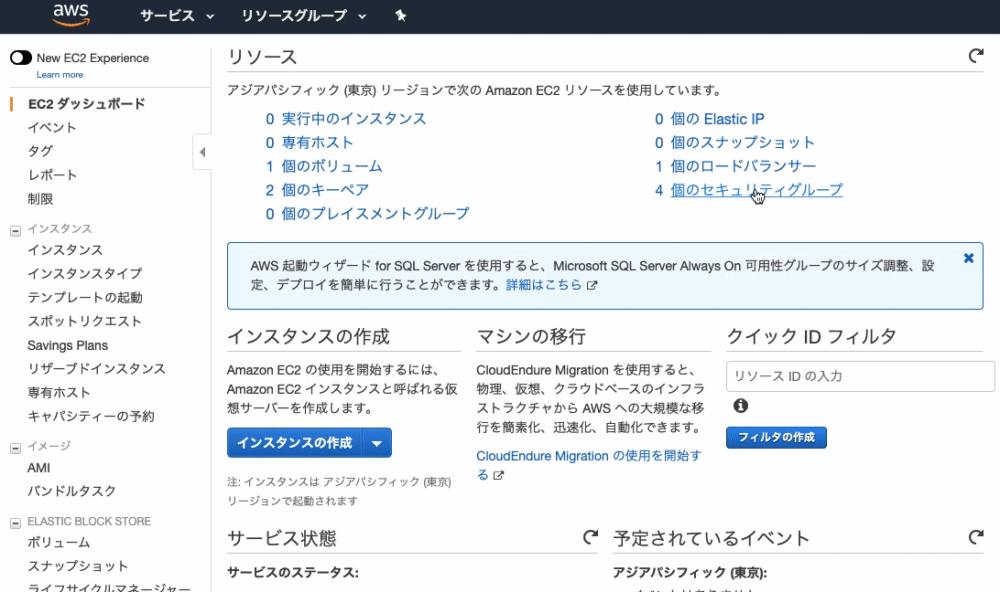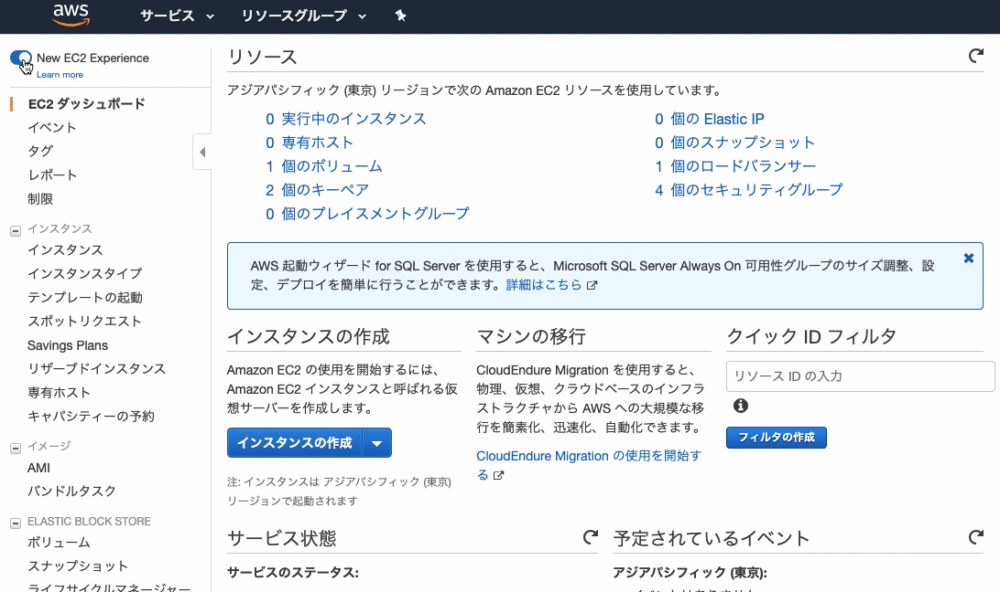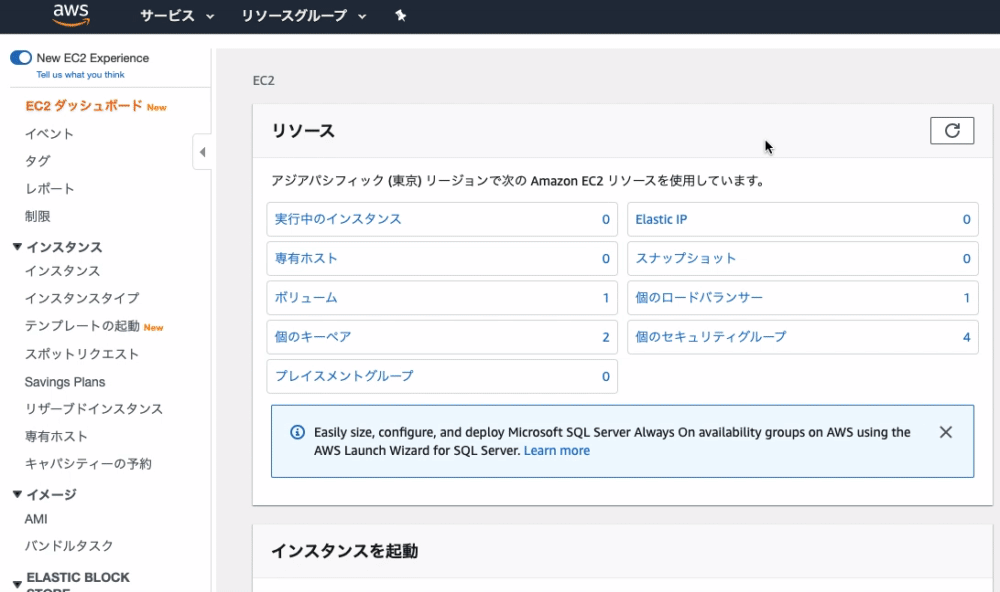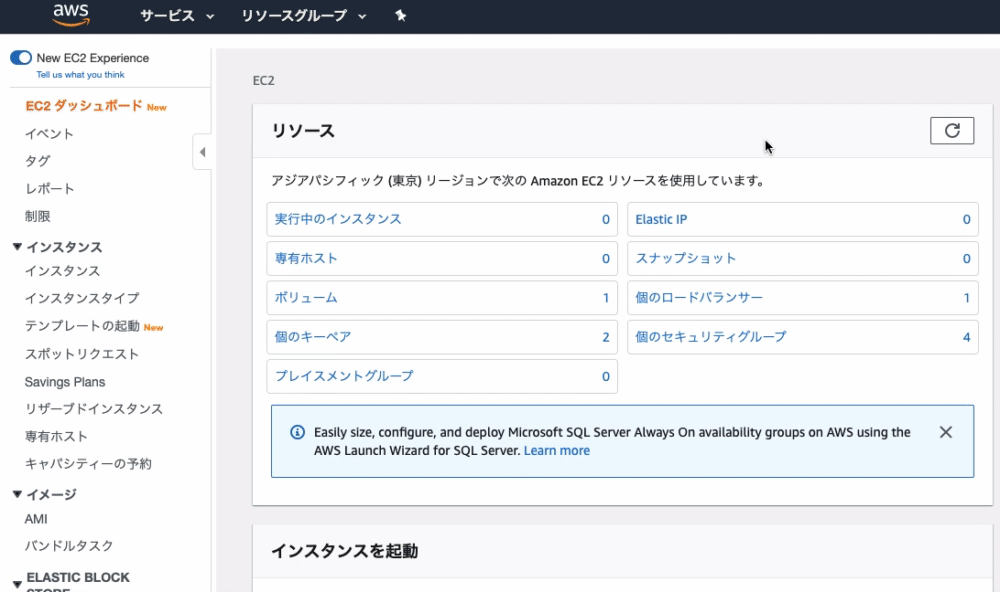
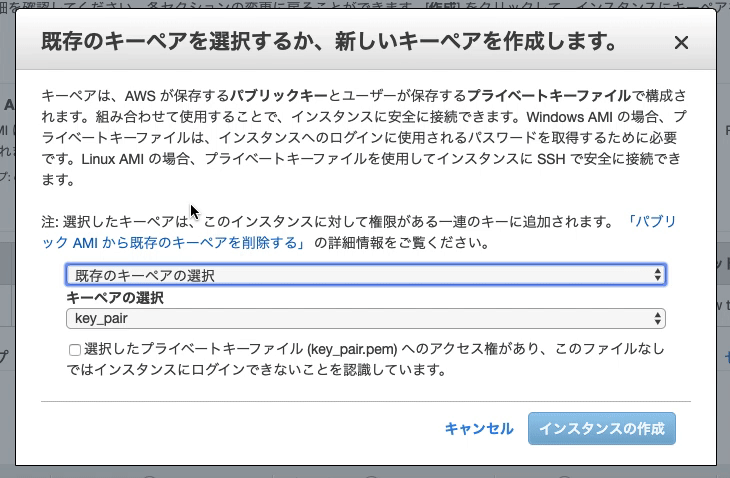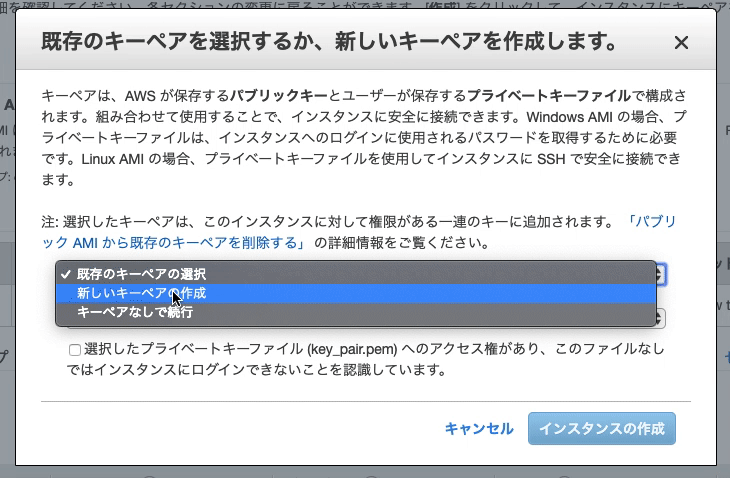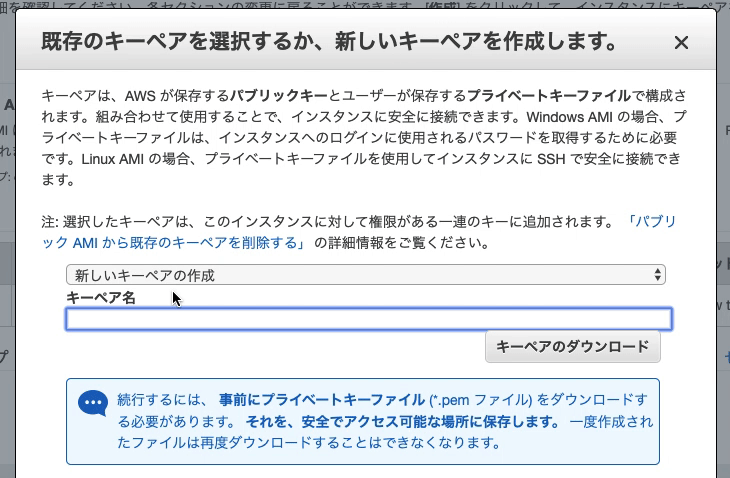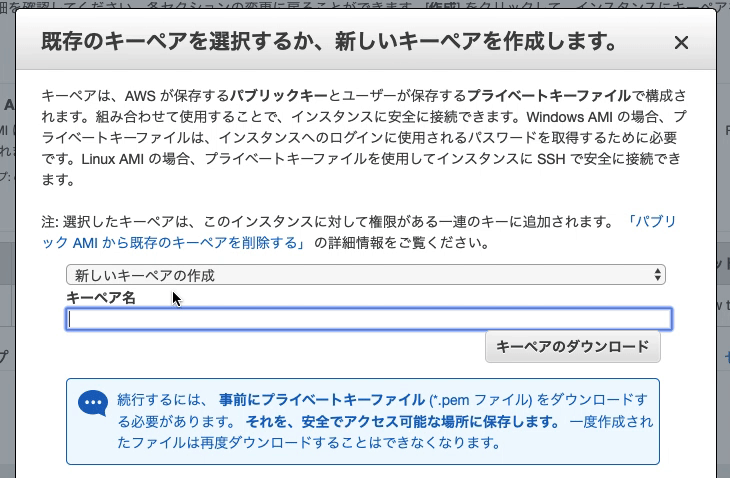
$bundle install--path vendor/bundle
[DEPRECATED] The `--path` flag is deprecated because it relies on being remembered across bundler invocations, which bundler will no longer do in future versions. Instead please use `bundle config set path 'vendor/bundle'`, and stop using this flag
もし非推奨警告の対応は後回しにして警告を非表示にしたい場合は、設定によってそのように変更できます。その場合はBUNDLE_SILENCE_DEPRECATIONSという環境変数を"true"に設定するか、bundle configコマンドを使って設定してください。グローバルに設定を変更したい場合はbundle config set silence_deprecations trueコマンドを使い、ローカルの設定だけ変更したい場合はbundle config set --local silence_deprecations trueコマンドを使います。これ以降、本ドキュメントではこの3つの設定方法がすべて有効である前提で執筆していきますが、記述するのはbundle config set <option> <value>の方法だけにします。
この仕様変更によって影響を受けるのは、この機能に依存する「よくあるワークフロー」です。たとえば、本番環境でbundle install --without development:testというコマンドを実行すると、このフラグがアプリケーションの設定ファイルに保存され、それ以降はbundleコマンドを実行してもdevelopmentとtestのgemをありがたく無視してくれます。Bundler 3以降はこの魔法が使えなくなります。同じ挙動を維持するためには明示的な設定が必要です。設定を入れる方法は、環境変数、アプリケーションの設定、マシン全体の設定のいずれかです。たとえば、bundle config set without development testというコマンドを使います。