- 投稿日:2020-12-06T21:32:43+09:00
【 Firebase + Vue + SpringBoot 】 Firebase の uid を MySQL で作ったテーブルにインサートしてみた
はじめに
皆さんおはこんばにちは。
エンジニア歴1年目、現場未経験の弱小自称 Web エンジニアです。本記事では、題名通りの処理の流れについてのみ記載していきます。
プロジェクトの作成方法や単語の意味(axios、JPA、… )などわからない事がありましたら
今回はこちらの記事を参考におおまかなシステムを構築しているので
下記のリンクからご参照ください↓↓↓
SpringBoot+Vue.js+ElementUI+Firebaseでマスタ管理アプリ入門やりたいこと
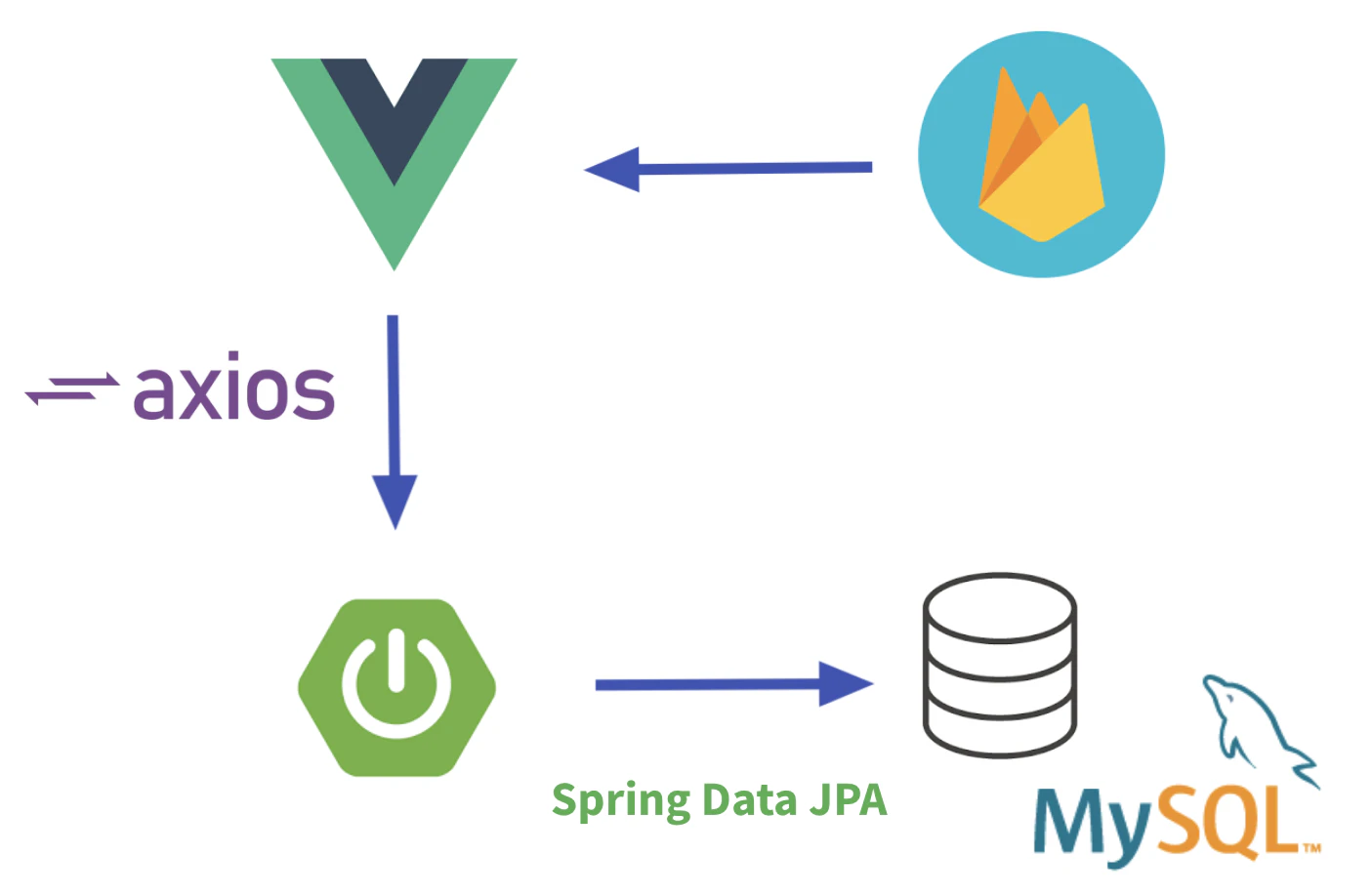
処理の流れ:
① Firebase にあるログインユーザー ID(uid)を Vue で取得する。
② axios を用いて uid を含んだユーザー情報を SpringBoot のREST API に POST する。
③ MySQL で作ったユーザーのテーブルに、その情報を INSERT する。
ログイン認証は Firebase + Vue で行いたい。
ユーザーのテーブルは他のテーブルと結合させる予定なので、MySQL側でも作っておきたい。それらのワガママを実現させるために、上記の方法を選択しました。
Firebase から uid を取得
今回は Firebase のメール / パスワード認証を用いて
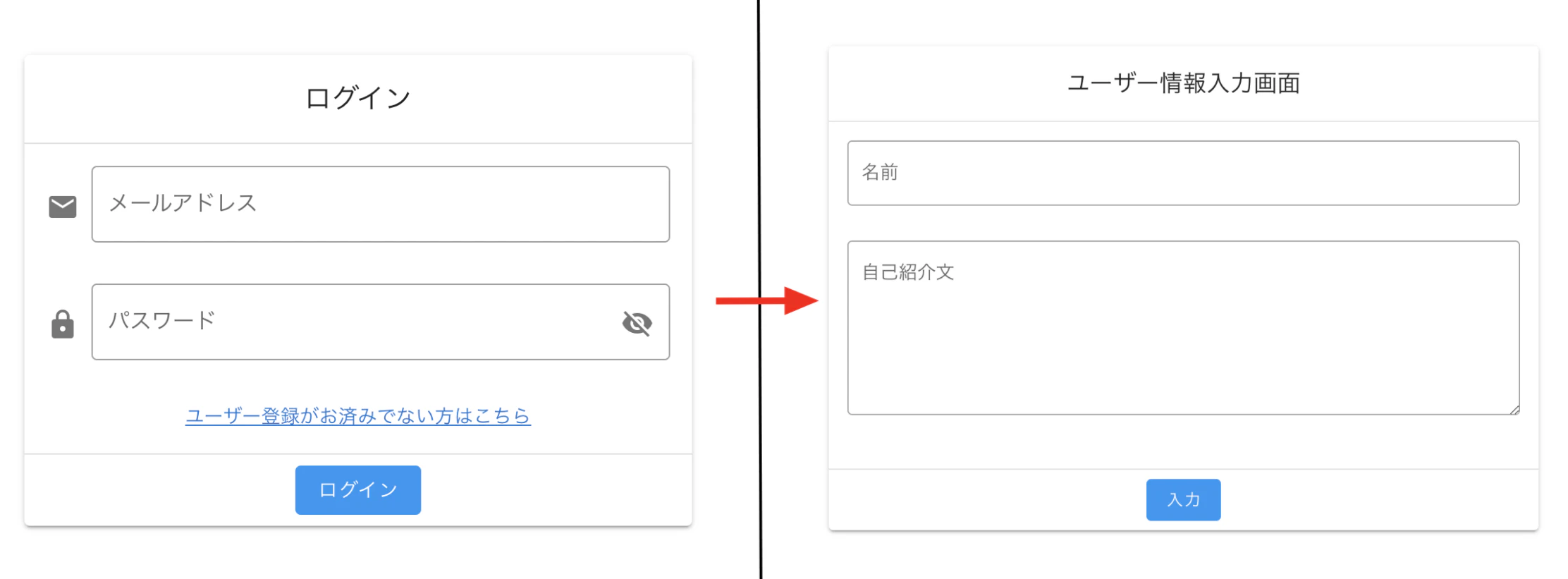
ログイン認証を行っています。ログイン済みのユーザーが入力した情報と共に uid をサーバーに送信したいので
ログイン画面を構築する View の後に遷移する View(今回だとユーザー情報入力画面)で
uid を取得する処理を書いていきます。
※ UI ライブラリは Vuetify を使用。
ProfileInput.vue. . . <v-text-field type="text" label="名前" v-model="userRequest.name" outlined ></v-text-field> <v-textarea type="text" label="自己紹介文" v-model="userRequest.profile" outlined ></v-textarea> . . . <v-btn dark depressed @click="onSubmit" color="info">入力</v-btn> . . . <script> import firebase from 'firebase' export default { data() { return { userRequest: { name: undefined, profile: undefined, firebaseId: undefined, }, } }, methods: { onSubmit: async function () { await firebase.auth().onAuthStateChanged((user) => { this.userRequest.firebaseId = user.uid }) } }, } </script>
firebase.auth().onAuthStateChanged(user => /* ... */)を用いて現在ログインしているユーザーのデータを取得し、自前で定義した userRequest オブジェクトの変数に uid を代入しています。axios で POST する
サーバーサイドの REST API にデータを追加する処理に
axiosを使用します。ProfileInput.vue<script> import firebase from 'firebase' import axios from 'axios' //axiosをインポート export default { data() { return { userRequest: { name: undefined, profile: undefined, firebaseId: undefined, }, } }, methods: { onSubmit: async function () { await firebase.auth().onAuthStateChanged((user) => { this.userRequest.firebaseId = user.uid axios.post('http://localhost:8080/addUser', this.userRequest) //userRequestオブジェクトをPOST }) } }, } </script>Spring Data JPA によるマッピング
Vue 側でデータを追加する処理を終えたので
サーバーサイドの処理を書いていきます。MySQL 側で作ったテーブルと Java のクラスのマッピングを行うために
Spring Data JPAを使用しています。Entity
UserEntity.javapackage com.example.jpamysql.domain; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import javax.persistence.Table; import lombok.Getter; import lombok.Setter; @Entity @Getter @Setter @Table(name = "users") public class UserEntity { /** 自動採番ID */ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; /** 名前 */ @Column(name = "name", columnDefinition = "VARCHAR(45)") private String name; /** 自己紹介文 */ @Column(name = "profile", columnDefinition = "VARCHAR(45)") private String profile; /** Firebase の uid */ @Column(name = "firebase_id", columnDefinition = "VARCHAR(45)") private String firebaseId; }Firebase の uid は文字列になっているので、String 型で受け取ります。
Repository
UserRepository.javapackage com.example.jpamysql.repository; import com.example.jpamysql.domain.UserEntity; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.stereotype.Repository; @Repository public interface UserRepository extends JpaRepository<UserEntity, Long> { }Service
UserService.javapackage com.example.jpamysql.service; import com.example.jpamysql.domain.UserEntity; import com.example.jpamysql.repository.UserRepository; import org.springframework.stereotype.Service; import lombok.RequiredArgsConstructor; @Service @RequiredArgsConstructor public class UserService { private final UserRepository userRepository; public void save (UserEntity user) { userRepository.save(user); } }RestController
Vue から送られてきたデータを受け取るためのクラスを先に定義しておきます。
Entity クラスで受け取っても問題なく処理されますが、保守性を高めるためです。UserRequest.javapackage com.example.jpamysql.request; import lombok.Getter; import lombok.Setter; @Getter @Setter public class UserRequest { private String name; private String profile; private String firebaseId; }UserRestController.javapackage com.example.jpamysql.controller; import com.example.jpamysql.domain.UserEntity; import com.example.jpamysql.request.UserRequest; import com.example.jpamysql.service.UserService; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RestController; import lombok.RequiredArgsConstructor; @RestController @RequiredArgsConstructor public class UserRestController { private final UserService userService; @RequestMapping(value = "/addUser", method = RequestMethod.POST) public void addUser(@RequestBody UserRequest userRequest) { UserEntity user = new UserEntity(); user.setName(userRequest.getName()); user.setProfile(userRequest.getProfile()); user.setFirebaseId(userRequest.getFirebaseId()); userService.save(user); } }YAML
接続情報の定義も忘れずに。
application.ymlspring: datasource: url: jdbc:mysql://localhost:3306/jpa_db?serverTimezone=JST username: qiita password: qiita driver-class-name: com.mysql.cj.jdbc.Driverこれで Enitity クラスに対応するテーブルを MySQL 側で作っていれば無事に INSERT されるはず。
まとめ
firebase.auth().onAuthStateChanged(user => /* ... */)を使用すればログインユーザーのデータを取得できる
- axios でデータを送信する場合は、フロント側の変数名とサーバー側の変数名を一致させておく必要がある
- Firebase の uid は文字列なので、Java 側では String 型で受け取る必要がある
(てっきり Spring プロジェクトにFirebase Admin SDKなんかを追加して、Firebase 独自のオブジェクトで受け取らなきゃいけないのかと思ったけど、その必要はなかった!!)
- 投稿日:2020-12-06T21:32:43+09:00
【Firebase + Vue + SpringBoot】 Firebase の uid を MySQL で作ったテーブルにインサートしてみた
はじめに
皆さんおはこんばにちは。
エンジニア歴1年目、現場未経験の弱小自称 Web エンジニアです。本記事では、題名通りの処理の流れについてのみ記載していきます。
プロジェクトの作成方法や単語の意味(axios、JPA、… )などわからない事がありましたら
今回はこちらの記事を参考におおまかなシステムを構築しているので
下記のリンクからご参照ください↓↓↓
SpringBoot+Vue.js+ElementUI+Firebaseでマスタ管理アプリ入門やりたいこと
処理の流れ:
① Firebase にあるログインユーザー ID(uid)を Vue で取得する。
② axios を用いて uid を含んだユーザー情報を SpringBoot のREST API に POST する。
③ MySQL で作ったユーザーのテーブルに、その情報を INSERT する。
ログイン認証は Firebase + Vue で行いたい。
ユーザーのテーブルは他のテーブルと結合させる予定なので、MySQL側でも作っておきたい。それらのワガママを実現させるために、上記の方法を選択しました。
Firebase から uid を取得
今回は Firebase のメール / パスワード認証を用いて
ログイン認証を行っています。ログイン済みのユーザーが入力した情報と共に uid をサーバーに送信したいので
ログイン画面を構築する View の後に遷移する View(今回だとユーザー情報入力画面)で
uid を取得する処理を書いていきます。
※ UI ライブラリは Vuetify を使用。
ProfileInput.vue. . . <v-text-field type="text" label="名前" v-model="userRequest.name" outlined ></v-text-field> <v-textarea type="text" label="自己紹介文" v-model="userRequest.profile" outlined ></v-textarea> . . . <v-btn dark depressed @click="onSubmit" color="info">入力</v-btn> . . . <script> import firebase from 'firebase' export default { data() { return { userRequest: { name: undefined, profile: undefined, firebaseId: undefined, }, } }, methods: { onSubmit: async function () { await firebase.auth().onAuthStateChanged((user) => { this.userRequest.firebaseId = user.uid }) } }, } </script>
firebase.auth().onAuthStateChanged(user => /* ... */)を用いて現在ログインしているユーザーのデータを取得し、自前で定義した userRequest オブジェクトの変数に uid を代入しています。axios で POST する
サーバーサイドの REST API にデータを追加する処理に
axiosを使用します。ProfileInput.vue<script> import firebase from 'firebase' import axios from 'axios' //axiosをインポート export default { data() { return { userRequest: { name: undefined, profile: undefined, firebaseId: undefined, }, } }, methods: { onSubmit: async function () { await firebase.auth().onAuthStateChanged((user) => { this.userRequest.firebaseId = user.uid axios.post('http://localhost:8080/addUser', this.userRequest) //userRequestオブジェクトをPOST }) } }, } </script>Spring Data JPA によるマッピング
Vue 側でデータを追加する処理を終えたので
サーバーサイドの処理を書いていきます。MySQL 側で作ったテーブルと Java のクラスのマッピングを行うために
Spring Data JPAを使用しています。Entity
UserEntity.javapackage com.example.jpamysql.domain; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import javax.persistence.Table; import lombok.Getter; import lombok.Setter; @Entity @Getter @Setter @Table(name = "users") public class UserEntity { /** 自動採番ID */ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; /** 名前 */ @Column(name = "name", columnDefinition = "VARCHAR(45)") private String name; /** 自己紹介文 */ @Column(name = "profile", columnDefinition = "VARCHAR(45)") private String profile; /** Firebase の uid */ @Column(name = "firebase_id", columnDefinition = "VARCHAR(45)") private String firebaseId; }Firebase の uid は文字列になっているので、String 型で受け取ります。
Repository
UserRepository.javapackage com.example.jpamysql.repository; import com.example.jpamysql.domain.UserEntity; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.stereotype.Repository; @Repository public interface UserRepository extends JpaRepository<UserEntity, Long> { }Service
UserService.javapackage com.example.jpamysql.service; import com.example.jpamysql.domain.UserEntity; import com.example.jpamysql.repository.UserRepository; import org.springframework.stereotype.Service; import lombok.RequiredArgsConstructor; @Service @RequiredArgsConstructor public class UserService { private final UserRepository userRepository; public void save (UserEntity user) { userRepository.save(user); } }RestController
Vue から送られてきたデータを受け取るためのクラスを先に定義しておきます。
Entity クラスで受け取っても問題なく処理されますが、保守性を高めるためです。UserRequest.javapackage com.example.jpamysql.request; import lombok.Getter; import lombok.Setter; @Getter @Setter public class UserRequest { private String name; private String profile; private String firebaseId; }UserRestController.javapackage com.example.jpamysql.controller; import com.example.jpamysql.domain.UserEntity; import com.example.jpamysql.request.UserRequest; import com.example.jpamysql.service.UserService; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RestController; import lombok.RequiredArgsConstructor; @RestController @RequiredArgsConstructor public class UserRestController { private final UserService userService; @RequestMapping(value = "/addUser", method = RequestMethod.POST) public void addUser(@RequestBody UserRequest userRequest) { UserEntity user = new UserEntity(); user.setName(userRequest.getName()); user.setProfile(userRequest.getProfile()); user.setFirebaseId(userRequest.getFirebaseId()); userService.save(user); } }YAML
接続情報の定義も忘れずに。
application.ymlspring: datasource: url: jdbc:mysql://localhost:3306/jpa_db?serverTimezone=JST username: qiita password: qiita driver-class-name: com.mysql.cj.jdbc.Driverこれで Enitity クラスに対応するテーブルを MySQL 側で作っていれば無事に INSERT されるはず。
まとめ
firebase.auth().onAuthStateChanged(user => /* ... */)を使用すればログインユーザーのデータを取得できる
- axios でデータを送信する場合は、フロント側の変数名とサーバー側の変数名を一致させておく必要がある
- Firebase の uid は文字列なので、Java 側では String 型で受け取る必要がある
(てっきり Spring プロジェクトにFirebase Admin SDKなんかを追加して、Firebase 独自のオブジェクトで受け取らなきゃいけないのかと思ったけど、その必要はなかった!!)
- 投稿日:2020-12-06T21:32:43+09:00
【SpringBoot + Vue + Firebase】 Firebase の uid を MySQL で作ったテーブルにインサートしてみた
はじめに
皆さんおはこんばにちは。
エンジニア歴1年目、現場未経験の弱小自称 Web エンジニアです。本記事では、題名通りの処理の流れについてのみ記載していきます。
プロジェクトの作成方法や単語の意味(axios、JPA、… )などわからない事がありましたら
今回はこちらの記事を参考におおまかなシステムを構築しているので
下記のリンクからご参照ください↓↓↓
SpringBoot+Vue.js+ElementUI+Firebaseでマスタ管理アプリ入門やりたいこと
処理の流れ:
① Firebase にあるログインユーザー ID(uid)を Vue で取得する。
② axios を用いて uid を含んだユーザー情報を SpringBoot のREST API に POST する。
③ MySQL で作ったユーザーのテーブルに、その情報を INSERT する。
ログイン認証は Firebase + Vue で行いたい。
ユーザーのテーブルは他のテーブルと結合させる予定なので、MySQL側でも作っておきたい。それらのワガママを実現させるために、上記の方法を選択しました。
Firebase から uid を取得
今回は Firebase のメール / パスワード認証を用いて
ログイン認証を行っています。ログイン済みのユーザーが入力した情報と共に uid をサーバーに送信したいので
ログイン画面を構築する View の後に遷移する View(今回だとユーザー情報入力画面)で
uid を取得する処理を書いていきます。
※UI ライブラリは Vuetify を使用。
ProfileInput.vue. . . <v-text-field type="text" label="名前" v-model="userRequest.name" outlined ></v-text-field> <v-textarea type="text" label="自己紹介文" v-model="userRequest.profile" outlined ></v-textarea> . . . <v-btn dark depressed @click="onSubmit" color="info">入力</v-btn> . . . <script> import firebase from 'firebase' export default { data() { return { userRequest: { name: undefined, profile: undefined, firebaseId: undefined, }, } }, methods: { onSubmit: async function () { await firebase.auth().onAuthStateChanged((user) => { this.userRequest.firebaseId = user.uid }) } }, } </script>
firebase.auth().onAuthStateChanged(user => /* ... */)を用いて現在ログインしているユーザーのデータを取得し、自前で定義した userRequest オブジェクトの変数に uid を代入しています。axios で POST する
サーバーサイドの REST API にデータを追加する処理に
axiosを使用します。ProfileInput.vue<script> import firebase from 'firebase' import axios from 'axios' //axiosをインポート export default { data() { return { userRequest: { name: undefined, profile: undefined, firebaseId: undefined, }, } }, methods: { onSubmit: async function () { await firebase.auth().onAuthStateChanged((user) => { this.userRequest.firebaseId = user.uid axios.post('http://localhost:8080/addUser', this.userRequest) //userRequestオブジェクトをPOST }) } }, } </script>Spring Data JPA によるマッピング
Vue 側でデータを追加する処理を終えたので
サーバーサイドの処理を書いていきます。MySQL 側で作ったテーブルと Java のクラスのマッピングを行うために
Spring Data JPAを使用しています。Entity
UserEntity.javapackage com.example.jpamysql.domain; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import javax.persistence.Table; import lombok.Getter; import lombok.Setter; @Entity @Getter @Setter @Table(name = "users") public class UserEntity { /** 自動採番ID */ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; /** 名前 */ @Column(name = "name", columnDefinition = "VARCHAR(45)") private String name; /** 自己紹介文 */ @Column(name = "profile", columnDefinition = "VARCHAR(45)") private String profile; /** Firebase の uid */ @Column(name = "firebase_id", columnDefinition = "VARCHAR(45)") private String firebaseId; }Firebase の uid は文字列になっているので、String 型で受け取ります。
Repository
UserRepository.javapackage com.example.jpamysql.repository; import com.example.jpamysql.domain.UserEntity; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.stereotype.Repository; @Repository public interface UserRepository extends JpaRepository<UserEntity, Long> { }Service
UserService.javapackage com.example.jpamysql.service; import com.example.jpamysql.domain.UserEntity; import com.example.jpamysql.repository.UserRepository; import org.springframework.stereotype.Service; import lombok.RequiredArgsConstructor; @Service @RequiredArgsConstructor public class UserService { private final UserRepository userRepository; public void save (UserEntity user) { userRepository.save(user); } }RestController
Vue から送られてきたデータを受け取るためのクラスを先に定義しておきます。
Entity クラスで受け取っても問題なく処理されますが、保守性を高めるためです。UserRequest.javapackage com.example.jpamysql.request; import lombok.Getter; import lombok.Setter; @Getter @Setter public class UserRequest { private String name; private String profile; private String firebaseId; }UserRestController.javapackage com.example.jpamysql.controller; import com.example.jpamysql.domain.UserEntity; import com.example.jpamysql.request.UserRequest; import com.example.jpamysql.service.UserService; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RestController; import lombok.RequiredArgsConstructor; @RestController @RequiredArgsConstructor public class UserRestController { private final UserService userService; @RequestMapping(value = "/addUser", method = RequestMethod.POST) public void addUser(@RequestBody UserRequest userRequest) { UserEntity user = new UserEntity(); user.setName(userRequest.getName()); user.setProfile(userRequest.getProfile()); user.setFirebaseId(userRequest.getFirebaseId()); userService.save(user); } }YAML
接続情報の定義も忘れずに。
application.ymlspring: datasource: url: jdbc:mysql://localhost:3306/jpa_db?serverTimezone=JST username: qiita password: qiita driver-class-name: com.mysql.cj.jdbc.Driverこれで Enitity クラスに対応するテーブルを MySQL 側で作っていれば無事に INSERT されるはず。
まとめ
firebase.auth().onAuthStateChanged(user => /* ... */)を使用すればログインユーザーのデータを取得できる
- axios でデータを送信する場合は、フロント側の変数名とサーバー側の変数名を一致させておく必要がある
- Firebase の uid は文字列なので、Java 側では String 型で受け取る必要がある
(てっきり Spring プロジェクトにFirebase Admin SDKなんかを追加して、Firebase 独自のオブジェクトで受け取らなきゃいけないのかと思ったけど、その必要はなかった!!)
- 投稿日:2020-12-06T20:10:52+09:00
お前らのLike検索は間違っている (QueryBuilder/Eloquent)
煽りタイトルすみません。
Laravelタグをつけてはいますが、特定の言語/フレームワークに限らない、Like検索時のエスケープの注意点についてお話します。
(@wand_ta 指摘ありがとうございます! 修正しました)本記事の対象読者
- 安易に以下のようなコードを書いてしまう方
$query->where('name', 'like', "%{$keyword}%")addcslashes? ナニソレ? 旨いの? って方- 1つのバックスラッシュを含むデータを検索するためにコードでは8個のバックスラッシュを書かなければならない場合があることに驚きを隠せない方
DB::select("SELECT * FROM items WHERE name LIKE '%\\\\\\\\%'")よくある間違い
商品テーブルに「100%りんご」という名前のデータが登録されているとします。
あなたの実装した部分一致検索APIは「%」を検索キーワードに指定して正しく検索できるでしょうか?
また、「 _ 」や「 \ 」を指定して正しく検索できるでしょうか?間違った実装
商品テーブルに対し、指定されたキーワードをSQLのLIKEを使って部分一致で検索するAPIを作るものとします。
とても素朴に、'%' . $keyword . '%'のような感じでリクエストパラメタから得たキーワードの両端に%をつけてLIKE検索した実装をしました。app/Http/Controllers/ItemController.phpclass ItemController extends Controller { public function index(Request $request): JsonResponse { $keyword = $request->input('keyword') ?? ''; // キーワードで商品名を検索 ***間違った実装*** $rows = Item::where('name', 'like', '%' . $keyword . '%')->get(); return response()->json($rows); } }何がまずいか?
テーブル
まず、こんな商品テーブルがあるとします。
商品名として「%」や「_」や「\」といった文字が含まれています。itemsテーブルmysql> SELECT * FROM items; +----+---------------+ | id | name | +----+---------------+ | 1 | 100%りんご | | 2 | abc_コーラ | | 3 | CC\1000 | +----+---------------+ 3 rows in set (0.00 sec)curlで確認 (意図した挙動をしない)
先程のLaravel APIにキーワードとして「100%」を指定して検索してみましょう。
「100%りんご」がヒットすることを期待しますが、
実際には「CC\1000」という商品もヒットしてしまいました。
※curlコマンドでは、キーワード「100%」をURLエンコードした?keyword=100%25というクエリ文字列が指定されています。# 「100%」を含む商品を探したいが。。。 % curl -s 'http://localhost/api/items?keyword=100%25' | jq . [ { "id": 1, "name": "100%りんご" }, { "id": 3, "name": "CC\\1000" # ※「CC\1000」のエスケープ文字列表現 } ]また、今度はキーワード「\」を含む商品を探したいとき、「CC\1000」がヒットすることを期待しますが、実際には何もヒットしません。
※キーワード「\」をURLエンコードした?keyword=%5cというクエリ文字列が指定されています。# 「\」を含む商品を探したいが。。。 % curl -s 'http://localhost/api/items?keyword=%5c' | jq . []解説
前置き
- 本記事は主にLIKE演算子のワイルドカードのエスケープについて説明します
- 照合順序、Locale等については言及しません
- 大文字小文字、バイナリ比較、ロケールに応じた照合、など
- いわゆる「全文検索」機能、形態素解析等については言及しません
- いわゆるSQL組み立てにおけるエスケープ、SQLインジェクションといったセキュリティについては直接言及しません。
- 本記事は以下の環境で検証しています。
- Laravel 7.4
- MySQL 8.0
- PostgreSQL 11.5
- 他のバージョン、他のDB(Oracle, SQL Serverなど)、他の言語/フレームワークでも基本的な考え方は同じですが、具体的な差異については言及しません。
SQLで検索するとき
1. 単純なLIKE検索
単純に「100」という文字列を検索したい場合は、ワイルドカード
%で挟んで検索パターン文字列を作り、LIKE演算子で比較します。単純なLIKE検索-- 「100」を含むものを探す mysql> SELECT * FROM items WHERE name LIKE '%100%';結果+----+---------------+ | id | name | +----+---------------+ | 1 | 100%りんご | | 3 | CC\1000 | +----+---------------+ 2 rows in set (0.00 sec)2. ワイルドカード文字そのものを検索したいとき (要エスケープ)
文字としての
%を検索したいときは\でエスケープして、\%としてパターン文字列を指定します。
部分一致で探したいので、前後を%で挟むと%\%%というパターン文字列になります。
このパターン文字列をLIKE演算子の右辺で指定するときに、シングルクォートで囲んであげましょう。
この際、クォート文字列のリテラル表現のために、さらに\をエスケープして\\とする必要があります。
結果として、クォート文字列表現としては'%\\%%'となります。エスケープしてLIKE検索-- 「%」を含むものを探す: 間違った例 mysql> SELECT * FROM items WHERE name LIKE '%%%'; -- 「%」を含むものを探す: 正しい例 (\でエスケープする) mysql> SELECT * FROM items WHERE name LIKE '%\\%%';結果+----+---------------+ | id | name | +----+---------------+ | 1 | 100%りんご | +----+---------------+ 1 row in set (0.00 sec)同様に、文字としての「_」や「\」を探したいときもエスケープが必要です。
※「\」が増殖しているところに注目-- 「_」を含むものを探す: 正しい例 (\でエスケープする) mysql> SELECT * FROM items WHERE name LIKE '%\\_%'; -- 「\」を含むものを探す: 正しい例 (\でエスケープする) mysql> SELECT * FROM items WHERE name LIKE '%\\\\%';LIKE検索パターンのエスケープまとめ
- LIKE検索パターン文字列中では、
%や_は ワイルドカード と呼ばれる特殊な役割を持ち、これらの文字列そのものを示したい場合はエスケープする必要があります- エスケープ文字は LIKE演算子の
ESCAPE句で指定可能ですが、多くのDBでは省略した場合はデフォルトは\です。- また、
\文字そのものを示したい場合も同様にエスケープする必要があります
文字 検索パターン内での役割 エスケープ後文字列 % (パーセント) 任意の長さの文字列(空文字列を含む) \% _ (アンダースコア) 任意の1文字 \_ \ (バックスラッシュ) エスケープ文字 \\ MS SQL Server のLIKE検索パターンのエスケープ
Microsoft SQL Serverは少し特殊で、文字クラス
[]を利用してメタ文字そのものを表現します。
文字 検索パターン内での役割 MS SQL Serverでのエスケープ後文字列 % (パーセント) 任意の長さの文字列(空文字列を含む) [%] _ (アンダースコア) 任意の1文字 [_] [ 文字クラスの開始 [[] SQLのシングルクォート リテラル表現でのメタ文字のエスケープまとめ
SQL中で文字列をリテラル表現する場合はシングルクォートで囲む必要があります。
例: 文字列abc=> クォート表現'abc'この際に シングルクォートそのものなどのメタ文字を含む場合はエスケープ文字として
\でエスケープする必要があります。
また、エスケープ文字\を含む場合も同様にエスケープします。
例: 文字列'=> クォート文字列表現'\'
例: 文字列\=> クォート文字列表現'\\'
文字 SQL文での役割 エスケープしたクォート文字列表現 ' (シングルクォート) 文字列の開始/終了 '\'' \ (バックスラッシュ) エスケープ文字 '\\' 正しいLike検索の実装
エスケープを意識して検索APIの実装を見直し
API実装
LIKE検索パターンのためにワイルドカード文字、及びエスケープ文字をそれぞれエスケープしてあげます。
phpの addcslashes 関数で指定文字をバックスラッシュでエスケープできます。
(THX @wand_ta)app/Http/Controllers/ItemController.phpclass ItemController extends Controller { public function index(Request $request): JsonResponse { $keyword = $request->input('keyword') ?? ''; // キーワードのメタ文字をエスケープして商品名を検索 $pat = '%' . addcslashes($keyword, '%_\\') . '%'; $rows = Item::where('name', 'LIKE', $pat)->get(); return response()->json($rows); } }※↑キーワードが空だったらエラーにする、結果を返さない、(Like条件で絞り込みせずに)全件を返す、 など実際には仕様に応じて実装すると思いますが、単純化のためここでは簡易な実装にしています。
なお、MS SQL Server の場合は以下のようにする必要があるかもしれません。(未検証)
また、preg_replace()の第1引数は正規表現を指定しますので、ここでもさらにエスケープしています。
もちろん、シングルクォート内の「\」をエスケープしています。SQLServerの場合$pat = '%' . preg_replace('/([\\[_%])/', '[$1]', $keyword) . '%';curlで確認
こんどは意図した検索ができるようになりましたね!
# 「100%」を含む商品を探して「100%りんご」がヒットする % curl -s 'http://localhost/api/items?keyword=100%25' | jq . [ { "id": 1, "name": "100%りんご" } ] # 「\」を含む商品を探して「CC\1000」がヒットする % curl -s 'http://localhost/api/items?keyword=%5c' | jq . [ { "id": 3, "name": "CC\\1000" } ]リファクタリング: likeスコープを提供するTrait
コントローラに複雑な処理を書きたくないので、Model側に処理を移しましょう。
Trait実装
以下のようなscopeを提供するトレイトを作成し、
app/Models/Traits/WhereLike.phpnamespace App\Models\Traits; trait WhereLike { // 部分一致検索 public function scopeWhereLike($query, string $column, string $keyword) { return $query->where($column, 'like', '%' . addcslashes($keyword, '%_\\') . '%'); } // 前方一致検索 public function scopeWhereLikeForward($query, string $column, string $keyword) { return $query->where($column, 'like', addcslashes($keyword, '%_\\') . '%'); } }ModelでTrait利用
商品モデルで先程のトレイトをuseします。
app/Models/Item.phpnamespace App\Models; use App\Models\Traits\WhereLike; use Illuminate\Database\Eloquent\Model; class Item extends Model { use WhereLike; }tinkerで確認
これで、Itemモデルに部分一致検索
whereLike()や前方一致検索whereLikeForward()といったクエリビルダ用メソッドが追加されました。tinker# 名前に「%」を含むものを検索 >>> Item::whereLike('name', '%')->get() => Illuminate\Database\Eloquent\Collection {#4324 all: [ App\Models\Item {#4317 id: 1, name: "100%りんご", }, ], } # 名前に「100」を含むものを検索 >>> Item::whereLike('name', '100')->get() => Illuminate\Database\Eloquent\Collection {#4326 all: [ App\Models\Item {#4318 id: 1, name: "100%りんご", }, App\Models\Item {#4328 id: 3, name: "CC\1000", }, ], } # 名前を「100」で前方一致検索 >>> Item::whereLikeForward('name', '100')->get() => Illuminate\Database\Eloquent\Collection {#4312 all: [ App\Models\Item {#4316 id: 1, name: "100%りんご", }, ], }おまけ: プログラム内で生SQLを利用するときのエスケープ
クエリビルダ/ORマッパーを利用せずに、生SQLを利用したい場合が稀にあります。
※もちろんそのような場合でも、バインド値・プレースホルダなどの安全に利用できる仕組みを極力活用すべきです。
- 再帰クエリ、JSON系の演算子、その他特殊な構文などDB固有の特殊な機能を使いたい場合
- DB固有のDDLを実行したい場合
- PostgreSQLの継承テーブルなどの都合で動的にテーブル名を導出したい場合
- 複雑なサブクエリで、クエリビルダ/ORマッパーでの組み立てがやりづらい場合
- 開発、検証中の一時的な仮実装
生SQLではLIKE文に限らずセキュリティの観点からエスケープを特に注意ください。
以下は、生SQLでLIKE文を書いた時のエスケープの例です。
※呆れるほど「\」が増殖しているところに注目tinker# 名前に「\」を含むものを検索 >>> DB::select("SELECT * FROM items WHERE name LIKE '%\\\\\\\\%'"); => [ {#4334 +"id": 3, +"name": "CC\1000", }, ]
- 検索対象としての「\」
- → LIKE検索パターンにするためにエスケープ → 「\\」 2倍!
- → SQLのクォート文字列表現のためのエスケープ → 「\\\\」 4倍!!
- → phpのクォート文字列表現のためのエスケープ → 「\\\\\\\\」 8倍!!!!
そうです、見ての通り バックスラッシュは増えるんです。
※ちなみに、Qiitaのこの記事を書くときに Qiita Markdownのためにエスケープするので、私は↑で16個の連続したバックスラッシュを書いています。※もちろん、Productionコードで↑のような実装をしてはいけませんし、このような実装が必要な場面は考えにくいですが、あえて想像するなら、seederの実装内でシードデータを別テーブルの情報から何かしら探して使うとき、複雑なサブクエリが必要で、SQLターミナルで検証したクエリをそのまま流用して一時的にコードで使う、というケースでしょうか。。。
最後に
いっぱいバックスラッシュを書いた。
それはともかく良い年末を!
- 投稿日:2020-12-06T17:53:51+09:00
【Rails】PrimaryキーをUUIDにしてみる。~MySQL~
はじめに
今回は
gem(ライブラリ)等を使わずに、PrimaryキーをUUIDにする方法(MySQLの場合)を解説していこうと思います!また、この記事では
Userモデルを作成する流れで、PrimaryキーにUUIDを設定する流れを実践していきます。UserモデルのPrimaryキーをUUIDにする
【1】Userモデルを作成
ともかく、モデルを作成しましょう。今回は「試し」なので、カラムは何も入れていません。
rails g model user【2】マイグレーションファイルを記述する。
create_table "users", id: false, force: :cascade, options: "ENGINE=InnoDB DEFAULT CHARSET=utf8mb4" do |t| t.string "id", limit: 36, null: false, primary_key: true t.datetime "created_at", null: false t.datetime "updated_at", null: false endポイントは二つです。
デフォルトの
idをfalseにする。
create_table "users", id: false,の部分ですね。ここをfalseにしています。uuid用のカラムを追加
t.string "id", limit: 36, null: false, primary_key: trueの部分ですね。
primary_key: trueのオプションをつけているのがポイントです。こうすることで、このカラムがprimary keyにすることができます。【3】moduleからuuidを作成
この部分に関しましては、この記事から引用させていただきました?♂️
app/models/concerns/id_generator.rbにuuid生成用のモジュールを作成してください。app/models/concerns/id_generator.rbmodule IdGenerator def self.included(klass) klass.before_create :fill_id end def fill_id self.id = loop do uuid = SecureRandom.uuid break uuid unless self.class.exists?(id: uuid) end end end順番に解説していきます。
self.included(klass)def self.included(klass) klass.before_create :fill_id endこのモジュールがインクルードされたタイミングで対象のクラスを引数にしてこのメソッドが呼び出されます
引用元:公式
つまり、このモジュールがインクルードされたタイミングで該当モデルで
before_create :fill_idが呼び出されます。fill_id
def fill_id self.id = loop do uuid = SecureRandom.uuid break uuid unless self.class.exists?(id: uuid) end end簡単にいうと、該当モデルの
idに対して、uuidを重複しないように設定します。【4】Userモデルでmoduleをincludeする。
app/models/user.rbで先ほどのmoduleをincludeしてください。app/models/user.rbclass User < ApplicationRecord include IdGenerator endこうすることにより、
before_createのタイミングでfill_idにより、uuidを設定することができます。最後に
以上です。これでPrimaryキーをUUIDとして設定することができると思います。
とはいえ、UUIDにはメリデリがあるので考慮してから採用するようにしてください。
ではでは✌️
- 投稿日:2020-12-06T17:36:42+09:00
[MySQL]オプティマイザトレースでインデックス選択根拠を調べる[単一テーブル編]
この記事は Lancers(ランサーズ) Advent Calendar 2020 6日目のエントリーです。
バックエンドエンジニア&DBRE の まみー です。
僕は MySQL が大好きです。普段 ORM 任せでクエリを意識しないことも多い昨今。
だからこそクエリ 1 とインデックス 2 くらいはわかる僕らでありたいと思うんですが、思ってたんと違うインデックスが選択されることありますよね。じゃあ理由を明確にして本質を知った上で対応しよう。
というわけでインデックス選択の根拠をオプティマイザが算出するコストから検証してみます。オプティマイザトレースの使い方をサクッと知りたい方は コチラ からご覧ください。
条件
- 単一テーブル
- 複合インデックス
- 1番目で ID で絞り込み
- 2番目で前方一致 LIKE 検索
実例 3 として、TODO管理情報を
- ユーザーID
- キーワード前方一致
で検索していきます。
テーブル
TODO管理をするテーブルはこんな感じです。
mysql> show create table todos\G *************************** 1. row *************************** Table: todos Create Table: CREATE TABLE `todos` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL, `keyword` varchar(255) NOT NULL, `content` varchar(255) NOT NULL, `started` datetime DEFAULT NULL, `expired` datetime DEFAULT NULL, `completed` datetime DEFAULT NULL, `created` datetime NOT NULL, `modified` datetime NOT NULL, PRIMARY KEY (`id`) ) 1 row in set (0.01 sec)データ
検証用には十分かなというレコード数です。
mysql> select count(id) from todos; +-----------+ | count(id) | +-----------+ | 350932 | +-----------+ 1 row in set (0.89 sec)前方一致 LIKE 対象のデータパターンとしては、ある程度までは前方一致する数が多く、さらに絞り込める構造になっているとします。
上位 10 件しか表示していませんが、keyword の最後尾に ID 的な値があるため、3位以降のカーディナリティは高いです。mysql> select keyword, count(keyword) as key_count from todos group by keyword order by keyword_count desc limit 10; +-----------------------------------------------+---------------+ | keyword | keyword_count | +-----------------------------------------------+---------------+ | UserProjectFeedbackConfirmation | 40325 | | ClientProjectFeedbackConfirmation | 35189 | | ClientProjectUploadedFileConfirmation/aaaaaaa | 33 | | UserProjectUploadedFileConfirmation/bbbbbbb | 22 | | ClientProjectUploadedFileConfirmation/ccccccc | 20 | | ClientProjectUploadedFileConfirmation/ddddddd | 20 | | ClientProjectUploadedFileConfirmation/eeeeeee | 17 | | ClientProjectUploadedFileConfirmation/fffffff | 17 | | ClientProjectUploadedFileConfirmation/ggggggg | 15 | | ClientProjectUploadedFileConfirmation/hhhhhhh | 15 | +-----------------------------------------------+---------------+また、今回は user_id で最初に絞るので、ある程度レコード数が多いユーザーを選択するものとします。
mysql> select count(user_id) as count, user_id from todos group by user_id order by count desc limit 5; +-------+----------+ | count | user_id | +-------+----------+ | 5433 | 11000501 | | 1942 | 20018912 | | 1746 | 11000194 | | 1406 | 21354356 | | 1119 | 22663348 | +-------+----------+ 5 rows in set (0.08 sec)クエリ
該当ユーザーの Client に対応する TODO 一覧を取得する、シンプルなクエリです。
LIKE の文字列は条件によりどんどん絞り込める (文字列が長くなる) ものとします。SELECT * FROM todos WHERE user_id=11000501 AND keyword LIKE 'Client%'インデックス
user_id_keywordが今回追加したインデックスで、これが使われて欲しいです。
他は既存のインデックスです。mysql> show index from todos; +-------+------------+---------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+---------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | todos | 0 | PRIMARY | 1 | id | A | 342442 | NULL | NULL | | BTREE | | | | todos | 1 | user_id_keyword_completed | 1 | user_id | A | 28574 | NULL | NULL | | BTREE | | | | todos | 1 | user_id_keyword_completed | 2 | keyword | A | 291843 | NULL | NULL | | BTREE | | | | todos | 1 | user_id_keyword_completed | 3 | completed | A | 287793 | NULL | NULL | | BTREE | | | | todos | 1 | user_id_completed | 1 | user_id | A | 27407 | NULL | NULL | | BTREE | | | | todos | 1 | user_id_completed | 2 | completed | A | 41562 | NULL | NULL | | BTREE | | | | todos | 1 | user_id_keyword | 1 | user_id | A | 27861 | NULL | NULL | | BTREE | | | | todos | 1 | user_id_keyword | 2 | keyword | A | 288007 | NULL | NULL | | BTREE | | | +-------+------------+---------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 8 rows in set (0.00 sec)EXPLAIN(実行計画)
検索条件に合わせて新規で作った
user_id_keywordインデックスではなく、既存のuser_id_completedが選択されました。
ぐぬぬ、なぜ…mysql> explain SELECT -> * -> FROM -> todos -> WHERE -> user_id=11000501 -> AND -> keyword LIKE 'Client%'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: todos partitions: NULL type: ref possible_keys: user_id_keyword_completed,user_id_completed,user_id_keyword key: user_id_completed key_len: 4 ref: const rows: 5432 filtered: 11.11 Extra: Using where 1 row in set, 1 warning (0.00 sec)実行計画を、漢のコンピュータ道 MySQLのEXPLAINを徹底解説!! から引用しながら見ていきます。
type: ref
ref・・・ユニーク(PRIMARY or UNIQUE)でないインデックスを使って等価検索(WHERE key = value)を行った時に使われるアクセスタイプ。
今回、
key = valueなのはuser_id=11000501なので、この部分だけがインデックスで検索されたことになります。key: user_id_completed
オプティマイザによって選択されたキー。
読んで字の如く。このあとでトレースをし、オプティマイザが選択したコストを見ていきます。
短いキー長、今回は user_id でレコード取得し、その結果に対しインデックスを使わず LIKE 検索した方が高速である (コストが低い) と判断されたのかな、という推測ができます。key_len: 4
選択されたキーの長さ。インデックスの走査は、キー長が短い方が高速である。インデックスをつけるカラムを選ぶ時にはそのことを念頭に置いて欲しい。
user_id int(11)で Integer なので、4 byte、つまり user_id の検索にしかインデックスが利用されていない、ということがわかります。rows: 5432
そのテーブルからフェッチされる行数の見積もりである。このフィールドはあくまでもテーブル全体の行数やインデックスの分散具合から導き出された大まかな見積もりなので、実際にフェッチされる正確な行数ではないので注意が必要されたい。
ユーザーID別に件数を見た際、総件数は以下でした。
+-------+----------+ | count | user_id | +-------+----------+ | 5433 | 11000501 |ほとんど全てのレコードが検索対象として見積もられていることがわかります。
ここで以下が推測できました。
- 先頭が user_id であるインデックスを選択して行数・コスト計算
- 最も行数・コストの少ないインデックスを選択
なぜ、今回 WHERE 句で絞り込むために作ったインデックスが選択されず、既存のインデックスが使われてしまうのか。
ここまでの推測が正しいのか。
それを調べるため、オプティマイザトレースをしてみます。オプティマイザトレース
前準備1:オプティマイザトレースを有効化する
オプティマイザトレースは 有効化 しないとトレースしてくれません。
なので optimizer_trace 変数 に以下の設定を実行します。mysql> show variables like 'optimizer_trace'; +-----------------+--------------------------+ | Variable_name | Value | +-----------------+--------------------------+ | optimizer_trace | enabled=off,one_line=off | +-----------------+--------------------------+ 1 row in set (0.00 sec) mysql> SET optimizer_trace="enabled=on"; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'optimizer_trace'; +-----------------+-------------------------+ | Variable_name | Value | +-----------------+-------------------------+ | optimizer_trace | enabled=on,one_line=off | +-----------------+-------------------------+ 1 row in set (0.00 sec)
one_lineをオンにすると空白も改行もなく1行で表示されます。人間ではなくパーサーに渡すためのようですね。なお、設定時の注意点としては以下が挙げられます。
- 普段は無効になってるのでトレースしてくれない
- 常時有効にするとメモリに影響するので、使うときだけ有効にすること
- 都度コマンドで有効にした場合は、quit すれば設定は無効になります
- とはいえ設定を戻すことは忘れずに
前準備2:利用するメモリ容量を適切に設定する
オプティマイザトレースはメモリを適切に割り当てないと、出力結果が全部表示されない場合があります。
今回はデフォルト値が少なく、トレース結果の JSON が途中で欠落していました。なので以下のように optimizer_trace_max_mem_size 変数 設定を実行します。
1 MB あれば大丈夫でした。mysql> show variables like 'optimizer_trace_max_mem_size'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | optimizer_trace_max_mem_size | 16384 | +------------------------------+-------+ 1 row in set (0.00 sec) mysql> SET optimizer_trace_max_mem_size = 1048576; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'optimizer_trace_max_mem_size'; +------------------------------+---------+ | Variable_name | Value | +------------------------------+---------+ | optimizer_trace_max_mem_size | 1048576 | +------------------------------+---------+ 1 row in set (0.00 sec)クエリ実行
先ほどと同じく、EXPLAIN を実行します。
実際に結果を取得しなくても、オプティマイザトレースの結果は変わりません。mysql> explain SELECT -> * -> FROM -> todos -> WHERE -> user_id=11000501 -> AND -> keyword LIKE 'Client%'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: todos partitions: NULL type: ref possible_keys: user_id_keyword_completed,user_id_completed,user_id_keyword key: user_id_completed key_len: 4 ref: const rows: 5432 filtered: 11.11 Extra: Using where 1 row in set, 1 warning (0.00 sec)注意点としては以下が挙げられます。
- この1回がトレース結果としてメモリに保持される
- 2回目以降は上書きされるので、都度トレース結果をみる必要がある
トレース結果取得
クエリを実行すると、トレース結果がメモリ上に記録されます。
あとは以下のSQLで、トレース結果をSELECTしてあげればOKです。mysql> SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE\G *************************** 1. row *************************** QUERY: EXPLAIN SELECT (省略、実行したSQLが表示されます) TRACE: { (後述、オプティマイザトレースの内容) } MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0 --メモリ不足で切り捨てられたサイズ INSUFFICIENT_PRIVILEGES: 0 1 row in set (0.00 sec)結果は非常に長いので、全文は割愛し、重要な部分のみ解説していきます。
実際には下記の手前で行数見積もりするrows_estimationセクションがあったりと興味深い内容なので、ご興味ある方はぜひ 詳解MySQL 5.7 止まらぬ進化に乗り遅れないためのテクニカルガイド を読んでみて欲しいです。本当に詳解です。"considered_execution_plans": [ { "plan_prefix": [ ], "table": "`todos`", "best_access_path": { "considered_access_paths": [ { "access_type": "ref", "index": "user_id_keyword_completed", "rows": 11740, "cost": 14088, "chosen": true }, { "access_type": "ref", "index": "user_id_completed", "rows": 5432, "cost": 6518.4, "chosen": true }, { "access_type": "ref", "index": "user_id_keyword", "rows": 10804, "cost": 12965, "chosen": false }, { "access_type": "range", "range_details": { "used_index": "user_id_completed" }, "chosen": false, "cause": "heuristic_index_cheaper" } ] }, "condition_filtering_pct": 11.11, "rows_for_plan": 603.5, "cost_for_plan": 6518.4, "chosen": true } ]オプティマイザが検討した実行計画:considered_execution_plans
user_id_keyword_completeduser_id_completeduser_id_keywordのインデックスそれぞれの、行数とコストが出力されます。
この中から、最もコストが低いインデックスが採用されます。結果をみてみると、以下が最もコストが低いことがわかります。
{ "access_type": "ref", "index": "user_id_completed", "rows": 5432, "cost": 6518.4, "chosen": true },選択されたことが
"chosen": trueからわかります。結果
- インデックス上で LIKE 検索をかけるより、user_id で全件取ってきた結果を LIKE した方が高速であると判断された
- そもそも LIKE 検索対象が user_id で絞った件数とほぼ同一だった
- それならより短いインデックスを使い高速に処理する
- 統計情報上、新規インデックスではなく既存インデックスが高速と判断された
- 本当にこのクエリを高速化したいなら、LIKE で指定する文字列を長くしてより絞り込む必要がある
結果からの検証
LIKE 検索をより絞り込んだ結果
より絞り込めばインデックスが有効に利用されるのではないかと推測できたので、実際に検証してみました。
rows: 5432->rows: 1176になったことで、LIKE 検索にもインデックスが選択されるようになりました。
Extra: Using index conditionとなり、インデックスコンディションプッシュダウンの最適化が行われ高速に動作しているのがわかります。
user_id_keyword_completedと、completed カラムが含まれるインデックスが選択されるのは、統計情報によるものではないかなと考えています。
ここは今後の深掘りの課題です。mysql> explain SELECT -> * -> FROM -> todos -> WHERE -> user_id=11000501 -> AND -> keyword LIKE 'ClientProjectMilestone%'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: todos partitions: NULL type: range possible_keys: user_id_keyword_completed,user_id_completed,user_id_keyword key: user_id_keyword_completed key_len: 1026 ref: NULL rows: 1176 filtered: 100.00 Extra: Using index condition 1 row in set, 1 warning (0.01 sec)user_id 単体インデックス
より短いインデックスが選択されるならば、インデックス自体を最も短くしてみたら選択されるのか、を検証してみました。
結果、既存インデックスが選択されました。これも統計情報なのだろうか…合わせて今後の課題ですね。
mysql> alter table todos add index user_id(user_id); Query OK, 0 rows affected (0.55 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain SELECT -> * -> FROM -> todos -> WHERE -> user_id=11000501 -> AND -> keyword LIKE 'Client%'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: todos partitions: NULL type: ref possible_keys: user_id_keyword_completed,user_id_completed,user_id_keyword,user_id key: user_id_completed key_len: 4 ref: const rows: 5432 filtered: 11.11 Extra: Using where 1 row in set, 1 warning (0.00 sec)課題
複数テーブルを JOIN した際のトレース
今回は単一テーブルでの検証でしたが、開発現場では JOIN されることの方が多いと思います。
次回は JOIN された際にどうインデックスが使われるのか、どのような順番で JOIN されるのか、などをトレースしたいと考えています。統計情報を知る
今回の結果は、新規に作ったインデックスは結局選択されませんでした。
それおそらく、既存インデックスの方が統計情報が多く存在し、より正確な行数見積もりとコスト計算ができたからではないかと推測しています。今後は、その裏付けをしていきたいと考えています。
未使用のインデックス調査
今回の主題とは違いますが、未使用では?というインデックスも時々見られるのが現状です。
インデックスショットガンにならないよう、未使用と思われるインデックス、他で代替できるインデックスは、今後ウォッチして削除したり統合したりしていきたいです。所感
DBRE として、通常の開発業務から何歩か踏み込んでいるのが僕の日常になりつつあります。
やってみて、今まで雰囲気で EXPLAIN してたかもしれないなって思いましたし、より根拠が明確になり、実際の行数やコスト算出の経緯をみていくことでいくつかの推測も成り立ち、さらなる検証につながり理解も深まりました。開発する人はここまでやる必要はないと思いますが、EXPLAIN とその見方は今後社内で展開し、エンジニアの底を地道に上げていきたいなと考えています。
RDB は沼だなってずっと思ってはいるんですが、これが何より楽しいので、今後もより高みを目指しつつアウトプットしていきたいと思います。
さて、明日は あだちん 先生の「ランサーズの各サービスをECS/Fargateへ移行する取り組みについて」です。インフラも楽しいですよ!
- 投稿日:2020-12-06T16:14:12+09:00
【Rails】マイグレーション時にコメントを追加する
マイグレーション時にコメントを追加する方法
Rails 5からこの機能が標準で装備されたそうです。
それ以前ではgemを利用していたそうです。
追加したコメントはデータベース側に保存されます。コメントの付け方
マイグレーションファイルを生成されたら、
以下のような書式でコメントをマイグレーションファイルに追加します。class CreateProducts < ActiveRecord::Migration[6.0] def change create_table :products do |t| t.string :name, comment: '雑誌名' t.integer :z_code, null: false, comment: '雑誌コード' t.integer :num, null: false, comment: '取置冊数' t.string :release, null: false, comment: '発売日' t.references :customer, null: false, foreign_key: true t.timestamps end end endその後、rails db:migrateで完了です!
Sequel Proの「構造」から確認できます。コメントをつける意味
カラムにコメントをつける機能は「定義」を記録するって事が一番だと思います。
実際、6個程度のモデルしか作っていないのですが、
「name」カラム5つ「date」カラム3つも使っているのですよね・・・。
これからさらに追加で機能をつけていくとしたら、自身の備忘録としても意味がある機能だと思います。
ちなみに、コメントはあくまでメモとして残すものなので、
テーブルの動作的には何も影響はないそうです!参考にさせていただいたサイト様
https://techracho.bpsinc.jp/hachi8833/2017_02_23/36083
ありがとうございます!!
- 投稿日:2020-12-06T11:41:59+09:00
MySQLが起動しない(Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2))
開発環境
- Ruby 2.5.8
- Rails 5.2.1
- MySQL 8.0.22
新規開発をしようと「rails db:create」をした時のこと・・・
ポートフォリオの大方の設計が出来上がってきたので、アプリの大枠だけでも作成しようと
rails newをして新規アプリを作成し、rails db:createでDBを作成しようとしたところ、エラーで止まった。rails db:create Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) Couldn't create 'myPF_development' database. Please check your configuration. rails aborted! Mysql2::Error::ConnectionError: Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)1週間ほど前に、実際の開発工程に入ってから躓くのは嫌だと思い、同じバージョンのRuby,Rails,MySQLで確りとテスト開発して確認したのになぜなのか…
1週間前は動いたmysql -u root -pを打っても、mysql -u root -p Enter password: ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)となるばかりでまるで反応はなく…。またか…先週MySQL周りの設定で2日潰れたというのにまたなのか…MySQL君…、といった気持ちで調べてみるとやはりこの状況になる方は多いようで様々な記事が見つかりました。
その中でも、今回解決に導いてくれた記事を以下に貼っておきます。この記事のお陰で無事MySQLが動いてくれました。とても助かりました。■ 参考にした記事
mysqlが起動できない(Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2))解決はしましたが、今後もちょくちょくMySQL周りのエラーは起きそうな気がするので、Qiita記事を書く練習も兼ねてまとめておきます。上の記事と殆ど同内容にはなってしまいますがご容赦下さい。
mysql.sockファイルを作成する
エラー文にも書いてあるとおり、
mysql.sockというファイルを通してローカルのMySQLサーバーに接続しているらしいのですが、そのmysql.sockファイルがないと言われています。
そして厄介なことに、このファイルがなんらかの原因で消えることがあるらしいと。なので、以下のコマンドを通してmysql.sockファイルを作成します。sudo touch /tmp/mysql.sockMySQLの再起動をする
mysql.sockファイルを作成したら、MySQLを起動し直します。sudo mysql.server restart Starting MySQL ... SUCCESS!やった!
再度rails db:createしてみる
rails db:create Created database 'myPF_development' Created database 'myPF_test'いけた!よかった!
おわりに
これからもMySQL関連を触る時はお祈りしながらコマンドを打つことになりそうです…笑
先人のQiita記事に大感謝。
おまけ(個人的メモ)
MySQLの起動:mysql.server start
MySQLへの接続:mysql -u root -p
- 投稿日:2020-12-06T09:09:40+09:00
MySQLデータベースに絵文字を保存する
MySQLでは、デフォルトで絵文字を取り扱うことはできず、保存しようとするとエラーが発生します。
理由は、MySQL上で設定されている文字コードがUTF-8であるのに対して、絵文字はutf8mb4という文字コードでコードされているためです。
よって、MySQLで使用する文字コード設定をutf8mb4に変える必要があります。実行環境
・Mac OS Catalina 10.15
・MariaDB 10.5.8文字コードの確認
次のコマンドで文字コードの設定を確認できます。
MariaDB [database]> show variables like 'character%';> +--------------------------+--------------------------------------------------------+ | Variable_name | Value | +--------------------------+--------------------------------------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/local/Cellar/mariadb/10.5.8/share/mysql/charsets/ | +--------------------------+--------------------------------------------------------+これをut8mb4に変えます。
文字コード設定の変更
/usr/local/etc/my.cnfに MySQLの設定ファイルがありますので、これに書き込みます。
/usr/local/etc/my.cnf[mysqld] character-set-server = utf8mb4 [client] default-character-set = utf8mb4my.cnfが見つからない場合は、次のコマンドで探しましょう。
$ mysql --help | grep my.cnfMySQLサーバーを再起動し、設定を改めて確認します。
MariaDB [training]> show variables like 'character%'; > +--------------------------+--------------------------------------------------------+ | Variable_name | Value | +--------------------------+--------------------------------------------------------+ | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb4 | | character_set_filesystem | binary | | character_set_results | utf8mb4 | | character_set_server | utf8mb4 | | character_set_system | utf8 | | character_sets_dir | /usr/local/Cellar/mariadb/10.5.8/share/mysql/charsets/ | +--------------------------+--------------------------------------------------------+実際に追加してみます。(user_idとcontentという要素を持つPostsテーブルがあるとします)
MariaDB [database]> INSERT INTO posts (user_id, content) VALUES (4, '?'); Query OK, 1 row affected (0.003 sec)できました。