- 投稿日:2020-12-06T23:32:58+09:00
Nodistコマンド覚書
すぐに忘れてしまうのでメモしておく
npm
- インストールしたもの一覧
npm ls --depth=0 npm ls -g --depth=0
- npxインストール
Nodistだとnpxがインストールされないので個別にインストールが必要
npm i npx -g
- インストールとpackage.jsonの関係
// package.json(dependencies)に追記 npm i %パッケージ% npm i %パッケージ% --save npm i %パッケージ% -S // package.json(devDependencies)に追記 npm i %パッケージ% --save-dev npm i %パッケージ% -D // package.jsonに追記しない npm install %パッケージ% --no-saveNodist
Node.jsとnpmの対応
インストール済みバージョン一覧
nodist ls nodist npm ls
- インストール可能バージョン一覧
nodist dist
- バージョンのインストール
nodist + %バージョン番号%
- バージョン指定(グローバル)
nodist %バージョン番号% nodist npm %バージョン番号% nodist global %バージョン番号% nodist npm global %バージョン番号%あまり意識することはないが、インストールディレクトリ(C:\Program Files (x86)\Nodist\)の
.node-version-global、.npm-version-globalに、現在のバージョンが設定される。
- バージョン指定(ローカル)
nodist local %バージョン番号% nodist npm local %バージョン番号%ディレクトリに.node-version、.npm-versionが作成され、ディレクトリ単位でnodeのバージョンを設定できる。
直接ファイルを作成しても良い。
- 現在のNode.jsのバージョンにnpmのバージョンを合わせる
nodist npm match nodist npm local match
- 投稿日:2020-12-06T23:10:28+09:00
Slack 新機能 socket modeを(妄想で)使う
この記事はTakumi Akashiro ひとり Advent Calendar 2020の9日目の記事です。
この記事は2021年上旬リリース予定のSocketModeに関して、
現在リリースされているコードを読んで妄想を垂れ流す記事です。何一つ試したコードはないので、そのことを配慮してください。Yoro!
始めに
つい数日目、SlackのPC版クライアントから更新してくれと、散々泣きつかれていた俺はようやく更新ボタンを押した。
そしてクライアント更新後、数か月にSlackの新機能を覗いた。
ワークフロービルダーのように思った以上に使える機能を期待していた。そして見つけてしまった。
…あ、いやこれじゃなかった…これも滅茶苦茶うれしいんだが。ありがとうSlack!
うおおおおおおおぉっぉおおおおおおおおおおお!!!!!!!!!
これだよ!!!これ!!!!!情シスににらまれて、下手こいて情報流出させて、退職処分になる悪夢を見なくてもSlackアプリを作れる!!!
もう仕方なく、いつ廃止されるのかわからないClassic Botを変なところから作らなくていいんだ!!!!ありがとぉおおおー!!!!!Slack!!!!!!
…というわけで、少しでも早く使いたいので、SocketModeについて調べます。
……あれ?まだリリースされてないはずじゃ?
まあ見てみましょう。@slack/socket-mode - npm を眺める
ドキュメントは…まだ見れないですね。
なるほど。
xappから始まるTokenを渡さないといけないんですね。
…まだ、xappから始まるTokenを作る手段はないので、使えないようです。そして、permissionには
connections:writeが必要なみたいです。
こちらも当然まだないですね。動かせないけど書いてみる
とりあえず読んだ感じで、
Helloを含むpostがあったときにHello @usernameと返す場合を書いてみると……const { SocketModeClient } = require('@slack/socket-mode'); const { WebClient } = require('@slack/web-api'); // xappから始まるトークンを環境変数[SLACK_APP_TOKEN]にセットしておく const socketModeClient = new SocketModeClient(process.env.SLACK_APP_TOKEN); const WebClient = new WebClient(process.env.BOT_TOKEN); // Send a messageに書いてあるmember_joined_channelイベントへの反応から改造。 // ackはboltのドキュメント曰くSlack側へイベントが正常に受信されたことを伝える。 // bodyは何なんだ?わからねえ…… client.on('message', async({event, body, ack}) => { try { await ack(); // 通常メッセージ以外を弾く。おそらくBotもはじけてるはず。 if ('subtype' in event) return; // Helloが含まれてないものを弾く。 if (!event.text.includes("Hello")) return; await WebClient.chat.postMessage({ text: `Hello <@${event.user}>.`, channel: event.channel }); } catch (error){ console.log('An error occurred', error); } }) (async() => { await client.start(); })();こんな感じですかね。
締め
あ゛あ゛ーーー2021年が待ち遠しい゛゛!!!!
最後に
この記事は2021年上旬リリース予定のSocketModeに関して、
現在リリースされているコードを読んで妄想を垂れ流す記事でした。





- 投稿日:2020-12-06T19:41:15+09:00
Docker Desktopを使ってNode.jsアプリをコンテナ上で動かしてみた
Docker Desktopを使ってみたい!
先日、こちらの投稿を拝見し、Docker Desktop for Windowsを無事にインストールできました。
せっかくなので、最近勉強しているNode.jsのアプリケーションをDocker Desktop上で動作させてみたいと思います。参考サイト:Node.js Web アプリケーションを Docker 化する
利用環境 バージョン Windows 10 Pro 64bit 1909 Visual Studio Code 1.51.1 Docker Engine 19.03.13 Node.js 12.16.3 npm 6.14.4 この記事でやってみること
①Dockerfileを使ってExpress.jsアプリを起動する
②VSCodeの拡張機能"Remote-Containers"を使ってみる①Dockerfileを使ってExpress.jsアプリを起動する
node-dockerディレクトリおよびDockerfileファイル、.dockerignoreファイルを作成します。mkdir node-docker cd node-docker New-Item -Type File Dockerfile
Dockerfileには、下記の通り入力します。Dockerfile#ローカルの環境にあわせてバージョン12 FROM node:12 # アプリケーションディレクトリを作成する WORKDIR /usr/src/app # expressインストール RUN npx express-generator --view=ejs . RUN npm install nodemon RUN npm install EXPOSE 3000 #express-generatorで作成されたサンプルアプリをnodemonで起動 CMD [ "npx", "nodemon", "./bin/www" ]この状態でDockerイメージのビルド&起動します。
#"flets708/myapp"という名前のDockerイメージを作成 docker build -t flets708/myapp . #作成したDockerイメージを元にtestappという名前のコンテナを起動 docker run -it -d --rm -p 13000:3000 --name testapp flets708/myappちなみに上記コマンドで
--rmオプションをつけていますが、これをつけるとコンテナを停止した時に勝手に削除されます。たくさんコンテナつくって遊んでいると乱立したりするので、自動削除は便利だなと思います。
docker psコマンドで起動状態を確認します。PS > docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 337cb52f6231 flets708/myapp "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:13000->3000/tcp testapp無事にExpressのWelcomeページが表示されました!
②VSCodeの拡張機能"Remote-Containers"を使ってみる
コンテナが無事に起動できたところで、VSCodeを使ってコンテナの中で直接開発できるとより良いなあとふと思いました。色々調べた結果、VSCodeの拡張機能「Remote-Containers」というのがあるらしいので早速使ってみました。
この拡張機能を使うと、Dockerコンテナ内で直接VSCodeを使った開発が可能とのこと。
個人的に特にメリットになりそうだなと感じたのは下記3点です。VSCodeを使ってDockerコンテナ内で開発するメリット
a. 環境設定まるごとコンテナとして保存できる
b. ローカルの環境に左右されない
c. 拡張機能を直接設定できる。ESLintとかが良い感じに使えるaとbはコンテナそのもののメリット、cは"Remote-Containers"ならではのメリットという感じでしょうか。
ということで、以下の手順で導入してみました。
node-dockerディレクトリ内に.devcontainerディレクトリを作成し、さらにdevcontainer.jsonファイルを作成します。cd ../node-docker mkdir .devcontainer cd .devcontainer New-Item -Type File devcontainer.jsondevcontainer.jsonには下記を記述します。それぞれの記述の説明はコメントを参照ください。
devcontainer.json{ // Remote-Containersを使ってVSCodeを開いたときのウィンドウのタイトル。何でもいい。 "name": "Existing Dockerfile", // 実行パスを指定。.devcontainerディレクトリの一階層上。 "context": "..", // Dockerfile上で指定したワークスペースディレクトリにあわせる。 "workspaceFolder": "/usr/src/app", // 利用するDockerfileの相対パス。 "dockerFile": "..\\Dockerfile", // Set *default* container specific settings.json values on container create. "settings": { "terminal.integrated.shell.linux": null }, // コンテナ作成時にインストールしたい拡張機能のIDを書く。 "extensions": [ "dbaeumer.vscode-eslint", ], // ローカルの13000盤ポートとコンテナの3000番ポートを接続。 "appPort": ["13000:3000"], }
extensions部分に拡張機能を色々設定できるのが便利です。お好みで色々設定してみると良いと思います!
devcontainer.jsonの準備が終わったら、コマンドパレット上でRemote-Containers: Open Folder in Container...を選択します。出てこない人は拡張機能Remote - Containers (ms-vscode-remote.remote-containers)もしくはRemote Development (ms-vscode-remote.vscode-remote-extensionpack)を先にインストールしてください。
Remote-ContainersはRemote Developmentのコンテナ接続部分だけに絞った拡張機能のようです。
ディレクトリ選択画面が出るので、
node-dockerディレクトリを指定した上でOpenすると、開発用コンテナのイメージ作成とコンテナ起動が自動で開始されます。
最終的に、下記画面になっていればOKです!
ターミナルもコンテナ内のExpressインストールディレクトリになっていることが確認できます。
ちなみに、作成されたイメージとコンテナは下記のようになっていました。PS > docker images REPOSITORY TAG IMAGE ID CREATED SIZE vsc-node-docker-ca6497fdb4b6eecf9b3f476bxxxxxxxx latest a853xxxxxxxx 4 hours ago 927MB PS > docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 376ab65ea05e vsc-node-docker-ca6497fdb4b6eecf9b3f476xxxxxxxx "/bin/sh -c 'echo Co…" 4 minutes ago Up 4 minutes 0.0.0.0:13000->3000/tcp bold_pasteur PS >終わりに
今回初めてRemote-Containersを触ってみたので、まだまだ「やってみた」レベルですが、これからしばらく触ってみて、真価を探っていこうと思います。
自分の備忘のため、というのが一番の目的の記事ですが、もしどなたかのご参考になれば幸いです!



- 投稿日:2020-12-06T19:35:41+09:00
N 高のキャンフェスのサイトを作った話
この記事は N 高等学校 Advent Calendar 2020の 7 日目の記事です。初めてアドベントカレンダーに投稿しますがよろしくお願います。
今年のキャンパスフェスティバルがオンラインでやることになったのでそのために web サイトを作ったのでそれについて振り返ります。
どんなサイトを作ったの?
自分の通ってるキャンパスのキャンフェスのサイトを作りました。
ソースコード→https://github.com/Mochichi2003/Campus-festival
上の画像みたいな感じです
作るのに使ったもの
- フレームワークNext.js
- CSS フレームワークtailwindcss
- React
- TypeScrpt ..etc
なんで Next.js で作ったの?
今回のキャンフェスは例のウイルスのせいでオンラインで開催されることになったので N 高の通学コースごとにサイトを作って開催することになったのでサイトを作りました。Next.js を採用したのは、Next.js はもともと他に候補のあった goolge site や wix に比べて圧倒的に軽く自分でほぼ全てをカスタマイズできるこれを選びました。Gatsbyjsも採用しようかと考えましたが自分が Next.js の仕組みのほうが好きなのと。Gatsbyjs をほとんど使ったことがなかったので採用しませんでした。
サイトを作るのに意識したところ
- サイトを軽くして読み込み速度を早くする
他の殆どキャンパスは多分 wix とか google site とかを使って作るだろうと重くなると思ったので Next.js の特徴であるFast Refreshを最大限利用して読み込みが早いサイトを作ろうと思いました。
試しに Lighthouse で測ってみましたがかなりいいスコアを出しています。多分全てのキャンパスで一番早いはず
このスピードを出すためにやったこと
1. Next/image で画像を圧縮
ちょうどこのサイトを作ってる途中に Next.js ver.10 がリリースされ Next/image で画像を圧縮できるようになったのでほぼすべての画像でこれを使って圧縮しています。圧縮の仕組み化使い方についてはこちら のサイトを見て下さい。
2. サイトのデプロイに Vercel を使う
このサイトのデプロイにはVercel.comを使いました。Next.js を作ってるのも Vercel なので一番相性がいいだろうと思ってここを選びました。サイトの更新も Github とのリポジトリと連携すれば、Github のコードを更新するだけでやってくれるのでとても楽です。
3.スタイリングに使ってる Tailwindcss で purge を指定
生徒の展示スペース
下の画像のように生徒やプロ N でやったことを展示しています。
まずは hackmd.io でそれぞれの生徒に投稿する内容を書いてもらい、それを markdown 形式でダウンロードして、Next js の公式チュートリアルを参考しに、posts/ にそれぞれの生徒に Markdown で書いてもったものを HTML に変換して表示しています。
生徒の作品物の展示のスタイリングには 0 から作ってる時間はないので Github の markdown ファイルのスタイルと同じものをここから取得して使用しています。(ちなみにこのブログも同じものを使ってスタイリングしています。)
デザイン
サイトのデザインにはtailwindcssを使っています。最初プロジェクトこのプロジェクトを作ったときはReact Bootstrapを使っていたのですが途中で tailwindcss のほうが便利でカスタマイズ性、メンテナンス性も良さそうなのでそちらに移行しました。
下のは Tailwind css を使った一例ですがクラス名がそのまま CSS スタイルに当てることができるので CSS ファイルをどこに置くかとか、クラス名をどうするのとかを考える必要がなくなるのでとても便利です。
<div class="px-6 pt-4 pb-6 "> <div class="font-bold text-3xl mb-2"> <h2>タイトル</h2> </div> <p class="text-grey-darker text-base">ホゲホゲ</p> </div>以上のこと使いシンプルで見やすく美しいサイトを作ることを意識してサイトをデザインしました。
反省
キャンフェスを作るのに時間が結構かかってしまったので最初からちゃんと計画を立てて行けばもっと短い時間でもっといいものができたと思いました。
最後に
Next.js はいいぞ


- 投稿日:2020-12-06T19:35:41+09:00
N高のキャンフェスのサイトを作った話
この記事は N 高等学校 Advent Calendar 2020の 7 日目の記事です。初めてアドベントカレンダーに投稿しますがよろしくお願います。
昨日は@hinatao3oさんの高校・インターン2年生の2020年振り返り
でした。(インターン行ったことないから行ってみたいけど時間がない)さて今から書いていくのは、今年のキャンパスフェスティバルがオンラインでやることになったのでそのために webサイトを作ったのでそれについて振り返ります。
どんなサイトを作ったの?
自分の通ってるキャンパスのキャンフェスのサイトを作りました。
ソースコード→https://github.com/Mochichi2003/Campus-festival
上の画像みたいな感じです
作るのに使ったもの
- フレームワークNext.js
- CSS フレームワークtailwindcss
- React
- TypeScrpt ..etc
なんで Next.js で作ったの?
今回のキャンフェスは例のウイルスのせいでオンラインで開催されることになったので N 高の通学コースごとにサイトを作って開催することになったのでサイトを作りました。Next.js を採用したのは、Next.js はもともと他に候補のあった goolge site や wix に比べて圧倒的に軽く自分でほぼ全てをカスタマイズできるこれを選びました。Gatsbyjsも採用しようかと考えましたが自分が Next.js の仕組みのほうが好きなのと。Gatsbyjs をほとんど使ったことがなかったので採用しませんでした。
サイトを作るのに意識したところ
- サイトを軽くして読み込み速度を早くする
他の殆どキャンパスは多分 wix とか google site とかを使って作るだろうと重くなると思ったので Next.js の特徴であるFast Refreshを最大限利用して読み込みが早いサイトを作ろうと思いました。
試しに Lighthouse で測ってみましたがかなりいいスコアを出しています。多分全てのキャンパスで一番早いはず
このスピードを出すためにやったこと
1. Next/image で画像を圧縮
ちょうどこのサイトを作ってる途中に Next.js ver.10 がリリースされ Next/image で画像を圧縮できるようになったのでほぼすべての画像でこれを使って圧縮しています。圧縮の仕組み化使い方についてはこちら のサイトを見て下さい。
2. サイトのデプロイに Vercel を使う
このサイトのデプロイにはVercel.comを使いました。Next.js を作ってるのも Vercel なので一番相性がいいだろうと思ってここを選びました。サイトの更新も Github とのリポジトリと連携すれば、Github のコードを更新するだけでやってくれるのでとても楽です。
3.スタイリングに使ってる Tailwindcss で purge を指定
生徒の展示スペース
下の画像のように生徒やプロ N でやったことを展示しています。
まずは hackmd.io でそれぞれの生徒に投稿する内容を書いてもらい、それを markdown 形式でダウンロードして、Next js の公式チュートリアルを参考しに、posts/ にそれぞれの生徒に Markdown で書いてもったものを HTML に変換して表示しています。
生徒の作品物の展示のスタイリングには 0 から作ってる時間はないので Github の markdown ファイルのスタイルと同じものをここから取得して使用しています。(ちなみにこのブログも同じものを使ってスタイリングしています。)
デザイン
サイトのデザインにはtailwindcssを使っています。最初プロジェクトこのプロジェクトを作ったときはReact Bootstrapを使っていたのですが途中で tailwindcss のほうが便利でカスタマイズ性、メンテナンス性も良さそうなのでそちらに移行しました。
下のは Tailwind css を使った一例ですがクラス名がそのまま CSS スタイルに当てることができるので CSS ファイルをどこに置くかとか、クラス名をどうするのとかを考える必要がなくなるのでとても便利です。
<div class="px-6 pt-4 pb-6 "> <div class="font-bold text-3xl mb-2"> <h2>タイトル</h2> </div> <p class="text-grey-darker text-base">ホゲホゲ</p> </div>以上のこと使いシンプルで見やすく美しいサイトを作ることを意識してサイトをデザインしました。
反省
キャンフェスを作るのに時間が結構かかってしまったので最初からちゃんと計画を立てて行けばもっと短い時間でもっといいものができたと思いました。
最後に
Next.js はいいぞ
- 投稿日:2020-12-06T19:17:49+09:00
Node.jsでも綺麗なコードでWebAPIを作る(routing-controllers)
はじめに
Node.jsでWebAPIを作ると、その自由度の高さからコードが綺麗に書けないことが多いと思います。
そんなときにはrouting-controllersを使うのがおすすめです。
今回はrouting-controllersを使ったモダンなWebAPIの書き方を紹介します。routing-controllersとは
https://github.com/typestack/routing-controllers
Allows to create controller classes with methods as actions that handle requests. You can use routing-controllers with express.js or koa.js.
いわゆるMVCのコントローラーをTypescriptのクラスベースで書くことができるライブラリで、express.jsやkoa.jsなどのフレームワークに適応しています。
クラスベースであることにより、構造的かつ綺麗なコードを書くことができます。
例として、以下のようにクラスのメソッドをコントローラーのハンドラーとして書くことができます。sampleController.tsimport { Controller, Param, Body, Get, Post, Put, Delete } from "routing-controllers"; @Controller() export class UserController { @Get("/users") getAll() { return "This action returns all users"; } @Get("/users/:id") getOne(@Param("id") id: number) { return "This action returns user #" + id; } @Post("/users") post(@Body() user: any) { return "Saving user..."; } @Put("/users/:id") put(@Param("id") id: number, @Body() user: any) { return "Updating a user..."; } @Delete("/users/:id") remove(@Param("id") id: number) { return "Removing user..."; } }Typescriptに馴染みのない人には見慣れない構文があるかと思います。
@Get("/users")などはTypescriptのデコレーターという機能になります。
https://www.typescriptlang.org/docs/handbook/decorators.html
デコレータとはクラスの宣言などに(ここではメソッドに対して)アタッチできる特別な宣言です。さっそく作ってみる
こちらに詳細なコードが載っています。
https://github.com/tonio0720/modernApiInTypescriptパッケージインストール
npm init # 初期化 npm i -S express reflect-metadata routing-controllers class-transformer class-validator npm i -D @types/express ts-nodeTSCONFIGの設定
tsc --init # tsconfig.jsonができればOK以下の3つの設定を変更
tsconfig.json{ "compilerOptions": { ~ "strictPropertyInitialization": false, /* Experimental Options */ "experimentalDecorators": true, "emitDecoratorMetadata": true ~ } }コントローラーを書いてみる
ポケモンのデータを返す処理を書いてみました。
controllers/PokemonController.tsimport { JsonController, Get, QueryParams, Param, } from 'routing-controllers'; import { IsInt, IsOptional } from 'class-validator'; interface Pokemon { id: number; name: string; type1: string; type2: string; } const pokemons: Pokemon[] = [ { id: 1, name: 'フシギダネ', type1: 'くさ', type2: 'どく' }, { id: 2, name: 'フシギソウ', type1: 'くさ', type2: 'どく' }, { id: 3, name: 'フシギバナ', type1: 'くさ', type2: 'どく' } ] class GetPokemonQuery { @IsInt() @IsOptional() limit?: number; @IsInt() @IsOptional() offset?: number; } @JsonController() export class PokemonController { @Get('/pokemons') async pokemons( @QueryParams() query: GetPokemonQuery ): Promise<Pokemon[]> { const { offset = 0, limit = 100 } = query; return pokemons.slice(offset, offset + limit); } @Get('/pokemon/:id') async pokemon( @Param('id') id: number ): Promise<Pokemon> { const pokemon = pokemons.find((pokemon) => pokemon.id === id); if (pokemon) { return pokemon; } throw new Error('no pokemon'); } }解説
- クラスに対して
@JsonControllerデコレーターを付けることでレスポンスをJSONとして扱うことを意味します。- リクエストのメソッドがGETのときは
@Get、POSTのときは@Postという風にデコレーターを付与します。- クエリパラメータを受け取るときは、
@QueryParamsを使います。
- クエリパラメータもクラスベースで書くことができます。
@IsIntを付けることによって、バリデートやサニタイズを自動でしてくれます。- 他にも
@IsBoolean、@IsPositiveなどが使えます。- 詳しくはclass-validatorのドキュメントをご参照ください。
- URL内のパラメータを受け取るときは
@Paramを使います。app.ts
app.tsがメインファイルになります。
Expressサーバーを起動し、ポート3000番でリッスンしています。
先ほど書いたコントローラーをインポートします。
比較的シンプルに書くことができます。app.tsimport 'reflect-metadata'; import express from 'express'; import bodyParser from 'body-parser'; import { useExpressServer } from 'routing-controllers'; import { PokemonController } from './controllers'; const PORT = 3000; async function bootstrap() { const app = express(); app.use(bodyParser.json()); useExpressServer(app, { controllers: [ PokemonController ] }); app.listen(PORT, () => { console.log(`Express server listening on port ${PORT}`); }); } bootstrap();実行してみる
ts-node app.ts # 「Express server listening on port 3000」となれば成功ブラウザなどから、
http://localhost:3000/pokemons?limit=1
にアクセスしてレスポンスが返れば成功です。Express単体との比較
非同期処理
Expressでハンドラーを書く際、非同期処理を即時間数でラップするなど面倒な書き方になってしまいます。
expressの場合const express = require('express'); const router = express.Router(); router.get('/users', (req, res, next) => { (async () => { const users = await getUsers(); res.status(200).json(users); })().catch(next); });一方でrouting-controllersでは、Promise型をそのまま返すだけでOKです。
rcの場合import { JsonController, Get, } from 'routing-controllers'; @JsonController() export class UserController { @Get('/users') async users(): Promise<User[]> { return getUsers(); } }バリデーション
Expressでバリデーションをするときは、express-validatorを使います。
express-validatorの場合const { body, validationResult } = require('express-validator'); app.post('/user', [ body('username').isEmail(), body('password').isLength({ min: 6 }) ], (req, res) => { const errors = validationResult(req); if (!errors.isEmpty()) { return res.status(400).json({ errors: errors.array() }); } // ... });routing-controllersでは、デコレーターで書くことができます。
rcの場合export class User { @IsEmail() email: string; @MinLength(6) password: string; } @JsonController() export class UserController { @Post('/login') async login( @Body() user: User ) { // ... } }おわりに
いかがでしたでしょうか?
routing-controllersを使うことで、バリデーションやサニタイズもしつつ綺麗にコードを書くことができました。
routing-controllersはexpress.js以外のフレームワークにも適用できるので是非お試しください。
- 投稿日:2020-12-06T17:01:29+09:00
Riot.js でローカルに HTML を生成する環境を作ってみた。
これは Riot.js Advent Calendar 2020 の 6 日目の記事 ? です。
動機
いままで、HTML を書くときは共通部分を一元化したりするために EJS とか Nunjucks などの HTML を生成するテンプレートエンジンを使っていました。
そんな折に、Riot.js の公式 Twitter アカウントの以下のツイートを目にします。
Riot.js from now on can be used also as #javascript server side engine https://t.co/4L2ZxFaYGh pic.twitter.com/gv2epBROP6
— Riot.js Framework (@riotjs_) August 6, 2020この水辺を楽しげにスキップしているおばあさん(?)が何者なのかわかりませんが、
ツイートのリンク先、GitHub のリリースを見てみると、Riot.js の SSR 用モジュールで、こんなサンプルが書いてありました。<html> <head> <title>{ state.message }</title> <meta each={ meta in state.meta } {...meta}/> </head> <body> <p>{ state.message }</p> <script src='path/to/a/script.js'></script> </body> <script> export default { state: { message: 'hello', meta: [{ name: 'description', content: 'a description' }] } } </script> </html>これをみて最初は「あ、head タグとかも生成できるんだー、へー、まあ SSR にはそりゃ必要だよねー」くらいの感想だったんですが、あとでよくよく考えたら、これって Nunjucks とかでやってることと一緒じゃね?じゃあ Numjucks でやってることも Riot.js でできるんじゃないの?と思いました。
やれるかも
SSR 用のモジュール、デザイナーのぼくにはこれまであんまり馴染みがなかったんですが、
もともと、なるべく Webpack とか Gulp みたいなものに依存しない環境を作りたいという気持ちから Riot.js を使う環境も riot/cli という公式のプリコンパイラーを npm-scripts から使うようにしててて、 node.js で実行するコードも簡単なものは少し書いたりしてたので、自分でもやれるかもとおもいました。やりたいこと
とりあえず、SSR 用のモジュールは、Node.js が動くサーバーで、リクエストに対して
.riotをコンパイルした結果を返す というものだろうとおもってたので、
その機能を npm-scripts から実行して、リクエストにコンパイル結果を返す代わりにローカルに HTML としてファイルを保存すればいいだろう、というのがやりたかったことです。(これができれば使っていた Nunjucks の代わりになりそうという発想)やってみた。
ディレクトリ構造
ちょっと省略しますが、だいたいこんな感じです。
dist ← ここに HTML が保存される node_scripts └ html.js ← これを実行すると .riot → .html src └ html ├ components ← HTML 生成する際の共通パーツを置く └ pages ← 生成する HTML に対応する .riot を置く package.json ← 必要な npm-scripts を記述.riot → .html の処理
SSR モジュールは Node.js から呼び出して使わないとなので、npm-scripts で呼び出すJSファイル
node_scripts/html.jsを作って、そこで @riotjs/ssr を使った処理を書いていきました。const fs = require('fs')// Node.js のファイル管理モジュール const path = require('path')// Node.js のパス扱うモジュール const glob = require('glob')// /**/*.js みたいにファイルを複数取得するために必要 const mkdirp = require('mkdirp')// ファイル保存時のディレクトリ作成に使用 const { render } = require('@riotjs/ssr')// Riot.jsのSSRモジュール const register = require('@riotjs/ssr/register')// Riot.js のおまじないに必要 const srcDirFromRoot = './src/html/pages' // HTML のテンプレートとなる .riot ファイルを置くディレクトリ const outputDir = './dist' // 生成した HTML を保存するディレクトリ // Riot コンポーネントを require できるように register() // HTML 生成のテンプレートとなる .riot ファイルを読み込んで、HTMLを生成する関数を実行 glob(`${srcDirFromRoot}/**/*.riot`, (err, files) => { if (err) return err generateHtml(files) }) // HTMLを生成する関数 const generateHtml = (files) => { /* * 引数で渡された配列から取り出したファイルパスごとに .riot → .html を実行。 * Riot.js の公式のサンプルリポジトリの中の SSR のサンプルを参考にした。 * https://github.com/riot/examples/blob/gh-pages/ssr/index.js */ files.forEach((file) => { const Root = require(`.${file}`).default const html = render('html', Root) const dir = path.join( outputDir, file.replace(srcDirFromRoot, '').replace(/riot$/, 'html') ) /* * 書き出すディレクトリが存在しないとエラーになっちゃうので * mkdirp でディレクトリ作成してそこに HTML を保存。 */ mkdirp(path.parse(dir).dir).then(() => { fs.writeFile(dir, html, (err) => { if (err) throw err }) }) }) }HTML に変換される .riot ファイルの中身
HTML に変換される .riot ファイルは、いくつかの共通パーツに分かれています。
まず全体の雛形を設定したsrc/html/components/html.riotはこんな感じです。<html> <head> <title>{ props.title ? props.title : state.title }</title> <meta if="{ props.meta }" each="{ meta in props.meta }" {...meta} /> <meta if="{ !props.meta }" each="{ meta in state.meta }" {...meta} /> <meta name="viewport" content="width=device-width,initial-scale=1"> <link rel="stylesheet" href="{ this.props.toRoot }css/main.css"> <script src="{ this.props.toRoot }js/main.js" defer></script> </head> <body> <h1>{ props.title ? props.title : state.title }</h1> <static-component></static-component> <slot name="default"></template> </body> <script> import StaticComponent from './static-component.riot' export default { components: { StaticComponent }, state: { title: 'Static', meta: [ { name: 'description', content: 'a description', }, { property: 'og:title', content: 'ogp title', }, ], }, } </script> </html>riot/ssr を使うことで、head タグとかにも Riot.js の props などが使えるので、それを使って、ページタイトルとか OGP なんかもページごとに設定できるようになっています。
また、あらかじめ import したコンポーネントは展開された状態で HTML ファイルが生成されます。
で、ページに対応した
src/html/pages/index.riotの中身はこんな感じです。<html> <template is="html" title="{ state.title }" meta="{ state.meta }"> <static-header></static-header> <p>page content</p> </template> <script> import Html from '../components/html.riot' import StaticHeader from '../components/static-header.riot' export default { components: { Html, StaticHeader }, state: { title: 'title from props', meta: [ { name: 'description', content: 'description from props', }, ], }, } </script> </html>ベースとなる
src/html/components/html.riotを読み込み、head タグなどに入れたい情報は、props として渡します。HTML の保存先の
distの中にディレクトリを切って HTML を保存したい場合は、src/html/pages/の中に任意のディレクトリを切って .riot ファイルを置きます。
src/html/pages/child/index.riotというファイル作ったとしたら以下のような内容に。<html> <template is="html" title="{ state.title }" meta="{ state.meta }" to-root="../"> <static-header></static-header> <p>page content</p> </template> <script> import Html from '../../components/html.riot' import StaticHeader from '../../components/static-header.riot' export default { components: { Html, StaticHeader }, state: { title: 'Child page: title from props', meta: [ { name: 'description', content: 'child page: description from props', }, ], }, } </script> </html>npm-scripts
あとは、最初の
node_scripts/html.jsを Node.js で実行する npm-scripts を用意すれば完成。"script": { "start": "run-s html watch:html", "html": "node node_scripts/html.js", "watch:html": "onchange src/html -- npm run html" }とりあえず、これでやりたいことができました。
ちょっと駆け足になりましたが、静的な HTML を生成する書き方と、動的に JS で展開される Riot.js のコンポーネントがどちらも同じ書式でかけるようになって個人的には大満足。ちょっとまだざっとやりたいことやれるようにしただけなので、なにか問題とかあるかもしれません?
デザイナーが頑張って作ってみた環境なので、なにかおかしいところとか改善できそうなことがあったらぜひやさしくおしえてください?♂️今回の記事は、個人的な Web 制作用のボイラープレートの中でやったことをかいつまんで書いてみました。
あまりリポジトリとして整理できてなくてちょっとお恥ずかしい感じですが、なにか「こうしたらいいよー」みたいなこととかがあれば issue とかで(やさしく)お知らせいただくのも大歓迎です。
↓
https://github.com/nibushibu/Getup
- 投稿日:2020-12-06T15:11:37+09:00
【nodejs】No 'Access-Control-Allow-Origin' header is present on the requested resourceを優しく解説
お疲れ様です、ラスカルです。
私は仕事でバックエンドもフロントエンドも担当しているのですが、実装した両者をGraphqlを使って繋ごうとしたときに次のエラーに遭遇しました。
Access to XMLHttpRequest at 'http://localhost:4000/graphql' from origin 'http://localhost:3000' has been blocked by CORS policy: Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource.ふむ、どうやらフロント側のリクエストに対して、バックエンドが何やらCORSなる規約に則って、
「おい、リクエストはちゃんと決まりを守って投げてこい?」
とお怒りの様子です?状況説明
バックエンド
バックエンドはNode.jsのExpressを使って、TypeScriptで実装しました。
自社AWSに繋がっていて、画像やらデータやらをリクエストに応じて返すことができます。
リクエストはGraphQLで受け取るように実装していて、実際ローカル環境でもちゃんとレスポンスが期待通りに返ってくることも確認できていました。このとき、ポートは4000、つまりlocalhost:4000/graphqlがバックエンド側のURIでした。
フロントエンド
フロントエンドはReactとTypeScriptで実装していて、最初の読み込みの際にGraphQLを使って、バックエンドにリクエストを投げ、受け取ったレスポンスの内容を表示するという至ってシンプルな実装です。
このとき、ポートは3000、つまりlocalhost:3000/がフロントエンド側のURIでした。
エラーの原因
エラーメッセージにも書いてありますが、要はCORSという決まり的にNGなリクエストの投げ方をしてしまったために、エラーになっているだけです。
CORSの詳細は一旦置いといて、簡単にまとめると違うドメインからのリクエストは、ブラウザを介して受け付けられませんよという決まりです。
確かに
- フロントエンドはlocalhost:3000/
- バックエンドはlocalhost:4000/
と異なるドメインになっているため、CORSに引っかかってしまったんですね。
まぁ考えれば当たり前ですが、違うドメインからのアクセスができてしまう方がセキュリティ的にはよろしくないですよね。
ありがとう、CORS?解決策
前置き長くなりましたね。
結論としては、corsなるnode_moduleをインストールすれば解決です。npm install --save corsさらにTypeScriptを使っている方は、
npm install --save-dev @types/corsをインストールしておきましょう。
終わったら、バックエンドの実装に入ります。
実装といっても、app.use(cors())を追加するだけ。const app = express() ++ app.use(cors()) app.use('/graphql', graphqlHTTP({ schema: schema, rootValue: root, graphiql: true })) app.listen(4000, () => { console.log('Start Express GraphQL Server. Listen to localhost:4000/graphql') });以上でエラーは解決すると思います。
ただこちらの実装だと、どのドメインからでもアクセスできてしまうため、(ローカルホストだからあんま影響ないとは思うけど、後々のために)特定のドメインからだけリクエストを受け付けられるように実装します。
const app = express() ++ const corsOptions = { origin: 'http://localhost:3000', optionsSuccessStatus: 200 } ++ app.use(cors(corsOptions)) -- app.use(cors()) app.use('/graphql', graphqlHTTP({ schema: schema, rootValue: root, graphiql: true })) app.listen(4000, () => { console.log('Start Express GraphQL Server. Listen to localhost:4000/graphql') });許可するドメインと成功次のステータスコードが設定されているcorsOptionsなる変数を作成。
それをcors()の引数で渡してあげればOKです?おまけ:解決しなかった対処法
CORS関連でいろいろ調べていると、corsモジュールをわざわざインストールせずとも、
const app = express() app.use('/graphql', graphqlHTTP({ schema: schema, rootValue: root, graphiql: true })) app.use(function(req, res, next) { res.header('Access-Control-Allow-Origin', 'http://localhost:3000'); res.header('Access-Control-Allow-Headers', 'X-Requested-With, X-HTTP-Method-Override, Content-Type, Accept'); res.header('Access-Control-Allow-Methods', 'POST, GET, PUT, DELETE, OPTIONS'); res.header('Access-Control-Max-Age', '86400'); next(); }); app.listen(4000, () => { console.log('Start Express GraphQL Server. Listen to localhost:4000/graphql') });のようにヘッダーの上書きを施せばOK的なのを散見したのですが、私の環境ではうまく行きませんでした。
もう少し調べて、わかり次第追記したいと思います?
- 投稿日:2020-12-06T14:59:49+09:00
Github Hacking ~Githubを容量無制限のクラウドストレージとして使用する試み~
警告
今回紹介している内容はGithubの公式からは「やるなよ!!」と言われている内容を紹介しています
私のディスク容量はいくつですか?
これを理解した上で以降を読み進めてください問い
Githubを容量無制限のクラウドストレージとして使用できるのか?Githubには
git pushした場合には容量制限があり、1ファイル100MBを超える場合は Git LFS を使ってgit pushを行わないとエラーが発生してしまいgit pushすることができません。
この仕様については共通の認識としてよく出てきますがリポジトリの総計の容量の上限については言及されていません。そのため、実際にやってみてどこまでできるのか試してみたいと思います。実際にやってみた結果
約1254652ファイル、約164.6GBのリポジトリ全てGithubにpushすることに成功しました!!
Githubすごい!!
リポジトリはこのような感じになっておりました。
(あまり広めたくないのでprivateにしています)ダウンロードできるの?
上記のリポジトリをGithub上のzipにしてダウンロードすることは怖かったのでやっていません。
git cloneを用いたダウンロードはできたので、ダウンロードするときはgit cloneを用いてダウンロードしてくださいきっかけ
去年(2019年)のアドベントカレンダーにてプチ炎上しましたこちらの記事
* ハッカソンの開催情報を自動でお知らせするBotをGithub Actionsに移行して運用費が0円になりました
この内容を実践していた時に1ファイル100MB以下にする仕様を満たしていれば、容量の際限Githubにアップロードできるのではないか?という疑問を抱いたため実験も兼ねて実践してみようと思いました。
(ちなみにプチ炎上した記事のその後の展開は後日記事にします。現在、この記事に書かれていることはGithubでは行なっておらず、Gitlabにて行なっております)そしてこちらの記事
記事を作成し、運営していた時に収集した画像ファイルが
AWS S3に保管していて管理費用がかかっていたので、費用削減も兼ねてできたらいいなという希望も込めて検証しました。実践してみて判明したGithubの仕様
1ファイル100MB以下にする → 1ファイル100MB以上のファイルをpushしたときはエラーになってpushができないため- 1回の
git pushで2GBを超えるを超える場合エラーになってpushできない(非公式な仕様)結論
- 1ファイル100MB以下
- 1回のpush(1回のcommit)が
2GB以下上記の条件を満たしていればGithubの物理的なサーバーストレージの範囲内で無制限のサーバーストレージとして利用できることがわかりました
めんどくさかったのでスクリプトを作った
上記の検証を行なっている時に最初は1回ずつ手作業で
git commitとgit pushを行なって行きましたが、途方のない作業でしたのでスクリプトを作成して、それを実行するようにしました。
今回はNode.jsで簡単に実行できるスクリプトを作成して実行するようにしました。
.gitignoreの設定は以下のようになります。*.DS_Store *~ Thumbs.db node_modules/スクリプトの中身は以下のようになります。
// roop-commit-and-push.js const fs = require('fs'); const { promisify } = require( 'util' ) const simpleGit = require('simple-git'); const git = simpleGit(); async function executeGitStatus(){ return git.status(); } const limitFileSize = 1900000000; const eachSlice = (arr, n = 2) => { const dup = [...arr] const result = []; let length = dup.length; while (0 < length) { result.push(dup.splice(0, n)); length = dup.length } return result; }; async function executeCommitAndPushRoutine(){ let statusResult = await executeGitStatus(); let remainFileCount = statusResult.created.length + statusResult.not_added.length; while(remainFileCount > 0){ let sumSize = 0; // ダブっているファイルがあるためSetにして除去する const addFileSet = new Set(); const createdFilePromises = []; // すでに git add されているファイルの容量を計算して、残りまだgit addできるもののみを全てgit addする for(const notAddFile of statusResult.created){ const statPromise = promisify(fs.stat)(notAddFile).then(stat => { sumSize = sumSize + stat.size; }); createdFilePromises.push(statPromise); } await Promise.all(createdFilePromises); console.log(sumSize); if(sumSize <= limitFileSize) { // 速度優先のため非同期でgit addするファイルの選別をファイルサイズを取得した上で行う const addFilePromises = []; for (const notAddFile of statusResult.not_added) { let isStop = false; const statPromise = promisify(fs.stat)(notAddFile).then(stat => { if(isStop){ return sumSize; } if (sumSize + stat.size > limitFileSize) { isStop = true; return sumSize; } sumSize = sumSize + stat.size; addFileSet.add(notAddFile.toString()); return sumSize; }); addFilePromises.push(statPromise); if (isStop) { break; } } await Promise.all(addFilePromises); } console.log(sumSize); const total = addFileSet.size; remainFileCount = remainFileCount - total; console.log("add files:" + total.toString()); // git addできるファイル数の上限が約2000。これ以上のファイル数をgit addするとエラーになるので分割する for(const files of eachSlice(Array.from(addFileSet), 2000)){ await git.add(files).catch(err => { console.error(err); }); } console.log("add file completed:" + total.toString()); const nowDate = new Date(); const dateString = [nowDate.getFullYear(), nowDate.getMonth(), nowDate.getDay()].join("/"); const timeString = [nowDate.getHours(), nowDate.getMinutes(), nowDate.getSeconds()].join(":"); const commitMessage = [dateString, timeString, total, "image files add"].join(" "); console.log(commitMessage); await git.commit(commitMessage); console.log("committed " + total.toString() + " files"); await git.push().catch(err => { console.error(err); }); console.log("pushed and remained " + remainFileCount.toString() + " files"); // git statusで取得できるファイル数には上限があるので、現状で取得できたファイルが無くなったら再度git statusを行なって補充できるか確認する if(remainFileCount <= 0) { statusResult = await executeGitStatus(); remainFileCount = statusResult.created.length + statusResult.not_added.length; } } } executeCommitAndPushRoutine();上記スクリプトを実行するためにまずは simple-git をインストールします。
(package.jsonを作るほどのものでもないと思うのでこちらは省略)npm install simple-gitそして、その後
node roop-commit-and-push.jsとして上記のスクリプトを実行すると、
git addする必要があるファイルがなくなるまでGithubにgit pushを行なってくれます。
(もちろん事前にgit initgit remote add origin urlなどの基本的な初期設定を事前に行なっている必要があります。)パッケージ化した方が良さそう?
Node.jsのインストールなどの初期設定が面倒な場合は上記スクリプトをパッケージ化して実行してもいいかもしれません。
以下参考
nodeアプリケーションを実行可能ファイルにして出力する闇の魔術に対する防衛術?
ここまで読んでいただいたらお分かりかと思いますが、防衛者側は
Githubになります。私もGithub Supportにゴルァされたら大人しくGitlabに移行するなど別の方法を模索するようにします...絶対にやってはダメですよ!!!
今回「もしかしてできるのではないか?」と思い至ったので実際に検証してみました。
しかし公式からは
私のディスク容量はいくつですか?
にあるようにやらないでくださいと明確に指摘されています。これをみた皆さんは絶対にマネしてはダメですよ!!!
もし同じことを真似しようと思った方はくれぐれも自己責任でやるようにしてください。



- 投稿日:2020-12-06T14:59:49+09:00
Github Hacking ~GitHubを容量無制限のクラウドストレージとして使用する試み~
警告
今回紹介している内容はGitHubの公式からは「やるなよ!!」と言われている内容を紹介しています
私のディスク容量はいくつですか?
これを理解した上で以降を読み進めてください問い
GitHubを容量無制限のクラウドストレージとして使用できるのか?GitHub には
git pushした場合には容量制限があり、1ファイル100MBを超える場合は Git LFS を使ってgit pushを行わないとエラーが発生してしまいgit pushすることができません。
この仕様については共通の認識としてよく出てきますがリポジトリの総計の容量の上限については言及されていません。そのため、実際にやってみてどこまでできるのか試してみたいと思います。実際にやってみた結果
約1254652ファイル、約164.6GBのリポジトリ全てGitHubにpushすることに成功しました!!
GitHubすごい!!
リポジトリはこのような感じになっておりました。
(あまり広めたくないのでprivateにしています)ダウンロードできるの?
上記のリポジトリをGitHub上のzipにしてダウンロードすることは怖かったのでやっていません。
git cloneを用いたダウンロードはできたので、ダウンロードするときはgit cloneを用いてダウンロードしてくださいきっかけ
去年(2019年)のアドベントカレンダーにてプチ炎上しましたこちらの記事
* ハッカソンの開催情報を自動でお知らせするBotをGithub Actionsに移行して運用費が0円になりました
この内容を実践していた時に1ファイル100MB以下にする仕様を満たしていれば、容量の際限[GitHub](https://github.com/)にアップロードできるのではないか?という疑問を抱いたため実験も兼ねて実践してみようと思いました。
(ちなみにプチ炎上した記事のその後の展開は後日記事にします。現在、この記事に書かれていることはGitHubでは行なっておらず、Gitlabにて行なっております)そしてこちらの記事
記事を作成し、運営していた時に収集した画像ファイルが
AWS S3に保管していて管理費用がかかっていたので、費用削減も兼ねてできたらいいなという希望も込めて検証しました。実践してみて判明したGitHubの仕様
1ファイル100MB以下にする → 1ファイル100MB以上のファイルをpushしたときはエラーになってpushができないため- 1回の
git pushで2GBを超えるを超える場合エラーになってpushできない(非公式な仕様)結論
- 1ファイル100MB以下
- 1回のpush(1回のcommit)が
2GB以下上記の条件を満たしていればGitHubの物理的なサーバーストレージの範囲内で無制限のサーバーストレージとして利用できることがわかりました
めんどくさかったのでスクリプトを作った
上記の検証を行なっている時に最初は1回ずつ手作業で
git commitとgit pushを行なって行きましたが、途方のない作業でしたのでスクリプトを作成して、それを実行するようにしました。
今回はNode.jsで簡単に実行できるスクリプトを作成して実行するようにしました。
.gitignoreの設定は以下のようになります。*.DS_Store *~ Thumbs.db node_modules/スクリプトの中身は以下のようになります。
// roop-commit-and-push.js const fs = require('fs'); const { promisify } = require( 'util' ) const simpleGit = require('simple-git'); const git = simpleGit(); async function executeGitStatus(){ return git.status(); } const limitFileSize = 1900000000; const eachSlice = (arr, n = 2) => { const dup = [...arr] const result = []; let length = dup.length; while (0 < length) { result.push(dup.splice(0, n)); length = dup.length } return result; }; async function executeCommitAndPushRoutine(){ let statusResult = await executeGitStatus(); let remainFileCount = statusResult.created.length + statusResult.not_added.length; while(remainFileCount > 0){ let sumSize = 0; // ダブっているファイルがあるためSetにして除去する const addFileSet = new Set(); const createdFilePromises = []; // すでに git add されているファイルの容量を計算して、残りまだgit addできるもののみを全てgit addする for(const notAddFile of statusResult.created){ const statPromise = promisify(fs.stat)(notAddFile).then(stat => { sumSize = sumSize + stat.size; }); createdFilePromises.push(statPromise); } await Promise.all(createdFilePromises); console.log(sumSize); if(sumSize <= limitFileSize) { // 速度優先のため非同期でgit addするファイルの選別をファイルサイズを取得した上で行う const addFilePromises = []; for (const notAddFile of statusResult.not_added) { let isStop = false; const statPromise = promisify(fs.stat)(notAddFile).then(stat => { if(isStop){ return sumSize; } if (sumSize + stat.size > limitFileSize) { isStop = true; return sumSize; } sumSize = sumSize + stat.size; addFileSet.add(notAddFile.toString()); return sumSize; }); addFilePromises.push(statPromise); if (isStop) { break; } } await Promise.all(addFilePromises); } console.log(sumSize); const total = addFileSet.size; remainFileCount = remainFileCount - total; console.log("add files:" + total.toString()); // git addできるファイル数の上限が約2000。これ以上のファイル数をgit addするとエラーになるので分割する for(const files of eachSlice(Array.from(addFileSet), 2000)){ await git.add(files).catch(err => { console.error(err); }); } console.log("add file completed:" + total.toString()); const nowDate = new Date(); const dateString = [nowDate.getFullYear(), nowDate.getMonth(), nowDate.getDay()].join("/"); const timeString = [nowDate.getHours(), nowDate.getMinutes(), nowDate.getSeconds()].join(":"); const commitMessage = [dateString, timeString, total, "image files add"].join(" "); console.log(commitMessage); await git.commit(commitMessage); console.log("committed " + total.toString() + " files"); await git.push().catch(err => { console.error(err); }); console.log("pushed and remained " + remainFileCount.toString() + " files"); // git statusで取得できるファイル数には上限があるので、現状で取得できたファイルが無くなったら再度git statusを行なって補充できるか確認する if(remainFileCount <= 0) { statusResult = await executeGitStatus(); remainFileCount = statusResult.created.length + statusResult.not_added.length; } } } executeCommitAndPushRoutine();上記スクリプトを実行するためにまずは simple-git をインストールします。
(package.jsonを作るほどのものでもないと思うのでこちらは省略)npm install simple-gitそして、その後
node roop-commit-and-push.jsとして上記のスクリプトを実行すると、
git addする必要があるファイルがなくなるまでGitHubにgit pushを行なってくれます。
(もちろん事前にgit initgit remote add origin urlなどの基本的な初期設定を事前に行なっている必要があります。)パッケージ化した方が良さそう?
Node.jsのインストールなどの初期設定が面倒な場合は上記スクリプトをパッケージ化して実行してもいいかもしれません。
以下参考
nodeアプリケーションを実行可能ファイルにして出力する闇の魔術に対する防衛術?
ここまで読んでいただいたらお分かりかと思いますが、防衛者側は GitHub になります。私も
Github Supportからゴルァされたら大人しくGitlabに移行するなど別の方法を模索するようにします...絶対にやってはダメですよ!!!
今回「もしかしてできるのではないか?」と思い至ったので実際に検証してみました。
しかし公式からは
私のディスク容量はいくつですか?
にあるようにやらないでくださいと明確に指摘されています。これをみた皆さんは絶対にマネしてはダメですよ!!!
もし同じことを真似しようと思った方はくれぐれも自己責任でやるようにしてください。なお
2020/12/06 現在、規約違反ではないのでペナルティはないと思われます。
- 投稿日:2020-12-06T14:59:49+09:00
GitHub Hacking ~GitHubを容量無制限のクラウドストレージとして使用する試み~
警告
今回紹介している内容はGitHubの公式からは「やるなよ!!」と言われている内容を紹介しています
私のディスク容量はいくつですか?
これを理解した上で以降を読み進めてください問い
GitHubを容量無制限のクラウドストレージとして使用できるのか?GitHub には
git pushした場合には容量制限があり、1ファイル100MBを超える場合は Git LFS を使ってgit pushを行わないとエラーが発生してしまいgit pushすることができません。
この仕様については共通の認識としてよく出てきますがリポジトリの総計の容量の上限については言及されていません。そのため、実際にやってみてどこまでできるのか試してみたいと思います。実際にやってみた結果
約1254652ファイル、約164.6GBのリポジトリ全てGitHubにpushすることに成功しました!!
GitHubすごい!!
リポジトリはこのような感じになっておりました。
(あまり広めたくないのでprivateにしています)ダウンロードできるの?
上記のリポジトリをGitHub上のzipにしてダウンロードすることは怖かったのでやっていません。
git cloneを用いたダウンロードはできたので、ダウンロードするときはgit cloneを用いてダウンロードしてくださいきっかけ
去年(2019年)のアドベントカレンダーにてプチ炎上しましたこちらの記事
* ハッカソンの開催情報を自動でお知らせするBotをGithub Actionsに移行して運用費が0円になりました
この内容を実践していた時に1ファイル100MB以下にする仕様を満たしていれば、容量の際限[GitHub](https://github.com/)にアップロードできるのではないか?という疑問を抱いたため実験も兼ねて実践してみようと思いました。
(ちなみにプチ炎上した記事のその後の展開は後日記事にします。現在、この記事に書かれていることはGitHubでは行なっておらず、Gitlabにて行なっております)そしてこちらの記事
記事を作成し、運営していた時に収集した画像ファイルが
AWS S3に保管していて管理費用がかかっていたので、費用削減も兼ねてできたらいいなという希望も込めて検証しました。実践してみて判明したGitHubの仕様
1ファイル100MB以下にする → 1ファイル100MB以上のファイルをpushしたときはエラーになってpushができないため- 1回の
git pushで2GBを超えるを超える場合エラーになってpushできない(非公式な仕様)結論
- 1ファイル100MB以下
- 1回のpush(1回のcommit)が
2GB以下上記の条件を満たしていればGitHubの物理的なサーバーストレージの範囲内で無制限のサーバーストレージとして利用できることがわかりました
めんどくさかったのでスクリプトを作った
上記の検証を行なっている時に最初は1回ずつ手作業で
git commitとgit pushを行なって行きましたが、途方のない作業でしたのでスクリプトを作成して、それを実行するようにしました。
今回はNode.jsで簡単に実行できるスクリプトを作成して実行するようにしました。
.gitignoreの設定は以下のようになります。*.DS_Store *~ Thumbs.db node_modules/スクリプトの中身は以下のようになります。
// roop-commit-and-push.js const fs = require('fs'); const { promisify } = require( 'util' ) const simpleGit = require('simple-git'); const git = simpleGit(); async function executeGitStatus(){ return git.status(); } const limitFileSize = 1900000000; const eachSlice = (arr, n = 2) => { const dup = [...arr] const result = []; let length = dup.length; while (0 < length) { result.push(dup.splice(0, n)); length = dup.length } return result; }; async function executeCommitAndPushRoutine(){ let statusResult = await executeGitStatus(); let remainFileCount = statusResult.created.length + statusResult.not_added.length; while(remainFileCount > 0){ let sumSize = 0; // ダブっているファイルがあるためSetにして除去する const addFileSet = new Set(); const createdFilePromises = []; // すでに git add されているファイルの容量を計算して、残りまだgit addできるもののみを全てgit addする for(const notAddFile of statusResult.created){ const statPromise = promisify(fs.stat)(notAddFile).then(stat => { sumSize = sumSize + stat.size; }); createdFilePromises.push(statPromise); } await Promise.all(createdFilePromises); console.log(sumSize); if(sumSize <= limitFileSize) { // 速度優先のため非同期でgit addするファイルの選別をファイルサイズを取得した上で行う const addFilePromises = []; for (const notAddFile of statusResult.not_added) { let isStop = false; const statPromise = promisify(fs.stat)(notAddFile).then(stat => { if(isStop){ return sumSize; } if (sumSize + stat.size > limitFileSize) { isStop = true; return sumSize; } sumSize = sumSize + stat.size; addFileSet.add(notAddFile.toString()); return sumSize; }); addFilePromises.push(statPromise); if (isStop) { break; } } await Promise.all(addFilePromises); } console.log(sumSize); const total = addFileSet.size; remainFileCount = remainFileCount - total; console.log("add files:" + total.toString()); // git addできるファイル数の上限が約2000。これ以上のファイル数をgit addするとエラーになるので分割する for(const files of eachSlice(Array.from(addFileSet), 2000)){ await git.add(files).catch(err => { console.error(err); }); } console.log("add file completed:" + total.toString()); const nowDate = new Date(); const dateString = [nowDate.getFullYear(), nowDate.getMonth(), nowDate.getDay()].join("/"); const timeString = [nowDate.getHours(), nowDate.getMinutes(), nowDate.getSeconds()].join(":"); const commitMessage = [dateString, timeString, total, "image files add"].join(" "); console.log(commitMessage); await git.commit(commitMessage); console.log("committed " + total.toString() + " files"); await git.push().catch(err => { console.error(err); }); console.log("pushed and remained " + remainFileCount.toString() + " files"); // git statusで取得できるファイル数には上限があるので、現状で取得できたファイルが無くなったら再度git statusを行なって補充できるか確認する if(remainFileCount <= 0) { statusResult = await executeGitStatus(); remainFileCount = statusResult.created.length + statusResult.not_added.length; } } } executeCommitAndPushRoutine();上記スクリプトを実行するためにまずは simple-git をインストールします。
(package.jsonを作るほどのものでもないと思うのでこちらは省略)npm install simple-gitそして、その後
node roop-commit-and-push.jsとして上記のスクリプトを実行すると、
git addする必要があるファイルがなくなるまでGitHubにgit pushを行なってくれます。
(もちろん事前にgit initgit remote add origin urlなどの基本的な初期設定を事前に行なっている必要があります。)パッケージ化した方が良さそう?
Node.jsのインストールなどの初期設定が面倒な場合は上記スクリプトをパッケージ化して実行してもいいかもしれません。
以下参考
nodeアプリケーションを実行可能ファイルにして出力する闇の魔術に対する防衛術?
ここまで読んでいただいたらお分かりかと思いますが、防衛者側は GitHub になります。私も
Github Supportからゴルァされたら大人しくGitlabに移行するなど別の方法を模索するようにします...絶対にやってはダメですよ!!!
今回「もしかしてできるのではないか?」と思い至ったので実際に検証してみました。
しかし公式からは
私のディスク容量はいくつですか?
にあるようにやらないでくださいと明確に指摘されています。これをみた皆さんは絶対にマネしてはダメですよ!!!
もし同じことを真似しようと思った方はくれぐれも自己責任でやるようにしてください。なお
2020/12/06 現在、規約違反ではないのでペナルティはないと思われます。
- 投稿日:2020-12-06T14:19:14+09:00
入力値のバリデーションはこれを使え(2年間でこう進化した)
Node.jsアドベントカレンダーとDenoアドベントカレンダーの9日目の記事です。
同じ記事のURLを複数のアドベントカレンダーに指定できなかったので、1つは短縮URLを使いました。Node.jsやDenoとはどういうものかついては、以前さくらのナレッジに寄稿したのでよければそちらもごらんください。非同期処理についての記事もどうぞ。
はじめに
value-schemaというライブラリーをご存知でしょうか。いや、誰も知るまい。
2年前のNode.jsアドベントカレンダーで紹介した入力データのバリデーションライブラリー"adjuster"の後継版です。adjusterも誰も知るまい。
正確には、後継というよりバージョン2からリネームした地続きのライブラリーなのですが、まあそんな細かいことはどうでもいいです。数カ月間、実際のアプリケーションなどで使い勝手を徹底的に試してきました。この記事を書いている段階ではバージョン3のリリース候補版ですが、おそらくみなさんが読んでいる頃には正式版としてリリースされています。
本記事では、
- value-schemaとは何か?
- なぜvalue-schemaが必要なのか?
- 2年前からどう変わったのか?
このあたりについて説明します。
対象者
- Node.jsまたはDenoで
- Webアプリケーションを作っている人が
- 対象です。
value-schemaの存在意義
2年前の記事から引用します。
Webアプリケーションを開発していて地味に面倒なのが入力パラメーターの処理です。異論は認めない。
だいたいこんな感じのことをほぼすべてのパスで行う必要があるんじゃないでしょうか。
- 存在チェック
- 必須パラメーターが存在するか?
- 例:
nameが存在するか?- 省略可能パラメーターが省略されていたらデフォルト値を設定
- 例:
statusが省略されたら"active"を設定- 型チェック
- 期待通りの型か?
- 例:
ageはNumber型か?- 必要なら型変換
- 例:
"20"→20- POSTやPUTではJSONデータのみを受け付けることで型変換を不要にできるが、GETでクエリストリングを処理する場合は型変換が必要
- 定義域チェック
- 定義域に収まっているか?
- 例:
ageは0以上の整数か?- 必要なら値の調整
- 例1:
-1→0- 例2:
20.3→20あらためて面倒ですよね、はい。
adjusterは、そんな面倒なバリデーション処理を簡潔に、宣言的に1記述できるライブラリーです。value-schemaもこの思想は変わらず、より使いやすく改善しました。
コードで語る
百聞は一見に如かず。実際にコードを見れば便利さはすぐわかります。
例えば、入力値として以下のようなスキーマを想定しているとしましょう。ユーザー管理APIなんかでよくある例だと思います。
id
- 数値型
- 1以上
name
- 文字列型
- 最大16文字(16文字を超えた分は切り捨てる)
age
- 数値型
- 0以上
- 整数(小数点以下は切り捨て)
- RFCに準拠したEメールアドレス(文字列型)
state
- 文字列型
"active","inactive"のどちらかskills
- 文字列型の配列(ただし入力データはカンマ区切りの文字列)
- 解析時のエラーは無視する(正常に解析できた部分だけで配列を構成する)
creditCard
- 数字文字列(数字しか含まない文字列)
- ただし、読みやすさのために
-で区切られている(-が含まれていてもエラーにはせず、最終的には数字文字列のみがほしい)- 全角数字も受け付ける(半角に変換する)
- クレジットカードとして有効な文字列
remoteAddr
- 文字列
- IPv4として有効な文字列
limit
- 数値型
- 整数(小数部分があればエラー)
- 1以上(1未満の場合は1にする)
- 100以下(100を超える場合は100にする)
- 省略可能(省略時は10)
以上の内容を全て間違えずにロジックに落とし込むのはかなり面倒だと思いませんか?
さらに、APIの数だけ入力データもあるので、他のAPIでも同じようなロジックを書かなければいけません。ロジックを完全に使い回せるならいいのですが、微妙に条件が違っていたりして使い回せないことも多いですよね。value-schemaを使うと、以下のように記述できます。
import assert from "assert"; import vs from "value-schema"; const schemaObject = { // 入力スキーマ id: vs.number({ // 数値型 / 1以上 minValue: 1, }), name: vs.string({ // 文字列型 / 最大16文字(超えた分は切り捨てる) maxLength: { length: 16, trims: true, }, }), age: vs.number({ // 数値型 / 0以上 / 整数(小数点以下は切り捨て) minValue: 0, integer: vs.NUMBER.INTEGER.FLOOR_RZ, }), email: vs.email(), // RFCに準拠したEメールアドレス(文字列型) state: vs.string({ // 文字列型 / "active", "inactive"のどちらか only: ["active", "inactive"], }), skills: vs.array({ // 配列型 / カンマ区切り文字列を配列化 / 配列の要素は文字列型 / 解析時のエラーは無視する separatedBy: ",", each: { schema: vs.string(), ignoresErrors: true, }, }), creditCard: vs.numericString({ // 数字文字列 / "-"で区切られている / 全角数字も受け付ける(半角に変換する) / クレジットカード用のチェックサムを行う separatedBy: "-", fullWidthToHalf: true, checksum: vs.NUMERIC_STRING.CHECKSUM_ALGORITHM.CREDIT_CARD, }), remoteAddr: vs.string({ // 文字列型 / IPv4として有効な形式 pattern: vs.STRING.PATTERN.IPV4, }), limit: vs.number({ // 数値型 / 整数(小数部分があればエラー) / 1以上(1未満の場合は1にする) / 100以下(100を超える場合は100にする) / 省略可能(省略時は10) integer: true, minValue: { value: 1, adjusts: true, }, maxValue: { value: 100, adjusts: true, }, ifUndefined: 10, }), }; const input = { // 入力値 id: "1", name: "Pablo Diego José Francisco de Paula Juan Nepomuceno María de los Remedios Ciprin Cipriano de la Santísima Trinidad Ruiz y Picasso", age: 20.5, email: "picasso@example.com", state: "active", skills: "c,c++,javascript,python,,swift,kotlin", creditCard: "4111-1111-1111-1111", remoteAddr: "127.0.0.1", }; const expected = { // 最終的にこんな値になってほしい id: 1, name: "Pablo Diego José", age: 20, email: "picasso@example.com", state: "active", skills: ["c", "c++", "javascript", "python", "swift", "kotlin"], creditCard: "4111111111111111", remoteAddr: "127.0.0.1", limit: 10, }; // 入力スキーマを適用してみる const actual = vs.applySchemaObject(schemaObject, input); // 検証 assert.deepStrictEqual(actual, expected);ね、簡単でしょう?
記事中のコードなので長く見えるかもしれませんが、同等の機能を自前で書こうと思ったら間違いなくコード量は数倍〜十倍以上にまで膨れ上がります。
そして、何よりこのコードにはロジックがありません。
ifやforなどの制御構文も何もありません。
「idは1以上の数値型」のようなデータのあるべき姿を宣言しているだけなので理解しやすく、「あ、条件に『整数であること』を忘れていた!」という発見もしやすくなります。adjusterからの変更箇所
3行で。
- Deno対応
- TypeScriptでより使いやすく
- 可読性の高いインターフェース
Deno対応
バージョン3からDenoにも対応しました。
Denoで使う場合は以下のようにインポートしてください。import vs from "https://deno.land/x/value_schema/mod.ts";
value-schema(ダッシュ)ではなくvalue_schema(アンダースコア)であることに注意してください。deno.landへはダッシュがついた名前は登録できなかったのでアンダースコアに変更しました。Node.jsで使う場合はハイフンです。
// npm i value-schema import vs from "value-schema";TypeScriptでより使いやすく
これまでもTypeScriptに対応はしていましたが、単に「TypeScriptでも使えます」というだけで型情報を使用者側であらためて定義しなくてはならず、二度手間だったり使い方の間違いをチェックできないといった問題がありました。
たとえばこんな感じです。
adjuster(いままで)import adjuster from "adjuster"; const input: unknown = {}; // 入力データ interface Parameters { foo: number; bar: string; } // どんな型のデータになるかはGenericsで指定する const parameters = adjuster.adjust<Parameters>(input, { foo: adjuster.number(), bar: adjuster.string(), });しかし、これでは例えば
Parameters.fooを間違えてstring型にしてしまってもTypeScriptコンパイラーは間違いを検出できず、実行時のどこかのタイミング、たとえば文字列型のメソッドを使った時点で実行時エラーが発生してしまいます。
実行時エラーが発生するならまだいいほうで、場合によってはエラーにならず想定と全く違う動作をして(文字列連結のつもりで数値演算をしてしまうなど)頭を抱えることもあるかもしれません。value-schema v3ではTypeScriptの型推論を最大限に活用することで、明示的に型を指定することなくプロパティーの型を自動認識できるようになりました。
value-schema(これから)import vs from "value-schema"; const input: unknown = {}; // メソッド名が変わっている&引数の順序が変わっているので注意 const parameters = vs.applySchemaObject({ foo: vs.number(), bar: vs.string(), }, input);Visual Studio CodeやIntelliJ IDEAなら、以下のようにコード補完もバッチリ使えます。
ちゃんと数値型として認識されているので、メソッドも補完できます。
簡単ですね!可読性の高いインターフェース
adjuster時代は(value-schema v2時代も)値の細かな挙動はメソッドチェーンで指定していました。例えば以下のような感じです。
import adjuster from "adjuster"; // パラメーターに求める制約 const constraints = { name: adjuster.string().minLength(1), age: adjuster.number().integer(true).minValue(0, true), status: adjuster.string().default("active").only("active", "inactive"), }; // parametersに検証済みのパラメーターが入っている const parameters = adjuster.adjust(input, constraints);このコードは、
integer(true)やminValue(0, true)のtrueが何を意味しているのかわからないですよね。
integer(true)は一見すると「整数型にする場合はtrue、しない場合はfalse」かと思いますが、実は「小数部分を切り捨てるならtrue、切り捨てずにエラーにするならfalse」という意味で誤解を招く内容でした。
minValue(0, true)は、「0より小さい値の場合は強制的に0にするならtrue、エラーにするならfalse(あるいは省略)」という意味です。初見でこんなことわかりませんよね。これは他の人からも指摘されていたことで、なんとかして改善できないかと考えた結果チェーンメソッドを廃止して、全てのパラメーターをオブジェクトで渡すことにしました。
先ほどのコードと同様の内容をvalue-schemaで書き直すと以下のようになります。
import vs from "value-schema"; // パラメーターに求める制約 const constraints = { name: vs.string({ minLength: 1, }), age: vs.number({ integer: vs.NUMBER.INTEGER.FLOOR_RZ, // 小数点部分を切り捨て(負の数は0に向けて切り上げ) minValue: { value: 0, adjusts: true, }, }), status: vs.string({ ifUndefined: "active", only: ["active", "inactive"], }), }; // parametersに検証済みのパラメーターが入っている const parameters = vs.applySchemaObject(constraints, input);これなら誤解はありませんね。
丸めの方法も「切り上げ」「切り捨て」「四捨五入」「五捨五超入」など細かく指定できるようになりました。負の数の場合にどうするかも含めて計10通りの指定方法があります。もちろんパラメーターも補完対象なので、他にどんな指定ができるかもわかります。
Q&A
動作環境は?
大抵の環境に対応しています。
- OS: Windows / macOS / Linux
- Node.js: v4以降(v4からv12までテスト済み)
- TypeScript: v3.4.1以降
- Deno: v1以降(v1.0からv1.6までテスト済み)
何が言いたいかというと、GitHub Actions最高!
Node.js版とDeno版の違いは?
違いはありません。importのパスにさえ注意すれば、後は全く同じように使えます。
// Node.js版: インストールは "npm i value-schema" import vs from "value-schema"; // Deno版: インストールは不要 / value-schemaではなくvalue_schemaなので注意 import vs from "https://deno.land/x/value_schema/mod.ts";nullableにしたいんだけど?
null時の挙動は
ifNullで指定できます。const constraints = { foo: vs.number({ ifNull: null, // nullが指定されたらnullを返す }), bar: vs.number({ ifNull: 10, // nullが指定されたら10を返す }), };型推論の結果は、ちゃんと
number | null型になります。
barはnullにはならないので、型推論の結果もnumber型です。
便利ですね!
これを実現するために型パズルに悩まされたけどね!また、「省略時はnull」「空文字列が指定されたらnull」という挙動も指定できます。
const constraints = { foo: vs.number({ ifUndefined: null, // 省略時はnull }), bar: vs.number({ ifEmptyString: null, // 空文字列が渡されたらnull }), };エラー処理はどうすればいい?
2通りの方法があります。
エラーが1つでも見つかったらすぐにエラー処理したい場合
エラーが発生したら例外がthrowされるので、catchして処理してください。
try { // parametersに検証済みのパラメーターが入っている const parameters = vs.applySchemaObject(constraints, input); } catch(err) { const key = err.keyStack.shift(); switch(key) { // エラーが発生したプロパティー case "foo": switch(err.cause) { // エラーの原因 case vs.CAUSE.TYPE: // 型エラー ... } case "bar": switch(err.cause) { case vs.CAUSE.TYPE: // 型エラー ... case vs.CAUSE.NULL: // nullが渡された ... } } }
err.causeはエラーが発生した原因(型エラー、nullalbeじゃない場所でnullが渡されたなど)です。
err.keyStackはエラーが発生したキーの配列です。入力スキーマが「文字列の配列のオブジェクト」という場合にネストしている場合に複数の値が入ります。エラー処理2import vs from "value-schema"; const input: unknown = { foo: { values: [1, 2, "a"], }, }; // パラメーターに求める制約 const constraints = { // 数値の配列のオブジェクト foo: vs.object({ schemaObject: { values: vs.array({ each: vs.number(), }), }, }), }; try { // parametersに検証済みのパラメーターが入っている const parameters = vs.applySchemaObject(constraints, input); } catch(err) { // "a"("foo"プロパティーのインデックス2)でエラーが発生したので // err.keyStackが["foo", 2]となる });全てのエラーをチェックしたい場合
実際のアプリケーションでは、入力エラーが複数あった場合に全てのエラーに対して一度に指摘してあげたほうが親切ですよね。
applySchemaObject()の3番目の引数に関数を指定すると、エラーが見つかるたびに関数が呼ばれます。この場合、err自体の型チェックやプロパティー補完ができます。
3番目の引数を指定した場合はエラーが見つかっても例外はthrowされません。エラー処理その1const parameters = vs.applySchemaObject(constraints, input, (err) => { // errの中身は例外バージョンと同じ const key = err.keyStack.shift(); switch(key) { case "foo": return 0; // ここで返した値がfooエラー時の値になる case "bar": return 1; // ここで返した値がbarエラー時の値になる } });また、4番目の引数に関数を指定すると、1つでもエラーが見つかった場合にパラメーター検証後に呼ばれます。これを利用すれば、以下のようにエラー情報をまとめてthrowできます。
try { // エラー情報の配列 const errors: string[] = []; // parametersに検証済みのパラメーターが入っている const parameters = vs.applySchemaObject(constraints, input, (err) => { const key = err.keyStack.shift(); switch(key) { // エラーが発生したプロパティー case "foo": errors.push("fooがなんかおかしいよ"); return 0; // とりあえず0を返す case "bar": switch(err.cause) { case vs.CAUSE.NULL: // nullが渡された errors.push("barにnullはあかんよ"); return 0; } errors.push("barがなんかおかしいよ"); return 0; } }, () => { // エラーがあれば、検証処理後に呼ばれる throw errors; }); } catch(errors) { // errorsにはエラー情報の配列が入っている }ちゃんとテストしてる?
これが目に入らぬか
まとめ
- 入力値のバリデーションはvalue-schemaが便利だよ
- adjuster時代から大幅に進化したよ
- Deno版もあるよ
- 名前は"value_schema"(アンダースコア)だから注意してね
- TypeScript補完もバッチリだよ
- めっちゃテストしてるから安心して使っていいよ
宣言的=型チェックや定義域チェックなどのロジックを実装せず、「
ageは数値型で0以上の整数」「数値文字列の場合は数値型に変換する」「負の値が入力されたら0にする」「小数部分は切り捨てる」のようにあるべき姿を記述する方式 ↩






- 投稿日:2020-12-06T12:34:18+09:00
子どもに嫌われないように小言をCLOVAに代弁してもらった
「そろそろご飯出来るよ~」
の後に秘められた母親の言葉を代弁してくれるclovaスキルを作りました。
なぜ作ろうと思ったのか
どこの家庭でもある夕飯時の一コマでもある
「そろそろご飯できるよ~」という一見やさしそうに見える声掛けの裏には●片づけなさい
●机をふきなさい
●箸や食器の準備を手伝いなさいなどなど、実は沢山の意味が含まれています。
これを毎日言い続けて「うるさいな~」と思われない為に、clovaに代弁してもらおうという企画です。
きっとclovaから声を掛ければ子どもたちも動いてくれるはず!clova 頼みます!
LINE CLOVAの設定
CLOVAの設定方法については今後再利用できるように別記事にさせていただきました。
CLOVAの設定方法登録した呼び出し名は
・ねぇCLOVA、夕飯出来たよを起動して
・ねぇCLOVA、夕飯出来たよをひらいて
・ねぇCLOVA、夕飯出来たよにつないで
・ねぇCLOVA、夕飯出来たよこの4パターンです
これ以外のサンプル対話だとうまく起動しない事もあるので要注意です。
node.jsを利用
node.jsを利用して、対話が出来るように設定をします。
新規ファイル作成
routine.jsというファイル名を作りました。
npm init -y初期化を忘れずに
CLOVA CEK/express/body-parserをインストール
npm i @line/clova-cek-sdk-nodejs express body-parser作成したコードは
const clova = require('@line/clova-cek-sdk-nodejs'); const express = require('express'); const clovaSkillHandler = clova.Client .configureSkill() //起動時に喋る .onLaunchRequest(responseHelper => { responseHelper.setSimpleSpeech({ lang: 'ja', type: 'PlainText', value: '夕飯が出来たよルーティンを代行します', }); }) //ユーザーからの発話が来たら反応する箇所 .onIntentRequest(async responseHelper => { const intent = responseHelper.getIntentName(); const sessionId = responseHelper.getSessionId(); console.log('Intent:' + intent); if (intent === 'DinnerActingIntent') { const slots = responseHelper.getSlots(); console.log(slots); //デフォルトのスピーチ内容を記載 - 該当スロットがない場合をデフォルト設定 let speech = { lang: 'ja', type: 'PlainText', value: `まだ登録されていないエリアです。` } if (slots.time === '夕飯') { speech.value = `${slots.time}がそろそろ出来ますよ。片づけは出来ていますか?お箸やお皿を準備して、積極的にお母さんのお手伝いをしてあげてくださいね`; } else if (slots.time === '昼食') { speech.value = `${slots.time}がそろそろ出来ますよ。片づけは出来ていますか?お箸やお皿を準備して、積極的にお母さんのお手伝いをしてあげてくださいね`; } else if (slots.time === '昼食') { speech.value = `${slots.time}がそろそろ出来ますよ。片づけは出来ていますか?お箸やお皿を準備して、積極的にお母さんのお手伝いをしてあげてくださいね`; } responseHelper.setSimpleSpeech(speech); responseHelper.setSimpleSpeech(speech, true); } }) //終了時 .onSessionEndedRequest(responseHelper => { const sessionId = responseHelper.getSessionId(); }) .handle(); const app = new express(); const port = process.env.PORT || 3000; //リクエストの検証を行う場合。環境変数APPLICATION_ID(値はClova Developer Center上で入力したExtension ID)が必須 const clovaMiddleware = clova.Middleware({ applicationId: 'YOUR_EXTENSION_IDに書き換え' }); app.post('/clova', clovaMiddleware, clovaSkillHandler); app.listen(port, () => console.log(`Server running on ${port}`));自分の情報へ書き換える箇所は3つです。
1.「YOUR_EXTENSION_IDに書き換え」という箇所は作成したCLOVAスキルのExtension IDを入力します。
//リクエストの検証を行う場合。環境変数APPLICATION_ID(値はClova Developer Center上で入力したExtension ID)が必須 const clovaMiddleware = clova.Middleware({applicationId: 'YOUR_EXTENSION_IDに書き換え'}); app.post('/clova', clovaMiddleware, clovaSkillHandler);
2.インテントを自分で作成したインテントへ変更
console.log('Intent:' + intent); if (intent === 'DinnerActingIntent') { const slots = responseHelper.getSlots(); console.log(slots); //デフォルトのスピーチ内容を記載 - 該当スロットがない場合をデフォルト設定
3.カスタムインテントで作成した自分のスロットへ変更
if (slots.time === '夕飯') { speech.value = `${slots.time}がそろそろ出来ますよ。片づけは出来ていますか?お箸やお皿を準備して、積極的にお母さんのお手伝いをしてあげてくださいね`; } else if (slots.time === '昼食') { speech.value = `${slots.time}がそろそろ出来ますよ。片づけは出来ていますか?お箸やお皿を準備して、積極的にお母さんのお手伝いをしてあげてくださいね`; } else if (slots.time === '昼食') { speech.value = `${slots.time}がそろそろ出来ますよ。片づけは出来ていますか?お箸やお皿を準備して、積極的にお母さんのお手伝いをしてあげてくださいね`; }
実行
node routine.jsで実行した後、ngrokを立ち上げます。
npx ngrok http 3000ngrokで発行されたURLをCLOVA Developerへ登録
【サーバー設定】の中にある【ExtensionサーバーのURL】という箇所へURLを入力します。
その際、最後に【/clova】を忘れずに。
CLOVA Developerでまずはテスト
返答返ってきました!
CLOVAでテスト
「すいませんわかりませんでした」と返ってきてしまいました。
解決した方法の備忘録呼び出しサブを変える事で解決!







- 投稿日:2020-12-06T11:34:00+09:00
npm-check-updates (ncu) v10 の引数まとめ
はじめに
npm-check-updates は、package.json に書かれている依存性を、特定されているバージョンを無視して最新版へと書き換えます。通常は
ncuとncu -uでそれぞれ更新のチェックと書き換えを行ってくれるのですが、引数を付けて細かい設定をしたい場合があります。引数については日本語の記述が無かったり、古いバージョンに対する記述があったりするので、まとめました。用いた ncu のバージョンは
10.2.2です。使い方
グローバルインストールする
npm i -g npm-check-updates基本的な使い方
ncu # 更新の確認するが、package.jsonの書き換えはしない ncu -u # 更新を確認して、package.jsonを書き換える npm i # 書き換えたpackage.jsonを元にインストールする ncu -v # バージョンの表示 ncu -h # ヘルプの表示同時接続数をデフォルトの8から1へと変更する(手元の環境ではHTTPリクエストが詰まってタイムアウトする事があった)。
ncu --concurrency 1メジャーバージョンを固定して、マイナーバージョンのみ更新する。
ncu --target minor # ncu --semverLevel major # semverLevelは廃止されたマイナーバージョンを固定して、パッチのみ更新する
ncu --target patch # ncu --semverLevel minor # semverLevelは廃止された参考リンク
- 公式GitHub
- package.jsonのnpmのバージョンを一括で書き変えてくれるncuが便利だった
- 2016年の記事で記述が古かった
- 投稿日:2020-12-06T06:12:55+09:00
Authorization Code Flow with PKCE Clientの実装(Node.js)
はじめに
RFC7636 PKCE(Proof Key for Code Exchange by OAuth Public Clients)は認可コード横取り攻撃の対策(authorization code interception attack)として策定された仕様です。
また、PKCEは認可コード横取り攻撃にかかわらず、OAuth2.0におけるCSRFの対策としても機能します。
なお、stateによるCSRF対策ではクライアントが検証を実施するのに対して、PKCEによるCSRF対策では認可サーバーが検証を実施するという違いがあります。(PKCEを利用した場合でも、クライアントが固定値などの脆弱なcode_challenge、code_verifierを利用するとCSRFに対して脆弱になるためクライアントに対策の責務がないわけではありません)PKCEはスマートフォンアプリなどのPublic Clientにおいて利用が強く推奨されている仕様ですが、現在策定中のThe OAuth 2.1 Authorization Framework (OAuth2.1)においてクライアントの種別にかかわらず認可コードフローを利用する場合は必須になっており、今後利用する機会が増える可能性があります。
一方、PKCEの仕様説明は多く存在しているものの、実装に関する説明はまだ少ないと感じています。
そこで、本記事ではNode.jsのopenid-clientというパッケージを元に、PKCEを利用したクライアントの実装について(個人的なメモとして)記載します。準備
今回は認可サーバーとしてGoogleを利用します。
このため、事前に以下のGoogle APIのダッシュボードで必要な情報を登録する必要があります。
すでに利用可能なクライアントがある場合などはこちらの手順を省略してください。プロジェクトの作成
まず、画面上部の
[プロジェクトの選択]を押下します。
今回新たにプロジェクトを作成する場合は
[新しいプロジェクト]を押下します。
プロジェクト名などを設定します。ここではデフォルトで設定されているMy Project 1958をプロジェクト名として設定しています。
以上でプロジェクトの作成は終了です。続いてOAuth同意画面の設定をおこないます。OAuth同意画面
User Typeを設定します。動作確認に利用する想定のユーザーに適したUser Typeを指定して
[作成]を押下してください。ここでは外部を選択しています。
アプリ名、ユーザーサポートメール、デベロッパーの連絡先情報などの必須項目を入力します。
続いて
[スコープを追加または削除]を押下し、適切なscopeを設定しておきます。ここではopenidを追加しています。
次のテストユーザーは必要に応じて設定し、順に画面を進めてOAuth同意画面の設定を終了してください。(今回は未設定)
認証情報
[認証情報]>[認証情報を作成]>[OAuthクライアントID]を順に押下してクライアントに関する情報を登録していきます。
アプリケーションの種類や名前、リダイレクトURIを登録します。
今回はあくまでPKCEの動作確認をすることが目的であるため、アプリケーションの種類をウェブアプリケーション、承認済みのリダイレクト URIをhttp://localhost:3000/cbとして作成します。
実際のサービスで利用する際は、必ずそのアプリケーションに適したアプリケーションの種類を選択し、リダイレクトURIもHTTPSのURIを設定してください。
[作成]を押下すると、クライアントIDとクライアントシークレットが表示されます。
こちらは、後ほど利用するのでメモしておいてください。(後から確認することもできます)以上で認可サーバーにおけるクライアントの設定は終了です。
ここまででお気づきかもしれませんが、PKCEを利用する場合において特別な設定は必要ありません。実装
今回はnode openid-clientというパッケージを利用して実装します。
node openid-clientはCertified OpenID Connect Implementationsに記載されており、一定の信頼が可能なライブラリであるという判断で今回利用しました。
その他の言語で利用するライブラリを選定する際にもCertified OpenID Connect Implementationsはきっと役に立つでしょう。実装については、openid-clientのREADMEに記載のコードをもとに説明しますが、サンプルコードも用意しているので細かい設定値などはこちらを参照いただければ幸いです。
なお、今回の利用環境については次の通りです。
- OS: macOS Catalina
- Node.js: 12.0
- openid-client: 4.3.1
インストール
以下のコマンドでインストールします。なお、サポートしているNode.jsのバージョンは適宜以下のリンクから確認してください。
$ npm install openid-client(参考: https://www.npmjs.com/package/openid-client#install)
OpenID Connect Discovery
OpenID Connect Discovery 1.0で定義されているとおり
/.well-known/openid-configurationのURLからissuerに関する情報を取得する設定をおこないます。const { Issuer } = require('openid-client'); Issuer.discover('https://accounts.google.com/.well-known/openid-configuration') // => Promise .then(function (googleIssuer) { console.log('Discovered issuer %s %O', googleIssuer.issuer, googleIssuer.metadata); });(引用元: https://github.com/panva/node-openid-client#quick-start)
Googleであれば
https://accounts.google.com/.well-known/openid-configurationから情報を取得することができます。認可コードフロー
クライアントに関する情報を次の通り設定していきます。
トークンエンドポイントにおける認証で利用するclient_id、client_secretとして先ほど事前準備でメモしておいた値を指定します。
また、オープンリダイレクト対策としてリダイレクトURIの検証が実施されるため、redirect_urisに先ほど事前準備で登録したURIを指定します。const client = new googleIssuer.Client({ client_id: '<CLIENT_ID>', client_secret: '<CLIENT_SECRET>', redirect_uris: ['http://localhost:3000/cb'], response_types: ['code'], // id_token_signed_response_alg (default "RS256") // token_endpoint_auth_method (default "client_secret_basic") }); // => Client(引用元: https://github.com/panva/node-openid-client#authorization-code-flow)
認可リクエスト
認可リクエストのパラメーターを指定します。
PKCEでは認可リクエストのパラメーターとしてcode_challengeとcode_challenge_methodを含める必要があります。
openid-clientではgeneratorsというstate、nonce、などのパラメーターを生成してくれる便利なユーティリティが用意されています。
PKCEで利用するcode_challengeやcode_verifierといったパラメーターも生成可能なのでこちらを利用します。const { generators } = require('openid-client'); const code_verifier = generators.codeVerifier(); // store the code_verifier in your framework's session mechanism, if it is a cookie based solution // it should be httpOnly (not readable by javascript) and encrypted. const code_challenge = generators.codeChallenge(code_verifier); const nonce = generators.nonce(); const state = generators.state(); client.authorizationUrl({ scope: 'openid', state, nonce, code_challenge, code_challenge_method: 'S256', });(引用元: https://github.com/panva/node-openid-client#authorization-code-flow)
トークンリクエスト
認可レスポンスを受け取り、トークンリクエストを送信する部分に関する設定をします。
ここで、client.callback()の第三引数のオブジェクトとしてcode_verifierを含めることにより、code_verifierがトークンリクエストにおいて送信されます。const params = client.callbackParams(req); client.callback('http://localhost:3000/cb', params, { code_verifier, state, nonce }) // => Promise .then(function (tokenSet) { console.log('received and validated tokens %j', tokenSet); console.log('validated ID Token claims %j', tokenSet.claims()); });これにより、認可サーバーは認可リクエストで送信したcode_challenge_methodおよびcode_challengeとトークンリクエストで送信されたcode_verifierをもとに認可コードが横取りされていないか検証可能になります。
動作確認
今回、実装済みのコードを用意しているので、こちらをもとに動作確認しています。
$ git clone https://github.com/kg0r0/google-pkce-client.git $ cd google-pkce-client $ npm install $ node index.js動作確認は
client.callback()の第三引数のcode_verifierの値ををデタラメな文字列に変更することなどで確認できます。
ただ、今回はせっかくなのでローカルプロキシ (Burp Suite) を利用してなるべく攻撃者視点っぽく確認してみます。認可コード横取り攻撃対策
PKCEが認可コード横取り攻撃の対策としてうまく動作しているか確認します。
まず、http://localhost:3000 にアクセスします。
すると、次のとおりGoogleにリダイレクトされるのでログインをしてみます。なお、このときのURLをみるとcode_challengeとcode_challenge_methodがパラメーターとして送信されていることが確認できます。
ログイン処理を進めていくと、
/signin/oauth/consentのレスポンスとしてLocationヘッダに認可コードが返ってきます。
ここで、悪意ある第三者のクライアントに認可コードが横取りされたと想定します。
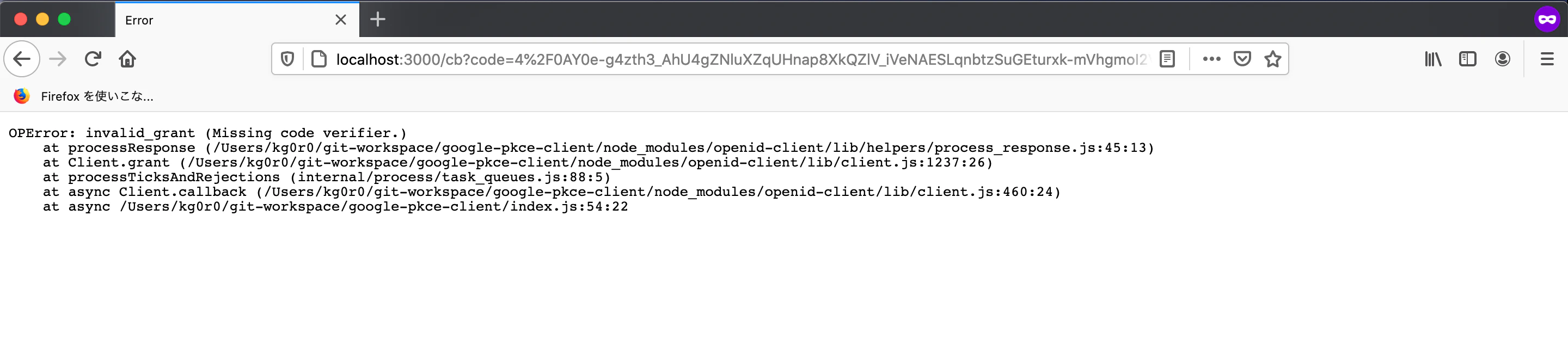
攻撃者は横取りした認可コードを利用して、以下のようなリクエストをトークンエンドポイントに対して送信し、トークンの取得を試みます。$ curl \ -d "client_id=<CLIENT_ID>" \ -d "client_secret=<CLIENT_SECRET>" \ -d "redirect_uri=http://localhost:3000/cb" \ -d "grant_type=authorization_code" \ -d "code=4%2F0AY0e-g6f5-HCQi5pqliTGbY5cXBa9uWkyucNO7g2VMRuVMamBwFEWE2296NLoVNKVfYrUQ" \ https://oauth2.googleapis.com/token { "error": "invalid_grant", "error_description": "Missing code verifier." }無事、
Missing code verifierと表示され、横取りした認可コードからトークンは取得できなかったようです。
ここまでの攻撃者が取得した認可サーバーからのレスポンスからはcode verifierを特定することは不可能なので、横取りした認可コードの悪用ができないことがわかりました。CSRF対策
続いて、PKCEがCSRF対策になっているか確認します。
事前にPKCEがCSRF対策になっていることを確認するため、client.authorizationURL()およびclient.callback()の引数からそのほかのCSRF対策となるパラメーターの設定を除外しておきます。client.authorizationUrl({ scope: 'openid', code_challenge, code_challenge_method: 'S256', }); . . . client.callback(redirect_uri, params, { code_verifier });上記の設定変更ができたら http://localhost:3000 にアクセスし、認可サーバーにリダイレクトされるのでログイン処理を進めていきます。
ログイン処理を進めていくと、先ほど同様に
/signin/oauth/consentのレスポンスとしてLocationヘッダが返ってきます。
ここで、Locationヘッダに設定されているURLを保存しておきます。
次に、被害者として攻撃者が配置した上記のURLを踏んでしまったと仮定します。
ここで、
Missing code verifierと表示され、CSRFが成功しませんでした。
よって、PKCEがCSRFの対策としても機能していることがわかりました。おわりに
今回はPKCEを利用したクライアントの実装例と動作確認を紹介しました。
PKCEの詳しい解説は多数記事が存在していると思うので、それらを参照いただければ幸いです。参考