- 投稿日:2020-11-30T23:53:06+09:00
AWS日記20 (Amazon ElastiCache)
はじめに
今回は Amazon ElastiCache を試します。
サポートされているエンジンのMemcached ( Amazon ElastiCache for Memcached ) を試します。
Lambda関数・SAMテンプレート準備
[Amazon ElastiCacheの資料]
Amazon ElastiCacheAWS SAM テンプレート作成
AWS SAM テンプレートで API-Gateway , Lambda, DynamoDB, Amazon Elasticsearch Serviceの設定をします。
[参考資料]
AWS SAM テンプレートを作成するAmazon ElastiCacheの設定は以下の部分
ElastiCacheSecurityGroup: Type: 'AWS::EC2::SecurityGroup' Properties: GroupDescription: Elasticache Security Group ElastiCacheCacheCluster: Type: AWS::ElastiCache::CacheCluster Properties: AutoMinorVersionUpgrade: 'true' AZMode: single-az CacheNodeType: cache.t2.micro Engine: memcached NumCacheNodes: '1' VpcSecurityGroupIds: - !GetAtt ElastiCacheSecurityGroup.GroupIdLambda関数作成
※ Lambda関数は aws-lambda-go を利用しました。Memcacheパッケージは bradfitz/gomemcache を利用しました。
memcache に値を入れるには gomemcacheの Set を使う
func setItem(key string, value string) { if memcacheClient == nil { memcacheClient = getMemcacheClient() } memcacheClient.Set(&memcache.Item{Key: itemKey, Value: []byte(value)}) return }memcache から値を取得するには gomemcacheの Get を使う
func getItem(key string)(string, error) { if memcacheClient == nil { memcacheClient = getMemcacheClient() } it, err := memcacheClient.Get(key) if err != nil { return "", err } return string(it.Value), nil }終わりに
Redis( Amazon ElastiCache for Redis ) もサポートされているため、今後試していこうと思います。
参考資料
- 投稿日:2020-11-30T23:53:06+09:00
AWS日記21 (Amazon ElastiCache)
はじめに
今回は Amazon ElastiCache を試します。
サポートされているエンジンのMemcached ( Amazon ElastiCache for Memcached ) を試します。
Lambda関数・SAMテンプレート準備
[Amazon ElastiCacheの資料]
Amazon ElastiCacheAWS SAM テンプレート作成
AWS SAM テンプレートで API-Gateway , Lambda, Amazon ElastiCache の設定をします。
[参考資料]
AWS SAM テンプレートを作成するAmazon ElastiCacheの設定は以下の部分
ElastiCacheSecurityGroup: Type: 'AWS::EC2::SecurityGroup' Properties: GroupDescription: 'Elasticache Security Group' SecurityGroupIngress: - IpProtocol: tcp FromPort: '11211' ToPort: '11211' CidrIp: '0.0.0.0/0' ElastiCacheCacheCluster: Type: AWS::ElastiCache::CacheCluster Properties: AutoMinorVersionUpgrade: 'true' AZMode: single-az CacheNodeType: cache.t2.micro Engine: memcached NumCacheNodes: '1' VpcSecurityGroupIds: - !GetAtt ElastiCacheSecurityGroup.GroupIdLambda関数作成
※ Lambda関数は aws-lambda-go を利用しました。Memcacheパッケージは bradfitz/gomemcache を利用しました。
memcache に値を入れるには gomemcacheの Set を使う
func setItem(key string, value string) { if memcacheClient == nil { memcacheClient = getMemcacheClient() } memcacheClient.Set(&memcache.Item{Key: itemKey, Value: []byte(value)}) return }memcache から値を取得するには gomemcacheの Get を使う
func getItem(key string)(string, error) { if memcacheClient == nil { memcacheClient = getMemcacheClient() } it, err := memcacheClient.Get(key) if err != nil { return "", err } return string(it.Value), nil }終わりに
Redis( Amazon ElastiCache for Redis ) もサポートされているため、今後試していこうと思います。
- 投稿日:2020-11-30T23:33:47+09:00
KeycloakのToken Exchangeを活用した一時的なAWSアクセスキーの発行
NRI OpenStandia Advent Calendar 2020の3日目は、2日目の続きとしてKeycloakのToken Exchangeを活用した話を紹介します。具体的には、AWSのCLIツールなどの利用で必要なAWSアクセスキーの発行をToken Exchange経由で行うというものです。
やりたいこと
皆さんAWSアクセスキーの管理はどのようにされているでしょうか?誤ってGitリポジトリにコミットしちゃって漏洩し、たくさんEC2インスタンスを起動されて高額請求されちゃう、なんていう事故をたまに聞きますよね。ベストプラクティスとしてそもそも発行しない (EC2インスタンスロールなど、IAMロールで制御する)という考え方がありますが、ローカルPCなどから作業したい場合はどうしても発行が必要になります。そのような場合は、有効期限付きの一時的なAWSアクセスキーを使うと漏洩したときのリスクを減らすことができます。
一時的なAWSアクセスキーの発行
いくつかやり方があります。
AWS SSOを使う
AWS SSOを使って認証を一元化しているのであれば、AWS SSOの画面から一時的なAWSアクセスキーを発行して取得することができます。詳しくは、https://dev.classmethod.jp/articles/aws-sso-temporary-credential/ などで紹介されています。
また、AWS CLI バージョン2からはCLIからもAWS SSOを利用して発行することができます。
(AWS SSOを使っている人には本記事はまったく役に立ちません...)
サードパーティ製ツールを使う
企業によっては諸事情によりAWS SSOを使わず、AWS管理コンソールへのログインを、KeycloakやADFS、Azure AD、Oktaなどの外部IdPと直接SAMLで連携させている場合があります。この場合は、例えば https://github.com/Versent/saml2aws のようなツールを使うとコマンドラインで一時的なAWSアクセスキーを取得可能になります。ただし saml2aws の実装はスクレイピング方式であり、各IdPのログイン画面に対してログイン処理をエミュレートする形になっています。https://github.com/Versent/saml2aws/blob/3968f0fa20fb71b2e78e1364bce68acc3f4b201a/pkg/provider/keycloak/keycloak.go#L76 あたりを見ると、Keycloakのログイン画面をパースしてログインしていることがわかります。
この方式ですと、ログイン画面のHTMLや認証シーケンスに強く依存しますので、バージョンアップで動かなくなったり、認証フローをカスタマイズしていると対応できなかったりします。また、パスワードをサードパーティ製ツールに渡すというところで懸念があります。理想的にはOpenID Connectなどのフェデレーションを利用して、スクレイピングなしで安全に行いたいところです。
というわけで作ってみた
(随分前ですが) https://github.com/openstandia/aws-cli-oidc というツールを勉強も兼ねて作ってみました。クライアントPCで動作するCLIのネイティブアプリケーションですので、RFC8252 OAuth 2.0 for Native Appsを参考にしつつ実装しています。CLIツールを起動するとブラウザが起動し、OpenID Provider(今回だとKeycloak)で認証が行われます。 ブラウザを使ってKeycloakに認証しているので、パスワードなどのクレデンシャルがCLIツールに流れることありません。 認証後、CLIツールは認可コードフローを経てIDトークンを受け取ります。このIDトークンをAWS STSに渡すことで一時的なアクセスキーを発行することができます(事前に、KeycloakとAWSアカウントとの間でOpenID Connectによるフェデレーション設定が必要です)。
なお、お気づきかもしれませんが、この方式だとToken Exchangeは出てきません(AWS STSがAWS側の独自実装のToken Exchangeではありますが)。
この方式を利用するにはAWS STSがIDトークンの検証を行うために、Keycloakに対して公開鍵を取得するためにHTTPSアクセスが必要になります(図中の番号9の箇所)。よって、Keycloakを社内に立てている場合はネットワーク制約のため実現は難しいでしょう。インターネット上にあるOpenID Provider(Googleやその他IDaaS、パブリッククラウド上にKeycloakを立てているなど)であればこの方式を使うことができますが、社内ネットワーク内にある場合は残念ながら使えません。
そこでSAML2とToken Exchangeを使う
そこで https://github.com/openstandia/aws-cli-oidc では、SAML2とToken Exchangeを使った方式も実装しています。事前に、社内にあるKeycloakとAWSをSAML2でフェデレーション設定をしておきます。SAML2の場合は、フェデレーション設定時にKeycloakの公開鍵を設定する方式になっているため、AWS STSからKeycloakに対して通信が行われることはありません。よって社内ネットワークに配置しても使うことができます。
問題は、CLIツールからKeycloakで認証した後にどうやってAWS STSに渡すSAMLResponseを取得するかです。CLIツールとKeycloakの間はOpenID Connectでフェデレーションしているだけであり、通常だと取得可能なトークンはCLIツール向けに発行されたIDトークンとアクセストークンのみです。ここからどうやってAWS向けのSAMLResponseを生成すればよいかが課題となります。
ここでようやくToken Exchangeが出てきます。つまり、 CLIツール向けに発行されたIDトークンまたはアクセストークンを、AWS向けのSAML2トークンに交換ができればいい わけです。下図でいうと、番号8の箇所ですね。ここでアクセストークンをKeycloakのToken Exchangeを使ってAWS STS用のSAML2アサーションに交換しています。Keycloakバージョン10まではSAML2トークンへの交換に対応していませんでしたが、2日目の記事で紹介したとおり、プルリクエストを送りバージョン11以降は対応しています。
SAML2アサーションに交換できたらそれをSAMLResponseとして少々ラップしてあげて(アサーションのみではAWS STS側が受け付けないため)、番号10のところでAWS STS APIを呼び出してあげれば無事に一時的なAWSアクセスキーを受け取ることができます。
終わりに
というわけで、本記事では2日目に書きました「KeycloakのToken ExchangeのSAML2対応」をどのように活用しているかを紹介しました。意外とSAML2トークンに交換するユースケースが他にあるかもしれません。是非皆さんも探してみてください。


- 投稿日:2020-11-30T23:16:40+09:00
【初心者】Amazon EKSを使ってみる #2(WordPressのデプロイ)
目的
- 以前、「【初心者】Amazon EKSを使ってみる (環境構築~サンプルアプリ起動まで)」という記事を書いたが、k8sの理解のため、もう少し各種機能を使ってみる。
やったこと
kubernetes.io のチュートリアル「例: Persistent Volumeを使用したWordpressとMySQLをデプロイする」を参考にして、wordpress/mysqlのpodをデプロイし、httpsでインターネットからWordPressサイトにアクセスできるようにする。
主な技術要素
- eksctl (eks環境のデプロイ)
- StorageClass (Volumeの作成)
- ACM連携 (https接続)
構成図
作業手順
1.eksctlによる環境構築
- 前の記事ではマネコンからステップバイステップで環境作成したが、面倒なので今回はeksctlで作成する。eksctlのコマンドで、VPC(Subnet、IGWなど含む)、eksのcluster(コントロールプレーン)、nodegroup(Worker Nodeのセット)を一気に作成する。
- 公式サイト「eksctl の開始方法」に従い作業する。
- 事前準備として、作業用のEC2インスタンス(Amazon Linux 2)にaws cli(v2)、kubectl、eksctl をインストールする。
[ec2-user@ip-172-16-0-29 ~]$ aws --version aws-cli/2.0.61 Python/3.7.3 Linux/4.14.193-149.317.amzn2.x86_64 exe/x86_64.amzn.2 [ec2-user@ip-172-16-0-29 ~]$ kubectl version --client Client Version: version.Info{Major:"1", Minor:"18+", GitVersion:"v1.18.8-eks-7c9bda", GitCommit:"7c9bda52c425d0d56d7b93f1377a826b4132c05c", GitTreeState:"clean", BuildDate:"2020-08-28T23:07:29Z", GoVersion:"go1.13.15", Compiler:"gc", Platform:"linux/amd64"} [ec2-user@ip-172-16-0-29 ~]$ eksctl version 0.30.0
- eksctlコマンドを実行して環境を構築する。実行したeksctlコマンドのパラメータは以下の通り。
eksctl create cluster \ --name mksamba-eks-cluster \ --version 1.18 \ --region ap-northeast-1 \ --nodegroup-name mksamba-eks-nodes \ --nodes 3 \ --nodes-min 1 \ --nodes-max 3 \ --with-oidc \ --ssh-access \ --ssh-public-key "key-pair" \ --managed \ --node-type t3.medium \ --node-volume-size=80 \ --vpc-nat-mode Disable \
- eksctlではあまり細かいパラメータの指定ができず、上記のコマンドにより、構成図のVPC(Public Subnet *3、Private Subnet *3)が作成され、CIDRも既定のもの(192.168.0.0/16を分割)になる。ノード(EC2インスタンス *3)は Public Subnetの中に作成される。
- デフォルト設定だとNat Gatewayが作成されるが、今回の検証ではPublic Subnetのみ使用するためNat Gatewayが不要なため、「--vpc-nat-mode Disable」でNat Gatewayを作成しないようにしている。
- 無事3ノード作成されたことを確認する。
[ec2-user@ip-172-16-0-29 ~]$ kubectl get nodes NAME STATUS ROLES AGE VERSION ip-192-168-16-195.ap-northeast-1.compute.internal Ready <none> 11m v1.18.9-eks-d1db3c ip-192-168-40-42.ap-northeast-1.compute.internal Ready <none> 11m v1.18.9-eks-d1db3c ip-192-168-83-21.ap-northeast-1.compute.internal Ready <none> 11m v1.18.9-eks-d1db3c
- ノードへのsshを許可するようにしたため、インターネット(0.0.0.0/0)からssh可能になっている。Security Groupの内容を変更して、適切なSrcIPのみにアクセスを制限する。
2.Volumeの作成
- wordpress/mysqlのコンテナで使用するVolumeを作成する。
- EKSにて最初からStorageClassが定義されており、EBSをVolumeとして使用することができる。
[ec2-user@ip-172-16-0-29 ~]$ kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE gp2 (default) kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 21m
- kubernetes.io チュートリアルからそのままコピペし、wordpressコンテナ用、mysqlコンテナ用のpvcを作成するyamlを準備する。
wordpress-pv-claim.yamlapiVersion: v1 kind: PersistentVolumeClaim metadata: name: wp-pv-claim labels: app: wordpress spec: accessModes: - ReadWriteOnce resources: requests: storage: 20Gimysql-pv-claim.yamlapiVersion: v1 kind: PersistentVolumeClaim metadata: name: mysql-pv-claim labels: app: wordpress spec: accessModes: - ReadWriteOnce resources: requests: storage: 20Gi
- pvcを作成しステータスを確認する。
[ec2-user@ip-172-16-0-29 myyaml]$ kubectl apply -f wordpress-pv-claim.yaml persistentvolumeclaim/wp-pv-claim created [ec2-user@ip-172-16-0-29 myyaml]$ kubectl apply -f mysql-pv-claim.yaml persistentvolumeclaim/mysql-pv-claim created [ec2-user@ip-172-16-0-29 myyaml]$ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE mysql-pv-claim Pending gp2 44s wp-pv-claim Pending gp2 52s3. podの作成
- kubernetes.io チュートリアルからほぼそのままコピペして、mysql、wordpressのpodを作成するyamlを準備する。(単純化のため、Secretを使わず環境変数の値をそのまま埋め込んでいる。)
mysql-deployment.yamlapiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2 kind: Deployment metadata: name: wordpress-mysql labels: app: wordpress spec: selector: matchLabels: app: wordpress tier: mysql strategy: type: Recreate template: metadata: labels: app: wordpress tier: mysql spec: containers: - image: mysql:5.6 name: mysql env: - name: MYSQL_ROOT_PASSWORD value: password ports: - containerPort: 3306 name: mysql volumeMounts: - name: mysql-persistent-storage mountPath: /var/lib/mysql volumes: - name: mysql-persistent-storage persistentVolumeClaim: claimName: mysql-pv-claimwordpress-deployment.yamlapiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2 kind: Deployment metadata: name: wordpress labels: app: wordpress spec: selector: matchLabels: app: wordpress tier: frontend strategy: type: Recreate template: metadata: labels: app: wordpress tier: frontend spec: containers: - image: wordpress:4.8-apache name: wordpress env: - name: WORDPRESS_DB_HOST value: wordpress-mysql - name: WORDPRESS_DB_PASSWORD value: password ports: - containerPort: 80 name: wordpress volumeMounts: - name: wordpress-persistent-storage mountPath: /var/www/html volumes: - name: wordpress-persistent-storage persistentVolumeClaim: claimName: wp-pv-claim
- deploymentを作成し、deployment, pod, pvcの状況を確認する。
[ec2-user@ip-172-16-0-29 qiita]$ kubectl apply -f mysql-deployment.yaml deployment.apps/wordpress-mysql created [ec2-user@ip-172-16-0-29 qiita]$ kubectl apply -f wordpress-deployment.yaml deployment.apps/wordpress created [ec2-user@ip-172-16-0-29 qiita]$ kubectl get deployment NAME READY UP-TO-DATE AVAILABLE AGE wordpress 1/1 1 1 32s wordpress-mysql 1/1 1 1 11m [ec2-user@ip-172-16-0-29 qiita]$ kubectl get pods NAME READY STATUS RESTARTS AGE wordpress-6c76bb8768-jjhsn 1/1 Running 0 39s wordpress-mysql-65bb879f6-kmxj2 1/1 Running 0 12m [ec2-user@ip-172-16-0-29 qiita]$ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE mysql-pv-claim Bound pvc-60ef7f20-8074-466f-a6e5-7c81ce2ba562 20Gi RWO gp2 21m wp-pv-claim Bound pvc-34f766a2-dc2d-4bc6-9f59-71e05e016679 20Gi RWO gp2 21m
- EBSの画面でも、volumeが自動生成されて、 in use になっていることが確認できる。
4.Serviceの作成
- kubernetes.io チュートリアルからほぼそのままコピペして、mysql、wordpressのServiceを作成するyamlを準備する。Service TypeをmysqlはClusterIP、wordpressはLoadbalancerとしている。(mysql用のServiceがHeadlessだったため、普通のClusterIPに変更)
mysql-service.yamlapiVersion: v1 kind: Service metadata: name: wordpress-mysql labels: app: wordpress spec: ports: - port: 3306 selector: app: wordpress tier: mysqlwordpress-service.yamlapiVersion: v1 kind: Service metadata: name: wordpress labels: app: wordpress spec: ports: - port: 80 selector: app: wordpress tier: frontend type: LoadBalancer
- Service を作成し、状況を確認する。wordpressのほうは「Type: LoadBalancer」としたため、CLBが自動作成される。
[ec2-user@ip-172-16-0-29 qiita]$ kubectl apply -f mysql-service.yaml service/wordpress-mysql created [ec2-user@ip-172-16-0-29 qiita]$ kubectl apply -f wordpress-service.yaml service/wordpress created [ec2-user@ip-172-16-0-29 qiita]$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 114m wordpress LoadBalancer 10.100.187.185 12345678901234567890123456789012-1234567890.ap-northeast-1.elb.amazonaws.com 80:31070/TCP 68s wordpress-mysql ClusterIP 10.100.251.124 <none>
- ブラウザでCLBのURLにhttpでアクセスし、WordPressの初期画面が表示されることを確認する。
- CLBが生成されていることを確認する。(インターネットからの80/tcpアクセスを、3つのノードの31070/tcp(NodePort)に転送するよう自動的に設定される)
- Serviceはこの後httpsで作り直すのでいったん消しておく。
5.https化
- 公式サイト「ACM で Amazon EKS ワークロードの HTTPS トラフィックを終了する方法を教えてください。」 を参考に作業を行う。
- ACMで証明書を取得する。ここでは仮にFQDNを「eks.mksambaaws.com」とする。証明書を取得したらARNをメモする。
- hpttsでServiceを作成するyamlを作成する。その中でパラメータとして証明書のARNを記載する。
wordpress-service-https.yamlapiVersion: v1 kind: Service metadata: name: wordpress labels: app: wordpress annotations: service.beta.kubernetes.io/aws-load-balancer-backend-protocol: http service.beta.kubernetes.io/aws-load-balancer-ssl-cert: "証明書のARN" service.beta.kubernetes.io/aws-load-balancer-ssl-ports: "https" spec: ports: - name: http port: 80 - name: https port: 443 targetPort: 80 selector: app: wordpress tier: frontend type: LoadBalancer
- Serviceを作成し状況を確認する。
[ec2-user@ip-172-16-0-29 qiita]$ kubectl apply -f wordpress-service-https.yaml service/wordpress created [ec2-user@ip-172-16-0-29 qiita]$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 9h wordpress LoadBalancer 10.100.173.16 12345678901234567890123456789012-1234567890.ap-northeast-1.elb.amazonaws.com 80:30765/TCP,443:31041/TCP 22s wordpress-mysql ClusterIP 10.100.251.124 <none> 3306/TCP 7h18m
- CLBが作成され、httpsを受け付けていること、また証明書のARNが設定されていることを確認する。
- Route 53でAレコードを登録する。「eks.mksambaaws.com」のAレコードとして、作成したCLBを指定する。
- 登録したFQDNにhttpsでにアクセスして、WordPressの初期画面が表示されることを確認する。
所感
- 少しだけk8sぽい感じになったので、引き続き勉強したい。







- 投稿日:2020-11-30T23:16:07+09:00
AWS/EC2 + nginxを使って、Swagger-ui,Swagger-editorの環境構築をする2/2
目的
AWSのEC2上にnginxを経由してSwagger-ui,Swagger-editorを配置、使用できるようにします。
かなり苦労しながら2日くらいかけて、調査、環境構築を終わらせたので、
同じように悩んでいる人の助けになれれば幸いです。長くなりそうなので、二部構成にします。(今回は後編・nginx/Swagger編です)
前編のAWS編は(こちら)
目次
環境構築 ~nginx編~
1.EC2にnginxを導入
1.a EC2インスタンスをアップデート
ターミナルを起動し、EC2インスタンスにSSH接続する。
その後、下記コマンドを実行し、インスタンスをアップデートします。sudo yum update1.b yumでnginxをインストールできるように設定
初期状態では、nginxをそのままインストールすることができません。
下記の魔法のコマンドを打つと、yum installでnginxをインストールすることができます。sudo amazon-linux-extras enable nginx11.c nginxをインストールする。
これで、準備が整いました。
下記コマンドを入力して、nginxをインストールしてください。sudo yum -y install nginx2.nginxを起動する
nginxはインストールしただけでは、まだ使用可能状態ではないので、
下記コマンドを入力して、nginxを起動します。sudo systemctl start nginx3.ターミナル上でnginxの状態確認をする
nginxが起動しているかどうか、下記コマンドを打ち込んで確認します。
sudo systemctl status nginxActive: active (running) since 月 2020-11-30 10:25:07 UTC; 4min 44s ago上記のようになっていればOKです。
4.サイト上でnginxの状態確認をする
http://(EC2のIPv4アドレス)/をウェブブラウザに打ち込んでください。
下記画像のように表示されればOKです。
環境構築 ~swagger編~
1.swaggerクローン前の準備
1.a swaggerを格納するディレクトリを作成する
sudo mkdir /www1.b ディレクトリの権限を変更する
sudo chmod 777 /www2.swagger-ui,swagger-editorをgithubからクローンする
2.a gitをインストールする
sudo yum -y install git2.b 先ほど作成したディレクトリに移動する
cd /www2.c githubからswagger-uiをクローンして取得する
git clone https://github.com/swagger-api/swagger-ui.git2.d swagger-editorをgithubからクローンして取得する
git clone https://github.com/swagger-api/swagger-editor.gitnginxを経由させて、swagger-ui,swagger-editorを表示させる
nginx.confをvimで開く
sudo vim /etc/nginx/nginx.confnginx.confに追記する
server { listen 80; root /www/; index index.html; location /swagger-editor { alias /www/swagger-editor; index index.html; } location /swagger-ui { alias /www/swagger-ui/dist; index index.html; } }nginxを再起動or再読み込みする
再起動
sudo systemctl restart nginx再読み込み
sudo systemctl reload nginxhttp://(IPv4アドレス)/swagger-ui/に遷移
下記のような画面が表示されればOKです。
http://(IPv4アドレス)/swagger-editor/に遷移
下記のような画面が表示されればOKです。
あとがき
お疲れ様でした。以上でswagger-ui,swagger-editorの環境構築完了です。
まだまだ勉強中の身なので、記事に関して不明点、わかりづらい点などありましたら、
コメント欄にて気軽に、コメント、質問、アドバイスいただけますと幸いです。



- 投稿日:2020-11-30T23:12:08+09:00
AWS/EC2 + nginxを使って、Swagger-ui,Swagger-editorの環境構築をする1/2
目的
AWSのEC2上にnginxを経由してSwagger-ui,Swagger-editorを配置、使用できるようにします。
かなり苦労しながら2日くらいかけて、調査、環境構築を終わらせたので、
同じように悩んでいる人の助けになれれば幸いです。長くなりそうなので、二部構成にします。(今回は前編/AWS編です)
AWSのEC2インスタンス作成はできているという方は、後編のnginx,swagger編から読んでください。
対象読者
- Macユーザー
- AWSを使ったことがない方
- nginxを使ったことがない方
- swaggerを初めて使ってみたい方
目次
- 環境構築手順 ~AWS編~
- VPC作成
- サブネット作成
- インターネットゲートウェイ作成
- ルートテーブル作成
- セキュリティグループ作成
- EC2インスタンス作成
- EC2にSSH接続
- EC2インスタンスにログインできない場合
- nginx/swagger編
環境構築手順 ~AWS編~
1.VPC作成
1.a AWSマネジメントコンソールにログイン
※ログイン時には、必ず多要素認証を設定するようにしてください。
セキュリティが、ガバガバだと多額の請求が来たりするらしいので、少しでもセキュリティレベルは高めておくのが吉です。
こわ〜い話の一部をどうぞ。。
初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話AWSが不正利用され300万円の請求が届いてから免除までの一部始終
AWS請求額5千ドル : アカウントのセキュリティ設定は「絶対に」端折るな
二段階認証を含む、アカウントのセキュリティレベルを上げる方法は、以下の記事が参考になります。
AWSアカウントを取得したら速攻でやっておくべき初期設定まとめ1.b VPC一覧画面に遷移
左上の「サービス▲」をクリックし、検索欄に「VPC」と入力する。
そして、一番上に出てきた「VPC」をクリック
下記画像が表示された後、もう一度「VPC」をクリック
下記のような画像が表示されれば、問題なくVPC一覧画面に遷移できています。
1.c VPCを作成する
上記画像、右上に位置するオレンジ色の「VPCを作成」ボタンをクリック
下記のVPC作成画面が表示される事を確認する
名前タグ(オプション)
任意の名前を追加する(今回は「vpc-swagger」とします。)IPv4 CIDRブロック
今回は、あくまでもswaggerを動かす事だけが目的なので、
あまり深く考えず、10.0.0.0/16を入力してください。
本当は、色々と考えて設定しないといけないらしいです。。
(よかったらコメント欄でCIDRブロックについて教えてください)IPv6 CIDRブロック
「IPv6 CIDRブロックなし」を選択してください。テナンシー
デフォルトを選択してください。上記の設定が終わりましたら、右下にある「VPCを作成」をクリックしてください。
上記画像のように表示が出れば、作成完了です。2.作成したVPCにサブネットを作成
2.a サブネット一覧画面に遷移する
左側のサイドメニューの「サブネット」をクリックしてください。
以下の画像のような、サブネット一覧画面が表示されることを確認してください。
サブネット作成が初めてであれば、サブネット一覧画面には何も表示されません。2.b サブネット作成画面に遷移する
サブネット一覧画面の右上に位置する「サブネットを作成」をクリック
以下の画像のような、サブネット登録画面が表示されることを確認してください。
2.c サブネットを作成する
まずは、上部のVPC欄設定から進めて行きます。
VPC ID欄は、プルダウン形式でどのVPCにサブネットを作成するか選択します。
今回は、先ほど作成した「vpc-swagger」のVPCにサブネットを作成するので、
「vpc-swagger」を選択してください。続いて、下部のサブネットの設定です。
サブネット名に関しては、vpcの名前タグ同様に好きな名前を入力してください。
今回は、「public-subnet-swagger」と入力します。アベイラビリティーゾーンも好きなゾーンを選択して構いません。
今回は、「アジアパシフィック(東京)/ap-northeast-1a」を選択します。IPv4 CIDR ブロックは、「10.0.1.0/28」と入力してください。
タグに関しては、サブネット名入力の際に自動で生成されているので、そのままで大丈夫です。
上の画像のように、入力が完了した後、「サブネットの作成」ボタンをクリックしてください。
「1件のサブネットが正常に作成されました」と表示されれば、完了です。
一応、サブネット一覧画面に戻り、本当に作成したサブネットがあるかどうか確認してください。
3. インターネットゲートウェイを作成して、VPCにアタッチする
3.a インターネットゲートウェイ一覧画面に遷移する
左側のサイドメニューから、「インターネットゲートウェイ」をクリックしてください。
下記のような、インターネットゲートウェイ一覧画面が表示されることを確認してください。
AWSを使用するのが初めての方の場合、一覧画面に表示されている
インターネットゲートウェイの数は1つです。
3.b インターネットゲートウェイ作成画面に遷移する
左上の「インターネットゲートウェイの作成」ボタンをクリック
下記のような、作成画面が表示されていることを確認してください。
3.c インターネットゲートウェイを作成する
名前タグに任意の値を入力してください。
今回は「igw-swagger」とします。タグに関しては、名前タグを入力すると自動で設定されます。
名前タグの入力後、右下の「インターネットゲートウェイの作成」をクリックしてください。
次のインターネットゲートウェイが作成されましたと表示されれば、OKです。
3.d インターネットゲートウェイをVPCに紐付ける
インターネットゲートウェイは、VPCに紐付けて初めて効果を発揮するものです。
作成したインターネットゲートウェイ(igw-swagger)を作成したVPC(vpc-swagger)に紐付けましょう。インターネットゲートウェイ一覧画面で、先ほど作成したigw-swaggerを選択し、
「アクション」をクリック、その後「VPCにアタッチ」をクリックします。
そして、使用可能なVPC欄に、「vpc-swagger」を選択してください。
AWSコマンドラインインターフェイスコマンドは触らなくても大丈夫です。正しいVPCが選択できたら、左下の「インターネットゲートウェイのアタッチ」をクリックしてください。
「インターネットゲートウェイが正常にアタッチされました」と表示されればOKです。
4.ルートテーブルを作成する
4.a ルートテーブル一覧画面に遷移する
左側のサイドメニューの、「ルートテーブル」をクリックしてください。
下記画像のような、ルートテーブル一覧画面が作成されることを確認してください。
そして、「ルートテーブルの作成」をクリックしてください。4.b ルートテーブルを作成する
ルートテーブル作成画面は下記画像のようになっています。
「名前タグ」には、これまで同様、任意の名前を入力してください。
「VPC」入力欄には、vpc-swaggerを選択し、入力してください。上記入力が完了した後、右下の「作成」ボタンをクリックしてください。
「次のルートテーブルが作成されました。」と表示されればOKです。
4.c ルートテーブルにインターネットゲートウェイのルートを登録する
ルートテーブル一覧画面に戻り、先ほど作成したルートテーブルを選択する
一覧画面下部に、下記画像のようなルートテーブル詳細画面が表示されるので、
そこから、ルートを選択する
そして、「ルートの編集」をクリックし、インターネットゲートウェイ(igw-swagger)を追加する
最後に、「ルートの保存」をクリックすれば完了です。
5.セキュリティグループを作成する
5.a セキュリティグループ一覧画面に遷移する
左上に位置する「サービス▲」を選択し、検索欄に「EC2」と入力してください。
その後、検索結果の一番上に出てくる「EC2」をクリックしてください。
左側のサイドメニューから、「セキュリティグループ」をクリックしてください。
下記画像のような、セキュリティグループ一覧画面が表示されればOKです。
AWSを使用するのが初めての方の画面には、デフォルトで1つセキュリティグループが用意されているはずです。
5.b セキュリティグループ作成画面に遷移する
セキュリティグループ一覧画面、右上に位置する「セキュリティグループを作成」をクリックしてください。
下記画像のような、作成画面が表示されればOKです。
5.c セキュリティグループを作成する
基本的な詳細
セキュリティグループ名には、任意のグループ名を入力してください。
(今回は、「securityGroupSwagger」とします。)説明欄は、書いても書かなくても大丈夫です。
※書いた方が、セキュリティグループが増えてきたときに、管理しやすくなります。VPCには、先ほど作成した「vpc-swagger」を選択、入力します。
インバウンドルール
作成画面遷移時は、何もインバウンドルールが書かれていないと思うので、
2つ追加してください。1)タイプ:HTTP,プロトコル:TCP(自動入力),ポート範囲:80(自動入力),ソース:任意の場所(0.0.0.0/0・::/0) 2)タイプ:SSH,プロトコル:TCP(自動入力),ポート範囲:22(自動入力),ソース:マイIPアウトバンドルール
特に初期状態から、操作を行う必要はないです。
以上の入力が終わりましたら、作成画面右下にある「セキュリティグループを作成」をクリックしてください。
そして、下記画像のように表示が出ればOKです。
6.EC2インスタンスを作成する
6.a EC2インスタンス一覧画面に遷移する
左側のサイドメニューの、「インスタンス」をクリックしてください。
下記画像のような、一覧画面に遷移します。
AWS使用するのが初めての方は、一覧画面にEC2インスタンスは1つもないはずです。
6.b EC2インスタンスを作成する
一覧画面右上の、「インスタンスを作成」をクリックしてください。
ここから1ステップごとの設定項目を見て行きましょう。ステップ1 Amazon マシンイメージ (AMI)
Amazon Linux 2 AMI (HVM), SSD Volume Type 64bit(x86)
ステップ2 インスタンスタイプの選択
「t2.micro」(初期値)
ステップ3 インスタンスの詳細の設定
ネットワーク:vpc-swagger
サブネット:public-subnet-swagger
自動割り当てパブリックIP:有効
それ以外の項目は初期値のままで大丈夫です。
ステップ4 ストレージの追加
全て初期値のままで大丈夫です。
ステップ5 タグの追加
ここも特に設定する必要はありません。
ステップ6 セキュリティグループの設定
セキュリティグループの割り当て:既存のセキュリティグループを選択する
セキュリティグループ選択:securityGroupSwagger
ステップ7 インスタンス作成の確認
ステップ1〜6までの内容が適切に入力されていることをこの画面で確認してください。
確認後、右下にある起動ボタンをクリックします。
6.c キーペアを作成する
キーペアは、EC2インスタンスにログインするために必要となるものです。
既存のキーペアを使い回すこともできますが、今回は新しいキーペアを作成します。
新しいキーペアの作成
キーペア名:keypair_swagger(任意)
必ずキーペアのダウンロードを忘れずにしてください!!!
ダウンロードしたキーペアは安全な場所に保管しておきましょう。
6.d 作成したEC2の状態を確認する
EC2インスタンス一覧画面に戻り、作成したEC2のステータスチェック欄を確認します。
「 2/2 のチェックに合格しました」と表示されていれば、EC2インスタンスの作成完了です。
チェックに合格するまでには、数分時間がかかります。(気長に待ちましょう)7.作成したEC2にSSH接続する
7.a ターミナルを開く
Macに最初から入っているターミナルを開いてください。
7.b pemファイルを保存してあるディレクトリに移動する
cd ~「~」を任意のディレクトリ名に変えてあげると、好きな場所に移動できます。
7.c EC2インスタンスにログインする
ssh -i keypair_swagger.pem ec2-user@※※※※※※※※と入力してください。
ec2-user@の後ろには、自身のパブリックIPv4アドレスを入力しましょう。
下記画像のように、インスタンス一覧画面に表示されているはずです。
上記コマンド入力後、下記画像のように表示されれば接続成功です。
お疲れ様でした。
EC2にログインできない場合の対処法
下記URLが参考になります。1つずつ確認してみてください。
https://dev.classmethod.jp/articles/creation_vpc_ec2_for_beginner_1/
上の画像のような表示が出る場合は、
pemファイル(キーペア)に付与されている権限が緩すぎるという警告です。
pemファイルの権限を少し強めましょう。
pemファイルを置いてあるディレクトリ上で、chmod 600 keypair_swagger.pemと入力すると権限変更ができます。
nginx/swagger編に続く
次回は、作成したEC2上にnginxをインストールし、
nginxを使ってswagger-editor,swagger-uiを動くようにします。ここまでで、質問・不明点などございましたら、コメント欄によろしくお願い致します。







































- 投稿日:2020-11-30T22:44:08+09:00
Bolt for Python が FaaS での実行のために解決した課題
Bolt とは & 自己紹介
近年、Slack のプラットフォーム機能開発チームは、Slack 連携アプリを作るための公式フレームワークである「Bolt(ボルト)」の開発と普及活動に力を入れています。私はこの Bolt の開発を担当しています(特に Python と Java は大部分を私が手がけたので、思い入れもひとしおです)。
Bolt を使うと Web API を使ってメッセージやファイルを投稿して通知するだけのシンプルな連携ではなく、ボタンやモーダルを活用したインタラクティブなアプリを簡単に作ることができます。また、そのような UI 部品を使わない場合でも、Bolt を使うと Events API の受信とリスナー関数の実装を非常に簡単に実装することができます。
今年のアドベントカレンダーは、まだそこそこ空きがあるようなので、埋まらなかった日については、この Bolt のノウハウを中心に記事を投稿していこうと思っています。
それでは本題
この記事では、Bolt for Python を使ったアプリ FaaS (Function as a Service) 上で稼働しやすくするために実装した「Lazy Listener」という機能について紹介します。
FaaS で Slack 連携を運用するときの課題
FaaS (Function as a Service) とは AWS Lambda や Google Cloud Functions のような、サーバー自体やそのキャパシティの管理をクラウドサービスに任せて、シンプルな関数の実行部分だけに集中することができるサービスです。
Slack の連携アプリは比較的シンプルなものやトラフィックが多くないものもよくあるので、FaaS で運用したいというニーズは珍しくありません。例えば、シンプルなスラッシュコマンドやショートカットを提供するだけのアプリであれば、非常に低コストで(場合によっては無料枠で)運用することができるでしょう。
しかし、FaaS で Slack 連携を動かすとき、以下のような点に注意する必要があります。
Slack からリクエストを受けたら 3 秒以内に応答する
Slack API サーバーから HTTP リクエストを受けるアプリケーションは、3 秒以内に HTTP レスポンスを返す必要があります(今後、ソケットモードという WebSocket ベースの連携方法もリリースを控えていますが、応答の仕方こそ違えど、この 3 秒以内の応答というルールは同様です)。
3 秒以内に応答を返さなかった場合は「タイムアウトエラー」という扱いになります。Events API の場合は 3 回まで同じイベントの再送が発生します。それ以外のユーザーアクションなどでは、エンドユーザーに固定のエラーメッセージが表示される結果になります(再送はされません)。
これへの対処のよくある実装は Slack の Web API 呼び出しなどを非同期処理に切り替えるやり方です。Bolt では、そのようなコードをできるだけシンプルにできるよう
ack()というユーリティティを使うことで、即 HTTP レスポンスを返すコードの行(=await ack())とそれ以外の処理の非同期実行の部分を同じリスナー関数内に簡単に共存させられるようになっています。以下は単純なボタンクリックイベントのハンドラーの例です。
app.action('button_click', async ({ ack, body }) => { await ack(); // この時点ですぐに 200 OK を返す // これ以降の処理がどれだけ時間がかかってもタイムアウトは発生しない await doSomething(body); });Python の場合は以下のようになります。
@app.action("button_click") def action_button_click(ack, body): ack() # この時点ですぐに 200 OK を返す # これ以降の処理がどれだけ時間がかかってもタイムアウトは発生しない do_something(body)asyncio でやりたい場合も
slack_bolt.Appの代わりにslack_bolt.async_app.AsyncAppを使って以下のように書きます。@app.action("button_click") async def action_button_click(ack, body): await ack() # この時点ですぐに 200 OK を返す # これ以降の処理がどれだけ時間がかかってもタイムアウトは発生しない await do_something(body)Java の場合は、非同期実行の仕組みをユーザー自身が選びたいケースも多いだろうということで、インターフェースが少し異なっています。しかし、手軽にやりたい場合は、以下のように組み込みの
ExecutorServiceを使うことができます。以下は Kotlin でのコード例です。app.blockAction("button_click") { req, ctx -> // 組み込みの ExecutorService の例 // 自前で管理する別の仕組みを使っても構わない app.executorService().submit { // この中の処理は別のスレッドで実行される doSomething(req.payload) } ctx.ack() // この時点ですぐに 200 OK を返す }HTTP トリガーの FaaS は非同期処理が使えない環境
・・と、Bolt のアプリがプロセスとしてずっと動いているような環境であれば、上記のやり方で良いのですが、FaaS で動かす場合は少し事情が異なります。HTTP リクエストをトリガーに起動する Function の場合、HTTP レスポンスを返した時点で、その実行中の環境は(プラットフォーム側によって)いつ破棄されてもおかしくない状態となるためです。
この環境下では、先ほどの例に出てきた
doSomething()のような Node の async 関数、Python asyncio での async 関数、Java や Python のスレッドを使った非同期処理の実行は、その完了を待たずに強制終了してしまう可能性があります。それ以外にもack()以外のsay()やrespond()といった Node や Python で非同期処理を前提とするユーリティリティメソッドでも同様の問題が発生します。これへの対処として Bolt for JavaScript v2 から導入されたのが
processBeforeResponseというフラグです(Python にも同名の設定が存在します。Java は自動的にack()が応答を返すインターフェースではないので、このオプションは存在しません)。デフォルトでは false になっています。false の場合は
ack()がリスナー関数の実行完了を待たずに HTTP レスポンスを返します。FaaS で動作させるときは、これを明に true に設定することで、全ての処理が終わるまで HTTP レスポンスを返さないように挙動を制御することができます。これにより、処理の途中でランタイムが終了することがなくなり、安定したリスナー関数の実行が可能になります。では、これで万事解決でしょうか?・・・いえ、察しの良い方はお分かりの通り、このオプションを true にしたアプリケーションは、最初に説明した 3 秒タイムアウトの問題を再び気にする必要が出てきます。また、3 秒という制約に対して影響しうる FaaS の cold start 問題によるオーバーヘッドも気にする必要があるでしょう。
では、どのような手段が取れるでしょうか?
時間のかかる処理を分ける
改めて、ここでやりたいことは:
- インターネットフェイシングな関数は Slack API サーバーに対して HTTP レスポンスを必ず 3 秒以内にする
- 受け取ったペイロードの必要な情報を非同期処理に引き渡してメインの時間がかかる処理はそちらで実行する
です。
おそらくパッと思いつくアイデアは「間にキューを挟む」といったやり方でしょう。AWS であれば SQS や Kinesis Data Streams などに enqueue し、HTTP レスポンスだけ返してしまえば、あとから別の Lambda 関数が SQS からメッセージを取り出して処理を継続することができます。これは、API Gateway と Lambda に加えて SQS を協調させるように設定・実装すれば、比較的容易に実現できるでしょう。
しかし、Slack 連携アプリを作る度に毎回このような構成をとるのも少し面倒です。やりたいことは同期処理の Lambda と非同期処理の Lambda を実行したいだけであり、キューが欲しいわけではありません。チームの中でも特にこの問題に関心を持っていた私は「もっと手軽に対応できないものだろうか?」と昨年から考えてきていました。
そして、今年の春、Bolt for Python の開発をしているときにふと閃きました。「Bolt for Python のデザインであれば、同じペイロードを複製して
ack()を担うリスナーと、ack()以外のことをできる非同期のリスナーを実行させることができるのではないか?」と。結果、このアイデアはうまく実装することができ、この記事のテーマである「Lazy Listener」という機能になりました。Lazy Listener がやっていること
Lazy Listener は、以下のように
ackとlazyにリスナー関数の処理を書き分けることができる仕組みです。以下の例はlazyにずいぶんたくさん関数を渡していますが、普通は一つだけで十分でしょう。def ack_within_3_seconds(ack, body): # モーダルの送信へのエラー応答など ack() で返す必要があるものはここでやる # 他にやることなければただ ack() するだけ ack() def notify_to_helpdesk_team(body, client): # いつも通り client にこのリクエスト処理用の token はセットされている client.chat_postMessage( channel=helpdesk_team_channel_id, blocks=build_notification_message_blocks(body), ) def call_very_slow_api(body): # 実行時間の制約なく処理を記述できる # AWS 上なら AWS Lambda の最大実行時間まで実行可能 send_to_backend(body) def open_modal_as_necessary(client, body): if is_modal_requested(body): client.views_open( # trigger_id は有効期限があるので注意 trigger_id=body["trigger_id"], view=build_modal_view(body), ) app.shortcut("helpdesk-request")( ack=ack_within_3_seconds, lazy=[notify_to_helpdesk_team, call_very_slow_api, open_modal_as_necessary], )cold start 問題についてですが、ライブラリのロードはほぼ無視できるレベルのコストです。Bolt for Python(
slack-bolt)は Python Slack SDK(slack-sdk)以外に必須の依存ライブラリがありません。そして Python Slack SDK も必須の依存ライブラリがありません。上記のサンプル例の場合だと
ack_within_3_secondsはほとんど何もしませんので、他のライブラリの初期化コストが異常に高いなどの状況でもなければ cold start 時にも 3 秒を超えるようなことはまずないでしょう。一つの AWS Lambda 関数だけで
lazy に指定されている関数は、すべてそれぞれ専用の AWS Lambda 関数の起動として実行されます。引数に渡せる
bodyやclientなどは、そのまま同じものが複製されます。ack の関数との違いはack()を実行できないことだけです。なお、lazy の関数は配列で渡しますが、実行順序はありません。可能になったタイミングでそれぞれバラバラに実行されます。この lazy 用に新しく別の Lambda 関数を追加する必要はありません。一つだけの AWS Lambda 関数をそのまま使い回してうまく動作します。lazy のものは HTTP トリガーではなく、内部からの起動になります。
Lazy Listeners は汎用的な仕組み
Lazy Listeners は AWS Lamdba などの環境を想定して考案されましたが、結果的にその実装は FaaS 専用の仕組みというわけではありません。その処理の仕組みを
LazyListenerRunnerというインタフェースの実装を指定するだけで Bolt 側に手を入れることなく、切り替えることができます。デフォルトでは lazy listener function はスレッドを使って同一のアプリ内で非同期実行されます。asyncio の場合も task として別途実行されます。AWS Lambda の場合は、それを Lambda 関数起動に切り替えています。実装に興味を持った方は
ListenerRunnerとLazyListenerRunnerの実装を追ってみるとどのように実装されているかわかると思います。簡単にいうと lazy 実行時には request についているマークをチェックし、ack 関数のスキップ、実行対象の lazy listener 関数の特定を行っています。Lazy Listeners の使いどころ
基本的には AWS Lambda で動かしたいというユースケースが使いどころになります。
しかし、先ほど AWS Lambda 専用の仕組みではないと書いたように、Lambda で動かさない場合にも使うことができます。もし「Lazy Listener の記述方式がわかりやすい・設計しやすい」「同じペイロードに対して複数の非同期処理を実行したい」などの場合、FaaS のユースケースに限らず Lazy Listeners を使ってみてもよいでしょう。
Lazy Listeners の今後
この記事執筆時点(v1.0.1)では、スレッド、asyncio、AWS Lambda に対応しています。将来のバージョンで Google Cloud Functions にも対応予定です。
Python 以外の Bolt に実装するかは未定です。Bolt for JavaScript は(そのような使い方をしている人がどれくらいいるかはともかく)実はリスナーを複数指定できるようになっており、その設計との相性を考えると Python と同じような形では入れられないだろうと考えています。
また、Java も ack / lazy のようなインターフェースが使いやすいかは、何とも言えないところがあります。AWS Lambda クライアントをラップしたユーティリティを提供する程度になるかもしれません。
2021 年はソケットモードの時代
そして、来年にはソケットモードのリリースが控えています。ソケットモードは HTTP エンドポイントで Slack からのリクエストを受けるのではなく、RTM API と同じように WebSocket でつないで、そのコネクションのメッセージでペイロードを受け取り、応答も WebSocket で送信する仕組みです。
ソケットモードのアプリを FaaS で動かすことはまずないでしょう。ソケットモードは AWS であれば ECS や Lightsail Containers のようなコンテナベースのサービスの相性が良いのはないかと思います。実際、私は開発中の Socket Mode 対応の Bolt for Python アプリを Lightsail Containers で稼働させて、様子を見ていたりしています(すでに問題なく動くようになっています!)。
ソケットモードがリリースされても、これまでの HTTP エンドポイント方式がなくなることはありませんが、おそらく FaaS で新しく始めるという人は少なくなるだろうなと予想しています。
最後に
長い記事を最後まで読んでいただきありがとうございました。関連する GitHub issue などのリンクを置いておきますので、興味がある方はアクセスしてみてください。
- 投稿日:2020-11-30T20:48:46+09:00
AWS Alexa資格に合格しました
はじめに
今日(11/30)「AWS Certified Alexa Skill Builder - Specialty」資格(以降AXS)に受かりました。
Alexaの開発を業務でやっている人はあまりいないかもしれませんが、試験としてはあまり難しくないので、頭の体操としては良い経験になったと思います。
誰かの役に立てば幸いです。ちなみにAlexa資格は2021年3月末をもって終了となるようなので、欲しい人はお早めに。
https://aws.amazon.com/certification/coming-soon/?nc1=h_ls
※過去の記事
AWS SAAに受かった話
AWS SOAに受かった話
AWS DVA(とCLP)に受かった話
AWS SAPに受かった話
AWS SCSに受かった話
AWS ANSに受かった話
AWS DBSに受かった話
AWS DASに受かった話獲得スコア
受験日 スコア/合格点/満点 結果 2020/11/30 873/750/1000 合格 試験中はあまり自信なかったですが、思ったより取れました。
勉強に使った教材
Alexa道場
AlexaはBlackbelt等の資料が無くなかなか勉強しにくかったですが、AWS公式の下記ウェビナーがかなり役に立ちました。
(Alexa開発の基本的な部分を解説しているウェビナーですが、試験自体も基本的なことしか出ないのでそのまま試験対策になる、というイメージです)Alexa道場ガイダンス
https://developer.amazon.com/ja-JP/alexa/alexa-skills-kit/get-deeper/webinars上記以外だと、公式の模擬試験とサンプル問題も実試験に近い形式なので、解説も含めて普段以上に読み込んでおくと良いと思います。
試験の所感
- 難易度はLinuc(LPIC) Lv1ぐらい
- コマンド入力問題が無い分それよりも低いかも
- Alexaを開発する上での基本的な用語を理解しているかが問われる
- インテント
- サンプル発話
- 呼び出し名
- スロット
- ダイアログ
- セッションアトリビュート(永続アトリビュート)
- などなど
- AWSのサービスについても問われるが、Lambdaについては多少細かい程度
- 意図したインテントや発話が呼ばれない場合の対処
- デバッグ方法(インテント履歴やCloudwatchの見方など)
- ビルドインのスロットが提供されているが、足りない場合は追加も可能
- 構成としては、「ユーザー→Alexa→スキル(Lambdaなど)」
- Lambda以外を使う場合は、構成要件を満たす必要がある(HTTPSで通信を暗号化する等)
- スキル関連のオブジェクト(画像等)はパブリックに公開(読み取り)する必要がある
- Alexaタイムアウト問題
- Lambdaを使っている場合はLambdaのタイムアウト問題もある(いつもの)
- オーディオファイルの制約
- 使えるのはMP3のみだが、MP3の中でも制約がある(ビットレートなど)
- スキル開発~リリースの流れ
- リリース時には認定があり、必要な機能が含まれているか、Alexaのポリシーに違反していないかなどを審査される
- 基本的には公開済みのスキルを直接修正することはできない(緊急のバグ修正などは例外)
- 試験が始まった2019年当時と2020年現在では、Alexaホスティングスキルの制約が変わっている
- 今回の試験では出なかったが、おそらく2019年の制約が適用されているはず
- 使用可能言語:node.jsのみ(2019年)→今はPythonも利用可能
- 永続アトリビュート保存先にS3しか使えない(2019年)→今はDynamoDBも利用可能
- 投稿日:2020-11-30T20:32:35+09:00
Go言語で作成した実行ファイルをEC2でデーモンとして実行する
概要
Go言語でbuildした実行ファイルをEC2上に配置しdeamon化します。
そうして、EC2の起動時に自動的にGoでビルドしたWebサーバを実行させます。経緯
Go言語+GinでビルドしたWebサーバをEC2上で構築していたのですが、
EC2の起動時に自動実行されなかったのでいろいろと試した結果、デーモン化しinit.dで自動起動させました。1 ビルドした実行ファイルのデーモン化
ディレクトリ /etc/systemd/system/サービス名.service [Unit] Description=説明文 [Service] User=root Group=root WorkingDirectory=ディレクトリ ExecStart=ディレクトリ/実行ファイル名 Restart=always KillMode=process [Install] WantedBy=multi-user.targetサービスの確認
systemctl status サービス名.service
systemctl start サービス名.service
systemctl stop サービス名.service上記でサービスの起動が出来たらデーモン化は完了です。
2. init.dでサービスの自動起動を設定
ディレクトリ /etc/int.d/app_start --------------init.d 内容------------------------- #!/bin/sh # chkconfig: 2345 99 10 # description: deamon wakeup scrupt case "$1" in start) date >> /home/user/start.txt echo "start!" >> /home/user/app_start.log sudo sh /home/user/scripts/application_start_server.sh ;; stop) echo date >> /home/user/app_stop.log sudo sh /home/user/scripts/application_stop_server.sh ;; *) break ;; esacapplication_start_server.sh の部分は直接コマンドを書いても良いですし、
今回はシェルスクリプトを実行させました。
(サービスの起動・停止時に時間をファイルに出力しています。)3 確認
EC2を再起動しサービスが正常に起動していれば完了です。
所感
インスタンスの再起動は物理マシンの起動と挙動のでその辺りが原因でバッチ処理ではうまく動かなかったのだと考えています。
- 投稿日:2020-11-30T19:45:36+09:00
AWS PrivateLinkで異なるアカウントのRDS(Aurora Serverless)にdata-apiで接続する
この記事でやること
AWS PrivateLinkを用いて、異なるアカウントにあるAurora Serverlessに対してdata-api接続で接続します
リージョンは同じである必要があります
ちょっとハマったのでメモとして記事にしました※data-api接続は2020年2月にPrivateLink経由で接続できるようになりました
https://aws.amazon.com/jp/about-aws/whats-new/2020/02/amazon-rds-data-api-now-supports-aws-privatelink/※Aurora Serverless v2っていうのがα版で来てるみたいです。要チェックですね!
https://dev.classmethod.jp/articles/aurora-serverless-v2/まずPrivateLinkとはなにか
AWSアカウント間接続に使う仕組みです
AWSのドキュメントを見ると、VPCのエンドポイントのページに書いてあります
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/endpoint-service.html最初かなり混乱したのですが、こういうこと↓です
https://qiita.com/mksamba/items/20903940b8b256ef2487VPC PrivateLinkというサービスメニューがあるわけではなく、「エンドポイントサービスとインターフェースエンドポイントをつなげること」=「PrivateLink」という感じなので、ちょっと分かりにくいなと感じた。
PrivateLinkとVPC Peeringの違い
AWSアカウント間接続には、どちらかを使うことになります
PrivateLink
比較的新しい方のサービスです。エンドポイントへのアクセスを別アカウントに飛ばします
接続元アカウントでエンドポイントを作成し、
- 許可する接続先のAWSサービス(例、com.amazonaws.ap-northeast-1.rds-data)
- 接続元のサブネット
- 許可する通信のSG(security group)
を設定してアクセス権限を管理します
エンドポイントごとにSGが紐づくため、「どこに対して」「どの通信を」許可しているのかが明示しやすいです。
そのため「想定外の通信を許可してしまっていた」ことが起こりにくいです接続先の指定はIPレンジではなく接続先エンドポイントの種類(例えばcom.amazonaws.ap-northeast-1.rds-data)
と対象リソースのarn(アカウントID情報を含む)で指定することになります
そのため複数の接続先とピアリングするケースで、接続先のIPレンジが被っていても問題ありません
接続元エンドポイントがリバースプロキシのように働き、接続を仲介していそうです料金
東京リージョンでは、インターフェースエンドポイントの場合
基本料金:0.014 * 24 * 30→10$/月
に加えて、下記がかかります
ネットワーク料金:10$/1TB
https://aws.amazon.com/jp/privatelink/pricing/VPC Peering
比較的古い方のサービスです。VPC同士をくっつけます
接続元アカウントのVPCのルートテーブルに対して、
特定のIPレンジ(例えば、22.192.0.0/16)に対する通信をピアリングに対して接続するようにさせます。
ピアリングはそのアクセスを別VPC(別アカウントや別リージョンでも良い)の同じIPアドレスに対して飛ばします。従って、接続元・接続先の間(または接続先と別の接続先)の間でIPレンジがバラけるようにする必要があります。
許可したいIPレンジに対するSGでのアクセス権限管理は、EC2インスタンス等に個別に付与することになります。
そのため、中央集権的なアカウント(弊社でいうとメインのサービスが乗っているアカウント)から見たときに、権限の統制がしづらいため、セキュリティが厳しい領域においてはあまり好まれません料金
Peering自体に料金は掛かりません
EC2と同じようにネットワーク間通信量のみがかかります
https://aws.amazon.com/jp/vpc/faqs/#Peering_Connections:~:text=Q%3AVPC%20%E3%83%94%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E6%8E%A5%E7%B6%9A%E3%81%AE%E6%96%99%E9%87%91%E3%81%AF%E3%81%84%E3%81%8F%E3%82%89%E3%81%A7%E3%81%99%E3%81%8B%3FAssume Role
異なるアカウントのリソースに対するアクセスには、
先に接続先アカウントでIAM roleを作成しておき、Assume Roleでそのroleを引き受けることになります
(直接元アカウントのIAMにアクセス許可させることはできません)接続元IAM
下記のようなcfn(cloud formation)テンプレートになります
ServiceUser: Type: AWS::IAM::User Properties: Path: "/" Policies: - PolicyName: "assume-for-rds-data" PolicyDocument: Version: '2012-10-17' Statement: - Sid: AssumeRdsData Effect: Allow Action: - sts:AssumeRole Resource: arn:aws:iam::YOUR_AWS_ACCOUNT_ID:role/DataApiAccessRole接続先IAM
DataApiAccessRole: Type: AWS::IAM::Role Properties: RoleName: DataApiAccessRole AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Action: "sts:AssumeRole" Principal: AWS: - "arn:aws:iam::接続元アカウントID:root" Policies: - PolicyName: "access-rds-data" PolicyDocument: # https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/data-api.html # https://aws.amazon.com/jp/premiumsupport/knowledge-center/secrets-manager-share-between-accounts/ Version: '2012-10-17' Statement: - Sid: SecretsManagerDbCredentialsAccess Effect: Allow Action: - secretsmanager:GetSecretValue Resource: arn:aws:secretsmanager:ap-northeast-1:接続先(KMS所有者)のアカウントID:secret:secretの名前 - Sid: CMKDecrypt Effect: Allow Action: - kms:Decrypt - kms:DescribeKey Resource: arn:aws:kms:ap-northeast-1:接続先(KMS所有者)のアカウントID:key/鍵のID - Sid: RDSDataServiceAccess Effect: Allow Action: - secretsmanager:ListSecrets, - secretsmanager:GetRandomPassword, - tag:GetResources, - rds-data:BatchExecuteStatement - rds-data:BeginTransaction - rds-data:CommitTransaction - rds-data:ExecuteStatement - rds-data:RollbackTransaction Resource: "*"data-apiの仕組み
data-apiとはsql接続をhttpsを通して行うAWSの仕組みのことです
data-apiをauroa serverlessで利用するには、コンソールからdata-apiを有効化する必要があります(cfnではできない)利用側はsqlドライバが不要で、認証もsecret manager経由のIAMで行うため鍵管理が不要です
コネクション管理も自動でやってくれて、同時接続への耐性が高いようです
(ただそれでもバッチを並列実行させて大量に叩くと重くなりましたが)
https://speakerdeck.com/iwatatomoya/aurora-serverlessfalsedata-apinituite?slide=16
https://dev.classmethod.jp/articles/how-data-api-manage-connection-pooling/secret manager
secret managerとはDBの鍵やIAMユーザのsecretなど、
隠さないとまずいものを保管してIAMで取得できるようにしてくれるサービスですCMK鍵とsecretがあり、CMK鍵を使ってsecretを施錠するイメージです
default鍵もありますが、他アカウントからアクセスさせる場合は、権限管理上新規に作ったほうがいいですCMK鍵1つにつき1$/月と、量に応じた料金がかかります
https://aws.amazon.com/jp/kms/pricing/#Key_Storage:~:text=%E3%82%AD%E3%83%BC%E3%82%B9%E3%83%88%E3%83%AC%E3%83%BC%E3%82%B8%E3%81%AE%E6%9C%88%E9%A1%8D%201%20USD%20%E3%81%8Cdata-api周りの設定
クロスアカウントだといろいろ複雑です
下記手順が必要です1.接続先のsecret managerで新規のCMK鍵を作る
2.CMK鍵の設定にて接続元アカウントからのアクセスを許可します
{ "Version": "2012-10-17", "Id": "key-consolepolicy", "Statement": [ { "Sid": "Enable IAM User Permissions", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::接続先(KMS所有者)のアカウントID:root" }, "Action": "kms:*", "Resource": "*" }, { "Sid": "Allow use of the key", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::接続元アカウントID:root", ] }, "Action": [ "kms:Decrypt", "kms:DescribeKey" ], "Resource": "arn:aws:kms:ap-northeast-1:接続先(KMS所有者)のアカウントID:key/鍵のID" } ] }3.CMK鍵を使って、secretを作る
secretにはDBのユーザとパスワードを格納します4.secretの設定にてASSUMEされる接続先IAMからのアクセスを許可
{ "Version" : "2012-10-17", "Statement" : [ { "Effect" : "Allow", "Principal" : { "AWS" : [ "arn:aws:iam::接続先(KMS所有者)のアカウントID:user/ASSUMEされるIAM" ] }, "Action" : "secretsmanager:GetSecretValue", "Resource" : "*", "Condition" : { "ForAnyValue:StringEquals" : { "secretsmanager:VersionStage" : "AWSCURRENT" } } } ] }5.接続先アカウントにDBに接続できる権限のIAMを作る
6.接続元アカウントに上記にassumeできるIAMを作る
7.接続元アカウントでエンドポイントを作成する
https://dev.classmethod.jp/articles/rds-data-api-now-supports-aws-privatelink/
その際、セキュリティグループをattachする。権限はhttpsのin-outを最低限許可する8.接続元・接続先双方のサブネットで該当のhttps通信がNetworkACLで遮断されないことを確認する
まとめ
Aurora Serverlessに対してdata-api接続をするだけならマニュアル通りにできるのですが、
異なるアカウントとなると直接書いてあるドキュメントが見当たらなかったのでまとめてみました
IAM周りがややこしいですねちなみにSQLAlchemyのdata-api接続用のプラグインもあります
https://pypi.org/project/sqlalchemy-aurora-data-api/

- 投稿日:2020-11-30T18:07:49+09:00
KubernetesのSecret情報をExternalSecretとAWS Secrets Managerで安全に管理する方法
はじめに
セゾン情報システムズ Advent Calendar 2020
2日目を担当させていただきます。よろしくお願いいたします!本記事では、以下を使用することで、機密情報をマニフェストファイルに記載することなく安全に管理する方法を紹介いたします。
Amazon EKS
AWS で Kubernetes を簡単に実行できるマネージド型の Kubernetes サービス
https://aws.amazon.com/jp/eks/ExternalSecret
kubernetesのSecretを安全に管理するためのオープンソースソフトウェア
https://github.com/external-secrets/kubernetes-external-secretsAWS Secrets Manager
秘匿情報をAWS上に保管し、APIコールで取得できるサービス
https://aws.amazon.com/jp/secrets-manager/概要
kubernetes上に作成されたExternalSecretリソースが、外部のSecretManagerに登録されている情報を読み取り、Secretリソースを作成します。
Secretリソースとして登録するKey名と、外部のSecretManagerに登録されているデータの参照情報で秘匿情報を取得できるため、
機密情報をマニフェストファイルに記載する必要はありません!手順
AWS Secrets Managerに登録されている秘匿情報を取得する手順を記載いたします。
サービスアカウントへのIAM権限付与設定
AWSリソースへアクセスするための権限をpod単位で付与したかったので、「IAM Roles for Service Accounts」の仕組みを使用
IAM IDプロバイダ作成
Kubernetes サービスアカウントでIAMロールの権限を使用するために、まずは以下のコマンドでOIDC IDプロバイダを作成
eksctl utils associate-iam-oidc-provider --cluster {CLUSTER_NAME} --approve --region ap-northeast-1IAMロール作成
既存のAWSのポリシーに「SecretsManagerReadWrite」があるので、そのポリシーを付与したIAMロールを作成し、
上記で作成したOIDC IDプロバイダのIDを信頼関係に設定{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::{AWS_ACCOUNT_ID}:oidc-provider/oidc.eks.ap-northeast-1.amazonaws.com/id/{PROVIDER_ID}" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "oidc.eks.ap-northeast-1.amazonaws.com/id/{PROVIDER_ID}:aud": "sts.amazonaws.com" }, "StringLike": { "oidc.eks.ap-northeast-1.amazonaws.com/id/{PROVIDER_ID}:sub": "system:serviceaccount:default:*" } } } ] }※「*」を使用する場合は、「StringEquals」ではなく「StringLike」を使用する必要あり!
AWS Secrets Managerで秘匿情報登録
e.g.
シークレット名:test-credentials
値:{"username":"admin","password":"admin123"}以下のようにAWS CLIで作成
aws secretsmanager create-secret --region ap-northeast-1 --name test-credentials --secret-string '{"username":"admin","password":"admin123"}'ExternalSecretリソース作成
helmでExternalSecretのリポジトリを追加
(リポジトリは最近移動したらしい -> 関連記事)helm repo add external-secrets https://external-secrets.github.io/kubernetes-external-secrets/helm installでExternalSecretリソースを作成
helm install {RELEASE_NAME} external-secrets/kubernetes-external-secrets --skip-crds \ --set securityContext.fsGroup=65534 \ --set nodeSelector."alpha\.eksctl\.io/nodegroup-name"={NODE_GROUP_NAME} \ --set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"='arn:aws:iam::{AWS_ACCOUNT_ID}:role/{ROLE_NAME}' \ --set env.AWS_REGION='ap-northeast-1' \ --set env.AWS_DEFAULT_REGION='ap-northeast-1'securityContext.fsGroup=65534 :
シークレット情報にアクセスするためのtokenファイルに、rootユーザー以外のユーザーがアクセスできるようにするための設定
(起動したpodのユーザーはrootではないため必要な設定)nodeSelector :
指定したNodeにpodを起動させたかったので設定serviceAccount.annotations :
サービスアカウントでIAMロールの権限を使用するための設定、上記で作成したIAMロールを指定その他オプション等については以下参照
https://artifacthub.io/packages/helm/external-secrets/kubernetes-external-secretsSecret Managerから秘匿情報取得
以下のyamlをkubectlでapply
externalSecret.yamlapiVersion: kubernetes-client.io/v1 kind: ExternalSecret metadata: name: test-external-secret spec: backendType: secretsManager data: - key: test-credentials #SecretManagerのシークレット名 name: username #変数名 property: username #取得したい値のキー$ kubeclt apply -f externalSecret.yaml $ kubectl get externalsecret NAME LAST SYNC STATUS AGE test-external-secret 2s SUCCESS 34h以下のコマンドで取得した秘匿情報の確認も可能
↓結果抜粋↓(値はbase64でエンコードされてます)$ kubectl get secret test-external-secret -o yaml data: username: YWRtaW4K password: YWRtaW4xMjMK :上記の秘匿情報を使用する場合は以下のようにyamlに環境変数を定義することで使用可能
env: - name: TEST_VALUE valueFrom: secretKeyRef: name: test-external-secret #ExternalSecretのmetadata.name key: username #ExternalSecretのspec.data.name

- 投稿日:2020-11-30T17:07:36+09:00
Amazon SNS で SMS を送信出来ないときに確認するところ
はじめに
DX 技術本部の yu-yama@sra です。
Amazon SNS を使用して VPC エンドポイント越しに SMS を送信しようとしたところ、
ややハマりしたので備忘メモを残します。構成図
TL;DR
- SMS を送信する AWS リソースに設定している IAM ロールのポリシーに aws:SourceIp を使用していないか確認しましょう
- SMS メッセージの送信に支払うことのできる上限額 (USD)を超えていないか確認しましょう
ハマりその1 - 権限
AWS リソースに IAM ロールをアタッチして VPC エンドポイント越しに SMS の送信を試みていたが、権限エラーが発生しており、修正前ポリシーの設定は以下のようになっていた。
修正前ポリシー{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sns:ListPhoneNumbersOptedOut", "sns:Publish", "sns:SetSMSAttributes", "sns:GetSMSAttributes", "sns:OptInPhoneNumber", "sns:CheckIfPhoneNumberIsOptedOut" ], "Resource": "*", "Condition": { "IpAddress": { "aws:SourceIp": "{AWSリソースの存在するサブネットのIPアドレスレンジ}" } } } ] }調べたところ、
リクエスト実行元が Amazon VPC エンドポイントを使用するホストである場合、aws:SourceIp キーは使用できません。
引用:AWS グローバル条件コンテキストキー - AWS Identity and Access Managementとのことで aws:SourceIp キーが使えないらしいので、以下のように修正
修正後ポリシー{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sns:ListPhoneNumbersOptedOut", "sns:Publish", "sns:SetSMSAttributes", "sns:GetSMSAttributes", "sns:OptInPhoneNumber", "sns:CheckIfPhoneNumberIsOptedOut" ], "Resource": "*" } ] }すると、権限エラーが返却されなくなった
ハマりその2 - メッセージ送信上限額
上記権限問題修正後、メッセージ送信で
200 statusが返却されているのに SMS が届かない事象に遭遇。修正前JavaコードMap<String, MessageAttributeValue> smsAttributes = new HashMap<String, MessageAttributeValue>(); smsAttributes.put("AWS.SNS.SMS.SenderID", new MessageAttributeValue() .withStringValue("mySenderID") //The sender ID shown on the device. .withDataType("String")); smsAttributes.put("AWS.SNS.SMS.MaxPrice", new MessageAttributeValue() .withStringValue("0.50") //Sets the max price to 0.50 USD. .withDataType("Number")); smsAttributes.put("AWS.SNS.SMS.SMSType", new MessageAttributeValue() .withStringValue("Promotional") //Sets the type to promotional. .withDataType("String"));AWSの提供しているAWS SDK for Java で、メッセージ属性値(上限価格を 0.50 USD、SMS 型をプロモーション)を設定しSMS メッセージを送信するサンプルコードまんまなのだが届かない。
ログを出力し確認したところ、
送信時刻に出力されていたログ{ "notification": { "messageId": "12345-6789-0123-456789012345", "timestamp": "2020-12-25 00:00:00.000" }, "delivery": { "numberOfMessageParts": 10, "destination": "+819012345678", "priceInUSD": 0.7451, "smsType": "Promotional", "providerResponse": "This delivery would exceed max price", "dwellTimeMs": 317, "dwellTimeMsUntilDeviceAck": 862 }, "status": "FAILURE" }
"This delivery would exceed max price"と最大価格を超えている旨のメッセージが出力されていた...
現在0.5なので1に修正修正後JavaコードMap<String, MessageAttributeValue> smsAttributes = new HashMap<String, MessageAttributeValue>(); smsAttributes.put("AWS.SNS.SMS.SenderID", new MessageAttributeValue() .withStringValue("mySenderID") //The sender ID shown on the device. .withDataType("String")); smsAttributes.put("AWS.SNS.SMS.MaxPrice", new MessageAttributeValue() .withStringValue("1.00") //Sets the max price to 1.00 USD. .withDataType("Number")); smsAttributes.put("AWS.SNS.SMS.SMSType", new MessageAttributeValue() .withStringValue("Promotional") //Sets the type to promotional. .withDataType("String"));すると、めでたく無事に送信されました...
まとめ
サンプルコードを無思考で使用するのはやめましょう
- サンプルコードはあくまでサンプルなので確実に動くことを保証するものではありません。使用する際は何を行っているか理解した上で使用しましょう。
ログをちゃんと読みましょう
- まずはログを読むこと。
ごくごく基本的なことが出来ていないためのハマりでした。基本は大切。

- 投稿日:2020-11-30T17:00:47+09:00
Amazon Connect Voice ID とAmazon Connect Wisdom がプレビュー公開されました!!
はじめに
この記事は株式会社ナレッジコミュニケーションが運営する Amazon AI by ナレコム Advent Calendar 2020 の 17日目にあたる記事になります。
Amazon Connect Voice ID とAmazon Connect Wisdom がプレビュー公開されることが発表されましたね!
私もさっそくこれらのサービスを検証するべくプレビュー申請をしてきました!Amazon Connect Voice ID とは?
いままでコールセンターに電話をした時に、本人確認のために生年月日やお客様番号などを聞かれることが多かったのではないでしょうか?
この煩わしいプロセスがなくなればユーザーにとっても職員にとっても嬉しいですよね。
Voice ID は機械学習を利用してリアルタイムで発信者認証を行うことで、
電話したら気づかぬうちに本人確認終わっていたという驚異のユーザー体験を提供することができます。Voice ID の認証プロセス
認証プロセスは非常にシンプルかつシームレスです。
ユーザーの音声通話をもとにユーザー固有の音声認証(Voice ID)を登録
※登録には30秒程度の通話が必要です。
↓
Voice ID 登録後に再度電話すると、対話型の自動音声かエージェントとの会話中に本人確認を実施
※本人確認には10秒程度の通話が必要です。
※本人確認の結果は信頼性を示す認証スコアとして 0 〜 100 で返されます。
※認証スコアが一定以下ならエージェントが口頭で本人確認を実施といった利用が可能です。Amazon Connect Wisdom とは?
ユーザーのお問い合わせに回答する場合、情報の検索に時間を要することがあったのではないでしょうか?
Amazon Connect Wisdom を利用すれば、エージェントがユーザーの課題を解決するための必要な情報を機械学習によって効率的に検索することができます。また会話から自動で課題を検出するContact Lens for Amazon Connect と併用することで、エージェントは検索操作せずとも必要な情報にアクセスすることが可能になります。
料金
Amazon Connect Voice ID とAmazon Connect Wisdom のどちらも現時点で利用料金は公表されていません。
プレビュー登録のやり方
プレビューを申し込むには、
以下のサイトにある"プレビューにサインアップ"をクリックしてください。
Amazon Connect Voice ID
Amazon Connect Wisdom
上記のような画面に変遷するはずです。それぞれの欄を埋めていきましょう。
登録申請が完了すると上記のメールが届きます。
結果が分かるまで時間がかかるので気長に待ちましょう。おわりに
今回は残念ながらプレビュー登録の結果が間に合わなかったため、実際に使用できませんでした。
プレビュー申請が通り次第、実際のレビュー記事を執筆していきたいと思います。
次回をお楽しみに!



- 投稿日:2020-11-30T16:58:10+09:00
Amazon Textract でポール・マッカートニーの直筆歌詞を文字起こしする
はじめに
この記事は株式会社ナレッジコミュニケーションが運営する Amazon AI by ナレコム Advent Calendar 2020 の 3日目にあたる記事になります。
この度、Amazon Textract がスペイン語、イタリア語、フランス語、ポルトガル語、ドイツ語のOCR(光学文字認識)と英語の手書きドキュメントからのOCRが可能になりました。
今回は新機能である英語の手書きドキュメントからのOCRを検証してみます!Amazon Textract とは?
Amazon Textract はスキャンしたドキュメントから印刷されたテキスト(英語、スペイン語、ポルトガル語、フランス語、ドイツ語、イタリア語)、
手書きの文字(英語のみ)を自動抽出するフルマネージド型の機械学習サービスです。また構造化されたデータの関連付けを保ったまま自動的に検出することができます。
引用:https://aws.amazon.com/jp/textract/Amazon Textract の利用料金
利用料金は以下となっています。
※東京リージョン非対応のためバージニアリージョンで計算Detect Document Text API (OCR)
※文書から印刷されたテキストと手書きの文字を抽出する機能
無料利用枠:月に 1,000 ページまでは無料(最初の3か月のみ)
1か月あたり ページあたりの料金 1,000 ページあたりの実質料金 最初の 100 万ページ 0.0015USD 1.50USD 100 万ページ超 0.0006USD 0.60USD Analyze Document API
※表を含む文書から文字を抽出する機能
無料利用枠:月に 1,00 ページまでは無料(最初の3か月のみ)
1か月あたり ページあたりの料金 1,000 ページあたりの実質料金 最初の 100 万ページ 0.015USD 15.00USD 100 万ページ超 0.01USD 10.00USD 検証内容
ビートルズ往年の名曲”Hey Jude”の手書き歌詞を文字起こしします。
”Hey Jude”は当時ジョン・レノンと最初の妻シンシア・レノンの離婚が決定的になり、精神的に不安定になっていたジョン・レノンの息子ジュリアン・レノンを慰めるためにポール・マッカートニーが書いた曲です。
YouTube動画:https://www.youtube.com/watch?v=A_MjCqQoLLA&list=PLi6stywEyD2KQLYZti2sXP7DGCWqGKkWI&index=30&t=0sレコーディング用楽譜類譜がロンドンで1996年にオークションに出された際には、
ジュリアンが「ポールが僕のために書いてくれた曲だから」として2万5千ポンド(約350万円)で落札しました。
引用:https://ja.wikipedia.org/wiki/%E3%83%98%E3%82%A4%E3%83%BB%E3%82%B8%E3%83%A5%E3%83%BC%E3%83%89分析に利用する画像
今回は2020年に91万ドル(約9800万円)で落札されたポール・マッカートニー直筆の歌詞原稿を利用します。
この原稿は1968年にロンドンでのレコーディングに使われたもので、黒のペンによる筆記体で歌詞や番号が書かれており「BREAK」といったメモ書きも残されています。
引用:https://www.cnn.co.jp/showbiz/35152283.html検証結果
コンソールにサインインしてサービスからAmazon Textract にアクセスします。
(東京リージョンはサポートしていません)
"ドキュメントのアップロード"から対象画像をアップロードし、完了したら"結果をダウンロードする"から出力フォルダを入手します。
ZIPフォルダを解凍すると上記のファイルを入手できます。
"rawText"を開くと上記の出力を確認できました。ほぼ完璧ですね。
続いてapiResponse.jsonからAPIのレスポンスを確認してみます。apiResponse.json{ "BlockType": "LINE", "Confidence": 99.11865234375, "Text": "Hey Jude don't make it bad", "Geometry": { "BoundingBox": { "Width": 0.6866654753684998, "Height": 0.052347924560308456, "Left": 0.09252239763736725, "Top": 0.06466802954673767 }, "Polygon": [ { "X": 0.09396231919527054, "Y": 0.06466802954673767 }, { "X": 0.7791878581047058, "Y": 0.07248140126466751 }, { "X": 0.7777479887008667, "Y": 0.11701595038175583 }, { "X": 0.09252239763736725, "Y": 0.10920257866382599 } ] },一部抜粋ですが認識したテキスト、信頼度、座標などといったインサイトを得ることができます。素晴らしいですね。
また今回は無料利用枠の範囲内なので安心して検証できました。皆さんもお好きな画像で是非お試しください!おわりに
今回、読みにくい走り書きの文書でも高い精度で認識できました。
現状Amazon Textract はまだ日本語に未対応ですが、いずれくるであろう日本語の対応が待ち遠しいですね!






- 投稿日:2020-11-30T16:54:35+09:00
Amazon Data Lifecycle Manager (DLM) でAMIライフサクル管理
概要
2020/11/09のアップデートで、「Data Lifecycle Manager で AMI ライフサイクル管理が利用可能に」の発表がありました。
DLMでAMIバックアップを試してみたいと思います。Data Lifecycle Manager で AMI ライフサイクル管理が利用可能に
Amazon Data Lifecycle Manager とは
EBSスナップショットとAMIの作成、保存、削除を自動化してくれる機能です。
【小ネタ】
2020/11/27時点で日本語公式サイトは更新されていませんでした。
最新情報は英語版を確認しましょう。
日本語
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/snapshot-lifecycle.html
英語
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/snapshot-lifecycle.htmlやってみた
マネジメントコンソールからEC2の管理画面を開き、左メニューの「ライフサイクルマネージャー!をクリックします。
「ライフサイクルポリシーを作成」ボタンを押します。
ライフサイクルポリシー作成画面に移動するので、ポリシータイプを「EBS-backed AMIポリシー」を選択、説明、ターゲットとなるタグを指定します。
IAMロールは、デフォルトロールを選択
※ 既にロールが存在する場合は、別のロールを選択でもOK
ポリシースケジュール1に「スケジュール名」、「頻度」、「取得間隔」、「開始時間」、「保持タイプ」、「保持する」を設定します。
サンプルでは1時間ごとに3世代保持と設定しました。
取得したバックアップに追加で設定するタグを指定します。
クロスリージョンコピーの設定をします。
(オプション)なので指定しなくても良いが検証のため設定しました。
最後にインスタンスの再起動の実施、作成後のポリシーステータスを指定し、「ポリシーの作成」ボタンを押します。
以下のような成功メッセージが表示されればライフサイクルポリシーの作成が完了です。
設定後の確認
しばらく待ちます・・・
東京リージョン
想定通り、1時間ごとに3世代AMIバックアップを取得できていました。
ソウルリージョン
クロスリージョンコピー先ですが、こちらは履歴管理はしてくれない模様です。
確かに設定はないですが、長時間放置したら、273個もAMIバックアップがコピーされていました。。。
クロスリージョンコピーを指定する場合は注意が必要そうです。
所感
数年前にEBSスナップショットのライフサイクルが取得可能となり、今回、AMIでも利用可能となりました。
以前は、Shell、Cronなど。その次にLambdaなどで自前実装していたため、機能として実装されると非常に楽になったなぁと感じました。誰かのご参考になれば幸いです。











- 投稿日:2020-11-30T14:53:30+09:00
node.jsとserverlessを使ってlambdaでアプリを動かす -複数の関数をlambdaにアップする-
前回までのあらすじ
node.jsとserverlessでローカル環境のコードをlambdaにアップできましたとさ
目的
ローカル環境で作成した複数の関数をLambdaにアップして動かしたい
実践
環境
node.js v12.18.2
ディレクトリ構成
ls -a . .gitignore node_modules package.json .. handler.js package-lock.json serverless.ymlpackage.jsonの確認
{ "name": "application-no-namae-desu", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC", "dependencies": { "serverless": "^2.13.0" } }handler.js
'use strict'; module.exports.hello = async event => { return { statusCode: 200, body: JSON.stringify( { message: 'Go Serverless v1.0! Your function executed successfully!', input: event, }, null, 2 ), }; // Use this code if you don't use the http event with the LAMBDA-PROXY integration // return { message: 'Go Serverless v1.0! Your function executed successfully!', event }; };前回までの状態を確認できたので、複数の関数をLambdaで使えるようにしていく。
handler.jsで複数エクスポートできるようにする
handler.jsを以下のように修正'use strict'; async function hello() { return { statusCode: 200, body: JSON.stringify( { message: "Go Serverless v1.0! Your function executed successfully!", }, null, 2 ), }; }; // bonjour関数を追加、メッセージをフランス語にする async function bonjour() { return { statusCode: 200, body: JSON.stringify( { message: "Passez à la v1.0 sans serveur! Votre fonction s'est exécutée avec succès!", }, null, 2 ), }; }; module.exports = { hello, bonjour };Lambdaの関数として使用するためには、Lambdaファンクションの設定を行わなければならない。
設定はserverless.ymlで行う。serverless.ymlの設定
service: application-no-namae-desu frameworkVersion: '2' provider: name: aws runtime: nodejs12.x functions: hello: handler: handler.hello # ここを追加 bonjour: handler: handler.bonjourbonjour関数をローカルで実行
sls invoke local --function bonjour Serverless: Running "serverless" installed locally (in service node_modules) { "statusCode": 200, "body": "{\n \"message\": \"Passez à la v1.0 sans serveur! Votre fonction s'est exécutée avec succès!\"\n}" }いけそうなので、AWSにデプロイしよう。
AWSにデプロイ
serverless deploy --region ap-northeast-1デプロイした関数を実行
sls invoke --function hello --region ap-northeast-1 Serverless: Running "serverless" installed locally (in service node_modules) { "statusCode": 200, "body": "{\n \"message\": \"Go Serverless v1.0! Your function executed successfully!\"\n}" }sls invoke --function bonjour --region ap-northeast-1 Serverless: Running "serverless" installed locally (in service node_modules) { "statusCode": 200, "body": "{\n \"message\": \"Passez à la v1.0 sans serveur! Votre fonction s'est exécutée avec succès!\"\n}" }おしまい
- 投稿日:2020-11-30T13:56:59+09:00
CodeBuildのプロビジョニングフェーズでdocker pullの制限を回避する
こんにちは
株式会社Diverseで働いている@python_spameggsです
Diverse Advend Calendar 2020の初日になります
CodeBuildのプロビジョニングフェーズでdocker pullの制限でエラーになってしまうことが多くなってきたのでSecrets Managerを使用して解決しましたCodeBuildのプロビジョニングフェーズでのエラー
- このようにエラーになってしまいます
- プロビジョニングフェーズでのエラーなのでbuildspecにdocker loginを設定しても意味がないので別の方法で回避します
Secrets Managerを使う
シークレットの種類は「その他のシークレット」を選択します
キーは
usernameとpasswordで値はdockerhubのユーザ名とパスワードになります
- 暗号化キーは使いたいものを選ぶ

次に進んでシークレットの名前と説明を入れます
次に進んでシークレットの自動ローテーションを設定します
- 設定は無効にする

後はレビューして問題なければ保存して作成したシークレットを選択して詳細を見ます
シークレットのARNをコピーします
- ↑で作ったシークレットの名前と違います、sampleです
CodeBuildへ
- ビルドプロジェクトのビルドの詳細から環境の項目を編集します
- イメージを上書きを選択すると↓の項目が出てくるので先程コピーしたシークレットのARNをペーストします
- 残りの空いている項目は今まで通りのものを入れて環境の更新をしてください

- これで完了ですので再度ビルドしてエラーにならないことを確認しましょう
aws-cliで更新する
Secrets Managerに登録
secret.json{ "username": "dockerhubのユーザ名", "password": "dockerhubのパスワード" }aws secretsmanager create-secret --name dockerhub --secret-string file://secret.jsonCodeBuildの更新をする
- 現在の設定を取得する
aws codebuild batch-get-projects --names プロジェクト名 > project-info.json
- project-info.jsonにSecrets ManagerのARNを追加する
"registryCredential": { "credential": "作成したSecrets ManagerのARNを入れる", "credentialProvider": "SECRETS_MANAGER" }
- プロジェクトを更新する
aws codebuild update-project --cli-input-json file://project-info.json
- これで完了です
おわり
これでCodeBuildを使うたびにdocker pullの制限でエラーになってしまうことを回避することができました
明日の2日目は@masashi-sutouさんになります!




- 投稿日:2020-11-30T13:35:42+09:00
node.jsとserverlessでローカル環境のコードをlambdaにアップする
はじめに
node.jsで作成したアプリをサーバーレスで動かしたい。
環境
node.js v12.18.2
Lambda関数の作成
ディレクトリ作成
mkdir serverless-node-sample cd serverless-node-samplenpmの初期化
npm initServerlessのインストール
npm install serverless --saveServerlessの動作確認
バージョン確認
sls -v以下のように表示されればOK
Framework Core: 2.13.0 (local) Plugin: 4.1.2 SDK: 2.3.2 Components: 3.4.2Serverlessのテンプレート生成
今回はnode.jsを使うので
aws-nodejsを使用、他にもpythonやruby用のテンプレートが用意されている
コマンド実行後、handler.jsserverless.yml.gitignoreが生成されるserverless create --template aws-nodejsディレクトリ構成の確認
確認
ls -aきっとこうなっているはず
. .gitignore node_modules package.json .. handler.js package-lock.json serverless.ymlローカルでの動作確認
今回のメインファイルとなる
handler.jsの中身を確認。
うまくいけばGo Serverless v1.0! Your function executed successfully!が表示するはず。'use strict'; module.exports.hello = async event => { return { statusCode: 200, body: JSON.stringify( { message: 'Go Serverless v1.0! Your function executed successfully!', input: event, }, null, 2 ), }; // Use this code if you don't use the http event with the LAMBDA-PROXY integration // return { message: 'Go Serverless v1.0! Your function executed successfully!', event }; };早速コマンドから実行する。
sls invoke はデプロイされた関数を呼び出すコマンド、sls invoke localにしてあげると、ローカル環境で関数を呼び出す。sls invoke local --function helloおお、表示された
Serverless: Running "serverless" installed locally (in service node_modules) { "statusCode": 200, "body": "{\n \"message\": \"Go Serverless v1.0! Your function executed successfully!\",\n \"input\": \"\"\n}" }AWSにアクセスするための設定
AWSにアクセスするコマンドを叩く。
aws_access_key_idaws_secret_access_keyはお手持ちのAWSアカウントから取得してもらえれば。serverless config credentials --provider aws --key aws_access_key_id --secret aws_secret_access_key補足:IAM ユーザーのアクセスキーとクレデンシャル情報の取得
AWSマネジメントコンソールの「サービスを検索する」という入力欄で「IAM」と入力すればIAMダッシュボードのページに飛びます。ページアクセス後はサイドバーのアクセス管理のタブからユーザーをクリック。あとはユーザーを追加して新しくアクセスキーを作成するもよし、既存のユーザーから取得するもよし。(詳しくはこちら)
AWSに関数をデプロイ
以下のコマンドでデプロイは完了
regionオプションはAWSの東京リージョンにアップするよっていう指定をしてくれる。serverless deploy --region ap-northeast-1デプロイした関数を実行
sls invoke --function hello --data Hello --region ap-northeast-1先ほどと同じ結果が帰ってきていればOK
{ "statusCode": 200, "body": "{\n \"message\": \"Go Serverless v1.0! Your function executed successfully!\",\n \"input\": \"Hello\"\n}" }以上です、やったぜ。
- 投稿日:2020-11-30T13:01:05+09:00
Amazon SageMakerで深層学習画風変換モデルのハイパーパラメータチューニングに挑戦してみた
この記事は、NTTテクノクロス Advent Calendar 2020の13日目です。
はじめまして。NTTテクノクロスの堀江と申します。
今年の弊社アドベントカレンダー執筆陣の中では最年少(現在入社4年目)となります。どうぞよろしくお願いします!業務では、パブリッククラウド上でのシステム設計や環境構築支援を担当しています。その関係もあって現在絶賛勉強中のAWSと、趣味で勉強している深層学習の2つを組み合わせた取り組みを本日は発表したいと思います。
目次
- はじめに
- 記事要約 - 調査の観点と成果
- 用語説明
- Neural Style Transferとは
- Amazon SageMakerとは
- 実施内容
- 環境構築
- 単発のトレーニングジョブを実行
- ハイパーパラメータチューニングを実行
- チューニング結果を比較
- おわりに
- Appendix
はじめに
TensorFlowで自作した画像生成深層学習モデル - Neural Style Transfer - のハイパーパラメータチューニングに、Amazon SageMakerを利用して挑戦してみました。
その結果得られた、Amazon SageMakerの使用方法に関するノウハウや、ハイパーパラメータチューニングの結果を本記事で展開していきます。
記事要約 - 調査の観点と成果
- Amazon SageMakerのトレーニングジョブやハイパーパラメータチューニングジョブって、そもそもどういう仕組みで実行されるの?
- 実際にトレーニングジョブとハイパーパラメータチューニングジョブを実行してみることで、データや処理の流れを理解できたので、自分なりに整理してみました。
- MNIST分類モデルのようなシンプルな構造のモデルだけじゃなく、画像生成モデルのような複雑な構造のモデルもAmazon SageMakerでトレーニングできるの?
- デフォルト設定のトレーニングジョブ実行時に遭遇したエラーと、その回避方法を記載しています。
- 例えばtf.functionとkerasが混在し、tf.Modulでクラス化されたような複雑な構造のモデルでも、トレーニングを実行することが出来ました。
- Neural Style Transferって、ハイパーパラメータチューニングの効果があるの?
- ハイパーパラメータをチューニングすることで、生成される画像の質が向上することを確認できました。(少なくとも自分の主観では…)
用語説明
本題に入る前に、重要な用語2つについては簡単にですが説明させてもらいます。
なお、「深層学習とは」「AWSとは」といった基本の部分については本記事での解説を省略させてもらいますのでご容赦ください。
Neural Style Transferとは
Neural Style Transfer(以降、長いのでnstとも省略します)とは、深層学習を利用した画像生成技術の一つです。
下記の例のように、ある画像の画風(スタイル)で、任意の別の画像(コンテンツ)の画風を変換することができます。
- 犬の写真をワシリー・カンディンスキーの画風(スタイル)で変換したデモgif動画1
- nstのサンプル作品集2
記事要約内では「自作の画像生成深層学習モデル」と誇張した表現を用いてしまいましたが…今回利用するnstモデルは、TensorFlowの公式サイトに載っているサンプルノートブックのコードを独自に(趣味で)リファクタリングしたものになります。数学的なアルゴリズムの詳細についても公式サイトに載っているので、興味のある方はそちらをご覧になってみてください。
今回使用するモデルのコード(一部を抜粋)class NstEngine(tf.Module): def __init__(self, content_shape, args, name=None): """ content_shape : コンテンツ画像のshape e.g. (1, 512, 512, 3) args : Namespaceオブジェクト。 """ super(NstEngine, self).__init__(name=name) # サンプノートブックの通り、VGG19を特徴量抽出器として利用する。 self.content_layers = ['block5_conv2'] self.style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1'] vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet') outputs = [ vgg.get_layer(target_layer).output for target_layer in self.content_layers + self.style_layers ] self.model = tf.keras.Model([vgg.input], outputs) self.model.trainable = False # tf.function内部では変数を宣言できないので、モデルの初期化時に # 変数も初期化しておく必要がある。 self.content_image = tf.Variable(tf.zeros(content_shape), dtype=tf.float32) self.loss = tf.Variable(tf.zeros((1)), dtype=tf.float32) self.style_image = None self.content_image_org = None self.style_image_org = None self.content_target = None self.style_target = None self.epoch = int(args.EPOCH) # 以下、後々チューニング対象になるハイパーパラメータ達 learning_rate = float(os.environ.get("SM_HP_LEARNING_RATE", args.LEARNING_RATE)) self.optimizer = tf.keras.optimizers.Adam( learning_rate=learning_rate, beta_1=0.99, epsilon=0.1, ) self.content_weights = float(os.environ.get("SM_HP_CONTENT_WEIGHTS", args.CONTENT_WEIGHTS)) self.style_weights = float(os.environ.get("SM_HP_STYLE_WEIGHTS", args.STYLE_WEIGHTS)) self.total_variation_weights = float(os.environ.get("SM_HP_TOTAL_VARIATION_WEIGHTS", args.TOTAL_VARIATION_WEIGHTS)) @tf.function def fit(self, content, style, content_org): """ 外部から呼び出されるエントリーポイント args: - content : 更新対象のコンテンツ画像 shape : (1, height, width, 3) - style : スタイル画像 shape : (1, height, width, 3) - content_org : オリジナルのコンテンツ画像 shape : (1, height, width, 3) return : - スタイル画像の画風で更新されたコンテンツ画像 shape : (1, height, width, 3) - loss値 shape : (1) """ self.content_image_org = content_org self.style_image_org = style self.content_image.assign(content) self.style_image = style self.content_target = self.call(self.content_image_org)['content'] self.style_target = self.call(self.style_image_org)['style'] for e in tf.range(self.epoch): self.loss.assign([self.step()]) return self.content_image, self.loss """ 以降の関数はサンプルノートブックの処理を流用。 詳細については省略 """ @tf.function def step(self): with tf.GradientTape() as tape: outputs = self.call(self.content_image) loss = self._calc_style_content_loss(outputs) loss += self.total_variation_weights*self._total_variation_loss() grad = tape.gradient(loss, self.content_image) self.optimizer.apply_gradients([(grad, self.content_image)]) self.content_image.assign(self._clip_0_1()) return loss def _calc_style_content_loss(self, outputs): style_outputs = outputs['style'] content_outputs = outputs['content'] style_loss = tf.add_n([ tf.reduce_mean((style_outputs[name] - self.style_target[name])**2) for name in style_outputs.keys() ]) style_loss *= self.style_weights / len(self.style_layers) content_loss = tf.add_n([ tf.reduce_mean((content_outputs[name] - self.content_target[name])**2) for name in content_outputs.keys() ]) content_loss *= self.content_weights / len(self.content_layers) loss = style_loss + content_loss return loss def _total_variation_loss(self): x_deltas, y_deltas = self._high_pass_x_y() return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas)) def _clip_0_1(self): clipped = tf.clip_by_value( self.content_image,clip_value_min=0.0, clip_value_max=1.0 ) return clipped def _high_pass_x_y(self): x_var = self.content_image[:, :, 1:, :] - self.content_image[:, :, :-1, :] y_var = self.content_image[:, 1:, :, :] - self.content_image[:, :-1, :, :] return x_var, y_var def call(self, input_image): input_image = input_image * 255. image = tf.keras.applications.vgg19.preprocess_input(input_image) outputs = self.model(image) content_outputs = outputs[:len(self.content_layers)] style_outputs = outputs[len(self.content_layers):] style_matrix = self._calc_gram_matrix(style_outputs) style_dict = { name: output for name, output in zip(self.style_layers, style_matrix) } content_dict = { name: output for name, output in zip(self.content_layers, content_outputs) } return {'style' : style_dict, 'content' : content_dict} def _calc_gram_matrix(self, input_tensors): results = [] for input_tensor in input_tensors: result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor) input_shape = tf.shape(input_tensor) num_locations = tf.cast(input_shape[1] * input_shape[2], tf.float32) results.append(result / num_locations) return results
Amazon SageMakerとは
Amazon SageMaker は、すべての開発者やデータサイエンティストが機械学習 (ML) モデルを迅速に構築、トレーニング、デプロイできるようにする完全マネージド型サービスです。SageMaker は高品質モデルの開発を容易にするため、機械学習の各プロセスから負荷の大きな部分を取り除きます。
Amazon SageMakerとは、その名の通りAWSが提供しているサービスの1つです。機械学習(特に深層学習)が必要とする高速かつ大規模な計算リソースを個人でも低コスト且つ気軽に利用することができます。
Amazon SageMakerのトレーニングジョブ環境はAWS側で管理してくれるため、EC2やECSを使用するよりも手軽にトレーニング環境を用意することがきで、かつ、コスト効率的に利用することが出来ます。(EC2やECSは仮想マシンが起動している時間で課金されるのに対し、SageMakerのトレーニング環境はトレーニングジョブが実行されている間のみ課金されます。)
Amazon SageMakerは機械学習モデルのトレーニング、チューニングに限らず、プロダクト開発者・研究者向けに様々な便利サービスを提供しています。しかし本記事ではあくまでもモデルのトレーニングとチューニング機能にのみフォーカスさせてもらいます。
実施内容
前置きが少々長くなりましたが…ここからが本題となります。nstモデルを実際にAmazon SageMakerでトレーニング、ハイパーパラメータチューニングしていきます。
環境構築
まずはSageMakerサービスの利用(クライアント)環境を、ローカルのMacBook(無印12インチ)上にDockerイメージとして構築していきます。
Amazon SageMakerでは、機械学習モデル開発に適した環境をAWS上に簡単に構築してくれるサービスも提供しています。必要なライブラリやJupyter環境がプレインストールされたノートブックインスタンスや、それに追加で更に統合開発環境的なユーティリティを備えたSageMaker Studio等です。
これらを使用する手もあるのですが、インスタンスに極力お金を掛けたくなかったのでオンプレ環境からもAmazon SageMakerのサービスを利用できるのか、今回ついでに確認したかったので、今回は使用しません。
Dockerイメージ
Dockerfile.dev# tensorflow 2.3.0をベースイメージとして使用。 # デフォルトでtensorboardも利用可能。 # 面倒だったので、GPU向けのイメージのみビルドします。 # GPU利用不可能な環境でも、特に不具合なく起動してくれるので。 FROM tensorflow/tensorflow:2.3.1-gpu USER root ENV PYTHONPATH=/app/notebook COPY ./src /app/notebook COPY ./keras /root/.keras COPY ./config /config # pipでsagemakerのSDKをインストールすることで、SageMakerサービスが利用可能になる。 RUN pip install --no-cache-dir \ matplotlib \ Pillow==7.1.1 \ boto3==1.14.44 \ sagemaker==2.16.1 \ jupyterlab # 念のためAWS CLIもインストール RUN curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" \ && unzip awscliv2.zip \ && ./aws/install \ && rm -fr awscliv2* RUN chmod +x /config/entrypoint.sh WORKDIR /app/notebook # コンテナ起動と同時にjupyterlabも立ち上がるようにエントリーポイントを作成 ENTRYPOINT ["/config/entrypoint.sh"]
docker-composeスタック
docker-compose-cpu.ymlversion: '2.4' services: notebook: image: notebook:dev # runtime: nvidia container_name: notebook hostname: notebook build: context: ./notebook dockerfile: ./dockerfile/Dockerfile.dev environment: - PYTHONPATH=/app/notebook - AWS_REGION=ap-northeast-1 volumes: - ./notebook/src:/app/notebook - ./notebook/config:/config - ./notebook/keras:/root/.keras - ~/.aws:/root/.aws # ホストマシン上のクレデンシャルを利用する ports: - "6006:6006" # tensorboard - "8888:8888" # jupyterlabあとはイメージをビルドしてコンテナを起動し、jupyterlab(
http://localhost:8888/)にアクセスすれば完了です。$ docker-compose -f docker-compose-cpu.yml build $ docker-compose -f docker-compose-cpu.yml up
CloudFormationスタック
AWS上に最低限用意する必要があるリソースは、モデルのトレーニング結果や訓練データを格納するためのS3バケットと、そのS3バケットにSageMakerがアクセスするためのIAMサービスロールのみです。
cloudformation.ymlAWSTemplateFormatVersion: 2010-09-09 Description: --- Parameters: BucketName: Description: a name for the bucket used by sagemaker Type: String Default: sagemaker-nst Resources: S3Bucket: Type: AWS::S3::Bucket Properties: BucketName: Ref: BucketName SageMakerExecRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - sagemaker.amazonaws.com Action: - sts:AssumeRole Path: / ManagedPolicyArns: - arn:aws:iam::aws:policy/AmazonSageMakerFullAccess Policies: - PolicyName: S3BucketAccessPolicy PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - "s3:GetObject" - "s3:PutObject" - "s3:DeleteObject" - "s3:ListBucket" Resource: Fn::Sub: 'arn:aws:s3:::${BucketName}' Outputs: S3Bucket4Train: Description: the s3 bucket used by sagemaker during training Value: Ref: BucketName SageMakerRole: Description: service role for sagemaker Value: Ref: SageMakerExecRole
単発のトレーニングジョブを実行
では、環境が構築できたので試しに1回、トレーニングジョブを実行してみます。
Amazon SageMakerの基本的なトレーニングジョブの流れは以下の通りです。
- ローカルのノートブック上で、モデルが定義されたトレーニングスクリプトを用意する
- ローカルのノートブック上でトレーニングの設定を定義する
- ローカルのノートブック上からトレーニングの実行をAmazon SageMakerにリクエストする
- ローカルのノートブック上から、トレーニングスクリプトをはじめとする、トレーニングに必要な資材がS3バケットにアップロードされる。
- AWS上でトレーニング環境(実態はコンテナ?)が起動し、必要なセットアップが為される。
- S3上のトレーニングスクリプトや訓練データがトレーニング環境にダウンロードされて、トレーニングスクリプトが実行される。この間トレーニングの進捗状況やスクリプト内でprintしたログはローカルのノートブック上やCloudWatchLogsに出力され続ける。
- 訓練中に生成されるデータ(TensorBoard用のログ等)や訓練が完了したモデルがトレーニング環境のファイルシステム上に出力される。
- トレーニングが完了したら、トレーニング環境のファイルシステム上に出力されたデータが、指定したS3バケットにアップロードされる。
- トレーニング環境が消滅する。
トレーニングジョブの具体例
- TrainingJob.ipynb
import json import boto3 import sagemaker from sagemaker.tensorflow import TensorFlow print("boto3 : ", boto3.__version__) print("sagemaker : ", sagemaker.__version__) # boto3 : 1.14.44 # sagemaker : 2.16.1# utilities get_s3_path = lambda *args: "s3://" + "/".join(args)# シークレット情報(アカウントID等)をノートブック上に貼りたくないので、 # ファイルに予め記載しておき、それを読み込む。 with open("./secrets.json", "r", encoding="utf-8") as fp: secrets = json.load(fp) role=secrets["RoleArn"] s3_bucket=secrets["S3Bucket"] print("S3 bucket for training : ", s3_bucket) # S3 bucket for training : sagemaker-nst# AWSとのセッションを確立する boto_session = boto3.Session(region_name="ap-northeast-1") sess = sagemaker.Session( # リージョンを東京リージョンに指定 boto_session=boto_session, # SageMkaerが使用するS3バケットを指定 default_bucket=s3_bucket, )# トレーニング設定の定義に必要なパラメータを用意 # トレーニングで使用されるデータのダウンロード元、 # トレーニングで生成されるデータのアップロード先となるS3のパスを指定 s3_train_path = get_s3_path(sess.default_bucket(), "train") # インスタンスタイプに"local"を指定すると、トレーニングジョブの実行環境のDockerイメージがpullされ、 # ローカル上でコンテナが起動しトレーニングが実行される # CPU、GPUともに安い価格帯のインスタンスを今回は使用する。 instance_types = {"CPU" : "ml.m5.large", "GPU" : "ml.g4dn.xlarge", "LOCAL" : "local"} # トレーニングスクリプトに渡したいパラメータ hyperparameters = { "EPOCH" : 50, "STEP" : 10, "MAX_IMAGE_SIZE" : 1024, "TB_BUCKET" : s3_train_path, "MAX_TRIAL" : 1, }# TensorFlowで書かれたモデルのトレーニングジョブ設定を定義 estimator = TensorFlow( # トレーニングスクリプト entry_point='train.py', # 指定したS3にSageMakerがアクセスするためのサービスロール role=role, # 起動されるインスタンス数 instance_count=1, # 起動されるインスタンスのタイプ instance_type=instance_types["GPU"], # トレーニングジョブ実行環境内で使用されるtensorflowのバージョン framework_version='2.3.0', # トレーニングジョブ実行環境内で使用されるPythonのバージョン py_version='py37', # トレーニング中のデバッグライブラリの使用を無効化。理由は後述 debugger_hook_config=False, # JSON形式で指定しtパラメータは、トレーニングジョブ実行時にコマンドライン引数としてトレーニングスクリプトに渡される。 hyperparameters=hyperparameters, # ユーザが指定したS3バケットやリージョンを使用したいので、カスタマイズしたセッション情報も渡す sagemaker_session=sess, # スポットインスタンスの使用を有効にする。nstモデルの場合、料金を約70%節約できる。 use_spot_instances=True, max_run=3600, max_wait=3600, )# トレーニングジョブを実行 # 指定したS3バケットのパスから訓練用データがトレーニングジョブ実行環境上に自動ダウンロードされる。 # デフォルト(logs="All")だとログが大量に出すぎるのでここでは抑制する。 estimator.fit( s3_train_path, job_name="TestSingleTrainingJob", logs="None", wait=False, )
- トレーニングスクリプト - train.py(一部を抜粋)
train.pydef _parse_args(): """ SageMakerは諸々のパラメータをコマンドライン引数または環境変数としてトレーニングスクリプトに渡してくるので、parseargでパラメータを取得可能。 return : Tuple(Namespace, List[str]) """ parser = argparse.ArgumentParser() # sagemakerが引数として渡してくるパラメータ parser.add_argument('--model_dir', type=str) parser.add_argument('--sm-model-dir', type=str, default=os.environ.get('SM_MODEL_DIR', "models")) parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAINING', "train")) parser.add_argument('--sm-output-dir', type=str, default=os.environ.get('SM_OUTPUT_DATA_DIR', "outputs")) parser.add_argument('--hosts', type=list, default=json.loads(os.environ.get('SM_HOSTS', "{}"))) parser.add_argument('--current-host', type=str, default=os.environ.get('SM_CURRENT_HOST', socket.gethostname())) # ユーザが設定したパラメータ。後々チューニングする予定 parser.add_argument('--CONTENT_WEIGHTS', type=float, default=10000) parser.add_argument('--STYLE_WEIGHTS', type=float, default=0.01) parser.add_argument('--TOTAL_VARIATION_WEIGHTS', type=float, default=30) parser.add_argument("--LEARNING_RATE", type=float, default=0.02) parser.add_argument("--STYLE_RESIZE_METHOD", type=str, default="original") # ユーザが設定したパラメータ parser.add_argument('--EPOCH', type=int, default=20) parser.add_argument('--STEP', type=int, default=25) parser.add_argument("--MAX_IMAGE_SIZE", type=int, default=512) parser.add_argument("--TB_BUCKET", type=str, default="") parser.add_argument("--MAX_TRIAL", type=int, default=25) return parser.parse_known_args() if __name__ =='__main__': # parse arguments args, _ = _parse_args() print(args) """ 以降、長いので省略 - 訓練データの前処理 - Tensorboardのロギングを設定 - nstを実行。 - モデルやnstされた画像の保存処理 """ returnトレーニングジョブを実行して5分ほど経過したら、AWS CLIでトレーニングジョブのステータスを確認してみます。
トレーニングジョブのステータスを確認$ aws sagemaker describe-training-job --training-job-name TestSingleTrainingJob | jq . { "TrainingJobName": "TestSingleTrainingJob", "TrainingJobArn": "arn:aws:sagemaker:ap-northeast-1:XXXXXXXXXXXX:training-job/testsingletrainingjob", "ModelArtifacts": { "S3ModelArtifacts": "s3://sagemaker-nst/TestSingleTrainingJob/output/model.tar.gz" }, "TrainingJobStatus": "Completed", "SecondaryStatus": "Completed", "HyperParameters": { "EPOCH": "50", "MAX_IMAGE_SIZE": "1024", "MAX_TRIAL": "1", "STEP": "10", "TB_BUCKET": "\"s3://sagemaker-nst/train\"", "model_dir": "\"s3://sagemaker-nst/tensorflow-training-2020-11-14-03-52-18-413/model\"", "sagemaker_container_log_level": "20", "sagemaker_job_name": "\"TestSingleTrainingJob\"", "sagemaker_program": "\"train.py\"", "sagemaker_region": "\"ap-northeast-1\"", "sagemaker_submit_directory": "\"s3://sagemaker-nst/TestSingleTrainingJob/source/sourcedir.tar.gz\"" }, ... }"TrainingJobStatus"が"Completed"と表示されいていることから、設定通りにジョブが実行され無事成功したことが確認できます。
最後に、トレーニングスクリプト内でS3に出力されたログをTensorboardで確認してみます。$ tensorboard --host 0.0.0.0 --port 6006 --logdir s3://sagemaker-nst/train/tensorflow-training-2020-11-14-03-52-18-413 2020-11-14 04:30:44.993654: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1 TensorBoard 2.3.0 at http://0.0.0.0:6006/ (Press CTRL+C to quit)
- TensorBoardでの、単発トレーニングジョブの確認結果3
無事、nstモデルのトレーニングジョッブ実行に成功しました。
余談ですが、TensorBoardのログディレクトリとしてS3バケット上のオブジェクトパスをダイレクトに指定できるということを、今回初めて知りました…。非常に便利ですね笑
トレーニングジョブ実行時に遭遇したエラーと、その回避方法
先述の具体例では、トレーニングジョブの定義時に
debugger_hook_config=False,という引数を指定しました(デフォルトではTrue)。この引数は、sagemaker-debuggerというライブラリを、Amazon SageMakerがトレーニングジョブ実行時に使用するかどうかを指定するためにあります。sagemaker-debugger自体の機能は自分も今回深掘りしていないのであまり把握していませんが、トレーニング中のモデルに発生する様々な問題(勾配消失等)を検出してくれるデバッグライブラリのようです。
私が今回使用しているnstモデルのコードでは、sagemaker-debuggerが有効になっているとトレーニング中にエラーを引き起こしてしまいます。事象再現のために使用したスクリプトimport tensorflow as tf class issueReproducer(tf.Module): def __init__(self, n_unit): """ n_unit : int """ self.variable = tf.Variable(tf.zeros((1, n_unit), dtype=tf.float32)) self.l1 = tf.keras.layers.Dense(n_unit) self.optimizer = tf.optimizers.Adam() @tf.function def fit(self, tensor): """ tensor : some tensor of shape : (1, n_unit) """ with tf.GradientTape() as tape: output = self.l1(self.variable) loss = tf.reduce_sum(output - self.variable) grad = tape.gradient(loss, self.variable) self.optimizer.apply_gradients([(grad, self.variable)]) return self.variable if __name__ == "__main__": model = issueReproducer(5) tensor = tf.constant([[1,2,3,4,5]], dtype=tf.float32) variable = model.fit(tensor) print("Returned variable : {}".format(variable))事象再現時のTracebackTraceback (most recent call last): File "issue_reproducer.py", line 34, in <module> variable = model.fit(tensor) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 780, in __call__ result = self._call(*args, **kwds) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 823, in _call self._initialize(args, kwds, add_initializers_to=initializers) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 697, in _initialize *args, **kwds)) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 2855, in _get_concrete_function_internal_garbage_collected graph_function, _, _ = self._maybe_define_function(args, kwargs) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 3213, in _maybe_define_function graph_function = self._create_graph_function(args, kwargs) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 3075, in _create_graph_function capture_by_value=self._capture_by_value), File "/usr/local/lib/python3.7/site-packages/tensorflow/python/framework/func_graph.py", line 986, in func_graph_from_py_func func_outputs = python_func(*func_args, **func_kwargs) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/def_function.py", line 600, in wrapped_fn return weak_wrapped_fn().__wrapped__(*args, **kwds) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/eager/function.py", line 3735, in bound_method_wrapper return wrapped_fn(*args, **kwargs) File "/usr/local/lib/python3.7/site-packages/tensorflow/python/framework/func_graph.py", line 973, in wrapper raise e.ag_error_metadata.to_exception(e) tensorflow.python.framework.errors_impl.OperatorNotAllowedInGraphError: in user code: issue_reproducer.py:23 fit * grad = tape.gradient(loss, self.variable) /usr/local/lib/python3.7/site-packages/smdebug/tensorflow/keras.py:956 run ** (not grads or not vars) /usr/local/lib/python3.7/site-packages/tensorflow/python/framework/ops.py:877 __bool__ self._disallow_bool_casting() /usr/local/lib/python3.7/site-packages/tensorflow/python/framework/ops.py:487 _disallow_bool_casting "using a `tf.Tensor` as a Python `bool`") /usr/local/lib/python3.7/site-packages/tensorflow/python/framework/ops.py:474 _disallow_when_autograph_enabled " indicate you are trying to use an unsupported feature.".format(task)) OperatorNotAllowedInGraphError: using a `tf.Tensor` as a Python `bool` is not allowed: AutoGraph did convert this function. This might indicate you are trying to use an unsupported feature.sagemaker-debuggerのドキュメントを確認すると、以下のような記載がありました。TensorFlowの一部の部品にはまだ対応しておらず、トレーニングスクリプトのコードを変更することなく利用できる範囲はまだ限られているようです。
* Debugger with zero script change is partially available for these TensorFlow versions. The inputs, outputs, gradients, and layers built-in collections are currently not available for these TensorFlow versions.
2020年11月27日時点のAmazon SageMaker DebuggerのDeveloper Guideより
Tracebackを確認してみると、確かに"not available"の例として挙げられている
grad = tape.gradient(loss, self.variable)の部分でエラーになっていますね。本エラーの回避方法としてひとまず有効だったのが、前述したとおりトレーニングジョブの定義時に
debugger_hook_config=Falseを指定してsagemaker-debugger自体を無効化することでした。
スクリプトの書き方を工夫すればsagemaker-debuggerがONのままでも大丈夫なのか分かりませんが、いったん以降はOFFにしたままで進めていきます。
ハイパーパラメータチューニングを実行
単発のトレーニングジョブが無事(?)成功したので、次は本題となるハイパーパラメータチューニングを実践してみます。
前述したトレーニングジョブの手順に幾つかの設定を追加するだけで、ハイパーパラメータチューニングを実施できます。
- ローカルのノートブック上でトレーニングスクリプトを用意する。
- ローカルのノートブック上でトレーニングの設定を定義する。
- ローカルのノートブック上でハイパーパラメータチューニングの設定を定義する。
- ローカルのノートブック上から、Amazon SageMakerに対してハイパーパラメータチューニングの実行をリクエストする。
- 設定したハイパーパラメータの組み合わせごとに、指定した回数だけトレーニングジョブが実行される。
- 各トレーニングジョブからCloudWatchLogsに出力される目標メトリクスの値を集計・比較する。
- 実行されたトレーニングのうち、最善の性能を発揮したハイパーパラメータの値の組み合わせが確認できる。
ハイパーパラメータチューニングの具体例
- HyperParameterTuning.ipynb
import boto3 import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner import json print("boto3 : ", boto3.__version__) print("sagemaker : ", sagemaker.__version__) # トレーニングジョブの設定定義 # この処理は単発のトレーニングジョブ実行時と同様なので省略 ... estimator = TensorFlow( ... )# チューニングするパラメータと、取り得るパラメータの範囲を定義 # 今回はloss値の計算に使用される3種類のパラメータと、 # Adamオプティマイザの学習率をチューニング対象にします。 hyperparameter_ranges = { "CONTENT_WEIGHTS" : ContinuousParameter( min_value=5000, max_value=15000, ), "STYLE_WEIGHTS" : ContinuousParameter( min_value=0.001, max_value=0.1, ), "TOTAL_VARIATION_WEIGHTS" : ContinuousParameter( min_value=10, max_value=50, ), "LEARNING_RATE" : ContinuousParameter( min_value=0.01, max_value=0.1, ), }# モデルの性能を比較するための目標メトリクスを定義 # loss値が最小になるハイパーパラメータの組み合わせを今回は探ってみる objective_metric_name = 'loss' objective_type = 'Minimize' metric_definitions = [ { 'Name': 'loss', # トレーニングスクリプト内でprint()標準出力された # メッセージはCloudWatchLogsにログ出力される。 # そのメッセージのうち、"FinalMeanLoss=([0-9\\.]+)"のパターンに合致する # 数値を目標メトリクスとして収集し、トレーニングジョブ間で比較する。 'Regex': 'FinalMeanLoss=([0-9\\.]+)', } ]# ハイパーパラメータチューニングジョブ設定を定義 tuner = HyperparameterTuner( # トレーニングジョブの定義 estimator=estimator, # チューニング対象のハイパーパラメータ hyperparameter_ranges=hyperparameter_ranges, # 目標メトリクスの定義(今回はloss値を最小にする) objective_type=objective_type, objective_metric_name=objective_metric_name, metric_definitions=metric_definitions, # トータルで実行されるトレーニングジョブの上限数 max_jobs=30, # 並列実行されるジョブの上限 # ml.g4dn.xlargeインスタンスの同時起動可能上限数は2 max_parallel_jobs=2, )# ハイパーパラメータチューニングの実行 tuner.fit(s3_train_loc, wait=False)
- トレーニングスクリプト - train.py(一部を抜粋)
train.pydef _parse_args(): parser = argparse.ArgumentParser() # sagemakerが引数として渡してくるパラメータ ... # 今回チューニングされるパラメータ # ハイパーパラメータチューニング時も、実際の値はコマンドライン引数として # トレーニングスクリプトに渡されるので、スクリプト内の処理を改修する必要無し。 parser.add_argument('--CONTENT_WEIGHTS', type=float, default=10000) parser.add_argument('--STYLE_WEIGHTS', type=float, default=0.01) parser.add_argument('--TOTAL_VARIATION_WEIGHTS', type=float, default=30) parser.add_argument("--LEARNING_RATE", type=float, default=0.02) parser.add_argument("--STYLE_RESIZE_METHOD", type=str, default="original") ... return parser.parse_known_args() if __name__ =='__main__': # parse arguments args, _ = _parse_args() print(args) ... print("FinalMeanLoss={}".format(loss_list.mean()))チューニングジョブが完了したら、AWS CLIでチューニングの結果を確認してみます。
$ aws sagemaker describe-hyper-parameter-tuning-job --hyper-parameter-tuning-job-name tensorflow-training-201118-1130 | jq . { ... "BestTrainingJob": { "TrainingJobName": "tensorflow-training-201118-1130-027-6b526460", "TrainingJobArn": "arn:aws:sagemaker:ap-northeast-1:XXXXXXXXXXXX:training-job/tensorflow-training-201118-1130-027-6b526460", "CreationTime": "2020-11-19T02:07:22+09:00", "TrainingStartTime": "2020-11-19T02:10:33+09:00", "TrainingEndTime": "2020-11-19T02:34:11+09:00", "TrainingJobStatus": "Completed", "TunedHyperParameters": { "CONTENT_WEIGHTS": "5277.5099011496795", "LEARNING_RATE": "0.03725186282831269", "STYLE_WEIGHTS": "0.0012957731765036497", "TOTAL_VARIATION_WEIGHTS": "10.0" }, "FinalHyperParameterTuningJobObjectiveMetric": { "MetricName": "loss", "Value": 2388418.5 }, "ObjectiveStatus": "Succeeded" } }コード上からも直接、最善のハイパーパラメータの組み合わせを取得してみましょう。
HyperParameterTuning.ipynbの続き# 最善の結果を出したモデルの、ハイパーパラメータの組み合わせを確認する。 from IPython.display import display best_hyperparameters = tuner.best_estimator().hyperparameters() display(best_hyperparameters) # 2020-11-18 17:34:11 Starting - Preparing the instances for training # 2020-11-18 17:34:11 Downloading - Downloading input data # 2020-11-18 17:34:11 Training - Training image download completed. Training in progress. # 2020-11-18 17:34:11 Uploading - Uploading generated training model # 2020-11-18 17:34:11 Completed - Training job completed # {'CONTENT_WEIGHTS': '5277.5099011496795', # 'EPOCH': '50', # 'LEARNING_RATE': '0.03725186282831269', # 'MAX_IMAGE_SIZE': '1024', # 'MAX_TRIAL': '9', # 'STEP': '10', # 'STYLE_WEIGHTS': '0.0012957731765036497', # 'TB_BUCKET': '"s3://sagemaker-nst/train"', # 'TOTAL_VARIATION_WEIGHTS': '10.0', # '_tuning_objective_metric': '"loss"', # 'sagemaker_container_log_level': '20', # 'sagemaker_estimator_class_name': '"TensorFlow"', # 'sagemaker_estimator_module': '"sagemaker.tensorflow.estimator"', # 'sagemaker_job_name': '"tensorflow-training-2020-11-18-11-30-35-845"', # 'sagemaker_program': '"train.py"', # 'sagemaker_region': '"ap-northeast-1"', # 'sagemaker_submit_directory': '"s3://sagemaker-nst/tensorflow-training-2020-11-18-11-30-35-845/source/sourcedir.tar.gz"', # 'model_dir': '"s3://sagemaker-nst/tensorflow-training-2020-11-18-11-26-25-821/model"'}ハイパーパラメータチューニングジョブについても、nstモデルを対象に実施できることが確認出来ました。
因みに今回のハイパーパラメータチューニングジョブ内で、GPU利用可能なインスタンスタイプ(ml.g4dn.xlarge : 0.994USD/h)で合計30トレーニング(2並列)のトレーニングジョブが実行されたわけですが、その課金額はざっと以下の通りです。
※スポットインスタンスの使用を有効化しているため、課金額は(課金対象時間(実際にトレーニングが実行されている時間) * インスタンスの時間単価)で計算されます。今回使用しているnstモデルとデータ量であれば、60~70%程度節約されています。
※今回は2並列で実行したので、体感の経過時間は総実行時間 / 2です。
総実行時間 課金対象トレーニング時間 割引率 課金額 12時間8分 4時間16分 65% $4.24(約440円) Amazon SageMakerを題材に勉強してみようと思い立った時は、文字通りの学習コストが最終的に幾ら位になるのかとビクビクしておりましたが、ス○バのカフェモカ一杯程度の金額に収まってくれて今はホッとしています笑。
チューニング結果を比較
ハイパーパラメータチューニンングが無事成功したので、それぞれのモデルのloss値や実際に生成された画像を比較してみたいと思います。
最善、最悪、デフォルトのハイパーパラメータの組み合わせと、その際のlossは以下の通りです。
なお、ここでの「デフォルト」とはTensorflowのサンプルコードに記載されていた設定値のことを指します。
PATTERN LOSS CONTENT_WEIGHT STYLE_WEIGHT TOTAL_VARIATION_WEIGHT LEARNING_RATE 最悪 20,893,880 5119.428 0.0752 12.171 0.078 デフォルト 10,061,276 10000 0.01 30 0.02 最善 2,388,418.5 5277.509 0.001 10 0.037 最善の結果はデフォルトのそれと比較しても4分の1以下、最悪のそれに対しては9分の1程もloss値が小さい結果となりました。
では、それぞれのトレーニングジョブで生成した9種類の画像をそれぞれ比較してみます。
※左から順に、「コンテンツ画像」、「スタイル画像」、「最悪のモデルの生成画像」、「デフォルトのモデルの生成画像」、「最善のモデルの生成画像」
最悪のモデルが生成した画像は論外として、デフォルトのモデルが生成した画像と比較しても、最善のモデルが生成した画像はスタイル画像の画風をしっかり反映しつつ、元の輪郭がよりハッキリと残っているように見えます。(少なくとも個人的には…)
最後に、モデルの汎化性能(めいたもの)も確認しておく意味で、新しい画像セットを対象に最良のモデルでnstを実施してみます。
- 検証画像セットに対するnst実行結果4
良い感じにの画像が生成できている気がします(自己暗示)!
nstモデルに対するハイパーパラメータチューニングの効果があったと言えるのではないでしょうか!
おわりに
以上で、Amazon SageMakerを使用したnstモデルのハイパーパラメータチューニングの挑戦は終了となります。
見切り発車的に思い切って初立候補した今回のアドベントカレンダーでしたが、何とか形になってホッとしております…。
今まで使用経験が全く無かったAWSサービスの一つ(Amazon SageMaker)を集中的に学べたのは大変有意義でしたし、ハイパーパラメータチューニングの結果として、nstモデルが実際に生成する画像の質の改善を確認できたのは、正直自分でも驚きでした笑。最後に。この記事で私が整理した図表、記載したコード、報告したエラーのいずれかが、少しでも誰かの役に立ってくれたり、刺激になってくれたりしたら大変嬉しいです。
みなさま。よいクリスマスを。NTTテクノクロス Advent Calendar 2020、明日は@geek_duckさんです。お楽しみに!
Appendix
- 今回使用したコード類一式
使用した画像:注釈欄に記載
- By derivative work: Djmirko (talk)wereweweewewewg.jpg - YellowLabradorLooking.jpg, CC BY-SA 3.0, Link
- By Wassily Kandinsky, Public Domain, Link
- By Vincent van Gogh - bgEuwDxel93-Pg at Google Cultural Institute, zoom level maximum, Public Domain, Link
- By Wassily Kandinsky, Public Domain, Link
- Image by Pete Linforth from Pixabay
- By After Katsushika Hokusai - Restored version of File:Great Wave off Kanagawa.jpg (rotated and cropped, dirt, stains, and smudges removed. Creases corrected. Histogram adjusted and color balanced.), Public Domain, Link
- By Johannes Vermeer - Copied from Mauritshuis website, resampled and uploaded by Crisco 1492 (talk · contribs), October 2014[4], Public Domain, Link
- Image by Sa Ka from Pixabay
- Image by muratkalenderoglu from Pixabay
- By Vincent van Gogh - bgEuwDxel93-Pg at Google Cultural Institute, zoom level maximum, Public Domain, Link
- Image by Gerd Altmann from Pixabay
- Image by マクフライ 腰抜け from Pixabay
- Image by falco from Pixabay
- Image by Free-Photos from Pixabay
- Image by ExposureToday from Pixabay
- Image by Aneta Foubíková from Pixabay
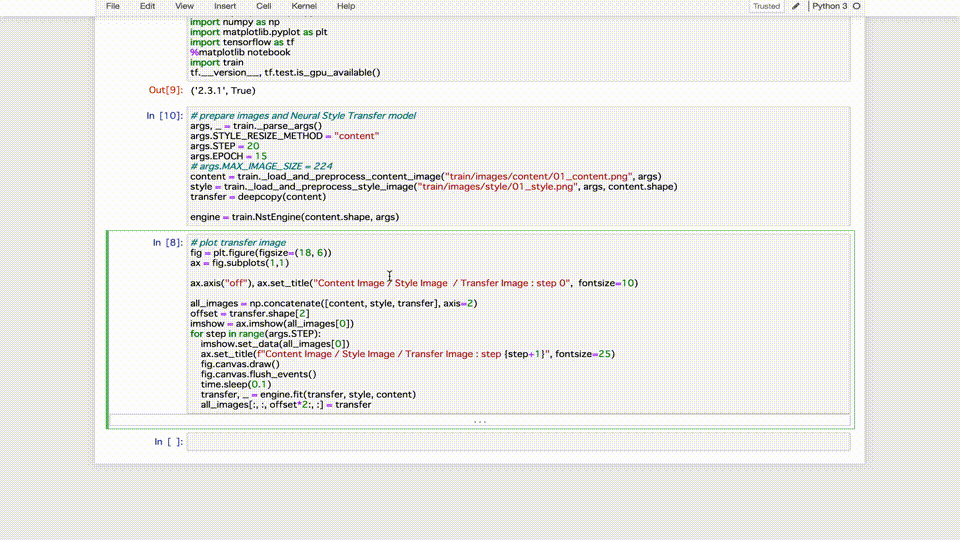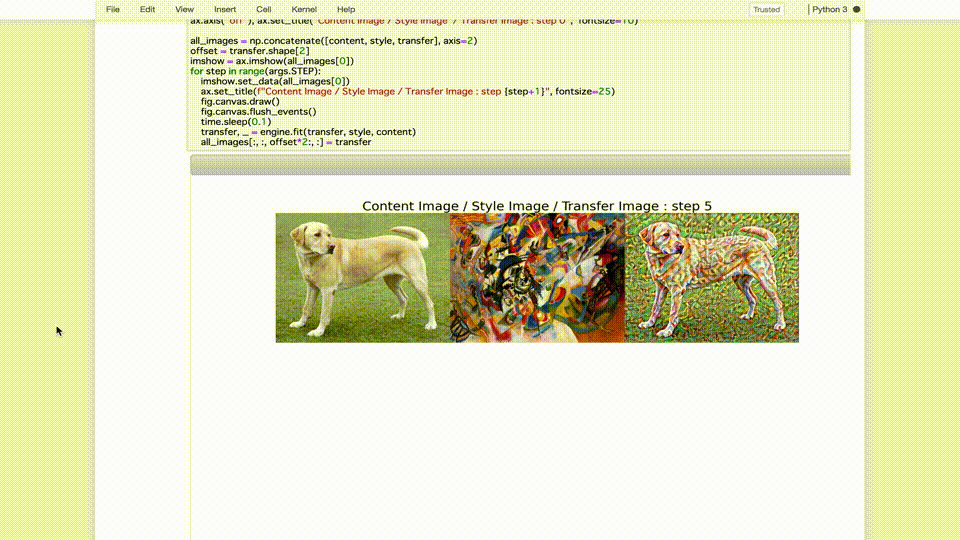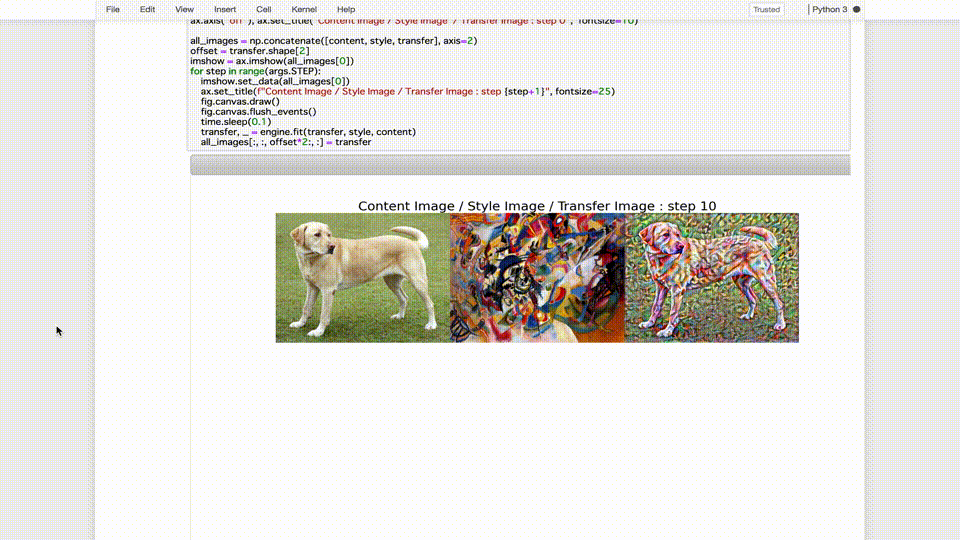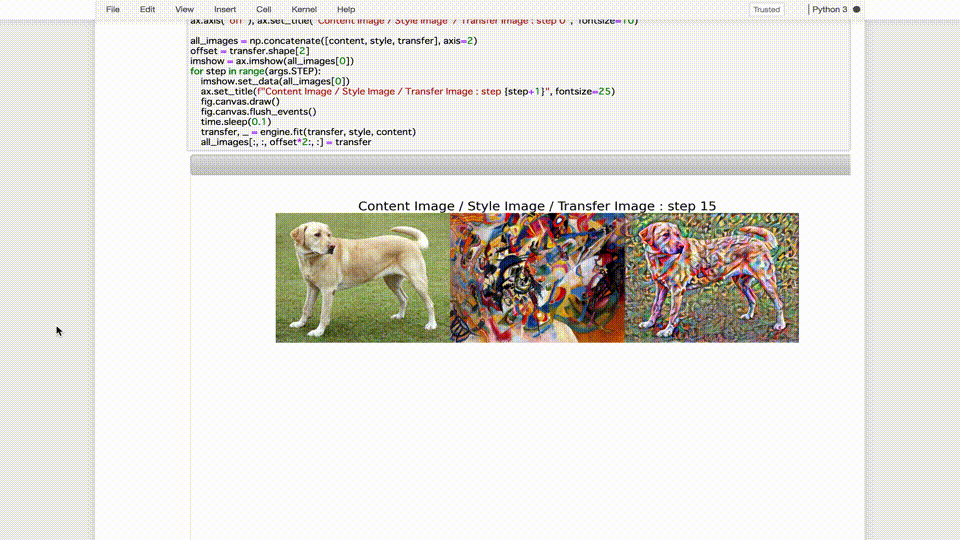






- 投稿日:2020-11-30T10:29:54+09:00
AWS CodeBuild のビルド環境に利用するコンテナイメージについて
AWS Containers Advent Calendar 2020 の 1 日目の記事です。
突然ですが、AWS CodeBuild というサービスをご存知でしょうか。
AWS CodeBuild は、完全マネージド型のビルドサービスです。
AWS でコンテナワークロードのための CI/CD パイプラインを構築する際、コンテナイメージのビルドに AWS CodeBuild を利用している方も多いのではないかと思います。
(つまり、AWS CodeBuild もコンテナファミリー?の一員ですね!)本記事では、この AWS CodeBuild について Tips を紹介したいと思います。
ビルド環境に利用する Docker イメージ
AWS CodeBuild では、ビルドプロジェクトに設定された Docker イメージを利用してビルド環境が作成されます。
ビルド環境の Docker イメージには、ユーザーによるカスタムイメージか、もしくは AWS CodeBuild が管理している Docker イメージを利用することができます。コンテナイメージをビルドするという目的の場合、Docker Engine がインストール済みであるため AWS CodeBuild が管理している Docker イメージをビルド環境に利用している方も多いかと思います。
イメージバージョンとビルド時間
AWS CodeBuild が管理している Docker イメージには「バージョン」が存在しています。例えば、イメージ
aws/codebuild/amazonlinux2-x86_64-standard:3.0-20.09.14における -20.09.14 の部分がイメージバージョンとなります。このイメージバージョンですが、バージョンの指定内容によってビルド時間が変化することがあります。
例えば、ビルド仕様やビルドプロジェクトの設定など、イメージバージョン以外を同一にした 2 つのビルドを比較してみます。
$ aws codebuild batch-get-builds --ids <MY_BUILD_ID_1> --query 'builds[0].environment.image' "aws/codebuild/amazonlinux2-x86_64-standard:3.0-20.09.14"$ aws codebuild batch-get-builds --ids <MY_BUILD_ID_2> --query 'builds[0].environment.image' "aws/codebuild/amazonlinux2-x86_64-standard:3.0-20.08.14"本記事を執筆している 11/30 における、イメージ
aws/codebuild/amazonlinux2-x86_64-standard:3.0のバージョンを確認してみます。$ aws codebuild list-curated-environment-images | jq '.platforms[] | select(.platform == "AMAZON_LINUX_2") | .languages[0].images[] | select(.name | endswith("amazonlinux2-x86_64-standard:3.0"))' { "name": "aws/codebuild/amazonlinux2-x86_64-standard:3.0", "description": "AWS CodeBuild - Docker image based on Amazon Linux 2 (x86_64) with multiple language support", "versions": [ "aws/codebuild/amazonlinux2-x86_64-standard:3.0-20.03.13", "aws/codebuild/amazonlinux2-x86_64-standard:3.0-20.05.05", "aws/codebuild/amazonlinux2-x86_64-standard:3.0-20.06.15", "aws/codebuild/amazonlinux2-x86_64-standard:3.0-20.08.14", "aws/codebuild/amazonlinux2-x86_64-standard:3.0-20.09.14" ] }上記より、
MY_BUILD_ID_1は最新バージョン、MY_BUILD_ID_2は一つ前のバージョンを指定してビルドを実行していることが分かります。ここで、
MY_BUILD_ID_1とMY_BUILD_ID_2、それぞれのビルドにおけるビルドフェーズを比較してみます。$ aws codebuild batch-get-builds --ids <MY_BUILD_ID_1> --query 'builds[0].phases[].[phaseType, durationInSeconds]' --output table ------------------------------ | BatchGetBuilds | +-------------------+--------+ | SUBMITTED | 0 | | QUEUED | 1 | | PROVISIONING | 37 | | DOWNLOAD_SOURCE | 4 | | INSTALL | 0 | | PRE_BUILD | 8 | | BUILD | 3 | | POST_BUILD | 3 | | UPLOAD_ARTIFACTS | 0 | | FINALIZING | 2 | | COMPLETED | None | +-------------------+--------+$ aws codebuild batch-get-builds --ids <MY_BUILD_ID_2> --query 'builds[0].phases[].[phaseType, durationInSeconds]' --output table ------------------------------ | BatchGetBuilds | +-------------------+--------+ | SUBMITTED | 0 | | QUEUED | 1 | | PROVISIONING | 262 | | DOWNLOAD_SOURCE | 4 | | INSTALL | 0 | | PRE_BUILD | 2 | | BUILD | 2 | | POST_BUILD | 2 | | UPLOAD_ARTIFACTS | 0 | | FINALIZING | 2 | | COMPLETED | None | +-------------------+--------+
PROVISIONINGフェーズの所要時間について、MY_BUILD_ID_1とMY_BUILD_ID_2で大きく差が開いている様子が伺えます。ではなぜ、このような状況が発生しているのでしょうか。
各イメージの最新バージョンはキャッシュされる
AWS CodeBuild が管理している Docker イメージについて、各イメージの最新バージョンはキャッシュされています。これは言い換えると、最新以外のバージョンについては、ビルド時にそのバージョンのプロビジョニングが行われているということになります。
CodeBuild に用意されている Docker イメージ - AWS CodeBuild
各イメージの最新バージョンがキャッシュされます。具体的なバージョンを指定すると、キャッシュされたバージョンではなく、そのバージョンのプロビジョニングが CodeBuild によって行われます。これにより、ビルド時間が長くなることがあります。
すなわち、AWS CodeBuild が管理している Docker イメージについては、最新バージョンを指定するとキャッシュが利用できるため、最新以外のバージョンを指定した場合よりもビルド時間が短縮できる、ということです。
なお、最新バージョンの利用については、ビルド環境の設定にて
aws/codebuild/amazonlinux2-x86_64-standard:3.0のように具体的なバージョンを指定しない形で設定することで、常に最新バージョンを利用するように設定することも可能です。CodeBuild に用意されている Docker イメージ - AWS CodeBuild
たとえば、キャッシュのメリットを得るには、aws/codebuild/amazonlinux2-x86_64-standard:3.0-1.0.0 のような詳細バージョンではなく aws/codebuild/amazonlinux2-x86_64-standard:3.0 を指定します。
最後に
今回は、AWS CodeBuild が管理している Docker イメージについて、最新バージョンを指定すると最新以外のバージョンを指定した場合よりもビルド時間が短縮できる、という内容について紹介しました。
ビルドの内容が特定のバージョンに依存しない場合は、キャッシュのメリットを受けられるように、最新バージョンを利用してビルドプロジェクトを設定することを検討されてみてはいかがでしょうか。
この情報が、みなさんのビルドライフのお役に立てますと幸いです ?
- 投稿日:2020-11-30T10:23:53+09:00
【PostgreSQL】『対向(peer)認証に失敗しました』―psqlログインできない際の対応
背景
以下の環境でWEBシステムを構築し、EC2上のPstgreSQLへマイグレーションを試みた際に、『対向(peer)認証に失敗しました』というエラーが発生。
その対処を以下に記します。先人たちの知恵をお借りするなどして解決できたことを、この場をお借りして感謝するとともに、大変恐縮ですが自分のメモとしても、こちらへまとめておきます。
環境
- AWS EC2 (Amazon Linux 2)
- Python 3.7.9 ※2020/11/29時点のAmazon Linux2でのデフォルト
- Django 3.1.3
- PostgreSQL 11.5 ※同上
- Nginx 1.12 ※同上
- Gunicorn
- Putty 0.74
1.現象
EC2上のPostgreSQLへ、pythonの仮想環境(venv)より
python manage.py migrateを試みた際に下記エラーが発生。
この時点までに、PostgreSQLでちゃんとユーザーにログイン権限とパスワードを設定しています。ターミナル(venv) > python manage.py migrate ・・・割愛・・・ psql: FATAL: ユーザ "postgres" で対向(peer)認証に失敗しました2.原因
peer認証という仕組みにあり。
Peer認証とは、カーネルからクライアント上のシステムユーザ名を取得し、PostgreSQLデータベースユーザと同一である場合のみ接続が許可される。
つまり、PostgreSQL内のユーザーとUNIXユーザで、ユーザー名が一致してさえいれば認証情報なしでログイン出来てしまう仕組みです。
ログインの際、postgresユーザー名とパスワードを指定しても、ローカルからのアクセスはUNIXユーザー名とパスワードがpostgresのものと同じでないとダメだったのです。ちなみに、peer認証のデメリットは以下とのこと。
peer認証のデメリットは、パスワードを入力せずに済むが、ユーザー毎に権限を変えて使い分けたいときや一時的に別のpsqlユーザーとしてログインしたいときは相当にやりづらいですし、psql側でユーザーを作る際に、同名のUNIXユーザーも追加する必要があるために面倒。
3.対処
以下の手順ですすめます。
1) postgresユーザー:"postgres"のパスワードをもう一度設定する
ターミナル$ sudo su postgres -c 'psql --username=postgres'2) psqlに入る
ターミナルpostgres=# ALTER USER postgres with encrypted password 'your_password';3) PostgreSQL側の挙動を変更するために、
pg_hba.confを編集
(上記環境ですと、/var/lib/pgsql/data/pg_hba.confにあります。)コマンドプロンプトより、
sudo vi /var/lib/pgsql/data/pg_hba.confと入力。
ファイルを開くと以下のようになっています。pg_hba.conf# ローカルで動いているpsqlへアクセスする場合 local all all peer # 他のクライアントからpsqlへアクセス可能にする場合(例) host all all 127.0.0.1/32 peerパスワード認証させたい場合は、
peerの部分をmd5に変更して保存します。pg_hba.conf#ローカルで動いているpsqlへアクセスする場合 local all postgres md5 #他のクライアントからpsqlへアクセス可能にする場合(例) host all all 127.0.0.1/32 md5編集時に「i」キー押下、編集後「esc」押下し
:wq!と入力して保存。
(保存せずに抜けたい場合は:q!を入力。)
コマンドプロンプトに戻ります。4) PostgreSQLの再起動
ターミナル> sudo service postgresql restartこれで再度ログインを行なうと今度はパスワードを求められ、正しい情報を入力することで、自分のUNIXユーザーでもログインできる設定になります。
4.結果
自分のUNIXユーザーからpostgresユーザー:"postgres"として、psqlログインできました。
ターミナル> psql -U postgres -h localhost -W ・・・【割愛】・・・ postgres=#
参考
- peer認証の関係でpsqlログインできない時の対処法 @tomlla様
- PostgreSQL “対向(peer)認証に失敗しました” エラーが出るときの対処法
- PostgreSQL 認証に失敗しないための Ident、MD5、Trust 比較
(編集後記)
Qiita初投稿です。
誤記や記載不足等ありましたら、ご指摘くださいませ。
何卒よろしくお願いいたします。
- 投稿日:2020-11-30T06:25:09+09:00
【AWS】Redmineの環境構築
AWSでRedmineの環境構築をしたときのメモ
失敗
最初はAWS上にDBを作成し、新規DBとRedmineを接続しようとしていました。
試行1
③のブログの記載どおりにPowershellのコマンドから接続しようとしましたが、
"command not found"が表示されたので、いったん諦めました。
後で調べてみるとRubyの必要なファイルをインストールしていなかったことが原因だったようです。
→Windows10にRubyGemsをインストールする方法※AWSのコンソールに表示されているエンドポイントを正しく指定していても接続できない場合
→セキュリティグループでポート番号”3306”(DBで使用しているポート)を追加すると接続できるようになります。▼その時参考にしたサイトたち
(MySQLのインストール方法)
①Windows10にインストーラーでMySQLをインストールする方法
②MySQLの開発環境を用意しよう(windows)
③EC2-RDSを使ってRedmineをインストールする。ついでにサブディレクトリで。(Redmineの設定方法)
④Redmineのインストール(MySQLの設定方法)
⑤MySQL データベースを作成して接続する成功
結局見つけた方法は、Redmine用のAMIから新規インスタンスを作成するというものでした。
こちらのブログの記載どおりにするとRedmineに接続できました…!Todo
- PowerShellのコマンドを勉強
- MySQLのサーバー接続について調べる
- 投稿日:2020-11-30T00:28:19+09:00
ECSを使うときに必要なポートを設定すべき3大箇所
前提
- 構成ECS+ALB
この解説の目的
ECSのネットワーク周りの設定でどこに何を設定すべきか度々わからなくなるので自分のための忘備録。
この設定をどこか間違えると502 Bat Gatewayとか受け取れます。
HTTPのみでSSLしない場合は、面倒なのですべてのポートを80に合わせて置くと、すべてのポートを80にしておけばいいので便利です。この解説で取り扱う所:
ECSを使う時にポートを使う箇所のみお断り
この解説は編集時(2020/11/27)時点でのAWSコンソール上の記述をもとにしているため,
用語が変わってしまう可能性があります。目次
- タスク定義のポート
- ECSのクラスター、サービスの追加時のロードバランサ
- セキュリティグループに追加すべきポート
1.タスク定義のポート
前提:
すでにECRにリポジトリがあり、イメージがpushされているECS/タスク定義/コンテナの編集
ポートマッピング/コンテナポート
- ここにはコンテナ化しているアプリが受け付けているポートを書く
- プロトコルは特にUDPに設定していない限りtcp例: GolangのEcho使うと以下のようにサーバ起動時のportを指定するが、
ここに書かれているポート番号「1323」main.goe.Logger.Fatal(e.Start(":1323"))2.ECSのクラスター、サービスの追加時のロードバランサ
この解説に含まれるもの
ECSの既存クラスターに新しくサービスを追加する際の「ロードバランサ用のコンテナ」のセクションのみ設定箇所の用語の説明:
- プロダクションポート
└ ALBが外から受け付けるポート、HTTPを受け付けるなら80.HTTPSを受け付けるなら443など
- プロダクションリスナープロトコル
└ALBが外から受け取るプロトコル
└例:サイトをssl化している場合はHTTPS443を設定する
└※注意※これはコンテナが受け付けているポートではない
- ターゲットグループ
└このECSのサービスを含めるターゲットグループ
└これをALBに登録することで、特定のパスへのアクセスを指定のターゲットグループ(サービス)へ転送する
- ターゲットグループのプロトコル
└ターゲットグループ内で使用されるプロトコル
└HTTP, HTTPSなど、大体はhttpだと思う
- パスパターン
└このサービスに転送すべきパスパターン
└後でALBのリスナーのルールから変更可能
- ヘルスチェックパス
└ALBからヘルスチェックが実行されてるので正常時に200を返却するURLを用意する
└ /health_check といったpathを用意しておくのが一般的3.セキュリティグループに追加すべきポート
- すべてのプロトコル、すべてのポートを開放していない限り以下を設定する
- 2で設定したターゲットグループのプロトコル、1で設定しているコンテナポートを設定しておく 例:アプリがTCP 1323ポートで動いている場合は カスタムポート TCP 1323 ソース:属するVPC
ここの設定をしていないと、ALBからヘルスチェックですら到達できないので、ECS上で起動しているけどヘルスチェックで失敗する時はここも確認する