- 投稿日:2020-08-14T19:29:33+09:00
監視カメラを用いたメールアラートシステムを開発してみる
日立製作所OSSソリューションセンタの横井です。
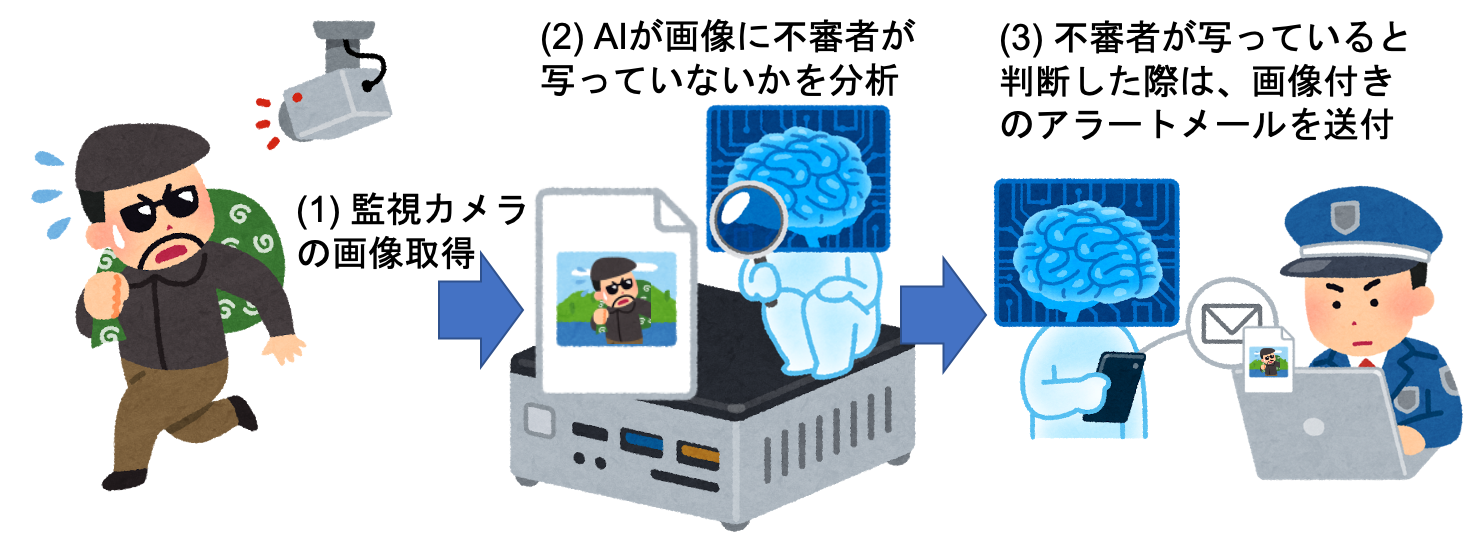
前回の記事では、TensorFlow.jsを用いた画像認識のフローの開発手順を紹介しました。今回は応用として、監視カメラと画像認識を連携させたメールアラートシステムを開発してみましょう。以下の図の様に、監視カメラの画像に不審者が写った際、自動でメールでアラートを送るフローを作成します。
開発するフロー
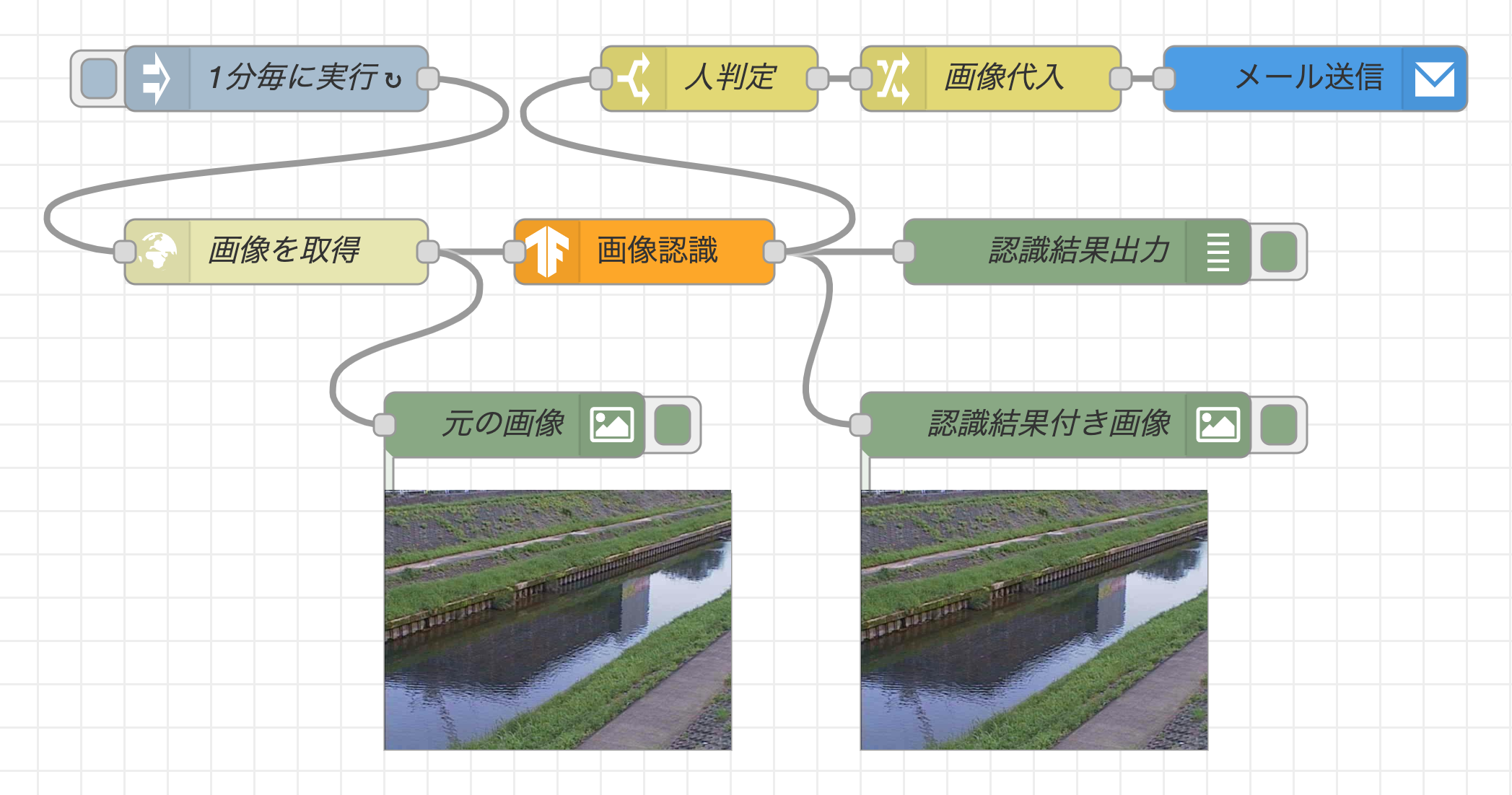
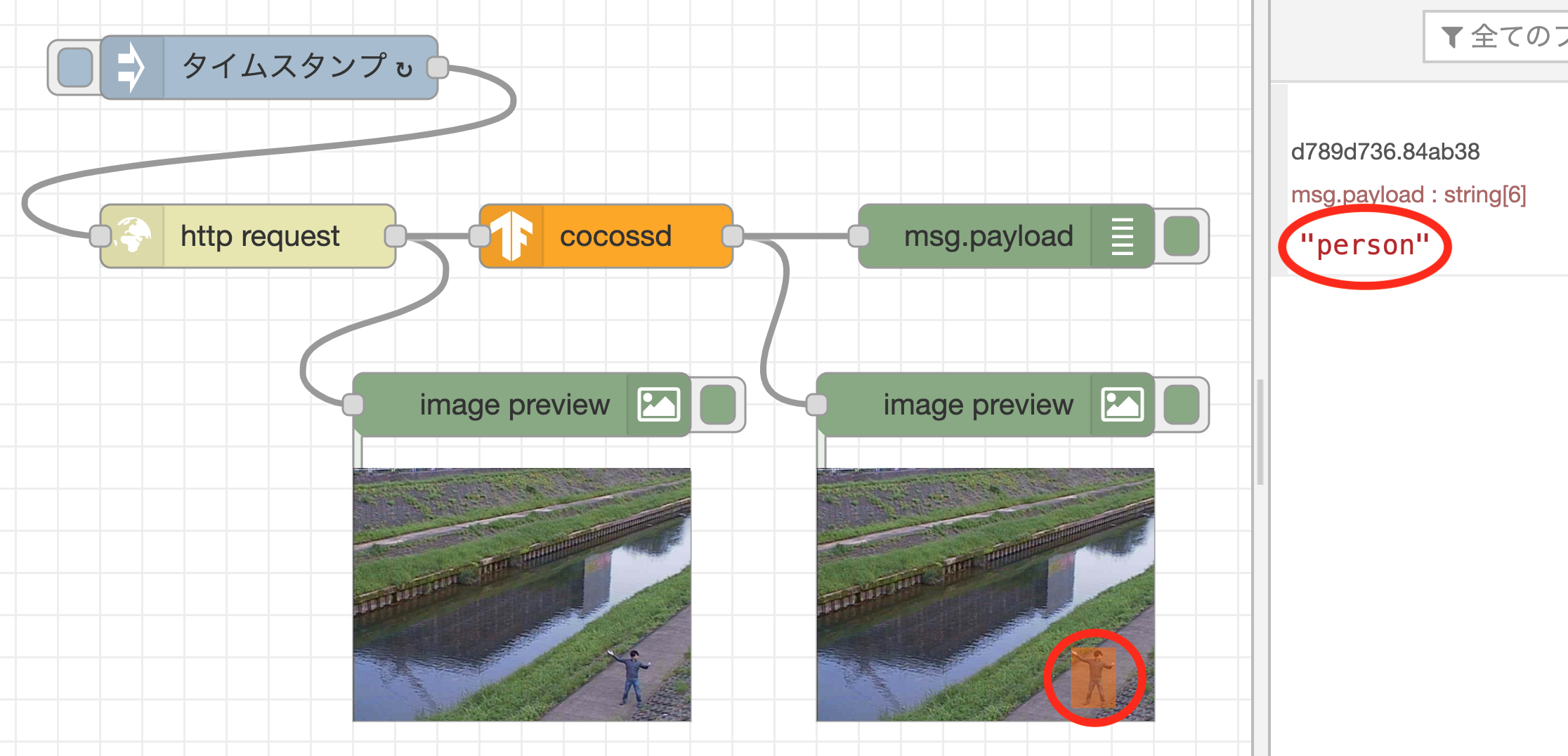
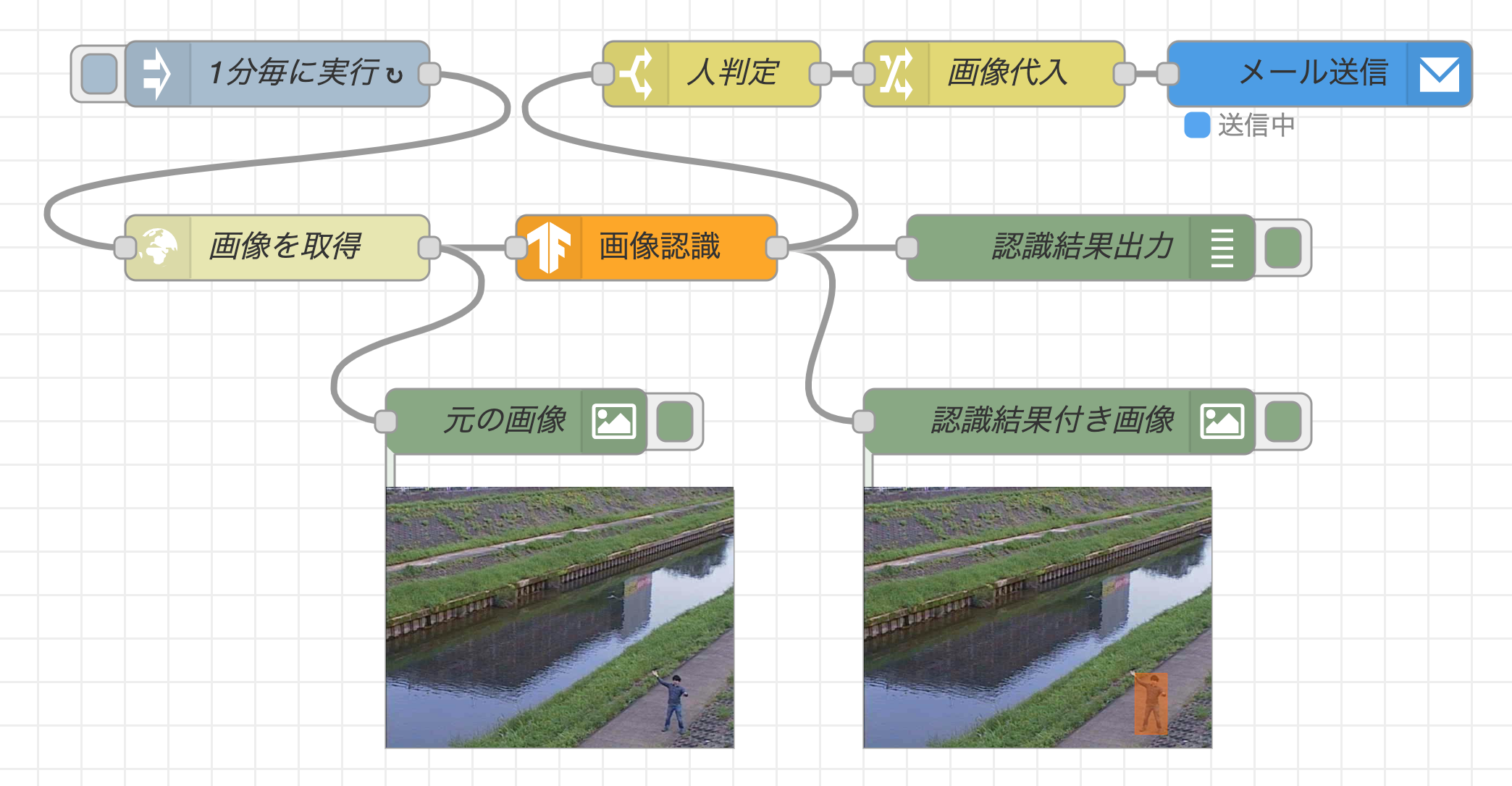
以下の様なフローを開発します。このフローでは、定期的にウェブサーバから監視カメラの画像を取得し、左下の「元の画像」のノードの下に画像を表示します。その後、TensorFlow.jsノードを用いて画像認識を行い、認識結果と認識結果付き画像をそれぞれデバッグタブと「認識結果付き画像」のノードの下に表示します。
もし、画像認識にて人物(person)が写っていると判定された場合は、SendGridノードを用いて画像ファイルを添付したアラートメールを送信します。実際に監視カメラを準備するのは大変なため、ここではサンプルとして、神奈川県が川の水量を確認するために設置している監視カメラの画像を活用してみました。
以降で本フローの作成手順を説明してゆきます。Node-RED環境は、ローカルPC環境、Raspberry Pi環境、クラウド環境などを用意してください。
必要なノードのインストール
Node-REDフローエディタの右上のハンバーガーメニューをクリックし、「パレットの管理」->「パレット」タブ->「ノードの追加」タブと遷移し、以下のノードをインストールします。
- node-red-contrib-tensorflow : TensorFlow.jsを用いた画像認識を行うノード
- node-red-contrib-image-output : フローエディタ上に画像を表示するノード
- node-red-contrib-sendgrid : SendGridを用いてメールを送信するノード
(1) 画像データを取得するフロー
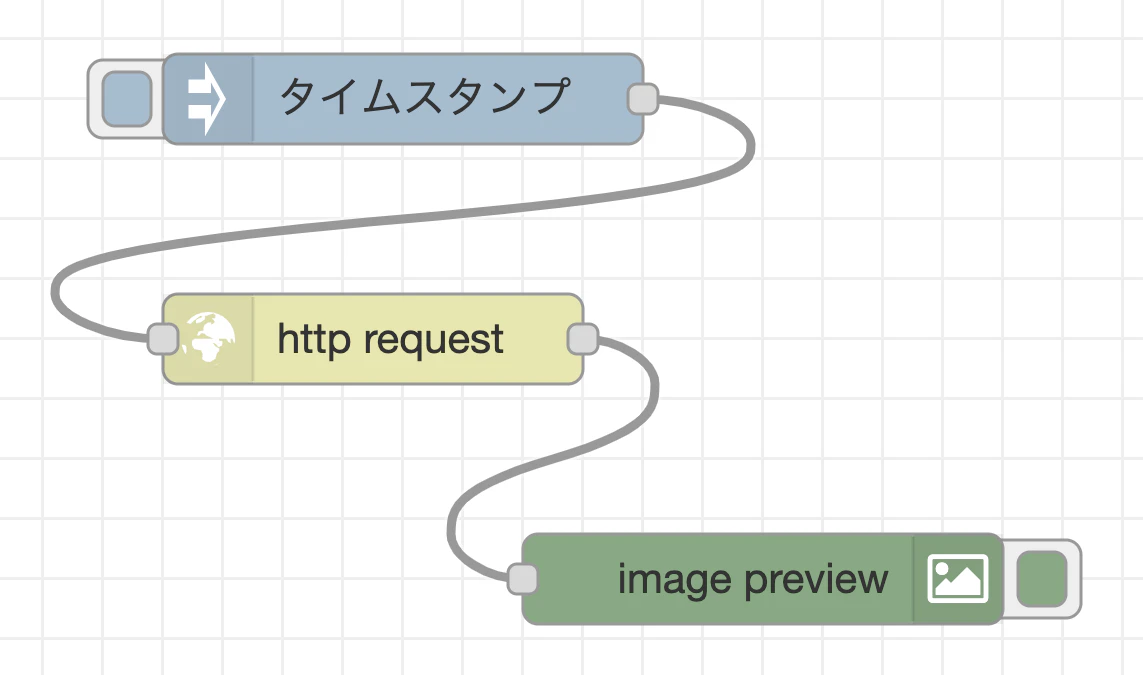
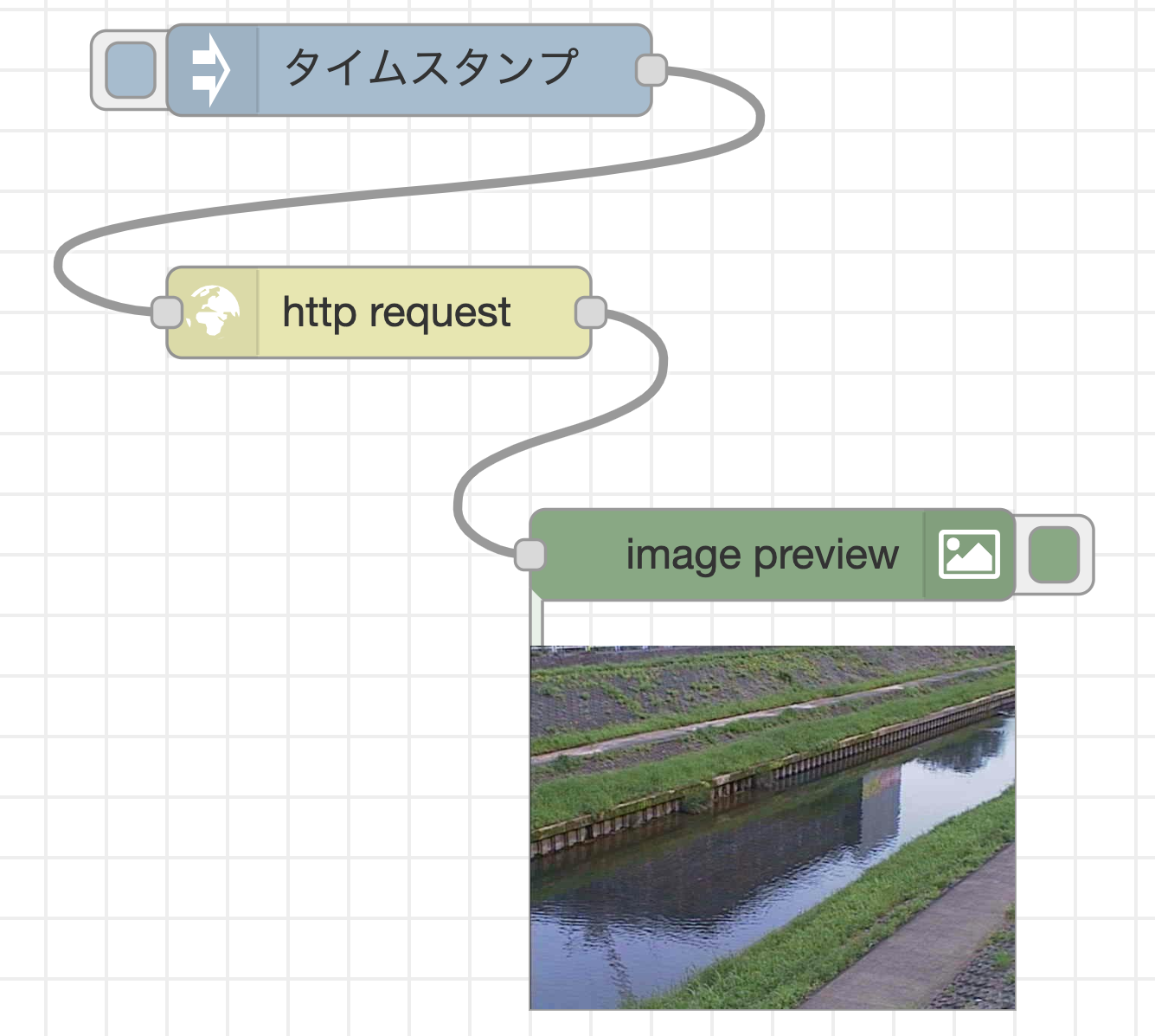
最初に、ウェブサーバから画像のバイナリデータを取得するフローを作成します。以下のフローの様に、injectノード(ワークスペースに配置すると名前が「タイムスタンプ」に変わります)、http requestノード、image previewノードを配置し、ワイヤーで接続します。
その後、http requestノードをダブルクリックして、ノードのプロパティ設定を変更します。
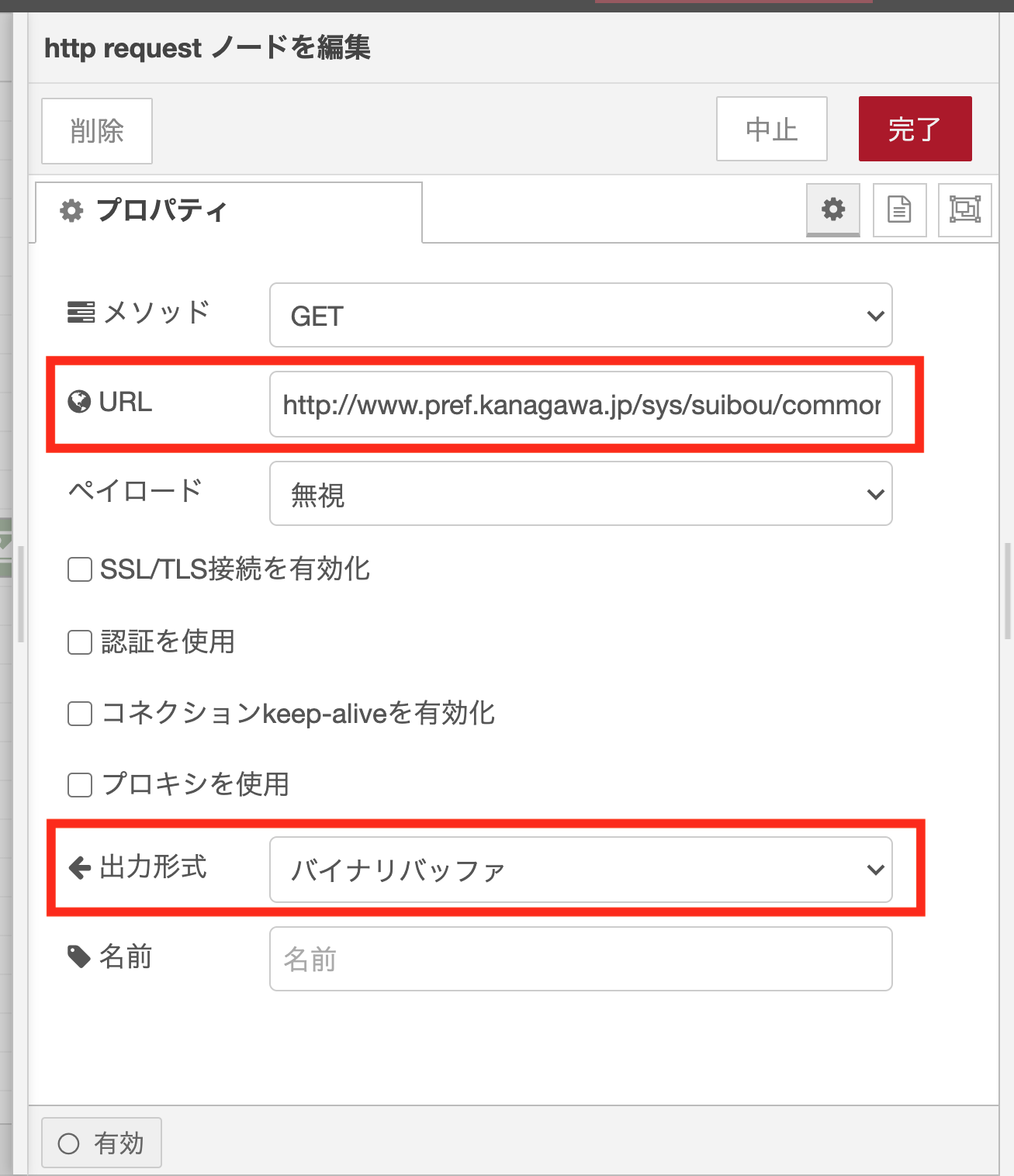
http requestノードのプロパティ設定
http requestノードのプロパティ設定画面にあるURLに、監視カメラの画像のURLを貼り付けます(Google Chromeでは、画像の上で右クリックすると現れるメニューから「画像アドレスをコピー」を選択すると、画像をURLがクリップボードへコピーされます)。また、出力形式として「バイナリバッファ」を選択します。
画像データを取得するフローを実行
フローエディタ右上のデプロイボタンをクリックした後、injectノードの左側のボタンをクリックします。すると、injectノードからワイヤーを通してメッセージがhttp requestノードに送られ、監視カメラの画像を提供するウェブサーバから画像を取得します。画像データを取得後、バイナリ形式のデータを含むメッセージがimage previewノードに送られ、image previewノードの下に画像が表示されます。
右下に監視カメラが撮影した川の画像が表示されましたね!
(2)取得した画像データに対して画像認識を行うフロー
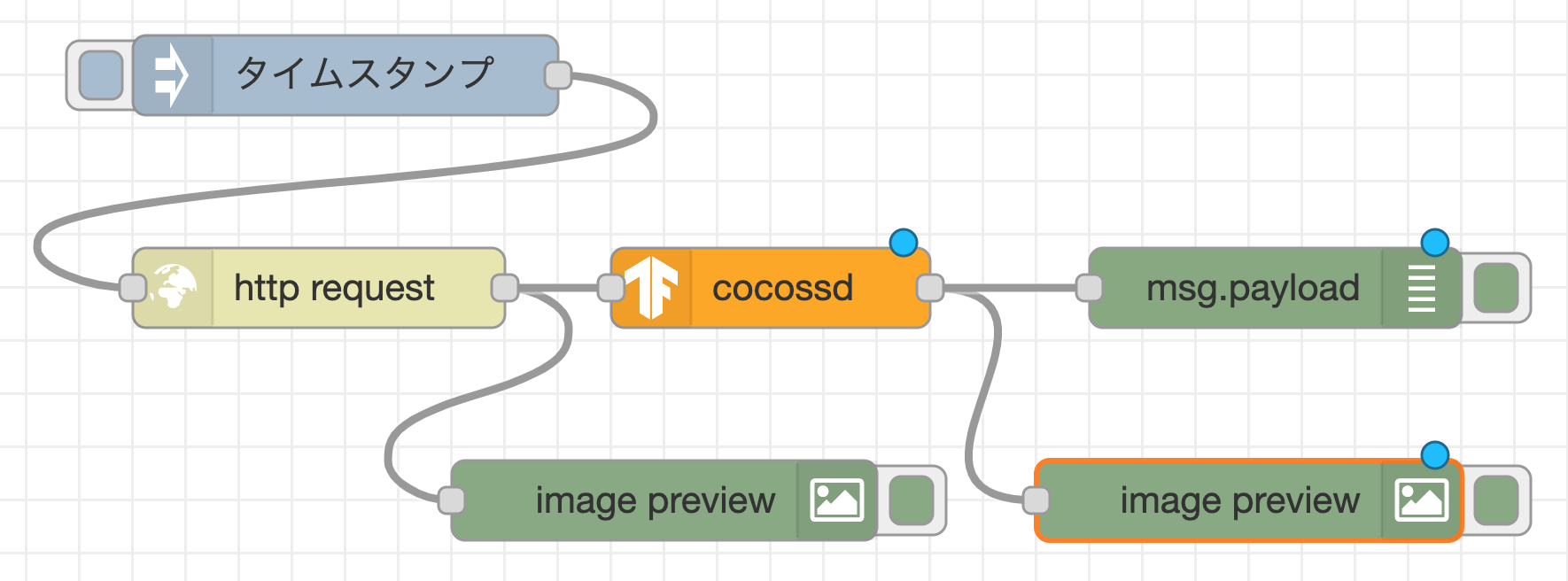
次に取得した画像に何が写っているかを分析するフローを作成します。cocossdノードと、debugノード(配置すると名前がmsg.payloadに変わります)、2つ目のimage previewノードを追加で配置します。その後、http requestノードの右側の出力端子とcocossdノードの左側の入力端子、cocossdノードの右側の出力端子とdebugノード、cocossdノードの右側の出力端子とimage previewノードの左側の入力端子をそれぞれワイヤーで接続します。これによって、監視カメラ画像のバイナリデータがcocossdノードに送られ、TensorFlow.jsを用いた画像認識が行われた後、物体名をdebugノードで表示し、画像認識結果付き画像をimage previewノードで表示します。
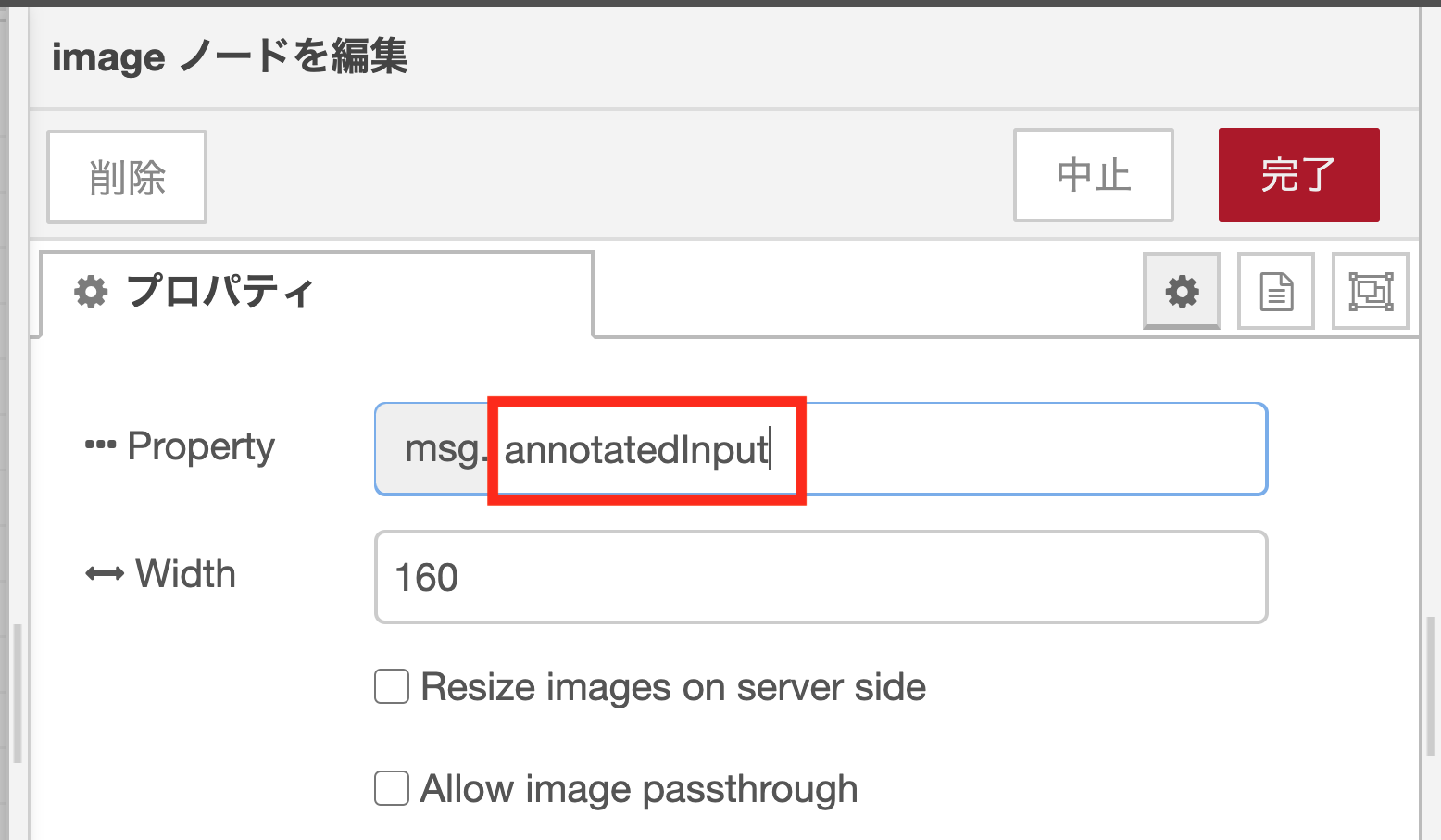
cocossdノードは、変数msg.payloadに物体名、変数msg.annotatedInputに画像認識結果付き画像のバイナリデータを格納する仕様になっています。そのため、画像の表示に用いるimage previewノードはダブルクリックをして、ノードプロパティ設定を変更する必要があります。
image previewノードのプロパティ設定
image previewノードはデフォルトで変数msg.payloadに格納された画像データを表示します。ここでは、このデフォルト変数をmsg.annotatedInputに変更します。
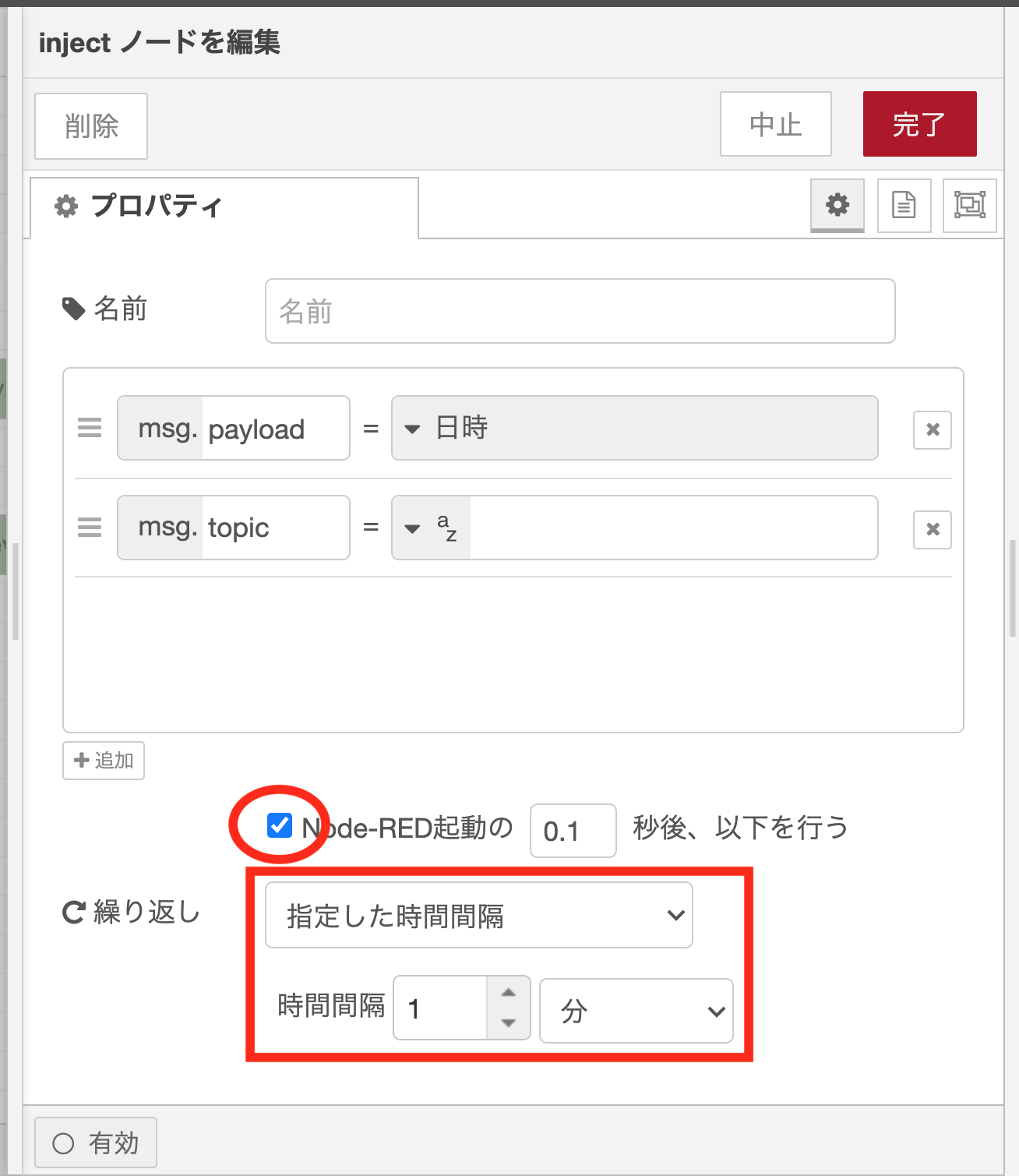
injectノードのプロパティ設定
1分毎にフローを定期実行するため、injectノードのプロパティも変更します。繰り返しのプルダウンメニューで、「指定した時間間隔」を選択し、時間間隔として「1分」を設定します。また、デプロイボタンを押した後、すぐに定期実行処理を開始したいため、「Node-REDの起動後、0.1秒後、以下を行う」の左側のチェックボックスをオンにします。
画像認識を行うフローを実行
デプロイボタンを押すと、すぐにフローの処理が実行されます。監視カメラに人物(著者本人)が写ると、右側のデバッグタブに"person"という画像認識結果が表示されます。またimage previewノードの下には、オレンジ色の四角でアノテーション付けされた画像が表示されます。
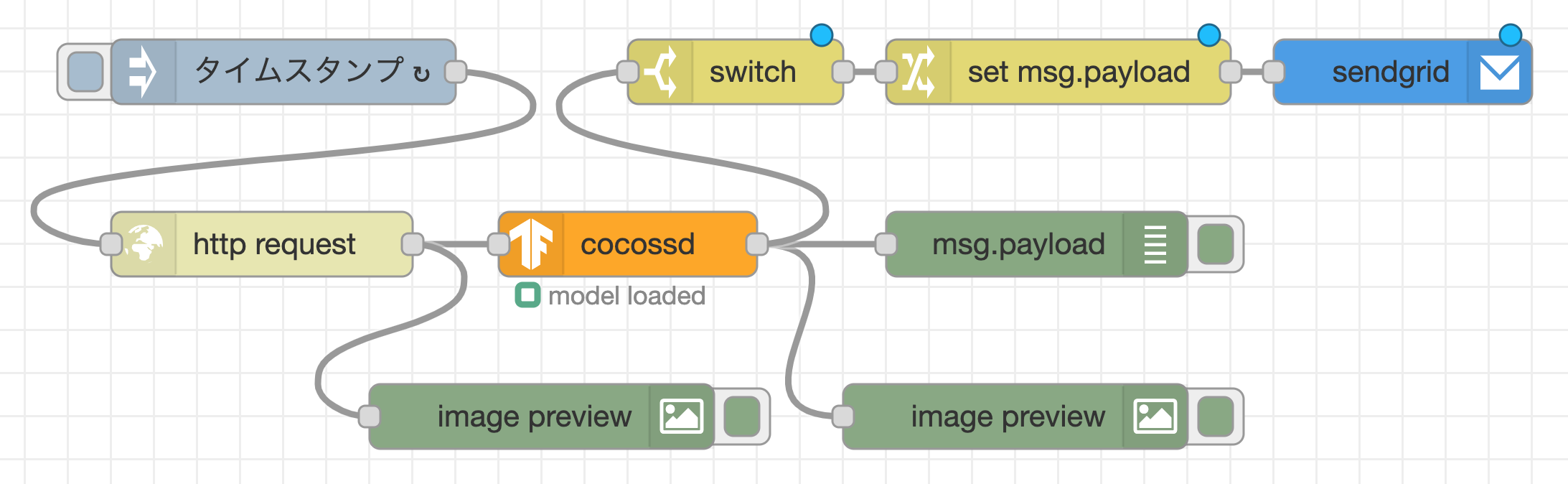
(3)監視カメラに人物が写った時に、メールを送信するフロー
最後に、画像認識結果の物体名が"person"だった時に、アノテーション付き画像をメールで送付するフローを作成します。cocossdノードの後続のノードとして、条件判定を行うswitchノード、値の代入を行うchangeノード、メールを送信するsendgridノードを配置し、それぞれのノードをワイヤーで接続します。
その後、各ノードのプロパティ設定を変更します。
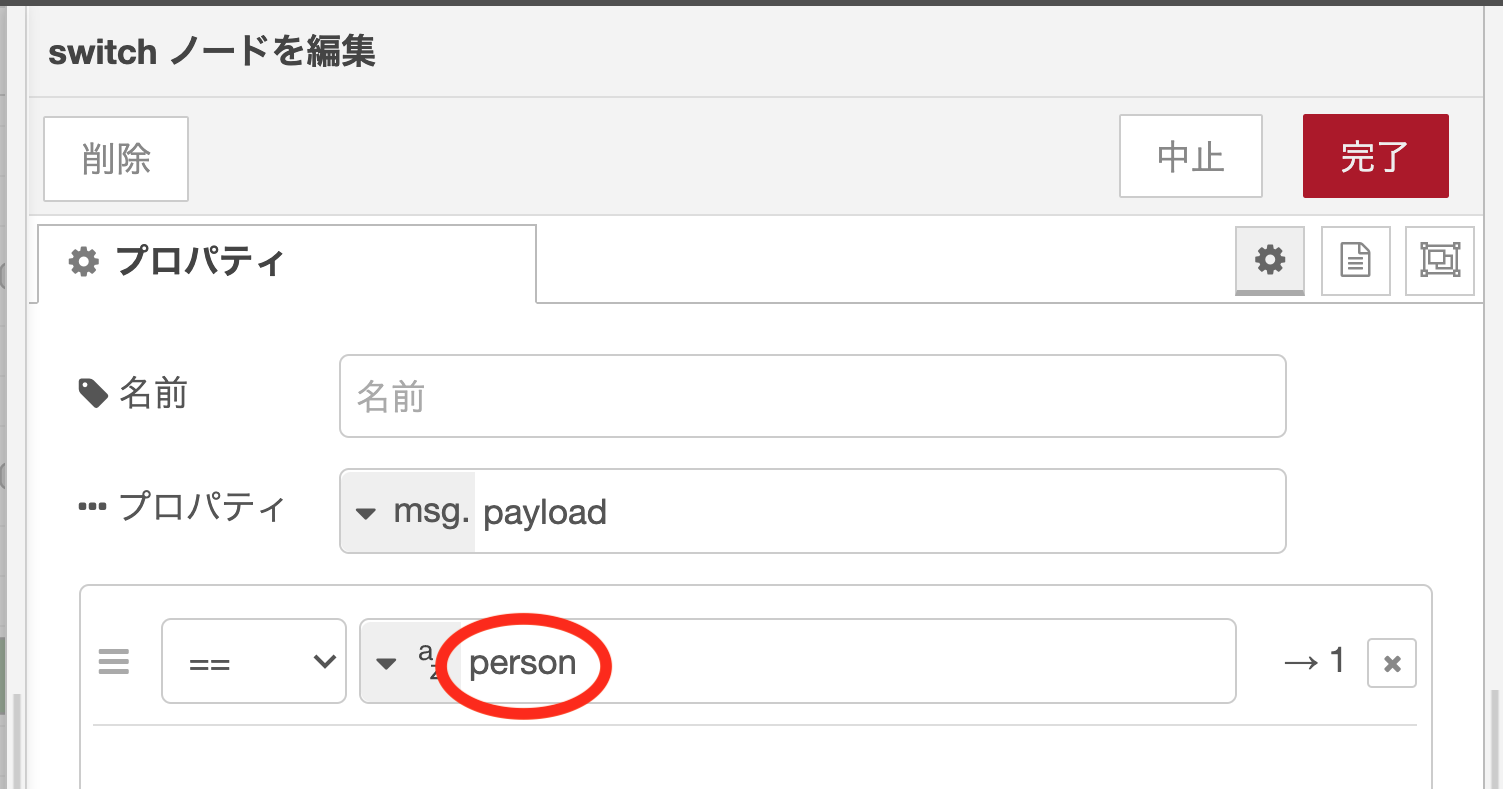
switchノードのノードプロパティ設定
msg.payloadに"person"という文字列を含む場合のみ、後続のフローが実行されるように設定します。それを実現するには、条件「==」の比較文字列(azの右側)に"person"を入力します。
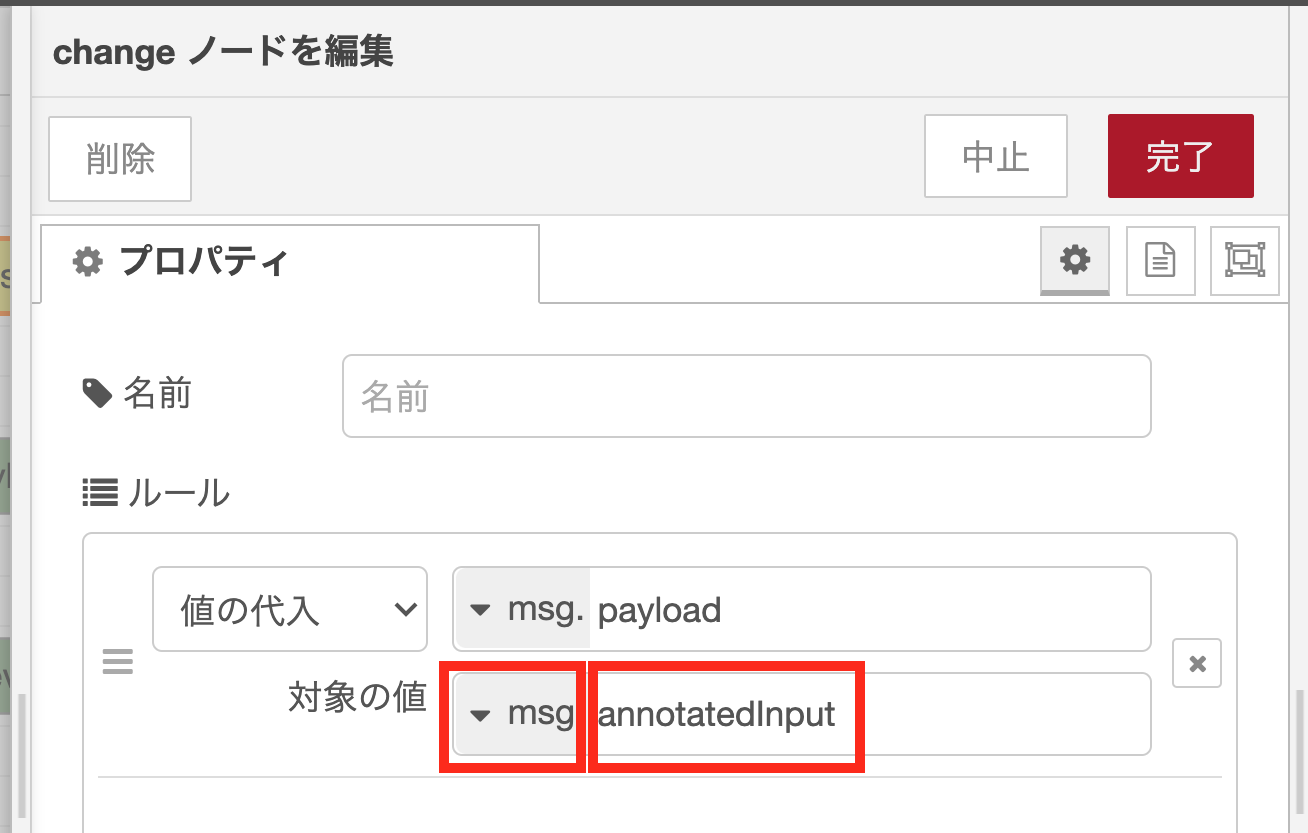
changeノードのノードプロパティ設定
認識結果付き画像をメールに添付するため、変数msg.annotatedInputに格納されている画像データを変数msg.payloadへ代入します。まず「対象の値」の右側の「AZ」のプルダウンメニューを開き「msg.」を選択します。その後、右側のテキストエリアに「annotatedInput」と入力します。
「AZ」をクリックすると表示されるプルダウンメニューで「msg.」に変更することを忘れることで、フローが上手く動かないことがよくありますので、「msg.」になっているか再度確認しましょう。
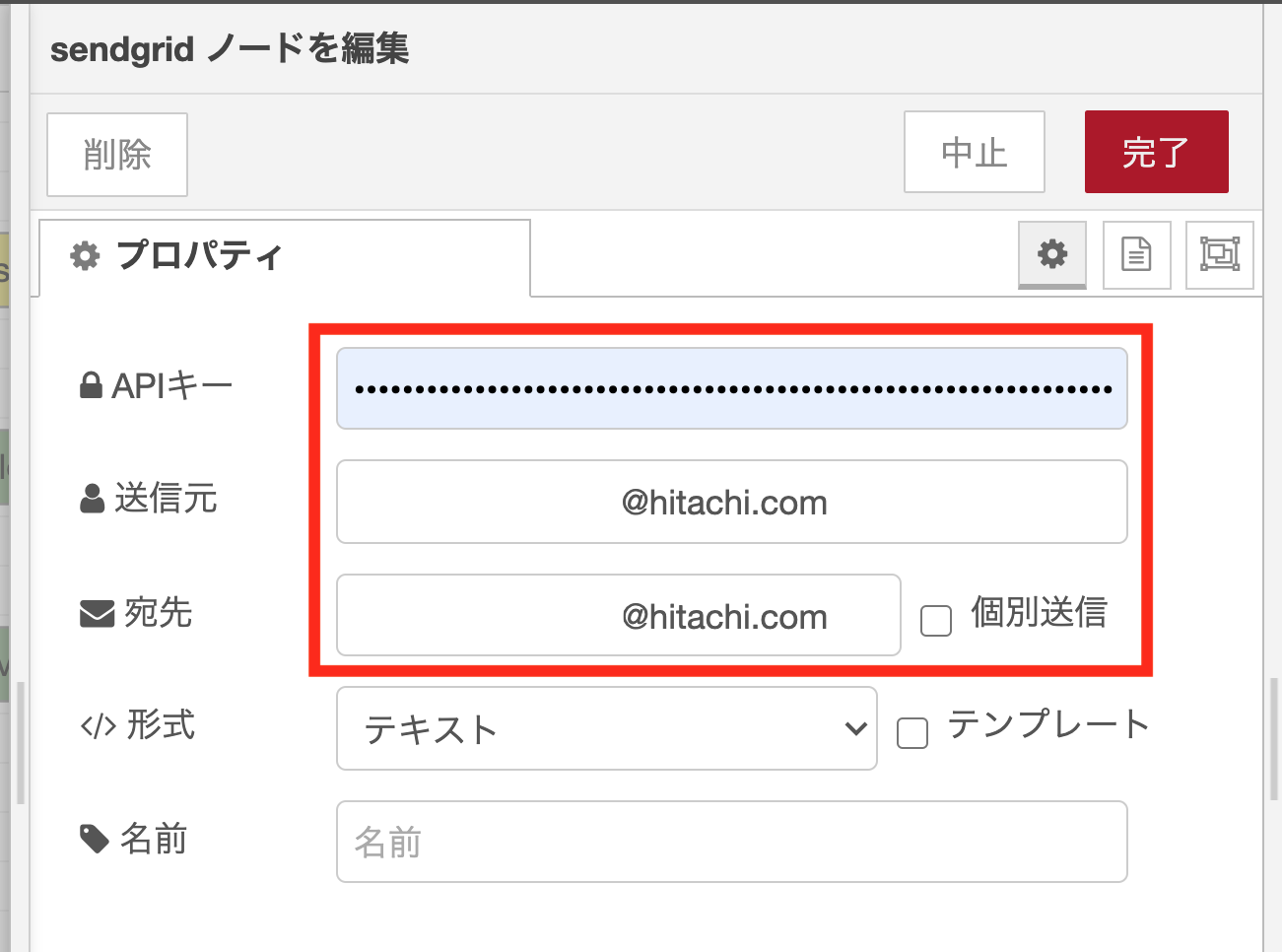
sendgridノードのノードプロパティ
SendGridの管理画面から取得したAPIキー、送信元メールアドレス、送信先メールアドレスを設定します。
最後に、各ノードでどんな処理を行っているか分かりやすくするために、各ノードのノードプロパティを開き、適切な名前を設定しました。
監視カメラに人物が写った時に、メールを送信するフローの動作確認
監視カメラの画像に人物が写ると、前のフローの実行確認の同様に、デバッグタブに画像認識結果が表示され、「認識結果付き画像」のimage previewノードの下の画像にオレンジ色の枠が描画され、人物を正しく認識されていることが分かります。
その後、判定処理や代入処理、メール送信処理が上手く動作すると、スマホにはアノテーション付きの画像ファイルが添付されたメールが届きます。
最後に
今回ご紹介した様なフローを用いて、Raspberry Piに接続したカメラを利用した、自宅の庭の簡易防犯システムを自分で構築することも可能です。また本格的には、ONVIF等のプロトコルに対応したネットワークカメラを用いて取得した画像データに対して画像認識を行うこともできそうです。

- 投稿日:2020-08-14T11:47:29+09:00
川の氾濫状況をAIで検知する
はじめに
川の氾濫状況をAIがモニタリングして、溢れてたら降りたり近づいたりしないように
警告できないか考えてみた。モチベーション:
(コロナで暇だった・・・訳ではない)
2020年7月は過去最長の梅雨でした。30年見てきている、京都の賀茂川も雨の度に氾濫気味で、市の方が川辺へ降りないように柵まで用意してくれたけど、
電子掲示板で逐一状況を表示してくれたらみんなハッピーかなと思った。
(防災カメラはあるはずで、もうやってたらごめんなさい。水位がわかると思うのでAIとの合わせ技が良いかも)
京都市防災カメラ
実装について
Kerasを使った3値分類にしました。
あんまり深く考えすぎず、信号みたいに
・安全な状況(青色)
・注意が必要な状態(黄色)
・危険な状態(赤色)
がでたらそれで十分かと思いました。・安全な状況(青色)
・注意が必要な状態(黄色)
↑はこちらから転載させていただいております。・危険な状態(赤色)
コードは後ほど以下のgitに挙げます。
https://github.com/nakamolinto/River_flood_detection
中身の学習用データは全てtwitterなどSNSに落ちている画像を使用させていただきました、
表示するのは引用元がないのは自分で撮影した画像です。コードの参照について
kaggleのAPTOSコンペのコードをベースに作成しました。
https://www.kaggle.com/c/aptos2019-blindness-detection/notebooks?sortBy=voteCount&group=everyone&pageSize=20&competitionId=14774必要なライブラリを読み込みます
import json import math import os import cv2 from PIL import Image import numpy as np from keras import layers from keras.applications import DenseNet121 from keras.callbacks import Callback, ModelCheckpoint from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.optimizers import Adam import matplotlib.pyplot as plt import pandas as pd from sklearn.model_selection import train_test_split from sklearn.metrics import cohen_kappa_score, accuracy_score import scipy import tensorflow as tf from tqdm import tqdm import glob %matplotlib inlineデータの読み込み
今回は3つのデータフォルダに入れて読み込みに行っています。
#安全な状況(青色) files=glob.glob("./images/ok/*") dfok=pd.DataFrame(files,columns=["id_code"]) dfok["diagnosis"]=0 dfok.shape #注意が必要な状態(黄色) files=glob.glob("./images/bad/*") dfbad=pd.DataFrame(files,columns=["id_code"]) dfbad["diagnosis"]=1 dfbad.shape #危険な状態(赤色) files=glob.glob("./images/ng/*") dfng=pd.DataFrame(files,columns=["id_code"]) dfng["diagnosis"]=2 dfng.shape dfall=pd.concat([dfok,dfbad,dfng]) dfall.shape dfall['diagnosis'].hist() dfall['diagnosis'].value_counts() dfall.shape
データの分割とサイズのリサイズなど
スペックの問題で画像サイズは32にしていますが、GPU使えるなら256*256のほうがいいです。
from sklearn.model_selection import train_test_split train_df, test_df=train_test_split(dfall,test_size=0.20) train_df.shape def get_pad_width(im, new_shape, is_rgb=True): pad_diff = new_shape - im.shape[0], new_shape - im.shape[1] t, b = math.floor(pad_diff[0]/2), math.ceil(pad_diff[0]/2) l, r = math.floor(pad_diff[1]/2), math.ceil(pad_diff[1]/2) if is_rgb: pad_width = ((t,b), (l,r), (0, 0)) else: pad_width = ((t,b), (l,r)) return pad_width def preprocess_image(image_path, desired_size=32): im = Image.open(image_path) im = im.resize((desired_size, )*2, resample=Image.LANCZOS) return imN = train_df.shape[0] x_train = np.empty((N, 32, 32, 3), dtype=np.uint8) for i, image_id in enumerate(tqdm(train_df['id_code'])): x_train[i, :, :, :] = preprocess_image(image_id) x_train.shape N = test_df.shape[0] x_test = np.empty((N, 32, 32, 3), dtype=np.uint8) for i, image_id in enumerate(tqdm(test_df['id_code'])): x_test[i, :, :, :] = preprocess_image(image_id) y_train = pd.get_dummies(train_df['diagnosis']).values print(x_train.shape) print(y_train.shape) print(x_test.shape) y_train_multi = np.empty(y_train.shape, dtype=y_train.dtype) y_train_multi[:, 2] = y_train[:, 2] for i in range(2): y_train_multi[:, i] = np.logical_or(y_train[:, i], y_train_multi[:, i+1]) print("Original y_train:", y_train.sum(axis=0)) print("Multilabel version:", y_train_multi.sum(axis=0)) x_train, x_val, y_train, y_val = train_test_split( x_train, y_train_multi, test_size=0.15, random_state=2019 )それぞれのクラスのデータ数を確認します。
クラスの定義
class MixupGenerator(): def __init__(self, X_train, y_train, batch_size=32, alpha=0.2, shuffle=True, datagen=None): self.X_train = X_train self.y_train = y_train self.batch_size = batch_size self.alpha = alpha self.shuffle = shuffle self.sample_num = len(X_train) self.datagen = datagen def __call__(self): while True: indexes = self.__get_exploration_order() itr_num = int(len(indexes) // (self.batch_size * 2)) for i in range(itr_num): batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2] X, y = self.__data_generation(batch_ids) yield X, y def __get_exploration_order(self): indexes = np.arange(self.sample_num) if self.shuffle: np.random.shuffle(indexes) return indexes def __data_generation(self, batch_ids): _, h, w, c = self.X_train.shape l = np.random.beta(self.alpha, self.alpha, self.batch_size) X_l = l.reshape(self.batch_size, 1, 1, 1) y_l = l.reshape(self.batch_size, 1) X1 = self.X_train[batch_ids[:self.batch_size]] X2 = self.X_train[batch_ids[self.batch_size:]] X = X1 * X_l + X2 * (1 - X_l) if self.datagen: for i in range(self.batch_size): X[i] = self.datagen.random_transform(X[i]) X[i] = self.datagen.standardize(X[i]) if isinstance(self.y_train, list): y = [] for y_train_ in self.y_train: y1 = y_train_[batch_ids[:self.batch_size]] y2 = y_train_[batch_ids[self.batch_size:]] y.append(y1 * y_l + y2 * (1 - y_l)) else: y1 = self.y_train[batch_ids[:self.batch_size]] y2 = self.y_train[batch_ids[self.batch_size:]] y = y1 * y_l + y2 * (1 - y_l) return X, yデータ水増しなど
#バッチサイズ BATCH_SIZE = 16 def create_datagen(): return ImageDataGenerator( zoom_range=0.15, # set range for random zoom # set mode for filling points outside the input boundaries fill_mode='constant', cval=0., # value used for fill_mode = "constant" horizontal_flip=True, # randomly flip images vertical_flip=True, # randomly flip images ) # Using original generator data_generator = create_datagen().flow(x_train, y_train, batch_size=BATCH_SIZE, seed=2019) # Using Mixup mixup_generator = MixupGenerator(x_train, y_train, batch_size=BATCH_SIZE, alpha=0.2, datagen=create_datagen())() class Metrics(Callback): def on_train_begin(self, logs={}): self.val_kappas = [] def on_epoch_end(self, epoch, logs={}): X_val, y_val = self.validation_data[:2] y_val = y_val.sum(axis=1) - 1 y_pred = self.model.predict(X_val) > 0.5 y_pred = y_pred.astype(int).sum(axis=1) - 1 _val_kappa = cohen_kappa_score( y_val, y_pred, weights='quadratic' ) self.val_kappas.append(_val_kappa) print(f"val_kappa: {_val_kappa:.4f}") if _val_kappa == max(self.val_kappas): print("Validation Kappa has improved. Saving model.") self.model.save('model.h5') return #DenseNetをしよう。ここのモデルを変えると色々なモデルが試せます。 densenet = DenseNet121( weights="imagenet", include_top=False, input_shape=(32,32,3) ) def build_model(): model = Sequential() model.add(densenet) model.add(layers.GlobalAveragePooling2D()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(3, activation='sigmoid')) model.compile( loss='binary_crossentropy', optimizer=Adam(lr=0.00005), metrics=['accuracy'] ) return modelモデルをビルドします
model = build_model() model.summary() kappa_metrics = Metrics()モデルのサマリー
学習します。epockは自由に変えてください。
history = model.fit_generator( data_generator, steps_per_epoch=x_train.shape[0] / BATCH_SIZE, epochs=50, validation_data=(x_val, y_val), callbacks=[kappa_metrics])推論します。
model.load_weights('model.h5') y_val_pred = model.predict(x_val)def compute_score_inv(threshold): y1 = y_val_pred > threshold y1 = y1.astype(int).sum(axis=1) - 1 y2 = y_val.sum(axis=1) - 1 score = cohen_kappa_score(y1, y2, weights='quadratic') return 1 - score simplex = scipy.optimize.minimize( compute_score_inv, 0.5, method='nelder-mead' ) best_threshold = simplex['x'][0] y_test = model.predict(x_test) > 0.5 y_test = y_test.astype(int).sum(axis=1) - 1 test_df['prediction'] = y_test test_df.to_csv('submission.csv',index=False)推論結果を確認しましょう。
test_df prediction=test_df.prediction id=test_df.id_code
↑上記は全然予測できていない結果です。。。最後の出力部分
%matplotlib inline plt.figure(figsize=(16,12)) for num,i in enumerate(zip(prediction,id)): plt.subplot(4,2,num+1) if i[0] == 0 : print("今日の川の水域は安全です。") image=cv2.imread(i[1],1) plt.title("safe") # plt.title(i[1]) plt.imshow(image) elif i[0] ==1 : print("川の水位が上がっていますので十分注意してください。") image=cv2.imread(i[1],1) # plt.title(i[1]) plt.title("be careful") plt.imshow(image) else : print("川が氾濫しています。絶対に川辺には降りないでください") image=cv2.imread(i[1],1) # plt.title(i[1]) plt.title("Do NOT enter") plt.imshow(image)出力例:
とりあえず出力しました。
感想
画像をしっかり集めて推測すれば、もしかしたら良いモデルが出来上がるかもしれませんが、今回はあまり推測がうまく行きませんでした。またGPUを使えばきちんと学習・推論ができるかもしれません。
川の氾濫は、すでにセンサー等で見ているので、AIは使う必要ないかもですが、
夜間に川の側に人がいないかなどの検知には、役立つかもしれません。
次は物体検知でやってみようかなと思います。コードの間違いなどありましたら、ご指摘ください。
安全な状態と、危険な状態はわかりやすいですが注意状態の画像はなかなかなく、
探すのが大変でした。ちゃんとやろうと思ったら、自分で撮った方が早いです。参考URL
https://qiita.com/yu4u/items/078054dfb5592cbb80cc
http://www.qsr.mlit.go.jp/useful/n-shiryo/kikaku/kenkyu/h30/04/4_03(18).pdf










- 投稿日:2020-08-14T11:47:29+09:00
川の氾濫状況をAIで検知する(3値分類)
はじめに
川の氾濫状況をAIがモニタリングして、溢れてたら降りたり近づいたりしないように
警告できないか考えてみた。モチベーション:
(コロナで暇だった・・・訳ではない。まずなんでも良いから、qiita初投稿してみたかった。)
2020年7月は過去最長の梅雨でした。30年見てきている、京都の賀茂川も雨の度に氾濫気味で、市の方が川辺へ降りないように柵まで用意してくれたけど、電子掲示板で逐一状況を表示してくれたらみんなハッピーかなと思った。
(防災カメラはあるはずで、もうやってたらごめんなさい。水位がわかると思うのでAIとの合わせ技が良いかも)
京都市防災カメラのURLはこちら
先に結論
画像を集めるのが大変で、途中で結果が出ないことに気がついた。
補足
機械学習ををこれからはじめようとする方々にも使えるように
簡単な3値分類のフレームワークを使いましたので、結果よりも、コードを
参考にしていただければ幸いです。文章やコードなどの書き方、見せ方はこれから勉強していきます。
下手くそなので、あらかじめご了承ください。実装について
Kerasを使った3値分類にしました。
あんまり深く考えすぎず、信号みたいに
・安全な状況(青色)
・注意が必要な状態(黄色)
・危険な状態(赤色)
がでたらそれで十分かと思いました。・安全な状況(青色)
・注意が必要な状態(黄色)
↑はこちらから転載させていただいております。・危険な状態(赤色)
コード
コードは以下のgitに挙げています。
https://github.com/nakamolinto/River_flood_detection
コード参照元
kaggleのAPTOSコンペのコードをベースに作成しました。
https://www.kaggle.com/c/aptos2019-blindness-detection/notebooks?sortBy=voteCount&group=everyone&pageSize=20&competitionId=14774中身の学習用データは全てtwitterなどSNSに落ちている画像を使用させていただきました、
表示するのは引用元がないのは自分で撮影した画像です。実装
必要なライブラリを読み込みます
import json import math import os import cv2 from PIL import Image import numpy as np from keras import layers from keras.applications import DenseNet121 from keras.callbacks import Callback, ModelCheckpoint from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.optimizers import Adam import matplotlib.pyplot as plt import pandas as pd from sklearn.model_selection import train_test_split from sklearn.metrics import cohen_kappa_score, accuracy_score import scipy import tensorflow as tf from tqdm import tqdm import glob %matplotlib inlineデータの読み込み
今回は3つのデータフォルダに入れて読み込みに行っています。#安全な状況(青色) files=glob.glob("./images/ok/*") dfok=pd.DataFrame(files,columns=["id_code"]) dfok["diagnosis"]=0 dfok.shape #注意が必要な状態(黄色) files=glob.glob("./images/bad/*") dfbad=pd.DataFrame(files,columns=["id_code"]) dfbad["diagnosis"]=1 dfbad.shape #危険な状態(赤色) files=glob.glob("./images/ng/*") dfng=pd.DataFrame(files,columns=["id_code"]) dfng["diagnosis"]=2 dfng.shape dfall=pd.concat([dfok,dfbad,dfng]) dfall.shape dfall['diagnosis'].hist() dfall['diagnosis'].value_counts() dfall.shape
データの分割とサイズのリサイズなど
スペックの問題で画像サイズは32にしていますが、GPU使えるなら256*256のほうがいいです。from sklearn.model_selection import train_test_split train_df, test_df=train_test_split(dfall,test_size=0.20) train_df.shape def get_pad_width(im, new_shape, is_rgb=True): pad_diff = new_shape - im.shape[0], new_shape - im.shape[1] t, b = math.floor(pad_diff[0]/2), math.ceil(pad_diff[0]/2) l, r = math.floor(pad_diff[1]/2), math.ceil(pad_diff[1]/2) if is_rgb: pad_width = ((t,b), (l,r), (0, 0)) else: pad_width = ((t,b), (l,r)) return pad_width def preprocess_image(image_path, desired_size=32): im = Image.open(image_path) im = im.resize((desired_size, )*2, resample=Image.LANCZOS) return imN = train_df.shape[0] x_train = np.empty((N, 32, 32, 3), dtype=np.uint8) for i, image_id in enumerate(tqdm(train_df['id_code'])): x_train[i, :, :, :] = preprocess_image(image_id) x_train.shape N = test_df.shape[0] x_test = np.empty((N, 32, 32, 3), dtype=np.uint8) for i, image_id in enumerate(tqdm(test_df['id_code'])): x_test[i, :, :, :] = preprocess_image(image_id) y_train = pd.get_dummies(train_df['diagnosis']).values print(x_train.shape) print(y_train.shape) print(x_test.shape) y_train_multi = np.empty(y_train.shape, dtype=y_train.dtype) y_train_multi[:, 2] = y_train[:, 2] for i in range(2): y_train_multi[:, i] = np.logical_or(y_train[:, i], y_train_multi[:, i+1]) print("Original y_train:", y_train.sum(axis=0)) print("Multilabel version:", y_train_multi.sum(axis=0)) x_train, x_val, y_train, y_val = train_test_split( x_train, y_train_multi, test_size=0.15, random_state=2019 )それぞれのクラスのデータ数を確認します。
クラスの定義
class MixupGenerator(): def __init__(self, X_train, y_train, batch_size=32, alpha=0.2, shuffle=True, datagen=None): self.X_train = X_train self.y_train = y_train self.batch_size = batch_size self.alpha = alpha self.shuffle = shuffle self.sample_num = len(X_train) self.datagen = datagen def __call__(self): while True: indexes = self.__get_exploration_order() itr_num = int(len(indexes) // (self.batch_size * 2)) for i in range(itr_num): batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2] X, y = self.__data_generation(batch_ids) yield X, y def __get_exploration_order(self): indexes = np.arange(self.sample_num) if self.shuffle: np.random.shuffle(indexes) return indexes def __data_generation(self, batch_ids): _, h, w, c = self.X_train.shape l = np.random.beta(self.alpha, self.alpha, self.batch_size) X_l = l.reshape(self.batch_size, 1, 1, 1) y_l = l.reshape(self.batch_size, 1) X1 = self.X_train[batch_ids[:self.batch_size]] X2 = self.X_train[batch_ids[self.batch_size:]] X = X1 * X_l + X2 * (1 - X_l) if self.datagen: for i in range(self.batch_size): X[i] = self.datagen.random_transform(X[i]) X[i] = self.datagen.standardize(X[i]) if isinstance(self.y_train, list): y = [] for y_train_ in self.y_train: y1 = y_train_[batch_ids[:self.batch_size]] y2 = y_train_[batch_ids[self.batch_size:]] y.append(y1 * y_l + y2 * (1 - y_l)) else: y1 = self.y_train[batch_ids[:self.batch_size]] y2 = self.y_train[batch_ids[self.batch_size:]] y = y1 * y_l + y2 * (1 - y_l) return X, yデータ水増しなど
#バッチサイズ BATCH_SIZE = 16 def create_datagen(): return ImageDataGenerator( zoom_range=0.15, # set range for random zoom # set mode for filling points outside the input boundaries fill_mode='constant', cval=0., # value used for fill_mode = "constant" horizontal_flip=True, # randomly flip images vertical_flip=True, # randomly flip images ) # Using original generator data_generator = create_datagen().flow(x_train, y_train, batch_size=BATCH_SIZE, seed=2019) # Using Mixup mixup_generator = MixupGenerator(x_train, y_train, batch_size=BATCH_SIZE, alpha=0.2, datagen=create_datagen())() class Metrics(Callback): def on_train_begin(self, logs={}): self.val_kappas = [] def on_epoch_end(self, epoch, logs={}): X_val, y_val = self.validation_data[:2] y_val = y_val.sum(axis=1) - 1 y_pred = self.model.predict(X_val) > 0.5 y_pred = y_pred.astype(int).sum(axis=1) - 1 _val_kappa = cohen_kappa_score( y_val, y_pred, weights='quadratic' ) self.val_kappas.append(_val_kappa) print(f"val_kappa: {_val_kappa:.4f}") if _val_kappa == max(self.val_kappas): print("Validation Kappa has improved. Saving model.") self.model.save('model.h5') return #DenseNetをしよう。ここのモデルを変えると色々なモデルが試せます。 densenet = DenseNet121( weights="imagenet", include_top=False, input_shape=(32,32,3) ) def build_model(): model = Sequential() model.add(densenet) model.add(layers.GlobalAveragePooling2D()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(3, activation='sigmoid')) model.compile( loss='binary_crossentropy', optimizer=Adam(lr=0.00005), metrics=['accuracy'] ) return modelモデルをビルドします
model = build_model() model.summary() kappa_metrics = Metrics()モデルのサマリー
学習します。epockは自由に変えてください
history = model.fit_generator( data_generator, steps_per_epoch=x_train.shape[0] / BATCH_SIZE, epochs=50, validation_data=(x_val, y_val), callbacks=[kappa_metrics])推論します
model.load_weights('model.h5') y_val_pred = model.predict(x_val)def compute_score_inv(threshold): y1 = y_val_pred > threshold y1 = y1.astype(int).sum(axis=1) - 1 y2 = y_val.sum(axis=1) - 1 score = cohen_kappa_score(y1, y2, weights='quadratic') return 1 - score simplex = scipy.optimize.minimize( compute_score_inv, 0.5, method='nelder-mead' ) best_threshold = simplex['x'][0] y_test = model.predict(x_test) > 0.5 y_test = y_test.astype(int).sum(axis=1) - 1 test_df['prediction'] = y_test test_df.to_csv('kamogawa_result.csv',index=False)推論結果を確認しましょう
test_df
↑上記は全然予測できていない結果です。。。最後の出力部分
prediction=test_df.prediction id=test_df.id_code %matplotlib inline plt.figure(figsize=(16,12)) for num,i in enumerate(zip(prediction,id)): plt.subplot(4,2,num+1) if i[0] == 0 : print("今日の川の水域は安全です。") image=cv2.imread(i[1],1) plt.title("safe") # plt.title(i[1]) plt.imshow(image) elif i[0] ==1 : print("川の水位が上がっていますので十分注意してください。") image=cv2.imread(i[1],1) # plt.title(i[1]) plt.title("be careful") plt.imshow(image) else : print("川が氾濫しています。絶対に川辺には降りないでください") image=cv2.imread(i[1],1) # plt.title(i[1]) plt.title("Do NOT enter") plt.imshow(image)出力例
とりあえず出力しました。
感想
安全な状態と、危険な状態はわかりやすいですが注意状態の画像はなかなかなく、
探すのが大変でした、途中で諦めてエイやでやってしまった。
ちゃんとやろうと思ったら、自分で撮った方が早いです。
またGPUを使えず画像サイズを32に落としましたが、224*224で学習すればきちんと推論ができるかもしれません。川の氾濫は、すでにセンサー等で見ているので、AIは使う必要ないかもですが、
夜間に川の側に人がいないかなどの検知には、役立つかもしれません。
次は物体検知でやってみようかなと思います。コードの間違いなどありましたら、ご指摘ください。
言い訳
綺麗な画像を十分に集められる人であれば、良い予測値が出ると思います。
もし川の関係者がいれば、やってみてください。参考URL
https://qiita.com/yu4u/items/078054dfb5592cbb80cc
http://www.qsr.mlit.go.jp/useful/n-shiryo/kikaku/kenkyu/h30/04/4_03(18).pdf
コード(再掲)
コードは以下のgitに挙げています。
コードなど、何か質問あればお気軽にご連絡ください
https://github.com/nakamolinto/River_flood_detection最後に
twitterもやってます。よかったらフォローしてください。
https://twitter.com/pythonmachine
- 投稿日:2020-08-14T11:47:29+09:00
川の氾濫状況をAIで検知してみたかった
はじめに
川の氾濫状況をAIがモニタリングして、溢れてたら降りたり近づいたりしないように
警告できないか考えてみた。モチベーション:
(コロナで暇だった・・・訳ではない。まずなんでも良いから、qiita初投稿してみたかった。)
2020年7月は過去最長の梅雨でした。30年見てきている、京都の賀茂川も雨の度に氾濫気味で、市の方が川辺へ降りないように柵まで用意してくれたけど、
電子掲示板で逐一状況を表示してくれたらみんなハッピーかなと思った。
(防災カメラはあるはずで、もうやってたらごめんなさい。水位がわかると思うのでAIとの合わせ技が良いかも)
京都市防災カメラ
先に結論
画像を集めるのが大変で、途中で結果が出ないことに気がついた。
補足
機械学習ををこれからはじめようとする方々にも使えるように
簡単な3値分類のフレームワークを使いましたので、結果よりも、コードを
参考にしていただければ幸いです。文章やコードなどの書き方、見せ方はこれから勉強していきます。
下手くそなので、あらかじめご了承ください。実装について
Kerasを使った3値分類にしました。
あんまり深く考えすぎず、信号みたいに
・安全な状況(青色)
・注意が必要な状態(黄色)
・危険な状態(赤色)
がでたらそれで十分かと思いました。・安全な状況(青色)
・注意が必要な状態(黄色)
↑はこちらから転載させていただいております。・危険な状態(赤色)
コードは後ほど以下のgitに挙げます(2020年8月末くらいには)。
https://github.com/nakamolinto/River_flood_detection
中身の学習用データは全てtwitterなどSNSに落ちている画像を使用させていただきました、
表示するのは引用元がないのは自分で撮影した画像です。コードの参照について
kaggleのAPTOSコンペのコードをベースに作成しました。
https://www.kaggle.com/c/aptos2019-blindness-detection/notebooks?sortBy=voteCount&group=everyone&pageSize=20&competitionId=14774必要なライブラリを読み込みます
import json import math import os import cv2 from PIL import Image import numpy as np from keras import layers from keras.applications import DenseNet121 from keras.callbacks import Callback, ModelCheckpoint from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.optimizers import Adam import matplotlib.pyplot as plt import pandas as pd from sklearn.model_selection import train_test_split from sklearn.metrics import cohen_kappa_score, accuracy_score import scipy import tensorflow as tf from tqdm import tqdm import glob %matplotlib inlineデータの読み込み
今回は3つのデータフォルダに入れて読み込みに行っています。
#安全な状況(青色) files=glob.glob("./images/ok/*") dfok=pd.DataFrame(files,columns=["id_code"]) dfok["diagnosis"]=0 dfok.shape #注意が必要な状態(黄色) files=glob.glob("./images/bad/*") dfbad=pd.DataFrame(files,columns=["id_code"]) dfbad["diagnosis"]=1 dfbad.shape #危険な状態(赤色) files=glob.glob("./images/ng/*") dfng=pd.DataFrame(files,columns=["id_code"]) dfng["diagnosis"]=2 dfng.shape dfall=pd.concat([dfok,dfbad,dfng]) dfall.shape dfall['diagnosis'].hist() dfall['diagnosis'].value_counts() dfall.shape
データの分割とサイズのリサイズなど
スペックの問題で画像サイズは32にしていますが、GPU使えるなら256*256のほうがいいです。
from sklearn.model_selection import train_test_split train_df, test_df=train_test_split(dfall,test_size=0.20) train_df.shape def get_pad_width(im, new_shape, is_rgb=True): pad_diff = new_shape - im.shape[0], new_shape - im.shape[1] t, b = math.floor(pad_diff[0]/2), math.ceil(pad_diff[0]/2) l, r = math.floor(pad_diff[1]/2), math.ceil(pad_diff[1]/2) if is_rgb: pad_width = ((t,b), (l,r), (0, 0)) else: pad_width = ((t,b), (l,r)) return pad_width def preprocess_image(image_path, desired_size=32): im = Image.open(image_path) im = im.resize((desired_size, )*2, resample=Image.LANCZOS) return imN = train_df.shape[0] x_train = np.empty((N, 32, 32, 3), dtype=np.uint8) for i, image_id in enumerate(tqdm(train_df['id_code'])): x_train[i, :, :, :] = preprocess_image(image_id) x_train.shape N = test_df.shape[0] x_test = np.empty((N, 32, 32, 3), dtype=np.uint8) for i, image_id in enumerate(tqdm(test_df['id_code'])): x_test[i, :, :, :] = preprocess_image(image_id) y_train = pd.get_dummies(train_df['diagnosis']).values print(x_train.shape) print(y_train.shape) print(x_test.shape) y_train_multi = np.empty(y_train.shape, dtype=y_train.dtype) y_train_multi[:, 2] = y_train[:, 2] for i in range(2): y_train_multi[:, i] = np.logical_or(y_train[:, i], y_train_multi[:, i+1]) print("Original y_train:", y_train.sum(axis=0)) print("Multilabel version:", y_train_multi.sum(axis=0)) x_train, x_val, y_train, y_val = train_test_split( x_train, y_train_multi, test_size=0.15, random_state=2019 )それぞれのクラスのデータ数を確認します。
クラスの定義
class MixupGenerator(): def __init__(self, X_train, y_train, batch_size=32, alpha=0.2, shuffle=True, datagen=None): self.X_train = X_train self.y_train = y_train self.batch_size = batch_size self.alpha = alpha self.shuffle = shuffle self.sample_num = len(X_train) self.datagen = datagen def __call__(self): while True: indexes = self.__get_exploration_order() itr_num = int(len(indexes) // (self.batch_size * 2)) for i in range(itr_num): batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2] X, y = self.__data_generation(batch_ids) yield X, y def __get_exploration_order(self): indexes = np.arange(self.sample_num) if self.shuffle: np.random.shuffle(indexes) return indexes def __data_generation(self, batch_ids): _, h, w, c = self.X_train.shape l = np.random.beta(self.alpha, self.alpha, self.batch_size) X_l = l.reshape(self.batch_size, 1, 1, 1) y_l = l.reshape(self.batch_size, 1) X1 = self.X_train[batch_ids[:self.batch_size]] X2 = self.X_train[batch_ids[self.batch_size:]] X = X1 * X_l + X2 * (1 - X_l) if self.datagen: for i in range(self.batch_size): X[i] = self.datagen.random_transform(X[i]) X[i] = self.datagen.standardize(X[i]) if isinstance(self.y_train, list): y = [] for y_train_ in self.y_train: y1 = y_train_[batch_ids[:self.batch_size]] y2 = y_train_[batch_ids[self.batch_size:]] y.append(y1 * y_l + y2 * (1 - y_l)) else: y1 = self.y_train[batch_ids[:self.batch_size]] y2 = self.y_train[batch_ids[self.batch_size:]] y = y1 * y_l + y2 * (1 - y_l) return X, yデータ水増しなど
#バッチサイズ BATCH_SIZE = 16 def create_datagen(): return ImageDataGenerator( zoom_range=0.15, # set range for random zoom # set mode for filling points outside the input boundaries fill_mode='constant', cval=0., # value used for fill_mode = "constant" horizontal_flip=True, # randomly flip images vertical_flip=True, # randomly flip images ) # Using original generator data_generator = create_datagen().flow(x_train, y_train, batch_size=BATCH_SIZE, seed=2019) # Using Mixup mixup_generator = MixupGenerator(x_train, y_train, batch_size=BATCH_SIZE, alpha=0.2, datagen=create_datagen())() class Metrics(Callback): def on_train_begin(self, logs={}): self.val_kappas = [] def on_epoch_end(self, epoch, logs={}): X_val, y_val = self.validation_data[:2] y_val = y_val.sum(axis=1) - 1 y_pred = self.model.predict(X_val) > 0.5 y_pred = y_pred.astype(int).sum(axis=1) - 1 _val_kappa = cohen_kappa_score( y_val, y_pred, weights='quadratic' ) self.val_kappas.append(_val_kappa) print(f"val_kappa: {_val_kappa:.4f}") if _val_kappa == max(self.val_kappas): print("Validation Kappa has improved. Saving model.") self.model.save('model.h5') return #DenseNetをしよう。ここのモデルを変えると色々なモデルが試せます。 densenet = DenseNet121( weights="imagenet", include_top=False, input_shape=(32,32,3) ) def build_model(): model = Sequential() model.add(densenet) model.add(layers.GlobalAveragePooling2D()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(3, activation='sigmoid')) model.compile( loss='binary_crossentropy', optimizer=Adam(lr=0.00005), metrics=['accuracy'] ) return modelモデルをビルドします
model = build_model() model.summary() kappa_metrics = Metrics()モデルのサマリー
学習します。epockは自由に変えてください。
history = model.fit_generator( data_generator, steps_per_epoch=x_train.shape[0] / BATCH_SIZE, epochs=50, validation_data=(x_val, y_val), callbacks=[kappa_metrics])推論します。
model.load_weights('model.h5') y_val_pred = model.predict(x_val)def compute_score_inv(threshold): y1 = y_val_pred > threshold y1 = y1.astype(int).sum(axis=1) - 1 y2 = y_val.sum(axis=1) - 1 score = cohen_kappa_score(y1, y2, weights='quadratic') return 1 - score simplex = scipy.optimize.minimize( compute_score_inv, 0.5, method='nelder-mead' ) best_threshold = simplex['x'][0] y_test = model.predict(x_test) > 0.5 y_test = y_test.astype(int).sum(axis=1) - 1 test_df['prediction'] = y_test test_df.to_csv('submission.csv',index=False)推論結果を確認しましょう。
test_df prediction=test_df.prediction id=test_df.id_code
↑上記は全然予測できていない結果です。。。最後の出力部分
%matplotlib inline plt.figure(figsize=(16,12)) for num,i in enumerate(zip(prediction,id)): plt.subplot(4,2,num+1) if i[0] == 0 : print("今日の川の水域は安全です。") image=cv2.imread(i[1],1) plt.title("safe") # plt.title(i[1]) plt.imshow(image) elif i[0] ==1 : print("川の水位が上がっていますので十分注意してください。") image=cv2.imread(i[1],1) # plt.title(i[1]) plt.title("be careful") plt.imshow(image) else : print("川が氾濫しています。絶対に川辺には降りないでください") image=cv2.imread(i[1],1) # plt.title(i[1]) plt.title("Do NOT enter") plt.imshow(image)出力例:
とりあえず出力しました。
感想
安全な状態と、危険な状態はわかりやすいですが注意状態の画像はなかなかなく、
探すのが大変でした、途中で諦めてエイやでやってしまった。
ちゃんとやろうと思ったら、自分で撮った方が早いです。
またGPUを使えばきちんと学習・推論ができるかもしれません。川の氾濫は、すでにセンサー等で見ているので、AIは使う必要ないかもですが、
夜間に川の側に人がいないかなどの検知には、役立つかもしれません。
次は物体検知でやってみようかなと思います。コードの間違いなどありましたら、ご指摘ください。
参考URL
https://qiita.com/yu4u/items/078054dfb5592cbb80cc
http://www.qsr.mlit.go.jp/useful/n-shiryo/kikaku/kenkyu/h30/04/4_03(18).pdf
最後に
twitterもやってます。よかったらフォローしてください。
https://twitter.com/pythonmachine
- 投稿日:2020-08-14T11:47:29+09:00
川の氾濫状況をAIで検知してみた(3値分類)
はじめに
川の氾濫状況をAIがモニタリングして、溢れてたら降りたり近づいたりしないように
警告できないか考えてみた。モチベーション:
(コロナで暇だった・・・訳ではない。まずなんでも良いから、qiita初投稿してみたかった。)
2020年7月は過去最長の梅雨でした。30年見てきている、京都の賀茂川も雨の度に氾濫気味で、市の方が川辺へ降りないように柵まで用意してくれたけど、電子掲示板で逐一状況を表示してくれたらみんなハッピーかなと思った。
(防災カメラはあるはずで、もうやってたらごめんなさい。水位がわかると思うのでAIとの合わせ技が良いかも)
京都市防災カメラのURLはこちら
先に結論
画像を集めるのが大変で、途中で結果が出ないことに気がついた。
補足
機械学習ををこれからはじめようとする方々にも使えるように
簡単な3値分類のフレームワークを使いましたので、結果よりも、コードを
参考にしていただければ幸いです。文章やコードなどの書き方、見せ方はこれから勉強していきます。
下手くそなので、あらかじめご了承ください。実装について
Kerasを使った3値分類にしました。
あんまり深く考えすぎず、信号みたいに
・安全な状況(青色)
・注意が必要な状態(黄色)
・危険な状態(赤色)
がでたらそれで十分かと思いました。・安全な状況(青色)
・注意が必要な状態(黄色)
↑はこちらから転載させていただいております。・危険な状態(赤色)
コード
コードは以下のgitに挙げています。
https://github.com/nakamolinto/River_flood_detection
中身の学習用データは全てtwitterなどSNSに落ちている画像を使用させていただきました、
表示するのは引用元がないのは自分で撮影した画像です。コードの参照について
kaggleのAPTOSコンペのコードをベースに作成しました。
https://www.kaggle.com/c/aptos2019-blindness-detection/notebooks?sortBy=voteCount&group=everyone&pageSize=20&competitionId=14774必要なライブラリを読み込みます
import json import math import os import cv2 from PIL import Image import numpy as np from keras import layers from keras.applications import DenseNet121 from keras.callbacks import Callback, ModelCheckpoint from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.optimizers import Adam import matplotlib.pyplot as plt import pandas as pd from sklearn.model_selection import train_test_split from sklearn.metrics import cohen_kappa_score, accuracy_score import scipy import tensorflow as tf from tqdm import tqdm import glob %matplotlib inlineデータの読み込み
今回は3つのデータフォルダに入れて読み込みに行っています。
#安全な状況(青色) files=glob.glob("./images/ok/*") dfok=pd.DataFrame(files,columns=["id_code"]) dfok["diagnosis"]=0 dfok.shape #注意が必要な状態(黄色) files=glob.glob("./images/bad/*") dfbad=pd.DataFrame(files,columns=["id_code"]) dfbad["diagnosis"]=1 dfbad.shape #危険な状態(赤色) files=glob.glob("./images/ng/*") dfng=pd.DataFrame(files,columns=["id_code"]) dfng["diagnosis"]=2 dfng.shape dfall=pd.concat([dfok,dfbad,dfng]) dfall.shape dfall['diagnosis'].hist() dfall['diagnosis'].value_counts() dfall.shape
データの分割とサイズのリサイズなど
スペックの問題で画像サイズは32にしていますが、GPU使えるなら256*256のほうがいいです。
from sklearn.model_selection import train_test_split train_df, test_df=train_test_split(dfall,test_size=0.20) train_df.shape def get_pad_width(im, new_shape, is_rgb=True): pad_diff = new_shape - im.shape[0], new_shape - im.shape[1] t, b = math.floor(pad_diff[0]/2), math.ceil(pad_diff[0]/2) l, r = math.floor(pad_diff[1]/2), math.ceil(pad_diff[1]/2) if is_rgb: pad_width = ((t,b), (l,r), (0, 0)) else: pad_width = ((t,b), (l,r)) return pad_width def preprocess_image(image_path, desired_size=32): im = Image.open(image_path) im = im.resize((desired_size, )*2, resample=Image.LANCZOS) return imN = train_df.shape[0] x_train = np.empty((N, 32, 32, 3), dtype=np.uint8) for i, image_id in enumerate(tqdm(train_df['id_code'])): x_train[i, :, :, :] = preprocess_image(image_id) x_train.shape N = test_df.shape[0] x_test = np.empty((N, 32, 32, 3), dtype=np.uint8) for i, image_id in enumerate(tqdm(test_df['id_code'])): x_test[i, :, :, :] = preprocess_image(image_id) y_train = pd.get_dummies(train_df['diagnosis']).values print(x_train.shape) print(y_train.shape) print(x_test.shape) y_train_multi = np.empty(y_train.shape, dtype=y_train.dtype) y_train_multi[:, 2] = y_train[:, 2] for i in range(2): y_train_multi[:, i] = np.logical_or(y_train[:, i], y_train_multi[:, i+1]) print("Original y_train:", y_train.sum(axis=0)) print("Multilabel version:", y_train_multi.sum(axis=0)) x_train, x_val, y_train, y_val = train_test_split( x_train, y_train_multi, test_size=0.15, random_state=2019 )それぞれのクラスのデータ数を確認します。
クラスの定義
class MixupGenerator(): def __init__(self, X_train, y_train, batch_size=32, alpha=0.2, shuffle=True, datagen=None): self.X_train = X_train self.y_train = y_train self.batch_size = batch_size self.alpha = alpha self.shuffle = shuffle self.sample_num = len(X_train) self.datagen = datagen def __call__(self): while True: indexes = self.__get_exploration_order() itr_num = int(len(indexes) // (self.batch_size * 2)) for i in range(itr_num): batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2] X, y = self.__data_generation(batch_ids) yield X, y def __get_exploration_order(self): indexes = np.arange(self.sample_num) if self.shuffle: np.random.shuffle(indexes) return indexes def __data_generation(self, batch_ids): _, h, w, c = self.X_train.shape l = np.random.beta(self.alpha, self.alpha, self.batch_size) X_l = l.reshape(self.batch_size, 1, 1, 1) y_l = l.reshape(self.batch_size, 1) X1 = self.X_train[batch_ids[:self.batch_size]] X2 = self.X_train[batch_ids[self.batch_size:]] X = X1 * X_l + X2 * (1 - X_l) if self.datagen: for i in range(self.batch_size): X[i] = self.datagen.random_transform(X[i]) X[i] = self.datagen.standardize(X[i]) if isinstance(self.y_train, list): y = [] for y_train_ in self.y_train: y1 = y_train_[batch_ids[:self.batch_size]] y2 = y_train_[batch_ids[self.batch_size:]] y.append(y1 * y_l + y2 * (1 - y_l)) else: y1 = self.y_train[batch_ids[:self.batch_size]] y2 = self.y_train[batch_ids[self.batch_size:]] y = y1 * y_l + y2 * (1 - y_l) return X, yデータ水増しなど
#バッチサイズ BATCH_SIZE = 16 def create_datagen(): return ImageDataGenerator( zoom_range=0.15, # set range for random zoom # set mode for filling points outside the input boundaries fill_mode='constant', cval=0., # value used for fill_mode = "constant" horizontal_flip=True, # randomly flip images vertical_flip=True, # randomly flip images ) # Using original generator data_generator = create_datagen().flow(x_train, y_train, batch_size=BATCH_SIZE, seed=2019) # Using Mixup mixup_generator = MixupGenerator(x_train, y_train, batch_size=BATCH_SIZE, alpha=0.2, datagen=create_datagen())() class Metrics(Callback): def on_train_begin(self, logs={}): self.val_kappas = [] def on_epoch_end(self, epoch, logs={}): X_val, y_val = self.validation_data[:2] y_val = y_val.sum(axis=1) - 1 y_pred = self.model.predict(X_val) > 0.5 y_pred = y_pred.astype(int).sum(axis=1) - 1 _val_kappa = cohen_kappa_score( y_val, y_pred, weights='quadratic' ) self.val_kappas.append(_val_kappa) print(f"val_kappa: {_val_kappa:.4f}") if _val_kappa == max(self.val_kappas): print("Validation Kappa has improved. Saving model.") self.model.save('model.h5') return #DenseNetをしよう。ここのモデルを変えると色々なモデルが試せます。 densenet = DenseNet121( weights="imagenet", include_top=False, input_shape=(32,32,3) ) def build_model(): model = Sequential() model.add(densenet) model.add(layers.GlobalAveragePooling2D()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(3, activation='sigmoid')) model.compile( loss='binary_crossentropy', optimizer=Adam(lr=0.00005), metrics=['accuracy'] ) return modelモデルをビルドします
model = build_model() model.summary() kappa_metrics = Metrics()モデルのサマリー
学習します。epockは自由に変えてください。
history = model.fit_generator( data_generator, steps_per_epoch=x_train.shape[0] / BATCH_SIZE, epochs=50, validation_data=(x_val, y_val), callbacks=[kappa_metrics])推論します。
model.load_weights('model.h5') y_val_pred = model.predict(x_val)def compute_score_inv(threshold): y1 = y_val_pred > threshold y1 = y1.astype(int).sum(axis=1) - 1 y2 = y_val.sum(axis=1) - 1 score = cohen_kappa_score(y1, y2, weights='quadratic') return 1 - score simplex = scipy.optimize.minimize( compute_score_inv, 0.5, method='nelder-mead' ) best_threshold = simplex['x'][0] y_test = model.predict(x_test) > 0.5 y_test = y_test.astype(int).sum(axis=1) - 1 test_df['prediction'] = y_test test_df.to_csv('kamogawa_result.csv',index=False)推論結果を確認しましょう。
test_df prediction=test_df.prediction id=test_df.id_code
↑上記は全然予測できていない結果です。。。最後の出力部分
%matplotlib inline plt.figure(figsize=(16,12)) for num,i in enumerate(zip(prediction,id)): plt.subplot(4,2,num+1) if i[0] == 0 : print("今日の川の水域は安全です。") image=cv2.imread(i[1],1) plt.title("safe") # plt.title(i[1]) plt.imshow(image) elif i[0] ==1 : print("川の水位が上がっていますので十分注意してください。") image=cv2.imread(i[1],1) # plt.title(i[1]) plt.title("be careful") plt.imshow(image) else : print("川が氾濫しています。絶対に川辺には降りないでください") image=cv2.imread(i[1],1) # plt.title(i[1]) plt.title("Do NOT enter") plt.imshow(image)出力例:
とりあえず出力しました。
感想
安全な状態と、危険な状態はわかりやすいですが注意状態の画像はなかなかなく、
探すのが大変でした、途中で諦めてエイやでやってしまった。
ちゃんとやろうと思ったら、自分で撮った方が早いです。
またGPUを使えず画像サイズを32に落としましたが、224*224で学習すればきちんと推論ができるかもしれません。川の氾濫は、すでにセンサー等で見ているので、AIは使う必要ないかもですが、
夜間に川の側に人がいないかなどの検知には、役立つかもしれません。
次は物体検知でやってみようかなと思います。コードの間違いなどありましたら、ご指摘ください。
言い訳
綺麗な画像を十分に集められる人であれば、良い予測値が出ると思います。
もし川の関係者がいれば、やってみてください。参考URL
https://qiita.com/yu4u/items/078054dfb5592cbb80cc
http://www.qsr.mlit.go.jp/useful/n-shiryo/kikaku/kenkyu/h30/04/4_03(18).pdf
コード(再掲)
コードは以下のgitに挙げています。
コードなど、何か質問あればお気軽にご連絡ください
https://github.com/nakamolinto/River_flood_detection最後に
twitterもやってます。よかったらフォローしてください。
https://twitter.com/pythonmachine
- 投稿日:2020-08-14T07:57:01+09:00
TFCoreMLで変換したモデルの出力がおかしい時の対処法
WWDC2020あたりを境に、tfcoremlで変換したGANの出力が全部真っ白になりました。
対処法
Core ML Tools 4.0をインストールして変換し直す。
pip install coremltools==4.0b2tfcoremlに比べて、変換メソッドのオプションがシンプルに変わっています。
import coremltools as ct image_input = ct.ImageType(shape=(1, 256, 256, 3,), scale=2/255,bias=[-1,-1,-1]) coreml_model = ct.convert( yourmodel, inputs=[image_input], ) coreml_model.save("yourmodel.mlmodel")これで出力されました。
Core MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。

- 投稿日:2020-08-14T03:13:56+09:00
tf.app.flags.FLAGSをargparseモジュールで代用する
これまで当たり前のようにPyTorchを使ってきた。
突然のTensorFlowのコードはさっぱり分からない。
なのでTensorFlowとPythonの対応を作りながら、両方を勉強することにしました。
初心者なので、記事の内容には期待しないでください。
それと、助言&訂正等はどしどし応募しております。どんな些細なことでもコメントお願いします!tf.app.flags.DEFINE_integer()
ファイル実行時にパラメータを付与してくれます。
tf.app.flags.DEFINE_integer('変数名', デフォルト値, "説明文")sample.pyimport tensorflow as tf tf.app.flags.DEFINE_integer('split', 0, "split") FLAGS = tf.app.flags.FLAGS print(FLAGS.split) # 0TensorFlowを使わずに書くなら
代わりにargparseモジュールで書けそうです。
argparse.pyimport argparse parser = argparse.ArgumentParser() parser.add_argument('--split', type=int, default=0, help='split') FLAGS = parser.parse_args() print(FLAGS.split) # 0Terminal>>> python3 argparse.py 0 >>> python3 argparse.py --split 10 10 >>> python3 argparse.py --help usage: argparse.py [-h] [--split SPLIT] optional arguments: -h, --help show this help message and exit --split SPLIT splitコマンドライン引数の面倒なところは入力が長くなってしまうんですよね。
あと、メインのコード内にいくつも引数を書くと読みにくくなってしまったり。
そこで、easydictモジュールとyamlモジュールを組み合わせることで、
引数をもっと簡単に変えられます!config.pyimport yaml from easydict import EasyDict as edict __C = edict() cfg = __C __C.IMAGE_SIZE = 224 __C.TRAIN_LENGTH = 200000 __C.SAVE_LENGTH = 50000 filename = "cfg/arguments.yml" """設定ファイルをロードして、デフォルトのオプションにマージします""" with open(filename, 'r') as f: yaml_cfg = edict(yaml.load(f, Loader=yaml.SafeLoader)) _merge_a_into_b(yaml_cfg, __C).ymlファイルの中身はこのように書けます。
cfg/arguments.ymlIMAGESIZE: 256 TRAIN_LENGTH: 50000 SAVE_LENGTH: 10000このようにすることで、config.py内で初期値を決められ、かつarguments.ymlで変更することができるようになります✨
最後に、_merge_a_into_b()ですが、
def _merge_a_into_b(a, b): """設定辞書 a を設定辞書 b にマージして、b のオプションが a で指定されている場合はいつでも b のオプションを破壊します。 """ if type(a) is not edict: return for k, v in a.items(): # a は b にあるキーを指定する必要があります。 if k not in b: raise KeyError('{} is not a valid config key'.format(k)) # 型も一致しなければなりません。 old_type = type(b[k]) if old_type is not type(v): if isinstance(b[k], np.ndarray): v = np.array(v, dtype=b[k].dtype) else: raise ValueError(('Type mismatch ({} vs. {}) ' 'for config key: {}').format(type(b[k]), type(v), k)) # 再帰的に辞書をマージする if type(v) is edict: try: _merge_a_into_b(a[k], b[k]) except: print('Error under config key: {}'.format(k)) raise else: b[k] = vこんな感じです。