- 投稿日:2020-03-15T23:56:08+09:00
[NLP]言葉の使い方が近い科学者のペアは?(その1)
はじめに
来春B4になる予定の大学生です。普段は統計学とかを勉強しています。最近自然言語処理に触れる機会があったんで、思いついたネタでCOTOHA APIを試してみました。
アイデア
同じ人物の名言が似ているかどうか!
という至極単純な発想です...結果
コードについてはCOTOHA 類似度算出APIを使って、FAQ検索システムを構築してみたを参考にさせていただきました。
では以下が結果となります。
岡潔さんの「人は極端になにかをやれば必ず好きになるという性質をもっています。好きにならぬのがむしろ不思議です。」と「人間が人間である中心にあるものは科学性でもなければ論理性でもなく理性でもない情緒である。」の類似度を比較してみました。
類似度は 0.877827 で同じ人の言葉であるだけにかなり近い結果が算出されました。今後はさらに発展させていきたいと思います。
参考(全て2020/03/15アクセス)
COTOHA API | NTTコミュニケーションズが開発した日本最大級の日本語辞書を活用した自然言語処理、音声認識APIプラットフォーム
COTOHA 類似度算出APIを使って、FAQ検索システムを構築してみた岡潔の名言 | 地球の名言
- 投稿日:2020-03-15T23:56:08+09:00
[NLP]同一人物の科学者の名言は近いのか?(その1)
はじめに
来春B4になる予定の大学生です。最近自然言語処理に触れる機会があったので、思いついたネタでCOTOHA APIを試してみました。
アイデア
同じ人物の名言が似ているかどうか!
という至極単純な発想です...結果
コードについてはCOTOHA 類似度算出APIを使って、FAQ検索システムを構築してみたを参考にさせていただきました。
では以下が結果となります。
岡潔さんの「人は極端になにかをやれば必ず好きになるという性質をもっています。好きにならぬのがむしろ不思議です。」と「人間が人間である中心にあるものは科学性でもなければ論理性でもなく理性でもない情緒である。」の類似度を比較してみました。
類似度は 0.877827 で同じ人の言葉であるだけにかなり近い結果が算出されました。今後はさらに発展させていきたいと思います。
参考(全て2020/03/15アクセス)
COTOHA API | NTTコミュニケーションズが開発した日本最大級の日本語辞書を活用した自然言語処理、音声認識APIプラットフォーム
COTOHA 類似度算出APIを使って、FAQ検索システムを構築してみた岡潔の名言 | 地球の名言
- 投稿日:2020-03-15T23:55:13+09:00
学習記録(4日目)#相対パスから絶対パスを取得する方法
学習内容
- 相対パスから絶対パスを取得する方法
- Python基本文法
相対パスから絶対パスを取得する方法
HTMLでリンク先が相対パスで記述されていた際には、
urllib.parse.urljon()を利用して絶対パスを取得する。記述例
from urllib.parse import urljoin base = "http://exsample.com/html/a.html" compurl = lambda q: print(urljoin(base,q)) compurl("b.html") compurl("sub/c.html") compurl("../index.html") compurl("../img/hoge.png")実行結果
http://example.com/html/b.html
http://example.com/html/sub/c.html
http://example.com/index.html
http://example.com/img/hoge.pngPython基本文法
pass文Pythonではインデントによって処理ブロックを定義するので、処理を行う必要のない時には処理ブロック自体がなくなってしまう。そこで、何も処理を行うことを明示的に記述するために
pass文を用いる。with open('exsample.txt', 'w'): pass条件分岐
if、elif、elseを用いて記述する。また、一つの条件式によって2通りの処理ブロックに分岐する場合は三項演算子を用いて記述することもできる。if 条件式1: <処理ブロック1> # 条件式1がTrueのときに実行される処理 elif 条件式2: <処理ブロック2> # 条件式1がFalse、かつ条件式2がTrueのときに実行される処理 else: <処理ブロック3> # 条件式1がFalse、かつ条件式2がFalse、かつ条件式3がTrueのときに実行される処理 # 三項演算子による条件分岐 # 条件式がTrueのとき値1、Falseのとき値2 値1 if 条件式 else 値2イテレータ
データを表す値そのものではなく、一連のデータを生成することができるルールとしてデータを保持する。大量のデータが必要なときには、イテレータを用いた方がメモリ効率が良い。以下に
range型のイテレータの記述例を示す。# 以下3つのrange()は,0から9まで、1ずつ増えるイテレータを返す range(0, 10, 1) range(0, 10) a = range(10) print(a) print(a[0])実行結果
range(0, 10)
0
range()は、Pythonでは使うことができないインクリメント演算子(++)の機能を備えている。デクリメント(--)はreversed()というイテレータを用いて行う。
break文とcontinue文ループ文の処理ブロック内に記述することで、実行中のループ文を制御することができる。
break文現在実行中のループを中断してループの外に抜ける。
b = 0 while True: b += 1 if b > 5 break # b = 6 となった時点でループから抜けて処理が終了する。 print(b)実行結果
1
2
3
4
5
continue文実行中の処理ブロックを中断して、ループの条件式評価まで処理を移動する。
c = 0 while True: c += 1 if c < 5 continue # b = 6 となるまでこの先の処理は実行されない。 print(c) break実行結果
6
まとめ
利用しているスクレイピングに関する参考書のコードの理解に苦労し始めたので、再びPythonの基礎文法についての学習を始めることにした。
CやJavaでは非常に便利だったインクリメント・デクリメントが使えないことには驚いたが、累算代入(+=,-=)やイテレータを用いてうまく対応していけるようにしたい。参考書
参考にした書籍から公開されているGitHubを添付しておきます。
増補改訂Pythonによるスクレイピング&機械学習 開発テクニック
- 投稿日:2020-03-15T23:52:00+09:00
Pythonでリストにデータを追加するときのappend()と"+="演算子の挙動の違い
Pythonでリストにデータを追加するときの
append()と+=演算子の挙動の違いを確認したのでメモ。
append()の場合いずれの型(文字列型、数値型、辞書型、配列型など)であっても、指定したデータのまま1要素として配列に追加される。
>>> d_list = [] >>> d_list.append('Hello') >>> d_list.append(123) >>> d_list.append({'a':1, 'b':2, 'c':3}) >>> d_list.append([1, 2, 3]) >>> d_list ['Hello', 123, {'a': 1, 'b': 2, 'c': 3}, [1, 2, 3]]
+=の場合イテレータとしての動作をし、指定したデータのイテラブル(iterable)のすべての要素が配列に追加される。
動作としてはextend()と同じとなる。文字列型のデータは各キャラクターが1要素として追加される。
>>> d_list = [] >>> d_list += ('Hello') >>> d_list ['H', 'e', 'l', 'l', 'o']数値型のデータはiterableではないのでエラーとなる。
>>> d_list += 123 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'int' object is not iterable辞書型のデータは各要素のキー名がそれぞれ1要素として追加される。
>>> d_list = [] >>> d_list += {'a':1, 'b':2, 'c':3} >>> d_list ['a', 'b', 'c']配列型のデータは各要素がそれぞれ1要素として追加される。
>>> d_list = [1, 2] >>> d_list += [3, 4, 5] >>> d_list [1, 2, 3, 4, 5]参考
5.1. リスト型についてもう少し
list.append(x)
リストの末尾に要素を一つ追加します。a[len(a):] = [x] と等価です。list.extend(iterable)
イテラブルのすべての要素を対象のリストに追加し、リストを拡張します。a[len(a):] = iterable と等価です。以上
- 投稿日:2020-03-15T23:45:10+09:00
再生数の多いYoutube動画タイトル文を「COTOHA API」でテキスト解析し、その特徴を探ってみた。
本記事の目的
- Cotoha APIを触ってみて、自然言語処理ライブラリとしての性能を確かめる。
- Youtube APIの使い方を学ぶ。
- 「効果的な動画タイトルの付け方」を知りたい。
- 心理学で有名な「人はネガティブに引かれる」のは本当なのか、実際に使われているのか
- どのような言語表現をしているものが多いのか
実験手順
- Youtube APIで、キーワードで検索した時の、動画再生数上位100件の情報を取得 (今回は「ヒカキン」「筋肉」「お寿司」で検証)
- 取得した動画のタイトル文を、COTOHA APIで分析 (今回は「感情分析」「文タイプ判定」を使用)
自分はMacでpython3.7.5を使用しました。
COTOHA APIの登録、使い方
詳しい説明は公式サイト(https://api.ce-cotoha.com/contents/index.html)
にお任せするとして、概要を記述します。
COTOHA APIとは、NTTコミュニーケーションが提供する自然言語処理&音声処理APIプラットフォームで、無料アカウントでは以下のAPIが1000回/日まで利用できます。
- 構文解析
- 固有表現抽出
- 照明解析
- キーワード抽出
- 類似度算出
- 文タイプ判定
- ユーザー属性推定
- 感情分析
- 要約
さらに、有料登録すると音声認識、音声合成のAPIも使用可能となります。
早速新規登録してみましょう。
ログインするとAPIを使うのに必要な情報が手に入ります。
各種APIの使い方ですが、先人の方が関数を呼ぶだけで使える素晴らしいスクリプトファイル(python)を掲載してくれており、ほぼこちらを参考にすれば使えます。config.iniの中身を画像中のアカウント情報と置き換えればOKです。
https://qiita.com/gossy5454/items/83072418fb0c5f3e269f
一部HTTPエンドポイントが変わっている場合があり、そこはリファレンスに掲載されているものに変更しましょう。
また、感情分析の関数は用意されていなかったのですが、送るJSONは他のAPIと同じなので、コピーしてHTTPエンドポイントのみを変更すれば使用可能です。これで文章処理の準備ができたので、
次はYoutubeからテキストデータ(動画タイトル)を受け取りたいと思います。Youtube APIの登録、使い方
こちらも、先人の方が素晴らしい先例(手順、コード)を残してくれています。
https://qiita.com/g-k/items/7c98efe21257afac70e9
ざっくりした手順は以下となります。
Google Cloud Platformに登録→プロジェクトの作成→youtube data APIの取得
(このAPI使用も、一定数以下回数は無料で、無料枠を超えると呼べなくなります。無力枠超えて課金はないので安心です。)サイトに記載されているコードの
- 「特定キーワードを含むタイトルの動画を再生回数順で取得する」
- 「一度に多数の動画の情報を取得する」
の関数を使用すれば、「調べたいワード」を変更するだけ(get_video_infoのpを変更するだけ)で、ワードにまつわる動画の、再生回数順のpandas形式データが手に入ります。
自分の場合は受け取ったデータを.to_csvで一度書き出しました。以上で再生数の多いYoutube動画タイトル文の取得、「COTOHA API」でテキスト解析の方法を紹介しました。
結果
「ヒカキン」「筋肉」「お寿司」で検証した結果の表を以下に示します。
- title: 動画のタイトル名
- channel: 動画のチャンネル名
- viewcount: 動画の再生数
- emotion: Positive/Negative/Neutralのいずれかを出力
- score:0~1の値
- modality:様相性(話している内容に対する話し手の判断や感じ方を表す言語表現) declarative(叙述)、interrogative(質問)、imperative(命令)の3種から提示
- act:20種類の行動から提示。詳しくは「発話行為種別一覧」をご確認下さい。 https://api.ce-cotoha.com/contents/reference/apireference.html#sentiment
「ヒカキン」で検索した場合
一番再生されてる動画、1億近いの凄いですね。
個人的にはビートボックスよりもゲーム実況の方が全体的に伸びているのが意外でした。
感情はほぼNeutral(中立)、発話行為はほぼinformation-providingになっています。
title channel viewcount emotion score modality act YouTubeテーマソング/ヒカキン&セイキン HikakinTV 96639615 Neutral 0.3140117 declarative information-providing Super Mario Beatbox HIKAKIN 47803202 Neutral 0.3140117 declarative information-providing 雑草 / ヒカキン&セイキン SeikinTV 43048679 Neutral 0.307152032 declarative information-providing 今 / ヒカキン & セイキン SeikinTV 35736354 Neutral 0.286147006 declarative information-providing ヒカキンのスーパーマリオ オデッセイ実況 Part1 HikakinGames 30731711 Neutral 0.3140117 declarative information-providing Beatbox Game - Hikakin vs Daichi HIKAKIN 27450560 Neutral 0.307511953 declarative information-providing 【暴露】実はヒカキンには2人の娘がいます。。。 HikakinTV 27331812 Neutral 0.353738814 declarative information-providing 【マインクラフト】ヒカキンのマイクラ実況 Part1 いきなりまさかの展開 !? HikakinGames 24297444 Neutral 0.58600426 interrogative information-seeking 【大食い】2.5kgジャンボ餃子大食い対決!ヒカキン vs 木下ゆうか HikakinTV 23262224 Neutral 0.3140117 declarative information-providing 謎のおしり出現!? ヒカキンのスプラトゥーン/Splatoon Part3 実況プレイ HikakinGames 22555841 Neutral 0.271291074 interrogative information-seeking ヒカキンさん家で卵投げてみた はじめしゃちょー(hajime) 22401744 Neutral 0.291121458 declarative information-providing Beatbox Game 2 - HIKAKIN vs Daichi Daichi Beatboxer 21840694 Neutral 0.263848257 declarative information-providing Beatbox Game 3 - HIKAKIN vs Daichi Daichi Beatboxer 21441808 Neutral 0.307867619 declarative information-providing 口に牛乳を含んでヒカキンさんの動画見てみた 東海オンエア 20955931 Neutral 0.259822104 declarative information-providing 【超巨大】アルミホイル250mハンマーで叩きまくったらピカピカ巨大鉄球出来たwww【アルミホイル玉】【ボール】 HikakinTV 20649399 Negative 0.635860265 declarative information-providing まるお & もふこをお風呂に2匹とも入れてみたら超大変だったwww HikakinTV 20001570 Neutral 0.300373615 declarative information-providing ヒカキン & セイキン - 夢 SeikinTV 19406213 Neutral 0.286492491 declarative information-providing 【マインクラフト】ヒカクラ最終回!ありがとうヒカキンくん!【ヒカキンのマイクラ実況 Part355】 HikakinGames 19114023 Positive 0.198225499 declarative information-providing 【ご報告】家族が増えました!猫飼います!【ヒカキンTV】【ねこ cat】 HikakinTV 18926330 Neutral 0.247030212 declarative information-seeking ヒカキン+セイキンのスーパーマリオ3Dワールド実況!Part12 HikakinGames 17824558 Neutral 0.3140117 declarative information-providing 【ドッキリ】超ヒカキン好きな女の子の家にいるドッキリしたら大変なことにw【感動】 HikakinTV 16849573 Positive 0.567815226 declarative information-providing 【ハズレは激辛唐辛子】ヒカキン VS セイキンのロシアンチョコエッグ対決! SeikinTV 15993091 Negative 0.545136738 declarative information-providing ヒカキンのスーパーマリオ オデッセイ実況 Part3【氷の大仏!?】 HikakinGames 15564248 Neutral 0.295933645 interrogative information-seeking はじめ、ヒカキン、シルクの詰問コーナー!!!! Fischer's-フィッシャーズ- 15519672 Neutral 0.424711251 declarative information-providing 【マインクラフト】ウィザーに乗ってワールド破壊!? ヒカキンくん大暴走www 【Animal Bikes Mod 後編】 HikakinGames 15144476 Neutral 0.252350987 interrogative information-seeking HIKAKIN(ヒカキン)さんとテンション0,100%で大爆笑!! Fischer's-フィッシャーズ- 15118665 Neutral 0.426777522 declarative information-providing ヒカキン、人生で最大の買い物をする 【1500万円】 HikakinTV 14656040 Positive 0.379163674 declarative information-providing ヒカキンのスーパーマリオオデッセイ実況 Part5【森の国のタマネギ】 HikakinGames 14166171 Neutral 0.297411335 declarative information-providing ヒカキンさんとアスレチック行ったら気合いが半端じゃなかった!! Fischer's-フィッシャーズ- 14076124 Neutral 0.540192176 declarative information-providing 【マインクラフト】家が大火事…お宝消滅…【ヒカキンのマイクラ実況 Part55】【ヒカクラ】 HikakinGames 13957963 Neutral 0.293479813 declarative information-providing ヒカキン×デカキンついに会う!初対面でデカキンさんにドッキリしたら号泣www【感動】 HikakinTV 13786115 Positive 0.686310987 declarative information-providing 最後の武器!ハイドラントカスタム使ってみた!ヒカキンのスプラトゥーン/ Splatoon - Part12 - 実況プレイ HikakinGames 13630225 Neutral 0.33411051 declarative information-providing ヒカキンさんのビートボックス講座で爆笑したwww Fischer's-フィッシャーズ- 13524451 Positive 0.552940436 declarative information-providing ヒカキン&セイキンがサンタになってファンの方の家に突撃!クリスマスプレゼント届けます! SeikinTV 13336712 Neutral 0.384100722 declarative information-providing 【マインクラフト】ヒカキンくんがエンダードラゴンに乗って帰ってきた!? マイクラ新シリーズ!【Animal Bikes Mod 前編】 HikakinGames 13202948 Neutral 0.392109869 interrogative information-seeking ハンドスピナーどれが一番長く回るか選手権!ヒカキン vs セイキン!【Fidget Spinner】 HikakinTV 13029079 Neutral 0.370209399 interrogative information-seeking ヒカキンの大暴走質問コーナー100連発www【令和Ver.】 HikakinTV 12685930 Negative 0.722566195 declarative information-providing 【スプラトゥーン2】悲報…ヒカキン、煽られてキレる…ガチマッチデビュー! HikakinGames 12411551 Negative 0.484687059 declarative information-providing 【しょぼんのアクション】1stステージ!ヒカキンの実況プレイ!HikakinGames HikakinGames 12273765 Neutral 0.316840029 declarative information-providing ヒカキンのスーパーマリオ オデッセイ実況 Part2【砂漠】 HikakinGames 11864344 Neutral 0.295832008 declarative information-providing 【閲覧注意】ヒカキン vs セイキン 美女ゾンビ サバゲー対決!【Last Empire War Z】 HikakinGames 11658417 Neutral 0.315489109 declarative information-providing 【最強決定】ハンドスピナー頂上決戦!民族 vs ニセ民族!【ヒカキン vs セイキン】【Fidget Spinner】 HikakinTV 11457587 Neutral 0.293550851 declarative information-providing ヒカキン密着24時 〜YouTuberの裏側〜 HikakinTV 11113934 Neutral 0.3140117 declarative information-providing 【家賃3倍】ヒカキン新居紹介ツアー2019!【引越費用?000万円】 HikakinTV 11079436 Neutral 0.294992639 interrogative information-seeking しまむら店内で本気のかくれんぼバトルしてみたw【ヒカキン vs セイキン】 HikakinTV 10922809 Positive 0.623581511 declarative information-providing HIKAKIN × SEKAI NO OWARI「RAIN」 HIKAKIN 10792595 Neutral 0.303504497 declarative information-providing 【マインクラフト】エンダードラゴンとウィザー同時に召喚してバトル!【ヒカキンのマイクラ実況Part300】【ヒカクラ】 HikakinGames 10717658 Neutral 0.287166251 declarative information-providing 【青鬼3】ヒカキンの青鬼3実況 Part6 (ひろし編最終回)【ホラーゲーム】 HikakinGames 10695118 Neutral 0.270149597 declarative information-providing にゃんこ大戦争にヒカキン登場!【ヒカキンゲームズ】 HikakinGames 10663546 Neutral 0.293736499 declarative information-providing 猫の名前が決まりました!【ヒカキンTV】【ねこ cat】 HikakinTV 10398923 Neutral 0.269381249 declarative information-seeking 【旅動画】 一泊16万の超高級ホテル!ヒカキン&マスオ愛媛松山の旅! HikakinTV 10393901 Neutral 0.283858121 declarative information-providing はじめしゃちょー×ヒカキン×シルクで虫入りチョコジャンケンバトルwww HikakinTV 10147502 Neutral 0.305600654 declarative information-providing ヒカキン握手会で大暴走www【名古屋】 HikakinTV 10057215 Neutral 0.299035651 declarative information-providing ヒカキンのスーパーマリオオデッセイ実況 Part8【都市の国 後編】 HikakinGames 9833931 Neutral 0.254225072 declarative information-providing 【マインクラフト】ヒカキン×まいぜんシスターズ初コラボでTNT1000個爆破ドッキリwww【ヒカキンゲームズ】 HikakinGames 9758510 Neutral 0.296610991 declarative information-providing ヒカキンのスーパーマリオオデッセイ実況 Part4【湖】 HikakinGames 9732901 Neutral 0.295832008 declarative information-providing 【青鬼2】ヒカキンの青鬼2実況プレイ Part0【ホラーゲーム】 HikakinGames 9713720 Neutral 0.294188263 declarative information-providing 弁当100種類食べれるまで帰れません!ヒカキン×フィッシャーズで語りまくる動画! HikakinTV 9651605 Neutral 0.397992906 declarative information-providing 【マインクラフト】ファミマついに完成へ!内装を一気に作る!【ヒカキンのマイクラ実況 Part277】【ヒカクラ】 HikakinGames 9634299 Positive 0.660641368 declarative information-providing 【ご報告】まるおの兄弟が家族になりました!まるおと初対面!【2匹目の猫】 HikakinTV 9354609 Neutral 0.274611997 declarative information-providing 【青鬼3】ヒカキンの青鬼3実況 Part5【ホラーゲーム】 HikakinGames 9161631 Neutral 0.293452177 declarative information-providing 【超閲覧注意】ヒカキン vs 巨大ゴキブリ【2017ver. 】 HikakinTV 8969739 Neutral 0.272414185 declarative information-providing 【セイキンジュニア誕生】ヒカキン、ガチでおじさんになりました!【ポンちゃん出産】 HikakinTV 8913135 Neutral 0.288684616 declarative information-providing 【マインクラフト】エメラルド鉱石見つけるまで帰れまてん!【ヒカキンのマイクラ実況 Part148】【ヒカクラ】 HikakinGames 8914397 Neutral 0.304358392 declarative information-providing 【元祖青鬼】新ヒカキン編 Part2【ヒカキンゲームズ】 HikakinGames 8896152 Neutral 0.295832008 declarative information-providing 【マインクラフト】ゾンビ100体と対決してみた!【ヒカキンのマイクラ実況 Part136】【ヒカクラ】 HikakinGames 8766752 Neutral 0.309436957 declarative information-providing 【超巨大】跳び箱20段にヒカキンが挑戦!余裕だろ!【モンスターボックス】 HikakinTV 8746587 Positive/Negative 0.538357153 declarative information-providing 【青鬼3】ヒカキンの青鬼3実況 Part0【HIKAKIN編】【ホラーゲーム】 HikakinGames 8701792 Neutral 0.292014801 declarative information-providing Ariana Grande - Break Free ft. HIKAKIN HIKAKIN 8576978 Neutral 0.304773989 declarative information-providing ヒカキンのスーパーマリオオデッセイ実況 Part7【都市の国 前編】 HikakinGames 8544734 Neutral 0.254225072 declarative information-providing ヒカキン vs 草なぎ剛!コーラ一気飲みバトルしたらまさかの結果に!【負けたらデスソース】 HikakinTV 8272861 Negative 0.715611991 declarative information-providing 【スライム700ℓ】超巨大スライムプールでASMRやったら大変なことにwww【ヒカキンTV】 HikakinTV 8203404 Neutral 0.33654365 declarative information-providing 新車購入!!ヒカキン & セイキン 東京ドライブ! 新型レクサス LS500h SeikinTV 8143394 Neutral 0.280167755 declarative information-providing 【マインクラフト】カズクラワールドで遊んでみた!前編【ヒカキンのマイクラ実況 Part202】【ヒカクラ】 HikakinGames 7939836 Neutral 0.311816451 declarative information-providing 【マインクラフト】村人ゾンビを治療してみた!【ヒカキンのマイクラ実況 Part53】【ヒカクラ】 HikakinGames 7931460 Neutral 0.308665018 declarative information-providing 【青鬼3】ヒカキンの青鬼3実況 たけし編(後編)【ホラーゲーム】 HikakinGames 7930029 Neutral 0.293452177 declarative information-providing Beatbox Game 4 - HIKAKIN vs Daichi Daichi Beatboxer 7741224 Neutral 0.305493632 declarative information-providing ヒカキン握手会でまた大暴走www【福岡】 HikakinTV 7624526 Neutral 0.296273981 declarative greeting ヒカキンのスーパーマリオオデッセイ実況 Part6【雲の上でクッパとバトル】 HikakinGames 7480439 Neutral 0.295832008 declarative information-providing 【超豪華】ヒカキンさん家探検してみた!! Fischer's-セカンダリ- 7476724 Positive 0.601263711 declarative information-providing 【人生最高額】てつや、時計をヒカキンさんと買う!! 東海オンエア 7307984 Neutral 0.532513207 declarative information-providing ヒカキンvsセイキンでタマゴ30個割りまくりバトル!【うまれて!ウーモ ミニ♡】 HikakinTV 7238466 Neutral 0.304977113 imperative directive 【元祖青鬼】新ヒカキン編 Part1【ヒカキンゲームズ】 HikakinGames 7175025 Neutral 0.295832008 declarative information-providing 【警察沙汰】今まで受けた迷惑行為について全て話します【暴露】 HikakinTV 7126105 Negative 0.227676477 declarative information-providing 【愚痴動画】ヒカキン、外歩けなくなるwww【悲報】 HikakinTV 7024088 Neutral 0.279289784 declarative information-providing 【青鬼オンライン】ヒカキンし○ねっていうユーザーにブチギレてガチ勝負www【ニケちゃんスキンゲット方法】 HikakinGames 6983620 Neutral 0.347753805 declarative information-providing 【悲報】ヒカキン、週刊誌に撮られる… HikakinTV 6901849 Neutral 0.277808384 declarative information-providing ヒカキンvsセイキン!ラスボスになってセイキンぶっ倒すよ HikakinTV 6809974 Neutral 0.483965222 declarative information-providing 【ヒカキン1日密着】プライベート&仕事 朝から晩まで丸一日撮ってみた。【全てiPhone11 Proで撮影】【Vlog】 HikakinTV 6747456 Neutral 0.282454541 declarative information-providing 【マインクラフト】悲報。ブタさん、逝く…実績解除してみた!【ヒカキンのマイクラ実況 Part70】【ヒカクラ】 HikakinGames 6728073 Positive 0.672989633 declarative information-providing 【マインクラフト】ヒカクラ村を一気に修理!色んなとこなおすぜ!【ヒカキンのマイクラ実況 Part267】【ヒカクラ】 HikakinGames 6722279 Neutral 0.300352657 declarative information-providing 【マインクラフト】公衆トイレと自販機作って公園拡大!【ヒカキンのマイクラ実況 Part217】【ヒカクラ】 HikakinGames 6695378 Neutral 0.322510004 declarative information-providing 【マインクラフト】悲報…お花収穫装置作ってたらやらかした…【ヒカキンのマイクラ実況 Part290】【ヒカクラ】 HikakinGames 6672919 Negative 0.566581422 declarative information-providing ヒカキンが3年ぶりに東京で車運転したらヤバかったwww【ヒカキン&セイキン】 SeikinTV 6365228 Neutral 0.266325842 declarative information-providing ヒカキンのスーパーマリオオデッセイ実況 Part12【最終章へ! 超巨大ドラゴンとバトル!】 HikakinGames 6217186 Neutral 0.247160075 declarative information-providing 【長編】ヒカキン & セイキンで本当の無人島に行ったら謎の巨大卵を発見!! SeikinTV 6137391 Negative 0.152884081 declarative information-providing 【スマブラSP】ユーチューバーみんなで発狂ガチンコ勝負www【ヒカキン vs PDS vs マスオ】 HikakinGames 6117603 Neutral 0.295832008 declarative information-providing 新ヒカキンTV スタート!! HikakinTV 6046932 Neutral 0.423244879 declarative information-providing 【青鬼2】ヒカキンの青鬼2実況プレイ Part11(ひろし編最終回)【ホラーゲーム】 HikakinGames 6021168 Neutral 0.294188263 declarative information-providing 【マインクラフト】ボロボロのヒカクラ村を一気に修復!【ヒカキンのマイクラ実況 Par349】【ヒカクラ】 HikakinGames 6005246 Negative 0.263600659 declarative information-providing 「筋肉」で検索した場合
みんな大好き筋肉です(筋肉系Youtuberが最近増えている気がします)
なすび屋さんの強さが目立ってます。結構似たタイトルも多いですね。
ヒカキンと同様に、感情はほぼNeutral(中立)、発話行為はほぼinformation-providingになっています。
title channel viewcount emotion score modality act 腕相撲も強い?神の粉で筋肉が覚醒した男 なすび屋 43135465 Neutral 0.336979602 interrogative information-seeking TVアニメ「ダンベル何キロ持てる?」OPテーマ Muscle Video KADOKAWAanime 23795293 Neutral 0.3140117 declarative greeting 神の粉で覚醒?筋肉野郎のクレイジーな日常 なすび屋 22821464 Neutral 0.31539335 interrogative information-seeking 世界の筋肉少年 TOP 3 なすび屋 20759578 Neutral 0.310650095 declarative information-providing これが神の粉か…? 筋肉への追い込みも匠の領域。 Blessing Awodibu Powder to power up !? なすび屋 17567137 Neutral 0.537315633 interrogative あれが神の粉か…? 筋肉への追い込みも限界突破。 Powder to power up?? なすび屋 10257969 Neutral 0.613538559 interrogative キレると変身!? 神の粉で筋肉が覚醒した男 なすび屋 10062640 Neutral 0.246968479 interrogative information-seeking 職務質問される神の粉で筋肉が覚醒した男 なすび屋 7900010 Neutral 0.328455816 declarative information-providing アフリカ人の身体能力と筋肉のエグさが分かる4分間 なすび屋 7161885 Positive 0.276833041 declarative information-providing [みんなで筋肉体操] 腕立て伏せ ~ 厚い胸板をつくる ~ NHK NHK 6543659 Neutral 0.318053369 declarative 筋肉、内臓がわかる!人体模型パズル / Human anatomical model puzzle. Japanese toy おもしろ雑貨コレクター 6245305 Positive 0.247989289 declarative information-providing シルクVSダンテ懸垂パトル【Youtuber筋肉番付】 PDS PDSKabushikiGaisha 6093085 Neutral 0.216346914 declarative information-providing どっちが化け物!?筋肉人間と妖怪人間 隙間男 Stalking Vampire 8 劇団スカッシュ(SQUASHfilms) 5015843 Negative 0.718932691 interrogative information-seeking シュワちゃんの全盛期の筋肉が凄すぎる! なすび屋 4504248 Positive 0.752814846 declarative information-providing ストリート最狂の男。激しい筋肉の鍛えかた【筋トレ】 なすび屋 4306002 Neutral 0.288148925 declarative information-providing 痛いけど頑張ります。(筋肉) 緒方友莉奈 3968754 Neutral 0.305030431 declarative information-providing プロ格闘家 VS 神の粉で筋肉が覚醒した男 なすび屋 3841108 Neutral 0.286734898 declarative information-providing [みんなで筋肉体操] 腹筋 ~ 凹凸ある腹筋をつくる ~ NHK NHK 3787920 Neutral 0.355231012 declarative 神の粉で筋肉が覚醒した男の『狩り』 なすび屋 3061109 Neutral 0.320798546 declarative information-providing [みんなで筋肉体操] スクワット ~ 強じんな足腰をつくる ~ NHK NHK 2965659 Positive 0.55213322 declarative 怒らすと怖い!? 神の粉で筋肉が覚醒した男 なすび屋 2892239 Negative 0.724352891 interrogative information-seeking [みんなで筋肉体操] 背筋 ~ 語れる男の背中をつくる ~ NHK NHK 2615039 Neutral 0.321853763 declarative 明石家電視台 「筋肉アスリート16人大集結」 ジュラシック木澤出演部分 2016 10 17 takeda yamanaka 2470927 Neutral 0.286099077 declarative information-providing 筋肉留学でやせて帰国!?なかやまきんに君に過去最高のライバル出現!憧れの海外留学で大失敗したコトとは?『しくじり先生 俺みたいになるな!!』#6 アベマTVオリジナル・未公開シーン含む完全版を公開中! AbemaTV【アベマTV】公式 2458717 Neutral 0.432159719 interrogative information-seeking 男4人で目隠しツイスターやったら筋肉痛不可避なほど辛かったわ!! Fischer's-フィッシャーズ- 2413088 Negative 0.48212253 declarative information-providing 筋肉とルックスが完璧な男。 ジェフ・シード Jeff Seid【筋トレ】 なすび屋 2381630 Positive 0.624242143 declarative 【脚やせ】ふくらはぎを細くするマッサージ方法【筋肉太り&ダイエットに】 石井亜美AmiIshii 2352664 Neutral 0.292224732 declarative information-providing [みんなで筋肉体操] スクワット 3 ~ 強い足腰をつくる ~ NHK NHK 2294235 Neutral 0.317960906 declarative [みんなで筋肉体操] サーキット~腕立て伏せ・腹筋・スクワット・背筋を5分で!~ 新春!豪華筋肉祭り NHK NHK 2215517 Positive 0.59731827 【3か月で-18kg】自宅でできる武田真治の筋肉リズム体操! 日テレ公式チャンネル 2197826 Neutral 0.382127758 declarative information-providing カズVSダンテ腕相撲対決 【YouTuber筋肉番付】 PDS PDSKabushikiGaisha 2127155 Neutral 0.188784607 declarative information-providing 楽して筋肉をつける方法 Easy Muscle training Invade London カズチャンネル/Kazu Channel 1985939 Positive 0.55140188 declarative information-providing 脂肪を落として筋肉を残す!!わざと太って4ヶ月で13キロ以上痩せました!! サイヤマングレート 1916788 Neutral 0.413526995 declarative information-providing リアル亀仙人の筋肉が凄すぎる【筋トレ】 なすび屋 1899600 Negative 0.680898762 declarative information-providing 蹴りが速すぎる格闘家。 瞬発力抜群の筋肉は必見!! なすび屋 1884009 Positive 0.614582875 declarative information-providing [みんなで筋肉体操] 腹筋 2 ~ 続・凹凸ある腹筋をつくる/Crunches ~ NHK NHK 1765473 Neutral 0.300709159 declarative 【寸劇】かき氷食べたら筋肉ムキムキになっちゃった!暑苦しい男達の肉乗せプロテイン入りマチョ氷 マッチョってかっこいい〜れおくんあおいちゃん Leoichannelれおいちゃんねる 1709132 Positive 0.560031327 declarative information-providing Twitterで話題の狂気的な筋肉ゲーム!? - マッスル行進曲 ポッキー 1665506 Neutral 0.253806104 interrogative information-seeking 現役Kー1選手の全力パンチ!!動ける筋肉と魅せる筋肉の違いが分かる! ぷろたん日記 1638927 Positive 0.266324599 declarative information-providing 【筋肉がみたい】大好きな細マッチョだった! ガリットチュウ 福島 1630399 Positive 0.565764447 declarative information-providing 【MV】筋肉少女帯「混ぜるな危険」 TOKUMAJAPAN 1550538 Neutral 0.280868074 declarative information-providing 神の粉で筋肉が覚醒した男の『筋肉料理』 なすび屋 1540029 Neutral 0.320798546 declarative information-providing 【4分で脂肪が減り筋肉が付く】太りにくい体に変えていく‼【サーキット筋トレ】 ジェットゆうの成長日記 1524759 Neutral 0.47334413 declarative information-providing 筋肉野球!日本代表選手の150キロに挑戦!!奇跡が!!! サイヤマングレート 1506651 Positive 0.539655616 declarative information-providing 俺んちで筋肉ギャルと筋トレが楽しすぎた!!お泊まり確定? サイヤマングレート 1454324 Positive 0.175522246 interrogative information-seeking 【衝撃】これ効果はんぱない?1回で筋肉痛になるトレーニングとは!!!!【お腹痩せ】 HIKARIやで 1394492 Neutral 0.3616634 declarative information-providing 海で出会った筋肉ギャルと焼肉に行ったらまさかの逆プロポーズ!?筋肉はモテる!! サイヤマングレート 1335730 Neutral 0.586053442 interrogative information-seeking [みんなで筋肉体操] 腕立て伏せ 3 ~ かっこいい上半身をつくる ~ NHK NHK 1316193 Positive 0.594560463 declarative なかやまきんに君、筋肉留学でジム行くペースが激減!?アメリカでのしくじり|しくじり先生 しくじり先生 俺みたいになるな!! 1303661 Neutral 0.334824652 interrogative information-seeking ダウンタウン・浜田雅功が筋肉に憧れ!?マッスルスーツで大変身! 『マッスルスーツ Every(エブリィ)』新CM「ハマダがいい人になった篇」 oricon 1238335 Positive 0.521848712 interrogative information-seeking ※飛ばしにおいての【コック】とは??筋肉量が女子判定されてもドライバーで300y飛ばせる秘密公開 DaichiゴルフTV 1240810 Neutral 0.310064326 interrogative information-seeking [みんなで筋肉体操] 腕立て伏せ 2 ~ 続・厚い胸板をつくる/Push-ups ~ NHK NHK 1215051 Neutral 0.268715823 declarative 信じられない…!!アジア人女性のありえない筋肉 なすび屋 1169286 Neutral 0.374130738 declarative information-providing 自重トレで筋肉なんか付く訳ない。 メトロンブログ 1099556 Neutral 0.268984249 declarative information-providing 【革命】着る筋肉!重いモノも持てるようになるマッスルスーツがやばいwwwwwムキムキ はじめしゃちょー(hajime) 1094317 Negative 0.744155682 declarative information-providing 【アニメ】ドーピングをするとどうなるのか?偽りの筋肉の誘惑… テイコウペンギン 1035609 Neutral 0.346415534 interrogative information-seeking 【衝撃!】波打つ筋肉 2選 ネック 1030206 Neutral 0.251803759 declarative information-providing ニューヨークの警察官の筋肉が超カッコいい…!!【筋トレ】 なすび屋 988717 Neutral 0.285571614 declarative information-providing ハイテンポDbD:筋肉式チェイス術 ~大胸筋編~ すき焼き大好きTV 976764 Neutral 0.3140117 declarative information-providing 筋肉少女帯 - 踊るダメ人間 siberiandm 956239 Neutral 0.304990534 declarative agreement [みんなで筋肉体操] スクワット 2 ~ 続・強じんな足腰をつくる/Squats ~ NHK NHK 958790 Positive 0.554224143 declarative 2015.09.03大學生了沒完整版 我的筋肉人同學 CTI Entertainment 888941 Neutral 0.313495298 declarative information-providing 【筋肉がみたい】大好きな細マッチョだ!【バキバキ】 ガリットチュウ 福島 873912 Positive 0.633469863 declarative information-providing 大胸筋の鍛え方を筋肉博士こと山本義徳先生から教わりました。101の理論〜胸トレ〜 【上越YG】山澤 礼明 872823 Neutral 0.295463407 declarative information-providing 【筋肉がみたい】これがチャンピオンの筋肉だ!! ガリットチュウ 福島 863009 Positive 0.583500993 declarative information-providing 若き怪力王者のパワーと筋肉のエグさが分かる5分間【筋トレ】 なすび屋 857723 Positive 0.300991443 declarative information-providing 【筋トレ】ステロイド無し!天然アフリカン・マッチョの筋肉 なすび屋 855045 Neutral 0.312060267 declarative information-providing 【筋肉対談】 「筋肉は2週間でつく!?」1週間の筋トレメニューについて。 ぷろたん日記 854732 Neutral 0.245551623 interrogative information-seeking ひたすら筋肉を強化して刑務所から脱獄してみた-The Escapists 2 一般刑務所前編【KUN】 KUN 845512 Neutral 0.238183482 declarative information-providing [みんなで筋肉体操] 背筋 2 ~ 続・語れる背中をつくる/Exercising the back muscles ~ NHK NHK 830004 Neutral 0.269296952 declarative [みんなで筋肉体操] 腹筋 3 ~ 最高の腹筋を手に入れる ~ NHK NHK 810580 Positive 0.543849334 declarative 【筋トレ】日本トップ選手達の500円筋肉メシ紹介!! サイヤマングレート 791948 Neutral 0.427833121 declarative information-providing 世界で最も格好いい筋肉女子【筋トレ】 なすび屋 788136 Neutral 0.27073383 declarative information-providing ハイテンポDbD:筋肉式チェイス術 すき焼き大好きTV 777726 Neutral 0.3140117 declarative information-providing 少林カンフーの筋肉の鍛え方【筋トレ】 なすび屋 770651 Neutral 0.295832008 declarative information-providing アフリカ人の身体能力と筋肉がエグすぎる…!! なすび屋 772714 Neutral 0.38973827 declarative information-providing 500円以内で買えるセブンの筋肉飯の紹介!! サイヤマングレート 762598 Neutral 0.409574771 declarative information-providing 【日本vs韓国】どっちの筋肉が凄いのか??【筋トレ】 なすび屋 760782 Positive 0.578203141 interrogative information-seeking 巨大鍋で水無し高タンパク筋肉カレー作ったら美味すぎて衝撃の展開が!!【サイヤ飯】 サイヤマングレート 757259 Neutral 0.287946325 declarative information-providing [公式]【6か月で-20kgウエスト-30cm】武田真治の筋肉リズム体操第二! 「有吉ゼミ」毎週月曜よる7時放送 日テレ公式チャンネル 754735 Neutral 0.305880571 declarative information-providing <筋肉対談>筋肉痛の時の過ごし方って?超回復! ぷろたん日記 752163 Neutral 0.38873027 interrogative information-seeking 【我々式】今日から君は「筋肉」だ!【大喜利】 主役は我々だ!【グルッペン・フューラー】 746034 Neutral 0.286083839 declarative information-providing 『みんなで筋肉体操』DVD付きブックが発売! ポプラ社 733374 Neutral 0.390010153 declarative information-providing 初心者が効率よく筋肉をつける方法【筋トレ編】 Yasu Fitness 732506 Positive/Negative 0.568800041 declarative information-providing 【ポケモンUSUM】色違いマッシブーン6体で「偽物」の筋肉を倒す【ゆっくり実況】 ぽへチャンネル 724122 Neutral 0.290778809 declarative information-providing [みんなで筋肉体操] 二の腕&尻~目指せ!メリハリボディー!~ 新春!豪華筋肉祭り NHK NHK 707581 Neutral 0.31445837 なかやまきんに君、仕上がった筋肉で見事な投球! 自画自賛の始球式 『福岡ソフトバンクホークス対東北楽天ゴールデンイーグルス戦セレモニアルピッチ』 oricon 711981 Positive 0.568804137 declarative information-providing 筋肉少女帯 - 日本印度化計画PV Tinbue1234 701649 Neutral 0.305934973 declarative information-providing 【Fortnite】筋肉VS筋肉!最強のミニガンを巡って脳筋サンタとブルータスがガチムチバトル!ゆっくり達のフォートナイト part301 ぐさお / Gusao 699789 Positive 0.579406795 declarative information-providing 【ゆっくり実況】筋肉と筋肉がぶつかり合ってオセロする【逆転オセロニア×幽遊白書】 酒桜 689910 Neutral 0.329293822 declarative information-providing ºoº ディズニー 美女と野獣 本格ミュージカルショー ライブ オン ステージ 筋肉隆々のガストンも登場する本格ミュージカル Beauty and the Beast-Live on Stage DuffyChannel 681003 Positive 0.510309726 declarative information-providing 細マッチョ・マッチョ・ゴリマッチョ、タイプの違う筋肉YouTuber海で一番モテる身体対決!!予想外の結果に!!! サイヤマングレート 677445 Neutral 0.445320099 declarative information-providing 【みんなで筋肉クイズ】アメリカ50州 ~ 厚い胸板をつくる QuizKnock 674053 Neutral 0.305436549 declarative information-providing 【筋トレ】一年でどれだけ筋肉つけられるの? Kanekin Fitness 666632 Neutral 0.632241697 interrogative information-seeking 第1回筋肉お披露目会!!人気No.1は誰だ!?【ザ・ラストヒーロー〜ヘラクレスの掟〜】#8前編(2016.8.25 O.A.) 劇団ヘラクレスの掟 662342 Neutral 0.300942493 interrogative information-seeking 第1回筋肉お披露目会!!人気No.1は誰だ!?【ザ・ラストヒーロー〜ヘラクレスの掟〜】#8前編(2016.8.25 O.A.) 劇団ヘラクレスの掟 662342 Neutral 0.300942493 interrogative information-seeking 身長206cm 巨人の驚くべき筋肉&運動能力 なすび屋 657897 Neutral 0.323164974 declarative information-providing 【Fortnite】ガチムチ脳筋サンタ、参上!ムキムキの筋肉が奏でるジングルベル!ゆっくり達のフォートナイト part18 ぐさお / Gusao 651404 Positive 0.591717368 declarative information-providing 【神回】なかやまきんに君に絶対笑える筋肉一発ギャグを習ったらもうヤバイwww ぷろたん日記 648267 Positive 0.424693171 declarative information-providing 筋肉少女帯人間椅子「地獄のアロハ」 TOKUMAJAPAN 636557 Neutral 0.304419599 declarative information-providing 「寿司」で検索した場合
寿司で検索すると英語のsushiも引っかかるみたいで、ワールドワイドな英語タイトルが上位に入ってきました。専門ジャンルではないためか、有名どころのYoutuberさんの動画が引っかかった印象です。
(今回の「文章の付け方で再生数を調査する」という目的には、チャンネル人気の影響が大きすぎてよくなかったかもしれません)
こちらも感情はほぼNeutral(中立)、発話行為はほぼinformation-providingになっています。
title channel viewcount emotion score modality act ヘイ!いらっしゃい!すしかたちパズルでお寿司やさんごっこ Kan & Aki's CHANNELかんあきチャンネル 38277831 Neutral 0.290976604 declarative greeting Japanese Street Food - BLUEFIN TUNA CUTTING SHOW & SUSHI / SASHIMI MEAL Travel Thirsty 22748630 Neutral 0.279988625 declarative information-providing 天井にいたらどのくらいでバレるの?【恐怖】 SUSHI RAMEN【Riku】 21224186 Negative 0.662780507 interrogative information-seeking まほうのお寿司屋さん まほうの楽しいパン屋さん まほうのティーセット Play house of magic 20sarasa(にーさら) 19010057 Positive 0.565512994 declarative greeting Sushi for Cats JunsKitchen 18440110 Neutral 0.3140117 declarative information-providing E17 Wanna have kaiten-sushi at office? You can make it by yourself Ms Yeah 办公室小野官方频道 Ms Yeah Official Channel 17217952 Neutral 0.271905771 interrogative How to Eat Sushi: You've Been Doing it Wrong Munchies 16378058 Neutral 0.314022026 declarative information-providing Japanese Street Food - Seared Bonito and Sushi Japan Food Adventure 16278639 Neutral 0.307511953 declarative information-providing バツゲームいり!?おっ寿司ゲーム! Kan & Aki's CHANNELかんあきチャンネル 16258315 Neutral 0.397646161 interrogative information-seeking Japanese Food - FUGU SAKE, OCTOPUS, SQUID Seafood Sushi Teruzushi Japan Travel Thirsty 15138357 Neutral 0.307767567 declarative information-providing A Day In The Life Of A Sushi Master • Tasty Tasty 14649540 Neutral 0.3140117 declarative information-providing A Japanese Take on American Sushi JunsKitchen 11497641 Neutral 0.3140117 declarative information-providing Chef Shion Uino Is the Sushi World's Next Big Thing — Omakase Eater 11091153 Neutral 0.303021999 declarative information-providing Saito: The Sushi God of Tokyo Simon and Martina 10838538 Neutral 0.305835319 declarative information-providing Japanese Food - GIANT GOLIATH GROUPER Sushi Teruzushi Japan Travel Thirsty 10755190 Neutral 0.307399607 declarative information-providing Best Sushi in Japan - Tsukiji Fish Market to $300 HIGH-END SUSHI in Tokyo! Japanese Food Mark Wiens 10247739 Neutral 0.307288003 declarative 白ミル貝のさばき方~握りと串焼き 寿司屋の仕込み how to clean a Mirugai Clam and make sushi イシ 9062625 Neutral 0.307306945 declarative information-providing Pikachu Sushi Cake ピカチュウ 寿司 ケーキ MosoGourmet 妄想グルメ 8936686 Neutral 0.3140117 declarative information-providing 【大食い】超高級寿司店で3人で食べ放題したらいくらかかるの!?【大トロ1カン2,000円】 HikakinTV 8923593 Positive 0.53840322 interrogative information-seeking ORANGE RANGE - SUSHI食べたい feat. ソイソース Victor Entertainment 8849940 Neutral 0.307511953 declarative information-providing Koi fish sushi コイ寿司 JunsKitchen 8710942 Neutral 0.3140117 declarative information-providing 寿司屋で喧嘩売られました HikakinTV 7938039 Neutral 0.343857877 declarative information-providing 【大食い】お寿司5人前食べて目指せ体重100kg! Fischer's-セカンダリ- 7614462 Neutral 0.399097819 declarative greeting 寿司100貫とラーメン10杯食べきるまで帰れません!!!【すしらーめん《りく》】 スカイピース 7101494 Neutral 0.317391205 declarative information-providing ★「わさびでドクロでた~!おうくんも寿司ネタに!!」おっ!すし屋さん★TO-FU oh! SUSHI★ プリンセス姫スイートTV Princess Hime Suite TV 7101995 Neutral 0.310696526 declarative information-providing $250 KOBE BEEF STEAK Teppanyaki & Sushi In Japan Travel Thirsty 6244397 Neutral 0.292408151 declarative information-providing Can you see? I'm SUSHI~NHK Minna no Uta ver(NHKみんなのうたバージョン)~ / PIKOTARO (ピコ太郎) #NAME? 6075377 Neutral 0.24535261 interrogative information-seeking Japanese Food - GIANT ABALONE Liver Rice Sushi Teruzushi Japan Travel Thirsty 5858066 Neutral 0.3140117 declarative information-providing 【ゆっくり実況】爆盛キャビア寿司を食べてみた結果!?一皿10000円の超高級"うp主スペシャル寿司"完成!【たくっち】 たくっち 5803787 Positive 0.645198641 interrogative information-seeking 【100億再生突破】寿司食べながらYouTube人生13年をランキング形式で振り返る! HikakinTV 5582147 Neutral 0.393633469 declarative information-providing 天空パーティー寿し大観覧車 Ferris Wheel Sushi 鈴川絢子/Suzukawa Ayako 5443637 Neutral 0.3140117 declarative information-providing How America’s First 3 Star Michelin Sushi Chef Serves His Fish Eater 5301221 Neutral 0.313177385 declarative information-providing 握ると寿司できちゃうトング / SUSHI TONGS. Japanese Cooking Gadgets おもしろ雑貨コレクター 4848607 Neutral 0.261272759 declarative information-providing Japanese Food - $300 HIGH END SUSHI Teruzushi SUSHIBAE Japan Travel Thirsty 4519356 Neutral 0.307511953 declarative information-providing Japanese Street Food - LOBSTER SUSHI Japan Seafood Travel Thirsty 4453309 Neutral 0.3140117 declarative information-providing 24 Hours With A Michelin Star Sushi Chef: Sushi Kimura SETHLUI.com 4401254 Neutral 0.284049712 declarative information-providing Temari Sushi (Sushi Balls) JunsKitchen 3891271 Neutral 0.290616634 declarative information-providing LARVA - SUSHI 2016 Full Movie Cartoon Videos For Kids LARVA Official WildBrain – Kids Videos 3887172 Neutral Japanese Food - FISH CUTTING SKILLS Salmon, Mackerel, Squid Sushi Kyoto Seafood Japan Travel Thirsty 3833132 Neutral 0.307767567 declarative information-providing 寿司打 23740円 58皿 1171打 6.6打/秒 ミス5回 パソ活 3658595 Neutral 0.3140117 declarative agreement 回転寿司の食べ放題やべえwwwwwwwマジでキツイwwwwwww はじめしゃちょーの畑 3412833 Negative 0.718782437 declarative information-providing Tokyo Best Sushi / The art of Sushi making - 寿司 - すし - 4K Ultra HD TokyoStreetView - Japan The Beautiful 3377349 Neutral 0.295041561 declarative information-providing 대왕연어초밥 리얼사운드먹방 / Giant Salmon Sushi Mukbang Eating Show суши サーモン ปลาแซลมอน Cá hồi Лосось 三文鱼 푸메Fume 3370833 Neutral 0.307713269 declarative information-providing Japanese Street Food - TSUKIJI MARKET SUSHI SASHIMI Japan Seafood Travel Thirsty 3348474 Neutral 0.3140117 declarative information-providing sushi Fadley Abdullah 3257644 Neutral 0.3140117 declarative information-providing Jun tries American sushi! Rachel and Jun 3104336 Neutral 0.397531994 declarative information-providing 高級すし屋なら100均の寿司を出されても気づかない説【Raphael】 ラファエル Raphael 3047128 Negative 0.693214583 declarative information-providing Master Sushi Chef "Noz" Wants to Transport His Diners to Japan — Omakase Eater 3013570 Neutral 0.302923023 declarative information-providing 倒したやつは約1万円分の寿司を自腹で食べていただきます。 Fischer's-フィッシャーズ- 2930392 Neutral 0.382905862 declarative information-providing MiniFood sushi 食べれるミニチュア寿司 Miniature Space 2913994 Positive 0.631484824 declarative information-providing ウィル・スミスと手巻き寿司を作りながらゆるトーク!こんな気さくなハリウッドスターいる??〔#834〕 バイリンガール英会話 Bilingirl Chika 2909910 Positive 0.433275543 interrogative 【大食い】寿司を握って食べる 総重量約6.5㎏~ウニ・カニ・その他魚卵たち~ /谷やん谷崎鷹人 2826442 Neutral 0.350082527 declarative information-providing Japanese Food - GIANT RED GROUPER Mackerel Flounder Sushi Teruzushi Japan Travel Thirsty 2812529 Neutral 0.3140117 declarative information-providing Japanese Food - HIGH END SUSHI in Bangkok Seafood Thailand Travel Thirsty 2793565 Neutral 0.3140117 declarative information-providing Spinning SUSHI Eat Forever はじめしゃちょーの畑 2707723 Neutral 0.3140117 declarative information-providing 500円皿のみ!回転寿司で一番高い大トロ頼み続けたら何個で在庫切れして会計いくらになる? ヒカル(Hikaru) 2696559 Neutral 0.664248717 interrogative information-seeking Japanese Food - EEL BURGER Sushi Teruzushi Japan Travel Thirsty 2620948 Neutral 0.307399607 declarative information-providing 寿司職人によるマグロの仕込みから握りまで〜How To Make Tuna Sushi〜 寿司マスターToshi 2569660 Neutral 0.309692562 declarative information-providing MANTAP! SUSHI PALING MURAH DI JEPANG! ¥100 SUSHI - HAMAZUSHI はま寿司で食べる Nihongo Mantappu 2545998 Neutral 0.298772957 declarative information-providing 【大食い】YouTuber限定の食べ放題⁉高級寿司100貫食べ切れるまで帰れません!!【きんのだし】 Fischer's-フィッシャーズ- 2540980 Positive 0.546844771 declarative information-providing 【寿司】銀座 久兵衛 美味しんブログ Delicious blog 2384675 Neutral 0.269338984 declarative information-providing Tokyo's Freshest Sushi Tsukiji Fishmarket Abroad in Japan 2341995 Neutral 0.31445837 declarative へい!おまち~? 家を回転すし屋さんにしてみた? KahoSei Channel from Canada 2053168 Neutral 0.358992707 declarative information-providing How Master Sushi Chef Keiji Nakazawa Built the Ultimate Sushi Team — Omakase Eater 2042702 Neutral 0.304097301 declarative information-providing 「大将、一番高いネタだけで」回らないお寿司で最も高価な握りを頼み続けたら会計いくらになる? ヒカル(Hikaru) 1856633 Neutral 0.698412268 interrogative information-seeking 映画 『デッド寿司』 予告編 Dead Sushi (Long Version) Trailer HD deadsushiiii 1802182 Neutral 0.280600307 declarative information-providing カワウソコタローとハナ 2歳の誕生日にお寿司をにぎってあげた! Kotaro the Otter Happy Sushi Birthday! KOTSUMET 1774859 Neutral 0.349771207 declarative information-providing 全員の食べた寿司覚えてられる?誰かが食べたネタ食べたら全額負担!! プリッとChannel 1753069 Neutral 0.454437816 interrogative information-seeking How To Roll Sushi Rolls - How To Make Sushi Rolls How To Make Sushi 1741081 Neutral 0.309461706 declarative information-providing タコのさばき方 茹で方~握り寿司と酢の物になるまで~how to fillet a Octopus and make sushi and vinegar dish 寿司屋の仕込み イシ 1724934 Neutral 0.361750487 declarative information-providing How to Fillet Salmon for Sushi with Special Knife (三文鱼寿司) (サーモン寿司) Sushi Everyday 1712185 Neutral 0.265939868 【大食い】好きな寿司ネタ対決なら絶対に負けない説 スカイピース 1674785 Positive 0.654393071 declarative information-providing 【食べログ】評価が一番低い寿司屋に食べに行ったら… タケヤキ翔/ラトゥラトゥ 1674790 Neutral 0.417676419 declarative information-providing 【オバマ大統領来店済み】世界一美味い寿司を握る男 小野二郎 すきやばし次郎【Sushi/Sukiyabashi Jiro】 musicgo5 1645544 Positive 0.607833754 declarative information-providing あの【EXIT】とコラボ!!英語禁止で寿司100貫食べきるまで帰れません!! プリッとChannel 1643839 Neutral 0.434209683 declarative information-providing はねとび 回転SUSHI 初回 2006年 かず子笹山 1593487 Neutral 0.29345369 declarative information-providing 一貫4000円?時価の寿司ネタだけを食べ続けたら会計が想像軽く超えてた… ヒカル(Hikaru) 1573279 Neutral 0.186717117 interrogative information-seeking 【フォートナイト】味方にバレずにお寿司1万円分食べながらビクロイチャレンジやってみたww【大食い】 総長ウララ 1557778 Positive 0.617320905 declarative information-providing SUB)매콤칼칼 김치우동 긴~꼬리 초밥 먹방 ? 리얼사운드 Sushi Kimchi Udon MUKBANG ASMR 문복희 Eat with Boki 1545441 Neutral 0.3140117 declarative information-providing 대왕연어초밥 10box 먹방ASMR great king salmon sushi サーモン寿司 ซูชิแซลมอน sushi cá hồi eating sounds mukbang 교광TV 1508850 Neutral 0.3140117 declarative information-providing 海外の寿司との違いに驚愕!外国人カップルが寿司を爆食!/ Weird and Great Sushi Experience! 日本食冒険記Tokyo Food Adventures 1471305 Neutral 0.394663773 declarative information-providing Snow Man【気持ちを読み取れ】ラウールの食べたいお寿司を当てろ! ジャニーズJr.チャンネル 1473699 Neutral 0.548673294 imperative directive 【鬼畜ゲーム】負けた奴から寿司100個食べていけ!! スカイピース 1468045 Negative 0.513468985 imperative directive これで8000円?…肉寿司の大食いで行った店がクソマズいぼったくり店だった…失礼承知でボロクソに言ってぶった斬る!!! ヒカル(Hikaru) 1446317 Negative 0.239764327 interrogative information-seeking 【回転寿司 魚べい】オーストラリア人家族が回転寿司を初体験 / Kids Love Conveyor-belt Sushi 日本食冒険記Tokyo Food Adventures 1360398 Neutral 0.305893295 declarative information-providing LARVA - SUSHI SPECIAL Cartoon Movie Cartoons For Children Larva Cartoon LARVA Official Larva TUBA 1349812 【Konapun】Sushi Cake making in Cooking Studio Miniature Room(ミニチュア ルーム) 1333368 Neutral 0.3140117 declarative information-providing ASMR SASHIMI SUSHI + STRAWBERRY WHITE CHOCOLATE MOCHI (EATING SOUNDS) NO TALKING SAS-ASMR SAS-ASMR 1321922 Neutral 0.289743569 declarative 母親が来日!人生初めて親孝行、お寿司をご馳走!??→?? あしや 1297983 Positive 0.461866448 declarative greeting 巨大なサーモン寿司を作って食べる!【モッパン】 かの/カノックスター 1289558 Negative 0.597178911 declarative information-providing 【喋りすぎ】岡山の奇跡の女と寿司いっぱい食べるよ テオくんホーム 1286420 Positive 0.583358174 declarative information-providing 【寿司1000個】Japanese 1000 SUSHI eating battle. はじめしゃちょーの畑 1282142 Neutral 0.352364704 declarative information-providing SUB)대왕연어초밥 리얼사운드 먹방ASMR?MUKBANG GIANT SALMON SUSHI EATING SOUNDS SHOW 大王鮭寿司 cá hồi แซลมอน [상윤쓰]Sangyoon 1265340 Neutral 0.3140117 declarative information-providing 【漫画】私「給料日は行きつけの寿司屋に行く」後輩「女のくせに生意気ですね!」→上司を巻き込む騒動にwww モナ・リザの戯言 1260619 Negative 0.590871436 declarative information-providing (実話)すしざんまい社長が海賊を絶滅させていた話(マンガで分かる) アシタノワダイ 1257142 Positive 0.180204352 declarative information-providing はねとび 回転SUSHI 2006年 かず子笹山 1214141 Neutral 0.3140117 declarative information-providing 食材かぶったら食べられません!【手巻き寿司】 プリッとChannel 1221387 Neutral 0.331901985 declarative information-providing Ninja Sushi's Rescue Mission Ice Creams, Hamburger Vending Machine, Donuts Baby Songs BabyBus BabyBus - Nursery Rhymes 1169758 Neutral THE KING OF SUSHI IN JAPAN:SUSHI SAITO 【 $300 HIGH-END SUSHI IN TOKYO Japanese Food 】 IKKO'S FILMS 1157439 Neutral 0.27331887 declarative クジで引いた色の寿司を20分間でどっちが多く食べれるか!? プリッとChannel 1145451 Neutral 0.695132498 interrogative information-seeking 結論
- 感情値ほぼニュートラル。心理学で有名な「ネガティブな記事は拡散されやすい」という現象は見られませんでした。
- 表現分類はほぼ「情報提供」になりました。この動画がどのような情報を提供するのか簡潔にわかるようなタイトルにすると再生数が上がりやすいかも(?) という結果になりました。 (厳密に比較するには「再生数が低い動画タイトルが他の表現分類になる」という調査が必要)
感想
無料で使える量がとても多く、判定の種類も豊富なため、日本語テキストを解析したい場合はGoogleやAzureが提供しているものより良さげな印象でした。次のハッカソンの時などに使ってみたいですね。
サンプルコード、事例がやや少ないのでコード事例がより増えること、特に他の言語(javascript,dart,c#,java)あたりがあると開発で使いやすくなると思いました。
今回のキャンペーンでPS4を貰いたいなあ!自然言語処理楽しかったので、今後も是非こういったイベント開催して欲しいですね。https://zine.qiita.com/event/collaboration-cotoha-api/
- 投稿日:2020-03-15T23:33:45+09:00
そうだ、ぶぶ漬け食べよう。【京都弁で始める自然言語処理】
はじめに
自然言語処理初めてやります。わくわく。
この記事はQiita x COTOHA APIプレゼント企画】COTOHA APIで、テキスト解析をしてみよう!に参加しています。景品ほしすぎ!投稿間に合った。早速本題。今からやること。
最初にざっと何やるか紹介します。
できたのが以下のやつ↓python3 bubuduke.py "ヘタクソ" 「お上手どすな」こんな感じの京都弁翻訳機を作っていきます。
ぶぶ漬けおいしい!やったー!
本記事の流れ
- とりあえずCOTOHA APIを使ってみる(初めて使いました)
- 自然言語処理って何
- テキストを自然言語処理してみる
という流れで、気がついたら上のような便利ツールができているわけですね。めっちゃ簡単。
とりあえずCOTOHA APIを使えるようにする
ここから今すぐ無料登録。メールアドレスを送信してアカウントを作りましょう。できたらログイン。そしたらこんな画面になる。(ここまで宣伝)
このサイトについてはあとでIDとか使うだけなのでこれで一旦終わり。
自然言語処理って何
めっちゃ簡単にいうと人間が普段使っている言葉(=自然言語)を処理すること。いや、そのままやないかい。
これの何が難しいかと言うと、自然言語、中でも日本語がwell-definedでない ということ。日本語はwell-definedでない
「well-definedでない」というのは、定義によって一意の解釈又は値が割り当てられないということ。
ここでは一文に対して複数の解釈が考えられると言うことですね。簡単な例を考えてみました。以下の通り。
これを見てうんこを流しちゃダメだと思う人間はいないですよね。
ただ、この文章を文字通り擬似コードで書いてみるとこうなります。if 流すもの == "トイレットペーパー" then 流していいあれ?うんこ流せない気がしてきました。
京都弁はその極みである。
今回取り扱ってみようと思った京都弁。例えばこんな感じ。
上のは有名なぶぶ漬けですね。
ぶぶ漬けというのは京都弁ではお茶漬けのことを指すはず。
それなのに、ぶぶ漬けを勧められるということは、もう帰ってくれと言う意味になるんですね。
訳がわからない。とにかく京都弁は陰湿
もう1つ例を上げてみます。
ごめんなさい脱線が長いですね。
その他にも嫌味な京都言葉がたくさんあるのですが割愛。気になる方はこちらが色々載ってていいと思います。
要するに、京都弁は陰湿で、well-definedでない言葉の極み。自然言語処理では、こういった自然言語から、単語や構文を情報に照らし合わせて処理していきます。
結局自然言語についての説明しかしていないのですが。今から日本語という自然言語を処理し、こういった陰湿な京都弁"風"のリプライができるbotを実装していきます。テキストを自然言語処理してみる
ひとまずbotを作る部分は無視して、自然言語処理をやっていきます。
正直言ってここが本質なのでここ以外読まなくていいです。
ここからが本質なのですがCOTOHA 凄すぎてすぐ終わっちゃった。サンプル1
とりあえず入力を受け付けて、軽く処理してみます。
文章を受け取って名刺だけを返すデモです。
名作を参考にしました。
ライブラリの威力が半端なさすぎて何もわかってなくてもできてしまう。
まずライブラリを入れます。pip install git+https://github.com/obilixilido/cotoha-nlp.git
作ったコードがこれ。
```python:samplecode1.py
from cotoha_nlp.parse import Parserparser = Parser("Client ID",
"Client secret",
"https://api.ce-cotoha.com/api/dev/nlp",
"https://api.ce-cotoha.com/v1/oauth/accesstokens"
)
s = parser.parse(input())print(" ".join([token.form for token in s.tokens if token.pos in ["名詞"]]))
```
あとでもう1度掲載しますが、サンプルコードはGitHubに上げているのでそちらもご覧になってください。
このコードを実行してみます。python ファイル名 文字列の順で入力すると文字列を処理した結果が返ってきます。python samplecode1.py 春はあけぼの。そうだ、京都行こう。そしたら返ってくる。
>>春 あけぼの 京都いかがでしょうか。これだけのコードで十分立派な自然言語処理ができました。やばすぎ。
何も理解してない。京都弁"風"変換スクリプト完成形
続いて、京都弁風botの実装に取り掛かっていこうと思います。
先ほどのサイトからスクレイピングして、抽出した名詞と一致する日本語直訳があればその京都弁を返す。
普通の日本語の入力から作るための流れはこう。
スクレイピングをするのでちょっとライブラリを入れます。
pip3 install requests pip3 install beautifulsoup4
こんな感じになりました。
bubuduke.pyfrom cotoha_nlp.parse import Parser import requests from bs4 import BeautifulSoup import re parser = Parser("Client ID", "Client secret", "https://api.ce-cotoha.com/api/dev/nlp", "https://api.ce-cotoha.com/v1/oauth/accesstokens" ) # input s = parser.parse(input()) # get nouns nouns = [token.form for token in s.tokens if token.pos in ["名詞"]] # web scraping r = requests.get('https://iirou.com/kazoekata/') soup = BeautifulSoup(r.content, "html.parser") block = soup.find_all("p") # output for noun in nouns: for tag in block: if noun in str(tag): #strongタグ内にある京都弁を切り出し output = re.findall('<strong>.*</strong>', str(tag)) out = output[0] out = out.replace("<strong>", "") out = out.replace("</strong>", "") print(out)早速実行。
python bubuduke.py "迷惑やで"陰湿な京都弁が返ってくる!
>>「お嬢ちゃん、ピアノ上手になったなぁw」これで自然言語処理パートは終わり。
次回、botを作るだけですね。ジャンルも変わりますし本記事はここまで。次回やりたいこと
LINEのbotにしたい。
もう少し精度はあげたい。完全一致していない単語でも拾いたい。今のところ対応してる単語がめっちゃ少ないので。
その辺はまた今度書きます。おわりに
今回使ったコードのリポジトリ
最後まで読んでいただきありがとうございました。
景品欲しすぎなのでLGTMお願いします。
LGTMが受け付けない方はこの辺参考にいいねにしてね。





- 投稿日:2020-03-15T23:24:35+09:00
Pythonの機械学習に関して初学者が超簡潔にまとめてみた。
Pythonの機械学習に関して超簡潔にまとめてみた。
Pythonでできることとして今話題の機械学習/人工知能(AI)に関してまとめました。
機械学習とは、あらかじめ用意されたデータなどをもとに学習を行い、それに基づいて新たに提示されたデータの予測を行うという技術です。
ですので、データの前処理やアルゴリズム(問題を解くための手順)の選定などが重要になります。
手法に関しては2種類。
①教師あり学習→学習データとセットで正解の情報(ラベル)も用意。既存の情報から、パターンを作成し、未知のデータを予測。
②教師なし学習→正解データを持たない方式。データの特徴を分析し、データをいくつかのグループに分類化。
これを実現するライブラリの一例がscikit-learn(初学者おすすめのライブラリ)やTensorFlow(Googleが開発)です。
【機械学習の一例】
犬の写真の見極め→与えられたデータが犬の写真かどうか判定して正解だった率などを求めるなど。(判断基準には学習記録されたモデルを用いる。)
発展して、迷惑メールの見極めや人の顔の認証などにも用いられているそうです。要するに、機械学習はモデルの選定や前処理(データを学習しやすい形にする)が重要で、それによって結果も変化します。
こういった前処理など、本質的な理解を得るために微分積分・線形代数・行列・統計学などの知識が必要になるとのことです。
(NumPyやmatplotlibなども活用して計算→可視化の実現など。)※補足※
ディープラーニングをざっくり説明すると、機械学習からさらに発展させて、自ら見極めポイントなどを定めて学習していく技術みたいです。(おもろい)
おわりに
データ分析に興味があり、Pythonの学習を始めましたが、データ分析と機械学習は切っても切れないということがやっとわかりました。。。追加して、本質を理解するためには数学の知識がマストということも。
(本当に高校・大学時代ちゃんと数学を勉強しておくべきだった。。。)
よし、頑張るぞ!!
ってことで、データ分析やら機械学習に関して興味があって、概要だけでも知りたいといった初学者の方々の参考になれば幸いです。
※僕も初学者なので間違いがある可能性があります。都度修正していく予定ですので、何か間違いございましたらご教示いただけますと幸いです。
おしまい
追記
現在、こちらを参考に学習をしていこうと考えております。
とても参考になる記事ですのでリンクを記載しておきます。【保存版・初心者向け】独学でAIエンジニアになりたい人向けのオススメの勉強方法
https://qiita.com/tani_AI_Academy/items/4da02cb056646ba43b9dP.S.
4か月間一人でもくもくと勉強していたので、モチベーション維持に限界を感じてきています。
現状打破、また同じ境遇の方と交友できることを期待して、学習記録を投稿しています。
一緒にもくもく会、勉強会の企画や共同ポートフォリオ制作など面白いことしたい!!って方おりましたら、お気軽にTwitterなりご連絡ください。(切実な願い)
- 投稿日:2020-03-15T23:23:00+09:00
COTOHA APIとCloud Vision API で音声合成して絵本を読ませてみた話
COTOHA APIとは
NTTさんが出している言語解析などに使えるAPI群です。
構文解析などだけではなく、音声認識や音声合成など(有料)もついているので、これがあれば会話ロボットや、発話解析などの大体のことはできます!
今までコツコツ実装していたキーワード抽出や、言いよどみ除去など、かゆいところに手が届くような機能も満載ですし、ディープラーニングでのユーザー応答の一致率とかも取れちゃうので、精度があれば日本語を扱う上では一番最強なのではないでしょうか。構文解析、照応解析、キーワード抽出、音声認識、要約など、様々な自然言語処理・音声処理APIを提供しているサービスです。NTTグループの40年にわたる研究成果である、日本語辞書や単語を3000種以上の意味性分類する技術などを活用し、高度な解析をAPIで手軽に利用できます。
今回の製作物
絵本を撮影した画像から文字を抽出し、その文章に解析をかけて、演出をつけ、シアターとしてアウトプット出来たらものすごく面白いかもしれない、と思ったので、そのプロトを試しに作ってみた。
コロナウィルスのせいで嫁の実家に帰っている娘と会えない日々を過ごしているので、おさまったら娘と遊びたくて作った。大まかな流れとしては、
1. Cloud Vision OCRで画像からテキストを抽出する
2. google transrateでひらがなを漢字に変換する
3. COTOHA APIの音声認識誤り検知(β)で、変換ミスを補正する
4. COTOHA APIの感情分析で文章の感情を認識する
5. COTOHA APIのユーザ属性推定(β)で登場人物のペルソナを解析する
6. HOYA Voice Text APIで最適な話者と話し方を選定し、音声合成する
の手順である。1. Cloud Vision OCRで画像からテキストを抽出する
こちらに関しては今回メインではないので深くは触れない。
詳しく知りたい方は別で書いているこちらなどを参考にしてほしい。
今回テストに用いた絵本は、ガース・ウィリアムズの"しろいうさぎとくろいうさぎ"である。
これを選んだ理由は、なんとなく認識しやすそうだったのと、自分自身が初めて買ってもらった絵本で、もう死ぬほど読んでもらったやつだからである。
ソースコードは以下。
基本的に、出現するのは日本語のみであるという仮定の下、英語は除去している。
ソースコード
```python
import copy
from google.cloud import vision
from pathlib import Path
import redef is_japanese(text):
if re.search(r'[ぁ-ん]', text):
return True
else:
return Falseclient = vision.ImageAnnotatorClient()
row_list = []
res_list = []
text_path = "./ehon_text/text.txt"with open(text_path, 'w') as f:
for x in range(1, 15):
p = Path(file).parent / "ehon_image/{}.png".format(x)
with p.open('rb') as image_file:
content = image_file.read()
image = vision.types.Image(content=content)
response = client.text_detection(image=image)
if len(response.text_annotations) == 0:
row_list.append("-")
for lines in response.text_annotations:
if lines.locale != "ja":
for text in str(lines.description).split("\n"):
if is_japanese(text):
print(text)
f.write(text + '\n')
else:
print(lines.description)
f.write(lines.description)
break
f.write("\n")
```
実行結果は以下のような感じ(一部抜粋)さすがに100%とはいかないが、中々の精度である。
文章のほとんどがひらがなであるし、認識しやすいのかもしれない。
"き"と"さ"や、"ぽ"と"ぼ"などが難しいようで、よく間違える。
今回の絵本が全体的に絵に対して文字が小さいので、解像度の問題も大きい。
試しに文字だけを大きめに撮ると正しく認識した。
幸いにも今回結果のテキストは表示せず、音声合成されるので、仮に"たんぽぽ"が"たんぽぼ"になっていたとしても一瞬そう読まれた気がする程度でそこまで強い違和感はない。
娘にもばれないはず。しばらくすると、くろいうさぎは すわりこみました。 そして、とても かなしそうな かおをしました。 「どうかしたの?」 しろいうきぎが ききました。 「うん、ほく、ちょっと かんがえてたんだ」 くろいうさぎは こたえました。2. google transrateでひらがなを漢字に変換する
画像からの認識に関してはひらがなの方がありがたいが、これ以降のテキストを用いた捜査は漢字かな交じりの文章の方がよい結果が出る(はず)。
日本語というのはメンドクサイ言語で、漢字かな交じりか、ひらがなのみかでプログラムが理解する難易度が大きく変わってくる。音の情報しかないひらがなのみでは、意味を解析することは難しい。
音声合成の際の読み上げのイントネーションも違うし、解析にかける際の精度も漢字が入っているほうがよいはず。とりあえず今回はgoogle transrateを使った。
ソースコードは以下。
ソースコード
```python
import urllib
import jsonkanji_text_path = "./ehon_text/kanji_text.txt"
with open('./ehon_text/text.txt', 'r') as f:
lines = f.readlines()url = "http://www.google.com/transliterate?"
kanji_text = ""with open('./ehon_text/kanji_text.txt', 'w') as f:
for line in lines:
if line == "\n":
f.write(line)
else:
param = {'langpair':'ja-Hira|ja','text':line.strip().replace(' ','').replace(' ','')}
paramStr = urllib.parse.urlencode(param)
readObj = urllib.request.urlopen(url + paramStr)
response = readObj.read()
data = json.loads(response)
for text in data:
kanji_text += text[1][0]
print(kanji_text)
f.write(kanji_text)
kanji_text = ""```
実行結果はこんな感じ。
"同化"がつらい。。
金鳳花(きんぽうげ)なんかもちゃんと変換されているのだが、これはむしろ音声合成が読み上げられるか微妙になってくるので、あまりよくないかもしれない。しばらくすると、黒いうさぎは座り込みました。 そして、とても悲しそうな顔をしました。 「同化したの?」白いウサギ歌が聞きました。 「うん、僕、ちょっと考えてたんだ」黒いうさぎは答えました。 それから、二引きは、ヒナギクゃ金鳳花の咲いている野原で、かくれんぼをしました。3. COTOHA APIの音声認識誤り検知(β)で、変換ミスを補正する
ここで、少し興味があったので、上記の変換ミスの混じった文章を音声認識誤り検知(β)にかけると補正できないかと思い、試してみた。
音声認識でも、発話が短かったりすると構文解析が不十分で誤変換が起こったりする。それを補正するものなので、今回の目的で使用しても、目的としてはあっているはず。
ソースコードは以下。
一応信頼度が0.9を超えるものだけ、第一候補の結果と入れ替えるようにした。
ソースコード
```python
import requests
import jsonaccess_token_publish_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens"
api_base_url = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
clientid = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
clientsecret = "XXXXXXXXXXXXXXXXXXXXX"headers = {'Content-Type': 'application/json',}
data = json.dumps({"grantType": "client_credentials","clientId": clientid,"clientSecret": clientsecret})
response = requests.post(access_token_publish_url, headers=headers, data=data)
print(response)
access_token = json.loads(response.text)["access_token"]api_url = api_base_url + "nlp/beta/detect_misrecognition"
headers = {"Authorization": "Bearer " + access_token, "Content-Type": "application/json;charset=UTF-8"}with open('./ehon_text/kanji_text.txt', 'r') as f:
lines = f.readlines()with open('./ehon_text/kanji_text2.txt', 'w') as f:
for line in lines:
print(line)
data = json.dumps({"sentence": line})
response = requests.post(api_url, headers=headers, data=data)
result = json.loads(response.text)
if result["result"]["score"] > 0.9:
for candidate in result["result"]["candidates"]:
if candidate["detect_score"] > 0.9:
line = line.replace(candidate["form"], candidate["correction"][0]["form"])
# print(response)
# print(json.loads(response.text))
print(line)
f.write(line)```
結果は以下のようになった、google transrateでは"二匹"がすべて"二引き"に変換されていたが、これらの一部(すべてではない)が改善された。
改悪された部分はなかったので、こちらはかけておいて正解だと思う。
(っていうかウサギって匹で数えるんだっけ)before
毎朝、二引きは、寝床から跳ね起きて、朝の光の中へ、飛び出していきました。そして、一日中、一緒に楽しく遊びました。after
毎朝、二匹は、寝床から跳ね起きて、朝の光の中へ、飛び出していきました。そして、一日中、一緒に楽しく遊びました。4. COTOHA APIの感情分析で文章の感情を認識する
COTOHA APIでは、テキストから感情を表す単語を抽出したり、その文章全体でのネガ・ポジをとることができる。
実は音声合成でも一部感情をパラメータとして与えることができるものが存在するので、この結果を音声合成時のパラメータとして用いることができれば、より感情のこもった音読ができるはず。
また、今回は音声認識をやっていないので使わないが、使いようによってはユーザーの"ありよりのなし"といったような細かい感情もとることができるかもしれない。感情を扱うものは、単純にネガ・ポジのみを結果として与えるものと、happy, sad, angry, などの複数の感情をパーセンテージで返すもの等が多いが、COTOHA APIでは文章全体に関してが前者、特徴的な単語の単位に対してが後者が近い。
今回、しろいうさぎと、くろいうさぎと、語り手で音声を分けるつもりだったのだが、例えば、
"どうしたの(sad)"としろうさぎは言いました(happy)
みたいに、ひとつの文章内でこの三人の感情の違いがあるとおかしくなる気がしたのと、単純に長いサンプルのほうが結果も出やすいだろうと思って、APIに投げるのは"文章"の単位にしている。
ソースコードは以下。
ソースコード
```python
import requests
import json
import copyaccess_token_publish_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens"
api_base_url = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
clientid = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
clientsecret = "XXXXXXXXXXXXXXXXXXXXX"headers = {'Content-Type': 'application/json',}
data = json.dumps({"grantType": "client_credentials","clientId": clientid,"clientSecret": clientsecret})
response = requests.post(access_token_publish_url, headers=headers, data=data)
access_token = json.loads(response.text)["access_token"]api_url = api_base_url + "nlp/v1/sentiment"
headers = {"Authorization": "Bearer " + access_token, "Content-Type": "application/json;charset=UTF-8"}with open('./ehon_text/kanji_text2.txt', 'r') as f:
lines = f.readlines()story = []
text_list = []
page_sentenses = []
aa = {"sentiment": "", "text": ""}
with open('./ehon_json/ehon.json', 'w') as f:
for line in lines:
for text in line.split("。"):
if text != "\n":
data = json.dumps({"sentence": text})
response = requests.post(api_url, headers=headers, data=data)
result = json.loads(response.text)
# print(text)
# print(result["result"]["sentiment"])
text_list.append({"sentiment": result["result"]["sentiment"], "text": text})
story.append(copy.deepcopy(text_list))
text_list = []
json.dump(story, f, indent=4, ensure_ascii=False)```
結果(レスポンスの一例)は以下のような感じ。
文章的にNeutralばかりになるかと思ったが、意外と感情の起伏がある。
ネガもポジもちゃんと出てきたので、感情のこもった読み上げに一役買っていると思う。毎朝、二匹は、寝床から跳ね起きて、朝の光の中へ、飛び出していきました {'result': {'sentiment': 'Neutral', 'score': 0.3747452771403413, 'emotional_phrase': []}, 'status': 0, 'message': 'OK'} そして、とても悲しそうな顔をしました {'result': {'sentiment': 'Negative', 'score': 0.6020340536995118, 'emotional_phrase': [{'form': 'とても悲しそうな', 'emotion': 'N'}]}, 'status': 0, 'message': 'OK'}5. COTOHA APIのユーザ属性推定(β)で登場人物のペルソナを解析する
COTOHA APIには、ユーザ属性推定(β)の機能があり、結構事細かなペルソナが返ってくる。
音声合成のほうも話者数が多いので、この情報から自動で話者を一致させることができないかとかんがえた。
本当はすべてプログラム内で自動でやりたかったが、どの発話が誰のものなのかを決めるロジックが思いつかなず。。今回、ここは手作業になってしまった。
日本語の絵本の場合、セリフはきちんと「」でくくってあることが多いので、
登場人物が何人なのかを最初に入力し、正規表現で「」の中身を抜き出し、ユーザーに発話ごとにidを振ってもらう仕様とした。なお、語り手のidは0に設定される。
ソースコードは以下
ソースコード
```python
import requests
import re
import jsonchar0 = []
char_num = int(input("Please input number of characters =>"))
for i in range(1, char_num+1):
exec('char{} = []'.format(i))with open('./ehon_json/ehon.json', 'r') as f:
story = json.load(f)story_list = []
for page in story:
page_list = []
for sentense in page:
# try:
speech_list = re.split("(?<=」)|(?=「)", sentense["text"])
for speech in speech_list:
if speech != "":
if speech.find("「") > -1:
while True:
try:
print(sentense)
print(speech)
id = int(input("Please input char ID =>"))
if id <= char_num and id > 0:
break
except:
print("once again")
exec('char{}.append(speech)'.format(id))
page_list.append({"sentiment": sentense["sentiment"], "text": speech, "char": id})
else:
char0.append(speech)
page_list.append({"sentiment": sentense["sentiment"], "text": speech, "char": 0})
story_list.append(copy.deepcopy(page_list))
print(story_list)access_token_publish_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens"
api_base_url = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
clientid = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
clientsecret = "XXXXXXXXXXXXXXXXXXXXX"headers = {'Content-Type': 'application/json',}
data = json.dumps({"grantType": "client_credentials","clientId": clientid,"clientSecret": clientsecret})
response = requests.post(access_token_publish_url, headers=headers, data=data)
access_token = json.loads(response.text)["access_token"]api_url = api_base_url + "nlp/beta/user_attribute"
headers = {"Authorization": "Bearer " + access_token, "Content-Type": "application/json;charset=UTF-8"}char_list = []
for i in range(0, char_num+1):
exec('l = char{}'.format(i))
data = json.dumps({"document": l})
response = requests.post(api_url, headers=headers, data=data)
result = json.loads(response.text)
char_list.append(result)
print(result)with open('./ehon_json/char.json', 'w') as f:
json.dump(char_list, f, indent=4, ensure_ascii=False)```
こうやって、語り手、しろいうさぎ、くろいうさぎと、話者ごと発話のリストを作り、APIに投げてみた。
結果はこちら。{ "result": { "age": "40-49歳", "civilstatus": "既婚", "habit": [ "SMOKING" ], "hobby": [ "COLLECTION", "COOKING", "FORTUNE", "GOURMET", "INTERNET", "SHOPPING", "STUDY", "TVGAME" ], "location": "近畿", "occupation": "会社員" }, "status": 0, "message": "OK" }, { "result": { "age": "40-49歳", "civilstatus": "既婚", "earnings": "-1M", "hobby": [ "COOKING", "GOURMET", "INTERNET", "TVDRAMA" ], "location": "関東", "occupation": "会社員" }, "status": 0, "message": "OK" }, { "result": { "age": "40-49歳", "earnings": "-1M", "hobby": [ "INTERNET" ], "location": "関東", "occupation": "会社員" }, "status": 0, "message": "OK" }上から、語り手、しろいうさぎ、くろいうさぎである。
うーーーーーん?
この結果は少しイマイチだったかもしれない。というか、ドキュメントには"gender"とかが返ってくるとあったのだが、この結果には含まれていなかった。まだベータ版だからだろうか。
でも結婚する話だし、意外と大人だと思うから、もしかしたら案外正しいのかもしれない。
これだけの精度で出そうと思ったら、膨大な会話ログを送らないと無理なんだろうか。ここの精度が上がってくると、登場人物ごとのキャラ付けなどがある程度テンプレート化出来て、音声認識を使って絵本の中の登場人物と会話する、等の体験も考えられるかもしれない。
とりあえず今回は、この結果を参考に手作業でそれっぽい声を選定した。6. HOYA Voice Text APIで最適な話者と話し方を選定し、音声合成する
最後に、これらの情報を複合して音声合成する。
音声合成に関しては、COTOHA APIのものは感情が指定できなかったのと、あと自分が無料プランのみの登録のため、今回はHOYAのVOICE TEXTを使ってみた。
本当はコエステーションで、自分の声で音声合成作って、いつでも父が読んであげるアプリにしたかったんだけど、個人の力では無理でした。ちなみに、HOYAの合成音声も、二次配布等は禁止のライセンスなので注意
無料版で作成した音声データの商用利用、二次利用及び配布する行為は禁止されております。利用規約をご確認の上、本サービスをご利用ください
今回は
語り手:"hikari" しろいうさぎ:"haruka" くろいうさぎ:"takeru"とした。また、感情は、
"Neutral":"" "Positive":"happiness" "Negative":"sadness"として設定している。
また、普通に合成すると後ろのバッファが足りないのか、声が途切れるので、SSMLタグである<vt_pause=1000/>をすべての文言の後ろに着け、ファイルを長くしている。
ソースコード
```python
from voicetext import VoiceText
import copy
import jsonspeaker = {
0:"hikari",
1:"haruka",
2:"takeru"
}emotion = {
"Neutral":"",
"Positive":"happiness",
"Negative":"sadness"
}play_list = []
vt = VoiceText('XXXXXXXXXXXXXXXXX')
with open('./ehon_json/story.json', 'r') as f:
story = json.load(f)
for i, page in enumerate(story):
play = {"image": "./ehon_image/{}.png".format(i+1), "voice":[]}
voice_list = []
for j, speech in enumerate(page):
print(speech)
if speech["sentiment"] == "Neutral":
vt.speaker(speaker[speech["char"]])
else:
vt.speaker(speaker[speech["char"]]).emotion(emotion[speech["sentiment"]])
with open('./ehon_speech/{}{}.wav'.format(i+1, j+1), 'wb') as f:
print(speech["text"])
f.write(vt.to_wave(speech["text"] + ''))
voice_list.append('./ehonspeech/{}{}.wav'.format(i+1, j+1))
play["voice"] = copy.deepcopy(voice_list)
playlist.append(copy.deepcopy(play))
voice_list = []with open('./play_json/play.json', 'w') as f:
json.dump(play_list, f, indent=4, ensure_ascii=False)```
最後に
これらの方法で今回生成した音声を、読み込んだ画像と同期させて再生しているのが以下。
娘と仲良くなろうと、絵本自動読みのプロトを作った。
— たくみ@スカジャンのエンジニア (@hatt_takumi) March 15, 2020
画像を放りこんで実行すると合成されるかんじ。
cotoha APIでやったので今から記事化します。。間に合うかな、、#駆け出しエンジニアと繋がりたい#エンジニアと繋がりたい#python pic.twitter.com/6DjNDkzdGy一応、載せるのは一部に留めておく。
今回作ってみて、結構おもしろかった。
今後の展望として、ラズパイとかで"絵本読み上げカメラ"としてデバイス化するのも面白いし、プロジェークターとつないでシアターにするのもいいと思った。
VisionAPI周りとももっとうまくつなげば、言葉と画像がリンクして面白い体験が作れそう。
感情も結構細かい単位でとれるので、BGMや効果音ももう少し手を加えれば入れられる。COTOHA APIは他にもまだまだ遊べそうなので、引き続き実装したら記事にしていきたい。
一応断っておくが、娘にはもちろん自分でも絵本は読んであげるつもりである。
ちなみに娘は今生後1.5ヵ月である。

- 投稿日:2020-03-15T23:20:32+09:00
djangoでGmailから登録完了メールを送ろうとしてみた。
先日Djangoを学び始め、ユーザー登録機能の実装にtryしています。
Djangoで、メールを送信←概ねこちらの記事に則ってプログラムを書いています。
何度かエラーが出てしまったので、備忘録として残します。TemplateDoesNotExist
最初に直面したのが上記のエラーでした。
ユーザー登録時に送信されるメールのタイトル・本文のテンプレートが見つからず、エラーになってしまいました。
下記の通りディレクトリを修正したところ解決しました。
mail_templatesフォルダもtemplatesの中に入れておかなければならなかったようです。×修正前
users(アプリ名)
├mail_templates
| └create
| └subject.txt(メールタイトルのテンプレート)
└templates〇修正後
users
└templates
└mail_templates
└create
└subject.txt(メールタイトルのテンプレート)[WinError 10061] 対象のコンピューターによって拒否されたため、接続できませんでした。
拒否されてしまいました。
これは私のGmailから登録者へメールしようとしたにもかかわらず、プログラム中にGmailのユーザ名、パスワード等を書いていなかったのが原因でした。
settings.pyに下記の通り加筆したら解決しました。settings.pyEMAIL_HOST = 'smtp.gmail.com' EMAIL_PORT = 587 EMAIL_HOST_USER = 'メアド' EMAIL_HOST_PASSWORD = 'パスワード' EMAIL_USE_TLS = TrueSMTPAuthenticationError at /user_create/
続いては上記のエラーが生じるとともに、本プログラムで送信元として使用予定だったGmailから「誰かが不正ログインしようとしています」の注意喚起メールが届きました。
これはエラーに表示されていたGoogleのアドレスに飛び、安全性の低いアプリへのアクセスを有効にすることで解決しました。(安全性のしょぼいアプリでごめんね…)BadHeaderError
使用していたAtomでファイル末尾に自動で改行が挿入されてしまうため、「改行できないsubject.txtが二行になっているよ!困った!」とエラーが発生してしまいました。
下記サイトを参考に、自動で改行する機能をストップして解決しました。
【Atom】ファイル末尾に自動改行させない設定以上を解決したら無事にDjangoアプリを利用してメールを送信できました!わーい!
- 投稿日:2020-03-15T22:39:46+09:00
茶色コーダーがパナソニックコンテスト2020A~C解いてみた
はじめに
パナソニックプログラミングコンテスト2020 3完(Python3 95:30 8WA)できたのでA~Cの解法を投稿します。
パナソニックプログラミングコンテスト2020のリンクはこちら
https://atcoder.jp/contests/panasonic2020目次
A-Kth Term
問題文
次の長さ32の数列のK番目の項を出力してください。
1, 1, 1, 2, 1, 2, 1, 5, 2, 2, 1, 5, 1, 2, 1, 14, 1, 5, 1, 5, 2, 2, 1, 15, 2, 2, 5, 4, 1, 4, 1, 51
https://atcoder.jp/contests/panasonic2020/tasks/panasonic2020_a
この数列をリストにいれてしまって入力されたK番目を出力すれば良いと考えます。
提出コード
main.pyk = int(input()) x = [1, 1, 1, 2, 1, 2, 1, 5, 2, 2, 1, 5, 1, 2, 1, 14, 1, 5, 1, 5, 2, 2, 1, 15, 2, 2, 5, 4, 1, 4, 1, 51] print(x[k-1])B-Bishop
問題文
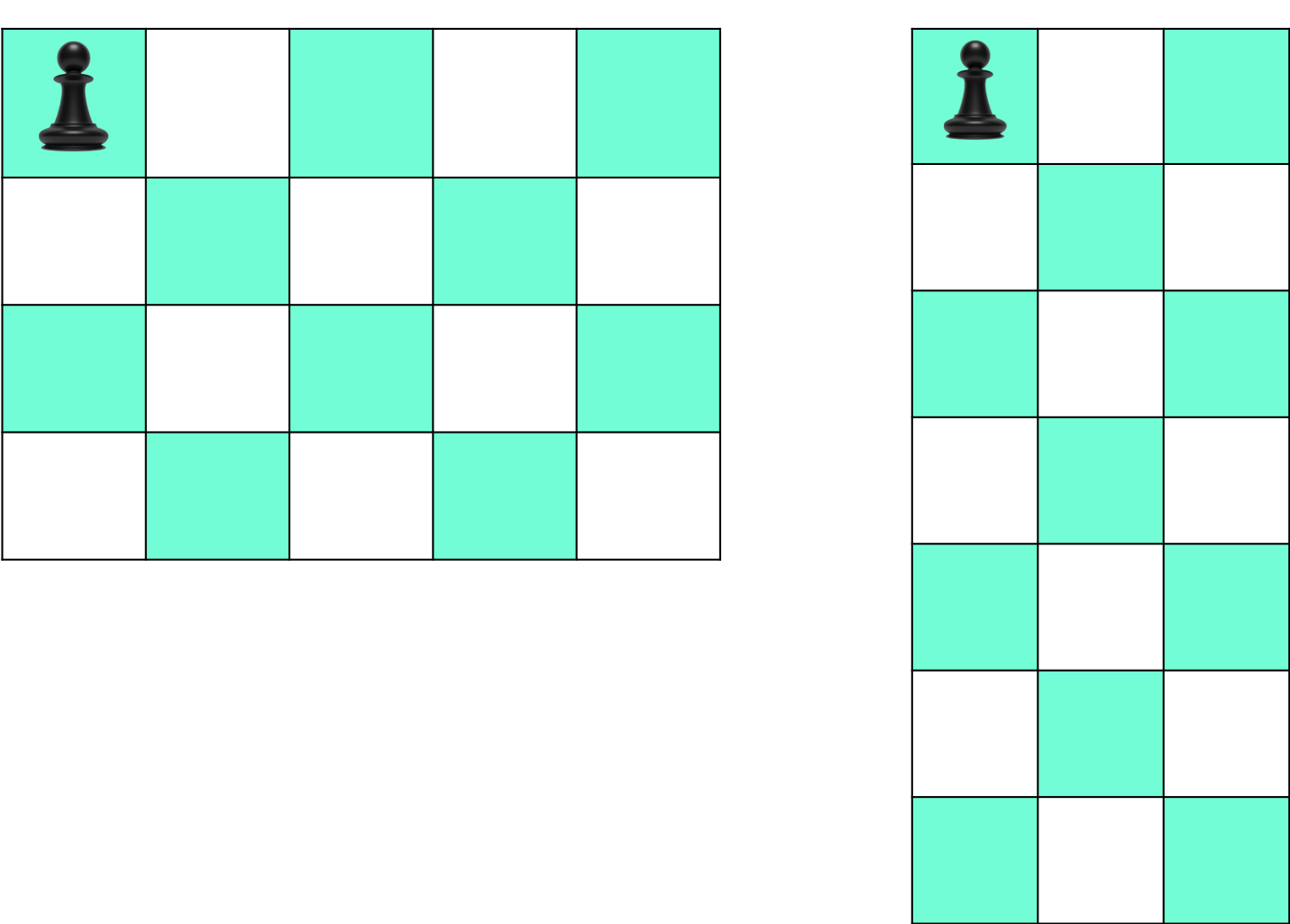
縦Hマス、横Wマスの盤面があります。この盤面の左上隅のマスに角行の駒が置かれています。コマが0回以上の好きな回数の移動が繰り返して到達できるマス目は何個あるでしょうか
例えば、コマが図のところにある時、1回で移動できる場所は赤くなっているマスです。
https://atcoder.jp/contests/panasonic2020/tasks/panasonic2020_b問題文をぱっと見てもさっぱりわかりません。
そこで、入力例1、入力例2の図を眺めると、色のついたマスはマスの数hw/2を切り上げた数であることに気づきます。
しかし、下記の図のようなh=1もしくはw=1の場合必ず色がつくマスは1です。
提出コード
main.pyimport math h,w = map(int, input().split(' ')) if h == 1 or w == 1: print(1) else: res = math.ceil(h*w / 2) print(res)C-Sqrt Inequality
問題文
$\sqrt{a}+\sqrt{b}<\sqrt{c}$ ですか?
https://atcoder.jp/contests/panasonic2020/tasks/panasonic2020_c問題文を安直にそのままコードを書くとこう。
main.pyimport math a,b,c = map(int, input().split(' ')) if math.sqrt(a) + math.sqrt(b) < math.sqrt(c): print('Yes') else: print('No')これだと、WA出ます。そこで
$\sqrt{a} + \sqrt{b} > 0 $かつ$\sqrt{c}>0$から
$\sqrt{a}+\sqrt{b}<\sqrt{c}$
$\Rightarrow a+2\sqrt{ab}+b<c$
$\Rightarrow 4ab < (c-a-b)^2$
と式変形して、無限小数にならないようにします。こうすることで桁落ちがなくなるようにします。
違いを確かめたコードが下記。確かにWAが出てしまいますね。check.pyfrom math import sqrt as sq x = 10000 y = sq(467544468) z = 10**9 print(x+y<sq(z)) print(4*x*y < (z-x-y)**2)False True提出コード
main.pyimport math a,b,c = map(int, input().split(' ')) x = 4 * a * b y = c - a -b if y <= 0: print('No') elif x < y**2: print('Yes') else: print('No')c-a-b<0となることもあります。

- 投稿日:2020-03-15T22:15:09+09:00
wikipediaにpythonからアクセスする方法
http://www.minekawada.com/wikipedia-python.html
目次
インストール方法について
pythonでwikipedia検索結果の候補一覧を出す方法
pythonでwikipediaのページを出力する方法
wikipediaのページをさらに詳しく見ていく
- 投稿日:2020-03-15T22:13:33+09:00
COTOHA APIを用いて、人のレポートをうまくパクるアプリを作る
都内の大学に通う者です。大学に入学してから一年、プログラミングを始めてから7ヶ月が経とうとしています。普段は友人とアプリを作ったり機械学習のコンペに参加したりしています。
昨日【Qiita x COTOHA APIプレゼント企画】というイベントを知りました。
Macが欲しいので、入賞目指して、初めての記事を書きます。(今日が締め切りですが...
)
大学のレポートがめんどくさい
大学では多くのレポートを課されます。これはとても苦痛なイベントです。
うまくすり抜けられないか
楽にすます方法としては、人のレポートをパクるということが挙げられます。しかし、一言一句パクれば流石にバレます。そこで、レポートの内容をそのままに表現だけを変えられないか、と考えました。
題材
今回は以下のような文章(先月書いたレポートの一部)をパクろうと思います。
'また、厚生労働省の「精神疾患による患者数」によると精神疾患の患者数は年々増加しており平成29年には400万人を超えた。この増加は今後も続くと思われており、このことからも50年後の都市において休息の場としての公園が必要であることがわかる。また、人口減少に加え、高齢化が顕著に進んでいることがわかる。また、国立社会保障・人口問題研究所の『日本の地域別将来推計人口(平成30(2018)年推計)』によると、今後、65歳未満の人口はすべての都道府県で減少する。'
パクりたいと思うほど上手な文章ではないですね... 「また」が多いし...ルール
- 『』の中の言葉は変えない。(書籍やホームページの名前なので)
- 地名や人物名、組織名は変えない。
- 数字は変えない。
それっぽいロジックを作る
類語辞典やGCPなどを使って、元の表現を少しずついじります。
その結果がこれです。
'厚生労働省の「精神疾患患者」によると、精神疾患患者の数は年々増加しており、2017年には400万人を超えています。この増加は今後も続くと予想され、50年後の都市には休息の場所が必要です。さらに、人口が減少しており、人口が著しく高齢化していることがわかります。全国人口社会保障研究所「日本の地域別推定人口(2018年推定)」によると、65歳未満の人口は将来的にすべての都道府県で減少します。'
所々表現が変わっています。
三つ目のルールは守られていますが、「国立社会保障・人口問題研究所」が「全国人口社会保障研究所」に変わってしまいました。人物名や組織名に対応できていません。COTOHA APIを使う。
満を持してCOTOHA APIの登場です。
COTOHA APIのリンク
COTOHA APIは「構文解析、照応解析、キーワード抽出、音声認識、要約など、様々な自然言語処理・音声処理APIを提供しているサービスです。NTTグループの40年にわたる研究成果である、日本語辞書や単語を3000種以上の意味性分類する技術などを活用し、高度な解析をAPIで手軽に利用できます。」
この優れたAPIの中で、今回は固有表現抽出APIを使用して、人物名や組織名を判定します。COTOHA APIの無料枠に登録
ここから簡単に登録できます。
登録したらここでAPI BASE URL、 CLIENT ID、 CLIENT secretを確認します。get_token.pydata = { "grantType": "client_credentials", "clientId": "Your CLIENT ID", "clientSecret": "Your CLIENT secret" } str_json = json.dumps(data) url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" headers={ "Content-Type": "application/json" } result=requests.post(url,headers=headers,data=str_json) print(result.text)これでアクセストークンを確認できます。
get_koyu.pydef get_koyu_(text, token): data = { "sentence":text, "type": "default" } headers = { "Content-Type":"application/json", "Authorization":"Bearer " + token } str_json = json.dumps(data) url = "https://api.ce-cotoha.com/api/dev/nlp/v1/ne" rr=requests.post(url,headers=headers,data=str_json) result = json.loads(rr.text)["result"]上のコードで文中の固有表現を抽出できます。
[{'begin_pos': 3, 'end_pos': 8, 'form': '厚生労働省', 'std_form': '厚生労働省', 'class': 'ORG', 'extended_class': '', 'source': 'basic'}, {'begin_pos': 42, 'end_pos': 47, 'form': '平成29年', 'std_form': '平成29年', 'class': 'DAT', 'extended_class': '', 'source': 'basic'}, {'begin_pos': 84, 'end_pos': 88, 'form': '50年後', 'std_form': '50年後', 'class': 'DAT', 'extended_class': '', 'source': 'basic'}, {'begin_pos': 156, 'end_pos': 170, 'form': '国立社会保障・人口問題研究所', 'std_form': '国立社会保障・人口問題研究所', 'class': 'ORG', 'extended_class': '', 'source': 'basic'},...
地名、人名、組織名などのカテゴリがふられているので、これらを頼りに地名、人名、組織名を判定します。あとはこれらの固有表現を変えないようにコードを書き換えます。
完成
パクる前
'また、厚生労働省の「精神疾患による患者数」によると精神疾患の患者数は年々増加しており平成29年には400万人を超えた。この増加は今後も続くと思われており、このことからも50年後の都市において休息の場としての公園が必要であることがわかる。また、人口減少に加え、高齢化が顕著に進んでいることがわかる。また、国立社会保障・人口問題研究所の『日本の地域別将来推計人口(平成30(2018)年推計)』によると、今後、65歳未満の人口はすべての都道府県で減少する。'
パクった後
'厚生労働省の「精神疾患による患者数」によると、精神疾患患者数は年々増加しており、2017年には400万人を超えています。この増加は今後も続くと予想されます。 50年後の都市には休息の場所としての公園が必要であることを示しています。さらに、人口が減少しており、人口が著しく高齢化していることがわかります。 国立社会保障・人口問題研究所『日本の地域別将来推計人口(平成30(2018)年推計)』によると、65歳未満の人口は今後すべての都道府県で減少します。'
『』の中の言葉や、組織名はそのままに、表現だけが変わっています。微妙な部分もありますが、とりあえずよしとします。実際に完成したアプリがこちらです。
追記
COTOHA APIの無料枠の関係で、現在COTOHA APIの無料枠を使い切ってしまったため、COTOHA APIを使ったときのような高い精度の文が帰ってきません。対策が出来次第修正します。
- 投稿日:2020-03-15T22:05:33+09:00
機械学習のアルゴリズム(サポートベクターマシン)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
今回はサポートベクターマシンについて。その歴史こそ古いものの、機械学習の分野では人気の手法です。汎化性能も高く、ILSVRC2012でディープラーニングに破られるまでは最強のアルゴリズムでした。これを覚えてるとだいぶよい気がします(語彙)。
今回参考にしたのは以下のサイト。ありがとうございます。他にも良書籍がたくさんあるようなのでそういうのもご参考に。
- PRML第7章のサポートベクターマシン(SVM)をPythonで実装
- SVM(サポートベクターマシン)
- サポートベクターマシンを理解する
- SVMについて簡単に理解する。
- SVM(サポートベクターマシン)について
- サポートベクターマシンを手計算して理解する
- SMO徹底入門
- Python + NumPy で SMO 実装した
理論編
理論をしっかり理解しようと思いましたが、とても複雑で、おまけにこれ以上ないくらいしっかりと理論に触れているエントリがあったので、エッセンスだけ記述していこうと思います。
ざっくりと概論
サポートベクターマシン(Support Vector Machine)は、パーセプトロンやロジスティック回帰のような教師ありの二値分類器です。サポートベクターの考え方を導入することで、未知データに対する汎化性能が高く、カーネル法を用いることで線形分類が不可能な分類問題(XORなど)も分類できるようになります。
乱暴に言うとパーセプトロンにマージン最大化とカーネル法を持ち込んだ分類器と言えるようです。理論編
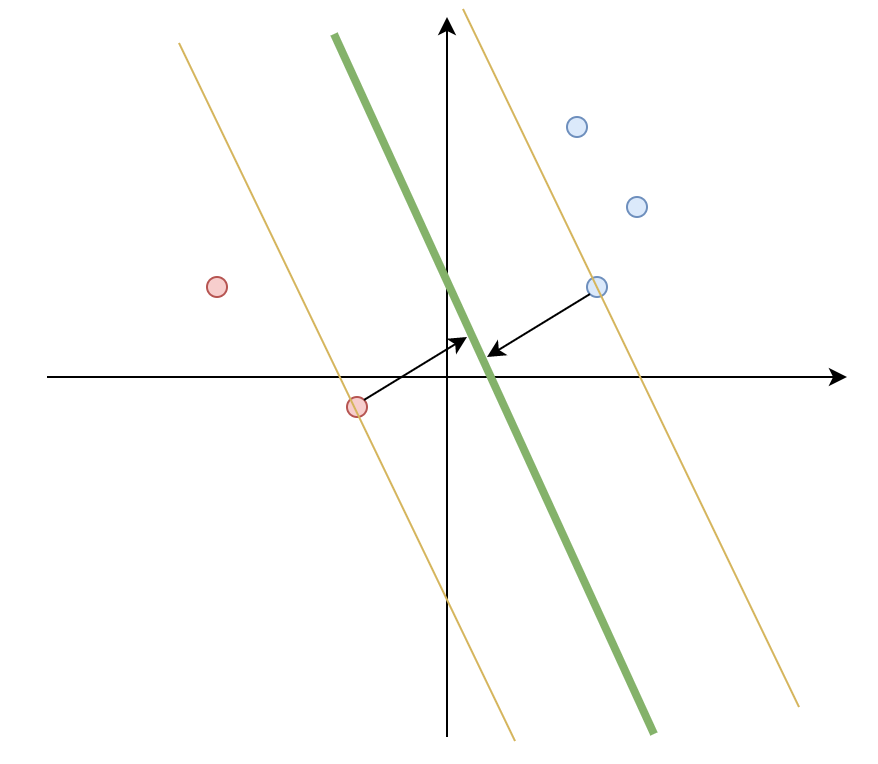
次のような特徴量が2つに対し、二値分類が必要な状況を考えます。青い丸と赤い丸がそれぞれ学習データで、青い点を1(正例)、赤い点を-1(負例)とします。境界に引かれた緑の線を$$y=ax+b$$とします。正例、負例それぞれのうち、緑の線に一番近い点をサポートベクター、サポートベクターから境界までの距離をマージンと呼ぶことにします。
サポートベクターマシンは、教師データに対し、このマージンを最大化するような$a$と$b$を求めるという問題になります。
現実はこう都合よくいくケースばかりでもなく、きちんと分かれない場合が多くあるんですが、まずはこのシンプルなケースをもとに考えていきます。サポートベクターマシンがいろんなケースでうまく分類できる理由は、このマージン最大化のおかげで、未知のデータに対してもいい感じに分類してくれるのと、境界面の近傍のデータを用いることで、外れ値にあまり影響しないという点があるようです。
初期設定
N個の教師データを$\boldsymbol{x}=(x_0, x_1, \cdots, x_{N-1})$、分類ラベルを $\boldsymbol{t}=(t_0, t_1, \cdots, t_{N-1})$、境界の式(識別関数という)を$g(x)=\boldsymbol{w}^Tx+w_0$とおきます。$\boldsymbol{w}$は、$\boldsymbol{x}$の重みベクトルです。
マージン最大化
$y=ax+b$とある点$x_n$との距離は$$\frac{|ax+b|}{\sqrt{a^2}}$$(参考)ですが、これを$g(x)$で考える。ある点$x_n$と$g(x)$の距離$|r|$は、$$|r|=\frac{|g(x)|}{|w|}$$と表せる。ラベル$t_n$は、$|t_n|=1$かつ、$t_ng(x)>=0$であることから、$$|r|=\frac{t_n(\boldsymbol{w}^Tx_n+w_0)}{|w|}$$となる。
$g(x)$から一番近い点$x_{min}$における$|r_{min}|$を最大化するために、$$|r_{min}|=\frac{t_{min}(\boldsymbol{w}^Tx_{min}+w_0)}{|w|}$$が最大となる$\boldsymbol{w}$と$w_0$を求めていきます。
制約条件
上記の式を最大化するには、分母が小さいほどよいですが、0になると不定になってしまう(解が一意に決まらない)ので、制約を加えます。
正例の点において、$g(x)=1$、負例は$g(x)=-1$であるとすると、$$t_ng(x)=t_n(\boldsymbol{w}^Tx_n+w_0) \geq 1$$という条件下で求めることにします。
これは、境界と最近傍の点$t_ng(x_{min})=1$とのマージン、$\frac{1}{|w|}$を最大化するので、$|w|$を最大化すればいいことになります。あとで微分することを考えて、$\frac{1}{2}|w|^2$を最大化すると置き換えても問題ありません。整理すると、$$t_n(\boldsymbol{w}^Tx_n+w_0) \geq 1$$という条件下で、$$\frac{1}{2}|w|^2$$を最大化する$\boldsymbol{w}$と$w_0$を求めていきます。
ラグランジュの未定乗数法
上式のような制約条件のある関数を最大化するためには、ラグランジュの未定乗数法という手法を使います。これは、双対問題と言って、書き換えられた問題を解くことでもともとの問題を解いたことになるという理論を利用しています。
制約式$h(x)=t_n(\boldsymbol{w}^Tx_n+w_0)-1$のもとで、$f(x)=\frac{1}{2}|w|^2$を最大化するために、ラグランジュ定数$\lambda$を導入したラグランジュ関数$$L(w, w_0, \lambda)=f(w, w_0)-\sum_{i=1}^{N}\lambda_ih(w, w_0)$$を定義します。
L(w,w_0,\lambda)=\frac{1}{2}|w|^2-\sum_{i=1}^{N}\lambda_i \{ t_n(\boldsymbol{w}^Tx_n+w_0)-1\}なので、$w$と$w_0$について偏微分し、偏微分を0とおくとラグランジュ関数が$\lambda$だけの式になり、
L(\lambda)=\sum_{n=1}^{N}\lambda_n-\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}\lambda_n\lambda_mt_nt_mx_n^Tx_mという式が導かれる。制約条件は、
\lambda_n\geq 0 \\ \sum_{i=1}^N\lambda_nt_n=0です。これで$L(\lambda)$を最大化する$\lambda$を求めればいいという問題に置き換えできたことになります。
上式を$w$で偏微分すると、
$$w=\sum_{i=1}^{N}\lambda_it_ix_i$$が求まります。$w$が求まったので、$w_0$を求めます。$$g(x)=\boldsymbol{w}^Tx+w_0=\sum_{i=1}^{N}\lambda_it_ix_ix+w_0$$であり、サポートベクトルとのマージンを1とおいたので、全サポートベクトルについて、
t_n(\sum_{m} \lambda_mt_mx_mx_n+w_0)=1が成り立ちます。実際には変形して
w_0=\frac{1}{N_M}\sum_{n}(t_n-\sum_{m}\lambda_mt_mx_mx_n)として求めます。整理すると、$\lambda$が求めた後、
w=\sum_{i=1}^{N}\lambda_it_ix_i \\ w_0=\frac{1}{N_M}\sum_{n}(t_n-\sum_{m}\lambda_mt_mx_mx_n)を最終的には計算で求めます。ではその$\lambda$はどのようにして求めればよいでしょうか。実際にはSMO(Sequential Minimal Optimization)という方法を使って求めることができます。
SMO
まず、解くべき問題を再掲します。
L(\lambda)=\sum_{n=1}^{N}\lambda_n-\frac{1}{2}\sum_{n=1}^{N}\sum_{m=1}^{N}\lambda_n\lambda_mt_nt_mx_n^Tx_m \\制約条件
\lambda_n\geq 0 ,\sum_{i=1}^N\lambda_nt_n=0このように、制約条件のある$L(\lambda)$を最大化する問題は、$\lambda$をSMOを使って求めることができます。
Wikipediaによれば、SMOは日本語で逐次最小問題最適化法というそうです。勾配法のように反復しながら解に近づけていく手法で、任意の2変数を選択し、収束するまで繰り返します。
この任意の2変数のことをWorking Setと呼び、この2変数をどうやって選ぶかがキモになります。流れとしては、
- KKT条件に反する変数$\lambda_1$を選択する
- $\lambda_2$を決める
- $\lambda_1, \lambda_2$を更新する
という処理をKKT条件に反する変数が存在しなくなるまで繰り返します。
KKT条件
カルーシュ・クーン・タッカー条件(Karush-Kuhn-Tucker condition)、以下KKT条件とは、一階導関数が満たすべき最適条件を指します。
実はKKT条件は上のラグランジュ未定乗数法のときにも使っており、
(1) $\frac{\partial{L}}{\partial{w}}=0$
(2) $\frac{\partial{L}}{\partial{w_0}}=0$
(3) $t_n(\boldsymbol{w}^Tx_n+w_0) \geq 1$
(4) $\lambda_n \geq 0$
(5) $\lambda_n(t_n(\boldsymbol{w}^Tx_n+w_0)-1) = 0$という条件です。特に5番目の条件を相補性条件と言うそうです。
KKT条件違反のチェックして変数を1つ決定する
相補性条件$$\lambda_n(t_n(\boldsymbol{w}^Tx_n+w_0)-1) = 0$$を場合分けして、
(1) $\lambda_n=0$の場合、$t_n(\boldsymbol{w}^Tx_n+w_0) \geq 1$
(2) $\lambda_n > 0$の場合、 $t_n(\boldsymbol{w}^Tx_n+w_0) = 1$が導かれるため、これを満たさない$\lambda$を選べばいいことになります。逆に$\lambda$が無くなったら解が求まったとします。ここで選んだ$\lambda$を$\lambda_1$とします。
変数をもう1つ決定する
もう一つの変数は、以下の順で選択します。まず、現在の$\lambda$で$\boldsymbol{w}$と$w_0$を求める必要があります。
この時の誤差関数を$$E_n=(\boldsymbol{w}^Tx_n+w_0)-t_n$$
とします。
- (1) 変数の更新量が最大になるように選択
- $\lambda_1$の場合の$E_1$との誤差が最大になるような$n$を選ぶ。
- (2) 境界上に存在しない
- $t_n(\boldsymbol{w}^Tx_n+w_0) = 1$ではない任意の点
- (3) 残り
変数を更新する
更新する$\lambda_1$と$\lambda_2$は決定したが、更新する際には線形制約$$\sum_{i=1}^N\lambda_nt_n=0$$があるため、この条件下で更新する必要がある。つまり、片方の$\lambda$を更新した場合は、もう一方の$\lambda$を調整しなければならない。更新後の$\lambda_1$と$\lambda_2$をそれぞれ$\lambda_1^{new}$、$\lambda_2^{new}$とすると
\lambda_1^{new}t_1+\lambda_2^{new}t_2=\lambda_1t_1+\lambda_2t_2となります。これを$t_1=t_2$の場合と$t_1 \ne t_2$で場合分けし、
\lambda_1^{new}=\lambda_1+\frac{t_1(E_2-E_1)}{x_1^2+x_1x_2+x_2^2} \\ \lambda_2^{new}=\lambda_2+t_1t_2(\lambda_1-\lambda_1^{new})を得ます。実際には、$\lambda_1$と$\lambda_2$の取りうる範囲を求めてクリッピングという処理が必要ですが力尽きました。
pythonの実装
まず最初に、理論編で力尽きたのと、長くなりすぎたのでscikit-learnの実装だけにします。ごめんなさい。いつか必ず自力で実装するつもりです。
scikit-learnの実装
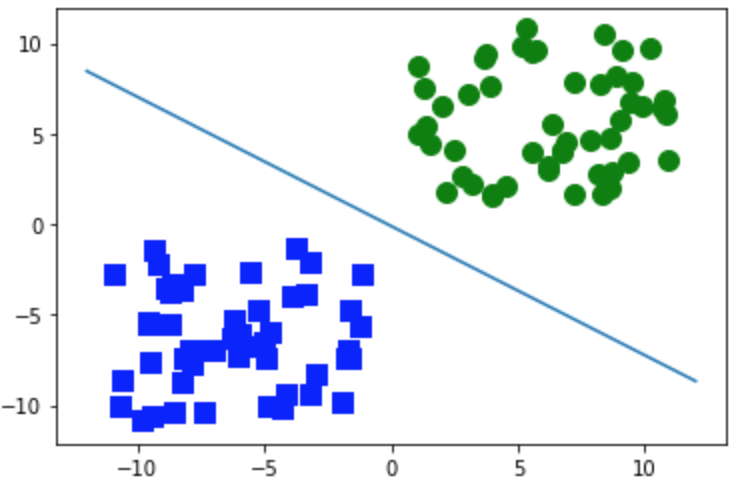
pythonの実装はなんともあっさりです。scikit-learnでサポートベクトルマシンを使った分類をやるにはsklearn.svm.LinearSVCを使います。今回は分かりやすいように、正例50個負例50個がちゃんと分離されたサンプルを使います。
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline from sklearn import svm fig, ax = plt.subplots() x1_1=np.ones(50)+10*np.random.random(50) x1_2=np.ones(50)+10*np.random.random(50) x2_1=-np.ones(50)-10*np.random.random(50) x2_2=-np.ones(50)-10*np.random.random(50) x1 = np.c_[x1_1,x1_2] x2 = np.c_[x2_1,x2_2] y = np.array(np.r_[np.ones(50), -np.ones(50)]) model = svm.LinearSVC() model.fit(np.array(np.r_[x1,x2]), y) ax.scatter(x1[:,0],x1[:,1],marker='o',color='g',s=100) ax.scatter(x2[:,0],x2[:,1],marker='s',color='b',s=100) w = model.coef_[0] x_fig = np.linspace(-12.,12.,100) y_fig = [-w[0]/w[1]*xi-model.intercept_/w[1] for xi in x_fig] ax.plot(x_fig, y_fig) plt.show()
このように分類されました。あたり前ですね。
まとめ
最後力尽きてしまいましたが、雰囲気はつかめたんではないでしょうか(つかめてないですねw)。今回扱ったのは、基本中の基本、線形分離可能かつ正例と負例がきちんと分類できる例(ハードマージン)で導出しました。
より高度というか、現実に近いなサポートベクターマシンには、線形分離できないケース(カーネル法)と、正例と負例がきちんと分類できない例(ソフトマージン)を考える必要がありますが、基本的な理論は今回の内容とほとんど変わらないです。
次回以降ではその辺を扱っていきたいです。
- 投稿日:2020-03-15T21:41:07+09:00
pythonを用いた衛星軌道LSTの計算(真太陽、平均太陽)
Local Sun Timeの計算方法
前回の続きです。今度は平均太陽も計算します。
真の太陽と、一年の太陽を基にした時刻のスピードを平均化した平均太陽の時差を均時差といいます。均時差の要因は地球の楕円公転と地軸傾斜です。以下は、Local Sun Time(LST)の、真太陽と平均太陽を両方を計算するプログラムです。
準備
軌道情報を用意します。今回もALOS-2(だいち2号)のTLE(Two Line Element,2行要素)を用います。TLEはテキストファイルで保存しておきます。("./TLE/ALOS-2.tle")
ALOS-2 1 39766U 14029A 19271.21643628 .00000056 00000-0 14378-4 0 9997 2 39766 97.9225 6.5909 0001371 85.1486 274.9890 14.79472450288774計算
TLEを、skyfieldを駆使して、接触軌道6要素に変換して計算します。太陽方向ベクトルの赤経と昇交点赤経
raの差分をとって、時刻に変換するだけです。
skyfieldだと184deg 09' 18.9"のように度分秒で表示されてしまうので、無理やり文字列操作しました。平均太陽は、太陽視赤緯と均時差計算に関する一考察にある式(2)を利用しました。ユリウス日からJ2000からのユリウス世紀数(JC)を計算し、平均太陽の赤経$α_{m}$[h]を計算しています。
#!/usr/bin/env python3.3 # -*- coding: utf-8 -*- import numpy as np import math import sys import datetime from skyfield.api import Loader, Star, Topos, load, JulianDate from skyfield.api import EarthSatellite from skyfield.elementslib import osculating_elements_of TLE_NAME = './TLE/ALOS-2.tle' def loc_time_calc(elm): ra = elm[5] # raan[rad] ## True Sun ### planets = load('de421.bsp') earth = planets['earth'] sun = planets['sun'] astrometric = earth.at(elm[0]).observe(sun) #earth->sun vector true_sun, dec, distance = astrometric.radec() true_sun = math.radians(_to_10deg(true_sun.dstr(warn=False))) # get angle true_sun_angle = ra - true_sun if true_sun_angle * 12/math.pi + 12 < 0: true_loc_time = _to_str(24 + true_sun_angle * 12 / math.pi + 12) else: true_loc_time = _to_str(true_sun_angle * 12/math.pi + 12) ## Mean Sun ### JD = elm[0].ut1 # Julian date Tu = (JD-2451545)/36525 # Julian Julian Century, JC # mean sun right ascension[h] alpha_m = 18 +(41+50.54841/60)/60 + Tu*8640184.812866/60/60 + (0.093104/60/60)*(Tu**2) - (0.0000062/60/60)*(Tu**3) alpha_m = alpha_m % 24 mean_sun = (alpha_m/24) * 2 * np.pi mean_sun_angle = ra - mean_sun if mean_sun_angle * 12/math.pi + 12 < 0: mean_loc_time = _to_str(24 + mean_sun_angle * 12 / math.pi + 12) else: mean_loc_time = _to_str(mean_sun_angle * 12/math.pi + 12) return true_loc_time, mean_loc_time def _to_10deg(val): spl1 = val.split() spl2 = spl1[0].split("deg",1) spl3 = spl1[1].split("'",1) spl4 = spl1[2].split('"',1) degrees = (float(spl4[0]) / 3600) + (float(spl3[0]) / 60) + float(spl2[0]) return degrees def _to_str(hour): h_str = datetime.datetime.strftime(datetime.datetime.strptime((str(int(hour))), "%H"),"%H") m_str = datetime.datetime.strftime(datetime.datetime.strptime(str(int((hour-int(hour))*60)), "%M"),"%M") return h_str + ":" + m_str def main(): with open(TLE_NAME) as f: lines = f.readlines() sat = EarthSatellite(lines[1], lines[2], lines[0]) print(lines[0], sat.epoch.utc_jpl()) pos = sat.at(sat.epoch) print(sat.epoch) elm = osculating_elements_of(pos) i = elm.inclination.degrees e = elm.eccentricity a = elm.semi_major_axis.km omega = elm.argument_of_periapsis.degrees ra = elm.longitude_of_ascending_node.degrees M = elm.mean_anomaly.degrees print(i,e,a,omega,ra,M) # Osculating Orbit osc_elm = [0 for i in range(7)] osc_elm[0] = sat.epoch osc_elm[1] = a osc_elm[2] = e osc_elm[3] = np.radians(i) osc_elm[4] = np.radians(omega) osc_elm[5] = np.radians(ra) osc_elm[6] = np.radians(M) true_loc_time, mean_loc_time = loc_time_calc(osc_elm) print("交点通過地方時(LST True Sun)",true_loc_time) print("交点通過地方時(LST Mean Sun)",mean_loc_time) return結果
均時差は、このサイトで2019/9/28の均時差を計算すると約9分強なので、だいたい合ってそうなことがわかります。
ALOS-2 A.D. 2019-Sep-28 05:11:40.0946 UT <Time tt=2458754.717237021> 97.92987988479214 0.0012760645968402655 7015.220028255803 69.31302830191312 6.32305263767209 290.71632630644746 交点通過地方時(LST True Sun) 00:08 交点通過地方時(LST Mean Sun) 23:58
- 投稿日:2020-03-15T21:06:42+09:00
プロレスの熱戦をUMLで図示化したった(概要)
Backgorund
【Qiita x COTOHA APIプレゼント企画】関連の投稿です。
スポーツ記事から選手と技名を抽出してみたで人物と技の名前を抽出したのですが、ここではこの応用でUMLを使って図示化してみようと思います。
アプローチとしてはCOTOHA APIで構文分析かキーワード抽出して選手が何をしているのかを取得し、その後でPlantUMLで図示化する流れです。
土日の休みを少し返上して開発しようとしたのですが(謎の忙しいアピール
)、構文分析のレスポンス内にあるラベルを理解するのに時間がかかりそうだったので、ここではスポーツ記事からUMLに図示化する方法のみ着手しました。(単に時間切れ
)
Dataset
東京スポーツ
前回と同様です。【新日1・5東京ドーム】みのる US王座防衛のモクスリー襲撃「誰にケンカ売ってんだ!」
https://www.tokyo-sports.co.jp/prores/njpw/1682622/
新日本プロレスの年間最大興行「レッスルキングダム14」(5日、東京ドーム)で行われたIWGP・USヘビー級王座戦は、王者ジョン・モクスリー(34)がIWGPタッグ王者のジュース・ロビンソン(30)の挑戦を退け、初防衛に成功した。 前夜(4日)の東京ドーム大会では、モクスリーがランス・アーチャー(32)から王座を奪回。ジュースはデビッド・フィンレー(26)とのコンビでタッグ王座を獲得した。その翌日に新王者同士の決戦となったが、モクスリーは昨年6月にジュースから同王座を奪っており、前夜のリング上で決着をつけることを宣言していた。 序盤はジュースが快調に先制したものの、モクスリーは場外でイスを持ち出して背中に一撃。さらにはジュースの額にかみついた。WWE時代に“狂犬”として暴れ回った荒くれ者が、強引にペースを奪い返した。 ジュースは豪快なハイアングルパワーボムで反撃したが、王者は足4の字固めから鉄柱を使った4の字と意表を突いた攻撃を連発した。挑戦者は雪崩式ブレーンバスターからジャックハマーにジャーマン。モクスリーのデスライダー(ダブルアーム式DDT)をかわして、ラリアートでぶち抜いた。 だが、王者は乱打戦から強烈なランニングニーを一閃。ジュースのパルプフリクションを切り返して、DDTから必殺のデスライダーを炸裂させて12分48秒、3カウントを奪った。 試合後には入場テーマ曲が流れ、いきなり鈴木みのる(51)が登場。昨年12月8日の広島大会でモスクリーからデスライダーを見舞われており、険しい表情で怒りを隠せない。花道でジャージーを脱いで戦闘態勢に入ると、リング上で王者とエルボーを打ち合った。ド迫力のみのるは裸絞めからゴッチ式パイルドライバーでモクスリーをKOした。 みのるはマイクを握ると「誰にケンカ売ってんだ、このヤロー! オレはプロレスラーの鈴木みのるだ。こいつのケンカ、オレが買ってやる!」と宣戦布告。US王座を巡る“狂犬”対“性悪男”の抗争勃発で、危険な香りが漂ってきた。 みのるの話「誰にケンカ売ってんだ、おい。俺は、お前が俺の前に来るのを待ってたんだよ。ジョン・モクスリー…いや、ジョン・ボーイ、心してかかってこい。ぶち殺す」 ジュースの話「すべてはここで終わりだ。ジョン・モクスリーは今日も俺より強かった。また超えられなかった。今日のことを考えたのは昨日の試合が終わってから。それまでまったく今日の試合のことなんて考えていなかった」Method
タイトルマッチ名と場所(日程)
スポーツ記事とはいえ、小説や随筆のような自由な記述とは違って形式は決まっていて、大抵はいつどこで誰が対戦したかの内容は1行目に書かれている。
UMLはパッケージを使えば雰囲気が出そうです。
対戦者
対戦者は固有表現抽出(/nlp/v1/ne)で取得できます。
(参照:スポーツ記事から選手と技名を抽出してみた)懸念点としては過去の対戦で登場するプレイヤーをどのように識別するかです。「獲得した。」「宣言していた。」で過去に行われたとしてこの文章中にのみ出てくるプレイヤーはこのタイトルマッチでは出場していないと判断できそうですが、記事自体過去の時制で書かれているので過去の過去を判別する場合は「前夜(4日)」「昨年6月に」のような日時があるかどうかで判定すればいいかもしれません。
もし判定できたとした場合はリング外で表示できるのが理想です。前夜(4日)の東京ドーム大会では、モクスリーがランス・アーチャー(32)から王座を奪回。ジュースはデビッド・フィンレー(26)とのコンビでタッグ王座を獲得した。その翌日に新王者同士の決戦となったが、モクスリーは昨年6月にジュースから同王座を奪っており、前夜のリング上で決着をつけることを宣言していた。
クラス名はPlayer1を使わずに直接選手名を書きたいのですが、クラスにリンクさせるスクリプトを書く構造上英数字しか許容しないのでfieldに名前を記載しました。
王座奪回
モクスリーがランス・アーチャー(32)から王座を奪回。誰かから何かを得る・奪う時は関連クラスを使うといいかもしれんす。
タッグ王座獲得
ジュースはデビッド・フィンレー(26)とのコンビでタッグ王座を獲得した。何かを得る場合は
Compositionを使っています。
背中に一撃
モクスリーは場外でイスを持ち出して背中に一撃。この表現は少し難しいです。直接クラスにリンクすればいいのですが、選手のどの部位に攻撃したかがわかりにくいです。それで「選手が持っている背中に攻撃した。」として下記の表示にしています。
また、何らかの行為をするごとにクラスのattributeに追加しています。
ハイアングルパワーボムで反撃
ジュースは豪快なハイアングルパワーボムで反撃した選手に技をかける時はクラスの
attributeに技名を追加しつつ、誰が誰に技をかけたかを表示します。
選手コメント
ジュースの話「すべてはここで終わりだ。ジョン・モクスリーは今日も俺より強かった。また超えられなかった。今日のことを考えたのは昨日の試合が終わってから。それまでまったく今日の試合のことなんて考えていなかった」最後の2~3行で試合後のコメントを書く場合があります。その場合はnoteを吹き出しがわりに使えば良さそうです。
Development
上記のmethodをもとにPlantUMLを使ってスクリプト化しました。
スクリプトコード (クリックするとコードが表示されます。)
@startuml rectangle "レッスルキングダム14 IWGP・USヘビー級王座戦" { frame 東京ドーム { class Player1 { username = ジョン・モクスリー 奪回() 宣言() 一撃() かみつく() 足4の字固め() デスライダー(ダブルアーム式DDT)() ランニングニー() エルボー() } class Player2 { username = ジュース・ロビンソン ハイアングルパワーボム() 雪崩式ブレーンバスター() ジャックハマー() ジャーマン() ラリアート() パルプフリクション() エルボー() } class senaka { name = 背中 } class hitai { name = 額 } class Player5 { username = 鈴木みのる エルボー() 裸絞め() ゴッチ式パイルドライバー() } } } class Player3 { username = ランス・アーチャー } class Player4 { username = デビッド・フィンレー } class oza { name = 王座 } class tag_oza { name = タッグ王座 } Player1 --> Player3 : 奪回 > (Player1, Player3) .. oza Player2 -- Player4 Player2 *- tag_oza Player4 *- tag_oza Player1 --> Player2 : 奪回 > (Player1, Player2) .. oza Player1 --> senaka : 一撃 > Player1 --> hitai : かみつく > Player2 *- senaka Player2 *- hitai Player2 --> Player1 : ハイアングルパワーボム > Player2 --> Player1 : 足4の字固め > Player2 --> Player1 : 雪崩式ブレーンバスター > Player2 --> Player1 : ジャックハマー > Player2 --> Player1 : ジャーマン > Player2 --> Player1 : ラリアート > Player1 x-- Player2 : デスライダー(ダブルアーム式DDT) > Player1 --> Player2 : ランニングニー > Player2 x-- Player1 : パルプフリクション > Player1 --> Player2 : デスライダー(ダブルアーム式DDT) > Player1 --> Player5 : エルボー > Player5 --> Player1 : エルボー > Player5 --> Player1 : 裸絞め > Player5 --> Player1 : ゴッチ式パイルドライバー > note "すべてはここで終わりだ。\nジョン・モクスリーは今日も俺より強かった。\nまた超えられなかった。\n今日のことを考えたのは昨日の試合が終わってから。\nそれまでまったく今日の試合のことなんて考えていなかった" as N1 note "誰にケンカ売ってんだ、このヤロー! \nオレはプロレスラーの鈴木みのるだ。\nこいつのケンカ、オレが買ってやる!" as N2 note "誰にケンカ売ってんだ、おい。\n俺は、お前が俺の前に来るのを待ってたんだよ。\nジョン・モクスリー…いや、ジョン・ボーイ、心してかかってこい。\nぶち殺す" as N3 Player1 .. N1 Player5 .. N2 Player5 .. N3 @endumlFigure
もっと見やすくするのにクラスの配置やラインのつなぎ方を最適化した方が良さそうです。出力はデフォルトです。
Future
ここではスポーツ記事からUMLに図示化する方法をまとめてみました。おそらくあと数記事を使って図示化しようとした時に新規で表現方法を考えなければならないパターンがいくつか出てくるかもしれません。次にCOTOHAを使って文章の主従関係を抽出する方法を考える必要があるのですが、構文解析(nlp/v1/parse)のレスポンスには「依存関係ラベル」があるのでこれが使えそうです。
しかしながら、下記の通りパターンが多いです。何回か文章をリクエストしてみてどのラベルが返ってくるかを判別しないと厳しそうです。
依存関係ラベル名称 説明 例 構文 nsubj 主格で述語に係る名詞句。 空気が美味い 美味い → nsubj 空気 nsubjpass 主格で受身の助動詞を伴う用言に係る名詞句。 希望が託される 託さ → nsubjpass 希望 dobj 目的格で述語に係る名詞句。 手を繋ぐ 繋ぐ → dobj 手 iobj 格助詞「に」を伴うなどして述語に係る名詞句。 花子にあげる あげる → iobj 花子 nmod 「が」「を」「に」以外の格の名詞句や、時相名詞により用言を修飾する場合。 ここで叫ぶ 叫ぶ → nmod ここ csubj 主語になる名詞節。準体助詞を伴う用言句が主語となる場合。 笑うのが下手 下手 → csubj 笑う csubjpass 準体助詞を伴う用言句が主語となる場合に、受身の助動詞を伴う用言を修飾する場合。 言ったのが悔やまれる。 悔やま → csubjpass 言っ ccomp 補文。 甘えたいと思う 思う → ccomp 甘え advcl 副詞節。主に接続助詞を伴って用言を修飾する節。 平凡だけどそこが良い 良い → advcl 平凡 advmod 副詞による修飾。 絶対許さない 許さ → advmod 絶対 neg 否定語の付与。 絶対許さない 許さ → neg ない nummod 数量の指定。 3冊の本 冊 → nummod 3 appos 同格の表現。 友達(♀) 友達 → appos ♀ acl 連体修飾節。ただしamodに該当する場合を除く。また「てからの」「ながらの」等の接続表現。 愛を込めたプレゼント プレゼント → acl 込め amod 形容詞・形状詞・連体詞(DET(この、その、あんな、どんな等)以外)が格を伴わずに名詞を修飾する場合。 偉大な力 力 → amod 偉大 det DET(この、その、あんな、どんな等)による修飾。 この本 本 → det この compound 名詞と名詞・動詞と動詞の複合。 自覚症状 症状 → compound 自覚 name 固有名詞の複合語。 山田太郎 山田 → name 太郎 conj 並列構造。左側の要素を主辞とする。 アダムとイブ アダム → conj イブ cc 等位接続詞。 アダムとイブ アダム → cc と aux 用言につく助動詞や、非自立の補助用言。「か」などの終助詞を含む。 甘えたいと思う 甘え → aux たい auxpass 受動態で動詞句を形成するために、動詞に接続する助動詞。「れる/られる」。 希望が託される 託さ → auxpass れる cop コピュラ。 太郎は学生だ。 学生 → cop だ case 助詞による格の表示。 空気が美味い 空気 → case が mark 従属接続詞、接続助詞、補文標識の「と」「か」等が付く場合。 笑うのが下手 笑う → mark の punct 句読点。 食べます。 食べ → punct 。 vocative 呼びかけ。 太郎君、走れ 走る → vocative 君 discourse 談話要素。 あー疲れる 疲れる → discourse あー PostScript
このコンテンツは実現するのに実感としてボリュームがあります。
いくつかのプロレスの記事からUMLに落とし込むことと記事をCOTOHAで構文分析して特徴を捉えることをしつつ、傾向がつかめたらPlantUMLに記述するスクリプトを書くことまでを全てやるには時間がかかりそうです。
【Qiita x COTOHA APIプレゼント企画】ではできたてのコンテンツかCOTOHA自体の使い方についてのことが多いのですが、サクラダファミリア的に中途半端な状態で書くのもありと思ったので締め切りギリギリに書いてみましたReference








- 投稿日:2020-03-15T21:03:54+09:00
VPC内で動くGlue開発エンドポイントでPyCharmを使用する方法
基本は以下の記事に従う。
チュートリアル: 開発エンドポイントで PyCharm Professional をセットアップするしかしこの記事はVPCの外で動く開発エンドポイントを想定しているためVPC内で動くエンドポイントの場合は大きく手順が違ってくる。
VPC内のエンドポイントを扱う際に気をつけること
- プライベートなVPC内にいるので直接触れない
- SFTPでコネクションを貼るために踏み台サーバーを作成する必要がある
- さらにPyCharmで接続するためにローカルでsshトンネルを作る必要がある
そもそもVPC内にエンドポイントを作る理由
GlueがデータソースとしてS3だけを相手する場合は別にVPCの外でいいが、JDBC系をデータソースとして扱う際にはVPCの中に置く必要がある。
構成図
環境・前提
- Mac OS
- PyCharm Professional
- チュートリアルの前提条件 がJDBC用のVPCでの開発エンドポイントまで終わっていること
- チュートリアルの前提で作成したエンドポイントに公開鍵を設定しておく
実装
1. 踏み台サーバーの作成
- よくある方法で踏み台サーバーの作成
- sshキーだけ忘れないように取得
- 開発エンドポイントと同じVPCに作成
- 開発エンドポイントが属しているVPCは開発エンドポイントをクリックしたら出てくるエンドポイントの詳細で確認可能
2. private subnetのSSHセキュリティグループの設定
- private subnetのセキュリティグループで踏み台が置かれているpublic subnetからだけsshを許可する
3. SSHトンネルの作成
- 以下の様にSSHトンネルを作成
ssh -i <踏み台サーバーのpem> ec2-user@<踏み台サーバーのpublic dns> -L <設定したいローカルポート>:<開発エンドポイントのプライベートアドレス>:22 -N
- うまく行かなくてデバッグをしたいときなどはvオプションを付与する
- 開発エンドポイントのプライベートアドレスは詳細で確認可能
4. PyCharmの設定
- コードとライブラリをチュートリアルに書かれているようにセットアップする
- デプロイの部分が大きくチュートリアルと違う
Hostはローカルホストを指定Portはトンネルで設定したローカルポートを指定User nameはglueAuthenticationはKey pair OpenSSHPrivate key pathは開発エンドポイントに設定した公開鍵の秘密鍵のパス(EC2の秘密鍵ではない)Test Connectionして成功すればOK
あとはチュートリアルと同じ用にやればOK。
その他
- 開発エンドポイントには公開鍵を複数設定することができるので、鍵の共有をする必要がない
- PyCharmで開発しているときはSSHトンネルが生きている必要がある
参考
チュートリアル: 開発エンドポイントで PyCharm Professional をセットアップする
Securely Connect to Linux Instances Running in a Private Amazon VPC | AWS Security Blog
AWS GlueでSpark開発をする - おおたの物置
リモート PyCharmによるデバッグ - ヘルプ | PyCharm

- 投稿日:2020-03-15T20:31:25+09:00
機械学習でフルマラソンのゴールタイムを予測~③:Pythonでデータ可視化してみた~
概要
前回からの続きです。
【機械学習でフルマラソンのゴールタイムを予測】と題して、ランニングの練習時のデータからフルマラソン(42.195㎞)を走った場合のゴールタイムを予測するために、データ収集からモデル作成・予測までの一連の流れを書いていきます。前回記事(機械学習でフルマラソンのゴールタイムを予測~②:Garminで学習データを作成してみた~)では、学習データを作成するために、不要な項目の削除と必要なデータの追加を行う手順について記載しました。
今回は作成した学習データを使ってフルマラソンのゴールタイムを予測する予測モデルを作成する前に、データを可視化して全体の傾向を見ていくところについて記載していきます。
Excelで簡単にできるものも含まれますが、同じことをPythonでやるとしたらどうやってコードを書けばいいのか知る機会として頂ければ幸いです。
pixtabayより学習データの中身
ランニング時の距離やペースに影響を与えると考えられる14個の項目を特徴量とする学習データを作成しています。
- 練習日付(yyyy/mm/dd HH:MM:ss) 項目名:Practice Time
- 距離(㎞) 項目名:Distance
- タイム(HH:MM:ss) 項目名:Time
- 平均心拍数(bpm) 項目名:Average heart rate
- 最大心拍数(bpm) 項目名:Max heart rate
- 有酸素TE 項目名:Aerobic TE
- 平均ピッチ(歩/分) 項目名:Average pitch
- 1㎞あたりの平均ペース(HH:MM:ss/㎞) 項目名:Average pace
- 1㎞あたりの最高ペース(HH:MM:ss/㎞) 項目名:Max pace
- 平均歩幅(cm/歩) 項目名:Average stride
- 走り始めの気温(℃) 項目名:temperature
- 走り始めの風速(m/秒) 項目名:Wind speed
- その週の就業時間(h/週) 項目名:Work
- その週の1日あたりの平均睡眠時間(HH:MM:ss/日) 項目名:Average sleep time
1レコード分のサンプルデータ
Practice Time Distance Time Average heart rate Max heart rate Aerobic TE Average pitch Average pace Max pace Average stride temperature Wind speed Work Average sleep time 2020/2/23 16:18:00 8.19 0:59:35 161 180 3.6 176 00:07:16 00:06:11 0.78 7.9 9 44.5 6:12:00 1か月ごとの走行距離
まずはデータを可視化する上で必要になりそうなものをインポートしておきます。
とりあえずこのくらいあれば事足りるかと思います。RunnningDataVisualization.ipynbimport pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import matplotlib.dates as mdates import seaborn as sns1か月ごとの走行距離のグラフ描画は以下のコードでできます。
RunnningDataVisualization.ipynbdf = pd.read_csv(r'Activities.csv', index_col=["PracticeTime"],parse_dates=True) #"PracticeTime"を日付型として読み込むために、インデックスの指定を引数index_colで行い、 #parse_datesにTrueを指定し、index_colで指定した項目を日付型のインデックスとする #グラフを描画 df_m = df.resample(rule="M").sum() df_m_graph = df_m['Distance'] df_m_graph.plot.bar() #グラフの表示形式をいろいろ設定 plt.title("Distance per month", fontsize = 22) #グラフにタイトル名をつける plt.grid(True) #グラフに目盛り線をつける plt.xlabel("month", fontsize = 15) #グラフの横軸にラベルをつける plt.ylabel("km", fontsize = 15) #グラフの縦軸にラベルをつける plt.yticks( np.arange(0, 60, 5) ) #グラフのサイズを調整する<実行結果>
こうやって見ると、夏の暑い時期にいかに練習できていないかがよくわかりますw
散布図~ペースとピッチの関係性~
次に、1㎞あたりのペースとピッチに相関があるのか調べるため、散布図を書いていきます。
一般的に考えると、ペースが落ちればピッチ(1分間あたりの歩数)も減少していきそうですが、実際のところどうなのでしょうか。RunnningDataVisualization.ipynbdf = df.sort_values("Average pace") #ペースを速い順に並べ替える plt.scatter(df['Average pace'], df['Average pitch'],s=40 ,marker="*", linewidths="4", edgecolors="orange") #散布図を描画 plt.title("Scatter plot of pace and pitch", fontsize = 22) plt.ylabel('Average pitch', fontsize = 15) plt.xlabel('Average pace', fontsize = 15) plt.grid(True) plt.xticks(rotation=90) plt.figure(figsize=(50, 4))<実行結果>
ペースが速いか遅いかにかかわらず、ピッチはその時によってばらばらであることが分かります。
散布図~ペースとストライドの関係性~
それでは次に、ペースとストライドの関係性はどうでしょうか。
ペースが落ちれば、ストライド(1歩あたりの歩幅)も減少していきそうです。RunnningDataVisualization.ipynbdf = df.sort_values("Average pace") plt.scatter(df['Average pace'], df['Average stride'],s=40 ,marker="*", linewidths="4", edgecolors="blue") plt.title("Scatter plot of pace and stride", fontsize = 22) plt.ylabel('Average stride', fontsize = 15) plt.xlabel('Average pace', fontsize = 15) plt.grid(True) plt.xticks(rotation=90) plt.figure(figsize=(10, 10),dpi=200) plt.show()<実行結果>
さきほどのペースとピッチの散布図と違い、こちらは点の集まりが何となく右下がりになっていることが分かります。
つまり、ペースが下がれば下がるほど、ストライドは最大25㎝ほど小さくなっているということが読み取れます。距離をたくさん走っていくと、必ずペースががくっと落ちる瞬間が訪れますが、原因の1つはこれだったのか!とPythonで可視化したことで納得することができます。←
特徴量同士の相関係数
最後に、各特徴量同士の相関係数を出してみます。
Garminで記録されているデータに加えて自分で学習データに追加した4つの特徴量(気温、風速、週単位での就業時間、平均睡眠時間)の中に、走行距離や心拍数などとの相関の強い特徴量が現れれば、それはペースや走行距離に何かしらの影響を与えていると考えられます。今回は時刻データの相関係数の出し方が分からなかったので、数値データの特徴量間の相関係数のみ算出しています。
相関係数を算出するにあたり、csv読み込み時に文字列として読み込まれてしまった平均心拍数と最大心拍数の値を文字列から数値に型変換しておきます。
RunnningDataVisualization.ipynb#型変換 df['Average heart rate'] = df['Average heart rate'].fillna(0).astype(np.int64) df['Max heart rate'] = df['Max heart rate'].fillna(0).astype(np.int64) #相関係数を可視化 df_corr = df.corr() print(df_corr) #特徴量同士の相関係数を一覧で表示 fig = plt.subplots(figsize=(8, 8)) #分かりやすく可視化 sns.heatmap(df_corr, annot=True,fmt='.2f',cmap='Blues',square=True)<実行結果>
注目した3つの特徴量(気温、風速、週単位での就業時間)では、他の特徴量との相関係数の絶対値が0.5を超えるものがありません。
つまり、これら3つの特徴量はさほど走行距離やペースに影響しないということが分かります。まあ、考えてみれば暑すぎる日や寒すぎる日、風の強い日はそもそもランニングの練習をしませんし、その週の就業時間が多ければ体力的な疲労が少なからず溜まることになるので、これまたランニングの練習はしないという選択をすることになります。
というわけで、この結果もまたまた納得のいく結果です。残念ながら、相関係数を算出しただけでは走行距離やペースに影響を与える特徴量を見つけることはできませんでしたが、このようにいろいろとデータを見ながら可視化してみることで、走る時の自分の傾向や、練習の仕方について振り返る良い機会になります。
次回はいよいよ予測モデルを作成し、予測処理を回していきます。






- 投稿日:2020-03-15T20:17:56+09:00
Yahoo!ニュースの見出し生成にCOTOHA APIだけを使ってチャレンジ
はじめに
COTOHA APIがQiitaとコラボキャンペーンをやっている。
もうすぐFF7のリメイク出るしPS4が欲しい.. (-p-)https://zine.qiita.com/event/collaboration-cotoha-api/
完全に不純な動機ですが、COTOHA APIを使って自然言語処理をやってみました。
本日が投稿締め切りなのでかなりギリギリですが、何とか間に合いました...やったこと
COTOHAが提供するAPIだけを使って、ニュース記事の要約にチャレンジしてみました。
お題はYahoo!ニュースの見出し生成です。Yahoo!ニュースの見出し
みなさんご存知Yahoo!ニュースですが、各記事には見出しが付けられています。
例えば以下のような感じです。
普段何気なく見ているこの見出しですが、実は様々なルールの中で作られており奥が深いのです。
まず、限られたスペースで、シンプルに齟齬なく伝えるようにするために
文字数は最大13文字(正確には半角スペース込みの13.5文字)に制限されています。また、見出しには場所情報が含まれています。
事件や事故の場合、発生場所によってニュースの重要性やユーザーの関心度が大きく変わるためです。そして、見出しに使う言葉には基本的に記事中の言葉が使われています。
というのも、記事は各メディアに配信してもらっているため、字数に収まらない場合を除き、
記事の内容をねじ曲げることが無いようにそうしているそうです。記事中の言葉を使って見出しを作るのであれば、COTOHA APIを使って
ある程度出来るのではないかと思いました。他にもルールはありますが、今回取り上げたルールをまとめると以下のようになります。
- 【ルール1】 見出しの文字数は最大でも13文字以内
- 【ルール2】 見出しには場所情報を含める
- 【ルール3】 見出しには記事中の言葉を使う
※ルールについては以下のページにまとめられているので、興味がある方は是非みてください。
【参考】Yahoo!ニュース トピックス「13文字見出し」の極意
https://news.yahoo.co.jp/newshack/inside/yahoonews_topics_heading.htmlCOTOHA API
NTTコミュニケーションズが提供する自然言語処理・音声認識のAPIです。
構文解析や音声認識など14の自然言語処理・音声処理APIが提供されています。
https://api.ce-cotoha.com/contents/index.html今回は、COTOHA APIのDevelopers版を使いました。
Enterprise版と比べて一部制約はありますが、無料で利用することが出来ます。今回対象にした記事
今回対象にしたのは、ビル・ゲイツさんがMSを退任されたという以下の記事です。
https://news.yahoo.co.jp/pickup/6354056付けられていた見出しはこちらです。
ビル・ゲイツ氏 MS取締役退任うむ。確かに完結で分かりやすい。
ステップ1:まずは要約APIだけでチャレンジ
COTOHA APIでは要約APIが提供されています。
まだベータ版ではありますが、こちらを使うことにより文中で重要と思われる文章を抽出することが出来ます。まずは、このAPIを使い1文を抽出してみることにしました。
{ "result": "ゲイツ氏は2008年に経営の一線から退き、14年には会長を退任したが、取締役会には残っていた。", "status": 0 }無事抽出できましたが、このままだと13文字を明らかに超えているので、短縮しなければなりません。
どう短縮しようか悩みましたが、重要度が高いキーワードだけを残すというやり方で出来ないか進めてみることにしました。ステップ2:キーワード抽出APIを使って重要語抽出
以前、Qiitaの記事で
termextractを使うことで、重要度が高いキーワード抽出が出来ると書きました。【参考】Qiitaタグ自動ジェネレータ
https://qiita.com/fukumasa/items/7f6f69d4f6336aff3d90COTOHA APIでもキーワード抽出APIが提供されており、
テキストに含まれる特徴的なフレーズ・単語をキーワードとして抽出することが出来ます。先ほど抽出した1文を対象にキーワードを抽出してみます。
{ "result": [ { "form": "会長", "score": 14.48722 }, { "form": "一線", "score": 11.3583 }, { "form": "退任", "score": 11.2471 }, { "form": "取締役会", "score": 10.0 } ], "status": 0, "message": "" }この時点で既に怪しい感じになってきました・・・。
「誰が」という肝心な情報(ゲイツ氏)が抽出できていません。
まあ、、、とりあえず続けてみます。ステップ3:固有表現抽出APIを使って場所情報を抽出
冒頭のルールでも書きましたが、見出しには場所情報を含める必要があります。
場所情報を取得するのに便利なAPIがCOTOHAでは提供されています。固有表現抽出APIです。
このAPIを使うことで、人名や地名などの固有表現が取得できます。先ほど抽出した1文で試してみましたが、場所情報は含まれていませんでした。
もし含まれていた場合は、めちゃ安直ですが「抽出した場所情報」に「で」をつけて、
要約文の冒頭に含めることにしました。ステップ4:構文解析APIを使ってキーワードに助詞を付与
抽出出来たこれらのキーワードをただ並べるだけでは、見出し(文章)を生成するのは難しそうです。
キーワードをもとに文章を自動生成するなんて高度なこと出来ませんし、、結構悩みました。COTOHA APIだけを使うという制約を課しているため、改めてAPI一覧を眺めていたところ1つ閃きました。
構文解析APIを使って、抽出した各キーワードに「が」や「を」などの助詞を付与して各キーワードをつなげるという方法です。このAPIを使うことで、テキストが文節・形態素に分解され、文節間の係り受け関係や
形態素間の係り受け関係、品詞情報などの意味情報などが付与されます。これで、抽出したキーワードと助詞の関係にあるもの?(どう表現したらいいかよく分からない...)を抽出できそうです。例えば、「空気が美味い」の場合、「空気」というキーワードの助詞として「が」を抽出するという感じです。
このAPIを使って、先ほどのキーワードに助詞を付与してみます。
返却されたレスポンス(長いので折りたたみ)
{ "result": [ { "chunk_info": { "id": 0, "head": 7, "dep": "D", "chunk_head": 1, "chunk_func": 2, "links": [] }, "tokens": [ { "id": 0, "form": "ゲイツ", "kana": "ゲイツ", "lemma": "ゲイツ", "pos": "名詞", "features": [ "固有", "姓" ], "attributes": {} }, { "id": 1, "form": "氏", "kana": "シ", "lemma": "氏", "pos": "名詞接尾辞", "features": [ "名詞" ], "dependency_labels": [ { "token_id": 0, "label": "name" }, { "token_id": 2, "label": "case" } ], "attributes": {} }, { "id": 2, "form": "は", "kana": "ハ", "lemma": "は", "pos": "連用助詞", "features": [], "attributes": {} } ] }, { "chunk_info": { "id": 1, "head": 4, "dep": "D", "chunk_head": 0, "chunk_func": 1, "links": [] }, "tokens": [ { "id": 3, "form": "2008年", "kana": "ニセンハチネン", "lemma": "2008年", "pos": "名詞", "features": [ "日時" ], "dependency_labels": [ { "token_id": 4, "label": "case" } ], "attributes": {} }, { "id": 4, "form": "に", "kana": "ニ", "lemma": "に", "pos": "格助詞", "features": [ "連用" ], "attributes": {} } ] }, { "chunk_info": { "id": 2, "head": 3, "dep": "D", "chunk_head": 0, "chunk_func": 1, "links": [] }, "tokens": [ { "id": 5, "form": "経営", "kana": "ケイエイ", "lemma": "経営", "pos": "名詞", "features": [ "動作" ], "dependency_labels": [ { "token_id": 6, "label": "case" } ], "attributes": {} }, { "id": 6, "form": "の", "kana": "ノ", "lemma": "の", "pos": "格助詞", "features": [ "連体" ], "attributes": {} } ] }, { "chunk_info": { "id": 3, "head": 4, "dep": "D", "chunk_head": 0, "chunk_func": 1, "links": [ { "link": 2, "label": "adjectivals" } ] }, "tokens": [ { "id": 7, "form": "一線", "kana": "イッセン", "lemma": "一線", "pos": "名詞", "features": [], "dependency_labels": [ { "token_id": 5, "label": "nmod" }, { "token_id": 8, "label": "case" } ], "attributes": {} }, { "id": 8, "form": "から", "kana": "カラ", "lemma": "から", "pos": "格助詞", "features": [ "連用" ], "attributes": {} } ] }, { "chunk_info": { "id": 4, "head": 7, "dep": "P", "chunk_head": 0, "chunk_func": 1, "links": [ { "link": 1, "label": "goal" }, { "link": 3, "label": "object" } ], "predicate": [] }, "tokens": [ { "id": 9, "form": "退", "kana": "シリゾ", "lemma": "退く", "pos": "動詞語幹", "features": [ "K" ], "dependency_labels": [ { "token_id": 3, "label": "nmod" }, { "token_id": 7, "label": "dobj" }, { "token_id": 10, "label": "aux" }, { "token_id": 11, "label": "punct" } ], "attributes": {} }, { "id": 10, "form": "き", "kana": "キ", "lemma": "き", "pos": "動詞接尾辞", "features": [ "連用" ], "attributes": {} }, { "id": 11, "form": "、", "kana": "", "lemma": "、", "pos": "読点", "features": [], "attributes": {} } ] }, { "chunk_info": { "id": 5, "head": 7, "dep": "D", "chunk_head": 0, "chunk_func": 1, "links": [] }, "tokens": [ { "id": 12, "form": "14年", "kana": "ジュウヨネン", "lemma": "14年", "pos": "名詞", "features": [ "日時" ], "dependency_labels": [ { "token_id": 13, "label": "case" } ], "attributes": {} }, { "id": 13, "form": "には", "kana": "ニハ", "lemma": "には", "pos": "連用助詞", "features": [], "attributes": {} } ] }, { "chunk_info": { "id": 6, "head": 7, "dep": "D", "chunk_head": 0, "chunk_func": 1, "links": [] }, "tokens": [ { "id": 14, "form": "会長", "kana": "カイチョウ", "lemma": "会長", "pos": "名詞", "features": [], "dependency_labels": [ { "token_id": 15, "label": "case" } ], "attributes": {} }, { "id": 15, "form": "を", "kana": "ヲ", "lemma": "を", "pos": "格助詞", "features": [ "連用" ], "attributes": {} } ] }, { "chunk_info": { "id": 7, "head": 9, "dep": "D", "chunk_head": 0, "chunk_func": 3, "links": [ { "link": 0, "label": "agent" }, { "link": 4, "label": "manner" }, { "link": 5, "label": "time" }, { "link": 6, "label": "agent" } ], "predicate": [ "past" ] }, "tokens": [ { "id": 16, "form": "退任", "kana": "タイニン", "lemma": "退任", "pos": "名詞", "features": [ "動作" ], "dependency_labels": [ { "token_id": 1, "label": "nsubj" }, { "token_id": 9, "label": "advcl" }, { "token_id": 12, "label": "nmod" }, { "token_id": 14, "label": "nsubj" }, { "token_id": 17, "label": "aux" }, { "token_id": 18, "label": "aux" }, { "token_id": 19, "label": "mark" }, { "token_id": 20, "label": "punct" } ], "attributes": {} }, { "id": 17, "form": "し", "kana": "シ", "lemma": "し", "pos": "動詞活用語尾", "features": [], "attributes": {} }, { "id": 18, "form": "た", "kana": "タ", "lemma": "た", "pos": "動詞接尾辞", "features": [ "接続" ], "attributes": {} }, { "id": 19, "form": "が", "kana": "ガ", "lemma": "が", "pos": "接続接尾辞", "features": [ "連用" ], "attributes": {} }, { "id": 20, "form": "、", "kana": "", "lemma": "、", "pos": "読点", "features": [], "attributes": {} } ] }, { "chunk_info": { "id": 8, "head": 9, "dep": "D", "chunk_head": 0, "chunk_func": 1, "links": [] }, "tokens": [ { "id": 21, "form": "取締役会", "kana": "トリシマリヤクカイ", "lemma": "取締役会", "pos": "名詞", "features": [], "dependency_labels": [ { "token_id": 22, "label": "case" } ], "attributes": {} }, { "id": 22, "form": "には", "kana": "ニハ", "lemma": "には", "pos": "連用助詞", "features": [], "attributes": {} } ] }, { "chunk_info": { "id": 9, "head": -1, "dep": "O", "chunk_head": 0, "chunk_func": 4, "links": [ { "link": 7, "label": "manner" }, { "link": 8, "label": "place" } ], "predicate": [ "past", "past" ] }, "tokens": [ { "id": 23, "form": "残", "kana": "ノコ", "lemma": "残る", "pos": "動詞語幹", "features": [ "R" ], "dependency_labels": [ { "token_id": 16, "label": "advcl" }, { "token_id": 21, "label": "nmod" }, { "token_id": 24, "label": "aux" }, { "token_id": 25, "label": "aux" }, { "token_id": 26, "label": "aux" }, { "token_id": 27, "label": "aux" }, { "token_id": 28, "label": "punct" } ], "attributes": {} }, { "id": 24, "form": "っ", "kana": "ッ", "lemma": "っ", "pos": "動詞活用語尾", "features": [], "attributes": {} }, { "id": 25, "form": "て", "kana": "テ", "lemma": "て", "pos": "動詞接尾辞", "features": [ "接続", "連用" ], "attributes": {} }, { "id": 26, "form": "い", "kana": "イ", "lemma": "いる", "pos": "動詞語幹", "features": [ "A", "Lて連用" ], "attributes": {} }, { "id": 27, "form": "た", "kana": "タ", "lemma": "た", "pos": "動詞接尾辞", "features": [ "終止" ], "attributes": {} }, { "id": 28, "form": "。", "kana": "", "lemma": "。", "pos": "句点", "features": [], "attributes": {} } ] } ], "status": 0, "message": "" }['会長を', '一線から', '退任', '取締役会には']ステップ5:いざ見出しを生成する!
先ほど助詞を付与した各キーワードを組み合わせて、13文字以下の文章にしてみます。
ステップ4でほぼバレてますが、こんな結果になりました。会長を一線から退任「え?誰が退任したの?」って興味をそそるような見出しになっているような気がしないでもないですが、会長を辞めたのではなく取締役を辞めたので誤った情報を伝えてしまいそうです。
ただ、ステップ2でも書いた通り、「誰が」と言う情報や「マイクロソフト」「MS」といった会社名も無く微妙な気もするので、今回生成した見出しがどれ程いい感じなのかを客観的に調べてみることにしました。
ステップ6:類似度算出APIを使って生成した見出しの完成度を確認
生成した見出しの完成度についても、COTOHAのAPIを使って確認することができます。
類似度算出APIです。
このAPIを使うことで、2つの文における意味的な類似度を算出することが出来ます。
類似度は0から1の定義域で出力され、1に近づくほどテキスト間の類似性が大きいことを示します。記事につけられていた見出し
ビル・ゲイツ氏 MS取締役退任と、
生成した見出し会長を一線から退任の類似度を算出してみました。{ "result": { "score": 0.9716939 }, "status": 0, "message": "OK" }お〜、0.97って結構高くないですか・・・!?(困惑
COTOHAさんがそう言ってくれるなら。。おまけ
参考までに他の記事でもやってみました。
コンビニ「レンチン」で革命
全部で4ページの記事ですが、とりあえず1ページ目だけでやってみました。
https://news.yahoo.co.jp/pickup/6353834
- ●抽出した1文
- いま、コンビニ業界で進むレンジでチン革命を象徴する商品として注目されている。
- ●抽出したキーワード
- ['象徴', '注目', 'レンジ', 'コンビニ業界', 'チン革命']
●生成した見出し
象徴注目レンジで (類似度:0.45899978)見出し見ても何のこっちゃですね・・・類似度もめちゃ低い。
なんせ抽出したキーワードをスコアの高い順にくっつけて文章にしているだけなので、
こんな感じになっているんだと思います。
レンジでチンをレンチンと略すの初めて知ったかも。というか、チン革命ってなんぞや・・・。ゲームは1日60分 案に賛成8割
色々物議を醸している香川県のゲーム規制に関する記事です。
https://news.yahoo.co.jp/pickup/6353894
- ●抽出した1文
- 香川県議会が4月の施行を目指している「ゲーム依存」の対策条例。
- ●抽出したキーワード
- ['対策条例', '香川県議会', '施行', 'ゲーム依存']
●生成した見出し
対策条例香川県議会施行を (類似度:0.2842004)見出しを見れば香川県の例のゲームのやつかと分からんでも無いですが、この記事で伝えたいことは恐らく8割も賛成者がいるということでしょう。類似度もめちゃ低い。
ただ、抽出した1文および生成された見出しには数値情報が含まれていませんでした。
あと、記事中には84%という具体的な数値が含まれていますが、見出しでは8割と分かりやすい表現に変換されています。細かな数値を言われるよりも、ざっくりと言われた方が感覚的に把握しやすいですね。この辺りは人間ならではの技でしょうか。東京で降雪 都心はみぞれ
昨日の記事です。東京で雪が降ったそうですね。まだ寒い日が続きますね・・・。
https://news.yahoo.co.jp/pickup/6354091
- ●抽出した1文
- 昨日の正午より10℃以上低く東京都心では、14日0時過ぎに最高気温12.3℃を観測した後、どんどん気温が下がり、14時現在は2.5℃となっています。
- ●抽出したキーワード
- ['観測', '気温', '12.3°c', '2.5°c', '10°c以上']
- ●抽出した場所情報
- ['東京都心']
●生成した見出し
東京都心で観測気温 (類似度:0.99335754)場所情報が含まれているケースですが、東京都心で4文字も消費してしまい、出来た見出しも情報量があまり無いものになっています。抽出したキーワードも数値情報が多すぎる気もします。
でも、類似度が0.99とめちゃ高い・・・。まとめ
今回生成できた見出しが大成功かと言われれば若干微妙な気もしますが、、やってて楽しかったです。
そもそもですが、要約について調べたところ、ざっくり以下のような分類があるそうです。
- 抽出型
- 対象の文章の中から重要と思われる文を抽出して要約を作成する
- 抽象型
- 元の文章には含まれていない単語も使って文章の意味を汲み取ったうえで適切な要約を作成する
今回使ったCOTOHAが提供している要約APIは前者の抽出型です。
ただ、Yahoo!ニュースでやっているように、色んなルールや制約のもとで要約を作成しようとすると、抽出型だけでは難しいので、他のサービスと組み合わせや後者の抽象型の要約サービスを使うといったことが必要になりそうだと感じました。
また、字数を削減するために、国名などの場合はある程度ルール化されているので省略しやすそうですが、レンジでチンをレンチンと略したり、84%を8割と分かりやすく表現したりするのは、自然言語処理技術を使ってもまだハードルが高そうな気がします。
Yahoo!ニュースの見出し生成(巧みの技)がAIにとって変わられる日はまだまだ当分来ないんだろうなと感じました。
さいごに
自然言語処理、面白いので個人的に大好きです。
ただ、仕事でバリバリ使う機会があまりないので、引き続きプライベートで楽しみたいと思います。
あとPS4ください。参考サイト
要約については以下のQiita記事がすごく参考になりますよ。
- 大自然言語時代のための、文章要約 (Qiita)
【参考】ソースコード
突っ込みどころ多いかもしれませんが...興味ある人は見てね
import requests import pprint import json import re from bs4 import BeautifulSoup base_url = 'https://api.ce-cotoha.com/api/dev/nlp/' ''' COTOHA APIのアクセストークンを取得 ''' def get_access_token(): url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens' req_data = { 'grantType' : 'client_credentials', 'clientId' : 'クライアントID', 'clientSecret' : 'クライアントシークレット' } headers = { 'Content-Type' : 'application/json' } response = requests.post(url, json.dumps(req_data), headers=headers) token = response.json()['access_token'] return token ''' 要約APIを呼び出す ''' def get_summary(token, document) : url = base_url + '/beta/summary' req_data = { 'document' : document, 'sent_len' : '1' } headers = { 'Content-Type' : 'application/json;charset=UTF-8', 'Authorization' : 'Bearer {}'.format(token) } response = requests.post(url, json.dumps(req_data), headers=headers) summary = response.json()['result'] return summary ''' キーワード抽出APIを呼び出す ''' def get_keywords(token, document): url = base_url + '/v1/keyword' req_data = { 'document' : document, 'type' : 'default', 'do_segment' : True } headers = { 'Content-Type' : 'application/json;charset=UTF-8', 'Authorization' : 'Bearer {}'.format(token) } response = requests.post(url, json.dumps(req_data), headers=headers) keywords = [item.get('form') for item in response.json()['result']] return keywords ''' 固有表現抽出APIを呼び出し、場所に関する情報を取得 ''' def get_ne_loc(token,sentence): url = base_url + '/v1/ne' req_data = { 'sentence' : sentence } headers = { 'Content-Type' : 'application/json;charset=UTF-8', 'Authorization' : 'Bearer {}'.format(token) } response = requests.post(url, json.dumps(req_data), headers=headers) ne = response.json()['result'] ne_loc = [] for item in ne: if item['class'] == 'LOC': ne_loc.append(item['form']) #単語だけだと重複が発生するケースがある if ne_loc: ne_loc = list(set(ne_loc)) return ne_loc ''' 構文解析APIを呼び出す ''' def parse_doc(token, sentence) : url = base_url + '/v1/parse' req_data = { 'sentence':sentence } headers = { 'Content-Type' : 'application/json;charset=UTF-8', 'Authorization' : 'Bearer {}'.format(token) } response = requests.post(url, json.dumps(req_data), headers=headers) parsed_result = response.json()['result'] tokens = [] for tokens_ary in parsed_result: for token in tokens_ary['tokens']: if token: tokens.append(token) return tokens ''' 類似度算出APIを呼び出す ''' def get_similarity(token, doc1, doc2): url = base_url + '/v1/similarity' req_data = { 's1' : doc1, 's2' : doc2, 'type' : 'kuzure' } headers = { 'Content-Type' : 'application/json;charset=UTF-8', 'Authorization' : 'Bearer {}'.format(token) } response = requests.post(url, json.dumps(req_data), headers=headers) similarity = response.json()['result'] return similarity ''' Yahoo!ニュースの記事URLから内容を抽出する (単一ページのみに対応、複数ページや特定の記事フォーマットには対応していない...) ''' def get_contents(url): top_page = requests.get(url) soup = BeautifulSoup(top_page.text, 'lxml') article_url = soup.find('div',class_=re.compile('pickupMain_articleInfo')).find('a').get('href') article_page = requests.get(article_url) soup = BeautifulSoup(article_page.text, "lxml") for tag in soup.find_all('p',{'class':'photoOffer'}): tag.decompose() for tag in soup.find_all('a'): tag.decompose() contents = re.sub('\n|\u3000','',soup.find('div',class_=re.compile('articleMain')).getText()); return contents ''' Yahoo!ニュースの記事URLからタイトルを抽出する (これが正解になる) ''' def get_title(url): top_page = requests.get(url) soup = BeautifulSoup(top_page.text, "lxml") title = soup.find("title").getText().split(' - ')[0] return title ''' Yahoo!ニュース記事のトピックを生成する ''' def create_news_topic(token, contents): #記事要約を実施 summary = get_summary(token, contents) print(summary) print("------------") #要約文が13文字以下ならトピックとして返す if len(summary) <= 13: return summary[:-1] #要約文からキーワードおよび地名を抽出 keywords = get_keywords(token, summary) print(keywords) print("------------") ne_loc = get_ne_loc(token, summary) print(ne_loc) print("------------") topic = '' #場所情報があれば見出しに追加 #複数あってもとりあえず1個目だけ if ne_loc: topic += ne_loc[0] + 'で' #キーワードにも含まれている場合は取り除く if ne_loc[0] in keywords: keywords.remove(ne_loc[0]) #要約文を構文解析 tokens = parse_doc(token, summary) #キーワードの助詞を取得しつつ要約を作成 for keyword in keywords: for token in tokens: if token['form'] == keyword: print(token) for dependency_label in token['dependency_labels']: if dependency_label['label'] == 'case': keyword += tokens[int(dependency_label['token_id'])]['form'] break break if len(topic) + len(keyword) <= 13: topic += keyword else: return topic return topic ''' メイン ''' if __name__ == '__main__': #見出し生成したいYahoo!ニュースの記事URL url = 'https://news.yahoo.co.jp/pickup/6354056' #記事内容およびタイトルを抽出 contents = get_contents(url) title = get_title(url) print("------------") print(contents) print("------------") print(title) print("------------") #COTOHA APIのトークンを取得 token = get_access_token() #記事の見出しを生成 topic = create_news_topic(token, contents) print(topic) print("------------") #元の見出しと生成した見出しの類似度を算出 similarity = get_similarity(token, title, topic)['score'] print(similarity) print("------------")

- 投稿日:2020-03-15T20:00:37+09:00
Djangoテンプレートで呼び出し可能な変数を呼び出させないようにする
結論
オブジェクトに
do_not_call_in_templates = Trueを付与するclass SampleCallableClass: do_not_call_in_templates = True def __call__(self): pass def sample_method(self): pass sample_method.do_not_call_in_templates = True概要
Djangoテンプレートでは、ある変数が呼び出し可能かどうかをまずチェックし、呼び出し可能であれば引数無しで呼び出します。
例えば、
{{ Hoge.fuga }}において、Hogeが呼び出し可能である場合、これは{{ Hoge().fuga }}のように評価されます。しかしながら、呼び出し可能なオブジェクトを呼び出さずにそのプロパティにアクセスしたいという場合があります。
例えば
Hogeが列挙型である場合は引数無しでの呼び出しHoge()が出来ずにエラーとなり、残りの要素.fugaは評価されず、最終的に空の文字列が出力されます。こうした状況について、公式ドキュメントには以下のように記述されています。
Occasionally you may want to turn off this feature for other reasons, and tell the template system to leave a variable uncalled no matter what. To do so, set a
do_not_call_in_templatesattribute on the callable with the valueTrue. The template system then will act as if your variable is not callable (allowing you to access attributes of the callable, for example).https://docs.djangoproject.com/en/3.0/ref/templates/api/#variables-and-lookups
呼び出し可能オブジェクトに
do_not_call_in_templates = Trueを付与することで、呼び出し可能でないかのように振る舞わせることが出来るようになります。余談
Django3.0で追加された
Choicesの実装を読んでいた際に、ChoicesMetaの__new__メソッドにdo_not_call_in_templatesが使われているのを見つけて記事にしてみました。
- 投稿日:2020-03-15T19:26:45+09:00
DjangoのChoiceFieldを列挙型で指定する
Djangoの
modelsにおけるTextFieldやIntegerField、そしてformsにおけるChoiceFieldに用いるchoicesには、これまでは以下のような形式の値が必要でした。YEAR_IN_SCHOOL_CHOICES = [ ('FR', 'Freshman'), ('SO', 'Sophomore'), ('JR', 'Junior'), ('SR', 'Senior'), ('GR', 'Graduate'), ]Django3.0からは
TextChoicesとIntegerChoicesというクラスが追加され、以下のような書き方が出来るようになりました。class YearInSchool(models.TextChoices): FRESHMAN = 'FR', 'Freshman' SOPHOMORE = 'SO', 'Sophomore' JUNIOR = 'JR', 'Junior' SENIOR = 'SR', 'Senior' GRADUATE = 'GR', 'Graduate' YEAR_IN_SCHOOL_CHOICES = YearInSchool.choices
TextChoicesやIntegerChoicesはEnumクラスを継承しているので、それに近い感覚で書くことが出来るようになりました。もちろんただ列挙型として扱うことが出来るだけでなく、ラベル(フォームで表示される文字列、各タプルの2要素目の値)の値も保持しています。
プロパティ
names,values,FIELD.name,FIELD.value>>> YearInSchool.names ['FRESHMAN', 'SOPHOMORE', 'JUNIOR', 'SENIOR', 'GRADUATE'] >>> YearInSchool.values ['FR', 'SO', 'JR', 'SR', 'GR'] >>> YearInSchool.FRESHMAN.name 'FRESHMAN' >>> YearInSchool.FRESHMAN.value 'FR'
nameでは列挙型のフィールド名が、valueではDBに格納される文字列が返されます。これは
Enumの実装によるものです。
labels,FIELD.label>>> YearInSchool.labels ['Freshman', 'Sophomore', 'Junior', 'Senior', 'Graduate'] >>> YearInSchool.FRESHMAN.label 'Freshman'ラベルが返されます。モデルのフィールドに対しては
get_FOO_display(FOOはフィールド名)というプロパティが自動生成され、これを呼び出すことでもラベルが取得できます。https://docs.djangoproject.com/en/3.0/ref/models/instances/#django.db.models.Model.get_FOO_display
choices
>>> YearInSchool.choices [('FR', 'Freshman'), ('SO', 'Sophomore'), ('JR', 'Junior'), ('SR', 'Senior'), ('GR', 'Graduate')]以前の
choicesで指定する形式でのタプルのリストが返されます。文字列からラベルを取得する
>>> YearInSchool('FR').label 'Freshman' >>> YearInSchool['FRESHMAN'].label 'Freshman'上記のようにして
Enumのフィールドを取得し、name,value,labelが取得可能ですラベルを指定しない場合
class Vehicle(models.TextChoices): CAR = 'C' TRUCK = 'T' JET_SKI = 'J' >>> Vehicle.JET_SKI.label 'Jet Ski'アンダースコア(
_)を半角スペースに変換し、タイトルケース(各単語の先頭を大文字にする)を適用してラベルにするようです。公式ドキュメント
https://docs.djangoproject.com/en/3.0/ref/models/fields/#choices
- 投稿日:2020-03-15T18:46:52+09:00
KotlinでもPythonみたいに文字列操作したい!
kotlinの文字列操作も便利だけどやっぱりPythonみたいに文字列操作したいなぁ
というわけで、kotlinでもPythonと同等の文字列操作ができるようになるライブラリを作りました。
ktPyString
https://github.com/ChanTsune/ktPyString
Stringに対して拡張関数を定義することで、kotlinでもpythonみたいな文字列操作ができるようにしています。
導入
Gradle
build.gradledependencies { implementation fileTree(dir: 'libs', include: ['*.jar']) implementation"org.jetbrains.kotlin:kotlin-stdlib-jdk7:$kotlin_version" implementation 'dev.tsune:ktPyString:0.0.0' implementation 'androidx.appcompat:appcompat:1.0.2' implementation 'androidx.core:core-ktx:1.0.2' implementation 'androidx.constraintlayout:constraintlayout:1.1.3' testImplementation 'junit:junit:4.12' androidTestImplementation 'androidx.test.ext:junit:1.1.0' androidTestImplementation 'androidx.test.espresso:espresso-core:3.1.1' }Maven
<dependency> <groupId>dev.tsune</groupId> <artifactId>ktPyString</artifactId> <version>0.0.0</version> <type>pom</type> </dependency>依存ライブラリに追加します。
文字列操作
スライス
val str = "0123456789" str[0,5] // 01234 str[0,8,2] // 0246 str[null,null,-1] // 9876543210Pythonista御用達のスライス操作です。
一度慣れると他の言語でもやりたくなるやつです。ちなみに同じ動作をPythonで書くと以下のようになります。
str = "0123456789" str[0:5] # 01234 str[0:8:2] # 0246 str[::-1] # 9876543210文字列検索
// 先頭からの検索 "123412312312345".find("123") // 0 // 開始位置を指定して検索 "123412312312345".find("123",start:2) // 4 // 終了位置を指定して検索 "123412312312345".find("123",end:1) // -1 // 末尾からの検索 "123412312312345".rfind("123") // 10末尾からの検索も同様に開始位置と終了位置を指定して検索できます。
文字列結合
val array = ["abc","def","ghi"] "".join(array) // "abcdefghi" "-".join(array) // "abc-def-ghi" "++".join(array) // "abc++def++ghi"文字列分割
行ごとの分割
"abc\nabc".splitlines() // ["abc", "abc"] "abc\r\nabc\n".splitlines() // ["abc", "abc"] // 改行文字を残して分割 "abc\nabc\r".splitlines(true) // ["abc\n", "abc\r"] "abc\r\nabc\n".splitlines(true) // ["abc\r\n", "abc\n"]トリミング
// 右端のみ "rstrip sample ".rstrip() // "rstrip sample" "rstrip sample ".rstrip("sample ") // "rstri" " rstrip sample".rstrip() // " rstrip sample" // 左端のみ " lstrip sample".lstrip() // "lstrip sample" " lstrip sample".lstrip(" ls") // "trip sample" "lstrip sample".lstrip() // "lstrip sample" // 両端 " spacious ".strip() // "spacious" "www.example.com".strip("cmowz.") // "example"出現回数カウント
"abc abc abc".count("abc") // 3 // 開始位置の指定 "abc abc abc".count("abc", start:2) // 2 // 終了位置の指定 "abc abc abc".count("abc", end:1) // 0ゼロ埋め
"abc".zfill(1) // "abc" "abc".zfill(5) // "00abc" // 符号付きの場合 "+12".zfill(5) // "+0012" "-3".zfill(5) // "-0003" "+12".zfill(2) // "+12"符号付きの場合は符号の後ろにゼロが入ります。
さいごに
全部書いていると長くなってしまうので、紹介はこの辺りで。
このほかにも、Pythonのstr型で利用できるメソッドは言語機能的に実現不可能または、実現が難しいもの以外ほとんどサポートしています。
Pythonからプログラミングを始めたという人なら、慣れ親しんだPythonの文字列操作ができるようになるので比較的便利ではないでしょうか?
このメソッド実装できるよ、とかこっちの実装の方がパフォーマンスいいんじゃない?
kotlinだったらこう書くと綺麗だよ等ありましたら教えてください。プルリクお待ちしております。
もしあれば、バグ報告とかも嬉しいです。
余談ですが、Swift版のライブラリも過去に作っているので、iOSとAndroidで文字列操作周りの処理をほとんどコピペで動かすこともできるかも知れません。(Swiftとkotlin の文法が割と似ているので)
https://qiita.com/ChanTsune/items/bd611a4c778c0fb338e6
- 投稿日:2020-03-15T18:45:30+09:00
新型コロナは本当に驚異か? Stan で検証した (かった)
目的
- COVID-19 の致死率が本当に高いのか検証する
- 確率的プログラミング言語 Stan を触ってみる
確率的プログラミング言語とは
統計学的な関係性 (モデル) を記述したらいい感じに解いてくれるプログラミング言語です。実装としては、マルコフ連鎖モンテカルロ法によるサンプリングを行うようです。
手続き型プログラミング言語とは役割も手法も全く異なっているため、それを置き換える存在ではありません。
準備
データ
ダイヤモンド・プリンセス号の感染状況を使います。
なぜなら、世界でこれよりも詳しく感染状況の調査が行われた空間は存在せず、最も正確な検証ができると期待されるからです。
項目 データ 日時 ソース 感染者数 696人 3/5 時事ドットコム 1 感染者数 (有症状) 301人 2/20 国立感染症研究所 2 感染者数 (無症状) 318人 2/20 国立感染症研究所 2 死亡者数 7人 3/7 読売新聞 3 年齢別でのインフルエンザとの比較も行いたいので、 CDC の統計 4 を加工して国立感染症研究所 2 のデータと比較できるようにします。階級の変換は単純にその幅の比率によって行いました。
CDC の統計は有症状のインフルエンザ感染数についての数値しか存在しないので、 COVID-19 に関しても有症状の感染数データを使います。
階級 CODIV-19 有症状感染数 インフルエンザ致死率 (推定) 0-9 0 0.0050% 10-19 2 0.0063% 20-29 25 0.0206% 30-39 27 0.0206% 40-49 19 0.0206% 50-59 28 0.0614% 60-69 76 0.4465% 70-79 95 0.8315% 80-89 27 0.8315% 90-99 2 0.8315% Total 301 0.0962% 実行環境
Stan をインストールします。
Stan はコマンドライン単独でも動かせますが、ラッパーを使う方がいろいろと楽です。今回は
pipで簡単に導入できる、 Python インターフェイスの PyStan を使います。
numpyとcython、さらにグラフの表示にscipyとmatplotlibが必要なので、それも一緒に入れておきます。Anaconda を使う場合、
$ conda create -n dp-corona-stan python=3.7 numpy cython scipy matplotlib pystan $ conda activate dp-corona-stanとりあえずジャブから
感染者数 (696人) と死亡者数 (7人) から致死率を Stan で推定します。
import pystan model = pystan.StanModel(model_code=''' data { int N; // 感染者数 int D; // 死亡者数 } parameters { real<lower=0, upper=1> p; } model { D ~ binomial(N, p); } ''') data = { 'N': 696, 'D': 7 } fit = model.sampling(data=data, chains=4) print(fit)
StanModelに渡している文字列が Stan のコードです。この記事では Stan の書き方に関して深入りしませんが、簡単に説明すると、
dataに指定されたデータを入力し、parametersに指定した変数をmodelを満たすように最適化するという意味のコードになっています。感染者ごとに死亡したか・しなかったか、という事象は、統計的には二項分布 (binomial distribution) に従うことになります。すなわち、
modelの記述、D ~ binomial(N, p);は、 感染者
Nがそれぞれpの確率で死亡するとき、D人死亡した、という状況をモデル化したものです。このコードを実行すると、全感染者に対する致死率
pを推定できます。mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat p 0.01 9.8e-5 4.1e-3 5.0e-3 8.4e-3 0.01 0.01 0.02 1724 1.0 lp__ -44.22 0.02 0.73 -46.3 -44.4 -43.95 -43.76 -43.7 1531 1.0
pは 1% くらいと推定されます。
世間では 2% と言われたりもしていますが、このデータから、 2% というのは 95% 信頼区間 (5.0e-3〜0.02) の当落線上であり、 その可能性は棄却はできないがそんなに高くないだろうと推定できます。ただし、感染者の半分は無症状なので、有症状の感染者に対する致死率と基準を置き直せば確かに 2% くらいになります。 (ちなみに、インフルエンザは 1/3 が無症状と言われているらしいです 5。)
年齢を考慮する
しかしながら、ダイヤモンド・プリンセス号の乗員・乗客の半分以上は 60 歳以上でした。これは世間の人口分布とは違うので、実態に即した致死率を得るためには、その点を考慮する必要があります。
そこで、 COVID-19 の致死率がインフルエンザ相当であれば、ダイヤモンド・プリンセス号規模の感染があった場合、どの程度の死者が発生するのかを推定し、実際の死者数 (7 人) と比較します。
準備: データを Python で表現
データ で用意したデータを py ファイルに落としておきます。
S_xxが年代別の有症状の感染者数、p_flu_xxが年代別の有症状インフルエンザ感染者数に対する致死率の推定値です。# data.py data = { 'S_0x': 0, 'S_1x': 2, 'S_2x': 25, 'S_3x': 27, 'S_4x': 19, 'S_5x': 28, 'S_6x': 76, 'S_7x': 95, 'S_8x': 27, 'S_9x': 2, 'p_flu_0x': 0.000050, 'p_flu_1x': 0.000063, 'p_flu_2x': 0.000206, 'p_flu_3x': 0.000206, 'p_flu_4x': 0.000206, 'p_flu_5x': 0.000614, 'p_flu_6x': 0.004465, 'p_flu_6x': 0.008315, 'p_flu_7x': 0.008315, 'p_flu_8x': 0.008315, 'p_flu_9x': 0.000962 }まず NumPy で検証する
NumPy には二項分布に従う乱数を発生させる機能があります。その機能を使えば簡単にシミュレーションが行なえます。
import numpy as np from data import data N = 10000 MIN_DEATH = 7 sample = (np.random.binomial(data['S_0x'], data['p_flu_0x'], N) + np.random.binomial(data['S_1x'], data['p_flu_1x'], N) + np.random.binomial(data['S_2x'], data['p_flu_2x'], N) + np.random.binomial(data['S_3x'], data['p_flu_3x'], N) + np.random.binomial(data['S_4x'], data['p_flu_4x'], N) + np.random.binomial(data['S_5x'], data['p_flu_5x'], N) + np.random.binomial(data['S_6x'], data['p_flu_6x'], N) + np.random.binomial(data['S_7x'], data['p_flu_7x'], N) + np.random.binomial(data['S_8x'], data['p_flu_8x'], N) + np.random.binomial(data['S_9x'], data['p_flu_9x'], N)) probability = float(sum(sample >= MIN_DEATH)) / N print('Average # of deaths: %.2f' % (sample.mean())) print('# of deaths >= %d: %.2f%%' % (MIN_DEATH, probability * 100))こちらも深入りはしませんが、簡単に説明します。
np.random.binomial(n, p, N)は、確率pで発生する事象をn回試行するして発生回数を記録する作業をN回繰り返します。例えばnp.random.binomial(2, 0.5, 3)だったらarray([2, 0, 1])とかが返ってきます。NumPy の配列は普通に足し算すると要素ごとの足し算になるので、これにより全階級に亘っての発生回数が得られます。
また、 NumPy の配列に対して比較演算子を使うと、要素ごとに真偽判定してできた配列を返します。 例えば
np.array([2, 0, 1]) > 1をするとarray([ True, False, False])が返ってきます。Python の
sum関数はTrueを1、Falseを0と見なすので、結局、float(sum(sample >= MIN_DEATH)) / Nにより、試行N回中、死亡者数がMIN_DEATHを超えた割合を計算できます。結果は
Average # of deaths: 1.67 # of deaths >= 7: 0.21%のようになりました。
COVID-19 の死亡率がインフルエンザ並だったとしたら、 301 人の有症状感染者に対して 7 人も死亡するというのは相当にありえないと言えそうです。
※ 有症状感染者のデータは 2/20 時点のもので、 7 人目の死亡者が確認された時点 (3/7) では更に感染数が増えていましたが、それを考慮しても COVID-19 並に死亡する確率が 1% を超えることにはならなさそうです。
Stan で検証してみる
二項分布で解いてみる
最適化の対象が確率から死亡者数に変わるのと、年齢の階級を考慮する点が違うだけなので、さっきの Stan コードと同じようなものを書けばいけるはずです。
年齢別の推定死亡数を
d_xxとすると、data { int S_0x; int S_1x; int S_2x; int S_3x; int S_4x; int S_5x; int S_6x; int S_7x; int S_8x; int S_9x; real p_flu_0x; real p_flu_1x; real p_flu_2x; real p_flu_3x; real p_flu_4x; real p_flu_5x; real p_flu_6x; real p_flu_7x; real p_flu_8x; real p_flu_9x; } parameters { // upper = S_xx + 1 so that S_xx can be 0 int<lower=0, upper=S_0x+1> d_0x; int<lower=0, upper=S_1x+1> d_1x; int<lower=0, upper=S_2x+1> d_2x; int<lower=0, upper=S_3x+1> d_3x; int<lower=0, upper=S_4x+1> d_4x; int<lower=0, upper=S_5x+1> d_5x; int<lower=0, upper=S_6x+1> d_6x; int<lower=0, upper=S_7x+1> d_7x; int<lower=0, upper=S_8x+1> d_8x; int<lower=0, upper=S_9x+1> d_9x; } transformed parameters { int d; d = d_0x + d_1x + d_2x + d_3x + d_4x + d_5x + d_6x + d_7x + d_8x + d_9x; } model { d_0x ~ binomial(S_0x, p_flu_0x); d_1x ~ binomial(S_1x, p_flu_1x); d_2x ~ binomial(S_2x, p_flu_2x); d_3x ~ binomial(S_3x, p_flu_3x); d_4x ~ binomial(S_4x, p_flu_4x); d_5x ~ binomial(S_5x, p_flu_5x); d_6x ~ binomial(S_6x, p_flu_6x); d_7x ~ binomial(S_7x, p_flu_7x); d_8x ~ binomial(S_8x, p_flu_8x); d_9x ~ binomial(S_9x, p_flu_9x); }※ Stan は配列を扱えるのでもっとスッキリ書けますが、階級を配列の添字に落とし込むのが何となく嫌だったので愚直に列挙してます。
実行すると
ValueError: Failed to parse Stan model 'anon_model_fecb1e77228fe372ef4eb9bc4bcc8086'. Error message: SYNTAX ERROR, MESSAGE(S) FROM PARSER: Parameters or transformed parameters cannot be integer or integer array; found int variable declaration, name=d_0x error in 'unknown file name' at line 26, column 35 ------------------------------------------------- 24: parameters { 25: // upper = S_xx + 1 so that S_xx can be 0 26: int<lower=0, upper=S_0x+1> d_0x; ^ 27: int<lower=0, upper=S_1x+1> d_1x; -------------------------------------------------integer ではダメって怒られました。。。
StanとRでベイズ統計モデリング読書会Ch.9 6 の 20 ページ目には、 Stan の弱点として
parametersにintが使えないことが挙げられていました。
どうも本当に使えないみたいです。Ω\ζ゜) チーン♪
binomialは左辺にintを求めるため、d_xxたちをintではなくrealで宣言しておく裏技も使えません。Ω\ζ゜) チーン♪
ベータ分布で無理くり解いてみる
二項分布がダメだったので、ベータ分布を試しに使ってみました。
マサカリが飛んでくる覚悟で言えば、ベータ分布は二項分布の逆みたいなやつで、二項分布に従う事象の発生確率の確率分布です。くわしくはこちら。
d_xx ~ binomial(S_xx, p_flu_xx);と書いていたものを
p_flu_xx ~ beta(d_xx + 1, S_xx - d_xx + 1);に書き直し、
d_xxの型をrealにしてみます。import pystan from data import data model = pystan.StanModel(model_code=""" data { int S_0x; int S_1x; int S_2x; int S_3x; int S_4x; int S_5x; int S_6x; int S_7x; int S_8x; int S_9x; real p_flu_0x; real p_flu_1x; real p_flu_2x; real p_flu_3x; real p_flu_4x; real p_flu_5x; real p_flu_6x; real p_flu_7x; real p_flu_8x; real p_flu_9x; } parameters { // upper = S_xx + 1 so that S_xx can be 0 real<lower=0, upper=S_0x+1> d_0x; real<lower=0, upper=S_1x+1> d_1x; real<lower=0, upper=S_2x+1> d_2x; real<lower=0, upper=S_3x+1> d_3x; real<lower=0, upper=S_4x+1> d_4x; real<lower=0, upper=S_5x+1> d_5x; real<lower=0, upper=S_6x+1> d_6x; real<lower=0, upper=S_7x+1> d_7x; real<lower=0, upper=S_8x+1> d_8x; real<lower=0, upper=S_9x+1> d_9x; } transformed parameters { real d; d = d_0x + d_1x + d_2x + d_3x + d_4x + d_5x + d_6x + d_7x + d_8x + d_9x; } model { p_flu_0x ~ beta(d_0x + 1, S_0x - d_0x + 1); p_flu_1x ~ beta(d_1x + 1, S_1x - d_1x + 1); p_flu_2x ~ beta(d_2x + 1, S_2x - d_2x + 1); p_flu_3x ~ beta(d_3x + 1, S_3x - d_3x + 1); p_flu_4x ~ beta(d_4x + 1, S_4x - d_4x + 1); p_flu_5x ~ beta(d_5x + 1, S_5x - d_5x + 1); p_flu_6x ~ beta(d_6x + 1, S_6x - d_6x + 1); p_flu_7x ~ beta(d_7x + 1, S_7x - d_7x + 1); p_flu_8x ~ beta(d_8x + 1, S_8x - d_8x + 1); p_flu_9x ~ beta(d_9x + 1, S_9x - d_9x + 1); } """) fit = model.sampling(data=data, chains=4) print(fit)実行して得られた結果がこちら:
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat d_0x 0.1 1.4e-3 0.09 2.3e-3 0.03 0.07 0.14 0.35 4361 1.0 d_1x 0.12 1.7e-3 0.12 2.5e-3 0.03 0.08 0.16 0.43 4474 1.0 d_2x 0.19 2.6e-3 0.18 5.0e-3 0.06 0.14 0.27 0.67 4976 1.0 d_3x 0.2 3.1e-3 0.19 4.4e-3 0.06 0.14 0.27 0.71 3641 1.0 d_4x 0.19 2.5e-3 0.19 3.5e-3 0.05 0.13 0.26 0.69 5315 1.0 d_5x 0.25 3.2e-3 0.23 8.0e-3 0.08 0.18 0.34 0.85 5100 1.0 d_6x 0.93 0.01 0.73 0.04 0.36 0.77 1.33 2.8 4387 1.0 d_7x 1.06 0.01 0.8 0.04 0.43 0.9 1.51 3.01 4028 1.0 d_8x 0.54 7.0e-3 0.48 0.01 0.18 0.42 0.76 1.82 4729 1.0 d_9x 0.17 2.4e-3 0.16 4.3e-3 0.05 0.12 0.24 0.58 4580 1.0 d 3.73 0.02 1.25 1.66 2.84 3.59 4.51 6.57 4367 1.0 lp__ -1.64 0.08 2.58 -7.78 -3.13 -1.28 0.24 2.37 1048 1.0
dが死亡者数ですが、50%が3.59になっており、 NumPy により得られた1.67より明らかに多いです。Ω\ζ゜) チーン♪
なぜでしょう。
これはおそらく
dがrealとして定義されているために起こっている問題です。本来は整数値しか取れないd_xxが小数を取れることで、現実の問題から乖離してしまっているようです。実際、
d_xxをfloorで整数化して計算してみるとmean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat ... d 1.82 0.03 1.29 0.01 1.01 1.69 2.5 4.93 1710 1.0のようにそれっぽい値になりました。
※ 単に
floorを取るだけだと勾配がなくなってうまく収束しないので、inv_logitとかを使って、うまくスムージングしてやる必要があります。しかしながら、ここまでやるなら NumPy を使えばいいですね。なにかうまい方法はないものでしょうか。
まとめ
部分的ながら、 Stan を使って新型コロナウイルスの危険性を推定することができました。
ダイヤモンド・プリンセスの状況から、 COVID-19 はどうやら従来のインフルエンザと比べても、致死率の点で凶悪なものであることは相当に間違いなさそうです。加えて、インフルエンザは既に抗体を持っている人がたくさんいる一方で、 COVID-19 の抗体を持っている人はほとんどいない点も脅威です。個人のためというより社会全体のために、十分な警戒をしたほうがいいでしょう。
しかしながら、インフルエンザでも今回の規模で感染すると 1.67 人程度の死者が出るという推定から、 COVID-19 をここまで恐れるのであれば、普段のインフルエンザももっと警戒してはいいのではないかということを、個人的見解ながら、申し上げておきたいと思います。
付録

- 投稿日:2020-03-15T18:39:33+09:00
SlackのReminder機能をTeamsで実現する
Slackで利用できるreminderのような機能をTeamsで実現したいのですが、公式にはないみたい。
ないみたいなのでAWS Lamda + cloud watchの組み合わせで実現しました
今回はPythonで実装しました。MicrosoftのFeeoback Forumに同じように思ってる人もいるみたい。
https://microsoftteams.uservoice.com/forums/555103-public/suggestions/17062255-add-team-wide-reminders
今作ってるのかな?
コメント見た限り、待望してる人は多そう。作業手順
①teamsの特定チャンネルにincoming web hookを設定し、post先URLを作成
②作成したURLへ特定文字列をpostするlamda関数を実装
③cloudwatchに作成したLamda関数を呼び出すルールを追加
※下記の「参考にした記事」で読んだとおりに作業したので、詳細はリンク先の記事を参照してください。lamda関数を実装する際requestsモジュールを利用するのですが、Pythonの標準モジュールではないのでpipインストールしたプロジェクトをzip形式でアップして利用できるようにしました。
postする際に、文字コードの指定がないので怒られます。
data="Teamsに送信するテキスト".encode("utf-8"))
上記のように、文字コード指定しておくと問題ありません。実装コード
import json import requests def lambda_handler(event, context): data = '{"text": "Teamsに送信するテキスト"}'.encode("utf-8") response = requests.post('https://outlook.office.com/webhook/f5~(この部分可変)', data=data)Lamdaコンソールイメージ
実装したソースと、requestsモジュールインストールしたのでフォルダがいくつか存在している状態です。
参考にした記事
TeamsへのWeb Hook導入方法
https://qiita.com/wataash/items/72b49509c3964294dd67
ラムダへモジュール追加
https://qiita.com/SHASE03/items/16fd31d3698f207b42c9
postした時のエンコードエラー対応
https://qiita.com/yuji38kwmt/items/c6885cd7caa6b2fc195f
claod watchの時間設定方法
- 投稿日:2020-03-15T18:25:31+09:00
[Python] 複数行にわたる文字列の代入
SQLの操作などで長い文字列を変数に代入することがありますが,主に以下の2通りの方法があります.
- 丸括弧
()→非明示的な行継続の使用- トリプルクォート
'''や"""の使用Kosei Kitahara's Works: Google Python スタイルガイドによると前者の方が推奨されています.
後者は以下の通りインデントするとその空白も文字列に含まれてしまうためです.丸括弧
()→非明示的な行継続の使用text = ('a' # カンマは不要 'b') print(text) # ab # 以下と同じ text = 'ab' # 註1: カンマを付けると2つの文字列のタプルとして認識されてしまう text = ( 'a', 'b') print(text) # ('a', 'b') # 註2: 実用性があるかは分かりませんが1行にまとめることが可能 text = ('a' 'b') print(text) # ab # 註3: これも実用性は不明ですが,行継続とタプルを併用することも可能 text = ('a', 'b' 'c') print(text) # ('a', 'bc')改行には
\nが必要です.
またこの手法は文字列の代入のみならず関数のインポートなどにも有効です
(関数の引数が多くなったときには自然と使っている?).from some.deep.module.inside.a.module import ( a_nice_function, another_nice_function, yet_another_nice_function)formatとの併用
これとformatを併用するときは,最後にまとめて
.format()を書く必要があります:text = ( 'a = {0}, ' 'b = {1}'.format(1, 2)) print(text) # a = 1, b = 2各行に
.format()を書くとSyntaxErrorになります:# 以下はSyntaxError: invalid syntaxになる text = ( 'a = {}, '.format(1) 'b = {}'.format(2))あまりに
.format()の中身が複雑になるときは,文字列のリストを作成→str.join()で結合する方が良い?トリプルクォート
'''や"""の使用「三連引用符」や「三重引用符」とも言うようです.
この場合,コード上で改行した箇所で改行されます.text = '''hello world''' print( text ) # hello # world # 以下と同じ text = 'hello\nworld' # 註1: 改行したくないときは\を使う text = '''hello\ world''' print( text ) # helloworld # 註2: 最初と最後を改行するとその分改行が含まれてしまう text = ''' hello world ''' print( text ) # (改行) # hello # world # (改行) # 註3: コード上のインデントを合わせようとするとその空白も文字列として扱われてしまう text = '''hello world''' print( text ) # hello # worldLet's プログラミング: 三連引用符を使った複数行の文字列の記述
note.nkmk.me: Pythonで文字列生成(引用符、strコンストラクタ)
- 投稿日:2020-03-15T17:12:30+09:00
Python scikit-learnで実施した決定木の結果を可視化する
PCを新しくして、決定木を初めてやろうとしたら、可視化する環境にする方法を忘れていて少し時間がかかってしましました。ここに、自分用の備忘メモの意味を込めて記載します。
graphvizの公式ページ
ここからDownloadのページに行き、以下のstable版をダウンロードする。
.msiファイルをダウンロードします。
ダウンロードしたこのmsiファイルをダブルクリックしてインストールします。
コマンドプロンプト
pip install graphviz pip install pydotplus
そして、「dot.ext」ファイルがあるディレクトリをPathに追加する。
システムの詳細設定を開いて、環境変数をクリックします。
そしてPathに「dot.ext」があるディレクトリを追加します。私の場合は
C:\Users\ユーザー名\Anaconda3\envs\仮想環境名\Library\bin\graphviz
でした。
これで可視化できるようになりました!

- 投稿日:2020-03-15T16:59:15+09:00
Mask R-CNN とK-Meansクラスタリングで画像中の対象物の色を抽出する
概要
Mask R-CNNと提供されている学習済みのモデルを使って、画像中の対象物のみをRGBデータとして抽出する。
そのRGBデータをK-Meansでクラスタリングすると対象物のドミナントカラーを抽出できる。例
ピザ(pizza)


Photo by mahyar motebassem on Unsplash
信号機(traffic light)


Photo by Aleksandr Kotlyar on Unsplash
犬(dog)



使い方
$ git clone https://github.com/xy-gao/instance-dominant-colors.git $ cd instance-dominant-colors $ pip3 install -r requirements.txtfrom instance2color import Instance2Color inst = Instance2Color(image_file='sample_img/pizza.jpg', class_name='pizza', num_of_color=5) # 指定できるclass_name: # class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', # 'bus', 'train', 'truck', 'boat', 'traffic light', # 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', # 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', # 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', # 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', # 'kite', 'baseball bat', 'baseball glove', 'skateboard', # 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', # 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', # 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', # 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', # 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', # 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', # 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', # 'teddy bear', 'hair drier', 'toothbrush'] # 学習済みモデルは初回にダウンロードされる print(inst.dominant_colors()) # ドミナントカラーのRGBと割合 # [([174, 77, 68], 29.52), ([223, 140, 100], 26.31), ([99, 47, 38], 20.08), ([96, 181, 108], 12.91), ([227, 206, 189], 11.18)] inst.visualize_pie(output_file='sample_img/pizza_pie_chart.jpg')# 円グラフを描く inst.visualize_instance(output_file='sample_img/pizza_inst.jpg')# どこが対象物にされたか確認できる







- 投稿日:2020-03-15T16:53:31+09:00
jsonファイルからディレクトリを生成するスクリプト
はじめに
以下のようなjsonファイルがあったとします。
sample.json{ "data": [ { "no": "1", "date": "2020-01-28T00:00", "place": "japan", "age": "22", "sex": "female" }, { "no": "2", "date": "2020-02-14T00:00", "place": "australia", "age": "50", "sex": "male" } ], "last_update": "2020-03-14T23:14:01.849130+09:00" }このファイルから以下のようなディレクトリを生成するスクリプトです。
keyとlistのindexで階層分けという事です。
json2dir
https://github.com/Kanahiro/json2dir
jsonファイルを再帰的に解析して、生成すべきdirectoryリストを返します。
sample.pyimport json2dir jsondict = { #jsondictは前述のsample.jsonをdict型として読み込む } root_dir = 'api/sample' os.makedirs(root_dir, exist_ok=True) #api/sampleというディレクトリを生成 #本スクリプトによりディレクトリ一覧を生成 dirs = json2dir.dir_list_of(jsondict, root_dir) ''' dir = ['api/sample/data', 'api/sample/data/0', 'api/sample/data/0/no', 'api/sample/data/0/date', 'api/sample/data/0/place', 'api/sample/data/0/age', 'api/sample/data/0/sex', 'api/sample/data/1', 'api/sample/data/1/no', 'api/sample/data/1/date', 'api/sample/data/1/place', 'api/sample/data/1/age', 'api/sample/data/1/sex', 'api/sample/last_update'] ''' #api/sample以下に、dirに基づきディレクトリを生成 for d in dirs: os.makedirs(d, exist_ok=True)以上でディレクトリが生成されます。
終わりに
ちなみにpipでjson-to-dirというパッケージが配布されていますが、(たぶん)Python2.x系で書かれててちゃんと動きませんでした(ので作りました)。
必要性がありそうならpipパッケージにしたいなって思っていますが、自分の必要性は満たせたのでとりあえず後回しにしています。

- 投稿日:2020-03-15T16:23:40+09:00
深層学習モデルのパラメータの数を数える
1. はじめに
ふとディープラーニングのパラメータってどうやって数えるんだっけと思って、理解を確認するためにも計算してみました。
2. モデルの構成
Kerasを使ってモデルを構成してみます。
今回作成するモデルは256x256のRBGの画像を入力として、9つのカテゴリーに分類するモデルとなります。
実装
必要なモジュールをインポートします。
from keras.models import Sequential from keras.layers.convolutional import Conv2D from keras.layers.convolutional import MaxPooling2D from keras.layers.core import Activation from keras.layers.core import Flatten, Dropout from keras.layers.core import Dense分類するクラス数を定数として定義し、
num_class = 9モデルを構成します。
# モデルの作成 model = Sequential() model.add(Conv2D(32, kernel_size=3, padding="same", activation='relu', input_shape=(256, 256, 3))) model.add(Conv2D(32, kernel_size=3, padding="valid", activation='relu')) model.add(MaxPooling2D(pool_size=(3, 3))) model.add(Dropout(0.5)) model.add(Conv2D(32, kernel_size=3, padding="same", activation='relu')) model.add(Conv2D(32, kernel_size=3, padding="valid", activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(32, kernel_size=3, padding="same", activation='relu')) model.add(Conv2D(32, kernel_size=3, padding="valid", activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) #Flatten()により特徴マップをベクトルに変換 model.add(Dense(512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(num_class, activation='softmax')) #Softmax関数にて、9 クラスの確度として出力モデル情報を出力します。
model.summary() # モデル情報の表示以下の出力が得られます。この中で一番右側にパラメータ数が出力されています。今回のモデルでは、6,029,097のパラメータが学習によって調整されることになります。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 256, 256, 32) 896 _________________________________________________________________ conv2d_2 (Conv2D) (None, 254, 254, 32) 9248 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 84, 84, 32) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 84, 84, 32) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 84, 84, 32) 9248 _________________________________________________________________ conv2d_4 (Conv2D) (None, 82, 82, 32) 9248 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 41, 41, 32) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 41, 41, 32) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 41, 41, 32) 9248 _________________________________________________________________ conv2d_6 (Conv2D) (None, 39, 39, 32) 9248 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 19, 19, 32) 0 _________________________________________________________________ dropout_3 (Dropout) (None, 19, 19, 32) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 11552) 0 _________________________________________________________________ dense_1 (Dense) (None, 512) 5915136 _________________________________________________________________ dropout_4 (Dropout) (None, 512) 0 _________________________________________________________________ dense_2 (Dense) (None, 128) 65664 _________________________________________________________________ dropout_5 (Dropout) (None, 128) 0 _________________________________________________________________ dense_3 (Dense) (None, 9) 1161 ================================================================= Total params: 6,029,097 Trainable params: 6,029,097 Non-trainable params: 0 _________________________________________________________________3. パラメータ数の計算
3-1. CNN層
まず第1層のCNN層をみてみます。フィルタ数:32枚、フィルタサイズ:3x3、入力チャンネル:3(RGB)、出力チャンネル:3を指定しています。
model.add(Conv2D(32, kernel_size=3, padding="same", activation='relu', input_shape=(256, 256, 3)))================================================================= conv2d_1 (Conv2D) (None, 256, 256, 32) 896 _________________________________________________________________パラメータ数は以下の式で求められます。
パラメータ数 = フィルタ縦サイズ x フィルタ横サイズ x 入力チャンネル数 x 出力チャンネル数 + バイアス x 出力チャンネル数
param =3 x 3 x 3 x 32 + 1 x 32 = 896同じように第2層も計算してみます。
model.add(Conv2D(32, kernel_size=3, padding="valid", activation='relu', input_shape=(256, 256, 3)))================================================================= conv2d_2 (Conv2D) (None, 254, 254, 32) 9248 _________________________________________________________________今度は第2層への入力が32チャンネルとなっているので、
パラメータ数 = フィルタ縦サイズ x フィルタ横サイズ x 入力チャンネル数 x 出力チャンネル数 + バイアス x 出力チャンネル数
param =3 x 3 x 32 x 32 + 1 x 32 = 9248第3,4,5,6のConv2D層も同様に計算することができます。
3-2. Flatten層
特徴マップをベクトル化しています。1次元に落としています。ここでは学習によって調整するパラメータではありませんが、
_________________________________________________________________ dropout_3 (Dropout) (None, 19, 19, 32) 0 _________________________________________________________________よりベクトルの次元は19 x 19 x 32 = 11552となります。
3-3. Dense層(隠れ層)
特徴量をベクトル化するFlatten層の次のDense層では
パラメータ数 = 入力サイズ x 出力サイズ + バイアス となるため
param = 11552 x 512 + 512 = 5915136その次の隠れ層も同様に
dense_2 (Dense) param = 512 x 128 + 512 = 65664
dense_3 (Dense) param = 128 x 9 + 9 = 11614. まとめ
改めて構築したモデルを確認します。
一番右のParamの値を足すと、6,029,097となります。学習ではこのパラメータが調整されています。
そして学習によって調整されたパラメータがモデルの一部となり、推論においては、モデルを軽量化などしない限り、これらのパラメータが使われて計算されています。_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 256, 256, 32) 896 _________________________________________________________________ conv2d_2 (Conv2D) (None, 254, 254, 32) 9248 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 84, 84, 32) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 84, 84, 32) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 84, 84, 32) 9248 _________________________________________________________________ conv2d_4 (Conv2D) (None, 82, 82, 32) 9248 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 41, 41, 32) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 41, 41, 32) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 41, 41, 32) 9248 _________________________________________________________________ conv2d_6 (Conv2D) (None, 39, 39, 32) 9248 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 19, 19, 32) 0 _________________________________________________________________ dropout_3 (Dropout) (None, 19, 19, 32) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 11552) 0 _________________________________________________________________ dense_1 (Dense) (None, 512) 5915136 _________________________________________________________________ dropout_4 (Dropout) (None, 512) 0 _________________________________________________________________ dense_2 (Dense) (None, 128) 65664 _________________________________________________________________ dropout_5 (Dropout) (None, 128) 0 _________________________________________________________________ dense_3 (Dense) (None, 9) 1161 ================================================================= Total params: 6,029,097 Trainable params: 6,029,097 Non-trainable params: 0 _________________________________________________________________

- 投稿日:2020-03-15T16:17:03+09:00
Pythonで「インターネット アクセスなし」から蘇る
はじめに
みなさん、突然の「インターネットアクセスなし」に悩まされていませんか?
私は悩まされていました。
定型業務を自動化するためにスクリプトを組んで古いPCに常駐させているのですが、
PCをつけっぱなしにしているといつの間にか「インターネット アクセスなし」の状態になっていて、手動でPCのネットワークを切断、再接続する必要がありました。
自動化して放置しているのにいつの間にか処理が止まってるの、怖いですよね。そこで、スクリプト内でネットワークの状態確認、再接続を行うようにしてみたので紹介します。
(そもそもなんでインターネットアクセスなしになるのかとか分からないので詳しい人教えてください)
環境
・Windows7
・Anaconda3とりあえず結論(コード)
内容はほぼWindowsのコマンドですが、スクリプトの一部のためPythonからコマンドを呼び出しています。
def is_ping_ok(): proc = subprocess.run(["ping", "yahoo.co.jp"], stdout=subprocess.PIPE, stderr=subprocess.PIPE) ret = proc.stdout.decode("cp932") if "見つかりません" in ret: return False else: return True def restart_network(): subprocess.run(["netsh", "wlan", "disconnect"]) subprocess.run(["netsh", "wlan", "connect", 'name="接続したいSSID"']) time.sleep(5) def check_network(): if not is_ping_ok(): restart_network() if is_ping_ok(): return "Restarted!" else: return "Error" return "OK"とりあえず一回試して復活しなければあきらめるようにしていますが、負けず嫌いの方は復活するまで徹底的に再帰してもいいかと思います。
解説
ネットワークの状態を確認
インターネットアクセスがあるかどうかは ping コマンドで確認します。
突然出てきたsubprocessに関してはこの記事とか参照してみてください。下記はインターネットアクセスありの場合
>>> import subprocess >>> proc = subprocess.run(["ping","yahoo.co.jp"], stdout=subprocess.PIPE, stderr=subprocess.PIPE) >>> print(proc.stdout.decode("cp932")) yahoo.co.jp [182.22.59.229]に ping を送信しています 32 バイトのデータ: 182.22.59.229 からの応答: バイト数 =32 時間 =11ms TTL=50 182.22.59.229 からの応答: バイト数 =32 時間 =16ms TTL=50 182.22.59.229 からの応答: バイト数 =32 時間 =21ms TTL=50 182.22.59.229 からの応答: バイト数 =32 時間 =21ms TTL=50 182.22.59.229 の ping 統計: パケット数: 送信 = 4、受信 = 4、損失 = 0 (0% の損失)、 ラウンド トリップの概算時間 (ミリ秒): 最小 = 11ms、最大 = 21ms、平均 = 17msインターネットアクセスなしの場合
>>> proc = subprocess.run(["ping","yahoo.co.jp"], stdout=subprocess.PIPE, stderr=subprocess.PIPE) >>> print(proc.stdout.decode("cp932")) ping 要求ではホスト yahoo.co.jp が見つかりませんでした。ホスト名を確認してもう一度実行してください。返り値に「見つかりません」が含まれる場合に、インターネットアクセスなしと判定することにしました。
ここは端末の言語とかによると思います。def is_ping_ok(): proc = subprocess.run(["ping", "yahoo.co.jp"], stdout=subprocess.PIPE, stderr=subprocess.PIPE) ret = proc.stdout.decode("cp932") if "見つかりません" in ret: return False else: return Trueネットワーク再起動
インターネットアクセスなしになっていた場合、下記コマンドでネットワークの再接続を試みます。
コマンドの詳細はこの記事を参考にしました。> netsh wlan disconnect インターフェイス "ワイヤレス ネットワーク接続" の切断要求が正常に完了しました。 > netsh wlan connect name="接続したいSSID" 接続要求が正常に完了しました。pythonで呼び出すと下記のようになります。
接続完了しないまま次の処理へ移らないよう、sleepを入れてます。def restart_network(): subprocess.run(["netsh", "wlan", "disconnect"]) subprocess.run(["netsh", "wlan", "connect", 'name="接続したいSSID"']) time.sleep(5)まとめ
突然の「インターネットアクセスなし」と戦うすべを紹介しました。
もっとスマートなやり方募集してます。
- 投稿日:2020-03-15T15:50:41+09:00
趣味WebエンジニアがVue.js+Flask(&GCP)でWebアプリ開発
きっかけ
ここ1年くらい、Twitter等のSNSでいろんな方が発信されている自作Webアプリを色々見ているせいか、筆者の中でWeb技術・Web開発に対する熱が高く、なにか便利なWebアプリを作りたいという想いがあります。ただ、バックエンドのAPサーバやDBサーバを構築するための知識は現時点でそこまでありません。
そこで、「コーディングはなるべくHTMLやJavaScript、CSS(とそれらのフレームワーク)のようなフロントエンド中心に行い、なおかつ積極的にSaaSを使うことでサーバレスでさくっとWebアプリを構築できないか」を模索し、実際にアプリを作成・公開したのでここに手法を書き記します。作成するWebアプリ
今回作るアプリですが、友人からアイデアをもらい「こんな内容のマンガが読みたい、というざっくりとしたきもちからオススメの作品を推薦するアプリ」を協力して作ることにしました。機能はひとまずシンプルで良いと思ったので、次のような要件で作成します。
スマホでのアクセス・閲覧を前提とするがPCでも見られる
つまりモバイルファーストのレスポンシブデザインである。Webアプリ内でユーザ認証はなし
URLにアクセスするだけで誰でも使える。その代わりサービス内でユーザデータは保持しない(DBサーバの不使用)。ユーザのキーワード入力に対し、必要なものを検索してサイトに表示する
ただし、検索はDBに対してではなくHTMLやJSにハードコーディングされたもの、またはデータ検索用に公開されているWebAPIに対して行い、その結果データを取得し表示することとする(DBサーバの不使用)。クライアント(ブラウザ)側で動的なページ構築を行う
JavaScriptを使い、取得データを表示するためのhtmlをユーザ側で動的に作成し表示する(APサーバの不使用)。使用するWeb要素技術
要件を踏まえ、今回使用した言語【フレームワーク】を以下に記します。
HTML
CSS【Bootstrap】
公式ページはこちら(Bootstrap - 世界で最も人気のあるフロントエンドのコンポーネントライブラリ)。Bootstrapを使うと、整ったデザイン・レスポンシブデザインを楽に作ることができる。JavaScript【Vue.js】
公式ページはこちら(Vue.js)。Vue.jsを使うと、JavaScriptがクライアント(ブラウザ)側でhtmlを操作する動作をかなり直感的に記述できる(データバインディングという仕組みによりJavaScript上のデータを更新するとhtmlも同時に更新される)。Python【Flask】
公式ページはこちら(Flaskへ ようこそ — Flask v0.5.1 documentation)。Flaskを使うと、Pythonの文法を使いシンプルな記述でWebAPIを記述することができるので、もし必要なデータを公開しているWebAPIがなかったらFlaskを使って自分で作成できる。今回はキーワードをもとに作品名一覧を返却するAPIを作成した。Webアプリ構築に使用するSaaS
今回の要件でWebアプリを構築するために使用可能なSaaSの例を以下に記します。
さくらインターネット(今回はレンタルサーバライトプランで可)
公式ページはこちら(さくらのレンタルサーバ | 高速・安定WordPressなら!無料2週間お試し)。HTML、CSS、JavaScript等を配置して公開することができるWebホスティングサービス。その他に、独自ドメイン取得やSSL証明書の設定オプションサービスもある。各種設定は、基本Webインタフェースでポチポチ操作できるので初心者としてはとっつきやすい。無料お試し期間のあとは月額定額制。
その他、類似のホスティングSaaSとしては、Firebase Hosting(公式ページ)や、AWS(公式ページ)等があります。これらは、従量課金制で無料枠もあったりするので初期費用を抑えられる。Google App Engine
サービスの概要はこちら(App Engine | Google Cloud)。
上述のFlaskで記述したWebAPIを配置して公開するために利用できる。アクセスや負荷に応じて自動でスケールしてくれ、料金は従量課金制。システム構成図
これまでの話を踏まえ、フレームワーク・SaaSを活用したWebアプリの構成図(例)は以下のようになります。
FlaskでWebAPIを公開している部分ですが、Google App Engineにアップロードしているファイル構造は次のようなかんじです。
data_list.csvが作品名とその特徴量(タグ)が入ったリストデータ、main.pyがFlaskのpythonコード、それ以外はApp Engineのお作法で用意する設定ファイルです。設定ファイル作成には、次の記事を参考にさせていただきました。
- Google App Engine + Flask(Python3)で「Hello Flask!!」してみた part2 ~デプロイする~ - Qiita
- PythonのFlaskアプリをGoogle App Engineにデプロイしてみた - Qiita
main.pyの中身は次のようになっており、ユーザがWebAPIに対して作品検索用のデータ(json)を投げてきたときに、結果データ(json)を返却するように記述しています。main.pyfrom flask import Flask, jsonify, request from flask_cors import CORS import os import csv # このスクリプトが在るディレクトリの絶対パスが入る変数 CWD = os.path.dirname(__file__) # 作品データのファイル名 DATA_LIST_FILE = "data_list.csv" LEARN_DATA = None # 推薦に使うデータオブジェクト # CSVのパスを受け取って読み込み def loadStractualData(target_file): global LEARN_DATA # グローバル変数に代入するために必要な宣言 csv_list = [] # 単純にCSVをリストに変換しただけのリスト with open(target_file, 'r', encoding='utf-8', newline="") as f: csv_list = [row for row in csv.reader(f)] # 2次元リスト output = [] for row in csv_list: # CSVを一行ずつ処理 ################################################# # CSVの行を構造化データにしてoutputに格納していく処理(割愛) ################################################# print("file loading finished!") LEARN_DATA = output ############################### ## ここからサーバプロセスの設定 ## ############################### loadStractualData(os.path.join(CWD, LEARNED_FILE)) # CSVファイルを読み込む app = Flask(__name__) app.config['JSON_AS_ASCII'] = False # 出力JSONの日本語を文字化けさせない設定 CORS(app) # Access-Control-Allow-Originの設定 # HTTPのPOSTで/post_tagsにユーザ選択タグが送られて来たときの処理 @app.route('/post_tags', methods=['POST']) def post_tags(): json = request.get_json() # POSTされたJSONを取得 input_tags = json["tags"] # ユーザが入力したタグのリスト ########################################################### # ユーザの送ってきたタグで作品リストをフィルタしout_listに格納する処理(割愛) ########################################################### return jsonify({"title_num": len(out_list), "titles": out_list}) #jsonを返す # python実行時のエントリーポイント if __name__ == "__main__": print(" * Flask starting server...") app.run() # サーバプロセス起動Vue.jsからFlaskで作成したWebAPIにリクエストを投げる部分は、Axiosを使用しています。以下の記事を参考にしました。
完成したアプリ
完成したアプリはこんな感じです(emore | "きもち"で探すマンガ検索)。トップページ、検索ページ、検索結果ページからなるシンプルなアプリで、要件にあったようにスマホ前提のレスポンシブデザインになっています(Bootstrapのおかげ)。また、検索ページでは、特にVue.jsによるブラウザ側での動的描画が活かせている(ユーザがタグを選択すると逐一WebAPIに送信し結果の表示を更新するような、動きがあるデザインになっている)と思うので、是非見ていただければ幸いです。
所感
Webアプリ開発における、フロントエンド技術やSaaSがかなり発達していて、個人開発でも手軽にある程度のアプリは作れるようになっていると感じます。今回要件に含めなかったユーザ認証にしても、例えばSaaSのFirebase Authenticationを使えば、マルチプラットフォームログイン(Twitterでログイン、Facebookでログイン等)を実装できますし、ユーザデータを保存するDBにしてもFirebase,FireStore等のWebAPI経由で利用できるものがあります。
Vue.jsもFlaskも、高機能なWebサービスを作ろうと思ったらいくらでも技術的な発展性を含んでいるので、今後も適度に学んだ知識を作品としてアウトプットしつつ、引き続き技術にもチャッチアップして学習していこうと思います(とりあえず、Vue.jsのフレームワークであるNuxt.jsや、Flaskより高機能なDjangoについて勉強中)。

