- 投稿日:2020-11-08T22:59:23+09:00
プリザンターのAPIを使ってみる(python/FastAPI)
概要
https://qiita.com/donraku/items/147fbea348657a4ffbf1
↑の内容をベースにして、今度はpythonを使ってプリザンターの「API機能」を使ってみることにしました。
pythonを使うにあたってフレームワークを採用してみました。前提条件
- プリザンター(https://pleasanter.net/fs/publishes/420234/edit)
- API
- python
- フレームワーク
- FastAPI(https://fastapi.tiangolo.com/ja/)
これらの詳細は省略。
結論
pythonを使ってプリザンターにデータ登録ができた。(APIで)
フレームワークのFastAPIはなかなか使えることがわかった。詳細
pythonのフレームワークを選定
今後の展開を考えて、フレームワークを利用することに。
ざっと調べてFastAPIが良さそうなので採用。
インストール作業などについては、省略。情報はこちら。
https://fastapi.tiangolo.com/ja/FastAPIでの開発準備
マニュアルをもとに、最小のソースを作ってWebサーバーを起動。
Webサーバーはuvicornというやつ。ソースはこちら。これだけでOK。
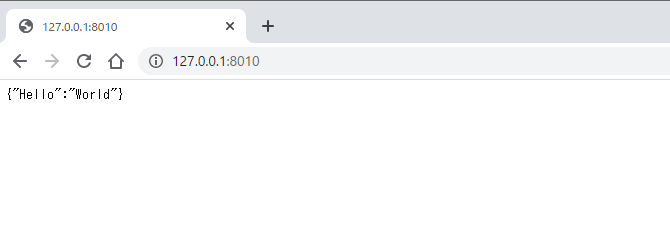
main.pyfrom fastapi import FastAPI app = FastAPI() @app.get("/") def read_root(): return {"Hello": "World"}コマンドプロンプトからWebサーバーを起動。
ポートはデフォルトだと競合したので8010を指定。
すぐ起動します。>uvicorn main:app --reload --port 8010 INFO: Uvicorn running on http://127.0.0.1:8010 (Press CTRL+C to quit) INFO: Started reloader process [26816] using statreload INFO: Started server process [22304] INFO: Waiting for application startup. INFO: Application startup complete.ブラウザで表示を確認。表示OK。
ドキュメントも勝手にできちゃう。
なかなかすごい。余談ですが。
FastAPI(python)からプリザンターへ登録
試しに「/test_create」というエンドポイントを作成して、その中でプリザンターへデータを登録するようにする。
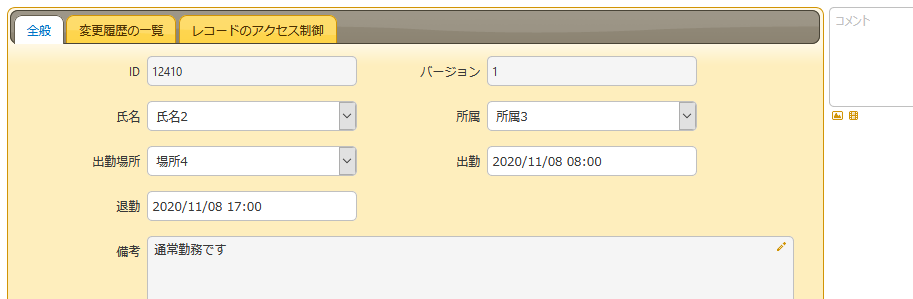
main.pyimport requests import json from fastapi import FastAPI from requests_ntlm import HttpNtlmAuth app = FastAPI() @app.get("/") def read_root(): return {"Hello": "World"} @app.get("/test_create") def test_create(): url = 'http://192.168.10.10/pleasanter/api/items/12389/create' json_str = '''\ { "ApiVersion": 1.1, "ApiKey": "ea55625bb586d27df01c281e5ef5464e4bbe6bc86d1451a24fd430351198ce0bbabc467cdd1d0ebdf4045ec22922dfce7a9f47a8241559229a7d5129d2329879", "ClassHash": { "ClassA": "氏名2", "ClassB": "所属3", "ClassC": "場所4" }, "DateHash": { "DateA": "2020/11/08 08:00", "DateB": "2020/11/08 17:00" }, "Body": "通常勤務です" } ''' json_data = json.loads(json_str) headers = {'content-type': 'application/json; charset=UTF-8'} response = requests.post(url, json=json_data, headers=headers, auth=HttpNtlmAuth('xxx\xxx', 'xxx')) return (response.text)
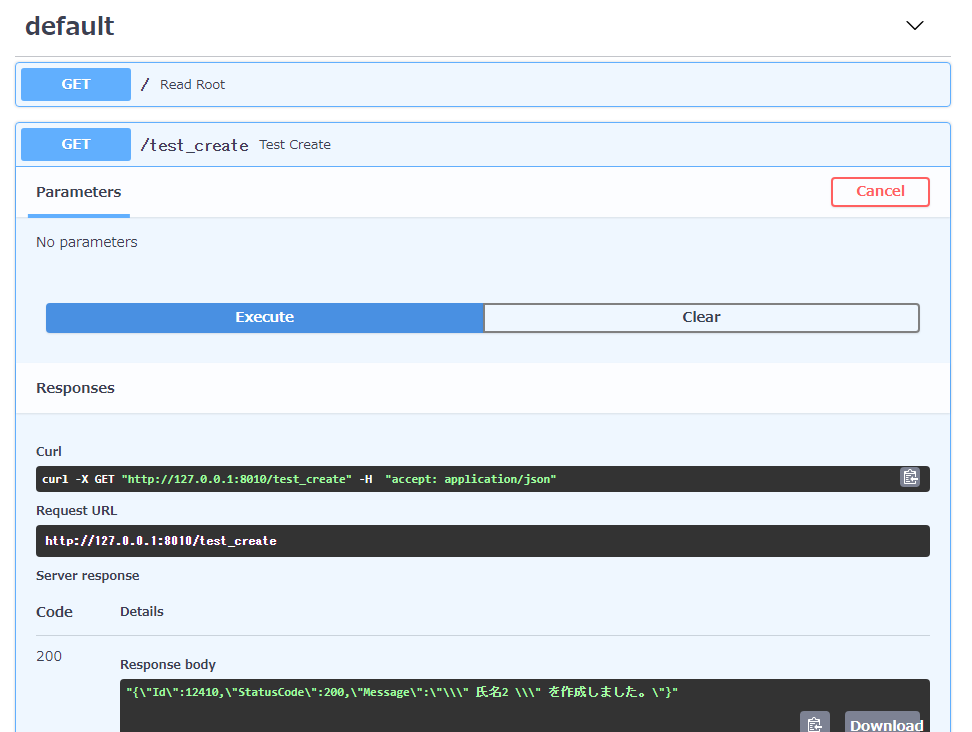
↑のドキュメントを使って実行すると。。。
成功!!
"{\"Id\":12410,\"StatusCode\":200,\"Message\":\"\\" 氏名2 \\" を作成しました。\"}"
プリザンターの画面で確認してOK!
登録できたので、ここまでで終わり。
- 投稿日:2020-11-08T22:58:13+09:00
AtCoder Beginner Contest 182 参戦記
AtCoder Beginner Contest 182 参戦記
ABC182A - twiblr
1分で突破. 書くだけ.
A, B = map(int, input().split()) print(2 * A + 100 - B)ABC182B - Almost GCD
4分で突破. 少し悩んだが全部試せばいいことに気づいた.
N, *A = map(int, open(0).read().split()) result = 0 for i in range(2, 1000): t = 0 for a in A: if a % i == 0: t += 1 result = max(result, t) print(result)ABC182C - To 3
6分で突破. 言うまでもないが、各桁の数の合計が3の倍数なら3の倍数. なので各桁の数の合計を3で割ったあまりを考えることになる. 余りが0であれば最初から3の倍数なので話はおしまい. 余りが1, 2の場合には1桁ないし、2桁消せば必ず3の倍数になるが、消せる桁数が足りているかをチェックする必要がある.
N = input() t = [int(c % 3) for c in N] x = sum(t) if x % 3 == 0: print(0) elif x % 3 == 1: if 1 in t: print(1) else: print(2) elif x % 3 == 2: if 2 in t: print(1) else: print(2)ABC182D - Wandering
17分で突破. 各ラウンドの開始時点の座標はそれまでの累積和の合計であることはすぐ分かる. 各ラウンド毎に座標が最大となるのは、ラウンドの開始時点の座標にそれまでの累積和の最大値を足したものとなるので、それの最大を取れば良い.
from itertools import accumulate N, *A = map(int, open(0).read().split()) a = list(accumulate(A)) result = 0 c = 0 m = 0 for i in range(N): m = max(a[i], m) result = max(result, c + m) c += a[i] print(result)ABC182E - Akari
60分で突破. 難しく考えすぎた. 何も考えずに色塗りすればよかった…….
from sys import stdin readline = stdin.readline H, W, N, M = map(int, readline().split()) AB = [tuple(map(lambda x: int(x) - 1, readline().split())) for _ in range(N)] CD = [tuple(map(lambda x: int(x) - 1, readline().split())) for _ in range(M)] t = [[0] * W for _ in range(H)] ly = [[] for _ in range(H)] lt = [[] for _ in range(W)] for a, b in AB: ly[a].append(b) lt[b].append(a) for i in range(H): ly[i].sort() for i in range(W): lt[i].sort() by = [[] for _ in range(H)] bt = [[] for _ in range(W)] for c, d in CD: by[c].append(d) bt[d].append(c) for i in range(H): by[i].append(W) by[i].sort() for i in range(W): bt[i].append(H) bt[i].sort() result = 0 for h in range(H): lyh = ly[h] i = 0 pd = -1 for d in by[h]: j = i while j < len(lyh) and lyh[j] < d: j += 1 if i != j: for w in range(pd + 1, d): t[h][w] = 1 i = j pd = d for w in range(W): ltw = lt[w] i = 0 pc = -1 for c in bt[w]: j = i while j < len(ltw) and ltw[j] < c: j += 1 if i != j: for h in range(pc + 1, c): t[h][w] = 1 i = j pc = c print(sum(sum(x) for x in t))
- 投稿日:2020-11-08T22:45:10+09:00
購入済みUdemy講座 (2020/11/08時点)
独学の教材として、先月頃からUdemyを使用し始めました。
自分が購入したものを以下記載していきたいと思います。
(セールでとりあえず買っておいた、という未着手のものが多々あります)そもそもUdemyとは
Udemyトップページ
Udemyの仕組みに関するよくある質問上記ページをご覧いただくとお分かりになると思いますが、動画配信のオンライン学習サービスです。
一度購入しておくと、その後期間無制限で何度も見ることができます。
"2万円"などの高額な講座もあるのですが、毎月と言ってよいほど頻繁にセールが開催され、1500円で購入できたりするので、そのタイミングでまとめ買いをするとお得かと思います。
(買って満足してしまう罠がありますが)購入した講座一覧
※購入して積みっぱなしにしないよう戒めのために公開しておきます。
★★★受講完了済み★★★
「はじめての AI」 by Grow with Google
講座内容
AI の基礎知識とその仕組みについて学習し、画像認識や音声認識について実際のデモをご覧いただきながら体感していただきます。基本知識だけでなく、事例や具体的にそれがどのような仕組みで動いているかも紹介することで、AI を活用するヒントを得ることを目指します。「AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得」 by 山浦 清透
講座内容
★ゼロからAWSの重要サービスを使いこなせるように!実際にネットワークやサーバーを構築し、インフラの基礎概念を習得します。
本講座は、「はじめてAWSを学ぶ方」や「インフラにあまり詳しくない方」を対象に、「AWSの重要サービスを使い、自分でネットワークやサーバーを構築できるようになる」ことを目指したコースです。
セクションごとに、インフラの基礎概念を学びながら、手を動かし実際に構築していく、という構成になっています。
(以下略)「Git: もう怖くないGit!チーム開発で必要なGitを完全マスター」 by 山浦 清透
講座内容
★ゼロからプロのチーム開発の現場でGitを使いこなせるよう完全マスターします
こちらのコースは未経験の方でも、プロのチーム開発の現場で必要とされるGitの全てを習得することを目的としたコースです。
(略)
こちらのコースでは、まずGitの仕組みを図解でしっかりと理解していきます。
Gitってそもそも何のためにあるのか、コミットした時にどういう風にデータを保存しているのか、マージやリベースした時に何が起こっているのか、ブランチってどういう風に実現しているのか。
そういうことを仕組みから理解することで、Gitの分かりづらいコマンドを自信を持って使えるようになります。なにより、Gitを使う上でのハードルであるステージやブランチ、HEADの概念を完全に理解することができます。
その上で、実際にプロジェクトを作成しGitHubを用いながら、コマンドを実行して学んでいきます。
スキルを身につける上で、実際に作りながら学んでいくことはとても大切です。理解したものを実践することで本当に使えるスキルを身に付けていきます。
(以下略)★★★受講中★★★
「現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル」 by 酒井 潤
講座内容
このコースでは、Python3の基礎である入門コースを一通り終えた後に、今後のアプリケーション開発に役立つためのPythonのテクニックやデーターベースアクセス(SQLite, MySQL, MongoDB, SQLAlchemy, memcached, Hbase, neo4j etc)、WEB(Flask, socket, RPC etc)、インフラ自動化(Fabric, Ansible)、並列化(スレッド、マルチプロセス)、テスト(Unittest, pytest, Tox, Selenium, etc)、暗号化(pycrypto, hashlib)、グラフィック(turtle, Tkinter)、データ解析(numpy, pandas, matplotlib, scikit-learn), キューイングシステム(ZeroMQ, Celery)、非同期処理(asyncio)などのPythonを使った応用編を取り入れております。
(以下略)★★★今後着手★★★
Python
「現役シリコンバレーエンジニアが教えるPythonで始めるスクラッチからのブロックチェーン開発入門」 by 酒井 潤
講座内容
このコースではブロックチェーンの技術とPythonを用いて仮想通貨の送金システムを構築しながらブロックチェーンの根幹にある技術、考え方とその応用方法をハンズオンで学びます。
(以下略)「現役シリコンバレーエンジニアが教えるPythonでFXのシストレFintechアプリの開発」 by 酒井 潤
講座内容
今回扱うFintech技術では、日本でも人気のあるFXの自動トレードをPythonで行い、グローバルで使われているOandaサービスのAPIを使って行います。日本で人気があるという理由でFXにしましたが、FXではなくても、APIを使ってトレードするやり方さえ学べば、例えば株式や仮想通貨のトレードなどでも十分に使える技術を学ぶことができますので、FXにご興味ない方でも自動トレードが何かということを学べる講座になっております。
(以下略)「Python+FlaskでのWebアプリケーション開発講座!!~0からFlaskをマスターしてSNSを作成する~」 by N Matsumoto
講座内容
【この講座について】
Pythonの基本的な使い方、Flaskのウェブアプリケーション開発の基本的な技術、Flaskの機能の有効活用方法、サーバサイドウェブフレームワークで利用されるMVTモデル、サーバサイドのセキュリティ、テーブル設計、SNSサンプルアプリケーション開発を通じた実践的なアプリケーション開発など、PythonのWebエンジニア必修のスキルが身につきます!!
(以下略)「Python デザインパターンマスター講座~Pythonの基本文法、コーディング規約、命名規約、プログラミング技術~」 by N Matsumoto
講座内容
【この講座について】
プログラミングを勉強し、オブジェクト指向を覚えたが実際にどういう風にコードを書けばよいか。良いコード、恥ずかしくないコードというのはどういうコードなのか理解するためにこの講座を作成しました。
コーディング規約、命名規約、コードレビュー、オブジェクト指向のベストプラクティスのSOLIDの原則、デザインパターンを通じて、良いプログラムが何なのかを理解し、技術力を身に着けます。
また、デザインパターンは転職活動の面接などでも聞かれることがあり、身に着けて損のないスキルです
(以下略)「【E資格の前に】PyTorchで学ぶディープラーニング実装」 by 株式会社 AVILEN
講座内容
<概要>
ディープラーニングの実装、実務活用のイメージが沸かない、難しそう...そんなお悩みはありませんか?
当講座は、Pythonの基本文法とNumpyの知識さえあれば、誰でもディープラーニング(DL)を実装できるPyTorchの入門講座となっています。
特別な理論や数式は扱わず、まずは実装して、ディープラーニングのイメージを掴むことをゴールとしています。
AIスペシャリスト集団、株式会社AVILENの執行役員である吉川武文氏が、PyTorchによるディープラーニング実装術を公開。
当講座で扱うプログラムは全て皆様にプレゼントします、実務でもご活用ください。Go
「現役シリコンバレーエンジニアが教えるGo入門 + 応用でビットコインのシストレFintechアプリの開発」 by 酒井 潤
講座内容
このコースでは、Goの基礎である入門コースを一通り終えた後に、次世代のFintech(金融+テクノロジー)のアプリケーションとしてビットコインを自動でシステムトレードを行うアプリを開発します。
多くの言語の良い部分を取りれたGoは、コードを実行する際のパフォーマンスも良く、近年急速にライブラリも充実して来ており、シリコンバレーで多くの企業が取り入れ始めました。日本では、ドキュメントも少なく、Go言語を使う機会があまりないかもしれませんが、世界のトップ企業はすでに使い始めているため、技術レベルで世界から遅れないように今からGo始めると良いかと思います。
(以下略)AWS
「これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)」 by Edutech Global , inc.
本講座は全てのIT従事者にとって必須となるAWSの基本資格「AWS 認定ソリューションアーキテクト – アソシエイト試験」を合格を目指し、そのための知識や経験を獲得できるように設計されています。
この講座を通して、AWSの知識とノウハウを獲得し、「AWS 認定ソリューションアーキテクト – アソシエイト試験」を突破しましょう!!「Ultimate AWS Certified Solutions Architect Associate 2020」 by Stephane Maarek
講座内容
Concretely, here's what we'll learn to pass the AWS Certified Solutions Architect Associate exam:
- The AWS Fundamentals: IAM, EC2, Load Balancing, Auto Scaling, EBS, EFS, Route 53, RDS, ElastiCache, S3, CloudFront
- The AWS CLI: CLI setup, usage on EC2, best practices, SDK, advanced usage
- In-Depth Database comparison: RDS, Aurora, DynamoDB, Neptune, ElastiCache, Redshift, ElasticSearch, Athena
- Monitoring, Troubleshooting & Audit: AWS CloudWatch, CloudTrail
- AWS Integration & Messaging: SQS, SNS, Kinesis
- AWS Serverless: AWS Lambda, DynamoDB, API Gateway, Cognito
- AWS Security best practices: KMS, SSM Parameter Store, IAM Policies
- VPC & Networking in depth
- AWS Other Services Overview: CICD (CodeCommit, CodeBuild, CodePipeline, CodeDeploy), CloudFormation, ECS, Step Functions, SWF, EMR, Glue, OpsWorks, ElasticTranscoder, AWS Organizations, Workspaces, AppSync, Single Sign On (SSO)
- Tips to ROCK the examDocker
「米シリコンバレーDevOpsエンジニア監修!超Docker完全入門(2020)【優しい図解説とハンズオンLab付き】」 by CS Career Kaizen
講座内容
このコースを一文でまとめると?
このコースは、アプリ開発やDevOps経験初心者の方が、Linuxの簡単な基礎(カーネル・シェル・STDIN・STDOUT・TTY)とDocker(イメージ・コンテナ・VMとの違い・Docker compose・ネットワーキング・Volume)を初心者として1から学び、コンテナ化できるデベロパーやDevOpsとしてキャリアアップを目指す方向けのコースです。「米国AI開発者がゼロから教えるDocker講座」 by かめ れおん
講座内容
Dockerの基本的な使い方から現場で役立つ応用的な使い方まで,米国で活躍するAI開発者が講師となって徹底的に解説します.
プログラミングの知識がない人でも,問題なく受講できます.Kubernetes
「米シリコンバレーDevOpsエンジニア監修!超Kubernetes完全入門(2020)【優しい図解説とハンズオン】」 by CS Career Kaizen
講座内容
このコースを一文でまとめると?
このコースは、アプリ開発やDevOps経験初心〜中級者の方が、Linuxの簡単な基礎(カーネル・シェル・STDIN・STDOUT・TTY)とDocker(イメージ・コンテナ・VMとの違い・Docker compose・ネットワーキング・Volume)をベースにして、Kubernetesクラスター上にコンテナ化されたアプリをディプロイ・構築・起動というK8sデベロパー初心者として1から学び、コンテナ化できるデベロパーやDevOpsとしてキャリアアップを目指す方向けのコースです。アジャイル開発
「現役シリコンバレーエンジニアが教えるアジャイル開発」 by 酒井 潤
講座内容
このコースでは、あらゆるレベルのビジネスプロフェッショナルが理解しやすい方法でアジャイルとスクラムの基本をカバーします。アジャイルとスクラムの基礎に関するこのコースから得られる知識を使用して、アジャイルとスクラムに適した環境を作成できます。
アジャイルとスクラムの開発方法を取り入れれば、プロジェクトが失敗するのを防ぐことにも繋がる可能があります。このAjailプロジェクト管理方法は、チームワークが特に重要であり、チームメンバー間の相互信頼を高め、対人関係を改善することもできるでしょう。
このコースは、シリコンバレーでアジャイル開発経験14年の現役エンジニアが教授いたします。アルゴリズム
「現役シリコンバレーエンジニアが教えるアルゴリズム・データ構造・コーディングテスト入門」 by 酒井 潤
講座内容
恐らく、皆さん「アルゴリズムって本当に必要なの?」っと疑問に思っている方もいらっしゃるかと思います。例えば、「実際の現場であまり使わないなー」とか、「今の仕事はWEBのフレームワークのやり方さえ覚えれば、WEBアプリなんて簡単に作れちゃうし」などなどあるとは思います。
ただ、考えていただきたいのですが、なぜあのGAFAと言われるGoogle、Apple, Facebook、Amazonが入社試験で必ずアルゴリズム、データ構造のコーディング面接があるかを考えてみてください。
皆さんもお聞きしたことがあるかもしれませんが、Google検索アルゴリズム、Tesla自動運転アルゴリズムなど世界をリードして最先端の技術革新をしている会社では、ちょっとでもコードが早くなるように、プログラマーが、最適なコードを書く必要があるのです。
(以下略)Unity(C#)
「Unity3D入門の決定版!RPG開発の基本をUnityインストラクターと共に進めるハンズオンコース【スタジオしまづ】」 by 嶋津 恒彦
【講座内容】
・Unityのインストール
・Unityの操作方法とゲームを作る基礎(コードでものを変化させる方法)
・C#プログラミングの基礎(基礎的な文法をイラストと演習問題付き)
・3Dミニゲーム開発(キャラクターを移動せさてゴールしたら終了するゲーム制作)
・3Dアニメーションの基礎(設定・Scriptによる切り替えスキル)
------ここまでが準備-------
・3DRPGの開発
・Playerキャラクターの移動と攻撃実装
・Enemyキャラクターの移動と攻撃実装
・各キャラクターの非ダメージとHP実装
・コンボとスタミナとHPゲージの演出実装「Unity ゲーム開発:インディーゲームクリエイターが教える C#の基礎からゲームリリースまで【スタジオしまづ】」 by 嶋津 恒彦
講座内容
初心者の方でもゲームをリリースできるように、講座の構成は
Unityのインストール
Unityでゲームを作る基礎(コードでものを変化させる簡単な方法)
プログラミングの基礎(ゲーム開発に必要な最低限のスキル)
ゲーム開発のテクニック(ボタンの取得やデータの保存など)
を1話完結形式で学び、基礎力をつけた後
RPGの作成
AppStore/Google Playへのリリース
に取り掛かかります。講座を終えたときには自身のゲームを実際にストアに並べることができるようになっています。「Unityゲーム開発入門:Unityインストラクターが教えるマリオ風2Dアクションゲームを作成する方法【スタジオしまづ】」 by 嶋津 恒彦
講座内容
任天堂からこの夏Nintendo Switch向けに発売されたスーパーマリオメーカー 2。ゲーム開発の専門的な知識がなくても
オリジナルのゲームが開発できることで注目を浴びています。この講座ではスーパーマリオメーカー 2のようにステージを作成するUnityのテクニックが習得できます。
また、ステージ作成だけではなくアクションゲーム開発に必要なC#・アニメーション・当たり判定など総合的なUnityの力がこれ一本で身につく完全攻略版です。
- 投稿日:2020-11-08T22:40:16+09:00
Numpyはじめて、随時更新してく
1.Numpyはじめた
Numpyの勉強を始めて引数の指定方法や使用例など調べだすと、どうしても忘れてしまうので
随時更新してメモ帳代わりにしていこうと思います。
順番やわかりやすさは二の次なので、わかりにくいかもしれませんがご了承ください
軽く調べて見たところ、Numpyは数値計算を得意とするライブラリーなので、
たくさんの計算用の関数が用意されてるらしい2.こういうのにも感動する
pythonの四則演算を+, -, *, / の4つを使って、配列の各要素に対して四則演算をしてくれるというスグレモノ
いちいち要素取り出したりせずに演算してくれる。
最近はずっとpandas触ってたので気付きませんでしたが、先輩にnumpyは覚えてしまうくらい使ったほうがいいとの勧めがあったので、色々遊びながら調べながら覚えていこうかなと思ってます3.やっていきますか
<np.array(object, dtype=None)>
array.py#np.array()でndarrayを生成 A = np.array([1,3,5,7,9]) #--->array([1, 3, 5, 7, 9]) A -= 4 #---> array([-3, -1, 1, 3, 5]) #各要素に対して4が引き算されてる。各要素に対して引き算されてるってすごいな
これにはブロードキャストとやらが関係してるらしい(後で調べます)
objectにはarray_likeという型が入るらしい。
そのarray_likeとは配列をndarrayの他、多重リストやタプルで表現したもの。
このndarrayはnがn次元配列を扱うためのクラスです
ndarrayは基本的にすべて同じ型の要素で構成されていないといけないので、
複数のデータ型を含む配列(数値型、文字列など)を処理する場合はpandasのほうが扱いやすい<np.sin>
・課題でnp.sin()使うのでついでにゆっくり調べてみた。。。
- 投稿日:2020-11-08T22:31:52+09:00
Pythonをとりあえず何とかする(0)
はじめまして。
その辺にいる会社員です。いろいろなことが欠如しているのですが、
業務でいろいろやらないといけいないため、
メモ代わりに残すことにしました。既に知っている方からすれば、薄っぺらい内容かと思います。
コーディングレベルも低いので突っ込みどころは満載かと思います。何とかするシリーズではそこは無視していきます。
質問を書く場合があります。
見つけたら教えていただけると嬉しいです。
よろしくお願いします。使用バージョン:Python 3.8.5
使用エディタ :VS Code追記:コーディング規約もいったん無視します。
- 投稿日:2020-11-08T21:43:41+09:00
静岡のGoToEat公式サイトをスクレイピング
はじめに
静岡のGoToEat公式サイトをスクレイピング、伊豆のキャンペーン対象店をリスト化する
の記事の中に
import urllib.request html = urllib.request.urlopen(url).read()検索条件の指定が効かず同じページばかり表示されてしまう事象が発生。
ブラウザで同じURLを開く場合も新規と2回目で表示内容が異なる。どうやらSessionを判断している様子。ということなので調べてみた
URLが変わる
「伊豆市」検索直後のページ
https://premium-gift.jp/fujinokunigotoeat/use_store?events=search&id=&store=&addr=%E4%BC%8A%E8%B1%86%E5%B8%82&industry=検索直後のページと戻る(1ページ目)との違いが「events=search」と「events=page」、「id=」と「id=1」でURLが変わっているみたい
戻る(1ページ目)と次へ(2ページ目)との違いが「id=1」と「id=2」なのでidがページ数とわかりました
アクセス
試しに戻る(1ページ目)のURLからスタートすると検索結果が反映されていないので表示内容が違うため
- 「伊豆市」検索直後のページのURLにアクセス
- 戻る(1ページ目)のURLにアクセス
の順番でアクセスするといけるようです
次のページのURLはheadのlinkのなかにURLが見つかりましたのでそちらを利用、
試しに検索直後のページから次のページを取得していくと「id=2」次は「id=22」次は「id=222」と
2が増えたページが返ってきます(wスクレイピング
import requests from bs4 import BeautifulSoup import time headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" } with requests.Session() as s: # 全部取得する場合はサーチは不要 # url = "https://premium-gift.jp/fujinokunigotoeat/use_store" # 検索の場合はサーチページを一旦表示してからアクセス s.get("https://premium-gift.jp/fujinokunigotoeat/use_store?events=search&id=&store=&addr=%E4%BC%8A%E8%B1%86%E5%B8%82&industry=") url = "https://premium-gift.jp/fujinokunigotoeat/use_store?events=page&id=1&store=&addr=%E4%BC%8A%E8%B1%86%E5%B8%82&industry=" result = [] while True: r = s.get(url, headers=headers) r.raise_for_status() soup = BeautifulSoup(r.content, "html.parser") for store in soup.select("div.store-card__item"): data = {} data["店舗名"] = store.h3.get_text(strip=True) for tr in store.select("table.store-card__table > tbody > tr"): data[tr.th.get_text(strip=True).rstrip(":")] = tr.td.get_text( strip=True ) result.append(data) tag = soup.select_one("head > link[rel=next]") print(tag) if tag: url = tag.get("href") else: break time.sleep(3)import pandas as pd df = pd.DataFrame(result) # 登録数確認 df.shape df.to_csv("shizuoka.csv", encoding="utf_8_sig") # 重複確認 df[df.duplicated()] df
- 投稿日:2020-11-08T21:38:06+09:00
PythonとTwitterAPIで作るブログ記事自動ツイートbot
はじめに
自分の勉強用に運営している用語辞典的なブログがあるのですが、記事の数も増えてきて人様にみていただけるようになってきたので更なる発展のため、Twitterで宣伝してみることにしました。
ということで定期的に記事をツイートするBotをPython+BeautifulSoup+TwitterAPIで作ってみます。大まかな流れ
- TwitterAPIを使えるようにする
- Pythonコードを実行してツイートできるようにする
- ツイートしたいブログの全記事のURLを一覧化したページを作る
- 作成した全記事一覧ページからURLを取得し、ツイートする
- 適当なサーバーでcronを用いて定期実行されるようにする
それでは作っていきましょう!!!
TwitterAPIを使えるようにする
Twitterアカウントを作る
Twitterアカウントを作成します。
出てくる指示に従っていけば作れます。デベロッパー申請をする
作ったアカウントに関してTwitterAPIを利用するためにデベロッパー申請をしていきます。
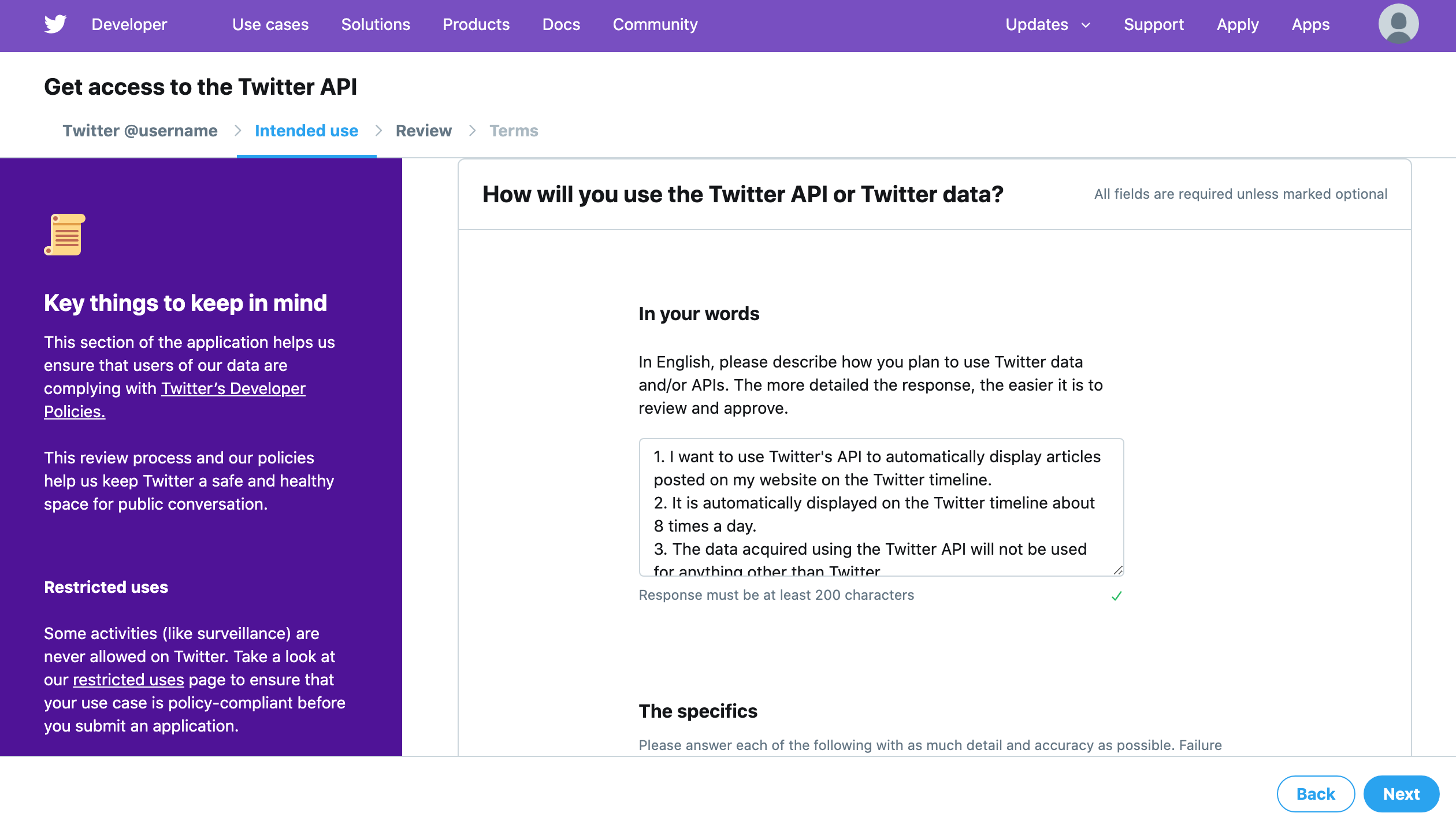
Twitterにログインした状態で、Developerサイトへアクセスします。
「Create an app」ボタンをクリック。
Applyをクリック。
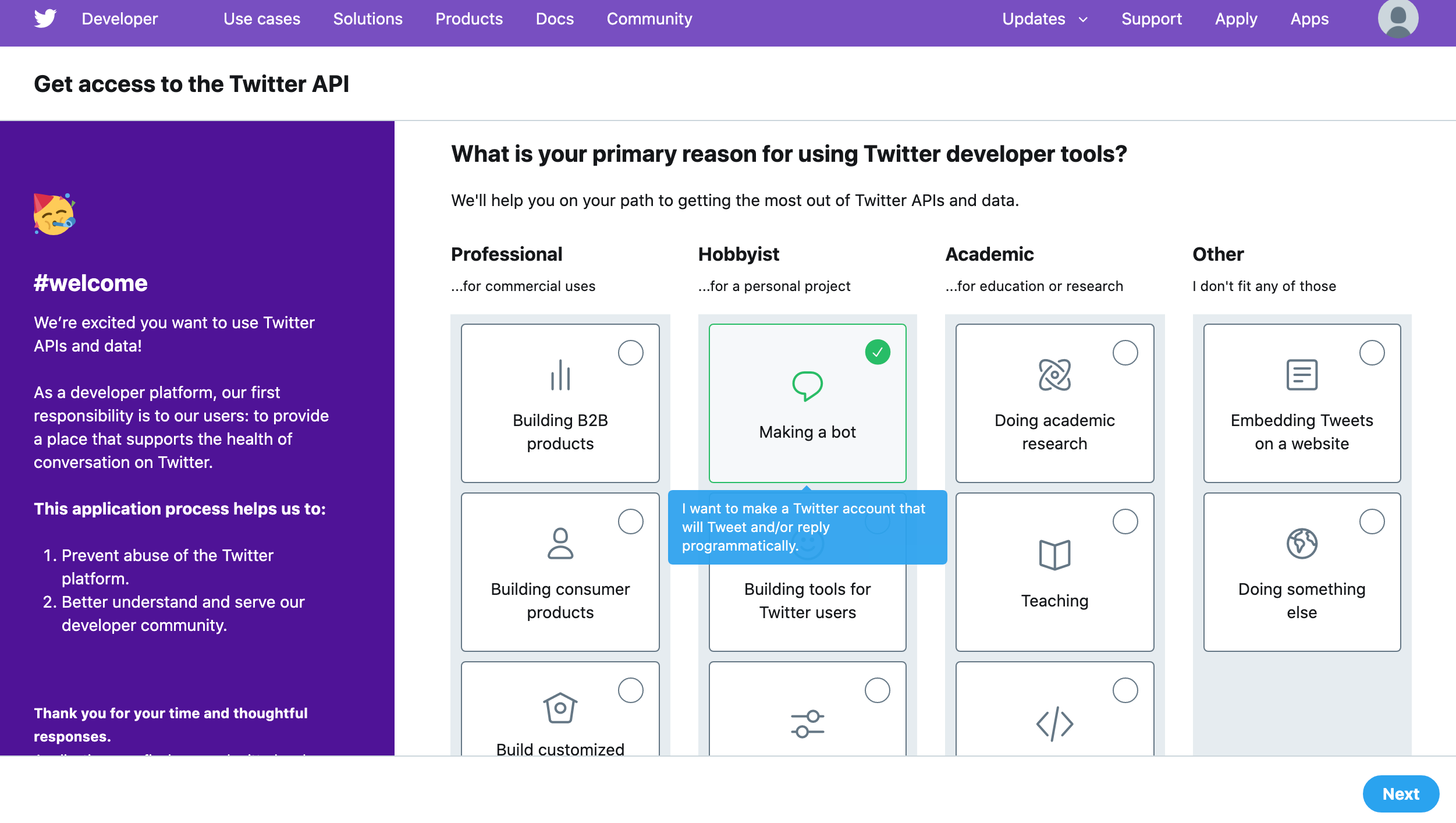
デベロッパーツールの利用目的を選択。今回はBot作成なのでMaking a botを選択。Nextをクリック。
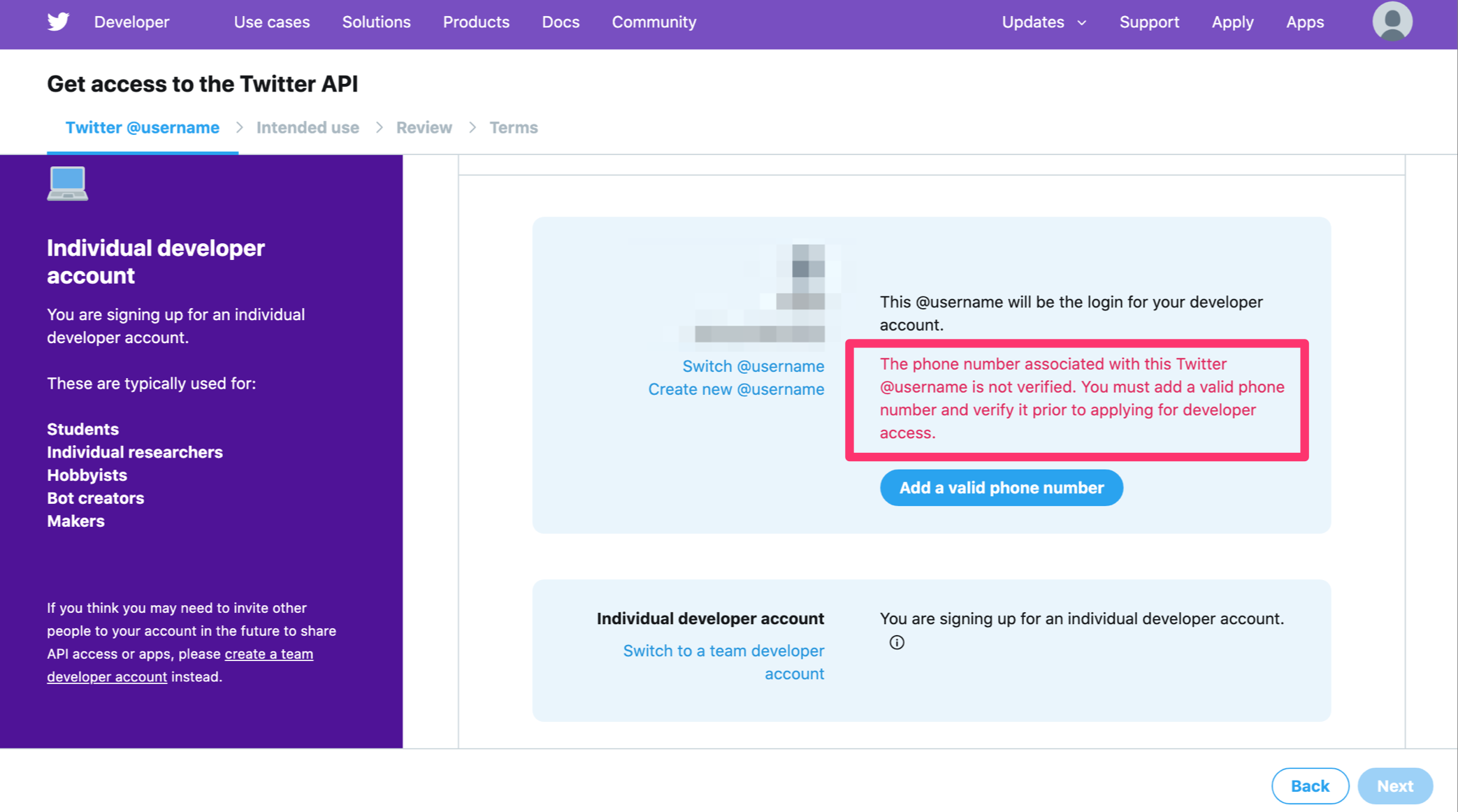
ここで電話番号認証がまだの場合は以下のように求められますので登録しましょう。
またこのページでは以下のようなことを登録していきます。
- デベロッパーアカウントのユーザーネーム
- 個人のアカウントかチームアカウントか
- 登録するメールアドレス
- 住んでいる国
- ニックネーム
- APIのアップデート情報をメールで受け取りたいか?
ぽちぽち設定していきましょう。設定を終えたらNextをクリック。
英文でTwitter APIの利用目的を回答していきます。
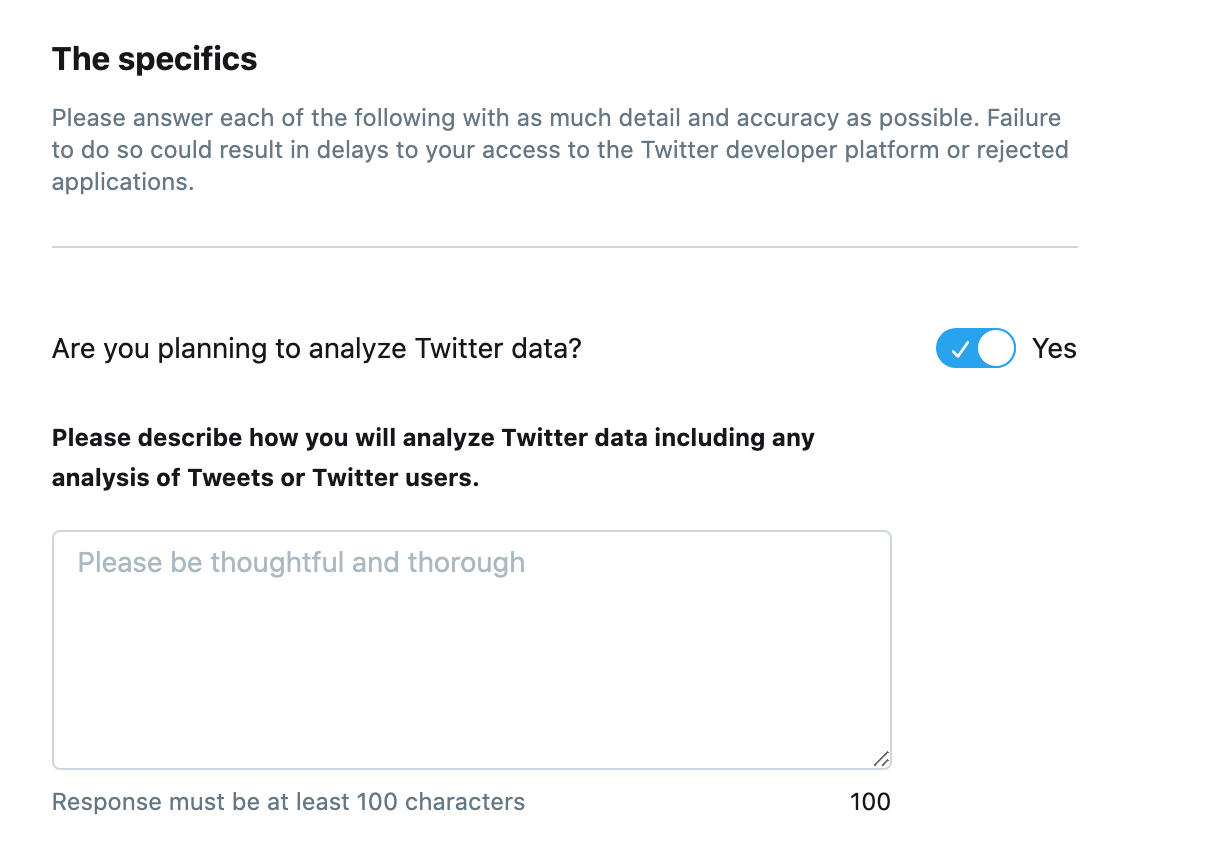
1つ目は「TwitterAPIと取得できるデータの利用目的を英語で教えてね!詳しく書けば承認されやすくなるよ。」といった感じに書いてあるので以下のように回答しました。・自分で作ったブログに投稿した記事をTwitterのAPIを利用して、定期的に自動でツイートしたい。 ・Twitterのタイムラインに自動的に表示させるのは1日に8回程度です。 ・TwitterAPIを利用して取得したデータをTwitter以外で利用することはありません。 #英訳 ・I want to use Twitter's API to automatically display articles posted on my website on the Twitter timeline. ・It is automatically displayed on the Twitter timeline about 8 times a day. ・The data acquired using the Twitter API will not be used for anything other than Twitter.
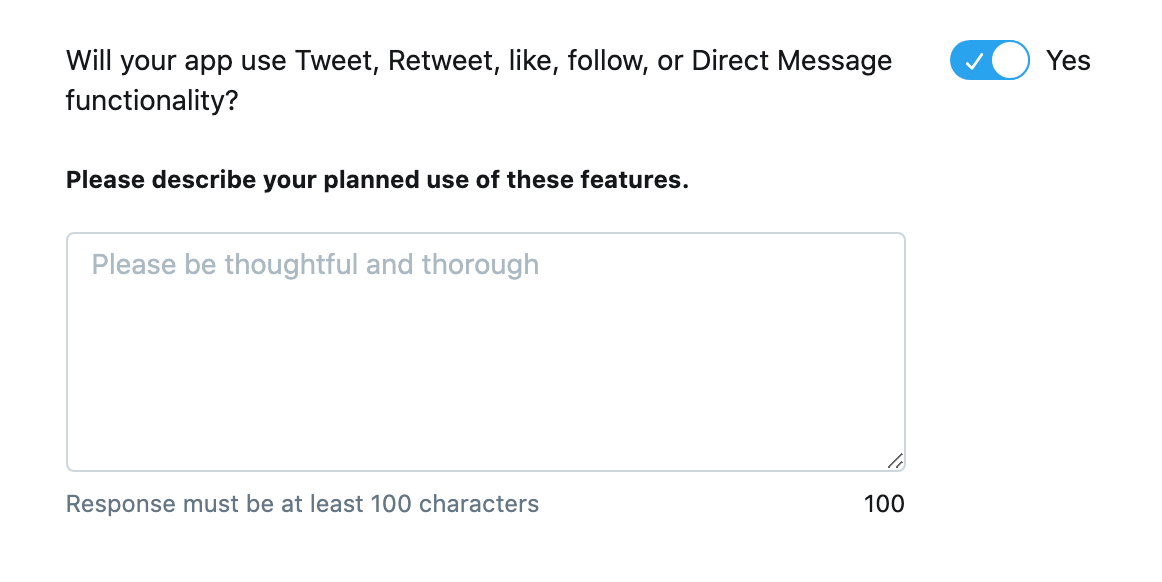
2つ目は「Twitterのデータを分析する予定ある?」といった感じに書いてあるので以下のように回答しました。自分のブログ記事を記載した自動ツイートで、ユーザーに人気のあるツイートを分析したい。 #英訳 I want to analyze tweets that are popular with users with automatic tweets that describe my blog article.3つ目は「アプリはツイート、リツイート、お気に入り、フォロー、ダイレクトメッセージを利用する?」といった感じに書いてあるので以下のように回答しました。
私のアプリは自分で作ったブログに投稿した記事をTwitterのAPIを利用して、定期的に自動でツイートしたいのでツイート、リツイート、お気に入り、フォロー、ダイレクトメッセージを利用する。 #英訳 My app uses Twitter's API to automatically tweet articles posted on my blog, so I use tweets, retweets, favorites, followers, and direct messages.4つ目は「Twitter以外でデータとかを利用する?」といった感じに書いてあり、今回は使わないので、Noにしました。
5つ目は「開発するアプリや分析結果を政府機関が利用するか?」といった感じに書いてあり、今回は使わないので、Noにしました。
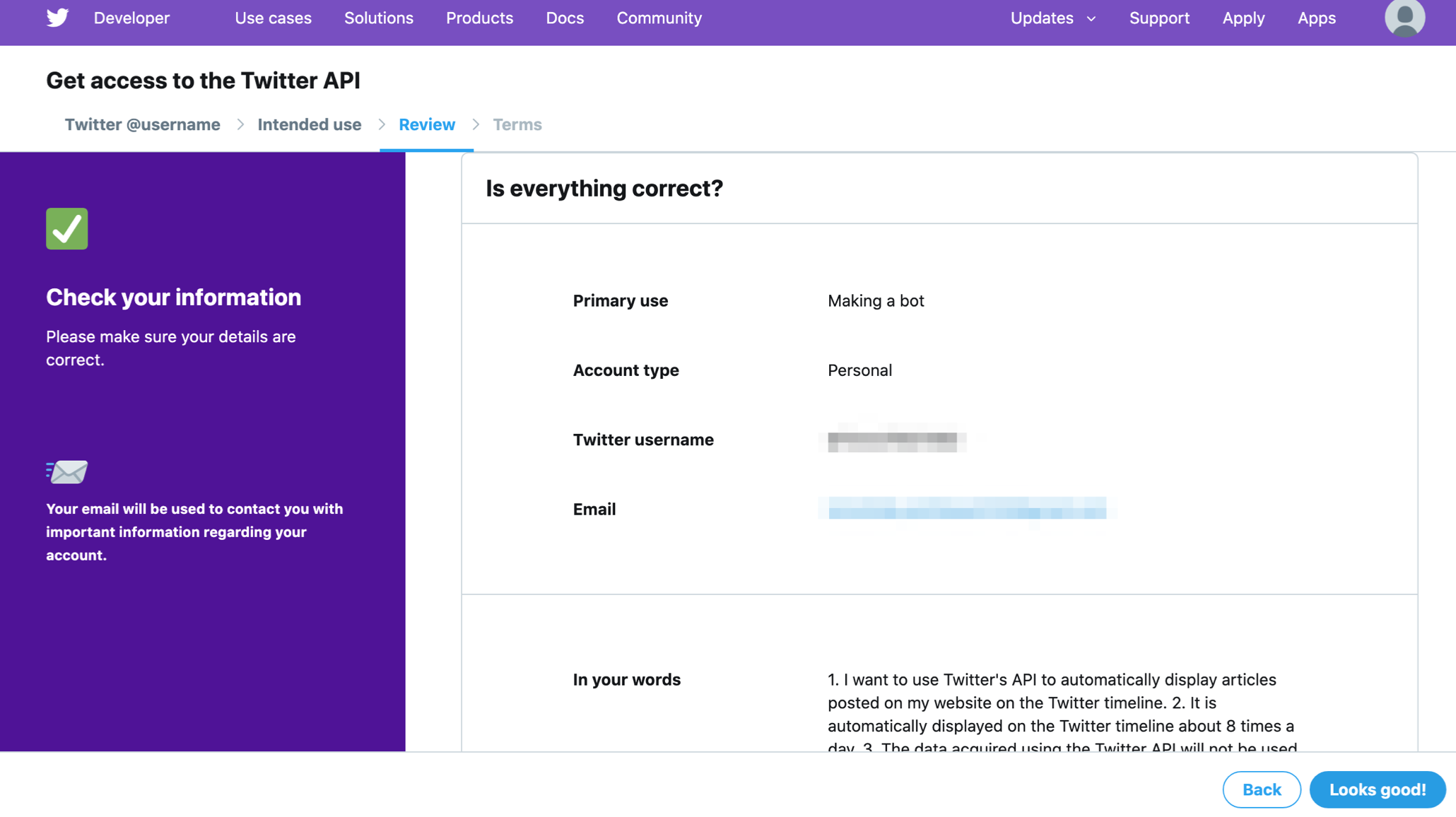
ここまで入力したらNextをクリック。
入力内容の確認画面になります。入力内容に間違いがなければLooks good!をクリック。
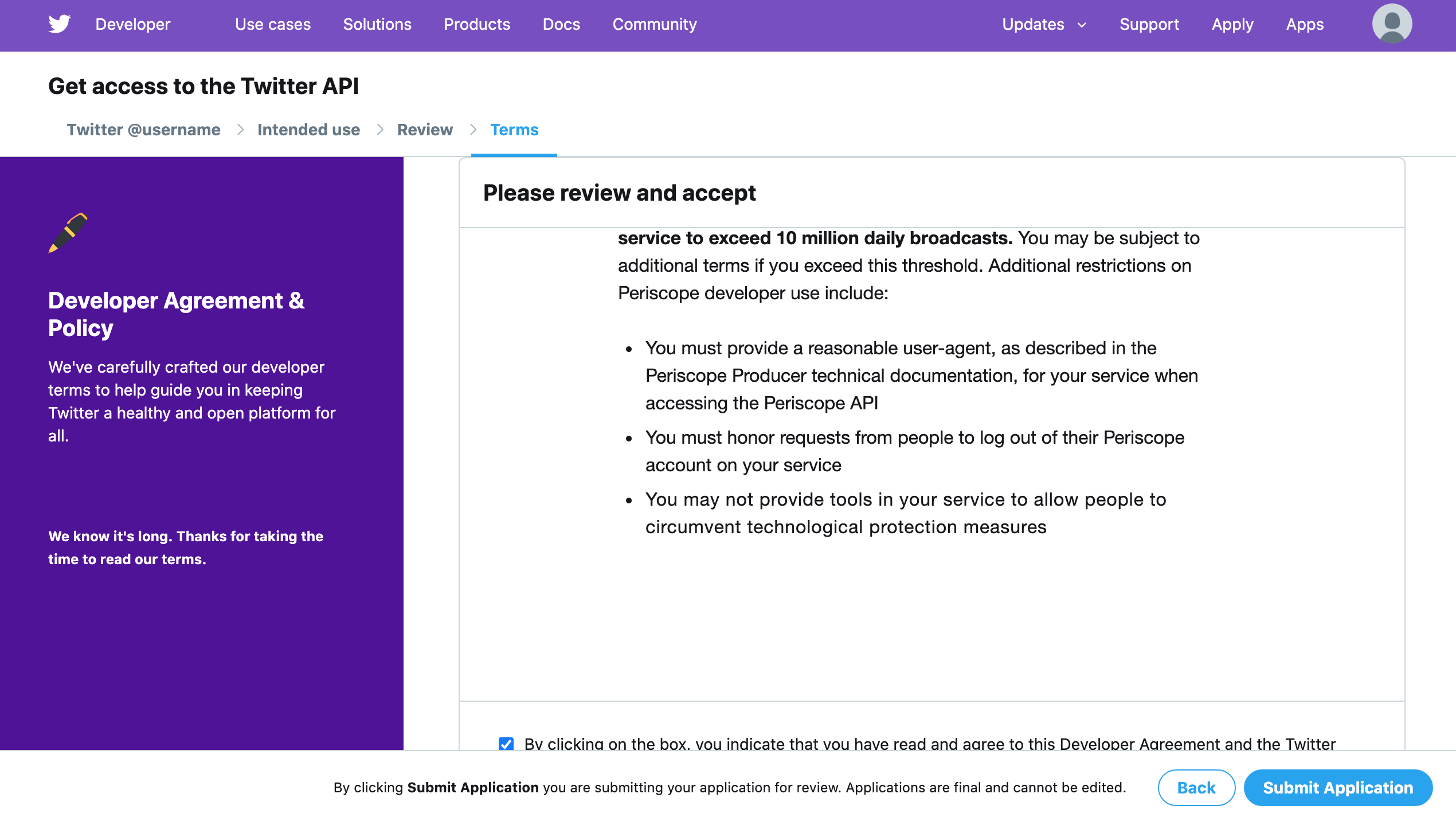
利用規約に同意して申請します。
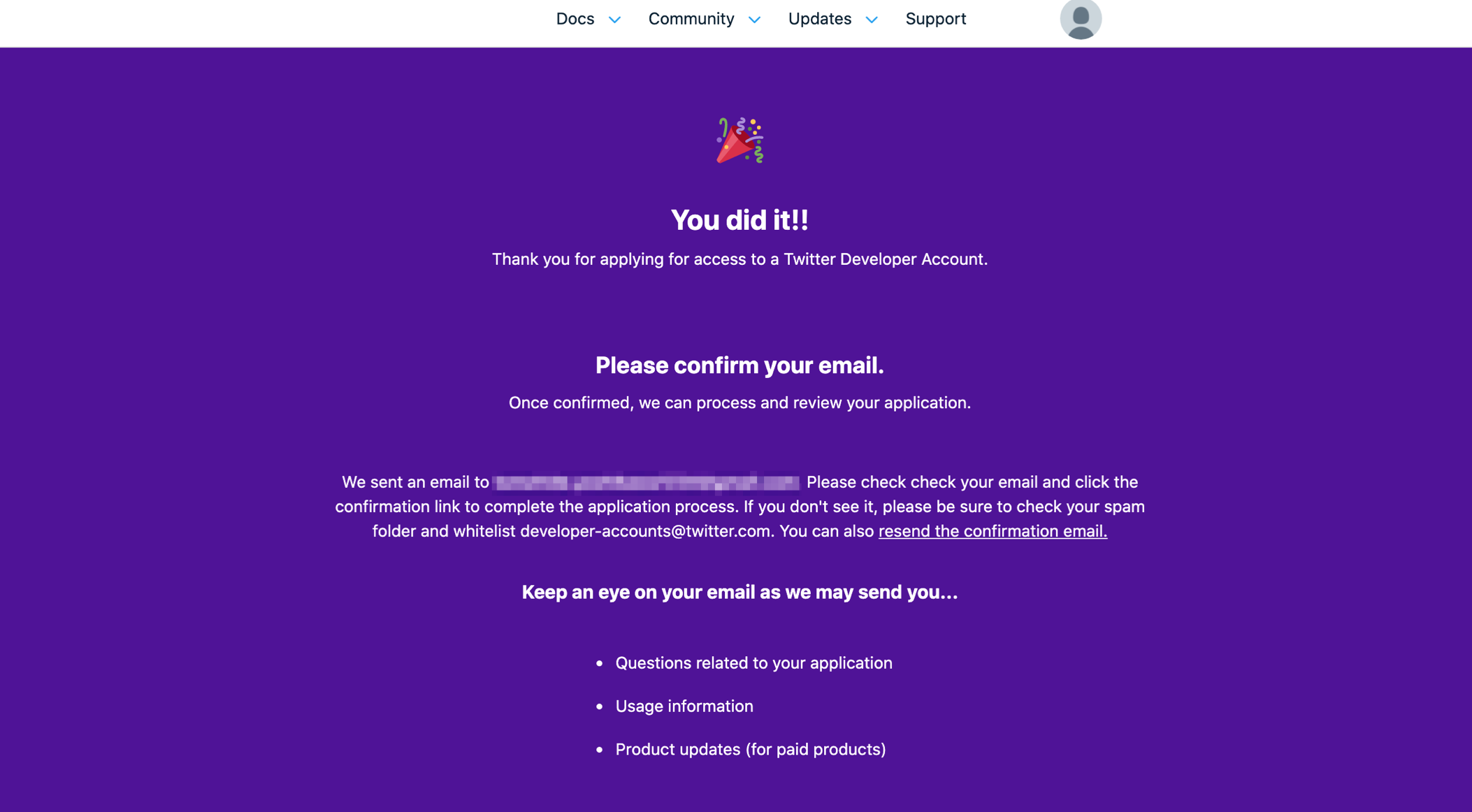
以下の画面が表示されれば申請完了です。あとは神に祈るだけ。
Twitterから以下のような本登録メールが届いているので、メールに記載されているURLにアクセスすれば登録が完了です。
Pythonコードを実行してツイートできるようにする
TwitterAPIのAPIキー、トークンを取得
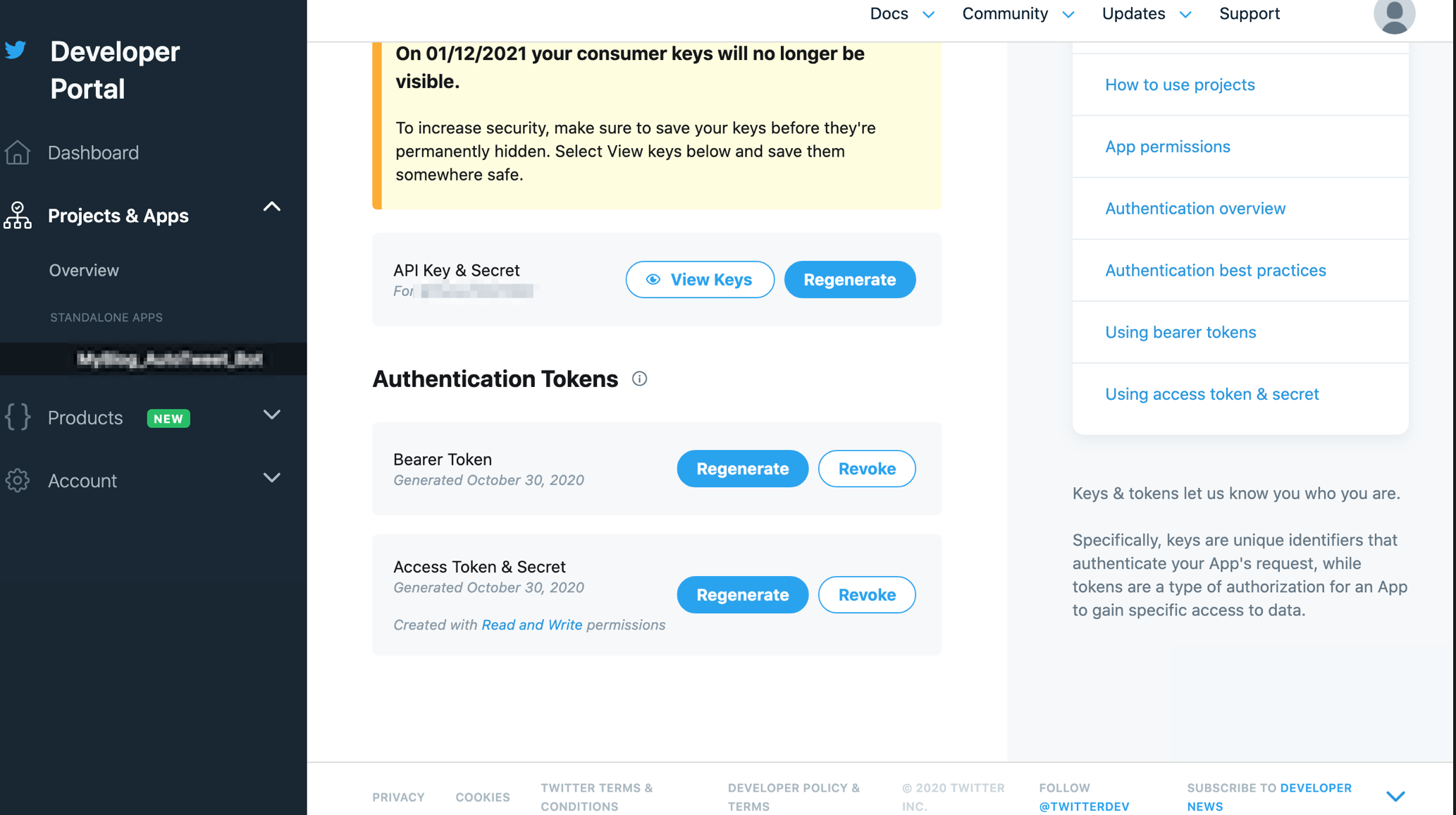
登録したデベロッパーアカウントを使ってAPIキー、トークンを取得します。
Developerサイトへアクセスすると下のような画面に入れます。
スクロールするとCreate Appがあるのでクリック。
アプリ名を入力。
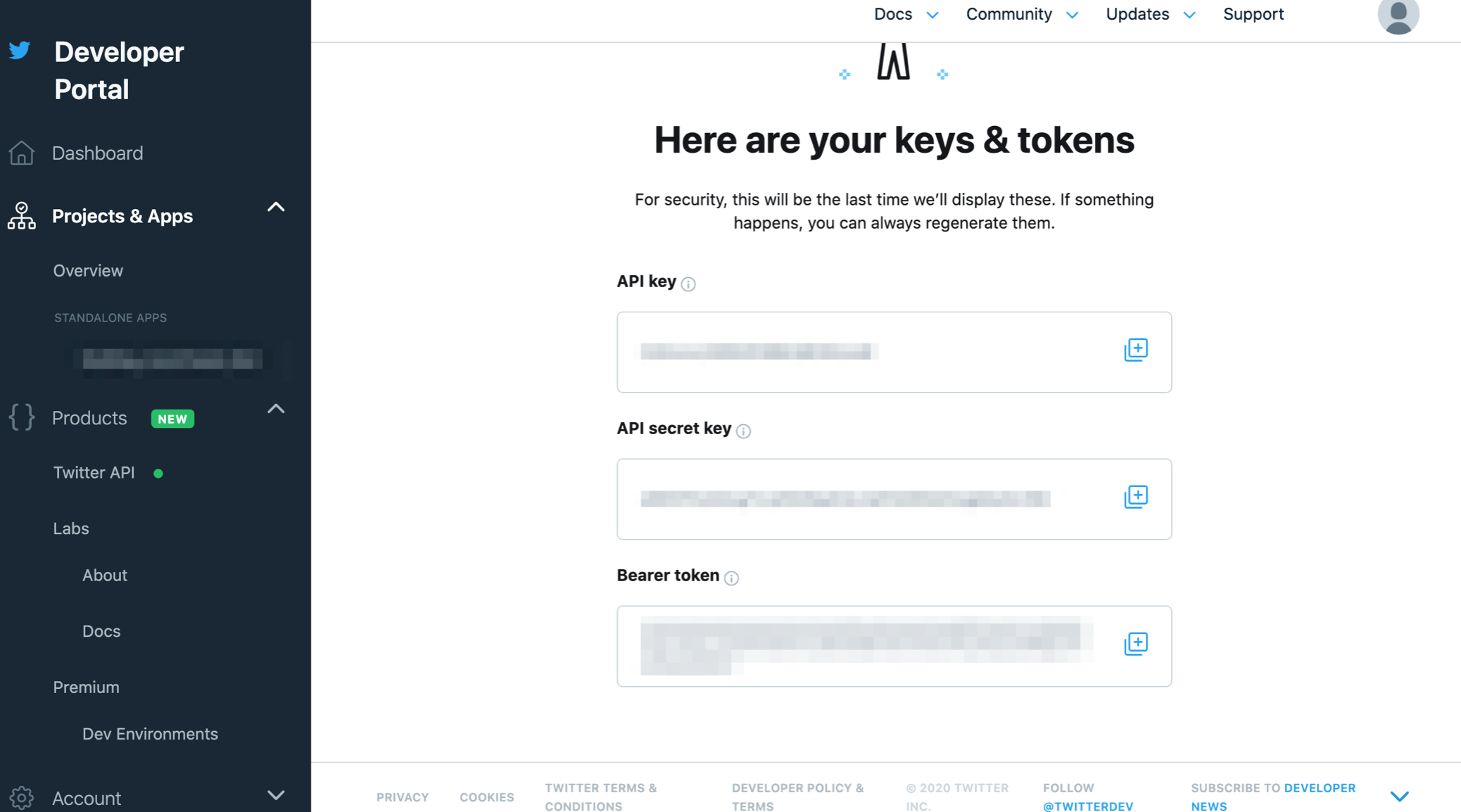
取得できました。人に見せちゃダメですぞ!!
あと今回はツイートをしたいのでAPIの特権の変更が必要です。やっておきましょう。
登録したアプリ名をクリック。
Settingsをクリック。
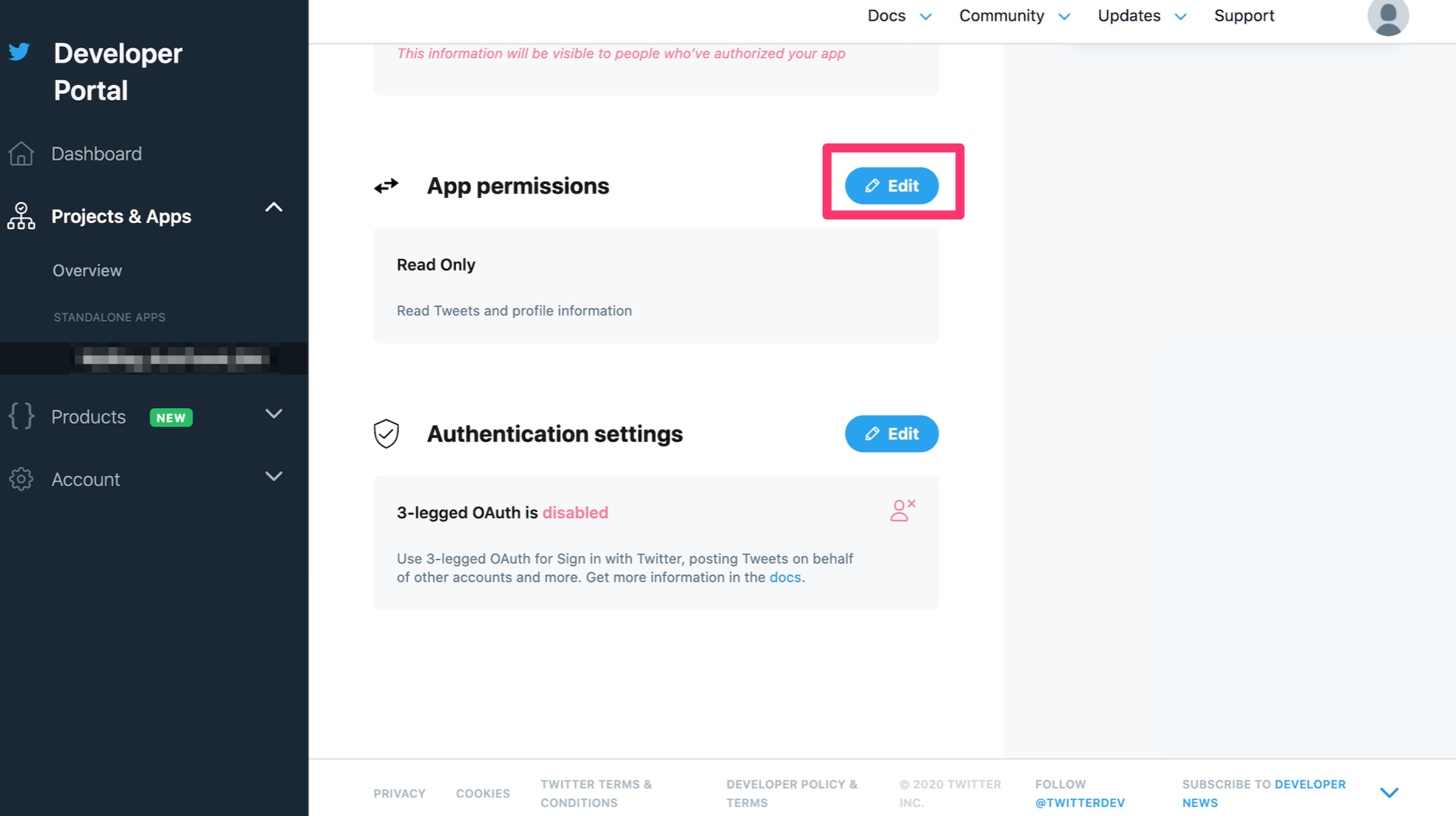
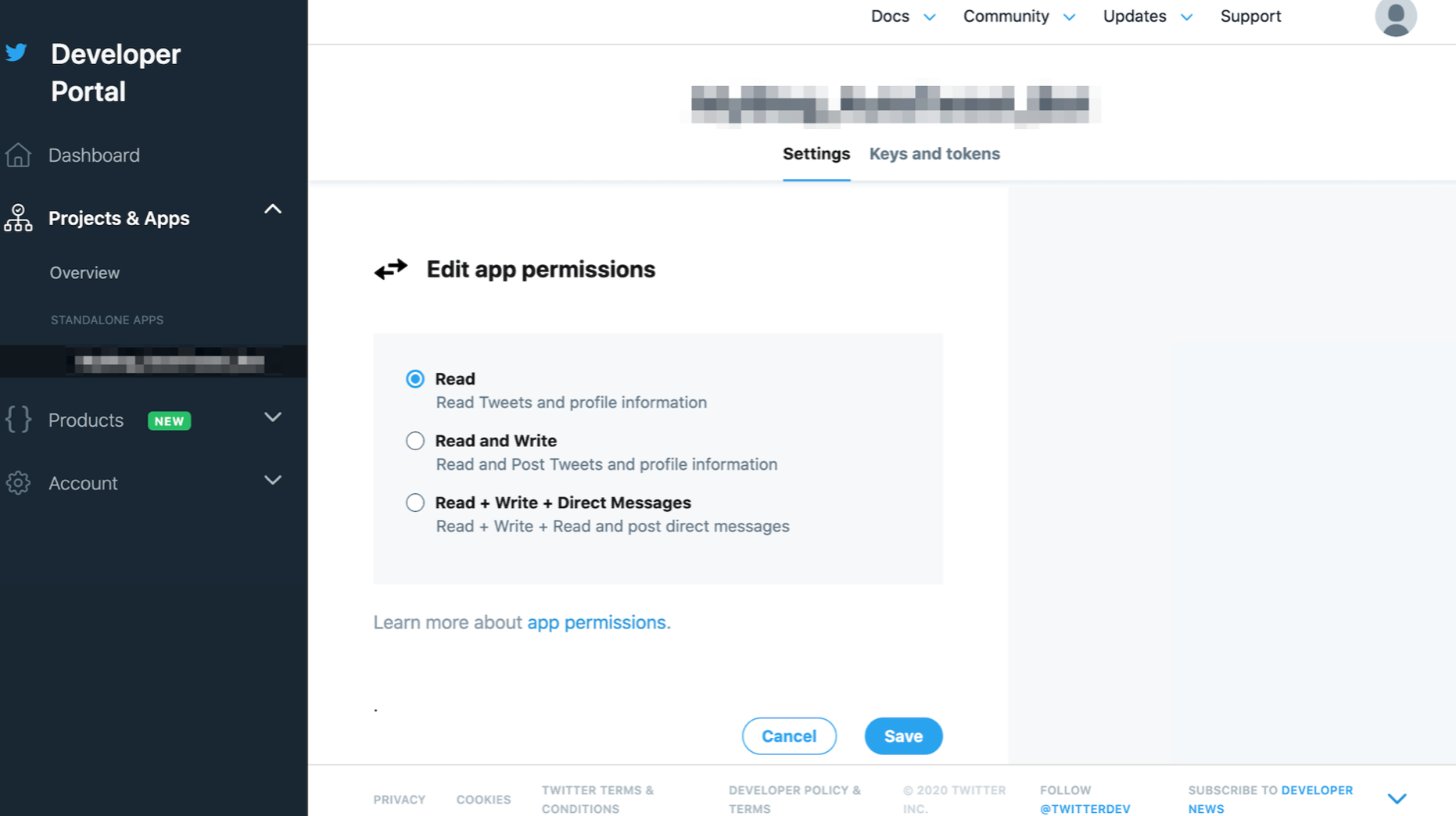
スクロールをして出てくるApp permissionsをRead OnlyからRead and Writeにします。
Editをクリック。
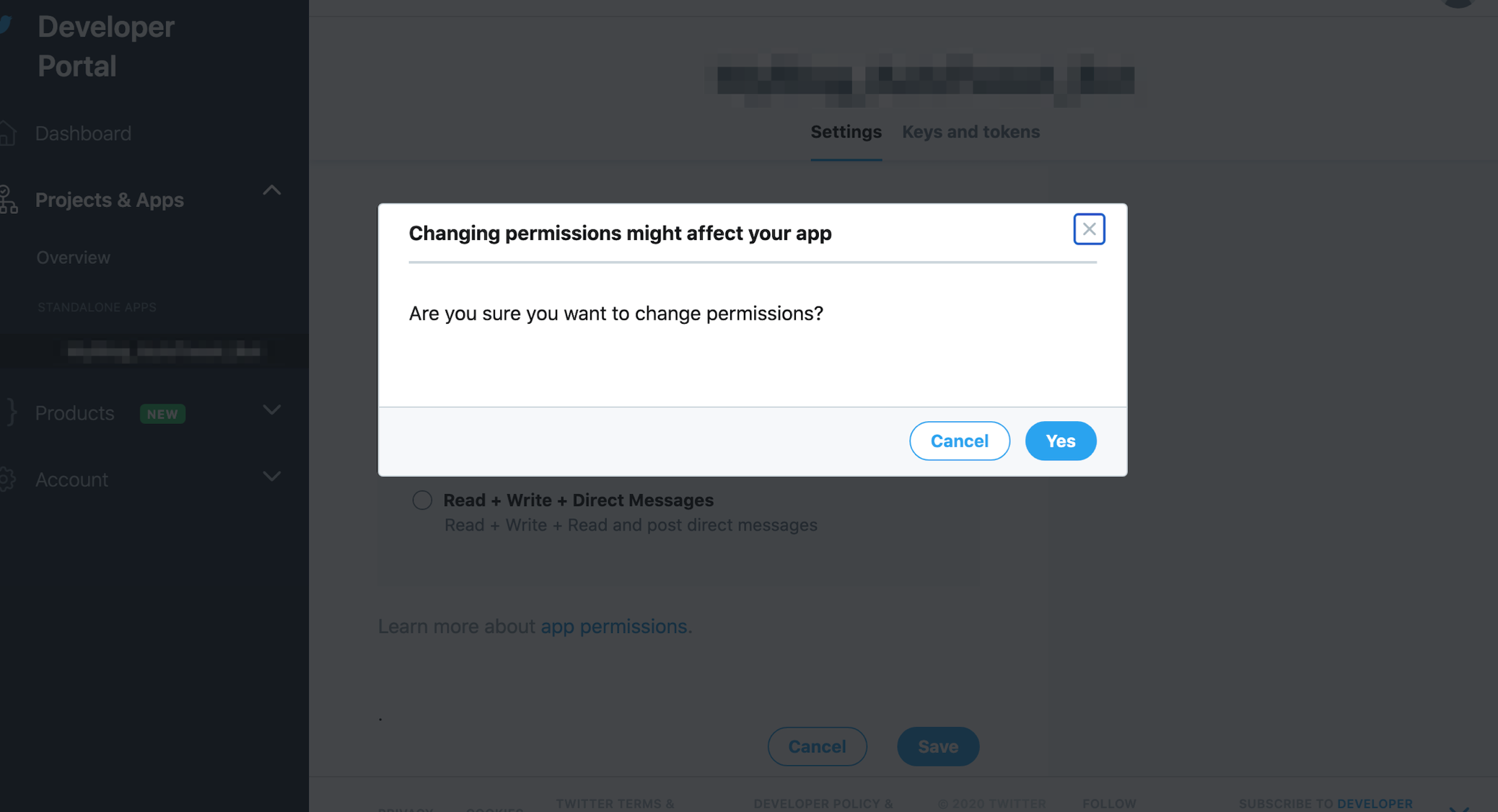
変更できるようになるので、Read and Writeをチェック、Save。
ええんか?と聞かれるのでええんやでとYesをクリック。
TwitterAPIでツイートできる権限を付与できました。
TwitterAPIのAPIキー、トークンを使ってまずはツイートしてみる
TwitterAPIを使うにはリクエスト処理と認証が必要になります。
リクエスト処理はrequestsというライブラリでやるのが一般的です。
また認証はrequests_oauthlibというライブラリがよく使われているみたいですね。ちなみにTwitterは認証方式としてOAuth認証 という認証方法を利用しているので、PythonからTwitterの情報にアクセスする場合はOAuth認証を利用し、TwitterAPIを通して情報のやり取りを行う必要があります。
- OAuth 認証に必要なもの
- Consumer key
- Consumer secret
- Access token
- Access token secret
これらのキーとトークンはさっき作ったやつです!
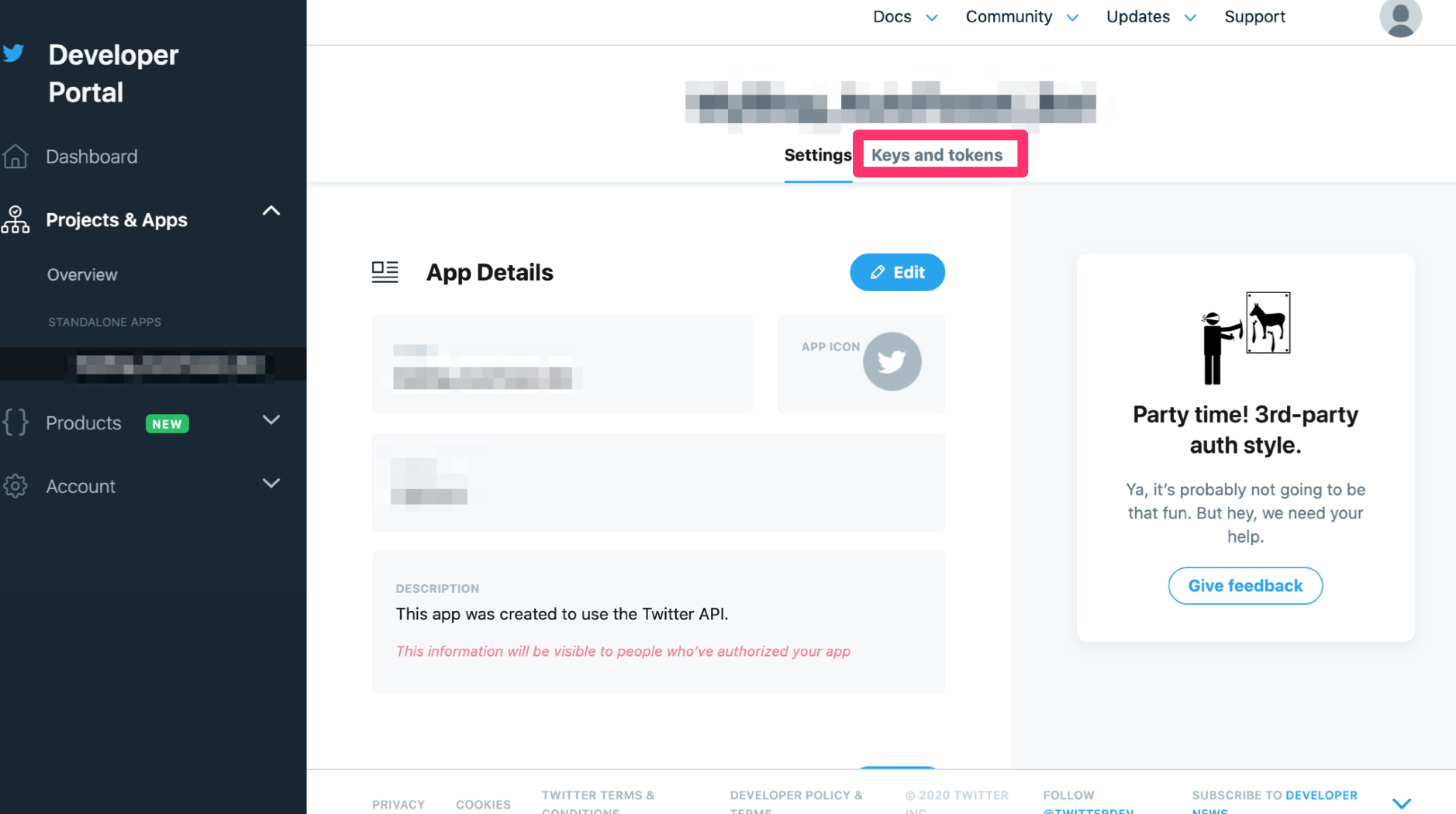
Developerサイトへアクセス。先ほど登録したアプリ名をクリック。
Keys and tokensをクリック。
ここから取得できます。
ではではrequestsとrequests_oauthlibをインストールしましょう。
Windowsの方はAnaconda Powershell Promptで、Macの方はターミナルで以下を実行。
ライブラリをインストールしましょう。pip install requests requests_oauthlibあとはコードを実行するだけです。サンプルコードは以下です!取得したAPIキーとトークンを打ち込んで実行してみてください。ツイッターアカウントから「Pythonからのテストツイート」とツイートされているはずです。(感動の涙!!!)
TwitterBot_autoTweet.py
# coding: UTF-8 from requests_oauthlib import OAuth1Session #ここにKeyとToken CONSUMER_KEY = "XXXXXXXXXXXX" CONSUMER_SECRET = "XXXXXXXXXXXXXXXXXXXXXXXXXX" ACCESS_TOKEN = "XXXXXXXXXXXX-XXXXXXXXXXXXXXXX" ACCESS_TOKEN_SECRET = "XXXXXXXXXXXXXXXXXXXXXXXXXX" twitter = OAuth1Session(CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET) url = "https://api.twitter.com/1.1/statuses/update.json" tweet = "Pythonからのテストツイート" #ツイート内容 params = {"status" : tweet} req = twitter.post(url, params = params) #ここでツイート if req.status_code == 200: #成功 print("Succeed!") else: #エラー print("ERROR : %d"% req.status_code)ツイートしたいブログの全記事のURLを一覧化したページを作る
無事にツイートできたので本命のブログ記事を自動ツイートするための下ごしらえです。
ブログの記事一つ一つをスクレイピングしてツイートするコードを書いてもいいのですが、記事が増えるたびに手直しが必要になるので、ツイートしたいブログの全記事を一覧化したページを作り、そこからURLをスクレイピングしてくるといった方法を取ります。
ブログはWordpressで作成している前提で話を進めます。
Wordpressでブログを作っているなら全記事一覧はプラグイン1つで簡単に作成できます。
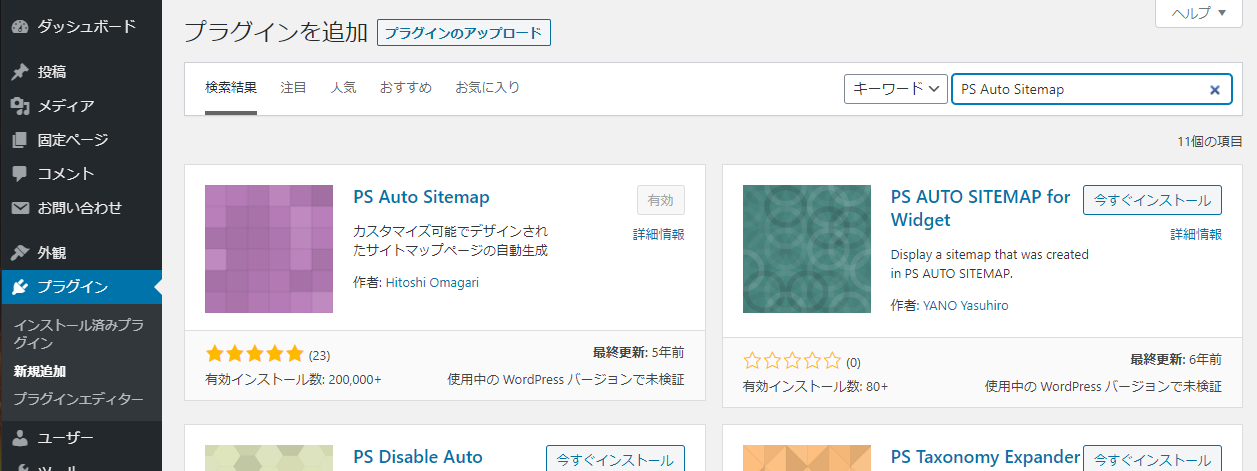
使うプラグインは「PS Auto Sitemap」です。
Wordpressの管理画面からプラグインページに入り、新規追加で「PS Auto Sitemap」と検索してインストール、有効化します。
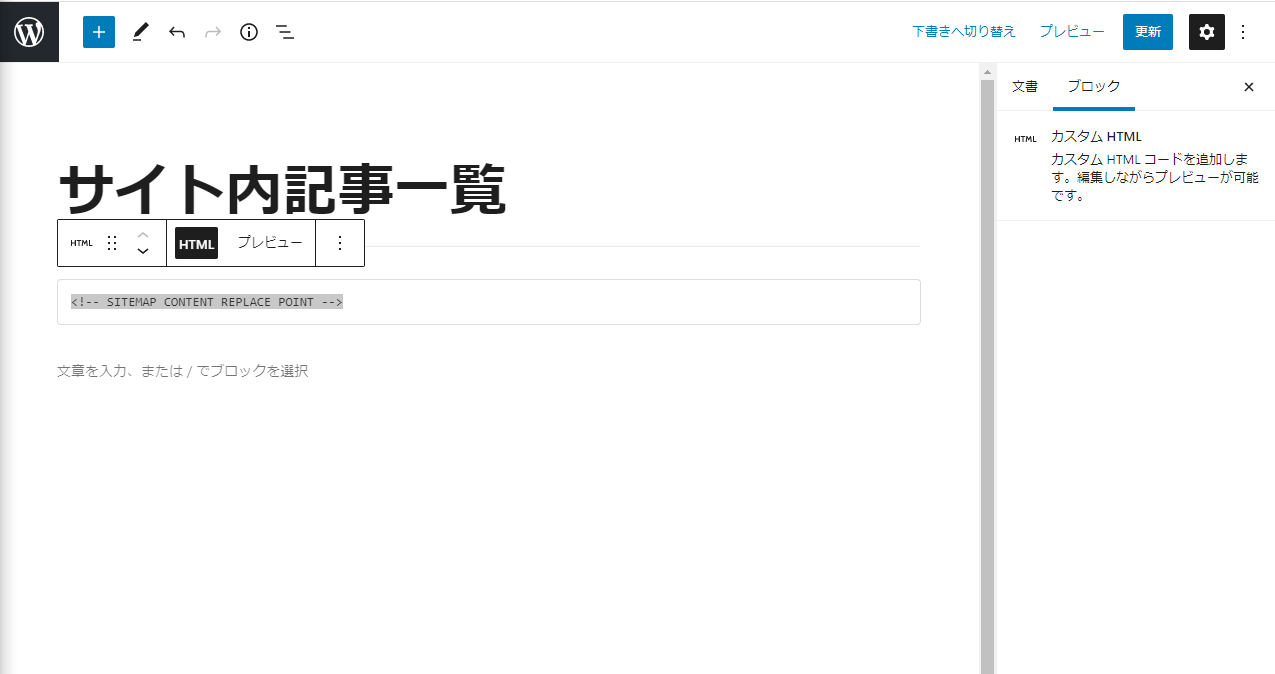
次にページを作成します。固定ページで「全記事一覧」という名前にでもして作成すれば良いと思います。(←なんでも大丈夫です)
記事の中にカスタムHTMLコードで以下のコードを書きます。<!-- SITEMAP CONTENT REPLACE POINT -->
コードを書いたら記事を公開、その記事のIDを控えておいておきます。
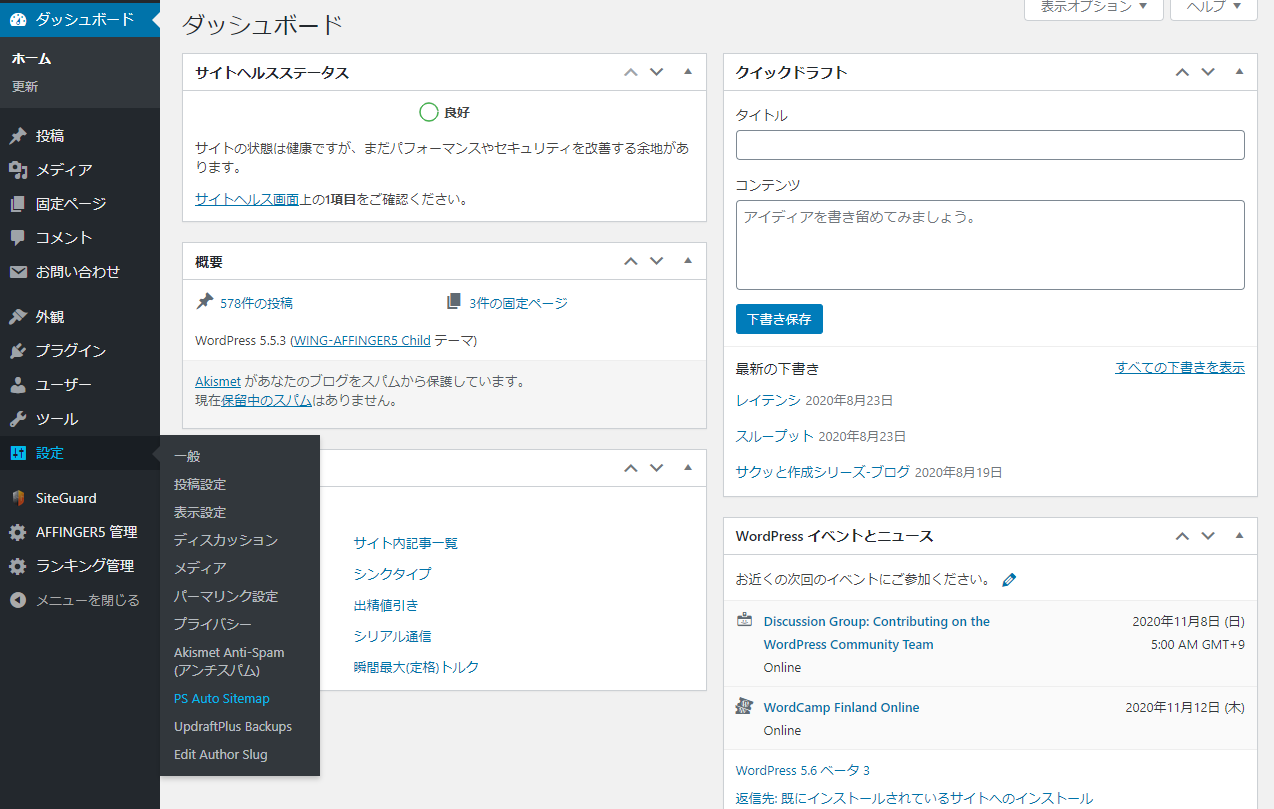
PS Auto Sitemapの設定画面に入り「サイトマップを表示する記事」にIDを入力します。
これで全記事一覧が作成されるはずです。作成した全記事一覧ページからURLを取得し、ツイートする
作成した全記事一覧ページからURLをスクレイピングして取得します。
スクレイピングにはBeautifulSoupを用います。
ライブラリをインストールしましょう。pip install beautifulsoup4あとはAPIを使った時のようにコードを実行するだけです。サンプルコードは以下です。
これら2つのプログラムを同一フォルダに作成して、TwitterBot.pyに取得したAPIキーとトークンを、getBlogURL.pyに全記事一覧ページのURLを打ち込んで実行してみてください。TwitterBot.py
# coding: UTF-8 from requests_oauthlib import OAuth1Session from getBlogURL import post_article #ここにKeyとToken CONSUMER_KEY = "XXXXXXXXXXXXXXXXXXXX" CONSUMER_SECRET = "XXXXXXXXXXXXXXXXXXX" ACCESS_TOKEN = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" ACCESS_TOKEN_SECRET = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" twitter = OAuth1Session(CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET) url = "https://api.twitter.com/1.1/statuses/update.json" tweet = post_article #ツイート内容 params = {"status" : tweet} req = twitter.post(url, params = params) #ここでツイート if req.status_code == 200: #成功 print("Succeed!") else: #エラー print("ERROR : %d"% req.status_code)getBlogURL.py
import requests from bs4 import BeautifulSoup import random # 全記事一覧のURLからツイートしたいURLを引っ張ってくる res = requests.get("全記事一覧のURL") soup = BeautifulSoup(res.text, "html.parser") links = [] for url in soup.find_all('a'): url.get = url.get('href') #URLが取得できない場合はパス if url.get is None: continue #URLに文字"abc"があったらURLをツイートしない if "abc" not in url.get: links.append(url.get) post_article=random.choice(links)ちなみにgetBlogURL.pyの以下の実装部分で"abc"を任意の文字に変更すると入力した文字がURLに含まれないときだけがツイートされるようになります。逆に含まれるものだけツイートしたい場合はnot inをinにすればよいです。
if "abc" not in url.get:いろいろとツイートする記事に条件を付けたい場合は以下のようにgetBlogURL.pyのfor文内を変更すれば良いです。
for url in soup.find_all('a'): url.get = url.get('href') if url.get is None: continue #URLに文字"abc"があったらURLをツイートする if "abc" not in url.get: continue #URLに文字"def"があったらURLをツイートしない if "initial-search" in url.get: continue #URLが"https://abc.com/"だったらURLをツイートしない if url.get == "https://abc.com/": continue #URLに文字"jkl"があったらURLをツイートする if "jkl" in url.get: links.append(url.get)適当なサーバーでcronを用いて定期実行されるようにする
最後です。作成したプログラムを家にある適当なUbuntuサーバー(Macでも可)で定期実行しましょう!
定期実行にはcronでスクリプトを定刻実行するのが楽だと思います。作成したいプログラムをサーバーにコピーする
FTPなりUSBなり何でもよいのでサーバーにコピーしてください。
cronをroot権限で開く。
サーバーのコマンドラインで以下を実行。
crontab -u root -eコマンドを登録
以下のコマンドをcronに登録してください。(必要なツイートの頻度などに変更してね!)
サンプルは4時間おきに「/home/tweet/TwitterBot.py」を実行するといったコマンドになっています。* * /4 * * * python3 /home/tweet/TwitterBot.pyこれで4時間ごとに記事をツイートするBotの完成です。
参考にした、参考になるサイト



- 投稿日:2020-11-08T21:34:51+09:00
[Django] aws cloud9環境でpython manage.py実行したらsqliteのバージョンエラー
今までmac上でdocker環境を立ち上げてDjangoの学習をしていましたが、cloud9で行う記事を見てawsの勉強になるかもしれないと考えcloud9を試してみました。ただコードを書く前のmanage.pyの実行でエラーしてしまい解決するまで時間がかかったのでメモを残します。
環境 : aws cloud9のamazon linux2
/etc/system-release$ cat /etc/system-release Amazon Linux release 2 (Karoo)$ python manage.py startapp blog Traceback (most recent call last): File "manage.py", line 21, in <module> ・・・略・・・ raise ImproperlyConfigured('SQLite 3.8.3 or later is required (found %s).' % Database.sqlite_version) django.core.exceptions.ImproperlyConfigured: SQLite 3.8.3 or later is required (found 3.7.17) $ python -V Python 3.7.9 $ sqlite3 --version 3.33.0 2020-08-14 13:23:32バージョンは問題なさそう。
$ which sqlite3 /home/linuxbrew/.linuxbrew/bin/sqlite3 $ /usr/bin/sqlite3 --version 3.7.17 2013-05-20 00:56:22コマンドラインからはlinuxbrew配下のsqlite3が見えているがpythonからは/usr/bin/sqlite3が見えている?
調べるとsqlite3が古いから最新版をインストールする記事が多かったが、その中で最新版インストール先のlibをLD_LIBRARY_PATHに設定するというの記事があったので真似してみた。export LD_LIBRARY_PATH=/home/linuxbrew/.linuxbrew/lib:${LD_LIBRARY_PATH}無事manage.pyの実行ができました。linuxbrewは知りませんでしたがhomebrewのlinux版
。LD_LIBRARY_PATHも設定しておくと良いと見つけた記事にありましたが、cloud9ではlinuxbrewはインストールされているがLD_LIBRARY_PATHは設定されていないようでした(.bashrcへの記述はなかった)。### LD_LIBLARY_PATHを設定しないといけないのはなんとなくわかるが何で必要かよくわかっていない。
参考
https://qiita.com/rururu_kenken/items/8202b30b50e3bfa75821
https://qiita.com/thermes/items/926b478ff6e3758ecfea
- 投稿日:2020-11-08T21:28:50+09:00
PyCharmでCmderを使う方法(Windows)
ご覧下さりありがとうございます。
掲題の件について、私が取り組んだ際に日本語で得られる情報の乏しさを感じたため、以下記事として記します。手順
- 環境変数の追加
- コントロールパネル→システム→システムの詳細設定→環境変数 と進み、ユーザーの環境変数として「CMDER_ROOT」、値(パス)にはCmder.exeの格納ディレクトリを記入(大抵は「C:\hogehoge\cmder」のはず)
- PyCharmの設定を変更
- PyCharmのSettings→Terminalに進み、Shell Path欄に「"cmd.exe" /k ""%CMDER_ROOT%\vendor\init.bat""」と入力する(ダブルクオーテーション二重は誤植ではありません)
- PyCharm再起動→Alt + F12でCmderが起動する(≒Linux系のコマンド[lsなど]が通る)ことを確認
参考
- https://stackoverflow.com/questions/8713960/cmd-exe-k-switch
- https://github.com/cmderdev/cmder/issues/282
(以上)
- 投稿日:2020-11-08T21:28:37+09:00
Dockerのベースイメージの記述方法
ベストプラクティスを読んでみた
可能であれば、自分のイメージの元として現在の公式レポジトリを使います。私たちは Debian イメージ を推奨します。これは、非常にしっかりと管理されており、ディストリビューションの中でも最小(現在は 100 MB 以下)になるよう維持されているからです。
というわけでDebian系を使うようにしましょう。
どうやって選ぶの?
- ベースのOSを決める。ubuntuとかcentosとかpythonとか。
- docker searchコマンドで公式を選ぶ。無難にSTARSが一番多いやつでいいでしょう。
- Dockerhubで公式のイメージを検索するとTags一覧があるのでそこから選ぶ。
- FROM {イメージ名}:{タグ名}
例
FROM python:rc-alpine3.12
- 投稿日:2020-11-08T20:58:28+09:00
TMDbのAPIの映画情報をPythonで取得してみた
TMDb、TMDbのAPIについて
TMDb1 (The Movie Database)は映画やテレビ番組のデータをコミュニティベースで集めているデータベースだそうです。このサービスにはAPIがあり2、様々な情報をプログラムを介して取得することができます。APIの利用のためには、アカウントの登録後、利用申請が必要です。(ちなみに、このAPIは現時点でAPI rate limitingが無いようです!3)
Pythonで実装
- python 3.6.5
APIを叩くPythonのクラスを定義します。今回はmovieの情報に絞って試してみます。tokenはAPI利用申請後に生成される、APIリードアクセストークンと呼ばれるものを使用します。
import requests import json from pprint import pprint class TMDB: def __init__(self, token): self.token = token self.headers_ = {'Authorization': f'Bearer {self.token}', 'Content-Type': 'application/json;charset=utf-8'} self.base_url_ = 'https://api.themoviedb.org/3/' self.img_base_url_ = 'https://image.tmdb.org/t/p/w500' def _json_by_get_request(self, url, params={}): res = requests.get(url, headers=self.headers_, params=params) return json.loads(res.text) def search_movies(self, query): params = {'query': query} url = f'{self.base_url_}search/movie' return self._json_by_get_request(url, params) def get_movie(self, movie_id): url = f'{self.base_url_}movie/{movie_id}' return self._json_by_get_request(url) def get_movie_account_states(self, movie_id): url = f'{self.base_url_}movie/{movie_id}/account_states' return self._json_by_get_request(url) def get_movie_alternative_titles(self, movie_id, country=None): url = f'{self.base_url_}movie/{movie_id}/alternative_titles' return self._json_by_get_request(url) def get_movie_changes(self, movie_id, start_date=None, end_date=None): url = f'{self.base_url_}movie/{movie_id}' return self._json_by_get_request(url) def get_movie_credits(self, movie_id): url = f'{self.base_url_}movie/{movie_id}/credits' return self._json_by_get_request(url) def get_movie_external_ids(self, movie_id): url = f'{self.base_url_}movie/{movie_id}/external_ids' return self._json_by_get_request(url) def get_movie_images(self, movie_id, language=None): url = f'{self.base_url_}movie/{movie_id}/images' return self._json_by_get_request(url) def get_movie_keywords(self, movie_id): url = f'{self.base_url_}movie/{movie_id}/keywords' return self._json_by_get_request(url) def get_movie_release_dates(self, movie_id): url = f'{self.base_url_}movie/{movie_id}/release_dates' return self._json_by_get_request(url) def get_movie_videos(self, movie_id, language=None): url = f'{self.base_url_}movie/{movie_id}/videos' return self._json_by_get_request(url) def get_movie_translations(self, movie_id): url = f'{self.base_url_}movie/{movie_id}/translations' return self._json_by_get_request(url) def get_movie_recommendations(self, movie_id, language=None): url = f'{self.base_url_}movie/{movie_id}/recommendations' return self._json_by_get_request(url) def get_similar_movies(self, movie_id, language=None): url = f'{self.base_url_}movie/{movie_id}/similar' return self._json_by_get_request(url) def get_movie_reviews(self, movie_id, language=None): url = f'{self.base_url_}movie/{movie_id}/reviews' return self._json_by_get_request(url) def get_movie_lists(self, movie_id, language=None): url = f'{self.base_url_}movie/{movie_id}/lists' return self._json_by_get_request(url) def get_latest_movies(self, language=None): url = f'{self.base_url_}movie/latest' return self._json_by_get_request(url) def get_now_playing_movies(self, language=None, region=None): url = f'{self.base_url_}movie/now_playing' return self._json_by_get_request(url) def get_popular_movies(self, language=None, region=None): url = f'{self.base_url_}movie/popular' return self._json_by_get_request(url) def get_top_rated_movies(self, language=None, region=None): url = f'{self.base_url_}movie/top_rated' return self._json_by_get_request(url) def get_upcoming_movies(self, language=None, region=None): url = f'{self.base_url_}movie/upcoming' return self._json_by_get_request(url)以下の実行結果はすべて次のリンクのノートブックで確認できます
https://colab.research.google.com/drive/11jK7yuluSdA-YBAsrm7wmHJpEwJSyE7L?authuser=0
映画の検索
インスタンスを作成して、まずは映画を検索してこのAPIにおける映画のIDを取得します
api = TMDB(token) # tokenは発行された文字列を代入 res = api.search_movies("万引き家族") pprint(res){'page': 1, 'results': [{'adult': False, 'backdrop_path': '/xOpQ4jIQJ0HSUhVDixZA9yWqVBP.jpg', 'genre_ids': [18, 80], 'id': 505192, 'original_language': 'ja', 'original_title': '万引き家族', 'overview': 'After one of their shoplifting sessions, Osamu and ' 'his son come across a little girl in the freezing ' 'cold. At first reluctant to shelter the girl, ' 'Osamu’s wife agrees to take care of her after ' 'learning of the hardships she faces. Although the ' 'family is poor, barely making enough money to ' 'survive through petty crime, they seem to live ' 'happily together until an unforeseen incident ' 'reveals hidden secrets, testing the bonds that ' 'unite them.', 'popularity': 16.385, 'poster_path': '/4nfRUOv3LX5zLn98WS1WqVBk9E9.jpg', 'release_date': '2018-06-02', 'title': 'Shoplifters', 'video': False, 'vote_average': 7.9, 'vote_count': 1128}], 'total_pages': 1, 'total_results': 1}詳細情報
今回は検索結果が1件だったので、最初のインデックスを指定して映画のIDを保持しておきます。このIDを指定して詳細情報を取得できます
movie_id = res['results'][0]['id'] api.get_movie(movie_id) #=> {'adult': False, 'backdrop_path': '/xOpQ4jIQJ0HSUhVDixZA9yWqVBP.jpg', 'belongs_to_collection': None, 'budget': 0, 'genres': [{'id': 18, 'name': 'Drama'}, {'id': 80, 'name': 'Crime'}], 'homepage': 'https://www.shopliftersfilm.com', 'id': 505192, 'imdb_id': 'tt8075192', 'original_language': 'ja', 'original_title': '万引き家族', 'overview': 'After one of their shoplifting sessions, Osamu and his son come across a little girl in the freezing cold. At first reluctant to shelter the girl, Osamu’s wife agrees to take care of her after learning of the hardships she faces. Although the family is poor, barely making enough money to survive through petty crime, they seem to live happily together until an unforeseen incident reveals hidden secrets, testing the bonds that unite them.', 'popularity': 16.385, 'poster_path': '/4nfRUOv3LX5zLn98WS1WqVBk9E9.jpg', 'production_companies': [{'id': 84048, 'logo_path': '/nu8Q8IvG2fazeI7axTnUhAvzrqy.png', 'name': 'Gaga Corporation', 'origin_country': 'JP'}, {'id': 3341, 'logo_path': '/dTG5dXE1kU2mpmL9BNnraffckLU.png', 'name': 'Fuji Television Network', 'origin_country': 'JP'}, {'id': 39804, 'logo_path': None, 'name': 'AOI Promotion', 'origin_country': 'JP'}, {'id': 75214, 'logo_path': None, 'name': 'Bunbuku', 'origin_country': 'JP'}], 'production_countries': [{'iso_3166_1': 'JP', 'name': 'Japan'}], 'release_date': '2018-06-02', 'revenue': 0, 'runtime': 121, 'spoken_languages': [{'iso_639_1': 'ja', 'name': '日本語'}], 'status': 'Released', 'tagline': '', 'title': 'Shoplifters', 'video': False, 'vote_average': 7.9, 'vote_count': 1128}ポスターなどの画像
画像はbackdropsとpostersの2つに別れており、backdropsは映画中のワンショット、postersは上映国におけるポスターの画像の情報が取得できます。試しにbackdropsのみ置いておきます。
また以下のリンクですべての画像を確認できます。結構な数があるので見ていて楽しいです(というか日本バージョンには無いポスターが結構ある...)
res = api.get_movie_images(movie_id) for backdrop in res['backdrops']: print(f"<img src={api.img_base_url_}{backdrop['file_path']}>") #=>
国によるタイトルの違い
国によっていろんなタイトルの付け方がされている場合は、国ごとのタイトルを取得できます。この辺は他のデータやサービスでは得づらい情報な気がします
pprint(api.get_movie_alternative_titles(movie_id)) #=> {'id': 505192, 'titles': [{'iso_3166_1': 'JP', 'title': 'Manbiki Kazoku', 'type': 'romaji'}, {'iso_3166_1': 'US', 'title': 'Shoplifting Family', 'type': 'literal translation'}, {'iso_3166_1': 'KR', 'title': '어느 가족', 'type': ''}, {'iso_3166_1': 'UA', 'title': 'Магазинні злодюжки', 'type': ''}, {'iso_3166_1': 'GB', 'title': 'Shoplifters', 'type': ''}, {'iso_3166_1': 'JP', 'title': 'Manbiki kazoku (Shoplifters)', 'type': ''}, {'iso_3166_1': 'AR', 'title': 'Somos una familia', 'type': ''}, {'iso_3166_1': 'CN', 'title': '小偷家族', 'type': ''}, {'iso_3166_1': 'BR', 'title': 'Assunto de Família', 'type': ''}]}売上?、収入?
返ってくる値にbudgetとかrevenueとかがあるので、お金の話みたいですが、今回は特に情報がなく良く分かってないです
pprint(api.get_movie_changes(movie_id, start_date="2018/06/08", end_date="2018/06/15")) #=> {'adult': False, 'backdrop_path': '/xOpQ4jIQJ0HSUhVDixZA9yWqVBP.jpg', 'belongs_to_collection': None, 'budget': 0, 'genres': [{'id': 18, 'name': 'Drama'}, {'id': 80, 'name': 'Crime'}], 'homepage': 'https://www.shopliftersfilm.com', 'id': 505192, 'imdb_id': 'tt8075192', 'original_language': 'ja', 'original_title': '万引き家族', 'overview': 'After one of their shoplifting sessions, Osamu and his son come ' 'across a little girl in the freezing cold. At first reluctant to ' 'shelter the girl, Osamu’s wife agrees to take care of her after ' 'learning of the hardships she faces. Although the family is ' 'poor, barely making enough money to survive through petty crime, ' 'they seem to live happily together until an unforeseen incident ' 'reveals hidden secrets, testing the bonds that unite them.', 'popularity': 16.385, 'poster_path': '/4nfRUOv3LX5zLn98WS1WqVBk9E9.jpg', 'production_companies': [{'id': 84048, 'logo_path': '/nu8Q8IvG2fazeI7axTnUhAvzrqy.png', 'name': 'Gaga Corporation', 'origin_country': 'JP'}, {'id': 3341, 'logo_path': '/dTG5dXE1kU2mpmL9BNnraffckLU.png', 'name': 'Fuji Television Network', 'origin_country': 'JP'}, {'id': 39804, 'logo_path': None, 'name': 'AOI Promotion', 'origin_country': 'JP'}, {'id': 75214, 'logo_path': None, 'name': 'Bunbuku', 'origin_country': 'JP'}], 'production_countries': [{'iso_3166_1': 'JP', 'name': 'Japan'}], 'release_date': '2018-06-02', 'revenue': 0, 'runtime': 121, 'spoken_languages': [{'iso_639_1': 'ja', 'name': '日本語'}], 'status': 'Released', 'tagline': '', 'title': 'Shoplifters', 'video': False, 'vote_average': 7.9, 'vote_count': 1128}キャスト、スタッフ情報
出演したキャストやスタッフの情報が取得できるようです。これらのデータもcredit_idが振られているようなので、ここからさらにその人の情報が取れるようです。画像もあるみたいです
pprint(api.get_movie_credits(movie_id)) #=> {'cast': [{'cast_id': 0, 'character': 'Osamu Shibata', 'credit_id': '5a845387c3a3682dbf012ac5', 'gender': 2, 'id': 123739, 'name': 'Lily Franky', 'order': 0, 'profile_path': '/8T3I7KQX0SH6twXsuqe12Sc7Hxr.jpg'}, {'cast_id': 1, 'character': 'Nobuyo Shibata', 'credit_id': '5a845394c3a36862e100c84a', 'gender': 1, 'id': 100766, 'name': 'Sakura Ando', 'order': 1, 'profile_path': '/lR1YVfjMYKCMOHzvY3pHTFM5zSI.jpg'}, ...キーワード
TMDb上のキーワードです
pprint(api.get_movie_keywords(movie_id)) #=> {'id': 505192, 'keywords': [{'id': 1328, 'name': 'secret'}, {'id': 10235, 'name': 'family relationships'}, {'id': 12279, 'name': 'family drama'}, {'id': 12369, 'name': 'tokyo, japan'}, {'id': 12987, 'name': 'poverty'}, {'id': 13014, 'name': 'orphan'}, {'id': 155419, 'name': 'shoplifting'}, {'id': 190823, 'name': 'social realism'}, {'id': 209085, 'name': 'shoplifter'}, {'id': 232817, 'name': 'petty crimes'}, {'id': 241445, 'name': 'asian origins'}]}公開日
上映国における公開日の一覧
pprint(api.get_movie_release_dates(movie_id)) #=> {'id': 505192, 'results': [{'iso_3166_1': 'TR', 'release_dates': [{'certification': '', 'iso_639_1': '', 'note': 'Filmekimi', 'release_date': '2018-10-06T00:00:00.000Z', 'type': 1}, {'certification': '', 'iso_639_1': '', 'note': '', 'release_date': '2019-01-18T00:00:00.000Z', 'type': 3}]}, {'iso_3166_1': 'HU', 'release_dates': [{'certification': '', 'iso_639_1': '', 'note': '', 'release_date': '2019-01-10T00:00:00.000Z', 'type': 3}]}, ...Youtube, Vimeoにおける予告編動画
pprint(api.get_movie_videos(movie_id)) #=> {'id': 505192, 'results': [{'id': '5bd4ea970e0a2622dd022b3b', 'iso_3166_1': 'US', 'iso_639_1': 'en', 'key': '9382rwoMiRc', 'name': 'Shoplifters - Official Trailer', 'site': 'YouTube', 'size': 1080, 'type': 'Trailer'}]}このkeyを使ってYoutubeの動画を表示できます
翻訳
タイトルだけでなく概要の文の翻訳文が得られます。これも上映国のみのものと思われます
pprint(api.get_movie_translations(movie_id)) #=> {'id': 505192, 'translations': [{'data': {'homepage': '', 'overview': 'Едно семейство живее на ръба на ' 'бедността като джебчии на дребно. ' 'След един „набег” из магазините, ' 'Осаму и синът му откриват едно малко ' 'момиченце, изоставено в студа. ' 'Съпругата на Осаму решава да помогне ' 'на детето, след като научава през ' 'какви перипетии е преминало. Всички у ' 'дома са задружни и щастливи, въпреки ' 'обстоятелствата, които са ги ' 'принудили да връзват двата края с ' 'помощта на малки кражби всеки ден, но ' 'непредвиден инцидент разкрива тайни, ' 'които поставят на изпитание връзките ' 'между членовете на семейството.', 'runtime': 121, 'tagline': '', 'title': 'Джебчии'}, 'english_name': 'Bulgarian', 'iso_3166_1': 'BG', 'iso_639_1': 'bg', 'name': 'български език'}, ...レコメンデーション
TMDbによるこの映画に対するレコメンデーションを返してくれます。アルゴリズムは不明です
1つ目のレコメンドは村上春樹原作の韓国リメイクでした
pprint(api.get_movie_recommendations(movie_id)) #=> {'page': 1, 'results': [{'adult': False, 'backdrop_path': '/v6eOq707lwWFIG96Rv9sSR6lnnT.jpg', 'genre_ids': [9648, 18, 53], 'id': 491584, 'original_language': 'ko', 'original_title': '버닝', 'overview': 'Deliveryman Jongsu is out on a job when he runs ' 'into Haemi, a girl who once lived in his ' "neighborhood. She asks if he'd mind looking after " "her cat while she's away on a trip to Africa. On " 'her return she introduces to Jongsu an enigmatic ' 'young man named Ben, who she met during her trip. ' 'And one day Ben tells Jongsu about his most unusual ' 'hobby...', 'popularity': 19.981, 'poster_path': '/8ak33l6lfvBPmWOMH9sUCOaC6lq.jpg', 'release_date': '2018-05-17', 'title': 'Burning', 'video': False, 'vote_average': 7.4, 'vote_count': 801}, ...
類似する作品
レコメンデーションとは異なり、keywordsやgenreの情報を用いて類似度を計算しているらしいです
pprint(api.get_similar_movies(movie_id)) #=> {'page': 1, 'results': [{'adult': False, 'backdrop_path': '/gSIfujGhazIvswp4R9G6tslAqW7.jpg', 'genre_ids': [18, 10751, 14], 'id': 11236, 'original_language': 'en', 'original_title': 'The Secret Garden', 'overview': 'A young British girl born and reared in India loses ' 'her neglectful parents in an earthquake. She is ' "returned to England to live at her uncle's castle. " 'Her uncle is very distant due to the loss of his ' 'wife ten years before. Neglected once again, she ' 'begins exploring the estate and discovers a garden ' 'that has been locked and neglected. Aided by one of ' "the servants' boys, she begins restoring the " 'garden, and eventually discovers some other secrets ' 'of the manor.', 'popularity': 11.531, 'poster_path': '/2B8yOYHrp0AopX3gk4b7jWH3Q5a.jpg', 'release_date': '1993-08-13', 'title': 'The Secret Garden', 'video': False, 'vote_average': 7.3, 'vote_count': 571}, ...
レビュー
ユーザーによるレビューが取れるらしいです。今回は何もなかったですが(焦)
pprint(api.get_movie_reviews(movie_id)) #=> {'id': 505192, 'page': 1, 'results': [], 'total_pages': 0, 'total_results': 0}この映画が含まれているリスト
この映画が属しているリストが返ってくるとドキュメントにはありました。(TMDbにおけるリストとは...)
pprint(api.get_movie_lists(movie_id)) #=> {'id': 505192, 'page': 1, 'results': [{'description': '', 'favorite_count': 0, 'id': 107706, 'iso_639_1': 'en', 'item_count': 4434, 'list_type': 'movie', 'name': 'Watched Movies', 'poster_path': None}, {'description': 'Vari', 'favorite_count': 0, 'id': 137511, 'iso_639_1': 'en', 'item_count': 89, 'list_type': 'movie', 'name': 'Film esteri', 'poster_path': None}, {'description': '', 'favorite_count': 0, 'id': 130541, 'iso_639_1': 'it', 'item_count': 196, 'list_type': 'movie', 'name': '2020', 'poster_path': None}, ...最新の作品
これ以降は検索した映画ではなく、作品全体から抽出する形式です
pprint(api.get_latest_movies()) #=> {'adult': False, 'backdrop_path': None, 'belongs_to_collection': None, 'budget': 0, 'genres': [], 'homepage': '', 'id': 761504, 'imdb_id': None, 'original_language': 'fr', 'original_title': 'Otto Skorzeny, chef de commando nazi et agent du Mossad', 'overview': '', 'popularity': 0.0, 'poster_path': None, 'production_companies': [], 'production_countries': [], 'release_date': '', 'revenue': 0, 'runtime': 0, 'spoken_languages': [{'iso_639_1': 'fr', 'name': 'Français'}], 'status': 'Released', 'tagline': '', 'title': 'Otto Skorzeny, chef de commando nazi et agent du Mossad', 'video': False, 'vote_average': 8.0, 'vote_count': 1}公開中の作品
pprint(api.get_now_playing_movies()) #=> {'dates': {'maximum': '2020-11-12', 'minimum': '2020-09-25'}, 'page': 1, 'results': [{'adult': False, 'backdrop_path': '/86L8wqGMDbwURPni2t7FQ0nDjsH.jpg', 'genre_ids': [28, 53], 'id': 724989, 'original_language': 'en', 'original_title': 'Hard Kill', 'overview': 'The work of billionaire tech CEO Donovan Chalmers ' 'is so valuable that he hires mercenaries to protect ' 'it, and a terrorist group kidnaps his daughter just ' 'to get it.', 'popularity': 2025.862, 'poster_path': '/ugZW8ocsrfgI95pnQ7wrmKDxIe.jpg', 'release_date': '2020-10-23', 'title': 'Hard Kill', 'video': False, 'vote_average': 4.8, 'vote_count': 86}, ...人気の作品
pprint(api.get_popular_movies()) #=> {'page': 1, 'results': [{'adult': False, 'backdrop_path': '/86L8wqGMDbwURPni2t7FQ0nDjsH.jpg', 'genre_ids': [28, 53], 'id': 724989, 'original_language': 'en', 'original_title': 'Hard Kill', 'overview': 'The work of billionaire tech CEO Donovan Chalmers ' 'is so valuable that he hires mercenaries to protect ' 'it, and a terrorist group kidnaps his daughter just ' 'to get it.', 'popularity': 2025.862, 'poster_path': '/ugZW8ocsrfgI95pnQ7wrmKDxIe.jpg', 'release_date': '2020-10-23', 'title': 'Hard Kill', 'video': False, 'vote_average': 4.8, 'vote_count': 86}, ...レートの高い作品
pprint(api.get_top_rated_movies()) #=> {'page': 1, 'results': [{'adult': False, 'backdrop_path': '/jtAI6OJIWLWiRItNSZoWjrsUtmi.jpg', 'genre_ids': [10749], 'id': 724089, 'original_language': 'en', 'original_title': "Gabriel's Inferno Part II", 'overview': 'Professor Gabriel Emerson finally learns the truth ' "about Julia Mitchell's identity, but his " 'realization comes a moment too late. Julia is done ' 'waiting for the well-respected Dante specialist to ' 'remember her and wants nothing more to do with him. ' 'Can Gabriel win back her heart before she finds ' "love in another's arms?", 'popularity': 9.491, 'poster_path': '/pci1ArYW7oJ2eyTo2NMYEKHHiCP.jpg', 'release_date': '2020-07-31', 'title': "Gabriel's Inferno Part II", 'video': False, 'vote_average': 8.9, 'vote_count': 915}, ...もうすぐ公開される作品
pprint(api.get_upcoming_movies()) #=> {'dates': {'maximum': '2020-11-30', 'minimum': '2020-11-13'}, 'page': 1, 'results': [{'adult': False, 'backdrop_path': '/8rIoyM6zYXJNjzGseT3MRusMPWl.jpg', 'genre_ids': [14, 10751, 12, 35, 27], 'id': 531219, 'original_language': 'en', 'original_title': "Roald Dahl's The Witches", 'overview': 'In late 1967, a young orphaned boy goes to live ' 'with his loving grandma in the rural Alabama town ' 'of Demopolis. As the boy and his grandmother ' 'encounter some deceptively glamorous but thoroughly ' 'diabolical witches, she wisely whisks him away to a ' 'seaside resort. Regrettably, they arrive at ' "precisely the same time that the world's Grand High " 'Witch has gathered.', 'popularity': 1867.444, 'poster_path': '/betExZlgK0l7CZ9CsCBVcwO1OjL.jpg', 'release_date': '2020-10-26', 'title': "Roald Dahl's The Witches", 'video': False, 'vote_average': 7.1, 'vote_count': 530}, ...













- 投稿日:2020-11-08T20:49:54+09:00
Django シフト表に公開未公開機能を実装 希望シフトかの背景色コントロールも追加
シフト表機能を見てもらった時に、管理者である人がみんなの要望をラインとかで連絡してもらってから、かなり時間をかけながら作業していることがわかりました。
なので、作成途中のシフトは公開したくないということで、公開、未公開機能を実装しました。
管理者が編集中であれば、状態は非公開になっているので公開ボタンが表示されています。
管理者権限がなかったら同じものみても
表示されていません。
コントロールは、Userのグループをうまく使うべきなのかもしれませんが、スーパーユーザーかどうかで判断しています。
モデルにフラグをもつことにして、それがONかOFFかで判断します。月テーブルをもつことも考えましたが、根本的に締め日とかいろいろ考えなおして作り変える時の考えようと思います。
まずはつかって喜んでもらえることが技術の習得を加速させると思っているので、頑張って実装を頑張ります(⌒∇⌒)
python.suchedule.modell.pyclass Schedule(models.Model): id = models.AutoField(verbose_name='スケジュールID',primary_key=True) user = models.ForeignKey(User, on_delete=models.CASCADE, verbose_name='社員名') date = models.DateField(verbose_name='日付') year = models.PositiveIntegerField(validators=[MinValueValidator(1),]) month = models.PositiveIntegerField(validators=[MaxValueValidator(12),MinValueValidator(1),]) shift_name_1 = models.ForeignKey(Shift, verbose_name='1シフト名', related_name='shift_name1',on_delete=models.SET_NULL,null= True) shisetsu_name_1 = models.ForeignKey(Shisetsu, verbose_name='1施設', related_name='shisetsu_name1',on_delete=models.SET_NULL,blank=True, null=True) shift_name_2 = models.ForeignKey(Shift, verbose_name='2シフト名', related_name='shift_name2',on_delete=models.SET_NULL,blank=True, null=True) shisetsu_name_2 = models.ForeignKey(Shisetsu, verbose_name='2施設', related_name='shisetsu_name2',on_delete=models.SET_NULL,blank=True, null=True) shift_name_3 = models.ForeignKey(Shift, verbose_name='3シフト名', related_name='shift_name3',on_delete=models.SET_NULL,blank=True, null=True) shisetsu_name_3 = models.ForeignKey(Shisetsu, verbose_name='3施設', related_name='shisetsu_name3',on_delete=models.SET_NULL,blank=True, null=True) shift_name_4 = models.ForeignKey(Shift, verbose_name='4シフト名', related_name='shift_name4',on_delete=models.SET_NULL,blank=True, null=True) shisetsu_name_4 = models.ForeignKey(Shisetsu, verbose_name='4施設', related_name='shisetsu_name4',on_delete=models.SET_NULL,blank=True, null=True) day_total_worktime = models.IntegerField(verbose_name='日労働時間', default=0) kibou_shift = models.BooleanField(verbose_name='希望シフト',default=False) open_flag = models.BooleanField(verbose_name='公開フラグ',default=False) class Meta: unique_together = ('user', 'date')python/schedule/month.html{% extends 'accounts/base.html' %} {% load static %} {% block customcss %} <link rel="stylesheet" href="{% static 'schedule/month.css' %}"> {% endblock customcss %} {% block header %} <div class="header"> <div class="cole-md-1"> <a href="{% url 'schedule:KibouList' %}" class="btn-secondary btn active">希望シフト一覧</a></p> {% ifnotequal month 1 %} <a href="{% url 'schedule:monthschedule' year month|add:'-1' %}" class="btn-info btn active">前月</a> {% else %} <a href="{% url 'schedule:monthschedule' year|add:'-1' 12 %}" class="btn-info btn active">前月</a> {% endifnotequal %} {% ifnotequal month 12 %} <a href="{% url 'schedule:monthschedule' year month|add:'1' %}" class="btn-info btn active">次月</a> {% else %} <a href="{% url 'schedule:monthschedule' year|add:'1' 1 %}" class="btn-info btn active">次月</a> {% endifnotequal %} </div> <!-- モーダルを開くボタン・リンク --> {% if perms.schedule.add_schedule %}<!--権限--> <button type="button" class="btn-info btn active" data-toggle="modal" data-target="#createModal">シフト作成</button> {% endif %} <!-- 作成確認 --> <div class="modal fade" id="createModal" tabindex="-1" role="dialog" aria-labelledby="basicModal" aria-hidden="true"> <div class="modal-dialog"> <div class="modal-content"> <div class="modal-header"> <h4><class="modal-title" id="myModalLabel">確認画面</h4></h4> </div> <div class="modal-body"> <label>シフト作成するとデータが上書きされますが実行しますか?</label> </div> <div class="modal-footer"> <button type="button" class="btn btn-default" data-dismiss="modal">閉じる</button> <a href="{% url 'schedule:schedulecreate' year month %}" class="btn-info btn active">シフト作成</a> </div> </div> </div> </div> <!-- モーダルを開くボタン・リンク --> {% if perms.schedule.add_schedule %}<!--権限--> {% if open_flag.open_flag == False %} <button type="button" class="btn-info btn active" data-toggle="modal" data-target="#openModal">公開</button> {% elif open_flag.open_flag == True %} <button type="button" class="btn-info btn active" data-toggle="modal" data-target="#closeModal">非公開</button> {% endif %} {% endif %} <!-- 公開確認 --> <div class="modal fade" id="openModal" tabindex="-1" role="dialog" aria-labelledby="basicModal" aria-hidden="true"> <div class="modal-dialog"> <div class="modal-content"> <div class="modal-header"> <h4><class="modal-title" id="myModalLabel">確認画面</h4></h4> </div> <div class="modal-body"> <label>シフト公開しますか?</label> </div> <div class="modal-footer"> <button type="button" class="btn btn-default" data-dismiss="modal">閉じる</button> {% ifnotequal month 12 %} <a href="{% url 'schedule:scheduleopen' year month %}" class="btn-info btn active">公開</a> {% else %} <a href="{% url 'schedule:scheduleopen' year|add:'1' month %}" class="btn-info btn active">公開</a> {% endifnotequal %} </div> </div> </div> </div> <!-- 非公開確認 --> <div class="modal fade" id="closeModal" tabindex="-1" role="dialog" aria-labelledby="basicModal" aria-hidden="true"> <div class="modal-dialog"> <div class="modal-content"> <div class="modal-header"> <h4><class="modal-title" id="myModalLabel">確認画面</h4></h4> </div> <div class="modal-body"> <label>シフト非公開にしますか?</label> </div> <div class="modal-footer"> <button type="button" class="btn btn-default" data-dismiss="modal">閉じる</button> {% ifnotequal month 12 %} <a href="{% url 'schedule:scheduleclose' year month %}" class="btn-info btn active">非公開</a> {% else %} <a href="{% url 'schedule:scheduleclose' year|add:'1' month %}" class="btn-info btn active">非公開</a> {% endifnotequal %} </div> </div> </div> </div> <div class="cole-md-2"> {% for shift in shift_object %} {% if shift.name != "休" and shift.name != "有" %} {{ shift.name }} : {{ shift.start_time | date:"G"}}~{{ shift.end_time | date:"G"}} {% endif %} {% endfor %} </div> <p> <a href="{% url 'schedule:monthschedule' year month %}" button type="button" class="btn btn-outline-dark">すべて</a> {% for shisetsu in shisetsu_object %} {% for UserShozoku in UserShozoku_list %} {% if shisetsu.name|stringformat:"s" == UserShozoku.shisetsu_name|stringformat:"s" %} <a href="{% url 'schedule:monthschedulefilter' year month shisetsu.pk %}" button type="button" class="btn btn-outline-dark" span style="background-color:{{ shisetsu.color }}">{{ shisetsu.name }}</span></a> {% endif %} {% endfor %} {% endfor %} </p> </div> {% endblock header %} {% block content %} <table class="table"> <thead> <tr> <!--日付--> <th class ="fixed00" rowspan="2">{{ kikan }}</th> {% for item in calender_object %} <th class ="fixed01">{{ item.date | date:"d" }}</th> {% endfor %} <tr> <!--曜日--> {% for item in youbi_object %} <th class ="fixed02">{{ item }}</th> {% endfor %} </tr> </thead> <tbody> {% if perms.schedule.add_schedule or open_flag.open_flag == True %}<!--権限--> {% for profile in profile_list %} {% for staff in user_list %} {% if profile.user_id == staff.id %} <tr align="center"> <th class ="fixed03" ><a href="{% url 'schedule:monthschedulekojin' year month staff.id %}">{{ staff.last_name }} {{ staff.first_name }}</a></th> <!--staff_id要素はjsで使う--> {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> {% if item.kibou_shift == True %} <td class="meisai03"> {% elif item.shift_name_1|stringformat:"s" == "休" %} <td class="meisai01"> {% elif item.shift_name_1|stringformat:"s" == "不" %} <td class="meisai04"> {% else %} <td class="meisai01"> {% endif %} {% if item.shift_name_1 != None %} {% if item.shift_name_1|stringformat:"s" == "有" %} {{ item.shift_name_1 }} {% elif item.shift_name_1|stringformat:"s" == "休" %} {% elif item.shift_name_1|stringformat:"s" == "不" %} {{ item.shift_name_1 }} {% else %} <span style="background-color:{{ item.shisetsu_name_1.color }}">{{ item.shift_name_1 }}</span> {% endif %} {% endif %} {% if item.shift_name_2 != None %} {% if item.shift_name_2|stringformat:"s" == "有" or item.shift_name_2|stringformat:"s" == "休" %} {{ item.shift_name_2 }} {% else %} <span style="background-color:{{ item.shisetsu_name_2.color }}">{{ item.shift_name_2 }}</span> {% endif %} {% endif %} {% if item.shift_name_3 != None %} {% if item.shift_name_3|stringformat:"s" == "有" or item.shift_name_3|stringformat:"s" == "休" %} {{ item.shift_name_3 }} {% else %} <span style="background-color:{{ item.shisetsu_name_3.color }}">{{ item.shift_name_3 }}</span> {% endif %} {% endif %} {% if item.shift_name_4 != None %} {% if item.shift_name_4|stringformat:"s" == "有" or item.shift_name_4|stringformat:"s" == "休" %} {{ item.shift_name_4 }} {% else %} <span style="background-color:{{ item.shisetsu_name_4.color }}">{{ item.shift_name_4 }}</span> {% endif %} {% endif %} {% endif %} {% endfor %} </td> <tr align="center"> {% for month in month_total %} {% if month.user == staff.id %}<!--usernameが同一なら--> {% if perms.schedule.add_schedule %}<!--権限--> <td class="fixed04"><b>{{ month.month_total_worktime }}</b></td> {% else %} <td class="fixed04"><b>―</b></td> {% endif %} {% endif %} {% endfor %} {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> {% if perms.schedule.add_schedule %}<!--権限--> <td class="meisai02" id="s{{ staff.id }}d{{ item.date }}"> <a href="{% url 'schedule:update' item.pk %}">{{ item.day_total_worktime }} </a> </td> {% else %} <td class="meisai02" id="s{{ staff.id }}d{{ item.date }}"> {% if item.day_total_worktime != 0 %} {{ item.day_total_worktime }} {% endif %} </td> {% endif %} {% endif %} {% endfor %} </tr> {% endif %} {% endfor %} {% endfor %} </tbody> </table> </div> </div> {% endif %} {% endblock content %}実際使う人とどれだけコミュニケーションをとって想像力(妄想力)を働かせて検討するかが大切だと痛感しました。


- 投稿日:2020-11-08T20:40:58+09:00
PyTorchでDeepChemのConvMolFeaturizerでfeaturizeしたミニバッチを返すDataLoaderを実装する
はじめに
Keras, TensorflowからPyTorchに乗り換え、化合物によるGraph Convolutional Network(GCN)を実装することとした。
まずは、SMILESで表される化合物を学習に利用できる形に変換する必要がある。
これらの処理を自前で実装してもよいが、Keras, Tensorflow ベースのライブラリである DeepChem の前処理を流用すれば楽ができると考えた。
そこで SMILES を DeepChem の ConvMolFeaturizer で feturize し、それを Pytorch の DataLoaderで使えるようにする。
これにより、面倒な化合物のハンドリング処理を自前で実装することなく、PyTorchでGCNの実装ができると考えている。環境
- PyTorch 1.7.0
実装方法
- Datasetは、単純にSMILESと正解データのリストを保持するものとした。
- ミニバッチ毎に、ミニバッチ内の全化合物をグラフに変換し、結合次数行列や、隣接行列を生成する必要があるため、collate_fn を独自に実装し、DataLoader の引数に与えることとした。
- collate_fn では、DeepChem の ConvMolFeaturizer によりSMILES を featulize しリスト化したものを、ConvMolクラスのagglomerate_molsメソッドに与える。これによりミニバッチ内の全化合物の結合次数行列、隣接行列が生成されるため、それぞれPyTorchのテンソル形式に変換し、正解データと共に返却している。
ソース
import torch from torch.utils import data from deepchem.feat.graph_features import ConvMolFeaturizer from deepchem.feat.mol_graphs import ConvMol class GCNDataset(data.Dataset): def __init__(self, smiles_list, label_list): self.smiles_list = smiles_list self.label_list = label_list def __len__(self): return len(self.smiles_list) def __getitem__(self, index): return self.smiles_list[index], self.label_list[index] def gcn_collate_fn(batch): from rdkit import Chem cmf = ConvMolFeaturizer() mols = [] labels = [] for sample, label in batch: mols.append(Chem.MolFromSmiles(sample)) labels.append(torch.tensor(label)) conv_mols = cmf.featurize(mols) multiConvMol = ConvMol.agglomerate_mols(conv_mols) atom_feature = torch.tensor(multiConvMol.get_atom_features(), dtype=torch.float64) deg_slice = torch.tensor(multiConvMol.deg_slice, dtype=torch.float64) membership = torch.tensor(multiConvMol.membership, dtype=torch.float64) return atom_feature, deg_slice, membership, labels def main(): dataset = GCNDataset(["CCC", "CCCC", "CCCCC"], [1, 0, 1]) dataloader = data.DataLoader(dataset, batch_size=3, shuffle=False, collate_fn =gcn_collate_fn) for atom_feature, deg_slice, membership, labels in dataloader: print(atom_feature) print(deg_slice) print(membership) if __name__ == "__main__": main()実行結果
3化合物によるミニバッチの結果は以下の通りとなる。
3化合物内の12原子の特徴および、結合次数行列、隣接行列が生成される。
結合次数行列、隣接行列の解説は別の機会に説明する。tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.]], dtype=torch.float64) tensor([[ 0., 0.], [ 0., 6.], [ 6., 6.], [12., 0.], [12., 0.], [12., 0.], [12., 0.], [12., 0.], [12., 0.], [12., 0.], [12., 0.]], dtype=torch.float64) tensor([0., 0., 1., 1., 2., 2., 0., 1., 1., 2., 2., 2.], dtype=torch.float64)今後
今後は、GCNのモデルをPyTorchで生成し、今回のDataLoaderを用いて予測モデルを作成していく。
- 投稿日:2020-11-08T20:40:58+09:00
DeepChemのConvMolFeaturizerでfeaturizeしたミニバッチを返すPyTorchのDataLoaderを実装する
はじめに
Keras, TensorflowからPyTorchに乗り換えることとした。
そして、PyTorchを使って化合物によるGraph Convolutional Network(GCN)を実装することとした。
まずは、SMILESで表される化合物を学習に利用できる形に変換する必要がある。
これらの処理を自前で実装してもよいが、Keras, Tensorflow ベースのライブラリである DeepChem の前処理を流用すれば楽ができると考えた。
そこで SMILES を DeepChem の ConvMolFeaturizer で feturize し、それを Pytorch の DataLoaderで使えるようにしてみた。
これにより、面倒な化合物のハンドリング処理を自前で実装することなく、GCNの実装に集中することができると目論んでいる。環境
- PyTorch 1.7.0
- DeepChem 2.3
実装方法
- Datasetは、単純にSMILESと正解データのリストを保持するものとした。
- ミニバッチ毎に、ミニバッチ内の全化合物をグラフに変換し、結合次数行列や、隣接行列を生成する必要があるため、collate_fn を独自に実装し、DataLoader の引数に与えることとした。
- collate_fn では、DeepChem の ConvMolFeaturizer によりSMILES を featulize しリスト化したものを、ConvMolクラスのagglomerate_molsメソッドに与える。これによりミニバッチ内の全化合物の結合次数行列、隣接行列が生成されるため、それぞれPyTorchのテンソル形式に変換し、正解データと共に返却している。
ソース
import torch from torch.utils import data from deepchem.feat.graph_features import ConvMolFeaturizer from deepchem.feat.mol_graphs import ConvMol class GCNDataset(data.Dataset): def __init__(self, smiles_list, label_list): self.smiles_list = smiles_list self.label_list = label_list def __len__(self): return len(self.smiles_list) def __getitem__(self, index): return self.smiles_list[index], self.label_list[index] def gcn_collate_fn(batch): from rdkit import Chem cmf = ConvMolFeaturizer() mols = [] labels = [] for sample, label in batch: mols.append(Chem.MolFromSmiles(sample)) labels.append(torch.tensor(label)) conv_mols = cmf.featurize(mols) multiConvMol = ConvMol.agglomerate_mols(conv_mols) atom_feature = torch.tensor(multiConvMol.get_atom_features(), dtype=torch.float64) deg_slice = torch.tensor(multiConvMol.deg_slice, dtype=torch.float64) membership = torch.tensor(multiConvMol.membership, dtype=torch.float64) return atom_feature, deg_slice, membership, labels def main(): dataset = GCNDataset(["CCC", "CCCC", "CCCCC"], [1, 0, 1]) dataloader = data.DataLoader(dataset, batch_size=3, shuffle=False, collate_fn =gcn_collate_fn) for atom_feature, deg_slice, membership, labels in dataloader: print(atom_feature) print(deg_slice) print(membership) if __name__ == "__main__": main()実行結果
3化合物によるミニバッチは以下の通りとなる。
3化合物内の12原子の特徴および、結合次数行列、隣接行列が生成される。
これらについては別の機会に説明する。tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0.]], dtype=torch.float64) tensor([[ 0., 0.], [ 0., 6.], [ 6., 6.], [12., 0.], [12., 0.], [12., 0.], [12., 0.], [12., 0.], [12., 0.], [12., 0.], [12., 0.]], dtype=torch.float64) tensor([0., 0., 1., 1., 2., 2., 0., 1., 1., 2., 2., 2.], dtype=torch.float64)今後
今後は、GCNモデルのコード、および今回のDataLoaderを用いて学習を行うコードを書いていく。
感想
Kerasの窮屈感、Tensorflowのそっけなさに比べ、PyTorchの丁度良さがすごく心地いい(今のところ)。
- 投稿日:2020-11-08T20:22:13+09:00
Google Colabで今使っているNotebook名を取得する方法
Stackoverflowに回答がありました。
from requests import get filename = get('http://172.28.0.2:9000/api/sessions').json()[0]['name']
- 投稿日:2020-11-08T20:06:24+09:00
「画像でゴミ分類!」アプリ作成日誌day1~データセットの作成~
はじめに
みなさん、ごみの分類についてどれぐらい知っていますか?
たとえば、旅行の際には手放せない延長コード。デスク周りでも大活躍していることと思います。そんな、延長コードですが例えば接触不良で使えなくなってしまって捨てるとき、あなたは何ごみに捨てていますか?
適当に可燃ごみとして捨ててしまいますか?
答えは資源品(金属類)と筆者の住む地域ではなっていますが、正確には市町村によって異なります。
例えば横浜市では可燃ごみだそうです。また、流山市では不燃ごみとして扱われるようです。
このように同じごみでも捨て方は焼却設備や人口(すなわち出るごみの量)によって異なりますが、皆さんはゴミを正しく捨てているでしょうか?ゴミの出し方を熟知している人は少ないでしょうし、ましてや引越しなんかをして捨て方が変わった日には全部一から確認しなければなりません。
そこで、ごみの写真を撮れば適切な分類を教えてくれるwebアプリを作っていこうと思い立ちました。せっかくなので、この経過を日誌という形で記録をつけていきたいと思います。もしよければ続編を楽しみにしていただけると幸いです。
作るアプリの説明
まず、写真を撮ったらゴミの分類が表示されるところが最低限のやりたいことになります。分類の基準はとりあえず筆者の住んでいる柏市のものとします(需要があればもっと広げたいな)。
また、分類だけでなく出し方など、出す際の注意点も表示できるようにしたいです。
もっと言えば、自動でカレンダーに追加して通知する機能なんかをつけられると最高です。
上記のようなことをイメージしながら開発していきたいと思います。具体的な流れ
- データセットの作成
- モデルの作成(VGG16をfine tuning)
- バックエンドの実装(Django)
- フロントエンドの実装(HTML,CSS,Bootstrap)
- カレンダーに追加する機能の作成
こんな感じで行きたいと思います。
データセットの作成
まず初日はデータセットを作成していきたいと思います。選択肢は以下の3点です
- 既存のデータセットを転用する
- スクレイピング
- 自作
結論から言うと、今回は自作しようと思います。理由は自分が利用することを考えてなるべく身の回りにあるものを分類できるようになりたいことが一番の理由です。また、ほかの方法だと、既存のデータセットには家庭ゴミとしてありそうなものがあまり含まれていないこと(当然ですね)、スクレイピングは意外と検索結果に違うものが含まれてしまうことから断念しました。しかし、自作できるデータの数は限られているので、もっとデータ増やしたいと思ったらスクレイピングすると思います。
写真を撮る
データセットを作るために写真を撮っていきます。
PETボトル ティッシュ(未使用) 電池 こんな感じで写真を撮り終えました。合計499枚です。2,3時間撮り続けてだいぶ大変だったのに意外と集まってない…水増しで頑張ります泣
フォルダ構造
画像のフォルダ構成はこのようにしておきます。
train
├可燃ごみ
│ └画像たち(以下同様)
├資源品
├不燃ごみ
├包装容器プラスチック類
└有害ごみ
val
├可燃ごみ
│ └画像たち(以下同様)
├資源品
├不燃ごみ
├包装容器プラスチック類
└有害ごみこれはモデルを作る際に分類を自動で生成してもらえるようにこのような構成にしています。
githubリポジトリ
このアプリの開発はgithubを使って行おうと思います。リンク( https://github.com/eycjur/garbage )です。
さて、初日はこんなもんで締めたいと思います。
次回も楽しみにしていてください



- 投稿日:2020-11-08T18:52:54+09:00
営業職からMOOCsを利用して機械学習エンジニアを目指す
はじめに
-年齢: 35歳 (2020年現在)
-キャリア: 新卒から11年ほどソフトウェアの営業職、直近7年は外資のセールスに従事(業務でプログラミングを行う機会は無し)
-きっかけ: 転職とコロナ禍での新しい働き方を真剣に実現するためにプログラミングの学習を開始。
主にデータサイエンス、AI/ML領域のエンジニアを目指し日々勉強の記録を残していきます。これまでの学習経緯
2018
- Progate (HTML, CSS, Python)
- Tech Academy Python/AIコース 終了
- Coursera Machine Learning Course →挫折
しかし、その後何かプロダクトを作るわけでもなく、仕事で使うわけでもなく、お勉強で終了。2020
- PyQ (Python)
- Udemy (Python, HTML, CSS)
- ドットインストール (HTML, CSS)上記を経て2020年9月以降からMOOCs(Massive Open Online Courses)を利用した学習を開始
MOOCsとは
https://education-career.jp/magazine/data-report/2016/moocs/2020.09~
- edX: Python for Everybody 終了
- Udacity: Programming for Data Science with Python ★取組中
https://www.udacity.com/course/programming-for-data-science-nanodegree--nd104なぜMOOCsを利用?
自分がプログラミングで何をやりたいのかが定まっていなかったこともありますが、プログラミング学校や各プログラミング学習サイトでは
「ある言語を習得する」為にプログラムが組まれており、ポイントポイントでの学習となってしまっていました。
結果、なんとなくわかった気にはなるが、自分で何か成果物を作れるレベルには全く至らないということを繰り返していました。また、改めてプログラミングスクールを受けるには費用面もあり今回の選択肢には入っていないので、ある程度手頃な値段で無数にある学習コンテンツから学んでいこうと考えました。
なぜ今Udacityで学習している?
■企業運営でより実務にフォーカスしている
Udacityは本格的にMOOCsを調べ始めてから知りましたが、Udacityでは各言語を習得する為ではなく、各業務、キャリアで必要となるスキルをセットにして一つのコースが組まれています。
例えば今学んでいるProgramming for Data Science with Pythonのプログラムは以下のようなものです。
- Introduction to SQL
- Command Line Essentials
- Introduction to Python
- Introduction to Version Control
- Career Services
- Congratulations and Next Steps
Udacityは大学が中心となって運営されているCourseraやedXと違い、テクノロジー企業を中心に運営されている組織なので、企業での業務によりそった形でコースが組まれている点も魅力を感じました。CourseraやedXはいかにも大学の講義、という感じで、理論や各言語について学ぶというイメージです。
■nanodegree
また、nanodegreeという形でCertificationが発行され、Linkedinなどで訴求できるスキルとして残せる点も良いと思いました。
(日本のプログラミングスクールなどでの実績はLinkedinなどでは理解されないため、実績としては弱いと感じています)■費用面
日本のプログラミングスクールは30万~場所によっていは80万程度とそれなりの費用感となりますが、Udacityのコースは3ヶ月10万程度。
最初はキャンペーンを利用して50%offの5万程度で受講することができました。
CourseraやedXの1コース5,000程度(Certification発行代)と比べたら高いですが、UIやシラバスも非常にわかりやすく設計されており、費用以上の効果を感じています。■デメリット
デメリットは言うまでもなく、すべてのコースが英語で提供されている点です。
英語に抵抗がない方であれば問題ないですが、英語が苦手な方には難しいかもしれません。まとめ
オンライン学習であるMOOCsを利用して、どこまで独学で行けるかどうかを試してみようと思います。
まずはUdacityのProgramming for Data Science(Beginner)を終わらせた上で、AI Programming with Python(Beginner)、
Data Engineer or Data Analyst(Intermediate)、Machine Learning Engineer or Data Scientist(Advanced)といった順にレッスンを進めつつ、これまでおろそかになっていたポートフォリオづくりをしっかり進めたいと思います。
- 投稿日:2020-11-08T17:53:26+09:00
Windows の Atom の Pylint でエラーが出るとき
この記事について
結構いろんな原因でエラーが出るので、備忘録として書いていきます。
故障かな?と思ったら
pylint.exe への PATH は合っていますか?
過去記事:WindowsのAtomでPylint
コメントブロックに問題はありませんんか?
原因
コメントブロックに
\が含まれるとエラーになる。def your_function(): """ こんなふうに \ が含まれていると linter-pylint が機能しない """ pass解決策①
def your_function(): """ こんなふうに \\ すれば機能する。 """ pass解決策②
def your_function(): r""" こんなふうにraw文字列として設定 \ すれば機能する。 """ pass
- 投稿日:2020-11-08T17:41:59+09:00
seleniumを用いたiタウンページのスクレイピング
前書き
2020年頃に、iタウンページの仕様が変更されたので、それに対応したスクリプトを作成してみました。
作成するのは以下のようなスクリプトですキーワードとエリアを入力してiタウンページ上で検索→検索結果から店名と住所を取得してcsv形式で出力する
注意
※Webスクレイピングはサイトの利用規約などによって禁止されている可能性があります
今回の題材とするiタウンページでは以下が主に禁止されています
- iタウンページのサービスに多大な影響を与える行為
- 自動的にアクセスするプログラムを使用してiタウンページに繰り返しアクセスする行為
- 不正なプログラム・スクリプトなどを用いて、サーバーに負荷を与える行為
本記事で紹介するプログラムではユーザが通常利用する際の速度を大幅に上回るような速度での連続アクセスは行わないため、禁止事項には該当しない(と思われます)
また、第三者が閲覧可能な環境での利用のために複製することは禁じられているため、
説明の際にサイトの画像などは載せられませんあしからずiタウンページ
2020年頃にサイトが更新され、検索結果を下にスクロールしていくとさらに表示というボタンが出現し、
これを何度も押さなければ全ての検索結果(最大表示1000件)を取得できないようになりました。プログラム概要
とりあえずざっとした説明とプログラム全体を載せます。(詳しい説明は後述)
- 動作環境:
- Python3.9
- ライブラリ:
- selenium 3.141.0
- pandas 1.1.4
- PySimpleGUI 4.30.0
- beautifulsoup4 4.9.3
- ソフトウェア:
- Firefox 82.0.2
- geckodriver 0.28.0 (firefox使用時)
- Chrome 86.0.4240.183
- chromedriver 86.0.4240.22 (chrome使用時)
PysimpleGUIを使って入力インターフェースを作ります(なくても問題ありません)
seleniumのwebdriverを使用してchrome(or firefox)を起動し、該当ページを表示 & さらに表示ボタンを全部押します
beautifulsoupを使って必要な要素を取得します(今回は店名と住所の2種類)
pandasを使ってデータを成形しますmain.py#It is python3's app #install selenium, beautifulsoup4, pandas with pip3 #download firefox, geckodriver from selenium import webdriver #from selenium.webdriver.firefox.options import Options from selenium.webdriver.chrome.options import Options from selenium.common.exceptions import NoSuchElementException from bs4 import BeautifulSoup import pandas as pd import time import re import csv import PySimpleGUI as sg #plese download browserdriver and writedown driver's path #bdriverpath='./chromedriver' bdriverpath="C:\chromedriver.exe" #make popup window layout= [ [sg.Text('Area >> ', size=(15,1)), sg.InputText('町田')], [sg.Text('Keyword >> ', size=(15,1)), sg.InputText('コンビニ')], [sg.Submit(button_text='OK')] ] window = sg.Window('Area and Keyword', layout) #popup while True: event, values = window.read() if event is None: print('exit') break if event == 'OK': show_message = "Area is " + values[0] + "\n" show_message += "Keyword is " + values[1] + "\n" print(show_message) sg.popup(show_message) break window.close() area =values[0] keyword = values[1] #initialize webdriver options = Options() options.add_argument('--headless') driver=webdriver.Chrome(options=options, executable_path=bdriverpath) #search page with keyword and area driver.get('https://itp.ne.jp') driver.find_element_by_id('keyword-suggest').find_element_by_class_name('a-text-input').send_keys(keyword) driver.find_element_by_id('area-suggest').find_element_by_class_name('a-text-input').send_keys(area) driver.find_element_by_class_name('m-keyword-form__button').click() time.sleep(5) #find & click readmore button try: while driver.find_element_by_class_name('m-read-more'): button = driver.find_element_by_class_name('m-read-more') button.click() time.sleep(1) except NoSuchElementException: pass res = driver.page_source driver.quit() #output with html with open(area + '_' + keyword + '.html', 'w', encoding='utf-8') as f: f.write(res) #parse with beautifulsoup soup = BeautifulSoup(res, "html.parser") shop_names = [n.get_text(strip=True) for n in soup.select('.m-article-card__header__title')] shop_locates = [n.get_text(strip=True) for n in soup.find_all(class_='m-article-card__lead__caption', text=re.compile("住所"))] #incorporation lists with pandas df = pd.DataFrame([shop_names, shop_locates]) df = df.transpose() #output with csv df.to_csv(area + '_' + keyword + '.csv', quoting=csv.QUOTE_NONE, index=False, encoding='utf_8_sig') sg.popup("finished")ブロック毎に解説
環境構築
以下が今回impoprtしたライブラリ群です。
全てpip3でインストールできます。
コメントアウトしているのは、chromeを使用するかfirefoxを使用するかの部分ですので、好みと環境に合わせて書き換えてください。import.pyfrom selenium import webdriver #from selenium.webdriver.firefox.options import Options from selenium.webdriver.chrome.options import Options from selenium.common.exceptions import NoSuchElementException from bs4 import BeautifulSoup import pandas as pd import time import re import csv import PySimpleGUI as sgdriver
この後解説するwebdriverを使用する場合には、chromeならchromedriver、firefoxならgeckodriverが必要になります。
該当するものを下記サイトからダウンロードしてください。
https://github.com/mozilla/geckodriver/releases
https://chromedriver.chromium.org/downloads
また、このとき自分の使用しているブラウザ、python、driverの3つのバージョンが噛み合っていないと動作しません
- まずブラウザは基本的に最新のものを使用してください
- driverはそれに合わせてダウンロードしましょう
- geckoなら最新を使用する(たぶん)
- chromeならchromeのバージョン名とdriverのバージョン名が連動しているので、同じものを選ぶ
ドライバをダウンロードしたら環境変数としてpathを通すか、わかりやすい場所に置いてプログラム内でpathを書きます。
私のwindows環境ではCドライブ直下に置いています。
コメントアウトしていますが、linux(mac)ではプログラムが置いてある場所と同じ場所に置いて使用しました。driver.py#plese download browserdriver and writedown driver's path #bdriverpath='./chromedriver' bdriverpath="C:\chromedriver.exe"PySimpleGUI
参考文献
Tkinterを使うのであればPySimpleGUIを使ってみたらという話レイアウトを決定し、デフォルトの入力を書いておきます(町田、コンビニ)
layout.py#make popup window layout= [ [sg.Text('Area >> ', size=(15,1)), sg.InputText('町田')], [sg.Text('Keyword >> ', size=(15,1)), sg.InputText('コンビニ')], [sg.Submit(button_text='OK')] ]
ウィンドウを作成し、ループで読み込み続けます。
ウィンドウにあるOKボタンがおされると、入力内容がvalues[]に読み込まれます。
処理終了後はwindow.close()で終了し、プログラム内の変数に入力内容を渡します。window.pywindow = sg.Window('Area and Keyword', layout) #popup while True: event, values = window.read() if event is None: print('exit') break if event == 'OK': show_message = "Area is " + values[0] + "\n" show_message += "Keyword is " + values[1] + "\n" print(show_message) sg.popup(show_message) break window.close() area =values[0] keyword = values[1]webdriverの起動
webdriver(selenium)は通常のブラウザ(firefox, chrome等)をプログラムから操作するためのライブラリです
まず起動時のオプションに
--headlessを追加します。これはブラウザをバックグラウンド実行にするオプションです。
もしブラウザが自動で動く様子がみたい場合はoptions.add_argument('--headless')をコメントアウトしてください。
次に、driver=webdriver.Chrome()でchromeを起動します。
同時にoptionと、driverのパスを入力します。options=options, executable_path=briverpathinit.py#initialize webdriver options = Options() options.add_argument('--headless') driver=webdriver.Chrome(options=options, executable_path=briverpath)webdriverで検索
driver.getでタウンページのトップにアクセスします。
driver.find~でキーワードとエリアを入力するinputボックスを探して、.send_keys()で入力も行います。
また、同じ方法で検索開始ボタンも探して、.click()でボタンを押します。
※htmlは、chrome等でiタウンページのサイト開いた状態でデベロッパーツール(ソースを見る)などすると見せてくれます。search.py#search page with keyword and area driver.get('https://itp.ne.jp') driver.find_element_by_id('keyword-suggest').find_element_by_class_name('a-text-input').send_keys(keyword) driver.find_element_by_id('area-suggest').find_element_by_class_name('a-text-input').send_keys(area) driver.find_element_by_class_name('m-keyword-form__button').click() time.sleep(5)htmlの例
例えば以下のページでは、キーワードの入力ボックスがあるのはidが
keyword-suggestで、classがa-text-inputです。keyword.html<div data-v-1wadada="" id="keyword-suggest" class="m-suggest" data-v-1dadas14=""> <input data-v-dsadwa3="" type="text" autocomplete="off" class="a-text-input" placeholder="キーワードを入力" data-v-1bbdb50e=""> <!----> </div>さらに表示を押しまくる
ループを使って、さらに表示ボタン
class_name = m-read-moreが見つかり続ける限りボタンを押すようにします。
また、ボタンを押してからすぐに同じボタンを探そうとすると、新しいボタンがまだ読み込まれておらず途中で終了ということが起きるのでtime.sleep(1)で待機時間を設けます
ボタンが見つからなくなると、webdriverがエラーを起こしてプログラムが終了してしまうので、前もってエラーを予測exceptしておきます
except後はそのまま次へと進み、手に入れたhtml(さらに表示を全部押してある)をresに入れて、driver.quit()
でwebdriverは終了しますbutton.pyfrom selenium.common.exceptions import NoSuchElementException #find & click readmore button try: while driver.find_element_by_class_name('m-read-more'): button = driver.find_element_by_class_name('m-read-more') button.click() time.sleep(1) except NoSuchElementException: pass res = driver.page_source driver.quit()htmlを出力
念の為、手に入れたhtmlを出力しておきます。必須ではありません
html.py#output with html with open(area + '_' + keyword + '.html', 'w', encoding='utf-8') as f: f.write(res)htmlの解析
beautifulsoupに先程取得したhtmlを渡します。
soup.selectで要素を検索し、.get_text()で店名(住所)だけを取得します。
get_text()だけだと改行や空白が含まれてしまいますが、strip=Trueオプションをつけてあげると、ほしい文字だけになります。
また、住所についてですがタウンページのサイトではclass_name=m-article-card__lead__captionというクラスが、住所だけでなく電話番号や最寄駅といったものにも設定されていたため、文字列による抽出で住所だけを入手しています。text=re.compile("住所")parse.py#parse with beautifulsoup soup = BeautifulSoup(res, "html.parser") shop_names = [n.get_text(strip=True) for n in soup.select('.m-article-card__header__title')] shop_locates = [n.get_text(strip=True) for n in soup.find_all(class_='m-article-card__lead__caption', text=re.compile("住所"))]データの成形
pandasを使用してデータを整えています。
beautifulsoupで入手したデータはリストになっているので、2つを合体します。
それだけだと横向きのデータになってしまうので、縦向きにするためにtranspose()します。pandas.py#incorporation lists with pandas df = pd.DataFrame([shop_names, shop_locates]) df = df.transpose()データの出力
今回はcsv形式で出力しました。
ファイル名には、ユーザが入力したareaとkeywordを使用します。
pandasのデータは出力すると縦に番号が振られますが、邪魔なのでindex=Falseで消しています。
また、出力したデータをエクセルで開くと文字化けするという問題があるので、encoding='utf_8_sig'で回避します。csv.py#output with csv df.to_csv(area + '_' + keyword + '.csv', quoting=csv.QUOTE_NONE, index=False, encoding='utf_8_sig')終わりに
seleniumを使用したwebスクレイピングをしてみましたが、感想としては動作が安定しなかったです。
実際にブラウザを動かしているため、読み込みを行った後やボタンを押した後の動作が保証されません。
今回はそれを回避するためにtime.sleepを使用しました。
(本来はseleniumの暗黙的・明示的待機を使用するのですが、私はうまく動作しませんでした。)
あと、webdriverをダウンロードしたらなぜか古いバージョンになっており、それに気づかず2日位エラーに悩まされていたのでめちゃくちゃ腹立ちました(自分に)
- 投稿日:2020-11-08T17:21:25+09:00
Scrapyをaws Lambdaで動かす
Python製のクローラーフレームワークであるScrapyを使うと、簡単にクローラーを作成することができます。
実際のクローラーの開発・運用ではクローラーを定期的に動かす必要が多いです。
Scrapy単体は定期実行の機能を提供していないため、何かしらの外部の仕組みを活用して定期実行をする必要が出てきます。
例えば、Scrapyの開発元であるScrapingHub社が提供しているPaaSであるScrapy Cloudを使うと定期実行を行うことができます。
このクラウドはScrapyに特化したものであり、ヘッドレスブラウザやIPアドレス偽装などの便利機能とのインテグレーションも容易です。
しかし、この記事ではaws Lambda(以下Lambda)の上でScrapyを動作させてみます。
Lambdaで動かすことで、他のawsサービスとのインテグレーションがやりやすくなります。PythonコードからScrapyを呼ぶ方法
通常はScrapyを呼び出すために、shellから
scrapy run <spiderの名前>実行します。
しかし、LambdaのエントリーポイントはPython関数であるため、何らかの方法でPythonからScrapyを呼び出す必要があります。
標準ライブラリのsubprocessを使いshellを呼びだすこともできますが、ここではより直接的な方法でScrapyを呼び出してみます。
以下の公式ドキュメントを参考にして、PythonからScrapyを呼び出します。https://docs.scrapy.org/en/latest/topics/practices.html#run-scrapy-from-a-script
crawl.pyimport os import csv from multiprocessing import Process, Queue from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings from .spiders.hoge import HogeSpider def crawl(file_name): # settings.pyに書いていた設定をここに書く settings = get_project_settings() settings.set('FEEDS', { file_name: {"format": "csv"}}) process = CrawlerProcess(settings) process.crawl(HogeSpider) process.start() # csvをslackに通知したり、S3に保存したりする def run(): file_name = '/tmp/hoge.csv' process = Process(target=do_crawl, args=(file_name,)) process.start() process.join() if __name__ == '__main__': run()crawl関数がScrapyを呼び出す処理の本体です。
ただPythonから呼び出すだけならばこれで十分ですが、LambdaがPythonプロセスを再利用した場合はこのままだとエラーになります。
これはScrapyが内部的に使っている非同期処理ライブラリのtwistによるものです。
そのため、run関数内部でプロセスを生成しそれを使い捨てることで、毎実行ごとに独立したプロセス空間でScrapyを動作させています。Lambdaから呼び出す
ここまで出来ればあとは簡単です。
Lambdaから呼び出されるハンドラーを作成します。hander.pyfrom crawl import run def start(event, context): run() response = { "statusCode": 200, "body": "Success" } return responseデプロイ
最後に、この設定をLambdaにデプロイします。
デプロイにはServerless Frameworkを利用します。
以下のYAMLファイルを用意し、serverless deplyコマンドを実行すれば定期的にLambdaの上でScrapyが動きます。serverless.ymlservice: hoge-crawler provider: name: aws runtime: python3.8 region: ap-northeast-1 plugins: - serverless-python-requirements custom: pythonRequirements: dockerizePip: true functions: start: handler: handler.start timeout: 600 # 10 min events: - schedule: cron(0 15 * * ? *) # every day at 00:00 JST注意点
awsの利用規約
awsのAcceptable Use Policyには以下のように書かれています。
Monitoring or Crawling. Monitoring or crawling of a System that impairs or disrupts the System being monitored or crawled.
そのため、クローリング対象のシステムを妨害するレベルでの大量アクセスをした場合はawsのアカウントが停止される恐れがあります。
Lambda上でクローラーを運用する時は特に適切なダウンロード間隔が設定されているかどうかをしっかりと確認しましょう。https://aws.amazon.com/jp/aispl/aup/
Lambdaの実行時間制限
Lambda関数の実行時間には最大15分の制限があるため、この方法は大規模なサイトをクローリングするのには向いていません。
その場合はEC2にScrapyをインストールしてcronで定期実行したり、ECS Scheduled Taskの機能で定期実行をしたりを考える必要があります。
- 投稿日:2020-11-08T17:15:06+09:00
PythonとGmail APIでGmailの件名と本文を取得する
はじめに
PythonとGmail APIを使用して、受信トレイに保存されている対象のメールの件名と本文を取得して、ファイルに保存していきます。
前提条件
・Google Cloud Platformプロジェクトを作成し、Gmail APIを有効にする。
・Gmail APIを利用するための認証情報の取得。
以下の記事が参考になります。
https://qiita.com/muuuuuwa/items/822c6cffedb9b3c27e21実行環境
Python 3.9
必要なライブラリ
・google-api-python-client
・google-auth-httplib2
・google-auth-oauthlibソースコード
今回使用したコードはGitHubよりダウンロードできます。
https://github.com/kirinnsan/backup-gmail
Dockerfileも併せてアップロードしているので、Dockerが使える場合は、pip install でライブラリをインストールする必要はありません。認証
作成した認証情報はclient_id.jsonというファイル名で同じディレクトリに配置します。
認証フローは、InstalledAppFlowクラスで実装されており、ユーザが指示された認証URLを開き、認証コードを取得してコンソールに貼り付けるrun_consoleと、ウェブサーバを用いて認証を行うrun_local_serverの2種類のメソッドが用意されています。今回は、run_consoleメソッドを用いて認証を行っています。
初回の認証に成功すると、アクセストークンと更新トークンが格納されたtoken.pickleがディレクトリ内に作成されます。以降はこちらを使用して認証が行われます。
auth.pyimport pickle import os.path from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request from google.auth.exceptions import GoogleAuthError def authenticate(scope): creds = None # The file token.pickle stores the user's access and refresh tokens, and is # created automatically when the authorization flow completes for the first # time. if os.path.exists('token.pickle'): with open('token.pickle', 'rb') as token: creds = pickle.load(token) # If there are no (valid) credentials available, let the user log in. if not creds or not creds.valid: try: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file( 'client_id.json', scope) creds = flow.run_console() except GoogleAuthError as err: print(f'action=authenticate error={err}') raise # Save the credentials for the next run with open('token.pickle', 'wb') as token: pickle.dump(creds, token) return credsGoogle APIを使用したメールの取得
Gmail APIを使用して、受信トレイのメールのリストを取得するメソッドと対象メールの件名と本文を取得するメソッドを実装しています。
メールのリストには、最大取得件数や検索条件を指定することができます。client.pyfrom googleapiclient.discovery import build from googleapiclient.errors import HttpError import util class ApiClient(object): def __init__(self, credential): self.service = build('gmail', 'v1', credentials=credential) def get_mail_list(self, limit, query): # Call the Gmail API try: results = self.service.users().messages().list( userId='me', maxResults=limit, q=query).execute() except HttpError as err: print(f'action=get_mail_list error={err}') raise messages = results.get('messages', []) return messages def get_subject_message(self, id): # Call the Gmail API try: res = self.service.users().messages().get(userId='me', id=id).execute() except HttpError as err: print(f'action=get_message error={err}') raise result = {} subject = [d.get('value') for d in res['payload']['headers'] if d.get('name') == 'Subject'][0] result['subject'] = subject # Such as text/plain if 'data' in res['payload']['body']: b64_message = res['payload']['body']['data'] # Such as text/html elif res['payload']['parts'] is not None: b64_message = res['payload']['parts'][0]['body']['data'] message = util.base64_decode(b64_message) result['message'] = message return result以下は、base64 エンコーディングされた本文をデコードする処理と取得したメッセージを保存する処理になります。ファイルは、指定したディレクトリにメールの件名.txtの形で保存されます。
util.pyimport base64 import os def base64_decode(b64_message): message = base64.urlsafe_b64decode( b64_message + '=' * (-len(b64_message) % 4)).decode(encoding='utf-8') return message def save_file(base_dir, result): os.makedirs(base_dir, exist_ok=True) file_name = base_dir + '/' + result['subject'] + '.txt' with open(file_name, mode='w') as f: f.write(result['message'])メイン処理
以下が、実行部分のソースコードになります。処理の流れとしては、
1. 認証
2. 最大取得件数と検索条件をもとにメールのリストを取得
3. 各メールのIDから対象メールの件名と本文を取得
4. 件名.txtの形でファイルに保存
になります。main.pyfrom __future__ import print_function import auth from client import ApiClient import util # If modifying these scopes, delete the file token.pickle. SCOPES = ['https://www.googleapis.com/auth/gmail.readonly'] # Number of emails retrieved MAIL_COUNTS = 5 # Search criteria SEARCH_CRITERIA = { 'from': "test@gmail.com", 'to': "", 'subject': "メールの件名" } BASE_DIR = 'mail_box' def build_search_criteria(query_dict): query_string = '' for key, value in query_dict.items(): if value: query_string += key + ':' + value + ' ' return query_string def main(): creds = auth.authenticate(SCOPES) query = build_search_criteria(SEARCH_CRITERIA) client = ApiClient(creds) messages = client.get_mail_list(MAIL_COUNTS, query) if not messages: print('No message list.') else: for message in messages: message_id = message['id'] # get subject and message result = client.get_subject_message(message_id) # save file util.save_file(BASE_DIR, result) if __name__ == '__main__': main()今回は、最大取得件数を5件、受信者がtest@gmail.com、件名がメールの件名を検索条件にしています。受信者を指定する場合は、from:test@gmail.comやfrom:花子の形で設定します。件名の場合はsubject:件名の形で設定します。
以下の公式ページにGmailで使用可能な条件や使い方が記載されています。
https://support.google.com/mail/answer/7190取得したメールは、mail_boxディレクトリ内に保存されるようにしています。
アプリを実行します。
python3 main.py実行すると以下のように、コンソールから認証URLを開くよう指示あるのでURLを開きます。
URLを開くと、以下の画面になるので、詳細→安全でないページに移動をクリックします。
許可をクリックします。
許可をクリックします。
コードが表示されるので、コピーして、コンソールのEnter the authorization codeの部分に貼り付けます。
認証が成功すれば、後続処理が実行され、メールが保存されます。
最後に
公式リファレンスに、Pythonを使用した場合のアプリのサンプルが載っているので、こちらも参考にするとよいです。
https://developers.google.com/gmail/api/quickstart/python検索条件を指定して対象のメールを保存することができました。今回は、受信したメールのタイトルと本文を保存するだけでしたが、Gmail APIには、他にも様々なAPIが用意されているので、方法次第で色々できそうです。


- 投稿日:2020-11-08T16:51:20+09:00
pytest-dockerでデータベースをfixtureする
「データベースをDockerでfixtureするpytest環境例」として次を用意した。
こちらの記事はMySQLだったがPostgreSQLでも確認してみた。
なお、データベース接続インターフェースのライブラリーとして、
を利用したが、他のものを利用する場合もほぼ同じだと思う。
conftest.py の fixture例
pytest-dockerのサンプルでhttpbinの起動待ちしているところ、
def is_responsive(url): try: response = requests.get(url) if response.status_code == 200: return True except ConnectionError: return False @pytest.fixture(scope="session") def http_service(docker_ip, docker_services): """Ensure that HTTP service is up and responsive.""" # `port_for` takes a container port and returns the corresponding host port port = docker_services.port_for("httpbin", 80) url = "http://{}:{}".format(docker_ip, port) docker_services.wait_until_responsive( timeout=30.0, pause=0.1, check=lambda: is_responsive(url) ) return urlこれのデータベース版。アプリケーション側ではSQLAlchemy等のORMを使う場合でも直接接続ライブラリーでconnectしてみた。ORM経由だとSQLAlchemyのcreate_engine()のタイミングなのかどうなのかよくわからないし。ドライバーライブラリー経由で接続して起動確認してるってことを明示する感じで。
MySQL container の場合
MySQLコンテナーが立ち上がりconnect()に対してExceptionがでなくなるまで待つ
def is_mysqld_ready(docker_ip): try: pymysql.connect( host=docker_ip, user=os.getenv('MYSQL_USER', ''), password=os.getenv('MYSQL_PASSWORD', ''), db=os.getenv('MYSQL_DATABASE', '') ) return True except: return False@pytest.fixture(scope="session") def database_service(docker_ip, docker_services): docker_services.wait_until_responsive( timeout=30.0, pause=0.1, check=lambda: is_mysqld_ready(docker_ip) ) returnPostgreSQL container の場合
一緒ですね。
def is_postgresql_ready(docker_ip): try: psycopg2.connect( "postgresql://{user}:{password}@{host}/{db}".format( user=os.getenv('POSTGRES_USER', ''), password=os.getenv('POSTGRES_PASSWORD', ''), host=docker_ip, db=os.getenv('POSTGRES_DB', '') ) ) return True except: return False@pytest.fixture(scope="session") def database_service(docker_ip, docker_services): docker_services.wait_until_responsive( timeout=30.0, pause=0.1, check=lambda: is_postgresql_ready(docker_ip) ) returndocker-compose.yml
# MySQLの場合 version: "3" services: database: image: mysql:5.7 ports: - 3306:3306 volumes: - ./initdb.d:/docker-entrypoint-initdb.d environment: - MYSQL_ROOT_PASSWORD=${MYSQL_ROOT_PASSWORD} - MYSQL_USER=${MYSQL_USER} - MYSQL_PASSWORD=${MYSQL_PASSWORD} - MYSQL_DATABASE=${MYSQL_DATABASE}# PostgreSQLの場合 version: "3" services: database: image: postgres:13 ports: - 5432:5432 volumes: - ./initdb.d:/docker-entrypoint-initdb.d environment: - POSTGRES_USER=${POSTGRES_USER} - POSTGRES_PASSWORD=${POSTGRES_PASSWORD} - POSTGRES_DB=${POSTGRES_DB}スキーマとテストデータの準備
あとはdocker-composeでヴォリュームマウントされ初期化実行される
./initdb.d:/docker-entrypoint-initdb.dの./initdb.dフォルダにSQLや初期化シェルスクリプトなどを放り込んでおけばテスト可能に。Qiitaの記事だと、Docker で MySQL 起動時にデータの初期化を行う など。
- 投稿日:2020-11-08T16:50:45+09:00
LINEでyahoo天気から好きな地域の天気を通知してもらおう!~PART2~
前回のおさらい
前回まではこちらの記事で「LINEでyahoo天気から好きな地域の天気を通知してもらおう!」にもあるように
yahoo天気から全国地域のURLを取得するところまでを説明しました。今回
今回このPART2では全国地域のURLから詳細な地域(市区町村)のURLを取得するまでを簡単に説明しようと
思います。まず、前回取得したURLがこちらです。
このURLの中の、例えば1つ目のから得られるページの情報としてはこのようになっています。
地方に属している主な市区町村の天気が簡単にわかります。この画面の「稚内」などをクリックすると「稚内」の詳しい天気や降水確率が表示されます。
ここからやることは
・「地域と市区町村の名前とURLを取得すること」
・「市区町村のURLから天気情報を取得すること」
の2つです。プログラム実装編
ここからは実際にどうやって情報を取ってくるかを説明していきます。
まずは、「地域と市区町村の名前とURLを取得すること」を説明します。プログラムとしては次の通りです。
with open("yahooChiku.csv", "r", encoding="utf-8") as readChikuNum: reader = csv.reader(readChikuNum) with open("shosaiChiku.csv", "w", encoding="cp932", newline="") as schiku: writer = csv.writer(schiku) column = ["地方", "市区町村", "URL"] writer.writerow(column) for target_url in reader: res = requests.get(target_url[0]) soup = BeautifulSoup(res.text, 'lxml') chiku = re.search(r".*の", str(soup.find("title").text)).group().strip("の") elems = soup.find_all("a") chikuList, shosaiNumList = [], [] chikuNameList = [chikuName.get_text() for chikuName in soup.find_all(class_= "name")] for e in elems: if re.search(r'data-ylk="slk:prefctr', str(e)): if re.search(r'"https://.*html"', str(e)): row = re.search(r'"https://.*html"', str(e)).group().strip('"') chikuList.append(chiku) shosaiNumList.append(row) for p, e, c in zip(chikuList, chikuNameList, shosaiNumList): writeList = [p, e, c] writer.writerow(writeList)初めのwith openでURLファイルの読み込み、2つ目のwith openでは地方と市区町村そしてそれぞれのURLを書き込むファイルを開きます。
次にsoupにhtmlの情報を格納して順次必要な情報を取得していきます。chikuには取得先の地方名を正規表現で地方の名前だけになるように調整して代入します。
elemsには市区町村先のURLを取得するためにhtmlのaタグをfind_allで取っておきます。ここからファイルに書き込まれる変数が登場します。chikuNameListでは地方のhtmlからタグが「name」であるものを内包表記を使って取得しています。
運が良いことに市区町村の名前は「name」タグにすべてあります。
for文についてですが、こちらは「data-ylk="slk:prefctr」タグに市区町村のURLがあるので1つ目のif文で条件を設定しておきます。
「data-ylk="slk:prefctr」タグには市区町村のURL以外にもデータがあるのでその中でもURLの形式に一致するものだけを正規表現のsearchで判定します。
そしてchikuListには地区名をshosaiNumListには市区町村のURLを追加します。最後のfor文でリストに格納された地方名、市区町村、URLを1行ずつ「shosaiChiku.csv」に書き込んでいきます。
そして得られたファイルが次のようになります。
このままでも市区町村ごとのURLにアクセスし、正規表現やスクレイピングでも欲しいデータを持ってくることは可能ですが、RSSがあることに気づいたためそちらもファイルに追加することにしました。
df = pd.read_csv("shosaiChiku.csv", encoding="cp932") with open("dataBase.csv", "w", encoding="cp932", newline="") as DBcsv: writer = csv.writer(DBcsv) #ヘッダ書き込み columns = ["地方", "市区町村", "URL", "RSS"] writer.writerow(columns) #データ(地区名、市区町村、URL、RSS)を一行ずつ書きこみ for place, city, url in zip(df["地方"], df["市区町村"], df["URL"]): row = [place, city, url] rssURL = "https://rss-weather.yahoo.co.jp/rss/days/" #URLから「数字.html」を取得>「数字.rss」に成形 url_pattern = re.search(r"\d*\.html", url).group() url_pattern = url_pattern.replace("html", "xml") rssURL = rssURL + url_pattern row.append(rssURL) writer.writerow(row)ほぼやることは先ほどのソースと同様です。shosaiChikuにほとんどデータは入っているのでRSSのURLを
ちょちょいと追加するだけです。(趣向を変えてpandasのread_csvを使ってみました。)
RSSのベースとなるURLは、rssURLにある文字列「https://rss-weather.yahoo.co.jp/rss/days/」です。
プログラムでは何を行っているかというと、まずはshosaiChikuを1行ずつ読み込み「地方」「市区町村」、「URL」取得します。
RSSの「days/」以降のURLが市区町村のURLの数字部と同じということに気づいたので、
次は正規表現で市区町村のURLの数字部だけを抜き出します。
また、RSSは「.html」ではなく「.xml」となっているので変換しておきます。
こうしてRSSのURLがわかったため、リストにappendして書き込むという流れです。こうして出来上がったファイルがこちら。
直接開いて使用することがないので、見えにくくなっていますがこれでやりたいことを実現するためのデータが揃いました。(時間があるときにsqliteとか使ってdatabeseらしくする予定)おわりに
いろいろ書きましたが、長くなってしまったので2つあるうちの「地域と市区町村の名前とURLを取得すること」でいったん止めます。
また次の更新で、天気情報を取得してLINEで送るところまで説明できるといいなぁ。。。ということで、また次回。
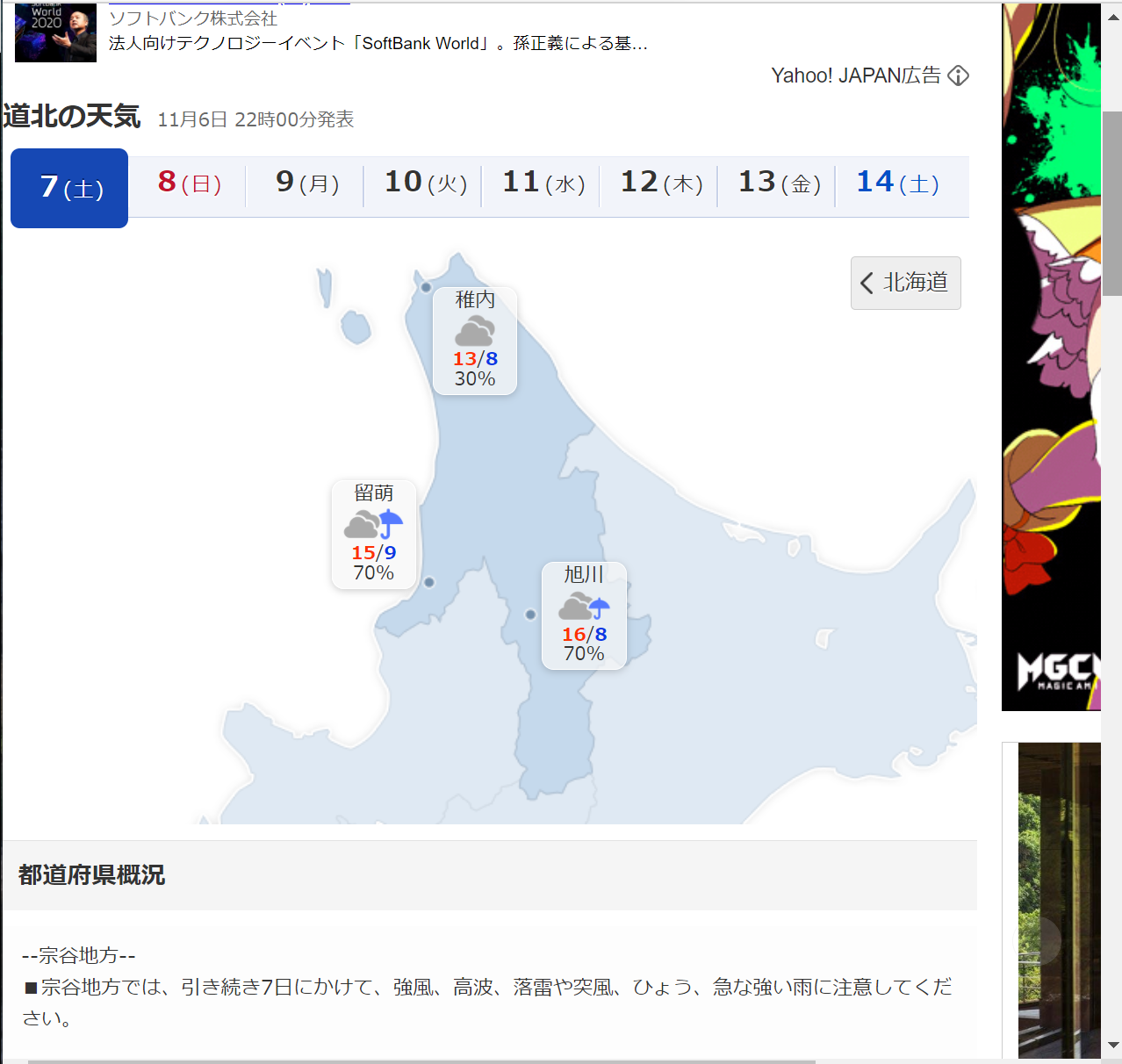
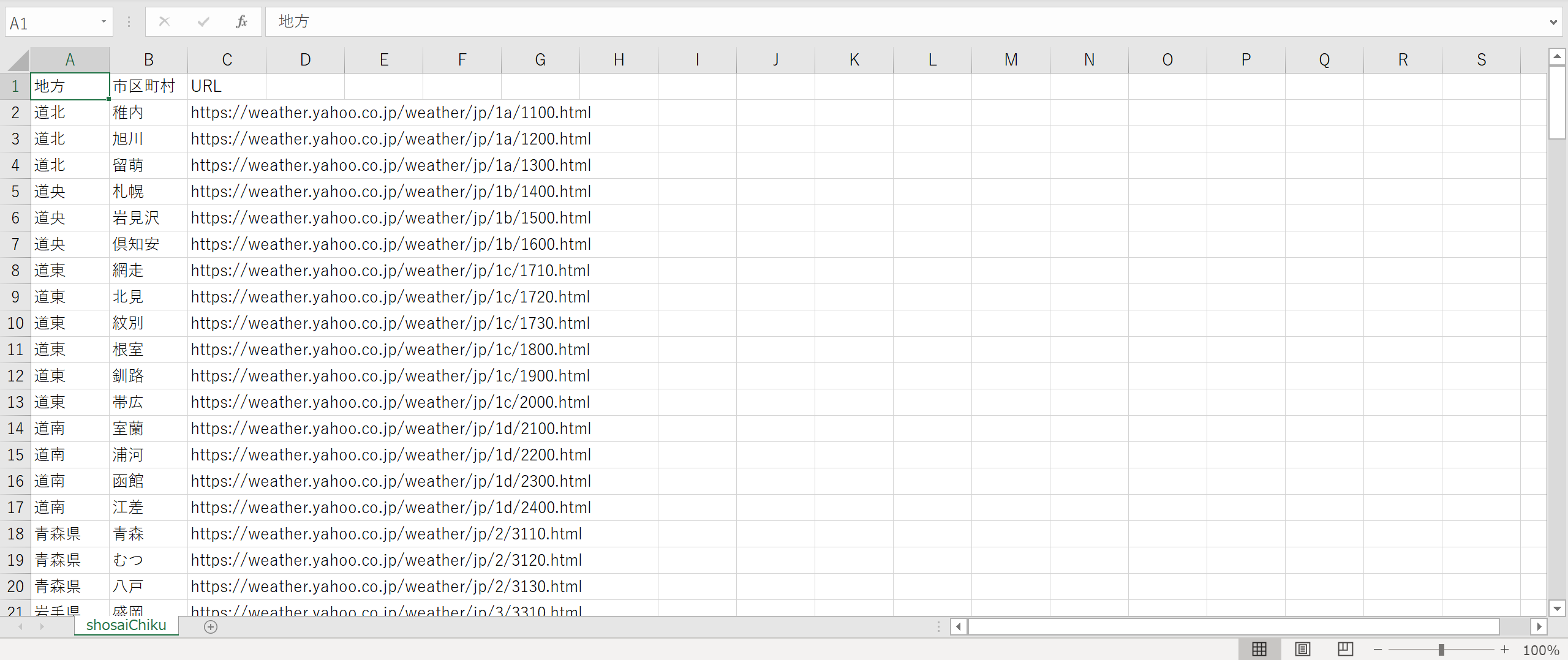
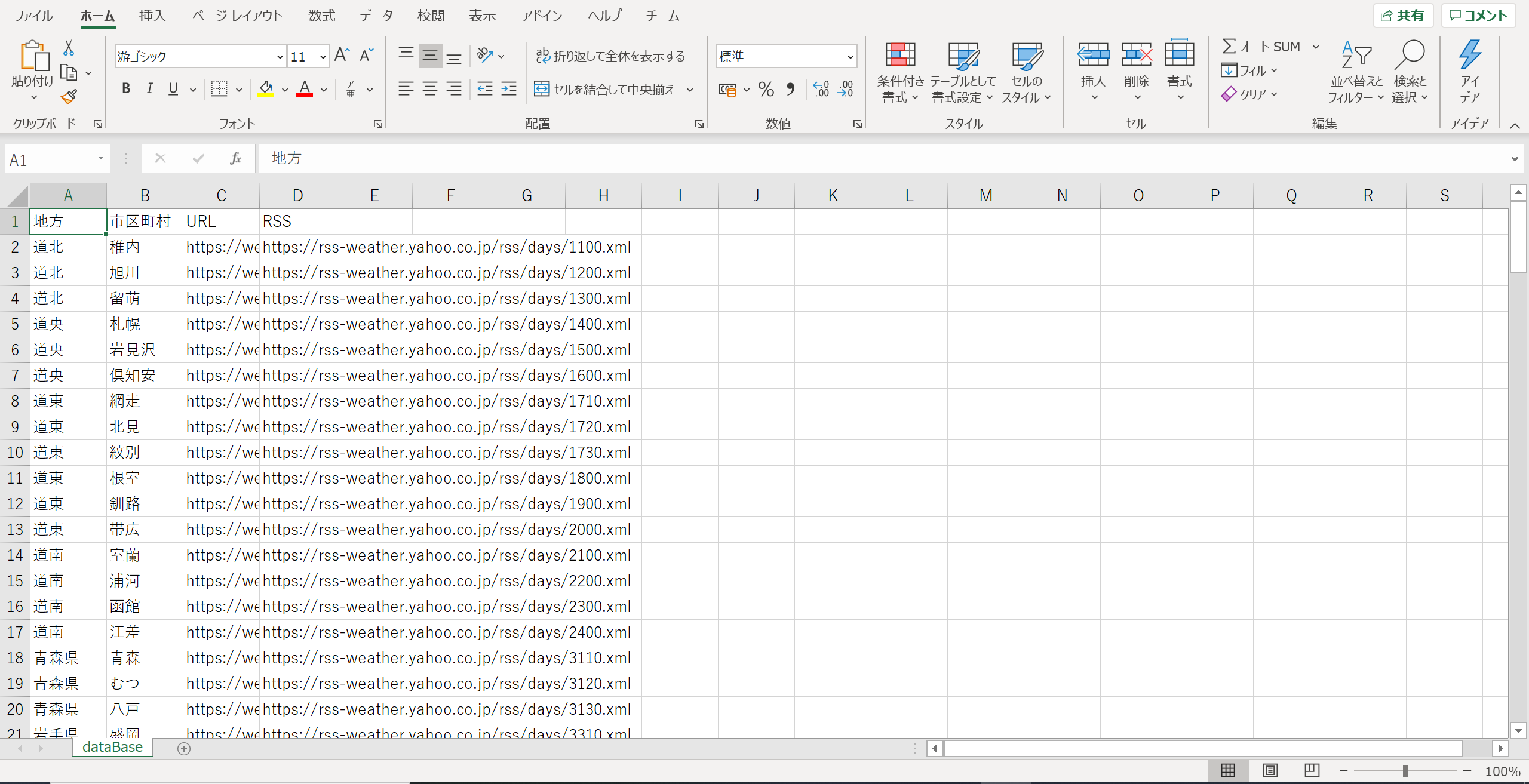
- 投稿日:2020-11-08T16:32:17+09:00
「pythonで遺伝的アルゴリズム(GA)を実装して巡回セールスマン問題(TSP)をとく」 をやってみた
はじめに
Qiita初投稿のため、内容だけでなく形式や書き方についてなどあらゆる野次をください。
pythonで遺伝的アルゴリズム(GA)を実装して巡回セールスマン問題(TSP)をとく
を実際にやってみました。
コーディングに慣れればいちいち言及しなくて良いのでろうなぁと思いつつ、
気になったことをなるべく記録していきます。ここをめちゃくちゃ参考(&引用)にしています。
いきなりぼやき
上にも貼ったリンク先のコードをそのままコピペしてもうまく動作しないことがありました。
それは当然で例えば
こんなこと
import numpy as np import random import matplotlib.pyplot as plt
を書かなきゃいけない。当然こんな初歩に言及するはずないよなぁ...
スペルミスがあったし...僕もしてるかも...さぁ本題に入りましょう。
遺伝的アルゴリズム(GA = Genetic Algorithm)とは
優れた遺伝子を持つものの子孫が繁栄する。
遺伝的アルゴリズムでは、これと同じような考え方で優れた解法を繁栄させていく。子孫繁栄
あらゆる要素について優位な個体がたくさんの子を産み、
劣位の個体はわずかな子しか産めない。
さらに同じことが子世代から孫世代への移動でも起こる。
この繰り返しにより環境に対して適応した洗練された子たちが生まれる。突然変異
交叉が続いていくと、似たような個体ばかりになる。我々の遺伝子は突然変異を時々起こすことで多様性を担保している。
巡回セールスマン問題(TSP = Travelling Salesman Problem)とは
巡回セールスマン問題は、
セールスマンがn個の営業先をどのような順番でまわるのが良いかと言う類の問題のことで、
理論上n!通りの順路があるため総当たりはしんどいって言うやつ。今回はこのTSPを用いてGAを解いてみたい。
フロー
初期個体生成
初期個体として、都市と遺伝子を作る必要があります。
都市
x,y座標がともに0~1の範囲にある都市をn個生み出します。
入力は都市数、出力は(都市数)×2の行列
実装例:generate_rand_cities#都市を生成 def generate_rand_cities(num_cities): positions = np.zeros((num_cities, 2)) for i in range(num_cities): positions[i, 0] = random.random() positions[i, 1] = random.random() return positions #試しに generate_rand_cities(10)randomについて(random.random)
random.random()は0.0以上1.0未満の浮動小数点数をランダムに生成
遺伝子
遺伝子に都市を巡る順序についての情報を持たせます。
遺伝子の長さは都市の数と一致させます。
例えば都市の数が6の時は、
[3, 5, 1, 0, 4, 2]
[0, 4, 2, 1, 5, 3]
などのような個体が考えられます。遺伝子は一世代のうちに複数の個体作るため、
遺伝子は(遺伝子の個体数)×(都市の個数)の行列で表されます。入力は都市の数と一世代の個体数、出力は(遺伝子の個体数)×(都市の個数)の行列
実装例:generate_init_genes
#遺伝子を生成 def generate_init_genes(num_individual, num_cities): genes = np.zeros((num_individual, num_cities), dtype=np.int16) for i in range(num_individual): genes[i,] = random.sample(range(num_cities), k=num_cities) return genes #試しに generate_init_genes(15,10)randomについて(random.sample)
random.sampleは重複なしでランダムに取り出す。
例えばl = [0, 1, 2, 3, 4] random.sample(l, 3)で[4, 2, 1]や[1, 0, 3]といったものが出力される。
評価
今回の課題では、より短い経路を示す遺伝子が高く評価される必要がある。
そのために、まずは遺伝子に対応する経路の長さを求める。
その後、世代内で比較し評価する。遺伝子に対応する経路
参考元では遺伝子ごとに都市間の距離を計算していた。
都市間の距離についてのテーブルを作り、遺伝子の順序に合わせて参照する。都市間の距離のテーブル
実装例
#都市間の距離についてのテーブル def generate_dist_table(positions): path_table = np.zeros((len(positions), len(positions))) for i in range(len(positions)): for j in range(len(positions)): path_table[i,j] = np.linalg.norm(positions[i]-positions[j]) return path_table #試しに num_cities = 4 positions = generate_rand_cities(4) generate_dist_table(positions)ある2都市の距離について2回計算している。ここはまだ削れるなぁ...
遺伝子に対応する経路の長さ
このテーブルをもとに遺伝子に対応する経路の長さを求める。
#テーブルを参照して、遺伝子に対応させた経路の和を求める def sum_path2(path_table, gene): sum = 0. for i in range(len(gene)-1): sum += path_table[int(gene[i]),int(gene[i+1])] return sum #試しに cities = generate_rand_cities(10) genes = generate_init_genes(15,10) dist_table = generate_dist_table(cities) for i in range(len(genes)): print(sum_path2(dist_table, genes[i]))世代ごとに遺伝子の評価をまとめて行いため、一世代の遺伝子についてまとめて出力する関数を設定する。
#経路の和について、一世代計算 def genes_path2(path_table, genes): pathlength_vec = np.zeros(len(genes)) for i in range(len(genes)): pathlength_vec[i] = sum_path2(path_table, genes[i]) return pathlength_vec #試しに cities = generate_rand_cities(10) genes = generate_init_genes(15,10) dist_table = generate_dist_table(cities) genes_path2(dist_table, genes)ルーレット
遺伝子に対応する経路の長さがわかった。今回は経路が短いものほど高く評価したい。
経路が短いものほど子孫を残すものとして選ばれる確率を高くしたい。
正規化を行う。#ルーレット def generate_roulette(fitness_vec): total = np.sum(fitness_vec) roulette = np.zeros(len(fitness_vec)) for i in range(len(fitness_vec)): roulette[i] = fitness_vec[i]/total return roulette #試しに fitness = np.array([20,50,30]) generate_roulette(fitness)これに対して
array([0.2, 0.5, 0.3])となる。
遺伝子をいざ評価
遺伝子に対応する経路の長さはすでにわかった。
今回は経路が短いものほど高く評価したい。
経路が短いものほど子孫を残すものとして選ばれる確率を高くしたい。
そのために今回は経路の長さの逆数を用いる。#ルーレット実行例 cities = generate_rand_cities(20) genes = generate_init_genes(21, 20) dist_table = generate_dist_table(cities) paths = genes_path2(dist_table, genes) inverse_path = 1/paths print("path length: "+str(paths)) print("roulette table: "+str(generate_roulette(inverse_path)))roulette tableは合計が1となるため、対応する遺伝子が選択される確率と解釈できる。
これを利用して遺伝子の選択を行う。選択(淘汰)
#ルーレットをもとに交叉をする個体を選ぶ def roulette_choice(fitness_vec): roulette = generate_roulette(fitness_vec) choiced = np.random.choice(len(roulette), 2, replace=True, p=roulette) return choiced #試しに cities = generate_rand_cities(20) genes = generate_init_genes(21, 20) dist_table = generate_dist_table(cities) fitness_vec = 1 / genes_path2(dist_table, genes) roulette_choice(fitness_vec)generate_rouletteでルーレットテーブルを作る。
ルーレットテーブルをもとにrouletteの中から2つの遺伝子を選ぶ。randomについて(random.choice)
random.choiceは重複ありでランダムに値を選ぶ。
第1引数が選ぶ数字の範囲、
第2引数は選ぶ個数、
replaceで重複ありかなしかを指定(Trueで重複あり)
pでそれぞれが選ばれる確率を指定している。交叉
roulette_choiceを用いて相対的に優秀な二個体を選ぶことができるようになった。
その二個体を掛け合わせる。
交叉法は遺伝子の形によって、また同じ遺伝子の形に対しても複数ある。
例えば順序交叉や循環交叉などがあるらしい→順序問題へのGAの適用
今回は部分的交叉を行なった。
部分的交叉の方法は以下の画像を参考にしていただきたい。引用元
部分的交叉の実装
#部分的交叉の実装 def partial_crossover(parent1, parent2): num = len(parent1) cross_point = random.randrange(1,num-1) #切れ目 child1 = parent1 child2 = parent2 for i in range(num - cross_point): #切れ目の直ぐ右の値 target_index = cross_point + i target_value1 = parent1[target_index] target_value2 = parent2[target_index] exchange_index1 = np.where(parent1 == target_value2) exchange_index2 = np.where(parent2 == target_value1) #交換 child1[target_index] = target_value2 child2[target_index] = target_value1 child1[exchange_index1] = target_value1 child2[exchange_index2] = target_value2 return child1, child2 #試しに genes = generate_init_genes(2, 10) print("parent1: "+str(genes[0])) print("parent2: "+str(genes[1])) child = partial_crossover(genes[0], genes[1]) print("child1: "+str(child[0])) print("child2: "+str(child[1]))突然変異
突然変異にも様々な手法がある。
今回は転座と呼ばれるものを行う。
ランダムで選んだ二箇所を入れ替える。def translocation_mutation2(genes, p_value): mutated_genes = genes for i in range(len(genes)): mutation_flg = np.random.choice(2, 1, p = [1-p_value, p_value]) if mutation_flg == 1: mutation_value = np.random.choice(genes[i], 2, replace = False) mutation_position1 = np.where(genes[i] == mutation_value[0]) mutation_position2 = np.where(genes[i] == mutation_value[1]) mutated_genes[i][mutation_position1] = mutation_value[1] mutated_genes[i][mutation_position2] = mutation_value[0] return mutated_genes #試しに genes = generate_init_genes(5, 10) print("before") print(genes) print("after") print(translocation_mutation2(genes, 0.7))mutation_flagは確率p_valueで1になる。
よって、遺伝子が確率p_valueで突然変異を起こす。可視化
フローチャートには書かれていないが、GAの推移を確認するためにmatplotlibを用いて可視化する。
都市の位置
#都市の位置可視化 def show_cities(cities): for i in range(len(cities)): plt.scatter(cities[i][0], cities[i][1]) #試しに cities = generate_rand_cities(10) show_cities(cities)経路の可視化
def show_route(cities, gene): for i in range(len(gene)-1): if i == 0: plt.text(cities[int(gene[i])][0], cities[int(gene[i])][1], "start") else: plt.text(cities[int(gene[i])][0], cities[int(gene[i])][1], str(i)) plt.plot([cities[int(gene[i])][0], cities[int(gene[i+1])][0]], [cities[int(gene[i])][1], cities[int(gene[i+1])][1]]) plt.text(cities[int(gene[i+1])][0], cities[int(gene[i+1])][1], "goal") #試しに cities = generate_rand_cities(10) show_cities(cities) genes = generate_init_genes(10,10) show_route(cities,genes[0])統合
これまで作ってきた関数を利用して、TSPをGAで解くプログラムを実装します。
パラメータ
#パラメータ num_cities = 10 individuals = 21 generation = 10000 elite = 9 p_mutation = 0.01初期化
#初期化 cities = generate_rand_cities(num_cities) genes = generate_init_genes(individuals, num_cities) dist_table = generate_dist_table(cities) show_cities(cities) show_route(cities, genes[0]) plt.show()こんなのが見れるはず
実行部
親世代のうち優秀なelite個と
親世代間の交叉によって生まれた(individual-elite)個の子が子世代を担う。
子世代の中で突然変異が起きて、最終的な子世代が形成される。#実行部 top_individual=[] #各世代の最も優れた適応度のリスト max_fit = 0 #歴代最高の適応度 fitness_vec = np.reciprocal(genes_path2(dist_table, genes)) for i in range(generation): children = np.zeros(np.shape(genes)) for j in range(int((individuals-elite)/2+1)): parents_indices = roulette_choice(fitness_vec) children[2*j], children[2*j+1] = partial_crossover(genes[parents_indices[0]], genes[parents_indices[1]]) for j in range(individuals-elite, individuals): children[j] = genes[np.argsort(genes_path2(dist_table, genes))[j-individuals+elite]] children = translocation_mutation2(children, p_mutation) top_individual.append(max(fitness_vec)) genes = children fitness_vec = np.reciprocal(genes_path2(dist_table, genes)) if max(fitness_vec) > max_fit: #過去最高の適応度を記録したら、経路を表示する max_fit = max(fitness_vec) show_cities(cities) show_route(cities, genes[np.argmax(fitness_vec)]) plt.text(0.05, 0.0, "generation: " + str(i) + " distance: " +str(sum_path2(dist_table,genes[np.argmax(fitness_vec)]))) plt.show()top_individualは各世代の最も優れた適応度を格納したリスト。
最後に表示されたものは
のように経路が短くなるような順序で巡ったものになる。
また、plt.plot(top_individual)で世代が変わることによる適応度の推移が確認できる。
numpyについて(メモ)
np.reciprocal()→各要素を逆数にしたやつをくれる
np.argmax()→各要素のうち最大のもののインデックスをくれる
np.argsort()→各要素をソートした時のインデックスの順番まとめ
初期設定として
都市の数、
遺伝子の個体数、
進化の世代数、
eliteの数、
突然変異の確率、
を与えた。都市の数を増やすと明らかにもっといい経路があるのに、その経路に進化してくれない。
また、計算に時間がかかる
まだまだ改善の余地があるということだ。
考えられる点として、交叉の仕方
他の交叉の仕方を知らないため、なんともわからない。より適した交叉法があるかも。
また、突然変異と結びつけたい。突然変異の確率
親の類似度によって突然変異の確率が変わるようにすれば効率がよくなると考えられる。
ピックアップされるエリートの数
今回は初期設定で決めた。
が、これも突然変異の確率と同様、親の類似度で変えたほうがよくなるかも。
試しに、eliteの数を少なくすると適応度が伸びずに振動する。
交叉によって悪い要素を拾わされるから、序盤で適応度の伸びが起きないと考えられる。世代数
世代数も初期設定によって与えたが、これも改善の余地がある。
世代の数は計算の負担に直接関わってくる。
適応度の変化率から終了条件を設定すれば世代数の指定が必要なくなるだろう。遺伝子の個体数
同様に遺伝子の個体数も計算に関わる。
個体数が少ないと進化の世代を増やさなければならなくなる。
与えられた都市の数に対して適した割合で設定すれば入力する必要はなくなるだろう。展望
最終的に都市について入力するだけで、適した経路を導いてくれそう。
そのために、交叉法、突然変異の確率の与え方、遺伝子の個体数と世代数の適した値などについて調べる必要がありそうです。頑張ります。randomまとめ
・ランダムに要素を一つ選択: random.choice()
・ランダムに複数の要素を選択(重複なし): random.sample()
・ランダムに複数の要素を選択(重複あり): random.choices()
・0~1の浮動小数点数をランダムに生成 : random.random()
pythonでrandomを使うより

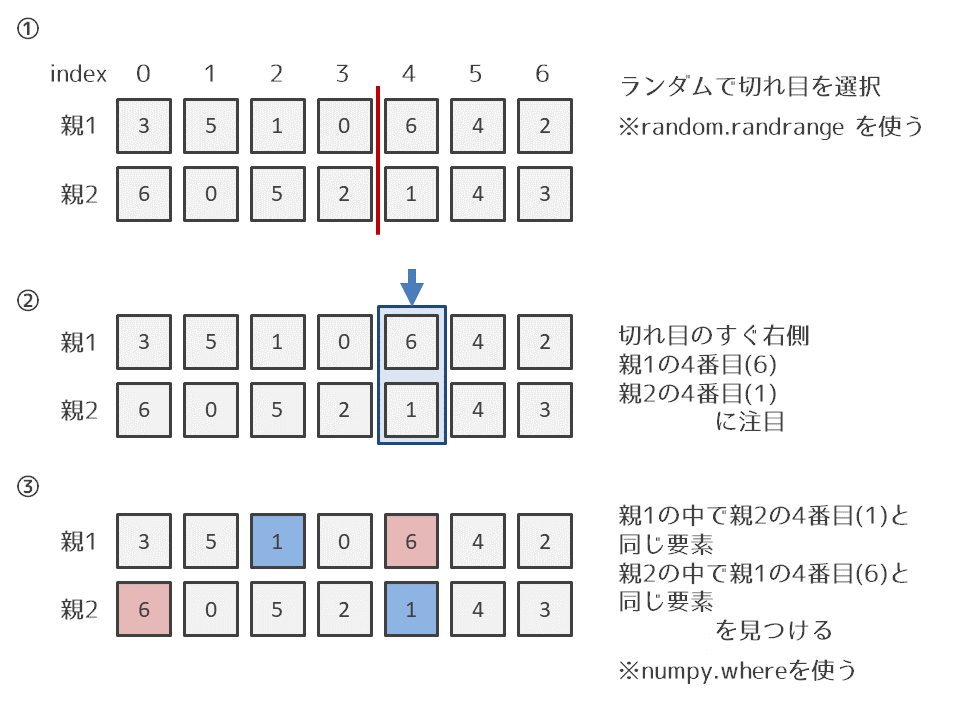
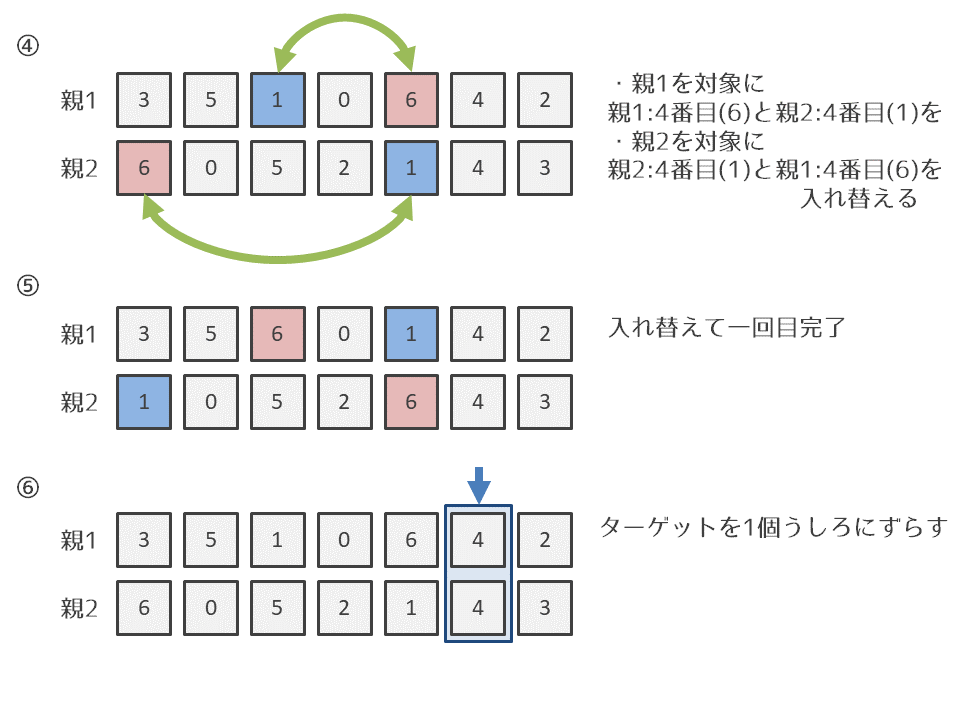
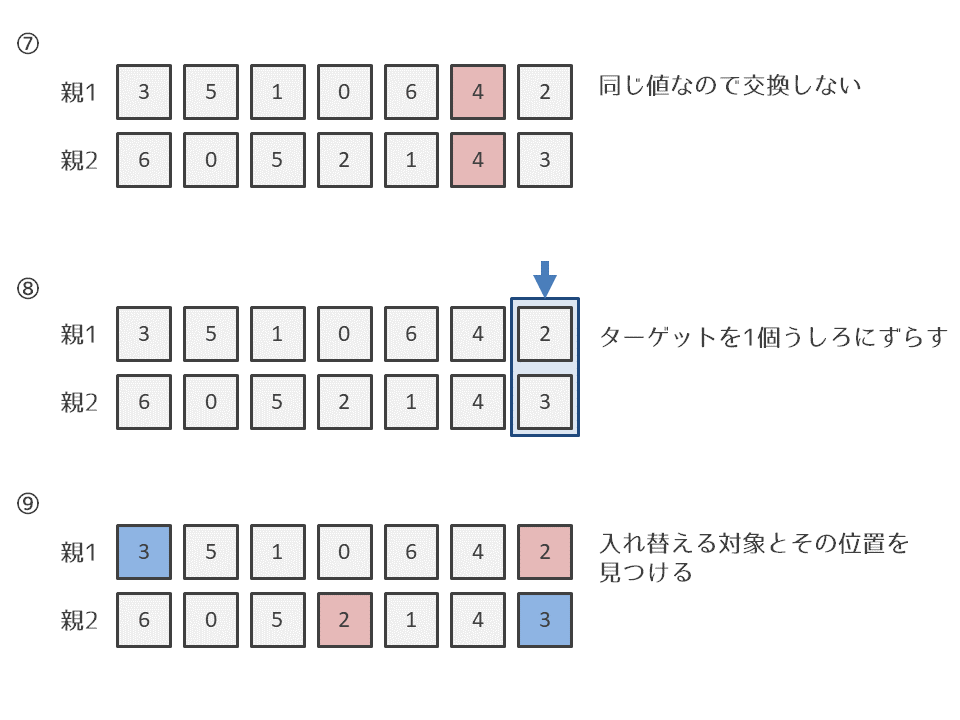
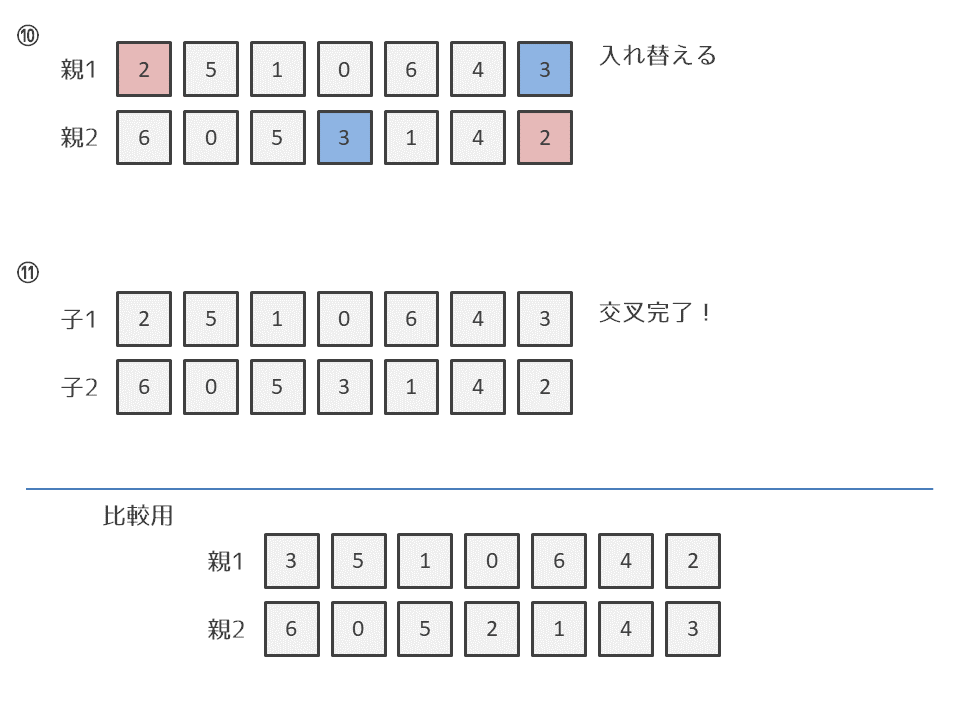
- 投稿日:2020-11-08T16:29:01+09:00
Pandas.DataFrame 小技集
- 投稿日:2020-11-08T16:23:59+09:00
[Python]2次元のk平均法を自分で書いてみる
scikit-learnなどを使うとさくっと利用できてしまうk平均法を、アルゴリズム理解と勉強のため、自分でPythonを使って書いていってみます。
k平均法とは
k平均法(英語ではk-means clustering)とは、クラスタリング(データの特徴に応じたグループ分け)のアルゴリズムの一つです。
参考 : k平均法 - Wikipedia
クラスタリングのグループの1つ1つをクラスター(cluster)と呼びます。
k平均法では各クラスターの平均を用いた計算を行い、k個のクラスターにデータを分類行うためk-means clusteringという名前になっています。k平均法の特徴と活用の一例
k平均法のクラスタリングはデータさえあれば実行することができます。
いわゆる教師無し学習といった挙動をするので、正解ラベルなどを用意する必要がありません。そのためデータだけある状態で、データの傾向の把握などに利用することができます。
たとえば、どんな傾向のユーザーグループが存在するのかを把握し、施策をそれぞれに向けて分けるといったケースに使うことができます。一方で計算内容の都合で、通常のk平均法ではクラスター数を事前に自分で決める必要があります。そのため「実はクラスター数が7個が最適だったのにクラスター数を5個に設定していた」といったケースが発生しうるアルゴリズムになります。
また、各値の平均やクラスターとの距離などを利用する計算なので、値の中に異常値が含まれていて且つクラスターの初期位置が異常値の近くになってしまうと、そこでクラスターが固定されてしまうケースがある(異常値に弱い)といった特徴も持ちます。
それらを解決するためのk-means++やx-meansといったアルゴリズムも存在しますが、本記事ではそこまでは触れません。
k平均法の計算方法
k平均法は以下のような流れの計算を行います。
- [1]. クラスタリングを反映したいデータを用意します。
- [2]. データの標準化(後述)を行います。
- [3]. データの範囲内で、ランダムな位置にk個のクラスターを作成します。
- [4]. 各データを位置的にもっとも近い距離にあるクラスターに所属させます。
- [5]. 各クラスターの位置を、そのクラスターに属しているデータの平均の位置に移動させます。
- [6]. 設定したイテレーション数に達するか、もしくはクラスターの位置が変わらなくなるまで[4]~[5]の計算を繰り返します。
Pythonでの実装
前述の計算をPythonで書いてみて、可視化までやってみます。
使うもの
- Python 3.8.5
- matplotlib==3.3.2
- VS Code上のJupyter
※過去の記事と同様、勉強のためなるべくアルゴリズム部分はライブラリを使わずにPythonの標準モジュールを使って進めていきます。ただし、可視化などの目的でmatplotlibのみは今回利用します。
この記事では割愛するもの
本記事ではアルゴリズムの理解を深めることを目的とするため、シンプルになるように以下のものは扱いません。
- 2次元を超えるデータでのk平均法。
- k平均法を発展させたもの。
- 例 : 初期のクラスターの初期位置をより最適なものにしたり、kの個数が自動決定されるようなk-means++やx-meansなど。
- 細かいパフォーマンスの最適化はスキップします。
必要なモジュールのimportと初期設定
まずは必要なもののimportや可視化のためのmatplotlibのプロット設定などを行います。
from __future__ import annotations from typing import List from math import sqrt from copy import deepcopy from statistics import pstdev, mean import random from datetime import datetime import matplotlib.pyplot as plt import matplotlib matplotlib.style.use('ggplot') %matplotlib inline
annotationsはPython3.10からデフォルトとなる、一部の型アノテーション関係の挙動を有効化するためにimportしています。また、型アノテーションを利用して型チェックを行いつつ書き進めるため、typingモジュールのものを一部import1しています。sqrt、pstdev、meanはそれぞれ平方根計算、標準偏差の計算、平均計算用の関数です。前者2つは標準化(standardize)の計算で利用し、平均はクラスターの位置更新時に利用します。
また、クラスターの更新が終わるまで過程の各イテレーションのクラスターを、過程の可視化目的で保持しようと思うため値のディープコピー用にdeepcopy関数をimportしています。
randomモジュールはランダムな座標の生成目的で一様分布用の関数(uniform)で使います。
あとは可視化用にmatplotlib関係のimportや設定を行っています。
座標用のクラスの定義
今回は2次元空間でのk平均法を進めていくので、横軸(X)と縦軸(Y)の値が扱えれば計算ができるので、XとYの属性を持つPointクラスを追加していきます。
class Point: def __init__(self, x: float, y: float) -> None: """ 特定の2次元空間の座標単体を扱うクラス。matplotlibに合わせて、 左下を(0, 0)とし、右上にいくごとにインクリメントする形の座標 空間で扱う。 Parameters ---------- x : float X座標。 y : float Y座標。 """ self.x: float = x self.y: float = yk平均法の計算過程で、各座標がどのクラスターに一番近いのかの計算が必要になるので、他の座標とのユークリッド距離を取得できるメソッドを追加します。
参考 : 2次元ユークリッド距離の性質
計算としては1つ目のX座標を$x$, 2つ目のX座標を$x'$, 1つ目のY座標を$y$, 2つ目のY座標を$y'$, 求まる距離を$D$とすると、以下の計算式で対応ができます。懐かしの中学の数学で学ぶ計算ですね。
D = \sqrt{(x - x')^2 + (y - y')^2}def distance(self, other_point: Point) -> float: """ 引数に指定された座標間のユークリッド距離を取得する。 Parameters ---------- other_point : Point 対象の座標。 Returns ------- distance_val : float 算出された2つの座標間のユークリッド距離の値。 """ x1: float = self.x x2: float = other_point.x y1: float = self.y y2: float = other_point.y distance_val: float = sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2) return distance_valまた、計算家計のイテレーションで各クラスターの座標がイテレーションで変動していないことの判定を行うために、
__eq__メソッドを追加しPointクラス同士の比較ができる(XとYが一致していればTrueになる)ようにしておきます。def __eq__(self, other: object) -> bool: """ 他のPointのインスタンスと等値かどうかの比較を行う。 Parameters ---------- other : object 比較対象のインスタンス。もしPoint関係のインスタンスではない 場合には比較処理はスキップされる。 Returns ------- is_equal : bool 等値かどうかの真偽値。座標の比較で処理される。 """ if not isinstance(other, Point): return NotImplemented is_equal: bool = self.x == other.x and self.y == other.y return is_equal計算では1つ前の各クラスターと現在の各クラスターが一致していることを比較しますが、Pythonでは以下のようにリスト内に値を入れる形での比較でも計算することができるのでそちらを後々利用します。
>>> point_list_A: List[Point] = [Point(x=10, y=20)] >>> point_list_B: List[Point] = [Point(x=10, y=20)] >>> print(point_list_A == point_list_B) Trueクラスター用のクラスの定義
次はクラスター用のクラスを定義していきます。
こちらはシンプルで、centroidとpointsという2つの属性を持つだけのクラスとなります。centroidは「重心」とか「質量中心」といった意味を持つ単語です。k平均法ではクラスターに属する座標の中心(平均)位置として使われます。イテレーションを繰り返す度に属する座標が変動するため、このcentroidの座標値も同様にイテレーションの度に変化します。
pointsの属性はこのクラスターに属する各座標を格納するためのリストです。
class Cluster: def __init__(self, centroid: Point, points: List[Point]): """ 1つ分のクラスターを扱うためのクラス。 Parameters ---------- centroid : Point クラスターの中央位置となる座標情報。 points : list of Point 対象のクラスターに属している座標のリスト。 """ self.centroid = centroid self.points = pointsk平均法のアルゴリズム用のクラスの定義
k平均法のアルゴリズム制御用のクラスを追加していきます。
コンストラクタの定義
コンストラクタではクラスター数としての
kとクラスタリング対象の座標群としてのpointsという2つの引数を受け付けるようにしています。また、事前に各座標の標準化(後述)を行って各座標値を変換してしまう(
_get_standardized_points部分)ので、元の座標を保持するために_original_pointsという属性を設けてあります。その他、各クラスターの初期化(後述)もコンストラクタで行っています(
_initialize_clusters部分)。class KMeans: def __init__(self, k: int, points: List[Point]) -> None: """ KMeansのアルゴリズム制御用のクラス。 Parameters ---------- k : int 設定するクラスター数。 points : list of Point 対象とする座標のリスト。 """ self._original_points = points self._k = k self._standardized_points: List[Point] = self._get_standardized_points() self._initialize_clusters()各座標を標準化する
今回扱うケースではそこまで大きな差ではありませんが、通常は次元(軸)によって数値のスケールが大きく異なる場合があります。たとえば横軸が年齢、縦軸が売り上げといった2次元のデータを扱うケースを考えると、横軸の数値は縦軸の数値と比べると大分小さくなってしまいがちでクラスタリングで扱うには不適切です。
そのため今回の記事でも標準化(standardized)の処理を各座標に対して入れていきます。機械学習方面でもライブラリでよくScaler(例 : StandardScaler, MinMaxScalerなど)や正規化(normalization)などの変換処理の単語が出てきますが、そういった感じの前処理の変換となります。
今回はZ値(z-score)と呼ばれる標準化の処理を入れていきます。
z-scoreの概要と計算方法
z-scoreは、値(今回は座標)が平均値から標準偏差の何個分離れているのかという値になります。z-scoreを$Z$とすると式で表すと以下のようになります。
Z = (座標値 - 平均値) ÷ 標準偏差これをX軸とY軸の座標値に反映することで、縦と横のスケールが合うようになります。
z-score反映用のメソッドの定義
KMeansクラスにz-score用の各メソッドを追加していきます。
まずは元の座標とは別にしたいため、
deepcopy(self._original_points)という記述部分で各座標のディープコピーを作っています。コピーしたものに対して、X軸とY軸の各座標値にそれぞれ標準化の処理を反映しています。
前節で触れたz-scoreの計算は
_apply_z_scoreメソッド内で記述しています。平均はmean関数、標準辺さはpstdev関数で取っています。def _get_standardized_points(self) -> List[Point]: """ 標準化された座標のリストを取得する。 Notes ----- 標準化にはz-scoreの計算が使われる。 Returns ------- standardized_points : list of Point 標準化後の各座標を格納したリスト。 """ standardized_points: List[Point] = deepcopy(self._original_points) self._standardize_x(points=standardized_points) self._standardize_y(points=standardized_points) return standardized_points def _standardize_x(self, points: List[Point]) -> None: """ 指定された座標のリストのX座標の標準化を行う。 Parameters ---------- points : list of Point 変換対象の座標のリスト。 """ x_list: List[float] = [point.x for point in points] x_list = self._apply_z_score(list_val=x_list) for i, point in enumerate(points): point.x = x_list[i] def _standardize_y(self, points: List[Point]) -> None: """ 指定された座標のリストのY座標の標準化を行う。 Parameters ---------- points : list of Point 変換対象の座標のリスト。 """ y_list: List[float] = [point.y for point in points] y_list = self._apply_z_score(list_val=y_list) for i, point in enumerate(points): point.y = y_list[i] def _apply_z_score(self, list_val: List[float]) -> List[float]: """ 指定された座標値を格納したリストにz-scoreの標準化を反映する。 Parameters ---------- list_val : list of float 座標値を格納したリスト。 Returns ------- list_val : list of float z-score反映後の座標値のリスト。 """ mean_val: float = mean(list_val) std_val: float = pstdev(list_val) for i, coordinate in enumerate(list_val): standardized_val: float = (coordinate - mean_val) / std_val list_val[i] = standardized_val return list_valクラスターの初期化を行う
引き続きコンストラクタで必要な処理(コンストラクタで呼び出されているメソッド)の追加を進めていきます。今度はクラスターの初期化です。
やることとしては、
- コンストラクタに指定されたk(クラスター数)分のClusterインスタンスを生成してリストに追加。
- 各クラスターのcentroid(クラスターの重心点)の値(初期値)は、標準化された座標の最小~最大値の範囲内でランダムに決定する。
- クラスターに属する各座標はまだこの時点では無し(空のリスト)で生成する。
といった処理になります。
def _initialize_clusters(self) -> None: """ クラスターの初期化を行う。クラスター中心点(centroid)は ランダムな位置が設定され、属する座標点は空の状態でリストが 生成される。 """ self._clusters: List[Cluster] = [] for _ in range(self._k): random_point: Point = self._get_standardized_random_point() cluster: Cluster = Cluster( centroid=random_point, points=[]) self._clusters.append(cluster) def _get_standardized_random_point(self) -> Point: """ ランダムな座標点を生成・取得する。 Returns ------- random_point : Point 生成された座標点。 """ x_min: float = self._get_standardized_x_min() x_max: float = self._get_standardized_x_max() y_min: float = self._get_standardized_y_min() y_max: float = self._get_standardized_y_max() random_x: float = random.uniform(a=x_min, b=x_max) random_y: float = random.uniform(a=y_min, b=y_max) random_point: Point = Point(x=random_x, y=random_y) return random_point def _get_standardized_x_max(self) -> float: """ 標準化された座標値の中でのX座標の最大値を取得する。 Returns ------- x_max : float X座標の最大値。 """ x_list: List[float] = self._get_standardized_x_list() x_max: float = max(x_list) return x_max def _get_standardized_x_min(self) -> float: """ 標準化された座標値の中でのX座標の最小値を取得する。 Parameters ---------- x_min : float X座標の最小値。 """ x_list: List[float] = self._get_standardized_x_list() x_min: float = min(x_list) return x_min def _get_standardized_x_list(self) -> List[float]: """ 存在する標準化された座標値(クラスターの中心座標を除く)のX座標の リストを取得する。 Returns ------- x_list : list of float X座標のリスト。 """ x_list: List[float] = [point.x for point in self._standardized_points] return x_list def _get_standardized_y_max(self) -> float: """ 標準化された座標値の中でのY座標の最大値を取得する。 Returns ------- y_max : float Y座標の最大値。 """ y_list: List[float] = self._get_standardized_y_list() y_max: float = max(y_list) return y_max def _get_standardized_y_min(self) -> float: """ 標準化された座標値の中でのY座標の最小値を取得する。 Returns ------- y_min : float Y座標の最小値。 """ y_list: List[float] = self._get_standardized_y_list() y_min: float = min(y_list) return y_min def _get_standardized_y_list(self) -> List[float]: """ 存在する標準化された座標値(クラスターの中心座標を除く)のY座標の リストを取得する。 Returns ------- y_list : list of float Y座標のリスト。 """ y_list: List[float] = [point.y for point in self._standardized_points] return y_list各座標をいずれかのクラスターに所属させるための処理の実装
ここからはコンストラクタではなく、k平均法を動かした際の各イテレーションで利用する処理を書いていきます。
k平均法の計算で、各イテレーションで「各座標をいずれかのクラスターに所属させる」「各クラスターの中央(重心)点を更新する」といった計算が繰り返し必要になりますが、そのうちの各座標をクラスターに所属させる部分を書いていきます。
処理としては、
- 各クラスターに所属している座標のリストを一旦リセット(空に)する。
- 各座標を(ユークリッド距離で)一番近いクラスターに所属(クラスターのpointsのリストに追加)させる。
といった処理になります。
def _assign_points_to_cluster(self) -> None: """ 各座標を一番近いクラスターへ割り当てる(クラスターの座標のリストへ 各座標を追加する)。 Notes ----- 実行時点での割り当てられている座標は最初にリセットされる。 """ self._reset_clusters_assignment() for standardized_point in self._standardized_points: nearest_cluster: Cluster = self._get_target_point_nearest_cluster( standardized_point=standardized_point) nearest_cluster.points.append(standardized_point) def _reset_clusters_assignment(self) -> None: """ 各クラスターへの座標の割り当てをリセット(空に)する。 """ for cluster in self._clusters: cluster.points.clear() def _get_target_point_nearest_cluster( self, standardized_point: Point) -> Cluster: """ 対象の座標に対して一番近いクラスターを取得する。 Parameters ---------- standardized_point : Point 対象の標準化された座標。 Returns ------- nearest_cluster : Cluster 対象の座標に一番近いクラスター。 """ min_distance: float = self._clusters[0].centroid.distance( other_point=standardized_point) nearest_cluster: Cluster = self._clusters[0] for cluster in self._clusters: distance: float = cluster.centroid.distance( other_point=standardized_point) if distance >= min_distance: continue min_distance = distance nearest_cluster = cluster return nearest_cluster各クラスターの中心(重心)点の更新処理の実装
こちらも各イテレーションで利用するメソッドです。
各座標の最も近いクラスターへの所属が終わったタイミングで、クラスターに所属している各座標の平均を取って、その平均の座標をクラスターの中心(重心)点(centroid)に設定します。計算自体はmean関数を使ったシンプルなものになります。
def _update_cluster_centroid(self) -> None: """ クラスターに属している座標のリストを参照して、各クラスターの 中央座標(各座標の平均値)を更新する。 """ for cluster in self._clusters: if not cluster.points: continue x_list: List[float] = [point.x for point in cluster.points] y_list: List[float] = [point.y for point in cluster.points] mean_x: float = mean(x_list) mean_y: float = mean(y_list) cluster.centroid.x = mean_x cluster.centroid.y = mean_yアルゴリズムのイテレーションのためのメソッドの実装
前セクションまでに用意した、「各座標を一番近いクラスターに所属させる」処理と「各クラスターの中心(重心)点を更新する」処理をループで繰り替えし実行する処理を追加します。
各イテレーションでクラスターがどんな感じに変化していっているのかを後々確認(可視化)するため、イテレーションごとにクラスターのリストをコピーし、イテレーションが終わったらクラスターのヒストリーとしてそのデータを返却しています。
def run_algorithm(self, max_iterations: int=100) -> List[List[Cluster]]: """ k-meansのアルゴリズムを実行する。 Parameters ---------- max_iterations : int イテレーションの最大数。 Returns ------- clusters_history : list of list 各イテレーションにおける、クラスター群を格納する多次元のリスト。 1次元目は各イテレーション、2次元目はそのイテレーションにおける 一通りのクラスターを格納する。 """ clusters_history: List[List[Cluster]] = [] for iteration in range(max_iterations): if iteration % 10 == 0: print( datetime.now(), 'イテレーション%sの計算を開始...' % iteration) self._assign_points_to_cluster() previous_clusters: List[Cluster] = deepcopy(self._clusters) self._update_cluster_centroid() if self._clusters == previous_clusters: print('クラスターが変動しなくなったため処理を停止します。') break clusters_history.append(deepcopy(self._clusters)) return clusters_history可視化用のメソッドの追加
今回はX座標とY座標の2次元空間なので可視化が容易にできるのでそのためのメソッドを追加していきます。
。
元々の座標と各イテレーションでのクラスター群の可視化の2つのメソッドを追加します。各クラスターの方ではクラスターごとの所属座標を色を分けて、且つクラスターの中心(重心)点を★でプロットしています(
marker='*'の指定で★の表示になります)。def plot_original_points(self) -> None: """ 標準化前の各座標のプロットを行う。 Parameters ---------- points : list of Point 各座標を格納したリスト。 """ x_list = [point.x for point in self._original_points] y_list = [point.y for point in self._original_points] plt.figure(figsize=(6, 6)) plt.scatter(x_list, y_list) def plot_clusters(self, clusters: List[Cluster]) -> None: """ 各クラスターの中心座標と属している各座標のプロットを行う。 Parameters ---------- clusters : list of Cluster プロット対象のクラスターのリスト。 """ plt.figure(figsize=(6, 6)) for cluster in clusters: x_list: List[float] = [point.x for point in cluster.points] y_list: List[float] = [point.y for point in cluster.points] plt.scatter(x_list, y_list) centroid_x: float = cluster.centroid.x centroid_y: float = cluster.centroid.y plt.scatter([centroid_x], [centroid_y], marker='*', s=200)ランダムな座標を生成するヘルパーを追加
アルゴリズムを動かすために、ランダムな座標を生成・リストに追加する関数を追加しておきます。
def _append_random_point_to_list( num: int, x_min: float, x_max: float, y_min: float, y_max: float, points: List[Point]) -> None: """ 座標のリストへ、指定された件数分ランダムに生成された座標を 追加する。 Parameters ---------- num : int リストに追加する座標数。 x_min : float ランダムな座標範囲のX座標の最小値。 x_max : float ランダムな座標範囲のX座標の最大値。 y_min : float ランダムな座標範囲のY座標の最小値。 y_max : float ランダムな座標範囲のY座標の最大値。 points : list of Point 追加先となるリスト。 """ for _ in range(num): random_x = random.uniform(a=x_min, b=x_max) random_y = random.uniform(a=y_min, b=y_max) point: point = Point(x=random_x, y=random_y) points.append(point)アルゴリズムを動かす
諸々の準備ができたのでアルゴリズムを動かしていきます。
今回はある程度ランダムな範囲を被らせつつ、3つの設定で初期座標を生成しました。
points: List[Point] = [] _append_random_point_to_list( num=50, x_min=0, x_max=400, y_min=0, y_max=500, points=points) _append_random_point_to_list( num=100, x_min=200, x_max=400, y_min=300, y_max=500, points=points) _append_random_point_to_list( num=70, x_min=300, x_max=500, y_min=400, y_max=700, points=points) kmeans = KMeans(k=3, points=points) clusters_history: List[List[Cluster]] = kmeans.run_algorithm()2020-11-07 16:02:58.607707 イテレーション0の計算を開始... 2020-11-07 16:02:58.660701 イテレーション10の計算を開始... 2020-11-07 16:02:58.723702 イテレーション20の計算を開始... 2020-11-07 16:02:58.772699 イテレーション30の計算を開始... 2020-11-07 16:02:58.826700 イテレーション40の計算を開始... 2020-11-07 16:02:58.875700 イテレーション50の計算を開始... 2020-11-07 16:02:58.922701 イテレーション60の計算を開始... 2020-11-07 16:02:58.968699 イテレーション70の計算を開始... 2020-11-07 16:02:59.017699 イテレーション80の計算を開始... 2020-11-07 16:02:59.068731 イテレーション90の計算を開始...可視化してみる
まずは元のランダムな座標(_append_random_point_to_list関数で生成された座標)をプロットしてみます。
kmeans.plot_original_points()
続いて各イテレーションでのアルゴリズム反映後のものを見ていきます。イテレーション数が少ない段階だとまだ微妙な感じのクラスタリングになります。また、軸の値も標準化された後の値になります。
イテレーション : 0
kmeans.plot_clusters(clusters=clusters_history[0])
イテレーション : 1
kmeans.plot_clusters(clusters=clusters_history[1])
イテレーション : 2
kmeans.plot_clusters(clusters=clusters_history[2])
最後のイテレーション(イテレーション99)
kmeans.plot_clusters( clusters=clusters_history[len(clusters_history) - 1])
それっぽく動いていそうです。無事クラスタリングを行うことができました。
コード全体
from __future__ import annotations from typing import List from math import sqrt from copy import deepcopy from statistics import pstdev, mean import random from datetime import datetime import matplotlib.pyplot as plt import matplotlib matplotlib.style.use('ggplot') %matplotlib inline class Point: def __init__(self, x: float, y: float) -> None: """ 特定の2次元空間の座標単体を扱うクラス。matplotlibに合わせて、 左下を(0, 0)とし、右上にいくごとにインクリメントする形の座標 空間で扱う。 Parameters ---------- x : float X座標。 y : float Y座標。 """ self.x: float = x self.y: float = y def distance(self, other_point: Point) -> float: """ 引数に指定された座標間のユークリッド距離を取得する。 Parameters ---------- other_point : Point 対象の座標。 Returns ------- distance_val : float 算出された2つの座標間のユークリッド距離の値。 """ x1: float = self.x x2: float = other_point.x y1: float = self.y y2: float = other_point.y distance_val: float = sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2) return distance_val def __eq__(self, other: object) -> bool: """ 他のPointのインスタンスと等値かどうかの比較を行う。 Parameters ---------- other : object 比較対象のインスタンス。もしPoint関係のインスタンスではない 場合には比較処理はスキップされる。 Returns ------- is_equal : bool 等値かどうかの真偽値。座標の比較で処理される。 """ if not isinstance(other, Point): return NotImplemented is_equal: bool = self.x == other.x and self.y == other.y return is_equal class Cluster: def __init__(self, centroid: Point, points: List[Point]): """ 1つ分のクラスターを扱うためのクラス。 Parameters ---------- centroid : Point クラスターの中央位置となる座標情報。 points : list of Point 対象のクラスターに属している座標のリスト。 """ self.centroid = centroid self.points = points class KMeans: def __init__(self, k: int, points: List[Point]) -> None: """ KMeansのアルゴリズム制御用のクラス。 Parameters ---------- k : int 設定するクラスター数。 points : list of Point 対象とする座標のリスト。 """ self._original_points = points self._k = k self._standardized_points: List[Point] = self._get_standardized_points() self._initialize_clusters() def _get_standardized_points(self) -> List[Point]: """ 標準化された座標のリストを取得する。 Notes ----- 標準化にはz-scoreの計算が使われる。 Returns ------- standardized_points : list of Point 標準化後の各座標を格納したリスト。 """ standardized_points: List[Point] = deepcopy(self._original_points) self._standardize_x(points=standardized_points) self._standardize_y(points=standardized_points) return standardized_points def _standardize_x(self, points: List[Point]) -> None: """ 指定された座標のリストのX座標の標準化を行う。 Parameters ---------- points : list of Point 変換対象の座標のリスト。 """ x_list: List[float] = [point.x for point in points] x_list = self._apply_z_score(list_val=x_list) for i, point in enumerate(points): point.x = x_list[i] def _standardize_y(self, points: List[Point]) -> None: """ 指定された座標のリストのY座標の標準化を行う。 Parameters ---------- points : list of Point 変換対象の座標のリスト。 """ y_list: List[float] = [point.y for point in points] y_list = self._apply_z_score(list_val=y_list) for i, point in enumerate(points): point.y = y_list[i] def _apply_z_score(self, list_val: List[float]) -> List[float]: """ 指定された座標値を格納したリストにz-scoreの標準化を反映する。 Parameters ---------- list_val : list of float 座標値を格納したリスト。 Returns ------- list_val : list of float z-score反映後の座標値のリスト。 """ mean_val: float = mean(list_val) std_val: float = pstdev(list_val) for i, coordinate in enumerate(list_val): standardized_val: float = (coordinate - mean_val) / std_val list_val[i] = standardized_val return list_val def _initialize_clusters(self) -> None: """ クラスターの初期化を行う。クラスター中心点(centroid)は ランダムな位置が設定され、属する座標点は空の状態でリストが 生成される。 """ self._clusters: List[Cluster] = [] for _ in range(self._k): random_point: Point = self._get_standardized_random_point() cluster: Cluster = Cluster( centroid=random_point, points=[]) self._clusters.append(cluster) def _get_standardized_random_point(self) -> Point: """ ランダムな座標点を生成・取得する。 Returns ------- random_point : Point 生成された座標点。 """ x_min: float = self._get_standardized_x_min() x_max: float = self._get_standardized_x_max() y_min: float = self._get_standardized_y_min() y_max: float = self._get_standardized_y_max() random_x: float = random.uniform(a=x_min, b=x_max) random_y: float = random.uniform(a=y_min, b=y_max) random_point: Point = Point(x=random_x, y=random_y) return random_point def _get_standardized_x_max(self) -> float: """ 標準化された座標値の中でのX座標の最大値を取得する。 Returns ------- x_max : float X座標の最大値。 """ x_list: List[float] = self._get_standardized_x_list() x_max: float = max(x_list) return x_max def _get_standardized_x_min(self) -> float: """ 標準化された座標値の中でのX座標の最小値を取得する。 Parameters ---------- x_min : float X座標の最小値。 """ x_list: List[float] = self._get_standardized_x_list() x_min: float = min(x_list) return x_min def _get_standardized_x_list(self) -> List[float]: """ 存在する標準化された座標値(クラスターの中心座標を除く)のX座標の リストを取得する。 Returns ------- x_list : list of float X座標のリスト。 """ x_list: List[float] = [point.x for point in self._standardized_points] return x_list def _get_standardized_y_max(self) -> float: """ 標準化された座標値の中でのY座標の最大値を取得する。 Returns ------- y_max : float Y座標の最大値。 """ y_list: List[float] = self._get_standardized_y_list() y_max: float = max(y_list) return y_max def _get_standardized_y_min(self) -> float: """ 標準化された座標値の中でのY座標の最小値を取得する。 Returns ------- y_min : float Y座標の最小値。 """ y_list: List[float] = self._get_standardized_y_list() y_min: float = min(y_list) return y_min def _get_standardized_y_list(self) -> List[float]: """ 存在する標準化された座標値(クラスターの中心座標を除く)のY座標の リストを取得する。 Returns ------- y_list : list of float Y座標のリスト。 """ y_list: List[float] = [point.y for point in self._standardized_points] return y_list def _assign_points_to_cluster(self) -> None: """ 各座標を一番近いクラスターへ割り当てる(クラスターの座標のリストへ 各座標を追加する)。 Notes ----- 実行時点での割り当てられている座標は最初にリセットされる。 """ self._reset_clusters_assignment() for standardized_point in self._standardized_points: nearest_cluster: Cluster = self._get_target_point_nearest_cluster( standardized_point=standardized_point) nearest_cluster.points.append(standardized_point) def _reset_clusters_assignment(self) -> None: """ 各クラスターへの座標の割り当てをリセット(空に)する。 """ for cluster in self._clusters: cluster.points.clear() def _get_target_point_nearest_cluster( self, standardized_point: Point) -> Cluster: """ 対象の座標に対して一番近いクラスターを取得する。 Parameters ---------- standardized_point : Point 対象の標準化された座標。 Returns ------- nearest_cluster : Cluster 対象の座標に一番近いクラスター。 """ min_distance: float = self._clusters[0].centroid.distance( other_point=standardized_point) nearest_cluster: Cluster = self._clusters[0] for cluster in self._clusters: distance: float = cluster.centroid.distance( other_point=standardized_point) if distance >= min_distance: continue min_distance = distance nearest_cluster = cluster return nearest_cluster def _update_cluster_centroid(self) -> None: """ クラスターに属している座標のリストを参照して、各クラスターの 中央座標(各座標の平均値)を更新する。 """ for cluster in self._clusters: if not cluster.points: continue x_list: List[float] = [point.x for point in cluster.points] y_list: List[float] = [point.y for point in cluster.points] mean_x: float = mean(x_list) mean_y: float = mean(y_list) cluster.centroid.x = mean_x cluster.centroid.y = mean_y def run_algorithm(self, max_iterations: int=100) -> List[List[Cluster]]: """ k-meansのアルゴリズムを実行する。 Parameters ---------- max_iterations : int イテレーションの最大数。 Returns ------- clusters_history : list of list 各イテレーションにおける、クラスター群を格納する多次元のリスト。 1次元目は各イテレーション、2次元目はそのイテレーションにおける 一通りのクラスターを格納する。 """ clusters_history: List[List[Cluster]] = [] for iteration in range(max_iterations): if iteration % 10 == 0: print( datetime.now(), 'イテレーション%sの計算を開始...' % iteration) self._assign_points_to_cluster() previous_clusters: List[Cluster] = deepcopy(self._clusters) self._update_cluster_centroid() if self._clusters == previous_clusters: print('クラスターが変動しなくなったため処理を停止します。') break clusters_history.append(deepcopy(self._clusters)) return clusters_history def plot_original_points(self) -> None: """ 標準化前の各座標のプロットを行う。 Parameters ---------- points : list of Point 各座標を格納したリスト。 """ x_list = [point.x for point in self._original_points] y_list = [point.y for point in self._original_points] plt.figure(figsize=(6, 6)) plt.scatter(x_list, y_list) def plot_clusters(self, clusters: List[Cluster]) -> None: """ 各クラスターの中心座標と属している各座標のプロットを行う。 Parameters ---------- clusters : list of Cluster プロット対象のクラスターのリスト。 """ plt.figure(figsize=(6, 6)) for cluster in clusters: x_list: List[float] = [point.x for point in cluster.points] y_list: List[float] = [point.y for point in cluster.points] plt.scatter(x_list, y_list) centroid_x: float = cluster.centroid.x centroid_y: float = cluster.centroid.y plt.scatter([centroid_x], [centroid_y], marker='*', s=200) def _append_random_point_to_list( num: int, x_min: float, x_max: float, y_min: float, y_max: float, points: List[Point]) -> None: """ 座標のリストへ、指定された件数分ランダムに生成された座標を 追加する。 Parameters ---------- num : int リストに追加する座標数。 x_min : float ランダムな座標範囲のX座標の最小値。 x_max : float ランダムな座標範囲のX座標の最大値。 y_min : float ランダムな座標範囲のY座標の最小値。 y_max : float ランダムな座標範囲のY座標の最大値。 points : list of Point 追加先となるリスト。 """ for _ in range(num): random_x = random.uniform(a=x_min, b=x_max) random_y = random.uniform(a=y_min, b=y_max) point: point = Point(x=random_x, y=random_y) points.append(point) points: List[Point] = [] _append_random_point_to_list( num=50, x_min=0, x_max=400, y_min=0, y_max=500, points=points) _append_random_point_to_list( num=100, x_min=200, x_max=400, y_min=300, y_max=500, points=points) _append_random_point_to_list( num=70, x_min=300, x_max=500, y_min=400, y_max=700, points=points) kmeans = KMeans(k=3, points=points) clusters_history: List[List[Cluster]] = kmeans.run_algorithm() kmeans.plot_original_points() kmeans.plot_clusters(clusters=clusters_history[0]) kmeans.plot_clusters(clusters=clusters_history[1]) kmeans.plot_clusters(clusters=clusters_history[2])参考サイト・参考文献
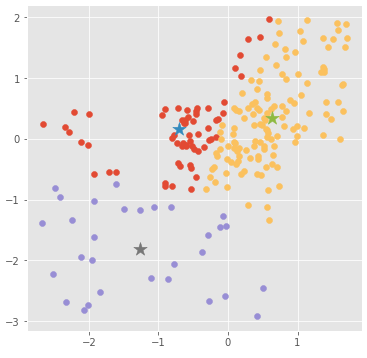

- 投稿日:2020-11-08T16:20:31+09:00
かなの手書き文字認識を作ってみた Part 2/3 データの作成と学習
概要
前回 (1/3): https://qiita.com/tfull_tf/items/6015bee4af7d48176736
次回 (3/3):コード: https://github.com/tfull/character_recognition
かな認識システムの作成において、まずは CNNを使ったモデルを構築して MNIST でどのくらいの精度が出るかを確かめました。次に、かなの画像データを用意して同じようにモデルを構築し、モデルを改良していきます。
データの作成
かなの画像データというと特に思いつくものがないので、自動で作ってしまいます。一応、公開されているデータセットもあるようです。
自動生成するために、 ImageMagick を使います。 convert コマンドで画像に文字を入れられるので、真っ黒の画像をまず作成し、それに白い文字を1つだけ書く、という手順で作成します。
データ増殖手法
一文字について複数の画像を用意するために、データを増やす方法を用意しました。
1: フォントを複数用いる
違うフォントで書けば、同じ文字でもフォントの種類数だけ異なる画像が生成できます。
次のコマンドでフォントが見れるので、使えそうなやつをピックアップします。
convert -list font気をつけないといけないのは、全てが日本語に対応しているわけではないので、かなを出力しようとしても何も書き出されないケースがあります。
メインで作業していた Mac OS 10.15 には良さそうなフォントが無かったため、 Ubuntu で画像を生成しました。次のようなフォントが最初から入っていたので、これらを使うことにしました。
font_list = [ "Noto-Sans-CJK-JP-Thin", "Noto-Sans-CJK-JP-Medium", "Noto-Serif-CJK-JP" ]2: 文字の大きさを変える
画面に目一杯の文字を書くか、ちょっと控えめに書くかでも、異なる画像を生成できます。今回は、約半分のサイズから目一杯ちょっと下のサイズまで、少しずつ大きくしながら文字を書きました。
3: 文字をずらす
小さめの文字を書いた場合、空白が上下左右にできますので、縦方向と横方向それぞれに、文字をずらすという手法が使えます。例えば、空白 / 2 と 空白 / 3 をずらすことを上下左右に考えれば、 5 x 5 通りの画像が生成できます。
4: 文字を回転させる
convert では文字を回転させることができます。時計回り、反時計回りに少し回転させることで、画像を増やすことができます。
(未使用) ぼかしを入れる
ぼかしを入れた画像を用意することで画像が増やせますが、画像の半分がボケた画像というのはどうなんだ?と思ったため、やりませんでした。1~4で十分な画像数が確保できています。
(未使用) ノイズを入れる
画像に小さい点などのノイズを入れることで、単純に画像が増えるだけでなく、ノイズに強くなる可能性は考えられます。いい感じのノイズを入れる簡単な手法が見つからないためやりませんでしたが、今後の課題としても良いかもしれません。
結果
1~4の組み合わせ(掛け算)で文字入りの画像を生成します。縦横 256px で作成し、一文字につき、4000枚以上の画像が得られました。手法に使う種々のパラメーターを弄れば、枚数は変化させることができます。ひらがな (0x3041 ~ 0x3093) とカタカナ (0x30A1 ~ 0x30F6) で 169 種類あるため、結構な容量になります。
コード
data_directory = "/path/to/data" image_size = 256 # 真っ黒な画像作成 def make_template(): res = subprocess.call([ "convert", "-size", "{s}x{s}".format(s = image_size), "xc:black", "{}/tmp.png".format(data_directory) ]) # 白文字の画像を作成 def generate(path, font, pointsize, character, rotation, dx, dy): res = subprocess.call([ "convert", "-gravity", "Center", "-font", font, "-pointsize", str(pointsize), "-fill", "White", "-annotate", format_t(rotation, dx, dy), character, "{}/tmp.png".format(data_directory), path ]) # 移動フォーマットの関数 def format_t(rotation, x, y): xstr = "+" + str(x) if x >= 0 else str(x) ystr = "+" + str(y) if y >= 0 else str(y) return "{r}x{r}{x}{y}".format(r = rotation, x = xstr, y = ystr)最初の1回だけ真っ黒な画像を作成し、ループで font, pointsize, character, rotation, dx, dy のパラメーターを変えながら白文字の画像を作成していきます。
モデル構築
画像ができたので、 MNIST と同様にモデル構築をしていくわけですが、最初からうまくは行きませんでした。毎バッチで Cross Entropy 誤差の値が同じになっており、デバッグとして学習させるときの層の中の値を観察していると、絶対値が数百、数千といった大きな値が入っており、出力が常に同じようになっていました。そういうわけで Batch Normalization を挿入して、精度を大きく向上させることができました。
import torch.nn as nn class Model(nn.Module): def __init__(self, image_size, output): super(Model, self).__init__() n = ((image_size - 4) // 2 - 4) // 2 self.conv1 = nn.Conv2d(1, 4, 5) self.relu1 = nn.ReLU() self.normal1 = nn.BatchNorm2d(4) self.pool1 = nn.MaxPool2d(2, 2) self.dropout1 = nn.Dropout2d(0.3) self.conv2 = nn.Conv2d(4, 16, 5) self.relu2 = nn.ReLU() self.normal2 = nn.BatchNorm2d(16) self.pool2 = nn.MaxPool2d(2, 2) self.dropout2 = nn.Dropout2d(0.3) self.flatten = nn.Flatten() self.linear1 = nn.Linear(n * n * 16, 1024) self.relu3 = nn.ReLU() self.normal3 = nn.BatchNorm1d(1024) self.dropout3 = nn.Dropout(0.3) self.linear2 = nn.Linear(1024, 256) self.relu4 = nn.ReLU() self.normal4 = nn.BatchNorm1d(256) self.dropout4 = nn.Dropout(0.3) self.linear3 = nn.Linear(256, output) self.softmax = nn.Softmax(dim = 1) def forward(self, x): x = self.conv1(x) x = self.relu1(x) x = self.normal1(x) x = self.pool1(x) x = self.dropout1(x) x = self.conv2(x) x = self.relu2(x) x = self.normal2(x) x = self.pool2(x) x = self.dropout2(x) x = self.flatten(x) x = self.linear1(x) x = self.relu3(x) x = self.normal3(x) x = self.dropout3(x) x = self.linear2(x) x = self.relu4(x) x = self.normal4(x) x = self.dropout4(x) x = self.linear3(x) x = self.softmax(x) return x学習
基本的に MNIST でやったのと同じような手順で学習させていきます。 Cross Entropy Loss, Adam (learning rate = 0.001) を使いました。
学習時に気をつけた点
ループでパラメータを変えながら画像を生成したため、順番通りに学習させるとデータが偏りそうなので避けます。また、それぞれの文字を満遍なく学習させたいため、こちらは順番に並べて学習させたいと思います。
ループで画像を読みながら学習させると、1バッチで1枚の学習になってしまいます。とはいえ、画像データが沢山あるので、全部を一度に読み込むとメモリが足りなくなる可能性があります。その両方を避けるために、 yield を使って chunk 枚数ずつデータを読むことにしました。
# a1, a2 の2重ループを chunk 個数ずつ取得 def double_range(a1, a2, chunk = 100): records = [] for x1 in a1: for x2 in a2: records.append((x1, x2)) if len(records) >= chunk: yield records records = [] if len(records) > 0: yield records配列を2つ与えて、二重ループで得られる組を chunk の数ずつ返す関数です。これをさらに for に与えます。
擬似コードfor indices in double_range("1~Nまでのシャッフルされた画像番号", "文字に割り振った番号 (0~168)"): inputs = [] for i_character, i_image in indices: inputs.append("i_character 番目の文字の i_image 枚目の画像を読み込み") model.train(inputs) # 学習これで、バッチサイズの分だけ画像を読み出して学習させるループを行うことで、メモリ使用を抑えられます。
モデルの性能
4236 [枚/文字] ✕ 169 [文字] の画像データを作成してから実験に取り組みました。全体の 5%をテストデータとし、エポック数2で学習させてテストデータの正答率を測ったところ、約 71.4% でした。最初プログラムを間違えて169択ではなく4236択にしていたのですが、そのときは 80% くらい出ていたのが謎です。もう少し性能を良くしたいですが、とりあえず認識システムを作って動かしてみるくらいはできそうです。
- 投稿日:2020-11-08T16:09:52+09:00
Pythonによる人工知能入門2 「遺伝的アルゴリズム~実践編~」
やってみよう
さあ、Pythonを使って実際にGAというものを動かしてみよう。ここでは、Pythonの基礎知識はすでにあるものとして進めていく。関数は使用するが、説明が混沌となるのでクラスは使わないでおく。
ONEMAX問題
具体的に何をするのか。
よくある例として、ONEMAX問題が取り上げられる。これは、
{1,0,0,1,0,1,1,1,0,0}
のように、「1」か「0」で構成された配列から、
{1,1,1,1,1,1,1,1,1,1}
というすべて1の配列をどのように作り出すか、というものを考えたものである。
これをGAで解決する。流れとしては、「1」か「0」を要素に持った配列をランダムに生成して、これを遺伝子情報とし、配列の合計値を評価基準として、アルゴリズムを組むのだ。まずは全体のコードを示す。
コード
GA.pyimport random from decimal import Decimal GENOM_LENGTH = 20 # 遺伝子情報の長さ MAX_GENOM_LIST = 200 #遺伝子集団の大きさ SELECT_GENOM = 10 #エリート遺伝子選択数 INDIVIDUAL_MUTATION = 0.01 #個体突然変異確率 GENOM_MUTATION = 0.01 #遺伝子突然変異確率 MAX_GENERATION = 20 #繰り返す世代数 def genom(length): """ 遺伝子をランダムに生成する。 戻り値は、一個体の遺伝子配列 """ genom_list = [] for i in range(length): a = random.randint(0,1) genom_list.append(a) return genom_list def evaluation(ga): """ 個体の評価関数。 引数で得られた遺伝子配列から、その合計値を評価値として返している。 """ genom_total = sum(ga) genom_num = len(ga) return Decimal(genom_total) / Decimal(genom_num) def select_elite(ga,elite_length): """ 優秀な個体を取り出す関数。 """ sort_result = sorted(ga, reverse=True, key=evaluation) result = [sort_result.pop(0) for i in range(elite_length)] return result def crossover(ga_one,ga_second): """ 交叉関数。 引数で与えられた2個体の親から、2個体の子を返している。 ここでは、二点交叉で遺伝させている。 """ genom_list = [] cross_one = random.randint(0,GENOM_LENGTH) cross_second = random.randint(cross_one,GENOM_LENGTH) one = ga_one second = ga_second progeny_one = one[:cross_one] + second[cross_one:cross_second] + one[cross_second:] progeny_second = second[:cross_one] + one[cross_one:cross_second] + second[cross_second:] genom_list.append(progeny_one) genom_list.append(progeny_second) return genom_list def create_next_generation(ga,ga_elite,ga_progeny): """ 次の世代の集団を生成する。 第一引数で前世代の集団を取得し、 第2、3引数のエリートと子供を加えて、その分優秀でない個体を取り除いている。 """ next_generation_geno = sorted(ga, reverse = False, key = evaluation) for i in range(0, len(ga_elite) + len(ga_progeny)): next_generation_geno.pop(0) next_generation_geno.extend(ga_elite) next_generation_geno.extend(ga_progeny) return next_generation_geno def mutation(ga, individual_mutation, genom_mutation): """ 突然変異を行う。 一定確率で個体が突然変異するか選別し、 引っかかった個体の遺伝子配列要素をまた確率で選別し、 引っかかった要素を1か0に改変する。 """ ga_list = [] for i in ga: if individual_mutation > (random.randint(0,100) / Decimal(100)): genom_list = [] for i_ in i: if genom_mutation > (random.randint(0,100)/Decimal(100)): genom_list.append(random.randint(0,1)) else: genom_list.append(i_) ga_list.append(genom_list) else: ga_list.append(i) return ga_list if __name__ == '__main__': current_generation = [] for i in range(MAX_GENOM_LIST): current_generation.append(genom(GENOM_LENGTH)) for count_ in range(1,MAX_GENERATION + 1): current_evaluation = [] for i in range(MAX_GENOM_LIST): evaluation_result = evaluation(current_generation[i]) current_evaluation.append(evaluation_result) elite_genes = select_elite(current_generation,SELECT_GENOM) progeny_gene = [] for i in range(0,SELECT_GENOM): progeny_gene.extend(crossover(elite_genes[i-1],elite_genes[i])) next_generation = create_next_generation(current_generation,elite_genes,progeny_gene) next_generation = mutation(next_generation,INDIVIDUAL_MUTATION,GENOM_MUTATION) fits = [] j = 0 for i in current_generation: fits.append(current_evaluation[j]) j = j + 1 min_ = min(fits) max_ = max(fits) avg_ = sum(fits) / Decimal(len(fits)) print ("-----------第{}世代----------".format(count_)) print (" Min:{}".format(min_)) print (" Max:{}".format(max_)) print (" avg:{}".format(avg_)) print("\n") current_generation = next_generation print ("最も優れた個体は、{}".format(elite_genes[0]))概略
前回の記事、理論編で示した通りの手順で行っている。
このプログラムでは、1世代あたりの個体数は 200、
一個体あたりの遺伝子配列の長さは 20、
繰り返す世代数は 20、
突然変異確率は、二種とも 1%、
エリートの選択数は 20、という値で動かしている。もちろんこの値は自由に決める。
基本的に、世代数を多くすればするほど良い個体が出てくるし、遺伝子配列の長さが大きいほど、最適解への収束速度は遅くなるため、世代数、集合の大きさを大きくする必要がある。そしてこれを実行すると、
-----------第20世代---------- Min:0.9 Max:1 avg:0.96875 最も優れた個体は、[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]のように出力され、見事ONEMAX問題を解いた!!
(最後の数行のみ記載。)これがGAの力だ!!
課題
さて、これでGAがどういったものか、そしてその力を理解できたことだろう。そこで、この記事を用いて学習してくださってる方に課題を出してみようと思う。
⑴上のコードから突然変異の処理を除いたものを作成し実行せよ。またその結果を考察せよ。
⑵最適解を、
{1,0,1,0,1,0,1,0,..........0,1}
のように、「1」と「0」が交互に並ぶような個体であるとしてGAを組め。以上である。
まとめ
AIというものはものすごく難解でとっかかりにくいといったイメージがあるそうだ。しかし意外にも、その基礎はおもしろくかつイメージしやすい。この記事で、AIの片鱗を見ることができただろう。あとは君たちのアイデアを導入するだけだ。
また次で会おう。
読んでくれてありがとう。
- 投稿日:2020-11-08T15:03:05+09:00
入力した文章から特定の文字をぬかすプログラム
どうも 山田長政です。
文章からある文字を抜けないか、試してみました。
使ったエディタ
googleColaboratory
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja#scrollTo=bXqBzduB4o0dプログラム
g =input() p=input() h=g.split(sep=p) b="".join(h) print(b)最初のインプットには文章を、もうひとつには抜かしたい言葉を入力します
splitが文字列をある文字で分割しリストに入れるときに
ある文字が消える性質を利用してます