- 投稿日:2020-04-21T23:21:55+09:00
AWS Shield/WAF/Inspector
AWS Shield
- [https://aws.amazon.com/jp/shield/:title]
- マネージド型の分散サービス妨害(DDoS攻撃)に対する保護サービス。
- サービスは Standard(無償) と Advanced(有償) の2つのレベルがある。
- Advancedの特徴
- DDoS対応チームによるサポート
- DDoS攻撃によるコスト増加分の払い戻し
AWS WAF
- Web Application Firewall
- 基本利用料は無料。
- 設定内容(Webセキュリティルール)によって課金が行われる。
- Webセキュリティルール(許可、ブロック等)の設定はユーザーが行う。
- 以下のサービスから利用できる。
- CloudFront
- Application Load Balancer
- API Gateway
Amazon Inspector
- EC2上にあるアプリケーションの脆弱性等を評価するサービス。
- 評価はスケジューリングの設定により自動で行える。
- 脆弱性の定義となるナレッジベースがある。AWSのセキュリティ研究者により定期的に更新される。
- PCI DSS に関するチェックも可能。
- AWS Artifact から、コンプライアンスレポートを確認・ダウンロードできる。
- 投稿日:2020-04-21T23:19:25+09:00
部屋のCO2濃度を、Raspberry Pi / AWS IoT / Kibanaで可視化/通知する
動機
部屋に長くこもっているとだんだん眠くなって集中力が落ちてくるのは酸素が薄くなっている(≒二酸化炭素濃度が上がっている)からなのでは?と思い調べたらやはりそういう研究結果があるらしい。
参考: https://www.excite.co.jp/news/article/Rocketnews24_259718/
室内では1000ppmを超えない方が良いらしいけど自宅の家電で測れないので換気のタイミングがわからない。
=> Raspberry PiにCO2センサーくっつけてデータをクラウドに送ったら色々出来るだろうし、AWS IoTとAWS IoT Greengrassのハンズオンがてらやってみよう。目標
以下のような構成で、Raspberry Pi上のCO2センサーデータ取得し、Kibanaでデータを可視化します。
さらにCO2濃度が閾値を超えたらSlackに通知するようにします。
AWS IoT Greengrassを使いLambda関数をRaspberry Pi上で稼働させてCO2センサーの値を読み取り、AWS IoT Coreに送信します。そこから、IoT Rule Actionを使いAmazon Elasticsearch Serviceにデータを連携するという構成です。単にデータを送信して可視化するだけにしては大げさですが、Greengrassの導入やAWS IoTへのデータ送信が出来ていれば、このあとAWSの様々なサービスを組み合わせることで色々な応用が効きます。(AWS IoT Analyticsでデータ処理/蓄積してQuickSightで可視化したり、SageMakerで機械学習モデルを作成してGreengrassにモデル配布、エッジで画像認識、異常値検出など。。。)Disclaimer
- 自宅向けの日曜大工のため手順やコードはプロダクションレベルの品質、セキュリティレベルではありません。
- センサーや配線を扱う際はショートなどに十分気をつけてください。
- AWS IoTやAmazon Elasticsearch Service等、 AWS利用料金が発生します。
準備するもの
- Raspberry Pi(この記事では3 Model B+) + SDカード/キーボード/HDMIケーブル等の起動/設定に必須なもの
- MH-Z19 (CO2センサー)
- メス-メスのジャンパーワイヤー x 4本
- ピンヘッダ
- AWSアカウント
Raspberry Piやセンサー周りで準備必要なものについては、こちらの記事:Raspberry Pi 3 で CO2濃度を測る (Raspbian OS)がとても参考になります。
前提条件
- 作業環境 : Mac OS or Linux
- Node.js :10.3.0以上
- AWS CDK version : 1.33.0以上
- Raspberry Pi Model : Raspberry Pi 3 Model B+
- Rasbpian OS version : Buster
- AWS IoT Greengrass version : 1.10.0
構築手順
AWS CLIのセットアップ
手元の作業環境にAWS CLIをインストールし、リソースを構築するAWSアカウントのクレデンシャルとリージョンの設定を実施しておきます。(手順省略)
Greengrass Core用 クライアント証明書の作成
Raspberry PiにインストールするGreengrass Core用のクライアント署名書を作成します。
1 Click証明書の場合 (ファイル名は例)
aws iot create-keys-and-certificate \ --certificate-pem-outfile "raspi01.cert.pem" \ --public-key-outfile "raspi01.public.key" \ --private-key-outfile "raspi01.private.key" \ --set-as-active 上記コマンドの出力結果から、"certificateArn"の値を控えておく。(参考) 手元でキーペアとCSRを作成し、CSRから証明書を作成する場合 (ファイル名は例)
openssl genrsa -out client.key 2048 openssl req -new -key client.key -out client.csr aws iot create-certificate-from-csr \ --certificate-signing-request=file://client.csr --set-as-active 上記コマンド結果から、"certificateArn"を控えておく。クラウド環境の構築
AWS CDKのインストール
AWS CDKをインストールします。AWS CDKと使い方についてはBlackbelt参照。
npm install -g aws-cdk本構成のサンプルコードのダウンロード
CDKをTypescript、Lambda関数をPython3で記述した本構成のコードをGitHubに置いてあります。
git clone https://github.com/f-daiki-86/mh-z19-aws-greengrass-cdk-sample.git cd mh-z19-aws-greengrass-cdk-sampleファイル構成(一部省略)├── README.md ├── bin │ └── app.ts # CDK App本体 ├── cdk.context.json ├── cdk.json # CDK設定ファイル。今回はコンテキスト(パラメータ)を追記します ├── handlers # Lambda関数コード用のフォルダ │ └── co2-sensor-reader │ ├── handler.py # Lambda関数コード │ └── requirments.txt ├── lib │ ├── elasticsearch-stack.ts # Elasticsearch用Stack定義 │ ├── greengrass-lambda-stack.ts # Lambda用Stack定義 │ ├── greengrass-stack.ts # Greengrass用Stack定義 │ └── iot-rule-stack.ts # IoT Rule用 Stack定義 ├── package.json依存パッケージのインストール
CDKのTypeScriptコードとLambda関数のPythonコードの依存パッケージをインストールします。
# CDKの依存パッケージをインストール npm install # Lamdda関数の依存パッケージをインストール cd handlers/co2-sensor-reader/ mkdir lib pip3 install -r requirments.txt -t lib/ cd ../../CDKコンテキスト(パラメータ)の編集
コンテキストはSSM Parameterストアなどから取得する方法もありますが今回はcdk.jsonファイルに記載します。
cdk.json内のcontextの各項目を更新します。
- "greengrassCoreThingName": Greengrass Coreに紐づくThingの名前です。iot-thing01など任意の名前でOK。
- "grenngrassGroupName": Greengrass Groupの名前です。gg-group01など任意の名前でOK。
- "greengrassCoreCertArn :"AWS IoT Core用クライアント明書の作成"で作成した証明書のARN。
- "esSourceIp": 簡単のためKibanaのアクセス制限をCognitoによる認証ではなくIPアドレスでの制限としているため、自身のグローバルIPアドレスをCMANなどで調べて入力。
cdk.json{ "app": "npx ts-node bin/app.ts", "context": { "greengrassCoreThingName": "[Greengrass CoreのThingに付与するName(任意)]", "grenngrassGroupName": "[Greengrass Group名(任意)]", "greengrassCoreCertArn": "[Greengrass Core用 クライアント証明書のARN]", "esSourceIp": "[Kibanaにアクセスを許可するIPアドレスレンジ]" } }スタックのデプロイ
aws cdkのコマンドを使用してスタックをデプロイします。
# ビルド npm run build # デプロイのためのS3バケット作成 cdk bootstrap # Elasticsearchスタックのデプロイ cdk deploy ElasticSearchStack # Lambdaスタックのデプロイ cdk deploy GreengrassLambdaStack # Greengrassスタックのデプロイ cdk deploy GreengrassStack # IoT Ruleスタックのデプロイ cdk deploy IoTRuleStack全てエラーなく終了すればOKです。
MH-Z19(CO2)センサーを接続するためのRaspberry Piセットアップ
参考
- https://qiita.com/UedaTakeyuki/items/c5226960a7328155635f
- https://qiita.com/revsystem/items/5a362e749ef80358e801
- https://qiita.com/revsystem/items/76ab1e21d386c5977892
UART有効化とシリアルコンソールの無効化
(Raspberry PiへのRaspian OSのインストール、Wifiのセットアップなどの準備は他の記事に譲ります。)
MH-Z19はUARTという仕組みでシリアル通信するため、Raspberri Piで有効にします。また、デフォルトではUARTが使うシリアルコンソールに使われてしまっているため、無効化します。SSHでRaspberry Piに接続します。
ssh pi@[Raspberry PiのIP Address]UARTを有効化します。
sudo vi /boot/config.txt/boot/config.txt以下の行を追加する。 enable_uart=1シリアルコンソールを無効化します。
sudo vi /boot/cmdline.txt/boot/cmdline.txt以下の記述を削除する。 console=serial0,115200シリアルサービスを無効化します。
sudo systemctl stop serial-getty@ttyS0.service sudo systemctl disable serial-getty@ttyS0.servicRaspberry Piを再起動します。
sudo reboot確認
ls -ld /dev/ttyS0 crw-rw---- 1 root dialout 4, 64 Apr 5 22:54 /dev/ttyS0 => 再起動後にグループがttyではなくdialoutになっていれば恐らくOK.Raspberry PiとCO2センサーの配線
こちらの記事:Raspberry Pi 3 で CO2濃度を測る (Raspbian OS)を参考に、Raspberry PiとMH-Z19を接続し、センサーの値が取得できることを確認します。
AWS IoT Greengrassのインストールと初期設定
参考
- https://docs.aws.amazon.com/ja_jp/greengrass/latest/developerguide/setup-filter.rpi.html
- https://docs.aws.amazon.com/ja_jp/greengrass/latest/developerguide/module2.html
インストールに必要な依存関係の設定
SSHでRaspberry Piに接続します。
ssh pi@[Raspberry PiのIP Address]Greengrass Core用User/Groupを作成します。
sudo adduser --system ggc_user sudo addgroup --system ggc_groupハードリンクとソフトリンクの保護を有効化します。
sudo vi /etc/sysctl.d/98-rpi.conf/etc/sysctl.d/98-rpi.conf以下を追加 fs.protected_hardlinks = 1 fs.protected_symlinks = 1リブートします。
sudo rebootメモリcgroup有効化します。
sudo vi /boot/cmdline.txt/boot/cmdline.txt以下を既存の行の末尾に追加 cgroup_enable=memory cgroup_memory=1リブートします。
sudo rebootGreengrass 依存関係チェッカーを実行し、要件が満たされていることを確認します。
cd /home/pi/Downloads mkdir greengrass-dependency-checker-GGCv1.10.x cd greengrass-dependency-checker-GGCv1.10.x wget https://github.com/aws-samples/aws-greengrass-samples/raw/master/greengrass-dependency-checker-GGCv1.10.x.zip unzip greengrass-dependency-checker-GGCv1.10.x.zip cd greengrass-dependency-checker-GGCv1.10.x sudo modprobe configs sudo ./check_ggc_dependencies | more実行結果に問題が表示されてないか確認します。
以下のResultではResultにNode.jsとJava8に関するNoteが出ていますが、LambdaのRuntimeとして使用しない場合は修正必須ではありません。実行結果(抜粋)<...snip...> Result ------------------------------------Results----------------------------------------- Note: 1. It looks like the kernel uses 'systemd' as the init process. Be sure to set the 'useSystemd' field in the file 'config.json' to 'yes' when configuring Greengrass core. Missing optional dependencies: 1. Could not find the binary 'nodejs12.x'. If NodeJS 12.x or later is installed on the device, name the binary 'nodejs12.x' and add its parent directory to the PATH environment variable. NodeJS 12.x or later is required to execute NodeJS lambdas on Greengrass core. 2. Could not find the binary 'java8'. If Java 8 or later is installed on the device name the binary 'java8' and add its parent directory to the PATH environment variable. Java 8 or later is required to execute Java lambdas as well as stream management features on Greengrass core. Supported lambda isolation modes: No Container: Supported Greengrass Container: SupportedGreengrass Coreのインストール
Greengrass Coreをダウンロード、展開します。
(アーキテクチャごとにダウンロードするファイルが違うので注意。RaspiはArmv7l)wget https://d1onfpft10uf5o.cloudfront.net/greengrass-core/downloads/1.10.0/greengrass-linux-armv7l-1.10.0.tar.gz sudo tar -xzvf greengrass-linux-armv7l-1.10.0.tar.gz -C /AWS IoT Core クライアント証明書の作成で生成したクライアント証明書と秘密鍵を、SCP等で"/greengrass/certs"にコピーしておきます。
また以下の様にAmazon root CAのCA証明書を"/greengrass/certs/"にダウンロードします。cd /greengrass/certs/ sudo wget -O root.ca.pem https://www.amazontrust.com/repository/AmazonRootCA1.pemGreengrass Coreのコンフィグを編集します。[XXX]の箇所を適切な値に変更します。
sudo vi /greengrass/config/config.json/greengrass/config/config.json```json # 変更前 { "coreThing": { "caPath": "[ROOT_CA_PEM_HERE]", "certPath": "[CLOUD_PEM_CRT_HERE]", "keyPath": "[CLOUD_PEM_KEY_HERE]", "thingArn": "[THING_ARN_HERE]", "iotHost": "[HOST_PREFIX_HERE]-ats.iot.[AWS_REGION_HERE].amazonaws.com", "ggHost": "greengrass-ats.iot.[AWS_REGION_HERE].amazonaws.com" }, "runtime": { "cgroup": { "useSystemd": "[yes|no]" } }, "managedRespawn": false, "crypto": { "caPath" : "file://certs/[ROOT_CA_PEM_HERE]", "principals": { "IoTCertificate": { "privateKeyPath": "file://certs/[CLOUD_PEM_KEY_HERE]", "certificatePath": "file://certs/[CLOUD_PEM_CRT_HERE]" }, "SecretsManager": { "privateKeyPath": "file://certs/[CLOUD_PEM_KEY_HERE]" } } } } # 変更後(例) { "coreThing": { "caPath": "AmazonRootCA1.pem", "certPath": "raspi01.cert.pem", "keyPath": "raspi01.private.key", "thingArn": "arn:aws:iot:ap-northeast-1:[自アカウントのAccount Id]:thing/raspi01", "iotHost": "[自アカウントのIoT Endpoint Prifix]-ats.iot.ap-northeast-1.amazonaws.com", "ggHost": "greengrass-ats.iot.ap-northeast-1.amazonaws.com" }, "runtime": { "cgroup": { "useSystemd": "yes" } }, "managedRespawn": false, "crypto": { "caPath" : "file://certs/AmazonRootCA1.pem", "principals": { "IoTCertificate": { "privateKeyPath": "file://certs/raspi01.private.key", "certificatePath": "file://certs/raspi01.cert.pem" }, "SecretsManager": { "privateKeyPath": "file://certs/raspi01.private.key" } } } }Greengrassを起動します。
sudo /greengrass/ggc/core/greengrassd startOS起動時にGreengrassが起動するようにします。
sudo vi /etc/systemd/system/greengrass.service/etc/systemd/system/greengrass.service[Unit] Description=Greengrass Daemon [Service] Type=forking PIDFile=/var/run/greengrassd.pid Restart=on-failure ExecStart=/greengrass/ggc/core/greengrassd start ExecReload=/greengrass/ggc/core/greengrassd restart ExecStop=/greengrass/ggc/core/greengrassd stop [Install] WantedBy=multi-user.targetsudo systemctl enable greengrassGreengrassへのLambdaのデプロイ
GreengrassへのLambdaデプロイ
全てのCDKスタックのデプロイが完了したら、クラウドからRaspberry Pi上のGreengrass CoreにLambda Functionをデプロイします。
GG_NAME="[Greengrass Group名]" GG_ID=$(aws greengrass list-groups --query "Groups[?Name==\`${GG_NAME}\`].Id" --output text) GG_VERSION=$(aws greengrass list-groups --query "Groups[?Name==\`${GG_NAME}\`].LatestVersion" --output text) GG_DEPLOYMENT_ID=$(aws greengrass create-deployment --deployment-type NewDeployment --group-id $GG_ID --group-version-id $GG_VERSION --query "DeploymentId" --output text) aws greengrass get-deployment-status --group-id ${GG_ID} --deployment-id ${GG_DEPLOYMENT_ID}上記コマンドの結果が以下のように"DeploymentStatus": "Success"になればデプロイ成功です。
(In Progressの場合は少し待ってもう一度実行する。){ "DeploymentStatus": "Success", "DeploymentType": "NewDeployment", "UpdatedAt": "2020-04-19T12:30:25.841Z" }動作確認
Raspberry Piにログインし、Lambdaのログを確認します。
# /greengrass/ggc/var/log/user/[Region]/[Account ID] 以下にLambdaのログが出力されるはずです。 sudo tail -f /greengrass/ggc/var/log/user/[Region]/[Account ID]/GreengrassLambdaStack-GreengrassLambdaHandlerxxxxx-xxxxxxxxxxxx.log 問題なければ以下のようなログが出力されます。 [2020-04-19T19:50:20.522+09:00][DEBUG]-Lambda.py:96,Invoking Lambda function "arn:aws:lambda:::function:GGRouter" with Greengrass Message "{"device_name": "raspi01", "co2": 559, "timestamp": "2020/04/19 10:50:20"}" [2020-04-19T19:50:20.522+09:00][INFO]-ipc_client.py:167,Posting work for function [arn:aws:lambda:::function:GGRouter] to http://localhost:8000/2016-11-01/functions/arn:aws:lambda:::function:GGRouter [2020-04-19T19:50:20.533+09:00][INFO]-ipc_client.py:177,Work posted with invocation id [7f8cca07-301d-4438-5601-4cdd834f77bb] [2020-04-19T19:50:25.564+09:00][INFO]-ipc_client.py:167,Posting work for function [arn:aws:lambda:::function:GGRouter] to http://localhost:8000/2016-11-01/functions/arn:aws:lambda:::function:GGRouter [2020-04-19T19:50:25.564+09:00][DEBUG]-handler.py:49,CO2:560 ppm <= 取得されたCo2濃度 [2020-04-19T19:50:25.564+09:00][DEBUG]-IoTDataPlane.py:126,Publishing message on topic "data/raspi01/sensor/co2" with Payload "{"device_name": "raspi01", "co2": 560, "timestamp": "2020/04/19 10:50:25"}"Kibanaの設定
- Elasticsearchにデータが届いているはずなので、普通にKibanaを設定すれば終わりです。
- インデックスパターンの作成、ダッシュボードの作成、Monitorの作成 (準備中)

- 投稿日:2020-04-21T21:18:19+09:00
fastlane matchでAWS CodeCommitのリポジトリを使用する
前提
以下のURLを参考にgit-remote-codecommitのセットアップを行い、remote-codecommit形式でgit cloneできる状態にします。
https://docs.aws.amazon.com/ja_jp/codecommit/latest/userguide/setting-up-git-remote-codecommit.htmlfastlane matchで使う
git_urlに remote-codecommit形式のURLを指定します。
app_certificatesというCodeCommitのリポジトリを使うとすると以下のようになります。export CERT_REPO=codecommit::ap-northeast-1://app_certificates bundle exec fastlane match development -a $MAIN_BUNDLE_ID --verbose --git_url=$CERT_REPOちなみにSwitchRoleなどを使っておりプロファイル名を指定する必要がある場合は以下のようにリポジトリを指定します。
export CERT_REPO=codecommit::ap-northeast-1://{プロファイル名}@app_certificates
- 投稿日:2020-04-21T20:47:40+09:00
アメリカ国防総省のクラウドベストプラクティスを参考にお勉強
いつも忘れないように、コンセプトから。
コンセプト
・お金かけてまでやりたくないのでほぼ無料でAWSを勉強する
→ちょっとしたサービスを起動すると結構高額になりやすい。
・高いレベルのセキュリティ確保を目指す
→アカウントを不正に使われるととんでもない額を請求されるので防ぐ今回はセキュリティの話ではないですが、昨日の続きというか、流れで調べていたのでその備忘というかメモです。昨日はアメリカ国防総省のAWSセキュリティを参考にお勉強について書いてました。
今日は、アメリカ国防総省のクラウドベストプラクティス
(Best Practices Guide for Department of Defense
Cloud Mission Owners)を読んでみました。一番面白かったのは、可用性を高めるための方法です。P.18にAchieving High Availabilityという項目があります。アメリカ国防総省の可用性に対する考え方
中段くらいから、「クラウド上で発生しうるシステムやアプリケーションの5つのシステムトラブルを考えてみよう」と書かれています。
1. アプリケーション障害
2. サーバー障害
3. データセンター障害
4. クラウド全体の障害
5. ネットワーク障害
これらが5つの分類になるんですが、個人的に興味深かったのは3のデータセンター障害と、4のクラウド全体の障害についてです。まず、データセンターの障害についてですが、1つのソリューションとして異なったゾーンに分割するようにと書かれています。AWSの場合はAZ(Availability Zones)で、Azureの場合はリージョンで分けると書かれています。よく勘違いしている人がいますが、AWSのリージョンと、Azureのリージョンは違います。AWSのAZ=Azureのリージョンが正しいです。また、他のクラウドサービスでは違う名前かもしれないけど、コンセプトはみんな同じだと記載されています。要はどういうレベルで冗長化されているかを確認すべき、ということなんです。
続いて面白いのがクラウド全体の障害についてです。この場合は別のクラウドにデータのバックアップをするようにと書かれています。当たり前すぎじゃん、って思うのですが、こうやって明示的に書いてくれるのは助かる部分が多いと思います。いちいちいろいろ聞かれると回答が面倒なこともありますが、アメリカ国防総省の名前を出すと、良く知らない人をけむに巻くことが可能です(笑)。水戸黄門の印籠みたいなもんで、便利に使っていきましょう。
ちなみに、ポイントはデータのバックアップなので、必ずしもシステムをマルチクラウドで冗長に組むようにとは書いていないところです。まあ、AWSでマルチAZで組んでいて全ダウンしたからといって、他のクラウドで同じように動かすのは事実上困難でしょうね。そもそもS3もなければLambdaなどの連携方法も違うので、別物になってしまいます。非常に発生率の低い障害に対して二重投資するのは賢明な判断とは言えないでしょう。
まあ、ここまで読んで、当たり前のことしか書いてないじゃんと思うかもしれませんが、経験上その当たり前を当たり前として説明するのに苦労したことが何度もあります。そういう時にはこういう文章やホワイトペーパーを出すと、すんなり話が進むこともあるので、困った時に使ってみるといいかもしれません。
- 投稿日:2020-04-21T20:04:45+09:00
AWSアカウントのプロファイル切り替え
AWS接続アカウントをプロファイル名つきで登録する
ターミナル$ aws configure --profile プロファイル名 AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]: Default output format [None]:登録したプロファイルを確認する
ターミナル$ aws configure list登録したプロファイルは以下のファイルに保存されている
~/.aws/config[default] region = ap-northeast-1 [profile staging-profile] region = ap-northeast-1~/.aws/credentials[default] aws_access_key_id = AKIAXXXXXXXXXXXXXXXX aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [staging-profile] aws_access_key_id = AKIAYYYYYYYYYYYYYYYY aws_secret_access_key = YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYプロファイルを指定して実行する
ターミナル$ aws --profile staging-profile s3 ls環境変数に設定する
ターミナル$ export AWS_PROFILE=staging-profile
- 投稿日:2020-04-21T20:04:45+09:00
AWS CLIアカウントのプロファイル切り替え
AWS CLIアカウントをプロファイル名つきで登録する
ターミナル$ aws configure --profile プロファイル名 AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]: Default output format [None]:登録したプロファイルを確認する
ターミナル$ aws configure list登録したプロファイルは以下のファイルに保存されている
~/.aws/config[default] region = ap-northeast-1 [profile staging-profile] region = ap-northeast-1~/.aws/credentials[default] aws_access_key_id = AKIAXXXXXXXXXXXXXXXX aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [staging-profile] aws_access_key_id = AKIAYYYYYYYYYYYYYYYY aws_secret_access_key = YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYプロファイルを指定して実行する
ターミナル$ aws --profile staging-profile s3 ls環境変数に設定する
ターミナル$ export AWS_PROFILE=staging-profile
- 投稿日:2020-04-21T19:43:04+09:00
AWS Lambdaに外部モジュール(numpy,scipy,requests等)をデプロイする
AWS Lambda(以下、Lambda)に外部モジュールをデプロイする方法を見ていきたいと思います。ここではPythonを例に見ていきます。
実行順序
1. Amazon Linux 2(Lambdaの実行環境)を準備する
2. ソースファイルとともにLambdaにデプロイ
2. Lambda Layerを使う方法*2はどちらを選んでも構いません。
1. Amazon Linux 2(Lambdaの実行環境)を準備する
requestsモジュール等、内部でC言語などを使わず、Pure Pythonで書かれたモジュールの場合、このステップは不要です。
しかし、numpyやscipyといった、C言語に依存するモジュールの場合、Lambdaの実行環境と同じ環境で開発するのが開発しやすくなります。 windowsやMacでインストールしたnumpyをzipで固めてデプロイしてもエラーとなります。ここでは、Amazon Linux 2の環境として、公に公開されているDockerイメージ、lambci/lambda:build-python3.7 を使います。
適当なディレクトリを作って、Lambdaで実行するソースコード(lambda_function.py)とDockerfileを作成してください。
Dockerfileの中身
FROM lambci/lambda:build-python3.7 CMD pip3 install numpy -t /var/tasklambda_function.pyの中身は適当
import numpy as np def lambda_handler(event,context): print(np.arange(10).reshape(2,5))ソースとDockerfile作成完了
~$ ls Dockerfile lambda_function.pyあとは、ビルドして、runしてください。
~$ docker image build -t numpy:latest . ~$ docker container run --rm -v ${PWD}:/var/task numpy:latestコンテナ内でインストールした外部モジュールを、ホストOSでも参照するために、-v ${PWD}:/var/taskしています。
ちなみに、/var/taskはLambdaが外部モジュールをインポートするために参照するパスの1つです。Dockerコンテナで実行する場合は、このパスの中に外部モジュールを置く必要があります。
試しに、Lambdaで以下のようにして、パスを確認してみてください。import sys def lambda_handler(event,context): print(sys.path) """ python3.7 における実行結果 ['/var/task', '/opt/python/lib/python3.7/site-packages', '/opt/python', '/var/runtime', '/var/lang/lib/python37.zip', '/var/lang/lib/python3.7', '/var/lang/lib/python3.7/lib-dynload', '/var/lang/lib/python3.7/site-packages', '/opt/python/lib/python3.7/site-packages', '/opt/python'] """上記コマンドが成功していると、ソースと外部モジュール(numpy)が同じ階層にあるはずです。あとは、Lambda Layer、もしくはソースファイルとともにzipで固めてデプロイするだけです。なので、以下2のどちらかを選んでください。
~$ ls Dockerfile bin lambda_function.py numpy numpy-1.18.3.dist-info numpy.libs2. Lambda Layerを使う方法
前述の通り、Lambdaが外部モジュールを読み込めるように、python ディレクトリを作成して、そこにnumpy関連のファイル、ディレクトリを移動します。
実行手順の最初の段階で python ディレクトリを作成していれば以下の作業は不要です。~$ mkdir python ~$ mv bin numpy numpy-1.18.3.dist-info numpy.libs python外部モジュールをzipで固めてLambda Layerにデプロイします。
~$ zip -rq numpy.zip pythonソースファイルをzipで固めて、Lambda コンソール or AWS CLIでデプロイします。
~$ zip -q lambda_function.zip lambda_function.py2. ソースファイルとともにLambdaにデプロイ
zipで固めて、Lambda コンソール or AWS CLIでデプロイします。Lambda Layerを使う場合は、外部モジュールとソースファイルを分けますが、今回はすべてまとめてzip化します。なので、zip対象は * です。
~$ zip -rq numpy.zip *Lambdaにデプロイする際にサイズが大きくて、画面に表示できない場合がありますが(numpyはほぼ表示不可能)実行自体はできます。
- 投稿日:2020-04-21T18:51:27+09:00
AWS EC2間でSSH接続する
はじめに
- AWS VPCの勉強がてら、管理用サブネット~公開サブネット間のSSH接続の試験をしたメモです。
Internal SSH
- 公開サーバのインスタンス作成時に、キーペアを作成する。
- TeraTermを使って、踏台サーバに、xxx.pemをSCPで送信する
 アップロードしたファイルのパーミッションを変更する
アップロードしたファイルのパーミッションを変更するsudo chmod 600 xxx.pem踏台サーバにコンフィグファイルを作るtouch ~/.ssh/config vi .ssh/config.ssh/configHost wss HostName 172.10.0.xxx #IPアドレス User ubuntu IdentityFile ~/xxx.pem Port 22ターゲットにssh接続するssh wssyes/noを聞かれるので応答するyes接続完了Welcome to Ubuntu 18.04.4 LTS (GNU/Linux 4.15.0-1057-aws x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage System information as of Wed Apr 15 09:47:18 UTC 2020 System load: 0.12 Processes: 92 Usage of /: 18.8% of 7.69GB Users logged in: 0 Memory usage: 18% IP address for eth0: 172.10.0.xxx Swap usage: 0% 0 packages can be updated. 0 updates are security updates. *** System restart required *** Last login: Wed Apr 15 09:41:44 2020 from 172.10.200.xxx ubuntu@ip-172-10-0-xxx:~$ネットワークACL
ManagementNetworkACL
ExternalNetworkACL
セキュリティグループ
ManagedServer
Inbound
Outbound
WebServiceServer
Inbound
Outbound
おわりに
- ネットワークACLは、ステートレス
- セキュリティグループは、ステートフル
- WebServiceServerのセキュリティグループは、開発専用 - ポート:8000 → 80、ソース:0.0.0.0/0






- 投稿日:2020-04-21T18:18:08+09:00
AWS ログの場所を探す方法
それぞれのログの場所は以下の通り。
①Nginx =>[自分のアプリ名]/log/nginx.error.log
②Unicorn =>[自分のアプリ名]/log/unicorn.log
③Rails =>[自分のアプリ名]/log/production.log
- 投稿日:2020-04-21T18:18:08+09:00
AWS接続できない際のログの場所一覧
それぞれのログの場所は以下の通り。
①Nginx
[ユーザ名@ip-10-0-0-58 自分のアプリ名]$ cat log/nginx.error.log②Unicorn
[ユーザ名@ip-10-0-0-58 自分のアプリ名]$ cat log/unicorn.log③Rails
[ユーザ名@ip-10-0-0-58 自分のアプリ名]$ cat log/production.log
- 投稿日:2020-04-21T17:50:16+09:00
EC2 Amazon Linux 2でS3をマウント
EC2からS3をマウントする備忘録です。
色々方法はあるみたいですが、今回はgoofysを使用します。S3のバケットを作成
awscliでもできるらしいですが、AWSコンソールからS3に移動しバケットを作成しました。
ブロックパブリックアクセスのバケット設定は「パブリックアクセスをすべてブロック」にしました。IAMロール作成
EC2からS3にアクセスできるようにIAMロールを作成します。
新規作成、もしくは既存のロールで「AmazonS3FullAccess」ポリシーを付加します。
作成したロールを該当のEC2にアタッチします。SSH接続して以下を実行する
ルートに切り替え
sudo su -Go、fuse、gitをインストール
yum install golang fuse gitGoパスを設定
ホームディレクトリにパスを設定しました。
export GOPATH=$HOME/gogoofysをインストール
go get github.com/kahing/goofys go install github.com/kahing/goofysマウント用のディレクトリを作成
今回はホームフォルダ配下にしました。
mkdir ~/s3S3をマウント
$GOPATH/bin/goofys {S3のバケット名} ~/s3マウント確認
dfコマンドで確認してマウントできていたら完了です。
df -hT結果Filesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 475M 0 475M 0% /dev tmpfs tmpfs 492M 0 492M 0% /dev/shm tmpfs tmpfs 492M 408K 492M 1% /run tmpfs tmpfs 492M 0 492M 0% /sys/fs/cgroup /dev/xvda1 xfs 8.0G 3.0G 5.1G 37% / tmpfs tmpfs 99M 0 99M 0% /run/user/0 {S3バケット名} fuse 1.0P 0 1.0P 0% /root/s3
- 投稿日:2020-04-21T17:43:12+09:00
在宅勤務なら AWS のサービスを活用しよう!
はじめに
コロナウイルスの影響で、在宅ワークをせざるを得ない状況となりました。
皆様が少しでも良い環境で、在宅ワークを行えるように
AWS の公式ブログ、そのサービスの内容をご紹介したいと思います!在宅勤務について
たった数週間で多くのことが変わりました。
これまでのスタイルの生活、仕事、会議、挨拶、コミュニケーションは、しばらく姿を消しています。
友好的な握手と温かいハグは、現時点では健康的でなく、社会的にも受け入れられないものとなっています。自分たちは、多くの人々が仕事、学校、コミュニティ環境の変化に対応するべきことを認識しています。
AWS では、お客様、コミュニティ、従業員が状況に合わせて対応できるようにするための措置を講じています。現在、多くの都市や国々において、人々は、在宅勤務や自宅学習を求められています。
AWS のいくつかのサービスをご利用いただくことで、オフィスや教室から自宅への移行を少しだけ簡単にすることができます。ソリューションの概要
Amazon WorkSpaces
仮想 Windows デスクトップ仮装 Linux デスクトップを起動でき、あらゆるデバイスでどこからでもアクセスできます。
これらのデスクトップは、リモートワーク、リモートトレーニングなどに使用できます。Amazon WorkDocs
他のユーザーとの共同作業を簡単にします。
場所とデバイスを問わないのは同様です。コンテンツを作成、編集、共有、および確認することができ、すべて AWS に一元的に保存されます。Amazon Chime
最大 100 人 (今月後半に 250 人に増加) が参加するオンライン会議 (チャットやビデオ通話など) をサポートします。
すべて単一のアプリケーションから行えます。Amazon Connect
着信コールやメッセージを何万人ものエージェントにルーティングする機能を使用して、コールセンターまたはコンタクトセンターをクラウドにセットアップできます。
これを使用して、エージェントが在宅勤務をしていても、緊急情報や個別のカスタマーサービスを提供できます。Amazon AppStream
デスクトップアプリケーションを任意のコンピューターに配信できます。
計算や 3D レンダリングに GPU を使用するものなど、エンタープライズ、教育、または遠隔医療のアプリを大規模に配信できます。AWS Client VPN
どこからでも AWS およびオンプレミスネットワークへの安全な接続をセットアップできます。
従業員、学生、または研究者に、既存のネットワークに「ダイヤルイン」(過去に私たちが使っていた言葉と同じ意味です) する機能を提供できます。料金体系について
これらのサービスの一部には、無料で簡単に開始できます。
その他は、AWS 無料利用枠で既に利用可能となっています。
詳細については、各公式サービスのホームページと、新しい Remote Working & Learning ページをご覧ください。在宅ワークに役立つコンテンツ
AWS では、これらのサービスと在宅勤務を可能な限り効率的に使用するのに役立つ AWS 関連コンテンツの取りまとめを開始しています。
特別な機器はいらない Twitch で Meetup をライブストリーミングする
Amazon Connect でリモートコンタクトセンターエージェントをすばやくセットアップ
Amazon Kendra、Amazon Comprehend、Amazon Translate などを使用して、学生を大規模に参加させ、教育するオンライン学習プラットフォームを構築する
Jitsi 入門 – オープンソースウェブ会議ソリューション
Amazon Chime を使用したリモートワークのベストプラクティス
Amazon WorkSpaces および Amazon WorkDocs で在宅勤務を可能にする新しいオファー終わりに
今後、様々な状況により在宅勤務が長引いたり
もしくは在宅ワークのほうが、効率的に業務を進められるという気づきがあって
本格的に、永続的に在宅ワークが主流になった場合に備えても、これらのサービスはとても役立つと思います。
何事も備えておきたい。是非今すぐご活用ください!
- 投稿日:2020-04-21T17:31:12+09:00
【備忘録】AWS Lambda関数でLambda関数を呼ぶ invoke
Lambda関数から別のLambhda関数を呼びに行きたい時ってありますよね!
そんな時に使える方法を備忘録として残します。
呼び出す側のLambda関数(main.js)
main.jsconst AWS = require('aws-sdk') const lambda = new AWS.Lambda() let params = { FunctionName: `invoked.js`, InvocationType: 'Event', Payload: JSON.stringify({ id: "xxxxxxxxxx", message: "xxxx" }) } console.log(params) // 呼び出される側のLambda関数を実行する lambda.invoke(params).promise()呼び出される側の関数
invoked.jsexports.handler = async (event, context) => { console.log(event) }参考になるページ
- 投稿日:2020-04-21T17:13:10+09:00
コードを書かずにAIを構築してみる ー 失敗編
- コードを書かず、AWSのサービスを使いAIを構築してみる
- 例として、六角ボルト長の判別を行う
- ちなみに肉眼では、ぱっと見で違いが判りにくかった
- AIもうまく判別できていなかった より学習データの量・質共に向上させる必要がある
学習データの作成
学習データの拡張
学習データ数の見積
パラメータ: 1(ボルト長)
- 10倍の法則より: 学習データ数 10以上
回転方向数 * マスク・切抜パターン数 * 撮影枚数 > 10
ここで、
マスク・切抜パターン数 = 3パターン
回転画像数 = 4方向
なので、
必要撮影枚数は最低1枚以上学習結果のテスト用も含め、今回は2つのボルトを15枚ずつ 計30枚撮影する
学習データ数は計 360となる学習データの登録
- S3に上げる前に余白の切取り・正規化・回転処理・マスク・切り抜き処理は済ませておく
- Amazon SageMaker Ground Truthでラベリングする
参考:
Amazon SageMaker Ground Truth を試してみる学習
Amazon Rekognition Custom Labelsは2020/04現在東京リージョンでは使えない
学習データ例:20mm
学習データ例:25mm
参考:
Amazon Rekognition Custom Labels でアーモンドとピーナッツの判別モデルを作ってみた。
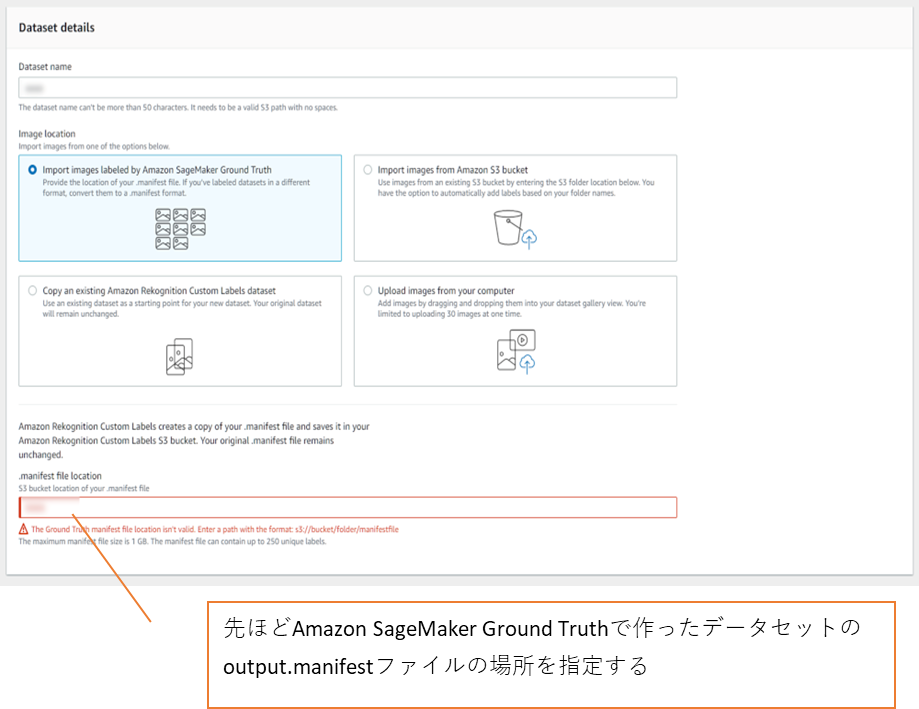
Amazon SageMaker 物体検出モデルの構築 ~Honey Bees~学習データセットの作成
先ほど作ったAmazon SageMaker Ground Truthのデータを使う
学習実行
- 今回は40分で終了
学習結果評価
- この時点ではまずまずの結果だとおもっていた
参考:
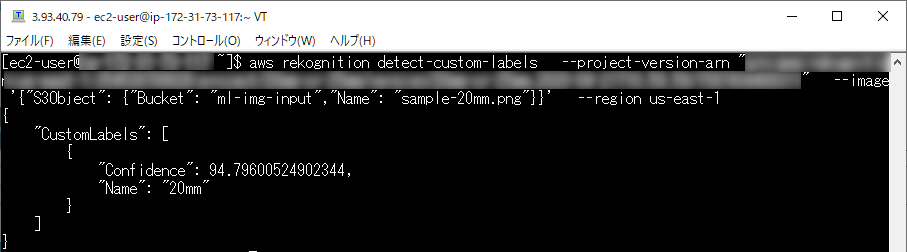
Amazon Rekognition Custom Labels を使って自分ちの猫を見分ける!テスト
CLIにて確認
2020/04現在 Windows最新版CLI未対応
!???
まとめ
- 学習時の評価とは違い、実際にはうまく判別できていなかった
- より学習データの量・質共に向上させる必要がある
- Sagemakerほど機能は豊富でない
- チューニングはできない AWSのアルゴリズムに完全にお任せである
- 学習を中断することはできない
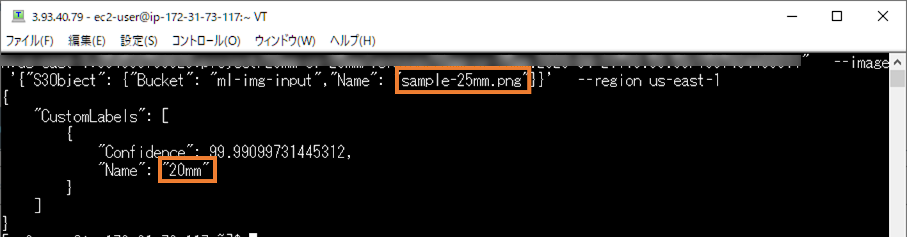
参考: Amazon SageMakerの自動モデルチューニングにおいて学習ジョブの早期停止機能がサポートされました – Amazon SageMaker Advent Calendar 2018複数の物体の判別はできない
- sample-20mm-25mm.png





- 投稿日:2020-04-21T17:07:46+09:00
【AWS・EC2】unicornを起動の際のエラー文master failed to start, check stderr log for detailsの解決法
したいこと
unicornの起動を成功させたい。(エラー文master failed to start, check stderr log for details)
経緯
本番環境としてEC2を使ってポートフォリオをデプロイしようとしています。
下記記事を参考にしています。
https://qiita.com/Yuki_Nagaoka/items/dbb185feb6d4f051c2f2
https://qiita.com/naoki_mochizuki/items/5a1757d222806cbe0cd1#unicorn%E3%81%AE%E8%A8%AD%E5%AE%9A出ているエラー
下記コマンドを実行し、
$ bundle exec unicorn_rails -c /var/www/rails/アプリ名/config/unicorn.conf.rb -D -E production以下の様にエラーが表示される。
master failed to start, check stderr log for details考えられる原因
・設定したunicorn.conf.rbに問題がある?
・unicornのバージョンが悪い?
・EC2にあるアプリのcredentials.yml.enc、master.key周りの設定?とりあえずログを見る。
試したこと
・unicornのエラーログを見るために下記を実行。
$ cd log $ tail unicorn.log間違っている部分は見つからず、よくわかりませんでした。
・次にproduction.logをみるために下記を実行。
$ tail production.log間違っている部分は見つからず、よくわかりませんでした。
・次にunicorn_error.logを見るために下記を実行。
$ tail unicorn_error.logファイルがない、とのことで記録を見ることができませんでした。
次に、unicorn_stderr.logがあると思い下記を実行。
$ tail unicorn_stderr.logファイルがありませんでした。
次にアプリのディレクトリに戻り、下記を実行したところログが表示されました。
$ cat log/unicorn.log -n気になるエラーが表示されました。
ActiveSupport::MessageEncryptor::InvalidMessage: ActiveSupport::MessageEncryptor::InvalidMessage check_for_activated_spec!': You have already activated unicorn 5.5.4, but your Gemfile requires unicorn 5.4.1. Prepending `bundle exec` to your command may solve this. (Gem::LoadError)→調べたところそれぞれmaster.key周りのエラーとunicornのバージョンのエラー。
・unicornのgemのバージョンが5.5.0の場合はエラーが出るとのことなので5.4.1に変えてみました。
参考記事→https://qiita.com/TeruhisaFukumoto/items/f1f0be91bc7b43b4f79d
→EC2内のアプリのgemを変えてbundle intallができたので、再び下記コマンドを実行したところ同じエラーが表示されました。bundle exec unicorn_rails -c /var/www/rails/Portfolio/config/unicorn.conf.rb -D -E production→すると下記のエラー。
master failed to start, check stderr log for details先ほどおぼえた
cat log/unicorn.log -nコマンドを使って558番以上の最新のログをみてみたところ、下記のエラー文が見つかりました。ActiveSupport::MessageEncryptor::InvalidMessage: ActiveSupport::MessageEncryptor::InvalidMessage・
ActiveSupport::MessageEncryptor::InvalidMessage: ActiveSupport::MessageEncryptor::InvalidMessageというエラー文があったのでcredentials.yml.enc、master.keyを確認。ローカルのアプリにて以下を実施し、master.keyをメモ。
$ vi config/master.keyサーバー環境のアプリ内でmaster.keyを開きローカル環境のmaster.keyを貼り付け:wq。
$ vi config/master.keyローカル環境にて下記コマンドでシークレットキーを発行し、サーバー環境にあるアプリのcredentials.yml.encに貼り付けて保存。
$ bundle exec rake secretそして下記を実行したところ、同じエラーが表示されました。
$ bundle exec unicorn_rails -c /var/www/rails/Portfolio/config/unicorn.conf.rb -D -E productionここまでの考察
・credentials.yml.enc、master.key周りの設定が怪しい。
・unicornのバージョンの問題はなし。
・ログの中にdirectory for pid=/home/username/appname/tmp/pids/unicorn.pid not writable (ArgumentError)というエラーが見つからないので、権限周りの問題ではない。
・ArgumentError: wrong number of arguments (given 0, expected 2)というエラーはないので、unicorn.conf.rbの設定ファイルによるエラーではない。
・他にエラーログがある?というわけで、とりあえずローカル、サーバーのcredentials.yml.enc、master.key周りを確認してみる。
解決法
犯人はローカル環境にて行った
$ bundle exec rake secretだった。
$ bundle exec rake secretにより、ローカル環境のmaster.key、credentials.yml.enc、サーバー環境のmaster.key、credentials.yml.encが噛み合わなくなっていたのが原因です。私の環境はrails6.0。したがって
credentials.yml.encでのキーの管理をする必要がある。もっと詳しくいうと、私は以前ローカル環境にある
master.key、credentials.yml.encを消して、ローカル環境で何回もEDITOR=vim bundle exec rails credentials:editをすることによって2つのキーを作っては壊しを繰り返してました。当然サーバーとローカルの両アプリ内のキーが合わなくなるわけです。
ローカル、サーバーそれぞれ合計4つのmaster.key、credentials.yml.enc作成して紐づける手順
・ローカルの
master.keyとcredentials.yml.encを手作業で削除し、以下コマンドで新しく2つのキーを作成し、secret key baseをコピーしておく。ローカル.EDITOR=vim bin/rails credentials:edit※念の為目視でローカル環境のcinfig内に2つのキーが作られたか確認しましょう。
・次にサーバーのmaster.keyとcredentials.yml.encを以下のコマンドで削除。
サーバ.[ユーザ名@ip-10-0-0-58 アプリ名]$ rm config/master.key [ユーザ名@ip-10-0-0-58 アプリ名]$ rm config/credentials.yml.encls configで消されたか確認。
サーバ.[ユーザ名@ip-10-0-0-58 アプリ名]$ ls config application.rb cable.yml database.yml environments locales routes.rb storage.yml unicorn.conf.rb webpacker.yml boot.rb credentials environment.rb initializers puma.rb spring.rb unicorn webpack消されている。
で、サーバー環境で
EDITOR=vim bin/rails credentials:editをして2つのキーを作成し、vimの編集画面に入る。
編集画面ですかさずローカル環境の際にメモをしておいたsecret key baseを貼り付けます。[ユーザ名@ip-10-0-0-58 アプリ名]$ EDITOR=vim bin/rails credentials:edit Adding config/master.key to store the encryption key: d1616fa3117dd0c4a662c547e0c5ba28 Save this in a password manager your team can access. If you lose the key, no one, including you, can access anything encrypted with it. create config/master.key File encrypted and saved.作れた。
念の為目視でファイルがあるかどうか確認。サーバ.[ユーザ名@ip-10-0-0-58 アプリ名]$ ls config application.rb cable.yml credentials.yml.enc environment.rb initializers master.key routes.rb storage.yml unicorn.conf.rb webpacker.yml boot.rb credentials database.yml environments locales puma.rb spring.rb unicorn webpackcredentials.yml.enc、master.keyが作れている。
で、本記事の本題である以下を実行。
[ユーザ名@ip-10-0-0-58 アプリ名]$ bundle exec unicorn_rails -c /var/www/rails/アプリ名/config/unicorn.conf.rb -D -E production [ユーザ名@ip-10-0-0-58 アプリ名]$ ps -ef | grep unicorn | grep -v grep ユーザ名 27923 1 2 07:13 ? 00:00:01 unicorn_rails master -c /var/www/rails/アプリ名/config/unicorn.conf.rb -D -E production ユーザ名 27926 27923 0 07:13 ? 00:00:00 unicorn_rails worker[0] -c /var/www/rails/アプリ名/config/unicorn.conf.rb -D -E production ユーザ名 27927 27923 0 07:13 ? 00:00:00 unicorn_rails worker[1] -c /var/www/rails/アプリ名/config/unicorn.conf.rb -D -E productionunicornが起動できたっぽい。
credentials.yml.encについての参考記事
https://qiita.com/scivola/items/cc06ddbfd94d3118f693まとめ|この認識を持ちましょう。
master.key・・・カギ。
credentials.yml.enc・・・鍵穴。
- 投稿日:2020-04-21T17:01:41+09:00
ローカルPCでAWS KMSを使った処理をテストする
KMSを使った処理をローカルPCでテストしたときのメモ。
必要なもの
- Java開発環境
- Docker
実行手順
1.local-kmsの準備
AWS SDKから呼び出すlocal-kmsをコンテナで起動する。
今回は暗号化と復号のテストをするので、暗号化で使用するKeyを設定する。
local-kmsのドキュメントそのままに、seed.yamlファイルを作成する。Keys: - Metadata: KeyId: bc436485-5092-42b8-92a3-0aa8b93536dc BackingKeys: - 5cdaead27fe7da2de47945d73cd6d79e36494e73802f3cd3869f1d2cb0b5d7a9 Aliases: - AliasName: alias/testing TargetKeyId: bc436485-5092-42b8-92a3-0aa8b93536dcyamlを作成したら、local-kmsを起動する。
docker run -p 8080:8080 \ --mount type=bind,source="$(pwd)"/init,target=/init \ nsmithuk/local-kms2.AWS SDKの準備
KMSClientインスタンスの生成時にEndpointConfigurationからlocal-kmsにアクセスするように指定する。
リージョンはなんでもいい。// EndpointにローカルKMSを指定.RegionはどこでもOK AwsClientBuilder.EndpointConfiguration endpointConfig = new AwsClientBuilder.EndpointConfiguration("http://localhost:8080/", "ap-northeast-1"); kmsClient = AWSKMSClientBuilder.standard().withEndpointConfiguration(endpointConfig).build();あとは生成したKMSClientから必要なメソッドを呼ぶ。
local-kmsはKMSと同じように暗号化と復号を実行してくれる。カスタマーキーの登録もできる。
AWSにデプロイしたり、KMSのセットアップしなくていいので楽です。ちなみに、呼び出されたlocal-kms側のLogはこんな感じ。アカウント、リージョンのところは適当っぽい。
Encryption called: arn:aws:kms:eu-west-2:111122223333:key/bc436485-5092-42b8-92a3-0aa8b93536dc参考
- 投稿日:2020-04-21T17:00:32+09:00
AWS Lambda関数でNode.js レイヤーを作る
対象者
AWSでLamdbaを使っている人/どんなことができるのか調べている人
LINEBotをサーバーレスで作りたい人
Lambdaのレイヤーという機能を知らない人/興味ある人下準備
とりあえずデスクトップに移動
$ cd Desktop
ディレクトリ作る
$ mkdir nodejs
nodejsディレクトリに移動
$ cd nodejs
初期化
$ npm init -y
レイヤーにしたいパッケージをインストール
$ npm i xxxxx
ex)LINEBotのSDKをインストールする場合
$ npm i @line/bot-sdk
nodejsディレクトリ自体をzipファイルに圧縮して下準備完了AWSコンソール
ログイン→Lambda→レイヤー→レイヤーの作成
名前はそのパッケージが分かる名前ならなんでもいい。
↓例えばの完成図
Lambda関数で読み込む
index.jsconst line = require('@line/bot-sdk')こんな感じでレイヤーを使うことができます!
毎回全ファイルをZipしてアップロードしている人には超おすすめです(これを知ってから超楽になった。)


- 投稿日:2020-04-21T16:12:27+09:00
【AWS CDK】AWS CloudWatch AlarmsからのメッセージをGoogle Hangouts Chatに自動通知する構成を速攻で作る
AWS CloudWatch AlarmsからのメッセージをGoogle Hangouts Chatに通知したいことがあるかと思います。
今回はその構成をCDKで作成してみました。環境
CDK CLI: 1.32.0
ローカルのNode: 11.15.0構成
今回は、
trigger-chat-cdkというLambda関数を監視対象とし、「1分間に2回以上、関数が呼び出されたらエラーを挙げる」という条件を設定します。
以下は手順になりますが、このリポジトリをcloneすれば、手順の3,4は省略できるので、より速攻で作れるかと思います。
1. Hangouts ChatのWebhook URLを作成する
まず前準備として、Hangouts ChatのWebhook URLを作成する必要があります。
作成は以下リンク先の「準備」を参照すれば可能です。
https://qiita.com/iitenkida7/items/3c8f9f8f6ee1e809558d#%E6%BA%96%E5%82%992. Webhook URLをパラメータストアに設定する
AWSマネジメントコンソールを開き、
System Manager→パラメータストア→パラメータの作成
と進み、名前:HANGOUTS_CHAT_WEBHOOK_URL
値:取得したWebhook URL
種類:SecureStringで設定します。
3. CDKでスタックの作成
ここまでの準備ができたら、CDKのスタックを定義していきます。
lib/cdk-alarm-stack.tsimport * as cdk from '@aws-cdk/core' import * as sns from '@aws-cdk/aws-sns' import * as subs from '@aws-cdk/aws-sns-subscriptions' import * as cw from '@aws-cdk/aws-cloudwatch' import * as lambda from '@aws-cdk/aws-lambda' import * as iam from '@aws-cdk/aws-iam' import * as cw_actions from '@aws-cdk/aws-cloudwatch-actions' export class CdkAlarmStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); const layer = new lambda.LayerVersion(this, 'node-fetch', { code: lambda.Code.asset('layer/forChat'), compatibleRuntimes: [ lambda.Runtime.NODEJS_10_X, lambda.Runtime.NODEJS_12_X ], layerVersionName: 'node-fetch' }) const triggerFunction = new lambda.Function(this, 'triggerFunction', { runtime: lambda.Runtime.NODEJS_12_X, handler: 'index.handler', code: lambda.Code.asset('lambda/trigger-chat-cdk'), functionName: 'trigger-chat-cdk' }) const sendChatFunction = new lambda.Function(this, 'sendChatFunction', { runtime: lambda.Runtime.NODEJS_12_X, handler: 'index.handler', code: lambda.Code.asset('lambda/send-chat-cdk'), functionName: 'send-chat-cdk', layers: [ layer ] }) sendChatFunction.addToRolePolicy(new iam.PolicyStatement({ actions: [ 'sts:AssumeRole', 'ssm:GetParameter' ], resources: [ '*' ] })) const topic = new sns.Topic( this, 'sendChatTopic', { displayName: 'send chat', topicName: 'sendChatTopicCdk' } ) topic.addSubscription(new subs.LambdaSubscription(sendChatFunction)) const alarm = new cw.Alarm(this, 'sendChatAlarm', { evaluationPeriods: 1, metric: triggerFunction.metricInvocations(), threshold: 2, period: cdk.Duration.minutes(1), alarmName: 'sendChatCdk' }) alarm.addAlarmAction(new cw_actions.SnsAction(topic)); } }
triggerFunctionを別のリソースに書き換えれば、アラームの監視対象を変えることができますし、alarmを書き換えれば、アラームの定義を自由に設定することができます。4. Chatにメッセージを送るLambda関数を書く
今回はLambda関数として
- 監視対象となるtrigger-chat-cdk
- Chatにメッセージを送るsend-chat-cdk
の2つを定義する必要がありますが、trigger-chat-cdkの中身は正直なんでも良いので、説明を省略します。
send-chat-cdkの中身は以下の通りです。send-chat-cdk.jsconst fetch = require('node-fetch') const AWS = require('aws-sdk') exports.handler = async (event, context, callback) => { const ssm = new AWS.SSM() const res = await ssm.getParameter({ Name: 'HANGOUTS_CHAT_WEBHOOK_URL', WithDecryption: true }).promise() const fromSNS = event.Records[0].Sns.Message const data = JSON.stringify({ text: `${fromSNS}` }) fetch(res.Parameter.Value, { method: 'POST', headers: { 'Content-Type': 'application/json; charset=UTF-8' }, body: data }) callback(null, event) }この関数で、
node-fetchというモジュールをインポートしているので、このモジュールを使えるようにします。5. Layerで使用するモジュールをインストールする
今回使用するモジュールはLayerにセットします。
そのため、lambda/layer/forChat/nodejsというディレクトリを作成し、このディレクトリで$ npm i node-fetchを実施し、インストールします。
6. デプロイ
ここまで完了したら、
$ cdk deployで、スタックをデプロイします。
7.実行テスト
AWSのマネジメントコンソールから、Lambdaの
trigger-chat-cdkの管理画面を開き、適当なテストイベントを2回以上実行します。
1分ほど待って、作成したHangouts ChatのチャットルームにCloudWatchからのエラーメッセージが届けば成功です!
メッセージ文の内容は、Lambdaの中身を適宜アレンジして頂ければと思います。
以上、ありがとうございました。


- 投稿日:2020-04-21T15:35:32+09:00
AWSのCICDの練習(CodePipeline/ECS/Lambda)
AWSでCICD、FargateのBlueGreenDeployの練習を行う。
使用サービス
- CodeCommit/Build/Deploy/Pipeline
- CloudWatch Events
- Fargate
- Lambda
作業で使用する資材は以下となる。
. ├── 01-codecommit-ecr.yaml ├── 02-codebuild-pipeline-events.yaml ├── 03-ecs-alb.yaml ├── 04-codebuild-pipeline-events-update.yaml └── httpd-repo ├── appspec.yaml ├── buildspec.yml ├── Dockerfile ├── fargate-task.json └── index.html資材のGithubのリンク
作業内容
Repository作成
「01-codecommit-ecr.yaml」を使用し、CodeCommitのRepositoryとECRのRepositoryを作成する。
Stack作成後、http-repoの中身をCodeCommitのRepoにPushする。
CodePipeline(未完)を作成
「02-codebuild-pipeline-events.yaml」を使用し、CodeBuild、CodePipeline、CloudWatch Eventsを作成する。EventsはCommitのRepoの更新を検知した際、PipelineからDocker ImageのBuildを行う。
Dockerfileの中身
FROM httpd COPY index.html /usr/local/apache2/htdocs/ EXPOSE 80index.htmlの中身
<html> <head> <title>Amazon ECS Sample App</title> <style>body {margin-top: 40px; background-color: #333;} </style> </head> <body> <div style=color:white;text-align:center> <h1>Amazon ECS Sample App</h1> <h2>Congratulations!</h2> <p>Your application is now running on a container in Amazon ECS.</p> <p>Application Version is 2.0</p> <p>httpd-task-def:10</p> </div> </body> </html>buildspec.ymlの中身
version: 0.2 phases: pre_build: commands: - echo Logging in to Amazon ECR... - $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION) build: commands: - echo Build started on `date` - echo Building the Docker image... - docker build -t $IMAGE_REPO_NAME:$IMAGE_TAG . - docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG post_build: commands: - echo Build completed on `date` - echo Pushing the Docker image... - docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAGFargateとALBを作成
「03-ecs-alb.yaml」を使用し、Fargate、ALBを作成する。Stack作成後のOutputからALBのDNS Nameを確認し、WEBページが正常に表示することを確認する。
作成後、ALBのDNSNameからWEBページを確認。
CodeDeployを追加
「02-codebuild-pipeline-events.yaml」で作成したStackを、「04-codebuild-pipeline-events-update.yaml」でUpdateする。Pipelineが更新され、CodeDeployが追加される。
CloudFormationではECS BlueGreenに対応していないため、Custom ResourceでLambdaを作成し、LambdaでDeployment Groupを作成する。
Lambdaの部分。
LambdaCodeDeploy: Type: AWS::Lambda::Function Properties: Code: ZipFile: | import json import boto3 import cfnresponse def lambda_handler(event, context): print(event) if event['RequestType'] == 'Delete' or event['RequestType'] == 'Update' : responseData = {} responseData['Data'] = 'test' cfnresponse.send(event, context, cfnresponse.SUCCESS, responseData, "CustomResourcePhysicalID") client = boto3.client('codedeploy') applicationName = event['ResourceProperties']['applicationName'] deploymentGroupName = event['ResourceProperties']['deploymentGroupName'] serviceRoleArn = event['ResourceProperties']['serviceRoleArn'] targetGroups1 = event['ResourceProperties']['targetGroups1'] targetGroups2 = event['ResourceProperties']['targetGroups2'] listenerArns = event['ResourceProperties']['listenerArns'] serviceName = event['ResourceProperties']['serviceName'] clusterName = event['ResourceProperties']['clusterName'] response = client.create_deployment_group( applicationName=applicationName, deploymentGroupName=deploymentGroupName, serviceRoleArn=serviceRoleArn, autoRollbackConfiguration={ 'enabled': True, 'events': ['DEPLOYMENT_FAILURE'] }, deploymentStyle={ 'deploymentType': 'BLUE_GREEN', 'deploymentOption': 'WITH_TRAFFIC_CONTROL' }, blueGreenDeploymentConfiguration={ 'terminateBlueInstancesOnDeploymentSuccess': { 'action': 'TERMINATE', 'terminationWaitTimeInMinutes': 5 }, 'deploymentReadyOption': { 'actionOnTimeout': 'CONTINUE_DEPLOYMENT', 'waitTimeInMinutes': 0 } }, loadBalancerInfo={ 'targetGroupPairInfoList': [ { 'targetGroups': [ { 'name': targetGroups1 }, { 'name': targetGroups2 } ], 'prodTrafficRoute': { 'listenerArns': [ listenerArns, ] } }, ] }, ecsServices=[ { 'serviceName': serviceName, 'clusterName': clusterName }, ] ) cfnresponse.send(event, context, cfnresponse.SUCCESS, response, "CustomResourcePhysicalID") Handler: index.lambda_handler Runtime: python3.7 Timeout: 30 Role: !GetAtt LambdaExecutionRole.Arn CreateCodeDeployGroup: Type: Custom::LambdaCallout Properties: ServiceToken: !GetAtt LambdaCodeDeploy.Arn applicationName: httpd-bluegreen deploymentGroupName: httpd-bluegreen-dg serviceRoleArn: !GetAtt CodeDeployRole.Arn targetGroups1: !ImportValue targetgroup1-name targetGroups2: !ImportValue targetgroup2-name listenerArns: !ImportValue listener1-arn serviceName: !ImportValue ecs-servicename clusterName: !ImportValue ecs-clustername全体構成
作業完了後の全体構成は下記となる。
テスト
index.htmlを更新する。
appsec.yamlを更新する。
httpd-repoをPushする。
Pipelineが反応する。
Deploymentが実行する。
WEBページが更新されることを確認。












- 投稿日:2020-04-21T15:26:55+09:00
AWS認定 機械学習 - 専門知識に合格したので、実践した勉強方法を共有します
はじめに
AWS認定 機械学習 - 専門知識にスコア849点で合格しました。勉強期間は約1ヶ月でした。
私が実践した勉強方法を共有しますので、これから受験する方の参考になれば幸いです。
私とAWSと機械学習
AWS歴は約4年です。
機械学習を業務で扱ったことはありません。機械学習系のAWSサービスで言うとAmazon PersonalizeとAmazon Forecastのハンズオンセミナーに参加したことがあるくらいです。
元々の機械学習に関する知識もほぼ皆無でした。絞り出すとしたら、以下くらいです。
- 教師あり学習と教師なし学習というものがあるらしい
- 最近は強化学習というものも注目されているらしい
- がっつり学習しようとすると高性能なマシンが必要になるらしい
こんな感じの人が以下の勉強方法で約1ヶ月勉強したら合格できたと思ってください。
実践した勉強方法
私が実践した勉強方法を共有します。基本的に上から順番に実施していきました。
先駆者の方々のまとめ記事を見る
既に受験された方々のまとめ記事を見て、出題範囲のAWSサービスや問われる知識分野を把握しました。
私は以下の記事を参考にさせて頂きました。
- AWS 認定 機械学習 – 専門知識(Machine Learning – Specialty)合格に向けたオレオレ学習ガイドライン
- AWSの機械学習エンジニア認定試験を受けてきた
- AWS認定 機械学習 合格しました
BlackBeltを読む
出題範囲のAWSサービスが分かったら、対象サービスのBlackBeltを読んで、サービス概要をざっくり理解しました。
機械学習入門本を読む
機械学習の基礎知識が全く無かったので、「機械学習入門 ボルツマン機械学習から深層学習まで」を読みました。
AWSトレーニングルーム(eラーニング)を受講する
AWS認定 機械学習 - 専門知識のトレーニングルームを受講しました。
講義内でサンプル問題を解くことができるので、満点を取るまで繰り返し解きました。サンプル問題を解く
サンプル問題を解きました。なぜか日本語訳が公式から提供されていないので、日本語訳されている記事を見て解いてました。満点取るまで繰り返し解きました。
公式の模擬試験を受験する
公式の模擬試験を受験しました。正答率は50%(20問中10問正解)でした。
終わった後も繰り返し解けるように、問題文と選択肢の画面を試験時間中にスクショしておきました。
公式の模擬試験は各問の回答が分かりません。なので、公式ドキュメントや機械学習系の記事を調べて、自分で答えを見つける必要があります。
本当に合っている答えかは分かりませんが、満点が取れるまで繰り返し解きました。非公式の問題集を解く
Amazonで以下の非公式の問題集(電子書籍)を購入して解きました。どちらも¥1000ちょっとで購入できます。英語だと問題内容を理解するのに疲れてしまうので、DeepL用の翻訳ブックマークレットを利用して日本語にして解いてました。
- AWS Certified Machine Learning Specialty Practice Dumps: AWS Certified Machine Learning Specialty Practice test questions 2020. 100% pass guarantee on first attempt. (English Edition)
- こちらの問題集はおすすめしません。実際の試験問題よりも難しくて、本番ではほぼ出てこなかったAmazon Machine Learningサービスの問題が大半でした。
- AWS Certified Machine Learning – Specialty- LATEST VERSION: Pass you Exam & Validate your ability to build, train, & deploy machine learning models using the AWS Cloud, (MLS-C01) (English Edition)
- こちらの問題集はおすすめします。実際の試験問題の内容とレベルにマッチした問題が多くありました。ただし、2割くらいの問題の回答が間違っているので注意が必要です。回答をそのまま鵜呑みにせずに、自分で調べて本当に回答が合っているかを見極める必要があります(調べる過程で知識が付いた気もするのでそれが良かったかも)。累計5周くらい解きました。
感想
先駆者の方々も言われていますが、AWS認定試験の中で一番AWS色が薄い試験だと思いました。問題文にAWSサービスが1つも出てこないものが全問題の1/3くらいを占めてた感覚でした。その分やはり勉強に苦労しました。機械学習の前提知識がある人にとっては簡単なのかもしれませんが、ほぼゼロから勉強するのはけっこう大変でしたね。。
今回の勉強を通して、機械学習のフローや用語をなんとなく理解できる程度にはなれたと思います。今のところ業務で扱う予定はありませんが、今後何かで使える日がくれば良いなと思います。
- 投稿日:2020-04-21T14:41:09+09:00
Amazon Linux2のEC2にCloudWatchのLogAgentを導入する
まいど。ゆうべはお楽しみでしたね。
AWS東京リージョンで発生した障害について(4.20)
CloudWatchやSQS,Lambda辺りが対象だったようなので
ウチのEC2やS3とかには特に影響無かったようですが、
逆に言うと古き良きサーバマネジメントしか出来てないという事実を突きつけられました。
世の中どんどん進化してるので上記のようなサービスも知ってないといけないなぁと痛感。ということで昨日障害が起きたサービスを一つずつ理解しようと思い、
CloudWatchから触ってみることにしました。そもそもCloudWatchとは何なのか
調べりゃ分かることなんで詳細は書きませんが要は監視ツールです。
コンソールにあるのでインスタンスを持ってたら見れるでしょう。
log取りを導入してみる
とりあえずapacheのaccess_logを収集出来るようにしてみようということで
他の記事や公式資料を参考にしてみましたがなんかsetup.pyが対応してないような?
AmazonLinux2はyumから導入出来るようなのでそっちの手段を使います。
EC2 Linux インスタンスの起動時に CloudWatch Logs エージェントをインストールして設定するyum install awslogs/etc配下にawslogディレクトリが切られるので中のconfを編集
IAMでCloudWatchLogsFullAccessを割り当てたユーザのアクセスキーを追加し、
EC2のawscli経由でCloudWatchLogにアクセス出来るようにしておく。awscli.conf[plugins] cwlogs = cwlogs #これはなんだ、分からん [default] region = ap-northeast-1 #regionを変更 #以下awscliのアクセスキー情報 aws_access_key_id=XXXXXXXXXXXXX aws_secret_access_key=XXXXXXXXXXXXXXXXXXXXXawslogs.conf#色々書かれてるが一番下にmessesagesの定義が書いてるのでこれを参考にする [/var/log/messages] datetime_format = %b %d %H:%M:%S file = /var/log/messages buffer_duration = 5000 log_stream_name = {instance_id} initial_position = start_of_file log_group_name = /var/log/messages #↓今回これをこうした [/var/log/httpd/access_log] datetime_format = %b %d %H:%M:%S file = /var/log/httpd/access_log buffer_duration = 5000 log_stream_name = {instance_id} initial_position = start_of_file log_group_name = /var/log/httpd/access_logサービスを開始...systemctlの書き方をなかなか覚えられない...
service awslogsd start動作してるのを確認
access_logが更新されるように適当に作ったWebページにアクセスしてコンソールを見る。
出てた。けど名前なんとかならないのか。
awslogs.conf[Apache-access_log] #多分識別子なだけなので任意 datetime_format = %b %d %H:%M:%S file = /var/log/httpd/access_log buffer_duration = 5000 log_stream_name = {instance_id} initial_position = start_of_file log_group_name = shindev-log #ここを変えるサービスを再起動して再確認
service awslogsd restart
行けた。
グループ単位で他のログを取ってみる。
なんでもいいんだけどerror_logを追記、ついでにlog_stream_nameを変更してログファイル単位で分別する形にした。awslogs.conf[Apache-error_log] datetime_format = %b %d %H:%M:%S file = /var/log/httpd/error_log #対象ファイル buffer_duration = 5000 log_stream_name = shindev-ec2-error_log #ここを変更 initial_position = start_of_file log_group_name = shindev-log #ここは同じこうなりました。
使い方大体分かったような気がする。
終わり。



- 投稿日:2020-04-21T14:07:30+09:00
【機械学習に役立つ3つのAWSサービス】SageMaker・Athena・Glueについて解説
AWSで機械学習を行うときに、役に立つサービスを紹介します!
なお当記事の読者として、以下の知識がある方を想定しています。
・ EC2、S3及びRDSといったAWSの基本的な機能
・ 機械学習のおおまかな流れについて
・ Jupyter notebookとは?この記事では、特に使用頻度の多い「SageMaker」「Athena」「Glue」の三つのサービスについて、それぞれの特徴と使用場面をざっくり理解していただけたらと思います!
AWSで機械学習を行うメリット
- ライブラリを標準装備しているため、環境設定を行う必要がない
- 学習に時間がかかる場合でも、インスタンスの性能を引き上げることで高速化が可能
- 既にAWSを使っていて、S3などのストレージに学習データがある場合、処理がスムーズ
- データベースや学習の実装、デプロイまでを一貫してAWS上で行うことができる
ローカルマシンではなく、AWS上で機械学習を行うことで、このようなメリットがあります。
SageMaker
機械学習を行う際、多くの人がJupyter notebookを使うことでしょう。
SageMakerとは、AWSのインスタンス上でJupyter notebookを使用できるサービスです。
SageMakerを使うことで、クラウド上でnotebookでの学習を完結することができます。
SageMaker上でコードを書きながら実行することもできますし、ローカルで作成したnotebook形式のファイルを読み込んで動かすこともできます。また、組み込みアルゴリズムを利用できたり、作成したアルゴリズムの保存、モデルに関する分析など、機械学習に役立つ様々な機能がついています。
Athena
容量無制限のストレージであるS3は、「ファイルの置き場」としてよく使われます。
機械学習をする際、学習にこのS3内のデータを使いたいという場面があるでしょう。
このような場合に役に立つのがAthenaというサービスです。Athenaは、S3内のデータをSQLのクエリで操作できるサービスです。
S3内にあるファイルに対し、スキーマを定義すれば、SQL文を実行するだけで必要なデータを取り出すことができます。「S3のファイル内の膨大な情報から、数種類のデータだけ取ってきて機械学習にかけたい」というときは、Athenaで必要な部分だけ出力したCSVを作ることができます!
Glue
Athenaはとても便利ですが、S3内のファイルがスキーマを定義できないほど散らかっている場合は困ってしまいます。
そういった場合、まず散らかったS3のデータをある程度使いやすい形に加工して別ファイルとしてS3に保存し、その上でAthenaを使用したいですよね。ここで活躍するサービスがGlueです。Glueは、RDSやS3といったストレージ内のデータを加工したり変換するためのサービスです。
S3内のデータを加工してS3に再び保存する場合にも使えますし、RDS内のデータをS3に変換するといったデータ変換にも使うことができます。「機械学習を行うために、ファイルの形をまとめて整えてあげたい」という際はGlueを使ってみてください!
まとめ
- 「SageMaker」はクラウド上でJupyter notebookが使え、さらにAWSオリジナルの機械学習に役立つ便利機能もついてくるサービス
- 「Athena」はS3のファイル内のデータをSQLクエリで操作できるサービス
- 「Glue」はRDSやS3内のデータを機械学習に使いやすい形に加工するのに役立つサービス
- 投稿日:2020-04-21T13:43:19+09:00
コロナリモートに打ち勝つAWSログイン問題解決方法の提案
はじめに
AWSアカウントのセキュリティを守るため、ログイン時に多要素認証する検討を行いましたが、簡単に多要素認証を実装するには、メンバーの私用スマホにアプリをインストールする必要がありました。私用スマホには入れるのはあまり好ましくないので、アプリをインストールせずにセキュリティ面を強化できると良い!ということで、IPアドレス制限をかけることにしました!
しかし、IPアドレス制限をかけていることで、リモート勤務するにあたり弊害があったので、解決方法を提案します!
状況整理
IAMユーザのIP制限
全てのIAMユーザにIP制限のIAMポリシーがアタッチされているため、決められたIPアドレスからしかログインができません。
アタッチされているIAMポリシーは以下の通りです。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Deny", "Action": "*", "Resource": "*", "Condition": { "NotIpAddress": { "aws:SourceIp": [ "[オフィスのIPアドレス]/32" ] } } } ] }自宅のIPアドレスが毎日変わる
コロナの影響で自宅勤務になりましたが、ポケットWi-FiのIPアドレスが毎日変わり、IAMポリシーで事前に自宅のIPアドレスを登録することができません。
期間限定
現状はコロナの影響での在宅勤務なので、期限はコロナが落ち着くまで。あんまりコストもかけたくない!
解決方法
IPアドレスを追加する処理とIAMポリシーをお掃除する処理の2つの処理を実行することにしました。
IPアドレス追加処理
自宅から許可したいIPアドレスを持たせてAPI Gatewayを叩きます。そのAPI GatewayをトリガーとしてLambdaを実行し、最新のIAMポリシーに先ほど持たせたIPアドレスを追加します。API Gatewayはフルオープンになっていますが、AWSへログイン時に認証情報が必要なので、そこでセキュリティは担保しています。
ポリシーお掃除処理
毎日IPアドレスが追加されるので、IAMポリシーをお掃除(リセット)するためのLambdaを定期実行させます。S3に保存してあるIPアドレス追加処理前のIAMポリシーオブジェクトを取得し、IAMポリシーを更新します。こちらはCloudWatch Eventsをトリガーとします。
IAMポリシーを更新するときに必要なこと
IAMポリシーは最大5つまでバージョンを保存することができます。コンソール上でIAMポリシーを更新する際には、保存されているバージョンのうち1つ削除することで、5つ以上増えないようになっています。しかし、Lambda関数でIAMポリシーを更新する際には、削除処理を実装しなければいけません。また、デフォルト と表記があるバージョンが使用されるIAMポリシーなので、新しく追加するIAMポリシーをデフォルトに設定する必要があります。
IP制限IAMポリシーの作成
今回は例として
123.123.123.123のIPアドレスのみを許可したIAMポリシーを作成しました。実際にはこのポリシーをユーザにアタッチしておきます。{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Deny", "Action": "*", "Resource": "*", "Condition": { "NotIpAddress": { "aws:SourceIp": [ "123.123.123.123/32" ] } } } ] }IPアドレス追加処理
IP制限IAMポリシーに、許可したいIPアドレスを追加します。
Lambda関数の作成
Lambda関数を作成していきます。
IAMポリシー
AWSにIP制限をかけているIAMポリシーに対しての以下の権限を付与します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:GetPolicyVersion", "iam:ListPolicyVersions", "iam:CreatePolicyVersion", "iam:DeletePolicyVersion" ], "Resource": "[IP制限IAMポリシーarn]" } ] }このポリシーをアタッチしたIAMロールを作成し、Lambdaに紐づけてください。
ソースコード
golangで書いてみました。
ソースコード : https://github.com/Maika995/aws-sourceip/blob/master/add/main.goAPI Gatewayの作成
GETメソッドを作成します。作成方法は下記の記事を参考にさせていただきました。
参考:AWS Lambdaにクエリ文字列(get値)を引数で渡すトリガを設定する前述のLambdaのコードに合わせて、クエリとしてIPアドレスを持たせるため、メソッドリクエストは以下のように設定しました。
そして、統合リクエストのマッピングテンプレートはテンプレートが定義されていない場合を選択し、以下のテンプレートを入力しました。
application/json{ "SourceIp": "$input.params('SourceIp')" }
最後にリソースのデプロイを行い、発行されたURLをコピーしておきます。
実行結果
コピーしておいたURLにIPアドレスをクエリとして持たせてブラウザからたたきます。
ブラウザにはLambda関数の戻り値として設定していた文字列が返ってきたので成功したっぽいです。
IAMポリシーを確認すると…
無事先ほど指定したIPアドレスが許可されています!
これで、無事自宅からでもAWSにログインできるようになりました!ポリシーお掃除処理
定期実行でIAMポリシーを元々のIAMポリシーに戻す、お掃除バッチの実装です。
S3の作成
元バージョンのIAMポリシーを保管するために、S3バケットを作成します。パブリックアクセスもすべてブロックしたバケットを作成し、先ほどのIP制限IAMポリシーをJSONファイルにしてアップロードします。
Lambda関数の作成
Lambda関数を作成していきます。
IAMポリシー
IAMポリシーに関する権限に加えて、S3のオブジェクトを取得する権限を付与します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::[バケット名]/[オブジェクト名]" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "iam:ListPolicyVersions", "iam:CreatePolicyVersion", "iam:DeletePolicyVersion" ], "Resource": "[IP制限IAMポリシーarn]" } ] }このポリシーをアタッチしたIAMロールを作成し、Lambdaに紐づけてください。
ソースコード
golangで書いています。
ソースコード : https://github.com/Maika995/aws-sourceip/blob/master/clean/main.goCloudWatch Events
夜中の0時に定期実行するように設定しました。
そしてお掃除Lambdaに紐付けます。
Cron式で設定します。UTCなので-9時間で表記します。
実行結果
0時をすぎて、IAMポリシーがリセットされていることが確認できました!
おわりに
注意事項
1回目の実行時は削除できるIAMポリシーのバージョンがないので、(デフォルトのバージョンは削除できません。)バージョンの削除処理の部分で409エラーが返ってきていますが、その他の処理は普通に実行されます。2回目以降はバージョンが2つ保存されているので、409エラーも出ることなく、古いバージョンが削除されるようになります。
ボツになった施策
第一弾は、以下のようにポリシーのバージョンの中で1番古いバージョン(3番)をお掃除処理に使用するバージョンにしていました。
- 最新ポリシー(デフォルト)
- 2番目に新しいポシリー
- お掃除に使用する、元々のIP制限ポリシー
両方の処理とも2番目に新しいポリシーを削除して更新します。お掃除処理は3つ目のポリシーを取得してそのまま使うようにしていましたが…ある日、リセットされてない!ってことに気づきました。3番のバージョンがなくなっていました。おそらく複数人が利用しているAWSなので、手動でIAMポリシーを変更したなど、無意識に3番のバージョンが削除されてしまったのかなと思います。そういう経緯もあり、いろいろな人が使うものなので、お掃除用のバージョンはS3にファイルを置くことにしました!
より良くするには
上記の設定であれば、API Gatewayはフルオープンでどこからでもたたくことができます。あまり手間をかけずセキュリティ面でより固くするなら、クエリの条件にパスワードとかを追加してみるのもいいかなと思います!あとは、APIキーとかを使ってみるのも良さそう。
感想
現在、在宅勤務なので実際に使っていますが問題なく自宅からAWSにログインができています!
これでAWSログイン問題解決しました!めでたしめでたし!あと、golangを使う機会も少しずつ増えてきて、golangとSDKの苦手意識薄まってきたなあと感じました!









- 投稿日:2020-04-21T11:16:54+09:00
【AWS EC2】Amazon Linux2にnginxをインストールする方法
概要
AWS EC2(AMI: Amazon Linux 2)にnginxをインストールする
環境
- AWS EC2
- OS: Amazon Linux 2
- AMI ID: amzn2-ami-hvm-2.0.20200304.0-x86_64-gp2
構築手順
1. Amazon Linux Extrasを確認する
Amazon Linux2にはnginxのyumが無いので、Amazon Linux Extrasでnginxを探します。
$ yum search nginx Loaded plugins: extras_suggestions, langpacks, priorities, update-motd 31 packages excluded due to repository priority protections ============================================================ N/S matched: nginx ============================================================= pcp-pmda-nginx.x86_64 : Performance Co-Pilot (PCP) metrics for the Nginx Webserver Name and summary matches only, use "search all" for everything. $ amazon-linux-extras list | grep nginx 38 nginx1 available [ =stable ] $ amazon-linux-extras info nginx1 nginx1 recommends nginx # yum install nginx2. nginxをインストールする
Amazon Linux Extrasでnginxをインストールします。
$ sudo amazon-linux-extras install nginx1 Installed: nginx.x86_64 1:1.16.1-1.amzn2.0.1 Dependency Installed: gd.x86_64 0:2.0.35-26.amzn2.0.2 gperftools-libs.x86_64 0:2.6.1-1.amzn2 libXpm.x86_64 0:3.5.12-1.amzn2.0.2 nginx-all-modules.noarch 1:1.16.1-1.amzn2.0.1 nginx-filesystem.noarch 1:1.16.1-1.amzn2.0.1 nginx-mod-http-geoip.x86_64 1:1.16.1-1.amzn2.0.1 nginx-mod-http-image-filter.x86_64 1:1.16.1-1.amzn2.0.1 nginx-mod-http-perl.x86_64 1:1.16.1-1.amzn2.0.1 nginx-mod-http-xslt-filter.x86_64 1:1.16.1-1.amzn2.0.1 nginx-mod-mail.x86_64 1:1.16.1-1.amzn2.0.1 nginx-mod-stream.x86_64 1:1.16.1-1.amzn2.0.1 Complete! 38 nginx1=latest enabled [ =stable ] $ nginx -v nginx version: nginx/1.16.13. nginxを起動する
nginxを起動して、次回以降はサーバー起動時に自動で起動するように設定します。
$ sudo systemctl start nginx $ sudo systemctl status nginx ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset: disabled) Active: active (running) since Mon 2020-03-30 15:38:21 JST; 7s ago $ sudo systemctl enable nginx Created symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service. $ systemctl is-enabled nginx enabledセキュリティグループで80を開放していれば、EC2のパブリックIPでnginxのデフォルト画面が表示されます。
参考
- 投稿日:2020-04-21T11:00:11+09:00
AWS Launch Wizard で SAP のデプロイを加速させる
はじめに
2019年から「AWS Launch Wizard for SQL Server」というサービスが AWS から発表されました。
今回もそのブログ内容と利用方法をご紹介させて頂きます!
AWS Launch Wizard for SAP について
- ※エンタープライズワークロード向けの AWS に、高可用性 SQL ソリューションをデプロイ
- 迅速、簡単、柔軟、安全、コスト効率が高い
- AWS CloudFormation と AWS Systems Manager を使用
- 基盤となる AWS リソースのプロビジョニングを調整することで、SAP アプリケーションを AWS にデプロイするのに役立つ
- AWS に新しい SAP ワークロードをデプロイするか、既存のオンプレミスの SAP ワークロードを AWS に移行する利用者向けに設計されている
※ミッションクリティカルなアプリケーションを稼働するプラットフォームを
「エンタープライズ ワークロード」と定義し、高性能・高信頼・高セキュリティなクラウド基盤を提供しているSAP ってなぁに
「SAP社」が製造する「ERP」製品のことです。(英: Enterprise Resource Planning)
- 全部門共通システムと呼ばれたりする
- 企業全体の資源(人・もの・金・情報)を管理するシステム
- 企業内で発生する、様々なデータを一元的に管理することによって、業務の最適化につなげていくという考え
- システムを統合することのメリットを、強く意識して生み出されたのが「ERP」という概念
- 個別に機能していたシステムを、会社全体で1つのシステムに統合するLaunch Wizard を使う利点
AWS の数千の利用者様が、AWS Quick Start と Amazon Elastic Compute Cloud (EC2) を使用して、SAP ワークロードを構築および移行しました。
これには、x1、x1e、ハイメモリインスタンスが含まれます。
さらに、AWS Partner Network (APN) for SAP を利用して、自分に合ったソリューションを見つけています。
SAP の利用者様は、AWS リソースを最大限に活用して SAP システムをデプロイするために、
利用者に一つずつ質問や設定項目を提示して、選択や入力を促し処理を進める、直感的な操作方式を求めています。■デプロイ効率
- SAP ワークロード要件に適合する、 Amazon EC2 インスタンスを推奨
- 推奨設定と最小限の手動入力で SAP システム向けの AWS のサービスの起動を自動化
- プロビジョニング評価の時間を短縮、SAP アプリケーションのデプロイを 2 倍高速化
■規範的ガイダンス
数千の SAP on AWS のデプロイのベストプラクティスに基づいて、SAP システム用の AWS のサービスの正しいサイジングとプロビジョニングを提供
■学習曲線の高速化
SAP のデプロイパターンに合わせた、ガイド付きのデプロイの手順を提供し、SAP 用語を使用して
SAP ユーザーになじみのあるサービス体験を提供SAP 環境を迅速に起動できることで、新しいビジネスの取組みの俊敏性が向上します。
スタートガイドを試してみた
なるべく分かりやすいように、ページを日本語に翻訳しています。
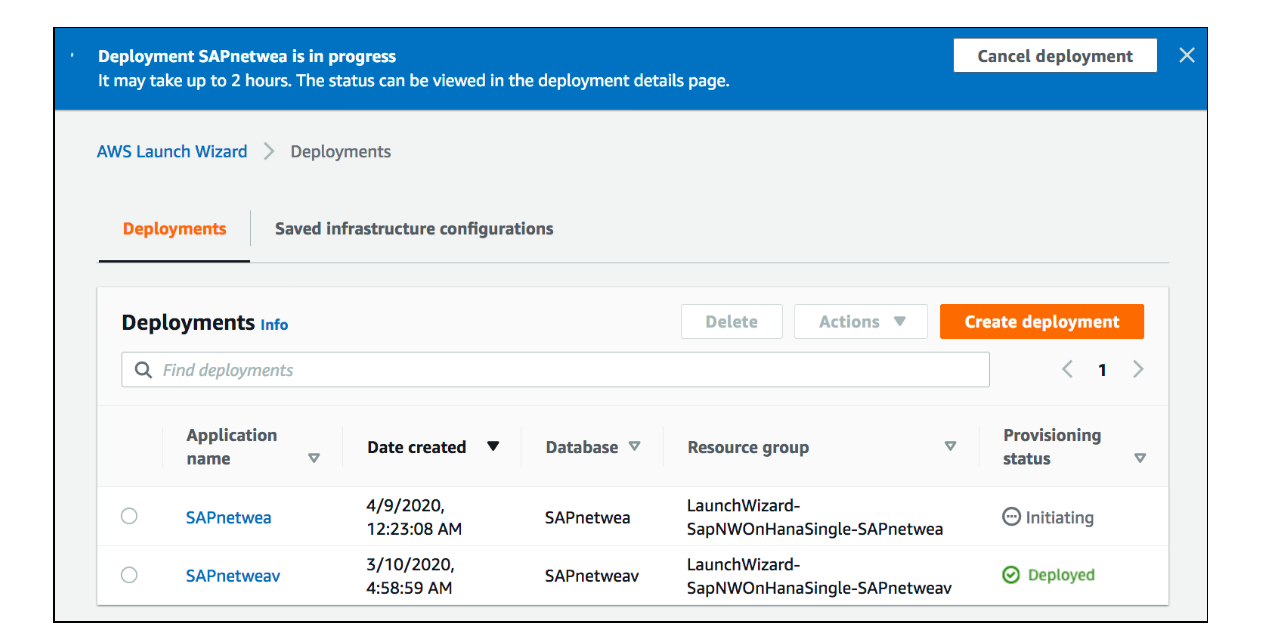
ステップ1 アプリケーションの選択
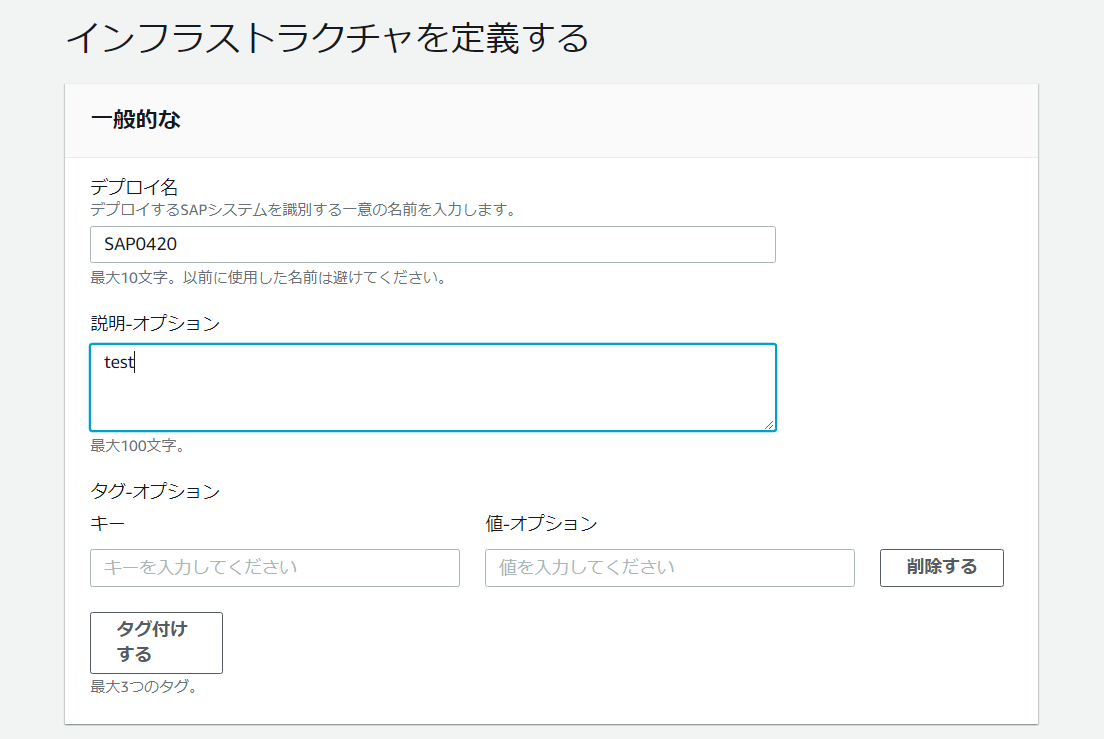
Launch Wizard コンソールで、[デプロイの作成] ボタンをクリックし、SAP アプリケーションを選択します。
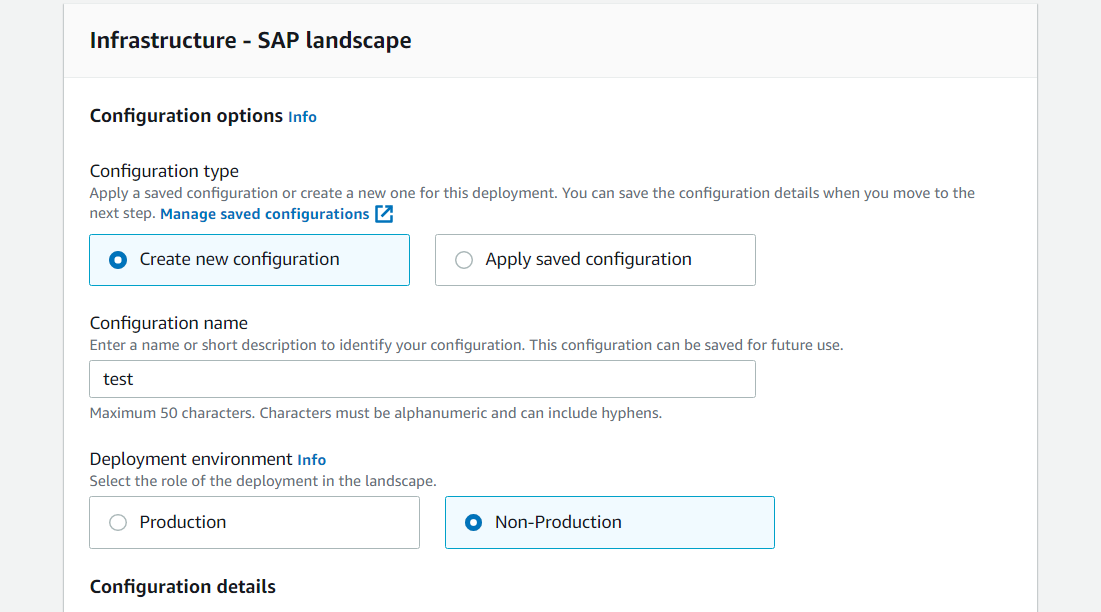
[次へ] ボタンをクリックすると、デプロイ名とインフラストラクチャ設定を指定できます。
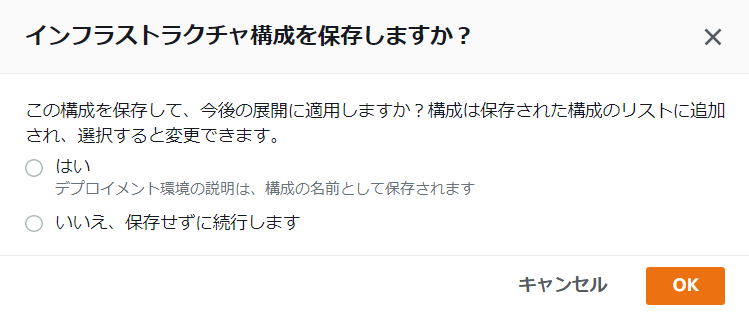
インフラストラクチャ設定は、インフラストラクチャを使用してデプロイを分類する方法に基づいて保存できます。
これらの設定は、同じインフラ設定を共有する SAP システムのデプロイに再利用できます。
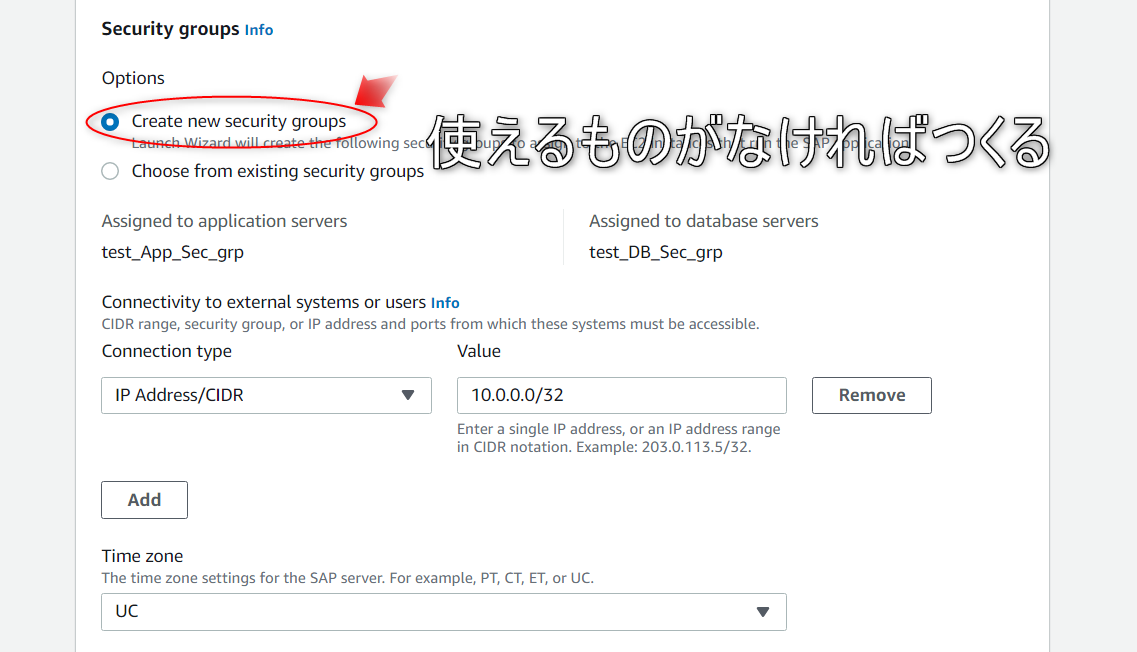
[Verify connectivity]にチェックをいれます。
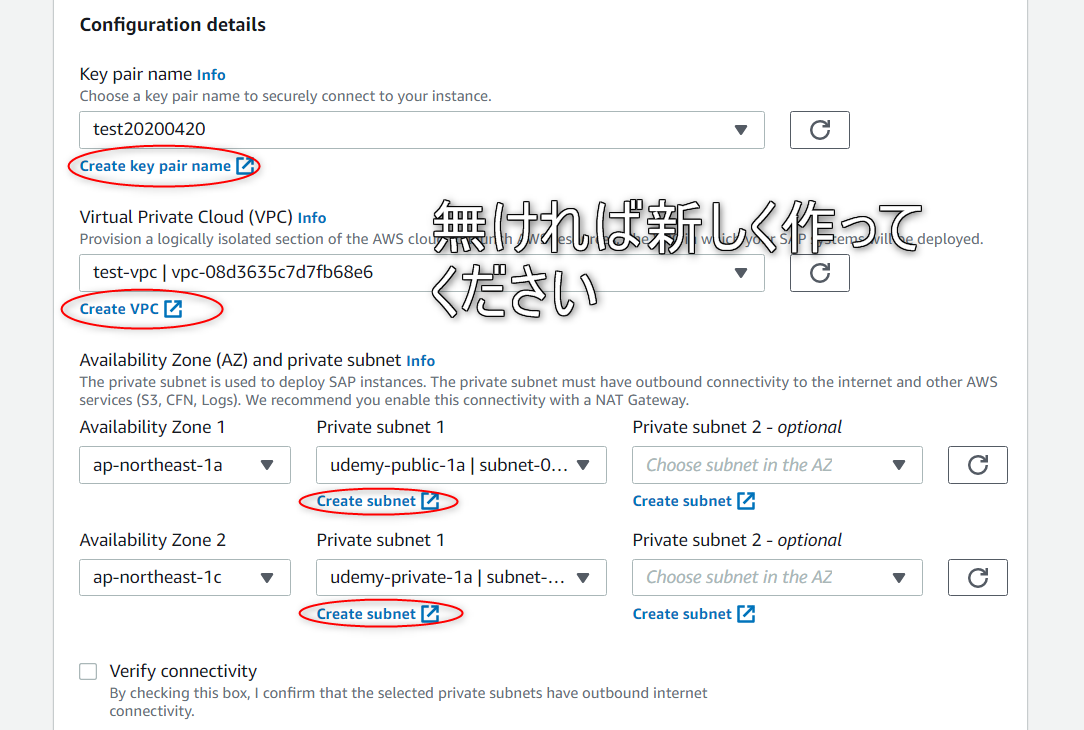
キーペアを割り当て、SAP インスタンスをデプロイする VPC を選択します。
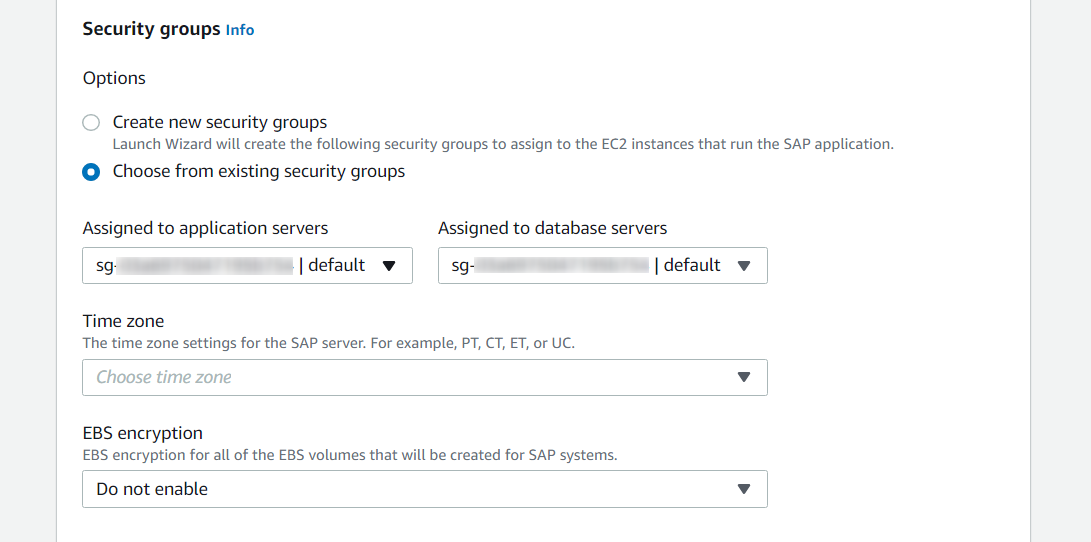
アベイラビリティーゾーンおよびプライベートサブネットを選択した後に、SAP アプリケーションを実行する EC2 インスタンスにセキュリティグループを割り当てることができます。
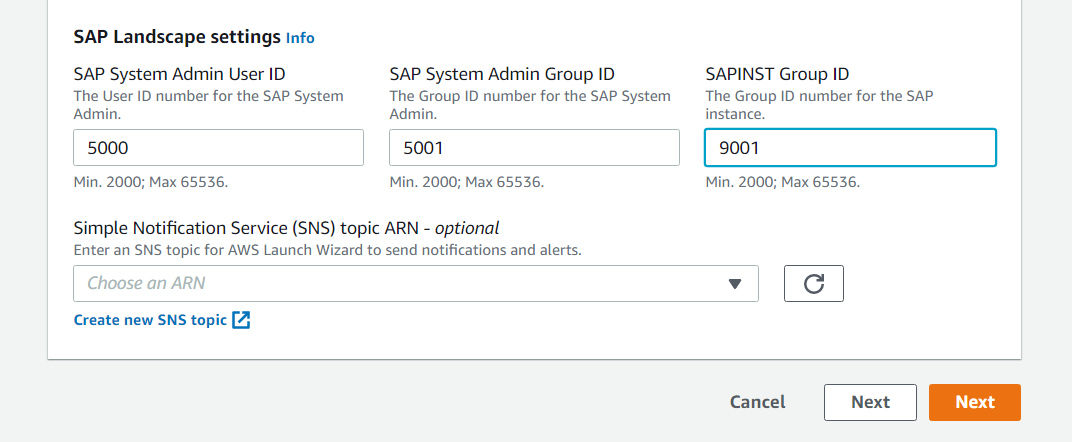
SAP システム管理者 ID を設定したら、Amazon Simple Notification Service (SNS) のトピックを設定して、SAP デプロイに関するアラートを取得できます。
[次へ] ボタンをクリックすると、アプリケーションの設定に移動できます。
インフラストラクチャ設定を保存すると、次回のデプロイに適用するために再利用できます。
ステップ2 インフラストラクチャを定義する
アプリケーション設定を構成すると、AWS Launch Wizard for SAP は、2 種類の SAP アプリケーションをサポートします。
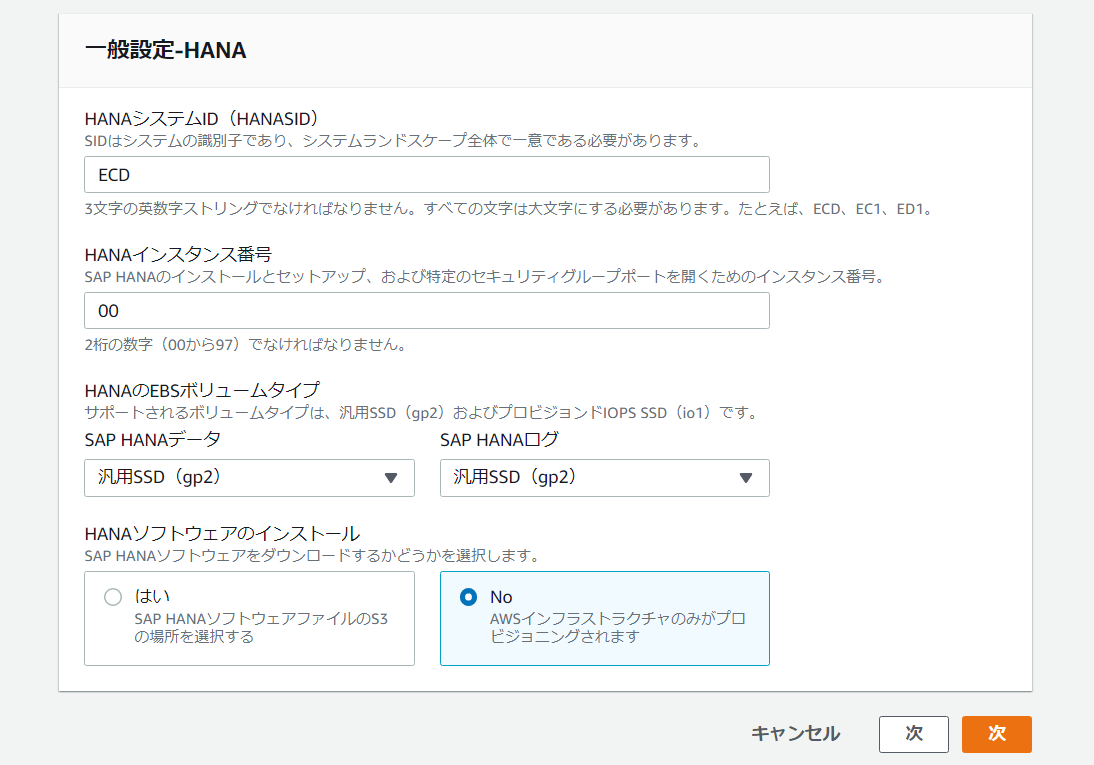
SAPHANA データベースデプロイとHANA データベースデプロイの NetWeaver スタックです。
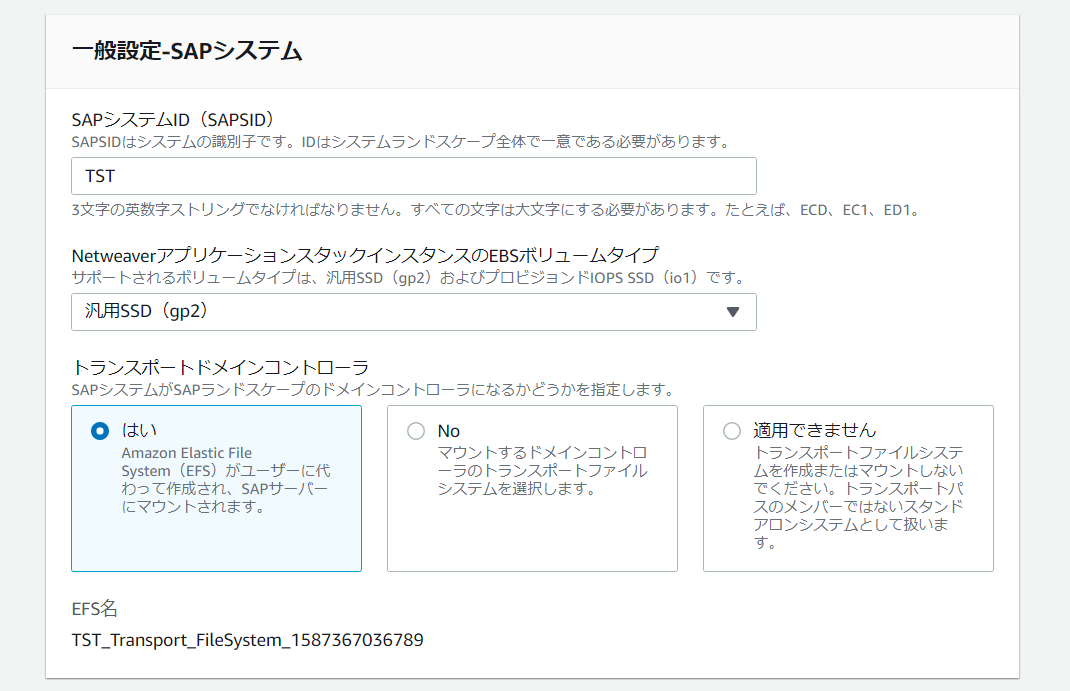
SAP HANA インストールで使用されるSAPSID、HANASID、およびインスタンス番号を指定し、これらの入力に基づいて AWS リソースを設定できます。
「SAP HANA Data and Log」 の 2 つの EBS ボリュームタイプをサポートします。
HANA データおよびログ – 汎用 SSD (gp2) および プロビジョンド IOPS SSD (io1) です。
オプションで、SLES/RHE を使用して高可用性を実現するために設定された HANA をデプロイするために、S3 バケットでホストされる HANA ソフトウェアを選択できます。
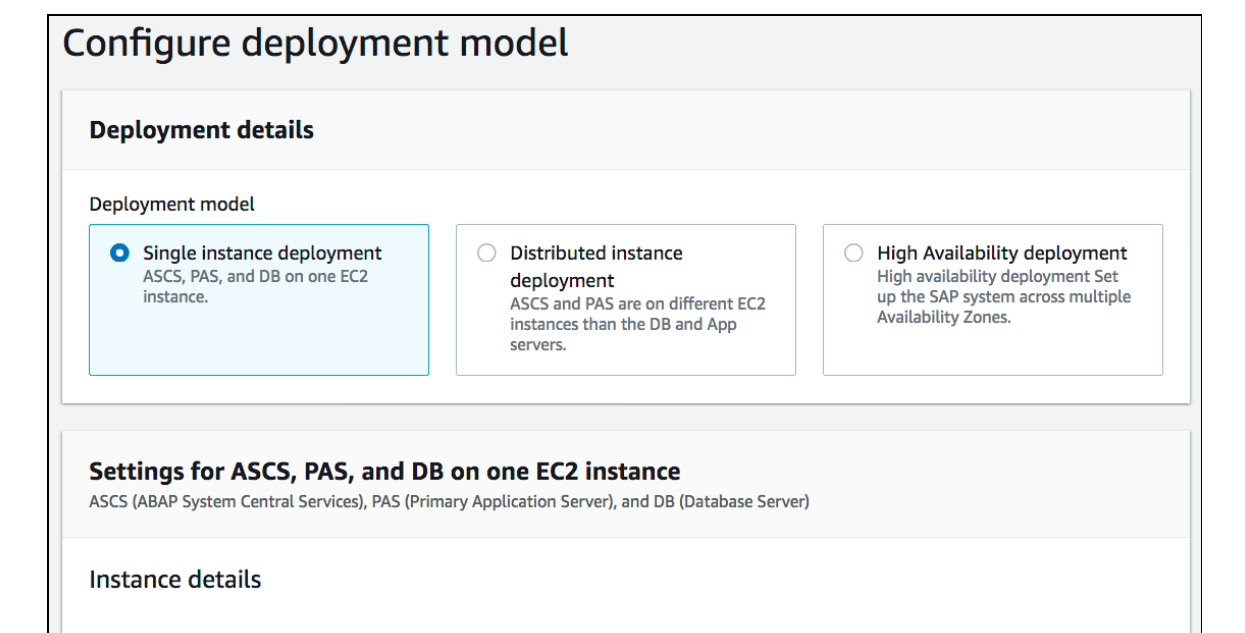
次に、SUSE Linux や RedHat Enterprise などの SAP がサポートするオペレーティングシステムを使用して、単一インスタンス、分散インスタンス、マルチ AZ の高可用性パターンにおけるデプロイモデルを設定できます。
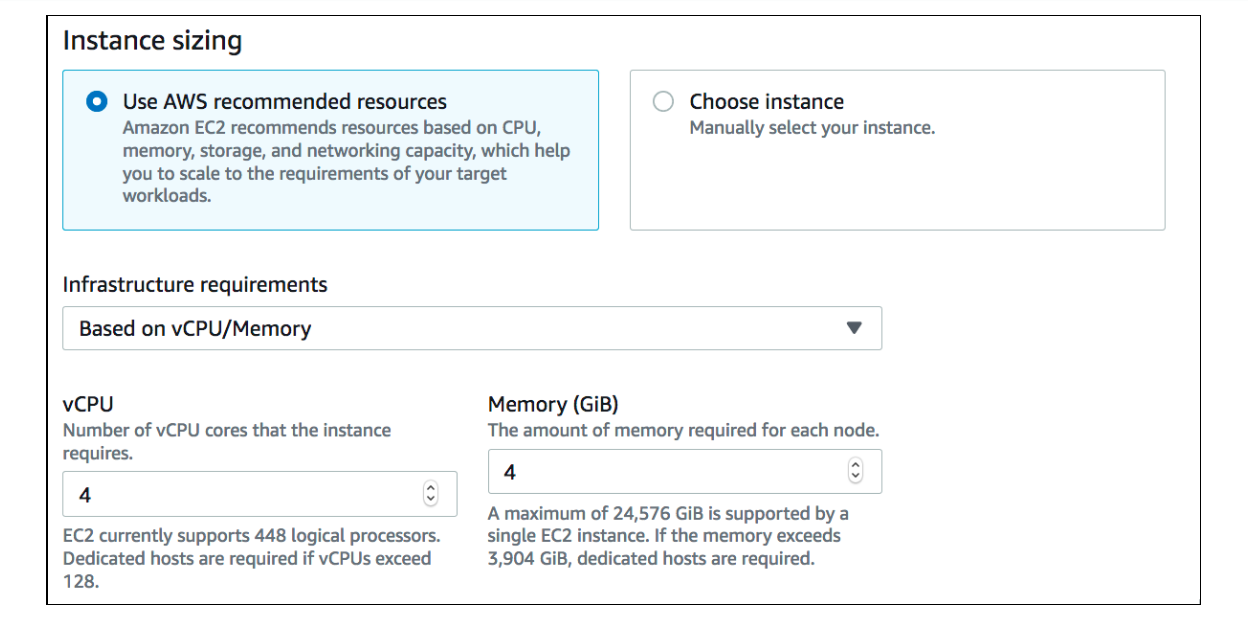
インフラストラクチャ要件を定義するときは、推奨ガイドを使用して vCPU/Memory を提供するか、
SAP コンポーネント (ASCS、ERS、APP、または HANA DB) の SAP がサポートする EC2 インスタンスのリストからインスタンスを手動で選択して、その上に SAP コンポーネントをデプロイできます。
特定のデプロイのためにプロビジョニングされる AWS リソース (Amazon EC2、EBS、および EFS ボリューム) のコストの見積もりを確認できます。
確認してみる
すべての設定を確認したら、[デプロイ] ボタンをクリックするだけでデプロイできます。
選択したデプロイに応じて、1~3 時間かかります。
デプロイされた SAP システム、デプロイに使用されたインフラストラクチャ設定、デプロイされた SAP のコンポーネント、 EC2 インスタンスへの SAP コンポーネントのマッピングを確認できます。
AWS Launch Wizard のご使用には追加料金はかかりません。
作成したリソースに対してのみ、料金が発生します。所感
「ERP」製品自体あまり触れたことがないので、イメージはしづらいですが、
一括で、基盤となる AWS リソースのプロビジョニングを調整することができるので確かに簡単、迅速であることを実感できました!
AWS リソースを最大限に活用して SAP システムをデプロイするために、是非活用してみてはいかがでしょうか。公式サイト




- 投稿日:2020-04-21T10:14:49+09:00
【AWSリソース操作自動化】制限緩和申請を行う
はじめに
皆さん、業務でAWSは使われているでしょうか。
AWS上でお客様ごとに環境を管理していたりすると、デフォルトの制限ではリソースが足りないということがよくあると思います。
そういう場合、今まではサポートに直接文章で連絡していたと思いますが、AWS Service Quotasを使用することでCLIで制限緩和を行えるようになりました。(2019/07)
https://aws.amazon.com/jp/blogs/news/aws-service-quotas/
自動化するうえでの注意点として、試しにcliでなげてみようとするとAWS運営側に本当に申請がいってしまうため、テストする場合は無駄にコマンドを実行しないようにしましょう。本題
そこで、今回は事前に1環境当たりの必要リソース数とリージョン当たりの必要環境数が明らかになっている前提の元、まとめてServiceQuotasで制限緩和を提出するスクリプトを書いてみました。
このスクリプトでは、現在のquotaを確認し、必要環境数に対して不足しているかどうかを判定、不足していれば必要数まで拡張を申請します。
ついでに、再実行しても問題ないように申請ステータスも確認し、処理されていないものがあればそのリソースについては申請を行いません。実装
リソース事に1環境当たり必要な数を記載したaws-resource.ymlを用意しておく
quota_info: AutoScalingGroup: adjustable: true count: 4 default: 200.0 global: false need_increase: true quota_code: L-CD****** quota_name: Auto Scaling groups per region service_code: autoscaling EIP:...以下のジョブで制限緩和を実行
pipeline { options { buildDiscarder(logRotator(daysToKeepStr: '30', numToKeepStr: '30')) disableConcurrentBuilds() } parameters { string(name: 'NODE_LABEL', defaultValue: "sre_slave", description: '') string(name: 'AWS_ACCESS_KEY', description: 'Specify the access key to be used.') password(name: 'AWS_SECRET_ACCESS_KEY', description: 'Specify the AWS Secret Access Key to be used.') booleanParam(name: 'TEST_FLAG', defaultValue: true, description: 'If set to true, no Request will be submitted.') } environment { AWS_ACCESS_KEY_ID = "${params.AWS_ACCESS_KEY}" AWS_SECRET_ACCESS_KEY = "${params.AWS_SECRET_ACCESS_KEY}" AWS_DEFAULT_REGION = "ap-northeast-1" AWS_DEFAULT_OUTPUT = "json" } agent { docker { label "${NODE_LABEL}" image 'amazon/aws-cli'//AWSの公式cliイメージ args "-t --entrypoint='' --init --cap-add=SYS_ADMIN -e LANG=C.UTF-8 -e AWS_ACCESS_KEY_ID=\$AWS_ACCESS_KEY_ID -e AWS_SECRET_ACCESS_KEY=\$AWS_SECRET_ACCESS_KEY -e AWS_DEFAULT_REGION='ap-northeast-1' -e AWS_DEFAULT_OUTPUT='json'" } } stages { stage('Request limit increase') { steps { script{ def regions = ["ap-northeast-1":110,"ap-southeast-1":15]//region_id:environment_number def environment_number = 0//想定環境数 def current_quota = 0//現在の制限数 def need_quota = 0 //必要な制限数 def margin = 0 //current_quota - need_quota def count_all = 0 //複数countがあった場合の合計値 def region_id //作業対象リージョン def resource_name //aws_resources.yml quota_infoのどの要素か def info //aws_resources.yml quota_infoの要素が持つ属性の集合 def execute_flg //trueなら制限緩和申請を行う def current_status //現在の制限情報の集合 def requested_quotas //提出された制限緩和申請の履歴の集合 def update_targets_region = [:] //TEST_FLAGがtrueの場合、ここに実行コマンドを格納 resource_name:command def update_targets = [] //update_targets_regionの集合 def resources_yaml = readYaml(file: "./aws_resources.yml") def quota_infos = resources_yaml //環境が立つリージョンそれぞれに実行 for (region in regions.entrySet()){ //aws-resourceからまずservice quotaで管理されているリソースの制限緩和申請を行う for (quota_info in quota_infos.quota_info.entrySet()){ execute_flg = true resource_name = quota_info.getKey() info = quota_info.getValue() print("${resource_name}:${info.quota_name}-${info.quota_code} need_increase: ${info.need_increase}") //need_increase(環境の増加によって拡張が必要)がtrueの場合のみ制限緩和対象となる if (info.need_increase){ //グローバルサービスはリージョンが固定 if (info.global){ print("${resource_name}:${info.service_code} is grobal service") region_id = "us-east-1" environment_number = 100 } else { region_id = region.getKey() environment_number = region.getValue() } current_quota = 0 need_quota = 0 margin = 0 //まず対象リソースの現状を取得 //get-service-quotaできないものがあるので、その場合はDefaultの値を使用する。 def check_result = sh( script:"export AWS_DEFAULT_REGION='${region_id}' && aws service-quotas get-service-quota --service-code ${info.service_code} --quota-code ${info.quota_code}", returnStatus: true ) if (check_result){//exit 0以外はtrue print("can't get current quota. so use default value.") current_quota = info.default } else { //ステータスをとるか標準出力を取るかしかできないので再実行 def current_status_json = sh( script:"export AWS_DEFAULT_REGION='${region_id}' && aws service-quotas get-service-quota --service-code ${info.service_code} --quota-code ${info.quota_code}", returnStdout: true ) current_status = readJSON text: current_status_json current_quota = current_status["Quota"]["Value"] } //必要なquotaを計算 need_quota = environment_number * info.count margin = current_quota - need_quota print("current:${current_quota} - need:${need_quota} = ${margin}") //現在の値が必要なリソース数未満の場合は更新リクエストを投げる if (margin >= 0){ print("There is enough margin ${resource_name}:${info.service_code}") execute_flg = false } else { print("need update ${resource_name}:${info.quota_name} to ${need_quota} ${region_id}") //リクエスト一覧を参照し、CASE_OPENDかになっているものがあれば更新対象からはずす //リクエストより低い値で適用されると再実行時に排除できない。 def requested_quotas_json = sh ( script: "export AWS_DEFAULT_REGION='${region_id}' && aws service-quotas list-requested-service-quota-change-history --service-code ${info.service_code}", returnStdout: true, ) requested_quotas = readJSON text: requested_quotas_json if (requested_quotas["RequestedQuotas"].size() > 0 ){ for (requested_quota in requested_quotas["RequestedQuotas"]){ if (requested_quota["QuotaCode"] == "${info.quota_code}"){ if (requested_quota["Status"] == "CASE_OPENED" | requested_quota["Status"] == "PENDING"){ print("The request cannot be made because there are ${requested_quota["Status"]} requests. id:${requested_quota["ServiceName"]} CaseId:${requested_quota["CaseId"]}") execute_flg = false break } } } } } } else { print("No update required ${resource_name}:${info.service_code}") execute_flg = false } //更新flgがtrueなら更新 if (execute_flg){ if (params.TEST_FLAG){//TEST_FLAGがtrueなら更新せず配列に結果を入れていく update_targets_region.put("${resource_name}", "aws service-quotas request-service-quota-increase --service-code '${info.service_code}' --quota-code '${info.quota_code}' --desired-value ${need_quota}") } else { sh "export AWS_DEFAULT_REGION='${region_id}' && aws service-quotas request-service-quota-increase --service-code '${info.service_code}' --quota-code '${info.quota_code}' --desired-value ${need_quota}" print("Requested ${resource_name}:${info.quota_name} to ${need_quota} ${region_id}") } } } if (params.TEST_FLAG){ sh "echo '{ \'${region_id}\' : \'${update_targets_region}\' }' >${region_id}_quota.json" archiveArtifacts "${region_id}_quota.json" } } } } } } post { always { cleanWs() } } }おわりに
今回も、すでにあるかなと思ったらなかったので書いてみたシリーズです。
正直、私はコーディングは体系的に学んできたわけでもなく、OJTのみでやってきたので、あまり格好いいコードはかけていないと思います。(ぶっちゃけ晒したくない。怖い)
なので、そういった観点からもコメントいただければありがたく思います!以上、お疲れ様でした。
- 投稿日:2020-04-21T09:25:17+09:00
AWS Client VPN で1つのエンドポイントで複数のクライアント証明書を利用する方法
相互認証利用し、1つのエンドポイントでクライアント証明書を各ユーザーごとに分けたい場合の設定
- 相互認証用のサーバーとクライアントの証明書とキーを生成
- クライアント VPN エンドポイントの作成
- クライアントの設定
- ログの確認
- クライアント証明書失効リストを利用した、接続の取り消し
相互認証用のサーバーとクライアントの証明書とキーを生成
手順は、一部を除いてこの通りに作っていきます
https://docs.aws.amazon.com/ja_jp/vpn/latest/clientvpn-admin/authentication-authrization.html#mutualOpenVPN Easy-RSA レポジトリのクローンを作成し、新しい PKI 環境を初期化します
以後、証明書や鍵の管理はこの環境で実施します。$ git clone https://github.com/OpenVPN/easy-rsa.git $ cd easy-rsa/easyrsa3 $ ./easyrsa init-pki新しい認証機関 (CA) を構築します
Common Name を聞かれるので、管理しやすい名前を指定します。デフォルトでも構いません。$ ./easyrsa build-ca nopass Using SSL: openssl LibreSSL 2.8.3 Generating RSA private key, 2048 bit long modulus ..........................................+++ ...................................................................................................................+++ e is 65537 (0x10001) You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Common Name (eg: your user, host, or server name) [Easy-RSA CA]:Private CA CA creation complete and you may now import and sign cert requests. Your new CA certificate file for publishing is at: /xxx/yyyy/easy-rsa/easyrsa3/pki/ca.crtサーバー証明書とキーを生成します
$ ./easyrsa build-server-full server.example.com nopassクライアント証明書とキーを生成します
今回はクライアントごとに証明書とキーを作成するので、名前を変えて複数枚作ります
とりあえず Common Name をclient1.example.comとclient2.example.comにします
100ユーザー分欲しいなら100個作ってくださいパスフレーズなしでないとインポートできないので、いったん nopass で作ります
$ ./easyrsa build-client-full client1.example.com nopass $ ./easyrsa build-client-full client2.example.com nopassサーバー証明書とキー、およびクライアント証明書とキーを適当なフォルダにコピーして移動します
$ cp pki/ca.crt /custom_folder/ $ cp pki/issued/server.crt /custom_folder/ $ cp pki/private/server.key /custom_folder/ $ cp pki/issued/client1.domain.tld.crt /custom_folder $ cp pki/private/client1.domain.tld.key /custom_folder/ $ cd /custom_folder/サーバー証明書とキーを ACM にアップロードします
$ aws import-certificate --certificate file://server.example.com.crt --private-key file://server.example.com.key --certificate-chain file://ca.crt --region us-east-1クライアント証明書とキーを ACM にアップロードします
注意:
client1.example.comの証明書とキーのみアップロードします。何枚作成したとしてもそのうち1枚のみで構いません。$ aws acm import-certificate --certificate file://client1.example.com.crt --private-key file://client1.example.com.key --certificate-chain file://ca.crt --region us-east-1以上で、サーバーとクライアントの証明書とキー準備が完了です。
ポイントは、VPN エンドポイント作成時に必要な1つだけアップロードすれば良いところです。クライアント VPN エンドポイントの作成
Management Console でエンドポイントを作成してきます。
こちらの公式blogを参考にしてます。差異は、認証の部分です。公式の記事ではAD認証を利用しています。
https://aws.amazon.com/jp/blogs/news/introducing-aws-client-vpn-to-securely-access-aws-and-on-premises-resources/
- 下記以外の項目はデフォルト
- そのほかのオプションパラメーターは任意で設定ください
- CloudWatch Logs のロググループとログストリームは事前に作成してください
設定項目 値 名前タグ 適当に 説明 適当に クライアント IPv4 CIDR 172.24.0.0/22 サーバ証明書 ARN 先ほどアップロードした server.example.com を指定 認証オプション 相互認証の使用 クライアント証明書 ARN 先ほどアップロードした client1.example.com を指定 クライアント接続の詳細を記録しますか? はい CloudWatch Logs ロググループ名 /aws/clientvpn CloudWatch Logs ログストリーム名 example
VPN エンドポイントに、VPC を紐付けます
これにより VPC 内に ENI が作成されます
既存のVPCとそのサブネットを選択して関連付けします
環境によって違いますが、今回は4つほど関連づけてみました。
VPCへのエンドユーザーアクセスを有効ににします(承認ルールを追加)
承認ルールは、クライアントVPNエンドポイントを介して指定されたネットワークにアクセスできるユーザーのセットを制御します。
いったん 0.0.0.0/0 を追加して、全てアクセスできるようにしてみます。
セキュリティグループの設定をします
公式サイトの情報によると、このセキュリティグループは以下のような動きになっているようです。
クライアントVPNエンドポイントはセキュリティグループをサポートします。セキュリティグループを使用して、アプリケーションへのアクセスを制限できます。セキュリティグループは、VPCに関連付けられたENIからの下りトラフィックのみを制御することに注意してください。
今回は検証用なので、いったんアウトバウンドを全て許可する設定の Security Group を利用してみます。
基本的な Security Group を作って設定するだけなので、手順は割愛させていただきます。ルートを作成します
関連付けられたVPCのルートは、クライアントVPNルートテーブルに自動的に追加されます。
今回は4つ関連づけたので、4つ追加されています。
もし、このVPCがVPNクライアントにインターネット接続を提供するようにしたい場合は、0.0.0.0/0 を追加し、[ターゲットVPCのサブネットID] はそれぞれ関連づけたVPCサブネットにして登録します。今回の場合であれば都合4つです。
4つ追加したあと
いったんこれで VPN エンドポイント の設定を終わります。
クライアントの設定
公式サイトの情報では、Tunnelblick を使っていたので、VPN接続クライアントはこれを使ってみます。
クライアント構成(設定ファイル)をダウンロードします
作成したクライアントキーにパスフレーズを追加します
client1.example.comとclient2.example.comの秘密鍵作成時に、パスフレーズを設定していませんでしたので、パスフレーズを追加しておきますopenssl rsa -aes256 -in client1.example.com.key -out client1.example.com.pass-ari.key openssl rsa -aes256 -in client2.example.com.key -out client2.example.com.pass-ari.key設定ファイルの最後に、クライアントクライアント証明書とキーの設定を追加します
client1.example.comとclient2.example.comの2つの設定ファイルを作るので、ダウンロードした設定ファイルはコピーして、それぞれ次のような設定を追加します。client1.example.comcert /path/client1.example.com.crt key /path/client1.example.com.pass-ari.keyclient2.example.comcert /path/client2.example.com.crt key /path/client2.example.com.pass-ari.keyあとは、出来上がった設定ファイルを Tunnelblick で読み込んで接続するだけです。
クライアントの秘密鍵にパスフレーズを設定している場合は、次のようにパスフレーズを要求されます。
接続の確認
実際に接続したあと、管理画面から
共通名の項目を見ると Common Name を確認できます。
CloudWatch Logs でログの内容を確認してみます
common-name が記録されるので、接続したクライアントを確認することができます。{ "connection-log-type": "connection-reset", "connection-attempt-status": "NA", "connection-attempt-failure-reason": "NA", "connection-id": "cvpn-connection-xxxxxxxxxxxxxxxxx", "client-vpn-endpoint-id": "cvpn-endpoint-yyyyyyyyyyyyyyyyy", "transport-protocol": "udp", "connection-start-time": "2020-04-20 14:30:00", "connection-last-update-time": "2020-04-20 14:31:02", "client-ip": "172.22.3.2", "common-name": "client2.example.com", "device-type": "mac", "device-ip": "xxx.xx.xx.xx", "port": "23771", "ingress-bytes": "3051", "egress-bytes": "2629", "ingress-packets": "9", "egress-packets": "6", "connection-end-time": "2020-04-20 14:31:02", "connection-reset-status": "NA" }クライアント証明書失効リストを利用した、接続の取り消し
何らかの理由で、クライアント証明書を紛失した場合やアクセスをブロックしたい場合に備え、クライアント証明書失効リスリストの動作も確認しておきます。
こちらの方法で、
client2.example.comを失効リストに追加し、特定クライアントのクライアント VPN エンドポイントへのアクセスを取り消してみます。証明書作成時に使った、easyrsa の環境で失効作業を実施します
./easyrsa revoke client2.example.comプロンプトが表示されたら、yes と入力します。
証明書失効リストを作成します
$ ./easyrsa gen-crl Using SSL: openssl LibreSSL 2.8.3 Using configuration from /Users/h-matsu/Documents/code/easy-rsa/easyrsa3/pki/easy-rsa-40453.izPBCL/tmp.BwkfBg An updated CRL has been created. CRL file: /path/to/easy-rsa/easyrsa3/pki/crl.pemクライアント証明書失効リストをインポートします
VPN エンドポイントをチェックしたら、[アクション]で[クライアント証明書CRLのインポート]を選択します
先ほど作成した
/path/to/easy-rsa/easyrsa3/pki/crl.pemの中身をテキストで貼り付けインポートします。
client2.example.comで再度接続してみますTunnelblick で、次のようなログが出て接続に失敗しているのが確認できます。
2020-04-21 00:17:46.684079 TLS Error: TLS key negotiation failed to occur within 60 seconds (check your network connectivity) 2020-04-21 00:17:46.684190 TLS Error: TLS handshake failed以上です。















- 投稿日:2020-04-21T07:13:19+09:00
AWS操作練習【3】(AWS BackupによるEC2バックアップ・復元)
前回「AWS操作練習【2】(SystemsManagerパッチ配信設定)」の続きとなります。
■■ 筆者情報 ■■
・AWSの資格試験はプロフェッショナルまで取得済。
・AWSの操作経験は初心者並み。
・理論は解っていても操作は解っていない状況。
※資格試験取得に興味のある方は「AWS認定試験の勉強方法」を参照ください。■■ この記事を読んでほしい対象 ■■
・AWSの知識はある程度ついたので、AWS操作を一通り実施したい人。
・AWS公式ドキュメントをベースに手順を確認したい人。
※手順を簡単にまとめてくれているサイトも多々ありますが、可能な限りAWSの公式ドキュメントを読み解きながら確認を実施しています。その為、この記事のリンクの多くは公式ドキュメントに対して貼られており、どうしても公式ドキュメントのみだと解らない場合に、個人のHPを頼っています。■■ AWSのEC2バックアップの方法 ■■
まずバックアップの動作確認を実施する前に前提を整理しました。AWSのバックアップは「AWSを使用したバックアップと復元の手法」に整理されています。その中でサーバのバックアップに関しては「EBSのスナップショット」と「AMIイメージ」でバックアップが必要なことが記載されています。「EBSのスナップショット」と「AMIイメージ」の違いは「AWSトレーニングでよくいただくご質問シリーズ - 第一回 Amazon Machine Image (AMI) とスナップショットの違い」というAWS公式ブログに以下のように記載されています。
スナップショット = 「EBS ボリュームの中のデータ」を特定のタイミングで取得しS3に保存したもの
AMI = 「EBS ボリュームの中のデータ(スナップショット) とインスタンスを構成する管理情報」を含む起動テンプレート
上記の条件だとAMIイメージだけ取得すればすべて包括されていると考えると思いますが、AMIイメージのバックアップ取得はAWSの標準機能だけでは自動化できないのがネックです。
しかし、AWSは2020年1月に新機能を発表しました。AWS BackupでAMIイメージも含めたバックアップの取得及び自動化が可能になったのです。ですので、私の理解は以下の通りとなります。
バックアップ機能 バックアップ対象 スケジュール自動化 AMIイメージ 構成情報+EBSスナップショット × EBSスナップショット EBSスナップショット 〇 AWS Backup 構成情報+EBSスナップショット 〇 今だとAWS Backupを利用するのがよいと思ったので、そのテストを実施することにしました。
■AWS BackupによるEC2バックアップ実施(スケジュール実行)
バックアップ方法にはスケジュール実行できるものと、即時実行できるものがあります。まずはスケジュール実行できるものを実施しました。
バックアッププランの作成(AWS Backup)
まずプランを作成します。今回は既存ルールから「Daily-Monthry-1yr-Retention」を選択しました。これは、日次と月次のバックアッププランがセットになったものです。
「Daily-Monthry-1yr-Retention」のバックアップルールは以下の通りです。
バックアップがすぐに開始されるように「DailyBackups」のスケジュールで「バックアップウィンドウをカスタマイズ」を選択して、現在時刻の少し後に時間を設定しました。ただし、この設定時間でバックアップ処理がはじまるのではなく、実際には「次の時間以内に開始」の範囲内で処理が始まるようです。
バックアッププランへのリソースの割当(AWS Backup)
リソースの選択では、バックアップ対象のEC2を指定します。サーバ単位でも設定できますが、今回はタグで対象サーバを設定しました。この設定のおかげで同じタグ設定しているサーバは、同時にバックアップを取得することができます。
バックアップ結果の確認(AWS Backup)
しばらく時間を置いて確認するとAWS Backupダッシュボード画面に以下のように表示されました。
登録していたバックアップが正常に完了したようです。
「バックアップジョブ」の詳細を確認すると「2020年4月20日23:48」(UTC+09:00=日本時間)に開始されていました。バックアップ設定では「PM02:45」(UTC)に設定しており日本時間では「PM11:45」なので、概ね設定どおりに開始されていることが解ります。
「バックアップジョブID」から結果の詳細を確認します。処理時間は36分でした。OS環境はWindows2016のAMIから起動させてほとんど触っていない状況でのバックアップでした。
バックアップ対象であったOS環境のシステムログを確認するとバックアップ取得時間帯にOS停止した形跡がありません。その為、バックアップはOS起動状態で取得されたことが解ります。業務によっては事前にサービスを停止しておく等、何らかの事前処理が必要になりそうです。
保護されたリソースには取得したバックアップ情報が表示されます。
保護されたリソースの詳細情報は以下の通りです。
また、EC2のAMI画面に新規のAMIが作成されています。
EBSスナップショットにも新規のスナップショットが作成されています。
これを見る限り、AWS Backupは結果的にはAMI作成とEBSスナップショットを操作や管理を一元的に実施できるツールであることが解ります。特段問題が内容ならAWSのEC2バックアップはAWS backup一択でよいのかと思いました。■AWS BackupによるEC2復元実施
先ほど取得したバックアップを復元します。
復元(AWS Backup)
復元では以下の設定画面が表示されます。VPCやサブネット、セキュリティグループ等を設定して復元を開始します。
■AWS BackupによるEC2復元後の問題
問題が2つ発生しました。1つはキーペアが設定されていない状況になっていること。2つ目はパブリックIPが設定されていない状況になっていること。
2つ目のパブリックIPが設定されていない状況になっているのは、サブネットの問題でした。サブネットの「パブリックのIPv4アドレスの自動設定」が「いいえ」になっていたのが原因です。その為、この設定を「はい」にした上で、再度バックアップからの復元を実施しました。この結果、パブリックIPの表示は問題なく実施されるようになりました。
もう一つの問題であるキーペアが表示されなくなった点ですが、これは現状における仕様のようです。色々調べた結果、バックアップ前のキーペアがそのまま使用できるとのことだったので、実際にそれでRDP接続を実施した結果、問題なく接続できました。ただ、キーペアを覚えておく必要がでてくるので、管理上は懸念が生じる仕様です。
OS接続後に下記のメッセージが出力されていました。バックアップを実施する際にシャットダウンは実施されていないのですが、予期せぬシャットダウンがされていたとOS側では受け取っていたようです。
OS上のシステムログでは、バックアップを取得した23:50頃でログが止まっており、次のログは復元後に起動したタイミングでの出力となっています。
■AWS BackupによるEC2バックアップ実施(手動)
スケジュール設定ではなく手動での即時バックアップ手順も実施しました。
バックアップの作成(AWS Backup)
手動での作成手順ですが、基本的には手順通り実施すれば簡単に実施できました。ただし、バックアップは即時で始まるわけではなく、画面上に表示される1時間以内のどこかで始まる仕様のようでした。その為、急ぎでバックアップを取得する必要があるときには、EBSスナップショットも併用したほうがいいのかと思いました。
■■ まとめ ■■
今回はバックアップ・復元のテストを実施しました。操作自体は簡単ですが、スケジューリングしたりタグを付けたりして運用負荷軽減する方法を考えると、もう一段階掘り下げて知識を整理する必要がありそうだと感じました。

















- 投稿日:2020-04-21T07:12:06+09:00
AWS LambdaのProvisioned ConcurrencyをServerless Frameworkで設定してみたら2つの課題が出た
注:本記事はnote記事の転載です。内容の更新があった場合noteのほうを更新します。qiita記事が古くなってきている場合、noteもご確認ください。
https://note.com/thiroyoshi/n/n32f664596a48
こんにちは。thiroyoshiです。
今回は、最近AWS Lambdaに実装された設定の ProvisionedConcurrencyをServerless Frameworkで設定して、そのときに起こった課題について書いていきたいと思います。
目次
- Provisioned Concurrencyは、AWSが公式に提供するLambda in VPCのコールドスタート対策の設定
- Provisioned ConcurrencyのServerless Frameworkでの設定は、たった一行…!
- デプロイするとバージョンが作られて同時実行数が割り当てられる
- バージョンが作られることで起こる2つの課題
- 最後に
Provisioned Concurrencyは、AWSが公式に提供するLambda in VPCのコールドスタート対策の設定
Lambdaは特にVPC内にあった場合、ENIの起動に関わって、初回のリクエストの処理時間が非常に大きいという問題がありました。これがLambdaのコールドスタート問題です。
Provisioned Concurrencyは、簡単に言うと、Lambdaの同時実行数の中から指定の数だけ占有して、その数だけLambdaを常時起動させることができる設定です。常時起動するので、常にリクエストに即応できるからコールドスタート問題を解消できる、というわけです。
Provisioned Concurrencyについて、もっと詳しく知りたい人は ↓ の記事を参照ください。
https://aws.amazon.com/jp/blogs/news/new-provisioned-concurrency-for-lambda-functions/Provisioned ConcurrencyのServerless Frameworkでの設定は、たった一行…!
設定は以下のように一行だけ、functionsに追加するだけです。めちゃ簡単。
serverless.ymlfunctions: hello: handler: handler.hello events: - http: path: /hello method: get provisionedConcurrency: 5 // これだけ!ここで設定している数は、同時実行数です。つまり、この設定分だけLambdaを常時起動するということです。
アカウントで持っている同時実行数の上限を超えないように、設定値の総数には気を付ける必要があります。
以下でServerless Frameworkの人が設定方法を解説してくれてますので、詳しくはこちらを参照ください。
https://serverless.com/blog/aws-lambda-provisioned-concurrency/デプロイするとバージョンが作られて同時実行数が割り当てられる
Serverless Frameworkでは、先に見た通り設定は一行ですが、マネジメントコンソールで見ると、設定する時には同時実行数だけでなく、エイリアスまたはバージョンを指定する必要があります。つまり、$LATESTは設定できないので、本来は事前にエイリアスかバージョンを作る必要があるのです。
しかし、Serverless Frameworkでデプロイすると、勝手にバージョンを新たに作って割り当ててくれます。すごい便利。
バージョンが作られることで起こる2つの課題
しかし、バージョンを勝手に作るのは、いいことばかりではなく、実は以下の課題を発生させる危険性を秘めています。
- デプロイするたびにバージョンが溜まって、ストレージを圧迫
- CloudFormationの制限に引っかかる
デプロイするたびにバージョンが溜まって、ストレージを圧迫
Serverless Frameworkでデプロイを何度もすると、新たなバージョンが勝手に作られます。それは消さない限りどんどん溜まっていって、アカウントあたりに割り当てられているLambdaのソースのストレージを圧迫してしまいまいます。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/gettingstarted-limits.html
上記のように、上限は75GBですので、なかなか溜まらないと思いがちですが、放っておくといつかは上限に達し、本番ではリリース障害になりかねません。
そうならないために、バージョニングを無効化するようServerless Frameworkには従来から ↓ の設定をすることが可能でした。
serverless.ymlversionFunctions: falseしかし、Provisioned Concurrencyではバージョニングが必須だからか、この設定をしていても、これを無視して新しいバージョンを作ってくれてしまいます。つまり、ストレージの上限に達する危険性を残してしまうわけです。
であるならば、デプロイのたびに古いバージョンを削除すればよいのです。
Serverless Frameworkには、古いバージョンを削除するためのプラグインがあります。
https://serverless.com/plugins/serverless-prune-plugin/
基本的な使い方は、以下の3つの手順を踏むだけです。
npmでプラグインをインストール
npm install --save-dev serverless-prune-pluginserverless.ymlにpluginの設定を書き込む
serverless.ymlplugins: - serverless-prune-pluginコマンドで削除を実行
serverless prune -n 1"-n"は必須のオプションですが、これが意味するところは、残すバージョンの数です。つまり、Provisioned Concurrencyで必要なのは最新のバージョン一つなので、1に設定します。
CloudFormationの制限に引っかかる
そこそこ大きなサービスの開発をしていると、以下と同じエラーに見舞われてしまいます。私はこれに実際に出会いました…。
Template format error: Outputs count 81 is greater than max allowed 60.https://github.com/dougmoscrop/serverless-plugin-split-stacks/issues/15
つまり、以下のCloudFormationの制限における”出力”の制限に引っかかってしまったようです。
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/cloudformation-limits.html
この出力はバージョニングしたものも新たに追加されてしまうらしく、これまでは問題なかったのに、新たにProvisioned Concurrencyを設定すると引っかかってしまったようです。
実は、これに関しては私は明確な解決方法が今のところありません…。対症療法のようになりますが、一回あたりのデプロイする関数等を減らすくらいしかないかな、と思っています。
私に関して言うと、現状Provisioned Concurrencyは必須な設定ではなかったので、設定を一旦取りやめて、今後解決しようと心に決めました()
最後に
Provisioned Concurrencyの設定は、世界中のAWS Lambdaユーザが待ち望んだ機能だったと思うのですが、本番で使おうとすると気を付けるべき点がいくらかあるということが明らかになりました。
解決方法がまだ見いだせてない部分もあるので、これについては今後も模索していきたいと思います。

