{"responses":[{"error":{"code":7,"message":"We're not allowed to access the URL on your behalf. Please download the content and pass it in."}}]}{"responses":[{"error":{"code":4,"message":"We can not access the URL currently. Please download the content and pass it in."}}]}assitin."}}]}
Step 1: Create an IAM instance profile
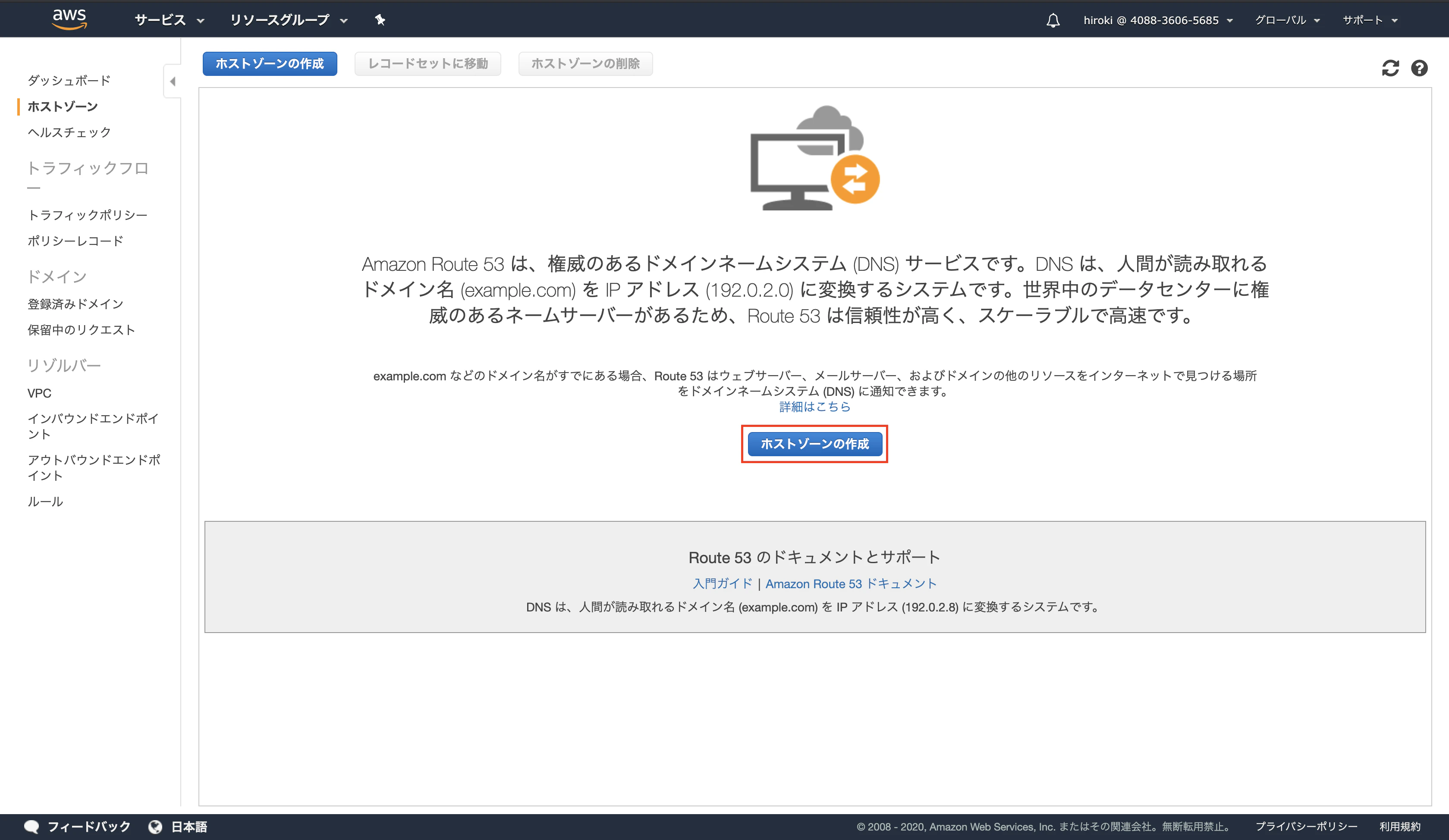
Step 2: Create an OpsWorks stack
Step 3: Create a Lambda function
Step 4: Create an SNS topic
Step 5: Create a launch configuration
Step 6. Create an Auto Scaling group
ログを分析し、異常と思われる挙動がある場合警告を行う仕組み。例えば以下のような警告例がある。2018/1 時点、EC2 と IAM のみが警告対象。
Inspector
EC2 の脆弱性自動チェックサービス。対象範囲はネットワーク・OS・ミドルウェアで、あらかじめ AWS が CVE などを元に準備したチェック項目に従い、不正アクセスができたりしないかなどを実際にチェックする。EC2 に専用のエージェントをインストールする必要あり。対象 OS は Windows または Linux 系 OS。EC2 以外に対して脆弱性チェックを行うことはできない。自作の Web アプリケーションの脆弱性チェックをしてくれるわけではない。