- 投稿日:2020-04-21T23:52:40+09:00
動かして覚えるPythonコード一覧
本記事について
プログラムングから長く離れていたので、練習・復讐を兼ねてPythonの超初心者用コードを実際に動かしてみました。
プログラムを実際に動かした経験を備忘録を兼ねて残しています。
誰かのお役に立てれば幸いです。変数宣言
Pythonでは変数を事前に宣言する必要はありませんが、変数宣言は可能です。
必要性は薄いですが、可読性を高める必要がある場合などに利用します。
※実行結果は type()で確認してみてください。# integer 型 num: int = 1 # string型 text: str = '1' # boolean型 isEnabled: bool = True変数名に使える文字
- 英字(小文字)
- 英字(大文字)
- 数字
- アンダースコア( _ )
変数名のルール
- 数字から始まるものは使えない
型の確認方法
pythonは、変数宣言(型指定)の必要がありません。
何の型が設定されているか確認する場合は、オブジェクトの型を取得・確認するtype()関数を使用します。num: int = 1 print(num , type(num)) #1 <class 'int'> text: str = '1' print(text, type(text)) #1 <class 'str'> isEnabled: bool = True print(isEnabled , type(isEnabled)) #True <class 'bool'>
- 投稿日:2020-04-21T23:42:34+09:00
PythonとSymPyで連立常微分方程式を解く。
ここではPythonにsympyをインストールして連立常微分方程式を解いてみたいと思います。
sympyのサイト
https://docs.sympy.org/latest/index.html
ウォーミングアップ
まずはsympyを用いた基本的な関数の微分の例を書いておきます。
import sympy as sym x = sym.Symbol('x') h = x**3 + 3*x + 1 h.diff(x,1)連立一次常微分方程式
ではおもむろに連立一次常微分方程式を解いてみましょう。
x = sym.Symbol('x') f = sym.Function('f') g = sym.Function('g') h = sym.Function('h') eq1 = sym.Eq(f(x).diff(x,1),g(x)+h(x)) eq2 = sym.Eq(g(x).diff(x,1),h(x)+f(x)) eq3 = sym.Eq(h(x).diff(x,1),f(x)+g(x)) sym.dsolve([eq1, eq2, eq3])偏微分方程式には対応してない?
調子に乗って偏微分方程式を解いてみましょう。
偏微分の計算自体は可能です。
x = sym.Symbol('x') y = sym.Symbol('y') u = x**2 - y**2 u.diff(x,1)しかし、以下の様な計算をさせようとしても上手く答えが出てきません。
x = sym.Symbol('x') y = sym.Symbol('y') u = x**2 - y**2 v = sym.Function('v') eq1 = sym.Eq(u.diff(x,1), v(x,y).diff(y,1)) eq2 = sym.Eq(u.diff(y,1), -v(x,y).diff(x,1) ) sym.dsolve([eq1, eq2])う~む…。大学2年生相当くらいまでは対応していて、3年生相当以上になるとまだちょっと対応できてないのですかね。(;^_^A
- 投稿日:2020-04-21T23:23:22+09:00
Pythonの応用: データクレンジングその2: DataFrameを用いたデータクレンジング
CSV
Pandasを用いたCSVの読み込み
CSVは値をカンマで区切って羅列したファイルで
データ分析等において非常に扱いやすいので、一般的によく使われます。Pandasでcsvファイルを読み込むには、read_csv()関数を用います。
read_csv("csvファイルが置いてあるファイルパス", header=)headerの法則として
- headerオプションを省略すると読み込んだファイルの1行目を列名とし
header=Noneを指定するとPandasが適当な列名を割り当てます。
header=1のように行番号を指定すると、読み込んだファイルの2行目のデータを列名とし
それ以降の行から読み込みを開始します。なお、行番号は0から開始するのでデータの1行目の行番号は0になります。
例えば、列名の情報を持たないワインのデータセットをディレクトリから読み込みます。
そのままでは数値が何を表しているのか分からないので、値の内容を示す列名(カラム)を追加します。import pandas as pd df = pd.read_csv("./4050_data_cleansing_data/wine.csv", header=None) # それぞれの数値が何を表しているのかカラムを追加します df.columns = ["", "Alcohol", "Malic acid", "Ash", "Alcalinity of ash", "Magnesium","Total phenols", "Flavanoids", "Nonflavanoid phenols", "Proanthocyanins","Color intensity", "Hue", "OD280/OD315 of diluted wines", "Proline"] dfファイルパスの./はカレントディレクトリを示しています。
カレントディレクトリとは、現在Pythonを実行している作業ディレクトリのことです。CSVライブラリを用いたCSVの作成
Python3に標準で搭載されているCSVライブラリを用いてCSVデータファイルを作成します。
過去10回分のオリンピック開催の都市、開催の年、季節のデータをCSVデータファイルとして出力します。
import csv # with文を用います # csv0.csvファイルを変数csvfileとして、書き込みモード ("w")で開きます with open("./4050_data_cleansing_data/csv0.csv", "w") as csvfile: # writerメソッドには引数として、変数csvfileと改行コード(\n)を指定します writer = csv.writer(csvfile, lineterminator="\n") # writerow(リスト)を用いて行を追加します writer.writerow(["city", "year", "season"]) writer.writerow(["Nagano", 1998, "winter"]) writer.writerow(["Sydney", 2000, "summer"]) writer.writerow(["Salt Lake City", 2002, "winter"]) writer.writerow(["Athens", 2004, "summer"]) writer.writerow(["Torino", 2006, "winter"]) writer.writerow(["Beijing", 2008, "summer"]) writer.writerow(["Vancouver", 2010, "winter"]) writer.writerow(["London", 2012, "summer"]) writer.writerow(["Sochi", 2014, "winter"]) writer.writerow(["Rio de Janeiro", 2016, "summer"]) # 出力 # csv0.csvファイルを変数csvfileとして、読み込みモード("r")で開きます with open("./4050_data_cleansing_data/csv0.csv", "r") as csvfile: print(csvfile.read())実行するとcsv0.csvというCSVデータファイルが作成され、データの内容が表示されます。
なお、CSVデータファイルを作成した場所を調べるにはimport os # を行い print(os.getcwd()) # を実行します。Pandasを用いたCSVの作成
CSVライブラリを用いずに
Pandasを用いてもCSVデータを作成 することができます。
PandasDataFrame形式のデータをCSVデータにする時はPandasを用いた方が便利です。Pandasでcsvファイルを作成するには、to_csv()関数を用います。
to_csv("作成するcsvファイル名")DataFrameの例として先のサンプルと同様、過去10回分のオリンピック開催の都市、開催の年、季節のデータをCSVデータファイルとして出力します。
import pandas as pd data = {"city": ["Nagano", "Sydney", "Salt Lake City", "Athens", "Torino", "Beijing", "Vancouver", "London", "Sochi", "Rio de Janeiro"], "year": [1998, 2000, 2002, 2004, 2006, 2008, 2010, 2012, 2014, 2016], "season": ["winter", "summer", "winter", "summer", "winter", "summer", "winter", "summer", "winter", "summer"]} df = pd.DataFrame(data) df.to_csv("4050_data_cleansing_data/csv1.csv") # これを実行するとcsv1.csvというファイルがcleansing_dataディレクトリに作成されます。欠損値
リストワイズ削除/ペアワイズ削除
読み込んだデータに空白などがあると欠損値NaN(Not a Number)であると認識されます。データの精度を高めるために、欠損値NaNを削除するには
dropna()関数を用います。# まずは、わざと表の一部を欠損させた表をランダムに作成します。 import numpy as np from numpy import nan as NA import pandas as pd sample_data_frame = pd.DataFrame(np.random.rand(10, 4)) # 一部のデータをわざと欠損させます sample_data_frame.iloc[1, 0] = NA sample_data_frame.iloc[2, 2] = NA sample_data_frame.iloc[5:, 3] = NA sample_data_frameリストワイズ削除
データ欠損のある行や列(NaNを含む行)をまるごと消去することを
リストワイズ削除といいます。dropna()関数を用いて1つでもNaNを含む行をすべて取り除きます。また
引数にaxis=1を指定すると1つでもNaNを含む列を取り除きます。sample_data_frame.dropna()ペアワイズ削除
リストワイズ法で欠損のある行をすべて削除してしまうとデータが少なすぎる場合
利用可能なデータのみを用いる方法もあります。
欠損の少ない列(例えば、0列目と1列目)を残し
そこからNaNを含む行を消去することをペアワイズ削除といいます。sample_data_frame[[0, 1]].dropna()
欠損値の補完
データの精度を高めるには欠損値を削除する以外に
代替データを欠損値に代入する方法もあります。欠損値NaNに代替データを代入(置き換え)するには
fillna()関数を用います。わざと表の一部を欠損させた表をランダムに作成します。
import numpy as np from numpy import nan as NA import pandas as pd sample_data_frame = pd.DataFrame(np.random.rand(10, 4)) # 一部のデータをわざと欠損させます sample_data_frame.iloc[1, 0] = NA sample_data_frame.iloc[2, 2] = NA sample_data_frame.iloc[5:, 3] = NA # fillna()関数を用いると、引数として与えた数をNaNの部分に代入します。今回は0で埋めてみます。 sample_data_frame.fillna(0)# methodにffillを指定すると前行の値で埋めることができます。 sample_data_frame.fillna(method="ffill")欠損値の補完(平均値代入法)
欠損値をその列(または行)の平均値によって穴埋めをする方法を平均値代入法といいます。
平均値はmean()関数を用いて算出します。import numpy as np from numpy import nan as NA import pandas as pd sample_data_frame = pd.DataFrame(np.random.rand(10, 4)) # 一部のデータをわざと欠損させます sample_data_frame.iloc[1, 0] = NA sample_data_frame.iloc[2, 2] = NA sample_data_frame.iloc[5:, 3] = NA # fillnaを用いてNaNの部分にその列の平均値を代入します sample_data_frame.fillna(sample_data_frame.mean())データ集約
キーごとの統計量の算出
統計量は代表値と散布度に区分できます。
代表値とはデータの基本的な特徴を表す値のことで
例えば、平均値、最大値、最小値などのことです。import pandas as pd df = pd.read_csv("./4050_data_cleansing_data/wine.csv", header=None) df.columns=["", "Alcohol", "Malic acid", "Ash", "Alcalinity of ash", "Magnesium","Total phenols", "Flavanoids", "Nonflavanoid phenols", "Proanthocyanins","Color intensity", "Hue", "OD280/OD315 of diluted wines", "Proline"] # DataFrame `df` のキー"Alcohol"の平均値を算出します df["Alcohol"].mean() # 出力結果 13.000617977528091重複データ
データの重複がある場合、そのデータを削除してデータの精度を高めます。
実際にデータの重複があるDataFrameを用意して
重複データの抽出や削除を行ってみます。import pandas as pd from pandas import DataFrame dupli_data = DataFrame({"col1":[1, 1, 2, 3, 4, 4, 6, 6] ,"col2":["a", "b", "b", "b", "c", "c", "b", "b"]}) dupli_dataduplicated()メソッドを用いると重複がある行にTrueを返すSeries型のデータを生成し、重複データを抽出します。
# 重複データを抽出します dupli_data.duplicated() # 出力結果 0 False 1 False 2 False 3 False 4 False 5 True 6 False 7 True dtype: booldtypeとは "Data Type" のことで、要素のデータ型を示します。
drop_duplicates()メソッドを用いると、重複するデータを削除します。dupli_data.drop_duplicates()マッピング
マッピングとは共通のキーを持つデータに対して
別のテーブルからキーに対応する値を参照する処理です。
実際にDataFrameを用意して、マッピング処理を行ってみます。import pandas as pd from pandas import DataFrame attri_data1 = {"ID": ["100", "101", "102", "103", "104", "106", "108", "110", "111", "113"] ,"city": ["Tokyo", "Osaka", "Kyoto", "Hokkaido", "Tokyo", "Tokyo", "Osaka", "Kyoto", "Hokkaido", "Tokyo"] ,"birth_year" :[1990, 1989, 1992, 1997, 1982, 1991, 1988, 1990, 1995, 1981] ,"name" :["Hiroshi", "Akiko", "Yuki", "Satoru", "Steeve", "Mituru", "Aoi", "Tarou", "Suguru", "Mitsuo"]} attri_data_frame1 = DataFrame(attri_data1) attri_data_frame1cityに対応する地域名を持つ、辞書型のデータを作成します。
city_map ={"Tokyo":"Kanto" ,"Hokkaido":"Hokkaido" ,"Osaka":"Kansai" ,"Kyoto":"Kansai"} city_mapはじめに用意したattri_data_frame1のcityカラムをキーに、city_mapから対応する地域名データを参照して、新しいカラムに追加します。これがマッピング処理です。Excelに詳しい方であればvlookup関数のような処理をイメージしてください。
map()関数を用いてマッピング処理を行い、新しいカラムとしてregionをattri_data_frame1に追加します。attri_data_frame1["region"] = attri_data_frame1["city"].map(city_map) attri_data_frame1出力結果を見ると、regionカラムに地域名が追加されているのが分かります。
対応するデータがcity_mapに存在しない要素にはNaNが埋められます。ビン分割
ビン分割とは、数値データを大まかに区切ってカテゴリ分けをする処理のことです。
例えば、年齢を0~9歳、10~19歳、20~29歳のように分ける処理です。
あらかじめビン分割したリストを用意してpandasのcut()関数を用いて処理を行います。import pandas as pd from pandas import DataFrame attri_data1 = {"ID": [100,101,102,103,104,106,108,110,111,113] ,"city": ["Tokyo", "Osaka", "Kyoto", "Hokkaido", "Tokyo", "Tokyo", "Osaka", "Kyoto", "Hokkaido", "Tokyo"] ,"birth_year" :[1990, 1989, 1992, 1997, 1982, 1991, 1988, 1990, 1995, 1981] ,"name" :["Hiroshi", "Akiko", "Yuki", "Satoru", "Steeve", "Mituru", "Aoi", "Tarou", "Suguru", "Mitsuo"]} attri_data_frame1 = DataFrame(attri_data1)分割の粒度をリストで指定し、ビン分割を実施します。ここではbirth_yearに着目します。
# 分割の粒度のリストを作成します birth_year_bins = [1980,1985,1990,1995,2000] #ビン分割を行いします birth_year_cut_data = pd.cut(attri_data_frame1.birth_year,birth_year_bins) birth_year_cut_data # 出力結果 0 (1985, 1990] 1 (1985, 1990] 2 (1990, 1995] 3 (1995, 2000] 4 (1980, 1985] 5 (1990, 1995] 6 (1985, 1990] 7 (1985, 1990] 8 (1990, 1995] 9 (1980, 1985] Name: birth_year, dtype: category Categories (4, interval[int64]): [(1980, 1985] < (1985, 1990] < (1990, 1995] < (1995, 2000]]"()"はその値を含まず、"[]"はその値を含むことを意味します。
例えば (1985, 1990] の場合、1985年は含まず,1990年は含まれます。それぞれのビンの数を集計したい場合は
value_counts()メソッドを用います。pd.value_counts(birth_year_cut_data) # 出力結果 (1985, 1990] 4 (1990, 1995] 3 (1980, 1985] 2 (1995, 2000] 1 Name: birth_year, dtype: int64それぞれのビンに名前をつけることも可能です。
group_names = ["first1980", "second1980", "first1990", "second1990"] birth_year_cut_data = pd.cut(attri_data_frame1.birth_year,birth_year_bins,labels = group_names) pd.value_counts(birth_year_cut_data) # 出力結果 second1980 4 first1990 3 first1980 2 second1990 1 Name: birth_year, dtype: int64あらかじめ分割数を指定して分割することも可能です。
これを用いると、ほぼ同じサイズのビンを作成することができます。cut()関数の第2引数に分割数を指定します。pd.cut(attri_data_frame1.birth_year,2) # 出力結果 0 (1989.0, 1997.0] 1 (1980.984, 1989.0] 2 (1989.0, 1997.0] 3 (1989.0, 1997.0] 4 (1980.984, 1989.0] 5 (1989.0, 1997.0] 6 (1980.984, 1989.0] 7 (1989.0, 1997.0] 8 (1989.0, 1997.0] 9 (1980.984, 1989.0] Name: birth_year, dtype: category Categories (2, interval[float64]): [(1980.984, 1989.0] < (1989.0, 1997.0]]
- 投稿日:2020-04-21T22:39:50+09:00
slugsizeの削減
herokuでデプロイする際に、slugsizeに気を付ける必要があります。(現時点では500MB以下)
ググれば、slugsizeの削減方法が出てきます。
それだけでもダメなら、djangoのrequirement.txtからインストールに必要のないパッケージを削除すればうまくいきます。僕の場合、Tensor-flowのサイズが大きく、原因でした。
- 投稿日:2020-04-21T22:10:49+09:00
low-code機械学習ライブラリ「PyCaret」でモデルを可視化してみた
概要
- low-codeで、機械学習ができるライブラリのPyCaretがついに、v1.0になりました。
- 下記の様な記事でも、すでに紹介されています。(概要はこちらを参照下さい。)
- 私が触ってみた印象だと、機械学習モデルの 可視化 がかなり便利に感じました。
- よって、モデルの可視化 に着目し、記事にしてみたいと思います。
- なお、ソースを確認すると、部分的に内部でYellowbrickを利用しているようです。
やること
列挙してみると下記の通りですが、pycaretの自動化により数行で実行できます。
- ①クレジットカードデフォルトのデータをロード
- ②前処理
- ③モデル比較(アルゴリズム間の性能比較)
- ④パラメータチューニング
- ⑤モデルの可視化(★ここがメインなので、冒頭でここを説明★)
やってみる(⑤モデルの可視化)
- 手順上は 1番最後 なのですが、この記事の目的が可視化なので、最初 に扱いたいと思います。
⑤モデルの可視化
- 出来上がったモデル(tuned_model)に対してモデルの特性を可視化していきます。
- evaluate_model関数に、出来上がったモデルを渡すことで、下記のメニューが表示されます。
- tuned_modelがどう出来上がったか?は後述します。まずは可視化を説明。
evaluate_model(tuned_model)
- ハイパーパラメータの列挙、ROC曲線、混同行列等々、様々なプロットが可能です。
- 気になったものを取り上げて、一つ一つ見ていきたいと思います。
AUC (ROC曲線)
- AUCとは書いてありますが、ROC曲線を描画できます。
- 2クラス分類だったので、Positive/Negativeクラスに対して2種類描画されます。
Confusion Matrix
- こちらもよく見る混同行列です。ヒートマップで出力されます。
Error
- 実際のクラス毎に、Positive/Negativeのどちらに予測をしたか?が表示されます。

Threshold
- しきい値毎の、precision/recall/f-measureが出力されます。
- 求められる予測特性に対して、しきい値をどの程度に設定すればいいかの検討に利用できます。
Precision Recall
- 同じく予測特性の議論に利用できるのが、Precision-Recallのグラフです。
- PrecisionとRecall共に、どの程度のしきい値であれば、予測特性を満たすことができるか?の検討 に利用できます。
Learning Curve
- 学習曲線(学習の回数 vs 精度)が表示されます。
- TrainとCVセットに対してスコアが表示されるので、Underfittng/Overfittingの判断に利用できます。
- 学習曲線とunder/overfittingの判断については、StanfordのAndrewNg先生の資料が参考になります。
Validation Curve
- モデル毎の正則化パラメータに対する、Trainセット/CVセットのスコアが表示されます。
- LightGBMの場合は、max_depth(木の深さを制御する)パラメータを横軸に取ります。
- このモデルの場合、
- max_depth=7のときに、汎化性能(CVスコア)が高い。
- それ以上のときは汎化性能は上昇しない一方、Trainセットに対して(若干)過学習している。
- よって、max_depthを制御したほうが良さそう。
- といった判断に利用できます。
- 正則化を制御するパラメータはモデルにより異なるため、横軸はアルゴリズム毎に異なります。
- 例えばロジスティック回帰では、正則化のパラメータは C なので、横軸はCとなります。

Feature Importance
- このモデルがどの特徴量を重要視しているか?が表示できます。
Manifold Learning
- t-SNEを利用した多様体学習(次元圧縮)の結果を表示します。
- モデルというよりは、用いている特徴量、データ自体に分解能があるのか?
- 2値分類の場合、Positive/Negativeに分離可能なのかが確認できます。
- 今回のデータでは、前処理で24列->90列まで特徴量を増やしている(後述)なので、90列を次元圧縮により2次元にし、その結果を可視化しています。
Dimensions
- こちらも、データ自体の可視化で、RadViz Visualizerの結果を表示します。
やってみる(①データロード~④チューニング)
①データロード
- pycaretには、様々なデータが搭載されています。詳細は、Getting Data - PyCaretを参照。
- 今回はクレジットカードのデフォルトを予測してみたいと思います。
from pycaret.datasets import get_data # creditデータセットをロードします。 # profileオプションをTrue指定すると、pandas-profilingによるEDAが走ります。 data = get_data('credit',profile=False)②前処理
- creditデータセットは、2値分類(予測対象は、 default列)です。
- よって、分類のライブラリをインポートし、targetにdefaultを指定します。
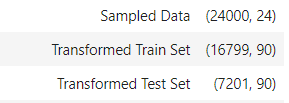
from pycaret.classification import * exp1 = setup(data, target = 'default')
- 様々な前処理が自動で走ります。
- このデータセットの場合は、24列→90列まで特徴量が展開されます。
③モデル比較
- 下記で、複数の分類アルゴリズムに対するモデリングが可能です。
- 求める予測の特性にもよりますが、まずは、AUCで並べておきます。
compare_models(sort="AUC")
- GBM、XGB、CatBoost、LightGBM等が並びます
④パラメータチューニング
- AUCが一番良かったGBMで試しても良いのですが、比較的計算の早いlightGBMで試してみます。
tuned_model = tune_model(estimator='lightgbm')まとめ
- モデルの可視化の方法をバラバラと書いてしまったので、最後に用途毎に整理して終えたいと思います。
- 入力データ→モデリング→結果を想定し、下記5用途でグルーピングしてみたいと思います。
- A) 入力データや特徴量自体を理解する。
- B) モデルが見ている特徴量を理解する。
- C) モデルの予測特性や、目的が達成できるしきい値を検討する。
- D) モデルの学習状況(学習が足りない、過学習)を判断する。
- E) モデルの予測性能や予測結果を理解する。
用途 観点 可視化手段 A)入力データや特徴量自体を理解する。 正/負のデータが分離可能か Manifold Learning 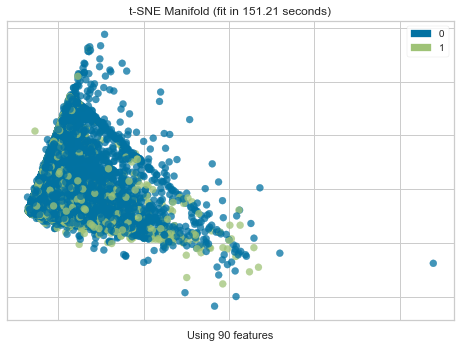
同上 Dimensions 
B)モデルが見ている特徴量を理解する。 どの特徴量が重要か Feature Importance 
C)モデルの予測特性や、目的が達成できるしきい値を検討する。 求める予測特性に対応するしきい値はどれか Threshold 
PrecisionとRecallの関係性はどうか Precision Recall 
D)モデルの学習状況(学習が足りない、過学習)を判断する。 予測性能向上を学習回数増で実現できるか Learning Curve 
正則化により過学習をおさえられているか Validation Curve 
E)モデルの予測性能や予測結果を理解する。 AUC(予測性能)はどの程度か。 AUC 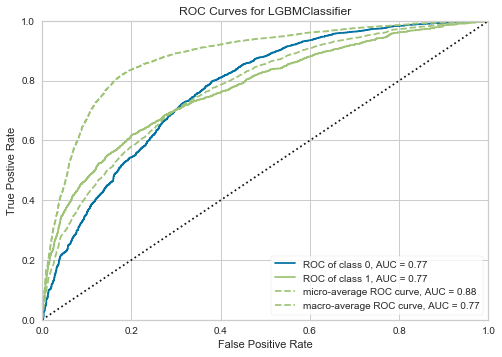
予測の間違い方を理解する Confusion Matrix 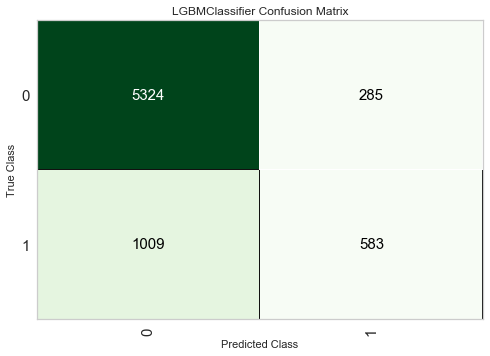
同上 Error



- 投稿日:2020-04-21T22:03:51+09:00
ROC曲線とPR曲線-分類性能の評価方法を理解する②-
はじめに
機械学習の分類タスクにはその目的に応じて幾つかの性能評価指標があります。二項分類の主な性能評価指標であるROC曲線やPR曲線、そしてそのAUC(曲線の下側面積)についてまとめます。
参考
ROC曲線とPR曲線の理解にあたって下記を参考にさせていただきました。
分類タスク
文書分類タスクの具体例を交えて性能評価方法の説明を行います。その前段としてこの章では分類タスクの実施手法を簡単に記載しますが、分類タスク自体についての記事ではないためモデルの詳細な解説は省いています。
使用したライブラリ
- numpy 1.15.4
- lightgbm 2.3.1
- pandas 0.25.1
- scikit-learn 0.22.2
データセット
今回データセットは「livedoor ニュースコーパス」を使用しています。データセットの詳細やその形態素解析の方法は以前投稿した記事で投稿をご参照ください。
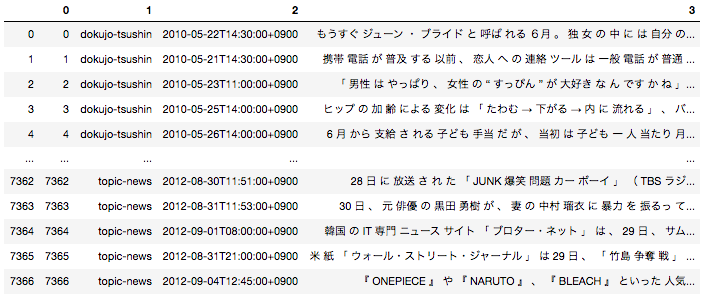
日本語の場合は事前に文章を形態素単位に分解する前処理が必要となるため、全ての文章を形態素に分解した後下記のようなデータフレームに落とし込んでいます。
一番右のカラムが文章を全て形態素解析して半角スペースごとに区切ったものになります。こちらを使用して分類タスクを実施します。
モデルの作成と分類の実施
今回は「Peachy」の記事と「独女通信」の記事(どちらも女性向けの記事)を分類します。今回は二項分類であるため、「独女通信」の記事か否かを判定する分類タスクと同義になっています。データセットを7:3に分割し、7を学習用、3を評価用にしています。
import pandas as pd import numpy as np import pickle from sklearn.feature_extraction.text import TfidfVectorizer #形態素分解した後のデータフレームはすでにpickle化して持っている状態を想定 with open('df_wakati.pickle', 'rb') as f: df = pickle.load(f) #今回に2つの種類の記事を分類できるかを検証 ddf = df[(df[1]=='peachy') | (df[1]=='dokujo-tsushin')].reset_index(drop = True) vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(ddf[3]) def convert(x): if x == 'peachy': return 0 elif x == 'dokujo-tsushin': return 1 target = ddf[1].apply(lambda x : convert(x)) from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, target, train_size= 0.7, random_state = 0) import lightgbm as lgb from sklearn.metrics import classification_report train_data = lgb.Dataset(X_train, label=y_train) eval_data = lgb.Dataset(X_test, label=y_test) params = { 'boosting_type': 'gbdt', 'objective': 'binary', 'random_state':0 } gbm = lgb.train( params, train_data, valid_sets=eval_data, ) y_preds = gbm.predict(X_test)こちらで予測が完了しました。y_predsにはその文書が「独女通信」である確率の値が入っています。
分類性能の評価方法
ROC曲線とPR曲線を見ていく前にその前段である混合行列について復習しておきます。
混合行列は二項分類タスクの出力結果をまとめたマトリクスで、下記のように表されます。
Positiveと予測された Negativeと予測された 実際にPositiveクラスに属する TP(真陽性) FN(偽陰性) 実際にNegativeクラスに属する FP:(偽陽性) TN(真陰性) 混合行列の中の各値を使用してROC曲線を描くことができます。
ROC曲線
ROC曲線の概要
\text{FPR} = \frac{FP}{TN + FP}\text{TPR(recall)} = \frac{TP}{TP + FN}ROC曲線とは$\text{FPR}$(偽陽性率)に対する$\text{TPR}$(真陽性率)をプロットしたものです。
このプロットが何を意味するのかという話ですが、まずは$\text{FPR}$と$\text{TPR(recall)}$の意味を具体例に当てはめて考えます。{{\begin{eqnarray*} \text{FPR} &=& \frac{分類モデルが「\text{Peachy}」の記事を誤って「独女通信」の記事であると予測した件数}{実際の「\text{Peachy}」の記事の全件数} \\ \end{eqnarray*}}}{{\begin{eqnarray*} \text{TPR(recall)} &=& \frac{分類モデルが「独女通信」の記事であると予測した結果が正解であった件数}{実際の「独女通信」の記事の全件数} \\ \end{eqnarray*}}}この意味を整理すると下記のように言えます。
- $\text{FPR}$は誤って陽性(「独女通信」の記事)と分類された陰性(「Peachy」の記事)データの割合を表している→陰性データの判別の不正確さ表している(低いほど良い)
- $\text{TPR}$は正しく陽性(「独女通信」の記事)と分類された陽性(「独女通信」の記事)データの割合を表している→陽性判定の網羅性を表している(高いほど良い)
つまり、$\text{FPR}$が低い状態でありながら$\text{TPR}$が高いというのが理想的です。
様々な閾値における$\text{FPR}$と$\text{TPR}$をプロットすることでROC曲線を描くことができます。「$\text{FPR}$が低い状態でありながら$\text{TPR}$が高いというのが理想的である」ということを考えると、ROC曲線のカーブの形が直角に近いほどよい=AUC(ROC曲線の下側面積)が大きいほどよい、という発想に繋がっていきます。
ROC曲線の描画
ROC曲線を実際に描画してみましょう。
from sklearn import metrics import matplotlib.pyplot as plt fpr, tpr, thresholds = metrics.roc_curve(y_test, y_preds) auc = metrics.auc(fpr, tpr) print(auc) plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc) plt.plot(np.linspace(1, 0, len(fpr)), np.linspace(1, 0, len(fpr)), label='Random ROC curve (area = %.2f)'%0.5, linestyle = '--', color = 'gray') plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) plt.show()
今回作成した分類器を用いてROC曲線を描画しました。ROC曲線の曲線が直角に近く、AUCが$0.98$(最大値が$1$)であることを考えると非常に精度が良いことがわかるかと思います。ランダムの分類器の場合AUCは$0.5$となることが決まっているため、ランダムとの比較の容易です。
PR曲線
PR曲線の概要
\text{precision} = \frac{TP}{TP + FP}\text{recall(TPR)} = \frac{TP}{TP + FN}PR曲線とは$\text{recall}$(再現率)に対する$\text{precition}$(適合率)をプロットしたものです。
このプロットが何を意味するのかという話ですが、まずは$\text{precition}$と$\text{recall}$の意味を具体例に当てはめて考えます。{{\begin{eqnarray*} \text{precision} &=& \frac{分類モデルが「独女通信」の記事であると予測した結果が正解であった件数}{分類モデルが「独女通信」の記事であると予測した全件数} \\ \end{eqnarray*}}}{{\begin{eqnarray*} \text{recall} &=& \frac{分類モデルが「独女通信」の記事であると予測した結果が正解であった件数}{実際の「独女通信」の記事の全件数} \\ \end{eqnarray*}}}
- $\text{precision}$は分類モデルが陽性と分類したデータ内、本当に陽性(「独女通信」の記事)であるデータの割合を表している→陽性判定の確からしさを表している(高いほど良い)
- $\text{recall}$は正しく陽性(「独女通信」の記事)と分類された陽性(「独女通信」の記事)データの割合を表している→陽性判定の網羅性を表している(高いほど良い)
つまり、$\text{precision}$が高い状態でありながら(確からしさを担保しながら)$\text{recall}$もできるだけ高い(網羅もできている)というのが理想的です。
様々な閾値における$\text{precision}$と$\text{recall}$をプロットすることでPR曲線を描くことができます。これもまたROC曲線と場合と同様にAUC(PR曲線の下側面積)が大きいほど精度が良いと言えます。
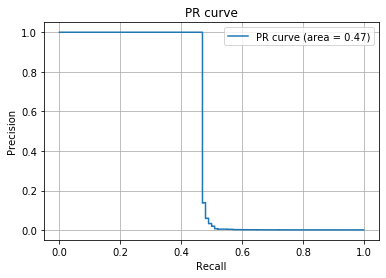
precision, recall, thresholds = metrics.precision_recall_curve(y_test, y_preds) auc = metrics.auc(recall, precision) print(auc) plt.plot(recall, precision, label='PR curve (area = %.2f)'%auc) plt.legend() plt.title('PR curve') plt.xlabel('Recall') plt.ylabel('Precision') plt.grid(True) plt.show()
今回作成した分類器を用いてPR曲線を描画しました。AUCが$0.98$(最大値が$1$)であることを考えると、PR曲線の観点で見ても非常に精度が良いことがわかるかと思います。ただROC曲線の場合とは違ってランダムの分類器の場合でおAUCは$0.5$となるとは限りません。
ROC曲線とPR曲線
ROC曲線とPR曲線のどちらを使えばよいのか、という話ですが一般的には不均衡データの場合(negativeの数がpositiveの数よりも圧倒的に多い等)はPR曲線を使い、それ以外はROC曲線を使用するのがよいとされています。
解釈としては、ROC曲線においてはPositiveをPositiveであると判断できていること、NegativeをNegativeと判断できること両方を観点として持っていますが、PR曲線はPositiveをPositiveと判断できるていることのみに着目しています。なので、分類器の性能指標としては両方のバランスを見ているROC曲線を使用するのがよいのですが、Negativeの方が圧倒的に多い場合は大多数のNegativeをNegativeと判断することによって精度が良いと判断されてしまいます。(Positveの判断は適当であっても。)なので、少数のPositiveをちゃんと判断できているか見るためにPR曲線を使用する、というのが私の見解です。
極端な例ですが、Positive100件のデータとNegative99900件のデータにおいて、Positiveは適当に予測し、NegativeはNegativeと確実に判断するモデルがあったとします。するとROC曲線とPR曲線は下記のようになります。
rand_predict = np.concatenate((np.random.rand(100) , 0.5*np.random.rand(99900))) rand_test = np.concatenate((np.ones(100), np.zeros(99900))) from sklearn import metrics import matplotlib.pyplot as plt fpr, tpr, thresholds = metrics.roc_curve(rand_test, rand_predict) auc = metrics.auc(fpr, tpr) print(auc) #ROC曲線 plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc) plt.plot(np.linspace(1, 0, len(fpr)), np.linspace(1, 0, len(fpr)), label='Random ROC curve (area = %.2f)'%0.5, linestyle = '--', color = 'gray') plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) plt.show() ##PR曲線 precision, recall, thresholds = metrics.precision_recall_curve(rand_test, rand_predict) auc = metrics.auc(recall, precision) print(auc) plt.plot(recall, precision, label='PR curve (area = %.2f)'%auc) plt.legend() plt.title('PR curve') plt.xlabel('Recall') plt.ylabel('Precision') plt.grid(True) plt.show()
AUCに大きな差があることがわかるでしょうか(ROC曲線のAUCは$0.72$、PR曲線のAUCは$0.47$)。同じデータにも関わらずみる指標によって精度の判断が大きく変わってしまいます。基本は上記の観点でROC曲線とPR曲線を使い分けつつ、タスクに応じて個別で判断することが重要です。
Next
分類以外の機械学習の性能評価についてもまとめていければと思います。



- 投稿日:2020-04-21T21:59:39+09:00
AttributeError: module 'tensorflow' has no attribute 'log' を解決した話。
Mask R-CNNを実装してみたかった
深層学習超初心者がエラーを解決した話です。
誰かの助けになればと思い、記事を書きました。画像認識でMask R-CNNを使ってみたい場合、matterport社のMask_RCNNというコードを利用するのが近道です。
https://github.com/matterport/Mask_RCNN
これだけ読んでも良くわからなかったので、下記のサイトを読みながら、
Google colaboratory上でdemo.ipynbを実行しようとしました。https://tech-blog.optim.co.jp/entry/2019/03/28/173000
http://maruo51.com/2020/02/22/mrcnn/しかし!
そのまま実行しようとしても、AttributeError: module 'tensorflow' has no attribute 'log'が発生してしまうのです。(2020年4月20日時点)
そこで、これを解決するために2日間くらい試行錯誤したので、
書き記しておきます。解決方法(仮)
参考になるのは、以下に示すgithubのお悩み相談箱みたいなものです。
https://github.com/matterport/Mask_RCNN/issues/1797#
全部英語なのですが、頑張って読み進めたところ、ヒントになるような投稿を見つけました。
どうやら、tensorflowのバージョンが違ってメゾットが変更になっていることに起因するエラーのようです。
この通りに、mrcnn/model.pyの該当箇所を書き直せばいいはずです。
注意点!
注意すべきは、エラーが出る最後まで行ってからmodel.pyを変更するのではなく、
最初にレポジトリをクローンした直後にmodel.pyを書き換えてしまうことです。修正版model.pyでsetupとかを進めることで解決できたようでした。
(本当の原因を知っている人がいたら教えてください。)一件落着!
参考になったらいいねお願いします!

- 投稿日:2020-04-21T21:55:14+09:00
機械学習モデルの推論web APIサーバーのよくある構成 [FastAPIの実装例あり]
本記事の目的
機械学習の推論web APIの典型的な構成を紹介します。必ずしもWEBの知識や機械学習の知識はなくても読める内容だと思います。(実装例は除く)
紹介する構成は、業務でいくつかの機械学習モデルの推論web APIをたてた経験からきていますが、あくまでも個人的見解なので、こっちのほうがいいよーってのがあればコメントで教えていただけると幸いです。
実装例ではweb frameworkは非同期処理の扱いやすさ、実装のシンプルさの観点からFastAPIを使います。目次
- 機械学習の推論web APIの構成
- 実装例
1. 機械学習の推論web APIの構成
本記事では、2つのパターンを紹介します。
注) まず、共通部分の説明をします。機械学習の知見が必要なのは基本的に共通部分だけです。もし、機械学習に詳しくない or webに詳しくない場合は、共通部分と後述の部分で役割を分担できるので、そんなもんかと流してもらってもかまいません。
推論API (共通部分)
学習させたモデルに推論させる場合、一般的に以下のような機械学習モデルの推論APIを構築すると思います。
ローカルPCやJupyter Notebook上での開発しかしていない場合でもこのようなAPI (パイプライン) は作ると思います。詳細は割愛しますが、負荷分散やモデル管理の便利さのためにクラウド上のサーバに機械学習モデルを使うAPIだけ切り出してもいいと思います (参考: GCP AI platform Prediction)。 負荷だけではなく、推論にもGPUを使わないとパフォーマンスに問題がでるような重いモデルの場合、よくあるWEBアプリ用のサーバーでは対応できないので、切り分けできるようにしたほうが柔軟だと思います。
また、学習済みモデルを用いた外部サービスを用いる場合も同じ構成になると思います。
データ量が大きくなってくると前処理などをGoogle Cloud Dataflowのような大規模データ処理エンジンに置き換えるなどの工夫が必要になると思います。
上記のようなローカルPCやJupyter Notebook上で開発した推論APIをベースにしてweb APIをたてる際、主に2種類のパターンが考えられます。これらは、入出力データの扱いが異なります。
- 1.1. オンライン予測(HTTP予測とも呼ばれる)
- 1.2. バッチ予測
(GCPのAI platformで使われている名称を用いています。参考: オンライン予測 vs バッチ予測)
1.1. オンライン予測
http requestが来たらMLの関数を動かして、outputをhttp responseで即時返すというシンプルな構成です。サーバーの起動時に一度だけ重みをloadしておきます。重みのload時に、cloudのstorage(google storageなど)から重みを取得するようにしておくとモデルの変更がしやすくなります。
利点
- ローカルで動かすような推論用の関数をweb frameworkの中に移すだけでだいたい動く
- 1つのAPIを叩くだけで推論結果が返るのでたたきやすいAPIになる
- モデルが小さく、データが少ない場合は、レスポンスが速い
欠点
- web APIは、負荷分散の観点から数十秒から数分でタイムアウトするように設定されることが多いので、推論に時間が長時間かかると処理が失敗してしまいます。なので、重いモデルや一度に大量のデータをさばくのには適していないです。
1.2. バッチ予測
即時にレスポンスを返せない or 返す必要がない場合には以下のようにML APIの推論結果を直接レスポンスせずに、何らかのstorageに格納します。以下の様に、処理を3段階に分けて考えることができます。(2と3が分かれていればいいです。upload APIはML APIに統合してもいいです)
- upload API: 入力用のデータをStorage (Databaseやcloud storageなど) に貯める
- ML API(非同期で実行): Storageからデータを取得、MLの関数を動かし、結果をStorageに保存。ただし、処理が終わるより先にレスポンスを返しておく
- download API: Storageから結果を取得し、返す
それぞれのAPIは疎結合にできます。なので、upload APIとdownload APIの実装はかなり自由度が高いです。
使い方は以下の様に様々です。
- 入力データをに一定期間ためて、1日の終りに一気に推論
- タイムアウトしてしまうような複雑なモデルを用いて推論
- 推論結果をキャッシュして、同じ入力に対して繰り返し推論を行わない
- など
また、uploadとdownload APIの実装はPython以外の言語でも何の問題もないですし、同じstorageに読み書きできれば、異なるサーバーにAPIがたっていてもいいです。APIを経由せずStorageにフロントエンドから直接読み書きしてもいいです。特に入出力が画像の場合はcloud storageを直接扱うほうが簡潔なフローになります。
利点
- タイムアウトで失敗することがなくなる
- 自由度が高い
- 学習用のAPIも同様な構成で実装できる
欠点
- オンライン予測よりも構成が複雑なので、使いにくい
- オンライン予測よりも処理に時間がかかる
2. 実装例
online予測とbatch予測のAPIをFastAPIで実装してみます。
以下の例を見ると、ローカルで推論のパイプラインをちゃんと関数化しておけばweb APIにするのは結構ハードルが低いなと感じてもらえるのではないかと思っています。やらないこと
本記事では以下は扱いません。
- security
- deploy
FastAPIとは
PythonのWeb frameworkで、Flaskのようなマイクロフレームワークにあたります。
パフォーマンスの高さ、書きやすさ、本番運用を強く意識した設計、モダンな機能などが強みです。
特に、非同期処理が扱いやすいです。以下、FastAPIの基本知識を前提としています。
もし細かいことが知りたい場合は、適宜以下などを参照して下さい。推論API (共通部分)
汎用性をもたせるために、非常にざっくりとしたmockを定義します。
特に意味はないですが簡単のため、自然言語処理の感情分析のタスクということにします。必要な機能は、以下のようになります。ただし、モデルだけ別サーバーに切り出されている場合は、loadとモデルの保持は要りません。
- 重みのloadやjoblib, pickleなどを用いたmodel instanseの読み込み
- モデルの保持
- 推論パイプライン
今回は、predictでランダムな感情を返すモデルとします。処理時間はリアルにしたいのでload時に20秒間フリーズし、predict時に10秒間フリーズするようにしています。
ml.pyfrom random import choice from time import sleep class MockMLAPI: def __init__(self): # model instanse self.model = None def load(self, filepath=''): """ when server is activated, load weight or use joblib or pickle for performance improvement. then, assign pretrained model instance to self.model. """ sleep(20) pass def predict(self, x): """implement followings - Load data - Preprocess - Prediction using self.model - Post-process """ sleep(10) preds = [choice(['happy', 'sad', 'angry']) for i in range(len(x))] out = [{'text': t.text, 'sentiment': s} for t, s in zip(x, preds)] return outリクエスト・レスポンスのデータ形式
リクエストデータの形式を定義します。
以下の様に、複数入力に対応できるようにしてみます。{ "data": [ {"text": "hogehoge"}, {"text": "fugafuga"} ] }レスポンスデータは、入力に推論結果を加えて返すような形式にします。
{ "prediction": [ {"text": "hogehoge", "sentiment": "angry"}, {"text": "fugafuga", "sentiment": "sad"} ] }なので、以下の様にSchemaを定義します。
schemas.pyfrom pydantic import BaseModel from typing import List # request class Text(BaseModel): text: str class Data(BaseModel): data: List[Text] # response class Output(Text): sentiment: str class Pred(BaseModel): prediction: List[Output]2.1. オンライン予測
上述の共通部分を使ってオンライン予測を行うweb APIを実装します。
必要なのは、
- サーバーの起動時に学習済み機械学習モデルを読み込む
- データの受け取り、ML APIで推論、結果を返す
です。以下の様に実装すると最低限のAPIが完成します。
main.pyfrom fastapi import FastAPI from ml_api import schemas from ml_api.ml import MockMLAPI app = FastAPI() ml = MockMLAPI() ml.load() # load weight or model instanse using joblib or pickle @app.post('/prediction/online', response_model=schemas.Pred) async def online_prediction(data: schemas.Data): preds = ml.predict(data.data) return {"prediction": preds}動作確認
ローカルで動作確認します。
CuRLでsampleの入力をpostします。すると、想定していた出力が返ってくることが確認できます。
また、レスポンスが返ってくるまでにかかった時間は10秒なので、ほぼpredictの処理時間だけしかかかっていないことも確認できます。$ curl -X POST "http://localhost:8000/prediction/online" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"data\":[{\"text\":\"hogehoge\"},{\"text\":\"fugafuga\"}]}" -w "\nelapsed time: %{time_starttransfer} s\n" {"prediction":[{"text":"hogehoge","sentiment":"angry"},{"text":"fugafuga","sentiment":"happy"}]} elapsed time: 10.012029 s2.1. バッチ予測
上述の共通部分を使ってバッチ予測を行うweb APIを実装します。
- upload API: 入力用のデータをStorage (Databaseやcloud storageなど) に貯める
- ML API(非同期で実行): Storageからデータを取得、MLの関数を動かし、結果をStorageに保存。ただし、処理が終わるより先にレスポンスを返しておく
- download API: Storageから結果を取得し、返す
Input/Output
本来であれば、cloudのstorageやDBにデータを保存すべきですが、簡単のため、本記事ではローカルのストレージにcsv形式でデータを保存します。
まず、読み書きのための関数を定義します。入力データの保存時にランダムな文字列でファイル名を作成し、そのランダムな文字列をapiでやりとりすることで一連のバッチ予測を行います。
実装が長く感じるかもしれないですが、実際は、以下の3つの処理しかないです。
- csvの読み書き
- fileのpathを調整
- ランダムな文字列の生成
io.pyimport os import csv from random import choice import string from typing import List from ml_api import schemas storage = os.path.join(os.path.dirname(__file__), 'local_storage') def save_csv(data, filepath: str, fieldnames=None): with open(filepath, 'w') as f: writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() for f in data: writer.writerow(f) def load_csv(filepath: str): with open(filepath, 'r') as f: reader = csv.DictReader(f) out = list(reader) return out def save_inputs(data: schemas.Data, length=8): letters = string.ascii_lowercase filename = ''.join(choice(letters) for i in range(length)) + '.csv' filepath = os.path.join(storage, 'inputs', filename) save_csv(data=data.dict()['data'], filepath=filepath, fieldnames=['text']) return filename def load_inputs(filename: str): filepath = os.path.join(storage, 'inputs', filename) texts = load_csv(filepath=filepath) texts = [schemas.Text(**f) for f in texts] return texts def save_outputs(preds: List[str], filename): filepath = os.path.join(storage, 'outputs', filename) save_csv(data=preds, filepath=filepath, fieldnames=['text', 'sentiment']) return filename def load_outputs(filename: str): filepath = os.path.join(storage, 'outputs', filename) return load_csv(filepath=filepath) def check_outputs(filename: str): filepath = os.path.join(storage, 'outputs', filename) return os.path.exists(filepath)web API
upload、推論、uploadの3つのAPIをたてます。なお、バッチ推論では即時にレスポンスを返さないので、モデルのloadはAPIがたたかれる度に行います。
ここではFastAPIのBackgourndTasksを使ってモデルの推論を非同期処理させています。推論はバックグラウンドで処理を行い、終了を待たずに先にレスポンスを返すことができます。
main.pyfrom fastapi import FastAPI from fastapi import BackgroundTasks from fastapi import HTTPException from ml_api import schemas, io from ml_api.ml import MockBatchMLAPI app = FastAPI() @app.post('/upload') async def upload(data: schemas.Data): filename = io.save_inputs(data) return {"filename": filename} def batch_predict(filename: str): """batch predict method for background process""" ml = MockMLAPI() ml.load() data = io.load_inputs(filename) pred = ml.predict(data) io.save_outputs(pred, filename) print('finished prediction') @app.get('/prediction/batch') async def batch_prediction(filename: str, background_tasks: BackgroundTasks): if io.check_outputs(filename): raise HTTPException(status_code=404, detail="the result of prediction already exists") background_tasks.add_task(ml.batch_predict, filename) return {} @app.get('/download', response_model=schemas.Pred) async def download(filename: str): if not io.check_outputs(filename): raise HTTPException(status_code=404, detail="the result of prediction does not exist") preds = io.load_outputs(filename) return {"prediction": preds}動作確認
オンライン予測と同様に動作確認します。
CuRLでsampleの入力をpostします。すると、想定していた出力が返ってくることが確認できます。
また、download APIをたたくまでに30秒待っています。しかし、それぞれのresponseは非常に早く返ってきていることがわかります。$ curl -X POST "http://localhost:8000/upload" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"data\":[{\"text\":\"hogehoge\"},{\"text\":\"fugafuga\"}]}" -w "\nelapsed time: %{time_starttransfer} s\n" {"filename":"fdlelteb.csv"} elapsed time: 0.010242 s $ curl -X GET "http://localhost:8000/prediction/batch?filename=fdlelteb.csv" -w "\nelapsed time: %{time_starttransfer} s\n" {} elapsed time: 0.007223 s $ curl -X GET "http://localhost:8000/download?filename=fdlelteb.csv" -w "\nelapsed time: %{time_starttransfer} s\n" [12:58:27] {"prediction":[{"text":"hogehoge","sentiment":"happy"},{"text":"fugafuga","sentiment":"sad"}]} elapsed time: 0.008825 sおわりに
機械学習の推論web APIの典型的な構成であるオンライン予測とバッチ予測の2つを紹介しました。
一般的なweb APIの構成から多少ひねりが必要となっていますが、FastAPIを使ってシンプルに構築する実装例も紹介しました。ローカルで推論のパイプラインをちゃんと関数化しておけばweb APIにするのはハードルが低いなと感じてもらえたら嬉しいです。
機械学習の盛り上がりは留まるところをしらないですが、web APIの構成などの情報はまだまだ少ないと感じています。本記事で紹介した構成も荒削りだと思います。改善点などあればコメントしていただけるとありがたいです!



- 投稿日:2020-04-21T21:55:14+09:00
FastAPIで機械学習モデルの推論web APIを爆速で構築する
本記事の目的
機械学習の推論web APIの典型的な構成を紹介します。必ずしもWEBの知識や機械学習の知識はなくても読める内容だと思います。(実装例は除く)
紹介する構成は、業務でいくつかの機械学習モデルの推論web APIをたてた経験からきていますが、あくまでも個人的見解なので、こっちのほうがいいよーってのがあればコメントで教えていただけると幸いです。
実装例ではweb frameworkは非同期処理の扱いやすさ、実装のシンプルさの観点からFastAPIを使います。目次
- 機械学習の推論web APIの構成
- 実装例
1. 機械学習の推論web APIの構成
本記事では、2つのパターンを紹介します。
注) まず、共通部分の説明をします。機械学習の知見が必要なのは基本的に共通部分だけです。もし、機械学習に詳しくない or webに詳しくない場合は、共通部分と後述の部分で役割を分担できるので、そんなもんかと流してもらってもかまいません。
推論API (共通部分)
学習させたモデルに推論させる場合、一般的に以下のような機械学習モデルの推論APIを構築すると思います。
ローカルPCやJupyter Notebook上での開発しかしていない場合でもこのようなAPI (パイプライン) は作ると思います。詳細は割愛しますが、負荷分散やモデル管理の便利さのためにクラウド上のサーバに機械学習モデルを使うAPIだけ切り出してもいいと思います (参考: GCP AI platform Prediction)。 負荷だけではなく、推論にもGPUを使わないとパフォーマンスに問題がでるような重いモデルの場合、よくあるWEBアプリ用のサーバーでは対応できないので、切り分けできるようにしたほうが柔軟だと思います。
また、学習済みモデルを用いた外部サービスを用いる場合も同じ構成になると思います。
データ量が大きくなってくると前処理などをGoogle Cloud Dataflowのような大規模データ処理エンジンに置き換えるなどの工夫が必要になると思います。
上記のようなローカルPCやJupyter Notebook上で開発した推論APIをベースにしてweb APIをたてる際、主に2種類のパターンが考えられます。これらは、入出力データの扱いが異なります。
- 1.1. オンライン予測(HTTP予測とも呼ばれる)
- 1.2. バッチ予測
(GCPのAI platformで使われている名称を用いています。参考: オンライン予測 vs バッチ予測)
1.1. オンライン予測
http requestが来たらMLの関数を動かして、outputをhttp responseで即時返すというシンプルな構成です。サーバーの起動時に一度だけ重みをloadしておきます。重みのload時に、cloudのstorage(google storageなど)から重みを取得するようにしておくとモデルの変更がしやすくなります。
利点
- ローカルで動かすような推論用の関数をweb frameworkの中に移すだけでだいたい動く
- 1つのAPIを叩くだけで推論結果が返るのでたたきやすいAPIになる
- モデルが小さく、データが少ない場合は、レスポンスが速い
欠点
- web APIは、負荷分散の観点から数十秒から数分でタイムアウトするように設定されることが多いので、推論に時間が長時間かかると処理が失敗してしまいます。なので、重いモデルや一度に大量のデータをさばくのには適していないです。
1.2. バッチ予測
即時にレスポンスを返せない or 返す必要がない場合には以下のようにML APIの推論結果を直接レスポンスせずに、何らかのstorageに格納します。以下の様に、処理を3段階に分けて考えることができます。(2と3が分かれていればいいです。upload APIはML APIに統合してもいいです)
- upload API: 入力用のデータをStorage (Databaseやcloud storageなど) に貯める
- ML API(非同期で実行): Storageからデータを取得、MLの関数を動かし、結果をStorageに保存。ただし、処理が終わるより先にレスポンスを返しておく
- download API: Storageから結果を取得し、返す
それぞれのAPIは疎結合にできます。なので、upload APIとdownload APIの実装はかなり自由度が高いです。
使い方は以下の様に様々です。
- 入力データをに一定期間ためて、1日の終りに一気に推論
- タイムアウトしてしまうような複雑なモデルを用いて推論
- 推論結果をキャッシュして、同じ入力に対して繰り返し推論を行わない
- など
また、uploadとdownload APIの実装はPython以外の言語でも何の問題もないですし、同じstorageに読み書きできれば、異なるサーバーにAPIがたっていてもいいです。APIを経由せずStorageにフロントエンドから直接読み書きしてもいいです。特に入出力が画像の場合はcloud storageを直接扱うほうが簡潔なフローになります。
利点
- タイムアウトで失敗することがなくなる
- 自由度が高い
- 学習用のAPIも同様な構成で実装できる
欠点
- オンライン予測よりも構成が複雑なので、使いにくい
- オンライン予測よりも処理に時間がかかる
2. 実装例
online予測とbatch予測のAPIをFastAPIで実装してみます。
以下の例を見ると、ローカルで推論のパイプラインをちゃんと関数化しておけばweb APIにするのは結構ハードルが低いなと感じてもらえるのではないかと思っています。やらないこと
本記事では以下は扱いません。
- security
- deploy
FastAPIとは
PythonのWeb frameworkで、Flaskのようなマイクロフレームワークにあたります。
パフォーマンスの高さ、書きやすさ、本番運用を強く意識した設計、モダンな機能などが強みです。
特に、非同期処理が扱いやすいです。以下、FastAPIの基本知識を前提としています。
もし細かいことが知りたい場合は、適宜以下などを参照して下さい。推論API (共通部分)
汎用性をもたせるために、非常にざっくりとしたmockを定義します。
特に意味はないですが簡単のため、自然言語処理の感情分析のタスクということにします。必要な機能は、以下のようになります。ただし、モデルだけ別サーバーに切り出されている場合は、loadとモデルの保持は要りません。
- 重みのloadやjoblib, pickleなどを用いたmodel instanseの読み込み
- モデルの保持
- 推論パイプライン
今回は、predictでランダムな感情を返すモデルとします。処理時間はリアルにしたいのでload時に20秒間フリーズし、predict時に10秒間フリーズするようにしています。
ml.pyfrom random import choice from time import sleep class MockMLAPI: def __init__(self): # model instanse self.model = None def load(self, filepath=''): """ when server is activated, load weight or use joblib or pickle for performance improvement. then, assign pretrained model instance to self.model. """ sleep(20) pass def predict(self, x): """implement followings - Load data - Preprocess - Prediction using self.model - Post-process """ sleep(10) preds = [choice(['happy', 'sad', 'angry']) for i in range(len(x))] out = [{'text': t.text, 'sentiment': s} for t, s in zip(x, preds)] return outリクエスト・レスポンスのデータ形式
リクエストデータの形式を定義します。
以下の様に、複数入力に対応できるようにしてみます。{ "data": [ {"text": "hogehoge"}, {"text": "fugafuga"} ] }レスポンスデータは、入力に推論結果を加えて返すような形式にします。
{ "prediction": [ {"text": "hogehoge", "sentiment": "angry"}, {"text": "fugafuga", "sentiment": "sad"} ] }なので、以下の様にSchemaを定義します。
schemas.pyfrom pydantic import BaseModel from typing import List # request class Text(BaseModel): text: str class Data(BaseModel): data: List[Text] # response class Output(Text): sentiment: str class Pred(BaseModel): prediction: List[Output]2.1. オンライン予測
上述の共通部分を使ってオンライン予測を行うweb APIを実装します。
必要なのは、
- サーバーの起動時に学習済み機械学習モデルを読み込む
- データの受け取り、ML APIで推論、結果を返す
です。以下の様に実装すると最低限のAPIが完成します。
main.pyfrom fastapi import FastAPI from ml_api import schemas from ml_api.ml import MockMLAPI app = FastAPI() ml = MockMLAPI() ml.load() # load weight or model instanse using joblib or pickle @app.post('/prediction/online', response_model=schemas.Pred) async def online_prediction(data: schemas.Data): preds = ml.predict(data.data) return {"prediction": preds}動作確認
ローカルで動作確認します。
CuRLでsampleの入力をpostします。すると、想定していた出力が返ってくることが確認できます。
また、レスポンスが返ってくるまでにかかった時間は10秒なので、ほぼpredictの処理時間だけしかかかっていないことも確認できます。$ curl -X POST "http://localhost:8000/prediction/online" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"data\":[{\"text\":\"hogehoge\"},{\"text\":\"fugafuga\"}]}" -w "\nelapsed time: %{time_starttransfer} s\n" {"prediction":[{"text":"hogehoge","sentiment":"angry"},{"text":"fugafuga","sentiment":"happy"}]} elapsed time: 10.012029 s2.1. バッチ予測
上述の共通部分を使ってバッチ予測を行うweb APIを実装します。
- upload API: 入力用のデータをStorage (Databaseやcloud storageなど) に貯める
- ML API(非同期で実行): Storageからデータを取得、MLの関数を動かし、結果をStorageに保存。ただし、処理が終わるより先にレスポンスを返しておく
- download API: Storageから結果を取得し、返す
Input/Output
本来であれば、cloudのstorageやDBにデータを保存すべきですが、簡単のため、本記事ではローカルのストレージにcsv形式でデータを保存します。
まず、読み書きのための関数を定義します。入力データの保存時にランダムな文字列でファイル名を作成し、そのランダムな文字列をapiでやりとりすることで一連のバッチ予測を行います。
実装が長く感じるかもしれないですが、実際は、以下の3つの処理しかないです。
- csvの読み書き
- fileのpathを調整
- ランダムな文字列の生成
io.pyimport os import csv from random import choice import string from typing import List from ml_api import schemas storage = os.path.join(os.path.dirname(__file__), 'local_storage') def save_csv(data, filepath: str, fieldnames=None): with open(filepath, 'w') as f: writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() for f in data: writer.writerow(f) def load_csv(filepath: str): with open(filepath, 'r') as f: reader = csv.DictReader(f) out = list(reader) return out def save_inputs(data: schemas.Data, length=8): letters = string.ascii_lowercase filename = ''.join(choice(letters) for i in range(length)) + '.csv' filepath = os.path.join(storage, 'inputs', filename) save_csv(data=data.dict()['data'], filepath=filepath, fieldnames=['text']) return filename def load_inputs(filename: str): filepath = os.path.join(storage, 'inputs', filename) texts = load_csv(filepath=filepath) texts = [schemas.Text(**f) for f in texts] return texts def save_outputs(preds: List[str], filename): filepath = os.path.join(storage, 'outputs', filename) save_csv(data=preds, filepath=filepath, fieldnames=['text', 'sentiment']) return filename def load_outputs(filename: str): filepath = os.path.join(storage, 'outputs', filename) return load_csv(filepath=filepath) def check_outputs(filename: str): filepath = os.path.join(storage, 'outputs', filename) return os.path.exists(filepath)web API
upload、推論、uploadの3つのAPIをたてます。なお、バッチ推論では即時にレスポンスを返さないので、モデルのloadはAPIがたたかれる度に行います。
ここではFastAPIのBackgourndTasksを使ってモデルの推論を非同期処理させています。推論はバックグラウンドで処理を行い、終了を待たずに先にレスポンスを返すことができます。
main.pyfrom fastapi import FastAPI from fastapi import BackgroundTasks from fastapi import HTTPException from ml_api import schemas, io from ml_api.ml import MockBatchMLAPI app = FastAPI() @app.post('/upload') async def upload(data: schemas.Data): filename = io.save_inputs(data) return {"filename": filename} def batch_predict(filename: str): """batch predict method for background process""" ml = MockMLAPI() ml.load() data = io.load_inputs(filename) pred = ml.predict(data) io.save_outputs(pred, filename) print('finished prediction') @app.get('/prediction/batch') async def batch_prediction(filename: str, background_tasks: BackgroundTasks): if io.check_outputs(filename): raise HTTPException(status_code=404, detail="the result of prediction already exists") background_tasks.add_task(ml.batch_predict, filename) return {} @app.get('/download', response_model=schemas.Pred) async def download(filename: str): if not io.check_outputs(filename): raise HTTPException(status_code=404, detail="the result of prediction does not exist") preds = io.load_outputs(filename) return {"prediction": preds}動作確認
オンライン予測と同様に動作確認します。
CuRLでsampleの入力をpostします。すると、想定していた出力が返ってくることが確認できます。
また、download APIをたたくまでに30秒待っています。しかし、それぞれのresponseは非常に早く返ってきていることがわかります。$ curl -X POST "http://localhost:8000/upload" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"data\":[{\"text\":\"hogehoge\"},{\"text\":\"fugafuga\"}]}" -w "\nelapsed time: %{time_starttransfer} s\n" {"filename":"fdlelteb.csv"} elapsed time: 0.010242 s $ curl -X GET "http://localhost:8000/prediction/batch?filename=fdlelteb.csv" -w "\nelapsed time: %{time_starttransfer} s\n" {} elapsed time: 0.007223 s $ curl -X GET "http://localhost:8000/download?filename=fdlelteb.csv" -w "\nelapsed time: %{time_starttransfer} s\n" [12:58:27] {"prediction":[{"text":"hogehoge","sentiment":"happy"},{"text":"fugafuga","sentiment":"sad"}]} elapsed time: 0.008825 sおわりに
機械学習の推論web APIの典型的な構成であるオンライン予測とバッチ予測の2つを紹介しました。
一般的なweb APIの構成から多少ひねりが必要となっていますが、FastAPIを使ってシンプルに構築する実装例も紹介しました。ローカルで推論のパイプラインをちゃんと関数化しておけばweb APIにするのはハードルが低いなと感じてもらえたら嬉しいです。
機械学習の盛り上がりは留まるところをしらないですが、web APIの構成などの情報はまだまだ少ないと感じています。本記事で紹介した構成も荒削りだと思います。改善点などあればコメントしていただけるとありがたいです!
- 投稿日:2020-04-21T20:36:26+09:00
『python django超入門』のNoReverseMatchエラーについての解説
前置き
テキスト『python django超入門』(秀和システム)をやっているところで、テキスト通りに入力してエラーが発生しました。出版社提供の正誤表に記載がなかったので勉強を兼ね投稿させていただきました。
テキストではhelloアプリケーションを作成しています。実行環境
django:3.0.2
python:3.7.4
OS:macOS Mojave 10.14.6エラー内容
それは、2-2のP.82(複数ページの移動)をやっていた時に起こりました。
index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>{{ title }}</title> </head> <body> <h1>{{ title }}</h1> <p>{{ msg }}</p> <p><a href="{% url goto %}">{{ goto }}</a></p> </body> </html>views.py# 修正前 # index()のみ抜粋 def index(request): params = { 'title': 'Hello/index', 'msg': 'これは、サンプルで作ったページです。', 'goto': 'next', } return render(request, 'hello/index.html', params)この状態でindex.htmlにアクセスすると下記エラーが発生しました。
NoReverseMatch at /hello/ Reverse for 'next' not found. 'next' is not a valid view function or pattern name.「next」って??と怒られています。。。
#おかしいな、何度見直してもテキスト通りなんだけど。。。原因、解決方法
結論から書くと、views.py内の'goto'の書き方が原因でした。
下記の通りに修正したら正常になりました。views.py# 5行目 # 変更前: 'goto': 'next', # 変更後: 'goto': 'hello:next',実行結果画面:
リンク部分の表示がテキストと違っていますが、そこは本質ではないのでここでは触れません。
(テキストでは「next」だけが表示されることになっている)
原因は、index.html内のテンプレート{% url goto %}部分に正しい書式で送信されていないためでした。
goto部分の書式は'アプリ名:name'となるはずが、nameしか来ていないので不整合が起きていました。あとがき
上記は出版社サポートページの正誤表に記載がなく、同じ部分でつまづく人がいるかもと思い、自身の勉強を兼ねて投稿させていただきました。
私自身djangoはまだ勉強中ですので、ツッコミなどありましたらお願いしますm(_ _)m

- 投稿日:2020-04-21T20:26:46+09:00
最近のポケモンはデザインが複雑になったのか?【Python】【OpenCV】
はじめに
先日、ポケモンたかさおじさんこと、生㌔Pのブログにて次のような記事が投稿された。
ポケモンらしさ-2_意見分析 マスコット感検証
https://pkmnheight.blogspot.com/2020/04/2.htmlざっくり引用すると、以前バズってた以下の海外の分析画像を、転載したTweetがあった。
ポケモンのデザインはどんどん生物的じゃなくなって行ってて、色んな部位が丸みを帯びてただの可愛いマスコットキャラクターと化してるっていう海外の分析画像が凄い pic.twitter.com/qHHVaHzEue
— Χ十 ◤カイジュー◢(⃔ *`꒳´ * )⃕↝♡ (@KaijuXO) June 13, 2019このTweetに対して、ポケモンたかさおじさんが 猛撃 していたというものである。
ざっっっくり要約すると、各世代ごとに幼虫・昆虫ごとに部位をピックアップし、
そう単純にマスコット化しているわけではないと分析している。
恐ろしい観察・分析力とボリュームなので、是非読んでいただきたい。
ところで、ポケモンという巨大なコンテンツは20年以上続いているだけあり、
各人のポケモンに対する思い入れや付き合い方は異なる。最も大きなインパクトだった1996年のポケモン赤緑直撃世代にとって
ポケモンは今でも初代のポケモン151匹なのだろう。音楽バンドの古参ファンが
「やっぱ初期のアルバムの方がいいよね」
「最近はPOPになったなあ・・・」 などと言いがちなのと同様に、「最近のポケモンはポケモンらしくない」
「昔のポケモンの方がよかった」
と言いがちなのである。そんな古参ファンにとって、最近のポケモンがポケモンらしくない理由については、それぞれ思うところがあったのだろう。(だからこそ、先程の海外の分析画像を転載した方のように、昔のポケモン・最近のポケモンの一部を切り取り、その理由を求めるのだ)
先日のポケモンたかさおじさんのアンケートでは、古くからポケモンを嗜んできた者たちによって、以下のような意見が多く寄せられた。
- 最近のポケモンは、デザインが複雑になってきた。
- 最近のポケモンは、シンプルさがない。
- 最近のポケモンは、マスコットキャラっぽい。
- 最近のポケモンは、ゆるキャラっぽい。
- 最近のポケモンは、丸い。
- 最近のポケモンは、生物感がない。
各々で感じる方向性は違えども、デザインについて今と昔で変わったと感じる意見が非常に多かった。
先程紹介したポケモンたかさおじさんの記事では、これらの意見に対してポケモンのデザインについて、主に生物的な面から分析が成されていた。
私の方はこの件に関して、「最近のポケモンは複雑になった」 かどうかについて調査を行った。
ポケモンのデザインの複雑さを情報量として定量化する
左のポケモンは1996年初出のメタモン。
右のポケモンは2019年初出のムゲンダイナである。
なるほど!!!!たしかに最近のポケモンは複雑である。
・・・・・・・・。
これで話を終わらせても良いが、
ポケモンは現在、全890種類もいる。
更に、リージョンフォーム・メガシンカなど、姿の違う者をあわせると、私の集計だと1056種類にもなる。全てのポケモンについて、デザインの複雑さを調べてみなければ、最近のポケモンほど複雑かどうかはわからないはずだ。
そもそも我々が感じるデザインにおける複雑さとは何だろうか?
私は、以下のような手法で全ポケモンの複雑さ≒情報量として定量化した。
ポケモンの情報量=「描き込み量」の数値化
アンパンマンのデザインにおける情報量は、北斗の拳のケンシロウに比べれば少ないのは明らかだ。
ここからは、情報量=「描き込み量」として、各ポケモンを数値化していく。
1.グレースケールへの変換
import cv2 import numpy as np def read_cv2(filename,method): #windowsでは日本語ファイルを開くにはこうしなきゃいけない stream = open(filename, "rb") bytes = bytearray(stream.read()) numpyarray = np.asarray(bytes, dtype=np.uint8) bgrImage = cv2.imdecode(numpyarray, method) return bgrImage filename = "フシギダネ.png" img_gray = read_cv2(filename,cv2.IMREAD_GRAYSCALE)
2.白部分を膨張させる
kernel = np.ones((4,4),np.uint8) dilation = cv2.dilate(img_gray,kernel,iterations = 1)
3.グレースケールとの差分を取る
diff = cv2.subtract(dilation, img) negaposi = 255 - diff
このような処理で、結果として輪郭や色の境が残る。
最後に、抽出された線部分の全ピクセル数を、画像内でポケモンに使われている全ピクセル数で割って規格化する
#主線部分が残った画像の黒い部分のピクセル数を合計する black_area= np.where(np.array(img_negaposi).flatten().reshape(-1)<250,1,0).sum() # アルファチャンネルのわかる画像ファイルを使用 # 公式のポケモン図鑑の画像にはアルファチャンネルが使用されている。 alpha_img = Image.open("フシギダネ_アルファ.png") alpha_array = 255-np.array(alpha_img)[:,:,3] used_area=np.where(alpha_array<255,1,0).sum() #これがポケモンの情報量となる poke_entropy = black_area/used_area #フシギダネの部分のピクセル数:48114 #主線部分のピクセル数:23366 #フシギダネの情報量: 23366/48114 = 0.4856この処理でフシギダネの情報量=0.4853となる
ポケモン世代ごとの情報量の集計
同様に、全ポケモンの情報量を計算し、情報量の多いポケモン。少ないポケモンごとに集めたのがこちらである。
- 情報量の少ないポケモン

- 情報量の多いポケモン
こうして眺めてみると、前述した方法で求めた情報量が直感的にも間違いではないのがわかる。
- 情報量多いポケモン:複雑。描き込みが多い。細長い。ゴツい。伝説のポケモン。
- 情報量少ないポケモン:シンプル。丸い。かわいい。未進化ポケモン。
と、情報量多い・少ない組でそれぞれ明らかに特徴が表れている。
今回使用する画像は全てポケモンずかん公式サイトから入手した。
ポケモンずかん(公式)
https://zukan.pokemon.co.jp/
やっぱり最近のポケモンはデザインが複雑だった!?
「フシギダネの情報量は0.4853」と書いても、この数字が多いのか少ないのか直感的に分かりにくいので、各情報量から平均値を引き、標準偏差で割ることで、標準化を行った。
以降は標準化後の情報量を、改めて情報量として扱う。
情報量が0に近いほど、全ポケモン中平均的な情報量。
プラスの値が大きいほど情報量が多く、
マイナスの値が大きいほど情報量が少ない。
と考えていただきたい。なお、先の画像の2者は、最も情報量の少ないポケモン・多いポケモンである。
情報量が多い方も少ない方もだいたいプラマイ0.6くらいになれば、全ポケモン中で両極端にいると思っていただきたい。
こうして求めた情報量に基づいて、各世代ごとに集計した。(メガシンカ・キョダイマックスは除外)
たしかに1世代に比べて後の世代は情報量が多くなっているようだ。
1世代の情報量中央値-0.025に対し、最新作の8世代では0.0235まで増加している。
世代 中央値 最小値 最大値 25% 75% 1 -0.025 -0.667 0.420 -0.140 0.094 2 -0.053 -0.476 0.412 -0.148 0.069 3 -0.017 -0.508 0.519 -0.159 0.141 4 0.033 -0.452 0.495 -0.096 0.147 5 -0.002 -0.517 0.402 -0.149 0.126 6 -0.007 -0.563 0.543 -0.145 0.123 7 0.013 -0.497 0.544 -0.112 0.148 8 0.024 -0.455 0.560 -0.141 0.164 5世代以降は中央値
-0.002,
-0.007,
0.013,
0.024と増加を続け、6世代以降は最大値を
0.543,
0.544,
0.56と更新している。つまり、古参ポケモンファンが物申す際の
「最近のポケモンはデザインが複雑になった」
と言うのは、根拠の無いものではないということらしい。「ほら!!最近のポケモンは複雑じゃないか!!!
俺は知っていたぞ!!だから俺は最近のポケモンは好きじゃなかったんだ!」
と思う古参の方々の気持ちをどうすることもできない。
話は変わるが、1世代のゲームボーイと、最新作のNintendo Switchでハードの解像度による表現力の差は著しいものである。
解像度が変わっただけではなく、色もゲームボーイの白黒4段階ドット絵から
256×256×256色の3Dモデルとなり、ポケモンの息づく表現も可能になった。

このようにハード性能が開放されることによって、より複雑なデザイン・よりシンプルなデザインをも表現が可能になった。
一方で、この著しいハード能力の向上にしては、ポケモンデザインの情報量を、ある程度の範囲にコントロールしようと努めているのかもしれない。
また、これは増やす時は意識して情報量を増やしている形跡でもある。
4世代以降のポケモンで、デザインが極めて特集な群がある。以下の性質を持つデザインだ。これらの要素は、各ポケモン世代を代表する要素と言っても過言ではない。
- 4世代:追加進化(ドサイドン・モジャンボなど)
- 6世代:メガシンカ
- 7世代:ウルトラビースト・カプ
- 8世代:キョダイマックス
我々は新しいポケモンが発表される度に、言葉に形容し難い「こいつらは何かが違うぞ!?!?!?」と思わせるモノがある!そう感じていたが、その一つが、情報量だったのだろう。
キョダイマックスのみこの方法ではむしろ情報量が低い分類となってしまった。
キョダイマックスポケモンは以下のように大幅にパースがついている。手前の部位で面積が増えている分、今回の手法では情報量が大きくならない
各世代のポジション別の情報量変動
古くからポケモンを嗜んできた方々はお気づきだろうが、毎世代、新しく登場するポケモンには、ある程度お決まりが存在する。
序盤の草むらにはほぼ確実に鳥ポケモンや小動物ポケモンが登場,少し進めば森に虫ポケモンが現れる。
毎回ストーリー終盤には600族と言われる、バトルで強いポケモンが捕まえられるようになる。
更に言えば、ゲームスタート直後に草・炎・水タイプから一匹を選べる言わゆる”御三家”といわれるポケモンも恒例だ。それらポジション毎での世代別情報量の変化を見れば、何かがわかるのではないかと思い、調査してみた。
皆もそれぞれ思い当たる節があるだろうが、4つに絞って紹介する。
序盤鳥ポケモン枠(未進化)
赤い線は全ポケモンの平均である。
日本人が転載してバズっていた海外のTweetでも取り上げられていたポッポ・ヤヤコマ・ツツケラが含まれている。
YO ? I never really noticed this about some of the newer Pokémon and now I can't unsee it ? pic.twitter.com/YEvNRIsULT
— DM me for Toilet Paper ? (@Mega_Arcanine1) June 6, 2019(翼を広げている画像か、畳んでいるかで情報量が変化してしまうので一概には言えないが)ポッポからヤヤコマまで情報量が減少しているため、このことから「最近のポケモンはマスコット化している」という印象を受けているのかもしれない。
ピカチュウ枠
皆は何と呼んでいるかは知らないが、私は「ピカチュウ枠」と呼ぶ。私のカウントでは、毎世代必ずこういったカワイイポケモンが存在するのだ。
特にパチリス以降のピカチュウ枠は、ポケモンアニメでサトシの同行者、もしくはライバルの手持ちポケモンとなっているのもあり、このポケモンのグッズを売らなければいけない!!! という何らかの力を感じる。
「最近のポケモンはマスコット化している」という文言のマスコットとは何なのか改めて考えるとよくわからないが、ピカチュウ枠はマスコット的なのだろう。皆かわいらしい見た目であり、情報量も平均値を下回っている。丸い形状のトゲデマルを除けば、世界一有名なポケモンであるピカチュウが最も情報量が低いく、徐々に情報量が増えているのがわかる。
ひょっとすると、「最近のポケモンは複雑」というのは、情報量が低いはずのピカチュウ枠ですら、最近は情報量が多い。 ということかもしれない。
幻ポケモン枠(配布ポケモン)
幻ポケモンといえば、ポケモン映画の顔となることもあり、ポケモンのゲーム自体やったこと無くても名前や姿を知っている人も出てくるだろう。
初代・金銀くらいまでをポケモンだと思っている方々にとっては、後の世代のポケモンはあまりにも情報過多に思えるかもしれない。
パッケージの伝説ポケモン枠
第二世代以降はストーリーに関わってくる伝説のポケモンがパッケージを飾っている。ポケモンを買わなくなった方々はパッケージを見て「最近のポケモンってこうなってるんだ・・・」と思うのだろう。
ホウホウの情報量は比較的多い。しかし、主に羽の描き込みによるところが大きい。主観的な感想だが、ホウオウは基本的にはタダの派手な鳥である。数値上の情報量ほどにはホウオウ複雑なポケモンには見えないのかもしれない。
一方、カイオーガ以降は体に特別な模様のようなものがあり、情報量を増やす要因となっている。
新作タイトルのパッケージを飾るようなポケモンは、その世代の顔であるのと同時に「これは新しいポケモンだ!!!」と思わせなくてはいけない。情報量が増えてでも、新しく、特別なデザインに挑戦したのだろう。
種族値の高いポケモンほどデザインが複雑!!!???
多くのポケモンガチ勢にとっては、バトルで強いポケモンこそ愛すべきポケモンであり、デザインは二の次・三の次であろう。
だが、強いポケモンとは、
- 爪
- 牙
- 翼
- 武器
- 首
- 炎
- トゲ
- ウロコ
- 子供
など、より強力な武器を、時には多く持つことで、様々なライバルと戦えるポケモンではないだろうか?
つまり、「種族値の合計が多い=情報量が多い」 が成立しうるのではないか?と考えた。
(異論はあるだろう。本当はタイプや覚える技。特性やバトルでのメタれ具合なども考慮したいが、それだけで一つの研究になってしまう)
まず、特に条件を設けず、伝説・幻・進化前・メガシンカなど、全て引っくるめて情報量と種族値合計の相関を見てみる。
相関係数0.443と、それなりの相関が見て取れる。
「情報量が多い=種族値合計が大きい」という傾向はあるようだ。
公式大会のガチバトルに出すポケモンに絞ったらどうか?
さきほどの散布図には進化前や伝説のポケモン・メガシンカポケモンまで含まれているが、では、公式大会のバトルに出す選択肢となりうるポケモンに絞ったらどうなるだろう。
先程の相関から
- 進化前ポケモン
- 伝説・幻ポケモンを除外したポケモンでの、情報量と種族値合計の相関がこちら。(斜めの赤い線は、相関図にフィットさせた回帰線である)
バトルに出すポケモンに絞っても、やはり情報量と種族値合計は相関があるということらしい。
また、条件を絞ったことで、ある程度どんなポケモンが図のどこに位置するのかが認知しやすくなった。
例えば、左下のピンク色の部分方には、ピカチュウ枠に属するポケモンが集まっている。
右下の緑色の部分には、序盤に捕まえられる虫ポケモンが固まっている。
「進化でポケモンは可愛くなくなる」が数値化できるか?
「生き物の赤ちゃんは、親に世話してもらえるように普遍的にカワイく見えるように生まれる」みたいな話を聞いたことがあると思う。
説明はすっ飛ばすが、生き物の赤ちゃんの共通した特徴として、以下のようなものがあるらしい。
これをベビースキーマという。
ベビースキーマによると、あらゆる動物の赤ちゃんに共通する特徴として、以下のようなものがあるらしい
- 手足が短い
- 頭が丸い
- 頭が大きい
- 顔が平坦
いかにも情報量を減らしそうな要因が揃っているではないか?
そこで、ポケモンが、情報量も進化しているのかを確かめて見る。(ポケモンでは、生物学的な意味での『変態』のことも『進化』と言う)
2段階進化ポケモンと、1段階進化ポケモンそれぞれで集計した結果がこちら。
やはり、一段階進化・二段階進化共に、「情報量が増える(≒カワイくなくなる)」という傾向が表れている!!!!
ベイビィポケモンから0進化目
メガシンカ
メガシンカによる情報量増は、分散が広すぎてよくわからないが、ポケモンにとって基本的に進化するということは情報量が増えるということらしい。
ポケモンは生き物の体をなしているが、ワザを使って戦うモンスターである。そのため、進化において、より強くなるために要素を追加していくのは戦闘を生業とする生命として理に叶っている。
ちなみに、情報量の変化が激しかったポケモンはこちら。
ポケモンはこちらの想像を超える進化を見せるものだなあ。と改めて実感した。
まとめ
- 「最近のポケモンは複雑になった」とか言われがちである
- ポケモンのデザインの複雑さを定量化するために、openCVを用いてデザインの境界線部分を取得し、情報量 を計算した。
- 最近のポケモンほど、情報量が増す傾向はある。
- 種族値の高いポケモンほど、情報量が高い傾向もあった。
- 進化によってポケモンは情報量を増やす。
課題
今回の情報量の算出法には欠点が多い。
例えば、エルレイド→メガエルレイドのように、
メガシンカでマントが追加されたにもかかわらず、情報量が大幅に下がっている。これはマントの追加によって描き込み量よりも分母の面積の方が大きく増えてしまったためだ。
この方法はフラクタル次元による画像の複雑度を使用することによって解決することが出来る。
参考にさせていただいたコード
https://gist.github.com/viveksck/1110dfca01e4ec2c608515f0d5a5b1d1def boxcount(Z, k): # 2値化したZについて、サイズkのボックス化 S = np.add.reduceat( np.add.reduceat(Z, np.arange(0, Z.shape[0], k), axis=0), np.arange(0, Z.shape[1], k), axis=1) return S threshold=0.9 image_file = image_files[0] img = Image.open(image_file) Z = np.array(img)[:,:,0]/256.0 # しきい値によって2値化 Z = (Z < threshold) # 短い方の幅を使用 p = min(Z.shape) #2のべき乗で、画像の幅を超えない最大値 n = 2**np.floor(np.log(p)/np.log(2)) n = int(np.log(n)/np.log(2)) # 2のべき乗の配列(256,128,,,,4) sizes = 2**np.arange(n,1,-1) # ボックスの数をカウント。 box_list = [] for size in sizes: box = boxcount(Z,size) size=box.shape[0] plt.figure(figsize=(size/12,size/12)) plt.imshow(255-box,cmap="gray") box_list.append(box) # ボックス内の点の数をカウント counts=[len(np.where((box > 0) & (box < size*size))[0]) for box,size in zip(box_list,sizes)] plt.plot(np.log(sizes),np.log(counts),label="黒点の数",marker="o") plt.plot(np.log(sizes),coeffs[1] + np.log(sizes)*coeffs[0],label="近似式",ls="--") plt.title("両対数軸") plt.xlabel("log(ボックスの大きさ)") plt.ylabel("log(点の数)") plt.legend()
ボックスの大きさ・ボックスの数を対数にして近似線を作成した際の、傾きがフラクタル次元となる。
#両対数軸について、回帰線を作成 coeffs = np.polyfit(np.log(sizes), np.log(counts), 1) print("フシギダネのフラクタル次元:{}".format(-coeffs[0])) # フシギダネのフラクタル次元:1.4960451082147515この手法では、エルレイドはメガシンカによって情報量が増加するので、今回使用した手法に比べれば、この点では優れているかもしれない。
しかし、全体的に見れば、解釈が難しかったため、採用に至れなかった。
フラクタル次元の小さいポケモンは比較的、今回の手法と一致するのと、直感的にも正しそうなのだが、
フラクタル次元の多いポケモンでは解釈が難しかったため、採用を断念した。なぜ、アローラニャースが最もフラクタル次元が大きいのか?なぜヤバチャ(最下端のティーカップのようなポケモン)がフラクタル次元が大きいのか?直感的にわかりにくい。フラクタル次元の小さいポケモンの例
フラクタル次元の多いポケモンの例
また、今回の手法ではイラストでのポーズが情報量に大きく影響してしまうのも不完全である。より正確に行うには、3Dモデルによる分析が必要不可欠だろう。




































- 投稿日:2020-04-21T20:03:04+09:00
擬似フラクタル図形をPythonを使って描いてみた
今日は落書きで書いた図形をプログラムで描いてみようと思い,Pythonを使って描いてみた。
今回使うプログラム
fractal.pyimport matplotlib.pyplot as plt import matplotlib.collections as mc import numpy as np def return_point(p1, p2): point = (p2-p1)*0.08 + p1 return point N = 1000 x = np.linspace(-1, 1, N) x_point = [0, 100, 200] y_point = [0, 200, 0] for i in range (N): new_x_point = return_point(x_point[i], x_point[i+1]) new_y_point = return_point(y_point[i], y_point[i+1]) x_point.append(new_x_point) y_point.append(new_y_point) fractal = [[(x_point[i], y_point[i]), (x_point[i+1], y_point[i+1])] for i in range(N)] lc = mc.LineCollection(fractal, colors='#333333', linewidths=1, antialiased=True) fig = plt.figure(figsize=(10,10)) ax = fig.add_subplot(1,1,1) # ↓非本質的な設定 ax.set_axis_bgcolor('#f3f3f3') plt.gca().spines['right'].set_visible(False) plt.gca().spines['left'].set_visible(False) plt.gca().spines['top'].set_visible(False) plt.gca().spines['bottom'].set_visible(False) plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False) # ↑非本質的な設定 ax.add_collection(lc) ax.autoscale() plt.savefig('./fractal.png')7行目
point = (p2-p1)*0.08 + p1の0.08の値を変えてみるのも一興.実行後
あら,美しい(CDのジャケットにありそう)
(ところで,何か名前がついていたらコメント欄で教えてください)【追記】
厳密にはフラクタル図形でないと考え,タイトルを"フラクタル図形をPythonを使って描いてみた"から"擬似フラクタル図形をPythonを使って描いてみた"に変更しました。
参考にした記事
ありがとうございました。
pythonでフラクタル図形を作成part1(シェルピンスキーのギャスケット)
https://qiita.com/okakatsuo/items/f2e79fc501ed9f799734Matplotlibで複数の線分を描画する方法
https://omedstu.jimdofree.com/2019/10/04/matplotlibで複数の線集合を描画する方法/matplotlibのめっちゃまとめ
https://qiita.com/nkay/items/d1eb91e33b9d6469ef51#2-グラフaxesの作成

- 投稿日:2020-04-21T19:43:04+09:00
AWS Lambdaに外部モジュール(numpy,scipy,requests等)をデプロイする
AWS Lambda(以下、Lambda)に外部モジュールをデプロイする方法を見ていきたいと思います。ここではPythonを例に見ていきます。
実行順序
1. Amazon Linux 2(Lambdaの実行環境)を準備する
2. ソースファイルとともにLambdaにデプロイ
2. Lambda Layerを使う方法*2はどちらを選んでも構いません。
1. Amazon Linux 2(Lambdaの実行環境)を準備する
requestsモジュール等、内部でC言語などを使わず、Pure Pythonで書かれたモジュールの場合、このステップは不要です。
しかし、numpyやscipyといった、C言語に依存する場合、Lambdaの実行環境と同じ環境で開発するのが開発しやすくなります。 windowsやMacでインストールしたnumpyをzipで固めてデプロイしてもエラーとなります。ここでは、Amazon Linux 2の環境としてDockerを使用します。Lambdaイメージ、lambci/lambda:build-python3.7 が公開されているので、それを使います。
適当なディレクトリを作って、Lambdaで実行するソースコード(lambda_function.py)とDockerfileを作成してください。
Dockerfileの中身
FROM lambci/lambda:build-python3.7 ADD . . CMD pip3 install numpy -t /var/tasklambda_function.pyの中身は適当
import numpy as np def lambda_handler(event,context): print(np.arange(10).reshape(2,5))ソースとDockerfile作成完了
~$ ls Dockerfile lambda_function.pyあとは、ビルドして、runしてください。
~$ docker image build -t numpy:latest . ~$ docker container run --rm -v ${PWD}:/var/task numpy:latestコンテナ内でインストールした外部モジュールを、ホストOSでも参照するために、-v ${PWD}:/var/taskしています。
ちなみに、/var/taskはLambdaが外部モジュールをインポートするために参照するパスの1つです。Dockerコンテナで実行する場合は、このパスの中に外部モジュールを置く必要があります。
試しに、Lambdaで以下のようにして、パスを確認してみてください。import sys def lambda_handler(event,context): print(sys.path) """ python3.7 における実行結果 ['/var/task', '/opt/python/lib/python3.7/site-packages', '/opt/python', '/var/runtime', '/var/lang/lib/python37.zip', '/var/lang/lib/python3.7', '/var/lang/lib/python3.7/lib-dynload', '/var/lang/lib/python3.7/site-packages', '/opt/python/lib/python3.7/site-packages', '/opt/python'] """上記コマンドが成功していると、ソースと外部モジュール(numpy)が同じ階層にあるはずです。あとは、Lambda Layer、もしくはソースファイルとともにzipで固めてデプロイするだけです。なので、以下2のどちらかを選んでください。
~$ ls Dockerfile bin lambda_function.py numpy numpy-1.18.3.dist-info numpy.libs2. Lambda Layerを使う方法
前述の通り、Lambdaが外部モジュールを読み込めるように、python ディレクトリを作成して、そこにnumpy関連のファイル、ディレクトリを移動します。
実行手順の最初の段階で python ディレクトリを作成していれば以下の作業は不要です。~$ mkdir python ~$ mv bin numpy numpy-1.18.3.dist-info numpy.libs python外部モジュールをzipで固めてLambda Layerにデプロイします。
~$ zip -rq numpy.zip pythonソースファイルをzipで固めて、Lambda コンソール or AWS CLIでデプロイします。
~$ zip -q lambda_function.zip lambda_function.py2. ソースファイルとともにLambdaにデプロイ
zipで固めて、Lambda コンソール or AWS CLIでデプロイします。
~$ zip -rq numpy.zip *Lambdaにデプロイする際にサイズが大きくて、画面に表示できない場合がありますが(numpyはほぼ表示不可能)実行自体はできます。
- 投稿日:2020-04-21T19:38:40+09:00
郵便番号から住所を取得する
郵便番号から住所を特定したい時に使う
郵便局の地域検索を利用
https://www.post.japanpost.jp/zipcode/index.html上記フォームの結果をパースして戻り値をdictionaryで返すfunction
import requests from bs4 import BeautifulSoup import re pref_key = { '北海道': 1, '青森県': 2, '岩手県': 3, '宮城県': 4, '秋田県': 5, '山形県': 6, '福島県': 7, '茨城県': 8, '栃木県': 9, '群馬県': 10, '埼玉県': 11, '千葉県': 12, '東京都': 13, '神奈川県': 14, '新潟県': 15, '富山県': 16, '石川県': 17, '福井県': 18, '山梨県': 19, '長野県': 20, '岐阜県': 21, '静岡県': 22, '愛知県': 23, '三重県': 24, '滋賀県': 25, '京都府': 26, '大阪府': 27, '兵庫県': 28, '奈良県': 29, '和歌山県': 30, '鳥取県': 31, '島根県': 32, '岡山県': 33, '広島県': 34, '山口県': 35, '徳島県': 36, '香川県': 37, '愛媛県': 38, '高知県': 39, '福岡県': 40, '佐賀県': 41, '長崎県': 42, '熊本県': 43, '大分県': 44, '宮崎県': 45, '鹿児島県': 46, '沖縄県': 47 } def get_html_text(url: str) -> str: try: req = requests.get(url) except requests.exceptions.ConnectionError: return False return req.content def getAddress(postal_code: int) -> dict: url = f'https://www.post.japanpost.jp/smt-zipcode/zipcode.php?zip={postal_code}' content = get_html_text(url) if not content: return False soup = BeautifulSoup(content, 'html.parser') dds = [i.text.strip() for i in soup.body.findAll('dd')] if not dds: return False dds = dds[:4] info = { 'postal': dds[0].replace('-', ''), 'pref': dds[1], 'city': dds[2], 'address': re.sub(r'\(.*', '', dds[3]) } info['pref_no'] = pref_key[info['pref']] return info if __name__ == "__main__": data = getAddress(1000004) print(data) """ 結果 { 'postal': '1000004', 'pref': '東京都', 'city': '千代田区', 'address': '大手町(次のビルを除く・JAビル)', 'pref_no': 13 } """
- 投稿日:2020-04-21T19:26:29+09:00
Pythonの応用: データクレンジングその1: Python記法
lambda式の基礎
無名関数の作成
Pythonで関数を作成する際には以下のように定義します。
# 例: x^2を出力する関数 pow1(x) def pow1(x): return x ** 2 # ここで 無名関数(lambda式(ラムダ式)) を用いるとコードを簡素化することができます。 # pow1(x)と同じ働きを持つ無名関数 pow2 pow2 = lambda x: x ** 2 # lambda式を用いることで、式をpow2という 変数 に格納できます。lambda式の構造は以下のようになっており、上記のpow2には引数xをx**2にして返すことを意味しています。
lambda 引数: 返り値lambda式に引数を渡して実際に計算する場合は以下のように指定するだけで、defで作成した関数と同じように使用できます。
# pow2 に引数 a を渡して、計算結果を b に格納する b = pow2(a)lambdaによる計算
lambda式で多変数の関数を作成したい場合は、以下のように記述します。
# 例: 2つの引数を足し合わせる関数 add1 add1 = lambda x, y: x + ylambda式は変数に格納できますが
変数に格納しなくても使用できます。
例えば、上記add1のlambda式に2つの引数3, 5を代入した結果を直接得たければ
以下のように記述します。(lambda x, y: x + y)(3, 5) # 出力結果 8これでは手間が増えただけですが、「変数に格納する」=「関数に名前を付けて定義する」
必要がないことは、関数の利用を非常に簡便にします。ifを用いたlambda
lambdaはdefによる関数と異なり、返り値の部分には式以外を指定することができません。
例えばdefによる関数では以下のような処理が可能でしたが、これをlambdaで表現することはできません。# "hello."と出力する関数 def say_hello(): print("hello.")ただし、ifを用いた条件分岐に関しては三項演算子(条件演算子)という手法を用いてlambdaで作成できます。
# 引数xが3未満ならば2を掛け、3以上ならば3で割って5を足す関数 def lower_three1(x): if x < 3: return x * 2 else: return x/3 + 5 # 上記の関数をlambdaで表現すると、このようになります。 # lower_three1と同じ関数 lower_three2 = lambda x: x * 2 if x < 3 else x/3 + 5三項演算子の表記は以下の通りです。
若干わかりにくいですが
条件を満たす時の処理
if 条件
else 条件を満たさない時の処理このように、三項演算子を使用するとlambda以外にも様々な場面で
コードの行数を節約することができます。lambda式の利用
listの分割(split)
文字列を空白やスラッシュなどで分割したい場合
split()関数を用います。split()関数で分割された文字列はリスト型で返されます。分割したい文字列.split("区切る記号", 分割回数)例えば英文を空白で分割して単語のリストにすることができます。
# 分割したい文字列 test_sentence = "this is a test sentence." # splitでリストにする test_sentence.split(" ") # 出力結果 ['this', 'is', 'a', 'test', 'sentence.']引数に分割回数を指定すると、先頭から指定した回数で文字列を分割します。指定した回数を超えるとそれ以上は分割しません。
# 分割したい文字列 test_sentence = "this/is/a/test/sentence." # splitでリストにする test_sentence.split("/", 3) # 出力結果 ['this', 'is', 'a', 'test/sentence.']listの分割(re.split)
標準のsplit()関数は一度に複数の記号で分割することができません。
一度に複数の記号で文字列を分割するにはreモジュールの re.split()関数を用います。re.split()関数は[区切る記号]の[ ]内に複数の記号を指定することで
一度に複数の記号で分割することが可能です。re.split("[区切る記号]", 分割したい文字列) # reモジュールのインポート import re # 分割したい文字列 test_sentence = "this,is a.test,sentence" # ","と" "と"."で分割して、リストにする re.split("[, .]", test_sentence) # 出力結果 ['this', 'is', 'a', 'test', 'sentence']高階関数(map)
他の関数を引数とする関数を
高階関数と言いますlistの各要素に関数を適用したい場合は
map()関数を用います。# イテレータ(計算の方法を格納)を返す 計算は行わない map(適用したい関数, 配列) # 計算結果をlist に返す list(map(関数, 配列))例えばa = [1, -2, 3, -4, 5]という配列の各要素の絶対値を得るにはforループを用いると以下のように書きます。
a = [1, -2, 3, -4, 5] # forループで関数適用 new = [] for x in a: new.append(abs(x)) print(new) # 出力結果 [1, 2, 3, 4, 5] # これをmap()関数を用いると、以下のように簡潔に書くことが可能です。 a = [1, -2, 3, -4, 5] # mapで関数適用 list(map(abs, a)) # 出力結果 [1, 2, 3, 4, 5] ## absなどユニバーサル関数を初めとして ## lambdaで設定した変数(関数も有効です)list()関数で囲むことにより、
map()関数の適用結果(上の例では abs を適用した結果)を
再度リストに格納することができます。この際、変数名で単純に list = としてしまうと
list()関数を呼び出すつもりが、変数listに値を格納しており
エラーになるので注意が必要です。イテレータ
複数の要素を順番に取り出す機能をもったクラスを指します。
この、要素を順番に取り出す機能を使うことでforループを用いるよりも
実行時間を短くすることができるので
膨大な要素を持つ配列に関数を適用したい場合にはmap()関数を用います。filter
listの各要素から条件を満たす要素だけを取り出す場合は
filter()関数を用います。# イテレータを返す filter(条件となる関数, 配列) # 計算結果をlistに返す list(filter(関数, 配列)) # 条件となる関数とは、lambda x: x>0 のように入力に対してTrue/Falseを返す関数のことをいいます。 # 例えば a = [1, -2, 3, -4, 5] # という配列から正の要素を得るにはforループを用いると以下のように書きます。 a = [1, -2, 3, -4, 5] # forループでフィルタリング new = [] for x in a: if x > 0: new.append(x) print(new) # 出力結果 [1, 3, 5] # これをfilter用いると、以下のように簡潔に書くことが可能です。 a = [1, -2, 3, -4, 5] # filterでフィルタリング list(filter(lambda x: x>0, a)) # 出力結果 [1, 3, 5]sotred
listのソートにはsort()関数がありますが、より複雑な条件でソートしたい場合は
sorted()関数を用います。# キーを設定してソート sorted(ソートしたい配列, key=キーとなる関数, reverse=True または False)# キーとなる関数にはどの要素を基準にソートを行うかを指定します。 # ここにlambda x: x[n]と指定することで第n要素を基準にソートを行います。 # reverseをTrueにすると降順にソートします。 # 例えば要素数が2つの配列を要素に持つ配列(入れ子の配列)について # 各要素の第2要素が昇順になるようにソートを行いたい場合は、以下のように書きます。 # 入れ子の配列 nest_list = [ [0, 9], [1, 8], [2, 7], [3, 6], [4, 5] ] # 第2要素をキーとしてソート sorted(nest_list, key=lambda x: x[1]) # 出力結果 [[4, 5], [3, 6], [2, 7], [1, 8], [0, 9]]リスト内包表記
リストの生成
map()関数は本来イテレータの作成に特化しているため
list()関数で配列を生成するタイミングで時間がかかってしまいます。
そのためmap()関数と同様の手法で単純に配列を生成したいのであれば
forループのリスト内包表記を用います[適用したい関数(要素) for 要素 in 適用する元の配列] # 例えば a = [1, -2, 3, -4, 5] # という配列の各要素の絶対値を取るには以下のように書きます。 a = [1, -2, 3, -4, 5] # リスト内包表記で各要素の絶対値を取る [abs(x) for x in a] # 出力結果 [1, 2, 3, 4, 5] # 以下のようにmap()関数を用いるよりも、括弧の数を見ても簡潔に書けていると言えます。 # mapでlist作成 list(map(abs, a)) # 出力結果 [1, 2, 3, 4, 5] # イテレータを作成する場合はmap()関数 # 直接配列を得たい場合はリスト内包表記と使い分けると良いでしょう。if文を用いたループ
リスト内包表記の中で条件分岐を行うと
filter()関数と同様の操作をすることができます。
後置ifの使い方は以下の通りです。[適用したい関数(要素) for 要素 in フィルタリングしたい配列 if 条件]単に条件を満たす要素を取り出したい場合は
(適用したい関数(要素))の部分を(要素)と記述します。# 例えば a = [1, -2, 3, -4, 5] # という配列から正の要素を取り出すには以下のように書きます。 a = [1, -2, 3, -4, 5] # リスト内包表記フィルタリング(後置if) [x for x in a if x > 0] # 出力結果 [1, 3, 5] lambda で紹介した三項演算子とは異なるので、注意が必要です。 三項演算子は条件を満たさない要素についても 何らかの処理の定義が必要なのに対し ifを後置する場合は条件を満たさない要素を無視することが可能です。複数配列の同時ループ
複数の配列を同時にループしたい場合は
zip()関数を用います。# 例えば a = [1, -2, 3, -4, 5], b = [9, 8, -7, -6, -5] # という配列を同時にループする場合、for文を用いると以下のように書きます。 a = [1, -2, 3, -4, 5] b = [9, 8, -7, -6, -5] # zipを用いた並列ループ for x, y in zip(a, b): print(x, y) # 出力結果 1 9 -2 8 3 -7 -4 -6 5 -5 # リスト内包表記でも同様にzip()関数を用いて複数の配列を並列に処理することが可能です。 a = [1, -2, 3, -4, 5] b = [9, 8, -7, -6, -5] # リスト内包表記で並列に処理 [x**2 + y**2 for x, y in zip(a, b)] # 出力結果 [82, 68, 58, 52, 50]多重ループ
同時にループする場合にはzip()関数を用いましたが
ループの中でさらにループを行う多重ループは、for文では以下のように書きます。a = [1, -2, 3] b = [9, 8] # 二重ループ for x in a: for y in b: print(x, y) # 出力結果 1 9 1 8 -2 9 -2 8 3 9 3 8 # 同様にリスト内包表記では、for文を単純に2回並べて書くだけで二重ループになります。 a = [1, -2, 3] b = [9, 8] # リスト内包表記で二重ループ [[x, y] for x in a for y in b] # 出力結果 [[1, 9], [1, 8], [-2, 9], [-2, 8], [3, 9], [3, 8]]辞書オブジェクト
defaultdict
Pythonの辞書型のオブジェクトは
新たなkeyを追加するために毎回そのkeyの初期化が必要になるため
処理が煩雑になります。例えばリストlstに入っている各要素の個数を
辞書dに反映するプログラムは以下のようになります。存在しないキーは「KeyError」になるため
dに新たな要素を登録するたびに要素の個数の初期化が必要になります。# 辞書dにリストlstの各要素の出現回数を記録 d = {} lst = ["foo", "bar", "pop", "pop", "foo", "popo"] for key in lst: # dにkey(要素)がすでに登録されているかいないかで処理を分ける if key in d: # dにkey(要素)が登録されている場合 # 要素の個数を加算する d[key] += 1 else: # dにkey(要素)が登録されていない場合 # 要素の個数の初期化が必要 d[key] = 1 print(d) # 出力結果 {'foo': 2, 'bar': 1, 'pop': 2, 'popo': 1}そこで、collectionsモジュールの
defaultdictクラスを用いることで この問題を解決します。defaultdictクラスは以下のように定義します。
valueの型にはintやlistなどデータ型を指定します。from collections import defaultdict d = defaultdict(valueの型)defaultdictは辞書型と同じように使用でき
defaultdictで上記と同じ処理をするプログラムを書くと以下のようになります。
値の初期化をせずとも要素の個数の数え上げができていることが分かります。from collections import defaultdict # 辞書dにリストlstの各要素の出現回数を記録 d = defaultdict(int) lst = ["foo", "bar", "pop", "pop", "foo", "popo"] for key in lst: d[key] += 1 # else: d[key] = 1 を書いて初期化する必要がない print(d) # 出力結果 defaultdict(<class 'int'>, {'foo': 2, 'bar': 1, 'pop': 2, 'popo': 1})出力結果の辞書型のオブジェクトをキーやバリューでソートする場合は
sorted()関数を用います。
sorted()関数はsorted(ソート対象, ソートに使用するkey, ソートオプション)の書式で呼び出します。sorted(辞書名.items(), key=lambdaで配列を指定, reverse=True)ソートに使用するkeyはitemsを指定して(key, value)のリスト形式で取り出し
keyでソートする場合はlambdaで「リストの1番目」つまりx[0]と指定します。また、valueでソートする場合はlambdaで「リストの2番目」つまりx[1]と指定します。
ソートオプションは昇順がデフォルトで、reverse=Trueと指定すると降順になります。
前述のプログラム例の出力結果をvalueで降順にソートして出力するには以下のように記述します。print(sorted(d.items(), key=lambda x: x[1], reverse=True))value内の要素の追加
defaultdictを使用してlist型の辞書に要素を追加します。
from collections import defaultdict defaultdict(list)valueがlist型なので
辞書名[key].append(要素)と指定するとvalueに要素を追加することができます。
これも標準の辞書型オブジェクトでは以下のように一手間かかります。# 辞書にvalueの要素を追加 d ={} price = [ ("apple", 50), ("banana", 120), ("grape", 500), ("apple", 70), ("lemon", 150), ("grape", 1000) ] for key, value in price: # keyの存在で条件分岐 if key in d: d[key].append(value) else: d[key] = [value] print(d) # 出力結果 {'apple': [50, 70], 'banana': [120], 'grape': [500, 1000], 'lemon': [150]}ここでdefaultdictを使用すると条件分岐が不要になります。
これを利用することで、keyごとにvalueをまとめることができます。Counter
collectionsモジュールにはdefaultdictクラス以外にも
いくつかのデータ格納クラスがあります。Counterクラスは、defaultdict同様
辞書型のオブジェクトと同じように使用できますが
より要素の数え上げに特化したクラスです。Counterクラスは以下のように定義します。
数え上げたいデータには、例えば単語を分解した配列や文字列、辞書などを指定します。from collections import Counter d = Counter(数え上げたいデータ)Counterクラスを用いると
単語をkey、出現回数をvalueとした辞書を作成するのに
以下のように記述するだけで実現でき
forループを用いないのでdefaultdictよりも
実行時間を短く簡潔に数え上げることができます。# Counterのインポート from collections import Counter # 辞書に要素の出現回数を記録 lst = ["foo", "bar", "pop", "pop", "foo", "popo"] d = Counter(lst) print(d) # 出力結果 Counter({'foo': 2, 'pop': 2, 'bar': 1, 'popo': 1})Counterクラスにはいくつかの数え上げを助ける関数が用意されており
most_common()関数は要素を頻度で降順にソートした配列を返します。most_common()関数の使い方は以下の通りです。
取得する要素数には整数を指定します。
例えば1と指定すると最頻の要素を返し
何も指定しないと、すべての要素をソートして返します。# 辞書名.most_common(取得する要素数) # Counterに文字列を格納、文字の出現頻度を数え上げる d = Counter("A Counter is a dict subclass for counting hashable objects.") # 最も多い5要素を並べる print(d.most_common(5)) # 出力結果 [(" ", 9), ("s", 6), ("o", 4), ("c", 4), ("a", 4)]
- 投稿日:2020-04-21T19:18:00+09:00
図解「コルーチン・native coroutine・with」 〜 関心やコードを分離する文法と、処理順序・構造 〜
概要
この記事では、以下のような事を扱います。
- (Pythonの)generator、native coroutine、withの文法と、普通の関数呼び出しとの違いを図解で説明
- コルーチン・native coroutineという言葉にまつわるPythonの"混乱"の整理
- これらの文法のメリット・よりバグを生みにくいコードの書き方についての考察
細かい関数に分けることと、スパゲティコードと、バグりにくいコードと...というような事について、図解を交えながら、文法的な部分から考察します。native coroutineといった用語の話以外は、必ずしもPythonに限定した話ではないので、他の言語を使用されている方もある程度は自然に読めるかなと思います。
なお、似たような観点で、コールバックやポリモーフィズムを扱った姉妹記事もあります。(こちらはJavaScriptですが)
コールバックと、ポリモーフィズムと、それからコルーチンを構造的に見る関数呼び出し
Pythonでは、defという語を用いて、関数を定義することができます。
次のコード断片では、fという名前の関数を定義します。def f(name: str) -> str: return 'Hello, ' + name f('taro') # Hello, taro定義した関数は、関数名の後ろに()をつけて記述することによって呼び出す(call)ことができます。
関数を構成する要素には引数(argument)と戻り値(return value)というものがあり、関数には引数を受け取って戻り値を返す、という機能性があります。関数定義において、defと書いた行の()の中身が引数で、returnの後ろに書いてあるものが戻り値です。
そもそも関数とは
中学や高校で習う数学においては、関数とは「ある二つの数量$x,y$において、$x$の値に対して対応する$y$の値が一つ定まるとき、$y$は$x$の関数であるという。」などと定義されています。このような関係のとき、$y$が$x$によって決まることを強調して、$y=f(x)$というような書き方をするのでした。
「$y$の話をしていたのに、いきなり出てくる$f$は一体何だ?」
と思うのですが、$x$の値に対して対応する値を計算する決め方のルールのことを$f(x)$と表現しているのでした。
このような関数の考え方と先程の関数定義を対比すると、$x$は引数、$y$は戻り値ということになります。また、高校までの数学における関数は数と数の対応でしたが、先程のものは文字列(str)と文字列の対応になっているのでした。しかし、Pythonに限らず、プログラミングにおける関数にはもう少し別の側面があります。
例えば、高校までの数学で、関数を呼び出すというようなことは、普通は言わないはずです。証明の問題で「関数 $f(x)=x^2$ を呼び出すと」などという事を書いている人はほとんど居ないと思います。これは、プログラミングにおける関数には、数学における関数とは少し別の由来があることを意味します。手続きとルーチン
プログラミングは、しばしばコンピュータに対する命令をまとめる作業に例えられます。
実際、Pythonをコマンドラインで起動すると、以下のような文字列が表示され、Pythonは命令待ち状態になります。Python 3.7.7 (default, Mar 10 2020, 15:43:27) [Clang 10.0.0 (clang-1000.11.45.5)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>この >>> というのは、人間からの指示を待っている事を意味していて、Pythonの言語仕様に沿った命令(コマンド)を書くと、それに従ってPythonが適当な計算を行うようになっています。ゲームなどによってすっかり馴染みのある「コマンド」という単語ですが、これは「命令する」という意味ですね。
さて、いくつかのコマンドを並べる事によって、まとまった手続きをPythonに行わせる事ができます。例えば、以下のようにして、幅20・高さ45の長方形の面積を求める事ができます。(これはPythonの公式チュートリアルから引っ張ってきた例です。なぜそのようなものを計算しているのかは不明ですが...)
>>> width = 20 >>> height = 5 * 9 >>> width * height 900このような手続きについて、頻繁に用いる決まった手続き:ルーチンとして記述する事で、再利用しやすくできます。Pythonを含む多くのプログラミング言語では、関数をルーチンの定義に用いることもできます。例えば、以下のようにして、関数にルーチンの機能をもたせることができます。
def okan(): print('飯を食え') print('歯を磨け') print('着替えろ') okan() # 飯を食え # 歯を磨け # 着替えろこのようにして関数をルーチンとして扱う際には、「関数に代入する」という考え方よりも、「関数(ルーチン)を呼び出す」という考え方の方がよりしっくりと来る場合があります。そこで、関数に対しても「呼び出す」という言葉遣いをする場合があるのでした。
ちなみに、ここで出てくるprint()というのも関数で、print()は引数に指定した文字列を画面などに出力するのでした。関数の中でさらに別の関数を呼び出すという、関数の呼び出しの連続によってプログラミングは行われている、と言っても過言ではありません。呼び出しという部分について興味を持った方は、ぜひコールスタックというものを調べてみてください。(例えば、【図解】コールスタックとクロージャーを理解する)
ちなみに、先程のokan()には引数は存在せず、戻り値も存在しません。高校までの数学では、そのような関数は存在しない(引数と戻り値以外には関数の要素というものはない)のですが、プログラミングの関数においては、引数や戻り値以外にも、何らかの作用が存在するということになります。
関数呼び出しの図解
さて、ようやく本題の図解に入ります。以下のようなプログラムがあったとします。
def main(): print('first') sub_routine() return def sub_routine(): print('second') return main()このプログラムが実行される時の処理の流れを、行ごとに分割して可視化すると以下のようになります。
main()を実行するときには、途中でsub_routine()が呼ばれますが、sub_routine()が呼ばれてからはその処理を一通り実行して戻ってくる、というような流れになっています。
重要なポイントとしては、サブルーチンが呼び出されてからは終了するまでmain()に戻ってくることはないということです。しかし、一般にルーチンを作る時、AルーチンとBルーチンの間で行ったり来たりした方が表現がわかりやすい、という事があるかもしれません。例えば、さきほど例であげたokan()は言いたい事を全て言うだけのokanになっていますが、「飯を食え」と言った後は子供が飯を食べるまで待ち、その後に「歯を磨け」と言った方が適切なように思われます。このような、ある種の対話性を持ったルーチン呼び出しが求められる場合があります。そこで、コルーチンというものを考えます。
コルーチン
コルーチンは、プログラミング言語全般における用語です。単純な関数呼び出しによるサブルーチンとは異なり、呼び出し元と呼び出し先を行ったり来たりするような関係性のルーチンを指します。コルーチンのコとは、コラボのコと同じで、「共に」というようなニュアンスの接頭語です。
後ほど詳しく説明しますが、Pythonでは別の概念に対して「coroutine」という語を用いているため、この記事ではコルーチンと書いた時には今述べた意味でのコルーチンを表すものとします。Pythonで、一般的なコルーチンを実現するには、generatorというものを用います。文法的には、yieldというものをreturnの代わりに書くだけです。
def main(): a = simple() print('first') x = a.send(None) print(x) # third y = a.send(None) print(y) # fifth def simple(): print('second') yield 'third' print('forth') yield 'fifth' main()では、これを図解してみます。
まず、generatorの変わった特徴として、simple()のように呼び出しをしても、そのタイミングでは後続の処理が行われないという事があります。simple()は処理を行うのではなくて、処理を順番に行うための「generator object」を返します。このgenerator objectに対してsend()というメソッドが定義されているので、send()を繰り返すことによって実際の処理を行う、という流れになっています。単純な関数呼び出しとは異なり、呼び出し元のルーチンと呼び出し先のsimple()というルーチンを行ったり来たりしていることになります。
このsimple()の'third'や'fifth'を返却しているところで、'飯を食え'や'歯を磨け'を返すようにすれば、言いたいことを言って終了するだけではないokan()を作る事ができます。
なお、この例では処理順序に注目をしているため説明を省略したのですが、generatorの重要な特徴として、yieldした後にsend()するとその時の状態を引き継いで処理が継続されるという事があります。処理の順序だけではなく、関数の中で計算した変数の値などもそのまま再利用できるため、柔軟な書き方ができる文法になっています。
ただ、この書き方では、複数のokan()が同時に処理をするような場合をうまく記述することができません。同時に一人のokan()しか扱うことができないので、複数のokan()が居る家庭では一人ずつokan()が行動することになり、実に効率の悪い家庭になってしまいます。
(どういう家庭だろうか)native coroutine(Pythonでいうcoroutine)・async/await
複数のokan()を効率よく扱う方法として、Pythonではnative coroutineというものを用意しています。これは、先程のカタカナのコルーチンとはまた違う意味を持っているのですが、説明していきます。
...okan()の例が少し苦しくなってきたので、真面目な話をします。
多くのコンピューターには複数の計算装置が備わっており、これらのリソースをできる限り並列で動かした方が計算効率がよくなります。また、計算装置を扱う場合以外でも、例えば複数箇所との通信が必要なプログラムにおいて、通信を同時に投げておいてから、返答があったものから順番に処理をするというような仕組みにした方が効率的な場合があります。
そうしたプログラミングを行うときは、これまでの図解でみたフローのような常に一本道のフローではなくなります。例えば、同時に三つの道を並行で通る、というような計算の仕方が必要になるのです。それを、Pythonではどのような文法で表現すればよいのでしょうか。
以下に、それを実現するnative coroutineのサンプルを示します。
import asyncio import random async def main(): print('first') await asyncio.gather( native_coroutine(1), native_coroutine(2), native_coroutine(3), ) async def native_coroutine(x): await asyncio.sleep( random.random()) print(x) asyncio.run(main())このプログラムを実行すると、firstと出力されたあとに、ランダムで1,2,3が並び替わって出力されます。
await asyncio.sleep(random.random())
というところが、ランダムで0〜1秒待つという処理になっているので、その時間の長さによって1,2,3のどれが先に出るかが変わってくる、というような並列処理のサンプルです。
これまでの文法との大きな違いは、defの前にさらにasyncという用語が付いたり、関数呼び出しの前にawaitという用語が付いたりしている部分ですが、それらの説明の前に、まずはどのような順序で処理が行われるかをフローで見ます。
まず、asyncの付いている関数定義は、generatorと同じように、呼び出しをしても直ちに実行はされない関数になります。generatorの場合はsend()を都度実行するのでしたが、native coroutineの場合はasyncio.run()やasyncio.gather()などによって実行します。
asyncio.runでmain()を実行すると、まずfirstと出力されますが、次のawaitでnative(1),native(2),native(3)の結果が返されるまで処理を待つようになります。
native(1),native(2),native(3)は"同時に"実行されます。その事を模式的に表現したのが三本の矢印たちです。ところで、このフローを見ると、(カタカナ表記の)コルーチンのような行ったり来たりする構造がありません。
どういうことでしょうか。実は、await asyncio.gather()をすると、その引数のnative coroutine達の処理が終了するか、またはタイムアウトするまで待ち続けてしまうので、コルーチンにおける行ったり来たりという処理ができないのです。ですが、Pythonではこれを(native) coroutineと呼んでいます。
native coroutineという名前がついた経緯
なぜ、このようなモノのことをcoroutineと呼ぶ事になったのか?
その経緯は新雑誌「n月刊ラムダノート」の『「コルーチン」とは何だったのか?』の草稿を公開しますに詳しくまとまっています。掻い摘んで書くと
JavaScript界隈(やUnity界隈など)で「非同期の処理を含む特殊なコルーチン」の事を、単に「コルーチン」と呼ぶ事があり、それに引きずられた形になっています。
もう少し詳しく書くと、通常、JavaScriptで非同期処理を書こうとすると、コールバック関数を渡すなどして複雑な書き方をする必要がありました。しかし、上記の特殊なコルーチンを使って書くと、同期処理の時のように平易な書き方をすることができたのです。
例えば、対話的okan()のprintを通信処理と思うことにして、各通信処理が終わったらokan()自身にsend()させると、全てのyield(≒通信処理)が完了するまで待つコードを簡単に書くことができ、通信処理などを書く時に複雑なコールバック関数を渡さずに同期処理的な書き方をすることができるのでした。ただし、この書き方においては「呼び出した元と行ったり来たりする」という事はありませんでした(自分自身にsend()するので)
でもそのような事情があるとはいえ、元々コルーチンの一種ではあるので、そのような特殊なコルーチンについても単にコルーチンと呼ばれることがあったのでした。
(これは先程のラムダノートの草稿に具体的なJSのコード付きで書いてあります)これを受けて、Pythonの仕様PEP492に落とし込んだ時にcoroutineと呼ぶことになってしまったのでした。
実は、これを行ったり来たりできるようにした async generator というものも存在していて、それはPEP525でPEP492と同じ方が提案して実際に使えるようになっていますが、この記事ではasync generatorの使い方については省略します。
なお、generatorはPEP342で導入されていますが、ここでははっきりCoroutines via Enhanced Generatorsと書いてあるので、ここのCoroutineの概念ともPEP492の概念は異なる状態になってしまいました。関数呼び出しやコルーチンと、スパゲティコード
さて、ここで話をがらりと変えてみます。
保守しにくいコードの代表格として、「スパゲティコード」というものが取り上げられます。これは、次のような性質を持つと言われます。
- goto文が濫用されている
- グローバル変数など、広い範囲に影響する変数が様々なところで使用され、様々な処理が変数の状態に依存するようになっている
しかし、ではgoto文やグローバル変数などを使わなければスパゲティコードではないのか?というと、そうではありません。
実際、関数呼び出しというのは、プログラムソースを文字列の集まりとして見た時、「その関数の定義された場所に行け」というのと近い意味を持つものであって、gotoに似た機能性があります。そこで無闇に関数を作ってしまうと逆に処理を追いかけにくくなります。
また、コルーチンでyieldしたりsend()したりというのもgotoに近い性質を持ちます。さらにコルーチンでyieldするということは、何らかの状態を保持させたまま元のルーチンに戻るという事なので、関数呼び出しと比較してある種の状態依存性を作り出しているとも言えます。
従って、これらの文法も、悪用するとスパゲティコードを生産する元になってしまうわけです。
しかし一方で、うまく使えば分かりやすい・バグりにくいコードを書くことに繋がります。うまく使うためには、どうすればよいのでしょうか。その特性を比較してみましょう。ただ、native coroutineに関しては、主目的が非同期処理を扱うことであるのは明らかなので、ここでは特に関数呼び出しとコルーチンを比較する形で考察をします。
関数呼び出しとコルーチンの比較
コルーチンでyieldによって挟まれている部分を、別の関数に分けて実装することを考えてみます。
コードブロックの呼び出し順序の保証
その場合、関数呼び出しを組み合わせる場合は呼び出し順序を規定することはできません。例えば、関数begin(), middle(), end()を順番に実行してもらいたいと実装した人が思ったとしても、必ずbegin(), middle(), end()という順番で実行されているかどうかを文法は保証してくれません。
また、関数が定義されているコードを読む人も、begin(), middle(), end()が順番に呼ばれるものだと思って読んでくれるとは限りません。(名前から、類推をする可能性はありますが)
一方、コルーチンでは必ず呼び出し順序が保たれますし、yieldを挟んで続けて処理が書かれているので、連続する処理は読みやすくなります。そのような意味で、ある種の非同期的な処理も記述がしやすくなります。呼び出し元で次の処理を行う時のわかりやすさ
呼び出し元でコルーチンの続きを取得するにはsend()などのような関数(メソッド)を使いますが、これには「どこまで進んだ続きなのか」という情報が含まれません。begin(), middle(), end()は明確にどの関数が呼ばれるかがわかりますが、send()ではどこから処理が再開するかがわからないということです。その意味では、呼び出し元のコードを読む時・書く時はsend()だと意味がわかりにくい可能性があります。(ただし、yieldから再開する時にsend()の引数を受け取る事はできるので、それによって分岐させるというような実装はありえます。)
また、もし、1番目のyieldで初期化完了、2番目のyieldで処理、3番目のyieldで後始末、というコルーチンを期待したインターフェイスになっているコードがあったとします。そうすると、もしコルーチン(generator)の中に新しく「処理(yield)」の追加が必要になった場合は、現在の3番目の処理が4番目にずれてしまい、既存の処理に大きく影響を与えてしまう可能性があります。(つまり、そのようにyieldで取り出す時の回数に意味をもたせるような実装はアンチパターンということになります。)
これに対して、begin(), middle(), end()等とそれぞれ関数で実装していれば、middle2()を追加しても既存コードへの影響はありません。呼び出し先での返却のしやすさ、不特定回数のデータ取得
一方で、send()だけでyieldの結果が受け取れることを利用して、ループ等で不定回数のデータを取得するという事もできます。
少し見方を変えると、呼び出し元がループでsend()の結果を全て取得するような実装になっていれば、呼び出し先のコルーチン側は自由にyieldで結果を返すことができるという事もできます。このようなコルーチン(generator)の実装は、例えばストリーミング処理等で威力を発揮します。全ての計算・処理が終了する前に、ちょっとずつ結果を返却する、というような事が可能になるからです。Webアプリで、レスポンスを実際に処理するような部分についてはyieldした値を受け取る側のフレームワーク的な部分で実装をしておくことで、返却する内容の計算処理と、その周りの処理について関心・コードをきれいに分離して実装することができます。(例えばFlaskにはそのような実装があります)そもそも、genertor(発生器)という名称は、何らかの結果を複数回生成・発生させるようなニュアンスで付けられたものなのでした。実際、next()で結果を取得するiteratorと似たようなところがありますね。
総じて、良くも悪くも、コルーチンは呼び出し元や呼び出し先のインターフェイスが簡素になっていると言えます。(send()とyieldでつながっている)
コルーチンを使うと見通しがよくなるところ
他にも使い方は色々あると思いますが、代表的なものとしては以下のようなものがあります。
- ストリーミングなど、少しずつ・何度も結果を返却する必要があるところ
- 特に、不特定回数になる場合
- 全てのデータをメモリに展開するとパンクするような大きなデータを扱う場合
- 複雑な計算による配列など
- 特に、無限長になりえる場合
- 非同期的な扱いをする必要のある対象の表現
- ゲームなど
いずれの場合も、コルーチンの中では、目的とする計算に注力しやすくなります。
おまけ:withを用いた簡単な処理構造
さきほどの、コルーチンを使うことに関して検討をしたところで、begin(), middle(), end()などと実装をした方が見通し・保守性が良い可能性もありました。
このような場面において適した書き方として、Pythonにはwithを用いた記述があるので、これを簡単に説明しておきます。def main(): with EnterExit() as ee: print('second') x = ee.method() print(x) # third # withを抜ける return class EnterExit: def __enter__(self): print('first') return self def method(self): return 'third' def __exit__( self, exc_type, exc_val, exc_tb): print('forth') main()このプログラムの処理の流れを見てみましょう。
Pythonでは、withを用いたコードブロックにおいては、その先頭で必ず
__enter__()が呼ばれ、末尾または例外による抜け出しで必ず__exit__()が呼ばれる、という事が保証されます。
この構文で使用する代表格は、ファイルのオープンwith open('file_name.txt') as f:というようなものかと思います。一般に、ファイルのオープンをしたらクローズが必要になりますが、withでオープンをすると、そのスコープを抜ける時に必ずクローズされる事が保証されます。また、asで開いたファイルをfに代入することによって、スコープ内でfを自由に使うこともできます。コルーチンで実現した「行ったり来たり」という部分については、実質的にはこのような書き方でも再現することができます。この書き方では、無限に要素を処理するという事は難しいですが、代わりに呼び出し先の処理の先頭と末尾以外の処理を柔軟に書くことができるようになっています。
また、これはPythonの標準の決まりなので、全てを単純な関数呼び出しに分解した場合とも異なり、呼び出し順序なども意識させることができます。まとめ
普通の関数呼び出し・コルーチン・native coroutine・withのそれぞれについて、どのように処理が流れるかという事を図解で確認しました。
オブジェクト指向的な考え方では、様々なオブジェクトのメソッドを呼び出す≒関数を呼び出すことによって処理を記述しますが、以下のような条件を満たすことが理想的です。
- 読むときには追いかけやすい
- 処理のフローを追いかけやすい
- 関心事・役割・目的によってまとまったコードになっている
- 書くときにはある程度のパターンに沿いながら無駄なく簡潔に書きやすい
- 抜け漏れや、その他の書き間違いが発生しにくい
それを改めて意識するために"図解"をして、お互いの処理がどのようなフローで流れるのかを把握できるようにしてみました。特殊な構文が実際にどのように機能しているか、このような形で見ると分かりやすいのではないかと思いました。
適切な書き分けを意識して、保守性の高いコードを書きたいですね!




- 投稿日:2020-04-21T19:18:00+09:00
図解「generator・native coroutine・with」 〜 関心やコードを分離する文法と、処理順序・構造 〜
概要
この記事では、以下のような事を扱います。
- (Pythonの)generator、native coroutine、withの文法と、普通の関数呼び出しとの違いを図解で説明
- コルーチン・native coroutineという言葉にまつわるPythonの"混乱"の整理
- これらの文法のメリット・よりバグを生みにくいコードの書き方についての考察
細かい関数に分けることと、スパゲティコードと、バグりにくいコードと...というような事について、図解を交えながら、文法的な部分から考察します。native coroutineといった用語の話以外は、必ずしもPythonに限定した話ではないので、他の言語を使用されている方もある程度は自然に読めるかなと思います。
なお、似たような観点で、コールバックやポリモーフィズムを扱った姉妹記事もあります。(こちらはJavaScriptですが)
コールバックと、ポリモーフィズムと、それからコルーチンを構造的に見る関数呼び出し
Pythonでは、defという語を用いて、関数を定義することができます。
次のコード断片では、fという名前の関数を定義します。def f(name: str) -> str: return 'Hello, ' + name f('taro') # Hello, taro定義した関数は、関数名の後ろに()をつけて記述することによって呼び出す(call)ことができます。
関数を構成する要素には引数(argument)と戻り値(return value)というものがあり、関数には引数を受け取って戻り値を返す、という機能性があります。関数定義において、defと書いた行の()の中身が引数で、returnの後ろに書いてあるものが戻り値です。
そもそも関数とは
中学や高校で習う数学においては、関数とは「ある二つの数量$x,y$において、$x$の値に対して対応する$y$の値が一つ定まるとき、$y$は$x$の関数であるという。」などと定義されています。このような関係のとき、$y$が$x$によって決まることを強調して、$y=f(x)$というような書き方をするのでした。
「$y$の話をしていたのに、いきなり出てくる$f$は一体何だ?」
と思うのですが、$x$の値に対して対応する値を計算する決め方のルールのことを$f(x)$と表現しているのでした。
このような関数の考え方と先程の関数定義を対比すると、$x$は引数、$y$は戻り値ということになります。また、高校までの数学における関数は数と数の対応でしたが、先程のものは文字列(str)と文字列の対応になっているのでした。しかし、Pythonに限らず、プログラミングにおける関数にはもう少し別の側面があります。
例えば、高校までの数学で、関数を呼び出すというようなことは、普通は言わないはずです。証明の問題で「関数 $f(x)=x^2$ を呼び出すと」などという事を書いている人はほとんど居ないと思います。これは、プログラミングにおける関数には、数学における関数とは少し別の由来があることを意味します。手続きとルーチン
プログラミングは、しばしばコンピュータに対する命令をまとめる作業に例えられます。
実際、Pythonをコマンドラインで起動すると、以下のような文字列が表示され、Pythonは命令待ち状態になります。Python 3.7.7 (default, Mar 10 2020, 15:43:27) [Clang 10.0.0 (clang-1000.11.45.5)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>この >>> というのは、人間からの指示を待っている事を意味していて、Pythonの言語仕様に沿った命令(コマンド)を書くと、それに従ってPythonが適当な計算を行うようになっています。ゲームなどによってすっかり馴染みのある「コマンド」という単語ですが、これは「命令する」という意味ですね。
さて、いくつかのコマンドを並べる事によって、まとまった手続きをPythonに行わせる事ができます。例えば、以下のようにして、幅20・高さ45の長方形の面積を求める事ができます。(これはPythonの公式チュートリアルから引っ張ってきた例です。なぜそのようなものを計算しているのかは不明ですが...)
>>> width = 20 >>> height = 5 * 9 >>> width * height 900このような手続きについて、頻繁に用いる決まった手続き:ルーチンとして記述する事で、再利用しやすくできます。Pythonを含む多くのプログラミング言語では、関数をルーチンの定義に用いることもできます。例えば、以下のようにして、関数にルーチンの機能をもたせることができます。
def okan(): print('飯を食え') print('歯を磨け') print('着替えろ') okan() # 飯を食え # 歯を磨け # 着替えろこのようにして関数をルーチンとして扱う際には、「関数に代入する」という考え方よりも、「関数(ルーチン)を呼び出す」という考え方の方がよりしっくりと来る場合があります。そこで、関数に対しても「呼び出す」という言葉遣いをする場合があるのでした。
ちなみに、ここで出てくるprint()というのも関数で、print()は引数に指定した文字列を画面などに出力するのでした。関数の中でさらに別の関数を呼び出すという、関数の呼び出しの連続によってプログラミングは行われている、と言っても過言ではありません。呼び出しという部分について興味を持った方は、ぜひコールスタックというものを調べてみてください。(例えば、【図解】コールスタックとクロージャーを理解する)
ちなみに、先程のokan()には引数は存在せず、戻り値も存在しません。高校までの数学では、そのような関数は存在しない(引数と戻り値以外には関数の要素というものはない)のですが、プログラミングの関数においては、引数や戻り値以外にも、何らかの作用が存在するということになります。
関数呼び出しの図解
さて、ようやく本題の図解に入ります。以下のようなプログラムがあったとします。
def main(): print('first') sub_routine() return def sub_routine(): print('second') return main()このプログラムが実行される時の処理の流れを、行ごとに分割して可視化すると以下のようになります。
main()を実行するときには、途中でsub_routine()が呼ばれますが、sub_routine()が呼ばれてからはその処理を一通り実行して戻ってくる、というような流れになっています。
重要なポイントとしては、サブルーチンが呼び出されてからは終了するまでmain()に戻ってくることはないということです。しかし、一般にルーチンを作る時、AルーチンとBルーチンの間で行ったり来たりした方が表現がわかりやすい、という事があるかもしれません。例えば、さきほど例であげたokan()は言いたい事を全て言うだけのokanになっていますが、「飯を食え」と言った後は子供が飯を食べるまで待ち、その後に「歯を磨け」と言った方が適切なように思われます。このような、ある種の対話性を持ったルーチン呼び出しが求められる場合があります。そこで、コルーチンというものを考えます。
コルーチン
コルーチンは、プログラミング言語全般における用語です。単純な関数呼び出しによるサブルーチンとは異なり、呼び出し元と呼び出し先を行ったり来たりするような関係性のルーチンを指します。コルーチンのコとは、コラボのコと同じで、「共に」というようなニュアンスの接頭語です。
後ほど詳しく説明しますが、Pythonでは別の概念に対して「coroutine」という語を用いているため、この記事ではコルーチンと書いた時には今述べた意味でのコルーチンを表すものとします。Pythonで、一般的なコルーチンを実現するには、generatorというものを用います。文法的には、yieldというものをreturnの代わりに書くだけです。
def main(): a = simple() print('first') x = a.send(None) print(x) # third y = a.send(None) print(y) # fifth def simple(): print('second') yield 'third' print('forth') yield 'fifth' main()では、これを図解してみます。
まず、generatorの変わった特徴として、simple()のように呼び出しをしても、そのタイミングでは後続の処理が行われないという事があります。simple()は処理を行うのではなくて、処理を順番に行うための「generator object」を返します。このgenerator objectに対してsend()というメソッドが定義されているので、send()を繰り返すことによって実際の処理を行う、という流れになっています。単純な関数呼び出しとは異なり、呼び出し元のルーチンと呼び出し先のsimple()というルーチンを行ったり来たりしていることになります。
このsimple()の'third'や'fifth'を返却しているところで、'飯を食え'や'歯を磨け'を返すようにすれば、言いたいことを言って終了するだけではないokan()を作る事ができます。
なお、この例では処理順序に注目をしているため説明を省略したのですが、generatorの重要な特徴として、yieldした後にsend()するとその時の状態を引き継いで処理が継続されるという事があります。処理の順序だけではなく、関数の中で計算した変数の値などもそのまま再利用できるため、柔軟な書き方ができる文法になっています。
ただ、この書き方では、複数のokan()が同時に処理をするような場合をうまく記述することができません。同時に一人のokan()しか扱うことができないので、複数のokan()が居る家庭では一人ずつokan()が行動することになり、実に効率の悪い家庭になってしまいます。
(どういう家庭だろうか)native coroutine(Pythonでいうcoroutine)・async/await
複数のokan()を効率よく扱う方法として、Pythonではnative coroutineというものを用意しています。これは、先程のカタカナのコルーチンとはまた違う意味を持っているのですが、説明していきます。
...okan()の例が少し苦しくなってきたので、真面目な話をします。
多くのコンピューターには複数の計算装置が備わっており、これらのリソースをできる限り並列で動かした方が計算効率がよくなります。また、計算装置を扱う場合以外でも、例えば複数箇所との通信が必要なプログラムにおいて、通信を同時に投げておいてから、返答があったものから順番に処理をするというような仕組みにした方が効率的な場合があります。
そうしたプログラミングを行うときは、これまでの図解でみたフローのような常に一本道のフローではなくなります。例えば、同時に三つの道を並行で通る、というような計算の仕方が必要になるのです。それを、Pythonではどのような文法で表現すればよいのでしょうか。
以下に、それを実現するnative coroutineのサンプルを示します。
import asyncio import random async def main(): print('first') await asyncio.gather( native_coroutine(1), native_coroutine(2), native_coroutine(3), ) async def native_coroutine(x): await asyncio.sleep( random.random()) print(x) asyncio.run(main())このプログラムを実行すると、firstと出力されたあとに、ランダムで1,2,3が並び替わって出力されます。
await asyncio.sleep(random.random())
というところが、ランダムで0〜1秒待つという処理になっているので、その時間の長さによって1,2,3のどれが先に出るかが変わってくる、というような並列処理のサンプルです。
これまでの文法との大きな違いは、defの前にさらにasyncという用語が付いたり、関数呼び出しの前にawaitという用語が付いたりしている部分ですが、それらの説明の前に、まずはどのような順序で処理が行われるかをフローで見ます。
まず、asyncの付いている関数定義は、generatorと同じように、呼び出しをしても直ちに実行はされない関数になります。generatorの場合はsend()を都度実行するのでしたが、native coroutineの場合はasyncio.run()やasyncio.gather()などによって実行します。
asyncio.runでmain()を実行すると、まずfirstと出力されますが、次のawaitでnative(1),native(2),native(3)の結果が返されるまで処理を待つようになります。
native(1),native(2),native(3)は"同時に"実行されます。その事を模式的に表現したのが三本の矢印たちです。ところで、このフローを見ると、(カタカナ表記の)コルーチンのような行ったり来たりする構造がありません。
どういうことでしょうか。実は、await asyncio.gather()をすると、その引数のnative coroutine達の処理が終了するか、またはタイムアウトするまで待ち続けてしまうので、コルーチンにおける行ったり来たりという処理ができないのです。ですが、Pythonではこれを(native) coroutineと呼んでいます。
native coroutineという名前がついた経緯
なぜ、このようなモノのことをcoroutineと呼ぶ事になったのか?
その経緯は新雑誌「n月刊ラムダノート」の『「コルーチン」とは何だったのか?』の草稿を公開しますに詳しくまとまっています。掻い摘んで書くと
JavaScript界隈(やUnity界隈など)で「非同期の処理を含む特殊なコルーチン」の事を、単に「コルーチン」と呼ぶ事があり、それに引きずられた形になっています。
もう少し詳しく書くと、通常、JavaScriptで非同期処理を書こうとすると、コールバック関数を渡すなどして複雑な書き方をする必要がありました。しかし、上記の特殊なコルーチンを使って書くと、同期処理の時のように平易な書き方をすることができたのです。
例えば、対話的okan()のprintを通信処理と思うことにして、各通信処理が終わったらokan()自身にsend()させると、全てのyield(≒通信処理)が完了するまで待つコードを簡単に書くことができ、通信処理などを書く時に複雑なコールバック関数を渡さずに同期処理的な書き方をすることができるのでした。ただし、この書き方においては「呼び出した元と行ったり来たりする」という事はありませんでした(自分自身にsend()するので)
でもそのような事情があるとはいえ、元々コルーチンの一種ではあるので、そのような特殊なコルーチンについても単にコルーチンと呼ばれることがあったのでした。
(これは先程のラムダノートの草稿に具体的なJSのコード付きで書いてあります)これを受けて、Pythonの仕様PEP492に落とし込んだ時にcoroutineと呼ぶことになってしまったのでした。
実は、これを行ったり来たりできるようにした async generator というものも存在していて、それはPEP525でPEP492と同じ方が提案して実際に使えるようになっていますが、この記事ではasync generatorの使い方については省略します。
なお、generatorはPEP342で導入されていますが、ここでははっきりCoroutines via Enhanced Generatorsと書いてあるので、ここのCoroutineの概念ともPEP492の概念は異なる状態になってしまいました。関数呼び出しやコルーチンと、スパゲティコード
さて、ここで話をがらりと変えてみます。
保守しにくいコードの代表格として、「スパゲティコード」というものが取り上げられます。これは、次のような性質を持つと言われます。
- goto文が濫用されている
- グローバル変数など、広い範囲に影響する変数が様々なところで使用され、様々な処理が変数の状態に依存するようになっている
しかし、ではgoto文やグローバル変数などを使わなければスパゲティコードではないのか?というと、そうではありません。
実際、関数呼び出しというのは、プログラムソースを文字列の集まりとして見た時、「その関数の定義された場所に行け」というのと近い意味を持つものであって、gotoに似た機能性があります。そこで無闇に関数を作ってしまうと逆に処理を追いかけにくくなります。
また、コルーチンでyieldしたりsend()したりというのもgotoに近い性質を持ちます。さらにコルーチンでyieldするということは、何らかの状態を保持させたまま元のルーチンに戻るという事なので、関数呼び出しと比較してある種の状態依存性を作り出しているとも言えます。
従って、これらの文法も、悪用するとスパゲティコードを生産する元になってしまうわけです。
しかし一方で、うまく使えば分かりやすい・バグりにくいコードを書くことに繋がります。うまく使うためには、どうすればよいのでしょうか。その特性を比較してみましょう。ただ、native coroutineに関しては、主目的が非同期処理を扱うことであるのは明らかなので、ここでは特に関数呼び出しとコルーチンを比較する形で考察をします。
関数呼び出しとコルーチンの比較
コルーチンでyieldによって挟まれている部分を、別の関数に分けて実装することを考えてみます。
コードブロックの呼び出し順序の保証
その場合、関数呼び出しを組み合わせる場合は呼び出し順序を規定することはできません。例えば、関数begin(), middle(), end()を順番に実行してもらいたいと実装した人が思ったとしても、必ずbegin(), middle(), end()という順番で実行されているかどうかを文法は保証してくれません。
また、関数が定義されているコードを読む人も、begin(), middle(), end()が順番に呼ばれるものだと思って読んでくれるとは限りません。(名前から、類推をする可能性はありますが)
一方、コルーチンでは必ず呼び出し順序が保たれますし、yieldを挟んで続けて処理が書かれているので、連続する処理は読みやすくなります。そのような意味で、ある種の非同期的な処理も記述がしやすくなります。呼び出し元で次の処理を行う時のわかりやすさ
呼び出し元でコルーチンの続きを取得するにはsend()などのような関数(メソッド)を使いますが、これには「どこまで進んだ続きなのか」という情報が含まれません。begin(), middle(), end()は明確にどの関数が呼ばれるかがわかりますが、send()ではどこから処理が再開するかがわからないということです。その意味では、呼び出し元のコードを読む時・書く時はsend()だと意味がわかりにくい可能性があります。(ただし、yieldから再開する時にsend()の引数を受け取る事はできるので、それによって分岐させるというような実装はありえます。)
また、もし、1番目のyieldで初期化完了、2番目のyieldで処理、3番目のyieldで後始末、というコルーチンを期待したインターフェイスになっているコードがあったとします。そうすると、もしコルーチン(generator)の中に新しく「処理(yield)」の追加が必要になった場合は、現在の3番目の処理が4番目にずれてしまい、既存の処理に大きく影響を与えてしまう可能性があります。(つまり、そのようにyieldで取り出す時の回数に意味をもたせるような実装はアンチパターンということになります。)
これに対して、begin(), middle(), end()等とそれぞれ関数で実装していれば、middle2()を追加しても既存コードへの影響はありません。呼び出し先での返却のしやすさ、不特定回数のデータ取得
一方で、send()だけでyieldの結果が受け取れることを利用して、ループ等で不定回数のデータを取得するという事もできます。
少し見方を変えると、呼び出し元がループでsend()の結果を全て取得するような実装になっていれば、呼び出し先のコルーチン側は自由にyieldで結果を返すことができるという事もできます。このようなコルーチン(generator)の実装は、例えばストリーミング処理等で威力を発揮します。全ての計算・処理が終了する前に、ちょっとずつ結果を返却する、というような事が可能になるからです。Webアプリで、レスポンスを実際に処理するような部分についてはyieldした値を受け取る側のフレームワーク的な部分で実装をしておくことで、返却する内容の計算処理と、その周りの処理について関心・コードをきれいに分離して実装することができます。(例えばFlaskにはそのような実装があります)そもそも、genertor(発生器)という名称は、何らかの結果を複数回生成・発生させるようなニュアンスで付けられたものなのでした。実際、next()で結果を取得するiteratorと似たようなところがありますね。
総じて、良くも悪くも、コルーチンは呼び出し元や呼び出し先のインターフェイスが簡素になっていると言えます。(send()とyieldでつながっている)
コルーチンを使うと見通しがよくなるところ
他にも使い方は色々あると思いますが、代表的なものとしては以下のようなものがあります。
- ストリーミングなど、少しずつ・何度も結果を返却する必要があるところ
- 特に、不特定回数になる場合
- 全てのデータをメモリに展開するとパンクするような大きなデータを扱う場合
- 複雑な計算による配列など
- 特に、無限長になりえる場合
- 非同期的な扱いをする必要のある対象の表現
- ゲームなど
いずれの場合も、コルーチンの中では、目的とする計算に注力しやすくなります。
おまけ:withを用いた簡単な処理構造
さきほどの、コルーチンを使うことに関して検討をしたところで、begin(), middle(), end()などと実装をした方が見通し・保守性が良い可能性もありました。
このような場面において適した書き方として、Pythonにはwithを用いた記述があるので、これを簡単に説明しておきます。def main(): with EnterExit() as ee: print('second') x = ee.method() print(x) # third # withを抜ける return class EnterExit: def __enter__(self): print('first') return self def method(self): return 'third' def __exit__( self, exc_type, exc_val, exc_tb): print('forth') main()このプログラムの処理の流れを見てみましょう。
Pythonでは、withを用いたコードブロックにおいては、その先頭で必ず
__enter__()が呼ばれ、末尾または例外による抜け出しで必ず__exit__()が呼ばれる、という事が保証されます。
この構文で使用する代表格は、ファイルのオープンwith open('file_name.txt') as f:というようなものかと思います。一般に、ファイルのオープンをしたらクローズが必要になりますが、withでオープンをすると、そのスコープを抜ける時に必ずクローズされる事が保証されます。また、asで開いたファイルをfに代入することによって、スコープ内でfを自由に使うこともできます。コルーチンで実現した「行ったり来たり」という部分については、実質的にはこのような書き方でも再現することができます。この書き方では、無限に要素を処理するという事は難しいですが、代わりに呼び出し先の処理の先頭と末尾以外の処理を柔軟に書くことができるようになっています。
また、これはPythonの標準の決まりなので、全てを単純な関数呼び出しに分解した場合とも異なり、呼び出し順序なども意識させることができます。まとめ
普通の関数呼び出し・コルーチン・native coroutine・withのそれぞれについて、どのように処理が流れるかという事を図解で確認しました。
オブジェクト指向的な考え方では、様々なオブジェクトのメソッドを呼び出す≒関数を呼び出すことによって処理を記述しますが、以下のような条件を満たすことが理想的です。
- 読むときには追いかけやすい
- 処理のフローを追いかけやすい
- 関心事・役割・目的によってまとまったコードになっている
- 書くときにはある程度のパターンに沿いながら無駄なく簡潔に書きやすい
- 抜け漏れや、その他の書き間違いが発生しにくい
それを改めて意識するために"図解"をして、お互いの処理がどのようなフローで流れるのかを把握できるようにしてみました。特殊な構文が実際にどのように機能しているか、このような形で見ると分かりやすいのではないかと思いました。
適切な書き分けを意識して、保守性の高いコードを書きたいですね!
- 投稿日:2020-04-21T19:18:00+09:00
図解「generator・native coroutine・with」 〜 関心やコードを分離する文法と、処理順序・構造 〜(Pythonだよーん)
概要
この記事では、以下のような事を扱います。
- (Pythonの)generator、native coroutine、withの文法と、普通の関数呼び出しとの違いを図解で説明
- コルーチン・native coroutineという言葉にまつわるPythonの"混乱"の整理
- これらの文法のメリット・よりバグを生みにくいコードの書き方についての考察
細かい関数に分けることと、スパゲティコードと、バグりにくいコードと...というような事について、図解を交えながら、文法的な部分から考察します。native coroutineといった用語の話以外は、必ずしもPythonに限定した話ではないので、他の言語を使用されている方もある程度は自然に読めるかなと思います。
なお、似たような観点で、コールバックやポリモーフィズムを扱った姉妹記事もあります。(こちらはJavaScriptですが)
コールバックと、ポリモーフィズムと、それからコルーチンを構造的に見る関数呼び出し
Pythonでは、defという語を用いて、関数を定義することができます。
次のコード断片では、fという名前の関数を定義します。def f(name: str) -> str: return 'Hello, ' + name f('taro') # Hello, taro定義した関数は、関数名の後ろに()をつけて記述することによって呼び出す(call)ことができます。
関数を構成する要素には引数(argument)と戻り値(return value)というものがあり、関数には引数を受け取って戻り値を返す、という機能性があります。関数定義において、defと書いた行の()の中身が引数で、returnの後ろに書いてあるものが戻り値です。
そもそも関数とは
中学や高校で習う数学においては、関数とは「ある二つの数量$x,y$において、$x$の値に対して対応する$y$の値が一つ定まるとき、$y$は$x$の関数であるという。」などと定義されています。このような関係のとき、$y$が$x$によって決まることを強調して、$y=f(x)$というような書き方をするのでした。
「$y$の話をしていたのに、いきなり出てくる$f$は一体何だ?」
と思うのですが、$x$の値に対して対応する値を計算する決め方のルールのことを$f(x)$と表現しているのでした。
このような関数の考え方と先程の関数定義を対比すると、$x$は引数、$y$は戻り値ということになります。また、高校までの数学における関数は数と数の対応でしたが、先程のものは文字列(str)と文字列の対応になっているのでした。しかし、Pythonに限らず、プログラミングにおける関数にはもう少し別の側面があります。
例えば、高校までの数学で、関数を呼び出すというようなことは、普通は言わないはずです。証明の問題で「関数 $f(x)=x^2$ を呼び出すと」などという事を書いている人はほとんど居ないと思います。これは、プログラミングにおける関数には、数学における関数とは少し別の由来があることを意味します。手続きとルーチン
プログラミングは、しばしばコンピュータに対する命令をまとめる作業に例えられます。
実際、Pythonをコマンドラインで起動すると、以下のような文字列が表示され、Pythonは命令待ち状態になります。Python 3.7.7 (default, Mar 10 2020, 15:43:27) [Clang 10.0.0 (clang-1000.11.45.5)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>この >>> というのは、人間からの指示を待っている事を意味していて、Pythonの言語仕様に沿った命令(コマンド)を書くと、それに従ってPythonが適当な計算を行うようになっています。ゲームなどによってすっかり馴染みのある「コマンド」という単語ですが、これは「命令する」という意味ですね。
さて、いくつかのコマンドを並べる事によって、まとまった手続きをPythonに行わせる事ができます。例えば、以下のようにして、幅20・高さ45の長方形の面積を求める事ができます。(これはPythonの公式チュートリアルから引っ張ってきた例です。なぜそのようなものを計算しているのかは不明ですが...)
>>> width = 20 >>> height = 5 * 9 >>> width * height 900このような手続きについて、頻繁に用いる決まった手続き:ルーチンとして記述する事で、再利用しやすくできます。Pythonを含む多くのプログラミング言語では、関数をルーチンの定義に用いることもできます。例えば、以下のようにして、関数にルーチンの機能をもたせることができます。
def okan(): print('飯を食え') print('歯を磨け') print('着替えろ') okan() # 飯を食え # 歯を磨け # 着替えろこのようにして関数をルーチンとして扱う際には、「関数に代入する」という考え方よりも、「関数(ルーチン)を呼び出す」という考え方の方がよりしっくりと来る場合があります。そこで、関数に対しても「呼び出す」という言葉遣いをする場合があるのでした。
ちなみに、ここで出てくるprint()というのも関数で、print()は引数に指定した文字列を画面などに出力するのでした。関数の中でさらに別の関数を呼び出すという、関数の呼び出しの連続によってプログラミングは行われている、と言っても過言ではありません。呼び出しという部分について興味を持った方は、ぜひコールスタックというものを調べてみてください。(例えば、【図解】コールスタックとクロージャーを理解する)
ちなみに、先程のokan()には引数は存在せず、戻り値も存在しません。高校までの数学では、そのような関数は存在しない(引数と戻り値以外には関数の要素というものはない)のですが、プログラミングの関数においては、引数や戻り値以外にも、何らかの作用が存在するということになります。
関数呼び出しの図解
さて、ようやく本題の図解に入ります。以下のようなプログラムがあったとします。
def main(): print('first') sub_routine() return def sub_routine(): print('second') return main()このプログラムが実行される時の処理の流れを、行ごとに分割して可視化すると以下のようになります。
main()を実行するときには、途中でsub_routine()が呼ばれますが、sub_routine()が呼ばれてからはその処理を一通り実行して戻ってくる、というような流れになっています。
重要なポイントとしては、サブルーチンが呼び出されてからは終了するまでmain()に戻ってくることはないということです。しかし、一般にルーチンを作る時、AルーチンとBルーチンの間で行ったり来たりした方が表現がわかりやすい、という事があるかもしれません。例えば、さきほど例であげたokan()は言いたい事を全て言うだけのokanになっていますが、「飯を食え」と言った後は子供が飯を食べるまで待ち、その後に「歯を磨け」と言った方が適切なように思われます。このような、ある種の対話性を持ったルーチン呼び出しが求められる場合があります。そこで、コルーチンというものを考えます。
コルーチン
コルーチンは、プログラミング言語全般における用語です。単純な関数呼び出しによるサブルーチンとは異なり、呼び出し元と呼び出し先を行ったり来たりするような関係性のルーチンを指します。コルーチンのコとは、コラボのコと同じで、「共に」というようなニュアンスの接頭語です。
後ほど詳しく説明しますが、Pythonでは別の概念に対して「coroutine」という語を用いているため、この記事ではコルーチンと書いた時には今述べた意味でのコルーチンを表すものとします。Pythonで、一般的なコルーチンを実現するには、generatorというものを用います。文法的には、yieldというものをreturnの代わりに書くだけです。
def main(): a = simple() print('first') x = a.send(None) print(x) # third y = a.send(None) print(y) # fifth def simple(): print('second') yield 'third' print('forth') yield 'fifth' main()では、これを図解してみます。
まず、generatorの変わった特徴として、simple()のように呼び出しをしても、そのタイミングでは後続の処理が行われないという事があります。simple()は処理を行うのではなくて、処理を順番に行うための「generator object」を返します。このgenerator objectに対してsend()というメソッドが定義されているので、send()を繰り返すことによって実際の処理を行う、という流れになっています。単純な関数呼び出しとは異なり、呼び出し元のルーチンと呼び出し先のsimple()というルーチンを行ったり来たりしていることになります。
このsimple()の'third'や'fifth'を返却しているところで、'飯を食え'や'歯を磨け'を返すようにすれば、言いたいことを言って終了するだけではないokan()を作る事ができます。
なお、この例では処理順序に注目をしているため説明を省略したのですが、generatorの重要な特徴として、yieldした後にsend()するとその時の状態を引き継いで処理が継続されるという事があります。処理の順序だけではなく、関数の中で計算した変数の値などもそのまま再利用できるため、柔軟な書き方ができる文法になっています。
ただ、この書き方では、複数のokan()が同時に処理をするような場合をうまく記述することができません。同時に一人のokan()しか扱うことができないので、複数のokan()が居る家庭では一人ずつokan()が行動することになり、実に効率の悪い家庭になってしまいます。
(どういう家庭だろうか)native coroutine(Pythonでいうcoroutine)・async/await
複数のokan()を効率よく扱う方法として、Pythonではnative coroutineというものを用意しています。これは、先程のカタカナのコルーチンとはまた違う意味を持っているのですが、説明していきます。
...okan()の例が少し苦しくなってきたので、真面目な話をします。
多くのコンピューターには複数の計算装置が備わっており、これらのリソースをできる限り並列で動かした方が計算効率がよくなります。また、計算装置を扱う場合以外でも、例えば複数箇所との通信が必要なプログラムにおいて、通信を同時に投げておいてから、返答があったものから順番に処理をするというような仕組みにした方が効率的な場合があります。
そうしたプログラミングを行うときは、これまでの図解でみたフローのような常に一本道のフローではなくなります。例えば、同時に三つの道を並行で通る、というような計算の仕方が必要になるのです。それを、Pythonではどのような文法で表現すればよいのでしょうか。
以下に、それを実現するnative coroutineのサンプルを示します。
import asyncio import random async def main(): print('first') await asyncio.gather( native_coroutine(1), native_coroutine(2), native_coroutine(3), ) async def native_coroutine(x): await asyncio.sleep( random.random()) print(x) asyncio.run(main())このプログラムを実行すると、firstと出力されたあとに、ランダムで1,2,3が並び替わって出力されます。
await asyncio.sleep(random.random())
というところが、ランダムで0〜1秒待つという処理になっているので、その時間の長さによって1,2,3のどれが先に出るかが変わってくる、というような並列処理のサンプルです。
これまでの文法との大きな違いは、defの前にさらにasyncという用語が付いたり、関数呼び出しの前にawaitという用語が付いたりしている部分ですが、それらの説明の前に、まずはどのような順序で処理が行われるかをフローで見ます。
まず、asyncの付いている関数定義は、generatorと同じように、呼び出しをしても直ちに実行はされない関数になります。generatorの場合はsend()を都度実行するのでしたが、native coroutineの場合はasyncio.run()やasyncio.gather()などによって実行します。
asyncio.runでmain()を実行すると、まずfirstと出力されますが、次のawaitでnative(1),native(2),native(3)の結果が返されるまで処理を待つようになります。
native(1),native(2),native(3)は"同時に"実行されます。その事を模式的に表現したのが三本の矢印たちです。ところで、このフローを見ると、(カタカナ表記の)コルーチンのような行ったり来たりする構造がありません。
どういうことでしょうか。実は、await asyncio.gather()をすると、その引数のnative coroutine達の処理が終了するか、またはタイムアウトするまで待ち続けてしまうので、コルーチンにおける行ったり来たりという処理ができないのです。ですが、Pythonではこれを(native) coroutineと呼んでいます。
native coroutineという名前がついた経緯
なぜ、このようなモノのことをcoroutineと呼ぶ事になったのか?
その経緯は新雑誌「n月刊ラムダノート」の『「コルーチン」とは何だったのか?』の草稿を公開しますに詳しくまとまっています。掻い摘んで書くと
JavaScript界隈(やUnity界隈など)で「非同期の処理を含む特殊なコルーチン」の事を、単に「コルーチン」と呼ぶ事があり、それに引きずられた形になっています。
もう少し詳しく書くと、通常、JavaScriptで非同期処理を書こうとすると、コールバック関数を渡すなどして複雑な書き方をする必要がありました。しかし、上記の特殊なコルーチンを使って書くと、同期処理の時のように平易な書き方をすることができたのです。
例えば、対話的okan()のprintを通信処理と思うことにして、各通信処理が終わったらokan()自身にsend()させると、全てのyield(≒通信処理)が完了するまで待つコードを簡単に書くことができ、通信処理などを書く時に複雑なコールバック関数を渡さずに同期処理的な書き方をすることができるのでした。ただし、この書き方においては「呼び出した元と行ったり来たりする」という事はありませんでした(自分自身にsend()するので)
でもそのような事情があるとはいえ、元々コルーチンの一種ではあるので、そのような特殊なコルーチンについても単にコルーチンと呼ばれることがあったのでした。
(これは先程のラムダノートの草稿に具体的なJSのコード付きで書いてあります)これを受けて、Pythonの仕様PEP492に落とし込んだ時にcoroutineと呼ぶことになってしまったのでした。
実は、これを行ったり来たりできるようにした async generator というものも存在していて、それはPEP525でPEP492と同じ方が提案して実際に使えるようになっていますが、この記事ではasync generatorの使い方については省略します。
なお、generatorはPEP342で導入されていますが、ここでははっきりCoroutines via Enhanced Generatorsと書いてあるので、ここのCoroutineの概念ともPEP492の概念は異なる状態になってしまいました。関数呼び出しやコルーチンと、スパゲティコード
さて、ここで話をがらりと変えてみます。
保守しにくいコードの代表格として、「スパゲティコード」というものが取り上げられます。これは、次のような性質を持つと言われます。
- goto文が濫用されている
- グローバル変数など、広い範囲に影響する変数が様々なところで使用され、様々な処理が変数の状態に依存するようになっている
しかし、ではgoto文やグローバル変数などを使わなければスパゲティコードではないのか?というと、そうではありません。
実際、関数呼び出しというのは、プログラムソースを文字列の集まりとして見た時、「その関数の定義された場所に行け」というのと近い意味を持つものであって、gotoに似た機能性があります。そこで無闇に関数を作ってしまうと逆に処理を追いかけにくくなります。
また、コルーチンでyieldしたりsend()したりというのもgotoに近い性質を持ちます。さらにコルーチンでyieldするということは、何らかの状態を保持させたまま元のルーチンに戻るという事なので、関数呼び出しと比較してある種の状態依存性を作り出しているとも言えます。
従って、これらの文法も、悪用するとスパゲティコードを生産する元になってしまうわけです。
しかし一方で、うまく使えば分かりやすい・バグりにくいコードを書くことに繋がります。うまく使うためには、どうすればよいのでしょうか。その特性を比較してみましょう。ただ、native coroutineに関しては、主目的が非同期処理を扱うことであるのは明らかなので、ここでは特に関数呼び出しとコルーチンを比較する形で考察をします。
関数呼び出しとコルーチンの比較
コルーチンでyieldによって挟まれている部分を、別の関数に分けて実装することを考えてみます。
コードブロックの呼び出し順序の保証
その場合、関数呼び出しを組み合わせる場合は呼び出し順序を規定することはできません。例えば、関数begin(), middle(), end()を順番に実行してもらいたいと実装した人が思ったとしても、必ずbegin(), middle(), end()という順番で実行されているかどうかを文法は保証してくれません。
また、関数が定義されているコードを読む人も、begin(), middle(), end()が順番に呼ばれるものだと思って読んでくれるとは限りません。(名前から、類推をする可能性はありますが)
一方、コルーチンでは必ず呼び出し順序が保たれますし、yieldを挟んで続けて処理が書かれているので、連続する処理は読みやすくなります。そのような意味で、ある種の非同期的な処理も記述がしやすくなります。呼び出し元で次の処理を行う時のわかりやすさ
呼び出し元でコルーチンの続きを取得するにはsend()などのような関数(メソッド)を使いますが、これには「どこまで進んだ続きなのか」という情報が含まれません。begin(), middle(), end()は明確にどの関数が呼ばれるかがわかりますが、send()ではどこから処理が再開するかがわからないということです。その意味では、呼び出し元のコードを読む時・書く時はsend()だと意味がわかりにくい可能性があります。(ただし、yieldから再開する時にsend()の引数を受け取る事はできるので、それによって分岐させるというような実装はありえます。)
また、もし、1番目のyieldで初期化完了、2番目のyieldで処理、3番目のyieldで後始末、というコルーチンを期待したインターフェイスになっているコードがあったとします。そうすると、もしコルーチン(generator)の中に新しく「処理(yield)」の追加が必要になった場合は、現在の3番目の処理が4番目にずれてしまい、既存の処理に大きく影響を与えてしまう可能性があります。(つまり、そのようにyieldで取り出す時の回数に意味をもたせるような実装はアンチパターンということになります。)
これに対して、begin(), middle(), end()等とそれぞれ関数で実装していれば、middle2()を追加しても既存コードへの影響はありません。呼び出し先での返却のしやすさ、不特定回数のデータ取得
一方で、send()だけでyieldの結果が受け取れることを利用して、ループ等で不定回数のデータを取得するという事もできます。
少し見方を変えると、呼び出し元がループでsend()の結果を全て取得するような実装になっていれば、呼び出し先のコルーチン側は自由にyieldで結果を返すことができるという事もできます。このようなコルーチン(generator)の実装は、例えばストリーミング処理等で威力を発揮します。全ての計算・処理が終了する前に、ちょっとずつ結果を返却する、というような事が可能になるからです。Webアプリで、レスポンスを実際に処理するような部分についてはyieldした値を受け取る側のフレームワーク的な部分で実装をしておくことで、返却する内容の計算処理と、その周りの処理について関心・コードをきれいに分離して実装することができます。(例えばFlaskにはそのような実装があります)そもそも、genertor(発生器)という名称は、何らかの結果を複数回生成・発生させるようなニュアンスで付けられたものなのでした。実際、next()で結果を取得するiteratorと似たようなところがありますね。
総じて、良くも悪くも、コルーチンは呼び出し元や呼び出し先のインターフェイスが簡素になっていると言えます。(send()とyieldでつながっている)
コルーチンを使うと見通しがよくなるところ
他にも使い方は色々あると思いますが、代表的なものとしては以下のようなものがあります。
- ストリーミングなど、少しずつ・何度も結果を返却する必要があるところ
- 特に、不特定回数になる場合
- 全てのデータをメモリに展開するとパンクするような大きなデータを扱う場合
- 複雑な計算による配列など
- 特に、無限長になりえる場合
- 非同期的な扱いをする必要のある対象の表現
- ゲームなど
いずれの場合も、コルーチンの中では、目的とする計算に注力しやすくなります。
おまけ:withを用いた簡単な処理構造
さきほどの、コルーチンを使うことに関して検討をしたところで、begin(), middle(), end()などと実装をした方が見通し・保守性が良い可能性もありました。
このような場面において適した書き方として、Pythonにはwithを用いた記述があるので、これを簡単に説明しておきます。def main(): with EnterExit() as ee: print('second') x = ee.method() print(x) # third # withを抜ける return class EnterExit: def __enter__(self): print('first') return self def method(self): return 'third' def __exit__( self, exc_type, exc_val, exc_tb): print('forth') main()このプログラムの処理の流れを見てみましょう。
Pythonでは、withを用いたコードブロックにおいては、その先頭で必ず
__enter__()が呼ばれ、末尾または例外による抜け出しで必ず__exit__()が呼ばれる、という事が保証されます。
この構文で使用する代表格は、ファイルのオープンwith open('file_name.txt') as f:というようなものかと思います。一般に、ファイルのオープンをしたらクローズが必要になりますが、withでオープンをすると、そのスコープを抜ける時に必ずクローズされる事が保証されます。また、asで開いたファイルをfに代入することによって、スコープ内でfを自由に使うこともできます。コルーチンで実現した「行ったり来たり」という部分については、実質的にはこのような書き方でも再現することができます。この書き方では、無限に要素を処理するという事は難しいですが、代わりに呼び出し先の処理の先頭と末尾以外の処理を柔軟に書くことができるようになっています。
また、これはPythonの標準の決まりなので、全てを単純な関数呼び出しに分解した場合とも異なり、呼び出し順序なども意識させることができます。まとめ
普通の関数呼び出し・コルーチン・native coroutine・withのそれぞれについて、どのように処理が流れるかという事を図解で確認しました。
オブジェクト指向的な考え方では、様々なオブジェクトのメソッドを呼び出す≒関数を呼び出すことによって処理を記述しますが、以下のような条件を満たすことが理想的です。
- 読むときには追いかけやすい
- 処理のフローを追いかけやすい
- 関心事・役割・目的によってまとまったコードになっている
- 書くときにはある程度のパターンに沿いながら無駄なく簡潔に書きやすい
- 抜け漏れや、その他の書き間違いが発生しにくい
それを改めて意識するために"図解"をして、お互いの処理がどのようなフローで流れるのかを把握できるようにしてみました。特殊な構文が実際にどのように機能しているか、このような形で見ると分かりやすいのではないかと思いました。
適切な書き分けを意識して、保守性の高いコードを書きたいですね!
- 投稿日:2020-04-21T19:12:13+09:00
Pythonチュートリアル(2章)の内容を箇条書きでまとめた
前の記事:Pythonチュートリアル(1章)の内容を箇条書きでまとめた
はじめに
Python3 エンジニア認定基礎試験対策として、Pythonチュートリアル(書籍)の内容を暗記しやすい箇条書きにまとめた自分用メモです。
参考資料
Pythonチュートリアル: https://docs.python.org/ja/3/tutorial/
2章: https://docs.python.org/ja/3/tutorial/interpreter.html
書籍: https://www.oreilly.co.jp/books/9784873117539/"2章 Pythonインタープリタの使い方" テーマ
2.1 インタープリタの起動
- UNIXの場合
- Pythonのインストール場所
- 通常 /usr/local/bin/python3.5 としてインストールされている。
ディレクトリはインストール時に指定可能。- 起動方法
- シェルで "/usr/local/bin/python3.5" と入力。
- UNIXシェルのサーチパスに /usr/local/bin が入っていれば、"python3.5" で起動できる。
- 終了方法
- プライマリプロンプト (>>>) が出ているときに [Ctrl] + [D] を入力。
- quit() コマンドを入力。
- Windowsの場合
- Pythonのインストール場所
- 通常 C:\python35 にインストールされる。
これもインストール時に変更可能。- 起動方法
- DOSプロンプトで "C:\python35\python" と入力。
- 以下のコマンドで環境変数pathに C:\python35 を入れれば、"python" で起動できる。
- set path=%path%;C:\python35
- 終了方法
- プライマリプロンプト (>>>) が出ているときに [Ctrl] + [Z] を入力。
- quit() コマンドを入力。
- ちなみに、[Ctrl] + [D]や[Ctrl] + [Z]はOSにおけるEOF(End Of File: ファイル終端キャラクタ)を意味する。
2.1.1 引数を渡す
- スクリプトを起動した際の引数は、sys.argvに割り当てられる。
- sysは組込モジュールで、import sys を実行することで参照できる。
- arvgは引数を格納したリストであり、長さは最小1である。
- スクリプト名も引数も与えられない場合、sys.argv[0]は空の文字列になる。
- スクリプト名が標準入力を意味する "-" の場合、sys.argv[0]も "-" になる。
- "-C コマンド" の形式で実行した場合、sys.argv[0]は "-C" になる。
- "-m モジュール名" の形式で実行した場合、sys.argv[0]は指定したモジュールの完全な名前になる。
- "-C コマンド" や "-m モジュール名" の後に続くオプションはsys.argvに残される。
2.1.2 対話モード
- コマンドをtty(標準入出力となっている端末デバイス)から読み込んでいるとき、インタープリタは対話モードになっている。
- 対話モードでは、インタープリタは以下を表示する。
- ウェルカムメッセージ ... 最初に表示。バージョンと著作権から始まる。
- プライマリプロンプト (>>>) ... コマンド入力を促す。
- セカンダリプロンプト(...) ... if文などを入力した際に表示され、継続行の入力を促す。
2.2 インタープリタとその環境
2.2.1 ソースコード・エンコーディング
- Pythonのソースファイルは、デフォルトではUTF-8でエンコードしてあるものとして扱われる。
- UTF-8では、世界のほとんどの言語の文字を扱える。
- ただし標準ライブラリでは識別子(クラス、変数、関数などの名前)にASCIIキャラクタのみを使っているので、倣ったほうがいい。
- ソースコードの編集にはUTF-8を認識するエディタを使う必要がある。
- UTF-8以外のエンコーディングを使うこともできる。
- 方法は、# *_*_ coding: エンコーディング名 _*_ の特殊コメント行をソースの1行目か2行目に記載する。
- 使えるエンコーディング一覧は、ライブラリリファレンスのcodecsの項にある。
- 投稿日:2020-04-21T19:05:13+09:00
100日後にエンジニアになるキミ - 32日目 - Python - Python言語の基礎7
今回もPythonの基礎の続きです。
前回はこちら
100日後にエンジニアになるキミ - 31日目 - Python - Python演習2関数
少し前に組み込み関数についてやっていますが今回は
関数についてです。
組み込み関数はPython言語に初めから備わっている機能になりますが
関数は自分で定義することができます。関数の定義の仕方
def 関数名(引数): return 戻り値関数に関係する用語ですが、まずは
引数があります。
関数の()かっこの中に書くことができます。
引数は関数の中で使えるデータを受け渡す際に用います。次に
戻り値ですが、関数の中で計算された結果を
関数の外に戻す際に用います。早速関数を定義して見ましょう。
# 関数の定義 def abc(aaa=0): print(aaa) return 1 # 関数の実行 print(abc()) print(abc(2))0
1
2
1
引数の変数名の後に=イコールをつけて値を代入しておくと、
引数が指定されなかった場合に、初期値として使われる値になります。
戻り値は関数の実行結果なので
変数に格納したりする事もできます。# 関数の実行結果が変数に格納される a = abc(3) print(a)3
1
戻り値や引数は設定しなくても関数として定義できますdef defg(): print('dd') defg()dd
特に値を戻す必要がなければ
return無しで戻り値をなくしても大丈夫です。関数の結果を用いて次に処理を行いたい場合は
returnを付けて値を戻すようにします。
引数は何個でもつけることができますが、
あまり多すぎると使うときに困ると思います。なので5-6個くらいに納めた方が良いかと思います。
それ以上になるようであれば処理を改めたほうが良いでしょう。関数を定義するときに
引数を定義したら、
使うときもその引数の分だけ指定することが必要になりますが、
関数によっては引数で処理を変えたりしたいというニーズもあったりします。そんな時は
引数に**をつけると
引数をタプル型や辞書型で受け取ることができます。def aaa1(**karg): print(karg) # 関数の引数に辞書型を渡す aaa1(aws=[1,2]){'aws': [1, 2]}
複数の引数にまとめてデータを渡せます。
def aaa2(arg1, arg2, arg3): print(arg1) print(arg2) print(arg3) lis = ['one', 'two', 'three'] # 関数の実行にリストをタプル型にして渡す。 aaa2(*lis)one
two
threeただしこの場合は引数の数と合わなければなりません。
個数が合わないとエラーが発生します。lis2 = ['one', 'two', 'three','four'] # 引数の数と渡す数が合わ無いとエラーになる。 aaa2(*lis2)TypeError: aaa2() takes 3 positional arguments but 4 were given
関数の使い方としては、複数行にまたがる処理が
2回以上行われる場合は、関数化していった方が
コードがスッキリして見やすく、メンテナンスもしやすくなります。同じような処理を2度書くくらいであれば、全体を見直して
簡略化、省力化ができる部分を書き直してゆく、という感じで
関数を作っていくのが良いと思います。
特定の関数は別名でメソッドとも読んでいます。
プログラミングでは必須になる概念のため必ず覚えておいてください。global変数とスコープ
関数などを使う際に必ず付いてくるのが、スコープという概念です。
これは宣言した変数が使える範囲を示す概念のことです。
スコープにはグローバルとローカルの2種類があります。ざっくり説明すると、一番外にあるものが
グローバル
関数のブロックの中がローカルということになります。ではその違いについて見て見ましょう。
まずはグローバルで使える変数を用意します。global_var = 'global'次に関数を定義して、その中で使える変数を用意します。
def local_def(): # ローカル用の変数 local_var = 'local' return local_var両方の変数を呼び出してみましょう。
グローバル変数の呼び出しはprint(global_var)global
ローカル変数の呼び出しはprint(local_var)NameError Traceback (most recent call last)
in ()
----> 1 print(local_var)
NameError: name 'local_var' is not defined変数が定義されていないと、エラーが出てしまいます。
ローカルで定義したものは、
そのローカルのブロックの中でしか使えないからです。なのでこの
local変数が使えるのは、
定義した関数の中だけになります。次に関数をいじって、
グローバル変数を関数の中で読んでみましょう。def local_def(): # グローバル変数の参照 print(global_var) local_def()global
グローバルで宣言した変数はどこでも使用することができます。
ローカルで宣言したものを
グローバルで使うにはどうすればいいでしょうか?
関数であれば戻り値として
グローバルの方に戻すことで使い回すことができます。def local_def(): local_var = 'local' # ローカルで定義した変数を戻す return local_var g2 = local_def() print(g2)local
for文の方も見て見ましょう。global_var = 'g' for i in range(5): j = global_var*i # ローカルの変数をそのままプリントする print(i,j)``` 4 gggg 結果は最終的に代入された結果のみが反映されることになります。 `for`文のブロックで使用していた`変数`などを 気づかずに再利用してしまうケースなどがありえると思いますが、 `変数`に格納した値によってはプログラムの結果に大きく影響が出てきます。 最後に、`グローバル`と`ローカル`で変数名がかぶってしまった場合どうなるでしょうか? ```python sp = 'global' def local_def(): sp = 'local' print(sp) local_def() print(sp)local
global一旦
ローカルで同じ変数名で定義していますが
関数を呼び出した際はその関数で定義した変数名で
上書きされる形になるのでローカルで代入した値が表示されます。その後
グローバルの変数を呼び出す際には
元の値が表示されるという仕組みです。
globalという予約語を用いると、
このグローバル変数をローカル側で操作することできます。sp = 'global' def local_def(): # ローカルでグローバル変数として定義 global sp sp= 'local' print(sp) local_def() print(sp)local
local一旦
ローカルで変数の前にglobalをつけて宣言し、
その後に変数に代入するとグローバルの変数の操作をすることができます。
グローバルとローカルで同じ変数を用いると、
不慮のバグの元になりやすいです。なので慣れないうちは
変数名はなるべく被らないような
名称にすることをお勧めします。無名関数
さてこれまでは
関数についての授業を行ってきましたが、
今回は無名関数というものについてのお話です。
ソートの回で少しだけ触れた
lambdaラムダというものについてです。
ラムダ式とも呼び、名前のない関数を作ることができます。ラムダ式の書き方
lambda 引数 : 処理普通の関数の書き方だと
def add (a,b): return a+b print(add(2,3))5
このようになりますが
ラムダを使った無名関数だとadd = lambda a,b : a+b print(add(2,3))5
ラムダの後に書いた変数を受け取って:の後の処理が実行されます。
ラムダ式で変数addに関数を代入し
その変数を用いると関数が実行される仕組みです通常の関数との違いはほとんどなく関数を定義したほうが無難です。
ラムダ式が効力を発揮するのはsortなどの時です。
辞書型の値でソートの際にこのラムダ式が出てきました。dct ={ 3:7 , 5:6 ,1:3 } # 辞書型を値で昇順ソートする。 print(sorted(dct.items(), key=lambda x:x[1]))[(1, 3), (5, 6), (3, 7)]
key=以降がラムダ式です。
sorted関数の引数keyが関数を受け取れます。複雑なソートをする場合に
ラムダ式が役立ちます。lis1 = [2,3,4,5,7] # 要素を3で割った余りでソートするような場合 print(sorted(lis1 , key=lambda x:x%3))[3, 4, 7, 2, 5]
辞書型の際は
キーと値をタプル型で返してきます。dct ={ 3:7 , 5:6 ,1:3 } print(sorted(dct.items(), key=lambda x:x[1]))[(1, 3), (5, 6), (3, 7)]
key=lambda x:x[1]のインデックス部分で
[0]がキー、[1]が値となります。
値でソートしたいのなら、
ラムダ式ではインデックスの二つ目すなわち1となるので
key=lambda x:x[1]と指定することになるのです。これは複合したデータの並び替えなどで役立つことになります。
# 多重のリストを定義 complex_list = [[1,2,3],[3,5,2],[2,6,8]] print(complex_list)[[1, 2, 3], [3, 5, 2], [2, 6, 8]]
# リストの最初の値で並び替え print(sorted(complex_list,key=lambda x : x[0])) # リストの2番目の値で並び替え print(sorted(complex_list,key=lambda x : x[1])) # リストの3番目の値で並び替え print(sorted(complex_list,key=lambda x : x[2]))[[1, 2, 3], [2, 6, 8], [3, 5, 2]]
[[1, 2, 3], [3, 5, 2], [2, 6, 8]]
[[3, 5, 2], [1, 2, 3], [2, 6, 8]]大きな
リストの要素として存在するリストの並べ替えのキーを
リストの各項目で定義することができます。このようにすればどのようなデータの形でも対応できるようになるので
ラムダ式が大活躍します。関数を定義するまでもないような小さな処理に向いていますので
関数やソートでの利用の仕方を覚えておきましょう。まとめ
関数は処理を簡略化させたり、まとめたりするのに非常に役立つ機能です。
関数の定義の仕方と、スコープでの変数の取り扱いが
どう働くのかをしっかり押さえておき、バグが起きないように心がけよう。君がエンジニアになるまであと68日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython



- 投稿日:2020-04-21T19:02:11+09:00
Pythonでファイルを一行ずつ読み込む
すごく基本的なことなんだけど、pythonであるテキストファイルを一行ずつ読み込む方法を調べてみた。
一番スマートだと感じた方法
with open('./test.txt') as f: for line in f: print linehttps://journal.lampetty.net/entry/wp/418
他にも色々るあるけど
多分上記のが一番スマートかな。
read(), readline(), readlines()などを使うサンプルをいくつもみたけど、一行ずつ処理するならば使う必要ない気がした。read()を使うwith open('./test.txt') as f: lines = f.read() for l in lines.split("\n"): print(l)readline()を使うwith open('./test.txt') as f: line = f.readline() while line: print(line.rstrip("\n")) line = f.readline()readlines()を使うwith open('./test.txt') as f: lines = f.readlines() for l in lines: print(l.rstrip("\n"))pythonはやりたい事に対して解決方法がたくさんありすぎるので、どれが良いか考えている時間が無意味に長くなってしまうのが良くないな。。
- 投稿日:2020-04-21T18:15:33+09:00
pythonではじめるデータ分析 (データの可視化)
はじめに
CEML (Clinical Engineer Machine Learning)初投稿です。
今回は初心者向けにpythonでのデータ解析について解説したいと思います。
ソースコード
https://gitlab.com/ceml/qiita/-/blob/master/src/python/notebook/first_time_data_analysis.ipynb本記事の内容
無料で公開されているデータセットを使用して、データの読み込みから簡単なデータ解析までを解説します。
データセットについて
・提供元:カルフォルニア工科大学
・内容:心臓病患者の検査データ
・URL :https://archive.ics.uci.edu/ml/datasets/Heart+Disease
・上記URLにあるprocessed.cleveland.dataのみを使用します。解析目的
データセットは患者の病態を5つのクラスに分類しています。
各クラスの特徴を掴む事を目的に解析を進めてみようと思います。データのダウンロード
上記URLにアクセスし、Data Folder内にあるprocessed.cleveland.dataをダウンロードします。
データの読み込み
pandasをインポートして、pandasのread_csvメソッドでデータを読み込みます。
データの読み込み時にカラム名を指定しています。カラム名はリストにして、read_csvメソッドのnemesに引数として渡します。import pandas as pd columns_name = ["age", "sex", "cp", "trestbps", "chol", "fbs", "restecg", "thalach", "exang", "oldpeak","slope","ca","thal","class"] data = pd.read_csv("/Users/processed.cleveland.data", names=columns_name) # dataの上5行を表示 data.head()以下が読み込まれたデータです。
簡単にカラムの説明を載せておきます。詳しくはデータ元を参照してください。
・age
・sex (1 = male; 0 = female)
・cp: chest pain type
1:typical angina 2: atypical angina 3: non-anginal pain
4: asymptomatic
・trestbps:resting blood pressure (in mm Hg on admission to the hospital)
・chol:serum cholestoral in mg/dl
・fbs:fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
・restecg:resting electrocardiographic results
0: normal
1: having ST-T wave abnormality
(T wave inversions and/or ST elevation or depression of > 0.05 mV)
2: showing probable or definite left ventricular hypertrophy by Estes'criteria
・thalach:maximum heart rate achieved
・exang:exercise induced angina (1 = yes; 0 = no)
・oldpeak:ST depression induced by exercise relative to rest
・slope:the slope of the peak exercise ST segment
1: upsloping
2: flat
3: downsloping
・ca:number of major vessels (0-3) colored by flourosopy
・thal:3 = normal; 6 = fixed defect; 7 = reversable defect
・class : 0~5 (0は正常,数字が大きほど悪い)データの前処理
今回は前処理として、各カラムのデータ型を確認し、数値型でなければ数値型へ変換します。
?と入力された欠損値が存在するので、nullに置換します。#dataの型を確認 data.dtypes #型をfloatに変換,?はnull値に置換 data = data.replace("?",np.nan).astype("float")データの基礎統計量と欠損値を確認する
各特徴量(変数)毎の確認
# 統計量を算出 data.describe() # 欠損値をカウント data.isnull().sum()たったこれだけで、各列の統計量を欠損値がわかります。
以下の図は統計量の計算結果です。
各クラス毎の各特徴量(変数)の確認
ここからが本題です。
確認ですが今回の解析目的は各クラス毎の特徴把握です。
この場合pandasのgroup_byメソッドを使用します。# class列でグループ化 class_group = data.groupby("class") # クラスを指定して統計量を取得する場合 # class_group.get_group(0).describe() # カラムが全表示できるようにオプションを指定(notebook) pd.options.display.max_columns = None # 全クラスの統計量表示 class_group.describe()以下は全クラスの統計量を表示させています。
簡単ですね。今回のデータは特徴量(変数)や分類されているクラス数(5つ)も少ないので,全クラスの統計量を表示しても確認出来ますが,これらが多い場合,全て表示させて確認することは難しくなります。
データを可視化する
各特徴量(変数)の分布を確認
ヒストグラムでデータの分布を確認します。
data.hist(figsize=(20,10)) #グラフが重ならないようにする plt.tight_layout() plt.show()
各クラス毎の各特徴量(変数)のヒストグラムを表示
# 単体でのプロット # class_group["age"].hist(alpha=0.7) # plt.legend([0,1,2,3,4]) # 全てを表示させる plt.figure(figsize=(20,10)) for n, name in enumerate(data.columns.drop("class")): plt.subplot(4,4,n+1) class_group[name].hist(alpha=0.7) plt.title(name,fontsize=13,x=0, y=0) plt.legend([0,1,2,3,4])
各クラス毎の各特徴量(変数)の平均値と分散を棒グラフに表示
# 単体でのプロット # class_group.mean()["age"].plot.bar(yerr=class_group.std()["age"]) # 全てを表示させる plt.figure(figsize=(20,10)) for n, name in enumerate(data.columns.drop("class")): plt.subplot(4,4,n+1) class_group.mean()[name].plot.bar(yerr=class_group.std()[name], fontsize=8) plt.title(name,fontsize=13,x=0, y=0)
ざっと可視化してみましたがクラス毎のヒストグラムなどはこのままではよく見えないです。
次回はグリグリ動かせるグラフや3dプロットなどを使って解析していこうと思います。

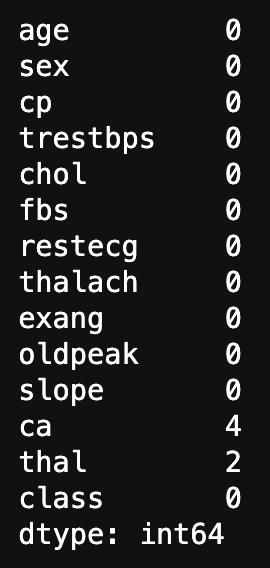

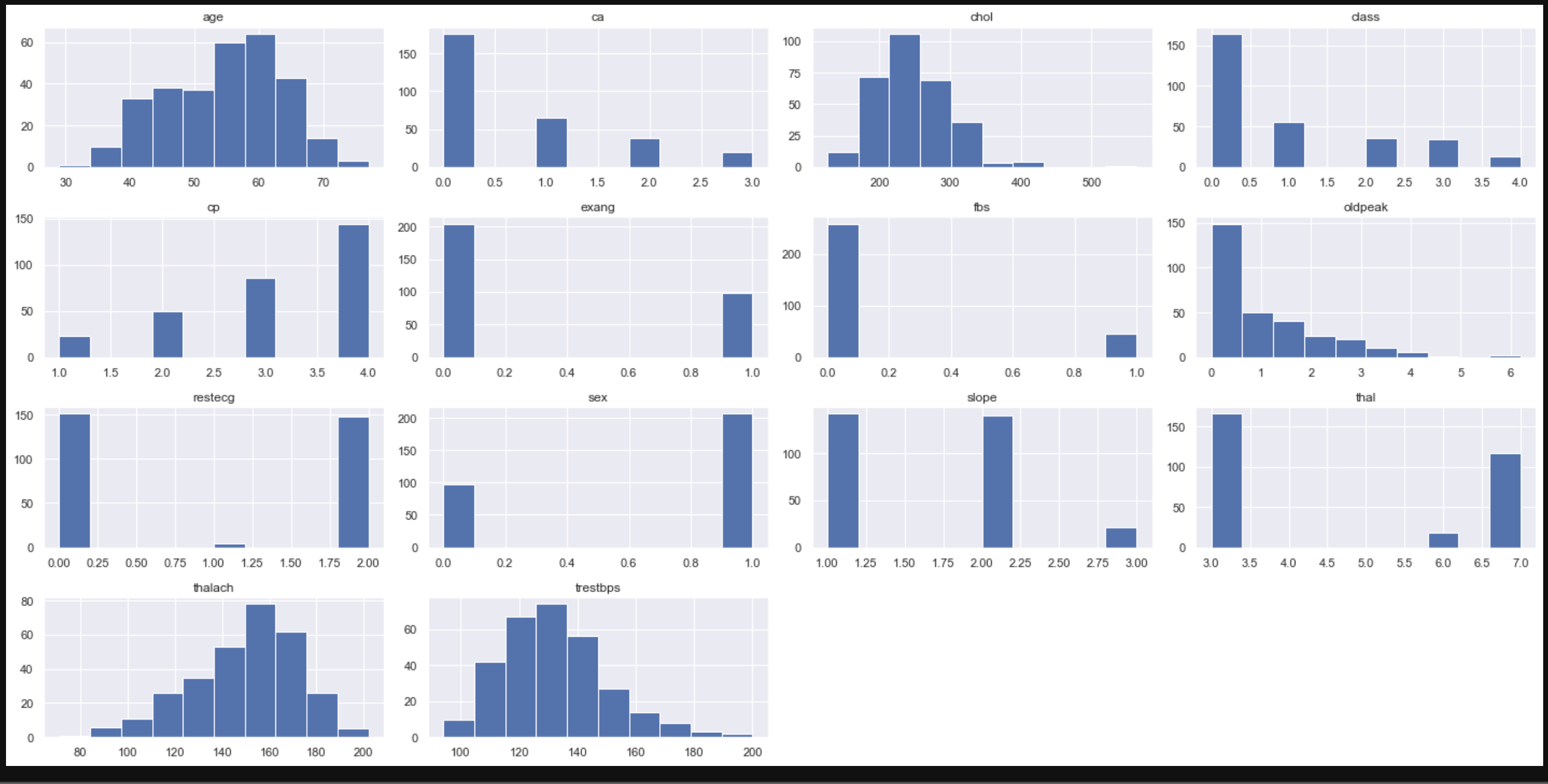
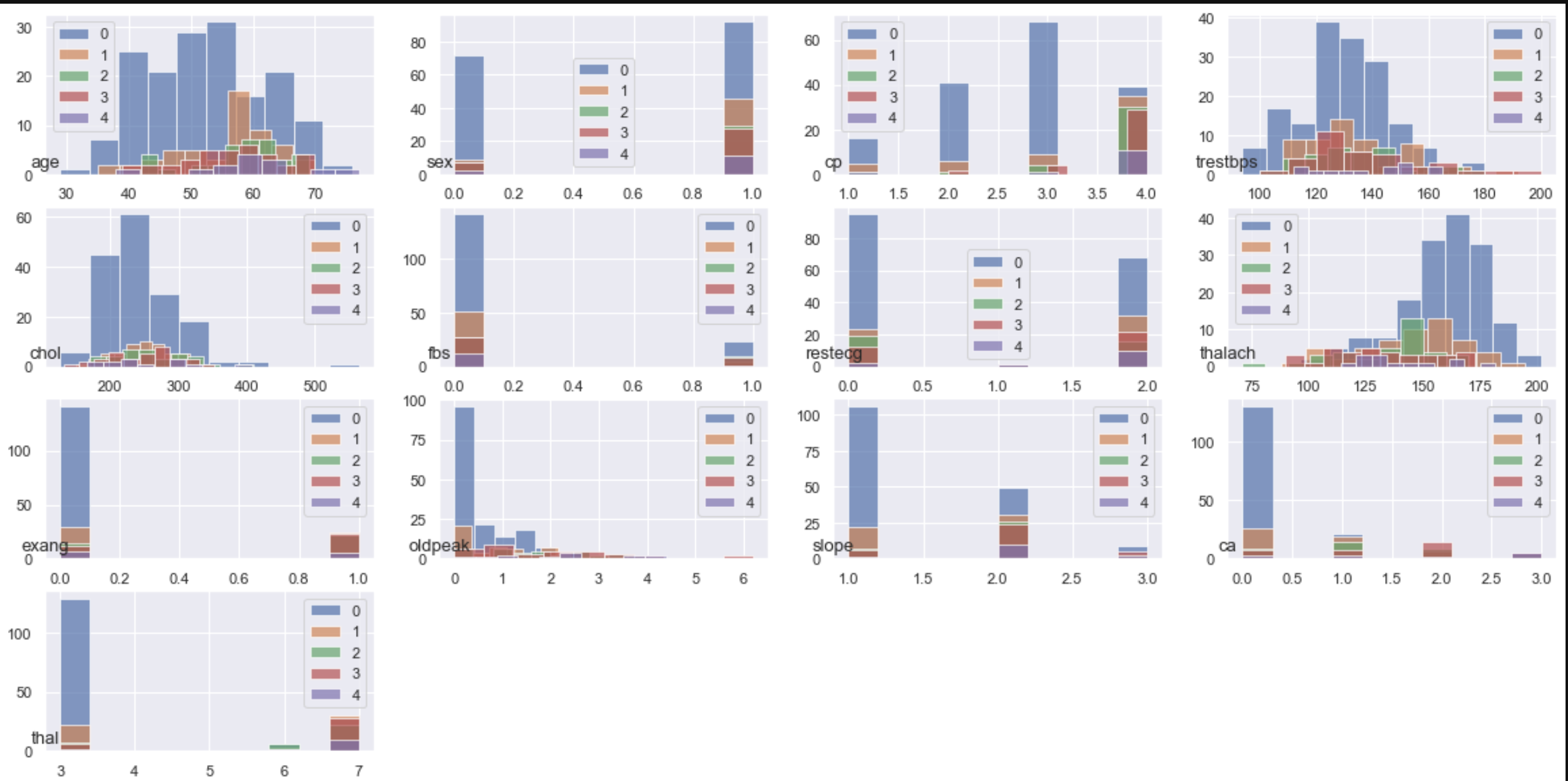
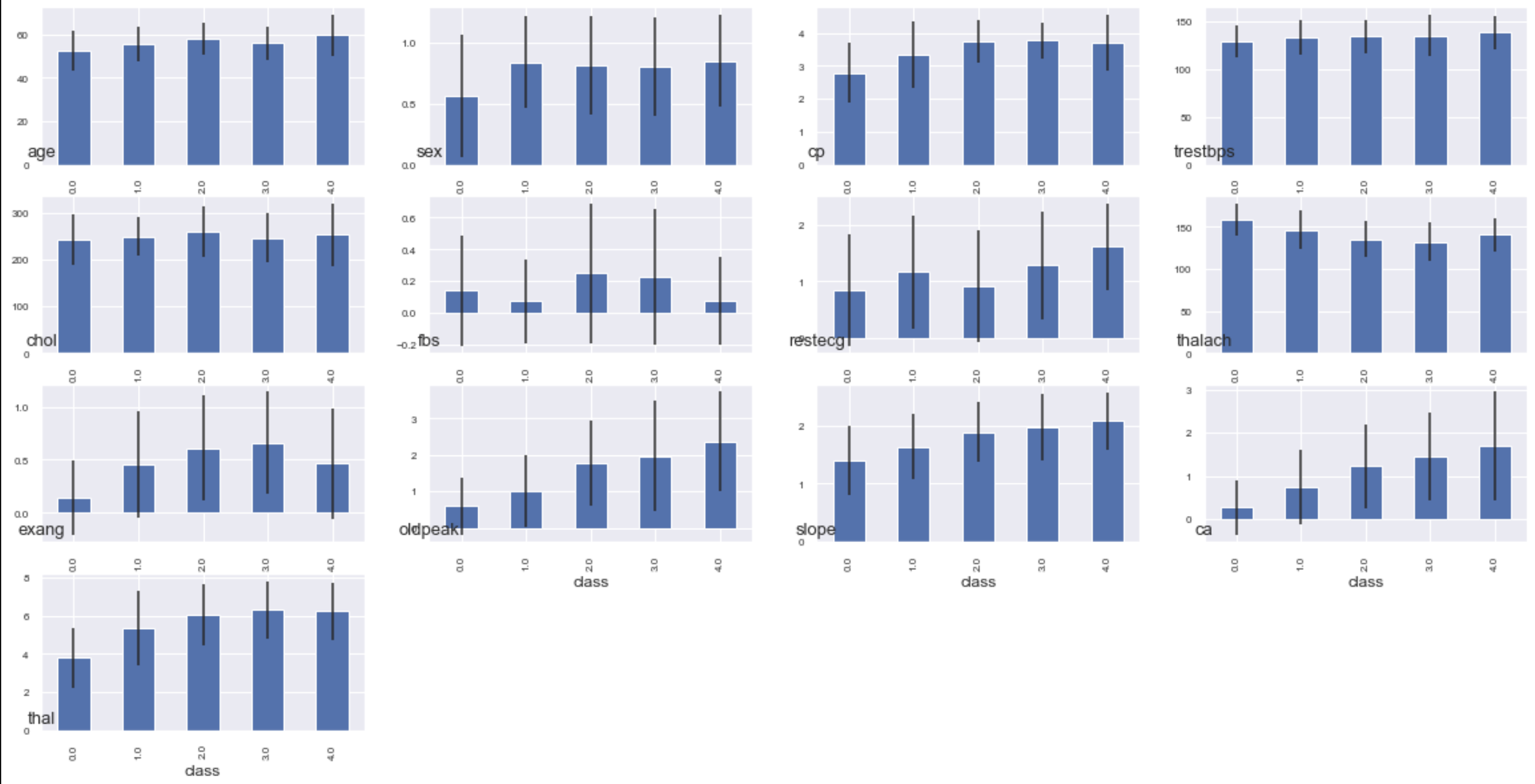
- 投稿日:2020-04-21T17:52:09+09:00
【Python】2資産ポートフォリオのリスクリターンマップを作る
TwitterでSPXLとTMFを組み合わせたポートフォリオのリスクリターンマップを紹介しました。
ここに、そのグラフを作るためのコードを保存しておきます。
あらかじめ以下のサイトからTMF,SPXL,VTIのcsvファイルを取得しておきます(期間はMAX)。
(本当は、取得するcodeをかければ良いのですが・・・)TMF: https://www.nasdaq.com/market-activity/funds-and-etfs/tmf/historical
SPXL: https://www.nasdaq.com/market-activity/funds-and-etfs/spxl/historical
VTI: https://www.nasdaq.com/market-activity/funds-and-etfs/vti/historicalそれぞれ、"TMF.csv", "SPXL.csv", "VTI.csv"というファイル名で保存しておきます。
1. ライブラリの読み込み。
#Invite frends to the party... import numpy as np import pandas as pd from datetime import datetime import seaborn as sns sns.set() import matplotlib.pyplot as plt from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()2. csvファイルを1つのDataFrameにまとめる関数
def make_df(etfs): df = pd.DataFrame() for etf in etfs: csvfile = etf +'.csv' csv_data = pd.read_csv(csvfile) csv_data.Date = pd.to_datetime(csv_data.Date) csv_data = csv_data.set_index('Date') csv_data= csv_data.rename(columns={' Close/Last': etf}) df[etf] = csv_data[etf] df = df.sort_index().dropna() return df3. 分散ポートフォリオ指数をDataFrameに追加する関数
def make_port_df(df): #リターン算出 rtn = (df / df.shift(1) -1).fillna(0) #各比率のポートフォリオデータを作成 for w in [9, 8, 7, 6, 5, 4, 3, 2, 1]: rtn['SPXL'+str(w)+' : TMF'+str(10-w)] =rtn['SPXL']*(w/10) + rtn['TMF']*(1-w/10) rtn += 1 df = rtn.cumprod() return df4. リスクリターンマップを作成する関数
def rr_map(df): #月次リターン算出 dfm = df.resample('M').ffill() m_rtn = (dfm / dfm.shift(1) -1).dropna() #リスク算出 std = (m_rtn.std())*(12**0.5) #年率リターン算出 cum = m_rtn+1 a_rtn = (cum.product())**(12/len(m_rtn))-1 #リスクリターンマップ作成 plt.figure(figsize=(6, 6)) for asset in list(a_rtn.index): plt.scatter(x = std[asset], y = a_rtn[asset],label = asset) plt.xlabel('Risk') plt.ylabel('Return') plt.xlim(0,std.max()*1.1) plt.ylim(0,a_rtn.max()*1.1) plt.legend(loc = 'best') plt.title('Risk Return Map') plt.savefig('rr_map.png',bbox_inches="tight")4. 上記関数を実行する
etfs = ['SPXL','TMF','VTI'] df = make_df(etfs) df = make_port_df(df) rr_map(df)↓このグラフが表示される。
5. まとめ
SPXLとTMFをだいたい半分ずつ持つことで、リスクリターン特性がVTIより優れたポートフォリオになりそうです(投資は自己責任でおねがいします)。
6.次の課題
- 複数資産の分散ポートフォリオ

- 投稿日:2020-04-21T17:36:33+09:00
Pythonで毎日AtCoder #43
はじめに
#43
考えたこと
コンテスト中に解けませんでした。この問題が難しいのはルンルン数を生成するコードを書けないからだと思います。私も書けませんでした。解説によると、10と9で割った余りに着目するようです。$x$を10で割った余りが0の時は一の位は0になり、生成可能なルンルン数は減ります。同様に$x$を9で割った余りが0の時も生成可能なルンルン数は減ります。なぜなら、一の位が0のとき隣合う数の差が1になるようなルンルン数は0、1しかありません。9のときも8、9しかありません。
それぞれどういったルンルン数を生成するかを整理すると、x != 0 mod(10) → 10x+(x%10)-1 x != 9 mod(10) → 10x+(x%10)+1となります。これを実装すると
from collections import deque k = int(input()) lun = deque([]) for i in range(1,10): lun.append(i) for i in range(k): x = lun.popleft() if x % 10 != 0: lun.append(10*x+(x%10)-1) lun.append(10*x+x%10) if x % 10 != 9: lun.append(10*x+(x%10)+1) print(x)データの両端にしかアクセスしないので、dequeを使っています
まとめ
本番に解きたかった。余りを使った計算が苦手なので整数問題周りを練習します。ではまた。
- 投稿日:2020-04-21T17:18:47+09:00
N cross法
N-cross法
ILRMAによる、音声を対象としたブラインド音源分離(BASS)を適応した際、音声が完全分離(対象としていない話者の音声をゼロにする)ではなく抑制された分離となってしまったので、こういった音声でも{VAD}できるように考案した手法です。N-cross法という名前は私が適当に付けた名前なので、検索しても多分参考文献は出てこないと思います。
概要
音声の発話区間検出(voice activity detection: VAD)に用いられるゼロ交差法という手法が有りますがこれは耐騒音に弱いので、一般的には混合ガウス分布モデル (Gaussian mixture model; GMM) に基づくフレーム単位の音声・非音声識別に基づく区間検出が行われています。しかし今回のILRMAにより分離された音源では目的としない音声に対して音圧レベルの抑制は可能ではありますが完全にゼロにはできないので、GMMによる手法では必要のない部分の音声まで発話区間として扱ってしまいます。そこで背景に音声が存在していても目的とする音声を検出できる方法を実装しました。今回この手法を 「N-cross法」 と呼ぶことにします。この手法は今回のような使い方だけではなく、例えばカフェでの商談など外部の音声が混入しやすい状況であったり、音源にBGMが入ってしまった時などにも使えると思います。
理論
理論としては単純で、ゼロ交差法では音声波形に対してY=0のラインでの交差頻度が高い区間を発話区間として検出しますが、この方法では小さな音声でも検出されてしまうので、N-cross法では任意のY=Nの値での交差点を利用します。このNの値をN-cross Lineあるいは感度と呼ぶことにします。
実装
Pythonで実装しました。ColabとかJupyterで動かしてください。
以下の
Ncross()では、モノラル音源dataを入力すると、音源の最大音圧を1とした時にN(=0〜1)以下の音圧の音声をVAD対象として見なさず、音声データをhop_lengthごとに分けてそれぞれ対象の発話区間であると検出すれば「1」、そうでなければ「0」とする時間軸リストを返します。また、対象区間を音声区間であると見なす域値をパラメータmで与えます。小さくすればするほど厳しく、大きくするほどノイズなども拾うようになります。そしてさらに下に書いた
kukan()では、Ncross()で得られた時間軸リストN_cross_listを使って、実際の音声から話始めの時間インデックスと、話終わりの時間インデックスをそれぞれ格納するリストを返します。パラメータについてですが、N_cross_listでは発話区間を「1」、沈黙区間を「0」で与えているので、この値をnumで与えてやれば任意の区間の時間インデックスを得ることができます。次にMですが、会話では話してる最中であっても「ひと息」入れることがあると思います。この沈黙を挟んだ発話において、何秒沈黙をおいても一続きの会話とみなすかを決める値になっています。今回ではM=200と設定しているので、実際の時間ではサンプリング周波数が44000ですので、M * hop_length / SampleRate = 2.32...と、大体2秒程度の沈黙があれば発話区間の途切れとして見做しています。また、入力パラメータには入れてませんが、chouseiは検出された発話区間に余裕を持たせるパラメータです。ここではchousei=30としているのでchousei * hop_length / SampleRate = 0.348...秒のゆとりを持って発話区間と見做しています。なぜこんなことをしているかというと、会話はじめの摩擦音や破裂音が音声として検出されないことが多発しているので与えています。Ncross.py#N-クロス法 #無声区間で0,有声区間で1の時間軸リストを返します def Ncross(data,N,m,hop_length): """ N-クロス法 無声区間で1,有声区間で0の時間軸リストを返します ''' data : Sound N : 域値(0~1) m : ゼロクロス法でいいうところの域値 hop_length : フレームで切り出す回数 """ y=data/np.max(np.abs(data)) # フレームで切り出す回数 nms = ((y.shape[0])//hop_length)+1 # 最初と最後をフレームで切り出せるようにゼロパディング y_bf = np.zeros(hop_length*2) y_af = np.zeros(hop_length*2) y_concat = np.concatenate([y_bf, y, y_af]) zero_cross_list = [] for j in range(nms): zero_cross = 0 # フレームによる切り出し y_this = y_concat[j*512:j*512+2048] for i in range(y_this.shape[0]-1): # もし正負が変わったらという条件 if (np.sign(y_this[i]-N) - np.sign(y_this[i+1]-N))!=0: zero_cross += 1 zero_cross_list.append(zero_cross) # 最大値が1になるように正規化 zero_cross_list = np.array(zero_cross_list)/max(zero_cross_list) # 閾値は0.4に設定(ヒューリスティックですが…) zero_cross_list = (zero_cross_list<m)*1 return zero_cross_list hop_length = 2**9 cross_list = [] for i in range(N_person): N_cross_list= Ncross(sep[:, -(i+1)],0.3,0.2,hop_length) cross_list.append(N_cross_list) N_cross_list1 = cross_list[0] N_cross_list2 = cross_list[1] for i in range(N_person): plt.plot(sep[:, -(i+1)]) plt.show()separation.pynum = 2 M = 200 chousei = 30 def kukan(N_cross_list,num,M): A = N_cross_list A_index = np.where(A == num)[0] startlist = [A_index[0]] endlist = [] for i in range(len(A_index)-1): dif = A_index[i+1]-A_index[i] if dif > M: endlist.append(A_index[i]) startlist.append(A_index[i+1]) endlist.append(A_index[-1]) return startlist,endlist for i in range(N_person): startpoint,endpoint = kukan(cross_list[i],num=0,M=M) print("start point",startpoint) print("end point",endpoint) for n in range(len(startpoint)): target = sep[:, -(i+1)] audio=target[hop_length*(startpoint[n]-chousei):hop_length*(endpoint[n]+chousei)] display(Audio(audio, rate=RATE))


- 投稿日:2020-04-21T17:05:12+09:00
サンプリングによるクラスタリング実験
移行記事その3。
今回は簡単な実験。コードのメモ書き。
サンプリングによるクラスタの推定
EM アルゴリズムは解くべき方程式がモデルによって変わるため、使い勝手が悪い(と個人的に思う)。そのため、モデルから直接サンプリングして得ることを考える。ここでは pymc3 を使ってサンプリングを行う。
学習データ
サンプリング対象のデータは以下で生成した。
N=1000 X, y = datasets.make_blobs(n_samples=N, random_state=8) transformation = [[0.6, -0.6], [-0.4, 0.8]] X_aniso = np.dot(X, transformation) df = pd.DataFrame() df['x'] = X_aniso.T[0] df['y'] = X_aniso.T[1] df['c'] = yまた、学習データをプロットすると以下のようになる。目視でもクラスタが3つあることがわかる。
plt.figure(figsize=(10, 10)) sns.scatterplot(x='x', y='y', data=df, hue='c') plt.show()
モデル
観測データを $x$、クラスタを $z$、パラメータを $\theta_z$ とする。これらは以下のように生成されているとする。
\displaystyle{ \begin{aligned} x_i &\sim N(x|, \mu_{z_i}, I)\\ \mu_k &\sim N(\mu_k| 0, I)\\ z_i &\sim Cat(z_i|\pi)\\ \pi &\sim Dir(\pi|\alpha) \end{aligned} }これをプログラムで書くと以下のようになった。ライブラリは pymc3 を使用した。なお、データを眺めたらクラスタ数が3と明らかだったので、ここではクラスタ数3でサンプリングを行った。
k=3 data_dim = len(df.T) -1 data_size = len(data) with pm.Model() as model: pi = pm.Dirichlet('p', a=np.ones(k), shape=k) pi_min_potential = pm.Potential('pi_min_potential', tt.switch(tt.min(pi) < .1, -np.inf, 0)) z = pm.Categorical('z', p=pi, shape=data_size) mus = pm.MvNormal('mus', mu=np.zeros(data_dim), cov=np.eye(data_dim), shape=(k, data_dim)) y = pm.MvNormal('obs', mu=mus[z], cov=np.eye(data_dim), observed=df.drop(columns='c').to_numpy()) tr = pm.sample(10*data_size, random_seed=0, chains=1)また、得られたサンプリング結果のうち、クラスタは最頻値を使用する。
df['pred'] = scipy.stats.mode(tr['z'], axis=0).mode[0]結果
結果を以下のコードを使ってプロットをする。良い感じにクラスタリングされていることがわかる。
plt.figure(figsize=(10, 10)) sns.scatterplot(x='x', y='y', data=df, hue='pred') plt.show()
その他コメント
- 正規分布を使用しているので、複雑なクラスタリング (e.g. 二重のリング) などは不可能
- colab で上の pymc3 のコードを回すととにかく重い
参考
- Pythonによるベイズ統計モデリング: PyMCでのデータ分析実践ガイド
- https://pymc3.readthedocs.io/en/latest/notebooks/gaussian_mixture_model.html


- 投稿日:2020-04-21T16:56:09+09:00
pythonで簡単にlineでメッセージを送る方法
初めましてamzonと言うものです
今回は、pythonでlineでメッセージを送信する方法をご紹介します
まず
py
pip install Nectrlline
コマンドプロクトまたは、端末に入力しましょう
次は、tokenの取得です
https://notify-bot.line.me/ja/
こちらでログインし
ここでtokenを発行し指示に従いましょう
次にソースを書いていきましょう
py
from line import tokenline
from line import line
tokenline("トークン")
line("送信メッセージ")
こんな感じにして
保存
実行すると送信されてるはずです
されていない場合は、
botが、グループに入ってるか確認してください(1対1の設定は、パス)
上のパッケージをインストールしたときにインストールされるはずの前提パッケージがインストールされていないかもしれません
py:コマンドプロンクト
pip install requests
を実行して再挑戦してみましょう
これでダメだったら他の記事を参考にしてみてください
それではまた会いましょう

- 投稿日:2020-04-21T16:54:49+09:00
import を楽になる
新たなスクリプトを書く時、毎回importを書くか?前のコードをコピペするか。内容は難しくないが、時間がかかります。
pyforestを使うと、importを書く作業が楽にする。
例:
何もimportしなくでも、pandaを使えます。インストール
(Python3.6以上が必要)
pip install pyforest使い方
from pyforest import *一行を書くのみで、登録済のライブラリーを使えます。
JupyterやIPythonを使えば、pyforestがそれ自体を自動起動に追加するので、上記の一行も必要ない。
スクリプトが完成すると、下記コマンドでスクリプトが関わっている全てのライブラリーを見ることができる。
active_imports ()スクリプトが使用したライブラリーしかimportしないので、スクリプトが重くならないはず。
新たなライブラリー追加
pyforestは主流のデータサイエンスライブラリをサポートしている。例えば、pandas、numpy、matplotlib、seaborn、sklearn、tensorflowなどがある。(詳細はpyforest/_imports.pyを参照)
新規ライブラリーを追加時、user_specific_imports.pyファイに、一行を追記すればよい。
user_specific_imports.pyTEMPLATE_TEXT = """# Add your imports here, line by line # e.g # import pandas as pd # from pathlib import Path # import re """目次 非IT業種のITメモ


- 投稿日:2020-04-21T16:44:06+09:00
【Python】Atcoderの過去精鋭問題10問を解く
背景
入社試験のプログラミングテスト対策のために、勉強しようと思った。そこで、日本語で多くの解説が載っているサイトとして、AtCoderがあったため勉強する。
目的
プログラミングテストの対策のために勉強する
はじめに
プログラミングテストを受ける上で、多くの解説があるサイトが、自分の勉強につながると思った。
そのため、日本語のコミュニティで、プログラミングテストを多く実施している所を探していたところ、AtCoderがあったため、勉強している。要件定義
- AtCoder Beginners Selectionをとく
- 関連問題をとく
- LeetCode60問をとく
環境
- Windows10Pro
- Python3.7
- Anaconda
やった結果
第1問: ABC 086 A - Product
a,b=map(int,input().split()) if a*b%2==0: print('Even') else : print('Odd')第2問: ABC 081 A - Placing Marbles
s=input() count=0 for i in s: # print(i) if int(i)==1: count+=1 # print(count) print(count)別解1
シンプルだし、こっちの方が好きです。
04/19の時にcountを使ったら、RunTimeErrorで失敗したので、最初の回答を使うのがおすすめです。
Python
print(input().count('1'))
別解2
数学力が試される導き方
あんまりおすすめじゃないです。
数学が得意な人は、好きな書き方かも。
```Python
print(int(input())%9)## 第3問: [ABC 081 B - Shift Only](https://atcoder.jp/contests/abc081/tasks/abc081_b) ```Python N = int(input()) A = map(int, input().split()) count = 0 while all(a % 2 == 0 for a in A): A = [a / 2 for a in A] count += 1 print(count)第4問: ABC 087 B - Coins
A=int(input()) B=int(input()) C=int(input()) X=int(input()) count=0 for a in range(A+1): for b in range(B+1): for c in range(C+1): if X==500*a+100*b+50*c: count+=1 print(count)第5問: ABC 083 B - Some Sums
mapを使うと便利に仕分けをすることが出来るということを知った。
初めて使った。
```Python
N = int(input())
A = int(input())
B = int(input())
N,A,B=map(int,input().split())def FindSumOfDigits(num):
count = 0
while num > 0:
count += num % 10
# ここが違う一つ/が足りない
num=num // 10return countfor n in range(1, N+1):
count = FindSumOfDigits(n)
if A<= count <=B:
ans += nprint(ans)
```第6問: ABC 088 B - Card Game for Two
N=int(input()) A=list(map(int,input().split())) A.sort(reverse=True) Alice=Bob=0 for i in range(N): if i%2==0: Alice+=A[i] else: Bob+=A[i] print(Alice-Bob)第7問: ABC 085 B - Kagami Mochi
N=int(input()) d=[input() for _ in range(N)] print(len(set(d)))第8問: ABC 085 C - Otoshidama
連立方程式などを解くという数学的な技能を使う問題だった。
```Python
N, Y = map(int, input().split())res10000 = res5000 = res1000 = -1
for a in range(N + 1):
for b in range(N + 1 - a):
c = N - a - b
if Y == 10000 * a + 5000 * b + 1000 * c:
res10000 = a
res5000 = b
res1000 = cprint(a, b, c)
```第9問: ABC 049 C - Daydream
s = input().replace("eraser","").replace("erase","").replace("dreamer","").replace("dream","") # if文の書き換え # print('NO' if s else 'YES') if s: print("NO") else: print("YES")後ろから、検索していって、消していくという考え方
```Python
def main():
S = input()while len(S) >= 5: if len(S) >= 7 and S[-7:] == "dreamer": S = S[:-7] continue if len(S) >= 6 and S[-6:] == "eraser": S = S[:-6] continue elif S[-5:] == "dream" or S[-5:] == "erase": S = S[:-5] continue else: break if len(S) == 0: print("YES") else: print("NO")main()
```第10問: ABC 086 C - Traveling
数学的な解き方
```Python
n=int(input())
for i in range(n):
t,x,y=map(int,input().split())
if (x+y) > t or (x+y+t)%2:
print('No')
exit()print('Yes')
```別解1 王道な解き方
N = int(input()) t = [0] * (N+1) x = [0] * (N+1) y = [0] * (N+1) for i in range(N): t[i+1], x[i+1], y[i+1] = map(int, input().split()) f = True for i in range(N): dt = t[i+1] - t[i] dist = abs(x[i+1]-x[i]) + abs(y[i+1]-y[i]) if dt < dist: f = False if dist%2 != dt%2: f = False print('Yes' if f else 'No')import sys def main(): N = int(input()) t, x, y = 0, 0, 0 for _ in range(N): next_t, next_x, next_y = [int(__) for __ in input().split()] delta_t = next_t - t distance = abs(next_x - x) + abs(next_y - y) if distance > delta_t: print("No") sys.exit() if (delta_t - distance) % 2 != 0: print("No") sys.exit() t, x, y = next_t, next_x, next_y print("Yes") main()感想
数学的な解き方は、学校で数学をがっつりやって法則性を見つけるのが、苦ではない人が挑戦してみてもいかなと思った。
数学的に解くのは、競技プログラミングに思考がよりすぎる気がしたので、あんまり使わない気がする。出来るようになったこと
- AtCoderの基本的な考えが身についた
- 難解な問題文から意訳する力 # 課題
- 参考リンクから似た問題を解いてみる
- LeetCodeにも挑戦する # 参考文献
- AtCoder Beginners Selection をPythonで解く
- Atcoderの過去問精選10問をpythonで解いてみた!
- AtCoder に登録したら次にやること ~ これだけ解けば十分闘える!過去問精選 10 問 ~
- AtCoder に登録したら解くべき精選過去問 10 問を別解で解いてみた
- AtCoder Beginners SelectionをPythonで解いてみた
- 投稿日:2020-04-21T15:48:07+09:00
pipの再インストール
winpython pip使用時のエラー対策で、pipを再インストールした。
pip listpip使用時、下記のエラーがよく出ている。ネットに調べると、"PATHが汚くなってます。"大体書いています。pipを再インストールすると対応できたので、メモします。
Fatal error in launcher: Unable to create process using '""c:\program files\python36\python.exe" "C:\Program Files\Python36\Scripts\pip.exe" '既存pipの削除:
python -m pip uninstall pip下記の参考ページに、get-pip.pyをダウンロードして、python get-pip.pyで実行すると、再インストール完了です。(英語で読みづらいので、「get-pip.py」で検索できます)
python get-pip.py参考(英語):
https://packaging.python.org/tutorials/installing-packages/#use-pip-for-installing目次 非IT業種のITメモ