- 投稿日:2020-01-26T23:57:59+09:00
Re:ゼロから始める競技プログラミング生活 第1章2『涙のPython』
第2の敵
今回は前回より難しいB問題を解いていきます!!
では早速、問題どーん!!
...何じゃこれ
難易度一気に上げ過ぎではないでしょうかねぇ...
とりあえず図を描いて何を求めていけば良いのかを整理してみます。
なるほど、この小学生でもまだマシなものを描きそうなこの図を見ると、Lの回数に最初の1回を加えたものがこの問題の解答になると言うことですね。意外と簡単だった!!
では早速、C++で書いていきたと...Python「(´・ω・`)」
OT「どうしたPython!?」
Python「もう僕は使わないの?(´・ω・)」
OT「だってPython、君を使ってコードを書くスキルが自分にはないんだ...ないんだよ.....」
Python「じゃあ僕はいらない子なの?(´°̥̥̥̥̥̥̥̥ω°̥̥̥̥̥̥̥̥`)」
OT「そんな悲しい顔しないでくれパイソぉおおおおおおおおおん」
...
...
...はい、と言う訳で今回はPythonでコードを書いていきます。
N, X = map(int, input().split()) L = list(map(int, input().split())) distance = 0 bounds = 1とりあえず、使う変数を全て宣言!!
N,X,Lは前回いただいたコメント等を参考に記述、ここさえクリアできればなんとかなるはず!!
boundsはボールが跳ねる回数で、最初から座標D0の文の1回を入れています。
deistanceはボールが跳ねて進んだ距離です。for i in range(n): distance += l[i] if distance <= x: bounds += 1 else: break print(bounds)この繰り返し文でdistanceがXを超えるまでboundsが加算されるようにします。
これでなんとかACいただきました!!最後に
今回は前回より早く解けましたが、前回のコメントの力がかなり大きかったです。
コメントしてくださった方、ありがとうございますm(_ _)m
これでもうPythonの泣き顔を見る日はやってこないであろう...
問題Cからはなんか無理めな予感がするぜ...ご拝読いただき、ありがとうございました。

- 投稿日:2020-01-26T23:44:47+09:00
モンティ・ホール問題の数式に頼らない直感的な解説と、Pythonによるシミュレーション
モンティ・ホール問題は、確率のパラドックスとして有名な問題です。本記事では、私が考えて最も納得できた数式に頼らない直感的な説明をしてみます。
モンティ・ホール問題
Wikipediaより引用
プレーヤーの前に閉じた3つのドアがあって、1つのドアの後ろには景品の新車が、2つのドアの後ろには、はずれを意味するヤギがいる。プレーヤーは新車のドアを当てると新車がもらえる。プレーヤーが1つのドアを選択した後、司会のモンティが残りのドアのうちヤギがいるドアを開けてヤギを見せる。ここでプレーヤーは、最初に選んだドアを、残っている開けられていないドアに変更してもよいと言われる。
ここでプレーヤーはドアを変更すべきだろうか?答「プレーヤーはドアを変更すべきである。なぜなら変更しなかった場合の当たる確率が$\frac{1}{3}$なのに対し、変更した場合の当たる確率は$\frac{2}{3}$だからだ。」
解説
プレーヤーが最初に1つドアを選んだ段階では、どのドアも当たりである確率は$\frac{1}{3}$であるはずだ。それがなぜ、司会者が外れのドアを1つ見せた後では変わってしまうのだろうか?
これを理解するために、モンティ・ホール問題に似た以下のような問題を考えてみる。
- プレーヤーはドアを1つ選択する
- プレーヤーは、「選択しているドア」か、「残り2つのドア」のどちらに当たりがあるか選択を促される。
この場合、誰もが後者の「残り2つのドア」を選択するだろう。なぜなら、当たる確率が前者は$\frac{1}{3}$なのに対し、後者は$\frac{2}{3}$だからだ。
この問題とモンティ・ホール問題の決定的な違いは、「選択していないドアのうち、外れのドアを1つ見せる」という行為の有無である。
モンティ・ホール問題では、この行為により「残り2つのドア」のうちの1つが当たり確率0として確定する。これを整理すると、
- 「残り2つのドア」に当たりがある確率は$\frac{2}{3}$,
- 「残り2つのドア」の一方の当たり確率が0に確定
以上より、最後に残った今選択していないドアが当たりである確率が$\frac{2}{3}$となる。
司会者がドアを開示する前後での当たり確率の変化:
よくある誤解
どのドアも当たる確率は同じであるはずだ。よって、一つ外れのドアが確定したのならば、残り2つのドアが当たりである確率はそれぞれ$\frac{1}{2}$である。
この考えは、以下のような問題であれば正しい。
- プレーヤーはドアを1つ選択する
- 司会者は、(プレーヤーが選択中のものも含め)3つのドアのうち外れのドアを1つランダムに見せる
- プレーヤーは、残った2つのドアのうち1つを選択する
この問題とモンティ・ホール問題の決定的な違いは、「司会者が、プレーヤーが選択中のドアを見せることができるか否か」である。
モンティ・ホール問題では、上記はできないことになっている。プレーヤーが選択しているドアが当たりだった場合はこの違いは関係ないが、外れだった場合に大いに影響する。
プレーヤーが選択しているドアが外れであった場合、モンティ・ホール問題では、必ずもう一方の外れのドアが開示される。対して上記の問題では、どの外れのドアが選ばれるかは完全にランダムで、当たりのドアを当てるための何のヒントも得られない。以上、直感的な説明ではあるが、とりあえず当たる確率がそれぞれ$\frac{1}{2}$にはならないということには納得できるのではないだろうか。
Pythonによるシミュレーション
Python によるシミュレーション例を載せておく。
1万回ゲームを行い、ドアを変更する場合と変更しない場合の勝率をそれぞれ計算した。import random random.seed(1) doors = ["当たり", "ヤギ", "ヤギ"] stay_wins, change_wins = 0, 0 # 十分な試行回数繰り返す loop = 10000 for _ in range(loop): # 最初にドアを選ぶ choose = random.choice(doors) # ドアを変更しない場合と変更する場合で、当たりを引いた方に勝数+1 if choose == "当たり": stay_wins += 1 else: change_wins += 1 print("--- 勝率 ---") print(f"ドアを変更しない場合: {stay_wins / loop}") print(f"ドアを変更する場合 : {change_wins / loop}")出力結果--- 勝率 --- ドアを変更しない場合: 0.3323 ドアを変更する場合 : 0.6677最後に
Qiita初投稿です。
どんなコメントでもお待ちしています!!

- 投稿日:2020-01-26T23:20:40+09:00
AtCoder Beginner Contest 153 参戦記
AtCoder Beginner Contest 153 参戦記
ABC153A - Serval vs Monster
1分半で突破. 書くだけ.
H, A = map(int, input().split()) print((H + (A - 1)) // A)ABC153B - Common Raccoon vs Monster
2分半で突破. 書くだけ.
H, N = map(int, input().split()) A = list(map(int, input().split())) if sum(A) >= H: print('Yes') else: print('No')ABC153C - Fennec vs Monster
2分半で突破. 書くだけ. できるだけ体力が多いやつを必殺技で倒したいので、ソートして先頭K匹以降を攻撃で倒すものとして集計すればいいだけ.
N, K = map(int, input().split()) A = list(map(int, input().split())) A.sort(reverse=True) print(sum(A[K:]))ABC153D - Caracal vs Monster
7分半で突破. log なので TLE にはならないので、再帰関数で定義通りカウントしていくだけで OK.
from sys import setrecursionlimit setrecursionlimit(1000000) H = int(input()) def f(n): if n == 1: return 1 else: return 1 + (n // 2) * 2 print(f(H))ABC153E - Crested Ibis vs Monster
55分半で突破. DP で総当り.
package main import ( "bufio" "fmt" "math" "os" "strconv" ) func main() { H := readInt() N := readInt() AB := make([]struct{ A, B int }, N) for i := 0; i < N; i++ { AB[i].A = readInt() AB[i].B = readInt() } dp := make([]int, 100000) for i := 0; i < 100000; i++ { dp[i] = math.MaxInt64 } dp[0] = 0 for i := 0; i < H; i++ { if dp[i] == math.MaxInt64 { continue } for j := 0; j < N; j++ { a := AB[j].A b := AB[j].B if dp[i]+b < dp[i+a] { dp[i+a] = dp[i] + b } } } result := math.MaxInt64 for i := H; i < 100000; i++ { if dp[i] < result { result = dp[i] } } fmt.Println(result) } const ( ioBufferSize = 1 * 1024 * 1024 // 1 MB ) var stdinScanner = func() *bufio.Scanner { result := bufio.NewScanner(os.Stdin) result.Buffer(make([]byte, ioBufferSize), ioBufferSize) result.Split(bufio.ScanWords) return result }() func readString() string { stdinScanner.Scan() return stdinScanner.Text() } func readInt() int { result, err := strconv.Atoi(readString()) if err != nil { panic(err) } return result }ABC153F - Silver Fox vs Monster
敗退. AtCoder の Go のバージョンがもっと新しくて、スライスのソートができたら突破していたと思う. そうでなくてももう少し時間が残っていたら C# で書き直したのだが…….
- 投稿日:2020-01-26T23:10:19+09:00
Qiskit: Quantum Hypergraph Statesの実装
はじめに
量子計算を行う際に初期状態を欲しい形にしたい場合があると思います。
特に量子ニューラルネットワークなどで必要かと思われます。仮に
\frac{|000>+|001>-|010>+|011>-|100>-|101>+|110>+|111>}{2 \sqrt{2}}を作るgateの組み合わせがすぐ分かれば便利じゃありませんか?
それを実現する考え方がQuantum Hypergraph Stateです。詳しくは Quantum Hypergraph statesをご覧ください。
Quantum Hypergraph states
軽くQuantum Hypergraph statesの説明をしたいと思います。
\frac{i_0|000>+i_1|001>+i_2|010>+i_3|011>+i_4|100>+i_5|101>+i_6|110>+i_7|111>}{2 \sqrt{2}} \\ i_k = -1 \ or \ 1
- 係数が$-1$である$|0...1...0>$が存在するとき、$1$であるqubitに対してZ gateを作用させる。
- 係数を更新する。
- 係数が$-1$である$|0...1...1...0>$が存在するとき、$1$であるqubitに対してCZ gateを作用させる。
- 係数を更新する。
- 係数が$-1$である$|0...1...1...1...0>$が存在するとき、$1$であるqubitに対してCCZ gateを作用させる。
3qubitの場合は、これですべての係数が1になります。
例
\frac{|000>+|001>-|010>+|011>-|100>-|101>+|110>+|111>}{2 \sqrt{2}}
- $|010>$と$|100>$の係数が$-1$なので、第二qubitと第三qubitにZ gateを作用させます。その結果、
\frac{|000>+|001>+|010>-|011>+|100>+|101>+|110>+|111>}{2 \sqrt{2}}
- $|011>$の係数が$-1$なので、第一qubitと第二qubitにCZ gateを作用させます。その結果、
\frac{|000>+|001>+|010>+|011>+|100>+|101>+|110>-|111>}{2 \sqrt{2}}
- $|111>の係数が$-1$なので、第一qubitと第二qubitと第三qubitにCCZ gateを作用させます。その結果、
\frac{|000>+|001>+|010>+|011>+|100>+|101>+|110>+|111>}{2 \sqrt{2}}以上で回路の構築は終わりです。
Code
Codeは以下の通りです。正直Pythonが得意なわけでは無いので、無駄な箇所があるかもしれません。効率的な書き方があったら教えてくださると有難いです。
ちなみに、今回は3qubitまでのものですが、同じようにすればいくらでも増やせると思います。#matplotlib inline #coding: utf-8 from math import log2 from qiskit import QuantumCircuit, QuantumRegister from qiskit.quantum_info.operators import Operator def count_ones_by_bin(num): bin_num = bin(num)[2:] count = 0 for i in bin_num: count += int(i) return count class QuantumHypergraphState: def __init__(self, numqubits, states, circuit=None, qubit_index=None): ''' make Quantum HyperGraph State in circuit :param circuit: :param numqubits: maximum 3 :param states: ''' self.numqubits = numqubits self.states = states if circuit is not None: self.qc = circuit self.index = range(numqubits) else: qr = QuantumRegister(self.numqubits) self.qc = QuantumCircuit(qr) if qubit_index is not None: self.index = qubit_index else: self.index = range(numqubits) def bin_length(self, num): bin_num = bin(num)[2:] dif_len = self.numqubits - len(bin_num) for i in range(dif_len): bin_num = '0' + bin_num return bin_num def get_z_tgt(self, num): bin_num = self.bin_length(num)[::-1] z_tgt = [] for i in range(len(bin_num)): if int(bin_num[i]) == 1: z_tgt.append(i) return z_tgt def tgt_0(self, num, tgt): """ e.g. tgt = [0] num = 011 """ bin_num = self.bin_length(num)[::-1] # 011 count = 0 for i in range(len(bin_num)): if i in tgt: count += int(bin_num[i]) if count == len(tgt): return True else: return False def renew_states(self, tgt): for st in range(len(self.states)): if self.tgt_0(st, tgt): self.states[st] *= -1 def construct_circuit(self): czz = Operator([[1, 0, 0, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 0, -1]]) self.qc.h(self.index) for num in range(1, self.numqubits+1): # statesの分だけloop if num == 1: for st in range(len(self.states)): if count_ones_by_bin(st) == num: if self.states[st] == -1: tgt = int(log2(st)) self.qc.z(tgt) self.renew_states([tgt]) elif num == 2: for st in range(len(self.states)): if count_ones_by_bin(st) == num: if self.states[st] == -1: tgt_list = self.get_z_tgt(st) self.qc.cz(tgt_list[0], tgt_list[1]) self.renew_states(tgt_list) else: for st in range(len(self.states)): if count_ones_by_bin(st) == num: if self.states[st] == -1: tgt_list = self.get_z_tgt(st) self.qc.unitary(czz, range(self.numqubits), label='czz') self.renew_states(tgt_list) def draw(self): print(self.qc.draw(output='mpl'))以上です。ありがとうございました。

- 投稿日:2020-01-26T23:07:06+09:00
Lambda(Python)でGoogle Vision APIを利用して日本語文字検出する
Lambda(Python)でGoogle Vision APIを利用して日本語文字検出する
はじめに
サーバーレスWebアプリ Mosaicを開発して得た知見を振り返り定着させるためのハンズオン記事を書き連ねていて、合計17記事を予定して現在13記事、あと4記事なのですが、少し飽きてきてしまいました。
飽きてきたというか、新しい機能の実装にも着手したくなってきてしまって。
で、着手してしまったわけです。文字検出の機能追加に。文字検出?文字認識?OCR(Optical Character Recognition)って言うみたいですね。
AWSのRekognitionでも文字検出できるみたいなのですが、残念ながら日本語非対応らしく。(2020年1月現在)
しかしGoogleのVision APIは日本語もサポートしているということで、こちらを利用することにしました。Cloud Vision API 有効化
ということで、早速やってきましょう。
Google Cloud Platform もしくは Google Developpers のコンソール > APIとサービス にアクセス。
https://console.cloud.google.com/apis
https://console.developers.google.com/apis画面上部にある「+APIとサービスを有効化」ボタンを押下。
Cloud Vision API を探して、有効化。
認証情報として、サービスアカウントを追加しますが、こちらの記事と重複しますので、ここでは割愛します。
Lambda(Python3)でGoogle Vision APIを利用する
サービスアカウントでGoogleのAPIを呼ぶために必要なライブラリのインポートについても、先ほど同様、こちらの記事を参照ください。
ローカル画像ファイルをVision APIに渡して、顔とテキストを検出するコードは以下のような感じです。
lambda_function.py: def detectFacesByGoogleVisionAPIFromF(localFilePath, bucket, dirPathOut): try: keyFile = "service-account-key.json" scope = ["https://www.googleapis.com/auth/cloud-vision"] api_name = "vision" api_version = "v1" service = getGoogleService(keyFile, scope, api_name, api_version) ctxt = None with open(localFilePath, 'rb') as f: ctxt = b64encode(f.read()).decode() service_request = service.images().annotate(body={ "requests": [{ "image":{ "content": ctxt }, "features": [ { "type": "FACE_DETECTION" }, { "type": "TEXT_DETECTION" } ] }] }) response = service_request.execute() except Exception as e: logger.exception(e) def getGoogleService(keyFile, scope, api_name, api_version): credentials = ServiceAccountCredentials.from_json_keyfile_name(keyFile, scopes=scope) return build(api_name, api_version, credentials=credentials, cache_discovery=False)このサンプルコードでは、
FACE_DETECTIONとTEXT_DETECTIONを指定しています。
それ以外にもLABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTIONなどが指定できますが、指定するとその分料金が加算されてきます。なので、目的が文字検出だけの場合にはTEXT_DETECTIONだけ指定するなどしたほうがいいですね。
featuresに指定できるものや返されるjsonの詳細についてはここでは書きません。Cloud Vision API ドキュメントを参照ください。料金の詳細についてはこちら。本当はGoogle Driveにアップロードしたファイルに対してVisionしたかった
のですが、できませんでした。
test.pyimageUri = "https://drive.google.com/uc?id=" + fileID service_request = service.images().annotate(body={ "requests": [{ "image":{ "source":{ "imageUri": imageUri } }, "features": [ { "type": "FACE_DETECTION" }, { "type": "TEXT_DETECTION" } ] }] }) response = service_request.execute()こんな感じでイケると思ったのですが、以下のようなエラーが返ってきてしまい、色々試したのですが結局できませんでした。
response.json{"responses": [{"error": {"code": 7, "message": "We're not allowed to access the URL on your behalf. Please download the content and pass it in."}}]} {"responses": [{"error": {"code": 4, "message": "We can not access the URL currently. Please download the content and pass it in."}}]}ass it in."}}]}Visionを呼び出すことは出来てるのですが、VisionからWeb上の画像(imageUri)にアクセスできてないみたいですね。S3のPublicバケット上の画像の直リンクを指定してもダメでした。謎です。誰か教えて下さい。
動作確認
TEXT_DETECTIONでは、
textAnnotationsとfullTextAnnotationという2つの要素が得られます。
textAnnotationsで検出された領域をブルー、fullTextAnnotationで検出された領域をグリーンで囲った結果は以下のような感じでした。
まずまずの結果が得られていると思うのですが、日本語だからかどうなのか、ブルーの方は若干1文字の範囲がズレているような印象を受けますね。
また、下の画像のように1文字1文字が独立しているような場合に弱そうです。これも日本語特有の問題なのか、はたまた違ったfeaturesだったら検出できるのか、その他パラメータで調整できるのか、深追いはしていませんがとにかく期待した結果は得られていません。
将来的にAPIの学習が進んでこの画像にある文字が漏れなく検出できる日がくることを祈るしか無いのが辛いところです。
AWSのRekognitionが文字検出で日本語をサポートしたあかつきには、まずはこの画像で評価をしようと思っています!あとがき
記事としてまとめることは大切なことだし必要なことだと分かっているのですが、、やっぱり何か新しい機能を作っている時が一番楽しいですね。
その流れでこのVision APIの記事もサラサラと書くことができました。
記事の作成を後回しにすると面倒になってしまうので、記憶の新しいうちに、そしてテンションが高いうちに、さっさと書いてしまうことは大切なことかもしれないなと思った次第です。今作ってるMosaicというサーバーレスWebアプリ、基本的にはAWSのインフラを利用しているのですが、ゆくゆくはGCPで同じものを構築するということもやりたいと思っています。2020年内には。
インフラはどちらかに統一して構築したほうが良いだろうなと思いますが、RekognitionやVisionAPIのようなWebAPIサービスは、どちらでも良いというか、やりたいことが実現できる方を選択することになりますね。
どちらもAPIを呼ぶだけなので大した事はなく、結局何のシステムもそうなのかもしれませんが、部品を組み合わせて作っている、プラモデルのような、そんな感じがより強くします。
全てを知っておく必要はないと思いますが、1つにこだわりすぎるのも良くないと思いますね。機械学習された高精度のサービスをこんなに簡単に利用できるのは喜ばしい限りなのですが、それが期待する結果を返してくれなかった場合に手詰まりになってしまうのは辛いところですね。とはいえ、この先の研究分野で何かできるかというと手も足も出ないわけで、いつの日か学習が進んで期待する結果が出てくるのを正座して待つしかできないワタシです。







- 投稿日:2020-01-26T23:07:06+09:00
PythonでGoogleのCloud Vision APIを利用して画像から日本語文字検出する
PythonでGoogleのCloud Vision APIを利用して画像から日本語文字検出する
はじめに
サーバーレスWebアプリ Mosaicを開発して得た知見を振り返り定着させるためのハンズオン記事を書き連ねていて、合計17記事を予定して現在13記事、あと4記事なのですが、少し飽きてきてしまいました。
飽きてきたというか、新しい機能の実装にも着手したくなってきてしまって。
で、着手してしまったわけです。文字検出の機能追加に。文字検出?文字認識?OCR(Optical Character Recognition)って言うみたいですね。
AWSのRekognitionでも文字検出できるみたいなのですが、残念ながら日本語非対応らしく。(2020年1月現在。試してないのですが、まだ未サポートらしい。)
しかしGoogleのCloud Vision APIは日本語もサポートしているということで、こちらを利用することにしました。Cloud Vision API 有効化
ということで、早速やってきましょう。
Google Cloud Platform もしくは Google Developpers のコンソール > APIとサービス にアクセス。
https://console.cloud.google.com/apis
https://console.developers.google.com/apis画面上部にある「+APIとサービスを有効化」ボタンを押下。
Cloud Vision API を探して、有効化。
認証情報として、サービスアカウントを追加しますが、こちらの記事と重複しますので、ここでは割愛します。
Lambda(Python3)でGoogle Vision APIを利用する
サービスアカウントでGoogleのAPIを呼ぶために必要なライブラリのインポートについても、先ほど同様、こちらの記事を参照ください。
ローカル画像ファイルをVision APIに渡して、顔とテキストを検出するコードは以下のような感じです。
lambda_function.py: def detectFacesByGoogleVisionAPIFromF(localFilePath, bucket, dirPathOut): try: keyFile = "service-account-key.json" scope = ["https://www.googleapis.com/auth/cloud-vision"] api_name = "vision" api_version = "v1" service = getGoogleService(keyFile, scope, api_name, api_version) ctxt = None with open(localFilePath, 'rb') as f: ctxt = b64encode(f.read()).decode() service_request = service.images().annotate(body={ "requests": [{ "image":{ "content": ctxt }, "features": [ { "type": "FACE_DETECTION" }, { "type": "TEXT_DETECTION" } ] }] }) response = service_request.execute() except Exception as e: logger.exception(e) def getGoogleService(keyFile, scope, api_name, api_version): credentials = ServiceAccountCredentials.from_json_keyfile_name(keyFile, scopes=scope) return build(api_name, api_version, credentials=credentials, cache_discovery=False)このサンプルコードでは、
FACE_DETECTIONとTEXT_DETECTIONを指定しています。
それ以外にもLABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTIONなどが指定できますが、指定するとその分料金が加算されてきます。なので、目的が文字検出だけの場合にはTEXT_DETECTIONだけ指定するなどしたほうがいいですね。
featuresに指定できるものや返されるjsonの詳細についてはここでは書きません。Cloud Vision API ドキュメントを参照ください。料金の詳細についてはこちら。本当はGoogle Driveにアップロードしたファイルに対してVisionしたかった
のですが、できませんでした。
test.pyimageUri = "https://drive.google.com/uc?id=" + fileID service_request = service.images().annotate(body={ "requests": [{ "image":{ "source":{ "imageUri": imageUri } }, "features": [ { "type": "FACE_DETECTION" }, { "type": "TEXT_DETECTION" } ] }] }) response = service_request.execute()こんな感じでイケると思ったのですが、以下のようなエラーが返ってきてしまい、色々試したのですが結局できませんでした。
response.json{"responses": [{"error": {"code": 7, "message": "We're not allowed to access the URL on your behalf. Please download the content and pass it in."}}]} {"responses": [{"error": {"code": 4, "message": "We can not access the URL currently. Please download the content and pass it in."}}]}ass it in."}}]}Visionを呼び出すことは出来てるのですが、VisionからWeb上の画像(imageUri)にアクセスできてないみたいですね。S3のPublicバケット上の画像の直リンクを指定してもダメでした。謎です。誰か教えて下さい。
動作確認
TEXT_DETECTIONでは、
textAnnotationsとfullTextAnnotationという2つの要素が得られます。
textAnnotationsで検出された領域をブルー、fullTextAnnotationで検出された領域をグリーンで囲った結果は以下のような感じでした。
まずまずの結果が得られていると思うのですが、日本語だからかどうなのか、ブルーの方は若干1文字の範囲がズレているような印象を受けますね。
また、下の画像のように1文字1文字が独立しているような場合に弱そうです。これも日本語特有の問題なのか、はたまた違ったfeaturesだったら検出できるのか、その他パラメータで調整できるのか、深追いはしていませんがとにかく期待した結果は得られていません。
将来的にAPIの学習が進んでこの画像にある文字が漏れなく検出できる日がくることを祈るしか無いのが辛いところです。
AWSのRekognitionが文字検出で日本語をサポートしたあかつきには、まずはこの画像で評価をしようと思っています!あとがき
記事としてまとめることは大切なことだし必要なことだと分かっているのですが、、やっぱり何か新しい機能を作っている時が一番楽しいですね。
その流れでこのVision APIの記事もサラサラと書くことができました。
記事の作成を後回しにすると面倒になってしまうので、記憶の新しいうちに、そしてテンションが高いうちに、さっさと書いてしまうことは大切なことかもしれないなと思った次第です。今作ってるMosaicというサーバーレスWebアプリ、基本的にはAWSのインフラを利用しているのですが、ゆくゆくはGCPで同じものを構築するということもやりたいと思っています。2020年内には。
インフラはどちらかに統一して構築したほうが良いだろうなと思いますが、RekognitionやVisionAPIのようなWebAPIサービスは、どちらでも良いというか、やりたいことが実現できる方を選択することになりますね。
どちらもAPIを呼ぶだけなので大した事はなく、結局何のシステムもそうなのかもしれませんが、部品を組み合わせて作っている、プラモデルのような、そんな感じがより強くします。
全てを知っておく必要はないと思いますが、1つにこだわりすぎるのも良くないと思いますね。機械学習された高精度のサービスをこんなに簡単に利用できるのは喜ばしい限りなのですが、それが期待する結果を返してくれなかった場合に手詰まりになってしまうのは辛いところですね。とはいえ、この先の研究分野で何かできるかというと手も足も出ないわけで、いつの日か学習が進んで期待する結果が出てくるのを正座して待つしかできないワタシです。
- 投稿日:2020-01-26T23:05:44+09:00
PytorchでShake-Shake Regularizationを実装してみようとした
Shake-Shake Regularizationとは?
正則化の1つです。
擬似的に学習データを増大させることで、長くゆっくり学習できる利点があります。データ数が少ないときにdata augmentationとして有効なのかも?
とりあえず今回はCIFAR10で試してみたいと思います。
Shake-Shake Regularizationを簡単に説明すると、上のような図になります。
Resnetにおいてredisual blockを2つ並列に作り、residual blockの出力に対し、以下の操作を加えます。
- 学習時の順伝播では0〜1の乱数αをかける
- 誤差逆伝播させるときは0〜1の乱数βをかける(αとは別に生成する)
- 推論時は乱数でなく、定数0.5をかける
詳しくは他の方の記事を参考にしてみてください。私はこちらの記事を読んで理解できました。
https://qiita.com/masataka46/items/fc7f31073c89b02f8a04residual blockの作成
resnetではplainアーキテクチャとbottleneckアーキテクチャの2つがありますが、今回はbottleneck アーキテクチャを使いたいと思います。
test.pyclass ResidualBottleneckBlock(nn.Module): expansion = 4 def __init__(self, in_channels, out_channels, stride): super(ResidualBottleneckBlock, self).__init__() bottleneck_channels = out_channels // self.expansion self.conv1 = nn.Conv2d(in_channels, bottleneck_channels, kernel_size=1, stride=1, padding=0, bias=False) self.bn1 = nn.BatchNorm2d(bottleneck_channels) self.conv2 = nn.Conv2d(bottleneck_channels, bottleneck_channels, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(bottleneck_channels) self.conv3 = nn.Conv2d(bottleneck_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False) self.bn3 = nn.BatchNorm2d(out_channels) self.conv1_2 = nn.Conv2d(in_channels, bottleneck_channels, kernel_size=1, stride=1, padding=0, bias=False) self.bn1_2 = nn.BatchNorm2d(bottleneck_channels) self.conv2_2 = nn.Conv2d(bottleneck_channels, bottleneck_channels, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2_2 = nn.BatchNorm2d(bottleneck_channels) self.conv3_2 = nn.Conv2d(bottleneck_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False) self.bn3_2 = nn.BatchNorm2d(out_channels) self.shortcut = nn.Sequential() # identity mapping if in_channels != out_channels: # downsampling self.shortcut.add_module('conv', nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=0, bias=False)) self.shortcut.add_module('bn', nn.BatchNorm2d(out_channels)) def forward(self, x): if self.training: #1つ目のresidual block out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = self.bn3(self.conv3(out)) #2つ目のresidual block out2 = F.relu(self.bn1_2(self.conv1_2(x))) out2 = F.relu(self.bn2_2(self.conv2_2(out2))) out2 = self.bn3_2(self.conv3_2(out2)) #ショートカットと2つのresidual blockの出力(に乱数をかけたもの)を足し合わせる output = self.shortcut(x) + ShakeShake.apply(out,out2) #通常のresnetならこっち #output = out + self.shortcut(x) return F.relu(output) else: #1つ目のresidual block out = F.relu(self.bn1(self.conv1(x)), inplace=True) out = F.relu(self.bn2(self.conv2(out)), inplace=True) out = self.bn3(self.conv3(out)) #2つ目のresidual block out2 = F.relu(self.bn1_2(self.conv1_2(x)), inplace=True) out2 = F.relu(self.bn2_2(self.conv2_2(out2)), inplace=True) out2 = self.bn3_2(self.conv3_2(out2)) #ショートカットと2つのresidual blockの出力(に0.5をかけたもの)を足し合わせる output = self.shortcut(x) + out*0.5 + out2*0.5 #通常のresnetならこっち #output = out + self.shortcut(x) return F.relu(output)コンストラクタはごちゃごちゃしてますが、forward関数を見ればなんとなく理解できるのではないでしょうか。
forward関数の中身は、
1:受け取ったxを2つのblockに与える
2:out,out2を出力させる
3:out,out2をShakeShake.apply()に処理してもらう
4:ショートカットと3を足し合わせて1つにまとめて出力するforward関数内の"ShakesShake.apply(out,out2)"って?
ShakeShakeクラスというクラスを定義して、forwardとbackwardでの処理を定義することができます。
test.pyclass ShakeShake(torch.autograd.Function): @staticmethod def forward(ctx, i1, i2): alpha = random.random() result = i1 * alpha + i2 * (1-alpha) return result @staticmethod def backward(ctx, grad_output): beta = random.random() return grad_output * beta, grad_output * (1-beta)forwardでは乱数alphaを生成してout,out2にかけています。
backwardでは新たに乱数betaを生成して、grad_output(誤差逆伝播により伝わってきた値)にかけています。
調べたところ、こうすることで新しいautograd関数を定義できるみたいです。
(確信がない理由は後述します。)肝心の精度だが・・・
精度は82%程度でした。
同じ条件で訓練してない(pretrained=Falseの)Resnet50を使ってみると、精度は82%以下だったので、一応成功しているのかな・・・?
しかし、訓練済み(pretrained=True)のResnet50は初めから80%以上の精度を出し、正則化をきちんと行えば95%付近まで到達します。
で、今回は82%...
あまり精度が出てない原因は次のように考えてます。
- ソースコードがどこか間違えている(実装できてない)
- 訓練誤差が早めに収束してしまっている(過学習)
最後に
ShakeShake regularizationは強力な正則化であるため、学習時間が半端なく伸びます。
今回は頑張って1000epochで学習させましたが大変でした笑
最後にソースコードを全文載せておきますので、参考にしてみてください。
また、「ここが不十分だ!」という箇所がありましたらご教授いただけると嬉しいです。
test.pyimport torch import random import numpy as np import pandas as pd import torch.nn as nn from torch import optim import torch.nn.functional as F from torch.autograd import Variable import torch.nn.init as init import torchvision.transforms as transforms from torchvision import models from torch.utils.data import Dataset,DataLoader from torch.utils.data.dataset import Subset import torchvision.datasets as dsets import os import sys import matplotlib.pyplot as plt import random class ShakeShake(torch.autograd.Function): @staticmethod def forward(ctx, i1, i2): alpha = random.random() result = i1 * alpha + i2 * (1-alpha) return result @staticmethod def backward(ctx, grad_output): beta = random.random() return grad_output * beta, grad_output * (1-beta) class ResidualBottleneckBlock(nn.Module): expansion = 4 def __init__(self, in_channels, out_channels, stride): super(ResidualBottleneckBlock, self).__init__() bottleneck_channels = out_channels // self.expansion self.conv1 = nn.Conv2d(in_channels, bottleneck_channels, kernel_size=1, stride=1, padding=0, bias=False) self.bn1 = nn.BatchNorm2d(bottleneck_channels) self.conv2 = nn.Conv2d(bottleneck_channels, bottleneck_channels, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(bottleneck_channels) self.conv3 = nn.Conv2d(bottleneck_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False) self.bn3 = nn.BatchNorm2d(out_channels) self.conv1_2 = nn.Conv2d(in_channels, bottleneck_channels, kernel_size=1, stride=1, padding=0, bias=False) self.bn1_2 = nn.BatchNorm2d(bottleneck_channels) self.conv2_2 = nn.Conv2d(bottleneck_channels, bottleneck_channels, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2_2 = nn.BatchNorm2d(bottleneck_channels) self.conv3_2 = nn.Conv2d(bottleneck_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False) self.bn3_2 = nn.BatchNorm2d(out_channels) self.shortcut = nn.Sequential() # identity mapping if in_channels != out_channels: # downsampling self.shortcut.add_module('conv', nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=0, bias=False)) self.shortcut.add_module('bn', nn.BatchNorm2d(out_channels)) def forward(self, x): if self.training: #1つ目のresidual block out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = self.bn3(self.conv3(out)) #2つ目のresidual block out2 = F.relu(self.bn1_2(self.conv1_2(x))) out2 = F.relu(self.bn2_2(self.conv2_2(out2))) out2 = self.bn3_2(self.conv3_2(out2)) #ショートカットと2つのresidual blockの出力(に乱数をかけたもの)を足し合わせる output = self.shortcut(x) + ShakeShake.apply(out,out2) #通常のresnetならこっち #output = out + self.shortcut(x) return F.relu(output) else: #1つ目のresidual block out = F.relu(self.bn1(self.conv1(x)), inplace=True) out = F.relu(self.bn2(self.conv2(out)), inplace=True) out = self.bn3(self.conv3(out)) #2つ目のresidual block out2 = F.relu(self.bn1_2(self.conv1_2(x)), inplace=True) out2 = F.relu(self.bn2_2(self.conv2_2(out2)), inplace=True) out2 = self.bn3_2(self.conv3_2(out2)) #ショートカットと2つのresidual blockの出力(に0.5をかけたもの)を足し合わせる output = self.shortcut(x) + out*0.5 + out2*0.5 #通常のresnetならこっち #output = out + self.shortcut(x) return F.relu(output) class MyNet(nn.Module): def __init__(self): super(MyNet,self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = nn.Sequential( ResidualBottleneckBlock(64,64,1), ResidualBottleneckBlock(64,64,1), ResidualBottleneckBlock(64,64,1) ) self.layer2 = nn.Sequential( ResidualBottleneckBlock(64,128,2), ResidualBottleneckBlock(128,128,1), ResidualBottleneckBlock(128,128,1), ResidualBottleneckBlock(128,128,1) ) self.layer3 = nn.Sequential( ResidualBottleneckBlock(128,256,2), ResidualBottleneckBlock(256,256,1), ResidualBottleneckBlock(256,256,1), ResidualBottleneckBlock(256,256,1), ResidualBottleneckBlock(256,256,1), ResidualBottleneckBlock(256,256,1) ) self.layer4 = nn.Sequential( ResidualBottleneckBlock(256,512,2), ResidualBottleneckBlock(512,512,1), ResidualBottleneckBlock(512,512,1) ) self.avgpool = nn.AdaptiveAvgPool2d((2, 2)) self.fc = nn.Linear(512 * 4, 10) def forward(self,x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.view(-1,512*4) x = self.fc(x) return x def weight_initializer(self): for m in self.modules(): if isinstance(m,nn.Conv2d): init.kaiming_uniform_(m.weight.data,nonlinearity='relu') #画像の読み込み batch_size = 100 train_data = dsets.CIFAR10(root='./tmp/cifar-10', train=True, download=False, transform=transforms.Compose([transforms.RandomHorizontalFlip(p=0.5), transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]), transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)])) train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=True) test_data = dsets.CIFAR10(root='./tmp/cifar-10', train=False, download=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])) test_loader = DataLoader(test_data,batch_size=batch_size,shuffle=False) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(device) net = MyuNet().to(device) net.weight_initializer() criterion = nn.CrossEntropyLoss() learning_rate = 0.01 optimizer = optim.SGD(net.parameters(),lr=learning_rate,momentum=0.9,weight_decay=0.00005) scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[650], gamma=0.1) loss = 0 loss100 = 0 count = 0 acc_list = [] loss_list = [] max_acc = 0 #訓練・推論 for i in range(1000): net.train() for j,data in enumerate(train_loader,0): optimizer.zero_grad() inputs,labels = data inputs = inputs.to(device) labels = labels.to(device) outputs = net(inputs) loss = criterion(outputs,labels) loss.backward() optimizer.step() scheduler.step() loss100 += loss count += 1 print('%d: %.3f'%(j+1,loss)) print('%depoch:mean_loss=%.3f\n'%(i+1,loss100/count)) loss_list.append(loss100/count) loss100 = 0 count = 0 correct = 0 total = 0 accuracy = 0.0 net.eval() for j,data in enumerate(test_loader,0): inputs,labels = data inputs = inputs.to(device) labels = labels.to(device) outputs = net(inputs) _,predicted = torch.max(outputs.data,1) correct += (predicted == labels).sum() total += batch_size accuracy = 100.*correct / total acc_list.append(accuracy) print('epoch:%d Accuracy(%d/%d):%f'%(i+1,correct,total,accuracy)) torch.save(net.state_dict(),'Weight'+str(i+1)) for i in range(len(acc_list)): print('epoch:%d Accuracy:%.3f'%(i+1,acc_list[i])) plt.plot(acc_list) plt.show(acc_list) plt.plot(loss_list) plt.show(loss_list)

- 投稿日:2020-01-26T22:17:48+09:00
【AWS IoT】AWS IoT Python SDKを使ってAWS IoTにモノを登録する
目的
AWS IoTへのモノの登録を、AWS IoT Python SDKを用いて行います。
モノが大量になると、コンソールで毎回登録するのが大変なため。補足
モノの登録と同時に下記のことを行います。
- 各種情報登録
- "属性"に情報を登録
- デバイスシャドウに情報を登録
- モノを"モノのグループ"に追加
- 証明書の発行、アタッチ
- デバイス証明書・キーを発行して保存
- ポリシーを証明書にアタッチ
- モノを証明書にアタッチ
実行
事前準備
モノを所属させるグループを作成しておきます。(手順は割愛)
証明書にアタッチするポリシーを作成しておきます。(手順は割愛)
コード
import boto3 import json import os class AWSIoT(): # 証明書、キーのファイル名 FILENAME_PUBLIC_KEY = 'public_key.pem' FILENAME_PRIVATE_KEY = 'private_key.pem' FILENAME_CERT = 'cert.pem' def __init__(self, dirpath_cert): # 使用するクラスをインスタンス化 self.client_iot = boto3.client('iot') self.client_iotdata = boto3.client('iot-data') # 証明書を保存するディレクトリ self.DIRPATH_CERT = dirpath_cert return def enroll_thing(self, thing_name, dict_attr, group_name, property_desired, property_reported, policy): ''' AWS IoTにモノを登録する ''' # AWS IoTにモノを登録("属性"にモノの情報を登録) self.__create_thing(thing_name, dict_attr) # 登録したモノをグループに追加 self.client_iot.add_thing_to_thing_group(thingGroupName=group_name, thingName=thing_name) # デバイスシャドウに情報を登録 self.__update_shadow(thing_name, property_desired, property_reported) # デバイス証明書・キーを発行、保存 response = self.__create_keys_and_cert(thing_name) # ポリシーを証明書にアタッチ self.client_iot.attach_policy(policyName=policy, target=response['certificateArn']) # デバイスに証明書を紐付け self.client_iot.attach_thing_principal(thingName=thing_name, principal=response['certificateArn']) return def __create_thing(self, thingname, dict_attr): ''' AWS IoTにモノを登録("属性"にモノの情報を登録) ''' # 登録情報(属性)を生成 attributePayload = self.__create_attribute_payload(dict_attr) # モノを登録 self.client_iot.create_thing( thingName=thingname, attributePayload=attributePayload ) return def __create_attribute_payload(self, dict_attr): ''' 登録情報(属性)を生成 ''' attributePayload = { 'attributes': dict_attr } return attributePayload def __update_shadow(self, thing_name, property_desired, property_reported): ''' デバイスシャドウに情報を登録 ''' # バージョン情報をデバイスシャドウに書き込む形式に整形 payload = self.__create_payload(property_desired, property_reported) # デバイスシャドウに情報を登録 self.client_iotdata.update_thing_shadow( thingName=thing_name, payload=payload ) return def __create_payload(self, property_desired, property_reported): ''' バージョン情報をデバイスシャドウに書き込む形式に整形 ''' payload = json.dumps({'state': {"desired": {"property": property_desired}, "reported": {"property": property_reported}}}) return payload def __create_keys_and_cert(self, thing_name): ''' デバイス証明書・キーを発行、保存 ''' # 証明書、キーを発行 response = self.client_iot.create_keys_and_certificate(setAsActive=True) # 保存先のディレクトリパスを生成 dirpath_save = self.DIRPATH_CERT + thing_name + '/' # ファイルに書き込んで保存 self.__write_to_file(dirpath_save, self.FILENAME_PUBLIC_KEY, response['keyPair']['PublicKey']) self.__write_to_file(dirpath_save, self.FILENAME_PRIVATE_KEY, response['keyPair']['PrivateKey']) self.__write_to_file(dirpath_save, self.FILENAME_CERT, response['certificatePem']) return response def __write_to_file(self, dirpath, filename, contents): ''' ファイルに書き込み ''' os.makedirs(dirpath, exist_ok=True) filepath = dirpath + filename with open(filepath, mode='w') as f: f.write(contents) return実行
- 登録情報を定義
- 今回は"ThingName"という名前のモノを登録します。
- 属性には、'BuildingName'として'hogehoge_building'を、'Floor'として'6'を登録します。
- デバイスシャドウには理想の気温と、現在の気温を登録します。
# モノの名前 thing_name = 'ThingName' # モノの属性(属性キー:値) dict_attr = {'BuildingName':'hogehoge_building', 'Floor':'6'} # モノを所属させるグループの名前 group_name = 'hogehoge_group' # デバイスシャドウに登録する情報 temp_desired = 26 temp_reported = 22 # 証明書にアタッチするポリシー policy = 'policy_thermometer' # 証明書、キーを保存するディレクトリのパス dirpath_cert = './cert/'
- クラスをインスタンス化して実行
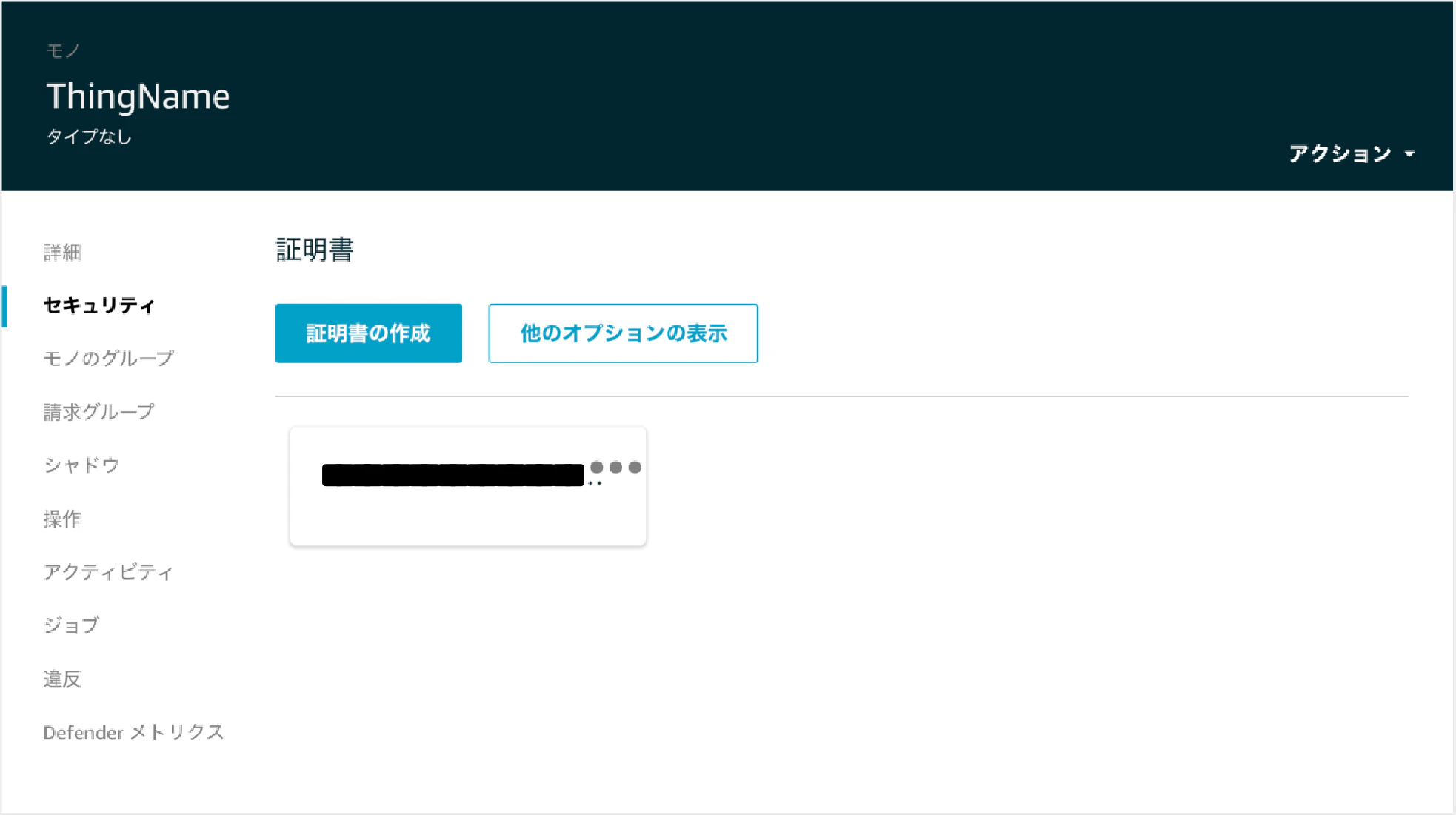
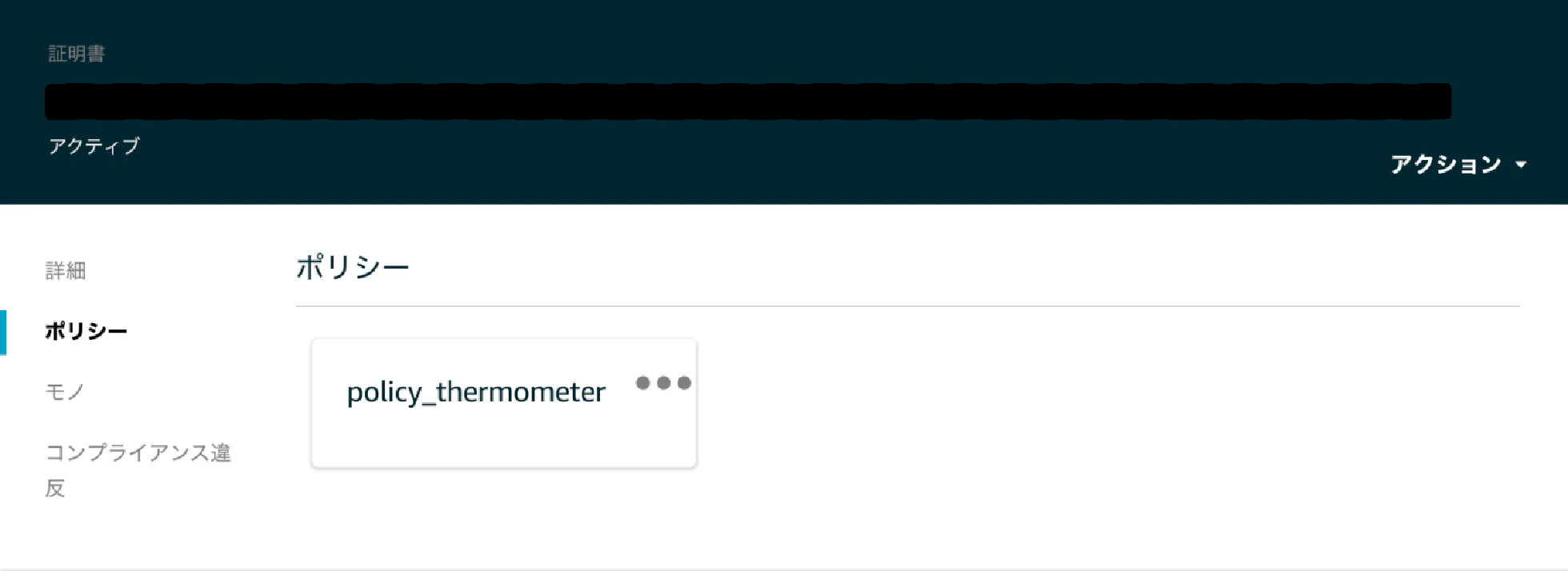
awsiot = AWSIoT(dirpath_cert) awsiot.enroll_thing(thing_name, dict_attr, group_name, temp_desired, temp_reported, policy)結果
デバイスの登録が出来ました。
属性も正しく登録されています。
シャドウも正しく登録されています。("delta"は自動で作成されます。詳細は割愛。)
証明書も正しく紐付けられていて、
証明書にはポリシーがアタッチされています。
あとがき
めちゃめちゃ初心者なので、本当に些細なことでもご指摘・コメントいただけますと幸いです。
Twitterやってます→@shin_job




- 投稿日:2020-01-26T21:05:52+09:00
Tkinterで画面切り替え・画面遷移
Tkinterで画面切り替え
超シンプルなコード紹介。
別記事( ここ )はOpenCV関係のコードで長くなっちゃったんでこっちは短くまとめる。
pillowが入ってれば動くはず。コード
main.py# -*- coding: utf-8 -*- import tkinter as tk import PIL.Image, PIL.ImageTk class App(tk.Tk): # 呪文 def __init__(self, *args, **kwargs): # 呪文 tk.Tk.__init__(self, *args, **kwargs) # ウィンドウタイトルを決定 self.title("Tkinter change page") # ウィンドウの大きさを決定 self.geometry("800x600") # ウィンドウのグリッドを 1x1 にする # この処理をコメントアウトすると配置がズレる self.grid_rowconfigure(0, weight=1) self.grid_columnconfigure(0, weight=1) #-----------------------------------main_frame----------------------------- # メインページフレーム作成 self.main_frame = tk.Frame() self.main_frame.grid(row=0, column=0, sticky="nsew") # タイトルラベル作成 self.titleLabel = tk.Label(self.main_frame, text="Main Page", font=('Helvetica', '35')) self.titleLabel.pack(anchor='center', expand=True) # フレーム1に移動するボタン self.changePageButton = tk.Button(self.main_frame, text="Go to frame1", command=lambda : self.changePage(self.frame1)) self.changePageButton.pack() #-------------------------------------------------------------------------- #-----------------------------------frame1--------------------------------- # 移動先フレーム作成 self.frame1 = tk.Frame() self.frame1.grid(row=0, column=0, sticky="nsew") # タイトルラベル作成 self.titleLabel = tk.Label(self.frame1, text="Frame 1", font=('Helvetica', '35')) self.titleLabel.pack(anchor='center', expand=True) # フレーム1からmainフレームに戻るボタン self.back_button = tk.Button(self.frame1, text="Back", command=lambda : self.changePage(self.main_frame)) self.back_button.pack() #-------------------------------------------------------------------------- #main_frameを一番上に表示 self.main_frame.tkraise() def changePage(self, page): ''' 画面遷移用の関数 ''' page.tkraise() if __name__ == "__main__": app = App() app.mainloop()ざっと解説
ポイントはtkraiseというコマンド。tkraiseは指定のフレームを最前面に表示させる。
フレームを重ねて配置して、ボタンを押すたびに裏にあるフレームを持ってくる構成。
ボタンにはなんの装飾もせず超シンプルにしてあります。図解
こんなイメージ
詳しく説明
コード中のコメントアウトに大体のことは書いてあるけど一応、、
まずメインフレーム(main_frame)と移動先のフレーム(frame1)を作成。
2つのフレームをgridメソッドを使って座標(0,0)に配置
gridを使うことで重ねて配置することが出来る。
タイトルラベルについては特に言うことなし。
ボタンウィジェットはcommandにchangePage関数を指定する。
changePage関数は引数にフレーム名をとる。
因みにボタンウィジェットのcommandに引数(selfはカウントしない)をとる関数を指定する場合、
command=lambda :関数
とする必要がある。おわり
かなり短いコードにしたので分かりやすいと思う。
今まで僕が見た中で最短だもの。
もちろんtkraiseを使わずその都度ページを表示したり消したりするやり方もあるけど一番簡単なのはtkraiseだと思う。

- 投稿日:2020-01-26T20:48:42+09:00
Atcoder Beginner Contest 146参戦日記
C
範囲より全探索が難しいことがわかる。何らかの法則性があると考えてごにょごにょしたが、解けなかった。
この問題のポイントは、
1. $A×N+B×d(N)$円が線型性を持つことに気づくこと
2. 二分探索が線形問題を解決できることに気づくこと
である。
- は自明。
- は昇順ソートされた配列は線形関数と同義であることを意識しなければいけない
私は、2.について理解していなかった。
A , B , X = map(int,input().split()) ans = 10**9 // 2 diff = ans digit_ans = len(str(ans)) while not A * ans + B * digit_ans <= X < A * (ans+1) + B * len(str(ans+1)): diff = max(diff // 2 , 1) if A * ans + B * digit_ans > X: ans -= diff else: ans += diff digit_ans = len(str(ans)) #print(ans) if ans >= 10 ** 9: print(10**9) exit() elif ans <= 0: print("0") exit() print(ans)D
ルートを一つ定め、使った色以外を色付けすることで解ける。貪欲法。
配色、探索済みを二次元リストで行おうとしたところTLE。
辞書型を使うことで解決した為、メモリの問題?だと考えられる。
(中盤の大きなコメントアウトは二次元リスト仕様の残党)from collections import deque # 入力、初期化 N = int(input()) tree = [[] for _ in range(N)] input_list = [] for _ in range(N - 1): a, b = map(int, input().split()) a, b = a - 1, b - 1 input_list.append([a, b]) tree[a].append(b) tree[b].append(a) # visitedにノードの色を格納する # visited_edge = [[0] * N for _ in range(N)] dict = {} ''' # bfsによる色付けを行う def bfs(now_node, max_val=0): queue = deque([[tree[now_node], -1, now_node]]) while queue: next_nodes, before_color, now_node = queue.pop() now_color = 1 for next_node in next_nodes: if visited_edge[now_node][next_node] != 0: continue if now_color == before_color: now_color += 1 if max_val < now_color: max_val = now_color visited_edge[next_node][now_node] = now_color visited_edge[now_node][next_node] = now_color queue.appendleft([tree[next_node], now_color, next_node]) now_color += 1 return max_val ''' def bfs(now_node, max_val=0): queue = deque([[tree[now_node], -1, now_node]]) while queue: next_nodes, before_color, now_node = queue.pop() now_color = 1 for next_node in next_nodes: key = tuple(sorted([now_node, next_node])) if not dict.get(key) is None: continue if now_color == before_color: now_color += 1 if max_val < now_color: max_val = now_color dict[key] = now_color # visited_edge[now_node][next_node] = now_color queue.appendleft([tree[next_node], now_color, next_node]) now_color += 1 return max_val ans = bfs(0) print(ans) for a, b in input_list: # print(visited_edge[a][b]) print(dict[tuple(sorted([a,b]))])
- 投稿日:2020-01-26T20:29:19+09:00
xgboostとは(2)(初心者向け)
xgboostは、ブースティングの中でも勾配ブースティング(Gradient Boosting)を使う。
イメージしておくポイントをまとめておく。勾配ブースティング(Gradient Boosting)
ある関数、損失関数を定義したときに損失を最小化する方向を探すことで学習するモデル。
数式でイメージをもっておく。
損失関数
予測値と実績値がどれくらいか、差分があるかを判断するためにある指標を(=関数)を使う。
その指標が最小になるようにモデルのパラメータを動かしていく。XGBoostの損失関数は、以下。
予測値と目的値の誤差の合計に正則化項を足したもの。2つ目の式は正則化項を表す。回帰木の重みwがあることで、損失関数の最小化時にwによって考慮され、過学習になることを防ぐ。
各変数の説明は以下。
関数最適化
損失関数が出来上がったので、あとは損失関数を最適化するだけです。
上記損失関数を変形してwで微分すると
となる。この式を0とした時のwが、損失関数を最小化する。(高校数学レベル)
となる。これを近似した損失関数に代入すると最小の損失値が求まる。
ここで、XGBoostの構造をq。
これがxgboostを評価する数式。まとめ
xgboostは、ブースティングによってモデルの作成と学習、学習時に勾配情報でパラメータを決定し更新していくモデル。
参考





- 投稿日:2020-01-26T20:25:20+09:00
Python(Flask)での画像の送受信メモ
はじめに
今回は、pythonのフレームワーク flaskでの画像の受け取り方の一つをメモします。
具体的には、画像をbase64にエンコードされた形式で受け取り、flask側でデコードして画像を復元します。
ついでに、open-cvを使用して復元した画像をグレースケールに変換して、再度base64にエンコードして返却するところまでメモします。ソース
使用するライブラリは下記です。
requirements.txtflask flask-cors opencv-python opencv-contrib-pythonリクエストでもらうデータは、複数枚扱いたいのでjson形式にします。
[ { id : 0 Image : id4zFjyrkAuSI2vUBKVLP...(base64でエンコードされたイメージ) }, { id : 1 Image : k75GN/oll7KUCulSpSM/S...(base64でエンコードされたイメージ) } ]main.pyfrom flask import Flask, jsonify, request from flask_cors import CORS import cv2 import numpy as np import base64 app = Flask('flask-tesseract-api') CORS(app) @app.route("/image/", methods=["POST"]) def post(): """ 画像をグレースケールに変換する """ response = [] for json in request.json: # Imageをデコード img_stream = base64.b64decode(json['Image']) # 配列に変換 img_array = np.asarray(bytearray(img_stream), dtype=np.uint8) # open-cv でグレースケール img_gray = cv2.imdecode(img_array, 0) # 変換結果を保存 cv2.imwrite('result.png', img_before) # 保存したファイルに対してエンコード with open('result.png', "rb") as f: img_base64 = base64.b64encode(f.read()).decode('utf-8') # レスポンスのjsonに箱詰め response.append({'id':json['id'], 'result' : img_base64}) return jsonify(response) if __name__ == '__main__': app.run(host='0.0.0.0',port=5000,debug=True)まとめ
複数の画像をエンコードした状態で、json形式としてflaskに送ることができました。
これで、複数枚の画像を同時に扱う機能が実装できますね。
- 投稿日:2020-01-26T20:23:53+09:00
venv環境でpythonスクリプトをcronで周期実行
cronにpythonのジョブを登録してvenv環境で周期実行するためには
結論
使いたいvenv環境下のpythonを使えばよい。
$ crontab -e * * * * * cd [絶対パス]; venv/bin/python foo.py具体例
一分に一回、日時をjsonline形式でファイルに書き出したい。
OS環境
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G87ディレクトリを作り、venv仮想環境作り、今回使うパッケージjsonlinesをインストール。
$ mkdir [場所] $ cd [場所] $ python -V Python 3.7.1 $ python -m venv venv $ source venv/bin/activate (venv) $ pip install jsonlinespythonスクリプトを書く。処理された日時をjsonlineとして、out.jsonlに書き出す、というものです。確認のためprintも。
dt2jsonl.pyimport datetime import jsonlines dt = datetime.datetime.now() dict_now = {'date': str(dt.date()), 'time': str(dt.time())} with jsonlines.open('out.jsonl', mode='a') as writer: writer.write(dict_now) print('updated: '+ str(dt))処理させるとこんな感じでアウトプットが。
(venv) $ python dt2jsonl.py updated: 2020-01-26 17:39:23.435616 (venv) $ cat out.jsonl {"date": "2020-01-26", "time": "17:39:23.435616"}
python dt2jsonl.pyのままcronに登録してみる。* * * * *なので一分に一回処理されるはず。
エラーとprint結果を確認するため、>> /tmp/cron.log 2>&1でstderrとstdoutを/tmp/cron.logに書き出すようにする。(venv) $ crontab -e * * * * * python dt2jsonl.py >> /tmp/cron.log 2>&1待っていると
/tmp/cron.logにエラーが(venv) $ tail -f /tmp/cron.log python: can't open file 'dt2jsonl.py': [Errno 2] No such file or directory
dt2jsonl.pyが見つからないらしいので、cronがどこにいるのか確認。(venv) $ crontab -e * * * * * pwd >> /tmp/cron.log 2>&1(venv) $ tail -f /tmp/cron.log /Users/[ユーザ]ユーザディレクトリにいるので、スクリプトの絶対パスを教えてあげる。
(venv) $ crontab -e * * * * * python /Users/[ユーザ]/[場所]/dt2jsonl.py >> /tmp/cron.log 2>&1(venv) $ tail -f /tmp/cron.log Traceback (most recent call last): File "/Users/[ユーザ]/[場所]/dt2jsonl.py", line 2, in <module> import jsonlines ImportError: No module named jsonlines今度はpythonスクリプトにたどり着いたが、jsonlinesがないと。venv環境で実行されてないので、cronはどのpythonを使っているのか確認。
(venv) $ crontab -e * * * * * which python >> /tmp/cron.log 2>&1; python -V >> /tmp/cron.log 2>&1(venv) $ tail -f /tmp/cron.log /usr/bin/python Python 2.7.10システムのpython2.7を使っているので、なんとかするべき。
どのpythonを使うべきかチェック。(venv) $ which python /Users/[ユーザ]/[場所]/venv/bin/pythonvenv下のpythonに書き換える。
(venv) $ crontab -e * * * * * /Users/[ユーザ]/[場所]/venv/bin/python /Users/[ユーザ]/[場所]/dt2jsonl.py >> /tmp/cron.log 2>&1ちょっと待つと、
/tmp/cron.logにprintの結果がでた。(venv) $ tail -f /tmp/cron.log updated: 2020-01-26 17:48:00.924120(venv) $ cat out.jsonl {"date": "2020-01-26", "time": "17:39:23.435616"}out.jsonlにもjsonlineとして書き出されていると思いきや、最初に手動で実行したもので、cronで実行された結果ではない。
ユーザディレクトリで実行されたので、ユーザディレクトリにあった。(venv) $ cat ~/out.jsonl {"date": "2020-01-26", "time": "17:48:00.924120"} {"date": "2020-01-26", "time": "17:49:01.102146"} {"date": "2020-01-26", "time": "17:50:00.278025"}アウトプットの場所が違いますが、cronはvenv環境で処理してくれた。
pythonスクリプトのアウトプットを絶対パスで指定するのもいいですが、
今回はcronの実行ディレクトリを変える。(venv) $ crontab -e * * * * * cd /Users/[ユーザ]/[場所]; venv/bin/python dt2jsonl.py >> /tmp/cron.log 2>&1これで期待通りになった。
(venv) $ tail -f /tmp/cron.log updated: 2020-01-26 17:55:00.837256(venv) $ cat out.jsonl {"date": "2020-01-26", "time": "17:39:23.435616"} {"date": "2020-01-26", "time": "17:55:00.837256"}ちょっと待つと
(venv) $ cat out.jsonl {"date": "2020-01-26", "time": "17:39:23.435616"} {"date": "2020-01-26", "time": "17:55:00.837256"} {"date": "2020-01-26", "time": "17:56:00.986909"} {"date": "2020-01-26", "time": "17:57:01.167183"} {"date": "2020-01-26", "time": "17:58:00.273073"}
- 投稿日:2020-01-26T19:53:04+09:00
AtCoder Beginner Contest 119 過去問復習
所要時間
感想
C問題解くの面倒臭がってたのに結局素直な解法で解けたので、バチャコン中の集中力のなさを感じました。
あと、数式を$で囲んで表示しているのですが、なぜか改行が入るようになってしまいました。有識者の方、対処法を教えていただけるとありがたいです。A問題
2019年かどうかの場合わけはいらなかった…、誤読…。
splitを使えばバックスラッシュで分割ができる。answerA.pys=list(map(int,input().split("/"))) if s[0]<2019: print("Heisei") elif s[0]>2020: print("TBD") else: print("TBD" if s[1]>4 else "Heisei")answerA_better.pys=list(map(int,input().split("/"))) print("TBD" if s[1]>4 else "Heisei")B問題
bitコインかどうかで場合わけしながら全てのsumを考えれば良い。
answerB.pyn=int(input()) cnt=0.0 for i in range(n): x,u=input().split() x=float(x) cnt+=(x if u=="JPY" else x*380000.0) print(cnt)C問題
Dより難しかったです(白目)。
全通り試せることは明らかですが全通りを書き出すのが面倒だったので工夫する方法を考えていたら時間が途方もなく過ぎていきました。
全通り試す際には、竹の選び方のみにMPは依存してその順番には依存しないことにまず注意します。このもとでA,B,Cのどの竹を作るためにそれぞれの竹を使うのかを考えれば良いです(A,B,C,使わない,の4通りに分けて考えると綺麗に実装することができ、解答はこの方法で実装していました。)。
まず、A,B,Cのどの竹に使うかを考えるために元のn本の竹に対してそれぞれ(A~Cに対応する)0~2の番号をつけます(1)。この時点でA,B,Cそれぞれの竹を作るために使うことのできる(使わなくても良い)竹が決まりました。また、この時点で0~2の番号は少なくとも一つ現れる必要があるので、一つもない番号がある場合は次のループへと処理を移します(2)。このもとでそれぞれのA,B,Cをどの竹で作るのかを考えますが、A,B,Cそれぞれの竹を作るために使うことのできる竹の中から任意の本数を選んで良いので、bit列により部分集合を考えます(3)。ただし、この際も一つも竹を選ばない場合は考えないので、そのような場合は除いて考えます(4)。このように考えることでそれぞれの場合においてA,B,Cの長さを決めるために必要なMPは一意に決めることができる(5)ので、それぞれの最小値を考えていくことで、題意の最小のMPを求めることができます。
以上を実装して以下のようになるのですが、変数名をつけるのが下手すぎて混乱してしまったのと上記の議論をうまく頭の中で整理できておらず、解くのに非常に時間がかかってしまいました。毎回のように頭の中を整理するために書き出すべきと思っているのですが、いざ解くと忘れてしまいます。繰り返して解く際の姿勢を刷り込むしかないかなと思いました。answerC.pyimport itertools n,*abc=map(int,input().split()) l=[int(input()) for i in range(n)] inf=100000000000000 mi=inf for i in list(itertools.product([i for i in range(3)],repeat=n)):#(1)↓ sub=[[] for j in range(3)] for j in range(n): sub[i[j]].append(j) mi_sub=0 for j in range(3): l_sub=len(sub[j]) if l_sub==0:#(2) mi_sub=inf break mi_subsub=inf for k in range(2**l_sub):#(3)↓ mi_subsubsub=[0,0] for l_subsub in range(l_sub):#(5)↓ if ((k>>l_subsub) &1): mi_subsubsub[0]+=1 mi_subsubsub[1]+=l[sub[j][l_subsub]] if mi_subsubsub[0]!=0:#(4) mi_subsub=min(mi_subsub,abs(mi_subsubsub[1]-abc[j])+mi_subsubsub[0]*10-10) mi_sub+=mi_subsub mi=min(mi,mi_sub) print(mi)itertools.product
複数のリストの直積を生成することができる関数(多重ループのイテレータを簡潔に書くことができる)。
引数にそのリストを複数指定することで返り値としてitertools.product型のオブジェクトを生成して返す。そして、for文を回すことでその全組み合わせを一つずつ取り出すことができる(リスト化することも可能)。
さらに、repeatに繰り返しの回数を指定することで同じリスト同士の直積を生成することも可能で、この問題ではリストmについてrepeat=nとして直積を生成している。D問題
初めは区間スケジューリングやいもす法っぽさがあるなと思ったのですが、冷静に考えてそうではありませんでした。アルゴリズムベースではなくその問題ベースで問題を考察すると沼にハマりにくく考察力も上がる気がします。
ここで、あるxにいた時を考えます。すると、xは$s_{i-1}$,$s_i$に囲まれてるかつ$t_{j-1}$,$t_j$に囲まれていることになります($s_0$,$t_0$,$s_{a-1}$,$t_{b-1}$より外側にある場合は少し異なります。)。この時、$s_{i-1}$,$s_i$のどちらかの点、$t_{j-1}$,$t_j$のどちらかの点をそれぞれ通るように移動することで最小の移動距離が達成できることは明らか(このことに気付くまでにちゃんと図を書いて考える)なので、$2\times2$の4通りを全て調べれば良いです(また、$s_0$,$t_0$,$s_{a-1}$,$t_{b-1}$より外側にある場合は通るべき候補の点が少なくなります。)。さらに、xがどの範囲にあるかは二分探索を用いることでlogの計算量で求めることができるので十分高速なプログラムになります。これらを実装して以下のとおりです。また、選んだ二点のうち近い方から訪問することで移動距離は小さくなります。answerD.pya,b,q=map(int,input().split()) s=[int(input()) for i in range(a)] t=[int(input()) for i in range(b)] x=[int(input()) for i in range(q)] from bisect import bisect_left for i in range(q): y=bisect_left(s,x[i]) z=bisect_left(t,x[i]) k=([0] if y==0 else [a-1] if y==a else [y-1,y]) l=([0] if z==0 else [b-1] if z==b else [z-1,z]) mi=100000000000000 for n in k: for m in l: if abs(s[n]-x[i])>abs(t[m]-x[i]): sub1,sub2=t[m],s[n] else: sub1,sub2=s[n],t[m] mi=min(mi,abs(sub1-x[i])+abs(sub2-sub1)) print(mi)bisect
挿入の度にリストをソートすることなく、リストをソートされた順序に保つことをサポートするようなモジュール。
logのオーダーで動作する二分法アルゴリズムを用いているためにbisectと呼ばれる。
bisect_leftとbisect_right,insort_leftとinsort_rightの四つの関数を主に用いる。
まず、bisect_leftとbisect_rightについて考える。調べたい要素をx、調べるソート済みの配列をaとした時、前者であれば既存のxのうちの一番左側のaへの挿入箇所が返され、後者であれば既存のxのうちの一番右側のaへの挿入箇所が返される(以上二つの動作はどちらもソートされた順序を保つ)。すなわち、前者はx以上でもっとも小さい要素のインデックスを返し、後者はxより大きくもっとも小さい要素のインデックスを返す事がわかる(挿入の挙動の図を書けば容易にわかる。)。
また、insort_leftとinsort_rightについては、bisect_leftとbisect_rightでそれぞれ示した位置に挿入を行うような関数であり、ソートされた順序をそのままに保つ。

- 投稿日:2020-01-26T18:44:27+09:00
Djangoでテスト駆動開発 その2
Djangoでテスト駆動開発 その2
これはDjangoでテスト駆動開発(Test Driven Development, 以下:TDD)を理解するための学習用メモです。
参考文献はTest-Driven Development with Python: Obey the Testing Goat: Using Django, Selenium, and JavaScript (English Edition) 2nd Editionを元に学習を進めていきます。
本書ではDjango1.1系とFireFoxを使って機能テスト等を実施していますが、今回はDjagno3系とGoogle Chromeで機能テストを実施していきます。また一部、個人的な改造を行っていますが(Project名をConfigに変えるなど、、)、大きな変更はありません。
⇒⇒その1はこちら
Part1. The Basics of TDD and Django
Chapter2 Extending Our Functional Test Usinng the unittest Module
Chapter1ではDjangoの環境構築から初めての機能テストを記述し、DjangoのDefaultページが機能しているかどうかを機能テストを通して確認することができました。
今回はToDoアプリケーションを作成しながらこれを実際のフロントページに適用していきたいと思います。ChromeのWebドライバーとSeleniumをつかったテストはユーザー視点でアプリケーションがどう機能するのかを確認することができるため、機能テストと呼ばれています。
これはユーザーがアプリケーションを使用するときの ユーザーストーリー をなぞるものであり、ユーザーがアプリケーションをどう利用して、それに対してアプリケーションがどうレスポンスを返すのかを決定づけるものと言えます。Functional Test == Acceptance Test == End-To-End Test
今回参考にしているTest-Driven Development with Python: Obey the Testing Goat: Using Django, Selenium, and JavaScript (English Edition) 2nd Editionではアプリケーションの機能(function)をテストすることをfunctional testsと呼んでいるため、本記事では機能テストと呼んでいます。これは acceptance tests(受け入れテスト) 、End-To-End tests(E2Eテスト、インテグレーションテスト) と呼ばれたりもします。このテストを行うのは外から見てアプリケーション全体がどう機能するのかを確認するためです。
それでは実際のユーザーストーリー想定しながら、機能テストにコメントとして記述していきます。
# django-tdd/functional_tests.py from selenium import webdriver browser = webdriver.Chrome() # のび太は新しいto-doアプリがあると聞いてそのホームページにアクセスした。 browser.get('http://localhost:8000') # のび太はページのタイトルがとヘッダーがto-doアプリであることを示唆していることを確認した。 assert 'To-Do' in browser.title # のび太はto-doアイテムを記入するように促され、 # のび太は「どら焼きを買うこと」とテキストボックスに記入した(彼の親友はどら焼きが大好き) # のび太がエンターを押すと、ページは更新され、 # "1: どら焼きを買うこと"がto-doリストにアイテムとして追加されていることがわかった # テキストボックスは引続きアイテムを記入することができるので、 # 「どら焼きのお金を請求すること」を記入した(彼はお金に関してはきっちりしている) # ページは再び更新され、新しいアイテムが追加されていることが確認できた # のび太はこのto-doアプリが自分のアイテムをきちんと記録されているのかどうかが気になり、 # URLを確認すると、URLはのび太のために特定のURLであるらしいことがわかった # のび太は一度確認した特定のURLにアクセスしてみたところ、 # アイテムが保存されていたので満足して眠りについた。 browser.quit()Titleに関するassertを"Django"から"To-Do"に変更しました。このままでは機能テストが失敗することが予想されます。
ということで機能テストを実行してみます。# ローカルサーバーの起動 $ python manage.py runserver # 別のコマンドラインを立ち上げて # 機能テストの実行 $ python functional_tests.py Traceback (most recent call last): File "functional_tests.py", line 11, in <module> assert 'To-Do' in browser.title AssertionErrorテストは予想していた通り失敗しました。
したがって、このテストが成功できるように開発を進めて行けばいいことがわかります。unittest Moduleを使用する
先ほど実行した機能テストでは
AssertioErrorが親切でない(browser titleが実際に何だったのか知れると嬉しい)
Seleniumで起動させたブラウザが消されず残っている
という煩わしさがありました。これらはPythonの標準モジュールであるunittestモジュールを使うと解決することができます。
機能テストを下記のように書き換えてみます。
# django-tdd/functional_tests.py from selenium import webdriver import unittest class NewVisitorTest(unittest.TestCase): def setUp(self): self.browser = webdriver.Chrome() def tearDown(self): self.browser.quit() def test_can_start_a_list_and_retrieve_it_later(self): # のび太は新しいto-doアプリがあると聞いてそのホームページにアクセスした。 self.browser.get('http://localhost:8000') # のび太はページのタイトルがとヘッダーがto-doアプリであることを示唆していることを確認した。 self.assertIn('To-Do', self.browser.title) self.fail('Finish the test!') # のび太はto-doアイテムを記入するように促され、 # のび太は「どら焼きを買うこと」とテキストボックスに記入した(彼の親友はどら焼きが大好き) # のび太がエンターを押すと、ページは更新され、 # "1: どら焼きを買うこと"がto-doリストにアイテムとして追加されていることがわかった # テキストボックスは引続きアイテムを記入することができるので、 # 「どら焼きのお金を請求すること」を記入した(彼はお金にはきっちりしている) # ページは再び更新され、新しいアイテムが追加されていることが確認できた # のび太はこのto-doアプリが自分のアイテムをきちんと記録されているのかどうかが気になり、 # URLを確認すると、URLはのび太のために特定のURLであるらしいことがわかった # のび太は一度確認した特定のURLにアクセスしてみたところ、 # アイテムが保存されていたので満足して眠りについた。 if __name__ == '__main__': unittest.main(warnings='ignore')機能テストはunittest.TestCaseを継承して書くことができます。
今回のポイントを整理してみます。
- 実行させたいテスト関数は test_ から始めることでテストランナーが自動でテストを走らせる。
- setUp と tearDown はテストが走る前後で実行される特別な関数。
- tearDown はテストエラーでも実行される。
- self.fail()は何がなんでもテストは失敗し、エラーが吐き出される。
- unittest.main()でテストが実行され、自動的にテストケースとそのメソッドが実行される。
- warnings='ignore'のオプションを追加すると過剰なResoureWarningなどを無視することができる。
それでは実行してみましょう。
$ python functional_tests.py ====================================================================== FAIL: test_can_start_a_list_and_retrieve_it_later (__main__.NewVisitorTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "functional_tests.py", line 20, in test_can_start_a_list_and_retrieve_it_later self.assertIn('To-Do', self.browser.title) AssertionError: 'To-Do' not found in 'Django: 納期を逃さない完璧主義者のためのWebフレームワーク' ---------------------------------------------------------------------- Ran 1 test in 7.956s FAILED (failures=1)unittestモジュールを使うことで AssertionError の中身がより理解しやすくなりました。
ここで self.assertIn('To-Do', self.brower.title) を self.assertIn('Django', self.brower.title) としたらテストがクリアできるはずです。これを確認してみます。
# django-tdd/functional_tests.py # ~~省略~~ def test_can_start_a_list_and_retrieve_it_later(self): # のび太は新しいto-doアプリがあると聞いてそのホームページにアクセスした。 self.browser.get('http://localhost:8000') # のび太はページのタイトルがとヘッダーがto-doアプリであることを示唆していることを確認した。 self.assertIn('Django', self.browser.title) # 変更 self.fail('Finish the test!') # ~~省略~~$ python functinal_tests.py ====================================================================== FAIL: test_can_start_a_list_and_retrieve_it_later (__main__.NewVisitorTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "functional_tests.py", line 21, in test_can_start_a_list_and_retrieve_it_later self.fail('Finish the test!') AssertionError: Finish the test! ---------------------------------------------------------------------- Ran 1 test in 6.081s FAILED (failures=1)実行した結果、テストは成功するはずですが、テストはFAILとされてしましました。
AssertionError を確認すると、self.fail('Finish the test') で設定したメッセージが反映されました。
これは self.fail('message') はエラーが無くても必ず設定したエラーメッセージを吐き出す機能を持っているためです。
ここではテストが終わったことがわかるようにリマインダーとして設定されています。ということで今度は self.fail('Finish the test!') をコメントアウトして実行してみます。
# django-tdd/functional_tests.py # ~~省略~~ def test_can_start_a_list_and_retrieve_it_later(self): # のび太は新しいto-doアプリがあると聞いてそのホームページにアクセスした。 self.browser.get('http://localhost:8000') # のび太はページのタイトルがとヘッダーがto-doアプリであることを示唆していることを確認した。 self.assertIn('Django', self.browser.title) # self.fail('Finish the test!') # コメントアウト # ~~省略~~$ python functinal_tests.py . ---------------------------------------------------------------------- Ran 1 test in 7.698s OK確かにエラーは無くテストが成功したことが確認できました。最終的な機能テストの出力はこのような形になるはずです。
functional_tests.py の 変更した箇所を元に戻しておきましょう。# django-tdd/functional_tests.py # ~~省略~~ def test_can_start_a_list_and_retrieve_it_later(self): # のび太は新しいto-doアプリがあると聞いてそのホームページにアクセスした。 self.browser.get('http://localhost:8000') # のび太はページのタイトルがとヘッダーがto-doアプリであることを示唆していることを確認した。 self.assertIn('To-do', self.browser.title) self.fail('Finish the test!') # ~~省略~~Commit
ユーザーストーリーをコメントで追加しながら作成することで、to-doアプリケーションの機能テストを作成して実行することができました。ここでコミットしておきましょう。git statusをすると変更したファイルを確認することができました。
git diffをすると最後のコミットとの差分を確認することができます。
これを実行するとfunctional_tests.pyが大きく変更されていることがわかります。それではコミットしておきます。
$ git add . $ git commit -m "First FT specced out in comments, and now users unittest"Chapter2まとめ
機能テストをDjangoのプロジェクトの立ち上げを確認するレベルから、To-Doアプリケーションを使用するユーザーストーリに基づいたものに変更することができました。更にunittestを使用することでエラーメッセージをよりうまく活用することができることがわかりました。
- 投稿日:2020-01-26T18:42:34+09:00
[Python3 入門 17日目]8章 データの行き先(8.1〜8.2.5)
8.1 ファイルの入出力
- fileobj=open(filename,mode)でファイルを開く。
- fileobjはopen()が返すファイルのオブジェクト
- filenameはファイル名
- ファイルをどうしたいかの選択。
- rは読み出し、wは書き込みで上書き及び新規作成も可能、xは書き込みだがファイルが存在しない場合のみ。
- modeの第二文字目はファイルのタイプを示す。tはテキスト、bはバイナリの意味。
8.1.1 write()によるテキストファイルへの書き込み
>>> poem = """There was a young lady named Bright, ... Whose speed was far faster than light, ... She started one day, ... In a relative way, ... And returned on the previous night.""" >>> len(poem) 151 #write()関数は、書き込んだバイト数を返す。 >>> f=open("relatibity","wt") >>> f.write(poem) 151 >>> f.close() #print()でもテキストファイルに書き込み可能。 #print()は個々の引数の後にスペース、全体の末尾に改行を追加している。 >>> f=open("relatibity","wt") >>> print(poem,file=f) >>> f.close() #print()をwrite()と同じように動作させるにはsep,endを使う。 #sep:セパレータ。デフォルトでスペース(" ")になる。 #end:末尾の文字列。デフォルトで改行("\n")になる。 >>> f=open("relatibity","wt") >>> print(poem,file=f,sep="",end="") >>> f.close() #ソース文字列が非常に大きい場合は、chunkに分割してファイルに書き込みできる。 >>> f=open("relatibity","wt") >>> size=len(poem) >>> offset=0 >>> chunk=100 >>> while True: ... if offset>size: ... break ... f.write(poem[offset:offset+chunk]) ... offset+=chunk ... 100 51 >>> f.close() #xモードにより上書きを防ぐことでファイル破壊を防げる。 >>> f=open("relatibity","xt") Traceback (most recent call last): File "<stdin>", line 1, in <module> FileExistsError: [Errno 17] File exists: 'relatibity' #例外ハンドラとしても使える。 >>> try: ... f=open("relatibity","xt") ... f.write("stomp stomp stomp") ... except FileExistsError: ... print("relativity already exists!. That was a close one.") ... relativity already exists!. That was a close one.8.1.2 read(),readline(),headlines()によるテキストファイルの読み出し
#ファイル全体を一度に読み出すことができる。 >>> fin=open("relatibity","rt") >>> poem=fin.read() >>> fin.close() >>> len(poem) 151 #read()の引数に字数を入れることで一度に返すデータ量を制限できる。 #ファイルを全て読んだ後でさらにread()を呼び出すと、空文字列("")が返される。→if not f:でFalseと評価される。 >>> poem="" >>> fin=open("relatibity","rt") >>> chunk=100 >>> while True: ... f=fin.read(chunk) ... if not f: ... break ... poem+=f ... >>> fin.close() >>> len(poem) 151 #readline()を使えば、ファイルを1行ずつ読み出すことができる。 #ファイルを全て読み込むとread()同様に空文字列を返し、Falseと評価される。 >>> poem="" >>> fin=open("relatibity","rt") >>> while True: ... line=fin.readline() ... if not line: ... break ... poem+=line ... >>> fin.close() >>> len(poem) 151 #イテレータと使って簡単に読み出すことができる。 >>> poem="" >>> fin=open("relatibity","rt") >>> for line in fin: ... poem+=line ... >>> fin.close() >>> len(poem) 151 #readlines()は一度に一行ずつ読み出して、一行文字列のリストを返す。 >>> fin=open("relativity","rt") >>> lines=fin.readlines() >>> fin.close() >>> for line in lines: ... print(line,end="") ... There was a young lady named Bright, Whose speed was far faster than light, She started one day, In a relative way, And returned on the previous night.>>>8.1.3 write()によるバイナリファイルの書き込み
- モード文字列に"b"を追加するとファイルはバイナリモードで開かれる。この場合、文字列ではなくbytesを読み書きすることになる。
#0から255までの256バイトを生成しよう。 >>> bdata=bytes(range(0,256)) >>> len(bdata) 256 >>> f=open("bfile","wb") >>> f.write(bdata) 256 >>> f.close() #テキストの場合と同様にchunk単位で書き込むこともできる。 >>> f=open("bfile","wb") >>> size=len(bdata) >>> offset=0 >>> chunk=100 >>> while True: ... if offset>size: ... break ... f.write(bdata[offset:offset+chunk]) ... offset+=chunk ... 100 100 56 >>> f.close8.1.4 read()によるバイナリファイルの読み出し
#"rb"として開けば良い。 >>> f=open("bfile","rb") >>> bdata=f.read() >>> len(bdata) 256 >>> f.close()8.1.5 withによるファイルの自動的なクローズ
- with以下のコンテキストブロックが終わると自動でファイルを閉じてくれる。
- with expression as variableという形式で使う。
>>> with open("relatibity","wt") as f: ... f.write(poem) ... 1518.1.6 seek()による位置の変更
tell()関数は、ファイルの先頭から現在地までのオフセットをバイト単位で返す。
seek()関数はファイルオブジェクトの位置を変更できる。
- ファイルオブジェクトの位置を変更するには、f.seek(offset, whence)を使う。標準のosモジュールでも定義されている。
- ファイル位置は基準点にオフセット値を足して計算される。
- 参照点はwhence引数で選択。0なら先頭からoffsetまでの位置、1なら現在の位置からoffsetバイトまでの位置、2なら末尾からoffsetバイトの位置にそれぞれ移動する。
- whenceは省略可能で、デフォルト値は0、すなわち参照点としてファイルの先頭を使う。
>>> f=open("bfile","rb") >>> f.tell() 0 #seek()を使ってファイルの末尾の1バイト手前に移動する。 #場所(255)まで移動して、そこから後ろを読み出した。→最後の1バイトが読み込まれた。 #254と255の間に位置し、最後の読み込みで、255を読み込んだイメージ。 >>> f.seek(255) 255 >>> b=f.read() >>> len(b) 1 #seek()は移動後のオフセットも返してくる。 >>> b[0] 255 >>> import os >>> os.SEEK_SET 0 >>> os.SEEK_CUR 1 >>> os.SEEK_END 2 >>> f=open("bfile","rb") #末尾から-1オフセットした位置に移動した。 >>> f.seek(-1,2) 255 #ファイルの先頭からオフセットをバイト単位で返す。 >>> f.tell() 255 >>> b=f.read() >>> len(b) 1 >>> b[0] 255 #ファイルの先頭から末尾の2バイト前まで移動 #253と254の間にいるイメージ >>> f=open("bfile","rb") >>> f.seek(254,0) 254 >>> f.tell() 254 #ファイルの末尾の2バイト前から1バイト前まで移動 #254と255の間にいるイメージ >>> f.seek(1,1) 255 >>> f.tell() 255 >>> b=f.read() >>> len(b) 1 >>> b[0] 2558.2 構造化されたテキストファイル
- 構造的なデータを作るには以下のような方法がある。
- セパレータ、区切り子。タブ("\t")、カンマ(",")、縦棒("|")などで区切る。CSV形式。
- タグを"<"と">"で区切る。XMLやHTMLがこれにあたる。
- 記号を駆使するもの。JSONがそう。
- インデント。例えば、YAMLがこれに当たる。
CSV
- 区切り子によってフィールドに区切られているファイルは、スプレッドシートやデータベースとのデータ交換形式に用いられる。
- 一部のファイルはエスケープシーケンスを使っている。区切り子の文字がフィールド内で使われる可能性がある場合、フィールド全体をクォート文字で囲むか、区切り子の前にエスケープ文字をつける。
>>> import csv >>> villains=[ ... ["Doctor","No"], ... ["R","K"], ... ["Mister","Big"], ... ["Auric","Goldfinger"], ... ["E","B"], ... ] >>> with open ("villains","wt") as fout: #writer()で書き込み ... csvout=csv.writer(fout) #villainsというcsvファイルが作られた。 ... csvout.writerows(villains)実行結果Docter,No R,K Miser,Big Auric,Goldfinger E,B>> import csv >>> with open("villains","rt") as fin: #reader()で読み込み ... cin=csv.reader(fin) ... villains=[row for row in cin] ... >>> print(villains) [['Doctor', 'No'], ['R', 'K'], ['Mister', 'Big'], ['Auric', 'Goldfinger'], ['E', 'B']]#DictReader()を使って列名を指定する。 >>> import csv >>> with open("villains","rt") as fin: ... cin=csv.DictReader(fin,fieldnames=["first","last"]) ... villains=[row for row in cin] ... >>> print(villains) [{'first': 'Docter', 'last': 'No'}, {'first': 'R', 'last': 'K'}, {'first': 'Miser', 'last': 'Big'}, {'first': 'Auric', 'last': 'Goldfinger'}, {'first': 'E', 'last': 'B'}] >>> import csv >>> villains= [ ... {"first":"Docter","last":"No"}, ... {"first":"R","last":"K"}, ... {"first":"Miser","last":"Big"}, ... {"first":"Auric","last":"Goldfinger"}, ... {"first":"E","last":"B"}, ... ] >>> with open("villains","wt") as fout: ... cout=csv.DictWriter(fout,["first","last"]) #writeheader()を使ってCSVファイルの先頭に列名も書き込むことができる。 ... cout.writeheader() ... cout.writerows(villains) ...実行結果first,last Docter,No R,K Miser,Big Auric,Goldfinger E,B#ファイルからデータを読み直す。 #DictReader()呼び出しの中でfieldnames引数を省略すると、ファイルの第一行の値(first,last)を列ラベルの辞書キーとして使えという意味になる。 >>> import csv >>> with open("villains","rt") as fin: ... cin=csv.DictReader(fin) ... villains=[row for row in cin] ... >>> print(villains) [OrderedDict([('first', 'Docter'), ('last', 'No')]), OrderedDict([('first', 'R'), ('last', 'K')]), OrderedDict([('first', 'Miser'), ('last', 'Big')]), OrderedDict([('first', 'Auric'), ('last', 'Goldfinger')]), OrderedDict([('first', 'E'), ('last', 'B')])]8.2.2 XML
- XMLを簡単に読み取るためにはElementTreeを使う。
menu.xml<?xml version="1.0"?> <menu> #開始タグにはオプションの属性を組み込める。 <breakfast hours="7-11"> <item price="$6.00">breakfast burritos</item> <item price="$4.00">pancakes</item> </breakfast> <lunch hours="11-3"> <item price="$5.00">hamburger</item> </lunch> <dinner hours="3-10"> <item price="$8.00">spaghetti</item> </dinner> </menu>>>> import xml.etree.ElementTree as et >>> tree=et.ElementTree(file="menu.xml") >>> root=tree.getroot() >>> root.tag 'menu' #tagはタグの文字列、attribはその属性の辞書である。 >>> for child in root: ... print("tag:",child.tag,"attributes:",child.attrib) ... for grandchild in child: ... print("\ttag:",grandchild.tag,"attributes:",grandchild.attrib) ... tag: breakfast attributes: {'hours': '7-11'} tag: item attributes: {'price': '$6.00'} tag: item attributes: {'price': '$4.00'} tag: lunch attributes: {'hours': '11-3'} tag: item attributes: {'price': '$5.00'} tag: dinner attributes: {'hours': '3-10'} tag: item attributes: {'price': '$8.00'} #menuセクション数 >>> len(root) 3 #breakfastの項目数 >>> len(root[0]) 28.2.3 JSON
- JavaSciriptという枠を超えて非常に使われているデータ交換形式になっている。
- JSON形式はJavaSciriptのサブセットであり、Pythonで用いられることも多い。
- JSONモジュールのjsonはPythonデータをJSON文字列にエンコード(ダンプ)したり、JSON文字列をPythonデータにデコード(ロード)したりする。
#データ構造を作成 >>> menu=\ ... { ... "breakfast":{ ... "hours":"7-11", ... "items":{ ... "breakfast burritos":"$6.00", ... "pancakes":"$4.00" ... } ... }, ... "lunch":{ ... "hours":"11-3", ... "items":{ ... "hamburger":"$5.00" ... } ... }, ... "dinner":{ ... "hours":"3-10", ... "items":{ ... "spaghetti":"$8.00" ... } ... } ... } #dumps()を使ってこのデータ構造(menu)をJSON文字列(menu_json)にエンコードする。 >>> import json >>> menu_json=json.dumps(menu) >>> menu_json `{"breakfast": {"hours": "7-11", "items": {"breakfast burritos": "$6.00", "pancakes": "$4.00"}}, "lunch": {"hours": "11-3", "items": {"hamburger": "$5.00"}}, "dinner": {"hours": "3-10", "items": {"spaghetti": "$8.00"}}}` #loads()を使って、JSON文字列のmenu_jsonをPythonデータ構造menu2に戻す。 >>> menu2=json.loads(menu_json) >>> menu2 {'breakfast': {'hours': '7-11', 'items': {'breakfast burritos': '$6.00', 'pancakes': '$4.00'}}, 'lunch': {'hours': '11-3', 'items': {'hamburger': '$5.00'}}, 'dinner': {'hours': '3-10', 'items': {'spaghetti': '$8.00'}}} #datetimeなどの一部のオブジェクトをエンコード、デコードしようとすると、以下のような例外が発生する。 #これはJSON標準が日付、時刻型を定義していないため。 >>> import datetime >>> now=datetime.datetime.utcnow() >>> now datetime.datetime(2020, 1, 23, 1, 59, 51, 106364) >>> json.dumps(now) #...省略 TypeError: Object of type datetime is not JSON serializable #datetimeを文字列やUnix時間へ変換すれば良い。 >>> now_str=str(now) >>> json.dumps(now_str) '"2020-01-23 01:59:51.106364"' >>> from time import mktime >>> now_epoch=int(mktime(now.timetuple())) >>> json.dumps(now_epoch) '1579712391' #通常変換されるデータ型にdatetime型の値が含まれている場合には、都度変換するのは煩わしい。 #そこで、json.JSONEncoderを継承したクラスを作成する。 #defaultメソッドをオーバーライド。 #isinstance()関数はobjがdatetime.datetimeクラスのオブジェクトか確認。 >>> class DTEncoder(json.JSONEncoder): ... def default(self,obj): ... #isinstance()はobjの型をチェックする。 ... if isinstance(obj,datetime.datetime): ... return int(mktime(obj.timetuple())) ... return json.JSONEncoder.default(self,obj) ... #now=datetime.datetime.utcnow()と定義しているのでTrueが返される。 >>> json.dumps(now,cls=DTEncoder) `1579712391` >>> type(now) <class `datetime.datetime`> >>> isinstance(now,datetime.datetime) True >>> type(234) <class `int`> >>> type("hey") <class `str`> >>> isinstance("hey",str) True >>> isinstance(234,int) True8.2.4 YAML
JSONと同様にYAMLはキーと値を持つが、日付と時刻を始めとして、JSONよりも多くのデータ型を処理することができる。
YAMLの処理をするためにはPyYAMLをというライブラリをインストールする必要がある。
mcintyre.yamlname: first:James last:McIntyre dates: birth:1828-05-25 death:1906-03-31 details: bearded:true themes:[cheese,Canada] books: url:http://www.gutenberg.org/files/36068/36068-h/36068-h.htm poems: - title: "Motto" #半角スペースがなかったためにエラー発生。 text: | Politeness,perseverance and pluck, To their possessor will bring good luck. - title: "Canadian Charms" #半角スペースがなかったためにエラー発生。 text: | Here industry is not in vain, For we have bounteous crops of grain, And you behold on every field Of grass and roots abundant yield, But after all the greatest charm Is the snug home upon the farm, And stone walls now keep cattle warm.>>> import yaml >>> with open("mcintyre.yaml","rt") as fin: ... text=fin.read() ... >>> data=yaml.load(text) >>> data["details"] 'bearded:true themes:[cheese,Canada]' >>> len(data["poems"]) 28.2.5 pickleによるシリアライズ
- Pythonのデータ階層を取り、文字列表現に変換することをシリアライズという。文字列表現からデータを再構築することをデシリアライズという。
シリアライズされてからデシリアライズされるまでの間に、オブジェクトの文字列表現はファイルやデータの形で保存したり、ネットワークを通じて離れたマシンに送ったりすることができる。
Pythonは特別なバイナリ形式で、あらゆるオブジェクトを保存、復元できるpickleモジュールを提供している。
>>> import pickle >>> import datetime >>> now1=datetime.datetime.utcnow() >>> pickled=pickle.dumps(now1) >>> now2=pickle.loads(pickled) >>> now1 datetime.datetime(2020, 1, 23, 5, 30, 56, 648873) >>> now2 datetime.datetime(2020, 1, 23, 5, 30, 56, 648873) #pickleはプログラム内で定義された独自クラスやオブジェクトも処理できる。 >>> import pickle >>> class Tiny(): ... def __str__(self): ... return "tiny" ... >>> obj1=Tiny() >>> obj1 <__main__.Tiny object at 0x10af86910> >>> str(obj1) 'tiny' #pickledはobj1オブジェクトからpickleでシリアライズしたバイナリシーケンス。 #dump()を使ってファイルにシリアライズ。 >>> pickled=pickle.dumps(obj1) >>> pickled b'\x80\x03c__main__\nTiny\nq\x00)\x81q\x01.' #obj2に変換し戻して、obj1のコピーを作っている。 #loads()を使ってファイルからオブジェクトをデシリアライズ。 >>> obj2=pickle.loads(pickled) >>> obj2 <__main__.Tiny object at 0x10b21cdd0> >>> str(obj2) 'tiny'感想
ようやく次はRDBMSへ。
参考文献
「Bill Lubanovic著 『入門 Python3』(オライリージャパン発行)」
「Pythonチュートリアル 3.8.1ドキュメント 7.入力と出力」
https://docs.python.org/ja/3/tutorial/inputoutput.html#old-string-formatting
- 投稿日:2020-01-26T18:38:19+09:00
『退屈なことはPythonにやらせよう』 7章演習問題回答例
『退屈なことはPythonにやらせよう』 7章演習問題回答例
書いてみました。
もっといいやり方は絶対あると思いますが・・・。import re strongPassword_regex = re.compile(r'''( [a-z]+[A-Z]+[0-9]+| [a-z]+[0-9]+[A-Z]+| [A-Z]+[a-z]+[0-9]+| [A-Z]+[0-9]+[a-z]+| [0-9]+[a-z]+[A-Z]+| [0-9]+[A-Z]+[a-z]+| )''', re.VERBOSE) while True: print('パスワードを入力してください:') print('(英数字で大文字、小文字、数字をそれぞれ1文字以上使用し、8文字以上にしてください)') password = input() mo = strongPassword_regex.search(password) if mo is not None and len(password) >= 8: print('強いパスワードです。') break else: print('弱いパスワードです、再度入力してください。')
- 投稿日:2020-01-26T18:31:06+09:00
はじめてMacで Pythonやってみた。
はじめに
はじめまして。Qiita初投稿のタロウと申します。
社会人歴4年くらいで、開発者としてゴリゴリにコード書いてたのは2年半くらい、
他は要件定義したり、PMに近いことしたり、採用コンサルしたりフラフラしてるタイプの人間です。自宅ではデスクトップPC使ってごく稀にPython書いたり、
gasでやりたくもない業務ツールの開発したりしてましたが、
なんとなくMacに手を出したくなり昨年末にMacbookを購入しました。
さっそくPythonで簡単なクロールツール書いてみようと思ったのですが、
Windowsの時と違って環境構築になんか時間がかかったので、
そのときにやったことを今回は(雑)メモとして残そうと思ってます。
※ローカルで雑にコード書くだけならデフォルトでPython2系は入ってるみたいですスキル
- Java
- 業務用システム開発で2年弱くらい (
class?継承? なにそれおいしry)- Python
- Webアプリ開発(FW:Django)…1年弱くらい
- 簡単なクロールツールくらいは作れる(
と信じたい)環境
・MacBook Pro (13-inch 2016)
・macOS Catalina Version 10.15.2
・Xcode Version 11.3目標とやること
目標
- Python3系の環境を構築
- ターミナルに「Hello world!」を表示させる
やること
- Xcodeをインストール
- Homebrewのインストール
- pyenvのインストール
- Python3.○.○のインストール(自分が入れたいもの)
- 「Hello world!」の表示
※Homebrewはざっくり言うとMacでの環境構築が楽になるパッケージ管理ツール
※2〜4はこの辺参照Xcodeをインストール
App storeから適宜インストール。
Homebrewのインストール
Homebrewの公式HPからインストール用のコマンドをコピペして実行します。
【例】
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"実行すると
returnとPasswordを求められるタイミングがあるので、適宜入力してください。
※Passwordはログイン時のPasswordインストールに成功すると以下のようなログが表示されます。
(中略) Tapped 2 commands and 4889 formulae (5,148 files, 12.8MB). Already up-to-date. ==> Installation successful! ==> Homebrew has enabled anonymous aggregate formulae and cask analytics. Read the analytics documentation (and how to opt-out) here: https://docs.brew.sh/Analytics ==> Homebrew is run entirely by unpaid volunteers. Please consider donating: https://github.com/Homebrew/brew#donations ==> Next steps: - Run `brew help` to get started - Further documentation: https://docs.brew.shこの時、以下のようなログが表示されてインストールに失敗した場合、
アップルの開発者ページに飛んで、『Comand line tools for xcode』を適宜必要なバージョンのものをダウンロードして、再度Homebrewのコマンドを実行すると回避できます。
※私はこれで回避できましたが原因まで調べていないので、誰か教えてくださいm(_ _)m(中略) xcode-select: error: invalid developer directory '/Library/Developer/CommandLineTools' Failed during: /usr/bin/sudo /usr/bin/xcode-select --switch /Library/Developer/CommandLineToolsインストール成功後、以下のコマンドを実行してHomebrewの最新化とバージョンの確認をしてください。
brew update
brew -v
以下のようなログが表示されます。user@host $ brew update Already up-to-date. user@host $ brew -v Homebrew 2.2.4 Homebrew/homebrew-core (git revision 5889; last commit 2020-01-24)pyenvのインストール
pyenvはPythonのインストールとバージョン管理を行うソフトウェアです。
先ほどインストールしたHomebrewを使って、pyenvのインストールをします。
brew install pyenv
インストールに成功すると、以下コマンドでバージョン確認ができます。
pyenv -vuser@host $ pyenv -v pyenv 1.2.16Python3.○.○のインストール(自分が入れたいもの)
pyenvを使って、Pythonをインストールします。
今回は最新のものもインストールします。
pyenv install 3.8.1インストール後、使用するPythonのバージョンをインストールしたものに変更します。
pyenv global 3.8.1
変更後、設定が反映されているか確認します。
pyenv versions
反映されていると、使用するPythonのバージョンの横に『*』が表示されているかと思います。user@host $ pyenv versions system * 3.8.1 (set by /Users/***/.pyenv/version)「Hello world!」の表示
あとは雑に以下コマンドを入力して表示させてみてください。
python3
print("Hello world!")user@host $ python3 Python 3.8.1 (v3.8.1:1b293b6006, Dec 18 2019, 14:08:53) [Clang 6.0 (clang-600.0.57)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> print("Hello world!") Hello world!これでようやくMacでのPythonライフのスタートです。
お疲れ様でした!
- 投稿日:2020-01-26T18:03:13+09:00
画像を加工・変形して機械学習のためのデータ拡張をしてみた
概要
ディープラーニングでは、効果的な学習用を行なうために大量のデータを準備する必要があります。しかし、大量のデータを準備することが難しい場合、データ拡張(Data Augmentation)というテクニックによって、少量の手元のデータを水増し(割り増し、増殖)して学習に利用することがあります。
データが「画像」の場合、次のように 平行移動、回転、拡大縮小、上下反転、左右反転、明度調整などの変形や加工を組み合わせた画像処理によってデータ拡張を行ないます。
Tensorflow(2.x) + Keras の環境では、データ拡張用に
ImageDataGeneratorというクラスが用意されており、これを使えばランダムな画像処理を加えたデータ(これを、この記事では「拡張画像」とします)を比較的簡単に生成することができます。この記事では、このImageDataGeneratorを使ったデータ拡張について説明します。また、
ImageDataGeneratorは使わずに、OpenCV と tf.keras のアフィン変換などのライブラリ(cv2.warpAffineとtensorflow.keras.preprocessing.image.apply_affine_transform)を使って平行移動、回転、拡大縮小の処理を施して、マニュアルでのデータ拡張を試みます。また、両ライブラリの処理速度を比較します(結果は OpenCV の圧勝)。実行環境
Google Colab. 環境で、実行の確認をしています。
opencv-python 4.1.2.30 tensorflow 2.1.0rc1ImageDataGenerator による画像データの拡張
準備:ライブラリのインポート
Tesorflow のバージョン切り替えと、ライブラリのインポートをします。また、処理前後の画像を確認するために matplotlib を使うので、それもインポートします。
準備:ライブラリのインポート%tensorflow_version 2.x import numpy as np import tensorflow as tf import matplotlib.pyplot as plt準備:画像データの準備
処理を施すための対象データを取得してきます。ここでは「CIFAR-10」のトレーニングデータを利用します。CIFAR-10は「飛行機」「自動車」「トリ」「ネコ」「シカ」「イヌ」「カエル」「ウマ」「船」「トラック」の10種の画像から構成されるデータセットです。
準備:画像データの準備(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data() img_cifar10 = x_train/255. print(img_cifar10.shape) # -> (50000, 32, 32, 3) 32x32 3ch RGB
img_cifar10には、$32\times 32$ px の $3$ch-RGB の $50,000$ 枚の画像が、 numpy.ndarray 形式で格納されています。準備:画像表示関数の定義
画像を表示するための関数を作成します。画像を1枚だけを表示する
showImage(...)と、画像配列を与えて複数画像を同時表示するshowImageArray(...)を定義します。準備:画像表示関数の定義def showImage(img,title=None): plt.figure(figsize=(3, 3)) plt.gcf().patch.set_facecolor('white') plt.xticks([]) plt.yticks([]) plt.title(title) plt.imshow(img) plt.show() plt.close() def showImageArray(img_arry): n_cols = 8 n_rows = ((len(img_arry)-1)//n_cols)+1 fig, ax = plt.subplots(nrows=n_rows, ncols=n_cols, figsize=(10, 1.25*n_rows)) fig.patch.set_facecolor('white') for i,ax in enumerate( ax.flatten() ): if i < len(img_arry): ax.imshow(img_arry[i]) ax.set_xticks([]) ax.set_yticks([]) else : ax.axis('off') # 余白処理 plt.show() plt.close()これらの関数は、次のように呼び出します。
画像表示関数の呼出し# img_cifar10 の 12枚目の画像を表示 showImage(img_cifar10[12],title='CIFAR-10 Train Data [12]') # 0枚目から39枚目までの画像(=40枚)を表示 showImageArray(img_cifar10[:40])
showImage(...)には、shape が(32,32,3)の numpy.ndarray を引数として与えます。また、showImageArray(...)には、shape が(arr_len,32,32,3)の numpy.ndarray を引数として与えます(ここでarr_lenは画像配列の長さです)。実行結果は、次のようになります。
ImageDataGenerator による画像データの拡張
ImageDataGeneratorクラス は、指定ディレクトリにある画像ファイルをロードしたり、データ拡張したりすることができます。ここでは、データ拡張の用途で使用します。
データ拡張に使用する場合、初期化時に「どんな処理(移動?回転?拡大?)を、どの程度の強度でランダムに行なうのか」のパラメータを与えます。例えば、次のようにパラメータを与えて初期化します。
ImageDataGeneratorの初期化ImageDataGenerator = tf.keras.preprocessing.image.ImageDataGenerator image_data_generator = ImageDataGenerator( rotation_range=20, # ランダムに±20度範囲で回転 width_shift_range=8, # ランダムに±8px範囲で左右方向移動 height_shift_range=4, # ランダムに±4px範囲で上下方向移動 zoom_range=(0.8, 1.2), # ランダムに0.8~1.2倍の範囲でズーム horizontal_flip=True, # ランダムで左右反転する channel_shift_range=0.2) # チャンネル値(明度)のランダムシフト範囲
width_shift_rangeとheight_shift_rangeは $1$ 未満の小数値で与えると、画像サイズに対する割合でランダム範囲を指定できます。また、今回は使っていませんがvertical_flip=Trueで上下反転の処理も加えることができます。拡張画像を1枚だけ生成
このジェネレータを使って、
img_cifar10[12]の「ウマ」の画像を対象にデータ拡張をしてみます(まずは1枚だけ拡張画像を生成します)。次のコードを実行すると、上記の初期化で与えたパラメータ範囲内で、ランダムに画像処理が行われます。拡張画像を1枚だけ生成org_img = img_cifar10[12].copy() # ターゲットは12番目の「ウマ」 ex_img = image_data_generator.flow( org_img.reshape(1,32,32,3), batch_size=1)[0][0] print(ex_img.shape) # -> (32, 32, 3) showImage(ex_img,title='CIFAR-10 Train Data [12] Ex')拡張した画像を得るためには
flow(...)メソッドを使用します。引数として、オリジナルの画像配列(単一入力には対応していないので.reshape(1,32,32,3)で1要素を持つ配列に変換して)を与えます。戻り値は、NumpyArrayIterator になるので、[0][0]で評価と0番目要素の取得をして、ex_imgに格納しています。実行結果は、次のようになります。左右が反転し、水平移動がかかり、全体的に明るくなっています(実行結果は、実行毎に変化します)。
ところで、画像を回転させたり、上下左右に移動させたりすると隙間ができますが、そこは自動的に画像端が引き伸ばされて埋められます(自然な画像に仕上がります)。この処理を適用したくない場合は、初期化で
fill_mode='constant'を指定します。すると、次のように余白は黒色で埋められます。そのほかに、fill_mode='reflect'やfill_mode='wrap'、fill_mode='nearest'(デフォルト)が指定できます。
拡張画像を複数枚生成
つづいて、
img_cifar10[12]の「ウマ」の画像から39枚の拡張画像を生成します。image_data_generator.flow(...)は、NumpyArrayIteratorを返すので、next()を使って順次画像を取り出します。拡張画像を1複数枚生成org_img = img_cifar10[12].copy() ex_img = np.empty([40, 32, 32, 3]) # オリジナルを含め40枚格納可能な領域を準備 ex_img[0,:,:,:] = org_img # 0枚目にオリジナルを格納 iter_ = image_data_generator.flow( org_img.reshape(1,32,32,3), batch_size=1) for i in range(1,40): ex_img[i,:,:,:] = iter_.next()[0] # 生成した画像を逐次格納 showImageArray(ex_img)実行結果は、次のようになります。
CIFAR-10 の 0~23枚目までの画像について、各1枚の拡張画像を生成
前セクションでは、1枚の画像について複数枚の拡張画像を生成しました。今度は、CIFAR-10 のトレーニングデータの 0~23枚目までの40枚の画像について、各1枚の拡張画像を生成します。
画像配列に対して各1枚の拡張画像を生成showImageArray(img_cifar10[:24]) # CIFAR-10 オリジナル 0~23枚目を表示 ex_img = np.empty([24, 32, 32, 3]) ex_img = image_data_generator.flow(img_cifar10[:24], batch_size=24, shuffle=False)[0] showImageArray(ex_img) # CIFAR-10 拡張 0~23枚目 を表示実行結果は次のようになります。まず、こちらが CIFAR-10 のトレーニングデータの 0~23枚目までのオリジナルデータです。
つづいて、こちらが ImageDataGenerator で拡張した画像になります。各画像に対して、それぞれ異なる処理(移動、回転、拡大縮小、反転などの組合せ)が適用されていることが分かります。
なお、
flow(...)の引数に、shuffle=Falseを指定しないと、出力される画像配列の順番がシャッフルされます。OpenCV と tf.keras による処理の比較
移動量や回転角、倍率をマニュアルで指定し、OpenCV と tf.keras の各ライブラリで拡張画像を生成します。また、処理時間の比較をします。
回転
画像を反時計方向に45度回転させる処理を行ないます。回転軸は、画像の中心とします。
OpenCV のライブラリを使うプログラムは次のようになります。OpenCV では反時計方向が「正」なので、そのまま回転角
45を与えています。cv2.warpAffine(...)が処理の本体になります。borderMode=cv2.BORDER_REPLICATEを指定しないと隙間が黒で塗りつぶされます。OpenCV版のCIFAR10の50,000枚の回転処理import time import cv2 deg = 45 # 反時計方向が「正」 w, h = 32, 32 # 画像サイズ m = cv2.getRotationMatrix2D((w/2,h/2), deg, 1) # 変換行列 img_cifar10_ex = np.empty([50000, 32, 32, 3]) # 結果の格納先 t1 = time.time() for i,img in enumerate( img_cifar10 ) : img = cv2.warpAffine(img, m, (w,h), borderMode=cv2.BORDER_REPLICATE) img_cifar10_ex[i,:,:,:] = img t2 = time.time() print(f'処理時間 {t2-t1:.1f}[sec]') showImageArray(img_cifar10_ex[:24]) # 24枚だけを表示実行結果は次のようになります。また、処理時間は 1.3[sec] でした。
一方、tf.keras のライブラリを使ったプログラムは次のようになります。こちらは、反時計方向が「負」になるので、回転角には
-45を与えています。tf.keras版のCIFAR10の50,000枚の回転処理import time from tensorflow.keras.preprocessing.image import apply_affine_transform deg = -45 # 反時計方向が「負」 img_cifar10_ex = np.empty([50000, 32, 32, 3]) # 結果の格納先 t1 = time.time() for i,img in enumerate( img_cifar10 ) : img = apply_affine_transform(img, theta=deg) img_cifar10_ex[i,:,:,:] = img t2 = time.time() print(f'処理時間 {t2-t1:.1f}[sec]') showImageArray(img_cifar10_ex[:24])実行結果は次のようになります。また、処理時間は 16.2[sec] でした。処理速度は、圧倒的に OpenCV のほうが高速でした。
平行移動
画像を、右方向に $2$px、下方向に $5$px 移動させる処理を行ないます。
まずは、OpenCV版です。変換行列
mの内容が違うだけで、処理はさきほどの「回転」と同じです。OpenCV版のCIFAR10の50,000枚の移動処理import time import cv2 tx, ty = 2, 5 w, h = 32, 32 # 画像サイズ m = np.float32([[1,0,tx],[0,1,ty]]) # 変換行列 img_cifar10_ex = np.empty([50000, 32, 32, 3]) # 結果の格納先 t1 = time.time() for i,img in enumerate( img_cifar10 ) : img = cv2.warpAffine(img, m, (w,h), borderMode=cv2.BORDER_REPLICATE) img_cifar10_ex[i,:,:,:] = img t2 = time.time() print(f'処理時間 {t2-t1:.1f}[sec]') showImageArray(img_cifar10_ex[:24])実行結果は、次のようになります。処理時間は 1.3[sec] でした(本質的な処理は「回転」と同じなので、実行時間も変わりません)。
次に、tf.keras 版です。どうしてそのような設計になっているのか分からなかったのですが「右方向に2px、下方向に5px移動させるためには、
apply_affine_transform(img, tx=-5, ty=-2)のように」指定しないといけません。謎です。tf.keras版のCIFAR10の50,000枚の回転処理import time from tensorflow.keras.preprocessing.image import apply_affine_transform tx, ty = 2, 5 img_cifar10_ex = np.empty([50000, 32, 32, 3]) # 結果の格納先 t1 = time.time() for i,img in enumerate( img_cifar10 ) : img = apply_affine_transform(img, tx=-ty, ty=-tx) # 引数の与え方に注意 img_cifar10_ex[i,:,:,:] = img t2 = time.time() print(f'処理時間 {t2-t1:.1f}[sec]') showImageArray(img_cifar10_ex[:24])実行結果は、次のようになります。処理時間は 13.9[sec] で、さきほどと同様に OpenCV の処理時間よりも約10倍の時間がかかっています。
拡大
画像を、1.2倍に拡大する処理を行ないます(拡大しても画像サイズは変化させません)。
まずは、OpenCV版です。
resizeで拡大して、その後、$32\times 32$ px にトリミングしています。OpenCV版のCIFAR10の50,000枚の拡大処理import cv2 f = 1.2 w, h = 32, 32 # 画像サイズ w2, h2 = int(w*f), int(h*f) # 拡大画像のサイズ tx, ty = int((w2-w)/2),int((h2-h)/2) # トリミングの開始座標 m = np.float32([[1,0,tx],[0,1,ty]]) # 変換行列 img_cifar10_ex = np.empty([50000, 32, 32, 3]) # 結果の格納先 t1 = time.time() for i,img in enumerate( img_cifar10 ) : img = cv2.resize(img,(w2,h2)) img_cifar10_ex[i,:,:,:] = img[tx:tx+w,ty:ty+h,:] # 拡大画像から32x32をトリミング t2 = time.time() print(f'処理時間 {t2-t1:.1f}[sec]') showImageArray(img_cifar10_ex[:24])実行結果は、次のようになります。処理時間は 1.2[sec] でした。
次に、tf.keras 版です。先ほど同様に大変に分かりにくいのですが、
apply_affine_transform(img, zx=1/f, zy=1/f)のように引数zxとzyには「倍率の逆数」を与えます。tf.keras版のCIFAR10の50,000枚の拡大処理import time from tensorflow.keras.preprocessing.image import apply_affine_transform f = 1.2 img_cifar10_ex = np.empty([50000, 32, 32, 3]) # 結果の格納先 t1 = time.time() for i,img in enumerate( img_cifar10 ) : img = apply_affine_transform(img, zx=1/f, zy=1/f) # 引数注意 img_cifar10_ex[i,:,:,:] = img t2 = time.time() print(f'処理時間 {t2-t1:.1f}[sec]') showImageArray(img_cifar10_ex[:24])処理時間は 13.4[sec] で、結果は次のようになります。













- 投稿日:2020-01-26T17:56:39+09:00
PythonのNetaddrでアドレス集約
■前提
Windows10 64bit
Anacondaインストール済■netaddrインストール
Anaconda Prompt起動
> pip install netaddr■使い方
Anaconda Promptで
> python
>>> from netaddr import *
>>> ip_list = [IPNetwork('192.168.0.0/24')]
>>> ip_list.append(IPNetwork('192.168.1.0/24'))
>>> cidr_merge(ip_list)
[IPNetwork('192.168.0.0/23')]■参考
https://netaddr.readthedocs.io/en/latest/tutorial_01.html#summarizing-list-of-addresses-and-subnets
- 投稿日:2020-01-26T17:55:33+09:00
【Pythonやってみた!】「みんなPython!Python!って何なのよ!」から今日で卒業!
私がPython超初心者ですので,偉そうなことは言えないのですが,
本日は,最近流行りの「Python」について,ざっくりとどんなもんかお話できればと思います.この記事を読んで,「みんなPython!Python!って何なのよ!」という悶々とした日々の気持ちから,
今日でめでたくご卒業される方が増えることを切に願っています.■Pythonって何?
端的に申しますと,Pythonはプログラミング言語です.
wikipediaから引用させていただきますが,
私が思うPythonの利点は下記3つです.
(1)無料で始めることができる
(2)無料のパッケージが色々ある
(3)統計解析に使いやすい上記3つとも,流行した要因になっていると思いますが,
(3)はわりと大きい要因である気がします.■統計解析に使いやすいことがどうしてPythonが流行することにつながるの?
ここ最近AI(人工知能)が話題になっていますが,
私の考えでは,AIの理論は,統計や数学の応用です.
したがって,AIの注目度に比例して統計解析が得意なPythonも注目度が上がっているのではないでしょうか.■AIとか機械学習とか少し興味あるけど,難しそうやから私には無理でしょう?
私はそうは思いません.
文系,理系関係ないと思っています.
私も初心者ですので,一緒に頑張りましょう!!■Pythonのソースコードってどんななの?どうせ,難しいのでしょう?
ちょっと,命令文と実行結果の例を記載しますので,ご覧ください.
【命令文1】
print("Hello,Python!")【実行結果1】
Hello,Python!どうでしょうか...?すみません.これでは実感がわきませんね...
【命令文2】
df['Age'].hist() plt.show()【実行結果2】
※タイタニックデータ(Kaggleより入手)の「Age」データを使用
横軸:年齢
縦軸:数(人)
どうでしょうか?
難しいかどうかは,人それぞれですが,
2行の命令で,ヒストグラムという,統計分析では欠かすことのできない,立派な統計分析の結果(図)を出力できます.先程のPythonの利点には挙げていませんでしたが,
シンプルな命令文で統計的な解析が可能なことも,
Pythonの利点だと考えられます.■Python興味あるけど,何から始めればいいかわからん!
おすすめは,今すぐ,Pythonを自分のPCにインストールして
(私はwindowsのノートPCにインストールしてます),
手を動かしながら学んでいくことです.
幸運なことに,インターネットが充実しているこの時代ですから,
無料のデータと無料の教材がネット中にあふれています.
もちろん,PythonをPCにインストールする方法もネット中にあります!
(私もそれを頼りにPCの環境を整えました!)■何を目標にしたらいい?
私自身は,
世界的なデータ分析コンペである「Kaggle」に参加すること!と,
日本のデータ分析コンペである「SIGNATE」に参加すること!を目標にしています.■結論
Pythonはシンプルなプログラミング言語で,統計解析が得意です.
少しでも興味があれば,今すぐ自分のPCにインストールしてデータを分析することをおすすめいたします.■最後に
本日も最後までお読みいただきありがとうございました.
なんだか,Pythonの説明から話がそれた気もしますが...
Python興味あるのに,踏み出せない人がいるとしたら,とてももったいないという気持ちに駆られて,
今回の記事を書いてみました.
よかったら,「いいね!」を頂けると,投稿の励みになりますので,
お願いいたします.
お叱りも受け付けます.(毎度のこと,受付方法が分かっていませんが...)
またどこかでお会いしましょう!
さようなら~(^^)/”

- 投稿日:2020-01-26T17:54:22+09:00
RaspberryPiでスマートロックをDIY
n番煎じですが、スマートロックを自作しました。
MESHボタンでの解錠/施錠が可能になりました
— Daiki Ebisawa ? (@d_ebi_k) January 20, 2020
これで宅配の応対時、手ぶらで応対してもロック解除できるのでいつでも対応ができますね#IoT pic.twitter.com/GHd5WluoNUプラ棒とプラ板とサーボモータ、100均のネオジム磁石らしきもので構成されてます
— Daiki Ebisawa ? (@d_ebi_k) January 19, 2020
ラズパイで制御していますね pic.twitter.com/ZLU01OfIED概要
ソースコード
GitHubにおいてあります。
https://github.com/d-ebi/smartlockできること
- スマホのブラウザから開錠/施錠ができる
- Slackのbotにメッセージを送信してリモートで開錠/施錠ができる
- MESHのボタンタグから開錠/施錠ができる
なぜつくったのか
- 買い物帰りで両手がふさがっているとき、鍵探して刺して開けるのが結構辛い
- セサミ高い(1人暮らしなのでオーバースペックだと思った)
- サーボモーター使ってみたかった
- 持て余しているラズパイZero WHを有効に使いたかった
- 持て余しているMESHタグを有効に使いたかった
要件
- スマホから開け閉めができること
- 開け閉めしたらSlackに通知がくること
- 内側から操作するとき、物理錠同様に簡単に開け閉めができること
- 外から物理鍵でも開けられること
作ってみて
楽しかったですが、手が接着剤まみれになったり、中々に大変でした。セサミ買った方が楽ではあると思います。作ったことには後悔してないです。
ちなみに利便性の方ですが、スマートロック、これはとても便利なのでおすすめです。買い物後本当に楽になりました。構成
ブラウザから操作するパターン
図
説明
BottleというPythonの超軽量Webアプリケーションフレームワークで作ったWebアプリケーションをラズパイ上で立ち上げています。スマホブラウザからラズパイのIPアドレスでアクセスができ、WebUIが表示されます(動画に写ってます)。あとはこれをタップすることで、鍵開けたり閉めたりができる、という単純なものです。鍵の開け閉めを行なった場合、Slackbotを介してSlackに開け閉めの通知が飛んできます。
このパターンでの開け閉めを行なうためには、スマホとラズパイが同じLANに属している必要があります。なので、家から出るときによく使いますね。Slackbotを介して操作するパターン
図
説明
Slackbotに決められたメッセージをメンションすることで操作するパターンです。Web UIと違って文章を打たないといけないのでやや面倒なんですが、この後の「MESHのボタンタグから操作するパターン」で必要だったこと、自宅のWi-Fiを捕まえるのに若干時間がかかり、扉の前でもたついてしまうということがあり、同一LAN内にいなくても操作したいということで、このパターンで操作できるようにしました。
MESHボタンタグから操作するパターン
図
説明
あらかじめラズパイをMESHハブ化しておき、MESHボタンを1回押すとIFTTTを通しSlackに開錠メッセージを、MESHボタンを2回押すとIFTTTを通しSlackに施錠メッセージを飛ばすことで操作できます。物理鍵を直接操作することができなくなってしまったため、それの代わりですね。とっさの訪問に対応するために設置したやつです。MESHのレシピは本当に単純にSlackbotにメッセージをダイレクトメッセージで送っているだけなので、後の処理は「Slackbotを介して操作するパターン」と同じです。ただし、IFTTTからの投稿に対し、デフォルトでは反応してくれなかったため、下記を参考にライブラリに手を加えたりはしました。
IFTTTからslackに投稿した内容をpythonのslackbotライブラリが拾えない現象について - Qiitaまとめ
使ったサーボモータやもろもろは下記を参考にしました。
スマートロックを自作してAlexaに鍵を開けてもらう。 - Qiita一番大変だったのは、内鍵の形状に合わせてプラ棒やプラ板を加工したところですね。ちょっとでも力が正しく伝わらないと上手く開かなかったり、設置するためのフレーム部分に干渉してしまったり、とにかく微調整の連続でした。このハードウェア部分の調整がかなり大変で、これを作るなら出来合いのものを買った方がいいな…と思いました。
とはいえ物を作るのは好きなので、そういう意味ではかなり楽しめたと思います。ソフトウェア部分も地味に汎用的に作ってあったり、久々に工夫を凝らして作れたと思います。参考リンク



- 投稿日:2020-01-26T17:33:46+09:00
各言語で、継承の挙動はかなり違うという話
はじめに
この記事は、私が色んな言語でひたすら似たようにクラス継承を書いてみて、実際にどんな値が出力されるのかを調査した結果をまとめたものです。時には既知の言語でも「こんな文法あったんだ」と思いながら、時にはHello Worldから頑張りました。
まとめるのが大変だった割に誰得?という内容ですが、同じことが気になった人のために置いておきます。
いやでも新しい発見があるかもしれないのでとりあえず読んでみてください。
意外と面白い結果になったかもしれません。調べた言語
静的型付け
- Java (Corretto 1.8.0_232)
- C# (3.4.0)
- C++ (11.0.0)
- Scala (2.13.1)
- Kotlin (1.3.61)
- Swift (5.1.3)
動的型付け
- Python (3.7.1)
- Ruby (2.6.5)
- PHP (7.1.32)
- JavaScript (node v12.14.1)
オプショナルな静的型付け
- TypeScript (3.7.2)
- Dart (2.7.0)
調査で使うコード
ある親クラスを子クラスが継承します。
その親クラスと子クラスには、同じ名前のインスタンス変数があります。(クラス変数ではありません)
親クラスにはメソッドがあり、そのメソッドを使うとインスタンス変数をコンソールに出力できます。実行時には、子クラスのインスタンスで、継承した親のメソッドを呼びます。
さぁ親と子どっちのインスタンス変数が出力されるでしょうか……というストーリーです。多分読める人が多いであろうJS(ES6以降)のコードで書くと、こういうコードです。
class SuperClass { constructor() { // ※JSではインスタンス変数は実行時に定義されるので、コンストラクタに書く this.instanceVariable = "SuperClass" // 同じ名前で違う値 } superClassMethod() { console.log(this.instanceVariable) } } class SubClass extends SuperClass { constructor() { super() this.instanceVariable = "SubClass" // 同じ名前で違う値 } } const sub = new SubClass() // 子クラスをインタンス化 sub.superClassMethod() // 継承した親クラスのメソッドを呼ぶ自分が普段使っている言語でどういう値が出力されるかぜひ想像してみてください。
(良し悪しはともかくとして)たまにある書き方なので、自分の得意な言語のものは知っているかもしれません。
でも他の言語でどう動くのかを知っていたら、いつか別の会社や別の案件に入った時、もしくは興味本位で他言語に入門した時に役に立つかもしれません。今回は一応、インスタンス変数のみならず、メソッド(クラスメソッドではないインスタンスのメソッド)で
return "SuperClass"をした時にどうなるのかも見たりしています。
この場合は、親クラスと子クラスに同じ名前のメソッドがあり、親クラスのメソッドでそれを呼ぶ……というシナリオです。どんなコードを書いて調べたかは、
コードを見る(hoge言語)
class Hoge {}こんな風に詳細折りたたみ要素が置いてあるので、クリックして開いてもらえると中身のコードを読むことができます。
何をしているか見やすくするために原則としてコピペを採用したかなりWETなコードですが、それはわざとなのでマサカリを投げないでください。今回のポイント
ご存知の通り、プログラミング言語によって存在する文法は異なりますし、評価の仕方も違います。
今回の結果が変わるポイントは、下記であると思います。
- アクセス修飾子が存在するか。また、どんな種類のものがあるか
- 親クラスと子クラスで同名のインスタンス変数をそもそも定義可能か
- インスタンス変数のオーバーライド、メソッドのオーバーライドがそれぞれ存在するか。
- 継承そのものを、各言語がどう処理しているか
結果発表
Java
エンタープライズシステムの覇者、Java。
Javaにはアクセス修飾子として、privateやprotectedがあります。
privateは、現在のクラスからしか見ることはできません。protectedは、現在のクラスと子クラスからアクセスできます。Javaではインスタンス変数のオーバーライドは存在しません。
なので、メソッドでオーバーライドをした時にどうなるのかも見てみます。
条件 結果 インスタンス変数がprivate "SuperClass" インスタンス変数がprotected "SuperClass" インスタンス変数の代わりにprivateなメソッド "SuperClass" インスタンス変数の代わりにprotectedなメソッド(override) "SubClass" オーバーライドは文字通り「上書き」してしまいます。
今回は関係ありませんでしたが、Javaは、子クラス側のメソッドで親クラスのインスタンス変数に
super.instanceVariableのようにしてアクセスすることができます。オーバーライドしないゆえにできる芸当ですね。
コードを見る(Java)
public class JavaSample { public static void main(String[] args) { System.out.println("---- SubClass ----"); SubClass sub = new SubClass(); sub.superClassMethod(); System.out.println("---- SubClassProtected ----"); SubClassProtected subp = new SubClassProtected(); subp.superClassMethod(); System.out.println("---- SubClassGetter ----"); SubClassGetter subg = new SubClassGetter(); subg.superClassMethod(); System.out.println("---- SubClassGetterProtected ----"); SubClassGetterProtected subgp = new SubClassGetterProtected(); subgp.superClassMethod(); } } class SuperClass { // privateのインスタンス変数はサブクラスから参照できない private String instanceVariable = "SuperClass"; public void superClassMethod() { System.out.println(instanceVariable); } } class SubClass extends SuperClass { private String instanceVariable = "SubClass"; } // ------------------------------------------- class SuperClassProtected { protected String instanceVariable = "SuperClass"; public void superClassMethod() { System.out.println(instanceVariable); } } class SubClassProtected extends SuperClassProtected { protected String instanceVariable = "SubClass"; // public void subClassMethod() { // System.out.println(instanceVariable); と書くと、 // System.out.println(this.instanceVariable); と同じ。"SubClass"が出る。 // superをつけると、"SuperClass"と表示させることもできる // System.out.println(super.instanceVariable); // } } // ------------------------------------------- class SuperClassGetter { private String instanceVariable() { return "SuperClass"; } public void superClassMethod() { System.out.println(instanceVariable()); } } class SubClassGetter extends SuperClassGetter { private String instanceVariable() { return "SubClass"; } } // ------------------------------------------- class SuperClassGetterProtected { protected String instanceVariable() { return "SuperClass"; } public void superClassMethod() { System.out.println(instanceVariable()); } } class SubClassGetterProtected extends SuperClassGetterProtected { protected String instanceVariable() { return "SubClass"; } }C#
Javaの次はやっぱりC#。歴史的経緯からかなりJavaに近い文法を持ちます。その結果もまたJavaや、後述するC++と似ていますが、Javaには無いものもあります。
ちなみにC#にはプロパティがあるので、メソッドの代わりにプロパティで書きました。C#には
virtualとoverrideがあります。virtualは、「このメソッドはオーバーライドされる可能性があるぞ」と教える修飾子で、overrideは、ここでメソッドはオーバーライドしているぞと教える修飾子です。そこまではいいのですが、C#には更に、
newという変わった修飾子があります。このnewは、インスタンス生成のときのnew Human()のnewとは別モノです。overrideの代わりにnewをつけることで、子クラスからの呼び出しであっても、親クラスのメソッドを親クラスの文脈のままで評価させることができます。なぜかというと、親クラスのメソッドをオーバーライド(上書き)しているわけではなく、ただ隠しているだけだからです。ややこしいですね。
条件 結果 インスタンス変数がprivate "SuperClass" インスタンス変数がprotected "SuperClass" プロパティがprivate "SuperClass" プロパティがprotected(override) "SubClass" プロパティがprotected(new) "SuperClass"
コードを見る(C#)
using System; public class CSharpSample { public static void Main(string[] args) { Console.WriteLine("---- SubClass ----"); var sub = new SubClass(); sub.SuperClassMethod(); Console.WriteLine("---- SubClassProtected ----"); var subp = new SubClassProtected(); subp.SuperClassMethod(); Console.WriteLine("---- SubClassGetter ----"); var subg = new SubClassGetter(); subg.SuperClassMethod(); Console.WriteLine("---- SubClassGetterProtectedOverride ----"); var subgpo = new SubClassGetterProtectedOverride(); subgpo.SuperClassMethod(); Console.WriteLine("---- SubClassGetterProtectedNew ----"); var subgpn = new SubClassGetterProtectedNew(); subgpn.SuperClassMethod(); } } class SuperClass { private string instanceVariable = "SuperClass"; public void SuperClassMethod() { Console.WriteLine(instanceVariable); } } class SubClass : SuperClass { // warning CS0414: The field 'SubClass.instanceVariable' is assigned but its value is never used private string instanceVariable = "SubClass"; } // ---------------------------- class SuperClassProtected { protected string instanceVariable = "SuperClass"; public void SuperClassMethod() { Console.WriteLine(instanceVariable); } } class SubClassProtected : SuperClassProtected { // newはオーバーライドではなく、継承元のインスタンス変数隠しているよと明示している new protected string instanceVariable = "SubClass"; } // ---------------------------- class SuperClassGetter { private string instanceVariable { get { return "SuperClass"; } } public void SuperClassMethod() { Console.WriteLine(instanceVariable); } } class SubClassGetter : SuperClassGetter { private string instanceVariable { get { return "SubClass"; } } } // ---------------------------- class SuperClassGetterProtected { protected virtual string instanceVariable { get { return "SuperClass"; } } public void SuperClassMethod() { Console.WriteLine(instanceVariable); } } class SubClassGetterProtectedOverride : SuperClassGetterProtected { protected override string instanceVariable { get { return "SubClass"; } } } class SubClassGetterProtectedNew : SuperClassGetterProtected { protected new string instanceVariable { get { return "SubClass"; } } }C++
C++は組み込みの現場などで使われることが多いらしいですが私は何も知りません。
C++ナニモワカラナイ……。Javaとともに、C#の元となった言語なだけあって、C#に挙動がとても似ています。
インスタンス変数の代わりにメソッドを使った場合で、かつoverrideしないというのは、C#でいうところのnewと同じ挙動をします。
条件 結果 インスタンス変数がprivate "SuperClass" インスタンス変数がprotected "SuperClass" インスタンス変数の代わりにprivateなメソッド "SuperClass" インスタンス変数の代わりにprotectedなメソッド(override) "SubClass" インスタンス変数の代わりにprotectedなメソッド(overrideしない) "SuperClass"
コードを見る(C++)
#include <iostream> class SuperClass { // デフォルトだとprivate(クラス外からアクセス不可になる) std::string instanceVariable = "SuperClass"; public: void superClassMethod() { std::cout << instanceVariable << std::endl; } }; class SubClass : public SuperClass { std::string instanceVariable = "SubClass"; }; // ------------------------------- class SuperClassProtected { protected: std::string instanceVariable = "SuperClass"; public: void superClassMethod() { std::cout << instanceVariable << std::endl; } }; class SubClassProtected : public SuperClassProtected { protected: std::string instanceVariable = "SubClass"; }; // ------------------------------- class SuperClassGetter { std::string instanceVariable() { return "SuperClass"; } public: void superClassMethod() { std::cout << instanceVariable() << std::endl; } }; class SubClassGetter : public SuperClassGetter { std::string instanceVariable() { return "SubClass"; } }; // ------------------------------- class SuperClassProtectedGetter { protected: std::string instanceVariable() { return "SuperClass"; } public: void superClassMethod() { std::cout << instanceVariable() << std::endl; } }; class SubClassProtectedGetter : public SuperClassProtectedGetter { protected: std::string instanceVariable() { return "SubClass"; } }; // ------------------------------- class SuperClassProtectedGetterOverride { protected: virtual std::string instanceVariable() { return "SuperClass"; } public: void superClassMethod() { std::cout << instanceVariable() << std::endl; } }; class SubClassProtectedGetterOverride : public SuperClassProtectedGetterOverride { protected: std::string instanceVariable() override { return "SubClass"; } }; int main() { std::cout << "---- SubClass ----" << std::endl; SubClass sub; sub.superClassMethod(); std::cout << "---- SubClassProtected ----" << std::endl; SubClassProtected subp; subp.superClassMethod(); std::cout << "---- SubClassGetter ----" << std::endl; SubClassGetter subg; subg.superClassMethod(); std::cout << "---- SubClassProtectedGetter ----" << std::endl; SubClassProtectedGetter subpg; subpg.superClassMethod(); std::cout << "---- SubClassProtectedGetterOverride ----" << std::endl; SubClassProtectedGetterOverride subpgo; subpgo.superClassMethod(); return 0; }Scala
関数型の風を取り込んだAltJavaです。
JavaやC#と大きく違うところは、インスタンス変数のオーバーライドができることです。新機能来ました!
条件 結果 インスタンス変数がprivate "SuperClass" インスタンス変数がprotected(override) "SubClass"
コードを見る(Scala)
object ScalaSample { def main(args: Array[String]): Unit = { println("---- SubClass ----") val sub = new SubClass sub.superClassMethod() println("---- SubClassProtected ----") val subp = new SubClassProtected subp.superClassMethod() } } class SuperClass { private val instanceVariable = "SuperClass"; def superClassMethod(): Unit = { println(instanceVariable); } } class SubClass extends SuperClass { private val instanceVariable = "SubClass"; } // ---------------------------- class SuperClassProtected { protected val instanceVariable = "SuperClass"; def superClassMethod(): Unit = { println(instanceVariable); } } class SubClassProtected extends SuperClassProtected { override protected val instanceVariable = "SubClass"; }Kotlin
Scalaに大きな影響を受けたAltJavaです。Androidアプリの開発で多く用いられています。
オーバーライドする予定のインスタンス変数にはopenをつけなくてはならないこと以外、Scalaと同じです。
つまりopenはC++やC#のvirtualみたいなものですね。
条件 結果 インスタンス変数がprivate "SuperClass" インスタンス変数がprotected(override) "SubClass"
コードを見る(Kotlin)
fun main(args: Array<String>) { println("---- SubClass ----"); val sub = SubClass(); sub.superClassMethod(); println("---- SubClassOverride ----"); val subo = SubClassOverride(); subo.superClassMethod(); } open class SuperClass { private val instanceVariable = "SuperClass"; fun superClassMethod() { println(instanceVariable); } } class SubClass : SuperClass() { private val instanceVariable = "SubClass"; } // ----------------------------------- open class SuperClassOverride { open val instanceVariable = "SuperClass"; fun superClassMethod() { println(instanceVariable); } } class SubClassOverride : SuperClassOverride() { override val instanceVariable = "SubClass"; }Swift
アプリと言ったらAndroidだけではありません。iOSを忘れて貰っては困ります。
Swiftのprivateはバージョンによって挙動が変わったりするようですが、今回はSwift 5で検証したので、Javaと同じく、クラス内のみ有効で、継承されません。Swiftの
letは再代入を禁止した変数宣言です。JSでいうとconstです。
そしてSwiftのvarは再代入可能な普通の変数宣言です。JSでいうletです。ややこしや。Swiftでは、インスタンス変数(Swiftではプロパティという)を、継承元と同じものを定義することはできません。
代わりにComputed Property(C#でいうプロパティのようなもの)を使うと、オーバーライドすることができます。
privateのようなアクセス修飾子をつけないと、internalというスコープになります。internalはJavaでいうpublicみたいなものです(雑)。
条件 結果 インスタンス変数がprivate "SuperClass" インスタンス変数がinternal 定義不可 Computed Propertyがprivate "SuperClass" Computed Propertyがinternal(override) "SubClass"
コードを見る(Swift)
class SuperClass { private let instanceVariable = "SuperClass"; func SuperClassMethod() { print(instanceVariable); } } class SubClass: SuperClass { private let instanceVariable = "SubClass"; } // -------------------------------- class SuperClassInternal { let instanceVariable = "Error"; func SuperClassMethod() { print(instanceVariable); } } class SubClassInternal: SuperClassInternal { // error: cannot override with a stored property 'instanceVariable' // let instanceVariable = "SubClass"; } // -------------------------------- // Computed Propertyにしてgetterを生やす。こうしたら関数扱いなのでoverrideができるようになる。 class SuperClassGetter { // letだと、error: 'let' declarations cannot be computed properties private var instanceVariable: String { get { return "SuperClass" } } func SuperClassMethod() { print(instanceVariable); } } class SubClassGetter: SuperClassGetter { private var instanceVariable: String { get { return "SubClass" } }; } // -------------------------------- // Computed Propertyにしてgetterを生やす。こうしたら関数扱いなのでoverrideができるようになる。 class SuperClassInternalGetter { // letだと、error: 'let' declarations cannot be computed properties var instanceVariable: String { get { return "SuperClass" } } func SuperClassMethod() { print(instanceVariable); } } class SubClassInternalGetter: SuperClassInternalGetter { override var instanceVariable: String { get { return "SubClass" } }; } print("---- SubClass ----"); let sub = SubClass(); sub.SuperClassMethod(); print("---- SubClassInternal ----"); let subi = SubClassInternal(); subi.SuperClassMethod(); print("---- SubClassGetter ----"); let subg = SubClassGetter(); subg.SuperClassMethod(); print("---- SubClassInternalGetter ----"); let subig = SubClassInternalGetter(); subig.SuperClassMethod();Python
ここからは動的型付け言語!
Qiitaのタグ投稿ランキングで1位を取り続けるなど、その人気を盤石なものにしたPythonです。Pythonのクラスで特徴的なのは、メソッドの第一引数にインスタンス自身がやってくるので宣言時には第1引数に
selfと書くところです。別にselfじゃなくても良いのですが、みんなselfと書きます。あとは動的型付け言語らしく、インスタンス変数を動的に生み出すので、クラス宣言直下ではなくコンストラクタの中でインスタンス変数を定義します。ここはRubyもJavaScriptも同じですね。
Pythonにはメンバのアクセス制限がありません。修飾子
privateはありません。
関数名の先頭にアンダースコアを1つつけて「privateだからアクセスしないでね」とする文化です。しかしPythonでは、子クラスと名前が衝突した場合に備えた機能があります。アンダースコアを2つつけると、内部的なメンバ名が変わり(ネームマングリング)、元の変数名に簡単にアクセスできなくすることができます。この機能を使うことで、子クラスで同名のメンバがあった場合でも、実行時に元の親クラスの文脈で結果を評価することができるようになります。
pep8-ja - 命名規約 - メソッド名とインスタンス変数
結果を見てみましょう。
条件 結果 インスタンス変数 "SubClass" インスタンス変数の代わりにメソッド "SubClass" インスタンス変数(アンスコ2つ付き) "SuperClass" インスタンス変数の代わりにメソッド(アンスコ2つ付き) "SuperClass"
コードを見る(Python)
class SuperClass: def __init__(self): self.instance_variable = "SuperClass" def super_class_method(self): print(self.instance_variable) class SubClass(SuperClass): def __init__(self): super().__init__() self.instance_variable = "SubClass" # ------------------------------ class SuperClassPrivate: def __init__(self): self.__instance_variable = "SuperClass" def super_class_method(self): print(self.__instance_variable) class SubClassPrivate(SuperClassPrivate): def __init__(self): super().__init__() self.__instance_variable = "SubClass" # ------------------------------ class SuperClassGetter: def instance_variable(self): return "SuperClass" def super_class_method(self): print(self.instance_variable()) class SubClassGetter(SuperClassGetter): def instance_variable(self): return "SubClass" # ------------------------------ class SuperClassPrivateGetter: def __instance_variable(self): return "SuperClass" def super_class_method(self): print(self.__instance_variable()) class SubClassPrivateGetter(SuperClassPrivateGetter): def __instance_variable(self): return "SubClass" print('---- SubClass ----') sub = SubClass() sub.super_class_method() print('---- SubClassPrivate ----') subp = SubClassPrivate() subp.super_class_method() print('---- SubClassGetter ----') subg = SubClassGetter() subg.super_class_method() print('---- SubClassPrivateGetter ----') subpg = SubClassPrivateGetter() subpg.super_class_method()Ruby
「オブジェクト指向の動的型付け言語といったら?」
という連想クイズをされたプログラマは、真っ先にこの言語を思い浮かべる方も多いのではないでしょうか。Rubyにはメソッドに対して使える
privateがありますが、Javaのような言語のprivateとは挙動が違います。詳しくはレシーバとかを説明しなきゃいけなくなるので書きませんが、とりあえず言えることはprivateがあっても継承先にはそのメソッドが見えるということです。なのでJavaでいうとprotectedの方が近いかもしれません。
[Ruby] privateメソッドの本質とそれを理解するメリットちなみにRubyは変数とメソッドの名前空間が別れているので、メソッドをカッコなしで書いても呼び出せます。
それからメソッドはreturnを書かなくても、最後に評価した式の結果を返します。
@変数名がインスタンス変数です。Rubyでは変数名の1文字目で変数の種別(スコープ)がわかります。
条件 結果 インスタンス変数 "SubClass" インスタンス変数の代わりにメソッド "SubClass" インスタンス変数の代わりにprivateなメソッド "SubClass"
コードを見る(Ruby)
class SuperClass def initialize() @instance_variable = "SuperClass" end def super_class_method p @instance_variable end end class SubClass < SuperClass def initialize() super() @instance_variable = "SubClass" end end # -------------------------------- class SuperClassGetter def instance_variable() "SuperClass" end def super_class_method p instance_variable end end class SubClassGetter < SuperClassGetter def instance_variable() "SubClass" end end # -------------------------------- class SuperClassGetterPrivate def super_class_method p instance_variable end private def instance_variable() "SuperClass" end end class SubClassGetterPrivate < SuperClassGetterPrivate private def instance_variable() "SubClass" end end p '---- SubClass ----' subc = SubClass.new subc.super_class_method p '---- SubClassGetter ----' subg = SubClassGetter.new subg.super_class_method p '---- SubClassGetterPrivate ----' subgp = SubClassGetterPrivate.new subgp.super_class_methodPHP
PHPにはJavaのような
privateやprotectedやpublicがあります。
PythonやRubyやJavaScriptには基本的に無いのに! 羨ましい!
でもJavaとは違って、protectedなインスタンス変数はサブクラスのものを読みに行きます。
そこは他の動的型付け言語と足並みを揃えた動きですね。
条件 結果 インスタンス変数がprivate "SuperClass" インスタンス変数がprotected "SubClass" インスタンス変数の代わりにprivateなメソッド "SuperClass" インスタンス変数の代わりにprotectedなメソッド "SubClass"
コードを見る(PHP)
<?php function println($message) { echo $message.PHP_EOL; } // ---------------------------------------- class SuperClass { private $instanceVariable = "SuperClass"; public function superClassMethod() { println($this->instanceVariable); } } class SubClass extends SuperClass { private $instanceVariable = "SubClass"; } // ---------------------------------------- class SuperClassProtected { protected $instanceVariable = "SuperClass"; public function superClassMethod() { println($this->instanceVariable); } } class SubClassProtected extends SuperClassProtected { protected $instanceVariable = "SubClass"; } // ---------------------------------------- class SuperClassGetter { private function instanceVariable() { return "SuperClass"; } public function superClassMethod() { println($this->instanceVariable()); } } class SubClassGetter extends SuperClassGetter { private function instanceVariable() { return "SubClass"; } } // ---------------------------------------- class SuperClassGetterProtected { protected function instanceVariable() { return "SuperClass"; } public function superClassMethod() { println($this->instanceVariable()); } } class SubClassGetterProtected extends SuperClassGetterProtected { protected function instanceVariable() { return "SubClass"; } } // ---------------------------------------- println("---- SubClass ----"); $sub = new SubClass(); $sub->superClassMethod(); println("---- SubClassProtected ----"); $subp = new SubClassProtected(); $subp->superClassMethod(); println("---- SubClassGetter ----"); $subg = new SubClassGetter(); $subg->superClassMethod(); println("---- SubClassGetterProtected ----"); $subgp = new SubClassGetterProtected(); $subgp->superClassMethod();JavaScript
フロントエンドの覇者です。
プロトタイプベースオブジェクト指向言語という、プログラミング言語Selfから影響を受けた言語です。
ES6以降のJavaScriptではクラスベースの書き方も取り入れているため、extendsして継承もできます。
条件 結果 インスタンス変数 "SubClass" 古い書き方でインスタンス変数 "SubClass" インスタンス変数で、呼び出しメソッドがアロー関数 "SubClass" インスタンス変数の代わりにアロー関数 "SubClass"
コードを見る(JavaScript)
class SuperClass { constructor() { this.instanceVariable = "SuperClass" } superClassMethod() { console.log(this.instanceVariable) } } class SubClass extends SuperClass { constructor() { super() this.instanceVariable = "SubClass" } } // ------------------------ function LegacySuperClass() { this.instanceVariable = "SuperClass"; }; LegacySuperClass.prototype.superClassMethod = function() { console.log(this.instanceVariable) }; function LegacySubClass() { this.instanceVariable = "SubClass"; }; LegacySubClass.prototype = new LegacySuperClass(); // ------------------------ class SuperClassArrow { constructor() { this.instanceVariable = "SuperClass" } superClassMethod = () => { console.log(this.instanceVariable) } } class SubClassArrow extends SuperClassArrow { constructor() { super() this.instanceVariable = "SubClass" } } // ------------------------ class SuperClassGetterArrow { instanceVariable = () => { return "SuperClass" } superClassMethod = () => { console.log(this.instanceVariable()) } } class SubClassGetterArrow extends SuperClassGetterArrow { instanceVariable = () => { return "SubClass" } } // ------------------------ console.log('---- SubClass ----') const sub = new SubClass() sub.superClassMethod() console.log('---- LegacySubClass ----') var lsub = new LegacySubClass() lsub.superClassMethod() console.log('---- SubClassArrow ----') const suba = new SubClassArrow() suba.superClassMethod() console.log('---- SubClassGetterArrow ----') const subga = new SubClassGetterArrow() subga.superClassMethod()TypeScript
静的に型をつけられる、イケてるJavaScriptですね。
union型という、高度な型システムを持つHaskellに見られるような型に近いものがあったり、Conditional TypesやらMapped Typesやら表現力のある型があるのが特徴です。TypeScriptでは
privateな同名のメンバを親クラス子クラスで定義するとコンパイルエラーになります。protectedであれば問題ありません。Swiftとは真逆ですね。
条件 結果 インスタンス変数がprivate 定義不可 インスタンス変数がprotected "SubClass" インスタンス変数の代わりにprivateなメソッド 定義不可 インスタンス変数がprotectedで、呼び出しメソッドがアロー関数 "SubClass" インスタンス変数の代わりにprotectedなアロー関数 "SubClass"
コードを見る(TypeScript)
class SuperClass { private readonly instanceVariable: string constructor() { this.instanceVariable = "Error" } public superClassMethod() { console.log(this.instanceVariable) } } class SubClass extends SuperClass { // instanceVariableで定義しようとすると、 // TS2415: Class 'SubClass' incorrectly extends base class 'SuperClass'. // private readonly instanceVariable: string // constructor() { // super() // this.instanceVariable = "SubClass" // } } // ------------------------ class SuperClassGetter { private instanceVariable() { return "Error" } public superClassMethod() { console.log(this.instanceVariable()) } } class SubClassGetter extends SuperClassGetter { // instanceVariableで定義しようとすると、 // TS2415: Class 'SubClassGetter' incorrectly extends base class 'SuperClassGetter'. // Types have separate declarations of a private property 'instanceVariable'. // private instanceVariable() { // return "SubClass" // } } // ------------------------ class SuperClassProtected { protected readonly instanceVariable: string constructor() { this.instanceVariable = "SuperClass" } public superClassMethod() { console.log(this.instanceVariable) } } class SubClassProtected extends SuperClassProtected { protected readonly instanceVariable: string constructor() { super() this.instanceVariable = "SubClass" } } // ------------------------ class SuperClassProtectedGetterArrow { protected instanceVariable = () => { return "SuperClass" } public superClassMethod = () => { console.log(this.instanceVariable()) } } class SubClassProtectedGetterArrow extends SuperClassProtectedGetterArrow { protected instanceVariable = () => { return "SubClass" } } // ------------------------ // アロー関数版 class SuperClassProtectedArrow { protected readonly instanceVariable: string constructor() { this.instanceVariable = "SuperClass" } public superClassMethod = () => { console.log(this.instanceVariable) } } class SubClassProtectedArrow extends SuperClassProtectedArrow { protected readonly instanceVariable: string constructor() { super() this.instanceVariable = "SubClass" } } console.log('---- SubClass ----') const sub = new SubClass() sub.superClassMethod() console.log('---- SubClassGetter ----') const subg = new SubClassGetter() subg.superClassMethod() console.log('---- SubClassProtected ----') const subp = new SubClassProtected() subp.superClassMethod() console.log('---- SubClassProtectedArrow ----') const subpa = new SubClassProtectedArrow() subpa.superClassMethod() console.log('---- SubClassProtectedGetterArrow ----') const subpga = new SubClassProtectedGetterArrow() subpga.superClassMethod()Dart
Flutterが流行りだしてから急に存在感が出てきた印象な言語です。
Dartではprivateやpublicを書くことはありません。メンバの名前にアンダースコアをつけることでprivateにすることはできますが、ライブラリ外から見えなくするというだけなので、Javaなどのprivateとは違います。
条件 結果 インスタンス変数(アンスコ付き) "SubClass" インスタンス変数 "SubClass" インスタンス変数の代わりにメソッド "SubClass"
コードを見る(Dart)
void main() { print("---- SubClassPrivate ----"); final subp = new SubClassPrivate(); subp.superClassMethod(); print("---- SubClass ----"); final sub = new SubClass(); sub.superClassMethod(); print("---- SubClassGetter ----"); final subg = new SubClassGetter(); subg.superClassMethod(); } class SuperClassPrivate { // アンダースコアをつけるとPrivateになるが、 // privateは同一ライブラリに対して可視のため、ここではサブクラスから普通に見えちゃう final String _instanceVariable = "SuperClass"; void superClassMethod() => print(_instanceVariable); } class SubClassPrivate extends SuperClassPrivate { final String _instanceVariable = "SubClass"; } // ------------------------------------ class SuperClass { final String instanceVariable = "SuperClass"; void superClassMethod() => print(instanceVariable); } class SubClass extends SuperClass { final String instanceVariable = "SubClass"; } // ------------------------------------ class SuperClassGetter { String instanceVariable() => "SuperClass"; void superClassMethod() => print(instanceVariable()); } class SubClassGetter extends SuperClassGetter { String instanceVariable() => "SubClass"; }まとめ
ある程度使い慣れた言語でも知らないことがあったりして、意外と楽しかったです。
挙げた例の中には今回初めて書いた言語もあるので、こんな書き方あるよ! とか、間違ってるよ! とかあったらコメントください。全体的にまとめると、動的型付け言語だとスーパークラスのメソッドを呼んだ時でもサブクラスの文脈でまずは評価させようとするような印象でした。一方の静的型付け言語では、「スーパークラスのメソッドなんだから基本はスーパークラスで評価する。ただしオーバーライドしたらその限りじゃない」という感じでした。
個人的に印象深かったのは、下記の5つでした。
- C#には
newというオーバーライドしない用の修飾子がある- ScalaとKotlinは静的型付け言語なのにインスタンス変数のオーバーライドができる
- Pythonのアンダースコア2つのメンバ名はただの名前じゃなく効果もあった
- PHPには動的型付け言語なのにJavaみたいな
privateがある- TypeScriptは重複する
privateな同名メンバをコンパイル時にエラーにして予期せぬ動作になることを防いでくれる更新履歴
- Pythonのprivateな命名規約の説明について誤りがあったため、修正を行いました。 @shiracamus さんありがとうございました。
- 投稿日:2020-01-26T17:28:52+09:00
動画ファイルをndarrayに変換
動画ファイルをndarrayに変換
readClipimport cv2 import numpy as np def readClip(filepass):#ファイルパスを取得しndarrayを返す cap = cv2.VideoCapture(filepass) print(cap.isOpened())#読み込めたかどうか ret,frame = cap.read() array = np.reshape(frame,(1,int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)),int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),3)) while True: ret, frame = cap.read()#1フレーム読み込み if ret == False :#フレームが読み込めなかったら出る break frame = np.reshape(frame,(1,int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)),int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),3)) array = np.append(array,frame,axis=0) cap.release() return array b_array = readClip("./clip/battle.mp4") print(np.shape(b_array)) o_array = readClip("./clip/ordinary.mp4") print(np.shape(o_array))注意
めっちゃ時間かかる
- 投稿日:2020-01-26T17:06:50+09:00
「日程くん」から得られたスケジュールをGoogleカレンダーにインポートする
概要
上記の投稿で、Jリーグの日程が取得できたので活用したいと思います。
日頃使っているカレンダーアプリにインポートできれば、逐一入力する手間が省けます。そこで
Google カレンダーにインポートできる形式のファイルを作成しましょう。iCalender形式について
基本形
sample.icsBEGIN:VCALENDAR VERSION:2.0 BEGIN:VEVENT DTSTART;TZID=Asia/Tokyo:20200223T130000 DTEND;TZID=Asia/Tokyo:20200223T150000 SUMMARY;LANGUAGE=jp-JP:第1節第3日 FC東京 DESCRIPTION;LANGUAGE=jp-JP:キックオフ:13:00\n スタジアム:アイスタ\n クラブ:http://www.fctokyo.co.jp/\n JAL:https://www.jal.co.jp/\n ANA:https://www.ana.co.jp/\n END:VEVENT END:VCALENDAR
BEGIN:VCALENDAR VERSION:2.0がヘッダー行で、END:VCALENDARがフッター行で構成される。BEGIN:VEVENTとEND:VEVENTで一つのスケジュールを記述する。アイテムが複数あればこの繰り返しが必要になる。DTSTART:開始時間、DTEND:終了時間、時間の表示形式は%Y%m%dT%H%M%Sです。例:20200223T130000- タイムゾーンは
;TZID=Asia/Tokyoと指定する。- 言語は
;LANGUAGE=jp-JPと指定する。DESCRIPTIONで複数行に分けたい場合は、\nを行末に付与する。内容については、例では航空会社2社を追加していますが、宿泊サービスやスタジアムの位置情報などがあれば便利です。コード
schedule_all.pyimport datetime import pandas as pd # 'https://data.j-league.or.jp/'の日程結果から取得する data = pd.read_csv('./csv/Game_Schedule_2020.csv', sep=',', encoding='utf-8')
schedule_all.py# クラブHPのアドレスを収集したローカルファイルを準備する club = pd.read_csv('./csv/master_club_2020.csv', sep=',', encoding='utf-8')対戦するクラブのアドレスを詳細データに入れるために、独自で作成したデータを準備しました。
schedule_all.pyyyyy = 2020 # 抽出したいチーム名を指定する team = data[(data['ホーム'] == 'チーム名') | (data['アウェイ'] == 'チーム名')]「チーム名」を取得したいチーム名に変更する。
schedule_all.py# 固定文字列を作成する header = (r'BEGIN:VCALENDAR' + '\n' r'VERSION:2.0' + '\n') footer = (r'END:VCALENDAR') info = (' JAL:https://www.jal.co.jp/\\n\n' ' ANA:https://www.ana.co.jp/\\n') timezone = ';TZID=Asia/Tokyo' language = ';LANGUAGE=jp-JP'テンプレートを構成する文字列を作成する。
schedule_all.pyschedule_all = [] for i in range(len(team)): if team['KO時刻'].iloc[i] == '●未定●': break # 特定チームデータから節単位に以下の項目を作成する # start_datetime, end_datetime, section, home or away team, kick_off, stadium, club HP tmp_date = team['試合日'].iloc[i] tmp_date = str(yyyy) + '/' + tmp_date[:5] start_time = team['KO時刻'].iloc[i] tmp_date_time = tmp_date + ' ' + start_time + ':00' tmp_dtstart = datetime.datetime.strptime(tmp_date_time, '%Y/%m/%d %H:%M:%S') tmp_dtend = tmp_dtstart + datetime.timedelta(hours=2) # start_datetime dtstart = tmp_dtstart.strftime('%Y%m%dT%H%M%S') # end_datetime dtend = tmp_dtend.strftime('%Y%m%dT%H%M%S') # section sec = team['節'].iloc[i] # team name team_name = team['アウェイ'].iloc[i] if team['ホーム'].iloc[i] == 'チーム名' else team['ホーム'].iloc[i] # kick off kickoff = str(team['KO時刻'].iloc[i]) # stadium stadium = team['スタジアム'].iloc[i] # club HP club_url = club[club['略称'] == team_name]['オフィシャルサイトURL'] # 節単位のデータからiCalender形式で文字列を作成する。 begin = 'BEGIN:VEVENT' dstart = 'DTSTART' + timezone + ':' + dtstart dend = 'DTEND' + timezone + ':' + dtend summary = 'SUMMARY' + language + ':' + sec + ' ' + team_name description1 = r'DESCRIPTION' + language + ':' + 'キックオフ:' + kickoff + '\\n' description2 = r' スタジアム:' + stadium + '\\n' description3 = r' クラブ:' + club_url.values[0] + '\\n\n' + info end = 'END:VEVENT' + '\n' # 節単位のデータをリスト化する contents = [begin, dstart, dend, summary, description1, description2, description3, end] schedule_all.append(contents)
- 後半戦はキックオフ時間がまだ未定のため、KO時刻が決定しているデータのみ作成
- イベントの終了時間は、
datetime.timedelta(hours=2)で2時間後と指定- 節単位のデータを
schedule_allに追加schedule_all.py# カレンダーファイルの作成 path = './csv/schedule_all_2020.ics' with open(path, mode='a', encoding='utf-8') as f: f.write(header) for s in schedule_all: f.write('\n'.join(s)) f.write(footer)最後は、節単位のリストをループ処理し、テキストファイルを作成する。(※説明のため、節データの作成するループ処理とテキストファイルを作成するループ処理に分けました。)
参考にさせていただいた記事


- 投稿日:2020-01-26T16:57:34+09:00
【Python】ファイル一覧をCSV出力
1. はじめに
Pythonを使って、指定した1つのディレクトリの中にあるファイル一覧をCSVで出力。
. ├── create_csv.py └── sample_images ├── five.svg ├── four.svg ├── one.svg ├── three.svg └── two.svg 1 directory, 6 files実行すると、こんな感じのCSVが出力される。
$ python create_csv.py ./sample_images
- ヘッダーには通し番号、ファイル名、最終更新日を設定。
- 出力先は指定していないので、create_csv.pyと同じ階層に作成(今回だとfile_list.csvというファイル名)。
2. コード
create_csv.pyimport argparse import csv import datetime import glob import os import sys # CSV出力 def create_csv(lists, field_names): with open('file_list.csv', 'w') as f: # もし出力先指定したければ編集 writer = csv.DictWriter(f, lineterminator='\n', fieldnames=field_names) writer.writeheader() writer.writerows(lists) # ファイル一覧のリストを作成 def make_list(work_dir): items = [] num = 0 for file_path in glob.glob(os.path.join(work_dir, "*")): num += 1 f = os.path.basename(file_path) # ファイル名の取得 u = datetime.datetime.fromtimestamp(os.path.getmtime(file_path)) #更新日の取得 item = {'No.': num, 'File Names': f, 'Update': u} items.append(item) create_csv(items, item.keys()) # itemで定義したkeyをそのまま出力に使う # create_csv.py実行時にディレクトリを指定(引数で渡す) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("work_dir", type=str, help ="画像ファイルを格納しているディレクトリ") args = parser.parse_args() # 指定したディレクトリが無ければ処理終了 if not os.path.isdir(args.work_dir): print('Error: The directory (%s) does not exist.' % args.work_dir) sys.exit() make_list(args.work_dir)作成してみて…
勉強になりました。笑
結局、CSVで一覧出力しておく…ってそんな出番ない。
でもこれを応用して業務効率上げれたらいいと思っています。Pythonで実行時に引数追加できるようにするとか
ファイルの更新日の取得とか
ファイル名の取得とか
ファイルの出力とか…
組み合わせ次第ではいろいろ使えそう。参考サイト
Python ドキュメント
note.nkmk.me
いつも隣にITのお仕事 PythonあとVS codeでCSV見るときにはExcel Viewer(拡張機能)を使いました。

- 投稿日:2020-01-26T16:17:30+09:00
【Pythonやってみた!】タイタニックデータ編_vol.1(ヒストグラム,散布図,相関係数)
本日は,あまり難しいことは考えずに,
とりあえず「タイタニックデータ」を使って,
統計的分析をしていきます.
※本日は,超初心者向けです!
(ヒストグラム,散布図,相関係数 程度まで)■はじめに
<私の実行環境>
Microsoft Windows Version:10.0
Python Version:3.8.1
※コマンドプロンプト使用
(Linuxの方が適しているという噂を聞いたのですが,私が持っているのはwindowsのPCだし...
ということでとりあえず,windowsで頑張っています.)↓(参考)windowsのバージョン確認
C:\Users\ユーザ名>ver↓(参考)Pythonのバージョン確認
C:\Users\ユーザ名>python<仮想環境について>
Pythonは仮想環境上で実行していくと都合がいいらしいので,
私も仮想環境を使っています.
※仮想環境の作り方についてはまた後日紹介できればと思います.↓(参考)仮想環境の立上げ
C:\Users\ユーザ名>仮想環境名\scripts\activate↓(参考)仮想環境を立上げたらこのように表示される
(仮想環境名)C:\Users\ユーザ名>■必要なパッケージのインストール
今回使用するパッケージは,
・numpy
・pandas
・matplotlib
・seaborn
です.↓インストール
(仮想環境名)C:\Users\ユーザ名>pip install パッケージ名↓インストール済みのパッケージ一覧表示
(仮想環境名)C:\Users\ユーザ名>pip list↓結果はこんな感じ.
■pythonの起動
(仮想環境名)C:\Users\ユーザ名>python↓(参考)Pythonが起動したらこのように表示される
(>>>しか表示されなくなった...)>>>■データの読込み
今回は,世界的なデータコンペ「Kaggle」から入手可能な「タイタニックデータ」を使います.
※こちらも詳細は後日紹介できればと思います.<データの保存フォルダ>
私自身が超初心者なもので,よく分からなかったので,
一旦,「C:\Users\ユーザ名」フォルダ直下にデータを保存しました.
(絶対パスとか相対パスとか試したのですが,なぜか上手くいきませんでした...(TT))<データ読込み>
↓パッケージのインポートimport pandas as pd※完了すると,再び「>>>」が出てくる.
↓「train.csv」を,「pandas(pd)」の「read_csv」クラスを使って,
「df」に格納する.df = pd.read_csv("train.csv")■いよいよデータ分析をやってみる!
ここまで来たら,あとは,好きなようにデータを見ていきます.<生存・死亡者数>
必要なパッケージをインポートをしてから,
「df」に格納したデータの項目「Survived(生存者=1,死亡者=0)」を棒グラフに表示してみます.import seaborn as sns import matplotlib.pyplot as plt sns.countplot("Survived",data=df,palette='rainbow') plt.show()↓「plt.show()」実行結果
上下左右のずれの調整とか,画像の保存もここからできて便利でした!
<相関係数行列(ヒートマップ)>
sns.heatmap(df.corr(),annot=True,cmap='RdYlGn',vmin=-1,vmax=1,fmt=".2f",square=True) plt.show()
<ペアプロット図>
sns.pairplot(df) plt.show()
■最後に
本日はお読みいただきありがとうございました.
本投稿が初投稿なもので,いろいろ分かりにくいところもあったかと思いますが,
ご容赦ください.
ご指摘があれば受け付けますので,(受付方法がよくわかっていませんが...)
どうぞよろしくお願いいたします.
自分でも誤りを見つけましたら都度修正します.
ご質問もできる限り回答しますので,(これも受付方法がわかりませんが...)
どうぞご自由にご質問ください.
ではまたどこかでお会いしましょう~(^^)♪



- 投稿日:2020-01-26T16:17:30+09:00
【Pythonやってみた!】タイタニックデータ編_vol.1(棒グラフ,散布図,相関係数)
本日は,あまり難しいことは考えずに,
とりあえず「タイタニックデータ」を使って,
統計的分析をしていきます.
※本日は,超初心者向けです!
(棒グラフ,散布図,相関係数 程度まで)■はじめに
<私の実行環境>
Microsoft Windows Version:10.0
Python Version:3.8.1
※コマンドプロンプト使用
(Linuxの方が適しているという噂を聞いたのですが,私が持っているのはwindowsのPCだし...
ということでとりあえず,windowsで頑張っています.)↓(参考)windowsのバージョン確認
C:\Users\ユーザ名>ver↓(参考)Pythonのバージョン確認
C:\Users\ユーザ名>python<仮想環境について>
Pythonは仮想環境上で実行していくと都合がいいらしいので,
私も仮想環境を使っています.
※仮想環境の作り方についてはまた後日紹介できればと思います.↓(参考)仮想環境の立上げ
C:\Users\ユーザ名>仮想環境名\scripts\activate↓(参考)仮想環境を立上げたらこのように表示される
(仮想環境名)C:\Users\ユーザ名>■必要なパッケージのインストール
今回使用するパッケージは,
・numpy
・pandas
・matplotlib
・seaborn
です.↓インストール
(仮想環境名)C:\Users\ユーザ名>pip install パッケージ名↓インストール済みのパッケージ一覧表示
(仮想環境名)C:\Users\ユーザ名>pip list↓結果はこんな感じ.
■pythonの起動
(仮想環境名)C:\Users\ユーザ名>python↓(参考)Pythonが起動したらこのように表示される
(>>>しか表示されなくなった...)>>>■データの読込み
今回は,世界的なデータコンペ「Kaggle」から入手可能な「タイタニックデータ」を使います.
※こちらも詳細は後日紹介できればと思います.<データの保存フォルダ>
私自身が超初心者なもので,よく分からなかったので,
一旦,「C:\Users\ユーザ名」フォルダ直下にデータを保存しました.
(絶対パスとか相対パスとか試したのですが,なぜか上手くいきませんでした...(TT))<データ読込み>
↓パッケージのインポート
import pandas as pd※完了すると,再び「>>>」が出てくる.
↓「train.csv」を,「pandas(pd)」の「read_csv」クラスを使って,
「df」に格納する.df = pd.read_csv("train.csv")■いよいよデータ分析をやってみる!
ここまで来たら,あとは,好きなようにデータを見ていきます.
<生存・死亡者数>
必要なパッケージをインポートをしてから,
「df」に格納したデータの項目「Survived(生存者=1,死亡者=0)」を棒グラフに表示してみます.import seaborn as sns import matplotlib.pyplot as plt sns.countplot("Survived",data=df,palette='rainbow') plt.show()↓「plt.show()」実行結果
上下左右のずれの調整とか,画像の保存もここからできて便利でした!
<相関係数行列(ヒートマップ)>
sns.heatmap(df.corr(),annot=True,cmap='RdYlGn',vmin=-1,vmax=1,fmt=".2f",square=True) plt.show()
<ペアプロット図>
sns.pairplot(df) plt.show()
■最後に
本日はお読みいただきありがとうございました.
本投稿が初投稿なもので,いろいろ分かりにくいところもあったかと思いますが,
ご容赦ください.
ご指摘があれば受け付けますので,(受付方法がよくわかっていませんが...)
どうぞよろしくお願いいたします.
自分でも誤りを見つけましたら都度修正します.
ご質問もできる限り回答しますので,(これも受付方法がわかりませんが...)
どうぞご自由にご質問ください.
ではまたどこかでお会いしましょう~(^^)♪
- 投稿日:2020-01-26T15:42:44+09:00
data augmentationの1種mixupの簡単実装例
mixupの概要
(編集予定)
↓参照
https://arxiv.org/pdf/1710.09412.pdf簡単実装例
def mixup(x, y, batch_size, alpha = 0.2): l = np.random.beta(alpha, alpha, batch_size) shape = tuple(-1 if i == 0 else 1 for i in range(len(x.shape))) x = l.reshape(shape) * x + (1 - l).reshape(shape) * x[::-1] shape = tuple(-1 if i == 0 else 1 for i in range(len(y.shape))) y = l.reshape(shape) * y + (1 - l).reshape(shape) * y[::-1] return x, yコードの解説
引数
引数名 説明(type) x 入力データ(numpy.ndarray) y 出力データ(numpy.ndarray) batch_size 文字通りバッチサイズ(int) alpha β分布を決定するパラメタ(float)
xとyはそれぞれバッチ単位で入力され,また,データセットはエポックが終わるたびにシャッフルされるという想定.関数の中身
l = np.random.beta(alpha, alpha, batch_size)
ここでは,ブレンディングの重みを計算する.lのshapeは(batch_size)になる.
shape = tuple(-1 if i == 0 else 1 for i in range(len(x.shape)))
ここでは,lをxにブロードキャスト可能にするためのshapeを求めている.
たとえば,xのshapeが(batch_size, width, height, ch)のようになっていたとして,lのshapeが(batch_size)である場合,l * xをしたときに期待通りの計算結果にならない.また,xのshapeのよってはoperands could not be broadcast ...といったエラーが出る場合がある.
x = l.reshape(shape) * x + (1 - l).reshape(shape) * x[::-1]
ここでは,xをブレンディングしている.なお,x[::-1]はxの逆順を表している.
shape = tuple(-1 if i == 0 else 1 for i in range(len(y.shape)))
ここでは,lをyにブロードキャスト可能にするためのshapeを求めている.
y = l.reshape(shape) * y + (1 - l).reshape(shape) * y[::-1]
ここでは,yをブレンディングしている.なお,y[::-1]はyの逆順を表している.返り値
返り値名 説明(type) x ミックスされた入力データ(numpy.ndarray) y ミックスされた出力データ(numpy.ndarray) Reference
- mixup: BEYOND EMPIRICAL RISK MINIMIZATION ( https://arxiv.org/pdf/1710.09412.pdf)
- 投稿日:2020-01-26T15:36:45+09:00
Pycairoで正多角形を描く
正多角形の角の位置を算出する
正n角形を描くには、円周上に等間隔にn個の点をプロットし、それを直線で結べばいい。
例えば、n=3(正三角形)のとき、360゜を3で割り、円周上の0゜、120゜、240゜に点をプロットする。
図示すると、こんな感じ(手描きの雑な図で恐縮だが)。
Pycairoできれいに出力するとこう。
正多角形を回転させる
図を出力するとき、正多角形を回転させたい。
上の例で示した正三角形も、そのままだと横を向いている。0゜を90゜にずらして、上を向かせたい。図示すると、こんな感じ。
Pycairoで出力するとこう。
コード
以下、コード。出力するときの色は適当。
正七角形を90゜回転させて描画する。"""正多角形描画""" import cairo import math # 角の数 EDGE_TOTAL_CNT = 7 # 回転角度 ROTATION_ANGLE_DEGREE = 90 # コンテクスト作成 side_length = 300 surface = cairo.ImageSurface(cairo.FORMAT_RGB24, side_length, side_length) ctx = cairo.Context(surface) # 背景色セット ctx.rectangle(0, 0, side_length, side_length) ctx.set_source_rgb(1, 1, 0) ctx.fill() # 正多角形描画 x_center = side_length / 2 y_center = side_length / 2 line_width = 10 radius = (side_length / 2) - line_width rotation_angle = math.radians(ROTATION_ANGLE_DEGREE) for edge_cnt in range(0, EDGE_TOTAL_CNT): theta = ((2 * math.pi * edge_cnt) / EDGE_TOTAL_CNT) + rotation_angle x = x_center + (radius * math.cos(theta)) y = y_center - (radius * math.sin(theta)) if edge_cnt == 0: ctx.move_to(x, y) else: ctx.line_to(x, y) ctx.close_path() ctx.set_source_rgb(0, 1, 1) ctx.set_line_width(line_width) ctx.stroke() surface.write_to_png("somepath.png")出力されたPNGファイルはこんな感じ。




