- 投稿日:2020-08-14T23:10:34+09:00
【Docker】コンテナ構築時に、MySQLデータベースが立ち上がらない
エラー内容
ERROR: for db Cannot start service db: Ports are not available: listen tcp 0.0.0.0:3306: bind: address already in useどうやら、すでにポート番号3306が使われている様子
まずは、プロセス確認
$ sudo lsof -i -P | grep "LISTEN" rapportd 315 user 4u IPv4 0xb08837e7170ea82d 0t0 TCP *:59397 (LISTEN) rapportd 315 user 5u IPv6 0xb08837e7098fcf3d 0t0 TCP *:59397 (LISTEN) com.docke 19101 user 10u IPv4 0xb08837e717a7d30d 0t0 TCP localhost:56362 (LISTEN) com.docke 19102 user 50u IPv6 0xb08837e709900c7d 0t0 TCP *:8080 (LISTEN) mysqld 20618 _mysql 21u IPv4 0xb08837e7180b7e4d 0t0 TCP localhost:3306 (LISTEN)とりま、ID指定して停止。
$ kill -9 20618 $ docker-compose up -d --build ERROR: for db Cannot start service db: Ports are not available: listen tcp 0.0.0.0:3306: bind: address already in useまだダメ、、、。
mysqldはまだ起動していた。そこで、思い出した。
他のプロジェクトで、
$ mysql.server startしていたことを。
エラー解決
mysql自体を止めましょう
$ mysql.server stop$ docker-compose up -d --build Starting db ... done成功!
- 投稿日:2020-08-14T22:51:58+09:00
VSCodeとRemote-Containersを用いたC++開発環境
ぼくのかんがえたさいきょうの C++ 開発環境
概要
- Docker コンテナ上に C++ 開発環境を構築するサンプル一式を公開
- Google Test による単体テスト機能付き
- Visual Studio Code の Remote-Containers の機能を用いて、上記コンテナのC++開発環境にリモートアクセスによる開発が可能
- ホスト環境を汚すことなく開発が可能
動作環境
- macOS Catalina : 10.15.6
- docker desktop community : 2.3.0.4(46911)
- Visual Studio Code : 1.48.0
構築手順
- Docker/Visual Studio Codeをセットアップ (Visual Studio Code は Remote-ContainersのExtensionも併せてインストール)
- GitHub - takanassyi/cpp-gtest-dev からクローン
- クローンしたフォルダで Visual Studio Code を開く
- 画面右下に現れる "Reopen in Container" で開発環境のコンテナへリモートアクセス
- コンパイラを選択 (GCC 10.2)
src/およびtest/フォルダにソースコード/単体テストコードを記述、テストテスト実行
- Visual Studio Code の下部の
Build、Launchボタン(▷ボタン)を押下すると実行
終了方法
画面左下の
Dev Container:cpp-gtest-devを選択し、Close Remote Connectionを選択するとコンテナへのリモートアクセスを終了サンプルソース
フォルダ構成
. ├── .devcontainer │ └── devcontainer.json ├── .gitignore ├── .vscode │ ├── c_cpp_properties.json │ ├── launch.json │ ├── settings.json │ └── tasks.json ├── CMakeLists.txt ├── Dockerfile ├── README.md ├── build ├── docker-compose.yml ├── src │ ├── CMakeLists.txt │ ├── calculator.cc │ └── calculator.h └── test ├── CMakeLists.txt └── test_calculator.cc
.devcontainer/Remote-Containersに関わる設定。リモートアクセスしたときに導入するExtensionもここに記述(主にC++用のExtension)。.vscode/Visual Studio Code上でのC++開発に関わる設定(gdbへのパス、コーディングスタイル・・・etc)Dockerfiledocker-compose.yml開発環境を構築するDockerfileとdocker-compose.yml。 devcontainer.jsonが参照してリモートアクセス環境をセットアップ
- 今回はDocker Hubで公開されているgcc (10.2.0)の公式イメージをベースイメージに設定
- src/ 今回はシンプルな四則演算のソース
- test/ srcの内容を単体テスト
おわりに
- DockerコンテナとVisual Studio Code & Remote-Containers を用いることで、(C++に限らず)様々な開発環境をホスト環境を汚すことなく開発が可能
- 開発環境そのものもコード (Dockerfile) で管理することで、再現性を確保
- Visual Studio Code & Remote-Containers & Docker バンザイ


- 投稿日:2020-08-14T19:36:51+09:00
Docker初心者でも分かったDockerfileの作り方(API環境の共有)
flaskでwebAPIを作ったものの、Dockerイメージ(1.4GBくらい)でその環境を渡したら冷ややかな目で見られました。おしん
まあ、そんな訳でこの記事では、Python環境をDockerfileにして渡す方法を書き殴ります。目次
- Dockerとは?
- ディレクトリ構造
- .dockerignoreについて
- requirements.txtについて
- Dockerfileの心
- ビルド
- ラン。コンテナを作る
- コンテナの起動
- 最後に
Dockerとは?
linux系のOSを簡単に共有したりやりたい放題環境を荒らしたりできる便利なサービスです。OSレベルの仮想環境を扱うことのできるソフトと考えて下さい。インストール方法はこちら
dockerイメージという1~2GBくらいのOSの素をdocker run ~ とすることでdockerコンテナができます。コンテナが仮想環境(OS)みたいなものです。コンテナができればもう"""勝ち"""なのです。
ではこの環境をどうやって共有しましょう?取り敢えず、dockerイメージを共有すれば相手側でもrunしてコンテナを立ち上げることができますね。まあ、そうすると環境のパッケージによっては大きな容量になって不便ですね...
そこで、Dockerfileを利用します
Dockerfileとは、dockerイメージの設計図みたいなテキストのファイルで容量を軽っかっるなやつです。例としてはこんなんです⇓FROM ubuntu:18.04 # install python RUN apt-get update RUN apt-get install -y python3 python3-pip # setup directory RUN mkdir /api ADD . /api WORKDIR /api # install py RUN pip3 install -r requirements.txtこれで、Python3系と必要なパッケージが揃ったubuntu18.04の環境ができます。8行で!
こうやってDockerfileで相手と共有して、相手はdocker build ~ とすることでDockerイメージを作ることができます。後はdocker run ~ とイメージからコンテナを立ち上げ仮想OSの中に入ることができます。おんのじ!ディレクトリ構造
僕を含め初心者の方がここまで聞くと「Dockerすげえええええええーーーーーーーーー!!!!!何でもできんじゃん!すげえええええええええーーーーーひゃっほいーーーーー!!1hぃさfyいうぇb」
となります。皆なります。まあ、しかしOS環境ができても、肝心なのはAPIのファイルであったり、機械学習だとネットワークのモデルファイルなどがDocker内に配置されていないと元も子もないので、共有するディレクトリ構造について確認します。
kyoyu/
├ data/
├ ganbari/
├ api_server.py
├ gomi/
├ .dockerignore
├ requirements.txt
└ Dockerfile
例としてこの様なディレクトリ構造を考え、githubなどでこのkyoyuディレクトリを相手と共有するとします。共有するディレクトリの内部にDockerfileを置きます。dataとganbariとapi_sever.pyが環境で利用したいデータやコードのファイル・フォルダとします。gomiディレクトリはDocker環境には不要なもの(.mdでの仕様書など)とします。.dockerignoreについて
後ほど説明しますが、DockerfileでDocker内でディレクトリを作る命令文を書き、kyoyuディレクトリ内のディレクトリをDocker内に配置します。その時、Docker内に不要なディレクトリをわざわざ配置しないように命令することができます。それが.dockerignoreです。テキストのファイルでこのように書きます。
gomi/*これでgomiディレクトリ以下全てがDocker内に配置されません。
requirements.txtについて
環境で使いたいPythonパッケージをまとめます。
(例)例.pyabsl-py==0.9.0 alembic==1.4.2 astor==0.8.1 attrs==19.3.0 backcall==0.2.0 bcolz==1.2.1 bleach==3.1.5 Bottleneck==1.3.2 certifi==2020.6.20 chardet==3.0.4 click==7.1.2こんな感じにひたすらパッケージとそのバージョンが書かれたテキストファイルです。作るのが面倒臭そうですが、
/kyoyu$ pip freeze > requirements.txtで一発でファイルができます。
Dockerfileの心
Dockerfileの書き方について詳しいことはネットに転がっているので調べて下さい。今回はDockerfileのお気持ちを解説します。
Dockerfileは拡張子の無いテキストのファイルです(windowsでは.dockerfileで認識されるらしい)。FROM ubuntu:18.04 # install wget, cmake RUN apt-get update RUN apt-get install -y python3 python3-pip # setup directory RUN mkdir /api ADD . /api WORKDIR /api # install py RUN pip3 install -r requirements.txtお気持ちとしてはFROMで基となるOSを決め、以降は一捻りしたlinuxコマンドで環境を整えていく感じです。
FROMコマンド
FROMコマンドで基本となるDockerイメージを指定します。「ちょ!?待て、Dockerイメージの設計図がDockerfileでしょ!?」と思うかもしれませんが、ここではDockerhubというサービスに登録されたDockerイメージを利用することができます。様々なDockerイメージが登録されており、大抵わざわざ自分でDockerfileを書かなくてもここにあります。
(実は、Python3系のDockerイメージも既にありますが、今回は解説用にわざわざコマンドで書きました。)RUNコマンド
普通にlinuxのターミナルで書くようなコードを書くことができます。ただし、cdだけは後で説明するWORKDIRで書きます。
WORKDIRコマンド
linuxのcdコマンドの用に作業するディレクトリを変更します。
ADDコマンド
このDockerfileをdocker build ~ とビルドしてコンテナを作成しますが、このbuildしている環境のファイルをDocker内に送ることができます。
ADD [実行している環境のファイルのパス] [送りたいdocker内のディレクトリのパス]今回は、kyoyuディレクトリ内でビルドすると仮定し、"." (kyoyuディレクトリ内の全てのディレクトリ・ファイル) を/apiに送っています。この時、.dockerignoreで指定したgomiディレクトリはdocker内に配置されません。
install -r requirements.txt
docker内のapiディレクトリにkyoyuディレクトリの中身を配置しました。docker内のディレクトリ構造はこの様になります。
api
├ data/
├ ganbari/
├ api_server.py
└ requirements.txt
ここで、WORKDIR /api のコマンドでapiディレクトリ内に入りrequirements.txtを参照してライブラリをインストールします。RUN pip3 install -r requirements.txt以上がDockerfileの書き方となります。他にも沢山便利なコマンドがあるのでググってみて下さい。
ビルド
Dockerfileができたので早速イメージを作ります。DockerfileからDockerイメージを作ることをビルドと言います。
/kyoyu$ docker build -t [イメージの名前(名付ける)] [Dockerfileが存在するディレクトリのパス](-tは今は呪文と思っていて下さい)
今回、testという名前でイメージを作成し、"." (カレントディレクトリ(kyoyu))内にDockerfileが存在するので、実行するコードは次の様になります。/kyoyu$ docker build -t test .ラン。コンテナを作る
Dockerイメージからコンテナを作ることをランと言います。
$ docker run -p [外部からアクセスされるポート番号]:[コンテナ側のポート番号を指定] -it [イメージ名] --name [コンテナの名前(名付ける)](-itは後ほどDockerをstartした時に環境を維持するコマンドなので今は呪文だと思って下さい)
例えば、今回の例でDocker側の5000番ポートでAPIなどを実行する予定で、それをパソコン実機の8888番ポートに送りたいとする。コンテナ名をtestconとすると$ docker run -p 8888:5000 -it test --name testconとなる。
コンテナの起動
最後に、作ったDockerコンテナの中に入る。
$ docker ps -aこのコマンドでコンテナの一覧を見られるが、まず、ここにtestconがあることを確認する。
$ dockr start testconこれで、停止しているtestconコンテナを動かすことができる。お気持ちとしては、dockerコンテナは通常停止している状態で存在し、それをstartすることで動かす。動いたコンテナにattach(触る)ことで、仮想OS内に入ることができる。
$ dockr attach testconroot@hogehoge:/api#先頭が上の様な文字列になり、仮想OS内に入ることができた。ここで最初から/apiとなっているのはDockerfileでWORKDIR /apiと指定されているからである。
最後に
Dockerのお気持ち分かりましたか?Dockerって聞いたことある!くらいの層を対象にしているので、細かいところはググって下さい。
- 投稿日:2020-08-14T18:14:10+09:00
docker importでイメージを作るとき、storage driverにより途中ディレクトリのパーミッションが異なる
環境
# docker version Client: Version: 17.05.0-ce API version: 1.29 Go version: go1.7.5 Git commit: 89658be Built: Thu May 4 22:09:06 2017 OS/Arch: linux/amd64準備
単純のため、busybox static binaryを/bin/busyboxに置く設定にします。
chdir /tmp mkdir bin wget -O bin/busybox https://www.busybox.net/downloads/binaries/1.31.0-defconfig-multiarch-musl/busybox-x86_64 chmod 755 bin/busyboxテスト
tar -c bin/busybox | docker import /dev/stdin importtest; docker run -it --rm importtest /bin/busybox ls -l /; docker image rm importtest結果
dockerd --storage-driver=overlaydrw------- 2 0 0 4096 Aug 14 06:24 bin drwxr-xr-x 5 0 0 360 Aug 14 06:24 dev drwxr-xr-x 2 0 0 4096 Aug 14 06:24 etc dr-xr-xr-x 559 0 0 0 Aug 14 06:24 proc dr-xr-xr-x 13 0 0 0 Aug 14 06:24 sys
dockerd --storage-driver=overlay2drwxr-xr-x 2 0 0 4096 Aug 14 06:19 bin drwxr-xr-x 5 0 0 360 Aug 14 06:19 dev drwxr-xr-x 2 0 0 4096 Aug 14 06:19 etc dr-xr-xr-x 557 0 0 0 Aug 14 06:19 proc dr-xr-xr-x 13 0 0 0 Aug 14 06:19 sys
dockerd --storage-driver=aufsdrwxr-xr-x 2 0 0 4096 Aug 14 06:31 bin drwxr-xr-x 5 0 0 360 Aug 14 06:31 dev drwxr-xr-x 2 0 0 4096 Aug 14 06:31 etc dr-xr-xr-x 561 0 0 0 Aug 14 06:31 proc dr-xr-xr-x 13 0 0 0 Aug 14 06:31 sys
dockerd --storage-driver=vfsdrw------- 2 0 0 4096 Aug 14 06:08 bin drwxr-xr-x 5 0 0 360 Aug 14 06:19 dev drwxr-xr-x 2 0 0 4096 Aug 14 06:19 etc dr-xr-xr-x 554 0 0 0 Aug 14 06:19 proc dr-xr-xr-x 13 0 0 0 Aug 14 06:19 sysoverlayとvfsではパーミッションが非想定値になっていることがわかります。実際に、
docker run -it --rm --user $(id -u nobody) importtest /bin/busybox ls -l /binはPermission deniedとなり失敗します。結論
usr/bin/busyboxを置いてusr/binをtarした場合も同様でした(/usr/binは755だが/usrは600になる)。動的にイメージを作る場合は特に注意しましょう(Dockerfileを使う場合は影響がないようですが…)。
https://qiita.com/cielavenir/items/05e50fa6bb493040085e で「そういえば/var/lib/dockerがVOLUME指定されているかでdocker内dockerの挙動が変わるよな〜」とか思い出せたんですが、この経験がなかったら今日の仕事は死んでた(暗黙的にvfs driverに切り替わってたのが原因だった)。きっと。
- 投稿日:2020-08-14T18:07:15+09:00
チュートリアル - Docker odooコンテナで実行するカスタムアドオン
odoo のカスタムアドオン
このチュートリアルでは、Docker odoo コンテナを起動し、カスタムアドオンのひな形アプリケーションの実行と、サンプルアプリケーション「Open Academy」の実行を行います。
https://www.odoo.com/documentation/13.0/howtos/backend.html#build-an-odoo-module準備
Dockerのインストールを行います。
Dockerのインストール
Windows10で、Docker Desktop for Windowsをインストールします。
https://docs.docker.jp/docker-for-windows/toc.htmlodooの起動
Dockerを用いて、カスタムアドオン用ディレクトリをマウントしたodooコンテナを起動します。
カスタムアドオン用ディレクトリのマウント
odooコンテナ内で、カスタムアドオン用の
/mnt/extra-addonsディレクトリがodoo.confファイルで定義されています。odoo.conf[options] addons_path = /mnt/extra-addons :このチュートリアルでは、カスタムアドオンのソースコードを、Docker odoo コンテナ内ではなく、Dockerを起動しているWindows10の
C:\odoo13\addonsフォルダに保存します。このフォルダを Docker odoo コンテナから/mnt/extra-addonsフォルダとして読み書きできるようにマウントします。
オプション Windows10 コンテナ -v C:/odoo13/addons /mnt/extra-addons 2つのコマンド
Dockerでodooを起動する為には、コマンドプロンプトで、2つのコマンドを順に実行する必要があります。
1つ目は、postgreSQLであり、2つ目は、odooです。db.cmddocker run -d -e POSTGRES_USER=odoo -e POSTGRES_PASSWORD=odoo -e POSTGRES_DB=postgres --name db postgres:10odoo.cmddocker run -v C:/odoo13/addons:/mnt/extra-addons -p 8069:8069 --name odoo --link db:db -t odoo※ マウントされるディレクトリをShare(共有)するかどうか、聞かれますので、「
Share it」を選びます。データベースの作成とログイン
http://localhost:8069/ へアクセスし、
Create databeseでデータベースを作成します。
項目 値 Database Name openacademy admin Password admin Phone number (空欄) Language Japanese / 日本語 Country Japan Demo data チェック
カスタムアドオン・アプリケーション
2つの方法で、カスタムアドオン・アプリケーションを作成し、実行します。
- ひな形からの作成
- ソースコードのダウンロード
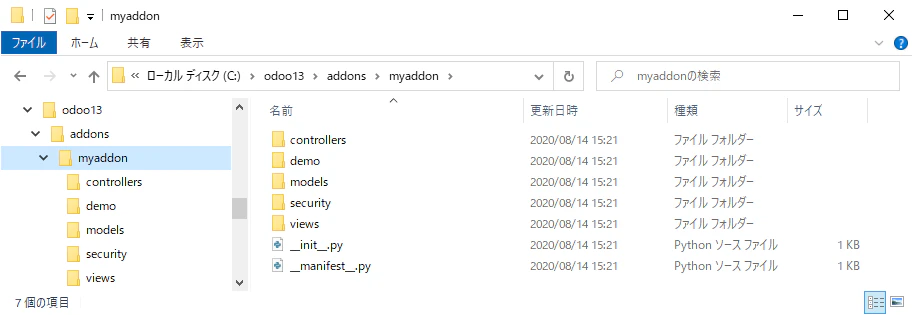
ひな形からの作成 - myaddon
odoo scaffold コマンド
odoo コンテナ内で、カスタムアドオン・アプリケーションのひな形'myaddon'を
/mnt/extra-addonsフォルダ内に作成します。
DockerのDashboardを開き、odooコンテナのCLIをクリックして、CLIを開いて、次のコマンドを実行します。CLI.cmdodoo scaffold myaddon /mnt/extra-addonsこのコマンドを実行すると、
/mnt/extra-addons/myaddonフォルダ内にひな形が作成されます。これは、Windows10上のC:\odoo13\addons\myaddonフォルダとして確認できます。
アプリケーション化
作成したひな形をアプリケーションとして認識させる為、
C:\odoo13\addons\myaddon\__manifest__.pyファイルを編集します。
applictation項目をTrueにすることにより、odooのアプリ管理画面のフィルターで、「アプリ」として表示されます。__manifest__.py# only loaded in demonstration mode 'demo': [ 'demo/demo.xml', ], # As application 'application': True, }アプリリストの更新
odooには、アプリを管理する機能があり、まずは、作成したアドオンをodooに認識させる必要があります。その為、「リスト更新」を行う必要があるのですが、デフォルトでは、それが無効化されています。
次の手順で有効化し、リストを更新します。
- 「アプリ」で、何らかのアプリをインストール - 例えば、「ディスカス」をインストールします(※)。
- 「管理設定」の「一般設定」で、「開発者ツール」の「開発者モードを有効化」をクリックします(※)。
- 「アプリ」で、「アプリリストを更新」メニューが現れますので、それで更新します。
- 検索欄に
myaddonを入力して、アプリリストの検索を行います。myaddonアプリが表示されていることを確認できます。※注:1で何らかのアプリをインストールするまでは、2の「一般設定」は表示されません。
アプリのインストール
「アプリ」で表示された
myaddonのインストールで、myaddonアプリをインストールします。
ただし、インストールに成功しても、ひな形のままでは、myaddonアプリは、表示されません。ひな形アプリの編集
myaddonアプリが動作するようにソースコードのコメントアウトを削除します。
C:\odoo13\addons\myaddon\__manifest__.py(L.27)__manifest__.py: # always loaded 'data': [ 'security/ir.model.access.csv', 'views/views.xml', 'views/templates.xml', ], :
C:\odoo13\addons\myaddon\controllers\controllers.pycontrollers.py# -*- coding: utf-8 -*- from odoo import http class Myaddon(http.Controller): @http.route('/myaddon/myaddon/', auth='public') def index(self, **kw): return "Hello, world" @http.route('/myaddon/myaddon/objects/', auth='public') def list(self, **kw): return http.request.render('myaddon.listing', { 'root': '/myaddon/myaddon', 'objects': http.request.env['myaddon.myaddon'].search([]), }) @http.route('/myaddon/myaddon/objects/<model("myaddon.myaddon"):obj>/', auth='public') def object(self, obj, **kw): return http.request.render('myaddon.object', { 'object': obj })
C:\odoo13\addons\myaddon\demo\demo.xmldemo.xml<odoo> <data> <record id="object0" model="myaddon.myaddon"> <field name="name">Object 0</field> <field name="value">0</field> </record> <record id="object1" model="myaddon.myaddon"> <field name="name">Object 1</field> <field name="value">10</field> </record> <record id="object2" model="myaddon.myaddon"> <field name="name">Object 2</field> <field name="value">20</field> </record> <record id="object3" model="myaddon.myaddon"> <field name="name">Object 3</field> <field name="value">30</field> </record> <record id="object4" model="myaddon.myaddon"> <field name="name">Object 4</field> <field name="value">40</field> </record> </data> </odoo>
C:\odoo13\addons\myaddon\models\models.pymodels.py# -*- coding: utf-8 -*- from odoo import models, fields, api class myaddon(models.Model): _name = 'myaddon.myaddon' _description = 'myaddon.myaddon' name = fields.Char() value = fields.Integer() value2 = fields.Float(compute="_value_pc", store=True) description = fields.Text() @api.depends('value') def _value_pc(self): for record in self: record.value2 = float(record.value) / 100
C:\odoo13\addons\myaddon\views\templates.xmltemplates.xml<odoo> <data> <template id="listing"> <ul> <li t-foreach="objects" t-as="object"> <a t-attf-href="#{ root }/objects/#{ object.id }"> <t t-esc="object.display_name"/> </a> </li> </ul> </template> <template id="object"> <h1><t t-esc="object.display_name"/></h1> <dl> <t t-foreach="object._fields" t-as="field"> <dt><t t-esc="field"/></dt> <dd><t t-esc="object[field]"/></dd> </t> </dl> </template> </data> </odoo>
C:\odoo13\addons\myaddon\views\views.xmlviews.xml<odoo> <data> <!-- explicit list view definition --> <record model="ir.ui.view" id="myaddon.list"> <field name="name">myaddon list</field> <field name="model">myaddon.myaddon</field> <field name="arch" type="xml"> <tree> <field name="name"/> <field name="value"/> <field name="value2"/> </tree> </field> </record> <!-- actions opening views on models --> <record model="ir.actions.act_window" id="myaddon.action_window"> <field name="name">myaddon window</field> <field name="res_model">myaddon.myaddon</field> <field name="view_mode">tree,form</field> </record> <!-- server action to the one above --> <record model="ir.actions.server" id="myaddon.action_server"> <field name="name">myaddon server</field> <field name="model_id" ref="model_myaddon_myaddon"/> <field name="state">code</field> <field name="code"> action = { "type": "ir.actions.act_window", "view_mode": "tree,form", "res_model": model._name, } </field> </record> <!-- Top menu item --> <menuitem name="myaddon" id="myaddon.menu_root"/> <!-- menu categories --> <menuitem name="Menu 1" id="myaddon.menu_1" parent="myaddon.menu_root"/> <menuitem name="Menu 2" id="myaddon.menu_2" parent="myaddon.menu_root"/> <!-- actions --> <menuitem name="List" id="myaddon.menu_1_list" parent="myaddon.menu_1" action="myaddon.action_window"/> <menuitem name="Server to list" id="myaddon" parent="myaddon.menu_2" action="myaddon.action_server"/> </data> </odoo>アプリのアップグレード
アプリの「アップグレード」で、ひな形アプリ
myaddonの編集を反映します。
※ 「アップグレード」する際に「モデルが見つかりません: myaddon.myaddon」のエラーが発生しますので、事前にodooコンテナを再起動します。
アプリの確認
「myaddon」を選択すると、デモ用データの一覧が表示されます。
ソースコードのダウンロード - Open Academy
ダウンロードと展開
Open Academy のソースコードをダウンロードします(
Code>Download ZIP)。
https://github.com/ugurcanusta55/openAcademy-Odoo13ダウンロードしたファイルを
C:\odoo13\addonsフォルダにopenacademyアプリとして、展開します。
ソースコードの修正
ダウンロードしたソースコードのままでは、デモ用データの読み込みに失敗しますので、
C:\odoo13\addons\openacademy\__manifest__.pyファイルを修正します。
また、アプリとして認識されるように'application': True,を追記します。__manifest__.py: ], # only loaded in demonstration mode 'demo': [ 'demo/demo.xml', ], 'application': True, }アプリリストの更新とインストール
「アプリ」画面で、「アプリリストの更新」を実施し、
openacademyをインストールします。
インストールすると、「Open Academy」を開くことができますが、ユーザーには、閲覧権限しかありません。
権限の付与
アプリの権限は、ユーザーに付与することができます。「管理設定」>「ユーザーと会社」>「ユーザー」で、ユーザーの編集を行います。「OpenAcademy / Manager」をチェックし、保存します。
再ログイン後に有効
再ログインすると、権限が有効化され、Open Academyの編集が可能となります。
おわりに
このチュートリアルでは、Windows10のDocker環境でodooのカスタムアドオンを実行しました。
- Windows10のフォルダをDocker odoo コンテナから読み書きできるようにしました。
- odoo scaffold コマンドで、カスタムアドオンのひな形を生成し、実行できるようにしました。
- Open Academyというサンプルアプリケーションのソースコードをダウンロードし、実行できるようにしました。
- odoo上でカスタムアドオンを認識できるように「アプリリストの更新」のコツを学びました。
- アプリケーション特有の権限をユーザーに付与する方法を学びました。
尚、odooでは、RDBMSにpostgreSQLを使用していますが、DDLやDMLを直接的に記述する必要はありません。odooに搭載されたORM機構により、高速開発を可能としています。







- 投稿日:2020-08-14T14:50:57+09:00
DockerのMySQLへのinsertでError Code: 1366. Incorrect string value: 'xx' for column 'name' at row 1
事象
日本語を含むinsert分で上記エラーが発生。
対応
以下を確認すると文字コードが
latin1になっているのが原因。mysql> status; -------------- mysql Ver 14.14 Distrib 5.7.31, for osx10.15 (x86_64) using EditLine wrapper Connection id: 174 Current database: xxx Current user: root@xxx SSL: Cipher in use is DHE-RSA-AES256-SHA Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 5.7.26 MySQL Community Server (GPL) Protocol version: 10 Connection: 127.0.0.1 via TCP/IP Server characterset: latin1 Db characterset: latin1 Client characterset: utf8 Conn. characterset: utf8 TCP port: 13307 Uptime: 2 days 3 hours 37 min 13 sec Threads: 3 Questions: 2106 Slow queries: 0 Opens: 219 Flush tables: 1 Open tables: 212 Queries per second avg: 0.011 --------------以下で確認したところmy.cnfがない。
docker container exec -it xxx bash cat /etc/mysql/conf.d/my.cnfDockerfileが間違っていた。(mysqlではなくmusql)
ADD ./Docker/mysql/conf.d/my.cnf /etc/musql/conf.d/my.cnf上記修正をした上で、以下でコンテナを再作成。
(再起動でも良いのだけど、もう一度マイグレーションをロールバックして、再実行するのが手間だと感じたので)docker-compose down --rmi all --volumes docker-compose up -d参考
- 投稿日:2020-08-14T14:35:02+09:00
【学習メモ】Docker(コンテナの詳細)
コンテナについて
docker runの「run」って?
run = create + start
create:コンテナを作る
start:コンテナを起動してデフォルトコマンドを実行しExitedされるdocker: Error response from daemon: OCI runtime create failed: container_linux.go:349: starting container process caused "exec: \"bash\": executable file not found in $PATH": unknown.こうなったとき、Ubuntuは指定しなくても、bashが自動的に実行される
ただ、デフォルトコマンドは下記のように上書きできる
user$ docker run ubuntu ls #デフォルトにするコマンド-itの正体
-i:インプット可能な状態にする(キーボードで
打ったものをちゃんとコンテナに反映させる)
-t:出力結果をきれいにするコンテナの削除
exitしたコンテナは業務で使うことないので削除が必要
またSTATUSが「UP」にある場合、削除ができないので、下記コマンドで削除
docker stop コンテナのNAMEコンテナの名前を指定して使いたいとき
・起動させ続けるコンテナを立てるとき
・共有サーバーを使うとき
・他のプログラムで使用するときdocker run --name <コンテナ名:sample_container> <image:ubuntu>コンテナの削除ーdetachedとforeground
$ docker run -d <image> #コンテナ起動後にdetachする(バックグラウンドで動かす) $ docker run --rm <image> #コンテナをExitしたら削除する(1回きりのコンテナ)
- 投稿日:2020-08-14T13:16:06+09:00
Docker Hub の新しいコンテナ・イメージ保管ポリシー(参考訳)
原文:
Container Image Retention Policy | Docker
https://www.docker.com/pricing/retentionfaqこちらに書かれている内容を把握するためのものです。
TL;DR(今北産業)
- Docker Hub の Free プランは、6ヶ月間使っていない(inactive)イメージが削除対象で、2020 年 11 月 1 日から適用
- 「inactive」タグとは、一定期間(現在の Free プランは 6ヶ月間)使われていないイメージ(pullもpushもしていない)が対象
- Docker Hub の容量は 15PB で、半年以上使われていないイメージが 4.5PB →運用最適化とサービス強化のため実施
コンテナ・イメージ保管ポリシー (Container Image Retention Policy)
FAQ
Docker 利用規約とは何ですか?
Docker 利用規約(Terms of service)とは、Docker プロダクトとサービスの利用に適用する、あなたと Docker 間における合意です。リンクをクリックすると、 Docker 利用規約 の全文を表示します。
Docker 利用規約の発行はいつですか?
Docker 利用規約 の更新は、直ちに発行します。
利用規約の何が変わりましたか?
最も著しい変更はセクション 2.5 です。全ての変更を確認するために、私たちは 利用規約 全文を読むのを推奨します。
コンテナ・イメージの保管期限とは何ですか? 私のアカウントにどのような影響がありますか?
イメージの保管(image retention)は、ユーザ・アカウントで保管している各イメージの利用状況に基づきます。自分のサブスクリプション・プランで定められた期間において、もしもイメージが pull あるいは push のどちらもなければ、そのイメージにはタグ「inactive」(使用されていない)が付けられます。「inactive」タグが付いたあらゆるイメージが削除予定です。 Free individual(個人)または organization プランのアカウントのみ、イメージの保管期限に従う必要があります。Docker Hub で利用可能になる新しいダッシュボードでは、コンテナイメージの全ての状態を一覧表示できるようになります。
コンテナ・イメージ保管期限とは何が新しいのですか?
Docker はコンテナ・イメージ保管期限ポリシーを 2020 年 11 月 1 日から実施します。コンテナ・イメージ保管ポリシーは、以下のプランが適用対象です。
- Free プランでは、イメージ保管期限が6ヶ月
- Pro および Team プランでは、イメージ保管期限が無制限
「inactive」なイメージとは何ですか?
「inactive」イメージとは、イメージのリポジトリから6ヶ月(半年間) push も pull のどちらも行われていないコンテナ・イメージです。
どのようにしてイメージの状態を確認できますか?
Docker Hub リポジトリ内にある全てのイメージに「Last pushed」(最終送信)の日付があり、これはアカウントでリポジトリにログインすると簡単に見つけられます。
inactive イメージが有効期限に至るとどうなりますか?
2020 年 11 月 1 日の当初、「inactive」とマークされた全てのイメージが削除予定になります。また、アカウントの所有者は「inactive」イメージが削除予定であるというメールの通知が届きます。
コンテナ・イメージを無期限にできますか?
イメージ保管期限が適用されるのは Free の個人および organization アカウントのみです。 Pro および Team アカウントは保管期限の適用対象外です。もしも Free アカウントをお持ちであれば、Pro や Team アカウントに定期プランで月額5ドルからでアップグレードできます。詳しい情報はこちらをご覧ください:https://www.docker.com/pricing
なぜ Docker は「inactive」イメージ・ポリシーを導入するのですか?
Docker Hub は 15PB のデータを保管する世界最大のコンテナ・イメージ保管庫(リポジトリ)です。Docker Hub に保管されているコンテナ・イメージの詳細を解析したところ、4.5PB のデータが半年以上にわたって push または pull されていないことが分かりました。
私たちは運用の最適化にこのような取り組みを行い、そして、アプリケーションの構築と移動のために Docker Hub サービスを使う世界中の開発者と開発チームのため、一層のサービス強化を行います。原文
Container Image Retention Policy | Docker
https://www.docker.com/pricing/retentionfaq
- 投稿日:2020-08-14T12:02:14+09:00
KubeadmでインストールしたAlibaba CloudにKubernetes Clusterをインストールする
このチュートリアルでは、Kubernetesの管理をより簡単にするツールであるKubeadmを使ってインストールしたAlibaba CloudにKubernetesクラスタをインストールする方法を紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
前提条件
このチュートリアルを開始する前に、以下の項目が揃っていることを確認してください。
- 3台のAlibaba Cloud ECSインスタンスがUbuntu 16.04でインストールされており、最低1GBのRAMを搭載しています。
- 3台のサーバーへのルートアクセス
- Dockerイメージからのコンテナ起動経験があること。
具体的には、以下のように3つのサーバーやホストにkube-1、kube-2、kube-3などの馴染みのある名前をつけておくと良いでしょう。
Server Hostname 1 kube-01 2 kube-02 3 kube-03 このチュートリアルでは、3台のホストにマスターと2台のワーカーとしてロールを作成します。Kubernetes クラスタの設定には必須ではありませんが、以下のことを覚えておいてください。
Assigned roles Hostname Master kube-01 Worker kube-02 Worker kube-03 それでは、サーバーの準備を進めます。
手順
以下の手順に従って、Kubernetes クラスタを Kudeadm で Alibaba にインストールしてください。
サーバーの準備
このステップでは、Kubernetes クラスターの設定のためにサーバーを準備します。サーバーを準備する最初のステップは、仮想サーバーに固有のホスト名を設定することです。このチュートリアルでは、kube-1、kube-2、およびkube-3を使用することをお勧めします。また、MACアドレスやその他のユニークな識別子も必要になります。実際には、Alibaba Cloudが自動的にユニークな識別子をサーバに割り当ててくれるので、ホスト名もユニークなものにしておきましょう。
サーバーを準備する次のステップは、Kubernetes API Server用のポート6443とKubelet API用のポート10250をそれぞれ有効にすることです。要件として、以下のコマンドをrootユーザで実行する必要があります。
コマンドを実行します。
firewall-cmd --get-Active-zones次に、以下のコマンドを実行してポートを有効にします。
firewall-cmd --zone=public --add-port=6443/tcp --permanent firewall-cmd --zone=public --add-port=10250/tcp —permanent最後に、以下のコマンドを実行してswapパーティショニングをオフにする必要があります。
sudo swapon -s sudo swapoff -a最初のコマンドはスワップリストをチェックし、次のコマンドはスワップリストを無効にします。3つのサーバーインスタンスのすべてのコマンドを繰り返して、次のステップに進みます。しかし、永久的に無効にするには、お気に入りのエディタで
/etc/fstabファイルにアクセスする必要があります。sudo nano /etc/fstab次に、以下の行を見つけて、以下のように
a#コメントをつけます。#/dev/mapper/hakase--labs--vg-swap_1 none swap sw 0 0 0以下のコマンドで保存して終了し、システムを再起動します。
sudo rebootDockerのインストール
私たちは、コンテナランタイムのためにDockerをステップアップし、将来のプロジェクトのために、そしてもちろん、このチュートリアルのレッスンを実演する目的でコンテナを実行するためにDockerをiinstallします。UbuntuサーバーへのDockerのインストールは、3つのサーバーすべてで以下のコマンドを実行するだけで簡単です。
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add ¨C sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" sudo apt-get update apt-get install -y docker-ce注意したいのは、Kubernetesは最新のDocker Engineのバージョンをサポートしており、新しいバージョンをインストールした場合に競合が発生する可能性があるということです。そのため、インストールされているKubernetesリリースのサポートされているバージョンを確認するようにしてください。
以下のコマンドでDockerのバージョンを確認します。
docker version正しいバージョンがインストールされている場合は、間違って更新されてしまい、結果的にKubernetesとの互換性がなくなってしまうことがないように、ホールドする必要があるかもしれません。
sudo apt-mark hold docker-ce以下のコマンドでDockerを有効化して起動します。
sudo systemctl enable docker sudo systemctl start dockerこれでコンテナランタイムがインストールされ、Kubeadmツールキットをデプロイする準備が整いました。
Kubeadm、Kubelet、Kubectl のインストール
このステップでは、クラスタを構成する 3 台のサーバに SSH 接続し、3 つのコンポーネントをインストールする必要があります。ここでも、これらのコマンドを実行するためには root でログインする必要があります。
したがって、以下のコマンドを Kube-1, Kube-2, Kube-3 で実行してください。
apt-get update && apt-get install -y apt-transport-https curl curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cd /etc/apt sudo nano sources.list.d/kubernetes.list下の行をファイルに貼り付けてください。
deb http://apt.kubernetes.io/ kubernetes-xenial mainそして、以下のコマンドを実行します。
apt-get update apt-get install -y kubelet kubeadm kubectlしかし、KubernetesがDockerと互換性のないバージョンにアップデートされないようにしなければなりません。以下のコマンドを実行して、パッケージマネージャを更新して、Kubernetesを潜在的な更新から除外するようにします。
sudo apt-mark hold kubelet kubeadm kubectlパッケージが同期していることを確認したので、cgroup ドライバの設定を行います。
kube-1 でデフォルトの cgroup Driver を設定する
これは必須のステップではなく、このステップを進めるかバイパスするかは、以下のコマンドの結果に依存します。kube-1サーバでは、以下のコマンドを実行します。
sudo docker info | grep -i cgroupこのコマンドの出力がこの種のものであれば、cgroup の設定が必要になります。
Cgroup Driver: cgroupfsここで、
kubeletのデフォルトファイルを修正し、上で見たCgroupドライバをインクルードします。お気に入りのエディタ (私は nano を使用しています) で、以下のコマンドを実行します。sudo nano /etc/default/kubeletファイルに以下の行を含めてください。
KUBELET_KUBEADM_EXTRA_ARGS= - cgroup-driver=< cgroupfs >ここで、以下のコマンドを実行してKubeletを再起動します。
systemctl daemon-reload systemctl restart kubeletこれで、次のステップのマスター設定の準備が整いました。
マスターノードの初期化
kube-1サーバにSSHしてマスターノードを起動します。必要なコマンドは以下の通りです。
kubeadm init --pod-network-cidr=192.168.100.10/6433サーバーの準備中に、ポート6443と10250を有効にしました。ここで、上のコマンドの
10.244.0.0.0/16をIP/ポートの組み合わせに置き換えてください。上記の
kubeadm initコマンドを分解してみましょう。
--pod-network-cidr: クラスタのPodネットワークセグメントを定義します。--apiserver-advertis-address: この引数はKubernetes APIで使用するIPアドレスを定義します。--apiserver-cert-extra-sans:この引数は、証明書のsansに含まれるIPやドメインを定義し、ホストマシンのホスト名とIP以外の情報を含むようにします。 実行すると、黒い画面に数字が表示され、最後にYour Kubernetes master has initialized successfully!となります。また、あなたがマスターにリンクするためにワーカーノードで実行される行を取得する必要があります。さて、これらのコマンドを実行するためにrootではないユーザを使用している場合は、以下の手順でユーザシェル環境を変更してください。
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config先ほども述べたように、ワーカーノードで実行してマスターと連携させるための行も取得しておきましょう。
kubeadm join 192.168.100.10/6433--token bkz1q4.yuevvvhvve90jk --discovery-token-ca-cert-hash sha256. F3409C6C295F87249D5C08DA11791F3452950A0ACE646DF2BAD06514940DF847この行は非常に便利で、これがないとワーカーノードをクラスタに参加させることができません。2つのワーカーをリンクする準備のためにコピーしておきましょう。ただし、生成してから24時間以上経過している場合は、以下のコマンドで再生成する必要があります。
kubeadm token create --print-join-commandさて、次のステップでクラスタネットワークを展開してみましょう。
Kubernetesクラスタネットワーキングの展開
クラスタネットワークは、ポッド、コンテナ、外部サービスとノード間の通信を容易にします。選択したモデルはFlannelで、以下のコマンドを実行して適用します。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlここまででクラスタネットワークの設定を行いましたが、以下のコマンドを実行することで確認することができます。
kubectl get deployments --all-namespaces自分のマスターが一覧表示されているはずです。では、ワーカーを追加していきましょう。
Workerを追加
マスターノードを起動したところ、初期化コマンドが届きました。残りのサーバ(kube-1とkube-2)では、以下のコマンドを実行してWorkerとして追加します。
kubeadm join 192.168.100.10/6433--token bkz1q4.yuevvhvve90jk --discovery-token-ca-cert-hash sha256: F3409C6C295F87249D5C08DA11791F3452950A0ACE646DF2BAD06514940DF847注意点として、このステップの前にワーカーノードにDocker、kubeadm、kubernetesをインストールしておく必要があります。コマンドが実行されると、
This node has joined the clusterというメッセージが表示されるはずです。すべてのホストにコマンドを繰り返します。
クラスタの検証
クラスタは、さまざまな理由でセットアップ時に失敗する可能性があります。そのため、すべてのノードが正常に動作していることを確認することが重要です。以下のSSHコマンドでマスターノードから確認します。
ssh ubuntu@master_ip次に、以下のコマンドを実行してクラスタの状態を取得します。
kubectl get nodes同じような出力を受けるはずです。
Output NAME STATUS ROLES AGE VERSION Kube-1 Ready master 1d v1.10.1 Kube-2 Ready <worker> 1d v1.10.1 Kube-3 Ready <worker> 1d v1.10.1出力がすべてのノードの準備ができていることを示している場合は、いくつかのワークロードの実行に進むことができます。準備ができていない場合は、5分ほど待ってから再度実行してみてください。失敗した場合は、成功するまでインストールを繰り返します。
結論
このチュートリアルでは、Kubeadmを使用してUbuntuでKubernetesクラスタをセットアップする方法をご案内しました。クラスタに新しいサービスをデプロイしてみて、Kubernetesでの作業を快適にすることができます。Kubernetesは、Kubernetes公式ドキュメントから学ぶことができる機能や大きなアドバンテージを提供しています。アリババクラウドは、これらのKubernetesで作られたコンテナ化されたアプリケーションを実行するための安定した信頼性の高いクラウドプラットフォームを提供しています。
Alibaba Cloudのアカウントをお持ちですか?アカウントにサインアップして、最大1200ドル相当の40以上の製品を無料でお試しください。Alibaba Cloudの詳細については、「Get Started with Alibaba Cloud」を参照してください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-08-14T11:07:34+09:00
docker image を使って Elasticsearch & Kibana を実行してみるまで
1.はじめに
Elasticsearch は、分散型の RESTful 検索/分析エンジンです。Kibana は Elasticsearch でインデックスされたデータに、検索や可視化の機能を提供するフロントエンドアプリケーションです。
本格的に使うためには、複数のノードからなる Elasticsearch クラスタの構築が必要となりますが、手元のローカル環境でお試しに実行してみることも可能です。
Kibana と共に構築することで、Elasticsearch に対するクエリを簡単に実行することが出来ます。
今回は、Elasticsearch と Kibana の Docker Image を使用し、ローカル環境で Elasticsearch と Kibana を実行していきます。2.(参考) 実行環境
2-1. docker と docker-compose がインストールされている
それぞれがインストールされていることが前提になっています。
$ docker -v Docker version 19.03.6, build 369ce74a3c$ docker-compose -v docker-compose version 1.17.1, build unknown2-2. スペック
メモリはトータルで8GB搭載されているマシンを使用しました。(コンテナを計4つ起動させるため、4GB程度では厳しいかもしれません)
$ cat /etc/issue Ubuntu 18.04.2 LTS$ cat /proc/meminfo | grep Mem MemTotal: 8168284 kB MemFree: 6812556 kB MemAvailable: 7545960 kB3. docker network の作成
専用の docker network を使用し、コンテナに割り当てるIPアドレスを固定させるため、以下のコマンドで定義します。
$ docker network create spark-nw --subnet=172.30.0.0/16 --gateway=172.30.0.254将来的に Apache spark のアプリケーションと連携させることを想定しているため、spark-nw という名前に個人的にしていますが、実際にところは何でも構わないです。
4. docker-compose の準備
以下のようなファイル(docker-compose.yml)を用意します。
Elastic社は、Elasticsearch や kibana 用の Docker Image を公式に提供してくれていますので、今回はそれを使います。
執筆時点で最新の 7.8.1 を指定していますが、最近の Elasticsearch は非常に頻繁に更新されています。
バージョンが 8.x.x などになると、インタフェースなどの仕様が大きく変更されているかもしれません。docker-compose.ymlversion: '2' services: elasticsearch1: image: docker.elastic.co/elasticsearch/elasticsearch:7.8.1 hostname: doc-elastic101 container_name: es01 environment: - cluster.name=es-docker-cluster - network.host=0.0.0.0 - node.name=es01 - node.master=true - node.data=true - discovery.seed_hosts=es02,es03 - cluster.initial_master_nodes=es01,es02,es03 - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 mem_limit: 1g ports: - "9200:9200/tcp" networks: spark-nw: ipv4_address: 172.30.10.1 volumes: - elasticsearch1-data:/usr/share/elasticsearch/data extra_hosts: - "doc-elastic102:172.30.10.2" - "doc-elastic103:172.30.10.3" - "doc-kibana101:172.30.20.1" elasticsearch2: image: docker.elastic.co/elasticsearch/elasticsearch:7.8.1 hostname: doc-elastic102 container_name: es02 environment: - cluster.name=es-docker-cluster - network.host=0.0.0.0 - node.name=es02 - node.master=true - node.data=true - discovery.seed_hosts=es01,es03 - cluster.initial_master_nodes=es01,es02,es03 - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 mem_limit: 1g networks: spark-nw: ipv4_address: 172.30.10.2 volumes: - elasticsearch2-data:/usr/share/elasticsearch/data extra_hosts: - "doc-elastic101:172.30.10.1" - "doc-elastic103:172.30.10.3" - "doc-kibana101:172.30.20.1" elasticsearch3: image: docker.elastic.co/elasticsearch/elasticsearch:7.8.1 hostname: doc-elastic103 container_name: es03 environment: - cluster.name=es-docker-cluster - network.host=0.0.0.0 - node.name=es03 - node.master=true - node.data=true - discovery.seed_hosts=es01,es02 - cluster.initial_master_nodes=es01,es02,es03 - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 mem_limit: 1g networks: spark-nw: ipv4_address: 172.30.10.3 volumes: - elasticsearch3-data:/usr/share/elasticsearch/data extra_hosts: - "doc-elastic101:172.30.10.1" - "doc-elastic102:172.30.10.2" - "doc-kibana101:172.30.20.1" kibana: image: docker.elastic.co/kibana/kibana:7.8.1 hostname: doc-kibana101 container_name: kibana1 environment: SERVER_NAME: "kibana" ELASTICSEARCH_HOSTS: "http://doc-elastic101:9200" ELASTICSEARCH_REQUESTTIMEOUT: "60000" ports: - "5601:5601/tcp" mem_limit: 1g networks: spark-nw: ipv4_address: 172.30.20.1 extra_hosts: - "doc-elastic101:172.30.10.1" - "doc-elastic102:172.30.10.2" - "doc-elastic103:172.30.10.3" depends_on: - elasticsearch1 - elasticsearch2 - elasticsearch3 volumes: elasticsearch1-data: driver: local elasticsearch2-data: driver: local elasticsearch3-data: driver: local networks: spark-nw: external: trueこちらの docker-compose.yml ファイルからは、3つの elasticsearch[1-3] と 1つの kibana コンテナが生成されることになります。
本来、elasticsearch.yml や kibana.yml を設定ファイルとして使用しますが、今回は設定ファイルを用意する手間を省くため、docker-compose 内の environment から定義 しています。5. コンテナのビルド・開始
docker-compose.yml が配置されているディレクトリで以下のコマンドを実行します。
$ docker-compose up --build -d Pulling elasticsearch1 (docker.elastic.co/elasticsearch/elasticsearch:7.8.1)... 7.8.1: Pulling from elasticsearch/elasticsearch (省略) Creating es03 ... Creating es01 ... Creating es02 ... Creating es03 Creating es02 Creating es01 ... done Creating kibana1 ... Creating kibana1 ... doneコマンドで確認すると、docker-compose.yml 内で指定した docker image がローカルにダウンロードされたことが確認できます。
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE docker.elastic.co/kibana/kibana 7.8.1 22bc1dd9a48a 3 weeks ago 1.3GB docker.elastic.co/elasticsearch/elasticsearch 7.8.1 a529963ec236 3 weeks ago 811MBデフォルトでは、kibana の方が elasticsearch の Image よりもサイズが大きいようです。Plugin などを含めるとサイズは大きく変わると思います。
また、それぞれのコンテナ(elasticsearch 3つ、kibana 1つ)が起動されていることが確認できます。
$ docker ps --format "{{.Names}}" kibana1 es01 es02 es03Webブラウザもしくは、curl コマンドなどで Elasticsearch にアクセスしてみます。
cluster_name("es-docker-cluster") や、Elasticsearch のバージョン("7.8.1")など、正しく返ってきているようです。$ curl http://localhost:9200/ { "name" : "es01", "cluster_name" : "es-docker-cluster", "cluster_uuid" : "FYnfjxEpQ6OFvFc5_NdT5A", "version" : { "number" : "7.8.1", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "b5ca9c58fb664ca8bf9e4057fc229b3396bf3a89", "build_date" : "2020-07-21T16:40:44.668009Z", "build_snapshot" : false, "lucene_version" : "8.5.1", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }6. Kibana からクエリを実行
Dev tools 画面を開く
Web ブラウザから http://localhost:5601 にアクセスすると、Kibana コンソールが起動します。
※kibana is not ready yet が表示された場合は、しばらく経ってから再度アクセスしてみます。実行マシンのスペックによって、時間がかかるもしくは起動できない場合があります。左サイドのメニューから
"Dev tools" を開きます。
こちらの画面から Elasticsearch に対して、クエリを実行することが出来ます。
Cluster の状態チェック
GET /_cluster/health
"number_of_nodes" : 3 とあるように、Elasticsearch のノードが3つ(Docker container 3つ)存在していることが分かります。
node や インデックス情報を取得する _cat API
クエリは次の行以降に続けて書くことができます。また、?v を付けることで各情報を意味するヘッダー付きで出力されます。
GET /_cat/nodes?v
es01 が Master として動作していることが分かります。
インデックスを調べる
GET /_cat/indices?v
この画面上には多くのインデックスが既に存在していますが、実際に初めて起動した段階では、数個のインデックス(Kibana が管理用にデフォルトで作成するもの)のみが存在しているはずです。
インデックス内のドキュメント数とサイズが確認できるので、将来的なクラスタのサイズ設計に役立ちます。7. さいごに
Elasticsearch はRESTful 検索/分析エンジンと呼ばれるだけあって、様々なAPIが用意されています。クエリは curl コマンドから実行することも可能ですが、Kibana Dev tool は見易いクエリ実行環境を提供してくれます。
今回は GET クエリしか実行していませんが、PUT クエリからサンプルデータを投入し、その内容をすぐに GET で取り出すなど可能です。
Kibana はデータの Visualize Tool に特化しているだけでなく、開発時の補助ツールとして使用することが検討できます。
docker image を使用することで、最短5分ほどで Elasticsearch, Kibana の実行環境まで用意することができます。







- 投稿日:2020-08-14T11:04:45+09:00
Jenkinsを使って、Docker内でビルドしてからDocker imageを作成する。
はじめに
Jenkinsを使って、Mavenコンテナ内でビルドしていました。
どうせならDocker imageまでも一気通貫でやりたくて作成。
思っていたよりも作成に時間がかかった。リポジトリ構成
src Dockerfile Jenkinsfile pom.xmlgitリポジトリにソースと上記のファイルを格納しています。
Dockerfile
FROM tomcat:jdk14-openjdk COPY target/*.war /usr/local/tomcat/webapps/ビルドでできたwarファイルをwebapps配下に格納しています。
コードと同じリポジトリで管理します。Jenkinsfile
pipeline { agent any stages { stage('delete_workspace') { steps { deleteDir() } } stage('build') { agent { docker { label 'master' image 'maven:3.6.3-openjdk-14' } } steps { // Run Maven on a Unix agent. sh "mvn clean package" } post { success { archiveArtifacts 'target/*.war' } } } stage('docker build') { agent { label 'master'} steps { sh 'docker build -t test-tomcat:0.1 .' } //// 事後に削除する場合。 // post { // always { // deleteDir() // } // } } } }Declarative Pipelineで作成。
stage
エージェント指定
pipeline { agent any stages {agent any がないとジョブが失敗したので記載している。
delete_workspace
stage('delete_workspace') { steps { deleteDir() } }事前にworkspaceを削除、事後に必ずやるパターンもあるがジョブにエラーが出たとき、削除されると個人的に切り分けが困るので、ジョブの事前にやる派です。
build
agent { docker { label 'master' image 'maven:3.6.3-openjdk-14' } }マスターノードにてでmavenコンテナを起動しています。
地味にノードの指定がこの位置だと気づくのに時間がかりました。steps { // Run Maven on a Unix agent. sh "mvn clean package" } post { success { archiveArtifacts 'target/*.war' } }maven ビルドして、成果物を保存しています。
docker build
stage('docker build') { agent { label 'master'} steps { sh 'docker build -t test-tomcat:0.1 .' } //// 事後に削除する場合。 // post { // always { // deleteDir() // } // } }マスターでdockerを起動したので、agentをマスターに指定。
ホストのworkspace配下にmavenコンテナでビルドした成果物とDockerfileが格納されているので、
そのままdocker build を実行。まとめ
コンテナないでビルドしてもホストのworkspaceにビルド結果が残るのを知らなかったので、
すっごく作成に時間がかかった。
また、jenkinsでdockerを利用して色々やるにはScripted Pipelineで書かなければいけないことがわかった。
jenkinsに限っては、pipelineで頑張るより、Ansibleやdocker-composeのコマンドを呼び出すほうがシンプルだし、
保守性も高いのではと感じた。実際はどっちなのだろうか。参考文献
- 投稿日:2020-08-14T10:52:54+09:00
Ubuntu 18.04をインストールしたAlibaba CloudにマルチノードHadoopクラスタをインストールする方法
このチュートリアルでは、Ubuntu 18.04をインストールしたAlibaba Cloud ECSインスタンス上にマルチノードHadoopクラスタをセットアップする方法を紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
前提条件
このチュートリアルでは、特に2つの異なるAlibaba Cloud ECSインスタンス上でDataNodeを実行します。2つのECSインスタンスを以下のように設定します。
最初のインスタンス(マスターマシン/システムとして設定されている)はHadoop-masterで、IPアドレスは172.31.129.196です。
2つ目のインスタンス(スレーブマシン/システムとして設定されている)は、Hadoop-slaveで、IPアドレスは172.31.129.197です。手順
Javaのインストール
今、我々はHadoopマルチノードクラスタを設定する方法に入る前に、両方のシステムは、それらにインストールされているJava 8を持っている必要があります。これを行うには、まず、Java 8をインストールするために、マスターとスレーブの両方のマシンで以下のコマンドを実行します。
root@hadoop-master:~# sudo add-apt-repository ppa:openjdk-r/ppa root@hadoop-master:~# sudo apt-get update root@hadoop-master:~# sudo apt-get install openjdk-8-jdk root@hadoop-master:~# sudo update-java-alternatives --list java-1.8.0-openjdk-amd64 1081 /usr/lib/jvm/java-1.8.0-openjdk-amd64 root@hadoop-master:~# java -version openjdk version "1.8.0_212" OpenJDK Runtime Environment (build 1.8.0_212-8u212-b03-0ubuntu1.18.04.1-b03) OpenJDK 64-Bit Server VM (build 25.212-b03, mixed mode)その後、マスターマシンとスレーブマシンのホスト名とIPアドレスを指定して、
/etc/hostsファイルを編集します。root@hadoop-master:~# vi /etc/hosts/ # The following lines are desirable for IPv6 capable hosts ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 172.31.129.196 hadoop-master 172.31.129.197 hadoop-slave 127.0.0.1 localhost localhostHadoopのインストール
次に、マルチノードクラスタにHadoop-2.7.3をインストールします。以下のコマンドでHadoopのtarファイルをダウンロードします。まず、マスターマシンで以下のコマンドを実行します。
root@hadoop-master:~# wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz次に、ダウンロードしたHadoopのtarファイルを以下のコマンドで解凍します。
root@hadoop-master:~# tar -xzf hadoop-2.7.3.tar.gz次に、lsコマンドを実行して、抽出されたHadoopパッケージがあるかどうかを確認します。
root@hadoop-master:~# ls hadoop-2.7.3 hadoop-2.7.3.tar.gzこのチュートリアルでは、マスターとスレーブの 2 台のマシンを使用しているので、SSH 鍵交換を使用してマスターシステムからスレーブシステムにログインします。これを行うには、
ssh-keygenコマンドを使って公開鍵と秘密鍵を生成します。そして、ファイル名を聞かれたら、ENTER を押します。root@hadoop-master:~# ssh-keygen -t rsa -P "" Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:OawYX8MzsF8iXeF1FhIJcdqtf7bMwaoPsL9Cq0t/Pi4 root@hadoop-master The key's randomart image is: +---[RSA 2048]----+ | +o=o+. | | . *.= | | . + . . | | * o . | | . o S.. . | | + = Oo .. | | . o.o... .oo| | . .E.o. +oo| | oo.**=o + | +----[SHA256]-----+両方の鍵は
.sshディレクトリに保存されます。公開鍵(id_rsa.pub)を、authorized_keysファイル内の.sshディレクトリ内のスレーブマシンにコピーします。スレーブマシンのパスワードを聞かれたら入力します。root@hadoop-master:~# cat .ssh/id_rsa.pub | ssh root@172.31.129.197 'cat >> .ssh/authorized_keys' The authenticity of host '172.31.129.197 (172.31.129.197)' can't be established. ECDSA key fingerprint is SHA256:XOA5/7EcNPfEu/uNU/os0EekpcFkvIhKowreKhLD2YA. Are you sure you want to continue connecting (yes/no)? yes root@172.31.129.197's password:これでマスターマシンからスレーブマシンにパスワードを入力せずにログインできるようになりました。
Hadoopディレクトリをスレーブマシンにコピーします。
root@hadoop-master:~# scp -r hadoop-2.7.3 root@172.31.129.197:/root/マスターマシンから、sshを使ってスレーブマシンにログインします。
root@hadoop-master:~# ssh root@172.31.129.197 Welcome to Ubuntu 18.04.2 LTS (GNU/Linux 4.15.0-52-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Welcome to Alibaba Cloud Elastic Compute Service ! Last login: Mon Jul 29 22:16:16 2019 from 172.31.129.196 Run ls command to check if the Hadoop directory got copied to the slave machine root@hadoop-slave:~# ls hadoop-2.7.3スレーブマシンから退出します。
root@hadoop-slave:~# exit logout Connection to 172.31.129.197 closed. root@hadoop-master:~#Hadoopを設定する
これで、HadoopとJavaの環境変数を以下のように.bashrcファイルに入れて、マスターシステムとスレーブシステムの両方に配置することができます。
root@hadoop-master:~# sudo vi .bashrc export HADOOP_PREFIX="/root/hadoop-2.7.3" export PATH=$PATH:$HADOOP_PREFIX/bin export PATH=$PATH:$HADOOP_PREFIX/sbin export HADOOP_MAPRED_HOME=${HADOOP_PREFIX} export HADOOP_COMMON_HOME=${HADOOP_PREFIX} export HADOOP_HDFS_HOME=${HADOOP_PREFIX} export YARN_HOME=${HADOOP_PREFIX} #export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre/この後、以下のコマンドを実行して環境変数を初期化します。
root@hadoop-master:~# source .bashrcすべてのパスが設定されているわけではないので、両方のマシンにインストールされているjavaとHadoopのバージョンを確認することができます。
root@hadoop-master:~# java -version openjdk version "1.8.0_212" OpenJDK Runtime Environment (build 1.8.0_212-8u212-b03-0ubuntu1.18.04.1-b03) OpenJDK 64-Bit Server VM (build 25.212-b03, mixed mode) root@hadoop-master:~# hadoop version Hadoop 2.7.3 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff Compiled by root on 2016-08-18T01:41Z Compiled with protoc 2.5.0 From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4 This command was run using /root/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar root@hadoop-master:~#次に、両方のマシンにnamenodeとdatanodeディレクトリを作成します。
root@hadoop-master:~# mkdir hadoop-2.7.3/hdfs root@hadoop-master:~# mkdir hadoop-2.7.3/hdfs/namenode root@hadoop-master:~# mkdir hadoop-2.7.3/hdfs/datanode次に、Hadoopメインディレクトリ内で、すべてのHadoop設定ファイルが存在する
/etc/Hadoopディレクトリに移動します。root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# cd root@hadoop-master:~# cd hadoop-2.7.3/etc/hadoop/ root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# ls capacity-scheduler.xml kms-log4j.properties configuration.xsl kms-site.xml container-executor.cfg log4j.properties core-site.xml mapred-env.cmd hadoop-env.cmd mapred-env.sh hadoop-env.sh mapred-queues.xml.template hadoop-metrics2.properties mapred-site.xml hadoop-metrics.properties mapred-site.xml.template hadoop-policy.xml masters hdfs-site.xml slaves httpfs-env.sh ssl-client.xml.example httpfs-log4j.properties ssl-server.xml.example httpfs-signature.secret yarn-env.cmd httpfs-site.xml yarn-env.sh kms-acls.xml yarn-site.xml kms-env.sh次に、マスターシステム上でマスターファイルを編集します。
root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# vi masters hadoop-masterまた、スレーブファイルを編集します。
root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# vi slaves hadoop-master hadoop-slaveスレーブシステムでは、スレーブファイルのみを編集します。
root@hadoop-slave:~/hadoop-2.7.3/etc/hadoop# vi slaves hadoop-slaveそれでは、マスターとスレーブの両方のシステムで、Hadoopの設定ファイルを一つずつ編集していきます。まず、下記のような
core-site.xmlファイルを両方のマシンで編集します。このファイルには、HDFSやMapReduceと共通のI/O設定など、Hadoop Coreの構成設定が含まれています。root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# vi core-site.xml <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-master:9000</value> </property> </configuration>次に、両方のマシンで以下のように
hdfs-site.xmlを編集します。このファイルには、HDFSデーモンの構成設定、ネームノード、セカンダリネームノード、データノードが含まれています。root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# vi hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/root/hadoop-2.7.3/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/root/hadoop-2.7.3/hdfs/datanode</value> </property> </configuration>両方のシステムで
mapred-site.xmlファイルを編集します。このファイルには、MapReduceデーモンの構成設定が含まれています。root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# cp mapred-site.xml.template mapred-site.xml root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# vi mapred-site.xml <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> Edit yarn-site.xml. This file contains the configuration settings for YARN. root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# vi yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>最後に両システムのHadoop環境設定ファイルを編集し、
JAVA_HOMEのパスを指定します。root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# vi hadoop-env.sh export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jreここまでで、マスターシステムとスレーブシステムの両方にApache Hadoopをインストールして設定しました。
マルチノードHadoopクラスタの起動
これでマスターマシンからHadoopのメインディレクトリに移動し、namenodeをフォーマットすることができます。
root@hadoop-master:~/hadoop-2.7.3/etc/hadoop# cd .. .. root@hadoop-master:~/hadoop-2.7.3# bin/hadoop namenode -formatすべてのHadoopデーモンを起動したくなります。
root@hadoop-master:~/hadoop-2.7.3# ./sbin/start-all.shこのスクリプトは非推奨なので、代わりに
start-dfs.shとstart-yarn.shを使うことができます。Starting namenodes on [hadoop-master] hadoop-master: starting namenode, logging to /root/hadoop-2.7.3/logs/hadoop-root-namenode-hadoop-master.out hadoop-master: starting datanode, logging to /root/hadoop-2.7.3/logs/hadoop-root-datanode-hadoop-master.out hadoop-slave: starting datanode, logging to /root/hadoop-2.7.3/logs/hadoop-root-datanode-hadoop-slave.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /root/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-hadoop-master.out starting yarn daemons starting resourcemanager, logging to /root/hadoop-2.7.3/logs/yarn-root-resourcemanager-hadoop-master.out hadoop-slave: starting nodemanager, logging to /root/hadoop-2.7.3/logs/yarn-root-nodemanager-hadoop-slave.out hadoop-master: starting nodemanager, logging to /root/hadoop-2.7.3/logs/yarn-root-nodemanager-hadoop-master.outマスターマシン上で
jpsコマンドを実行して、1 つの datanode を含むすべての Hadoop デーモンが実行されているかどうかを確認します。root@hadoop-master:~/hadoop-2.7.3# jps 4144 NameNode 4609 ResourceManager 4725 NodeManager 4456 SecondaryNameNode 4283 DataNode 5054 Jps次に、もう一台のデータノードはスレーブマシン上で動作するので、マスターマシンからSSHでスレーブマシンにログインします。
root@hadoop-master:~/hadoop-2.7.3# ssh root@172.31.129.197 Welcome to Ubuntu 18.04.2 LTS (GNU/Linux 4.15.0-52-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Welcome to Alibaba Cloud Elastic Compute Service ! Last login: Mon Jul 29 23:12:51 2019 from 172.31.129.196 Run the jps command to check if the datanode in up and running. root@hadoop-slave:~# jps 23185 DataNode 23441 Jps 23303 NodeManager root@hadoop-slave:~#これで、datanodeはマスターマシンとスレーブマシンの両方で実行されています。言い換えれば、Alibaba Cloud ECSインスタンスにマルチノードApache Hadoopクラスタを正常にインストールしたことになります。クラスタに別のノードまたはそれ以上のノードを追加するには、ここでスレーブマシンに行ったのと同じ手順を繰り返す必要があります。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-08-14T09:58:40+09:00
dockerからローカルにファイルをコピーしたい
まず、dockerの中に入る。
docker psでコンテナの情報を取得
docker cp コンテナid:コピーしたいファイルの場所 コピー先の場所


- 投稿日:2020-08-14T09:38:15+09:00
Dockerで計算用途で使うときのオプションのまとめ
Dockerでよく計算をすることがあるので、その時に使うオプションをまとめます。
GPUを使うとき
--gpus=<number>でGPUの個数を指定する。
使うGPUのIDは環境変数NVIDIA_VISIBLE_DEVICESへ0,1やallなどと指定する。
NVIDIA_DRIVER_CAPABILITIESについて使いたい機能に応じて環境変数を指定する必要がある。デフォルトではnvidia-smiやNVMLが使えるutilityのみ。カンマ区切りで複数指定可能。
Supported driver capabilities(https://github.com/NVIDIA/nvidia-container-runtime/blob/master/README.md より)
compute: required for CUDA and OpenCL applications.compat32: required for running 32-bit applications.graphics: required for running OpenGL and Vulkan applications.utility: required for usingnvidia-smiand NVML.video: required for using the Video Codec SDK.display: required for leveraging X11 display.シェルを起動しているUserを引き継いで実行したいとき
nfsマウント等していて、特にユーザを一致する必要があるときに使います。
-v /etc/group:/etc/group:ro -v /etc/passwd:/etc/passwd:ro -u $(id -u $USER):$(id -g $USER)を使う。GUIを使いたいとき
-e DISPLAY=$DISPLAY --net host -v /tmp/.X11-unix:/tmp/.X11-unix:ro -v $HOME/.Xauthority:/root/.Xauthority:ro
(GUI周りはsshからX11 forwardingをしたほうがいいかも。今は面倒屋なので直接シェルを使っています)ホームディレクトリをバインドマウントしたいとき
-v $HOME:$HOMEを使う。共有メモリの上限を増やすとき
特にGPUを使うアプリケーションでは共有メモリが足りなくなりがち。
[size]には16gなどと指定する。
--shm-size=[size]シェルをその場で使いたいとき
-itをつけるとシェルが使える。よく使う組はエイリアスはっちゃえ!
- ユーザの設定
- X11のディスプレイの設定
- ホームディレクトリと共有NASのマウント設定
- 共有メモリの設定(16g)
- シェル
をまとめておきます。
alias docker-run-it="sudo docker run -v /etc/group:/etc/group:ro -v /etc/passwd:/etc/passwd:ro -u $(id -u $USER):$(id -g $USER) -e DISPLAY=$DISPLAY --net host -v /tmp/.X11-unix:/tmp/.X11-unix:ro -v $HOME/.Xauthority:/root/.Xauthority:ro -v /data02/$USER/:/data02/$USER -v $HOME:$HOME:Z --shm-size 16g -it"こんなことになるくらいなら
singularityとかも使ってみたいですね。もっと簡単になってルート権限も不要らしい。
- 投稿日:2020-08-14T05:41:38+09:00
docker-compose を用いて Apache・PHP・MySQL の開発環境を構築してみた
はじめに
docker-compose を用いて Apache・PHP・MySQL の開発環境を構築してみた備忘録になります。
バージョン情報
docker-compose はインストールされていることが前提になります。
今回は以下のバージョンでの動きになります。$ docker-compose -v docker-compose version 1.26.2, build eefe0d31PHP のバージョンは 5.4、MySQL のバージョンは 5.5 の環境を構築します。
Apache のバージョンは特に気にしていません。ディレクトリ構造
ディレクトリ構造は以下のようになります。
. ├── config │ ├── mysql │ │ ├── Dockerfile │ │ ├── initdb.d │ │ │ └── init.sql │ │ └── my.cnf │ └── php │ ├── Dockerfile │ ├── apache2.conf │ ├── php.ini │ └── sites │ ├── 000-default.conf │ └── default-ssl.conf ├── data ├── docker-compose.yml └── html └── test ├── connect.php └── index.phpGitHub にもあげました。ご参考まで。
設定
各サービスに以下のような設定ファイルがそれぞれあると思いますが、それらを変更したものを動かしたいと思います。
Apache の設定
今回は DocumentRoot を変更してみます。
公式ドキュメント をみると以下のように Dockerfile を記述することで DocumentRoot を変更できるようです。
いろいろな記事をみるとコンテナから 000-default.conf などの設定ファイルをホスト側にもってきてそれを修正した後、Dockerfile のCOPYでコンテナ側にコピーするようでした。
やはり公式ドキュメントをみるのが一番ですね。公式ドキュメントのように行ったらコンテナが再起動ループに陥ってしまいました。
※ 理由をよく調べたら php:5.5-apache 以降であればそれでよかったらしいです。
なので、php:5.4-apache のイメージからコンテナを立ち上げて、元ファイルをホスト側にコピーして、それを編集することにしました。
# とりあえず php:5.4-apache のコンテナを動かしてログインする $ docker image pull php:5.4-apache $ docker container run --name php54apache -d php:5.4-apache $ docker exec -it php54apache /bin/bash # 設定ファイルを確認 ( php:5.4-apache 以前は apache2.conf の修正も必要) $ ls /etc/apache2/apache2.conf httpd.conf $ ls /etc/apache2/sites-available 000-default.conf default-ssl.conf # コンテナを抜ける $ exit # ホスト側にコピー $ docker container cp php54apache:/etc/apache2/apache2.conf ./config/php $ docker container cp php54apache:/etc/apache2/sites-available/000-default.conf ./config/php/sites $ docker container cp php54apache:/etc/apache2/sites-available/default-ssl.conf ./config/php/sitesこれらの
apache2.conf、000-default.conf、default-ssl.confに記述してある DocumentRoot を変更します。今回は以下のように変更しました。
# DocumentRoot /var/www/html DocumentRoot /var/www/html/testこれで DocumentRoot の変更の準備は完了です。
PHP の設定
PHP は
php.iniによって設定を行います。公式ドキュメント をみると以下のように記述することで php.ini を指定するらしいです。
しかし、コンテナを立ち上げてログインしてみても、
php.ini-developmentやphp.ini-producitonのようなファイルは存在しませんでした。おそらく Apache の設定でもそうであったように公式のドキュメントは過去のバージョンまで挙動は保証していないようです。
サンプルにあるような
php:7.4-fpm-alpineならそれで良さそうですね。今回は
php.ini-developmentやphp.ini-producitonについては GitHub で公開してあったのでそちらの php.ini-development を元に php.ini を作成することにしました。php.ini の修正についてはこちらを参照して、ロケーションや言語の設定を修正しました。
MySQL の設定ファイルの変更
MySQL の設定ファイルは
my.cnfによって行います。MySQL の設定ファイルの my.cnf は 公式ドキュメント によると
/etc/mysql/my.cnfに配置してあるとのことでした。
なのでそちらをローカルホストに持ってきて、適宜修正していきたいと思います。
# とりあえず mysql:5.5 のコンテナを動かしてログインする $ docker image pull mysql:5.5 $ docker container run -e MYSQL_ROOT_PASSWORD=sample_pw --name mysql55 -d mysql:5.5 $ docker exec -it mysql55 /bin/bash # /etc/mysql/my.cnf を確認 $ ls /etc/mysql/my.cnf /etc/mysql/my.cnf # コンテナを抜ける $ exit # my.cnf をホスト側にコピー $ docker container cp mysql55:/etc/mysql/my.cnf ./config/mysql/あとは環境に合わせて修正して、
my.cnfを作成してください。※ ちなみに今回は
my.cnfの修正は行っていません。Dockerfile の作成
Dockerfile は
php:5.4-apacheとmysql:5.5のイメージについて作成しました。php:5.4-apache
config/php/Dockerfile# image FROM php:5.4-apache # Set php.ini COPY ./php.ini /usr/local/etc/php/ # Set apache conf (Before tag:5.4-apache) COPY ./apache2.conf /etc/apache2/ COPY ./sites/*.conf /etc/apache2/sites-available/ # Set apache conf (After tag:5.5-apache) # ENV APACHE_DOCUMENT_ROOT /var/www/html/test # RUN sed -ri -e 's!/var/www/html!${APACHE_DOCUMENT_ROOT}!g' /etc/apache2/sites-available/*.conf # RUN sed -ri -e 's!/var/www/!${APACHE_DOCUMENT_ROOT}!g' /etc/apache2/apache2.conf /etc/apache2/conf-available/*.conf # Install MySQL connection module RUN apt-get update \ && apt-get install -y libpq-dev \ && docker-php-ext-install pdo_mysql pdo_pgsql mysqli mbstringここでは「DocumentRoot の変更」、「php.ini の配置」、「MySQL と疎通するためのモジュールを追加」しています。
mysql:5.5
config/mysql/Dockerfile# image FROM mysql:5.5 # Set my.cnf COPY ./my.cnf /etc/mysql/conf.d/ # Set Japanese RUN apt-get update && apt-get install -y \ locales \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* RUN sed -i -E 's/# (ja_JP.UTF-8)/\1/' /etc/locale.gen \ && locale-gen ENV LANG ja_JP.UTF-8 CMD ["mysqld", "--character-set-server=utf8", "--collation-server=utf8_unicode_ci"]デフォルトのままであると MySQL にログインした後に日本語の入力ができなかったため、ここでは日本語を入力可能にするような設定をおこなています。
MySQL の日本語の設定は こちら を参照しました。
MySQL の初期データの投入
docker-compose 起動時に MySQL に初期データを投入してみたく、以下のような SQL を用意しました。
init.sqlDROP TABLE IF EXISTS sample_table; CREATE TABLE sample_table ( id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, name TEXT NOT NULL ) charset=utf8; INSERT INTO sample_table (name) VALUES ("太郎"),("花子"),("令和");コンテナ起動後にここで記述した SQL が実行されていることを確認します。
docker-compose.yml の作成
以下のように docker-compose.yml を作成しました。
docker-compose.ymlversion: '3.8' services: # PHP Apache php-apache: build: ./config/php ports: - "8080:80" volumes: - ./html:/var/www/html restart: always depends_on: - mysql # MySQL mysql: build: ./config/mysql ports: - 3306:3306 volumes: - ./config/mysql/initdb.d:/docker-entrypoint-initdb.d - ./data:/var/lib/mysql restart: always environment: MYSQL_ROOT_PASSWORD: sample_root_passward MYSQL_DATABASE: sample_db MYSQL_USER: sample_user MYSQL_PASSWORD: sample_passMySQL のデータの永続化について
MySQL のデータディレクトリは /var/lib/mysql であり、
- ./data:/var/lib/mysqlとあるようにホスト側の./dataディレクトリにマウントすることによってデータを永続化しております。試してみたところ
docker-compose stopやdocker-compose downしてもデータが永続化されていることが確認できました。docker-compose 使い方
いよいよ docker-compose を動かします。
docker-compose 起動
まずはなにも起動されていないことを確認します。
$ docker-compose ps Name Command State Ports ------------------------------ $ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES今回はわかりやすいようにコンテナも空の状態にしておきます。
docker-compose.yml が存在する階層で
docker-compose up -dコマンドを実行することで、docker-compose.yml の記述をもとにコンテナが作成されます。※ docker-compose のコマンドの
buildとupの違いやオプションについてはこちらがわかりやすかったです。# image の作成 $ docker-compose build --no-cache Successfully tagged docker-compose-sample_php-apache:latest # コンテナの構築・起動 $ docker-compose up -d Creating network "docker-compose-sample_default" with the default driver Creating docker-compose-sample_mysql_1 ... done Creating docker-compose-sample_php-apache_1 ... done # docker-compose の確認 $ docker-compose ps Name Command State Ports ------------------------------------------------------------------------------------------------- docker-compose-sample_mysql_1 docker-entrypoint.sh mysqld Up 0.0.0.0:3306->3306/tcp docker-compose-sample_php-apache_1 apache2-foreground Up 0.0.0.0:8080->80/tcp # コンテナの確認 $ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 26b0cec2daad docker-compose-sample_php-apache "apache2-foreground" 3 minutes ago Up 3 minutes 0.0.0.0:8080->80/tcp docker-compose-sample_php-apache_1 eaae044f4bba mysql:5.5 "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:3306->3306/tcp docker-compose-sample_mysql_1コンテナが動いていることが確認できました。
PHP-Apache コンテナの確認
DocumentRoot の直下に配置する、php:5.4-apache コンテナの疎通確認用のページとして以下のようなファイルを用意しました。
html/test/index.php<?php echo __DIR__; phpinfo();
http://localhost:8080にアクセスすると以下のように表示されるはずです。
echo __DIR__;はその PHP ファイルが置かれている絶対パスを出力するので DocumentRoot の変更が行われていることが確認できます。また、
php.iniについてオリジナルものから修正を加えていれば、phpinfo();の出力でそちらも反映されていることも確認できるかと思います。
MySQL コンテナの確認
mysql:5.5のイメージで作成されたコンテナにログインして、初期データが投入されていることを確認します。shell# コンテナにログイン $ docker exec -it eaae044f4bba /bin/bash # MySQL にログイン $ mysql -p Enter password:パスワードを求められるので docker-compose.yml で
MYSQL_ROOT_PASSWORDの環境変数に登録したsample_root_passwardと入力するとログインできます。docker-compose.yml に登録した
MYSQL_DATABASE、MYSQL_USERが登録されていることを確認します。mysql> select user, host from mysql.user; +-------------+-----------+ | user | host | +-------------+-----------+ | root | % | | sample_user | % | | root | localhost | +-------------+-----------+ 3 rows in set (0.00 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sample_db | +--------------------+ 4 rows in set (0.00 sec)
sample_userとsample_dbがあることが確認できました。続いて
init.sqlで作成したテーブルとカラムについても確認してみます。mysql> use sample_db; Database changed mysql> show tables; +---------------------+ | Tables_in_sample_db | +---------------------+ | sample_table | +---------------------+ 1 row in set (0.00 sec) mysql> select * from sample_table; +----+--------+ | id | name | +----+--------+ | 1 | 太郎 | | 2 | 花子 | | 3 | 令和 | +----+--------+ 3 rows in set (0.00 sec)テーブルとカラムについても問題なく確認できました。
PHP-Apache から MySQL コンテナへの疎通確認
PHP-Apache から MySQL コンテナへの疎通確認用のページとして以下のようなファイルを用意しました。
html/test/connect.php<?php try { // host=XXXの部分のXXXにはmysqlのサービス名を指定します $dsn = 'mysql:host=mysql;dbname=sample_db;'; $db = new PDO($dsn, 'sample_user', 'sample_pass'); $sql = 'SELECT * FROM sample_table;'; $stmt = $db->prepare($sql); $stmt->execute(); $result = $stmt->fetchAll(PDO::FETCH_ASSOC); var_dump($result); } catch (PDOException $e) { echo $e->getMessage(); exit; }※ 注意点として、ホスト名は
localhostや127.0.0.1ではなく、docker-compose.yml でサービス名として指定してたmysqlを使用します。
http://localhost:8080/connect.phpにアクセスすると以下のように表示されればが PHP-Apache から MySQL コンテナへの疎通がうまく行っています。
さきほど、初期投入されたデータが確認できますね。docker-compose 停止・削除
以下のコマンドで 停止・削除 を行います。
# コンテナを停止 $ docker-compose stop # コンテナを停止し、そのコンテナとネットワークの削除 $ docker-compose down # コンテナを停止し、そのコンテナとネットワークを削除、さらにイメージも削除 $ docker-compose down --rmi all --volumes
./config/mysql/initdb.d/init.sqlの初期データ投入からやり直したい時などはdocker-compose down --rmi all --volumesしてから./dataディレクトリの中身も削除してdocker-compose up -dでコンテナの構築・起動からやり直してください。まとめ
以下を自動化する docker-compose の開発環境構築を行いました。
- DocumentRoot の変更
- php.ini の変更
- my.cnf の変更
- MySQL への初期データの投入
- MySQL のデータの永続化
- PHP-Apache コンテナから MySQL コンテナへの疎通
つまり、これらの環境がワンライナーで構築できるようになりました。
学んだこと
今回初めて docker-compose で開発環境を構築してみて学んだことを羅列します。
- 公式ドキュメント(DockerHub)は読んだ方がいい
- Qiita よりも DockerHub を先に見た方がよさそうです。
- docker-compose.yml と Dockerfile はかき分ける
- 一度変更すればコンテナ起動後に変更のない設定ファイルなどは Dockerfile で
COPYでコンテナ側にファイルを配置して、コンテナ起動後に変更のあるものは docker-compose.yml でマウントさせるという書き分けがよさそうです。- Dockerfile をいきなり書くのは難しい
- 以下の手順で Dockerfile を書くと良いです。
- ベースイメージを決める
- ベースイメージのコンテナ内で作業しつつ、うまくいった処理をメモ
- 全て成功したらDockerfileを作成
以上になります。