- 投稿日:2020-04-26T21:57:13+09:00
【Kotlin】kotlessをやってみました(API Gatewayまで)【kotless】
今回公式のGetting startedをやってみたので、それを日本語で書いていこうと思います。
kotlessとは?
Kotlinのみを使ってServerlessApplicationを作成し、デプロイすることがでるServerless Frameworkです。
まず必要なもの
- AWS アカウント
- AWS CLIのインストー
- IAMユーザー
- CLIの初期設定
- Profileをつけるのをオススメ
- S3バケット
こちらについてのインストールや設定などの説明は省きます。
必要ないもの
- Terraformは自動でDLしてくるので元々持ってる必要はないです。
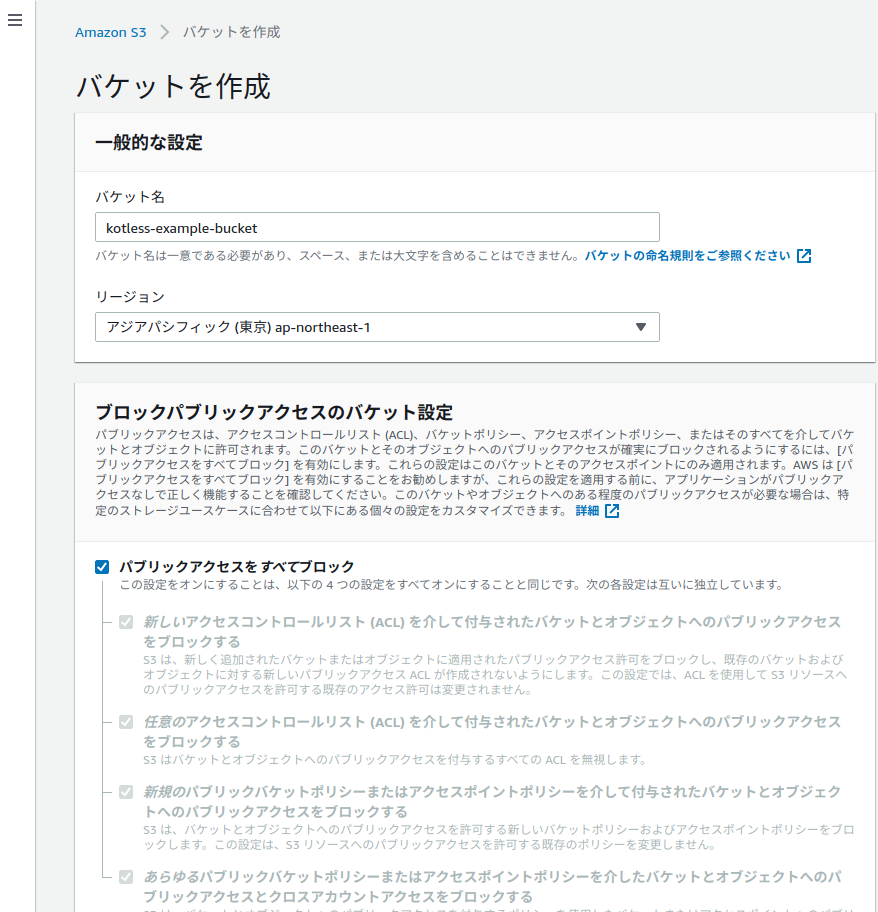
S3バケットの準備
kotlessはTerraformが裏で動くため、Terraformの
state.tfstateを保存するため先にS3のバケットだけは必要になります。
今回はkotless-example-bucketという名前で作成しました。
リージョンも東京リージョンで作ってます。
IAMユーザーの作成
権限としては以下の権限があれば十分動きます。
Route53、ACM、CloudFrontはAPIGatewayにカスタムドメインを利用する際に必要になります。
GradleProjectの作成
今回は
InteliJでGradleProjectを作成しています。
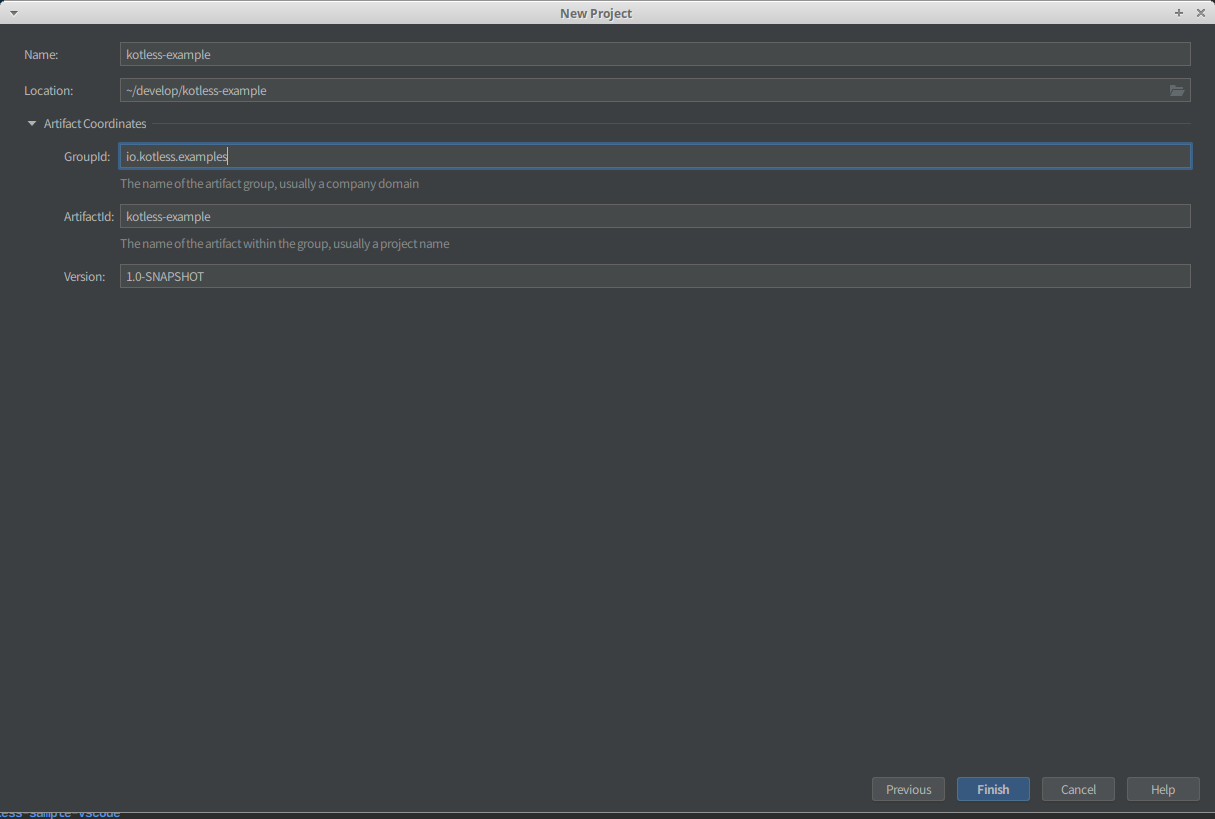
まずはプロジェクトの作成から以下のように選びます。
この時Kotlin DSL build scripのチェックボックスにチェックを入れると、プロジェクトの作成時にbuild.gradle.ktsが生成されるようになります。
次に
プロジェクト名とLocationを指定します。
同時にArtifact Coordinatesを開いて
- Group ID
- ArtifactId
- Verson
これらも指定します。
今回は公式サンプルに習った名称にしています。
これで以下の
build.gradle.ktsが作成されます。build.gradle.ktsplugins { kotlin("jvm") version "1.3.72" } group = "io.kotless.examples" version = "1.0-SNAPSHOT" repositories { mavenCentral() } dependencies { implementation(kotlin("stdlib-jdk8")) } tasks { compileKotlin { kotlinOptions.jvmTarget = "1.8" } compileTestKotlin { kotlinOptions.jvmTarget = "1.8" } }build.gradleの追記
公式のGetStartedの記述だけでは動きません
というわけで必要な追記を行います。importの追記
kotlessのタスクを追加するのですが、
importがされていないので追記します。
公式のGetStartedには書かれていないですが、公式のサンプルには書かれていますbuild.gradle.ktsimport io.kotless.plugin.gradle.dsl.kotlesspluginsの追記
kotlessのタスクを追加するので、もちろんpluginも必要なので追記します。
公式のGetStartedには書かれていないですが、公式のサンプルには書かれていますbuild.gradle.ktsplugins { kotlin("jvm") version "1.3.72" id("io.kotless") version "0.1.3" apply true }repositoriesの変更
repositoriesをmavenCentralからjcenterに変更します
build.gradle.ktsrepositories { jcenter(( }dependenciesの変更
dependenciesに
kotlessを追加します。build.gradle.ktsdependencies { implementation(kotlin("stdlib-jdk8")) implementation("io.kotless", "lang", "0.1.3") }kotlessタスクの追加
Lambda作成の最低限設定
まずはGradleにkotless用のTaskを追加していきます。
build.gradle.ktskotless { config { //build後のモジュールとTerraformのstateファイルを配置するためのBucket bucket = "kotless-example-bucket" //作成したリソースにつくprefix prefix = "dev" terraform { profile = "kotless" region = "ap-northeast-1" } } //webApplicationの設定 webapp { //作成するlambdaのメモリとTimeout設定 lambda { memoryMb = 1024 timeoutSec = 120 } } }最終的なGradle
一応ここまででAPIGatewayのURLからLambdaを直接呼び出せるところまではできます。
build.gradle.ktsimport io.kotless.plugin.gradle.dsl.kotless plugins { kotlin("jvm") version "1.3.72" id("io.kotless") version "0.1.3" apply true } group = "io.kotless.examples" version = "1.0-SNAPSHOT" repositories { jcenter() } dependencies { implementation(kotlin("stdlib-jdk8")) implementation("io.kotless", "lang", "0.1.3") } tasks { compileKotlin { kotlinOptions.jvmTarget = "1.8" } compileTestKotlin { kotlinOptions.jvmTarget = "1.8" } } kotless { config { //build後のモジュールとTerraformのstateファイルを配置するためのBucket bucket = "kotless-example-bucket" //作成したリソースにつくprefix prefix = "dev" // terraformの設定 terraform { // AWS CLIのcredentiaで設定したProfile profile = "kotless" // リソースの構築先リージョン(S3のリージョンと合わせる) region = "ap-northeast-1" } } //webApplicationの設定 webapp { //作成するlambdaのメモリとTimeout設定 lambda { memoryMb = 1024 timeoutSec = 120 } } }サンプルコードの追加
公式にあるサンプルコードをそのまま使います。
PackageについてはGradleのGroupと合わせておきますMain.ktpackage io.kotless.examples import io.kotless.dsl.lang.http.Get object Main { @Get("/") fun root(): String = "Hello world!" }デプロイ
API Gatewayでの接続まで
実際にデプロイをしてみます。
予めどのようなものが作成されるかを確認する場合は以下のコマンド
ここでエラーにならないか確認はできます。console$ ./gradlew plan実際にデプロイする場合は以下のコマンドになります。
console$ ./gradlew deploy ~~~~~~~~~~~~~~~~~~~~~~~ リソース作成ログ ~~~~~~~~~~~~~~~~~~~~~~~ Apply complete! Resources: 14 added, 0 changed, 0 destroyed. Outputs: application_url = https://l19upnzkwc.execute-api.ap-northeast-1.amazonaws.com/1 BUILD SUCCESSFUL in 24s 6 actionable tasks: 2 executed, 4 up-to-dateこのようにうまくデプロイできた場合は、アクセス先のURLが表示されます。
アクセスすると以下のような返答が返ってきます。
リソースのDestroy
中身はTerraformなので、もちろん作ったリソースは一括削除が可能です。
ですが、デフォルトでコマンドを封じられているのでONにする必要があります。
build.gradle.ktsのkotlessタスクに追記を行います。build.gradle.ktskotless { config { //build後のモジュールとTerraformのstateファイルを配置するためのBucket bucket = "kotless-example-bucket" //作成したリソースにつくprefix prefix = "dev" terraform { profile = "kotless" region = "ap-northeast-1" } } //webApplicationの設定 webapp { //作成するlambdaのメモリとTimeout設定 lambda { memoryMb = 1024 timeoutSec = 120 } } // 追加機能 extensions { terraform { //Destroyコマンドを有効にする allowDestroy = true } } }これで以下のコマンドで作成したリソースを一括削除できます。
console$ ./gradlew destroy Initializing the backend... Successfully configured the backend "s3"! Terraform will automatically use this backend unless the backend configuration changes. Initializing provider plugins... - Checking for available provider plugins on https://releases.hashicorp.com... - Downloading plugin for provider "aws" (1.60.0)... Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary. ~~~~~~~~~~~~~~~~~~~~~~~ リソース削除ログ ~~~~~~~~~~~~~~~~~~~~~~~ Destroy complete! Resources: 14 destroyed. BUILD SUCCESSFUL in 2m 28s 6 actionable tasks: 3 executed, 3 up-to-dateまとめ
"Kotlinのみ"とは言っても、ほとんどScriptなのであまりKotlinで書いてる気はしないかも・・・
まだ去年にできたばかりなので、今後にはとても期待してます!書いてたら結構時間かかってしまったので、ここまでにしておきます。
あとはカスタムドメインの設定もできますが、ここに追記するか別でもう一つ記事を書こうと思います。



- 投稿日:2020-04-26T20:22:32+09:00
AWSのCI/CDを体験するのに「Amazon Web Services アプリ 開発運用入門」をトレースして詰まったところ一覧
今自社のサービスをAWS上で運用していますが、CI/CDの仕組みを整備しなければなあと思っていたところで、ひとまずAWS上で提供されているCI/CDサービスをさらっと理解したく、「Amazon Web Services アプリ 開発運用入門」をトレースしてみました。
https://www.amazon.co.jp/dp/B07PHQS6NZ/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
AWSが提供するCI/CDサービスの中で、本書では以下の利用を体験できます。
- CodeCommit : ソースコード管理サービス
- CodeBuild : ビルドサービス
- CodeDeploy : デプロイサービス
- CodePipeline : リリースプロセスの自動化サービス
いずれもAWSではごく当たり前となっているフルマネージドサービスで、利用者からするとごく簡単なCUI, GUI経由の操作だけで環境構築ができます。
参考までに、フルマネージドサービスの定義をこちらから引用しておきます。
「フルマネージドのサービス」は、利用者がサービスを利用する際に、「コンピュータ障害監視・バックアップ・ソフトウェアのバージョンアップ」など「運用に関わる作業」をクラウド業者が行ってくれる形態のサービス
最終目的である、CodePipelineでのCI/CIパイプラインの構築がChapter4(全部でChapter8あります)ですが、Chapter4まで終えるのに、自分の場合2時間程度で済みました。
内容がそんなに濃くない?とも言えますが笑、さらっと体験したい方には打ってつけではあると思います。
さて、本書の内容は手取り足取り丁寧な内容となっているので、書籍の発行日が2019年2月1日で本記事執筆日(2020/4/26)から1年以上前であるものの、多少の画面の変更はありつつ、今でも十分トレースできる内容となっています。
ですが、一瞬詰まったところがないではなく、せっかくなのでメモしておきます。
Chapter2-2 Step9 Gitクライアントの設定
GitクライアントにAWS CLIの認証情報ヘルパーを使用する設定するプロセスがあります。
ここで以下のコマンドを実行しろ、とあります。
$ git config --global credential.helper "!aws codecommit credential-helper $@"しかしこのまま先のプロセスに進むと、ローカルレポジトリからコミットをプッシュする
git pull時にusernameを聞かれてしまい、認証情報の設定がうまくいっていないことが分かります。原因と対処方法はこちらの記事にありました。
vi ~/.gitconfigでgitconfigの内容を確認してみると、[credential] helper = "aws --version codecommit credential-helper "となっているので、これを修正しましょう。
[credential] helper = "!aws codecommit credential-helper $@"Chapter2-3 Step1 CodeCommitリポジトリURLを取得
リポジトリのURLのクローンのところで、「HTTPSのクローン」が指定されています。
これで初回のリポジトリアクセスは可能なのですが、しばらく経ってからアクセスすると、
$ git pull origin master fatal: unable to access 'https://git-codecommit.us-east-1.amazonaws.com/v1/repos/awesome-app/': The requested URL returned error: 403と、403エラーが返ってきてしまいます。
これの原因と対処方法ですが、こちらの記事にありました。以下、引用します。
OSXにプリインストールされているGitは、credentialを保存するのにKeychain Accessを使います。ですが、セキュリティ上の理由からCodeCommitへアクセスするためのcredentialはテンポラリなものであるため、リポジトリに初回アクセスした際に保存されたcredentialは約15分後には使えなくなります。
なんと。そういう仕様にせざるを得ないんでしょうか。
とにかく、Keychain Accessは運用上は使えないので、引用記事中に示されているいずれかの方法を代替として対処する必要があります。
個人的には、sshでアクセスするのが最も楽で、環境も汚さなくて良いと思います。
手順は以下公式にある通り。手順通りにやれば問題なくできます。
https://docs.aws.amazon.com/ja_jp/codecommit/latest/userguide/setting-up-ssh-unixes.html
Chapter4-3 Step1 アプリケーションの差分ファイルをリポジトリにマージ
最後に、些細な点。
アプリケーションの差分ファイルが含まれる4-3.zipのsrcディレクトリに、Application.javaが含まれていないので、srcディレクトリごと上書きするとbuildに失敗します。
ここは表示メッセージを書き換えるだけですし、HelloWorldController.javaを直接書き換えてしまうのが良いと思います。
AWSのCI/CDサービスに対する所感
実際にCodePipelineでリリースプロセスの自動化を体験してみましたが、一度パイプラインを作ってしまえばデプロイまでは非常に早く、開発環境のようにテスターとインタラクティブにやりとりしたい環境ではなかなか有用ではないかと思いました。
CodeCommitについてはGitHubやBitbucketといった他のVCSと比較して細かい機能が十分でないという話を聞いたりするので、実際に業務で利用するには「痒いところに手が届かない」があるのかもしれませんが、CodeCommitの代わりにGitHubを使うことはできるので、マイクロサービスとしての利点を生かせばやはり有用なのかなと思っています。
https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/sample-github-pull-request.html
あとはAWSのサービスに限らないですが、CI/CDのプロセスを作り込むことでリリースプロセスの柔軟性はなくなるわけなので、人間がプロセスに合わせていくのか、プロセスを人間に合わせていくのか、という問題は残るかと思います。
- 投稿日:2020-04-26T20:21:55+09:00
AWS X-RayをJavaで色々動かして試してみる
前提条件
X-Ray初心者向け。なんとなくは知ってるけど、具体的に何がどこまでできて、どうやって実装するかを色々試してみながら確認した記事。
環境としては、Spring Boot+MavenでWebアプリを実装している。依存関係の解決方法以外はGradleも同じはず。
X-RayのDockerコンテナイメージを作る。
まずは、適当なEC2とかでコンテナイメージを作る。
今回は、AWSのサンプルをベースに作ってみよう。$ git clone https://github.com/aws-samples/aws-xray-fargatebuildspec.yml に書いてあるコマンドを、実行していってみる。
$ aws ecr get-login --no-include-email --region ap-northeast-1でログイン情報を取得後、実行。
ap-northeast-1は利用しているリージョンを指定する。$ docker build -t xray:latest .作ったコンテナイメージは正常性確認をしてみよう。以下を参考にする。
それぞれのdocker runのオプションの意味も記載されているので読んでみると良い。$ docker run \ --attach STDOUT \ -v ~/.aws/:/root/.aws/:ro \ --net=host \ -e AWS_REGION=ap-northeast-1 \ --name xray \ -p 2000:2000/udp \ xray -oあと、EC2のロールに
AWSXRayDaemonWriteAccessのIAMポリシをつけておく。アプリケーションのX-Ray対応
受信リクエスト対応
以下の開発者ガイドを参考にしながら、アプリケーション側でX-Rayのログをデーモンに送るようにする。
受信リクエストの対応をするだけなら簡単なようだ。
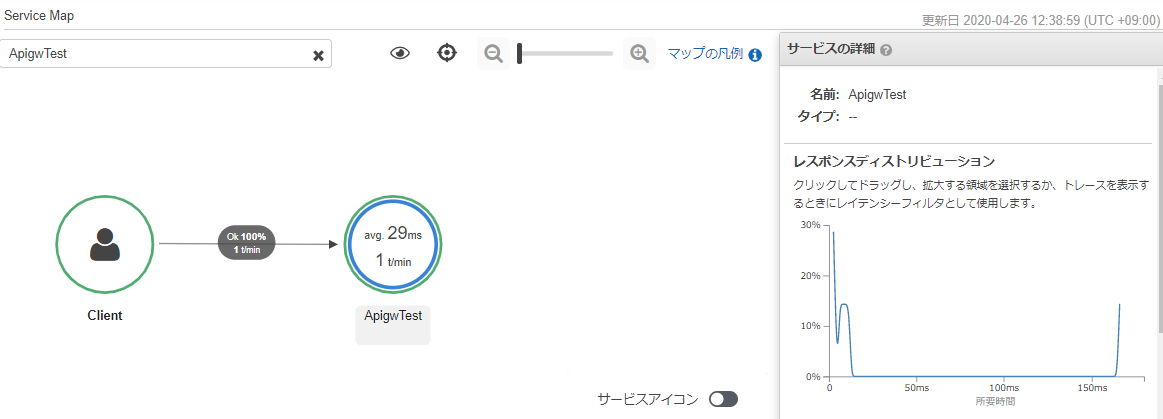
WebConfig.javaなクラスを以下の様に実装する。ApigwTestは、サンプルで作ったWebアプリの名前。WebConfig.javapackage com.example; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Bean; import javax.servlet.Filter; import com.amazonaws.xray.javax.servlet.AWSXRayServletFilter; @Configuration public class WebConfig { @Bean public Filter TracingFilter() { return new AWSXRayServletFilter("ApigwTest"); } }X-RayはAWSのSDKを使う必要があるため、pom.xmlに以下を記述して依存関係を解決する。
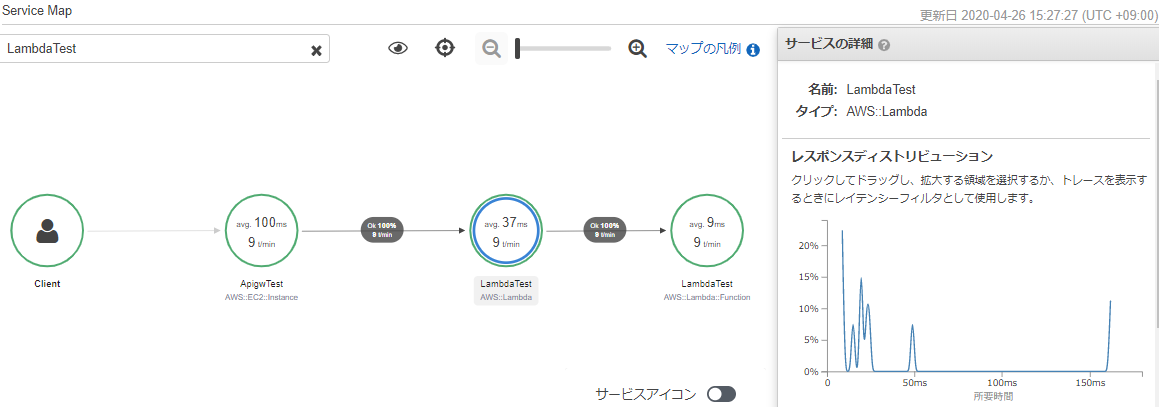
pom.xml<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-xray-recorder-sdk-bom</artifactId> <version>2.4.0</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-xray-recorder-sdk-core</artifactId> </dependency> </dependencies>さて、このアプリを起動してアクセスすると、↓こんな感じでトレースができるようになる。
詳細情報の取得
さらに、受信リクエストを受けたノードの情報を取得できるように、↑で作った
WebConfigクラスに以下のコードを入れてみる。import com.amazonaws.xray.AWSXRay; import com.amazonaws.xray.AWSXRayRecorderBuilder; import com.amazonaws.xray.plugins.EC2Plugin; import com.amazonaws.xray.plugins.ECSPlugin; static { AWSXRayRecorderBuilder builder = AWSXRayRecorderBuilder.standard().withPlugin(new EC2Plugin()).withPlugin(new ECSPlugin()); AWSXRay.setGlobalRecorder(builder.build()); }これをEC2上で実行した場合は、以下のように、サービスマップにEC2インスタンスであることが表示されるようになる。
ダウンストリームのトレース対応
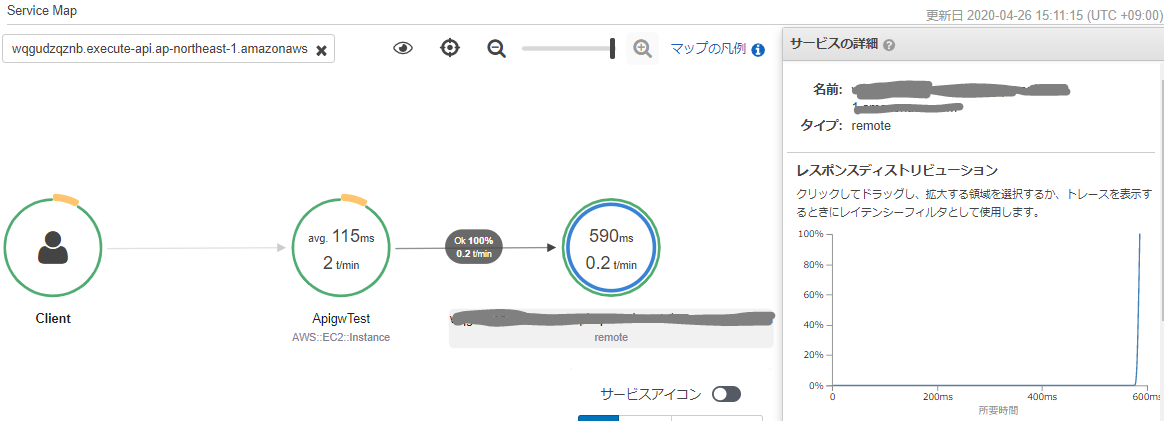
さらに、HTTPクライアントとして、ダウンストリームのWebサービスの情報も取得する場合は、コントローラの中に↓こんなのを入れてみる。
import com.amazonaws.xray.proxies.apache.http.HttpClientBuilder; import org.apache.http.client.methods.HttpGet; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.impl.client.CloseableHttpClient; import java.io.IOException; (中略) public int HttpClient(String URL) throws IOException { int statusCode = 500; CloseableHttpClient httpclient = HttpClientBuilder.create().build(); HttpGet httpGet = new HttpGet(URL); CloseableHttpResponse clientResponse = httpclient.execute(httpGet); try { statusCode = clientResponse.getStatusLine().getStatusCode(); } finally { clientResponse.close(); } return statusCode; }また、
com.amazonaws.xray.proxies.apache.http.HttpClientBuilderをインポートするために、pom.xmlにも以下の依存関係を追記する。pom.xml<dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-xray-recorder-sdk-apache-http</artifactId> </dependency> </dependencies>すると、以下のようにダウンストリームの情報も取得できるようになる。
ちなみに、このダウンストリームのサービスはLambda関数で実装していたので、ふと気になってLambda関数側でX-Rayの設定を有効化すると、↓こんな感じで、重複した要素は取得しなくなった。賢い。
ECS on Fargateで動かす
まずは、ここまでで動作確認したX-RayのコンテナをECRにPUSHする。
事前にxrayのリポジトリを作っておくのを忘れないように。$ docker tag xray:latest [AWSのアカウントID].dkr.ecr.[リージョン].amazonaws.com/xray:latest $ docker push [AWSのアカウントID].dkr.ecr.[リージョン].amazonaws.com/xray:latestまた、ここでもECSのタスクロールとタスク実行ロールに
AWSXRayDaemonWriteAccessを付与しておく。コンテナのタスク定義に、↑でPUSHしたxrayのイメージを入れる。
CloudFormationテンプレートで言えば、ContainerDefinitions内で、既存のコンテナ定義に並べて以下の定義を書く。awsvpcを使わないECS on EC2の場合は他にも設定が必要だが、Fargateの場合は、awsvpcで動くので、簡単に加えられるようだ。- Name: X-Ray-Daemon Image: !Sub ${AWS::AccountId}.dkr.ecr.${AWS::Region}.amazonaws.com/xray:latest Cpu: 32 MemoryReservation: 256 PortMappings: - ContainerPort: 2000 Protocol: udpLambda側のアクティブトレースを有効化すると、EC2と同様に取得することができた。
ただし、Lambda側のアクティブトレースを無効にすると、リクエストに対するトレースは取得できたが、ダウンストリームのトレースが取得できなかった。何かまだ足りていない設定があるのかもしれない。


- 投稿日:2020-04-26T20:03:43+09:00
Capistranoを噛み砕く
近況報告
実はコーヒーマイスターを前職で取得した経緯がありまして,若干のコーヒーの知識があるので,少しひけらかしたいと思います。まず,コーヒーってどんな飲み物のイメージがあります?多分,苦いイメージですよね。では,現在世界的に高品質なコーヒーはどのように評価されているでしょうか。実は苦さの評価はありません。酸味の評価が主流です。
理由はいたって簡単。苦味は焙煎によって生まれるものであり,酸味はコーヒー豆がそもそも持っているものだからです。細かい説明はしませんが,生のコーヒー豆は食べられたものではありません,それを美味しくするために火を入れます。その時に豆の成分が焦げて苦味になります。酸味は熱によって分解されていくので,結果として深煎りのコーヒーは酸味のないものになります。一方,苦味は焙煎度合いや焙煎師の腕,設備により変化します。ということは,豆が本来持っている酸味が評価の基準になるのはまあ納得ですね。
ただ,この評価はスペシャリティコーヒー(世界のコーヒー生産のうち10%程度に該当する)の概念が生まれた10数年前のものであり,以前は苦味,そもそもそんな評価なかったかも。。。今後も同じ評価をしていくとは限りません。やはり常に情報は更新されていきます。だから,常にアンテナを張っていないと時代遅れになっちゃいますね。全てが動いているのに自分が動かなかったら動いている相手から見たら不安定です。だから動くこと,不安定であることこそが安定ってね。
今回の目標
Capistranoで実施していることの言語化
大まかな流れ
・Capistranoについて
・Capistrano導入
・各ファイルの設定事前準備
デプロイ環境整備
rails5.2以降ならマスターキーを本番環境に環境変数にして入れといてね
ruby 2.5.1Capistranoについて
一言で言えば,自動デプロイツールです。
デプロイには
SSH内の情報(アプリケーション)の更新
SSH接続
アセットコンパイル更新
Unicorn再起動
といくつかコードを打ち込んでいく必要があります。ただCapistranoを導入さえできれば,
** bundle exec cap production deploy**
これだけで上の作業が終了します。
個人的にはCircleCiを勉強して導入したかったのですが,間に合わずカリキュラムのこちらをCapistrano導入
railsにおいてCapistranoにはGemが存在します。そこからチョチョイと生成しましょう。
gemfile.group :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano3-unicorn' endterminal.$ bundle install $bundle exec cap install ⇨gemfileにあるものを参照してcap(istrano)の関連ファイルをインストールこれで1つのフォルダと2つのファイルが生成されます
◆capfile----capistranoで実行することを決めるファイル
◆deploy-----デプロイする環境ごとに設定されるファイル
・staging.rb-----ステージング環境(つまり開発環境,テスト環境)に適用される
・pruduction.rb--本番環境に適用される
◆deploy.rb--デプロイする内容を決めるフォルダ
capfileで実行することをきめて,残りがGithubへの接続に必要なsshキーの指定、デプロイ先のサーバのドメイン、AWSサーバへのログインユーザー名、サーバにログインしてからデプロイのために何をするか、といった設定が入るわけです。各ファイルの設定
capfile
capfile.require "capistrano/setup" ←準備しますー(これ抜けてたら動かない) require "capistrano/deploy" ←デプロイ実行するねー require 'capistrano/rbenv' ←rbenvの状態みるね require 'capistrano/bundler' ←必要なGem確認するね require 'capistrano/rails/assets' ←アセットファイルをコンパイルするね require 'capistrano/rails/migrations' ←DB:migrateするね require 'capistrano3/unicorn' ←unicorn再起動するね Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r } ⇨ディレクトリ内の.rakeを昇順で抽出に編集
pruduction.rbpruduction.rbserver '12.345.678.90'←用意したElastic I, user: 'ec2-user', roles: %w{app db web} |「どのサーバーつなぐ?」,「ユーザー名は?」「マイグレートするのは(データベース選択)」
staging.rbは今回必要ないので無視deploy.rb
deploy.rb# capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '<Capistranoのバージョン>'←ローカルで確認 # Capistranoのログの表示に利用する set :application, '自身のアプリケーション名' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:<Githubのユーザー名>/<レポジトリ名>.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, '<このアプリで使用しているrubyのバージョン>' #ローカルで確認 # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['****.pem 自分のに書き換える'] # プロセス番号を記載したユニコーンファイルの場所はここだよ set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所(ローカルの位置と同じ) set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end endに編集
◆set :xx, xx ⇨DSL(Domain-Specific Language)の一種
ある特定の処理における効率をあげるために特化した形の文法を擬似的に用意したプログラムです。
上記のset :名前, 値について、これは言わば変数のようなものです。
例えばset: Name, 'value' と定義した場合、fetch Name とすることで 'Value'が取り出せます。
また、一度setした値はdeploy.rbやproduction.rbなどの全域で取り出すことができます。
また、ファイル内には、desc '◯◯'やtask:XX doといった記述がよく見受けられます。これは、先ほどCapfileでrequireしたものに加えて追加のタスクを記述している形です。ここで記述したものもcap deploy時に実行されることとなります。Capistranoによる自動デプロイ後のディレクトリ構成について
一度Capistranoによる自動デプロイを実行すると、本番環境のアプリケーションのディレクトリが変化します。
Capistranoによるアプリのバックアップなど、複数のディレクトリが作成されます。その中でも特に重要なのが、releases、current、sharedディレクトリです。releasesディレクトリ
capistranoを通じてデプロイされたアプリは、releasesというフォルダにひとまとめにされます。
ここに過去分のアプリが残っていることにより、デプロイ時に何か問題が発生しても一つ前のバージョンに戻ったりすることができます。
そして、その過去分の保存数を指定しているのがdeploy.rbのset :keep_releasesの記述となります。今回は5つ、過去のバージョンを保存するよう設定しました。currentディレクトリ
releasesフォルダの中で一番新しいものが、自動的にcurrentというフォルダ内にコピーされているような状態になります。そのため、このcurrent内に入っているアプリの内容が、現在デプロイされている内容ということになります。
db:seedもここに入れないと反映されない。
sharedディレクトリ
バージョンが変わっても共通で参照されるディレクトリが格納されるディレクトリです。具体的には、log、public、tmp、vendorディレクトリが格納されます。config/unicorn.rbapp_path = File.expand_path('../../', __FILE__) worker_processes 1 working_directory app_path pid "#{app_path}/tmp/pids/unicorn.pid" listen "#{app_path}/tmp/sockets/unicorn.sock" stderr_path "#{app_path}/log/unicorn.stderr.log" stdout_path "#{app_path}/log/unicorn.stdout.log" ↓↓↓↓↓↓↓ 以下のように変更 ↓↓↓↓↓↓ # ../が一つ増えている app_path = File.expand_path('../../../', __FILE__) worker_processes 1 # currentを指定 working_directory "#{app_path}/current" # それぞれ、sharedの中を参照するよう変更 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" pid "#{app_path}/shared/tmp/pids/unicorn.pid" stderr_path "#{app_path}/shared/log/unicorn.stderr.log" stdout_path "#{app_path}/shared/log/unicorn.stdout.log"nginxの設定ファイル
同様に、Nginxの設定ファイルも変更が必要です。これまでは/var/www/以下のアプリケーションに対して連携を設定していたので、/var/www/chat-space以下のcurrent、sharedなどのディレクトリと連携するように設定を変更する必要があります。全て消して編集
$ sudo vim /etc/nginx/conf.d/rails.confupstream app_server { # sharedの中を参照するよう変更 server unix:/var/www/<アプリケーション名>/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name <Elastic IPを記入>; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }各サーバー再起動
$ sudo service nginx reload
$ sudo service nginx restart
$ sudo service mysqld restart
$ ps aux | grep unicorn
$ kill [master number]
$ bundle exec cap production deploy
- 投稿日:2020-04-26T17:32:46+09:00
AWSの障害情報をチェックする
4/20の夜にAWSの東京リージョンでSQSやLambdaに障害があったようです。
AWSも無敵ではありません。障害があった際にすぐに気づきたいですね。
Service Health Dashboardをチェック
AWSに障害が発生した場合には、こちらのサイトでアナウンスされます。
https://status.aws.amazon.com/こちらのサイトにはRSSも配信されているので、RSSリーダーでチェックしておくと良いですね。
しかし、、、サービスごとにチェックするRSSファイルが分かれている!!!
「Tokyo」で検索しても120件。。。全件手動で登録するのは無理ですね。
(Slackに通知を行うとか今どきのものを考えたのですが、手動で120件も登録できません。。。)全RSSファイルをまとめたRSSファイルを作る
Lambdaで定期的にスクレイピングする作戦です。やってやれんことはない。
できたファイルはS3にでも格納して外から見れるようにしましょう。
この例ではService Health Dashboardのタブを一つ指定して処理をするようにしました。
Asia Pacificタブは数が多く、1回に5分ほど時間がかかります。import os import requests from bs4 import BeautifulSoup base_url = 'https://status.aws.amazon.com' rss_template = ('<?xml version="1.0" encoding="UTF-8"?>' '<rss version="2.0">' ' <channel>' ' <title><![CDATA[AWS Service Status]]></title>' ' <link>http://status.aws.amazon.com/</link>' ' <description><![CDATA[AWS Service Status]]></description>' ' </channel>' '</rss>' ) def get_rss_list(block): print('start get_rss_list') res = requests.get(base_url) aws_soup = BeautifulSoup(res.text, 'lxml') tables = aws_soup.find(id=block).find_all('table') links = [] for tr in tables[1].find('tbody').find_all('tr'): tds = tr.find_all('td') links.append({'service': tds[1].text, 'url': tds[3].find('a').get('href')}) return links def get_rss_item(rss_url): print(rss_url) response = requests.get(rss_url) return response.text def add_rss_item(rss_text, rss_path, service_name, output_soup): rss = BeautifulSoup(rss_text, 'xml') items = rss.find_all('item') for item in items: category = rss.new_tag('category') category.append(service_name) item.append(category) output_soup.find('channel').append(item) def put_object(rss_string, block): import boto3 client = boto3.client('s3') client.put_object( ACL='public-read', Body=rss_string.encode('utf-8'), Bucket=os.getenv('S3_BUCKET'), Key='aws-status'+block+'.rss', ContentType='application/rss+xml' ) def lambda_handler(event, context): block = event['block'] print(block) output_soup = BeautifulSoup(rss_template, 'xml') for rss in get_rss_list(block): url = base_url + rss['url'] text = get_rss_item(url) add_rss_item(text, url, rss['service'], output_soup) put_object(str(output_soup), block)全リージョンの障害情報が取得できるJSONの存在
ここまで頑張って作ったあとに、全リージョンの障害情報が取得できるJSONファイルがあることを知りました。さすがClassmethodさん。憧れる。
【小ネタ】AWSで過去に発生した障害の履歴を確認する方法 | Developers.IO
https://dev.classmethod.jp/articles/service-health-status-history/https://status.aws.amazon.com/data.json
がそのJSONです。RSSとだいたい同じ情報が取得できます。
これをRSSにしてやれば、良さそうですね。
処理時間も30秒以内に終わるので、API GatewayでRSSを配信できます。import requests from bs4 import BeautifulSoup from bs4.element import CData from datetime import datetime, date, time, timezone, timedelta rss_template = ('<?xml version="1.0" encoding="UTF-8"?>' '<rss version="2.0">' ' <channel>' ' <title><![CDATA[AWS Service Status]]></title>' ' <link>http://status.aws.amazon.com/</link>' ' <description><![CDATA[AWS Service Status]]></description>' ' </channel>' '</rss>' ) item_template = ('<item>' ' <title></title>' ' <link>http://status.aws.amazon.com/</link>' ' <pubDate></pubDate>' ' <guid isPermaLink="false"></guid>' ' <description></description>' ' <category></category>' '</item>') def lambda_handler(event, context): soup = BeautifulSoup(rss_template, 'xml') r = requests.get('https://status.aws.amazon.com/data.json') json = r.json() JST = timezone(timedelta(hours=+9), 'JST') for item in json['archive']: title = item['summary'] pubDate = item['date'] pubDate = datetime.fromtimestamp(int(item['date']),JST).strftime('%a, %d %b %Y %H:%M:%S %Z') guid = item['service'] + item['date'] description = item['description'] category = item['service_name'] item = BeautifulSoup(item_template, 'xml') item.title.append(title) item.pubDate.append(pubDate) item.guid.append(guid) item.description.append(CData(description)) item.category.append(category) soup.find('channel').append(item) response = { 'statusCode': 200, 'isBase64Encoded': False, 'headers': {'Content-Type': 'text/xml;charset=UTF-8'}, 'body': str(soup) } return responseWebサイトにもしてみました。
data.jsonを使って履歴を確認するWebサイトにしてみました。
4/20の東京リージョンの障害のあとにもバージニアのEC2、4/22のCloudFrontにも障害があったようです。https://aws-status-rss.s3-ap-northeast-1.amazonaws.com/index.html
JSONを取得して整形しているだけですが、data.jsonの取得はCORSに引っかかるため、API GatewayのHTTP APIにてCORSを有効にしたHTTP プロキシ統合を作って回避しました。



- 投稿日:2020-04-26T15:56:49+09:00
IAM resource を Terraformで管理する
背景
IAM userをTerraformで管理し始めて、 policyを importして、Roleを。。とやっていたが、policy attachmentや group memberなどもTerraform化しなくてはいけなくなってかなり大変になった。
要件
以下の要件くらいは満たしてほしい
- Userの追加・削除
- User削除時に関連する グループに所属する、UserPolicyAttachmentなどの削除が可能
- Groupの作成と同時にUserの追加
- Policyの作成と同時にUser/Role/GroupへのAttachment
- Role/Group/Userの作成とPolicyのAttachment
材料
terraform import利点:
1. officialで既存のリソースのImportができる
難点:
1. tfstateはimportできるがtfファイルは準備しないといけない。 → すでに大量のリソースがあると大変terraforming
利点:
1. ほとんどのリソースカバーされてる
2. tf と tfstate既存が既存リソースに対して生成できる難点:
1. プロジェクトがActiveではないのでPRとか出したがマージされたり更新されることはなさそう
1. ResourceごとにImportするので、上記の異なるResource間のDependencyを解決できない解決策
とりあえずあるもの使って自分で作ればいいかという感じになったので、勉強がてら作った
基本は 「terraformingがどうやってるか理解」+「リソース間の依存までを自分で実現する」
出来たもの
使ったもの:
1. terraforming
2. pratice_terraforming <- terraformingの勉強しつつ、自分の必要なリソースでterraformingになかったものを作った
3. shell (汚くstateを移動したり、無理くりやってるのは愛嬌w)とりあえず2ステップだけでできるようになった
生のtfとtfstateのimport
./import.shインポートしたやつの依存関係を考えたModule構造に変換する
./convert.sh
- 投稿日:2020-04-26T13:53:31+09:00
chmod 600 ←600ってなんやねん
近況報告
とりあえずデプロイは完了しました。readmeを書いて,投稿物を揃え,エラー対応すれば見世物としての体裁はできあがるのかな。某雑食系さんのツイートに,ポートフォリオはサーバーサイドの実力はもちろんのこと,コンテンツ力,そして見た目も評価の対象になりうるとありましたね(めっちゃ噛み砕いた)。自分のはサーバーサイドの記述,実力はまだまだですけど,見た目は手を抜かなければよくできるので,今の自分の最善を尽くした作品を作っていこうと思います。
今回の目的
chmodに続く数字を知る。
結論
ファイルへの権限の種類だよ
詳細
chmodは「change mode」の略で,桁数,数字の組み合わせによって編集の権限とかを設定しています。
これにより,第三者からの不正アクセスの予防に繋がります。
桁数 意味 1桁目(百の位) 所有者のアクセス権限の範囲 2桁目(十の位) グループのアクセス権限の範囲 3桁目(一の位) その他のユーザーのアクセス権限の範囲
数字 意味 4 読み出し許可 2 書き込み許可 1 実行許可 0 権限なし 数字の足し算で権限は増えていきます。例えば全ての権限なら
4+2+1+0で7に
読み出しと書き込みだけなら4+2で6になります。
このように編集できるユーザーを適宜設定できます。おわりに
Linuxのコマンドは他にもごっそりあるのでそれの一部と考えていただければ。
微量でも参考になったらLGTM,ご指導はコメント欄にお願いします!
- 投稿日:2020-04-26T13:41:35+09:00
AWS Cloud9でRuby on Railsを動かしてみた
こんにちは!モリタケンタロウです!
今回はAWSのCloud9で、Ruby on Railsを動かす方法について紹介します。AWS Cloud9とは
AWS Cloud9については↓をご参考にどうぞ
Ruby on Railsとは
Ruby on RailsはRubyで動作するMVCモデルのフレームワークです。
Webアプリケーション開発に向いていて、世の中のあらゆるサービスがこのRuby on Railsでできています。
Railsはオワコンと言われていたりもしますが、僕が会社でRailsのWebアプリ開発をやっていたときに、勉強しやすくて書きやすかったので、とりあえず今回はRailsを使ってみようと思います。とにかくやってみよう!
AWS Cloud9では最初からRubyもRailsもインストールされています。
ruby -vとrails -vのコマンドで確認できます。
確認できたら早速アプリを作成してみましょう。
rails new [アプリ名]コマンドで作ります。
そうすると、指定した名前のアプリのディレクトリが作成されました!
作ったアプリのディレクトリの中に入って、rails serverコマンドでアプリを動かしてみましょう。
動いている様子は、Preview > Preview Running Application で確認できます。
上手くいくと、こんな画面が出てきます。めでたしめでたし!
上手くいかないと、こんな画面が出てくるかもしれません。
そんなときは、↓を参考にしてみてください。ちょっとつまづきながらも無事に「Yay!…」という画面が出せたので、これからコツコツRails開発を始めていきます!
それでは~






- 投稿日:2020-04-26T13:40:32+09:00
Railsで新しいアプリを作ったらActiveRecord::ConnectionNotEstablishedが出てきた
こんにちは!モリタケンタロウです!
今回はRailsでアプリを新規作成して動かしてみたら、「ActiveRecord::ConnectionNotEstablished」というエラーが出てきたので、それを解決する方法について紹介します。開発環境
- ruby 2.6.3p62
- Rails 5.0.0
エラー内容
rails serverコマンドでアプリを動かすと、画面にはこんなエラーが出てきます。
ActiveRecord::ConnectionNotEstablished
No connection pool with id primary found
なにこれ!?分からん…
ということでググると、RailsのORM機能であるActiveRecordが、sqlite3の新しいバージョンに対応してないことが原因らしい。(参考:ActiveRecord::ConnectionNotEstablished No connection pool)対処内容
ということで、Railsがインストールしているパッケージを管理しているGemfileを編集します。
gem 'sqlite3', '~> 1.3.6'
- 修正前

- 修正後

Gemfileを編集したら、
bundle installコマンドでインストールパッケージを更新します。
そしてrails serverコマンドでアプリを起動すると…
見事、アプリが正常に起動しました。めでたしめでたし!
ということで一件落着(^^)
それでは~




- 投稿日:2020-04-26T12:40:51+09:00
AWSを用いてrailsアプリをデプロイするプロセスを頑張って噛み砕いてみるvol.6
近況報告
大海に糸を垂らして魚を釣るのと鱒がそこにいるとわかっている生簀で鱒を釣るの,どちらが先に釣れるでしょうか。価値があるから売れるのと,売れるから価値がある,どちらが始まりなのでしょうか。鶏と卵論争ではないけれども,考えていくべきことですよね。
ついに最後,Nginxですね。
まだやりたいことはあって,予定ではCapistranoとベーシック認証があるのでvol.8以上あるのか笑
さあいってみようかぁ!今回の内容
・インフラ整備での各アクションの言語化
・コードを単に打っているだけでは理解しきれないし,他に応用できないので言語化して整理
・テックキャンプ受講生支援()大まかな流れ&設定
Nginxインストール
事前準備
Nginxインストール&設定
EC2.sudo yum -y install nginxsudo yum の解説は前の項で触れています。
インストールできたら設定を編集していきます。むやみやたらにいじられたくないファイルなので権限も強いです。sudo権限でvim形式で編集していきます。EC2.$ sudo vim /etc/nginx/conf.d/rails.confrails.confupstream app_server { server unix:/var/www/<アプリケーション名>/tmp/sockets/unicorn.sock; } ⇨Unicornと連携させるための設定。アプリケーション名を自身のアプリ名に書き換えることに注意。upstreamは上流の意。ここでunixが登場していることはよくわかんなかった。 server { ⇨ {}で囲った部分をブロックと呼ぶ。サーバの設定ができる listen 80; ⇨このプログラムが接続を受け付けるポート番号 server_name <Elastic IP>; ⇨接続を受け付けるリクエストURL client_max_body_size 2g; ⇨クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガ root /var/www/<アプリケーション名>/public; ⇨接続が来た際のrootディレクトリ location ^~ /assets/ { ←assetファイルはここに入っているのを参照するよ gzip_static on; ←圧縮状態のものを配信。容量が小さくなるのでメモリの負担減らせる expires max; ←キャッシュの有効期限。maxは限界までの意 add_header Cache-Control public; ←キャッシュを受け取る範囲の選択 ⇨assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 } try_files $uri/index.html $uri @unicorn; ⇨ファイルの選択,右の$からアクセスされる location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; ⇨Nginxからユニコーンにむけた設定 } error_page 500 502 503 504 /500.html; ⇨エラーが表示された時のページ }と<アプリケーション名>計三箇所直したら,脱出(:wq)
補足
プロキシ
ブラウザとウェブサーバーの中間役。ウェブサーバーの情報をブラウザで写すが,プロキシはウェブサーバーの代理としてウェブサーバーからの情報を写す。 ⇨わかりやすかった説明
location unicornではHTMLメソッドの受け取る方法とか表示の仕方とか設定してるっぽい。権限変更を行ったあと,再起動をします。
EC2.$ cd /var/lib $ sudo chmod -R 775 nginx ←-RはNginxに対してって意味 $ cd ~ $ sudo service nginx restart ⇨初めにfailed出ても再起動でOKがでれば大丈夫カリキュラムで分からなかった点
POSTメソッドを用いるとエラーが発生する可能性があるから権限変更を行うらしいのですが,このコマンドが通信量の多いPOSTメソッドのエラーを防ぐのかまだ理解できていません。●補足chmodについて
UnicornをNginxに接続
config/unicorn.rblisten 3000 ↓以下のように修正 listen "#{app_path}/tmp/sockets/unicorn.sock"githubに反映後,EC2に読み込み。
unicorn再起動処理をして,ブラウザにElastic IPを直打ちしてアプリケーションのルートページが表示できれば成功。うまく表示できない場合はもう一回やり方を見直す。URLが見つからないことで表示されてない可能性があるので注意して見る。終わりに
テックキャンプのカリキュラム,はしょりすぎぃ!!!
まあ多分目的は完全理解というより大枠を捉えよ的な教科書みたいなアプローチですな。
10週間でやれることなんてたかがしれてるし,Nginxひとつとっても理解しようとすれば数百ページの本を読まないとだから無難なのかな(しかもオープンソースだから今この瞬間にアップデートされているかもしれない...)。微量でも参考になったらLGTM,ご指導はコメント欄にお願いします!
- 投稿日:2020-04-26T12:11:30+09:00
DynamoDB知見
はじめに
この記事は2020年3月31日時点のものです。
どこかで見た情報を適当にメモして、あとから自分の言葉で書き直したりものです。
それでも良い方のみご覧ください。
*CUやモードについては書いてません。DynamoDB知見
用語
・項目
レコードのこと
・属性
カラムのこと
・スキャン
対象テーブルの全ての項目を取得すること。RDBとNoSQLの違い
・RDB
柔軟にクエリできるが比較的コストが高い、トラフィックが多いと柔軟にスケールできないことも。正規化重要。
・NoSQL
特定のクエリを爆速にする代わりにそれ以外は高コストで低速に。NoSQLの設計について
・ビジネス上の問題とアプリケーションのユースケースを理解してからスキーマを作ろうね。
・出来るだけ少ないテーブル数にしようね。一つがベスト
・関連するデータをまとめること(非正規化)
例外として、大容量の時系列データが必要な場合や、データセットのアクセスパターンが非常に異なる場合などがあります。
キーの設計が原因でソートされている場合は、関連項目をグループ化して、効率的にクエリできます。パーティションキー
必須。
これが一緒=同じパーティションに置かれる
が、パーティションキーの数だけパーティションが作られるわけではない。
各パーティションへのアクセスがなるべく均一になるようパーティションキーを設計すると良い。
パーティションとテーブルは一対一ではない
昔はhashキーと呼ばれていた。ソートキー
必須ではない。
これを設定した=パーティションキーとソートキーの複合プライマリキーにした
これを元にパーティション内でソートされて近くに置かれる(まとめて取り出しやすくなる)
もちろんソート、絞り込みにも使える
昔はrangeキーと呼ばれていた。プライマリキー
データを一意に識別するためのキーの呼び名で、「パーティションキー」または「パーティションキーとソートキーの複合キー」のこと。
ドキュメントに出てきたりするが、「パーティションキー」または「パーティションキーとソートキーの複合キー」以上でも以下でもない。
当たり前だが注意点として、複合キーにする(パーティションキーとソートキー両方設定する)場合はその組み合わせで一意でなければいけない。
たとえば、「パーティションキー=1,ソートキー=2」が同じで、それ以外の属性が違う50レコードをいくらput(RDB的に言えばinsert)してもDynamoDBに入るのは1レコードだけ。49回updateされることになる。DynamoDBは基本upsertっぽい。セカンダリインデックス
https://qiita.com/shibataka000/items/e3f3792201d6fcc397fd ←とてもわかりやすかったのでこちらから引用
あるテーブルをベースに、異なるパーティションキー・ソートキーのテーブルを作成する仕組みを グローバルセカンダリインデックス(GSI)
あるテーブルをベースに、パーティションキーはそのままに、異なるソートキーのテーブルを作成する仕組みを ローカルセカンダリインデックス(LSI)LSIはテーブル作成後には作れない
一般的に、LSIではなく、GSIを使用するでOK。(ちょっとリンクが見つからなかったけど公式にそう書いてあったはず…)
例外として、クエリに強力な整合性が必要な場合は、LSI。
GSIのクエリは結果整合性のみサポート。GSI
GSIでは元テーブルのPK,SKは自動で射影される。
テーブルでは、各キーの値は一意である必要があるが、グローバルセカンダリインデックスのキーの値は一意である必要はない。
PK,SKのどちらかがないレコードはGSIには反映されない射影(Projection)
テーブルに定義された属性をインデックス側にも含めることを「射影」という。
インデックスのテーブルに属性を追加しておかなければ、インデックスを使ったクエリにそれぞれの属性がふくまれない。クエリ
絶対にパーティションキーを指定して検索しなければならない。
ソートキーの指定は必須ではない。
パーティションキー以外の属性を使って検索したい場合はGSIを使おう。
クエリは一回1MBまでしか取ってこられない。
そのためそれ以上の容量のデータをクエリで取得するには再帰的に何度もリクエストすることになる。
そのせいでデータ量が多い場合はクエリが信じられないくらい遅くなる。(RDBで取得に1秒くらいだったものがオンデマンドモードなのにDynamoDBで6秒になってしまった…)クエリでソートキーに対して(キー条件式で)できないこと
部分一致検索ができない
関数が前方一致のbegins_withしか使えない。
部分一致検索の関数のcontainsが使えない。
Filterとしてならcontainsが使えるが、Filterにはソートキー、プライマリキーが使えない(含めることすら許されない)
つまりsortキーに対しての部分一致検索はできない
さらにキー条件式ではnotが使えないのでnot sort_key= hoge検索ができないLimitについて
これは返すアイテム数の上限指定ではなく、評価する(filter適用前の)件数の上限。
2万項目あるテーブルに、limit2000とかでクエリすると2000件評価してマッチした5件だけ取得したら残りの1万8000件は評価せず戻ってきてしまう。(こんなlimitは果たして必要なのだろうか…?)batchGetItemについて
クエリは一回で1MBまでしか取れないが、これは一回で16MBまで取れる。
ただし、パーティションキーとソートキーしか指定できない(filterできない)し、複合プライマリキーならソートキーが必須となるし、100アイテムまでしか取得できない。フィルタ適用時のQueryのリザルト
- ScannedCount — フィルタ式 (存在する場合) が適用される前に、キー条件式に一致する項目数。
- Count — フィルタ式 (存在する場合) が適用された後に残っている項目数。
スキャン
大量のCUを使うので基本使わない方が良い。
個人的感想
とにかく落とし穴が多く、融通が効かない。
クエリで大量のデータを取って来なければならないのならDynamoDBはやめた方がよいと思う。
もしくはPKの設計をやり直した方が良いが、クエリのことを考えるとそうはいかない。
あと、この辺りは探せばいくらでも出てくると思うが、DynamoDBは「全件取得」にめちゃくちゃ弱い。
DynamoDBの強みはNoSQLであることと、スケールを考えないでもよいところだが、それは結構もろ刃のつるぎだったりする。
個人的にはRDBではデータ取得時に大量にjoinしなければいけないなどの問題がある場合に、書き込みはRDBで、読み込みは非正規化したテーブルを持たせたDynamoDBを置くなどの使い方が良いと思う。参考・引用文献
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Introduction.html
https://www.ketancho.net/entry/2018/01/30/075500
https://qiita.com/shibataka000/items/e3f3792201d6fcc397fd
- 投稿日:2020-04-26T11:33:37+09:00
Slackのスラッシュコマンドとダイアログを使ってEC2のセキュリティグループを編集する
経緯
フルリモート体制になっているので、sshの接続元などにオフィス以外の任意のIPアドレスを追加する必要が出てきた。
メンバーの自宅はIPが固定されていないため、IPアドレスが変わるたびにインフラ担当に作業を依頼する必要がある。
作業の手間とヒューマンエラーをなくすために、自動化を試みた。
要件
- 許可したいIPアドレスと対象のセキュリティグループを入力するとインバウンドルールが追加される。
- 追加された任意のIPアドレスを削除する機能も用意する。
- 機能を使用できるユーザーと対象のセキュリティグループをあらかじめ制限する。
- 誰がいつどんな操作を行ったのか履歴を残す。
使用技術
やっぱりこういうボットはSlackかなあと思ったのでスラッシュコマンドで作ることにしました。
バックエンドはLambda+API Gatewayです。
スラッシュコマンドはGASで作る人が多い気がするんですが、今回はAWSのAPIを用いるのでこれ以外の選択肢はまあないですね。
1. Slackアプリの設定
以下からアプリを新しく作成する。
https://api.slack.com/apps[Slash Commands] を選択し、コマンドとURLを入力する。
この時点ではURLが決まっていないので適当に入れておく。
コマンドは/ipとする。Usageにはパラメータのヒントなどを入れておくのだが、とりあえず空にしておく。
ワークスペースにインストールして一旦作業は終わり。
Verification TokenとBot User OAuth Access Tokenがあとで必要になるのでコピーしておく。2. Lambdaの作成
ロジックの作り込みはちょっと長くなるので、まずは疎通確認用にシンプルに200を返す関数を作る。
ランタイムはNode.js 12.x
exports.handler = async (event, context) => { console.log(event) return { statusCode: 200 } }3. API Gatewayの作成
POSTリソースを作成する。ここでは
menuというリソース名にする。
統合リクエストに先ほどの関数を指定して、マッピングテンプレートを追加する。
Slackから送られてくるリクエストは
application/x-www-foorm-urlencodedなので、これを扱いやすいようにJSONに変換する処理を入れる。このテンプレートのベストプラクティスについてはAWS Developer Forumでも議論されているようだが、下記の記事のものが良い感じの落とし所だと思う。
公式で提供してほしい。。。https://qiita.com/tmiki/items/32654e85a925bb841f7d
これで適当にステージ作ってデプロイして、生成されたURLをさっき作ったSlackアプリの方に設定します。
これでSlackに
/ipとポストすると{ statusCode: 200 }が返ります。CloudWatch Logsにはパラメータのログが出るのでスキーマを確認しておきます。
{ token: "**********", team_id: "**********", team_domain: "**********", channel_id: "**********", channel_name: "privategroup", user_id: "**********", user_name: "**********", command: "/ip", response_url: "https://hooks.slack.com/commands/**********", trigger_id: "**********" }
tokenは最初にメモしたVerification Tokenに相当します。これが一致すると、正しくSlackからリクエストが送られてきているという証明になります。
user_idはコマンドを実行したユーザーです。ここを見れば権限が制御できそうですね。4. 認証
最初に基本的な認証を入れておきます。
Verfication Tokenはすでに説明した通りです。ちなみにこれすでにDeprecatedになっている方法です。気になる人はsigned secretsを使ってください。https://api.slack.com/authentication/verifying-requests-from-slack
あとはユーザーに制限をかけておきます。
許可するユーザーのSlackのIDを環境変数ALLOWED_USERSにカンマ区切りで持っておき判定することにします。ユーザーIDの調べ方ですが、自分のアカウントは設定から、
ワークスペースの管理者であれば管理画面から一括でCSVダウンロードができます。
2つの認証をかけた状態です。
if (event["token"] != process.env.VERIFY_TOKEN) { return { "statusCode": 400, "body": "invalid verification token" } } if (!process.env.ALLOWED_USERS.split(",").includes(event['user_id'])) { return { "statusCode": 400, "body": "non-allowed user" } }5. dialog.open
中身の実装に移っていくわけですが、少しアーキテクチャを考えます。
スラッシュコマンドからパラメータを受け取って処理する場合、ユーザーに手順を覚えてもらう必要があります。引数の順番やフォーマットが正しくないとパースする側でしんどいという問題もあります。
application/x-www-form-urlencodedで送られてくるパラメータは、ユーザーが入力した部分は全てtextというキーに入れられ、スペースが+に置換された一つの文字列となるので、順番を間違えるともう終わりです。やはりUIが必要になります。
今回は
dialog.openというAPIを使って、ダイアログでユーザーの入力を補助することにします。
なので本命の追加・削除処理の前に、ダイアログを開くための関数を別で作ります。
6. 追加ダイアログの実装
対象となるセキュリティグループを取得します。
環境変数ALLOWED_SGSにカンマ区切りでグループIDを入れておきます。
取得したセキュリティグループをセレクトボックスで選択式にして、あとはIPアドレスとコメントの入力欄を用意したダイアログを返します。const aws = require("aws-sdk") const ec2 = new aws.EC2() const axios = require("axios") exports.handler = async (event, context) => { /* (中略)認証 */ const headers = { "Content-Type": "application/json; charset=utf-8", "Authorization": `Bearer ${process.env.SLACK_TOKEN}` } const body = await build_body(event["trigger_id"]) const res = await axios.post('https://slack.com/api/dialog.open', body, {"headers":headers}) .then(function (response) { console.log(response.data); return response.data; }).catch(function (err) { console.error(err) return }) if(!res || !res["ok"]) return { statusCode: 400, body: "something went wrong." } return { statusCode: 200 } }; async function getGroup() { return ec2.describeSecurityGroups({"GroupIds": process.env.ALLOWED_SGS.split(",")}).promise().then(function(data) { return data }) } async function build_body(triggerId) { const groups = await getGroup() return { "trigger_id": triggerId, "dialog": { "callback_id": "add", "title": "ssh接続元許可IPアドレスの追加", "notify_on_cancel": false, "elements": [ { "type": "select", "label": "Security Group", "name": "securityGroup", "options": groups["SecurityGroups"].map(group => { return { "value": group["GroupId"], "label": group["GroupName"] } }) }, { "type": "text", "label": "IP Address", "name": "ipAddress" }, { "type": "text", "label": "Comment", "name": "comment" } ] } } }ダイアログの出し方については
dialog.openAPIのドキュメントを参照してください。
https://api.slack.com/methods/dialog.openユーザーがスラッシュコマンドを実行した時のパラメータに含まれる
trigger_idを使ってダイアログを表示させます。このIDは有効期限が3秒しかないため、時間のかかる処理は組めません。ダイアログの中身の
elementsの仕様はドキュメントがまとまっていないので少しハマりました。BlockKitとも微妙に違うのでいろいろ試す必要があります。
セレクトボックス にはセキュリティグループの一覧が表示されます。
あらかじめ分かりやすいDescriptionをつけておく必要があります。
GroupNameにしていないのは、値が必須ではないからです。
あとは、SlackAPIの仕様としてヘッダーにcharsetを指定しないとWarningが出るのでつけています。また、
AuthorizationヘッダーでBearerトークン形式で認証をします。Lambdaの環境変数にトークンを追加するのを忘れずに。const headers = { "Content-Type": "application/json; charset=utf-8", "Authorization": `Bearer ${process.env.SLACK_TOKEN}` }実装は終わりで、あとはセキュリティグループを取得するためにLambdaの実行ロールに以下のインラインポリシーを追加します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "0", "Effect": "Allow", "Action": [ "ec2:DescribeSecurityGroups" ], "Resource": "*" } ] }7. 追加APIの実装
ダイアログのsubmitをトリガーにして発火する関数を作ります。
リソースを/addとしてAPI Gatewayに登録し、URLを[Interactivity]の[Request Url]に設定します。
const aws = require("aws-sdk") const ec2 = new aws.EC2() const axios = require("axios") exports.handler = async (event, context) => { /* (中略)認証 */ const res = await addGroup( event["submission"]["securityGroup"], event["submission"]["ipAddress"], event["submission"]["comment"] ) const res2 = await postResult(event, res) return { } } async function addGroup(groupId, ipAddress, comment) { const params = { GroupId: groupId, IpPermissions: [ { FromPort: 22, ToPort: 22, IpProtocol: "tcp", IpRanges: [ { CidrIp: `${ipAddress}/32`, Description: comment } ] } ] } return ec2.authorizeSecurityGroupIngress(params).promise() .then(function(data) { return true }).catch(function (err) { console.error(err) return }) } async function getGroup(groupId) { return ec2.describeSecurityGroups({"GroupIds": [groupId]}).promise().then(function(data) { return data }) } async function postResult(event, res) { const headers = { "Content-Type": "application/json; charset=utf-8", "Authorization": `Bearer ${process.env.SLACK_TOKEN}` } const groups = await getGroup(event["submission"]["securityGroup"]) let body = { "channel": "#ip_address_changer", "icon_emoji": ":hammer:", "text": "", "attachments": [ { "color": "#36a64f", "author_name": "IPアドレスの追加/削除", "fields": [ { "title": "■ Executed By", "value": event["user"]["name"], "short": false }, { "title": "■ Security Group", "value": groups["SecurityGroups"][0]["GroupName"], "short": false }, { "title": "■ Ip Address", "value": event["submission"]["ipAddress"], "short": false }, { "title": "■ Comment", "value": event["submission"]["comment"], "short": false } ] } ] } if (res) body["text"] = "Success." else body["text"] = "Something went wrong." return axios.post("https://slack.com/api/chat.postMessage", body, {"headers":headers}) .then(function (response) { return response.data; }).catch(function (err) { console.error(err) return }) }まずフォームの受信ですが、スラッシュコマンドの時とSlackから送られてくるペイロードの形式が異なります。同じ
application/x-www-form-urlencodedなんですが、中途半端にJSON文字列化されたフォームがパーセントエンコードされた状態になっています。payload%3D%7B%22type%22%3A%22dialog_submission%22%2C%22token%22%3A%22xxxxxx%22%2C%22action_ts%22%3A%221587799384.191353%22%2C%22team%22%3A%7B%22id%22%3A%22xxxxxxx%22%2C%22domain%22%3A%22xxxxxx%22%7D%2C%22user%22%3A%7B%22id%22%3A%22xxxxxx%22%2C%22name%22%3A%22xxxxxx%22%7D%2C%22channel%22%3A%7B%22id%22%3A%22xxxxxx%22%2C%22name%22%3A%22xxxxxx%22%7D%2C%22submission%22%3A%7B%22securityGroup%22%3A%22xxxxxx%22%2C%22ipAddress%22%3A%221.1.1.1%22%2C%22comment%22%3A%22test%22%7D%2C%22callback_id%22%3A%22add%22%2C%22response_url%22%3A%22xxxxxx%22%2C%22state%22%3A%22%22%7Dデコードするとこんな感じです。
payload={"type":"dialog_submission","token":"xxxxxx","action_ts":"1587799384.191353","team":{"id":"xxxxxxx","domain":"xxxxxx"},"user":{"id":"xxxxxx","name":"xxxxxx"},"channel":{"id":"xxxxxx","name":"xxxxxx"},"submission":{"securityGroup":"xxxxxx","ipAddress":"1.1.1.1","comment":"test"},"callback_id":"add","response_url":"xxxxxx","state":""}これをJSONにマッピングするためにまたVTLを書きます。
あまりない形式っぽく、探してもネットに落ちてなかったので適当に自作します。#set($raw = $input.body) #set($payload = $raw.replace("payload=","")) #set($jsonPayload = $util.urlDecode($payload)) $jsonPayloadこれでLambda側で普通のJSONとして受け取れます。
ユーザーが選択・入力した値は
submissionに入っているので、それを使ってAWSのAPIを呼びます。試しにプロトコルtcpの22番ポートを許可してみます。
サブネットマスクも/32に限定します。Lambdaの実行ロールに
ec2:AuthorizeSecurityGroupIngressを追加しておいてください。次にレスポンスです。
submit後にダイアログを閉じるためには、ボディが空のレスポンスを返す必要があります。
{ statusCode: 200 }だとダイアログが残り続けます。監査のために実行したコマンドと結果を投稿します。
ここで、リクエストに含まれるresponse_urlは使いません。
なぜかというとこのresponse_urlに対してポストしたメッセージはephemeral、つまりそのユーザーにしか見えないメッセージになるので監査になりません。普通に
chat.postMessageAPIを使います。
Slackアプリの設定でスコープを追加してください。これでひとまず完成です。
8. 削除用ダイアログの実装
次は削除の方を実装します。
ダイアログの返却に条件分岐を入れます。スラッシュコマンドで引数を取るようにして
/ip addまたは/ip removeで条件分岐します。ここの引数は空白スペースが+で置換されるので、余計なパラメータは取り除きます。const command = event["text"] === undefined ? "" : event["text"].split("+")[0] let res if (command == "add") res = await openAddMenu(event) else if (command == "remove") res = await openRemoveMenu(event) else return { statusCode: 400, body: "type `/ip add` or `/ip remove`" }削除のときは
Descriptionがいらなくなるのでフィールドを削除します。
IPアドレスは依然、手入力してもらいます。
理想は、セキュリティグループが選択されたら、そのグループにあるルールのIPアドレスを列挙して動的にセレクトボックスを構築したいんですが、仕組みが結構面倒なのでさぼります。9. 削除APIの実装
ダイアログを構築する際に
callback_idを指定していましたが、これはsubmit時に送られてきます。ここの値を見て、追加のダイアログか削除のダイアログかを判定します。[Interactivity] の [Request URL]って複数設定できないんですかね ?
if (event["callback_id"] == "add") { res = await addRule( event["submission"]["securityGroup"], event["submission"]["ipAddress"], event["submission"]["comment"] ) } else { res = await removeRule( event["submission"]["securityGroup"], event["submission"]["ipAddress"] ) }インバウンドルールの削除は
revokeSecurityGroupIngressポリシーが必要です。例によって実行IAMロールに追加してください。終わり
思いの外時間がかかってしまった。
ハマりどころはVTLのマッピングテンプレートやSlackAPIのドキュメントですね。
結構このドキュメントは足りないし嘘つきます。コードは全部置いておくので使ってください。
https://github.com/Blue-Pix/slack-ip-manager









- 投稿日:2020-04-26T10:57:32+09:00
AWS Appflow で ServiceNow からデータを連携させる
はじめに
AWS から Appflow というデータ連携の新しいサービスがリリースされましたね!
連携できるサービスの中に ServiceNow があったので、AWS & ServiceNow の有資格者としては早速試さないわけにはいかないので、簡単に実装してみました。1.事前準備
ServiceNow にてアカウントを作る。
何も見ずに早速 Appflow を作ろうとすると、こんな画面が出てきました。
まぁ、当たり前ですが、然るべき権限(role)を持ったユーザを指定してほしい、という事です。早速 ServiceNow で作りましょう。
ServiceNow のインスタンスは、Orland の Developer instance を使用しています。
role は以下の2つと指定されたので、まずはそれでやってみましょう。
- web_service_admin
- rest_api_explorer
2. Appflow を作成する
2-1. Appflow の作成
じゃあ、準備完了したので早速作りましょうかね。
テーブルの指定が出てきました。まぁ当たり前ですね。っていうか、テーブルの参照権限(role)をappflow_userに付与していないのに出てくる、という事は、このテーブルは現在は固定値なんですね。テーブルから明らかですが、現在サポートしているのは、以下の2つだという事がわかります。
- CMDB
- ITSM
そのまま進んでみると、権限がなくて取れないエラーが起きますね。
2-2. ServiceNow で再権限付与
Incident を対象にしてみましょう。なので、
ITILをつける事にします。
でもやっぱりまだエラーです。
よくよく考えてみると、フィールドって書いてあるので、テーブルのカラム名を取得に行っているんじゃないかと想定。
ServiceNow 上では、テーブルのカラムはsys_dictionaryというテーブルに保持しているため、そのアクセス権がないんじゃないかと想定されますね。早速personalize_dictionaryを付与しましょう。
出来ました!
2-3. Appflow 作成の続き
それでは続けていきましょう。
フィールドがマッピングされます。
作成完了!
3. 動作確認
早速、動かしてみましょう。右上の
フローを実行を押すと、実行され、完了すると以下の様になります。
S3を見てみましょう。
何かファイルが出来ていますね。test-appflow/4d37c1d95cdbe26802f050b51695b4c2{"business_stc":"28800","calendar_stc":"102197","caller_id":{"link":"https://devxxxxx.service-now.com/api/now/v2/table/sys_user/681ccaf9c0a8016400b98a06818d57c7","value":"681ccaf9c0a8016400b98a06818d57c7"},"category":"inquiry","caused_by":"","child_incidents":"0","close_code":"Solved (Permanently)","hold_reason":"","incident_state":"7","notify":"1","parent_incident":"","problem_id":"","reopened_by":"","reopened_time":"","reopen_count":"0","resolved_at":"2016-12-13 21:43:14","resolved_by":{"link":"https://devxxxxx.service-now.com/api/now/v2/table/sys_user/5137153cc611227c000bbd1bd8cd2007","value":"5137153cc611227c000bbd1bd8cd2007"},"rfc":"","severity":"3","subcategory":"email","sys_id":"1c741bd70b2322007518478d83673af3"} {"business_stc":"1749949","calendar_stc":"7333549","caller_id":{"link":"https://devxxxxx.service-now.com/api/now/v2/table/sys_user/5137153cc611227c000bbd1bd8cd2006","value":"5137153cc611227c000bbd1bd8cd2006"},"category":"inquiry","caused_by":"","child_incidents":"","close_code":"Closed/Resolved by Caller","hold_reason":"","incident_state":"7","notify":"1","parent_incident":"","problem_id":"","reopened_by":"","reopened_time":"","reopen_count":"","resolved_at":"2019-09-05 19:56:12","resolved_by":{"link":"https://devxxxxx.service-now.com/api/now/v2/table/sys_user/6816f79cc0a8016401c5a33be04be441","value":"6816f79cc0a8016401c5a33be04be441"},"rfc":"","severity":"3","subcategory":"","sys_id":"46b66a40a9fe198101f243dfbc79033d"} {"business_stc":"1864990","calendar_stc":"7851790","caller_id":{"link":"https://devxxxxx.service-now.com/api/now/v2/table/sys_user/5137153cc611227c000bbd1bd8cd2005","value":"5137153cc611227c000bbd1bd8cd2005"},"category":"database","caused_by":"","child_incidents":"","close_code":"Closed/Resolved by Caller","hold_reason":"","incident_state":"7","notify":"1","parent_incident":"","problem_id":"","reopened_by":"","reopened_time":"","reopen_count":"","resolved_at":"2019-09-05 19:56:12","resolved_by":{"link":"https://devxxxxx.service-now.com/api/now/v2/table/sys_user/6816f79cc0a8016401c5a33be04be441","value":"6816f79cc0a8016401c5a33be04be441"},"rfc":"","severity":"3","subcategory":"","sys_id":"46b9490da9fe1981003c938dab89bda3"} {"business_stc":"1720500","calendar_stc":"7246500","caller_id":{"link":"https://devxxxxx.service-now.com/api/now/v2/table/sys_user/9ee1b13dc6112271007f9d0efdb69cd0","value":"9ee1b13dc6112271007f9d0efdb69cd0"},"category":"inquiry","caused_by":"","child_incidents":"","close_code":"Closed/Resolved by Caller","hold_reason":"","incident_state":"7","notify":"1","parent_incident":"","problem_id":"","reopened_by":"","reopened_time":"","reopen_count":"","resolved_at":"2019-09-05 19:56:12","resolved_by":{"link":"https://devxxxxx.service-now.com/api/now/v2/table/sys_user/6816f79cc0a8016401c5a33be04be441","value":"6816f79cc0a8016401c5a33be04be441"},"rfc":"","severity":"3","subcategory":"","sys_id":"46c03489a9fe19810148cd5b8cbf501e"} ~~~略~~~連携されていますね!
4. Appflow のオプション機能(少し脱線)
右上の方に、
式を追加と値を変更というボタンがありますので、押してみました。
4-1. 式を追加
取得したカラム同士の数値演算や文字列連結が出来ます。
試しに一番下の連結を押したらこうなります。
これは文字列として連結する事が出来るようです。4-2. 値を変更
こちらは値をマスクしたり、文字列そのものではなく、文字数にしたりすることが可能です。
値をマスクする
テキスト値の切り捨て
5. 考察
さて、本題に戻ります。データが連携されたのはいいんですが…
例えば、ServiceNow のインシデントとしては割と重要な以下とかがないんですよね…
- short description
- description
- comments
- work_notes
まじまじと連携できるカラムを眺めてもやっぱりありません。
データ分析目的のデータ連携だから、という話なのかもしれません。
また、Problemなどは取れてはいますが、SYS_ID で取れている状態なので、分析するにしても Lookup で実レコードの値を持ってきたいですよね。
『それはRedshiftでやる』というのもまぁ当然の意見としてはありますが、Flow Designer+Database viewの方が楽なのでは?という場合もあるでしょうから、やりたい事に対して、いくつか方式案を検討した方がよさそうですね。
まだ機能の出始めという事ですし、データ連携は結構煩わしい箇所なので、それをGUIベースで簡単に出来るようにしたのは良いと思います。今後に期待しています。






















- 投稿日:2020-04-26T09:08:13+09:00
AWS 基礎
前提
AWSについて基本的な言語の意味などを書いていきます。
こちらについては、これからも更新していきます。本題
・リージョン
AWSの各サービスが提供されている地域のこと。
日本では東京リージョンがおすすめ。
応答時間が早くなるため・アベイラビリティゾーン
独立したデータセンターのこと
リージョンのなかに最低でも2つはアベイラビリティゾーンが存在する
リージョンを選び、どのアベイラビリティゾーンを使うか選ぶ・VPC
AWS上に仮想ネットワークを作成できるサービス。
リージョンを選択する・サブネット
VPCを細かく区切ったネットワーク
1つはインターネットに接続できてもう一つは接続できないようにする
パブリックサブネットとプライベートサブネットVPCは東京リージョンに設定
東京には3つのアベイラビリティゾーンがある
IPアドレスをまず決める・IPアドレスとは
インターネット上の住所・2進数
各桁を0か1を使って数値を表す
コンピューターは2進数で計算を行う・ビット
2進数の1桁(0か1)
最小単位・バイト
8ビットを1バイト
1バイトは8ビット
2バイトは16ビット・10進数
0〜9の10種類の数値を使って数値を表す
普段使用している数値表現・IPアドレスの範囲を表記
ネットワーク部
ホスト部(下辺部)・CIDR表記
IPアドレスの後ろに/を書き、その後ろにネットワーク部が先頭から何ビット目までなのかを記載する・サブネットマスク表記
IPアドレスの後ろに/を書き、ネットワーク部を表すビットと同じ部分を1にホスト部を表すビットと同じ部分を0にする・設定するネットワークのIPアドレス
1、VPC作成
2、サブネット作成
3、ルーティング設定2、サブネット作成
パブリックサブネット作成
プライベートサブネット作成
- 投稿日:2020-04-26T05:06:34+09:00
AWS Service health dashboardのRSSを、Slackに一括登録する
背景
- Personal Health dashboardがありつつ、やはりService health dashboardの情報は、それはそれとして購読したい。
- SlackにRSSリーダーがあるけど、1 URLずつ
/feed subscribe https://.....rssと実行する必要があり拷問である。複数をベタっと貼ってもエラーになる。どうにか一括登録したい。- https://status.aws.amazon.com/rss/all.rss という全部入りがあるけど、使ってないリージョンのまで入ってるので、購読すると無駄にうるさい。また直近15記事しかなく、広域障害発生時は猛烈に流れて使い物にならないことが想定できる。製品ごとリージョンごとRSSで見るしかなさそう
- ググると手製の東京リージョンOPMLとか見つかるけど、数年前のものだったりする。常に最新のRSSであってほしい
解法
- https://status.aws.amazon.com/ からRSSのURLを、グローバルサービス、リージョナルサービスにバラして、ほしいリージョンだけにする。CLIで。
- Slack API から
/feed subscribeコマンドを実行して登録するRSSのURLぜんぶ取ってくる
curlしたものをモゴモゴして取ってきます。
curl -s https://status.aws.amazon.com/ \ | perl -wpl -e 's|\"|\n|g' | grep "/rss/" \ | perl -wpl -e 's|^|https://status.aws.amazon.com|g' \ | sort -u \ > all.txtグローバルとリージョナルに分割する
URLリストを眺めると、リージョナルサービスにはリージョン名がURLに含まれており、グローバルサービスはサービス名だけであることがわかります。すっごく雑に、
- ハイフンが複数個なければグローバルサービス
- ハイフンが複数個あるならリージョナルサービス
とバラせそうでした。
cat all.txt \ | grep -Ev '.*-.*-.*-' > global-products.txt cat all.txt \ | grep -E '.*-.*-.*-' > regional-products.txt最初はハイフンの有無で分けてみたのですが、以下の例外があることがわかり、「ハイフンが複数個の有無」で、としました。
https://status.aws.amazon.com/rss/import-export.rss https://status.aws.amazon.com/rss/management-console.rss https://status.aws.amazon.com/rss/s3-us-standard.rssリージョンごとに分割
せいぜい2 - 3リージョンしか使ってないでしょうから、欲しいリージョンのものだけに絞りたい、なので分割します。
rm -f regional-products.*.txt cat regional-products.txt \ | rev | awk -F'[.-]' '{print $0 " " $2 "-" $3 "-" $4}' | rev \ | awk '{print "echo " $2 " >> regional-products." $1 ".txt"}' \ | bashSlackのAPIトークンを発行する
ここあまり詳しくなく申し訳ないのですが https://api.slack.com/legacy/custom-integrations/legacy-tokens で生成したトークンで動いたのでヨシとしています。
手元にrubyをインストールする
2.6系で最新を選んでおけばいいのではないでしょうか。この後で使う
slack-ruby-clientも入れておいてください。brew install rbenv ruby-build rbenv install 2.6.6 rbenv global 2.6.6 gem install slack-ruby-clientSlackに一括登録するRubyスクリプトを用意する
https://gist.github.com/sasasin/28fbb22d3e40dd8518be5f2f30df5e42 をテキトーな場所に転がしてください。
以下のように動かすことができます。
export SLACK_API_TOKEN="xoxp-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" ./slack_slash_command.rb "#general" "/feed" "subscribe https://status.aws.amazon.com/rss/iam.rss"Slackに一括登録する
これまでの情報を総合して、以下のように実行することで一括登録できます。
export SLACK_API_TOKEN="xoxp-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" export CHANNEL_NAME="#投稿先チャンネル名" cat global-products.txt \ | xargs -L1 -I XXX ./slack_slash_command.rb "${CHANNEL_NAME}" "/feed" "subscribe "XXX cat regional-products.ap-northeast-1.txt \ | xargs -L1 -I XXX ./slack_slash_command.rb "${CHANNEL_NAME}" "/feed" "subscribe "XXX cat regional-products.us-east-1.txt \ | xargs -L1 -I XXX ./slack_slash_command.rb "${CHANNEL_NAME}" "/feed" "subscribe "XXXCodeBuildで定期実行する
一回やってそれきりではないはず。利用するAWS製品もリージョンも増減していくでしょうから、それなり簡単に自動登録したいでしょう。CodeBuildで定期実行させましょう。
こんなbuildspecです。
version: 0.2 env: parameter-store: # 格納先のSSMパラメータストア名は好みで SLACK_CHANNEL_NAME: "/CodeBuild/SLACK_CHANNEL_NAME" SLACK_API_TOKEN: "/CodeBuild/SLACK_API_TOKEN" phases: install: commands: - gem install slack-ruby-client - curl -s -o ./slack_slash_command.rb https://gist.githubusercontent.com/sasasin/28fbb22d3e40dd8518be5f2f30df5e42/raw/0294724cc31abeb2f02b04ac05fd95d28732d37d/slack_slash_command.rb - chmod +x slack_slash_command.rb build: commands: - | curl -s https://status.aws.amazon.com/ \ | perl -wpl -e 's|\"|\n|g' | grep "/rss/" \ | perl -wpl -e 's|^|https://status.aws.amazon.com|g' \ | sort -u \ > all.txt - cat all.txt | grep -Ev '.*-.*-.*-' > global-products.txt - cat all.txt | grep -E '.*-.*-.*-' > regional-products.txt - | rm -f regional-products.*.txt cat regional-products.txt \ | rev | awk -F'[.-]' '{print $0 " " $2 "-" $3 "-" $4}' | rev \ | awk '{print "echo " $2 " >> regional-products." $1 ".txt"}' \ | bash - ls -alF *.txt - | cat global-products.txt \ regional-products.ap-northeast-1.txt \ regional-products.us-east-1.txt \ | while read FEED_URL; do ./slack_slash_command.rb "${SLACK_CHANNEL_NAME}" "/feed" "subscribe ${FEED_URL}" sleep 3 done
- コンテナイメージは
ruby:2.6-busterで動作確認しています- チャンネル名やSlackトークンは、SSMパラメータストアなどに入れましょう。
SLACK_CHANNEL_NAMEはパブリックチャンネルの場合は#generalのように#を付ける必要があります- いますぐ使うCodeBuild を参考に、好みの周期で定期実行させます
- 例として東京とバージニア北部リージョンで動かしてます
- 当初
sleep 3は入れずに動かしたら、途中から「お前やりすぎ3秒後にリトライしろ」でコケるようになったので追加してます参考
- 投稿日:2020-04-26T02:19:31+09:00
【AWS】CloudWatchでEC2のネットワークログを取得する
CloudWatch Logsについて
全てのシステム、アプリケーション、AWSのサービスからのログを高度にスケーラブルな単一のサービスに集中管理する事ができます。
EC2のネットワークアダプタのログの取得設定
ロググループを作成し、ネットワークアダプタの情報をロググループで確認できるように設定します。
ロググループの作成
CloudWatchのサービス画面で、
ロググループのページを開きます。
アクションのボタンを選択し、ロググループの作成を選択します。
ロググループ名に任意の名前を指定します。EC2インスタンスの設定
確認したいEC2インスタンスの
詳細モニタリングを有効にする必要があります。
EC2のサービスメニューに移動し、インスタンスの一覧から、モニタリングしたいEC2インスタンスを選択し、アクションボタンから詳細モニタリングを有効化をクリックしてください。
※ 上記の操作は追加料金が発生します。
料金に注意してください。ネットワークインターフェイスへの設定
インスタンスの詳細モニタリングが完了したら、次はネットワークインターフェイスのフローログの設定です。
確認したいインスタンスを選択し、下に表示される詳細情報から、ネットワークインターフェイスの部分をクリックします。
下記の図のように、インターフェイスIDが表示されているので、IDをクリックする
ネットワークインターフェイスが表示されたら、選択してから、
アクションボタンを押して、フローログの作成をクリックします。下記の設定内容で設定します。
- Filter: All
- Maximum aggregation interval: 10 minutes
- Destination log group :先ほど作成したグループ
- IAM role: 一番初めは「Set Up Permission」を選択する
確認
上記の設定でネットワークの情報が全て、CloudWatch Logsに転送する事ができ、簡単に確認する事ができるようになりました。
集まったログを「インサイト」機能を利用して分析する事で、さらに詳しい分析を行う事が可能になります。
まとめ
今回の設定でCloudWatch Logsの必要性をしみじみと感じる事ができました。
今後、EC2でサービスを構築する際は、CloudWatch Logsを上手く利用し、運用していければと思います。


- 投稿日:2020-04-26T01:51:15+09:00
【AWS】CloudWatchの新規サービスについて 2020年4月
CloudWatchの新規サービスが利用できるようになっていたので、どんなものが存在するのか調べてみました。
ServiceLens 2019年12月
メトリクスをより、詳細に確認できる物
様々なマイクロサービスのメトリクス、ログ、トレースなどを統合して可視化する事ができるマイクロサービスとは・・・
- Docker
- コンテナサービスなど利用方法
サービスマップを作成して、ログ等の情報をまとめる
トレースのタブで情報を絞り込んで確認する事ができる!Synthetics 2020年1月
Canaryテストを使用して、ウェブアプリケーションをモニタリングするサービスです。
Canaryテストは、顧客と同じアクションを設定して、テストを実行する事ができます。
エンドポイントの可用性とレイテンシーをチェックして、ロード時間データとUIのスクリーンショットを保存できます。Canaryでチェックできる項目
下記の項目をチェックできるようにカスタマイズする事が可能です。
- 可用性
- レイテンシー
- トランザクション
- リンク切れ・リンク壊れ
- タスクのステップごとの完了
- ページロードエラー
- UIアセットのロードレイテンシー
- 複雑なウィザードのフロー
- アプリケーションでのチェックアウトフロー
- など
Contributor Insights 2020年4月 一般提供開始
システムとアプリケーションのパフォーマンスに影響を与えている上位のコントリビューターをリアルタイムで簡単に表示できます。
利用方法
ルールを作成し、何かしらのコントリビューターを特定します。
- 投稿日:2020-04-26T00:36:39+09:00
猫の画像が次々届くサーバーレスなシステム
はじめに
コロナ禍ですっかり疲れ切っている方も多いと思いますが、そんな時こそ一服の清涼剤が必要...ということで、Slackのチャンネルに猫の画像が定期的に届くサーバーレスなシステムを作ってみました。
なお、今回はThe Cat APIから猫の画像を拝借しています。
1. Cat APIのAPIキーの取得
- The Cat APIのページを開いて、
SIGNUP FOR FREEと書かれたボタンを押します。
- 遷移先のページで、メールアドレスを記入して
SIGNUPを押してしばらく待つと、Welcome to The Cat API!Welcome to The Cat API!というタイトルのメールが届きます。
App Discriptionについては任意項目らしいので、拙い英語で書いても大丈夫でした(笑)- このメールの中にAPIキーが記載されているので、それをメモしておきます。
2. 猫画像配信用のチャンネルの作成
- 猫の画像がSlackのチャンネルにどんどん投稿されるため、猫画像配信用のチャンネルを作成しておきます。
3. SlackのWebhook URLの取得
- 前の工程で作成したSlackのチャンネルに入り、
アプリを追加するをクリックします。
- 遷移先の画面で検索欄に
webhookと入力して、Incoming Webhookをインストールします。
- ブラウザに以下の画面が表示されたら、
Slackに追加を押してIncoming Webhookをインストールします。
- 遷移先の画面で、前の工程で作成したSlackのチャンネルを選択して、
Incoming Webhookインテグレーションの追加を押します。
- 次の画面で、「Incoming Webhook ○○○さんによって ○○○○年○○月○○日に追加されました」と表示されれば、アプリのインストールは完了です。
- このページに
Webhook URLと書かれている欄があるので、そこに書かれているURLをメモしておきます。- また、このページの下部に
インテグレーションの設定という設定画面があるため、今回はこの設定画面で以下の設定を変更しました。
- 名前をカスタマイズ:「The Cat API」に変更。
- アイコンをカスタマイズする:こちらの記事で作成した猫の画像をアップロード。
4. Lambdaのコードの作成
4-1. Lambda関数の基本情報
- 以下の内容を関数の
基本的な情報に設定しました。
- 関数名:GetCatImage
- ランタイム:Ruby2.7
- アクセス権限(実行ロール):基本的なLambdaアクセス権限で新しいロールを作成
4-2. lambda_function.rbの作成
- 幾つかのサイトを参考にして以下のコードを書いてみましたが、
slack-notifierが存在しないためエラーになってしまいました。- そこで、以下のサイトを参考にして「Gemfileを作成」→「bundle install」→「bundle install --deployment」→「ZIPとしてアップロード」という手順で試してみたところ、ようやく正常に動作しました。
lambda_function.rbrequire 'json' require 'net/http' require "bundler/setup" require 'slack-notifier' def lambda_handler(event:, context:) # Get image url from TheCatAPI. res = Net::HTTP.get(URI.parse('https://api.thecatapi.com/v1/images/search?api_key=xxxxxxxxxx')) json = JSON.parse(res) url = json[0]["url"] # Notification to Slack channel using Incoming Webhook. notifier = Slack::Notifier.new('https://hooks.slack.com/services/xxxxxxxxxx') notifier.ping(url, unfurl_links: true) end
- なお、作成したGemfileは以下の通りです。
Gemfilesource 'https://rubygems.org' gem 'slack-notifier'
- また、Linux環境で
bundle installを実行すると、以下のフォルダ構成となります。>bundle-installの実行結果@Windows環境. │ Gemfile │ Gemfile.lock │ lambda_function.rb └─vendor └─bundle4-3. ZIPファイルのアップロード
bundle install --deploymentを実行したフォルダを、丸ごとZIPで圧縮します。- 次にLambdaの関数(GetCatImage)の画面に入り、関数コードの[コードエントリ]を
.zipファイルをアップロードとして、ZIPファイルをアップロードします。
- アップロードファイルを選んだあと、画面右上の[保存]を押すとAWS側にアップロードされるようです。
- ここまで出来上がったら、[テスト]を実行して、Slackに通知が飛ぶかを確認します。
5. CloudWatchのイベントの作成
- Lambdaの関数のページの上部で[設定]タブを選び、[Designer]の領域で
トリガーを追加を押します。トリガーを追加画面で、以下の内容を記入して[追加]を押します。
- トリガーの種類:CloudWatch Events/EventBridge
- ルールタイプ:スケジュール式
- スケジュール式:rate(1 hour)
- トリガーの有効化:チェックあり
- 上記のように、今回は「毎時1回猫の画像(のURL)を取得して、Slackに通知する」という形になります。
6. 完成形
- 以下のように、指定されたチャンネルに毎時猫の画像が投稿されます。
- 疲れた時は、このチャンネルを見てちょっとだけリフレッシュしましょう!
参考URL
AWS CLI
Lambda
- 【ハンズオン】Ruby support for AWS Lambdaを使ってみる
- AWS Lambda の Ruby ランタイムを試す
- AWS Lambda上でgemがつかえない
- 【AWS】lambdaファンクションを定期的に実行する
SlackのWebhook









