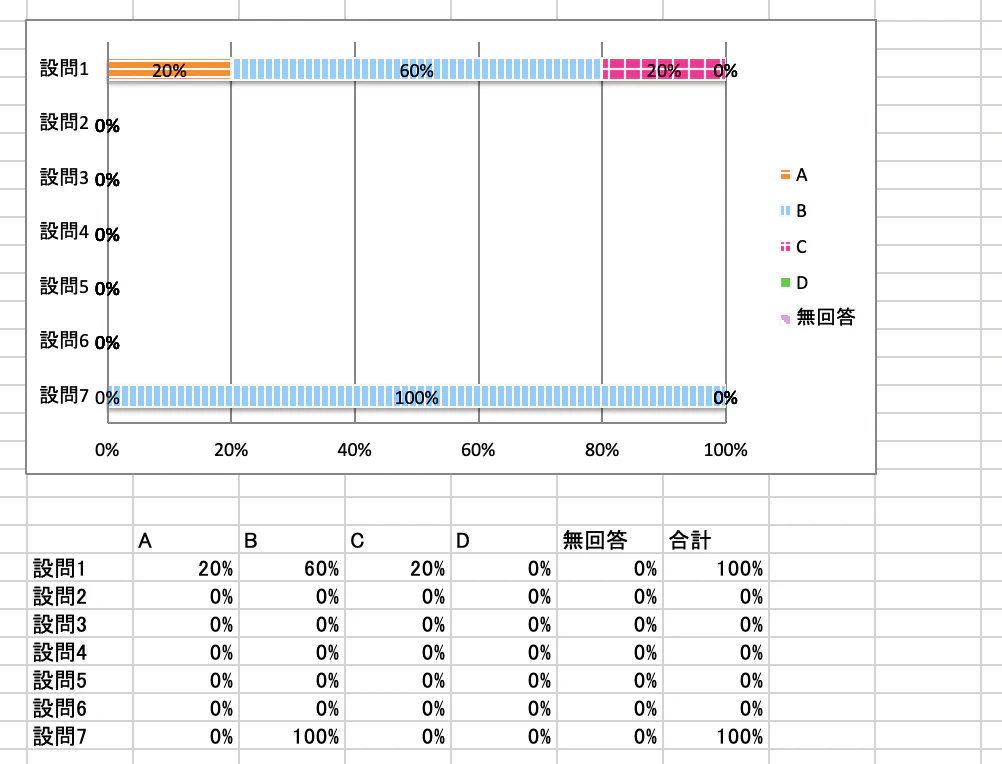
- 投稿日:2020-12-06T23:53:05+09:00
Pythonで簡単なライフゲームアニメーション
はじめに
jupyter notebook上で、できるだけシンプルにライフゲームを再現してみる。
下準備
%matplotlib notebookはjupyter notebookにアニメーションを描画するためのおまじない。(%matplotlib nbaggでもできそう)
import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation %matplotlib notebookフィールド
最初にサイズheight×widthのランダムな01領域を作る。今回は50×50領域で作成。
height=50 width=50 fig=plt.figure() #figオブジェクト作成 ims=[] field=np.random.randint(0,2,(height,width))初期状態の例
状態の更新
100回更新する。
for i in range(100): im=plt.imshow(field) ims.append([im]) #リストに突っ込んでいく field=update(field) #更新update関数
見ているマスが生存している場合、
隣接するマスの2または3つが生きている→生存見ているマスが生存していない場合、
隣接しているマスの3つが生きている→生存
と遷移させていく。def update(field): field2=np.zeros((height,width)) dx=[1,1,1,0,0,-1,-1,-1] dy=[1,0,-1,1,-1,1,0,-1] for i in range(height): for j in range(width): count=0 for k in range(8): count+=field[(i+dx[k])%height][(j+dy[k])%width] if(field[i][j]==1): if(count==2 or count==3): field2[i][j]=1 else: if(count==3): field2[i][j]=1 return field2アニメーション描画
0.1秒ごとに切り替わる。
ani=animation.ArtistAnimation(fig,ims,interval=100) plt.show()コード全体
import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation %matplotlib nbagg def update(field): field2=np.zeros((height,width)) dx=[1,1,1,0,0,-1,-1,-1] dy=[1,0,-1,1,-1,1,0,-1] for i in range(height): for j in range(width): count=0 for k in range(8): count+=field[(i+dx[k])%height][(j+dy[k])%width] if(field[i][j]==1): if(count==3 or count==2): field2[i][j]=1 else: if(count==3): field2[i][j]=1 return field2 height=50 width=50 fig=plt.figure() ims=[] field=np.random.randint(0,2,(height,width)) for i in range(100): im=plt.imshow(field) ims.append([im]) field=update(field) ani=animation.ArtistAnimation(fig,ims,interval=100) plt.show()
良さげ。一瞬グライダーがいる。


- 投稿日:2020-12-06T23:41:28+09:00
現場で使われるディープラーニング手法9選を一切コードを使わず解説 part1
画像認識と転移学習(VGG16)
このpartでは、
- VGG16
- 転移学習
- ファインチューニング
- 画像認識の流れ
の4つを解説します。
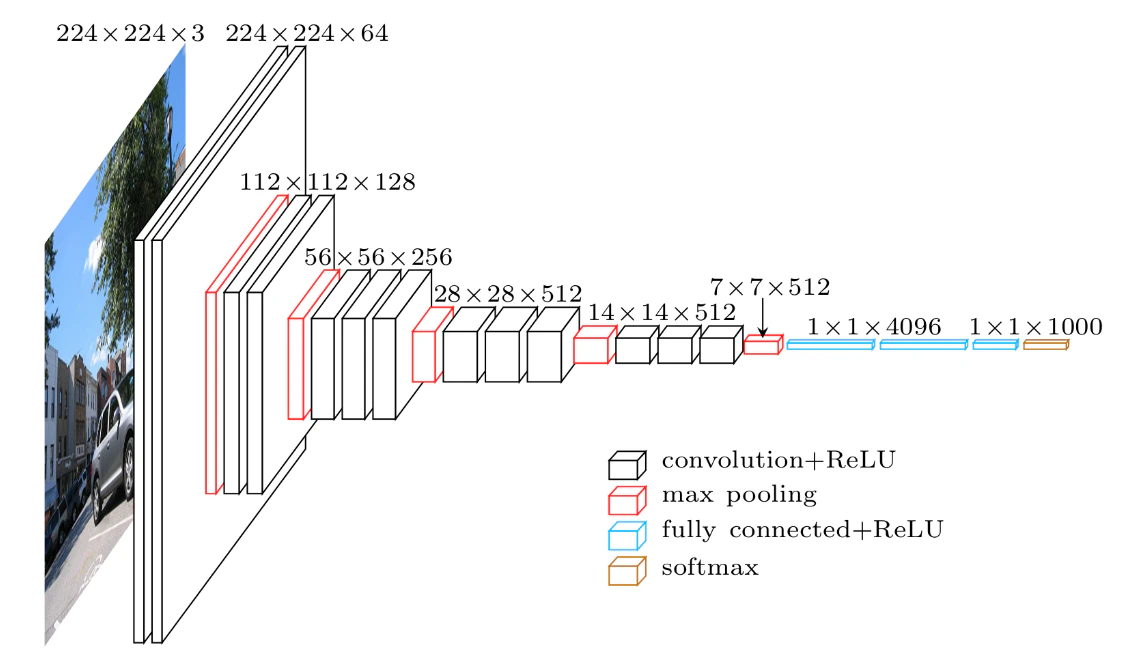
VGG16
ImageNetデータセットで事前にパラメータ学習されたモデル。1000クラスを分類可能。
Input:(channel,height,width)=(3,224,224) Output:1000
転移学習
パラメータ学習済みモデル(VGG16など)をベースに、最終出力層を分類したいクラス数に付け替え、さらにその数層手前までを自前のデータセットで学習し直す手法。少ないデータセットで高い精度を出すことが可能。
ファインチューニング
学習済みモデルを利用するという点で転移学習に近い手法だが、違いとして出力層だけでなく全層自前のデータセットで学習し直す(チューニングする)という点が挙げられる。一般的には入力層付近の学習率は小さめに、出力層に近づくに連れて大きくしていく。
画像認識の流れ
1.前処理クラス…画像をリサイズしたり反転・回転させたり標準化したりすることで、
- モデルの入力サイズに調整
- データの水増し
- 精度の向上
などが期待される。
2.パスリスト作成クラス…今いる階層から自前のデータまでのアクセスルートをパスとして取得し、リスト化する。3.データセットクラス…上記1と2を組み合わせ、(前処理済み画像,正解クラス)のタプルを作る。
4.データローダークラス…3で作成した(前処理済み画像,正解クラス)が画像枚数分あるリストから、ミニバッチサイズに応じてデータを抽出する。
5.モデルを学習させる関数…実際に学習を行う場所。
- ネットワークの定義(or既存モデルのロードと層の付け替え)
- 損失関数の定義(分類→交差エントロピー、回帰→平均二乗誤差が一般的)
- 最適化手法の定義
- エポック数の定義
- 投稿日:2020-12-06T23:41:28+09:00
現場で使われるディープラーニング手法9選を一切コードを使わず解説 画像分類編
画像認識と転移学習(VGG16)
このpartでは、
- VGG16
- 転移学習
- ファインチューニング
- 画像認識の流れ
の4つを解説します。
VGG16
ImageNetデータセットで事前にパラメータ学習されたモデル。1000クラスを分類可能。
Input:(channel,height,width)=(3,224,224) Output:1000
転移学習
パラメータ学習済みモデル(VGG16など)をベースに、最終出力層を分類したいクラス数に付け替え、さらにその数層手前までを自前のデータセットで学習し直す手法。少ないデータセットで高い精度を出すことが可能。
ファインチューニング
学習済みモデルを利用するという点で転移学習に近い手法だが、違いとして出力層だけでなく全層自前のデータセットで学習し直す(チューニングする)という点が挙げられる。一般的には入力層付近の学習率は小さめに、出力層に近づくに連れて大きくしていく。
画像認識の流れ
1.前処理クラス…画像をリサイズしたり反転・回転させたり標準化したりすることで、
- モデルの入力サイズに調整
- データの水増し
- 精度の向上
などが期待される。
2.パスリスト作成クラス…今いる階層から自前のデータまでのアクセスルートをパスとして取得し、リスト化する。3.データセットクラス…上記1と2を組み合わせ、(前処理済み画像,正解クラス)のタプルを作る。
4.データローダークラス…3で作成した(前処理済み画像,正解クラス)が画像枚数分あるリストから、ミニバッチサイズに応じてデータを抽出する。
5.モデルを学習させる関数…実際に学習を行う場所。
- ネットワークの定義(or既存モデルのロードと層の付け替え)
- 損失関数の定義(分類→交差エントロピー、回帰→平均二乗誤差が一般的)
- 最適化手法の定義
- エポック数の定義
- 投稿日:2020-12-06T23:37:43+09:00
PythonでGoogle Cloud Loggingへログ出力
概要
Pythonのloggingモジュールから、Google Cloud のLoggingにログを出力する方法です。
手順
おおよそ以下の手順でログを出力できます。
Google側の設定
IAMでサービスアカウントを作成して、Logs Writerの権限を付与します。
ローカル(Python実行環境)の設定
Pythonを動かす環境に、IAMからKeyをダウンロードしておきます。
あとは、以下のようなコードでログを出力できます。from google.cloud.logging_v2.client import Client as LogClient from google.oauth2 import service_account from google.cloud.logging_v2.handlers import CloudLoggingHandler from logging import getLogger credentials = service_account.Credentials.from_service_account_file('service_account.json') client = LogClient(project='project-id', credentials=credentials) handler = CloudLoggingHandler(client, name='log name') cloud_logger = getLogger() cloud_logger.addHandler(handler) cloud_logger.error('log message')
- 投稿日:2020-12-06T23:21:34+09:00
DjangoでGoogleのアバター画像を扱う
いくつか参考記事があったが、記事の通りやっても下記エラーとなり詰まってたのでメモ。
エラー内容
KeyError at /oauth/complete/google-oauth2/ 'image'解決策
def get_avatar(backend, strategy, details, response, user=None, *args, **kwargs): url = None if backend.name == 'facebook': url = "http://graph.facebook.com/%s/picture?type=large"%response['id'] if backend.name == 'twitter': url = response.get('profile_image_url', '').replace('_normal','') if backend.name == 'google-oauth2': url = response["picture"] #ここが「image」だと✗だったが、pictureで無事表示できた if url: user.profile_icon = url user.save()参考記事:
https://hodalog.com/python-social-auth-get-google-avatar/https://stackoverflow.com/questions/25734611/python-social-auth-get-google-avatar
- 投稿日:2020-12-06T23:02:29+09:00
[Python]bit全探索 ABC045C,ARC061C
ABC045C
$2^n$通りを探索する場合は、bit全探索が適切である。
下は、けんちょんさんのビット演算のまとめ表
サンプルコードs = input() n = len(s) ans = 0 for bit in range(1 << (n - 1)): # n-1左シフト f = s[0] for i in range(n - 1): # フラグが立っている所に+を挿入 if bit & (1 << i): f += "+" f += s[i + 1] ans += sum(map(int, f.split("+"))) print(ans)

- 投稿日:2020-12-06T22:55:38+09:00
[python][selenium]エラー「selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable may have wrong permissions.」
エラー内容
pythonにて seleniumを実行しようとしたところ、下記エラーが発生。
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable may have wrong permissions.原因
permissionsと書かれているので、権限を確認してみる。mba:scraping kk$ ls -l total 49720 -rw-r--r-- 1 konoken staff 15720316 Dec 6 22:24 chromedriver実行権限である
xが振られていないのが原因。解決法
以下コマンドで実行権限をファイルに付与する。
chmod ugo+x chromedriver
- 投稿日:2020-12-06T22:49:22+09:00
FalconでAPIの前処理・後処理をHooksとMiddlewareで実装
FalconでAPIの前処理・後処理を実装する
Flaskに比べて高速なAPIを実装できるFalconを利用した場合、共通的な前処理・後処理は2つの実装方法がある。
認証処理やデータベースの接続処理の共通化の調査結果をメモとしてまとめておく。
Hooks
API単位にデコレータをセットし、前処理・後処理はそれぞれのHooksで設定する。API単位に細かく設定を変更した場合に向く。Middleware
ソースのAPI全体にミドルウェアとして設定する。前処理・後処理のほかメインルーチンも設定できる。Hooks ... API単位に設定
API単位に前処理・後処理をHooks(デコレータ)で設定する。Flaskでいうbefore_request、after_requestメソッドに相当する。
[処理の実装]
def before_hook(req, resp, resource, params): # 前処理を実装する def after_hook(req, resp, resource): # 後処理を実装する class TestResource(object): @falcon.before(before_hook) @falcon.after(after_hook) def on_post(self, req, res): # POSTメソッドの処理 app = falcon.API(middleware=[]) app.add_route("/", TestResource())[処理の中断]
処理途中で例外を発生させる場合はraiseを利用する
たとえば前処理を途中で打ち切る場合、以下のようなコードを記載することで後続処理は実行されない。def before_hook(req, resp, resource, params): raise falcon.HTTPBadRequest('Bad request')Middleware ... ソース内のAPI全体に設定
前処理、メインルーチン、後処理をそれぞれのメソッドで作成する。
[処理の実装]
middleware.pyclass TestMiddleware(object): # 前処理 def process_request(self, req, resp): # 前処理を実装する # メインルーチン def prrocess_resource(self, req, resp, resource, params): # メインルーチンを実装する # 後処理 def process_response(self, req, resp, resource, req_succeeded): # 後処理を実装する[Middlewareの登録]
falconの初期化時にMiddlewareを組み込む。パラメタは配列形式なので複数指定できる。Falconからは標準機能としてCORSMiddlewareが提供されている。
app = falcon.API(middleware=[middleware.TestMiddleware()])[処理の中断]
resp.complete、resp.statusを設定する。
たとえば前処理を途中で打ち切る場合、以下のようなコードを記載することで後続処理は実行されない。class TestMiddleware(object): # 前処理 def process_request(self, req, resp): resp.complete = True resp.status = falcon.HTTP_400その他
Flaskでのグローバル機能(g変数)に近い機能は、将来実装予定だと思われる。
このやり方が正しいかは不明だが、たとえば前処理でreqに独自のメンバ変数を格納することで、後続処理でその変数を参照した動作を作成できる。[例]
- 前処理でSQLiteのコネクションを取得しreq.curにcursorオブジェクトを格納
- API内部でreq.curを利用してSQLite3にINSERT
- 後処理でcommit / rollback
# -*- coding:utf-8 -*- import json import falcon import sqlite3 # SQLite3データベースの準備 conn = sqlite3.connect(':memory:') cur = conn.cursor() cur.execute('create table test(data text)') conn.commit() cur.close() # 前処理のHooks def before_hook(req, resp, resource, params): # SQLite3データベースのcursorオブジェクトを作成 req.cur = conn.cursor() # 後処理のHooks def after_hook(req, resp, resource): # statusコードによりcommitかrollbackを実行 if resp.status != falcon.HTTP_200: conn.rollback() else: conn.commit() req.cur.close() class TestResource(object): @falcon.before(before_hook) @falcon.after(after_hook) def on_post(self, req, res): # POSTメソッドの実装 data = json.load(req.bounded_stream) req.cur.execute("insert into test values(?)", (str(data),)) msg = {"message": "POST OK"} #res.status = falcon.HTTP_400 res.body = json.dumps(msg) app = falcon.API(middleware=[]) app.add_route("/", TestResource()) if __name__ == "__main__": from wsgiref import simple_server httpd = simple_server.make_server("0.0.0.0", 8000, app) httpd.serve_forever()参考ページ
- 投稿日:2020-12-06T21:33:56+09:00
Pytorchで勉強したモジュール等のメモ
2020/12/06
torch.nn.init.normal_(tensor, mean=0.0, std=1.0)
- tensor: n次元のTensor型
- mean: 正規分布の平均値
- std: 正規分布の標準偏差
Gans生成の重みの初期化で出てきた。
例 w = torch.empty(2, 5) nn.init.normal_(w, 0.0, 0.02) --> tensor([[-0.0038, -0.0077, -0.0248, 0.0167, -0.0318], [-0.0232, -0.0192, -0.0027, -0.0211, 0.0047]])随時更新
- 投稿日:2020-12-06T21:12:40+09:00
忘年会の余興に使えるSlackスタンプ活用術
こんにちは。みっきーです。
この記事は Voicy Advent Calendar 2020 の 6 日目の記事です。
先日は, @miyukiaizawa さんの 外部ライブラリのMockの実装例Tips でした。もうすぐ、忘年会の季節ですね。年末となると今年の振り返りをする機会も多いのではないでしょうか?
そこでオススメなのが、Slackの絵文字スタンプを集めて、どれくらい絵文字スタンプが押されているのか収集してランキングすると、忘年会の余興に使えます!今回は、Slack絵文字の集め方を解説したいと思います。記事の内容について
これは自分が技術書典9のVoicy Tech Story Vol.2の「chapter 9. Slack 絵文字リアクションを活用した組織カルチャー作り」を忘年会用に書き直して、さらに参考実装プログラム(slack-reaction-collector α版)を追記した記事です。このプログラムをForkして、カスタマイズして使うと良いでしょう。
はじめに
Slackのスタンプを収集するために使う道具です。
- Slack SDK: slackapi/python-slack-sdk
- MySQL
今回は、プログラミング言語にPythonとデータベースにMySQLを使います。Pythonを使っている理由はSlackのSDKがよく出来ているからです。MySQLを使っている理由は、SlackAPIで取得したリアクションのJSONデータをそのままJSON型で格納したほうが、集計とランキングが簡単だからです。
動作確認
Python: 3.8.3
MySQL : 8.0.18 Homebrew
(JSON型を利用しているため、MySQL 5.7以上であれば動くと思います。)ライブラリのインストール
pip install slack_sdk pip install SQLAlchemy pip install mysql-connector-python-rfrequirements.txtslack-sdk==3.1.0 mysql-connector-python-rf==2.2.2 SQLAlchemy==1.3.20SLACK API TOKENの取得
APIへのアクセスには
xoxp-で始まるアクセストークンが必要です。Build a Slack app in less than 10 minutes!のTable of contentsに取得方法が記載されていますので、手順にしたがって取得してください。
補足:Create a Slack app
初めは、OAuth & PermissionsのOAuth Tokens & Redirect URLsの、Install to Workspaceボタンは押せません。Scopesにある、Add an Oauth Scopeを追加していくことで、Install to Workspaceを押せるようになります。デフォルトで何もAPIを実行できず、Scopeを追加していくことで、操作できるAPIが増えます。
User Token Scopesに、下記の3つを有効にしてください。今回はBOTを作るわけではないため、
Bot Token Scopesは使いません。xoxbで始まるアクセストークンを利用してしまうと、channels:historyで会話を取得するとき、各チャンネルごとにBOTのインストールが必要になります。チャンネルがあるのにエラーでnot_in_channelが出てしまった場合は、使っているアクセストークンの確認が必要です。ハマりました・・
取得したアクセストークンをslack_tokenに記載し、
xoxpで始まる、xoxp-xxxxの部分を書き換えてご利用ください。Botのxoxbではありません。config.iniSLACK_TOKEN = xoxp-xxxxxxクライアント
Slackのクライアントを使います。これ以降は、
clientを使っていきます。
簡単に利用する場合は、環境変数でSLACK_TOKENを渡すと良いでしょう。import os from slack_sdk import WebClient client = WebClient(token=os.environ['SLACK_TOKEN'])チャンネル一覧の取得
主にチャンネルの会話履歴を取得するために使います。
チャンネル一覧は、conversations.list APIで取得できます。SDKからは、conversations_list関数を呼び出すことで利用できます。limitオプションで一度に取得できるチャンネル数を変更できます。何も指定しない場合は100です。チャンネル数は1000以下が多いと思いますので、ページネーションを考慮しない場合は、最大値を指定する取得が楽です。
channels = client.conversations_list( limit=1000, exclude_archived=1 )['channels']参考プログラムはこちらです。
主に使うのは、idとnameです。
for channel in channels: print(channel['id'],channel['name'])ユーザ一覧の取得
主に、誰が多くスタンプを押してたかなどに使います。スタンプ統計だけであれば不要です。
ユーザーリストは、users.listで取得できます。SDKからは、users_list関数を呼び出すことで利用できます。exclude_archivedオプションを指定するとアーカイブされたユーザーを除くことができます。
users = client.users_list(exclude_archived=1)主に使うのは、idとプロフィールにあるrealnameとdisplay_nameです。
プロフィールに入力していない人もいるので、どちらか一方を取得すると良いでしょう。for user in users['members']: print(user['id'], user['profile']['real_name'], user['profile']['display_name'])参考プログラムはこちら
会話履歴の取得
会話の履歴を取得するには、conversations.history APIを利用します。SDKからは、conversations_history関数を呼び出すことで利用できます。必須パラメーターにはchannelを指定します。この値は、conversions.listで取得したchannnelのid属性に記載されているID(例:C1234567890)になります。この属性の正式名称は、Conversation IDなのですが互換性のためなのか変わらず残っています。例では2つの引数を指定します。1つ目の引数はoldestです。これは、指定した日付から最新の会話まで取得します。日付はタイムスタンプ形式(例:1234567890.123456)です。strptime関数で年月日をタイムスタンプに変換すると使いやすいです。2つ目の引数はcountで、取得件数を指定します。
from datetime import datetime oldest = datetime.strptime("2020-09-01", "%Y-%m-%d").timestamp() histories = client.conversations_history( channel="C1234567890", oldest=oldest, count=1 )参考プログラムはこちら
レスポンス結果は下記の通りです。
{'channel_actions_count': 0, 'channel_actions_ts': None, 'has_more': False, 'messages': [{'blocks': [{'block_id': 'ZiwA', 'elements': [{'elements': [{'text': 'これはテストです。', 'type': 'text'}], 'type': 'rich_text_section'}], 'type': 'rich_text'}], 'client_msg_id': 'xxxxx', 'last_read': '1599436735.030600', 'latest_reply': '1599436735.030600', 'reactions': [{'count': 1, 'name': 'makevalue', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'givefirst', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'towardthegoal', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'beprofessional', 'users': ['UQ2UTCBKM']}], 'reply_count': 1, 'reply_users': ['UQ2UTCBKM'], 'reply_users_count': 1, 'subscribed': True, 'team': 'T0APX46NS', 'text': 'これはテストです。', 'thread_ts': '1599436053.030100', 'ts': '1599436053.030100', 'type': 'message', 'user': 'UQ2UTCBKM'}], 'ok': True, 'oldest': '1599404400.000000', 'pin_count': 0}conversations.history APIは、会話の取得のみで、会話に対する返信は、conversations.replies APIを利用します。
SDKからは、conversations_replies関数を呼び出すことで利用できます。conversations.history APIとの違いでは、引数にtsを指定することで、会話の履歴を取得できます。タイムスタンプはメッセージを一意に識別します。
このタイムスタンプの値は、先程のconversations.history APIのレスポンス結果で取得できるmessagesのtsの値を利用します。oldest = datetime.strptime("2020-09-07", "%Y-%m-%d").timestamp() replies = client.conversations_replies( channel="C1234567890", oldest=oldest, count=1, ts="1599436053.030100", )レスポンス結果は下記の通りです。
{'has_more': False, 'messages': [{'blocks': [{'block_id': 'ZiwA', 'elements': [{'elements': [{'text': 'これはテストです。', 'type': 'text'}], 'type': 'rich_text_section'}], 'type': 'rich_text'}], 'client_msg_id': 'xxxxx', 'last_read': '1599436735.030600', 'latest_reply': '1599436735.030600', 'reactions': [{'count': 1, 'name': 'makevalue', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'givefirst', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'towardthegoal', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'beprofessional', 'users': ['UQ2UTCBKM']}], 'reply_count': 1, 'reply_users': ['UQ2UTCBKM'], 'reply_users_count': 1, 'subscribed': True, 'team': 'T0APX46NS', 'text': 'これはテストです。', 'thread_ts': '1599436053.030100', 'ts': '1599436053.030100', 'type': 'message', 'user': 'UQ2UTCBKM'}, {'blocks': [{'block_id': 'zUpes', 'elements': [{'elements': [{'text': 'これは返信のテストです。', 'type': 'text'}], 'type': 'rich_text_section'}], 'type': 'rich_text'}], 'client_msg_id': '66c5e0f7-38b2-4923-a572-9174be856f8f', 'parent_user_id': 'UQ2UTCBKM', 'reactions': [{'count': 1, 'name': 'makevalue', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'givefirst', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'towardthegoal', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'beprofessional', 'users': ['UQ2UTCBKM']}], 'team': 'T0APX46NS', 'text': 'これは返信のテストです。', 'thread_ts': '1599436053.030100', 'ts': '1599436735.030600', 'type': 'message', 'user': 'UQ2UTCBKM'}], 'ok': True}おそらく、conversations.repliesが一番API呼び出しが多く、RateLimitにひっかります。Rate Limitは、Tier 3で、50回/分です。一番簡単なのは、1リクエストごとに、1~2秒sleepをいれておけば、制限にひかからないので気長に待ちましょう。
絵文字リアクションの取得
APIから取得したリアクションを集計しやすくするために、関連する値をデータベースに保存します。
MySQLのJSON型で保存しておくと、集計が楽になります。下記がスキーマの例です。
CREATE TABLE reactions ( `id` int(11) NOT NULL AUTO_INCREMENT, `channel` varchar(255), `ts` varchar(255), `user` varchar(255), `reactions` json DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;conversations.historyのレスポンス結果のreactionsを取得します。
'reactions': [{'count': 1, 'name': 'makevalue', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'givefirst', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'towardthegoal', 'users': ['UQ2UTCBKM']}, {'count': 1, 'name': 'beprofessional', 'users': ['UQ2UTCBKM']}]JSONの値のまま保存します。
import json sql = "INSERT INTO reactions(channel, user, ts, reactions) VALUES(%s, %s, %s, %s)" channel = "C1234567890" user = "UQ2UTCBKM" ts = "1599436735.030600" con.execute( sql, channel, user, ts, json.dumps(reactions) )参考プログラムはこちらです。
ユーザー別に会話へのリアクションが押された回数を集計する
MySQLに格納したデータは、SQLの集計関数で計算します。特定のスタンプを取得したい場合は、MySQLのJSON_CONTAINS関数を利用することでリアクション対象を絞ることができます。
会話に対してどれだけリアクションが押されたかは、JSONの中のcountに格納されています。すべての会話のcountを合計することで、ユーザー別のリアクションランキングを作成できます。下記がリアクションランキングのSQLの例です。
SELECT t2.cnt, users.display_name FROM ( SELECT t.user, SUM(count) as cnt FROM ( SELECT user, JSON_EXTRACT(reactions, '$.count') as count FROM reactions ORDER BY count DESC ) AS t GROUP BY user ) AS t2 INNER JOIN users ON (t2.user = users.user_id) ORDER BY cnt DESC参考プログラムはこちら
スタンプ別のリアクションランキング
こちらは、
下記がリアクションランキングのSQLの例です。
SELECT JSON_UNQUOTE(JSON_EXTRACT(reactions, '$.name')) as reaction_name, SUM(JSON_EXTRACT(reactions, '$.count')) as count FROM reactions GROUP BY JSON_UNQUOTE(JSON_EXTRACT(reactions, '$.name')) ORDER BY count desc LIMIT 100参考プログラムはこちらです。
出力例
╒═════════════════╤═════════╕ │ reaction_name │ count │ ╞═════════════════╪═════════╡ │ eyes │ 2 │ ├─────────────────┼─────────┤ │ blush │ 1 │ ├─────────────────┼─────────┤ │ urayama │ 1 │ ╘═════════════════╧═════════╛特定のスタンプがついたメッセージが知りたい
リアクションのランキングが出来上がり1位が誰なのかがわかるようになりました。そうすると次に、実際にどの会話が一番リアクションを獲得できたのか知りたいと思います。Slackでは会話ごとにパーマリンクがあり、chat.getPermalink APIで取得できます。SDKからは、chat_getPermalink関数を呼び出すことで利用できます。必須パラメータは、チャンネルID(channel)と、会話のタイムスタンプ(message_ts)です。
parma_link = client.chat_getPermalink( channel="C1234567890", message_ts="1598353527.019300" )レスポンス結果は下記の通りです。一部、ダミーの値に書き換えています。
{ 'ok': True, 'permalink': 'https://example.slack.com/archives/C1234567890/p1598353527019300?thread_ts=1598002394.002300&cid=C1234567890', 'channel': 'C1234567890' }プログラムはまだ書いていません・・・
参考プログラムについて
- Dockerファイルがなかったりちょっと不便
- 1回のAPI最大1000件のメッセージしか取得できません。年間を通すと1000件超えるので、has_moreを駆使して取得できます。
- トランザクションいれてません。いれます。
- APIのRateLimitは考慮していません。いれます。
- Python3の型に対応していません。今時のPythonはこう書く2020を見てアップデートします。
近いうちに更新したいと思います。
最後に
いかがだったでしょうか? 忘年会イベントまであともう少し。1年間どれだけSlackで絵文字スタンプで
コミュニケーションしたのか見てみて、皆さんで祝うと、良い年越しを迎えると思います。
実際に絵文字スタンプを集めてどんな余興になったのかコメント欄にご報告いただけると幸いです。
では、よい落としを〜。

- 投稿日:2020-12-06T20:47:26+09:00
Python関連の記事まとめ
Python関連の過去記事をまとめます
Django関連
Django Rest API + JWT
Reactアプリから Django Rest API を叩いてみる
Django の Class-Based Views と Function-Based Views
Django Model FormSet について
Django mediaファイルとAWS S3
Django staticファイルとAWS S3
DjangoのページをReactで作る - Webpack4その他
D3.jsで気温グラフを描く - Flask + PostgreSQL
Python でいろいろスクレイピング
【AWS】Pythonの開発環境Chaliceを使ってみる - アマゾン売れ筋ランキング
FlaskでReactアプリを走らせる
【AWS】Pythonの開発環境Chaliceを使ってみる - CloudWatch Events
【AWS】Pythonの開発環境Chaliceを使ってみる - API Key
【AWS】Python Lambdaのdeploy - Chalice
【AWS】Python Lambdaのdeploy - CloudFormation確率・統計・機械学習・ディープラーニング
【機械学習】誤差逆伝播法のコンパクトな説明
【機械学習 誤差逆伝播法】word2vecメモ (1)
【機械学習 誤差逆伝播法】word2vecメモ (2)Juliaをはじめてみる
JuliaのPlotsでフォントが小さすぎる
Julia のPlotsでエラー:could not load library "libGR.so"統計学入門のお供 Julia (1) - 標準得点、偏差値得点 - Qiita
統計学入門のお供 Julia (2) - ピアソンの積率相関係数 - Qiita
統計学入門のお供 Julia (3) - 順位相関係数と自己相関係数 - Qiita
統計学入門のお供 Julia (4) - 最小二乗法と決定係数 - Qiita
統計学入門のお供 Julia (5) - ベイズの定理 - Qiita
統計学入門のお供 Julia (6) - ド・メレの問題 = OiitaJuliaで学ぶ確率変数(1) - 確率変数の定義 - Qiita
Juliaで学ぶ確率変数(2) - 2項分布(離散型) - Qiita
Juliaで学ぶ確率変数(3) - 幾何分布(離散型) - Qiita
Juliaで学ぶ確率変数(4) - ポアソン分布(離散型) - Oiita
Juliaで学ぶ確率変数(5) - 正規分布(連続型) - Qiita
Juliaで学ぶ確率変数(6) - 一様分布(連続型) - Qiita
Juliaで学ぶ確率変数(7) - 指数分布(連続型) - Qiita
Juliaで学ぶ確率変数(8) - ガンマ分布(連続型) - Qiita
Juliaで学ぶ確率変数(9) - ベータ分布(連続型) - Qiita
Juliaで学ぶ確率変数(10) - コーシー分布(連続型) - Qiita
Juliaで学ぶ確率変数(11) - まとめ - Qiita【2変数の確率変数1】独立性 - Qiita
【2変数の確率変数2】平均と分散Pythonで「中心極限定理」を確かめてみる - Qiita
母平均の区間推定で「中心極限定理」を使う - Qiita
Pythonで「カイ2乗分布の定理」を確かめてみる - Qiita/////
- 投稿日:2020-12-06T20:14:09+09:00
pytest で単体テストの方法まとめ
概要
Python には pytest という単体テストを書く機能があり、便利なのですが、他の言語と若干仕様が異なるので、よく使う機能を備忘録としてまとめておきます。
テストの書き方・実行方法
CreateXxxというクラスがprint_aaaというメソッドを持っている場合のテストケース。tests/test_create_xxx.pyimport pytest from xxx import CreateXxx, XxxError class CreateXxxTest: # 通常の評価 def test__can_print_aaa(self): xxx = CreateXxx() assert xxx.print_aaa(111) == 'aaa' # エラーがでることを評価 def test__can_raise_error(self): xxx = CreateXxx() with pytest.raises(XxxError): xxx.print_aaa(222)このようなファイルを用意し、
sh実行$ pytest tests/test_create_xxx.pyと実行することで実行。
いわゆる setup 的なもの
tests/test_create_xxx.py@pytest.fixture def init_xxx(self): self.xxx = CreateXxx() def test__can_print_aaa(self, init_xxx): assert self.xxx.print_aaa() == 'aaa'
- fixture という機能を使って setup を実現します。
- 引数に fixture として定義したメソッド名を書くことでテスト開始直前に実行されることになります。
いわゆる teardown 的なもの
tests/test_create_xxx.py@pytest.fixture def init_xxx(self): self.xxx = CreateXxx() yield # ここから teardown self.xxx.close() def test__can_print_aaa(self, init_xxx): assert self.xxx.print_aaa() == 'aaa'
- fixture の中で
yieldを呼ぶと、その段階でいったん実行が中断され、テストメソッド本体が実行され、その後、yield以降の処理が実行されることになります。つまり teardown 相当の処理となります。- 変数をローカルに閉じ込められるので可読性を高められます。
- なお、
yieldは1回しか使えません。複数書くと怒られます。戻り値を返す、いわゆる fixture
tests/test_create_xxx.py@pytest.fixture def xxx(self): return CreateXxx() def test__can_print_aaa(self, xxx): assert xxx.print_aaa() == 'aaa'戻り値を複数返す fixture
tests/test_create_xxx.py@pytest.fixture def init_xxx(self): return CreateXxx(), 'aaa' def test__can_print_aaa(self, init_xxx): xxx, expected = init_xxx assert xxx.print_aaa() == expectedデータジェネレート
同じテストケースを引数違いで何度も実行したい場合
@pytest.mark.parametrize を使う方法 (テストケースごとに定義)
シンプル。fixture ではないので、共有はできないし、複雑な処理もできないが、とにかくシンプルにかける。
tests/test_create_xxx.py@pytest.mark.parametrize('val, expected', [ ('aa', 'bb'), ('xx', 'yy'), ]) def test__can_print_aaa(self, val, expected): assert xxx.print_aaa(val) == expectedfixture を使う方法 (複数のテストケースで共有可能)
tests/test_create_xxx.py@pytest.fixture(params=[ ('aa', 'bb'), ('xx', 'yy'), ]) def case__printable(self, request) -> Tuple[str, str]: return request.param def test__can_print_aaa(self, case__printable): val, expected = case__printable assert xxx.print_aaa(val) == expectedファイルをまたいで共通化したい場合: conftest.py
conftest.pyに書いたものはファイル間で共有される。tests/conftest.py@pytest.fixture def xxx(): return CreateXxx()tests/test_create_xxx.pydef test__can_print_aaa(self, xxx): assert xxx.print_aaa() == expectedfixture の実行タイミングを明示する
デフォルトは(引数で fixture 名を指定している)テストケースメソッドの開始直前。
これを変更できる。下記のように明示する。@pytest.fixture(scope='class')
スコープ名 実行されるタイミング function テストケースごとに1回実行(デフォルト) class テストクラス全体で1回実行 module テストファイル全体で1回実行 session テスト全体で1回だけ実行 モック
たとえば、下記のような場合にモックしたくなる。
- AWSなど外部と繋ぐ部分(単体Testでは繋げたくない)
- 現在時、ランダム値を使う部分(毎回変わるのでテストしづらい)
- 外部の責務(=別の単体テストですでにテストしている)部分(テストのメンテで別の責務に引きずられたくない)
import される関数の中身を一時的に差し替える
- テストケース終了時に元に戻る。
mocker.patch.object で何もしないようにする
tests/test_create_xxx.pyimport hoge class TestCreateXxx: def test__can_print_aaa(self, mocker, xxx): mocker.patch.object(hoge, 'fuga') # hoge の fuga という関数を何もしないモックに差し替える assert xxx.print_aaa() == 'aaa'mocker.patch.object で戻り値を定義する
tests/test_create_xxx.pyimport hoge class TestCreateXxx: def test__can_print_aaa(self, mocker, xxx): mocker.patch.object(hoge, 'get_fuga', return_value='fuga') assert xxx.print_aaa() == 'aaa'mocker.patch.object で例外が発生するようにする
tests/test_create_xxx.pyimport hoge class TestCreateXxx: def test__can_print_aaa(self, mocker, xxx): mocker.patch.object(hoge, 'get_fuga', side_effect=hoge.PiyoError('test')) with pytest.raises(hoge.PiyoError): xxx.print_aaa()mocker.patch.object で関数に渡された引数をチェックする
tests/test_create_xxx.pyimport hoge class TestCreateXxx: def test__can_print_aaa(self, mocker, xxx): mocker.patch.object(hoge, 'get_fuga', return_value='fuga') xxx.print_aaa() assert hoge.get_fuga.call_args[0][0] = 1 # 初回呼び出しの第1引数が 1 assert hoge.get_fuga.call_args[0][1] = 'a' # 初回呼び出しの第2引数が 'a'環境変数を一時的に差し替える
- テストケース終了時に元に戻る。
monkeypatch.setenv で差し替える
tests/test_create_xxx.pyimport hoge class TestCreateXxx: def test__can_print_aaa(self, monkeypatch, xxx): monkeypatch.setenv('HOGE', '1234') assert xxx.print_aaa(111) == 'aaa'以上!
随時、更新していきます。
- 投稿日:2020-12-06T18:50:40+09:00
PythonでZoomミーティングをスケジュールする
はじめに
時世もありzoom会議のミーティングをスケジュールすることが多いのですが、けっこうzoomのミーティングの予約って面倒くさいなーと思います。ログインしてポチポチボタンを押して、ってそれだけなんですけど。トピック名を設定して、日付をカレンダーから選択して、時間も設定して、、と意外にやることが多いです。
調べたところ、pythonでapiキーを使って簡単にスケジュール作成ができるみたいなので、試してみました。apiキーとシークレットの取得
ZOOMのマーケットプレイスから取得します。
https://marketplace.zoom.us/user/build
Build Appを選択します。
JWTのCreateをクリックして作成に進めます。
作成が完了すると、API KeyとAPI Secretが取得できます。
pyzoomの使用
作成したAPI KeyとAPI Secretを使って実際にmeetingをスケジュールしてみます。
pyzoomというライブラリを使うと簡単に作成できるみたいです。https://pypi.org/project/pyzoom/
from pyzoom import ZoomClient from datetime import datetime as dt from datetime import timedelta as td from pprint import pprint api_key = 'your api key' secret = 'you api secret' client = ZoomClient(api_key, secret) # meetingを作成する meeting = client.meetings.create_meeting(topic='テストミーティング', start_time=dt(2020, 12, 9, 20, 30).isoformat(), timezone='Osaka, Sapporo, Tokyo', duration_min=10, password='1234') # 作成したmeetingの情報を取得 meeting_info = client.meetings.get_meeting(meeting.id) topic = meeting_info.topic zoom_start_time = meeting_info.start_time # UTC時刻、isoformatで取得されるので、datetimeに変換後に9時間足す zoom_start_time = dt.fromisoformat(zoom_start_time[:-1]) # 右端にZの文字があるので除去 zoom_start_time = zoom_start_time + td(hours=9) join_url = meeting_info.join_url password = meeting_info.password print('zoom meetingを作成しました') print('--------------') print('トピック : {}'.format(topic)) print('時間 : {}'.format(zoom_start_time)) print('Zoomミーティングに参加する') print(join_url) print('ミーティングID : {}'.format(meeting.id)) print('パスコード : {}'.format(password)) print('---------------')出力
-------------- トピック : テストミーティング 時間 : 2020-12-09 20:30:00 Zoomミーティングに参加する https://your/meeting/join/url ミーティングID : yourmeetingid パスコード : 1234 ---------------作成したミーティングの情報はclient.meetings.get_meeting(meeting.id)というメソッドで呼び出せるみたいです。
zoomにログインしてスケジュールされていることが確認できました。
予めスケジュールが決まっている会議を一気に予約する、予約すると同時に参加者にメールをする、等、工夫の余地はありそうです。



- 投稿日:2020-12-06T18:27:33+09:00
#全集中 スクレイピングの呼吸 + 今週の積み上げ python 学習記録#4,5,6,7
今週の積み上げ(笑)
更新さぼったけど学習続けております。学習記録自体はエクセルシートに記録してるのでこちらにわざわざ書き込む必要もないかも知れませんが
日に大体3~5時間学習しております。progate python とhtml cssの初級を学習し、その後paizaの入門レベルを本日終了しました。
ざっくりですが基本的な事は調べたらわかるくらいになったと思います。
で、これからどうすればいいのかなと思いましたがpython始めた一番の理由はスクレイピング、クローピングをしたかったのでudemyで購入した株式会社キカガクさんのpythonによるwebスクレイピング入門編を勉強開始しました。この2、3週間入門編の基礎ばかりだったのでつまらなかったけど今回はめっちゃ楽しいです。環境構築に手間取りましたがw
しばらくはスクレイピングに関する知識を集め、作りたいツールが2,3個あるのでそれができるようになるまでは 全集中 スクレイピングの呼吸 じゃなくて 全集中常駐でいこうと思います。
- 投稿日:2020-12-06T18:07:48+09:00
google-cloud-rubyがなぜかPythonを呼び出している件について
BigQueryの運用を行っていると定期的に無駄なテーブルを削除することは良くあると思います。
テーブル数が少ない場合はwebからぽちぽちと削除するので対応可能ですが、テーブル数が多い場合はスクリプトを作って削除したほうが楽です。最初は以下のようなスクリプトを書いていたのですが、削除対象のテーブル数が膨大なため、なかなか終わりませんでした。
※ロギング部分は省略require 'google/cloud/bigquery' table_names = [削除したいテーブル名の配列] project_name = プロジェクト名 dataset_name = データセット名 table_names.each do |table_name| bq_client = ::Google::Cloud::Bigquery.new(project: project_name) dataset = bq_client.dataset(dataset_name) table = dataset.table(table_name) table.delete endテーブルの削除処理はクライアントサイドのCPU・メモリーをほぼ使わず、ほとんどの待ち時間がBigQuery側での処理待をポーリングしているだけであるため、parallelというgemを使って並列化しました。
https://github.com/grosser/parallelRubyのマルチスレッド処理の実装はGVLによって同時に実行されるスレッドが1つだけになってしまっていますが、IO系のブロッキング処理に対してはGVLの解放をするので、今回のケースでは高速化が見込まれます。
require 'google/cloud/bigquery' require 'parallel' table_names = [削除したいテーブル名の配列] project_name = プロジェクト名 dataset_name = データセット名 ::Parallel.each(table_names, in_threads: 30).each do |table_name| bq_client = ::Google::Cloud::Bigquery.new(project: project_name) dataset = bq_client.dataset(dataset_name) table = dataset.table(table_name) table.delete endこれで、爆速になると思いプログラムを実行したところ、一瞬でCPU使用率が100%に張り付きました。
あまりにもこのプログラムがCPUを使うせいで、discordで通話中の相手から「やたらエコーかかっているんですが、風呂場で仕事してます?」と言われてしまいました。
discordはクライアントサイドで音声のノイズ除去などの信号処理をしているらしいというムダ知識が1つ増えました。さて、あまりにもCPUを使いすぎるので、ちょっと気になってdtraceでシステムコール呼び出しの様子を調べてみたら、大量のforkが呼ばれていました。
どんなサブプロセスを生成しているのかを確認するために、topコマンドを実行したところ、なぜかRubyが大量のPythonを呼び出していることが分かりました。
CPUが100%になる原因はこれです。では、google-cloud-rubyのどこコードがPythonを呼び出しているのでしょうか?
ソースコードを確認していたら見つかりました。gcloud_json = IO.popen("#{gcloud} #{GCLOUD_CONFIG_COMMAND}", &:read)このpopenメソッドの第一引数は部分は最終的に
gcloud config config-helper --format json --verbosity noneになります。
gcloudコマンドはPythonで実装されているため、このpopenによってPythonが呼び出されていました。この処理はGCPクライアントインスタンスの初期化をする際に呼ばれる処理で、システムデフォルトの認証情報を取得するものです。
::Google::Cloud::Bigquery.newをループの中で毎回呼び出す必要はなかったので、ループの外に出して1回だけ呼ばれるようにしました。require 'google/cloud/bigquery' require 'parallel' table_names = [削除したいテーブル名の配列] project_name = プロジェクト名 dataset_name = データセット名 bq_client = ::Google::Cloud::Bigquery.new(project: project_name) ::Parallel.each(table_names, in_threads: 30).each do |table_name| dataset = bq_client.dataset(dataset_name) table = dataset.table(table_name) table.delete endこれにより、CPUが100%に張り付くことはなくなり、またテーブルの削除速度も大幅に向上しました。
- 投稿日:2020-12-06T16:47:57+09:00
Discordで問題を出してくれるBOTをPythonで作る。
きっかけ
友達とのサーバーでお勉強がしたい!
BOTの登録
https://qiita.com/1ntegrale9/items/9d570ef8175cf178468f
こちらの記事でわかりやすく解説してくださっています。やりたいこと
問題を登録して、ランダムに出してくれるBOTをつくりたい!
欲しい機能
・問題登録
・問題を出す
・問題一覧
・問題削除
・問題初期化プログラム
import discord import random client = discord.Client() token = "xxxxxxxxxxxxxx..." @client.event async def on_ready(): print('Logged in as') print(client.user.name) print(client.user.id) print('------') q = [] @client.event async def on_message(message): global q if message.author.bot: return elif message.content.startswith('qadd'): q.append(message.content[5:]) await message.add_reaction('?') elif message.content == 'qrand': if(len(q) == 0): await message.channel.send('問題がありません。') else: await message.channel.send(random.choice(q)) elif message.content == 'qclear': q = [] await message.channel.send('初期化しました。') elif message.content == 'qqueue': await message.channel.send(q) elif message.content.startswith('qrem'): num = int(message.content[5:]) q.pop(num - 1) await message.add_reaction('?') client.run(token)
- 投稿日:2020-12-06T16:41:11+09:00
[Python] BFS(幅優先探索) ABC168D
ABC168D
連結グラフなので、BFSの原理から最小性が保障されることに注意する。
参考
BFS (幅優先探索) 超入門! 〜 キューを鮮やかに使いこなす 〜サンプルコードfrom collections import deque # 頂点数と辺数 N, M = map(int, input().split()) # 辺 AB = [map(int, input().split()) for _ in range(M)] # 無向グラフの隣接リスト設定 link = [[] for _ in range(N + 1)] for a, b in AB: # aとbをそれぞれ紐付け link[a].append(b) link[b].append(a) # BFSのデータフレーム dist = [-1] * (N + 1) # 看板未設定 que = deque([1]) # 頂点1を始点とした訪問キュー # BFS 開始 (キューが空になるまで探索を行う) while que: v = que.popleft() # キューから先頭頂点(現在地)v取得 for i in link[v]: - # 未設定頂点iに現在地への看板を設定し訪問キューに追加する + # 未設定頂点iに現在地への看板を設定し、iを訪問キューに追加する if dist[i] == -1: dist[i] = v que.append(i) # 結果出力(各頂点に設置する看板) print('Yes') print('\n'.join(str(v) for v in dist[2:]))
- 投稿日:2020-12-06T16:36:31+09:00
if文付きの内包表記のやり方【Python】
この記事では、
if文付きの内包表記のやり方
を紹介します。内包表記とは
内包表記とは、リストや辞書などののループ処理をシンプルに記述できる記法です。
[式 for 任意の変数名 in イテラブルオブジェクト]
の式で表されます。
内包表記の書き方【Python】 - Qiita
上の記事で主なやり方を載せてますので、内包表記自体が全くわからない方はこちらの記事からご覧ください。やり方
まずは、サンプルデータを用意します。
ランダムで10個の1~100の数をリストに取得します。from random import s = [randint(1, 100) for _ in range(10)]もし上記コードの意味がわからなかったら下の記事から内包表記の基本的なやり方を学習してください。
内包表記の書き方【Python】 - Qiitaif付きの内包表記
その数を、2で割って余りが0ではないもの。
つまり奇数のみを取得します。s_odd = [data for data in s if data % 2 != 0]if文はforの後に書きます。
if else:を用いた場合の内包表記
その数が50以上だったら2倍、50未満の場合は10倍というコードを書いていきます。
s_50 = [data * 2 if data >= 50 else data * 10 for data in s]elseがつくと、forの前にif文が来るので気をつけましょう。
if elif elseを用いた場合の内包表記
有名なFizzBuzzをやってみましょう。
FizzBuzzの条件は、1~50までの数字で、
- 3で割り切れれば、「Fizz!」を表示する
- 5で割り切れれば、「Buzz!」を表示する
- 3と5で割り切れれば、「Fizz Buzz!」を表示する
- 上記以外の場合は、そのままの数字を表示する
fizz_buzz = ['FizzBuzz!' if i % 15 == 0 else 'Fizz!' if i % 3 == 0 else 'Buzz!' if i % 5 == 0 else i for i in range(1, 50)]実行結果
[1, 2, 'Fizz', 4, 'Buzz', 'Fizz', 7, 8, 'Fizz', 'Buzz', 11, 'Fizz', 13, 14, 'FizzBuzz', 16, 17, 'Fizz', 19, 'Buzz', 'Fizz', 22, 23, 'Fizz', 'Buzz', 26, 'Fizz', 28, 29, 'FizzBuzz', 31, 32, 'Fizz', 34, 'Buzz', 'Fizz', 37, 38, 'Fizz', 'Buzz', 41, 'Fizz', 43, 44, 'FizzBuzz', 46, 47, 'Fizz', 49]長いですが、これでできているのがわかると思います。
- リストに入れたいもの
- if 条件
- else if 条件
の繰り返しです。
最後は今まで通りのfor文を書いて終わりです。まとめ
今回は、
if文付きの内包表記のやり方
について書きました。elifだと複雑で自分自身もあまりわかっていない部分が多いですが、
是非参考にしていただけると幸いです。ありがとうございました。
参考
内包表記の書き方【Python】 - Qiita
vol.029 脱初学者!知ってると超便利なPythonの内包表記とは? | 中学生でもわかるPython入門シリーズ - いまにゅのプログラミング塾 -注意
この記事は、プログラミング初学者が書いており、内容に誤りがある場合がございます。
あしからずご了承願います。
また、誤りにお気づきの場合にはご指摘いただけると幸いです。
よろしくお願いいたします。
- 投稿日:2020-12-06T16:35:14+09:00
GIFの作成
コード
durationの単位はmsで、このコード内だと1秒の間隔でアニメションが実行されます。loopはアニメーションが何回再生させるかを指定します。loopに「0」を指定すると無限再生となります。
gifcreate.pyfrom PIL import Image #open first image img1 = Image.open("kick1.png") #open second image img2 = Image.open("kick2.png") #open third image img3 = Image.open("kick3.png") #generate gif img1.save("kick.gif",format="GIF",append_images=[img2,img3],save_all=True,duration=1000,loop=0)使用した画像
kick1.png
kick2.png
kick3.png
実行結果
上記のコードを実行するとこのようなGIFを作れます。
durationを100msにしたら下記のようにアニメーションが早くなります。



- 投稿日:2020-12-06T16:17:36+09:00
TensorFlow 2.4.0-rc4のビルド手順(Windows10, CUDA11.1.1, cuDNN 8.0.5, Python 3.8.6)
2020/12/06時点でのTensorFlow 2.4.0-rc4のビルド方法の概要を残しておきます。
今回の組み合わせでは、PythonとNumpyのバージョンに気をつければ正常にビルドできました。
Pythonは3.9.0を利用すると依存パッケージの組み合わせ起因(だと思われる)のため、作成したwheelパッケージのインストールで失敗します。
Numpyは最新の1.19.4だと、Windows環境でimportするだけでエラーになるので、1つ前の1.19.3を使用します。(これはWindows側の問題で、2021年1月くらいに修正される予定らしいです)環境情報
ビルドに利用した環境です。CUDAやcuDNNのフォルダなど、事前にパスを通した状態になっています。
- Windows 10 Pro 20H2 (64bit)
- Visual Studio Community 2019 Ver 16.8.2
- Python 3.8.6(3.9.0を使うとwheelパッケージインストール時にエラーになります)
- MSYS2(
pacman -S git patch unzipで必要なパッケージを導入済み)- Bazel 3.7.1 (3.1.0以上のバージョンを使う必要あり)
- CUDA 11.1.1
- cuDNN 8.0.5.39
ビルド用のフォルダ構成など
今回は
S:\build\build_tf240rc4フォルダ配下にTensorFlowのソースコードをダウンロードしてビルドしています。Pythonの仮想環境も、TensorFlowビルド用に用意します。S:/build/build_tf240rc4 # 作業フォルダRoot + tensorflow # gitで取得してくるソースコード + venv # Python仮想環境 + wheelhouse # 作成したwhlファイルを格納するフォルダビルド手順
x64 Native Tools Command Prompt for VS 2019を起動して以下の手順でビルドを行います。# 仮想環境を作成して有効化する python -m venv s:\build\build_tf240rc4\venv cd /d s:\build\build_tf240rc4 .\venv\Scripts\activate.bat # 必要なパッケージのインストール # 注意:Numpyは最新の1.19.4を使うとエラーになるので1.19.3を使用(利用時もNumpy 1.19.3を使用すること) python -m pip install --upgrade pip setuptools pip install numpy==1.19.3 pip install six wheel pip install keras_applications==1.0.8 --no-deps pip install keras_preprocessing==1.1.2 --no-deps # ソースコード取得(v2.4.0-rc4のタグ指定) git clone -b v2.4.0-rc4 https://github.com/tensorflow/tensorflow.git cd tensorflow # 環境によってはコマンドのパラメーターが長くなりすぎてエラーになるので不要な環境変数を削除 set _OLD_VIRTUAL_PATH= # ビルド構成の設定 # CUDA support: Y # CUDA compute capabilities: 7.5 (利用環境に合わせて変更) # Optimization: /arch:AVX2 (利用環境に合わせて変更) # それ以外はデフォルト設定(Enter) python ./configure.py # ビルド # TensorFlow 2.3.x+CUDA11の場合は「DTHRUST_IGNORE_CUB_VERSION_CHECK」のおまじない(CUB互換チェックのスキップ)が必要だったが2.4.xは不要 bazel build --config=opt --config=avx2_win --config=short_logs --config=cuda --define=no_tensorflow_py_deps=true --copt=-nvcc_options=disable-warnings //tensorflow/tools/pip_package:build_pip_package # パッケージの作成(wheelhouseフォルダにパッケージを作成) # 数分間画面が更新されないので心配になりますが、きちんと処理されているのでしばらく待ちましょう bazel-bin\tensorflow\tools\pip_package\build_pip_package ..\wheelhouseこれで完了です。
なおビルドに使用したbazelの中間ファイル等は%UserProfile%\_bazel_%UserName%フォルダに作成され、容量も20GB近くになるので、不要であれば削除しても問題ありません。Bazelが起動していると削除できないので、その場合はコマンドプロンプトでbazel shutdownとして、Bazelを終了してから削除してください。作成したTensorFlowのwheelパッケージを利用する際は、
pip install numpy==1.19.3という感じでTensorFlowよりも先にNumpyをバージョン指定で導入しておくことをおすすめします。最新のNumpy 1.19.4は現時点では利用できません。
- 投稿日:2020-12-06T16:12:34+09:00
OpenCVでのデモの見栄えを工夫したまとめ(ディープラーニング系)
- この記事はOpenCV Advent Calendar 2020の12日目の記事です。
- 他の記事は目次にまとめられています。
対象者
以下みたいな作業依頼を受けることのある人。
つまり、デザインに予算はつかないけど、ある程度の工夫を求められるやつ。。。上長「部内とかで見せるちょっとしたデモをパパッと作って欲しい」
高橋「デザインは○○さんか、△△社さんにお願いします?」
※○○さん:デザイン会社から派遣で来ているデザイナーさん
※△△社:デザイン会社
上長「今回、デザインに出すお金は無い」
高橋「What?」
高橋「それじゃ、見た目は気にしな」
上長「偉い人も見る可能性あるからソレっぽくしといてもらわないと困る」
高橋「短い間ですが、お世話になりました」Flaskとか立てて、UI作る人とデザイナーと役割分担出来るようなプロジェクトは対象外
はじめに
OpenCVとかPillowで出来る範囲の工夫をします。
実際に業務で使ったものではなく、
雰囲気とか工夫を再現したものですが、以下に8つほど例を記載しています。
何かの参考になれば幸い今回まとめたソースコードは以下リポジトリにあります。
例01.画像分類(Classification)
ソースコード:
01_classification_demo.py (折り畳み内に描画処理を抜粋したものを記載)
def draw_demo_image( image, detection_count, classification_string, display_fps, trim_point, ): image_width, image_height = image.shape[1], image.shape[0] # フォント font_path = './utils/font/KosugiMaru-Regular.ttf' # 四隅枠表示 if detection_count < 4: gap_length = int((trim_point[2] - trim_point[0]) / 10) * 9 cv.line(image, (trim_point[0], trim_point[1]), (trim_point[2] - gap_length, trim_point[1]), (255, 255, 255), 3) cv.line(image, (trim_point[0] + gap_length, trim_point[1]), (trim_point[2], trim_point[1]), (255, 255, 255), 3) cv.line(image, (trim_point[2], trim_point[1]), (trim_point[2], trim_point[3] - gap_length), (255, 255, 255), 3) cv.line(image, (trim_point[2], trim_point[1] + gap_length), (trim_point[2], trim_point[3]), (255, 255, 255), 3) cv.line(image, (trim_point[0], trim_point[3]), (trim_point[2] - gap_length, trim_point[3]), (255, 255, 255), 3) cv.line(image, (trim_point[0] + gap_length, trim_point[3]), (trim_point[2], trim_point[3]), (255, 255, 255), 3) cv.line(image, (trim_point[0], trim_point[1]), (trim_point[0], trim_point[3] - gap_length), (255, 255, 255), 3) cv.line(image, (trim_point[0], trim_point[1] + gap_length), (trim_point[0], trim_point[3]), (255, 255, 255), 3) line_x1 = int(image_width / 1.55) line_x2 = int(image_width / 1.1) line_y = int(image_height / 5) # 回転丸表示 if detection_count > 0: draw_angle = int(detection_count * 45) cv.ellipse(image, (int(image_width / 2), int(image_height / 2)), (10, 10), -45, 0, draw_angle, (255, 255, 255), -1) # 斜線表示 if detection_count > 10: cv.line(image, (int(image_width / 2), int(image_height / 2)), (line_x1, line_y), (255, 255, 255), 2) # 横線・分類名・スコア表示 if detection_count > 10: font_size = 32 cv.line(image, (line_x1, line_y), (line_x2, line_y), (255, 255, 255), 2) image = CvDrawText.puttext( image, classification_string, (line_x1 + 10, line_y - int(font_size * 1.25)), font_path, font_size, (255, 255, 255)) # FPS描画 ####################################################### fps_string = u"FPS:" + str(display_fps) image = CvDrawText.puttext(image, fps_string, (30, 30), font_path, 32, (255, 255, 255)) return image
工夫点:
・ImageNetのラベルを英語のまま表示しない
・柔らか目の日本語フォント(小杉丸フォント)を使用
→日本語フォント表示にはPillowを利用
→表示用のクラスは「Kazuhito00/cvdrawtext」で公開したものを利用
・何か解析している風な動きを付ける(実際には即時推論結果が出ていますが、、、例02.画像分類(Classification)
ソースコード:
02_classification_demo.py (折り畳み内に描画処理を抜粋したものを記載)
def draw_demo_image( image, classifications, display_fps, ): image_width, image_height = image.shape[1], image.shape[0] cvuiframe = np.zeros((image_height + 6, image_width + 6 + 200, 3), np.uint8) cvuiframe[:] = (49, 52, 49) # 画像:撮影映像 display_frame = copy.deepcopy(image) cvui.image(cvuiframe, 3, 3, display_frame) # 文字列:FPS cvui.printf(cvuiframe, image_width + 15, 15, 0.4, 0xFFFFFF, 'FPS : ' + str(display_fps)) # 文字列、バー:クラス分類結果 if classifications is not None: for i, classification in enumerate(classifications): cvui.printf(cvuiframe, image_width + 15, int(image_height / 4) + (i * 40), 0.4, 0xFFFFFF, classification[1]) cvui.rect(cvuiframe, image_width + 15, int(image_height / 4) + 15 + (i * 40), int(181 * float(classification[2])), 12, 0xFFFFFF, 0xFFFFFF) return cvuiframe
工夫点:
・推論結果のスコアをバー表示で表示
・実装を簡易にするために「cvui」を利用例03.顔検出(Face Detection)
ソースコード:
03_face_detection_demo.py (折り畳み内に描画処理を抜粋したものを記載)
# 顔検出 ############################################################## dets, lms = centerface(resize_frame, frame_height, frame_width, threshold=0.35) # デバッグ表示 ######################################################## # バウンディングボックス for det in dets: bbox, _ = det[:4], det[4] # BBox, Score x1, y1 = int(bbox[0]), int(bbox[1]) x2, y2 = int(bbox[2]), int(bbox[3]) # 顔の立幅に合わせて重畳画像をリサイズ image_height, image_width = images[0].shape[:2] resize_ratio = (y2 - y1) / image_height resize_image_height = int(image_height * resize_ratio) resize_image_width = int(image_width * resize_ratio) resize_image_height = int( (resize_image_height + (ceil_num - 1)) / ceil_num * ceil_num) resize_image_width = int( (resize_image_width + (ceil_num - 1)) / ceil_num * ceil_num) resize_image_height = int(resize_image_height * image_ratio) resize_image_width = int(resize_image_width * image_ratio) resize_image = cv.resize(images[animation_counter], (resize_image_width, resize_image_height)) # 画像描画 overlay_x = int((x2 + x1) / 2) - int(resize_image_width / 2) overlay_y = int((y2 + y1) / 2) - int(resize_image_height / 2) resize_frame = CvOverlayImage.overlay( resize_frame, resize_image, (overlay_x + x_offset, overlay_y + y_offset)) animation_counter += 1 if animation_counter >= len(images): animation_counter = 0
工夫点:
・笑い男オマージュ
・透過Pngを用いて四角くない画像でオーバーレイ表示
→表示用のクラスは「Kazuhito00/cvoverlayimg」で公開したものを利用
・オーバーレイする画像をアニメーションさせる
・FPS表示に軽くSF感を出すためにスキャンラインフォントを利用
その他:
・「Kazuhito00/FaceDetection-Image-Overlay」でも公開中例04.物体検出:手検出(Hand Detection)
ソースコード:
04_hand_detection_demo.py (折り畳み内に描画処理を抜粋したものを記載)
以下は一例です。その他実装は「Kazuhito00/object-detection-bbox-art」を参照ください。def bba_rotate_dotted_ring3( image, p1, p2, color=(255, 255, 205), thickness=None, # unused font=None, # unused text=None, # unused fps=10, animation_count=0, ): draw_image = copy.deepcopy(image) animation_count = int(135 / fps) * animation_count x1, y1 = p1[0], p1[1] x2, y2 = p2[0], p2[1] radius = int((y2 - y1) * (5 / 10)) ring_thickness = int(radius / 20) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 0 + animation_count, 0, 50, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 80 + animation_count, 0, 50, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 150 + animation_count, 0, 30, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 200 + animation_count, 0, 10, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 230 + animation_count, 0, 10, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 260 + animation_count, 0, 60, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 337 + animation_count, 0, 5, color, ring_thickness) radius = int((y2 - y1) * (4.5 / 10)) ring_thickness = int(radius / 10) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 0 - animation_count, 0, 50, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 80 - animation_count, 0, 50, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 150 - animation_count, 0, 30, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 200 - animation_count, 0, 30, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 260 - animation_count, 0, 60, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 337 - animation_count, 0, 5, color, ring_thickness) radius = int((y2 - y1) * (4 / 10)) ring_thickness = int(radius / 15) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 30 + int(animation_count / 3 * 2), 0, 50, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 110 + int(animation_count / 3 * 2), 0, 50, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 180 + int(animation_count / 3 * 2), 0, 30, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 230 + int(animation_count / 3 * 2), 0, 10, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 260 + int(animation_count / 3 * 2), 0, 10, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 290 + int(animation_count / 3 * 2), 0, 60, color, ring_thickness) cv.ellipse(draw_image, (int((x1 + x2) / 2), int( (y1 + y2) / 2)), (radius, radius), 367 + int(animation_count / 3 * 2), 0, 5, color, ring_thickness) return draw_image
工夫点:
・色々雑多に試してみる(ぐるぐる回るやつの評判が良かった)
・G:255やB:255などの原色は意識して利用しない
その他:
・「Kazuhito00/object-detection-bbox-art」でも公開中(学習済モデル込み)
→順次追加予定例05.物体検出:フィンガーフレーム検出(FingerFrame Detection)
ソースコード:
05_finger_frame_detection_demo.py (折り畳み内に描画処理を抜粋したものを記載)
# 検出実施 ############################################################# frame = frame[:, :, [2, 1, 0]] # BGR2RGB image_np_expanded = np.expand_dims(frame, axis=0) output = run_inference_single_image(image_np_expanded, inference_func) num_detections = output['num_detections'] for i in range(num_detections): score = output['detection_scores'][i] bbox = output['detection_boxes'][i] # class_id = output['detection_classes'][i].astype(np.int) if score < score_th: continue # 検出結果可視化 ################################################### x1, y1 = int(bbox[1] * frame_width), int(bbox[0] * frame_height) x2, y2 = int(bbox[3] * frame_width), int(bbox[2] * frame_height) risize_ratio = 0.15 bbox_width = x2 - x1 bbox_height = y2 - y1 x1 = x1 + int(bbox_width * risize_ratio) y1 = y1 + int(bbox_height * risize_ratio) x2 = x2 - int(bbox_width * risize_ratio) y2 = y2 - int(bbox_height * risize_ratio) x1 = int((x1 - 5) / 10) * 10 y1 = int((y1 - 5) / 10) * 10 x2 = int((x2 + 5) / 10) * 10 y2 = int((y2 + 5) / 10) * 10 deque_x1.append(x1) deque_y1.append(y1) deque_x2.append(x2) deque_y2.append(y2) x1 = int(sum(deque_x1) / len(deque_x1)) y1 = int(sum(deque_y1) / len(deque_y1)) x2 = int(sum(deque_x2) / len(deque_x2)) y2 = int(sum(deque_y2) / len(deque_y2)) ret, video_frame = video.read() if ret is not False: video.grab() video.grab() debug_add_image = np.zeros((frame_height, frame_width, 3), np.uint8) map_resize_image = cv.resize(video_frame, ((x2 - x1), (y2 - y1))) debug_add_image = CvOverlayImage.overlay( debug_add_image, map_resize_image, (x1, y1)) debug_add_image = cv.cvtColor(debug_add_image, cv.COLOR_BGRA2BGR) # cv.imshow('1', debug_add_image) debug_image = cv.addWeighted(debug_image, 1.0, debug_add_image, 2.0, 0) else: video = cv.VideoCapture('map.mp4')
工夫点:
・検出座標の移動平均を取り、ヌルヌル拡大縮小するよう描画
その他:
・「Kazuhito00/FingerFrameDetection-TF2」でも公開中(学習用データ、学習済モデル込み)例06.物体検出:NARUTO 印検出(NARUTO’s Hand Signe Detection)
ソースコード:
06_naruto_hand_sign_demo.py (折り畳み内に描画処理を抜粋したものを記載)
def draw_debug_image( debug_image, font_path, fps_result, labels, result_inference, score_th, erase_bbox, use_display_score, jutsu, sign_display_queue, sign_max_display, jutsu_display_time, jutsu_font_size_ratio, lang_offset, jutsu_index, jutsu_start_time, ): frame_width, frame_height = debug_image.shape[1], debug_image.shape[0] # 印のバウンディングボックスの重畳表示(表示オプション有効時) ################### if not erase_bbox: num_detections = result_inference['num_detections'] for i in range(num_detections): score = result_inference['detection_scores'][i] bbox = result_inference['detection_boxes'][i] class_id = result_inference['detection_classes'][i].astype(np.int) # 検出閾値未満のバウンディングボックスは捨てる if score < score_th: continue x1, y1 = int(bbox[1] * frame_width), int(bbox[0] * frame_height) x2, y2 = int(bbox[3] * frame_width), int(bbox[2] * frame_height) # バウンディングボックス(長い辺にあわせて正方形を表示) x_len = x2 - x1 y_len = y2 - y1 square_len = x_len if x_len >= y_len else y_len square_x1 = int(((x1 + x2) / 2) - (square_len / 2)) square_y1 = int(((y1 + y2) / 2) - (square_len / 2)) square_x2 = square_x1 + square_len square_y2 = square_y1 + square_len cv.rectangle(debug_image, (square_x1, square_y1), (square_x2, square_y2), (255, 255, 255), 4) cv.rectangle(debug_image, (square_x1, square_y1), (square_x2, square_y2), (0, 0, 0), 2) # 印の種類 font_size = int(square_len / 2) debug_image = CvDrawText.puttext( debug_image, labels[class_id][1], (square_x2 - font_size, square_y2 - font_size), font_path, font_size, (185, 0, 0)) # 検出スコア(表示オプション有効時) if use_display_score: font_size = int(square_len / 8) debug_image = CvDrawText.puttext( debug_image, '{:.3f}'.format(score), (square_x1 + int(font_size / 4), square_y1 + int(font_size / 4)), font_path, font_size, (185, 0, 0)) # ヘッダー作成:FPS ######################################################### header_image = np.zeros((int(frame_height / 18), frame_width, 3), np.uint8) header_image = CvDrawText.puttext(header_image, "FPS:" + str(fps_result), (5, 0), font_path, int(frame_height / 20), (255, 255, 255)) # フッター作成:印の履歴、および、術名表示 #################################### footer_image = np.zeros((int(frame_height / 10), frame_width, 3), np.uint8) # 印の履歴文字列生成 sign_display = '' if len(sign_display_queue) > 0: for sign_id in sign_display_queue: sign_display = sign_display + labels[sign_id][1] # 術名表示(指定時間描画) if lang_offset == 0: separate_string = '・' else: separate_string = ':' if (time.time() - jutsu_start_time) < jutsu_display_time: if jutsu[jutsu_index][0] == '': # 属性(火遁等)の定義が無い場合 jutsu_string = jutsu[jutsu_index][2 + lang_offset] else: # 属性(火遁等)の定義が有る場合 jutsu_string = jutsu[jutsu_index][0 + lang_offset] + \ separate_string + jutsu[jutsu_index][2 + lang_offset] footer_image = CvDrawText.puttext( footer_image, jutsu_string, (5, 0), font_path, int(frame_width / jutsu_font_size_ratio), (255, 255, 255)) # 印表示 else: footer_image = CvDrawText.puttext(footer_image, sign_display, (5, 0), font_path, int(frame_width / sign_max_display), (255, 255, 255)) # ヘッダーとフッターをデバッグ画像へ結合 ###################################### debug_image = cv.vconcat([header_image, debug_image]) debug_image = cv.vconcat([debug_image, footer_image]) return debug_image
工夫点:
・01~05の複合
その他:
・「Kazuhito00/NARUTO-HandSignDetection」でも公開中(学習済モデル込み)例07.画像セグメンテーション(Semantic Segmentation)
ソースコード:
07_semantic_segmentation_demo.py (折り畳み内に描画処理を抜粋したものを記載)
def create_pascal_label_colormap(): colormap = np.zeros((256, 3), dtype=int) ind = np.arange(256, dtype=int) for shift in reversed(range(8)): for channel in range(3): colormap[:, channel] |= ((ind >> channel) & 1) << shift ind >>= 3 colormap[15] = [0, 0, 0] return colormap def create_pascal_label_personmask(): colormap = np.zeros((256, 3), dtype=int) colormap[15] = [255, 255, 255] return colormap def label_to_color_image(label): colormap = create_pascal_label_colormap() return colormap[label] def label_to_person_mask(label): colormap = create_pascal_label_personmask() return colormap[label] def draw_demo_image( image, segmentation_map, display_fps, inf_size=(480, 320), ): # フォント font_path = './utils/font/x12y20pxScanLine.ttf' # ピクセル塗りつぶし image_width, image_height = image.shape[1], image.shape[0] draw_image = copy.deepcopy(image) draw_image = cv.resize(draw_image, inf_size) seg_image = label_to_color_image(segmentation_map).astype(np.uint8) seg_mask = label_to_person_mask(segmentation_map).astype(np.uint8) draw_image = np.where(seg_mask == 255, seg_image, draw_image) draw_image = cv.resize(draw_image, (image_width, image_height)) # FPS描画 fps_string = u"FPS:" + str(display_fps) draw_image = CvDrawText.puttext(draw_image, fps_string, (15, 15), return draw_image
工夫点:
・PASCAL VOC 2012のセグメンテーションで良く見るカラーマップは使用しない
・デモで必要なクラス以外は表示しない
・探偵マンガの黒塗り犯人が監視カメラを壊すシーンぽく録画例08.画像変換:White-box-Cartoonization(Style Transfer:White-box-Cartoonization)
ソースコード:
08_style_transfer_demo.py
(折り畳み内に描画処理を抜粋したものを記載)
# カメラキャプチャ ##################################################### ret, frame = cap.read() if not ret: continue frame_width, frame_height = frame.shape[1], frame.shape[0] debug_image = copy.deepcopy(frame) # 変換実施 ############################################################# out = session_run(sess, debug_image, input_photo, final_out) # 画面反映 ############################################################# cvwindow.imshow(frame, out, fps=display_fps)
工夫点:
・Webでよく見る画像Before/After比較パーツ風に作成
→表示用のクラスは「Kazuhito00/cv-comparison-slider-window」で公開したものを利用おわりに
本来は、デザイナーさんやUI作る人とガッツリチーム組めると良いのですが、、、
そーいうのが無理な時は○○さん曰く、以下だけでも意識してみると良いかも。だそうです。
・デフォルトのフォントを使わない
・画像系のデモでちょいちょい見るG:255みたいな色は避ける
→Webセーフカラーとか流行色使ってみるとか次は、12/13:@shinnkun様の「アイトラッカー作ってみた.」です。
以上。









- 投稿日:2020-12-06T15:46:23+09:00
LeetCodeに毎日挑戦してみた 69. Sqrt(x)(Python、Go)
はじめに
無料英単語サイトE-tanを運営中の@ishishowです。
プログラマとしての能力を上げるために毎日leetcodeに取り組み、自分なりの解き方を挙げていきたいと思います。
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
17問目(問題69)
69. Sqrt(x)
問題内容
Given a non-negative integer
x, compute and return the square root ofx.Since the return type is an integer, the decimal digits are truncated, and only the integer part of the result is returned.
(日本語訳)
2つのバイナリ文字列
aとが与えられた場合b、それらの合計をバイナリ文字列として返します。負でない整数が与えられた場合
x、の平方根を 計算して返しxます。戻り値の型は整数であるため、10進数は切り捨てられ、結果の整数部分のみが返されます。
Example 1:
Input: x = 4 Output: 2Example 2:
Input: x = 8 Output: 2 Explanation: The square root of 8 is 2.82842..., and since the decimal part is truncated, 2 is returned.Constraints:
0 <= x <= 231 - 1考え方
バイナリーサーチという探索方法を使用します。
左端と右端(l,r)を定義し、検索する間隔を半分にしながらループで回していきます。
midの二乗とmid+1の二乗に値が入った時midを返します
- 解答コード
class Solution(object): def mySqrt(self, x): l, r = 0, x while l <= r: mid = l + (r-l)//2 if mid * mid <= x < (mid+1)*(mid+1): return mid elif x < mid * mid: r = mid - 1 else: l = mid + 1
- Goでも書いてみます!(goではバイナリーサーチしていません)
func mySqrt(x int) int { for i := 1; i <= x; i++ { if i*i == x { return i } if i*i > x { return i-1 } } return 0 }
- 投稿日:2020-12-06T15:10:03+09:00
[2020/11最新]wxPython インストール方法
Python3.9がリリースされました!
それをダウンロードして、さぁ、wxPythonをはじめよう!と思ったら…
あれ?できない!!!
インストールできない理由
wxPythonはまだ、Python3.9用のをリリースしていないようです。
そのため、このような現象に至ったのです。解決策
1つ目→Python3.9用のリリースをまつ。
2つ目→スナップショットを使うcmd.exepip install -U --pre -f https://wxpython.org/Phoenix/snapshot-builds/ wxPython==4.1.1a1.dev5063+1d243a37おわりに
無事、インストール出来たでしょうか。
wxPythonがPython3.9に対応したら、もう気にする必要はありません。
- 投稿日:2020-12-06T14:46:20+09:00
HerokuでSeleniumを使う方法
はじめに
HerokuでSleniumを使おうとしたときに「ValueError: Could not get version for Chrome with this command: google-chrome --version || google-chrome-stable --version heroku」というエラーで苦しめられたので対処法をメモします。
対処法
「Settings」から、
以下の2つをBuildpacksに追加する。
・ https://github.com/heroku/heroku-buildpack-google-chrome.git
・ https://github.com/heroku/heroku-buildpack-chromedriver.git
おわりに
かなり悩みましたが無事に解決できてホッとしました。
参考URL


- 投稿日:2020-12-06T14:46:20+09:00
HerokuでSeleniumを使いたいとき発生するValueError解決法
はじめに
HerokuでSleniumを使おうとしたときに「ValueError: Could not get version for Chrome with this command: google-chrome --version || google-chrome-stable --version heroku」というエラーで苦しめられたので対処法をメモします。
対処法
「Settings」から、
以下の2つをBuildpacksに追加する。
・ https://github.com/heroku/heroku-buildpack-google-chrome.git
・ https://github.com/heroku/heroku-buildpack-chromedriver.git
おわりに
かなり悩みましたが無事に解決できてホッとしました。
参考URL
- 投稿日:2020-12-06T14:44:16+09:00
備忘:Shade3D ver16 pythonスクリプトで正十二面体をつくる
備忘:Shade3D ver16 pythonスクリプトで正十二面体をつくる
正十二面体、頂点は20個。辺は30個。
手順
①20個の頂点の座標を調べる。
②30辺の点の組み合わせをセットする。
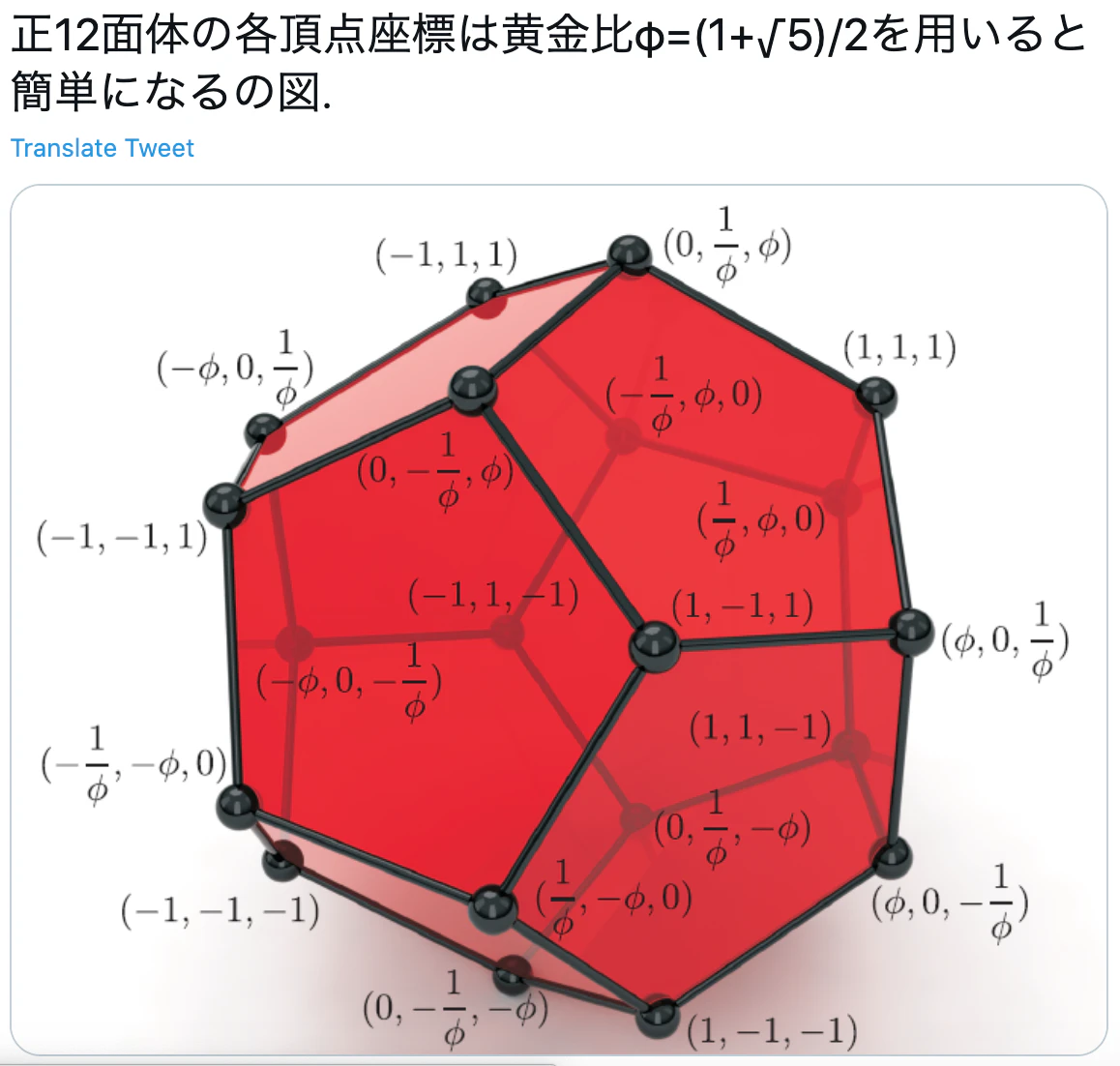
③3次元内の2点間を結ぶスクリプトを書き、辺を結ぶ。20個の頂点の座標
以下のツイートを参考にさせていただきました。ありがとうございます。
↓引用ここから
↑引用ここまで
φを、1.618として、
lst = [0] * 21 lst[1]= [1,1,1] lst[2]= [1.618,0,1/1.618] lst[3]= [1.618,0,-1/1.618] lst[4]= [1,1,-1] lst[5]= [1/1.618,1.618,0] lst[6]= [0,1/1.618,1.618] lst[7]= [1,-1,1] lst[8]= [1,-1,-1] lst[9]= [0,1/1.618,-1.618] lst[10]= [-1/1.618,1.618,0] lst[11]= [-1,1,1] lst[12]= [0,-1/1.618,1.618] lst[13]= [1/1.618,-1.618,0] lst[14]= [0,-1/1.618,-1.618] lst[15]= [-1,1,-1] lst[16]= [-1.618,0,1/1.618] lst[17]= [-1,-1,1] lst[18]= [-1/1.618,-1.618,0] lst[19]= [-1,-1,-1] lst[20]= [-1.618,0,-1/1.618]30個の辺の組み合わせをセット
[i,j]として、i番の頂点と、j番の頂点を結ぶ
hen = [0] * 31 hen[1] = [1,2] hen[2] = [2,3] hen[3] = [3,4] hen[4] = [4,5] hen[5] = [5,1] hen[6] = [1,6] hen[7] = [2,7] hen[8] = [3,8] hen[9] = [4,9] hen[10] = [5,10] hen[11] = [6,11] hen[12] = [6,12] hen[13] = [7,12] hen[14] = [7,13] hen[15] = [8,13] hen[16] = [8,14] hen[17] = [9,14] hen[18] = [9,15] hen[19] = [10,15] hen[20] = [10,11] hen[21] = [11,16] hen[22] = [12,17] hen[23] = [13,18] hen[24] = [14,19] hen[25] = [15,20] hen[26] = [16,17] hen[27] = [17,18] hen[28] = [18,19] hen[29] = [19,20] hen[30] = [20,16]3次元内の2点間を結ぶスクリプト
*1)2点を結ぶもの
点P1(x1,y1,z1)から点P2(x2,y2,z2)への単位ベクトルは、
(X,Y,Z) = (x2-x1,y2-y1,z2-z1)
を用いて、r、θ、φを求め、
dx = sinθ cosφ
dy = sinθ sinφ
dz = cosθ
方向に、動かせばよい。本プログラムでは、rの距離を、20ステップで移動している
import math import random scene = xshade.scene() scene.begin_creating() s = 8 #点、となる、球の大きさ #i x1 = 10 y1 = 20 z1 = 30 #j x2 = 100 y2 = 100 z2 = 100 px = -x1+x2 py = -y1+y2 pz = -z1+z2 r = math.sqrt(px*px + py*py + pz*pz) th = math.acos(pz / r) if math.sqrt(px * px + py * py) == 0: fi = 0 else: if py >= 0: fi = 1 * math.acos(px / math.sqrt(px * px + py * py)) else: fi = -1 * math.acos(px / math.sqrt(px * px + py * py)) dx = math.sin(th) *math.cos(fi) * (r/20) dy = math.sin(th) *math.sin(fi) * (r/20) dz = math.cos(th) * (r/20) cx = x1 cy = y1 cz = z1 for ii in range(0,20+1,1): scene.create_primitive_sphere(None,3,True,s,s,[cx, cy, cz],s) cx += dx cy += dy cz += dz scene.end_creating()↓wikipediaより
(参考)
https://ja.wikipedia.org/wiki/%E7%90%83%E9%9D%A2%E5%BA%A7%E6%A8%99%E7%B3%BB
↑wikipediaより
*2)30の辺のループ
for i in range(1,30+1,1): rd = 50 pt1 = hen[i][0] pt2 = hen[i][1] x1 = lst[pt1][0] * rd y1 = lst[pt1][1] * rd z1 = lst[pt1][2] * rd x2 = lst[pt2][0] * rd y2 = lst[pt2][1] * rd z2 = lst[pt2][2] * rd出来上がり
ソース
https://github.com/santarou6/shade/blob/main/shade_script_2020_11_A018.py
STL
https://github.com/santarou6/shade/blob/main/shade_script_2020_11_A018.stl
参考
①Pythonで画像から色情報抜き出す、②PythonでShade3Dスクリプトで濃淡絵を書く、③3Dプリンタで書き出す
https://qiita.com/santarou6/items/92d4b3f245642bea9862



- 投稿日:2020-12-06T14:44:16+09:00
Shade3D(ver16), pythonスクリプトで正十二面体をつくる
備忘:Shade3D ver16 pythonスクリプトで正十二面体をつくる
正十二面体、頂点は20個。辺は30個。
オイラーの多面体定理:「頂点の数」−「辺の数」+「面の数」=2
20−30+12=2手順
①20個の頂点の座標を調べる。
②30辺の点の組み合わせをセットする。
③3次元内の2点間を結ぶスクリプトを書き、辺を結ぶ。20個の頂点の座標
以下のツイートを参考にさせていただきました。ありがとうございます。
↓引用ここから
↑引用ここまで
φを、1.618として、
lst = [0] * 21 lst[1]= [1,1,1] lst[2]= [1.618,0,1/1.618] lst[3]= [1.618,0,-1/1.618] lst[4]= [1,1,-1] lst[5]= [1/1.618,1.618,0] lst[6]= [0,1/1.618,1.618] lst[7]= [1,-1,1] lst[8]= [1,-1,-1] lst[9]= [0,1/1.618,-1.618] lst[10]= [-1/1.618,1.618,0] lst[11]= [-1,1,1] lst[12]= [0,-1/1.618,1.618] lst[13]= [1/1.618,-1.618,0] lst[14]= [0,-1/1.618,-1.618] lst[15]= [-1,1,-1] lst[16]= [-1.618,0,1/1.618] lst[17]= [-1,-1,1] lst[18]= [-1/1.618,-1.618,0] lst[19]= [-1,-1,-1] lst[20]= [-1.618,0,-1/1.618]30個の辺の組み合わせをセット
[i,j]として、i番の頂点と、j番の頂点を結ぶ
hen = [0] * 31 hen[1] = [1,2] hen[2] = [2,3] hen[3] = [3,4] hen[4] = [4,5] hen[5] = [5,1] hen[6] = [1,6] hen[7] = [2,7] hen[8] = [3,8] hen[9] = [4,9] hen[10] = [5,10] hen[11] = [6,11] hen[12] = [6,12] hen[13] = [7,12] hen[14] = [7,13] hen[15] = [8,13] hen[16] = [8,14] hen[17] = [9,14] hen[18] = [9,15] hen[19] = [10,15] hen[20] = [10,11] hen[21] = [11,16] hen[22] = [12,17] hen[23] = [13,18] hen[24] = [14,19] hen[25] = [15,20] hen[26] = [16,17] hen[27] = [17,18] hen[28] = [18,19] hen[29] = [19,20] hen[30] = [20,16]3次元内の2点間を結ぶスクリプト
*1)2点を結ぶもの
点P1(x1,y1,z1)から点P2(x2,y2,z2)への単位ベクトルは、
(X,Y,Z) = (x2-x1,y2-y1,z2-z1)
を用いて、r、θ、φを求め、
dx = sinθ cosφ
dy = sinθ sinφ
dz = cosθ
方向に、動かせばよい。本プログラムでは、rの距離を、20ステップで移動している
import math import random scene = xshade.scene() scene.begin_creating() s = 8 #点、となる、球の大きさ #i x1 = 10 y1 = 20 z1 = 30 #j x2 = 100 y2 = 100 z2 = 100 px = -x1+x2 py = -y1+y2 pz = -z1+z2 r = math.sqrt(px*px + py*py + pz*pz) th = math.acos(pz / r) if math.sqrt(px * px + py * py) == 0: fi = 0 else: if py >= 0: fi = 1 * math.acos(px / math.sqrt(px * px + py * py)) else: fi = -1 * math.acos(px / math.sqrt(px * px + py * py)) dx = math.sin(th) *math.cos(fi) * (r/20) dy = math.sin(th) *math.sin(fi) * (r/20) dz = math.cos(th) * (r/20) cx = x1 cy = y1 cz = z1 for ii in range(0,20+1,1): scene.create_primitive_sphere(None,3,True,s,s,[cx, cy, cz],s) cx += dx cy += dy cz += dz scene.end_creating()↓wikipediaより
(参考)
https://ja.wikipedia.org/wiki/%E7%90%83%E9%9D%A2%E5%BA%A7%E6%A8%99%E7%B3%BB
↑wikipediaより
*2)30の辺のループ
for i in range(1,30+1,1): rd = 50 pt1 = hen[i][0] pt2 = hen[i][1] x1 = lst[pt1][0] * rd y1 = lst[pt1][1] * rd z1 = lst[pt1][2] * rd x2 = lst[pt2][0] * rd y2 = lst[pt2][1] * rd z2 = lst[pt2][2] * rd出来上がり
ソース
https://github.com/santarou6/shade/blob/main/shade_script_2020_11_A018.py
STL
https://github.com/santarou6/shade/blob/main/shade_script_2020_11_A018.stl
参考
①Pythonで画像から色情報抜き出す、②PythonでShade3Dスクリプトで濃淡絵を書く、③3Dプリンタで書き出す
https://qiita.com/santarou6/items/92d4b3f245642bea9862
- 投稿日:2020-12-06T14:15:39+09:00
openpyxlとOpenCVでexcelにお絵かき
暇つぶしに、excelにお絵かきしてみました。
Pythonには、openpyxlというexcelファイルを扱うためのライブラリがあります。
また、画像の扱いについてはOpenCVを使用しました。OpenCVを使用して画像からそれぞれの画素値を取得し、openpyxlを使用してその色をセルに塗っていく、という流れになります。
※画像はPixabayのフリー画像を使用
環境
言語はPython、環境はGoogle Colaboratoryを使用しました。
コード全体
import openpyxl from openpyxl.utils import get_column_letter from openpyxl.styles import PatternFill import cv2 input_file = '/path/to/image' # 画像ファイルのパス output_file = '/path/to/excel' # excelファイルのパス(拡張子はxlsx) wb = openpyxl.Workbook() # excelファイルの新規作成 ws = wb.worksheets[0] # シートの取得 img = cv2.imread(input_file) # 画像の読み込み height, width = img.shape[:2] for row, h in enumerate(range(height)): for col, w in enumerate(range(width)): cell = ws.cell(row+1, col+1) # セルのインデックスは1始まり ws.column_dimensions[get_column_letter(col+1)].width = 0.2 # 列幅の調整 ws.row_dimensions[row].height = 1 # 行幅の調整 cell.value = ' ' # セル確保のためスペースを記入 b, g, r = img[h, w] color_code = format(r, '02x') + format(g, '02x') + format(b, '02x') # 16進数に変換 ws.cell(row+1, col+1).fill = PatternFill(patternType='solid', fgColor=color_code) # セルに色付け wb.save(output_file) # ファイルの保存補足
セルをちょうどよい大きさの正方形にしようとして試行錯誤した結果、以下の値に落ち着いた。
ws.column_dimensions[get_column_letter(col+1)].width = 0.2 # 列幅の調整 ws.row_dimensions[row].height = 1 # 行幅の調整get_column_letterは、数字列を対応する英字列に変換する関数で、列を操作する際に使用。
print(get_column_letter(1)) print(get_column_letter(2)) print(get_column_letter(10)) print(get_column_letter(100)) # A # B # J # CVまた、色付けする際にうまくセルが確保できなかった(デフォルトで用意されている行・列から追加されなかった)ため、あらかじめスペースを記入してセルを確保。
※よい方法があればお知らせ下さいcell.value = ' ' # セル確保のためスペースを記入

- 投稿日:2020-12-06T13:59:36+09:00
plotlyで貸借対照表(BalanceSheet)を描画する
Plotlyで貸借対照表(BS)を描画する
先日某オンラインウェビナーでplotlyのハンズオンに参加して、Plotlyを使ったデータビジュアライゼーションの創作意欲が高まってきたので、練習がてら、以下のブログの記事を参考に、企業決算の貸借対照表(BS、いわゆるBalanceSheet)をplotlyでグラフ描画してみた。
Stacked and Grouped Bar Charts Using Plotly (Python)
https://dev.to/fronkan/stacked-and-grouped-bar-charts-using-plotly-python-a4p
※スウェーデン在住のフレデリク・ベングトソンさんのブログ記事企業決算のBSは、右側にある借方の純資産と負債は「Stacked Bar chart(積み上げ棒グラフ)」の要素を持っていて、また左側の貸方の総資産と右側の借方の部分がくっついていて「Grouped bar chart」の要素も持っていて、いわばStacked-BarとGrouped-barの両方を組み合わせた複合的な「Stacked and Grouped Bar chart」といったグラフを描画するイメージになるのだが、これをPlotlyでどのように指定して描画するのか?というのが今回のイシュー。
script
asahi_bs.pyfrom plotly import graph_objects as go #朝日新聞社のBSの数値をサンプルのデータとして利用 # (子会社の朝日放送HDもしくはテレビ朝日HDが適時開示に「親会社の決算」を発表している) data = { "総資産":[ 594628,605226,611502 ,607605 ,614114 ,599162,554408], "負債": [256320,288806, 278072,234054,231745,223782,217897], "純資産": [338307,316419,333429 ,373551 ,382368 ,375380,336511], "labels": [ "2015/03本", "2016/03本", "2017/03本", "2018/03本", "2019/03本", "2020/03本", "2020/09中" ] } # グラフ描画 fig1 = go.Figure( # データの指定 data=[ go.Bar( name="総資産", x=data["labels"], y=data["総資産"], offsetgroup=0, ), go.Bar( name="負債", x=data["labels"], y=data["負債"], offsetgroup=1, base=data["純資産"], ), go.Bar( name="純資産", x=data["labels"], y=data["純資産"], offsetgroup=1, ) ], # レイアウトの指定 layout=go.Layout( title="朝日新聞社_貸借対照表(BS)", xaxis_title="決算期", yaxis_title="JPY(単位:百万円)" ) ) fig1.show()上記のスクリプトでは、
go.Figure()のDataの指定の箇所で、go.Bar()を3つ、総資産と負債と純資産の3種類の棒グラフを指定するのだが、ポイントはこの時に、offsetgroup句で右側借方と左側貸方の2グループに分類する記述をする点である。
つまり左側の総資産は単一でグルーピングするoffsetgroup=0とし、また右側の負債と純資産の借方を1つのグループoffsetgroup=1と記述する。
あとはoffsetgroup=1の右側(借方)の負債Barの記述だが、純資産Barの上に負債Barを積み上げるイメージでグラフを描画するので、負債のgo.Bar()の箇所で、base=data["純資産"]というように、どのデータの上に載せるのかという記述すればよろしい。描画結果
※上図は、Google Colaboratory上でplotlyでグラフ描画した結果2020/9月時点で、総資産を500億円も減らしているようだ...
(とは言っても、総資産5500億円の巨大企業...優良有価証券ないし優良不動産物件を数多く保有していて、リストラする原資は過分にあるものと思われ)補足
今回サンプルにした朝日新聞社(未上場)の決算だが、朝日新聞社は金融庁のEDINETに有価証券報告書を毎年提出しており、また朝日新聞社の子会社、朝日放送ホールディングス(SIC:9405)もしくは、テレビ朝日ホールディングス(SIC:9409)が、「親会社の決算の状況」をJPX適時開示情報に本決算(3月決算)と中間決算(9月決算)の概況を開示しているので、その開示資料等から朝日新聞社の決算の数値は取得可能である。
参考URL:
・IRbank(朝日放送HD):https://irbank.net/E04380/tdnet
・IRbank(テレビ朝日HD):https://irbank.net/E04414/tdnet

- 投稿日:2020-12-06T13:52:20+09:00
openpyxlで縦軸の項目の順序を揃える
デフォルトの設定のまま、openpyxlを使ってグラフありのExcelファイルを出力すると、下図のようにテーブルとグラフで縦軸の項目の順序が逆順になってしまい見づらくなってしまいます。
以下のリンクのようにExcelで操作すればテーブルとグラフで縦軸の項目の順序を同じにできますが、今回はプログラムで順序が同じになるよう設定します。
まず、項目の順序を同じにするためには
pythonchart.x_axis.scaling.orientation = 'maxMin'の設定を追加すると、項目の順序を同じにできます。
項目の順序が同じになったのは良いですが、横軸まで上部に移動してしまいました。
横軸は下部のままにしたいので、
pythonchart.y_axis.crosses = 'max'の設定を追加します。
上記で縦軸の項目の順序だけをテーブルとグラフで同じにすることができました。