- 投稿日:2020-11-30T19:40:12+09:00
TensorFlow/Kerasでカスタム最適化アルゴリズムを実装する
はじめに
TensorFlow/Kerasで最適化アルゴリズムを自作したくなる場面はまず無いが、興味のある人もそれなりにいるだろう、と思い記事を作成。
環境
- TensorFlow(2.3.0)
- Google Colab(GPU/TPU)で動作確認済み
基本
tensorflow.python.keras.optimizer_v2.optimizer_v2.OptimizerV2を継承して作る。
VanillaSGDを実装すると以下の通りになる。
VanillaSGD.pyfrom tensorflow.python.keras.optimizer_v2.optimizer_v2 import OptimizerV2 class VanillaSGD(OptimizerV2): def __init__(self, learning_rate=0.01, name='VanillaSGD', **kwargs): super().__init__(name, **kwargs) self._set_hyper("learning_rate", kwargs.get("lr", learning_rate)) def get_config(self): config = super(VanillaSGD, self).get_config() config.update({ "learning_rate": self._serialize_hyperparameter("learning_rate"), }) return config def _resource_apply_dense(self, grad, var, apply_state=None): var_device, var_dtype = var.device, var.dtype.base_dtype lr_t = self._get_hyper("learning_rate", var_dtype) return var.assign(var - lr_t * grad) def _resource_apply_sparse(self, grad, var, indices): raise NotImplementedError("not implemented")
__init__()は各種初期化処理を実装する。
- 主にハイパーパラメーターの登録を
_set_hyper()を使用して行う- この例の場合はlearning_rateを登録しているが、
kwargs.get("lr", learning_rate)というのは"lr="と指定しても扱えるようにするため。get_config()はシリアライズのための処理を入れる。
- ModelのSave時に呼ばれる。
- ハイパーパラメーターは全てここで
configに追加する。- 値の取得には
_serialize_hyperparameter()を使う。_resource_apply_dense()で変数の更新処理を行う。
- gradは勾配のテンソル
- varは変数(つまり重み)のテンソル。gradと同じShape。
- apply_stateはハイパーパラメーター等が格納されている辞書
- ハイパーパラメーターの取得には
_get_hyper()を使う- 戻り値は「変数を更新するOperater」が要請されているので、varをassign系の関数で更新したものを返す必要がある。この例では、重みから勾配に学習率を掛けたものを引いて新しい重みとする。
_resource_apply_sparse()はSparseなネットワークを更新する場合に使用される。通常は実装しなくても問題ない。保存したモデルからLoadを実行する際には、下記のようにcustom_objectsとして追加しておく。
tf.keras.models.load_model('model.h5', custom_objects={'VanillaSGD': VanillaSGD})decay対応
基本的にOptimizerV2を継承しているOptimizerはdecayパラメータにも対応している。
先に作成したVanillaSGDも対応させると、下記のようになる。VanillaSGD.pyclass VanillaSGD2(OptimizerV2): def __init__(self, learning_rate=0.01, name='CustomOptimizer', **kwargs): super().__init__(name, **kwargs) self._set_hyper("learning_rate", kwargs.get("lr", learning_rate)) self._set_hyper('decay', self._initial_decay) def get_config(self): config = super(VanillaSGD, self).get_config() config.update({ "learning_rate": self._serialize_hyperparameter("learning_rate"), "decay": self._serialize_hyperparameter("decay"), }) return config def _resource_apply_dense(self, grad, var, apply_state=None): var_device, var_dtype = var.device, var.dtype.base_dtype lr_t = self._decayed_lr(var_dtype) return var.assign(var - lr_t * grad) def _resource_apply_sparse(self, grad, var, indices): raise NotImplementedError("not implemented")
__init__()でハイパーパラメーターとして'decay'を登録するが、super().__init__でself._initial_decayがすでに定義済みなので、それを利用する。_resource_apply_dense()内では、学習率を取得する際に定義済みの_decayed_lr()を使用する。自動的にdecayが効いた学習率が返ってくる。変数の追加
実用的な最適化アルゴリズムでは、各重みに付随した変数を保持して計算に利用する必要がある。
このような例としてMomentumSGDを実装すると下記のようになる。MomentumSGD.pyclass MomentumSGD(OptimizerV2): def __init__(self, learning_rate=0.01, momentum=0.0, name='MomentumSGD', **kwargs): super().__init__(name, **kwargs) self._set_hyper("learning_rate", kwargs.get("lr", learning_rate)) self._set_hyper('decay', self._initial_decay) self._set_hyper('momentum', momentum) def get_config(self): config = super(MomentumSGD, self).get_config() config.update({ "learning_rate": self._serialize_hyperparameter("learning_rate"), "decay": self._serialize_hyperparameter("decay"), "momentum": self._serialize_hyperparameter("momentum"), }) return config def _create_slots(self, var_list): for var in var_list: self.add_slot(var, 'm') def _resource_apply_dense(self, grad, var, apply_state=None): var_device, var_dtype = var.device, var.dtype.base_dtype lr_t = self._decayed_lr(var_dtype) momentum = self._get_hyper("momentum", var_dtype) m = self.get_slot(var, 'm') m_t = m.assign( momentum*m + (1.0-momentum)*grad) var_update = var.assign(var - lr_t*m_t) updates = [var_update, m_t] return tf.group(*updates) def _resource_apply_sparse(self, grad, var, indices): raise NotImplementedError("not implemented")
_create_slots()で、追加したい変数を登録する。
- 慣性項のために、
add_slot()を使用して各varごとに'm'という名前で追加。- 追加した変数は、
get_slot()で取り出す。_resource_apply_denseの戻りとしては、更新する変数のOperationをtf.group()を使ってまとめて返す。今回の場合はvar_updateとm_tが対象。ちなみに今回作成したMomentumSGDは、tf.kerasのSGDを使ったものとは学習率の解釈が違うので、同じ学習率でも結果が違う。
こちらの学習率に(1-momentum)を掛けると、tf.kerasのSGDと同じ結果になる。例えばMomenutumSGD(0.01,momentum=0.9)はSGD(0.001,momentum=0.9)と同じ。ステップ数に応じて処理を変える
実行回数に応じて係数を調整したりする処理が必要な場合がある。
そのような場合はすでに定義済みのself.iterationsが利用できる。
MomentumSGDの慣性項は初期値の0.0に引っ張られてしまうバイアスが存在するが、それを補正する処理を入れてみたものが以下の例。(Adamでも同様の補正をしている)
とりあえず"Centered Momentum SGD"と名付けておく。CMomentumSGD.pyclass CMomentumSGD(OptimizerV2): def __init__(self, learning_rate=0.01, momentum=0.0, centered=True, name='CMomentumSGD', **kwargs): super().__init__(name, **kwargs) self._set_hyper("learning_rate", kwargs.get("lr", learning_rate)) self._set_hyper('decay', self._initial_decay) self._set_hyper('momentum', momentum) self.centered = centered if momentum!=0.0 else False def get_config(self): config = super(CMomentumSGD, self).get_config() config.update({ "learning_rate": self._serialize_hyperparameter("learning_rate"), "decay": self._serialize_hyperparameter("decay"), "momentum": self._serialize_hyperparameter("momentum"), 'centered': self.centered, }) return config def _create_slots(self, var_list): for var in var_list: self.add_slot(var, 'm') def _resource_apply_dense(self, grad, var, apply_state=None): var_device, var_dtype = var.device, var.dtype.base_dtype lr_t = self._decayed_lr(var_dtype) momentum = self._get_hyper("momentum", var_dtype) m = self.get_slot(var, 'm') m_t = m.assign( momentum*m + (1.0-momentum)*grad) if self.centered: local_step = tf.cast(self.iterations+1, var_dtype) m_t_hat = m_t * 1.0 / (1.0-tf.pow(momentum, local_step)) var_update = var.assign(var - lr_t*m_t_hat) else: var_update = var.assign(var - lr_t*m_t) updates = [var_update, m_t] return tf.group(*updates) def _resource_apply_sparse(self, grad, var, indices): raise NotImplementedError("not implemented")
- centeredが真の場合に、補正を入れる。ここでself.iterationsを使用している
- centeredはハイパーパラメーターではあるが、途中で変更すこともないので、
_set_hyper()等は使用していない。せっかく作ったので、各最適化アルゴリズムの比較をしてみる。
比較方法は、この記事に準じている
- MomentumSGDとVanillaSGDの比較
- MomentumSGDのほうが立ち上がりが遅い(角度がつくまで時間がかかる)。慣性があるため、初期値の0から動き出すのに時間がかかっていると解釈できる。
- VanillaSGDと同じ角度になってからは、全く同じ角度で推移する。
- 最適値(0.0)をやや大きく通りすぎるのは慣性項の効果。
- VanillaSGDでは最適値付近で細かく振動するが、MomentumSGDではゆるく振動する。これも慣性項の効果。
- CenteredMomentumSGDとMomentumSGDの比較
- 初期値バイアスの補正の結果、立ち上がりの遅さが改善されて、VanillaSGDと全く同じ軌道をとるようになった。
- 最適値を通りすぎた後は、MomentumSGD特有の動きとなる。
繰り返しになるが、ここで実装したMomentumSGDはKeras等で通常実装されているものとは若干処理が異なるので注意。(こちらのほうが慣性項の真の効果がわかりやすくて、個人的には良いと思うが)
参考
TensorFlowの実装
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/python/keras/optimizer_v2Optimizerの実装方法
第6回 カスタマイズするための、TensorFlow 2.0最新の書き方入門関連記事

- 投稿日:2020-11-30T15:44:08+09:00
【初心者必読】VGG16を動かしたいなら、まずはColabが正解です。
〜本記事でわかること〜
・VGG16の実装方法
1.はじめに
「わたしの備忘録」 兼 「初心者向け」の内容です。
・Deep Learningって分かんないけど、とにかく動かしたい!
・原理とかは後回し、実装方法だけ知りたい!って方は、ぜひ読んでみてください!
2.動作環境
動作環境は以下の通り。
・Windows 10
・Google Colab
・tensorflow ver.2.3今回はGoogle Colabにて
コーディングしていくので、
OSとかは特に関係ないです。ネット環境だけ整ってれば、とりあえずオーケー!
3.前準備
本記事で取り上げるVGG16というモデルは、
深層学習の中でも「画像の分類」が得意です。なので、まずは皆さんに
自前のデータを用意してほしいんですね。わたしはマーベル作品が大好きなので、
「キャプテンアメリカ」
「アイアンマン」
「ハルク」
「ソー」
の画像を用意しました!画像の枚数は適当でいいのですが、
手始めに各50枚ほど用意してみましょう。用意できましたら、
VGG16が学習しやすいように
フォルダを作っていきます。というわけで、
以下のようにフォルダを作ってください。image/ ├ train/ │ ├ captain/ │ ├ ironman/ │ ├ hulk/ │ └ thor/ │ ├ valid/ │ ├ captain/ │ ├ ironman/ │ ├ hulk/ │ └ thor/ │ └ test/ ├ captain/ ├ ironman/ ├ hulk/ └ thor/そうしましたら、
「train」・「valid」・「test」フォルダの
各「captain」・「ironman」・「hulk」・「thor」フォルダに
画像を入れていきます。各ヒーローごとに50枚あるので、
「train」に30枚、「valid」に10枚、「test」に10枚
入れていきます。なので、全体の画像配置は
train:150枚
valid: 50枚
test : 50枚
になりますね。前準備はこれで終了。
4.実装
4−1 まずは、Google Driveへ
Google Colabでコーディングしていくのですが
そのためにも、まずGoogle Driveへ移動します。みなさん、現代っ子のはずなので、
Googleアカウントは、さすがに持ってますよね??
(無ければこの際に作っちゃいましょ!)Googleアカウントにログインできましたら、
Google Driveへアクセス。先程作った「image」フォルダをアップロードします。
4−2 実際にコードを書いてみよう
現時点では、おそらくGoogle Colabが
インストールされていないと思うので、下に示した図のようにインストールしていきます。
4−3 学習開始!
それでは、学習していきましょう。
まずは、Google DriveとGoogle Colabを接続します。from google.colab import drive drive.mount('/content/drive')そして、VGG16のモデルを作成していきます。
import matplotlib import numpy as np %matplotlib inline from tensorflow.python.keras.callbacks import TensorBoard from tensorflow.python.keras.applications.vgg16 import VGG16 vgg16 = VGG16(include_top=False, input_shape=(224, 224, 3), weights='imagenet')クラスの設定をします。
ここは皆さんの用意したデータによって変えてください。import random classes = ['captain', 'ironman', 'hulk', 'thor']モデルの生成とコンパイルをします。
from tensorflow.python.keras.models import Sequential, Model from tensorflow.python.keras.layers import Dense, Dropout, Flatten, GlobalAveragePooling2D from tensorflow.keras.optimizers import SGD def build_transfer_model(vgg16): model = Sequential(vgg16.layers) for layer in model.layers[:15]: layer.trainable = False model.add(Flatten()) model.add(Dense(256, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(len(classes), activation='softmax')) return model model = build_transfer_model(vgg16) model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=1e-5, momentum=0.9), metrics=['accuracy'] )ここでは、ジェネレータとイテレータを生成します。
カンタンに言うと、画像の拡張やスケール変換をしています。from tensorflow.python.keras.preprocessing.image import ImageDataGenerator from tensorflow.python.keras.applications.vgg16 import preprocess_input idg_train = ImageDataGenerator(rescale=1/255., shear_range=0.1, zoom_range=0.1, horizontal_flip=True, preprocessing_function=preprocess_input ) idg_valid = ImageDataGenerator(rescale=1/255.) img_itr_train = idg_train.flow_from_directory(directory='/content/drive/My Drive/image/train/', target_size=(224, 224), color_mode='rgb', classes=classes, batch_size=1, class_mode='categorical', shuffle=True ) img_itr_validation = idg_valid.flow_from_directory(directory='/content/drive/My Drive/image/valid/', target_size=(224, 224), color_mode='rgb', classes=classes, batch_size=1, class_mode='categorical', shuffle=True )モデル保存用のディレクトリの準備をします。
import os from datetime import datetime model_dir = os.path.join('/content/drive/My Drive/image/', datetime.now().strftime('%y%m%d_%H%M') ) os.makedirs(model_dir, exist_ok = True) print('model_dir:', model_dir) dir_weights = os.path.join(model_dir, 'weights') os.makedirs(dir_weights, exist_ok = True)学習の途中経過を保存したり、保存方法を設定します。
from tensorflow.python.keras.callbacks import CSVLogger, ModelCheckpoint import math file_name='vgg16_fine' batch_size_train=1 batch_size_validation=1 steps_per_epoch=math.ceil(img_itr_train.samples/batch_size_train ) validation_steps=math.ceil(img_itr_validation.samples/batch_size_validation ) cp_filepath = os.path.join(dir_weights, 'ep_{epoch:02d}_ls_{loss:.1f}.h5') cp = ModelCheckpoint(cp_filepath, monitor='loss', verbose=0, save_best_only=False, save_weights_only=True, mode='auto', save_freq=5 ) csv_filepath = os.path.join(model_dir, 'loss.csv') csv = CSVLogger(csv_filepath, append=True)そして、ついに学習です。
hist=model.fit_generator( img_itr_train, steps_per_epoch=steps_per_epoch, epochs=50, verbose=1, validation_data=img_itr_validation, validation_steps=validation_steps, shuffle=True, callbacks=[cp, csv] ) model.save(file_name+'.h5')コーディングが終わったので、
上からソースコードを実行していきます。以下が途中経過の一例になります。
これが「Epoch 50/50」まで続きます。
それが学習終了の合図です。Epoch 1/50 80/80 [==============================] - 18s 228ms/step - loss: 1.2106 - accuracy: 0.5000 - val_loss: 1.2738 - val_accuracy: 0.3500 Epoch 2/50 80/80 [==============================] - 22s 276ms/step - loss: 1.0407 - accuracy: 0.5875 - val_loss: 1.1765 - val_accuracy: 0.5000 Epoch 3/50 80/80 [==============================] - 34s 419ms/step - loss: 0.9078 - accuracy: 0.6375 - val_loss: 1.2011 - val_accuracy: 0.5500 Epoch 4/50 80/80 [==============================] - 31s 387ms/step - loss: 0.9747 - accuracy: 0.5625 - val_loss: 1.2541 - val_accuracy: 0.50004−4 結果は・・・??
さて、学習は終了しましたが、
まだ不完全です。それもそのはず。
大学生に例えれば「講義」を受けて「課題」を
解いたにすぎないからです。ある一定の評価(=単位)をもらうには、
「試験(テスト)」が残っています。といわけで、次のコードを実行しましょう。
import matplotlib.pyplot as plt from tensorflow.python.keras.preprocessing.image import load_img, img_to_array, array_to_img idg_test = ImageDataGenerator(rescale=1.0/255) img_itr_test = idg_test.flow_from_directory(directory='/content/drive/My Drive/image/test/', target_size=(224,224), batch_size=1, class_mode='categorical', shuffle=True ) score=model.evaluate_generator(img_itr_test) print('\n test loss:',score[0]) print('\n test_acc:',score[1]) plt.figure(figsize=(10,15)) for i in range(4): files=os.listdir('/content/drive/My Drive/image/test/' + classes[i] + '/') for j in range(5): temp_img=load_img('/content/drive/My Drive/image/test/' + classes[i] + '/' + files[j], target_size=(224,224)) plt.subplot(4,5,i*5+j+1) plt.imshow(temp_img) temp_img_array=img_to_array(temp_img) temp_img_array=temp_img_array.astype('float32')/255.0 temp_img_array=temp_img_array.reshape((1,224,224,3)) img_pred=model.predict(temp_img_array) plt.title(str(classes[np.argmax(img_pred)]) + '\nPred:' + str(math.floor(np.max(img_pred)*100)) + "%") plt.xticks([]),plt.yticks([]) plt.show()結果は、こんな感じ。
test loss: 1.0708633661270142 test_acc: 0.550000011920929全体の精度にして、55%となりました。
まぁ、まずまずといったところでしょうか。それではもっと詳しく見ていきます。
各画像の予測結果はこんな感じ。
うん、アイアンマンの正答率がいい感じ。
アイアンマンが好きな私としては嬉しい結果です〜♪パラメータや学習回数などをいじれば
もっと精度は向上するでしょうが・・・
今日のところはお開きとしたいです。5.おわりに
いかがでしたか??
原理などは一切説明しませんでしたが、
少しでもAIに関して興味をもってもらえると嬉しいです。本記事では、VGG16の実装方法を紹介しましたが、
実はこのモデル、結構古いんですよね・・・。
(2015年に論文が執筆されています。詳しくはこちら。)今は新しく精度の高いモデルも
たくさん出ているので、興味がある方は
ぜひ試してみてください!では、よいAIライフを〜 ^^

- 投稿日:2020-11-30T13:01:05+09:00
Amazon SageMakerで深層学習画風変換モデルのハイパーパラメータチューニングに挑戦してみた
この記事は、NTTテクノクロス Advent Calendar 2020の13日目です。
はじめまして。NTTテクノクロスの堀江と申します。
今年の弊社アドベントカレンダー執筆陣の中では最年少(現在入社4年目)となります。どうぞよろしくお願いします!業務では、パブリッククラウド上でのシステム設計や環境構築支援を担当しています。その関係もあって現在絶賛勉強中のAWSと、趣味で勉強している深層学習の2つを組み合わせた取り組みを本日は発表したいと思います。
目次
- はじめに
- 記事要約 - 調査の観点と成果
- 用語説明
- Neural Style Transferとは
- Amazon SageMakerとは
- 実施内容
- 環境構築
- 単発のトレーニングジョブを実行
- ハイパーパラメータチューニングを実行
- チューニング結果を比較
- おわりに
- Appendix
はじめに
TensorFlowで自作した画像生成深層学習モデル - Neural Style Transfer - のハイパーパラメータチューニングに、Amazon SageMakerを利用して挑戦してみました。
その結果得られた、Amazon SageMakerの使用方法に関するノウハウや、ハイパーパラメータチューニングの結果を本記事で展開していきます。
記事要約 - 調査の観点と成果
- Amazon SageMakerのトレーニングジョブやハイパーパラメータチューニングジョブって、そもそもどういう仕組みで実行されるの?
- 実際にトレーニングジョブとハイパーパラメータチューニングジョブを実行してみることで、データや処理の流れを理解できたので、自分なりに整理してみました。
- MNIST分類モデルのようなシンプルな構造のモデルだけじゃなく、画像生成モデルのような複雑な構造のモデルもAmazon SageMakerでトレーニングできるの?
- デフォルト設定のトレーニングジョブ実行時に遭遇したエラーと、その回避方法を記載しています。
- 例えばtf.functionとkerasが混在し、tf.Modulでクラス化されたような複雑な構造のモデルでも、トレーニングを実行することが出来ました。
- Neural Style Transferって、ハイパーパラメータチューニングの効果があるの?
- ハイパーパラメータをチューニングすることで、生成される画像の質が向上することを確認できました。(少なくとも自分の主観では…)
用語説明
本題に入る前に、重要な用語2つについては簡単にですが説明させてもらいます。
なお、「深層学習とは」「AWSとは」といった基本の部分については本記事での解説を省略させてもらいますのでご容赦ください。
Neural Style Transferとは
Neural Style Transfer(以降、長いのでnstとも省略します)とは、深層学習を利用した画像生成技術の一つです。
下記の例のように、ある画像の画風(スタイル)で、任意の別の画像(コンテンツ)の画風を変換することができます。
- 犬の写真をワシリー・カンディンスキーの画風(スタイル)で変換したデモgif動画1
- nstのサンプル作品集2
記事要約内では「自作の画像生成深層学習モデル」と誇張した表現を用いてしまいましたが…今回利用するnstモデルは、TensorFlowの公式サイトに載っているサンプルノートブックのコードを独自に(趣味で)リファクタリングしたものになります。数学的なアルゴリズムの詳細についても公式サイトに載っているので、興味のある方はそちらをご覧になってみてください。
今回使用するモデルのコード(一部を抜粋)class NstEngine(tf.Module): def __init__(self, content_shape, args, name=None): """ content_shape : コンテンツ画像のshape e.g. (1, 512, 512, 3) args : Namespaceオブジェクト。 """ super(NstEngine, self).__init__(name=name) # サンプノートブックの通り、VGG19を特徴量抽出器として利用する。 self.content_layers = ['block5_conv2'] self.style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1'] vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet') outputs = [ vgg.get_layer(target_layer).output for target_layer in self.content_layers + self.style_layers ] self.model = tf.keras.Model([vgg.input], outputs) self.model.trainable = False # tf.function内部では変数を宣言できないので、モデルの初期化時に # 変数も初期化しておく必要がある。 self.content_image = tf.Variable(tf.zeros(content_shape), dtype=tf.float32) self.loss = tf.Variable(tf.zeros((1)), dtype=tf.float32) self.style_image = None self.content_image_org = None self.style_image_org = None self.content_target = None self.style_target = None self.epoch = int(args.EPOCH) # 以下、後々チューニング対象になるハイパーパラメータ達 learning_rate = float(os.environ.get("SM_HP_LEARNING_RATE", args.LEARNING_RATE)) self.optimizer = tf.keras.optimizers.Adam( learning_rate=learning_rate, beta_1=0.99, epsilon=0.1, ) self.content_weights = float(os.environ.get("SM_HP_CONTENT_WEIGHTS", args.CONTENT_WEIGHTS)) self.style_weights = float(os.environ.get("SM_HP_STYLE_WEIGHTS", args.STYLE_WEIGHTS)) self.total_variation_weights = float(os.environ.get("SM_HP_TOTAL_VARIATION_WEIGHTS", args.TOTAL_VARIATION_WEIGHTS)) @tf.function def fit(self, content, style, content_org): """ 外部から呼び出されるエントリーポイント args: - content : 更新対象のコンテンツ画像 shape : (1, height, width, 3) - style : スタイル画像 shape : (1, height, width, 3) - content_org : オリジナルのコンテンツ画像 shape : (1, height, width, 3) return : - スタイル画像の画風で更新されたコンテンツ画像 shape : (1, height, width, 3) - loss値 shape : (1) """ self.content_image_org = content_org self.style_image_org = style self.content_image.assign(content) self.style_image = style self.content_target = self.call(self.content_image_org)['content'] self.style_target = self.call(self.style_image_org)['style'] for e in tf.range(self.epoch): self.loss.assign([self.step()]) return self.content_image, self.loss """ 以降の関数はサンプルノートブックの処理を流用。 詳細については省略 """ @tf.function def step(self): with tf.GradientTape() as tape: outputs = self.call(self.content_image) loss = self._calc_style_content_loss(outputs) loss += self.total_variation_weights*self._total_variation_loss() grad = tape.gradient(loss, self.content_image) self.optimizer.apply_gradients([(grad, self.content_image)]) self.content_image.assign(self._clip_0_1()) return loss def _calc_style_content_loss(self, outputs): style_outputs = outputs['style'] content_outputs = outputs['content'] style_loss = tf.add_n([ tf.reduce_mean((style_outputs[name] - self.style_target[name])**2) for name in style_outputs.keys() ]) style_loss *= self.style_weights / len(self.style_layers) content_loss = tf.add_n([ tf.reduce_mean((content_outputs[name] - self.content_target[name])**2) for name in content_outputs.keys() ]) content_loss *= self.content_weights / len(self.content_layers) loss = style_loss + content_loss return loss def _total_variation_loss(self): x_deltas, y_deltas = self._high_pass_x_y() return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas)) def _clip_0_1(self): clipped = tf.clip_by_value( self.content_image,clip_value_min=0.0, clip_value_max=1.0 ) return clipped def _high_pass_x_y(self): x_var = self.content_image[:, :, 1:, :] - self.content_image[:, :, :-1, :] y_var = self.content_image[:, 1:, :, :] - self.content_image[:, :-1, :, :] return x_var, y_var def call(self, input_image): input_image = input_image * 255. image = tf.keras.applications.vgg19.preprocess_input(input_image) outputs = self.model(image) content_outputs = outputs[:len(self.content_layers)] style_outputs = outputs[len(self.content_layers):] style_matrix = self._calc_gram_matrix(style_outputs) style_dict = { name: output for name, output in zip(self.style_layers, style_matrix) } content_dict = { name: output for name, output in zip(self.content_layers, content_outputs) } return {'style' : style_dict, 'content' : content_dict} def _calc_gram_matrix(self, input_tensors): results = [] for input_tensor in input_tensors: result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor) input_shape = tf.shape(input_tensor) num_locations = tf.cast(input_shape[1] * input_shape[2], tf.float32) results.append(result / num_locations) return results
Amazon SageMakerとは
Amazon SageMaker は、すべての開発者やデータサイエンティストが機械学習 (ML) モデルを迅速に構築、トレーニング、デプロイできるようにする完全マネージド型サービスです。SageMaker は高品質モデルの開発を容易にするため、機械学習の各プロセスから負荷の大きな部分を取り除きます。
Amazon SageMakerとは、その名の通りAWSが提供しているサービスの1つです。機械学習(特に深層学習)が必要とする高速かつ大規模な計算リソースを個人でも低コスト且つ気軽に利用することができます。
Amazon SageMakerのトレーニングジョブ環境はAWS側で管理してくれるため、EC2やECSを使用するよりも手軽にトレーニング環境を用意することがきで、かつ、コスト効率的に利用することが出来ます。(EC2やECSは仮想マシンが起動している時間で課金されるのに対し、SageMakerのトレーニング環境はトレーニングジョブが実行されている間のみ課金されます。)
Amazon SageMakerは機械学習モデルのトレーニング、チューニングに限らず、プロダクト開発者・研究者向けに様々な便利サービスを提供しています。しかし本記事ではあくまでもモデルのトレーニングとチューニング機能にのみフォーカスさせてもらいます。
実施内容
前置きが少々長くなりましたが…ここからが本題となります。nstモデルを実際にAmazon SageMakerでトレーニング、ハイパーパラメータチューニングしていきます。
環境構築
まずはSageMakerサービスの利用(クライアント)環境を、ローカルのMacBook(無印12インチ)上にDockerイメージとして構築していきます。
Amazon SageMakerでは、機械学習モデル開発に適した環境をAWS上に簡単に構築してくれるサービスも提供しています。必要なライブラリやJupyter環境がプレインストールされたノートブックインスタンスや、それに追加で更に統合開発環境的なユーティリティを備えたSageMaker Studio等です。
これらを使用する手もあるのですが、インスタンスに極力お金を掛けたくなかったのでオンプレ環境からもAmazon SageMakerのサービスを利用できるのか、今回ついでに確認したかったので、今回は使用しません。
Dockerイメージ
Dockerfile.dev# tensorflow 2.3.0をベースイメージとして使用。 # デフォルトでtensorboardも利用可能。 # 面倒だったので、GPU向けのイメージのみビルドします。 # GPU利用不可能な環境でも、特に不具合なく起動してくれるので。 FROM tensorflow/tensorflow:2.3.1-gpu USER root ENV PYTHONPATH=/app/notebook COPY ./src /app/notebook COPY ./keras /root/.keras COPY ./config /config # pipでsagemakerのSDKをインストールすることで、SageMakerサービスが利用可能になる。 RUN pip install --no-cache-dir \ matplotlib \ Pillow==7.1.1 \ boto3==1.14.44 \ sagemaker==2.16.1 \ jupyterlab # 念のためAWS CLIもインストール RUN curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" \ && unzip awscliv2.zip \ && ./aws/install \ && rm -fr awscliv2* RUN chmod +x /config/entrypoint.sh WORKDIR /app/notebook # コンテナ起動と同時にjupyterlabも立ち上がるようにエントリーポイントを作成 ENTRYPOINT ["/config/entrypoint.sh"]
docker-composeスタック
docker-compose-cpu.ymlversion: '2.4' services: notebook: image: notebook:dev # runtime: nvidia container_name: notebook hostname: notebook build: context: ./notebook dockerfile: ./dockerfile/Dockerfile.dev environment: - PYTHONPATH=/app/notebook - AWS_REGION=ap-northeast-1 volumes: - ./notebook/src:/app/notebook - ./notebook/config:/config - ./notebook/keras:/root/.keras - ~/.aws:/root/.aws # ホストマシン上のクレデンシャルを利用する ports: - "6006:6006" # tensorboard - "8888:8888" # jupyterlabあとはイメージをビルドしてコンテナを起動し、jupyterlab(
http://localhost:8888/)にアクセスすれば完了です。$ docker-compose -f docker-compose-cpu.yml build $ docker-compose -f docker-compose-cpu.yml up
CloudFormationスタック
AWS上に最低限用意する必要があるリソースは、モデルのトレーニング結果や訓練データを格納するためのS3バケットと、そのS3バケットにSageMakerがアクセスするためのIAMサービスロールのみです。
cloudformation.ymlAWSTemplateFormatVersion: 2010-09-09 Description: --- Parameters: BucketName: Description: a name for the bucket used by sagemaker Type: String Default: sagemaker-nst Resources: S3Bucket: Type: AWS::S3::Bucket Properties: BucketName: Ref: BucketName SageMakerExecRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - sagemaker.amazonaws.com Action: - sts:AssumeRole Path: / ManagedPolicyArns: - arn:aws:iam::aws:policy/AmazonSageMakerFullAccess Policies: - PolicyName: S3BucketAccessPolicy PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - "s3:GetObject" - "s3:PutObject" - "s3:DeleteObject" - "s3:ListBucket" Resource: Fn::Sub: 'arn:aws:s3:::${BucketName}' Outputs: S3Bucket4Train: Description: the s3 bucket used by sagemaker during training Value: Ref: BucketName SageMakerRole: Description: service role for sagemaker Value: Ref: SageMakerExecRole
単発のトレーニングジョブを実行
では、環境が構築できたので試しに1回、トレーニングジョブを実行してみます。
Amazon SageMakerの基本的なトレーニングジョブの流れは以下の通りです。
- ローカルのノートブック上で、モデルが定義されたトレーニングスクリプトを用意する
- ローカルのノートブック上でトレーニングの設定を定義する
- ローカルのノートブック上からトレーニングの実行をAmazon SageMakerにリクエストする
- ローカルのノートブック上から、トレーニングスクリプトをはじめとする、トレーニングに必要な資材がS3バケットにアップロードされる。
- AWS上でトレーニング環境(実態はコンテナ?)が起動し、必要なセットアップが為される。
- S3上のトレーニングスクリプトや訓練データがトレーニング環境にダウンロードされて、トレーニングスクリプトが実行される。この間トレーニングの進捗状況やスクリプト内でprintしたログはローカルのノートブック上やCloudWatchLogsに出力され続ける。
- 訓練中に生成されるデータ(TensorBoard用のログ等)や訓練が完了したモデルがトレーニング環境のファイルシステム上に出力される。
- トレーニングが完了したら、トレーニング環境のファイルシステム上に出力されたデータが、指定したS3バケットにアップロードされる。
- トレーニング環境が消滅する。
トレーニングジョブの具体例
- TrainingJob.ipynb
import json import boto3 import sagemaker from sagemaker.tensorflow import TensorFlow print("boto3 : ", boto3.__version__) print("sagemaker : ", sagemaker.__version__) # boto3 : 1.14.44 # sagemaker : 2.16.1# utilities get_s3_path = lambda *args: "s3://" + "/".join(args)# シークレット情報(アカウントID等)をノートブック上に貼りたくないので、 # ファイルに予め記載しておき、それを読み込む。 with open("./secrets.json", "r", encoding="utf-8") as fp: secrets = json.load(fp) role=secrets["RoleArn"] s3_bucket=secrets["S3Bucket"] print("S3 bucket for training : ", s3_bucket) # S3 bucket for training : sagemaker-nst# AWSとのセッションを確立する boto_session = boto3.Session(region_name="ap-northeast-1") sess = sagemaker.Session( # リージョンを東京リージョンに指定 boto_session=boto_session, # SageMkaerが使用するS3バケットを指定 default_bucket=s3_bucket, )# トレーニング設定の定義に必要なパラメータを用意 # トレーニングで使用されるデータのダウンロード元、 # トレーニングで生成されるデータのアップロード先となるS3のパスを指定 s3_train_path = get_s3_path(sess.default_bucket(), "train") # インスタンスタイプに"local"を指定すると、トレーニングジョブの実行環境のDockerイメージがpullされ、 # ローカル上でコンテナが起動しトレーニングが実行される # CPU、GPUともに安い価格帯のインスタンスを今回は使用する。 instance_types = {"CPU" : "ml.m5.large", "GPU" : "ml.g4dn.xlarge", "LOCAL" : "local"} # トレーニングスクリプトに渡したいパラメータ hyperparameters = { "EPOCH" : 50, "STEP" : 10, "MAX_IMAGE_SIZE" : 1024, "TB_BUCKET" : s3_train_path, "MAX_TRIAL" : 1, }# TensorFlowで書かれたモデルのトレーニングジョブ設定を定義 estimator = TensorFlow( # トレーニングスクリプト entry_point='train.py', # 指定したS3にSageMakerがアクセスするためのサービスロール role=role, # 起動されるインスタンス数 instance_count=1, # 起動されるインスタンスのタイプ instance_type=instance_types["GPU"], # トレーニングジョブ実行環境内で使用されるtensorflowのバージョン framework_version='2.3.0', # トレーニングジョブ実行環境内で使用されるPythonのバージョン py_version='py37', # トレーニング中のデバッグライブラリの使用を無効化。理由は後述 debugger_hook_config=False, # JSON形式で指定しtパラメータは、トレーニングジョブ実行時にコマンドライン引数としてトレーニングスクリプトに渡される。 hyperparameters=hyperparameters, # ユーザが指定したS3バケットやリージョンを使用したいので、カスタマイズしたセッション情報も渡す sagemaker_session=sess, # スポットインスタンスの使用を有効にする。nstモデルの場合、料金を約70%節約できる。 use_spot_instances=True, max_run=3600, max_wait=3600, )# トレーニングジョブを実行 # 指定したS3バケットのパスから訓練用データがトレーニングジョブ実行環境上に自動ダウンロードされる。 # デフォルト(logs="All")だとログが大量に出すぎるのでここでは抑制する。 estimator.fit( s3_train_path, job_name="TestSingleTrainingJob", logs="None", wait=False, )
- トレーニングスクリプト - train.py(一部を抜粋)
train.pydef _parse_args(): """ SageMakerは諸々のパラメータをコマンドライン引数または環境変数としてトレーニングスクリプトに渡してくるので、parseargでパラメータを取得可能。 return : Tuple(Namespace, List[str]) """ parser = argparse.ArgumentParser() # sagemakerが引数として渡してくるパラメータ parser.add_argument('--model_dir', type=str) parser.add_argument('--sm-model-dir', type=str, default=os.environ.get('SM_MODEL_DIR', "models")) parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAINING', "train")) parser.add_argument('--sm-output-dir', type=str, default=os.environ.get('SM_OUTPUT_DATA_DIR', "outputs")) parser.add_argument('--hosts', type=list, default=json.loads(os.environ.get('SM_HOSTS', "{}"))) parser.add_argument('--current-host', type=str, default=os.environ.get('SM_CURRENT_HOST', socket.gethostname())) # ユーザが設定したパラメータ。後々チューニングする予定 parser.add_argument('--CONTENT_WEIGHTS', type=float, default=10000) parser.add_argument('--STYLE_WEIGHTS', type=float, default=0.01) parser.add_argument('--TOTAL_VARIATION_WEIGHTS', type=float, default=30) parser.add_argument("--LEARNING_RATE", type=float, default=0.02) parser.add_argument("--STYLE_RESIZE_METHOD", type=str, default="original") # ユーザが設定したパラメータ parser.add_argument('--EPOCH', type=int, default=20) parser.add_argument('--STEP', type=int, default=25) parser.add_argument("--MAX_IMAGE_SIZE", type=int, default=512) parser.add_argument("--TB_BUCKET", type=str, default="") parser.add_argument("--MAX_TRIAL", type=int, default=25) return parser.parse_known_args() if __name__ =='__main__': # parse arguments args, _ = _parse_args() print(args) """ 以降、長いので省略 - 訓練データの前処理 - Tensorboardのロギングを設定 - nstを実行。 - モデルやnstされた画像の保存処理 """ returnトレーニングジョブを実行して5分ほど経過したら、AWS CLIでトレーニングジョブのステータスを確認してみます。
トレーニングジョブのステータスを確認$ aws sagemaker describe-training-job --training-job-name TestSingleTrainingJob | jq . { "TrainingJobName": "TestSingleTrainingJob", "TrainingJobArn": "arn:aws:sagemaker:ap-northeast-1:XXXXXXXXXXXX:training-job/testsingletrainingjob", "ModelArtifacts": { "S3ModelArtifacts": "s3://sagemaker-nst/TestSingleTrainingJob/output/model.tar.gz" }, "TrainingJobStatus": "Completed", "SecondaryStatus": "Completed", "HyperParameters": { "EPOCH": "50", "MAX_IMAGE_SIZE": "1024", "MAX_TRIAL": "1", "STEP": "10", "TB_BUCKET": "\"s3://sagemaker-nst/train\"", "model_dir": "\"s3://sagemaker-nst/tensorflow-training-2020-11-14-03-52-18-413/model\"", "sagemaker_container_log_level": "20", "sagemaker_job_name": "\"TestSingleTrainingJob\"", "sagemaker_program": "\"train.py\"", "sagemaker_region": "\"ap-northeast-1\"", "sagemaker_submit_directory": "\"s3://sagemaker-nst/TestSingleTrainingJob/source/sourcedir.tar.gz\"" }, ... }"TrainingJobStatus"が"Completed"と表示されいていることから、設定通りにジョブが実行され無事成功したことが確認できます。
最後に、トレーニングスクリプト内でS3に出力されたログをTensorboardで確認してみます。$ tensorboard --host 0.0.0.0 --port 6006 --logdir s3://sagemaker-nst/train/tensorflow-training-2020-11-14-03-52-18-413 2020-11-14 04:30:44.993654: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1 TensorBoard 2.3.0 at http://0.0.0.0:6006/ (Press CTRL+C to quit)
- TensorBoardでの、単発トレーニングジョブの確認結果3
無事、nstモデルのトレーニングジョッブ実行に成功しました。
余談ですが、TensorBoardのログディレクトリとしてS3バケット上のオブジェクトパスをダイレクトに指定できるということを、今回初めて知りました…。非常に便利ですね笑
トレーニングジョブ実行時に遭遇したエラーと、その回避方法
先述の具体例では、トレーニングジョブの定義時に
debugger_hook_config=False,という引数を指定しました(デフォルトではTrue)。この引数は、sagemaker-debuggerというライブラリを、Amazon SageMakerがトレーニングジョブ実行時に使用するかどうかを指定するためにあります。sagemaker-debugger自体の機能は自分も今回深掘りしていないのであまり把握していませんが、トレーニング中のモデルに発生する様々な問題(勾配消失等)を検出してくれるデバッグライブラリのようです。
私が今回使用しているnstモデルのコードでは、sagemaker-debuggerが有効になっているとトレーニング中にエラーを引き起こしてしまいます。事象再現のために使用したスクリプトimport tensorflow as tf class issueReproducer(tf.Module): def __init__(self, n_unit): """ n_unit : int """ self.variable = tf.Variable(tf.zeros((1, n_unit), dtype=tf.float32)) self.l1 = tf.keras.layers.Dense(n_unit) self.optimizer = tf.optimizers.Adam() @tf.function def fit(self, tensor): """ tensor : some tensor of shape : (1, n_unit) """ with tf.GradientTape() as tape: output = self.l1(self.variable) loss = tf.reduce_sum(output - self.variable) grad = tape.gradient(loss, self.variable) self.optimizer.apply_gradients([(grad, self.variable)]) return self.variable if __name__ == "__main__": model = issueReproducer(5) tensor = tf.constant([[1,2,3,4,5]], dtype=tf.float32) variable = model.fit(tensor) print("Returned variable : {}".format(variable))事象再現時のTracebackTraceback (most recent call last): File "issue_reproducer.py", line 34, in <module> variable = model.fit(tensor) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 780, in __call__ result = self._call(*args, **kwds) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 823, in _call self._initialize(args, kwds, add_initializers_to=initializers) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 697, in _initialize *args, **kwds)) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 2855, in _get_concrete_function_internal_garbage_collected graph_function, _, _ = self._maybe_define_function(args, kwargs) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 3213, in _maybe_define_function graph_function = self._create_graph_function(args, kwargs) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 3075, in _create_graph_function capture_by_value=self._capture_by_value), File "/usr/local/lib/python3.7/site-packages/tensorflow/python/framework/func_graph.py", line 986, in func_graph_from_py_func func_outputs = python_func(*func_args, **func_kwargs) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 600, in wrapped_fn return weak_wrapped_fn().__wrapped__(*args, **kwds) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 3735, in bound_method_wrapper return wrapped_fn(*args, **kwargs) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/framework/func_graph.py", line 973, in wrapper raise e.ag_error_metadata.to_exception(e) tensorflow.python.framework.errors_impl.OperatorNotAllowedInGraphError: in user code: issue_reproducer.py:23 fit * grad = tape.gradient(loss, self.variable) /usr/local/lib/python3.7/site-packages/smdebug/tensorflow/keras.py:956 run ** (not grads or not vars) /usr/local/lib/python3.7/site-packages/tensorflow/python/framework/ops.py:877 __bool__ self._disallow_bool_casting() /usr/local/lib/python3.7/site-packages/tensorflow/python/framework/ops.py:487 _disallow_bool_casting "using a `tf.Tensor` as a Python `bool`") /usr/local/lib/python3.7/site-packages/tensorflow/python/framework/ops.py:474 _disallow_when_autograph_enabled " indicate you are trying to use an unsupported feature.".format(task)) OperatorNotAllowedInGraphError: using a `tf.Tensor` as a Python `bool` is not allowed: AutoGraph did convert this function. This might indicate you are trying to use an unsupported feature.sagemaker-debuggerのドキュメントを確認すると、以下のような記載がありました。TensorFlowの一部の部品にはまだ対応しておらず、トレーニングスクリプトのコードを変更することなく利用できる範囲はまだ限られているようです。
* Debugger with zero script change is partially available for these TensorFlow versions. The inputs, outputs, gradients, and layers built-in collections are currently not available for these TensorFlow versions.
2020年11月27日時点のAmazon SageMaker DebuggerのDeveloper Guideより
Tracebackを確認してみると、確かに"not available"の例として挙げられている
grad = tape.gradient(loss, self.variable)の部分でエラーになっていますね。本エラーの回避方法としてひとまず有効だったのが、前述したとおりトレーニングジョブの定義時に
debugger_hook_config=Falseを指定してsagemaker-debugger自体を無効化することでした。
スクリプトの書き方を工夫すればsagemaker-debuggerがONのままでも大丈夫なのか分かりませんが、いったん以降はOFFにしたままで進めていきます。
ハイパーパラメータチューニングを実行
単発のトレーニングジョブが無事(?)成功したので、次は本題となるハイパーパラメータチューニングを実践してみます。
前述したトレーニングジョブの手順に幾つかの設定を追加するだけで、ハイパーパラメータチューニングを実施できます。
- ローカルのノートブック上でトレーニングスクリプトを用意する。
- ローカルのノートブック上でトレーニングの設定を定義する。
- ローカルのノートブック上でハイパーパラメータチューニングの設定を定義する。
- ローカルのノートブック上から、Amazon SageMakerに対してハイパーパラメータチューニングの実行をリクエストする。
- 設定したハイパーパラメータの組み合わせごとに、指定した回数だけトレーニングジョブが実行される。
- 各トレーニングジョブからCloudWatchLogsに出力される目標メトリクスの値を集計・比較する。
- 実行されたトレーニングのうち、最善の性能を発揮したハイパーパラメータの値の組み合わせが確認できる。
ハイパーパラメータチューニングの具体例
- HyperParameterTuning.ipynb
import boto3 import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner import json print("boto3 : ", boto3.__version__) print("sagemaker : ", sagemaker.__version__) # トレーニングジョブの設定定義 # この処理は単発のトレーニングジョブ実行時と同様なので省略 ... estimator = TensorFlow( ... )# チューニングするパラメータと、取り得るパラメータの範囲を定義 # 今回はloss値の計算に使用される3種類のパラメータと、 # Adamオプティマイザの学習率をチューニング対象にします。 hyperparameter_ranges = { "CONTENT_WEIGHTS" : ContinuousParameter( min_value=5000, max_value=15000, ), "STYLE_WEIGHTS" : ContinuousParameter( min_value=0.001, max_value=0.1, ), "TOTAL_VARIATION_WEIGHTS" : ContinuousParameter( min_value=10, max_value=50, ), "LEARNING_RATE" : ContinuousParameter( min_value=0.01, max_value=0.1, ), }# モデルの性能を比較するための目標メトリクスを定義 # loss値が最小になるハイパーパラメータの組み合わせを今回は探ってみる objective_metric_name = 'loss' objective_type = 'Minimize' metric_definitions = [ { 'Name': 'loss', # トレーニングスクリプト内でprint()標準出力された # メッセージはCloudWatchLogsにログ出力される。 # そのメッセージのうち、"FinalMeanLoss=([0-9\\.]+)"のパターンに合致する # 数値を目標メトリクスとして収集し、トレーニングジョブ間で比較する。 'Regex': 'FinalMeanLoss=([0-9\\.]+)', } ]# ハイパーパラメータチューニングジョブ設定を定義 tuner = HyperparameterTuner( # トレーニングジョブの定義 estimator=estimator, # チューニング対象のハイパーパラメータ hyperparameter_ranges=hyperparameter_ranges, # 目標メトリクスの定義(今回はloss値を最小にする) objective_type=objective_type, objective_metric_name=objective_metric_name, metric_definitions=metric_definitions, # トータルで実行されるトレーニングジョブの上限数 max_jobs=30, # 並列実行されるジョブの上限 # ml.g4dn.xlargeインスタンスの同時起動可能上限数は2 max_parallel_jobs=2, )# ハイパーパラメータチューニングの実行 tuner.fit(s3_train_loc, wait=False)
- トレーニングスクリプト - train.py(一部を抜粋)
train.pydef _parse_args(): parser = argparse.ArgumentParser() # sagemakerが引数として渡してくるパラメータ ... # 今回チューニングされるパラメータ # ハイパーパラメータチューニング時も、実際の値はコマンドライン引数として # トレーニングスクリプトに渡されるので、スクリプト内の処理を改修する必要無し。 parser.add_argument('--CONTENT_WEIGHTS', type=float, default=10000) parser.add_argument('--STYLE_WEIGHTS', type=float, default=0.01) parser.add_argument('--TOTAL_VARIATION_WEIGHTS', type=float, default=30) parser.add_argument("--LEARNING_RATE", type=float, default=0.02) parser.add_argument("--STYLE_RESIZE_METHOD", type=str, default="original") ... return parser.parse_known_args() if __name__ =='__main__': # parse arguments args, _ = _parse_args() print(args) ... print("FinalMeanLoss={}".format(loss_list.mean()))チューニングジョブが完了したら、AWS CLIでチューニングの結果を確認してみます。
$ aws sagemaker describe-hyper-parameter-tuning-job --hyper-parameter-tuning-job-name tensorflow-training-201118-1130 | jq . { ... "BestTrainingJob": { "TrainingJobName": "tensorflow-training-201118-1130-027-6b526460", "TrainingJobArn": "arn:aws:sagemaker:ap-northeast-1:XXXXXXXXXXXX:training-job/tensorflow-training-201118-1130-027-6b526460", "CreationTime": "2020-11-19T02:07:22+09:00", "TrainingStartTime": "2020-11-19T02:10:33+09:00", "TrainingEndTime": "2020-11-19T02:34:11+09:00", "TrainingJobStatus": "Completed", "TunedHyperParameters": { "CONTENT_WEIGHTS": "5277.5099011496795", "LEARNING_RATE": "0.03725186282831269", "STYLE_WEIGHTS": "0.0012957731765036497", "TOTAL_VARIATION_WEIGHTS": "10.0" }, "FinalHyperParameterTuningJobObjectiveMetric": { "MetricName": "loss", "Value": 2388418.5 }, "ObjectiveStatus": "Succeeded" } }コード上からも直接、最善のハイパーパラメータの組み合わせを取得してみましょう。
HyperParameterTuning.ipynbの続き# 最善の結果を出したモデルの、ハイパーパラメータの組み合わせを確認する。 from IPython.display import display best_hyperparameters = tuner.best_estimator().hyperparameters() display(best_hyperparameters) # 2020-11-18 17:34:11 Starting - Preparing the instances for training # 2020-11-18 17:34:11 Downloading - Downloading input data # 2020-11-18 17:34:11 Training - Training image download completed. Training in progress. # 2020-11-18 17:34:11 Uploading - Uploading generated training model # 2020-11-18 17:34:11 Completed - Training job completed # {'CONTENT_WEIGHTS': '5277.5099011496795', # 'EPOCH': '50', # 'LEARNING_RATE': '0.03725186282831269', # 'MAX_IMAGE_SIZE': '1024', # 'MAX_TRIAL': '9', # 'STEP': '10', # 'STYLE_WEIGHTS': '0.0012957731765036497', # 'TB_BUCKET': '"s3://sagemaker-nst/train"', # 'TOTAL_VARIATION_WEIGHTS': '10.0', # '_tuning_objective_metric': '"loss"', # 'sagemaker_container_log_level': '20', # 'sagemaker_estimator_class_name': '"TensorFlow"', # 'sagemaker_estimator_module': '"sagemaker.tensorflow.estimator"', # 'sagemaker_job_name': '"tensorflow-training-2020-11-18-11-30-35-845"', # 'sagemaker_program': '"train.py"', # 'sagemaker_region': '"ap-northeast-1"', # 'sagemaker_submit_directory': '"s3://sagemaker-nst/tensorflow-training-2020-11-18-11-30-35-845/source/sourcedir.tar.gz"', # 'model_dir': '"s3://sagemaker-nst/tensorflow-training-2020-11-18-11-26-25-821/model"'}ハイパーパラメータチューニングジョブについても、nstモデルを対象に実施できることが確認出来ました。
因みに今回のハイパーパラメータチューニングジョブ内で、GPU利用可能なインスタンスタイプ(ml.g4dn.xlarge : 0.994USD/h)で合計30トレーニング(2並列)のトレーニングジョブが実行されたわけですが、その課金額はざっと以下の通りです。
※スポットインスタンスの使用を有効化しているため、課金額は(課金対象時間(実際にトレーニングが実行されている時間) * インスタンスの時間単価)で計算されます。今回使用しているnstモデルとデータ量であれば、60~70%程度節約されています。
※今回は2並列で実行したので、体感の経過時間は総実行時間 / 2です。
総実行時間 課金対象トレーニング時間 割引率 課金額 12時間8分 4時間16分 65% $4.24(約440円) Amazon SageMakerを題材に勉強してみようと思い立った時は、文字通りの学習コストが最終的に幾ら位になるのかとビクビクしておりましたが、ス○バのカフェモカ一杯程度の金額に収まってくれて今はホッとしています笑。
チューニング結果を比較
ハイパーパラメータチューニンングが無事成功したので、それぞれのモデルのloss値や実際に生成された画像を比較してみたいと思います。
最善、最悪、デフォルトのハイパーパラメータの組み合わせと、その際のlossは以下の通りです。
なお、ここでの「デフォルト」とはTensorflowのサンプルコードに記載されていた設定値のことを指します。
PATTERN LOSS CONTENT_WEIGHT STYLE_WEIGHT TOTAL_VARIATION_WEIGHT LEARNING_RATE 最悪 20,893,880 5119.428 0.0752 12.171 0.078 デフォルト 10,061,276 10000 0.01 30 0.02 最善 2,388,418.5 5277.509 0.001 10 0.037 最善の結果はデフォルトのそれと比較しても4分の1以下、最悪のそれに対しては9分の1程もloss値が小さい結果となりました。
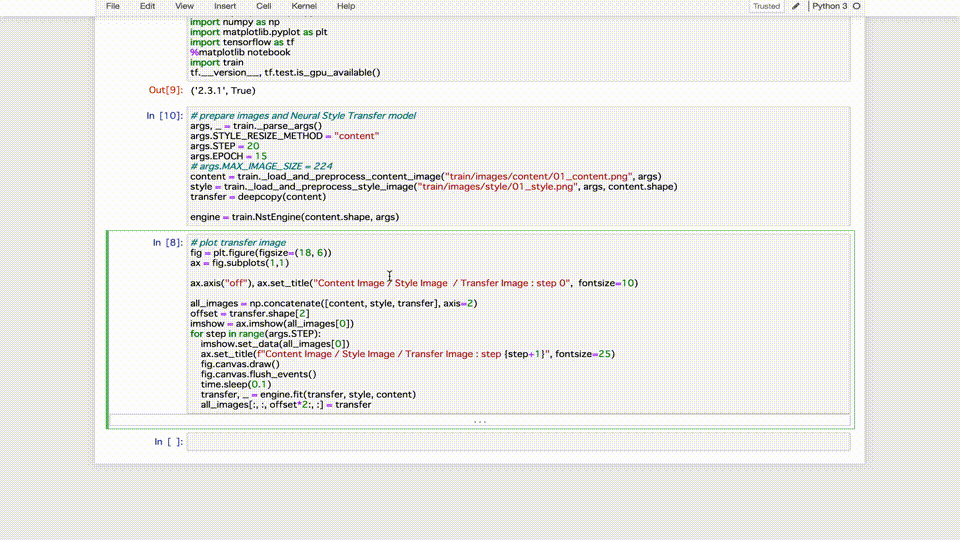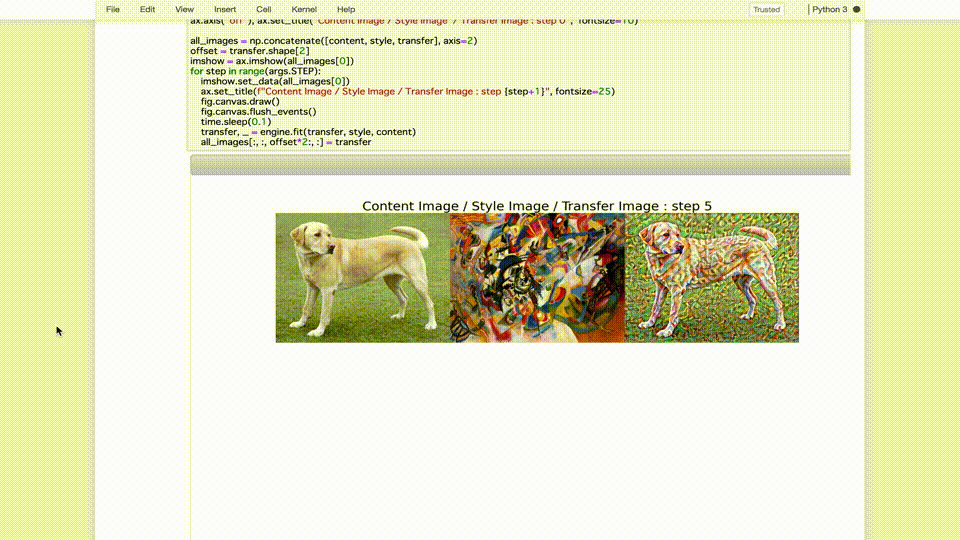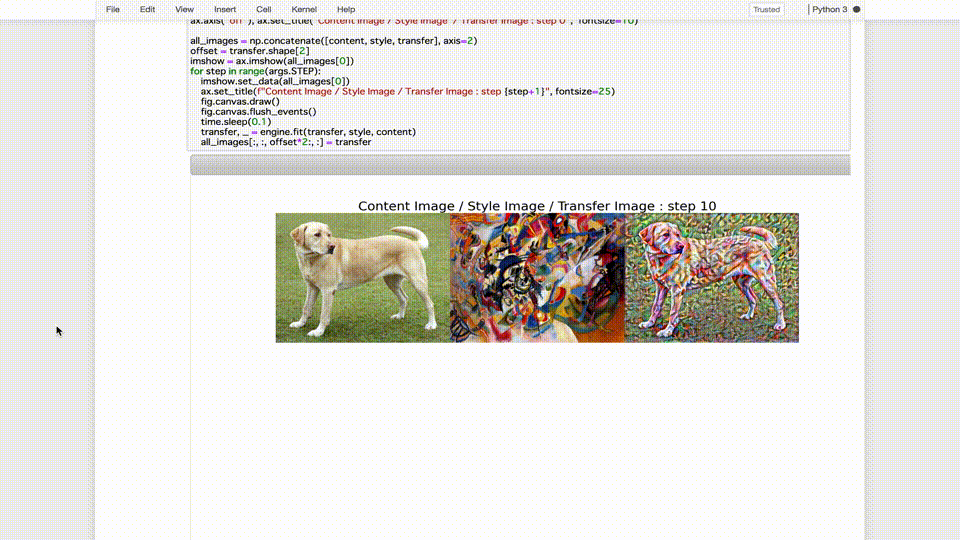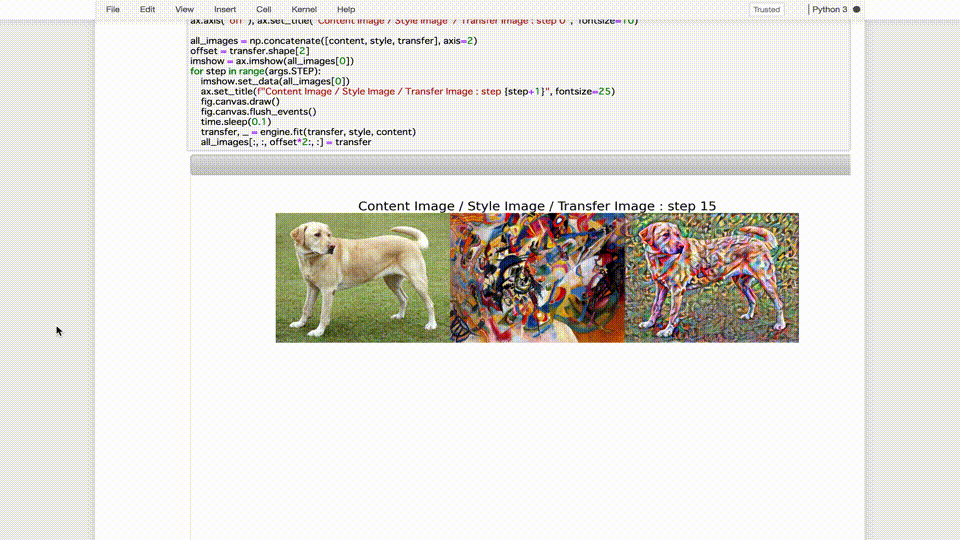
では、それぞれのトレーニングジョブで生成した9種類の画像をそれぞれ比較してみます。
※左から順に、「コンテンツ画像」、「スタイル画像」、「最悪のモデルの生成画像」、「デフォルトのモデルの生成画像」、「最善のモデルの生成画像」
最悪のモデルが生成した画像は論外として、デフォルトのモデルが生成した画像と比較しても、最善のモデルが生成した画像はスタイル画像の画風をしっかり反映しつつ、元の輪郭がよりハッキリと残っているように見えます。(少なくとも個人的には…)
最後に、モデルの汎化性能(めいたもの)も確認しておく意味で、新しい画像セットを対象に最良のモデルでnstを実施してみます。
- 検証画像セットに対するnst実行結果4
良い感じにの画像が生成できている気がします(自己暗示)!
nstモデルに対するハイパーパラメータチューニングの効果があったと言えるのではないでしょうか!
おわりに
以上で、Amazon SageMakerを使用したnstモデルのハイパーパラメータチューニングの挑戦は終了となります。
見切り発車的に思い切って初立候補した今回のアドベントカレンダーでしたが、何とか形になってホッとしております…。
今まで使用経験が全く無かったAWSサービスの一つ(Amazon SageMaker)を集中的に学べたのは大変有意義でしたし、ハイパーパラメータチューニングの結果として、nstモデルが実際に生成する画像の質の改善を確認できたのは、正直自分でも驚きでした笑。最後に。この記事で私が整理した図表、記載したコード、報告したエラーのいずれかが、少しでも誰かの役に立ってくれたり、刺激になってくれたりしたら大変嬉しいです。
みなさま。よいクリスマスを。NTTテクノクロス Advent Calendar 2020、明日は@geek_duckさんです。お楽しみに!
Appendix
- 今回使用したコード類一式
使用した画像:注釈欄に記載
- By derivative work: Djmirko (talk)wereweweewewewg.jpg - YellowLabradorLooking.jpg, CC BY-SA 3.0, Link
- By Wassily Kandinsky, Public Domain, Link
- By Vincent van Gogh - bgEuwDxel93-Pg at Google Cultural Institute, zoom level maximum, Public Domain, Link
- By Wassily Kandinsky, Public Domain, Link
- Image by Pete Linforth from Pixabay
- By After Katsushika Hokusai - Restored version of File:Great Wave off Kanagawa.jpg (rotated and cropped, dirt, stains, and smudges removed. Creases corrected. Histogram adjusted and color balanced.), Public Domain, Link
- By Johannes Vermeer - Copied from Mauritshuis website, resampled and uploaded by Crisco 1492 (talk · contribs), October 2014[4], Public Domain, Link
- Image by Sa Ka from Pixabay
- Image by muratkalenderoglu from Pixabay
- By Vincent van Gogh - bgEuwDxel93-Pg at Google Cultural Institute, zoom level maximum, Public Domain, Link
- Image by Gerd Altmann from Pixabay
- Image by マクフライ 腰抜け from Pixabay
- Image by falco from Pixabay
- Image by Free-Photos from Pixabay
- Image by ExposureToday from Pixabay
- Image by Aneta Foubíková from Pixabay






- 投稿日:2020-11-30T09:44:46+09:00
どうにかしてTorchVisionのPre-TrainedをTensorFlowで使いたい
どうにかしてTorchVisionのPre-TrainedをTensorFlowで使いたい
はじめに
この記事は、NTTテクノクロス Advent Calendar 2020 の24日目です?
メリークリスマス!NTTテクノクロスの広瀬です?
普段の業務では高精細VR配信エンジン1や機械学習による画像認識AIエンジンの研究開発に取り組んでいます。
その他にも、社内で取り組まれているAI関連開発で起きた「ちょっと困った」をサポートする活動をしています。さて、今回はTorchVisionにあってTensorFlowにはないVGG-11やらResNet-18をTensorFlowで使うためにはどうしたらいいんだ?と疑問が湧いたので、使える方法はないか考えてみました。
概要
数年前と比べるとエッジデバイス向けのモデル等の研究が進んでおり、IoTと機械学習の親和性も高まってきました。
GitHubに公開されているソースも軽量なモデルを使用しているものも多いのですが、Servingの便利さから普段使いのフレームワークにTensorFlowを選択しているとここで問題が発生します。
TensorFlowにはResNet18や34が無いのです❗TorchVisionが羨ましい
ただ変換するだけならツール2を使う手もあるのですが、業務では最先端の研究結果を検証も行う為、ONNX経由による制約3を受けてしまいます。
そこで今回は、力技でのパラメータ移植にチャレンジしていこうと思います戦略
レイヤーが保持するパラメータは大きく2つ。重みとバイアスです。
この重みとバイアスは一体何なんだというと、要は行列とベクトルで表されるパラメータでしか無いわけです。
下の式で言うところのwとbですね。z = \sum_{i=0}^n w_ix_i+b_i↓こんなイメージです。このwとbを表す行列が取り出せれば上手くいくのではないでしょうか。
早速試してみる
1. Pytorchのレイヤーから行列を取り出す
まずは、Pytorchのレイヤーから重みとバイアスを行列として取り出してみましょう。
今回始めてPytorchに触りますが、TensorFlow(keras)でいうところのget_weightsの様な関数が用意されていれば完璧です。https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
.weightと.biasで取り出せそうです。
出力されるtorchのTensor型を調べると.numpy()でndarrayが取り出せると書いてあったのでやってみましょう。torch_conv2d = torch.nn.Conv2d(in_channels=5, out_channels=64, kernel_size=3) print(torch_conv2d.weight.numpy()) > "RuntimeError: Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead."一発じゃうまくいきません……。detachしてくれとのことなのでしてみましょう。
print(torch_conv2d.weight.detach().numpy().shape) > (64, 5, 3, 3)上手にできました。
初めてPytorchAPIリファレンスを見てみましたが、数学的な解説がしっかり載っていて凄いですね。
ディープラーニングを理論で理解するための教科書になりそうです。2. TensorFlowのレイヤーに行列を突っ込む
続いて、TensorFlowのレイヤーに行列を突っ込めるか確認です。
こちらはset_weights関数があるので、何を入れればよいか分かればOKです。
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Layer#set_weightsapitf.keras.layers.Layer.set_weights(weights)Argumentsweights a list of Numpy arrays. The number of arrays and their shape must match number of the dimensions of the weights of the layer (i.e. it should match the output of get_weights).APIリファレンスをチェックするとNumpy配列でいいようですね。
get_weights関数の出力と一致する必要があるようなので、get_weights関数を叩いてみましょう。inputs = tf.keras.Input(shape=(28, 28, 5),) tf_conv2d = tf.keras.layers.Conv2D(filters=64, kernel_size=3)(inputs) model = tf.keras.Model(inputs=inputs, outputs=tf_conv2d) print(model.layers[1].get_weights()) >[array([[[[-1.39296055e-02, -2.36416906e-02, -4.50647622e-03, 省略, > dtype=float32), array([0., 0.,省略 dtype=float32)] print(model.layers[1].get_weights()[0].shape) > (3, 3, 5, 64) print(model.layers[1].get_weights()[1].shape) > (64,)サイズが2のリスト、要素はそれぞれnumpy配列で、weightsとbiasの順番で入力されることが期待されていることがわかりました。
2.1 channel lastとchannel first
どうやら、PytorchとTensorFlowでは重みを表す行列の並びが違うようです。
Pytorchは(64, 5, 3, 3)、TensorFlowでは(3, 3, 5, 64)でしたので、TensorFlowに合わせて変換してあげましょう。lastとfirstの違いはhttps://keras.io/ja/backend/ に↓の様に解説されています。
"channels_last" は (rows, cols, channels) とみなし,"channels_first" は (channels, rows, cols)とみなします.
torch_np = torch_conv2d.weight.detach().numpy() print(torch_np.transpose((2, 3, 1, 0)).shape) > (3, 3, 5, 64)3. パラメータをコピーして推論結果を確認
3.1 まずは全層結合層だけのモデル
なんとなく行けそうな感触をつかめたので、早速試してみましょう。
TensorFlowモデルの各レイヤーが持っているset_weights関数に、Pytrochから取り出した行列を流し込んでいきます。
Pytorchにはstate_dict関数というものがあるようなので使ってみましょう。
用意したモデルは全層結合層2層だけのモデルなので簡単です。torch_model = TorchSimpleNet() tf_model = TFSimpleNet() tf_model.layers[1].set_weights( [ torch_model .state_dict()["fc1.weight"].numpy().transpose((1, 0)), torch_model .state_dict()["fc1.bias"].numpy() ]) tf_model.layers[2].set_weights( [ torch_model .state_dict()["fc2.weight"].numpy().transpose((1, 0)), torch_model .state_dict()["fc2.bias"].numpy() ])3.2 全層結合モデルで出力確認
2モデル間の出力から、要素ごとの差の最大を取って確認していきます。
非常に小さい誤差となったので、狙い通りの結果になっているようですね。#tfの出力 tf_output = tf_model.predict(image) # eval関数を使用後torchのTensorに変換して入力 torch_model.eval() torch_output = torch_model(img_torch) # 出力ベクトルの差の最大を取得 print(np.max(np.abs(tf_output - torch_output.detach().numpy()))) > 2.9802322e-08 # コピーしない場合の出力 > 0.233956753.3 畳み込み層を追加
続いて畳み込み層を追加しています。よくあるMNISTですね。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 28, 28, 1)] 0 _________________________________________________________________ conv2d (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________ conv2d_1 (Conv2D) (None, 24, 24, 64) 18496 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 12, 12, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 9216) 0 _________________________________________________________________ dense (Dense) (None, 128) 1179776 _________________________________________________________________ dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 1,199,882 Trainable params: 1,199,882 Non-trainable params: 0 _________________________________________________________________ collected 1 itemパラメータのコピーも手順は変わりません。
Transposeで与える次元数が増えるので、それに合わせて増えている程度の変化ですね。
さぁ、早速動かしましょう❗tf_model.layers[1].set_weights( [ torch_model .state_dict()["conv1.weight"].numpy().transpose((2, 3, 0, 1)), torch_model .state_dict()["conv1.bias"].numpy() ])3.4 畳み込み層を追加して動作確認
確認手順は変わりません。最終出力の要素ごとの差の最大を取っていきます。
print(np.max(np.abs(tf_output - torch_output))) # 出力 > 0.6776662おや???????
結果が一致しません……。
いったい何が起きているんでしょう?4. なぜうまくいかない?
全層結合モデルの結果は、すでに実験によってほぼ等しいことが分かっています。
では、畳み込み層だけのNWの場合はどうでしょう。確認してみます。4.1 畳み込み層だけのNWの出力は?
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 28, 28, 1)] 0 _________________________________________________________________ conv2d (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________ conv2d_1 (Conv2D) (None, 24, 24, 64) 18496 ================================================================= Total params: 18,816 Trainable params: 18,816 Non-trainable params: 0channel-firstとlastで結果と比較するために、出力をTransposeしています。
出力は畳み込み層にも問題はなさそうですね。tf_output = tf_model.predict(inp_keras) torch_output = np.transpose(model(inp_pyt).data.numpy(), (0, 2, 3, 1)) print(np.max(np.abs(tf_output - torch_output))) > 4.5776367e-054.2 何がいけなかったのか
結論としては畳み込み層のあとにFlattenレイヤーを置いたことが原因でした。
Pytorchで学習した結果を流し込んでいるので、全層結合層が期待する特徴量はNCHWの並びを1次元化したものを期待しています。
それに対してTensorFlowはNHWCの並びで一次元化するので、期待する並びと変わってしまい識別がうまくいかなくなっていたようです。
確認のために1層だけの畳み込み層のあとにFlattenをおいて出力してみましたが、先頭は同じですが後ろの並びが一致していません。
# TensorFlowの出力 > 8.3867350e+00 -1.5191419e+01 2.6989546e+01 ... # Pytorchの出力(TFでもこうなってほしい) > 8.3867, 8.4628, 8.5389 ...畳み込み層を挿入しないでFlattenを入れた場合は問題なし。
畳み込み層のパラメータをNCWHのものに置き換えたことで、Flattenの結果が意図しないものとなっていると推測できます。# TensorFlowの出力 [[ 0. 1. 2. 3. 4. 5. ... # Pytorchの出力 [[ 0. 1. 2. 3. 4. 5. ...4.3 解決策
いろいろ試してみた結果、Convの後Flattenする前に順番を入れ替えてあげることで解決しました。
先程に比べて誤差も小さくなっているので、成功したようですね。x = tf.keras.layers.Conv2D(64, 3, activation="relu")(x) x = tf.keras.layers.MaxPool2D(2)(x) # Flattenの前に入れ替えている x = tf.keras.layers.Flatten()(tf.keras.layers.Permute((3,1,2))(x)) x = tf.keras.layers.Dense(128, activation="relu")(x) print(np.max(np.abs(tf_output - torch_output))) > 1.1920929e-075. VGGで動作確認
では、TensorFlowで実装したVGG11にTorochVisionのパラメータを流し込んで推論してみましょう。
テスト画像は我が家の同居人です?Model: "functional_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 224, 224, 3)] 0 _________________________________________________________________ conv2d (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 56, 56, 128) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ conv2d_3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 28, 28, 256) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ conv2d_5 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 14, 14, 512) 0 _________________________________________________________________ conv2d_6 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv2d_7 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ max_pooling2d_4 (MaxPooling2 (None, 7, 7, 512) 0 _________________________________________________________________ permute (Permute) (None, 512, 7, 7) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ dense (Dense) (None, 4096) 102764544 _________________________________________________________________ dense_1 (Dense) (None, 4096) 16781312 _________________________________________________________________ dense_2 (Dense) (None, 1000) 4097000 ================================================================= Total params: 132,863,336 Trainable params: 132,863,336 Non-trainable params: 0
デフォルトパラメータ パラメータコピー後 ハンミョウ(Tiger Beetle)からノウサギ(Hare)になっているので、正解ですね。
ハンミョウってなんとかの森でしか見たこと無いんですが、ImageNetの1000カテゴリに採用されているんですね……。さて、これで問題なく重みのコピーが出来ましたし、TensorFlow版のモデルのソースも手元にあるので遊び放題ですね。
あとはCheckPointでもSavedModelでもHDF5でも好きなように保存することが出来るでしょう。完成
さて、長くなりましたが完成です。
フレームワーク間の仕様の違いで少しハマりましたが、なんとか最初のイメージ通り行列を取り出してフレームワーク間のやり取りができそうなことがつかめました。
もう少しフレームワークの完成度が高まってきて、こういった事も容易にできるようになればなと期待します。ここまで動作確認してきたソースコードを公開していますので、お手元でも試してみてください。
参考ソースではPoetryを使って環境を提供していますので、興味を持った方は別記事も参照いただければと思います。おわりに
ネットで調べてもツールを使ったやり方ばかりが引っかかって出来るのか半信半疑だったんですが、やってみたらそこそこ簡単にできました。
ディープラーニングはブラックボックスというワードが独り歩きしてしまい、とっつくにくいイメージを持たれている方も多いと思いますが、既存のモデルに対して手を加える程度であればそんなに難易度が高いものではなさそうだと感じて頂けたでしょうか。TensorFlow0.xxの頃から比べると格段にフレームワークも使いやすくなってます。
Gitからcloneしてサンプルを動かしたりファインチューニングしてみるだけではなく、もう一歩進んだ改良を加えるのもそんなに難しくないので、是非チャレンジしてみてください。さて、いよいよ明日が最終日です!昨年の記事もとても勉強になったので、今年も期待したいと思います。
それでは、締めの記事となるNTTテクノクロス アドベントカレンダー 2020 25日目をお楽しみください。
普段は高精細VR配信エンジンや、深層学習を使った映像/画像処理エンジンの開発をしています。 ↩
Torchからonnxに変換して、onnxからtfにというのは王道パターン。流れをまとめたpytorch2kerasなんてものも。 ↩
↓は私が感じている制約なので、解決策はあるかもしれません。
- 変換後のモデルをガチャガチャ動かしたい時にソースがないので不自由を感じてしまう
- NCHW→NHWC変換の関係でTransposeレイヤーが至るところに挟まってパフォーマンスが下がる ↩





