- 投稿日:2020-04-26T23:21:06+09:00
vtkThresholdのまとめ(随時更新)
vtkThresholdとは
指定した範囲内の値を含む要素のみ抽出するフィルターです
classリファレンス
https://vtk.org/doc/nightly/html/classvtkThreshold.html具体的には、次のparaviewでの例がわかりやすいです
paraviewで機能の確認
計算例は
OpenFOAMのtutorialのpitzDailyを用いましたThreshold適用前
計算結果を読みこんた後、このボタンを押します
Threshold適用後
圧力pに対して5から15の範囲を指定し適用した結果
TInvertオプション適用後
補集合をとります
pythonでの動作確認
環境
python 3.7
vtk 8.1.2確認方法import Vtk print(vtk.vtkVersion.GetVTKSourceVersion()) >> vtk version 8.1.2ベースとなるコード
OpenFOAMの結果を読みこむために
vtkOpenFOAMReaderを用いてます
vtkOpenFOAMReaderについてはこちらでもまとめていきますimport vtk # OpenFOAMの結果を読み込み filename = "case1.foam" reader = vtk.vtkOpenFOAMReader() reader.SetFileName(filename) reader.CreateCellToPointOn() reader.DecomposePolyhedraOn() reader.EnableAllCellArrays() reader.Update() # latestTimeの結果を適用 n_step = reader.GetTimeValues().GetNumberOfValues() latest_time = reader.GetTimeValues().GetValue(n_step-1) reader.UpdateTimeStep(latest_time) reader.Update() filter_threshold = vtk.vtkThreshold() filter_threshold.SetInputConnection(reader.GetOutputPort()) ################### # ここに設定を加える # ################### filter_threshold.Update() filter = vtk.vtkGeometryFilter() filter.SetInputConnection(filter_threshold.GetOutputPort()) filter.Update() mapper = vtk.vtkCompositePolyDataMapper2() mapper.SetInputConnection(filter.GetOutputPort()) #mapperにfilterを設定 mapper.SetScalarModeToUseCellFieldData() #scalarデータ用に設定 # renderer renderer = vtk.vtkRenderer() renderer.AddActor(actor) #rendererにactorを設定 ##背景色の設定 renderer.GradientBackgroundOn() #グラデーション背景を設定 renderer.SetBackground2(0.2,0.4,0.6) #上面の色 renderer.SetBackground(1,1,1) #下面の色 #Window renWin = vtk.vtkRenderWindow() renWin.AddRenderer(renderer) #Windowにrendererを設定 iren = vtk.vtkRenderWindowInteractor(); iren.SetRenderWindow(renWin); renWin.SetSize(850, 850) renWin.Render() iren.Start();基本
ThresholdBetween()
上下限値指定による制限
# 閾値を5から15の間に設定 filter_threshold.ThresholdBetween(5,15) #enum FieldAssociations # { # FIELD_ASSOCIATION_POINTS, # FIELD_ASSOCIATION_CELLS, # FIELD_ASSOCIATION_NONE, # FIELD_ASSOCIATION_POINTS_THEN_CELLS, # FIELD_ASSOCIATION_VERTICES, # FIELD_ASSOCIATION_EDGES, # FIELD_ASSOCIATION_ROWS, # NUMBER_OF_ASSOCIATIONS # }; FIELD_ASSOCIATION_POINTS = 0 FIELD_ASSOCIATION_CELLS = 1 # "p"で圧力に対してフィルターをかけている filter_threshold.SetInputArrayToProcess(0,0,0,FIELD_ASSOCIATION_CELLS ,"p") filter_threshold.Update()前掲のparaviewでの結果と一致しました
もしメソッドの使い方がわからない場合は、help関数を使うと解決するかもしれません
help(filter_threshold.SetInputArrayToProcess) >> Help on built-in function SetInputArrayToProcess: SetInputArrayToProcess(...) method of vtkFiltersCorePython.vtkThreshold instance V.SetInputArrayToProcess(int, int, int, int, string) C++: virtual void SetInputArrayToProcess(int idx, int port, int connection, int fieldAssociation, const char *name) V.SetInputArrayToProcess(int, int, int, int, int) C++: virtual void SetInputArrayToProcess(int idx, int port, int connection, int fieldAssociation, int fieldAttributeType) V.SetInputArrayToProcess(int, vtkInformation) C++: virtual void SetInputArrayToProcess(int idx, vtkInformation *info) V.SetInputArrayToProcess(int, int, int, string, string) C++: virtual void SetInputArrayToProcess(int idx, int port, int connection, const char *fieldAssociation, const char *attributeTypeorName) Set the input data arrays that this algorithm will process. Specifically the idx array that this algorithm will process (starting from 0) is the array on port, connection with the specified association and name or attribute type (such as SCALARS). The fieldAssociation refers to which field in the data object the array is stored. See vtkDataObject::FieldAssociations for detail.ThresholdByUpper()
上限値指定による制限
指定した値より大きい領域のみ表示されます#filter_threshold.ThresholdBetween(5,15) filter_threshold.ThresholdByUpper(10)対象となる領域が存在しないため、何も表示されていません
ThresholdByLower()
下限値指定による制限
指定した値より小さい領域のみ表示されます#filter_threshold.ThresholdBetween(5,15) filter_threshold.ThresholdByLower(5)結果的に、前掲のparaviewでのInvertの結果と一致しました
Invert関係
どうやらInvert関係はc++では実装済みですが、python版には実装されていないようです
filter_threshold.SetInvert(True) AttributeError ---> 31 filter_threshold.SetInvert(True) AttributeError: 'vtkFiltersCorePython.vtkThreshold' object has no attribute 'SetInvert'その他メソッド
GetUpperThreshold
閾値の上限値を取得
filter_threshold.ThresholdBetween(-100,100) filter_threshold.GetUpperThreshold() >> 100GetLowerThreshold
閾値の下限値を取得
filter_threshold.ThresholdBetween(-100,100) filter_threshold.GetLowerThreshold() >> -100Set/GetAttributeMode
filter_threshold.SetAttributeModeToDefault() filter_threshold.GetAttributeMode() >>0 filter_threshold.SetAttributeModeToUsePointData() filter_threshold.GetAttributeMode() >>1 filter_threshold.GetAttributeModeAsString() >>'UsePointData' filter_threshold.SetAttributeModeToUseCellData() filter_threshold.GetAttributeMode() >>2 filter_threshold.GetAttributeModeAsString() >>'UseCellData' filter_threshold.SetAttributeMode(2) filter_threshold.GetAttributeModeAsString() >>'UseCellData'気が向いた時に更新していきます







- 投稿日:2020-04-26T23:04:44+09:00
やり忘れのBacklog課題を定期的にSlackに通知してみる
きっかけ
いつも見るのはSlack。メールもBacklogもあまり見ない。
そしてBacklogで振られている課題を忘れてしまう。。
よし、毎朝Slackに対応していないBacklog課題を連絡するようにしよう。
Google Apps ScriptからBacklogのAPIで該当の課題一覧を引っ張ってきて、それをSlackに投げればいいかな。BacklogのAPIで課題情報を取得
Backlogの課題一覧取得方法は公式の課題一覧の取得ページに載っているので参考にGASで取得してみます。
BacklogのAPIキー
おっと、その前にBacklogのAPIキーを取得していきます。
Backlogページの右上にある自分のアイコンをクリックしたメニューの中の 個人設定 をクリックし、左のメニューの API から取得しておきます。
APIキーを取得したらGASから早速APIを叩いて課題一覧を取得してみましょう。function myFunction() { const baseUrl = 'https://xxxxx.backlog.jp'; // 利用しているBacklogのドメイン const apiKey = 'xxxxxxxxxxxxxxxxxxxxxxx'; // Backlogから取得したAPIキー const endpoint = '/api/v2/issues'; // 公式の課題一覧の取得に記載されているURL const url = baseUrl + endpoint + '?apiKey=' + apiKey; // 問い合わせるURLにする const response = UrlFetchApp.fetch(url); // fetchメソッドでHTTPリクエストを送る const json = JSON.parse(response.getContentText()); // テキストデータを取り出す Logger.log(json); // ログに出力 }色々ログに出力されました。
これだと各課題のログの量が多すぎて見にくいので一旦各課題の課題のIDだけ表示させることにします。function myFunction() { const baseUrl = 'https://xxxxx.backlog.jp'; // 利用しているBacklogのドメイン const apiKey = 'xxxxxxxxxxxxxxxxxxxxxxx'; // Backlogから取得したAPIキー const endpoint = '/api/v2/issues'; // 公式の課題一覧の取得に記載されているURL const url = baseUrl + endpoint + '?apiKey=' + apiKey; // 問い合わせるURLにする const response = UrlFetchApp.fetch(url); // fetchメソッドでHTTPリクエストを送る const json = JSON.parse(response.getContentText()); // テキストデータを取り出す for (let i in json) { // 課題の数だけループを回して Logger.log(json[i]['issueKey']); // ログに課題のIDを出力 } }余計なログがなくなり見やすくはなりましたが、Backlog全体を対象にして取得しているので余計な課題が混ざってしまっています。
そのため以下の条件でフィルターをかけ必要な課題だけ取得します。
* 指定の担当者
* 指定の種別
* 指定のステータス担当者のユーザーIDを探す
担当者を絞り込むには担当者のユーザーIDが必要なようですが、どうもGASで担当者のユーザーIDを出力するのがうまくいかず...
仕方ないので BacklogでAPIを使ってユーザーのID(数値)を調べる方法 を参考にしてPythonからBacklogのAPIを叩いてユーザーIDを取得します。
この方法では課題を指定してその課題の担当者のユーザーIDを取得するので、課題を指定するために課題IDを取得します。
と言ってもこれは簡単で、課題を開いた時にURLの最後(xxxx-xx)になります。
具体的には課題URLの末尾の太字の部分になります。(後ろのxxは数字)
xxxxx.backlog.jp/view/xxxx-xx
課題IDが分かったらPythonで担当者のユーザーIDを取得します。import requests baseUrl = 'https://xxxxx.backlog.jp'; # 利用しているBacklogのドメイン apiKey = 'xxxxxxxxxxxxxxxxxxxxxxx'; # Backlogから取得したAPIキー ticket_id = 'xxxx-xx' # 課題のID url = base_url + ticket_id # 問い合わせるURLにする json = requests.get(url, {'apiKey': apiKey}).json() # テキストデータを取り出す print(json['assignee']['id']) # 取得結果の担当者のユーザーIDを出力担当者で絞り込む
担当者のユーザーIDが分かったのでGASで担当者で絞り込みます。
下記の通り、問い合わせるURLのパラメータに&assigneeId[]=担当者のユーザーIDを追加します。function myFunction() { const baseUrl = 'https://xxxxx.backlog.jp'; const apiKey = 'xxxxxxxxxxxxxxxxxxxxxxx'; const endpoint = '/api/v2/issues'; const url = baseUrl + endpoint + '?apiKey=' + apiKey + '&assigneeId[]=' + xxxxxxx; // 問い合わせるURLにする // (以下略。上と同じ。) }課題の種別で絞り込む
次は種別(タスク、バグ、要望..)で絞り込みます。
種別はissueTypeIdで絞り込みます。
issueTypeIdの確認も簡単で、Backlogの左メニューの プロジェクト設定 の 種別 タブの確認したい種別をクリックします。
クリックして表示された種別の編集ページのURLの issueType.id がそれになります。
issueTypeIdが分かったのでGASで絞り込みます。
これは問い合わせるURLのパラメータにissueTypeId[]=issueType.idを追加します。function myFunction() { const baseUrl = 'https://xxxxx.backlog.jp'; const apiKey = 'xxxxxxxxxxxxxxxxxxxxxxx'; const endpoint = '/api/v2/issues'; const url = baseUrl + endpoint + '?apiKey=' + apiKey + '&assigneeId[]=' + xxxxxxx + '&issueTypeId[]=' + xxxxxxx; // 問い合わせるURLにする // (以下略。上と同じ。) }課題のステータスで絞り込む
最後は課題のステータス(未対応、処理中、処理済み、完了)で絞り込みます。
ステータスはstatusIdで絞り込みます。
statusIdはAPIを使って調べられるのですが、多分以下で固定だと思います。
* 未対応: 1
* 処理中: 2
* 処理済み: 3
* 完了: 4
これは問い合わせるURLのパラメータにstatusId[]=xを追加します。function myFunction() { const baseUrl = 'https://xxxxx.backlog.jp'; const apiKey = 'xxxxxxxxxxxxxxxxxxxxxxx'; const endpoint = '/api/v2/issues'; const url = baseUrl + endpoint + '?apiKey=' + apiKey + '&assigneeId[]=' + xxxxxxx + '&issueTypeId[]=' + xxxxxxx + '&statusId[]=' + 1; // 問い合わせるURLにする // (以下略。上と同じ。) }Slackに送信する
BacklogのAPIで必要な情報を取得できるようになったので、Slackに送信できるようにします。
SlackのIncoming Webhooksの設定
まずSlack送信に必要なWebhooksの設定を行います。
以前はSlackのカスタムインテグレーションでIncoming Webhookを作っていましたが、今はSlackアプリを作ってその中の機能としてIncoming Webhookを設定するらしいのでその方法で行います。
(参考:Slack カスタムインテグレーションが非推奨へ や slackのIncoming webhookが新しくなっていたのでまとめてみた)
具体的には
1. https://api.slack.com/apps にアクセス
2. Create New App ボタンをクリック
3. 作成するSlackアプリの情報を入力して Create App ボタンをクリック
- App Name : 作成するSlackアプリ名
- Development Slack Workspace : 作成するSlackアプリの設置先スペース(プルダウンメニューから選択)
4. 左のメニューから Incoming Webhooks をクリック
5. Activate Incoming Webhooks をONにする
6. Add New Webhook to Workspace ボタンをクリック
7. Slackを送信したいチャンネルかDMを選択し、許可する ボタンをクリック
8. 該当のSlackチャンネルかDMに以下のメッセージが表示されるadded an integration to this channel: 設定したアプリ名
Incoming Webhooksの設定が終わったらWebhookのURLをコピーしておきます。
このURLをGASで設定してSlack送信先にします。
なお、Incoming WebhooksでSlack通知される時のSlackアプリの表示名や画像は、左のメニューの Basic Information の Display Information で設定可能です。
Slackアプリを削除する時はBasic Information の Delete App から。GASコード
取得したWebhook URLを postUrl に貼り、以下のように書きます。
function sendSlack() { const postUrl = '取得したWebhook URL'; const json = { 'text': 'Slackに送りたいメッセージ' }; const payload = JSON.stringify(json); const options = { 'method': 'post', 'contentType': 'application/json', 'payload': payload }; UrlFetchApp.fetch(postUrl, options); }お約束なので説明は省略します。
スプレッドシートから設定変更
スプレッドシートのGASを使っていて、せっかくなのでスプレッドシート自体も使ってみました。
スプレッドシートで以下のように設定できるようにしました。
スプレッドシート上でチェックを入れたもので絞り込むことにします。// スプレッドシートから設定を取得 function getConfig() { const sheet = SpreadsheetApp.getActiveSheet(); const range = sheet.getRange(1, 1, 5, 2); const values = range.getValues(); // ステータス設定を取得 let statusId = ''; for (let i in [...Array(4).keys()]) { let row = Number(i) + 1; if (true == values[row][0]) { statusId += '&statusId[]=' + row; } } return statusId; }完成
全部合わせるとこんな感じです。
const baseUrl = 'https://xxxxx.backlog.jp'; const apiKey = 'xxxxxxxxxxxxxxxxxxxxxxx'; function myFunction() { const statusId = getConfig(); issues(statusId) } // 課題一覧の取得 function issues(statusId) { // Backlogから課題一覧を取得 const endpoint = '/api/v2/issues'; const url = baseUrl + endpoint + '?apiKey=' + apiKey + statusId + '&issueTypeId[]=' + xxxxxx + '&assigneeId[]=' + xxxxxx; const resp = UrlFetchApp.fetch(url); const json = JSON.parse(resp.getContentText()); // Backlogから取得した課題一覧から必要な情報(課題ID、課題の件名、課題のURL)を取り出す let message = ''; for (let i in json) { const issueKey = json[i]['issueKey']; // 課題のID const summary = json[i]['summary']; // 課題の件名 message += issueKey + ' ' + summary + '\n' + baseUrl + '/view/' + issueKey; // 課題が複数の場合、ループ毎に改行を入れる if (json[i] != json[json.length - 1]) { message += '\n'; } } // Slackで送信したい内容(message)を渡す sendSlack(message); } // Slackに送信 function sendSlack(message) { // テスト用Webhook URL const postUrl = '取得したWebhook URL'; const json = { 'text': message }; const payload = JSON.stringify(json); const options = { 'method': 'post', 'contentType': 'application/json', 'payload': payload }; UrlFetchApp.fetch(postUrl, options); } // スプレッドシートから設定を取得 function getConfig() { const sheet = SpreadsheetApp.getActiveSheet(); const range = sheet.getRange(1, 1, 5, 2); const values = range.getValues(); // ステータス設定を取得 let statusId = ''; for (let i in [...Array(4).keys()]) { let row = Number(i) + 1; if (true == values[row][0]) { statusId += '&statusId[]=' + row; } } return statusId; }これをトリガーで毎朝9時起動とかにしておくと、毎朝Slackに以下のような通知が来るようになります。
We're hiring!
AIチャットボットを開発しています。
ご興味ある方は Wantedlyページ からお気軽にご連絡ください!参考記事
課題一覧の取得(公式)
課題情報の取得(公式)
Slack カスタムインテグレーションが非推奨へ
slackのIncoming webhookが新しくなっていたのでまとめてみた
BacklogでAPIを使ってユーザーのID(数値)を調べる方法
Pythonを使ってBacklog APIで課題を追加する


- 投稿日:2020-04-26T22:58:46+09:00
AtCoder Beginner Contest 164 参戦記
AtCoder Beginner Contest 164 参戦記
ABC164A - Sheep and Wolves
2分半で突破. 書くだけだったけど、コードテストが詰まってて、慌ててローカルでテストしたりして時間がかかった.
S, W = map(int, input().split()) if W >= S: print('unsafe') else: print('safe')ABC164B - Battle
2分半で突破. B問題なので、素直にシミュレートしても TLE しないので書くだけですね.
A, B, C, D = map(int, input().split()) while True: C -= B if C <= 0: break A -= D if A <= 0: break if A > 0: print('Yes') else: print('No')ABC164C - gacha
2分半で突破. set で distinct して個数を数えるだけ. C問題にしたって簡単すぎませんかね.
N = int(input()) print(len(set(input() for _ in range(N))))ABC164D - Multiple of 2019
敗退.
- 投稿日:2020-04-26T22:57:29+09:00
AtCoder(ABC)164にPythonで挑戦!A~C問題
はじめに
AtCoder ABC164にPythonで挑戦しました!
Ratedとしては2回目の挑戦です。
A〜Cまで解けました。
D問題はTLEでした。A問題
sがwより大きければsafe、その他の時はunsafeを出力すれば終わりです
A.pys, w = map(int, input().split()) if s > w: print("safe") else: print("unsafe")B問題
無限ループで、aまたはcが0以下になるまで回しましょう
高橋くんが先攻なので、両方とも負になってしまう回は、高橋くんの勝ちなので先にflg1を処理するようにコードを書きましょうB.pya, b, c, d = map(int, input().split()) flg1 = False flg2 = False while True: c -= b a -= d if c <= 0: flg1 = True if a <= 0: flg2 = True if flg1: print("Yes") exit() if flg2: print("No") exit()C問題
set()に直すことにより、重複を省くことができます。重複を除いた個数が答えです。
C.pyn = int(input()) s = [str(input()) for _ in range(n)] print(len(set(s)))D問題
二重ループになっているので計算量が大きくなりすぎましたね
このコードではTLEになります。D.pys = input() keta = len(s) ans = 0 mul = [] for i in range(100): if "0" in str(2019 * i): pass else: mul.append(str(2019 * i)) for i in range(len(mul)): for j in range(0, keta + 1 - len(str(mul[i]))): if s[j : j + len(mul[i])] == mul[i]: ans += 1 print(ans)まとめ
今回は2回目の挑戦でした
A問題はどうせ解けただろうと思っていたのですが、まさかのunsafeとsafeを反対にしてしまっていることに気づかずにB,Cと解いてしまっていたので、かなりパフォーマンスが落ちてしまいました。
次からは気をつけたいと思います
- 投稿日:2020-04-26T22:41:00+09:00
PythonでABC164のA~D問題を解きたかった
はじめに
A~Cの三完でした。
A問題
考えたこと
はいs, w = map(int,input().split()) if w >= s: print('unsafe') else: print('safe')B問題
考えたこと
互いの体力を攻撃力で割って大小を考えるだけですが、同じ値の時の処理を書き忘れて1WA。とても痛いimport math a, b, c, d = map(int,input().split()) x = math.ceil(a/d) y = math.ceil(c/b) if x == y: print('Yes') elif x > y: print('Yes') else: print('No')C問題
考えたこと
setにいれてlenするだけ。簡単。なんでこっちがCなんだ。n = int(input()) s = [input() for _ in range(n)] s = set(s) print(len(s))D問題
わかりません
まとめ
CとDの間に大きい壁があったので、Bの1WAが響いた。くやしい。ではまた、おやすみなさい。
- 投稿日:2020-04-26T21:52:15+09:00
藤井聡太七段のタイトル獲得数を勾配ブースティングで予測
概要
史上最年少でプロデビューし、デビューから前人未到の29連勝を達成して世間に'藤井フィーバー'を巻き起こした天才棋士、藤井聡太七段がプロになって早くも3年が過ぎました。タイトルを獲るのも時間の問題と思われていましたが、昨年はタイトル挑戦まであと1勝と迫るも惜敗し、2020年4月現在まだタイトル挑戦は決めていません。一方で将棋界ではここ数年で大きな変動がありました。30年近くタイトルを保持し続けた羽生善治九段をはじめとした'羽生世代'が若手に押され始め、さらにAIを用いた将棋ソフトの進展によって将棋界は群雄割拠となり、誰がタイトルを獲ってもおかしくない状況になりました。藤井七段をもってしても常に勝つことは難しく、タイトルの厳しさを感じます。
そこで、ここ3年間でのタイトル戦登場棋士の成績から、藤井七段のタイトル獲得数を予測し、どれくらいタイトルに近いのか評価してみました。1
コードはGitHubに挙げています。データセット
学習用データとして、日本将棋連盟のHPから、2020年4月1日時点でのB級1組以上の棋士、2017年~2019年のタイトル戦に登場した棋士、永世称号有資格者の①年齢、②プロ入り年齢、③順位戦クラス2、④竜王戦クラス3、⑤王位リーグ4在位数、⑥王将リーグ5在位数、⑦勝数、⑧対局数、⑨一般棋戦優勝数6をまとめ、タイトル戦登場数とタイトル獲得数をtsvファイルにまとめました。該当棋士は28名いました。(本来なら全棋士を対象とするべきですが、かなり手間がかかるので絞っています。)ここで、③~⑧は過去3年間で計上し、順位戦ならばA級:5点、B級1組:4点、B級2組:3点、C級1組:2点、C級2組1点で加算、竜王線も同様に1組:5点、2組:4点、3組:3点、4組:2点、5組:1点、6組:0点で加算し(最大15点)、王位/王将リーグは在籍数*1点(最大3点)を足しています。
手法
今回はKaggle界で良く使われているlightGBMの勾配ブースティングを使い、①~⑨の変数を学習変数としてタイトル獲得数またはタイトル戦登場数を予測しました。勾配ブースティングについてはこちらが参考になります。決定木を使ったアンサンブル学習で、勾配降下法を用いて前の木の誤差を改善していくという特徴があります。また、比較としてscikit-learnの線形回帰およびニューラルネットワークでも予測してみました。
実装
今回もGoogle Colaboratoryを使って実装していきます。
ライブラリインポート
ライブラリインポートimport numpy as np import pandas as pd % matplotlib inline import matplotlib.pyplot as plt !pip install japanize-matplotlib import japanize_matplotlib import seaborn as sns sns.set(font='IPAexGothic') import lightgbm as lgb from lightgbm import LGBMRegressormatplotlibはそのままでは日本語表記が使えないのでライブラリをインポートしています。(参考)
学習データ
学習データ読み込みtrain_path = "/content/drive/My Drive/Colab Notebooks/成果物/将棋タイトル/棋士解析(2017_2019) - train.tsv" train = pd.read_csv(train_path, delimiter='\t')今回データは自作なので、Google Driveに置いてマウントして読み込みにいきます。データ情報を見てみましょう。
学習データ情報train.head(len(train))
順番は日本将棋連盟での上座順(竜王→名人→その他タイトル→永世称号有資格者→段位(棋士番号順))に則っています。おおよそ若い番号ほど強いと考えて差し支えないです。タイトル獲得数を見るとここ数年では豊島竜王・名人と渡辺三冠が突出しており、次いで永瀬二冠や羽生九段が追っています。
上記でタイトル獲得者の変数をグラフ化してみます。可視化train[train['get_titles'] > 0].plot.bar(x='name', figsize=(20,20), sharex=True, subplots=True, layout=(4,3))
特に上位3人の特徴として、年齢が20代~30代、プロ入りは10代、勝数や対局数が多い(勝ちまくっている)という共通点があります。これは直感とも一致します。
テストデータ
テストデータ読み込みtest_path = "/content/drive/My Drive/Colab Notebooks/成果物/将棋タイトル/棋士解析(2017_2019) - test.tsv" test = pd.read_csv(test_path, delimiter='\t') test.head(len(test))
続いてテストデータを見ていきます。せっかくなので藤井七段に加え、個人的に将来有望だと思う若手棋士を4人持ってきました。
可視化test.plot.bar(x='name', figsize=(15,10), sharex=True, subplots=True, layout=(3,3))
佐々木大地五段もすごいですが、藤井七段の対局数と勝数からどれだけ勝ってるか良くわかりますね。
学習
train_x = train.loc[:, 'age' : 'champions'] train_y = train['get_titles'] test_x = test.loc[:, "age" : "champions"] params = { 'learning_rate' : 0.01, 'min_child_samples' : 0, } model = LGBMRegressor(**params) model.fit(train_x, train_y) y_pred = model.predict(test_x)実際に学習していきます。まず「タイトル獲得数」をターゲットとします。
paramsでLGBMRegressorに渡すハイパパラメタを設定できます。今回は学習データが少ないので学習率は小さくし、min_child_samples(最終的な予測ノードに含まれるサンプル数)は最小にします。結果
結果をプロットします。
結果表示names = test["name"] display(pd.DataFrame(y_pred, index=names, columns=['タイトル獲得数']))
藤井七段は約4期獲れるという予測になりました。これはすでにトップ棋士に匹敵する数字ですね。次いで増田六段が約3期、佐々木大地五段が1期半でした。誰をとってもタイトルを獲得できると予測されるほど活躍していることが分かりました。
なお、今回学習したモデルで重要視された変数を見ることができます。学習変数重要度features = test.loc[:, 'age' : 'champions'] display(pd.DataFrame(model.feature_importances_, index=features.columns, columns=['importance']).sort_values('importance', ascending=False))
最も重要視された変数は「年齢」でした。将棋は一般に年齢が若いほど有利であること、近年の若手棋士の活躍ぶりからこれは納得です。続いて勝利数(勝てば勝つほどタイトルに近づく)、プロ入り年齢(大棋士は総じて若くしてプロになっている)、対局数(勝てば勝つほど対局が増える)が重要なようです。上記で抜群の数字を持つ藤井七段が高く評価されるのは必然です。一方で王位リーグや王将リーグに在籍することは重要でないと判断されています。もしかすると値のオーダーが小さいからでしょうか?
タイトル戦登場数予測
タイトル戦登場数予測train_y2 = train['titles'] model.fit(train_x, train_y2) y_pred2 = model.predict(test_x) display(pd.DataFrame(y_pred2, index=names, columns=['タイトル登場数']))ターゲットを「タイトル獲得数」の代わりに、「タイトル戦登場数」にして予測もしてみました。おおよそ同じ結果になるはずですが、獲得数よりは大きな数になるはずです。
興味深いことに藤井七段と増田六段が並びました。次いで佐々木大地五段、佐々木勇気七段と青嶋五段が同じになるのは変わりませんでした。先ほどの結果と比べると、藤井七段はタイトル戦に5回登場して内4回は勝てるということでしょうか(末恐ろしいですね…)
学習変数重要度display(pd.DataFrame(model.feature_importances_, index=features.columns, columns=['importance']).sort_values('importance', ascending=False))
今度はプロ入り年齢を最も重視しています。タイトル戦登場数の多い羽生九段(プロ入り15歳)の寄与が効いたのでしょうか。
線形回帰
勾配ブースティングでの回帰と比べ、線形回帰ではどうなるのでしょうか。線形回帰とは、下式のように線形関数でフィッティングすることです。
y=b_0+b_1x_1+b_2x_2+\cdots+b_Nx_N \\ (b_0,b_1,\cdots,b_N \in \mathbb{R}, x_1, x_2,\cdots, x_N \in 学習変数)線形回帰from sklearn.linear_model import LinearRegression reg = LinearRegression() reg.fit(train_x, train_y) lr_pred = reg.predict(test_x)
藤井七段はやはり4期という結果になりましたが、他の棋士は値が変わりました。青嶋五段に至ってはマイナスとなってしまいました。線形回帰の場合直線になるので確かにマイナスとなる可能性はありますが、ここまで差が出たのは意外でした。
ちなみにこのモデルの係数と切片は次のようになりました。係数可視化display(pd.DataFrame(reg.coef_, index=features.columns, columns=['coef'])) print('intercept = {}'.format(reg.intercept_))
係数がマイナスのものは変数値が低いほど予測値が高くなるので、年齢、プロ入り年齢がマイナスなのは分かりますが、順位戦の点数と対局数がマイナスなのは不可解です。順位戦に関してはA級やB1にいながらもタイトルには絡んでいないベテラン勢の寄与かもしれません。
ニューラルネットワーク
最後にニューラルネットワークでも予測してみます。
ニューラルネットワークfrom sklearn.neural_network import MLPRegressor nn = MLPRegressor() nn.fit(train_x, train_y) nn_pred = nn.predict(test_x) display(pd.DataFrame(nn_pred, index=names, columns=['タイトル獲得数']))
なんと藤井七段よりも佐々木勇気七段の方が高くなりました。佐々木大地五段が最下位になるなど、直感とは異なる結果です。ニューラルネットワークは非線形変換をして予測しているので、今回のタスクに有効なのか疑問ですが、他の方法と比べても少なくともデフォルトでは上手くいきませんでした。
まとめ
今回は将棋新時代でのデータから、藤井七段のタイトル獲得数を予測してみました。これほど活躍しているにも関わらずまだタイトルは獲れていませんが、タイトルを獲った棋士と成績を比較するとこの3年間で約4期は獲れているという予測となり、十分タイトルに近いという結果となりました。また、今回変数として考慮していないシードも多くの棋戦でされるようになり、今後タイトルを獲る確率はますます上がっていると思われます。将棋ファンとして楽しみな限りです。
また、今回性能比較(例えば正解値と予測値の差の二乗和を比較)は、テストデータの棋士が全員タイトル獲得数0のため行っていませんが、個人的な直感と比べて勾配ブースティングが最も正しく予測できていたように思います。できればもっとデータを集めて、また何か分析したいです。参考文献
棋士プロ入り年齢
棋士年齢
pandasグラフ描画
lightGBM予測が同じになる時
将棋に詳しくない方に簡単に説明すると、将棋界には現在8つのタイトルがあり、各棋戦で一年を通して争って挑戦者を1名決定し、挑戦者と現タイトル保持者が番勝負を行い、勝者がタイトルを得ます。タイトルを一つでも取ることは大偉業です。 ↩
順位戦はA級からC級2組まで5つのクラスに分かれ、1年を通してクラス内で対局をし、上位者が一つ上のクラスへ昇級、下位者が一つ下のクラスへ降級します。最上位のA級は10人しかいないトップ棋士の証であり、A級優勝者が名人(将棋界で最も伝統のあるタイトル)に挑戦します。藤井七段は現在B級2組、現名人は豊島将之名人。 ↩
竜王戦は1組から6組まで6つのクラスに分かれ、クラス内でトーナメント戦を行って上位者が一つ上のクラスへ昇級、下位者が一つ下のクラスへ降級します。その後、各クラスの上位者から竜王(将棋界最高タイトル)への挑戦者を決めます。順位戦との大きな違いとして、名人はA級にならなければ挑戦もできないのに対し、竜王はどのクラスにいてもチャンスがあります。藤井七段は現在3組、現竜王は豊島将之竜王。 ↩
王位リーグは紅組と白組2つのリーグに分かれ、王位への挑戦者を決定するリーグです。厳しい予選を抜けてリーグ入りしなければ挑戦できません。藤井七段は現在王位リーグに在籍中、現王位は木村一基王位。 ↩
王将リーグは王将への挑戦者を決定するリーグです。こちらも厳しい予選を抜けてリーグ入りしなければ挑戦できません。枠も少ないことから棋界屈指の難関リーグと言われています。藤井七段は現在王将リーグに在籍中、現王将は渡辺明王将。 ↩
8大タイトルとは別にテレビ棋戦など1年を通して優勝者を決める棋戦もあります。タイトル戦と違い優勝しても翌年もトーナメントを勝ち抜かなければ優勝できません。藤井七段は朝日杯将棋オープン戦で2連覇し、若手のみ出場の新人王戦でも優勝しています。 ↩











- 投稿日:2020-04-26T21:50:37+09:00
電車の運行情報をLINEに通知する
どんなアプリ?
Yahoo!路線情報から運行情報をスクレイピングし、LINEに通知する。
スクレイピングする
import os from concurrent.futures import ThreadPoolExecutor import requests from bs4 import BeautifulSoup class NotFoundElementError(Exception): """要素が存在しない時のエラー""" class Collecter: """収集クラス""" def __init__(self): """環境変数取得""" try: self.urls = list(os.environ['TRAIN_URLS'].split()) except KeyError: raise NotFoundElementError('url get failed!') def format_train_info(self, info, err_trains): """運行情報整形 @param: info [ <str: 路線>, <str: 詳細> ] err_trains [ <str: 運行情報失敗URL> ] @return: train_info <str: 運行情報> """ train_info = '\n' for i in info: try: lead, _, detail = i[1].strip('\n').split('\n') train_info += '{0}\n{1}\n{2}\n\n'.format(i[0], lead, detail) except ValueError: raise ValueError('format failed!') if not err_trains: train_info += 'Collect Complete!' else: train_info += 'This is Error url!' for url in err_trains: train_info += '\n' + url return train_info def get_train_info(self): """運行情報収集 @return: format_train_info(train_info, err_trains) <str: 運行情報> """ pool = ThreadPoolExecutor() res_list = pool.map(requests.get, self.urls) train_info, err_trains = [[], []] for res in res_list: try: res.raise_for_status() except requests.exceptions.RequestException: err_trains.append(res.url) continue bs_obj = BeautifulSoup(res.text, 'lxml') try: route = bs_obj.h1.text detail = bs_obj.find(id='mdServiceStatus').text except AttributeError: err_trains.append(res.url) else: train_info.append([route, detail]) if not train_info: raise NotFoundElementError('collect failed!') return self.format_train_info(train_info, err_trains)マルチスレッドによる並列タスク処理を実装してみた。
6つのURLを並列でGETリクエストした結果、約1秒速くなった。pool = ThreadPoolExecutor() res_list = pool.map(requests.get, self.urls)オーバーヘッドによる高速化が見込めない場合もあるので、使い所を見極める必要がある。
LINEに通知する
import os import requests class Line: """LINE通知クラス""" def __init__(self): """環境変数取得""" try: self.url = os.environ['LINE_API_URL'] self.token = os.environ['LINE_API_TOKEN'] self.headers = {'Authorization': 'Bearer ' + self.token} except KeyError as err: raise KeyError(err) def send_success(self, info): """収集成功 @param: info <str: 運行情報> """ requests.post(self.url, headers=self.headers, params={'message': info}) def send_error(self, err_msg): """収集失敗 @param: err_msg <str: エラーメッセージ> """ requests.post(self.url, headers=self.headers, params={'message': err_msg})最後に
Seleniumの場合、WebDriveのダウンロードが必要だが、Beautiful Soupはライブラリのインストールだけで手軽に使用できる。
ブラウザ操作も行わないため、Seleniumより動作が速い。
JavaScriptによる動的サイトでは、Seleniumの方が便利。
基本はBeautiful Soupを使用し、部分的にSeleniumを使用するのが良さそう。参考

- 投稿日:2020-04-26T21:49:46+09:00
【画像分類】犬の表情分析
1.はじめに
動物の表情分析に興味本位で手を出してみた。
2.参考文献
"Kerasで「笑っている犬」と「怒っている犬」を判別する機械学習モデルを作る"
https://qiita.com/ariera/items/545d48c961170a7840753.内容
3-1.データ前処理
# 画像を読み込んで、行列に変換する関数を定義 from keras.preprocessing.image import load_img, img_to_array def img_to_traindata(file, img_rows, img_cols, rgb): if rgb == 0: img = load_img(file, color_mode = "grayscale", target_size=(img_rows,img_cols)) # grayscaleで読み込み else: img = load_img(file, color_mode = "rgb", target_size=(img_rows,img_cols)) # RGBで読み込み x = img_to_array(img) x = x.astype('float32') x /= 255 return x # 学習データ、テストデータ生成 import glob, os img_rows = 224 # 画像サイズはVGG16のデフォルトサイズとする img_cols = 224 nb_classes = 2 # 怒っている、笑っているの2クラス img_dirs = ["./dog_angry", "./dog_smile"] # 怒っている犬、笑っている犬の画像を格納したディレクトリ X_train = [] Y_train = [] X_test = [] Y_test = [] for n, img_dir in enumerate(img_dirs): img_files = glob.glob(img_dir+"/*.jpg") # ディレクトリ内の画像ファイルを全部読み込む for i, img_file in enumerate(img_files): # ディレクトリ(文字種)内の全ファイルに対して x = img_to_traindata(img_file, img_rows, img_cols, 1) # 各画像ファイルをRGBで読み込んで行列に変換 if i < 8: # 1~8枚目までを学習データ X_train.append(x) # 学習用データ(入力)に画像を変換した行列を追加 Y_train.append(n) # 学習用データ(出力)にクラス(怒=0、笑=1)を追加 else: # 9枚目以降をテストデータ X_test.append(x) # テストデータ(入力)に画像を変換した行列を追加 Y_test.append(n) # テストデータ(出力)にクラス(怒=0、笑=1)を追加 import numpy as np # 学習、テストデータをlistからnumpy.ndarrayに変換 X_train = np.array(X_train, dtype='float') Y_train = np.array(Y_train, dtype='int') X_test = np.array(X_test, dtype='float') Y_test = np.array(Y_test, dtype='int') # カテゴリカルデータ(ベクトル)に変換 from keras.utils import np_utils Y_train = np_utils.to_categorical(Y_train, nb_classes) Y_test = np_utils.to_categorical(Y_test, nb_classes) # 作成した学習データ、テストデータをファイル保存 np.save('models/X_train_2class_120.npy', X_train) np.save('models/X_test_2class_120.npy', X_test) np.save('models/Y_train_2class_120.npy', Y_train) np.save('models/Y_test_2class_120.npy', Y_test) # 作成したデータの型を表示 print(X_train.shape) print(Y_train.shape) print(X_test.shape) from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D # 【パラメータ設定】 batch_size = 20 epochs = 30 input_shape = (img_rows, img_cols, 3) nb_filters = 32 # size of pooling area for max pooling pool_size = (2, 2) # convolution kernel size kernel_size = (3, 3) # 【モデル定義】 model = Sequential() model.add(Conv2D(nb_filters, kernel_size, # 畳み込み層 padding='valid', activation='relu', input_shape=input_shape)) model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層 model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層 model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層 model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層 model.add(Dropout(0.25)) # ドロップアウト(過学習防止のため、入力と出力の間をランダムに切断) model.add(Flatten()) # 多次元配列を1次元配列に変換 model.add(Dense(128, activation='relu')) # 全結合層 model.add(Dropout(0.2)) # ドロップアウト model.add(Dense(nb_classes, activation='sigmoid')) # 2クラスなので全結合層をsigmoid # モデルのコンパイル model.compile(loss='binary_crossentropy', # 2クラスなのでbinary_crossentropy optimizer='adam', # 最適化関数のパラメータはデフォルトを使う metrics=['accuracy']) # 【各エポックごとの学習結果を生成するためのコールバックを定義(前回より精度が良い時だけ保存)】 from keras.callbacks import ModelCheckpoint import os model_checkpoint = ModelCheckpoint( filepath=os.path.join('models','model_2class120_{epoch:02d}.h5'), monitor='val_accuracy', mode='max', save_best_only=True, verbose=1) print("filepath",os.path.join('models','model_.h5')) # 【学習】 result = model.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test, Y_test), callbacks=[model_checkpoint],validation_split=0.1)3-2.学習
from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D # 【パラメータ設定】 batch_size = 20 epochs = 30 input_shape = (img_rows, img_cols, 3) nb_filters = 32 # size of pooling area for max pooling pool_size = (2, 2) # convolution kernel size kernel_size = (3, 3) # 【モデル定義】 model = Sequential() model.add(Conv2D(nb_filters, kernel_size, # 畳み込み層 padding='valid', activation='relu', input_shape=input_shape)) model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層 model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層 model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層 model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層 model.add(Dropout(0.25)) # ドロップアウト(過学習防止のため、入力と出力の間をランダムに切断) model.add(Flatten()) # 多次元配列を1次元配列に変換 model.add(Dense(128, activation='relu')) # 全結合層 model.add(Dropout(0.2)) # ドロップアウト model.add(Dense(nb_classes, activation='sigmoid')) # 2クラスなので全結合層をsigmoid # モデルのコンパイル model.compile(loss='binary_crossentropy', # 2クラスなのでbinary_crossentropy optimizer='adam', # 最適化関数のパラメータはデフォルトを使う metrics=['accuracy']) # 【各エポックごとの学習結果を生成するためのコールバックを定義(前回より精度が良い時だけ保存)】 from keras.callbacks import ModelCheckpoint import os model_checkpoint = ModelCheckpoint( filepath=os.path.join('models','model_2class120_{epoch:02d}_{val_acc:.3f}.h5'), monitor='val_acc', mode='max', save_best_only=True, verbose=1) # 【学習】 result = model.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test, Y_test), callbacks=[model_checkpoint])3-3.分類
from keras.models import load_model from keras.preprocessing.image import load_img, img_to_array import matplotlib.pyplot as plt model = load_model('models/model_2class120_04.h5') model.summary() def img_to_traindata(file, img_rows, img_cols, rgb): if rgb == 0: img = load_img(file, color_mode = "grayscale", target_size=(img_rows,img_cols)) # grayscaleで読み込み else: img = load_img(file, color_mode = "rgb", target_size=(img_rows,img_cols)) # RGBで読み込み x = img_to_array(img) x = x.astype('float32') x /= 255 return x import numpy as np img_rows = 224 # 画像サイズはVGG16のデフォルトサイズとする img_cols = 224 ## 画像読み込み filename = "dog_smile/n02085936_37.jpg" x = img_to_traindata(filename, img_rows, img_cols, 1) # img_to_traindata関数は、学習データ生成のときに定義 x = np.expand_dims(x, axis=0) ## どのクラスかを判別する preds = model.predict(x) pred_class = np.argmax(preds[0]) print("識別結果:", pred_class) print("確率:", preds[0]) from keras import backend as K import cv2 # モデルの最終出力を取り出す model_output = model.output[:, pred_class] # 最後の畳込み層を取り出す last_conv_output = model.get_layer('conv2d_3').output #'block5_conv3').output # 最終畳込み層の出力の、モデル最終出力に関しての勾配 grads = K.gradients(model_output, last_conv_output)[0] # model.inputを入力すると、last_conv_outputとgradsを出力する関数を定義 gradient_function = K.function([model.input], [last_conv_output, grads]) # 読み込んだ画像の勾配を求める output, grads_val = gradient_function([x]) output, grads_val = output[0], grads_val[0] # 重みを平均化して、レイヤーのアウトプットに乗じてヒートマップ作成 weights = np.mean(grads_val, axis=(0, 1)) heatmap = np.dot(output, weights) heatmap = cv2.resize(heatmap, (img_rows, img_cols), cv2.INTER_LINEAR) heatmap = np.maximum(heatmap, 0) heatmap = heatmap / heatmap.max() heatmap = cv2.applyColorMap(np.uint8(255 * heatmap), cv2.COLORMAP_JET) # ヒートマップに色をつける heatmap = cv2.cvtColor(heatmap, cv2.COLOR_BGR2RGB) # 色をRGBに変換 img = plt.imread(filename, cv2.IMREAD_UNCHANGED) print(img.shape) # (330, 440, 4) fig, ax = plt.subplots() ax.imshow(img) plt.show()4.分類結果
2020-04-26 21:12:46.904489: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7fded852e7f0 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2020-04-26 21:12:46.904528: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 222, 222, 32) 896 _________________________________________________________________ conv2d_2 (Conv2D) (None, 220, 220, 32) 9248 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 110, 110, 32) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 108, 108, 32) 9248 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 54, 54, 32) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 54, 54, 32) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 93312) 0 _________________________________________________________________ dense_1 (Dense) (None, 128) 11944064 _________________________________________________________________ dropout_2 (Dropout) (None, 128) 0 _________________________________________________________________ dense_2 (Dense) (None, 2) 258 ================================================================= Total params: 11,963,714 Trainable params: 11,963,714 Non-trainable params: 0 _________________________________________________________________ 識別結果: 1 確率: [0.27252397 0.6845933 ] (375, 500, 3)5.今後の課題
精度をあげるための問題点を絞り込む必要がある。
- 投稿日:2020-04-26T21:22:53+09:00
【Python】新型コロナウイルス感染症のデータを7日間移動平均でみる
はじめに
先日twitterで7日間移動平均で新型コロナウイルスの感染者数を見ている、というツイートを何件か見かけました。
自分でオープンデータ等から可視化までしてみたかったのでやってみました。
今回使用したデータは東京都が公開しているデータとなります。グラフ
まずグラフを見てもらうのがはやいと思います。
青軸の棒グラフがその日明らかになった陽性患者さんの数、ピンクの折れ線グラフが7日間移動平均をとった陽性患者さんの数です。
油断はもちろんいけませんし、これだけを見て一概にコロナの封じ込めに成功しているとは言えませんが、折れ線グラフは右肩下がりになっているように見えます。
移動平均
統計学で用いられるもので、
時系列データにおいて、ある一定区間ごとの平均値を区間をずらしながら求めたものです。
引用先:https://bellcurve.jp/statistics/blog/15528.html
つまり、以下のようなデータがあった時、3項の移動平均はそれぞれ前後1つずつの値の平均を計算するので、
1 2 3 4 5 6 7 以下のようになります。
1 2 3 4 5 6 7 X 2 3 4 5 6 X 今回は±3日間の7日間移動平均をとったので、前後3日間の平均をとっています。
numpyを使った移動平均の取得
こちらのサイトを参考にさせていただきました。
numpy.convolveを使います。numpy.convolve(ndaaray, karnel, mode)
引数 内容 ndaaray 時系列データのnumpy配列 karnel カーネル関数(何点で移動平均を求めるかで決定) mode same:時系列データと同じ要素数で結果出力, valid:時系列データよりも短い要素数で結果出力 データの可視化
からあげさんの記事で公開されていたGoogle Colab をまるまる使わせていただきました。ありがとうございます。
話はそれますがからあげさんという方は自分の研究分野でもあるロボット関係の方でもよく記事を参考にさせていただいています。いつもありがとうございます。(急に信者)からあげさんのものからの変更部分だけ抜粋して以下に記載します。
まず、完全に個人的な好みでseabornをimportしました。【変更】日付データの読み込み
ここはx軸のラベルをきれいにしたかったのでdatetime型にしました。
date_data = np.array([]) for i in range(len(data['inspection_persons']['labels'])): date_data = np.append(date_data, pd.to_datetime(data['inspection_persons']['labels'][i][0:10])) print(date_data)【追加】7日間移動平均の計算
もともとあった陽性の患者さんの配列をnumpy配列にして、上記の移動平均を計算しています。
また、±3日分をnp.nanで埋めていますpatients_data_np_array = np.array(patients_data) patients_data_move_ave = np.convolve(patients_data_np_array, np.ones(n)/float(n), 'valid') nan_array = np.array([np.nan,np.nan,np.nan]) patients_data_move_ave = np.insert(patients_data_move_ave,0,nan_array) patients_data_move_ave = np.insert(patients_data_move_ave,len(patients_data_move_ave),nan_array)【変更】データ可視化部分
上記の7日間移動平均を折れ線グラフでいれました。
plt.figure(figsize=(9,6)) plt.bar(date_data, patients_data,label='number of patients') plt.plot(date_data, patients_data_move_ave,color='salmon', linewidth = 3.0,label='moving average of number of patients') plt.legend()すべてのプログラム
以下、今回のプログラムです。
環境はGoogle Colabratoryとなるので最初のbashはマジックコマンド(!)を付けて実行するものです。
普通にwgetしているだけなのでGoogle Colabratoryでなくとも使えます。!wget --no-check-certificate --output-document=covid19_tokyo.json 'https://raw.githubusercontent.com/tokyo-metropolitan-gov/covid19/development/data/data.json'以下がPythonプログラムです。
# ライブラリのとデータの読み込み import pandas as pd import numpy as np data = pd.read_json('covid19_tokyo.json') import matplotlib.pyplot as plt import seaborn as sns sns.set() # 日付データ date_data = np.array([]) for i in range(len(data['inspection_persons']['labels'])): date_data = np.append(date_data, pd.to_datetime(data['inspection_persons']['labels'][i][0:10])) # 陽性患者データ patients_data = [] for i in range(len(data['inspection_persons']['labels'])): patients_data.append(data['patients_summary']['data'][i]['小計']) # 7日間移動平均の計算 patients_data_np_array = np.array(patients_data) patients_data_move_ave = np.convolve(patients_data_np_array, np.ones(n)/float(n), 'valid') # nanで埋める nan_array = np.array([np.nan,np.nan,np.nan]) patients_data_move_ave = np.insert(patients_data_move_ave,0,nan_array) patients_data_move_ave = np.insert(patients_data_move_ave,len(patients_data_move_ave),nan_array) # 可視化 plt.figure(figsize=(9,6)) plt.bar(date_data, patients_data,label='number of patients') plt.plot(date_data, patients_data_move_ave,color='salmon', linewidth = 3.0,label='moving average of number of patients') plt.legend()結果は以下のグラフになります。
おわりに
twitterで見かけたものをすぐ自分で可視化できたのもデータを公開していただいている東京都のおかげであったり、データの収集方法や移動平均の手法を公開していただいている皆さんのおかげだと感じることができました。
これからもやろう!と思ったらすぐやれるように色々知識をつけていきたいです。参考にさせていただいたサイト
移動平均
移動平均 統計WEB 統計学の時間
移動平均の計算方法 統計WEB ブログ可視化
新型コロナウイルス感染症(COVID-19)のオープンデータをGoogle Colaboratoryで手軽に可視化・分析する方法
上記記事のGoogleClobratory


- 投稿日:2020-04-26T20:35:02+09:00
機械学習用データ前処理ライブラリDataLinerを作ってみた
はじめに
機械学習用のデータ前処理ライブラリDataLinerを作りました。
機械学習モデリングを行う際、データ加工・特徴量エンジニアリングの部分で私が汎用的に使う処理を前処理一覧としてまとめたものになります。
scikit-learnのtransformerに準拠しているので、単体でfit_transformすることもpipelineに流し込むこともできます。
まだまだ詰め込みきれていない機能や前処理があるので今後も定期的にアップデートしていきますが、他にもバグ報告・FIXや新機能・新しい前処理のプルリクなどを頂けると励みになります。
GitHub: https://github.com/shallowdf20/dataliner
PyPI: https://pypi.org/project/dataliner/インストール
pipを使ってインストールします。
Anacondaを使ってPython環境を構築している方はAnaconda Promptで以下のコードを実行してください。! pip install datalinerデータ準備
みんな大好きTitanicのDatasetsを例に使ってみます。
現時点ではXはpandas.DataFrame, yはpandas.Seriesでのみ動きますが次回のバージョンアップで対応するデータタイプを増やす予定です。
それでは、処理を行うデータを準備します。import pandas as pd import dataliner as dl df = pd.read_csv('train.csv') target_col = 'Survived' X = df.drop(target_col, axis=1) y = df[target_col]こんな感じの見覚えのあるデータがXに格納されます。
使い方
では、早速使ってみます。まずはカテゴリ数が多すぎる特徴量を自動的に消してくれるDropHighCardinalityを使ってみます。
dhc = dl.DropHighCardinality() dhc.fit_transform(X)
NameやTicketといったカテゴリ数が非常に多い特徴量が削除されているのがわかります。
余談ですが、Titanicの場合はこれらの列から情報をひねり出して精度を上げに行くと思います。次は、おなじみTarget Encodingをやってみます。事前確率としてy全体の平均を用いてスムージングを行うバージョンとなっています。
tme = dl.TargetMeanEncoding() tme.fit_transform(X, y)
自動でカテゴリカル変数の列を認識し、各カテゴリーを目的変数を使ってEncodingしてくれました。また、多くのデータサイエンティストの方々は効率化のためにPipelineを使われていると思います。
もちろんDataLinerの各クラスも同様に使用することができます。from sklearn.pipeline import make_pipeline process = make_pipeline( dl.DropNoVariance(), dl.DropHighCardinality(), dl.BinarizeNaN(), dl.ImputeNaN(), dl.OneHotEncoding(), dl.DropHighCorrelation(), dl.StandardizeData(), dl.DropLowAUC(), ) process.fit_transform(X, y)諸々の処理を行った結果、こうなりました。
Titanicでは評価用にあらかじめhold outされているtest.csvというデータがあるので、読み込んで同じ処理をかけてみます。
X_test = pd.read_csv('test.csv') process.transform(X_test)
以上になります。
含まれているもの
現時点では以下になります。今後のアップデートで機能拡充・処理も増やしていきたいと思っています。
すべて引数はオプションですが、GitHubのコードにsklearnと似たフォーマットで説明を記載していますのでしきい値の変更なども可能です。リファレンスも作成予定です。BinarizeNaN - 欠損値が含まれる列を見つけ、その列が欠損していたかどうかという新しい特徴量を作成します
ClipData - 数値データをqパーセンタイルで区切り、上限以上・下限以下の値を上限・下限で置き換えます
CountRowNaN - 各データの行方向の欠損値の合計値を新しい特徴量として作成します
DropColumns - 指定した列を削除します
DropHighCardinality - カテゴリ数の多い列を削除します
DropHighCorrelation - ピアソンの相関係数がしきい値を超えた特徴量を削除します。削除の際、目的変数に対してより相関の高い特徴量を残します。
DropLowAUC - 全特徴量に対して、yを目的変数としたロジスティック回帰を特徴量1つずつで行い、AUCがしきい値を下回った特徴量を削除します。
DropNoVariance - 1種類のデータしか含まれない特徴量を削除します。
GroupRareCategory - カテゴリ列のうち、出現頻度の低いカテゴリーをグルーピングします。
ImputeNaN - 欠損値を補完します。デフォルトでは数値データは平均、カテゴリカル変数は最頻値で補完されます。
OneHotEncoding - カテゴリ変数をダミー変数化します。
StandardizeData - 数値データを平均0分散1となるよう変換します。
TargetMeanEncoding - カテゴリ変数の各カテゴリーを、目的変数の平均をスムージングしたもので置き換えます。さいごに
自分が何度も繰り返している処理をまとめたものの、もしかしたら他の方にも同様のニーズがあるのでは?と思い公開しました。
無数にある前処理のうち、主要なものがまとまったライブラリとなればいいなと思っています。繰り返しになりますが、バグ報告やFIX、新機能や新しい処理のプルリク待ってます!!





- 投稿日:2020-04-26T20:33:27+09:00
raspberry piとhx711を使った重量測定器(TkinterでGUI表示)
これまた仕事で重量測定と重量に応じた結果表示のニーズが出てきたので、プロトタイプを作ってみました。
1. タッチパネルディスプレイのセットアップ
表示だけならHDMI接続のディスプレイでも無機質なCLIでもいいのですが、使用する対象は自分のようななんちゃってプログラマーではなく素人です。
なのでGUI表示&タッチパネルを用いた簡単な操作ができるようタッチパネルディスプレイを手配します。
https://www.amazon.co.jp/dp/B075K56C12/
これならGPIOを占有しないので、ロードセル接続に最適ですね!セットアップ方法は先人の方が分かりやすく紹介していただいているので、リンクを貼っておきます。
neuralassemblyのメモ:Raspberry PiのGPIOが引き出せる小型タッチスクリーンが届いたので電子工作に使ってみた
https://neuralassembly.blogspot.com/2017/12/raspberry-pigpio.html2. 重量測定用ロードセル・アンプ
raspberrypiで重量測定するにはA/Dコンバータのhx711をロードセルアンプとして用いるのが簡単で一般的みたいです。
(ノイズが多いので予算に余裕があれば仕様はお勧めしないと書いてあるところもありますが…)今回、ロードセルも欲しかったので下記のMAX5kgのロードセル・hx711に加えて重量測定用テーブル一式がそろったキットを買いました。
https://www.amazon.co.jp/dp/B07JL7NP3F/
2.1. hx711とraspbberrypiとの接続
hx711のキットに付属のフラットケーブルでraspberrypiと接続します。
hx711 raspberypi GND GND(6pin) DT GPIO5(29pin) SCK GPIN6(31pin) VCC 5V(4pin) 2.2. hx711のセットアップ
githubからpythonのhx711ライブラリを入手します。
$ git clone https://github.com/tatobari/hx711py Cloning into 'hx711py'... remote: Counting objects: 77, done. remote: Compressing objects: 100% (7/7), done. remote: Total 77 (delta 3), reused 5 (delta 2), pack-reused 68 Unpacking objects: 100% (77/77), done.実際に実行してみます。
$ python hx711/example.py Tare done! Add weight now... 490 458 445 451 459 483 467 486 511 412 ^CCleaning... ←ctrl+c で終了 Bye!正しく接続されているならこのように数値がパラパラと出るはずです。
さて、この数値はロードセルの出力をただ表示しているだけなので、キャリブレーションして重量に相当する数値にしないといけません。例えば重量が明確な分銅(無ければキッチンスケールなどで重量が分かっているものを錘とする)をロードセルに乗せたとき
Tare done! Add weight now... 458 445 451 ←ココで錘を載せる 4475 13929 212399 212419 212441 212402 212399 212460 212422 212385 212456 212424 212463 212451 212455 212379 212438 212457 212451 212390 ^CCleaning... Bye!のような結果が得られたとします。
この場合、数値が安定している212399~212390の平均値を実際の重量で割った数値を補正値にします。
錘の重量が200gとすると、212417(平均値)/200g(実際の重量)=1062 が補正値ということです。
補正値はexample.pyの中のreferenceUnitに代入します。example.py… #referenceUnit = 1 referenceUnit = 1062 …ですね。
これで(ノイズや温度などの外乱はともかく)実際の重量を得ることができるようになりました。3. TkinterでGUI表示
自己満足なら無機質なCLI表示で十分なんですが、素人さん相手に「すごーい!」って言われたいならGUI表示は必要でしょう(笑)
でも実際、GUI表示できるだけでぐーんとプログラムの完成度が違って見え、上司や同僚からのウケは変わってくるはずです。今回は下記サイトを参考にTkinterでGUI表示してみることにしてみました。
※Tkinterについて語れるほど私に知識はありません。詳しくはググってください。設備のマニアどっとこむ:ラズパイとTkinterで温度のGUI監視
http://setsubi.no-mania.com/raspberry%20pi/%E3%83%A9%E3%82%BA%E3%83%91%E3%82%A4%E3%81%A8tkinter%E3%81%A7%E6%B8%A9%E5%BA%A6%E3%81%AEgui%E7%9B%A3%E8%A6%96コードの全文は以下の通りです。
分かりやすいように重量と100円玉を載せた数に応じた表示を行うようにしています。
冗長ですがexample.pyから追記・修正される方のためにコメントアウトした部分はそのまま残しておきます。
※日本語をUTF-8で表示するので、sudo raspi-configで文字コードをja_JP.UTF-8 UTF-8にしておかないと表示が文字化けします。weight_choose.py#! /usr/bin/python3 # -*- coding: utf-8 -*- import time import sys import math import tkinter as tk EMULATE_HX711=False #referenceUnit = 1 referenceUnit = 1062 if not EMULATE_HX711: import RPi.GPIO as GPIO from hx711 import HX711 else: from emulated_hx711 import HX711 def cleanAndExit(): print("Cleaning...") if not EMULATE_HX711: GPIO.cleanup() print("Bye!") root.destroy() root.quit() sys.exit() hx = HX711(5, 6) # I've found out that, for some reason, the order of the bytes is not always the same between versions of python, numpy and the hx711 itself. # Still need to figure out why does it change. # If you're experiencing super random values, change these values to MSB or LSB until to get more stable values. # There is some code below to debug and log the order of the bits and the bytes. # The first parameter is the order in which the bytes are used to build the "long" value. # The second paramter is the order of the bits inside each byte. # According to the HX711 Datasheet, the second parameter is MSB so you shouldn't need to modify it. hx.set_reading_format("MSB", "MSB") # HOW TO CALCULATE THE REFFERENCE UNIT # To set the reference unit to 1. Put 1kg on your sensor or anything you have and know exactly how much it weights. # In this case, 92 is 1 gram because, with 1 as a reference unit I got numbers near 0 without any weight # and I got numbers around 184000 when I added 2kg. So, according to the rule of thirds: # If 2000 grams is 184000 then 1000 grams is 184000 / 2000 = 92. #hx.set_reference_unit(113) hx.set_reference_unit(referenceUnit) hx.reset() hx.tare() print("Tare done! Add weight now...") # to use both channels, you'll need to tare them both #hx.tare_A() #hx.tare_B() #while True: # try: # These three lines are usefull to debug wether to use MSB or LSB in the reading formats # for the first parameter of "hx.set_reading_format("LSB", "MSB")". # Comment the two lines "val = hx.get_weight(5)" and "print val" and uncomment these three lines to see what it prints. # np_arr8_string = hx.get_np_arr8_string() # binary_string = hx.get_binary_string() # print binary_string + " " + np_arr8_string # Prints the weight. Comment if you're debbuging the MSB and LSB issue # val = hx.get_weight(5) # print(val) # To get weight from both channels (if you have load cells hooked up # to both channel A and B), do something like this #val_A = hx.get_weight_A(5) #val_B = hx.get_weight_B(5) #print "A: %s B: %s" % ( val_A, val_B ) # hx.power_down() # hx.power_up() # time.sleep(0.1) # except (KeyboardInterrupt, SystemExit): # cleanAndExit() def zero(): hx.reset() hx.tare() root = tk.Tk() root.geometry("800x500") root.title(u"重量計") sbtn = tk.Button(root, text='終了',font = ('', 50), command=cleanAndExit) sbtn.pack(side = 'bottom') zbtn = tk.Button(root, text='ゼロリセット',font = ('', 30), command=zero) zbtn.pack(side = 'bottom') title = tk.Label(text='重量[g]',font = ('', 70)) title.pack() while True: val = hx.get_weight(5) print(val) weight = tk.Label(text='{:.1f}'.format(val),font = ('', 70)) weight.pack() txit = tk.Label(text='',font = ('', 70)) if val >= 3.8 and val <= 5.8: txit = tk.Label(text='100円玉1枚',font = ('', 70)) elif val >= 8.1 and val <= 11.0: txit = tk.Label(text='100円玉2枚',font = ('', 70)) elif val >= 12.6 and val <= 16.1: txit = tk.Label(text='100円玉3枚',font = ('', 70)) elif val >= 17.2 and val <= 21.2: txit = tk.Label(text='100円玉4枚',font = ('', 70)) elif val >= 21.7 and val <= 26.2: txit = tk.Label(text='100円玉5枚',font = ('', 70)) txit.pack() weight.update() txit.update() weight.forget() txit.forget() hx.power_down() hx.power_up() time.sleep(0.5) root.mainloop()ゼロリセットのボタンで0gリセット、終了ボタンでプログラムを終了するようにしました。
実際に動作させた結果が以下です。あとはautostartで自動起動するなどすればより本物の計測器っぽくてかっこいいですね!
お疲れ様でした。




- 投稿日:2020-04-26T20:25:21+09:00
【最強の英単語帳爆誕ww】Pythonでエンジニア必須の英単語帳を自動生成-後編
はじめに
こちらは後編の記事になりますので、まずは前編をご覧下さい。
↓ 今回作成した単語データを使用した学習の様子(記事の最後にダウンロードリンクがあります!)
実行結果だけ見たい!という方はこちら→実行結果
目次
- 前回の振り返り
- 改善方法について
- プログラム内で使用する単語が多い
- case insensitiveになっていない
- stackoverflowのページにオーバフィットしている
- コードの全体像
- 改善点と追加機能
- プログラム内で使用する単語が多い
- case insensitiveになっていない
- stackoverflowのページにオーバフィットしている
- 単語の翻訳
- その他
- 実行結果
- 結論
- 【重要】英単語帳を作るには
- データのダウンロード
前回の振り返り
仮説と検証結果
前回は前編ということで、プログラムで自動生成してしまえば
もう英単語帳購入の必要はないんじゃないか?
という仮説の簡単な検証を行なっていきました。
前回の実行結果の一部がこちら。rank:0 word: ('i', 96) rank:1 word: ('python', 86) rank:2 word: ('ago', 50) rank:3 word: ('bronze', 36) rank:4 word: ('have', 29) rank:5 word: ('×', 25)問題点
前回の検証結果として下記3つの問題点があることが見えてきました。
- プログラムのみで使用する単語が存在する
- case insensitiveになっていない
- stackoverflowのページにオーバフィットしている
今回はこれらの課題を解決し、
エンジニアにとって必要な英単語を最効率で学習
できる英単語帳の作成を目指していきます。改善方法について
プログラム内で使用する単語が多い
def、jやkなどの単語のことになるのですが、プログラム的に除去していく方法としては以下のようなものが挙げられます。
- プログラムのみで使用するような単語のリストデータを作成し、フィルタリング
- 自然言語として意味のなさないものを除去する+2文字以下は単語とみなさない※1
- 品詞の解読精度を向上させる
1と3は時間がかかるので、TextBlobの機能が生かせる2を採用していきます。
まずは、こちらをご覧下さい。
>>from textblob import Word >>print(Word("list").definitions) >>['a database containing an ordered array of items (names or topics)',...]こちらで分かる通り、単語に意味が存在する場合
definitionsというアトリビュートを呼ぶと、定義をリストで返してくれます。同様に'def'の定義を見てみると
>>from textblob import Word >>print(Word("def").definitions) >>[]のように、空のリストが返されますので、こちらを利用して本来の英語には存在しない単語を除去していきます。
case insensitiveになっていない
これは下記のようにstringのメソッドlowerを呼んで、全て小文字にすることで対応していきます。
'string'.lower()stackoverflowのページにオーバフィットしている
ここが良い単語帳を作成するにのに最も重要なポイントとなりそうです。「エンジニア」をターゲットとすると少し幅が広くてデータをとるのが大変なので、下記2点を行っている人にフォーカスした単語帳を作成することとして5つのwebページをピックアップしてみました。
- Pythonを使用している
- AIを使用したバックエンド開発を行っている
1/5 AWS Lamda
https://aws.amazon.com/lambda/
2/5 Python3.8 What's new
https://docs.python.org/3/whatsnew/3.8.html
3/5 Docker what is container
https://www.docker.com/resources/what-container
4/5 Wikipedia Artificial intelligence
https://en.wikipedia.org/wiki/Artificial_intelligence
コードの全体像
基本的には前回のコードを使いまわしていますが、今回は複数のサイトにアクセスするためのfor文が必要となったので、一部関数の切り出しと修正を行っています。
from enum import Enum, unique from typing import List, Tuple, Dict import requests from bs4 import BeautifulSoup as bs from textblob import TextBlob, Word from textblob.exceptions import NotTranslated URLS = ( ('stackoverflow', 'https://stackoverflow.com/questions/tagged/python'), ('AWS', 'https://aws.amazon.com/lambda/'), ('wikipedia AI', 'https://en.wikipedia.org/wiki/Artificial_intelligence'), ('Docker', 'https://www.docker.com/resources/what-container'), ('Python3.8 doc', 'https://docs.python.org/3/whatsnew/3.8.html'), ) PARSER = "html.parser" UNACCEPTABLE_LENGTH_OF_WORD = 2 @unique class PartOfSpeechToLearn(Enum): JJ = 'Adjective' VB = 'Verb' NN = 'Noun' RB = 'Adverb' def single_page_text_from_url(url: str) -> str: res = requests.get(url) raw_html = bs(res.text, PARSER) texts_without_html: str = raw_html.text return texts_without_html def filter_for_wordbook(morph: TextBlob) -> List[str]: word_and_tag: List[Tuple[str, str]] = morph.tags part_of_speech_to_learn = tuple(pos.name for pos in PartOfSpeechToLearn) filtered_words = [] for wt in word_and_tag: word: str = wt[0].lower() part_of_speech: int = wt[1] if part_of_speech not in part_of_speech_to_learn: continue if word in filtered_words: continue if ( len(word) <= UNACCEPTABLE_LENGTH_OF_WORD or len(Word(word).definitions) == 0 ): continue filtered_words.append(word) return filtered_words def show_top_50_common_and_uncommon_words(word_and_count: Dict[str, int]) -> None: words_by_descending_order: List[Tuple[str, int]] = sorted( word_and_count.items(), key=lambda x: x[1], reverse=True ) print('the most common words') for i, word_and_count in enumerate(words_by_descending_order[:10]): word: str = word_and_count[0] count: int = word_and_count[1] try: meaning_jp = str(TextBlob(word).translate(to='ja')) except NotTranslated: meaning_jp = word print(f'rank:{i + 1} word: {word} count: {count} meanings: {meaning_jp}') print('the most uncommon words') for j, word_and_count in enumerate(words_by_descending_order[:-11:-1]): word: str = word_and_count[0] count: int = word_and_count[1] try: meaning_jp = str(TextBlob(word).translate(to='ja')) except NotTranslated: meaning_jp = word print(f'rank:{j + 1} word: {word} count: {count} meanings: {meaning_jp}') if __name__ == '__main__': word_and_count: Dict[str, int] = {} for url in URLS: print(f'website: {url[0]} url: {url[1]}') texts_without_html = single_page_text_from_url(url[1]) morph = TextBlob(texts_without_html) filtered_words = filter_for_wordbook(morph) for word in filtered_words: count = morph.words.count(word, case_sensitive=False) if count == 0: continue if word not in word_and_count.keys(): word_and_count[word] = count else: word_and_count[word] += count print(f'length of word_and_count: {len(word_and_count)}') show_top_50_common_and_uncommon_words(word_and_count)それでは、前回から改良した点をみていきましょう!
改善点と追加機能
プログラム内で使用する単語が多い
前回内包表記でフィルタリングしていた部分を全て関数に切り出して
ifでフィルターするようにしています。シンプルな処理であれば内包表記がnamespaceの節約と処理効率の面で便利ですが、複数の条件でデータを処理する場合にはif文を使用する方がシンプルでベターかと思います。
ifに関してはネストを避けるために、処理が軽そうなものから順にcontinueしていくようにしています。def filter_for_wordbook(morph: TextBlob) -> List[str]: word_and_tag: List[Tuple[str, str]] = morph.tags part_of_speech_to_learn = tuple(pos.name for pos in PartOfSpeechToLearn) filtered_words = [] for wt in word_and_tag: word = wt[0].lower() part_of_speech = wt[1] if part_of_speech not in part_of_speech_to_learn: continue if word in filtered_words: continue if ( len(word) <= UNACCEPTABLE_LENGTH_OF_WORD or len(Word(word).definitions) == 0 ): continue filtered_words.append(word) return filtered_words上記コードのここで、プログラムでしか使用しない単語をフィルタリングしています。
if ( len(word) <= UNACCEPTABLE_LENGTH_OF_WORD or len(Word(word).definitions) == 0 ): continuecase insensitiveになっていない
先ほどのコードの下記部分で、大文字小文字が違うだけで同じ単語を同一データとして重複を避ける処理を入れています。
for wt in word_and_tag: word = wt[0].lower() if word in filtered_words: continuestackoverflowのページにオーバフィットしている
先ほど紹介したwebサイトを
tuple型でURLSとして定義しています。URLS = ( ('stackoverflow', 'https://stackoverflow.com/questions/tagged/python'), ('AWS', 'https://aws.amazon.com/lambda/'), ('wikipedia AI', 'https://en.wikipedia.org/wiki/Artificial_intelligence'), ('Docker', 'https://www.docker.com/resources/what-container'), ('Python3.8 doc', 'https://docs.python.org/3/whatsnew/3.8.html'), )単語の翻訳
中身はGoogle翻訳ですが、単語の翻訳もTextBlobライブラリを使用しています。
NotTranslatedは、pythonという単語のように、翻訳してもpythonとなるようなものを翻訳しようとした時にraiseされるものになります。try: meaning_jp = str(TextBlob(word).translate(to='ja')) except NotTranslated: meaning_jp = wordその他
お気づきになった方もいらっしゃるかもしれませんが、下記のコードで
for word in filtered_words: count = morph.words.count(word) if count == 0: continue if word not in word_and_count.keys(): word_and_count[word] = count else: word_and_count[word] += countこのように、カウントがゼロの場合、次のループを移行する文があります。
count = morph.words.count(word) if count == 0: continue具体的には
e.g.,のような文字列を解析した際、トークナイズ時はe.g.、品詞毎に分解した際はe.gとなるため、e.g.,のような単語がきた時にcount==0となるのでこちらのコードを挿入しています。
自然言語処理とTextBlobの使い方に関してまだまだ勉強不足ですので、ある程度知見がたまったら別途TextBlobの使い方まとめ、みたいな形で記事を出した際に解説していきたいと思います。
実行結果
前回の問題点は無事改良されているのでしょうか................?
実行結果はこちら..................................!
the most common words rank:1 word: intelligence count: 327 meanings: 知性 rank:2 word: artificial count: 280 meanings: 人工的な rank:3 word: help count: 190 meanings: 助けて rank:4 word: python count: 186 meanings: python rank:5 word: error count: 184 meanings: エラー rank:6 word: target count: 168 meanings: 目標 rank:7 word: new count: 134 meanings: 新着 rank:8 word: learning count: 129 meanings: 学習する rank:9 word: machine count: 125 meanings: 機械 rank:10 word: have count: 120 meanings: 持ってる the most uncommon words rank:1 word: donate count: 1 meanings: 寄付 rank:2 word: math count: 1 meanings: 数学 rank:3 word: inspect count: 1 meanings: 調べる rank:4 word: ignore count: 1 meanings: 無視する rank:5 word: processor count: 1 meanings: プロセッサー rank:6 word: queue count: 1 meanings: キュー rank:7 word: depend count: 1 meanings: 依存する rank:8 word: pretend count: 1 meanings: ふり rank:9 word: decrease count: 1 meanings: 減少 rank:10 word: allocator count: 1 meanings: アロケータおおおおおおおおっ!
結論
まずはもう一度仮説に振り返ってみたいと思います。今回のシリーズでの仮説は
Pythonで自動的に作成すれば、
もう英単語帳購入の必要はないんじゃないか?
というものでした。
こちらの仮説に対しての結論としては、
英単語帳は購入しなくても、プログラムで作れる!
といえそうです!!!※1【重要】市販のような英単語帳を作るには
実行結果をみていただければわかりますが、今回抽出できた単語だけでもかなり有用なことが分かります。ただ、市販の単語帳と同等のものを作るにはインターフェースと3つの追加情報が必要になってきます。
インターフェース
市販の単語帳には、本、もしくはアプリといった問題形式で覚えたり、内容の確認をしやすくするためのインターフェースを備えています。
今回のように自作英単語データを学習に使用したいという方には、私のブログでも紹介していますAnkiアプリが超おすすめです!!素のAtom使ってる人がIDEを使いこなした時ぐらい感動します!
先日Twitterでたまたま見かけたのですが、連続起業家で有名な家入一真さんもAnkiを使用しているようです。
会食が無い分、毎晩ずっとNGSL3000語、NAWL1000語、英単語を暗記しまくってる。AnkiとQuizlet便利すぎ
— 家入 一真@クラファンのCAMPFIRE (@hbkr) April 9, 2020PC版は無料でインストールできるので、PCだけであれば完全無料で英単語学習ができそうです。※2
【英語学習に必須】Ankiアプリとは?
3つの情報
市販の英単語帳には通常、下記の3つの情報がほぼ確実に含まれています。
- 単語の翻訳詳細(品詞、他の意味)
- 例文
- 例文の翻訳
1.単語の翻訳詳細(品詞、他の意味)や2.例文に関してはTextBlobの機能を使えばうまく引っ張ってくることができるのですが、例文の翻訳が問題となってきます。
こちらの記事でも紹介しましたが、Google翻訳を使用して文章を翻訳するとコンテクストの問題やそもそもの翻訳が違うなどの問題がでてくるので、正しい学習ができない可能性があります。
まだGoogle翻訳で消耗してるの?
しかし
人力であれば、例文の自然な翻訳をしていくことはまだ可能です。
もし、私のTwitterのフォロワーが1000を超えたら、今回作成したプログラムをさらに改良し例文も含めた、
エンジニア向けの最強英単語帳
のデータを配布していきたいと思います。
英語学習に関するTipsや万が一英単語帳の配布が決定した場合のお知らせなどはこちらのTwitterで随時お知らせしていきますので、この機会にぜひフォローして頂けると幸いです。
(会社のPCだからフォローし辛いという方は、スマホで「hossyan-blog.com」もしくは「ほっしゃん エンジニア 英語」で検索してみてください。)
Twitter:ほっしゃん@エンジニア&英会話講師

データのダウンロード
私のブログのこちらのページから単語データのダウンロードと、10秒でできるAnkiへのデータインポート方法を紹介していますので、参考にしてみて下さい。
https://hossyan-blog.com/2020/04/26/how-to-download-text-data/
注釈
※1 英単語帳を英単語とその翻訳のデータセットとして定義すれば
※2 Ankiさん、広告費貰えるわけでもないのに激推ししておきましたよ!

















- 投稿日:2020-04-26T20:12:04+09:00
【AWS】API Gateway + LambdaでAPIをつくる
やりたいこと
サーバを使わずにAPIを作成したい。
EC2インスタンスからAPI Gatewayで作成したREST APIにリクエストを投げて返ってくるのを確認します。

手順
Amazon API GatewayとLambdaを使用して、REST APIを作成してみます。
1. Lambda関数を作成する
2. API GatewayでREST APIを作成する
3. REST APIをデプロイする
4. 2番目のLambda関数を作成する
5. API GatewayでREST APIにリソース、メソッド、パラメータを追加する1. Lambda関数を作成する
API Gatewayを作成する際に、Lambda関数を指定する必要があるので、先にLambda関数を作成します。
Lambdaのコンソール画面から「関数」→「関数の作成」を選択します。
関数の作成画面で「一から作成」を選択します。関数名: my-function
ランタイム: Python 3.7
を設定して「関数の作成」を押下します。
「関数 my-functionを正常に作成しました。」と出れば関数の作成は完了です。
ちなみに、作成した関数はデフォルトで「Hello from Lambda!」を返すようになっています。
2. API GatewayでREST APIを作成する
API Gatewayのコンソール画面から「APIの作成」を押下します。
今回は検証なので、「REST API プライベート」で「構築」を選択します。
ポップアップが出るのでOKを選択します。
下記画像のように設定していきます。
選択と入力が完了したら、「APIの作成」を押下します。
完了すると「/」のみが表示されます。
この「/」がルートレベルのリソースであり、APIのベースパスのURLに対応しています。
次にメソッドの追加を行います。
「アクション」→「メソッドの作成」を選択します。
「GET」を選択し、チェックマークを押下します。
すると、GETのセットアップ画面になるので、必要事項を入力して、「保存」します。
設定された内容が表示されます。
各項目の詳細については公式をご参照ください。
REST APIの作成はここで完了です。
3. REST APIをデプロイする
実際に使用するには、作成したREST APIをデプロイする必要があります。
作成したREST APIの「アクション」→「APIのデプロイ」を選択します。
ポップアップが出現するので、「新しいステージ」を選択し、
ステージ名を「dev」にして「デプロイ」を押下します。
すると、ステージエディターの画面が表示されURLの呼び出しのURLで実際にAPIにリクエストを送ることができます。
EC2インスタンスから実際にリクエストを投げてみましょう。
$ curl -X GET '呼び出しのURL' "Hello from Lambda!"設定しているLambdaが返却する「Hello from Lambda!」がレスポンスされればOKです。
4. 2番目のLambda関数を作成する
次に、GETリクエストでパラメータを持つパターンも行っていきます。
先ほどのAPIではLambdaが固定値で'Hello from Lambda!'を返却するようになっていました。
なので、今回は受け取ったGETリクエストのパラメータをレスポンスに乗せるようなLambdaでAPIを作成していきます。先ほどと同じ要領でLambda関数を作成していきます。
関数名:my-function2
ランタイム:Python 3.7
実行ロール:既存のロールを使用するで先ほど作成したロールを選択します。
作成が完了したら、関数コードを書き換えます。
受け取ったパラメータをレスポンスに乗せるようにします。
lambda_function.pyimport json def lambda_handler(event, context): myParam = event['myParam'] return { 'statusCode': 200, 'body': json.dumps(myParam) }Lambdaの設定は完了です。
5. API GatewayでREST APIにリソース、メソッド、パラメータを追加する
API Gatewayでリソースの作成をしていきます。
「アクション」→「リソースの作成」
リソース名:my-resource
→「リソースの作成」
次にメソッドの作成をしていきます。
my-resourceを選択した状態で、「アクション」→「メソッドの作成」
「GET」を選択してチェックボタンで決定する。
my-resource GETのセットアップ画面になるので、Lambda関数に先ほど作成した「my-function2」を選択して保存する。
権限追加のポップアップが出るので、「OK」
メソッドの実行画面で「統合リクエスト」を選択します。
下の方に「マッピングテンプレート」の設定があるので、
リクエスト本文のパススルー:テンプレートが定義されていない場合(推奨)
Content-Type:application/json
を指定します。
テンプレートを入力して保存します。
テンプレート{ "myParam": "$input.params('myParam')" }これで、リクエストパラメータの"myParam"という項目をLambda関数側でevent['myParam']で取得できるようになります。
lambda_function.pyimport json def lambda_handler(event, context): myParam = event['myParam'] #←ここ return { 'statusCode': 200, 'body': json.dumps(myParam) }これでAPI側の設定は完了になりますので、先ほどと同様にデプロイして実行してみます。
確認してみる
パラメータに「my-resource?myParam=Hello%20from%20API%20Gateway!」を付与してリクエストしてみます。
$ curl -X GET 'https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev/my-resource?myParam=Hello%20from%20API%20Gateway!' {"statusCode": 200, "body": "\"Hello from API Gateway!\""}リクエストパラメータに付与した「Hello from API Gateway!」がbodyとしてレスポンスすることを確認できました。
今回は必要最低限の設定で実施したので、導入する際はもっと調査が必要になりそうですが、サーバレスとしてのAPI Gateway + Lambdaの全体像はつかめたかと思います。

























- 投稿日:2020-04-26T20:02:02+09:00
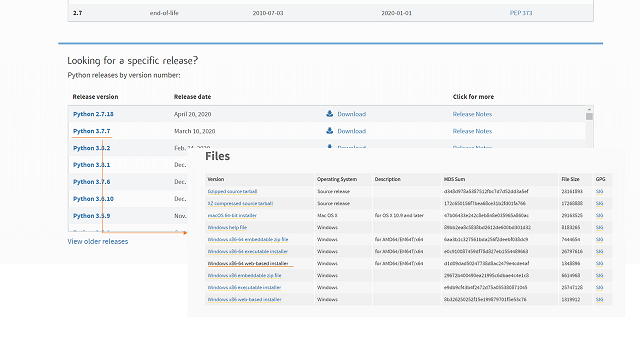
Python(Python 3.7.7 )のインストールおよび基本文法
pythonをインストールして基本文法を平たくまとめました。
何らかのPG言語に取り組んだ事のある人であれば見ただけで理解できるような記事にします
都度ブラッシュアップしていきたいと思いますインストール
■インストールパッケージ
必要なVersionをダウンロード(今回は3.7.7のWindows x86-64 web-based installerを選択)して、インストールします。Install for all usersの☑は外しました。完了すると下記にファイルが作成されます。
C:\Users\odaka\AppData\Local\Programs\Python
IDELの利用
インストールが完了すると、図のようにPythonがメニューに追加されます。
代表的な開発支援ツールとしてPyCharmやMicrosoft Visual Studioやeclipse(PyDevアドイン)などありますが、本ページではデフォルトインストールされている開発ツールであるIDELを利用します。
IDELを選択、起動します。
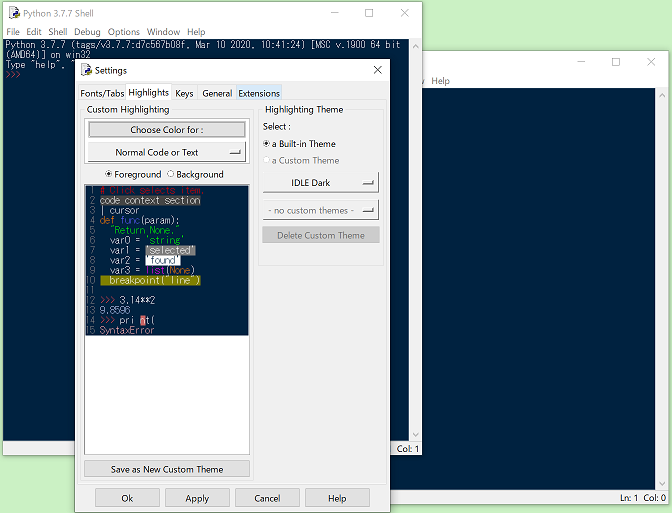
画面が真っ白で嫌いな人はOption→configIDLE→HighlightsでIDLE Darkを選択。File → New Fileを選択すると別ウインドウが開きます。
別ウインドウにpythonで命令文を記載し、保存(Ctrl+S) → Run Module(F5) を実行するとShell画面上で処理が実行されます。
基本文法
ざっと使い方を記載します。解説はコメントをご参照ください。
最低これだけあれば、なんとなく読めるようになると思います。#コメントはシャープです。 # < その1:hello world ・・・printの前にspaceは入れない、全角スペースも禁止 > print('hello world') # < その2:print関数の引数について > print('hello world',10,10.5) #複数の引数での出力 print('hello world',10,10.5,sep=':') #区切り文字 # < その3:変数(型は自動変換)とデータ入力(inputだと型は数字入れてもStrになります) > test = input('何か入れてください') print(test) #変数の出力 print((int(test))*1.08) #計算するときはstrをintに変換にして計算する # < その4:文字列操作のやり方 > test ='SAMPLE'.replace('A','I') #文字列置換 print(test) # < その5:条件分岐 > test = input('馬番をいれてください') if test.isdigit(): #数値かどうかの判定(逆の場合は if not) umaban = int(test) if umaban <6 : #6以下の場合(条件文のネスト) print('内枠') elif umaban <12 : #12以下の場合 print('中枠') else: #12以下でない場合 print('外枠') else: #数値でない場合 print('数値をいれてください') # < その6:ループ for文 > dayOfWeek =['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday'] for day in dayOfWeek : #配列のリストすべて print(day) print('--------------------') for day in dayOfWeek[1:6] : #配列のリスト2番目から5番目まで print(day) print('--------------------') for test2 in range(5) : #5回繰り返す print(test2) test2 = test2 + 1 print('--------------------') for test3 in range(6,11) : #6が10回まで繰り返す print(test3,'カウンタ') test3 = test3 + 2 #実験。test3 print(test3,'手動で加算したとき') print('--------------------') # < その7:関数の定義 > def method1(): #引数なし print('みんな','のコメント1') def method2(other): #引数あり print(other,'のコメント2') method1() method2('ほげほげ') print('--------------------')以上です。
- 投稿日:2020-04-26T18:34:50+09:00
Excel×Pythonで作業フローを効率化する方法を調べてみた①
外出自粛の影響もあり、様々なジャンルの本を買って読んでいます。
起こった出来事はいい機会だととらえて、楽しんで勉強しています(笑)それはさておき、
自動化?効率化?という事に憧れがあり、簡単なことから始めようと思い、
ExcelとPythonでExcelの作業フローを効率化する”方法だけ”を調べてみました。
実践はまた、次の記事で。。業種に関係なく汎用的に利用できるスキルであるってことも、
勉強しておこうと思った理由の1つでした。
あとは、VBAはあまり気が進まなく必要に迫られた時しか作っていません、
Pythonに逃げられるの?いいねという気持ちです(笑)調べたこと
VBAとは
Visual Basic for Applicationsの略であり、
ざっくりいうとMicrosoftのoffice製品(Excel,Wordなど)を拡張できるプログラムである。
マクロは、VBAで作成したプログラムの事。(あまりわかってなかった。。プログラムじゃあかんのか(゜-゜))
⇒スキルの適用範囲が限定される。Pythonとは
windows,mac,linux等、多様なOSで実行できるプログラミング言語である。
初心者でもわかりやすいといわれている。
また、ライブラリが豊富でいろんなことができます ('ω')漠然。。Pythonインストール
▼ここから
https://www.python.org/downloads/エディタ(なんでもいいですが。)
Visual Studio Code・・・Microsoftのソース作成支援の無料ツール
https://code.visualstudio.com/
▼入れておきたい拡張機能
・日本語化(Japanese Langbuage Pack for Visial Studio Code)
・Pythonのコード入力支援拡張(Python Extension for Visual Studio Code)Pythonライブラリ
openpyxl
Excelファイル(.xlsx)の読み書きができる
Visula Studioのターミナルで、「pip install openpyxl」
https://pypi.org/project/openpyxl/
▼リファレンス
https://openpyxl.readthedocs.io/en/stable/api/openpyxl.reader.excel.html#openpyxl.reader.excel.load_workbook
https://openpyxl.readthedocs.io/en/stable/api/openpyxl.workbook.workbook.htmlpandas
Excelのピボットテーブルができる
Visula Studioのターミナルで、「pip install pandas」
https://pypi.org/project/pandas/pathlib
ファイルや、フォルダをオブジェクトとして扱うことができる
Visula Studioのターミナルで、「pip install pathlib」
https://pypi.org/project/pathlib/参考
https://qiita.com/seradaihyo/items/91c78b05401c9c328bb8
https://qiita.com/RIKIgigasu/items/9614ad4c1887157fe6c2
https://qiita.com/KAWAII/items/a7ec5b4fc3c9365cf9fc
https://qiita.com/Takuya_Fujitani/items/93b534ad94ceaa06b89cまとめ
これで、Excelの作業フローを効率化する準備は整ったと思います。
次回は具体的にこういうのをやるぞ!って決めて実行した結果を記事にしたいと思います。
役立つものがいいですねぇ。考えます。以上です。
- 投稿日:2020-04-26T18:29:20+09:00
Macに入れていた python を 3.7 -> 3.8 にアプデする
AtCoderがPython3.8に対応してくれたのを機に、Macに入れていたPythonもアプデすることにした。
が、ググっても断片的な情報しか出てこなくて変に時間がかかってしまった。
ので、自分用にアプデ手順をまとめた。3.9が出た頃にまた同じ状況に陥りそうなので。筆者の環境
MacBook Air
OS Catalina version 10.15手順
pyenvからPython3.8.2をインストールしようとしたらこんなこと↓を言われた。
python-build: definition not found: 3.8.2 See all available versions with `pyenv install --list'. If the version you need is missing, try upgrading pyenv: brew update && brew upgrade pyenvHomeBrewとpyenvが古い、、、?
この辺を頻繁に触っている方なら問題ないだろうが、私のようにたまにしか触らずホコリを被らせている人は諸々アプデしていかなければいけなさそう。#HomeBrewのアプデ brew update # pyenvのアプデ(1.2.13 -> 1.2.15) brew upgrade pyenv10分くらいかかってようやくアプデが終わる。(遅すぎ?)
念の為pyenv install --listで3.8.2があることを確認した上でPythonインストール開始。# Python3.8.2をインストール pyenv install 3.8.210分くらい経ってインストールは完了したが、古いのを見ていたので、Global設定をしてやる。
python -V # Python 3.7.4 pyenv versions # system #* 3.7.4 (set by /Users/****/.pyenv/version) # 3.8.2 pyenv global 3.8.2 python -V # Python 3.8.2おわり
- 投稿日:2020-04-26T18:28:01+09:00
メールでGitHubに新規issueを追加する (Amazon SES活用版)
はじめに
以前、IFTTTのEmailサービス1をメールの受け口にしてAWS Lambda経由でGitHub API2を叩き、メールでGitHubに新規issueを追加する機能を作りました。自作サービスのバグや改善点に気づいたときに、メール一本でGitHubのissueを立てられる、というのは実はとても便利です。今後も継続的に使いそうなので、メールの受け口も含めてAWS上で動くよう作り直してみました。
方針
メールの受け口として、Amazon SES (Simple Email Service)3を使います。自分で管理しているドメインのメール配送先をSESの受信用エンドポイントに向けることで、メールを、Amazon SES → Amazon S3 → AWS Lambdaとバケツリレー。メールの中身に応じてGitHub API2を叩きGitHubレポジトリにissueを追加するLambda関数を、PythonフレームワークのAWS Chalice4を使って実装しました。
実現手順はざっと以下のとおりです。
- ドメイン管理 : メール配送先(MXレコード)に、SESのEメール受信用エンドポイントを設定5
- S3 : SESで受信したメールを保存するためのS3バケットをセットアップ
- SES : S3バケットに受信メールを保存するよう受信ルールを作成
- GitHub : GitHub APIを使用するためのアクセストークン("repo"権限付与)を発行
- Lambda : S3バケットから受信メールを読み込みGitHubレポジトリにissueを追加する関数を実装し配備
- S3 : 配備したLambda関数を受信メール保存時に実行するようS3バケットにイベントを設定
1から3については、AWSの開発者ガイド『Amazon SES を使用した E メールの受信 - Amazon Simple Email Service』やサポート情報『Amazon SES を使用して Amazon S3 で E メールを受信して保存する』が詳しいです。
また、4については、『GitHub「Personal access tokens」の設定方法 - Qiita』あたりで具体的な手順が解説されています。というわけで、本記事では、5と6の実装を以下でまとめます。
実装
上記の5と6でやりたいことは、結局、S3バケットに新たな受信メールが保存されたら、S3バケットから受信メールを読み込み、GitHubレポジトリにissueを追加する、という処理です。この処理、Lambda活用した開発のためのPythonフレームワークであるChalice4では、
on_s3_eventというデコレーターを使ってとても簡単に実現できます。Chalice.on_s3_event()
S3には、バケットに何らかの変更があった場合に、Lambdaなどへ通知を飛ばす仕掛けがあります。この仕掛を使うには、S3で通知を飛ばすイベントを設定すると共に、Lambdaで通知を受け取る関数を作成する必要があるのですが、Chaliceを使えばこれらの設定をほぼ自動でやってくれます。
ChaliceでS3イベントを受け取るLambda関数を実装する基本的なコードは、以下のとおりです6。
app.py(sample)from chalice import Chalice app = chalice.Chalice(app_name='s3eventdemo') app.debug = True @app.on_s3_event(bucket='mybucket-name', events=['s3:ObjectCreated:*']) def handle_s3_event(event): app.log.debug("Received event for bucket: %s, key: %s", event.bucket, event.key)
Chalice.on_s3_event()デコレーターを付けた関数を定義してコードを書けば、chalice deployで関数をLambda上に配備する際に、S3とLambdaに対するロールやイベントの設定を全て自動でやってくれます。コード
というわけで、今回は、この
Chalice.on_s3_event()デコレーターを付けた関数の中で、S3バケットから受信メールを読み込み7、GitHubレポジトリにissueを追加する処理を記述しました。Chaliceのメインコードであるapp.pyは以下のとおりとなりました。app.pyfrom chalice import Chalice import logging, os, json, re import boto3 from botocore.exceptions import ClientError import email from email.header import decode_header from email.utils import parsedate_to_datetime import urllib.request # setup chalice app = Chalice(app_name='mail2issue') app.debug = False # setup logger logger = logging.getLogger() logger.setLevel(logging.INFO) logformat = ( '[%(levelname)s] %(asctime)s.%(msecs)dZ (%(aws_request_id)s) ' '%(filename)s:%(funcName)s[%(lineno)d] %(message)s' ) formatter = logging.Formatter(logformat, '%Y-%m-%dT%H:%M:%S') for handler in logger.handlers: handler.setFormatter(formatter) # on_s3_event @app.on_s3_event( os.environ.get('BUCKET_NAME'), events = ['s3:ObjectCreated:*'], prefix = os.environ.get('BUCKET_KEY_PREFIX') ) def receive_mail(event): logger.info('received key: {}'.format(event.key)) # read S3 object (email message) obj = getS3Object(os.environ.get('BUCKET_NAME'), event.key) if obj is None: logger.warning('object not found!') return # read S3 object (config) config = getS3Object(os.environ.get('BUCKET_NAME'), 'mail2issue-config.json') if config is None: logger.warning('mail2issue-config.json not found!') return settings = json.loads(config) # メールを解析 msg = email.message_from_bytes(obj) msg_from = get_header(msg, 'From') msg_subject = get_header(msg, 'Subject') msg_content = get_content(msg) # メールアドレスを抽出 pattern = "[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+" adds = re.findall(pattern, msg_from) # メールアドレスに対応する設定を抽出 config = None for add in settings: if add in adds: config = settings[add] break if config is None: logger.info('there is no config for {}'.format(', '.join(adds))) return # レポジトリを取得 repos = getRepositories(config['GITHUB_ACCESS_TOKEN']) logger.info('repositories: {}'.format(repos)) # メールタイトルからレポジトリを判定 repo = config['GITHUB_DEFAULT_REPOSITORY'] title = msg_subject spaceIdx = msg_subject.find(' ') if spaceIdx > 0: repo_tmp = msg_subject[0:spaceIdx] if repo_tmp in repos: title = msg_subject[spaceIdx+1:] repo = repo_tmp title = title.lstrip().rstrip() logger.info("repository: '{}'".format(repo)) logger.info("title: '{}'".format(title)) # issueをPOST postIssue( config['GITHUB_ACCESS_TOKEN'], config['GITHUB_OWNER'], repo, title, msg_content ) # メールを削除 deleteS3Object(os.environ.get('BUCKET_NAME'), event.key) # S3からオブジェクトを取得 def getS3Object(bucket, key): ret = None s3obj = None try: s3 = boto3.client('s3') s3obj = s3.get_object( Bucket = bucket, Key = key ) except ClientError as e: logger.warning('S3 ClientError: {}'.format(e)) if s3obj is not None: ret = s3obj['Body'].read() return ret # S3のオブジェクトを削除 def deleteS3Object(bucket, key): try: s3 = boto3.client('s3') s3.delete_object( Bucket = bucket, Key = key ) except ClientError as e: logger.warning('S3 ClientError: {}'.format(e)) # メールヘッダを取得 def get_header(msg, name): header = '' if msg[name]: for tup in decode_header(str(msg[name])): if type(tup[0]) is bytes: charset = tup[1] if charset: header += tup[0].decode(tup[1]) else: header += tup[0].decode() elif type(tup[0]) is str: header += tup[0] return header # メール本文を取得 def get_content(msg): charset = msg.get_content_charset() payload = msg.get_payload(decode=True) try: if payload: if charset: return payload.decode(charset) else: return payload.decode() else: return "" except: return payload # githubレポジトリ一覧を取得 def getRepositories(token): req = urllib.request.Request( 'https://api.github.com/user/repos', method = 'GET', headers = { 'Authorization': 'token {}'.format(token) } ) repos = [] try: with urllib.request.urlopen(req) as res: for repo in json.loads(res.read().decode('utf-8')): repos.append(repo['name']) except Exception as e: logger.exception("urlopen error: %s", e) return set(repos) # githubレポジトリにissueを追加 def postIssue(token, owner, repository, title, content): req = urllib.request.Request( 'https://api.github.com/repos/{}/{}/issues'.format(owner, repository), method = 'POST', headers = { 'Content-Type': 'application/json', 'Authorization': 'token {}'.format(token) }, data = json.dumps({ 'title': title, 'body': content }).encode('utf-8'), ) try: with urllib.request.urlopen(req) as res: logger.info(res.read().decode("utf-8")) except Exception as e: logger.exception("urlopen error: %s", e)送信元のメールアドレスに応じて、GitHub APIを使用するためのアクセストークンを切り替えられるよう、以下のような設定ファイルをS3上から読み込むようにしています。
mail2issue-config.json{ "<送信元メールアドレス>": { "GITHUB_OWNER": "<GitHubユーザ名>", "GITHUB_ACCESS_TOKEN": "<GitHubアクセストークン>", "GITHUB_DEFAULT_REPOSITORY": "<メールタイトルで指定がなかった場合のレポジトリ名>" }, ... }おわりに
別の目的でたまたまAmazon SESを触る機会があり、AWSでメールを受けられるならと、今回のリファクタリングに至りました。メールをトリガーにしたサービスはまだ色々とありそうなので、今回のパターンの応用も引き続き考えてみます。
私は、自分で取得したドメインを管理しているVALUE-DOMAINで設定しました。無料のDynamicDNSサービスを活用した事例などもあるようです。(参考:無料DDNSとAmazon SESを使ってメール受信を行う - Qiita) ↩
Lambda Event Sources — Python Serverless Microframework for AWS 1.14.0 documentation ↩
Pythonの標準ライブラリを使ってメールをデコードしています。(参考:Python の標準ライブラリでメールをデコードする - Qiita) ↩
- 投稿日:2020-04-26T18:25:28+09:00
Python: Queue に型を付ける
皆さん、普段 Python でコードを書くときはちゃんと型を書いてますよね?
まだ型の書き方を知らない場合は Software Design 2020年 5月号の『Python でも型チェックしよう』を読むといいと思いますよ (宣伝)。レビューのお手伝いをした『Python でも型チェックしよう』(by @t2y)が掲載されているSDが発売されました。型ヒントを使ってみたい方におすすめです。また、3.8で導入された Protocolなども紹介されており、すでに使っている方にもお勧め! / Software Design 2020年5月号 https://t.co/JL5GgO0mcq
— tk0miya (@tk0miya) April 18, 2020私はコードに型をつけ始めておおよそ 3年ぐらいになるのですが、いまでは型がないと落ち着かなくなっています。
コード規模がある程度大きくなるとコードを書くときにツッコミをくれたり、バグを未然に防いだりしてくれるので、プログラム開発強制ギプス的な役割として非常に助かっています。
慣れるまではしばらく時間がかかりますが、とてもおすすめです。キューの型を書きたい
そんなある日、ふとデータ型としてキューを使おうとしたときにこんなことに気づきました。
ふむー、typing.Queue って存在しないのかー
— tk0miya (@tk0miya) April 25, 2020
queue.Queueクラスを使って型を書くことはできますが、typing.Queueに相当する型がないのです。q: queue.Queue = queue.Queue() q.put(1) value = q.get()この状態でも型チェッカーによるサポートは得られるのですが、もう少し詳細な型をつけたくなります。
たとえば、キューでやり取りするデータが数値である、文字列であるといった情報も指定できると嬉しいですよね。リストの場合は
List[int]やList[str]とアノテーションしますが、Queue の場合はどうするとよいのでしょうか。試しにQueue[int]とアノテーションしてみたところエラーになってしまいました。>>> from queue import Queue >>> q: Queue[int] = Queue() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'type' object is not subscriptable数値を扱うキューの型ってどう書くのか
どのように書くべきか調べてみたところ、 bpo-33315 や python 3.6 - What is the correct way to type hint a homogenous Queue in Python3.6 (especially for PyCharm)? - Stack Overflow に解決方法が書かれていました。
I think this issue appeared previously on typing tracker. The current recommendation is to escape problematic annotations with quotes:
q: 'Queue[int]'
現状の回避策としては文字列として型を記述するとよい、ということのようです。
実際に Python インタプリタで指定してみるとエラーにはなりません。>>> from queue import Queue >>> q: "Queue[int]" = Queue() >>>そして、mypy も正しく判定してくれるようです。
example.pyfrom queue import Queue q: "Queue[int]" = Queue() q.put(1) i: int = q.get() print(i) q.put("2") s: str = q.get() print(s)$ mypy example.py example.py:9: error: Argument 1 to "put" of "Queue" has incompatible type "str"; expected "int" example.py:10: error: Incompatible types in assignment (expression has type "int", variable has type "str") Found 2 errors in 1 file (checked 1 source file)仕組み
この動作は Python インタプリタと mypy で型アノテーションの扱いが異なるために発生します。
Queue[int] の場合
Python インタプリタでは
Queue[int]は Queue クラスの辞書アクセスとして解釈され、Queue.__getitem__(int)を呼び出そうとします。しかし、 Queue クラスには__getitem__()メソッドが存在しないためエラーになります。一方、mypy の方では、Queue クラスはジェネリッククラスとして認識されており、
Queue[int]は 「int の値を持つキュー」として扱われます。typeshed1 の Queue クラスの型定義 を見てみると、Queue クラスは Generic を継承していることがわかります。"Queue[int]" (文字列)の場合
今度は
"Queue[int]"という文字列表記の型アノテーションについて見てみましょう。
Python インタプリタでは単なる文字列として扱うため、「文字列でアノテーションされた変数」として扱います。Python インタプリタは型アノテーションを評価しないため、中身は気にせず先に進みます。一方、mypy は文字列表記されている型アノテーションは中身を展開して型ヒントとして扱います。そのため、
Queue[int]が指定されたものと同様に扱います。ということで、文字列で
"Queue[int]"と書くとうまくいくのでした。
Queue[int]"Queue[int]"Pythonインタプリタ エラーになる(評価しようとする) エラーにならない(単なる文字列扱い) mypy 型チェックできる 型チェックできる Python3.7 の遅延評価機能を使おう
型アノテーションの評価について説明したところでピンときた方もいるかも知れません。お気づきの方はこのブロックは読み飛ばしていただいて結構です。
先ほどは回避方法として文字列でアノテーションする方法をお伝えしましたが、Python3.7 を使っている場合はもうひとつ別のアプローチがあります。Python3.7 で先行導入された機能のひとつである PEP 563 -- Postponed Evaluation of Annotations を利用する方法です。この機能は読んで字の如し、型アノテーションの遅延評価機能です。
この機能を利用すると、型アノテーションは次のように扱われます。
- Python インタプリタでは型アノテーションを評価しない
- mypy などの型チェックツールでは型アノテーションを評価する
先ほどの表に照らし合わせると次のようになります。
Queue[int]"Queue[int]"Pythonインタプリタ エラーになる(評価しようとする) エラーにならない(単なる文字列扱い) PEP 563 ( __future__)無視される (評価しない) 無視される (評価しない) mypy 型チェックできる 型チェックできる この機能を利用するには、コードの先頭に future 文を書きます(参考: future --- future 文の定義)。
from __future__ import annotations from queue import Queue q: Queue[int] = Queue() q.put(1) i: int = q.get() print(i) q.put("2") s: str = q.get() print(s)この機能を利用すると、型アノテーションを文字列にせずにすむため、スッキリ書けますね。
余談
以前の記事(PEP 585 (Type Hinting Generics In Standard Collections) を読んだよメモ - Qiita) で紹介しましたが、PEP 585 の導入が決定した場合
Queue[int]と書けるようになるはずです。記事の途中でリンクを張った bpo-33315 でも PEP 585 に言及されています。いずれはこうした小手先のテクニックを使わずに自然なアノテーションができるようになることが期待されます。
まとめ
- int のキューを書きたい場合は文字列で
"Queue[int]"と書きましょう- Python 3.7 以降に利用している場合は
from __future__ import annotationsのほうがよさそう- 将来的には単に
Queue[int]で良くなると思われる謝辞
この記事を書くに当たり、雑談 & ボヤキに付き合ってくれた @t2y, @masahito に感謝します。
Python の標準ライブラリの型データベース ↩
- 投稿日:2020-04-26T18:21:11+09:00
Pythonで毎日AtCoder #48
はじめに
前回
今日はABC#48
考えたこと
前に見たことがあるような気がします。それぞれの要素ごとにcountしているとTLEします。ですので、sortして疑似count的なことをします。あとは、要素の数が少ない順に書き換えていくだけです。n, k = map(int,input().split()) a = list(map(int,input().split())) a.sort() num = [0] * n c = 0 t = 0 for i in range(n-1): if a[i] != a[i+1]: c += 1 num[a[i]-1] += c t += 1 c = 0 else: c += 1 s = sum(num) t += 1 num[a[i+1]-1] = n - s num.sort() ans = 0 for i in range(n): if num[i] == 0: continue if t <= k: print(ans) break ans += num[i] t -= 1まとめ
すごく不調なので、ABCまでに回復できるようにします。早く茶色になりたい。ではまた。
- 投稿日:2020-04-26T18:17:38+09:00
Azure Speech to Text 使ってみた.
Microsoft Azureの音声認識APIの使い方
MacOS Catalina(ver. 10.15.4)における音声認識APIの簡単な使い方について説明します.
Cognitive Services のSpeech to Textを使用し日本語を認識させてみました.
シェルはzshなのでbashの方はできないかもしれません.リソース作成
まず前提条件として,Azureのアカウントを作っておいてください.無料でアカウント作成はできます.200$のデポジットがついて,1年間いろんなAPIが無料で使えるのでおすすめです.
- アカウントが作成できたら,ポータルサイトのリソースの作成をクリックしてください.
- 検索バーでSpeechと検索すると,音声またはSpeechというAPIの選択肢が出てきます.
- Speechの選択肢をクリックし,さらに作成をクリックしてください.
- 作成フォーム画面になり,以下の項目が出てきます.
- 名前: リソースの名前(なんでも良い)
- サブスクリプション: Free Trial(デフォルトで表示されている)
- 場所: 東日本(日本のリージョンを指定した場合)
- 価格レベル: F0
- リソースグループ: 新規作成をクリックしてリソース名を決めてください.なんでもいいです.
- リソースが作成できたら,ダッシュボードに作成したリソースが反映されているはずなのでクリックしてください.
- すると,概要にキーの管理という項目があるので,クリックしてください.そこに,リソース名,エンドポイント,サブスクリプションキー2つが書いてあります.サブスクリプションキーは後で使うので覚えておいてください.
サブスクリプションキーは他人に絶対見られないようにしておいてください.
ここまでが音声認識インスタンス作成です.実装
次に,PC上での設定を行います.
はじめに,Speech SDKをインストールします..zshpython3 -m pip install --upgrade pip pip install azure-cognitiveservices-speech次にMicroSoftが用意している音声認識用のサンプルコードがGIT上にあるのでローカルにquickstart.pyファイルを作成して,コピペしてください.gitにはquickstart.pyとjupyter用のコード(Quickstart.ipynb)とREADME.mdがあるので,quickstart.pyの中身をコピペしてください.(コードはこちら)
こんな感じのコードが書いてあります.コピペしたら変更する箇所が一箇所,追記が一つあります.quickstart.py# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. See LICENSE.md file in the project root for full license information. # <code> import azure.cognitiveservices.speech as speechsdk # Creates an instance of a speech config with specified subscription key and service region. # Replace with your own subscription key and service region (e.g., "westus"). ''' 以下変更箇所 サブスクリプションキー:先ほど確認したリソースの概要から確認できる二つのキーのうちどちらか一つ 場所:東日本なら'japaneast', 西日本なら'japanwest'としてください. ''' speech_key, service_region = "サブスクリプションキー", "場所" speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) ''' 以下追記箇所 日本語を認識させるための設定.これがないとデフォルトで英語しか認識してくれない. ''' speech_config.speech_recognition_language="ja-JP" # Creates a recognizer with the given settings speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config) print("Say something...") # Starts speech recognition, and returns after a single utterance is recognized. The end of a # single utterance is determined by listening for silence at the end or until a maximum of 15 # seconds of audio is processed. The task returns the recognition text as result. # Note: Since recognize_once() returns only a single utterance, it is suitable only for single # shot recognition like command or query. # For long-running multi-utterance recognition, use start_continuous_recognition() instead. result = speech_recognizer.recognize_once() # Checks result. if result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(result.text)) elif result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(result.no_match_details)) elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) # </code>これで準備が整ったので,実際にターミナルから次を実行してください.
.zshpython quickstart.py私の場合VScode経由で実行すると音声が認識されなかったので,もしそのようなことが起きたら,ターミナルで実行してください.
VScodeでできるやり方,設定を知っている方は是非教えてくれると嬉しいです.
実行するとsay something...と表示されるので,何か一言発言してみてください.
認識結果が出力されるはずです.
設定上,一言しか認識しませんが,シーケンスの認識に変更も可能です.以上で終わりです.
- 投稿日:2020-04-26T17:46:46+09:00
multiprocessを使ったコードをpython setup.py testする
要約
- setup.pyでmultiprocessモジュールを含むunittestを実行すると無限ループになる
- どうやらmultiprocessモジュールの仕様らしい
- 回避策として「__main__」を一時的に書き換える
前提
pythonでマルチプロセスで関数を動作させるのは「multiprocess」モジュールを使用します。
使い方やサンプルコードは公式が十分に分かりやすいです。
https://docs.python.org/ja/3/library/multiprocessing.htmlさて、次のコードを見てください
from multiprocessing import Pool def f(x): return x*x def main(): with Pool(5) as p: print(p.map(f, [1, 2, 3])) main()公式のサンプルコードから「if __name__ == '__main__':」を省きました。
これを実行するとえらいことになります。
(無限ループに入ってプロセスキルが必要になります)公式にも記載があるので、これは仕様のようです
https://docs.python.org/ja/3/library/multiprocessing.html#the-spawn-and-forkserver-start-methodsひとまず
multiprocessを使用したコードでは「if __name__ == '__main__':」を省いてはいけない
ということになります。本題
さて、マルチプロセスを使ったモジュールを作成して、unittestを実行するとします。
mp_test.pyfrom multiprocessing import Pool def f(x): return x*x def main(): with Pool(5) as p: print(p.map(f, [1, 2, 3])) if __name__ == '__main__': passtest_mp_test.py"""Tests for `multiprocess_test` package.""" import unittest import mp_test class TestMultiprocess_test(unittest.TestCase): """Tests for `multiprocess_test` package.""" def setUp(self): """Set up test fixtures, if any.""" def tearDown(self): """Tear down test fixtures, if any.""" def test_000_something(self): mp_test.main() if __name__ == "__main__": unittest.main()$python test_mp_test.pyこれは実行できます。
では、このテスト、setup.pyを経由して実行するとどうなるでしょうか。
mp_test.py tests |-test_mp_test.py setup.py$python setup.py testそうです。無限ループになります。
回避策
setup.pyのテスト実行プロセスがmultiprocessの仕様にあっていないのではとは思うのですが、
行きついた回避策は次のようなものでしたtest_mp_test.py"""Tests for `multiprocess_test` package.""" import unittest import sys import mp_test class TestMultiprocess_test(unittest.TestCase): """Tests for `multiprocess_test` package.""" def setUp(self): """Set up test fixtures, if any.""" def tearDown(self): """Tear down test fixtures, if any.""" def test_000_something(self): old_main = sys.modules["__main__"] old_main_file = sys.modules["__main__"].__file__ sys.modules["__main__"] = sys.modules["mp_test"] sys.modules["__main__"].__file__ = sys.modules["mp_test"].__file__ mp_test.main() sys.modules["__main__"] = old_main sys.modules["__main__"].__file__ = old_main_file if __name__ == "__main__": unittest.main()https://stackoverflow.com/questions/33128681/how-to-unit-test-code-that-uses-python-multiprocessing
実行中の"__main__"を書き換えます。
こうすることで、setup.pyからのunittestも実行可能です。おわりに
toxでテスト環境を構築しているときに気が付いて調査しました。
VSCや単体でのUnittestでは気が付かないので、開発終盤で「わぁぁぁぁぁっぁぁ」となることもあるのではないでしょうか。
ただ、もっとスマートな回避策がありそうなのですが、知っている人がいれば教えてもらえるとありがたいです。
- 投稿日:2020-04-26T17:46:37+09:00
カイ二乗分布を手を動かして理解する
https://bellcurve.jp/statistics/course/9208.html
上のURLによると、カイ二乗分布は標準正規分布に従う確率変数の二乗の和である。しかし、いまいち分布をみても実感がわかないのでJupyterで試してみる。
定義に従ってN(0,1)に従う確率変数を生成し、二乗和を取るという試行を複数回実施し、分布を確認する。下図の左側がKDEを描画したもの。右側がヒストグラムである。
左の図は、分布とほぼ同じ形が再現できているのが確認できる。右の図は、形状はほぼ同じ。ちょっと違和感があるが、サンプル数増やしたり縦軸と横軸を調整すれば近づきそう。
これによって「カイ二乗分布は、標準正規分布に従う確率変数の二乗の和」というのが体感として少し理解できた。自由度1のときはほぼ0に近い値を取ることが多いが、自由度が大きくなるとそれらの和を取ることになるので、分布の山は少しずつ右にずれていく。自由度1のときの平均値は1である(図から見るとパッとわかりにくいが)ことを前提とすると、自由度=独立した標準正規分布の個数なのであるから、期待値が自由度と一致するのも納得できる。
一方、「だから何なの?」という疑問が残る。調べたところ、以下がわかりやすかった。
https://atarimae.biz/archives/13511
ただ、標本平均だけでは、例えば「サイコロを120回投げたら1と6ばかり出た」のに対して「偶然とは考えにくい結果だ」という結論を下すことができません。
標本「平均」だけでは、当然ながらその標本の偏りは表現できない。従って、「平均だけ見ると妥当だが明らかに偏りがある結果」の矛盾を指摘できない。それを解決するための発想としては「標本の二乗和(≒分散)の分布を確認する」となり、それをチェックするためのツールがカイ二乗分布であるといえる。
これまでは表面的な理解しかしていなかったが、ちょっとカイ二乗分布の理解が深まった気がする。
利用したノートブックは以下。

- 投稿日:2020-04-26T17:30:31+09:00
Pythonパッケージ管理ツール個人的まとめ
同種の記事は数多くあるが、今となってはマイナーなツールが混じっていたり、役割の違いがわかりにくかったりしていたので、簡単にまとめ直した。
機能まとめ
Pyflowによる比較表を書き直した。pipとvenvはPython 3.4以降標準で付属している。
ツール パッケージインストール 依存関係解決 Pythonバージョン管理 仮想環境構築 ビルド・パブリッシュ pip 〇 venv 〇 Anaconda 〇 〇 〇 〇 pyenv(-virtualenv) 〇 (〇) Pipenv 〇 〇 〇 Poetry 〇 〇 〇 〇 Pyflow 〇 〇 〇 〇 〇 個人の感想
Anaconda
- PATHを上書きする怪しい仕様があり、Homebrewと競合したりアンインストールに苦労したりする
- venv同様仮想環境を使うときにいちいち
activateする必要がある
- これらの問題があるのでpyenv経由で使うのが良い
conda installでパッケージが見つからないときにanaconda cloudで検索する手間が発生する- Anacondaを推奨しているパッケージを使いたいときは使う
pip + pyenv (+pyenv-virtualenvプラグイン)
- Pythonバージョン管理に関しては最強
- AnacondaやPyPyも扱える
- pyenv-virtualenvによる仮想環境管理もとても楽
- 仮想環境をプロジェクト間で使い回しやすい?
- (Windows環境は知らん)
Pipenv
- 動作がどんどん遅くなっていく...
- 別バージョンのPythonを使いたくなったらpyenvと併用
Poetry
- コードを配布する予定があるときは良さそう
- 別バージョンのPython (ry
Pyflow
- まだまだ開発中という感じ
- 投稿日:2020-04-26T17:10:41+09:00
モンテカルロ法によるπの推定
モンテカルロ法によって円の面積を求める。
方法
正方形の中に、x,y座標ともに一様な乱数を点としてプロットする。そのうち、円の中にある点の数を数え上げることで、円の中に存在する点の確率が計算できる。
この確率から面積を求めることができる。
具体的には、x,y座標ともに(-1,-1)と(1,1)となる正方形とそこに密接する円を想定する。
import matplotlib.pyplot as plt import matplotlib.patches as patches import numpy as np fig,ax = plt.subplots(figsize=(5, 5)) rect = patches.Rectangle((-1,-1),2,2,linewidth=1, fill=False, color='blue') ax.add_patch(rect) ax.add_artist(plt.Circle((0, 0), 1, fill=False, color='r')) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_xlim(-2,2) ax.set_ylim(-2,2)
この赤の円の中に入る点の数を数える。
1000個の点を打ってみる
df = pd.DataFrame( (1 + 1) * np.random.rand(1000, 2) - 1, columns=['x', 'y']) fig, ax = plt.subplots(figsize=(5, 5)) ax.scatter(df.x, df.y, s=1, color='black') rect = patches.Rectangle((-1,-1),2,2,linewidth=1, fill=False, color='blue') ax.add_patch(rect) circle = plt.Circle((0, 0), 1, fill=False, color='r') ax.add_artist(circle) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_xlim(-2,2) ax.set_ylim(-2,2)
この点群のうち幾つが円の中にあるかを計算する。
df["is_inside_circle"] = df.x**2 + df.y**2 <= 1 len(df[df.is_inside_circle]) # 798数え方は
$$ x^{2} + y^{2} \leq 1 $$
となる点の数を数えている。
結果として、1000個のうち、798個が円の中に存在する点である。
正方形の中の79.8%が点が円を構成していると考えると、円の面積は
$$ 2 \times 2 \times 0.798 = 3.192 $$
円の公式では、π=3.14とすると
$$ 1 \times 1 \times 3.14 = 3.14 $$
より近い値が出ている。
1000個の点の配置の仕方は、numpyの乱数の生成の仕方に由来する。そのため、円の中にたまたま点が多く置かれるような偏りが起こる。
そこで、試行回数(シミュレーション回数)を増やすことで、計算されるπの値の確率分布を探ることができる。
それでは、これを1000回シミュレーションしてみる。
四角形の中に点を1000個打ち、πを計算する作業を1000回やってみる
results = [] # この変数のなかに推定されるπの値を入れる for i in range(1000): rand_num = 1000 xy = (1 + 1) * np.random.rand(rand_num, 2) - 1 df = pd.DataFrame(xy, columns=['x', 'y']) df["is_inside_circle"] = df.x**2 + df.y**2 <= 1 ans = 4*len(df[df.is_inside_circle == True])/rand_num results.append(ans) # 描画のために整形 r_df = pd.DataFrame(results, columns=['area']) plt.hist(r_df.area, bins=50) print(f"mean: {np.mean(results)}") # 平均: 3.1412359999999997 print(f"variance: {np.var(results)}") # 分散: 0.0026137523040000036
1000回試行してみることで
「1000個の点を用いたモンテカルロ法では、πは平均3.1412、分散0.0026の範囲の値を取りうる」ことがわかった。
分散の平方根を取ることで、標準偏差がわかる。
np.sqrt(np.var(results)) # 0.051124869721105436πの推定値の確率分布が正規分布に従っていると仮定すると以下のことがわかる。
値の68%は平均から±1σ、値の95%は平均から±2σ、99.7%は平均から±3σ以内に入る。(σ = 標準偏差 = ここでは0.051)
実際に計算してみよう。
平均から±1σの範囲にある点の個数
result_mean = np.mean(results) sigma = np.sqrt(np.var(results)) # 平均から±1σの範囲にある点の個数 len([result for result in results if result >result_mean + (-1) * sigma and result < result_mean + 1 * sigma]) # 686 # 平均から±2σの範囲にある点の個数 len([result for result in results if result >result_mean + (-2) * sigma and result < result_mean + 2 * sigma]) # 958 # 平均から±3σの範囲にある点の個数 len([result for result in results if result >result_mean + (-3) * sigma and result < result_mean + 3 * sigma]) # 998より、正規分布に近いような個数が得られることが分かる。
まとめ
この記事では、「四角形の中に点を1000個打ち、πを計算する作業を1000回やってみる」というのをおこなった。これは、四角形の中に打つ点の数と、πのシミュレーション回数という2つの変数を持つ。
この変数を変えることで
- 四角形の中に打つ点の数を増やす => 一試行あたりのπの値が真の値に近くなる。
- πのシミュレーション回数を増やす => πの推定値の平均は真の値に近くなり、分散は小さくなる。
ということが実現される。



- 投稿日:2020-04-26T17:05:51+09:00
Python + GLFW + OpenGL
スタートまで
底本
GLUT/freeglutによる OpenGL入門/床井 浩平/工学社
です。環境
主はLinux Mint,副でWindows。
OpenGL
あちこちで「古の」とか「今さら」とか書かれているglBegin方式です。
ベースとなるコード
「pyglfw tutorial」で検索して出てきたページ Python で OpenGL (2) PyOpenGLのインストール をスタートにする。エッセンスだけを残すと,
# based on https://maku.blog/p/665rua3/ import glfw from OpenGL.GL import * if not glfw.init(): raise RuntimeError('Could not initialize GLFW3') window = glfw.create_window(300, 300, 'Program', None, None) if not window: glfw.terminate() raise RuntimeError('Could not create an window') glfw.make_context_current(window) while not glfw.window_should_close(window): glfw.poll_events() glfw.terminate()ところが,システムモニターを動かしながらこれを実行すると,CPUコアの1個が100%になってしまう。
poll_events()は一瞬で終わるが,これを繰り返し呼び続けるからだ。少し休みを入れるといい。というわけでimport time time.sleep(1e-3)を入れてやればよい。が,こんなことを自分でやらなければならないのか。用意されていた。
glfw.wait_events_timeout(1e-3)である。よって,先ほどのコードの
poll_events()をwait_events_timeout(1e-3)にしたものをベースにする。なお,何もしないのだからloopは
passでもいいのかというと,プログラムを終了するために押す×のイベントさえ受付けなくなり,終了させる手段がなくなる。×を押し続けると「Programから応答がありません」になってしまう。まずはバージョンの取得
version.pyimport glfw from OpenGL.GL import * print('GLFW version:', glfw.get_version()) if not glfw.init(): raise RuntimeError('Could not initialize GLFW3') window = glfw.create_window(300, 300, 'prog1 5.1', None, None) if not window: glfw.terminate() raise RuntimeError('Could not create an window') glfw.make_context_current(window) print('Vendor :', glGetString(GL_VENDOR)) print('GPU :', glGetString(GL_RENDERER)) print('OpenGL version :', glGetString(GL_VERSION)) glfw.terminate()自分の環境ではGLFWのバージョンはLinux Mintが3.2.1,Windowsが3.3.2だった。(2020/4/26)
が。古めのマシン2台でWindows上で
The driver does not appear to support OpenGL.
というメッセージが出てクラッシュした。いずれもグラフィックスはCPU内蔵である。
1台はi3 M380で,OpenGL Extension Viewerというソフトで見るとOpenGL Versionの項がN/Aなので,当然である。
もう1台はi5-2500で,ViewerはVersion 3.1と言っているのだが,ViewerのRendering Testをするとクラッシュする。グラフィックシステムがOpenGLをサポートしていることになっているのにちゃんとできていないようである。イベント
イベント・ドリヴンであるから,まずはイベントを知らなければいけない。event.pyはウィンドウ関係の重要な2つのイベントwindow_sizeとwindow_refreshを検知するプログラムである。GLFWではイベントにcallbackを結びつける関数は
glfw.set_xxx_callbackという名前である。これらの関数の第1引数はwindowであるから,windowが作られた後(glfw.create_windowの後)にこれらを呼ぶことになる。event.py# mini version # size is NOT invoked at start. # refresh is NOT invoked at start on Windows. import glfw from OpenGL.GL import * def init(): glClearColor(0.0, 0.0, 1.0, 1.0) def window_size(window, w, h): global n_size n_size += 1 print('Size', n_size, w, h) def window_refresh(window): global n_refresh n_refresh += 1 print('Refresh', n_refresh) n_size = 0 n_refresh = 0 if not glfw.init(): raise RuntimeError('Could not initialize GLFW3') window = glfw.create_window(300, 300, 'prog1 5.1', None, None) if not window: glfw.terminate() raise RuntimeError('Could not create an window') glfw.set_window_size_callback(window, window_size) glfw.set_window_refresh_callback(window, window_refresh) glfw.make_context_current(window) init() while not glfw.window_should_close(window): glfw.wait_events_timeout(1e-3) glfw.terminate()さて,Windows OS上でこれを実行すると,ウィンドウは作られるのに,イベントは何も発生していなことがわかる。なお,Linux上ではrefreshが発生する。OSにより動作が異なるのは大変困ったことである。一つのコードで両方のOSで動くようにするためには,OSを検出するか,発生しないWindowsに合わせることになる。
さて,考えてみると,refreshはあくまでもre-(再)である。このような場面でよく使われるexposeではない。最初の描画はあんただよ,というのがGLFWの言い分なのかもしれない。また,sizeについてはglfw.create_windowを呼ぶときに我々が指定する。初期サイズはあんたが知っているよね,というのがGLFWの言い分なのかもしれない。
このようなことから,初期動作をcallbackに任せっぱなしにできないのが面倒なところである。
次に,ウィンドウを一旦アイコン化してからまた開くと,Linuxではイベントは何も発生しないが,Windowsでは発生する。他のウィンドウで当該ウィンドウの一部を隠してからまた前面に出したりする際には何もイベントは発生しない。
次に,マウス操作でウィンドウのサイズを静かに少しだけ変えてみると,sizeとrefreshのイベントがペアで,この順で発生することがわかる。
フル版も載せておく。
event_full.py# full version # size is NOT invoked at start. # refresh is NOT invoked at start on Windows. # size is invoked at iconify on Windows. import glfw from OpenGL.GL import * def init(): glClearColor(0.0, 0.0, 1.0, 1.0) def window_size(window, w, h): global n_size n_size += 1 print('Size', n_size, w, h) def framebuffer_size(window, w, h): global n_FB_size n_FB_size += 1 print('Framebuffer Size', n_FB_size, w, h) def window_pos(window, x, y): global n_pos n_pos += 1 print('Position', n_pos, x, y) def window_iconify(window, iconified): global n_icon n_icon += 1 print('Iconify', n_size, iconified) def window_refresh(window): global n_refresh n_refresh += 1 print('Refresh', n_refresh) n_size = 0 n_FB_size = 0 n_pos = 0 n_icon = 0 n_refresh = 0 if not glfw.init(): raise RuntimeError('Could not initialize GLFW3') window = glfw.create_window(300, 300, 'prog1 5.1', None, None) if not window: glfw.terminate() raise RuntimeError('Could not create an window') glfw.set_window_size_callback(window, window_size) glfw.set_framebuffer_size_callback(window, framebuffer_size) glfw.set_window_pos_callback(window, window_pos) glfw.set_window_iconify_callback(window, window_iconify) glfw.set_window_refresh_callback(window, window_refresh) glfw.make_context_current(window) init() while not glfw.window_should_close(window): glfw.wait_events_timeout(1e-3) glfw.terminate()静止画の基本
全く動きのない静止画の基本となるプログラムである。ファイル名中の5.1は底本によっており,気にしないでいただきたい。
prog1_5.1_GLFW.pyimport glfw from OpenGL.GL import * def display(): glClear(GL_COLOR_BUFFER_BIT) glBegin(GL_LINE_LOOP) glVertex2d(-0.9, -0.9) glVertex2d( 0.9, -0.9) glVertex2d( 0.9, 0.9) glVertex2d(-0.9, 0.9) glEnd() glfw.swap_buffers(window) def init(): glClearColor(0.0, 0.0, 1.0, 1.0) display() # necessary only on Windows def window_refresh(window): display() if not glfw.init(): raise RuntimeError('Could not initialize GLFW3') window = glfw.create_window(300, 300, 'prog1 5.1', None, None) if not window: glfw.terminate() raise RuntimeError('Could not create an window') glfw.set_window_refresh_callback(window, window_refresh) glfw.make_context_current(window) init() while not glfw.window_should_close(window): glfw.wait_events_timeout(1e-3) glfw.terminate()描画は初期とwindow_refreshの際に必要なので,displayという名前でcallback関数window_refreshからは独立させてある。
GLFWでは初めからダブル・バッファリングなので,display関数の最後はglfw.swap_buffersである。
入力
マウス
イベントは以下のようなものである。
cursor_pos カーソルが移動したとき
cursor_enter カーソルが当該ウィンドウに入ったとき,出たとき
mouse_button マウスのボタンが押されたとき
scroll マウス中央のダイヤルを回したとき(y),左右に倒したとき(x)GLFWでは,座標x, yは得られないので,座標が必要であればglfw.get_cursor_posで取得する。
mouse_event.pyimport glfw from OpenGL.GL import * def init(): glClearColor(0.0, 0.0, 1.0, 1.0) display() # necessary only on Windows def display(): glClear(GL_COLOR_BUFFER_BIT) glfw.swap_buffers(window) def cursor_pos(window, xpos, ypos): print('cursor_pos:', xpos, ypos) def cursor_enter(window, entered): print('cursor_enter:', entered) def mouse_button(window, button, action, mods): pos = glfw.get_cursor_pos(window) print('mouse:', button, end='') if button == glfw.MOUSE_BUTTON_LEFT: print('(Left)', end='') if button == glfw.MOUSE_BUTTON_RIGHT: print('(Right)', end='') if button == glfw.MOUSE_BUTTON_MIDDLE: print('(Middle)', end='') if action == glfw.PRESS: print(' press') elif action == glfw.RELEASE: print(' release') else: print(' hogehoge') x, y = pos print(pos, x, y) def scroll(window, xoffset, yoffset): print('scroll:', xoffset, yoffset) def window_refresh(window): display() if not glfw.init(): raise RuntimeError('Could not initialize GLFW3') window = glfw.create_window(300, 300, 'mouse on GLFW', None, None) if not window: glfw.terminate() raise RuntimeError('Could not create an window') glfw.set_cursor_pos_callback(window, cursor_pos) glfw.set_cursor_enter_callback(window, cursor_enter) glfw.set_mouse_button_callback(window, mouse_button) glfw.set_scroll_callback(window, scroll) glfw.set_window_refresh_callback(window, window_refresh) glfw.make_context_current(window) init() while not glfw.window_should_close(window): glfw.wait_events_timeout(1e-3) glfw.terminate()キーボード
keyで得られるのはkey codeという整数値である。だが,〇〇というキーのキーコードはいくらだろう,ということを知る必要はない。すべてのキーに定数が付けられている。プログラムではA,上向きカーソルキー,エンターの例を示している。
keyboard.pyimport glfw from OpenGL.GL import * def display(): glClear(GL_COLOR_BUFFER_BIT) glfw.swap_buffers(window) def init(): glClearColor(0.0, 0.0, 1.0, 1.0) display() # necessary only on Windows def keyboard(window, key, scancode, action, mods): print('KB:', key, chr(key), end=' ') if action == glfw.PRESS: print('press') elif action == glfw.REPEAT: print('repeat') elif action == glfw.RELEASE: print('release') if key == glfw.KEY_A: print('This is A.') elif key == glfw.KEY_UP: print('This is Up.') elif key == glfw.KEY_ENTER: print('This is Enter.') def window_refresh(window): display() if not glfw.init(): raise RuntimeError('Could not initialize GLFW3') window = glfw.create_window(300, 300, 'KB on GLFW', None, None) if not window: glfw.terminate() raise RuntimeError('Could not create an window') glfw.set_key_callback(window, keyboard) glfw.set_window_refresh_callback(window, window_refresh) glfw.make_context_current(window) init() while not glfw.window_should_close(window): glfw.wait_events_timeout(1e-3) glfw.terminate()Referenceの見方
pyglfwの プロジェクトページと見られるページ には大したことは書かれていない。このページにホームページというリンクがあるが,リンク切れである。Mirrorというページはある。このようなページにReferenceがあってほしいのだが,どうも見当たらない。
そこで,GLFWのページ を見てみる。ここは Documentation > HTML Documentation と進んでいくとTutorialもReferenceもある。
問題は,GLFWのページはC言語で書かれているが,それがPythonではどうなるか,ということである。
今までのものを関数で見比べてみると,
glfwCreateWindow → glfw.create_window
こんな感じである。キャメルケース → スネークケースである。
CとPythonで引数の数が違うことがある。Pythonの glfw.get_cursor_pos(window) は引数が1つ,windowだけで,座標をタプルで返したが,Cでは
void glfwGetCursorPos(GLFWwindow * window, double * xpos, double * ypos);
という形になっている。定数については,GLFW_MOUSE_BUTTON_LEFT → glfw.MOUSE_BUTTON_LEFT といった感じである。
初期にウィンドウサイズに対処が必要なプログラム
このようなコードになろう。関数resizeにおいて,Windowsではアイコン化の際にwindow_sizeイベントが発生し,ウィンドウサイズが0になることに対する処置が必要である。
8.4_GLFW.pyimport glfw from OpenGL.GL import * from OpenGL.GLU import * W_INIT = 360 H_INIT = 300 VERTEX = [ [0.0, 0.0, 0.0], # A [1.0, 0.0, 0.0], # B [1.0, 1.0, 0.0], # C [0.0, 1.0, 0.0], # D [0.0, 0.0, 1.0], # E [1.0, 0.0, 1.0], # F [1.0, 1.0, 1.0], # G [0.0, 1.0, 1.0] # H ] EDGE = [ [0, 1], # a (A-B) [1, 2], # i (B-C) [2, 3], # u (C-D) [3, 0], # e (D-A) [4, 5], # o (E-F) [5, 6], # ka (F-G) [6, 7], # ki (G-H) [7, 4], # ku (H-E) [0, 4], # ke (A-E) [1, 5], # ko (B-F) [2, 6], # sa (C-G) [3, 7] # shi (D-H) ] def display(): glClear(GL_COLOR_BUFFER_BIT) glBegin(GL_LINES) for edge1 in EDGE: for i in edge1: glVertex3dv(VERTEX[i]) glEnd() glfw.swap_buffers(window) def set_view(w, h): glLoadIdentity() gluPerspective(35.0, w/h, 1.0, 100.0) gluLookAt(3.0, 4.0, 5.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0) def resize(window, w, h): # for iconify on Windows if h==0: return glViewport(0, 0, w, h) set_view(w, h) def init(): gray = 0.6 glClearColor(gray, gray, gray, 1.0) set_view(W_INIT, H_INIT) display() # necessary only on Windows def window_refresh(window): display() if not glfw.init(): raise RuntimeError('Could not initialize GLFW3') window = glfw.create_window(W_INIT, H_INIT, 'Wireframe', None, None) if not window: glfw.terminate() raise RuntimeError('Could not create an window') glfw.set_window_size_callback(window, resize) glfw.set_window_refresh_callback(window, window_refresh) glfw.make_context_current(window) init() while not glfw.window_should_close(window): glfw.wait_events_timeout(1e-3) glfw.terminate()アニメーション
ループにおいて,動作中であれば次の描画をして,poll_events,そうでなければいつものwait_events_timeout,という方法でできる。動作中のとき,poll_eventsではなく,wait_events_timeoutにすると遅くなる。
冒頭にあるDOUBLE_BUFFERINGをFalseにするとシングル・バッファリングになり,速い代わりにちらつく。9.1-2_GLFW.pyimport glfw from OpenGL.GL import * from OpenGL.GLU import * DOUBLE_BUFFERING = True W_INIT = 320 H_INIT = 240 VERTEX = [ [0.0, 0.0, 0.0], # A [1.0, 0.0, 0.0], # B [1.0, 1.0, 0.0], # C [0.0, 1.0, 0.0], # D [0.0, 0.0, 1.0], # E [1.0, 0.0, 1.0], # F [1.0, 1.0, 1.0], # G [0.0, 1.0, 1.0] # H ] EDGE = [ [0, 1], # a (A-B) [1, 2], # i (B-C) [2, 3], # u (C-D) [3, 0], # e (D-A) [4, 5], # o (E-F) [5, 6], # ka (F-G) [6, 7], # ki (G-H) [7, 4], # ku (H-E) [0, 4], # ke (A-E) [1, 5], # ko (B-F) [2, 6], # sa (C-G) [3, 7] # shi (D-H) ] def display(): global r glClear(GL_COLOR_BUFFER_BIT) glLoadIdentity() gluLookAt(3.0, 4.0, 5.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0) glRotated(r, 0.0, 1.0, 0.0) glColor3d(0.0, 0.0, 0.0) glBegin(GL_LINES) for edge1 in EDGE: for i in edge1: glVertex3dv(VERTEX[i]) glEnd() if DOUBLE_BUFFERING: glfw.swap_buffers(window) else: glFlush() r += 1 if r==360: r = 0 def set_view(w, h): glMatrixMode(GL_PROJECTION) glLoadIdentity() gluPerspective(35.0, w/h, 1.0, 100.0) glMatrixMode(GL_MODELVIEW) def resize(window, w, h): # for iconify on Windows if h==0: return glViewport(0, 0, w, h) set_view(w, h) def mouse_button(window, button, action, mods): global rotation if action == glfw.PRESS: rotation = ( button == glfw.MOUSE_BUTTON_LEFT ) def init(): gray = 0.8 glClearColor(gray, gray, gray, 1.0) set_view(W_INIT, H_INIT) display() # necessary only on Windows def window_refresh(window): # for resize display() r = 0 rotation = False if not glfw.init(): raise RuntimeError('Could not initialize GLFW3') if not DOUBLE_BUFFERING: glfw.window_hint(glfw.DOUBLEBUFFER, glfw.FALSE) window = glfw.create_window(W_INIT, H_INIT, 'Animation on GLFW', None, None) if not window: glfw.terminate() raise RuntimeError('Could not create an window') glfw.set_mouse_button_callback(window, mouse_button) glfw.set_window_size_callback(window, resize) glfw.set_window_refresh_callback(window, window_refresh) glfw.make_context_current(window) init() while not glfw.window_should_close(window): if rotation: display() glfw.poll_events() # glfw.wait_events_timeout(1e-2) else: glfw.wait_events_timeout(1e-3) glfw.terminate()
- 投稿日:2020-04-26T17:00:21+09:00
イミュータブルな型を作った話
はじめに
自己紹介
H1ronoです。
この記事でやること
pure pythonでイミュータブル(変更不可能)な型を作りました。具体的に何をしたのか、詳しく伝えられたらと思っています。
何を作るの?
ベクトルの型を作ります。具体的に言うと、
- クラス名は
MyVector- 2次元のベクトルを表す
- イミュータブル
- 大きさを
length、方向をdirection(degree)として保存する(座標は保存しない)- インタプリタで
MyVector(length=大きさ, direction=方向)のように表示される- 位置ベクトルとしての座標を
x、yという名前のpropertyで参照できる(例:vector.xなど)+、-でベクトルどうしの加算、減算ができる*でベクトルどうしを乗算した場合は内積を返す*でベクトルと実数を乗算した場合はベクトルの大きさがその実数倍になったものを返す/でベクトルと実数を除算した場合はベクトルの大きさがその実数で割り算されたものを返すこのような要件のクラスを作ります。
ステップ1 - イミュータブル
まずは、"イミュータブル"の要件を実装します。
イミュータブルって?
公式の用語集より、イミュータブルの引用
immutable
(イミュータブル) 固定の値を持ったオブジェクトです。イミュータブルなオブジェクトには、数値、文字列、およびタプルなどがあります。これらのオブジェクトは値を変えられません。別の値を記憶させる際には、新たなオブジェクトを作成しなければなりません。イミュータブルなオブジェクトは、固定のハッシュ値が必要となる状況で重要な役割を果たします。辞書のキーがその例です。つまり、
vector.direction = 256といったことができないということのようです。実装
なんと素晴らしいことに、組み込みのcollectionsモジュールにあるnamedtuple関数で、
tupleのサブクラス(つまりイミュータブル)で、その要素に名前が割り当てられたクラスが簡単にできちゃいます。pythonってすごい。vec.pyfrom collections import namedtuple _MyVector = namedtuple('_MyVector', ('length', 'direction')) class MyVector(_MyVector): pass #ここで他の要件を満たしていく if __name__ == '__main__': vec = MyVector(4, 2) print(vec) #MyVector(length=4, direction=2)実行結果:
MyVector(length=4, direction=2)これで、上述した要件の内、
- クラス名は
MyVector- 2次元のベクトルを表す
- イミュータブル
- 大きさを
length、方向をdirection(degree)として保存する(座標は保存しない)- インタプリタで
MyVector(length=大きさ, direction=方向)のように表示されるは一応実装できました。残りの要件は、
- 位置ベクトルとしての座標を
x、yという名前のpropertyで参照できる+、-でベクトルどうしの加算、減算ができる*でベクトルどうしを乗算した場合は内積を返す*でベクトルと実数を乗算した場合はベクトルの大きさがその実数倍になったものを返す/でベクトルと実数を除算した場合はベクトルの大きさがその実数で割り算されたものを返すです。一気に減っちゃいましたね。
ステップ2 - プロパティの作成
次は、"位置ベクトルとしての座標を
x、yという名前のpropertyで参照できる"の要件を実装します。組み込みのmathモジュールを使用します。
xの式はlength * cos(pi * direction / 180)、yの式はlength * sin(pi * direction / 180)です。vec.pyfrom collections import namedtuple from math import pi, cos, sin #インポートを追加 _MyVector = namedtuple('_MyVector', ('length', 'direction')) class MyVector(_MyVector): # ここから追加部分 # @property def x(self): theta = pi * self.direction / 180 return self.length * cos(theta) @property def y(self): theta = pi * self.direction / 180 return self.length * sin(theta) # ここまで追加部分 # if __name__ == '__main__': from math import sqrt root2 = sqrt(2) vec = MyVector(root2, 45) print('x = {}'.format(vec.x)) #x = 1 print('y = {}'.format(vec.y)) #y = 1上記のコードを実行するとわかるのですが、実行結果はコメントの通りにはなりません。筆者の環境だと、
x = 1.0000000000000002 y = 1.0と表示されます。この挙動は、おそらくこちら(浮動小数点演算、その問題と制限)と関連があると思います。気になる方はどうぞ。とにかく、一応は
- 位置ベクトルとしての座標を
x、yという名前のpropertyで参照できるは実装できました。残りは、
+、-でベクトルどうしの加算、減算ができる*でベクトルどうしを乗算した場合は内積を返す*でベクトルと実数を乗算した場合はベクトルの大きさがその実数倍になったものを返す/でベクトルと実数を除算した場合はベクトルの大きさがその実数で割り算されたものを返すです。全部演算の実装ですね。
ステップ3 - 演算の実装
どうやって?
今回実装する演算子とメソッド名の対応は、大体つぎの表のようになります。
演算子 メソッド名 +__add__,__radd__-__sub__,__rsub__*__mul__,__rmul__/__truediv__,__rtruediv__どの関数も引数は
(self, other)です。つまり、vector = Myvector(8, 128)としたとき、vector + xはvector.__add__(x)を呼び出し、その結果を計算結果として返すということです。
__radd__などの、最初にrがついたメソッドは、「被演算子が反射した(入れ替えられた)もの」(上記URLより引用)を実装します。つまり、x + vectorとして、x.__add__(vector)がNotImplementedを返した際にvector.__radd__(x)の結果が返される、ということです。せっかくなのでこっちも追加します。
実装方法についてはこんな感じです。それでは書いていきましょう。
...と言いたいところなんですが、加算、減算の実装に、(x, y)の座標から(length, direction)で表したベクトルを得る必要があります。まずはそのメソッドを実装します。実装(座標から方向、大きさ)
vec.pyfrom collections import namedtuple from math import pi, cos, sin, sqrt, acos # インポートを追加 _MyVector = namedtuple('_MyVector', ('length', 'direction')) class MyVector(_MyVector): # ここから追加部分 # @classmethod def from_coordinates(cls, p1, p2=None): #p1: (x, y) #p2: (x, y) または None if p2 is None: #位置ベクトルとして扱う x, y = p1 else: #p1を始点,p2を終点のベクトルとして扱う x = p2[0] - p1[0] y = p2[1] - p1[1] r = sqrt(x**2 + y**2) if r == 0: #0ベクトル return cls(0, 0) #逆三角関数 theta = 180 * acos(x / r) / pi if y < 0: # 180 < direction < 360 #theta=32 -> direction=328 #theta=128 -> direction=232 theta = 360 - theta return cls(r, theta) # ここまで追加部分 # @property def x(self): theta = pi * self.direction / 180 return self.length * cos(theta) @property def y(self): theta = pi * self.direction / 180 return self.length * sin(theta) if __name__ == '__main__': vec = MyVector.from_coordinates((2, 2)) print('x = {}'.format(vec.x)) #x = 2 print('y = {}'.format(vec.y)) #y = 2
from_coordinates関数を追加しました。名前の通り、座標からMyVectorオブジェクトを生成します。クラスメソッドとしたのは、なかなか便利だと感じたためです。実行結果:x = 1.9999999999999996 y = 2.0000000000000004またか... 後で
round関数入れて丸めればいいでしょう。とにかく、(x, y)の座標から(length, direction)で表したベクトルを得ることができました。実装(加算、減算)
次は加算、減算を実装します。サポートする演算対象は同型のベクトルなので、ベクトルであることを判別する条件は"長さが2で、1番目、2番目どちらの要素も実数である"とします。この判別は後でまた使うので、関数化します。
vec.pyfrom collections import namedtuple from math import pi, cos, sin, sqrt, acos from numbers import Real #インポートを追加 _MyVector = namedtuple('_MyVector', ('length', 'direction')) class MyVector(_MyVector): # ここから追加部分 # def __add__(self, other): #加算の実装 if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((self.x + v.x, self.y + v.y)) else: return NotImplemented #加算のいわゆる反射版 __radd__ = __add__ def __sub__(self, other): #減算の実装 if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((self.x - v.x, self.y - v.y)) else: return NotImplemented def __rsub__(self, other): #減算の反射版 if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((v.x - self.x, v.y - self.y)) else: return NotImplemented @staticmethod def isvector(obj): #ベクトルかどうかを判別する関数 try: return ( isinstance(obj[1], Real) and isinstance(obj[0], Real) and len(obj) == 2) except: return False # ここまで追加部分 # @classmethod def from_coordinates(cls, p1, p2=None): if p2 is None: x, y = p1 else: x = p2[0] - p1[0] y = p2[1] - p1[1] r = sqrt(x**2 + y**2) if r == 0: return cls(0, 0) theta = 180 * acos(x / r) / pi if y < 0: theta = 360 - theta return cls(r, theta) @property def x(self): theta = pi * self.direction / 180 return self.length * cos(theta) @property def y(self): theta = pi * self.direction / 180 return self.length * sin(theta) if __name__ == '__main__': vec1 = MyVector.from_coordinates((1, 1)) vec2 = MyVector.from_coordinates((-1, -1)) print(vec1 + vec2) #MyVector(length=0, direction=0) print(vec1 - vec2) #MyVector(length=2.8284...[2√2], direction=45)組み込みのnumbersモジュールの
Realクラスは、実数の基底クラスです。isinstance(1024, Real)、isinstance(1.024, Real)などはすべてTrueを返します。
__radd__ = __add__としているのは、vector + xとx + vectorは同値だからです。javascript風に翻訳すると、this.__radd__ = this.__add__といった感じでしょうか。
実行結果:MyVector(length=4.965068306494546e-16, direction=153.43494882292202) MyVector(length=2.8284271247461903, direction=45.00000000000001)合ってるのかどうか分かりませんね。
round関数で丸めて見やすくします。実装(round)
vec.pyfrom collections import namedtuple from math import pi, cos, sin, sqrt, acos from numbers import Real _MyVector = namedtuple('_MyVector', ('length', 'direction')) class MyVector(_MyVector): def __add__(self, other): if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((self.x + v.x, self.y + v.y)) else: return NotImplemented __radd__ = __add__ def __sub__(self, other): if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((self.x - v.x, self.y - v.y)) else: return NotImplemented def __rsub__(self, other): if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((v.x - self.x, v.y - self.y)) else: return NotImplemented @classmethod def from_coordinates(cls, p1, p2=None): if p2 is None: x, y = p1 else: x = p2[0] - p1[0] y = p2[1] - p1[1] #ここ r = round(sqrt(x ** 2 + y ** 2), 3) if r == 0: return cls(0, 0) #ここ theta = round(180 * acos(x / r) / pi) if y < 0: theta = 360 - theta return cls(r, theta) @property def x(self): theta = pi * self.direction / 180 #ここ return round(self.length * cos(theta), 3) @property def y(self): theta = pi * self.direction / 180 #ここ return round(self.length * sin(theta), 3) if __name__ == '__main__': vec1 = MyVector.from_coordinates((1, 1)) vec2 = MyVector.from_coordinates((-1, -1)) print(vec1 + vec2) #MyVector(length=0, direction=0) print(vec1 - vec2) #MyVector(length=2.828, direction=45)実行結果:
MyVector(length=0, direction=0) MyVector(length=2.828, direction=45)いい感じですね。ちなみに足し算の結果の
directionが153.43...から0になってますが、これはfrom_coordinates内のif r == 0:に引っかかったためですね。想定通りです。ひとまず、
+、-でベクトルどうしの加算、減算ができるは実装できました。残りの要件は、
*でベクトルどうしを乗算した場合は内積を返す*でベクトルと実数を乗算した場合はベクトルの大きさがその実数倍になったものを返す/でベクトルと実数を除算した場合はベクトルの大きさがその実数で割り算されたものを返すです。次は乗算を実装します。
実装(乗算)
乗算は演算対象によって挙動が変わる要件となっています。実数の場合とベクトルの場合です。実数の判定には先程使用した
Realクラスが使えます。ベクトルの判別にはisvector関数が役立ちます。vec.pyfrom collections import namedtuple from math import pi, cos, sin, sqrt, acos from numbers import Real _MyVector = namedtuple('_MyVector', ('length', 'direction')) class MyVector(_MyVector): def __add__(self, other): if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((self.x + v.x, self.y + v.y)) else: return NotImplemented __radd__ = __add__ def __sub__(self, other): if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((self.x - v.x, self.y - v.y)) else: return NotImplemented def __rsub__(self, other): if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((v.x - self.x, v.y - self.y)) else: return NotImplemented # ここから追加部分 # def __mul__(self, other): cls = self.__class__ if isinstance(other, Real): #実数の場合 l = round(self.length * other, 3) return cls(l, self.direction) elif cls.isvector(other): #ベクトルの場合 theta = pi * (other[1] - self[1]) / 180 product = self[0] * other[0] * cos(theta) return round(product, 3) else: #それ以外の場合 return NotImplemented __rmul__ = __mul__ # ここまで追加部分 # @staticmethod def isvector(obj): try: return ( isinstance(obj[1], Real) and isinstance(obj[0], Real) and len(obj) == 2) except: return False @classmethod def from_coordinates(cls, p1, p2=None): if p2 is None: x, y = p1 else: x = p2[0] - p1[0] y = p2[1] - p1[1] r = round(sqrt(x**2 + y**2), 3) if r == 0: return cls(0, 0) theta = round(180 * acos(x / r) / pi) if y < 0: theta = 360 - theta return cls(r, theta) @property def x(self): theta = pi * self.direction / 180 return round(self.length * cos(theta), 3) @property def y(self): theta = pi * self.direction / 180 return round(self.length * sin(theta), 3) if __name__ == '__main__': vec1 = MyVector(2, 45) vec2 = MyVector(2, 135) print(vec1 * 2) #MyVector(length=4, direction=45) print(vec1 * vec2) #0実行結果:
MyVector(length=4, direction=45) 0.0これで、
*でベクトルどうしを乗算した場合は内積を返す*でベクトルと実数を乗算した場合はベクトルの大きさがその実数倍になったものを返すは実装できました。残りの要件は、
/でベクトルと実数を除算した場合はベクトルの大きさがその実数で割り算されたものを返すです。あと1つ!
実装(除算)
乗算と同じ感じで実装していきます。書きながら気づいたんですけど、
vector1 / vector2 = vector1 * (1 / vector2)ですね(ベクトルどうしの除算もあるということです)。そっちも追加しようと思います。vec.pyfrom collections import namedtuple from math import pi, cos, sin, sqrt, acos from numbers import Real _MyVector = namedtuple('_MyVector', ('length', 'direction')) class MyVector(_MyVector): def __add__(self, other): if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((self.x + v.x, self.y + v.y)) else: return NotImplemented __radd__ = __add__ def __sub__(self, other): if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((self.x - v.x, self.y - v.y)) else: return NotImplemented def __rsub__(self, other): if self.isvector(other): cls = self.__class__ v = cls(*other) return cls.from_coordinates((v.x - self.x, v.y - self.y)) else: return NotImplemented def __mul__(self, other): cls = self.__class__ if isinstance(other, Real): l = round(self.length * other, 3) return cls(l, self.direction) elif cls.isvector(other): theta = pi * (other[1] - self[1]) / 180 product = self[0] * other[0] * cos(theta) return round(product, 3) else: return NotImplemented __rmul__ = __mul__ # ここから追加部分 # def __truediv__(self, other): cls = self.__class__ if isinstance(other, Real): l = round(self.length / other, 3) return cls(l, self.direction) elif cls.isvector(other): return self * (1 / cls(*other)) else: return NotImplemented #除算の反射版 def __rtruediv__(self, other): cls = self.__class__ if isinstance(other, Real): l = round(other / self.length, 3) return cls(l, self.direction) elif cls.isvector(other): return other * (1 / self) else: return NotImplemented # ここまで追加部分 # @staticmethod def isvector(obj): try: return ( isinstance(obj[1], Real) and isinstance(obj[0], Real) and len(obj) == 2) except: return False @classmethod def from_coordinates(cls, p1, p2=None): if p2 is None: x, y = p1 else: x = p2[0] - p1[0] y = p2[1] - p1[1] r = round(sqrt(x**2 + y**2), 3) if r == 0: return cls(0, 0) theta = round(180 * acos(x / r) / pi) if y < 0: theta = 360 - theta return cls(r, theta) @property def x(self): theta = pi * self.direction / 180 return round(self.length * cos(theta), 3) @property def y(self): theta = pi * self.direction / 180 return round(self.length * sin(theta), 3) if __name__ == '__main__': vec1 = MyVector(2, 45) print(vec1 / 2) #MyVector(length=1, direction=45) print(vec1 / vec1) #1実行結果:
MyVector(length=1.0, direction=45) 1.0上手くいきました。これで要件はすべて実装完了です!
ステップ4 - 使ってみる
>>> vec1 = MyVector(2, 45) >>> vec2 = MyVector(2, 135) >>> vec3 = MyVector(2, 225) >>> vec1.direction = 256 Traceback (most recent call last): File "<string>", line 1, in <module> AttributeError: can`t set attribute >>> vec1 + vec3 MyVector(length=0, direction=0) >>> vec1 - vec3 MyVector(length=3.999, direction=45) >>> vec1 * vec2 0.0 >>> vec1 * (2, 135) 0.0 >>> vec1 * 2 MyVector(length=4, direction=45) >>> vec1 / 2 MyVector(length=1.0, direction=45) >>> vec1 += vec3 >>> vec1 MyVector(length=0, direction=0)
vec1 - vec3の結果だけ少しおかしいですが、大まかには意図通りです。終わりに
pure pythonでイミュータブルなベクトルの型を作成しました。ここおかしいんじゃない、ここわかんないとかあったら、なんでも言って下さい。
途中で値のズレが目立ちましたが、気になる方はこちら(decimal組み込みモジュール)などを使ってみてはいかがでしょうか。おまけ
(x, y)のベクトル型
vec2.pyfrom math import pi, sqrt, acos from numbers import Real from operator import itemgetter class MyVector2(tuple): _ROUND_DIGIT = 2 __slots__ = () def __new__(cls, x=0, y=0): return tuple.__new__(cls, (x, y)) def __repr__(self): t = (self.__class__.__name__, *self) return ('{0}(x={1}, y={2})'.format(*t)) __bool__ = (lambda self: bool(self.length)) def __add__(self, other): cls = self.__class__ if cls.isvector(other): return cls(self[0] + other[0], self[1] + other[1]) else: return NotImplemented def __sub__(self, other): cls = self.__class__ if cls.isvector(other): return cls(self[0] - other[0], self[1] - other[1]) else: return NotImplemented def __mul__(self, other): cls = self.__class__ if cls.isvector(other): return self[0]*other[0] + self[1]*other[1] elif isinstance(other, Real): return cls(self.x * other, self.y * other) else: return NotImplemented def __truediv__(self, other): cls = self.__class__ if cls.isvector(other): v = cls(*other) return self * (1 / v) elif isinstance(other, Real): return cls(self.x / other, self.y / other) else: return NotImplemented __radd__ = __add__ __rmul__ = __mul__ def __rsub__(self, other): return -(self - other) def __rtruediv__(self, other): cls = self.__class__ if isinstance(other, Real): return cls(other / self.x, other / self.y) elif cls.isvector(other): return other * (1 / self) else: return NotImplemented __abs__ = (lambda self: abs(self.length)) __pos__ = (lambda self: self) def __neg__(self): x, y = -self.x, -self.y return self.__class__(x, y) def __complex__(self): return self.x + self.y * 1j @staticmethod def isvector(obj): try: return ( isinstance(obj[1], Real) and isinstance(obj[0], Real) and len(obj) == 2) except: return False @classmethod def _round(cls, a): return round(a, cls._ROUND_DIGIT) x = property(itemgetter(0)) y = property(itemgetter(1)) @property def length(self): r = sqrt(self.x**2 + self.y**2) return self._round(r) @property def direction(self): r = self.length if r == 0: return 0 x, y = self theta = self._round(180 * acos(x / r) / pi) if y < 0: theta = 360 - theta return theta使ってみます。
>>> v1 = MyVector2(1, 1) >>> v2 = MyVector2(-1, -1) >>> v1 + v2 MyVector2(x=0, y=0) >>> v1 - v2 MyVector2(x=2, y=2) >>> v1 * v2 -2 >>> v1 / v2 -2.0 >>> v1.direction 44.83 >>> v1.length 1.41 >>> v2.direction 224.83 >>> v1 / (-1, -1) -2.0 >>> v1 + (1, 1) MyVector2(x=2, y=2) >>> (1, 1) + v1 MyVector2(x=2, y=2) >>> v1 - (1, 1) MyVector2(x=0, y=0) >>> (1, 1) - v1 MyVector2(x=0, y=0) >>> v1 * 2 MyVector2(x=2, y=2) >>> v1 / 2 MyVector2(x=0.5, y=0.5)
- 投稿日:2020-04-26T16:50:19+09:00
cibuildwheel で python bwheel(C++ モジュール含む) を CI で一括ビルドし PyPI へアップロードするメモ
漢なら Python pip で Windows, macOS, Linux で C++ モジュール含んだ prebuilt wheel インストールしたいですね!
cibuildwheel でやりましょう!
https://github.com/joerick/cibuildwheel
いろんな環境と python バージョンでビルドしてくれるスクリプトです. 素晴らしいですね.
これを自前プロジェクトの CI(travis, GitHub Actions, etc)に取り込めばいいです.ちょっとわかりずらいですが,
$ python3 -m cibuildwheel --output-dir wheelhouseを実行することで,
python setup.py bdist_wheel相当を実行してくれるようです.ビルド前にスクリプトを実行する
cibuildwheel では, Linux, macOS ですと Docker コンテナで実行されるため, Travis などで CI ビルドを行う場合は,
git submodule updateみたいなのは docker コンテナの内部で実行しないといけません.cibuildwheel の環境変数で, いくつか設定することができます.
https://cibuildwheel.readthedocs.io/en/latest/options/
pypi にアップロードする
PyPI に Linux バイナリでパッケージをアップロードするメモ
https://qiita.com/syoyo/items/6185380b8d9950b25561あたりを参照ください
C++ コードを含んだ実際のサンプル
cibuildwheel して, pypi アップロード, tinyobjloader にサンプルありますので参照ください.
https://github.com/tinyobjloader/tinyobjloader/tree/master/python
- 投稿日:2020-04-26T16:32:21+09:00
Twitter APIを使ってみる
TwitterAPIを使ってやりたいことがあったので、
今回使うAPIの使い方を、自己学習的なメモも含め残しておきます。バージョン
今回使用した環境とツールの各バージョンを書いておきます。
python: 3.8.2 (pyenv: 1.2.18)
pip: 20.0.2
tweepy: 3.8.0
(多分依存関係のやつら:
PySocks-1.7.1
certifi-2020.4.5.1
chardet-3.0.4
idna-2.9
oauthlib-3.1.0
requests-2.23.0
requests-oauthlib-1.3.0
six-1.14.0
tweepy-3.8.0
urllib3-1.25.9)セットアップ記録
自分の辿った記録のメモなので、あしからず。
(私は今回、pipってなに? から始まってます)Pythonの環境設定で参考にしました。
https://prog-8.com/docs/python-env
こういうサポートまであるんですね。Progateってすごいサービスだなって思いました(小並感)。大感謝。あとpipがよくわかった。Macだったので、なんか勝手にうごいた。
https://gammasoft.jp/python/python-library-install/Twitter APIのためにDeveloper登録
下記記事を参考にしてほとんどやりました。
https://qiita.com/kngsym2018/items/2524d21455aac111cdee
https://www.torikun.com/entry/twitter-developer-api/(ふるいが、API日本語)
http://westplain.sakuraweb.com/translate/twitter/Documentation/REST-APIs/Public-API/The-Search-API.cgitweepyを使う
tweepyというライブラリを使うことにしました。
http://docs.tweepy.org/en/latest/install.html理由は検索で引っ掛かったからで、他のtwitter API関連でもっと使いやすいライブラリはあるかもしれないです。
OAuth 1a認証ってのがあるようですが、今回は使用しませんまずはGetting Startにある通りに進めていきます。
import tweepy consumer_key = 'consumer_key' consumer_secret = 'consumer_secret' access_token = 'access_token' access_token_secret = 'access_token_secret' auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth) public_tweets = api.home_timeline() for tweet in public_tweets: print('-------------------------') print(tweet.text) api.update_status("TEST post from tweepy [get timeline complete] ")この動作チェックでは。取り合えずTimeLineを取得して、処理が終わったら投稿するところまで動作確認。
次に特定のidのユーザー情報を取得する例を実行してみます。
下記処理を追加しました。# Get the User object for twitter... user = api.get_user('zooshima_k') print(user.screen_name) print(user.followers_count) for friend in user.friends(): print(friend.screen_name)結果↓
zooshima_k 188 ・・・・(フレンドName一覧)自分のアカウントでやってみましたが、見事にでてきました。
フォロワー数やフォローしているユーザーの名前が出てきます。おもしろいですね。このあと、Steramingで情報を持ってこれるというのに期待したのですが。
残念ながら2018年からできなくなってるんですね。悲しい・・・やりたいことがあったのですが、いったん諦めます。記事はここまでです。
なにかできるようになったら、また更新するかもです。
- 投稿日:2020-04-26T16:26:53+09:00
グリーンバックはもういらない!?Background-Mattingでどこでも合成(Windows10、Python 3.6、CUDA10.0)
はじめに
Zoomでバーチャル背景が流行っていますね。グリーンバックを必要とせずに一枚の背景画像から人物を切り抜き、ピクセルレベルで違和感なく合成できるBackground Mattingをやってみました。CPUでも動くよ。
システム環境
- Windows10(RTX2080 Max-Q, i7-8750H、RAM16GB)
- Anaconda 2020.02
- Python 3.6
- CUDA 10.0
- cuDNN
導入
Background-Mattingからクローンします。
back-matting環境を作ります。
cd Background-Matting-master conda create -n back-matting python=3.6 conda activate back-mattingPytorch(CUDA 10.0)をインストールします。
pip install torch==1.2.0 torchvision==0.4.0 -f https://download.pytorch.org/whl/torch_stable.html必要なライブラリをインストールします。
pip install tensorflow-gpu==1.14.0 pip install -r requirements.txtここからモデルをダウンロードし、Modelsフォルダに置きます。
下記からCUDA 10.0をインストールします。
システム環境変数に、C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\binを追加します。
システム環境変数を編集したら、Anacondaを再起動します。
cuDNNも必要なので、Download cuDNN v7.6.4 (September 27, 2019), for CUDA 10.0をダウンロードします。
ダウンロードしたら、cudnn-10.0-windows10-x64-v7.6.4.38\cuda\bin\cudnn64_7.dllをC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\binに移動
cudnn-10.0-windows10-x64-v7.6.4.38\cuda\lib\x64\cudnn.libをC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\lib\x64に移動
cudnn-10.0-windows10-x64-v7.6.4.38\cuda\include\cudnn.hをC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\includeに移動します。
下記を実行します。
python test_segmentation_deeplab.py -i sample_data/inputsample_data\inputに_masksDL.pngの画像が生成されます。
下記を実行します。
python test_pre_process.py -i sample_data/inputDone: sample_data/input
と出力されます。Alignmentされたらしい。test_background-matting_image.pyの20行目をコメントアウトし、19行目のコメントを外し、os.environ["CUDA_VISIBLE_DEVICES"]を"0"にします。
os.environ["CUDA_VISIBLE_DEVICES"]="0" # "4" # print('CUDA Device: ' + os.environ["CUDA_VISIBLE_DEVICES"])下記を実行します。
python test_background-matting_image.py -m real-hand-held -i sample_data/input/ -o sample_data/output/ -tb sample_data/background/0001.pngsample_data\outputに結果が表示されました!
バックグラウンド(背景)の例
CPUでやーる
test_background-matting_image.pyの19行目のos.environ["CUDA_VISIBLE_DEVICES"]を"-1"にします。
os.environ["CUDA_VISIBLE_DEVICES"]="-1"57行目のtorch.load(model_name1)をtorch.load(model_name1,map_location='cpu')にします。
そして、cuda()の部分を取っ払います!netM.load_state_dict(torch.load(model_name1, map_location='cpu')) # netM.cuda(); netM.eval()あとは156行目付近のcuda()を取り除けば、動くはず。
img,bg,rcnn_al,multi_fr=Variable(img),Variable(bg),Variable(rcnn_al),Variable(multi_fr) input_im=torch.cat([img,bg,rcnn_al,multi_fr],dim=1) alpha_pred,fg_pred_tmp=netM(img,bg,rcnn_al,multi_fr) al_mask=(alpha_pred>0.95).type(torch.FloatTensor)塩さん、ありがとうございます!
そのcuda()とほかcuda関連系のメソッド取っ払ってみてください!
— 塩 (@shiomasa1218) April 26, 2020動画はこれからやーる





- 投稿日:2020-04-26T16:24:54+09:00
pywin32 で起動中のパワポに画像を連続挿入する
Windows での使用を想定し、下記の powershell コマンドレットから
.pyファイルを呼び出して実行します。コマンドレット名がやたら長いですが補完が効くので問題はない……はずです。起動中の Office 製品の操作には もっと直接的な方法 もありますが、powershell 6 以降は
[System.Runtime.InteropServices.Marshal]::GetActiveObject()が使用できなくなっているので pywin32 で代用しています。function Add-Image2ActivePptSlideWithPython { <# .SYNOPSIS pywin32 を利用して現在開いているパワポのスライドに画像を連続挿入する #> if ((Get-Process | Where-Object ProcessName -EQ "POWERPNT").Count -lt 1) { return } $targetPath = @($input).Fullname if (-not $targetPath) { return } if ((Read-Host "「ファイル内のイメージを圧縮しない」の設定はオンになっていますか? (y/n)") -ne "y") { return } $tmp = New-TemporaryFile $targetPath | Out-File -Encoding utf8 -FilePath $tmp.FullName # BOMつき # このスクリプトと同じディレクトリに後述の python スクリプトを配置しておく $pyCodePath = "{0}\activeppt_insert-image.py" -f $PSScriptRoot 'python -B "{0}" "{1}"' -f $pyCodePath, $tmp.FullName | Invoke-Expression Remove-Item -Path $tmp.FullName }最初のほうでは 画像の圧縮を無効化 できているか確認しています(これを忘れると挿入された画像の解像度が落ちてしまうため)。
実際のコマンドライン上では下記のようにパイプライン経由で挿入したい画像オブジェクトを渡してやります。
ls -File | Add-Image2ActivePptSlideWithPythonパイプライン経由で渡された画像のパスを引数として渡す方法もありますが、それだと特殊文字のエスケープや引数の上限などが厄介なので
New-TemporaryFileで作成した一時ファイルに書き出しています。
この際、powershell の仕様によりUTF8を指定しても BOM つきになるので文字コードには注意が必要。呼び出し先の python ファイルは下記のようにします。パワポを立ち上げた状態で実行すると
ActivePresentationで起動中のプロセスを捕まえられます。
前もって呼び出し側で PowerPoint が起動していることを確認していますが、それでもプレゼンテーションが開かれていなかった場合は何もしないようにしています。また、不可視のゾンビプロセスを捕まえてしまったときはプロセス自体を終了させます。activeppt_insert-image.py""" pywin32 を使用して現在開いている PowerPoint スライドに画像を連続を挿入する """ import win32com.client import argparse class vb: msoFalse = 0 msoTrue = -1 ppLayoutBlank = 12 def main(file_list_path): pptApp = win32com.client.Dispatch("PowerPoint.Application") if pptApp.Presentations.Count < 1: if not pptApp.Visible: pptApp.Quit() return with open(file_list_path, "r", encoding="utf_8_sig") as f: all_lines = f.read() image_path_list = all_lines.splitlines() presen = pptApp.ActivePresentation slide_width = presen.PageSetup.SlideWidth slide_height = presen.PageSetup.SlideHeight for img_path in image_path_list: slide_index = presen.Slides.Count + 1 presen.Slides.Add(slide_index, vb.ppLayoutBlank) last_slide = presen.Slides(slide_index) inserted_img = last_slide.Shapes.AddPicture( FileName = img_path, LinkToFile = vb.msoFalse, SaveWithDocument = vb.msoTrue, Left = 0, Top = 0 ) inserted_img.Left = (slide_width - inserted_img.Width) / 2 inserted_img.Top = (slide_height - inserted_img.Height) / 2 print(f"inserted: {img_path}") if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("file_list_path") args = parser.parse_args() main(args.file_list_path)最後に
(´-`).。oO(
GetActiveObject()はやく実装されないかな……)