- 投稿日:2020-08-14T23:40:45+09:00
condaで手軽にpysparkを試す
1. 背景・対象
ローカル環境でcondaを使ってpysparkを動かすためのメモ。
他の一般的なPythonライブラリと同じような感じでpysparkをインストール・実行する。想定する主な対象:
- 細かい設定は置いておいて、少ない手順でとにかく動く環境を作りたい
- SparkやJavaのバージョンを仮想環境毎に分けて管理したい
- PC本体で使うJavaとSparkで使うJavaを区別したい
- Spark2.4とSpark3.0を使い分けたい(あるいはプロジェクト毎に区別してSparkをインストールしたい)
- でもDockerや仮想マシンなどは使いたくない
といった状況を考えています。
2. condaでSparkとJavaをインストール
対象とするconda仮想環境に入って、
- Apache Spark3.0を使う場合
conda install -c conda-forge pyspark=3.0 openjdk=8
- Apache Spark2.4を使う場合
# 注意:Python3.8は未対応なのでPython3.7.xなどの環境を使う conda install -c conda-forge pyspark=2.4 openjdk=8とすると、pysparkライブラリだけでなくApache Spark本体も仮想環境下にインストールされます。(ちなみにpandasや、pandasとSpark間のデータ連携を担うpyarrowなども一緒に入ります)
また、上の例のようにcondaでopenjdkを入れると、conda activateで仮想環境に入ったときにJAVA_HOMEをcondaで入れたものに合わせて勝手に設定してくれます。(conda-forgeチャンネルから入れる場合、2020-08-14現在でバージョンは1.8.0_192 (Azul Systems, Inc.)になります。)実行
conda activate <仮想環境名>してからCLI上で
- Spark3
shell(conda環境)$ pyspark Python 3.8.5 (default, Aug 5 2020, 08:36:46) [GCC 7.3.0] :: Anaconda, Inc. on linux Type "help", "copyright", "credits" or "license" for more information. 20/08/14 22:00:15 WARN Utils: Your hostname, <***> resolves to a loopback address: 127.0.1.1; using 192.168.3.17 instead (on interface wlp3s0) 20/08/14 22:00:15 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address 20/08/14 22:00:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.0.0 /_/ Using Python version 3.8.5 (default, Aug 5 2020 08:36:46) SparkSession available as 'spark'. >>>
- Spark2
shell(conda環境)$ pyspark Python 3.7.7 (default, May 7 2020, 21:25:33) [GCC 7.3.0] :: Anaconda, Inc. on linux Type "help", "copyright", "credits" or "license" for more information. 20/08/14 22:16:09 WARN Utils: Your hostname, <***> resolves to a loopback address: 127.0.1.1; using 192.168.3.17 instead (on interface wlp3s0) 20/08/14 22:16:09 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address 20/08/14 22:16:09 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.4.6 /_/ Using Python version 3.7.7 (default, May 7 2020 21:25:33) SparkSession available as 'spark'. >>>のようにしてそれぞれで
pysparkが使えることを確認出来ます。
- condaで仮想環境を用意して
conda installしただけなので、他の普通のPythonライブラリと同じ感覚でpysparkをインストール・実行出来ています。補足(Java)
なお、Spark3からはJava11も対応しているのですが、簡単に試してみたところメモリ関係のエラーが出るとかで満足に動かせていないです。。。
ここなどを見てもJava11を使う場合は追加で設定が必要そうですし(上述のエラーとは違いそうな気もしますが)、タイトルの通りに「手軽にとりあえず」で動かす場合はSpark3でもJavaのバージョンは8が無難だと思います。(なお、Spark2系ではJava8でないと動かないです。)補足(Windows)
そこそこの機能は上の通りで動きますが、
spark.sqlのデータベース・テーブル操作をするときなどにデフォルトでは権限周りのエラーが起きます。
ここなどを参考にして、を追加でやっておく必要があります。
3. 追加で設定が必要な場合
ここまでで簡易的に(デフォルトの設定で)pysparkを実行出来るようになっているはずですが、ときにはconfigの設定や調整をしなくてはならないときがあります。
本格的にカスタマイズをしていくとタイトルの「手軽に」の範囲を超えてしまいますが、最低限のところだけ補足します。
(一般的な環境変数の設定など、condaで入れた場合に特有でない共通した話は省きます。)
SPARK_HOMEの設定環境変数
JAVA_HOME(Sparkの実行に必要)は勝手にconda側で設定してくれると書きましたが、Apache Sparkを使う際によく設定する環境変数SPARK_HOMEは実は設定されていません。(未設定でも割と動きますが、たまに困るときがある)仮想環境上でのインストール場所を指定すれば良いのですが、若干場所が分かりづらいです。
やり方は色々あると思いますが、個人的に使う調べ方として、
- condaでpysparkをインストールすると
scalaのSparkシェルであるspark-shellも実行可能(PATHも通っているはず)なので、CLI上でspark-shellを実行する- ローカルで動かす想定なので、1.の後で http://localhost:4040 にアクセスしてSpark UIを開く
- Environmentタブの
spark.homeにあるパスを控えて、環境変数SPARK_HOMEに設定するなどとやります。(ここを参考にした方法です。)
例えばSPARK_HOME=/path/to/miniconda3-latest/envs/<仮想環境名>/lib/python3.7/site-packages/pysparkみたいな感じになります。要するにscalaのspark-shellではSparkSession内においてのみ自動で適切な
spark.homeを設定してくれているのですが、何故かpysparkではやってくれないのでspark-shellを使って調べる、といった感じです。設定ファイルの場所
公式などからダウンロードしてきたSparkには
confディレクトリが存在しますが、condaで自動インストールしたものにはconfディレクトリが存在しないようです。。。
が、自分で然るべき場所にconfディレクトリを作って設定ファイルを置けば読み込んでくれるようです。(spark-defaults.confで検証)設定ファイルの置き場所は先程調べた
SPARK_HOMEのパスを使って、$SPARK_HOME/conf/下になります。
そこで、例えば$SPARK_HOME/conf/spark-defaults.confを作成・記入していくことでconfigの設定が可能です。
※
SPARK_HOME未設定でも読み込んでくれたので、上記読み込みに環境変数SPARK_HOMEは必須でないようです。他の設定ファイル(例えば
conf/spark-env.shなど)は試していませんが、おそらく同じような感じで作成・記入すれば動くのではないかと思います。(違っていたらすみません。)※余談ですが、紹介しておいてなんですがcondaで入れた個別のパッケージに手を加えるのは可搬性が落ちて設定が汚くなるので、個人的にはあまりここまでやりたくはないです。
(必要だったら出来る、という話です。)まとめ
condaでpysparkを手軽にインストール・管理出来ることと、その気になれば設定ファイルのカスタマイズなども可能なところまで確認した。
- 投稿日:2020-08-14T23:40:45+09:00
condaで手軽にpysparkをインストールする
1. 背景・対象
ローカル環境でcondaを使ってpysparkを動かすためのメモ。
他の一般的なPythonライブラリと同じような感じでpysparkをインストール・実行する。想定する主な対象:
- 細かい設定は置いておいて、少ない手順でとにかく動く環境を作りたい
- SparkやJavaのバージョンを仮想環境毎に分けて管理したい
- PC本体で使うJavaとSparkで使うJavaを区別したい
- Spark2.4とSpark3.0を使い分けたい(あるいはプロジェクト毎に区別してSparkをインストールしたい)
- でもDockerや仮想マシンなどは使いたくない
といった状況を考えています。
2. condaでSparkとJavaをインストール
対象とするconda仮想環境に入って、
- Apache Spark3.0を使う場合
conda install -c conda-forge pyspark=3.0 openjdk=8
- Apache Spark2.4を使う場合
# 注意:Python3.8は未対応なのでPython3.7.xなどの環境を使う conda install -c conda-forge pyspark=2.4 openjdk=8とすると、pysparkライブラリだけでなくApache Spark本体も仮想環境下にインストールされます。(ちなみにpandasや、pandasとSpark間のデータ連携を担うpyarrowなども一緒に入ります)
また、上の例のようにcondaでopenjdkを入れると、conda activateで仮想環境に入ったときにJAVA_HOMEをcondaで入れたものに合わせて勝手に設定してくれます。(conda-forgeチャンネルから入れる場合、2020-08-14現在でバージョンは1.8.0_192 (Azul Systems, Inc.)になります。)実行
conda activate <仮想環境名>してからCLI上で
- Spark3
shell(conda環境)$ pyspark Python 3.8.5 (default, Aug 5 2020, 08:36:46) [GCC 7.3.0] :: Anaconda, Inc. on linux Type "help", "copyright", "credits" or "license" for more information. 20/08/14 22:00:15 WARN Utils: Your hostname, <***> resolves to a loopback address: 127.0.1.1; using 192.168.3.17 instead (on interface wlp3s0) 20/08/14 22:00:15 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address 20/08/14 22:00:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.0.0 /_/ Using Python version 3.8.5 (default, Aug 5 2020 08:36:46) SparkSession available as 'spark'. >>>
- Spark2
shell(conda環境)$ pyspark Python 3.7.7 (default, May 7 2020, 21:25:33) [GCC 7.3.0] :: Anaconda, Inc. on linux Type "help", "copyright", "credits" or "license" for more information. 20/08/14 22:16:09 WARN Utils: Your hostname, <***> resolves to a loopback address: 127.0.1.1; using 192.168.3.17 instead (on interface wlp3s0) 20/08/14 22:16:09 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address 20/08/14 22:16:09 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.4.6 /_/ Using Python version 3.7.7 (default, May 7 2020 21:25:33) SparkSession available as 'spark'. >>>のようにしてそれぞれで
pysparkが使えることを確認出来ます。
- condaで仮想環境を用意して
conda installしただけなので、他の普通のPythonライブラリと同じ感覚でpysparkをインストール・実行出来ています。補足(Java)
なお、Spark3からはJava11も対応しているのですが、簡単に試してみたところメモリ関係のエラーが出るとかで満足に動かせていないです。。。
ここなどを見てもJava11を使う場合は追加で設定が必要そうですし(上述のエラーとは違いそうな気もしますが)、タイトルの通りに「手軽にとりあえず」で動かす場合はSpark3でもJavaのバージョンは8が無難だと思います。(なお、Spark2系ではJava8でないと動かないです。)補足(Windows)
そこそこの機能は上の通りで動きますが、
spark.sqlのデータベース・テーブル操作をするときなどにデフォルトでは権限周りのエラーが起きます。
ここなどを参考にして、を追加でやっておく必要があります。
3. 追加で設定が必要な場合
ここまでで簡易的に(デフォルトの設定で)pysparkを実行出来るようになっているはずですが、ときにはconfigの設定や調整をしなくてはならないときがあります。
本格的にカスタマイズをしていくとタイトルの「手軽に」の範囲を超えてしまいますが、最低限のところだけ補足します。
(一般的な環境変数の設定など、condaで入れた場合に特有でない共通した話は省きます。)
SPARK_HOMEの設定環境変数
JAVA_HOME(Sparkの実行に必要)は勝手にconda側で設定してくれると書きましたが、Apache Sparkを使う際によく設定する環境変数SPARK_HOMEは実は設定されていません。(未設定でも割と動きますが、たまに困るときがある)仮想環境上でのインストール場所を指定すれば良いのですが、若干場所が分かりづらいです。
やり方は色々あると思いますが、個人的に使う調べ方として、
- condaでpysparkをインストールすると
scalaのSparkシェルであるspark-shellも実行可能(PATHも通っているはず)なので、CLI上でspark-shellを実行する- ローカルで動かす想定なので、1.の後で http://localhost:4040 にアクセスしてSpark UIを開く
- Environmentタブの
spark.homeにあるパスを控えて、環境変数SPARK_HOMEに設定するなどとやります。(ここを参考にした方法です。)
例えばSPARK_HOME=/path/to/miniconda3-latest/envs/<仮想環境名>/lib/python3.7/site-packages/pysparkみたいな感じになります。要するにscalaのspark-shellではSparkSession内においてのみ自動で適切な
spark.homeを設定してくれているのですが、何故かpysparkではやってくれないのでspark-shellを使って調べる、といった感じです。設定ファイルの場所
公式などからダウンロードしてきたSparkには
confディレクトリが存在しますが、condaで自動インストールしたものにはconfディレクトリが存在しないようです。。。
が、自分で然るべき場所にconfディレクトリを作って設定ファイルを置けば読み込んでくれるようです。(spark-defaults.confで検証)設定ファイルの置き場所は先程調べた
SPARK_HOMEのパスを使って、$SPARK_HOME/conf/下になります。
そこで、例えば$SPARK_HOME/conf/spark-defaults.confを作成・記入していくことでconfigの設定が可能です。
※
SPARK_HOME未設定でも読み込んでくれたので、上記読み込みに環境変数SPARK_HOMEは必須でないようです。他の設定ファイル(例えば
conf/spark-env.shなど)は試していませんが、おそらく同じような感じで作成・記入すれば動くのではないかと思います。(違っていたらすみません。)※余談ですが、紹介しておいてなんですがcondaで入れた個別のパッケージに手を加えるのは可搬性が落ちて設定が汚くなるので、個人的にはあまりここまでやりたくはないです。
(必要だったら出来る、という話です。)まとめ
condaでpysparkを手軽にインストール・管理出来ることと、その気になれば設定ファイルのカスタマイズなども可能なところまで確認した。
- 投稿日:2020-08-14T23:37:51+09:00
蟻本のFence Repairがすんなり理解できなかったので細かく追ってみる
用語の定義
蟻本
- プログラミングコンテストチャレンジブック
- 競技プログラミング界隈でのバイブル的な本
- 競プロ参戦にあたって必要なベーシックな知識が網羅的に掲載されている
Fence Repair
- POJ 3253
- 北京大学のオンラインジャッジの3253番の問題
- 一般化するとハフマン符号の問題らしい
- 蟻本の49ページから解説が掲載されている
貪欲法を使うという問題ですが、なぜそれが貪欲的になるのかがスッと理解できなかったので、検証しようというのが発端です。
問題文
農夫ジョンは、フェンスを修理するため、とても長い板から$N$個の板を切り出そうとしています。切り出そうとしている板の長さは$ L_1,L_2,\dots ,L_N$であり、元の板の長さはちょうどこれの合計になっています。板を切断する際には、その板の長さの分だけのコストがかかります。例えば、長さ$21$の板から$5,8,8$の$3$つの板を切り出したいとします。長さ$21$の板を長さ$13$と$8$の板に切断すると、コストが$21$かかります。その$13$の板をさらに$5$と$8$の板に切断すると、コストが$13$かかります。合計で$34$のコストがかかります。最小で、どれだけのコストで全ての板を切り出すことができるでしょうか。
制約
- $1\leqq N\leqq 20000$
- $1\leqq L_i\leqq 20000$
多くの問題では、木であったり、そうでなくともある種のグラフ構造に一般化できることが多いです。
今回の問題文で示されている例を二分木で表すと以下のようになります。
各切断時のコストは親ノードの値となるので、総コストは葉でないノードの値を全て足した値です。
上の例では葉でないノード(白色)の総和が、$13+21=34$で問題文の総コストと一致します。このときの総コストを最小にするというのが題意です。
解答の方針
蟻本の解説方針
- 与えられた板のうち、短い順に$2$枚を取り除き、代わりにマージした長さの板を加える。
- マージした板の長さの和をコストに加算し、最後の1枚になるまで再帰させる。
- その際に得られるコストが最小になっている。
読むとなんとなく正しそうな気はするものの、本当にそうかがパッと納得できませんでした。
トップダウンで解いていくと条件分けがエグいのでボトムアップで考えるという発想の転換を伝えることが主旨だとは思いますが、のちのちにもっと難しい問題が解説されたときにここを理解していないと詰みそうに感じたので、追求することにします。固定条件と変動要素
何が固定(前提)で、変動はどんな操作によって生じるかを見ることがあらゆる問題を解く上での基本的な方針です。
今回は貪欲法の章で紹介されている問題なので、必ず総コストが小さくなる操作があるということはメタ的にわかります。
実際に解く場面においては、その判断も含めてアルゴリズムを選定していく必要があります。さて、本問では切断完了時の全ての板の長さが与えられるので、最終的に葉となるノードの数は確定しています。
すなわち、どのような順序で葉を組み合わせていくかで、木構造が変化します。変動要素の検証
変化のしかたを捉えるといっても、いきなり複雑なケースで考えても失敗します。
かの偉大な数学者であるデカルトも「困難は分割せよ」と言いました。めちゃくちゃ単純なケースに分割して考えていくというのが、あらゆる問題を解く上で重要なスキームです。
では、最も単純なケースはなんでしょう?一緒に考えていきましょう。N=1のケース
言うまでもなく$N=1$のケースが最も単純です。つまり、元の板のままで切断することはありません。
これだと変動もクソもなくて、コストは常に$0$です。$N$を増やしていきましょう。N=2のケース
これは切断回数が$1$となるケースです。これも、切断後の板の長さが確定している時点でバリエーションはありません。
さらに$N$を増やしましょう。N=3のケース
お待たせしました。$N=3$からようやくバリエーションが出てきます。
まずは簡単のために、$3$枚ある切断後の板の長さを$A\leqq B \leqq C$というように置いてみます。
これは一般性を失わない仮定でしょう。さて、ここでの切り方は$3$パターン考えられます。
- $(A+B+C) \rightarrow (A+B),C \rightarrow A,B,C$
- $(A+B+C) \rightarrow A,(B+C) \rightarrow A,B,C$
- $(A+B+C) \rightarrow B,(C+A) \rightarrow A,B,C$
ちょっと文字で書いても分かりにくいので、面倒ですが図を作りました。
総コストに影響するのは、図の赤色部分の違いだけです。そのほかの部分は位置こそ違えど和の値は変わりません。
つまり、このケースにおいて総コストを最小にすることは$(A+B),(B+C),(C+A)$の中から最小を選ぶという問題と同値です。バリエーションが十分かを丁寧に見ると、$3$つの中から$2$つ選ぶ、つまり${}_3 \mathrm{C} _2 = {}_3 \mathrm{C} _1 = 3$で、たしかに$3$パターンしかあり得ません。
では、どのパターンが最小かといえば、当然ながら値が小さい方から$2$つ選んだ$(A+B)$になります。まとめると、$N=3$であれば小さい方から$2$つ選んで切り出せばよいということになります。
この事実を用いて、$N=4$のケースも考えてみましょう。N=4のケース
$N=3$では、総コストが最小になるパターンを1通りに絞ることが出来ました。
メタ的に考えれば、貪欲法なのでこれ以降は漸化式的な感じでパターンを絞っていけるということになりそうです。さて、$N=4$のケースは板が$4$枚です。
最初の切断でケース分けをすると、板$ABCD$を$1+3$枚で切り分けるか、$2+2$枚で切り分けるかでパターンが分かれます。
1+3枚のパターン
$1+3$枚で切り分けるパターンは、$N=3$のケースを根側に拡張した形です。最初に$1$回切ったあとは$N=3$と同じ形になり、板$ABC$が$\{ABC,ABD,ACD,BCD\}$のいずれかに変わるだけです。
つまり、全部で$4\times 3=12$パターンあるものの、実質は最初にどれを切り分けるかの$4$パターンに帰着します。
ここで、$N=3$のケースの総コストを一般化すると、$2A+2B+C$です。
($3$つの中から小さいものを$2$つ選ぶのと、最も大きいものを選ぶことは同じ)これに対して、$A\leqq B \leqq C \leqq D$となる$D$を追加すると、$N=4$のケースになります。
総コストを整理すると以下の$4$パターンです。
- $3A+3B+2C+D$:最初に$D$を切る
- $3A+3B+2D+C$:最初に$C$を切る
- $3A+3C+2D+B$:最初に$B$を切る
- $3B+3C+2D+A$:最初に$A$を切る
さて、ここでいったん止めておいて$2+2$枚のパターンを見てみましょう。
2+2枚のパターン
少し考えると、どんな組み合わせで切り分けても総コストは$2\times(A+B+C+D)$になることが分かります。
まとめて比較する
ここまでの場合分けにより、$N=4$のケースとして今考えなくてはならないパターンは先ほどの$4$パターンと合わせて、全部で$5$つに絞られることがわかりました。
では、ここで$5$つの大小関係を比較するために、$2\times(A+B+C+D)$を全てのケースから引いてみましょう。
- $\;\;\;\;\;\;0\;\;\;\;\;\;$:最初に$2+2$枚に切り分ける
- $A+B-D$:最初に$D$を切る
- $A+B-C$:最初に$C$を切る
- $A+C-B$:最初に$B$を切る
- $B+C-A$:最初に$A$を切る
この中で最小のコストとなり得る値は、どれになるでしょうか。
$A\leqq B \leqq C \leqq D$を考えると以下が分かります。
- $\;\;\;\;\;\;0\;\;\;\;\;\;$:$A+B-D$が正の値の場合に最小
- $A+B-D$:負となるケースで最小
- $A+B-C$:負になる得るが、より大きな数$D$を引く$1$つ上のパターンの方が小さいので候補とならない
- $A+C-B \geqq 0$:大小関係より必ず$0$以上なので候補とならない
- $B+C-A \geqq 0$:大小関係より必ず$0$以上なので候補とならない
すなわち、$A+B\leqq D$の判定結果によって最小のケースが変わるということになります。
蟻本の解説に立ち返る
$A+B\leqq D$をよく見てみましょう。
これって要するに$A+B$のマージ結果を加えて再度ソートしているのと同じことですよね。なぜならば、$C\leqq D$である時点で、いずれのケースでも$C$は最大値にはなり得ないためです。$3$つの中の小さい方から$2$つ選ぶことは、最大を$1$つ選ぶのと同値になります。しからば最大になり得ない$C$の情報は不要です。
これを図でもう少し分かりやすく可視化していきましょう。
$N=4$のケースにおいて、最小側から$2$つ選んでマージした$A+B$を$M$とした問題を考えます。先ほど示した通り、ケースは以下の$2$通りしかありません。
$M$が最大のケース、あるいは$D$が最大のケースです。
そうなんです。結局トップダウンでいろいろこねくり回しても、最も小さい方からマージして置換していくと$N=4$のケースが$N=3$のケースに帰着するんです。確認のためにあらためて$M$に$A+B$を戻すと、以下のように先ほどまでトップダウンで議論していた場合分けの形にちゃんとなります。
ボトムアップで捉え直す
さて、ここで各葉についてかかるコストを見てみましょう。
すると葉$1$枚が総コストに占める値は、その葉ノードの値と深さの積であることはすぐに分かります。ためしに先ほどの図の葉$A$を根まで辿ってみてください。根に至るまでの$1$本道全てに$A$が含まれており、かつ他のルートには$A$が含まれていないことが分かります。そして、値と深さという$2$軸を同時に考えるのは難しいので、同じ深さという観点で考えます。どういう木構造になるかは未知だったとしても、同じ深さにおいてはより値が小さい方がコストを小さくします。ということは、最も深い方から順に葉を埋めていくことを考えると、常に最小のペアで埋めていくことが貪欲的になります。なぜなら、重ねてになりますが“同じ深さなら値が小さい方がコストが小さくなる”からです。
これをトップダウンでやろうとすると、深さ$1$の時点で複数選択を取らなければならず、いきなり場合分けが発生します。$N=4$で十分面倒なことはご理解いただけたかと思いますので、最大ケースの$N=20000$など実質無理だということになります。
得られた教訓
- 困難は分割する
- 逆の方向からできないか試してみる
- 複数軸ある場合は、いずれかの軸を固定して考えてみる
実際の解答コードはプログラミングコンテストチャレンジブックを参照してください。
余談
競プロは$2020$年の$8$月に入ってからはじめました。
普段は個人ブログに記事を投稿しています。





- 投稿日:2020-08-14T23:34:23+09:00
【簡易版】最低限の読書メーターの記録情報をエクスポートする方法
はじめに
はじめに言っておきますが、読書メーターの情報はエクスポートできません。詰みました。お疲れ様です。
しかし、エクスポートの目的は過去情報を抽出することなので、とりあえず強引にでも抽出できればOKなわけです。これは疑似エクスポートみたいな感じですかね(そんな大したことやってるわけじゃない)。
僕は読書メーターを使っていたんですが、あまり使い勝手がよくないと思って使っていました。「もういっそのことスプレッドシートで読書管理・記録しよう!」と決めたのです。
自分が欲しいと思った情報は、読了した書籍の読了日、タイトル、著者名ぐらいでした(+αのページ数)。感想とかは全部書いているわけじゃないし、スプレッドシートで管理はしないだろうなーと思ったので不要でした(感想文はノートで記録するか、書くなら本のキーワードぐらいでいいかな)。Webスクレイピングもダルイし、簡単な方法ないかなーって感じ。
簡単な方法ありました。
※プログラミングとか全然わからない人いたら「最後に」のところだけ読んでください。
完成図
読書メーターの記録をスプレッドシートへ移行できました~。
必要事項
- 環境:Python 3.7.4
- 読書メーターの情報
- 読了日
- タイトル
- 著者名
- ページ数
準備:読書メーターの情報の入手
1.「読んだ本」→「テクストのみ」にしてそのままコピーします。
これが意外と盲点だったこと。「テキストのみ」の機能使ったことなかったんですが、「めっちゃ使えるじゃん!」って思いました。
この記事の最大のポイントです。あとはコピペで終わり。楽勝。あなたの発想力で煮るなり焼くなりできると思います。
2.Excelにすべてをそのまま張り付ける
※実は張り付け方もっといい方法あるんですかね?これがよく分からなかったのでPythonで整地したんですけど。よくわからなかったので縦コピーになっちゃったんですよね笑。それで「どうするか」ってなって強引に弄りました。
3.不足情報を追加または修正する
たまに情報がないやつがあります(以下の画像)。タイトルと著者名が一緒のセルに入っていることもある。適宜修正してください。僕はプログラムを実行しながら修正していきました。そっちのほうが分かりやすいかも。
4.ExcelをCSVにして保存する
とりあえず名前は
input.csvにしておきます。プログラムを実行する
アニメ見ながら脳死で書きました笑。自分用に適当に作ったのでクソ汚いです。
一回書いたら終わりの捨てプログラムだったのでお許しください。main.pyimport csv import pandas as pd RESULT_CSV_TITLE = 'output.csv' date_list = [] title_person_list = [] page_list = [] df = pd.DataFrame() with open('input.csv', mode='r', encoding='utf-8') as f: all_row = csv.reader(f) for row in all_row: # 空白と余計な列を削除 if len(row) == 0 or row[0] == '編集する': continue # 日付 try: if '日付不明' in row[0] : date_list.append(row[0]) continue date_split = row[0].split('/') year = date_split[0] month = date_split[1] day = date_split[2] date_list.append(f'{year}/{month}/{day}') continue except: pass # ページ try: page = int(row[0]) page_list.append(page) continue except: pass # タイトルと著者のリスト title_person_list.append(row[0]) title_list = title_person_list[::2] person_list = title_person_list[::-2] # print(len(date_list)) # print(len(page_list)) # print(len(title_list)) # print(len(person_list)) person_list.reverse() df['日付'] = date_list df['タイトル'] = title_list df['著者'] = person_list df['ページ'] = page_list print(df) df.to_csv(RESULT_CSV_TITLE, index=False)結果
PyCharmを使って結果を見ているので以下に示す画像のようになります。
日付、タイトル、著者名、ページ数って感じになりました。
あとは煮るなり焼くなりしてください。
僕はスプレッドシートにoutput.csvの中身を全コピーして、コンマ区切りで分割しました。
最後に
「プログラムも何もわからない!」って人は @yuki_imamura_ のDMにでも連絡ください。お手伝いできればします。
いや~、それにしても読書管理・記録アプリは色々使ってきたけど、どれも微妙だね。結局はGoogle スプレッドシートとかで自分で管理するのがいいのかね。
Webスクレイピングを使えば読書感想文も抽出できると思います(サービスの規約は見てません)が、今回僕は必要なかったので簡単にやりました。どうしても必要だという方がいればプログラム作るのでそれもDM飛ばしてください。
ページ数は…一個のモチベーション指標として使っていこうかな~。
てなわけで読書生活を思う存分楽しみましょう!
何かの参考になれば幸いです。
参考文献







- 投稿日:2020-08-14T23:33:46+09:00
import torchで「OSError:[WinError 126] 指定されたモジュールが見つかりません。」が出た時の対処
はじめに
これまでテーブルデータの機械学習を中心に勉強してきましたが、画像処理についても勉強するために書籍「Pytorchによる発展ディープラーニング」を購入しました。さっそく、サンプルコードを実行するべくPytrochをインストールしましたが、コード実行時にモジュールのimportエラーが発生しました。事象の解消になかなか苦戦したので対処法を残します。
※ちなみにQiita初投稿です
実行環境
OS: Windows10
Anaconda3環境(Python3.7.6)発生した事象
Pytorchの公式サイトにて該当するインストールコマンドを確認し、Anaconda Prompt上でコマンドを実行。
自分の場合は以下のコマンド
(バージョンはpytorch==1.6.0 torchvision==0.7.0)conda install pytorch torchvision cpuonly -c pytorchPytorchのインストール完了後に、書籍付属のサンプルコードをJupyter Notebook上で実行したところ以下のエラーが「import torch」の行で発生。
OSError:[WinError 126] 指定されたモジュールが見つかりません。 Error loading "C:\Users\●●●\anaconda3\lib\site-packages\torch\lib\asmjit.dll" or one of its dependencies.試したこと
いろいろと試しましたが結果、④の旧バージョンPytorchのインストールで解決しました。
①condaではなくpipでインストール
以下の記事で、pipでインストールし直したところ、エラーが出なくなったと書かれていたためpipで再度インストール。
【python】import torchがエラーで失敗した時の対処方法
しかし、pipでインストールし直すも事象は解消せず。
②Anacondaの再インストール
モジュールがインストールされるフォルダ内にPytorchのモジュールがちゃんと存在していたため、環境変数のpathがしっかりと通せていない、もしくはPythonのバージョンの影響と想定。しかし、Anacondaを再度インストールするも事象は解消せず。
③CUDAの再インストール
CUDAを半年ほど前にインストールした際には、自分のPCのOSがまだWindows8.1でした。その後、OSをWindows10へアップデートしたため、それが悪さをしていると想定。しかし、Windows10対応のCUDAを再度インストールするも事象は解消せず(そもそも、実行したサンプルコードではGPUの使用がないので関係ない?)。
④旧バージョンのPytorchをインストール
海外の記事で、旧バージョンのPytorchをインストールしたところ解消したという事例を見つけたので試してみました。
error while import pytorch module. (The specified module could not be found.)
自分の場合は以下のコマンド
(バージョンはpytorch==1.5.0 torchvision==0.6.0)conda install pytorch==1.5.0 torchvision==0.6.0 -c pytorch結果、これで今回のエラーが出る事象は解消しました!サンプルコードも実行できました。
事象解消に数日溶かしました
文章で書くと一瞬で解決したように見えますが、自分は②、③でAnacondaやCUDAのバージョンをいろいろと変えて再インストールするのに時間を費やしてしまい、事象解消に数日かかってしまいました。
(最初から④を試していれば速攻で解決してたんでしょうけど…)同じような事象が発生したという日本語の記事も少なかったので今回メモとして残しておきます。同じ事象で困っている方はぜひ参考にして下さい。
- 投稿日:2020-08-14T23:28:13+09:00
yukicoder contest 261 参戦記
yukicoder contest 261 参戦記
A 1168 Digit Sum Sequence
増えていったりしないので、何も考えずに99回ループを回せば OK.
N = int(input()) for _ in range(99): N = sum(int(c) for c in str(N)) print(N)B 1169 Row and Column and Diagonal
解けず.
- 投稿日:2020-08-14T23:14:54+09:00
【Python】データサイエンス100本ノック(構造化データ加工編) 027 解説
Youtube
動画解説もしています。
問題
P-027: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、降順でTOP5を表示せよ。
解答
コードdf_receipt.groupby('store_cd').amount.mean().reset_index().sort_values('amount', ascending=False).head(5)出力
store_cd amount 28 S13052 402.867470 12 S13015 351.111960 7 S13003 350.915519 30 S14010 348.791262 5 S13001 348.470386 解説
・PandasのDataFrame/Seriesを使用します。
・同じ値を持つデータをまとめて処理し、同じ値を持つデータの合計や平均などを確認したい時に使用します。
・'groupby'は、同じ値や文字列を持つデータをまとめて、それぞれの同じ値や文字列に対して、共通の操作(合計や平均など)を行いたい時に使います。
・'.amount.mean()'は、amountの平均値を表示させます。
・'.reset_index()'は、'groupby'によってバラバラになったインデックス番号を0始まりの連番に振り直す操作を行いたい時に使います。
・'.sort_values('amount', ascending=False)'で'amount'を降順に表示しています。※こちらのコードでも同様の結果を出力します
コードdf_receipt.groupby('store_cd').agg({'amount':'mean'}).reset_index().sort_values('amount', ascending=False).head(5)
- 投稿日:2020-08-14T22:14:10+09:00
私を5歳児だと思ってScikit-learnのPermutation_Importanceを教えてください。
Scikit-learnのPermutationImportanceを使ってみた
PermutationImportanceのライブラリーは、今までは、ELI5ELI5公式ドキュメントというライブラリーでした。
(ELI5とはExplain Like I'm 5.(私を5歳児だと思って説明して)の略です。)
最近、Scikit-Learn0.22からPermutationImportanceが実装されました。今までサポートベクターで計算した後は、特徴量の何が寄与したかよくわからなかったのですが、今後は、PermutationImportanceで特徴量の何が重要か見ることができるようになりました。
PermutationImportanceは、簡単に言うと、特徴量の中の一つを選ぶ、その中の値をシャッフルして意味のない数値にします。そのデータを用いて精度を求め、正しい特徴量のデータセットと精度の比較をし、選んだ特徴量がどれくらい精度に影響しているのか計算するものです。計算するのは結構簡単でした。
sklearn.inspectionからpermutation_importanceをインポートします。
サポートベクターでパラメーターをoputunaで最適化して作ったインスタンスoptimised_regrと、データセットを、permutation_importanceの引数として読み込ませて計算するだけでした。#ここからsklearnのpermutation_importanceです from sklearn.inspection import permutation_importance result = permutation_importance(optimised_regr, X_test_std, y_test, n_repeats=10, n_jobs=-1, random_state=0) #結果をPandasのデータフレームに入れて、表示します df = pd.DataFrame([boston.feature_names,result.importances_mean,result.importances_std],index=['Featue','mean','std']).T df_s = df.sort_values('mean',ascending=False) print(df_s)結果を
pandasに読み込んで表にしてみました。
Featue mean std 5 RM 0.466147 0.066557 12 LSTAT 0.259455 0.0525053 8 RAD 0.141846 0.0203266 9 TAX 0.113393 0.0176602 7 DIS 0.0738827 0.0178893 10 PTRATIO 0.0643727 0.0205021 6 AGE 0.0587429 0.010226 4 NOX 0.0521941 0.0235265 2 INDUS 0.0425453 0.0185133 0 CRIM 0.0258689 0.00711088 11 B 0.017638 0.00689625 3 CHAS 0.0140639 0.00568843 1 ZN 0.00434593 0.00582095 サポートベクターでの計算だと、今まではどの特徴量が影響していたかわかりませんでしたが、
permutation_importanceが実装されたので、これでどの特徴量が影響しているか、よくわかるようになりました。
- 投稿日:2020-08-14T22:11:41+09:00
python orm
何故かqiita界隈ではsqlalchemy一択(検索561件、タグ161件)だけど他にもあるよね?と思ったら当然あった。
いずれもクエリで、かなり特殊な記述をするのが特徴。ぱっと見、python/DBどっちで動くものなのかわからなくなるやつ。 linqに影響を受けてるのだろうか?
peewee 検索35 タグ8
coleifer/peewee: a small, expressive orm -- supports postgresql, mysql and sqlite
peewee — peewee 3.13.3 documentationfrom peewee import * import datetime db = SqliteDatabase('my_database.db') class BaseModel(Model): class Meta: database = db class User(BaseModel): username = CharField(unique=True) class Tweet(BaseModel): user = ForeignKeyField(User, backref='tweets') message = TextField() created_date = DateTimeField(default=datetime.datetime.now) is_published = BooleanField(default=True)query = (Facility .select(Facility.facid, Facility.name, Facility.membercost, Facility.monthlymaintenance) .where( (Facility.membercost > 0) & (Facility.membercost < (Facility.monthlymaintenance / 50))))ponyorm ←これだけ
PonyORM - Python ORM with beautiful query syntax
ponyorm/pony: Pony Object Relational Mapperfrom pony.orm import * db = Database() class MyEntity(db.Entity): attr1 = Required(str)select(c for c in Customer if sum(c.orders.price) > 1000)SELECT "c"."id" FROM "customer" "c" LEFT JOIN "order" "order-1" ON "c"."id" = "order-1"."customer" GROUP BY "c"."id" HAVING coalesce(SUM("order-1"."total_price"), 0) > 1000
- 投稿日:2020-08-14T22:00:05+09:00
暇なので『RPAツール』を作る 番外編
はじめに
皆さん、どうも。enp(えん)です。冬より夏が好きです。
この記事は今から『RPAツール』を作ろうとする人の進捗報告になります。
RPAやRPAツールの作り方が書いてあるものではございませんので、ご了承ください。
今回は番外編ということで#3の延長線上で出来ちゃったRPAのご紹介です。
大変私欲を極めたRPAなのでグレーゾーンのような気もしますが、なにとぞよろしくお願いいたします。面倒くさいんじゃ!
はい。タイトルそのまんまです。多分、同じようなことを考える人は多いと思うんです。
マビノギって、なぜブラウザから立ち上げなきゃならないの?
マビノギに限らずブラウザからでのみ立ち上げるゲーム全てに言えます。
いちいちホームページに行くの面倒! どうにかしたい!
そこで私は思います。自動化できるんじゃね?
#3で自動ログインは出来るようになりました。そのため、マビノギへログインすることは出来ます。
あとはゲームを立ち上げるボタンをクリックすれば出来る! そう思い作り始めました。実装に必要なモノ
早速自動化を始めるのですが、今回必要なものがいくつかあります。
そのため、ここで列挙しておきたいと思います。【実装に必要なものリスト】
・ Python
・ selenium
・ ChromeDriver
・ PyOTP
・ 一度ゲームを立ち上げたことのあるユーザープロファイル(重要)PythonからPyOTPまでは普通にブラウザを自動で操作する上で必要なモノたちです。
最後の『一度ゲームを立ち上げたことのあるユーザープロファイル』はある問題を解決するために使います。
ユーザープロファイルとはChromeと同期しているユーザーのファイルです。最大の壁『モーダルダイアログ』
さて、早速実装していきましょう。しかし、一つ大きな問題があります。
それはモーダルダイアログの存在です。
モーダルダイアログとはダイアログ以外操作できなくなるダイアログのことです。
ちょっとダイアログがゲシュタルト崩壊しそうな感じですね。ちょっと分かりやすくしましょう。
上の図が問題のモーダルダイアログです。このダイアログが表示されている間、マビノギのファンアートやお知らせなどをクリックしても何も起きません。このようにダイアログ以外操作できなくなるヤツをモーダルダイアログと言います。
しかし、このダイアログはseleniumで認識しませんでした。seleniumの機能でダイアログのボタンを押すものがありますが、反応せず。javaScriptを利用しようと思いましたが、そもそもクラス名など分からないためボタンを取得することができませんでした。
さて、ここでマビノギをプレイしている皆さんに質問です。
このダイアログ見たことあります?
初めてマビノギをプレイした人は新しい記憶として残っていると思いますが、マビノギを何年と続けている方はもう忘却の彼方だと思います。
そう、普通このダイアログは二回目以降表示されないのです。まぁ、チェックボックスにチェックした人だけですが。
では、なぜ表示されなくなるのでしょうか?
ネクソン側が保存してるんじゃないの? と思った方、不正解です。
かといってウェブページに保存されているわけでもありません。ウェブページを作っているHTMLやjavaScriptなどは情報を保存する機能を持っていないからです。データベースと組み合わせていれば保存することも可能だと思いますが、一般的ではありません。
じゃあ、何?
答えはクッキーと呼ばれる小さなファイルです。聞いたことがある人もいるかもしれません。
仕組み等を詳しくは話しませんが『私、一回ゲーム立ち上げたことあるよ』というクッキーさえあれば表示されません。
もうモーダルダイアログとか言う訳分かんないものを相手にしなくていいのです。
そこで『一度ゲームを立ち上げたことのあるユーザープロファイル』が重要性を帯びてきます。
なぜなら、必要なクッキーを持っているからです。Chromeさんを知ろう
クッキーを使いモーダルダイアログを克服するのは分かりました。しかし、こう思った人がいるかもしれません。
わざわざユーザープロファイルを使わなきゃならないの?
答えはYesです。なぜならChromeでクッキーはユーザープロファイルごとで管理されているからです。
しかし、この『ユーザープロファイルごとで管理されている』というのは私の所感でしかありません。
なので、正しいという訳ではありませんのでご了承ください。
なぜ『ユーザープロファイルごとで管理されている』と感じたのかというと、seleniumで単純にクッキーを取得しただけではダイアログ問題は解決しなかったからです。
また、ユーザープロファイルごとで所持しているクッキーが違ったのでそう思いました。
さらに、デフォルトで用意されているユーザープロファイルを使おうとしましたが、少々不都合なことが起きるので使いませんでした。
その不都合な事とはもともとChromeが開いてる状態ではプログラムが壊れてしまうというものです。
どうやら参照するディレクトリが被ってしまうとエラーを吐くようです。なんてこったい。
そのため、個別にユーザープロファイルを置くディレクトリを用意しました。ようやく実装
ここまでグダグダと話してきましたが、要は以下の二点を抑えてくれたらいいです。
・ ダイアログ問題を解決するにはクッキーが必要
・ 必要なクッキーを持つユーザープロファイルを使えばダイアログ問題が解決できる
はい。この二点を踏まえて実装していきます。
プログラムは以下の通りです。nexon.py# モジュール等をインポート from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.chrome.options import Options import chromedriver_binary import pyotp import time # ドライバの設定 options = Options() PROFILE_PATH = r"個別に用意したユーザープロファイルディレクトリ" options.add_argument('--no-sandbox') options.add_argument('--disable-gpu') options.add_argument("--user-data-dir=" + PROFILE_PATH) # ユーザープロファイルディレクトリの指定 options.add_argument("--profile-directory=Profile 1") # ユーザープロファイルの指定 # ドライバーの指定 chrome = webdriver.Chrome(options=options) chrome.get("https://login.nexon.co.jp/login/?gm=mabinogi") # ログインページへ移動 chrome.implicitly_wait(10) # 必要な要素が表示されるまで待機(最大10秒間) # ログインに必要な情報 user_name = "user_name" password = "password" # ログイン情報を入力するテキストボックスを取得 element_user = chrome.find_element_by_id("NexonID") element_password = chrome.find_element_by_id("Password") element_totp = chrome.find_element_by_id("OTP") # ユーザー名などを入力 element_user.send_keys(user_name) element_password.send_keys(password) # ワンタイムパスワードを生成 totp = pyotp.TOTP("ワンタイムパスワードを設定するときに使用する英数字") # ワンタイムパスワードはあらかじめ設定しておく # 必要な英数字は控えておく # ワンタイムパスワードを入力してEnterで確定 element_totp.send_keys(totp.now()) element_totp.send_keys(Keys.ENTER) # ゲームスタートのボタンをクリック btn = chrome.find_element_by_xpath("//div[@id='left']/div[@class='bt-login']/div[@class='btn-web-gamestart']/a") btn.click() # 待機(待機しないとゲームが起動しなかったため) time.sleep(10) # Chromeを閉じる chrome.quit()クッキーはユーザープロファイルで実行した時点で利用可能のようで特に何かする必要はないようです。
また、headlessモードを使用するとゲームが立ち上がりませんので注意してください。
あと、ゲームを起動するために管理者の許可を求められますが、そこは自分でクリックしてください。
理由はウェブブラウザで操作できる管轄外だからです。
しかし、残念ながらこのプログラムには致命的な欠点があります。
クッキーの有効期限が切れたらダイアログ問題が再発します。
その時はまたクッキーを作るために使用して自分でゲームを立ち上げる必要があります。最後に
最後までお付き合いありがとうございます。番外編いかがだったでしょうか?
かなりグダグダとお話してしまいましたが、この記事が何かの一助になれば幸いです。
しかし、結構グレーゾーンなプログラムだと思いますので、ご了承ください。
以上、enpがお送りいたしました。

- 投稿日:2020-08-14T20:53:59+09:00
nimpyでnimからpythonを使って主成分分析をする
概要
Nimからsklearnをつかって主成分分析を行う手順をまとめました。
言わずとしれたsklearnを使うことで主成分分析を数行で行うことができますので、Nimから実行するためnimpyというライブラリをつかって実行してみます。実際にsklearnを使って主成分分析を行う部分はPythonで記述します。nimpyでPythonを呼ぶ方法については以前やったのでその応用になります。
Nimpyでnimからpythonを呼ぶPython側の準備
pyenv等で任意のPythonをいれる際に例のごとく(上記の記事を参考に)、
CONFIGURE_OPTS="--enable-shared"を付与してlibpythonが生成されるようにします。
そしてpoetry等を使ってsklearnをいれます。pyproject.toml[tool.poetry] name = "nimpy_pca" version = "0.1.0" description = "" authors = ["Your Name <you@example.com>"] [tool.poetry.dependencies] python = "^3.7" numpy = "^1.18" scikit-learn = "^0.22.2" [tool.poetry.dev-dependencies] [build-system] requires = ["poetry>=1.0"] build-backend = "poetry.masonry.api"sklearnでのPCAの書き方がnimから呼ぶのが難しいため、pythonで処理を書きます。(nimpyではメソッドをcall仕組みなのでイニシャライザのような書き方や戻り値のない構文が使えない)
型の受け渡しを簡略化するためにJSONを使ってデータや結果のやり取りを行うようにしています。pca.pyfrom sklearn.decomposition import PCA import numpy as np import json def pca(json_text): data = json.loads(json_text) pca = PCA(n_components=2) A = np.array(data) pca.fit(A) return { "components": pca.components_.tolist(), "varianceRatio": pca.explained_variance_ratio_.tolist() }nimpyでNimからPythonを呼ぶ
まず、poetryで入れたsklearnが読み込みできるようにlibpythonのpathを指定します。
import nimpy import nimpy/py_lib as pyLib pyLib.pyInitLibPath("/root/.pyenv/versions/3.7.7/lib/libpython3.7m.so")また、先程つくったPythonを読み込めるようにファイルのある場所のpathを追加します。
discard pyImport("sys").path.append("/workspace/src")そしてJSONデータをつかって先程のメソッドにデータを渡します。
toJsonをつかって 戻り値のPyObjectという型からJsonNode型に変換しています。let pcaResult = pyImport("pca.py").callMethod("pca", json).toJsonあとはpcaResultにはいっている値を展開すれば完成です。
import sugar let projectedValues = datas.map(data => pcaResult["components"].getElems.map(c => c.getElems.zip(data).map(n => n[0].getFloat * n[1]).foldl(a + b)) )まとめ
pyImportのパスの指定の仕方やpythonファイルの名前衝突などにつまりましたが、pythonの読み込みがこちらのやり方できました。
これを応用すれば、他の統計処理や線形処理もPythonにまかせて簡単に実行することができそうです。
- 投稿日:2020-08-14T20:25:50+09:00
【Python】Pyroで混合ガウスモデル
Pyroで混合ガウスモデルの推定を試してみました。
公式のexampleをベースにして、適宜補足的な内容を入れながら実行しています。※本記事のソースコードは、Jupyter Notebookで実行しています。
環境
Windows10
Python: 3.7.7
Jupyter Notebook: 1.0.0
PyTorch: 1.5.1
Pyro: 1.4.0
scipy: 1.5.2
numpy: 1.19.1
matplotlib: 3.3.0
seaborn: 0.10.1
※Pyroについて他の記事も書いているので、よろしければご覧ください
【Python】Pyroでベイズ推定import os import numpy as np from scipy import stats import torch import pyro import pyro.distributions as dist from pyro import poutine from pyro.infer.autoguide import AutoDelta from pyro.optim import Adam from pyro.infer import SVI, TraceEnum_ELBO, config_enumerate, infer_discrete import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline pyro.set_rng_seed(0) pyro.enable_validation(True)データの準備
seabornからirisデータセットを呼び出し、petal_lengthの値を対象のデータとします。df = sns.load_dataset('iris') data = torch.tensor(df['petal_length'], dtype=torch.float32) sns.swarmplot(data=df, x='petal_length')
プロットを見ると、クラスタを2個に分けるのが良さそうです 1
modelの設定
Pyroでは、modelメソッドに分布のモデルを記述します。
データ$x_1, \cdots, x_n \in \mathbb{R}$の各クラスタを$z_1, \cdots, z_n \in \{ 1, \cdots, K \}$として、混合ガウスモデルを適用します。\begin{align} p &\sim Dir(\tau_0/K, \cdots, \tau_0/K) \\ z_i &\sim Cat(p) \\ \mu_k &\sim N(\mu_0, \sigma_0^2) \\ \sigma_k &\sim InvGamma(\alpha_0, \beta_0) \\ x_i &\sim N(\mu_{z_i}, \sigma_{z_i}^2) \end{align}$K$はクラスタの数、$\tau_0, \mu_0, \sigma_0, \alpha_0, \beta_0$は事前分布のパラメータです。2
$\mu_1, \cdots, \mu_K$及び$\sigma_1, \cdots, \sigma_K$をベイズ推定し、クラスタ$z_1, \cdots, z_n$を確率的に算出するモデルを作成します。K = 2 # Fixed number of clusters TAU_0 = 1.0 MU_0 = 0.0 SIGMA_0_SQUARE = 10.0 ALPHA_0 = 1.0 BETA_0 = 1.0 @config_enumerate def model(data): alpha = torch.full((K,), fill_value=TAU_0) p = pyro.sample('p', dist.Dirichlet(alpha)) with pyro.plate('cluster_param_plate', K): mu = pyro.sample('mu', dist.Normal(MU_0, SIGMA_0_SQUARE)) sigma = pyro.sample('sigma', dist.InverseGamma(ALPHA_0, BETA_0)) with pyro.plate('data_plate', len(data)): z = pyro.sample('z', dist.Categorical(p)) pyro.sample('x', dist.Normal(locs[z], scales[z]), obs=data)
@config_enumerateは、離散変数pyro.sample('z', dist.Categorical(p))を並列的にサンプリングするためのデコレータです。サンプリングされた値の確認
poutine.traceを使うことで、modelにデータを与えた場合のサンプリング値を確認することができます。trace_model = poutine.trace(model).get_trace(data) tuple(trace_model.nodes.keys())>> ('_INPUT', 'p', 'cluster_param_plate', 'mu', 'sigma', 'data_plate', 'z', 'x', '_RETURN')
trace_model.nodesの型はOrderedDictで、上記のkeyを保持しています。
_INPUTはmodelに与えられたデータ、_RETURNはmodelの返り値(この場合はNone)、それ以外はmodel内で定義したパラメータを指します。試しに、
pの値を確認してみましょう。これは、$Dir(\tau_0/K,⋯,\tau_0/K)$からサンプリングされるパラメータです。
trace_model.nodes['p']もdictであり、valueで値を見ることができます。trace_model.nodes['p']['value']>> tensor([0.8638, 0.1362])次に、各データのクラスタを表す
zの値を確認してみましょう。trace_model.nodes['z']['value']>> tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0])
pの値から0がサンプリングされやすいと言えますが、その通りの結果になっています。
これは事前分布からのサンプリングなので、まだ正しい推定をできないことに注意してください。guideの設定
Pyroではguideに事後分布を設定します。
pyro.infer.autoguide.AutoDeltaは、MAP推定を行うためのクラスです。guide = AutoDelta(poutine.block(model, expose=['p', 'mu', 'sigma']))
poutine.blockは、推定の対象とするパラメータを選ぶメソッドです。
AutoDeltaでは離散的なパラメータzを扱えないようなので、exposeで指定していません。zの推定は、分布のフィッティングの後に行います。このguideは、データに対して、推定した値のパラメータをdictで返します。
guide(data)>> {'p': tensor([0.5000, 0.5000], grad_fn=<ExpandBackward>), 'mu': tensor([4.0607, 2.8959], grad_fn=<ExpandBackward>), 'sigma': tensor([1.3613, 1.6182], grad_fn=<ExpandBackward>)}現時点では初期値を返しているだけですが、これから、SVIによるフィッティングでMAP推定された値を返すようにします。
分布のフィッティング
guideでは、
zを推定せずに他のパラメータを推定するモデルを構成しました。
つまり、zを周辺化して計算する必要があります。
これを行うため、確率的変分推定のlossにTraceEnum_ELBO()を設定します。optim = pyro.optim.Adam({'lr': 1e-3}) svi = SVI(model, guide, optim, loss=TraceEnum_ELBO())フィッティングを行います。
NUM_STEPS = 3000 pyro.clear_param_store() history = [] for step in range(1, NUM_STEPS + 1): loss = svi.step(data) history.append(loss) if step % 100 == 0: print(f'STEP: {step} LOSS: {loss}')各ステップにおけるlossをプロットすると、次のようになります。
plt.figure() plt.plot(history) plt.title('Loss') plt.grid() plt.xlim(0, 3000) plt.show()
lossの値が収束しており、推定が終わっていると判断できます。
推定した分布の確認
$p,\mu, \sigma$の推定値を
guideから取得します。map_params = guide(data) p = map_params['p'] mu = map_params['mu'] sigma = map_params['sigma'] print(p) print(mu) print(sigma)>> tensor([0.6668, 0.3332], grad_fn=<ExpandBackward>) tensor([4.9049, 1.4618], grad_fn=<ExpandBackward>) tensor([0.8197, 0.1783], grad_fn=<ExpandBackward>)分布をプロットします。
下図で、xマークのプロットはデータの値を意味しています。x = np.arange(0, 10, 0.01) y1 = p[0].item() * stats.norm.pdf((x - mu[0].item()) / sigma[0].item()) y2 = p[1].item() * stats.norm.pdf((x - mu[1].item()) / sigma[1].item()) plt.figure() plt.plot(x, y1, color='red', label='z=0') plt.plot(x, y2, color='blue', label='z=1') plt.scatter(data.numpy(), np.zeros(len(data)), color='black', alpha=0.3, marker='x') plt.legend() plt.show()
分布をうまく推定できています。
クラスタの推定
まず、
guideにて推定されたパラメータをmodelに設定します。
Pyroでは、traceを経由してパラメータを設定します。trace_guide_map = poutine.trace(guide).get_trace(data) model_map = poutine.replay(model, trace=trace_guide_map)
modelに設定されたパラメータを確認します。ここでは$\mu$だけ確認します。trace_model_map = poutine.trace(model_map).get_trace(data) trace_guide_map.nodes['mu']['value']>> tensor([4.9048, 1.4618], grad_fn=<ExpandBackward>)
guideの$\mu$の値と一致していますね。
次に、各データの$z$の値を推定します。このとき、pyro.infer.infer_discreteを使います。model_map = infer_discrete(model_map, first_available_dim=-2)
first_available_dim=-2は、data_plateの次元との衝突を避けるための設定です。
これによって$z$の推定値がmodelに設定されたので、traceから取得することができます。trace_model_map = poutine.trace(model_map).get_trace(data) z_inferred = trace_model_map.nodes['z']['value'] z_inferred>> tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])$z$の値ごとにデータをプロットしてみます。
df['z'] = trace_model_map.nodes['z']['value'] df['z'] = df['z'].apply(lambda z: f'z={z}') sns.swarmplot(data=df, x='petal_length', y='z')
うまく推定できることが分かります。
おわりに
Pyroで混合ガウスを構成し、フィッティングさせてみました。
私はオブジェクト指向的な考え方に慣れているため、推定した値を取り出すのにpoutine.traceを使うのは少し面倒だと感じました。
実際に使うときには、GaussianMixtureModelのようなクラスを作って、値を取り出す処理を内部に記述した方が良さそうです。
Pyroについては、今後も触ってみて理解を深めようかと思います。




- 投稿日:2020-08-14T20:14:45+09:00
Pythonでゆっくり学ぶ「依存関係逆転の原則」
「依存関係逆転の原則」についてのテキストは数多くありますが、
- 理由がよくわからない
- やり方がよくわからない
という人向けに、自分なりの「こう説明してくれればわかりやすかった」という記事を書いてみます。
github
https://github.com/koboriakira/koboridip
つくるもの
四則演算をたしかめるツール。次のように結果をCLIに出力します。
$ python -m koboridip.main 8 2 8 + 2 = 10 8 - 2 = 6 8 * 2 = 16 8 / 2 = 4.0言われた通りに作る。バージョン1
プロジェクト構成
. └── koboridip ├── calculator.py └── main.pyソース
calculator.pyclass Calculator(): def __init__(self, a: int, b: int) -> None: self.a = a self.b = b def print(self) -> None: print(f'add: {self.a + self.b}') print(f'subtract: {self.a - self.b}') print(f'multiply: {self.a * self.b}') print(f'divide: {self.a / self.b}')main.pyimport sys from koboridip.calculator import Calculator if __name__ == '__main__': # 引数を取得 a = sys.argv[1] b = sys.argv[2] # Calculatorインスタンスを作成 calculator = Calculator(int(a), int(b)) # 四則演算の結果をそれぞれ出力 calculator.print()説明
シンプルなプログラムです。
Calculatorクラスに数値を与えたら、あとはインスタンスに「計算(処理)」と「出力」を任せます。突然の仕様変更。バージョン2
このプロダクトについて、「出力結果をjson形式で保存したい」という要望があがりました。そのためソースを改修します。
出力はCalculatorクラスに書いているので、これを直しましょう。
ソース
calculator.pyimport json from typing import Dict class Calculator(): def __init__(self, a: int, b: int) -> None: self.a = a self.b = b def print(self) -> None: # print(f'add: {self.a + self.b}') # print(f'subtract: {self.a - self.b}') # print(f'multiply: {self.a * self.b}') # print(f'divide: {self.a / self.b}') result: Dict[str, int] = { "add": self.a + self.b, "subtract": self.a - self.b, "multiply": self.a * self.b, "divide": self.a / self.b } with open('result.json', mode='w') as f: f.write(json.dumps(result))念のため、実行すると
result.jsonに次のようなテキストが出力されます(フォーマット済)。result.json{ "add":10, "subtract":6, "multiply":16, "divide":4.0 }リファクタリング
Calculatorクラスは四則演算の処理と、結果の出力を行っています。これらを分けたほうが良いと判断して、出力処理を担当する
Printerクラスを作ることにしました。. └── koboridip ├── calculator.py ├── main.py └── printer.pyprinter.pyimport json from typing import Dict class Printer(): def print(self, add, subtract, multiply, divide) -> None: result: Dict[str, int] = { "add": add, "subtract": subtract, "multiply": multiply, "divide": divide } with open('result.json', mode='w') as f: f.write(json.dumps(result))calculator.pyfrom koboridip.printer import Printer class Calculator(): def __init__(self, a: int, b: int) -> None: self.a = a self.b = b def print(self) -> None: add = self.a + self.b subtract = self.a - self.b multiply = self.a * self.b divide = self.a / self.b printer = Printer() printer.print(add, subtract, multiply, divide)イヤな予感。バージョン3
その後の方針転換で、「CLIへの結果出力とjson形式の保存をどちらも利用したい」という判断がくだされました。次のようにしてモードを切り替えます。
$ python -m koboridip.main 8 2 simple > (CLIに出力) $ python -m koboridip.main 8 2 json > (result.jsonを出力)そのため
Printerクラスを2種類に分割して、切り替えられるようにしました。. └── koboridip ├── calculator.py ├── json_printer.py -> json形式で出力 ├── main.py ├── simple_printer.py -> CLIに出力simple_printer.pyclass SimplePrinter(): def print(self, add, subtract, multiply, divide) -> None: print(f'add: {add}') print(f'subtract: {subtract}') print(f'multiply: {multiply}') print(f'divide: {divide}')json_printer.pyimport json from typing import Dict class JsonPrinter(): def print(self, add, subtract, multiply, divide) -> None: result: Dict[str, int] = { "add": add, "subtract": subtract, "multiply": multiply, "divide": divide } with open('result.json', mode='w') as f: f.write(json.dumps(result))どちらで出力するかの判断は
calculator.pyに任せます。指定される"simple"もしくは"json"という文字列を、
mode変数に格納することで切り替えられるようにします。calculator.pyfrom koboridip.simple_printer import SimplePrinter from koboridip.json_printer import JsonPrinter class Calculator(): def __init__(self, a: int, b: int, mode: str) -> None: self.a = a self.b = b self.mode = mode def print(self) -> None: add = self.a + self.b subtract = self.a - self.b multiply = self.a * self.b divide = self.a / self.b # 出力方法を切り替える if self.mode == 'json': json_printer = JsonPrinter() json_printer.print(add, subtract, multiply, divide) elif self.mode == 'simple': simple_printer = SimplePrinter() simple_printer.print(add, subtract, multiply, divide)引数を取得できるように
main.pyも変更しましょう。main.pyimport sys from koboridip.calculator import Calculator if __name__ == '__main__': # 引数を取得 a = sys.argv[1] b = sys.argv[2] # 出力方式 mode = sys.argv[3] # Calculatorインスタンスを作成 calculator = Calculator(int(a), int(b), mode) # 四則演算の結果をそれぞれ出力 calculator.print()【重要】プロダクトの問題点
いまどうなっているのか
現状は、四則演算"処理"の
Calculatorクラスが結果**"出力"のPrinterクラスをimportしています。この状態を、
「
Calculator(処理)はPrinter(出力)に依存している」と表現します。
「依存している」とは
依存(import)が意味するのは、依存先の変更によって依存元も変更が必要になるという点です。
バージョン3で見たように、本プロジェクトは出力方式の追加(変更)をするために
Calculatorクラスも修正されました。出力を変えたいだけなのに、処理も変えないといけなくなったのです。
仮に今後、「csv形式で出力したい」、「どこかのサーバに結果を飛ばしたい」といったような要望が増えたとしましょう。
そのたびに
Printerクラスはもとより、Calculatorクラスもなんらかの変更を余儀なくされます。繰り返しになりますが、「処理(四則演算)」については一切の仕様変更が無いにも関わらず、処理機能の修正が必要になる。
ここに「違和感」を感じるところが重要です。
適切な依存関係をつくる
ここまで来ると「じゃあ依存先の変更に影響されないよう、依存を減らせばいいのか」という結論が出てくるかもしれません。
しかしPythonのプロジェクトでimportを使わないことはできないため、必ず依存は存在します。
つまり我々に必要な工夫は、「適切な依存関係」をつくることなのです。
それは「変更の少ないほうに依存していること」を指します。
補足(飛ばしてもOK)
このプロジェクトの問題点はもうひとつ、
Calculatorが出力の詳細について知っていること、が挙げられます。あくまで
Calculatorは「結果を出力する」ことができればよくて、それがCLIだろうがjson形式だろうが、これを気にすることは避けたい、という目的もあります。依存、そして逆転。バージョン4
それでは依存関係を逆転させましょう。
calculator.pyに抽象クラスであるPrinterクラスを置き、必要なABCMeta、abstractmethodもインポートします。calculator.pyfrom abc import ABCMeta, abstractmethod from koboridip.simple_printer import SimplePrinter from koboridip.json_printer import JsonPrinter class Calculator(): def __init__(self, a: int, b: int, mode: str) -> None: self.a = a self.b = b self.mode = mode def print(self) -> None: add = self.a + self.b subtract = self.a - self.b multiply = self.a * self.b divide = self.a / self.b # 出力方法を切り替える if self.mode == 'json': json_printer = JsonPrinter() json_printer.print(add, subtract, multiply, divide) elif self.mode == 'simple': simple_printer = SimplePrinter() simple_printer.print(add, subtract, multiply, divide) class Printer(metaclass=ABCMeta): @abstractmethod def print(self, add, subtract, multiply, divide): passそして
SimplePrinter、JsonPrinterそれぞれを、Printerクラスを継承するように変更します。simple_printer.pyfrom koboridip.calculator import Printer class SimplePrinter(Printer): def print(self, add, subtract, multiply, divide) -> None: print(f'add: {add}') print(f'subtract: {subtract}') print(f'multiply: {multiply}') print(f'divide: {divide}')json_printer.pyimport json from typing import Dict from koboridip.calculator import Printer class JsonPrinter(Printer): def print(self, add, subtract, multiply, divide) -> None: result: Dict[str, int] = { "add": add, "subtract": subtract, "multiply": multiply, "divide": divide } with open('result.json', mode='w') as f: f.write(json.dumps(result))ここで重要なのは
SimplePrinterたちがcalculator.pyに依存していることです。ここで依存関係が逆転しました。"出力"が"処理"に依存しています。
当然まだ完璧ではありませんので、
CalculatorクラスがSimplePrinterクラスに依存している状態を取り除きます。そのために、コンストラクタでどちらのPrinterを利用するかを決めさせるようにしましょう。
calculator.pyfrom abc import ABCMeta, abstractmethod class Calculator(): def __init__(self, a: int, b: int, printer) -> None: self.a = a self.b = b self.printer = printer def print(self) -> None: add = self.a + self.b subtract = self.a - self.b multiply = self.a * self.b divide = self.a / self.b self.printer.print(add, subtract, multiply, divide) class Printer(metaclass=ABCMeta): @abstractmethod def print(self, add, subtract, multiply, divide): passそして
main.pyでどちらのPrinterを使うか指定させます。main.pyimport sys from koboridip.calculator import Calculator, Printer from koboridip.json_printer import JsonPrinter from koboridip.simple_printer import SimplePrinter if __name__ == '__main__': # 引数を取得 a = sys.argv[1] b = sys.argv[2] # 出力方式 mode = sys.argv[3] # Printerクラスを指定("simple"を判定するのは面倒なのでelseにしてしまいました) printer: Printer = JsonPrinter() if mode == 'json' else SimplePrinter() # Calculatorインスタンスを作成 calculator = Calculator(int(a), int(b), printer) # 四則演算の結果をそれぞれ出力 calculator.print()
calculate.pyにはimportがなく、代わりにsimple_printer.pyたちにimportがあります。これで依存関係逆転が完成しました。
エピローグ。バージョン5
さきほど想定した通り、csv形式での出力も要望されました。
これまでは出力方式に変更があるたびに
Calculatorクラスも影響を受けていましたが、これがどうなるかを確認してみましょう。. └── koboridip ├── calculator.py ├── csv_printer.py ├── json_printer.py ├── main.py └── simple_printer.pycsv_printer.pyimport csv from typing import List from koboridip.calculator import Printer class CsvPrinter(Printer): def print(self, add, subtract, multiply, divide) -> None: result: List[List] = [] result.append(["add", add]) result.append(["subtract", subtract]) result.append(["multiply", multiply]) result.append(["divide", divide]) with open('result.csv', 'w') as f: writer = csv.writer(f) writer.writerows(result)main.pyimport sys from koboridip.calculator import Calculator, Printer from koboridip.json_printer import JsonPrinter from koboridip.simple_printer import SimplePrinter from koboridip.csv_printer import CsvPrinter if __name__ == '__main__': # 引数を取得 a = sys.argv[1] b = sys.argv[2] # 出力方式 mode = sys.argv[3] # Printerクラスを指定 printer: Printer = JsonPrinter() if mode == 'json' else CsvPrinter( ) if mode == 'csv' else SimplePrinter() # Calculatorインスタンスを作成 calculator = Calculator(int(a), int(b), printer) # 四則演算の結果をそれぞれ出力 calculator.print()こうすることでcsvファイルの出力もできました。
以降も簡単に出力方式を変更できることが想像できるかと思います。
さいごに
依存関係逆転の原則を理解する手助けになれば幸いです。最後に1点補足を。
これまでのバージョンは誤りだったのか
「依存関係逆転の原則を理解した!」となった人は、つぎに適切な依存関係でなさそうなプロジェクトを見ると「これは問題だ!」と設計・実装を即座に直そうとします(自分がそうです)。
たとえばバージョン2のリファクタリング後で
CalculatorクラスがPrinterクラスに依存しているので、この時点で依存関係逆転の原則を適用したくなるはずです。しかしこれは時期尚早です。もちろんこのタイミングで「出力方式はいくらでも増えることがある」と分かっていれば適用すべきですが、一方で「出力方式が変更されることはあまりなさそう」であれば、適用を《保留》することも良い判断になりえると思います。
個人的には出力のような「詳細」は早めに依存関係を整理しておきたくなりますが、すくなくとも「いつでも変更はできるよなー」と思っておけることが重要なのかなと考えています。
依存性の注入(インジェクション)
時間があれば、この題材のまま「DI=依存性の注入」についても書ければと思います。
指摘や質問などあれば、ぜひコメントいただければ嬉しいです。
- 投稿日:2020-08-14T19:46:07+09:00
深層学習とかでのエラー『ImportError: DLL load failed: 指定されたモジュールが見つかりません。 』での「指定されたモジュール」を知る方法。
目的
Pythonにおいて、
以下のエラーに出会うことはよくある。
ImportError: DLL load failed: 指定されたモジュールが見つかりません。もう少し手前から示すと、以下のようなエラー。
ImportError: Traceback (most recent call last): File "C:\Users\XYZZZ\AppData\Local\Programs\Python\Python37\lib\site-packages\tensorflow\python\pywrap_tensorflow.py", line 64, in <module> from tensorflow.python._pywrap_tensorflow_internal import * ImportError: DLL load failed: 指定されたモジュールが見つかりません。気分としては、
指定されたモジュール
が何か、具体的なファイル名を知りたい場合がある。「指定されたモジュール」を知る方法
Process Monitor をインストール
以下のサイトから取得できる。
https://docs.microsoft.com/ja-jp/sysinternals/downloads/procmon#introduction「指定されたモジュール」を知る
以下のような画面で、見つからないDLLがわかる。
(沢山の表示が出るので、適宜、フィルターをかけて下さい。python.exe等で。)
下記は、pygameで、「SDL.dll」というのを隠してみた例。
まとめ
見つからないDLLのファイル名がわかっても、対処方法としては、pathが変になっているとか、インストールがうまくいってないとか、何か、具体的な対処方法をとる必要があるので、ファイル名がわかるだけでは解決にならないですが、全然、原因がわからないときとかには、有効かも。。。
あちこちどこに探しにいっているかとかも、わかるので、自分の認識と、実際の動きの違いがわかり、原因究明になるかも。(Windows等に詳しい方は、もっと、簡単に、調べられるのかも。。。)
コメントなどあれば、お願いします。

- 投稿日:2020-08-14T19:36:51+09:00
Docker初心者でも分かったDockerfileの作り方(WebAPI環境の共有)
flaskでwebAPIを作ったものの、Dockerイメージ(1.4GBくらい)でその環境を渡したら冷ややかな目で見られました。おしん
まあ、そんな訳でこの記事では、Python環境をDockerfileにして渡す方法を書き殴ります。目次
- Dockerとは?
- ディレクトリ構造
- .dockerignoreについて
- requirements.txtについて
- Dockerfileの心
- ビルド
- ラン。コンテナを作る
- コンテナの起動
- 最後に
Dockerとは?
linux系のOSを簡単に共有したりやりたい放題環境を荒らしたりできる便利なサービスです。OSレベルの仮想環境を扱うことのできるソフトと考えて下さい。インストール方法はこちら
dockerイメージという1~2GBくらいのOSの素をdocker run ~ とすることでdockerコンテナができます。コンテナが仮想環境(OS)みたいなものです。コンテナができればもう"""勝ち"""なのです。
ではこの環境をどうやって共有しましょう?取り敢えず、dockerイメージを共有すれば相手側でもrunしてコンテナを立ち上げることができますね。まあ、そうすると環境のパッケージによっては大きな容量になって不便ですね...
そこで、Dockerfileを利用します
Dockerfileとは、dockerイメージの設計図みたいなテキストのファイルで容量を軽っかっるなやつです。例としてはこんなんです⇓FROM ubuntu:18.04 # install python RUN apt-get update RUN apt-get install -y python3 python3-pip # setup directory RUN mkdir /api ADD . /api WORKDIR /api # install py RUN pip3 install -r requirements.txtこれで、Python3系と必要なパッケージが揃ったubuntu18.04の環境ができます。8行で!
こうやってDockerfileで相手と共有して、相手はdocker build ~ とすることでDockerイメージを作ることができます。後はdocker run ~ とイメージからコンテナを立ち上げ仮想OSの中に入ることができます。おんのじ!ディレクトリ構造
僕を含め初心者の方がここまで聞くと「Dockerすげえええええええーーーーーーーーー!!!!!何でもできんじゃん!すげえええええええええーーーーーひゃっほいーーーーー!!1hぃさfyいうぇb」
となります。皆なります。まあ、しかしOS環境ができても、肝心なのはAPIのファイルであったり、機械学習だとネットワークのモデルファイルなどがDocker内に配置されていないと元も子もないので、共有するディレクトリ構造について確認します。
kyoyu/
├ data/
├ ganbari/
├ api_server.py
├ gomi/
├ .dockerignore
├ requirements.txt
└ Dockerfile
例としてこの様なディレクトリ構造を考え、githubなどでこのkyoyuディレクトリを相手と共有するとします。共有するディレクトリの内部にDockerfileを置きます。dataとganbariとapi_sever.pyが環境で利用したいデータやコードのファイル・フォルダとします。gomiディレクトリはDocker環境には不要なもの(.mdでの仕様書など)とします。.dockerignoreについて
後ほど説明しますが、DockerfileでDocker内でディレクトリを作る命令文を書き、kyoyuディレクトリ内のディレクトリをDocker内に配置します。その時、Docker内に不要なディレクトリをわざわざ配置しないように命令することができます。それが.dockerignoreです。テキストのファイルでこのように書きます。
gomi/*これでgomiディレクトリ以下全てがDocker内に配置されません。
requirements.txtについて
環境で使いたいPythonパッケージをまとめます。
(例)例.pyabsl-py==0.9.0 alembic==1.4.2 astor==0.8.1 attrs==19.3.0 backcall==0.2.0 bcolz==1.2.1 bleach==3.1.5 Bottleneck==1.3.2 certifi==2020.6.20 chardet==3.0.4 click==7.1.2こんな感じにひたすらパッケージとそのバージョンが書かれたテキストファイルです。作るのが面倒臭そうですが、
/kyoyu$ pip freeze > requirements.txtで一発でファイルができます。
Dockerfileの心
Dockerfileの書き方について詳しいことはネットに転がっているので調べて下さい。今回はDockerfileのお気持ちを解説します。
Dockerfileは拡張子の無いテキストのファイルです(windowsでは.dockerfileで認識されるらしい)。FROM ubuntu:18.04 # install wget, cmake RUN apt-get update RUN apt-get install -y python3 python3-pip # setup directory RUN mkdir /api ADD . /api WORKDIR /api # install py RUN pip3 install -r requirements.txtお気持ちとしてはFROMで基となるOSを決め、以降は一捻りしたlinuxコマンドで環境を整えていく感じです。
FROMコマンド
FROMコマンドで基本となるDockerイメージを指定します。「ちょ!?待て、Dockerイメージの設計図がDockerfileでしょ!?」と思うかもしれませんが、ここではDockerhubというサービスに登録されたDockerイメージを利用することができます。様々なDockerイメージが登録されており、大抵わざわざ自分でDockerfileを書かなくてもここにあります。
(実は、Python3系のDockerイメージも既にありますが、今回は解説用にわざわざコマンドで書きました。)RUNコマンド
普通にlinuxのターミナルで書くようなコードを書くことができます。ただし、cdだけは後で説明するWORKDIRで書きます。
WORKDIRコマンド
linuxのcdコマンドの用に作業するディレクトリを変更します。
ADDコマンド
このDockerfileをdocker build ~ とビルドしてコンテナを作成しますが、このbuildしている環境のファイルをDocker内に送ることができます。
ADD [実行している環境のファイルのパス] [送りたいdocker内のディレクトリのパス]今回は、kyoyuディレクトリ内でビルドすると仮定し、"." (kyoyuディレクトリ内の全てのディレクトリ・ファイル) を/apiに送っています。この時、.dockerignoreで指定したgomiディレクトリはdocker内に配置されません。
install -r requirements.txt
docker内のapiディレクトリにkyoyuディレクトリの中身を配置しました。docker内のディレクトリ構造はこの様になります。
api
├ data/
├ ganbari/
├ api_server.py
└ requirements.txt
ここで、WORKDIR /api のコマンドでapiディレクトリ内に入りrequirements.txtを参照してライブラリをインストールします。RUN pip3 install -r requirements.txt以上がDockerfileの書き方となります。他にも沢山便利なコマンドがあるのでググってみて下さい。
ビルド
Dockerfileができたので早速イメージを作ります。DockerfileからDockerイメージを作ることをビルドと言います。
/kyoyu$ docker build -t [イメージの名前(名付ける)] [Dockerfileが存在するディレクトリのパス](-tは今は呪文と思っていて下さい)
今回、testという名前でイメージを作成し、"." (カレントディレクトリ(kyoyu))内にDockerfileが存在するので、実行するコードは次の様になります。/kyoyu$ docker build -t test .ラン。コンテナを作る
Dockerイメージからコンテナを作ることをランと言います。
$ docker run -p [外部からアクセスされるポート番号]:[コンテナ側のポート番号を指定] -it [イメージ名] --name [コンテナの名前(名付ける)](-itは後ほどDockerをstartした時に環境を維持するコマンドなので今は呪文だと思って下さい)
例えば、今回の例でDocker側の5000番ポートでAPIなどを実行する予定で、それをパソコン実機の8888番ポートに送りたいとする。コンテナ名をtestconとすると$ docker run -p 8888:5000 -it test --name testconとなる。
コンテナの起動
最後に、作ったDockerコンテナの中に入る。
$ docker ps -aこのコマンドでコンテナの一覧を見られるが、まず、ここにtestconがあることを確認する。
$ dockr start testconこれで、停止しているtestconコンテナを動かすことができる。お気持ちとしては、dockerコンテナは通常停止している状態で存在し、それをstartすることで動かす。動いたコンテナにattach(触る)ことで、仮想OS内に入ることができる。
$ dockr attach testconroot@hogehoge:/api#先頭が上の様な文字列になり、仮想OS内に入ることができた。ここで最初から/apiとなっているのはDockerfileでWORKDIR /apiと指定されているからである。
最後に
Dockerのお気持ち分かりましたか?Dockerって聞いたことある!くらいの層を対象にしているので、細かいところはググって下さい。
- 投稿日:2020-08-14T19:36:51+09:00
Docker初心者でも分かったDockerfileの作り方(API環境の共有)
flaskでwebAPIを作ったものの、Dockerイメージ(1.4GBくらい)でその環境を渡したら冷ややかな目で見られました。おしん
まあ、そんな訳でこの記事では、Python環境をDockerfileにして渡す方法を書き殴ります。目次
- Dockerとは?
- ディレクトリ構造
- .dockerignoreについて
- requirements.txtについて
- Dockerfileの心
- ビルド
- ラン。コンテナを作る
- コンテナの起動
- 最後に
Dockerとは?
linux系のOSを簡単に共有したりやりたい放題環境を荒らしたりできる便利なサービスです。OSレベルの仮想環境を扱うことのできるソフトと考えて下さい。インストール方法はこちら
dockerイメージという1~2GBくらいのOSの素をdocker run ~ とすることでdockerコンテナができます。コンテナが仮想環境(OS)みたいなものです。コンテナができればもう"""勝ち"""なのです。
ではこの環境をどうやって共有しましょう?取り敢えず、dockerイメージを共有すれば相手側でもrunしてコンテナを立ち上げることができますね。まあ、そうすると環境のパッケージによっては大きな容量になって不便ですね...
そこで、Dockerfileを利用します
Dockerfileとは、dockerイメージの設計図みたいなテキストのファイルで容量を軽っかっるなやつです。例としてはこんなんです⇓FROM ubuntu:18.04 # install python RUN apt-get update RUN apt-get install -y python3 python3-pip # setup directory RUN mkdir /api ADD . /api WORKDIR /api # install py RUN pip3 install -r requirements.txtこれで、Python3系と必要なパッケージが揃ったubuntu18.04の環境ができます。8行で!
こうやってDockerfileで相手と共有して、相手はdocker build ~ とすることでDockerイメージを作ることができます。後はdocker run ~ とイメージからコンテナを立ち上げ仮想OSの中に入ることができます。おんのじ!ディレクトリ構造
僕を含め初心者の方がここまで聞くと「Dockerすげえええええええーーーーーーーーー!!!!!何でもできんじゃん!すげえええええええええーーーーーひゃっほいーーーーー!!1hぃさfyいうぇb」
となります。皆なります。まあ、しかしOS環境ができても、肝心なのはAPIのファイルであったり、機械学習だとネットワークのモデルファイルなどがDocker内に配置されていないと元も子もないので、共有するディレクトリ構造について確認します。
kyoyu/
├ data/
├ ganbari/
├ api_server.py
├ gomi/
├ .dockerignore
├ requirements.txt
└ Dockerfile
例としてこの様なディレクトリ構造を考え、githubなどでこのkyoyuディレクトリを相手と共有するとします。共有するディレクトリの内部にDockerfileを置きます。dataとganbariとapi_sever.pyが環境で利用したいデータやコードのファイル・フォルダとします。gomiディレクトリはDocker環境には不要なもの(.mdでの仕様書など)とします。.dockerignoreについて
後ほど説明しますが、DockerfileでDocker内でディレクトリを作る命令文を書き、kyoyuディレクトリ内のディレクトリをDocker内に配置します。その時、Docker内に不要なディレクトリをわざわざ配置しないように命令することができます。それが.dockerignoreです。テキストのファイルでこのように書きます。
gomi/*これでgomiディレクトリ以下全てがDocker内に配置されません。
requirements.txtについて
環境で使いたいPythonパッケージをまとめます。
(例)例.pyabsl-py==0.9.0 alembic==1.4.2 astor==0.8.1 attrs==19.3.0 backcall==0.2.0 bcolz==1.2.1 bleach==3.1.5 Bottleneck==1.3.2 certifi==2020.6.20 chardet==3.0.4 click==7.1.2こんな感じにひたすらパッケージとそのバージョンが書かれたテキストファイルです。作るのが面倒臭そうですが、
/kyoyu$ pip freeze > requirements.txtで一発でファイルができます。
Dockerfileの心
Dockerfileの書き方について詳しいことはネットに転がっているので調べて下さい。今回はDockerfileのお気持ちを解説します。
Dockerfileは拡張子の無いテキストのファイルです(windowsでは.dockerfileで認識されるらしい)。FROM ubuntu:18.04 # install wget, cmake RUN apt-get update RUN apt-get install -y python3 python3-pip # setup directory RUN mkdir /api ADD . /api WORKDIR /api # install py RUN pip3 install -r requirements.txtお気持ちとしてはFROMで基となるOSを決め、以降は一捻りしたlinuxコマンドで環境を整えていく感じです。
FROMコマンド
FROMコマンドで基本となるDockerイメージを指定します。「ちょ!?待て、Dockerイメージの設計図がDockerfileでしょ!?」と思うかもしれませんが、ここではDockerhubというサービスに登録されたDockerイメージを利用することができます。様々なDockerイメージが登録されており、大抵わざわざ自分でDockerfileを書かなくてもここにあります。
(実は、Python3系のDockerイメージも既にありますが、今回は解説用にわざわざコマンドで書きました。)RUNコマンド
普通にlinuxのターミナルで書くようなコードを書くことができます。ただし、cdだけは後で説明するWORKDIRで書きます。
WORKDIRコマンド
linuxのcdコマンドの用に作業するディレクトリを変更します。
ADDコマンド
このDockerfileをdocker build ~ とビルドしてコンテナを作成しますが、このbuildしている環境のファイルをDocker内に送ることができます。
ADD [実行している環境のファイルのパス] [送りたいdocker内のディレクトリのパス]今回は、kyoyuディレクトリ内でビルドすると仮定し、"." (kyoyuディレクトリ内の全てのディレクトリ・ファイル) を/apiに送っています。この時、.dockerignoreで指定したgomiディレクトリはdocker内に配置されません。
install -r requirements.txt
docker内のapiディレクトリにkyoyuディレクトリの中身を配置しました。docker内のディレクトリ構造はこの様になります。
api
├ data/
├ ganbari/
├ api_server.py
└ requirements.txt
ここで、WORKDIR /api のコマンドでapiディレクトリ内に入りrequirements.txtを参照してライブラリをインストールします。RUN pip3 install -r requirements.txt以上がDockerfileの書き方となります。他にも沢山便利なコマンドがあるのでググってみて下さい。
ビルド
Dockerfileができたので早速イメージを作ります。DockerfileからDockerイメージを作ることをビルドと言います。
/kyoyu$ docker build -t [イメージの名前(名付ける)] [Dockerfileが存在するディレクトリのパス](-tは今は呪文と思っていて下さい)
今回、testという名前でイメージを作成し、"." (カレントディレクトリ(kyoyu))内にDockerfileが存在するので、実行するコードは次の様になります。/kyoyu$ docker build -t test .ラン。コンテナを作る
Dockerイメージからコンテナを作ることをランと言います。
$ docker run -p [外部からアクセスされるポート番号]:[コンテナ側のポート番号を指定] -it [イメージ名] --name [コンテナの名前(名付ける)](-itは後ほどDockerをstartした時に環境を維持するコマンドなので今は呪文だと思って下さい)
例えば、今回の例でDocker側の5000番ポートでAPIなどを実行する予定で、それをパソコン実機の8888番ポートに送りたいとする。コンテナ名をtestconとすると$ docker run -p 8888:5000 -it test --name testconとなる。
コンテナの起動
最後に、作ったDockerコンテナの中に入る。
$ docker ps -aこのコマンドでコンテナの一覧を見られるが、まず、ここにtestconがあることを確認する。
$ dockr start testconこれで、停止しているtestconコンテナを動かすことができる。お気持ちとしては、dockerコンテナは通常停止している状態で存在し、それをstartすることで動かす。動いたコンテナにattach(触る)ことで、仮想OS内に入ることができる。
$ dockr attach testconroot@hogehoge:/api#先頭が上の様な文字列になり、仮想OS内に入ることができた。ここで最初から/apiとなっているのはDockerfileでWORKDIR /apiと指定されているからである。
最後に
Dockerのお気持ち分かりましたか?Dockerって聞いたことある!くらいの層を対象にしているので、細かいところはググって下さい。
- 投稿日:2020-08-14T18:28:53+09:00
【Raspberry Pi】人感センサーが感知したらtimestampをFirebase Realtime Databaseに格納する
はじめに
この記事は全4章からなる記事の第2章です。
- IoTを駆使してお年寄りの家を見守るシステムを作った【SORACOM Summer Challenge 2020】
- LTE-M Buttonが押されたらLINE BotへPushメッセージを送る【SORACOM】
- 【Raspberry Pi】人感センサーが感知したらtimestampをFirebase Realtime Databaseに格納する
今ココ
- SORACOMと家電とLINE Botを連携させる【Python / Flask / Raspberry Pi】 全ソース公開
きっかけ
人感センサーが反応した時刻や1時間以内に反応した回数をLINE Botに通知したい。ローカルでSQLを動かしてもいいが、人感センサーを取り付けたラズパイとLINE Botのサーバとして使っているラズパイが別々なのでクラウドデータベースに格納したほうが楽なのではないかと思い、定番のFirebaseを使用。
ラズパイと人感センサーを繋ぐ
使ったもの
- Raspberry Pi 3 Model A+(これより上位のものならOK)
- 人感センサーモジュール
- ジャンパーワイヤー(メス-メス)
人感センサーはこちらのメーカのものを使いました。
接続
【Raspberry Pi】自作人感センサーの使い方と活用法をそのまま使わせてもらいました。
GPIOの接続間違いには気を付けてください(私は12番ピンとGroundを間違えて動かないというミスをしでかしました)。Firebase
[python] Firebase Realtime Databaseのはじめ方を参考しさせていただきました。
パッケージのインストール
以下のコマンドでラズパイにfirebase-adminをインストールします
$ pip install firebase-adminDatabaseの作成とルールの変更
FirebaseのコンソールからDatabaseを作成します。
Cloud FirestoreとRealtime Databaseがありますが、今回はRealtime Databaseなので注意してください。
ルールを以下のように変更します。
※ テスト用ですので実際に運用する場合は適切なルール設定をしてください
また、「プロジェクトの概要」の右側にある歯車から
プロジェクトを設定 > サービスアカウント > Firebase Admin SDKに移動し、Pythonを選択してコピー、また新しい秘密鍵の生成をクリックして、ダウンロードした秘密鍵をラズパイに保存します。
人感センサーとDatabaseの連携
以下がコードです
firebase.pyimport firebase_admin from firebase_admin import credentials from firebase_admin import db from datetime import datetime import time import RPi.GPIO as GPIO cred = credentials.Certificate("<ダウンロードした秘密鍵>.json") firebase_admin.initialize_app(cred, { 'databaseURL': 'https://<databaseURL>.firebaseio.com/' }) ref = db.reference('data') INTERVAL = 3 SLEEPTIME = 20 GPIO_PIN = 18 GPIO.setmode(GPIO.BCM) GPIO.setup(GPIO_PIN, GPIO.IN) while True: if(GPIO.input(GPIO_PIN) == GPIO.HIGH): print(datetime.now().strftime('%Y/%m/%d %H:%M:%S')) new_data_ref = ref.push() new_data_ref.set({ 'timestamp': {'.sv': 'timestamp'} }) time.sleep(SLEEPTIME) else: print(GPIO.input(GPIO_PIN)) time.sleep(INTERVAL)感知したらDatabaseにtimestampとともにPushします。Pushすることで一意のIDが生成されます。どうやらそのIDも時系列みたいです。
timestampの登録について
こちらのIssueでもありますが、Pythonのfirebase-adminモジュールからタイムスタンプを登録するには一癖あるみたいなので、上記の
'timestamp': {'.sv': 'timestamp'}のところが参考になれば幸いです。デモンストレーション
このように、検知するとRealtime Databaseに書き込まれます。
UNIX時間の
1597307961996は2020/08/13 17:39:21なので完璧ですね。まとめ
以上、人感センサーの反応時刻をFirebase Realtime Databaseに格納するまででした。
次はそのデータを別のラズパイから取得します。




- 投稿日:2020-08-14T18:28:30+09:00
LTE-M Buttonが押されたらLINE BotへPushメッセージを送る【SORACOM】
はじめに
この記事は全4章からなる記事の第2章です。
- IoTを駆使してお年寄りの家を見守るシステムを作った【SORACOM Summer Challenge 2020】
- LTE-M Buttonが押されたらLINE BotへPushメッセージを送る【SORACOM】
- 【Raspberry Pi】人感センサーが感知したらtimestampをFirebase Realtime Databaseに格納する
- SORACOMと家電とLINE Botを連携させる【Python / Flask / Raspberry Pi】 全ソース公開
きっかけ
離れて暮らす年老いた親に何かがあったときにLTE-M Buttonが押されるという想定です。SORACOM LagoonからLINE Notifyに通知をする機能はありますが、テキストメッセージで通知が来るだけでその後のアクションを選択できないのでLINE Botを作ることにしました。
このようにボタンが1つだけというシンプルな機構だと機械が苦手なお年寄りでも見た目でわかるのでいいですね。
動作環境
Raspberry Pi 3 Model B
Python 3.7.3
Flask==1.1.2
line-bot-sdk==1.16.0LTE-M ButtonとLINE Botを連携するまで
① SORACOM Lagoonからアラートを発する
具体的な使い方に関しては公式のSORACOM Lagoon を利用してダッシュボードを作成するとSORACOM Lagoon を利用してアラートを設定するに詳しく書かれているので割愛させていただきます。
LTE-M Buttonは1クリックが1、ダブルクリックが2、長押しが3というInt型のデータが送信されます。今回は緊急時ですからどんなボタン操作が行われるかわかりません。そこで、値が0.5以上(すべてのボタン操作)でアラートを送るという形にしました(画像参照)。
また、通知チャンネルでは
Webhookを選択します。URLは後で設定するので今はhttps://test.exampleとでもしておいてください。
② LINE Botを登録する
LINE Developersから新しいChannelを作成します。「Choose a channel type to continue」ではMessaging APIとしてください。
Basic settingsにあるChannel secretとMessaging APIのChannel access tokenは後で使うので控えておいてください。
③ ラズパイをサーバとして使う
Raspberry Pi上でFlaskを動かしてWebhookを受け取ったり、メッセージを返したりします。各種設定はPython・ラズパイでLINE BOTを作ってみる!に従ってください。
注意点
上記サイト、pyenv-virtualenvの設定は無視してもいいですが、それ以外の.bash_profile等の書き換えは必ず行ってください。そうでないと動きません。
また、上記サイト内にも書かれているようにChannel secretやChannel access tokenは環境変数に設定するようにしてください。④ Pushメッセージを送る
Pushメッセージを送るには
userIdを知る必要があります。このuserIdは個人で任意に設定した、友だち追加するときに使うIDとは別物ですので別の方法で知る必要があります。
次のコードを使えばテキストメッセージを送るとuserIdを返してくれます。line_bot.pyfrom flask import Flask, request, abort from linebot import LineBotApi, WebhookHandler from linebot.exceptions import InvalidSignatureError from linebot.models import MessageEvent, TextMessage, TextSendMessage import os app = Flask(__name__) LINE_BOT_ACCESS_TOKEN = os.environ["LINE_BOT_ACCESS_TOKEN"] LINE_BOT_CHANNEL_SECRET = os.environ["LINE_BOT_CHANNEL_SECRET"] line_bot_api = LineBotApi(LINE_BOT_ACCESS_TOKEN) handler = WebhookHandler(LINE_BOT_CHANNEL_SECRET) @app.route("/callback", methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info("Request body: " + body) try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): profile = line_bot_api.get_profile(event.source.user_id) messages = str(profile.user_id) line_bot_api.reply_message(event.reply_token, TextSendMessage(text=messages)) if __name__ == "__main__": port = int(os.getenv("PORT", 6000)) app.run(host="0.0.0.0", port=port)きちんと設定できていればこのようにUから始まるIDが返ってくるはずです。
ここまでできたら、ようやくSORACOM Lagoonとの連携です。
先ほどのコードに少し追記します。/webhookにPOSTがあったときにユーザにPushメッセージを送れるようにします。importも追加しているので注意してください。line_bot.pyfrom flask import Flask, request, abort from linebot import LineBotApi, WebhookHandler from linebot.exceptions import InvalidSignatureError from linebot.models import MessageEvent, TextMessage, TextSendMessage import os import json #追加 app = Flask(__name__) LINE_BOT_ACCESS_TOKEN = os.environ["LINE_BOT_ACCESS_TOKEN"] LINE_BOT_CHANNEL_SECRET = os.environ["LINE_BOT_CHANNEL_SECRET"] line_bot_api = LineBotApi(LINE_BOT_ACCESS_TOKEN) handler = WebhookHandler(LINE_BOT_CHANNEL_SECRET) # 以下追記 @app.route("/webhook", methods=['POST']) def webhook(): print(json.dumps(request.get_json(), indent=2)) object = request.get_json() if object['title'] == "[Alerting] Emergency alert": user_id = "U03xxxxxx(先ほど取得したuserId)" messages = TextSendMessage(text="アラートがきました") line_bot_api.push_message(user_id, messages=messages) return request.get_data() # ここまで @app.route("/callback", methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info("Request body: " + body) try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): profile = line_bot_api.get_profile(event.source.user_id) messages = str(profile.user_id) line_bot_api.reply_message(event.reply_token, TextSendMessage(text=messages)) if __name__ == "__main__": port = int(os.getenv("PORT", 6000)) app.run(host="0.0.0.0", port=port)最後にSORACOM Lagoonの通知チャネルを設定します。
Raspberry Pi上で動かしてるngrokのURLを入力し、末尾に/webhookを追加します。こうすることでLagoonからのWebhookを受け取ることができます。
デモ動画
[YouTube] SORACOM LTE-M Buttonを押すとLINEへ通知する
予想以上に反応が早い!これなら緊急時に1秒でも早く行動することができますね。







- 投稿日:2020-08-14T18:27:04+09:00
SORACOMと家電とLINE Botを連携させる【Python / Flask / Raspberry Pi】
はじめに
この記事は全4章からなる記事の第2章です。
- IoTを駆使してお年寄りの家を見守るシステムを作った【SORACOM Summer Challenge 2020】
- LTE-M Buttonが押されたらLINE BotへPushメッセージを送る【SORACOM】
- 【Raspberry Pi】人感センサーが感知したらtimestampをFirebase Realtime Databaseに格納する
- SORACOMと家電とLINE Botを連携させる【Python / Flask / Raspberry Pi】 全ソース公開
動作イメージはYouTubeで確認できるので是非ご覧ください。
きっかけ
日本で8000万人が利用し、UIに馴染みのあるLINEでインタラクティブにSORACOMデバイスで収集したデータを確認したり、家電の操作ができたらと思いました。
使ったもの
- GPSマルチユニットSORACOM Edition
- SORACOM LTE-M Button Plus
- 接点入力は使用していないので実質LTE-M Button単体
- Raspberry Pi 3 Model A+
- 人感センサー(焦電型赤外線センサー)を接続
- サーボモータを接続
- Raspberry Pi 3 Model B+
- サーバーとして使用
- 赤外線学習リモコン(ADRSIR)を接続
環境
- Python 3.7.3
- Flask==1.1.2
- line-bot-sdk==1.16.0
- firebase-admin==4.3.0
- Pillow==7.2.0
- paramiko==2.7.1
インストール
$ pip install flask $ pip install line-bot-sdk $ pip install firebase-admin $ pip install pillow $ pip install paramiko主な機能
- 温度と湿度を表示
- GPSマルチユニットSORACOM Editionで測った温度と湿度をLINEで閲覧します
- 人感センサーデータを表示
- Firebase Realtime Databaseに格納されたデータをフェッチしてLINEで閲覧します
- 緊急事態発生時にPushメッセージを送信
- SORACOM LTE-M Buttonが押されるとLINEにPushメッセージを送ります
- エアコンの制御
- 熱中症の危険が高くなると自動でエアコンをONにします
- エアコンをONにする条件は「気温30℃・湿度60%以上」かつ「人感センサーが15分以内に反応」です
- 誤作動の場合に備えてエアコンOFF操作もできます
それぞれについてソースコードとともに解説します。
まずは全体像から
ソース全体になります。以降、モジュールのimportやアクセストークンの部分は掲載しないので気を付けてください。
ソースコード
クリックして開く
line_bot.pyfrom flask import Flask, request, abort from linebot import LineBotApi, WebhookHandler from linebot.exceptions import InvalidSignatureError from linebot.models import MessageEvent, TextMessage, TextSendMessage, FlexSendMessage import subprocess import os import json import time import datetime import base64 import requests import ast import paramiko import firebase_admin from firebase_admin import credentials from firebase_admin import db from PIL import ImageFont, Image, ImageDraw from image import add_text_to_image #自作モジュール app = Flask(__name__) # LINE Messaging API Settings LINE_BOT_ACCESS_TOKEN = os.environ["LINE_BOT_ACCESS_TOKEN"] LINE_BOT_CHANNEL_SECRET = os.environ["LINE_BOT_CHANNEL_SECRET"] line_bot_api = LineBotApi(LINE_BOT_ACCESS_TOKEN) handler = WebhookHandler(LINE_BOT_CHANNEL_SECRET) user_id = "U0..." #メッセージをPushするユーザーのID FQDN = 'https://xxx.ngrok.io' #ngrokのURL # Firebase Settings cred = credentials.Certificate("<secret key file>.json") firebase_admin.initialize_app(cred, { 'databaseURL': 'https://xxx.firebaseio.com/' }) ref = db.reference('data') # ssh settings HOST = '192.168.11.xxx' PORT = 22 USER = 'username' KEY_FILE = '../.ssh/<secret_key_file>' #相対パス @app.route("/webhook", methods=['POST']) def webhook(): print(json.dumps(request.get_json(), indent=2)) object = request.get_json() if object['title'] == "[Alerting] Emergency alert": json_message = { "type": "bubble", "hero": { "type": "image", "url": "https://xxxx.ngrok.io/static/sos.png", "size": "full", "aspectRatio": "16:9", "aspectMode": "cover" }, "body": { "type": "box", "layout": "vertical", "contents": [ { "type": "text", "text": "緊急ボタンが押されました", "weight": "bold", "size": "lg", "color": "#E9462B", "align": "center" }, { "type": "box", "layout": "vertical", "margin": "lg", "spacing": "sm", "contents": [ { "type": "box", "layout": "baseline", "spacing": "sm", "contents": [ { "type": "text", "text": "場所", "color": "#aaaaaa", "size": "sm", "flex": 1 }, { "type": "text", "text": "脱衣所", "wrap": True, "color": "#666666", "size": "sm", "flex": 5 } ] }, { "type": "box", "layout": "vertical", "margin": "lg", "spacing": "sm", "contents": [ { "type": "box", "layout": "baseline", "spacing": "sm", "contents": [ { "type": "text", "text": "緊急措置として玄関の鍵を開錠しました", "color": "#4764a6", "size": "md", "flex": 1, "wrap": True } ] } ] } ] } ] }, "footer": { "type": "box", "layout": "vertical", "spacing": "sm", "contents": [ { "type": "button", "style": "primary", "height": "sm", "action": { "type": "message", "label": "救急", "text": "救急" }, "color": "#E9462B" }, { "type": "spacer", "size": "sm" } ], "flex": 0 } } messages = FlexSendMessage(alt_text='[SOS] 緊急ボタンが押されました', contents=json_message) line_bot_api.push_message(user_id, messages=messages) key = paramiko.ECDSAKey.from_private_key_file(KEY_FILE) ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect(HOST, PORT, USER, pkey=key) ssh.exec_command('python3 key_open.py') elif object['title'] == "[Alerting] Temperature & Humidity alert": current_time = int(time.time()*1000) fifteen_minutes_ago = current_time - 900000 data = ref.order_by_key().limit_to_last(1).get() for key, val in data.items(): if val['timestamp'] >= fifteen_minutes_ago: json_message = { "type": "bubble", "hero": { "type": "image", "url": "https://xxx.ngrok.io/static/aircon.png", "size": "full", "aspectRatio": "16:9", "aspectMode": "cover" }, "body": { "type": "box", "layout": "vertical", "contents": [ { "type": "text", "text": "エアコンをつけました", "weight": "bold", "size": "xl", "color": "#7077BE" }, { "type": "box", "layout": "vertical", "contents": [ { "type": "text", "text": "熱中症の危険性が高い温度・湿度です。", "size": "xs", "wrap": True }, { "type": "text", "text": "15分以内に人感センサーが反応したため、家にいると判断し冷房をつけました。", "size": "xs", "wrap": True } ], "margin": "sm" } ] }, "footer": { "type": "box", "layout": "vertical", "spacing": "sm", "contents": [ { "type": "button", "style": "primary", "height": "sm", "action": { "type": "message", "label": "現在の温度・湿度を見る", "text": "温度・湿度" }, "color": "#6fb1bf" }, { "type": "button", "style": "primary", "height": "sm", "action": { "type": "uri", "label": "SORACOM Lagoonで確認する", "uri": "https://jp.lagoon.soracom.io/" }, "color": "#34CDD7" }, { "type": "button", "style": "secondary", "height": "sm", "action": { "type": "message", "label": "エアコンを消す", "text": "エアコンを消す" }, "color": "#DDDDDD" }, { "type": "spacer", "size": "sm" } ], "flex": 0 } } messages = FlexSendMessage(alt_text='エアコンをつけました', contents=json_message) line_bot_api.push_message(user_id, messages=messages) subprocess.run("python3 IR-remocon02-commandline.py t `cat filename4.dat`", shell = True, cwd="/home/pi/I2C0x52-IR") return request.get_data() @app.route("/callback", methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info("Request body: " + body) try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): password = os.environ["soracom_pass"] if event.message.text == "温度・湿度": headers = { 'Content-Type': 'application/json', } data = '{"email": "test@example.jp", "password": "' + password + '"}' response = requests.post('https://api.soracom.io/v1/auth', headers=headers, data=data) apikey = response.json()['apiKey'] token = response.json()['token'] current_time = int(time.time()*1000) headers = { 'Accept': 'application/json', 'X-Soracom-API-Key': apikey, 'X-Soracom-Token': token, } params = ( ('to', current_time), ('sort', 'desc'), ('limit', '1'), ) response = requests.get('https://api.soracom.io/v1/data/Subscriber/44xxxxxxxxxxxxx', headers=headers, params=params) request_body = response.json() content = [d.get('content') for d in request_body] payload = content[0] payload_dic = ast.literal_eval(payload) message = base64.b64decode(payload_dic['payload']).decode() temp = ast.literal_eval(message)['temp'] humi = ast.literal_eval(message)['humi'] base_image_path = './image.png' base_img = Image.open(base_image_path).copy() base_img = base_img.convert('RGB') temperature = str(temp) font_path = "/usr/share/fonts/downloadfonts/DSEG7-Classic/DSEG7Classic-Regular.ttf" font_size = 80 font_color = (255, 255, 255) height = 90 width = 180 img = add_text_to_image(base_img, temperature, font_path, font_size, font_color, height, width) humidity = str(humi) height = 330 img = add_text_to_image(base_img, humidity, font_path, font_size, font_color, height, width) img_path = 'static/{}.png'.format(datetime.datetime.now().strftime('%H-%M-%S')) img.save(img_path) json_message = { "type": "bubble", "hero": { "type": "image", "url": FQDN + '/' + img_path, "size": "full", "aspectRatio": "1:1", "aspectMode": "fit", }, "body": { "type": "box", "layout": "vertical", "contents": [ { "type": "text", "text": "温度 & 湿度", "weight": "bold", "size": "xl", "color": "#6fb1bf" }, { "type": "box", "layout": "vertical", "margin": "lg", "spacing": "sm", "contents": [ { "type": "box", "layout": "baseline", "spacing": "sm", "contents": [ { "type": "text", "text": "温度", "color": "#aaaaaa", "size": "sm", "flex": 1 }, { "type": "text", "text": temperature + '℃', "wrap": True, "color": "#666666", "size": "sm", "flex": 5 } ] }, { "type": "box", "layout": "baseline", "spacing": "sm", "contents": [ { "type": "text", "text": "湿度", "color": "#aaaaaa", "size": "sm", "flex": 1 }, { "type": "text", "text": humidity + "%", "wrap": True, "color": "#666666", "size": "sm", "flex": 5 } ] } ] } ] }, "footer": { "type": "box", "layout": "vertical", "spacing": "sm", "contents": [ { "type": "button", "style": "primary", "height": "sm", "action": { "type": "uri", "label": "SORACOM Lagoonで確認する", "uri": "https://jp.lagoon.soracom.io/" }, "color": "#34CDD7" }, { "type": "button", "style": "secondary", "height": "sm", "action": { "type": "message", "label": "人感センサー", "text": "人感センサー" }, "color": "#DDDDDD" }, { "type": "spacer", "size": "sm" } ], "flex": 0 } } messages = FlexSendMessage(alt_text='温度 & 湿度', contents=json_message) line_bot_api.reply_message(event.reply_token, messages) elif event.message.text == "人感センサー": current_time = int(time.time()*1000) one_hour_ago = current_time - 3600000 data = ref.order_by_key().limit_to_last(1).get() for key, val in data.items(): timestamp = datetime.datetime.fromtimestamp(int(val['timestamp']/1000)) last_time = timestamp.strftime('%m月%d日 %H時%M分') count = 0 data = ref.order_by_key().get() for key, val in data.items(): timestamp = val['timestamp'] if timestamp >= one_hour_ago: count += 1 json_message = { "type": "bubble", "hero": { "type": "image", "url": "https://xxx.ngrok.io/static/sensors.png", "size": "full", "aspectRatio": "16:9", "aspectMode": "cover" }, "body": { "type": "box", "layout": "vertical", "contents": [ { "type": "text", "text": "人感センサー", "weight": "bold", "size": "xl", "color": "#72D35B" }, { "type": "box", "layout": "vertical", "margin": "lg", "spacing": "sm", "contents": [ { "type": "box", "layout": "baseline", "spacing": "sm", "contents": [ { "type": "text", "text": "1時間以内に検知した回数", "color": "#aaaaaa", "size": "sm", "flex": 10 }, { "type": "text", "text": str(count) + "回", "wrap": True, "color": "#666666", "size": "sm", "flex": 4, "align": "end" } ] }, { "type": "box", "layout": "baseline", "spacing": "sm", "contents": [ { "type": "text", "text": "最後に検知した時間", "color": "#aaaaaa", "size": "sm", "flex": 5 }, { "type": "text", "text": last_time, "wrap": True, "color": "#666666", "size": "sm", "flex": 5, "align": "end" } ] } ] } ] }, "footer": { "type": "box", "layout": "vertical", "spacing": "sm", "contents": [ { "type": "spacer", "size": "sm" } ], "flex": 0 } } messages = FlexSendMessage(alt_text='人感センサー', contents=json_message) line_bot_api.reply_message(event.reply_token, messages) elif event.message.text == "救急": messages = "落ち着いて 119 に電話してください" line_bot_api.reply_message(event.reply_token, TextSendMessage(text=messages)) elif event.message.text == "エアコンを消す": messages = "エアコンを消しました" line_bot_api.reply_message(event.reply_token, TextSendMessage(text=messages)) subprocess.run("python3 IR-remocon02-commandline.py t `cat filename5.dat`", shell = True, cwd="/home/pi/I2C0x52-IR") if __name__ == "__main__": port = int(os.getenv("PORT", 6000)) app.run(host="0.0.0.0", port=port)
➊ 温度と湿度を表示
SORACOM HarvestにはSORACOMデバイスから送信されたデータが保存されています。そのデータをAPIで取得することができます。以下の部分でAPIを使うのに必要なKeyとTokenを取得します。Passwordは念のため環境変数に設定しています。
line_bot.pypassword = os.environ["soracom_pass"] headers = { 'Content-Type': 'application/json', } data = '{"email": "test@example.jp", "password": "' + password + '"}' response = requests.post('https://api.soracom.io/v1/auth', headers=headers, data=data) apikey = response.json()['apiKey'] token = response.json()['token']そして、最新の温度と湿度を取得します。これ以外のAPIを利用したい場合はAPI Referenceから参照できます。cURLのコマンドが書かれてあるので、それをこのサイトでPythonの形式に変換します。
request_bodyはリストで返ってくるのでその中のcontentを取り出し、payloadをastというモジュールで辞書に変換します。そのメッセージをbase64でデコードすることで気温と湿度が得られます。line_bot.pycurrent_time = int(time.time()*1000) headers = { 'Accept': 'application/json', 'X-Soracom-API-Key': apikey, 'X-Soracom-Token': token, } params = ( ('to', current_time), ('sort', 'desc'), ('limit', '1'), ) response = requests.get('https://api.soracom.io/v1/data/Subscriber/44xxxxxxxxxxxxx', headers=headers, params=params) request_body = response.json() content = [d.get('content') for d in request_body] payload = content[0] payload_dic = ast.literal_eval(payload) message = base64.b64decode(payload_dic['payload']).decode() temp = ast.literal_eval(message)['temp'] humi = ast.literal_eval(message)['humi']データを取得したら、温度と湿度が書かれた画像をPillowで作成します。こちらの記事を参考にさせていただきました。次のようなBaseイメージをPowerPointで作成し、そこにDSEGフォントで温度・湿度を書き込みます。
line_bot.pytemperature = str(temp) font_path = "/usr/share/fonts/downloadfonts/DSEG7-Classic/DSEG7Classic-Regular.ttf" font_size = 80 font_color = (255, 255, 255) height = 90 width = 180 img = add_text_to_image(base_img, temperature, font_path, font_size, font_color, height, width) humidity = str(humi) height = 330 img = add_text_to_image(base_img, humidity, font_path, font_size, font_color, height, width) img_path = 'static/{}.png'.format(datetime.datetime.now().strftime('%H-%M-%S')) img.save(img_path)image.pyfrom PIL import ImageFont, Image, ImageDraw def add_text_to_image(img, text, font_path, font_size, font_color, height, width, max_length=740): position = (width, height) font = ImageFont.truetype(font_path, font_size) draw = ImageDraw.Draw(img) if draw.textsize(text, font=font)[0] > max_length: while draw.textsize(text + '…', font=font)[0] > max_length: text = text[:-1] text = text + '…' draw.text(position, text, font_color, font=font) return img最後に、Flex Messageを送ります。Flex Message Simulatorを使うと簡単に作成することができます。
- 注意
- Flex Message Simulatorでは
trueとなっていますが、Pythonでは先頭が大文字のTrueなので注意してください。
line_bot.pyjson_message = { "type": "bubble", "hero": { "type": "image", "url": FQDN + '/' + img_path, "size": "full", "aspectRatio": "1:1", "aspectMode": "fit", }, "body": { "type": "box", "layout": "vertical", "contents": [ { "type": "text", "text": "温度 & 湿度", "weight": "bold", "size": "xl", "color": "#6fb1bf" }, { "type": "box", "layout": "vertical", "margin": "lg", "spacing": "sm", "contents": [ { "type": "box", "layout": "baseline", "spacing": "sm", "contents": [ { "type": "text", "text": "温度", "color": "#aaaaaa", "size": "sm", "flex": 1 }, { "type": "text", "text": temperature + '℃', "wrap": True, "color": "#666666", "size": "sm", "flex": 5 } ] }, { "type": "box", "layout": "baseline", "spacing": "sm", "contents": [ { "type": "text", "text": "湿度", "color": "#aaaaaa", "size": "sm", "flex": 1 }, { "type": "text", "text": humidity + "%", "wrap": True, "color": "#666666", "size": "sm", "flex": 5 } ] } ] } ] }, "footer": { "type": "box", "layout": "vertical", "spacing": "sm", "contents": [ { "type": "button", "style": "primary", "height": "sm", "action": { "type": "uri", "label": "SORACOM Lagoonで確認する", "uri": "https://jp.lagoon.soracom.io/" }, "color": "#34CDD7" }, { "type": "button", "style": "secondary", "height": "sm", "action": { "type": "message", "label": "人感センサー", "text": "人感センサー" }, "color": "#DDDDDD" }, { "type": "spacer", "size": "sm" } ], "flex": 0 } } messages = FlexSendMessage(alt_text='温度 & 湿度', contents=json_message) line_bot_api.reply_message(event.reply_token, messages)➋人感センサーデータを表示
Firebase Realtime Databaseから値を取得します。サーバータイムスタンプはUNIX時間(ミリ秒)なので、適宜変換しています。Firebaseからの値の取得は公式ドキュメントを参考にしました。line_bot.pycurrent_time = int(time.time()*1000) one_hour_ago = current_time - 3600000 data = ref.order_by_key().limit_to_last(1).get() for key, val in data.items(): timestamp = datetime.datetime.fromtimestamp(int(val['timestamp']/1000)) last_time = timestamp.strftime('%m月%d日 %H時%M分') count = 0 data = ref.order_by_key().get() for key, val in data.items(): timestamp = val['timestamp'] if timestamp >= one_hour_ago: count += 1Flex Messageの部分は長くなるので省略しましたが、➊と同じです。
➌ 緊急事態発生時にPushメッセージを送信
SORACOM Lagoonから受け取ったWebhookはobject = request.get_json()で中身を見ることができます。詳しくはこちら
その次の行にif object['title'] == "[Alerting] Emergency alert":とありますが、これは、Lagoonが[No Data]または[OK]になった場合にもWebhookを送ってくるためです。また、Pythonで別のRaspberry PiにSSH接続してコマンド実行するために
Paramikoを使用しました。
ECDSAKeyの部分は適宜、自分が設定しているキーの種類に変更してください。RSAでもEd25519でもいけるはずです。line_bot.pykey = paramiko.ECDSAKey.from_private_key_file(KEY_FILE) ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect(HOST, PORT, USER, pkey=key) ssh.exec_command('python3 key_open.py')
key_open.pyはサーボモーターを回すだけの簡単なプログラムです。key_open.pyimport time import RPi.GPIO as GPIO GPIO.setmode(GPIO.BCM) GPIO.setup(4, GPIO.OUT) p = GPIO.PWM(4, 50) p.start(0.0) p.ChangeDutyCycle(3.0) time.sleep(0.4) p.ChangeDutyCycle(0.0) GPIO.cleanup()➍ エアコンの制御
「気温30℃・湿度60%以上」かつ「人感センサーが15分以内に反応」という条件が成立した時に自動でエアコンをONにします。
リモコンを操作するためのプログラムはビットトレードワンの公式サイトからダウンロードできます。line_bot.pycurrent_time = int(time.time()*1000) fifteen_minutes_ago = current_time - 900000 data = ref.order_by_key().limit_to_last(1).get() for key, val in data.items(): if val['timestamp'] >= fifteen_minutes_ago: #Flex Messageの部分は省略 subprocess.run("python3 IR-remocon02-commandline.py t cat `filename4.dat`", shell = True, cwd="/home/pi/I2C0x52-IR")まとめ
LINE BotとSORACOMのサービスとRaspberry Pi2台、その他外部モジュールを駆使してデータの閲覧や家電の操作をすることができました。
PythonでSORACOM APIを触ってみた系の記事や、SORACOMとLINE Botを連携させた記事は私が見たところ少なかったので誰かのためになれば幸いです。
ご指摘・疑問点などあればお気軽にコメントください。参考サイト
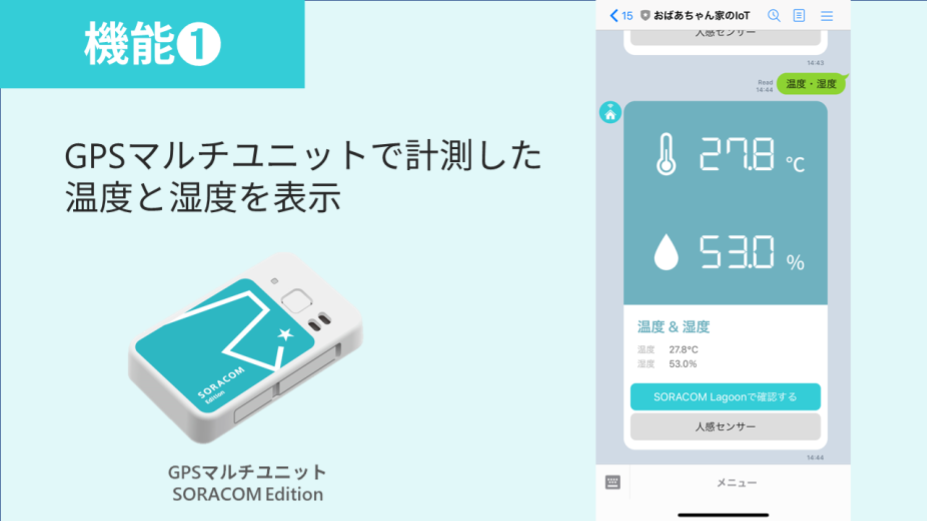


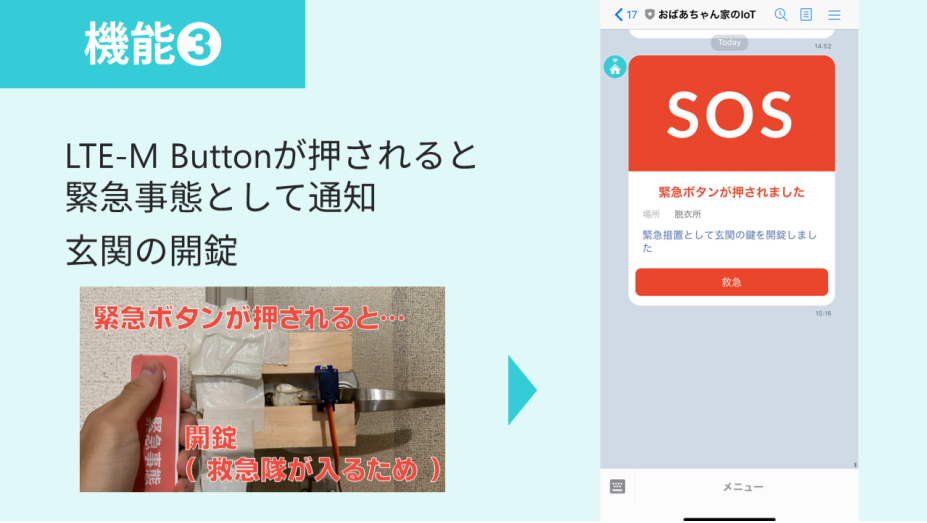

- 投稿日:2020-08-14T18:24:15+09:00
IoTを駆使してお年寄りの家を見守るシステムを作った【SORACOM Summer Challenge 2020】
はじめに
SORACOM Summer Challenge 2020の参加レポートです。
ネットでたまたま見つけたこのイベント、研究室でIoT向けの楕円曲線暗号の研究をしているものの、実際にIoTを使って何かを作ったことがなかったのでいい機会だと思い応募しました。
- IoTを駆使してお年寄りの家を見守るシステムを作った【SORACOM Summer Challenge 2020】
- LTE-M Buttonが押されたらLINE BotへPushメッセージを送る【SORACOM】
- 【Raspberry Pi】人感センサーが感知したらtimestampをFirebase Realtime Databaseに格納する
- SORACOMと家電とLINE Botを連携させる【Python / Flask / Raspberry Pi】 全ソース公開
SORACOMとは
IoT向けの無線通信をグローバルに提供するプラットフォームです。セルラー、LPWA(LoRaWAN、Sigfox、LTE-M)を、1回線からリーズナブルに使うことができます。[SORACOMの概要]
配布された機材
GPSマルチユニットSORACOM Edition(バッテリー内蔵タイプ)
- 「位置情報(GPS)」「温度」「湿度」「加速度」の4つのセンサーと充電式バッテリーを内蔵し、 セルラーLPWAであるLTE-M通信が利用可能なデバイスです。
- SORACOM LTE-M Button Plus はIoT SIM(plan-KM1)内蔵のボタンおよび接点入力を備えたデバイスです。 plan-KM1による LTE-M 通信を使用し、乾電池(交換可能)で駆動します。
その他、期間中は全プラットフォームサービスを無料で使わせていただきました。
作ったもの
おばあちゃんの家を見守るシステム
離れて暮らすおじいちゃん、おばあちゃん、ずっと元気でいてほしいけどいつ何があるかわかりませんよね?そんなお年寄りの方を見守るサービスは世の中にたくさんあります。(セコムさんや、象印さんのポットを利用すると通知が行くサービス、写真立てにセンサーが内蔵されたものなんかもあります)
見守るんだったらカメラを設置すれば早い?いやいや、いくら身内だからと言ってプライバシーには配慮しなければなりません。今回作ったシステムではそういった行動が特定されてしまうような情報は一切用いていません。
また、既存のサービスをSORACOMサービスを用いて作るのではは「車輪の再発明」にすぎません。そこで、「痒い所に手が届く」そんなオリジナリティを加えました。
使ったもの
- GPSマルチユニットSORACOM Edition
- SORACOM LTE-M Button Plus
- 接点入力は使用していないので実質LTE-M Button単体
- Raspberry Pi 3 Model A+
- 人感センサー(焦電型赤外線センサー)を接続
- サーボモータを接続
- Raspberry Pi 3 Model B+
- サーバーとして使用
- 赤外線学習リモコン(ADRSIR)を接続
全貌
YouTubeにて公開しています。Qiitaでは画像中心ですが、YouTubeなら実際の動きが確認できるので是非ご覧ください。
[YouTube] IoTを駆使してお年寄りの家を見守るシステム作った機能➊ 温度と湿度を計測・表示
これは既存サービスによくあるものですね。GPSマルチユニットは温度と湿度を測る機能があるのでそれを利用します。5分毎に気温と湿度をSORACOM Harvest Dataに送ります。
また、温度と湿度はLINE Botから確認することができます。お年寄りの見守りサービスでなくともこの機能は役に立ちそうです。
機能➋ 人感センサー
これまた既存サービスによくあるものです。Raspberry Piに接続した人感センサーが反応するとタイムスタンプとともにFirebase Realtime Databaseにデータを格納します。
そしてLINEから「1時間以内に反応した回数」と「最後に反応した回数」を確認することができます。
これを家の導線に配置しておけば動いていることがわかるので安心ですね。
機能➌ 緊急ボタン
いくら見守っていたところで、「何かあったとき」に対応できなくては意味がないですよね?
でも、「何かあったとき」にお年寄りの方自身が119番に電話する余裕はあるでしょうか?
余裕があったとしても、携帯電話を手の届くところに置いていなかったら…?そう、危険はどこに孕んでいるかわからないし、家中どこでも携帯電話を持ち歩いているとは限らないのです。
そこで、家のあらゆるところにこの緊急ボタンを設置しておきます。ワンクリックするだけなので、もしものことがあった時も手の届く範囲にこれがあればどうにか知らせることができます。
脱衣所の床近くやトイレの床近くなんかに設置しておくといいかもしれません。なぜ床近くかって?それは倒れたときを想定しているからです。「手の届くところに」がポイントです。
それでもまだ問題があります。実は、救急車を呼べても玄関の鍵が締まっていて入れないという事例が多々あるんです。「救急隊はすぐそこにいるのに助けてもらえなかった。」そんな悲しいことは起こってほしくありません。
そこで、LTE-M ButtonとRaspberry Piのサーボモータを連動させました。ボタンがクリックされると玄関に設置された(見た目はスマートじゃない)スマートロックにより開錠されます。こうして、一刻も早く助け出す環境を作るわけです。
機能➍ 熱中症の危険が高くなるとエアコンON
お年寄りの室内における熱中症の症例が多いのをご存知ですか?[Yahoo!ニュース参照]
体温を調節する機能が衰えてきた高齢者は、気温を感知する皮膚や中枢神経がうまく働かなくなっていることも考えられる
とあります。
せっかく温度と湿度を測っているんだから、エアコンも自動で制御できたらいいですよね?SORACOM Lagoonを使えば温度と湿度を簡単に可視化でき、アラートも簡単に設定することができるので熱中症の危険が高くなったらRaspberry Piの赤外線送信モジュールから信号を送ろう!…ちょっと待った!
そのままでは、不在の時だってエアコンがONにされてしまいますよね?お年寄りを見守るシステムのはずなのに、不在時にエアコンがついて電気代も増し、環境に負荷をかけるようじゃたまったもんじゃありません。
そこで、先ほどの人感センサーが役に立つわけです。15分以内に人感センサーが作動したのであれば家にいる確率は高いでしょう。というわけで、「アラートが発され、かつ15分以内に人感センサーが作動する」という条件を満たせばエアコンをONにします。
システム構成図
Raspberry Pi上でFlaskを動かし、そこでSORACOM Harvestからデータを取得したり、LagoonからのWebhookを受け取ったりしてLINEに流しています。
以上、
1. 温度と湿度を計測・表示
2. 人感センサー
3. 緊急ボタン
4. 熱中症の危険が高くなるとエアコンONの4大機能でした
…Raspberry Piだけでできるくない?
と思った方いらっしゃいませんか?(いないか)
「Raspberry Piにも温度や湿度を測るモジュールはあるし…」
「緊急ボタンぐらいなら作れるのでは?」
そうなんです。が、1つ問題点があります。あなたのおばあちゃん家にインターネット環境はありますか?
最近でこそ、家にネット環境が整っており、スマホを使いこなしているおじいちゃんおばあちゃんもいるかもしれません。とはいえ、まだその数は多くないのではないでしょう。それに、無線LANルーターなんかは時々調子が悪くなることがあります。
孫「おばあちゃん、Wi-Fiルーター再起動してくれない?」
お年寄りにはなかなか難しいでしょう。
だからこそ、設置も簡単で、難しい設定も必要ないSORACOMのLPWAが有効なのです。
「Raspberry PiでWi-Fi使ってるじゃん、どうするの?」
SORACOMではRaspberry Pi等に接続し、セルラー通信が可能となるUSBドングルなるものもあるそうです。そういう訳で、LAN環境がなくとも上で書いたことは実現可能です。まとめと感想
というわけで離れて暮らすおじいちゃん、おばあちゃんをプライバシーを保護しつつ、痒いところにも手が届くような総合型見守りシステムでした。
最後に書いたように、「Raspberry Piだけではできない」、逆に言うと「SORACOMのサービスを使うからこそできる」そんなシステムを組み上げられたと自負しています。感想
- まず、〆切の30分前に出したにもかかわらずアクセプトしてくださった運営の皆さんありがとうございました
- 学祭以外で髪が青い人初めて見た(わかる人にはわかる)
- 期間中はメンターの方々にわからないことを伺うと即答してくださったので滞りなく進められた
- SORACOM関連のサービスの使い方はもちろんのこと、cURLやRaspberry PiのGPIO、LINE BotのFlex Message、その他Pythonの各モジュール(paramiko, Pillow etc...)など、これまで自分が使ったことない要素技術に触れることができたので大変勉強になった
- 上記のことから、Summer Challengeの応募ページに書かれてあった次の言葉の意味がよくわかった。本当に総合格闘技でした。
ハードウェアから通信、ソフトウェア、クラウド、AIといった様々な専門知識を必要とする IoT は、テクノロジーの総合格闘技と呼ばれています。
以上、最後までご覧いただきありがとうございました!

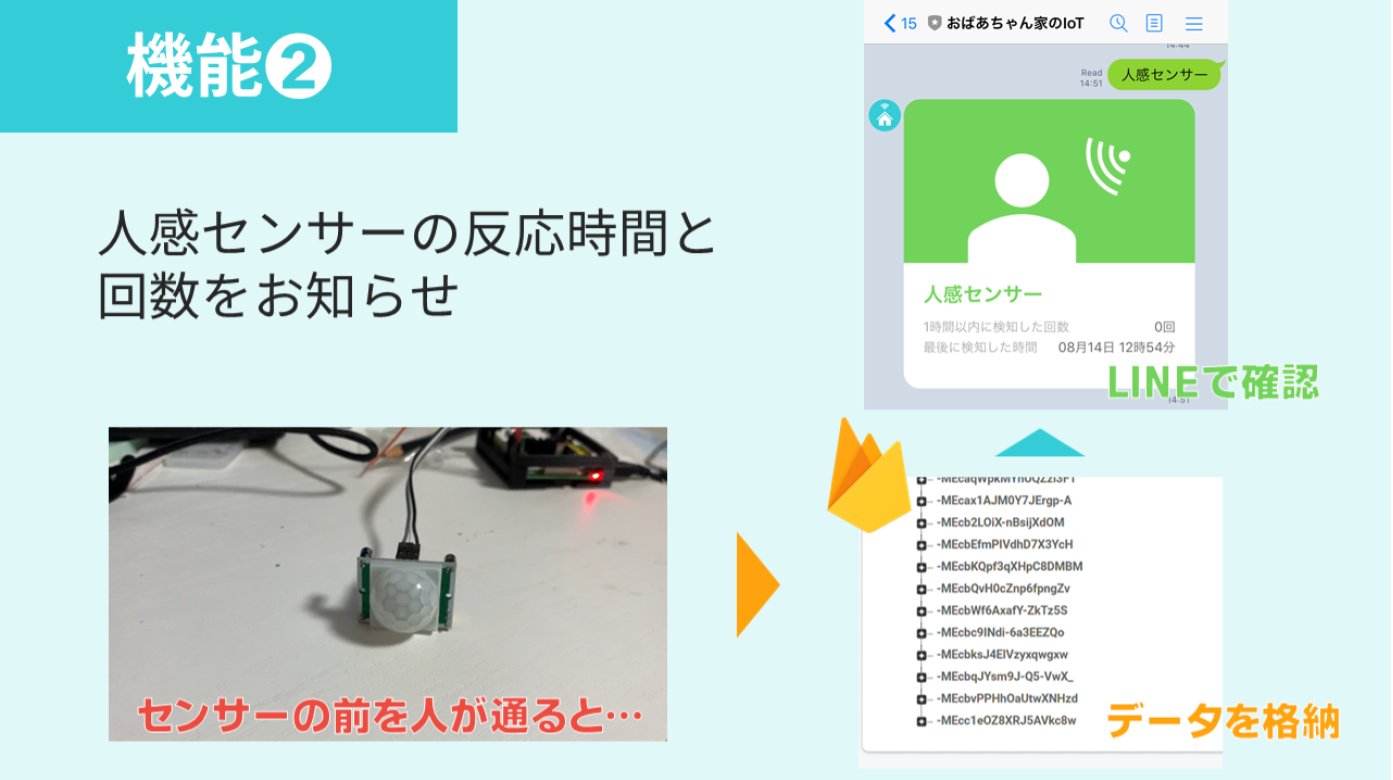

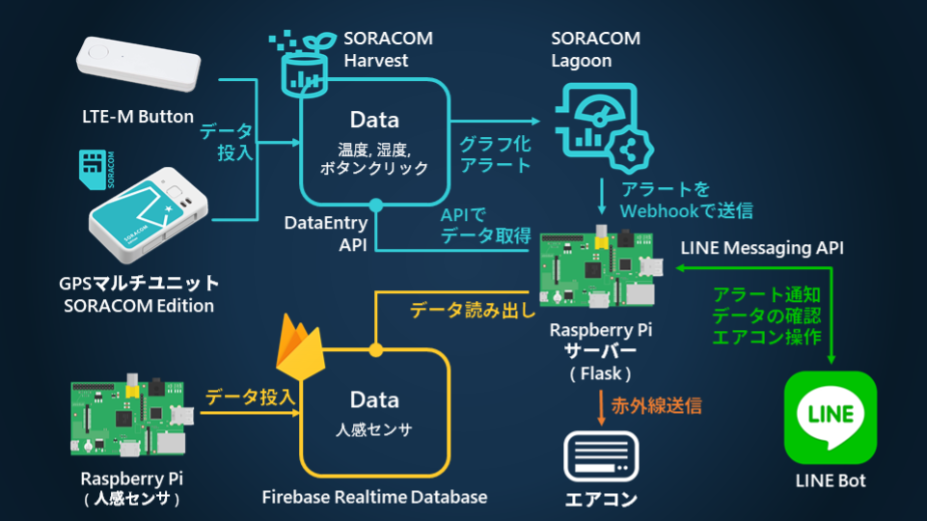

- 投稿日:2020-08-14T18:24:15+09:00
IoTを駆使してお年寄りの家を見守る「だけじゃない」システムを作った【SORACOM Summer Challenge 2020】
はじめに
SORACOM Summer Challenge 2020の参加レポートです。
ネットでたまたま見つけたこのイベント、研究室でIoT向けの楕円曲線暗号の研究をしているものの、実際にIoTを使って何かを作ったことがなかったのでいい機会だと思い応募しました。
- IoTを駆使してお年寄りの家を見守るシステムを作った【SORACOM Summer Challenge 2020】
- LTE-M Buttonが押されたらLINE BotへPushメッセージを送る【SORACOM】
- 【Raspberry Pi】人感センサーが感知したらtimestampをFirebase Realtime Databaseに格納する
- SORACOMと家電とLINE Botを連携させる【Python / Flask / Raspberry Pi】 全ソース公開
SORACOMとは
IoT向けの無線通信をグローバルに提供するプラットフォームです。セルラー、LPWA(LoRaWAN、Sigfox、LTE-M)を、1回線からリーズナブルに使うことができます。[SORACOMの概要]
配布された機材
GPSマルチユニットSORACOM Edition(バッテリー内蔵タイプ)
- 「位置情報(GPS)」「温度」「湿度」「加速度」の4つのセンサーと充電式バッテリーを内蔵し、 セルラーLPWAであるLTE-M通信が利用可能なデバイスです。
- SORACOM LTE-M Button Plus はIoT SIM(plan-KM1)内蔵のボタンおよび接点入力を備えたデバイスです。 plan-KM1による LTE-M 通信を使用し、乾電池(交換可能)で駆動します。
その他、期間中は全プラットフォームサービスを無料で使わせていただきました。
作ったもの
おばあちゃんの家を見守るシステム
離れて暮らすおじいちゃん、おばあちゃん、ずっと元気でいてほしいけどいつ何があるかわかりませんよね?そんなお年寄りの方を見守るサービスは世の中にたくさんあります。(セコムさんや、象印さんのポットを利用すると通知が行くサービス、写真立てにセンサーが内蔵されたものなんかもあります)
見守るんだったらカメラを設置すれば早い?いやいや、いくら身内だからと言ってプライバシーには配慮しなければなりません。今回作ったシステムではそういった行動が特定されてしまうような情報は一切用いていません。
また、既存のサービスをSORACOMサービスを用いて作るのではは「車輪の再発明」にすぎません。そこで、「痒い所に手が届く」そんなオリジナリティを加えました。
使ったもの
- GPSマルチユニットSORACOM Edition
- SORACOM LTE-M Button Plus
- 接点入力は使用していないので実質LTE-M Button単体
- Raspberry Pi 3 Model A+
- 人感センサー(焦電型赤外線センサー)を接続
- サーボモータを接続
- Raspberry Pi 3 Model B+
- サーバーとして使用
- 赤外線学習リモコン(ADRSIR)を接続
全貌
YouTubeにて公開しています。Qiitaでは画像中心ですが、YouTubeなら実際の動きが確認できるので是非ご覧ください。
[YouTube] IoTを駆使してお年寄りの家を見守るシステム作った
機能➊ 温度と湿度を計測・表示
これは既存サービスによくあるものですね。GPSマルチユニットは温度と湿度を測る機能があるのでそれを利用します。5分毎に気温と湿度をSORACOM Harvest Dataに送ります。
また、温度と湿度はLINE Botから確認することができます。お年寄りの見守りサービスでなくともこの機能は役に立ちそうです。
機能➋ 人感センサー
これまた既存サービスによくあるものです。Raspberry Piに接続した人感センサーが反応するとタイムスタンプとともにFirebase Realtime Databaseにデータを格納します。
そしてLINEから「1時間以内に反応した回数」と「最後に反応した回数」を確認することができます。
これを家の導線に配置しておけば動いていることがわかるので安心ですね。
機能➌ 緊急ボタン
いくら見守っていたところで、「何かあったとき」に対応できなくては意味がないですよね?
でも、「何かあったとき」にお年寄りの方自身が119番に電話する余裕はあるでしょうか?
余裕があったとしても、携帯電話を手の届くところに置いていなかったら…?そう、危険はどこに孕んでいるかわからないし、家中どこでも携帯電話を持ち歩いているとは限らないのです。
そこで、家のあらゆるところにこの緊急ボタンを設置しておきます。ワンクリックするだけなので、もしものことがあった時も手の届く範囲にこれがあればどうにか知らせることができます。
脱衣所の床近くやトイレの床近くなんかに設置しておくといいかもしれません。なぜ床近くかって?それは倒れたときを想定しているからです。「手の届くところに」がポイントです。
それでもまだ問題があります。実は、救急車を呼べても玄関の鍵が締まっていて入れないという事例が多々あるんです。「救急隊はすぐそこにいるのに助けてもらえなかった。」そんな悲しいことは起こってほしくありません。
そこで、LTE-M ButtonとRaspberry Piのサーボモータを連動させました。ボタンがクリックされると玄関に設置された(見た目はスマートじゃない)スマートロックにより開錠されます。こうして、一刻も早く助け出す環境を作るわけです。
機能➍ 熱中症の危険が高くなるとエアコンON
お年寄りの室内における熱中症の症例が多いのをご存知ですか?[Yahoo!ニュース参照]
体温を調節する機能が衰えてきた高齢者は、気温を感知する皮膚や中枢神経がうまく働かなくなっていることも考えられる
とあります。
せっかく温度と湿度を測っているんだから、エアコンも自動で制御できたらいいですよね?SORACOM Lagoonを使えば温度と湿度を簡単に可視化でき、アラートも簡単に設定することができるので熱中症の危険が高くなったらRaspberry Piの赤外線送信モジュールから信号を送ろう!…ちょっと待った!
そのままでは、不在の時だってエアコンがONにされてしまいますよね?お年寄りを見守るシステムのはずなのに、不在時にエアコンがついて電気代も増し、環境に負荷をかけるようじゃたまったもんじゃありません。
そこで、先ほどの人感センサーが役に立つわけです。15分以内に人感センサーが作動したのであれば家にいる確率は高いでしょう。というわけで、「アラートが発され、かつ15分以内に人感センサーが作動する」という条件を満たせばエアコンをONにします。
システム構成図
Raspberry Pi上でFlaskを動かし、そこでSORACOM Harvestからデータを取得したり、LagoonからのWebhookを受け取ったりしてLINEに流しています。
以上、
1. 温度と湿度を計測・表示
2. 人感センサー
3. 緊急ボタン
4. 熱中症の危険が高くなるとエアコンONの4大機能でした
…Raspberry Piだけでできるくない?
と思った方いらっしゃいませんか?(いないか)
「Raspberry Piにも温度や湿度を測るモジュールはあるし…」
「緊急ボタンぐらいなら作れるのでは?」
そうなんです。が、1つ問題点があります。あなたのおばあちゃん家にインターネット環境はありますか?
最近でこそ、家にネット環境が整っており、スマホを使いこなしているおじいちゃんおばあちゃんもいるかもしれません。とはいえ、まだその数は多くないのではないでしょう。それに、無線LANルーターなんかは時々調子が悪くなることがあります。
お年寄りにはなかなか難しいでしょう。
だからこそ、設置も簡単で、難しい設定も必要ないSORACOMのLPWAが有効なのです。
「Raspberry PiでWi-Fi使ってるじゃん、どうするの?」
SORACOMではRaspberry Pi等に接続し、セルラー通信が可能となるUSBドングルなるものもあるそうです。そういう訳で、LAN環境がなくとも上で書いたことは実現可能です。まとめと感想
というわけで離れて暮らすおじいちゃん、おばあちゃんをプライバシーを保護しつつ、痒いところにも手が届くような総合型見守りシステムでした。
最後に書いたように、「Raspberry Piだけではできない」、逆に言うと「SORACOMのサービスを使うからこそできる」そんなシステムを組み上げられたと自負しています。感想
- まず、〆切の30分前に出したにもかかわらずアクセプトしてくださった運営の皆さんありがとうございました
- 学祭以外で髪が青い人初めて見た(わかる人にはわかる)
- 期間中はメンターの方々にわからないことを伺うと即答してくださったので滞りなく進められた
- SORACOM関連のサービスの使い方はもちろんのこと、cURLやRaspberry PiのGPIO、LINE BotのFlex Message、その他Pythonの各モジュール(paramiko, Pillow etc...)など、これまで自分が使ったことない要素技術に触れることができたので大変勉強になった
- 上記のことから、Summer Challengeの応募ページに書かれてあった次の言葉の意味がよくわかった。本当に総合格闘技でした。
ハードウェアから通信、ソフトウェア、クラウド、AIといった様々な専門知識を必要とする IoT は、テクノロジーの総合格闘技と呼ばれています。
以上、最後までご覧いただきありがとうございました!
お気軽にコメントお願いします。

- 投稿日:2020-08-14T18:09:06+09:00
(Python)100万ハンド分析してみた〜①スターティングハンド集計〜
閲覧いただき、ありがとうございます。
pbirdyellowです。早速ですが、有名なポーカーサイト"PokerStars"で私がプレーした約100万ハンドを分析します。
今回はテキサスホールデムのスターティングハンドを集計しました。スターティングハンドとはトランプの全カード54枚のうち、jokerを除いた52枚の中からランダムに2枚配られたものをいいます。
ソースコードも記載しているので、是非みなさまも利用してみてください。
プログラミングは私自身初心者レベルなので、アドバイス等いただけると嬉しいです。
↓100万ハンド集計結果
ハンドログを集計すると、各ハンドの出現率が収束しているように見えました。
各ハンドの出現率はこちらをご覧ください。 ※近日公開予定です。PokerStarsのハンドログは、プレーヤーの皆さまのPC内に保存されています。
ハンドログの抽出方法はこちらをご覧ください。 ※近日公開予定です。このログデータは非常にデータの加工がしやすいので便利です。
HoldemManager2.2020-07-31-09-22-31.PS.Hand1-1000.txtPokerStars Zoom Hand #155136535392: Hold'em No Limit ($0.05/$0.10) - 2016/06/24 9:17:52 ET Table 'Aludra' 6-max Seat #1 is the button Seat 1: xxx ($8.18 in chips) Seat 2: xxx ($9.90 in chips) Seat 3: pbirdyellow ($10 in chips) Seat 4: xxx ($17.30 in chips) Seat 5: xxx ($21.93 in chips) Seat 6: xxx ($10 in chips) ccc: posts small blind $0.05 pbirdyellow: posts big blind $0.10 *** HOLE CARDS *** Dealt to pbirdyellow [Qc Ad] xxx: folds xxx: folds xxx: raises $0.15 to $0.25 xxx: folds xxx: folds pbirdyellow: raises $0.55 to $0.80 xxx: folds Uncalled bet ($0.55) returned to pbirdyellow pbirdyellow collected $0.55 from pot pbirdyellow: doesn't show hand *** SUMMARY *** Total pot $0.55 | Rake $0 Seat 1: xxx (button) folded before Flop ・・・(以下続く)※プレーヤー情報は隠しています。
以下がソースコードになります。"path"の値を設定すると動くはずです。
プログラミングはまだまだ初心者レベルですので、どんどんご指摘をください。
コードの内容で疑問等ございましたら、qiitaアカウントもしくはtwitterアカウントよりDM等でご連絡ください。twitter:@pbirdyellow
pokermain.pyfrom holdcards import Holdcards from plotgraph import Plotgraph import os import glob path='ここにlogのパスを記述' filelist = glob.glob(os.path.join(path,"*.txt"),recursive=True) totcards = [] graphdata = [] for item in filelist: with open(item) as f: data = f.readlines() card = Holdcards() h_cards = card.find_holdcards(data) totcards += h_cards cardscount = card.count_holdcards(totcards) graph= Plotgraph() graph.writegraph(cardscount,card.handlist,card.hands)Holdcards.pyclass Holdcards: def __init__(self): self.trump={"A":"14","K":"13","Q":"12","J":"11","T":"10","9":"9","8":"8","7":"7","6":"6","5":"5","4":"4","3":"3","2":"2"} self.r_trump={"14":"A","13":"K","12":"Q","11":"J","10":"T","9":"9","8":"8","7":"7","6":"6","5":"5","4":"4","3":"3","2":"2"} self.hands = 0 self.handlist = [] def find_holdcards(self,data): holdcards = [] for item in data: if 'Dealt to' in item: item = item[-7:-2] if item[1] == item[4]: if int(self.trump.get(item[0])) > int(self.trump.get(item[3])): item = item[0] + item[3] + 's' else: item = item[3] + item[0] + 's' else: if int(self.trump.get(item[0])) > int(self.trump.get(item[3])): item = item[0] + item[3] + 'o' elif item[0] == item[3]: item = item[0] + item[3] else: item = item[3] + item[0] + 'o' holdcards.append(item) return holdcards def count_holdcards(self,list): totlist = [] i = 0 while i < 13: j=0 rowlist = [] rowhandlist = [] while j < 13: if i < j: hand = (self.r_trump.get(str(14-i))+self.r_trump.get(str(14-j))+"s") count = list.count(hand) rowlist.append(count) elif i == j: hand = (self.r_trump.get(str(14-i))+self.r_trump.get(str(14-j))) count = list.count(hand) rowlist.append(count) else: hand = (self.r_trump.get(str(14-j))+self.r_trump.get(str(14-i))+"o") count = list.count(hand) rowlist.append(count) self.hands += count rowhandlist.append(hand) j += 1 self.handlist.append(rowhandlist) totlist.append(rowlist) i += 1 return totlistPlotgraph.pyimport numpy as np import matplotlib.pyplot as plt class Plotgraph: def __init__(self): pass def writegraph(self,graphlist,handlist,hands): column_labels = list('AKQJT98765432') row_labels = list('AKQJT98765432') data = np.array(graphlist) fig,ax = plt.subplots() heatmap = ax.pcolor(data, cmap=plt.cm.Blues) ax.set_xticks(np.arange(data.shape[0])+0.5, minor=False) ax.set_yticks(np.arange(data.shape[1])+0.5, minor=False) ax.invert_yaxis() ax.xaxis.tick_top() ax.set_xticklabels(row_labels, minor=False) ax.set_yticklabels(column_labels, minor=False) i = 0 while i < 13: j = 0 while j < 13: plt.text(0.25+j,0.75+i,str(handlist[i][j])) j += 1 i += 1 plt.title("totalhands = "+str(hands), y=-0.1) fig.colorbar(heatmap, ax=ax) plt.show()

- 投稿日:2020-08-14T17:49:29+09:00
Pythonで学ぶ生存時間解析2 -Kaplan-Meier推定量
前回の記事はこちら
Pythonで学ぶ生存時間解析1 -生存時間データとは
https://qiita.com/Goriwaku/items/8d00696d853da73505bd今回使用しているデータについては前回の記事を参考にしていただくか、私のgit(https://github.com/goriwaku/survival_analysis )からダウンロード(whas500.csv)してください。
生存関数とは
前回の記事で取り上げたWHAS500を使用して生存関数について解説していきます。連続変数としての時間tに対して、確率変数としての生存時間をTと定義します。この時、Tの累積分布関数はランダムに抽出された被験者がある時間t以下であることを表し、以下のように定義されます。
F(t)=Pr(T \leq t)ここで、生存関数はある時間tよりも大きな生存時間Tを得る確率で表すことが可能で、
S(t)=Pr(T > t)となります。このとき、任意の時点tにおいて、生存を死亡の余事象として考えることによって確率の公理により以下の等式が成立します。
S(t)=1-F(t)ここからは、この生存関数の推定、特に右側打ち切りが存在しているときの生存時間関数の推定量であるKaplan-Meier推定量について見ていきます。
生存関数の推定
実際に生存関数を推定していきます。例として、以下のような5人分の生存時間と生存状態から生存関数を推定することを考えます。
被験者番号 時間 死亡に伴う打ち切り 1 6 1 2 44 1 3 21 0 4 14 1 5 62 1 時点0においては、5人とも生存しているので$\hat{S}(t)=1.0$となります。6日目に被験者番号1が死亡するため、6日目の少し前から始まり、6日目で終了する微小区間$(6-\delta, 6]$を考えると、この微小区間で死亡する条件付確率の推定値が$1/5$で、生存確率は$4/5$となる。任意の時点において生存している被験者は死亡のリスクにさらされているリスク集合であり、この人数をnumber at riskと表します。生存時間の推定量は、(その時点まで生きている確率)×(上記微小区間で生存する条件付確率)によってあらわすことができます。以下、区間$I_i$を上の表の時間を昇順にして区切ったもの(ex: $I_0 = [0, 6)$)、$n_i$をその時点でのnumber at risk、$d_i$をその時点で死亡した人数とします。このとき、何らかのイベントが起こっている日に近い微小区間において、推定された死亡確率は$d_1/n_1$、生存確率は$(n_1 - d_1)/n_1$と表すことができます。よって、6日目、および14日目の生存確率を推定すると、
\hat{S}(6)=1 \times \frac{4}{5}=\frac{4}{5}\\ \hat{S}(14)=1 \times \frac{4}{5} \times \frac{3}{4} = \frac{3}{5}となります。
次のイベントでは、21日目において被験者番号3が死亡に依らない打ち切りでat risk集合から脱落します。その微小区間において、$n_3=3$、$d_3=0$となることから、生存関数の推定値は、\hat{S}(21)=1 \times \frac{4}{5} \times \frac{3}{4} \times \frac{3}{3} = \frac{3}{5}当然ですが、区間$I_3$では死亡が発生していないため、生存関数の推定値は変化しません。以下の区間も同様に生存関数の推定値を求めることができます。この手法によって求めた生存関数の推定値をKaplan-Meier推定値といいます。
ここでKaplan-Meier推定値を階段関数としてプロットしてみましょう。
test_data = [[6, 1],[44, 1],[21, 0],[14, 1],[62, 1]] test_data = sorted(test_data, key=lambda x: x[0], reverse=False) s = 1 n = 5 pre = 0 for t, censor in test_data: plt.plot((pre, t), (s, s), color='blue') if censor == 1: plt.plot((t, t), (s, s * (n - 1) / n), color='blue') s = s * (n - 1) / n n -= 1 pre = t plt.show()先ほどの表を2次元配列として格納し、扱いやすいようにtによって昇順でソートしました。2次元配列に対してソートを施したいときはkey=lambda x: x[0]などとキーワード引数によって何でソートするのかを明示します。もしcensorでソートしたいのであればx[1]を入れてあげれば大丈夫です。その後、for文で生存確率を計算し、それをプロットしたものが以下の図になります。
このように、Kaplan=Meier曲線は階段関数として出力されます。死亡が観測された時点で減少し、その間は一定です。$t=62$において生存者は0であるため、最後は$\hat{S}(62)=0$となります。今回の例では同一のtにおいて複数死亡することはありませんでしたが(このことをtieといいます)、tieが起こっても乱数を発生させてランダムに順序を割り振ることで同様の議論を展開できます。さらに、KM推定量においてtieデータを一律に扱ったとしても最終的な推定量は等しいため、調整を行う必要性は基本的にはありません。実務上は少ないですが、極端に多くのtieが発生している場合には、KM推定量ではなく離散時間モデルの使用を検討したほうが良いでしょう。また、最終観測時間が右側打ち切りの場合、それ以降の生存時間の推定量は定義できないことにも注意が必要です。Kaplan-Meier推定量の一般化
生存時間解析において、Kaplan-Meier推定量は非常によく使われるため、ここで一般的な定式化を与えておきます。tが有限の時、ソートすることは一般性を失わないため、tを昇順にソートして$t_i$時点における死亡によるセンサーかどうかの2値変数$c_i$、$t_i$時点のat risk人数$n_1$、観測される死亡数$d_i$のもとで、時点tでの生存関数のKaplan-Meier推定量は、
\hat{S}(t)=\prod_{t_i \leq t}\frac{n_i - d_i}{n_i}ただし、$t \leq t_1$のとき$\hat{S}(t)=1$となります。
Kaplan-Meier曲線のplot -lifelines編
先ほどは自力でKaplan-Meier曲線をプロットしましたが、わざわざ自分で実装しなくてもpythonにはlifelinesと呼ばれる生存時間解析用のライブラリが存在します。この節では、そのlifelinesを使用して前回のWHAS500のKaplan-Meier曲線を描画してみます。
lifelinesはデフォルトでは含まれていないので、一度も使用したことのない方はターミナルもしくはコマンドプロンプトで最初に以下を実行してください。pip install lifelinesでは、ここからpythonコードを示します。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import lifelines as ll from lifelines import KaplanMeierFitter whas = pd.read_csv('whas500.csv') kmf = KaplanMeierFitter() kmf.fit(whas.LENFOL, event_observed=whas.FSTAT) kmf.plot_survival_function() print(kmf.survival_function_) plt.show()lifelinesのKaplanMeierFitterのfitの第一引数に時間tを、キーワード引数event_observedに観測したいイベント(死亡)が発生したかどうかの2値変数を入れて、フィッティングさせてあげます。そうすると、モデルの.plot_survival_fuction()関数によって簡単にKM曲線をプロットすることができます。また、推定された生存関数を得るにはsurvival_function_を使用します。pandasのDataFrame型で時点と推定値のペアを返してくれます。また、survival_functionをcumulative_densityに置き換えることで前述の累積分布関数$F(t)$を得ることも可能です。実際にKM曲線をプロットしたものが以下になります。
図の水色の幅は信頼区間です。以上でKaplan-Meier推定量とその実装の解説を終えます。次回は、Kaplan-Meier推定量の解釈や2群比較を行いたいと思いますので、引き続き読んでいただけると幸いです。
参考文献・参照リンク
生存時間解析入門 Hosmer DW, Lemeshow S, May S
LIFELINES https://lifelines.readthedocs.io/en/latest/index.html
京都大学OCW 京都大学大学院医学研究科 聴講コース 臨床研究者のための生物統計学「生存時間解析の基礎」 https://www.youtube.com/watch?v=NmZaY2tDKSA&feature=emb_title


- 投稿日:2020-08-14T17:48:53+09:00
RobomasterS1をハックしたい ②Python実行環境について
以前の記事の続きです。
(draftですが一応公開します。)概要
Robomasters1をPythonでハックします。
- アプリで書いたPythonプログラムがどのように実行されているのか探る
- UDPで通信をさせてみる
- Robomasterのアプリから画像を拾ってくる
- 画像を元にコントロール(次回)
前提
- ルート化or内部ファイルへのアクセス(前回の記事を参照)
Python in Robomaster S1
Robomasters1のPython環境はPython3.6.6です。
binは
/data/python_scripts以下にあり,root化したコマンドラインからも実行できます。アプリ上で書いたファイルの場所と形式
アプリ上で編集したPythonファイルは
/data/scripts/filesにあります。アプリ上とは名前が違うので
ls -lとかで更新日時とかで頑張って追うしかなさそうです。前回書いたroot化のプログラムに当たる部分を開いてみると,諸機能でwrapされていることがわかります。
クリックして展開
import event_client import rm_ctrl import rm_define import math import traceback import rm_log logger = rm_log.dji_scratch_logger_get() event = event_client.EventClient() modulesStatus_ctrl = rm_ctrl.ModulesStatusCtrl(event) gun_ctrl = rm_ctrl.GunCtrl(event) armor_ctrl = rm_ctrl.ArmorCtrl(event) vision_ctrl = rm_ctrl.VisionCtrl(event) chassis_ctrl = rm_ctrl.ChassisCtrl(event) gimbal_ctrl = rm_ctrl.GimbalCtrl(event) robot_ctrl = rm_ctrl.RobotCtrl(event, chassis_ctrl, gimbal_ctrl) log_ctrl = rm_ctrl.LogCtrl(event) # scratch mode only led_ctrl = rm_ctrl.LedCtrl(event) media_ctrl = rm_ctrl.MediaCtrl(event) # need replaced when app changed the method name time = rm_ctrl.RobotTools(event) tools = rm_ctrl.RobotTools(event) debug_ctrl = rm_ctrl.DebugCtrl(event) mobile_ctrl = rm_ctrl.MobileCtrl(event) blaster_ctrl = gun_ctrl AI_ctrl = vision_ctrl show_msg = log_ctrl.show_msg print_msg = log_ctrl.print_msg info_msg = log_ctrl.info_msg debug_msg = log_ctrl.debug_msg error_msg = log_ctrl.error_msg fatal_msg = log_ctrl.fatal_msg print=print_msg robot_mode = rm_define.robot_mode chassis_status = rm_define.chassis_status gimbal_status = rm_define.gimbal_status detection_type = rm_define.detection_type detection_func = rm_define.detection_func led_effect = rm_define.led_effect led_position = rm_define.led_position pwm_port = rm_define.pwm_port line_color = rm_define.line_color def robot_reset(): robot_ctrl.set_mode(rm_define.robot_mode_free) gimbal_ctrl.resume() gimbal_ctrl.recenter(90) def robot_init(): if 'speed_limit_mode' in globals(): chassis_ctrl.enable_speed_limit_mode() robot_ctrl.init() modulesStatus_ctrl.init() gimbal_ctrl.init() chassis_ctrl.init() led_ctrl.init() gun_ctrl.init() chassis_ctrl.init() mobile_ctrl.init() tools.init() robot_reset() def ready(): robot_init() robot_ctrl.set_mode(rm_define.robot_mode_gimbal_follow) tools.program_timer_start() def register_event(): armor_ctrl.register_event(globals()) vision_ctrl.register_event(globals()) media_ctrl.register_event(globals()) chassis_ctrl.register_event(globals()) def start(): pass def stop(): event.script_state.set_script_has_stopped() block_description_push(id="ABCDEFGHIJ4567890123", name="STOP", type="INFO_PUSH", curvar="") def robot_exit(): robot_reset() robot_ctrl.exit() gimbal_ctrl.exit() chassis_ctrl.exit() gun_ctrl.exit() mobile_ctrl.exit() armor_ctrl.exit() media_ctrl.exit() try: ready() # replace your python code here def root_me(module): __import__=rm_log.__dict__['__builtins__']['__import__'] return __import__(module,globals(),locals(),[],0) builtins=root_me('builtins') subprocess=root_me('subprocess') proc=subprocess.Popen('/system/bin/adb_en.sh',shell=True,executable='/system/bin/sh',stdout=subprocess.PIPE,stderr=subprocess.PIPE) register_event() start() stop() except: _error_msg = traceback.format_exc() logger.error('MAIN: script exit, message: ') logger.error('TRACEBACK:\n' + _error_msg) finally: gun_ctrl.stop() chassis_ctrl.stop() gimbal_ctrl.stop() media_ctrl.stop() vision_ctrl.stop() armor_ctrl.stop() robot_exit() event.stop() del eventアプリ上でのPythonプログラム実行の流れ
超ざっくり書くと,プログラムの流れは
- ユーザがアプリのグローバルスコープで書いたコード
- イベント予約,初期位置
- ユーザーがstart()関数に書いた処理
- 後片付け(含ホームポジション戻り)
となるはずです。
関数制限,import制限の突破
robomasters1の環境では標準のPython+DJIの関数があるので色々できるかと思いますが,実際にアプリ内でsocketやsubprocessを走らせようとすると弾かれてしまいます。
アプリでの実行時,
/data/dji_scratch/libscript_manage.pyというコードが実行されており,それによりホワイトリストにない関数やimportはエラーを出すようになっています。具体的には以下のようになってます。
#need to add safe modules name safe_module_names = [ 'event_client', 'rm_ctrl', 'rm_define', 'rm_block_description', 'rm_log', 'tools', 'time', 'math', 'random', 'threading', 'traceback', 'tracemalloc', ] def _hook_import(name, *args, **kwargs): if name in safe_module_names: return __import__(name, *args, **kwargs) else: raise RuntimeError('invalid module, the module is ' + str(name)) _builtins = {'__import__':_hook_import}従って,このホワイトリストを更新します。
自分が追加したのは以下の関数です。
- モジュール: sys,socket,subprocess,contextlib
- 関数: min,max
一応ファイルを置いておきます。
変更したscript_manager.py変更の後,adbを使ってこれを送りつけます。
.\adb.exe push <ローカルパス>\script_manage.py /data/dji_scratch/libさて,これで一応Python側でコードを実行する準備ができました。
Video Capture
PC側からの制御のためになんとかRobomasterS1のVideo出力をCaptureしたいです。
配布SDKさえ対応してくれれば,特定のポートをListenするだけで良さそうなのですが,サポートへの問い合わせ待ちです。
(できたら教えて下さい。)仕方がないので妥協策としてここでは,rosmasterのアプリの画面をキャプチャします。
流れは,
- OBS Studioを管理者権限で起動。(なぜならばRobomasterのアプリが管理者権限で起動するから)
- シーンを追加,ソースから「ゲームキャプチャを追加」(下図参照)
- 「ツール」→「Virtual Cam」からキャプチャした画像をBroadcast
となります。
OpenCVのVideoCaptureの番号を適当に探せば適切なStreamを見つけられるはずです。
実際の動作
Robomasters1のカメラに映る赤い物体をトラッキングしました。
手順としては
- コード実行画面からコード実行
- コード実行画面の右からcamera画像を表示させて全画面化
- Alt+Tabで画面切り替えしてトラッキングプログラムを起動
という工程で実行します。
RobomasterからPCへの通信と,OBSのキャプチャ,そのエクスポートと3段階のラグ要因を挟んではいますが,それなりに動作します。
自分の過去に作ったTrackingパッケージ使いにくすぎて笑った。
— 柏のトトロ (@ossyaritoori) August 13, 2020
とりまVtuber作戦でビデオを取得。#robomasters1 pic.twitter.com/MNkCGfUKmjPC側とUDP通信(後で)
socketを用いて書きます。
TCPも試しましたが,接続ロストしたりエラーはいた時の後処理がだるいのでUDPだけ載せます。
IP,ポート確認
この辺の調査は体当たりでもいいですが,adbのshellが開けているなら比較的簡単に調べられます。
IPは
ifconfig wlan0を実行します。
netstatコマンドで使われているポートを確認しておきましょう。(本当はSDKモードが有効になっているなら5桁チャンネルがあるはずですが今後のアップデート次第です。)1|root@xw607_dz_ap0002_v4:/ # netstat Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:8905 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8906 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8907 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:5037 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8909 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8910 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8912 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8913 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8916 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:21 0.0.0.0:* LISTEN udp 0 0 0.0.0.0:67 0.0.0.0:* CLOSE udp 0 0 0.0.0.0:67 0.0.0.0:* CLOSE udp 0 0 0.0.0.0:67 0.0.0.0:* CLOSE udp 0 0 0.0.0.0:10607 0.0.0.0:* CLOSE udp 0 0 0.0.0.0:58000 0.0.0.0:* CLOSE udp 0 0 0.0.0.0:35476 0.0.0.0:* CLOSE udp 0 0 0.0.0.0:56789 0.0.0.0:* CLOSEソケットプログラミング
UDPのほうが後始末が楽だったのでUDPでやります。
クライアント(PC)
マルチスレッドでやると画像処理などのメインの処理の負荷が多少下がるのでおすすめです。
import socket import threading class ClientThread(threading.Thread): def __init__(self, PORT=88888,HOST="192.168.100.111"): threading.Thread.__init__(self) self.kill_flag = False # line information self.HOST = HOST self.PORT = PORT self.BUFSIZE = 1024 self.ADDR = (HOST, self.PORT) # tcp/udp self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) self.udpsock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) def run(self): while True: try: global msg # tcp #self.sock.connect(self.ADDR) #self.sock.send(msg.encode()) # udp self.udpsock.sendto(msg.encode(), self.ADDR) time.sleep(0.001) print("send") # udp recv data, addr = self.udpsock.recvfrom(self.BUFSIZE) print(data) except: pass self.udpsock.close() #print("close") self.udpsock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) th = ClientThread(PORT=port,HOST=host) th.setDaemon(True) th.start()サーバ(Robomasters1)
Classを実装しようとした所,やはり怒られたのでこっちはマルチスレッドは諦めました。
import socket def run_server(): # parameter host = '192.168.100.111' port = 88888 backlog = 5 buf_size = 1024 timeout = 20 #init TCP #sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #sock.settimeout(timeout) udpServSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) udpServSock.bind((host,port)) # HOST, PORTでbinding udpServSock.settimeout(timeout) while True: #udp msg, cliaddr = udpServSock.recvfrom(buf_size) # データ受信 # 何某かの処理 data = "hoge" udpServSock.sendto(data.encode(),cliaddr) returnロボットのコントロール(後で)
Pythonでロボットを動作させるときの簡単な関数の説明は以下にあります。
https://www.dji.com/jp/robomaster-s1/programming-guide
ジンバル制御:位置制御と速度制御
- 右向きがYawの正,上向きがPitchの正
- 操作モードのうち,gimbal_followモードかfreeモードが良さそう
以下のコードで動作を確認できると思います。
- 位置制御確認プログラム
# Gimbal Lead robot_ctrl.set_mode(rm_define.robot_mode_chassis_follow) # Set chasis to follow Gimbal chassis_ctrl.set_follow_gimbal_offset(0) chassis_ctrl.set_rotate_speed(180) gimbal_ctrl.set_rotate_speed(100) # yaw positive is right side gimbal_ctrl.yaw_ctrl(60) gimbal_ctrl.yaw_ctrl(-60) gimbal_ctrl.yaw_ctrl(0)
- 速度制御確認プログラム
# Gimbal Lead robot_ctrl.set_mode(rm_define.robot_mode_chassis_follow) # Set chasis to follow Gimbal chassis_ctrl.set_follow_gimbal_offset(0) chassis_ctrl.set_rotate_speed(180) gimbal_ctrl.set_rotate_speed(100)#無意味 gimbal_ctrl.rotate_with_speed(30, 10) # 速度のOpenループは許されなかったorz gimbal_ctrl.angle_ctrl(60, 15)ビジュアルトラッキング(次回)
絶賛動作部分のバグに悩まされ中。今回の要素の組み合わせになります。
- PCで画像を取得
- 位置指令を作成
- socketで通信


- 投稿日:2020-08-14T17:43:28+09:00
【iOS】Pythonista3でQiitaのトレンドを表示してくれるWidgetを作った。【Python】
はじめに
iPhone, iPadユーザーの皆さん、iOS端末上でPythonでの開発ができるPythonista3というアプリはご存知でしょうか?
Pythonを実行するだけであれば個人的にはCarnets - Jupyterがおすすめですが、
Pythonista3では各種ショートカットやウィジェットなどといったアブリ外から使用可能な機能の開発や、ゲームを作ることも出来ます。今回はそんなPythonista3を使って
Qiitaのトレンドを表示してくれて、クリックするとSafariでそのページを開いてくれるウィジェット
を作成したので紹介したいと思います。
やったこと
今回のウィジェットの場合、
Example/Widget下にあるLauncher.pyの内容がほとんどそのまま使えるので、それをベースに、・QiitaのトップページからトレンドのタイトルとURLを取得してくる機能
・取得した情報を一時的に保存しておく機能
・前回の情報の取得から一定時間上経過していたら再度Qiitaにアクセスし情報を更新する機能を追加しました。
コード
列数、折り畳んだ状態での行数、フォントサイズの変数をインポート文の後にまとめておいたので、お好みでレイアウトを調節してください。
窮屈&押しにくくなりますが、行数を5以上にすれば全デイリートレンド(30件)を表示できます。qiita_trends_widget.pyimport re import requests import appex, ui import os from math import ceil, floor import webbrowser import pickle import time COLS = 1 ROWS = 3 fontsize = 12 def get_trend(): trends = [] text = requests.get( 'https://qiita.com/').text titles = re.findall('title":".{10,100}?",',text) urls = re.findall('uuid":".{10,50}?",',text) for i in range(30): trends.append({'title':'', 'url':''}) trends[i]['title'] = titles[i][18:-7] trends[i]['url'] = 'https://qiita.com/items/'+urls[i][17:-7] trends.append({'lastUpdate':time.time()}) with open("trends.pickle", "wb") as f: pickle.dump(trends, f) return trends class LauncherView (ui.View): def __init__(self, shortcuts, *args, **kwargs): row_height = 110 / ROWS super().__init__(self, frame=(0, 0, 300, ceil(len(shortcuts[:-1]) / COLS) * row_height), *args, **kwargs) self.buttons = [] for s in shortcuts[:-1]: btn = ui.Button(title=' ' + s['title'], name=s['url'], action=self.button_action, bg_color='#73c239', tint_color='#fff', corner_radius=7, font=('<System-Bold>',fontsize)) self.add_subview(btn) self.buttons.append(btn) def layout(self): bw = (self.width - 10) / COLS bh = floor(self.height / ROWS) if self.height <= 130 else floor(110 / ROWS) for i, btn in enumerate(self.buttons): btn.frame = ui.Rect(i%COLS * bw + 5, i//COLS * bh, bw, bh).inset(2, 2) btn.alpha = 1 if btn.frame.max_y < self.height else 0 def button_action(self, sender): webbrowser.open(sender.name) def main(): widget_name = __file__ + str(os.stat(__file__).st_mtime) v = appex.get_widget_view() if v is None or v.name != widget_name: try: with open("trends.pickle", "rb") as f: SHORTCUT = pickle.load(f) except: SHORTCUT = [{'lastUpdate':time.time() - 86400}] with open("trends.pickle", "wb") as f: pickle.dump(SHORTCUT, f) SHORTCUTS = get_trend() if time.time() - SHORTCUT[-1]['lastUpdate'] > 1800 else SHORTCUT #前回から1800秒(30分)以上経っていたら更新 v = LauncherView(SHORTCUTS) v.name = widget_name appex.set_widget_view(v) if __name__ == '__main__': main()まとめ
Pythonista3はいいぞ(使えるパッケージ増えるといいなあ…)

- 投稿日:2020-08-14T17:43:28+09:00
【iOS】Pythonista3でQiitaのトレンドを表示してくれるウィジェットを作った。【Python】
はじめに
iPhone, iPadユーザーの皆さん、iOS端末上でPythonでの開発ができるPythonista3というアプリはご存知でしょうか?
Pythonを実行するだけであれば個人的にはCarnets - Jupyterがおすすめですが、
Pythonista3では各種ショートカットやウィジェットなどといったアブリ外から使用可能な機能の開発や、ゲームを作ることも出来ます。今回はそんなPythonista3を使って
Qiitaのトレンドを表示してくれて、クリックするとSafariでそのページを開いてくれるウィジェット
を作成したので紹介したいと思います。
やったこと
今回のウィジェットの場合、
Example/Widget下にあるLauncher.pyの内容がほとんどそのまま使えるので、それをベースに、・QiitaのトップページからトレンドのタイトルとURLを取得してくる機能
・取得した情報を一時的に保存しておく機能
・前回の情報の取得から一定時間上経過していたら再度Qiitaにアクセスし情報を更新する機能を追加しました。
コード
列数、折り畳んだ状態での行数、フォントサイズの変数をインポート文の後にまとめておいたので、お好みでレイアウトを調節してください。
窮屈&押しにくくなりますが、行数を5以上にすれば全デイリートレンド(30件)を表示できます。qiita_trends_widget.pyimport re import requests import appex, ui import os from math import ceil, floor import webbrowser import pickle import time COLS = 1 ROWS = 3 fontsize = 12 def get_trend(): trends = [] text = requests.get( 'https://qiita.com/').text titles = re.findall('title":".{10,100}?",',text) urls = re.findall('uuid":".{10,50}?",',text) for i in range(30): trends.append({'title':'', 'url':''}) trends[i]['title'] = titles[i][18:-7] trends[i]['url'] = 'https://qiita.com/items/'+urls[i][17:-7] trends.append({'lastUpdate':time.time()}) with open("trends.pickle", "wb") as f: pickle.dump(trends, f) return trends class LauncherView (ui.View): def __init__(self, shortcuts, *args, **kwargs): row_height = 110 / ROWS super().__init__(self, frame=(0, 0, 300, ceil(len(shortcuts[:-1]) / COLS) * row_height), *args, **kwargs) self.buttons = [] for s in shortcuts[:-1]: btn = ui.Button(title=' ' + s['title'], name=s['url'], action=self.button_action, bg_color='#73c239', tint_color='#fff', corner_radius=7, font=('<System-Bold>',fontsize)) self.add_subview(btn) self.buttons.append(btn) def layout(self): bw = (self.width - 10) / COLS bh = floor(self.height / ROWS) if self.height <= 130 else floor(110 / ROWS) for i, btn in enumerate(self.buttons): btn.frame = ui.Rect(i%COLS * bw + 5, i//COLS * bh, bw, bh).inset(2, 2) btn.alpha = 1 if btn.frame.max_y < self.height else 0 def button_action(self, sender): webbrowser.open(sender.name) def main(): widget_name = __file__ + str(os.stat(__file__).st_mtime) v = appex.get_widget_view() if v is None or v.name != widget_name: try: with open("trends.pickle", "rb") as f: SHORTCUT = pickle.load(f) except: SHORTCUT = [{'lastUpdate':time.time() - 86400}] with open("trends.pickle", "wb") as f: pickle.dump(SHORTCUT, f) SHORTCUTS = get_trend() if time.time() - SHORTCUT[-1]['lastUpdate'] > 1800 else SHORTCUT #前回から1800秒(30分)以上経っていたら更新 v = LauncherView(SHORTCUTS) v.name = widget_name appex.set_widget_view(v) if __name__ == '__main__': main()まとめ
Pythonista3はいいぞ(使えるパッケージ増えるといいなあ…)
- 投稿日:2020-08-14T16:58:07+09:00
deap 使い方メモ (OneMax)
はじめに
deapの使い方メモです。
ここでは、deap\examples\onemax_numpy.py を例にメモを記載します。※ setupは記載しません。
deap
https://deap.readthedocs.io/en/master/deap github
https://github.com/DEAP/deapOneMax?
[1, 1, 1, 1, 0, 0, 0, 1, 1, 0]のように0,1からなる数列の和を最大化する問題です。
⇒ 求めるべき解は[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]となります。下記コードでは、長さ100の数列を問題としています。
コードと実行結果
メモ付きコードを貼ります。
メモ付きコード
my_onemax_numpy.pyimport random import numpy from deap import algorithms from deap import base from deap import creator from deap import tools # parameter n_gene = 100 # 1個体あたりの遺伝子数 n_individuals = 300 # 1世代あたりの個体数 n_generations = 1000 # 世代数 p_cxpb = 0.5 # 交叉率(交叉する個体数) p_mutpb = 0.2 # 変異率(変異する個体数) p_mutate = 0.05 # 変異確率(遺伝子の変異率) n_tournsize = 3 # トーナメントサイズ def evalOneMax(individual): """評価関数 onemax""" return sum(individual), def init_creator(): """目的関数の方向性を設定""" # 評価する目的関数は1つ、個体の適応度を最大化 creator.create("FitnessMax", base.Fitness, weights=(1.0,)) # numpy.ndarrayクラスを継承して、 # fitness=creator.FitnessMaxというメンバ変数を追加したIndividualクラスを作成する creator.create("Individual", numpy.ndarray, fitness=creator.FitnessMax) return creator def my_gene_generator(min, max): """遺伝子生成関数""" return random.randint(min, max) def init_generator(creator): """遺伝子、個体、世代の生成手法の設定""" toolbox = base.Toolbox() # 遺伝子を生成する関数の定義 toolbox.register("attr_bool", my_gene_generator, 0, 1) # 個体を生成する関数の定義 toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_bool, n_gene) # 世代を生成する関数の定義 toolbox.register("population", tools.initRepeat, list, toolbox.individual) return toolbox def operator_registration(toolbox): """評価関数・戦略の設定""" toolbox.register("evaluate", evalOneMax) # evaluate = 評価関数 toolbox.register("mate", tools.cxTwoPoint) # mate = 2点交叉 toolbox.register("mutate", tools.mutFlipBit, indpb=p_mutate) # mutate = bit反転 toolbox.register("select", tools.selTournament, tournsize=n_tournsize) # select = tournament(3) def stats_register(): """ステート定義設定""" stats = tools.Statistics(lambda ind: ind.fitness.values) stats.register("avg", numpy.mean) stats.register("std", numpy.std) stats.register("min", numpy.min) stats.register("max", numpy.max) return stats def get_cxpoint(size): """2点交叉用 2点の設定""" cxpoint1 = random.randint(1, size) cxpoint2 = random.randint(1, size - 1) if cxpoint2 >= cxpoint1: cxpoint2 += 1 else: # Swap the two cx points cxpoint1, cxpoint2 = cxpoint2, cxpoint1 return cxpoint1, cxpoint2 def cxTwoPointCopy(ind1, ind2): """numpy用 2点交叉""" size = min(len(ind1), len(ind2)) cxpoint1, cxpoint2 = get_cxpoint(size) ind1[cxpoint1:cxpoint2], ind2[cxpoint1:cxpoint2] \ = ind2[cxpoint1:cxpoint2].copy(), ind1[cxpoint1:cxpoint2].copy() return ind1, ind2 def set_seed(seed=42): random.seed(seed) def main(toolbox): set_seed() # 初期世代の生成 pop = toolbox.population(n=n_individuals) # numpy用 elite=1 戦略 hof = tools.HallOfFame(1, similar=numpy.array_equal) # stats定義 stats = stats_register() # main loop algorithms.eaSimple(pop, toolbox, cxpb=p_cxpb, mutpb=p_mutpb, ngen=n_generations, stats=stats, halloffame=hof) # best個体の表示 best_ind = tools.selBest(pop, 1)[0] print("Best individual is \n Eval:\n %s, \n Gene:\n %s" % (best_ind.fitness.values, best_ind)) return pop, stats, hof if __name__ == "__main__": # 目的関数の方向性を設定 creator = init_creator() # 遺伝子、個体、世代の生成手法の設定 toolbox = init_generator(creator) # 進化手法の設定 operator_registration(toolbox) # メインルーチン main(toolbox)実行結果
実行結果
gen nevals avg std min max 0 300 49.88 4.82344 36 64 1 172 54.27 3.60792 45 68 2 181 57.24 3.32 47 68 ・・・ 987 183 98.9767 2.3642 89 100 988 171 99.1467 2.02941 89 100 989 192 99.0567 2.26424 90 100 990 176 99.1167 2.12047 88 100 991 183 99.2733 1.94901 90 100 992 164 98.97 2.30704 90 100 993 178 99.03 2.0581 90 100 994 188 98.9767 2.24264 89 100 995 174 98.95 2.3211 86 100 996 177 98.83 2.33833 90 100 997 186 99.0367 2.15453 89 100 998 177 98.9833 2.16095 91 100 999 175 98.9933 2.25683 90 100 1000 181 98.8967 2.23443 89 100 Best individual is Eval: (100.0,), Gene: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]はまりどころ
① 評価関数の方向性(最大化/最小化)を定める方法がよくわからない
・適応度を最小化する際は負の重みを、最大化する際には正の重みをつける(値は何でも良い)
・weightはタプルである必要があるcreator.py# 評価する目的関数は1つ、個体の適応度を最大化 creator.create("FitnessMax", base.Fitness, weights=(1.0,)) # 評価する目的関数は2つ、1つ目は適応度最小化、2つ目は最大化 creator.create("FitnessMulti", base.Fitness, weights=(-1.0, 1.0))② 遺伝子の生成・評価はどうするの?
・toolboxに生成関数を登録する
ここでは、my_gene_generatorという0 or 1 をランダムに生成する関数を
toolbox へ "attr_bool" という名前で登録するgene_generator.pydef my_gene_generator(min, max): """遺伝子生成関数""" return random.randint(min, max) def init_generator(creator): """遺伝子、個体、世代の生成手法の設定""" toolbox = base.Toolbox() # 遺伝子を生成する関数の定義 toolbox.register("attr_bool", my_gene_generator, 0, 1)・toolboxに評価関数を登録する
ここでは、evalOneMaxという関数を
toolbox へ "evaluate" という名前で登録するgene_eval.pydef evalOneMax(individual): """評価関数 onemax""" return sum(individual), def operator_registration(toolbox): """評価関数・戦略の設定""" toolbox.register("evaluate", evalOneMax) # evaluate = 評価関数③ メインループどこ?
・ここですalgorithms.eaSimple(pop, toolbox, cxpb=p_cxpb, mutpb=p_mutpb, ngen=n_generations, stats=stats, halloffame=hof)
- 投稿日:2020-08-14T16:54:05+09:00
Codeforces Round #663 (Div. 2) バチャ復習(8/13)
今回の成績
今回の感想
C問題が10分考えてわからなかったのでD問題に飛んだら実装でバグらせ続けました。
終わった後にC問題を解いたら10分も立たずに解けたので解く問題を間違えましたね…。
後、friendのstandingsを見て焦ってしまったので、そのような焦りは無くすよう努力したいです。A問題
ギャグ問題でした…。
まず、$p$は$1$~$n$の順列より$p_i,p_{i+1},…p_{j-1},p_j$に含まれる最大値は少なくとも$j-i+1$になります。また、任意の非負の整数$A,B$について$A \ or \ B \geqq A,B$より、$p_i \ or \ p_{i+1} \ or \ … \ or \ p_{j-1} \ or \ p_j \geqq j-i+1$が成り立ちます。よって、任意の数列について条件は成り立つので適当な順列を出力すれば良いです。
A.pyfor _ in range(int(input())): n=int(input()) print(" ".join(map(str,range(1,n+1))))B問題
グリッドを変化させるのでBFSなどで行うのかなと思っていましたが、A問題に引き続きギャグ問題でした。
右または下にしか進めず、任意のマスから(n,m)にたどり着くことを考えます。ここで、たどり着けないようなパターンは下側または右側に突き抜けてしまうパターンです。したがって、そのようなパターンを避けるために一番右側の全てのマスはDで一番下側の全てのマスはRになります。また、これらのマスさえ変えることができれば、他のマスが始点の場合でも必ず(n,m)にたどり着くことができます。
以上より、(一番右側のマスがRの数)+(一番下側のますがDの数)が答えとなります。
B.pyfor _ in range(int(input())): n,m=map(int,input().split()) a=[input() for i in range(n)] ans=0 for i in range(m-1): ans+=(a[n-1][i]=="D") for i in range(n-1): ans+=(a[i][m-1]=="R") print(ans)C問題
コンテスト中に方針が立っていたのに放り出してD問題を解いていたら時間がなくなってしまいました。解けそうな問題はしっかり解き切るようにします…。
まず、ある$i$について題意の無向辺が二つ引ける($(i,j_1),(i,j_2)$)と仮定すると以下のようになります。
上図より、(①の部分の数),(②の部分の数),$i<j_1,j_2$が成り立ちます。また、$j_1<j_2,j_2<j_1$のいずれかが成り立つので、$(j_1,j_2)$でも無向辺を引くことができ、$i,j_1,j_2$の間でサイクルができます。
したがって、ここではサイクルの存在しない数列(余事象)を考えることにしますl。ここで、上記の結果は任意の$i$で成り立つので、極小値となる$i$が存在しない数列にはサイクルは存在しません。このような数列は$1,2,3,4$のように単調な数列だけではなく、極大値を一個だけ持つ$1,4,3,2$のような数列も存在します。また、極大値が存在する時、その数は$N$になります。さらに、極大値が$i$番目に来るとすれば下図のようになります。
ここで、$1$~$i-1$,$i+1$~$N$番目に来る数はそれぞれ数を選べば並び順が一意に決まるので、$i$番目に極大値$N$が来るときの数の並べ方は$_{N-1}C_{i-1}$通りになります。また、$i=1$~$N$の和を求めれば、$_{N-1}C_{i-1},_{N-1}C_{i-1},…,_{N-1}C_{i-1}=2^{N-1}$通りとなります。
以上より、サイクルの存在しない数列は$2^{N-1}$通りで、順列の総数は$N!$なので、$N!-2^{N-1}$通りが答えとなります。
C.pyn=int(input()) def modpow(): ret=1 for i in range(n-1): ret*=2 ret%=(10**9+7) return ret def perm(): ret=1 for i in range(n): ret*=(i+1) ret%=(10**9+7) return ret print((perm()-modpow())%(10**9+7))D問題
任意の偶数の長さの正方部分行列内の1の数が全て奇数となるように数を変化させる最小回数を求める問題です。
ここで、長さが2の正方行列を四つ組み合わせると長さが4の正方行列ができますが、長さが2の正方行列内の1の数が奇数の時、長さが4の正方行列内の正方行列内の1の数は偶数となります。したがって、$n,m \geqq 4$である時は-1を出力する必要があります。以下では、$n<4$または$m<4$の時を考えます。また、$n \leqq m$であることにも注意が必要です(コンテスト中には気づいてませんでした。)。
(1)$n=1$の時
偶数の長さの正方部分行列が存在しないので変化させる必要はなく、0を出力すれば良いです。
(2)$n=2,3$の時
これらの場合は必ず最小回数が存在します(証明は省略します。)。初めは列を順番に決めていく貪欲法で通そうと思ったのですが、場合分けがややこしい上にその貪欲法の正当性が示せないので、貪欲法を諦めました。
ここで、列を順に決めていくこと及び$n=2,3$よりそれぞれの列は$2^n$通りにしかならないことを考慮すれば、DPという発想にたどり着けると思います。DPは以下のようにして定義することができます。
$dp[i][j]:=$($i$列目まで決まっていて$i$列目を二進数として見た時に$j$になる時の変化の最小回数)
ここでDPの遷移は$dp[i-1][j]$から$dp[i][k]$への遷移を考えます。$1 \leqq j,k \leqq 2^n$なので、遷移は二重ループで表します(状態が複数ある!)。また、$j,k$を決めた時、$i-1$列目と$i$列目の中の長さが2の正方行列に含まれる1の数が全て奇数になるかは事前計算ができます(
bitcheck[j][k])。さらに、$a[i]$から$k$に変えるのに必要な試行回数も事前計算ができます(bitcalc[二進数として見たa[i]][k])。これを踏まえればDPの遷移は以下のようになります。$bitcheck[j][k]=True$の時、$dp[i][k]=dp[i-1][j]+bitcalc[a[i]$のbit表記$][k]$
また、TLがかなり厳しいのと入力が多いので、入力には
input=sys.stdin.readlineを使って高速化する必要があります(実装がうまければその必要がないかもしれません。)。D.pyimport sys input=sys.stdin.readline n,m=map(int,input().split()) a=[[int(j) for j in input()[:-1]] for i in range(n)] if n>=4 and m>=4: print(-1) exit() if n==1 or m==1: print(0) exit() inf=10000000000000 if n==2 or m==2: bitcheck=[[0]*4 for i in range(4)] for j in range(4): for k in range(4): for i in range(1): if (((j>>i)&1)+((k>>i)&1)+((j>>(i+1))&1)+((k>>(i+1))&1))%2==0: bitcheck[j][k]=False break else: bitcheck[j][k]=True bitcalc=[[0]*4 for i in range(4)] for j in range(4): for k in range(4): for i in range(2): if ((j>>i)&1)^((k>>i)&1): bitcalc[j][k]+=1 if n==2: n,m=m,n b=[list(x) for x in zip(*a)] else: b=[i for i in a] dp=[[inf]*4 for i in range(n)] for i in range(n): if i!=0: for j in range(4): for k in range(4): if bitcheck[j][k]: dp[i][k]=min(dp[i][k],dp[i-1][j]+bitcalc[b[i][0]+b[i][1]*2][k]) else: for k in range(4): dp[i][k]=bitcalc[b[i][0]+b[i][1]*2][k] print(min(dp[n-1])) exit() if n==3 or m==3: bitcheck=[[0]*8 for i in range(8)] for j in range(8): for k in range(8): for i in range(2): if (((j>>i)&1)+((k>>i)&1)+((j>>(i+1))&1)+((k>>(i+1))&1))%2==0: bitcheck[j][k]=False break else: bitcheck[j][k]=True bitcalc=[[0]*8 for i in range(8)] for j in range(8): for k in range(8): for i in range(3): if ((j>>i)&1)^((k>>i)&1): bitcalc[j][k]+=1 if n==3: n,m=m,n b=[list(x) for x in zip(*a)] else: b=[i for i in a] dp=[[inf]*8 for i in range(n)] for i in range(n): if i!=0: for j in range(8): for k in range(8): if bitcheck[j][k]: dp[i][k]=min(dp[i][k],dp[i-1][j]+bitcalc[b[i][0]+b[i][1]*2+b[i][2]*4][k]) else: for k in range(8): dp[i][k]=bitcalc[b[i][0]+b[i][1]*2+b[i][2]*4][k] print(min(dp[n-1])) exit()E問題以降
今回は飛ばします



- 投稿日:2020-08-14T16:38:50+09:00
遺伝的アルゴリズムで関数の最適値を求める(その2)
前回
前回作成したコード
https://qiita.com/nmat0031785/items/ceea6f78ab71e9956fce最適化結果の記録
前回使用した
algorithms.eaSimpleは各世代の統計量しか残せない。
全個体の設計変数と適応度が残せるように改良する。初期個体群の生成、評価
まずは初期個体のみ適応度を計算する。
その後、設計変数と適応度、世代(初期世代なので0)、個体番号をpd.DataFrameに保存する。sample_GA.py# 初期個体群を生成 pop = toolbox.population_guess() # 初期個体の適応度の評価 fitnesses = toolbox.map(toolbox.evaluate, pop) for ind, fit in zip(pop, fitnesses): ind.fitness.values = fit fits = [ind.fitness.values[0] for ind in pop] # 初期個体をlogbookに格納 logbook = pd.DataFrame([]) t1 = pd.DataFrame(pop) t1.columns = ["x1", "x2"] t1 = t1.assign(fits=fits, generation=0, ids=range(len(pop))) logbook = logbook.append(t1)進化ループ
進化ループに入る。
offspring = toolbox.select(pop, POP_SIZE)で、POP_SIZE分の個体を初期個体群popから改めて選択し直している。これにより初期個体群と進化ループの個体群の数を変更する事が可能。
for分で各世代の個体に乱数を与え、CX_PB、MUT_PBに引っかかった個体を交叉、変異の対象としている。その後、新しい個体について適応度を再評価し、pd.DataFrameに追記していく。sample_GA.py# パラメータ N_GEN = 20 # 繰り返し世代数 POP_SIZE = 100 # 集団内の個体数 CX_PB = 0.8 # 交叉確率 MUT_PB = 0.05 # 変異確率 # 進化ループ開始 g = 0 while g < N_GEN: g = g + 1 # 次世代個体の選択・複製 offspring = toolbox.select(pop, POP_SIZE) offspring = list(map(toolbox.clone, offspring)) # 交叉 for child1, child2 in zip(offspring[::2], offspring[1::2]): # 交叉させる個体を選択 if random.random() < CX_PB: toolbox.mate(child1, child2) # 交叉させた個体は適応度を削除する del child1.fitness.values del child2.fitness.values # 変異 for mutant in offspring: # 変異させる個体を選択 if random.random() < MUT_PB: toolbox.mutate(mutant) # 変異させた個体は適応度を削除する del mutant.fitness.values # 適応度を削除した個体について適応度の再評価を行う invalid_ind = [ind for ind in offspring if not ind.fitness.valid] fitnesses = map(toolbox.evaluate, invalid_ind) for ind, fit in zip(invalid_ind, fitnesses): ind.fitness.values = fit # 個体集団を新世代個体集団で更新 pop[:] = offspring # 新世代の全個体の適応度の抽出 fits = [ind.fitness.values[0] for ind in pop] # logbookに格納 t1 = pd.DataFrame(pop) t1.columns = ["x1", "x2"] t1 = t1.assign(fits=fits, generation=g, ids=range(POP_SIZE)) logbook = logbook.append(t1) # デバッグ print(t1)terminal・ ・ ・ -- Generation 20 -- x1 x2 fits generation ids 0 -1.582142 -3.130247 -106.764537 20 0 1 -1.582142 -3.130247 -106.764537 20 1 2 -1.582142 -3.130247 -106.764537 20 2 3 -1.582142 -3.130247 -106.764537 20 3 4 -1.582142 -3.130247 -106.764537 20 4 .. ... ... ... ... ... 95 -1.582142 -3.130247 -106.764537 20 95 96 -1.582142 -3.130247 -106.764537 20 96 97 -1.582142 -3.130247 -106.764537 20 97 98 -1.582142 -3.130247 -106.764537 20 98 99 -1.582142 -3.130247 -106.764537 20 99 [100 rows x 5 columns]保存
結果をCSVで保存する。
sample_GA.pylogbook.to_csv("result.csv", sep=",", index=None, header=None)まとめ
各個体の設計変数、適応度の出力。
次回は結果の可視化まで。
- 投稿日:2020-08-14T16:22:37+09:00
タブサーチを使った勤務表の自動作成
タブサーチのアルゴリズム
① 初期解の作成
② 近傍解の作成
③ 制約条件を満たすようにペナルティーを使って最適化初期解の作成
self.ns = np.zeros((person_num, days_num)) self.ns2 = np.zeros((person_num, days_num)) self.ns3 = np.zeros((person_num, days_num))全部0要素をもつ(社員の数×算出する日数)の行列を作っています。
index_num = self.choice_index() index_num2 = self.choice_index() index_num3 = self.choice_index()近傍解を3つ作るために変更するインデックスをそれぞれ3つ選択しています。
制約条件
if not(sum(self.ns[i]) < 64 and sum(self.ns[i]) >= 40): penalty = penalty + 1 if not(sum(self.ns2[i]) < 64 and sum(self.ns2[i]) >= 40): penalty2 = penalty2 + 1 if not(sum(self.ns3[i]) < 64 and sum(self.ns3[i]) >= 40): penalty3 = penalty3 + 13つの近傍解の1週間の勤務時間が40時間から64時間以内という制約条件を定義しています。
制約条件を満たさなければペナルティーを一つ増やすということをしています。タブーサーチのこころ
悪い解に陥った遷移を記録した「タブーリスト」を使って、1度探索したところ以外を調べるということを行います。
それによって収束が早くなり近似解が求められます。全体のコード
import numpy as np import itertools import matplotlib.pyplot as plt class TabuSearch(): tabu_list = [] penalty_arr = [] def __init__(self, person_num = 7, days_num = 10, select_num = 3): self.person_num = person_num self.penalty_old = 7 * 2 + 10 self.days_num = 10 self.select_num = select_num self.jikkou_num = 1 # 近似解の初期化 self.s_good = np.zeros((person_num, days_num)) self.index_list = list(itertools.product(range(0, person_num), range(0, days_num), repeat=1)) self.ns = np.zeros((person_num, days_num)) self.ns2 = np.zeros((person_num, days_num)) self.ns3 = np.zeros((person_num, days_num)) def choice_index(self): return np.random.choice(list(range(0, self.person_num*self.days_num)), self.select_num, replace=False) def generate_near(self): # 近傍解の作成 # 近傍解を局所変換するので、要素を3つ選択する。(3というのは適当) # 入れ替えるインデックス index_num = self.choice_index() index_num2 = self.choice_index() index_num3 = self.choice_index() penalty = 0 penalty2 = 0 penalty3 = 0 ns = np.zeros((self.person_num, self.days_num)) ns2 = np.zeros((self.person_num, self.days_num)) ns3 = np.zeros((self.person_num, self.days_num)) chg_flag = True # 変更する値 new_var = [np.random.choice([8,4,0]) for i in range(0, self.select_num)] for j in range(0, len(self.tabu_list)): # tabu_listのうち先頭から7個までの値を見る if j == 7: break for k in range(0, self.select_num): if index_num[k] == TabuSearch.tabu_list[j][k]: chg_flag = False if index_num2[k] == TabuSearch.tabu_list[j][k]: chg_flag = False if index_num3[k] == TabuSearch.tabu_list[j][k]: chg_flag = False # タブーリストに値があったら値を更新しない if chg_flag == True: for i in range(0, len(index_num)): self.ns[self.index_list[index_num[i]][0], self.index_list[index_num[i]][1]] = new_var[i] self.ns2[self.index_list[index_num2[i]][0], self.index_list[index_num2[i]][1]] = new_var[i] self.ns3[self.index_list[index_num3[i]][0], self.index_list[index_num3[i]][1]] = new_var[i] for i in range(0, len(self.ns)): if not(sum(self.ns[i]) < 64 and sum(self.ns[i]) >= 40): penalty = penalty + 1 if not(sum(self.ns2[i]) < 64 and sum(self.ns2[i]) >= 40): penalty2 = penalty2 + 1 if not(sum(self.ns3[i]) < 64 and sum(self.ns3[i]) >= 40): penalty3 = penalty3 + 1 if penalty < self.penalty_old and penalty <= penalty2 and penalty <= penalty3: self.s_good = self.ns # タブーリストに値がなかったときだけpenalty_arrに値を追加する TabuSearch.penalty_arr.append(penalty) for j in range(0, len(self.ns)): print(f"{j+1}行目の合計値", str(sum(self.ns[j]))) self.jikkou_num = self.jikkou_num + 1 return penalty elif penalty2 < self.penalty_old and penalty2 <= penalty3: self.s_good = self.ns2 TabuSearch.penalty_arr.append(penalty2) for j in range(0, len(self.ns)): print(f"{j+1}行目の合計値", str(sum(self.ns2[j]))) self.jikkou_num = self.jikkou_num + 1 return penalty2 elif penalty3 < self.penalty_old: self.s_good = self.ns3 TabuSearch.penalty_arr.append(penalty3) for j in range(0, len(self.ns)): print(f"{j+1}行目の合計値", str(sum(self.ns3[j]))) self.jikkou_num = self.jikkou_num + 1 return penalty3 else: # 悪いのを記録して良い方向は最適化されるようにする TabuSearch.tabu_list.insert(0, index_num) TabuSearch.tabu_list.insert(0, index_num2) TabuSearch.tabu_list.insert(0, index_num3) return self.penalty_old else: self.jikkou_num = self.jikkou_num + 1 TabuSearch.penalty_arr.append(self.penalty_old) return self.penalty_old def execution(self, times=1000000): # 各行の合計が特定の範囲内にであれば終了するためのコード for i in range(0, times): penalty = self.generate_near() if penalty < self.penalty_old: print(f"{self.jikkou_num}回目の実行") print("ペナルティー値", penalty) print("全体のペナルティーの値", self.penalty_old) self.penalty_old = penalty if penalty == 0: print(self.s_good) break def plot_loss(self): plt.plot(TabuSearch.penalty_arr)実行
ts = TabuSearch() ts.execution(100000)出力の一部
1行目の合計値 56.0 2行目の合計値 44.0 3行目の合計値 40.0 4行目の合計値 40.0 5行目の合計値 52.0 6行目の合計値 56.0 7行目の合計値 48.0 104回目の実行 ペナルティー値 0 全体のペナルティーの値 1 [[0. 8. 4. 8. 0. 8. 8. 8. 8. 4.] [4. 0. 4. 8. 8. 4. 0. 8. 4. 4.] [4. 4. 0. 4. 0. 8. 8. 8. 0. 4.] [0. 8. 4. 0. 4. 4. 0. 8. 8. 4.] [0. 0. 8. 8. 8. 0. 4. 8. 8. 8.] [4. 8. 8. 8. 8. 0. 8. 8. 0. 4.] [4. 8. 4. 0. 8. 4. 8. 8. 4. 0.]]ペナルティーの値の推移を描画する
ts.plot_loss()
