- 投稿日:2020-11-08T23:47:32+09:00
【AWS】EC2インスタンス(ターゲットグループ)のヘルスチェックにどうしても失敗する。。
現在個人開発しているRailsアプリがやっと完成し、AWSへのデプロイ作業にチャレンジしました。(ECR × ECS × CircleCIを利用し、gitからmasterブランチへpushするとCIがビルドされ、テストが通ると自動デプロイされるといった感じの構成です)
その際、EC2インスタンスへのヘルスチェックが通らずに困り果ててしまったので、ついにプログラミング独学勢?の切り札であるMENTAを利用しました。
そしたら1~2週間程悩んでいた問題が開始わずか10分ほどで解決してしまい、あっけなく終わってしまいました。。調べてもこの解決方法はなかなか見当たらなかった(多分僕の探し方の問題)ので、僕と同じように膨大な時間を無駄にしないためにも、ここに備忘録として残そうと思います!
今回相談させていただいたメンタ―さん
ルビコン@クラウド(AWS)エンジニアさん
ルビコンさんのTwitter単発の利用だったにもかかわらず、本題とは関係ない質問にも親切丁寧に教えてくださりました。(しかも15分ぐらいお時間サービスしていただきました。)
この記事でもどうにもならない場合、是非一度相談してみてください!僕もまた困ったら是非利用したいと思える方でした
そもそもヘルスチェックとは?
ヘルスチェックは、特定のサーバー上のサービスに、作業を正常に実行できるかどうかを確認する方法です。 ロードバランサーは、各サーバーにこの質問を定期的に行い、トラフィックを転送しても安全なサーバーを判断します。
イメージ的には、定期的にロードバランサ―からターゲットグループ(EC2インスタンス)にリクエストを送り返ってきたHTTPステータスを確認しているといった感じです。
このヘルスチェックが失敗してしまうせいでタスクが強制終了してしまい、また新しいタスクが起動するといったことを20分毎ぐらいのペースで繰り返していました。(
health checks failed with these codes: [301]というエラーが出てました)
そのせいで、アクセスするタイミングによってページが表示されたり、50xエラーが返ってきたりしているといった状況でした。解決方法
結論から言いますと、ターゲットグループの設定でHTTPステータスコードの301を許可したら治りました。
上記にも述べました通り、
health checks failed with these codes: [301]というのはページがリダイレクトされたということを意味します。なぜリダイレクトされるかというと、Railsアプリの設定で以下のような設定をしていたためです。production.rbconfig.force_ssl = trueSSL化をしていたので、httpからhttpsにリダイレクトさせる設定をしていました。
ですので、ヘルスチェックを行ったときにHTTPステータスコードで301が返ってきて当然です。しかし、ターゲットグループの設定では200しか許可されていないので、unhealthyとなってしまいタスクが終了してしまうのです。
設定方法
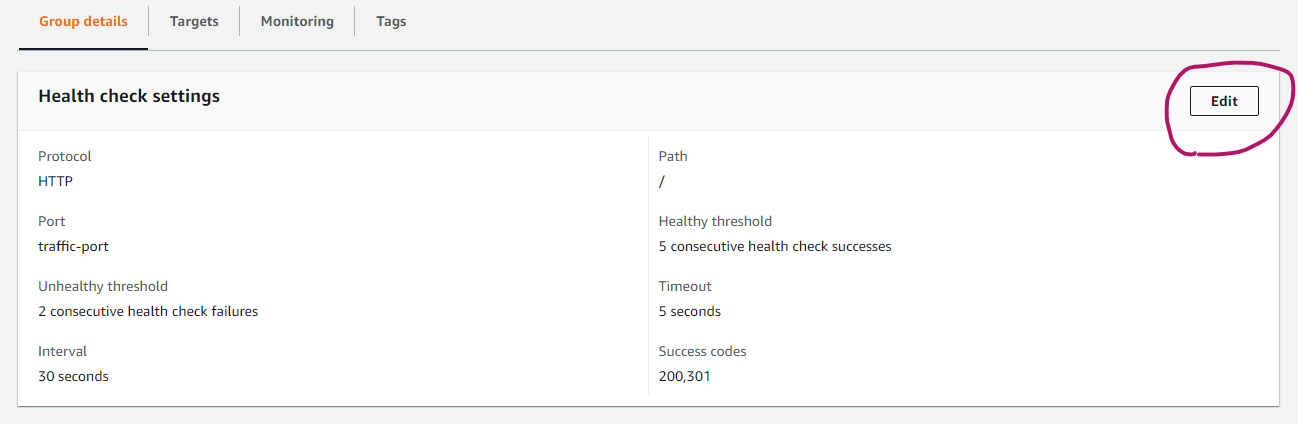
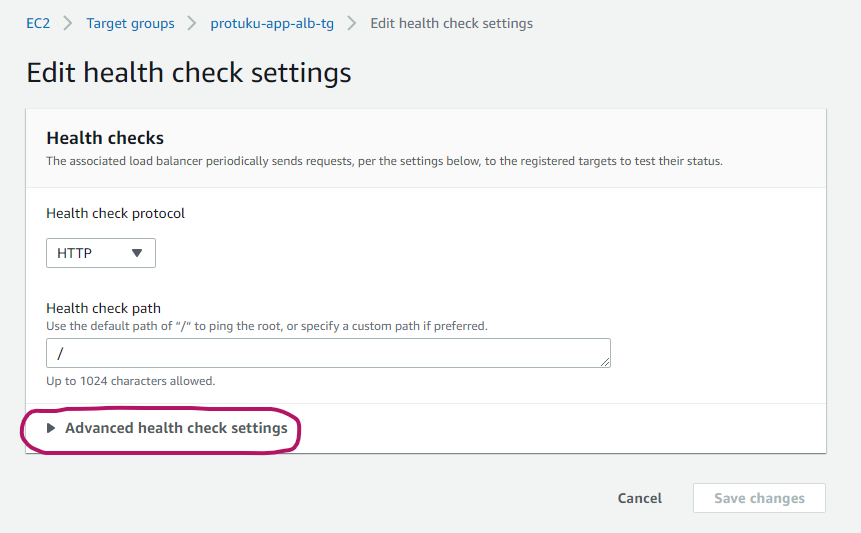
まず、サービスからEC2を選択し、ターゲットグループをクリックします。すると以下のような画面が出てくるので、そこにあるGroup detailsタブのEditをクリックします。
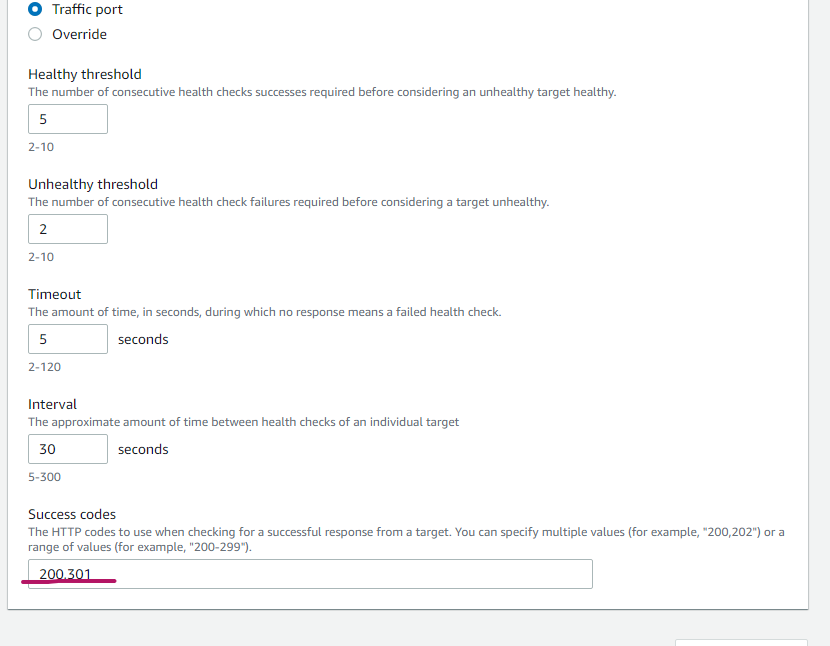
次に赤丸の部分をクリックします。
Success codesに200と書いてあると思いますので、ここに301を追加して許可します。(カンマで区切って記述してください!)
記述したら変更を保存して終了です。
これで数分すればhealthyに変わるはずです!(ALBやセキュリティグループなどの設定が正しくできていれば)
これでもヘルスチェックに失敗する場合はセキュリティグループやALBの設定、ヘルスチェックの猶予時間などの設定に問題がある能性がありますので、見直してみてください!
それでも解決しない場合、是非ルビコン@クラウド(AWS)エンジニアさんに相談してみてください

最後まで読んでいただきありがとうございます!
日々学んだことをアウトプットしております!!ご指摘などございましたらコメントいただけますと幸いです。

- 投稿日:2020-11-08T23:47:32+09:00
【AWS】ALBでEC2インスタンス(ターゲットグループ)のヘルスチェックにどうしても失敗する。。
現在個人開発しているRailsアプリがやっと完成し、AWSへのデプロイ作業にチャレンジしました。(ECR × ECS × CircleCIを利用し、gitからmasterブランチへpushするとCIがビルドされ、テストが通ると自動デプロイされるといった感じの構成です)
その際、EC2インスタンスへのヘルスチェックが通らずに困り果ててしまったので、ついにプログラミング独学勢?の切り札であるMENTAを利用しました。
そしたら1~2週間程悩んでいた問題が開始わずか10分ほどで解決してしまい、あっけなく終わってしまいました。。調べてもこの解決方法はなかなか見当たらなかった(多分僕の探し方の問題)ので、僕と同じように膨大な時間を無駄にしないためにも、ここに備忘録として残そうと思います!
今回相談させていただいたメンタ―さん
ルビコン@クラウド(AWS)エンジニアさん
ルビコンさんのTwitter単発の利用だったにもかかわらず、本題とは関係ない質問にも親切丁寧に教えてくださりました。(しかも15分ぐらいお時間サービスしていただきました。)
この記事でもどうにもならない場合、是非一度相談してみてください!僕もまた困ったら是非利用したいと思える方でしたそもそもヘルスチェックとは?
ヘルスチェックは、特定のサーバー上のサービスに、作業を正常に実行できるかどうかを確認する方法です。 ロードバランサーは、各サーバーにこの質問を定期的に行い、トラフィックを転送しても安全なサーバーを判断します。
イメージ的には、定期的にALB(ロードバランサ)―からターゲットグループ(EC2インスタンス)にリクエストを送り、返ってきたHTTPステータスを確認しているといった感じです。
このヘルスチェックが失敗してしまうせいでタスクが強制終了してしまい、また新しいタスクが起動するといったことを20分毎ぐらいのペースで繰り返していました。(
health checks failed with these codes: [301]というエラーが出てました)
そのせいで、アクセスするタイミングによってページが表示されたり、50xエラーが返ってきたりしているといった状況でした。解決方法
結論から言いますと、ターゲットグループの設定でHTTPステータスコードの301を許可したら治りました。
上記にも述べました通り、
health checks failed with these codes: [301]というのはページがリダイレクトされたということを意味します。なぜリダイレクトされるかというと、Railsアプリの設定で以下のような設定をしていたためです。production.rbconfig.force_ssl = trueSSL化をしていたので、httpからhttpsにリダイレクトさせる設定をしていました。
ですので、ヘルスチェックを行ったときにHTTPステータスコードで301が返ってきて当然です。しかし、ターゲットグループの設定では200しか許可されていないので、unhealthyとなってしまいタスクが終了してしまうのです。
設定方法
まず、サービスからEC2を選択し、ターゲットグループをクリックします。すると以下のような画面が出てくるので、そこにあるGroup detailsタブのEditをクリックします。
次に赤丸の部分をクリックします。
Success codesに200と書いてあると思いますので、ここに301を追加して許可します。(カンマで区切って記述してください!)
記述したら変更を保存して終了です。
これで数分すればhealthyに変わるはずです!(ALBやセキュリティグループなどの設定が正しくできていれば)
これでもヘルスチェックに失敗する場合はセキュリティグループやALBの設定、ヘルスチェックの猶予時間などの設定に問題がある能性がありますので、見直してみてください!
それでも解決しない場合、是非ルビコン@クラウド(AWS)エンジニアさんに相談してみてください
最後まで読んでいただきありがとうございます!
日々学んだことをアウトプットしております!!ご指摘などございましたらコメントいただけますと幸いです。
- 投稿日:2020-11-08T23:00:53+09:00
Serverless のプラグインを TypeScript で作成する方法
はじめに
Serverless Framework を使っていて、度々デプロイ時に手動で設定していた作業内容を自動化したいなと思い、プラグイン作成の知識習得も兼ねてライブラリを作成し NPM で公開してみました。
今後も開発する可能性はありそうなので Serverless のプラグインを TypeScript で作成する際の手順をまとめておきました。各手順はザックリと紹介しつつ、主にその過程でハマった点や工夫した点に重きをおいて記事を書いていきます。
動作環境
- Node.js 12.19.0
- Serverless Framework
- Framework Core: 2.10.0
- Plugin: 4.1.1
- SDK: 2.3.2
- Components: 3.3.0
TypeScript で Serverless Plugin を開発する環境を整える
本記事の内容を最後まで実践した際の最終的なプロジェクトのディレクトリ構造は下記になります。
tree -I node_modules -L 2 ./ ./ ├── example # ライブラリの動作検証用のサンプルコードを配置するフォルダ │ ├── handler.js │ ├── package.json │ └── serverless.yml ├── lib # src フォルダ内のファイルをコンパイルした結果を配置するフォルダ (ライブラリとして利用する際に含まれるソースコード群) │ ├── index.js │ └── index.js.map ├── package-lock.json ├── package.json ├── src # Serverless プラグインのソースコードを配置するフォルダ │ └── index.ts └── tsconfig.json基本的には TypeScriptでServerless FrameworkのPluginを書いてみる | Developers.IO の手順をなぞっていくだけで環境構築自体は可能です。そこで、ここでは自分なりに工夫した箇所について記載していきます。
まずは、開発に必要なパッケージを下記コマンドでまとめてインストールします。
# TypeScript の開発に必要なパッケージインストール npm i -D typescript # TypeScript の型定義ファイルのインストール npm i -D @types/node @types/serverless # 今回は AWS プロバイダー向けの開発を行うため SDK をインストールする npm i --save aws-sdkTypeScript のコンパイル時に必要となる
tsconfig.jsonは下記のように設定しました。tsconfig.json{ "compilerOptions": { "target": "es6", "module": "commonjs", "moduleResolution": "node", "strict": true, "strictBindCallApply": false, "strictNullChecks": false, "outDir": "lib", "sourceMap": true }, "include": [ "src/**/*" ] }
compilerOptions.strictにはtrueを設定しつつ、compilerOptions.strictNullChecks等にはfalseを設定することで、部分的に TypeScript のコンパイルチェックを外すようにしました。
outDirにはlibを指定することで、コンパイルされた TypeScript ファイルはlibフォルダに出力されるよう設定しました。
includeにはsrc/**/*を明示的に指定しており、src フォルダ内の全ファイルをコンパイル対象にしております。
package.jsonの内容は部分的に抜粋し、説明が必要そうな項目について説明いたします。
全容を把握したい方は こちら からご確認いただけます。package.json{ "main": "lib/index.js", "files": [ "lib" ], "scripts": { "build": "rm -rf lib && tsc", "test": "echo \"Error: no test specified\" && exit 1" } }
mainにはsrc/index.tsをコンパイルすると生成されるlib/index.jsを指定しました。そのため、ライブラリのエントリーポイントはlib/index.jsが設定されます。
filesにはlibフォルダを指定することで、TypeScript をコンパイルした結果のみがライブラリのソースコードとして取り込まれるようになります。TypeScript で Serverless Plugin の開発を進める
開発環境が整ったところで早速 Serverless Plugin のソースコードを書いていきます。TypeScript のソースコードは
src/index.tsに配置します。Serverless Plugin のプログラムを書く
src/index.tsimport * as Serverless from 'serverless' import { SharedIniFileCredentials, config, } from 'aws-sdk' /** * serverless.yml の custom property の型定義 */ interface Variables { value1: string value2: number value3: boolean profile?: string } export default class Plugin { serverless: Serverless options: Serverless.Options hooks: { [event: string]: () => Promise<void> } variables: Variables /** * プラグインの初期化関数。 * 注意点として、初期化関数内では serverless.yml 内の変数展開が行われないので、 * ${ssm:~} 等で設定した値を呼び出しても、適切に値が設定されない状態で呼び出すことになる。 */ constructor(serverless: Serverless, options: Serverless.Options) { this.serverless = serverless this.options = options /** * serverless.service.custom 内の特定プロパティを取得するための記述 * 今回は Serverless のプラグイン名に serverless-typescript を設定したため、 * serverless-typescript 文字列をキーとして指定する。 */ this.variables = serverless.service.custom['serverless-typescript'] /** * プラグインがフックする関数を指定する。複数指定することも可能だが、 * 今回は before:package:createDeploymentArtifacts を指定して、 * パッケージングの手前の処理を定義した run 関数でフックする。 */ this.hooks = { 'before:package:createDeploymentArtifacts': this.run.bind(this), } } /** * before:package:createDeploymentArtifacts 時に実行される関数 */ async run() { /** * プラグイン実行時に必要となるフィールドがセットされていなければ処理をスキップする */ if (!this.variables) { this.serverless.cli.log( `serverless-typescript: Set the custom.serverless-typescript field to an appropriate value.`, ) return } /** * this.serverless.getProvider 関数を用いることで、 * デプロイ時のアカウントの各種情報について取得することが出来る */ const awsProvider = this.serverless.getProvider('aws') const region = await awsProvider.getRegion() const accountId = await awsProvider.getAccountId() const stage = await awsProvider.getStage() /** * serverless.yml で指定した値や AWS 情報が取得できているか、 * 確認するために標準出力する */ this.serverless.cli.log( `serverless-typescript values: ${JSON.stringify({ stage: stage, region: region, accountId: accountId, variables: this.variables, })}`, ) /** * プラグイン内で処理を実行する際、別の特定 Profile を用いたい際は、 * AWS SDK の SharedIniFileCredentials を用いて切り替えると楽に切替可能。 * その際は process.env.AWS_SDK_LOAD_CONFIG に値を設定しておくこと */ if (this.variables.profile) { process.env.AWS_SDK_LOAD_CONFIG = 'true' const credentials = new SharedIniFileCredentials({ profile: this.variables.profile, }) config.credentials = credentials } } } module.exports = Pluginソースコード内にいくつかコメントを残しましたが、何点か補足の説明をしていきます。
serverless.service.custom['serverless-typescript']を呼び出すことで、serverless.yml内の下記の記述内容をObjectとして取得できます。serverless.ymlcustom: # custom.serverless-typescript 内の定義を Object として取得可能 serverless-typescript: value1: "value1" value2: 0 value3: true # profile: default (optional)
this.hooksには必要に応じてフックを指定します。フックの書き方については 公式ドキュメント に詳細が記載されています。フックの種類については Gist でまとめてくださっている方がいました。
this.serverless.getProvider('aws')を用いることで、デプロイ時にアカウントの各種情報について取得することが出来ます。この記述を利用することで Serverless Pseudo Parameters のようなシンタックスを自身のプラグインに取り込むことが可能になります。
私が作成したプラグインでも serverless.yml で ARN を構築する際に利用していて、index.ts 内で利用しました。また、プラグイン内でデプロイ時とは異なる Profile を使用したいケースもあるかと存じます。それは AWS SDK の SharedIniFileCredentials を用いることで簡易に実装できました。1
それでは、次にプラグインの動作検証用コードを
exampleフォルダに配置していきます。Serverless Plugin の動作検証用プログラムを書く
exampleフォルダ内には検証用プロジェクトを作成するので、その前準備としてexample/package.jsonを作成します。# package.json ファイルを作成する cd example && npm init -y
example/package.jsonファイルを作成したら開発用のスクリプトをexample/package.jsonに追記します。example/package.json{ "scripts": { "prestart": "cd ../ && npm run build", "start": "sls package", "test": "echo \"Error: no test specified\" && exit 1" } }
scripts内のprestartはstartスクリプト実行前に実行されるスクリプトです。npm startを実行するとprestartでプラグインのbuildタスクを実行した後、 Serverless Framework のパッケージングを行うことでプラグインの動作確認が行えます。2次に動作検証用の
serverless.ymlをexampleフォルダに配置します。serverless.ymlservice: name: serverless-typescript publish: false # プラグイン内で利用する設定値を定義する custom: serverless-typescript: value1: "value1" value2: 0 value3: true profile: custom_profile provider: name: aws runtime: nodejs12.x region: ap-northeast-1 # プラグインのパスを指定して読み込む plugins: localPath: '../../' modules: - serverless-typescript # 何でも良いので動作検証用の関数を定義する (関数の定義は後述) functions: hello: handler: handler.hello
exampleフォルダ内にhandler.jsを配置してfunctions.hello.handlerで用いる検証用の関数を定義します。example/handler.js'use strict'; // 検証用の関数。serverless.yml 内では handler.hello で参照可能 module.exports.hello = (event, context, callback) => { callback(null, { statusCode: 200, body: "Hello World!" }); };上記作業が完了次第、
cd example && npm startを実行して動作検証してみます。cd example && npm start > example@1.0.0 prestart /Users/nika/Desktop/serverless-typescript/example > cd ../ && npm run build > serverless-typescript@1.0.0 build /Users/nika/Desktop/serverless-typescript > rm -rf lib && tsc > example@1.0.0 start /Users/nika/Desktop/serverless-typescript/example > sls package Serverless: Configuration warning at 'service': unrecognized property 'publish' Serverless: Serverless: Learn more about configuration validation here: http://slss.io/configuration-validation Serverless: # src/index.ts 内の this.serverless.cli.log の出力内容 # 各種値が正常にセットされていることが確認出来る Serverless: serverless-typescript values: {"stage":"dev","region":"ap-northeast-1","accountId":"XXXXXXXXXX","variables":{"value1":"value1","value2":0,"value3":true,"profile":"custom_profile"}} Serverless: Packaging service... Serverless: Excluding development dependencies...標準出力にあるプラグイン内で出力したログから、適切に値が取得出来ていることが確認出来れば OK です。
Serverless プラグインの中で AWS Profile の切り替えが行えるか確認してみる
Serverless プラグインでの Profile の切り替えについて、動作検証がまだ出来ていないので確認していきます。
serverless.yml内のcustom.serverless-typescript.profileに設定箇所は既に用意してあるので、~/.aws/credentialsに実在する Profile 名を指定します。serverless.ymlcustom: serverless-typescript: profile: <プラグイン実行時に使用したい Profile 名>動作検証のため、
src/index.ts内にログ出力の記述を加えます。src/index.tsimport * as Serverless from 'serverless' import { SharedIniFileCredentials, config, } from 'aws-sdk' interface Variables { value1: string value2: number value3: boolean profile?: string } export default class Plugin { serverless: Serverless options: Serverless.Options hooks: { [event: string]: () => Promise<void> } variables: Variables constructor(serverless: Serverless, options: Serverless.Options) { this.serverless = serverless this.options = options this.variables = serverless.service.custom['serverless-typescript'] this.hooks = { 'before:package:createDeploymentArtifacts': this.run.bind(this), } } async run() { if (!this.variables) { this.serverless.cli.log( `serverless-typescript: Set the custom.serverless-typescript field to an appropriate value.`, ) return } const awsProvider = this.serverless.getProvider('aws') const region = await awsProvider.getRegion() const accountId = await awsProvider.getAccountId() const stage = await awsProvider.getStage() this.serverless.cli.log( `serverless-typescript values: ${JSON.stringify({ stage: stage, region: region, accountId: accountId, variables: this.variables, })}`, ) if (this.variables.profile) { process.env.AWS_SDK_LOAD_CONFIG = 'true' const credentials = new SharedIniFileCredentials({ profile: this.variables.profile, }) config.credentials = credentials // Profile が切り替えられたか確認するためにログを出力する this.serverless.cli.log(`serverless-typescript profile: ${JSON.stringify(config.credentials)}`); } } } module.exports = Plugin早速
cd example && npm startを実行して正常に profile が切り替えられていそうか確認してみます。# 成功時の実行結果 cd example && npm start # ... # accessKeyId のフィールドに ~/.aws/credentials 内に存在する値が出力されている Serverless: serverless-typescript profile: {"expired":false,"expireTime":null,"refreshCallbacks":[],"accessKeyId":"XXXXXXXXXXXXXX","profile":"XXXXXXXXXXXXXX","disableAssumeRole":false,"preferStaticCredentials":false,"tokenCodeFn":null,"httpOptions":null} # ...ちなみに存在しない Profile を指定した場合の出力は下記のようになります。
# 失敗時の実行結果 cd example && npm start # ... # accessKeyId のフィールドが存在しない時は Profile が正しく設定出来ていない Serverless: serverless-typescript profile: {"expired":false,"expireTime":null,"refreshCallbacks":[],"profile":"custom_profile","disableAssumeRole":false,"preferStaticCredentials":false,"tokenCodeFn":null,"httpOptions":null} # ...おわりに
今回初めて Serverless プラグインの開発をしてみて、手軽に出来ることが分かったので自動化出来そうな作業は積極的にプラグイン化していきたいなと感じました。
プラグイン化した後は Git リポジトリにアップするだけでなく、NPM のパッケージ や GitHub Packages として公開しておくと、後々プラグインを利用する際に便利です。また、公開してライブラリのスタッツを見るのは案外楽しく開発のモチベーションにも繋がるのでオススメです。
参考リンク
- TypeScriptでServerless FrameworkのPluginを書いてみる | Developers.IO
- typescript導入したprivateなnpmパッケージの作り方 - 30歳SIerからWEBエンジニアで奮闘
- How To Write Your First Plugin For The Serverless Framework - Part 1
設定しないと
ConfigError: Missing region in configというエラーが発生してしまい、プロファイルを切り替えることが出来ませんでした。
注意点として、
SharedIniFileCredentialsを用いてプロファイルを切り替える時は、環境変数に AWS_SDK_LOAD_CONFIG="true" を設定する必要がありました。 ↩今回は Serverless の
before:package:createDeploymentArtifactsフックを利用しているので、sls packageコマンドで動作検証が可能となっている。before:deploy:deploy等のデプロイ中に実行されるフックを利用する際はsls deploy --noDeployコマンド等で動作検証を行う必要がある。 ↩
- 投稿日:2020-11-08T22:45:10+09:00
購入済みUdemy講座・学習状況 (2020/11/08~ 2020/11/09更新)
独学の教材として、先月頃からUdemyを使用し始めました。
自分が購入したものを以下記載していきたいと思います。
(セールでとりあえず買っておいた、という未着手のものが多々あります)そもそもUdemyとは
Udemyトップページ
Udemyの仕組みに関するよくある質問上記ページをご覧いただくとお分かりになると思いますが、動画配信のオンライン学習サービスです。
一度購入しておくと、その後期間無制限で何度も見ることができます。
"2万円"などの高額な講座もあるのですが、毎月と言ってよいほど頻繁にセールが開催され、1500円で購入できたりするので、そのタイミングでまとめ買いをするとお得かと思います。
(買って満足してしまう罠がありますが)購入した講座一覧
※購入して積みっぱなしにしないよう戒めのために公開しておきます。
★★★受講完了済み★★★
「はじめての AI」 by Grow with Google
講座内容
AI の基礎知識とその仕組みについて学習し、画像認識や音声認識について実際のデモをご覧いただきながら体感していただきます。基本知識だけでなく、事例や具体的にそれがどのような仕組みで動いているかも紹介することで、AI を活用するヒントを得ることを目指します。「AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得」 by 山浦 清透
講座内容
★ゼロからAWSの重要サービスを使いこなせるように!実際にネットワークやサーバーを構築し、インフラの基礎概念を習得します。
本講座は、「はじめてAWSを学ぶ方」や「インフラにあまり詳しくない方」を対象に、「AWSの重要サービスを使い、自分でネットワークやサーバーを構築できるようになる」ことを目指したコースです。
セクションごとに、インフラの基礎概念を学びながら、手を動かし実際に構築していく、という構成になっています。
(以下略)「Git: もう怖くないGit!チーム開発で必要なGitを完全マスター」 by 山浦 清透
講座内容
★ゼロからプロのチーム開発の現場でGitを使いこなせるよう完全マスターします
こちらのコースは未経験の方でも、プロのチーム開発の現場で必要とされるGitの全てを習得することを目的としたコースです。
(略)
こちらのコースでは、まずGitの仕組みを図解でしっかりと理解していきます。
Gitってそもそも何のためにあるのか、コミットした時にどういう風にデータを保存しているのか、マージやリベースした時に何が起こっているのか、ブランチってどういう風に実現しているのか。
そういうことを仕組みから理解することで、Gitの分かりづらいコマンドを自信を持って使えるようになります。なにより、Gitを使う上でのハードルであるステージやブランチ、HEADの概念を完全に理解することができます。
その上で、実際にプロジェクトを作成しGitHubを用いながら、コマンドを実行して学んでいきます。
スキルを身につける上で、実際に作りながら学んでいくことはとても大切です。理解したものを実践することで本当に使えるスキルを身に付けていきます。
(以下略)「現役シリコンバレーエンジニアが教えるPythonで始めるスクラッチからのブロックチェーン開発入門」 by 酒井 潤
2020/11/09完了
講座内容
このコースではブロックチェーンの技術とPythonを用いて仮想通貨の送金システムを構築しながらブロックチェーンの根幹にある技術、考え方とその応用方法をハンズオンで学びます。
(以下略)★★★受講中★★★
「現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル」 by 酒井 潤
講座内容
このコースでは、Python3の基礎である入門コースを一通り終えた後に、今後のアプリケーション開発に役立つためのPythonのテクニックやデーターベースアクセス(SQLite, MySQL, MongoDB, SQLAlchemy, memcached, Hbase, neo4j etc)、WEB(Flask, socket, RPC etc)、インフラ自動化(Fabric, Ansible)、並列化(スレッド、マルチプロセス)、テスト(Unittest, pytest, Tox, Selenium, etc)、暗号化(pycrypto, hashlib)、グラフィック(turtle, Tkinter)、データ解析(numpy, pandas, matplotlib, scikit-learn), キューイングシステム(ZeroMQ, Celery)、非同期処理(asyncio)などのPythonを使った応用編を取り入れております。
(以下略)★★★今後着手★★★
Python
「現役シリコンバレーエンジニアが教えるPythonでFXのシストレFintechアプリの開発」 by 酒井 潤
講座内容
今回扱うFintech技術では、日本でも人気のあるFXの自動トレードをPythonで行い、グローバルで使われているOandaサービスのAPIを使って行います。日本で人気があるという理由でFXにしましたが、FXではなくても、APIを使ってトレードするやり方さえ学べば、例えば株式や仮想通貨のトレードなどでも十分に使える技術を学ぶことができますので、FXにご興味ない方でも自動トレードが何かということを学べる講座になっております。
(以下略)「Python+FlaskでのWebアプリケーション開発講座!!~0からFlaskをマスターしてSNSを作成する~」 by N Matsumoto
講座内容
【この講座について】
Pythonの基本的な使い方、Flaskのウェブアプリケーション開発の基本的な技術、Flaskの機能の有効活用方法、サーバサイドウェブフレームワークで利用されるMVTモデル、サーバサイドのセキュリティ、テーブル設計、SNSサンプルアプリケーション開発を通じた実践的なアプリケーション開発など、PythonのWebエンジニア必修のスキルが身につきます!!
(以下略)「Python デザインパターンマスター講座~Pythonの基本文法、コーディング規約、命名規約、プログラミング技術~」 by N Matsumoto
講座内容
【この講座について】
プログラミングを勉強し、オブジェクト指向を覚えたが実際にどういう風にコードを書けばよいか。良いコード、恥ずかしくないコードというのはどういうコードなのか理解するためにこの講座を作成しました。
コーディング規約、命名規約、コードレビュー、オブジェクト指向のベストプラクティスのSOLIDの原則、デザインパターンを通じて、良いプログラムが何なのかを理解し、技術力を身に着けます。
また、デザインパターンは転職活動の面接などでも聞かれることがあり、身に着けて損のないスキルです
(以下略)「【E資格の前に】PyTorchで学ぶディープラーニング実装」 by 株式会社 AVILEN
講座内容
<概要>
ディープラーニングの実装、実務活用のイメージが沸かない、難しそう...そんなお悩みはありませんか?
当講座は、Pythonの基本文法とNumpyの知識さえあれば、誰でもディープラーニング(DL)を実装できるPyTorchの入門講座となっています。
特別な理論や数式は扱わず、まずは実装して、ディープラーニングのイメージを掴むことをゴールとしています。
AIスペシャリスト集団、株式会社AVILENの執行役員である吉川武文氏が、PyTorchによるディープラーニング実装術を公開。
当講座で扱うプログラムは全て皆様にプレゼントします、実務でもご活用ください。Go
「現役シリコンバレーエンジニアが教えるGo入門 + 応用でビットコインのシストレFintechアプリの開発」 by 酒井 潤
講座内容
このコースでは、Goの基礎である入門コースを一通り終えた後に、次世代のFintech(金融+テクノロジー)のアプリケーションとしてビットコインを自動でシステムトレードを行うアプリを開発します。
多くの言語の良い部分を取りれたGoは、コードを実行する際のパフォーマンスも良く、近年急速にライブラリも充実して来ており、シリコンバレーで多くの企業が取り入れ始めました。日本では、ドキュメントも少なく、Go言語を使う機会があまりないかもしれませんが、世界のトップ企業はすでに使い始めているため、技術レベルで世界から遅れないように今からGo始めると良いかと思います。
(以下略)AWS
「これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)」 by Edutech Global , inc.
本講座は全てのIT従事者にとって必須となるAWSの基本資格「AWS 認定ソリューションアーキテクト – アソシエイト試験」を合格を目指し、そのための知識や経験を獲得できるように設計されています。
この講座を通して、AWSの知識とノウハウを獲得し、「AWS 認定ソリューションアーキテクト – アソシエイト試験」を突破しましょう!!「Ultimate AWS Certified Solutions Architect Associate 2020」 by Stephane Maarek
講座内容
Concretely, here's what we'll learn to pass the AWS Certified Solutions Architect Associate exam:
- The AWS Fundamentals: IAM, EC2, Load Balancing, Auto Scaling, EBS, EFS, Route 53, RDS, ElastiCache, S3, CloudFront
- The AWS CLI: CLI setup, usage on EC2, best practices, SDK, advanced usage
- In-Depth Database comparison: RDS, Aurora, DynamoDB, Neptune, ElastiCache, Redshift, ElasticSearch, Athena
- Monitoring, Troubleshooting & Audit: AWS CloudWatch, CloudTrail
- AWS Integration & Messaging: SQS, SNS, Kinesis
- AWS Serverless: AWS Lambda, DynamoDB, API Gateway, Cognito
- AWS Security best practices: KMS, SSM Parameter Store, IAM Policies
- VPC & Networking in depth
- AWS Other Services Overview: CICD (CodeCommit, CodeBuild, CodePipeline, CodeDeploy), CloudFormation, ECS, Step Functions, SWF, EMR, Glue, OpsWorks, ElasticTranscoder, AWS Organizations, Workspaces, AppSync, Single Sign On (SSO)
- Tips to ROCK the examDocker
「米シリコンバレーDevOpsエンジニア監修!超Docker完全入門(2020)【優しい図解説とハンズオンLab付き】」 by CS Career Kaizen
講座内容
このコースを一文でまとめると?
このコースは、アプリ開発やDevOps経験初心者の方が、Linuxの簡単な基礎(カーネル・シェル・STDIN・STDOUT・TTY)とDocker(イメージ・コンテナ・VMとの違い・Docker compose・ネットワーキング・Volume)を初心者として1から学び、コンテナ化できるデベロパーやDevOpsとしてキャリアアップを目指す方向けのコースです。「米国AI開発者がゼロから教えるDocker講座」 by かめ れおん
講座内容
Dockerの基本的な使い方から現場で役立つ応用的な使い方まで,米国で活躍するAI開発者が講師となって徹底的に解説します.
プログラミングの知識がない人でも,問題なく受講できます.Kubernetes
「米シリコンバレーDevOpsエンジニア監修!超Kubernetes完全入門(2020)【優しい図解説とハンズオン】」 by CS Career Kaizen
講座内容
このコースを一文でまとめると?
このコースは、アプリ開発やDevOps経験初心〜中級者の方が、Linuxの簡単な基礎(カーネル・シェル・STDIN・STDOUT・TTY)とDocker(イメージ・コンテナ・VMとの違い・Docker compose・ネットワーキング・Volume)をベースにして、Kubernetesクラスター上にコンテナ化されたアプリをディプロイ・構築・起動というK8sデベロパー初心者として1から学び、コンテナ化できるデベロパーやDevOpsとしてキャリアアップを目指す方向けのコースです。アジャイル開発
「現役シリコンバレーエンジニアが教えるアジャイル開発」 by 酒井 潤
講座内容
このコースでは、あらゆるレベルのビジネスプロフェッショナルが理解しやすい方法でアジャイルとスクラムの基本をカバーします。アジャイルとスクラムの基礎に関するこのコースから得られる知識を使用して、アジャイルとスクラムに適した環境を作成できます。
アジャイルとスクラムの開発方法を取り入れれば、プロジェクトが失敗するのを防ぐことにも繋がる可能があります。このAjailプロジェクト管理方法は、チームワークが特に重要であり、チームメンバー間の相互信頼を高め、対人関係を改善することもできるでしょう。
このコースは、シリコンバレーでアジャイル開発経験14年の現役エンジニアが教授いたします。アルゴリズム
「現役シリコンバレーエンジニアが教えるアルゴリズム・データ構造・コーディングテスト入門」 by 酒井 潤
講座内容
恐らく、皆さん「アルゴリズムって本当に必要なの?」っと疑問に思っている方もいらっしゃるかと思います。例えば、「実際の現場であまり使わないなー」とか、「今の仕事はWEBのフレームワークのやり方さえ覚えれば、WEBアプリなんて簡単に作れちゃうし」などなどあるとは思います。
ただ、考えていただきたいのですが、なぜあのGAFAと言われるGoogle、Apple, Facebook、Amazonが入社試験で必ずアルゴリズム、データ構造のコーディング面接があるかを考えてみてください。
皆さんもお聞きしたことがあるかもしれませんが、Google検索アルゴリズム、Tesla自動運転アルゴリズムなど世界をリードして最先端の技術革新をしている会社では、ちょっとでもコードが早くなるように、プログラマーが、最適なコードを書く必要があるのです。
(以下略)Unity(C#)
「Unity3D入門の決定版!RPG開発の基本をUnityインストラクターと共に進めるハンズオンコース【スタジオしまづ】」 by 嶋津 恒彦
【講座内容】
・Unityのインストール
・Unityの操作方法とゲームを作る基礎(コードでものを変化させる方法)
・C#プログラミングの基礎(基礎的な文法をイラストと演習問題付き)
・3Dミニゲーム開発(キャラクターを移動せさてゴールしたら終了するゲーム制作)
・3Dアニメーションの基礎(設定・Scriptによる切り替えスキル)
------ここまでが準備-------
・3DRPGの開発
・Playerキャラクターの移動と攻撃実装
・Enemyキャラクターの移動と攻撃実装
・各キャラクターの非ダメージとHP実装
・コンボとスタミナとHPゲージの演出実装「Unity ゲーム開発:インディーゲームクリエイターが教える C#の基礎からゲームリリースまで【スタジオしまづ】」 by 嶋津 恒彦
講座内容
初心者の方でもゲームをリリースできるように、講座の構成は
Unityのインストール
Unityでゲームを作る基礎(コードでものを変化させる簡単な方法)
プログラミングの基礎(ゲーム開発に必要な最低限のスキル)
ゲーム開発のテクニック(ボタンの取得やデータの保存など)
を1話完結形式で学び、基礎力をつけた後
RPGの作成
AppStore/Google Playへのリリース
に取り掛かかります。講座を終えたときには自身のゲームを実際にストアに並べることができるようになっています。「Unityゲーム開発入門:Unityインストラクターが教えるマリオ風2Dアクションゲームを作成する方法【スタジオしまづ】」 by 嶋津 恒彦
講座内容
任天堂からこの夏Nintendo Switch向けに発売されたスーパーマリオメーカー 2。ゲーム開発の専門的な知識がなくても
オリジナルのゲームが開発できることで注目を浴びています。この講座ではスーパーマリオメーカー 2のようにステージを作成するUnityのテクニックが習得できます。
また、ステージ作成だけではなくアクションゲーム開発に必要なC#・アニメーション・当たり判定など総合的なUnityの力がこれ一本で身につく完全攻略版です。
- 投稿日:2020-11-08T22:45:10+09:00
購入済みUdemy講座 (2020/11/08時点)
独学の教材として、先月頃からUdemyを使用し始めました。
自分が購入したものを以下記載していきたいと思います。
(セールでとりあえず買っておいた、という未着手のものが多々あります)そもそもUdemyとは
Udemyトップページ
Udemyの仕組みに関するよくある質問上記ページをご覧いただくとお分かりになると思いますが、動画配信のオンライン学習サービスです。
一度購入しておくと、その後期間無制限で何度も見ることができます。
"2万円"などの高額な講座もあるのですが、毎月と言ってよいほど頻繁にセールが開催され、1500円で購入できたりするので、そのタイミングでまとめ買いをするとお得かと思います。
(買って満足してしまう罠がありますが)購入した講座一覧
※購入して積みっぱなしにしないよう戒めのために公開しておきます。
★★★受講完了済み★★★
「はじめての AI」 by Grow with Google
講座内容
AI の基礎知識とその仕組みについて学習し、画像認識や音声認識について実際のデモをご覧いただきながら体感していただきます。基本知識だけでなく、事例や具体的にそれがどのような仕組みで動いているかも紹介することで、AI を活用するヒントを得ることを目指します。「AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得」 by 山浦 清透
講座内容
★ゼロからAWSの重要サービスを使いこなせるように!実際にネットワークやサーバーを構築し、インフラの基礎概念を習得します。
本講座は、「はじめてAWSを学ぶ方」や「インフラにあまり詳しくない方」を対象に、「AWSの重要サービスを使い、自分でネットワークやサーバーを構築できるようになる」ことを目指したコースです。
セクションごとに、インフラの基礎概念を学びながら、手を動かし実際に構築していく、という構成になっています。
(以下略)「Git: もう怖くないGit!チーム開発で必要なGitを完全マスター」 by 山浦 清透
講座内容
★ゼロからプロのチーム開発の現場でGitを使いこなせるよう完全マスターします
こちらのコースは未経験の方でも、プロのチーム開発の現場で必要とされるGitの全てを習得することを目的としたコースです。
(略)
こちらのコースでは、まずGitの仕組みを図解でしっかりと理解していきます。
Gitってそもそも何のためにあるのか、コミットした時にどういう風にデータを保存しているのか、マージやリベースした時に何が起こっているのか、ブランチってどういう風に実現しているのか。
そういうことを仕組みから理解することで、Gitの分かりづらいコマンドを自信を持って使えるようになります。なにより、Gitを使う上でのハードルであるステージやブランチ、HEADの概念を完全に理解することができます。
その上で、実際にプロジェクトを作成しGitHubを用いながら、コマンドを実行して学んでいきます。
スキルを身につける上で、実際に作りながら学んでいくことはとても大切です。理解したものを実践することで本当に使えるスキルを身に付けていきます。
(以下略)★★★受講中★★★
「現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル」 by 酒井 潤
講座内容
このコースでは、Python3の基礎である入門コースを一通り終えた後に、今後のアプリケーション開発に役立つためのPythonのテクニックやデーターベースアクセス(SQLite, MySQL, MongoDB, SQLAlchemy, memcached, Hbase, neo4j etc)、WEB(Flask, socket, RPC etc)、インフラ自動化(Fabric, Ansible)、並列化(スレッド、マルチプロセス)、テスト(Unittest, pytest, Tox, Selenium, etc)、暗号化(pycrypto, hashlib)、グラフィック(turtle, Tkinter)、データ解析(numpy, pandas, matplotlib, scikit-learn), キューイングシステム(ZeroMQ, Celery)、非同期処理(asyncio)などのPythonを使った応用編を取り入れております。
(以下略)★★★今後着手★★★
Python
「現役シリコンバレーエンジニアが教えるPythonで始めるスクラッチからのブロックチェーン開発入門」 by 酒井 潤
講座内容
このコースではブロックチェーンの技術とPythonを用いて仮想通貨の送金システムを構築しながらブロックチェーンの根幹にある技術、考え方とその応用方法をハンズオンで学びます。
(以下略)「現役シリコンバレーエンジニアが教えるPythonでFXのシストレFintechアプリの開発」 by 酒井 潤
講座内容
今回扱うFintech技術では、日本でも人気のあるFXの自動トレードをPythonで行い、グローバルで使われているOandaサービスのAPIを使って行います。日本で人気があるという理由でFXにしましたが、FXではなくても、APIを使ってトレードするやり方さえ学べば、例えば株式や仮想通貨のトレードなどでも十分に使える技術を学ぶことができますので、FXにご興味ない方でも自動トレードが何かということを学べる講座になっております。
(以下略)「Python+FlaskでのWebアプリケーション開発講座!!~0からFlaskをマスターしてSNSを作成する~」 by N Matsumoto
講座内容
【この講座について】
Pythonの基本的な使い方、Flaskのウェブアプリケーション開発の基本的な技術、Flaskの機能の有効活用方法、サーバサイドウェブフレームワークで利用されるMVTモデル、サーバサイドのセキュリティ、テーブル設計、SNSサンプルアプリケーション開発を通じた実践的なアプリケーション開発など、PythonのWebエンジニア必修のスキルが身につきます!!
(以下略)「Python デザインパターンマスター講座~Pythonの基本文法、コーディング規約、命名規約、プログラミング技術~」 by N Matsumoto
講座内容
【この講座について】
プログラミングを勉強し、オブジェクト指向を覚えたが実際にどういう風にコードを書けばよいか。良いコード、恥ずかしくないコードというのはどういうコードなのか理解するためにこの講座を作成しました。
コーディング規約、命名規約、コードレビュー、オブジェクト指向のベストプラクティスのSOLIDの原則、デザインパターンを通じて、良いプログラムが何なのかを理解し、技術力を身に着けます。
また、デザインパターンは転職活動の面接などでも聞かれることがあり、身に着けて損のないスキルです
(以下略)「【E資格の前に】PyTorchで学ぶディープラーニング実装」 by 株式会社 AVILEN
講座内容
<概要>
ディープラーニングの実装、実務活用のイメージが沸かない、難しそう...そんなお悩みはありませんか?
当講座は、Pythonの基本文法とNumpyの知識さえあれば、誰でもディープラーニング(DL)を実装できるPyTorchの入門講座となっています。
特別な理論や数式は扱わず、まずは実装して、ディープラーニングのイメージを掴むことをゴールとしています。
AIスペシャリスト集団、株式会社AVILENの執行役員である吉川武文氏が、PyTorchによるディープラーニング実装術を公開。
当講座で扱うプログラムは全て皆様にプレゼントします、実務でもご活用ください。Go
「現役シリコンバレーエンジニアが教えるGo入門 + 応用でビットコインのシストレFintechアプリの開発」 by 酒井 潤
講座内容
このコースでは、Goの基礎である入門コースを一通り終えた後に、次世代のFintech(金融+テクノロジー)のアプリケーションとしてビットコインを自動でシステムトレードを行うアプリを開発します。
多くの言語の良い部分を取りれたGoは、コードを実行する際のパフォーマンスも良く、近年急速にライブラリも充実して来ており、シリコンバレーで多くの企業が取り入れ始めました。日本では、ドキュメントも少なく、Go言語を使う機会があまりないかもしれませんが、世界のトップ企業はすでに使い始めているため、技術レベルで世界から遅れないように今からGo始めると良いかと思います。
(以下略)AWS
「これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)」 by Edutech Global , inc.
本講座は全てのIT従事者にとって必須となるAWSの基本資格「AWS 認定ソリューションアーキテクト – アソシエイト試験」を合格を目指し、そのための知識や経験を獲得できるように設計されています。
この講座を通して、AWSの知識とノウハウを獲得し、「AWS 認定ソリューションアーキテクト – アソシエイト試験」を突破しましょう!!「Ultimate AWS Certified Solutions Architect Associate 2020」 by Stephane Maarek
講座内容
Concretely, here's what we'll learn to pass the AWS Certified Solutions Architect Associate exam:
- The AWS Fundamentals: IAM, EC2, Load Balancing, Auto Scaling, EBS, EFS, Route 53, RDS, ElastiCache, S3, CloudFront
- The AWS CLI: CLI setup, usage on EC2, best practices, SDK, advanced usage
- In-Depth Database comparison: RDS, Aurora, DynamoDB, Neptune, ElastiCache, Redshift, ElasticSearch, Athena
- Monitoring, Troubleshooting & Audit: AWS CloudWatch, CloudTrail
- AWS Integration & Messaging: SQS, SNS, Kinesis
- AWS Serverless: AWS Lambda, DynamoDB, API Gateway, Cognito
- AWS Security best practices: KMS, SSM Parameter Store, IAM Policies
- VPC & Networking in depth
- AWS Other Services Overview: CICD (CodeCommit, CodeBuild, CodePipeline, CodeDeploy), CloudFormation, ECS, Step Functions, SWF, EMR, Glue, OpsWorks, ElasticTranscoder, AWS Organizations, Workspaces, AppSync, Single Sign On (SSO)
- Tips to ROCK the examDocker
「米シリコンバレーDevOpsエンジニア監修!超Docker完全入門(2020)【優しい図解説とハンズオンLab付き】」 by CS Career Kaizen
講座内容
このコースを一文でまとめると?
このコースは、アプリ開発やDevOps経験初心者の方が、Linuxの簡単な基礎(カーネル・シェル・STDIN・STDOUT・TTY)とDocker(イメージ・コンテナ・VMとの違い・Docker compose・ネットワーキング・Volume)を初心者として1から学び、コンテナ化できるデベロパーやDevOpsとしてキャリアアップを目指す方向けのコースです。「米国AI開発者がゼロから教えるDocker講座」 by かめ れおん
講座内容
Dockerの基本的な使い方から現場で役立つ応用的な使い方まで,米国で活躍するAI開発者が講師となって徹底的に解説します.
プログラミングの知識がない人でも,問題なく受講できます.Kubernetes
「米シリコンバレーDevOpsエンジニア監修!超Kubernetes完全入門(2020)【優しい図解説とハンズオン】」 by CS Career Kaizen
講座内容
このコースを一文でまとめると?
このコースは、アプリ開発やDevOps経験初心〜中級者の方が、Linuxの簡単な基礎(カーネル・シェル・STDIN・STDOUT・TTY)とDocker(イメージ・コンテナ・VMとの違い・Docker compose・ネットワーキング・Volume)をベースにして、Kubernetesクラスター上にコンテナ化されたアプリをディプロイ・構築・起動というK8sデベロパー初心者として1から学び、コンテナ化できるデベロパーやDevOpsとしてキャリアアップを目指す方向けのコースです。アジャイル開発
「現役シリコンバレーエンジニアが教えるアジャイル開発」 by 酒井 潤
講座内容
このコースでは、あらゆるレベルのビジネスプロフェッショナルが理解しやすい方法でアジャイルとスクラムの基本をカバーします。アジャイルとスクラムの基礎に関するこのコースから得られる知識を使用して、アジャイルとスクラムに適した環境を作成できます。
アジャイルとスクラムの開発方法を取り入れれば、プロジェクトが失敗するのを防ぐことにも繋がる可能があります。このAjailプロジェクト管理方法は、チームワークが特に重要であり、チームメンバー間の相互信頼を高め、対人関係を改善することもできるでしょう。
このコースは、シリコンバレーでアジャイル開発経験14年の現役エンジニアが教授いたします。アルゴリズム
「現役シリコンバレーエンジニアが教えるアルゴリズム・データ構造・コーディングテスト入門」 by 酒井 潤
講座内容
恐らく、皆さん「アルゴリズムって本当に必要なの?」っと疑問に思っている方もいらっしゃるかと思います。例えば、「実際の現場であまり使わないなー」とか、「今の仕事はWEBのフレームワークのやり方さえ覚えれば、WEBアプリなんて簡単に作れちゃうし」などなどあるとは思います。
ただ、考えていただきたいのですが、なぜあのGAFAと言われるGoogle、Apple, Facebook、Amazonが入社試験で必ずアルゴリズム、データ構造のコーディング面接があるかを考えてみてください。
皆さんもお聞きしたことがあるかもしれませんが、Google検索アルゴリズム、Tesla自動運転アルゴリズムなど世界をリードして最先端の技術革新をしている会社では、ちょっとでもコードが早くなるように、プログラマーが、最適なコードを書く必要があるのです。
(以下略)Unity(C#)
「Unity3D入門の決定版!RPG開発の基本をUnityインストラクターと共に進めるハンズオンコース【スタジオしまづ】」 by 嶋津 恒彦
【講座内容】
・Unityのインストール
・Unityの操作方法とゲームを作る基礎(コードでものを変化させる方法)
・C#プログラミングの基礎(基礎的な文法をイラストと演習問題付き)
・3Dミニゲーム開発(キャラクターを移動せさてゴールしたら終了するゲーム制作)
・3Dアニメーションの基礎(設定・Scriptによる切り替えスキル)
------ここまでが準備-------
・3DRPGの開発
・Playerキャラクターの移動と攻撃実装
・Enemyキャラクターの移動と攻撃実装
・各キャラクターの非ダメージとHP実装
・コンボとスタミナとHPゲージの演出実装「Unity ゲーム開発:インディーゲームクリエイターが教える C#の基礎からゲームリリースまで【スタジオしまづ】」 by 嶋津 恒彦
講座内容
初心者の方でもゲームをリリースできるように、講座の構成は
Unityのインストール
Unityでゲームを作る基礎(コードでものを変化させる簡単な方法)
プログラミングの基礎(ゲーム開発に必要な最低限のスキル)
ゲーム開発のテクニック(ボタンの取得やデータの保存など)
を1話完結形式で学び、基礎力をつけた後
RPGの作成
AppStore/Google Playへのリリース
に取り掛かかります。講座を終えたときには自身のゲームを実際にストアに並べることができるようになっています。「Unityゲーム開発入門:Unityインストラクターが教えるマリオ風2Dアクションゲームを作成する方法【スタジオしまづ】」 by 嶋津 恒彦
講座内容
任天堂からこの夏Nintendo Switch向けに発売されたスーパーマリオメーカー 2。ゲーム開発の専門的な知識がなくても
オリジナルのゲームが開発できることで注目を浴びています。この講座ではスーパーマリオメーカー 2のようにステージを作成するUnityのテクニックが習得できます。
また、ステージ作成だけではなくアクションゲーム開発に必要なC#・アニメーション・当たり判定など総合的なUnityの力がこれ一本で身につく完全攻略版です。
- 投稿日:2020-11-08T22:22:53+09:00
四国クラウドお遍路 2020に参加してきました!
お久しぶりです。ちなです。
しばらく療養しており、おさぼりしておりました。昨日、四国クラウドお遍路 2020に参加しました。
参加したきっかけ
関西在住の友人がJAWS-UGの存在を教えてくれ、FBでJAWS-UGうどん県のグループに参加しました。
AWS・クラウドの知識はショボいですが、勢いで参加しました。四国クラウドお遍路 2020 #とは
四国クラウドお遍路 は、クラウド活用をめざして発足した四国各県のJAWS-UG(Amazon Web Service ユーザ会)と合同で開催しています。コミュニティイベントを通して、クラウドの技術や活用について共に学び、交流し、情報を共有する活動などを行っています。
(Doorkeeperより引用させて頂きました)AM プレハンズオン
Amazon ECS, AWS Fargate を用いてのハンズオンでした。
手順書が丁寧で、あまりハマることなく進めることができました。
4/5しか終わらなかったですが、本日無事完走しました。
コンテナの知識はふわふわのままなので、もっと知りたいと思います。AWSシニアアドボケイトの亀田様、本当にありがとうございます!
PM サテライト会場からオンライン配信
ドキがムネムネ()しながら会場に向かいました。
うどん県支部の参加者は4名。
どなたも素敵な方ばかりで、新しい出会いに感謝です。マスクとTシャツを頂いたのですが、お遍路感があっていいですね!かわいい!!
以下、セミナーやLTで感じたこと・心に留めて置きたいことを記載します。
クラウドとコミュニティ活用で先取りした、地方のニューノーマルな働き方 JAWS-UG高知 片岡様
・リモートに必要なスキル
①コミュニケーション
②アウトプット
→存在をアピールして認知してもらう
現状を知ってもらって協力体制を作る
成果をアウトプットする
⇒コミュニティ活動に類似しているのでは?
③バランス・業務
→オンオフの切り替え。
成果にコミットする。
業務分野のスキルを獲得して進化を続ける。AWSの基礎を改めて学ぶ AWSJシニアエバンジェリスト 亀田様
・AWSのモデル
固定資産型⇒サービス型へ
・AI領域の優先順位
世の中のSaaS>AWS
・まとめ
AWSでは必要なITリソースが数分で調達可能。
1回触ったものは手触りとしてイメージが付くので、どんどん触ろう◎
・さいごに、クラウド #とは
今までできていたことをより早く、簡単に、柔軟に拡張できる
→今までできなかったことができる!S3 バケット間でオブジェクトをコピーする方法』を考えてみた JAWS-UG愛媛 沖様
レプリケーションよね?と思ってたら正解だったみたいです。笑
Lambda、SQSの説明もされていて復習になりました!
お話がとてもおもしろかったです♡ニューノーマル!田んぼとクラウドと私 JAWS-UGうどん県 野口様
最近うどん県では以下の2つが話題となっていることが触れられていましたね〜!
・香川県ネット・ゲーム依存症対策条例
・デジタル改革(担当大臣が香川から選出)
セミナーは、竹の中に水位センサー入れてみたという内容でした。
実際に出向かれる行動力がとても素敵だと思いました。行動力の神ですね…!休憩
うどん県vs徳島の美味しいものバトルが繰り広げられてました。
うどん県の完敗でしたねw美波町における新たなデジタル社会資本整備 徳島県美波町役場 大地様
人口減少が課題となっている中で、関係人口を増やすという考えに驚きました。
ライブラリ・サービスの仕変、エンジニア不足、アウトプットとシステム規模がマッチしてないなどの課題があるとのことでしたが、その辺のIT企業より発展しているような気もしました。すごかった。文系学生が、エンジニアコミュニティーに求めること 高知工科大学 本田様
Café NOVA、行ってみたいなと思いました。
https://cafe.caminova.com/
喋りがとても上手で、ただただ圧倒されていました…
エンジニアに関わらず、コミュニティを広げるってとても難しいことだなーと思っていたので、とても惹かれる内容でした。
個人的にはアウトプットを繰り返すことで、知ってもらえる機会を増やすのがベストなのかなとは思いました。コミュニティ活動から振り返る自分の働き方の変化 JAWS-UG愛媛 影浦様
つながりが増えることで勉強会やイベントに参加できる回数も増えますし、つながりって本当に大切だと思います。
また、勉強会でインプットしたことを業務を当てはめてみることの大切さを再認識しました。
今後は勇気を出してイベントや勉強会に参加し、エンジニアさんとどんどん繋がり、成長したいと思います゚(๑•̀ㅁ•́๑)✧LineとAWSでおうち制御を改善した話 JAWS-UGうどん県 藤田様
ひたすら話を聞くのに必死でした。
・AWS IoT Core Device Shadow
→デバイスの状態を把握・管理可能
LINE BOTについてもっと知りたいと思います。。クラウドお遍路~第二章~ AWSでシラサギを立ち上げて感じたこと JAWS-UG徳島 野原様
とにかくお話がおもしろかったです。
AWSの問題点?もお話されていて、SAA試験の復習になりました。
(徳島で勉強会あるなら行きたいな…!!)以下、LTです
JAWS-UG愛媛 中村様
再就職についてのお話でした。
私も療養中なので、ぐさっと来るお話でした。
就職・転職は準備が大切だなと再認識させられました。AWSJ 沼口様
登壇+アウトプットをしないとやっていないと同じ!!
アウトプットしないは知的な便秘!!!JAWS-UG大阪・Sales 山田様
・JAWS-UG Sales #とは
営業が楽しむためのコミュニティ
・売りたいサービス:困っている人に最適なサービスかつ、売っていきたいサービス
Amazon Connect、Amazon AppFlow、Amazon Honeycode
・興味をひくことができて使えるサービス
デモ映えかつ盛りすぎないことが大切
・今後の付き合いにつなげやすいサービス
この人に相談したら解決できるヒントをGETできる!と思わせられるのが営業として重要!
新サービス等を複数組み合わせて使うサービスを伝える必要あり=アウトプット力が必要!JAWS-UG 大阪, 京都, IoT, ネットワーク, 朝会 山中様
Auto Scalingを設定したら大変だったお話。
・Metric Mathを使えばCloudWatchメトリクスの計算が可能
・ジョブ実行中のEC2が終了しないように、インスタンスのスケールイン保護機能を使用する
・Fargateはスケールイン保護が不可能さいごに
無知だった技術やサービスを知ることができ、とても勉強になりました*
また、復習になる内容も多く、SAA取得に向けて頑張ろうと思います。
インプット・アウトプットの両方を心がけたいと思いましたので、Qiitaの更新頻度をもっと上げれるように精進します( ^^ )また、JAWS-UGうどん県組で打ち上げを実施した際に、『勉強会をやろう』という話になりました。
内容はまだ決まっていませんが、全力で協力していきます・・・!ざーーーっと書いたので、変なところがあればご指摘ください。
それでは〜〜〜?

- 投稿日:2020-11-08T22:19:17+09:00
【初級編】AWS初心者が知っておくべき用語集
AWSでサーバー構築・運用する上で覚えておいた方がいい用語 10個
用語一覧
- Amazon EC2
- Instance(インスタンス)
- IAM(アイアム)
- Amazon S3
- Amazon RDS
- Amazon CloudWatch(クラウドウォッチ)
- VPC
- Region(リージョン)
- AZ(エーゼット、アベイラビリティゾーン)
- サブネット
1. Amazon EC2
仮想サーバーをすぐに実行できる環境を用意することができます。また複数の仮想サーバーを立てることも可能です。
これまでデータセンターで物理的なサーバーの構築を行っていたのが、Web上から数クリックで仮想サーバーを構築することができるので、業務の効率化に寄与することが期待できます。
Amazon EC2(Amazon Elastic Compute Cloud)とは、AWSが提供する「仮想サーバー」のことです。EC2を用いてLinuxやWindowsなどさまざまなOSの
2. Instance(インスタンス)
AWS クラウドに立てられた仮想サーバーをインスタンスと呼びます。EC2やRDSなどの仮想サーバーを数える時に単位として使われます。
インスタンスを複数使って仮想サーバーを分割することで、可用性や信頼性を考慮した運用ができます。またインスタンスによって柔軟にWeb上のインフラ環境を構築することができるため、サーバーの増強が必要になった場合などに対応がしやすくなります。インスタンスはコピーも削除も簡単に行えるので、効率良くインフラ環境を改善することが出来ます。
3. IAM(アイアム)
AWS上のサービスを操作するユーザーとアクセス権限を管理するのがIAM(AWS Identity and Access Management)です。ユーザーがアクセスするための認証情報やAWSリソースを制御するための権限を集中管理することができます。
IAMでは、以下の機能が用意されています。
・IAMユーザー(グループ)
・IAMポリシー
・IAMロールa) IAMユーザー(グループ)とは
IAMユーザーとは、AWSを利用するアカウントです。AWSを操作するコンソール画面にログインを行うときに利用します。ログイン用のIDを決めて作成します。IAMユーザーが作成されると、以下のような画面から、AWSコンソール画面にログインを行うことができます。
b) IAMポリシーとは
IAMポリシーとは、IAMユーザや後述のIAMロールにアタッチすることができる、AWSリソースへの操作権限を設定する機能です。IAMポリシーにも大きく分けて3種類あります。
・AWS管理ポリシー
AWSが提供するIAMポリシーです。各サービスに対して大まかな制御ポリシーが設定できます。・カスタマー管理ポリシー
ユーザがJSONファイルなどを利用して設定するポリシーです。IPアドレスの制御など、AWS管理ポリシーよりも細やかな制御が可能です。・インラインポリシー
インラインポリシーは特定のIAMユーザやIAMロール専用に作成されるポリシーです。AWS管理ポリシーやカスタマー管理ポリシーは1つのポリシーを作成すれば多くのIAMユーザなどにアタッチすることができますが、インラインポリシーは1つのIAMユーザなど、1対1でのアタッチしかできません。4. Amazon S3
AmazonS3(Amazon Simple Storage Service)は、Amazonが提供するストレージサービスです。バケットと呼ばれるリソース(入れ物)にデータを保存します。S3は非常にコストパフォーマンスに優れたストレージサービスで、保存できるデータ容量に上限がありません。
5. Amazon RDS
Amazon RDS(Amazon Relational Database Service)はAmazonの提供するリレーショナルデータベースサービスです。MySQLやPostgreSQL、Oracle、SQL Serverなど多くの種類のデータベースを、管理画面から設定するだけで構築・設定して利用できます。
RDSの特徴は主に3つになります。
・Multi-AZ機能
・RR(リードレプリカ機能)
・自動バックアップとリストアa) Multi-AZ機能
データベースの可用性を高める事ができる機能です。
通常データベースは、冗長構成を組む際に必ず、親機と子機のデータの同期を取らなくてはいけません。
この同期を取る構成をユーザー自身が組む必要があり、ここでも運用の手間がありましたが、このMulti-AZ機能を利用することで、AWS側が自動で親機と子機のデータの同期を取ってくれ、さらに、フェイルオーバー機能を使い、親機に障害があった際に自動で子機に切り替えが行われます。b) RR(リードレプリカ)機能
リードレプリカ機能は、読み取り専用のレプリケーションを作成できる機能です。
この機能を使うことで、親機に読み取りにかかる負荷を軽減できます。
これにより、親機のパフォーマンスが向上します。c) 自動バックアップとリストア
RDSの最大の特徴の自動バックアップ機能は、最大5分前までのリカバリが出来る機能です。
障害時や誤作動が起きた際に、5分前の状態に戻すことが出来ます。
このバックアップも、簡単な設定を行うだけで、後はAWS側で勝手にバックアップを撮り続けてくれます。
さらに、このバックアップデータは最長で35日間まで保存することが出来ます。6. Amazon CloudWatch(クラウドウォッチ)
Amazon CloudWatchは、AWSが提供する「フルマネージド運用監視サービス」で、AWSの各種リソースを監視してくれるサービスです。異常が生じた時にはそれをアラートで知らせるだけではなく、自動復旧も可能で、AWS上で監視を行う際には欠かせない存在です。
7. VPC
AWS VPC(Amazon Web Service Virtual Private Cloud)とは、ユーザー専用のプライベートなクラウド環境を提供するサービスです。AWSでは、基本的にVPCが必須ですが、最初に使うVPCはAWS側が自動的に用意してくれます。
8. Region(リージョン)
AWSサービスのバックボーンは、「リージョン」と呼ばれる地理的に離れた領域のデータセンター群がそれぞれ接続されることで構成されています。各リージョンではAWSのサービスがそれぞれ独立して提供されています。例をあげると、日本には東京リージョン(ap-northeast-1)があり、米国にはバージニア北部リージョン(us-east-1)、オレゴンリージョン(us-west-2)などがあります。
9. AZ(エーゼット、アベイラビリティゾーン)
AZとは、「データセンター」のことです。各リージョンには複数のデータセンター(AZ)が置かれており、システムを複数のAZに置くことができます(Multi-AZと呼ばれます)。AZには固有の名称が付けられており、東京リージョンでは4つのAZ が提供されています。
10. サブネット
サブネットとは、ある1つの大きなネットワークの中をさらに小さく分割した小規模ネットワーク=ネットワークの範囲のことをさします。サブネットは「サブネットマスク」という考え方で分割を行いその範囲を示します。IPアドレスとサブネットマスクを組み合わせることで、ネットワークの範囲(サブネット)を指定することができます。(例:172.16.0.1 / 255.255.255.0 など)
さいごに
AWSで知っておきたい用語10個をまとめてみました。まだまだ知っておきたい用語が沢山あるので引き続きまとめていけたらと思います。











- 投稿日:2020-11-08T20:59:19+09:00
AWS Data Analytics資格に合格しました
はじめに
今日(11/8)にAWS Certified Data Analytics - Specialty資格(以降DAS)に受かったので、いつものようにその時の所感や実践した勉強など。
ネットワークの時と同様、データ分析系のサービスは実務未経験だったので、なかなか難しい試験でした。(一発合格でしたが、合格点は751/750の超ぎりぎりでした)
誰かの役に立てば幸いです。※過去の記事
AWS SAAに受かった話
AWS SOAに受かった話
AWS DVA(とCLP)に受かった話
AWS SAPに受かった話
AWS SCSに受かった話
AWS ANSに受かった話
AWS DBSに受かった話獲得スコア
受験日 スコア/合格点/満点 結果 2020/11/8 751/750/1000 合格 勉強に使った教材
※親の顔よりも見たWhizlabsとBlackbelt、あと公式模擬試験は省略
AWS Summit 2020/2019資料
Blackbelt以外だと、Summitでデータ分析系やRedshiftのセッションを観ました。
「データ分析とは何ぞやか」を知る上では良い教材だったと思います。
https://aws.amazon.com/jp/summits/tokyo-osaka-2019-report/
https://resources.awscloud.com/aws-summit-online-japan-2020-on-demandQuickSightセミナー
直近(10/14)に開催されたQuickSightのオンラインセミナー資料が公開されていました。
QuickSightのアーキテクチャーやアクセス制御の考え方など、詳しく説明されています。
https://aws.amazon.com/jp/blogs/news/quicksight-matome-20201014/チュートリアル/ハンズオン
Kinesisは直近の案件で触る機会がありましたが、GlueやEMRなど実務で触っていないサービスは公式のチュートリアルやハンズオンで補いました。
(言いつつ、Kinesis以外のハンズオンは横着してあまりやらなかったのですが)
Kinesisだと例えば下記のようなハンズオンをやりました(他にもいくつかやりましたが)
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-kinesis-example.htmlExam Readiness
公式のデジタルトレーニング。
勉強始めであれば最初から通してやった方が良いと思いますが、終盤だったので最後の練習問題だけ何度か解きました。
Exam Readiness: AWS Certified Data Analytics - Specialty
https://www.aws.training/Details/eLearning?id=46612試験の所感
- 全体的に「データ分析とは何か」が問われている試験だった
- DASに限らず、専門資格はAWSサービスだけではなくその分野自体の一般的な知識が問われている(気がする)
- Glueなどを使ったデータ分析やETLのハンズオンをやっていればイメージ付きやすいかも
- DAS試験は(ネットワークやSAPに比べて)簡単、という話はたまに聞いていたが、今回受けた感じだと「当たらずも遠からず」といった印象
- Glue/EMR/Kinesisはそこそこ詳しく出る
- サービスの使い分け問題は非常に多かった
- KinesisとMSKとSQS(FIFO)や、GlueとEMRとRedshiftなど
- どのサービスにもメリデメはあるので、問題文の要件に応じた回答をする
- コストを最小限にするとか
- アクセス権限の制御問題は多数出た
- 分析クエリ遅い問題は鉄板
- 読み込むデータセットのサイズを減らすか、処理効率の良い形式(Parquetなど)に変換するか、性能が良いサービス(EMRやRedshiftなど)に変えるかが基本的な対応
- リアルタイムのデータ分析&可視化ではElasticSearchが強い
- 難しい問題は多かったが、一方で簡単な問題(というより他に選びようがない問題)も多かったので、諦めずに最後まで解く
- Quicksightで可視化する際にどのグラフ形式にするのが良いかは出た
- それぞれのグラフの特徴や用途を(ざっくりでも)把握しておく
- データ同期用途で意外と出てくるDatasyncとDMS
- 投稿日:2020-11-08T20:10:33+09:00
AWS(VPC)
はじめに
こちらではAWS機能について書いていきたいと思います。
公式ドキュメントやAWS認定試験(ソリューションアーキテクトやDevOpsなど)の勉強教材など細かい内容をかかず、ざっくりとした内容で。
試験などに興味はないし!公式ドキュメントなど長ったらしくて読めん!
という方に向けに作っていきたいと思います。
(私の備忘録も兼ねて)今回はネットワークな内容です。
写真はつけられればつけます。(Qiitaの制限の範囲内で)
環境
AWS
ドキュメント
https://docs.aws.amazon.com/index.html
Virtual Private Cloud(VPC)とは
AWSクラウド内に倫理的に分離されたセクションを作り、ユーザーが定義した仮想ネットワークを構築するサービス
端的にいうと仮想のネットワークサービス・任意のIPアドレス範囲を選択して仮想ネットワークを構築(IPアドレスはCIDR方式)
AWSで予約されているIPアドレスなどもあるので使用するさいは注意!
・サブネットの作成、ルートテーブルやネットワークゲートウェイの設定など仮想ネットワーキング環境を制御
・必要に応じてクラウド内のネットワーク同士をつなげることもできる
・複数の接続オプションが利用できる
インターネット経由
VPN
・設定を跨がせて設定することもできる
・サブネットが使えるのでVPC内で分割することも可能サブネット
ネットワークをやってると聞くがAWSでも存在する
CIDR/16、サブネットに/24の設定が推奨らしいパブリックネットワーク
外部インターネットに公開するネットワーク
プライベートネットワーク
内部のネットワーク
外部ににつなぎたい場合NATゲートウェイを使用するらしいそとのリソースにつにつなぎたい場合はAWSネットワークを使うかエンドポイントを使っての接続ができる。
インターネットの設定
・ルートテーブルでパケットの行先を設定
・VPC作成時にデフォルトで一つだけ作れられている。
・VPC内はCIDRアドレスでルーティングされている。VPCトラフィック設定
・セキュリティグループ
・ネットワークACLs
要はAWSの設定にしてしまうかACLで設定してしまうかセキュリティグループ
・ステートフルで戻りのトラフィックの考慮が入らない
・サーバ単位で適応可能
・許可のみをIn/Outで設定
・デフォルトでは同じセキュリティグループ内の通信のみ許可
・必要な通信は許可設定が必要
・全てのルールを適応ネットワークACLs
・ステートフルで戻りのトラフィックの考慮がいる
・サブネット単位で適応
・許可と拒否をIn/Outで指定
・デフォルトでは全ての送信元IPを許可
・番号の順序通りに適応VPCとのオンプレ接続
・VPN接続
・Direct ConnectDirect Connect
AZ以外にDirect Connectがあり
そこにDirect Connectデバイスで接続してそこから
AWSにいくという流れになる・安価なアウトバウンドトラフィック料金
・ネットワーク信頼性の向上
・ネットワーク帯域幅の向上
・Direct ConnectDirect Connect gateway
Direct Connect gatewayにより同一アカウントに所属する複数のリージョンの複数AZから複数リージョン複数VPCに接続可能
例 東京リージョン>Direct Connect gateway>米国北部リージョンVPNとDirect Connect
VPNとDirect Connectの特徴の差を簡単にまとめてみたいと思います
VPN
・安価
・設定すれば即日疎通が取れる
・暗号化のオーバーヘッドにより帯域幅に制限がある
・インターネット経由のため他のネットワークの影響をうける
・自社で保持している範囲い以外の障害時に対応が難しいDirect Connect
・専用キャリアに契約が必要であり割高
・物理的な対応が必要なため疎通に数週間かかる
・ポートあたり1G/10Gbps
・キャリアにより品質が保証されている
・物理的に経路が確保されているため障害時の特定が比較的容易VPCエンドポイント
VPCエンド
VPC設計ポイント
こちらはUdemyであったものを参照したいとおもいます。(他に良さげなものが見つかりませんでした....)
・設計時には将来の拡張も見据えたアドレッシングや他ネットワークとの接続性も考慮する
・CIDR(IPアドレス)は既存のVPC、社内のDCやオフィスと被らないアドレス帯を設定し、組織構成やシステム構成の将来像も考えながら前もって計画する
・VPC構成は自社業務に合わせたVPC単体ではなくVPC全体の関係性も視野に入れる
・組織とシステム境界からVPCをどのように分割するか将来構成も考慮して検討する
・複数のAZを利用して可溶性の高いシステムを構成
・サブネットは大きいサブネットを使い、パブリック/プライベートサブネットへのリソースの配慮をインターネットアクセス可否から検討する
・セキュリティグループを使ってリソース感のトラフィックを適切に制御する
・実装や運用を保持するツールも有効利用し、VPC Flow Logsを使ってモニタリングできるようにする。
- 投稿日:2020-11-08T17:56:17+09:00
Secrets Managerのシークレットを.envrcにコピーする
ひじょーにしょうもないことだが、またいつか使う気がしたのですかさずmemo✍️
シークレットの欄をコピー
ターミナルで以下
.envrcに貼り付けるなりする$ pbpaste | awk '{print "export "toupper($1)"="$2}' | sort export XXXXXXX=abcdef 略

- 投稿日:2020-11-08T17:45:36+09:00
AWS(EBS)
はじめに
こちらではAWS機能について書いていきたいと思います。
公式ドキュメントやAWS認定試験(ソリューションアーキテクトやDevOpsなど)の勉強教材など細かい内容をかかず、ざっくりとした内容で。
試験などに興味はないし!公式ドキュメントなど長ったらしくて読めん!
という方に向けに作っていきたいと思います。
(私の備忘録も兼ねて)写真はつけられればつけます。(Qiitaの制限の範囲内で)
ストレージなどは種類が多くてややこしいですね
環境
AWSドキュメント
https://docs.aws.amazon.com/index.htmlAWSのストレージサービスは主に3つの種類に別れる
・ブロックストレージ
例 EBSインスタンスストア・オブジェクトストレージ
例 S3、Glacier・ファイルストレージ
例 EFSブロックストレージ
ブロック形式でデータを保存
高速・広帯域幅オブジェクトストレージ
安価で高い耐久性を持つオンラインストレージ
オブジェクト形式でデータを保存
デフォルトで複数のAZの冗長化されているファイルストレージ
複数のEC2インスタンスから同時にアタッチ可能な共有ストレージサービス
ファイル形式で保存ストレージ
EC2で直接利用するストレージ
・インスタンスストア
・Elastic Block Store(EBS)インスタンスストア
EC2についたストレージ
一時的に保存されEC2の停止・終了するとクリアされる。
無料提供Elastic Block Store(EBS)
EC2とは別のところで管理され独立されている。
snapshotをS3に保存てきたりできる。EBSとは
EBSはEC2インスタンスと共に利用されるブロックストレージ
インスタンス時上のワークロードなどに利用される
https://aws.amazon.com/jp/ebs/?ebs-whats-new.sort-by=item.additionalFields.postDateTime&ebs-whats-new.sort-order=descOSやアプリケーションなどのデータを置くなど
サイズは1~16G特徴
・ボリュームデータはAZ内で複数のHWにデフォルトでレプリケーションされている
(つまり冗長化の必要がないがただしAZ内のことなのでAZ障害には弱い)
・セキュリティグループによる通信制御の対象外のため全てのポートを閉じても使用することはできる
・データを永続的に保存
・EC2インスタンスに複数のEBSを接続することはできるが同じEBSを複数のEC2で共有することはできない
(ただしプロビジョンドIOPSのみ複数インスタンスで共有できるらしい...ビックデータを扱う際に便利だからとか)
・共有はできないが付け替えることはできるEBSボリュームタイプ
・SSD
・HDD
・マグネティックSSD
汎用SSD
提供されている一般的ななSSD
プロビジョンドIOSP
汎用SSDより性能が高い
スループットも高いが値段もたかい
公式ではきわめて低いレイテンシーを必要とする IOPS 負荷の高いワークロードと、高いスループットが必要なワークロードの両方に最適です。
高いI/O性能やビックデータなど高性能なSSDが必要な場合などに使うとか
HDD
スループット最適化HDD
公式では
データセットや I/O サイズが大きく高いスループットを必要とする、アクセス頻度の高いワークロードに最適です。
スループットが必要なログやアクセスなどつかうとか
ただしルート(ブート)ボリュームとして利用はできないコールドHDD
EBSの中では性能が低いが安価
公式では大容量のコールドデータセットを含むアクセス頻度の低いワークロードに最適です
バックアップなど利用するなど
RAIDの構成
RAIDとは
ふくすのディスクをひとつのディスクとして読み込ませるもの
冗長化や高速化などをはかるRAID0
高速化などパフォーマンスを重視したものストライピングとも呼ぶらしい
RAID1
冗長性重視
二つのボリュームをミラーリングし、障害時の対策するなど
- 投稿日:2020-11-08T16:10:45+09:00
Glacierと Glacier Deep Archive
Glacierと Glacier Deep Archiveのメモです。
主な目的は取り出し期間をまとめたかっただけです。Glacierとは
- バックアップなど中長期保存用のS3よりも安価なストレージ(大切)
- 99.999999999%% の耐久性
- 毎月わずか 1 USD/テラバイトでデータを保存
- 1 つのアーカイブの最大サイズは 40 TB
- 保存可能なアーカイブ数とデータ量に制限なし
Glacierの取り出しタイプ
迅速
- 通常1〜5分以内(早い)
標準
- 3〜5時間
大容量
- 大量のデータを1日以内に低コストで取得
- 大体5〜12時間で完了
プロビジョニングキャパシティ
- 迅速取り出しの取得容量を必要なと きに利用できることを保証する仕組み
Glacier Deep Archiveとは
- 中長期保存用ストレージタイプ
- Glacierよりも値段が安い
- データ取得はGlacierより遅い
- 最小保存期間は180日
- 基本的なデータモデル・管理はGlacierと同じ
データの取り出し
- 標準取り出しで、データは12時間以内 (Glacierの場合は標準で3〜5時間)
- 大量取り出しで、48 時間以内にデータを取り出す大容量取り出しをすることで取得 コストを低減
ポイント
- 1-5分以内ならGlacier(迅速)
- 3-5時間以内ならGlacier(標準)
- 12時間以内でOKならGlacier Deep Archive
- 投稿日:2020-11-08T16:10:42+09:00
AWS(Organizations)
はじめに
こちらではAWS機能について書いていきたいと思います。
公式ドキュメントやAWS認定試験(ソリューションアーキテクトやDevOpsなど)の勉強教材など細かい内容をかかず、ざっくりとした内容で。
試験などに興味はないし!公式ドキュメントなど長ったらしくて読めん!
という方に向けに作っていきたいと思います。
(私の備忘録も兼ねて)写真はつけられればつけます。(Qiitaの制限の範囲内で)
環境
AWSドキュメント
https://docs.aws.amazon.com/index.htmlOrganizationsとは?
IAMのアクセス管理を大きな組織でもらくに実施できるよにするマネージド型サービス
つまり複数アカウントを運用するうえで楽をする仕組み
主にできること
・複数のアカウントの一元管理
・新アカウントの作成の自動化
・一括請求設定
・マスターアカウントの設定
・組織にアカウントを追加(招待)
・組織単位(OU)の作成
・サービスコントロールポリシー(SCP)を設立手順
マスターアカウントの設定
Organizationsへ
↓
組織の作成
↓
メールが送られるので確認招待
アカウントの追加
↓
アカウントの招待
↓
招待された側は承認OUの作成
アカウントの管理
↓
組織単位の作成
↓
名前の入力
↓
アカウントの移動
↓
移動する組織を選択サービスコントロールポリシー(SCP)の設定
設定JSONドキュメント
https://docs.aws.amazon.com/ja_jp/organizations/latest/userguide/orgs_manage_policies_scps_syntax.html
タブのポリシー選択
↓
サービスコントロールポリシーの有効化
↓
ポリシーの作成
↓
ポリシー名と説明を入力
↓
サービスを選択
↓
リソースを選択
↓
条件の追加
↓
条件キーなどの設定
↓
ポリシーの作成
↓
右のサービスコントロールポリシーの有効化
↓
作った組織を選択
↓
右のサービスコントロールポリシー
↓
設定したいポリシーをアタッチ
- 投稿日:2020-11-08T15:23:40+09:00
Amazon Aurora カスタムエンドポイントの検証と考察
1. はじめに
- 2018年11月12日のリリース時から気になっていた Amazon Aurora カスタムエンドポイント をようやく試すきっかけができたので、いろいろ検証してみた結果と考察の備忘録。
- 定時バッチの重い参照系クエリによる長時間DB負荷を、カスタムエンドポイントを使えばサービス用DBから分離できるのか、というのが今回の検証の目的。
2. 使うべきかどうかの最重要ポイント
リリース内容はいい感じに書いてあるけど、実際は「目的」「コスト」「スケールアウト/イン」「フェイルオーバー」といった要素を総合的に考慮して、利用すべきかどうかを検討する必要がある。
特に注意すべきポイント
編集アクションによる変更の進行中は、カスタムエンドポイントへの接続やカスタムエンドポイントの使用はできません。エンドポイントのステータスが [使用可能] に戻り、再度接続できるようになるまでに数分かかることがあります。
(引用元: https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html#aurora-endpoint-editing)これの挙動を確認したところ、カスタムエンドポイントの設定変更進行中は、そのカスタムエンドポイントを名前解決してもメンバーのインスタンス情報が返ってこなくなる状態が数分間あった。
つまり、カスタムエンドポイントに新しくレプリカを追加する、あるい、カスタムエンドポイントからレプリカを削除するなどで、カスタムエンドポイント設定に何からの編集を行うと、変更進行中の数分間、そのカスタムエンドポイントのメンバーインスタンスにDB接続ができなくなる。そのカスタムエンドポイントが集計や分析などのバッチ用途ならまだ許容できるが、サービス用の読み込み利用であれば致命的だ。
サービスへ影響を与えることなくカスタムエンドポイントのメンバーを変更する方法はあるが、手順が増えるため対応スピードは落ちる。
- レプリカを追加する場合の手順
- 「クラスター内に新たに作成されたインスタンスをクラスターエンドポイントに自動的に追加するかどうかを設定」を無効
- レプリカ作成
- 新しいメンバー構成を設定したカスタムエンドポイントを新規に作成
- プログラム側でエンドポイントを入れ替える
- レプリカを削除する場合の手順
- 新しいメンバー構成を設定したカスタムエンドポイントを新規に作成
- プログラム側でエンドポイントを入れ替える
- レプリカ削除
3. バッチ用 replicaインスタンス 導入検証
- いくつかのAuroraクラスター構成を想定して、実際に設定を行い挙動を確認する。
- カスタムエンドポイントの作成や設定変更は terraform を使う。
- AWSマネジメントコンソールからカスタムエンドポイントを作成した場合は、カスタムエンドポイントのタイプが必ず「ANY」になってしまう。
- terraform は、カスタムエンドポイントのタイプを「READER」に設定することができる。
3.1. 検証1
元の構成
- 1つの primary インスタンス「test-nishimura-01」で「サービス用書き込み」と「サービス用読み込み」を行う構成。
- コスト重視で冗長性はない。
- 図
バッチ用 replica インスタンスを追加した構成
- バッチ用 replica インスタンス「test-nishimura-10」を作成する。
- フェイルオーバー優先順位を primary インスタンスと同じにする(ここでは "1" にしている)。
- 「バッチ用読み取り」のカスタムエンドポイント「batch-reader」を作成する。
- タイプは「READER」
- スタティックメンバーは「test-nishimura-01」と「test-nishimura-10」
- カスタムエンドポイントのタイプについて
- スタティックメンバーに primary の「test-nishimura-01」が設定されているが、タイプが「READER」なのでカスタムエンドポイントの名前解決で返されるメンバーは 「test-nishimura-10」だけになる。
- タイプが「READER」ではなく「ANY」の場合は、でカスタムエンドポイントの名前解決でprimaryインスタンスの「test-nishimura-01」も引けるようになる。
- 「サービス用読み取り」の接続設定を reader endpoint から cluster endpoint へ変更する。
- 図
primary インスタンス「test-nishimura-01」をフェイルオーバーする
- 「test-nishimura-01」と「test-nishimura-10」のフェイルオーバー優先順位が同じ "1" なので、replica だった 「test-nishimura-10」 が昇格して primary になり、「test-nishimura-01」が replica となった。
- cluster endpoint のインスタンスが 「test-nishimura-01」から「test-nishimura-10」へ変わった。
- custom endpoint「batch-reader」のインスタンスが 「test-nishimura-10」から「test-nishimura-01」へ変わった。
- カスタムエンドポイント「batch-reader」の指すメンバーが変更されたが、これはカスタムエンドポイントの設定を編集したわけではなく、既存設定通りの動きなので、この変更によりカスタムエンドポインが一時的に名前解決ができなくなるわけではなく、即座に切り替わる。
- 「test-nishimura-01」と「test-nishimura-10」インスタンスの役割が入れ替わった。
- 図
考察
- フェイルオーバー後も、サービス用とバッチ用でインスタンスを分離することができる。
- フェイルオーバーによりインスタンスの役割が入れ替わったので、サービス用とバッチ用のインスタンスクラスは同じにする必要がある。
- 追加した replica インスタンスは、バッチ用に加えてサービス用のフェイルオーバーとしても機能するので、クラスターの冗長性を確保できるようになった。
3.1. 検証2
元の構成
- 1つの primary インスタンス「test-nishimura-01」で「サービス用書き込み」を、1つの replica インスタンス「test-nishimura-02」で「サービス用読み込み」を行う構成。
- フェイルオーバー優先順位を同じにする(ここでは "1" にしている)。
- 図
バッチ用 replica インスタンスを追加した構成
- バッチ用 replica インスタンス「test-nishimura-10」を作成する。
- フェイルオーバー優先順位をサービス用インスタンス群より低い数値にする(ここでは "10" にしている)。
- 「バッチ用読み取り」のカスタムエンドポイント「batch-reader」を作成する。
- タイプは「READER」
- スタティックメンバーは「test-nishimura-10」
- 「サービス用読み取り」のカスタムエンドポイント「serv-reader」を作成する。
- タイプは「READER」
- スタティックメンバーは「test-nishimura-01」と「test-nishimura-02」
- 「サービス用読み取り」の接続設定を reader endpoint から costum endpoint 「serv-reader」へ変更する。
- 図
primary インスタンス「test-nishimura-01」をフェイルオーバーする
- 「test-nishimura-01」と「test-nishimura-02」のフェイルオーバー優先順位が同じ "1" なので、replica だった 「test-nishimura-02」 が昇格して primary になり、「test-nishimura-01」が replica となった。
- cluster endpoint のインスタンスが 「test-nishimura-01」から「test-nishimura-02」へ変わった。
- custom endpoint「serv-reader」のインスタンスが 「test-nishimura-02」から「test-nishimura-01」へ変わった。
- バッチ用のカスタムインスタンスや replica インスタンスには特に影響はない。
図
考察
- フェイルオーバー後も、サービス用インスタンス と バッチ用インスタンス を完全に分離できる。
- フェイルオーバー後も、インスタンスの役割は入れ替わらない (test-nishimura-10 はバッチ用読み取りのまま)。
- バッチ用 replica インスタンスのクラスをサービス用インスタンスと同じにしなくても良いので、バッチ処理の完了を時間かけてもよいのであれば、低いスペックのクラスでもよい。
- バッチの時間帯だけバッチ用 replica インスタンスを作成して、バッチ処理が完了したら replica インスタンスを削除してもよい。
- ただし、都度カスタムエンドポイントも作成・削除する必要がある。カスタムエンドポイントの設定だけ残しておいて、スタティックメンバーで設定してある同じ識別子で replica インスタンスを作成しても、カスタムエンドポイントは新しいインスタンスを見つけられないため。
3.3. 検証3
元の構成
- 1つの primary インスタンス「test-nishimura-01」で「サービス用書き込み」を、2つの replica インスタンス「test-nishimura-02」と「test-nishimura-03」で「サービス用読み込み」を行う構成。
- フェイルオーバー優先順位を同じにする(ここでは "1" にしている)。
- 図
バッチ用 replica インスタンスを追加した構成
- 設定ポイントは、検証2 と同じ
- 図
primary インスタンス「test-nishimura-01」をフェイルオーバーする
- 挙動は 検証2 と同じ
- 図
考察
- 検証2 と同じ
4. カスタムエンドポイントにメンバーを追加する検証
元の構成
- 1つの primary インスタンス「test-nishimura-01」で「サービス用書き込み」を、
1つの replica インスタンス「test-nishimura-02」で「サービス用読み込み」を、
1つの replica インスタンス「test-nishimura-10」でバッチ用読み込みを行う構成
(検証2 のバッチ用 replica インスタンスを追加した構成と同じ)。
元の構成に サービス用読み取り replica を追加する
まずは、サービス用読み取り replica「test-nishimura-03」を新規作成する (terraformで)。
新しい replica 「test-nishimura-03」は、reader endpoint に自動的に追加されるが、custom endpoint「serv-reader」には追加されない
カスタムエンドポイント「serv-reader」の static_members 設定に 「test-nishimura-03」を追加する (terraformで)。
カスタムエンドポイントserv-readerの設定部分を抜粋resource "aws_rds_cluster_endpoint" "serv-reader" { cluster_endpoint_identifier = "serv-reader" cluster_identifier = "test-nishimura" custom_endpoint_type = "READER" #static_members = ["test-nishimura-01", "test-nishimura-02"] static_members = ["test-nishimura-01", "test-nishimura-02", "test-nishimura-03"] }
- この時、各エンドポイントに対して1秒間隔で名前引きするスクリプトを動かしておく。
1秒間隔でカスタムエンドポイント「serv-reader」の名前引きするスクリプトの例#!/bin/bash LANG=C for i in {1..2000} do date dig +short serv-reader.cluster-custom-※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com sleep 1 echo done
- 結果
- 11:03:24 ころに terraform plan を実施 (カスタムエンドポイント変更を開始)
- cluster endpoint, reader endpoint, batch-reader endoint の名前引きは途切れることなく返ってきた
- カスタムエンドポイント「serv-reader」 の名前引きは、11:05:03 くらいから途切れ、11:06:22 くらいから徐々に返ってきて、設定変更が完了した 11:07:00 以降は途切れることなく返ってきた。
1秒間隔でカスタムエンドポイント「serv-reader」の名前引きするスクリプトの実行結果を部分抜粋$ sh dig-serv-reader-ep.sh Sun Nov 8 11:03:24 JST 2020 test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com. 172.31.11.88 Sun Nov 8 11:03:25 JST 2020 test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com. 172.31.11.88 〜snip〜 Sun Nov 8 11:05:02 JST 2020 test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com. 172.31.11.88 Sun Nov 8 11:05:03 JST 2020 Sun Nov 8 11:05:04 JST 2020 〜snip〜 Sun Nov 8 11:06:21 JST 2020 Sun Nov 8 11:06:22 JST 2020 test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com. 172.31.11.88 Sun Nov 8 11:06:23 JST 2020 Sun Nov 8 11:06:24 JST 2020 test-nishimura-03.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com. 172.31.12.227 Sun Nov 8 11:06:25 JST 2020 Sun Nov 8 11:06:26 JST 2020 〜snip〜 Sun Nov 8 11:06:58 JST 2020 Sun Nov 8 11:06:59 JST 2020 Sun Nov 8 11:07:00 JST 2020 test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com. 172.31.11.88 Sun Nov 8 11:07:01 JST 2020 test-nishimura-02.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com. 172.31.11.88 Sun Nov 8 11:07:02 JST 2020 test-nishimura-03.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com. 172.31.12.227 Sun Nov 8 11:07:04 JST 2020 test-nishimura-03.※※※※※※※※※※※※.ap-northeast-1.rds.amazonaws.com. 172.31.12.227変更後の構成
考察
- やはり、カスタムエンドポイントの設定変更中は、数分間そのカスタムエンドポイントは使用できなくなる。
- これが許容範囲かどうかはそのサービスの特性や求められる信頼性によるので、それらを事前に把握・確認した上で、サービス用読み取りにカスタムエンドポイントを使うかどうかを判断する必要がある。
- 例えば、24/365リクエストや負荷が一定数のサービスであれば、サーバ増減はインスタンスの障害時くらいしか対応することはないので、カスタムエンドポイントは有効な手法となる。
- 例えば、平常時の何倍もリクエストが増える定時イベントを開催しているサービスにおいて、イベント前に事前にレプリカを増やしてそれらをメンバーにしたカスタムエンドポイントを新規に作成してイベントが始まる直前にプログラム側で接続先エンドポイントを切り替える方法を採用した場合、想定以上にリクエストが来てレプリカが足りなくなった時は、同じ手順では迅速な対応ができなくなる。
- 例えば、リクエストや負荷のタイミングは不特定で急にレプリカをスケールアウトしなければならないようなサービスの場合、Amazon Aurora Auto Scaling を使用して現在稼働中のレプリカインスタンスに関するスケーリングポリシー設定して増減させるのが一般的だけど、カスタムエンドポイントには auto scaling で起動された レプリカ を自動的にメンバーにすることができない。
5. 個人的着地点
その1
- もともとカスタムエンドポイントの利用を検討したきっかけは、検証1 のケースが発生したから。
- このケースの場合は、検証1 の「バッチ用 replica インスタンスを追加した構成」で良いと思う。

その2
- サービス用レプリカを頻繁に即座にスケールイン・アウトしたい場合
- サービス用読み取りのカスタムエンドポイントは作成せずに、reader endpoint を使う。
- バッチ用読み取りのカスタムエンドポイントを作成する。
- そのインスタンスのクラスを他のサービス用インスタンスよりも高めにする(サービス用読み取りクエリも受けるため)。
- そのインスタンスのフェイルオーバー優先順を他のサービス用インスタンスよりも低めにする(primaryのフェイルオーバーによって昇格させないため)。
- 必要に応じて、 Amazon Aurora Auto Scaling でレプリカをスケールアウト/インする設定をいれる。
6. その他気になったこと
AWSマネジメントコンソール
- AWSマネジメントコンソールからカスタムエンドポイントを作成した場合は、カスタムエンドポイントのタイプが必ず「ANY」になってしまう。タイプを指定できる設定項目が存在しない。何でだろう・・
- 「今後追加されるインスタンスをこのクラスターにアタッチする」の利用目的がわからない・・
- カスタムエンポイントを作成するときは、タイプを「READER」にしたいとので、現時点でAWSマネジメントコンソールからカスタムエンドポイントを作成することはないな・・
terraform
- aws_rds_cluster_endpoinリソースでカスタムエンドポイントの作成・削除・編集ができる。
- AWSマネジメントコンソール設定できる「今後追加されるインスタンスをこのクラスターにアタッチする」の設定は、terraform ではできない。
7. 今後の期待
- カスタムエンドポイント設定変更中も、クラスターやリーダーエンドポイント同様に、名前解決が途切れることなく切り変わってほしい。












- 投稿日:2020-11-08T12:32:24+09:00
【lightsail】Error establishing a database connection 対応
aws lightsail bitnamiで構築しているwordpress環境にアクセスすると、
Error establishing a database connectionが発生していた。ec2インスタンスにsshで接続して、ステータスチェック
$ sudo /opt/bitnami/ctlscript.sh status php-fpm already running apache not running mysql not runningmysql が起動していないので、start してみるも、disk full が発生している模様。
df -h Filesystem Size Used Avail Use% Mounted on udev 488M 0 488M 0% /dev tmpfs 100M 3.2M 96M 4% /run /dev/xvda1 9.7G 9.7G 2.3M 100% / tmpfs 496M 0 496M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 496M 0 496M 0% /sys/fs/cgroup /dev/loop0 98M 98M 0 100% /snap/core/9993 /dev/loop1 18M 18M 0 100% /snap/amazon-ssm-agent/1566 /dev/loop2 29M 29M 0 100% /snap/amazon-ssm-agent/2012 /dev/loop3 97M 97M 0 100% /snap/core/9804 tmpfs 100M 0 100M 0% /run/user/1000EBSボリュームを拡張後、ボリュームサイズ変更後の Linux ファイルシステムの拡張 をする
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/recognize-expanded-volume-linux.html
df -h Filesystem Size Used Avail Use% Mounted on udev 488M 0 488M 0% /dev tmpfs 100M 3.2M 96M 4% /run /dev/xvda1 20G 9.7G 9.7G 51% / tmpfs 496M 0 496M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 496M 0 496M 0% /sys/fs/cgroup /dev/loop0 98M 98M 0 100% /snap/core/9993 /dev/loop1 18M 18M 0 100% /snap/amazon-ssm-agent/1566 /dev/loop2 29M 29M 0 100% /snap/amazon-ssm-agent/2012 /dev/loop3 97M 97M 0 100% /snap/core/9804 tmpfs 100M 0 100M 0% /run/user/1000startして、mysqlが起動したことを確認した
$ sudo /opt/bitnami/ctlscript.sh start php-fpm already running apache not running mysql already runningFYI
https://docs.bitnami.com/aws/faq/administration/control-services/
- 投稿日:2020-11-08T12:10:15+09:00
AWS LambdaをTypescript+Webpackでデプロイする
Lambda関数をTypescriptで記述したくなった。
さらに、Webpackでバンドルした後にLambdaにアップロードすることを試みる。作業手順
- Typescript環境構築
- Lambda関数作成
- Webpack準備
1. Typescript環境構築
package.jsonを用意する。
Typescriptに必要なパッケージやWebpackでtsファイルをビルドするためのパッケージ、Lambda側で型定義するためのパッケージをインストールしておく。package.json{ "scripts": { "build": "webpack --mode production --config webpack.config.ts" }, "devDependencies": { "@types/aws-lambda": "^8.10.62", "@types/webpack": "^4.41.22", "ts-loader": "^8.0.4", "ts-node": "^8.1.0", "typescript": "^4.0.3", "webpack": "^4.42.1", "webpack-cli": "^3.3.11" } }2. Lambda関数作成
Lambda関数を用意する。
ハンドラに渡した引数に対して型を貼っておく。
以下はAPI Gatewayのイベントを受け取っている例だが、S3イベント用やCloudfront用イベントの型も用意されている。index.tsimport { APIGatewayEvent, APIGatewayProxyCallback, Context } from 'aws-lambda'; export async function handler(event: APIGatewayEvent, context: Context, callback: APIGatewayProxyCallback) { console.log("hello world"); return; };3. Webpack準備
Webpackで出力サイズを抑えた上でLambdaにアップロードする。
webpack.config.tsimport { Configuration } from 'webpack'; const config: Configuration = { target: 'node', entry: { 'index': `${__dirname}/index`, }, output: { path: `${__dirname}/dest`, filename: 'src/[name]/index.js', libraryTarget: 'commonjs2', }, externals: ['aws-sdk'], module: { rules: [ { test: /\.ts$/, use: [ { loader: 'ts-loader' } ]} ], }, resolve: { extensions: ['.js', '.ts'], }, }; export default config;ビルド実行すると、destディレクトリが作成され、出力ファイルが生成されていることが確認できる。
$ npm run build後は、出力されたファイルをzip化してアップロードすれば良い。
まとめ
型定義しておけばLambda関数の記述もWebpackの設定も簡単になったように感じました。
- 投稿日:2020-11-08T11:08:11+09:00
【Rails/AWS】RDSのMySQLに繋がらないエラーの考えられる原因(database.yml)
はじめに
本記事は、RailsアプリをAWSにデプロイした際に発生する可能性のある
MySQLに繋がらないという事象に対する原因例を紹介します。
原因はかなり初歩的な原因でしたが、筆者はこのエラー原因が特定できずとても苦労したため、
今後同じエラーに遭遇した方の助けになれば幸いです。開発環境
- Ruby 2.5.1
- Rails 5.2.4.4
- AWS(EC2, RDS)
- MySQL(RDS) 5.6.48
前提条件
- RailsアプリをEC2のWebサーバー上にgitクローン済み。
- 基本的な設定は完了済みで、rake db:create RAILS_ENV=productionのコマンドを実行する手前の状態。
- RDSのDBインスタンスを作成済み。
- Railsのdatabase.ymlは下記の内容です。
database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: socket: /tmp/mysql.sock production: <<: *default database: データベース名 host: <%= ENV['DATABASE_HOST_PRODUCTION'] %> username: <%= ENV['DATABASE_USER_NAME_PRODUCTION'] %> password: <%= ENV['DATABASE_PASSWORD_PRODUCTION'] %>エラー内容
以下のコマンドだとRDSのMySQLに繋がったのですが・・・・
[ec2-user@ip-10-0-1-10 アプリのディレクトリ]$ mysql -h RDSのエンドポイント -u root -P 3306 -p以下のコマンドだと繋がらず、MySQLに繋がらないというエラーが出ました。
[ec2-user@ip-10-0-1-10 アプリのディレクトリ]$ rake db:create RAILS_ENV=production Can't connect to MySQL server on '10.0.1.10' (111) Couldn't create 'データベース名' database. Please check your configuration. rake aborted! Mysql2::Error::ConnectionError: Can't connect to MySQL server on '10.0.1.10' (111) Tasks: TOP => db:create (See full trace by running task with --trace)原因/解決策
当初はホスト名の設定ができていなかったので、エンドポイントを環境変数に入れて修正したのですが、
mysqlコマンドだと繋がるのにrakeコマンドだと繋がらないという謎の現象が発生しました。
いろいろ調べたところ、MySQLのパスワードにパスワードに"#"が入っていることが原因でした。
YAMLファイルはコメントアウトの記法が#ということで、パスワードに"#"が入っているとコメントされてしまいます。
パスワードを変更したら無事rakeコマンドが通りました。
みなさんお気を付けください。まとめ
MySQLのパスワードに"#'を含めるのは良くない。
- 投稿日:2020-11-08T10:49:15+09:00
AWSWAFのAWSManagedRulesCommonRuleSet の動作確認方法
RestrictedExtensions_URIPATH
リクエストの URI パスに、クライアントが読み取りや実行を禁止されているシステムファイルの拡張子が含まれていないかを検査します。パターンの例には、.log や .ini などの拡張子があります。
- URL内に、
ini,logなどのアプリケーションの重要なファイルへのアクセスを防ぐcurl -i https://dev.vamdemic.jp/aaa.iniNoUserAgent_HEADER
HTTP User-Agent ヘッダーのないリクエストをブロックします。
- ツールなどによる総当たり攻撃を防ぐ
curl https://dev.vamdemic.jp -H "User-Agent:"参考
https://docs.aws.amazon.com/ja_jp/waf/latest/developerguide/aws-managed-rule-groups-list.html
- 投稿日:2020-11-08T10:29:56+09:00
AWSWAFでAWS-AWSManagedRulesLinuxRuleSetをセットしたときの動作確認方法
AWS-AWSManagedRulesLinuxRuleSet
Linux オペレーティングシステムルールグループには、Linux 固有のローカルファイルインクルージョン (LFI) 攻撃など、Linux 固有の脆弱性の悪用に関連するリクエストパターンをブロックするルールが含まれています。これは、攻撃者がアクセスすべきでないファイルの内容を公開したり、コードを実行したりする攻撃を防ぐのに役立ちます。アプリケーションの一部が Linux で実行されている場合は、このルールグループを評価する必要があります。このルールグループは、POSIX operating system ルールグループと組み合わせて使用する必要があります。
- LinuxOSの重要なファイルを指定するとWAFで予め弾いてくれる
- クラスメソッドさんのサイトでは、
/etc/passwdでやってた。ここらへんのあたりのファイルが対象のもようcurl -i https://dev.vamdemic.jp/proc/version動作確認
/proc/varsionを指定すると、ALBから403で弾かれるyuta:~ $ curl -i https://dev.vamdemic.jp/proc/version HTTP/1.1 403 Forbidden Server: awselb/2.0 Date: Sun, 08 Nov 2020 01:21:37 GMT Content-Type: text/html Content-Length: 118 Connection: keep-alive <html> <head><title>403 Forbidden</title></head> <body> <center><h1>403 Forbidden</h1></center> </body> </html> yuta:~ $
/proc/varsioだと、ALBはぬけてその先のEC2内のApacheが返しているyuta:~ $ curl -i https://dev.vamdemic.jp/proc/versio HTTP/1.1 404 Not Found Date: Sun, 08 Nov 2020 01:21:39 GMT Content-Type: text/html; charset=iso-8859-1 Content-Length: 196 Connection: keep-alive Server: Apache/2.4.46 () OpenSSL/1.0.2k-fips PHP/7.2.34 <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>404 Not Found</title> </head><body> <h1>Not Found</h1> <p>The requested URL was not found on this server.</p> </body></html>WAFコンソールでも検知している
参考
https://docs.aws.amazon.com/ja_jp/waf/latest/developerguide/aws-managed-rule-groups-list.html
https://dev.classmethod.jp/articles/generate_test_log_with_waf_rules/

- 投稿日:2020-11-08T09:44:58+09:00
AWS Elastic BeanstalkにLaravelをデプロイしてからAPIを動かすまでの全て
なぜ書くのか
AWS Elastic Beanstalk(以下、EB)にLaravelをデプロイするまでは、公式ドキュメントなど豊富に存在するが
それだけだととんでもなく不十分なので備忘もかねてかきます。この記事の趣向
初めて作る人にもわかるように段階を細かく分て書こうと思います。
「そこは知ってるー」という人は当たり前ですが、ガンガン飛ばして読んでください。前提
- AWSアカウントがあり、自分でEBを作成できる権限がある人
- local環境でLaravelが構築できる、もしくはその準備が整っている人
- 僕がMacしか持っていないのでMac視点のみのお届けでも良い人
1. EBでアプリケーション作成
まずはEBでアプリケーションをつくります。最初は画像のような設定で良いと思います。
(もしかしたら次の「環境の作成」で一緒につくれちゃうかもw)
2. 環境の作成
3. sshするための準備
sshできるとEBで作ったEC2にsshでログインできるし、RDSにも接続できて楽なのでつくります。
sshできるようにするには、作ったEBに移動して、左のナビゲーションから
「設定->セキュリティ」に移動して、「仮想マシンアクセス許可」に「EC2 キーペア」を設定します。
EC2 キーペアの作り方
AWSの管理画面からEC2に移動して、左にあるナビゲーションから「キーペア」を選択
あとは作成ボタンを押したら簡単につくれます。作ったら勝手にダウンロードされるのでしっかり管理しておくことをおすすめしますー。
4. sshしてみる
僕の場合は面倒なのでssh-confに書いちゃってます。
~/.ssh/config Host eb-laravel HostName {{あなたのEC2インスタンスのパブリックIPv4DNS}} IdentityFile ~/.ssh/key/key.pem User ec2-user Port 22あなたのEC2インスタンスのパブリックIPv4DNS
EC2管理画面に移動して、ナビゲーションから「インスタンス」を選択します。
するとEBの環境名と同じインスタンスがあります。
(※僕はlaravelという環境名でつくりました)あとは、インスタンスの概要から「パブリックIPv4DNS」をみることができます。
ちなみにsshが成功するとこんな感じ
5. EBにRDSをつくる
EBの環境に戻ります。
左のナビゲーションから「設定」に移動し、データベースの「編集する」を押します
設定は自分の環境に応じて変更してくださいね。6. 作ったRDSに接続してみる(SequelProで)
基本EC2を踏み台してしか入れないと思います。なのでそのような設定で入ります。(ターミナルでしたい人はもちろんどうぞ)
MySQL Host: EBでデータベースを作ると設定からエンドポイントが見れるようになります Username: さっき自分で作ったやつ Password: さっき自分で作ったやつ Database: まだないので「空」で Port: 3306のはず SSH Host: EC2インスタンスのパブリックIPv4DNS SSH User: ec2-user SSH Password: ダウンロードしたkey.pem SSH Port: 22これで接続できるはずです。
7. Laravelをローカル環境で作る
割愛!
php artisan serveして画面が表示できるようになってればOK!
8. EB CLIの準備
公式通りにすすめてください!
https://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/eb-cli3-install-osx.html9. EBでデプロイの準備
さっき作ったlocalのLaravelフォルダに移動します。
次にEBの初期化をします。eb initここも公式を元に設定してみてください。
(設定にはAWSのアカウントのシークレットキーとかが必要です。「?」という人は、AWSアカウント作ってくれた人に聞いてみてください)
https://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/eb-cli3-configuration.html10. デプロイ
ひとまずデプロイしてみます。成功するとこんな感じです。
$ eb deploy laravel Starting environment deployment via CodeCommit --- Waiting for Application Versions to be pre-processed --- Finished processing application version app-431a-201108_091707 2020-11-08 00:17:20 INFO Environment update is starting. 2020-11-08 00:17:26 INFO Deploying new version to instance(s). 2020-11-08 00:17:37 INFO Instance deployment completed successfully.11. ドキュメントルートの設定
ドキュメントルートを「/public」に設定しないと正常に表示されません。
EBのナビゲーションから「設定->ソフトウェア」の編集に移動します。「ドキュメントルート」に「/public」を入れて「適用」します
サービス画面に移動するとこのようなLaravelの初期画面が表示されてればOKです!
ここで終わりのように感じるのですが
Laravelで開発をしようと思うと実はまだまだ設定が足りません。
ここからは、Laravelでの開発を見越した設定をしていきます。.ebextensionsでenvとmigration
おそらくデプロイしたらmigrationしてくれよ!と思うはずです。僕は思いますw
その辺りの設定をしていきます。
- Laravelのrootディレクトリに「.ebextensions」フォルダを作成します
- .ebextensions以下に3つのファイルを作成します
01_settimezone.config
EC2のタイムゾーンの設定commands: 01-set_timezone: command: cp /usr/share/zoneinfo/Japan /etc/localtime02_documentroot.config
ドキュメントルートがpublicになる設定を念のためここにも書いておきます。
オートスケールした時とかにいいのかな・・・・(まだ知らない)option_settings: aws:elasticbeanstalk:container:php:phpini: document_root: /public03_migrate_and_cache_clear.config
Larvelに必要そうなコマンドを実行します。本当は.envはもっと安全に管理したほうが
いいと思うんですが、ひとまず.env.productionで管理しちゃってます。container_commands: 01_env: command: "mv .env.production .env" leader_only: true 02_config: command: "php artisan config:clear" leader_only: true 03_migrate: command: "php artisan migrate --force" leader_only: trues 04_route: command: "php artisan route:clear"12. .platformでnginxの設定をする
なんとEBのnginxの初期設定だと「/」以外にいくと404になっちゃいますw
なのでnginxの設定を上書きするための設定を書きます。
- Laravelのrootディレクトリに「.platform/nginx/conf.d/elasticbeanstalk」フォルダを作成します
- elasticbeanstalk以下に1つのファイルを作成します
laravel.conf
location / { try_files $uri $uri/ /index.php?$query_string; gzip_static on; }ここまで出来たら、変更をEBに再度デプロイして終わりです。
まとめ
公式のドキュメントも以外と不十分だったのでまとめて書いてみました。
しっかりとEBでLaravelを使おうと思うといろいろな設定が必要だったのですが
最初にしっかりとやれば後が楽なのでEBです。ぜひ試してみてはどうでしょう?長々とありがとうございました。
では、また!









- 投稿日:2020-11-08T00:13:50+09:00
プライベートなインスタンスだけSSMのVPCエンドポイントを利用したかった話
実現したかったこと
プライベートサブネットにあるEC2にSSMを利用してログインしたい。
※以降プライベートインスタンスと記載プライベートインスタンスは、VPCエンドポイントを利用すればインターネットアクセスすることなくSSMが使えるらしい。
以下を参考に設定した。
https://dev.classmethod.jp/articles/tsnote-private-ec2-ssm-vpc-endpoint/パブリックインスタンスにログイン出来なくなった
プライベートインスタンスにログイン出来るようになったが、パブリックインスタンスにSSMを利用してログイン出来なくなってしまった。
原因
VPCエンドポイントを作成する際、「プライベートDNS名を有効にする」という設定を有効にしていた。
これを有効にすると、インターネット経由でサービスのエンドポイントにアクセス出来ていたパブリックインスタンスもVPCエンドポイント経由でアクセスしようとする。しかし、VPCエンドポイントのセキュリティグループのインバウンドルールでパブリックサブネットの通信が許可されていない為SSMの利用が出来なくなっていた(と思う)。
ここの仕組みの理解は以下の記事がとても参考になりました。
参考記事
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpce-interface.html
https://devlog.arksystems.co.jp/2018/05/11/4896/#toc_id_6_2対策
対応策として2点修正を行いました。
VPCエンドポイントの「プライベートDNS名を有効にする」を無効化
これによりパブリックインスタンスは元通りインターネット経由でサービスのエンドポイントにアクセス出来るようになりました。プライベートインスタンスはVPCエンドポイント固有のDNS名を利用する
VPCエンドポイントを作成するといくつか固有のDNSが作成されています。
インスタンス内にあるSSMエージェントの設定ファイルにVPCエンドポイント固有DNS名を記載し、SSMエージェントを再起動することでVPCエンドポイントにアクセス出来るようになりました。ブライベートインスタンスにて$ cd /etc/amazon/ssm/ $ cp amazon-ssm-agent.json.template amazon-ssm-agent.json $ vim amazon-ssm-agent.json 〜抜粋〜 "Mds": { "CommandWorkersLimit" : 5, "StopTimeoutMillis" : 20000, "Endpoint": "ec2messagesのVPCエンドポイント固有DNS名", "CommandRetryLimit": 15 }, "Ssm": { "Endpoint": "ssmのVPCエンドポイント固有DNS名", "HealthFrequencyMinutes": 5, "CustomInventoryDefaultLocation" : "", "AssociationLogsRetentionDurationHours" : 24, "RunCommandLogsRetentionDurationHours" : 336, "SessionLogsRetentionDurationHours" : 336 }, "Mgs": { "Region": "", "Endpoint": "ssmmessagesのVPCエンドポイント固有DNS名", "StopTimeoutMillis" : 20000, "SessionWorkersLimit" : 1000 },補足
プライベートインスタンスから見たサービスのDNS名が変わるだけなので、CLIでSSMログインする際にエンドポイント指定は不要です。
セキュリティグループの穴あけすればいいのではという話ではありますが、こういうことも出来たので誰かの助けになれば!