- 投稿日:2020-08-14T22:48:39+09:00
外気の体感温度を教えてくれるLINEbotをAWS LambdaとSORACOMデバイスで作ってみた。
はじめに
先日SORACOMのデバイスとArduinoを用いて省エネIoT機器を作ったを書いた。
- ハッカソンでこういうモノ作ったよという記事。
完成したのがハッカソン終了の2日前とかだったので、残り時間でできることをやろうとLINE botを作ってみた。
話しかけると外の体感温度を教えてくれる。かわいい。アイコンをクール系美少女にしたい。
GPS情報とかとも組み合わせられるのでは?とこれを書きながらも拡張性を感じる作品である。
前提として、GPS マルチユニット SORACOM Editionを屋外に置いておく必要がある。
なぜ作ったか
- 実は今回のデバイスの使用言語はかなり迷走しており、C → JavaScript → Pythonと行きついた感じだった。
- JavascriptのプログラムはAPI呼び出しまで行ったがArduinoとの連携がうまくいかなかったので撤退したもので、これが上手くいっていればAWS Lambdaで幅広くできたのに……と恨み言を吐いていた。
- もったいないので、AWS LambdaをAPI呼び出しのプログラムで動かしてLINE botにしようということになった。
- 供養です。お盆なので。
構成
- 以下のページを参考にLINE botの作り方を学んだ。いじる部分はほとんどLINE Messenger APIの周りだけだったので実質コピペ。
- 今になって思えばこの記事だけで構築可能だが、結構時間を溶かした。
- API Gatewayの設定を行うときはAWS Lambdaの「トリガを追加」で追加したAPI Gatewayのリンクから飛ぶよ、などがわからず……
- でも他と比べたらめちゃめちゃわかりやすい。
- 以下のプログラムで用いられているsoracom_apiとatobは
npm installしなければならない。- その後、上の記事の3. index.jsとnode_modulesを圧縮しLambdaにアップロードするのときに一緒に圧縮した。
index.js"use strict"; const line = require("@line/bot-sdk"); const atob = require("atob"); const client = new line.Client({ channelAccessToken: process.env.ACCESSTOKEN }); // ①SDKをインポート const crypto = require("crypto"); exports.handler = function (event, context) { let body = JSON.parse(event.body); let signature = crypto .createHmac("sha256", process.env.CHANNELSECRET) .update(event.body) .digest("base64"); let checkHeader = (event.headers || {})["X-Line-Signature"]; if (signature === checkHeader) { // ②cryptoを使ってユーザーからのメッセージの署名を検証する //ここから追加部分 global.atob = require("atob"); var Soracom = require('soracom_api'); var soracom = new Soracom({email: 'メールアドレスをここに',password:'パスワードをここに'}); soracom.get('/data/Subscriber/マルチユニットのSIMの番号?sort=desc&limit=1',function(err,res){ console.log({err:err,res:res}); console.log(res[0].content); var d = res[0]["content"]; var e = JSON.parse(d); var decoded = atob(e["payload"]); var ans =JSON.parse(decoded); var temp = ans["temp"]; var humi = ans["humi"]; var A = ((temp - 1/2.3 * (temp-10) * (0.8-humi/100))); global.M = A.toFixed(1); }); //ここまで if (body.events[0].replyToken === "00000000000000000000000000000000") { let lambdaResponse = { statusCode: 200, headers: { "X-Line-Status": "OK" }, body: '{"result":"connect check"}', }; context.succeed(lambdaResponse); // ③接続確認エラーを確認する。 } else { //let text = body.events[0].message.text; //これも追加部分 if(global.M>26.5){ var t = "エアコンをつけた方が良いです。"; }else{ var t = "窓を開けても良いかもしれません。"; } let text = "現在の外気の体感気温は"+global.M+"℃です。"+t; const message = { type: "text", text: text, }; //ここまで client .replyMessage(body.events[0].replyToken, message) .then((response) => { let lambdaResponse = { statusCode: 200, headers: { "X-Line-Status": "OK" }, body: '{"result":"completed"}', }; context.succeed(lambdaResponse); }) .catch((err) => console.log(err)); // ④リクエストとして受け取ったテキストをそのまま返す } } else { console.log("署名認証エラー"); } };
- 追加したのはAPIアクセス部分と出力生成部分の2か所。
APIアクセス部分
- soracom_apiというライブラリのおかげでPythonの時よりもアクセスしやすくなっている。
ただ、データの取得が全て関数内で行われるが故に関数スコープで関数外に持ち出せないため、持ち出したい変数には
global.をつけないと使えない。
- これが載ってる記事見つからなかった……常識なんだろうな、すみません。
var Aで用いられているのはミスナールの体感温度関数。通常だと小数15桁まで得られてしまうので、
.toFixed(1)で丸め込んだ。出力生成部分
- 閾値以上ならエアコンを勧め、以下なら窓開けを勧める。
- Messaging APIリファレンス曰く、文字を送るにはJSON形式の
message = { type: "text", text: text, };をclient.replyMessage(replyToken, message)のメソッドとして用いるだけでいいらしい。感想
製作時間が短いので地味なものになってしまったが、SORACOMデバイスのデータを簡単にLINE botに活かせることが分かった。
- それとコードの供養もできた。
SORACOM Funcというものを用いるとより簡単にAWS Lambdaを活用できるらしい。
デバイスとの連携も夢ではないかも。少なくともボタンのクリックイベントはすぐに読めるようにできそう。

- 投稿日:2020-08-14T21:09:40+09:00
『AWS初学者向けハンズオン』 請求アラームの設定編
はじめに
この記事はAWS初学者が書いているAWS初学者の方や未経験の方向けの記事になります。
内容や説明が間違っていた場合はコメントいただけるとありがたいです。投稿者のレベル
AWS CLF持ってるレベル
AWS実務経験無し
AWS使用経験(個人用+会社作成アカウント使用):約2ヶ月
使用したことがあるサービス:IAM、EC2、EIP、VPC、RDS、CloudWatch(もしかしたら他にも使ったような気がする...)今回の目的
AWSのアカウントを初めて作成すると1年間無料でサービス(有料のものもあります)を使用することが出来ます。
1年間無料枠を使い切った際やサービスを停止せず利用料金が発生し続けていることで、気が付いたら想定していた利用料金より多くなっていたというのを防ぐためメールで通知することを目的としています。
実際にTwitterで想定していた請求額を大幅に超えてしまい嘆いている方を見かけました・・・
給料が少ないので請求額が多いと辛い...使用するサービス
・CloudWatch
AWSのリソースを監視やログの収集をしてくれるサービスになります。AutoScalingと言うサービスと組み合わせて使用するばCloudWatchのアラームに基づいてEC2インスタンスを停止したり追加させることも可能です。
設定の流れ
1. AWSマネジメントコンソールにログインします
ログインすると以下のページが表示されます。
表示されましたら画像右上の黄色で囲っている部分(アカウント名が表示されています)をクリックしてください
クリックするといくつかの項目が出てくると思いますが、その中の「マイ請求ダッシュボード」をクリックしてください。2. アラートの設定
クリックしていただくとこのようなページに行くかと思います。
このページが表示されたら左下あたりにある「Billingの設定」をクリックしてください。
クリックすると以下のページが表示されると思います。
表示されたら「無料利用枠の使用のアラートの受信」と「請求アラートを受け取る」にチェックを入れてください。
チェックを入れたら「無料利用枠の使用のアラートの受信」欄の少し下にある「Eメールアドレス」のところに自分のメールアドレスを入力してください。
上記の欄にチェックを入れておくとサービス利用料金が設定した料金を超えた際にメールを受け取ることが出来ます。
設定が終わったら「設定の保存」をクリックしてください。3. CloudWatchの設定
設定の保存が終わりましたら画面左上にあるサービスをクリックしてください。
クリックすると以下の画面が表示されると思います。
表示されたら「管理とガバナンス」欄にある「CloudWatch」をクリックしてください。
※見つからない場合は名前で検索すると出てくると思います。
「CloudWatch」をクリックしたら以下のページが表示されると思います。
ただし今のままだと設定ができませんので右上の「東京」と表示されているところをクリックしてください。
クリックすると国名が表示されると思います。
表示されたら一番上の「米国東部(バージニア北部)」をクリックしてください。こちらの設定はリージョンの設定を行っています。
※リージョンとはAWSが管理しているサーバが配置されている地域の事です。
「米国東部(バージニア北部)」でしか請求アラートの設定ができないそうです。
リージョンを変更したら左の欄にある「アラーム」をクリックしてください。
クリックすると以下のページが表示されると思います。
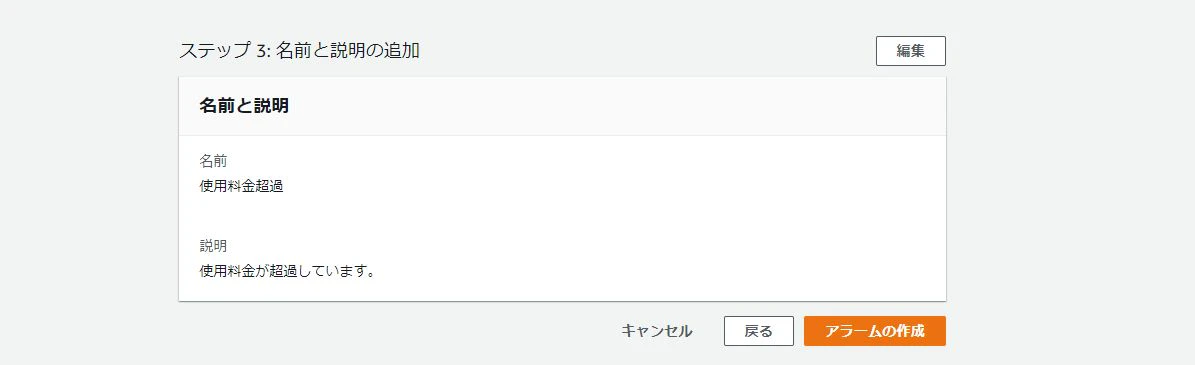
表示されたら「アラームの作成」をクリックしてください。
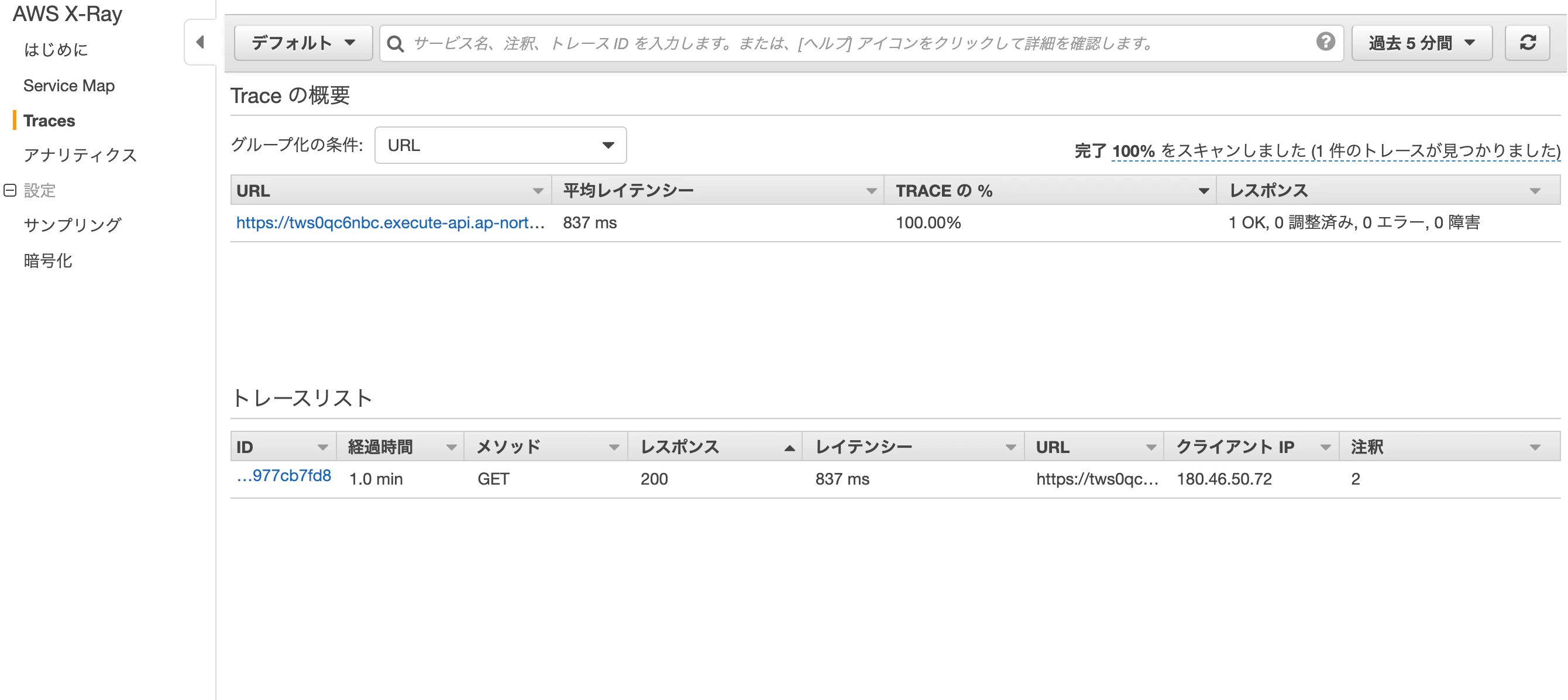
クリックした以下の項目が出てきますので「メトリクスの選択」をクリックしてください。
クリックしたらメトリクスの選択ができますので「すべてのメトリクス」の「請求」をクリックして「概算合計請求額」を選択してください。
選択すると以下の画面が表示されますので「USD」にチェックを入れて「メトリクスの選択」をクリックしてください。
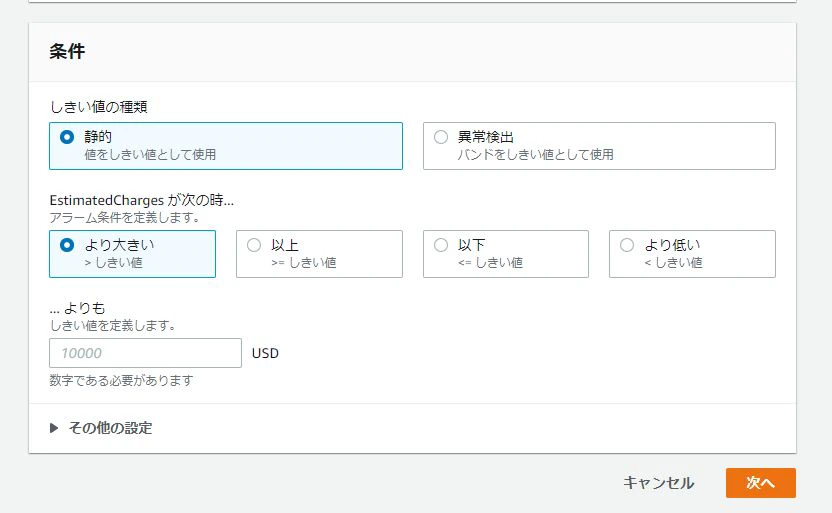
クリックすると以下のようなページが表示されます。表示されたら下までスクロールして「条件」の欄で「しきい値の種類」欄で「静的」、「EstimatedCharges が次の時...」欄で「より大きい」を選択してください。
「... よりも」欄では自分のお財布事情と相談して数値を設定しましょう。今回自分は50USD(約5000円)にしました。
※ここの設定は月に利用料金が○○円超えたら通知する設定を行っています。
入力が完了したら「次へ」をクリックしてください。
クリックすると以下のページが表示されるので「SNSトピックの選択」欄で「新しいトピックの作成」を選択しトピック名と「通知を受け取る E メールエンドポイント …」を入力し「トピックの作成」をクリックしてください。
作成後「SNSトピックの選択」欄で「既存のSNSトピックを選択」を選び「通知の送信先」が先程作成したトピック名になっていることと、「Eメール(エンドポイント)」欄が先程入力したメールアドレスになっていることを確認してください。
確認が出来たら一番下にスクロールして「次へ」をクリックしてください。
クリックすると以下のページが表示されます。表示されたらアラーム名とアラームの説明を入力してください。
入力が完了したら「次へ」をクリックしてください。
クリックするとプレビューが確認できるので問題が無ければ一番下までスクロールして「アラームの作成」をクリックします。
クリックすると以下のページが表示されます。
「一部サブスクリプションが確認待ちの状態です」と表示されますが、上記で設定したメールアドレス宛にAWSからメールが届いているので本文に書かれている「Confirm subscription」をクリックして認証を行ってください。
これで請求アラームの設定完了です。感想
今回はCloudWatchを使用してアラームの設定をしてみました。
結構多くの人がとんでもない料金を請求されていると聞いているので今後もこの設定は一番最初にやろうと思いました。
この設定をしておけばとりあえず料金系で恐れることなくAWSで遊べます。













- 投稿日:2020-08-14T20:57:53+09:00
自宅でAWS 認定デベロッパー アソシエイト取得しました
AWS認定デベロッパー アソシエイト(DVA)を自宅で受験し無事合格しました。
資格取得までに参考にしたものを投稿します。
私のAWSの知識
半年前にソリューションアーキテクトに合格しました。
https://qiita.com/gdtypk/items/52d96a5af0a05f06ebc4業務では、EC2,RDS,Lambda,S3を薄く触っている程度になります。
あとは、私が所属している班でCI/CDに最近取り組み始めたため、Code兄弟に関しても少し知識がありました。
やったこと
大体、2週間毎日1~2時間程度、勉強していました。
試験範囲の確認
https://aws.amazon.com/jp/certification/certified-developer-associate/
AWS認定アソシエイト3資格対策~ソリューションアーキテクト、デベロッパー、SysOpsアドミニストレータを読む
こちらが対象の書籍のリンク
これ一冊で、試験に対応できるとは思えませんが、ソリューションアーキテクトを受けて以来、
忘れていたサービスなどをぼんやり思い出すにはちょうどよかったです。AWS WEB問題集をこなす
デベロッパーアソシエイト試験の問題を見るためには、ダイヤモンドプランに登録する必要があり、
これが、6000円程度とけっこうなお値段します。こちらの問題集を3周しました。
回答にAWS公式のリンクが貼ってくれてたりするので、腹落ちしないものに関しては、
ざっくり目を通すようにしました。Black Beltを見る
問題集のリンクを読んでも意味の分からないものに関しては、youtubeを見ました。
試験を受けての感想
ソリューションアーキテクトの時は、あまり感じませんでしたが、今回は試験の日本語が酷かったです・・。
勘違いかもしれませんが、英語には記載されているのに日本語では言葉が抜けているものが1問ありました。Elastic BeansTalkとcloudformationを初めて見ましたが、使えるようになったら、かなり便利そうだなあと思いました。
(Infrastructure as Codeすごい)次は2週間後にSysOpsを受けます。
自宅で受けた感想
免許書やパスポートを手元に用意して、指示に従うだけなので、難しいことは無いと思います。
ただ、指示が全て英語なので、私は苦労しました。チェックインだけで25分くらいかけてしまい・・。
担当してくれた方も私の英語に終始笑ってくれていましたその他、重要そうなもののリンク
Beans Talkデプロイについて
https://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/using-features.deploy-existing-version.html
http://shepherdmaster.hateblo.jp/entry/2019/01/28/232511WCU RCUについて結果整合性・強力な読み込み・トランザクション
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/HowItWorks.ReadWriteCapacityMode.html#HowItWorks.ProvisionedThroughput.Manualグローバルセカンダリインデックス・ローカルインデックス
https://qiita.com/kazutomo/items/7c6123f6c8eea55dff33#%E3%83%95%E3%82%A3%E3%83%AB%E3%82%BF%E3%81%AB%E3%82%88%E3%82%8B%E7%B5%9E%E3%82%8A%E8%BE%BC%E3%81%BFLambda × X-Ray
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/services-xray.htmlLambda 実行コンテキスト(ハンドラー外に書く)
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/runtimes-context.htmlCodeBuildの環境変数の長さ制限
https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/troubleshooting.html#troubleshooting-large-env-varsマスターキーでデータキーを暗号化する
https://docs.aws.amazon.com/ja_jp/kms/latest/developerguide/programming-keys.html#generate-datakeysLambda@Edgeについて(cloudFront配信時にLambdaを実行)
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/lambda-at-the-edge.htmlDynamoDBパーティションキー
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/bp-partition-key-uniform-load.htmlLambdaベストプラクティス
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/best-practices.htmlEC2 インスタンスプロファイル(I AM ロール)
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles_use_switch-role-ec2_instance-profiles.htmlECR レジストリ
https://docs.aws.amazon.com/ja_jp/AmazonECR/latest/userguide/Registries.html#registry_authSystems Manager パラメータストア
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/systems-manager-parameter-store.htmlステップファンクション
https://aws.amazon.com/jp/step-functions/DynamoDB Accelerator (DAX)
https://aws.amazon.com/jp/dynamodb/dax/DynamoDB では、楽観的オプティミスティック同時実行制御を使用する
Cognito ユーザープールと ID プール
https://aws.amazon.com/jp/premiumsupport/knowledge-center/cognito-user-pools-identity-pools/フィルターを使用したログイベントからのメトリクスの作成
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/MonitoringLogData.htmlAWS AppSync プッシュ同期
https://docs.aws.amazon.com/ja_jp/cognito/latest/developerguide/push-sync.htmlCognito Sync
https://docs.aws.amazon.com/ja_jp/cognito/latest/developerguide/cognito-sync.htmlマッピングテンプレート
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/apigateway-override-request-response-parameters.html
https://qiita.com/tamura_CD/items/ca8e531f74ea5b82a5b7S3のバケットポリシーPrincipal(特定のユーザにアクセス許可)
https://dev.classmethod.jp/articles/summarize-principal-settings-in-s3-bucket-policy/IAM ポリシーエレメント: 変数およびタグ
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/reference_policies_variables.htmlKinesis Streams(リアルタイム分析)とKinesis Firehose(データの流し込み)の違い
https://dev.classmethod.jp/articles/difference-between-kinesis-streams-and-kinesis-firehose/SQS メッセージグループ ID の使用(FIFOを保証)
https://docs.aws.amazon.com/ja_jp/AWSSimpleQueueService/latest/SQSDeveloperGuide/using-messagegroupid-property.html
https://dev.classmethod.jp/articles/sqs-new-fifo/throttlingexception
https://aws.amazon.com/jp/premiumsupport/knowledge-center/cloudtrail-rate-exceeded/BatchWriteItem,BatchGetItem
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/WorkingWithItems.htmlSimple Workflow Service(SWF)
https://dev.classmethod.jp/articles/cm-advent-calendar-2015-getting-started-again-swf/SQS 可視性タイムアウト
https://docs.aws.amazon.com/ja_jp/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-visibility-timeout.html
https://qiita.com/tomoya_ozawa/items/dc0286cdb30763eab174SQS ロングポーリング
https://cloudpack.media/472インスタンスにロールを割り当てても、環境変数が優先される
https://aws.amazon.com/jp/premiumsupport/knowledge-center/security-token-expired/dynamoDB 並列スキャン
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Scan.html#Scan.ParallelScanウェブ ID フェデレーション
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles_providers_oidc.htmlOpsWorks レシピのデバッグ(EC2インスタンスのログ確認)
https://docs.aws.amazon.com/ja_jp/opsworks/latest/userguide/troubleshoot-debug.htmlエクスポネンシャルバックオフ(Exponential Backoff)
指数関数的にリトライ間隔を後退させる
https://yoshidashingo.hatenablog.com/entry/2014/08/17/135017クラウドフォーメーション触ってみる
https://qiita.com/tyoshitake/items/c5176c0ef4de8d7cf5d8Elastic BeansTals触ってみる
https://tech-lab.sios.jp/archives/17449

- 投稿日:2020-08-14T19:13:51+09:00
AWS Lambdaで外部モジュールを読み込めるようにする方法
- 普通にLambdaをアップロードしただけではAWSにデフォルトでインストールされているライブラリ(AWS SDKとか)以外は使用できないみたい
Cannot find moduleと言われてしまいます- 言語はNode.js
- AWS CDKを使っている
方法① LambdaのZipファイルに外部モジュールを含める
- AWSコンソールを使えば、LambdaファイルをZip圧縮したものをアップロードすることができるため、このZip内にnode_moduleディレクトリを含めて外部モジュールごとアップロードしてしまえば良いです
- ただし、AWS CDKを使用してアップロードする場合、この方法は使えません(/_;)
方法② 外部モジュールのZipファイルをLambda Layersへ登録する
- node_modulesディレクトリをZip圧縮して、AWSコンソールからLambda Layersにアップロードすれば良いです
- ただし、せっかくLambdaのアップロードをAWS CDKで自動化しているのに、別の手作業が発生してしまうのは悲しいです
方法③ AWS CDKを使ってLambda Layersに登録する
- これがやりたい
やり方
- CDKプロジェクトフォルダ内に「layer」というフォルダを作成します
- 「layer」フォルダ内に「nodejs」というフォルダを作成します
- 「nodejs」フォルダ内で
npm initを行い、必要なライブラリをインストールします- stackファイルに以下を追加します
const nodeModulesLayer = new lambda.LayerVersion(this, 'NodeModulesLayer', { code: lambda.AssetCode.fromAsset('layer'), compatibleRuntimes: [lambda.Runtime.NODEJS_10_X, lambda.Runtime.NODEJS_12_X] });
- lambda呼び出しのコードにも一行追加します
const myFunction = new lambda.Function(this, 'MyHandler', { functionName: 'SalesforceSample', runtime: lambda.Runtime.NODEJS_12_X, code: lambda.Code.fromAsset('lambda'), handler: 'salesforceSample.handler', layers: [nodeModulesLayer] // これ });問題点
- これだとコード作成時のnode_modulesと、アップロードされるnode_modulesを別々に管理する必要があるのがナンセンス
- node_modulesをnodejsフォルダ以下に自動的にコピーするような処理があると完璧なのかなあ・・・
- 投稿日:2020-08-14T17:26:25+09:00
Amazon Linux 2でEPELとRemi Repositoryを有効にする
What's?
Amazon Linux 2で、EPELとRemi Repositoryを有効にする方法をメモしておこうということで。
環境
タイトル通り、Amazon Linux 2を利用します。
AMI ID …
ami-0cc75a8978fbbc969実際に試した環境は、こんな感じですね。
$ cat /etc/os-release NAME="Amazon Linux" VERSION="2" ID="amzn" ID_LIKE="centos rhel fedora" VERSION_ID="2" PRETTY_NAME="Amazon Linux 2" ANSI_COLOR="0;33" CPE_NAME="cpe:2.3:o:amazon:amazon_linux:2" HOME_URL="https://amazonlinux.com/" $ uname -srvmpio Linux 4.14.186-146.268.amzn2.x86_64 #1 SMP Tue Jul 14 18:16:52 UTC 2020 x86_64 x86_64 x86_64 GNU/LinuxEPELを有効にする
CentOSなどと同じように、
yumでEPELを有効にしようとすると、失敗します。$ sudo yum install epel-release Loaded plugins: extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 No package epel-release available. Error: Nothing to do epel-release is available in Amazon Linux Extra topic "epel" To use, run # sudo amazon-linux-extras install epel Learn more at https://aws.amazon.com/amazon-linux-2/faqs/#Amazon_Linux_Extras
sudo amazon-linux-extras install epelを使えと言われているので、従いましょう。$ sudo amazon-linux-extras install epelEPELがインストールされます。
Dependencies Resolved =================================================================================================================================================================================== Package Arch Version Repository Size =================================================================================================================================================================================== Installing: epel-release noarch 7-11 amzn2extra-epel 15 k Transaction Summary =================================================================================================================================================================================== Install 1 Package
amazon-linux-extrasは、Amazon LinuxのExtra Libraryを扱うコマンドですね。Amazon Linux / Extras library (Amazon Linux 2)
使用可能なパッケージは、
amazon-linux-extras listで確認できます。$ amazon-linux-extras list 0 ansible2 available \ [ =2.4.2 =2.4.6 =2.8 =stable ] 2 httpd_modules available [ =1.0 =stable ] 3 memcached1.5 available \ [ =1.5.1 =1.5.16 =1.5.17 ] 5 postgresql9.6 available \ [ =9.6.6 =9.6.8 =stable ] 6 postgresql10 available [ =10 =stable ] 8 redis4.0 available \ [ =4.0.5 =4.0.10 =stable ] 9 R3.4 available [ =3.4.3 =stable ] 10 rust1 available \ [ =1.22.1 =1.26.0 =1.26.1 =1.27.2 =1.31.0 =1.38.0 =stable ] 11 vim available [ =8.0 =stable ] 13 ruby2.4 available \ [ =2.4.2 =2.4.4 =2.4.7 =stable ] 15 php7.2 available \ [ =7.2.0 =7.2.4 =7.2.5 =7.2.8 =7.2.11 =7.2.13 =7.2.14 =7.2.16 =7.2.17 =7.2.19 =7.2.21 =7.2.22 =7.2.23 =7.2.24 =7.2.26 =stable ] 17 lamp-mariadb10.2-php7.2 available \ [ =10.2.10_7.2.0 =10.2.10_7.2.4 =10.2.10_7.2.5 =10.2.10_7.2.8 =10.2.10_7.2.11 =10.2.10_7.2.13 =10.2.10_7.2.14 =10.2.10_7.2.16 =10.2.10_7.2.17 =10.2.10_7.2.19 =10.2.10_7.2.22 =10.2.10_7.2.23 =10.2.10_7.2.24 =stable ] 18 libreoffice available \ [ =5.0.6.2_15 =5.3.6.1 =stable ] 19 gimp available [ =2.8.22 ] 20 docker=latest enabled \ [ =17.12.1 =18.03.1 =18.06.1 =18.09.9 =stable ] 21 mate-desktop1.x available \ [ =1.19.0 =1.20.0 =stable ] 22 GraphicsMagick1.3 available \ [ =1.3.29 =1.3.32 =1.3.34 =stable ] 23 tomcat8.5 available \ [ =8.5.31 =8.5.32 =8.5.38 =8.5.40 =8.5.42 =8.5.50 =stable ] 24 epel=latest enabled [ =7.11 =stable ] 25 testing available [ =1.0 =stable ] 26 ecs available [ =stable ] 27 corretto8 available \ [ =1.8.0_192 =1.8.0_202 =1.8.0_212 =1.8.0_222 =1.8.0_232 =1.8.0_242 =stable ] 28 firecracker available [ =0.11 =stable ] 29 golang1.11 available \ [ =1.11.3 =1.11.11 =1.11.13 =stable ] 30 squid4 available [ =4 =stable ] 31 php7.3 available \ [ =7.3.2 =7.3.3 =7.3.4 =7.3.6 =7.3.8 =7.3.9 =7.3.10 =7.3.11 =7.3.13 =stable ] 32 lustre2.10 available \ [ =2.10.5 =2.10.8 =stable ] 33 java-openjdk11 available [ =11 =stable ] 34 lynis available [ =stable ] 35 kernel-ng available [ =stable ] 36 BCC available [ =0.x =stable ] 37 mono available [ =5.x =stable ] 38 nginx1 available [ =stable ] 39 ruby2.6 available [ =2.6 =stable ] 40 mock available [ =stable ] 41 postgresql11 available [ =11 =stable ] 42 php7.4 available [ =stable ] 43 livepatch available [ =stable ] 44 python3.8 available [ =stable ] 45 haproxy2 available [ =stable ]Remi Repositoryを有効にする
Remi Repositoryに関しては、ふつうにインストールするだけでした。
$ sudo yum install https://rpms.remirepo.net/enterprise/remi-release-7.rpm今回、インストールされるバージョン。
=================================================================================================================================================================================== Package Arch Version Repository Size =================================================================================================================================================================================== Installing: remi-release noarch 7.7-2.el7.remi /remi-release-7 26 k Transaction Summary =================================================================================================================================================================================== Install 1 PackageRPMをインストールする時に、どのOSバージョンを選ぶかやや困るのですが、Amazon Linux 2だとRHEL 7に近いようなので、とりあえずこちらで。
- 投稿日:2020-08-14T16:02:51+09:00
【AWS Lambda】S3に保存された画像をリサイズして別S3に保存(Ruby利用)
目標
S3に保存された画像データをLambda関数を利用してリサイズし、別S3に保存する。
プログラミング言語はRubyを利用しています。はじめに
あまりLambdaに関して詳しくないので、基本的にはLambdaの基本動作を手順として残すのが目的です。
AWSコンソールからS3にプットした画像をリサイズ(固定サイズ)して別S3に保存するという単純な処理を試してみました。前提
事前に2つのS3バケットを作成していること。
構成図
作業の流れ
項番 タイトル 1 Lambda関数の作成とアップロード 2 Lambda環境変数の設定 3 ハンドラーと実行ロールの設定 4 イベントトリガーの定義 5 実行ロールの設定 6 動作検証 手順
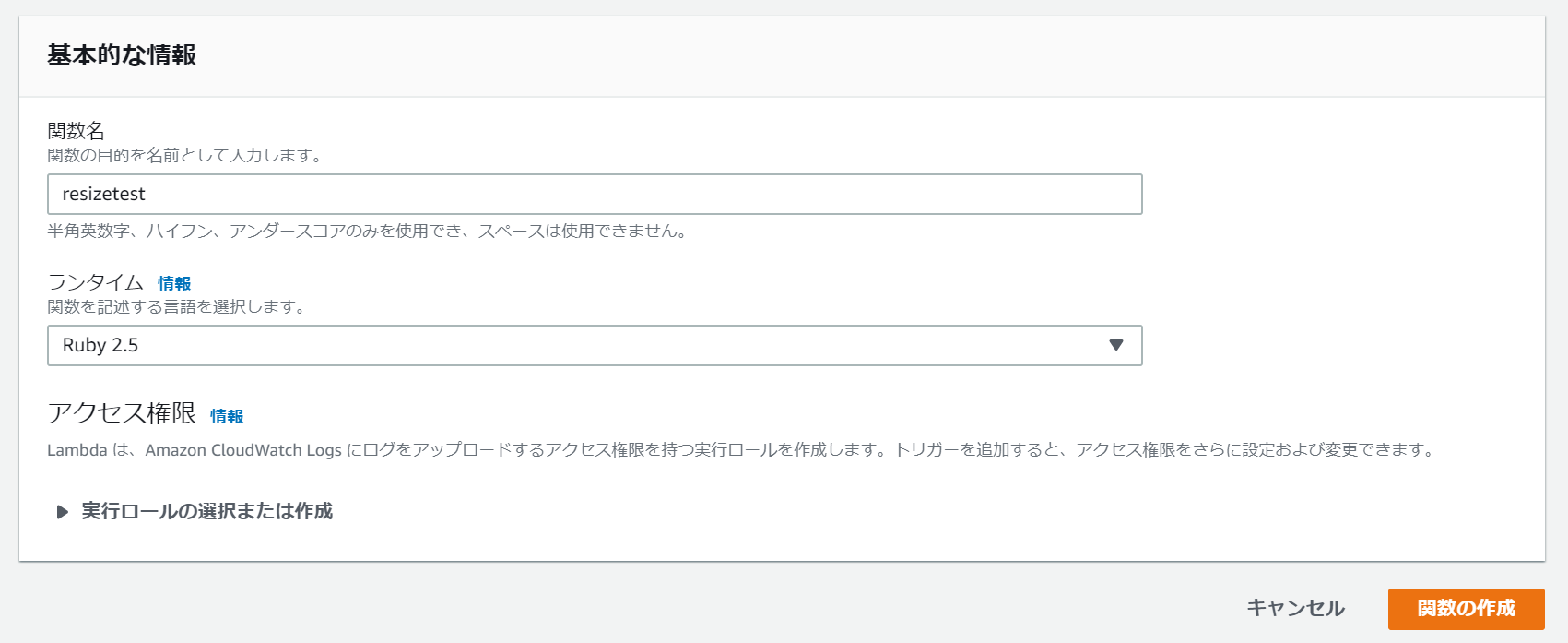
1.Lambda関数の作成とアップロード
任意の関数名とLambda関数で利用するプログラミング言語を選択します。
今回はRuby2.5で記述します。
配備するLambda関数本体と外部ライブラリ(mini_magick)をzip化したものを作成します。
作業ディレクトリ上で以下操作を行います。まずは
Gemfileの作成Gemfilesource 'https://rubygems.org' gem "mini_magick"
bundle install --path vendor/bundleを利用して作業ディレクトリ配下にgemをインストールします。bundle install --path vendor/bundle更にLambda関数本体となる
handler.rbを作成します。handler.rbrequire 'aws-sdk-s3' require 'base64' require 'mini_magick' def resize_image(event:, context:) s3_client = Aws::S3::Client.new( :region => ENV['REGION'], :access_key_id => ENV['ACCESS_KEY'], :secret_access_key => ENV['SECRET_ACCESS_KEY'] ) # イベントソースとして指定したS3から保存された画像を取り込む key = event['Records'][0]['s3']['object']['key'] image_file = s3_client.get_object(:bucket => ENV['BUCKET_BEFORE'], :key => key).body.read image = MiniMagick::Image.read(image_file) # リサイズした画像をLambda環境の/tmpに一時書き込み resized_tmp_file = "/tmp/#{key.delete("images/")}" image.resize("300x300").write(resized_tmp_file) # アップロード実行 s3_resource = Aws::S3::Resource.new() object = s3_resource.bucket(ENV['BUCKET_AFTER']).object(key).upload_file(resized_tmp_file) end
handler.rbとvenderをzip化します。
作成したzipファイルのアップロードを行います。
Lambdaコンソール上の関数コード欄アクションから.zipファイルをアップロードをクリック
handler.zipを選択し、保存
2.Lambda環境変数の設定
Lambdaコンソール上からLambda関数内で利用する環境変数を設定します。
3.ハンドラーと実行ロールの設定
どのファイルのどの関数を呼び出すか…という設定は、ハンドラーというパラメータで指示しているとのことなので、
今回作成したLambda関数に合わせて内容を編集します。Lambdaコンソール上の基本設定の
編集をクリック
ハンドラ欄に
実行ファイル名(拡張子除く).関数名の形式で値を入力し保存します。
4.イベントトリガーの定義
Lambdaコンソール上から
トリガーを追加をクリック
今回イベントトリガーとするAWSサービスはS3
トリガーの詳細設定を行います。
今回はimagesディレクトリ内にオブジェクトが作成されたタイミングでのイベント起動とします。
トリガーの有効化をいれることでS3がこのLambda関数に処理をキックすることが可能となります(Lambda関数ポリシーの設定)。
最後に追加をクリック
5.実行ロールの設定
更に今回はリサイズした画像を保存する際にLambdaからS3にアクセスをかける必要があるため、
S3へのアクセス権限付きの実行ロールを付与します。Lambdaコンソール上部にある
アクセス権限をクリック後、実行ロール名をクリック
ポリシーをアタッチしますをクリック
AmazonS3FullAccessを選択後、ポリシーのアタッチ
6.動作検証
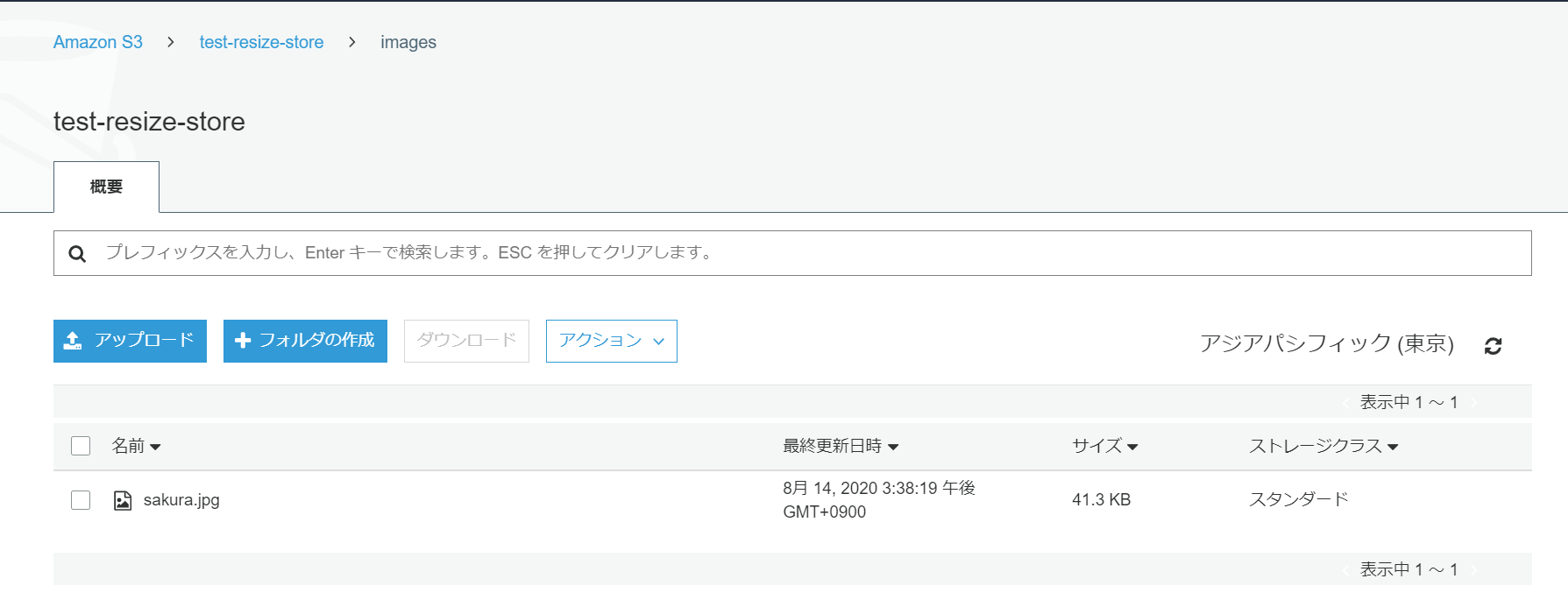
イベントソースとして指定したS3のimagesディレクトリ内に任意の画像をアップロードします。
ちなみにアップロードした画像はこちら
リサイズ後の画像保存先として指定したS3を確認したところ、画像が保存されていたのでOKです。
中身もリサイズされていました。
LambdaのログはCloudwatch Logsから確認可能です。
参考にさせて頂いた記事


















- 投稿日:2020-08-14T16:02:51+09:00
【AWS Lambda】S3に保存された画像をリサイズして別S3に保存
目標
S3に保存された画像データをLambda関数を利用してリサイズし、別S3に保存する。
はじめに
あまりLambdaに関して詳しくないので、基本的にはLambdaの基本動作を手順として残すのが目的です。
AWSコンソールからS3にプットした画像をリサイズ(固定サイズ)して別S3に保存するという単純な処理を試してみました。前提
事前に2つのS3バケットを作成していること。
構成図
作業の流れ
項番 タイトル 1 Lambda関数の作成とアップロード 2 Lambda環境変数の設定 3 ハンドラーと実行ロールの設定 4 イベントトリガーの定義 5 実行ロールの設定 6 動作検証 手順
1.Lambda関数の作成とアップロード
任意の関数名とLambda関数で利用するプログラミング言語を選択します。
今回はRuby2.5で記述します。
配備するLambda関数本体と外部ライブラリ(mini_magick)をzip化したものを作成します。
作業ディレクトリ上で以下操作を行います。まずは
Gemfileの作成Gemfilesource 'https://rubygems.org' gem "mini_magick"
bundle install --path vendor/bundleを利用して作業ディレクトリ配下にgemをインストールします。bundle install --path vendor/bundle更にLambda関数本体となる
handler.rbを作成します。handler.rbrequire 'aws-sdk-s3' require 'base64' require 'mini_magick' def resize_image(event:, context:) s3_client = Aws::S3::Client.new( :region => ENV['REGION'], :access_key_id => ENV['ACCESS_KEY'], :secret_access_key => ENV['SECRET_ACCESS_KEY'] ) # イベントソースとして指定したS3から保存された画像を取り込む key = event['Records'][0]['s3']['object']['key'] image_file = s3_client.get_object(:bucket => ENV['BUCKET_BEFORE'], :key => key).body.read image = MiniMagick::Image.read(image_file) # リサイズした画像をLambda環境の/tmpに一時書き込み resized_tmp_file = "/tmp/#{key.delete("images/")}" image.resize("300x300").write(resized_tmp_file) # アップロード実行 s3_resource = Aws::S3::Resource.new() object = s3_resource.bucket(ENV['BUCKET_AFTER']).object(key).upload_file(resized_tmp_file) end
handler.rbとvenderをzip化します。
作成したzipファイルのアップロードを行います。
Lambdaコンソール上の関数コード欄アクションから.zipファイルをアップロードをクリック
handler.zipを選択し、保存
2.Lambda環境変数の設定
Lambdaコンソール上からLambda関数内で利用する環境変数を設定します。
3.ハンドラーと実行ロールの設定
どのファイルのどの関数を呼び出すか…という設定は、ハンドラーというパラメータで指示しているとのことなので、
今回作成したLambda関数に合わせて内容を編集します。Lambdaコンソール上の基本設定の
編集をクリック
ハンドラ欄に
実行ファイル名(拡張子除く).関数名の形式で値を入力し保存します。
4.イベントトリガーの定義
Lambdaコンソール上から
トリガーを追加をクリック
今回イベントトリガーとするAWSサービスはS3
トリガーの詳細設定を行います。
今回はimagesディレクトリ内にオブジェクトが作成されたタイミングでのイベント起動とします。
トリガーの有効化をいれることでS3がこのLambda関数に処理をキックすることが可能となります(Lambda関数ポリシーの設定)。
最後に追加をクリック
5.実行ロールの設定
更に今回はリサイズした画像を保存する際にLambdaからS3にアクセスをかける必要があるため、
S3へのアクセス権限付きの実行ロールを付与します。Lambdaコンソール上部にある
アクセス権限をクリック後、実行ロール名をクリック
ポリシーをアタッチしますをクリック
AmazonS3FullAccessを選択後、ポリシーのアタッチ
6.動作検証
イベントソースとして指定したS3のimagesディレクトリ内に任意の画像をアップロードします。
ちなみにアップロードした画像はこちら
リサイズ後の画像保存先として指定したS3を確認したところ、画像が保存されていたのでOKです。
中身もリサイズされていました。
LambdaのログはCloudwatch Logsから確認可能です。
参考にさせて頂いた記事
- 投稿日:2020-08-14T15:24:11+09:00
AWS Device FarmでAppiumを使ったE2Eテストを動かす
これは何?
E2EテストをAppiumとCodeceptJSを使って、AndroidアプリをmacOS上のローカルで、またAWS Device Farmで実行させたときのメモです。(記載日:2020/08)
サンプルコード(サンプルアプリ同梱)を使うことで比較的簡単に再現できるかと思います。1. E2EテストをmacOS上のローカルで実行する
1.1. 環境を準備する
ここ→ appiumとCodeceptJS(node.js)を使ってAndroid & iOSのE2Eテストの実行環境構築 - Qiitaを参考に構築しています。
1.1.1. appium本体とappium-doctorをインストールする
appium-doctorはappiumが正しく動作するように設定されているかをチェックするツールです。
$ npm install -g appium $ npm install -g appium-doctor1.1.2. appium-doctorで動作確認をする
$ appium-doctor --androidサンプルコードを動作させるのが目的の場合
### Diagnostic for necessary dependencies starting ###の項目に全てチェック(✔)が入ればOKです。
以下がappium-doctorの実行時の一例です。バツ印(✖)があるところは、インストール、設定を実行してチェック(✔)になるようにしてください。$ appium-doctor --android info AppiumDoctor Appium Doctor v.1.15.3 info AppiumDoctor ### Diagnostic for necessary dependencies starting ### info AppiumDoctor ✔ The Node.js binary was found at: /Users/ryoya/.nvm/versions/node/v14.4.0/bin/node info AppiumDoctor ✔ Node version is 14.4.0 info AppiumDoctor ✔ ANDROID_HOME is set to: /Users/ryoya/Library/Android/sdk info AppiumDoctor ✔ JAVA_HOME is set to: /Library/Java/JavaVirtualMachines/jdk-14.0.1.jdk/Contents/Home info AppiumDoctor Checking adb, android, emulator info AppiumDoctor 'adb' is in /Users/ryoya/Library/Android/sdk/platform-tools/adb info AppiumDoctor 'android' is in /Users/ryoya/Library/Android/sdk/tools/android info AppiumDoctor 'emulator' is in /Users/ryoya/Library/Android/sdk/emulator/emulator info AppiumDoctor ✔ adb, android, emulator exist: /Users/ryoya/Library/Android/sdk info AppiumDoctor ✔ Bin directory of $JAVA_HOME is set info AppiumDoctor ### Diagnostic for necessary dependencies completed, no fix needed. ### (....略....) info AppiumDoctor Bye! Run appium-doctor again when all manual fixes have been applied! info AppiumDoctor以上で環境の準備は完了です。
1.1.3. サンプルコードをCloneしてNPMパッケージをインストールする
$ git clone https://github.com/ryoyakawai/aws_device_farm_appium.git $ cd uitest_sample_appium $ npm i mocha -D && npm installCloneしたリポジトリについて。
2つのディレクトリがあります。内容は以下の通りです。
aws_devicefarm: AWS Device Farm上で動作させるためのスクリプト等。詳細は「3. E2EテストをAWS Device Farmで実行する」で説明します。uitest_sample_appium: AppiumとCodeceptJSを使ったサンプルのE2Eテストスクリプト。詳細は「2. E2EテストをmacOS上のローカルで実行する」で説明します。1.2. Appiumを実行する
コマンドからAppiumを実行するとTerminalを1つ専有しますのでTerminalは2つ起動しておくことをオススメします。
$ appium1.3. Androidの実機を接続、または仮想マシンを起動しておく
サンプルテストがサンプルアプリをインストールしてテストを実行するAndroidのマシンになります。
1.3.1 デバイスの接続状況を確認する
adb devicesを実行して以下のように、デバイスがリストとして表示されていればOKです。emulator-5554とdeviceが一致している必要はなく、表示されれば準備完了です。以下の例はmacOS上でAndroidのエミューレータを起動したときの表示です。$ adb devices List of devices attached emulator-5554 device1.3.2. CodeceptJSの設定ファイルに実行するマシンを指定する
(ここからは
./uitest_sample_appium以下のファイルについての説明です。)
./uitest_sample_appium/codecept.android.conf.jsonに環境に合わせて指定する項目があるので確認する。(helpers.Appium以下のパラメータ’の詳細はこちら)確認する内容は以下の2つのパラメータ。
helpers.Appium.desiredCapabilities.deviceNamehelpers.Appium.desiredCapabilities.udidデバイスの接続状況を確認するで取得した内容に更新する。同じであれば更新は不要です。
{ "tests": "./test_cases/*_test.js", "output": "./output", "helpers": { "Appium": { "smartWait": 10000, "app_relative": "./lib/uitest_sample_android.apk", "app": "", "desiredCapabilities": { "platformName": "Android", "appWaitForLaunch": true, "deviceName": "device", "udid": "emulator-5554", "automationName": "UiAutomator2", "newCommandTimeout": 120, "appWaitDuration": 60000, "platformVersion": "10" } }, (....以下略....)1.4. E2Eテストを実行する
NPMスクリプトからE2Eテストを実行する。
$ cd uitest_sample_appium $ npm run test:android1.5. E2Eテストの結果を確認する
mochawesomeで
./uitest_sample_appium/output/mochawesome.htmlをインデックスとするHTML形式のレポートも作成されるようになっているのでブラウザで閲覧できる。macOS$ open output/mochawesome.html2. E2EテストをAWS Device Farmで実行する
macOSのローカル環境で実行したE2EテストをAWS Device Farm上で実行します。
2.1. AWSのアカウントを準備する
必要に応じて準備してください。
必要要件はアカウントに以下のポリシーを保持していることです。
arn:aws:iam::aws:policy/AWSDeviceFarmFullAccess2.2. クライアントでAWSへのCLIアクセスを設定する
この辺りを参照して設定するとよいと思います。
2.3. AWS Device Farmの環境を設定する
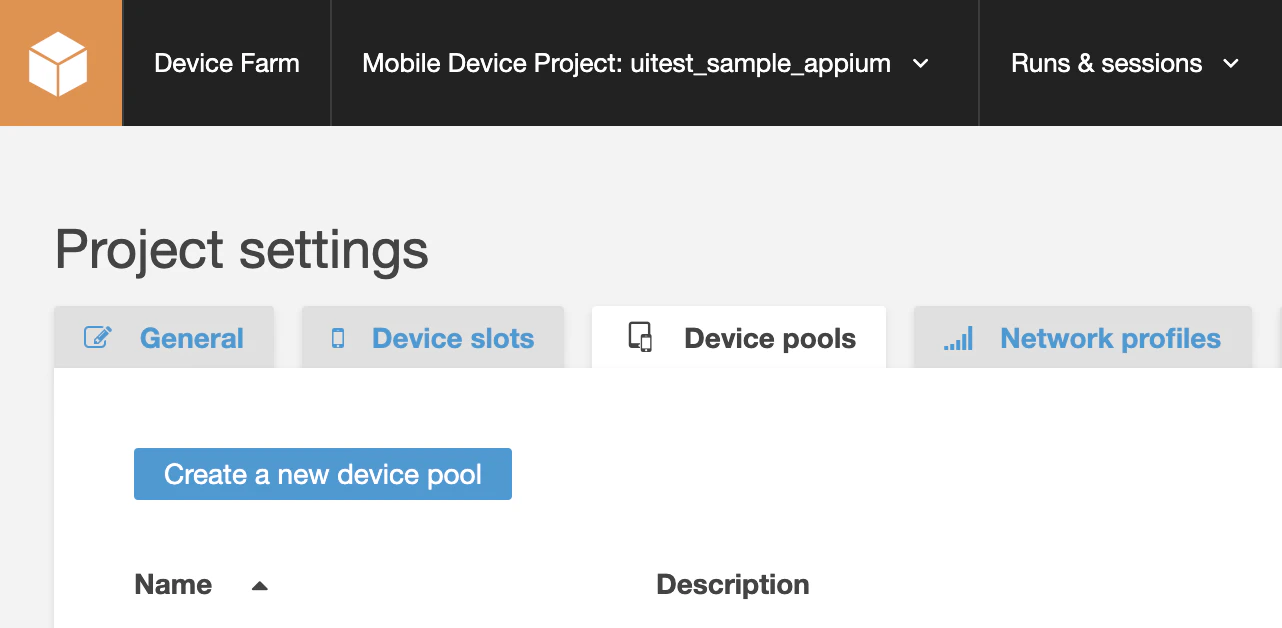
ここからプロジェクトを作成する。
デバイスプール(Device Pool)を作成する。1で作成したプロジェクトのページ右上の「⚙ Project settings」のリンクでプロジェクトの設定ページに遷移する。
遷移先のページで「Device pools」のタブを選択して表示する。
「Create a new device pool」を選択して、Pixel 3 XLのAndroidのOSバージョンは10を選択してデバイスプールを作成する。
2.4. AWSへのアクセス情報を指定する
ここからは
./aws_devicefarm以下のファイルについてお話です。
./aws_devicefarm/scheduletest_config_devicefarm.js
がAWS Device FarmでE2Eテストを実行する為の設定ファイル。
サンプルのテストスクリプトの実行には以下のパラメータの変更が確実に必要になる。
aws_access_user_arn_idaws_access_key_idaws_secret_access_keyaws_devicefarm_project_arnproject_namedevice_pool_nameそれぞれのパラメータの説明は以下の通り。
aws_region
- Device Farmを実行するAWSのRegion。(2020年8月現在は
us-west-2のみで提供)aws_access_user_arn_id
AWSDeviceFarmFullAccessのポリシーを保有するアカウントのIDかARNaws_access_key_id
aws_access_user_arn_idのkey IDaws_secret_access_key
aws_access_user_arn_idのAccessKeyaws_devicefarm_project_arn
- 「AWS Device Farmの環境を設定する」の1で作成したProjectのIDを指定する。
- URLからProject IDを見つける方法。
https://us-west-2.console.aws.amazon.com/devicefarm/home?#/projects/22d13d5c-6e34-4048-xxxx-b3aadbde00bb/runsがURLだとすると22d13d5c-6e34-4048-xxxx-b3aadbde00bbがProject IDとなる。project_name
- 「AWS Device Farmの環境を設定する」の1で指定した名前。
device_pool_name
- 「AWS Device Farmの環境を設定する」の2で作成したDevice Poolの名前
app_file_name_path
- APKファイルを相対パスで指定する。
test_script_file_name_path
- テストスクリプトファイルのディレクトリを相対パスで指定する。
test_spec_file_name_path
- Test Specファイル(AWS Device Farmを動作させる為のファイル)を相対パスで指定する。
2.4. AWS Device Farmで実行する
$ node scheduletest_exec_devicefarm.jsエラーが出ずに完了すれば、AWSのConsoleから動作を確認できるはずです。
2.5. E2Eテストの結果を確認する
指定したプロジェクトは以下のような表示されるはずです。
1つを選択すると、テストで実行したデバイスの一覧から1つ選択をすると動画、実行の結果、ログ出力などを見ることが可能です。
また、Files > Tests の項目内の「Customer Artifacts」からはmochawesomeで作成されたHTML形式のレポートを取得することが可能です。コメント
E2Eテストを手軽に書きたい&手軽に実行したい。そしてできれば開発と平行して実施したいという想いがありました。しかしながら、端末を1台E2Eのテストに費やすのもちょっと・・・と思ったときのAWS Device Farm、またはFirebase Test Labです。Firebase Test Labはブログ記事として書いていましたのでAWS Device Farmも試してみました。そして「E2Eテストを手軽に書く」部分もBDD(Behavior-driven development)で書けるCodeceptJSというのも導入してみました。
CodeceptJSもAWS Device Farmも情報が多いわけでないので苦戦しましたが、一旦動くとなにげに快適でしたので、もし気になったらお試しください。参考サイト




- 投稿日:2020-08-14T14:51:25+09:00
VPC の CIDR を変更する
IPv4 CIDR ブロックが一致または重複する VPC 間で VPC ピアリング接続を作成することはできません。
VPCPeering のために VPC の CIDR の変更をしたいが、既に VPC に紐付いているリソースが作成されていたため削除できない。
以下のリソースを削除することで解決。
- ServiceDiscovery
- EC2
- ALB
- SecurityGroup
- InternetGateway
Memo
Terraform でリソースを削除する場合に以下の設定を false にして削除できるようにする。
aws_instance
- disable_api_termination
ALB
- https://github.com/terraform-aws-modules/terraform-aws-alb
- enable_deletion_protection
その他
- lifecycle.prevent_destroy
- 投稿日:2020-08-14T14:01:38+09:00
Effective AppSync 〜 Serverless Framework を使用した AppSync の実践的な開発方法とテスト戦略 〜
AppSync は AWS が提供するマネージド GraphQL サービスです。Amplify と統合することにより、スキーマさえ宣言すれば GraphQL の Query, Mutation, Subscription コードを自動生成します。バックエンド GraphQL エンドポイントやデータソースを構築し、即座に動く環境が手に入ります。
こちら は過去の記事ですが、リアルタイム掲示板アプリの主要機能を 15 分で作った例を紹介しています。
PoC のように使用する分には Amplify CLI を使用してサクッと開発してしまう方法が効果的ですが、実際のプロダクト開発ではそれだけでは不十分な場合が多いでしょう。複数環境へのデプロイの戦略、テストをどうするか、マイクロサービスバックエンドと接続するにはどのようなパッケージ構成にするべきかなど、課題が山積します。
本記事では AppSync をどのようにテストするべきか、ローカルでどのように開発を行い、CI/CD のフローに乗せていくべきかを考察し、1つの案を提示します。
AppSyncの概要について理解している方は、このあたりから読むとよいかと思います。
なお、サンプルソースは以下のリポジトリにホストしています。Serverless Framework の template として公開していますので、以下コマンドで作成ください。
$ serverless create \ --template-url https://github.com/daisuke-awaji/serverless-appsync-offline-typescript-template \ --path myService
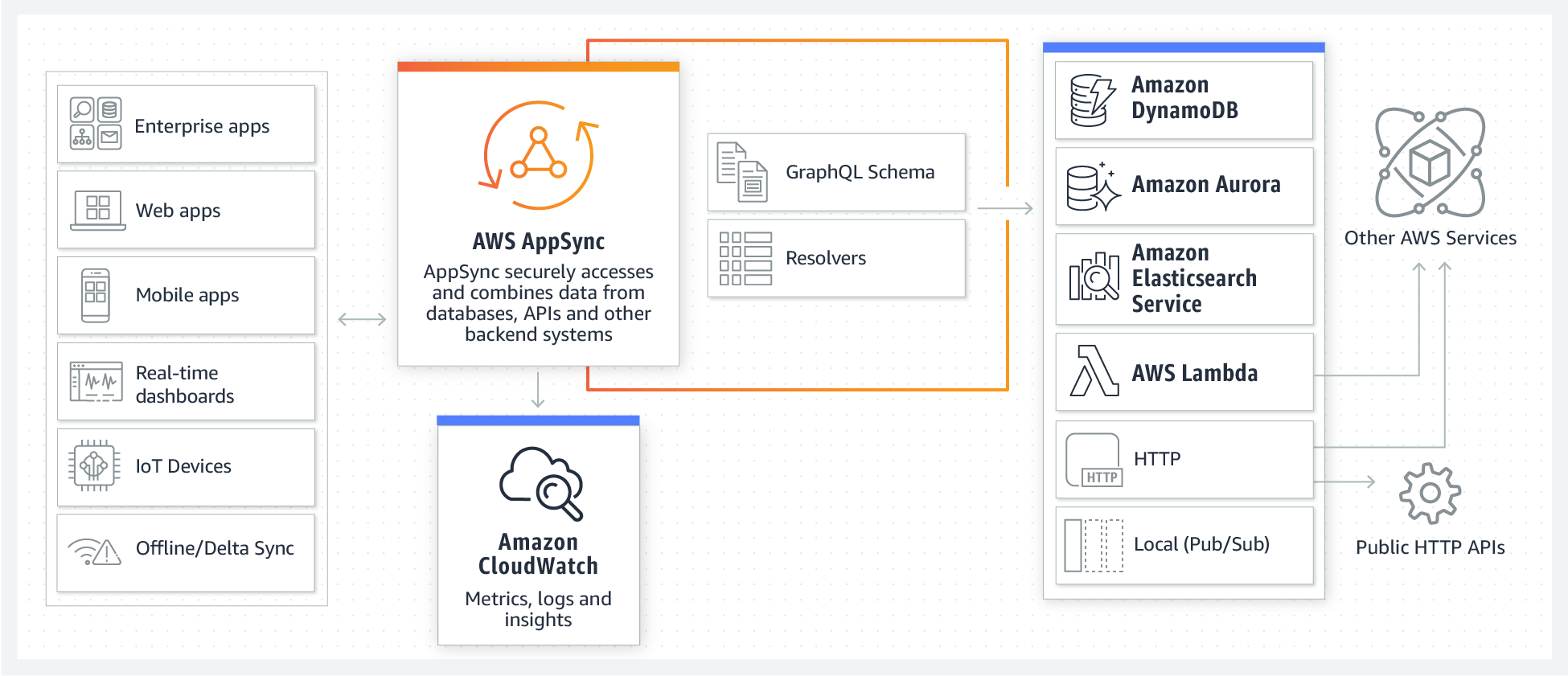
AppSync とは
AppSync は AWS が提供するマネージド GraphQL サービスです。AWS の各種バックエンド(DynamoDB, Aurora, Elasticsearch, Lambda など)とシームレスに結合ができ、すばやく API バックエンドを構築できます。また、Subscription という機能により、複数クライアントが同時編集できる Web アプリケーションや、リアルタイムなチャットアプリを簡単に実現できます。
なぜ GraphQL が求められるのか
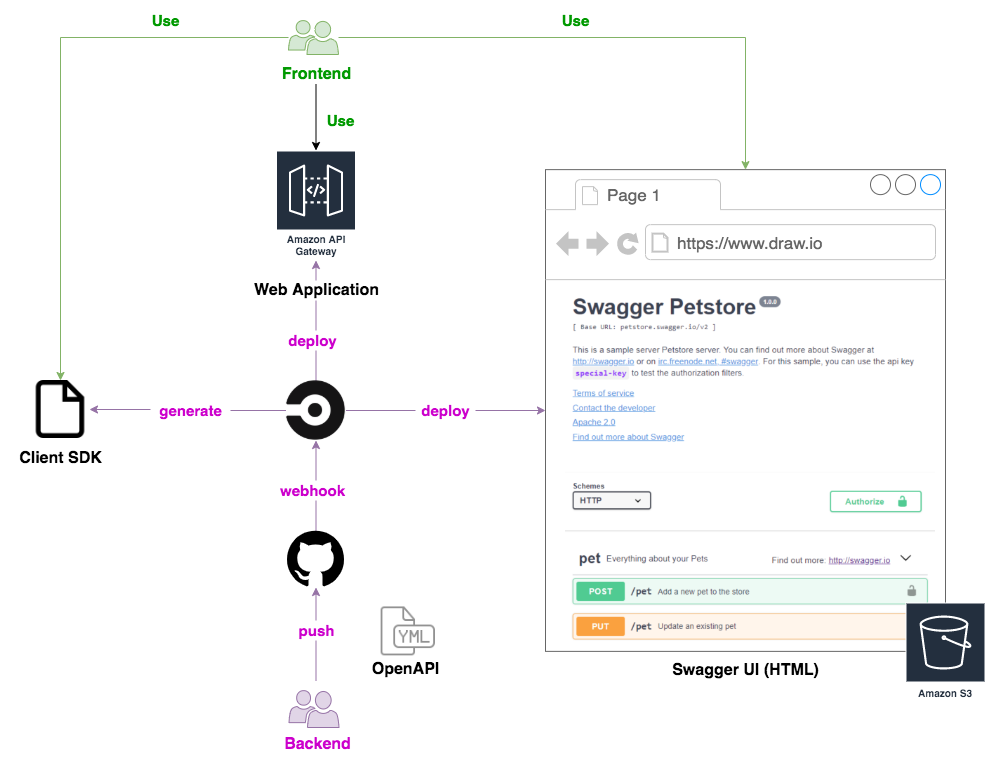
バックエンドに REST API、フロントエンドに React(または Vue.js や Angular)といった構成は一般的でしょう。バックエンドとフロントエンドは Rest の API 定義を互いに共有し、開発を進めます。有名なツールとして OpenAPI があります。OpenAPI による定義を介することで、私たちは以下のような恩恵を得ることができました。
OpenAPI による恩恵
- API 定義を YAML 形式のファイルで管理する
- HTML 形式の API ドキュメントを自動生成する
- API 定義をコミュニケーションのハブとし、フロントエンドとバックエンドの開発体制を分離する
- OpenAPI 定義からフロントエンドで使用する API コール用のコードを自動生成する
- バックエンドのバリデーションは OpenAPI 定義から自動生成する
- バックエンドのモックサーバを自動構築する
コードを自動生成するツールは、以下の openapi-generator が有名です。
REST API 開発の課題
OpenAPI とそのエコシステムの登場によって、REST API 開発は随分と楽になりましたが、依然として課題は残り続けるものです。REST API 開発における課題には以下のようなものが挙げられます。
- API の叩き方が決まっていない(API によって自由に決められてしまう)
- 1ページ表示するために、いくつも API を実行しなければいけない。
- 不要なフィールドまで API で取得してしまう。
REST という思想は素晴らしいですが、リソースベースにアプリケーションを作成していくとどうしてもこのような課題が発生します。フロントエンドは必要なデータを必要なだけ1クエリで取得したい。バックエンドは必要なデータを素早く漏れなく提供したいのです。
GraphQL が解決すること
REST API 開発の課題を解決するために GraphQL は誕生しました。
ちょうど Web 業界全体がモバイルにシフトしていた頃の話です。2012 年 2 月に、Facebook のエンジニアが GraphQL の最初のプロトタイプをチームに共有した時には最高にクールな瞬間だったでしょう。GraphQL: The Documentary というドキュメンタリーが製作されています。
GraphQL は以下のような特徴を持っており、REST API 開発の課題を解決します。
- スキーマとよばれる API の型定義により、フロントエンドとバックエンドがコミュニケーションをとる。
- クライアントは /graphql という単一のエンドポイントにアクセスすることでクリーンなインタフェースを保つ。
- クライアントが指定したフィールドだけを取得する。
- サブスクリプションを使用してリアルタイム処理を行う。
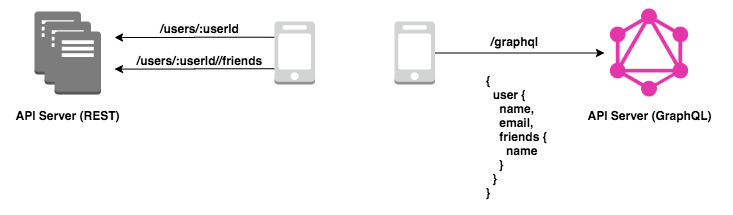
GraphQL を使用することでフロントエンドは必要なデータを必要なだけ1クエリで取得できるようになります。例えば以下の例では、SNS アプリケーションにおいて、ユーザと友達の情報を取得する場合のリクエストを表しています。
REST の場合、ユーザ1件取得の API(/uesrs/:userId)と友達一覧取得の API(/users/:userId/friends)の2つを呼び出しています。レスポンスには画面に表示する必要のない不必要なフィールドも含まれるのでしょう。一方で GraphQL の場合は必要なフィールドをネスト構造で指定し、1リクエストで画面表示に必要な情報を取得しています。
AppSync の役割
GraphQL は優れたソリューションですが、自前で構築するにはいくらかの苦労を伴います。
- 認証、認可処理を記述する。
- 各種バックエンドデータソースにアクセスするリゾルバーを作成する。
- WebSocket を使用するため、GraphQL サーバがスケールしても問題ないように、Redis などのデータストアを用意する。
- グローバルにエラーハンドリングして Node アプリケーションが落ちないように配慮する。
- ログを出力する。
- etc...(その他の数えきれない苦労)
AppSync は上記の苦労を限りなく少なくできます。例えば、認証・認可処理は Cognito UserPool と連携できますし、サーバのスケーラビリティは意識する必要がありません。ログ出力も標準搭載されており、INFO や ERROR などのレベルに応じて出力する設定ができます(もちろん CloudWatchLogs に出力されます)
AppSync の基本
AppSync の構成要素は大きく分けて、以下の3つです。
- Schema
- DataSource
- Resolver
GraphQL の型は Schema として宣言します。Resolver は GraphQL リクエストを Resolver リクエストに変換します。この Resolver に実質的なロジックが集約することになります。Resolver リクエストは、DataSource にアクセスし、データをクライアントに返却します。
一部、公式ドキュメントより抜粋しています。
Schema / スキーマ
各 GraphQL API は単一の GraphQL スキーマで定義されます。以下はスキーマの例です。
type Task { id: ID! name: String! status: String! } type Query { getTask(id: ID!, status: String!): Task }DataSource / データソース
データソースは、GraphQL API で操作できる AWS アカウント内のリソースです。AWS AppSync は、以下をデータソースとしてサポートしています。
- AWS Lambda
- Amazon DynamoDB
- リレーショナルデータベース (Amazon Aurora Serverless)
- Amazon Elasticsearch Service
- HTTP エンドポイント
AWS AppSync API は、複数のデータソースを操作するよう設定できます。これにより、単一の場所にデータを集約できます。
Resolver / リゾルバー
GraphQL リゾルバーは、タイプのスキーマのフィールドをデータソースに接続します。リゾルバーはリクエストを実行するメカニズムです。
AWS AppSync のリゾルバーは、Apache Velocity Template Language (VTL) で記述されたマッピングテンプレートを使用して、GraphQL 表現をデータソースで使用できる形式に変換します。
AppSync を構築するいくつかの方法
さて、そろそろ本題に移ります。AppSync を構築するためにはいくつかの方法があるでしょう。
方法 メリット デメリット AWS コンソール画面から作成 直感的なインタフェースで作成でき、簡単に検証できる 複数の環境に全く同じ構成で構築しづらい
デリバリーを自動化できないAWS CLI デリバリーを自動化できる 冪等性を持たないので、エラー発生時にリカバリが困難 AWS CloudFormation デリバリーを自動化できる
冪等性があり、エラー発生時に元の状態にもどるスキーマ定義ファイルを S3 に配置するなどの手間が多い
YAML のコード量が多すぎるAmplify CLI デリバリーを自動化できる
Cloudformation のコードを自動生成、即座に環境構築ができる
冪等性があり、エラー発生時に元の状態にもどるamplify コマンドが抽象化しすぎていて、何かあった時に解決が困難
Amplify CLI の学習コスト(かなり独特な使い心地)
ローカルでテストできるツールセットが少ないServerless Framework デリバリーを自動化できる
適度に抽象化しており、細部まで定義しようと思えば全てを記述できる
冪等性があり、エラー発生時に元の状態にもどる
ローカルでテストできるツールセットが豊富Serverless Framework の学習コスト(そんなにない)
それぞれ、開発するプロダクトの特性に合わせて選定すべきです。たとえば PoC 的にプロトタイプをすぐに作りたいのなら AWS コンソール画面から作成 するか Amplify CLI を使用する方法が良いでしょう。 プロダクションでの使用を見据えてテスト環境やステージング複数など、複数の環境にデプロイする必要があるのなら AWS CloudFormation か Serverless Framework の使用をお勧めします。
本記事では、AppSync をローカルでテストする方法を紹介するために、Serverless Framework を使用した開発方法をガイドします。
Serverless Framework for Appsync
Serverless Framework を使用して AppSync を構築するためには以下の2通りの方法があります。
Serverless AppSync Plugin
Serverless Framework のプラグインです。ローカルの schema.graphql や mapping-template を参照し、AppSync をデプロイします。Serverless Components / aws-app-sync
Serverless Components の AppSync コンポーネントです。最小限のコード量で AppSync に加えて、カスタムドメインまでついた意味のある単位のリソース群をデプロイします。本記事では Serverless AppSync Plugin の方法を説明します。基本的な Serverless Framework の使用方法は割愛します。公式のドキュメントか、堀家 さんの記事「Serverless Framework の使い方まとめ」がとてもわかりやすく説明されていますので。そちらをご参照ください。
Serverless AppSync Plugin
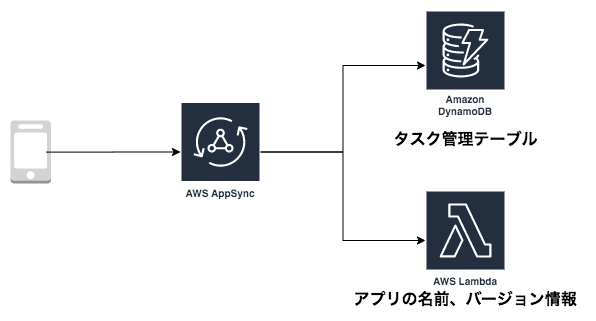
Serverless AppSync Plugin を使用して、DynamoDB と Lambda をデータソースとした AppSync を作成していきます。Serverless AppSync Plugin はその他に、Elasticsearch や HTTP データソースもサポートしています。
タスク管理アプリを想定した AppSync を実装します。タスク情報は DynamoDB テーブルにストアされ、各種 CRUD 操作ができます。アプリケーションのバージョンや名前の情報は Lambda が返却する構成にしています。
以下のような しょぼTrello のようなアプリケーションのバックエンドになります。
Serverless プロジェクトを開始する
まずは Serverless Framework の AWS/TypeScript ボイラーテンプレートからプロジェクトのひな形を作ります。
$ serverless create --template aws-nodejs-typescriptlulzneko さんの「Serverless Framework と TypeScript でサーバレス開発事始め
」という記事でとても分かりやすく説明されています。Serverless AppSync Plugin のインストール
プラグインを yarn インストールします。
$ yarn add serverless-appsync-pluginnpm を使用しても良いですが、yarn が推奨されています。
$ npm install serverless-appsync-pluginプラグインの設定
serverless.yml にプラグインを追加します。
serverless.ymlplugins: - serverless-webpack - serverless-appsync-plugin # これを追加custom 配下に appSync の設定を記載します。必要最小限しか説明していないので、詳しくは公式ドキュメントを参照ください。
serverless.ymlcustom: dynamodb: stages: - dev - stg - prod start: port: 8000 inMemory: true appSync: # AppSync API の名前 name: ${opt:stage, self:provider.stage}_taskboard_backend # 認証方式 今回は Cognito を使用する authenticationType: AMAZON_COGNITO_USER_POOLS userPoolConfig: awsRegion: ap-northeast-1 userPoolId: ap-northeast-1_XXXXXXXXX defaultAction: ALLOW # スキーマファイル 複数指定することも可能 schema: schema.graphql # データソース 今回は DynamoDB と Lambda を使用する dataSources: - type: AMAZON_DYNAMODB name: ${opt:stage, self:provider.stage}_task description: タスク管理テーブル config: tableName: { Ref: Table } serviceRoleArn: { Fn::GetAtt: [AppSyncDynamoDBServiceRole, Arn] } region: ap-northeast-1 - type: AWS_LAMBDA name: ${opt:stage, self:provider.stage}_appInfo description: "Lambda DataSource for appInfo" config: functionName: appInfo iamRoleStatements: - Effect: "Allow" Action: - "lambda:invokeFunction" Resource: - "*" # マッピングテンプレートファイルを格納しているディレクトリ mappingTemplatesLocation: mapping-templates mappingTemplates: # アプリケーションの情報を取得する - dataSource: ${opt:stage, self:provider.stage}_appInfo # dataSources で定義したデータソース名を指定 type: Query field: appInfo request: Query.appInfo.request.vtl response: Query.appInfo.response.vtl # タスク情報を1件取得する - type: Query field: getTask kind: PIPELINE # AppSync の関数を使ってパイプラインリゾルバを使う場合 request: "start.vtl" response: "end.vtl" functions: - getTask # functionConfigurations で定義した関数名を指定 # タスク情報を複数件取得する - dataSource: ${opt:stage, self:provider.stage}_task type: Query field: listTasks request: "Query.listTasks.request.vtl" response: "Query.listTasks.response.vtl" # タスク情報を作成する - dataSource: ${opt:stage, self:provider.stage}_task type: Mutation field: createTask request: "Mutation.createTask.request.vtl" response: "end.vtl" # タスク情報を更新する - dataSource: ${opt:stage, self:provider.stage}_task type: Mutation field: updateTask request: "Mutation.updateTask.request.vtl" response: "end.vtl" # タスク情報を削除する - dataSource: ${opt:stage, self:provider.stage}_task type: Mutation field: deleteTask request: "Mutation.deleteTask.request.vtl" response: "end.vtl" # AppSync の関数 functionConfigurations: - dataSource: ${opt:stage, self:provider.stage}_task name: "getTask" request: "getTask.request.vtl" response: "getTask.response.vtl" # Lambda Function は通常の Serverless Framework の使い方と一緒 functions: appInfo: handler: src/functions/handler.appInfo name: ${opt:stage, self:provider.stage}_appInfo resources: Resources: Table: Type: AWS::DynamoDB::Table Properties: TableName: ${opt:stage, self:provider.stage}_task AttributeDefinitions: - AttributeName: id AttributeType: S - AttributeName: status AttributeType: S KeySchema: - AttributeName: id KeyType: HASH - AttributeName: status KeyType: RANGE ProvisionedThroughput: ReadCapacityUnits: 5 WriteCapacityUnits: 5 # AppSync が DynamoDB を操作できるロール AppSyncDynamoDBServiceRole: Type: "AWS::IAM::Role" Properties: RoleName: ${opt:stage, self:provider.stage}-appsync-dynamodb-role AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "appsync.amazonaws.com" Action: - "sts:AssumeRole" Policies: - PolicyName: "dynamo-policy" PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: - "dynamodb:Query" - "dynamodb:BatchWriteItem" - "dynamodb:GetItem" - "dynamodb:DeleteItem" - "dynamodb:PutItem" - "dynamodb:Scan" - "dynamodb:UpdateItem" Resource: - "*"schema.graphql および、mapping-templates は以下のとおりです(コード量が多いので折りたたんでいます)。サンプルソース全体は こちらの GitHub リポジトリを参照ください。
schema.graphql と mapping-templates 配下の VTL ファイル
schema.graphqltype AppInfo { name: String! version: String! } type Task { id: ID! name: String! status: String! } type Query { appInfo: AppInfo getTask(id: ID!, status: String!): Task listTasks( filter: ModelTaskFilterInput limit: Int nextToken: String ): ListTasks } input ModelTaskFilterInput { id: ModelIDInput name: ModelStringInput and: [ModelTaskFilterInput] or: [ModelTaskFilterInput] not: ModelTaskFilterInput } type ListTasks { tasks: [Task] nextToken: String } type Mutation { createTask(input: CreateTaskInput!, condition: ModelTaskConditionInput): Task updateTask(input: UpdateTaskInput!, condition: ModelTaskConditionInput): Task deleteTask(input: DeleteTaskInput!, condition: ModelTaskConditionInput): Task } input CreateTaskInput { id: ID name: String! status: String! } input UpdateTaskInput { id: ID! name: String status: String } input DeleteTaskInput { id: ID! status: String! } input ModelTaskConditionInput { name: ModelStringInput and: [ModelTaskConditionInput] or: [ModelTaskConditionInput] not: ModelTaskConditionInput } # 以下、AppSyncとDynamoDBで使用可能な GraphQL Schema の共通定義 input ModelIDInput { ne: ID eq: ID le: ID lt: ID ge: ID gt: ID contains: ID notContains: ID between: [ID] beginsWith: ID attributeExists: Boolean attributeType: ModelAttributeTypes size: ModelSizeInput } enum ModelAttributeTypes { binary binarySet bool list map number numberSet string stringSet _null } input ModelBooleanInput { ne: Boolean eq: Boolean attributeExists: Boolean attributeType: ModelAttributeTypes } input ModelFloatInput { ne: Float eq: Float le: Float lt: Float ge: Float gt: Float between: [Float] attributeExists: Boolean attributeType: ModelAttributeTypes } input ModelIntInput { ne: Int eq: Int le: Int lt: Int ge: Int gt: Int between: [Int] attributeExists: Boolean attributeType: ModelAttributeTypes } input ModelSizeInput { ne: Int eq: Int le: Int lt: Int ge: Int gt: Int between: [Int] } enum ModelSortDirection { ASC DESC } input ModelStringInput { ne: String eq: String le: String lt: String ge: String gt: String contains: String notContains: String between: [String] beginsWith: String attributeExists: Boolean attributeType: ModelAttributeTypes size: ModelSizeInput }getTask.request.vtl{ "version": "2018-05-29", "operation": "GetItem", "key": { "id": $util.dynamodb.toDynamoDBJson($ctx.args.id), "status": $util.dynamodb.toDynamoDBJson($context.args.status) } }getTask.response.vtl$util.toJson($ctx.result)
デプロイ
あとはいつも通り、
serverless deployコマンドでリソースを構築します。$ serverless deployAppSync をテストする
Serverless Framework を使用して AppSync をデプロイできました。次はテストです。もちろん、AWS 上にデプロイした AppSync に対して Query を実行したり、Mutation を実行してデータを登録しても良いでしょう。ただしその場合、チーム開発は非常に難しくなります。データを共有しなければいけなくなりますし、そもそもユニットテストのようなものは書けません。Web 開発において私たちはこの課題をどう解決するかを知っています。ローカルで AppSync, DynamoDB, Lambda を起動し、データを登録し、API を実行してデータを取得 できる環境を用意すれば良いのです。
Serverless AppSync Simulator
Amplify CLI はローカルで AppSync を起動するシミュレータを提供しています。
新機能 – Amplify CLI を使用したローカルモックとテスト
$ amplify mock apiというコマンドを実行すると、ローカル環境に AppSync の API エンドポイント(シミュレータ)と、GrapiQl が起動します。
この機能は内部的には amplify-appsync-simulator
というパッケージを使用しています。これをラップする形で serverless-appsync-simulator という Serverless Framework のプラグインが公開されているので、こちらを使用します。
使用方法
DynamoDB リゾルバーを使用する場合、DynamoDB をローカルで立ち上げるので、
serverless-dynamodb-localプラグインも必要になります。
serverless.yml には以下のように記述しましょう。serverless.ymlplugins: - serverless-webpack - serverless-appsync-plugin - serverless-dynamodb-local - serverless-appsync-simulator # serverless-offline よりも上に記述する必要があります - serverless-offlineLambda Resolver のために、Lambda Function を実装します。Webpack を使用して nodejs あるいは TypeScript のソースをコンパイルする場合、 ビルド済みのファイルが ./webpack/service に展開されます。以下の設定を忘れないようにしましょう。
serverless.ymlcustom: appsync-simulator: location: ".webpack/service"起動するには以下のコマンドを使用します。package.json に npm-scripts を登録しておくと便利です。
$ sls offline start起動すると、以下のようなログが出力されます。
... Serverless: AppSync endpoint: http://localhost:20002/graphql Serverless: GraphiQl: http://localhost:20002 ...早速ローカルで起動した GrapiQl の画面を開いてみましょう。1回のリクエストで複数のリゾルバーが起動し、レスポンスを返却していることがわかります。
GraphQL リクエストをテストする
ローカルで AppSync のシミュレータを起動できたので、テストを記述していきます。テストのアプローチの方法は至極単純です。
- DynamoDB にデータを用意し
- GraphQL リクエストを実行すると
- 想定通りの結果が取得できること
を確認します。
GraphQL リクエストのテスト領域
テストの対象を図示すると以下のようになります。GrqphQL のリクエストとレスポンスをテストします。これはインテグレーションテストに相当します。
DynamoDB Local の seed データ
serverless-dynamodb-local には seed データを作成する機能があります。この機能を利用してもいいですね。
以下のように serverless.yml に追記します。
serverless.ymlcustom: dynamodb: stages: - dev start: port: 8000 inMemory: true migrate: true # DynamoDB Local 起動時にテーブルを作成する seed: true # DynamoDB Local 起動時にシードデータを挿入する seed: dev: sources: - table: ${self:provider.stage}_task # dev_task というテーブル名を想定している sources: [./migrations/tasks.json]
migrations/tasks.jsonには以下のように記述しておくことで、DynamoDB Local が起動した際にデータが自動的に挿入されます。migrations/tasks.json[ { "id": "1", "name": "掃除をする", "status": "NoStatus" }, { "id": "2", "name": "選択をする", "status": "InProgress" }, { "id": "3", "name": "宿題をする", "status": "Done" } ]Jest を使用してテストを行う
Jest を使用してテストを記述します。Cognito UserPool を使用している場合、リクエスト時に Authorization ヘッダーが必要です。ローカルで動かす際には形式さえ合っていればなんでも良いようです。API キーを必要としている場合は
x-api-keyというヘッダーを指定する必要があります。graphql-operation.test.tsimport { GraphQLClient, gql } from "graphql-request"; import { getTask } from "./query"; import { createTask, deleteTask } from "./mutation"; const client = new GraphQLClient("http://localhost:20002/graphql", { headers: { // format さえ合っていればなんでもいいようです Authorization: "euJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiI3ZDhjYTUyOC00OTMxLTQyNTQtOTI3My1lYTVlZTg1M2YyNzEiLCJlbWFpbF92ZXJpZmllZCI6dHJ1ZSwiaXNzIjoiaHR0cHM6Ly9jb2duaXRvLWlkcC51cy1lYXN0LTEuYW1hem9uYXdzLmNvbS91cy1lYXN0LTFfZmFrZSIsInBob25lX251bWJlcl92ZXJpZmllZCI6dHJ1ZSwiY29nbml0bzp1c2VybmFtZSI6InVzZXIxIiwiYXVkIjoiMmhpZmEwOTZiM2EyNG12bTNwaHNrdWFxaTMiLCJldmVudF9pZCI6ImIxMmEzZTJmLTdhMzYtNDkzYy04NWIzLTIwZDgxOGJkNzhhMSIsInRva2VuX3VzZSI6ImlkIiwiYXV0aF90aW1lIjoxOTc0MjY0NDEyLCJwaG9uZV9udW1iZXIiOiIrMTIwNjIwNjIwMTYiLCJleHAiOjE1OTY5NDE2MjkwLCJpYXQiOjE1NjQyNjQ0MTMsImVtYWlsIjoidXNlckBkb21haW4uY29tIn0.mKvvVDRN07IvChh1uHloKz5NdUe2bRu6fyPOpzVbE_M", }, }); describe("dynamodb resolver", () => { test("createTask / getTask by id and status / deleteTask", async () => { const valiables = { id: "123456789", name: "新しいタスク", status: "NoStatus", }; // 新規にデータを作成する const created = await client.request(createTask, valiables); expect(created).toStrictEqual({ createTask: valiables }); // 作成したデータが取得できる const got = await client.request(getTask, { id: valiables.id, status: valiables.status, }); expect(got.getTask).toEqual(valiables); // データが削除できる const deleted = await client.request(deleteTask, { id: valiables.id, status: valiables.status, }); expect(deleted).toStrictEqual({ deleteTask: valiables }); }); });ちなみに、データ作成・削除のミューテーションおよび、タスクデータを取得するクエリは以下のように作成しています。フロントエンドで使用できるように、クエリ、ミューテーション、サブスクリプションのソースはライブラリとして開発しておくとベターでしょう。
mutation.tsimport { gql } from "graphql-request"; export const createTask = gql` mutation create($id: ID!, $name: String!, $status: String!) { createTask(input: { id: $id, name: $name, status: $status }) { id name status } } `; export const deleteTask = gql` mutation delete($id: ID!, $status: String!) { deleteTask(input: { id: $id, status: $status }) { id name status } } `;query.tsimport { gql } from "graphql-request"; export const getTask = gql` query getTask($id: ID!, $status: String!) { getTask(id: $id, status: $status) { id name status } } `;VTL をテストする
AppSync は各リゾルバーにリクエスト処理を流す際に VTL(Velocity Template Language) を使用してクライアントからの GraphQL リクエストを、データソースへのリクエストに変換します。
認可処理(Cognito の UserGroup が Admin だったら実行できるようにするなど)、入力パラメータのバリデーション、パラメータの変換処理(大文字にするなど)など様々なビジネスロジックを VTL に記述することになります。この VTL ファイルが AppSync のサーバサイドの機能(関数)という位置付けになります。VTL テストの領域
GraphQL リクエストをテストする方法はインテグレーションテストのレイヤーでした。クライアントからのリクエストとレスポンスを検証するため、複雑な VTL を記述した場合、テストの網羅性を担保することが難しくなります。
VTL 単体でのユニットテストを検討しましょう。
テストの対象を図示すると以下のようになります。GrqphQL のリクエストとそれによって生成されるリゾルバーリクエストを検証します。
VTL のテストのためにヘルパー関数を作成する
VTL によって生成されるリゾルバーリクエストを検証するために、以下のようなヘルパー関数を用意しておきます。
amplify-velocity-template本体が提供しているCompileなどを使用します。vtl.helper.tsimport * as fs from "fs"; import * as path from "path"; import { Compile, parse } from "amplify-velocity-template"; import { map } from "amplify-appsync-simulator/lib/velocity/value-mapper/mapper"; import * as utils from "amplify-appsync-simulator/lib/velocity/util"; /** * VTLファイル内で展開される context を作成する */ const createVtlContext = <T>(args: T) => { const util = utils.create([], new Date(Date.now()), Object()); const context = { args, arguments: args, }; return { util, utils: util, ctx: context, context, }; }; /** * 指定パスのファイルを参照し、入力パラメータをもとに、vtlファイルによりマッピングされたリゾルバリクエストJSONをロードする */ const vtlLoader = (filePath: string, args: any) => { const vtlPath = path.resolve(__dirname, filePath); const vtl = parse(fs.readFileSync(vtlPath, { encoding: "utf8" })); const compiler = new Compile(vtl, { valueMapper: map, escape: false }); const context = createVtlContext(args); const result = JSON.parse(compiler.render(context)); return result; };VTL テストを実行する
まずはシンプルな
getTask.request.vtlというファイルをテストする方法を考えます。このファイルは入力値を元に DynamoDB に対してidとstatusという一意なキー検索を行うリクエストを発行します(id はプライマリーキー、status はソートキー)getTask.request.vtl{ "version": "2018-05-29", "operation": "GetItem", "key": { "id": $util.dynamodb.toDynamoDBJson($ctx.args.id), "status": $util.dynamodb.toDynamoDBJson($context.args.status) } }
getTask.request.vtlのテストです。GraphQL リクエストの引数を args として与え、生成されるリゾルバーリクエストの JSON を検証しています。getTask.resolver.test.tstest("getTask.request.vtl", () => { const args = { id: "000", status: "InProgress", }; const result = vtlLoader("../mapping-templates/getTask.request.vtl", args); expect(result).toStrictEqual({ version: "2018-05-29", operation: "GetItem", key: { id: { S: "000" }, status: { S: "InProgress" }, }, }); });ID 指定で1件取得するリゾルバーはシンプルすぎますね。次に
Mutation.createTask.req.vtlをみていきましょう。これは指定したパラメータをもとに、1件データを登録する処理です。Mutation.createTask.req.vtl## [Start] Prepare DynamoDB PutItem Request. ** $util.qr($context.args.input.put("createdAt", $util.defaultIfNull($ctx.args.input.createdAt, $util.time.nowISO8601()))) $util.qr($context.args.input.put("updatedAt", $util.defaultIfNull($ctx.args.input.updatedAt, $util.time.nowISO8601()))) $util.qr($context.args.input.put("__typename", "Task")) #set( $condition = { "expression": "attribute_not_exists(#id)", "expressionNames": { "#id": "id" } } ) #if( $context.args.condition ) #set( $condition.expressionValues = {} ) #set( $conditionFilterExpressions = $util.parseJson($util.transform.toDynamoDBConditionExpression($context.args.condition)) ) $util.qr($condition.put("expression", "($condition.expression) AND $conditionFilterExpressions.expression")) $util.qr($condition.expressionNames.putAll($conditionFilterExpressions.expressionNames)) $util.qr($condition.expressionValues.putAll($conditionFilterExpressions.expressionValues)) #end #if( $condition.expressionValues && $condition.expressionValues.size() == 0 ) #set( $condition = { "expression": $condition.expression, "expressionNames": $condition.expressionNames } ) #end { "version": "2017-02-28", "operation": "PutItem", "key": { "id": $util.dynamodb.toDynamoDBJson($util.defaultIfNullOrBlank($ctx.args.input.id, $util.autoId())), "status": $util.dynamodb.toDynamoDBJson($context.args.input.status) }, "attributeValues": $util.dynamodb.toMapValuesJson($context.args.input), "condition": $util.toJson($condition) } ## [End] Prepare DynamoDB PutItem Request. **複雑になってきました。入力として
condition(条件)を与えていたり、DynamoDB に登録する前処理としてcreatedAtやupdatedAtなどのフィールドを追加しています。このような複雑なロジックが組み込まれた VTL を単体でユニットテストできるのは非常に効果的です。以下テストコードで、
createdAtやupdatedAtなどのフィールドが正常に追加されているか確認します。※ 現在時刻が設定されるのでexpect.anything()を使用して曖昧な判定にしています。createTask.resolver.test.tstest("Mutation.createTask.req.vtl / expect attributeValues: createdAt, updateAt etc...", () => { const args = { input: { id: "001", name: "study", status: "InProgress", }, }; const result = vtlLoader("../mapping-templates/Mutation.createTask.req.vtl", args); expect(result).toEqual({ version: "2017-02-28", operation: "PutItem", key: { id: { S: "001" }, status: { S: "InProgress" }, }, attributeValues: { __typename: { S: "Task", }, createdAt: { S: expect.anything(), }, id: { S: "001", }, name: { S: "study", }, status: { S: "InProgress", }, updatedAt: { S: expect.anything(), }, }, condition: { expression: "attribute_not_exists(#id)", expressionNames: { "#id": "id", }, }, });CircleCI を使用してテストする
これまで実装してきたことを CircleCI 上で実行します。
CircleCI の最大の魅力である orbs を使いましょう。serverless-framework-orb が使用できます。
ただし、今回使用する DynamoDB Local は Java 製なので、ちょっと工夫が必要です。この orbs で使用される Docker イメージには nodejs, Python しか入っていないので Java をインストールしましょう。OpenJDK が入れられれば十分です。
.circleci/config.ymlは以下のようになります。circleci/config.ymlversion: 2.1 orbs: aws-cli: circleci/aws-cli@1.0 serverless: circleci/serverless-framework@1.0 jobs: build: docker: - image: circleci/node:12 steps: - checkout - run: name: install dependencies command: yarn install test: executor: serverless/default steps: - checkout - run: name: apt update command: sudo apt update - run: name: apt install java command: sudo apt install openjdk-8-jdk - run: name: install dependencies command: yarn install - run: name: setup for dynamodb local command: yarn sls:setup - run: name: unit test command: yarn ci workflows: version: 2 build_and_test: jobs: - build - test
package.jsonの npm-scripts はこのように記述しています。package.json"scripts": { "sls:setup": "sls dynamodb install", "start": "sls offline start", "test": "jest", "start-server": "yarn start", "ci": "start-server-and-test start-server http://localhost:20002 test" },AppSync Simulator の起動を待つ必要があるため、
start-server-and-testを使用しています。このライブラリを使用することで、http でリクエストを受け付けるサービスが起動したことを検知して、次の処理を実行できます。この仕組みを利用して、以下の一連の流れを実施します。
- AppSync Simulator を起動する。
- テストを実行する。
- AppSync Simulator を停止する。
デリバリの戦略
今回デリバリする対象の環境は
dev,stg,prodの3つとします。
それぞれ以下のような用途を想定しています。
- dev: テスト環境
- stg: ステージング環境(本番環境と同等のスペック)
- prod: 本番環境
以下のようにステージごとに参照できる変数を定義します。
serverless.ymlcustom: stages: dev: userPoolId: ap-northeast-1_XXXXXXXXX stg: userPoolId: ap-northeast-1_YYYYYYYYY prod: userPoolId: ap-northeast-1_ZZZZZZZZZ以下のように参照して使用できます。
serverless.ymluserPoolId: ${self:custom.stages.${opt:stage}.userPoolId}このようにしておくことで、ステージを指定してことなるパラメータを読み込み、デプロイできるようになります。
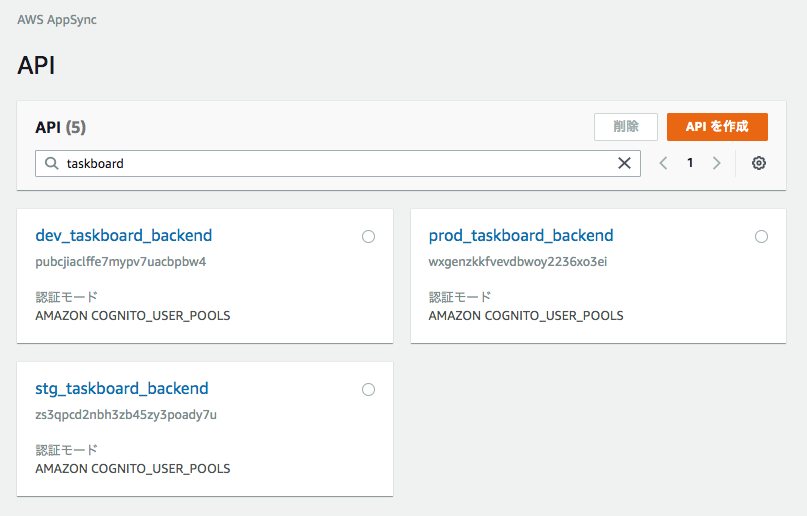
$ sls deploy --stage devCloudForamtion マネジメントコンソール画面
AppSync マネジメントコンソール画面
複数環境にデプロイできています。実際のユースケースでは、本番環境だけ AWS 環境を分離しておくという方法を採用するかもしれません。その場合は @kudedasumnさんの「CircleCI で複数の AWS アカウントを扱う方法」という記事が大変参考になります。
まとめ
AppSync をローカルで開発し、テストする。また、CircleCI 上でテストを行い、複数の環境にデプロイする方法を説明しました。AppSync をはじめとし、GraphQL はモバイルや IoT など、すべてのデバイスがインターネットに接続し、相互作用する現代のアプリケーションにおいて必須ともいえる技術要素です。これからも GraphQL 関連のエコシステムは継続的にウォッチし、コミットしていきたいですね。











- 投稿日:2020-08-14T13:49:00+09:00
お名前ドットコムのメール無視してたら制限かけられた話
awsでデプロイしてお名前ドットコムとroute53使ってドメイン取得したから就活するぞー!!!って息巻いていたらサイトにアクセス出来なくなってしまった話です。
結論
お名前ドットコムから送られてくる証人メールを無視していた事
たったこれだけです!!!くだらない!!!
もし初学者がデプロイしてこの画面になったらawsではなくメールを確認して見て欲しい。お名前ドットコムから重要メールがきているはずです。それを確認さえすればこんな事は起きないので!!何故起きたのか
言い訳にしかなりませんが、きっとお名前ドットコムさんからのメールがしつこいからです。ただの責任転嫁です。
ほぼ毎日スパムかよ!ってほどのメールが送られてくるのでメールを確認する前に開封済みにしていたため重要メールすらも無視してしまったのです。どうすれば防げたか
メールの確認!これだけです。ちゃんとメールを見ていたらお名前ドットコムさんから制限を食らう事がなかったはずです。皆さんもメールはきちんと見ましょう!

- 投稿日:2020-08-14T12:01:00+09:00
Deep Securityに関する備忘録
近況報告
勤務が始まってはや二週間。やはり思うのが,グループリーダー含め周りのレベルが高い。高すぎる。そんでもって,勉強中に自分が詰まったところがあっても,自分のレベルで答えが出せるギリギリのヒントをくれる。まだ二週間ぽっきり,何ができるようになったとかは実感少ないけど,着実に進んでいるとは思うのでこれからもがんばっていく。
P.S.
スクールでの親交のあった同期が,新規開発事業に内定をもらった報告を頂きました。その人はスクールの時,同期の中でも擢ん出た成績を残し,さらに自身の勉強時間を犠牲にして同期のカリキュラムの進行を手助けするほどの聖人でした。
先月,連絡を取った際にSESで妥協していたことを聞いて,「絶対もったいない」と思い,おこがましい話ですが就活を続ける打診をしたところ,そのあとも就活をつづけ,昨日,内定をいただいたとのことです。
「私のおかげでがんばれた」って言われたのですが,私個人の考えでは,「その人の能力的にその結果は当然」であると思っていました。なので,そんなたいしたことはした気がしないのですが,感謝されるほどのgiveができる能力を自身が持っていることには自信を持たないとですよね。とにかく,本人がスクールに通っていた時から願っていた環境に就職できたことは本当に素晴らしいことだと思いました。そんなわけで,明日,ウィスキーで祝杯をあげに行ってきます。本日のお題
Trend MicroのDSaaSのコンソール画面の備忘録(2020/08/14時点)
昨日コンソール画面について上司からレクチャーを受けたので一部をここに残します。おもにイベントとレポートのタブは何を管理しているものなのかの把握がゴールです。
DSaaSって
Deep Security as a Service
噛み砕くとセキュリティの総合サービス。EC2などのサーバーに設置してセキュリティ関連の管理を行うもの。基本的にDSA(Deep Security Agent)をサーバーにインストールして同期し,DSaaSで管理する感じ。30日の無料トライアルサービスが存在し,今回私はそれを用いた講義を上長から受けました。この記事はDSの使い方とか,アカウント作成方法とかを記載したものではありません。現在,DSaaSではなく,WorkLoad Securityって名前らしい。
イベントとレポート
システムイベント
サーバー内で生じたイベントが流れる空間。
ex.) パスワードの認証失敗とか不正プログラム対策イベント
ウィルスを見つけたら,「削除」「隔離」「駆除」してくれる,それに関するログが流れる。
「削除」・・・言葉の通りそのまま害悪なデータを削除する
「隔離」・・・害悪な因子を取り除き,隔離ファイルで管理する
「駆除」・・・害悪な因子を取り除き,削除する。ウィルスが混じっていても上のアクションが正常に取られているのであればセキュリティを憂いる必要がない。問題なのは上のアクションが失敗した場合。その場合はサーバーの中にウィルスが残留し続けているということなので,早急に解決する必要がある。
検出ファイル
処理されたウィルスが表示される。そのウィルスがいつ,どこのサーバーで見つかって,どんなウィルスなのかが表示されるとのこと。Webレプテーション(Reputation)イベント
滅多に起こらない分,このイベントは危険度が高い.
外部サイト,外部端末への不正な情報の送信を検知したらアラートが鳴る。そしてその通信を遮断する。HTTP通信をキャッチ。HTTPSは暗号化して予防しており,中間者攻撃を防いでいる。中間者攻撃
正規クライアント ▶️▶️▶️▶️▶️▶️▶️▶️▶️▶️▶️▶️▶️▶️・・・・・・・・・・▶️ サーバー
↑第三者が解析 ↓別のURLに飛ばすアプリケーションコントロール
DSで許可したアプリケーション以外はブロックする。これにより,ユーザーが意図していないアプリケーションの起動を防ぐことができる。逆を言えば,この機能を利用していて,かつ,DS管理者とサーバー管理者が異なる場合,サーバー管理者はDS側の許可なくアプリケーションを本番環境に投入できないため,業務にラグが生じることがある。
変更監視イベント
ファイルやディレクトリが変更された日付,権限の変更を管理する場所。しかし,変更された事実を管理するものではあるが,どこが変更されたか具体的な場所は追跡することができない。
セキュリティログ
セキュリティログの監視。作業内容の確認など
firewall
めっちゃ噛み砕くと許可されたIPを通す機能。AWSでいうセキュリティグループのような役割。もしこの機能をオフにしても,侵入防御イベントがオンになっている場合はアラートが鳴る可能性がある。
侵入防御イベント
侵入を防衛したことを残すアラート。
ex.) 攻撃確認▶️ブロック▶️どこからのアクセスか
データ詳細から攻撃元のIPや攻撃方法が解析できる。
善良なスキャンソフトがこれに引っかかる時もある。アラートについて
どのアラートを表示させるかはカスタマイズすることができる。またアラートが複数存在する場合,新しいアラートが出現した場合通知が出ないことがあるため,アラートが解決したらアラートを消去する癖をつける。
DSaaSで検知した問題はDSaaSのコンソールで消せるが,DSAなど別の場所由来のアラートはDSaaSでは消せない。終わりに
セキュリティど素人のまとめです。アドバイスは24365お待ちしています。

- 投稿日:2020-08-14T10:12:54+09:00
AWS Chaliceを触ってみた
AWS Chaliceって?
Amazon API Gateway や AWS Lambda をCLIから半自動でさくっと作れるものらしい。
AWS Lambda(とAmazon API Gateway)は好きだから触ってみました。準備
Pythonの仮想環境作り
AWSのChaliceハンズオンで仮想環境を作ることを推奨しているので、必要に応じて作ります。
仮想環境を作成するVirtualenvのインストール
$ pip install virtualenv仮想環境の作成
# 『~/.virtualenvs/chalice-handson』は環境名 # AWSのハンズオンに合わせているだけなので、任意の環境名で大丈夫です virtualenv ~/.virtualenvs/chalice-handson仮想環境の有効化
$ source ~/.virtualenvs/chalice-handson/bin/activate # 『source』は『.』でも代用可能なため以下のコマンドでも上と同じ意味になります $ . ~/.virtualenvs/chalice-handson/bin/activate仮想環境の終了
仮想環境を終了したい場合は以下のコマンドです。
仮想環境を終了しても作られた仮想環境のファイルは残るので、再度有効化のコマンドを打つことで仮想環境に入ることができます。$ deactivateChaliceのインストール
$ pip install chalice # インストールできたか確認 $ chalice --version chalice 1.12.0, python 3.7.3, darwin 19.6.0AWS認証情報
~/.aws/credentialsと~/.aws/configがない場合は以下のコマンドで設定しておきます。
ないとAWSにデプロイするときに怒られます。$ aws configureプロジェクトの新規作成
それでは準備ができましたので、軽くプロジェクト作成からAWSへデプロイまでの流れを見てみましょう。
最初に以下のコマンドでプロジェクトを作成します。# 『helloworld』はAWSのハンズオンで使っていたプロジェクト名で、任意のプロジェクト名を指定可 $ chalice new-project helloworldプロジェクト作成で以下のファイルが作られます。
. ├── .chalice │ └── config.json ├── .gitignore ├── app.py └── requirements.txt自動作成された
app.pyの中身は以下のようになっています。
中身はシンプルで、API Gatewayのエンドポイントのindexにアクセスしたらレスポンスボディとして{'hello': 'world'}を返すようになっています。
レスポンスボディの{'hello': 'world'}はプロジェクト名がhelloworld以外でも{'hello': 'world'}で設定されます。from chalice import Chalice app = Chalice(app_name = 'helloworld') @app.route('/') def index(): return {'hello': 'world'} # プロジェクト名がhelloworld以外でも、ここは {'hello': 'world'} ですローカルでのテスト
実際に上で説明した挙動になっているか(アクセスしたら{'hello': 'world'}が返ってくるか)ローカル環境で試してみましょう。
以下のコマンドでローカルサーバーを起動できます。簡単でいいね!
$ chalice local Serving on http://127.0.0.1:8000ブラウザでアクセスしてみると
{"hello": "world"}が表示されるはずです。AWSにデプロイ
大丈夫そうなので、AWSにデプロイして外からもアクセスできるようにしてみましょう。
デプロイは簡単で以下のコマンドを実行するだけです。$ chalice deployするとAWS上で以下が自動で作成されます。
- IAMロール
- Lambda関数
- API Gateway
デプロイを行うと以下の構成になります。
. ├── .chalice │ ├── config.json │ ├── deployed │ │ └── dev.json │ └── deployments │ └── xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-python3.8.zip ├── .gitignore ├── app.py └── requirements.txt最後に
Rest API URLとしてAPI Gatewayのエンドポイントが表示されるので、ブラウザでアクセスしてみましょう。
Rest API URLが分からなくなった場合は以下のコマンドで表示できます。$ chalice urlリクエストハンドリング
ここまででAWS Chaliceの基本的な使い方が見えてきたと思いますので、もう少しコントロールするための機能を見ていきましょう。
URLパラメータ
以下のように
app.pyの@app.route('/')のパスパターンにパラメータを記述することができ、パラメータとして受け取った値をメソッド内の引数として使用できます。from chalice import Chalice app = Chalice(app_name = 'helloworld') @app.route('/') def index(): return {'hello': 'world'} # 以下を追加 @app.route('/hello/{name}') def greet(name): return {'hello': name}
app.pyを編集したら再度chalice deployを行います。
デプロイが完了したらAPI Gatewayのエンドポイントに/hello/『任意の値』をつけてブラウザでアクセスしてみましょう。
{"hello": "『任意の値』"}の表示がされたはずです。
『任意の値』として渡された値は数値であっても文字列になるので注意してください。HTTPメソッド
以下のように
app.pyの@app.route('/')にメソッドを書くことでHTTPメソッドを指定可能。from chalice import Chalice app = Chalice(app_name = 'helloworld') @app.route('/') def index(): return {'hello': 'world'} @app.route('/hello/{name}') def greet(name): return {'hello': name} # 以下を追加 @app.route('/hello', methods = ['POST']) def hello(): return {'hello': 'POST world'}
app.pyを編集したら再度chalice deployを行います。
今回追加したPOSTはブラウザからでは確認できないので、Pythonの対話モードでさくっと確認してみましょう。$ python >>> import requests # requests が入っていなければ、pip install requests >>> response = requests.post('『API Gatewayのエンドポイント』/hello', data = {}) >>> print(response.text) {"hello":"POST world"}メタデータにアクセス
ここからのコードは変更ブロックとレスポンスだけ記載していきます。
メタデータ取得はapp.current_request.『ほにゃらら』の形で指定します。HTTP Method
@app.route('/hello') def hello(): return {'metadata': app.current_request.method} # レスポンス {"metadata":"GET"}Query Parameters
@app.route('/hello') def hello(): return {'metadata': app.current_request.query_params} # レスポンス(リクエストは /hello?test1=abc&test2=123&test2=456) # 同名のパラメータがリクエストで指定された場合、chaliceでは後勝ちになる(test2=123&test2=456 だと test2=456 になる) {"metadata":{"test1":"abc","test2":"456"}}Request Body - Raw
バイト型でリクエストボディを取得します。
もしContent-Type: application/jsonであれば、app.current_request.raw_bodyの代わりにapp.current_request.json_bodyが使えます。こちらは文字列型で取得します。@app.route('/hello') def hello(): return {'metadata': app.current_request.raw_body} # リクエスト $ python >>> import requests, json >>> response = requests.post('『API Gatewayのエンドポイント』/hello', data = json.dumps({'hello': 'world'}), headers = {'Content-Type': 'application/json' }) >>> print(response.text) # レスポンス {"metadata":{"hello":"world"}}レスポンスハンドリング
次にレスポンスを見ていきましょう。
カスタムHTTPレスポンス
任意のステータスコードやヘッダを返したい場合は、レスポンスクラスのオブジェクトに任意の情報を含めて返します。
import Responseを忘れないようにしてください。
(関係ないですが、json.dumpsをjson.dumpとs抜きで書いてしまい、{“Code”:“InternalServerError”,“Message”:“An internal server error occurred.“}のレスポンスが返ってきてミスに気づかずしばらくハマった...)
from chalice import Chalice, Response import json app = Chalice(app_name='helloworld') @app.route('/') def index(): return Response( body = json.dumps({'hello':'world'}), headers = {'Content-Type': 'application/json'}, status_code = 200 ) @app.route('/text') def text(): return Response( body = 'Hello, World', headers = {'Content-Type': 'text/plain'}, status_code = 200 )エラーHTTPレスポンス
エラーレスポンスを返すためのクラスがあるので、それを利用します。
下の例だと403 ForbiddenErrorです。
こちらもエラークラスのインポートを忘れないように。from chalice import Chalice, ForbiddenError app = Chalice(app_name='helloworld') @app.route('/forbidden') def forbidden(): raise ForbiddenError( '403!' )他には以下のエラークラスがあります。(【お手軽ハンズオンで AWS を学ぶ】サーバーレスな RESTful API を構築しよう! Chaliceで実現する Python アプリ開発 | AWS Startup ブログ 参照)
上で紹介したカスタムHTTPレスポンスを使えば、用意されていないエラーコードのレスポンスを返すことも可能です。(もちろんエラーコードが用意されているエラーをカスタムHTTPレスポンスで返すことも可能です。)
- BadRequestError - return a status code of 400
- UnauthorizedError - return a status code of 401
- ForbiddenError - return a status code of 403
- NotFoundError - return a status code of 404
- ConflictError - return a status code of 409
- UnprocessableEntityError - return a status code of 422
- TooManyRequestsError - return a status code of 429
- ChaliceViewError - return a status code of 500
CORSの有効化
シンプルに以下の書き方でOKです。
@app.route('/', methods = ['POST'], cors = True)デコレータ
今までずっと
@app.route('/')という形で書いてきましたが、これはAPI Gateway + AWS Lambdaでの形になります。
他のデコレータを使うことでAPI Gateway以外のAWS Lambda連携が可能です。
現在サポートしているものは以下になります。
- 単独AWS Lambda:
@app.lambda_function- Amazon CloudWatch Events + AWS Lambda:
@app.schedule- Amazon S3 + AWS Lambda:
@app.on_s3_event- Amazon SQS + AWS Lambda:
@app.on_sqs_message- Amazon SNS + AWS Lambda:
@app.on_sns_message詳しい使い方やサンプルコードは Lambda(Python) や API Gateway の管理を Chalice でやってみた がとても参考になります。
削除
chalice deployでAWSにデプロイされたIAMロール、Lambda、API Gateway(@app.routeの場合)は以下のコマンドで一括削除ができます。$ chalice deleteまとめ
AWS Chaliceを使うとだいぶ簡単にサーバーレス環境の構築が出来るようです。
削除も簡単なので気軽に作ったり消したり出来るのがいいですね。
もう少し具体的な例も書こうと思っていたのですが、すでに長い記事になってしまったので別の記事でまとめることにします。We're hiring!
AIチャットボットを開発しています。
ご興味ある方は Wantedlyページ からお気軽にご連絡ください!参考記事
- 投稿日:2020-08-14T10:03:36+09:00
AmazonのAWS , EC2とは?未経験者が解説します。
AWS( Amazon Web Services )
AWSとはAmazon Web Servicesの略で、Amazonが提供している100以上のクラウドコンピューティングサービスの総称です。他には
Microsoft Azure(アジュール)
Google Cloud Platform(GCP)この3社が超大規模クラウドベンダーとしてグループを構成しているのが現状です。
そもそもクラウドコンピューティングとは?
インターネット上のサーバーにあるコンピューターが提供している機能を、インターネット経由で利用する仕組みのことを指します。わかりやすく言うと、「インターネット上でアプリケーション込みでも利用できるサービス」のことです。GmailやYahoo!メールなどを例に挙げると、イメージしやすいかもしれません。
通常は、ローカル環境にあるコンピューター(PC)内にさまざまなアプリケーションをインストールして利用します。会社で使用するPCであれば、WordやExcel、Outlookといったアプリケーションがインストールされている状態です。
一方で、クラウドコンピューティング形態で提供するサービス(以下クラウドサービス)の場合は、自身のPCにアプリケーションをインストールする必要はありません。インターネットに接続できる環境があれば、サーバー上で提供している機能やサービスを利用することができます。会社のPCからでも、自宅でスマホからでも、同一のデータにアクセスでき、同一のサービスを利用できることが特長です。
ちなみに、クラウドとは「雲」のことです。インターネットを図式化する際に雲の図柄で表すことから、インターネット上の環境のことをクラウドと呼んでいます。さらに、クラウドコンピューティングという言葉が普及したことで、今まで使っていたローカルのサーバー環境は「オンプレミス」と呼称されるようになりました。(クラウド実践チャンネル内の記事より引用 https://www.cloud-for-all.com/ )EC2とは?
Amazonが提供している仮想サーバー構築サービスです。EC2を利用することで、OSを乗せた仮想環境をクラウド上にすばやく作ることができます。
インスタンスとは
Amazon EC2の中心となる仮想サーバーです。
インスタンスはインスタンスタイプと呼ばれるOSやCPU、メモリ、ストレージなどの構成から選んで作成します。
インスタンスは管理コンソールで起動や停止、セキュリティ等各種設定などを行います。
インスタンスは複数作成して実行することもできます。
例えば、アプリケーションサーバーとデータベースサーバーなど、合計で2つのサーバーが必要な場合は、インスタンスを2つ作成して対応できます。 必要に応じて複数のインスタンスを立ち上げることで、柔軟なインフラ構築ができるのがAmazon EC2の強みです。EC2の優れているところ
構築にかかる時間が短縮できる
EC2を利用する利点は、とにかくシステム構築にかかる時間が短いという点です。
サーバーを購入する場合は購入してから受け取るまでの間、何も作業が進められません。一方で、AWSのEC2上でインスタンスを立ち上げるには、ほんの数分あれば事足ります。冗長化が簡単にできる
冗長化する手間がかからないのも、魅力的なポイントです。 サーバーをローカルで作成する場合、サーバーの設定だけではなくネットワーク設計も必要になります。AWS EC2では、ネットワークを仮想ネットワーク構築するサービスが提供されており、インスタンスと組み合わせることで、簡単かつ短時間でサーバーの冗長化が実現できます。
冗長化とは?
「冗長」とは元々、文章表現などが長たらしくむだのある“望ましくない”状態を指す言葉ですが、ITの世界ではまったく反対に“望ましい”状態を指す表現となります。ITシステムにおける冗長化は、ハードウェアの二重化(多重化)を意味します。一番単純なものでは、今使っているPCと同じPCをもう1台、予備機として用意しておくなど。スペックの変更が柔軟に対応できる
サーバーをローカルで構築する場合に悩ましいことの1つとして、ハードディスクやメモリ不足の対応が挙げられます。 例えば、データベースサーバーを長年運用していると、データを削除しない限りはデータ容量が増え続けます。そのためデータを保持し続けるには、ハードディスクを増設するという対応が必要です。この場合もサーバー構築時と同様に、増設するハードディスクやらメモリを購入してセットする必要があります。 一方、AWS EC2を使えば、画面上で設定するだけでハードディスクやメモリの増設が簡単に行えます。
EC2の料金体系
AWS EC2の料金プランは、大きく分けて3つあります。
オンデマンドインスタンス
サーバーを立ち上げている時間または秒単位 (最低 60 秒) によって料金が発生するプランです。短時間のみ利用したい、週末や月に1回だけ使いたい場合に有益です。
リザーブドインスタンス
あらかじめ稼働期間を決めておき、先支払いする方式です。常時インスタンスを立ち上げていたい、長期間稼働させ続ける必要がある場合に使いやすいプランです。1ヶ月分バスの通勤定期券を購入した場合を想像すると良いかもしれません。乗車の度に運賃を支払うよりは安く済むことがほとんどです。
「オンデマンドインスタンスの利用料金を割り引いてもらえる定期券を購入すること」と考えるとわかり易いのではないでしょうか。スポットインスタンス
スポットインスタンスは、オークション形式でインスタンスを入札し、自分の価格より高く使いたいユーザーが出たときなどに停止&削除される代わりに非常に安い値段でインスタンスを利用する手段です。
スポットインスタンスは一時的な利用に限ります。自分の入札金額がスポットインスタンスの現在価格より下回ると削除されます。
そのため、短期間でコピー環境を作ってテストしたい場合や、負荷が上がる時間帯にスケールアウト(or スペックアップ)したい場合などで使うことができます。
入札金額はオンデマンド(通常料金)の金額が上限でオンデマンドよりも高い金額を払うことはありません。ただし、スポットインスタンスの価格がその金額まで達した場合には、削除されます。
初期費用ゼロ、低運用コスト
物理サーバーであれば、構築の前にハードウェア機器の購入やネットワーク回線の敷設が必要であり、膨大な初期費用が必要です。
Amazon EC2の場合初期費用は発生しません。
仮想サーバー(インスタンス)を作成しただけでは費用は発生せず、インスタンスを稼働させてからはじめて費用が発生します。
また、運用コストもインスタンスを稼働させた時間に応じた従量課金制です。
Amazon EC2は競合他社と比較優位になるように、これまで多くの値下げを行ってきており、仮想サーバーとしてはほぼ最安値といって良い運用コストで利用可能になっています。(TECH PLAY コラムからの引用あり https://techplay.jp/)
- 投稿日:2020-08-14T09:20:45+09:00
AWS CloudWatchの価格について
AWS CloudWatchは、オンプレミスのアプリケーションやインフラだけでなく、AWSのサービスを監視するのにも便利な監視ツールです。CloudWatchが強力なツールである理由というのは、幅広い種類のデータ監視機能を持っているということが挙げられます。基本的な機能としては、CloudWatchの粒度は最大1秒、データ保持期間は最大15ヶ月です。また、CloudWatchには70以上のAWSサービスのメトリクスが組み込まれ、AWS製品の監視に最も使いやすいツールとなっているため、AWSサービスで利用可能なデフォルトのメトリクスを見たときにAWS CloudWatchの真の威力は発揮されます。
しかし、サービスの価格設定を見てみると、大規模なシステムの監視には月に数万ドル以上の価格設定になることもあります。
この記事では、CloudWatchの価格体系のいくつかの例を調べ、CloudWatchのデータをMetricFireに送ることで監視コストを削減する方法を紹介します。
また、CloudWatchのお客様の多くは、より柔軟性の高いセカンダリ・プラットフォームを探しているときに、MetricFireに興味を持つようになります。MetricFireでは、幅広いプラグインを利用できるだけでなく、無制限のダッシュボード、クエリ、アラート機能を利用することができます。MetricFireの無料トライアルでAWS CloudWatchをデータソースとしてMetricFireに接続し、今すぐお試しください。
CloudWatchの料金体系
AWS CloudWatchの価格設定は、CloudWatchで何をするかによって異なります。価格はメトリクス、ダッシュボード、アラーム、ログ、イベントなどを考慮して計算されます。カスタムメトリクスには以下のような特別な価格設定があります。また、APIリクエストはそれごとに0.01ドルで課金されます。
メトリクスの価格は以下のようになっています。
- 最初の10,000メトリクス - 1メトリクスあたり0.30米ドル
- 次の 240,000 メトリクス - メトリクスあたり 0.10 米ドル
- 次の 750,000 メトリクス - メトリクスあたり 0.05米ドル
- 1,000,000以上のメトリクス - メトリクスあたり0.02米ドル
同様に、追加料金は以下のように計算されます。
- ダッシュボードは1枚あたり3.00米ドルです。
- アラームは60秒の標準解像度でアラーム1回あたり0.10米ドルです。
- ログは、最初の10 TBでGBあたり0.50米ドルです。
- APIリクエストは1リクエストあたり0.01米ドル
この内訳を見てみると、AWS CloudWatchで5,000のメトリクスを利用した場合、月々のコストはすでに1,500ドルになります。さらに100のダッシュボードと100のアラームを追加すると、コストは月1,810ドル、つまり1年で21,720ドルになり、API、ログ、ストレージ、カスタマイズ、イベント、コンサルテーションなどを考慮しなくても、コストは上がります。
別の例では、5つのメトリクスだけを監視したいが、50,000インスタンスの大規模なシステムの場合、AWS CloudWatchは25万メトリクス(5つのメトリクス*50,000インスタンス)とカウントします。これは月額27,000ドルのトータルコストになります。そして、各インスタンスでのAPIリクエストには0.01ドルのコストがかかるため、月に4,000ドル以上のコストがかかることになり、月の合計は30,000ドルを超えることになる。
このように、大規模なシステムの場合、AWS CloudWatchでの監視コストは非常に高くなる可能性があります。サーバー、インフラストラクチャ、アプリケーションの監視のための代替ツールは数多く存在しますが、ほとんどの場合、ユーザーはAWS CloudWatchから完全に離れようとはしていません。ほとんどの場合、ユーザーはAWS CloudWatchから完全に撤退はせず、コストを抑えつつ、監視スタックにさらなる機能性をもたらすツールを探しているのです。
MetricFireは、より強力なカスタマイズを実現するための素晴らしい選択肢であり、CloudWatchと一緒に使用することも非常に簡単です。
MetricFireとは?
MetricFireは、CloudWatchの代替サービスまたはパラレルサービスであり、CloudWatchを超えたユーザー主導のカスタマイズを低コストで実現します。MetricFireは、ホスティングされたオープンソースの監視ツールのスイートを使用して、インフラストラクチャ、システム、アプリケーションの監視を提供するフルスケールのプラットフォームです。このプラットフォームでは、Hosted PrometheusまたはGraphite-as-a-Serviceのいずれかを使用して、メトリクスをGrafanaのダッシュボードに表示することができます。MetricFireの無料トライアルをお試しいただき、今すぐMetricFireとAWS CloudWatchを接続してみてはいかがでしょうか。MetricFireの価格設定
MetricFireでは、オープンソースのPrometheus、Graphite、Grafanaをベースに構築された優れたモニタリングソリューションを、格安なコストで提供しています。プレミアム年間プランでは、2年間のリテンション、5秒のレゾリューション、250のアラート、150,000のメトリクス、50のチームユーザーと25のライトユーザーの場合、月額3,849ドルとなります。ダッシュボードごとの余分な課金、余分なプラグインのインストール、またはAPIリクエストはありません。当社のプランは、3,849ドル以下から月85ドルまで、どのような価格でもご利用いただけます。詳細については、価格設定ページでプランをチェックしてください。
AWS CloudWatchとMetricFireの連携
実際にAWS CloudWatchアカウントをMetricFireに接続することで、CloudWatchで監視するメトリクスの量を減らしつつ、CloudWatchで要所要所を監視するメリットを得ることができます。
MetricFireのHosted Graphiteでは、アカウントのアドオンページで利用できるAmazon AWS CloudWatchアドオンが提供されています。このアドオンは、指定したAWSサービス/地域のメトリクスをアカウントに同期します。
CloudWatchアカウントに接続するには、AWSアカウントにIdentity and Access Management(IAM)のアクセスキーを設定し、MetricFireのHosted Graphiteが接続してメトリクスを収集できるようにするための適切なパーミッションを設定する必要があります。
MetricFireでより柔軟性を。
MetricFireでは、Grafanaラボから事前に作成されたダッシュボードを無料でダウンロードして、MetricFireアカウントに直接適用することができるため、より柔軟性を高めることができます。また、企業のお客様には、CloudWatchでは提供されていない次のような柔軟性も提供しています。
- 2年間のデータ保持、またはそれ以上のデータ保持
- 無制限のアラート
- 数百万の測定基準
- 無制限のチームユーザー
- カスタマイズ可能なGrafanaダッシュボード
- カスタマイズ可能なデータソース
- サードパーティソース、Prometheus.io、Grafana.ioなどからの膨大なプラグインの選択
- エンジニアのためのエンジニアによる24時間365日のカスタマーサービス
まとめ
MetricFireはAWSよりも柔軟性が高いことで知られており、メトリクス、ダッシュボード、アラート、通知をカスタマイズすることができます。MetricFireでは、ユーザーはオープンソースの製品を自分でインストールするのと同じくらいの柔軟性がありますが、セットアップやメインテナンスの煩わしさはありません。
Hosted Grafanaでは、Grafanaを使ってダッシュボードの機能をフルに利用できます。ユーザーは、独自のダッシュボードを設定することも、GrafanaコミュニティからダッシュボードをダウンロードしてGrafanaのプラットフォームに適用することもできます。
ベンダーのロックインがないため、データに完全にアクセスすることができ、いつでも自由にPrometheusやGraphiteのモニタリングシステムを設定することができます。要望さえあれば、データの返却も可能です。CloudWatchの他の選択肢についての詳細は、こちらの記事をご覧ください。
MetricFireを試すには、無料トライアルにサインアップして、AWS CloudWatchデータを当社のプラットフォームに送信してください。また、デモを予約して、御社のモニタリングニーズについて直接お問い合わせいただくことも可能です(日本語対応)。
それでは、またの記事で!

- 投稿日:2020-08-14T08:17:14+09:00
Amazon Braketで量子コンピュータをはじめよう!
Amazon Braketがpublicになりました
AWSの量子コンピュータ・サービスであるAmazon Braketはprivate previewとして運用されていましたが、publicになり誰でも使えるようになりました。
この記事は、ひとまずAmazon Braketを触ってみよう、という趣旨です。
この記事では「量子コンピュータって何?」という点は説明しません。(すみませんが、これを書き始めると随分長くなってしまうので、書籍や他の記事などを参照してください)
また、AWSの利用経験が多少ある人を前提にしています。
(2020/08/14時点の情報にもとづいています)
Amazonのプレスリリースです。
https://press.aboutamazon.com/news-releases/news-release-details/aws-announces-general-availability-amazon-braketDeveloper Guideが公開されているので、詳しい内容はこちらを参照するのが良いと思います。
https://docs.aws.amazon.com/braket/latest/developerguide/what-is-braket.html料金表はこちらにあります。
https://aws.amazon.com/jp/braket/pricing/Amazon Braketでは複数の会社が提供する量子コンピュータを使い分けできます。
Rigettiが提供する量子コンピュータは1回実行すると、$0.65ですね(標準的な1000ショット前提)。1タスク(\$0.30000) + 1000ショット(\$0.35000) = \$0.65000
IonQが提供する量子コンピュータはもうちょっと高くて、1ショットが$0.01000となっています。
(「ショット」という量子コンピュータの概念があるのですが、ここではひとまず「そういうのがあるんですね」くらいでよいです)Amazon Braketのアイコンは、チップの周りを量子が回っているイメージのようです。
ログイン~バケット作成
というわけで、ひとまず触ってみましょう。
Amazon SageMaker(機械学習のサービス)と似た操作の流れなので、Amazon SageMakerの利用経験があると量子コンピュータが初めての人でもなじみやすいかもしれません。Amazonのブログにも始める際の手順が書いてありますので、これにしたがって進めるのがよいかもしれません。
- Amazon Braket – Go Hands-On with Quantum Computing
https://aws.amazon.com/jp/blogs/aws/amazon-braket-go-hands-on-with-quantum-computing/Amazon BraketのAWSコンソールはこちらからログインできます。
https://us-west-2.console.aws.amazon.com/braket/homeログインすると、Amazon Braket用のS3バケットを作成するかどうか、アカウントの権限をどうするか聞かれます。
どうしてS3が出てくのかと言うと、Amazon Braketは実行結果をS3に保存するためです。
利用規約をチェックするのも忘れずに。
ログインすると次の画面が出てきます。
画面左側のメニューの「Devices」をクリックしても行けます。
次の量子コンピュータを利用できます。
提供会社 デバイス名 物理方式 利用可能リージョン 利用可能時間 D-Wave DW_2000Q_6 量子アニーリング us-west-2(オレゴン) いつでも利用可能 IonQ ionQdevice イオントラップ量子コンピュータ us-east-1(バージニア北部) 日本時間で月~金の22時~翌6時 Rigetti Aspen-8 超伝導量子コンピュータ us-west-1(北カリフォルニア) 日本時間で火~土の0時~4時、6時~8時 AWS DefaultSimulator シミュレータ ローカルで動くため、リージョンに関係なく動作する いつでも利用可能 AWS SV1 シミュレータ 全リージョン いつでも利用可能 デバイスによって利用可能時間が異なるため、注意してください。
次のページに説明がありますが、ライブラリ(Amazon Braket SDK)側で適切なリージョンを判断して送信するため、リージョンはあまり気にしなくてよいです。
https://docs.aws.amazon.com/braket/latest/developerguide/braket-regions.htmlデバイス(量子コンピュータの実機)についての説明
この記事では、Rigettiのデバイスを利用します。
「Devices」の画面から「Rigetti」をクリックします。
Rigettiのデバイスの説明やキャリブレーション情報を記載した画面が表示されます。
- 概要
利用可能なリージョン、デバイスのarnなどの情報が書いてあります。
デバイスのトポロジー情報
重要な情報なのですが、はじめて実行するときは気にしなくてよいです。
量子コンピュータに慣れてきたら気にします。
キャリブレーション情報
これも重要な情報なのですが、はじめて実行するときは気にしなくてよいです。
量子コンピュータに慣れてきたら気にします。
notebookの起動
ひとまず実行してみましょう。
画面左のメニューにある「Notebooks」にある「Create notebook instance」をクリックしましょう。(こういうところ、Amazon Sagemakerに似ていますね)
notebookを作成する画面になりました。
インスタンス名はアカウント毎にリージョン内でユニークである必要があります。
notebookにアクセスするためのURLは「<インスタンス名>.notebook.<リージョン名>.sagemaker.aws」となります。
(内部的にAmazon Sagemakerを流用しているんですね?)インスタンスタイプは、ひとまず「ml.t2.medium」にしました。
設定を決めたら、画面右下にある「Create notebook instance」をクリックしましょう。すると、先ほどのNotebooksの画面に戻ります。
裏でインスタンスの作成が行われています。
しばらくすると「status」が「InService」になるので、それまで待ちましょう。
(画面は自動リフレッシュしないようなので、リフレッシュのボタンを押しましょう)「InService」の間はEC2の利用料が課金されますので、利用後は停止するのを忘れずに。
notebookから量子コンピュータを実行
「InService」になったら、「Name」か「URL」をクリックしましょう。
Jupyter Notebookの画面が表示されます。
ひとまず、examplesとして提供されているnotebookを実行してみましょう。
様々なデバイスのnotebookが混ざっているのと、はじめて量子コンピュータに触る人向けの内容じゃないので、分かりづらそうですね。。。
きっと、今後分かりやすいnotebookが追加されると思います。
この記事ではRigettiのデバイスを触りたいので、次のディレクトリに移動して「Running_quantum_circuits_on_different_devices.ipynb」というnotebookを開きましょう。[Braket examples] > [simple_circuits_algorithms] > [Backends_Devices] > [Running_quantum_circuits_on_different_devices.ipynb]
「Running_quantum_circuits_on_different_devices.ipynb」を開くと、次のような画面が表示されます。
量子コンピュータをはじめて触る人には何を言ってるのか分からない内容かもしれませんが、あまり気にしなくてよいです。
必要になったら、ちゃんと読みましょう。
(このnotebookは基本的な操作方法が書いてあるので、ガッツリ触る前には理解しておいた方が良さそうです)
2番目のセルに設定を入力する箇所があるので、変数my_bucketに「ログイン~バケット作成」で作成したバケット名を指定します。
In[2]# set up S3 bucket (where results are stored). Change the bucket_name to the S3 bucket you created. aws_account_id = boto3.client("sts").get_caller_identity()["Account"] my_bucket = f"★書き換える★" # the name of the bucket my_prefix = "simulation-output" # the name of the folder in the bucket s3_folder = (my_bucket, my_prefix)まずは、1番目と2番目のセルを実行します。
さあ、それでは、Rigettiの量子コンピュータを実行してみましょう!
このノートブックの前半はシミュレータの操作なので、飛ばしてしまい、中盤にある「Quantum Hardware: Rigetti」までスクロールしましょう。
「Quantum Hardware: Rigetti」の所に実行可能なセルが2個あるので、これを実行します。
うまくいくと、次のようになるはずです。(セキュリティの都合で一部を黒塗りにしています)
最初のセルを実行すると、タスクが作成され、Rigettiの量子コンピュータに送信されます。
「Status of task: CREATED」と表示されればOKです。非同期で実行しているため、しばらくしてから次のセルを実行します。
「Status of (reconstructed) task: COMPLETED」と表示されれば実行完了です。また、実行結果はjson形式でS3に保存されます。
ただ、これだと実行結果が分からないので、次のセルを作成して実行してみましょう。
result = rigetti_task.result() counts = result.measurement_counts print(counts) # plot using Counter plt.bar(counts.keys(), counts.values()); plt.xlabel('bitstrings'); plt.ylabel('counts');次のように、Counterの値とヒストグラムが表示されればOKです。
量子コンピュータの特性上、実行結果は確率的に変化するため、Counterの値は実行するたびに変わります。
この場合は正しく動作すれば「00」と「11」の値が大きくなります。これで、Rigettiの量子コンピュータを実行できました。
notebookインスタンスを立てずに実行する場合
「Amazon Braket Python SDK」が公開されているため、これを使います。
対応しているPythonのバージョンは3.7.2以降です。
Read the Docs
https://amazon-braket-sdk-python.readthedocs.io/「Amazon Braket Python SDK」以外だとboto3も対応してますが、実行するにはちょっと大変そうなAPIに見えます。
Developer Guide
https://docs.aws.amazon.com/braket/latest/developerguide/braket-using-boto3-client.htmlboto3のドキュメント
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/braket.htmlLocalSimulatorというのを使うと、量子コンピュータもS3も使わず、ローカルでシミュレータとして動作します。
次のページの「Usage」に書いてある実装方法が分かりやすいです。
- GitHub: amazon-braket-default-simulator-python
https://github.com/aws/amazon-braket-default-simulator-pythonおわりに
というわけで、Amazon Braketにひとまず触ってみました。
Amazonが量子コンピュータのマネージド・サービスを出したことにより、QaaS(Quantum as a Service)がさらに進みますね。
量子コンピュータに触る人が増えそうで楽しみです。最後にもう一度言いますが、「InService」の間はEC2の利用料が課金されますので、利用後は停止するのを忘れずに。



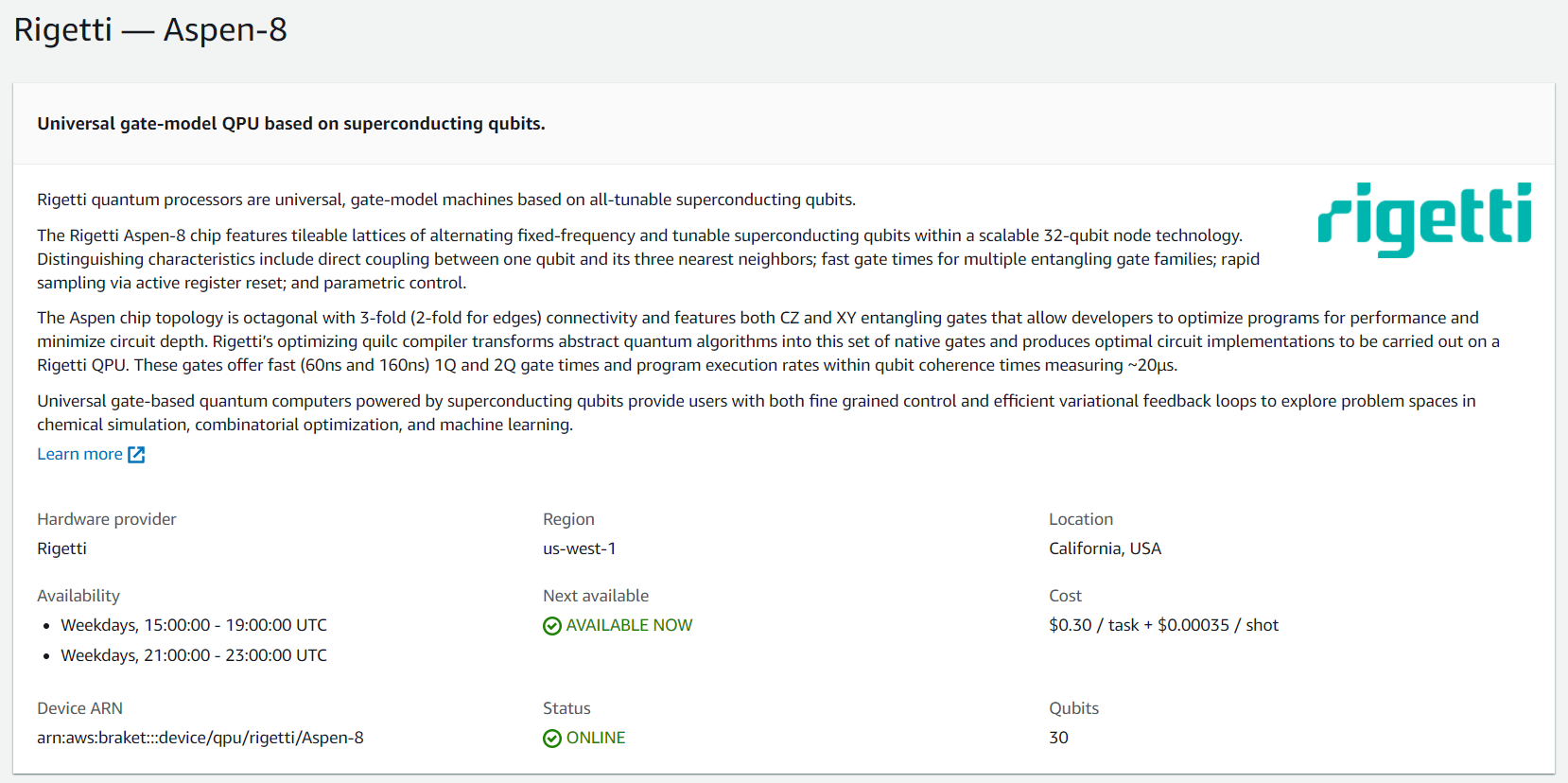
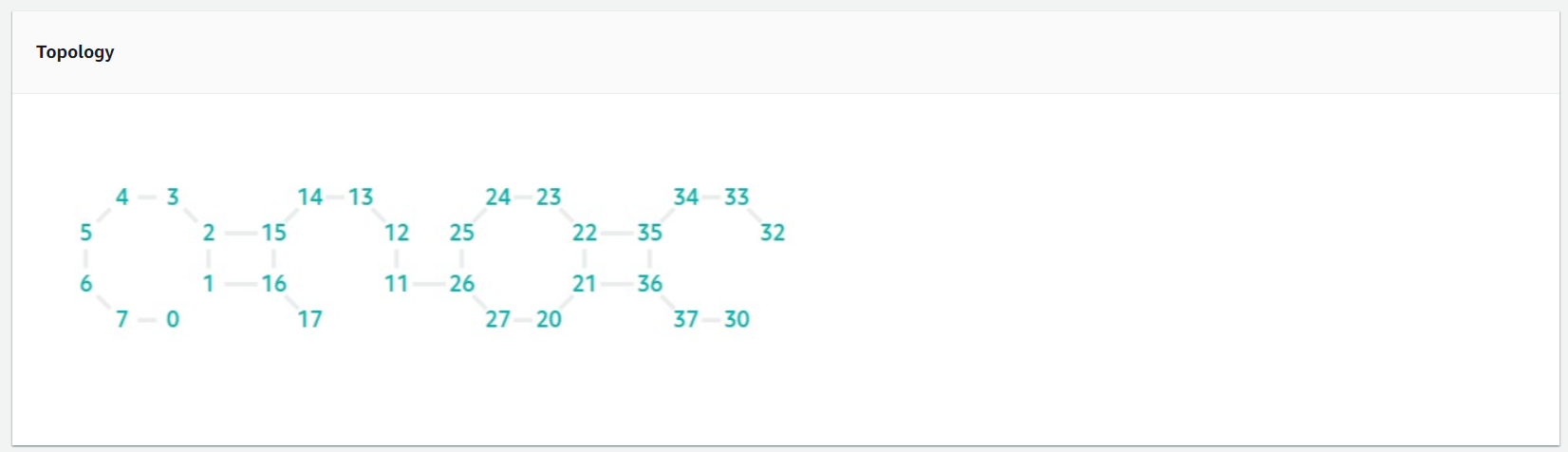
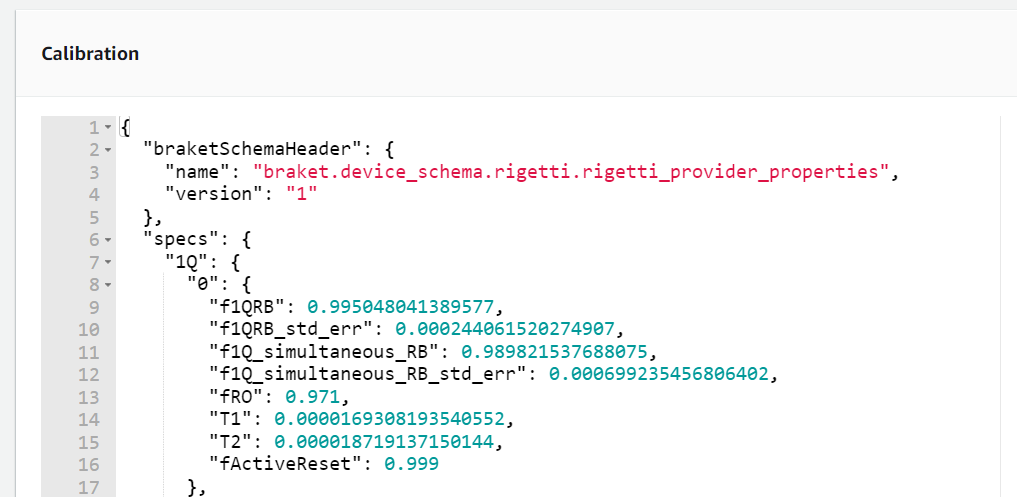

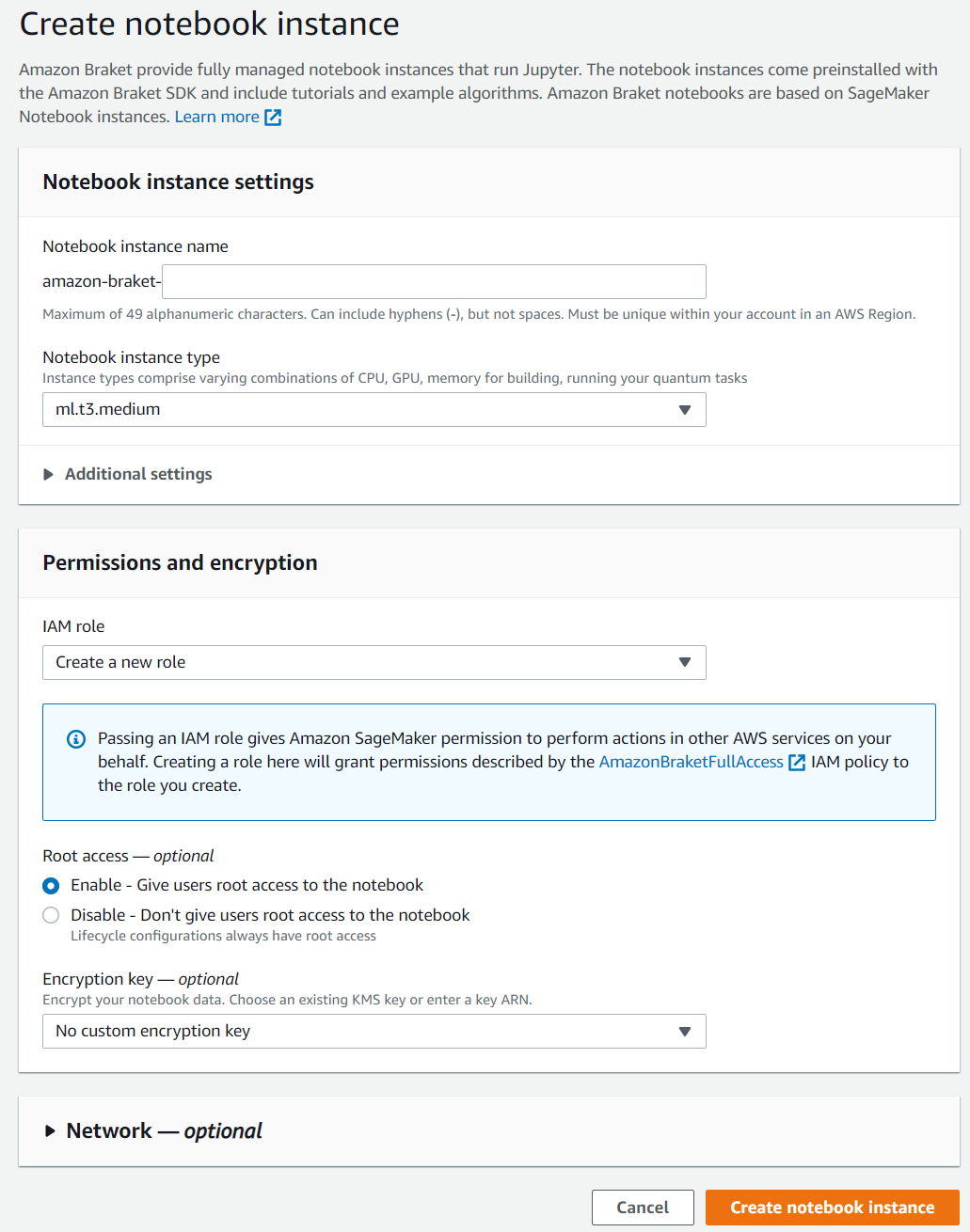



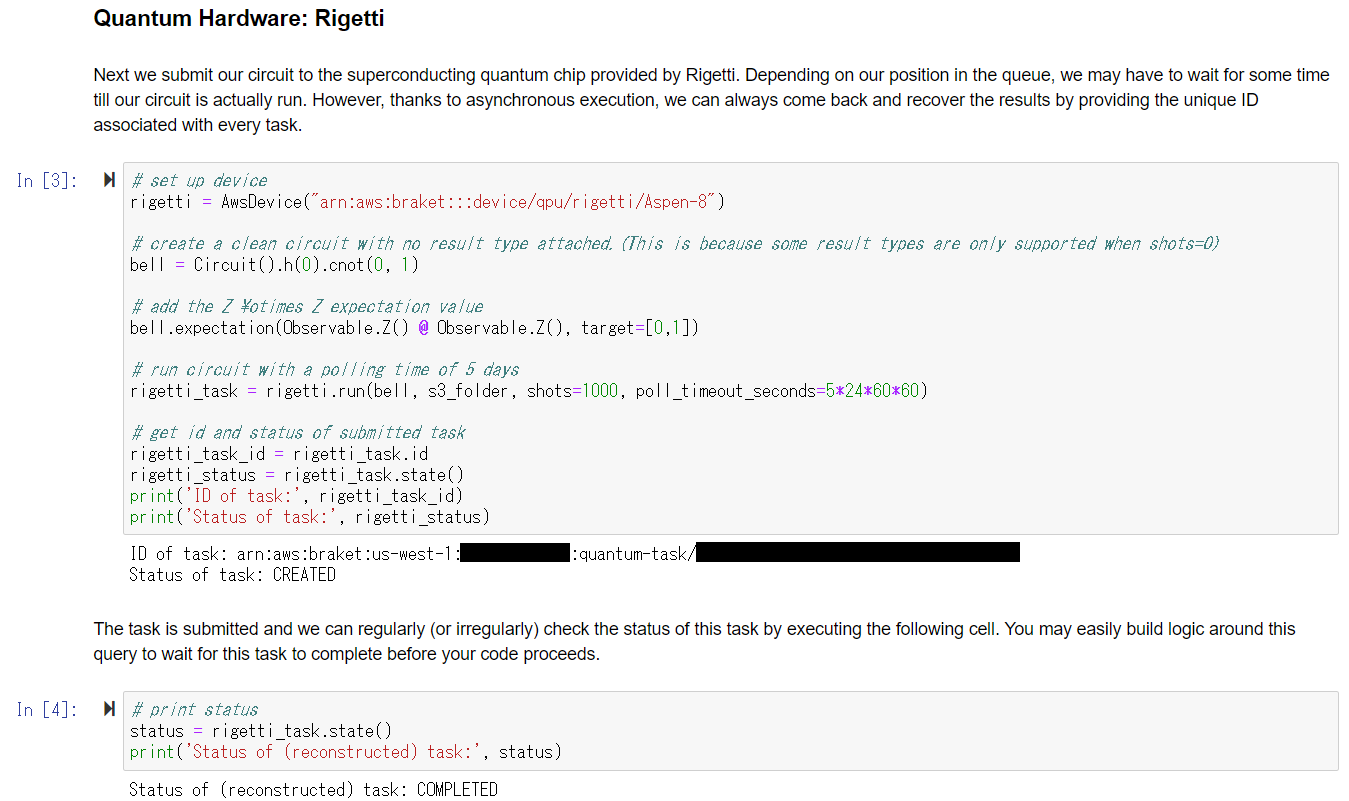

- 投稿日:2020-08-14T00:09:35+09:00
[AWS] API Gateway + LambdaをX-Rayでトレースしてみる
X-Rayとは
分散アプリケーションの分析とデバッグのためのサービスです。
詳細は、こちら。
AWS X-Ray前提
今回も、以下構成でサンプルを構築してみようと思います。
- SAM
- Python3.8
SAMをはじめとする基本知識は、こちらを参照願います。
- [AWS] Serverless Application Model (SAM) の基本まとめ
- [AWS] Serverless Application Model (SAM) でAPI Gateway + Lambda + DynamoDBなサンプルを作成してみる
サンプルを作ってみよう
プロジェクト作成
例によって、SAMでHello Worldベースのプロジェクトを作成していきます。
$ sam init --runtime=python3.8 Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Project name [sam-app]: Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git AWS quick start application templates: 1 - Hello World Example 2 - EventBridge Hello World 3 - EventBridge App from scratch (100+ Event Schemas) 4 - Step Functions Sample App (Stock Trader) 5 - Elastic File System Sample App Template selection: 1 ----------------------- Generating application: ----------------------- Name: sam-app Runtime: python3.8 Dependency Manager: pip Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./sam-app/README.mdX-Rayの追加
ソースコードへのデコレータ追加
まず、コードにX-Rayのデコレータを追記します。
デフォルトで生成されるhello_world/app.pyをリファクタリングも含めて、以下のようにしてみます。hello_world/app.pyimport json from aws_xray_sdk.core import xray_recorder @xray_recorder.capture('hello world') def lambda_handler(event, context): return { "statusCode": 200, "body": json.dumps({ "message": "hello world", }) }SDKの取り込み
LambdaにX-Ray SDKのライブラリを取り込むため、
hello_world/requirements.txtを以下のように修正します。hello_world/requirements.txtaws-xray-sdkSAMテンプレートの修正
最後に、Lambda関数、API Gatewayのトレーシングを有効にするため、Globalsの箇所を以下のように修正します。
template.yml修正前Globals: Function: Timeout: 3template.yml修正後Globals: Function: Timeout: 3 Tracing: Active Api: TracingEnabled: Trueビルド
$ sam build Building function 'HelloWorldFunction' Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guidedデプロイ
$ sam deploy --guided Configuring SAM deploy ====================== Looking for samconfig.toml : Found Reading default arguments : Success Setting default arguments for 'sam deploy' ========================================= Stack Name [sam-app]: AWS Region [us-east-1]: ap-northeast-1 #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [Y/n]: y #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: y HelloWorldFunction may not have authorization defined, Is this okay? [y/N]: y Save arguments to samconfig.toml [Y/n]: y Looking for resources needed for deployment: Found! Managed S3 bucket: aws-sam-cli-managed-default-samclisourcebucket-1rzppw621dkka A different default S3 bucket can be set in samconfig.toml Deploying with following values =============================== Stack name : sam-app Region : ap-northeast-1 Confirm changeset : True Deployment s3 bucket : aws-sam-cli-managed-default-samclisourcebucket-1rzppw621dkka Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {} Initiating deployment ===================== Saved arguments to config file Running 'sam deploy' for future deployments will use the parameters saved above. The above parameters can be changed by modifying samconfig.toml Learn more about samconfig.toml syntax at https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-config.html Deploying with following values =============================== Stack name : sam-app Region : ap-northeast-1 Confirm changeset : True Deployment s3 bucket : aws-sam-cli-managed-default-samclisourcebucket-1rzppw621dkka Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {} Initiating deployment ===================== HelloWorldFunction may not have authorization defined. Uploading to sam-app/8476bddd8c14756a7c801a61352b828d.template 1142 / 1142.0 (100.00%) Waiting for changeset to be created.. CloudFormation stack changeset ------------------------------------------------------------------------------------------------ Operation LogicalResourceId ResourceType ------------------------------------------------------------------------------------------------ + Add HelloWorldFunctionHelloWorldPe AWS::Lambda::Permission rmissionProd + Add HelloWorldFunctionRole AWS::IAM::Role + Add HelloWorldFunction AWS::Lambda::Function + Add ServerlessRestApiDeployment47f AWS::ApiGateway::Deployment c2d5f9d + Add ServerlessRestApiProdStage AWS::ApiGateway::Stage + Add ServerlessRestApi AWS::ApiGateway::RestApi ------------------------------------------------------------------------------------------------ Changeset created successfully. arn:aws:cloudformation:ap-northeast-1:************:changeSet/samcli-deploy1597324152/18c44433-12d1-4e03-9fb8-00737d018991 Previewing CloudFormation changeset before deployment ====================================================== Deploy this changeset? [y/N]: y 2020-08-13 22:09:28 - Waiting for stack create/update to complete CloudFormation events from changeset ------------------------------------------------------------------------------------------------- ResourceStatus ResourceType LogicalResourceId ResourceStatusReason ------------------------------------------------------------------------------------------------- CREATE_IN_PROGRESS AWS::IAM::Role HelloWorldFunctionRole - CREATE_IN_PROGRESS AWS::IAM::Role HelloWorldFunctionRole Resource creation Initiated CREATE_COMPLETE AWS::IAM::Role HelloWorldFunctionRole - CREATE_IN_PROGRESS AWS::Lambda::Function HelloWorldFunction - CREATE_IN_PROGRESS AWS::Lambda::Function HelloWorldFunction Resource creation Initiated CREATE_COMPLETE AWS::Lambda::Function HelloWorldFunction - CREATE_IN_PROGRESS AWS::ApiGateway::RestA ServerlessRestApi Resource creation pi Initiated CREATE_IN_PROGRESS AWS::ApiGateway::RestA ServerlessRestApi - pi CREATE_COMPLETE AWS::ApiGateway::RestA ServerlessRestApi - pi CREATE_IN_PROGRESS AWS::ApiGateway::Deplo ServerlessRestApiDeplo - yment yment47fc2d5f9d CREATE_IN_PROGRESS AWS::ApiGateway::Deplo ServerlessRestApiDeplo Resource creation yment yment47fc2d5f9d Initiated CREATE_IN_PROGRESS AWS::Lambda::Permissio HelloWorldFunctionHell Resource creation n oWorldPermissionProd Initiated CREATE_IN_PROGRESS AWS::Lambda::Permissio HelloWorldFunctionHell - n oWorldPermissionProd CREATE_COMPLETE AWS::ApiGateway::Deplo ServerlessRestApiDeplo - yment yment47fc2d5f9d CREATE_IN_PROGRESS AWS::ApiGateway::Stage ServerlessRestApiProdS - tage CREATE_COMPLETE AWS::Lambda::Permissio HelloWorldFunctionHell - n oWorldPermissionProd CREATE_IN_PROGRESS AWS::ApiGateway::Stage ServerlessRestApiProdS Resource creation tage Initiated CREATE_COMPLETE AWS::ApiGateway::Stage ServerlessRestApiProdS - tage CREATE_COMPLETE AWS::CloudFormation::S sam-app - tack ------------------------------------------------------------------------------------------------- CloudFormation outputs from deployed stack ------------------------------------------------------------------------------------------------- Outputs ------------------------------------------------------------------------------------------------- Key HelloWorldFunctionIamRole Description Implicit IAM Role created for Hello World function Value arn:aws:iam::************:role/sam-app-HelloWorldFunctionRole-IIPXQC9S1XKJ Key HelloWorldApi Description API Gateway endpoint URL for Prod stage for Hello World function Value https://tws0qc6nbc.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/ Key HelloWorldFunction Description Hello World Lambda Function ARN Value arn:aws:lambda:ap-northeast-1:************:function:sam-app- HelloWorldFunction-1OH75PSLQUSLC ------------------------------------------------------------------------------------------------- Successfully created/updated stack - sam-app in ap-northeast-1## 実行
curl https://tws0qc6nbc.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/ {"message": "hello world"}成功しました。
確認
では、マネジメントコンソールで、X-RayのService Map、Traces、アナリティクスを確認してみましょう。
Service Map
クライアントから呼び出され、API Gateway、Lambdaと順に呼び出されていく様子と、それぞれのレイテンシーを確認することができます。
Traces
こちらでは、トレースの状況を確認することができます。
ここでは、それぞれの条件に応じてフィルタリングすることができます。
- URL
- StatusCOde
- Method
- User
- UserAgent
- ClientIP
- InstanceId
- ResourceARN
- Response time root causes
- Error root causes
- Error root cause messages
- Fault root causes
- Fault root cause messages
- Annotation aws:api id
アナリティクス
最後にアナリティクスは、その名の通り、さまざまな分析をしたり、比較を行ったりすることができます。
AWSサービスをトレースしてみる
では、AWSサービスのトレースをしてみましょう。
今回は、DynamoDBにPutItemする時のトレースを追加してみます。細かい内容は、「[AWS] Serverless Application Model (SAM) でAPI Gateway + Lambda + DynamoDBなサンプルを作成してみる」を参照いただきたいて、X-Rayに関する部分だけポイントで説明したいと思います。
コードの追加
まず、HelloWorldとは別に、Function用のディレクトリを作成し、その中にファイルを作成していきます。
$ mkdir sam_ddb $ touch sam_ddb/app.py $ touch sam_ddb/requirements.txtまずは、Lambda関数の本体ですが、ここで重要なのが、
patch['boto3']の部分です。
これを行うことによって、boto3のAWSサービス呼び出しのトレースが行えるようになります。sam_ddb/app.pyimport json import boto3 from aws_xray_sdk.core import xray_recorder from aws_xray_sdk.core import patch from datetime import datetime patch(['boto3']) @xray_recorder.capture('put_item ddb') def lambda_handler(event, context): event_body = json.loads(event["body"]) dynamodb = boto3.resource("dynamodb") table = dynamodb.Table("Demo") table.put_item( Item={ "Key": event_body["key"], "CreateDate": datetime.utcnow().isoformat() } ) return { "statusCode": 200, "body": json.dumps({ "message": "succeeded", }), }sam_ddb/requirements.txtaws-xray-sdk boto3最後に、
template.ymlを編集します。
変更が必要なのは、Resourcesと、Outputsの部分です。
IAM Roleで、X-Rayに関する権限が必要なので注意してください。template.yml変更前AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > sam-app Sample SAM Template for sam-app # More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst Globals: Function: Timeout: 3 Tracing: Active Api: TracingEnabled: True Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.8 Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /hello Method: get Outputs: # ServerlessRestApi is an implicit API created out of Events key under Serverless::Function # Find out more about other implicit resources you can reference within SAM # https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#api HelloWorldApi: Description: "API Gateway endpoint URL for Prod stage for Hello World function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/" HelloWorldFunction: Description: "Hello World Lambda Function ARN" Value: !GetAtt HelloWorldFunction.Arn HelloWorldFunctionIamRole: Description: "Implicit IAM Role created for Hello World function" Value: !GetAtt HelloWorldFunctionRole.Arntemplate.yml変更後AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > sam-app Sample SAM Template for sam-app # More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst Globals: Function: Timeout: 3 Tracing: Active Api: TracingEnabled: True Resources: DynamoTable: Type: AWS::DynamoDB::Table Properties: TableName: Demo AttributeDefinitions: - AttributeName: Key AttributeType: S - AttributeName: CreateDate AttributeType: S KeySchema: - AttributeName: Key KeyType: HASH - AttributeName: CreateDate KeyType: RANGE ProvisionedThroughput: ReadCapacityUnits: 5 WriteCapacityUnits: 5 HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.8 Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /hello Method: get SamDdbFunction: Type: AWS::Serverless::Function Properties: Role: !GetAtt SamDdbFunctionIamRole.Arn CodeUri: sam_ddb/ Handler: app.lambda_handler Runtime: python3.8 Events: SamDdb: Type: Api Properties: Path: /ddb Method: post SamDdbFunctionIamRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - 'lambda.amazonaws.com' Action: - 'sts:AssumeRole' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/CloudWatchLogsFullAccess' Policies: - PolicyName: 'SamDdbPolicy' PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - dynamodb:PutItem Resource: !GetAtt DynamoTable.Arn - Effect: Allow Action: - xray:PutTraceSegments - xray:PutTelemetryRecords Resource: '*' Outputs: # ServerlessRestApi is an implicit API created out of Events key under Serverless::Function # Find out more about other implicit resources you can reference within SAM # https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#api HelloWorldApi: Description: "API Gateway endpoint URL for Prod stage for Hello World function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/" HelloWorldFunction: Description: "Hello World Lambda Function ARN" Value: !GetAtt HelloWorldFunction.Arn HelloWorldFunctionIamRole: Description: "Implicit IAM Role created for Hello World function" Value: !GetAtt HelloWorldFunctionRole.Arn SamDdbApi: Description: "API Gateway endpoint URL for Prod stage for SAM DDB function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/ddb/"ビルドとデプロイ
sam buildと、sam deploy --guidedを実行してください。
(内容は省略します)実行
今回はAPIを1個追加しているので、比較のためにHelloWorldのAPIも呼び出してみます。
$ curl https://fp8nyhpv87.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/ {"message": "hello world"}続いて、DynamoDBに書き込むPostのAPIを呼び出してみます。
$ curl -X POST -H "Content-Type: application/json" -d '{"key": "demo-data"}' https://fp8nyhpv87.execute-api.ap-northeast-1.amazonaws.com/Prod/ddb/ {"message": "succeeded"}X-Rayの確認
まずは、Service Mapから。
なぜか配置がねじれてますが、DynamoDBへのアクセス部分が切り出されて表示されているのがわかると思います。
DBの書き込み部分が620msかかっていることがわかりますね。
Tracesでも同様です。
DynamoDBの部分が独立してトレースできます。
念のためDynamoDBも確認
ばっちりデータが登録されてます。
まとめ
X-Rayによるトレーシングで、様々な分析、解析が可能になります。
事後でも簡単に追加できますが、できれば、初期の段階から導入されることをおすすめします。サンプルコードリポジトリ