- 投稿日:2020-12-06T23:53:02+09:00
LambdaのProvisioned Concurrencyについて調べました
はじめに
2019年12月に提供されたLambdaのProvisioned Concurrencyに関して調べました。
注意
2020年12月6日時点の仕様について記載していおります。
Lambdaに元々ある概念 → "同時並行性"(Concurrency) (公式でも日本語訳が曖昧)
Lambda関数を並行(水平方向)に実行する際のリソースとなる概念が同時並行性です。
同時並行性には制限が存在しており、定量化として同時実行数(Concurrency Executions)という単位になっています。
制限は、リージョンごとに適用され、引き上げることができます。引き上げをリクエストするには、サポートセンターコンソール経由で問い合わせる必要があります。
リソース デフォルトの制限 同時実行数 1000 予約した並行性(Reserved Concurrency)
Provisioned Concurrencyの機能が発表される前から、予約した同時並行性(Reserved Concurrency)の機能はありました。
予約した同時並行性の機能というのは、単にリージョン内のある対象Lambda関数に対して常にN個までの同時並行数を確保することを保証させる機能です。
(例えば、あるLambda関数Aに500、関数Bに300の予約数を設定した場合、関数Cは1000-500-300で200までしか同時並行数をどんなにリクエストが来てもスケールさせることができません。)Provisioned Concurrency とは
Provisioned Concurrencyは上述の同時並行数をリクエストが実際にくる前に事前に立ち上げておく機能です。
たとえ同時実行数自体を予約していたとしても、Lambda関数には以下の課題があります。
課題1: 初期リクエストに関してコールドスタートとなりレイテンシーが大きくなる課題
Lambdaの代表的な課題でLambdaは利用されないと実行環境が存在しない状態になるため、そこからの初期リクエストでは実行環境構築に時間がかかりレスポンスが遅くなってしまいます。
課題2: スパイクなリクエストが来た場合、スケーリングが追いつかない課題
根本的には課題1と同じですが、スパイクなリクエスト来ると下記図のようにスケーリングが追いつかず、スロットリングに引っかかってしまう場合があります。
そこでProvisioned Concurrencyの機能が提供された
下記図のように、事前に同時実行数を立ち上げておくことで上記の課題を解決することができます。
https://dev.classmethod.jp/articles/lambda-provisioned-concurrency-coldstart/ の記事などを見るとコールドスタートの問題が解決できるようです。
Provisioned Concurrency の料金
【公式】AWS Lambda 料金 を参照しています。
LambdaのProvisioned Concurrencyを利用した場合、合計料金は下記のように独立した3つの概念の和となる内訳になります。
合計料金 = Provisioned Concurrency 料金 + リクエスト料金 + コンピューティング料金
Provisioned Concurrency は1 GB-秒あたり 0.0000053835USD とTokyoリージョンでは設定されています。例として、 対象のLambda関数に
- 256 MB のメモリを割り当て
- 同時実行数100
の設定でその関数で Provisioned Concurrency を 31 日間有効したとき、その月のProvisioned Concurrencyの料金は、
279.02 USD になりますメモリ割り当て量と同時実行数はそれぞれ量に応じて料金に比例します。
Provisioned Concurrency を設定する上でのポイント
Auto Scaling設定をしよう
(https://dev.classmethod.jp/articles/lambda-support-scheduled-autoscaling/ と https://dev.classmethod.jp/articles/lambda-support-provisioned-concurrency-autoscaling-2/ を参照しました。)
Provisioned Concurrencyを利用するにあたり、コストの面から"リクエスト開始からのリクエストの増減を事前に把握"した上で、必要なときにのみProvisionedさせておくことがベターだと言えます。
AWSのEC2やFargateなどと同様にApplication Auto Scalingから実行数やCPU利用率などの①パラメータベースのスケーリング設定と、②時間帯ベースのスケーリング設定の両方ともLambdaのProvisioned Concurrencyに対して設定することができます。
本当にLambdaを利用する必要ありますか?
( 【クラメソ記事】安い?それとも高い?Provisioned Concurrencyを有効化したLambdaのコストに関する考察 #reinvent
を参照しました。)Provisioned Concurrencyはある意味Lambdaの良さを失わせていると言えるようです。
コールドスタートを避けたりスケジュールされたスケーリングを求める場合はFargateにすることはできないか、など再検討する価値はあるようです。
参考


- 投稿日:2020-12-06T23:43:49+09:00
AWSでALB(Application Load Balancer)を作成してみた。
はじめに
個人サイトのSSL化を実装するため、ALBを作成したのでその手順を記録として残す。
Load Balancerとは
アプリケーションへのトラフィックを複数のターゲット (Amazon EC2 インスタンス、コンテナ、IP アドレス、Lambda 関数など) に自動的に分散します。Elastic Load Balancing は、変動するアプリケーショントラフィックの負荷を、1 つのアベイラビリティーゾーンまたは複数のアベイラビリティーゾーンで処理できます。
ドキュメント:https://aws.amazon.com/jp/elasticloadbalancing/
外部からの処理を分散させることで、負荷(load)を分散(Balance)させ、結果的に可用性(availability)のあるシステムを作成するAWSのサービス。
手順
EC2ダッシュボードからロードバランサーを選択して作成します。
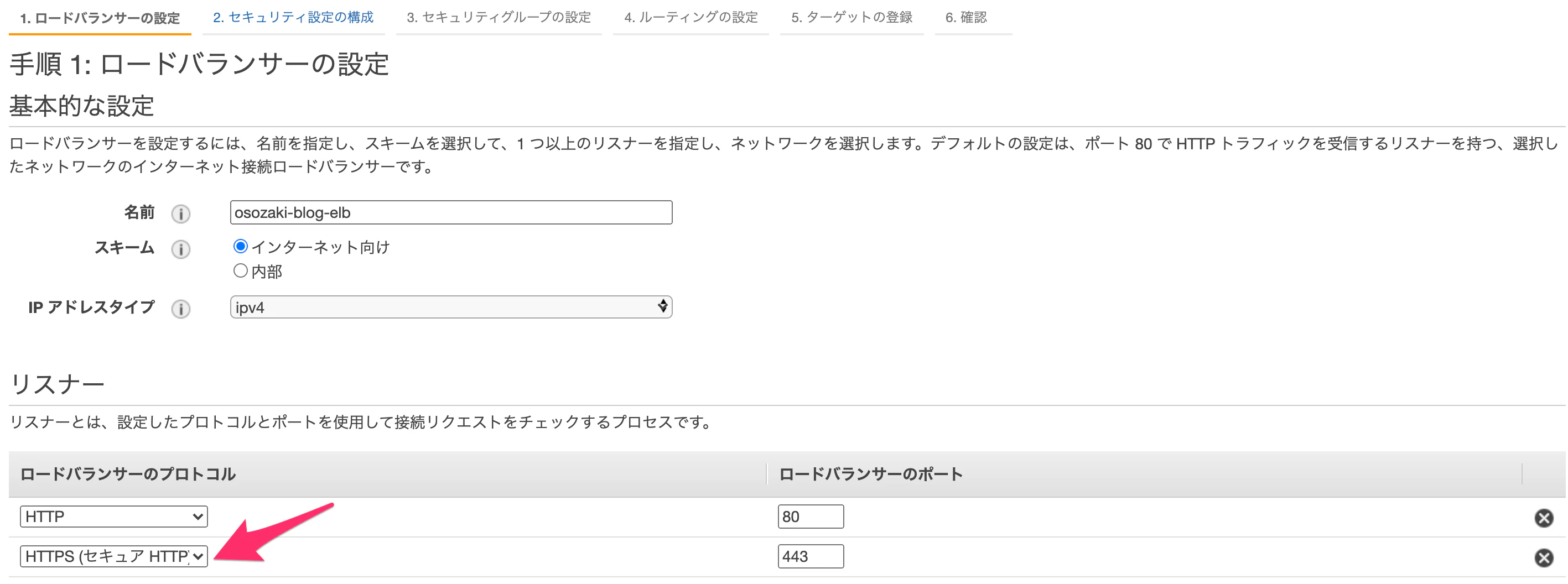
今回はALB(Application Load Balancer)で作成します。
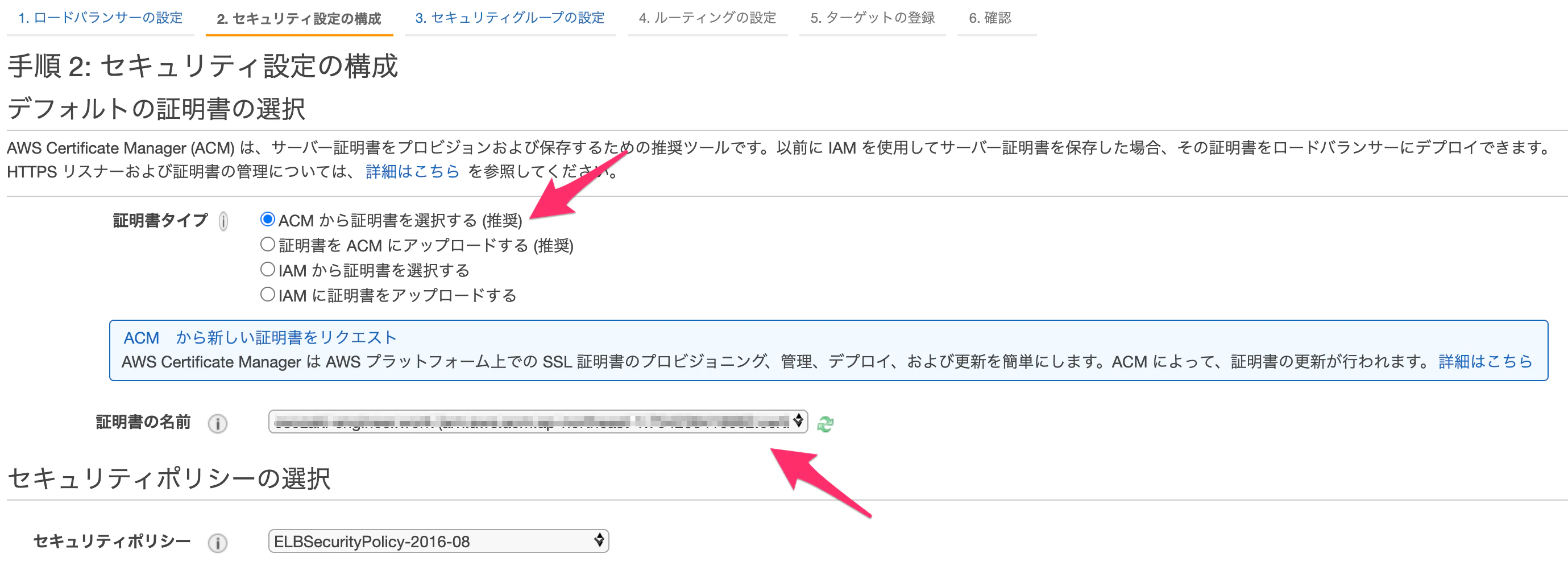
ロードバランサーのプロトコルにHTTPSを追加します。これを追加することで、手順2のセキュリティ設定の構成を行うことが可能となります。
AZを2つ指定します。
作成したACMを選択します。
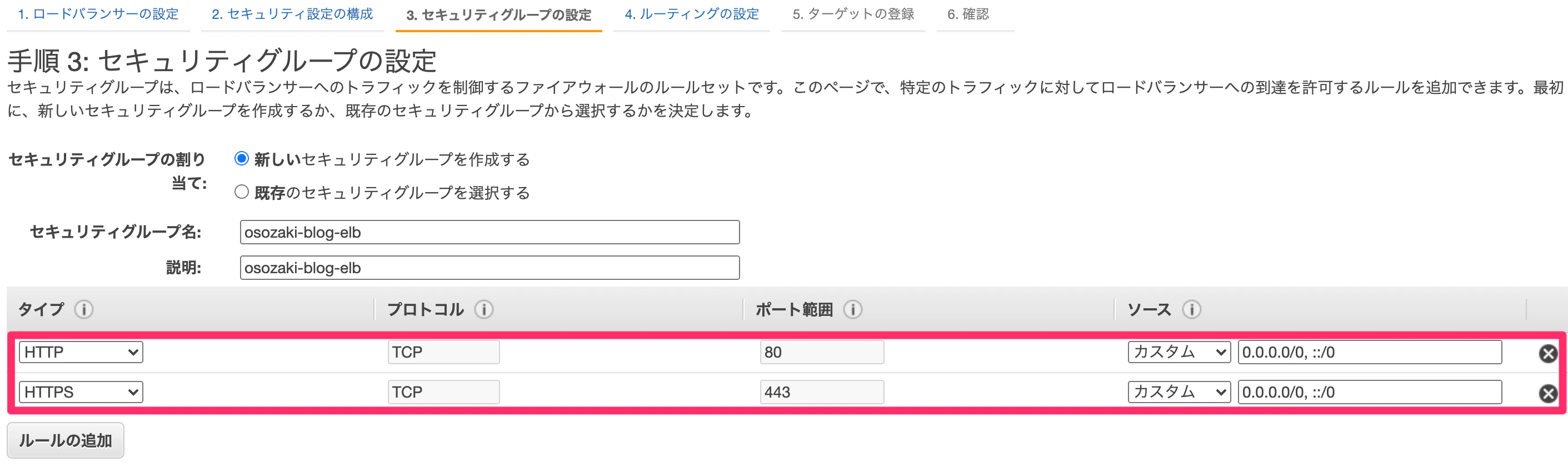
ELB用のセキュリティグループを作成し、HTTPとHTTPSのプロトコルを解放します。
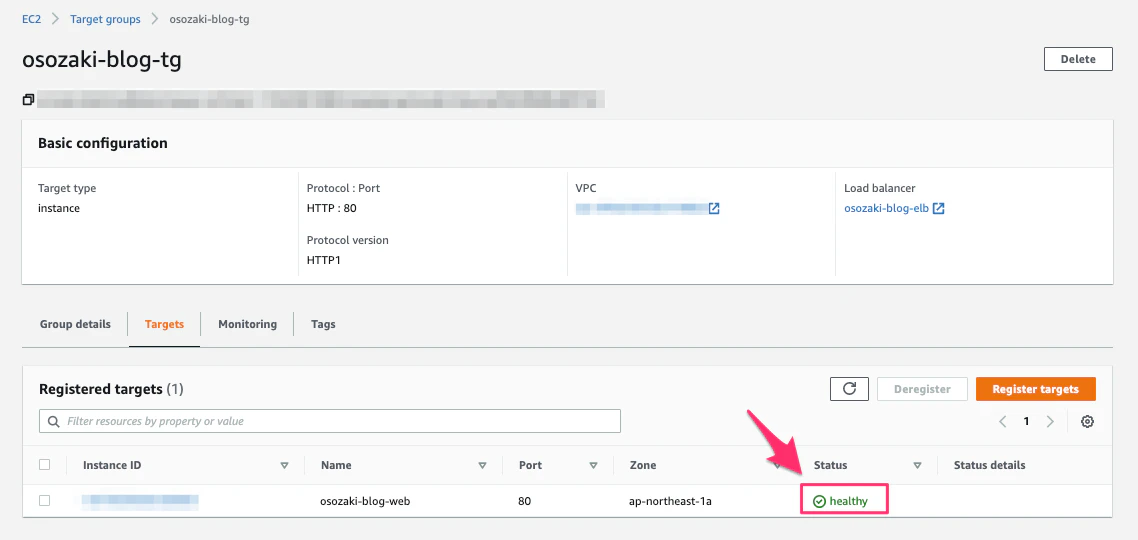
ターゲットグループを作成します。
ターゲットとなるインスタンスを指定します。
ターゲットグループのステータスがhealthyになったら設定完了です。





- 投稿日:2020-12-06T23:41:39+09:00
AWS ソリューションアーキテクトアソシエイト 問題 IAM編
概要
今回は会社の後輩向けにAWS ソリューションアーキテクトアソシエイト向けの問題を作成したのでそちらの公開を。
元ネタは公式の問題、BlackBeltなどからとっております
今回はIAMをみようと思います。IAM関係
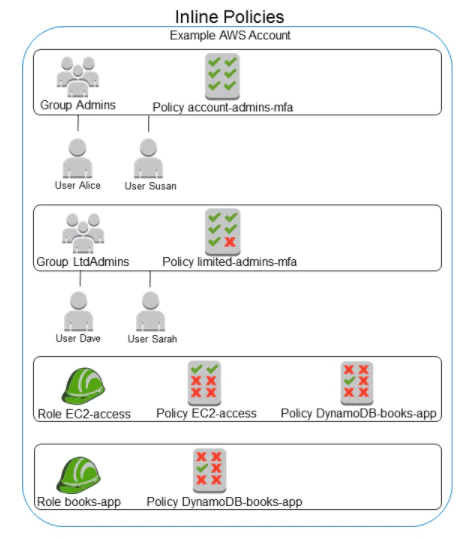
- EC2インスタンス(AWSアカウントをAとする)上で実行されるアプリケーションで別のAWSアカウント(Bとする)のS3のバケットへアクセスする実行したところ、アクセスできない問題が発生している。AのアプリからBのS3バケットへアクセスできるように対応する方法を以下から2つ選択してください。EC2インスタンスからは自分のAWSアカウントのS3バケットにはアクセスできるとする。
- BのアカウントにAのアカウントのIAMロールと同名のロールを作成しS3FullAccessの権限を付与する。
- AのアカウントのS3にBのアカウントと同名のバケットを作成しバケットポリシーにBのアカウントのアカウントからのprincipalを指定する。
- BのアカウントのS3バケットポリシーにAのアカウントのIAMロールをprincipalに指定する。
- AのアカウントのIAMロールにS3へのアクセス権を付与するリソースとしてBアカウントのバケットにアクセスできるように指定する。
回答
- 正解は
3. BのアカウントのS3バケットポリシーにAのアカウントのIAMロールをprincipalに指定する。 4. AのアカウントのIAMロールにS3へのアクセス権を付与するリソースとしてBアカウントのバケットにアクセスできるように指定する。 * アクセス先のS3バケットのprincipalにアクセス元のアカウントのIAMを許可するように記述しますこれはS3以外でも同様です。 * アクセス元のユーザはアクセス先のバケットへのアクセスできるように設定が必要です。
- 以下不正解の理由
1. 同名のロールを作成しても意味がありません。またS3FullAccessは権限が広すぎるので必要に応じて狭めるべきです。 2. まったく意味がありません。
- IAMのベストプラクティスではないものを以下から選択してください。
- AWS アカウントのルートユーザーアクセスキーをロックする。
- 認証情報を定期的にローテーションする。
- インラインポリシーを使用して権限を制御する。
- プログラムでAWSの各サービスにアクセスする場合ロールを使用する。
- IPアドレスや日付、MFA使用などを条件に追加する。
回答
- 正解は
3. インラインポリシーを使用して権限を制御する。 * インラインポリシーは個別に条件を設定できるが個別に設定することになるため管理ができなくなるのでカスタマー管理ポリシーを使用することが推奨されている。 * 個別に条件を設定したい場合(一次的に使わせるときなど)には有効
- 以下不正解の理由
- 他はすべてベストプラクティスとして推奨されています。
- 投稿日:2020-12-06T23:31:52+09:00
TerraformでAWS WAFを基礎から学ぶ(メトリクスとサンプリング編)
はじめに
基本のルール設定編の続き。
今回は、メトリクスとサンプリングについて確認をしていく。単純にメトリクスが取れるだけかと思いきや、Web ACL のマネージメントコンソールトップに表示されるメトリクスは一癖ある感じなので特性を理解しよう。
メトリクスは何が一癖あるのか
Web ACL のマネージメントコンソールトップに表示されるメトリクスを複雑にしているのは以下の3点。
- Web ACL のアクションが Allow か Block かによって計上・表示されるメトリクスが違うという点
- Web ACL 全体のメトリクスと個別ルールのメトリクスがあるという点
- 上記とは別に ALL AllowedRequests/ALL BlockedRequests というメトリクスがあるという点
上記をもう少し詳細に調べてみると、以下の仕様であった。
- Web ACL のデフォルトアクションが Allow の場合は、ルールの AllowedRequests と、ALL BlockedRequests が表示される
- Web ACL のデフォルトアクションが Block の場合は、ルールの BlockedRequests と、ALL AllowedRequests が表示される
- ALL AllowedRequests / ALL BlockedRequests は実際に許容/ブロックした件数ではなくて、あくまでも全体または個別のメトリクスの合計
このため、全体または個別のメトリクスをすべて Enable(TerraformではTrue) にしていないと、正確な件数を把握することはできない。
また、Web ACL のマネージメントコンソールでは全体像が見づらいので、コストをケチる目的がない限りは、すべてのメトリクスを Enable にして、CloudWatch メトリクスのコンソールで、すべてのメトリクスを表示するグラフを作った方が良いのではないかと感じた。
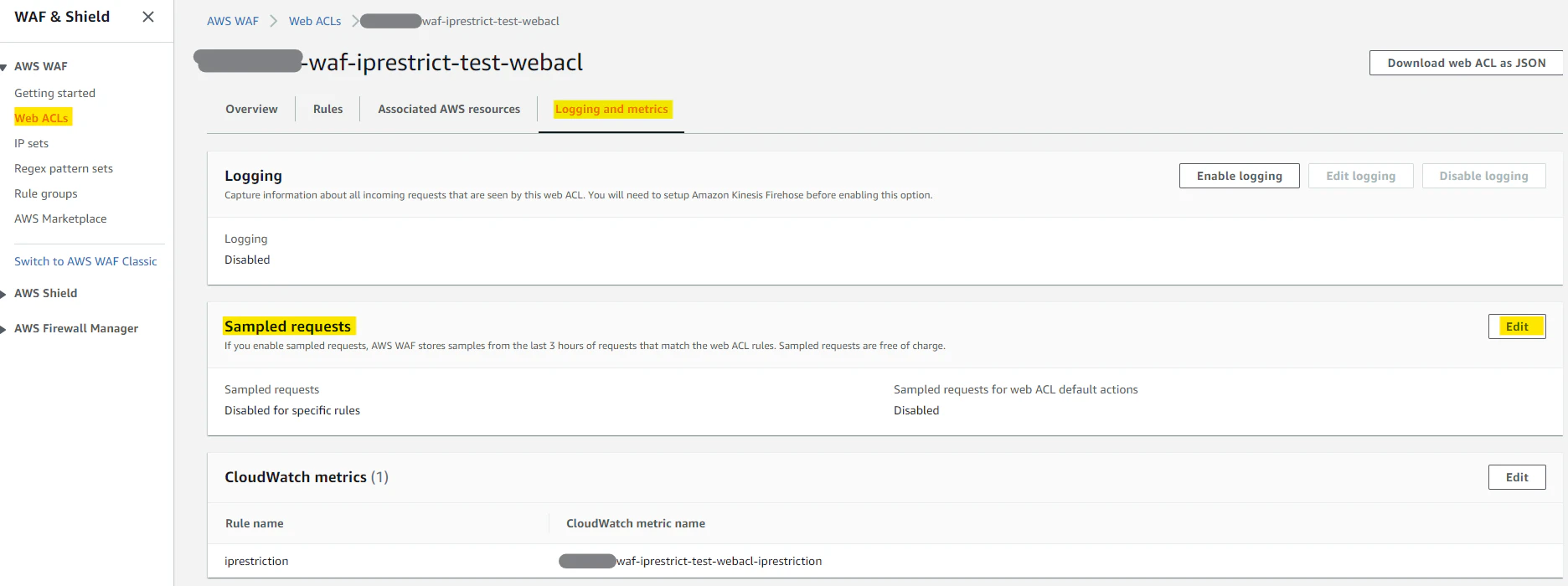
↓こんな感じ。これはデフォルトアクションが Allow、個別のアクションが Block でそれぞれメトリクスを Enable にした場合の全体像の把握のためのグラフ。
Terraform では、
aws_wafv2_web_acl本体とruleブロックの設定のcloudwatch_metrics_enabledをtrueにする。metric_nameはテキトーに分かりやすい名前をつけておこう。visibility_config { cloudwatch_metrics_enabled = true metric_name = local.webacl_metric_name sampled_requests_enabled = false }サンプリング
サンプリングは、有効化した
visibility_configについて、ALLOW ないし BLOCK の結果を記録してくれる。主にフィルタ内容のテスト目的ということだろうか?マネージメントコンソールの Web ACL の OverView のタブの下部で、以下のような情報を確認できる。
Terraform で有効化するには、
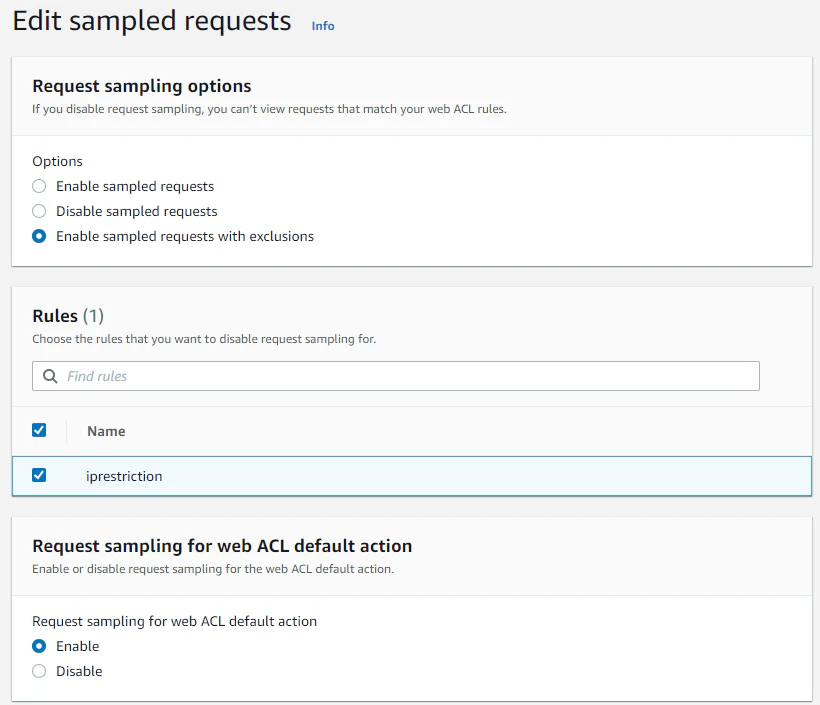
aws_wafv2_web_acl本体とruleブロックの設定のsampled_requests_enabledをtrueにする。メトリクスは関係ないかと思いきや、上記画面の右上のプルダウンで、メトリクス名で絞ることが可能なので、CloudWatch と同様に、metric_nameは分かりやすい名前にしておこう(CloudWatch メトリクスの名前と共用される)。visibility_config { cloudwatch_metrics_enabled = false metric_name = local.webacl_metric_name sampled_requests_enabled = true }HTTPリクエストに対してルールに引っかかって Allow したか Block したかのどちらかのみ出力される。
土のルールで引っかかったか(もしくは引っかからずデフォルトアクションとなったか)を確認する感じだろう。なお、マネージメントコンソールの Web ALC の Logging and Metrics のタブから設定の詳細を確認することが可能だ。
Web ACLのデフォルトの
visibility_configと、ルール単位のvisibility_configの設定内容によって以下のように表示される。
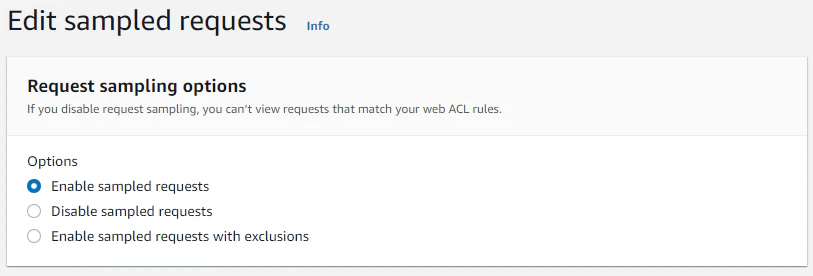
デフォルト=true, ルール=false
デフォルト=true, ルール=true
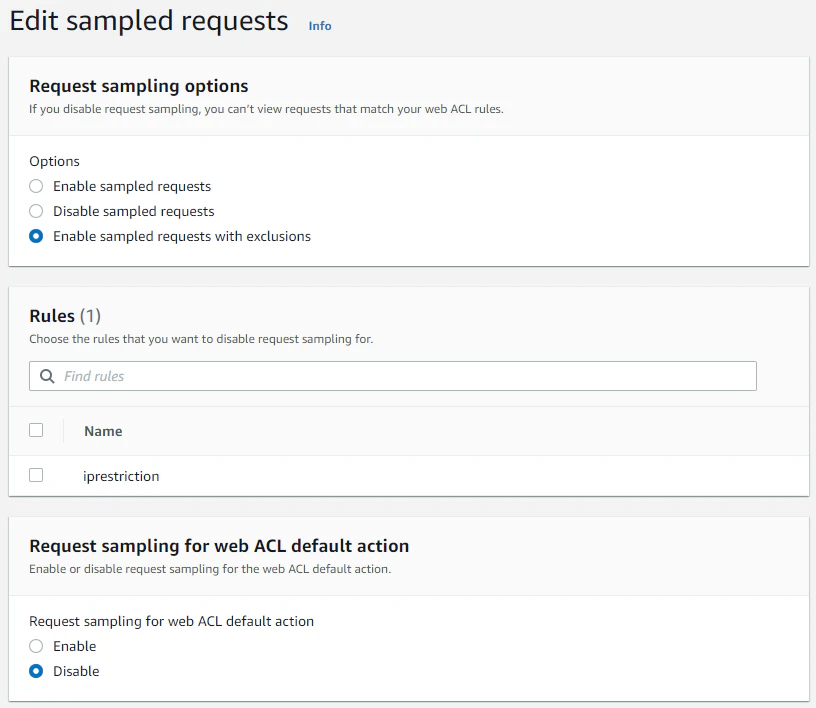
デフォルト=false, ルール=true
分かりにくい……。Terraform の方がよっぽどシンプルだ。
Request sampling for web ACL default action がデフォルトのvisibility_configの有効無効、Request sampling options は、デフォルトとルールで違う設定にしたいときにラジオボタンを付けるようだ。ともあれ、これでメトリクスとサンプリングについても設定方法と使い方は理解できた!


- 投稿日:2020-12-06T23:14:27+09:00
[AWS] EC2インスタンスにApacheをインストール
- 投稿日:2020-12-06T23:05:28+09:00
AWSをコマンドラインで扱うときに--profileってるけるのが面倒なのでdirenvをつかったほうがいい
aws cliを使うときに複数のprofileを使っていると時々間違えた環境に対して操作を行ってしまったりしてヒヤッとすることがある
--profileをつけわすれてワーみたいな
なのでdirenvという該当のディレクトリの中だけで環境変数を設定できるツールをつかっている
https://github.com/direnv/direnv該当のディレクトリに「.envrc」というファイルを作成して
以下のコマンドdirenv edit .中身をこんなふうにしておく⇣
export AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXXXXXX export AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxxxxxxそうしたらawsコマンドを使う前に
direnv arrowとすると.envrcの中の変数が該当ディレクトリ内だけで反映されるので
「--profile」ってつけなくても大丈夫になるのでヒューマンエラーを防げるおしまい
- 投稿日:2020-12-06T22:05:52+09:00
図説『実践Terraform』
はじめに
この記事はand factory Advent Calendar 2020 の7日目の記事です。
昨日は@y-okuderaさんのスクロールでNavigationBarとTabBarを隠す機能を自作してみるでした!インフラ構成をコード化するIaC(Infrastructure as Code)の代表的サービスであるTerraform。
このTerraformを学ぶ上で書籍『実践Terraform AWSにおけるシステム設計とベストプラクティス』がよく参考にされています。
本記事ではこの書籍をこれから読む方向けに、書籍内で紹介されているサンプルプロジェクトを構成するリソースを図にして紹介します。『実践Terraform』
タイトル:『実践Terraform AWSにおけるシステム設計とベストプラクティス』
著者:野村友樹(@tmknom)氏
発行:株式会社インプレスR&D@tmknomさん、インプレスR&Dさん、書影掲載許可いただきありがとうございます!
『実践Terraform AWSにおけるシステム設計とベストプラクティス』(以下『実践Terraform』とします)は、著者が技術書展やBOOTHなどで頒布されていた『Pragmatic Terraform on AWS』という同人誌を元にした内容となっています。
Terrafromの環境整備から、サンプルプロジェクトでのアーキテクチャ構築ハンズオン、Tipsまで幅広く掲載されており、初心者向けの参考書籍として最適です。さらに同人誌時代から、100ページ近くページ追記・改定した内容になっており、Terraform界隈では神本として多くの人に認知されているようです。
紹介記事(一部)
- 「Pragmatic Terraform on AWS」が神本だったので紹介する
- Terraformのエッセンスが凝縮された「Pragmatic Terraform on AWS」が素晴らしい
- 「Pragmatic Terraform on AWS」を読んだ
書籍を利用してみて
Terraformに初めて触れる初心者の私でも、この本の通りにイチから順序立てて作業することで、立派なAWSのアーキテクチャを構築することができました!
※なお、AWS SAAの学習をしている時期でもあったため、AWSの超基礎的な知識は持っていました。ただ、正直に言うと、組み上げているものの全体像が把握できず、とりあえず写経をしている、という状況になっていたのも事実です。
著者のサンプルコードリポジトリにコード等も載っているのですが、章ごとに追記する内容のみがまとめられているため、Terraform初心者の私としては全体の構造の把握に苦労してしまいました。そこで、実際にTerraformで構築するリソースを図式化してみて、理解を深めようと考えました。
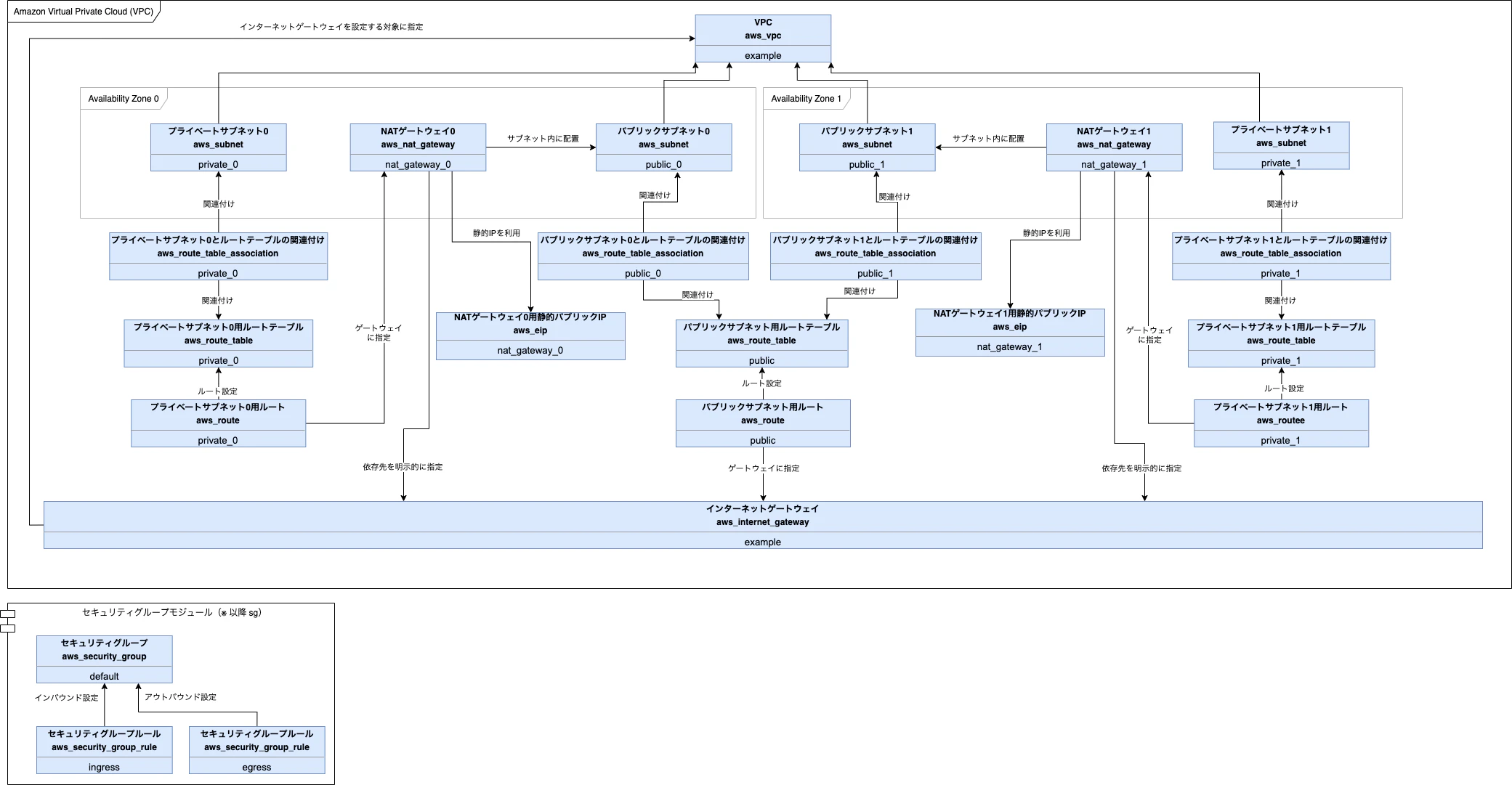
ここでは、その成果物とともに振り返り、同じ思いをする人を少しでも減らせられれば良いかなと思っています。全体図
今回は「第5章 権限管理」から「第16章 ロギング」までを対象として説明させていただきます。
1章から4章はTerraformの使い方や基本的な構文の説明で、17章以降はベストプラクティスとか継続的Applyとか、オプショナルな感じなので、図説はあまり有効ではないと判断しました。早速ですが下記が全体のイメージです。
※結構細かいのでクリックして拡大すると見やすいと思います。
作成するリソースは種類も数もとても多いため、大きくAWSサービスと、汎用的に用いるモジュールという分類で下記の形でレイヤーとして分割をしています。
さらに、具体的に作成するリソースやデータも下記のような形、色にて分類をしてみました。
リソース(青)は下記のような構造で表現しています。
上から順に「リソースの説明」「リソース種類名」「リソースに付けた名前」を表記しました。
書籍内ではリソースに名前をつけていない場合もあるのですが、そのような場合はとりあえずexampleと名付けています。(多分)
また、データ(黄)も同様の構造なので、同じルールにて記載しています。
モジュール(緑)は「リソース種類名」が必要ないため、除外しています。
その他、outputやproviderといった記載も書籍内では紹介されますが、アーキテクチャの理解にはそれほど影響を与えないため、除外しています。
矢印はリソース間の関係を示しています。
ただし、VPC等多くのリソースから依存されているものの関係性をすべて記載すると矢印の量がすごいことになるので、理解をする上でそれほど重要ではなさそうな部分は除外しています。上記の前提で図を見ていただければと思います。
なんとなく、作ろうとしているシステムの全体像が見えてくるのではないでしょうか。章ごとの対応箇所
ざっと全体のイメージをご紹介しました。
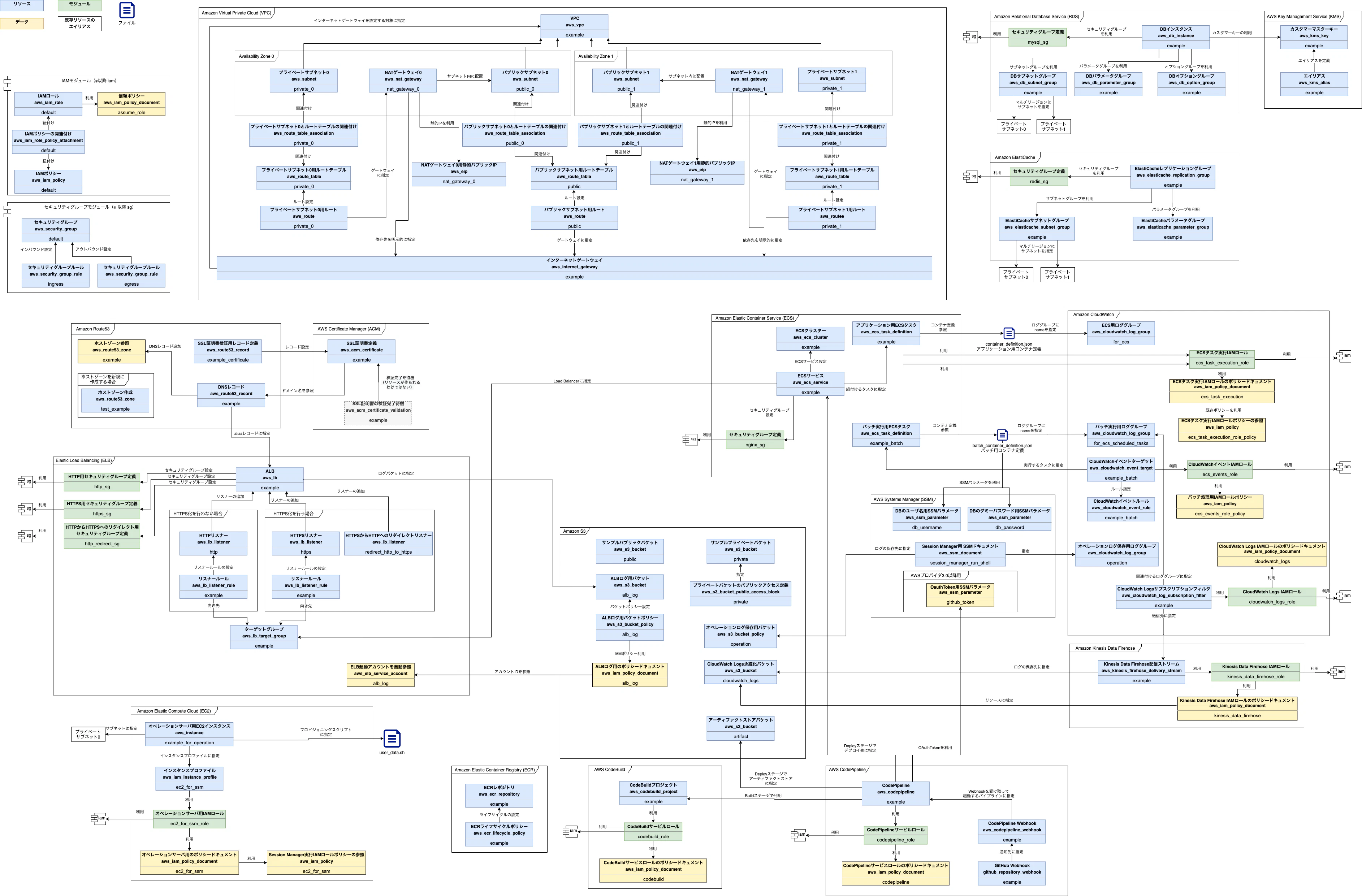
ここからは、各章ごとのイメージ箇所を抽出していこうと思います。第5章 権限管理
第5章では権限管理のためのIAMロールを作成します。
一通りのIAMロール説明が完了したところで、作成するサンプルプロジェクトで多様されるIAMロールモジュールを作成します。
図は最終的なIAMロールモジュールの構成です。作成したIAMロールモジュール用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_iam_role default IAMロール data aws_iam_policy_document assume_role 信頼ポリシー(ポリシードキュメント) resource aws_iam_policy default IAMポリシー resource aws_iam_role_policy_attachment default IAMポリシーのアタッチ(IAMロールにIAMポリシーをアタッチする) 第6章 ストレージ
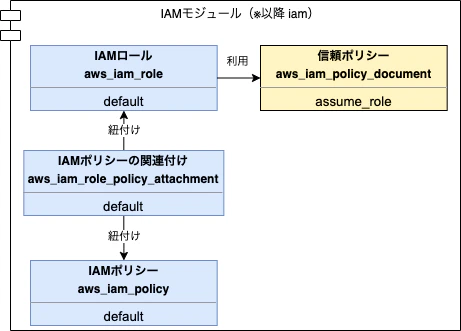
第6章ではストレージとして用いるS3バケットを作成します。
サンプルとしてパブリックバケット、プライベートバケット、ALBログ用バケットを作成しますが、ALBログ用バケットは第7章 ネットワークでも利用されます。作成したS3用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_s3_bucket private プライベートバケット resource aws_s3_bucket_public_access_block private プライベートバケットのパブリックアクセス定義 resource aws_s3_bucket public パブリックバケット resource aws_s3_bucket alb_log ログバケット(後に定義するALB用のログを格納する) data aws_iam_policy_document alb_log ALBログを書き込むためのIAMポリシー なお、
リスト6.5にidentifiersを直接記載する箇所がありますが、ソース管理上アカウントIDを直接記載したくないため、aws_elb_service_accountのデータを参照し、これを参照する形に調整を行いました。# ログの書き込みに使用されるアカウントIDを自動的にフェッチできる data "aws_elb_service_account" "alb_log" {} # リスト6.5 ALBログを書き込むためのIAMポリシー data "aws_iam_policy_document" "alb_log" { statement { effect = "Allow" actions = ["s3:PutObject"] resources = ["arn:aws:s3:::${aws_s3_bucket.alb_log.id}/*"] principals { type = "AWS" identifiers = ["${data.aws_elb_service_account.alb_log.id}"] # 参照 } } }追加したサービスアカウント取得用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_elb_service_account alb_log ログの書き込みに使用されるアカウントIDを自動的にフェッチする 第7章 ネットワーク
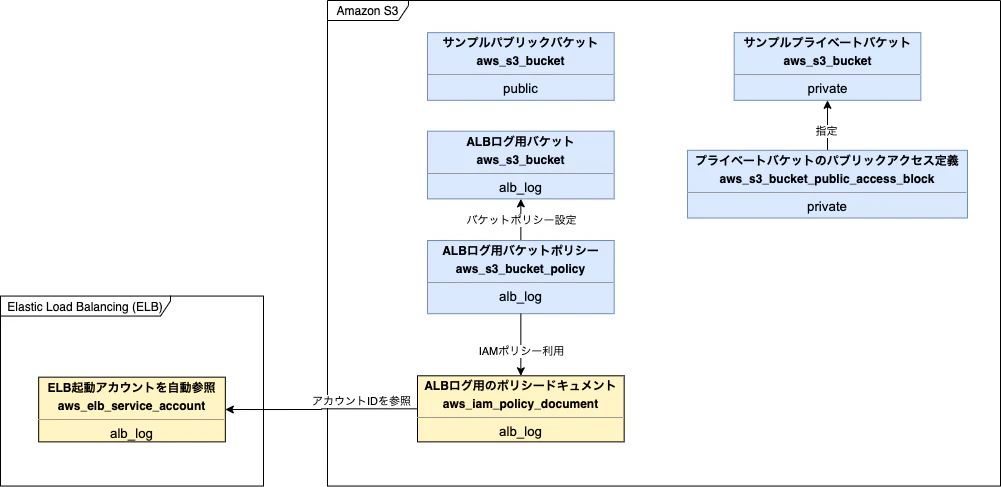
第7章ではネットワーク(VPC)とセキュリティグループを作成します。
章内の7.1パブリックネットワーク、7.2 プライベートネットワークで構築された下記リソースは、7.3マルチAZ以降でマルチAZ化に伴って細分化変更されます。
上図は7章完了状態の図のため、マルチAZ前のリソースは図中には存在しません。
調整前リストNo. 名称 調整後リストNo. リスト7.2 パブリックサブネット リスト7.12 リスト7.6 パブリックサブネット用ルートテーブルの関連付け リスト7.13 リスト7.7 プライベートサブネット リスト7.14 リスト7.8 プライベートサブネット用ルートテーブルと関連付け リスト7.16 リスト7.9 プライベートサブネット用のEIP リスト7.15 リスト7.10 プライベートサブネット用のNATゲートウェイ リスト7.15 リスト7.11 プライベートサブネット用のルート リスト7.16 作成したマルチAZのVPC用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_vpc example VPC resource aws_internet_gateway example インターネットゲートウェイ resource aws_subnet public_0 AZ0のパブリックサブネット resource aws_subnet public_1 AZ1のパブリックサブネット resource aws_route_table public パブリックサブネット用ルートテーブル resource aws_route public パブリックサブネット用ルート(ルートテーブルのレコード) resource aws_route_table_association public_0 AZ0のパブリックサブネットとルートテーブルの関連付け resource aws_route_table_association public_1 AZ1のパブリックサブネットとルートテーブルの関連付け resource aws_subnet private_0 AZ0のプライベートサブネット resource aws_subnet private_1 AZ1のプライベートサブネット resource aws_eip nat_gateway_0 AZ0のNATゲートウェイ用EIP resource aws_eip nat_gateway_1 AZ1のNATゲートウェイ用EIP resource aws_nat_gateway nat_gateway_0 AZ0のNATゲートウェイ resource aws_nat_gateway nat_gateway_1 AZ1のNATゲートウェイ resource aws_route_table private_0 AZ0のプライベートサブネットのルートテーブル resource aws_route_table private_1 AZ1のプライベートサブネットのルートテーブル resource aws_route private_0 AZ0のプライベートサブネットのルート resource aws_route private_1 AZ1のプライベートサブネットのルート resource aws_route_table_association private_0 AZ0のプライベートサブネットのルートテーブルの関連付け resource aws_route_table_association private_1 AZ1のプライベートサブネットのルートテーブルの関連付け 作成したセキュリティグループモジュール用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_security_group default セキュリティグループ resource aws_security_group_rule ingress セキュリティグループルール(インバウンド) resource aws_security_group_rule egress セキュリティグループルール(アウトバウンド) 第8章 ロードバランサーとDNS
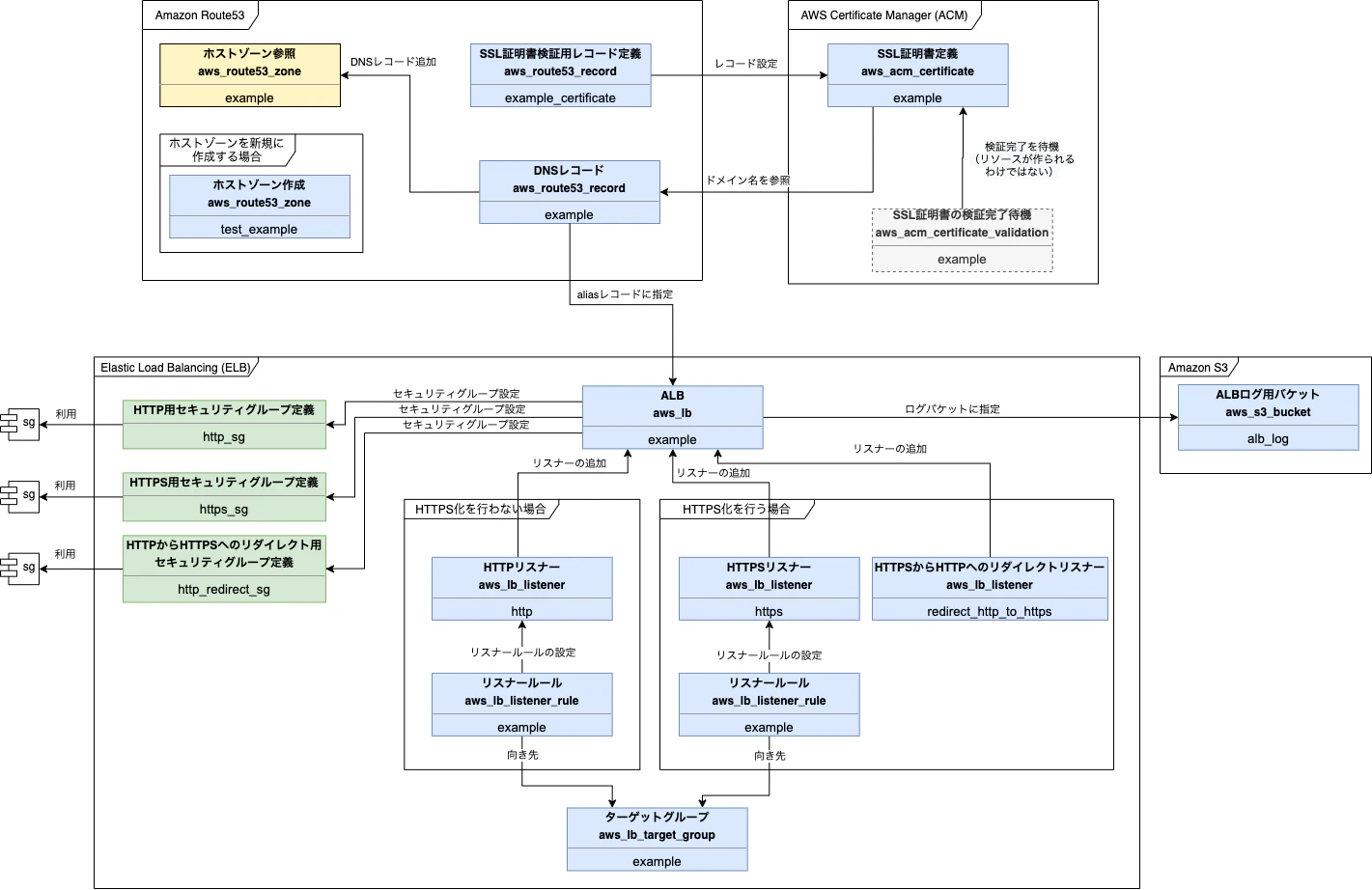
第8章ではロードバランサー(ALB)を作成し、Route53でDNSを設定します。また、SSL化のためにACMを利用します。
学習を行う上で、ドメインとSSLを入れない選択を取ることもできます。
その場合は、Route53、ACMを設定せずにELBのみ作成して試すことが可能なので、図内ELBのHTTPS化を行わない場合の構成を作成すれば良いです。図中に
sgというモジュールがありますが、これは第7章 ネットワークで作成したセキュリティモジュールを示しています。
また、図中のALBログ用バケットは第6章 ストレージで作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したELB用のリソースは下記です。
HTTPS化を行う場合と行わない場合、両方に関して記載しています。
種別 リソース種類 名前 備考 resource aws_lb example ALB module - http_sg HTTP用セキュリティグループ module - https_sg HTTPS用セキュリティグループ module - http_redirect_sg HTTPからHTTPSへのリダイレクト用セキュリティグループ resource aws_lb_listener http HTTPリスナーの定義(HTTPS化を行わない場合) resource aws_lb_listener https HTTPリスナーの定義(HTTP化を行う場合) resource aws_lb_listener redirect_http_to_https HTTPSからHTTPへのリダイレクトリスナーの定義(HTTP化を行う場合) resource aws_lb_target_group example ターゲットグループ resource aws_lb_listener_rule example リスナールール(HTTPS化を行う場合と行わない場合でlistener_arnの設定値が異なる) 作成したRoute53用のリソースは下記です。
図はホストゾーンが既にある状態を想定していますが、下記には新規に作成する場合に関しても記載しています。
また、SSL証明書を利用しない場合は、SSL証明書検証用レコード定義は必要なくなります。
種別 リソース種類 名前 備考 data aws_route53_zone example ホストゾーンの参照(ホストゾーンがすでにある場合) resource aws_route53_zone example_test ホストゾーンの作成(ホストゾーンを新規に作成する場合) resource aws_route53_record example ALBのDNSレコード resource aws_route53_record example_certificate SSL証明書の検証用レコード 作成したACM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_acm_certificate example SSL証明書 resource aws_acm_certificate_validation example SSL証明書の検証完了まで待機(apply時にSSL証明書の検証が完了するまで待つ。何かのリソースが作られるわけではない。) 第9章 コンテナオーケストレーション
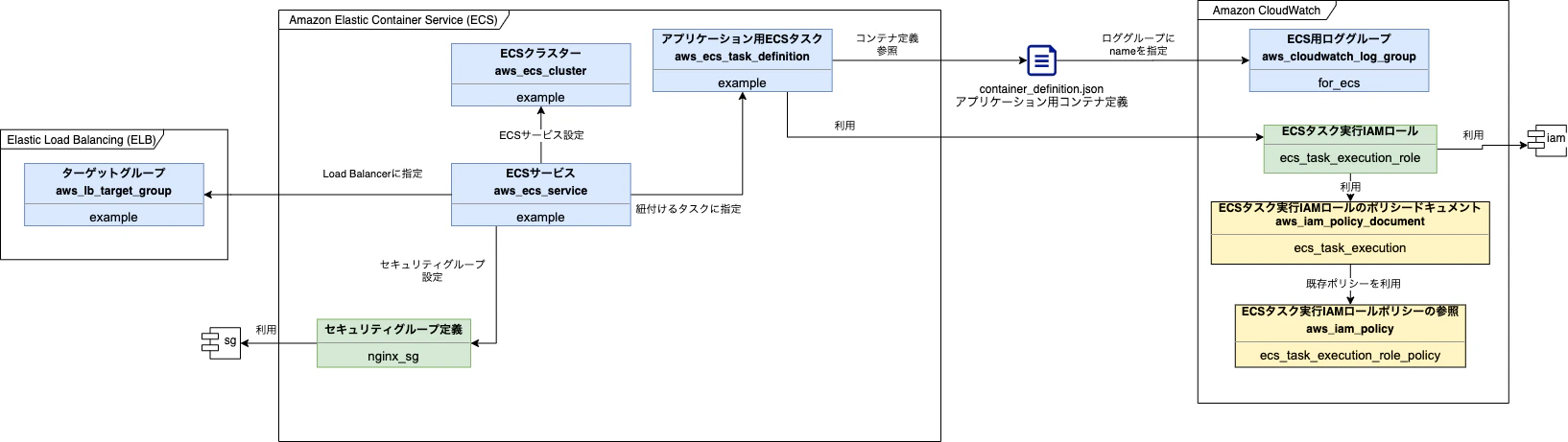
第9章ではコンテナオーケストレーション環境を作成します。
コンテナ定義はcontainer_definition.jsonで行われています。
これはTerraformプロジェクト内に置かれる定義ファイルで、構成図に本来載るものではないとは思うのですが、関係性を明示したかったので記載しました。(わかりやすければええやん精神)図中に
iamというモジュールがありますが、これは第5章 権限管理で作成したIAMモジュールを示しています。
また、図中のターゲットグループは第8章 ロードバランサーとDNSで作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したCloudWatch用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ecs_cluster example ECSクラスター resource aws_ecs_task_definition example ECSタスク定義 resource aws_ecs_service example ECSサービス(起動タスクの数やタスクの維持、ALBとの橋渡し) module - nginx_sg Nginx用セキュリティグループ 作成したACM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_cloudwatch_log_group for_ecs CloudWatch Logs data aws_iam_policy ecs_task_execution_role_policy ECSタスク実行IAMロールポリシーの参照(AWSが管理しているポリシー) data aws_iam_policy_document ecs_task_execution ECSタスク実行IAMロールのポリシードキュメント module - ecs_task_execution_role ECSタスク実行IAMロール 第10章 バッチ & 第12章 設定管理
第10章ではECSとCloudWatchを用いたバッチ処理を作成します。
バッチの作成で用いるバッチ用コンテナ定義は、第12章でSSMパラメータを使う形に調整されています。
そのため、第10章と第12章は一つにまとめて図を紹介しました。また、図中の
ECSタスク実行IAMロールは第9章 コンテナオーケストレーションで作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したECS用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ecs_task_definition example_batch バッチ用ECSタスク定義 作成したCloudWatch用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_cloudwatch_log_group for_ecs_scheduled_tasks バッチ用CloudWatch Logs module - ecs_events_role CloudWatchイベントIAMロール data aws_iam_policy ecs_events_role_policy CloudWatchイベントIAMロールポリシー resource aws_cloudwatch_event_rule example_batch CLoudWatchイベントルール resource aws_cloudwatch_event_target example_batch CloudWatchイベントターゲット 作成したSSM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ssm_parameter db_username DBのユーザ名の定義 resource aws_ssm_parameter db_password DBのダミーパスワードの定義 第11章 鍵管理
第11章では第13章で用いるためのカスタマーキーを作成します。
作成するカスタマーマスターキーにはUUIDが割り当てられているのですが、人には識別しづらい体系であるため、分かりやすい名前のエイリアスを作成しています。作成したKMS用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_kms_key example カスタマーマスターキー resource aws_kms_alias example エイリアスの定義(カスタマーキーのUUIDでは判別しづらいため) 第13章 データストア
第13章ではRDB向けデータストアのRDSとインメモリデータストアのElastiCacheを作成します。
作成するデータストアは、それぞれマルチAZに構築するため、第7章 ネットワークで作成したリージョンの異なるプライベートサブネット2つを指定しています。
※プライベートサブネット0、プライベートサブネット1はVPC内に作成したサブネットとして見ていただければと思います。(図示が難しかった)また、図中の
カスタマーマスターキーは第11章 鍵管理で作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したRDS用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_db_parameter_group example DBパラメータグループ resource aws_db_option_group example DBオプショングループ(DBエンジンにオプション機能を追加する。例はMariaDB監査プラグイン) resource aws_db_subnet_group example DBサブネットグループ(DBを稼働させるサブネットの定義) resource aws_db_instance example DBインスタンス module - mysql_sg DBインスタンスのセキュリティグループ 作成したElastiCache用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_elasticache_parameter_group example ElastiCacheパラメータグループ resource aws_elasticache_subnet_group example ElastiCacheサブネットグループ resource aws_elasticache_replication_group example ElastiCacheレプリケーショングループ(Redisサーバの作成) module - redis_sg ElastiCacheレプリケーショングループのセキュリティグループ 第14章 デプロイメントパイプライン
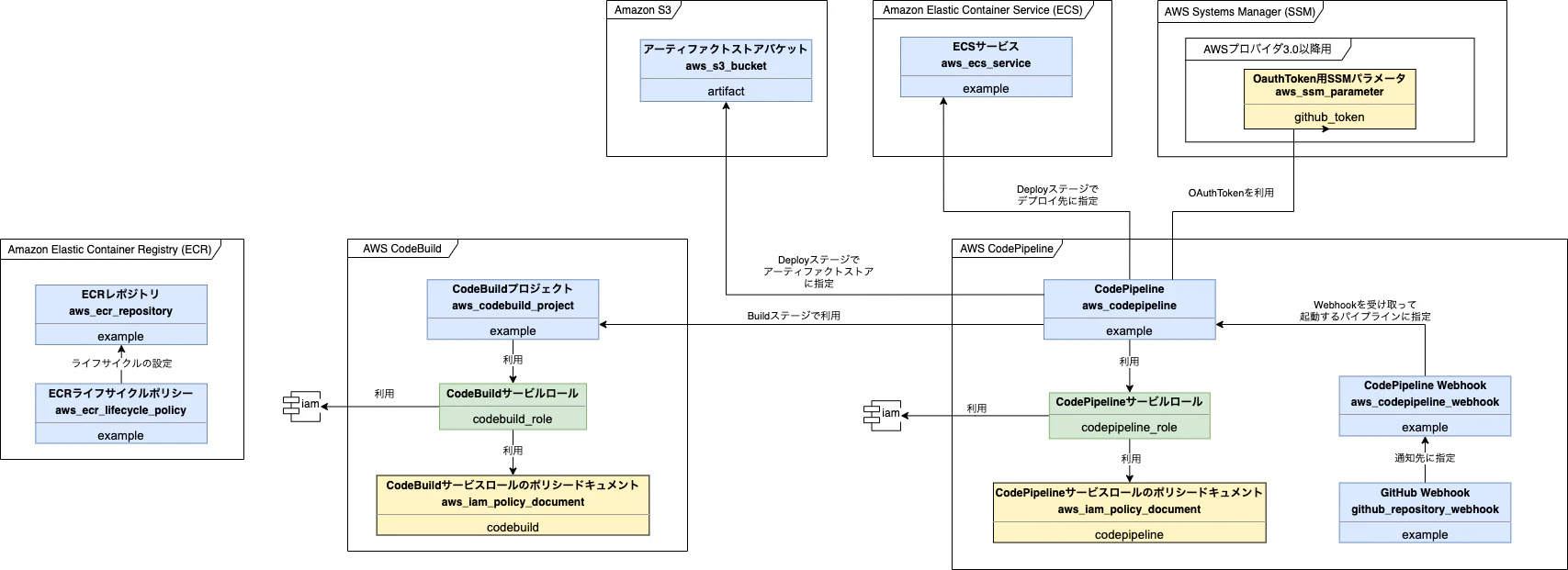
第14章では継続的にシステムをデプロイするためのデプロイパイプラインをCodePipelineを中心にして作成します。図中にECRへの矢印(関係性)が見えないと思うかもしれませんが、デプロイメントパイプラインで使われないわけではありません。
ビルドされるアプリケーションコード内にあるbuildspec.ymlにてプッシュ先リポジトリに指定されています。
今回はTerraformプロジェクト内には無いリソースのため、図中へは記載しませんでした。また、図中の
ECSサービスは第9章 コンテナオーケストレーションで作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したECR用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ecr_repository example ECRレポジトリ resource aws_ecr_lifecycle_policy example ECRライフサイクルポリシー 作成したS3用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_s3_bucket artifact アーティファクトストア用バケット 作成したCodeBuild用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document codebuild CodeBuildサービスロールのポリシードキュメント module - codebuild_role CodeBuildサービルロール resource aws_codebuild_project example CodeBuildプロジェクト 作成したCodePipeline用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document codepipeline CodePipelineサービスロールのポリシードキュメント module - codepipeline_role CodePipelineサービスロール resource aws_codepipeline example CodePipeline(例では3つのステージで実装する) resource aws_codepipeline_webhook example CodePipeline Webhook resource github_repository_webhook example GitHub Webhook(GitHub上でのイベントを検知し、コードの変更を通知するWebhookの定義) なお、AWSプロバイダ3.3.0から新規で作る時は
OAuthTokenが必須らしく、書籍内の14.10のコードのままだとSourceステージでコケてしまいます。
そのため、github_tokenをSSMパラメータとして定義し、それを用いることにしました。data "aws_ssm_parameter" "github_token" { name = "/continuous_apply/github_token" } # リスト14.10 # CodePipelineの定義(例では3つのステージで実装する) resource "aws_codepipeline" "example" { name = "example" role_arn = module.codepipeline_role.iam_role_arn # Sourceステージ:GitHubからソースコードを取得する stage { name = "Source" action { name = "Source" category = "Source" owner = "ThirdParty" provider = "GitHub" version = 1 output_artifacts = ["Source"] configuration = { ~中略~ PollForSourceChanges = false OAuthToken = data.aws_ssm_parameter.github_token.value # SSMパラメータから指定 } } } ~後略~追加したSSM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ssm_parameter github_token GitHub TokenをSSMパラメータとして定義 第15章 SSHレスオペレーション
第15章ではオペレーション用のサーバをSession ManagerとEC2を用いて作成します。
また、オペレーションログとしてSession Managerの操作ログを保存する仕組みを構築します。オペレーションサーバ自体は第7章 ネットワークでVPC内に作成したプライベートサブネットに作成します。
user_data.shはTerraformプロジェクト内に配置されているshファイルですが、EC2インスタンス作成時に実行されるプロビジョニングスクリプトとして指定されています。追加したEC2用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document ec2_for_ssm オペレーションサーバ用ポリシードキュメント data aws_iam_policy ec2_for_ssm Session Manager用に定義されているポリシーをベースに利用する module - ec2_for_ssm_role オペレーションサーバ用IAMロール resource aws_iam_instance_profile ec2_for_ssm インスタンスプロファイル(EC2は直接IAMロールを関連付けられないため、IAMロールをラップしたインスタンスプロファイルを関連付ける) resource aws_instance example_for_operation オペレーションサーバ用EC2インスタンス 追加したS3用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_s3_bucket operation_instance_id オペレーションログを保存するS3バケットの定義 作成したCloudWatch用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_cloudwatch_log_group operation オペレーションログを保存するCloudWatch Logs 作成したSSM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ssm_document session_manager_run_shell Session Manager用SSM document 第16章 ロギング
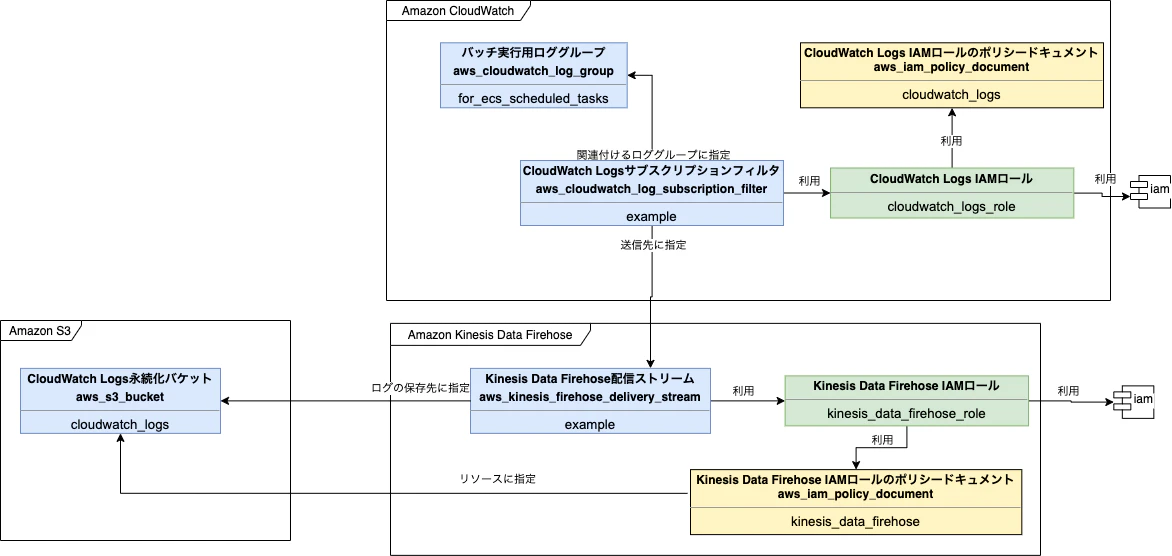
第16章ではロギングの仕組みを作成します。
ロギングにはCloudWatch Logsが便利であることを書籍では紹介した上で、サンプルプロジェクトではログをKinesis Data Firehoseの配信ストリームを用いてS3に永続化する方法を紹介しています。作成したS3用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_s3_bucket cloudwatch_logs CloudWatch Logs永続化バケット 作成したKinesis Data Firehose用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document kinesis_data_firehose Kinesis Data Firehose IAMロールのポリシードキュメントの定義 module - kinesis_data_firehose_role Kinesis Data Firehose用IAMロール resource aws_kinesis_firehose_delivery_stream example Kinesis Data Firehose配信ストリーム(Kinesis Data Firehoseにログが流れるとこの配信ストリームに設定したS3バケットへログを保存する) 作成したCloudWatch用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document cloudwatch_logs CloudWatch Logs用IAMロールポリシードキュメント module - cloudwatch_logs_role CloudWatch Logs用IAMロール resource aws_cloudwatch_log_subscription_filter example CloudWatch Logsサブスクリプションフィルタ おわりに
本記事で挙げている図は完全に筆者のイメージで作られています。
そのため、実際のものと異なる可能性が多分にあります。
何かお気づきの点等あればコメント等にてお知らせいただけますと幸いです。この記事が少しでも参考になっていたら嬉しいです。









- 投稿日:2020-12-06T22:05:52+09:00
図解『実践Terraform』
この記事はand factory Advent Calendar 2020 の7日目の記事です。
昨日は@y-okuderaさんのスクロールでNavigationBarとTabBarを隠す機能を自作してみるでした!はじめに
インフラ構成をコード化するIaC(Infrastructure as Code)の代表的サービスであるTerraform。
このTerraformを学ぶ上で書籍『実践Terraform AWSにおけるシステム設計とベストプラクティス』がよく参考にされています。
本記事ではこの書籍をこれから読む方向けに、書籍内で紹介されているサンプルプロジェクトを構成するリソースを図にして紹介します。『実践Terraform』
タイトル:『実践Terraform AWSにおけるシステム設計とベストプラクティス』
著者:野村友樹(@tmknom)氏
発行:株式会社インプレスR&D@tmknomさん、インプレスR&Dさん、書影掲載許可いただきありがとうございます!
『実践Terraform AWSにおけるシステム設計とベストプラクティス』(以下『実践Terraform』とします)は、著者が技術書展やBOOTHなどで頒布されていた『Pragmatic Terraform on AWS』という同人誌を元にした内容となっています。
出版にあたり、同人誌時代から、100ページ近くページ追記・改定した内容になっており、Terraform界隈では神本として多くの人に認知されているようです。Terrafromの環境整備から、サンプルプロジェクトでのアーキテクチャ構築ハンズオン、Tipsまで幅広く掲載されており、初心者向けの参考書籍として最適です。
紹介記事(一部)
- 「Pragmatic Terraform on AWS」が神本だったので紹介する
- Terraformのエッセンスが凝縮された「Pragmatic Terraform on AWS」が素晴らしい
- 「Pragmatic Terraform on AWS」を読んだ
書籍を利用してみて
Terraformに初めて触れる初心者の私でも、この本の通りにイチから順序立てて作業することで、立派なAWSのアーキテクチャを構築することができました!
※なお、AWS SAAの学習をしている時期でもあったため、AWSの超基礎的な知識は持っていました。ただ、正直に言うと、組み上げているものの全体像が把握できず、とりあえず写経をしている、という状況になっていたのも事実です。
著者のサンプルコードリポジトリにコード等も載っているのですが、章ごとに追記する内容のみがまとめられているため、Terraform初心者の私としては全体の構造の把握に苦労してしまいました。そこで、実際にTerraformで構築するリソースを図式化してみて、理解を深めようと考えました。
ここでは、その成果物とともに振り返り、同じ思いをする人を少しでも減らせられれば良いかなと思っています。全体図
今回は「第5章 権限管理」から「第16章 ロギング」までを対象として説明させていただきます。
1章から4章はTerraformの使い方や基本的な構文の説明で、17章以降はベストプラクティスとか継続的Applyとか、オプショナルな感じなので、図解はあまり有効ではないと判断しました。早速ですが下記が全体のイメージです。
※結構細かいのでクリックして拡大すると見やすいと思います。
作成するリソースは種類も数もとても多いため、大きくAWSサービスと、汎用的に用いるモジュールという分類で下記の形でレイヤーとして分割をしています。
さらに、具体的に作成するリソースやデータも下記のような形、色にて分類をしてみました。
リソース(青)は下記のような構造で表現しています。
上から順に「リソースの説明」「リソース種類名」「リソースに付けた名前」を表記しました。
書籍内ではリソースに名前をつけていない場合もあるのですが、そのような場合はとりあえずexampleと名付けています。(多分)
また、データ(黄)も同様の構造なので、同じルールにて記載しています。
モジュール(緑)は「リソース種類名」が必要ないため、除外しています。
その他、outputやproviderといった記載も書籍内では紹介されますが、アーキテクチャの理解にはそれほど影響を与えないため、除外しています。
矢印はリソース間の関係を示しています。
ただし、VPC等多くのリソースから依存されているものの関係性をすべて記載すると矢印の量がすごいことになるので、理解をする上でそれほど重要ではなさそうな部分は除外しています。上記の前提で図を見ていただければと思います。
なんとなく、作ろうとしているシステムの全体像が見えてくるのではないでしょうか。章ごとの対応箇所
ざっと全体のイメージをご紹介しました。
ここからは、各章ごとのイメージ箇所を抽出していこうと思います。第5章 権限管理
第5章では権限管理のためのIAMロールを作成します。
一通りのIAMロール説明が完了したところで、作成するサンプルプロジェクトで多様されるIAMロールモジュールを作成します。
図は最終的なIAMロールモジュールの構成です。作成したIAMロールモジュール用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_iam_role default IAMロール data aws_iam_policy_document assume_role 信頼ポリシー(ポリシードキュメント) resource aws_iam_policy default IAMポリシー resource aws_iam_role_policy_attachment default IAMポリシーのアタッチ(IAMロールにIAMポリシーをアタッチする) 第6章 ストレージ
第6章ではストレージとして用いるS3バケットを作成します。
サンプルとしてパブリックバケット、プライベートバケット、ALBログ用バケットを作成しますが、ALBログ用バケットは第7章 ネットワークでも利用されます。作成したS3用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_s3_bucket private プライベートバケット resource aws_s3_bucket_public_access_block private プライベートバケットのパブリックアクセス定義 resource aws_s3_bucket public パブリックバケット resource aws_s3_bucket alb_log ログバケット(後に定義するALB用のログを格納する) data aws_iam_policy_document alb_log ALBログを書き込むためのIAMポリシー なお、
リスト6.5にidentifiersを直接記載する箇所がありますが、ソース管理上アカウントIDを直接記載したくないため、aws_elb_service_accountのデータを参照する形に調整を行いました。# ログの書き込みに使用されるアカウントIDを自動的にフェッチできる data "aws_elb_service_account" "alb_log" {} # リスト6.5 ALBログを書き込むためのIAMポリシー data "aws_iam_policy_document" "alb_log" { statement { effect = "Allow" actions = ["s3:PutObject"] resources = ["arn:aws:s3:::${aws_s3_bucket.alb_log.id}/*"] principals { type = "AWS" identifiers = ["${data.aws_elb_service_account.alb_log.id}"] # 参照 } } }追加したサービスアカウント取得用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_elb_service_account alb_log ログの書き込みに使用されるアカウントIDを自動的にフェッチする 第7章 ネットワーク
第7章ではネットワーク(VPC)とセキュリティグループを作成します。
章内の7.1パブリックネットワーク、7.2 プライベートネットワークで構築された下記リソースは、7.3マルチAZ以降でマルチAZ化に伴って細分化変更されます。
上図は7章完了状態の図のため、マルチAZ前のリソースは図中には存在しません。
調整前リストNo. 名称 調整後リストNo. リスト7.2 パブリックサブネット リスト7.12 リスト7.6 パブリックサブネット用ルートテーブルの関連付け リスト7.13 リスト7.7 プライベートサブネット リスト7.14 リスト7.8 プライベートサブネット用ルートテーブルと関連付け リスト7.16 リスト7.9 プライベートサブネット用のEIP リスト7.15 リスト7.10 プライベートサブネット用のNATゲートウェイ リスト7.15 リスト7.11 プライベートサブネット用のルート リスト7.16 作成したマルチAZのVPC用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_vpc example VPC resource aws_internet_gateway example インターネットゲートウェイ resource aws_subnet public_0 AZ0のパブリックサブネット resource aws_subnet public_1 AZ1のパブリックサブネット resource aws_route_table public パブリックサブネット用ルートテーブル resource aws_route public パブリックサブネット用ルート(ルートテーブルのレコード) resource aws_route_table_association public_0 AZ0のパブリックサブネットとルートテーブルの関連付け resource aws_route_table_association public_1 AZ1のパブリックサブネットとルートテーブルの関連付け resource aws_subnet private_0 AZ0のプライベートサブネット resource aws_subnet private_1 AZ1のプライベートサブネット resource aws_eip nat_gateway_0 AZ0のNATゲートウェイ用EIP resource aws_eip nat_gateway_1 AZ1のNATゲートウェイ用EIP resource aws_nat_gateway nat_gateway_0 AZ0のNATゲートウェイ resource aws_nat_gateway nat_gateway_1 AZ1のNATゲートウェイ resource aws_route_table private_0 AZ0のプライベートサブネットのルートテーブル resource aws_route_table private_1 AZ1のプライベートサブネットのルートテーブル resource aws_route private_0 AZ0のプライベートサブネットのルート resource aws_route private_1 AZ1のプライベートサブネットのルート resource aws_route_table_association private_0 AZ0のプライベートサブネットのルートテーブルの関連付け resource aws_route_table_association private_1 AZ1のプライベートサブネットのルートテーブルの関連付け 作成したセキュリティグループモジュール用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_security_group default セキュリティグループ resource aws_security_group_rule ingress セキュリティグループルール(インバウンド) resource aws_security_group_rule egress セキュリティグループルール(アウトバウンド) 第8章 ロードバランサーとDNS
第8章ではロードバランサー(ALB)を作成し、Route53でDNSを設定します。また、SSL化のためにACMを利用します。
学習を行う上で、ドメインとSSLを入れない選択を取ることもできます。
その場合は、Route53、ACMを設定せずにELBのみ作成して試すことが可能なので、図内ELBのHTTPS化を行わない場合の構成を作成すれば良いです。図中に
sgというモジュールがありますが、これは第7章 ネットワークで作成したセキュリティモジュールを示しています。
また、図中のALBログ用バケットは第6章 ストレージで作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したELB用のリソースは下記です。
HTTPS化を行う場合と行わない場合、両方に関して記載しています。
種別 リソース種類 名前 備考 resource aws_lb example ALB module - http_sg HTTP用セキュリティグループ module - https_sg HTTPS用セキュリティグループ module - http_redirect_sg HTTPからHTTPSへのリダイレクト用セキュリティグループ resource aws_lb_listener http HTTPリスナーの定義(HTTPS化を行わない場合) resource aws_lb_listener https HTTPリスナーの定義(HTTP化を行う場合) resource aws_lb_listener redirect_http_to_https HTTPSからHTTPへのリダイレクトリスナーの定義(HTTP化を行う場合) resource aws_lb_target_group example ターゲットグループ resource aws_lb_listener_rule example リスナールール(HTTPS化を行う場合と行わない場合でlistener_arnの設定値が異なる) 作成したRoute53用のリソースは下記です。
図はホストゾーンが既にある状態を想定していますが、下記には新規に作成する場合に関しても記載しています。
また、SSL証明書を利用しない場合は、SSL証明書検証用レコード定義は必要なくなります。
種別 リソース種類 名前 備考 data aws_route53_zone example ホストゾーンの参照(ホストゾーンがすでにある場合) resource aws_route53_zone example_test ホストゾーンの作成(ホストゾーンを新規に作成する場合) resource aws_route53_record example ALBのDNSレコード resource aws_route53_record example_certificate SSL証明書の検証用レコード 作成したACM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_acm_certificate example SSL証明書 resource aws_acm_certificate_validation example SSL証明書の検証完了まで待機(apply時にSSL証明書の検証が完了するまで待つ。何かのリソースが作られるわけではない。) 第9章 コンテナオーケストレーション
第9章ではコンテナオーケストレーション環境を作成します。
コンテナ定義はcontainer_definition.jsonで行われています。
これはTerraformプロジェクト内に置かれる定義ファイルで、構成図に本来載るものではないとは思うのですが、関係性を明示したかったので記載しました。(わかりやすければええやん精神)図中に
iamというモジュールがありますが、これは第5章 権限管理で作成したIAMモジュールを示しています。
また、図中のターゲットグループは第8章 ロードバランサーとDNSで作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したCloudWatch用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ecs_cluster example ECSクラスター resource aws_ecs_task_definition example ECSタスク定義 resource aws_ecs_service example ECSサービス(起動タスクの数やタスクの維持、ALBとの橋渡し) module - nginx_sg Nginx用セキュリティグループ 作成したACM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_cloudwatch_log_group for_ecs CloudWatch Logs data aws_iam_policy ecs_task_execution_role_policy ECSタスク実行IAMロールポリシーの参照(AWSが管理しているポリシー) data aws_iam_policy_document ecs_task_execution ECSタスク実行IAMロールのポリシードキュメント module - ecs_task_execution_role ECSタスク実行IAMロール 第10章 バッチ & 第12章 設定管理
第10章ではECSとCloudWatchを用いたバッチ処理を作成します。
バッチの作成で用いるバッチ用コンテナ定義は、第12章でSSMパラメータを使う形に調整されています。
そのため、第10章と第12章は一つにまとめて図を紹介しました。また、図中の
ECSタスク実行IAMロールは第9章 コンテナオーケストレーションで作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したECS用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ecs_task_definition example_batch バッチ用ECSタスク定義 作成したCloudWatch用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_cloudwatch_log_group for_ecs_scheduled_tasks バッチ用CloudWatch Logs module - ecs_events_role CloudWatchイベントIAMロール data aws_iam_policy ecs_events_role_policy CloudWatchイベントIAMロールポリシー resource aws_cloudwatch_event_rule example_batch CLoudWatchイベントルール resource aws_cloudwatch_event_target example_batch CloudWatchイベントターゲット 作成したSSM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ssm_parameter db_username DBのユーザ名の定義 resource aws_ssm_parameter db_password DBのダミーパスワードの定義 第11章 鍵管理
第11章では第13章で用いるためのカスタマーキーを作成します。
作成するカスタマーマスターキーにはUUIDが割り当てられているのですが、人には識別しづらい体系であるため、分かりやすい名前のエイリアスを作成しています。作成したKMS用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_kms_key example カスタマーマスターキー resource aws_kms_alias example エイリアスの定義(カスタマーキーのUUIDでは判別しづらいため) 第13章 データストア
第13章ではRDB向けデータストアのRDSとインメモリデータストアのElastiCacheを作成します。
作成するデータストアは、それぞれマルチAZに構築するため、第7章 ネットワークで作成したリージョンの異なるプライベートサブネット2つを指定しています。
※プライベートサブネット0、プライベートサブネット1はVPC内に作成したサブネットとして見ていただければと思います。(図示が難しかった)また、図中の
カスタマーマスターキーは第11章 鍵管理で作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したRDS用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_db_parameter_group example DBパラメータグループ resource aws_db_option_group example DBオプショングループ(DBエンジンにオプション機能を追加する。例はMariaDB監査プラグイン) resource aws_db_subnet_group example DBサブネットグループ(DBを稼働させるサブネットの定義) resource aws_db_instance example DBインスタンス module - mysql_sg DBインスタンスのセキュリティグループ 作成したElastiCache用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_elasticache_parameter_group example ElastiCacheパラメータグループ resource aws_elasticache_subnet_group example ElastiCacheサブネットグループ resource aws_elasticache_replication_group example ElastiCacheレプリケーショングループ(Redisサーバの作成) module - redis_sg ElastiCacheレプリケーショングループのセキュリティグループ 第14章 デプロイメントパイプライン
第14章では継続的にシステムをデプロイするためのデプロイパイプラインをCodePipelineを中心にして作成します。図中にECRへの矢印(関係性)が見えないと思うかもしれませんが、デプロイメントパイプラインで使われないわけではありません。
ビルドされるアプリケーションコード内にあるbuildspec.ymlにてプッシュ先リポジトリに指定されています。
今回はTerraformプロジェクト内には無いリソースのため、図中へは記載しませんでした。また、図中の
ECSサービスは第9章 コンテナオーケストレーションで作成済みのリソースを利用するため、この章で追加で作る必要はありません。作成したECR用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ecr_repository example ECRレポジトリ resource aws_ecr_lifecycle_policy example ECRライフサイクルポリシー 作成したS3用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_s3_bucket artifact アーティファクトストア用バケット 作成したCodeBuild用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document codebuild CodeBuildサービスロールのポリシードキュメント module - codebuild_role CodeBuildサービルロール resource aws_codebuild_project example CodeBuildプロジェクト 作成したCodePipeline用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document codepipeline CodePipelineサービスロールのポリシードキュメント module - codepipeline_role CodePipelineサービスロール resource aws_codepipeline example CodePipeline(例では3つのステージで実装する) resource aws_codepipeline_webhook example CodePipeline Webhook resource github_repository_webhook example GitHub Webhook(GitHub上でのイベントを検知し、コードの変更を通知するWebhookの定義) なお、AWSプロバイダ3.3.0から新規で作る時は
OAuthTokenが必須らしく、書籍内の14.10のコードのままだとSourceステージでコケてしまいます。
そのため、github_tokenをSSMパラメータとして定義し、それを用いることにしました。data "aws_ssm_parameter" "github_token" { name = "/continuous_apply/github_token" } # リスト14.10 # CodePipelineの定義(例では3つのステージで実装する) resource "aws_codepipeline" "example" { name = "example" role_arn = module.codepipeline_role.iam_role_arn # Sourceステージ:GitHubからソースコードを取得する stage { name = "Source" action { name = "Source" category = "Source" owner = "ThirdParty" provider = "GitHub" version = 1 output_artifacts = ["Source"] configuration = { ~中略~ PollForSourceChanges = false OAuthToken = data.aws_ssm_parameter.github_token.value # SSMパラメータから指定 } } } ~後略~追加したSSM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ssm_parameter github_token GitHub TokenをSSMパラメータとして定義 第15章 SSHレスオペレーション
第15章ではオペレーション用のサーバをSession ManagerとEC2を用いて作成します。
また、オペレーションログとしてSession Managerの操作ログを保存する仕組みを構築します。オペレーションサーバ自体は第7章 ネットワークでVPC内に作成したプライベートサブネットに作成します。
user_data.shはTerraformプロジェクト内に配置されているshファイルですが、EC2インスタンス作成時に実行されるプロビジョニングスクリプトとして指定されています。追加したEC2用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document ec2_for_ssm オペレーションサーバ用ポリシードキュメント data aws_iam_policy ec2_for_ssm Session Manager用に定義されているポリシーをベースに利用する module - ec2_for_ssm_role オペレーションサーバ用IAMロール resource aws_iam_instance_profile ec2_for_ssm インスタンスプロファイル(EC2は直接IAMロールを関連付けられないため、IAMロールをラップしたインスタンスプロファイルを関連付ける) resource aws_instance example_for_operation オペレーションサーバ用EC2インスタンス 追加したS3用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_s3_bucket operation_instance_id オペレーションログを保存するS3バケットの定義 作成したCloudWatch用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_cloudwatch_log_group operation オペレーションログを保存するCloudWatch Logs 作成したSSM用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_ssm_document session_manager_run_shell Session Manager用SSM document 第16章 ロギング
第16章ではロギングの仕組みを作成します。
ロギングにはCloudWatch Logsが便利であることを書籍では紹介した上で、サンプルプロジェクトではログをKinesis Data Firehoseの配信ストリームを用いてS3に永続化する方法を紹介しています。作成したS3用のリソースは下記です。
種別 リソース種類 名前 備考 resource aws_s3_bucket cloudwatch_logs CloudWatch Logs永続化バケット 作成したKinesis Data Firehose用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document kinesis_data_firehose Kinesis Data Firehose IAMロールのポリシードキュメントの定義 module - kinesis_data_firehose_role Kinesis Data Firehose用IAMロール resource aws_kinesis_firehose_delivery_stream example Kinesis Data Firehose配信ストリーム(Kinesis Data Firehoseにログが流れるとこの配信ストリームに設定したS3バケットへログを保存する) 作成したCloudWatch用のリソースは下記です。
種別 リソース種類 名前 備考 data aws_iam_policy_document cloudwatch_logs CloudWatch Logs用IAMロールポリシードキュメント module - cloudwatch_logs_role CloudWatch Logs用IAMロール resource aws_cloudwatch_log_subscription_filter example CloudWatch Logsサブスクリプションフィルタ おわりに
本記事で挙げている図は完全に筆者のイメージで作られています。
そのため、実際のものと異なる可能性が多分にあります。
何かお気づきの点等あればコメント等にてお知らせいただけますと幸いです。この記事が少しでも参考になっていたら嬉しいです。
- 投稿日:2020-12-06T21:21:04+09:00
ドメイン移行に伴いS3でホスティングしているWebページを振り分ける
プライバシーポリシー表示できない事件
これは思い出話です。技術的に参考になる部分は少ないと思います。
発端
ある日、あるiOSアプリのプライバシーポリシーページが表示できなくなっているという報告が社内から上がりました。その報告とは、ざっくりいうと https://example.com/[service]/privacy.html が表示できないというもの。
現象
実はアプリのランディングページはもともと example.jp を使っていたものを example.com に変えていました。プライバシーポリシーのページも、もともとは https://example.jp/[service]/privacy.html でした。そして、 example.jp は example.com にリダイレクトしていました。
原因
example.jp を example.com にリダイレクトしただけだと問題なかったのですが、数日前にアプリのランディングページをリニューアルしていました。もともとはCloudFrontからS3にあるスタティックファイルを表示していましたが、これをSquarespaceに変更していたようです。そのタイミングで移行漏れがありました。
縛り
はじめ、その修正はアプリのプライバシーポリシーのURLを変更すれば良いのではないかと思っていました。しかし、実は停止することが決まっていたアプリで、会社的に担当できる人がいなかったためiOSアプリ内のコードを変更せずに修正する必要がありました。これが1つ目の縛りです。
そこで、リダイレクト先、つまり example.com の方で該当のURLが表示できるようにスタティックファイルを置いてあげれば良いと考えました。しかし、調査した結果Squarespaceでは /privacy.html のようなURLを作れないことがわかりました。それが2つ目の縛りです。
解決策
上記の縛りにより、できることは限られていて、担当もいないため私の情シスの権限内で行えることで対応しなければなりませんでした。そこで考えたのがリダイレクトする・しないを判別してURLを振り分けることです。
URL 対応 リダイレクト先 https://example.jp リダイレクト https://example.com https://example.jp/news リダイレクト https://example.com/news https://example.jp/[service]/privacy.html そのまま表示 - https://example.com そのまま表示 - https://example.com/news そのまま表示 - https://example.com/[service]/privacy.html 404 - 解決方法
example.com の方は特にいじる必要はありませんでした。 example.jp の方はリダイレクトするだけの設定だったので、これをS3にファイルが存在すれば表示、存在しなければ example.jp/ 以降の部分を維持したままリダイレクトするように設定しました。やり方は「Amazon S3 でリダイレクトを扱う」を参考にしました。
リダイレクションルルール
[ { "Condition": { "HttpErrorCodeReturnedEquals": "404" }, "Redirect": { "HostName": "example.com" } }, { "Condition": { "HttpErrorCodeReturnedEquals": "403" }, "Redirect": { "HostName": "example.com" } }, { "Condition": { "KeyPrefixEquals": "" }, "Redirect": { "HostName": "example.com", "ReplaceKeyPrefixWith": "" } } ]JavaScriptでも念の為リダイレクト
S3の静的ウェブサイトホスティングの設定ではインデックスドキュメントとエラードキュメントを指定できます。インデックスドキュメントは
.と指定していますが、おそらく example.jp にアクセスされたときに index.html が開かれると思う(?)ので index.html ファイルを置いておきます。何らかのエラーが有ったときのために念の為 error.html も置いておきました。その中身はJavaScriptでリダイレクトしているだけです。ちなみに index.html と error.html の中身は一緒です。index.html<html> <head> <title> sensy.jp </title> <script> (function () { location.href = '//example.com' })() </script> </head> <body> <a href="//example.com">example.com</a> </body> </html>最後に
こうやって書いてみると簡単な話なのですが、自分が入社前に作られたシステムで、どこにコードがあってどこでホスティングして…というのをいちから調査するのが大変でした。
でもこういった障害対応から知識を伸ばしていくことも多くて、それが教科書には載っていない業務知識と呼ばれるものかなーなんて思っています。
最近ひょんなことから未経験からエンジニアとして働きたくてSES企業に転職したという人の話を聞いたのですが、保守業務やキッティング業務ばかりだと聞きました。そういう業務ではいつまでも業務経験積めなくて本来やりたかったであろう開発の仕事はできないので、営業なら営業、経理なら経理と、これまでの経験を活かしつつ無理やりにでも開発の仕事に結びつけたほうが良いんじゃないかなーと感じて、こういう記事も書いてみました。
- 投稿日:2020-12-06T19:37:55+09:00
【AWS】AWSを学び始める前に知っておくべきこと【入門】
はじめに
AWS(Amazon Web Service)の学習を最近始めましたが、学習前に
「最低限これだけは押さえておいたほうがよかったな」
と思うことがいろいろあったので、それらをまとめてみました。
ぜひ最後までご覧下さい。
本記事の内容
0.インフラとは?
1.AWSとは?
2.AWSで何ができるのか?
3.まとめ
4.最後に0. インフラとは?
まずAWSについて知っていく前に、最低限インフラについて理解しておく必要があります。
では、インフラとは一体何でしょうか?
結論から言うと、インフラとは
サーバーやネットワークのことを指します。そもそもインフラとは、英語のinfrastractureの略称で、日本語に訳すと基盤という意味になります。
例えば、生活インフラといえば下水道やインターネット、電気や熱などの生活に欠かすことのできない基盤のことを指し、交通インフラといえば信号機、鉄道、バスといったものを指します。
なので、IT関連においてインフラといえば、システムやサービスの基盤となる設備を指し、これに当たるのがサーバーやネットワークになるということです。
では次にこのサーバーやネットワークについて詳しく見ていきましょう。サーバー
サーバーとは
クライアントに対してサービスを提供するコンピュータのことを言います。もっとわかりやすく言うと、お客様に何かしらのサービスを提供する機能を持ったパソコンのことを言います。
サーバーというのも、元々の語源は実は英語のserverであり、日本語に訳すと「仕える人」「給仕人」という意味になります。レストランなどで飲み物や食事のオーダーを取ったり、お料理を運ぶ人をサーバーと呼ぶことを想像してもらえればわかると思います。
そして、IT分野におけるサーバーも実はそんなに大差なく、この飲み物のオーダーを取ったり、お料理を運ぶ人がパソコンに置き換わっただけだと考えればいいだけです。つまり、
お客さん(IT分野では
クライアントと呼ばれる)の注文や要求(IT分野ではリクエストと呼ばれる)に対して、何かしら応える(IT分野ではレスポンスと呼ばれる)ものがサーバーであって、「そのレスポンスをどれに行わせているのか?」により違いが生じるということですね。
ネットワーク
続いてネットワークについて見ていきましょう。
ネットワークとは、
複数のコンピューターをつないで、データを送受信できるようにするものを指します。コンピューターとコンピューターを直接ケーブルでつないでデータを送受信できるようにするものもネットワークですし、インターネットのようにいろいろなコンピューターとつないでデータをやりとりすることができるようになるものもネットワークと呼ばれます。
ではここから本題に入っていきます。
1. AWSとは?
AWSとは、Amazon Web Services(アマゾンウェブサービス)の略で、米Amazon.comが提供する<クラウドサービスのことです。
100以上のサービスが存在し、クラウドサービスとしては世界最大規模で、日本を含む全世界15ヶ所で展開されています。
そしてAWSはクラウドサービスであるので、AWSを学習するには「クラウドとは何か?」について理解する必要があります。クラウドとオンプレミスについて
クラウド(別名:クラウドコンピューティング)とは、
ネットワークを利用してコンピューターリソースを利用する形態のことですしかし、これだけではいまいちわかりづらいので、クラウドと似た利用形態であるオンプレミスと見比べながら説明していきましょう。
オンプレミス
クラウドとよく比較されるものとして、オンプレミスと呼ばれるものがあります。
これは、
サーバーやネットワーク機器などをデータセンターと呼ばれる施設に持ち込んで、自前でインフラを構築して運用して、何かしらの情報システムを運用していく方法のことを指します。
まず前提として、オンプレミスでもクラウドのどちらにおいてもデータセンターと呼ばれる施設が必要になります。データセンターとは、インターネットなどにサービスを提供するためのサーバーやネットワーク機器などを置いて運用するための施設のことを言います。
そしてこのデータセンターに、情報システムやサービスを運用したい人であったり会社がサーバーやネットワーク機器などを持ち込んで、設置していきます。
こうして運用されるのが、オンプレミスと呼ばれるものです。
しかし、このオンプレミスにはいくつか欠点があります。
①サーバーの設置やネットワークの敷設に日数が必要当然、機材の調達や配置が必要なので、追加や変更をする際には日数が必要になります。いきなり「明日からサーバーの台数を増やしたい」というようなことは中々できません。
②保守が必要
サーバーやネットワーク機器などは自社で保有するため、初期コストがかかるのはもちろん、故障した時などには交換が必要となります。
さらにサーバーやネットワーク機器に異常がないかを日々監視する運用業務が必要となります。③障害対策にコストがかかりすぎる
サーバーやネットワークが壊れた時にはそれを交換する必要があります。
そのためには予備の設備を用意しておく必要があり、例えばサーバーが壊れた時のために2台以上用意しておく、回線を二重化しておくなどの方法があります。しかしこれらにはそれなりのコストがかかってきます。
このように、オンプレミスでインフラを構築していくためにはそれなりのデメリットがあり、サービス提供者側は非常に困っていました。そこで生まれたのが、クラウドと呼ばれるものだったのです。
なので、クラウドとは基本的には
オンプレミスと逆のことをするものだと理解すればわかりやすいかもしれません。クラウド
ではクラウドの説明に移ります。
クラウドとは、先ほども述べた通り、基本的にはオンプレミスとは逆のものであるので、まず
データセンターにサーバーやネットワークを各自が設置しません。その代わりに、
データセンターには予め十分な数のサーバーやネットワーク設備が用意されていて、必要に応じてそれらをすぐに借りて使っていけるという運用方法になっています。つまり、クラウドサービスとはサーバーやネットワークのレンタルサービスということになります。
そして、クラウドはオンプレミスによる課題を次のように解決します。
①サーバーの設置やネットワークの敷設は即時クラウドサービスでは、仮想的にサーバーやネットワークを構成しているため、物理的な配置が必要なく、クラウドサービスの管理画面から操作すると、ものの数分でサーバーやネットワークを作れます。
②保守は必要なし
サーバーやネットワーク機器などはクラウドサービス会社が保有し、管理しています。そのため、保守の必要はなく、いつでも最新の設備を使うことができます。
③障害対策のコストは抑えられる
クラウドサービスでは、すぐにサーバーやネットワークの代替を作れるため、予備の設備をあらかじめ用意しておく必要はありません。
またほとんどのクラウドサービスは、回線を二重化しており、データセンターも複数の拠点、そして世界各国で運用しています。
このため各拠点間でのデータ同期などで、大規模災害が発生した時にも耐えられるような、分散して運用するシステムも作りやすくなっています。
まとめ
ここまで長くなりましたので、最後にクラウドとオンプレミスの違いについて「車」を例に出して、ざっとまとめておきます。
車を買う 車を借りる ・自分のもの
・メンテナンスや車検は自分持ち
・最初にお金がかかる。税金(自動車税)もかかる
・買ったらしばらく同じ車に乗り続けなければならない
・ 自分のものではない
・メンテナンスや車検はやらなくていい
・使った分だけ払えば良い。税金もかからない
・たまにはスポーツカーなど別の車も借りれる
オンプレミス クラウド ・自分のもの
・保守や運用は自分の責任
・最初にお金がかかる。税金(固定資産税)もかかる
・買ったらしばらくは同じ構成で使い続けなければならない
・ 自分のものではない
・保守や運用はしてくれる
・使った分だけ払えばよい。税金もかからない
・性能が必要な時は、その時だけ高性能なサーバーを借りられる
2. AWSで何ができるのか?
では最後に、AWSを用いるとどういったことができるのか?ということについて考えていきましょう。
インターネット経由でAWSのコンソール画面にアクセスすると、様々な機能を利用することができ、AWSでは大きく分けて90以上、細分化すると700以上ものサービスが提供されています。そしてこれだけたくさんのサービスがあると
「そんなにたくさんあるサービスを全て使いこなすのなんて難しい!」
と考える人は多いかと思います。
しかし、そのような心配をする必要はありません。というのも、AWSを使う場合、よく使うサービスというのは多くても10個程度で、それら以外はある特定の目的に特化したものであるからです。
例えば、ビッグデータの集計目的で使うものや、機械学習をするためのもの、IoT機器を制御するときに使うものなどがあり、これらは
そういう分野の情報システムを使わない人にとっては全く関係のないものです。
そしてよく使うサービスの代表としては以下のようなものがあります。ざっと概要だけを載せておきます。
サービス 概要 IAM ユーザーやグループの管理、認証をする仕組み VPC 仮想ネットワーク EIP 固定IPアドレスを割り当てる EC2 仮想サーバー EBS 仮想サーバーなどで使うストレージ S3 Webサーバーとしても使えるストレージサービス。汎用的なファイル置き場として、様々な場面で使われる RDS データベースサービス Route 53 DNSサービス CloudFront Webコンテンツなどのキャッシュ機能を提供する。HTTPSで暗号化通信する機能もある ELB 複数台の仮想サーバー(EC2)に負荷分散する。HTTPSで暗号化する機能もある 3. まとめ
- インフラとはサーバーやネットワークのこと
- サーバーとはクライアントに対してサービスを提供するコンピューターのこと
- ネットワークとは複数のコンピューターをつないで、データを送受信できるようにするもの
AWSとは、Amazon Web Services(アマゾンウェブサービス)の略で、米Amazon社が提供するクラウドサービスのこと
オンプレミスとはサーバーやネットワーク機器などをデータセンターと呼ばれる施設に持ち込んで、自前でインフラを構築して運用して、何かしらの情報システムを運用していく方法のこと
クラウドとはネットワークを利用してコンピューターリソースを利用していく形態のこと
4. 最後に
本記事の内容がみなさんの参考になれば嬉しいです。
最後までご覧いただきありがとうございました。





- 投稿日:2020-12-06T19:37:55+09:00
【AWS】AWSを学び始める前に最低限知っておくべきこと【入門】
はじめに
AWS(Amazon Web Service)の学習を最近始めましたが、学習前に
「最低限これだけは押さえておいたほうがよかったな」
と思うことがいろいろあったので、それらをまとめてみました。
ぜひ最後までご覧下さい。
本記事の内容
0.インフラとは?
1.AWSとは?
2.AWSで何ができるのか?
3.まとめ
4.最後に0. インフラとは?
まずAWSについて知っていく前に、最低限インフラについて理解しておく必要があります。
では、インフラとは一体何でしょうか?
結論から言うと、インフラとは
サーバーやネットワークのことを指します。そもそもインフラとは、英語のinfrastractureの略称で、日本語に訳すと基盤という意味になります。
例えば、生活インフラといえば下水道やインターネット、電気や熱などの生活に欠かすことのできない基盤のことを指し、交通インフラといえば信号機、鉄道、バスといったものを指します。
なので、IT関連においてインフラといえば、システムやサービスの基盤となる設備を指し、これに当たるのがサーバーやネットワークになるということです。
では次にこのサーバーやネットワークについて詳しく見ていきましょう。サーバー
サーバーとは
クライアントに対してサービスを提供するコンピュータのことを言います。もっとわかりやすく言うと、お客様に何かしらのサービスを提供する機能を持ったパソコンのことを言います。
サーバーというのも、元々の語源は実は英語のserverであり、日本語に訳すと「仕える人」「給仕人」という意味になります。レストランなどで飲み物や食事のオーダーを取ったり、お料理を運ぶ人をサーバーと呼ぶことを想像してもらえればわかると思います。
そして、IT分野におけるサーバーも実はそんなに大差なく、この飲み物のオーダーを取ったり、お料理を運ぶ人がパソコンに置き換わっただけだと考えればいいだけです。つまり、
お客さん(IT分野では
クライアントと呼ばれる)の注文や要求(IT分野ではリクエストと呼ばれる)に対して、何かしら応える(IT分野ではレスポンスと呼ばれる)ものがサーバーであって、「そのレスポンスをどれに行わせているのか?」により違いが生じるということですね。
ネットワーク
続いてネットワークについて見ていきましょう。
ネットワークとは、
複数のコンピューターをつないで、データを送受信できるようにするものを指します。コンピューターとコンピューターを直接ケーブルでつないでデータを送受信できるようにするものもネットワークですし、インターネットのようにいろいろなコンピューターとつないでデータをやりとりすることができるようになるものもネットワークと呼ばれます。
ではここから本題に入っていきます。
1. AWSとは?
AWSとは、Amazon Web Services(アマゾンウェブサービス)の略で、米Amazon.comが提供する<クラウドサービスのことです。
100以上のサービスが存在し、クラウドサービスとしては世界最大規模で、日本を含む全世界15ヶ所で展開されています。
そしてAWSはクラウドサービスであるので、AWSを学習するには「クラウドとは何か?」について理解する必要があります。クラウドとオンプレミスについて
クラウド(別名:クラウドコンピューティング)とは、
ネットワークを利用してコンピューターリソースを利用する形態のことですしかし、これだけではいまいちわかりづらいので、クラウドと似た利用形態であるオンプレミスと見比べながら説明していきましょう。
オンプレミス
クラウドとよく比較されるものとして、オンプレミスと呼ばれるものがあります。
これは、
サーバーやネットワーク機器などをデータセンターと呼ばれる施設に持ち込んで、自前でインフラを構築して運用して、何かしらの情報システムを運用していく方法のことを指します。
まず前提として、オンプレミスでもクラウドのどちらにおいてもデータセンターと呼ばれる施設が必要になります。データセンターとは、インターネットなどにサービスを提供するためのサーバーやネットワーク機器などを置いて運用するための施設のことを言います。
そしてこのデータセンターに、情報システムやサービスを運用したい人であったり会社がサーバーやネットワーク機器などを持ち込んで、設置していきます。
こうして運用されるのが、オンプレミスと呼ばれるものです。
しかし、このオンプレミスにはいくつか欠点があります。
①サーバーの設置やネットワークの敷設に日数が必要当然、機材の調達や配置が必要なので、追加や変更をする際には日数が必要になります。いきなり「明日からサーバーの台数を増やしたい」というようなことは中々できません。
②保守が必要
サーバーやネットワーク機器などは自社で保有するため、初期コストがかかるのはもちろん、故障した時などには交換が必要となります。
さらにサーバーやネットワーク機器に異常がないかを日々監視する運用業務が必要となります。③障害対策にコストがかかりすぎる
サーバーやネットワークが壊れた時にはそれを交換する必要があります。
そのためには予備の設備を用意しておく必要があり、例えばサーバーが壊れた時のために2台以上用意しておく、回線を二重化しておくなどの方法があります。しかしこれらにはそれなりのコストがかかってきます。
このように、オンプレミスでインフラを構築していくためにはそれなりのデメリットがあり、サービス提供者側は非常に困っていました。そこで生まれたのが、クラウドと呼ばれるものだったのです。
なので、クラウドとは基本的には
オンプレミスと逆のことをするものだと理解すればわかりやすいかもしれません。クラウド
ではクラウドの説明に移ります。
クラウドとは、先ほども述べた通り、基本的にはオンプレミスとは逆のものであるので、まず
データセンターにサーバーやネットワークを各自が設置しません。その代わりに、
データセンターには予め十分な数のサーバーやネットワーク設備が用意されていて、必要に応じてそれらをすぐに借りて使っていけるという運用方法になっています。つまり、クラウドサービスとはサーバーやネットワークのレンタルサービスということになります。
そして、クラウドはオンプレミスによる課題を次のように解決します。
①サーバーの設置やネットワークの敷設は即時クラウドサービスでは、仮想的にサーバーやネットワークを構成しているため、物理的な配置が必要なく、クラウドサービスの管理画面から操作すると、ものの数分でサーバーやネットワークを作れます。
②保守は必要なし
サーバーやネットワーク機器などはクラウドサービス会社が保有し、管理しています。そのため、保守の必要はなく、いつでも最新の設備を使うことができます。
③障害対策のコストは抑えられる
クラウドサービスでは、すぐにサーバーやネットワークの代替を作れるため、予備の設備をあらかじめ用意しておく必要はありません。
またほとんどのクラウドサービスは、回線を二重化しており、データセンターも複数の拠点、そして世界各国で運用しています。
このため各拠点間でのデータ同期などで、大規模災害が発生した時にも耐えられるような、分散して運用するシステムも作りやすくなっています。
まとめ
ここまで長くなりましたので、最後にクラウドとオンプレミスの違いについて「車」を例に出して、ざっとまとめておきます。
車を買う 車を借りる ・自分のもの
・メンテナンスや車検は自分持ち
・最初にお金がかかる。税金(自動車税)もかかる
・買ったらしばらく同じ車に乗り続けなければならない
・ 自分のものではない
・メンテナンスや車検はやらなくていい
・使った分だけ払えば良い。税金もかからない
・たまにはスポーツカーなど別の車も借りれる
オンプレミス クラウド ・自分のもの
・保守や運用は自分の責任
・最初にお金がかかる。税金(固定資産税)もかかる
・買ったらしばらくは同じ構成で使い続けなければならない
・ 自分のものではない
・保守や運用はしてくれる
・使った分だけ払えばよい。税金もかからない
・性能が必要な時は、その時だけ高性能なサーバーを借りられる
2. AWSで何ができるのか?
では最後に、AWSを用いるとどういったことができるのか?ということについて考えていきましょう。
インターネット経由でAWSのコンソール画面にアクセスすると、様々な機能を利用することができ、AWSでは大きく分けて90以上、細分化すると700以上ものサービスが提供されています。そしてこれだけたくさんのサービスがあると
「そんなにたくさんあるサービスを全て使いこなすのなんて難しい!」
と考える人は多いかと思います。
しかし、そのような心配をする必要はありません。というのも、AWSを使う場合、よく使うサービスというのは多くても10個程度で、それら以外はある特定の目的に特化したものであるからです。
例えば、ビッグデータの集計目的で使うものや、機械学習をするためのもの、IoT機器を制御するときに使うものなどがあり、これらは
そういう分野の情報システムを使わない人にとっては全く関係のないものです。
そしてよく使うサービスの代表としては以下のようなものがあります。ざっと概要だけを載せておきます。
サービス 概要 IAM ユーザーやグループの管理、認証をする仕組み VPC 仮想ネットワーク EIP 固定IPアドレスを割り当てる EC2 仮想サーバー EBS 仮想サーバーなどで使うストレージ S3 Webサーバーとしても使えるストレージサービス。汎用的なファイル置き場として、様々な場面で使われる RDS データベースサービス Route 53 DNSサービス CloudFront Webコンテンツなどのキャッシュ機能を提供する。HTTPSで暗号化通信する機能もある ELB 複数台の仮想サーバー(EC2)に負荷分散する。HTTPSで暗号化する機能もある 3. まとめ
- インフラとはサーバーやネットワークのこと
- サーバーとはクライアントに対してサービスを提供するコンピューターのこと
- ネットワークとは複数のコンピューターをつないで、データを送受信できるようにするもの
AWSとは、Amazon Web Services(アマゾンウェブサービス)の略で、米Amazon社が提供するクラウドサービスのこと
オンプレミスとはサーバーやネットワーク機器などをデータセンターと呼ばれる施設に持ち込んで、自前でインフラを構築して運用して、何かしらの情報システムを運用していく方法のこと
クラウドとはネットワークを利用してコンピューターリソースを利用していく形態のこと
4. 最後に
本記事の内容がみなさんの参考になれば嬉しいです。
最後までご覧いただきありがとうございました。





- 投稿日:2020-12-06T19:37:55+09:00
【AWS】AWSを学び始める前に最低限知っておくべきこと
はじめに
AWS(Amazon Web Service)の学習を最近始めましたが、学習前に
「最低限これだけは押さえておいたほうがよかったな」
と思うことがいろいろあったので、それらをまとめてみました。
ぜひ最後までご覧下さい。
本記事の内容
0.インフラとは?
1.AWSとは?
2.AWSで何ができるのか?
3.まとめ
4.最後に0. インフラとは?
まずAWSについて知っていく前に、最低限インフラについて理解しておく必要があります。
では、インフラとは一体何でしょうか?
結論から言うと、インフラとは
サーバーやネットワークのことを指します。そもそもインフラとは、英語のinfrastractureの略称で、日本語に訳すと基盤という意味になります。
例えば、生活インフラといえば下水道やインターネット、電気や熱などの生活に欠かすことのできない基盤のことを指し、交通インフラといえば信号機、鉄道、バスといったものを指します。
なので、IT関連においてインフラといえば、システムやサービスの基盤となる設備を指し、これに当たるのがサーバーやネットワークになるということです。
では次にこのサーバーやネットワークについて詳しく見ていきましょう。サーバー
サーバーとは
クライアントに対してサービスを提供するコンピュータのことを言います。もっとわかりやすく言うと、お客様に何かしらのサービスを提供する機能を持ったパソコンのことを言います。
サーバーというのも、元々の語源は実は英語のserverであり、日本語に訳すと「仕える人」「給仕人」という意味になります。レストランなどで飲み物や食事のオーダーを取ったり、お料理を運ぶ人をサーバーと呼ぶことを想像してもらえればわかると思います。
そして、IT分野におけるサーバーも実はそんなに大差なく、この飲み物のオーダーを取ったり、お料理を運ぶ人がパソコンに置き換わっただけだと考えればいいだけです。つまり、
お客さん(IT分野では
クライアントと呼ばれる)の注文や要求(IT分野ではリクエストと呼ばれる)に対して、何かしら応える(IT分野ではレスポンスと呼ばれる)ものがサーバーであって、「そのレスポンスをどれに行わせているのか?」により違いが生じるということですね。
ネットワーク
続いてネットワークについて見ていきましょう。
ネットワークとは、
複数のコンピューターをつないで、データを送受信できるようにするものを指します。コンピューターとコンピューターを直接ケーブルでつないでデータを送受信できるようにするものもネットワークですし、インターネットのようにいろいろなコンピューターとつないでデータをやりとりすることができるようになるものもネットワークと呼ばれます。
ではここから本題に入っていきます。
1. AWSとは?
AWSとは、Amazon Web Services(アマゾンウェブサービス)の略で、米Amazon.comが提供する<クラウドサービスのことです。
100以上のサービスが存在し、クラウドサービスとしては世界最大規模で、日本を含む全世界15ヶ所で展開されています。
そしてAWSはクラウドサービスであるので、AWSを学習するには「クラウドとは何か?」について理解する必要があります。クラウドとオンプレミスについて
クラウド(別名:クラウドコンピューティング)とは、
ネットワークを利用してコンピューターリソースを利用する形態のことですしかし、これだけではいまいちわかりづらいので、クラウドと似た利用形態であるオンプレミスと見比べながら説明していきましょう。
オンプレミス
クラウドとよく比較されるものとして、オンプレミスと呼ばれるものがあります。
これは、
サーバーやネットワーク機器などをデータセンターと呼ばれる施設に持ち込んで、自前でインフラを構築して運用して、何かしらの情報システムを運用していく方法のことを指します。
まず前提として、オンプレミスでもクラウドのどちらにおいてもデータセンターと呼ばれる施設が必要になります。データセンターとは、インターネットなどにサービスを提供するためのサーバーやネットワーク機器などを置いて運用するための施設のことを言います。
そしてこのデータセンターに、情報システムやサービスを運用したい人であったり会社がサーバーやネットワーク機器などを持ち込んで、設置していきます。
こうして運用されるのが、オンプレミスと呼ばれるものです。
しかし、このオンプレミスにはいくつか欠点があります。
①サーバーの設置やネットワークの敷設に日数が必要当然、機材の調達や配置が必要なので、追加や変更をする際には日数が必要になります。いきなり「明日からサーバーの台数を増やしたい」というようなことは中々できません。
②保守が必要
サーバーやネットワーク機器などは自社で保有するため、初期コストがかかるのはもちろん、故障した時などには交換が必要となります。
さらにサーバーやネットワーク機器に異常がないかを日々監視する運用業務が必要となります。③障害対策にコストがかかりすぎる
サーバーやネットワークが壊れた時にはそれを交換する必要があります。
そのためには予備の設備を用意しておく必要があり、例えばサーバーが壊れた時のために2台以上用意しておく、回線を二重化しておくなどの方法があります。しかしこれらにはそれなりのコストがかかってきます。
このように、オンプレミスでインフラを構築していくためにはそれなりのデメリットがあり、サービス提供者側は非常に困っていました。そこで生まれたのが、クラウドと呼ばれるものだったのです。
なので、クラウドとは基本的には
オンプレミスと逆のことをするものだと理解すればわかりやすいかもしれません。クラウド
ではクラウドの説明に移ります。
クラウドとは、先ほども述べた通り、基本的にはオンプレミスとは逆のものであるので、まず
データセンターにサーバーやネットワークを各自が設置しません。その代わりに、
データセンターには予め十分な数のサーバーやネットワーク設備が用意されていて、必要に応じてそれらをすぐに借りて使っていけるという運用方法になっています。つまり、クラウドサービスとはサーバーやネットワークのレンタルサービスということになります。
そして、クラウドはオンプレミスによる課題を次のように解決します。
①サーバーの設置やネットワークの敷設は即時クラウドサービスでは、仮想的にサーバーやネットワークを構成しているため、物理的な配置が必要なく、クラウドサービスの管理画面から操作すると、ものの数分でサーバーやネットワークを作れます。
②保守は必要なし
サーバーやネットワーク機器などはクラウドサービス会社が保有し、管理しています。そのため、保守の必要はなく、いつでも最新の設備を使うことができます。
③障害対策のコストは抑えられる
クラウドサービスでは、すぐにサーバーやネットワークの代替を作れるため、予備の設備をあらかじめ用意しておく必要はありません。
またほとんどのクラウドサービスは、回線を二重化しており、データセンターも複数の拠点、そして世界各国で運用しています。
このため各拠点間でのデータ同期などで、大規模災害が発生した時にも耐えられるような、分散して運用するシステムも作りやすくなっています。
まとめ
ここまで長くなりましたので、最後にクラウドとオンプレミスの違いについて「車」を例に出して、ざっとまとめておきます。
車を買う 車を借りる ・自分のもの
・メンテナンスや車検は自分持ち
・最初にお金がかかる。税金(自動車税)もかかる
・買ったらしばらく同じ車に乗り続けなければならない
・ 自分のものではない
・メンテナンスや車検はやらなくていい
・使った分だけ払えば良い。税金もかからない
・たまにはスポーツカーなど別の車も借りれる
オンプレミス クラウド ・自分のもの
・保守や運用は自分の責任
・最初にお金がかかる。税金(固定資産税)もかかる
・買ったらしばらくは同じ構成で使い続けなければならない
・ 自分のものではない
・保守や運用はしてくれる
・使った分だけ払えばよい。税金もかからない
・性能が必要な時は、その時だけ高性能なサーバーを借りられる
2. AWSで何ができるのか?
では最後に、AWSを用いるとどういったことができるのか?ということについて考えていきましょう。
インターネット経由でAWSのコンソール画面にアクセスすると、様々な機能を利用することができ、AWSでは大きく分けて90以上、細分化すると700以上ものサービスが提供されています。そしてこれだけたくさんのサービスがあると
「そんなにたくさんあるサービスを全て使いこなすのなんて難しい!」
と考える人は多いかと思います。
しかし、そのような心配をする必要はありません。というのも、AWSを使う場合、よく使うサービスというのは多くても10個程度で、それら以外はある特定の目的に特化したものであるからです。
例えば、ビッグデータの集計目的で使うものや、機械学習をするためのもの、IoT機器を制御するときに使うものなどがあり、これらは
そういう分野の情報システムを使わない人にとっては全く関係のないものです。
そしてよく使うサービスの代表としては以下のようなものがあります。ざっと概要だけを載せておきます。
サービス 概要 IAM ユーザーやグループの管理、認証をする仕組み VPC 仮想ネットワーク EIP 固定IPアドレスを割り当てる EC2 仮想サーバー EBS 仮想サーバーなどで使うストレージ S3 Webサーバーとしても使えるストレージサービス。汎用的なファイル置き場として、様々な場面で使われる RDS データベースサービス Route 53 DNSサービス CloudFront Webコンテンツなどのキャッシュ機能を提供する。HTTPSで暗号化通信する機能もある ELB 複数台の仮想サーバー(EC2)に負荷分散する。HTTPSで暗号化する機能もある 3. まとめ
- インフラとはサーバーやネットワークのこと
- サーバーとはクライアントに対してサービスを提供するコンピューターのこと
- ネットワークとは複数のコンピューターをつないで、データを送受信できるようにするもの
AWSとは、Amazon Web Services(アマゾンウェブサービス)の略で、米Amazon社が提供するクラウドサービスのこと
オンプレミスとはサーバーやネットワーク機器などをデータセンターと呼ばれる施設に持ち込んで、自前でインフラを構築して運用して、何かしらの情報システムを運用していく方法のこと
クラウドとはネットワークを利用してコンピューターリソースを利用していく形態のこと
4. 最後に
本記事の内容がみなさんの参考になれば嬉しいです。
最後までご覧いただきありがとうございました。
- 投稿日:2020-12-06T19:17:28+09:00
aws-cdkをbeta版の0.20から最新版に上げた
この記事は Opt Technologies Advent Calendar 2020 3 日目記事です
さっそく遅刻しましたすいません2 日目の記事は @peko858 さんの 社内ISUCONの予習の予習としてやったこと です
4 日目の記事は @U1F419 さんの 新卒研修の振り返り記事 です
というわけで上げた。がんばった。
・・・ので、対処した点を書き残しておきます環境
- 対象となったパッケージ
- @aws-cdk/aws-elasticloadbalancingv2
- @aws-cdk/aws-cloudfront
- @aws-cdk/aws-ecr
- @aws-cdk/aws-ecs
- @aws-cdk/aws-iam
- @aws-cdk/aws-rds
- @aws-cdk/aws-sns
- @aws-cdk/aws-sns-subscriptions
- @aws-cdk/aws-sqs
- @aws-cdk/aws-s3
- @aws-cdk/core
- aws-cdk
- 言語: TypeScript
やった手順
コード量が多くなかったので力技
TypeScriptの実装が全部で700行弱程度だったので、cdk synthコマンドを使って吐き出したCloudFormation(以下CFn)テンプレートの内容を差分見て対処で十分やれるだろうと判断してエイッとやりました
npm install @aws-cdk/{...}する- コンパイルエラーが大量に出るので腕力で直す
cdk synthでCFnテンプレートを出力し、変更前との差分を取り、問題がなさそうかどうか目で確認&調整- 検証用環境で検証デプロイ
- 本番リリース
aws-cdkは結局の所CFnというサービス向けのjson/yamlを吐き出すだけのライブラリなので、aws-cdkのバージョンが変わってもCFnテンプレートの出力結果が多少変わるだけだと考えたらそんなに身構えなくてもよいという気持ちでした
対処した問題
クロススタックでのリソース参照の方法が変わった
CFnでStackを跨いでリソースを参照する場合、参照させたいリソースについてOutputsを定義する必要があります(参考: チュートリアル: 別の AWS CloudFormation スタックのリソース出力を参照する)
aws-cdkではこのクロススタック参照を、Stackクラスのインスタンスのプロパティなどを介して行えます
以下の例は、FooStackに定義してるS3バケットをBarStackで参照して利用する、というコードになりますclass FooStack extends cdk.Stack { bucket: s3.Bucket; constructor(scope: cdk.Construct, id: string) { super(scope, id); this.bucket = new s3.Bucket(this, 'FooBucket', { bucketName: 'foo-bucket', }); } } class BarStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, opts: { bucket: s3.Bucket }) { super(scope, id); // opts.bucketを使ってなにかやる } } const app = new cdk.App(); const fooStack = new FooStack(app, 'Foo'); new BarStack(app, 'Bar', { bucket: fooStack.bucket });このとき、aws-cdkはFooStackのbucketへの参照をCFn上でOutputsを使って表現してくれます
aws-cdkのbeta版とstable版でOutputsの出力内容が変わってしまったので、単純にバージョンアップした場合に問題が起こります
aws-cdkのアップデートをする場合、Stackごとに新しいバージョンで生成したCFnテンプレートを適用していくことになりますが、stable版で作ったStackとbeta版で作ったStackで相互に互換がないために、クロススタック参照するための仕組みが動かなくなってしまいます上記例だと、BarStack参照対象のリソースであるFooStackのbucketを読み取れなくなってしまう、ということになります
したがって、互換を保つためにbeta版で出力されるOutputsを自前でCFnテンプレートとして出力させるような実装を書いておく必要がありますclass FooStack extends cdk.Stack { bucket: s3.Bucket; constructor(scope: cdk.Construct, id: string) { super(scope, id); this.bucket = new s3.Bucket(this, 'FooBucket', { bucketName: 'foo-bucket', }); // aws-cdkのbeta版で出力したCFnテンプレートから参照した値をベタ書きしたらこんな感じ new cdk.CfnOutput(this, 'FooBucketNameXXXXXXXX', { value: cdk.objectToCloudFormation({ Ref: 'FooBucketYYYYYYYY' }), exportName: 'FooStack:FooBucketNameXXXXXXXX', }); } }ここに書いた例では
bucket変数をクロススタック参照するためにFooBucketNameXXXXXXXXというリソースIDのOutputsを定義しています
これは、 aws-cdkのbeta版でCFnテンプレート上に出力されていたものを流用して書いたものになります
このように、beta版で出力されていたOutputsを明示的に定義しておくことで、stable版で作ったStackに対してもbeta版で作ったStackからクロススタック参照を出来るように互換性を維持できます出力されるテンプレートに変更があった
使っていたAPIが消滅したということはなく、出力するリソースの細かい内容が変更されていただけだった(ただし自分が触っていた範囲に限る)が、そこに非互換な変更がないかを一つ一つ調査しました
やったこととしては、差分が出た部分について、CFnのドキュメントを見ながら差分の前後で意味的に変更がないかを調べる、ということを地道に行いました
例えばECRリポジトリのURIをOutputsとして出力する以下のコードについて、
const repository = new ecr.Repository(this, 'Repository', { repositoryName: 'foo-repository', }); new cdk.CfnOutput(this, 'RepositoryUri', { value: repository.repositoryUri, });beta -> stableにアップデートすることでCFnテンプレートのOutputsの項目について以下のような差分が出る
{ "Value": { "Fn::Join": [ "", [ { "Fn::Select": [4, { "Fn::Split": [":", { "Fn::GetAtt": ["RepositoryABCDE", "Arn"] }] }] }, ".dkr.ecr.", { "Fn::Select": [3, { "Fn::Split": [":", { "Fn::GetAtt": ["RepositoryABCDE", "Arn"] }] }] }, - ".amazonaws.com/", + ".", + { "Ref": "AWS::URLSuffix" }, + "/", { "Ref": "RepositoryABCDE" } ] ] } }この場合なら、
"Ref": "AWS::URLSuffix"で取得される値が このドキュメント から同値であると判断出来そう、という具合です
(ドキュメントだとリージョンごとに異なるとか書いてあるので別途検証したりもありましたが)正直インフラ規模が小さいから出来たことだとは思います
感想
思ったより難しくなかったので良かったという気持ちです
aws-cdkがbetaの時点で普通に動くライブラリとして仕上がってたおかげかなというのもありそうですねといってもバージョンアップ対象となるインフラの規模が大きかったりした場合は、Stackごとに段階的にバージョンを上げる、といった工夫をしないと現実的な工数で出来ないのかもとか思います
- 投稿日:2020-12-06T19:16:04+09:00
ちゃんと考えよう、IAMのはなし
はじめに
AWSを利用する際に必ず使用するIAM。
なんとなく利用することも多いのではないでしょうか。
IAMについて考える機会があったので、今一度整理してみようと思います。目次
- IAMとは
- IAMポリシーとは
- IAM設計で意識すべき4つのこと
- 本番運用に耐えうるIAMとは
1. IAMとは
AWS Identity and Access Management(IAM)
- AWSリソースへのアクセスを安全に管理
- 下記のいずれかの方法でアクセス許可を付与
- 適切なアクセス許可ポリシーがアタッチされたグループのメンバーにする (推奨)
- ポリシーをユーザーに直接アタッチする
2. IAMポリシーとは
AWSでのアクセスを管理するために権限を定義したもの。
IAMポリシーには6つのタイプがあります。
1. アイデンティティベースのポリシー
2. リソースベースのポリシー
3. アクセス許可の境界
4. 組織 SCP
5. アクセスコントロール (ACL)
6. セッションポリシーこのうち、アイデンティティベースのポリシーには大きく分けて3つの種類があります。
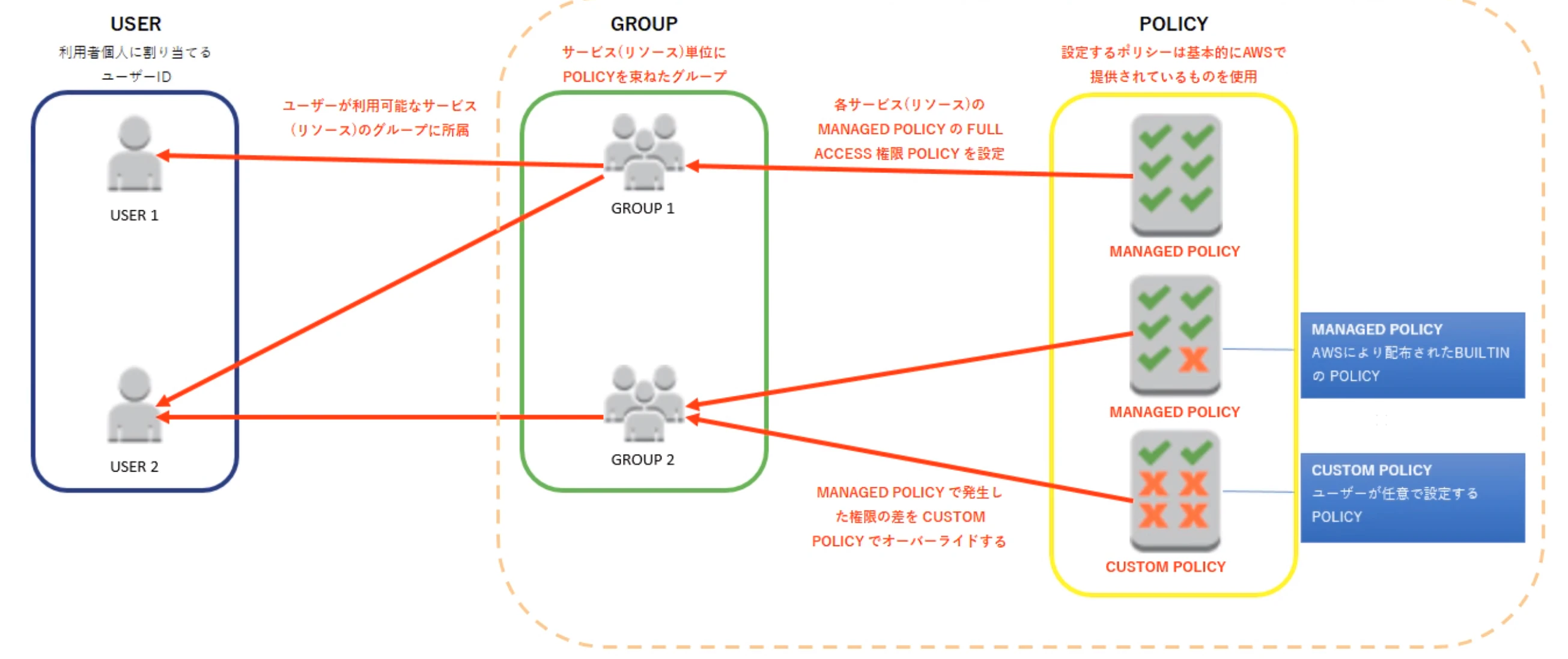
AWS管理ポリシー
- AWS が作成および管理するスタンドアロンポリシー
カスタマー管理ポリシー
- AWS利用者が作成および管理するスタンドアロンポリシー
インラインポリシー
- IAM アイデンティティ (ユーザー、グループ、またはロール) に埋め込まれたポリシー
3. IAM設計で意識すべき4つのこと
個人的所感ですが、IAM設計する場合は以下のことに気を付ける必要があります。
- 権限を付与する方法をどうするか?
- IAMロール
- IAMグループ
- インラインポリシー
- 付与する権限は頻繁に変更が入るか?
- 権限のパターンは多いか?少ないか?
- 独自の権限ルールが必要か?
4. 運用に耐えうるIAMとは
よくあるパターンを考えてみます。
- 権限を付与する方法はIAMグループ
- 付与する権限は頻繁に変更する可能性が高い
- 権限パターンは少ない
- 独自の権限ルールが必要
上記を満たすために、何をすべきか考えます。
1. 必要なAWSマネージドポリシーを洗い出します。
2. 要件に即したカスタマー管理ポリシーを作成します。
3. 必要となる権限要件を満たすように、AWSポリシーとカスタマー管理ポリシーを組み合わせたIAMグループを作成します。
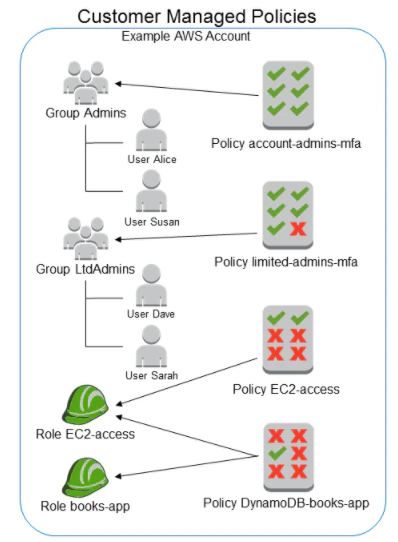
4. 作成したIAMグループに該当IAMユーザーをアタッチします。図にすると下記のようになります。
この設計の良いところは、下記だと思っています。
1. AWS管理ポリシーとカスタマー管理ポリシーを組み合わせて権限要件を満たすことで、メンテナンス対象ポリシーを絞ることができる
2. 権限パターンごとにIAMグループを作成するので、付与する権限を変更する場合はIAMグループを変更するだけで良い逆にデメリットとしては下記ですかね。
1. 権限パターンが多いと、IAMグループが乱立する
2. ポリシーの組み合わせでは、複雑な権限ルールを表現することが難しい最後に
IAMはAWSにおけるアクセス管理において非常に重要なサービスです。
権限設定を間違えると、AWSアカウントへの不正アクセスを許してしまい被害は計り知れません。
適切な権限を設定し、安全にAWSを利用しましょう。参考資料
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/introduction.html
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/access_policies_managed-vs-inline.html

- 投稿日:2020-12-06T19:09:04+09:00
NoSQL Workbench for Amazon DynamoDB 構築手順
Amazon DynamoDB のGUIツール「NoSQL Workbench」を調べる機会があり、せっかくなので構築手順書をブログにしてみました。
※(敢えて書きますが)本情報は2020年12月のものです。
NoSQL Workbench
GUIツールと言っても、「AWSコンソールで十分じゃないか?」と言う意見もあるかもしれませんが、NoSQL Workbenchには各種RDBのGUIツール同様(それ以上に)さまざまな機能が備わっているようです。
公式情報
2019年9月16日時点
Amazon DynamoDB 用 NoSQL Workbench のプレビュー版の発表
2020年5月7日時点
Amazon DynamoDB 向け NoSQL Workbench を使用したデータモデリング後者によると、
- 1つ以上のテーブルを使用してデータモデルを定義します。
- データモデルを視覚化して、さまざまなシナリオでどのように機能するかを理解します。
- 複数のプログラミング言語用のデータプレーン操作を構築します。
といったことが可能とのこと(しかし今回はあまり触れない!!)
前提
こちらの構築手順は
macOSのものです。インストーラーのダウンロード
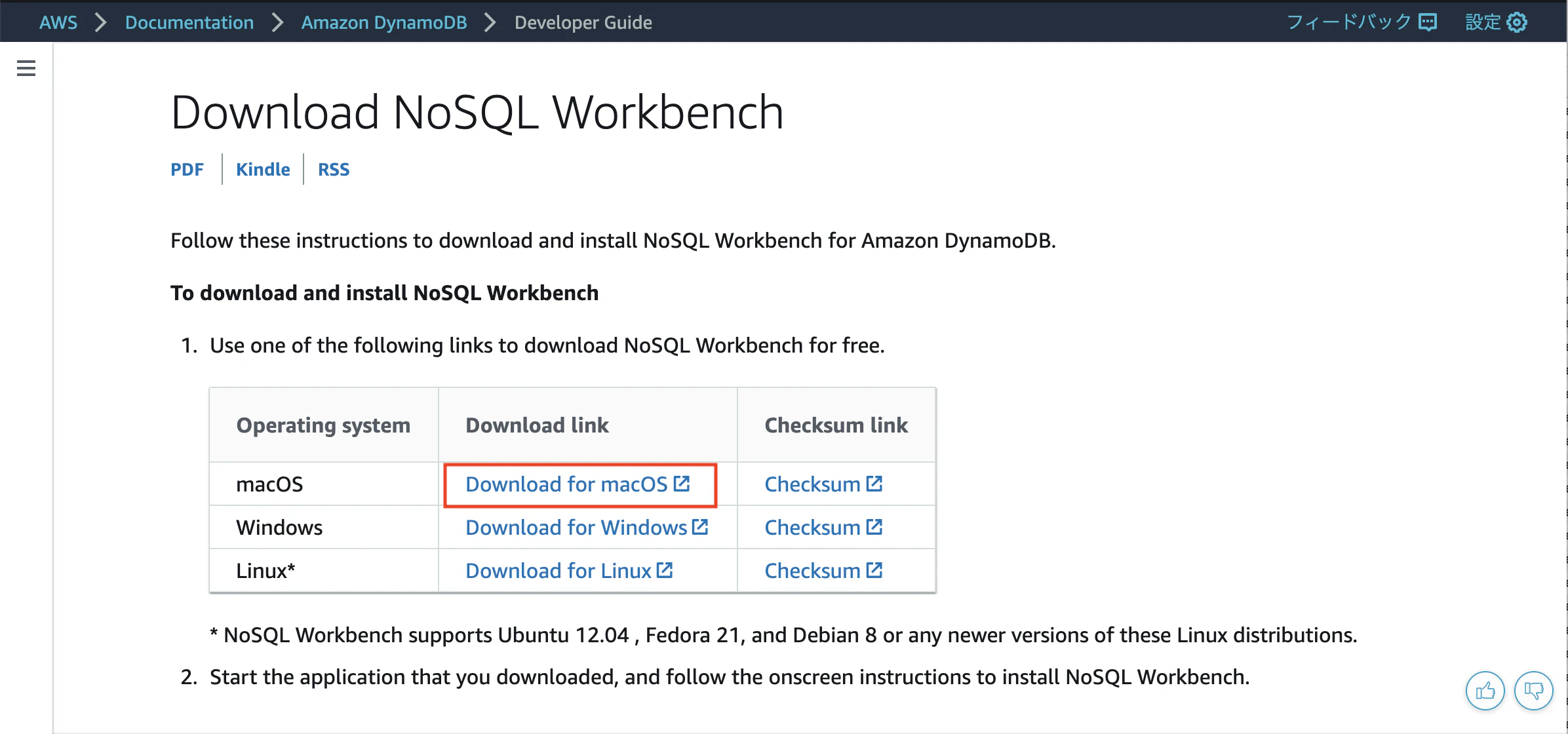
以下の公式サイトから各OSに対応したインストーラーをダウンロードします。
今回はmacOsなので赤枠の「Download for macOS」のリンクをクリックします。インストーラーを起動していつものようにApplicatioonsフォルダにアプリを移動。
アプリの起動→接続設定画面
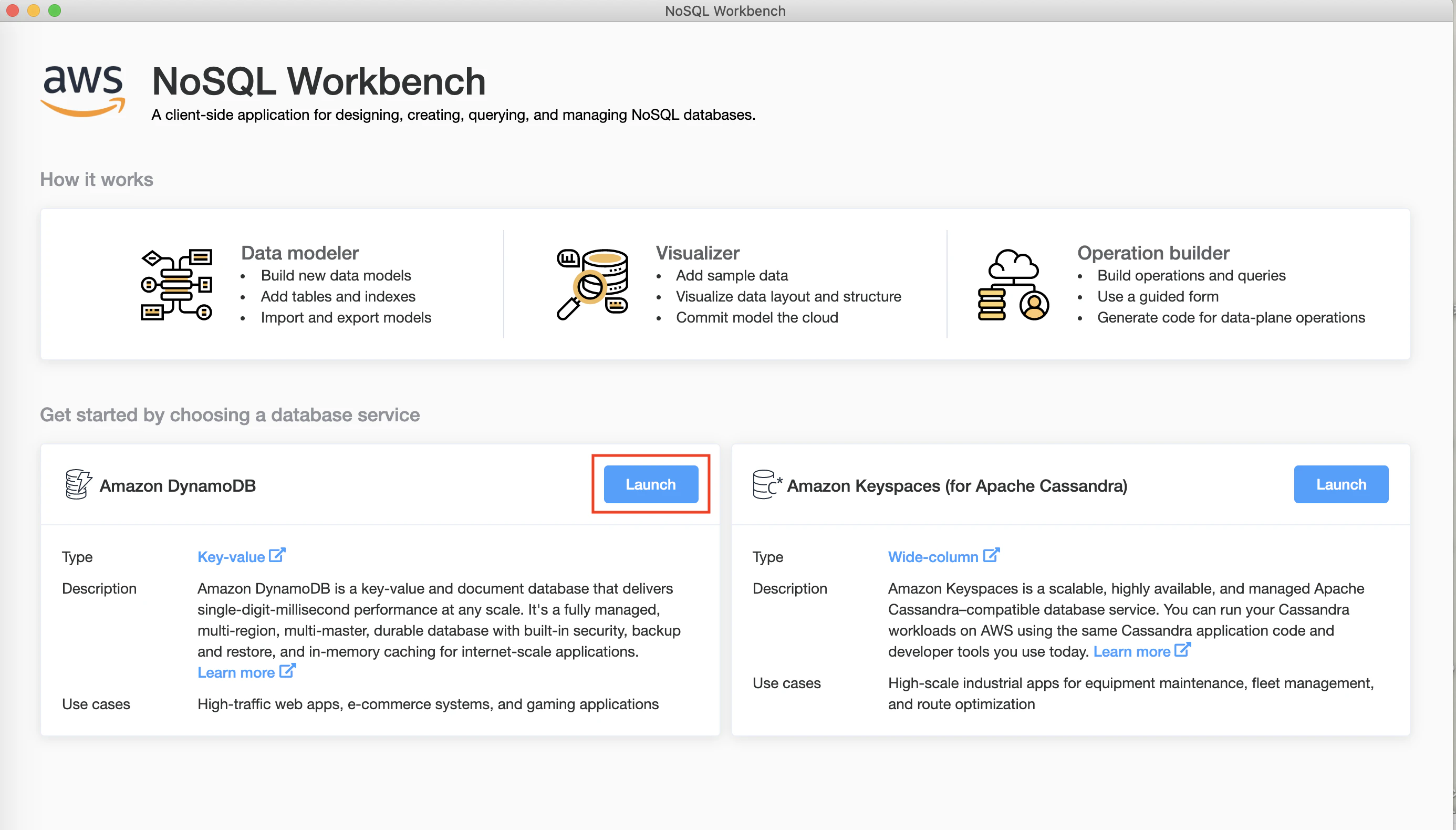
アプリを開く前にセキュリティの確認が出るので「開く」をクリック。
ホーム(?)画面で、Amazon DynamoDBの「Launch」を選択。
左のメニューの「Operation builder」を選択。
以下の画面までこれたらOK
接続設定(AWS CLIの設定が済んでいる場合)
AWS CLIで既にAWSと接続設定は済んでいるので、「open」を選択したらDynamoDBと接続されます。
設定しているAccess KeyとSecret KeyはDynamoDBアクセス権限を持っているユーザのものでないといけないはず。
open後はregionがDynamoDBを作成した場所と違ければ変更。
(ほぼほぼ「ap-northeast-1」でしょうか)
Nameもdefaultから変更する場合は変更。
ap-northeast-1に変更すると作成しているテーブル名が出てきます。
接続設定(AWS CLIの設定が済んでいない場合)
ちなみに、私は確認できてないですが、AWS CLIのインストールは少なくとも必要そうです。
参考
DynamoDB の GUI ツールが公式から出たよ!AWS CLIでAWSの接続設定が済んでいない。AWS CLIとは異なる接続設定を利用したい場合。
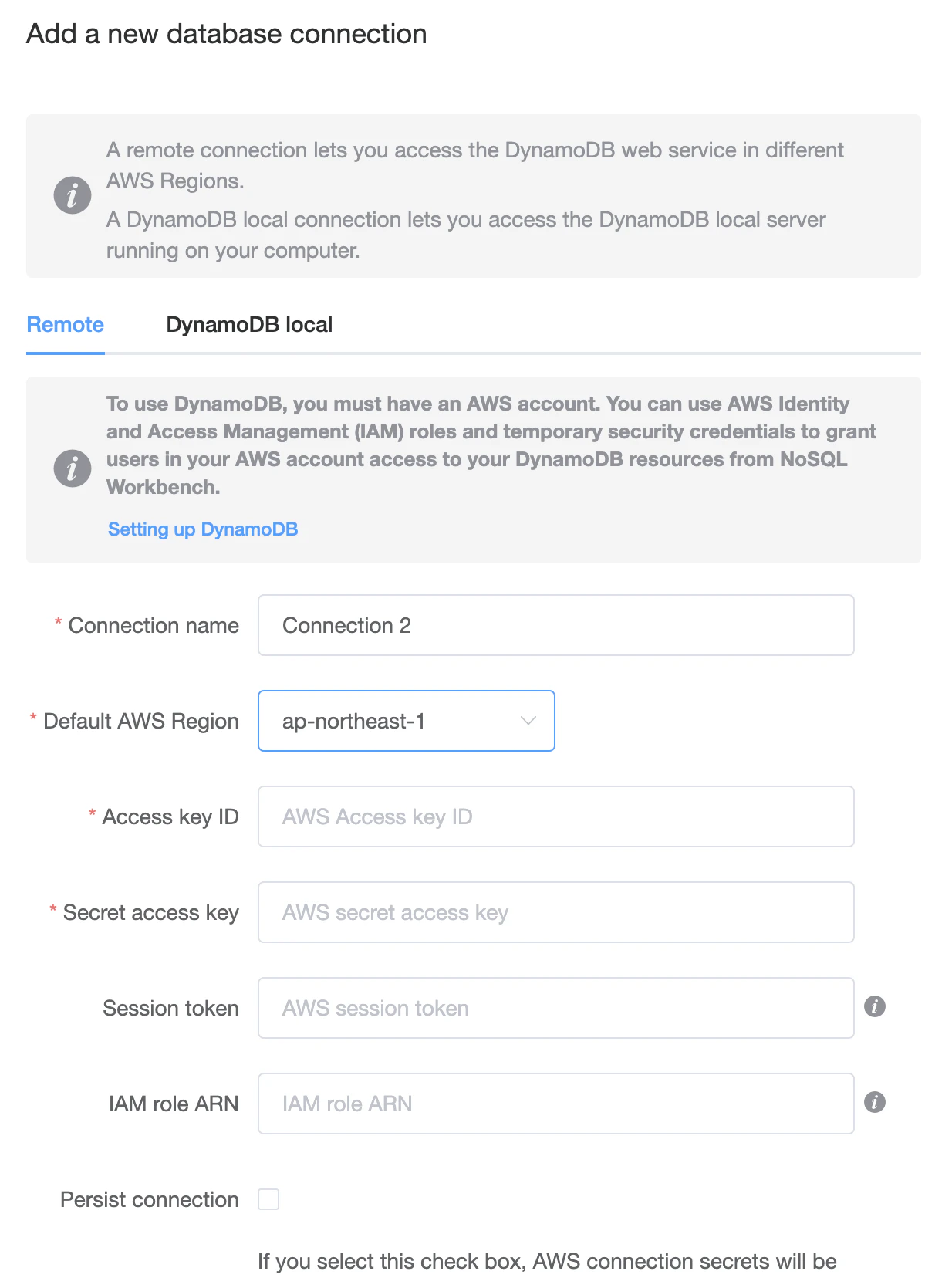
「+ Add connection」を選択。
以下の入力項目が出てくるのでそれぞれ設定。
最低限の設定項目
Connection name : 任意
Default AWS Region : ap-northeast-1 (DynamoDBを作成した場所)
Access key ID : 接続するユーザのもの
Secret access key : 接続するユーザのもの
必須でない項目
Session token
今のところ分かってない!!(以下参照ください)
Amazon DynamoDB用 NoSQL Workbenchでsession tokenを使って接続してみたIAM role Arn
今のところやってみた人いなさそう?(以下公式情報)
Amazon DynamoDB 用の NoSQL Workbench が、AWS Identity and Access Management (IAM) ロールと一時的なセキュリティ認証情報のサポートを追加Persist connection
チェックするとAWSの接続情報を/Users/[ユーザ名]/.aws/credentialsに保存される。動作確認
テーブルを選択して、DynamoDBに登録したデータが表示されたらOKです。
ちょっと使ってみる
DynamoDBを操作するには、今までみていた「Results」ではなく「Build operations」を開きます。
開くと「Data plane operations」という項目があり、このプルダウンの中の操作ができる模様。
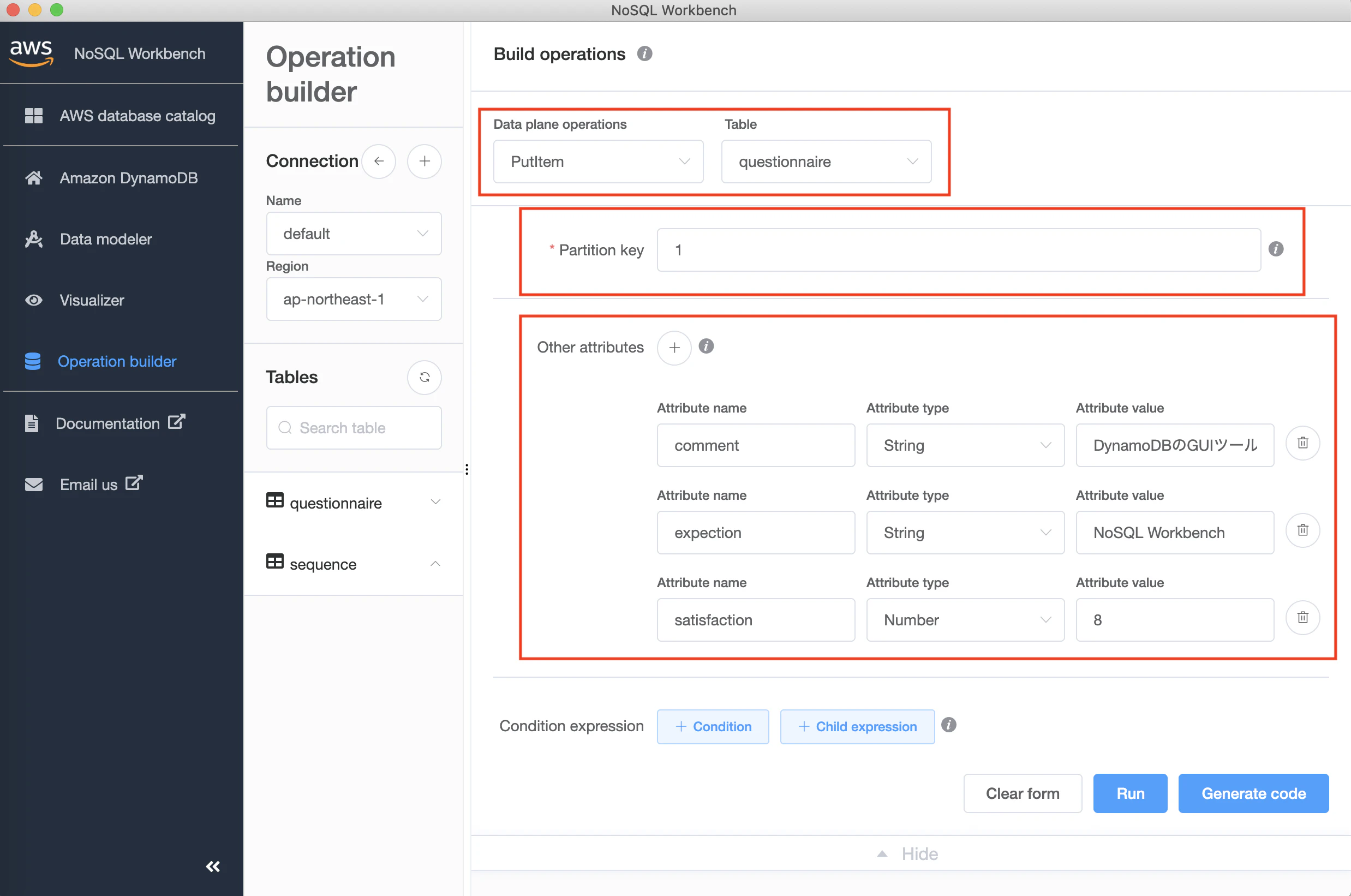
PutItem
書き込みやってみたかったので、
PutItemやってみます。
入力項目(ざっと)
Data plane operations : PutItem
Table : 操作したいテーブル名
Partition Key : Partition Keyの値の入力
Other attributes→その他の値
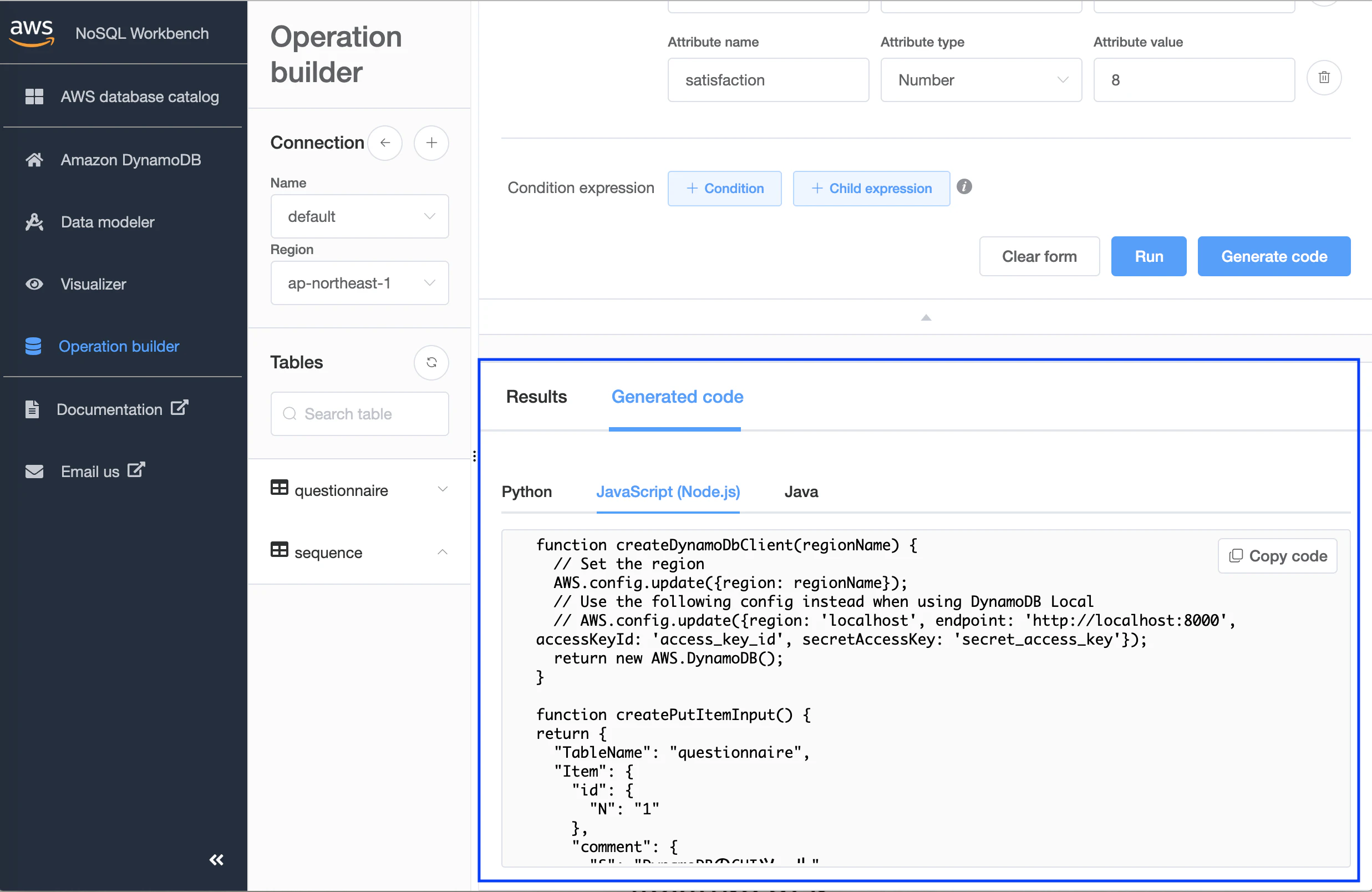
あとは「Run」をクリックして、入力項目に問題がなければデータが追加されます。
また「Generate code」をクリックすると、「Build operations」で指定した操作について「Python」「JavaScript」「Java」それぞれのコードを作成してくれます。(すごい)
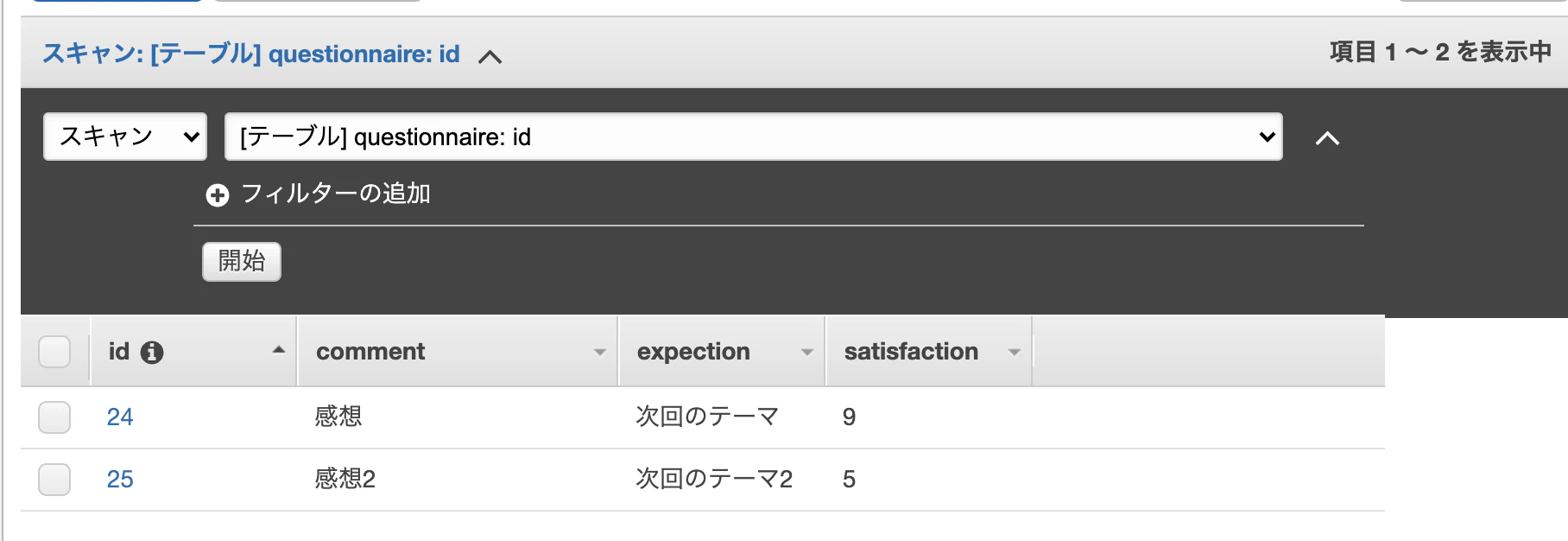
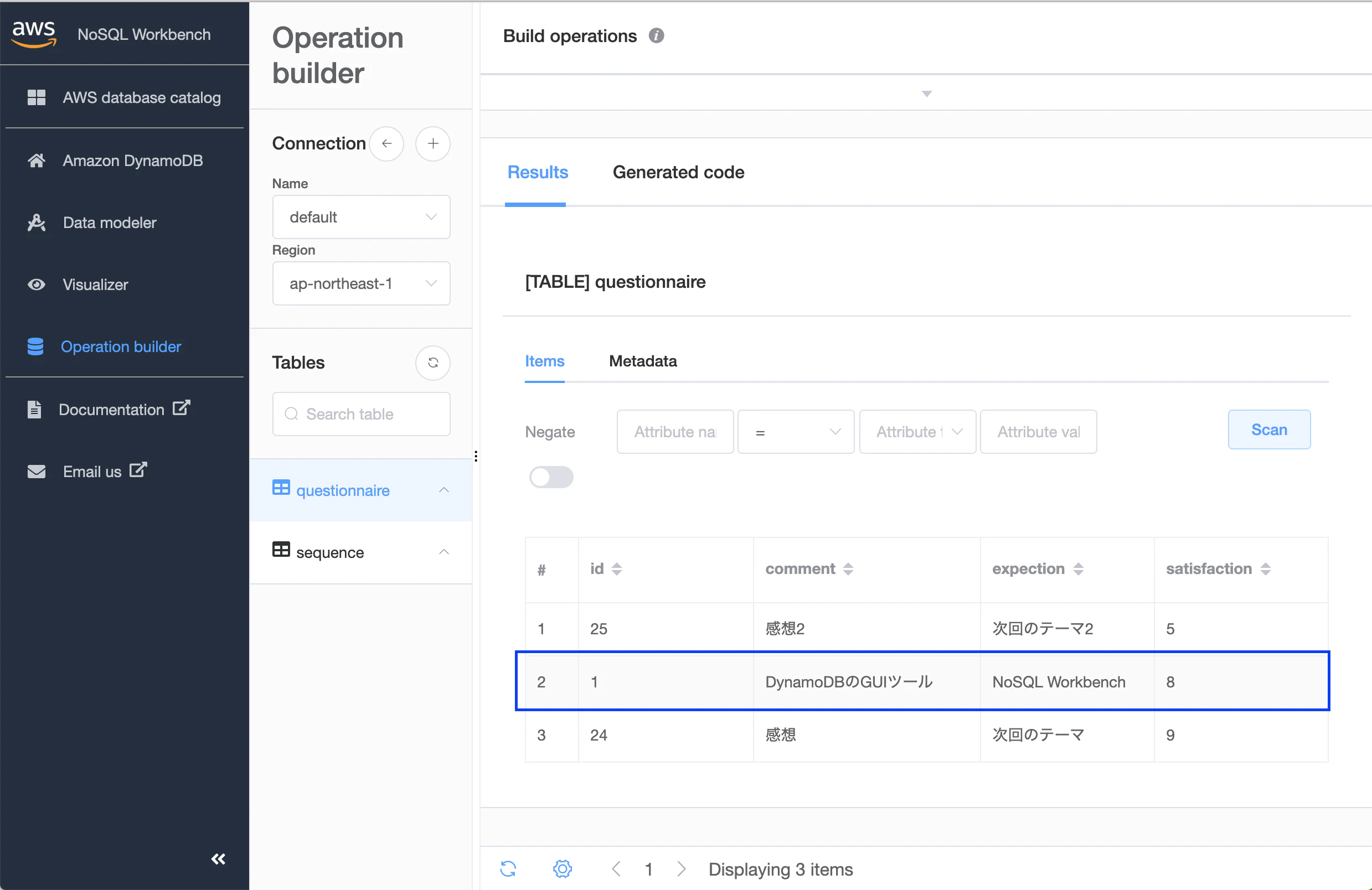
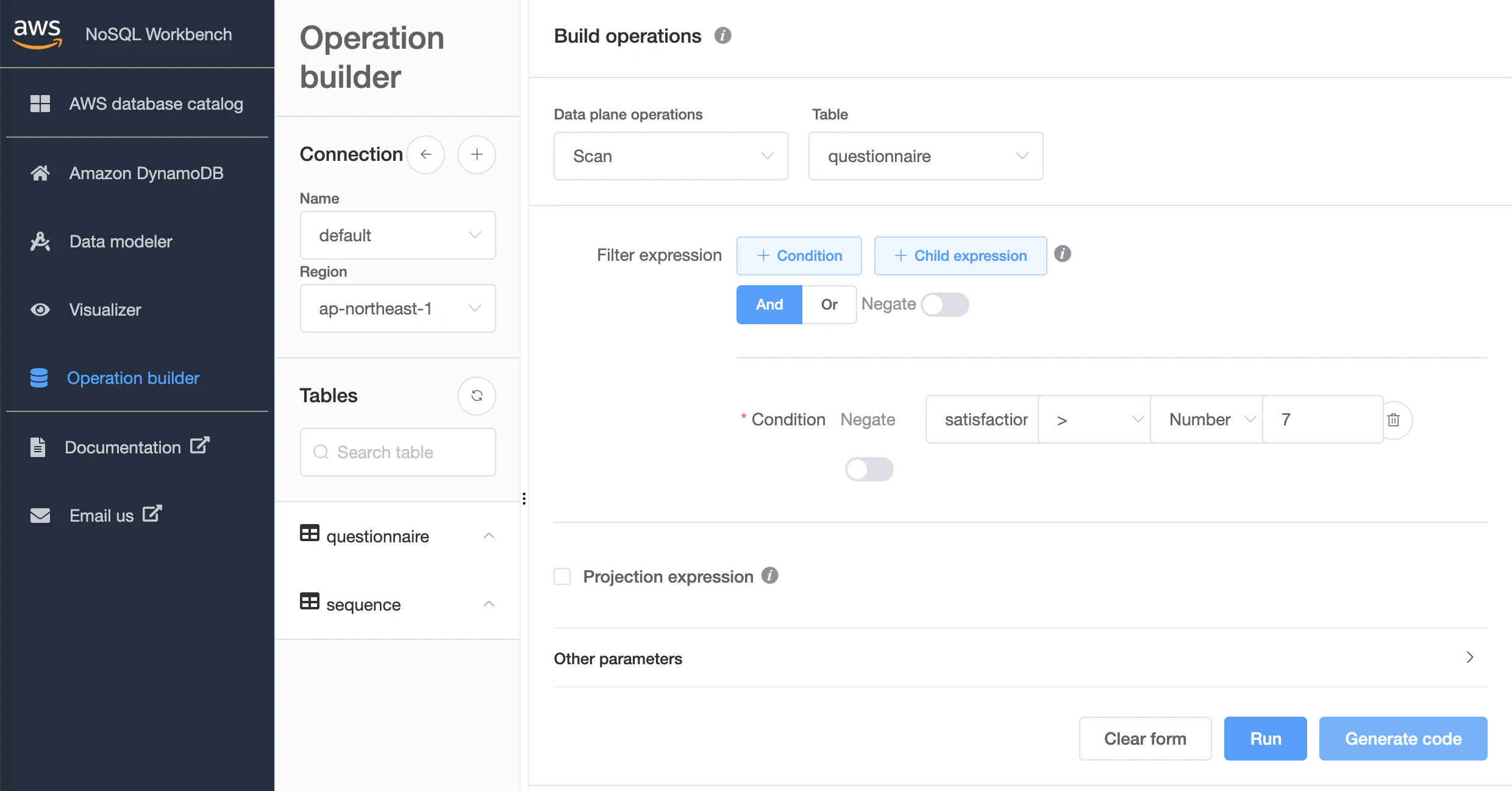
Scan
キャプチャのみにとどめますが
Scanの場合は以下のようになります。
(satisfaction)入力
結果
余談
普通にインストールするとデスクトップにアイコン配置されるのなんででしょうね。(macOSは個人的になくていい)
おわり
便利な機能たくさんありそうなので、何か発見したらまた記事にしようかと思います。
以上です!!







- 投稿日:2020-12-06T17:38:33+09:00
Amazon RDS DB (Aurora)インスタンスタイプを変更するスクリプト
Amazon Auroraを社内で検証中…
スケールアップしたときのパフォーマンスを見てみたいな。インスタンスタイプ変えておいて!
いや…スケールダウンして、違うパターンも試してみよう…!
なんてことが繰り返されていて、そのたびに AWS Console をポチポチしながらインスタンスタイプを変えていました。。。
(16個変えるのに20分以上マウス操作…)
さすがに面倒なのでドキュメントを参考に、一括変更できるスクリプトを作りました。
modifyInstance.sh#!/bin/bash INSTANCE_CLASS=db.r5.large aws rds modify-db-instance \ --db-instance-identifier main-core \ --db-instance-class $INSTANCE_CLASS \ --apply-immediately for (( i=1; i<= 15; i++ )) do id="0${i}" aws rds modify-db-instance \ --db-instance-identifier read${id: -2} \ --db-instance-class $INSTANCE_CLASS \ --apply-immediately doneドキュメントに記載されている [すぐに適用] 設定を使用する を設定するとスクリプトを実行した直後からインスタンスタイプの変更が始まるので、検証作業中にとても便利です。
- 投稿日:2020-12-06T15:24:29+09:00
Raspberry Pi 4でおうちAmazon EKS Distro (EKS-D) をやってみた
Re:Invent 2020でAmazon EKS Distro (EKS-D)が発表されましたね。
公式ブログはこちら
なぜか日本語の方にはEKS-Dの表記がないですねAmazon EKS Distro: Amazon EKS で使用される Kubernetes ディストリビューション
https://aws.amazon.com/jp/blogs/news/amazon-eks-distro-the-kubernetes-distribution-used-by-amazon-eks/Introducing Amazon EKS Distro (EKS-D)
https://aws.amazon.com/jp/blogs/opensource/introducing-amazon-eks-distro/早速手持ちのRaspberry Pi 4でやってみました。
先にまとめ
- CanonicalがEKS-Dのsnapパッケージをすでに提供している( https://snapcraft.io/eks )
- ただし2020/12/06時点ではAMD64向けしかない
- ソースコードはGitHub( https://github.com/canonical/eks-snap )で提供されているので、自前でビルドすればRaspberry Pi 4でも動作可
- ビルドしたもの置いておきますね( https://github.com/moritalous/eks-snap/releases/tag/eks_v1.18.9_arm64 )
環境
Raspberry Pi 4 (メモリ8GB)
microSDカード 32GB ※EKS-Dのビルドを行う際に10GBほど必要ですOSはUbuntu 20.04(64bit)です。
前準備
sudo apt update && sudo apt upgrade -y
- snapcraftのインストール
sudo snap install snapcraft --classic
/boot/firmware/cmdline.txtにcgroup_enable=memory cgroup_memory=1を追加(1行目の末尾)- net.ifnames=0 dwc_otg.lpm_enable=0 console=serial0,115200 console=tty1 root=LABEL=writable rootfstype=ext4 elevator=deadline rootwait fixrtc + net.ifnames=0 dwc_otg.lpm_enable=0 console=serial0,115200 console=tty1 root=LABEL=writable rootfstype=ext4 elevator=deadline rootwait fixrtc cgroup_enable=memory cgroup_memory=1
- LXDの初期化
ビルド時にLXDを使ってみました。初期化します。ディスクスペースが5GBでは不足するので10GBにしました。それ以外はデフォルト設定です。
sudo lxd initWould you like to use LXD clustering? (yes/no) [default=no]: Do you want to configure a new storage pool? (yes/no) [default=yes]: Name of the new storage pool [default=default]: Name of the storage backend to use (btrfs, dir, lvm, zfs, ceph) [default=zfs]: Create a new ZFS pool? (yes/no) [default=yes]: Would you like to use an existing empty block device (e.g. a disk or partition)? (yes/no) [default=no]: Size in GB of the new loop device (1GB minimum) [default=5GB]: 10GB ←ここだけ! Would you like to connect to a MAAS server? (yes/no) [default=no]: Would you like to create a new local network bridge? (yes/no) [default=yes]: What should the new bridge be called? [default=lxdbr0]: What IPv4 address should be used? (CIDR subnet notation, “auto” or “none”) [default=auto]: What IPv6 address should be used? (CIDR subnet notation, “auto” or “none”) [default=auto]: Would you like LXD to be available over the network? (yes/no) [default=no]: Would you like stale cached images to be updated automatically? (yes/no) [default=yes] Would you like a YAML "lxd init" preseed to be printed? (yes/no) [default=no]:EKS-Dのsnapパッケージのビルド
cd /tmp/ git clone https://github.com/canonical/eks-snap.git cd eks-snap/ snapcraft --use-lxd45分ほど待つと、eks_v1.18.9_arm64.snapが出来上がります
私のビルド成果物はこちらに格納しました。
https://github.com/moritalous/eks-snap/releases/tag/eks_v1.18.9_arm64EKS-Dのインストール
sudo snap install eks_v1.18.9_arm64.snap --classic --dangerousEKS-Dの起動
sudo eks.startステータス確認
ubuntu@ubuntu:~$ sudo eks status eks is running high-availability: no datastore master nodes: 127.0.0.1:19001 datastore standby nodes: none ubuntu@ubuntu:~$ubuntuユーザーで動作するように設定
mkdir ~/.kube cd ~/.kube sudo eks.config > config chmod 600 config sudo usermod -a -G eks ubuntu sudo chown -f -R ubuntu ~/.kube一度ログアウトして再ログインすると、
eks.kubectlコマンドが使えると思います。色々確認
eksに含まれるコマンドの確認
ubuntu@ubuntu:~$ eks help Available subcommands are: add-node config ctr dashboard-proxy dbctl join kubectl leave refresh-certs remove-node reset start status stop inspect ubuntu@ubuntu:~$kube-systemで起動しているPodの確認
ubuntu@ubuntueks kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-node-7js69 1/1 Running 1 83m metrics-server-f59887c58-5wxdp 1/1 Running 0 83m calico-kube-controllers-555fc8cc5c-6v286 1/1 Running 0 83m coredns-6788f546c9-vtbq5 1/1 Running 0 83m hostpath-provisioner-c77bfc987-vnbzk 1/1 Running 0 83m ubuntu@ubuntu:~$Serviceの確認
ubuntu@ubuntu:~$ eks kubectl get svc --all-namespaces NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.152.183.1 <none> 443/TCP 87m kube-system kube-dns ClusterIP 10.152.183.10 <none> 53/UDP,53/TCP,9153/TCP 87m kube-system metrics-server ClusterIP 10.152.183.182 <none> 443/TCP 87m ubuntu@ubuntu:~$イマイチどのあたりがEKSなのか、わかりませんでした。。。
- 投稿日:2020-12-06T14:44:49+09:00
AWS Lambdaをローカル環境に用意する(AWS-SAMのインストール)
前書き
lambdaを実装する必要があり、ローカルでプログラムのテストができないか調べてたところ、AWS SAMを用いて検証するようなので設定方法を書いていきます。
前提条件
Dockerがインストールが必要です。
+今回lamdaでgo言語を試すのでgoのインストール必要です。検証環境
OS:Windows 10 Pro 64bit ver 1909
言語環境:go version go1.14.1SAMで構築する検証環境について
AWS-SAMをインストールすることで下記のような環境をローカルに作成できます。
ローカルに仮想のAPI GaweWayを作りそこからLambda関数を実行する形です。
実行時にjsonを渡すことでevent発火時の動作も検証できます。lambda関数の実行時にdockerコンテナが起動し関数が実行されます。そのため、dockerのインストールが必要になります。
SAMのインストール
AWS SAM CLI のインストール
上記リンクからAWS-SAM CLIをダウンロードしインストールします。SAMをAPI GwateWay経由での実行する
チュートリアル
公式のチュートリアルを参考にHello-wouldを実行します。1.テンプレートからアプリケーションの作成
Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 What package type would you like to use? 1 - Zip (artifact is a zip uploaded to S3) 2 - Image (artifact is an image uploaded to an ECR image repository) Package type: 1 Which runtime would you like to use? 4 - go1.x Runtime: 4 Project name [sam-app]: Hello-Would AWS quick start application templates: 1 - Hello World Example 2 - Step Functions Sample App (Stock Trader) Template selection: 12.アプリケーションのビルド
cd .\Hello-Would\ sam build //アプリケーションのビルド3.アプリケーションの実行
まずローカル上のAPI Gatewayを起動しAPI叩くことでlamdaが実行されます。
sam local start-api //Gatewayの起動 > C:\Windows\System32\curl.exe http://127.0.0.1:3000/hello Hello, (IPアドレス)(参考)Windows 10上でcurlの実行
windows10 ver 1803以降は標準のcurlツールがあるのでそちらを使ってテストします。
ディレクトリ C:\Windows\System32 C:\Windows\System32\curl.exe http://127.0.0.1:3000/hello上記で実行ができました。
lambdaが呼び出されたときにdocker imageが起動するので初回や環境によって時間がかかります。
GawteWayを起動せず直接実行する際は、プロジェクトフォルダでsam local invokeで実行できます。
感想
ローカルの別のコンテナに接続する際は、docker networkを指定する必要だったり、
event時の環境変数をjsonで設定できます。
そちらも別記事にしようと思います。lambda関数を作成するうえでローカルに実行環境があるほうが便利ですが、意外と記事がなかったので作成しました。
誰かの役に立てば幸いです。
ありがとうございました。

- 投稿日:2020-12-06T14:32:21+09:00
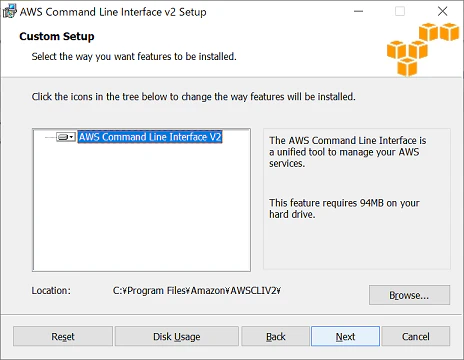
【AWS】WindowsでAWS CLI バージョン 2をインストール
Windows環境でAWS CLI バージョン 2をインストールする方法についての備忘メモです。
前提条件
この記事の対象者
- IAM ユーザ情報を持っており、AWS CLI を初めてインストールする
- AWS CLI バージョン 1 をインストール済で、バージョン 2 にアップグレードしたいがインストール方法を忘れた
この記事のゴール
AWS CLI バージョン 2をインストールし、基本設定を行う
必要なもの
- 64 ビットバージョンの Windows XP またはそれ以降
- ソフトウェアをインストールするための管理者権限
- IAMユーザの、アクセスキーIDとシークレットアクセスキー
環境情報
Windows 10 Home (64bit) バージョン 1909 (November 2019 Update)
AWS CLI バージョン 2 インストール手順
以下の手順でインストール、基本設定を行います。
- AWS CLI MSI インストーラのダウンロード
- ダウンロードした MSI インストーラの実行
- インストールの確認
- AWS CLI 設定
参考:公式ユーザガイド
基本的なインストール方法は公式ユーザガイドに記載されています。
実際にインストールしてみる
- 1. AWS CLI MSI インストーラのダウンロード
- こちら から最新のMSI インストーラをダウンロードします。

- 2. ダウンロードした MSI インストーラの実行
- MSI インストーラを実行し、画面の指示に従って進めます。
デフォルトでは、C:\Program Files\Amazon\AWSCLIV2にインストールされます。
Installをクリックして、インストールを開始します。
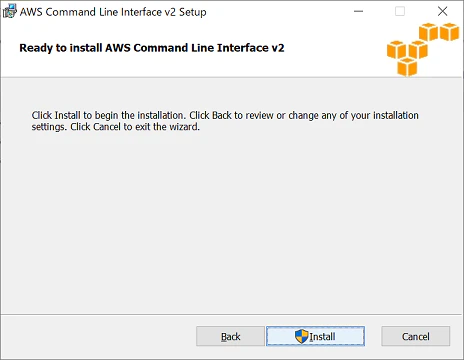
以下の画面が表示されたら、Finishをクリックし、インストールを完了します。

- 3. インストールの確認
- コマンドを入力して、インストールされていることを確認します。
コマンドaws --version実行結果aws-cli/2.1.7 Python/3.7.9 Windows/10 exe/AMD64 prompt/off
- 4. AWS CLI 設定
- コマンドを入力して、AWS CLI を使用するための基本設定を行います。
コマンドaws configure設定値の入力AWS Access Key ID [None]: [アクセスキーIDを入力] AWS Secret Access Key [None]: [シークレットアクセスキーを入力] Default region name [None]: ap-northeast-1 Default output format [None]: json
- 設定の確認を行います。
コマンドaws configure list実行結果Name Value Type Location ---- ----- ---- -------- profile <not set> None None access_key ****************XCOV shared-credentials-file secret_key ****************UJjg shared-credentials-file region ap-northeast-1 config-file ~/.aws/config
- 参考:公式ユーザガイド
AWS CLI バージョン 1 がインストール済みの場合
バージョン 1 をアンインストールする
公式ユーザガイド では、AWS CLI バージョン 2 を使用する際に、バージョン 1 をアンインストールすることが推奨されています。
推奨: – AWS CLI バージョン 1 をアンインストールし、AWS CLI バージョン 2 のみを使用します。
バージョン 1 と 2 では同じ
awsコマンドが使用され、検索パスで最初に見つかったバージョンが使用されるためとのことです。
バージョン 1 のアンインストール方法は こちら。バージョン 1 と 2 を併用する
PATH環境変数の設定を変更し、バージョン 2 の
awsコマンドを実行することが可能です。バージョン 2 インストール後すぐの状態
AWS CLI バージョン 1 がインストール済みの環境で、バージョン 2 のインストールを行うと、両方が共存した状態となります。
このまま
awsコマンドを実行すると、バージョン 1 のaws.exeが実行されます。コマンドaws --version実行結果aws-cli/1.18.190 Python/3.6.0 Windows/10 botocore/1.19.30これは、インストール時に自動設定されたPATH環境変数で、バージョン 1 のパスが優先されているためです。
PATH環境変数の設定
環境変数の設定で、バージョン 2 のパスを バージョン 1 のパスよりも上に移動すると、バージョン 2 の
aws.exeが実行されるようになります。バージョン1のデフォルトパスC:\Program Files\Amazon\AWSCLI\bin\バージョン2のデフォルトパスC:\Program Files\Amazon\AWSCLI2\バージョン 2 のパス
C:\Program Files\Amazon\AWSCLI2\を、
バージョン 1 のパスC:\Program Files\Amazon\AWSCLI\bin\よりも上に移動します。
aws --versionコマンドで、バージョン 2 の情報が表示されるようになりました。コマンドaws --version実行結果aws-cli/2.1.7 Python/3.7.9 Windows/10 exe/AMD64 prompt/offおわりに
IAM ユーザのアクセスキーIDとシークレットアクセスキーについて、AWS CLI の設定と認証情報については、別記事を書きたいと思います。
参考サイト
参考にしたAWS公式のユーザーガイド




- 投稿日:2020-12-06T13:58:38+09:00
TerraformでAWS WAFを基礎から学ぶ(基本のルール設定編)
はじめに
AWS WAF はフルマネージドで便利なファイアウォールであり、インターネットに面したゲートウェイ機能を有するシステムをお手軽に構築するなら、ほぼ必須で使うことになるサービスだろう(自前で手塩にかけて育てたWAFを持っているのであれば話は別だろうけど)。
ということで、お手軽に使える AWS WAF をお手軽に Terraform で構築しつつ基礎を理解していく。
インテグレーションは API Gateway を使う。
今回作る「IPアドレス制限」だけであれば、API Gateway のリソースポリシーを使った方が手っ取り早い。あくまでも練習のためにやっていると考えていただきたい。IPアドレス制限する AWS WAF の基本セット
今回の構成では、ブラックリスト形式で実施する。
ルール設定に必要になる Terraform のリソースは以下の2種類。
- aws_wafv2_web_acl
- aws_wafv2_ip_set
今回の設定は練習であり、マネージメントコンソールにも注意書きがあるように、ブラックリストとしては実質的に意味がないということは留意しておくこと。
When a request comes through a CDN or other proxy network, the source IP address identifies the proxy and the original IP address is sent in a header. Use caution with the option, IP address in header, because headers can be handled inconsistently by proxies and they can be modified to bypass inspection.
Web ACL 本体とルールの設定
Web ACL は以下のように定義する。
resource "aws_wafv2_web_acl" "iprestriction" { name = local.webacl_name description = "TEST IP Adress Restriction" scope = "REGIONAL" default_action { allow {} } rule { name = "iprestriction" priority = 1 action { block {} } statement { ip_set_reference_statement { arn = aws_wafv2_ip_set.test.arn } } visibility_config { cloudwatch_metrics_enabled = false metric_name = local.webacl_iprestriction_metric_name sampled_requests_enabled = false } } visibility_config { cloudwatch_metrics_enabled = false metric_name = local.webacl_metric_name sampled_requests_enabled = false } }
visibility_configは今の段階では使わないものの、必須パラメータなので設定しておく。
default_actionも必須パラメータで、ここでブラックリストにするかホワイトリストにするかを指定するようなイメージだ。デフォルトがallowであればブラックリストといった感じだ。IPアドレスリストの設定
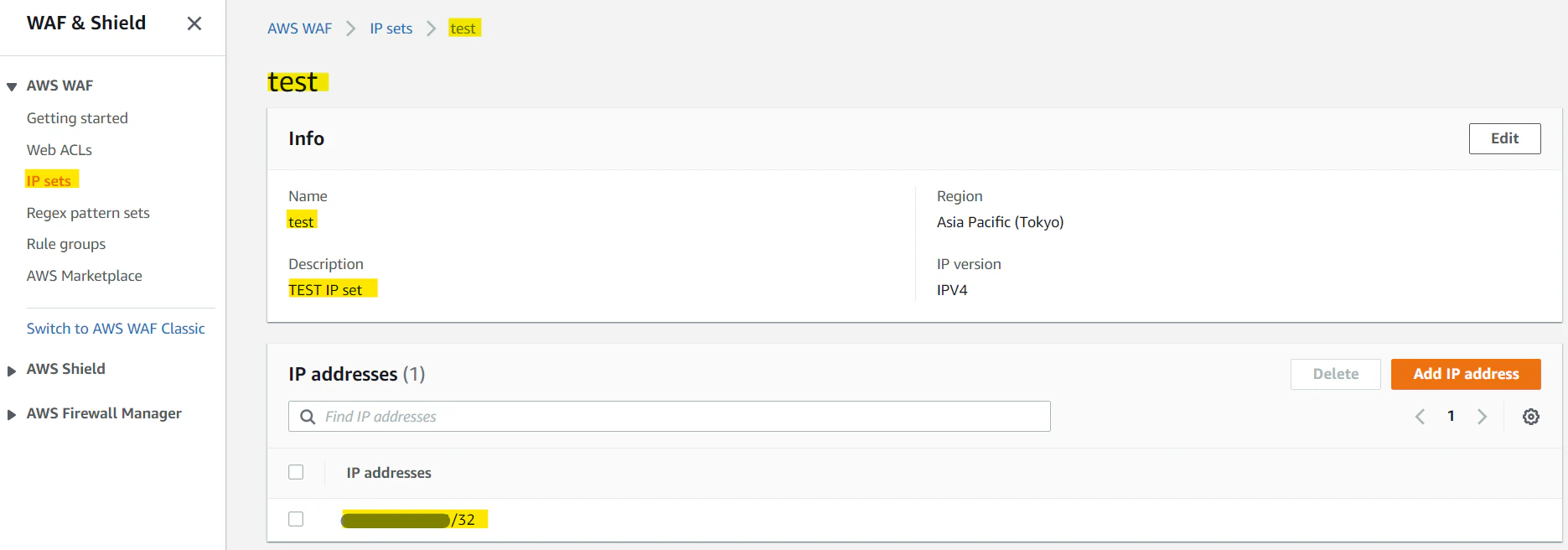
aws_wafv2_web_acl側でIPアドレス制限を直接書くのではなく、IPアドレスセットのリソースを準備し、それと比較するようなかたちになっている。おそらく、複数のルール間でお手軽に共通化ができるように、という思想なのだろうと推測。resource "aws_wafv2_ip_set" "test" { name = "test" description = "TEST IP set" scope = "REGIONAL" ip_address_version = "IPV4" addresses = [ "xxx.xxx.xxx.xxx/32", ] }アドレスはCIDRで指定する。今回はIPアドレスを1つだけ block したいので、
/32を指定する。API Gateway とインテグレーションする
さて、せっかくルールを作ってもインテグレーションしなければ意味がない。
インテグレーションには以下の Terraform リソースを使う。
- aws_wafv2_web_acl_association
使い方は簡単で、API Gateway と AWS WAF の ARN を繋ぐだけで良い。
API Gateway は REST API そのものではなくてステージと連動するという点だけ注意だ。resource "aws_wafv2_web_acl_association" "iprestriction" { resource_arn = aws_api_gateway_stage.prod.arn web_acl_arn = aws_wafv2_web_acl.iprestriction.arn }動作確認する
さて、本当にこれでIPアドレス制限されるのかを試してみよう。
IPアドレスリストに設定していないIPアドレスでアクセスした場合、
{ "data": { "hoge": "hige" }, "errorMessage": "" }と正しく取得され、リストに設定したIPアドレスでアクセスすると
{"message":"Forbidden"}と表示される。その他、
curl -iで取得されるヘッダ情報としては以下。
HTTPステータスコードは 403 として返却される。HTTP/2 403 content-type: application/json content-length: 23 date: Sun, 06 Dec 2020 02:57:37 GMT x-amzn-requestid: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx x-amzn-errortype: ForbiddenException x-amz-apigw-id: xxxxxxxxxxxxxxxx x-cache: Error from cloudfront via: 1.1 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.cloudfront.net (CloudFront) x-amz-cf-pop: NRT12-C4 x-amz-cf-id: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxAPI Gateway の HTTPステータスコードやワーディングの変更
API Gateway とインテグレーションする場合は、HTTP ステータスコードや応答の JSON はゲートウェイのレスポンスで変更可能だ。
api_gateway_gateway_responseリソースのresponse_type = "WAF_FILTERED"を使えば Terraform でもできる(詳細は記事を参照)。API Gateway のログ出力
API Gateway とインテグレーションする場合は、AWS WAF とのやり取りをアクセスログに出力することができる。アクセスログの設定に関する詳細は、手前味噌だがこの記事が分かりやすいと思う。
AWS WAF に関連する項目の出力例は以下の通り。
"waf_response_code": "$context.wafResponseCode", "webacl_arn": "$context.webaclArn", "waf_error": "$context.waf.error", "waf_latency": "$context.waf.latency", "waf_status": "$context.waf.status",これで実際に出力されたアクセスログを確認すると、以下のように出力される。
allow した場合"waf_response_code": "WAF_ALLOW", "webacl_arn": "arn:aws:wafv2:ap-northeast-1:xxxxxxxxxxxx:regional/webacl/waf-iprestrict-test-webacl/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "waf_error": "-", "waf_latency": "7", "waf_status": "200"block した場合"waf_response_code": "WAF_BLOCK", "webacl_arn": "arn:aws:wafv2:ap-northeast-1:xxxxxxxxxxxx:regional/webacl/waf-iprestrict-test-webacl/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "waf_error": "-", "waf_latency": "7", "waf_status": "403"AWS マネージメントコンソールでの確認
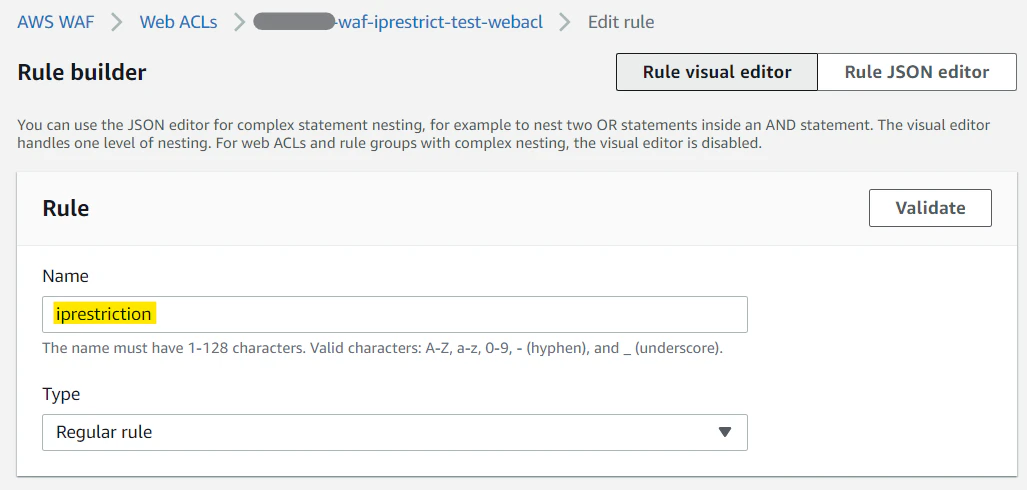
上記で作ったリソースをマネージメントコンソールで確認すると以下のようになる。
iprestrictionのルールを選択して、右上のEditボタンを押すと、以下のようにルール編集画面で設定内容を確認できる。
API Gateway とのインテグレーションに関する設定は以下。
IPアドレスリストに関する設定は以下。
基本のルール設定編はここまで。





- 投稿日:2020-12-06T11:37:26+09:00
「にゃーにゃーマップ」の制作
「にゃーにゃーマップ」の制作
はじめに
2019年末にはじめてQiitaへ投稿した「AWSを活用したサーバーレスWebアプリの制作」という記事は、自身の学習のために制作した『モザイク』というサーバーレスWebアプリの振り返りと定着のためのものでした。
2020年春頃、モザイクに続く自身2つ目の作品『にゃーにゃーマップ』というサーバーレスWebアプリを制作しましたので、今回も同じような感じで記事を書こうと思ってかれこれ数ヶ月。2020年内にある程度は書かなければっ、と、いよいよ着手します。
例によって日記のような記事になると思いますが、そういうものだと思ってますので、ご了承ください。
『にゃーにゃーマップ』とは
マップベースのサーバーレスWebアプリです。
近いという単語の「Near」(にやー)。
Stay Near, Enjoy Near, なるべく近くで楽しもう、近くの楽しいを見つけよう!
っていうコンセプトで名付けました。このアプリの見所は実はバックエンド、
WebスクレイピングとGooglePlaceAPIを利用した情報収集、DynamoDBやS3(+DataCatalog)での情報管理、位置情報をキーにした情報検索、あたりだと思っています。
(ちなみにモザイクの見所は、AppSyncを利用したサーバーレスでありながらも非同期的な制御です!)これをネタにしたLTスライドも記録としてリンクしておきます。
vol.1 (2020.06.26)
vol.2 (2020.07.08
vol.3 (2020.09.12)
vol.4 (2020.10.30)コンテンツ
いくつかの記事に分けて投稿を予定しています。
Nuxt.js+Vuetifyで新規作成したPWA対応済みWebアプリをAmplify Consoleで公開 (2020/12/6)
(Nuxt.js, Vue.js, Vuetify, PWA, AmplifyConsole)Nuxt.jsのWebアプリへGoogle Maps APIを利用して地図を表示したりピンを立てたり情報画面を表示したりする
(Nuxt.js, Vue.js, GoogleMapsAPI)Webサイトをスクレイピングして得た情報をS3に保存するPythonスクリプト
(Python, BeautifulSoup, S3)DynamoDBへのデータ投入とローカルセカンダリインデックスの利用
(Python, DynamoDB, LocalSecondaryIndexes)Google Places APIを利用した情報収集
(Python, GooglePlacesAPI)H3を利用した位置情報のインデックス化と周辺検索
(Python, H3)周辺検索をするためのAPI Gatewayを作成してWebアプリから利用する
(Nuxt.js, APIGateway, Lambda, DynamoDB, H3)複数のLambdaを条件分岐しつつ順に実行するStepFunctionsを定期実行させる
(Lambda, StepFunctions, EventBridge)DynamoDBへの操作をトリガーにLambdaを実行するDynamoDB Streamの利用
(DynamoDB, DynamoDBStream, Lambda)DynamoDBの内容をS3に落としてそれをAthenaで検索できるようにする
(DynamoDB, DynamoDBStream, S3, GlueDataCatalog, Athena)あとがき
モザイクのときは、7記事ほど書き溜めた状態で一気に放出したのですが、今回はまだゼロ記事の状態でこのインデックスのみ投稿します。最近怠け気味なので、プレッシャーを与えるために。年内に半分は書くぞ!
コンテンツを書いてみて、やばい結構忘れてるな、と。半年以上前ですからね、、ちょっと時間が経ち過ぎてる感。特にクライアントサイドまわり。
そういった意味では本来の目的である自分にとっての良い振り返りと定着機会にはなりそうです。
- 投稿日:2020-12-06T11:32:48+09:00
CloudFormationをゼロから勉強する。(その9:クロススタックリファレンス)
はじめに
その8ではスタックを
ネスト構成にしてテンプレートを分割しましたが、今回はクロススタックリファレンスで前回と同じようにテンプレートを分割してみようと思います。クロススタックリファレンスとは
クロススタックリファレンスも前回のネスト同様、テンプレートを分割する方法の1つとなりますが、クロススタックリファレンスは他のテンプレートで使用する変数だけを共有させるようにする方法となります。クロススタックリファレンスの書式
書式としては単純で、値を参照させる側のテンプレートの
Outputsセクションで参照させたい値・変数をExportで指定して、参照する側はImportValue関数で他テンプレートでExportしている値・変数を読み込むだけです。簡単ですね!参照させる側の書式例Outputs: EC2VPC1: Value: !Ref EC2VPC1 Export: Name: CrossStackVpcId参照する側の書式例Resources: EC2Subnet1: Type: 'AWS::EC2::Subnet' Properties: VpcId: !ImportValue CrossStackVpcId
クロススタックリファレンスは、前回のネスト構成のように、親となるスタックを実行すれば、テンプレート内で定義されている子スタックがまとめて作成されるようなものではないため、展開する際は個々に実行する必要があります。今回作成する構成
前回のテンプレートを手直しして以下のような構成を作ってみようと思います。
今回は親、子関係ないので、パラメータ入力・子テンプレート管理用のテンプレート(前回で言うと「cf.yaml」)は作成しません。
テンプレート、パラメータファイルの格納場所
今回は以下のファイル・ディレクトリ構成としようと思います。。
内容 VPCのパラメータ SUbnet1のパラメータ Subnet2のパラメータ EC2のパラメータ スタック名 cross-stack-vpc cross-stack-subnet1 cross-stack-subnet2 cross-stack-ec2 テンプレートファイルのパス /home/ec2-user/vpc.yaml /home/ec2-user/subnet1.yaml /home/ec2-user/subnet2.yaml /home/ec2-user/ec2.yaml パラメータファイルのパス /home/ec2-user/param1.json /home/ec2-user/param2.json /home/ec2-user/param3.json - VPCスタック用テンプレートの作成
VPCのレンジを入力で受け取って、VPCIDをExportで出力して他テンプレートから使用できるようにします。テンプレートは個々に実行するため、入力用jsonファイルも作ります。
VPCスタック用テンプレート(vpc.yaml)AWSTemplateFormatVersion: 2010-09-09 Parameters: VPCRange: Type: String Resources: EC2VPC1: Type: 'AWS::EC2::VPC' Properties: CidrBlock: !Ref VPCRange Tags: - Key: "Name" Value: "cf_VPC1" Outputs: EC2VPC1: Value: !Ref EC2VPC1 Export: Name: CrossStackVpcIdVPCレンジ入力用ファイル(param1.json)[ { "ParameterKey" : "VPCRange", "ParameterValue" : "172.24.0.0/16" } ]Subnet1スタック用テンプレートの作成
Subnet1用のレンジを入力で受け取って、SubnetIDをExportで出力して他テンプレートから使用できるようにします。サブネット作成で必要な
VPCIDはImportValue関数で先ほどVPC作成でExportした名前を指定して取得します。また、上記
VPCと同様、入力用jsonファイルも作ります。Subnet1スタック用テンプレート(subnet1.yaml)AWSTemplateFormatVersion: 2010-09-09 Parameters: SubnetRange1: Type: String Resources: EC2Subnet1: Type: 'AWS::EC2::Subnet' Properties: VpcId: !ImportValue CrossStackVpcId CidrBlock: !Ref SubnetRange1 Tags: - Key: "Name" Value: "cf_Subnet1" Outputs: EC2Subnet1: Value: !Ref EC2Subnet1 Export: Name: CrossStackSubnet1IdSubnet1レンジ入力用ファイル(param2.json)[ { "ParameterKey" : "SubnetRange1", "ParameterValue" : "172.24.0.0/24" } ]Subnet2スタック用テンプレートの作成
パラメータ名の違いだけで
Subnet1と同じなので説明割愛。Subnet2スタック用テンプレート(subnet2.yaml)AWSTemplateFormatVersion: 2010-09-09 Parameters: SubnetRange2: Type: String Resources: EC2Subnet2: Type: 'AWS::EC2::Subnet' Properties: VpcId: !ImportValue CrossStackVpcId CidrBlock: !Ref SubnetRange2 Tags: - Key: "Name" Value: "cf_Subnet2" Outputs: EC2Subnet2: Value: !Ref EC2Subnet2 Export: Name: CrossStackSubnet2IdSubnet2レンジ入力用ファイル(param3.json)[ { "ParameterKey" : "SubnetRange2", "ParameterValue" : "172.24.1.0/24" } ]EC2スタック用テンプレートの作成
ImportValue関数でSubnet1のIDを取得します。EC2スタック用テンプレート(ec2.yaml)AWSTemplateFormatVersion: 2010-09-09 Resources: EC2Instance: Type: 'AWS::EC2::Instance' Properties: ImageId: ami-0cc75a8978fbbc969 InstanceType: t2.micro KeyName: staging_key NetworkInterfaces: - AssociatePublicIpAddress: "true" SubnetId: !ImportValue CrossStackSubnet1Id DeviceIndex: 0 Tags: - Key: "Name" Value: "cf_EC2"スタックの作成
作成したテンプレートをいつも通り実行してスタックを作成すれば完成です。
但し、今回の場合、
Export値を参照するので、Export対象のスタックが先に完成していなければ、値が引けずに失敗します。そのため、一斉に
create-stackで実行するのではなく、スタック作成の成功を待ってから順に作成するようにしましょう。スタックの作成aws cloudformation create-stack --template-body file:///home/ec2-user/vpc.yaml --stack-name cross-stack-vpc --parameters file:///home/ec2-user/param1.json aws cloudformation create-stack --template-body file:///home/ec2-user/subnet1.yaml --stack-name cross-stack-subnet1 --parameters file:///home/ec2-user/param2.json aws cloudformation create-stack --template-body file:///home/ec2-user/subnet2.yaml --stack-name cross-stack-subnet2 --parameters file:///home/ec2-user/param3.json aws cloudformation create-stack --template-body file:///home/ec2-user/ec2.yaml --stack-name cross-stack-ec2削除について
ネスト構成の時と異なり、個々にスタック作成しているので、削除する場合も個々に削除する必要があります。但し、Exportしている値は依存関係があるため、もし他のスタックでExportしている値を使用していた場合は削除できません。
例えば、「vpc.yaml」を削除しようとすると「Export CrossStackVpcId cannot be deleted as it is in use by cross-stack-subnet1 and cross-stack-subnet2」といった理由により削除ができません。
スタックの削除と状態確認aws cloudformation delete-stack --stack-name cross-stack-vpc aws cloudformation describe-stacks --stack-name cross-stack-vpcdescribe-stacksの表示例{ "Stacks": [ { "StackId": "arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxxx:stack/cross-stack-vpc/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "EnableTerminationProtection": false, "DriftInformation": { "StackDriftStatus": "NOT_CHECKED" }, "Parameters": [ { "ParameterValue": "172.24.0.0/16", "ParameterKey": "VPCRange" } ], "Tags": [], "Outputs": [ { "ExportName": "CrossStackVpcId", "OutputKey": "EC2VPC1", "OutputValue": "vpc-xxxxxxxxxxxxxxxxx" } ], "StackStatusReason": "Export CrossStackVpcId cannot be deleted as it is in use by cross-stack-subnet1 and cross-stack-subnet2", "CreationTime": "YYYY-MM-DDThh:mm:ss.xxxZ", "StackName": "cross-stack-vpc", "NotificationARNs": [], "StackStatus": "CREATE_COMPLETE", "DisableRollback": false, "RollbackConfiguration": {} } ] }もし全てを削除したい場合は、以下の順番で削除するようにしましょう。
すべてのスタックの削除aws cloudformation delete-stack --stack-name cross-stack-ec2 aws cloudformation delete-stack --stack-name cross-stack-subnet2 aws cloudformation delete-stack --stack-name cross-stack-subnet1 aws cloudformation delete-stack --stack-name cross-stack-vpcおわりに
今回の
クロススタックリファレンスは前回のネストによるテンプレート呼び出しと比較し、簡単に値の共有ができると感じました。
ネストは多段構成になると、各スタックごとの繋がりを意識して作成する必要がありましたが、クロススタックリファレンスではスタックは個々に分離されているので、連携するテンプレート数が多くなっても書式があまり変わらずに書けるのは良いですね。次回は今までやってきた
Transform、ネスト、クロススタックリファレンスの使い分けについて私なりに考察してみようと思います。

- 投稿日:2020-12-06T10:40:00+09:00
AWSアカウント初期設定周りを先人の教えに沿ってやってみた
ナニコレ
この記事は Ubiregi Advent Calendar 2020 6日目のエントリです。
AWSアカウントを作成した直後に、サーバ起動させるとか様々なサービスを利用する前にやるべきこと。
ほとんど@tmknomさんの記事で初期設定できた(と思っている)んですが、
個人的に初期設定で詰まったところや、理解するのに時間が掛かったポイントをまとめてみようと思います。
https://qiita.com/tmknom/items/303db2d1d928db720888前提として
・本記事はAWSのアカウントがすでに作成されている前提の記事です
・公式ドキュメントは全く読んでおりません!
・本来は読むべきですが、触りながら理解するスタイルの方が性に合っているのでわからないところを逐一読んでいくスタイルで進めました。
・理解が間違っていることは往々にしてあると思いますので、ご指摘いただければ幸いです!そもそもなぜアカウントの初期設定をやる必要があるのか?
これは記事の中にも記載されているのですが、主にセキュリティ周りを強化することによって、クラウド破産なるものを防ぐのが目的。初期状態の場合、ユーザーIDとパスワードが合致してしまうと、ブルートフォースアタックなどで打ち破られる可能性もあり、お勧めできない。
おそらくAWSをこれから学ぼうという人は必見だと思われる。
ではここからは個人的に理解に時間が掛かった箇所を書いていく。AWSアカウント?IAMアカウント?なんじゃこりゃ?
・私がドキュメントを読んでいないのが諸悪の根源w
・AWSアカウント=rootアカウント(=root is GOD!)
・これが乗っ取られたら詰み!
・そういえばこの記事を書いていて思ったんですが、万が一乗っ取られてしまったらどうすれば良いんだろう・・・。アカウント停止すれば良いのかな?
仮想MFA認証コードが2つ必要
仮想MFA認証(Google Authenticatorなど)で認証コードを2つ入力する必要があるんですが、
「えっ、2つもコード無いんだけど・・・」となりました。
ドキュメント見ていない自分がダメ過ぎただけなんですけど、これは認証アプリを開いた時に表示された数字 + 30秒ぐらい経過した後の更新された数字をいれるだけでOKです。Qiita記事だけではなく、公式ドキュメントがいかに大事かがわかりました・・・。
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_credentials_mfa_enable_virtual.htmlセキュリティステータスが表示されていない
これは予想なんですが、現在はダッシュボードにある「ベストプラクティス」の項目がそれに該当するのではないでしょうか。あまり深く考えても仕方ないので、ここは適当に読み替えて進めました。
知らない用語がとにかく多い
こればかりはもう調べながらふんふんと理解するしかないと思いますが、AWSはサービス豊富ですね(白目)
AWSマネージメントコンソールの不正アクセス検知の構築が難しそう
自分も平穏な生活を送りたいwのとせっかく会社でslackを使っているので、試しに導入してみたいという気持ちで絶賛格闘中です。Lambdaってなんだよ・・・からです。
最後に
今年も非エンジニアではありますが、アドベントカレンダーイベントに参加させてもらえるということで、今学習中のAWSに関する記事を書かせてもらうことにしました!
大した記事にはなりませんが、その辺りはご愛敬でw
しかしながら記事を書くというのは難しいですね・・・

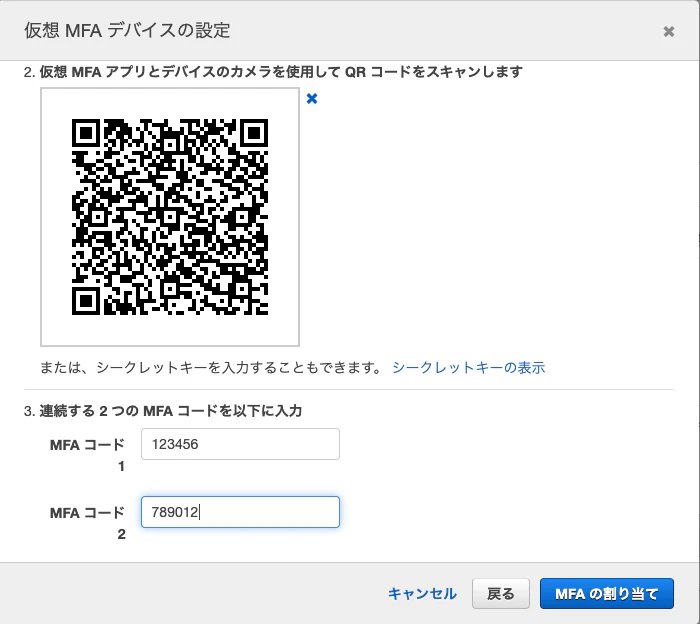

- 投稿日:2020-12-06T04:06:43+09:00
Partition Projectionを用いてAthenaのテーブルのパーティション管理を自動化する
2020年 6月 20日にAthenaに追加された機能Partition Projectionについて紹介していきたいと思います。
Partition Projectionについて
通常Athenaはパーティショニングされたテーブルに対してクエリを実行する際にAWS GlueのデータカタログやHive Metastoreからテーブルのメタデータ情報(パーティション情報やカラム情報など)を取得し、クエリを処理します。
その際にパーティションが多数存在する場合、メタデータを取得する時間がボトルネックとなる可能性があります。
一方、Partition Projectionを用いた場合、GlueやHive Metastoreへメタデータを取得せずにAthenaのテーブル設定を参照してパーティション情報を取得します。そのため、パーティションが多数存在することによるボトルネックを緩和することが可能になります。
また、Partition Projectionはパーティション管理を自動化することも可能です。
パーティションを更新する主流な方法は、
① Athenaで
MSCK REPAIR TABLE {table};を実行する② GlueのClawlerを実行する
などが挙げられます。
データの特性にもよりますが、Patition Projectionを用いることでこれらの方法を採用せずとも自動でパーティション管理を行うことが可能です。
データの準備
以下のcsvファイルを用意します。
2020-07.csv
"name","age","registration_date" "Aoki",19,"2020/7/14" "Saito",22,"2020/7/2" "Tanaka",21,"2020/7/22"2020-08.csv
"name","age","registration_date" "Aogasa",27,"2020/8/26" "Suzuki",32,"2020/8/6" "Fujiwara",18,"2020/8/18"2020-09-birthday.csv
"name","age,registration_date "Irie",33,"2020/9/11" "Sato",22,"2020/9/9" "Yoshida",21,"2020/9/5"この3つのファイルのうち、2つのファイルをS3へ配置します。
- s3://inu-is-dog/registration-dataset/year=2020/month=7/2020-07.csv
- s3://inu-is-dog/registration-dataset/year=2020/month=8/2020-08.csv
CTASを使ってテーブルの作成
AthenaのCTASを用いてPartition Projectionを適用されたテーブルを作成します。
CTASについてはこちらの記事をご参考ください。
CREATE EXTERNAL TABLE default.registration_table ( name string, age int, registration_date string ) PARTITIONED BY ( `year` int, `month` int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://inu-is-dog/registration-dataset/' TBLPROPERTIES ( 'projection.enabled' = 'true', 'projection.year.type' = 'integer', 'projection.year.range' = '2018,2020', 'projection.year.interval' = '1', 'projection.month.type' = 'integer', 'projection.month.range' = '1,12', 'projection.month.interval' = '1', 'storage.location.template' = 's3://inu-is-dog/registration-dataset/year=${year}/month=${month}/', 'classification'='csv', 'delimiter'=',', 'typeOfData'='file', 'skip.header.line.count'='1', 'serialization.encoding'='utf8' )今回ポイントとなるのがTBLPROPERTIESの以下の項目です。
projection.enabled:Partition Projectionが有効かどうか(true or false)projection.{partition_name}.type:パーティションのデータ型projection.{partition_name}.range:パーティションの値の範囲 今回はyearが2018~2020、monthが1~12が範囲となります。projection.{partition_name}.interval:パーティションの間隔になります。今回はyearもmonthも設定値が1ですが、例えばprojection.month.interval=3とするとmonthのパーティションはmonth=1,4,7,10になります。storage.location.template:s3パスの中のどこがパーティションの値なのかを指定する。projection.{partition_name}.typeにはdate型も使用できて範囲を現在日時(UTC)で制限できる点が特徴的です。
Supported Types for Partition Projection 公式ドキュメント
テーブルを作成できたのでクエリを投げてみます。
SELECT * FROM default.registration_table;
検証
s3://inu-is-dog/registration-dataset/year=2020/month=9/2020-09.csv にデータを配置して改めてクエリを実行します。
無事、9月分のデータが読み込まれていますね。
Partition Projectionを設定していない場合、
MSCK REPAIR TABLE default.registration;等を実行してメタデータを更新しなければ9月のデータはAthenaで読み取ることができません。したがって、パーティションの範囲や値がある程度予想できる場合はPartition Projectionを設定することでメタデータを更新する手間を省くことができます。
※Partiton Projectionで登録されたパーティション情報はAWS Glueのデータカタログ もしくは Hive metastoreに反映されないので注意が必要です。
動的なパーティション
device_idといった動的なパーティションを作成する場合はInjected TypeのProjectionを使用することがおすすめです
例えば、
s3://<bucket_name>/<prefix>/${device_id}/../..といった配置になるケースですねDynamic ID Partitioning 公式ドキュメント
GlueからPartition Projectionを設定
GlueからもPartition Projectionを設定することができます。
コンソールからGlueのサービスに遷移して
[データカタログ>データベース>テーブル] → [対象のテーブルを選択] → [テーブルの編集]
Partition Projectionに必要な項目を入力
これでPartition Projectionを設定したテーブルへ変更することができます。
最後に
今回はAthenaのPartition Projectionについて紹介させていただきました。
個人的にはQuickSightのデータセット更新でAthenaを使用することが多く、新しいパーティションが追加されるたびにメタデータを更新するということを手動で行っていたのでこの機能は大変助かりました。
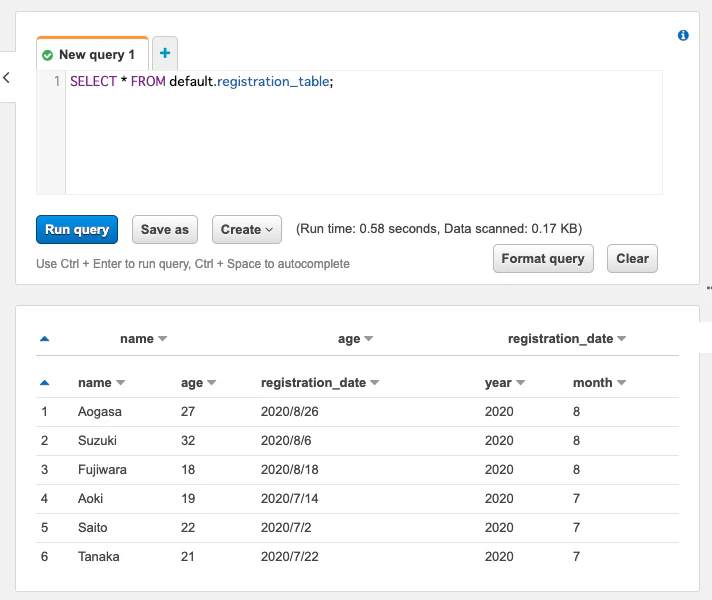

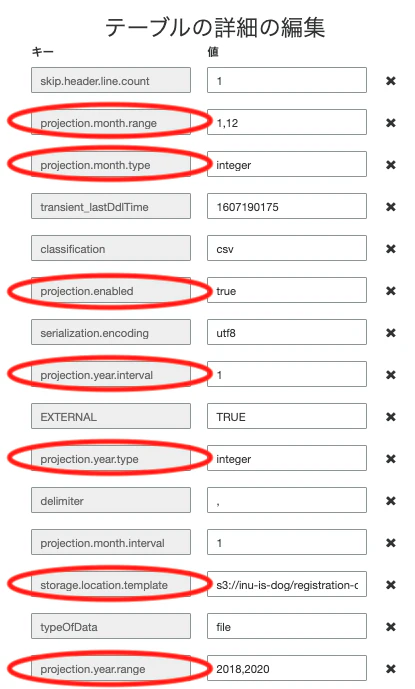
- 投稿日:2020-12-06T03:36:49+09:00
S3データ格納時のサーバ側暗号化(SSE-S3、SSE-KMS、SSE-C)と、クライアント側暗号化(CSE-KMS、CSE-C)
S3バケットへのデータ格納時にサーバーサイド暗号化のキーを指定できますが、SSE-S3だのSSE-KMSだの紛らわしい用語が出てきて混乱したので、整理してみた記事です。
1. 用語解説
SSE
Server Side Encryptionの略です。暗号化・復号をサーバー側で行う暗号化方式です。
CSE
Client Side Encryptionの略です。暗号化・復号をクライアント側で行う暗号化方式です。暗号化・復号のキーには、クライアント側で管理するキーだけでなく、KMSのカスタマー管理キーを使用することもできます。
CMK
Customer Master Keyの略です。CDKを暗号化するキーです。CMKは、KMS上では暗号化された状態で管理されています。
CMKには「カスタマー管理型CMK」と「AWS管理型CMK」の2種類があります(他にもAWS所有CMKがありますが、AWS内部で管理・使用されるCMKなので本記事では割愛します)。
- カスタマー管理型CMKは、KMSのコンソール画面からユーザーが作成できるCMKです。
- AWS管理型は、エイリアス名が
aws/サービス名(例「aws/ebs」)の、KMSビルトインのCMKです。以降で登場するCMKはすべて「カスタマー管理型CMK」を指します。
CDK
Customer Data Keyの略です。データの暗号化・復号時に実際に使用するキーです。
後述するCSE-KMSで暗号化キーを取得する際、KMS上でCDKが生成され、クライアント側に「CMKで暗号化されたCDK」と「平文のCDK」が払い出されます。
- この平文のCDKを使用して、クライアント側でデータを暗号化します。
- 復号時は、暗号化されたCDKをCMKで復号して平文のCDKを取得し、この平文のCDKを使用して復号します)。
クライアント側での具体的な手順は以下です。詳細は、KMSのDeveloper GuideのEnvelope encryptionを参照して下さい。
- (暗号化)CMKのARNまたはエイリアスをパラメータに指定して、KMS APIのGenerateDataKeyを呼び出すと「CMKで暗号化されたCDK」と「平文のCDK」が取得されます。クライアント側でこの平文のCDKを使ってデータを暗号化した後、「暗号化されたCDK」と「CDKで暗号化されたデータ」をクライアント側でDB等に保存して管理します。平文のCDKは、データの暗号化後すみやかに破棄することがベストプラクティスとされています。
GenerateDataKey$ aws kms generate-data-key \ --key-id "arn:aws:kms:ap-northeast-1:123456789012:alias/MyCMK" \ --key-spec "AES_256" { "CiphertextBlob": "(CMKで暗号化されたCDKのBase64表現)", "Plaintext": "(平文のCDKのBase64表現)", "KeyId": "arn:aws:kms:ap-northeast-1:123456789012:key/12345678-1234-1234-1234-123456789abcd" }
- (復号)
CipherTextBlobの値をパラメータに指定してKMS APIのDecryptを呼び出すことで、平文のCDK(PlainTextの値)を取得します。このCDKを使ってデータを復号します。Decrypt$ aws kms decrypt --ciphertext-blob "(GenerateDataKeyで得たCipherTextBlobの値)" { "KeyId": "arn:aws:kms:ap-northeast-1:123456789012:key/12345678-1234-1234-1234-123456789abcd", "Plaintext": "(平文のCDKのBase64表現)", "EncryptionAlgorithm": "SYMMETRIC_DEFAULT" }2. 暗号化方式
暗号化方式は、「どこで暗号化・復号するか(サーバー/クライアント)」と「暗号化のキーはどこで管理するか(S3/KMS/Client)」の組合せによって、以下の5パターンに分かれます。
S3 KMS Client サーバー SSE-S3 SSE-KMS SSE-C クライアント - CSE-KMS CSE-C 以下は、各暗号化方式について暗号化・復号の場所とキーの管理者を一覧化したものです。
# 方式 暗号化・復号の場所 キーの管理者 デフォルトの暗号化(※1) 1 SSE-S3 サーバー S3 ○ 2 SSE-KMS サーバー KMS ○(※2) 3 SSE-C(※3) サーバー クライアント(※4) × 4 CSE-KMS クライアント KMS - 5 CSE-C(※5) クライアント クライアント - ※1 … バケットのプロパティの「デフォルトの暗号化」の「暗号化キータイプ」で選択可能かを示します。これはサーバーサイドの暗号化方式に関する設定であるため、クライアントサイドの暗号化方式(CSE-xx)については「-」としています。
※2 … 対称暗号のCMKのみ指定可能です。非対称暗号(RSA、ECC)のCMKは指定できません。
※3 … 表にある通り、SSE-CではKMSは使用されません。
※4 … SSE-Cでは、S3側にはランダムなSALT値が付加されたキーのHMAC値が保存されます。このHMAC値は、クライアントからのリクエストをS3側で検証するために使用されます(参考「
Protecting data using server-side encryption with customer-provided encryption keys (SSE-C)
」)。
※5 … CSE-Cは、暗号化・復号にもキーの管理にもAWSは関与しないため、本記事では触れません。3. 暗号化されたオブジェクトの属性値
SSE系の各暗号化方式でS3に格納されたオブジェクトの属性値は、S3 APIのHeadObjectで参照することができます。以下は、各属性値の値をまとめた表です(「-」はヘッダそのものが存在しないことを示します)。
# 属性 暗号化なし SSE-S3 SSE-KMS SSE-C 1 ServerSideEncryption - "AES256" "aws:kms" - 2 SSEKMSKeyId - - (CMKのARN) - 3 SSECustomerAlgorithm - - - "AES256" 4 SSECustomerKeyMD5 - - - (暗号化キーのMD5のBase64表現) 4. S3 APIのサンプル
暗号化なし
PutObject(暗号化なし)$ aws s3api put-object --bucket mybucket \ --key sample_plain.txt \ --body sample.txt { "ETag": "\"900150983cd24fb0d6963f7d28e17f72\"" }HeadObject(暗号化なし)$ aws s3api head-object --bucket mybucket \ --key sample_plain.txt { "AcceptRanges": "bytes", "LastModified": "2020-12-05T10:38:15+00:00", "ContentLength": 3, "ETag": "\"900150983cd24fb0d6963f7d28e17f72\"", "ContentType": "binary/octet-stream", "Metadata": {} }SSE-S3
PutObject(SSE-S3)$ aws s3api put-object --bucket mybucket \ --key sample_SSE-S3.txt \ --body sample.txt \ --server-side-encryption AES256 { "ETag": "\"900150983cd24fb0d6963f7d28e17f72\"", "ServerSideEncryption": "AES256" }HeadObject(SSE-S3)$ aws s3api head-object --bucket mybucket \ --key sample_SSE-S3.txt { "AcceptRanges": "bytes", "LastModified": "2020-12-05T10:44:43+00:00", "ContentLength": 3, "ETag": "\"900150983cd24fb0d6963f7d28e17f72\"", "ContentType": "binary/octet-stream", "ServerSideEncryption": "AES256", "Metadata": {} }SSE-KMS
PutObject(SSE-KMS)$ aws s3api put-object --bucket mybucket \ --key sample_SSE-KMS.txt \ --body sample.txt \ --server-side-encryption aws:kms \ --ssekms-key-id "arn:aws:kms:ap-northeast-1:123456789012:alias/MyCMK" { "ETag": "\"a14e595d3104cc97d27e40d8a50d87c1\"", "ServerSideEncryption": "aws:kms", "SSEKMSKeyId": "arn:aws:kms:ap-northeast-1:123456789012:key/12345678-1234-1234-1234-123456789abcd" }HeadObject(SSE-KMS)$ aws s3api head-object --bucket mybucket \ --key sample_SSE-KMS.txt { "AcceptRanges": "bytes", "LastModified": "2020-12-05T10:47:52+00:00", "ContentLength": 3, "ETag": "\"a14e595d3104cc97d27e40d8a50d87c1\"", "ContentType": "binary/octet-stream", "ServerSideEncryption": "aws:kms", "Metadata": {}, "SSEKMSKeyId": "arn:aws:kms:ap-northeast-1:123456789012:key/12345678-1234-1234-1234-123456789abcd" }SSE-C
PutObject(SSE-C)$ aws s3api put-object --bucket mybucket \ --key sample_SSE-C.txt \ --body sample.txt \ --sse-customer-algorithm AES256 \ --sse-customer-key abcdefghijklmnopqrstuvwxyz012345 { "ETag": "\"769bb7a6b731cf4780a40986eeb23752\"", "SSECustomerAlgorithm": "AES256", "SSECustomerKeyMD5": "NX6C25NPxF9KJbS4Pci9GQ==" }HeadObject(SSE-C)$ aws s3api head-object --bucket mybucket \ --key sample_SSE-C.txt \ --sse-customer-algorithm AES256 \ --sse-customer-key abcdefghijklmnopqrstuvwxyz012345 { "AcceptRanges": "bytes", "LastModified": "2020-12-05T11:08:16+00:00", "ContentLength": 3, "ETag": "\"d5c7e37972ae63cf5c57ceb30e26f1e2\"", "ContentType": "binary/octet-stream", "Metadata": {}, "SSECustomerAlgorithm": "AES256", "SSECustomerKeyMD5": "NX6C25NPxF9KJbS4Pci9GQ==" }
- 投稿日:2020-12-06T03:01:22+09:00
AWSクラウドプラクティショナー取得までの記録
はじめに
会社でAWS資格取得を推進しているし費用補助もあるしいっちょ頑張ってみようと言うスタート。
産休前にSAA取るぞ!と大見得を切っていたけど結局勉強が滞ったので、ハードル低めにCLFからにしました。前提条件
・SE歴7年、インフラ経験無し、AWSはLambdaとCloudWatchを少し。
勉強方法
・AWSの基本が1日で学べる!超入門講座セミナー視聴(4H)
AWSのトレーナーの方が実際に画面で操作しながら主要機能を一通り解説してくれました。・AWS認定資格試験テキスト(2week)
1回読破。隅から隅まで読むけど深追いはせずにさらりと。章末問題も忘れずに。
https://www.amazon.co.jp/AWS認定資格試験テキスト-AWS認定-クラウドプラクティショナー-山下-光洋/dp/4797397403・WEB問題集(3week)
https://aws.koiwaclub.com
1周目:1問30秒程度のスピードで軽く。解説はさらりと。
問題に慣れる&出題傾向を把握する事が重点。※正答率1/7〜5/7
2周目:1問2、3分程度掛けてじっくり。正誤に関わらず解説もしっかり読む。
ググったりも。※正答率3/7〜6/7
3周目:2周目で間違えた問題のみ。解説もしっかり読む。※正答率5/7〜7/7
4周目:3周目で間違えた問題のみ。解説もしっかり読む。※正答率6/7〜7/7
5周目:4周目で間違えた問題のみ。解説もしっかり読む。※正答率6/7〜7/7
6周目:ゴリ押しで全問もう一度。1周目ぐらいのスピードで軽く。※全体の正答率95%
※2〜5周目では「なぜその選択肢が正なのか&他の選択肢ではなぜ誤なのか」を考えながら解きました。本番試験
ピアソンで予約し、最寄りの試験センターに行きました。
制限時間は100分で、見直し含め大体60分ちょっとくらいで出ました。
しかし教本にもweb問題集にも出てこなかったサービス名がちょくちょく出てきて焦りましたね。
心を乱してはいかん!と落ち着きを取り戻せたのは良かったです。
模擬試験を受けるとこの辺りカバーできたのかな?
結果、スコアは908/1000でした!中々健闘したのでは!!勝因
コツコツ積み重ねる事で知識が定着したのではと思います。
勉強時間は毎日バラバラで15分の日もあれば2時間の日も。平均1時間くらい?
煮物中とかもキッチンにPC置いてweb問を解いてました。
また、新人さん達がどんどん取得している様子を見て勝手に気合をもらいました。
資格試験の問題集や過去問と言うのは大抵1周目は惨敗するのですが、それは当たり前だと思ってあまり落ち込まずに淡々と進める。徐々に正答率が上がるのを楽しめると続けられる気がします。おわりに
資格取得は5,6年ぶりでしたが嬉しいものですね。
SAAの取得も考えているので、今回CLFで得た知識を忘れない内に受けようと思います。
- 投稿日:2020-12-06T00:16:30+09:00
paho-mqttを使ってAWS IoTcoreへpublish
paho-mqttを使ってAWS IoTcoreと通信
ラズパイをエッジデバイスとしたIoTシステムを作成するためのデモプログラム(publish)
※paho-mqttを使うとCloud9,EC2からの接続では環境によってうまくいかないことがあったのでAWSIoTSDKを使ったほうが良いかも?
***の部分は自分の環境に合わせて変更する
publish.pyimport paho.mqtt.client as mqtt import ssl import json import time endpoint = "****.amazonaws.com" #AWS IoT coreのエンドポイント port = *** #AWSのMQTTポート デフォルトは8883? topic = "sample/topic" #トピック rootCA = "***.pem" #ルート証明書のパス cert = "***.pem.crt" #デバイス証明書のパス key = "***-private.pem.key" #秘密鍵のパス publish_message = {"message":"hello"}#publishするメッセージ(連想配列) QoS = 1 #通信の品質(QoS=1 応答を確認するまで送信する) def on_connect(client, userdata, flags, respons_code): #ブローカー(IoTcore)に接続した後のcallback関数 print("Connected") #接続できた時に表示 def on_publish(client, userdata, mid): #メッセージをpublishした後のcallback関数 print("published : ", publish_message) #pulishできたときに表示 client = mqtt.Client() #Clientクラスのインスタンス化 client.on_connect = on_connect client.on_publish = on_publish client.tls_set(ca_certs=rootCA, certfile=cert, keyfile=key, cert_reqs=ssl.CERT_REQUIRED, #証明書関係を定義 tls_version=ssl.PROTOCOL_TLSv1_2, ciphers=None) client.loop_start() #通信のためのスレッド割り当て client.connect(endpoint, port=port, keepalive=60) #IoT coreと接続 time.sleep(2) #接続に時間がかかるようでsleepを入れる必要があることもある client.publish(topic, payload=json.dumps(publish_message),qos=QoS, retain=False) #メッセージをパブリッシュ client.loop_stop()エンドポイントの調べ方や,証明書類の入手方法,IoTcore側の設定についても書きたいとおもいます。