- 投稿日:2020-03-15T22:38:30+09:00
EC2上にどこからでも簡単にアクセスできるjupyter lab環境を構築する
3行で
- EC2のdeep learning用AMIを使えばよく使うライブラリだのCUDAだのは導入済み
- インスタンス起動時にjupyter lab自動起動して、かつ外部からブラウザを通じてアクセスできるようにできる
- EIPを使うか、動的DNSを使ってアクセス先のアドレスを固定すればブラウザのブクマだけでアクセスできる。動的DNSは無料でも使える
モチベーション
- いつでもどこでも同じ環境を使って開発したい
- 案件ごとに環境を分離したいし、そのための設定に手間をかけたくない
- EC2のdeep learning用AMIを使ってjupyter labを外部からアクセスできるようにした。ついでに動的DNSでアドレスを固定した。
注意
他の人のQiitaからの寄せ集めなので、あまり新規性はないです。
必要な作業
全体像は以下
* EC2インスタンスの作成
* EC2インスタンスへのSSH接続
* EC2インスタンスへのHTTPアクセス許可
* jupyter lab自動起動設定
* (オプション)EIPの設定
* (オプション)動的DNSの設定EC2インスタンスの作成
まずキーペアを作りましょう。
EC2インスタンスは当然AWS上にできるので、何らかの方法で遠隔操作する必要があります。
まず、一番基本的なSSHで接続したいわけですが、そのためにはキーペアが必要です。Amazon EC2 のキーペア
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-key-pairs.html
ページ最下部にやり方が書いてあります。windowsを使う場合、PuTTYを使うと思うので、ppkで保存しておいてください。
(注:「ナビゲーションペイン」ってのはEC2コンソールの左側のバーのことです。わからなかった・・・。)キーペアができたらここを押してあとは指示に従うだけ。
Amazon マシンイメージはDeep Learning AMIのうちのどれかを選びましょう。
私はDeep Learning AMI (Ubuntu 18.04) Version 27.0を選びました。
無料利用枠じゃないですが、小さいインスタンスタイプを選んでおけば大した額にはなりません。参考
https://aws.amazon.com/jp/ec2/instance-types/t2/
デバッグ用にはt2.mediumで十分かなと。0.0464 USD/hourです。EC2インスタンスへのSSH接続
接続の方法はいくつかありますが、スタンドアロンSSHクライアントを使ったSSH接続が一番シンプルだと思います。
(windowsの場合)下記参照のこと。PuTTY を使用した Windows から Linux インスタンスへの接続
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/putty.htmlパブリックDNSはこの、右側に表示されている値です
ただしこのパブリックDNS、インスタンスを停止して再起動すると値が毎回変わります。
そのたびにSSHクライアント側も設定をいじらなくてはいけません。
これを回避する方法は「(オプション)動的DNSの設定」で述べます。ともあれこれで、EC2に外部からアクセスしてなんやかんや中身をいじれるようになりました。
EC2インスタンスへのHTTPアクセス許可
最終的にはEC2上のjupyter labに外部からブラウザを通じてアクセスしたいので
HTTPでのアクセスを許可しておきます。
これはEC2コンソール側で行う操作です。
このlaunch-wizard-*(なにかの番号)をクリックするとセキュリティグループの操作画面にいけます。Inbound rulesのタブを選びます。
デフォルトだとSSHしかないと思いますが、ここにCustom TCPを追加します。edit inbound rulesを押すと次のような画面になります
Add rulesを押すと行が増えるので、Custom TCP、port 8888、Sourceに0.0.0.0を登録します。
これで任意のソースからポート8888へのTCPでのアクセスが許可されました。
(注:HTTPも選択肢にありますが、ポートが80固定なので、8888を開けるにはCustom TCPで行います)jupyter lab自動起動設定
Deep Learning AMIにはjupyter labがデフォルトでインストール済みです。
ただし、少し設定を変更します。
下記参考のこと。Jupyter事始め
https://qiita.com/taka4sato/items/2c3397ff34c440044978/etc/rc.localにjupyter lab起動用のシェルスクリプトを叩くよう記述しておけばOKです。
ここまでうまく行っていれば、ブラウザのURL欄に
<パブリックDNS>:8888 と入力すればjupyter labにアクセスできます。
(例:パブリックDNSがec2-3-88-70-204.compute-1.amazonaws.comならURLに入力する値はec2-3-88-70-204.compute-1.amazonaws.com:8888)(オプション)EIPの設定
このままだと、インスタンスを再起動するたびにパブリックDNSが変わってしまって、毎回それに合わせてアクセス先が変わって不便です。
対策として、インスタンスに固定のIPを振ることができます(有料)
ここで、Elastic IPの割り当てから、インスタンスにIPを割り当てられます。
EIPは便利ですが、インスタンス停止中にわずかながら料金が発生します。(0.01 USD/hourぐらい)
(無料、になるのはインスタンス起動中です。この場合EIPは無料ですがインスタンスの料金がかかりますし、なんかしらの料金は発生するわけです)(オプション)動的DNSの設定
やりたいことは、「いつでも同じ設定でjupyter labにアクセスする」ですから
何もIPを固定する必要はなく、IPが変わっても常に同じURLで接続できればいいわけです。
インスタンスのIPを固定せずこれを実現するには、変化するIPアドレスに対するホスト名の対応付けを追従させればいいわけです。
これをやってくれるのが動的DNSサービスです。例えばno-ipなんかがあります
https://www.noip.com/下記に従って設定してみてください。
Ubuntu 16.04 に noip を入れる
https://qiita.com/ikeyasu/items/96e2ff8594ae1f8beeabうまくいけば、
このIP/targetの欄が常に今起動しているEC2インスタンスのIPv4 パブリック IPと同じ値になり
<hostname>:8888
にブラウザからアクセスすれば、EC2上のjupyter labにアクセスできます。お疲れ様でした。
ぶっちゃけた話
Sagemakerのノートブックインスタンス使うと1ボタンでできます。
参考
Amazon EC2 のキーペア
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-key-pairs.htmlPuTTY を使用した Windows から Linux インスタンスへの接続
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/putty.htmlJupyter事始め
https://qiita.com/taka4sato/items/2c3397ff34c440044978no-ip
https://www.noip.com/Ubuntu 16.04 に noip を入れる
https://qiita.com/ikeyasu/items/96e2ff8594ae1f8beeab







- 投稿日:2020-03-15T21:48:52+09:00
Amazon Linux 2のsshd_configとauthorized_keysを学ぶ
内容
初期Amazon Linux 2の/etc/ssh/sshd_config設定を色々と変更しつつsshd_configについて学んでいく。
ついでにauthorized_keysも。ちょっとだけsshd_configを学ぶ
取り敢えず使いそうなところの設定
意味 該当箇所 パスワード認証 PasswordAuthentication チャレンジレスポンス認証 ChallengeResponseAuthentication 公開鍵認証 PubkeyAuthentication rootログイン PermitRootLogin 接続ポート Port XX(基本22) SSH接続バージョン Protocol Amazon Linux 2の初期設定
設定#Port 22 #PubkeyAuthentication yes # the setting of "PermitRootLogin without-password". # To disable tunneled clear text passwords, change to no here! #PasswordAuthentication yes #PermitEmptyPasswords no PasswordAuthentication no # Change to no to disable s/key passwords #ChallengeResponseAuthentication yes ChallengeResponseAuthentication no #PermitRootLogin yesどういう設定が良いのか
を調べてみた所共通して多く出てきたのが以下設定。
・rootログインの禁止
・パスワード認証の禁止
・公開鍵認証の
・SSH接続Verison 2のみ許可
・チャレンジレスポンス認証を無効化
推奨値 設定値 推奨値との比較 rootログインの禁止 #PermitRootLogin yes × チャレンジレスポンス認証 ChallengeResponseAuthentication no 〇 公開鍵認証の許可 #PubkeyAuthentication yes 〇 SSH接続Verison 2のみ許可 設定見つけられず ? パスワード認証の禁止 PasswordAuthentication no 〇 ここで、×と?だったものに関して接続を試してみるとどうなるのかを検証。
rootログインの禁止
/etc/ssh/sshd_configのrootログインに関する設定値は以下であった
#PermitRootLogin yesただし、公式サイトでは以下のように記載されている。
Amazon Linux 2デフォルトで安全
Amazon Linux 2 では、SSH キーペアの使用およびリモートルートログインの無効化により、リモートアクセスが制限されています。また、Amazon Linux 2 では、必須ではないにもかかわらずインスタンスにインストールされるパッケージの数が削減されるため、セキュリティの脆弱性のリスクを抑えることができます。深刻度が "緊急" または "重要" であるセキュリティアップデートは、初回起動時に自動的に適用されます。試してみないと良く分からないので試してみます。
Tera Termを使用して、ユーザーをrootとし接続してみます。
......
.......
........
.........Please login as the user "ec2-user" rather than the user "root"._人人人人人人_
> ナニコレ <
 ̄Y^Y^Y^Y^Y^Y^ ̄結果、公式通りrootでのログインはできなかったが、rootログイン時に出力される上記の文は
どこに設定されているのかは知っておきたかったので色々と調べてみた所以下に設定されていることが分かりました。/root/.ssh/authorized_keys no-port-forwarding,no-agent-forwarding,no-X11-forwarding,command="echo 'Please login as the user \"ec2-user\" rather than the user \"root\".';echo;sleep 10" ssh-rsa <文字列> <キーペア名>上記が何かというとauthorized_keysのオプションで、色々設定できるらしいです。初めて知りました。
今回の場合だとssh-rsaの前に記載されています。
オプション 意味 no-port-forwarding ポート転送禁止の設定 no-agent-forwarding 認証エージェント転送禁止の設定 no-X11-forwarding X11(画面)転送禁止の設定 command="command" 実行可能なコマンドの設定 オプション消したらrootでログインできるのでは...?
という事で、バックアップを取得してからssh-rsaより前を削除してみます。# cp -p /root/.ssh/authorized_keys /root/.ssh/authorized_keys_yyyymmdd # ls -a /root/.ssh/ # vi /root/.ssh/authorized_keys # cat /root/.ssh/authorized_keys # systemctl restart sshd.serviceauthorized_keysの設定が反映されたので、新しくSSH接続を試してみます。
※無いとは思いますが何かあって入れなくなると困るので現在の接続は保ったままとします。
できました。
念のためにユーザ確認をしてみます。# whoami rootログインすることができました。
authorized_keysのオプションを無くした状態でsshd_configの#PermitRootLogin yesを以下のように変更するとどうなるのかを試してみます。
(変更前)
#PermitRootLogin yes(変更後)
PermitRootLogin nosshd_configのバックアップを作成して、バックアップがあるかを確認します。
その後設定を変更して、設定反映をします。# cp -p sshd_config sshd_config_yyyymmdd # ls -l # vi /etc/ssh/sshd_config # systemctl restart sshd.serviceそれでは新しい接続でrootのログインを試してみます。
認証に失敗しました。再試行してくださいと表示されてrootにログインすることができなくなりました。
なので、デフォルトでauthorized_keysのオプションによりログインが出来なくなっていて、
そのオプションを削除するとsshd_configにてPermitRootLogin noとなっていないため
rootでログインできることが分かりました。結果
sshd_config authorized_keys 接続可否 #PermitRootLogin yes オプション有 × #PermitRootLogin yes オプション無 〇 PermitRootLogin no オプション有 × PermitRootLogin no オプション無 × sshd_configでPermitRootLogin noと設定した方が良いことが分かる。
SSH接続Verison 2のみ許可
Tera TermでSSHバージョン(V)を[SSH1]を選択して[OK]を押下します。
...
....
....._人人人人人人_
> できない <
 ̄Y^Y^Y^Y^Y^Y^ ̄/etc/ssh/sshd_configにはProtocolの設定がなかったが何故だろうと思い調べた所
OpenSSH 7.4でSSH v1は廃止されたとのこと。つまり何もせずともSSH v2となる。
OpenSSH 7.4/7.4p1 (2016-12-19)
- This release removes server support for the SSH v.1 protocol.
Amazon Linux 2はどのバージョンなのかを確認してみる。
# ssh -V OpenSSH_7.4p1, OpenSSL 1.0.2k-fips 26 Jan 2017OpenSSH 7.4p1でした。
結果
OpenSSH_7.4よりSSH v1が廃止されたため、特に何もせずともSSH v2となっていた。
終わり
最後にもう一度比較してみたいと思います。
推奨値 設定値 推奨値との比較 rootログインの禁止 #PermitRootLogin yes 〇 チャレンジレスポンス認証 ChallengeResponseAuthentication no 〇 公開鍵認証の許可 #PubkeyAuthentication yes 〇 SSH接続Verison 2のみ許可 設定見つけられず 〇 パスワード認証の禁止 PasswordAuthentication no 〇 初期Amazon Linux 2の設定は何も設定しなくても上記の推奨値に関しては問題ないことが分かった。
知らないことだらけだったためとても勉強になった。






- 投稿日:2020-03-15T21:48:52+09:00
(Amazon Linux 2の)sshd_configとauthorized_keysを学ぶ
内容
初期Amazon Linux 2の/etc/ssh/sshd_config設定を色々と変更しつつsshd_configについて学んでいく。
ついでにauthorized_keysも。ちょっとだけsshd_configを学ぶ
取り敢えず使いそうなところの設定
意味 該当箇所 パスワード認証 PasswordAuthentication チャレンジレスポンス認証 ChallengeResponseAuthentication 公開鍵認証 PubkeyAuthentication rootログイン PermitRootLogin 接続ポート Port XX(基本22) SSH接続バージョン Protocol Amazon Linux 2の初期設定
設定#Port 22 #PubkeyAuthentication yes # the setting of "PermitRootLogin without-password". # To disable tunneled clear text passwords, change to no here! #PasswordAuthentication yes #PermitEmptyPasswords no PasswordAuthentication no # Change to no to disable s/key passwords #ChallengeResponseAuthentication yes ChallengeResponseAuthentication no #PermitRootLogin yesどういう設定が良いのか
を調べてみた所共通して多く出てきたのが以下設定。
・rootログインの禁止
・パスワード認証の禁止
・公開鍵認証の
・SSH接続Verison 2のみ許可
・チャレンジレスポンス認証を無効化
推奨値 設定値 推奨値との比較 rootログインの禁止 #PermitRootLogin yes × チャレンジレスポンス認証 ChallengeResponseAuthentication no 〇 公開鍵認証の許可 #PubkeyAuthentication yes 〇 SSH接続Verison 2のみ許可 設定見つけられず ? パスワード認証の禁止 PasswordAuthentication no 〇 ここで、×と?だったものに関して接続を試してみるとどうなるのかを検証。
rootログインの禁止
/etc/ssh/sshd_configのrootログインに関する設定値は以下であった
#PermitRootLogin yesただし、公式サイトでは以下のように記載されている。
Amazon Linux 2デフォルトで安全
Amazon Linux 2 では、SSH キーペアの使用およびリモートルートログインの無効化により、リモートアクセスが制限されています。また、Amazon Linux 2 では、必須ではないにもかかわらずインスタンスにインストールされるパッケージの数が削減されるため、セキュリティの脆弱性のリスクを抑えることができます。深刻度が "緊急" または "重要" であるセキュリティアップデートは、初回起動時に自動的に適用されます。試してみないと良く分からないので試してみます。
Tera Termを使用して、ユーザーをrootとし接続してみます。
......
.......
........
.........Please login as the user "ec2-user" rather than the user "root"._人人人人人人_
> ナニコレ <
 ̄Y^Y^Y^Y^Y^Y^ ̄結果、公式通りrootでのログインはできなかったが、rootログイン時に出力される上記の文は
どこに設定されているのかは知っておきたかったので色々と調べてみた所以下に設定されていることが分かりました。/root/.ssh/authorized_keys no-port-forwarding,no-agent-forwarding,no-X11-forwarding,command="echo 'Please login as the user \"ec2-user\" rather than the user \"root\".';echo;sleep 10" ssh-rsa <文字列> <キーペア名>上記が何かというとauthorized_keysのオプションで、色々設定できるらしいです。初めて知りました。
今回の場合だとssh-rsaの前に記載されています。
オプション 意味 no-port-forwarding ポート転送禁止の設定 no-agent-forwarding 認証エージェント転送禁止の設定 no-X11-forwarding X11(画面)転送禁止の設定 command="command" 実行可能なコマンドの設定 オプション消したらrootでログインできるのでは...?
という事で、バックアップを取得してからssh-rsaより前を削除してみます。# cp -p /root/.ssh/authorized_keys /root/.ssh/authorized_keys_yyyymmdd # ls -a /root/.ssh/ # vi /root/.ssh/authorized_keys # cat /root/.ssh/authorized_keys # systemctl restart sshd.serviceauthorized_keysの設定が反映されたので、新しくSSH接続を試してみます。
※無いとは思いますが何かあって入れなくなると困るので現在の接続は保ったままとします。
できました。
念のためにユーザ確認をしてみます。# whoami rootログインすることができました。
authorized_keysのオプションを無くした状態でsshd_configの#PermitRootLogin yesを以下のように変更するとどうなるのかを試してみます。
(変更前)
#PermitRootLogin yes(変更後)
PermitRootLogin nosshd_configのバックアップを作成して、バックアップがあるかを確認します。
その後設定を変更して、設定反映をします。# cp -p sshd_config sshd_config_yyyymmdd # ls -l # vi /etc/ssh/sshd_config # systemctl restart sshd.serviceそれでは新しい接続でrootのログインを試してみます。
認証に失敗しました。再試行してくださいと表示されてrootにログインすることができなくなりました。
なので、デフォルトでauthorized_keysのオプションによりログインが出来なくなっていて、
そのオプションを削除するとsshd_configにてPermitRootLogin noとなっていないため
rootでログインできることが分かりました。結果
sshd_config authorized_keys 接続可否 #PermitRootLogin yes オプション有 × #PermitRootLogin yes オプション無 〇 PermitRootLogin no オプション有 × PermitRootLogin no オプション無 × sshd_configでPermitRootLogin noと設定した方が良いことが分かる。
SSH接続Verison 2のみ許可
Tera TermでSSHバージョン(V)を[SSH1]を選択して[OK]を押下します。
...
....
....._人人人人人人_
> できない <
 ̄Y^Y^Y^Y^Y^Y^ ̄/etc/ssh/sshd_configにはProtocolの設定がなかったが何故だろうと思い調べた所
OpenSSH 7.4でSSH v1は廃止されたとのこと。つまり何もせずともSSH v2となる。
OpenSSH 7.4/7.4p1 (2016-12-19)
- This release removes server support for the SSH v.1 protocol.
Amazon Linux 2はどのバージョンなのかを確認してみる。
# ssh -V OpenSSH_7.4p1, OpenSSL 1.0.2k-fips 26 Jan 2017OpenSSH 7.4p1でした。
結果
OpenSSH_7.4よりSSH v1が廃止されたため、特に何もせずともSSH v2となっていた。
終わり
最後にもう一度比較してみたいと思います。
推奨値 設定値 推奨値との比較 rootログインの禁止 #PermitRootLogin yes 〇 チャレンジレスポンス認証 ChallengeResponseAuthentication no 〇 公開鍵認証の許可 #PubkeyAuthentication yes 〇 SSH接続Verison 2のみ許可 設定見つけられず 〇 パスワード認証の禁止 PasswordAuthentication no 〇 初期Amazon Linux 2の設定は何も設定しなくても上記の推奨値に関しては問題ないことが分かった。
知らないことだらけだったためとても勉強になった。






- 投稿日:2020-03-15T21:03:54+09:00
VPC内で動くGlue開発エンドポイントでPyCharmを使用する方法
基本は以下の記事に従う。
チュートリアル: 開発エンドポイントで PyCharm Professional をセットアップするしかしこの記事はVPCの外で動く開発エンドポイントを想定しているためVPC内で動くエンドポイントの場合は大きく手順が違ってくる。
VPC内のエンドポイントを扱う際に気をつけること
- プライベートなVPC内にいるので直接触れない
- SFTPでコネクションを貼るために踏み台サーバーを作成する必要がある
- さらにPyCharmで接続するためにローカルでsshトンネルを作る必要がある
そもそもVPC内にエンドポイントを作る理由
GlueがデータソースとしてS3だけを相手する場合は別にVPCの外でいいが、JDBC系をデータソースとして扱う際にはVPCの中に置く必要がある。
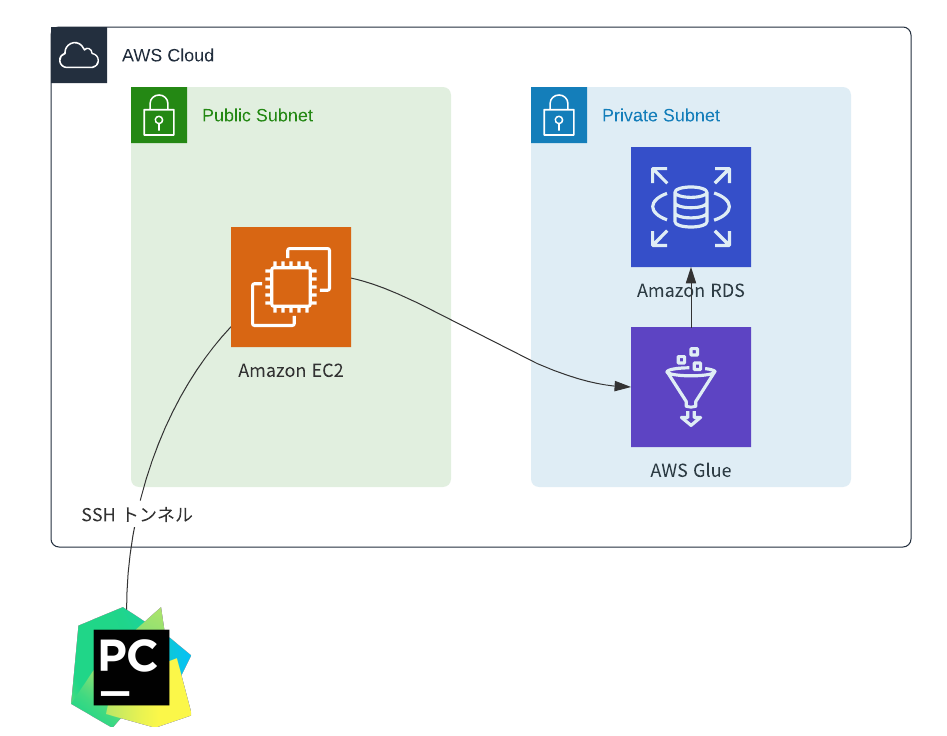
構成図
環境・前提
- Mac OS
- PyCharm Professional
- チュートリアルの前提条件 がJDBC用のVPCでの開発エンドポイントまで終わっていること
- チュートリアルの前提で作成したエンドポイントに公開鍵を設定しておく
実装
1. 踏み台サーバーの作成
- よくある方法で踏み台サーバーの作成
- sshキーだけ忘れないように取得
- 開発エンドポイントと同じVPCに作成
- 開発エンドポイントが属しているVPCは開発エンドポイントをクリックしたら出てくるエンドポイントの詳細で確認可能
2. private subnetのSSHセキュリティグループの設定
- private subnetのセキュリティグループで踏み台が置かれているpublic subnetからだけsshを許可する
3. SSHトンネルの作成
- 以下の様にSSHトンネルを作成
ssh -i <踏み台サーバーのpem> ec2-user@<踏み台サーバーのpublic dns> -L <設定したいローカルポート>:<開発エンドポイントのプライベートアドレス>:22 -N
- うまく行かなくてデバッグをしたいときなどはvオプションを付与する
- 開発エンドポイントのプライベートアドレスは詳細で確認可能
4. PyCharmの設定
- コードとライブラリをチュートリアルに書かれているようにセットアップする
- デプロイの部分が大きくチュートリアルと違う
Hostはローカルホストを指定Portはトンネルで設定したローカルポートを指定User nameはglueAuthenticationはKey pair OpenSSHPrivate key pathは開発エンドポイントに設定した公開鍵の秘密鍵のパス(EC2の秘密鍵ではない)Test Connectionして成功すればOK
あとはチュートリアルと同じ用にやればOK。
その他
- 開発エンドポイントには公開鍵を複数設定することができるので、鍵の共有をする必要がない
- PyCharmで開発しているときはSSHトンネルが生きている必要がある
参考
チュートリアル: 開発エンドポイントで PyCharm Professional をセットアップする
Securely Connect to Linux Instances Running in a Private Amazon VPC | AWS Security Blog
AWS GlueでSpark開発をする - おおたの物置
リモート PyCharmによるデバッグ - ヘルプ | PyCharm

- 投稿日:2020-03-15T18:35:36+09:00
JenkinsからCFnのスタックを作成してみた。
はじめに
Jenkinsを利用してCFnのテンプレートのスタックを実行するジョブを作成してみました。
使用するCFnのテンプレートは前回記事で作成した3つのテンプレートです。
Jenkinsサーバー作成
AWSのEC2を利用してJenkinsサーバーを作成します。
EC2その他の環境は以下のとおりです。
- インスタンスタイプ : t2.medium
- サブネット : パブリックサブネット
- 自動割り当てパブリックIP : 有効
- セキュリティグループ : SSH(22) カスタムTCP(8080) ※Jenkinsサーバーとの接続に8080番ポートが必要
SSH接続
作成したEC2にSSH接続を行います。
$ ssh -i ~/.ssh/aws-test.pem ec2-user@[パブリックIP]javaのインストール
Jenkinsを動作させるためにはJavaが必要となりますので、Javaをインストールします。
$ sudo yum install -y java-1.8.0-openjdk $ java -version openjdk version "1.8.0_242" OpenJDK Runtime Environment (build 1.8.0_242-b08) OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode)Jenkinsをyumリポジトリに追加
Jenkinsのインストールを行うために、Jenkinsのyumリポジトリを追加します。今回JenkinsはLTS版を使用します。
$ cd /etc/yum.repos.d #yum.repos.dフォルダーへ移動 $ sudo curl -O http://pkg.jenkins-ci.org/redhat-stable/jenkins.repo #curlコマンドでyumリポジトリを取得 $ sudo rpm --import http://pkg.jenkins.io/redhat-stable/jenkins.io.key #RPMパッケージの公開鍵をrpmコマンドでインポートJenkinsのインストール
$ sudo yum install jenkins -y $ rpm -qa | grep jenkins #インストール確認 jenkins-2.204.5-1.1.noarchgitのインストール
GitリポジトリからCFnのテンプレートコードを参照するためgitが必要になります。
$ sudo yum install git -y $ git --version git version 2.23.1Jenkinsの起動
$ sudo systemctl start jenkinsブラウザから
http://パブリックIPアドレス:8080でアクセスするとJenkinsのトップページが表示されます。
Jenkinsサーバー初期設定
トップページはアクセスがロックされていますので、
Administrator passwordを入力が必要となります。指示どおり/var/lib/jenkins/secrets/initialAdminPasswordで確認できるパスワードを入力します。$ sudo cat /var/lib/jenkins/secrets/initialAdminPassword 133d8a2572-------------------次に
Customize Jenkins画面が表示され、2つのカスタマイズ方法のうち一つを選択します。違いはプラグインを自分で選択するか推奨されるものにするか、になりますので、今回は推奨プラグインInstall suggested pluginsを選択します。
そうすると次のように自動的にインストールが開始されます。
次に、Adminユーザーの設定を行います。メールアドレスは実在しないものでも設定は可能です。
最後に
Save and Finishをクリックしてセットアップは完了です。
Start using Jenkinsをクリックして利用開始です。
ジョブの作成
CloudFormationのテンプレートを実行させるジョブを作成します。
説明欄に実行内容の概要を入力し、ソースコード管理のGitを選択します。GitHubから取得した対象リポジトリのURLを貼り付けて保存します。
作成したジョブのビルドを実行し、下図の②のように青が表示されたらgitcloneのビルドが成功です。
ターミナルで確認すると、workspaceのディレクトリが新たに追加されているのがわかります。その中には作成したジョブ名のディレクトリが入っており、中身はGitHubからcloneしたソースコードが格納されています。
$ ls /var/lib/jenkins/workspace CloudFormation続いて、ジョブの実行で実際にCFnのスタックが作成されるように設定します。現状、サーバーにログインしているのがec2-userでジョブを実行しているのはjenkinsユーザーとなるため、次の処理の実行が必要になります。
①AWS CLIにAWSのアカウント情報を紐付ける
AWSのマネジメントコンソール画面でIAMユーザーの認証情報(アクセスキーID、シークレットアクセスキー)を確認し以下のように入力します。
$ aws configure AWS Access Key ID: AKI------------- AWS Secret Access Key: iiYg------------- Default region name: ap-northeast-1 Default output format: json $ aws s3 ls #上記のキーが正しければS3のバケット情報が確認できます。② 実行権限を付与し、Jenkinsを再起動
$ sudo visudo Defaults visiblepwの下に以下の2行を追加 root ALL=(ALL:ALL) ALL jenkins ALL=(ALL) NOPASSWD:ALL $ sudo systemctl restart jenkins #jenkinsの再起動 jenkins画面が再起動されるビルドの設定
ジョブの設定画面からビルドの設定を行います。
シェルスクリプトに実行内容を入力して編集内容を保存します。
実際に入力した内容は以下になります。Application_LayerのスタックにはParameterを設定していたので各値の指定が必要になります。今回シェルスクリプト内に直に入力しましたが、もっとスマートな方法があると思います。Pluginとかいれたら変わるのかな?また勉強しておきます。
sudo -u ec2-user aws cloudformation create-stack --stack-name Network-Layer --template-body file://$WORKSPACE/Network_Layer.yml sudo -u ec2-user aws cloudformation wait stack-create-complete --stack-name Network-Layer sudo -u ec2-user aws cloudformation create-stack --stack-name Security-Layer --template-body file://$WORKSPACE/Network_Layer.yml sudo -u ec2-user aws cloudformation wait stack-create-complete --stack-name Security-Layer sudo -u ec2-user aws cloudformation create-stack --stack-name Application-Layer --template-body file://$WORKSPACE/Network_Layer.yml --parameters ParameterKey=KeyPair,ParameterValue="aws-test" ParameterKey=DBInstanceIdentifier,ParameterValue="sample-rds" ParameterKey=DBSubnetGroupDescription,ParameterValue="sample-rds-sg" ParameterKey=S3BucketName,ParameterValue="samples3bucketfromjenkins" sudo -u ec2-user aws cloudformation wait stack-create-complete --stack-name Application-Layerビルドの実行
ビルドの実行結果が青になったことを確認して、AWSのマネジメントコンソールで実際にスタックが作成されたかを確認します。途中に何度か赤で失敗したのは、Parameterの値の設定がうまくできておらず、次のように怒られていました。
An error occurred (ValidationError) when calling the CreateStack operation: Parameters: [KeyPair, S3BucketName, DBSubnetGroupDescription, DBInstanceIdentifier] do not exist in the template Build step 'Execute shell' marked build as failure Finished: FAILURE最後は、なんとか無事に作成できました。
参考記事
https://wiki.jenkins.io/display/JENKINS/Installing+Jenkins+on+Red+Hat+distributions
















- 投稿日:2020-03-15T18:24:17+09:00
事故を出さない虎の巻
「機能は追加(修正)する」「事故も起こさない」。 「両方」やらなくっちゃあならないってのが「エンジニア」のつらいところだな。 覚悟はいいか?オレはできてる。
事故の定義
ここで述べる事故とは、ユーザのサービス利用を妨げる事象、サービスの信頼が失われる事象を指す。
事故足りうる事象に次のものが挙げられる。
- インフラ障害(ネットワーク障害、サーバ障害)
- DB障害(データ不整合、デッドロック)
- 脆弱性(情報漏えい、インジェクション、改ざん、不正アクセス)
- メール・SNSの誤送信
- 実装バグ(二重課金、サーバエラー、操作不能、意図しない動作)
事故足り得る前提として1つ目に規模の問題がある。10人が使ってるサービスの障害と100万人が使ってるサービスの障害を比較するのであれば、明らかに後者のほうが重大な事故である。次にサービス全体へ影響を与えた障害なのか、ごく一部のユーザにのみ影響を与えた障害なのか事故の規模を考慮する必要がある。
(あまりにも規模が小さいものであれば、事故が起こった原因は置いておいて対応としては示談で済むかもしれない)
2つ目にサービスが取り扱っている情報の重要度に依存する。例えば、個人情報を扱っていないサービスであれば盗まれるものが無いのでセキュリティに関してあまり考えなくてもよいし(今どきそんなサービスほぼ無いけど)、銀行のシステムであればネットワークアクセスログはもちろん全て取る必要があるし、改ざんも不正アクセスも防がないといけない。人間はミスをする生き物なので、手動でやる限りいつか同じミスをしたり、別の人だったら同じミスを犯す。
いずれもチェックが手動だけでなく自動化できればそれに越したことがない。
事故が起こる要因として実施者の想定の範囲外で起こるケースが多々にしてあるので規模が大きいシステムを運用している場合はメンバー間で情報を共有することや修正によってどこに影響を与えるかキーワード検索したり想像力を働かせることが大事。
(例えば、修正変更がメインシステムだけでなく担当範囲外を超えたサブシステムに影響を与える場合など)
監視や通知の仕組みを作り、エラーメッセージを読むことが大事。
AWSやGCPなどのクラウドサービスでシステム構築してる際は、Datadogを使うのがおすすめ。なお、特に言語や実行プラットフォームは何でも良いのだがPaaSクラウドを用いて構築された一般的なウェブサービスを想定して書いている。
インフラ障害
主にネットワークや認証・認可周りの設定間違いやサーバリソース不足に関して事故が起こりやすい。
一度設定すればほぼいじらないものと、機能改修によって都度チェックが必要なものと、常に監視が必要なものと分類される。プライベートネットワークの設定間違い
AWSなどでVPC(Virtual Private Cloud)を使ってサーバ間のアクセスに仮想プライベートネットワークを構築する際、
以前まで疎通できていたサーバ間の通信が繋がらなくなるような事故。
対策としては設定したネットワークの各サーバ間、サーバからインターネットへの疎通確認をすること。
一度確認したらネットワークを再構築する際以外は起こりえない。DNSレコードの設定間違い
AWSのRoute53のようなサービスでDNSレコードを設定している場合にCNAMEレコードやAレコード、TXTレコードなどの設定を間違えてしまい起こる事故。
ドメインを変更した際などに設定忘れしたり、疎通確認を忘れた場合に事故が起きる。
一度確認したらドメインを変更する際やレコードを変更する以外は起こりえない。SSL証明書の期限切れ
SSL証明書の期限が切れて数年後にいきなりhttps通信できなくなり、ブラウザ警告が出る事故。
SSL証明書の自動更新設定をするか、期限が切れる前に通知するなどの対策が必要。認証・認可の設定間違い
クラウド関連の機能追加・変更する際にクラウドサービスへのアクセス権限を間違えて変更した場合などに起こる事故。
例えば、AWSのIAMを使っている場合などにS3アクセス権限をReadの権限のみでWriteの権限を忘れたりなどに起こる。
対策は実際にプログラムや設定したユーザ権限で実行してアクセスできているか書き込みできているか確認する。キャッシュの設定間違い(CDNの設定)
CloudFrontなどのCDNの設定で特定のURLパスに対してキャッシュを持つことができる。
キャッシュを持つことで2回目以降は高速にレスポンスを返すことができるが、
whitelistパラメータの設定漏れがある場合、パラメータがALBやサーバに渡されていない事故が発生する。
APIキャッシュを作成する際は実装パラメータを追加した際、whitelistにも追加する必要があるので注意したい。サーバ障害
ここで指すサーバはAPIサーバ・DBサーバなどを含む。いずれも常時監視が必要。
原則、単一障害点を作らない。
(例えば、サーバが一台しかなくてサーバを落としたらシステム全体が止まるなど)
以下のサーバのリソースが問題となる
- サーバのCPU性能不足による遅延
- サーバのメモリ不足
- サーバのディスク不足
具体的には次のような対策がある
CPUスペックを上げる
無限ループなど負荷が高い処理でCPUが100%に張り付いた状態が続くと他の処理ができなくなり、パフォーマンスが落ちる。CPU稼働率とAPIレスポンス時間などを監視し、CPUリソースが足りない場合は負荷がかかっている処理を修正したり、CPUスペックを引き上げる必要がある。
また、AWSのt2インスタンスやHerokuのdynoなどはCPUリソースの上限があり、上限を超える稼働はサーバが止まるので注意が必要。CPUブーストを使ったり、課金したりする必要がある。スワップ領域を作成する
スワップ領域を作成しておくことでメモリ不足になったときにディスク領域を一時的に使うことができる。
スワップ領域はディスク領域のため、IO処理が発生しパフォーマンスは落ちるがメモリ領域がパンクして最悪サーバが止まることはない。
(スワップ領域を使いだす前にはメモリを増やしたいが・・・)
メモリがパンクしてるとvimなどのエディタでファイルを開くこともできなくなったりするので、サーバを再起動したり、lessでファイルを開いて編集したりする。(過去の経験上lessが一番軽かった)ログローテーションを設定する、アップロードファイルはAPIサーバ内に保存しない
ログファイルを何もしないとサーバのディスクを専有していき、いずれディスクをパンクさせる。
logrotateコマンドを使うことで古いログファイルを定期的に消すことができる。(これによりログファイルでのパンクを防げる)
ファイルのアップロードなどをサービスで扱う場合はサーバに直接アップロードするのではなく、S3などのファイルストレージサービスにアップロードする。バックアップを残す
AWS EC2を使っているのであれば、AWSの設定画面にてEC2インスタンスまるごとバックアップを取ることができる。主にすぐに復旧できない不具合があった場合にDBのバックアップと合わせて、ロールバックする。
監視設定をする
CPU、メモリ、ディスクやヘルスチェックに対して一定時間レスポンスがないなどに関して、
Datadogで閾値を超えたら通知(メール、Slack)を飛ばすことが可能。冗長化、オートスケールする
サーバを複数台構成にして、ロードバランサー経由でのアクセスにすれば、1台落ちても別のサーバでカバーできるため、システムを止めなくてすむ。(ロードバランサーのヘルスチェックでサーバを死活監視している)
負荷が増えてきた場合はサーバの台数を増やしてオートスケールする。
AWS LambdaやFirebase Functionsなどのサーバレスなマネージドサービスで稼働するのであれば、オートスケーリングも自動でやってくれてメモリの増設などは設定のみで済む。
また、Dockerコンテナでサーバを作成している場合はAWS Fargateを使ってDockerコンテナをオートスケーリング稼働する方法もある。クラウド自体の障害を確認する
まれにだがクラウドサービス自体が障害を起こしている場合がある。
AWS:AWS Service Health Dashboard
GitHub:GitHub Status
長期的に復旧されない場合はビジネスインパクトが非常に大きい、対策としては一時的にリージョンを分散させて冗長化させるなどがある。実装バグ対策
事故の原因としてはこれが一番多い。
実装者がシステム仕様や言語仕様やライブラリに関する理解が乏しくて発生する場合が多い。
また技術的負債が溜まっており、設計ミスやコードの可読性や統一性、検索容易性が失われている場合、より事故が起きやすい。
コードレビューで見るべきものに関してはコードレビュー虎の巻にまとめた。セキュリティの事故
ユーザのシステムの信頼を失墜させる事故。個人情報の流失や最悪金銭的な損害にも発展する。
当然だが、httpだと盗聴される(というかもはやブラウザで警告出る)のでhttps通信する。
ユーザが比較的自由に入力できるフォーム入力周りはセキュリティホールになりがちなので特に注意する。
- XSS:悪意のあるユーザがブラウザで実行できる悪意のあるJSスクリプトなどをフォーム送信してDB保存する。DB保存されたデータを別のユーザがブラウザで参照した場合に悪意のあるJSスクリプトが実行され、ブラウザに保存されているログイントークンなどの情報を悪意のあるユーザに送信してしまう。対策としては入力時にエンコードしてしまう、フロントエンド側で実行コードとして表示しないなどがある。Reactなどのフレームワークを使っている場合は自動的に無害化してくれる。(dangerouslysetinnerhtmlは除く)
- SQLインジェクション:悪意のあるユーザがSQL文をフォーム送信し、DBの情報を盗み取ったり改ざんしたりする行為。直接ユーザ入力内容をクエリに埋め込むのでなく、プレイスホルダ機能を使うなどでクエリに問題がある際は実行させない方法などがある。
- セッションハイジャック:他のユーザのログイントークンを盗み出し、あるいは推測し、他のユーザとしてログインできてしまうこと。これができると他のユーザになりすましや情報取得できてしまう。ログイントークンを改ざんや流出させない、ログイントークンをユーザ別に発行せずにid=1など推測しやすい情報でセッション切り替えできてしまうなどの実装をしない。ログイントークンには改ざん不能なJsonWebTokenなどを使う。
- CSRF:APIサーバがCORFを許可している場合、外部のサイトからフォーム送信できてしまう。このためフィッシングサイトで本物サーバ側へリクエストさせ、ユーザの情報を盗む手段に使える。特にログイン情報など重要な情報を送信するフォームにはフォームを表示するたびにワンタイムトークンを埋め込み正規のフォーム送信か確認する。
- DoS攻撃:無意味な大量アクセスでサーバをダウンさせようとする攻撃。ファイアウォール機能でIPを一時的にbanするなどの対策がある。AWSだとWAFを使うなど
他にも色々あるが、パスワードは生でDB保存せずにハッシュ化する。認証必須のAPIと認証不要のAPIを切り分けるは必須。
ルーティング周りの事故
パス追加時に他のパスを上書きしてしまったりキャッシュ起因で発生する
ルーティング追加時に他のルーティングを上書きしてしまう
例えば、APIパスを追加した際に既存のルーティングを上書きしてしまい、対象のAPIにアクセスできなくなる事故。
(SPAであればReact Routerなどの疑似ルーティングのRouteを上書きして、対象のページが表示できなくなる事故もある。)POST /api/hoge POST /api/hoge/:id // ←追加 POST /api/hoge/:key // ←URLパラメータ的には異なるがパス的には上のAPIが優先され、到達できなくなる追加する際は他のパスのアクセスを上書きしていないか確認し、順番を変えたり、別のパスにするのが大事。
具体的にはAPIの呼び出しテストを作成することでCIで再帰テストをすることが可能。
指定のパスに対しての呼び出しテストなので呼び出される想定の関数はモック化して良い。キャッシュがあるのに古いAPIやページのパスを消してしまう
古いAPIやページのURLを削除してしまうとブラウザキャッシュが残っていて古いAPIやページのURLにアクセスが来てしまい問題となる。
特にSPAの場合、古いbundle.jsはCDNキャッシュ&ブラウザキャッシュが消えるまで&ブラウザリロードするまで残り続けるため、CDNキャッシュクリアと古いAPIは新しいAPIにリダイレクトする必要がある。
他にも、Google Botなどは古いパスのキャッシュを持っているため、古い方にアクセスが来る。
キャッシュを使ってる場合は古いAPIやページにアクセスが来るので新しいページに301リダイレクトする必要がある。外部API起因の事故
外部サービスのAPIを呼び出している場合、外部APIの仕様を確認する必要がある
エラー時の処理
考慮漏れしがち。API仕様を見てもどんなエラーが返ってくるかわからない場合や通信エラーの場合でも制御する必要がある。
エラー時に後の処理を行うかの判断もしないといけない。APIリクエスト上限
これもAPI仕様を見ていないと見落としがち、タチが悪いのはlocalだとリクエスト数少なくて問題ないが、本番環境に上げたら、大量にリクエストしてしまってエラーになる場合がある。課金などで上限を上げれる場合が多いが、代替手段がある場合はそもそも使わないか元が取れる場合に限る。上限を上げれない場合は、APIリクエスト数の上限を超えないようにキューイング(バッチ化)するか、リアルタイム性を求められる場合はエラーとして返す(ユーザに待ってもらう)方法がある。
API呼び出しアカウントのセッション切れ、セッション上限
ステートレスでない(Rest API)でないステートフルなAPIの場合、ユーザアカウントでのセッションを保つ場合がある。セッション切れした場合は再度ログインする必要があるので再ログイン処理の対応も必要となる。
外部サービスのセッションを持つAPIなどはセッション上限などを超えないようにする必要があるメモリリーク
GC(ガベージコレクション)が無い言語(C、C++など)はもちろん動的メモリ確保した際に利用後、明示的にメモリ解放しないとメモリ領域を食いつぶす。
GCがある言語(JavaScriptなど)でもnewでメモリアロケーションしたインスタンスが循環参照してる場合はGCでもメモリ解放されずメモリリークとなる。
メモリリーク箇所の検出を行い、循環参照している場合は弱参照(WeakRef)やスマートポインタを使う方法がある。
そもそもnewを極力使わない、循環参照させないのも手である。ちなみにJavaScriptの場合はプロポーサル段階だがWeakRefが存在しているのと
NodeJSのメモリリーク検出方法が参考になる。パフォーマンス低下による事故
レコード数が多いテーブルはパフォーマンスに注意する。
バックエンドの処理はパフォーマンスが低下するとレスポンス時間が遅くなりシステムがハングする。
readの方はテーブルのよく検索に使われるフィールドにindexを貼る、マイグレーションスクリプトやバッチ処理での大量Writeはbulk処理をして短時間で書き込む対策が必要。
あとはマルチプロセス(cluster)でCPUコア数分サーバ起動することで暫定的な負荷分散はできる。
システム全体のパフォーマンスのボトルネックを見つけるにはframegraphを出力する。例えば、NodeJSは0から始めるNode.jsパフォーマンスチューニングに調査方法がよくまとまっている。
データ不整合の事故
データ挿入などのデータマイグレーションスクリプトの実装間違えや途中エラーはデータの不整合を起こすので、トランザクションで実装し、問題がある場合はロールバックする。
さらには実行後に問題があった場合に備えて、実行前にはデータのバックアップも取っておく。
また、課金周りなど複数テーブルへの書き込みが必要な重要な処理はトランザクションして不整合を防ぐ。APIマイグレーションの事故
サブシステムのAPIをメインのシステムから参照している場合にサブシステムのAPIをアップグレードして別のデータを返す必要がある場合、
基本的にサブシステムとメインシステムを完全同時にリリースすることはできないので、ステップ踏む必要がある。
- サブシステムの新APIを実装、旧APIはまだ消さない。サブシステムをリリースする。
- メインシステムにサブシステムの新API呼び出しの処理を実装、旧APIを消す。メインシステムをリリース。
- サブシステムの旧APIを消す。サブシステムをリリースする。
変更がサブシステムに影響を与えてしまう事故
変更がメインシステムだけでなくサブシステムにも影響を与えないか考慮する。
この辺はシステムの全体像がわかっていないと厳しい、有識者が実装、レビューするしかない。
普段から情報をシェアし合う体制が必要。
特に起こりやすいのはDBのテーブルフィールドを変更・削除した場合に
redashなどのBIツールのクエリやsalesforceなどの別システムへのデータ同期を自動で行っている場合などに影響がでて事故る。排他制御の事故
DBトランザクション、マルチスレッドの排他制御などは、処理をブロッキングしてしまうため、解除し忘れるとシステムをハングさせる。(デットロック)
例えばトランザクション開始時にtry構文でwrapしてやり、finally文で必ずロック解除するようにするなどの対策がある。ライブラリ(OSS)のバージョンアップに伴う事故
これはnpmやgemなどのパッケージマネージャーツールで3rdパーティライブラリを管理している場合に起こる
ライブラリを使って良いのは保守を上回るメリットがある場合だけで、オーバスペックなライブラリは容量を食うし(特にユーザがアプリやJSファイルをDL際に影響する)、ライブラリのバージョンアップが義務付けられるのでそもそも不要なライブラリは入れずに言語仕様や標準のAPIで実装する。
ライブラリのバージョンは動作確認が取れるまで無闇に上げずに固定しておく(メジャーバージョン、マイナーバージョン、パッチバージョン)。
また、package-json.lockやyarn.lockなど詳細な依存関係を管理しているファイルは3rdパーティライブラリが依存しているライブラリのバージョンが記載されているため、無闇に消してはいけない。
これらのファイルを消してしまうと再インストールした際に3rdパーティライブラリが依存しているライブラリのバージョンが引き上がって事故ることがあるからだ(1回あった)。技術的負債
事故直接の要因ではないかもしれないが、怠ると事故を引き起こす要因となりえるもの。
型付きの言語で実装する
特にバックエンドは型付きの言語で実装したほうが良い(NodeJS+TypeScript、go、Java)。
理由としては、静的コンパイルによってケアレスミスが防げるからだ。
- 型チェックで意図しない型のパラメータが引数に渡ってしまうのを防げる
- 型チェックでパラメータの引数への渡し忘れを防げる
- 型があることでprimitiveなデータなのかクラスやオブジェクトの型なのかすぐに判別がつく
- 型チェックがあることでoptionalな引数かそうでないかが型定義でわかる(TypeScriptの場合)
- 戻り値の型がわかる
TypeScriptでの実装の場合、TypeScriptの為のクリーンコードが参考になる。
設計
KISS(シンプルな設計・実装にする)を心がける。
クラスを使う場合、SOLID原則、デメテルの法則も意識すると仕様変更にも強く、テストしやすい。(依存と関心の分離)
- デフォルト引数を与えてフェールセーフにする、ただし空関数をデフォルト引数に指定するなどの場合は実装漏れなどはエラーは握りつぶさずにエラーログを送信してすぐ発見できるように通知する
- DBテーブルフィールドの直接の変更、削除は事故になるので別フィールドを追加して処理とデータも移行してから元のフィールドを削除する
- DRYに則って同じような処理は関数に共通化する。変更が少ないユーティリティは共通化してもよいが、過度な共通化は無駄に影響範囲を広げてしまう・・・あなたはDRY原則を誤認している?
- 呼び出し箇所が多い関数やテーブルフィールドの修正時には影響範囲に注意する。依存グラフをツールで出力するなどで把握する
- ビジネスロジックはインタフェース、abstractで抽象化する方が仕様変更に対応しやすいので望ましい。実装は委ねられるが、引数と戻り値の型が保証される。
可読性、検索のしやすさ
命名規則、コーディングルールを統一する。プロジェクトが小さいうちは良いのだが、プロジェクトが大きくなるとファイルの即時検索ができないと明らかに作業効率が落ちる。
キャメルケース、スネークケースなどはどれか一つに統一する(混ぜない!)。
意外に大事なのがtypoを防ぐ、別の意味で使っているのに同じ変数名や関数名にしない、表記揺れをなくす。
これは、修正漏れを防いだり、誤解を招くことに起因する。(ドメインモデルを統一する)
プロジェクト内の既存のtypoの検索にはあいまい検索でfzfなどが使える。
コード量に比例してバグの量も増えるので、YAGNI(無駄な実装をしない、残さない)を常に心がける。
- lintを入れてコーディングルールを統一する
- 適切なコメントを入れる(主に機能やビジネスロジックの仕様の説明)、できる限り簡潔に書く
- ファイル名、変数名、関数名は命名規則を統一する、中身がわかりやすい名前をつける(typoしない)
- コードが追いにくくなるので関数の呼び出し(コールスタック)を深くしない
- ネストは深くしない(条件分岐の早期リターンする、非同期コールバック処理はawaitする)
- 変数、DBテーブルフィールドのダブルミーニングはしない
- 継承より合成を優先して使う(継承だと不要な変数、メソッドまで継承するリスクや可読性・メンテナンス性が落ちる)、継承自体を禁止する必要はないが、子継承までが限界だと思う
PRの掟(おきて)
事故を起こさないようにするためのPRのルール、PRの役割を複数持たせない(単一責任)
コード量に比例してエラー数も増えるため、修正量は少なくする。
特にソースファイルをまたいでいる数が多い修正や依存が強い箇所の修正は危険なので、極力修正を混ぜない。
リリース後作業が必要なもの、重要な修正に関してはチェックリストをつける。
- リファクタリングは機能追加、機能変更と同時にしない、PRを分ける
- 大きすぎるリファクタリングは小分けにリファクタリングして、PRを分ける
- PRを作成するときのテンプレートにチェックリストを作る
- PR作成時にlint、テストを実行する
テスト
資産になるテストを書き、CIで再帰テストを行う。
- 正常系、境界値、異常系の単体テストを書く
- 重複したテストを書かない
- できる限り並列テストにする
- 条件が複雑なものほど再現が困難なため単体テストで網羅する、単体テストできるような構造にする
- 単体テストとAPIテストなど異なる種別のテストは同じファイルに書かない(フォルダ分けする)
- E2Eテストは壊れやすいが網羅性が高いので、サービスのコア機能などにピンポイントで使う
- 表示の差分テストはビジュアルリグレッションテストが良い(UIライブラリのバージョンアップにも追従できる)
- 投稿日:2020-03-15T17:33:45+09:00
WindowsのEclipseからCodePipelineを起動してEC2にアプリをデプロイする
前提条件
まずは「AWS上でサーバレスなコンテナまで動かせた!」なところまでできていれば。
拙筆ながらこの記事あたりをやっていることを前提としている。
あと、↑の記事中のシンプルなSpring Boot アプリをAWS Code シリーズを利用して自動デプロイするハンズオンも、最後まで走らせて、CodePipelineでEC2にデプロイできるところまでやった上でこの記事を書いている。まずはWindowsでの統合開発環境構築から
イマドキならIntelliJ+SpringBootかもしれないけど、裾野の広さからEclipseでやってみる。
あと、AWS公式のドキュメントがあるのがEclipseだからという理由も。[Java]EclipseでSpring Bootを使ってみる。
この辺を見ながらWindowsでEclipse+SpringBootな環境を作っておく。
あんまり書いてないのだけど、javaのパス情報(PATHとJAVA_PATHの環境変数)が正しくないとGradleを使ったビルドが通らなかったりするので、しっかり設定しておく。GRADLE_PATHあたりも入れておかないと怪しい(ハマりポイント)。
参考情報は以下。Let's プログラミング PATHの設定及び環境変数JAVA_HOMEの設定
さらに、今回はCodeCommitと連携することを目的に、以下を見ながらAWS Toolkit for Eclipseの設定を入れる。
【AWS公式】Eclipse と AWS CodeCommit の統合
インストールしようとすると、以下のようなエラーになったりする(Eclipseを日本語化しているので以下のようなメッセージだけど、プレーンなままだと "No repository found containing" な感じで出力されていると思う)。
インストールする項目の収集中にエラーが発生しました セッション・コンテキスト:(プロファイル=C__Users_NERU_eclipse_jee-2019-12_eclipse、フェーズ=org.eclipse.equinox.internal.p2.engine.phases.Collect、オペランド=、アクション=)。 含まれているリポジトリーが見つかりません: osgi.bundle,org.eclipse.jgit,5.6.1.202002131546-r 含まれているリポジトリーが見つかりません: osgi.bundle,org.eclipse.jgit.archive,5.6.1.202002131546-r 含まれているリポジトリーが見つかりません: osgi.bundle,org.eclipse.jgit.http.apache,5.6.1.202002131546-r 含まれているリポジトリーが見つかりません: osgi.bundle,org.eclipse.jgit.ssh.apache,5.6.1.202002131546-r 含まれているリポジトリーが見つかりません: org.eclipse.update.feature,org.eclipse.jgit,5.6.1.202002131546-r 含まれているリポジトリーが見つかりません: org.eclipse.update.feature,org.eclipse.jgit.http.apache,5.6.1.202002131546-r 含まれているリポジトリーが見つかりません: org.eclipse.update.feature,org.eclipse.jgit.ssh.apache,5.6.1.202002131546-rエラーになったプラグインをググって、ダウンロードサイトを「ヘルプ」⇒「新規ソフトウェアのインストール」で開いたウィンドウでサイトを入力する。たとえば、↑のjgitとかは
http://download.eclipse.org/egit/updatesを入れれば見つけることができる。全てのプラグインがこの方法でできるかは不明。見つけられないものもあった。謎。あと、AWS Toolkit for Eclipseのリージョンはデフォルトで東京リージョンになっていない。↑のサイトを読んでも、
リポジトリが表示されない場合は、フラグアイコンを選択して AWS リージョンメニューを開き、リポジトリが作成された AWS リージョンを選択します。
としか書かれていなくて意味が分からない。「フラグアイコンって何だよ!」って思ったら、
これのことだった。東京リージョンを選択すると
無事、東京リージョンでお試しで作ってみたCodeCommitのプロジェクトにアクセスすることができた。
あとは、手順に従ってローカルにチェックアウトしてくればOK。
ローカル環境からgit commit&pushしてみる
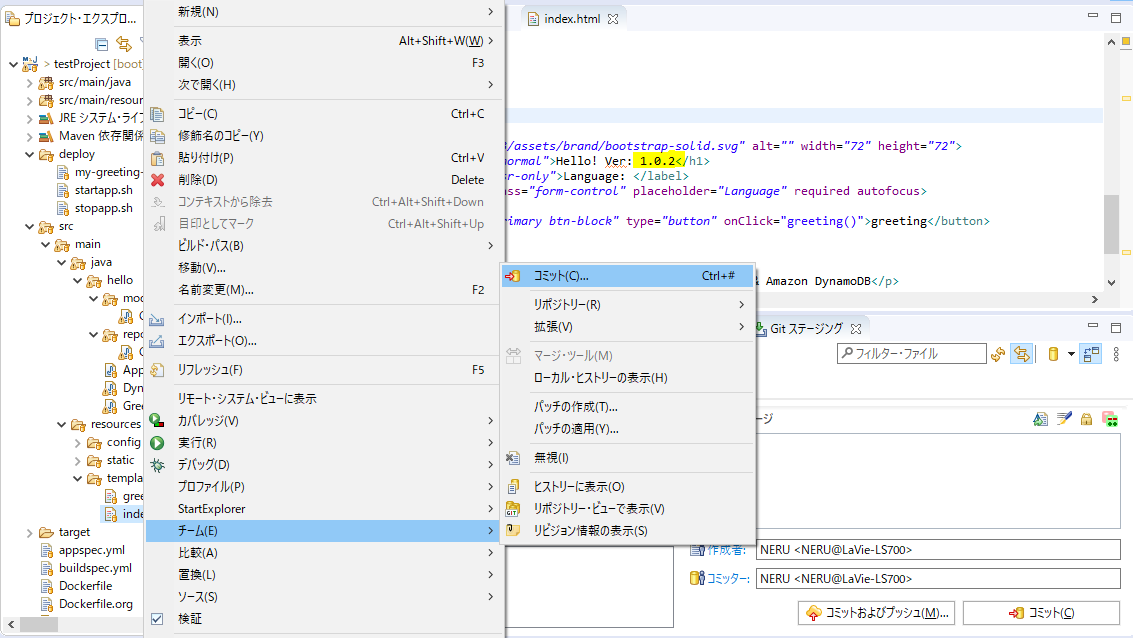
こんな感じでindex.htmlを編集(画像の蛍光ペンの場所)してみて、右クリックからの「チーム」⇒「コミット」でGitステージを開き、
作成者やコミッター、コミット・メッセージを入れて、「コミットおよびプッシュ」をクリック!
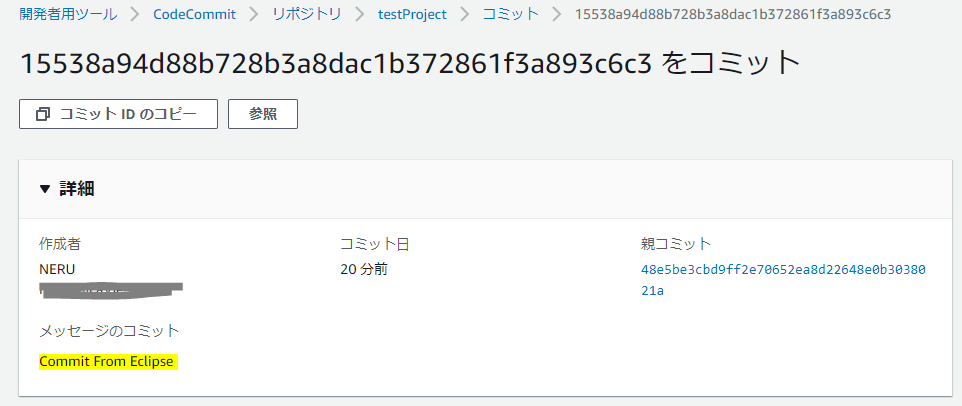
この時はCommit時にキャプチャを取り忘れたけど、コミット・メッセージにはCommit From Eclipseと入れている。で、正常終了してからAWSのマネジメントコンソールを見てみると、
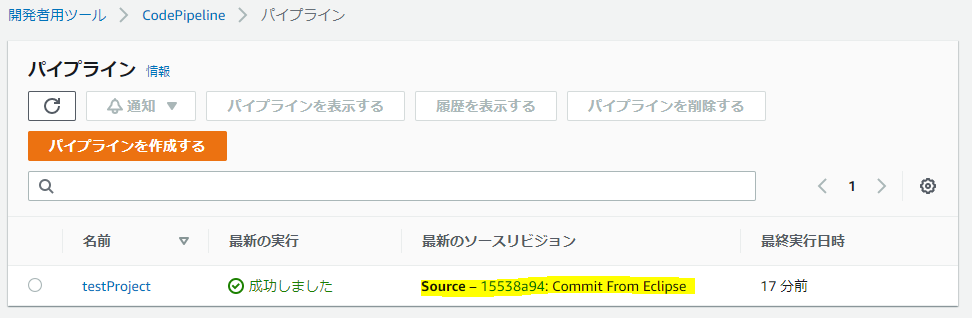
ちゃんとCommitされている。ということは、
無事、パイプラインの起動によるビルド&デプロイも成功!
EC2向けのパイプラインをECS+Fargateに組み替える
以下の書籍を参考にしながら。
CodeBuildでECRにpushするようにBuildSpecファイルを組み替える
まずは、ビルド結果をECRにPUSHするので、CodeBuildで使うIAMロールにECRにアクセスするためのポリシを設定しておく。CloudWatch Logsにログを出すならそのポリシ(CloudWatchLogsFullAccess)も必要。
ビルド環境は何でも良いかと思いきや、Amazon Linux2の全バージョンと、Ubuntu Standard 4.0についてはOpenJDKが入っていないので注意(Corettoになっている)。
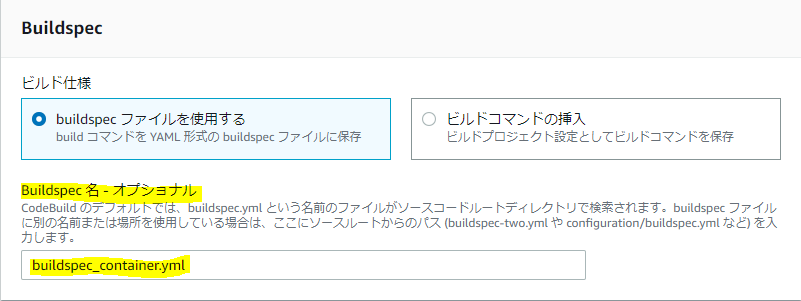
特権モードとか、何も考えずにEC2向けのCodeBuildの設定と同じと考えていると、書籍内で「ハマるから気を付けて」と書いてある箇所は100%ハマる。Buildspecファイルはこんな感じで。元のハンズオンのbuildspec.ymlを汚したくないのであれば、別名で作って、ビルドプロジェクトの設定で設定すると良い。
buildspec_container.ymlversion: 0.2 env: variables: AWS_REGION_NAME: ap-northeast-1 ECR_REPOSITORY_NAME: my-greeting-web phases: install: runtime-versions: java: openjdk11 pre_build: commands: - $(aws ecr get-login --region ${AWS_REGION_NAME} --no-include-email) - AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query 'Account' --output text) - REPOSITORY_URI=${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_REGION_NAME}.amazonaws.com/${ECR_REPOSITORY_NAME} - IMAGE_TAG=$(git rev-parse --short HEAD) build: commands: - echo Build started on `date` - mvn test package - docker build -t ${REPOSITORY_URI}:latest . - docker tag ${REPOSITORY_URI}:latest ${REPOSITORY_URI}:${IMAGE_TAG} post_build: commands: - docker push ${REPOSITORY_URI}:${IMAGE_TAG} artifacts: files: - target/my-greeting-web-0.1.0.jar - appspec.yml - deploy/* discard-paths: yes cache: paths: - '/root/.m2/**/*'あと、Buildspecファイルと同じディレクトリにDockerfileも必要なので注意。
さて、これでビルドが通るようになったはずなので、ビルドの実行をして確認してみる。
上手くいくと、ECRのリポジトリが更新されているはず。CodeDeployを組み替える
例によってCodeDeployが使うIAMロールがECSにアクセスできるようにポリシ(AWSCodeDeployRoleForECS)を設定する。
さらに、ECSにCodeDeployする場合はBlue/Greenデプロイメントになるので、ALBにもターゲットグループを追加して、2つのターゲットグループを打つようにしておく。
また、CodeDeploy用にECSのサービスを起動しておく必要があるので、これまでローリングアップデートで起動する設定の場合は、以下のように変更する。というか、デプロイメントの設定は作成時にしかできないため、新しくサービスを作る。
このときも、ECSのIAMロールにも、CodeDeployのアプリケーションを作成するためのポリシ(AWSCodeDeployRoleForECS)を設定しておく。うーん、↑のポリシと同じなのが本当に正しいのかはよく分からない……。新しいサービスが上手く作れると、CodeDeployにこんな感じでアプリケーションが作成される。
このアプリケーションに対して、デプロイを作成してみる。
S3にはまだアーティファクトを入れていないので、JSONかYAMLを直接以下のように定義。
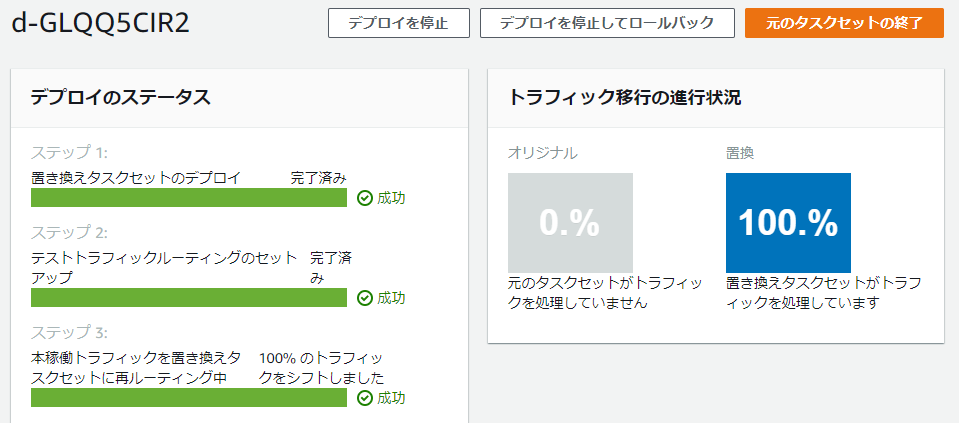
ググったり↑の書籍ではというプレースホルダが使えたりすると書いているが、これはCodePipelineで置換されるプレースホルダであるため、現時点では使えない。あくまでもここは、CodeDeployのお試しと考える。JSON{ "version": 1, "Resources": [ { "TargetService": { "Type": "AWS::ECS::Service", "Properties": { "TaskDefinition": "arn:aws:ecs:ap-northeast-1:[アカウントID]:task-definition/my-greeting-web:[タスクのバージョン番号]", "LoadBalancerInfo": { "ContainerName": "my-greeting-web", "ContainerPort": 8080 } } } } ] }YAMLversion: 0.0 Resources: - TargetService: Type: AWS::ECS::Service Properties: TaskDefinition: "arn:aws:ecs:ap-northeast-1:[アカウントID]:task-definition/my-greeting-web:2" LoadBalancerInfo: ContainerName: "my-greeting-web" ContainerPort: 8080デプロイに成功すると、↓こんな感じで成功の画面が出る。この前はプログレスバーが青かったので、BlueがGreenに切り替わるのが視覚的に分かって良い感じ。
右上の「元のタスクセットの終了」を押すと、ちゃんとタスクを停止してくれる。



- 投稿日:2020-03-15T17:32:58+09:00
(主に)Goの開発環境構築でWindowsユーザがMacに歩み寄る工夫
はじめに
チームの開発環境の構築手順って、みなさまどうしていますか?多くのチームはリポジトリ直下のREADMEや、チームWikiに用意することが多いのではないでしょうか?
その際、そのリポジトリ固有のBuild & Deploy & Release手順は記載することは普通だと思いますが、ここで問題になるのは、開発者の環境がWindows, Macなどで割れている場合です。全員Windows or Macで揃えろよってことですが、今の自分のチームはMac:Windows=7:3くらいです。
Windowsは参画したてのメンバーや、アルバイトer社員の方が多く、事実上スキルが低いメンバーが多いのですが、環境構築手順がMacに比重高めなので結構翻訳が大変な場合があります。ここでなるべくWindowsユーザがMacユーザ用に書かれた環境構築手順書でも対応できるようなTipsをまとめていきたいと思います。
1. 環境構築の設定
WindowsとMacで揺れているところです。
- Windows:
set AWS_REGION=ap-northeast-1- Mac:
export AWS_REGION=ap-northeast-1毎回、exportをsetと入力してもらうのは大変ですが、Windowsでも export のコマンドで環境変数を設定できます。
doskey export=set $*上記を実行すると、export を setのエイリアスのように認識してくれます。
これを永続化するためには以下のサイトにあるように、macroファイルを準備し、ショートカットの引数に追加すると良いようです。2. Makeコマンド
特にGoだとMakefileでビルドスクリプトを用意する文化があるので、Windowsユーザはちょっと対応が大変です。Makeコマンド自体は、Windowsでも追加でインストールできるものの、その内部でgrepコマンドなどを利用されたり、shellスクリプトを実行されるとお手上げです。とはいえ、このMakefileをWindows用も用意するのはダブルメンテですし、MacユーザはWindows側の実行テストするのがハードルが高いので、即座に腐っていきそうです。バッドスメルです?。
というわけで、WSL一択になります。この時点で1の環境変数設定もWSL側でやったほうが良いという結論になりがちですが、環境構築手順のレベル感を見てどこからWSLを使うかは個別判断になると思います。
Windows標準のコマンドプロンプトから、
wslまたはbashと入力するとコンソールがそのまま切り替わり、exitを打つとWindows側に戻れるので便利です。ワンラインで処理したい場合は
bashコマンドだと以下のように実行できます。bash -c "ls -la /c/mnt/Users/laqiiz/go/src | grep github"参考: https://docs.microsoft.com/ja-jp/windows/wsl/interop
というわけで、Makeコマンドを実行したい場合は以下のように実行できます。
bash -c "make"3. GOPATHの設定
2で動けば良いですが、おそらく課題として、内部で
go buildする時にWindows側とWSL側でGOPATHが異なるのでうまく動かないことも多いと思います。少しややこしいことになりました。対応としてはオススメは Windows側に WSL側のGOPATHを寄せることです。bash # WSL側へ移動 export GOPATH=/mnt/c/Users/<ユーザ名>/go exit # Windows側へ戻るこれで go build も問題なく動くと思います。
しかし、go generate系も動かない可能性があるので、PATHにも追加します
export PATH=${PATH}:${GOPATH}/binWindows側で
go get -uなどでインストールした実行ファイルは.exeなのでそのまま使えませんので、WSL側でも実行ファイルを作成する必要がありますが、MakefileにInstall手順も書かれている場合は問題にならないと思います。4. GoアプリのBuild
Goはクロスコンパイルできますので、Windowsでも問題なくLinux用の実行ファイルを作成できます。
しかし、環境手順には以下のようなワンラインで書かれていることも多いのではないでしょうか?ワンラインで書かれて辛いケースGOOS=linux GOARCH=amd64 go build ./cmd/your-app/your-app.goこの場合、Windowsに翻訳すると以下のように分割する必要があります。
Windowsだとこれset GOOS=linux set GOARCH=amd64 go build ./cmd/your-app/your-app.goコレでも良いのですが、このまま
go testすると内部でbuildされる実行ファイルがWindowsで実行できなくなるため、set GOOS=windowsと設定し直す必要があり非常にノイジーです。というわけで、これもWSL側で実行するのがオススメです。
bash -c "GOOS=linux GOARCH=amd64 go build ./cmd/your-app/your-app.go"4. AWSCLIのための設定
Goのよくある使い所の一つとして、サーバサイドのWebAPI開発があると思います。このときAWSにDeployする方も多いのではないでしょうか? AWSCLIはWindowsでもMacでも公式で準備されているため、何も問題が無いことが多いですがいくつかのAWSコマンド実行する上で、ややこしいことがあります。
AWS CLIの設定
Profileを利用している場合、Windows側とWSL側でダブルメンテになるのは、設定漏れで作業効率を落とす原因になる事が多いので、なるべく避けた方が良いと思います。
例によって、WSL側の設定をWindows側に寄せます。
ln -s /mnt/c/Users/<User-Name>/.aws ~/.awsこれでAWSCLIなどで利用する configやcredentialsをWindows側と共用できるようになりました。もちろん、credentialsは最上位の機密情報ですので、取り扱いはWindows側と同様に注意して取り扱いましょう。
Lambdaのデプロイ
LambdaでGoアプリをデプロイするときは、以下のようにZIP化する必要があります。
LambdaのデプロイGOOS=linux GOARCH=amd64 go build ./cmd/lambda/lambda.go # ZIPファイルを作成 zip -j lambda.zip lambda # Lambdaのコードデプロイ(Lambda関数自体はすでに作成されている前提) aws --profile <YOUR_ENV> lambda update-function-code --function-name <YOUR_LAMBDA_NAME> --zip-file fileb://lambda.zipこの、
zipコマンドはWindowsに無いのですが、公式にはbuild-lambda-zipツールのインストールが推奨されています。https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/lambda-go-how-to-create-deployment-package.html
これでももちろん良いですが、微妙にWindows側とコマンドが異なりややこしいです。ここでもWSLの出番となります。
複数ラインの場合はbash -c "コマンド"と渡すのではなく、bash + exit で切り替えがオススメです。bash # Bashを起動 GOOS=linux GOARCH=amd64 go build ./cmd/lambda/lambda.go zip -j lambda.zip lambda aws --profile <YOUR_ENV> lambda update-function-code --function-name <YOUR_LAMBDA_NAME> --zip-file fileb://lambda.zip exit # (必要に応じて)Windows側へ戻るDocker
DockerもVolume周りの設定をされていると、微妙にWindowsでうまく動かない可能性があります。Docker Desktop for WSL 2でお試し中です。うまくいき次第追記予定です(2020/03/15)
まとめ
- 環境変数設定くらいであればdoskeyで逃げられる
- それ以上になれば、WSLをうまく利用し逃げるのが楽。その際の設定周りはなるべくWindowsと共用し、ダブルメンテにならないようにするのがオススメ
- 投稿日:2020-03-15T17:32:58+09:00
AWSを用いたGoの開発環境構築でWindowsユーザがMacユーザに歩み寄るナレッジをまとめた
はじめに
チームの開発環境の構築手順って、みなさまどうしていますか?多くのチームはリポジトリ内のREADMEや、チームWikiに準備することが多いのではないでしょうか?
その際、そのリポジトリ固有のBuild & Deploy & Release手順は記載することは普通だと思いますが、ここで問題になるのは、開発者の環境がWindows, Macなどで割れている場合です。全員Windows or Macで揃えろよってことですが、今の自分のチームはMac:Windows=7:3くらいです。ハードやライセンスの問題から自分たちと同じ用に完全に開発環境を揃えるのも難しいチームも多いでしょう。Amazon Workspacesは一つの解には間違いないですが、なるべく既存の資産を有効活用したいPJも多いと思います。
私のチームの話ですがWindowsは参画したてのメンバーや、アルバイトer社員の方が多く、事実上スキルが低いメンバーが多いのですが、環境構築手順がMacに比重高めなので脳内翻訳が大変な場合があります。
ここではなるべくWindowsユーザがMacユーザ用に書かれた環境構築手順書でも対応できるようなTipsをまとめていきたいと思います。
1. 環境構築の設定
WindowsとMacで揺れやすいところです。
- Windows:
set AWS_REGION=ap-northeast-1- Mac:
export AWS_REGION=ap-northeast-1毎回、exportをsetと入力してもらうのは大変ですが、ここで朗報です。Windowsでも export のコマンドで環境変数を設定できます(!)
doskey export=set $*上記を実行すると、export を setのエイリアスのように認識してくれます。
これを永続化するためには以下のサイトにあるように、macroファイルを準備し、ショートカットの引数に追加すると良いようです。2. パスの指定
自分たちのチームでGo系だとよくあるのが、
cd ${GOPATH}/src/github.com/future-architect/<Repository>みたいな指定を書かれることです。Windowsだと
%GOPATH%と書き換える以外なく、早くも脱落感があります。次の3,4,5のようにWSLをうまく活用しましょう。3. Makeコマンド
特にGoだとMakefileでビルドスクリプトを用意する文化があるので、Windowsユーザはちょっと対応が大変です。Makeコマンド自体は、Windowsでも追加でインストールできるものの、その内部でgrepコマンドなどを利用されたり、shellスクリプトを実行されるとお手上げです。とはいえ、このMakefileをWindows用も用意するのはダブルメンテですし、MacユーザはWindows側の実行テストするのがハードルが高いので、即座に腐っていきそうです。バッドスメルです?。
というわけで、WSL一択になります。この時点で1の環境変数設定もWSL側でやったほうが良いという結論になりがちですが、環境構築手順のレベル感を見てどこからWSLを使うかは個別判断になると思います。
Windows標準のコマンドプロンプトから、
wslまたはbashと入力するとコンソールがそのまま切り替わり、exitを打つとWindows側に戻れるので便利です。ワンラインで処理したい場合は
bashコマンドだと以下のように実行できます。bash -c "ls -la /c/mnt/Users/laqiiz/go/src | grep github"というわけで、Makeコマンドを実行したい場合は以下のように実行できます。
bash -c "make"WSLを利用したワンラインでの実行方法は以下で詳しく説明されていておすすめです。
https://docs.microsoft.com/ja-jp/windows/wsl/interop
4. GOPATHの設定
2で動けば良いですが、おそらく課題として、内部で
go buildする時にWindows側とWSL側でGOPATHが異なるのでうまく動かないことも多いと思います。少しややこしいことになりました。対応としてはオススメは Windows側に WSL側のGOPATHを寄せることです。bash # WSL側へ移動 export GOPATH=/mnt/c/Users/<ユーザ名>/go exit # Windows側へ戻るこれで go build も問題なく動くと思います。
しかし、go generate系も動かない可能性があるので、PATHにも追加します
export PATH=${PATH}:${GOPATH}/binWindows側で
go get -uなどでインストールした実行ファイルは.exeなのでそのまま使えませんので、WSL側でも実行ファイルを作成する必要がありますが、MakefileにInstall手順も書かれている場合は問題にならないと思います。5. GoアプリのBuild
Goはクロスコンパイルできますので、Windowsでも問題なくLinux用の実行ファイルを作成できます。
しかし、環境手順には以下のようなワンラインで書かれていることも多いのではないでしょうか?ワンラインで書かれて辛いケースGOOS=linux GOARCH=amd64 go build ./cmd/your-app/your-app.goこの場合、Windowsに翻訳すると以下のように分割する必要があります。
Windowsだとこれset GOOS=linux set GOARCH=amd64 go build ./cmd/your-app/your-app.goコレでも良いのですが、このまま
go testすると内部でbuildされる実行ファイルがWindowsで実行できなくなるため、set GOOS=windowsと設定し直す必要があり非常にノイジーです。というわけで、これもWSL側で実行するのがオススメです。
bash -c "GOOS=linux GOARCH=amd64 go build ./cmd/your-app/your-app.go"6. AWSCLIのための設定
Goのよくある使い所の一つとして、サーバサイドのWebAPI開発があると思います。このときAWSにDeployする方も多いのではないでしょうか? AWSCLIはWindowsでもMacでも公式で準備されているため、何も問題が無いことが多いですがいくつかのAWSコマンド実行する上で、ややこしいことがあります。
AWS CLIの設定
Profileを利用している場合、Windows側とWSL側でダブルメンテになるのは、設定漏れで作業効率を落とす原因になる事が多いので、なるべく避けた方が良いと思います。
例によって、WSL側の設定をWindows側に寄せます。
ln -s /mnt/c/Users/<User-Name>/.aws ~/.awsこれでAWSCLIなどで利用する configやcredentialsをWindows側と共用できるようになりました。もちろん、credentialsは最上位の機密情報ですので、取り扱いはWindows側と同様に注意して取り扱いましょう。
Lambdaのデプロイ
LambdaでGoアプリをデプロイするときは、以下のようにZIP化する必要があります。
LambdaのデプロイGOOS=linux GOARCH=amd64 go build ./cmd/lambda/lambda.go # ZIPファイルを作成 zip -j lambda.zip lambda # Lambdaのコードデプロイ(Lambda関数自体はすでに作成されている前提) aws --profile <YOUR_ENV> lambda update-function-code --function-name <YOUR_LAMBDA_NAME> --zip-file fileb://lambda.zipこの、
zipコマンドはWindowsに無いのですが、公式にはbuild-lambda-zipツールのインストールが推奨されています。https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/lambda-go-how-to-create-deployment-package.html
これでももちろん良いですが、微妙にWindows側とコマンドが異なりややこしいです。ここでもWSLの出番となります。
複数ラインの場合はbash -c "コマンド"と渡すのではなく、bash + exit で切り替えがオススメです。bash # Bashを起動 GOOS=linux GOARCH=amd64 go build ./cmd/lambda/lambda.go zip -j lambda.zip lambda aws --profile <YOUR_ENV> lambda update-function-code --function-name <YOUR_LAMBDA_NAME> --zip-file fileb://lambda.zip exit # (必要に応じて)Windows側へ戻る7. Docker
DockerもVolume周りの設定をされていると、微妙にWindowsでうまく動かない可能性があります。Docker Desktop for WSL 2でお試し中です。うまくいき次第追記予定です(2020/03/15)
設定について
説明の簡略化のため、今回はコンソール内でexportコマンドで済ましていますが、GoやAWSCLIを毎回利用する場合はWSL側の
~/.profileなどに記載して永続化することをオススメします。まとめ
- 環境変数設定くらいであればdoskeyで逃げられる
- それ以上になれば、WSLをうまく利用し逃げるのが楽。その際の設定周りはなるべくWindowsと共用し、ダブルメンテにならないようにするのがオススメ
- 投稿日:2020-03-15T17:04:14+09:00
AWS IAMユーザーとは
はじめに
個人的に、AWSの使用で「難しい」と思うのは、独自の用語や日本人には馴染みのない用語が頻繁に出てくることです。
今回はAWSのアカウントとIAMユーザーについて簡単にまとめたいと思います。
ルートユーザー
IAMユーザについて理解するためには、まずルートユーザーについて知っておく必要があります。
AWSに登録するときは、他のwebサービスと同様に
メールアドレスとパスワードを使用します。
メールアドレスとパスワードでコンソール画面にアクセスしている状態が、ルートユーザーです。ルートユーザーは、全ての情報や権限にアクセスすることができます。
他要素認証
このままでは、
メールアドレスとパスワードが流出した際に全ての権限も一緒に流出してしまいます。
そこで、AWSでは他要素認証の設定ができます。
MFAデバイスの設定を行うことで、認証コードを使用することができるようになります。この設定を行うことで、次回ログインの際は
メールアドレスとパスワードとMFA認証コードの3つが必要になります。IAMユーザー
しかしながら、相変わらずルートユーザーは全ての権限にアクセスできることに代わりはありません。
IAMユーザーは、権限を限定したユーザーのことです。
AWSの機能と権限は多岐にわたるので、アクセス権限が限定されたユーザー設定があると、チームで使用する時なども便利なのです。
基本的には、IAMユーザーでAWSを使用をすることが推奨されています。
まとめ
ルートユーザー:全ての権限にアクセスできる(できてしまう)ユーザー
IAMユーザー:必要な権限にのみアクセスできる仮想ユーザー
- 投稿日:2020-03-15T14:50:20+09:00
【Amplify】APIのAuthorization方式「AWS_IAM」を理解する#1 ~解説編~【AWS】
はじめに
本稿は以下の二部構成となります。
【Amplify】APIのAuthorization方式「AWS_IAM」を理解する#1 ~解説編~【AWS】 ←いまココ
【Amplify】APIのAuthorization方式「AWS_IAM」を理解する#2 ~実践編~【AWS】 ※作成中昨今、新たなサービスの提供の際には、SPAやモバイルアプリで実現することが当たり前の状況になってきているかと思います。
AWSであればAmplifyというフレームワークを使うことで、基本的な構成をすぐに作ることができますが、そのベースとなる仕組みについての解説が少なく、少しでも想定構成を外れたものを作ろうとすると、途端に苦労します。
Amplifyで利用可能な(というより、GraphQL・API Gatewayで利用可能な)Authorizationには以下の4つの方式がありますが、主に利用する方式はAWS_IAMかAMAZON_COGNITO_USER_POOLSのいずれかになると思います。本稿ではこのうち「AWS_IAM」の仕組みについて説明します。
AWS Amplifyにて生成される環境と同等のものを手動で作成し、確認していくこととします。https://aws-amplify.github.io/docs/js/api#manual-configuration
- API_KEY
- AWS_IAM
- AMAZON_COGNITO_USER_POOLS
- OPENID_CONNECT
Prerequisite
本稿は、下記の前提知識があることを想定しています。
- AWS IAMの基本的な仕組みを理解している
- AWS Security Credentialsには、long-termのものとshort-termのものがある
- IAM RoleとAssumeRoleの仕組みを理解している
- API Gatewayの基本的な仕組みを知っている
- ResourceやMethodへの設定内容・変更内容を反映させるには、Deployが必要
環境/構成
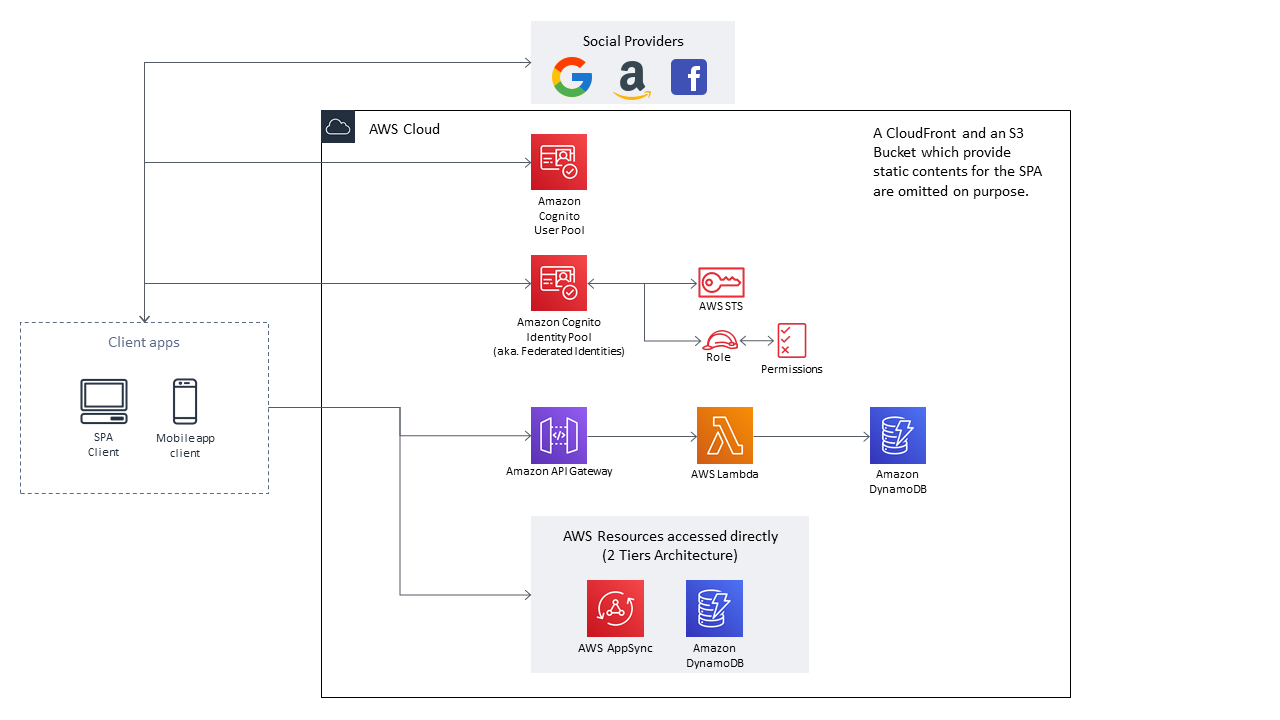
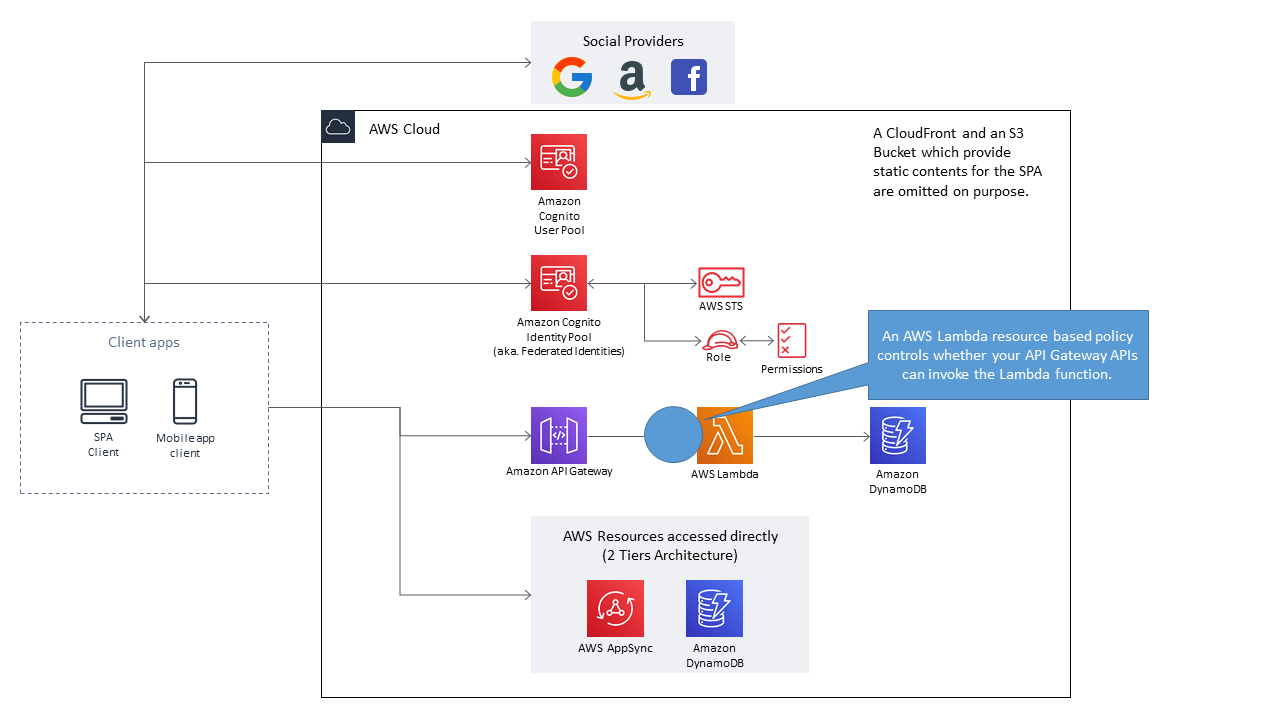
想定構成
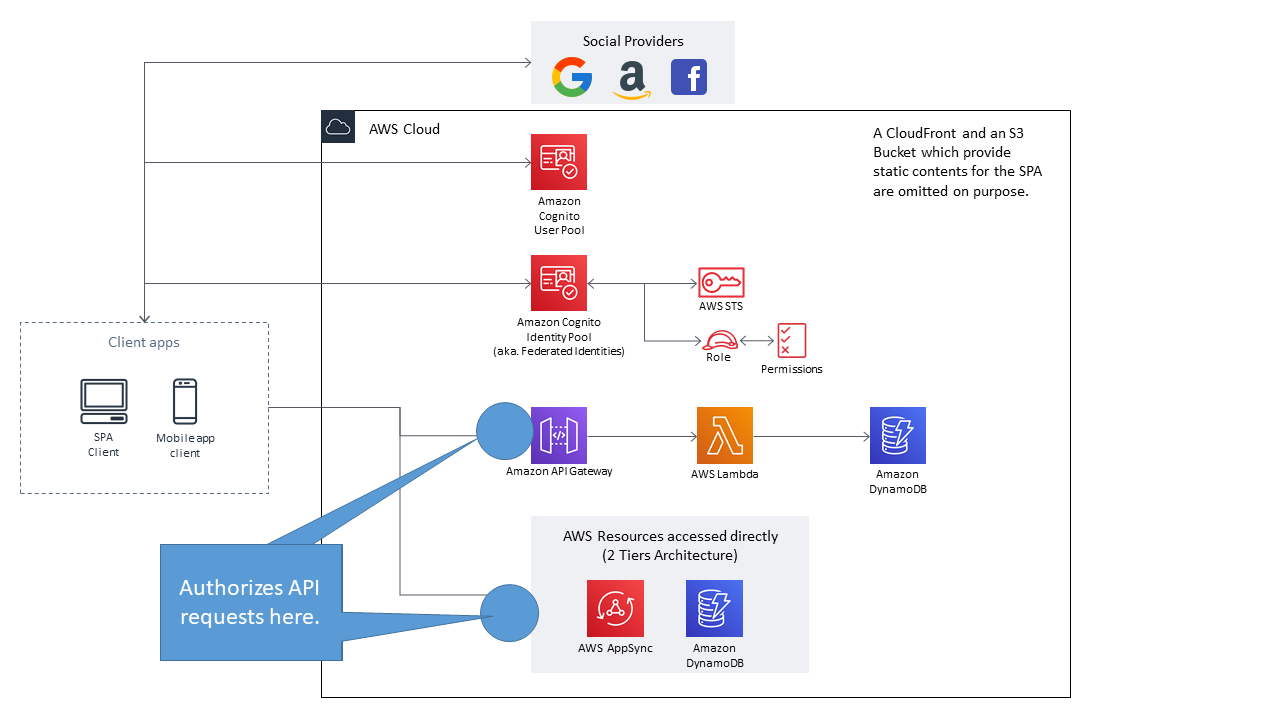
まず典型的なSPA/モバイルアプリの構成を考えます。概ね下記のようなるかと思います。
※通常であればSPA用の静的コンテンツ配信用のCloudFront及びS3 Bucketが存在しますが、本稿の趣旨とは関係がないため省略しています。
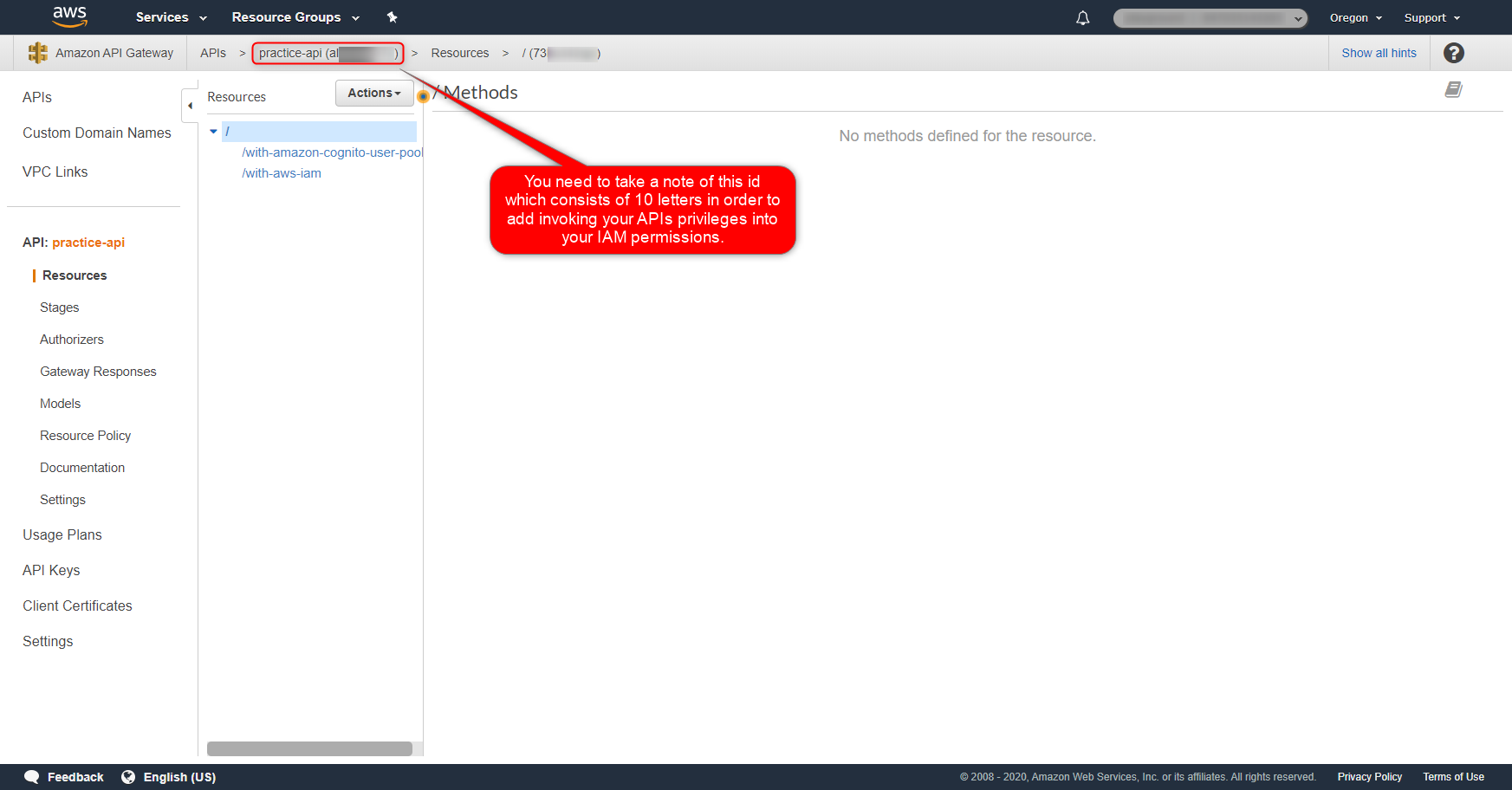
本稿の検証で作成するAWSリソース名はそれぞれ以下とします。
- Cognito User Pool
- Name:
- practice_userpool
- Id:
- us-west-2_sq*******
- App client:
- Name:
- practice_userpool_mobile_client
- App client id:
- 18rd**********************
- Cognito Identity Pool
- Name:
- practice_idpool
- Id:
- us-west-2:785e*----***********
- Unauthenticated role:
- Cognito_practice_idpoolUnauth_Role
- Authenticated role:
- Cognito_practice_idpoolAuth_Role
- API Gateway
- Name:
- practice-api
- Id
- al********
- AWS Lambda
- Name:
- echo-function
- DynamoDB
- ※今回は利用しない
APIにおけるAuthorization
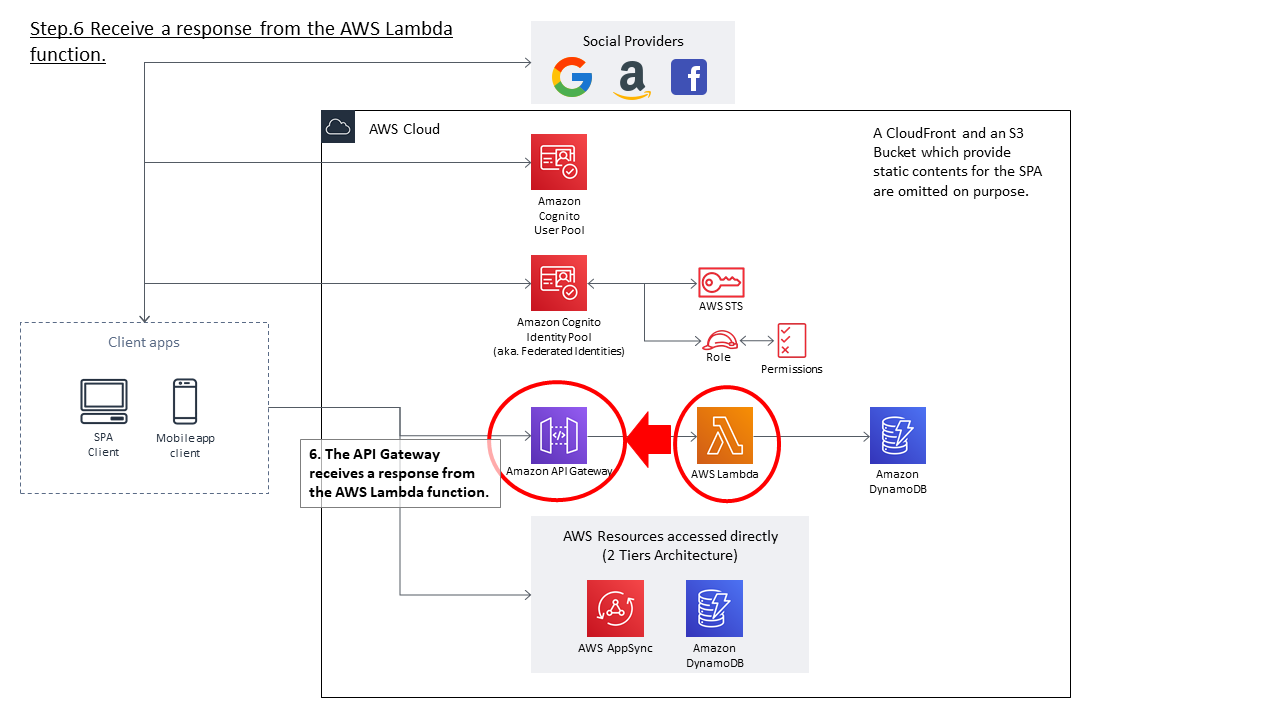
まず、APIのAuthorization設定により制御する箇所を確認します。下図の通り、API Gatewayの入り口、若しくは各AWSリソースの入り口で制御することとなります。
前提となる知識
AWS APIとSignature V4
アプリケーションプログラムから各AWSサービスを利用する場合、大体においてAWS SDKやその他フレームワーク/ライブラリを利用するものと思います。AWSサービスの仕組みを紐解いていくと、それらの機能は最終的にはRESTFulなAPI群(本稿ではAWS APIと呼びます)で提供されていることが分かります。
それらAWS APIにおいて、APIリクエスト発行者が正統なユーザであるかどうか(Authentication)をどのように確認し、必要な権限があるかどうか(Authorization)をどのようにチェックしているのか、まず理解する必要があります。【ASW】AWS APIの認証・認可の仕組みを理解する【Signature V4】 - Qiita
IAM RoleとAssumeRole
Cognito Identity Poolをはじめとし、各AWSサービスが連携する際にはAssumeRoleという仕組みが活用されています。
これは簡単に言うと、「あるIAM Entity(≒IAM Userなど)が、別のIAM Roleの権限を得ることを要求し、その権限を一時的に得ること」といえます。
AssumeRoleする主体は、IAM UserだけでなくAWSサービスも対象となりえます。本稿の範囲においては、Cognito Identity Poolがサービスが、あるIAM RoleをAssumeRoleしてAWS Temporary Security Credentialsを得る、という点が重要になってきます。AssumeRole - AWS Security Token Service
https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRole.htmlassume-role — AWS CLI 1.18.21 Command Reference
https://docs.aws.amazon.com/cli/latest/reference/sts/assume-role.htmlAWS_IAM方式の解説
概要
API GatewayのAuthorization方式「AWS_IAM」を簡単に説明すると、AWSではなくAWS利用者が提供するAPI(つまりAPI Gateway経由で提供するAPI)も、Signature V4を利用してAuthentication/Authorizationする、というものになります。
ということは、クライアントアプリからAPIリクエストを実行するにあたって、AWS Security Credentialsが必要となる、ということになります。ではクライアントアプリはどのようにしてAWS Security Credentialsを入手するのでしょうか?この役割を果たすのが「Amazon Cognito Identity Pool」(旧称:Federated Identities)です。
下記にある通り、これは一時なAWS Security Credentialsを得ることができるサービスとなります。Amazon Cognito Identity Pools (Federated Identities) - Amazon Cognito
https://docs.aws.amazon.com/cognito/latest/developerguide/cognito-identity.htmlAmazon Cognito identity pools (federated identities) enable you to create unique identities for your users and federate them with identity providers. With an identity pool, you can obtain temporary, limited-privilege AWS credentials to access other AWS services. Amazon Cognito identity pools support the following identity providers:
※以降省略
この方式でAPI GatewayのAuthorizationを実現する場合、以下の3つの設定をおこなう必要があります。
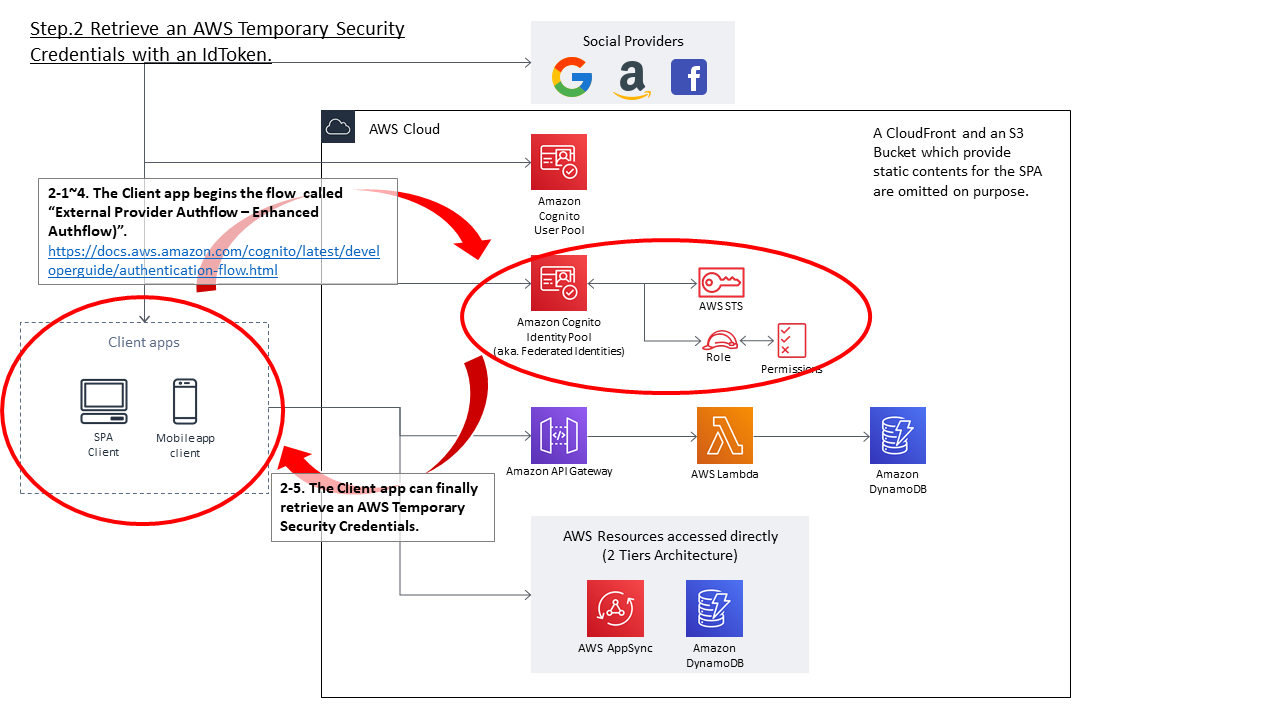
- Cognito Identity Poolに、認証を連携するための外部のIdentity Provider(IdP)を紐づける
- Cognito Identity PoolにIAM Roleを紐づける
- 紐づけたIAM RoleのPermissionsには、API GatewayのAPIを実行するための権限を付与する
- API Gateway上の必要なResource・Methodにて、Authorizationを「AWS_IAM」に変更する
まず重要なポイントとして、Cognito Identity Pool自体は認証機能は提供しません。飽くまで外部のIdentity Providerと連携して、認証が成功したらAWS Temporary Security Credentialsを生成する、というサービスになります。
認証機能を提供するの外部IdPの一つがCognito User Poolである、と言えます。
外部のIdPは大きく2種類に分かれます。OpenID ConnectやSAML2.0を提供する外部IdPと、独自に実装した認証機能(Developer Authenticated Identities)を用いることができます。次に、AWS Security Credentialsを発行するということは、何らかIAM Permissionsが紐づいている必要があります。Cognito Identity Pool作成時、認証されたユーザ/認証されないユーザに対して紐づけるIAM Roleを指定する必要がありますが、ここで指定したIAM Roleがこれに該当します。
クライアントアプリがAWS Temporary Security Credentialsを得ることができれば、あとはSignature V4に従ってAPIリクエストに署名を付与することで、Authorization方式が「AWS_IAM」に設定されているAPIを呼び出すことが可能となります。
以下から、各AWSリソースの設定がAWS Management Consoleのどの設定に対応しているのかを簡単に確認していきます。
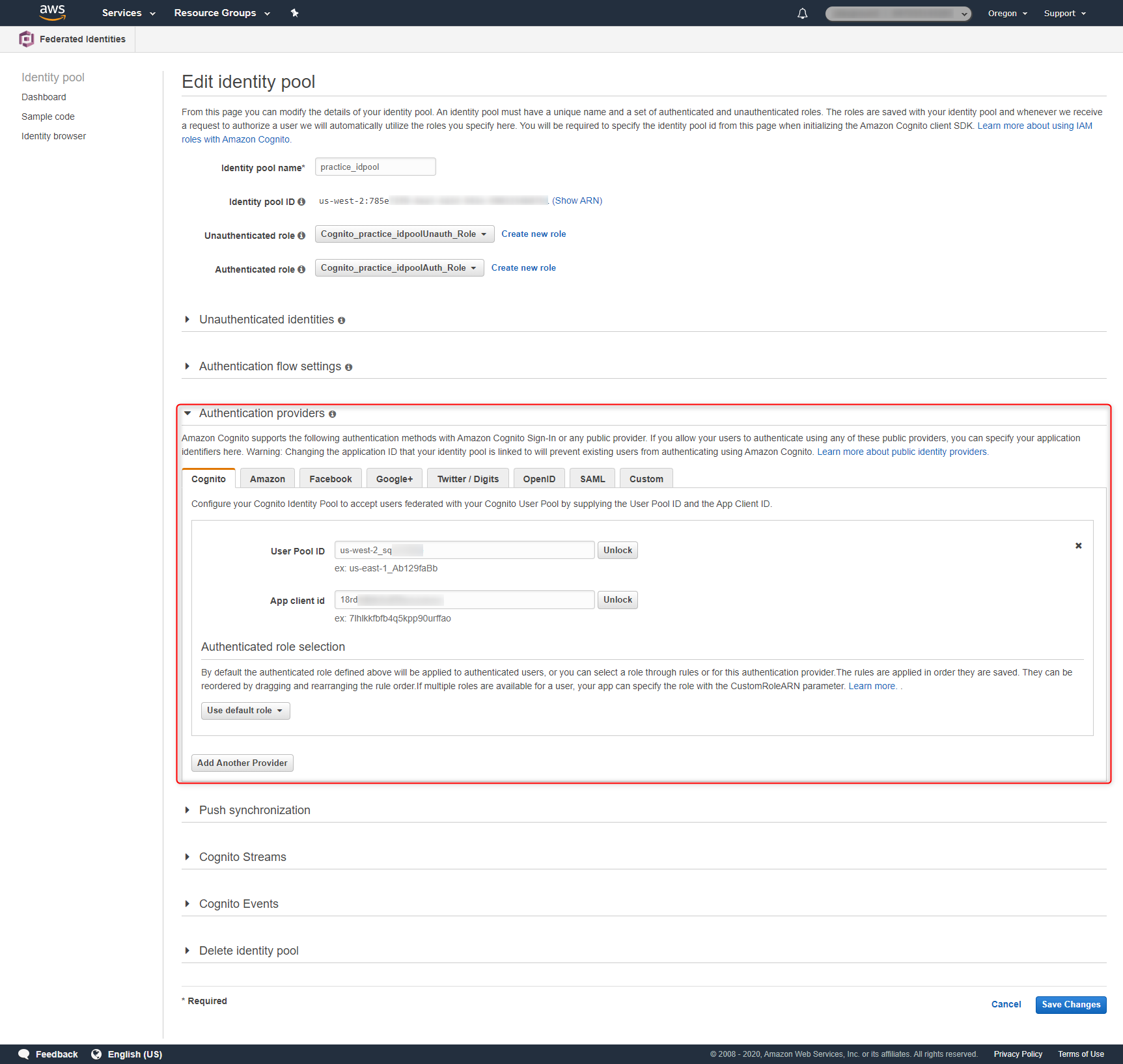
1. Cognito Identity Poolに、認証を連携するための外部のIdentity Provider(IdP)を紐づける
Identity Poolの設定にAuthentication Providersという箇所がありますが、ここで外部のIdPを設定することとなります。
当該IdPから見た場合、Cognito Identity Poolは一つのアプリケーションとなります。当たり前ですが、外部のIdP側にも設定が必要となります。
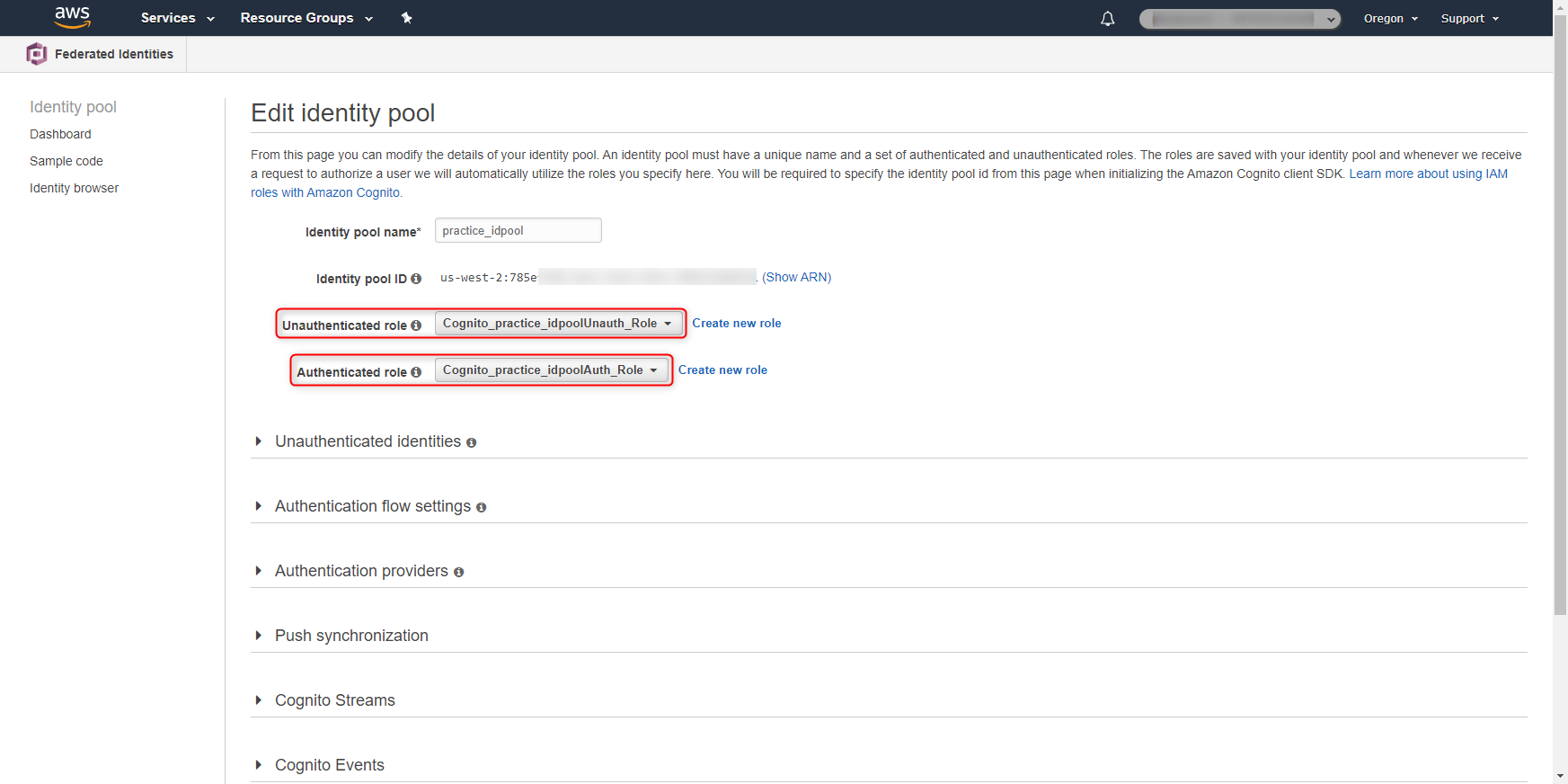
2. Cognito Identity PoolにIAM Roleを紐づける
Identity Pool作成時、Unauthenticated roleとAuthenticated roleの設定が必要になります。上記で設定したIdPとの認証が失敗した場合(若しくは認証を実施しない場合)はUnauthenticated roleの、IdPとの認証が成功した場合は、Authenticated roleの権限が付与されます。つまり、クライアントアプリはとIdPとの認証結果により、付与されるAWS Temporary Security Credentialsの権限が変わる、ということが言えます。
今回の検証においては、AWS Management ConsoleからGUIを利用してIdentity Poolを作成しています。以下の2つのIAM Roleが作成され、Identity Poolに付与されています。
- Cognito_practice_idpoolUnauth_Role
- Cognito_practice_idpoolAuth_Role
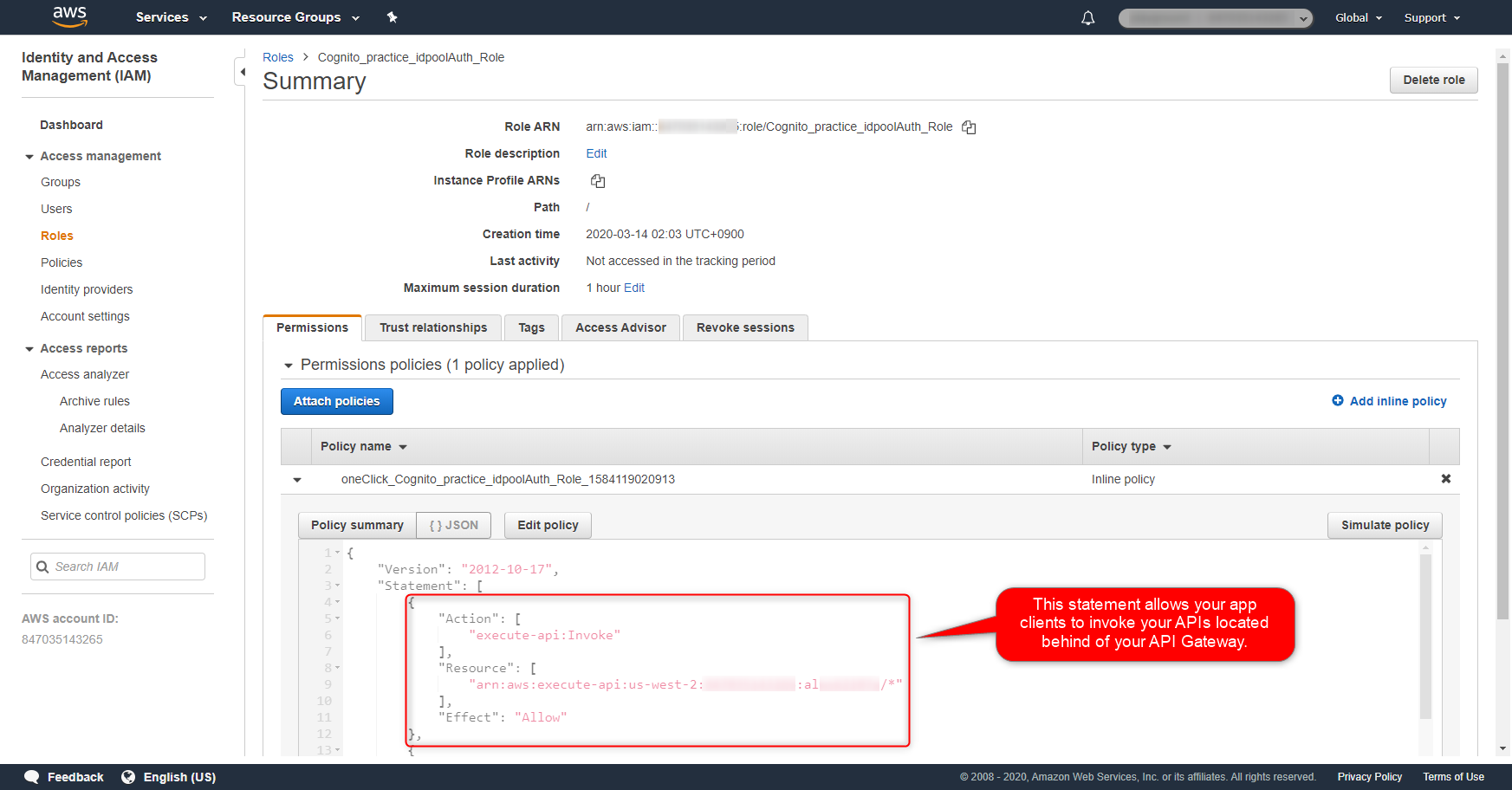
3. 紐づけたIAM RoleのPermissionsには、API GatewayのAPIを実行するための権限を付与する
上記で生成されたAuthenticated roleには、以下ようなPermissionsの付与が必要となります。これは、当該IAM Roleの権限を得たIAM Entityに対し、Resourceで指定したAPI(API Gatewayで定義されるAPI)の実行を可能とするものとなります。
IAM permissions{ "Version": "2012-10-17", "Statement": [ { "Action": [ "execute-api:Invoke" ], "Resource": [ "arn:aws:execute-api:us-west-2:************:al********/*" ], "Effect": "Allow" } ] }実際の設定内容は下記のような感じになります。
API GatewayのAPIのIdは、AWS Management Console上、下記から確認できます。
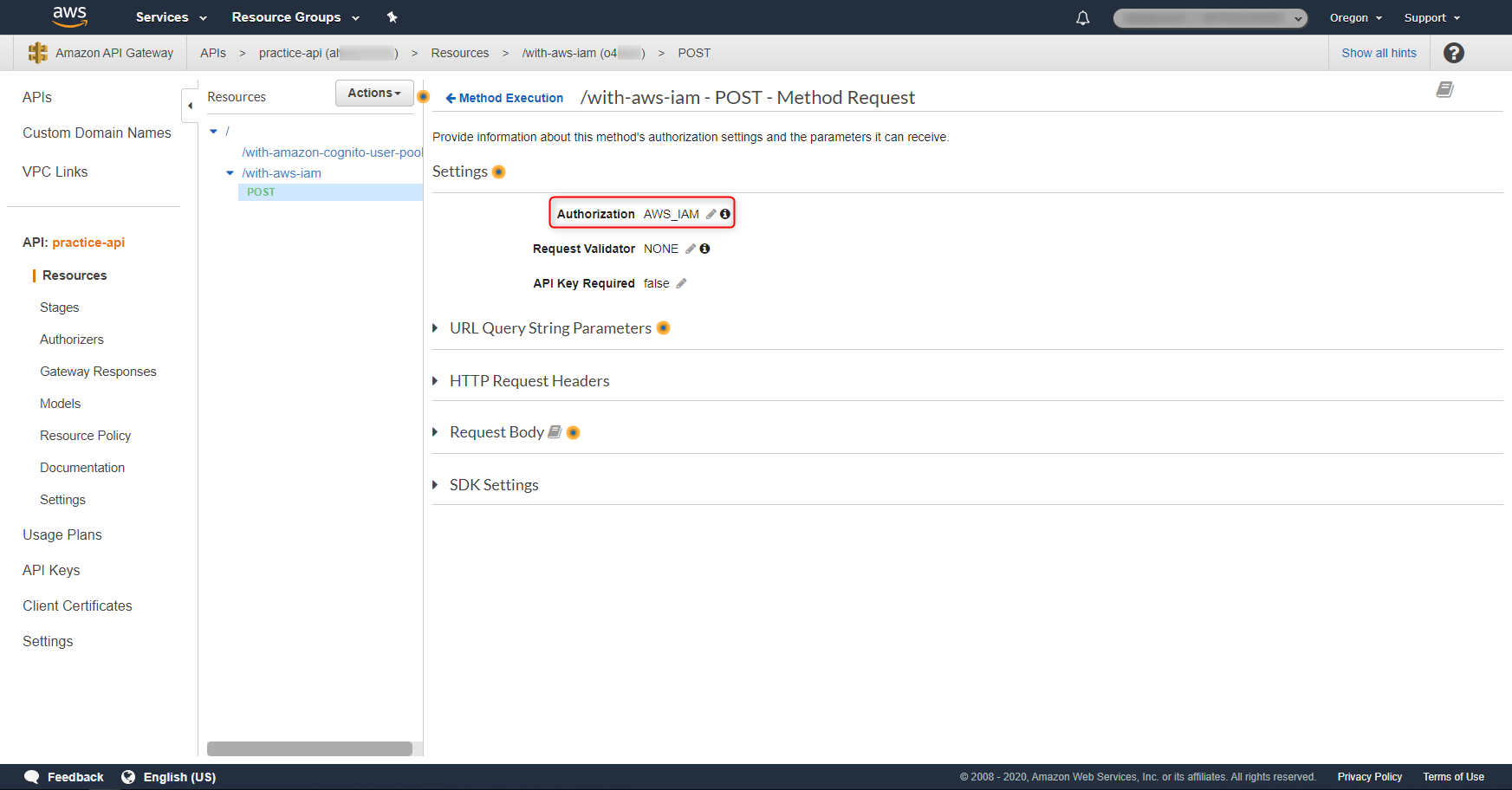
4. API Gateway上の必要なResource・Methodにて、Authorizationを「AWS_IAM」に変更する
Cognito Identity Pool及びAWS Temporary Security Credentialsを利用した方式で、APIのAuthorizationを行いたい場合、API Gatewayの対象のResource・Methodにて、Authorizationを「AWS_IAM」に変更します。
Cognito Identity Poolを少し解説する
詳細を説明すると長くなるので割愛しますが、Cognito Identity Poolのポイントは以下の通りです。
- 外部のIdentity Provider(以下、IdP)と認証を連携する。外部IdPでの認証に成功したユーザに対しAWS Temporary Security Credentialsを発行する
- 認証が成功したユーザに対し、Cognito Identity Pool内部でUniqueなIDを発行する
- 外部のIdPとして、FacebookやGoogleなどをはじめとし、SAMLのIdP、独自認証APIなど様々な認証方式に対応している。Cognito Identity Poolから見た場合、Cognito User PoolはそれらIdPの一つとして位置づけられる。
- 外部のIdPでの認証が成功した場合、IdPから当該ユーザ対してIdToken/Assertion(OpenID ConnectやSAML2.0で認証された場合)が発行される。これはAssumeRoleWithWebIdentity API、若しくはGetCredentialsForIdentity APIの引数として渡す。
ちなみに、Cognito User PoolはOAuth2.0/OpenId Connect準拠(独自機能/拡張は非常に多くありますが)ですが、Cognito Identity Poolは完全にAWS独自の仕組みです。
認証のフローについては下記スライドが分かりやすいです。OpenID ConnectやSAML2.0を提供する外部IdPとの認証、独自に実装した認証機能とで大きくフローが分かれます。
AWS Black Belt Tech シリーズ 2015 - Amazon Cognito
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-tech-2015-amazon-cognito/13
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-tech-2015-amazon-cognito/16Cognito Identity Poolでは、以下の4種類の認証フローがあります。前者2つが外部IdPを利用するパターン、後者2つが独自認証を利用するパターンとなります。それぞれが、上記スライドとも対応しています。
- External Provider Authflow
- Enhanced (Simplified) Authflow
- Basic (Classic) Authflow
- Developer Authenticated Identities Authflow
- Enhanced Authflow
- Basic Authflow
認証フローの詳細については下記公式ドキュメントが参考になります。
幾つか認証フローのパターンがありますが、最終的にはSTS(Security Token Service)にて、AWS Temporary Security Credentialsを発行していることが分かると思います。Identity Pools (Federated Identities) Authentication Flow - Amazon Cognito
https://docs.aws.amazon.com/cognito/latest/developerguide/authentication-flow.htmlちなみに余談ですが、Cognito Identity Poolの方がCognito User Poolより古いです。またCognito User Poolが存在しなかった時代、Cognito Identity Poolは、単に「Amazon Cognito」と呼ばれていました。
実際、公式ドキュメントの履歴を見てみると、Cognito Identity Poolのリリースが2014年、Cognito User Poolのリリースが2016年であることが分かります。
古い公式ドキュメントを参照する場合は、名称の変遷に気を付ける必要があります。Amazon Cognito のドキュメント履歴 - Amazon Cognito
https://docs.aws.amazon.com/ja_jp/cognito/latest/developerguide/cognito-document-history.html
変更 説明 日付 Cognito ユーザープールの一般提供 Cognito ユーザープール機能を追加しました。この機能を使用して、ユーザーディレクトリを作成、管理し、ユーザープールを使用してモバイルアプリケーションまたはウェブアプリケーションにサインアップとサインインを追加します。詳細については、「Amazon Cognito ユーザープール」を参照してください。 2016 年 7 月 28 日 Amazon Cognito の一般提供 2014 年 7 月 10 日 API GatewayからAWS Lambda関数を実行するための許可
上記までのAuthorizationとはまた別に、AWS Lambda関数には、誰がその関数を呼び出せるかを制御する仕組みがあります。
これは当該Lambda関数自体に設定するPolicyとなります。下図の個所で制御するイメージです。
API GatewayからLambda関数を実行するためには、当該Lambda関数側に、どのAPI Gatewayからの実行を許可するのか、という設定を付与する必要があります。
Using Resource-Based Policies for AWS Lambda - AWS Lambda
https://docs.aws.amazon.com/lambda/latest/dg/access-control-resource-based.htmlAWS内での権限制御において、その権限内容はPolicyドキュメントとして表現されますが、何らかAWS APIを実行する主体に付与するIAM Policyと、実行される客体に対するPolicyの2種類に分かれます。前者をIdentity-based policy、後者をResource-based policyと呼ぶことがあります。
後者のものとして、このLambdaのResource-based policyのほか、S3 BucketのBucket Policyがこれに該当します。認証からAPI実行完了までの流れを整理する
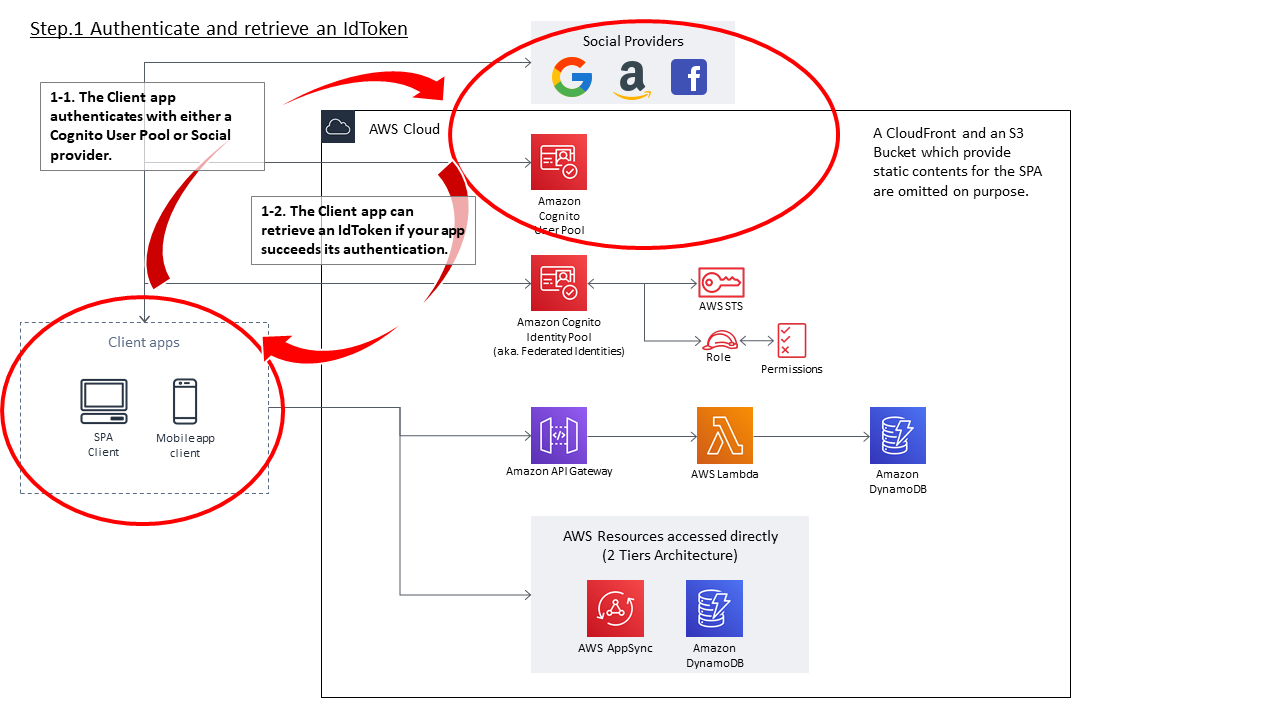
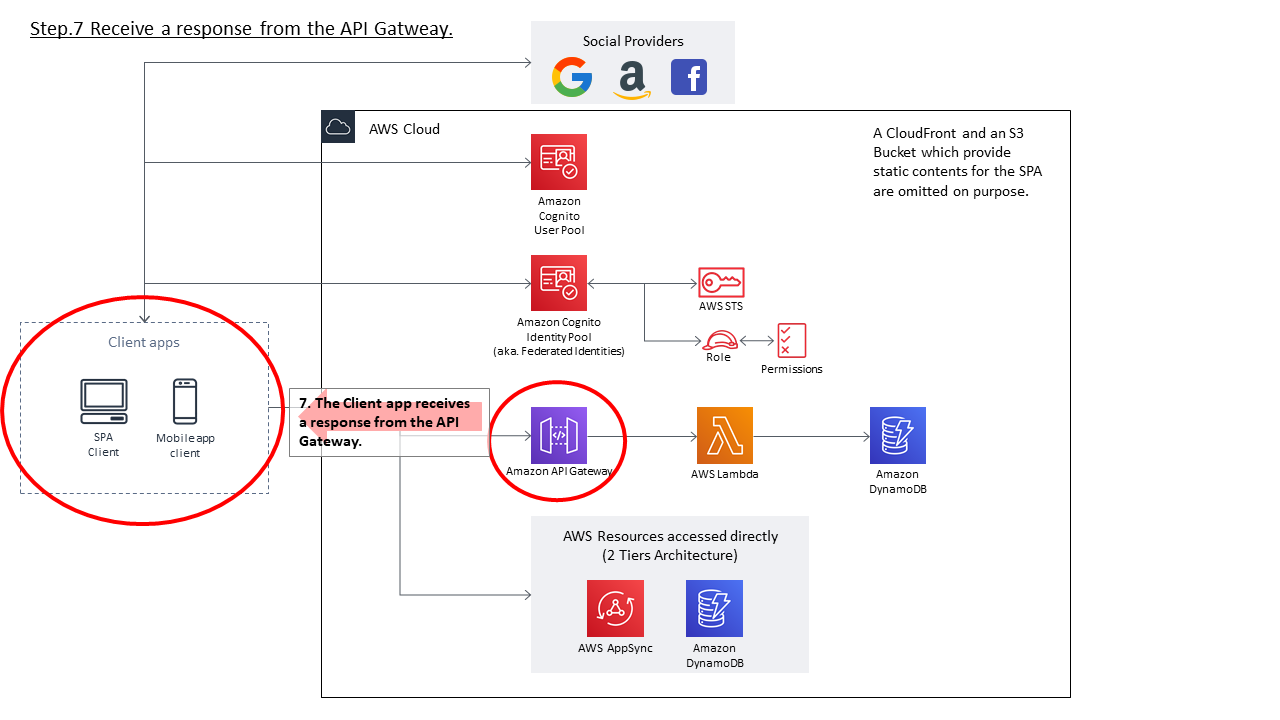
全ての設定が完了した状態で、クライアントアプリが外部IdPと認証してから、最終的にAWS Temporary Security Credentialsを得てAPIを実行し、レスポンスを得るまでの流れを整理します。クライアントアプリ⇔Cognito Identity Pool間のインタラクションについては、External Provider AuthflowのEnhanced (Simplified) Authflowを利用するものとします。
- 外部IdPとの認証とIdTokenの取得
- クライアントアプリは、Cognito Identity PoolのAuthentication Providersとして設定されたIdPと認証する。本稿のケースであれば、「practice_userpool」という名称のCognito User Pool。
- クライアントアプリは、外部IdPとの認証方式がOpenID Connect準拠であればIdTokenを、SAML2.0であればAssertionを取得する。本稿ではCognito User Poolを利用するので、ここではIdTokenを得る。
- IdTokenにはそのIdP内で必ずUniqueとなる値(sub)が含まれており、当該IdPの範囲内でユーザを特定できるようになっている。
- また、IdTokenはIdPによる署名が付与されており、改竄ができないようになっている(というより改竄されたら検出できる)ため、Cognito Identity Poolはその内容を信頼することができる。
- 得られたIdTokenをもとに、AWS Temporary Security Credentialsを取得する
- クライアントアプリは、External Provider AuthflowのEnhanced (Simplified) Authflowを開始する。
- まず、Cognito Identity Pool APIの GetId API を実行する。このAPIのLogins引数内に、上記で得られたIdTokenを指定する。
- クライアントアプリは、GetId API の実行の結果、Identity Idを取得することができる。
- 次にクライアントアプリは、API_GetCredentialsForIdentity APIを実行する。上記項番3で得られたIdentity Idと、項番1で指定したLoginsと同等の値を引数として指定する。
- API_GetCredentialsForIdentity APIが成功すると、クライアントアプリはAWS Temporary Security Credentialsを得ることができる。これは、Authenticated Roleに紐づけられたPermissionsの権限を持つ。
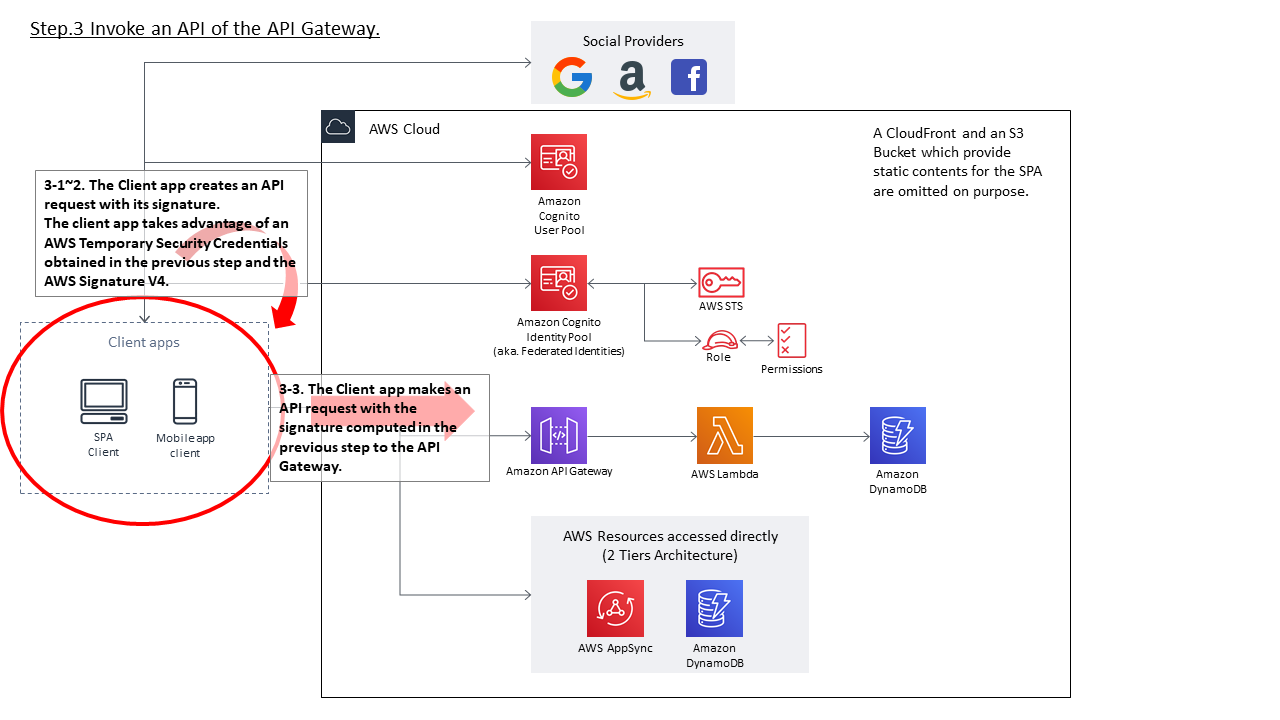
- 得られたAWS Temporary Security Credentialsをもとに、API GatewayのAPIを実行する
- クライアントアプリは、APIリクエストを作成する
- 作成したAPIリクエスト内容に対し、Signature V4で署名を作成する。
- 作成した署名等をリクエスト内容に付与し、API GatewayのAPIを実行する
- API Gatewayにてクライアントアプリからの署名をチェックする
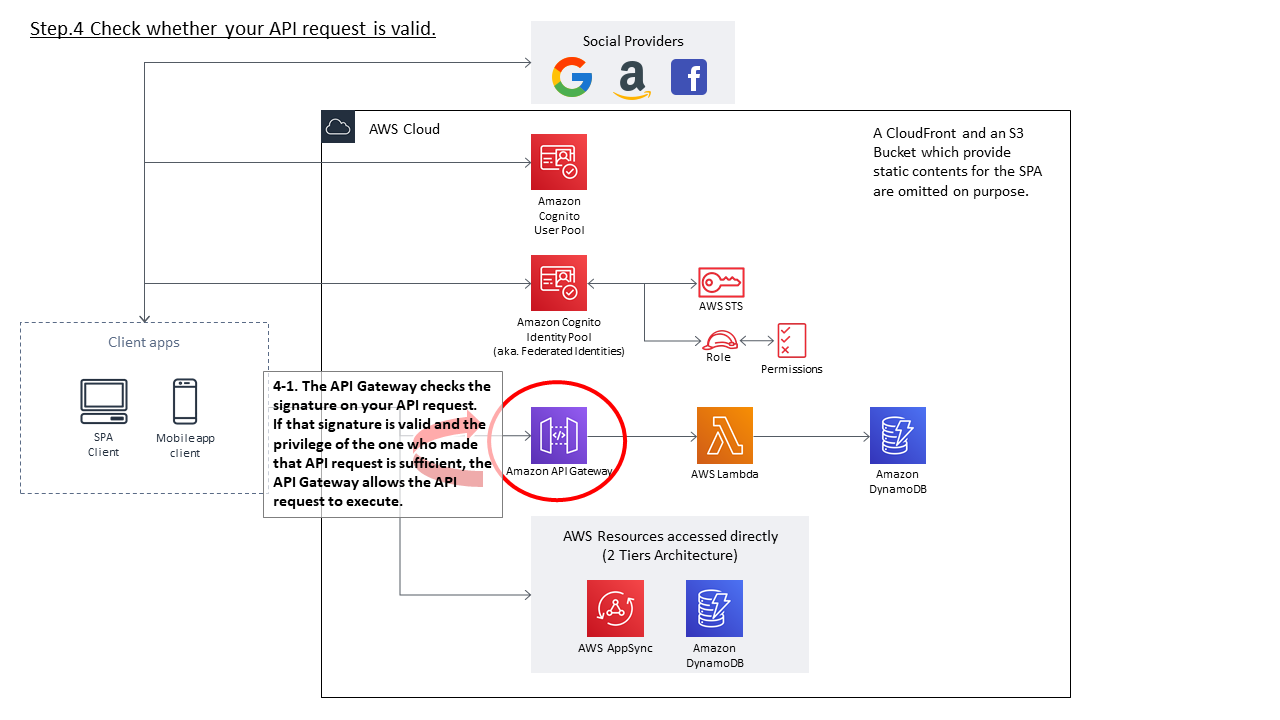
- リクエスト内容に付与された署名をもとに、当該APIリクエストが正統なユーザからのものであるか、必要な権限が足りているか(つまり、Cognito Identity Poolに付与されたAuthenticated Roleに、当該API Gatewayの実行権限があるか)をチェックする。
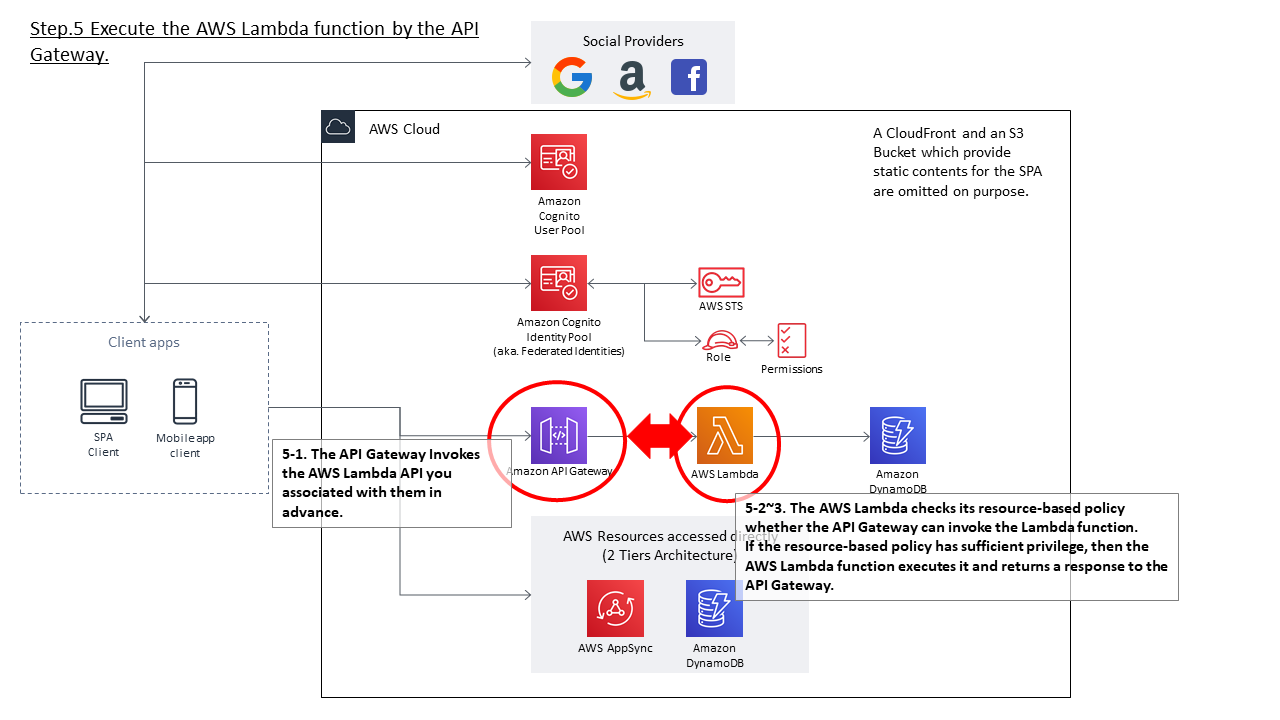
- API GatewayからLambda関数を実行する
- API Gatewayサービスが、Lambda関数 echo-function を実行する
- echo-function関数は、自身のResource based policyを確認し、当該API Gatewayインスタンスからの実行が許可されているかチェックする
- チェックの結果、必要な権限があれば、ハンドラ内に定義された内容を実行し、レスポンスを返却する
- API GatewayはLambda関数の実行結果を受け取る
- API Gatewayは、Lambda関数の実行結果をもとに、クライアントアプリにレスポンスを返却する
認証からAPI実行完了までの流れを図にする
上記の流れを図にすると、それぞれ下記のようになります。
1. 外部IdPとの認証とIdTokenの取得
2.得られたIdTokenをもとに、AWS Temporary Security Credentialsを取得する
3.得られたAWS Temporary Security Credentialsをもとに、API GatewayのAPIを実行する
4.API Gatewayにてクライアントアプリからの署名をチェックする
5.API GatewayからLambda関数を実行する
6.API GatewayはLambda関数の実行結果を受け取る
7.API Gatewayは、Lambda関数の実行結果をもとに、クライアントアプリにレスポンスを返却する
Loginsプロパティの指定について
GetId API や GetCredentialsForIdentity API の引数として「Logins」というプロパティがありますが、APIリファレンス上、これに関する説明が些か不足しているように思います。
https://docs.aws.amazon.com/cognitoidentity/latest/APIReference/API_GetId.html#API_GetId_ResponseSyntax
https://docs.aws.amazon.com/cognitoidentity/latest/APIReference/API_GetCredentialsForIdentity.html下記の配下のページに、FacebookやAmazonを利用する場合のLoginsプロパティの実装例が書いてありますが、Cognito User Pool用の例が無かったりします。
Identity Pools (Federated Identities) External Identity Providers - Amazon Cognito
https://docs.aws.amazon.com/cognito/latest/developerguide/external-identity-providers.htmlOpen ID Connect Providers (Identity Pools) - Amazon Cognito
https://docs.aws.amazon.com/cognito/latest/developerguide/open-id.htmlCognito User Poolを利用する場合は、おそらく下記のような指定になります。(※別途確認する)
Loginsプロパティ{ "cognito-idp.<region>.amazonaws.com/<YOUR_USER_POOL_ID>": "<IdToken>" }Loginsプロパティ(実際の例){ "cognito-idp.us-west-2.amazonaws.com/us-west-2_sq*******": "eyJ........" }その他補足
実はCognito Identity Poolの大きな役割としてもう一つ、外部のIdPのユーザアカウントを一つのIdentityIdに紐づけることができる(≒名寄せができる)というものがあります。
上述のLoginsプロパティには複数の値を指定することができ、Facebookでの認証結果やAmazonでの認証結果など、複数の認証結果を含めることができます。
それら外部IdPの認証結果を一つのIdentityIdに紐づけることで、どのSocial Providerでログインしても、AWS内では同一のユーザとして扱う、ということが実現できます。おわりに
AWS Amplifyはコマンド一つでこの構成を作成することができ、非常に便利に使えるようになっています。
しかしながら、中身をブラックボックスのまま使っていった場合、トラブル発生時に対応できなかったり、CloudFormationやCDKなどのIaCで管理する場合に管理しきれなくなったり、困ることとなります。
最初はブラックボックスのまま利用するというアプローチも良いと思いますが、どこかで必ずその仕組みを理解しなければならないタイミングが来ますので、ここに解説をまとめておきます。
- 投稿日:2020-03-15T13:52:38+09:00
【絶対消し忘れるな!】AWS初学者が高額請求を避けるために消すべき設定3選
概要
AWSを使う上で、不要になった設定は消しとこうねというお話です。
はじめに
AWSを学び始めてしばらくすると、無料枠以外の機能も使いたくなってきます。そしてそういう時期には新しいサービスに目移りし、「まぁこれぐらいの請求なら」と、作ったサービスを放置しがちです。
僕もそんな初心者のうちの1人でした。そして放置し続けた結果...
ひゃ、 120ドル!??? な なんじゃこりゃあああああああ!!!!
僕のようにならないように、本記事では不要になったら消しておくべき設定3選をまとめました。
不要になったら消して置くべき設定3選
1. EC2, RDS
AWSを学び始めたら、まず最初に作る構成は、「EC2コンテナ上でアプリケーションサーバーをたて、DBはRDSで構築」というパターンだと思います。
この構成は小さいサイズだと(AWSのアカウントを作成してから1年間は)無料で作れるのですが、無料枠を少しでも超えた設定だと、途端に高額な請求がくるので注意しましょう。注意しなければいけないのが例えばEC2の場合、無料枠は「t2.microを750時間分」であるということです。
たとえば、t2.microサイズのインスタンスを2台たてていた場合、AWS側では「t2.microを1500時間たてていた」という認識になり、しっかり750時間分の請求がきます。小さいサイズとはいえ地味に痛いです。2. ALB
AWS初心者を少し脱却した頃になると、「ALBを使った、負荷分散を意識した構成」を作りたいと思うはずです。
ただ、こいつがくせもの。ALBの料金は「LCU時間ごとの従量課金と使用時間あたりの従量課金の合計」できまります。
LCU時間ごとの課金はごく簡単に言えば、「ALBに接続することによって起こる課金」なので、今回は問題になりません。問題は「使用時間ごとの従量課金」。おおよそ0.024USD/時間なので、1ヶ月放置し続けるとおよそ2000円も取られてしまいます!た たけえ!
ALBはEC2やRDSに比べて「課金されている」という感覚がなくなりがちです。不要になったら忘れずに削除しましょう。3. Elastic IP Address
デフォルト設定だと、EC2のパブリックIPアドレスは固定されていません。つまりEC2を停止して再度起動するような場合、パブリックIPアドレスが変わってしまい「あれ、なぜか接続できない...」という事案がおこります。
これを避ける一つの方法がElastic IP Addressという、EC2専用の固定のIPアドレスを保持しておいて、使用するEC2に紐づけてあげるという方法です。ただ、これがまたまたくせもの。例えば、Elastic IP AddressをEC2に紐付ずに放置していた場合、時間あたり0.005USD, 1ヶ月で400円かかってしまうのです。
これだけ聞くというほど高くないように感じますが、もちろんこれはElastic IP Addressごとに課金されるので、5つ保持していた場合、これの5倍の2000円がかかります...考えたくないですね。
不要になったElastic IP Addressはかならず開放してあげましょう。高額課金をさけるための対策
では、このような消し忘れを防ぐためにはどうしたらよいのでしょうか
AWSの請求アラートを有効にする
AWSでは高額請求を防ぐためのしくみとして、「特定の請求額を超えた場合、メールで通知してくれるシステム」が存在します。消し忘れが不安な方は設定しておきましょう。
設定の仕方に関しては以下の記事がわかりやすかったです。請求書を逐一確認する
AWSの請求書には「何にいくら使ったか」が詳しく書いています。「今月の利用料高え!」と思った時には、請求書を確認し、同じ失敗をしないようにしましょう。
(請求書は「My請求ダッシュボード」の左側にある「Billing > 請求書」から確認できます)最後に
不要な課金をせず、賢く自己投資しましょう!

- 投稿日:2020-03-15T12:33:28+09:00
GoogleHomeで領収書をスプレッドシートに記録するアプリを作ってみた
確定申告の時期です(投稿時期は3月)
私はもう終わったのですが手打ちで記録するのがまあツラくて非効率だなと感じました。そこで音声入力だけで済むように今回のアプリを作りました。
※家計簿としても使えます。実際の動作様子
下記クリックすると動画再生されます。
簡単な流れ
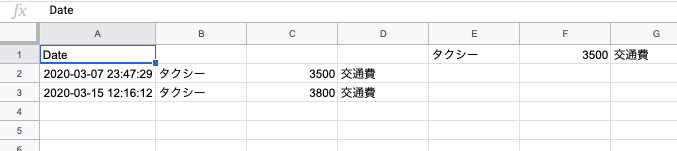
私:タクシーで3800円交通費
→一時的にスプレッドシートに記入されるGoogleアシ:タクシーで3800円交通費でよろしいですか?
私:はい
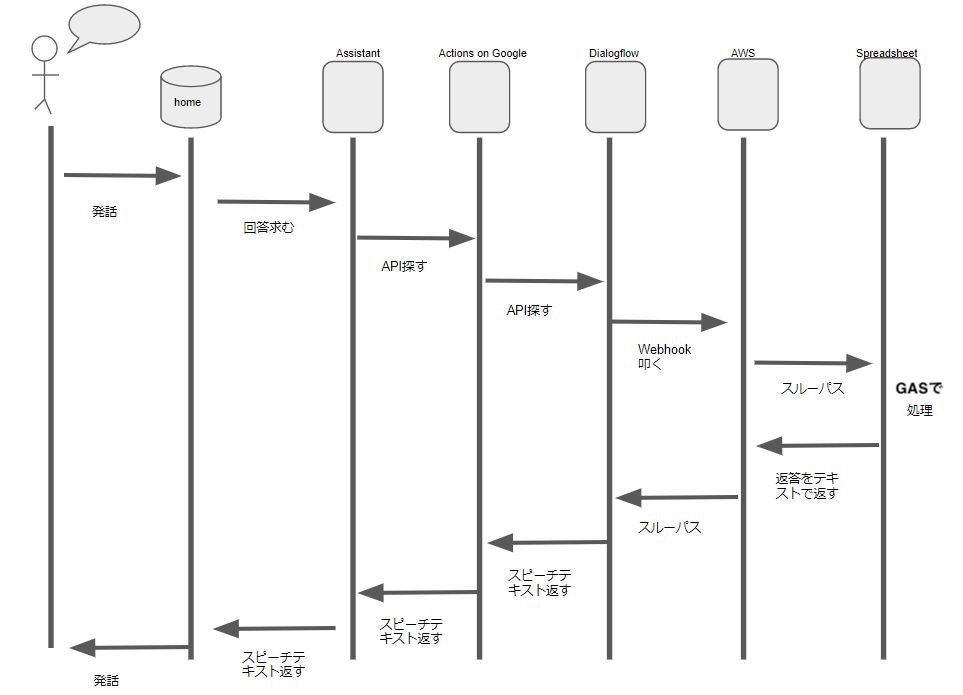
→スプレッドシートに登録される使用したサービス及びフロー図
●使用したサービス
・GoogleAppsScript
・AWS
lambda
API Gateway
・GoogleAssistant
・Dialogflowこうも色々サービスを使ってるのは、そもそも
GoogleAssistant→DialogFlow→スプレッドシートはIntegrationsで設定すればできますが、GoogleAssistantへテキストを返すことができません(要は会話形式ができない)またAWSを使ってるのははじめGASでデプロイしたエンドポイントをDialogFlowののWebhookに設定したのですが、302リダイレクトをしてできなかったので仕方なくLambdaとAPI gatewayを使いました。
●フロー図
※ google homeで子供の宿題管理をする
から拝借、一部追記
開発の流れ
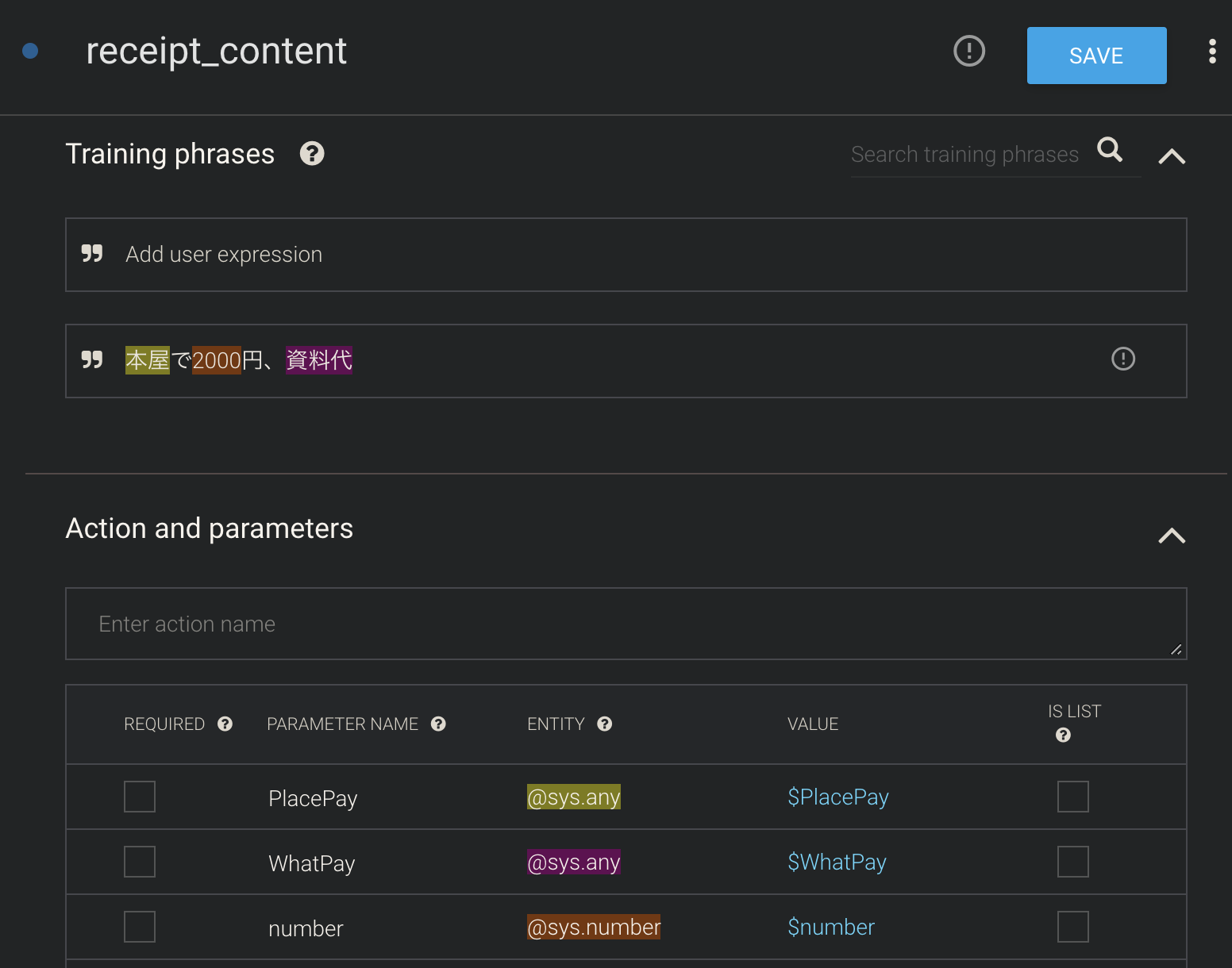
Dialogflowの設定例
・失敗の例-Entityにて-
この設定だと例えば交通費と言っても"なに"と判別されるので消しました。Dialogflow~AWS(API Gateway&Lambda)~
手順や注意点はこちらの記事に書いてあります
GoogleAssistantからWebhookでLineの特定人物へPush通知~GoogleAppsScript⇄スプレットシート
LambdaからWebhookで流れてきたJSONデータをGASであれこれしてます。
以下コードです(V8)code.gsfunction doPost(e) { try { let result; let ss = SpreadsheetApp.openById(sheetId); let sh = ss.getSheetByName(sheetName); let request = JSON.parse(e.postData.getDataAsString()); intentName = request.queryResult.intent.displayName; //領収書のIntent if (intentName == INTENT_RECEIPT_CONTENT) { let where = request.queryResult.parameters.PlacePay let howmuch = request.queryResult.parameters.number let what = request.queryResult.parameters.WhatPay //スプレッドシートに一時保存 sh.getRange(1, 5).setValue(where);//where sh.getRange(1, 6).setValue(howmuch);//howmuch sh.getRange(1, 7).setValue(what);//what let result = { "fulfillmentText": where + "で" + howmuch + "円," + what + "でよろしいでしょうか?" }; return returnAsJSON(result); } //Yes/NOの場合 if (intentName == INTENT_RECEIPT_YESNO) { let yesno = request.queryResult.parameters.YesNo switch (yesno) { case Yes: //一時保存から取り出す let temp_where = sh.getRange(1, 5).getValue();//where let temp_howmuch = sh.getRange(1, 6).getValue();//howmuch let temp_what = sh.getRange(1, 7).getValue();//what let lastrow = sh.getLastRow(); sh.insertRowAfter(lastrow); lastrow++; let now = new Date(); let date = Utilities.formatDate(now, 'Asia/Tokyo', 'yyyy-MM-dd'); let time = Utilities.formatDate(now, 'Asia/Tokyo', 'HH:mm:ss'); sh.getRange(lastrow, 1).setValue(date + " " + time); sh.getRange(lastrow, 2).setValue(temp_where);//where sh.getRange(lastrow, 3).setValue(temp_howmuch);//howmuch sh.getRange(lastrow, 4).setValue(temp_what);//what result = { "fulfillmentText": "登録しました" };//fulfillmentTextが大事! return returnAsJSON(result); case No: result = { "fulfillmentText": "キャンセルしました" }; return returnAsJSON(result); default: return returnAsJSON({ "fulfillmentText": "もう一度最初から" }); } } return returnAsJSON({ "fulfillmentText": "ごめんね。よくわからなかったよ" }); } catch (ex) { console.log(ex) return returnAsJSON({ "fulfillmentText": "エラーが発生しました。ログで確認できます" }); } } function returnAsJSON(obj) { return ContentService.createTextOutput(JSON.stringify(obj)).setMimeType(ContentService.MimeType.JSON); }軽く説明すると
request.queryResult.intent.displayName
の部分がDialogflowで設定したIntent名です。また
request.queryResult.parameters.***
の部分が各Intentで設定したパラメータ値($**)です。※大文字の変数はDialogflowで設定したIntent名等を各々入れること
スプレッドシートへ記入
記入および一時保存をスプレッドシートで行ってます。
GASだと時間指定で実行するトリガーが簡単に設定できるので、月や年度が変わった時に新規シートへ移行とかもできます。最後に
このアプリで信号待ちなので短い隙間時間でも領収書を登録できるようになりました。
これを応用すれば料理の注文アプリとか作れそうです。また今回GoogleHome系ですがアレクサでも作れそうですね。
それにしてもDialogflowの便利ですね〜
参考:
GoogleAssistantからWebhookでLineの特定人物へPush通知
google homeで子供の宿題管理をするあとDialogのIntent等の設定はこちらの本が分かりやすかった↓
やさしくはじめる スマートスピーカープログラミング

- 投稿日:2020-03-15T04:18:26+09:00
【まもなく終了!】【合格メモ】AWS認定ソリューションアーキテクト - アソシエイト(SAA)
はじめに
AWS認定(SAA-C01)(以下、旧試験)に無事合格したので、忘れないうちにやってきたこと投稿します。
なお、本試験は2020/3/22で終了し、新試験(SAA-C02)に移行されます。※本記事執筆時点では、残り1週間。。。想定読者
- 新試験移行前の駆け込みで試験に申し込み、3/20-22の3連休での受験予定の方
- 新試験を受験予定であるが、申し込み前で勉強法を検討中の方
似たような記事が既にたくさん存在するため、なるべくオリジナルな記事になるよう努めています。
似たようなラーニングパスの方の自信となれば幸いです。
テスト概要(新旧比較)
項目 旧試験(C01) 新試験(C02) 回答タイプ 選択問題と複数選択問題 同左 合格基準 720点(100〜1000) 同左 出題分野1(配分) 回復性の高いアーキテクチャを設計する(34%) レジリエントアーキテクチャの設計(30%) 出題分野2(配分) パフォーマンスに優れたアーキテクチャを定義する(24%) 高パフォーマンスアーキテクチャの設計(28%) 出題分野3(配分) セキュアなアプリケーションおよびアーキテクチャを規定する(26%) セキュアなアプリケーションとアーキテクチャの設計(24%) 出題分野4(配分) コスト最適化アーキテクチャを設計する(10%) コスト最適化アーキテクチャの設計(18%) 出題分野5(配分) オペレーショナルエクセレンスを備えたアーキテクチャを定義する(6%) 表現が一部変わった程度で、大きな変更はないように見えます。
CloudWatchを始めとするモニタリングやログの運用方法等に関する範囲が削除されているため、おそらく受講者の業務領域や役割の実態に合わせて見直しされたと想定。(AWS 認定 SysOpsとの住み分けも関係あるかも)
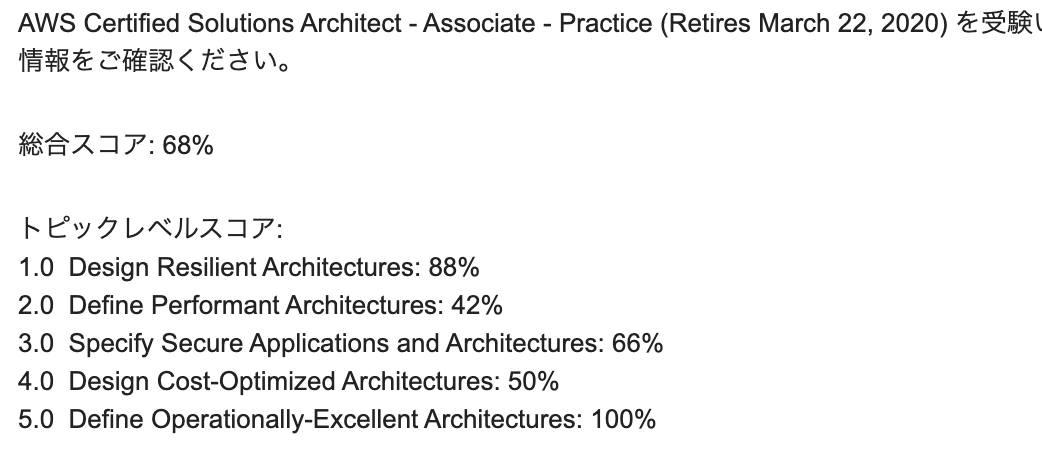
合格基準と項目反応理論
100〜1000点中、720点が合格点なので、65問中、概ね44問程度に正答すれば良いかというと、そうではありません。
また、勉強方法としても、例えば「回復性」に関する問題は出題範囲が広いので、広く浅く学習しておけば良いと考えてしまうのはあまり良くありません。難易度の高い問題が解けずに、正答数の感触の割には点数が低いということになりかねません。これは、項目反応理論(IRT)と呼ばれるテスト理論により、問題の難易度に応じて得点分布や出題範囲を事前にコントロールされているためです。
偏差値のように、受講生同士の学力の位置づけを測るだけであれば、例えばセンター試験の難易度が急に上がったとしても、全員が同じ条件で受講しているため、能力を測ることができます。
逆に、全員が同じ条件でなくても能力を測るには、この理論により、誰がいつ受験しても、人によって問題が異なっていたとしても、正しく能力がスコアリングされます。それを踏まえた上で、、、
例えばAWSソリューションアーキテクトの書籍を読んだだけでは、幅広い知識をつけることは可能ですが、読者の能力をあげるような工夫はされていないため、結果的に本番では簡易な用語で判断できる問題しか回答できません。
(TOEIC試験に対して、英単語を覚えただけでは解けない状態と同じです)おすすめの学習方法
1. まずは広く浅くサービスを網羅した知識をつける
書籍を1冊読み込みます。自分は黒本(徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書)を1冊買いました。
実際の試験と目次構成は同じでしたが、前述の通り、これを読んだだけで実践に近い問題に対応するには情報量が足らず、むしろ部分的に読み返すには探しにくい構成でした。サービスごとにまとまっている書籍 + AWS公式のサービス別資料集(AWS Black Belt)で学習することをおすすめします。
とくにAWS Black Beltの「動画」はわかりやすく、網羅的でかつベストプラクティスに沿ったポイントが説明されており、効率的に学ぶにはとても良い学習教材です。
2. 実際に手を動かし、パターン別の構築方法を身につける
書籍で一通り基本を抑えられれば、今度は構築パターンを身に着けます。
実際の問題では、「サーバからインターネットにアクセスする」要件や、「インターネットからサーバにアクセスする」要件など、要件ベースの出題が多く、「セキュリティグループとは何でしょう」というような直接的な知識は問われません。
例えば、
「インターネットからのhttpsアクセスのみを許可し、Webサーバを負荷分散したうえでプライベートサブネットに配置し、配下のAPサーバからインターネットへのアクセスできる構成」
を実際に構築しようとすると、
VPC、サブネット、インターネットゲートウェイ、セキュリティーグループ、ELB、NATゲートウェイ(インスタンス)といった機能やサービスを知っていないと構築できません。(少なくとも試験対策用の)書籍では、上記のような実現したい構成に沿った記載はないため、チュートリアル等を通して、必要な設定やサービスをイメージしやすくする必要があります。
Udemyの教材(これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(初心者向け22時間完全コース))は、ハンズオン形式の構成になっており、かつ小テストで復習可能であるため、ちょうど良い教材かと思います。
また、個人のAWSアカウントを持っていれば、実際に画面を操作して感覚を掴むことができます。基本的に「使った時間課金」なので、試しに作って削除すれば、コスパ良く学習できます。
自分は実務でEKS(少なくとも旧試験では登場しないサービス)を少し触っていたため、Udemyは模試のみしかやっておらず、個人アカウントでAWSを触ることも特にやってません。
他には、「AWS Summit」や「AWS Innovate Online Conference」などで事例動画を見たり、「AWS 認定 - 試験対策オンラインセミナー」など、AWSで定期的に配信されているセミナー動画を参考に、パフォーマンスや可用性を高めるために組み合わされたサービスの構成パターンを数多くインプットすると、実際の問題のイメージをつかみやすくなります。
3. 実際の問題に近い形式の問題を数多くこなす
上記までを全ての分野で理解できるようになれば問題ありませんが、実際にはそんな時間は取れない場合が多いかと思います。手を動かすにしても、環境や予算の制約もあるかと思います。
その場合は、模擬試験を含めた、実際の問題形式に「慣れる」ことで、得点を底上げすることは可能だと思います。
例えば、「Amazon Redshift」や「Amazon DynamoDB」「Amazon SQS」を組み合わせたシステムなどは、自身で構築するには限界があります。
これらはユースケースが限られているため、ある程度問題を解くだけで、問題のパターンとして覚えてしまうことができます。
自分は、試験1週間前に初めて模試で問題を解き、Udemy教材の模試×3と、黒本の特典である模試1回分を活用しました。これまでやってきたことと自身の得点率
- 実務でEKSを中心に、ELB、AutoScaling、RDSを触る。(付随してサブネットやセキュリティグループも)
- AWS公式動画を20本くらい見る
- 黒本を1週
- 公式模試試験を受講(試験1週間前):スコア68%
本番の問題形式を初めてやったのが上記のタイミング。
模擬試験よりも「本番は難しい」といろんな記事で書かれていたため、若干焦りを感じました。
パフォーマンスやコストが弱点分野だと明確に出たので、以降は重点的に学習しました。
多くの合格記事を書いてる人が使っていたWEB問題集は、4000円ということもあり購入をやめました。そのかわり、無料のWeb問題集を125問解き、Udemyの講座をキャンペーン価格の1500円で購入しました。(キャンペーンは常にやっている気がします。。。)
この時点で1週間前なので、Udemyの22時間の講座はスキップしました。
- 無料のweb問題集125問
- Udemy模試1:66%
- Udemy模試2:68%
- Udemy模試3:70%
Udemyの模試は、本番で似たような問題が出たものも多数あり、やっておいて良かったと思います。
ただ、たまに誤字があったり、答えそのものが誤っている問題も1問くらいあった気がします。
- 黒本の特典の模試試験(試験前日):74%
- 本番:836点
本番は、見返す用のフラグを付けた問題が20問程度あり、サービス・機能がわからない問題が3問ほどありました。
70分程度経過した段階で、フラグを付けた問題の見返しに入り、問題文から「高可用な」「スケーラブルな」「パフォーマンスが高い」「コストが最適な」「頻度(○回/日など)」「特定の時間帯」などの条件を読み取り、選択肢を消去することで、ほぼ2択には絞り込みました。
その後、時間いっぱいまでフラグを付けていない問題も再確認しましたが、選択肢は何も変更せずに終了。
その場で合格の通知がされ、半日経過したくらいで受験したアカウントに試験のスコアが掲載されました。
実際の本番の難易度はどの程度?
非公式の問題集や模擬試験と比べて、本番はどの程度難しかったかというと、体感はやや難しかったです。
というのも、問題集ではほとんど出てこなかったサービスや機能が出てきました。それでも、今までの模試よりもスコアが高かったのは、問題の難易度によるものとも考えられます。
知らないサービスが出てくると難しくは感じますが、逆に知っていれば解ける問題は難易度(配点)が低いため、人によって感じ方が異なるのだと思います。受験タイミングについて
模擬試験で6〜7割程度のスコアが取れてきたタイミングで、余裕をもったスケジュールで受験日を決めることをおすすめします。他の試験と異なり、誰がいつ受けても同じようにスコアリングされるので、準備ができてから受けるべきです。
それでも、今回のように試験内容が切り替わるタイミングを迎えた場合、最後の1週間の追い込みだけでも、得点率は確実にあがるので、問題のパターンを叩き込むのも一つの手法です。その他、意識したこと
- 受験時間帯は午前中を選ぶ(一日で最も集中できる時間)
- 本番と同じ時間帯に模試を受ける
- 公式動画は倍速で視聴し、試験範囲の箇所のみ見返す(だいたい前半に多い)
- 模試で得点が伸びなかった分野を重点的に再学習する
おすすめ公式資料集
以下は、個人的に2週ずつくらい視聴しておくべき内容をピックアップしたものです。
Amazon EC2
https://youtu.be/P5zX4DdlYOEAuto Scaling
https://d1.awsstatic.com/webinars/jp/pdf/services/20170315_AWS-BlackBelt-AutoScaling.pdfAWS Elastic Beanstalk
https://d1.awsstatic.com/webinars/jp/pdf/services/20170111_AWS-Blackbelt-Elastic-Beanstalk.pdfAmazon Elastic Block Store (EBS)
https://youtu.be/ffND-tX1QxsAmazon Simple Storage Service (S3)
https://youtu.be/oFG5kMZjKtcAWSの16あるデータベースを使いこなそう
https://youtu.be/0y4Py1_Nfe0Amazon DynamoDB
https://d1.awsstatic.com/webinars/jp/pdf/services/20170809_AWS-BlackBelt-DynamoDB.pdfAmazon ElastiCache
https://d1.awsstatic.com/webinars/jp/pdf/services/20171214_AWS-Blackbelt-ElastiCache.pdfAmazon Relational Database Service (RDS)
https://youtu.be/nDme-ET-_EYAmazon Redshift
https://d1.awsstatic.com/webinars/jp/pdf/services/20160720-AWS-BlackBelt-Redshift-public-v02.pdfElastic Load Balancing (ELB)
https://youtu.be/4laAoK-zXkoAmazon Virtual Private Cloud (VPC) Basic
https://youtu.be/aHEVvsk6pkIAmazon CloudFrontの概要
https://youtu.be/mmRKzzOvJJYAmazon CloudFront AWS Lambda@Edge
https://d1.awsstatic.com/webinars/jp/pdf/services/20170927_AWS-BlackBelt-CloudFront-LambdaEdge.pdfAmazon Route 53
https://d1.awsstatic.com/webinars/jp/pdf/services/20160113_aws-blackbelt-route53-public.pdfAmazon EC2 Auto Scaling and AWS Auto Scaling
https://youtu.be/o01IOnVvRxMAmazon CloudWatch
https://youtu.be/gOaZeJpb0Y4AWS CloudFormation
https://youtu.be/HU47ZAM3mtwAWS Config
https://youtu.be/vnqX0gMj6jwAmazon Simple Queue Service (SQS)
https://youtu.be/avfc0gQ7X0A

- 投稿日:2020-03-15T00:58:14+09:00
【Bubble x AWS】Bubble API Connector + AWS Lambda + Amazon API Gatewayで連携
はじめに
本記事はBubbleとAWSを連携させるために実施した作業内容を記載しています。
具体的には、Bubbleのプラグイン「API Connector」を使ってAWSのAPI Gatewayにリクエストを投げ、API Gatewayに統合されたLambda関数を実行します。
実装した処理の内容は、Bubble上に設置した入力項目の値をLambdaで受け取り、そのまま値を返してBubble上の表示項目に表示させるという簡単なものです。
AWSの設定
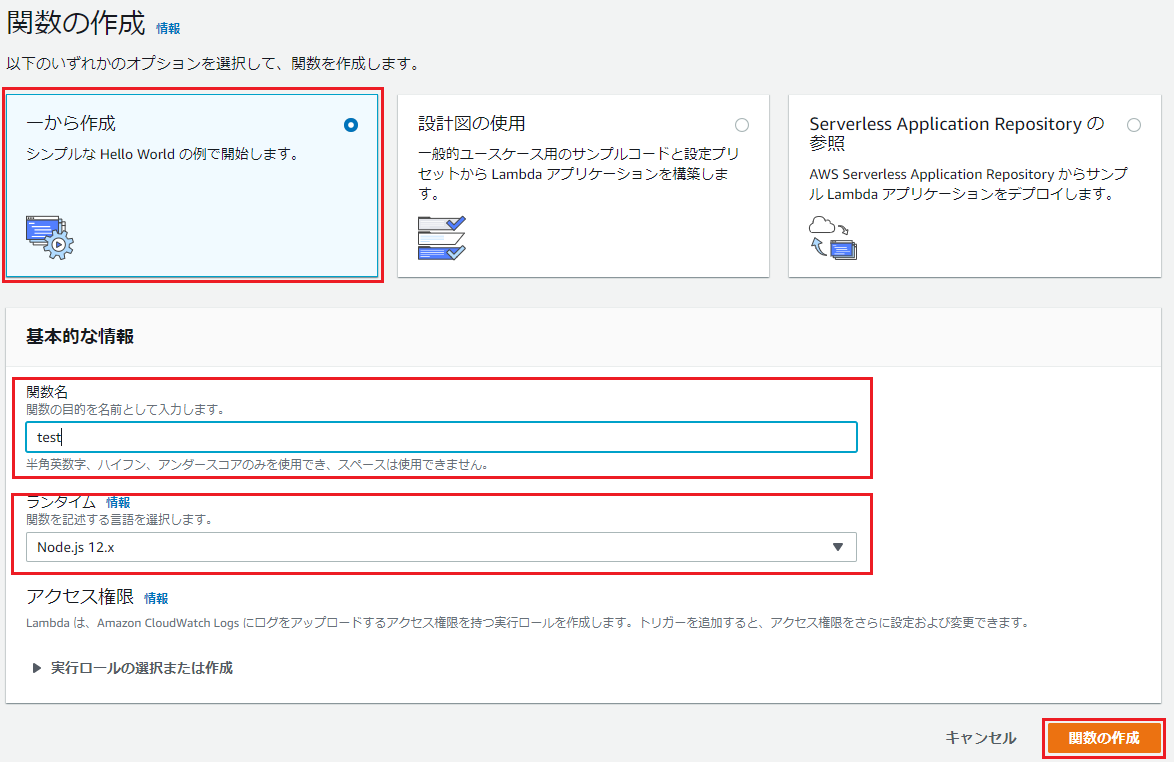
まずはLambda関数の作成です。次の通りに設定して[関数の作成]ボタンをクリックします。
- オプション: 位置から作成
- 関数名: 任意の名前(今回は
test)- ランタイム: 使用するプログラムのランタイム(今回は
Node.js 12.x)
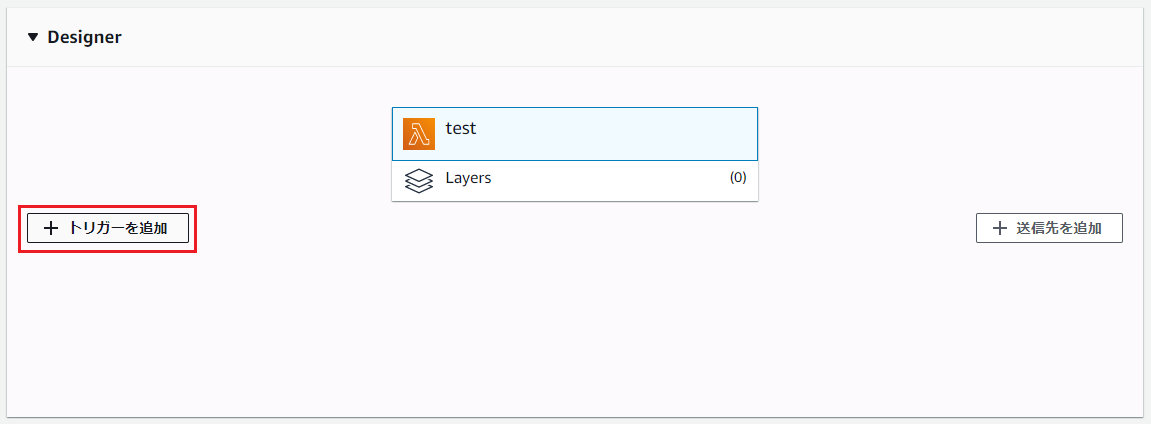
作成されると、次の画面になるので[トリガーを追加]ボタンをクリックします。
トリガーを「API Gateway」にして、次の通りに設定して[追加]ボタンをクリックします。
- API: 新規APIの作成
- テンプレート: HTTP API
元の画面に戻るので、API Gatewayの「API エンドポイント」をクリップボード等にコピーしておきます。(BubbleのAPI Connectorの設定時に使用)
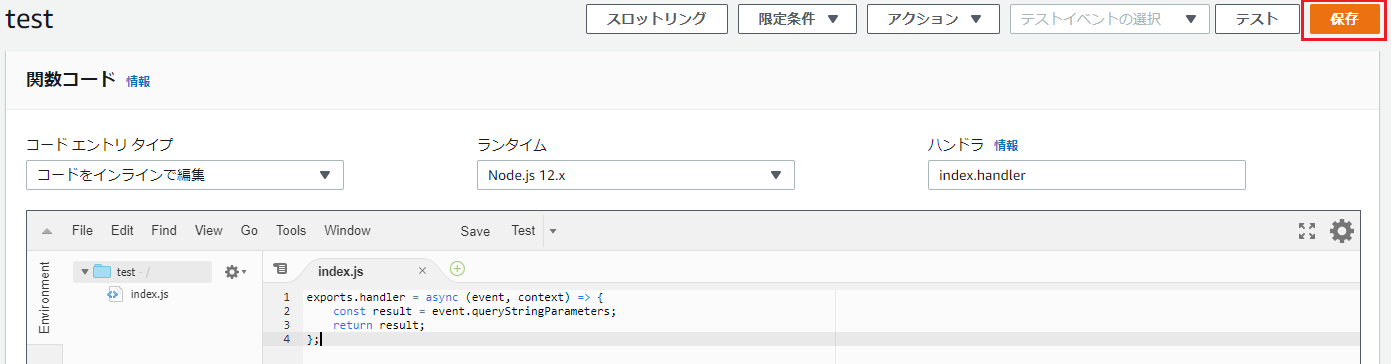
次はLambdaのコーディングを行いますので、Lambda functionをクリックします。
画面下部にコーディングの為の画面が表示されるので、次の内容をコーディング。
内容は受け取ったパラメーターの値を返すものです。node.jsexports.handler = async (event, context) => { const result = event.queryStringParameters; return result; };コーディングが終わったら画面右上の[保存]をクリック。
補足
Bubbleから送られたパラメーターは、
"queryStringParameters"として送信されます。(Amazon CloudWatchで確認)これらは、Lambdaの
exports.handler = async (event, context) => {...}のevent引数に格納されますので、event.queryStringParametersでBubbleから送付されたパラメーターを取得しています。{ ...: {...}, "queryStringParameters": { "key01-bubble": "value01-bubble", "key02-bubble": "value02-bubble" }, ...: {...}, }Bubbleの設定
API Connectorのインストール・設定
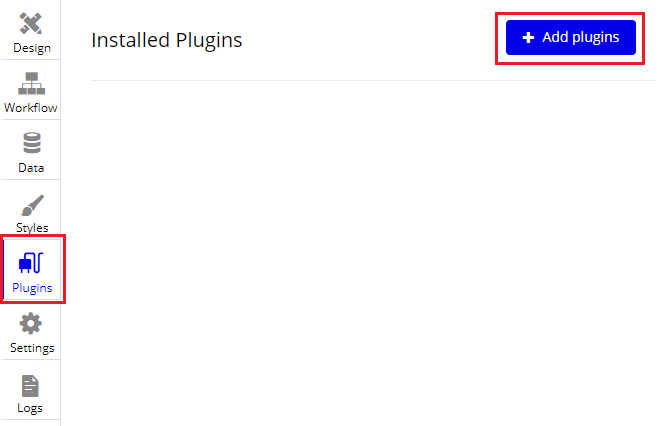
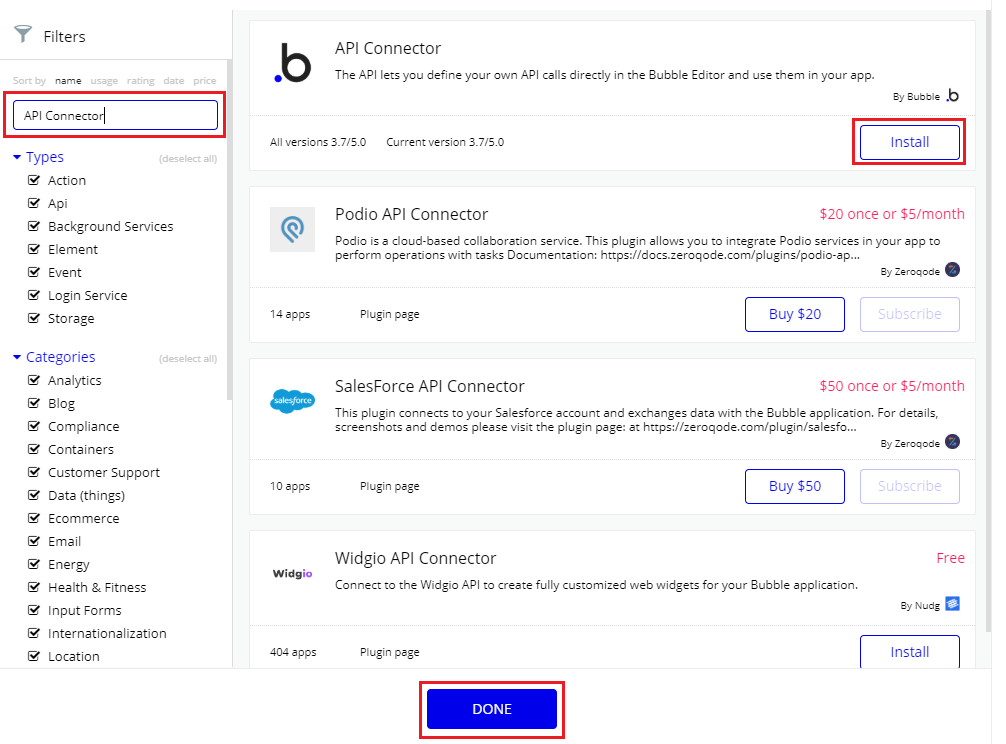
[Plugins]-[+Add plugins]ボタンをクリック
画面左上の検索窓に「API Connector」と入力し、表示された「API Connector」の[Install]ボタンをクリック。
インストールが始まるので、完了後に[DONE]ボタンをクリック
元の画面に自動的に戻ったら、API Connectorの設定画面が表示されます。
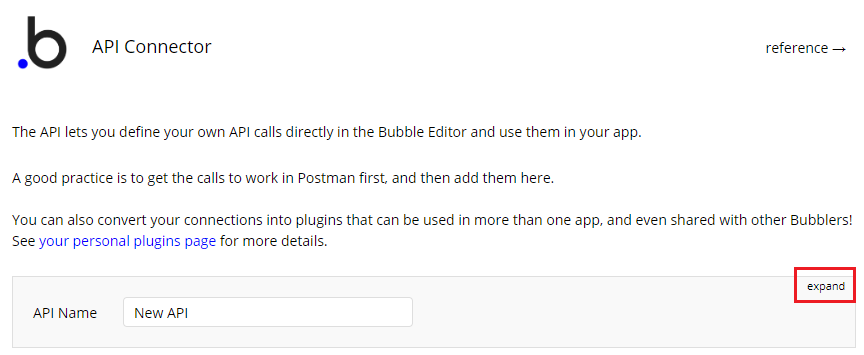
設定画面右上の[expand]ボタンをクリックします。
画面が展開され、他の項目が設定可能になります。
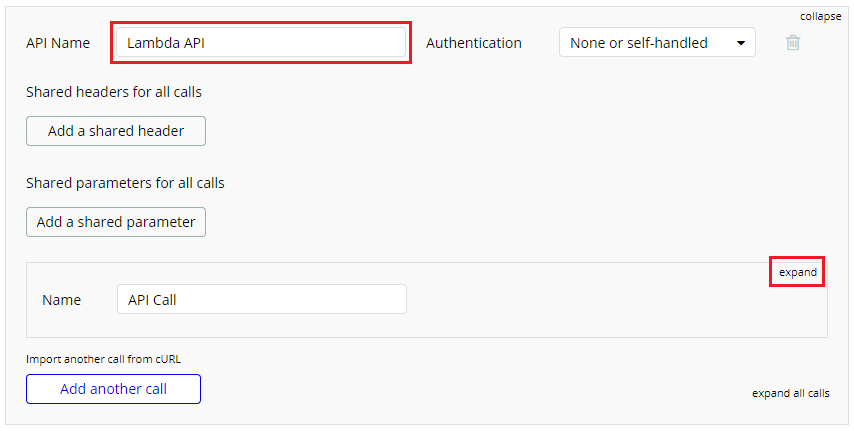
まずは[API Name]を自分が理解しやすい任意の名前にします。(今回はLambda API)
名前の入力が終わったら、その右側にある[expand]ボタンをクリックします。
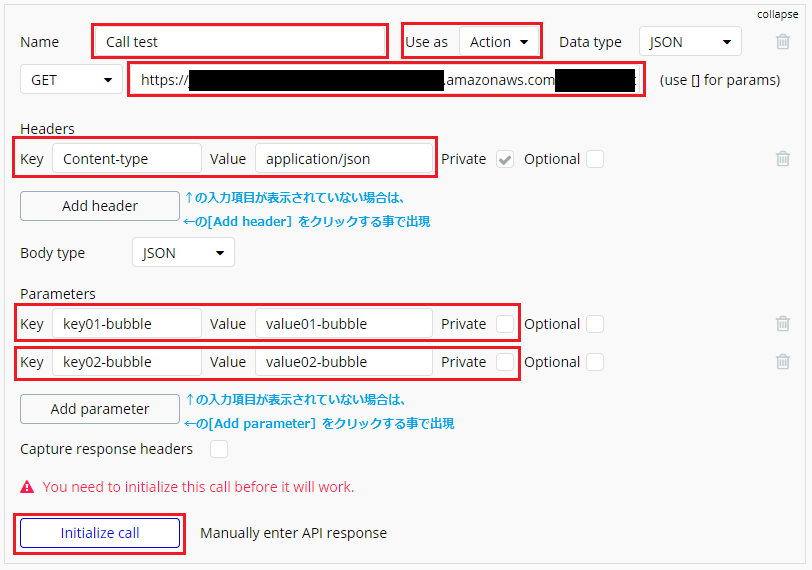
更に画面が展開され、他の項目が設定可能になりますので、次の通りに設定します。
- Name: 自分が理解しやすい任意の名前(今回は
Call test)- Use as: Action
- APIエンドポイント(上から2行目の赤枠部分): API Gatewayの「API エンドポイント」
- Headers
- Key: Content-type
- value: application/json
- Parameters
- 1行目
- Key: データを表す任意の値(今回は
key01-bubble)- value: データの値(任意でよい。今回は
value01-bubble)- Private: チェックを外す
- 2行目
- Key: データを表す任意の値(今回は
key02-bubble)- value: データの値(任意でよい。今回は
value02-bubble))- Private: チェックを外す
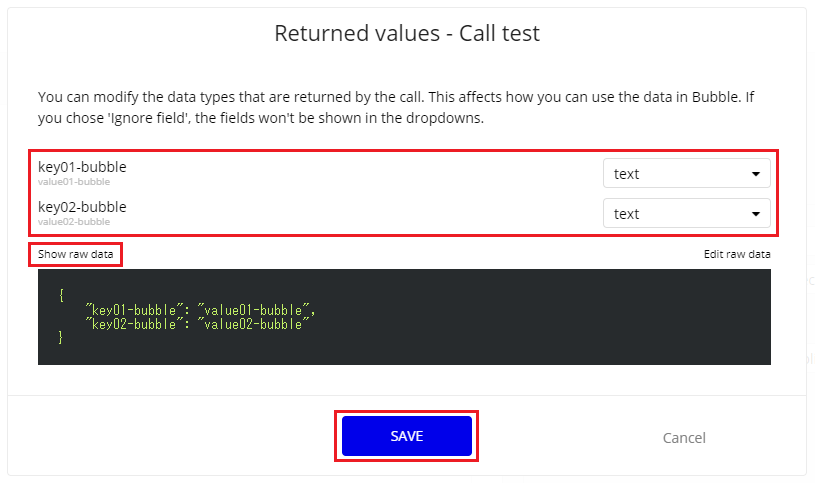
設定が完了したら[initialize call]ボタンをクリック。
Parametersで設定した値が、そのまま返ってきているのが確認できます。
返ってきた値に対してデータタイプを設定する必要があるので、値の右にあるドロップダウンメニューで設定して[SAVE]ボタンをクリックします。
(返ってきた値の生データを見たい場合は[Show raw data]をクリックすれば生データが表示されます)
SAVEが正常に完了して初めて、このAPIが設定可能になるので必ずここまで設定しましょう。後で設定するBubbleの[Type of content]等に作成したAPIが表示されない場合はSAVEを忘れている可能性大です。
これで通信の確認が出来ました。
UIの作成
Input elementに入力した値が、Button element押下時にLambdaに渡されて、その値をLambdaがBubbleに返してText elementに表示させるというものを作りますので、その為に必要なelementを設置します。
次のelementを画面に設置します。
- Group(Lambdaから返ってきた値の受皿用)
- Input(value01-bubble入力用)
- Input(value02-bubble入力用)
- Button(AWS Lambda実行用)
- Text(Lambdaから帰ってきたvalue01-bubble表示用)
- Text(Lambdaから帰ってきたvalue02-bubble表示用)
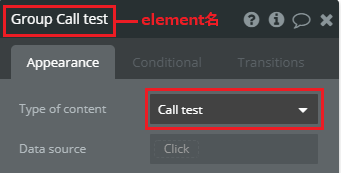
elementの設置が終わった後はGroup elementの設定です。次のとおりに設定します。
- element名: 任意の名前(今回は
Group Call test)- Type of content: API Connectorの[Name]に設定した値(今回は
Call test)
必須作業ではありませんが、先ほどのGroup elementと同様に、他の各elementにも判別しやすい任意のelement名をつけます。
今回は次の通りです。
- Group(Lambdaから返ってきた値の受皿用): Group Call test
- Input(value01-bubble入力用): Input key1's value
- Input(value02-bubble入力用): Input key2's value
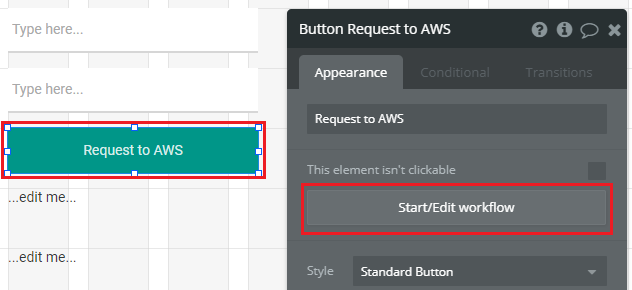
- Button(AWS Lambda実行用): Button Request to AWS
- Text(Lambdaから帰ってきたvalue01-bubble表示用): Text key1's value
- Text(Lambdaから帰ってきたvalue02-bubble表示用): Text key2's value
次にWorkflowを設定します。Button elementを押下した際にLambdaにRequestする処理の設定です。
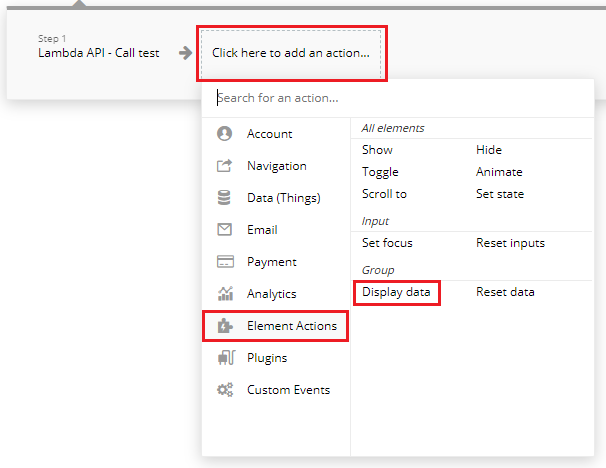
Button elementのプロパティから[Start\Edit workflow]ボタンをクリック。
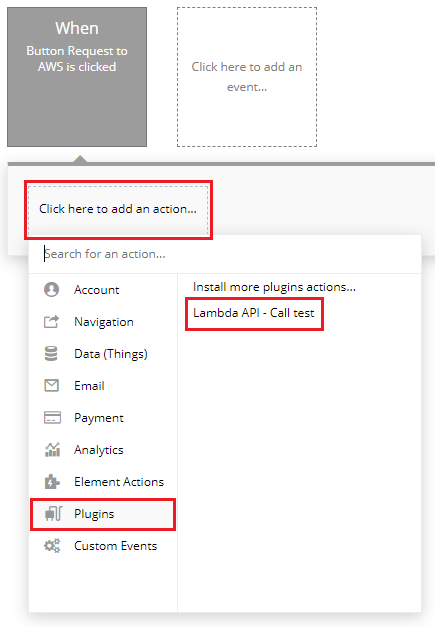
Workflowの画面に遷移した後は、[Click here to add an action...]をクリックして、表示されるメニューから[Plugins]-[Lambda API - Call test]をクリック。
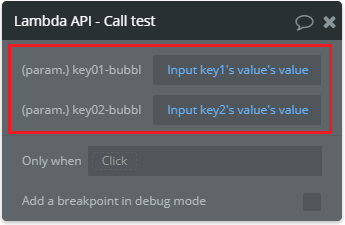
プロパティ画面が出現するので次の通りに設定します。
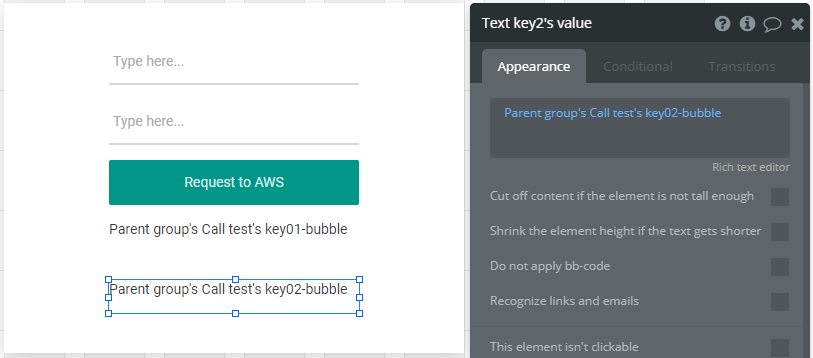
これで、パラメーターのvalueがInput elementに入力された値になります。
- (param.)key01-bubbl: Input key1's value's value(Insert dynamic dataを使用して設定する事)
- (param.)key02-bubbl: Input key2's value's value(Insert dynamic dataを使用して設定する事)
補足すると
Input key1's value's valueは「element名の(Input key1's value's)値(value)」という意味です。element名次第で今回の様に紛らわしい値になりますね、反省...。LambdaにRequestした後は、Lambdaから返ってくる値を受け取らなければいけません。
その為のActionを設定します。[Click here to add an action...]をクリックして、表示されるメニューから[Element Actions]-[Display data]をクリック。
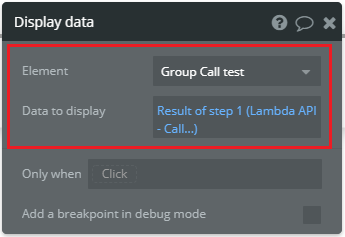
プロパティ画面が出現するので次の通りに設定します。
これは[Element]に[Data to display]をセットする設定です。
今回の例で言うと、Group Call testと名付けたGroup elementにstep1(Lambda API - Call test)の結果(Lambdaが返す値)をセットします。
次はText elementにLambdaから返ってきた値を表示させるように設定します。
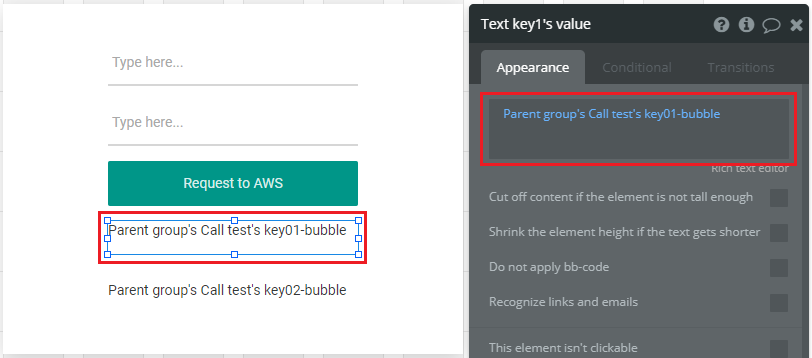
Designの画面に戻ってText key1's valueと名付けたText elementのプロパティ画面を表示し、次の通りに設定します。(Insert dynamic dataを使用して設定する事)
Text key2's valueも同様に設定します。
以上で設定は完了です。
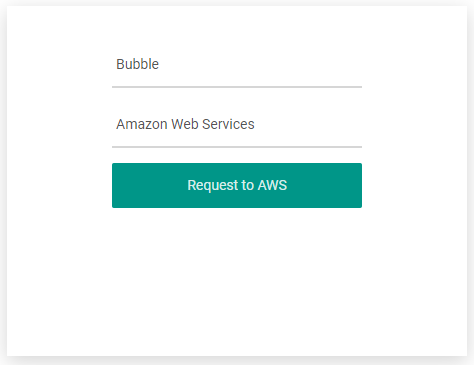
動作確認
最後にプレビュー機能で動作確認してみましょう。
次の様に入力してボタンをクリックして、
次の様になれば完成です。お疲れ様でした。