- 投稿日:2020-04-21T23:26:13+09:00
【Rails Docker Git】よく使うコマンド一覧
【Rails Docker Git】よく使うコマンド一覧
Dockerでサーバー立ち上げ
terminal> docker-compose upDockerでサーバーダウン
terminal> docker-compose downDockerでDB確認
terminal> docker-compose psrails db:create
terminal> docker-compose exec イメージ名 ./bin/rails db:createrailsタスク一覧(コマンド一覧)
terminal> docker-compose exec web ./bin/rails -Tgitのカレントブランチを確認
terminal> git branchgitのブランチを新規作成してテェックアウト
terminal> git checkout -b ブランチ名gitのステージングされテイルファイルのキャシュをみる
terminal> git diff -cashedterminal> docker-compose exec イメージ名 ./bin/rails db:create
- 投稿日:2020-04-21T23:13:22+09:00
初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)マニュフェスト(ConfigMap)編
背景
個人的にインフラの知識以上にこれからのアプリケーションが動く環境を作ってデプロイしたりしてこれからの知識を身に着けたい。そしてより一層、自分の知識のアップデートをしたいと思いました。
その中でこの本に出会い、これから少しずつやったことを残し、未来の自分への手紙としてもあり、見つめ直せればと思いました。
引用や参考と今回の自分の勉強用の書籍の紹介
技術評論社『Kubernetes実践入門』のサンプルコード
Kubernetes実践入門 プロダクションレディなコンテナ&アプリケーションの作り方
実際の学びについて
書籍を読みながら、章ごとに少しずつ進めていきたいと思います。
GitHub のソースコードも使いながら学んで行きたいと思います。
この章の勉強は本当に書籍の写経が主になるかもしれません・・・勉強開始
ConfigMap に保存下キーと値を Pod テンプレートの env から呼び出す
$ kubectl create cm common-env -o yaml --dry-run \ --from-literal MYSQL_USER=myuser \ --from-literal MYSQL_PASSWORD=mypassword \ --from-literal MYSQL_DATABASE=mattermost > cm.yaml $ cat cm.yaml apiVersion: v1 data: MYSQL_DATABASE: mattermost MYSQL_PASSWORD: mypassword MYSQL_USER: myuser kind: ConfigMap metadata: creationTimestamp: null name: common-envmattermost-deploy.yamlでConfigMapの値を参照させるcontainers: - image: k8spracticalguide/mattermost:4.10.2 name: mattermost env: - name: MM_USERNAME valueFrom: configMapKeyRef: name: common-env key: MYSQL_USER - name: MM_PASSWORD valueFrom: configMapKeyRef: name: common-env key: MYSQL_PASSWORD - name: DB_NAME valueFrom: configMapKeyRef: name: common-env key: MYSQL_DATABASE
MM_USERNAME / MM_PASSWORD / DB_NAMEを ConfigMap を参照するように修正したdb-deploy.yamlのConfigMapの値を参照させるenv: - name: MYSQL_ROOT_PASSWORD value: rootpassword envFrom: - configMapRef: name: common-env
MYSQQL_ROOT_PASSWORD以外を CoinfigMap を参照するように修正したmattermost-deployの環境変数を確認Environment: MM_USERNAME: <set to the key 'MYSQL_USER' of config map 'common-env'> Optional: false MM_PASSWORD: <set to the key 'MYSQL_PASSWORD' of config map 'common-env'> Optional: false DB_NAME: <set to the key 'MYSQL_DATABASE' of config map 'common-env'> Optional: false DB_HOST:db-deployの環境変数を確認Environment Variables from: common-env ConfigMap Optional: false Environment: MYSQL_ROOT_PASSWORD: rootpasswordPod 内で data の中身をファイルとして読み込む
config.jsonの内容が多いので中身割愛してコマンドのみとします$ curl -L -O https://raw.githubusercontent.com/kubernetes-practical-guide/examples/master/ch3.4.2.2/config.json $ kubectl create cm mm-config-file -o yaml --dry-run --from-file config.json > cm-file.yamlmattermost-deploy.yamlのConfigMapはファイルとして読み込むように設定volumeMounts: - name: cm-volume mountPath: /mm/config #マウントするボリューム名を指定 volumes: - name: cm-volume configMap: name: mm-config-file items: - key: config.json path: config.json
- config.json ファイルが Volume に保存されているのを確認
$ kubectl exec -it mattermost-846bf547c-zfwld -- ls /mm/config/ config.json次は 次は 3.4.2 章をやっていきます。
- Secret を使って今回設定した設定値を管理する方法を学びます
最後に
ちょっと、現在までの章を振り返ってやっと 1/3 ぐらいかなというところですが、これからもっと面白くなっていく部分だと思い、ConfigMap をもう少し次回までに腹落ちさせていきたいと思います。
今までの投稿
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)Pod編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)NameSpace 編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)Label 編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)ReplicaSet 編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)Deployment 編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)Service 編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)ConfigMap 編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)Secret 編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)操作編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)体感編
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)体感編パート2
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)体感編パート3(Label操作)
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)体感編パート3(OwnerReference 操作)
- 初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)マニュフェスト編

- 投稿日:2020-04-21T19:43:04+09:00
AWS Lambdaに外部モジュール(numpy,scipy,requests等)をデプロイする
AWS Lambda(以下、Lambda)に外部モジュールをデプロイする方法を見ていきたいと思います。ここではPythonを例に見ていきます。
実行順序
1. Amazon Linux 2(Lambdaの実行環境)を準備する
2. ソースファイルとともにLambdaにデプロイ
2. Lambda Layerを使う方法*2はどちらを選んでも構いません。
1. Amazon Linux 2(Lambdaの実行環境)を準備する
requestsモジュール等、内部でC言語などを使わず、Pure Pythonで書かれたモジュールの場合、このステップは不要です。
しかし、numpyやscipyといった、C言語に依存するモジュールの場合、Lambdaの実行環境と同じ環境で開発するのが開発しやすくなります。 windowsやMacでインストールしたnumpyをzipで固めてデプロイしてもエラーとなります。ここでは、Amazon Linux 2の環境として、公に公開されているDockerイメージ、lambci/lambda:build-python3.7 を使います。
適当なディレクトリを作って、Lambdaで実行するソースコード(lambda_function.py)とDockerfileを作成してください。
Dockerfileの中身
FROM lambci/lambda:build-python3.7 CMD pip3 install numpy -t /var/tasklambda_function.pyの中身は適当
import numpy as np def lambda_handler(event,context): print(np.arange(10).reshape(2,5))ソースとDockerfile作成完了
~$ ls Dockerfile lambda_function.pyあとは、ビルドして、runしてください。
~$ docker image build -t numpy:latest . ~$ docker container run --rm -v ${PWD}:/var/task numpy:latestコンテナ内でインストールした外部モジュールを、ホストOSでも参照するために、-v ${PWD}:/var/taskしています。
ちなみに、/var/taskはLambdaが外部モジュールをインポートするために参照するパスの1つです。Dockerコンテナで実行する場合は、このパスの中に外部モジュールを置く必要があります。
試しに、Lambdaで以下のようにして、パスを確認してみてください。import sys def lambda_handler(event,context): print(sys.path) """ python3.7 における実行結果 ['/var/task', '/opt/python/lib/python3.7/site-packages', '/opt/python', '/var/runtime', '/var/lang/lib/python37.zip', '/var/lang/lib/python3.7', '/var/lang/lib/python3.7/lib-dynload', '/var/lang/lib/python3.7/site-packages', '/opt/python/lib/python3.7/site-packages', '/opt/python'] """上記コマンドが成功していると、ソースと外部モジュール(numpy)が同じ階層にあるはずです。あとは、Lambda Layer、もしくはソースファイルとともにzipで固めてデプロイするだけです。なので、以下2のどちらかを選んでください。
~$ ls Dockerfile bin lambda_function.py numpy numpy-1.18.3.dist-info numpy.libs2. Lambda Layerを使う方法
前述の通り、Lambdaが外部モジュールを読み込めるように、python ディレクトリを作成して、そこにnumpy関連のファイル、ディレクトリを移動します。
実行手順の最初の段階で python ディレクトリを作成していれば以下の作業は不要です。~$ mkdir python ~$ mv bin numpy numpy-1.18.3.dist-info numpy.libs python外部モジュールをzipで固めてLambda Layerにデプロイします。
~$ zip -rq numpy.zip pythonソースファイルをzipで固めて、Lambda コンソール or AWS CLIでデプロイします。
~$ zip -q lambda_function.zip lambda_function.py2. ソースファイルとともにLambdaにデプロイ
zipで固めて、Lambda コンソール or AWS CLIでデプロイします。Lambda Layerを使う場合は、外部モジュールとソースファイルを分けますが、今回はすべてまとめてzip化します。なので、zip対象は * です。
~$ zip -rq numpy.zip *Lambdaにデプロイする際にサイズが大きくて、画面に表示できない場合がありますが(numpyはほぼ表示不可能)実行自体はできます。
- 投稿日:2020-04-21T15:27:02+09:00
dockerコンテナのIPアドレスを見る
起動中のdockerコンテナのIPアドレスなどを見る。
> docker inspect コンテナ名 or コンテナID [ { "Id": "a58cf841ba7f25af53ff2d71ac9d7ad00c0f363436297525df44e07765aae2a1", (省略) "IPAddress": "192.168.0.2", (省略) } ]
- 投稿日:2020-04-21T14:35:49+09:00
RaspberryのDocker上でGPIOをWiringPiで使う
はじめに
RaspberryもGPIO(というかハードウェア全般)も初心者がDockerのコンテナでタクトスイッチのオンオフをConsoleに出力するだけのお話
環境
・Raspberry
・.NetCore 3.1(開発側)
・WiringPi
・実行はDocker(インストールしておいてください)ソースはこちら
ハマりどころ
その1
現象
.NetCoreのruntimeコンテナでGPIOのアプリを起動したいので、マイクロソフトのイメージmcr.microsoft.com/dotnet/core/runtime:3.1-bionic-arm32v7を使ったところapt-getでWiringPiがインストールできませんでした(知っている方教えてください)
対処法
DockerfileにてラインタイムイメージにコンパイラをインストールしWiringPiをビルドすることで解決
その2
現象
RaspberryでGPIOを扱う場合に登場する/dev/gpioがコンテナ上ではアクセスができなくて困った。
対処法
Docerのコマンドに--deviceといパラメータがこれを使えばいいことが判明
だけど、今度はパーミッションエラーが発生
--privilegedコマンドを使えば回避できることが判明(特権モードで実行なので慎重に)手順
開発側
- TackInvokerというフォルダを作成
- TackInvokerフォルダに移動
- dotnet new console
- Program.csを下記のファイルで置き換える
- TackInvokerフォルダの上に下記のDockerfileを配置
- docker build -t {自身のDockerHubID}/Tackinvoker:latest .
- docker push {自身のDockerHubID}/Tackinvoker:latest
Raspberry側
- docker run -it --rm --device /dev/gpiomem --privileged {自身のDockerHubID}/Tackinvoker:latest
素材達
Program.cs
using System; using System.Runtime.InteropServices; using System.Threading; namespace TackInvoker { class Program { public const int INPUT = 0; public const int OUTPUT = 1; public const int INT_EDGE_FALLING = 1; public const int INT_EDGE_RISING = 2; public const int Tack_PIN = 17; [DllImport("wiringPi")] extern static int wiringPiSetupGpio(); [DllImport("wiringPi")] extern static void pinMode(int pin, int mode); [DllImport("wiringPi")] extern static void digitalWrite(int pin, int mode); [DllImport("wiringPi")] extern static int wiringPiISR(int pin, int edgeType, CallbackFunc func); [UnmanagedFunctionPointer(CallingConvention.Cdecl)] public delegate void CallbackFunc(); static void Main(string[] args) { int ret = 0; // wiringPiのセットアップ wiringPiSetupGpio(); // GPIO をINPUTに設定する. pinMode(Tack_PIN, INPUT); CallbackFunc callBackFunc = delegate () { Console.WriteLine("CallbackFunc is called !"); }; // GPIO がONになったらコールバック関数を呼ぶ. ret = wiringPiISR(Tack_PIN, INT_EDGE_RISING, callBackFunc); // 無限に待機する. Thread.Sleep(Int32.MaxValue); } } }Dockerfile
# ビルドイメージ FROM mcr.microsoft.com/dotnet/core/sdk:3.1 AS build WORKDIR /app # copy csproj and restore as distinct layers COPY *.sln . COPY TackInvoker/*.csproj ./ TackInvoker/ # copy everything else and build app COPY TackInvoker ./TackInvoker/ RUN dotnet restore TackInvoker WORKDIR /app/TackInvoker RUN dotnet publish -c Release -o out # ランタイムイメージ FROM mcr.microsoft.com/dotnet/core/runtime:3.1-bionic-arm32v7 # WiringPiをインストールする RUN apt-get update RUN apt-get install -y libi2c-dev RUN apt-get install -y git-core RUN apt-get install -y sudo RUN apt-get install -y make RUN apt-get install -y gcc RUN git clone https://github.com/WiringPi/WiringPi.git WORKDIR /WiringPi RUN ./build WORKDIR /app COPY --from=build /app/TackInvoker/out ./ ENTRYPOINT ["dotnet", "TackInvoker.dll"]
- 投稿日:2020-04-21T13:01:35+09:00
Docker Desktop for Windowsでschema v1 manifestを見分ける
Dockerバージョン
執筆時点では、Docker Desktop for Windowsの
Edge Release(stableではないほう)にある Docker Desktop Community 2.3.0.0を使っている。※ 2.2.2.0の時点でWindows10 HomeでもDocker Desktop for Windowsが使えるようになった

Windows 10 Home users can now use Docker Desktop through the experimental WSL 2 support. This requires Windows Insider Preview Build 19018 or later.
Windows10側はInsider Previewのビルド19041。
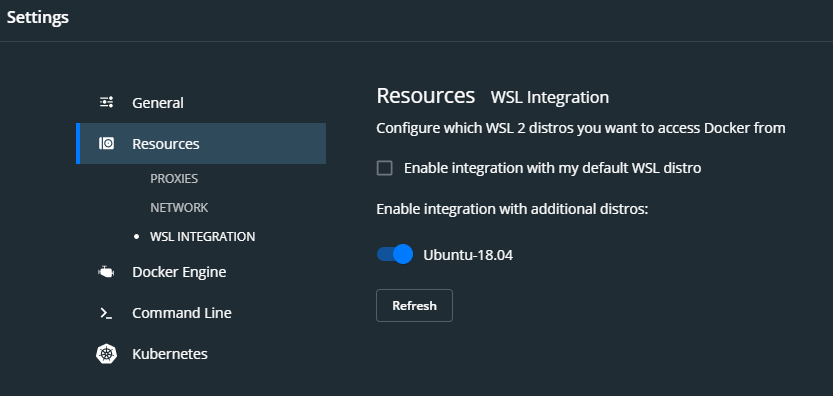
ちゃんとWSL2からDockerを使えるように、Docker Desktop for Windowsの設定でResources WSL IntegrationではEnable integration with additional distrosにチェックを入れている。
Dockerイメージがうまく動かない現象
DockerHubにある MariaDBの
v10.0.17とv10.2.15を使っていたが、どうもv10.0.17だけ挙動がおかしかった。ポート番号が割り当てられず、ログも吐かずにエラー状態となっている。Volume, Imageを削除してDuckerHubからpullし直してみたが、変わらず。
schema v1 manifest形式のイメージが怪しそう
イメージをpullした際に、こんなメッセージがコンソールに表示されていた。
Image docker.io/library/mariadb:10.0.17 uses outdated schema1 manifest format. Please upgrade to a schema2 image for better future compatibility. More information at https://docs.docker.com/registry/spec/deprecated-schema-v1/
「もう古いschema1 manifest formatを使っているからschema2にアップグレードしてくれ」と言われているように見える。
そう言われましても。。。 (Insider Previewする前に使っていたDocker Desktop v2.2.2だと元気に動いていた)
manifestについての公式ドキュメントもちらと見たが、謎 (原因は
v1だからだとは思うが。。。)c.f. https://docs.docker.com/registry/spec/manifest-v2-2/
ひとまず苦肉の策で、既にschema v2で書かれているMariaDBバージョンを使うことにした (たとえばv10.2.15は動くので)。
意図しないバージョンアップなので、既存のv10.0.17に一番近いバージョンにしたい。
しかし毎回イメージをpullして確認するのはしんどい。
v2 formatをDocker CLIから見分けて選ぶ
pullしなくても見分けられそう。
Docker Desktop for Windowsの設定からCommand Line >
Enable experimental featuresにチェックを入れ、CLIを使えるようにしておく。
docker manifestコマンドにinspectというコマンドがあり、manifest情報を調べられる。
c.f. https://docs.docker.com/engine/reference/commandline/manifest/#manifest-inspect
schema v1のmanifestは
そもそも調べられずエラーを吐くという反応を利用して、MariaDBのv10.0.19~v10.0.38を調べていった (やり口が汚い)schema v1の場合はこう。サポートされていない、とエラーを吐く。
> docker manifest inspect mariadb:10.0.24 unsupported manifest media type and no default available: application/vnd.docker.distribution.manifest.v1+prettyjwsschema v2の場合はこう。ちゃんと結果が返る。
> docker manifest inspect mariadb:10.0.25 { "schemaVersion": 2, "mediaType": "application/vnd.docker.distribution.manifest.v2+json", "config": { "mediaType": "application/octet-stream", "size": 7222, "digest": "sha256:bb3fc12095a70be54f3eb873e6770e9b396e3149a91af863cfaa669c851ca171" }, "layers": [ { "mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip", "size": 51352535, "digest": "sha256:5c90d4a2d1a8dfffd05ff2dd659923f0ca2d843b5e45d030e17abbcd06a11b5b" }, ... (長いので省略) { "mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip", "size": 120, "digest": "sha256:87e0c87d0ef1531bce04835a47418a657ee1692e1ab163cb7a49027fa6806734" } ] }どうやらschema v2形式のイメージはv10.0.25以降のようだった。Dockerも元気に動く。

- 投稿日:2020-04-21T11:59:02+09:00
WSLでDockerを動かすまで
WSLでDockerを動かすまで
はじめに
これは自分がWSLでDockerを入れる際に少し手間取ってしまったために、備忘録として残すための記事ですので、読みづらい、説明不足なところがあると思います。ご容赦ください。
起動手順
- Dockerのインストール
- 管理者権限でのWSLの実行
- 「sudo cgroupfs-mount」の実行
- 「sudo usermod -aG docker $USER」の実行
- 「sudo service docker start」の実行
です。
Dockerのインストールは公式サイトを見ながらおこなえば確実です。
毎回、sudoをつける必要がありますが、どうにかすればつけなくて良くなるそうです。
- 投稿日:2020-04-21T09:22:46+09:00
コーディング未経験のPO/PdMのためのRails on Dockerハンズオン、Rails on Dockerハンズオン vol.16 - Deploy to EKS -
はじめに
こんにちは!今回でラストです!
今回はAWSのマネージドKubernetesサービスであるElastic Kubernetes Service(EKS)にデプロイしてみたいと思います。
今まで作ってきたRailsアプリコンテナをEKSで動かし、DBは同じくAWSのマネージドRDBサービスのRelational Database Service(RDS)を使います。
インフラ構築にはInfrastructure as CodeツールのTerraformを使ってみます。あくまで「こいつ、動くぞ!」を目的にしているので、今回のハンズオンだけでこれらの全てを伝えるわけではありませんし、使いこなせるわけではありません。あくまでとっかかりとして捉えてみてください。
気になる方はどんどん調査して使ってみてください!AWSを使うので、各自AWSアカウントは取得しておいてくださいね。
では、最後のハンズオンを始めます!
前回のソースコード
ここまでのソースコードはこちらに格納してます。今回のハンズオンからやりたい場合はこちらからダウンロードしてください。
Kubernetes
Kubernetes(k8s)はコンテナオーケストレーションツールに位置付けられるOSSです。
コンテナオーケストレーションツールは、Dockerなどのコンテナ技術を使って作られたアプリケーションのデプロイ、スケーリング、サービスディスカバリー、負荷分散などなどを管理したり自動化したりできるもので、Docker単体だけでは難しかったコンテナの本番環境稼働を可能にしてくれます。(Docker単体ではボリュームやネットワークがサーバーと1対1だったり、サーバーとコンテナの関連の管理がおよそ人ではできなかったり困難がありました。)コンテナオーケストレーションツールとしては、Kubernetesの他にもDocker SwarmやMesosphereなどがありましたが、2020年現在、事実上Kubernetesがデファクトスタンダードとなっています。(参考:国内でDockerコンテナを本番利用している企業は9.2%、コンテナオーケストレーションツールはKubernetesがデファクト - ITmedia NEWS)
マネージドKubernetes
KubernetesはOSSなので誰でも自分のサーバーで環境構築することができます。
ただ、すごいことをやってくれるので仕組みもけっこう複雑です。「Kubernetesがデファクトか!じゃあ構築するぞ!」みたいなノリではできないんじゃないかと思います。
Kubernetesでは、全体をクラスターと呼び管理しています。クラスターを管理する部分を「マスターコンポーネント」、アプリコンテナが稼働する部分を「ノードコンポーネント」と分けたりします。(参考:Kubernetesのコンポーネント - Kubernetes)
特に「マスターコンポーネント」はクラスターのコントロールプレーンを担っておりとても重要かつ要素も複雑です。運用したくないです。そこで大手クラウドベンダーはマネージドKubernetesサービスとして、利用者は主にノードコンポーネントの一部(インスタンス数とかボリュームとか)だけに関心を持っていればKubernetesを使えるサービスを展開しています。
AWSであればElastic Kubernetes Service(EKS)、GCPであればGoogle Kubernetes Engine(GKE)、Microsoft AzureであればAzure Kubernetes Service(AKS)です。今回はEKSを使ってKubernetes上に作ってきたRailsアプリケーションをデプロイしてみましょう。
システム構成
Diagramsで描いてみました。(参考:Diagrams on Dockerでシステム構成図を書いてみた - Qiita)VPCの中でEKS(ノードコンポーネント)とRDSはPrivate Subnetに配置します。今回はあまり使う機会なしですが、ノードコンポーネントをPrivate Subnetにおいているのでインターネットと通信するためにPublic SubnetにNAT Gatewayをおきます。
また、Dockerイメージを管理するためにElastic Container Registry(ECR)を使います。このシステム構成を構築し、EKSでPodをデプロイしていくために、Infrastructure as CodeツールのTerraform、AWSリソースをコマンドラインで操作するためのAWS CLI、Kubernetesを操作するためのkubectlを使います。
まずは、これらのツールを使うためのコンテナを作成して、その中でシステム構成を実現していきます。システム構築、Kubernetes操作のためのコンテナを作る
これから、Railsアプリを公開するまでにやることは大まかに以下の流れです。
- Terraformでシステム構成図の通り必要なリソースを作成する
- ECRにRailsアプリのDockerイメージを登録する
- EKSにECRに登録したRailsアプリをデプロイする
今回はこの一連のデプロイ作業をするための
deployコンテナを作って、その中でデプロイ作業を進めていこうと思います。ディレクトリ構造を見直す
現状のホームディレクトリはRailsアプリのソースコードが置かれていますが、新たに
rails/ディレクトリを作成し一階層したで管理するようにします。そしてrails/ディレクトリと同じ階層にdeploy/ディレクトリを作成し、そちらにRailsアプリ以外のデプロイに必要なファイルを作っていくことにします。|-- rails_on_docker_handson |-- app/ |-- bin/ |-- ... |-- Gemfile |-- Gemfile.lock |-- Dockerfile |-- docker-compose.yml |-- .git/ |-- .gitignore |-- ...↓
|-- rails_on_docker_handson |-- docker-compose.yml |-- .git/ |-- .gitignore |-- rails/ | |-- app/ | |-- bin/ | |-- ... | |-- Gemfile | |-- Gemfile.lock | |-- Dockerfile | |-- deploy/ |-- Dockerfile |-- k8s/ |-- terraform/まずはこのディレクトリ・ファイル作成とファイル移動をやっていきましょう。
$ mkdir -p rails/ deploy/k8s/ deploy/terraform/ $ touch deploy/Dockerfile $ mv `ls -a | egrep -v ".git|README.md|docker-compose.yml|rails|deploy"` rails少し
mvコマンドで複雑なことしてます。「``」のコマンドの実行結果を使ってmv [実行結果] railsが実行されます。
「``」で囲まれたコマンドは|が間に入っていますが、これは左側の結果に対して右側のコマンドを実行する時に使います。ls -aはカレントディレクトリのディレクトリ、ファイルを隠しファイル含めて表示するコマンドです。この結果からegrepの-vオプションでその後に指定した文字列にマッチしない文字列を実行結果として返しています。
ま、そんなこんなでカレントディレクトリから.git、README.md、docker-compose.yml、rails、deployにマッチしないディレクトリやファイルをrailsディレクトリに移動しました。ディレクトリ構造を変更したので、
docker-compose.ymlのbuildとvolumesの位置を更新します。docker-compose.ymlversion: "3" services: db: image: postgres:12.1-alpine environment: - TZ=Asia/Tokyo volumes: - - ./tmp/db:/var/lib/postgresql/data + - ./rails/tmp/db:/var/lib/postgresql/data web: - build: . + build: rails/ volumes: - - .:/app + - ./rails:/app ports: - 3000:3000 depends_on: - db environment: - RAILS_SYSTEM_TESTING_SCREENSHOT=inlineこれでファイルの移動は完了です。念のため、イメージをビルドしなおしてコンテナを起動させてみるといいかもしれません。
$ docker-compose build --no-cache web $ docker-compose up -dエラーなくサイトにアクセスできていたらOKです!
$ docker-compose downデプロイ作業用のコンテナを作る
先にのべたデプロイ手順から、デプロイ作業用のコンテナは以下のことができなければなりません。
terraformコマンドが使えるawsコマンドが使えるkubectlコマンドが使えるdockerコマンドが使える(DockerイメージのビルドとECRへのpushのため)Dockerコンテナ上で
dockerコマンドを使うため、今回はDocker in Docker(dind)のDockerイメージをベースに各コマンドをインストールすることにします。deploy/DockerfileFROM docker:dind ENV HOME="/workspace" WORKDIR ${HOME} RUN apk update && \ apk upgrade && \ # Install terraform apk add --no-cache -q terraform && \ # Install aws cli apk add --no-cache -q curl unzip python3 groff && \ curl -sO https://bootstrap.pypa.io/get-pip.py && \ python3 get-pip.py && \ pip3 install awscli --upgrade && \ rm get-pip.py && \ # Install kubectl curl -s https://amazon-eks.s3-us-west-2.amazonaws.com/1.14.6/2019-08-22/bin/linux/amd64/kubectl -o kubectl && \ chmod +x ./kubectl && \ mv kubectl /usr/local/bin
terraformはapk addでインストールしました。
awsとkubectlはそれぞれの公式の手順に従ってインストールしています。
docker-compose.ymlも更新します。docker-compose.yml- version: "3" + version: "3.7" services: ... + deploy: + build: deploy/ + environment: + - AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID + - AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY + - AWS_DEFAULT_REGION=ap-northeast-1 + - KUBECONFIG=/workspace/k8s/.kube/config + volumes: + - ./rails:/workspace/rails + - ./deploy/k8s:/workspace/k8s + - ./deploy/terraform:/workspace/terraform + privileged: true
privileged: trueオプションをつけることでDockerコンテナの中からローカルのDockerデーモンを使ってdockerコマンドを操作できるようになります。
このprivilegedはdocker-composeのversionが3.4以上じゃないと使えないので、最新の3.7を指定しています。また、
AWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEYはそれぞれ$AWS_ACCESS_KEY_IDとRAWS_SECRET_ACCESS_KEYから取得するようにしています。$は環境変数を表していて同じディレクトリの.envファイルで定義することができます。
AWS_ACCESS_KEY_IDやAWS_SECRET_ACCESS_KEYはセンシティブな値なので、docker-compose.ymlとは別で管理して間違ってGitで公開したりしないようにするのがオススメです。$ touch .env.envAWS_ACCESS_KEY_ID=[AWS_ACCESS_KEY_IDを記述する] AWS_SECRET_ACCESS_KEY=[AWS_SECRET_ACCESS_KEYを記述する]とりあえず
AdministratorAccess権限を持っているIAMがあるといいです。まだ発行していない方は公式ドキュメントを参考に作成してください!それではデプロイ操作コンテナをビルドして、コマンドが使えるようになっているかチェックしておきましょう。
$ docker-compose build deploy $ docker-compose up -d deploy $ docker-compose exec deploy ash# docker -v Docker version 19.03.8, build afacb8b7f0 # terraform version Terraform v0.12.17 # aws --version aws-cli/1.18.36 Python/3.8.2 Linux/4.19.76-linuxkit botocore/1.15.36 # kubectl version Client Version: version.Info{Major:"1", Minor:"14+", GitVersion:"v1.14.7-eks-1861c5", GitCommit:"1861c597586f84f1498a9f2151c78d8a6bf47814", GitTreeState:"clean", BuildDate:"2019-09-24T22:12:08Z", GoVersion:"go1.12.9", Compiler:"gc", Platform:"linux/amd64"} The connection to the server localhost:8080 was refused - did you specify the right host or port? # exitちょっと
kubectlが怪しい感じですが今の段階ではクラスターと接続できていないのでエラーっぽい感じの表示がなされます。コマンド自体は使えているので問題ないです。これでデプロイ作業コンテナの準備ができました。
Terraformでシステム構築する
最初に提示したシステム構成図をTerraformで実現していきます。
これにはいろいろな記事を参考にさせていただきました。
- Terraformを使ってEKSを作成してみた | Developers.IO
- SubhakarKotta/aws-eks-rds-terraform: This setup creates AWS EKS cluster using terraform
- eksctl で VPC を作るのをやめて Terraform で作るようにしました - hatappi.blog
そして何よりもTerraformの公式ドキュメント(AWS)を読みました。
ではではTerraformの定義ファイルを作っていきましょう!
VPC周りを作る
まずはVPCなどの骨格となるネットワーク構成を作っていきます。
最初に、いろいろなところで共通的に使うことになる変数を定義してみます。
$ touch deploy/terraform/variables.tfdeploy/terraform/variables.tfvariable "project" { default = "handson" } variable "num_subnets" { default = 3 } variable "eks_name" { default = "handson-eks" }このように定義しておくことで他のファイルから
var.projectといった感じで変数を呼び出すことができます。あと、
providerを定義しておく必要がある。今回はAWS。$ touch deploy/terraform/provider.tfdeploy/terraform/provider.tfprovider "aws" { version = "~> 2.0" }では、VPC周りの定義ファイルを作成していきます。ここではVPC、Public Subnet、Private Subnet、Internet Gateway、NAT Gateway(with Elastic IP)、Route Table、 Route Table Associationを定義していきます。
$ touch deploy/terraform/vpc.tfdeploy/terraform/vpc.tfdata "aws_availability_zones" "available" { state = "available" } ############################## # VPC ############################## resource "aws_vpc" "vpc" { cidr_block = "10.0.0.0/16" tags = { Name = "${var.project}-vpc" } } ############################## # Subnet ############################## resource "aws_subnet" "public_subnet" { count = var.num_subnets vpc_id = aws_vpc.vpc.id availability_zone = data.aws_availability_zones.available.names[ count.index % var.num_subnets ] cidr_block = cidrsubnet(aws_vpc.vpc.cidr_block, 8, count.index) map_public_ip_on_launch = true tags = { Name = "${var.project}-public-subnet-${count.index+1}" "kubernetes.io/cluster/${var.eks_name}" = "shared" } } resource "aws_subnet" "private_subnet" { count = var.num_subnets vpc_id = aws_vpc.vpc.id availability_zone = data.aws_availability_zones.available.names[ count.index % var.num_subnets ] cidr_block = cidrsubnet(aws_vpc.vpc.cidr_block, 8, var.num_subnets + count.index) map_public_ip_on_launch = false tags = { Name = "${var.project}-private-subnet-${count.index+1}" "kubernetes.io/cluster/${var.eks_name}" = "shared" } } ############################## # Internet Gateway ############################## resource "aws_internet_gateway" "igw" { vpc_id = aws_vpc.vpc.id tags = { Name = "${var.project}-igw" } } ############################## # Elastic IP ############################## resource "aws_eip" "nat" { vpc = true tags = { Name = "${var.project}-nat" } } ############################## # NAT Gateway ############################## resource "aws_nat_gateway" "nat" { allocation_id = aws_eip.nat.id subnet_id = aws_subnet.public_subnet.0.id tags = { Name = "${var.project}-nat" } } ############################## # Route table ############################## resource "aws_route_table" "public_rtb" { vpc_id = aws_vpc.vpc.id route { cidr_block = "0.0.0.0/0" gateway_id = aws_internet_gateway.igw.id } tags = { Name = "${var.project}-public-rtb" } } resource "aws_route_table" "private_rtb" { vpc_id = aws_vpc.vpc.id route { cidr_block = "0.0.0.0/0" gateway_id = aws_nat_gateway.nat.id } tags = { Name = "${var.project}-private-rtb" } } ############################## # Route table association ############################## resource "aws_route_table_association" "rtba_public" { count = var.num_subnets subnet_id = element(aws_subnet.public_subnet.*.id, count.index) route_table_id = aws_route_table.public_rtb.id } resource "aws_route_table_association" "rtba_private" { count = var.num_subnets subnet_id = element(aws_subnet.private_subnet.*.id, count.index) route_table_id = aws_route_table.private_rtb.id }今回は「こいつ、動くぞ!」を目的にしているので、詳細は公式ドキュメントと見比べてみてください。
1点、aws_subnet.public_subnetとaws_subnet.private_subnetのタグに"kubernetes.io/cluster/${var.eks_name}" = "shared"を入れています。これはEKSの公式ユーザーガイドに記載があるのですが、EKSがターゲットのサブネットをディスカバリーするために必須のタグです。お忘れなきよう!これで環境の骨格ができましたので、次にEKSを定義してみます。
EKSを作る
EKSではマスターコンポーネントが動作するEKSクラスターとノードコンポーネントが動作するノードグループを作る必要があります。
それぞれ、Terraformのドキュメント(EKS Cluster、EKS Node Group)に従えばさほど難しくありません。$ touch deploy/terraform/eks.tfdeploy/terraform/eks.tf############################## # IAM Role for EKS Cluster ############################## resource "aws_iam_role" "eks_iam_role" { name = "eks-iam-role" assume_role_policy = <<POLICY { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "eks.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } POLICY } resource "aws_iam_role_policy_attachment" "eks-AmazonEKSClusterPolicy" { policy_arn = "arn:aws:iam::aws:policy/AmazonEKSClusterPolicy" role = aws_iam_role.eks_iam_role.name } resource "aws_iam_role_policy_attachment" "eks-AmazonEKSServicePolicy" { policy_arn = "arn:aws:iam::aws:policy/AmazonEKSServicePolicy" role = aws_iam_role.eks_iam_role.name } ############################## # EKS Cluster ############################## resource "aws_eks_cluster" "eks" { name = var.eks_name role_arn = aws_iam_role.eks_iam_role.arn vpc_config { subnet_ids = concat(aws_subnet.public_subnet.*.id, aws_subnet.private_subnet.*.id) } depends_on = [ aws_iam_role_policy_attachment.eks-AmazonEKSClusterPolicy, aws_iam_role_policy_attachment.eks-AmazonEKSServicePolicy ] } ############################## # IAM Role for EKS Node Group ############################## resource "aws_iam_role" "eks_node_group_iam_role" { name = "eks-node-group-iam-role" assume_role_policy = <<POLICY { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } POLICY } resource "aws_iam_role_policy_attachment" "eks_node_group_AmazonEKSWorkerNodePolicy" { policy_arn = "arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy" role = aws_iam_role.eks_node_group_iam_role.name } resource "aws_iam_role_policy_attachment" "eks_node_group_AmazonEKS_CNI_Policy" { policy_arn = "arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy" role = aws_iam_role.eks_node_group_iam_role.name } resource "aws_iam_role_policy_attachment" "eks_node_group_AmazonEC2ContainerRegistryReadOnly" { policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly" role = aws_iam_role.eks_node_group_iam_role.name } ############################## # EKS Node Group ############################## resource "aws_eks_node_group" "eks_ng" { cluster_name = aws_eks_cluster.eks.name node_group_name = "eks-ng" node_role_arn = aws_iam_role.eks_node_group_iam_role.arn subnet_ids = aws_subnet.private_subnet.*.id instance_types = ["t2.small"] scaling_config { desired_size = 3 max_size = 4 min_size = 2 } depends_on = [ aws_iam_role_policy_attachment.eks_node_group_AmazonEKSWorkerNodePolicy, aws_iam_role_policy_attachment.eks_node_group_AmazonEKS_CNI_Policy, aws_iam_role_policy_attachment.eks_node_group_AmazonEC2ContainerRegistryReadOnly ] }EKSではクラスター、ノードグループそれぞれにIAM Roleを付与してあげる必要があるので少し複雑に見えるかもしれませんが、Terraformに沿って書けばさほど難しくありません。
aws_eks_node_group.eks_ng.instance_typesでノードグループのインスタンスタイプを指定してます。今回はサンプルですし小さめのt2.small。aws_eks_node_group.eks_ng.scaling_configではノードの最小数、最大数を定義しています。これに合わせてEKSがスケーリングしてくれるわけです。ちょっとdesired_sizeとmin_sizeの関係がわかっていないのですが...基本的にdesired_sizeでノードが展開されます。もしリソースが足りなくなったらmax_sizeまでオートスケールしてくれます。RDSを作る
次はRDSです。
$ touch deploy/terraform/rds.tfdeploy/terraform/rds.tf############################## # Security Group for RDS ############################## resource "aws_security_group" "rds" { vpc_id = aws_vpc.vpc.id ingress { protocol = "tcp" from_port = 5432 to_port = 5432 security_groups = [aws_eks_cluster.eks.vpc_config[0].cluster_security_group_id] } tags = { Name = "sg-${var.project}-rds" } } ############################## # DB Subnet for RDS ############################## resource "aws_db_subnet_group" "default" { name = "${var.project}-db-subnet-group" subnet_ids = aws_subnet.private_subnet.*.id tags = { Name = "${var.project}-db-subnet-group" } } ############################## # RDS ############################## resource "aws_db_instance" "rds" { allocated_storage = 20 db_subnet_group_name = aws_db_subnet_group.default.name engine = "postgres" engine_version = "12.2" instance_class = "db.t2.micro" username = "handson_user" password = "handson2020" port = 5432 vpc_security_group_ids = [aws_security_group.rds.id] skip_final_snapshot = true tags = { Name = "${var.project}-db" } }Security Group、DB Subnet、DB Instanceを定義しています。
Security Groupでは
aws_security_group.rds.ingress.security_groupsでEKSに設定されたセキュリティグループをIngressで許可しており、これをaws_db_instance.rds.vpc_security_groups_idでRDSに付与しています。こうすることでEKSのノードグループの上のPodからRDSにアクセスできるようになります。そう言えばここまでPostgreSQLはversion12.1を使っていましたが、RDSでは12.2しか使えないようです...(参考:PostgreSQL on Amazon RDS - Amazon Relational Database Service)
問題はないとは思いますが、念のためテストを回しておきましょう。docker-compose.yml... db: - image: postgres:12.1-alpine + image: postgres:12.2-alpine ...$ docker-compose run web rspec Finished in 2 minutes 11.5 seconds (files took 18.92 seconds to load) 85 examples, 0 failuresOKOK。
ECRを作る
最後にECRも作成しておきます。
$ touch deploy/terraform/ecr.tfdeploy/terraform/ecr.tf############################## # ECR for Rails app ############################## resource "aws_ecr_repository" "ecr" { name = "${var.project}_app" }これはレポジトリの名前をつけてあげてるだけですね。
TerraformでAWSリソースを構築する
ここまでで定義ファイルの準備が整いましたので、TerraformでAWSリソースを作成・構築していきます。
まず、再びデプロイ作業用のコンテナに入ります。$ docker-compose exec deploy ash# cd terraform # terraform init # terraform plan # terraform applyこれだけです。
planでファイルから設定するべき項目をプランニングし、applyで適用するという感じです。
applyの時に「Do you want to perform these actions?」と聞かれますがyesと答えましょう。少し時間がかかりますが、
Apply Complete!となれば環境構築は完了です!RailsアプリをECRに登録する
次に、ECRにRailsアプリのDockerイメージを登録しようと思います。
EKSではproduction環境として動かしますし、RDSに接続できるように設定をできるようにしないといけません。DBの接続情報は
config/database.ymlで設定していましたね。
ということで、そのファイルでRAILS_ENVがproductionの場合は接続情報を環境変数から設定できるようにしてみます。rails/config/database.yml... production: <<: *default - database: app_production - username: app + host: <%= ENV['APP_DATABASE_HOST'] %> + database: <%= ENV['APP_DATABASE_DATABASE'] %> + username: <%= ENV['APP_DATABASE_USERNAME'] %> password: <%= ENV['APP_DATABASE_PASSWORD'] %>これでそれぞれの環境変数から接続情報が設定されるようになります。環境変数の指定はKubernetesのConfigMapを使ってやりますので、また後ほど。
また、Dockerfileもdevelopment環境とproduction環境では実行したいことが異なります。
例えば、development環境ではChromeブラウザがテスト用に必要ですが、production環境にはいりません。また、bundle installでインストールしたいgemにも差があります。
このような差分を同じDockerfileでできるように、docker buildコマンドのオプションで--build-argsを使って変数を送り込むことで動作を変えることができます。
具体的には、Dockerfileを以下のように更新します。(結構大きく変わるのでコピペしてください。)(参考:DockerFileにif文(条件分岐) - Qiita)rails/DockerfileARG BUILD_MODE="dev" FROM ruby:2.6.5-alpine3.11 ARG BUILD_MODE ARG PROD_MODE="prod" ARG RUNTIME_PACKAGES="gcc \ g++ \ less \ libc-dev \ libxml2-dev \ linux-headers \ make \ nodejs \ postgresql \ postgresql-dev \ tzdata \ yarn" ARG BUILD_PACKAGES="build-base \ curl-dev" ARG CHROME_PACKAGES="chromium \ chromium-chromedriver \ dbus \ mesa-dri-swrast \ ttf-freefont \ udev \ wait4ports \ xorg-server \ xvfb \ zlib-dev" ENV HOME="/app" ENV LANG=C.UTF-8 ENV TZ=Asia/Tokyo WORKDIR $HOME RUN apk update && \ apk upgrade && \ apk add --no-cache ${RUNTIME_PACKAGES} && \ apk add --virtual build-packs --no-cache ${BUILD_PACKAGES} && \ if [ "${BUILD_MODE}" != "${PROD_MODE}" ]; then \ apk add --no-cache ${CHROME_PACKAGES}; \ fi COPY Gemfile ${HOME} COPY Gemfile.lock ${HOME} RUN if [ "${BUILD_MODE}" = "${PROD_MODE}" ]; then \ bundle install --without development test -j4; \ else \ bundle install --without production -j4; \ fi && \ apk del build-packs COPY . ${HOME} RUN if [ "${BUILD_MODE}" = "${PROD_MODE}" ]; then \ bundle exec rails assets:precompile RAILS_ENV=production; \ else \ yarn install; \ fi EXPOSE 3000 CMD ["bundle", "exec", "rails", "server", "-b", "0.0.0.0"]
BUILD_MODEがprodかどうかによって挙動を分けています(デフォルトはdev)。ARGは変数で、docker buildの時に--build-arg [ARG_NAME]=[ARG_VALUE]で変数を外部から引き渡すこともできるやつです。なのでprodでビルドしたいときだけ--build-arg BUILD_MODE=prodと指定すればproduction用のビルドができるようになります。さらに、productionには不要なファイルもあります。テストシナリオとか今までのログファイルとかは不要です。これをビルドする時に無視するために
dockerigonoreファイルを作成して不要なファイルを定義しておきます。$ touch rails/.dockerignorerails/.dockerignore.local .pki log node_modules spec tmp .rspec yarn-error.logざっとみた感じ、この辺りが今のところ不要かなー。
またここまででGitからダウンロードしたりした場合は
config/master.keyがない状態だと思います。これだとproductionでビルドできないので生成します。$ rm rails/config/credentials.yml.enc $ docker-compose run -e EDITOR="mate --wait" web rails credentials:editこうすることで
master.keyを再生成することができる。今回は活用していませんが、credentialsについて詳しくはいろいろと参照してください。(参考:Rails5.2から追加された credentials.yml.enc のキホン - Qiita)これで準備が整いました。イメージをビルドしていきます。
イメージをビルドするに際して、イメージ名を決める必要があります。これはECRに作成したリポジトリ名と同一でなくてはなりません。まず、awsコマンドを使って名前を確認しておきます。# aws ecr describe-repositoriesJSON形式で情報が表示されますが、このうち
repositoryUriがDockerイメージに名付けるべき名前です。またタグは1.0.0としておきます。# cd /workspace/rails # docker build -t [repositoryUri]:1.0.0 --build-arg BUILD_MODE=prod .これで
repositoryUriの名前をつけて、production環境用にDockerイメージをビルドできました。次にECRにログインします。
# aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin [repositoryUri] Login SucceededログインができたらECRにDockerイメージを登録できるようになるので、今作成したDockerイメージをプッシュします。
# docker push [repositoryUri]:1.0.0これでイメージの登録も完了です。
あとはEKS上にこのイメージをベースとしたPodをデプロイしていきます!
EKSにデプロイする
環境変数用のConfigMapを生成する
最初にデプロイするPod(コンテナ)に渡す環境変数をConfigMapリソースに保存します。
$ mkdir deploy/k8s/config $ touch deploy/k8s/config/rails_config.yamldeploy/k8s/rails_config.yamlapiVersion: v1 kind: ConfigMap metadata: name: rails-config data: RAILS_ENV: production RAILS_SERVE_STATIC_FILES: "true" APP_DATABASE_HOST: [RDSのエンドポイント名] APP_DATABASE_DATABASE: app_production APP_DATABASE_USERNAME: handson_user APP_DATABASE_PASSWORD: handson2020ConfigMapではこんな感じでデータを保存できるんですね。
RAILS_ENVはRailsアプリケーションをproductionモードで起動するための環境変数です。
RAILS_SERVE_STATIC_FILESはassets:precompileしたCSS/JSファイルをpublicディレクトリから提供するための環境変数。何かしら設定されていれば有効になるので、今回はtrueの文字列を指定。(RAILS_SERVE_STATIC_FILESはconfig/environments/production.rbに記述があります。)rails/config/environments/production.rb... # Disable serving static files from the `/public` folder by default since # Apache or NGINX already handles this. config.public_file_server.enabled = ENV['RAILS_SERVE_STATIC_FILES'].present? ...
APP_DATABASE_*は先ほど、config/database.ymlにて指定した環境変数です。USERNAME、PASSWORDは先ほどterraform/rds.tfで定義したものです。DATABASEはこれからrails db:createで作成するものなので、好きな文字列で問題ありません。
HOSTは先ほどTerraformで作成したRDSのエンドポイント名を設定する必要があります。これもawsコマンドで確認してみましょう。# aws rds describe-db-instancesまたJSON形式で情報がアウトプットされたかと思いますが、このうち
Endpoint.Addressがエンドポイント名ですので、これを設定します。ConfigMapの宣言は以上です。
Jobリソースを宣言する
Railsアプリケーションを起動させる前にDBの作成とマイグレーションファイルの適用が必要です。
そのために1度だけ起動してコマンド発行されたら落ちるJobリソースを宣言して、Podをデプロイする前に実行しようと思います。$ mkdir deploy/k8s/settings $ touch deploy/k8s/settings/set_db_job.yamldeploy/k8s/settings/set_db_job.yamlapiVersion: batch/v1 kind: Job metadata: name: rails-db-setup spec: template: metadata: name: rails-db-setup spec: containers: - name: rails-db-setup image: [RepositoryUri]:1.0.0 imagePullPolicy: Always command: ["ash"] args: ["-c", "bundle exec rails db:create && bundle exec rails db:migrate"] envFrom: - configMapRef: name: rails-config restartPolicy: Never backoffLimit: 1ファイルの書き方は公式ドキュメントなどを参考に。
spec.template.spec.containers.imageに先ほどECRにプッシュしたRailsアプリのDockerイメージを宣言しています。そのイメージを使ってbundle exec rails db:create && bundle exec rails db:migrateを実行することでDBの作成とマイグレーションの適用を行おうとしています。
また、envFormで先ほど宣言したConfigMap(rails-config)から環境変数を読み取っています。そこにはRDSのエンドポイントがAPP_DATABASE_HOSTとして定義されているので、RDSに対してDBの作成とマイグレーションの適用がなされることがわかりますね。
kindにJobを宣言しているので、このリソースはコマンド実行が終わったら自動的に停止状態になります。PodをDeploymentする
最後に実際に動作し続けるPodリソースの宣言ファイルを作ります。Podの宣言と言いましたが、KubernetesではPodリソースの数を宣言するReplicaSetリソースのデプロイ戦略を宣言するDeploymentリソースのファイルを適用することでPodをデプロイすることが一般的です。
また、外部と通信するためのServiceリソースも一緒に宣言しちゃいましょう。$ touch deploy/k8s/deployment.yamldeploy/k8s/deployment.yamlapiVersion: apps/v1 kind: Deployment metadata: name: rails-deployment labels: app: rails spec: replicas: 3 selector: matchLabels: app: rails template: metadata: labels: app: rails spec: containers: - name: rails image: [RepositoryUri]:1.0.0 imagePullPolicy: Always ports: - containerPort: 3000 envFrom: - configMapRef: name: rails-config --- apiVersion: v1 kind: Service metadata: name: rails-service spec: type: LoadBalancer selector: app: rails ports: - protocol: TCP port: 80 targetPort: 3000
---を挟んでDeploymentリソースとServiceリソースが宣言されているのがわかりますね。Deploymentリソースの方ではJobリソースと似ていますが、
spec.template.spec.containers.imageでECRのRailsアプリイメージをベースにし、envFormでrails-configのConfigMapから環境変数を読み取り起動しようとしていることがわかります。
また、spec.replicasを3にしているので、Podは3つ起動され、起動され続けるようにKubernetesに管理してもらいます。Serviceリソースの方では、
spec.typeにLoadBalancerを宣言しています。これによってKubernetesのノードコンポーネントで外からの通信を許可することができます。
spec.selectorでapp: railsを定義していますが、これはDeploymentリソースのlabelを指定しているものです。ポートは80ポートを受け取り、3000ポートに流していることが読み取れ、Deploymentリソースの方でcontainerPortとして3000を開けていることも読み取れます。EKSではServiceリソースでLoadBalancerを作成すると、AWSのNLB(Network Load Balancer)が生成されます。これによって、NLBに付与されるドメインを通じてEKSで稼働しているRailsコンテナのPodにアクセスできるようになるわけです。
ここまででファイルの準備は揃いましたので、EKSに適用していきましょう。
デプロイ
デプロイするためにはまずデプロイするクラスターを指定する必要があります。
awsコマンドを使ってこれをやってみます。
Terraformのファイルを見返していただきたいのですが、今EKSクラスターにはhandson-eksという名前がついています。deploy/terraform/eks.tfresource "aws_eks_cluster" "eks" { name = var.eks_name ... }deploy/terraform/variables.tfvariable "eks_name" { default = "handson-eks" }デプロイするクラスターを指定するためにconfigを更新します。
# aws eks update-kubeconfig --name handson-eksこれで
docker-compose.ymlで定義したKUBECONFIGの場所にconfigファイルが生成されているはずです。また、これでEKSクラスターを特定できるようになったので、例えば
kubectl get nodesコマンドでノードグループのインスタンスの状態を確認することができるようになっているはずです。# kubectl get nodes NAME STATUS ROLES AGE VERSION ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal Ready <none> HhMMm v1.15.10-eks-bac369 ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal Ready <none> 3h10m v1.15.10-eks-bac369 ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal Ready <none> 3h10m v1.15.10-eks-bac369では、ConfigMap -> Job -> Deployment/Serviceの順番で適用していきます。
Kubernetesでは
kubectl apply -f [file_name]でリソースを適用していくことができます。これはとても統一的でめちゃくちゃ便利です。変更があった場合も同様のコマンドでアップデートをかけることができます(一部をのぞき)。ちなみに似たような感じで
kubectl delete -f [file_name]でそのファイルで適用していたリソース(もっと言えばそのファイル内でラベル付されてるリソース)を削除することができます。# kubectl apply -f k8s/config/rails_config.yaml configmap/rails-config created # kubectl get configmap NAME DATA AGE rails-config 6 81sConfigMapが作成されていることがわかります。もっと詳しく中身をみたい場合は
kubectl describe cm rails-configでみれます。次はJobです。
# kubectl apply -f k8s/settings/set_db_job.yaml job.batch/rails-db-setup created # kubectl get jobs -w NAME COMPLETIONS DURATION AGE rails-db-setup 0/1 29s 30s rails-db-setup 1/1 18s 36s
-wオプションは変化があった時に表示が更新されるモードです。Ctrl+Cで抜け出せます。
Jobもコンプリートしたことがわかりますね。最後はDeploymentとServiceです。
# kubectl apply -f k8s/deployment.yaml deployment.apps/rails-deployment created service/rails-service created # kubectl get pods -w NAME READY STATUS RESTARTS AGE rails-db-setup-lb9cs 0/1 Completed 0 4m27s rails-deployment-56b4695fdf-2jdgl 1/1 Running 0 2m17s rails-deployment-56b4695fdf-5dxsf 1/1 Running 0 2m17s rails-deployment-56b4695fdf-npf7b 1/1 Running 0 2m17s先ほどのJobもPodとして動いていたので
Status: Completedで残っていますね。他の3つがRailsアプリのPodです。Deploymentで宣言した通り3つ起動していますね。# kubectl get service -w NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP xxx.xxx.xxx.xxx <none> 443/TCP 3h42m rails-service LoadBalancer xxx.xxx.xxx.xxx xxxxxxxxxx.amazonaws.com 80:31230/TCP 3m47s今回生成したのは
rails-serviceの方ですね。EXTERNAL-IPに書かれているドメインがNLBに付与されているドメインです。これがRailsアプリのPodに流してくれるはず。アクセスしてみましょう。
ドメインが反映されるまで少し時間がかかりますが、ちょっと待てば今まで作ってきたサイトが表示されました。
独自ドメインやHTTPS化を考えると、他にもいろいろとやらねばならぬことはある(例えば)のですが、ひとまずこれでEKS+RDSでRailsアプリを公開することができました!!!!まとめ
最後の最後は少し難しめなお題、EKSでアプリをデプロイしてみように挑戦してみましたがいかがだったでしょうか?
実際にサービスとして本番環境で運用をしようとすると、いろいろと足りないところは多いのですが、ひとまず「こいつ、動くぞ!」というところには到達できたんじゃないかと思います。今回でハンズオンは終わりです。Dockerから始まり、Railsアプリ、TDD、そしてHerokuやEKSでのサービス公開。
一通りのサービス開発の流れを体験して、「あれ、意外と調べながらやったりすればできそうだな。」というような感覚を持っていただけたなら幸いです。そうです。開発は選ばれた物にしかできない魔法ではない。学びです。直接コーディングやデプロイに関わらないロールだとしても、サービス開発に携わっているならばこういったことを知っていることは確実に優位性になるでしょう!
もしさらなる興味が湧いてきたら、個人開発とかにも挑戦してみましょう!ここまでお付き合いいただきありがとうございました!
後片付け
あ、今日はAWSを使っていろいろやりました。放置しとくとちゃりんちゃりんなのでちゃんと後片付けをしておきましょう。
まず確実にDeployment、SVCは落としておきましょう。ずっと公開されっぱなしになっちゃうので。
# kubectl delete -f k8s/deployment.yaml deployment.apps "rails-deployment" deleted service "rails-service" deleted # kubectl delete -f k8s/settings/set_db_job.yaml job.batch "rails-db-setup" deleted # kubectl delete -f k8s/config/rails_config.yaml configmap "rails-config" deleted今回の環境を全部無かったことにする場合はTerraformで削除しちゃいましょう。
# cd /workspace/terraform # terraform destroy Do you really want to destroy all resources? ... Destroy complete! Resources: 31 destroyed.これまた
yesと答えてあげれば削除が始まります。これまた結構時間がかかりますが、跡形もなく消してくれている様子がみて取れます。本日のソースコード
Other Hands-on Links


- 投稿日:2020-04-21T01:15:51+09:00
簡単!GCP+Dockerで新型コロナウィルス解析プロジェクトに参加しよう
新型コロナウィルス解析プロジェクト
今更なので説明は省略しますが、私も分散コンピューティングプロジェクト Folding@Home の新型コロナウィルス解析プロジェクトに参加しました。
たくさんの参加者でかなりの演算能力になっているようですが、まだ解析は継続しています。
Folding@Home について素晴らしい記事を既に書かれた人達と同様に、新型コロナウィルス解析プロジェクトに参加される方が増え、1日でも早く解析が進み好転に繋がることを願いこの記事を書きました。
本記事は Google Cloud Platform (以降、GCP) で、Docker コンテナを使った方法を記載しています。解析プロジェクトの参加は簡単!
実際に GCP で参加するための環境構築手順を記載します。
環境構築の方法は複数ありますが、かなり簡単に構築できました。
GCP で Docker となると GKE が浮かびますが、GKE は使いません。前提条件
- GCP を触ったことがある人向け。ある程度わかっている人向け。(細かく説明していません。)
- 簡単に構築ということで・・・
- GPU 使用の手順は未記載。
- VPC は Default をそのまま使用。
- コマンドのオプションは使用したもののみ記載。
1. GCP プロジェクトを作成する
GCP の始め方など詳細説明は割愛しますが、本記事では analysis-covid19 という名前でプロジェクトを作成しました。
2. 実行用 Docker コンテナの Dokerfile の取得
Github にて john k tims さんが提供されている Folding@Home 実行用 Docker コンテナから Dokerfile などをダウンロードします。
Cloud Shell を立ち上げ、以下のコマンドを実行します。gitコマンドgit clone https://github.com/johnktims/folding-at-home.gitダウンロードされると、folding-at-home フォルダが作成されます。
3. Cloud Build で Docker イメージの作成、Container Registry に保存
作成された folding-at-home フォルダに移動し、以下のコマンドを実行します。(Cloud Build を使わなくてもできますが楽なので・・・)
gcloud builds submit --tag gcr.io/[PROJECT_ID]/[IMAGE_NAME] .Docker イメージ名を "folding-at-home" として、以下のコマンドを実行しました。(プロジェクト名は "analysis-covid19")
gcloudコマンドgcloud builds submit --tag gcr.io/analysis-covid19/folding-at-home .gcloud builds コマンドが SUCCESS となると、Cloud Build のビルド履歴画面に作成した履歴と Container Registry のリポジトリ画面に作成したイメージが表示されます。
Cloud Build ビルド履歴画面は履歴が表示されます。
Container Registry リポジトリ画面は指定したリポジトリ名が表示され、リポジトリが作成されています。
4. ファイアウォールルールの作成
Folding@home の WEB コントロール画面のアクセスは、ポート7396を空ける必要があるので、ファイアウォールルールを作成します。
gcloud compute firewall-rules create [FIREWALLRULE_NAME] --action (deny | allow ) --source-ranges [SOURCE_RANGE] --rules (PROTOCOL[:PORT[-PORT]])本記事では以下のコマンドを実行しました。
gcloudコマンドgcloud compute firewall-rules create default-allow-7396 --action allow --source-ranges 0.0.0.0/0 --rules tcp:7396ファイアウォールルールが作成され、リストの1番上に表示されました。
5. Compute Engine インスタンスの作成
Compute Engine インスタンスを、コンテナ専用コマンドで作成します。
オプションはいろいろありますが、使用したものだけ記載しています。
gcloud compute instances create-with-container [INSTANCE_NAME] --zone [ZONE_NAME] --machine-type [MACHINE_TYPE] --container-image [IMAGE_NAME]--machine-type を指定しない場合は、デフォルト n1-standard-1 になります。
前述していますが、本記事ではGPU使用の手順は未記載です。gcloudコマンドgcloud compute instances create-with-container foldingathome-covid19 --zone us-central1-b --machine-type n1-standard-4 --container-image gcr.io/analysis-covid19/folding-at-homeここでは、n1-standard-4(4Core)を指定しています。変更可能ですので課金を考慮して指定しましょう。
指定したインスタンス名が表示され、VM インスタンスが作成されます。
インスタンス作成と同時にコンテナが実行されている状態となります。
6. Folding@home WEB コントロール画面の表示
Compute Engine の画面でコンテナが乗っている Compute Engine の外部IPアドレスを確認し、ブラウザでURLを指定し、Folding@home の WEB コントロール画面を表示します。
http://[Compute Engine の外部IPアドレス]:7396正常に実行できていれば、以下のWEBコントロール画面が表示され実行中となっています。
終わりに
新型コロナウイルスの状況が好転する兆しはまだ見えませんが、好転に向けて少しでもできることがあればやっていきたいという思いはみなさん同じかと思います。
分散コンピューティングプロジェクトに更に多くの人が参加することで、早く解析が完了し次のステージに進めることを願っています。
みなさまが参加する上で、本記事が少しでも参考になったら幸いです。謝辞
Folding@home 関係者の方々、Folding@homeの情報提供の記事、参考URLの記事を執筆された方々に厚く御礼申し上げます。
参考URL
https://qiita.com/jey0taka/items/24c5590ae9cb2b66d383
https://qiita.com/hirosys-biz/items/fa19e596c3872059bf2c
https://cloud.google.com/container-optimized-os/docs/how-to/run-container-instance?hl=ja
https://www.newsweekjapan.jp/stories/world/2020/04/folding-home.php






