- 投稿日:2020-03-15T23:59:45+09:00
ざっくりDocker
Dockerをしっかり無理解状態で
docker-composeやKubernetesを学ぼうとしていて結果的にえらい回り道をしている気がしたので、まずはDockerについてざっくりでも理解するために書き残す。※ちなみに
docker-composeやKubernetes、ECSなどは復数のDockerを扱うための技術とのことで、Dockerのメリットを享受できていない内に学ぼうとしても頭に何も残らなかった。。。Dockerに関する記事はたくさんあるので、とりあえず、イメージとコンテナの二つを理解したら何となく使えるようになった。
※Dockerfileの書き方はそのうち追記します
イメージ
コンテナの元。コンテナを使うにはまずイメージがなければいけない。
イメージはダウンロードするか、人からもらうか、自分で作るかで手に入れたりできる。
シンプルなイメージなら公式からダウンロードで取得できるが、会社と同じ環境を自宅で再現したいとかであれば自分で作るか誰かが作ったのをもらうしかない。コンテナ
イメージから作成した別の環境
シンプルに自分のPC環境に別のPC環境を作る技術と理解している。
このおかげでぶっ壊しても平気なのでとにかく色々試せるし、人と共有も簡単にできるんだな〜ってこと。Dockerfile
Dockerfileはイメージを作成するためのファイル。
公式イメージから自分で手を加えて、自分専用のイメージを作成したりできる。コマンド
イメージ関連コマンド
イメージを検索。使いたいOSや言語などを検索すれば大抵の公式イメージが存在するdocker search イメージ名イメージを取得docker pull イメージ名DockerFileからイメージを作成する# イメージ作成基本コマンド。この場合イメージ名はランダムにつけられる docker build (DockerFileのある)パス # イメージ名を独自につける docker build -t 名付けたいイメージ名 (DockerFileのある)パス # イメージ名とタグを独自につける docker build -t 名付けたいイメージ名:タグ (DockerFileのある)パス # 例 docker build -t sample:1 . ・ ・ ・ # 省略 Successfully built 1234abcdefgh ←作成されたイメージID Successfully tagged sample:1 ←イメージ名とタグがつく。オプションつけなければこの表記されない保有するイメージ一覧を確認する$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE sample 1 1234abcdefgh 8 minutes ago 1.97GB # REPOSITORYがイメージ名dockerイメージの作成履歴を確認docker history イメージ名イメージを削除する# 対象を指定する際はイメージ名、イメージ名:タグ、イメージIDのどれかで指定する docker rmi イメージ名 docker rmi イメージ名:タグ docker rmi イメージIDコンテナ関連コマンド
コンテナの中でbashを利用して起動(2つとも同結果のコマンド)docker run -i -t イメージ名 bash docker run -it イメージ名 bash # 作成するコンテナに名前をつける場合 docker run --name 名付けたいコンテナ名 -it イメージ名 bash※
-iはコンテナの標準入力を有効化
※-tはttyを有効化※ ちなみにイメージを見取得で
docker run イメージ名を打つとイメージが存在していれば自動的にpullしてからrun(起動)してくれるコンテナの状態確認# 起動コンテナのみ表示 docker ps # 停止コンテナも含めて表示 docker ps -a # 停止コンテナも含めてコンテナIDのみ表示 docker ps -aqコンテナを起動docker start コンテナ名コンテナを停止docker stop コンテナ名バックグランドで起動しているコンテナに入るdocker attach コンテナ名dockerコンテナを削除docker rm コンテナ名 or コンテナIDdockerコンテナの標準出力のログを確認docker logs コンテナ名 or コンテナID
- 投稿日:2020-03-15T22:04:34+09:00
Node.js (TypeScript) におけるキャッシュの実装方法とその戦略
現代の Web アプリケーションにおいて、キャッシュはもはや不可欠と言っていいくらい需要な技術でしょう。アプリケーションの負荷を軽減し、ユーザーへのレスポンスを高めます。
本記事では Node.js (Typescript) を使用したバックエンド API を実装する際に、どのようなキャッシュのテクニックが使えるか解説します。※なお、説明の簡略化のためエラーハンドリングなどは省略しています。
Node.js を使用した非同期バッチパターンとキャッシュ機構
本章では以下の3つの実装パターンを比較し、Node.js を使用したキャッシュを実装していきます。
- キャッシュのないサンプルアプリケーション
- 非同期バッチ処理パターン
- キャッシュパターン
1. キャッシュのないサンプルアプリケーション
キャッシュの実装をする前に、簡単な Web API で提供されるアプリケーションを考えます。
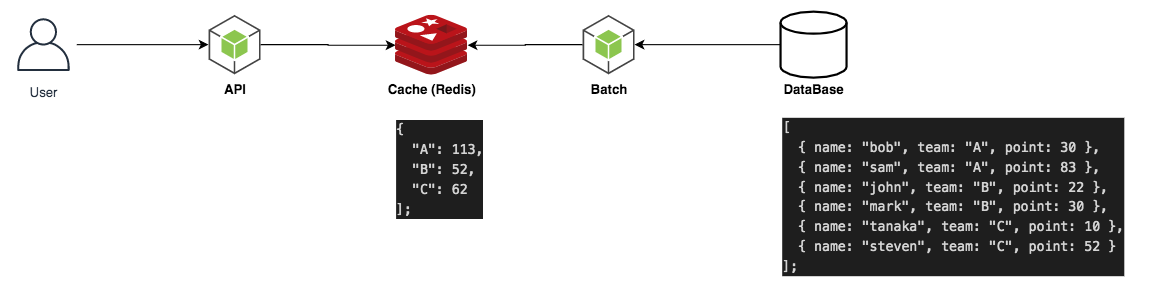
例えば、チーム参加型の競技において個人の点数をチーム毎に集計するような機能を実装するとしましょう。
データベースには以下のように、名前、チーム名,点数が含まれています。
このデータから点数を集計して返却しましょう。data.tsexport const data = [ { name: "bob", team: "A", point: 30 }, { name: "sam", team: "A", point: 83 }, { name: "john", team: "B", point: 22 }, { name: "mark", team: "B", point: 30 }, { name: "tanaka", team: "C", point: 10 }, { name: "steven", team: "C", point: 52 } ];このアプリケーションはクエリパラメータにチーム名を指定すると、そのチームの合計点数を返却します。
app.tsimport * as http from "http"; import * as url from "url"; import totalScore from "./totalScore"; http .createServer(async (req, res) => { const query = url.parse(req.url, true).query; const sum = await totalScore(query.team); res.writeHead(200); res.end(`チーム${query.team}の合計点数は${sum}です。\n`); }) .listen(8080, () => { console.log("server is now listening htttp://localhost:8080"); });キャッシュの効果を体感するために、わざと合計する処理に時間がかかるようにしておきます。今回は簡単な機能を実装していますが、実際の世界では複雑な計算をすることが多いでしょう。サーバサイドの処理で 5 秒かかってしまうアプリケーションは正直使い物になりませんね。キャッシュの仕組みを理解するには十分な題材です。
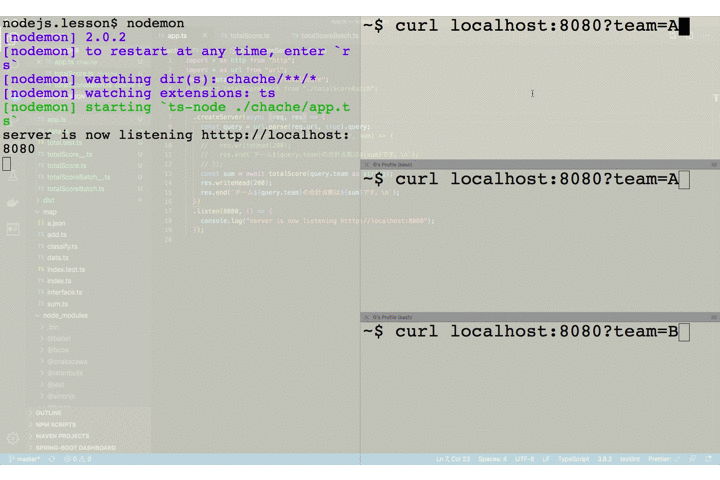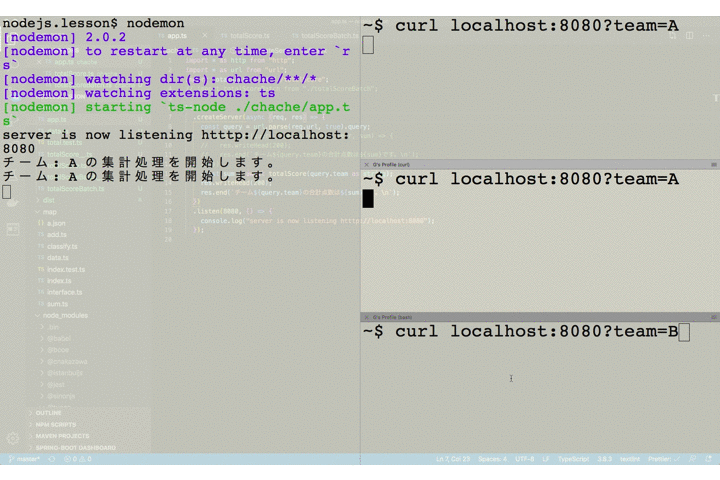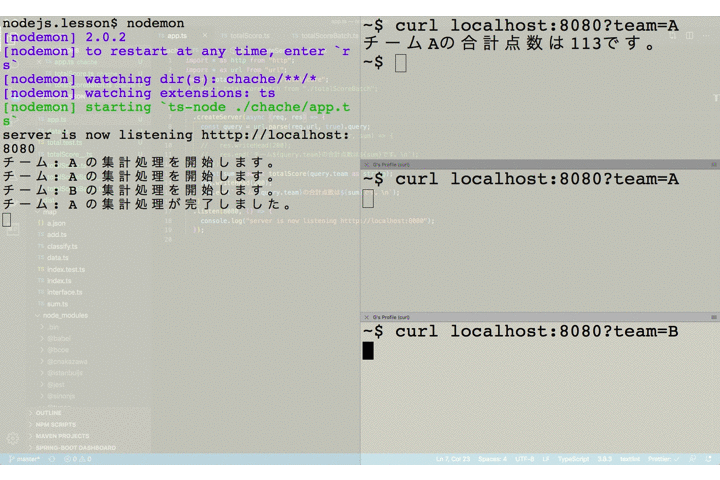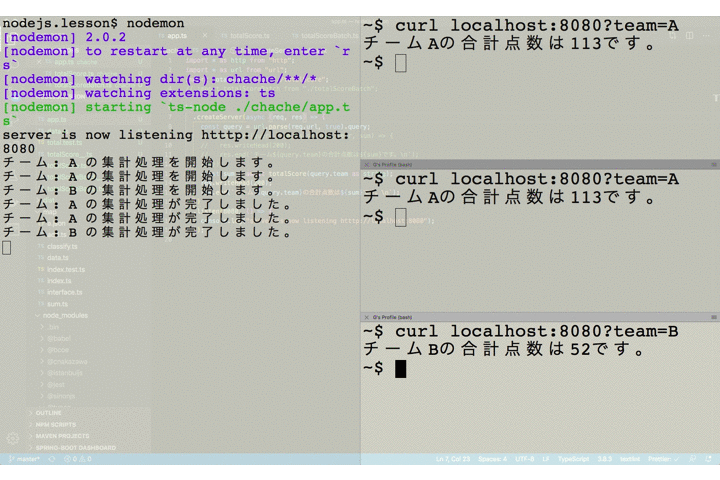
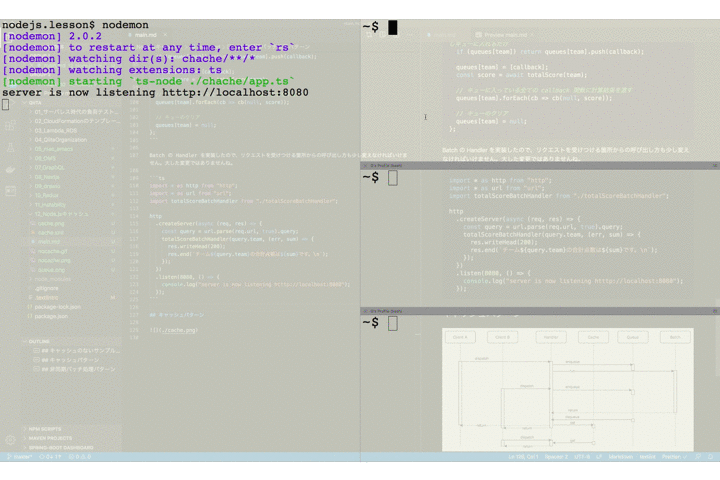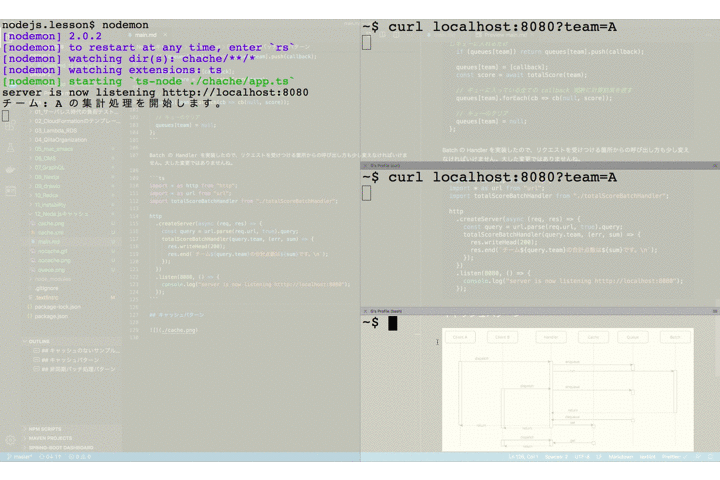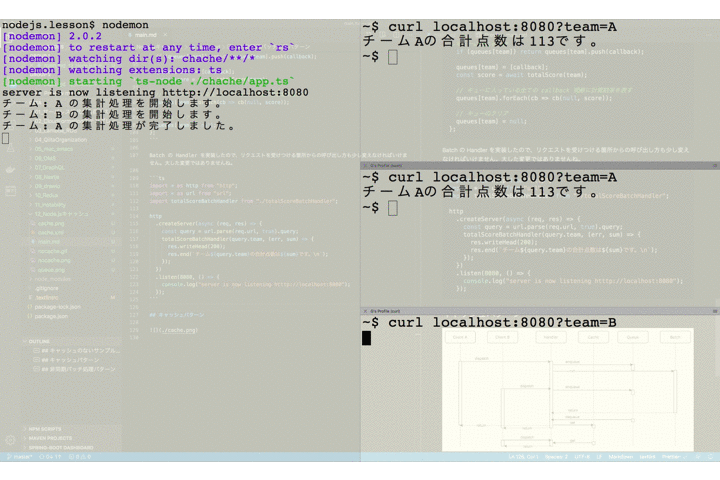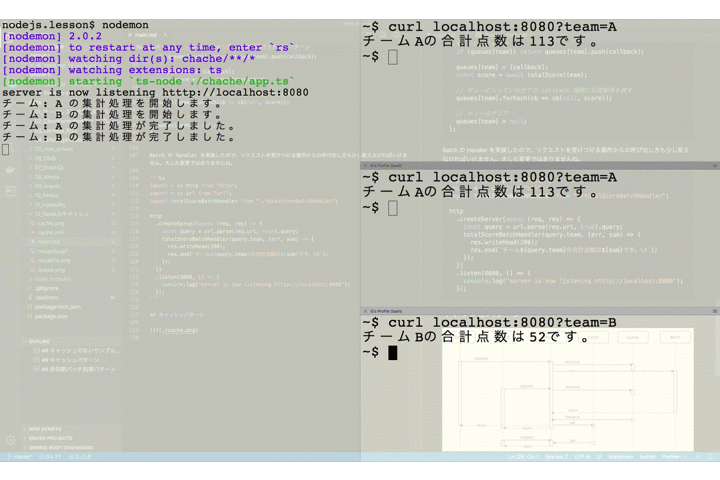
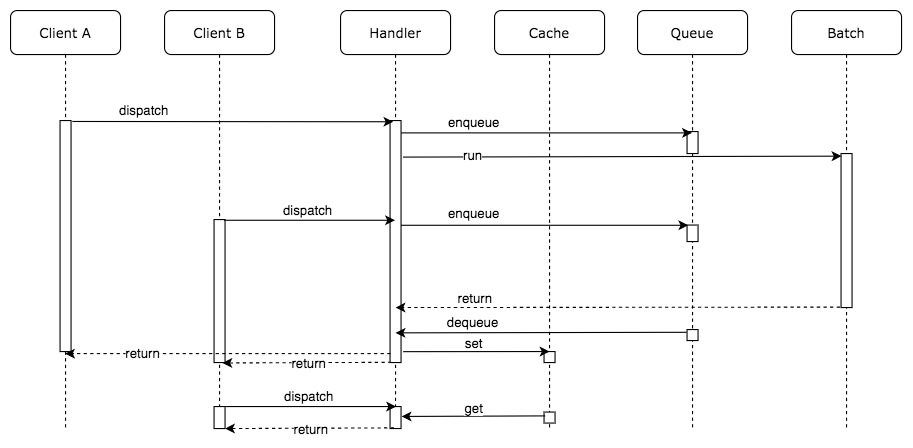
totalScore.tsimport { data } from "./data"; const sleep = msec => new Promise(resolve => setTimeout(resolve, msec)); const total = (team: string) => { let sum = 0; for (const item of data) { if (item.team === team) sum += item.point; } return sum; }; export default (team: string): Promise<number> => { return new Promise(async (resolve, reject) => { console.log(`チーム: ${team} の集計処理を開始します。`); const sum = total(team); // 無理やり時間がかかる処理に偽装する await sleep(5000); console.log(`チーム: ${team} の集計処理が完了しました。`); resolve(sum); }); };それでは実際に動作を確認してみましょう。以下では、3つのクライアントがサーバに対してリクエストを送っています。それぞれ独立して処理が実行されていることが確認できます。
さて、ここまでの処理の流れを整理しておきましょう。複数のクライアントからの処理はそれぞれ独立して実行されています。つまりクライアント A からのリクエストもクライアント B からのリクエストも同様に 5 秒ずつかかっているのです。
2. 非同期バッチ処理パターン
それではキャッシュを導入する前に、まずは Node.js 特有の非同期処理に目をつけて非同期バッチパターンを実装してみましょう。
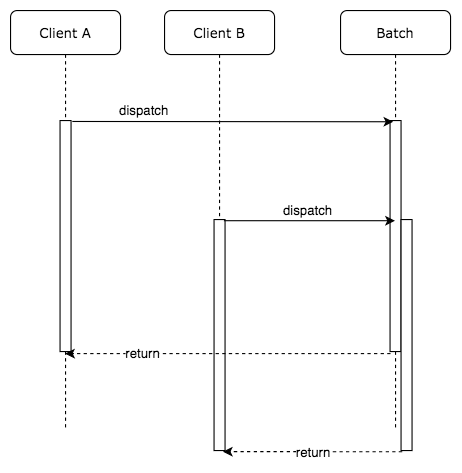
同じ API に対して複数の非同期処理の呼び出しがある場合、呼び出される処理をバッチ処理としてしまおうという発想です。非同期処理が終わらないうちにもう一度同じ非同期処理を呼び出すなら、新しいリクエストを作成するのではなく、すでに実行中のバッチの処理結果を返すような仕組みです。
処理の流れは以下のようになります。
この方法は極めてシンプルでありながら、アプリケーションの負荷を抑えつつキャッシュ機構を使う必要がありません。さて、実際に実装の流れを確認していきましょう。まずは Batch を呼び出す Handler の実装方法を考えます。
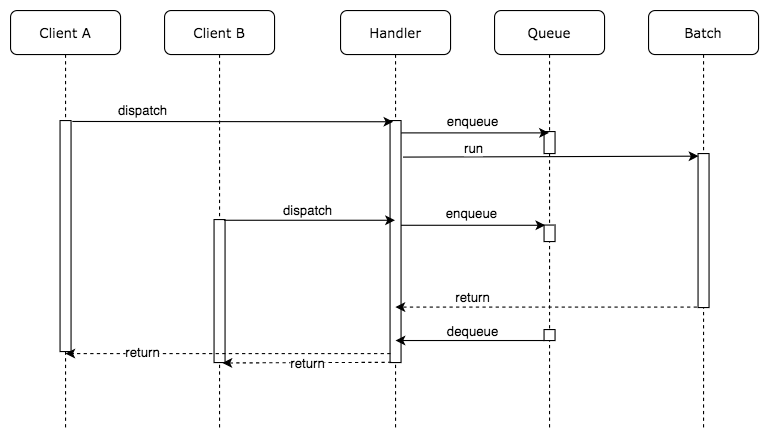
API が呼び出された時に、すでに実行中の処理があれば、コールバック関数をキューに追加します。このコールバック関数はチームの点数の集計結果を返します。非同期処理が完了した時点で、キューに保存された全てのコールバック関数を呼び出します。この結果、同じリクエストを送ってきた全てのクライアントに対して一斉にレスポンスを返却できます。
totalScoreBatchHandler.tsimport totalScore from "./totalScore"; const queues = {}; export default async (team: string, callback) => { // 他のリクエストによってすでにキューに入っている場合は、自身のリクエストも同じキューに入れるだけ if (queues[team]) return queues[team].push(callback); queues[team] = [callback]; const score = await totalScore(team); // キューに入っている全ての callback 関数に計算結果を渡す queues[team].forEach(cb => cb(null, score)); // キューのクリア queues[team] = null; };Batch の Handler を実装したので、リクエストを受けつける箇所からの呼び出し方も少し変えなければいけません。大した変更ではありませんね。
app.tsimport * as http from "http"; import * as url from "url"; import totalScoreBatchHandler from "./totalScoreBatchHandler"; http .createServer(async (req, res) => { const query = url.parse(req.url, true).query; totalScoreBatchHandler(query.team, (err, sum) => { res.writeHead(200); res.end(`チーム${query.team}の合計点数は${sum}です。\n`); }); }) .listen(8080, () => { console.log("server is now listening htttp://localhost:8080"); });アプリケーションの振る舞いを確認してみましょう。ここで、2つのクライアントはチーム A をクエリパラメータに指定し、1つのクライアントはチーム B をクエリパラメータに指定していることに注目して下さい。
チーム A を指定したリクエストが送られたあとで、2番目のクライアントが同じくチーム A を指定してリクエストを送っています。サーバのログには集計バッチ処理の開始と終了を出力するようにしていますが、チーム A の集計処理開始のログは1つしか出ていません。これは2番目のリクエストによる新たなバッチは起動されず、キューにコールバック関数が保存されるだけとなっているためです。
そして、1、2 番目のリクエストは(ほぼ)同時に 2 つのクライアントにレスポンスが返却されています。
3. キャッシュパターン
さあ、キャッシュを導入していきましょう。非同期バッチ処理パターンだけでも強力なテクニックでしたが、キャッシュを導入することでよりアプリケーションの負荷を減らし、スループットを向上させます。
非同期バッチ処理パターンよりも考え方は簡単かもしれません。処理が終わったものをキャッシュに有効期限つきで保存するだけです。
先ほどの Handler にキャッシュの機構を足していきます。集計処理が終わったら結果を一意なキー付きで Cache に格納します。一意となるキーは今回の場合、チーム名とします。キャッシュの保持期間は 10 秒とし、保持期間のうちに再度同じパラメータのリクエストがあった場合は Cache から値を取得してクライアントに返却します。
実際のユースケースではアプリケーションサーバはスケールアウトし、複数のプロセスに分散していることが一般的です。その場合は永続化する共有領域を Redis や memcached などに持たせることが好まれます。今回は説明を簡単にするため、グローバル変数にキャッシュを持つことにします。
totalScoreBatchHandler.tsimport totalScore from "./totalScore"; const queues = {}; const cache = {}; export default async (team: string, callback) => { if (cache[team]) { console.log(`キャッシュ ${team}: ${cache[team]} にヒットしました。`); return process.nextTick(callback.bind(null, null, cache[team])); } // 他のリクエストによってすでにキューに入っている場合は、自身のリクエストも同じキューに入れるだけ if (queues[team]) return queues[team].push(callback); queues[team] = [callback]; const score = await totalScore(team); // キューに入っている全ての callback 関数に計算結果を渡す queues[team].forEach(cb => cb(null, score)); // キューのクリア queues[team] = null; // キャッシュの保存 cache[team] = score; // キャッシュの削除予約 scheduleRemoveCache(team); }; function scheduleRemoveCache(team: string) { function delteCache(team) { console.log(`キャッシュ ${team}: ${cache[team]} を削除します`); delete cache[team]; } // 10 秒したらキャッシュを削除 setTimeout(() => delteCache(team), 10 * 1000); }実行してみると、その効果を体感できます。非同期バッチ処理パターンはそのまま保っています。さらに処理結果をキャッシュに保存することで、キャッシュの保持期間(10 秒間)は即座にレスポンスを返却できていることがわかります。また、実際に合計値計算を行わないためアプリケーションの負荷も下がることが期待されます。
それぞれの手法を評価する
最後に3つの実装方法でどの程度パフォーマンスに差が出るのか確認してみましょう。
検証には artillery を使用します。秒間 100 リクエストが 10 秒間、合計 1000 リクエスト発生するように負荷をかけていきます。
$ artillery quick -d 10 -r 100 -o cache.json http://localhost:8080/?team=A結果は以下のようになりました。
No バッチ処理 キャッシュ RPS 最小(ms) 最大(ms) 平均(ms) 1 なし なし 66.8 5003.6 5029.1 5006 2 あり なし 90.5 345.2 5340.8 2955.1 3 あり あり 95.6 3.1 5021.9 325.8
テスト結果の詳細結果(クリックして開く)
1. キャッシュのないサンプルアプリケーション
All virtual users finished Summary report @ 22:49:31(+0900) 2020-03-14 Scenarios launched: 1000 Scenarios completed: 974 Requests completed: 974 RPS sent: 66.8 Request latency: min: 5003.6 max: 5029.1 median: 5006 p95: 5009.5 p99: 5017.5 Scenario counts: 0: 1000 (100%) Codes: 200: 974 Errors: ENOTFOUND: 262. 非同期バッチ処理パターン
Summary report @ 22:51:21(+0900) 2020-03-14 Scenarios launched: 1000 Scenarios completed: 975 Requests completed: 975 RPS sent: 90.5 Request latency: min: 345.2 max: 5340.8 median: 2955.1 p95: 4904.8 p99: 5027.1 Scenario counts: 0: 1000 (100%) Codes: 200: 975 Errors: EMFILE: 15 ENOTFOUND: 103. キャッシュパターン
Summary report @ 22:53:23(+0900) 2020-03-14 Scenarios launched: 1000 Scenarios completed: 974 Requests completed: 974 RPS sent: 95.6 Request latency: min: 3.1 max: 5021.9 median: 325.8 p95: 4610.3 p99: 4988.9 Scenario counts: 0: 1000 (100%) Codes: 200: 974 Errors: ENOTFOUND: 26想定通り、キャッシュがあるの場合は最小数 ms でレスポンスを返却できています。あたりまえの話ですが、どの手法を使っても最大(ms)は 5 秒から変わりません。いくらキャッシュを使用しても、本来時間がかかる処理時間は減らないのです。キャッシュがない状態で受けたリクエストに対してはどうしても計算時間がかかってしまいます。ではこの課題に対する解決策はどのように考えたらよいでしょうか?
答えはいくつか考えられます。
本来時間がかかっている処理を見直す
DB からの取得がボトルネックであれば、DB のインデックスや検索条件をチューニングする。
アプリケーションの集計処理が雑なロジックの場合、高速化が見込めないか検討する。別プロセスで実行するバッチ処理に任せる
リクエストを受けてから計算するのではなく、事前に計算しておいた結果をキャッシュ用データストアに保存しておく。
この方式を採用する場合、ほぼ全てのクエリパラメータに対してバッチによる計算処理を実行するため、よほどサーバリソースが豊富に使用できる場合に限られる。また、リクエストの多いクエリパラメータを判定し、優先度をつけてバッチ処理をするなどの複雑な機構が要求される。今回は別プロセスで実行するバッチ処理に任せる方式を実装してみましょう。実行するマシン(あるいはプロセス)が異なるため、グローバル変数にキャッシュを持たせている今の仕組みは使えません。今こそ Redis を使用する時がきました。
Redis を使用して分散システムに対してキャッシュの機構を作る
スケーラブルなバッチ処理を行うために必要な永続化ストレージとして Redis を採用します。今回は Docker 上でオーケストレーションされるインフラを想定して、Redis は Docker コンテナで起動することとします。
$ docker run --name some-redis -d redis -p 6379:6379
起動された Redis に対して、JavaScript からアクセスしましょう。まずはクライアントライブラリをインストールします。
$ npm install redisいままでグローバル変数でキャッシュさせていた部分を Redis に接続するように変更するだけです。コールバック関数を Promise に変換する便利なライブラリ util/promisify を使用しています。コールバック関数で実装されている非同期処理を自分でラップして実装する手間が省けて便利です。
totalScoreBatchHandlerRedis.tsimport totalScore from "./totalScore"; import * as redis from "redis"; import { promisify } from "util"; const client = redis.createClient(); const getAsync = promisify(client.get).bind(client); const setAsync = promisify(client.set).bind(client); const delAsync = promisify(client.del).bind(client); const queues = {}; export default async (team: string, callback) => { const cache = await getAsync(team); if (cache) { console.log(`キャッシュ ${team}: ${cache} にヒットしました。`); return process.nextTick(callback.bind(null, null, cache)); } // 他のリクエストによってすでにキューに入っている場合は、自身のリクエストも同じキューに入れるだけ if (queues[team]) return queues[team].push(callback); queues[team] = [callback]; const score = await totalScore(team); // キューに入っている全ての callback 関数に計算結果を渡す queues[team].forEach(cb => cb(null, score)); // キューのクリア queues[team] = null; // キャッシュの保存; setAsync(team, score); // キャッシュの削除予約; scheduleRemoveCache(team); }; async function scheduleRemoveCache(team: string) { function delteCache(team) { console.log(`キャッシュ ${team} を削除します`); delAsync(team); } setTimeout(async () => delteCache(team), 30 * 1000); }バックエンドで完全に独立したバッチを実行する
さて、これで分散システムにおけるキャッシュ機構の準備が整いました。バックエンドで完全に独立して実行されるバッチを記述しましょう。
ここでは簡単のために node-cron ライブラリを使用して cron 実行することにしています。
サーバの cron によって実現したり、AWS であれば CloudWatch Events 、GCP であれば Cloud Scheduler などを使用すると良いでしょう。スケジューラとバッチ処理を分離することで、バッチ処理するサーバを常に起動することなく必要なときだけ立ち上げる構成を取ることができます。コンピューティング環境には Lambda や CloudFunction などの FaaS を使用しても良いでしょう。totalScoreAllTeam.tsimport totalScoreBatchHandler from "./totalScoreBatchHandlerRedis"; const main = () => { ["A", "B", "C"].forEach(team => { totalScoreBatchHandler(team, (err, sum) => { console.log(`バッチ処理が完了しました。`); console.log(`チーム${team}の合計点数は${sum}です。`); }); }); }; const cron = require("node-cron"); cron.schedule("*/10 * * * * *", () => main());結果は以下のようになりました。完全にバックグラウンドでバッチを独立して実行させることにより、常にキャッシュがある状態でユーザリクエストを受け付けることができるようになりました。実際のユースケースでは今回の例のようにチームが 3 つしかないような理想的な条件ではないでしょう。その場合はリクエストが多く集中するデータを優先的にキャッシュするような機構を考える必要がある場合もあるでしょう。
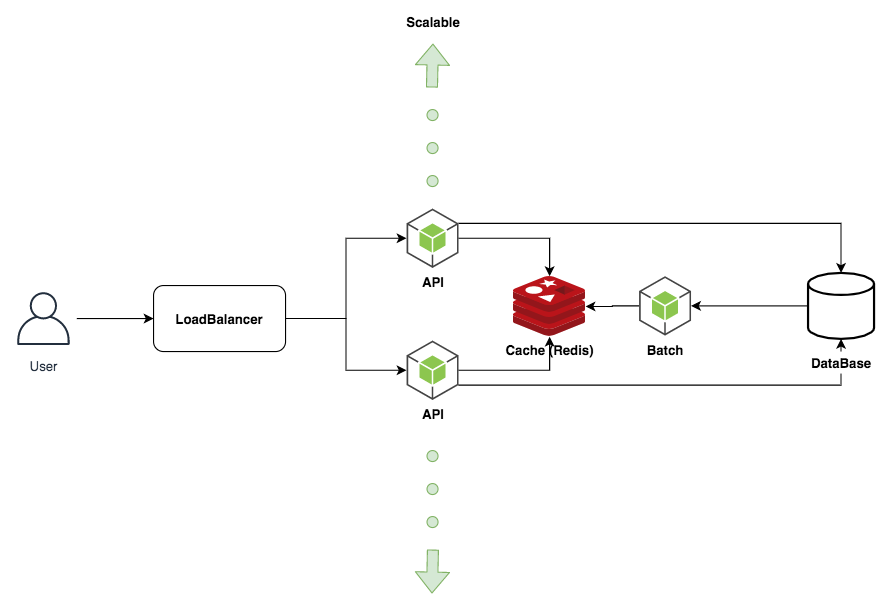
実装方式 RPS 最小(ms) 最大(ms) 平均(ms) 従来のキャッシュ方式 95.6 3.1 5021.9 325.8 完全にバッチを独立させる 95.5 5.7 139.3 9 最終的な構成はこのようになりました。複数のサーバが共有できるキャッシュ用の永続化ストレージを Redis を使用することで実現しました。あとは API サーバへのリクエストを LoadBalarncer によって分散させることでスケーラブルな Web API にできます。
以上が Node.js を使用したキャッシュの基本的な考え方と戦略です。最後に説明したバッチをバックグラウンドで処理する方法は、場合によっては求められる要件に対してオーバーエンジニアリングとなることもあるでしょう。ユーザリクエストが秒間 200~300 程度であれば特に気にする必要はないかもしれませんが、秒間 1000 リクエストを超えたあたりからキャッシュとは真剣に向き合わなければいけません。適切な構成を採用し、サイトのパフォーマンスを上げていきたいですね。


- 投稿日:2020-03-15T18:33:17+09:00
Railsアプリをcloneした後にDocker上で動かすまで
GitHubからソースをcloneした後、Dockerを使った開発環境を構築するまでにやることをまとめます。
Dockerfileやdocker-compose.ymlはすでにあるものとします。git管理外の必要なファイルを作成
database.yml.rspec.envmaster.keynode_modulesなどのファイルを必要に応じて作成
ビルド
Dockerfileを元にDockerイメージを作成します
$ docker-compose buildコンテナを立ち上げる
$ docker-compose up -dデータベースを作成
$ docker-compose exec <サービス名> /bin/bash $ rails db:create $ rails db:migrate $ rails db:seedここでブラウザにアクセスして、表示を確認しましょう。テストが書いてあればテストを走らせる。
DBクライアントアプリでDBに接続
docker-compose.ymlやdatabase.ymlの記述を参考に、データベースとTablePlusやSequelProなどのアプリを接続します。デプロイ周りの環境を構築する
Herokuとの接続や、capistranoを使ったデプロイができるように調整します。
- 投稿日:2020-03-15T18:01:47+09:00
Windows10のDockerでCentOSの遊べる環境を作る
概要
WindowsでDockerを使う。
CentOS7イメージを作成し、インストールやコマンドの練習に使えるようにする。
適宜追記していく。検証環境
- Windows10 Home
- Docker : 19.03.1
Docker系操作
CentOS7のイメージを取得
docker pull centos:7起動
docker run -it -d --name centos7 centos:7コンテナ内コマンドの実行
docker exec -it centos7 /bin/bash
- ユーザ指定で起動
docker exec -it --user <ユーザ名> centos7 /bin/bashイメージの確認
docker imagesイメージの削除
docker rmi <イメージID>コンテナの確認
- 起動中コンテナのみ
docker ps
- 起動中コンテナ以外も
docker ps -aコンテナの削除
docker rm <コンテナID>
- 複数削除
docker rm <コンテナID1> <コンテナID2>
- コンテナ一括削除
docker rm `docker ps -a -q`Linux系操作
ユーザの確認
cat /etc/passwdユーザ追加
useradd -m <ユーザ名>ユーザパスワード設定
passwd <ユーザ名>参考
- 投稿日:2020-03-15T16:43:24+09:00
最強のPySpark用Docker作った
はじめに
PySparkの勉強始めよう!っておもったら結構めんどくさいですよね。
- 正しいJava Versionのインストール(Java8じゃないとだめとか)
- pythonの設定(Python3?2?3.5以上じゃないとだめ??)
- Jupyter notebookで快適に勉強したい
- 当然bigdataに挑戦したくなったらS3やAzureStorageでデータの読み書きしたい。
- ちゃんとした環境変数の設定。(JAVA_HOME? SPARK_HOME? なにそれ?)
全部、まるっとDokcerイメージにしました。
イメージの内容物
baseimage: phusion/baseimage:0.11 (ubuntu 18.04ベース)
openjdk-8-jre
hadoop 3.2.1
spark 2.4.5
Anaconda3-2019.10-Linux-x86_64(python3.7.4)
Jupyter notebook
pixiedust 1.1.18実行方法
まずはローカルで作業用ディレクトリを作成
mkdir sparkstudy cd sparkstudy docker run -v `pwd`:/work -p8888:8888 -it --rm neppysan/pysparkすると、以下の表示が出ます。最後の行の
https://127.0.0.1...をコピペしてブラウザに貼る。To access the notebook, open this file in a browser: file:///root/.local/share/jupyter/runtime/nbserver-6-open.html Or copy and paste one of these URLs: http://2457d17b9863:8888/?token=7a466b3b8d558c34ea7b62ef3b6da95ed83a403d0a210847 or http://127.0.0.1:8888/?token=7a466b3b8d558c34ea7b62ef3b6da95ed83a403d0a210847するとJupyter Notebook ができるので、
workをクリックすると、自分のディレクトリに移動できる。
イメージが5Gぐらいあるので、最初のダウンロードはすこし時間がかかる。Jupyter Notebook
S3やAzureStorageの接続方法のサンプルを書いた。
sample.ipynbを同梱したからみてみて。参考
git にいろいろ詳しく書いた。
https://github.com/ShumpeiWatanabe/pyspark/blob/master/Dockerfile
- 投稿日:2020-03-15T16:11:28+09:00
すぐ使えるsyslogサーバーをPlay with Dockerで作ってみた
検証のためのサーバーをDockerで作りたい
ということでPlay with Dockerで遊んでみました!
●必要なもの
dockerアカウント
ブラウザ(Chrome推奨)●作ったもの
https://hub.docker.com/r/tt15/centos-syslogPlay with Docker操作
https://labs.play-with-docker.com
Play with DockerにDockerアカウントでログイン(Chrome推奨のよう)
+ ADD NEW INSTANCE を押すとDocker環境が立ち上がります
(IPアドレスは自動で振られ、インスタンス同士、インターネットへのpingは可能)
右側の画面でDockerコマンドを打ち、環境を構築していきます。docker.test$ docker pull centos:centos7 centos7: Pulling from library/centos ab5ef0e58194: Pull complete Digest: sha256:4a701376d03f6b39b8c2a8f4a8e499441b0d567f9ab9d58e4991de4472fb813c Status: Downloaded newer image for centos:centos7 docker.io/library/centos:centos7docker pullでDocker Hub上にあるイメージをダウンロードできます。
*メモ
”公開しているユーザー”:”タグと呼ばれるバージョンのようなもの”という感じです。▼▼▼▼▼▼▼▼▼
docker.test$ docker run -it -d --privileged --name centos -p 514:514/udp centos:centos7 /sbin/init 484bc681a2d879c94ecabc8401756fee3828f5d16c9ed8dfffb3937d91506100docker runでpullしたイメージを立ち上げます。ちなみに、docker psで今起動しているイメージが確認できます。
*メモ
-itはttyのため
-dを入れないと次のプロンプトが出てこない
--privilegedはsudo的なもの
--nameでわかりやすい名前をつけておかないとランダムでつけられる
-pでsyslogに使うポートを開けておく
pullしたイメージを引数として
/sbin/initを実行する、これをしないと後で使うsystemctlコマンドが使えなかった▼▼▼▼▼▼▼▼▼
docker.test$ docker exec -it centos /bin/bash [root@484bc681a2d8 /]#docker execでrunしているイメージ上のコマンドを実行できる。
*メモ
-itでttyを使って対話的な処理が可能、ということだと思う。。
/bin/bashでlsとかcatとか打てますよね。
ちなみにCtrl+Cでdocker側に戻れます。CentOS操作
bash.rx[root@484bc681a2d8 /]# yum -y install rsyslog [root@484bc681a2d8 /]# yum -y install net-toolsそれぞれ実行後にドバドバとダウンロードの様子が出ます。
syslogdに必要なパッケージをインストール。
CentOSのネットワーク情報を表示するコマンドのパッケージもインストール。後の動作確認で利用。
あとはrsyslogの設定を最小限して完成です。*メモ
net-toolsは廃止予定らしく非推奨とのこと。代替コマンドのssが使えなかったしnetstatが慣れているので利用しました。rsyslog.conf操作
bash.test[root@484bc681a2d8 /]# vi /etc/rsyslog.confrsyslog.conf# Provides UDP syslog reception $ModLoad imudp $UDPServerRun 514 # Provides TCP syslog reception $ModLoad imtcp $InputTCPServerRun 514rsyslogをインストールしたのでrsyslog.confがあるはず。
全ての設定が#でコメントアウトされているので上の4箇所の部分の#を削除。
vi的にはxでカーソル右隣の文字を削除できます。
保存はexcキーの後、:を押して、wq!を入力。▼▼▼▼▼▼▼▼▼
bash.rx[root@484bc681a2d8 /]# systemctl restart rsyslog [root@484bc681a2d8 /]# netstat -antup Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:514 0.0.0.0:* LISTEN 879/rsyslogd tcp6 0 0 :::514 :::* LISTEN 879/rsyslogd udp 0 0 0.0.0.0:514 0.0.0.0:* 879/rsyslogd udp6 0 0 :::514 :::* 879/rsyslogdrsyslogを再起動すると、変更したrsyslog.confが読み込まれる。
netstat -antupでTCP、UDPの接続状況が表示できる。ポート514でrsyslogが起動していることがわかる。*メモ
-antupは-a,-n,,,それぞれのオプションをくっつけて書いたもの。
-aは全て
-nは数字での表示
-tはTCP
-uはUDP
-pはプロセスIDの表示これでrsyslogの受信側は準備完了!
検証
ここまでと同じ流れでもう1つ+ ADD NEW INSTANCEして、rsyslogを立ち上げる。
送信側を立ち上げる時に違うのはrsyslog.confの設定部分のみ!bash.tx[root@484bc681a2d8 /]# vi /etc/rsyslog.conf *.info;mail.none;authpriv.none;cron.none* @192.168.0.1:514 *.info;mail.none;authpriv.none;cron.none* @@192.168.0.1:514rsyslog.confの一番最後にこの二行を追加。
IPアドレスは実環境のものに変更するのを忘れずに。
あとは、設定後のrestartも!*メモ
@がUDP、@@がTCPって雑だなぁ。。▼▼▼▼▼▼▼▼▼
bash.tx[root@484bc681a2d8 /]# logger test1 test2 test3送信側にて、loggerコマンドでlogを送りつけられるようです。
受信側の/var/log/messagesに送られるので見てみましょう。bash.rx[root@484bc681a2d8 /]# tail /var/log/messages Mar 15 07:05:43 484bc681a2d8 root: test1 Mar 15 07:05:45 484bc681a2d8 root: test2 Mar 15 07:05:46 484bc681a2d8 root: test3tailはテキストファイルの最終行から表示するコマンド。
ちゃんと送れてる!!感想
Play with Dockerを使うと送信側、受信側がサクッと作れるので楽でした!
ブラウザだけで完結するのもありがたい。
4時間が過ぎてもDocker Hub上に作ったイメージをpushしておけばどこからでもdocker pullできます。(docker login, docker tag, docker pushでいけます)
- 投稿日:2020-03-15T15:14:24+09:00
Windows10でのdockerのやり方について
初心者の私がWindows10でdockerを始めた時の備忘録です。
いろいろなサイトを参考にしながら行ったのですが、はまってしまった箇所について備忘録として、残したいと思います。
①WSL2のインストールではまってしまった所
Windowsのバージョンが低かったので、インストールが出来ませんでした。バージョンを最新にしたらできました。自分の場合 Windows10 HOMEなのですが、バージョンを2004にしました。②Dockerではまった所
インストールして、さて始めようかとしましたら、docker-compose upではまりました。つまり、docker-compose upを入力しても、下記のエラーが出て動作しない。
【エラー】
ERROR: Couldn't connect to Docker daemon at http+docker://localunixsocket - is it running?
If it's at a non-standard location, specify the URL with the DOCKER_HOST environment variable.いろいろ調べまして、監理者権限(sudo)で行えば出来るとあったで、行ってみましたが出来ませんでした。同じエラーです。
入力したコマンド → sudo docker-compose up
さらにいろいろ調べて、、、ここにたどりつきまして、 ココ → https://yukituna.com/2201
sudo /etc/init.d/docker start
をしたらできました。つまりdockerが起動していなかったみたいです。「かえるのほんだな」さんありがとうございました。
③ユーザー追加について
補足なのですが、Dockerでのユーザーをグループに登録すればsudoを使わなくてもできるよと、あったのですが、今使っているユーザーは何?どうやって登録するのとなってしまったので、それについてです。今のユーザーは下記のコマンドで知ることができます。
whoami今のユーザーが分からなくても下記のコマンドでユーザーに追加できます。
sudo groupadd docker
sudo usermod -aG docker $USERこれで sudo を付けなくても、compose出来るようになりました。
- 投稿日:2020-03-15T14:48:51+09:00
Win10で"docker-machine"コマンドを使う方法
はじめに
最近docker for Windowsを用いてやっとdockerの勉強を始めたのですが
いろんなサイトを参考にしてると”docker-machine”コマンドをつかって
dockerの停止・起動をされていました。でも、powershellから”docker-machine”コマンドがデフォルトでは使えないので
なんでやねん…!と思い調べて対処した結果をまとめてます。動作環境
OS:Win10Pro(Hyper-V)
docker-machineダウンロード
以下からダウンロードしました。
https://github.com/docker/machine/releases/環境調整
①docker-machine配置
ダウンロードしてきた"docker-machine-Windows-x86_64.exe"を"docker-machine"に
リネームして「C:\Git」に配置。
※配置するフォルダはどこでもよいです。わかりやすいとこで・・もうこの時点でdocker-machineは使えるのですが、いちいちC:\Git\docker-machine.exeと
打つのはめんどくさいので環境変数Pathを指定しておきます。②環境変数指定
Powershellを起動し以下コマンドを実行
$env:Path += ';C:\Git'以下コマンドを実行し、追加されているか確認
PS C:\Users\ユーザ名> $env:Path C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;C:\Windows\System32\OpenSSH\;C:\Program Files\Docker\Docker\resources\bin;C:\ProgramData\DockerDesktop\version-bin;C:\Program Files\Git\cmd;C:\Users\ユーザ名\AppData\Local\Microsoft\WindowsApps;C:\Users\ユーザ名\AppData\Local\GitHubDesktop\bin;C:\GitただこのままだとPowershell再起動すると消えてしまうので以下のファイルを作成する。
C:\Users\ユーザ名\Documents\WindowsPowerShell\Microsoft.PowerShell_profile.ps1ファイルに$env:Path += ';C:\Git'と記入し保存。
これで再起動後にもこのファイルを自動的に読み込み、docker-machineコマンドを楽に使えます。最後に確認としてPowershellからdocker-machine versionを実行してdockerバージョンが表示されることを確認してください。
PS C:\Users\ユーザ名> docker-machine version docker-machine.exe version 0.12.2, build 9371605これでOKです。
参考
https://qiita.com/ohhara_shiojiri/items/98573b074185381d46c8
- 投稿日:2020-03-15T13:59:02+09:00
自然言語処理のためのDocker環境
はじめに
自然言語処理ライブラリが入っていて、起動すれば始められる環境が欲しいのとdockerの勉強を兼ねてコンテナ(nlp-sandbox)を作りました。
nlp-sandboxはこちら
nlp-sandboxの内容
開発環境
- JupyterLab
- vim
ライブラリの使用確認のためのプログラム
- test_sandbox.py
- test_pytorch.py
自然言語処理
可視化
数値計算
データ分析
機械学習
インストール及び起動
nlp-sandboxディレクトリ直下で以下を実行し、image作成
$ docker build -t nlp-sandbox:1.0 .コンテナの起動(以降work直下のデータはホストに保存される)
$ docker run --name sandbox -itd -v $(pwd)/work:/home/work nlp-sandbox:1.0コンテナのシェルに入る
$ docker exec -it sandbox bashコンテナのシェル内でpython実行
$ python3 ./work/test_sandbox.pyコンテナのシェルから出る
$ exitコンテナ及びJupyterLabの起動
$ docker run --name sandbox -itd -p 8888:8888 -v $(pwd)/work:/home/work nlp-sandbox:1.0 jupyter lab --allow-root --ip=0.0.0.0 --no-browser終わりに
自然言語処理ライブラリインストールで依存関係のある物も入れなくてはいけないのでローカル環境を汚さずにプログラミングできるのは素晴らしいです。
今後、pytorchも入れたいです。pytorchはCPUバージョンを入れました。参考
下記記事を参考にさせていただきました。
DockerでPythonの環境構築を行う
Python/NLP/機械学習のためのDocker環境構築
docker 上で Ubuntu に Jupyterlab をインストールして 自分好みの機械学習環境を手に入れる
- 投稿日:2020-03-15T11:40:22+09:00
docker-composeで開発環境全部盛りしてみた
docker-composeで開発環境全部盛りしてみた
開発グループに必要なツールを用意しました。Gitlab、Redmineから始めて少しづつ、利用範囲を広めていった結果、だいぶマシマシになったのでレシピ公開します。
以下の環境下で動作確認済です。
Docker version 19.03.8, build afacb8b
docker-compose version 1.25.4, build 8d51620aこんなツールが構築できる
開発時に使用するツール
- Plantuml
plantuml/plantuml-server
redmineやgitlab内のドキュメントにPlantUMLで記述した図を埋め込むために使用します。- Gitlab
sameersbn/gitlab
公式ではないですがとても人気のあるdocker imageです。- Redmine
sameersbn/redmine
公式ではないですがとても人気のあるdocker imageです。- Jenkins
jenkinsci/blueocean
パイプラインを主としたblueoceanプラグインを使用することでJenkinsおじさんもイケてる見た目になります。
- Nexus3
sonatype/nexus3
mavenやnpmのローカルキャッシュリポジトリにしたり、成果物の配布用の置き場として使用します。運用時のモニタリング
- logstash
docker.elastic.co/logstash/logstash
ログ収集の中間に使用します。- ElasticSearch
docker.elastic.co/elasticsearch/elasticsearch
ログやメトリックスを貯めておきます。- Grafana
grafana/grafana
ElasticSearchのデータの可視化コミュニケーションツール
- RocketChat
rocketchat/rocket.chat
slackクローン(ほぼslackと同じAPI が使用できるのでgitlab,redmine,jenkinsとの連携もできます)- Hubot
rocketchat/hubot-rocketchat
Rocketchatのボットdocker-composeのレシピ全文
ファイル名 .env
docker-compose.yml と同じフォルダに入れておきます。各自の環境に合わせて設定をしてください。
社内サーバーに置いていますのでLDAP やDNS,PROXYなどの設定を入れています。
.env# Common settings DNS1=xxx.xxx.xxx.xxx DNS2=xxx.xxx.xxx.xxx SMTP_DOMAIN=xxx.xxx.xxx.xxx SMTP_HOST=mail.xxx.xxx.xxx SMTP_PORT=25 SMTP_USER= SMTP_PASS= LDAP_LABEL=xxxxxx LDAP_HOST=xxx.xxx.xxx.xxx LDAP_VERIFY_SSL=false LDAP_BIND_DN=CN=xxx,CN=xxx,DC=xxx,DC=xxx,DC=xxx,DC=xxx LDAP_PASS=xxx LDAP_ALLOW_USERNAME_OR_EMAIL_LOGIN=true LDAP_BASE=DC=xxx,DC=xxx,DC=xxx,DC=xxx HTTP_PROXY=http://proxy.xxx.xxx.xxx.xxx:8080 HTTPS_PROXY=http://proxy.xxx.xxx.xxx.xxx:8080 NO_PROXY=127.0.0.1,localhost HTTP_PROXY_HOST=http://proxy.xxx.xxx.xxx.xxx HTTP_PROXY_PORT=8080 # PlantUML settings PLANTUML_PORT=xxxxx # Nexus settings NEXUS_PORT=xxxxx # PostgreSQL settings POSTGRESQL_VERSION=10-2 # GitLab settings GITLAB_VERSION=12.7.6 GITLAB_DB_USER=gitlab GITLAB_DB_PASS=password GITLAB_HOST=xxx.xxx.xxx.xxx GITLAB_PORT=xxxxx GITLAB_SSH_PORT=xxxxx GITLAB_RELATIVE_URL_ROOT= GITLAB_EMAIL=gitlab@xxx.xxx.xxx.xxx GITLAB_EMAIL_REPLY_TO=noreply@example.com GITLAB_INCOMING_EMAIL_ADDRESS=gitlab@xxx.xxx.xxx.xxx GITLAB_ROOT_PASSWORD=password GITLAB_PROJECTS_ISSUES=true GITLAB_PROJECTS_MERGE_REQUESTS=true GITLAB_PROJECTS_WIKI=true GITLAB_PROJECTS_SNIPPETS=true GITLAB_PROJECTS_BUILDS=true GITLAB_PROJECTS_CONTAINER_REGISTRY=true GITLAB_PAGES_ENABLED=true GITLAB_MATTERMOST_ENABLED=true # Redmine settings REDMINE_VERSION=4.1.0 REDMINE_DB_USER=redmine REDMINE_DB_PASS=password REDMINE_PORT=xxxxx # Jenlins settings JENKINS_PORT=xxxxx # ElasticSearch settings ES_VERSION=7.6.1 ES_PORT=9200 LOGSTASH_PORT=9600 GRAFANA_VERSION=latest GRAFANA_PORT=xxxxx ELASTICSEARCH_PROTO=http ELASTICSEARCH_HOST=elasticsearch ELASTICSEARCH_PORT=9200 # Rocketchat settings ROCKETCHAT_VERSION=3.0.3 ROCKETCHAT_URL=http://xxx.xxx.xxx.xxx:yyyyy ROCKETCHAT_PORT=yyyyy HUBOT_PORT=xxxxxファイル名 docker-compose.yml
docker-compose.ymlversion: '2' services: # Settings for PlantUML plantuml: image: plantuml/plantuml-server:jetty restart: unless-stopped dns: - ${DNS1} - ${DNS2} environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} ports: - "${PLANTUML_PORT}:8080" gitlab-redis: image: sameersbn/redis:latest command: - --loglevel warning volumes: - gitlab-redis-vol:/var/lib/redis:Z gitlab-db: image: sameersbn/postgresql:${POSTGRESQL_VERSION} volumes: - gitlab-db-vol:/var/lib/postgresql:Z environment: - DB_USER=${GITLAB_DB_USER} - DB_PASS=${GITLAB_DB_PASS} - DB_NAME=gitlabhq_production - DB_EXTENSION=pg_trgm # Settings For Gitlab gitlab: image: sameersbn/gitlab:${GITLAB_VERSION} restart: unless-stopped dns: - ${DNS1} - ${DNS2} depends_on: - gitlab-redis - gitlab-db ports: - "${GITLAB_PORT}:80" - "${GITLAB_SSH_PORT}:22" volumes: - gitlab-vol:/home/git/data:Z - gitlab-socket-vol:/var/run/docker.sock environment: - DEBUG=false - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} - DB_ADAPTER=postgresql - DB_HOST=gitlab-db - DB_PORT=5432 - DB_USER=${GITLAB_DB_USER} - DB_PASS=${GITLAB_DB_PASS} - DB_NAME=gitlabhq_production - REDIS_HOST=gitlab-redis - REDIS_PORT=6379 - TZ=Asia/Tokyo - GITLAB_TIMEZONE=Tokyo - GITLAB_HTTPS=false - SSL_SELF_SIGNED=false - GITLAB_HOST=${GITLAB_HOST} - GITLAB_PORT=${GITLAB_PORT} - GITLAB_SSH_PORT=${GITLAB_SSH_PORT} - GITLAB_RELATIVE_URL_ROOT=${GITLAB_RELATIVE_URL_ROOT} - GITLAB_SECRETS_DB_KEY_BASE=long-and-random-alphanumeric-string - GITLAB_SECRETS_SECRET_KEY_BASE=long-and-random-alphanumeric-string - GITLAB_SECRETS_OTP_KEY_BASE=long-and-random-alphanumeric-string - GITLAB_ROOT_PASSWORD= - GITLAB_ROOT_EMAIL= - GITLAB_NOTIFY_ON_BROKEN_BUILDS=true - GITLAB_NOTIFY_PUSHER=false - GITLAB_EMAIL=gitlab@example.com - GITLAB_EMAIL_REPLY_TO=noreply@example.com - GITLAB_INCOMING_EMAIL_ADDRESS=reply@example.com - GITLAB_SIGNUP_ENABLED=false - GITLAB_BACKUP_SCHEDULE=daily - GITLAB_BACKUP_EXPIRY=604800 - GITLAB_BACKUP_TIME=01:00 - SMTP_ENABLED=true - SMTP_DOMAIN=${SMTP_DOMAIN} - SMTP_HOST=${SMTP_HOST} - SMTP_PORT=${SMTP_PORT} - SMTP_USER=${SMTP_USER} - SMTP_PASS=${SMTP_PASS} - SMTP_STARTTLS=false - SMTP_AUTHENTICATION=false - LDAP_ENABLED=true - LDAP_LABEL=${LDAP_LABEL} - LDAP_HOST=${LDAP_HOST} - LDAP_VERIFY_SSL=${LDAP_VERIFY_SSL} - LDAP_BIND_DN=${LDAP_BIND_DN} - LDAP_PASS=${LDAP_PASS} - LDAP_ALLOW_USERNAME_OR_EMAIL_LOGIN=${LDAP_ALLOW_USERNAME_OR_EMAIL_LOGIN} - LDAP_BASE=${LDAP_BASE} - GITLAB_PROJECTS_ISSUES=${GITLAB_PROJECTS_ISSUES} - GITLAB_PROJECTS_MERGE_REQUESTS=${GITLAB_PROJECTS_MERGE_REQUESTS} - GITLAB_PROJECTS_WIKI=${GITLAB_PROJECTS_WIKI} - GITLAB_PROJECTS_SNIPPETS=${GITLAB_PROJECTS_SNIPPETS} - GITLAB_PROJECTS_BUILDS=${GITLAB_PROJECTS_BUILDS} - GITLAB_PAGES_ENABLED=${GITLAB_PAGES_ENABLED} - GITLAB_MATTERMOST_ENABLED=${GITLAB_MATTERMOST_ENABLED} gitlab-runner: image: gitlab/gitlab-runner:latest restart: unless-stopped dns: - ${DNS1} - ${DNS2} environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} volumes: - gitlab-runner-config-vol:/etc/gitlab-runner - gitlab-socket-vol:/var/run/docker.sock # Redmineの設定 redmine-db: image: sameersbn/postgresql:${POSTGRESQL_VERSION} restart: unless-stopped environment: - DB_USER=${REDMINE_DB_USER} - DB_PASS=${REDMINE_DB_PASS} volumes: - redmine-db-vol:/var/lib/postgresql redmine: image: sameersbn/redmine:${REDMINE_VERSION} restart: unless-stopped dns: - ${DNS1} - ${DNS2} depends_on: - redmine-db environment: - TZ=Asia/Tokyo - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} - DB_ADAPTER=postgresql - DB_HOST=redmine-db - DB_PORT=5432 - DB_USER=${REDMINE_DB_USER} - DB_PASS=${REDMINE_DB_PASS} - DB_NAME=redmine_production - REDMINE_PORT=${REDMINE_PORT} - REDMINE_HTTPS=false - REDMINE_RELATIVE_URL_ROOT= - REDMINE_SECRET_TOKEN= - REDMINE_SUDO_MODE_ENABLED=false - REDMINE_SUDO_MODE_TIMEOUT=15 - REDMINE_CONCURRENT_UPLOADS=2 - REDMINE_BACKUP_SCHEDULE=daily - REDMINE_BACKUP_EXPIRY=604800 - REDMINE_BACKUP_TIME=02:00 - SMTP_ENABLED=true - SMTP_DOMAIN=${SMTP_DOMAIN} - SMTP_HOST=${SMTP_HOST} - SMTP_PORT=${SMTP_PORT} - SMTP_USER=${SMTP_USER} - SMTP_PASS=${SMTP_PASS} - SMTP_STARTTLS=false - SMTP_AUTHENTICATION=false - LDAP_ENABLED=true - LDAP_LABEL=${LDAP_LABEL} - LDAP_HOST=${LDAP_HOST} - LDAP_VERIFY_SSL=${LDAP_VERIFY_SSL} - LDAP_BIND_DN=${LDAP_BIND_DN} - LDAP_PASS=${LDAP_PASS} - LDAP_ALLOW_USERNAME_OR_EMAIL_LOGIN=${LDAP_ALLOW_USERNAME_OR_EMAIL_LOGIN} - LDAP_BASE=${LDAP_BASE} ports: - "${REDMINE_PORT}:80" volumes: - redmine-vol:/home/redmine/data:Z - gitlab-vol:/home/git/data:ro # Settings for nexus nexus: image: sonatype/nexus3 restart: unless-stopped dns: - ${DNS1} - ${DNS2} ports: - "${NEXUS_PORT}:8081" volumes: - nexus-vol:/nexus-data:Z environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} - JAVA_OPTS=-Duser.timezone=Asia/Tokyo -Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 # Settings for Jenkins jenkins: image: jenkinsci/blueocean restart: unless-stopped dns: - ${DNS1} - ${DNS2} user: root ports: - '${JENKINS_PORT}:8080' volumes: - jenkins-vol:/var/jenkins_home:Z - /etc/localtime:/etc/localtime:ro - /etc/docker:/etc/docker:ro - /var/run/docker.sock:/var/run/docker.sock environment: - JAVA_OPTS=-Duser.timezone=Asia/Tokyo -Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 - TZ=Asia/Tokyo - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} # Settings for ELK elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:${ES_VERSION} restart: unless-stopped dns: - ${DNS1} - ${DNS2} environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} - discovery.type=single-node - cluster.name=docker-cluster - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 ports: - ${ES_PORT}:9200 volumes: - elastic-vol:/usr/share/elasticsearch/data logstash: image: docker.elastic.co/logstash/logstash:${ES_VERSION} restart: unless-stopped dns: - ${DNS1} - ${DNS2} environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} - discovery.type=single-node - cluster.name=docker-cluster - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 depends_on: - elasticsearch ports: - ${LOGSTASH_PORT}:9600 volumes: - logstash-vol:/usr/share/logstash grafana: image: grafana/grafana:${GRAFANA_VERSION} restart: unless-stopped dns: - ${DNS1} - ${DNS2} environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} depends_on: - elasticsearch ports: - ${GRAFANA_PORT}:3000 volumes: - grafana-vol:/var/lib/grafana # Settings for Communications mongo: image: mongo:4.0.16 restart: unless-stopped dns: - ${DNS1} - ${DNS2} environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} - TZ=Asia/Tokyo volumes: - rocketchat-db-vol:/data - /etc/localtime:/etc/localtime:ro command: mongod --smallfiles --oplogSize 128 --replSet rs0 --storageEngine=mmapv1 # initialization mongodb for create replicaset no need restart mongoinitreplica: image: mongo:4.0.16 depends_on: - mongo environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} - TZ=Asia/Tokyo volumes: - /etc/localtime:/etc/localtime:ro command: 'mongo mongo/rocketchat --eval "rs.initiate({ _id: ''rs0'', members: [ { _id: 0, host: ''mongo:27017'' } ]})"' rocketchat: image: rocketchat/rocket.chat:${ROCKETCHAT_VERSION} restart: unless-stopped dns: - ${DNS1} - ${DNS2} volumes: - rocketchat-vol:/app/uploads - /etc/localtime:/etc/localtime:ro depends_on: - mongoinitreplica environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} - ROOT_URL=${ROCKETCHAT_URL} - MONGO_URL=mongodb://mongo:27017/rocketchat - MONGO_OPLOG_URL=mongodb://mongo:27017/local?replSet=rs0 - TZ=Asia/Tokyo ports: - ${ROCKETCHAT_PORT}:3000 hubot: image: rocketchat/hubot-rocketchat:latest restart: unless-stopped dns: - ${DNS1} - ${DNS2} environment: - HTTP_PROXY=${HTTP_PROXY} - HTTPS_PROXY=${HTTPS_PROXY} - NO_PROXY=${NO_PROXY} - ROCKETCHAT_URL=rocketchat:${ROCKETCHAT_PORT} - ROCKETCHAT_ROOM=GENERAL - ROCKETCHAT_USER=bot - ROCKETCHAT_PASSWORD=password - BOT_NAME=bot - EXTERNAL_SCRIPTS=hubot-help,hubot-seen,hubot-links,hubot-diagnostics,hubot-proxy-loader - TZ=Asia/Tokyo depends_on: - rocketchat labels: - "traefik.enable=false" volumes: - hubot-vol:/home/hubot - /etc/localtime:/etc/localtime:ro ports: - ${HUBOT_PORT}:8080 volumes: gitlab-redis-vol: gitlab-db-vol: gitlab-vol: gitlab-socket-vol: gitlab-runner-config-vol: redmine-db-vol: redmine-vol: nexus-vol: jenkins-vol: logstash-vol: elastic-vol: grafana-vol: rocketchat-db-vol: rocketchat-vol: hubot-vol:
- 投稿日:2020-03-15T07:46:14+09:00
商用環境でも使っている Laravel 用 php-fpm イメージの Dockerfile レシピ
これは何
Laravel 用 php-fpm イメージの Dockerfile。
(多少はフォーマット変わろうとも)色んなところでずっと使いまわししそうなのでメモ。完全に個人の秘伝のタレ化するよりは情報公開したほうが自社にとっても利益があるだろうと判断(笑)
異論は無限に受け付けるので改善点などあればコメントください。レシピ
FROM golang:1.13 as HTTP2FCGI_BUILD # http2fcgi のビルド RUN apt update -y \ && go get -v -ldflags '-w -s' github.com/alash3al/http2fcgi/... FROM php:7.4-fpm-alpine # Goバイナリが実行できるようにする # https://stackoverflow.com/questions/34729748/installed-go-binary-not-found-in-path-on-alpine-linux-docker RUN mkdir /lib64 \ && ln -s /lib/libc.musl-x86_64.so.1 /lib64/ld-linux-x86-64.so.2 # http2fcgi のインストール COPY --from=HTTP2FCGI_BUILD /go/bin/http2fcgi /bin/http2fcgi # Git のインストール RUN apk add --update --no-cache git # Composer のインストール RUN set -eux \ && curl -sS https://getcomposer.org/installer | php -- --install-dir=/usr/local/bin --filename=composer \ && composer global require hirak/prestissimo \ && composer config -g repos.packagist composer https://packagist.jp # PHP 拡張のインストール RUN set -eux \ && apk add --update --no-cache autoconf g++ libtool make libzip-dev libpng-dev libjpeg-turbo-dev freetype-dev \ && pecl install redis \ && docker-php-ext-configure gd --with-jpeg=/usr \ && docker-php-ext-configure opcache --enable-opcache \ && docker-php-ext-install opcache bcmath pdo_mysql gd exif zip \ && docker-php-ext-enable redis \ && apk del autoconf g++ libtool make \ && rm -rf /tmp/* # ビルド引数 ARG DEPLOY ARG PHP_COVERAGE_DRIVER="" # カバレッジ計測およびデバッグ用 PHP 拡張のインストール # - ローカルでは xdebug を入れる # - CI では pcov を入れる # - プロダクションでは何も入れない RUN set -eux \ && apk add --update --no-cache autoconf g++ libtool make \ && if [ "$DEPLOY" = "local" -a "$PHP_COVERAGE_DRIVER" = "pcov" ]; then \ pecl install pcov; \ docker-php-ext-enable pcov; \ echo "pcov.directory = /code/app" >> $PHP_INI_DIR/conf.d/docker-php-ext-pcov.ini; \ elif [ "$DEPLOY" = "local" ]; then \ pecl install xdebug; \ docker-php-ext-enable xdebug; \ fi \ && apk del autoconf g++ libtool make \ && rm -rf /tmp/* # php.ini のコピー(ビルド引数によって分岐) COPY docker/php-fpm/conf.d/$DEPLOY.ini /usr/local/etc/php/conf.d/custom.ini # Composer 依存パッケージ定義のコピー COPY composer.json /code/composer.json COPY composer.lock /code/composer.lock # Composer 依存パッケージをアプリケーションから分離して先にインストール(ビルド時間短縮のため) ARG GITHUB_TOKEN="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" RUN set -eux \ && mkdir -p ~/.composer \ && printf '{"github-oauth":{"github.com":"%s"}}' $GITHUB_TOKEN > ~/.composer/auth.json \ && cd /code \ && composer install --no-scripts --no-autoloader \ && rm ~/.composer/auth.json # アプリケーションのコードをコピー(.dockerignore で vendor や .git は除外されている) COPY . /code # オートロードファイルの生成 # (ローカルではキャッシュを生成しない) RUN set -eux \ && cd /code \ && composer dump-autoload -o \ && if [ "$DEPLOY" != "local" ] ; then \ php artisan config:cache; \ php artisan route:cache; \ fi \ && chown -R www-data:www-data storage USER www-data WORKDIR /code # php-fpm と http2fcgi を起動 # (プリロードを導入したら opcache:compile は消す) CMD ["sh", "-c", "\ { \ sleep 5 && \ http2fcgi --fcgi tcp://localhost:9000 \ --http localhost:8000 \ --root /code/public & \ sleep 10 && \ ./artisan opcache:compile & \ } & \ exec php-fpm"]ポイント
- ビルド引数としてデプロイ先環境を表す
DEPLOYが必要。ローカルおよび CI のテスト実行用ビルドではlocalを指定する。- ビルド高速化のため,パッケージインストールは
composer.jsoncomposer.lockに変更があった場合にしか走らないように工夫している。
composer.jsonとcomposer.lockをコンテナ内にコピーcomposer install --no-scripts --no-autoloaderで,スクリプト実行無しおよびオートローダ作成無しにして,vendorディレクトリへのファイル投入だけを目的として実行。- アプリケーションのコードをマウント。この際
vendorディレクトリは除外されている。composer dump-autoload -oで後からオートローダを作成。- パッケージインストール高速化のため, Composer の並列インストールプラグイン hirak/prestissimo および日本国内ミラー Packagist.JP を使用している。
- 但し, Circle CI などでのビルドを考慮する場合はミラーではなく本家を参照したほうがいいかもしれない。
ARGで分岐の余地あり。- GitHub のプライベートリポジトリからパッケージをインストールできるように, 会社の共用アカウントで発行したこの目的専用の
GITHUB_TOKENをARGのデフォルト値としてハードコーディング。- エクステンションとして,さまざまな PHP アプリケーションで頻繁に必要になりそうな
opcachebcmathpdo_mysqlgdexifzipあたりをカバー。必要に応じて追加と削除の余地あり。- カバレッジドライバとして krakjoe/pcov を採用。 CI の高速化のため,
xdebugはローカルのみインストール対象にし, CI ではpcovでカバレッジを取るようにしている。- OPCache のコントロールユーティリティ appstract/laravel-opcache および Golang 製の軽量 FastCGI リバースプロキシ alash3al/http2fcgi を採用。
- PHP 7.4 のプリロード対応が入った後は不要になるが,現状 Laravel ではまともに動かない。
- 起動時にキャッシュを温めている。但し若干 php-fpm が準備完了状態になるまで時間差があるため,適当な時間
sleepを入れている。- Golang バイナリのビルドのためにマルチステージビルドを使用している。
その他注意点
DEPLOYはあくまでビルド用に存在する環境変数であり,コンテナ実行時には存在しない。ところがビルド時にconfig:cacheを呼ぶタイミングでは存在しているため,設定ファイルにenv('DEPLOY')とか書いてしまうとそれが拾われてキャッシュされてしまい,キャッシュしないと動かないという歪んだ状態に陥ってしまうので注意する。この変数はアプリケーションからは参照してはいけない。
- 投稿日:2020-03-15T01:32:47+09:00
golang,docker,mysqlの環境をherokuにデプロイする
はじめに
言語: golang
コンテナ: docker-compose
RDB: mysql
ORM: gorm
マイグレーション: migrateな環境をherokuにデプロイするまで結構ハマったので残す。
コード
https://github.com/pokotyan/study-slack
実行したherokuのコマンド一覧
$ cd /hoge/huga # アプリケーションのコードがあるところに移動 $ heroku container:login # ログイン $ heroku create -a app_name # herokuアプリの作成 $ heroku git:remote -a app_name # herokuリポジトリをgit登録 $ heroku addons:add cleardb:ignite # mysqlのアドオンを追加 $ heroku config # CLEARDB_DATABASE_URLが登録されていることを確認 $ heroku config:set DATABASE_URL="<ユーザー名>:<password>@tcp(<ホスト名>:3306)/<DB名>?parseTime=true" # CLEARDB_DATABASE_URLの値を元にsql.Open()に渡す用の文字列に整形 $ heroku config # DATABASE_URLが登録されていることを確認 $ heroku stack:set container # heroku.ymlを使う時はこれがいるぽい $ git push heroku master # リリースheroku.yml
heroku.ymlを使うとCI/CDみたいなことができる。アプリのルートディレクトリに置いて使う。
buildにはdockerのビルドの指定ができる。
releaseにはリリースする際に挟みたい処理があれば書くことができる。ここではマイグレーションの実行をしている。
runはプロセスタイプ1ごとに実行するコマンドを指定する。./heroku.ymlbuild: docker: web: Dockerfile worker: dockerfile: Dockerfile target: builder release: image: worker command: - make up_migrate_prod run: web: /mainDockerfile
上述のheroku.ymlが参照するDockerfile。アプリのルートディレクトリに置く。
いくつかポイントがある。./DockerfileFROM golang:alpine as builder RUN apk update \ && apk add --no-cache git curl make gcc g++ \ && go get github.com/oxequa/realize WORKDIR /app COPY go.mod . COPY go.sum . RUN go mod download COPY . . RUN GOOS=linux GOARCH=amd64 go build -o /main FROM alpine:3.9 COPY --from=builder /main . ENV PORT=${PORT} ENTRYPOINT ["/main"]ライブラリのインストール
./DockerfileRUN apk update \ && apk add --no-cache git curl make gcc g++ \ && go get github.com/oxequa/realizerealizeは開発時のホットリロードのため。
make、gcc、g++はheroku.ymlのreleaseフェーズにてmakeコマンドでマイグレーションを流せるようにするため
curlはherokuのUI上でログを残すため(※)。※ curlを入れていないとこんな感じで何も表示されない。リリースが途中で死んでもなんで落ちたかが追えなくなるので入れておいた方がいいと思う。ログを出すためにcurlが必要なことは公式にも記載されている。
ビルド
builderのイメージはheroku.ymlでイメージのビルドをする際に使ったり、マイグレーションを実行する時のイメージとして利用している。
./DockerfileFROM golang:alpine as builder./heroku.ymlbuild: docker: web: Dockerfile worker: dockerfile: Dockerfile target: builder # builderのイメージをbuildする際に使う release: image: worker # 上記のworkerのイメージをreleaseフェーズでも使う command: - make up_migrate_prodアプリの実行
RUN GOOS=linux GOARCH=amd64 go build -o /mainでビルドしたファイルを実行する./DockerfileFROM alpine:3.9 COPY --from=builder /main . ENV PORT=${PORT} ENTRYPOINT ["/main"]./heroku.ymlrun: web: /maindocker-compose.yml
ローカルで開発する時のみに利用するdocker-compose.yml。
mysqlのコンテナが立ち上がる際にdocker-entrypoint-initdb.dを利用してCREATE DATABASEをするようにしている。herokuの本番環境ではdatabaseは
heroku addons:add cleardb:igniteで用意されたものを利用する。
そのため、本番環境ではこのdocker-compose.ymlは利用しない。dockers/docker-compose.ymlversion: "3.5" services: mysql: container_name: push_study_db image: mysql:5.7.22 volumes: - ./mysql/:/docker-entrypoint-initdb.d/ - ./mysql/my.cnf:/etc/mysql/conf.d/my.cnf environment: - MYSQL_ALLOW_EMPTY_PASSWORD=yes ports: - 4306:3306 app: build: context: .. target: builder volumes: - ../:/app command: realize start --server environment: - API_VERSION=development ports: - 7777:7777 depends_on: - mysql起動するポート
herokuはアプリが起動するたびにポートが変わるらしい。$PORTを指定して起動するようにする。
router.Run(":" + os.Getenv("PORT"))CLEARDB_DATABASE_URL
mysqlのアドオンを追加するとCLEARDB_DATABASE_URLという環境変数が自動で設定される。
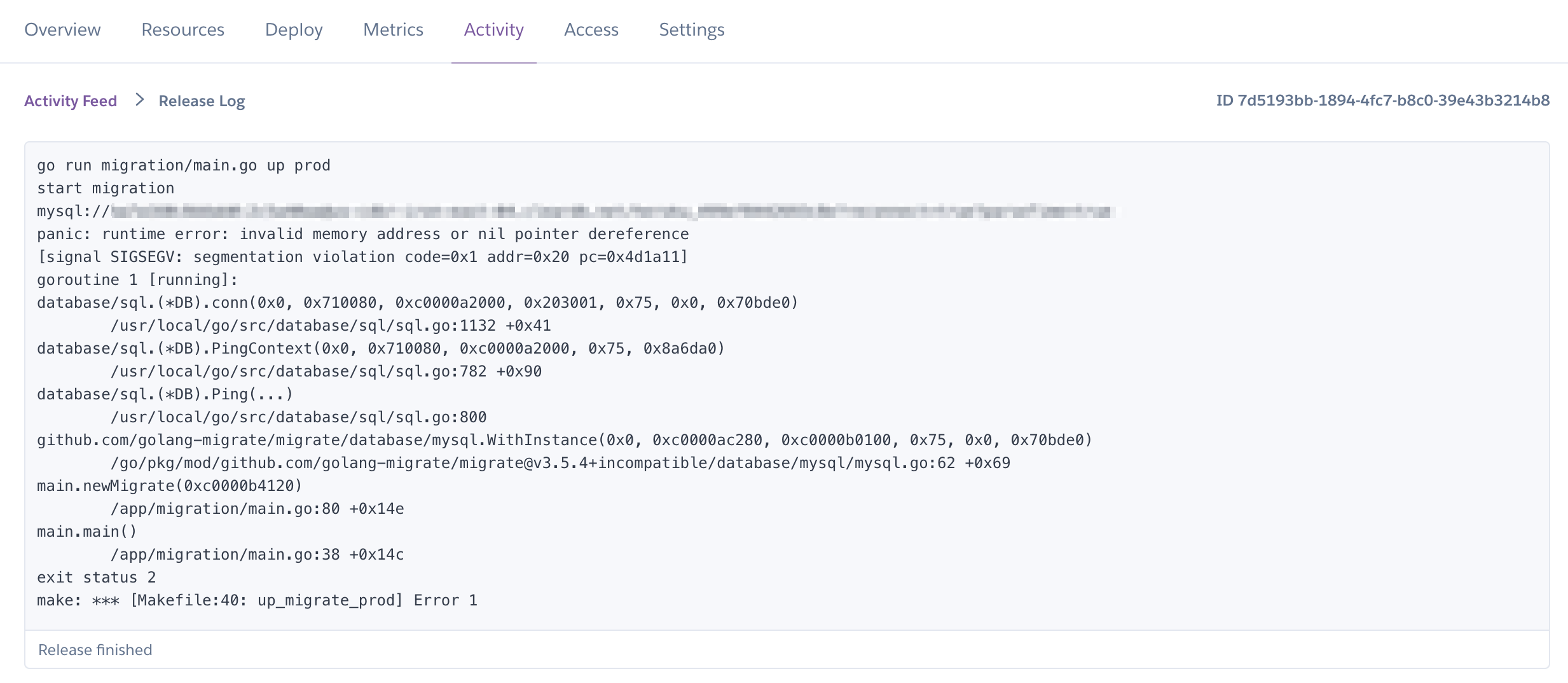
heroku.ymlのreleaseフェーズで流れるようにしたマイグレーションだが、そのコードでは以下のようにしてdbと接続していた。dbURL := os.Getenv("CLEARDB_DATABASE_URL") db, _ := sql.Open("mysql", dbURL)リリースを実行すると
invalid memory address or nil pointer dereferenceのエラーが出る。
結果として、herokuが自動で作成してくれるCLEARDB_DATABASE_URLの書式をsql.Openが求めている書式に変換する必要があった。こちらの記事を参考にさせていただきました。
冒頭のherokuのコマンド一覧のところでも記載しているが、"<ユーザー名>:<password>@tcp(<ホスト名>:3306)/<DB名>?parseTime=true"の形にしてあげる必要があった。最後に
herokuのリリース方法、色々ありすぎてまとまった情報を見つけるのが難しい。
ここで使ってるのはwebのプロセスタイプ。herokuが動くコンテナであるdynoのプロセスタイプは他にworker、one-offの計3つのプロセスタイプがあるぽい ↩
- 投稿日:2020-03-15T01:07:24+09:00
Azure App Serviceを使用してDockerコンテナ(Linux)を作成する
概要
本書ではAzure App Serviceを使用してLinuxのDockerコンテナを作成します。その後、作成したDockerコンテナでコマンド操作、FTPを使用します。
0. 前提条件
- Azureのアカウントを作成していること
- WinSCPなどのFTPによるファイル受け渡しソフトをインストールしていること
1. Linuxコンテナの作成
Azureポータルにログインし、左側メニューから「App Service」をクリックする。
左上メニューから「作成」をクリックする。
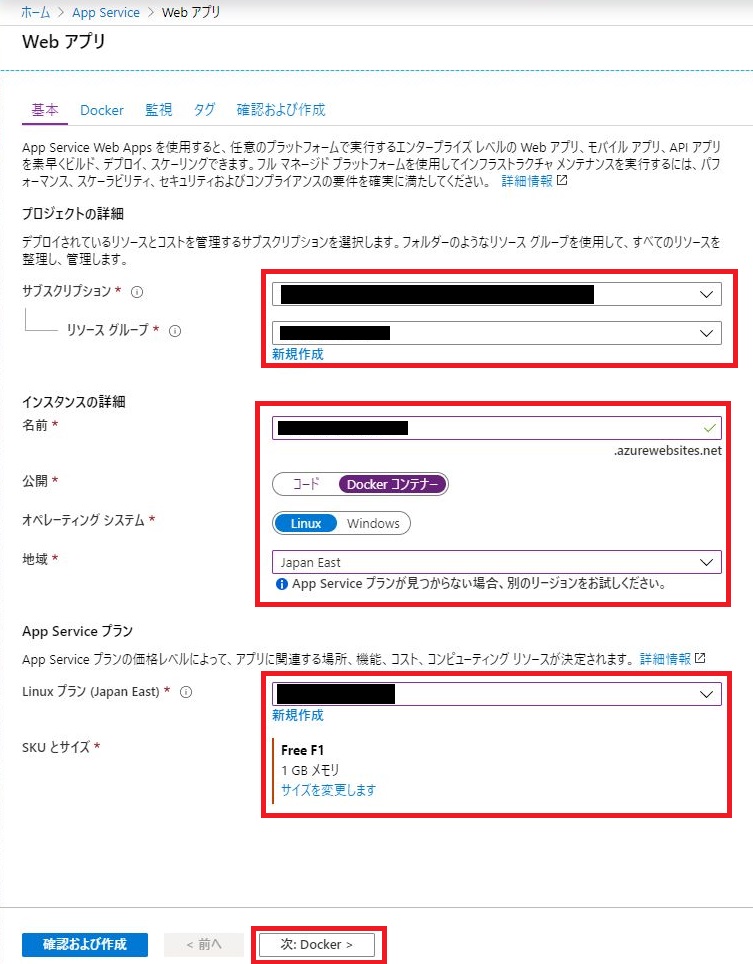
「基本」メニューより下記の項目を入力し「次:Docker」をクリックする。
- サブスクリプション
- リソースグループ
- 名前
- 公開 : Dockerコンテナ
- オペレーティングシステム : Linux
- 地域 : Japan East
- Linuxプラン
- SKUとサイズ : Free F1

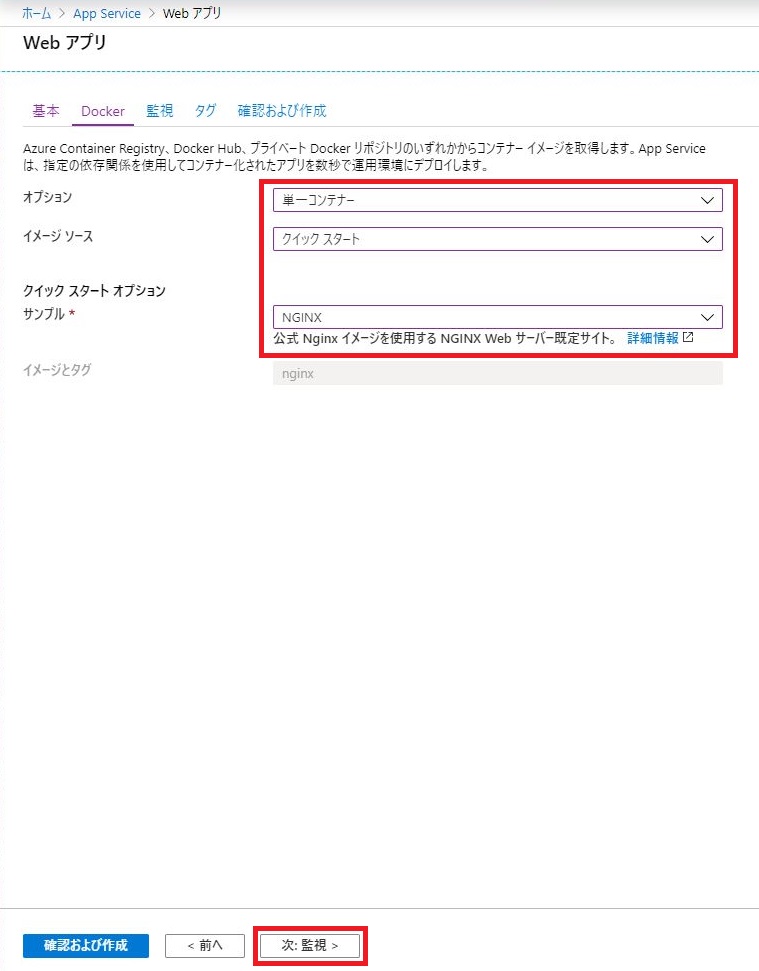
「Docker」メニューより下記の項目を選択し「次:監視」をクリックする。
- オプション : 単一コンテナー
- イメージソース : クリックスタート
- クイックスタートオプション : NGINX

「監視」メニューにて問題がなければ「次:タグ」をクリックする。
「タグ」メニューにて問題がなければ「次:確認および作成」をクリックする。
設定した項目を確認し「作成」をクリックする。
デプロイが進行しているので待機する。
デプロイが完了した画面が表示されたことを確認する。その後、「リソースに移動」をクリックする。
リソースが表示されたことを確認する。
2. コマンド操作を実施する
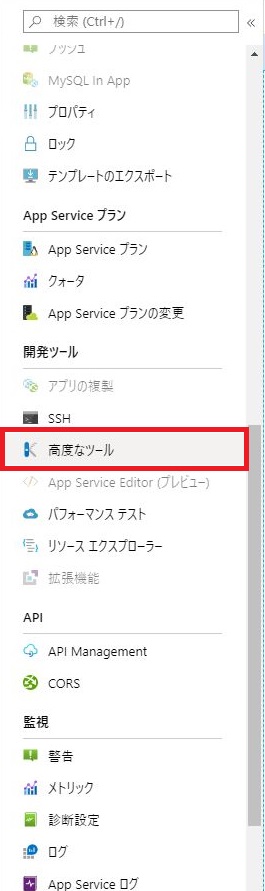
リソース画面の左側メニューから「高度なツール」をクリックする。
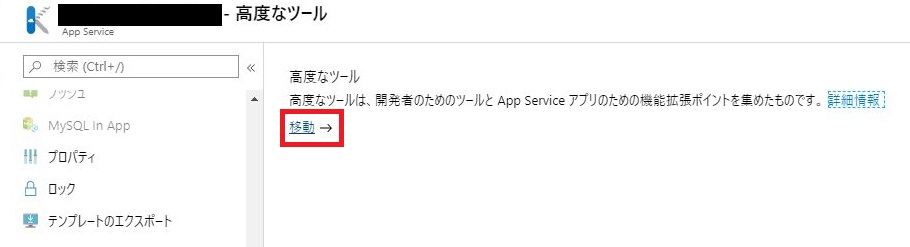
「移動」をクリックする。
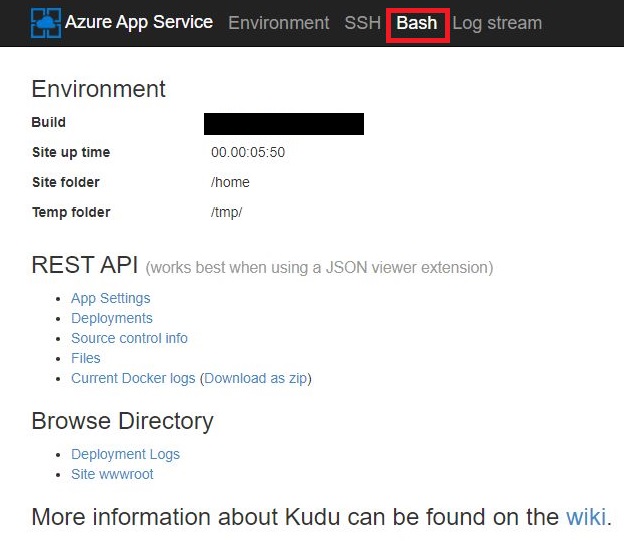
上側メニューから「Bash」をクリックする。
ターミナル画面が表示されたことを確認する。
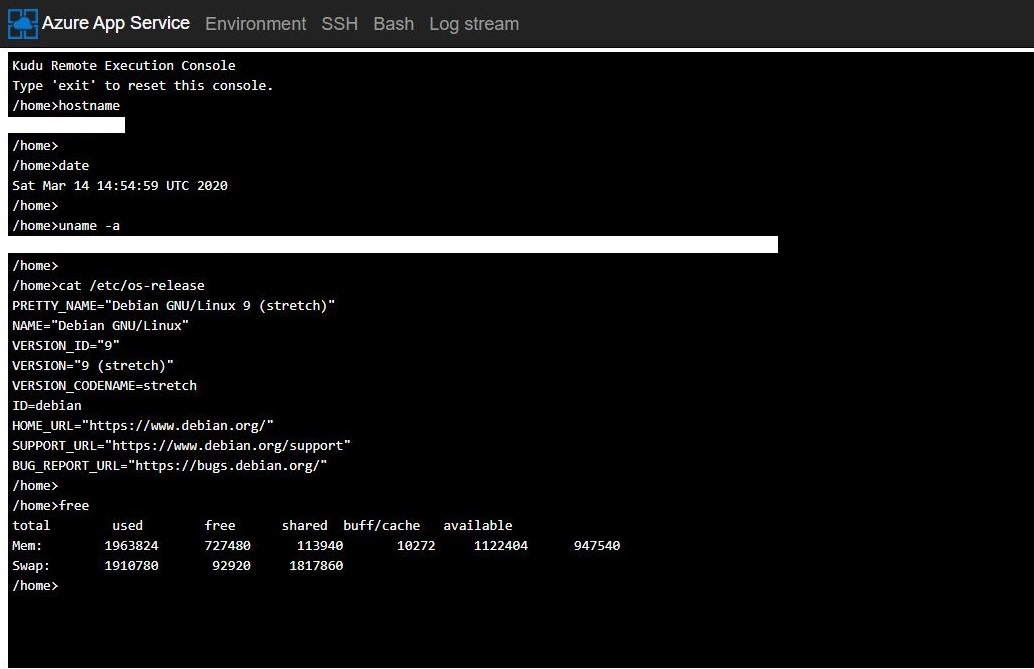
ターミナル画面にて基本的なコマンドを実行する。
> hostname > date > uname -a > cat /etc/os-release > free など
3. FTPを実施する
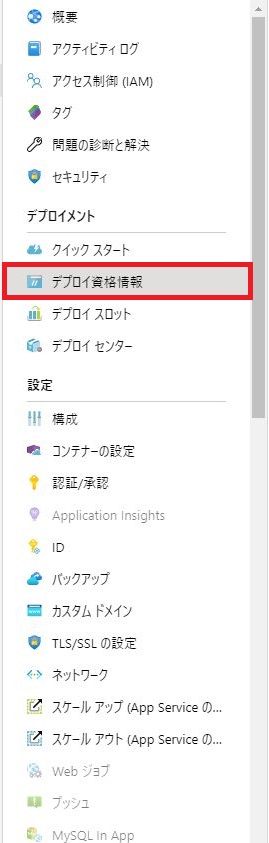
リソース画面の左側メニューから「デプロイ資格情報」をクリックする。
下記の項目を入力し「保存」をクリックする。
- FTP/デプロイユーザー名
- パスワード
- パスワードの確認

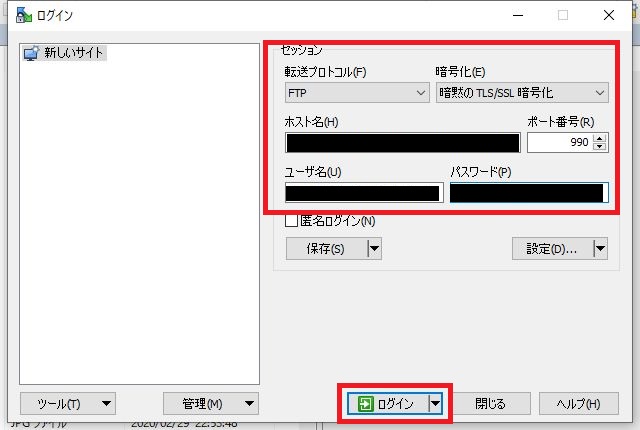
FTPデプロイユーザー名、FTPSホスト名をコピーする。
WinSCPを起動する。
下記の項目を入力し「ログイン」をクリックする。
- 転送プロトコル : FTP
- 暗号化 : 暗黙のTLS/SSL暗号化
- ホスト名
- ポート番号 : 990
- ユーザー名
- パスワード

作成したコンテナのディレクトリが表示されたことを確認する。
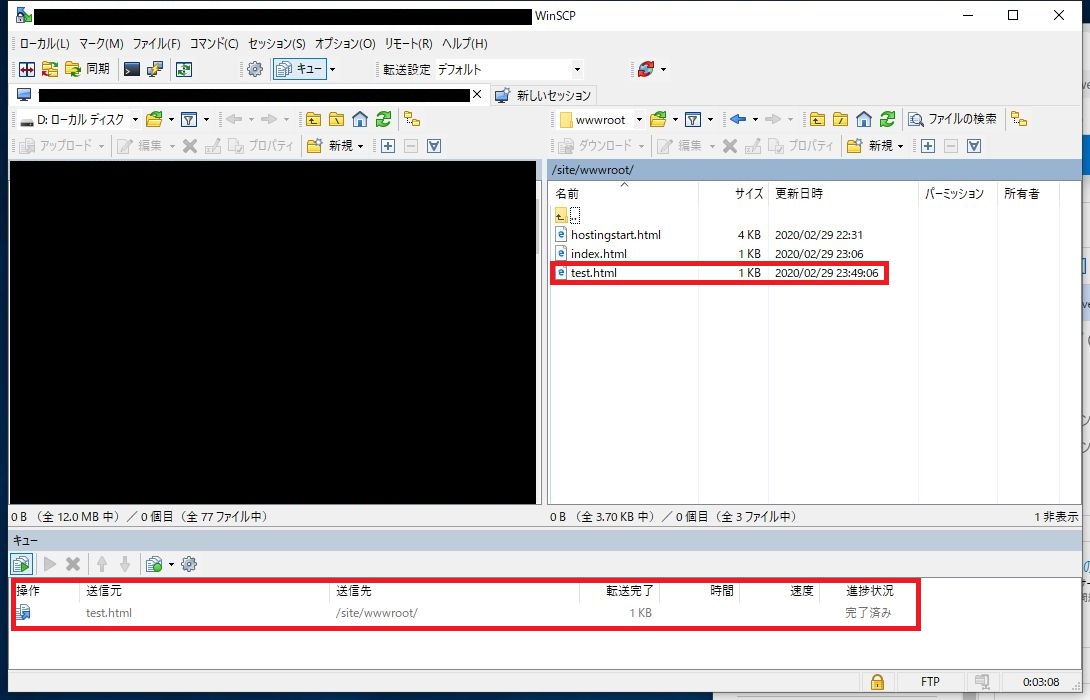
作成したファイルをコンテナに転送できたことを確認する。
最後に
Azure App Serviceを利用することですぐにLinuxのDockerコンテナを作成することができます。またApp Serviceで作成したDockerコンテナを使用することで、制限はありますがWebサイトなどを作成することができます。