- 投稿日:2020-08-09T23:00:09+09:00
Python は、なんでコロンを書かないといけないの?
Python では if, for, def, class などの複合文には、コロン
:が必要になります。if True: print('Hello, world!')各節のヘッダは一意に識別するキーワードで始まり、コロンで終わります。
8. 複合文 (compound statement) - Python 言語リファレンス公式ドキュメント
なぜ、コロン
:を書かないといけないかは、公式ドキュメントに記載があります。(妄想) 個人的には...
1. ABC 言語云々
セミコロン
;を使って1行で、ワンライナーで書くときは、あったほうがわかりやすいです。このときには:がないとかなり、わかりにくいことになります。def f(x): y = x + 1; z = y + 2; return z; f(0)>>> def f(x): y = x + 1; z = y + 2; return z; ... >>> f(0) 3 >>>公式ドキュメントでは ABC 言語云々という話の中で複数行で書く方式を例に出していますが、このセミコロン
;を使ったワンライナーの方がクリティカルだったのかなと個人的に思っています(ほとんど使いませんが笑)。単純文ですが lambda 式のときはコロン
:があったほうがわかりやすいかな、と思います。g = lambda x: x + 1 g(0)>>> g = lambda x: x + 1 >>> g(0) 1 >>>2. 解析云々
文のグループ化にインデントを使ってしまっているので、先頭だけコロン
:を使うと解析しやすいよ、と主張するのは厳しいのでは?と個人的に思っています。(妄想) 必要なのか?
このコロン
:は、いらなくない?と、よく批判を浴びます。自分も正直言っていらないと思っています。ワンライナーで複文を書くことは、ほとんどないからです。Python は、いまは、だいぶ多機能になりましたが「あればいいものはなくていい」の精神で、新規の機能の追加には慎重だったような気がします。その精神は、PEP 20 の以下の言葉が端的に表していると思います。
There should be one-- and preferably only one --obvious way to do it.
PEP 20 -- The Zen of Pythonここではコロン
:がいらないというよりも「セミコロン;でワンライナーで書ける機能がいらない」という方が正確かもしれませんが。どんな過程でコロンを書く流れになったのか、考えてみたのですが... セミコロン
;でワンライナーでも書けるようにしたい。そうするにはコロン:を書く必要がある。ワンライナーとそうでないときで、コロン:を書いたりかかなかったりするのは一貫性に欠ける。Special cases aren't special enough to break the rules.
PEP 20 -- The Zen of Pythonだから、コロン
:をつけるで統一しよう。そんな流れだったのかなと、個人的に思っています。
- 投稿日:2020-08-09T22:44:47+09:00
【成長日記:1日目】友達に教えてもらいながら中日ドラゴンズの選手の成績をWebスクレイピング→pandasでcsvファイルに処理
友達の「誰かにプログラミングを教えたい欲」が高まっているらしいので教えてもらうことにした
— ゆーさん (@fukannk0423) July 31, 2020
とりあえず今日は環境構築で終わった
明日は中日ドラゴンズのホームページから選手の成績を持ってきて各選手のOPSを出すプログラムを書く
疲れた、おやすみー初めまして。同級生の友人がプログラミングを教えてくれると言うので、教えてもらうついでにどこかでアウトプットして成長日記をつけようと思いQiitaを始めました。
やりたいこと
今のところ研究や就職先でPythonを活用する予定がない(後々できるかもしれない)ので、研究やビジネスライクな目的はなく個人的な好奇心のままにコードを書いていきます。
Webスクレイピング
- ニュースサイトの最新記事見出しや今日の天気をスクレイピングして毎朝自分の携帯にメールで送る
- 中日ドラゴンズの選手のデータをスクレイピングしてJSON形式のデータベースを作る
機械学習(Machine Learning, ML)
- 中日ドラゴンズの明日の采配予想プログラムを組んで実際のオーダーと比較し学習させる
データサイエンス
- Kaggleなんかにも手を出せたらいいな(初心者並感)
その他、おもしろそうなプログラムをいろいろ書いていく
目標
「自作の中日ドラゴンズの選手の成績データベースから明日の与田采配を予想するプログラムを作成し、実際のオーダーと比較してより正確な予想ができるように学習させる」
当面はこれを目標にいろいろなコードを書いていきたいと思います。
環境
$ python --version Python 3.8.3 $ conda --version conda 4.8.3Anacondaでjupyter notebookを起動してPythonのコードを書いています。
初心者なので環境に何を書いといたらいいか分からない…他に挙げておいた方がいいものがあったら教えてください。
ということで早速冒頭で引用したツイートのプログラムを書いていきましょう。
中日ドラゴンズの選手のデータを公式HPから
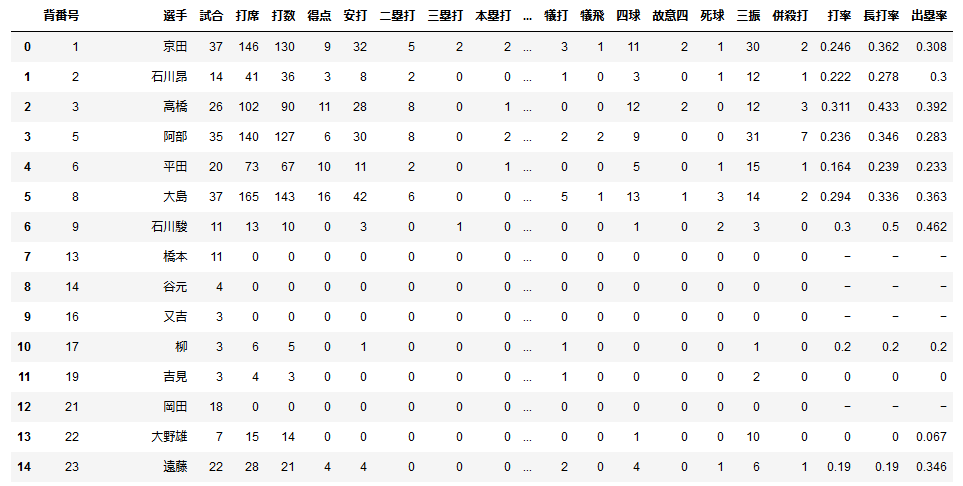
スクレイピングコピペしてpandasで処理今日はプログラミング初日ということでWebスクレイピングしたデータを処理していくのはさすがにハードルが高いので、あらかじめ手動で中日ドラゴンズの公式HPからコピペした、2020.8.1現在の中日の選手の打撃成績データをcsvファイルに保存しておき、pandasでいじることにしました。スクレイピングは次回からやっていきます。
#pandasでcsvファイルを読み込んでdf:DataFrameを作る import pandas as pd df = pd.read_csv('cd_seiseki2020.csv', encoding='Shift-jis') #エンコードは指定しないとutf-8で読み込まれてしまい文字化けする
公式サイトと同じような表が作れました。
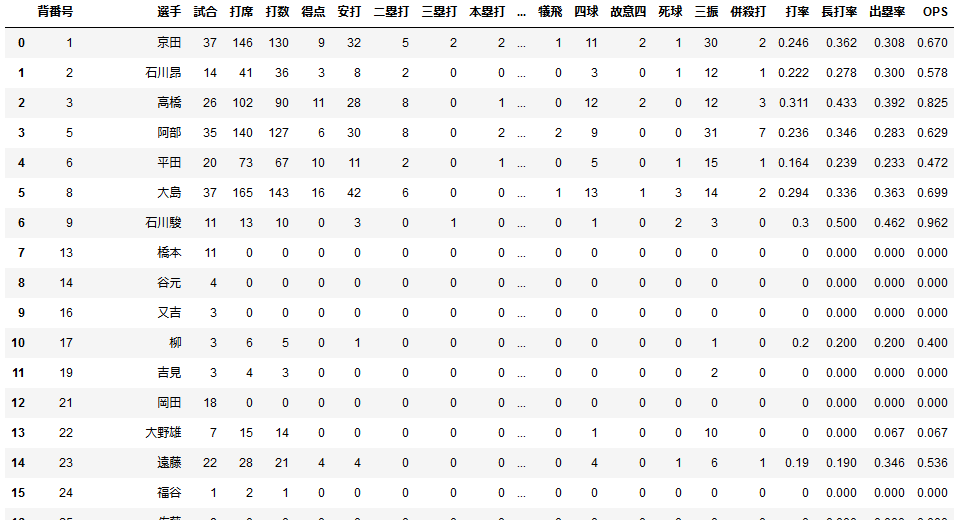
これだけではちょっと物足りないので、表の出塁率と長打率のデータを基に各選手のOPSを算出してみましょう。#表の各要素を数値に変換してOPSを算出 df_2 = df.replace('-', '0') df_3 = df_2.astype({'出塁率': float, '長打率': float}) df_3['OPS'] = df_3['出塁率'] + df_3['長打率'] df_3OPSは出塁率と長打率の和なので単純に数字を足せば得られますが、このままだと表の各要素はstring(文字列)なので演算できません(正確には文字列が連結されて0.3080.670のような結果が出てしまいます)。なので文字列を数値に変換する必要があります。
今回は出塁率のような確率を扱うのでfloat(浮動小数点)に変換しています。
その際まだ打席に立っていない選手の出塁率は"-"表記になっていたので、数値に変換できるよう今回は"0"に変換しておきました。
そして新しくOPSの列を作って数値を計算します。
表の一番右側にOPSが表示されました。
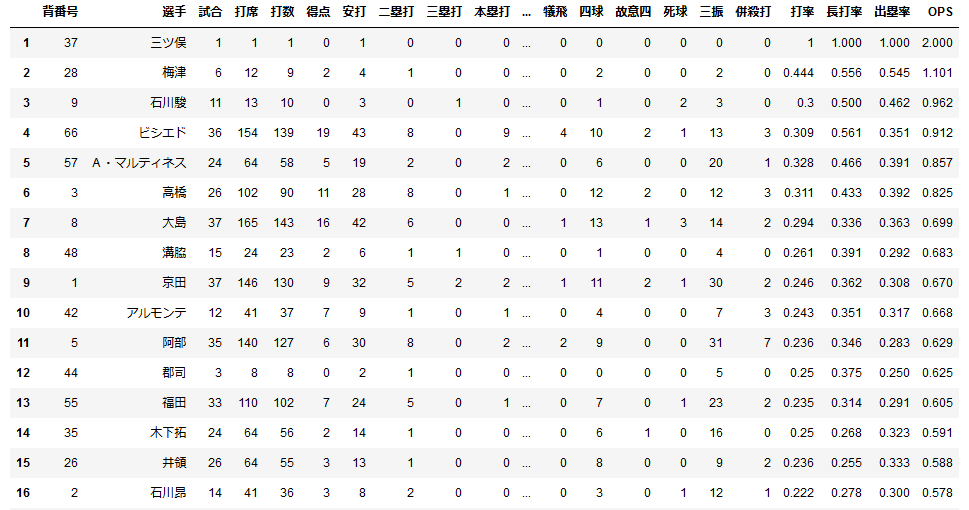
このままだと誰のOPSが一番高いのか見にくいので数値の大きい順にソートします。df_s = df_3.sort_values('OPS', ascending=False) df_r = df_s.reset_index() df_r2.index = df_r.index + 1 df_r2なんかいちいち変数を振りなおしてるのは、jupyternotebookで逐一セルを変えて出力を確認してたからです。
ついでにインデックスも振り直した結果が下の表です。
この日は三ツ俣が今季初めて代打で出てきて安打を記録したのでOPS2.000になっていますね。
ある程度打席をこなした選手を見ると、OPSの高い選手はスタメン起用されている選手が多いですね。
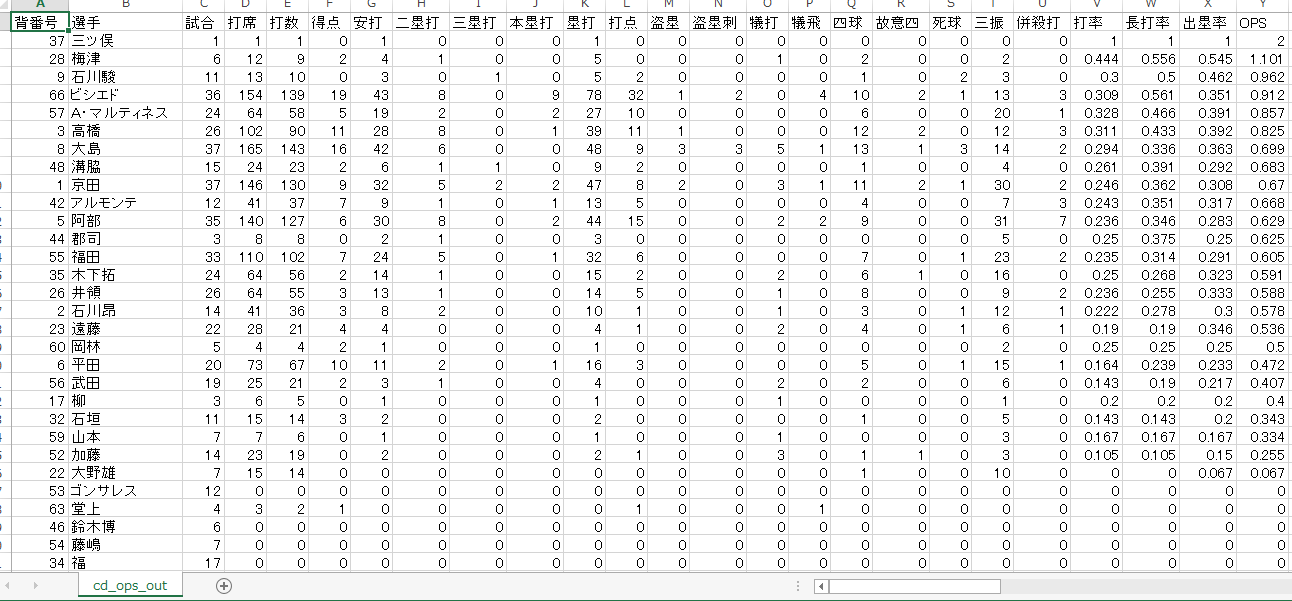
打席の数が30以上の選手だけピックアップする処理をしてみてもいいかもしれませんね(面倒なのでやらない)。最後にDataframeのデータをcsvファイルに出力します。
df_r2.to_csv('cd_ops_out.csv', index=False)
できました。
pandasはデータを扱うときデフォルトでutf-8のエンコーディングを使用しているらしいので、最終的に見る時はShift-JISに変換する必要がありそうです。.to.csv()の引数でエンコーディングの指定もできるそうです。とりあえず今回はここまでにしました。次回はrequestsやBeautisulSoupモジュールを使って、Webからデータを取得する工程もプログラムに組み込んでいきます。
明日の課題
- requestsやBeautifulSoupを使って自動でWebページからデータを取得する
- pandasのDataFrameやcsvファイルをQiitaでうまく表示する方法を考える(今回はスクショをとったけどマークダウン記法とかとうまく親和したやり方はないのかなあ。誰か教えてください)
おわりに
ウェブサイトによってはスクレイピングは規約で明示的に禁止されていることもあり、サーバーに負荷をかけるようなプログラムを組んでしまうとよくない結果を招くこともありえます。
もし僕のような初心者でWebスクレイピングをやってみたいと思った方は、プログラムの実行には十分気を付けましょう。定期的にサイトから情報を取得するコードなどを組む際は、事前にオフラインのデータを対象に試すなどして高頻度になりすぎていないか確かめましょう。
- 投稿日:2020-08-09T21:44:27+09:00
ベイズ推論の考え方(2)・・ベイズ推定と確率分布
Pythonで体験するベイズ推論より
一回書いたけど、なんか馴れてないので、この項目消してしまいました。
そういうわけで、もう一回書いてます。。トホホ。ベイズ主義とは
頻度主義とベイズ主義
頻度主義とは、昔からある古典的な統計学である。
頻度主義では、確率を「長期間における事象の頻度」とみなす.ベイズ主義では、確率を「ある事象が発生する信念(belief)」あるいは「確信(confidence)」の度合いとみなす。
確率を信念とみなすことは、実は人間にとって自然な考え方である。「確率とは信念である」
ある事象が生じる信念を$P(A)$と表し、事前確率と呼び、証拠$X$が与えられて更新された信念を$P(A|X)$と表す。これは証拠Xが与えられた時の$A$の確率である。これを事後確率と呼ぶ。
ベイズ推論の考え方
ベイズ主義の推論関数は確率を戻すが、頻度主義の推論関数は推定値を表す数値を戻す。。
これは重要なことなので、覚えておいた方が良い。例えば、プログラムの例題を考えると、
頻度主義の考え方で「このプラグラムはすべてのテストにパスした。(情報X)このプラグラムに問題はないか?」と考えた場合、「はいプログラムにバグはありません」となるだろう。これをベイズ主義で考えるとこう答える。
「はい、バグがない確率は0.8です。いいえ、バグがある確率は0.2です。」
ベイズ主義では、プログラムにはいつでもバグがあるという事前知識を引数として追加できる。証拠(情報X)が多くなり無限個(非常に大きな)の証拠が集まると、結果として頻度主義とベイズ主義は似たような推論結果を出してくることになる。
ビッグデータについて
ビッグデータを利用した分析、予測は比較的単純なアルゴリズムが用いられている。つまりビッグデータの解析の難しさは、アルゴリズムにあるのではない。
もっとも難しい問題は「中くらいのデータ」や「小さなデータ」です。ここでベイズ主義が生きてくる。ベイズの定理
ベイズの定理(ベイズ則)
P( A | X ) = \displaystyle \frac{ P(X | A) P(A) } {P(X) }ベイズ推論は事前確率$P(A)$と更新後の事後確率$P(A|X)$を数学的に結び付けているだけである。
確率分布
離散値の場合
$Z$が離散値の場合は、確率分布は確率質量分布となる。これは$Z$は$k$をとる確率である。これを$P(Z=k)$と表す。
確率質量関数にポアソン分布がある。
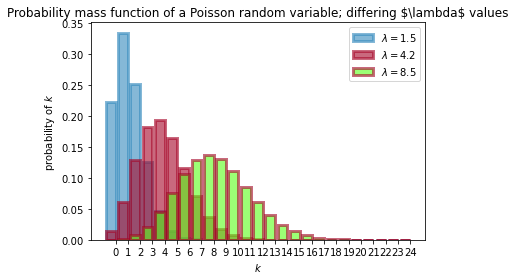
$Z$の確率質量関数は、ポアソン分布に従い、次の式で表されます。P(Z = k) =\frac{ \lambda^k e^{-\lambda} }{k!}, \; \; k=0,1,2, \dots$\lambda$は、分布の形状を決めるパラメーターで、ポアソン分布の場合は$\lambda$は正の実数である。$\lambda$を大きくすると大きな値の確率が高くなり、$\lambda$を小さくすると小さな値の確率が高くなる。つまり$\lambda$はポアソン分布の強度である。
$k$は、非負の整数である。$k$は整数であるところに注意する。
確率変数$Z$がポアソン分布に従うことを次のように書く。\sim \text{Poi}(\lambda)ポアソン分布の便利な性質は、期待値が分布パラメーターに等しいところである。
E\large[ \;Z\; | \; \lambda \;\large] = \lambda$\lambda$を変えて確率質量関数をプロットしたものである。
# -*- coding: utf-8 -*- import matplotlib.pyplot as plt import scipy.stats as stats import numpy as np a = np.arange(25) #scipy のポアソン分布関数 poi = stats.poisson lambda_ = [1.5, 4.25,8.50] colours = ["#348ABD", "#A60628","#5AFF19"] plt.bar(a, poi.pmf(a, lambda_[0]), color=colours[0], label="$\lambda = %.1f$" % lambda_[0], alpha=0.60, edgecolor=colours[0], lw="3") plt.bar(a, poi.pmf(a, lambda_[1]), color=colours[1], label="$\lambda = %.1f$" % lambda_[1], alpha=0.60, edgecolor=colours[1], lw="3") plt.bar(a, poi.pmf(a, lambda_[2]), color=colours[2], label="$\lambda = %.1f$" % lambda_[2], alpha=0.60, edgecolor=colours[1], lw="3") plt.xticks(a + 0.4, a) plt.legend() plt.ylabel("probability of $k$") plt.xlabel("$k$") plt.title("Probability mass function of a Poisson random variable;\ differing \$\lambda$ values");本は、$\lambda=1.5,4.25$の2つだったので、もう一つ8.5を入れて3つを計算してみた。
$\lambda$を大きくすると大きな値の確率が高くなり、$\lambda$を小さくすると小さな値の確率が高くなるが結果としてグラフに表れている。
連続値の場合
連続確率変数、確率質量変数ではなく、確率密度分布関数で表される。
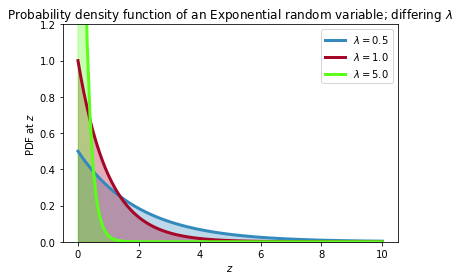
確率密度関数には指数分布がある。f_Z(z | \lambda) = \lambda e^{-\lambda z }, \;\; z\ge 0指数分布の確率変数は非負の値をとる。連続値であるので、時間や温度(ケルビン)などの正の実数値をとるデータに向いている。
確率変数$Z$は、密度分布関数が指数分布であれば、$Z$は指数分布に従います。つまりZ \sim \text{Exp}(\lambda)で表され、指数分布の期待値は、パラメータ$\lambda$の逆数になります。
E[\; Z \;|\; \lambda \;] = \frac{1}{\lambda}# -*- coding: utf-8 -*- import matplotlib.pyplot as plt import scipy.stats as stats import numpy as np a = np.linspace(0, 10, 100) expo = stats.expon lambda_ = [0.5, 1, 5] colours = ["#348ABD", "#A60628","#5AFF19"] for l, c in zip(lambda_, colours): plt.plot(a, expo.pdf(a, scale=1./l), lw=3, color=c, label="$\lambda =! %.1f$" % l) plt.fill_between(a, expo.pdf(a, scale=1./l), color=c, alpha=.33) plt.legend() plt.ylabel("PDF at $z$") plt.xlabel("$z$") plt.ylim(0,1.2) plt.title("Probability density function of an Exponential random variable;\ differing $\lambda$");
λとはなんだろう?
$\lambda$を得ることはできない。我々にわかるのは、$Z$のみである。また$\lambda$と$Z$にも1体1の関係がない。
ベイズ推論が扱うのは、$\lambda$の値が何なのか?の信念である。つまり重要なのは厳密に$\lambda$の値を求めるのではなく、$\lambda$はこの値になりそうだということにする、$\lambda$についての確率分布を考えることだ。
$\lambda$は定数だが、定数の値に確率を与えるということを思ったら、それは頻度主義に侵されているということである。
ベイズ主義は、確率を信念だとみなすので、実は、何にでも確率を割り当てることができる。つまり
「確率とは信念である」
ということである。

- 投稿日:2020-08-09T20:53:14+09:00
[AtCoder]ABC165C個人的メモ[Python]
ABC165 C - Many Requirements
考えられる数列Aをdfsによって全探索し,得点の最大値を求める.
解答例を2つ示す
解答例1-dfsを再帰関数で実装
- calc関数
数列Aから得点の計算をする関数
- dfs関数
考えられる数列Aをdfsによって全探索しつつ,得点の最大値を求める関数
数列Aの長さがNなら得点を計算した後,今までの最高得点と比較,最高得点を記録
それ以下の長さなら,数列Aの制約を満たす様に要素を1つ追加して再帰
Aが空リストなら$x=1$を,それ以外なら$A[-1]\leqq x\leqq M$の$x$をAに追加して再帰main.py#!/usr/bin/env python3 def main(): import sys def calc(A: list): score = 0 for a, b, c, d in lst: if A[b - 1] - A[a - 1] == c: score += d return score def dfs(A: list): nonlocal ans if len(A) == N: ans = max(ans, calc(A)) return for v in range(A[-1] if A else 1, M + 1): A.append(v) dfs(A) A.pop() input = sys.stdin.readline N, M, Q = map(int, input().split()) lst = [list(map(int, input().split())) for _ in range(Q)] ans = 0 dfs([]) print(ans) main()
- 解答例2-itertools.combinations_with_replacement(iterable, r)
itertools.combinations_with_replacementをつかって,数列Aを全探索する
公式ドキュメントによると,itertools.combinations_with_replacement(iterable, r)は,入力iterableから,それぞれの要素が複数回現れることを許して長さrの要素の部分列をタプルで返す
test.py# itertools.combinations_with_replacement(iterable, r)の使用例 from itertools import combinations_with_replacement for pattern in combinations_with_replacement('ABCD', 2): print(pattern, end='') # AA AB AC AD BB BC BD CC CD DD上記の関数を用いると,解答は以下の様に書ける
main.py#!/usr/bin/env python3 def main(): import sys from itertools import combinations_with_replacement input = sys.stdin.readline N, M, Q = map(int, input().split()) lst = [list(map(int, input().split())) for _ in range(Q)] ans = 0 for pattern in combinations_with_replacement(range(1, M + 1), N): res = 0 pattern = list(pattern) for a, b, c, d in lst: if pattern[b - 1] - pattern[a - 1] == c: res += d ans = max(ans, res) print(ans) main()参考URL
- あっとのTECH LOG
ABC165 C - Many Requirements
https://at274.hatenablog.com/entry/2020/05/20/213705- けんちょんの競プロ精進記録
よくやる再帰関数の書き方 〜 n 重 for 文を機械的に 〜
https://drken1215.hatenablog.com/entry/2020/05/04/190252- Python 3.8.5 ドキュメント
効率的なループ実行のためのイテレータ生成関数
https://docs.python.org/ja/3/library/itertools.html#itertools.combinations_with_replacement
- 投稿日:2020-08-09T20:51:43+09:00
自然言語処理入門の本を読んでみた
初めに
機会学習・深層学習による自然言語処理入門 著 中山光樹
を読んだ感想を書いてみる
pythonになれるためサンプルコードは自前でカスタマイズしてみた第一章、第二章
機械学習とは何かという話と、pythonの実行環境についての話
本著ではpythonの実行環境をMinicondaを使って作っているみたいだが、conda系の開発環境はトラウマしかないため、dockerでpython開発環境用のcontainerを作ったよ
次いでにviでpythonのコードが補完されるモジュールも導入したよ
viのコピペ、pythonでのマルチバイト文字列を扱えるようにするために苦労したことは秘密だ第三章
コーパスとは何ぞやを説明している
ぐるなびAPIから機械学習用のデータを取得するコードがあったので、自分なりにカスタマイズした。というか、カスタマイズしないと動かない
もともとのコードは検索キーにジャンルを指定していたけど、サンプルコードの通りに実行するとAPIの仕様が中間一致から完全一致に変わったのか、「検索結果が見つからない」という結果が返ってくる
(ぐるなびAPIいけてなさすぎる)
仕方がないので、経度をしていて検索結果を取得してみたsample.pyimport requests url ='https://api.gnavi.co.jp/PhotoSearchAPI/v3/' params = {'keyid': 'YourAPI','latitude': 35.5367971,'longitude':139.634745} response = requests.get(url,params=params).json() lists = list( map( lambda x:{'comment':response['response'][x]['``photo']['comment'],'socre':response['response'][x]['photo']['total_score']} , list( filter(lambda x1:response['response'][x1]['photo']['comment'] and response['response'][x1]['photo']['total_score'] ,list( filter(lambda x2:x2.isdigit(),response['response'].keys()) ) ) ) ) ) print(lists)コーディングをした雑感
箇条書きに書いてみる
ぐるなびAPIの戻り値のデータ構造が嫌がらせに近いくらい終わっている。なんで制御コード的な情報と個々の検索結果が同じ第二階層にあるんだよ?おかげでインデックスが数字かどうか判定する、無駄なロジックが入ってしまうではないか
関数型言語的な処理はJavaの
list.stream() .filter() .filter() .map() .collect()みたいにかけないのかのぉ
mapとかfilterを使うたびにlist()関数を使うのは冗長なんですが
たかだか、これだけのプログラムのために別関数にfor-yieldを使うのも面倒くさいし
これは私がpythonに慣れてないだけで別のpython的なやり方があるんだろうなと思いますが
- 投稿日:2020-08-09T19:57:51+09:00
【Emacs】Pythonの自動補完パッケージjediのインストールで困った話(mac)
はじめに
・環境
macOS Mojave 10.14.6
GNU Emacs 26.3macでemacs-jediを導入しようとしたところ、ハマりました。
もともとjediを使用していたのですが、python自体の環境が変わったのに伴い再インストールを試みました。
そういえば最初にインストールした時も、大変だった記憶があります。ちなみに、もともとの設定はこちら。
(add-hook 'python-mode-hook 'jedi:setup) (setq jedi:complete-on-dot t)macとjediは相性が悪いのか、例えばこんな情報もあります。
https://github.com/tkf/emacs-jedi/issues/346また、デフォルトではvirtualenvのpythonを見に行くというのもややこしい...。
その時の状況
jedi自体のインストールは
M-x package-list-packageから問題なくできたのですが、M-x jedi:install-serverでエラーが発生しました。deferred error : (error "Deferred process exited abnormally: command: virtualenv exit status: exit 1 event: exited abnormally with code 1 buffer contents: \"FileExistsError: [Errno 17] File exists: '/usr/local/opt/python@3.8/bin/pytho\ n3.8' -> '/Users/username/.emacs.d/.python-environments/default/bin/python' \"")ドキュメントhttp://tkf.github.io/emacs-jedi/latest/#jedi:install-server に
環境は〜/ .emacs.d / .python-environments / default /にあります
とあるので、ここに古いpython環境が残っているのが原因かと思い、これを削除
rm -r .emacs.d/.python-environments/defaultして再び
M-x jedi:install-serverを実行しましたが、以下のエラーが出て残念。Traceback (most recent call last): File "/Users/username/.emacs.d/.python-environments/default/bin/jediepcserver", line 5, in <module\ > from jediepcserver import main ModuleNotFoundError: No module named 'jediepcserver' Process epc:server:3 exited abnormally with code 1解決編
こちらの記事に救われました...!
http://proglab.blog.fc2.com/blog-entry-46.htmlこの記事を要約すると
結局、jedi, epc, jediepcserver がインストールされていれば virtualenv で仮想環境を構築してやらなくても良いのでは…、ということに気がつきました。
pip install --upgrade ~/.emacs.d/elpa/jedi-core-なんちゃらを実行して設定ファイル(ex. ~/.emacs)に
(setq jedi:server-command (list (executable-find "jediepcserver")))を追記すれば良い。
とのことで、実際に自分の手元でもこれで解決しました!
最後に
jediは便利なので、これが再び使えるようになったのは本当にありがたいです。
以上のエラーに対する有効な対策をご存知の方がいたら、教えていただきたいです。
- 投稿日:2020-08-09T19:22:20+09:00
Nature Remo を Python から操作する
はじめに
Nature Remo のデバイスは、APIを通じて操作することが可能です。最近 Nature Remo の第3世代を入手したため、これをプログラムやコマンドラインから操作したいと思い、Python 向けにライブラリを書きました。
ここではこのライブラリの使い方について解説していきます。Remo で遊ぶ上での選択肢の一つとしていただければ幸いです。
インストール
サポートしている Python のバージョンは 3.8 です。インストールは
pipからおこないます:$ pip install -U nature-remoなお、動作確認は Ubuntu と macOS にておこないました。
使い方
API を使用する前提として、
にてアクセストークンを発行しておいてください。
アクセストークンを入手したら、それを用いてクライアントを初期化します:
>>> from remo import NatureRemoAPI >>> api = NatureRemoAPI('access_token')生成したクライアントには、各 API に対応するメソッドが備わっています。たとえば、自分のアカウントに関連付けられた Nature Remo のデバイスのリストを取得したければ、
api.get_devicesメソッドを実行します:>>> devices = api.get_devices() >>> devices [Device(id='device-id', name='Remo', temprature_offset=0, humidity_offset=0, created_at=datetime.datetime(2020, 7, 23, 3, 10, 21, tzinfo=datetime.timezone.utc), updated_at=datetime.datetime(2020, 8, 8, 11, 4, 17, tzinfo=datetime.timezone.utc), firmware_version='Remo/1.0.23', mac_address='ab:cd:ef:12:34:56', serial_number='1W000000000000', newest_events={'hu': {'val': 54.0, 'created_at': datetime.datetime(2020, 8, 9, 6, 24, 19, tzinfo=datetime.timezone.utc)}, 'il': {'val': 0.0, 'created_at': datetime.datetime(2020, 8, 9, 6, 31, 46, tzinfo=datetime.timezone.utc)}, 'mo': {'val': 1.0, 'created_at': datetime.datetime(2020, 8, 8, 11, 4, 17, tzinfo=datetime.timezone.utc)}, 'te': {'val': 27.636597, 'created_at': datetime.datetime(2020, 8, 9, 6, 29, 19, tzinfo=datetime.timezone.utc)}})]
devicesはDeviceモデルのリストです。Deviceモデルのインスタンスは、idやnameなど、対応する Remo デバイスの情報をアトリビュートとして保持しています。たとえばデバイスのセンサーが取得した湿度や温度は、次のようにしてアクセスすることができます:>>> d.newest_events {'hu': SensorValue(val=54.0, created_at=datetime.datetime(2020, 8, 9, 7, 57, 28, tzinfo=datetime.timezone.utc)), 'il': SensorValue(val=21.0, created_at=datetime.datetime(2020, 8, 9, 7, 55, 21, tzinfo=datetime.timezone.utc)), 'mo': SensorValue(val=1.0, created_at=datetime.datetime(2020, 8, 8, 11, 4, 17, tzinfo=datetime.timezone.utc)), 'te': SensorValue(val=27.485535, created_at=datetime.datetime(2020, 8, 9, 7, 49, 28, tzinfo=datetime.timezone.utc))} >>> d.newest_events['hu'].val # 湿度 54.0 >>> d.newest_events['te'].val # 温度 27.485535他にも、
get_userやget_appliancesなどのメソッドにより、ユーザーや家電の情報を取得することが可能です。もちろん、情報を取得するだけでなく、家電の操作をおこなうことも可能です。たとえば、エアコンの設定を変更したい場合は、エアコンの ID を取得した上で、
update_aircon_settingsメソッドを実行します:>>> appliances = api.get_appliances() >>> appliances[0].type # 家電のタイプを確認 'AC' >>> # 26度の冷房に設定 >>> api.update_aircon_settings(appliances[0].id, operation_mode='cool', temperature=26)同様の流れで、テレビの操作なども可能です:
>>> appliances[1].type # 家電のタイプを確認 'TV' >>> appliances[1].tv.buttons # 登録されているボタンを確認 [Button(name='power', image='ico_io', label='TV_power'), ...] >>> api.send_tv_infrared_signal(appliances[1].id, 'power') # 電源ボタンを押すAPI を使用すると、クライアントのアトリビュートに Rate Limit (呼び出し制限) の状況がセットされます:
>>> api.get_user() User(id='user-id', nickname='Foo Bar') >>> api.rate_limit.limit, api.rate_limit.remaining # リミットと残りの呼び出し可能回数 (30, 28)この他にも、
api.rate_limit.resetから制限がリセットされるタイミングを知ることなどが可能です。また、クライアントの作成時に
debugをTrueとすることで、実際におこなわれている通信の様子を確認することもできます:>>> api = NatureRemoAPI('access_token', debug=True) >>> api.get_user() DEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): api.nature.global:443 send: b'GET /1/users/me HTTP/1.1\r\nHost: api.nature.global\r\nUser-Agent: nature-remo/0.3.1 (https://github.com/morinokami/nature-remo)\r\nAccept-Encoding: gzip, deflate\r\nAccept: application/json\r\nConnection: keep-alive\r\nAuthorization: Bearer access_token\r\n\r\n' reply: 'HTTP/1.1 200 OK\r\n' header: Date: Mon, 27 Jul 2020 15:53:12 GMT header: Content-Type: application/json; charset=utf-8 header: Content-Length: 72 header: Connection: keep-alive header: Access-Control-Allow-Origin: * header: Cache-Control: no-cache, no-store, must-revalidate, private, max-age=0 header: Expires: Thu, 01 Jan 1970 00:00:00 UTC header: Pragma: no-cache header: Strict-Transport-Security: max-age=86400 header: Vary: Accept-Encoding header: X-Accel-Expires: 0 header: X-Content-Type-Options: nosniff header: X-Frame-Options: SAMEORIGIN header: X-Rate-Limit-Limit: 30 header: X-Rate-Limit-Remaining: 29 header: X-Rate-Limit-Reset: 1595865300 header: X-Xss-Protection: 1; mode=block DEBUG:urllib3.connectionpool:https://api.nature.global:443 "GET /1/users/me HTTP/1.1" 200 72 User(id='user_id', nickname='your_nickname')以上のように、クライアントのインスタンスを生成し対応するメソッドを呼び出すことで、簡単に API を利用することができるようになっています。なお、API とメソッドの対応は次のようになっています (下記はすべて実装されていますが、
POST /1/detectapplianceなど、僕も動作確認できていないものがあることは述べておきます):
HTTP Method Endpoint API GET /1/users/meget_userPOST /1/users/meupdate_userGET /1/devicesget_devicesPOST /1/detectappliancedetect_applianceGET /1/appliancesget_appliancesPOST /1/appliancescreate_appliancePOST /1/appliance_ordersupdate_appliance_ordersPOST /1/appliances/{appliance}/deletedelete_appliancePOST /1/appliances/{appliance}update_appliancePOST /1/appliances/{appliance}/aircon_settingsupdate_aircon_settingsPOST /1/appliances/{appliance}/tvsend_tv_infrared_signalPOST /1/appliances/{appliance}/lightsend_light_infrared_signalGET /1/appliances/{appliance}/signalsget_signalsPOST /1/appliances/{appliance}/signalscreate_signalPOST /1/appliances/{appliance}/signal_ordersupdate_signal_ordersPOST /1/signals/{signal}update_signalPOST /1/signals/{signal}/deletedelete_signalPOST /1/signals/{signal}/sendsend_signalPOST /1/devices/{device}update_devicePOST /1/devices/{device}/deletedelete_devicePOST /1/devices/{device}/temperature_offsetupdate_temperature_offsetPOST /1/devices/{device}/humidity_offsetupdate_humidity_offset各メソッドに与える引数などは、Python の
help関数などにより確認できます。また、Local API 用のクライアントを生成するためには、Remo デバイスのローカルIPアドレスを調べた上で、それを引数として
NatureRemoLocalAPIクラスに与えます:>>> from remo import NatureRemoLocalAPI >>> local_api = NatureRemoLocalAPI('ip_addr')対応している API は以下のようになります:
HTTP Method Endpoint API GET /messagesget_ir_signalPOST /messagessend_ir_signalCLI
nature-remoをpipによりインストールすると、各 API をコマンドから実行することも可能となります。背後では、上で紹介した Python クライアントが動いています。各コマンドは、次のような形式で実行します:
$ remo [操作対象] [操作内容] [引数やオプション]操作対象には、
appliance、device、local、signal、userのいずれかを指定します。各捜査対象に対応する操作内容は、--helpを指定することで確認することができます:$ remo device --help Usage: remo device [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: delete Delete Remo. get Fetch the list of Remo devices the user has... update Update Remo. update_humidity_offset Update humidity offset. update_temperature_offset Update temperature offset.上の表示内容から、たとえばデバイスのリストを得るためには、
getを指定すればよいことがわかります。操作対象が
appliance、device、signal、userのいずれかである場合にはアクセストークンを指定する必要がありますが、CLI では環境変数とオプションのいずれかでアクセストークンを指定します。環境変数で指定する場合は、$ export REMO_ACCESS_TOKEN=<access_token>のように、REMO_ACCESS_TOKENに値をセットしておきます。また、オプションで指定する場合は次のようにします:$ remo device get --token <access_token> [{"created_at": "2020-07-23T03:10:21+00:00", ...}]また、更新や削除など、操作内容によっては引数を与える必要がありますが、それについても
--helpにより確認することができます:remo device update --help Usage: remo device update [OPTIONS] ID NAME Update Remo. ID: Device ID. NAME: Device name. Options: --token TEXT --debug --help Show this message and exit.上の表示内容から、デバイスの名前を変更するためには、
$ remo device update <device-id> <device-name>とコマンドを実行すればよいことがわかります。他のコマンドに関しても、同様の手順で実行に必要な情報を確認することが可能です。各コマンドと API の完全な対応表は次のようになります:
Command Nature Remo API remo user getGET /1/users/meremo user updatePOST /1/users/meremo device getGET /1/devicesremo device updatePOST /1/devices/{device}remo device deletePOST /1/devices/{device}/deleteremo device update_temperature_offsetPOST /1/devices/{device}/temperature_offsetremo device update_humidity_offsetPOST /1/devices/{device}/humidity_offsetremo appliance detectPOST /1/detectapplianceremo appliance createPOST /1/appliancesremo appliance getGET /1/appliancesremo appliance updatePOST /1/appliances/{appliance}remo appliance deletePOST /1/appliances/{appliance}/deleteremo appliance update_ordersPOST /1/appliance_ordersremo appliance update_aircon_settingsPOST /1/appliances/{appliance}/aircon_settingsremo appliance send_tv_infrared_signalPOST /1/appliances/{appliance}/tvremo appliance send_light_infrared_signalPOST /1/appliances/{appliance}/lightremo signal create/1/appliances/{appliance}/signalsremo signal getGET /1/appliances/{appliance}/signalsremo signal updatePOST /1/signals/{signal}remo signal delete/1/signals/{signal}/deleteremo signal send/1/signals/{signal}/sendremo signal update_orders/1/appliances/{appliance}/signal_ordersまとめ
Nature Remo の API にアクセスするための Python ライブラリを紹介しました。Remo の単純な操作をするには公式アプリが一番便利だと思いますが、プログラムから気軽に API を叩けることで、より柔軟に Remo を操作できるようになるはずです。Enjoy!?
- 投稿日:2020-08-09T19:07:38+09:00
【データサイエンティスト入門】Pythonの基礎♬条件分岐とループ
昨夜の続きです。
【注意】
「東京大学のデータサイエンティスト育成講座」を読んで、ちょっと疑問を持ったところや有用だと感じた部分をまとめて行こうと思う。
したがって、あらすじはまんまになると思うが内容は本書とは関係ないと思って読んでいただきたい。Chapter1-2 Pythonの基礎
演算子と演算が参考にまとめられている。
【参考】
とほほのPython入門 - 演算子1-2-4 条件分岐とループ
Pythonコードは、上から下に向けて実行される。その流れを変えて、条件分岐や繰り返しの処理をするための構文
1-2-4-1 比較演算子と真偽判定
print(1 == 1) print(1 == 2) print(1 != 2) print(1 > 0) print(1 > 2) print((1 > 0) and (10 > 5)) print((1 < 0) or (10 > 5)) print(not (1 < 0)) print(not (1 < 0)) print(not (1 < 0) and (10 > 5)) print(not (1 < 0) and not (10 > 5)) print(5 >= 50 or 5 < 20 and 5 == 5) print((5 >= 50 or 5 < 20) and 5 == 5)結果
True False True True False True True True True False True True【参考】
図解!Pythonのif文でand、orによる複数条件の指定方法を徹底解説!
参考によれば以下のコードは「Falseです。」x = 5 y = 5 if x >= 50 or x < 20 and y == 5: print("Trueです。") else: print("Falseです。")理由;andとorではandが優先される
とありますが、現在のPython3でのOperator precedenceは、orがandに優先し、Trueになります。
【参考】
6.17. Operator precedence
(一部引用)
Operator Description := Assignment expression lambda Lambda expression if – else Conditional expression or Boolean OR and Boolean AND not x Boolean NOT in, not in, is, is not, <, <=, >, >=, !=, == Comparisons, including membership tests and identity tests ^ Bitwise XOR & Bitwise AND ... ... 1-2-4-2 if文
基本
if 条件式1: `条件式1がTrueのときに行う処理` elif 条件式2: `条件式1がFalseで条件式2がTrueのときに行う処理` elif 条件式3: `条件式1, 2がFalseで条件式3がTrueのときに行う処理` ... else: `すべての条件式がFalseのときに行う処理`Pythonのif文の条件式において、偽Falseとみなされるのは以下のオブジェクト。 ・bool型のFalse ・None ・数値(int型やfloat型)の0, 0.0 ・空の文字列'' ・空のコンテナ(リスト、タプル、辞書など)[], (), {} これ以外はすべて真Trueとみなされる。ここまでは、以下の参考より引用
【参考】
Pythonのif文による条件分岐の書き方data_list = [1,2,3,4,5,6,7] findvalue = 8 if findvalue in data_list: print('{}は入っています'.format(findvalue)) else: print('{}は入っていません'.format(findvalue)) print('findvalueは{}でした'.format(findvalue))結果
最後のprint行はif文の外で必ず表示される。8は入っていません findvalueは8でしたformat記法
【参考】
【Python入門】format関数で文字列の書き方
参考を見つつ、面白そうな記法を試してみます。apple = 50 orange = 100 total = apple + orange print('りんご:{0}円 みかん:{1}円 合計:{2}円'.format(apple, orange, total)) print('りんご:{}円 みかん:{}円 合計:{}円'.format(apple, orange, total)) list1 = [apple, orange] #リストの作成 list2 = [total] print('りんご:{0[0]}円 みかん:{0[1]}円 合計:{1[0]}円'.format(list1,list2)) print('りんご:{0[0]}円 みかん:{0[1]}円 合計:{1}円'.format(list1,list2[0])) print('りんご:{}円 みかん:{}円 合計:{}円'.format(list1[0],list1[1],list2[0]))りんご:50円 みかん:100円 合計:150円 りんご:50円 みかん:100円 合計:150円 りんご:50円 みかん:100円 合計:150円 みかん:100円 りんご:50円 合計:150円 りんご:50円 みかん:100円 合計:150円浮動小数点の場合の記法はよく使うので、以下参照
【参考】
Pythonの文字列フォーマット(formatメソッドの使い方)line = "{0}さんの身長は{1:.0f}cm、体重は{2:.1f}kgです。".format("山田", 190, 105.3) print(line) line = "{1}さんの身長は{2:^10,.5f}mm、体重は{3:.0f}kgです。".format("山田","山", 1900, 105.3) print(line)結果
山田さんの身長は190cm、体重は105.3kgです。 山さんの身長は1,900.00000mm、体重は105kgです。
{2:^10,.5f} 1,900.00000 2 index : 書式開始 ^ 出力位置 10 出力幅 , 千の所に, .5 小数点以下5桁表示 f 浮動小数点数 1-2-4-3 for文
for文はよく使うのは以下の三種類(数値、list型, 辞書型)
1-2-4-4 数値
以下は普通に0~10まで回す。
演算は、足し合わせ。都度出力しています。
range(0,11,1);range(初期値,最終値+1,間隔)s=0 for i in range(0,11,1): s += i print(s)結果
0 1 3 6 10 15 21 28 36 45 55list型
s=0 list1 = [0,1,2,3,4,5,6,7,8,9,10] for i in list1: s += i print(s)結果
0 1 3 6 10 15 21 28 36 45 55辞書型
dict_data = {'apple':100,'banana':100,'orange':300,'mango':400,'melon':500} for dict_key in dict_data: print(dict_key,dict_data[dict_key])結果
apple 100 banana 100 orange 300 mango 400 melon 500辞書型から、dict_data.items()でkey, valueを取得して出力
dict_data = {'apple':100,'banana':100,'orange':300,'mango':400,'melon':500} for key, value in dict_data.items(): print(key,value)結果
apple 100 banana 100 orange 300 mango 400 melon 5001-2-4-5 内包表記
data_list = [1,2,3,4,5,6,7,8,9] data_list1 = [] data_list1 = [i*2 for i in data_list] print(data_list1)結果
[2, 4, 6, 8, 10, 12, 14, 16, 18]i%2==0(iを2で割った時の余りが0)の時だけ出力する
print([i*2 for i in data_list if i%2==0])[4, 8, 12, 16]1-2-4-6 zip関数
以下のように二つのリストがあるとき、それぞれから順番に要素を取り出せる。
list1 = ['apple','banana','orange','mango','melon'] list2 = [100, 100, 300, 400, 500] for one, two in zip(list1, list2): print(one, two)結果
因みに、要素数が不一致な場合は頭から少ない方に合わせて出力する。apple 100 banana 100 orange 300 mango 400 melon 500zip関数で二つのリストから辞書型データ作成
dict_new = {} list1 = ['apple','banana','orange','mango','melon','pinapple'] list2 = [100, 100, 300, 400, 500] for one, two in zip(list1, list2): dict_new.update({one: two}) print(dict_new) print(type(dict_new))結果
{'apple': 100, 'banana': 100, 'orange': 300, 'mango': 400, 'melon': 500} <class 'dict'>enumerate関数
list1 = ['apple','banana','orange','mango','melon','pinapple'] list2 = [100, 100, 300, 400, 500] for i, name in enumerate(list1): print(i, name)結果
0 apple 1 banana 2 orange 3 mango 4 melon 5 pinapple開始のindex指定
for i, name in enumerate(list1, 3): print(i, name)結果
3 apple 4 banana 5 orange 6 mango 7 melon 8 pinapplelist1とlist2をzipして、indexも付ける。
for i, name in enumerate(zip(list1, list2)): print(i, name)結果
0 ('apple', 100) 1 ('banana', 100) 2 ('orange', 300) 3 ('mango', 400) 4 ('melon', 500)1-2-4-7 while文を使った繰り返し処理
num = 0 s = 0 while num <= 10: s += num print(s) num += 1結果
0 1 3 6 10 15 21 28 36 45 55continueとbreak
以下のコードの結果は上記と同じですが、while 1:は常にTrueであり、処理の継続cotinueと処理の中断breakの役割を説明しています。
num = 0 s = 0 while 1: if num <= 10: s += num print(s) num += 1 continue break因みに、continueが無いと0で終わってしまうし、breakが無いと処理が終了しません。また、両方ない場合も処理が終了しません。
まとめ
・条件分岐とルール
・if文, for文, 内包表記, zip関数,enumerate関数, while文をまとめた基本に立ち返って、並べてみると分かり易い。
- 投稿日:2020-08-09T17:10:36+09:00
TensorFlow 2.3.0をCUDA11+cuDNN8向けに強制的にビルドする方法
TensorFlowでGPUを利用するためには、互換性のあるバージョンのCUDAやcuDNNを利用する必要があり、2020/8/9時点で最新のTensorFlow 2.3.0も、CUDA 11やcuDNN 8には対応していません。
そのため、ソースコードからビルドしても互換性の問題で失敗します。…が、利用している環境が「CUDA 11 + cuDNN 8」になっていて、それでもTensorFlowでGPUを使いたい人向けに「強制的に」TensorFlow 2.3.0をCUDA 11 + cuDNN 8向けにビルドする方法を残しておきます。
なお「本来なら対応していない」バージョンの組み合わせなので、全てが正常に動作する保証はありません。簡単なCNNモデルの学習や推論を試した限りでは正常に動作していますが、実験的な扱いに留めておくことをおすすめします。(CUDA11+cuDNN8に正式対応するまでの暫定的な処置)環境情報
ビルドに利用した環境です。CUDAやcuDNNのフォルダなど、事前にパスを通した状態になっています。
- Windows 10 Ver1909 (64bit)
- Visual Studio Community 2019 Ver 16.5.4
- Python 3.8.2
- MSYS2(
pacman -S git patch unzipで必要なパッケージを導入済み)- Bazel 3.4.1 (3.1.0以上のバージョンを使う必要あり)
- CUDA 11.0.3
- cuDNN 8.0.2
ビルド用のフォルダ構成など
今回は
S:\build\build_tf230フォルダ配下にTensorFlowのソースコードをダウンロードしてビルドしています。Pythonの仮想環境も、TensorFlowビルド用に用意します。S:/build/build_tf230 # 作業フォルダRoot + tensorflow # gitで取得してくるソースコード + venv # Python仮想環境 + wheelhouse # 作成したwhlファイルを格納するフォルダビルド手順
x64 Native Tools Command Prompt for VS 2019を起動して以下の手順でビルドを行います。# 仮想環境を作成して有効化する python -m venv s:\build\build_tf230\venv cd /d s:\build\build_tf230 .\venv\Scripts\activate.bat # 必要なパッケージのインストール # 注意:最新の1.19.xシリーズのNumPyを使うとビルドに失敗するので注意 python -m pip install --upgrade pip pip install numpy==1.18.5 pip install six wheel pip install keras_applications==1.0.8 --no-deps pip install keras_preprocessing==1.1.2 --no-deps # ソースコード取得(v2.3.0のタグ指定) git clone -b v2.3.0 https://github.com/tensorflow/tensorflow.git cd tensorflow # 環境によってはコマンドのパラメーターが長くなりすぎてエラーになるので不要な環境変数を削除 set _OLD_VIRTUAL_PATH= # ビルド構成の設定 # CUDA support: Y # CUDA compute capabilities: 7.5 (利用環境に合わせて変更) # Optimization: /arch:AVX2 (利用環境に合わせて変更) # それ以外はデフォルト設定(Enter) python ./configure.py # CUDA 11を使っていると、次のconfig.hの78行目の部分でエラーになる。 # C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include\thrust\system\cuda\config.h # CUBバージョンの互換性チェック部分だが、このチェックは「THRUST_IGNORE_CUB_VERSION_CHECK」を定義すればスキップ可能。 # bazelのパラメーターでTHRUST_IGNORE_CUB_VERSION_CHECKを有効にしてTensorFlowをビルド。 bazel build --config=opt --config=avx2_win --config=short_logs --config=cuda --define=no_tensorflow_py_deps=true --copt=-DTHRUST_IGNORE_CUB_VERSION_CHECK --copt=-nvcc_options=disable-warnings //tensorflow/tools/pip_package:build_pip_package # パッケージの作成(wheelhouseフォルダにパッケージを作成) # 数分間画面が更新されないので心配になりますが、きちんと処理されているのでしばらく待ちましょう bazel-bin\tensorflow\tools\pip_package\build_pip_package ..\wheelhouseこれで完了です。
ポイントとしては、bazelのビルドパラメーターに--copt=-DTHRUST_IGNORE_CUB_VERSION_CHECKを追加して、CUDA 11のCUB互換チェックをスキップさせることです。
- 投稿日:2020-08-09T17:00:47+09:00
Pandas個人的注意点まとめ
概要
自分用に使っていて注意したほうがいい点をまとめる。
順次追加予定。indexの型に関して
CSVの読み込み時index_colを利用するとindexの型はdtypeの指定とは別に
自動で決定されてしまうようだ。import pandas as pd # 例) input.csv #ID,param1,param2 #0001,01,AAA #0002,02,BBB #0003,10,CCC df = pd.read_csv("input.csv", dtype=object, index_col="ID") #型をobjectに指定しているがindexだけはint型となってしまい #先頭の0が抜け落ちてしまう型を保持するためにはindexの指定を後から行う必要があるようだ。
df = pd.read_csv("input.csv", dtype=object) df.set_index("ID", inplace=True) #これで元のデータのまま保持できる
- 投稿日:2020-08-09T16:53:48+09:00
いまさら聞けない Jupyter NotebookをWindowsで開けなくなった時のメモ
WindowsでAndaconda Nabigatorを使ってJupyter Notebookを開くとき,
Version upによる影響かわからないが,開けなくなった.Jupyter NotebookのBatファイルのディレクトリにあったerror.txtファイルの
[C 16:33:17.925 NotebookApp] Bad config encountered during initialization:
[C 16:33:17.925 NotebookApp] The 'contents_manager_class' trait of a NotebookApp instance must be a subclass of 'notebook.services.contents.manager.ContentsManager', but a value of class 'dict' (i.e. {}) was specified.をコピペして,原因を調査したところ,全く同じエラーが2015年ごろ言及されていた.
解決策は
「
1.管理者としてcmdを開く
2.jupyter notebook --config=/home/john/mystuff/jupyter_notebook_config.json と入力.注意: 上記スクリプトを実行する前に、AnacondaとJupyter Labをアンインストールし、C:/ドライブ内のすべてのファイルを削除する必要があることを確認してください。
そして、最新のPython3をインストールし直し、環境パスを正しく追加/設定し、C:/User/.../Pythonではなく、C:/PythonのメインルートフォルダにPyhonを作成することが推奨されていますが、Jupyterノートブックをインストールする必要があります。jupyter_notebook_config.pyが見つからないことがあります。 jupyter_notebook_config.pyを作成するには、pythonの.NET Frameworkをインストールした後に、jupyter_notebook_config.pyファイルを作成します。
とすると、以下のようなコマンドラインを使用することができます。
jupyter notebook --generate-config
」がベストアンサーとなっているっぽい.
指示に従い,Anaconda promptで(コマンドプロンプトでは jupyterなどのバッチファイルを入れていなかったため)入力したところ,改善を確認した.
この程度のerrorはさっさと直したいもの.備忘録として...
[参考記事]
https://github.com/jupyter/notebook/issues/274#issuecomment-522808247
- 投稿日:2020-08-09T16:35:15+09:00
OpenPoseのPython APIの使用方法
OpenPoseのPython APIを触ってみたので、備忘録がてら書きます
Python APIの導入手順は以下の記事で解説しております
https://qiita.com/hac-chi/items/0e6f910a9b463438fa81公式のPython APIサンプルコードはこちらにあります
サンプルコードを解説しているだけですので、ソース読んだ方が速い方はそちらを参照したほうが良いと思います
https://github.com/CMU-Perceptual-Computing-Lab/openpose/tree/master/examples/tutorial_api_pythonOpenPoseの開始
# Starting OpenPose opWrapper = op.WrapperPython() opWrapper.configure(params) opWrapper.start()のようにして、使用を開始します
ここで渡している
paramsは、辞書型です。
OpenPoseを使用するにあたってのさまざまな設定をparamsで渡します。たとえばモデルのパスの指定は以下のように
params = dict() params["model_folder"] = "../../../models/"以下にモデルのパラメーター一覧と、デフォルト値が記載されております
https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/include/openpose/flags.hpp独断と偏見で、重要そうなのをピックすると
DEFINE_int32(number_people_max, -1, "This parameter will limit the maximum number of people detected, by keeping the people with" " top scores. The score is based in person area over the image, body part score, as well as" " joint score (between each pair of connected body parts). Useful if you know the exact" " number of people in the scene, so it can remove false positives (if all the people have" " been detected. However, it might also include false negatives by removing very small or" " highly occluded people. -1 will keep them all."); DEFINE_string(model_pose, "BODY_25", "Model to be used. E.g., `BODY_25` (fastest for CUDA version, most accurate, and includes" " foot keypoints), `COCO` (18 keypoints), `MPI` (15 keypoints, least accurate model but" " fastest on CPU), `MPI_4_layers` (15 keypoints, even faster but less accurate)."); DEFINE_bool(3d, false, "Running OpenPose 3-D reconstruction demo: 1) Reading from a stereo camera system." " 2) Performing 3-D reconstruction from the multiple views. 3) Displaying 3-D reconstruction" " results. Note that it will only display 1 person. If multiple people is present, it will" " fail."); DEFINE_string(write_json, "", "Directory to write OpenPose output in JSON format. It includes body, hand, and face pose" " keypoints (2-D and 3-D), as well as pose candidates (if `--part_candidates` enabled)."); DEFINE_string(udp_host, "", "Experimental, not available yet. IP for UDP communication. E.g., `192.168.0.1`."); DEFINE_string(udp_port, "8051", "Experimental, not available yet. Port number for UDP communication.");画像の受け渡し
画像を読み込みます
注意なのですが、PILは使えず、OpenCVを使ってくださいとのことです公式に以下のように記述があります
Do not use PIL
In order to read images in Python, make sure to use OpenCV (do not use PIL). We found that feeding a PIL image format to OpenPose results in the input image appearing in grey and duplicated 9 times (so the output skeleton appear 3 times smaller than they should be, and duplicated 9 times).
出典:OpenPose Python Module and Demo読み込み方法ですが
まず、データの受け渡し用のオブジェクトををop.Datum()で作成し
OpenCVで読み込んだ画像をdatum.cvInputDataに格納します
そして、opWrapper.emplaceAndPopにリストとして渡しましょう
opWrapper.emplaceAndPopに返り値はありませんが、渡したdatum内に解析結果(出力画像、関節位置等々)が含まれていますdatum = op.Datum() imageToProcess = cv2.imread("image_path") datum.cvInputData = imageToProcess opWrapper.emplaceAndPop([datum])出力結果の表示
#関節座標 print("Body keypoints:" + str(datum.poseKeypoints)) #関節を表示した画像 cv2.imshow("Output Image", datum.cvOutputData cv2.waitKey(0)他にも、datumの中には
datum.faceKeypoints #顔の各パーツの座標 datum.handKeypoints[0]#左手の各パーツの座標 datum.handKeypoints[1]#右手の各パーツの座標等々、色々と含まれています
詳しくは、以下を参照してください
https://cmu-perceptual-computing-lab.github.io/openpose/html/structop_1_1_datum.html
- 投稿日:2020-08-09T15:55:16+09:00
【個人メモ】Python の仮想環境コマンドメモ
What
Python の仮想環境とコマンドについてのメモ。
参考になる立派な記事はたくさんあるので、あくまで自分の環境での内容を忘れないようにメモしておく。
他の方の参考になるのであれば嬉しい。環境
- Mac OS Mojave 10.14.6
仮想環境あれこれ
pyenv
複数バージョンの Python を共存させることができる。
例えば、Python 3.8.3 と Python 3.7.2 をPCにインストールし、
デフォルト(global)は Python 3.7.2 だが、特定ディレクトリのみ Python 3.8.3 にする。といったこともできる。virtualenv
同一バージョンの Python で、複数の環境を構築することができる。
例えば、
環境Aには、Python 3.7.2 + TensorFlow
環境Bには、Python 3.7.2 + Keras
といった環境を個別に作れる。venv
Python に標準搭載された仮想環境のプログラム。
virtualenv の方がコマンド操作などわかりやすい気がする。
(個人としては venv ではなく virtualenv を使うこととする。)conda
Anaconca に含まれる仮想環境プログラム
(学習不足で多くを語れません。機会を改めて...)環境構築メモ
pyenv の導入方法
- Homebrew をインストールしたあとに、pyenv をインストールする方法がある
- 以下のProgate のチュートリアルサイトが便利
- Pythonの開発環境を用意しよう!(Mac) | プログラミングの入門なら基礎から学べるProgate[プロゲート]
- git clone してインストールする方法もある
pyenv コマンド一覧
## インストールできる Python バージョンの確認 pyenv install --list ## 特定バージョンの Python のインストール pyenv install 3.7.2 ## インストールされた Python バージョンの確認 pyenv versions # * system (set by /Users/username/.pyenv/version) # 3.7.2 # 3.8.3 ## インストールされた Python の実体は、~/.pyenv/versions/ ディレクトリの下に保存される cd ~/.pyenv/versions ls # 3.7.2 3.8.3 ## PC全体で使う、デフォルトの Python のバージョンを指定 pyenv global 3.7.2 ## pyenv versions コマンド か python -V コマンドでバージョンの確認が取れる pyenv versions # system # * 3.7.2 (set by /Users/username/.pyenv/version) # 3.8.3 ## 特定ディレクトリのみ Python のバージョンを変える方法 (localにする) cd ./sample pyenv local 3.8.3 ## pyenv verions コマンド か python -V コマンドでバージョンの確認が取れる python -V # Python 3.8.3 ## 仮想環境の削除 pyenv uninstall 3.7.2virtualenv の導入方法
- pip install するのが一般的 注:pyenvからインストールする方法もある(後述)
## virtualenv のインストール方法 pip install virtualenv ## 仮想環境の作成と利用 (作成先はどこでも可) virtualenv ~/.virtualenvs/first-env source ~/.virtualenvs/first-env/bin/activate ## 仮想環境の無効化 deactivate ## 仮想環境の削除 rm -rf ~/.virtualenvs/first-env
- 【注意】
- pyenv で新しいバージョンの Python 環境を作成した際は、virtualenv もインストールをし直さなければならない。
virtualenv 補足
- 以下のサイトでは、pyenv からvirtualenvをインストールしている。便利そう。
- ただし、Homebrew を用いて pyenv をインストールした筆者の環境では、
pyenv virtualenv 3.7.2 project_xというコマンドは出来なかった。(pyenv: no such command `virtualenv')
- 原因等が分かったら追記します。
- 投稿日:2020-08-09T15:51:51+09:00
【Python】データサイエンス100本ノック(構造化データ加工編) 023 解説
Youtube
動画解説もしています。
問題
P-023: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)と売上数量(quantity)を合計せよ。
解答
コードdf_receipt.groupby('store_cd').agg({'amount':'sum', 'quantity':'sum'}).reset_index()出力store_cd amount quantity 0 S12007 638761 2099 1 S12013 787513 2425 2 S12014 725167 2358 3 S12029 794741 2555 4 S12030 684402 2403 5 S13001 811936 2347 6 S13002 727821 2340 7 S13003 764294 2197 8 S13004 779373 2390 9 S13005 629876 2004 10 S13008 809288 2491 11 S13009 808870 2486 12 S13015 780873 2248 13 S13016 793773 2432 14 S13017 748221 2376 15 S13018 790535 2562 16 S13019 827833 2541 17 S13020 796383 2383 18 S13031 705968 2336 19 S13032 790501 2491 20 S13035 715869 2219 21 S13037 693087 2344 22 S13038 708884 2337 23 S13039 611888 1981 24 S13041 728266 2233 25 S13043 587895 1881 26 S13044 520764 1729 27 S13051 107452 354 28 S13052 100314 250 29 S14006 712839 2284 30 S14010 790361 2290 31 S14011 805724 2434 32 S14012 720600 2412 33 S14021 699511 2231 34 S14022 651328 2047 35 S14023 727630 2258 36 S14024 736323 2417 37 S14025 755581 2394 38 S14026 824537 2503 39 S14027 714550 2303 40 S14028 786145 2458 41 S14033 725318 2282 42 S14034 653681 2024 43 S14036 203694 635 44 S14040 701858 2233 45 S14042 534689 1935 46 S14045 458484 1398 47 S14046 412646 1354 48 S14047 338329 1041 49 S14048 234276 769 50 S14049 230808 788 51 S14050 167090 580解説
・PandasのDataFrame/Seriesにて、同じ値を持つデータをまとめて処理する方法です。
・同じ値を持つデータの合計や平均などを確認したい時に使用します。
・'groupby'は、同じ値や文字列を持つデータをまとめて、それぞれの同じ値や文字列に対して、共通の操作を(合計や平均など)行いたい時に使います。
・'agg'は、Aggregationの略称(意味は"集合体")であり、グループごとに値を求めて表を作るような操作を行いたい時に使います。合計値は'sum'、平均値は'mean'、最大値は'max'、最小値は'min'です。
・'.reset_index()'は、'groupby'によってバラバラになったインデックス番号を0始まりの連番に振り直す操作を行いたい時に使います。
- 投稿日:2020-08-09T15:39:32+09:00
ベイズ推論の考え方・・ベイズ主義と確率分布
Pythonで体験するベイズ推論より
ベイズ推論の考え方
確率分布について理解しようと思ったけど、その前にまず序章的なところで、ベイズ的な考え方を書いてみる。つまり最初の確率を信念であるとみなすことを理解できないと、ベイズ推論の計算が理解できないと思うので。
ベイズ主義とは
ベイズ主義とは、確率をある事象が発生する信念(Belief)もしくは確信(Confidence)の度合いとみなす。つまり確率とは、我々が思っていることを要約したものだそうです。確率をある人が思う信念と考えるのは自然である。これは証拠を集めて信念を形作るということは普通にみんなが行っているからである。
最近流行のコロナ。最近、どこかの知事がポピドンヨード液が薬局から売り切れました。これは、情報をもとに信念が動いたと言えるのではないでしょうか。ちょっと例えが違うかもしれませんが。
このように新しい証拠が与えられたら事前の信念を完全に否定するものではなく、新しい証拠で事前確率の重みを変更してるということです、変更後の信念を事後確率と言います。頻度主義とベイズ主義
頻度主義とは、一般的な統計の考えたを頻度主義という。
推論関数の戻り値として、頻度主義は「推定値」を表す数値を戻すが、ベイズ主義は「確率」を戻す。デバックの例題で、
プログラムはすべてのテストにパスした場合、このプログラムにバグはあるか?と聞かれると、
頻度主義:「はいプログラムにバグはありません」
ベイズ主義:「はい、バグがない確率は0.8、いいえ、バグのある確率は0.2です」
となる。
つまり、プログラムを書くといつもバグがあるんだという信念を関数に伝えているということを表している。
これは頻度主義の手法が適用できない問題を解いたりするのにベイズ主義が適していることを示している。ビッグデータについて
逆説的に言うと、ビッグデータの解析には比較的単純なアルゴリズムが使われている。ビッグデータを用いた予測の難しさは、アルゴリズムにあるわけではない。
もっと難しい問題は「ミディアムなサイズのデータ」の場合で、特に困難なのは「スモールデータ」の場合である。
(この部分を理解するためには、この本の引用から、ゲルマンの文献を読む必要がありそうです。)ベイズ定理(ベイズ則)
P( A | X ) = \displaystyle \frac{ P(X | A) P(A) } {P(X) }難しそうに見えるが、ベイズ推論は、この式を使って初期の事前確率と$P(A)$と事後確率$P(A|X)$を結び付けているにすぎない。
ここまでが、ベイズ主義の考え方。ここからが確率分布の項である。
確率分布
数値が離散値か連続値かで確率分布は変わる。
Zを確率変数とする。Zが取りうる値のそれぞれに確率を与える関数がzの確率分布関数である。Zが離散値の場合:
確率分布は、確率質量関数と呼ばれる。Zが値kを取る関数となり、$P(Z=k)$で表す。確率質量関数は、確率変数Zが完全に決まる。よく使われる確率質量関数がポアソン分布である。
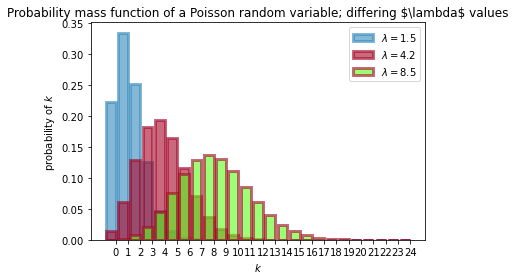
P(Z = k) =\frac{ \lambda^k e^{-\lambda} }{k!}, \; \; k=0,1,2, \dotsここで。、λは形状を決めるパラメーターで正の任意の実数。λ大では、大きな値の確率が高くなり、λを小さくすると小さな値の確率が高くなる。kは非負の整数である。
確率変数Zがポアソン分布に従うとは、以下のようにあらわす。Z \sim \text{Poi}(\lambda)また、ポアソン分布の便利な性質は期待値が分布パラメーター(λ)に等しいということであり、以下のようにあらわす。
E\large[ \;Z\; | \; \lambda \;\large] = \lambdaここで、やっと
pyhtonの出番です。
ポアソン分布については、以下の記事もとても参考になります。λの値を変えて、ポアソン分布を書いてみる。本の例は、λが1.5と4.25の場合でしたので、理解を深めるために、8.50の場合も計算してみた。
# -*- coding: utf-8 -*- import matplotlib.pyplot as plt import scipy.stats as stats import numpy as np a = np.arange(25) #scipy のポアソン分布関数 poi = stats.poisson lambda_ = [1.5, 4.25,8.50] colours = ["#348ABD", "#A60628","#5AFF19"] plt.bar(a, poi.pmf(a, lambda_[0]), color=colours[0], label="$\lambda = %.1f$" % lambda_[0], alpha=0.60, edgecolor=colours[0], lw="3") plt.bar(a, poi.pmf(a, lambda_[1]), color=colours[1], label="$\lambda = %.1f$" % lambda_[1], alpha=0.60, edgecolor=colours[1], lw="3") plt.bar(a, poi.pmf(a, lambda_[2]), color=colours[2], label="$\lambda = %.1f$" % lambda_[2], alpha=0.60, edgecolor=colours[1], lw="3") plt.xticks(a + 0.4, a) plt.legend() plt.ylabel("probability of $k$") plt.xlabel("$k$") plt.title("Probability mass function of a Poisson random variable; differing \$\lambda$ values");
確かに、「λ大では、大きな値の確率が高くなり、λを小さくすると小さな値の確率が高くなる。」が表されます。また、kは整数である点に注意しましょう。
Zが連続値の場合
zが連続値の場合は、確率密度関数で表される。連続値の確率密度関数は、指数分布があります。
f_Z(z | \lambda) = \lambda e^{-\lambda z }, \;\; z\ge 0確率変数Zは、非負の実数である。時間データや温度データの場合に向いている。
確率変数Zの密度分布関数が指数分布であれば、Zは指数分布に従う。Z \sim \text{Exp}(\lambda)指数分布の期待値はパラメーターλの逆数である。
E[\; Z \;|\; \lambda \;] = \frac{1}{\lambda}
pythonで異なるλに対する2つの指数分布を計算する。import matplotlib.pyplot as plt import scipy.stats as stats import numpy as np a = np.linspace(0, 10, 100) expo = stats.expon lambda_ = [0.5, 1, 5] colours = ["#348ABD", "#A60628","#5AFF19"] for l, c in zip(lambda_, colours): plt.plot(a, expo.pdf(a, scale=1./l), lw=3, color=c, label="$\lambda = %.1f$" % l) plt.fill_between(a, expo.pdf(a, scale=1./l), color=c, alpha=.33) plt.legend() plt.ylabel("PDF at $z$") plt.xlabel("$z$") plt.ylim(0,1.2) plt.title("Probability density function of an Exponential random variable;\ differing $\lambda$");
これらで設定したλとは何か
最後にλとは何かということであるが、我々が知りえるのは、Zのみである。つまりλの計算方法はわからないということです。では、どうやってλを決めて、計算をするのかというと、「λはこの値になりそうだ」と決めて計算するのです。そのために、λの確率分布を考えるのです。
λは定数のように思っている人は、頻度主義に侵されています。ベイズ主義の考え方で、確率を信念だとみなすので、何にでも確率を割り当てることができる。つまりパラメーターλについて信念を持つ(確率を割り与える)ことは、合理的な考えになるということです。
これで、最初のベイズの考え方に戻りました。最後にもう一度
「確率は信念である」
- 投稿日:2020-08-09T15:39:32+09:00
ベイズ推論の考え方・・pymc3による実際の計算
Pythonで体験するベイズ推論より
メッセージ数に変化はあったのか?
ここで実際に例題を計算します。
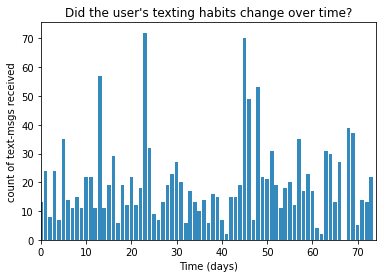
Pythonのスクリプトは、書籍はPyMC2で書いてあるけど、私の理解の範疇で、公式HPのPyMC3のスクリプトをもとに書いています。あるユーザーが毎日受信するメッセージ数があった時に、この受信メッセージ数に変化点があったかどうか?ということである。
データは、公式githubから入手ください。# -*- coding: utf-8 -*- #データの可視化 from matplotlib import pyplot as plt import numpy as np count_data = np.loadtxt("data/txtdata.csv") n_count_data = len(count_data) plt.bar(np.arange(n_count_data), count_data, color="#348ABD") plt.xlabel("Time (days)") plt.ylabel("count of text-msgs received") plt.title("Did the user's texting habits change over time?") plt.xlim(0, n_count_data) plt.show()これがそのグラフです。
これが、どこかに変化があるとわかるだろうか?グラフを見ただけではわかりません。
どう考えるかというと、ベイズ推論の考え方・・「ベイズ主義と確率分布」
まず、これは毎日の受信数になるので、離散値のデータになります。だからポアソン分布になります。
そこで。$i$日目のメッセージ数を$C_i$とすると、C_i \sim \text{Poisson}(\lambda)ここで$λ$をどう考えるかというと、この期間内にどこかで$λ$が変わったかもしれないと考えます。
これを$τ$日目にパラメーター$λ$が変わったと考える。
この急激に変わった点を、変化点(switchpoint)という。$λ$を次のようにあらわす。
\lambda = \begin{cases} \lambda_1 & \text{if } t \lt \tau \cr \lambda_2 & \text{if } t \ge \tau \end{cases}もしメールの受信数が変化がない場合は、$\lambda_1 = \lambda_2$となるはずである。
さてこの$λ$を考えるために、指数分布でモデル化することとする。(だって$λ$は連続値だから)
この時のパラメーターを$α$とすると、次の式で表される。\begin{align} &\lambda_1 \sim \text{Exp}( \alpha ) \\\ &\lambda_2 \sim \text{Exp}( \alpha ) \end{align}指数分布の期待値は、パラメーターの逆数なので、次で表される。
\frac{1}{N}\sum_{i=0}^N \;C_i \approx E[\; \lambda \; |\; \alpha ] = \frac{1}{\alpha}これで事前分布には主観が入らない。ここで、2つの$\lambda_i$に違う事前分布を使うと、観測期間中にどこかで受信数に変化が表れたと考えているという信念を表している。
後、$τ$をどう考えるかというと、$τ$は一様分布(uniform distribution)を使うことにする。つまりどの日も同等であるという信念である。
\begin{align} & \tau \sim \text{DiscreteUniform(1,70) }\\\\ & \Rightarrow P( \tau = k ) = \frac{1}{70} \end{align}ここまでくると、これをどう
pythonでプログラムを書くか迷うが、後はpymc3で書き表すことになる。import pymc3 as pm import theano.tensor as tt with pm.Model() as model: alpha = 1.0/count_data.mean() # Recall count_data is the # variable that holds our txt counts lambda_1 = pm.Exponential("lambda_1", alpha) lambda_2 = pm.Exponential("lambda_2", alpha) tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data - 1)
lambda_1 = pm.Exponential("lambda_1", alpha)
$\lambda_1$と$\lambda_2$に対応するPyMC変数を作る。
tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data - 1)
$\tau$を一様分布pm.DiscreteUniformで与える。with model: idx = np.arange(n_count_data) # Index lambda_ = pm.math.switch(tau > idx, lambda_1, lambda_2) with model: observation = pm.Poisson("obs", lambda_, observed=count_data)
lambda_ = pm.math.switch(tau > idx, lambda_1, lambda_2)
ここで、新しいlambda_を作ります。
switch()関数は、tauのどちら側にいるかに応じて、lambda_1の値またはlambda_2をlambda_の値として割り当てます。tauまでのlambda_の値はlambda_1で、それ以降の値はlambda_2になります。
observation = pm.Poisson("obs", lambda_, observed=count_data)ここは、データ
count_dataを、変数lambda_によって提供される変数により計算し、観測されるということになっているということです。with model: step = pm.Metropolis() trace = pm.sample(10000, tune=5000,step=step, cores=1) lambda_1_samples = trace['lambda_1'] lambda_2_samples = trace['lambda_2'] tau_samples = trace['tau']このコードの詳細は書籍では第3章になるようです。ここが学習ステップで、マルコフ連鎖モンテカルロ(MCMC)と呼ばれるアルゴリズムで計算しています。これは、トレースと呼ばれる$\lambda_1$$\lambda_2$$\tau$の事後分布から数千の確率変数を戻します。
この確率変数をプロットすることにより、事後分布の形を見ることができます。ここで計算が始まりますが、マルチコアやCudaが使えない(
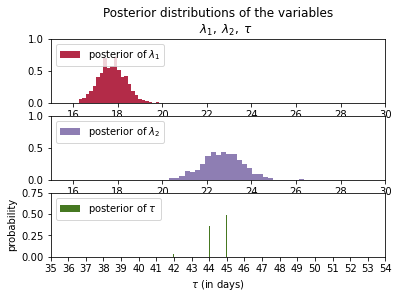
cores=1)ので、非常に時間がかかりますが答えは出ます。結果のグラフです。
結果を見てわかるように、
$\lambda_1=18$
$\lambda_2=23$
$\tau=45$$\tau$が45日が多く、その確率が50%になっている。
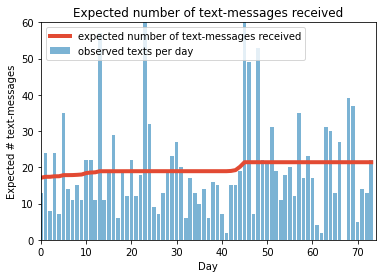
つまり理由はわからないが、45日目前後に、何かの変化(受信数を変える何かの行動・・でもこれは本人しかわからない)があり、$\lambda$が変わっている。最後に受信数の期待値を書いてみます。
このように、ベイズ推定を使うと、データから、いつ変化点があったかがわかります。
しかし注意する点は、この受信数の期待値も実際には分布になっている点です。また、原因は自分自身で考える必要があります。最後に全部のスクリプトです。
# -*- coding: utf-8 -*- #データの可視化 from matplotlib import pyplot as plt import numpy as np count_data = np.loadtxt("data/txtdata.csv") n_count_data = len(count_data) plt.bar(np.arange(n_count_data), count_data, color="#348ABD") plt.xlabel("Time (days)") plt.ylabel("count of text-msgs received") plt.title("Did the user's texting habits change over time?") plt.xlim(0, n_count_data); plt.show() import pymc3 as pm import theano.tensor as tt with pm.Model() as model: alpha = 1.0/count_data.mean() # Recall count_data is the # variable that holds our txt counts lambda_1 = pm.Exponential("lambda_1", alpha) lambda_2 = pm.Exponential("lambda_2", alpha) tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data - 1) with model: idx = np.arange(n_count_data) # Index lambda_ = pm.math.switch(tau > idx, lambda_1, lambda_2) with model: observation = pm.Poisson("obs", lambda_, observed=count_data) ### Mysterious code to be explained in Chapter 3. with model: step = pm.Metropolis() trace = pm.sample(10000, tune=5000,step=step, cores=1) lambda_1_samples = trace['lambda_1'] lambda_2_samples = trace['lambda_2'] tau_samples = trace['tau'] #histogram of the samples: ax = plt.subplot(311) ax.set_autoscaley_on(False) plt.hist(lambda_1_samples, histtype='stepfilled', bins=30, alpha=0.85, label="posterior of $\lambda_1$", color="#A60628", density=True) plt.legend(loc="upper left") plt.title(r"""Posterior distributions of the variables $\lambda_1,\;\lambda_2,\;\tau$""") plt.xlim([15, 30]) plt.xlabel("$\lambda_1$ value") ax = plt.subplot(312) ax.set_autoscaley_on(False) plt.hist(lambda_2_samples, histtype='stepfilled', bins=30, alpha=0.85, label="posterior of $\lambda_2$", color="#7A68A6", density=True) plt.legend(loc="upper left") plt.xlim([15, 30]) plt.xlabel("$\lambda_2$ value") plt.subplot(313) w = 1.0 / tau_samples.shape[0] * np.ones_like(tau_samples) plt.hist(tau_samples, bins=n_count_data, alpha=1, label=r"posterior of $\tau$", color="#467821", weights=w, rwidth=2.) plt.xticks(np.arange(n_count_data)) plt.legend(loc="upper left") plt.ylim([0, .75]) plt.xlim([35, len(count_data)-20]) plt.xlabel(r"$\tau$ (in days)") plt.ylabel("probability"); plt.show() # tau_samples, lambda_1_samples, lambda_2_samples contain # N samples from the corresponding posterior distribution N = tau_samples.shape[0] expected_texts_per_day = np.zeros(n_count_data) for day in range(0, n_count_data): # ix is a bool index of all tau samples corresponding to # the switchpoint occurring prior to value of 'day' ix = day < tau_samples # Each posterior sample corresponds to a value for tau. # for each day, that value of tau indicates whether we're "before" # (in the lambda1 "regime") or # "after" (in the lambda2 "regime") the switchpoint. # by taking the posterior sample of lambda1/2 accordingly, we can average # over all samples to get an expected value for lambda on that day. # As explained, the "message count" random variable is Poisson distributed, # and therefore lambda (the poisson parameter) is the expected value of # "message count". expected_texts_per_day[day] = (lambda_1_samples[ix].sum() + lambda_2_samples[~ix].sum()) / N plt.plot(range(n_count_data), expected_texts_per_day, lw=4, color="#E24A33", label="expected number of text-messages received") plt.xlim(0, n_count_data) plt.xlabel("Day") plt.ylabel("Expected # text-messages") plt.title("Expected number of text-messages received") plt.ylim(0, 60) plt.bar(np.arange(len(count_data)), count_data, color="#348ABD", alpha=0.65, label="observed texts per day") plt.legend(loc="upper left") plt.show()
- 投稿日:2020-08-09T15:39:32+09:00
ベイズ推論の考え方(3)・・pymc3による実際の計算
Pythonで体験するベイズ推論より
メッセージ数に変化はあったのか?
ここで実際に例題を計算します。
Pythonのスクリプトは、書籍はPyMC2で書いてあるけど、私の理解の範疇で、公式HPのPyMC3のスクリプトをもとに書いています。あるユーザーが毎日受信するメッセージ数があった時に、この受信メッセージ数に変化点があったかどうか?ということである。
データは、公式githubから入手ください。# -*- coding: utf-8 -*- #データの可視化 from matplotlib import pyplot as plt import numpy as np count_data = np.loadtxt("data/txtdata.csv") n_count_data = len(count_data) plt.bar(np.arange(n_count_data), count_data, color="#348ABD") plt.xlabel("Time (days)") plt.ylabel("count of text-msgs received") plt.title("Did the user's texting habits change over time?") plt.xlim(0, n_count_data) plt.show()これがそのグラフです。
これが、どこかに変化があるとわかるだろうか?グラフを見ただけではわかりません。
どう考えるかというと、ベイズ推論の考え方・・「ベイズ主義と確率分布」
まず、これは毎日の受信数になるので、離散値のデータになります。だからポアソン分布になります。
そこで。$i$日目のメッセージ数を$C_i$とすると、C_i \sim \text{Poisson}(\lambda)ここで$λ$をどう考えるかというと、この期間内にどこかで$λ$が変わったかもしれないと考えます。
これを$τ$日目にパラメーター$λ$が変わったと考える。
この急激に変わった点を、変化点(switchpoint)という。$λ$を次のようにあらわす。
\lambda = \begin{cases} \lambda_1 & \text{if } t \lt \tau \cr \lambda_2 & \text{if } t \ge \tau \end{cases}もしメールの受信数が変化がない場合は、$\lambda_1 = \lambda_2$となるはずである。
さてこの$λ$を考えるために、指数分布でモデル化することとする。(だって$λ$は連続値だから)
この時のパラメーターを$α$とすると、次の式で表される。\begin{align} &\lambda_1 \sim \text{Exp}( \alpha ) \\\ &\lambda_2 \sim \text{Exp}( \alpha ) \end{align}指数分布の期待値は、パラメーターの逆数なので、次で表される。
\frac{1}{N}\sum_{i=0}^N \;C_i \approx E[\; \lambda \; |\; \alpha ] = \frac{1}{\alpha}これで事前分布には主観が入らない。ここで、2つの$\lambda_i$に違う事前分布を使うと、観測期間中にどこかで受信数に変化が表れたと考えているという信念を表している。
後、$τ$をどう考えるかというと、$τ$は一様分布(uniform distribution)を使うことにする。つまりどの日も同等であるという信念である。
\begin{align} & \tau \sim \text{DiscreteUniform(1,70) }\\\\ & \Rightarrow P( \tau = k ) = \frac{1}{70} \end{align}ここまでくると、これをどう
pythonでプログラムを書くか迷うが、後はpymc3で書き表すことになる。import pymc3 as pm import theano.tensor as tt with pm.Model() as model: alpha = 1.0/count_data.mean() # Recall count_data is the # variable that holds our txt counts lambda_1 = pm.Exponential("lambda_1", alpha) lambda_2 = pm.Exponential("lambda_2", alpha) tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data - 1)
lambda_1 = pm.Exponential("lambda_1", alpha)
$\lambda_1$と$\lambda_2$に対応するPyMC変数を作る。
tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data - 1)
$\tau$を一様分布pm.DiscreteUniformで与える。with model: idx = np.arange(n_count_data) # Index lambda_ = pm.math.switch(tau > idx, lambda_1, lambda_2) with model: observation = pm.Poisson("obs", lambda_, observed=count_data)
lambda_ = pm.math.switch(tau > idx, lambda_1, lambda_2)
ここで、新しいlambda_を作ります。
switch()関数は、tauのどちら側にいるかに応じて、lambda_1の値またはlambda_2をlambda_の値として割り当てます。tauまでのlambda_の値はlambda_1で、それ以降の値はlambda_2になります。
observation = pm.Poisson("obs", lambda_, observed=count_data)ここは、データ
count_dataを、変数lambda_によって提供される変数により計算し、観測されるということになっているということです。with model: step = pm.Metropolis() trace = pm.sample(10000, tune=5000,step=step, cores=1) lambda_1_samples = trace['lambda_1'] lambda_2_samples = trace['lambda_2'] tau_samples = trace['tau']このコードの詳細は書籍では第3章になるようです。ここが学習ステップで、マルコフ連鎖モンテカルロ(MCMC)と呼ばれるアルゴリズムで計算しています。これは、トレースと呼ばれる$\lambda_1$$\lambda_2$$\tau$の事後分布から数千の確率変数を戻します。
この確率変数をプロットすることにより、事後分布の形を見ることができます。ここで計算が始まりますが、マルチコアやCudaが使えない(
cores=1)ので、非常に時間がかかりますが答えは出ます。結果のグラフです。
結果を見てわかるように、
$\lambda_1=18$
$\lambda_2=23$
$\tau=45$$\tau$が45日が多く、その確率が50%になっている。
つまり理由はわからないが、45日目前後に、何かの変化(受信数を変える何かの行動・・でもこれは本人しかわからない)があり、$\lambda$が変わっている。最後に受信数の期待値を書いてみます。
このように、ベイズ推定を使うと、データから、いつ変化点があったかがわかります。
しかし注意する点は、この受信数の期待値も実際には分布になっている点です。また、原因は自分自身で考える必要があります。最後に全部のスクリプトです。
# -*- coding: utf-8 -*- #データの可視化 from matplotlib import pyplot as plt import numpy as np count_data = np.loadtxt("data/txtdata.csv") n_count_data = len(count_data) plt.bar(np.arange(n_count_data), count_data, color="#348ABD") plt.xlabel("Time (days)") plt.ylabel("count of text-msgs received") plt.title("Did the user's texting habits change over time?") plt.xlim(0, n_count_data); plt.show() import pymc3 as pm import theano.tensor as tt with pm.Model() as model: alpha = 1.0/count_data.mean() # Recall count_data is the # variable that holds our txt counts lambda_1 = pm.Exponential("lambda_1", alpha) lambda_2 = pm.Exponential("lambda_2", alpha) tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data - 1) with model: idx = np.arange(n_count_data) # Index lambda_ = pm.math.switch(tau > idx, lambda_1, lambda_2) with model: observation = pm.Poisson("obs", lambda_, observed=count_data) ### Mysterious code to be explained in Chapter 3. with model: step = pm.Metropolis() trace = pm.sample(10000, tune=5000,step=step, cores=1) lambda_1_samples = trace['lambda_1'] lambda_2_samples = trace['lambda_2'] tau_samples = trace['tau'] #histogram of the samples: ax = plt.subplot(311) ax.set_autoscaley_on(False) plt.hist(lambda_1_samples, histtype='stepfilled', bins=30, alpha=0.85, label="posterior of $\lambda_1$", color="#A60628", density=True) plt.legend(loc="upper left") plt.title(r"""Posterior distributions of the variables $\lambda_1,\;\lambda_2,\;\tau$""") plt.xlim([15, 30]) plt.xlabel("$\lambda_1$ value") ax = plt.subplot(312) ax.set_autoscaley_on(False) plt.hist(lambda_2_samples, histtype='stepfilled', bins=30, alpha=0.85, label="posterior of $\lambda_2$", color="#7A68A6", density=True) plt.legend(loc="upper left") plt.xlim([15, 30]) plt.xlabel("$\lambda_2$ value") plt.subplot(313) w = 1.0 / tau_samples.shape[0] * np.ones_like(tau_samples) plt.hist(tau_samples, bins=n_count_data, alpha=1, label=r"posterior of $\tau$", color="#467821", weights=w, rwidth=2.) plt.xticks(np.arange(n_count_data)) plt.legend(loc="upper left") plt.ylim([0, .75]) plt.xlim([35, len(count_data)-20]) plt.xlabel(r"$\tau$ (in days)") plt.ylabel("probability"); plt.show() # tau_samples, lambda_1_samples, lambda_2_samples contain # N samples from the corresponding posterior distribution N = tau_samples.shape[0] expected_texts_per_day = np.zeros(n_count_data) for day in range(0, n_count_data): # ix is a bool index of all tau samples corresponding to # the switchpoint occurring prior to value of 'day' ix = day < tau_samples # Each posterior sample corresponds to a value for tau. # for each day, that value of tau indicates whether we're "before" # (in the lambda1 "regime") or # "after" (in the lambda2 "regime") the switchpoint. # by taking the posterior sample of lambda1/2 accordingly, we can average # over all samples to get an expected value for lambda on that day. # As explained, the "message count" random variable is Poisson distributed, # and therefore lambda (the poisson parameter) is the expected value of # "message count". expected_texts_per_day[day] = (lambda_1_samples[ix].sum() + lambda_2_samples[~ix].sum()) / N plt.plot(range(n_count_data), expected_texts_per_day, lw=4, color="#E24A33", label="expected number of text-messages received") plt.xlim(0, n_count_data) plt.xlabel("Day") plt.ylabel("Expected # text-messages") plt.title("Expected number of text-messages received") plt.ylim(0, 60) plt.bar(np.arange(len(count_data)), count_data, color="#348ABD", alpha=0.65, label="observed texts per day") plt.legend(loc="upper left") plt.show()
- 投稿日:2020-08-09T15:10:31+09:00
【MQTT/Python】PythonでMQTTのPub/Subをするクラスを実装した
はじめに
MQTTをPython/Javaで使ってみたので投稿しています。
実際にほかのシステムから呼び出すときは、どうやるんだろう、をやってみました
本記事は以下の2にあたります。まだの方は1をまずご覧ください。
- 【MQTT】コマンドベースでMQTTの導入(前回)
- 【Python】PythonでMQTTのPub/Subをするクラスを実装した(本記事)
- 【Java】JavaでMQTTのPub/Subをするクラスを実装した(次回)
- 【ROS】MQTT通信するノードを実装した(次々回)
動作環境
Python 2.7
Python 3.7ライブラリ、ブローカーのインストール
これは前回の記事にあるのでまだインストールしていない人のために書いておきます。
ライブラリ、ブローカーのインストール
1. windowsの場合
以下のサイトの、「Binary Installation」⇒「Windows」のところから自身の環境に合わせてインストーラーをダウンロードしてください。
https://mosquitto.org/download/
2. Linuxの場合
以下の2つのコマンドを実行してください。
# Mosquitto(Broker)をインストール $ sudo apt-get install mosquitto # Mosquittoクライアントをインストール $ sudo apt-get install mosquitto-clientsクライアントライブラリのインストール
次回以降に使うPythonとJavaのクライアントライブラリのインストール方法も記載しておきます。
Python
ライブラリpahoのインストール
$ pip install paho-mqtt
PythonでMQTT通信
公式のサンプルがあります。
Publisherは毎回繋げに行けばよいので以下の一行で済みます。連続でやりたかったら3行目をループさせてください。
simplepub.pyimport paho.mqtt.publish as publish publish.single("トピック名", "メッセージ内容", hostname="ホスト名")simplepub_loop.pyimport paho.mqtt.publish as publish import time i = 0 while True: time.sleep(3) i += 1 print(i) publish.single("testTopic2", i, hostname="localhost")Subscriberはcallback関数を設定して処理を行います。(ここもROS1と同じですね)
simplesub.pyimport paho.mqtt.subscribe as subscribe topics = 'test' def print_msg(client, userdata, message): print("%s : %s" % (message.topic, message.payload)) while True: subscribe.callback(print_msg, "test", hostname="localhost")実行
前回の記事と同じように、ブローカーを起動してからクライアントを起動しましょう。
$ cd C:\Program Files (x86)\mosquitto $ mosquitto -v以下のようにそれぞれ実行して、publishしたメッセージがsubscriberの画面に出てくれば成功です。
$ python simple_sub.py$ python simple_pub.pyまた、MQTTのクライアント(
paho.mqtt.client)にはデフォルトのメソッドがいくつか用意されていてます。
上記のように一行で済ませるのではなく、それぞれのメソッドを書く実装例もあります。
pythonでMQTT送受信
MQTTライブラリ Paho Python を理解しようとしてみるMQTT通信用クラス
以上はPub/Subともに単体での実装例でしたが、ROSやOpenRTMなど、別で動作しているシステムから呼び出したかったので、
自作モジュールとして簡単に読み込めるようにクラスにまとめました。以下がそのクラスになります。
mqtt.Clientを継承しています。参考は公式のGitHubの、client_sub-class.pyになります。MQTTClient.pyimport paho.mqtt.client as mqtt import paho.mqtt.publish as publish import time class MyMQTTClass(mqtt.Client): def __init__(self): super().__init__() self.recieve_data = "" self.recieve_time = "" self.lasttime = "" def on_connect(self, mqttc, obj, flags, rc): print("rc: "+str(rc)) def on_message(self, mqttc, obj, msg): print(msg.topic+" "+str(msg.qos)+" "+str(msg.payload)) self.recieve_time = time.time() self.recieve_data = (msg.payload).decode() def run(self, hostname, topic): self.connect(hostname, 1883, 60) self.subscribe(topic, 0) self.loop_start() rc = 0 return rc def publish_message(self, host_name, topic, message): publish.single(topic, message, hostname=host_name) def isNew(self): flag = False if self.lasttime==self.recieve_time: flag = False else: flag = True self.lasttime = self.recieve_time return flag # If you want to use a specific client id, use # mqttc = MyMQTTClass("client-id") # but note that the client id must be unique on the broker. Leaving the client # id parameter empty will generate a random id for you. mqttc = MyMQTTClass() rc = mqttc.run("localhost","testTopic1") print("rc: "+str(rc)) i=0 while(1): i+=1 print(i) mqttc.publish_message("localhost", "testTopic2",i) if mqttc.isNew(): print(mqttc.recieve_data)※Python 2系では、
super().__init__()の部分はsuper(MyMQTTClient, self).__init()__にしないとエラーが出るので注意してください。それぞれのメソッドの役割は以下の通りです。
メソッド名 役割 on_connect ブローカーと接続時に呼び出されるメソッド on_message メッセージ受け取り時に呼び出されるメソッド(recieve_dataに受け取ったメッセージを代入) run 外部から呼び出されるメソッド、subscriberのループをスタートさせる publish_message メッセージをpublishするメソッド、上記の simplepub.pyそのままisNew 受け取ったメッセージが新しいものか判断するメソッド 実は親クラスに
publish()メソッドがあるのですが、connect()した際のホストにしかできないのかな、と思ったのと、一つのクラスに収めたかったのでこのような形で実装しました。ほかに方法はありそうです。使用例
クラスの呼び出しを用いた実装例は以下のようになります。
先ほどのMQTTClient.pyと同じディレクトリにファイルを置いてください。sample_mqtt_lient.pyimport MQTTClient mqttc = MQTTClient.MyMQTTClass() mqttc.run("ホスト名","トピック名") # 1回だけpublish mqttc.publish_message("ホスト名", "トピック名","メッセージ") if(mqttc.isNew()): print(mqttc.receive_data)
mqttc.run()でSubscribe開始、mqttc.publish_message()で1回だけメッセージをpublishします。
また、recieve_dataにsubscribeした変数がはいります。mqttc.isNew()関数によってsubscribeしたかを判断しているので上記のようにセットで使ってください。(Open RTMと一緒ですね)mqttc = MQTTClient.MyMQTTClass() mqttc.run("ホスト名","トピック名")上の2行は一度実行される場所に、以下の3行はメインループの中にいれるイメージです。
# 1回だけpublish mqttc.publish_message("ホスト名", "トピック名","メッセージ") if(mqttc.isNew()): print(mqttc.receive_data)おわりに
PythonでMQTT通信ができるクラスを実装してみました。
ROSで使ってみたところ、うまく使えたので目的は達成できたかと思います。
- 投稿日:2020-08-09T14:42:36+09:00
Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(入門編)〜
はじめに
- 近年、人工衛星データを社会やビジネスで利用するケースが増えてきています
- 人工衛星は宇宙から地球の状態を様々なセンサーで観測しており、それらはオープンデータとして公開されています
- 衛星データはビッグデータであり、昨今の機械学習やAIの技術と親和性の高いのですが、必要とされる処理リソース(ストレージ・メモリ)が膨大になりがちであり、個人のPC環境で利用するにはハードルが高いです
- しかし、Googleが提供するクラウドリソースを利用することで、個人でも無料で衛星データ解析を行うことができます
- 本記事では、Google Earth Engine (GEE)とGoogle Colaboratory (Colab)を利用して衛星データ解析の手法を紹介します
- 後日公開予定の【応用編】では衛星データから取得できる代表的なデータ(地表面温度・植生指数・積雪指数)の取り扱いも紹介していきたいと思います
- 衛星データ解析では様々なセンサーを組み合わせることで、色々な地球環境の状態を捉えることができるので、本記事の内容を入門として、身近な環境状態のデータ解析に役立ててみると面白いかと思います
本記事の特徴
- 通常、GEEはブラウズ上でJavaScriptを用いて解析を行います
- しかし、機械学習や統計解析のライブラリが豊富なPythonで解析を行いたいので、最低限の処理(衛星画像の抽出と保存)のみGEEのPython APIで行い、可視化や解析はpythonの通常ライブラリ(numpyやmatplotlib)で行う方法を紹介します
- また、大容量の衛星画像データをローカルPCのリソースに依存せずに解析を行いたいので、Google Colab+Google Driveのクラウド環境のみで処理を完結する方法を紹介します(勿論、保存先をローカルに指定すれば、ローカル環境でも同様に解析が行えます)
サービスの使い分けイメージ ~Googleサービスを利用してクラウドサービスのみで衛星画像解析を行う~
Google Earth Engine (GEE) の 概要
- 2010年の12月にGoogleがサービスリリース
- 人工衛星画像を自前のパソコンにダウンロードすることなく、GEEサーバー上で解析を行うことが出来る
- 通常の衛星データ解析では、異なるデータフォーマットの対応やデータの前処理が必要だが、GEE上には様々な衛星データが準備されており、必要なデータのみロードして利用することができる
- 研究・教育・非営利目的に限り無償で利用することができる(有償プランもあり)
- 注)地球儀を閲覧できるGoogle Earthとは別サービスです
Google Colaboratory (Colab) の概要
- 環境構築不要でブラウザからPython を記述・実行できるサービス
- GPUも無料で利用することができる
- Google Colabの概要や利用方法は分かり易い記事が豊富にあるので、それらをご覧ください
【利用方法】 衛星画像解析 on GEE&Colab
アカウントの準備
- Google Earth Engine の公式ページよりサインアップを行う(Googleアカウントが必要です)
- サインアップが完了するとGEE上で利用できる衛星データの一覧であるデータカタログにアクセスできるようになる
Python環境(Google Colab)でのGEE利用
1. Google ColabからPython APIを用いてGEEの認証を行う
# Earth Engine Python APIのインポート import ee # GEEの認証・初期化 ee.Authenticate() ee.Initialize()
- GEE認証を実行すると認証に必要なURLが表示される
- URLへアクセスしてGoogleアカウントを指定すると、認証コードが表示される
- 認証コードをGoogle Colabのボックスへコピペする
2. GEEの衛星データをロードする
- データカタログからロードしたい衛星名を選択
- ここでは夜間光(NightTime-Light)のデータを収集しているDMSP-OLSを選択
- 夜間光については過去記事「夜間光データとは」を参照
- データロードしたいバンド名を選択
- 通常、人工衛星では複数のバンド(波長が異なるセンサー)でデータを取得しているので、目的にあったバンド名を指定する
- ここでは、夜間光データの本体である'avg_vis'を選択する
- 'avg_vis'は0~63の整数値で夜間光の強さを表現するセンサーである
- データロードしたい期間を指定
- 通常、衛星は再帰的に観測を継続している時系列データである(観測頻度は衛星によって異なる)
- そこで取得したいデータの期間を選択する
- データロードしたいエリアを指定
- 人工衛星は地球全域を観測しているので、必要なエリアを指定する
- ここでは緯度・経度を用いて、長方形でデータを抽出する方法を採用している
- ee.Geometry.Rectangle([xMin, yMin, xMax, yMax])で指定する
- xMin=(左下の経度), yMin=(左下の緯度), xMax=(右上の経度), yMax=(右上の緯度)
# 衛星名を指定 satellite = 'NOAA/DMSP-OLS/NIGHTTIME_LIGHTS' # バンド名を指定 band = 'avg_vis' # 期間を指定 from_date='2010-01-01' to_date='2012-12-31' ## エリアを指定(日本エリアを緯度・経度を指定) geometry = ee.Geometry.Rectangle([128.60, 29.97, 148.43, 46.12]) # 指定した条件でGEEからデータをロード dataset = ee.ImageCollection(satellite).filter( ee.Filter.date(from_date, to_date)).filter( ee.Filter.geometry(geometry)).select(band)
- 今回の衛星プロダクトは年ごとのデータセットなので、2010~2012年の3年分のデータが存在している
- 衛星によって計測頻度は異なり、時間解像度の細かい衛星(例:12日ごとに観測している衛星)では長期間を指定すると大量のデータがロードされるので注意が必要となる
- 対象のデータ数は下記のコマンドで確認することができる
# 対象データ数の確認 print(dataset.size().getInfo())3. 衛星画像データの保存
- 指定した衛星データをGoogle Driveへ保存する
- リスト形式へ変換しておくことで、任意の画像を保存することができる
- ee.batch.Export.image.toDriveを利用することで、Google DriveのMyDrive内の指定したフォルダへデータが保存される
- また画像をダウンロードする際に、scaleで画像の解像度を指定することができる
## リスト形式へ変換 data_list = dataset.toList(dataset.size().getInfo()) # 0番目の画像(2010年の画像)を取得 image = ee.Image(data_list.get(0)) # Gdriveへ保存 task = ee.batch.Export.image.toDrive(**{ 'image': image,# 対象データの指定 'description': 'sample_dataloading_NTL',# ファイル名の指定 'folder':'GEE_download',# Google Drive(MyDrive)のフォルダ名 'scale': 1000,# 解像度の指定 'region': geometry.getInfo()['coordinates']# 上記で指定した対象エリア }) # 処理の実行 task.start()
- 上記コマンドを実行すると、Google Drive > My Drive > GEE_downloadにsample_dataloading_NTLというファイルが保存される
- ロードするデータサイズによっては時間がかかり、task.active()によって進捗を確認することができる task.active()=Trueの場合はGEEが処理中なので、Falseになるまで待つ
# データの処理状況の確認(Trueで処理中を表す) task.active()4. 保存した衛星画像の確認
- データはTIF形式で保存されている
- そこでrasterioを利用しTIF形式のデータの読み込みとmatplotlibを用いた可視化を行う
- TIFデータの取り扱いとrasterioの利用方法については下記を参照 【入門】Pythonによる人工衛星データ解析(Google Colab環境)
# パッケージのインストール&インポート !pip install rasterio import numpy as np import matplotlib.pyplot as plt import rasterio # データの読み込み with rasterio.open('/content/drive/My Drive/GEE_download/sample_dataloading_NTL.tif') as src: arr = src.read() # numpy形式でデータを取得 -> (1, 1847, 2208)の配列で取得 print(arr.shape) # 可視化 plt.imshow(arr[0])"2010年 DMSP-OLSによる夜間光データ"
- arrはnumpy形式なので、衛星データの統計値を計算したり、翌年のデータを取得してきて時系列比較したり、自由に解析を行うことができます
- また過去記事で紹介している ベクターファイルやgeopandasを用いることで、国や都道府県単位でデータをくり抜いて可視化したり、データ変化を計算することも可能です
一連の処理の関数化
- 最後に上記の一連の処理を関数化しておきます
- 次回はこの関数を用いて、人工衛星を用いて観測されている様々な指標(地表面温度、植生指数、積雪指数など)を用いた解析を行ってみたいと思います
# GEEのデータロード def load_data(snippet, from_date, to_date, geometry, band): # パラメータの条件にしたがってデータを抽出 dataset = ee.ImageCollection(snippet).filter( ee.Filter.date(from_date, to_date)).filter( ee.Filter.geometry(geometry)).select(band) # リスト型へ変換 data_list = dataset.toList(dataset.size().getInfo()) # 対象データ数とデータリストを出力 return dataset.size().getInfo(), data_list # 衛星画像をGoogle Driveへ保存 def save_on_gdrive(image, geometry, dir_name, file_name, scale): task = ee.batch.Export.image.toDrive(**{ 'image': image,# ロードする衛星情報 'description': file_name,# 保存するファイル名 'folder':dir_name,# 保存先のフォルダ名 'scale': scale,# 解像度 'region': geometry.getInfo()['coordinates'],# 対象エリア 'crs': 'EPSG:4326' }) # Run exporting task.start() print('Done.') ## パラメーターの指定 # 衛星を指定 snippet = 'NOAA/DMSP-OLS/NIGHTTIME_LIGHTS' # バンド名を指定 band = 'avg_vis' # 期間を指定 from_date='2010-01-01' to_date='2012-12-31' # エリアを指定(日本エリアを緯度・経度を指定) geometry = ee.Geometry.Rectangle([128.60, 29.97, 148.43, 46.12]) # 保存するフォルダ名 dir_name = 'GEE_download' # ファイル名 file_name = 'fine_name' # 解像度 scale = 1000 ## 処理の実行 ---------------------------------------------- num_data, data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=geometry, band=band) print('#Datasets; ', num_data) ## 全件保存(ファイル名は衛星IDを利用) for i in range(data_list.size().getInfo()): image = ee.Image(data_list.get(i)) save_on_gdrive(image, geometry, dir_name, image.getInfo()['id'].replace('/', '_'), scale)さいごに
- 本記事ではGoogleの各種サービス(GEE, Colab and Drive)を利用した衛星画像解析の方法を紹介しました
- GEEを利用することで、データカタログに記載されている様々な衛星データセットを同じコマンドで利用できることが魅力的です(通常、衛星データセットを利用する際は、運用機関ごとの異なるフォーマットや複雑な前処理が必要になるのですが、GEEを利用するこで、解析者が分析・活用に注力することができます)
- また、Goole Colabを利用することで基本的な可視化や解析から、本記事では紹介していませんが、GPU環境へ切り替えて衛星データをインプットとした機械学習の訓練への拡張も簡単に行うことができます
- GEEのデータカタログには沢山のデータセットが掲載されているので、本記事をキッカケに地球環境分析に興味を持って頂ければと思います


- 投稿日:2020-08-09T14:20:32+09:00
7行インタプリタ実装まとめ
拙作まとめ/チートシート第四段.下記Webページを読んで,最初の7行インタプリタ(ラムダ計算)をPythonその他のプログラミング言語でも書いておこうと思ったのがきっかけ.このため,当面は,元言語のScheme記述と,Python記述のみ.
(λ x . x)
→ ((λ x . x))
((λ x . x) (λ a . a))
→ (λ a . a)
(((λ f . f) (λ g . g)) (λ a . a))
→ ((λ a . a))
(((λ f . (λ x . (f x))) (λ g . g )) (λ a . a))
→ ((λ a . a))なお,この記事では,ラムダ記号は(『λ』ではなく)『/』を用いている.
移植作業(?)の都合上,構成は各言語ごとに次のパートに分かれている.ただし,既存関数との重複を避けるため,
evalはeval7,applyはapply7の関数名としている.
- リスト構造の入力
- 環境用の連想リスト
evalの実装applyの実装- リスト構造の出力
- 動作確認
Scheme(処理内容の解説付き)(R5RS)
- リスト構造の入力
read一択.S式の字句・構文解析(パース)をしてくれる.gosh> (read (open-input-string "(hoge hage (hige (foo bar)) baz)")) (hoge hage (hige (foo bar)) baz)
- 環境用の連想リスト
assqでOK.gosh> (assq 'a '((a 10) (b 20) (c 30))) (a 10)
evalの実装式の評価部.上記Webページのほぼコピペ.式
eと環境envを受け取り,式eが変数ならば環境envから対応する値を取り出して戻し,式eが単独のラムダ式ならば値として環境envに追加して戻す,それ以外は,関数(car e)と関数に与える値(cadr e)のリストとみなし,関数・値それぞれを先に自己評価してから(applicative order),関数適用するためのapplyを呼び出す.(define (eval7 e env) (cond ((symbol? e) (cadr (assq e env))) ((eq? (car e) '/) (cons e env)) (else (apply7 (eval7 (car e) env) (eval7 (cadr e) env)))))
applyの実装関数適用部.上記Webページのほぼコピペ.関数
fと値xを受け取り,関数の変数(cadr (car f))と値xを対応付け,残りの未適用の値(cdr f)と併せて環境とし,関数本体の式(cddr (car f))と共に,式の評価部evalを呼び出す.実装上の注意点として,入力されたラムダ式のピリオドの右側はSchemeでは自動的にドット対のcdr部となるので,たとえば,
fが((/ a . (/ c . d)))の時の(cddr (car f))は,(. (/ c . d))ではなく(\ c . d)となる.(define (apply7 f x) (eval7 (cddr (car f)) (cons (list (cadr (car f)) x) (cdr f))))
- リスト構造の出力
displayをそのまま使用.gosh> (display '((/ a . a))) ((/ a . a))#<undef>
- 動作確認
gosh> (display (eval7 (read) '())) (((/ f . (/ x . (f x))) (/ g . g )) (/ a . a)) ((/ a . a))#<undef>Python(Python 3,Python2)
- リスト構造の入力
こちらの
read_from_tokens()のパクリ.エラー処理は亡き者にされた.def readlist(x): xl = x.replace('(', ' ( ').replace(')', ' ) ').split() def ret(ts): t = ts.pop(0) if t == '(': r = [] while ts[0] != ')': r.append(ret(ts)) ts.pop(0) return tuple(r) else: return t return ret(xl)>>> readlist('(hoge hage (hige (foo bar)) baz)') ('hoge', 'hage', ('hige', ('foo', 'bar')), 'baz')
- 環境用の連想リスト
最初は辞書型を使おうと思ったが,λ評価の時に面倒なことになりそうだったので,タプル型想定で実装.
def assoc(k, vl): if not vl: return False elif vl[0][0] == k: return vl[0] else: return assoc(k, vl[1:])>>> assoc('a', (('a', 10), ('b', 20), ('c', 30))) ('a', 10)
evalの実装添字大活躍.Scheme(LISP)の
(car x),(cdr x),(cadr x)がPythonのx[0],x[1:],x[1]なのは定番(普通は逆).def eval7(e, env): if isinstance(e, str): return assoc(e, env)[1] elif e[0] == '/': return (e,) + env else: return apply7(eval7(e[0], env), eval7(e[1], env))
applyの実装添字大活躍第二弾.
cddr=[2:]ではなくcdddr=[3:]なのは'.'除去のため(Scheme実装の解説参照).def apply7(f, x): return eval7(f[0][3:][0], ((f[0][1], x),) + f[1:])
- リスト構造の出力
入力の逆.こちらはさすがに自作.最後の
[:-1]はとても技巧的.def writelist(x): def ret(xs): r = ('(') for t in xs: if isinstance(t, tuple): r += ret(t) else: r = r + t + ' ' r = r[:-1] + ') ' return r return ret(x)[:-1]>>> writelist(('a', 'b', ('c', 'd'), (('e', 'f'), ('g', 'h')))) '(a b (c d) ((e f) (g h)))'
- 動作確認
Python3の場合(
input()を使う).>>> print(writelist(eval7(readlist(input()), ()))) (((/ f . (/ x . (f x))) (/ a . a )) (/ b . b)) ((/ b . b))Python2の場合(
raw_input()を使う).>>> print(writelist(eval7(readlist(raw_input()), ()))) (((/ f . (/ x . (f x))) (/ a . a )) (/ b . b)) ((/ b . b))備考
参考文献
- Matt Might:7 lines of code, 3 minutes: Implement a programming language from scratch
- Peter Norvig:(How to Write a (Lisp) Interpreter (in Python))
- Qiita:Pythonのリスト内包表記はチューリング完全だから純LISPだって実装できる
記事に関する補足
- Scheme版はGauche,GNU Guile,SCMで確認.SCMでは『\』が使えなかった….
変更履歴
- 2020-08-09:初版公開
- 投稿日:2020-08-09T13:38:44+09:00
NeovimでPythonのコード補完時に必要なImport文を挿入する
記事の対象者
- NeovimでPythonのIDE的な書き味を実現したい人
- coc.nvim を使用している人
はじめに
IntelliJを始めとした統合開発環境(IDE)においては以下のように
補完決定時に必要なImport文も同時に挿入してくれるというのはよくある話だと思います。
これをvimでPythonを書く時にも比較的ライトに実現したい というのが本記事の主旨です。
実現できること
拙作ですが https://github.com/relastle/vim-nayvy このプラグインを使用すると
以下のようなことが実現できます。
導入方法
以下で導入できます。
Plug 'neoclide/coc.nvim', {'branch': 'release'} Plug 'relastle/vim-nayvy'coc.nvimのcustom sourceの機能を使っているだけなので、
別途cocのプラグインを導入する必要はありません。補完決定時にimport文を挿入するので
なにも設定していなければ明示的に (Ctrl-y) キーで決定する必要はあります。(詳しくはREADME参照)
with-python3 なvimでも動作してくれると思います。
補足
Pythonのimport文は以下の点で他のいくらかの言語よりやや特殊だと思います。
- 別名でimport するというのが非常に一般的 (import xxxx as yy)
- パッケージ(サブパッケージ)をimportして、その名前空間で内部の関数を指定することもあれば、importする関数をダイレクトに指定することもある(import xxxx | from xxxx import zzz)
より具体的には
import os.path os.path.dirname('hoge/fuga')from os.path import dirname dirname('hoge/fuga')のどちらで書くかは基本的には書き手の自由だと思います。
極論ですが
import numpy as npと書くことが通例望ましいでしょうが、個人で開発する分には(或いはチーム内で合意が得られていれば)
import numpyとして開発していてもいいことになります。
こういった特性から、Pythonで補完時に自動でimport文を挿入するという問題を
全ての人に使用される前提で解決するのは困難だと思っています。本プラグインでは利用者側で事前に大量にimport文を用意してもらうことで解決しています。
$HOME/.config/nayvy/import_config.nayvy($XDG_CONFIG_PATH/nayvy/import_config.nayvy) に自分が普段使うimport文を大量に書いておくことで、それをcustom sourceとして使用しています。
(ファイルを置かない場合は標準ライブラリのパッケージ/モジュールだけが補完されます。)私個人の話をするとmypyで型検査を行って開発することがほとんどなので
from typing import Any, Callable, ClassVar, Generic, Optional, Tuple, Type, TypeVar, Union, AbstractSet, ByteString, Container, ContextManager, Hashable, ItemsView, Iterable, Iterator, KeysView, Mapping, MappingView, MutableMapping, MutableSequence, MutableSet, Sequence, Sized, ValuesView, Awaitable, AsyncIterator, AsyncIterable, Coroutine, Collection, AsyncGenerator, AsyncContextManager, Reversible, SupportsAbs, SupportsBytes, SupportsComplex, SupportsFloat, SupportsInt, SupportsRound, ChainMap, Counter, Deque, Dict, DefaultDict, List, OrderedDict, Set, FrozenSet, NamedTuple, Generator, AnyStr, cast, get_type_hints, NewType, no_type_check, no_type_check_decorator, NoReturn, overload, Text, TYPE_CHECKING, Protocolこのような行があったり
import numpy as np import pandas as pd import tensorflow as tf import seaborn as sns import requests import aiohttp from logzero import logger import yaml import click from click_help_colors import HelpColorsGroup, HelpColorsCommand import pytest import yamlこのように頻繁につかう 3rd-party製のプラグインのためのimport文を書いたりしています。


- 投稿日:2020-08-09T12:26:51+09:00
TkinterでCheckbuttonにチェックを付けると、Entryが編集できるようにする
環境:
Ubuntu 18.04.5 LTS (Windows Subsystem for Linux)
Python 3.8.0目標
PythonのTkinterでチェックボックス(Checkbutton)にチェックをつけると、入力欄(Entry)が有効になり入力できるようにする。
チェックを外すと、編集できなくする。
方法
import tkinter as tk def change_state(): if bool_check.get(): # チェックをつけたとき entry.config(state='normal') else: # チェックをはずしたとき entry.config(state='disabled') root = tk.Tk() entry = tk.Entry() entry.config(state='disabled') # 最初は無効 bool_check = tk.BooleanVar() bool_check.set(False) # 最初はチェックなし check = tk.Checkbutton(variable=bool_check, command=change_state) check.pack() entry.pack() root.mainloop()change_state関数を定義します。
変数名は何でもいいですが、例えばbool_check変数にtk.BooleanVar()を代入します。
tk.Checkbutton()の引数variableにbool_check変数を、引数commandにchange_state関数を渡してチェックボックスを作成します。チェックの有無はbool_check.get()でブール値で返されます。
チェックをつけはずしするとchange_state()が呼ばれます。change_state()では作製したentryのstateをチェックの有無に応じて変更します。
2つ以上作りたいとき
change_state()にbool_checkやentryを引数として渡せられれば、2つ以上の入力欄で同じことができそうです。
しかしながら例えば、def change_state(bool_check, entry): if bool_check.get(): entry.config(state='normal') else: entry.config(state='disabled')のようにchange_state関数を引数付きで定義して、
tk.Checkbutton(command=change_state(bool_check, entry))のようにtk.Checkbutton()のcommand引数に、引数付きの関数を渡しても正しく動作しません。
正しく動作するには、commandにlambda式を渡します。すなわち、import tkinter as tk def change_state(bool_check, entry): if bool_check.get(): entry.config(state='normal') else: entry.config(state='disabled') root = tk.Tk() # 1つ目 entry1 = tk.Entry() entry1.config(state='disabled') bool_check1 = tk.BooleanVar() bool_check1.set(False) check1 = tk.Checkbutton(text='1', variable=bool_check1, command=lambda: change_state(bool_check1, entry1)) check1.pack() entry1.pack() # 2つ目 entry2 = tk.Entry() entry2.config(state='disabled') bool_check2 = tk.BooleanVar() bool_check2.set(False) check2 = tk.Checkbutton(text='2', variable=bool_check2, command=lambda: change_state(bool_check2, entry2)) check2.pack() entry2.pack() root.mainloop()簡単な応用
チェックをはずすと、入力されていた文字列を削除して"無効"を表示してみる。
import tkinter as tk def change_state(): if bool_check.get(): # チェックをつけたとき entry.config(state='normal') entry.delete(0, tk.END) # normalにしてから"無効"をdeleteする else: # チェックをはずしたとき entry.delete(0, tk.END) # 0文字目から終わりまで文字列を削除する entry.insert(0, "無効") # Entryの0文字目に"無効"をinsert entry.config(state='disabled') # insertしてからdisableにする root = tk.Tk() entry = tk.Entry() entry.insert(0, "無効") # Entryの0文字目に"無効"をinsert entry.config(state='disabled') # insertしてからdisableにする bool_check = tk.BooleanVar() bool_check.set(False) check = tk.Checkbutton(variable=bool_check, command=change_state) check.pack() entry.pack() root.mainloop()初期値を与えるなど、応用ができそうです。
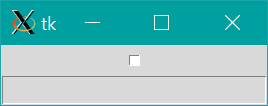
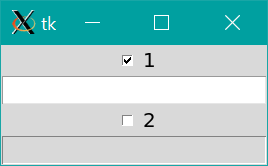
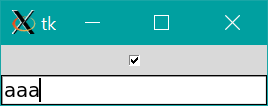
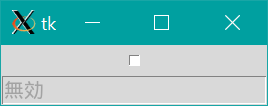
- 投稿日:2020-08-09T11:53:56+09:00
複数の圧縮ファイルを解凍のため(Python)
概要
Linux上で複数の圧縮ファイルを解凍する内容についてコード書いてみます。
圧縮ファイル名毎にディレクトリを生成、解凍及び、削除するPythonコードについて説明して行きたいと思います。
Redreamというエミュレーターでゲームを実行するため、ディレクトリ毎に圧縮ファイルを解凍する必要がありましたので、バッチを作ってみましたので、皆さんに共有します。事前作業
7zファイルを解凍するため、パッケージをインストールする。
次のコマンドで7zをインストールします。sudo apt-get install -y p7zip-fullPythonコード
以下のPythonコードを作成してbatch.pyファイルに保存します。
#!/usr/bin/python # -*- coding: utf-8 -*- import io import os import glob arr = glob.glob("*7z") #print(arr) path_w = '7z.sh' with open(path_w, mode='w') as f: for str in arr: dir = str.replace("[GDI] ","").replace("[CDI] ","").replace(".7z","").replace("'","") tmpstr = str.replace("'","").replace(",","") os.rename("./" + str , "./" + tmpstr) try: if not os.path.exists(dir): cmds = "7z x '" + tmpstr + "' -o'" + dir + "'\n" dels = "rm -rf '" + tmpstr + "'\n" #print(cmds) #print(dels) f.write(cmds) f.write(dels) except OSError: print("Error: " + dir)Pythonコードの説明
ソース上にコメントを書いてなかったので、こちらに説明したいと思います。
#!/usr/bin/python # -*- coding: utf-8 -*- # 提供されるメソッドを使用するため、パッケージを宣言する部分です。 import io import os import glob # 現在のディレクトリに拡張子が「7z」であるファイルのみ配列に保存します。 arr = glob.glob("*7z") # 以下のPrintは保存されている配列の中身を確認するためのコードです。 # print(arr) # シェルスクリプトファイルに 圧縮ファイルを解凍及び削除する # コマンドを保存するシェルスクリプトファイル名を指定します。 path_w = '7z.sh' # シェルスクリプトファイルを書き込みモードにオープン with open(path_w, mode='w') as f: # 「7z」ファイル毎に解凍・削除コマンドを作成します。 for str in arr: # 解凍するディレクトリ名を圧縮ファイル名から作成します。 # ディレクトリ名に不要な文字列を削除します。 dir = str.replace("[GDI] ","").replace("[CDI] ","").replace(".7z","").replace("'","") # ファイル名及びディレクトリ名に次の文字列があると回答が失敗するので、 # 文字を削除します。そしてファイル名も置換します。 tmpstr = str.replace("'","").replace(",","") os.rename("./" + str , "./" + tmpstr) try: # ディレクトリ名が存在しない場合、以下の処理を実行します。 if not os.path.exists(dir): # 圧縮ファイルを解凍するコマンドです。 cmds = "7z x '" + tmpstr + "' -o'" + dir + "'\n" # 解凍が終わったファイルを削除するコマンドです。 dels = "rm -rf '" + tmpstr + "'\n" # コマンドを確認するためのコードです。 #print(cmds) #print(dels) # コマンドをシェルスクリプトファイルに保存します。 f.write(cmds) f.write(dels) except OSError: # ディレクトリ関連エラーが発生した場合、出力します。 print("Error: " + dir)Pythonコードを実行
次のコマンドでPythonコードを実行します。
実行すると「7z.sh」ファイルが生成されます。pi@raspberrypi:~/Downloads/redream/rom $ python batch.py7z.shファイルの中身を確認
次のコマンドでファイルの中身を確認します。
各圧縮ファイル名毎に解凍・削除コマンドが生成されていることが確認できます。pi@raspberrypi:~/Downloads/redream/rom $ cat 7z.sh 7z x '[GDI] XXXXXXXX.7z' -o'XXXXXXXX' rm -rf '[GDI] XXXXXXXX.7z' 7z x '[CDI] XXXXXXXX.7z' -o'XXXXXXXX' rm -rf '[CDI] XXXXXXXX.7z'7z.shコマンドを実行
次のコマンドでシェルスクリプトファイルを実行します。
実行すると圧縮ファイルを解凍する画面が表示されます。
実行が終わったら圧縮ファイルはすべて削除されていることが確認できます。
もしファイル名に想定してない文字列によるエラーで止まっている可能性もありますが、
その場合、ファイル名・ディレクトリ名の処理に置換を追加します。
そうすると問題なく解決できるはずです。pi@raspberrypi:~/Downloads/redream/rom $ sh 7z.shその他
SDカードの容量が足りない場合、ファイルの解凍が失敗するケースもありますので、
注意してください。(笑)終わりに
これでRetropie OSにゲームを入れるのは簡単にできましたが、
次はgame.xmlにGDI・CDI及びプレビューの画像ファイルの指定が残ってます。
Raspbianで実行する場合は、上記のgame.xmlの指定は不要です。
手動で圧縮解凍するのも面倒だったので、作ってみました。
役に立ちましたか?少し例外処理が足りないですが、必要に応じて追加してください。
- 投稿日:2020-08-09T11:53:56+09:00
複数の圧縮ファイルを解凍(Python)
概要
Redreamというエミュレーターでゲームを実行するため、ディレクトリ毎に圧縮ファイルを解凍する必要がありましたので、バッチを作ってみました。
事前作業
7zファイルを解凍するため、パッケージをインストールする。
次のコマンドで7zをインストールします。sudo apt-get install -y p7zip-fullPythonコード
以下のPythonコードを作成してbatch.pyファイルに保存します。
#!/usr/bin/python # -*- coding: utf-8 -*- import io import os import glob arr = glob.glob("*7z") #print(arr) path_w = '7z.sh' with open(path_w, mode='w') as f: for str in arr: dir = str.replace("[GDI] ","").replace("[CDI] ","").replace(".7z","").replace("'","") tmpstr = str.replace("'","").replace(",","") os.rename("./" + str , "./" + tmpstr) try: if not os.path.exists(dir): cmds = "7z x '" + tmpstr + "' -o'" + dir + "'\n" dels = "rm -rf '" + tmpstr + "'\n" #print(cmds) #print(dels) f.write(cmds) f.write(dels) except OSError: print("Error: " + dir)Pythonコードの説明
ソース上にコメントを書いてなかったので、こちらに説明したいと思います。
#!/usr/bin/python # -*- coding: utf-8 -*- # 提供されるメソッドを使用するため、パッケージを宣言する部分です。 import io import os import glob # 現在のディレクトリに拡張子が「7z」であるファイルのみ配列に保存します。 arr = glob.glob("*7z") # 以下のPrintは保存されている配列の中身を確認するためのコードです。 # print(arr) # シェルスクリプトファイルに 圧縮ファイルを解凍及び削除する # コマンドを保存するシェルスクリプトファイル名を指定します。 path_w = '7z.sh' # シェルスクリプトファイルを書き込みモードにオープン with open(path_w, mode='w') as f: # 「7z」ファイル毎に解凍・削除コマンドを作成します。 for str in arr: # 解凍するディレクトリ名を圧縮ファイル名から作成します。 # ディレクトリ名に不要な文字列を削除します。 dir = str.replace("[GDI] ","").replace("[CDI] ","").replace(".7z","").replace("'","") # ファイル名及びディレクトリ名に次の文字列があると回答が失敗するので、 # 文字を削除します。そしてファイル名も置換します。 tmpstr = str.replace("'","").replace(",","") os.rename("./" + str , "./" + tmpstr) try: # ディレクトリ名が存在しない場合、以下の処理を実行します。 if not os.path.exists(dir): # 圧縮ファイルを解凍するコマンドです。 cmds = "7z x '" + tmpstr + "' -o'" + dir + "'\n" # 解凍が終わったファイルを削除するコマンドです。 dels = "rm -rf '" + tmpstr + "'\n" # コマンドを確認するためのコードです。 #print(cmds) #print(dels) # コマンドをシェルスクリプトファイルに保存します。 f.write(cmds) f.write(dels) except OSError: # ディレクトリ関連エラーが発生した場合、出力します。 print("Error: " + dir)Pythonコードを実行
次のコマンドでPythonコードを実行します。
実行すると「7z.sh」ファイルが生成されます。pi@raspberrypi:~/Downloads/redream/rom $ python batch.py7z.shファイルの中身を確認
次のコマンドでファイルの中身を確認します。
各圧縮ファイル名毎に解凍・削除コマンドが生成されていることが確認できます。pi@raspberrypi:~/Downloads/redream/rom $ cat 7z.sh 7z x '[GDI] XXXXXXXX.7z' -o'XXXXXXXX' rm -rf '[GDI] XXXXXXXX.7z' 7z x '[CDI] XXXXXXXX.7z' -o'XXXXXXXX' rm -rf '[CDI] XXXXXXXX.7z'7z.shコマンドを実行
次のコマンドでシェルスクリプトファイルを実行します。
実行すると圧縮ファイルを解凍する画面が表示されます。
実行が終わったら圧縮ファイルはすべて削除されていることが確認できます。
もしファイル名に想定してない文字列によるエラーで止まっている可能性もありますが、
その場合、ファイル名・ディレクトリ名の処理に置換を追加します。
そうすると問題なく解決できるはずです。pi@raspberrypi:~/Downloads/redream/rom $ sh 7z.shその他
SDカードの容量が足りない場合、ファイルの解凍が失敗するケースもありますので、
注意してください。(笑)終わりに
これでRetropie OSにゲームを入れるのは簡単にできましたが、
次はgame.xmlにGDI・CDI及びプレビューの画像ファイルの指定が残ってます。
Raspbianで実行する場合は、上記のgame.xmlの指定は不要です。
手動で圧縮解凍するのも面倒だったので、作ってみました。
役に立ちましたか?少し例外処理が足りないですが、必要に応じて追加してください。
- 投稿日:2020-08-09T11:09:51+09:00
[アルゴリズム×Python] リストの使い方
アルゴリズムとPythonについて書いていきます。
目次
0.アルゴリズムとは
1.リストとは
2.リストの使いかた0.アルゴリズムとは
計算や作業をするための手順のことです。
短時間で効率的に処理をすることを目指します。1.リストとは
データ構造の1つで、データを一直線に並べた構造をしています。
大量のデータを扱うアルゴリズムではよく使われます。
リストはデータの追加や削除がしやすい反面、アクセスに時間がかかります。Point : データ構造
データをコンピュータのメモリにいれる時に、データの順番や位置関係などを定めたものです。1-0.Pythonとリスト
Pythonでは、配列よりもリストを使うことが多いです。
リストの要素は、任意のPythonオブジェクトで良いです。
そして、要素の型は統一しなくて良いです。Point : 配列
データ構造の1つで、データを一列に並べるものです。
データへのアクセスは簡単に行える反面、追加や削除には手間がかかります。2.リストの使いかた
2-0.リストの作成
◯
リストの名前 = []という形でリストをつくります。#要素がない空のリストをつくる color_list = []もちろん最初から要素を入れてつくることもできます。
その場合は、下のようにカンマで区切って要素を入れます。#リストに要素をいれる color_list = ['Red','Yellow','Green']2-1.他のデータ型からリストをつくる
list()関数を使ったリストの作成
◯list()関数を使えば、他のオブジェクトをリストにすることができます。
#文字列をリストに変換する list('book')#文字列をリスト化した場合、文字の1つ1つがリストの要素となる ['b','o','o','k']split()関数を使ったリストの作成
◯split()関数を使えば、何らかのセパレータ文字列に基づいて、文字列を分割してリストにすることができます。
#オブジェクト birthday に中身をいれる birthday = '29/9/1993' #どこで分割したいかを決めて(今回はスラッシュ = /)分割する birthday.split('/')['9','29','1993']2-2.要素の取得
[offset]を使った要素の取得
◯[offset]を使ってリストから要素を取り出すことができます。
一番左の要素のオフセットは、0であることに注意してください。#文字列を要素に持つリストをつくる color_list = ['Red','Yellow','Green'] #オフセットで指定したリストの要素を取得する print(color_list[0]) print(color_list[2]) print(color_list[-1])'Red' 'Green' 'Green'リストの要素数が多い場合などは、リストの後ろから、-1,-2...という風にインデックスを使って、要素を指定することができます。
今回の場合では、文字列
'Green'をオフセットを使って、左から指定する場合は、color_list[2]となり、リストの最後から負のインデックスを使って、指定する場合は、color_list[-1]となります。enumerate()関数を使った要素とインデックスの取得
◯enumerate()関数を使うと、効率的に要素とインデックスを取得することができます。
enumerate0.py#オブジェクト(変数)sに文字列を代入する s = 'TOKYO' #forループを使って、効率的に要素(item)とそのインデックス(offset)を取得する for (offset,item) in enumerate(s): print(item,' のインデックスは ',offset)T のインデックスは 0 O のインデックスは 1 K のインデックスは 2 Y のインデックスは 3 O のインデックスは 4enumerate1.py#色の要素のリストをつくる color_list = ['Red','Yellow','Green','Blue','White'] #リストから要素(文字列)とそのインデックスを取得する for i,color in enumerate(color_list): print(color,' は ',i,' 番目です')Red は 0 番目です Yellow は 1 番目です Green は 2 番目です Blue は 3 番目です White は 4 番目ですスライスを使った複数の要素の取得
◯スライスを使って複数の要素を取り出すことができます。
リストをスライスしたものもリストになります。
[start:end]で要素を取得する場合は、オフセットでstartからend-1までの要素を取得します。("2-3.要素の更新"にスライスの詳しい説明があります。)alphabet = ['A','B','C','D','E']slice0.py#オフセットで、0から2(3-1)の要素を取得することができます。 alphabet[0:3]['A', 'B', 'C']ステップを使った複数の要素の取得
slice1.py#リストの先頭から2つ分のステップ(一つおきに)で要素を取得する alphabet[::2]['A', 'C', 'E']◯マイナスを使うと末尾から要素を取得することができます
slice2.py#リストの末尾から2つ分のステップ(一つおきに)で要素を取得する alphabet[::-2]['E', 'C', 'A']◯ステップを応用するとリストの要素を逆順にすることができます↓
slice3.py#リストの要素を末尾から順に取得する alphabet[::-1]['E','D','C','B','A']2-3.要素の更新
[オフセット]を使った要素の書き換え
#アジアの国名のリストをつくる asian_countries = ['China','India','Japan'] #リストの左から2番目の要素に'Russia'を代入する asian_countries[1] = 'Russia' print(asian_countries)スライスを使った要素の更新
◯スライスを使えば、指定した範囲にある要素を取得して、それを置き換えることができます。
[:]先頭から末尾までの要素を取得する
[start:]startオフセットから末尾までの要素を取得する
[:end]先頭からend-1オフセットまでの要素を取得する
[start:end]startオフセットからend-1オフセットまでの要素を取得する
[start:end:step]startオフセットから、stepごとに、end-1オフセットまでの要素を取得する。[:]を使った要素の更新
◯リストを丸々更新します。
numbers = [1,2,3,4,5,6,7,8,9] #先頭から末尾まで全ての要素を取得して、置き換えます。 numbers[:] = ['one','two','three','etc'] print(numbers)['one','two','three','etc'][start:]を使った要素の更新
◯指定した場所から末尾までの要素を置き換えます。
代入のようなイメージです。numbers = ['one','two','three','etc'] #オフセット3から末尾までの要素を指定して置き換える numbers[3:] = ['four','five','six'] print(numbers)['one', 'two', 'three', 'four', 'five', 'six'][:end]を使った要素の更新
◯先頭からend-1までの要素を取得して置き換えます。
numbers = [4,5,6,7,8,9] #先頭からend-1、つまり0から-1の範囲の要素を取得して置き換えます。 #-1から0までのスペースにリスト[1,2,3]を代入するイメージです。 numbers[:0] = [1,2,3] print(numbers)[1,2,3,4,5,6,7,8,9][start:end]を使った要素の更新
◯オフセットで、
start <= 要素 < endの範囲を取得して、置き換えます。numbers = [1,2,3,4,5,6,7,8,9] #オフセットで、0から2(3-1)までの範囲の要素を取得して、置き換えます。 numbers[0:3] = ['one','two','three'] print(numbers)['one', 'two', 'three', 4, 5, 6, 7, 8, 9][start : end : step] を使った要素の更新
◯startからend-1の範囲で、stepごとに要素を取得して置き換えます。
numbers = [1,2,3,4,5,6,7,8,9] #オフセット2から3つおきに要素を取得して、それをリスト['three','six','nine']と置き換えます。 numbers[2::3] = ['three','six','nine'] print(numbers)[1, 2, 'three', 4, 5, 'six', 7, 8, 'nine']2-4.要素の追加
append()関数を使った要素の追加
◯末尾に要素を追加します。
ex0.py#アジアの国名のリストをつくる asian_countries = ['China','India','Japan'] #末尾に要素を追加する asian_countries.append('Russia') print(asian_countries)['China', 'India', 'Japan','Russia']insert()関数を使った要素の追加
◯オフセットを使って、指定した場所に要素を追加します。
asian_countries = ['China','India','Japan'] #リストのオフセット2のところに文字列'Indonesia'を追加する。 asian_countries.insert(2,'Indonesia')['China', 'India', 'Indonesia', 'Japan']2-5.要素の削除
delと[オフセット]を使った要素の削除
◯del リストの名前[オフセット]という形で、指定した要素を削除します。
asian_countries = ['China','India','Indonesia','Japan'] #delはPythonの文で、代入(=)の逆のようなもの。 #delはメソッドではない del asian_countries[2] print(asian_countries)['China','India','Japan']remove()関数を使った要素の削除
◯消したい要素がどこにあるかわからない場合などに使います。
asian_countries = ['China','India','Indonesia','Japan'] #要素を指定して削除する asian_countries.remove('Indonesia') print(asian_countries)['China','India','Japan']pop()関数を使った要素の削除
◯リストから要素を取り出し、それと同時にその要素を削除することができます。
asian_countries = ['China','India','Indonesia','Japan'] #要素を指定して削除する print(asian_countries.pop(2))Indonesiaprint(asian_countries)['China','India','Japan']2-6.要素の並べ替え
sort()関数を使った並べ替え
◯その場でリストをソートします。デフォルトは昇順です。文字列の場合は、アルファベット順です。
alphabet = ['A','E','D','C','B'] #並べ替える文字列は全て同じ型である必要がある alphabet.sort() print(alphabet)['A', 'B', 'C', 'D', 'E']sorted()関数を使った並べ替え
◯リストをコピーしてそれをソートします。なのでリストのオリジナルは変更されません。
#整数と浮動小数点数は、混じっていてもソートできる numbers = [ 2 , 1.5 , 1 , 0 , 0.5 , 2.5] #新しいリストsorted_numbersをつくって #numbersリストをソートしたものを代入する sorted_numbers = sorted(numbers) print('sorted_numbers =' , sorted_numbers) print('numbers =' , numbers)sorted_numbers = [0, 0.5, 1, 1.5, 2, 2.5] numbers = [2, 1.5, 1, 0, 0.5, 2.5]2-7.リストのリスト
◯Pythonのリストは、Pythonオブジェクトを要素とすることができます。
なので、リストそのものも、他のリストの一要素として扱うことができます。#国の名前のリストをつくる asia = ['China','India','Indonesia'] americas = ['USA','Brazil','Mexico'] africa = ['Nigeria','Ethiopia','Egypt'] #リストを含むリストをつくる countries = [asia,americas,africa,'Japan']ex0.py#リストを含むリストを表示する print(countries)[['China', 'India', 'Indonesia'], ['USA', 'Brazil', 'Mexico'], ['Nigeria', 'Ethiopia', 'Egypt'], 'Japan']ex1.py#オフセットでリストの中の要素を指定する print(countries[0])['China', 'India', 'Indonesia']◯countriesリストの中のオフセット1の要素(americasリスト)中の、オフセット2の要素を取得します
ex2.py#2段階で要素を指定する print(countries[1][2])Mexico2-8.リストの結合
extend()関数を使ったリストの結合
◯extend()関数を使って、2つのリストを結合します。
リストの中の要素が全て1つのリストの中に入ります。list1 = ['a','b','c'] list2 = ['d','e','f'] #2つのリストを結合して新しいリストにする list1.extend(list2) print(list1)['a', 'b', 'c', 'd', 'e', 'f']+=を使ったリストの結合
◯+=を使って、2つのリストを結合します。
list_a = [1,2,3] list_b = [4,5,6] #2つのリストを結合して新しいリストにする list_a.extend(list_b) print(list_a)[1,2,3,4,5,6]※同じ状況で、append()を使ったら、リストが一つの要素として、他のリストに追加されます。
list_a = [1,2,3] list_b = [4,5,6] #リストが一要素として他のリストに追加される list_a.append(list_b) print(list_a)[1,2,3,[4,5,6]]2-9.その他の操作
index()関数を使ったオフセットの取得
◯要素のオフセットを知りたい場合に使います。
asian_countries = ['China','India','Indonesia','Japan'] #文字列'Japan'のオフセットを取得する print(asian_countries.index('Japan'))3inを使った値の有無のテスト
asian_countries = ['China','India','Indonesia','Japan'] #ある値がリストの中にあるかどうかを知る print('Japan' in asian_countries) print('Russia' in asian_countries)True Falsecount()関数を使った、値の個数の計算
#文字列をリスト化したものを変数charactersに代入する characters = list('personal_computer') print(characters) ['p', 'e', 'r', 's', 'o', 'n', 'a', 'l', '_', 'c', 'o', 'm', 'p', 'u', 't', 'e', 'r'] #charactersというリストの中に 'o' がいくつ含まれているかを調べる print(characters.count('o'))2len()関数を使った長さの取得
#リストcharactersの要素の数を調べる print(len(characters))17最後に
読んでいただきありがとうございました。
次はリストについてもう少し詳しく書いていきたいと思います。
間違いや改善点などございましたら、ご指摘の程よろしくお願い致します。
- 投稿日:2020-08-09T10:46:35+09:00
Python「SyntaxError: Non-ASCII character〜」が出てしまった時
# -*- coding: utf-8 -*-を確認
Python3 で UTF-8 なら、coding指定不要との事です。
参考: https://pep8-ja.readthedocs.io/ja/latest/ASCII (Python 2) や UTF-8 (Python 3) を使用しているファイルにはエンコーディング宣言を入れるべきではありません。
- 投稿日:2020-08-09T10:09:26+09:00
ベイズ推論の考え方・・事前確率と事後確率
Pythonで体験するベイズ推論
ベイズ推論の考え方・・例題:司書か農家か
夏休みなので、「Pythonで体験するベイズ推論」を少しずつ勉強しています。簡単に勉強したことを
Pythonとともに書いていこうと思います。問題
スティーブは親切だが内向的である。他人にはほとんど関心がなく順番通りにやることが好き。スティーブは図書館司書になるか?農家になるか?男性の農業家と男性の司書の比率は20:1(これを事前確率という)
スティーブが司書である・・A
スティーブが農家である・・Bスティーブが司書である事前確率 $?(?)$ は、
\displaystyle?(?)=1/21=0.047になる。
スティーブの性格についての情報(性格が内向的)が入ったことを$X$とする。
ここで考えるのは、$P(A | X )$である。これは、$X$という情報がはいった条件の元でのスティーブが司書である事後確率である。
ベイズの定理の式から考えます。
ベイズの定理の式P( A | X ) = \displaystyle \frac{ P(X | A) P(A) } {P(X) }近所の住人がスティーブの性格を内向的であると語る確率$?(B)$を0.95とする。
次に$?(X)$を考える。これは、誰かが近所の住人に内向的であると言われる確率である。これは分解して考える。\begin{align} P(X ) &= P(X \text{ and } A) + P(X \text{ and } \sim A)\\ &= P(X|A)P(A) + P(X | \sim A)P(\sim A)\\ &= P(X|A)p + P(X | \sim A)(1-p)\\ \\ &*P(\sim A)=P(notA) \end{align}1行目はこういう意味である。
スティーブが内向的$P(X)$で司書$P(A)$である確率と内向的$P(X)$で司書でない$P(\sim A)$(農家である)確率を足したもの。つまりスティーブの職業が何であれ(今回は司書か農家か)内向的な確率の総和である。ここまでで、わかっているのは、$P(X| A)=0.95$と$P(A)=0.047$である。また、$P(\sim A)$は、$P(\sim A)=1-P(A)=20/21$である。
後、わかっていないのは、$P(X | \sim A)$である。これは彼が農家である場合に近所の人が内向的と語る確率である。ここは設定するしかないようで、一応$0.5$とする。これで、$P(X)$がわかる。\begin{align} P(X ) &= P(X \text{ and } A) + P(X \text{ and } \sim A)\\ &= 0.95*1/21+0.5*20/21\\ &= 0.52 \end{align}これで、$P(X)$がわかったので、ここから、ベイズの定理で、$P(A | X )$がわかる
\begin{align} P( A | X ) &= \displaystyle \frac{ P(X | A) P(A) } {P(X) }\\ &= \displaystyle \frac{0.95*1/21}{0.52}\\ &= 0.087 \end{align}つまり、スティーブの性格の情報がない場合のスティーブが司書である確率$?(?)=0.047$であったのが、スティーブの性格が内向的としった後にスティーブが司書であると考える確率は$?(A | X )=0.087$と倍増しているのである。
これら事前確率と事後確率の関係とかは、基本となるのでしっかり覚えておきたいと思う。
ここで、
Pythonのスクリプトです。
jupyter notebook形式でgithubリポジトリにあります。
https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackersでも、よく見たら、この最初の例題の
Pythonスクリプトは、グラフを書くだけのスクリプトでした。。# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt colours = ["#348ABD", "#A60628"] prior = [0.20, 0.80] posterior = [1./3, 2./3] plt.bar([0, .7], prior, alpha=0.70, width=0.25, color=colours[0], label="prior distribution", lw="3", edgecolor=colours[0]) plt.bar([0+0.25, .7+0.25], posterior, alpha=0.7, width=0.25, color=colours[1], label="posterior distribution", lw="3", edgecolor=colours[1]) plt.xticks([0.20, .95], ["Bugs Absent", "Bugs Present"]) plt.title("Prior and Posterior probability of bugs present") plt.ylabel("Probability") plt.legend(loc="upper left") plt.show()

- 投稿日:2020-08-09T09:16:22+09:00
Pythonの定数、Noneとか(リファレンスによると)
はじめに
pythonの定数について調べた。
しっくりは、きていませんが。pythonの定数
python, 定数
とかでぐぐると、リファレンスの以下の項にたどり着く。
https://docs.python.org/ja/3/library/constants.html以下、引用。
組み込み定数
組み込み名前空間にはいくつかの定数があります。定数の一覧:念のため、
https://docs.python.org/3/library/constants.html
も引用しておくBuilt-in Constants
A small number of constants live in the built-in namespace. They are:ここでは、以下の6つが示されている。
False
True
None
NotImplemented
Ellipsis
__debug__値をみてみる
>>> False False >>> >>> True True >>> >>> None >>> >>> NotImplemented NotImplemented >>> >>> Ellipsis Ellipsis >>> >>> __debug__ True >>>値を代入してみる
>>> >>> False = 3 File "<stdin>", line 1 SyntaxError: can't assign to keyword >>> >>> True = 3 File "<stdin>", line 1 SyntaxError: can't assign to keyword >>> >>> None = 3 File "<stdin>", line 1 SyntaxError: can't assign to keyword >>> >>> NotImplemented = 3 >>> >>> Ellipsis = 3 >>> >>> __debug__ = 3 File "<stdin>", line 1 SyntaxError: assignment to keyword >>> >>>⇒ ↓↓↓NotImplementedとEllipsisは、値が代入できてしまう。(定数なのに。。)ちょっと、意味の違う定数なんでしょう。
>>> NotImplemented 3 >>> >>> Ellipsis 3 >>> >>> type(NotImplemented) <class 'int'> >>> type(Ellipsis) <class 'int'> >>>↑↑↑ 本気で、代入されていますね。。。intになっていますね。。。
補足
コメント頂いたので補足。
False
True
None
は、キーワードでしょう、とのこと。以下の
https://docs.python.org/ja/3/reference/lexical_analysis.html#identifiers
を引用すると、2.3.1. キーワード (keyword)¶
以下の識別子は、予約語、または Python 言語における キーワード (keyword) として使われ、通常の識別子として使うことはできません。キーワードは厳密に下記の通りに綴らなければなりません:False await else import pass
None break except in raise
True class finally is return
and continue for lambda try
as def from nonlocal while
assert del global not with
async elif if or yieldまた、
コメントで示して頂いた
http://python-history.blogspot.com/2013/11/story-of-none-true-false.html
https://www.python.org/dev/peps/pep-0285/
も参考になります。まとめ
あまりしっくりは、きませんでした。
コメントなどあればお願いします。どちらかというと、『リファレンスで残念な気分になったあるある』という感じの記事にいまのところなっています。。。
- 投稿日:2020-08-09T09:09:03+09:00
Flask GETのクエリパラメーターを取得する
Flask https://flask.palletsprojects.com/en/1.1.x/
でGETのパラメータを取得した時のメモ@app.route('/search') def analyzer(): query = "" if request.args.get('q') is not None: query = request.args.get('q') else: query = "パラメーターがないよ" return queryhttp://localhost/search?q=クエリだよ
で試す
- 投稿日:2020-08-09T04:09:34+09:00
Python de 3DCAD
仕事柄3DCADを使うことも数値計算(主にPythonを使って)を行う機会が多く、数値計算をもとに3D用のデータ(STEP, IGES, STL)を生成したい(しないといけない)という要求が増えていった中での解決策です。
結論
結論としてはOpenCASCADEを使います。
C++と死の秘宝OpenCascade Technologyで有名な、OpenCASCADEですが、オリジナルはC++で100万行で構成されたライブラリのため、使おうとするととっても大変です。
そこで、OpenCASCADEをほぼすべてPythonにWrapした偉大なコードpythonocc-coreを使います。Install方法
# Python 3.8 conda install -c conda-forge pythonocc-core # Python 3.7 or 3.6 conda install -c dlr-sc pythonocc-core追加で入れておくと良いコード群です。
- https://github.com/tpaviot/pythonocc-core
- https://github.com/tpaviot/pythonocc-demos
- https://github.com/tpaviot/pythonocc-utils
使い方
ごく簡単な使用例です。
from OCC.Display.SimpleGui import init_display from OCC.Core.gp import gp_Pnt, gp_Vec, gp_Dir from OCC.Core.gp import gp_Ax1, gp_Ax2, gp_Ax3 from OCC.Core.BRepBuilderAPI import BRepBuilderAPI_MakeEdge from OCC.Extend.DataExchange import write_step_file, read_step_file display, start_display, add_menu, add_function = init_display() display.DisplayShape(gp_Pnt()) p1 = gp_Pnt(0, 0, 0) p2 = gp_Pnt(0, 0, 10) edge = BRepBuilderAPI_MakeEdge(p1, p2) result = edge.Edge() write_step_file(result, "pythonocc-core.stp") display.DisplayShape(result) display.FitAll() display.View.Dump("pythonocc-core.png") start_display()実行すると3D ViewerとそのViewerの写真とpythonocc-core.stpというSTEP fileが出てきます。
使い方はこれからです。あとは、3D Viewerをぐりぐり動かすもよし、STEP以外のファイル(IGES, STL, BRep)を吐き出すもよし、好きな形状を作るもよしです。
サンプルはdemoにたくさんあります。
利点
3D Viewerとしてもそこそこ優秀(STEP, IGES, STLが表示できる)ということもありますが、なによりお仕事上有用な点はSTEPの吐き出しができる点です。これがあることで商用CADとの互換性がぐんとあがります。
ほかにも、Vector演算や座標系の変換、SpilneやBooleanが使えたりといわゆるCADとして最低限必要な演算機能が実装されているため、CADというより基本的な幾何演算ライブラリとして優秀という側面があります。
もちろん、変換の演算程度であれば、ちまちまコードを書いていけば実装は難しくないのですが、ほぼすべての幾何演算が実装済みというのは非常にありがたいです。
余談
使い始めて数年経ちますが、正直3D Viewerについてはどうやって動いているのかわかりません。
OpenCASCADEの描画機能をQt(PyQt)に埋め込んでいるんだろうな~程度の理解です。普段はWindowsを主に使っていますが、WindowsのNative環境でQtで3Dがconda installを実行するだけで動いたときは、かなり衝撃的でした。(そして、描画まで含めてC++でやるのは私の技量では無理だなとも悟りました)
