- 投稿日:2020-04-26T23:58:05+09:00
Herokuへのアップロードでつまづいた時の対処法 Node.js + MongoDB
自分の経験をここに記述します。
【経緯】先日、EJS, CSS, JavaScript, MongoDB, Nodeを使って作成したWebsiteをHerokuにアップロードしようと試みた時、正常にアップロードできず、丸2日間の時間を犠牲にした上でようやく問題解決までに至りました。ここで記載することがいつかこれを見た未来の困っている方々への手助けになればと思います。
【方法】ステップに分けて説明していきます。MongoDBを使用している場合には、別の記事でその追加で必要な方法を記述します。
1:Command Line(Hyper Terminal)がアップロードしようとしているファイルのパスを正しく選択しているか確認する。
2:Command Line(Hyper Terminal)からHerokuへとログインする。
コマンド:$heroku login3:GitをInitializeし、add、commitする。以下順々にコマンドを実行する。
コマンド:$git initコマンド:$git add .
コマンド:$git commit -m "sample message"
4:HerokuでURLを作成する。
コマンド(urlが何でもいい場合):$heroku create
コマンド(自分のオリジナルを作成する場合):$heroku create ここに半角英数でタイプする。但し他ユーザーがすでに使用している場合は、そのurlは使えない。5:Gitにpushをする。
コマンド:$git push heroku master6:現状では正しくHerokuへとアップロードはされません。ほぼ100%エラーの表示がでます。これからそのエラーを直していきましょう。
7:自分のファイル内にprocfileが作成しているか、確認する。procfileが何か分からない場合はこの方の記事を参考にしてみてください。 https://creepfablic.site/2019/06/15/heroku-procfile-matome/
8:procfileの中身が正しく記載されているか確認する。私の場合、web: node app.js、app.jsはあくまでも私がよく使うファイル名のためindex.jsや他のファイル名の場合はそちらに書き換えてください。
9:app.listen(process.env.PORT || 3000, function( ){
console.log("The server 3000 is now up and runnning")
});
私の場合、app.jsの中にローカルサーバーを立ち上げるためのapp.listenを入力しているので、そこにprocess.env.PORTと追加されているか確認する。
10:再度、Command Line(Hyper Terminal)の画面に戻る。そして自分のファイルへのパスが選択されている状態で、次のコマンドを入力する。コマンド:$heroku buildpacks
そのコマンドを入力した時にheroku/nodejsと表示されていれば特に何もしなくて良い。しかし、何も表示されない、もしくは別のものが表示された場合には次のコマンドを入力する。
コマンド:$heroku buildpacks:set heroku/nodejs11:もう一度、コマンド:$heroku buildpacksを入力して正しくheroku/nodejsと表示されるか確認する。
12:自分のパソコンにインストールされているNodeとNpmが最新版であるか確認する。どこでインストールするか分からない場合は? https://nodejs.org/ja/ で推奨版をダウンロードする。左のバージョン。
コマンド:$node --version
コマンド: $npm --version
13:自分のファイルの中にpackage-lock.jsonというファイルが作られているか確認する。作成されていない場合は次のコマンドを入力する。
コマンド:$npm install14:package-lock.jsonの中に以下のプログラムが記載されているか確認する。されていない場合は順番はどこでもいいのでファイル内に付け加える。NodeとNpmのバージョンは2020/04時点のものなので、最新かどうかは?https://nodejs.org/ja/
で確認する。右側の最新版のバージョンをnodeに記述する。最後のxの部分は変更しなくて大丈夫。scriptsのapp.jsはあくまでも私が使用しているファイル名なので、これは各個人のファイル名に直す。"engines": {
"node": "^14.0.x",
"npm": "6.14.x"
}"scripts": {
"start": "node app.js"
}15:.gitignoreファイルが作成しているか、確認する。まず次のコマンドを入力する。
コマンド:$git ls-files | grep node_modules
もしも、上記のコマンドを入力した際にリストがズラーーーっと表示された場合は以下のコマンドを順々に入力する。表示されなかった場合は多分.gitignoreが作成されていると思う。
コマンド:$echo "node_modules" >> .gitignore
コマンド:$git rm -r --cached node_modules
コマンド:$git commit -am 'untracked node_modules'
16:再度、.gitignoreが作成されているか、コマンド:$git ls-files | grep node_modules、を入力して確認する。自分のファイル内で.gitignoreというファイルが作成されているのを確認できればおっけい。
17:.gitignoreの中にnode_modulesと記載されていると思うので、その下に以下のコマンドを入力する。
/lib ←この4文字を記述する。
18:これであとは再度Herokuへのアップロードを試みる。以下の順でCommand Line(Hyper Terminal)内でコマンドを実行する。
コマンド:$heroku login
コマンド:$git init
コマンド:$git add .
コマンド:$git commit -m "whatever you want to type"
コマンド:$git push heroku master
これで正しくHerokuへとアップロードが完了するはずです。
19:最後に、冒頭にも書きましたが、MongoDBを使用している場合はもうワンステップ必要な作業がありますので次回のストーリーを参考にしてみてください。
- 投稿日:2020-04-26T21:58:03+09:00
Node.jsでお天気を取得してみよう
はじめに
OpenWeatherMap APIからお天気情報を取得しようという試みです。
色々な方が、さまざまな言語で同様の記事を上げています。
私は、勉強真っ最中のNode.jsでやってみようと思いました。
(Node.jsの導入はこちら)環境
wslの環境です。Editor: VSCode Shell : bash version 4.4.20 Ubuntu: 18.04.4 LTS node : v10.14.21.APIの取得
OpenWeatherMapの公式サイトで無料アカウントを作成後、
表示されるAPIキーを控えておいてください。
APIキー取得後は少し時間をおいてか試したほうがいいと思います。
公式もそういってますし。2.プロジェクトを作成
1.任意の位置(緯度経度)のお天気情報を取得
とりあえず福岡市にしてみました。
app.js'use strict'; const http = require('http'); const MY_WEATHER_APIKEY = {YOUR_API_KEY}; const LAT = 33.60639; //緯度 const LON = 130.41806; //経度 const req = 'http://api.openweathermap.org/data/2.5/weather?lat='+LAT+'&lon='+LON+'&appid='+ MY_WEATHER_APIKEY; http.get(req, res => { var body =''; res.setEncoding('utf8'); res.on('data', (chunk) => { body += chunk; }); res.on('end', () => { res = JSON.parse(body); console.log(res); }); }) .on('error', e => { console.error(e.message); });
{YOUR_API_KEY}に控えておいたAPIキーを入れてください。実行結果
$ node scripts/app.js { coord: { lon: 130.42, lat: 33.61 }, weather: [ { id: 803, main: 'Clouds', description: 'broken clouds', icon: '04n' } ], base: 'stations', main: { temp: 286.85, feels_like: 284.37, temp_min: 285.93, temp_max: 287.15, pressure: 1018, humidity: 58 }, visibility: 10000, wind: { speed: 2.1, deg: 300 }, clouds: { all: 75 }, dt: 1587901760, sys: { type: 1, id: 7998, country: 'JP', sunrise: 1587846896, sunset: 1587895019 }, timezone: 32400, id: 1863967, name: 'Fukuoka', cod: 200 }この結果をいろいろ触って特定の情報を抜き出せます。
weather:
[ { id: 803,
main: 'Clouds',
description: 'broken clouds',
icon: '04n' } ]が欲しければ、
console.log(res.weather);main: 'Clouds'
が欲しければ、
console.log(res.weather[0].main);
という風にすればいいですね。
おぉ、いま福岡の方は曇りなんですね。2.モジュール化
うまくいったので、モジュール化しました。
のちのちモジュール化しておいたほうが使いまわしやすいと思います。app.js'use strict'; const weather = require('./weatherFunc'); const MY_WEATHER_APIKEY = {YOUR_API_KEY}; weather.clweather(MY_WEATHER_APIKEY);weatherFunc.js'use strict'; const http = require('http'); function clweather(api){ const LAT = 33.60639; //緯度 const LON = 130.41806; //経度 const req = 'http://api.openweathermap.org/data/2.5/weather?lat='+LAT+'&lon='+LON+'&appid='+ api; http.get(req, res => { let body =''; res.setEncoding('utf8'); res.on('data', (chunk) => { body = body.concat(chunk); }); res.on('end', () => { res = JSON.parse(body); console.log(res); }); }) .on('error', e => { console.error(e.message); }); } module.exports = { clweather }さいごに
今後の展望としては、現在地の自動取得とか取り入れていけば、
経度、緯度指定にしていることが活きてきて、
もう少し実用的になると思います。拙い文章でしたしょうが、お付き合いありがとうございました。
さよなら
関連記事
- Linux環境におけるNode.jsの導入から利用
- Comming Soon
参考
- 投稿日:2020-04-26T17:36:26+09:00
Herokuを使ってみた
はじめに
適当にJSとかwebアプリケーションを勉強している学生が記録するために使っているので,あまり内容は期待しないでください。とりあえず今回はHTTPサーバをHerokuを使って公開してみます。
1.Herokuとは
webサービスを動かせるプラットフォームを提供してるサービスらしい。小規模なら無料で使えるとのこと。
2.Herokuのアカウント作成
とりあえずアカウント作成
https://jp.heroku.com/
でいろいろ個人情報を流出してきます。ここで開発言語を選択するらしいですがまぁJS程度しかやってないのでNode.js一択ですね。
ドラえもんが引っかかってしまう私はロボットではありませんチャレンジをクリアしてメールアドレス認証。パスワード設定したら登録完了です。いやぁ非常にスムーズ,毎回どこかでつまづくんじゃないかと冷や冷やしながら登録してます。
3.Heroku CLIをインストール
順番がゴチャゴチャしてきましたがherokuコマンドを利用しなきゃと思ったらHeroku CLIが必要らしい。まぁあるあるというか常識なのだろう。今回はUbuntuにインストールしちゃうのでiTerm2で仮想環境を起動するよ。
起動したところで
1.Virtual Box(バーチャルボックス)
2.Vagrant(ベイグラント)
という2つのソフトウェアを使った仮想環境でUbuntuを使用します。
cd ~/vagrant/ubuntu
vagrant up
vagrant ssh
Ubuntuがインストールされたディレクトリに移動。vagrant upは仮想的なPCにインストールされたUbuntuを起動するコマンドで,vagrant sshはVagrantの仮想マシンがセットされている状態でSSHに接続します。仮装環境を起動して以下のコマンドを実行。
sudo snap install --classic heroku
sudoは管理者として実行するコマンド。
snap install --classicはsnapパッケージのコマンドで,snappyというUbuntu向けに開発されたパッケージ管理システムの一部らしい。Snapには、ソフトウェアを隔離してセキュリティを高めるサンドボックス機能があるが,この制限をかけると使い勝手が悪くなるパッケージがあるので、 そのリスクを承知してインストールをするために –classic オプションを追加してます。まぁそんなこんなでHeroku CLIがインストールされましたね。
4.Heroku CLIからHerokuにログイン
というわけでHeroku CLI から Heroku にログイン。
heroku login -i
コンソールで以上を記入してログインします。5.Herokuで実際にデプロイしてみる(失敗)
とりあえずコンソールで使用したいファイルのディレクトリに移動します。
cd node-js-http-3016
そして以下のコマンドでHeroku 上で動かすための設定ファイルを作成します。
echo "web: node index.js" > Procfile
echoは文字をそのまま出力するコマンド。ProcfileはHerokuがアプリを動作する時Herokuのプラットフォーム上にあるWebアプリがどのようなコマンドで実行されるのかを記述するファイルのこと。Webアプリを動かす指示書みたいなものらしい。いろいろ書き方があるみたいだけどとりあえず割愛。はいここで問題発生
Herokuではサーバー上へソースコードを配置するためにGitを利用している!!!
そのため、Heroku での実行前にGitのリポジトリにコミットすることが必要!!!......まぁやりますよ、知らなかった自分が悪い
いろいろ調べた結果gitとリポジトリを保存しているgithubを連携する必要があるらしい。今回はSSHを使うのでsshを追加した後,新しい公開鍵情報をコンソールに表示させ,それをコピー。githubの右上アイコンからsettingという項目を表示し,SSH and GPG keysを選択してnew ssh keyでssh keyを追加。この設定の時に先ほどの公開鍵情報が必要。
まぁそんなこんなで追加が無事終了し,これでGitHubとマシンがSSHを利用した暗号化通信ができるらしい。もうなんか細かいことはわからなくなってきた。6.試しにGithubからクローンをしてみる
作ってきたリポジトリのclone or downloadの欄をクリックしSSHのリンクをコピー
コンソールに
git clone SSHのリンク
を記述。これでなんとかgithubからgitにクローンできた様子。さすがです
git pull origin gh-pages
を行ったところエラーなども表示せず,Already up-to-dateという感じでできてるっぽい。今度こそ実際にデプロイ!!
heroku create
これでサーバを用意して
git push heroku master-2020:master
以上でデプロイを実行!!
remote: Verifying deploy.... done.
実行後にデプロイが完了したというお知らせ。まぁこれでなんとかデプロイできました。実際のアプリケーションはというとなんか知らないけど問題がありそう。まぁそれについては今後考えます...とりあえずはお疲れ様でした
おまけ1 : iTerm2とは
Terminal.appより簡単に便利な機能が使えるという噂のアプリ。実際のところTerminal.appすらまともに扱ったことがないので便利かどうかは不明。
おまけ3 : Ubuntuとは
狭義ではカーネルに属すLinuxのOSとしての一つがUbuntu(Linuxディストリビュージョン)。PCとして使えたりする初心者におすすめしやすいものらしい(確証はないです)。
おまけ2 : SSHとは
よく高校で使われるスーパーなんちゃらじゃない。どうやらSSHは一種の通信プロトコルらしい。
- 投稿日:2020-04-26T16:42:36+09:00
Dockerでの環境構築(Rails)超入門1
はじめに
Ruby on Rails初心者です。今回はDockerを使ったRailsの環境構築の初歩を勉強のために備忘録として残したいと思います。
前提
DockerでRailsの開発環境を行う
※あくまで開発環境を構築するためだけの超入門であるため、DBや細かい設定等は次回以降投稿する手順
Dockerはインストールしていることが前提
1. Dockerfile, docker-compose.yamlの作成
2. Dockerのコンテナを起動
3. Railsの設定
4. Node.jsの設定
5. Yarnのインストール実践
- Dockerfile, docker-compose.yamlの作成
・ディレクトリを作成(今回はDocker/practice)
$ cd Desktop $ mkdir docker $ mkdir practice $ cd practice・Docker hubで「ruby」を検索し、バージョンを確認
・Dockerfile作成
FROM ruby:2.6.6-stretch・docker-compose.yaml作成
version: '3' services: app: build: . volumes: - ".:/app" ports: - "3000:3000" tty: true
- Dockerのコンテナを起動
$ docker-compose up下記が表示されればOK!
(省略) Creating practice_app_1 ... done Attaching to practice_app_1 (省略)・practice_app_1の中に入る
$ docker exec -it practice_app_1 /bin/bash # Appがローカルになっているので /# cd app/3.Railsの設定
/# gem install rails /# rails new # ローカルに接続 /# rails s -b 0.0.0.0・ローカルに接続したら下記のエラーが出た
# エラー「Please run rails webpacker:install」 /# rails webpacker:install # エラー Webpacker requires Node.js >= 6.14.4 and you are using 4.9.1 Please upgrade Node.js https://nodejs.org/en/download/4.Node.jsの設定
・そのためNode.jsをアップデートする
# Node.jsのバージョン管理ツールnvmをclone $ git clone git://github.com/creationix/nvm.git ~/.nvm $ echo . ~/.nvm/nvm.sh >> ~/.bashrc $ . ~/.bashrc # nvmバージョン確認 $ nvm --version 0.35.3 # 最新の安定版をインストール $ nvm install stable # バージョン確認 $ node -v v14.0.0 # 再度試す $ rails webpacker:install Yarn not installed. Please download and install Yarn from https://yarnpkg.com/lang/en/docs/install/↑Yarnのインストールが必要とのこと、、
5.Yarnのインストール
・node.jsをインストールするとnpmが入っているはずなので以下のコマンドを実行する# node.jsのバージョンを確認 node -v # npmのバージョンを確認 npm -v # npm 経由でyarnをインストール npm install -g yarn # yarnのバージョンを確認 yarn -v /app# yarn install /app# rails webpacker:install # 成功 Webpacker successfully installed ? ? # ローカルに接続 /app# rails s -b 0.0.0.0 # エラー error Couldn't find an integrity file error Found 1 errors. ======================================== Your Yarn packages are out of date! Please run `yarn install --check-files` to update. ========================================↑言われた通りコマンドを実行
/app# yarn install --check-files # 再度接続 /app# rails s -b 0.0.0.0・下記の画面が出ればOK!

- 投稿日:2020-04-26T16:42:36+09:00
Dockerでの環境構築(Rails)超入門
はじめに
Ruby on Rails初心者です。今回はDockerを使ったRailsの環境構築の初歩を勉強のために備忘録として残したいと思います。
前提
DockerでRailsの開発環境を行う
※あくまで開発環境を構築するためだけの超入門であるため、DBや細かい設定等は次回以降投稿する手順
Dockerはインストールしていることが前提
1. Dockerfile, docker-compose.yamlの作成
2. Dockerのコンテナを起動
3. Railsの設定
4. Node.jsの設定
5. Yarnのインストール実践
- Dockerfile, docker-compose.yamlの作成
・ディレクトリを作成(今回はDocker/practice)
$ cd Desktop $ mkdir docker $ mkdir practice $ cd practice・Docker hubで「ruby」を検索し、バージョンを確認
・Dockerfile作成
FROM ruby:2.6.6-stretch・docker-compose.yaml作成
version: '3' services: app: build: . volumes: - ".:/app" ports: - "3000:3000" tty: true
- Dockerのコンテナを起動
$ docker-compose up下記が表示されればOK!
(省略) Creating practice_app_1 ... done Attaching to practice_app_1 (省略)・practice_app_1の中に入る
$ docker exec -it practice_app_1 /bin/bash # Appがローカルになっているので /# cd app/3.Railsの設定
/# gem install rails /# rails new # ローカルに接続 /# rails s -b 0.0.0.0・ローカルに接続したら下記のエラーが出た
# エラー「Please run rails webpacker:install」 /# rails webpacker:install # エラー Webpacker requires Node.js >= 6.14.4 and you are using 4.9.1 Please upgrade Node.js https://nodejs.org/en/download/4.Node.jsの設定
・そのためNode.jsをアップデートする
# Node.jsのバージョン管理ツールnvmをclone $ git clone git://github.com/creationix/nvm.git ~/.nvm $ echo . ~/.nvm/nvm.sh >> ~/.bashrc $ . ~/.bashrc # nvmバージョン確認 $ nvm --version 0.35.3 # 最新の安定版をインストール $ nvm install stable # バージョン確認 $ node -v v14.0.0 # 再度試す $ rails webpacker:install Yarn not installed. Please download and install Yarn from https://yarnpkg.com/lang/en/docs/install/↑Yarnのインストールが必要とのこと、、
5.Yarnのインストール
・node.jsをインストールするとnpmが入っているはずなので以下のコマンドを実行する# node.jsのバージョンを確認 node -v # npmのバージョンを確認 npm -v # npm 経由でyarnをインストール npm install -g yarn # yarnのバージョンを確認 yarn -v /app# yarn install /app# rails webpacker:install # 成功 Webpacker successfully installed ? ? # ローカルに接続 /app# rails s -b 0.0.0.0 # エラー error Couldn't find an integrity file error Found 1 errors. ======================================== Your Yarn packages are out of date! Please run `yarn install --check-files` to update. ========================================↑言われた通りコマンドを実行
/app# yarn install --check-files # 再度接続 /app# rails s -b 0.0.0.0・下記の画面が出ればOK!
- 投稿日:2020-04-26T16:24:59+09:00
リングフィットアドベンチャーをガチるためにサーバレスアプリケーションを作る
TL;DR
リングフィットアドベンチャー の称号をコンプするための進捗管理を、以下の技術要素を詰め込んで自動で行えるようにしたお話です。
- serverless framework
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
- Amazon API Gateway
- Google Cloud Vision
- Twitter API
- Googleスプレッドシート
- Glide
ご注意
- エモ多め、技術の詳細少なめ
- 画像が多いです(ここを読んでる時点で手遅れだと思いますが)
- 掲載しているコードは実運用しているものとは異なり、参考程度の内容に編集しています
- 記事内のリングフィットアドベンチャーに関する画像は、任天堂公式より転載、またはゲーム画面のスクリーンショットを用いています
リングフィットアドベンチャー is 何
慢性的な運動不足に陥るか、筋肉だけは裏切らないと狂信しているかの二極化しがちなITエンジニアの方々はご存知だと思いますが、
リングフィットアドベンチャーは任天堂が生み出したSwitch向けの家庭用フィットネスゲームです。
ゲームの雰囲気についてはガッキーの公式動画 を見ていただければ伝わると思うのでここでは割愛しますが以下のようなゲームだと思ってください。
- ゆるい運動を
- 長期間に渡って
- 手軽に楽しく行える
(※ただしゆるいかどうかは人と遊び方による)
スキルについて
リングフィットアドベンチャーでは、戦闘パートにて
フィットネススキル(以下スキル)という、特定の運動を一定回数行うことで敵にダメージを与える(あるいは自身のダメージを回復する)ことができる、本ゲームのメインとなる要素が存在します。
(引用元)
スキルには、特定条件下のみで発動するもの(ラッシュスキル)などもありますが、本記事では便宜上、「戦闘中に使用でき、称号(後述)のコンプリートに必要な43種類」のことを「スキル」と呼びます対象となる43種類の
スキルが以下になります。アームツイスト アゲサゲコンボ アシパカパカ ウシロプッシュ カタニプッシュ グルグルアーム サゲテプッシュ スクワット ステップアップ スワイショウ チョウツガイのポーズ トライセプス ニートゥーチェスト ねじり体側のポーズ ハサミレッグ バタバタレッグ バンザイコシフリ バンザイサイドベンド バンザイスクワット バンザイツイスト バンザイプッシュ バンザイモーニング ヒップリフト プランク ベントオーバー マウンテンクライマー マエニプッシュ モモアゲアゲ モモアゲコンボ モモデプッシュ リングアゲサゲ リングアロー レッグレイズ ロシアンツイスト ワイドスクワット 椅子のポーズ 英雄1のポーズ 英雄2のポーズ 英雄3のポーズ 舟のポーズ 折りたたむポーズ 扇のポーズ 立木のポーズ
皆さんのお気に入りのスキルも入っているでしょうか?ちなみに私のお気に入りはステップアップやロシアンツイスト、舟のポーズあたりです。
称号とは
本記事でメインとして取り上げる
称号ですが、これはトロフィーや実績などと表記すると、他ハードのゲームをされる方にはピンと来ると思います。リングフィットアドベンチャーにおける
称号もそれらと同様で、「ゲーム内で何らかの基準を達成した場合に取得できるが、ゲーム本編には影響を与えない要素」のことです。
例えば上記画像では、
折りたたむポーズというスキルを一定回数ゲーム中で実施すると、回数に応じて折りたたむポーズに目覚めし者折りたたむポーズに愛されし者折りたたむポーズを極めしものといった称号が取得できます。2000回まで達すると、折りたたむポーズ関係の最後の称号が解禁できそうですが、まだそこまで達していないという状況です。この称号は、それをプロフィール上で名乗れるというだけで、ゲームを有利にすすめるような要素は一切ありません。
こんなん、埋めたくならないわけがないですよね??埋めましょうよ。
称号コンプ上の問題点
※ リングフィットアドベンチャーの称号は全部で
250種類ぐらいありますが、そのほとんどが 〇〇(スキル名)を行った回数が累計N回以上となった が解禁要件になるので、本記事ではそれについてのみ着目します。それぞれのスキルを、あとどれぐらいやれば該当の称号が手に入るのか。それを確認するには以下のような手順を取る必要があります。
1. 称号メニューから、該当の称号の要件を確認する
ふむふむ、2000回が目標か…。今は何回目なんだろう
2. プロフィールメニューから、該当のスキルの累計回数を確認する
ほうほう、いまは820回ね。
3. 差分から残りの回数を算出して絶望する
あと1180回か
以上の手順を、確認したいスキルの数だけ行わなければならず、スキルを累計N回使った / 称号取得まであとN回やる の全体進捗が把握しづらいという大きな問題があります。
しかし私達は筋肉を愛するものである前に、ITエンジニアだ。テックの力で解決しようじゃないか。
進捗をスプレッドーシートで管理する
「テックの力」とか言いながら、まずはGoogleスプレッドシートで進捗を管理するための基本となるシートを手作業で作成します。
(当時のは残ってないので、完成形を元にしたイメージ)
- スキルの基本情報
- 実施回数
- 目標回数
- 実施回数と目標回数から決定する進捗関係
以上の列を用意し、
実施回数を自動で更新できるような仕組みを目指します。リザルト画面をOCRする
リングフィットアドベンチャーでは、一日の活動を終了すると、
本日の運動結果という形で、その日行ったスキル及びこれまでの累計回数 が一覧で表示されます。
本記事では、この画面のスクリーンショットを撮影し、OCRにかけることで累計回数を抽出しようと試みます。
今回はGCPの
Cloud Vision APIを使ってみることにします。
(引用元)
Cloud Vision APIは、上記のように画像の中からテキスト情報とメタデータ取得できる上、その精度の高さと、無料枠でも充分収まるリーズナブルさを兼ね備えていたので採用しました。では実際に
Cloud Vision APIに対して、リングフィットアドベンチャーのスクリーンショットを安直に投げてみましょう。
惜しい!!
テキスト自体は認識できていますが、その区切りがガバガバで、どのスキルが何回なのかの関連付けができそうにはありません。また、
「本日の運動結果」や、画面を撮影するといった、本来の目的には不要なノイズまで混じってしまっています。
- 必要な部分だけOCRさせるようにする
- レイアウトの区切りがわかりやすいようにする
までは、こちら側でお膳立てしてから
Cloud Vision APIにお願いして上げる必要がありそうです。では以下のように、スクリーンショットから不要な部分を削ぎ落とし、3分割して、それぞれをOCRにかけるのはどうでしょうか。
分割後のスクリーンショットを投げてみると...
素晴らしい!!
スキル名、回数(累計回数)の順に解析され、多少のノイズはアレど充分に活用できることがわかりました。
Switchからスクリーンショットをツイートする
さて、OCRからは一度離れて、まずSwitchからスクリーンショットを投稿し、それをAWS Lamdaで処理する下準備をしていきます。
Switchでスクリーンショットを手っ取り早く共有するには、TwitterやFacebookと言った、SNS連携を使うのが一番です。Switchで撮影したスクショをTwitterで共有すると、以下のようにハッシュタグ付きのツイートが投稿されます。
これを
Twitter APIを用いて取得しましょう。ご丁寧にハッシュタグがついているので容易に絞り込めそうです。const Twitter = require('twitter') async function fetchImageUrls () { const client = new Twitter({ consumer_key: process.env.TWITTER_CONSUMER_KEY, consumer_secret: process.env.TWITTER_CONSUMER_SECRET, access_token_key: process.env.TWITTER_ACCESS_TOKEN, access_token_secret: process.env.TWITTER_ACCESS_SECRET }) const tweets = await client.get('statuses/user_timeline',{ count: 200 }) // 自身の直近のツイートのうち、対象となるハッシュタグが付いているものを絞り込み、 // そこから添付画像のURLを抽出する return tweets .filter((tweet) => tweet.text.includes('#RingFitAdventure')) .map((tweet) => tweet.entities.media[0].media_url_https + '?format=jpg&name=large') }上記コードでは、直近200件のツイートを対象としているため、取得したツイートが既に解析済みかどうかを把握する必要があります。コードは省略しますが、ここでは
DynamoDBを用いて、解析済みの画像URLにはチェックを入れ、初出の画像URLの場合は次の処理に進むという構成になっています。
抽出された画像ファイルの3分割処理は、次のLambdaに委譲されます。
画像ファイルの分割処理
画像の3分割は、nodeを用いて、jimpという画像編集ライブラリを用いて、以下のように行いました。
imageCreator.jsconst Jimp = require('jimp') const AWS = require('aws-sdk') const S3 = new AWS.S3() // 元のスクショから必要な部分だけ3分割するための座標情報 // スクショが3カラム構成になっていることを前提とする const WIDTH = 321 const HEIGHT = 462 const Y = 132 const X1 = 150 const X2 = 502 const X3 = 857 async function uploadToS3(image, key) { const imageBuffer = await image.getBufferAsync(Jimp.MIME_JPEG) return S3.putObject({ ACL: "public-read", Body: imageBuffer, Bucket: "bucket-name", ContentType: "image/jpeg", Key: key }).promise() } module.exports.index = async event => { const imageUrl = 'hoge' const dirName = 'fuga' const origin = await Jimp.read(imageUrl) await uploadToS3(origin.clone().crop(X1, Y, WIDTH, HEIGHT), `${dirName}/1.jpeg`) await uploadToS3(origin.clone().crop(X2, Y, WIDTH, HEIGHT), `${dirName}/2.jpeg`) await uploadToS3(origin.clone().crop(X3, Y, WIDTH, HEIGHT), `${dirName}/3.jpeg`) };上記コードでは、3分割した画像それぞれを
S3にアップロードして、このLambdaのお仕事は終了です。
OCRを実行する
S3にファイルがアップロードされたことをトリガに次のLambdaを実行します。このLambdaは、S3から受け取ったイベントに含まれている、分割後の画像をCloud Vision APIに投げ、その結果をさらに次のLambdaに委譲します。const axios = require('axios') module.exports.index = async event => { const TOKEN = process.env.TOKEN const ENDPOINT = `https://vision.googleapis.com/v1/images:annotate?key=${TOKEN}` const IMAGE_URL = event.imageUrl const imageResponse = await axios.get(IMAGE_URL, { responseType: 'arraybuffer'}) const imageBase64 = Buffer.from(imageResponse.data, 'binary').toString('base64') const postData = { requests: [ { image: { content: imageBase64 }, features: [ { type: 'DOCUMENT_TEXT_DETECTION', // これがOCRをやるぞっていう指令 maxResults: 1 } ] } ] } const response = await axios.post(ENDPOINT, postData).catch((e) => { console.log(e) }) // OCRのレスポンス内容見て成否を戻す
(正確にはCloud Vision APIのレスポンスをハンドリングして、エラー処理したり次のLambdaを呼んだりするLambdaが別にいるけど割愛)OCR結果を整形して永続化する
Cloud Vision APIの精度が高いとはいえ、Switchのスクリーンショットの画質が低かったり、レイアウトがギリギリを攻めすぎてることもあって、ノイズが入ることが多々あります。まずノイズを正規表現で殴ります。
text = text.split(/\n/) text = text.filter((line) => line) text = text.map((line) => { return line .replace('、', '') .replace('。', '') .replace('」', '') .replace(' ', '') .replace('バタバタレック', 'バタバタレッグ') .replace('ラッシュバンザイコシフリー', 'ラッシュバンザイコシフリ') .replace('ラッシュモモデプッシュ|', 'ラッシュモモデプッシュ') .replace(/(\d+)(\D)(\d+)(\D)\)$/, '$1$2($3$4)') // 171回1990回) → 171回(1990回) .replace(/(\d+)(\D)(\d+)(\D)$/, '$1$2($3$4)') // 1042m17253m → 1042m(17253m) .replace(/(\D+)(\d+)(\D)(\d+)\D?/, '$1$2$3($4$3)') // 引っぱりバンザイサイドベンド1081秒117999) → 引っ張りバンザイサイドベンド1081秒(117999秒) .replace(/^(\d{7,}).+$/, '0回(0回)') // 22139142650円) → 0回(0回) 不正データのため .replace(/^(\d+)(\D)\((\d+)(\D)$/, '$1$2($3$4)') // 602m(136893m → 602m(136893m) .replace(/^(\d+)(\D)\/(\d+)(\D)\)$/, '$1$2($3$4)') // 1694m/19577m) → 1694m(19577m) .replace(/^(\d+)(\D)\/(\d+)(\D)】$/, '$1$2($3$4)') // 1回(21回】→ 1回(21回) })ノイズを除外すると、概ね
スキル名\n回数(累計回数)\nの繰り返しパターンが出来上がっているので、これを良い感じにオブジェクトに変換します。
その辺りのコードは闇が深いので割愛しますが、最終的には以下のような、スキル別の累計回数と最終実行日だけが永続化されるように、DynamoDBを更新します。"results": { "舟のポーズ": { "updatedAt": "2020-04-21T17:20:24.362Z", "value": 1722 }, "英雄1のポーズ": { "updatedAt": "2020-04-25T16:20:24.095Z", "value": 1357 }, "英雄2のポーズ": { "updatedAt": "2020-04-25T16:20:24.197Z", "value": 1213 }, "英雄3のポーズ": { "updatedAt": "2020-04-25T16:20:24.197Z", "value": 1555 } }
updatedAtは本処理実行時点の時刻で、DynamoDBが持っている現在の記録を元に、OCR結果をマージした新しい記録で更新します。const aws = require('aws-sdk') const dynamoClient = new aws.DynamoDB.DocumentClient({region: 'ap-northeast-1'}) // これまでの累計記録と、今回OCRされた結果をマージする function mergeResults({currentResults, newResults}) { const mergedResults = {} Object.keys(currentResults).forEach((key) => { // まれにここでもノイズが入るので、最新記録のほうが高い数値の場合のみ更新する if (newResults[key] && newResults[key].value >= currentResults[key].value) { mergedResults[key] = newResults[key] } }) return mergedResults } // 現在の記録をDynamoから取得 async function fetchCurrentResult({userName}) { const params = { TableName: 'rfa-logs', Key: { 'hogehoge' } } const currentDoc = await dynamoClient.get(params).promise() if (currentDoc.hasOwnProperty('Item')) { return currentDoc.Item.results } } // これまでの累計記録と、今回OCRされた結果をマージして更新する async function updateResult(newResults) { const currentResults = await fetchCurrentResult() const mergedResults = mergeResults({ currentResults, newResults }) const newDoc await dynamoClient.update({ TableName: 'rfa-logs', Key: { 'hogehoge' }, UpdateExpression: 'set results = :r', ExpressionAttributeValues: { ':r': { ...currentResults, ...mergedResults } }, ReturnValues: 'UPDATED_NEW' }).promise() return newDoc }ここまでで、常に最新の進捗がDynamoDBに反映される状態に!
進捗を取得できるAPIを用意する
データが出来上がっちまえばこっちのもんです。
API Gatewayと、DynamoDBを参照するだけのLambdaを用意して、最新のデータを取得するWebAPIを提供します。const aws = require('aws-sdk') const dynamoClient = new aws.DynamoDB.DocumentClient({region: 'ap-northeast-1'}) const DYNAMO_TABLE_NAME = 'rfa-logs' async function fetchCurrentResult() { const params = { TableName: DYNAMO_TABLE_NAME, Key: { 'hogehoge' } } const currentDoc = await dynamoClient.get(params).promise() if (currentDoc.hasOwnProperty('Item')) { return currentDoc.Item.results } } module.exports.index = async (event, context, callback) => { const results = await fetchCurrentResult() callback(null, { statusCode: 200, body: JSON.stringify({ results }) }) }
API Gatewayは新しい公開エンドポイントを生成し、上記のLambdaに接続することで、特定URLを叩くだけで以下のようなJSONを取得できるようになります。"results": { "舟のポーズ": { "updatedAt": "2020-04-21T17:20:24.362Z", "value": 1722 }, "英雄1のポーズ": { "updatedAt": "2020-04-25T16:20:24.095Z", "value": 1357 }, "英雄2のポーズ": { "updatedAt": "2020-04-25T16:20:24.197Z", "value": 1213 }, "英雄3のポーズ": { "updatedAt": "2020-04-25T16:20:24.197Z", "value": 1555 } }
スプレッドシートでAPIを叩いて更新する
さぁ、いよいよスプレッドシートに戻ってきました。
以下のスプレッドシートがあるとき、今度はGASの力で前述のAPIを叩いて、レスポンスの内容に応じてシートを更新します。
GASは非常に簡単にAPIを叩けます。レスポンスのJSON文字列をパースしてシートの更新に使いましょう。
function fetchCurrentResults() { var url = 'https://hogehogehoge.execute-api.ap-northeast-1.amazonaws.com/dev' var response = UrlFetchApp.fetch(url); var content = response.getContentText("UTF-8") return JSON.parse(content).results; }function updateResults() { var results = fetchCurrentResults() // APIから最新の進捗を取得 Object.keys(results).forEach(function(key) { var name = key; var total = results[key].value; var updatedAt = new Date(results[key].updatedAt); var row = searchRow(name) // スキル名から、該当行を特定する if (row){ sheet.getRange(row, COL_TOTAL).setValue(total); // 累計回数列を更新 sheet.getRange(row, COL_UPDATED).setValue(updatedAt); // 最終実施日を更新 } }) }上記のようなコードを実行すると、シュバババっとシートが自動で埋められていきます。
実施回数カラムが埋まれば他のカラムも遷移的に決まっていくので、これで進捗が管理できるようになりました。
(画像はイメージです)さらに、Google Apps Script で毎日決まった時刻にスクリプトを実行するトリガー設定 を参考に、このスクリプトを毎時実行することによって、こちらは何もしなくても(正確にはTwitterにスクショをアップロードするだけで) 進捗が管理できるようになります。
Glideでスマホアプリ化
以上でスプレッドシート上でリングフィットアドベンチャーの進捗を自動管理できるようになりましたが、スプレッドシートはパソコンで開かないと使いづらいし、そもそも現状だと情報量が多くて視認性が少し悪い!!
ということで、本当に知りたい最低限の進捗のみを、スマホアプリで確認できるようにします。
といっても、整形されたスプレッドシートが用意されてる時点で、あとはGlideという、スプレッドシートを元にPWAなアプリを自動生成できるサービスを活用します。
これを用いることで、まるでネイティブアプリかのようにホーム画面にアイコンを配置し、ネイティブアプリ化のようなUI/UXで進捗を確認できるようになります。
まとめ
以上で全てのシステムが完成し、最終的には以下のような構成になりました。
技術的な好奇心も強かったため、必要以上に冗長な構成になってしまったようにも思えますが、AWS関係のリソースはserverless framework を使って構成管理したため、デプロイはもちろん、IAMの付与やAPIGatewayの設置なども非常に簡単に出来、管理も容易に行うことができました。
ちなみに実運用しているスプレッドシートは特に意味もなく公開しています。見ての通り、現在(2020/04/26時点)でも、まだまだコンプが遠い状態なので毎日頑張ってます。
長々とお付き合いいただきありがとうございました。良いリングフィットアドベンチャーライフを!























- 投稿日:2020-04-26T13:26:18+09:00
ImageMagickをJSから呼び出す
概要
ImageMagickを使って画像生成をしようと思っていて、簡単な処理ならターミナル等でコマンドを打って実行するのだが複数の画像を順番に合成するなどシーケンシャルな処理をする場合にそれだとしんどいので何かスクリプトを使いたいなと思って検討した結果JavaScript(以下JS)にしようと思い検討理由と実行記録を残しておきました。
なぜJSにしたのか
本当に簡単な処理ならShellscriptでもいいかなと思いますが今回はif文もいくつかケースがわかれたりJSONの読み込み等が発生するため除外。もちろんShellscriptでもできますが不慣れだし大抵の人にとっては見にくいケースもあるので。
次にPythonを検討した。PythonMagickなどのライブラリが用意されていて使いやすいということもあるし最近は画像処理で多く使われていたり人気の言語だったりするので。
迷った結果最終的にはElectronでGUI作る必要があるかもしれないというのがあったのでJSにしました。実行環境
- macOS Mojave 10.14.6
- node v12.16.1
- シェルは bin/bash
方法
上記で実行環境書いてますがやり方としてはnode.jsを使ってコマンドラインでJSを呼び出し、JS内でシェルコマンドを実行するものとなっています。JSにもnode-imagemagickなどの直接ImageMagickを使うライブラリがあるのですがライブラリ自体のバグがあった場合に追うのが面倒だなと思ったのと情報量は直接コマンド実行したものの方が多いだろうと思ったため今回はJS内から直接コマンドを実行するようにしています。
node.jsはその時の最新の安定板を使いました。nodeの最新版の入れ方は参考にある記事等を見ていただければと思います。
JSからシェルコマンドを実行する方法としてはexecとexecSyncというものがあって前者は非同期実行で後者は同期実行です。今回の例ではexecSyncを使います。
以下がプログラム。1行目でexecSyncを読み込み2行目でexecSyncを用いてImageMagickのコマンドを実行。
ちなみに今回のImageMagickのコマンドはconvertを用いて100x100の赤い画像を生成しています。convertExample.jsconst {execSync} = require('child_process'); execSync('convert -size 100x100 xc:red red.jpg');
変数を用いて画像の大きさを変更したといった場合もあるのでその場合はutil.formatを使います。
以下は先ほどと同様に100x100の赤い画像を作成した後に青文字で"hoge"という文字を描いています。
また、util.formatを用いてフォントサイズや色や文字の内容を変数で渡すようにしています。convertUseUtilExample.jsconst {execSync} = require('child_process'); const util = require('util'); const fontSize = 24; const color = 'blue'; const content = 'hoge'; execSync('convert -size 100x100 xc:red red.jpg'); execSync(util.format( 'convert -font Bookman-DemiItalic -gravity center -pointsize %d -fill %s -draw "text 0,0 %s" red.jpg red.jpg', fontSize, color, content));
上記のようにutil.formatを使ってコマンドをプログラムによって柔軟に変更することができるので組み合わせることで複雑な画像も生成できるかと思います。
画像を使う業務をしている方は使いこなすと思わぬところで業務効率もあがると思うのでで色々試してみましょう!参考


- 投稿日:2020-04-26T02:14:06+09:00
Google Analytics, Google SpreadSheet, Big Query, Google Ad ManagerのAPIをNode.jsで触ってみる
はじめに
データの可視化を行う当たってGoogleの各種APIを触ってみましたが、最初は認証の仕方とか基本的な書き方とかでつまづく所もあるので、ハンズオンとして触り方をなるべくわかりやすく紹介したいと思います。
今回紹介するのは
- Google Analyticsのレポート
- Google SpreadSheet
- Big Query
- Google Ad Managerのレポート
のAPIになります。
サンプルコードはこちらに上げています。Google Analytics の レポートAPI
概要
- GAのAPIドキュメントを検索すると、Reporting API v4 と Core Reporting API が出てきますが、最新は Reporting API v4 です。
- ガイドをみると、Node.js用のクライアントは無い様なので、HTTP POSTリクエストを自分で生成する必要があります。
- 認証に関してはサービスアカウントを作る方法が固いと思います。こちらからサービスアカウントを新規作成し、登録完了ページからクレデンシャルjsonをダウンロードしておいてください。
- サンプルコードでは
credentials/ga.jsonという名前で保存する想定です。- 参考: サービス アカウント キーの作成
- サービスアカウントの権限でクエリーを実行するので、作成したサービスアカウントをGAにユーザとして追加し、レポートを実行するための権限を与えておいてください。
- 実際にAPIリクエストを行う際の認証はOAuthトークンを使用します。なにやら難しそうな感じですが、
google-auth-libraryを使用すると簡単に取得ができる様になっています。- クエリの書き方はこちらが参考になります。
実装
パッケージのインストール
npm i --save google-auth-library axiosコード
// GAのAPIの利用例です // トークンの取得のため const { auth } = require( 'google-auth-library' ); // HTTPリクエストにはaxiosを使用します。 const axios = require( 'axios' ); const path = require( 'path' ); ( async () => { // --- start OAuthアクセストークンを手に入れる --- // credentialファイルを読み込む const credentialJson = require( path.resolve( `${__dirname}/../credentials/ga.json` ) ); const client = auth.fromJSON( credentialJson ); // 許可するスコープを定義 client.scopes = ['https://www.googleapis.com/auth/analytics.readonly']; await client.authorize(); const token = client.credentials.access_token; // --- end OAuthアクセストークンを手に入れる --- // --- start Queryを作成する --- // ブラウザに対するページビューを取得する const query = { reportRequests: [ { viewId: '{{ GAのビューIDを入力 }}', // todo // レポートの期間 dateRanges: [ { startDate: '2020-04-01', endDate: '2020-04-02', } ], // ディメンジョン dimensions: [ { name: 'ga:browser' } ], // 指標 metrics: [ { expression: 'ga:pageviews' }, ], // 指標のフィルターをかけたい場合は以下の様に記述する // dimensionFilterClauses: [ // { // operator: 'OR', // filters: [ // { // dimensionName: 'ga:pagePath', // operator: 'REGEXP', // or EXACT // expressions: ['hoge'] // } // ] // } // ], // GAのレポートはコンソールからの操作と同様にサンプリングされる可能性があることに注意する samplingLevel: 'DEFAULT' } ] }; // --- end Queryを作成する --- // --- start リクエストを実行する --- const response = await axios.post( 'https://analyticsreporting.googleapis.com/v4/reports:batchGet', query, { headers: { // アクセストークンを設定 Authorization: `Bearer ${token}` } } ); // --- start リクエストを実行する --- // 出力 console.table( response.data.reports[0].data.rows.map( row => { return [ ...row.dimensions, ...row.metrics[0].values ]; }) ); } )().catch( e => console.log( e ) );補足
- クエリーでどんなディメンジョンや指標が使えるかはDimensions & Metrics Explorerを参考
- GAのレポートはコンソールからの操作と同様に結果がサンプリングされる可能性があることに注意してください。
BigQueryのクエリをAPIで実行
概要
- BigQueryのAPIにはNode.jsのクライアントライブラリがありますのでこちらを利用します。
- 自身のGCPアカウントのプロジェクトでAPIを有効化します。
- こちらから有効化できます。https://console.cloud.google.com/apis/library/bigquery.googleapis.com?q=bigquery
- 有効化したアカウントのアカウント名は下記コードに記載します。
- 認証はGAと同じくサービスアカウントで行うのがいいでしょう。サービスアカウントに
BigQuery ジョブユーザーなどのAPIが実行可能な権限をつけてください。
- サンプルコードでは
credentials/bq.jsonという名前で保存する想定です。- こちらのページにサンプルがあるので簡単に記述ができますが、サービスアカウントで認証を行う部分だけ以下のコードに追記しておきます。
実装
パッケージのインストール
npm i --save @google-cloud/bigqueryコード
const path = require( 'path' ); ( async () => { // クライアントを初期化 const { BigQuery } = require( '@google-cloud/bigquery' ); const bigquery = new BigQuery( { // 認証はクレデンシャルファイルのパスを渡すだけでいい keyFilename: path.resolve( `${__dirname}/../credentials/bq.json` ), projectId: '{{ プロジェクト名を入力 }}' } ); // クエリを作成 const query = `SELECT name FROM \`bigquery-public-data.usa_names.usa_1910_2013\` WHERE state = 'TX' LIMIT 100`; // 全てのオプションは -> https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs/query const options = { query: query, location: 'US', }; // ジョブを実行 const [job] = await bigquery.createQueryJob( options ); // ジョブの完了を待つ const [rows] = await job.getQueryResults(); // 結果を表示 console.log( 'Rows:' ); console.table( rows ); } )();Google Spread Sheet の API
はじめに
- 今回はシートにデータを吐き出してみます。
- Google Sheets APIを使用します。
- Node.jsのクライアントがあるので、使用します。
- こちらも上記サンプルページの通りなのですが、認証の通し方を少し変えます。
- 自身のGCPのプロジェクトで Google Sheets APIを有効にします。
- マイドライブから操作したいSpreadSheetを任意のサービスアカウントに対して編集権限で共有します。
- サンプルコードでは
credentials/sheets.jsonという名前でサービスアカウントのクレデンシャルjsonを保存する想定です。実装
実装
パッケージのインストール
npm i --save googleapisコード
const path = require( 'path' ); const { google } = require( 'googleapis' ); ( async () => { // 認証する const authClient = await google.auth.getClient( { keyFile: path.resolve( `${__dirname}/../credentials/sheets.json` ), scopes: ['https://www.googleapis.com/auth/spreadsheets'] } ); const sheets = google.sheets( { version: 'v4', auth: authClient } ); // 保存するデータ const cells = [ [ 1, 2, 3 ], [ 4, 5, 6 ] ]; // 書き込み const req = { // スプレッドシートのID, URLの一部 // https://docs.google.com/spreadsheets/d/{{ここの部分}}/edit#gid=0 spreadsheetId: '{{SPREAD_SHEET_ID}}', range: `シート1!A:AZ`, valueInputOption: 'USER_ENTERED', resource: { values: cells } }; await sheets.spreadsheets.values.append( req ); } )();実装
Google Ad Manager のレポートAPI
はじめに
- 一番の曲者でした。
- Node.jsのクライアントライブラリは無いので、HTTPリクエストを自分で作る必要があります。
- クエリの方法ですが、SOAPという古いAPIの仕様が採用されているので、XMLでクエリを記述してPOSTのBODYに埋めこみます。
- JSでXMLを扱うために
xml-jsというライブラリを使用します。クエリはXMLに変換するので、xml-jsに合わせた形式で記述しています。- 執筆時点で最新バージョンはv202002
- 認証は同様にサービスアカウントで行う。GAMの管理画面からGCPコンソールで作成したサービスアカウントを追加し、レポート用の権限をつけてください。
- サンプルコードでは
credentials/gam.jsonにサービスアカウントのクレデンシャルが保存されている想定です。- GAMはレポートの条件によって、APIからは実行できないレポート条件が存在します。API経由で保存済みのレポートのクエリを取得する機能がありますので、GAMの管理画面からサービスアカウントのユーザに「成り代わる」をして、レポートを保存しておくとAPI経由でクエリの内容とAPIに対応しているかを取得できます。(こちらはサンプルコードに書いていません。)
レポート取得の流れ
こちらの通り
https://developers.google.com/ad-manager/api/reference/v202002/ReportService
ReportService.runReportJobでジョブを作成ReportService.getReportJobでジョブの状態を取得し、完了するまでポーリングする- 完了後、
ReportService.getReportDownloadURLを使用して、レポートのダウンロード用URLを取得する- ダウンロードする
実装
パッケージのインストール
npm i --save google-auth-library request axios xml-jsコード
const path = require( 'path' ); const { auth } = require( 'google-auth-library' ); const axios = require( 'axios' ); const { js2xml, xml2js } = require( 'xml-js' ); // SOAPのベース // soapenv:Body部分を色々変える const soapJsonBase = { _declaration: { _attributes: { version: '1.0', encoding: 'UTF-8' } }, 'soapenv:Envelope': { _attributes: { 'xmlns:soapenv': 'http://schemas.xmlsoap.org/soap/envelope/', 'xmlns:xsd': 'http://www.w3.org/2001/XMLSchema', 'xmlns:xsi': 'http://www.w3.org/2001/XMLSchema-instance' }, 'soapenv:Header': { 'ns1:RequestHeader': { _attributes: { 'soapenv:actor': 'http://schemas.xmlsoap.org/soap/actor/next', 'soapenv:mustUnderstand': '0', // APIのバージョンはここで指定 'xmlns:ns1': `https://www.google.com/apis/ads/publisher/v202002` }, 'ns1:networkCode': { _text: '{{ GAMのネットワークIDを指定 }}' }, 'ns1:applicationName': { _text: '{{ GCPのプロジェクト名を指定 }}' } } }, 'soapenv:Body': undefined } }; ( async () => { // --- クエリの作成 --- // 日時と広告ユニットごとの合計のインプレッションを取得 const query = { // ディメンジョン dimensions: [ { _text: 'DATE' }, { _text: 'AD_UNIT_NAME' }, // 広告ユニット ], adUnitView: { _text: 'FLAT' }, // 指標 columns: [ // 全体系 { _text: 'TOTAL_LINE_ITEM_LEVEL_IMPRESSIONS' }, // 合計のインプレッション ], // レポートの期間 startDate: { year: { _text: '2020' }, month: { _text: '4' }, day: { _text: '1' } }, endDate: { year: { _text: '2020' }, month: { _text: '4' }, day: { _text: '2' } }, // 日時範囲の期間は「固定」 dateRangeType: { _text: 'CUSTOM_DATE' }, // フィルターをかける場合は以下の様に記述 //statement: { // query: { // _text: ` where PARENT_AD_UNIT_ID = {{広告ユニットID}}` // } //}, // 管理画面とタイムゾーンを合わせる timeZoneType: { _text: 'PUBLISHER' } }; // --- クエリの作成 --- // --- アクセストークンを取得 --- const keys = require( path.resolve( `${__dirname}/../credentials/gam.json` ) ); const client = auth.fromJSON( keys ); client.scopes = ['https://www.googleapis.com/auth/dfp', 'https://www.googleapis.com/auth/analytics.readonly']; await client.authorize(); const token = client.credentials.access_token; // --- クエリの作成 --- // SOAPヘッダーに変換するオブジェクトを作成 // xml-jsでXMLに変換する // 変換後↓ // <runReportJob xmlns="https://www.google.com/apis/ads/publisher/v202002"> // <reportJob> // <reportQuery> クエリー </reportQuery> // </reportJob> // <runReportJob> let soapJson = { ...soapJsonBase }; let body = { // ここで実行するコマンドを指定 runReportJob: { // 中身はコマンドの引数 _attributes: { xmlns: `https://www.google.com/apis/ads/publisher/v202002` }, reportJob: { reportQuery: query } } }; soapJson['soapenv:Envelope']['soapenv:Body'] = body; // APIリクエストを実行 let soapXML = js2xml( soapJson, { compact: true } ); let response = await axios.post( `https://ads.google.com/apis/ads/publisher/v202002/ReportService`, soapXML, { headers: { Authorization: `Bearer ${token}` } } ); // レスポンスもXMLなのでjsonに変換する let data = xml2js( response.data, { compact: true } ); const jobId = data['soap:Envelope']['soap:Body']['runReportJobResponse']['rval']['id']['_text']; console.log( 'ジョブID', jobId ); // ジョブの完了をポーリングする const sleep = () => new Promise( resolve => setTimeout( () => resolve(), 1000 ) ); while ( true ) { console.log( 'ポーリング' ); soapJson = { ...soapJsonBase }; body = { getReportJobStatus: { _attributes: { xmlns: `https://www.google.com/apis/ads/publisher/v202002` }, reportJobId: { _text: jobId } } }; soapJson['soapenv:Envelope']['soapenv:Body'] = body; // APIリクエスト実行 soapXML = js2xml( soapJson, { compact: true } ); response = await axios.post( `https://ads.google.com/apis/ads/publisher/v202002/ReportService`, soapXML, { headers: { Authorization: `Bearer ${token}` } } ); data = xml2js( response.data, { compact: true } ); // ステータスを取得 const status = data['soap:Envelope']['soap:Body']['getReportJobStatusResponse']['rval']['_text']; console.log( 'ステータス', status ); if ( [ 'COMPLETED', 'FAILED' ].includes( status ) ) { console.log( '完了' ); break; } await sleep(); } // レポートのダウンロード用URLを取得する console.log( 'URLを取得' ); soapJson = { ...soapJsonBase }; body = { getReportDownloadURL: { _attributes: { xmlns: `https://www.google.com/apis/ads/publisher/v202002` }, reportJobId: { _text: jobId }, exportFormat: { _text: 'CSV_DUMP' }, } }; soapJson['soapenv:Envelope']['soapenv:Body'] = body; // APIリクエスト実行 soapXML = js2xml( soapJson, { compact: true } ); response = await axios.post( `https://ads.google.com/apis/ads/publisher/v202002/ReportService`, soapXML, { headers: { Authorization: `Bearer ${token}` } } ); data = xml2js( response.data, { compact: true } ); const downloadURL = data['soap:Envelope']['soap:Body']['getReportDownloadURLResponse']['rval']['_text']; console.log( downloadURL ); // ダウンロード const fs = require( 'fs' ); const request = require( 'request' ); await new Promise( ( resolve ) => { request( downloadURL ) .pipe( fs.createWriteStream( 'report.csv.gz' ) ) .on( 'close', async () => { resolve(); } ); } ); // gzipなので、解答する const child_process = require( 'child_process' ); await child_process.execSync( `gunzip -f ./report.csv.gz` ); } )().catch( e => console.log( e ) );補足
試して見ると結構エラーする条件があると思います。特に多いのはフィルター条件です。例えば定義済みのkey-valueでレポートを作成したい場合があるかと思いますが、GAMの管理画面のレポートと違い文字列でkay-valueを指定することはできません。この場合CUSTOM_CRITERIAと言うディメンジョンをしてすると、CUSTOM_TARGETING_VALUE_IDと言うカラムが追加されるので、これでフィルターをかけます。何でフィルターできて、できないのかはドキュメントにほとんどのディメンジョンごとに記載されています。
使用可能なディメンジョン、指標、フィルター条件などはこちらを参考ください。
https://developers.google.com/ad-manager/api/reference/v202002/ReportService.ReportQuery以上
参考になれば幸いです。
- 投稿日:2020-04-26T02:02:28+09:00
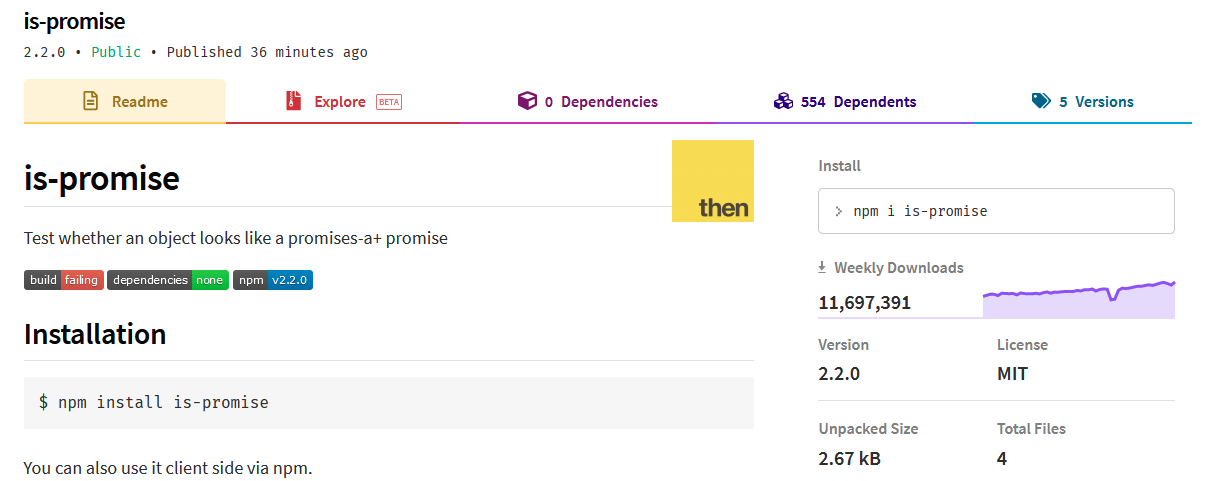
タイムリーに is-promise 2.2.0 破損に巻き込まれた話
Node.jsの環境をSSDに引越しして動作を確認していたところ、
yoがインストールできない・動かないという謎の現象に見舞われた。実は自分の環境が悪いのではなく、タイムリーにyoが依存するたった1行の関数を提供するis-promiseが壊れた直後にインストールしたことが原因と分かった。別のモジュールではNode.jsのバージョンが上がって動かなくなるケースでは対応が遅れることがあったので、今回はすぐ処置されてラッキーだった。(知らないだけで日常的に起きているのかもしれないが)
起きた現象
yoをインストールすると、ちゃんと動くかをチェックするYeoman Doctorが実行される。ここで、yo --versionでエラーが起きてしまっている。この後yoを実行しても、同じエラーで起動すらしない状況となった。> yo@3.1.1 postinstall K:\nodejs\npm_global\node_modules\yo > yodoctor Yeoman Doctor Running sanity checks on your system √ No .bowerrc file in home directory √ Global configuration file is valid √ NODE_PATH matches the npm root √ No .yo-rc.json file in home directory √ Node.js version Error: Command failed: C:\WINDOWS\system32\cmd.exe /s /c "yo "--version"" internal/modules/cjs/loader.js:584 if (e.code !== 'ERR_PACKAGE_PATH_NOT_EXPORTED') throw e; ^ Error [ERR_INVALID_PACKAGE_TARGET]: Invalid "exports" main target "index.js" defined in the package config /K:/nodejs/npm_global/node_modules/yo/node_modules/is-promise\package.json at resolveExportsTarget (internal/modules/cjs/loader.js:542:13) at resolveExportsTarget (internal/modules/cjs/loader.js:581:20) at applyExports (internal/modules/cjs/loader.js:455:14) at resolveExports (internal/modules/cjs/loader.js:508:23) at Function.Module._findPath (internal/modules/cjs/loader.js:632:31) at Function.Module._resolveFilename (internal/modules/cjs/loader.js:1001:27) at Function.Module._load (internal/modules/cjs/loader.js:884:27) at Module.require (internal/modules/cjs/loader.js:1074:19) at require (internal/modules/cjs/helpers.js:72:18) at Object.<anonymous> (K:\nodejs\npm_global\node_modules\yo\node_modules\run-async\index.js:3:17) { code: 'ERR_INVALID_PACKAGE_TARGET' }エラーの原因
エラーメッセージにある通り、
run-asyncが利用するis-promiseで、ERR_INVALID_PACKAGE_TARGETが起きてしまっているのが原因。npmのis-promiseのページを見てみると、以下のようにビルドエラーが起きたと表示されている。30分ほど前にPublishされたバージョンで何が起きたのか…
is-promiseのGitHubにはIssueが既に投稿されていて、同じエラーが起きていることが分かった。(ここで初めて、自分の環境が問題ではないかも…と分かった)
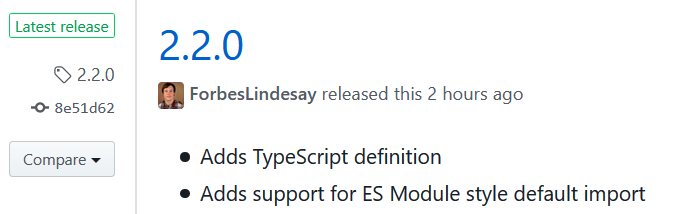
原因はPackage.json incorrectly formatted #12に投稿されていた(ejs/cjsといった、Javascriptのモジュールの形式の指定が間違っていたとのこと…あまり理解できていないが、ejsをサポートするNode.jsのバージョンでNGになるそう)。今回のバージョンで追加された機能が悪さをしてしまった模様。
その後、[BUGFIX] Use correct paths for CJS and ESM compatibility #15で修正があり、プルリクエストが発行されていた。
とりあえず、少し待てば反映されるかもしれないので待ってみる。Weekly download 1000万超の定番モジュールがほんの少しのミスで色々なモジュールに影響を与えてしまうとは…
暫定対策
とりあえず問題が起きているのは
yoのグローバルインストールが使っているrun-asyncなので、yoのnode_modules以下のrun-asyncのpackage.jsonを変更して、is-promiseのバージョンを2.1.0に固定する。package.jsonを変更したらrun-asyncのフォルダでnpm installを実行し、is-promiseの2.1.0をインストールする。package.json"dependencies": { "is-promise": "2.1.0" ← 元々は "^2.1.0" だった },この処置の後、
yoを実行したら動くようになった。>yo ? 'Allo! What would you like to do? (Use arrow keys) Run a generator > Code ────────────── Update your generators Install a generator Find some help Get me out of here! (Move up and down to reveal more choices)その後
2.2.0から3時間後に2.2.2がリリースされた。もう一度
npm install -g yoしてみたところ、正常にインストールできた。早く対応してくれて良かった…Yeoman Doctor Running sanity checks on your system √ No .bowerrc file in home directory √ Global configuration file is valid √ NODE_PATH matches the npm root √ No .yo-rc.json file in home directory √ Node.js version √ npm version √ yo version Everything looks all right!


- 投稿日:2020-04-26T01:30:43+09:00
ubuntu18.04にnode12系とnpm6系をインストールする
実行環境
- OS:ubuntu 18.04
前提条件
- 特に無し
実施手順
公式のREADME.md に従ってコマンドを実行するだけです。
node12系を指定し、インストール。
curl -sL https://deb.nodesource.com/setup_12.x | sudo -E bash - sudo apt-get install -y nodejs以上です。
結果確認
Node.js のバージョン
$ node -v v12.16.2npm のバージョン
$ npm -v 6.14.4まとめ
公式のREADME.md の手順をそのまま実行しただけでした。
- 投稿日:2020-04-26T00:28:01+09:00
代替手段の探し方
新しいものを勉強する時や久しぶりに触るミドルウェアとかアプリケーションについて、もっといいものあるんじゃないかなって時にどうしてます?
自分は
アプリケーション名 alternative
って検索してみてます。例)
nvm alternative
node.jsのversion managerの代替アプリを探した場合。
nveって製品が見つかりました。あとは出てきたものと、元の製品とあわせて
nvm nve
とか調べてみたりします。