- 投稿日:2020-01-10T23:59:11+09:00
Selenium(Python)で複数サイトを自動ブラウジングするツール作った
はじめに
ブラウジングしたいURLが書かれたテキストファイルを受け取り、自動でブラウジングしてくれるツールを作成しました。
こだわった点はyoutubeやyahooなど、スクロールするにつれてコンテンツが増えるページにも対応した点です。
参考になれば幸いです。コード
AutoBrowsing.pyimport os import re import sys import time import chromedriver_binary import requests from selenium import webdriver # *** main関数(実行は最下部) *** def main(): # URL一覧ファイルの受付 input_path = input_urls_file() # URLリストをファイルから取得 url_list = get_url_list(input_path) # URLリスト中のURLの検証 validate_url(url_list) # ブラウジング確認の受付 confirm_browsing() # ブラウジング browsing_urls(url_list) # *** URL一覧ファイルの入力を受け付ける関数 *** def input_urls_file(): print("\n########## Start processing ##########") print("Input filepath of urls : ") # ファイルの入力の受付(フルパス) input_path = input() print("\nCheck input file ...\n") # ファイルの存在チェック if os.path.exists(input_path): print(' [OK]: File exists. : ' + input_path) # ファイルが存在しない場合は終了 else: print(" [ERROR]: File doesn't exist! : " + input_path) print("\nSystem Exit.\n") sys.exit() return input_path # *** URLリストをファイルから取得する関数 *** def get_url_list(input_path): # ファイルのオープン targetFile = open(input_path) # 行ごとのURLのリスト url_list = targetFile.readlines() # ファイルのクローズ targetFile.close() return url_list # *** URLスキームとステータスコードを検証する関数 *** def validate_url(url_list): print("\nCheck url scheme and status code ...\n") # エラーフラグ hasError = False for url in url_list: # Tips:readlines()で読み込んだ1行には改行コードがついてくるので削除 unsafe_url = url.rstrip() # URLのスキームパターン URL_PTN = re.compile(r"^(http|https)://") # パターンに一致しない場合はエラー if not (URL_PTN.match(unsafe_url)): print(" [ERROR]: Url isn't valid! : " + unsafe_url) hasError = True # スキームが正しくない場合にはURLにリクエストしない continue # スキームが正しい場合にURLにリクエスト r = requests.get(unsafe_url) # ステータスコードが200(リダイレクトでも200)以外の場合はエラー if (r.status_code != 200): print(" [ERROR]: Status code isn't 200! : [" + r.status_code + "]:" + unsafe_url) hasError = True # スキームが正しくない、またはステータスコードが200以外のものがあった場合には終了 if hasError: print("\nSystem Exit.\n") sys.exit() print(" [OK]: All urls are valid and 200.") print(" [OK]: Number of urls : " + str(len(url_list))) # *** ブラウジング開始の入力を受け付ける関数 *** def confirm_browsing(): # Yes/No以外は無限ループ while True: print("\nStart browsing? y/n (default:y)") # 入力は全て小文字として受付(比較が楽) confirm_cmd = input().lower() # デフォルト(Enter)のみでもyとして扱う if ((confirm_cmd == "") or (confirm_cmd == "y")): break elif ((confirm_cmd == "n")): print("\nSystem Exit.\n") sys.exit() else: pass # *** ブラウジングを実行する関数 *** def browsing_urls(url_list): options = webdriver.ChromeOptions() # ブラウザを最大化 options.add_argument("--start-maximized") # 「Chromeは自動テストソフトウェアによって制御されています。」を消すためのオプションの指定 options.add_experimental_option("excludeSwitches", ["enable-automation"]) options.add_experimental_option('useAutomationExtension', False) driver = webdriver.Chrome(options=options) print("\n===== start =====") # 一行ずつブラウザを開く for i, url in enumerate(url_list): # URLリスト全体中何個目のURLを表示しているかを出力 print(" " + str(i+1) + "/" + str(len(url_list))) # URLにアクセス driver.get(url) # ↓各URLに行いたい処理があればここで呼び出す関数を変更する # 各URLを最下部までスクロールする処理 scrolle_to_end(driver) print("===== end =====\n") # 終了 driver.quit() print("Complete.\n") # *** ページの最下部までスクロールする関数 *** def scrolle_to_end(driver): # スクロールする速さ(1以上を指定) SCROLL_SPEED = 3 while not is_scrolle_end(driver): # 0.5秒待つ(基本的には不要だが読み込みが遅いときなどに使用する) # time.sleep(0.5) # 相対値でスクロール driver.execute_script("window.scrollBy(0, "+str(SCROLL_SPEED)+");") # 1秒待つ time.sleep(1) # *** 一番下までスクロールしたか否か判定する関数 *** def is_scrolle_end(driver): # 一番下までスクロールした時の数値を取得(window.innerHeight分(画面表示領域分)はスクロールをしないため引く) script = "return " + str(get_page_height(driver)) + \ " - window.innerHeight;" page_most_bottom = driver.execute_script(script) # スクロール量を取得(ブラウザの種類やバージョンなどによって取得方法が異なる) script = "return window.pageYOffset || document.documentElement.scrollTop;" scroll_top = driver.execute_script(script) is_end = scroll_top >= page_most_bottom return is_end # *** ページの高さを取得する関数 *** def get_page_height(driver): # ブラウザのバージョンやサイトによって異なるため、最大値を取る # https://ja.javascript.info/size-and-scroll-window#ref-633 # Tips:文字列を改行なしで複数行で書きたい場合には()で囲む script = ("return Math.max(" "document.body.scrollHeight, document.documentElement.scrollHeight," "document.body.offsetHeight, document.documentElement.offsetHeight," "document.body.clientHeight, document.documentElement.clientHeight" ");") height = driver.execute_script(script) return height # main関数の実行 main()↓サンプルのインプットファイル
test_url_list.txthttps://www.google.com/ https://qiita.com/ https://www.youtube.com/ https://www.yahoo.co.jp/↓実行時のコンソール
########## Start processing ########## Input filepath of urls : c:\Users\hoge\Desktop\work\python\AutoBrowsing\test_url_list.txt Check input file ... [OK]: File exists. : c:\Users\hoge\Desktop\work\python\AutoBrowsing\test_url_list.txt Check url scheme and status code ... [OK]: All urls are valid and 200. [OK]: Number of urls : 4 Start browsing? y/n (default:y) ===== start ===== 1/4 2/4 3/4 4/4 ===== end ===== Complete.実行準備
pipでのChromeDriverのインストール時のバージョンの罠
seleniumでChromeを走査する際にpipでインストールを行う場合、単純に
pip install chromedriver-binaryコマンドでインストールすると、バージョンの問題で実行時にエラーになります。
インストール時にはバージョンを指定してください。
バージョン指定なしでインストールしてからでも、バージョンを指定してインストールすれば、自動で前のものはアンインストールされます。※詳細については以下
[selenium向け] ChromeDriverをpipでインストールする方法(パス通し不要、バージョン指定可能)おわり
今回は自動でブラウザを立ち上げた後、最下部までスクロールするという処理を行いました。
リストを受け付けてそのURLに対して何かしらの処理を行うという処理は使い回せそうなので、他にも何か作ってみようと思います。
- 投稿日:2020-01-10T23:48:40+09:00
学習記録 その20(24日目)
学習記録(24日目)
勉強開始:12/7(土)〜
教材等:
・大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年):12/19(木)読了
・Progate Python講座(全5コース):12/21(土)終了
・Andreas C. Müller、Sarah Guido『(邦題)Pythonではじめる機械学習』(オライリージャパン、2017年):12月23日(土)読了
・Kaggle : Real or Not? NLP with Disaster Tweets :12月28日(土)投稿〜1月3日(金)まで調整
・Wes Mckinney『(邦題)Pythonによるデータ分析入門』(オライリージャパン、2018年):1月4日(土)〜『Pythonによるデータ分析入門』
p.346 10章 データの集約とグループ演算 まで読み終わり。
9章 プロットと可視化
・matplotlib, seabornといったデータ可視化ライブラリの解説
線種のような設定要素についてはDocString(関数名 + '?')で見られる。
(matplotlibをas pltでインポートしているなら、plt.plot?のように使う。)・基本はmatplotlibとし、必要に応じてpandasやseabornのようなアドオンライブラリを用いるとよい。
プロットの下準備import matplotlib.pyplot as plt fig = plt.figure() #プロット機能が含まれるオブジェクト。 ax1 = fig.add_subplot(1, 1, 1) #プロットするためにはサブプロットを1つ以上追加する。 #以下、図の形式や入力データについて記述・できること概要
余白の調整、軸の共有、タイトル、凡例及び表示位置の調整(loc='best'で最適位置)、
ラベル回転表示(rotation)、注釈の追加(annotate)、図の追加(add_patch)、
matplotlibのデフォルト値設定(rcメソッド)軸のクラス(AxesSubplot)のsetメソッドを用いた属性の一括設定props = {'title': 'namae no ikkatsu settei', 'xlabel': 'aiueo'} ax.set(**props)・DataFrameにもplotメソッドがある。データフレームにそのまま使える。
値の頻度の可視化s.value_counts().plot.bar() #barhで横棒・seabornパッケージを使用すると、プロットの前に集計や要約を要するデータを容易に可視化できる。
引数のdataにはデータを、xやyにはデータフレームの行と列の名前を指定する、・ヒストグラム:棒グラフの一種、値の頻度を離散データとして表示
・密度プロット:観測データを生み出したと推定される連続確率分布から生成される。
通常、この分布をカーネルという正規分布などのシンプルな和として近似する方法をとっている。
そのため、密度プロットは「カーネル密度推定(KDE)プロット」とも呼ばれる。(plot.kde)・すごいよく使いそうなメソッド
seaborn.distplot(ヒストグラムと密度推定のプロットを同時に作成できる)
seaborn.regplot(散布図を作成し、線形回帰による回帰直線をあてはめる)
seaborn.pairplot(各要素ずつを比較した散布図行列を一括で可視化できる)10章 データの集約とグループ演算
・pandasのgroupbyメソッド
データセット同士の要素を組み合わせて任意の処理が実行できる(ものと理解。)・グループ演算プロセスは 分離(split)−適用(apply)−結合(combine)の流れ。
・1つのデータセットに対しても、複数の要素を指定できる。
任意の値について抜き出し、処理(平均、カウント等)をした後、再度グループ化できる?・ディクショナリを用いたマッピング情報を使用して分類もできる。
・groupbyメソッドの関数(count, sum, mean, median...)基本的な算術計算は網羅してそう。
・groupbyでデータを集約した際につく名前は、タプルを渡すことで変更できる。
as_index = Falseでインデックスなしも指定できる。・applyは、オブジェクトを分離し、それぞれのピースに渡された関数を適用し、その後結合する。
applyに渡す関数はプログラマが自分で実装する必要があるため、想像力が求められる。・ピボットテーブルとクロス集計。データフレームの関数でもgroupbyでも実装dけいる。
これらを扱えるようになると、データクリーニングやモデリング、統計分析に役立つ。
- 投稿日:2020-01-10T23:38:25+09:00
[Python3 入門 4日目] 3章 リスト、タプル、辞書、集合(3.1〜3.2.6)
3.1 リストとタプル
pythonには文字列以外にタプルとリストの2種類のシーケンス構造があり、0個以上の要素を持つことができる。文字列との違いは要素は型が異なっても良い。
タプルの特徴
タプルはイミュータブルであり、要素を代入すると、それは焼き固められたように書き換えられなくなる。
リストの特徴
ミュータブルであり、要素の削除と挿入ができる。
3.2 リスト
リストは要素を順番に管理したい時、特に順序と内容が変わる場合がある時に向いている。文字列とは異なり、リストはミュータブルのため直接変更できる。
3.2.1 []またはlist()による作成
リストは0個以上の要素をそれぞれカンマで区切り、全体を角かっこで囲む。
>>> empty_list = [] >>> weekdays=['Monday','Tuesday','Wednsday','Thursday','Friday'] >>> another_empty_list=list()#list()関数で空リスト[]が作成できる。 >>> another_empty_list []3.2.2 list()による他のデータ型からのリストへの変換
>>> list('cat')#文字列を1文字ごとにの文字列リストに変換している。 ['c', 'a', 't'] >>> a_tuple=('ready','fire','aim')#タプルをリストに変換 >>> list(a_tuple) ['ready', 'fire', 'aim'] >>> birthday="1/4/1995" >>> birthday.split("/")#split()関数を使えばセパレータによって分割し、リストにする。 ['1', '4', '1995'] >>> splitme="a/b//c/d//e" >>> splitme.split('/') ['a', 'b', '', 'c', 'd', '', 'e']#セパレータが連続している場合、リスト要素として空文字列ができる。 >>> splitme="a/b//c/d///e" >>> splitme.split('//') ['a/b', 'c/d', '/e']3.2.3 [offset]を使った要素の取り出し
文字列と同様にオフセットを指定すればリストから個々の要素を取り出せる。
>>> marxes=["TTTTTT","aaaa","bbbb"] >>> marxes[0] 'TTTTTT' >>> marxes[1] 'aaaa' >>> marxes[2] 'bbbb' >>> marxes[-1] 'bbbb' >>> marxes[-2] 'aaaa' >>> marxes[-3] 'TTTTTT' >>> marxes[-34]#オフセットは対象のリストの中でも有効なものでなければならない。(すでに代入済みの位置である必要がある。) Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range3.2.4 リストのリスト
>>> small_birds=["a","b"] >>> extinct_birds=["c","d","e"] >>> carol_birds=["f","g","h","i"] >>> all_birds=[small_birds,extinct_birds,"AAA",carol_birds] >>> all_birds#リストのリスト [['a', 'b'], ['c', 'd', 'e'], 'AAA', ['f', 'g', 'h', 'i']] >>> all_birds[0] ['a', 'b'] >>> all_birds[1][0]#[1]はall_birdsの第二要素、[0]はそれの内蔵リストぼ先頭要素を指す。 'c'3.2.5 [offset]による要素の書き換え
ここでもリストオフセット対象リストの中で有効でなければならない。
>>> marxes=["TTTTTT","aaaa","bbbb"] >>> marxes[2]=["CCCC"] >>> marxes[2]="CCCC" >>> marxes ['TTTTTT', 'aaaa', 'CCCC']3.2.5 オフセットの範囲を指定したスライスによるサブシーケンス取り出し
['TTTTTT', 'aaaa', 'CCCC'] >>> marxes[0:2]#スライスは1以外のステップを指定できる。 ['TTTTTT', 'aaaa'] >>> marxes[::2] ['TTTTTT', 'CCCC'] >>> marxes[::-2] ['CCCC', 'TTTTTT'] >>> marxes[::-1]#リストを逆順にする。 ['CCCC', 'aaaa', 'TTTTTT']感想
4章入ったが眠いので今日は程々にした。
参考文献
「Bill Lubanovic著 『入門 Python3』(オライリージャパン発行)」
- 投稿日:2020-01-10T23:30:08+09:00
初心者がKaggle Titanicで上位1.5%(0.83732)以内に入るアプローチ手法_2
前回に続き、Kaggle Titanicで上位1.5%(0.83732)へのアプローチを解説していきます。
使用するコードはGithubのtitanic(0.83732)_2です。
今回、提出スコアを0.81339まで伸ばし、次回に0.83732となる準備をしていきます。
また、予測の前に、前回使用したデータの可視化を行い、データを分析していきます。1.必要なライブラリをインポートし、CSVを読み込む。
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import Pipeline,make_pipeline from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectKBest from sklearn import model_selection from sklearn.model_selection import GridSearchCV import warnings warnings.filterwarnings('ignore')# CSVを読み込む train= pd.read_csv("train.csv") test= pd.read_csv("test.csv") # データの統合 dataset = pd.concat([train, test], ignore_index = True) # 提出用に PassengerId = test['PassengerId']各データの関係性を見ていきます。
2.年齢と生存率に関係を確認
# 年齢と生存率の帯グラフ sns.barplot(x="Sex", y="Survived", data=train, palette='Set3') # 性別ごとの生存率 print("females: %.2f" %(train['Survived'][train['Sex'] == 'female'].value_counts(normalize = True)[1])) print("males: %.2f" %(train['Survived'][train['Sex'] == 'male'].value_counts(normalize = True)[1]))
females: 0.74
males: 0.19
女性のほうがはるかに助かってることが分かります。
チケットクラスごとの生存率はどうでしょう?3.チケットクラスごとの生存率の関係を確認
# チケットクラスと生存の帯グラフ sns.barplot(x='Pclass', y='Survived', data=train, palette='Set3') # チケットクラスごとの生存率 print("Pclass = 1 : %.2f" %(train['Survived'][train['Pclass']==1].value_counts(normalize = True)[1])) print("Pclass = 2 : %.2f" %(train['Survived'][train['Pclass']==2].value_counts(normalize = True)[1])) print("Pclass = 3 : %.2f" %(train['Survived'][train['Pclass']==3].value_counts(normalize = True)[1]))
Pclass = 1 : 0.63
Pclass = 2 : 0.47
Pclass = 3 : 0.24
高級なチケット購入者であるほど生存率が高いです。
料金についてはどうでしょう?4.料金による生存率の関係を確認
# 料金による生存率比較 fare = sns.FacetGrid(train, hue="Survived",aspect=2) fare.map(sns.kdeplot,'Fare',shade= True) fare.set(xlim=(0, 200)) fare.add_legend()
やはりチケット料金が安い人は生存率が低いことが分かります。5.年齢と生存率の関係を確認
# 年齢による生存率比較 age = sns.FacetGrid(train, hue="Survived",aspect=2) age.map(sns.kdeplot,'Age',shade= True) age.set(xlim=(0, train['Age'].max())) age.add_legend()
子供が優先的に助けられたのでしょうか?
10才以下の生存率が高いことが分かります。6.客室と生存率の関係を確認
ここからは、前回使用しなかったデータを確認していきます。
まずは客室情報です。
Cabin(部屋番号)は頭文字に応じて部屋の階層が異なっていたようです。
# 客室階層による生存率比較 dataset['Cabin'] = dataset['Cabin'].fillna('Unknown') # 客室データが欠損している場合はUnknownを代入 dataset['Deck'] = dataset['Cabin'].str.get(0) #Cabin(部屋番号)の頭文字(0番目の文字)取得 sns.barplot(x="Deck", y="Survived", data=dataset, palette='Set3')
それなりにバラつきがあります。
前回同様、欠損値に中央値を代入して欠損値がないことを確認したら、今回作った'Deck'(客室階層)情報を追加して予測を行います。6.1 客室情報を追加して前回と同じように予測を行う
# Age(年齢)とFare(料金)はそれぞれの中央値、Embarked(出港地)はS(Southampton)を代入 dataset["Age"].fillna(dataset.Age.mean(), inplace=True) dataset["Fare"].fillna(dataset.Fare.mean(), inplace=True) dataset["Embarked"].fillna("S", inplace=True) # 全体の欠損データの個数確認 dataset_null = dataset.fillna(np.nan) dataset_null.isnull().sum()# 使用する変数を抽出 dataset3 = dataset[['Survived','Pclass','Sex','Age','Fare','Embarked', 'Deck']] # ダミー変数を作成 dataset_dummies = pd.get_dummies(dataset3) dataset_dummies.head(3)# データをtrainとtestに分解 #( 'Survived'が存在するのがtrain, しないのがtest ) train_set = dataset_dummies[dataset_dummies['Survived'].notnull()] test_set = dataset_dummies[dataset_dummies['Survived'].isnull()] del test_set["Survived"] # trainデータを変数と正解に分離 X = train_set.as_matrix()[:, 1:] # Pclass以降の変数 y = train_set.as_matrix()[:, 0] # 正解データ # 予測モデルの作成 clf = RandomForestClassifier(random_state = 10, max_features='sqrt') pipe = Pipeline([('classify', clf)]) param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す 'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10) grid.fit(X, y) print(grid.best_params_, grid.best_score_) # testデータの予測 pred = grid.predict(test_set) # Kaggle提出用csvファイルの作成 submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)}) submission.to_csv("submission3.csv", index=False){'classify_max_depth': 8, 'classify_n_estimators': 22}
0.8327721661054994
提出したスコアは0.78947でした。客室階層の情報を入れたことで、前回より上がりました。7.チケットと生存率に関係を確認
次にチケット情報を試してみます。
とはいえ、どうグループ分けしましょう?
数字の頭文字や英字を含むか否か、文字数とそれぞれ場合分けしてもよいのですが、むやみに増やしすぎると精度を落とすことになります。
いったんチケットの文字数で分けて確認してみます。# チケットの文字数による生存率比較 Ticket_Count = dict(dataset['Ticket'].value_counts()) # チケットの文字数でグループ分け dataset['TicketGroup'] = dataset['Ticket'].apply(lambda x:Ticket_Count[x]) # グループの振り分け sns.barplot(x='TicketGroup', y='Survived', data=dataset, palette='Set3')
1つ前のCabin(客室階層)分けよりは差が出ています。7.1 チケットの頭文字情報を追加して予測を行う
# 使用する変数を抽出 dataset4 = dataset[['Survived','Pclass','Sex','Age','Fare','Embarked', 'Deck', 'TicketGroup']] # ダミー変数を作成 dataset_dummies = pd.get_dummies(dataset4) dataset_dummies.head(4)# データをtrainとtestに分解 #( 'Survived'が存在するのがtrain, しないのがtest ) train_set = dataset_dummies[dataset_dummies['Survived'].notnull()] test_set = dataset_dummies[dataset_dummies['Survived'].isnull()] del test_set["Survived"] # trainデータを変数と正解に分離 X = train_set.as_matrix()[:, 1:] # Pclass以降の変数 y = train_set.as_matrix()[:, 0] # 正解データ # 予測モデルの作成 clf = RandomForestClassifier(random_state = 10, max_features='sqrt') pipe = Pipeline([('classify', clf)]) param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す 'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10) grid.fit(X, y) print(grid.best_params_, grid.best_score_, sep="\n") # testデータの予測 pred = grid.predict(test_set) # Kaggle提出用csvファイルの作成 submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)}) submission.to_csv("submission4.csv", index=False){'classify_max_depth': 8, 'classify_n_estimators': 23}
0.8406285072951739
訓練スコアは上がりましたが、Kaggleへの提出スコアは0.77990と下がってしまいました。
そもそも、現実的に考えてチケットの文字数と生存率の相関は薄そうです。
とはいえ、せっかく出た特徴なので、高いグループと低いグループの2つに項目を抑えて学習をしてみます。7.2 チケットの頭文字情報をグループ分けして予測を行う
# チケットの文字数での生存率が高いグループと低いグループの2つに分ける。 # 高ければ2,低ければ1を代入 def Ticket_Label(s): if (s >= 2) & (s <= 4): # 文字数での生存率が高いグループ return 2 elif ((s > 4) & (s <= 8)) | (s == 1): # 文字数での生存率が低いグループ return 1 elif (s > 8): return 0 dataset['TicketGroup'] = dataset['TicketGroup'].apply(Ticket_Label) sns.barplot(x='TicketGroup', y='Survived', data=dataset, palette='Set3')
きれいに分かれたように見えます。# データをtrainとtestに分解 #( 'Survived'が存在するのがtrain, しないのがtest ) train_set = dataset_dummies[dataset_dummies['Survived'].notnull()] test_set = dataset_dummies[dataset_dummies['Survived'].isnull()] del test_set["Survived"] # trainデータを変数と正解に分離 X = train_set.as_matrix()[:, 1:] # Pclass以降の変数 y = train_set.as_matrix()[:, 0] # 正解データ # 予測モデルの作成 clf = RandomForestClassifier(random_state = 10, max_features='sqrt') pipe = Pipeline([('classify', clf)]) param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す 'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10) grid.fit(X, y) print(grid.best_params_, grid.best_score_, sep="\n") # testデータの予測 pred = grid.predict(test_set) # Kaggle提出用csvファイルの作成 submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)}) submission.to_csv("submission5.csv", index=False){'classify_max_depth': 7, 'classify_n_estimators': 23}
0.8417508417508418
Kaggleへの提出スコアは0.81339と大きく向上しました。8.まとめ
今回、新たに客室階層の情報とチケットの頭文字による生存率が高いグループと低いグループの2つに分けた情報を加えたことで、前回の提出スコア0.78468から0.81339と向上させました。
次回はいよいよ上位1.5%に相当する提出スコア0.83732へのアプローチを解説していきます。








- 投稿日:2020-01-10T23:02:41+09:00
初心者がKaggle Titanicで上位1.5%(0.83732)以内に入るアプローチ手法_1
1. Kaggleとは
データ分析を用いて、様々な問題を解くのを競い合って自分の腕を試すサイト。データセットがもらえ、さらに他の人の解説(カーネル)を見ることができるので、データ分析の勉強になります。
2. Titanicとは
Kaggleのコンペティションの1つ。
チュートリアルとして多くの初心者が利用します。
タイタニックに乗っていたどの乗客が生き残ったかを予測します。891人分の乗客データから他の418人の生存を予測するのがお題です。3.今回やること
ランダムフォレストを用いて提出スコア0.83732(上位1.5%相当)に至るまでのテクニックを初心者向けに解説していきます。
今回は提出スコア0.78468になるまでの解説です。
次回で0.81339までスコアを伸ばし、次次回で上位1.5%に相当する提出スコア0.83732で0.83732となるように構成しています。
尚、使用したコードは全てGithubに公開しています。今回使用したコードはtitanic(0.83732)_1です。4.コード詳細
必要なライブラリをimport
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import Pipeline,make_pipeline from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectKBest from sklearn import model_selection from sklearn.model_selection import GridSearchCV import warnings warnings.filterwarnings('ignore')CSVを読み込んで内容を確認
# CSVを読み込む train= pd.read_csv("train.csv") test= pd.read_csv("test.csv") # データの統合 dataset = pd.concat([train, test], ignore_index = True) # 提出用に PassengerId = test['PassengerId'] # trainの内容3つ目まで確認 train.head(3)
各カラムの簡単な説明をは以下の通り。
・PassengerId – 乗客識別ユニークID
・Survived – 生存フラグ(0=死亡、1=生存)
・Pclass – チケットクラス
・Name – 乗客の名前
・Sex – 性別(male=男性、female=女性)
・Age – 年齢
・SibSp – タイタニックに同乗している兄弟/配偶者の数
・parch – タイタニックに同乗している親/子供の数
・ticket – チケット番号
・fare – 料金
・cabin – 客室番号
・Embarked – 出港地(タイタニックへ乗った港)さらに各変数の簡単な説明も記載をしておきます。
pclass = チケットクラス
1 = 上層クラス(お金持ち)
2 = 中級クラス(一般階級)
3 = 下層クラス(労働階級)Embarked = 各変数の定義は下記の通り
C = Cherbourg
Q = Queenstown
S = Southampton
NaNはデータの欠損を表します。
(上の表だとcabinでNaNが2つ確認できます。)
全体の欠損データの個数を確認してみましょう。# 全体の欠損データの個数確認 dataset_null = dataset.fillna(np.nan) dataset_null.isnull().sum()Age 263
Cabin 1014
Embarked 2
Fare 1
Name 0
Parch 0
PassengerId 0
Pclass 0
Sex 0
SibSp 0
Survived 418
Ticket 0
dtype: int64Cabinだと1014個もデータに欠損があることがわかります。
次に全体の統計データを確認してみましょう。# 統計データの確認 dataset.describe()
まずは欠損データに中央値などを代入して精度を確認します。# Cabin は一旦除外 del dataset["Cabin"] # Age(年齢)とFare(料金)はそれぞれの中央値、Embarked(出港地)はS(Southampton)を代入 dataset["Age"].fillna(dataset.Age.mean(), inplace=True) dataset["Fare"].fillna(dataset.Fare.mean(), inplace=True) dataset["Embarked"].fillna("S", inplace=True) # 全体の欠損データの個数を確認 dataset_null = dataset.fillna(np.nan) dataset_null.isnull().sum()Age 0
Embarked 0
Fare 0
Name 0
Parch 0
PassengerId 0
Pclass 0
Sex 0
SibSp 0
Survived 418
Ticket 0
dtype: int64これで欠損データはなくなりました。
Survivedの418は、testデータの418個と一致しているので問題ないでしょう。
予測に向け、データを整理します。
まずはPclass(チケットクラス), Sex(性別), Age(年齢), Fare(料金), Embarked(出港地)を使用します。
また、機械が予測できるようにダミー変数に変換します。
(現在、sexの項目はmaleとfemaleがありますが、これを行うことでsex_maleとsex_femaleの2つに変換されます。maleならsex_maleが1、違うなら0が代入されます。)# 使用する変数のみを抽出 dataset1 = dataset[['Survived','Pclass','Sex','Age','Fare','Embarked']] # ダミー変数を作成 dataset_dummies=pd.get_dummies(dataset1) dataset_dummies.head(3)
機械に学習をさせていきます。
RandomForestClassifierのn_estimatorsとmax_depthを変えるなかで最も良い予測モデルを作成します。# データをtrainとtestに分解 #( 'Survived'が存在するのがtrain, しないのがtest ) train_set = dataset_dummies[dataset_dummies['Survived'].notnull()] test_set = dataset_dummies[dataset_dummies['Survived'].isnull()] del test_set["Survived"] # trainデータを変数と正解に分離 X = train_set.as_matrix()[:, 1:] # Pclass以降の変数 y = train_set.as_matrix()[:, 0] # 正解データ # 予測モデルの作成 clf = RandomForestClassifier(random_state = 10, max_features='sqrt') pipe = Pipeline([('classify', clf)]) param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す 'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10) grid.fit(X, y) print(grid.best_params_, grid.best_score_, sep="\n"){'classify_max_depth': 8, 'classify_n_estimators': 23}
0.8316498316498316
max_depthが8, n_estimatorsが23のとき、トレーニングデータの予測精度が83%となる最も良いモデルだと分かりました。
このモデルでtestデータの予測を行い、提出用ファイル(submission1.csv)を作成します。# testデータの予測 pred = grid.predict(test_set) # Kaggle提出用csvファイルの作成 submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)}) submission.to_csv("submission1.csv", index=False)実際に提出してみたところ、スコアは0.78468でした。
いきなり高い予測が出ちゃいました。今度はParch(同乗している親/子供の数), SibSp(同乗している兄弟/配偶者の数)を加えて予測します。
# 使用する変数を抽出 dataset2 = dataset[['Survived','Pclass','Sex','Age','Fare','Embarked', 'Parch', 'SibSp']] # ダミー変数を作成 dataset_dummies = pd.get_dummies(dataset2) dataset_dummies.head(3)
# データをtrainとtestに分解 #( 'Survived'が存在するのがtrain, しないのがtest ) train_set = dataset_dummies[dataset_dummies['Survived'].notnull()] test_set = dataset_dummies[dataset_dummies['Survived'].isnull()] del test_set["Survived"] # trainデータを変数と正解に分離 X = train_set.as_matrix()[:, 1:] # Pclass以降の変数 y = train_set.as_matrix()[:, 0] # 正解データ # 予測モデルの作成 clf = RandomForestClassifier(random_state = 10, max_features='sqrt') pipe = Pipeline([('classify', clf)]) param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す 'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10) grid.fit(X, y) print(grid.best_params_, grid.best_score_, sep="\n") # testデータの予測 pred = grid.predict(test_set) # Kaggle提出用csvファイルの作成 submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)}) submission.to_csv("submission2.csv", index=False){'classify_max_depth': 7, 'classify_n_estimators': 25}
0.8417508417508418
max_depthが7, n_estimatorsが25のとき、トレーニングデータの予測精度が84%となる最も良いモデルだと分かりました。
先程より高い精度ですが、このモデルでのtestデータ予測(submission2.csv)を提出したところ、スコアが0.76076と下がっていしまいました。
過学習を起こしてしまったようです。
Parch(同乗している親/子供の数), SibSp(同乗している兄弟/配偶者の数)は使用しないほうが良さそうです。5.まとめ
Kaggleのチュートリアルコンペ Titanic の予測を行いました。
提出最高スコアは0.78468でした。
次回はデータを可視化して提出スコア0.83732への過程を説明していきます。




- 投稿日:2020-01-10T22:47:25+09:00
UbuntuからPythonをアンインストールした話
どうも初めまして。普段はPython、時々CをいじっているIzawaです。タイトルを見た人は「バカじゃねぇの」と思うかもしれませんが、何も知らない人がこれをやってしまわないようにこの記事を書きました。
経緯
・OSが入っていないPCを持っていた
・予算が足りなかったのでUbuntuをインストール(なお完全な初心者、コマンドもよくわかってない)
・Pythonをインストールしようと思ったが、どうやら既に入っていた
・バージョンも最新ではなかったため、一旦古いバージョンを削除して、新しいものを入れようとした何をしたか
簡単に言うと、次のコマンドを打ちました。
sudo apt autoremove python
autoremoveは、依存するパッケージまで削除するコマンドです。
後からわかったのですが、UbuntuではPythonがOSの機能のために使われているらしいので、入っているものを削除してはいけないようです。影響
PCが突然落ちる、といったことはありませんでしたが、端末とFirefoxが使えなくなりました(アイコンがバーやアプリ一覧から消えた)。また、再起動をかけたところ、GUIではなく真黒な画面に白い文字(コンソールのよう)でユーザー名とパスワードを要求されました。
修復した方法
結局、黒い画面のまま使うわけにはいかないのでUbuntuを再インストールしました。
結論
最初からあるもの(プログラム、ファイル、何でも)を安易に削除するのはやめましょう。
参考文献
- 投稿日:2020-01-10T22:12:55+09:00
Udemy感想:PythonによるWebスクレイピング〜入門編〜【業務効率化への第一歩】 感想
はじめに
Udemyの年末1200円セール中に購入したものの感想書いていきます。
今回はこれPythonによるWebスクレイピング〜入門編〜【業務効率化への第一歩】
https://www.udemy.com/course/python-scraping-beginner/自分について
python初めて3か月ほど。最近、業界に転職活動している未経験エンジニアになります。
いろいろ勉強する中で、投稿しているので素人向きかと思います。どんな指摘でもコメントいただいたことに向き合ってます。この教材の対象
受講における必要条件
- Pythonの基本的な文法が理解できる方
- HTML, CSSのことが理解できている方
とあるとおり、基本的なことはできている前提でした。
Python
- リスト
- for文
HTML/CSS
- デベロッパーツールの使い方
- HTMLの構造理解
その他
―Jupyter Notebookの理解
この辺は、自然と使える前提で進んでいきますので、素人には難しめ。
Progateの対象言語をやっておけばなんとかついていけるレベル感でした。学べること
- seleniumによるWebページの要素を取得方法
- PillowによるWebページの画像を取得方法
- Pandasの超基礎
一周すれば、身につくボリューム感。
感想
動画見ながら進めますが、コード書きなれてる方なら1.5倍速でもついていけると思います。
講義→演習
という順番で進みます。演習も優しめ。自然と理解させる工夫が詰まってました。値段的にはセール中に買ってやるのがおすすめです。19800円の価値があるかといえば、正直微妙。
Udemyの値段設定は市場原理が効いてないってどっかの誰かが言ってたので、通常価格では高いですね。
スクレイピングをこれから学びたいって人には、最速で基礎が身につく講義内容が詰まってますので是非。
- 投稿日:2020-01-10T22:07:34+09:00
Flask+MySQLで作るAPIをDocker化するまで
これは?
APIを作リたい。Flask+MySQLで作りたい。そしてDocker化したい。
この手順をメモとして残す。個人的にDocker化するところが良く分かっていないので、ここを集中的に。やること
- Flask単体で簡単なAPIを作る。
- 1をDocker化する。
- MySQLを用意する。
- FlaskとMySQLの連携をdocker-composeで実行できるようにする。
1. Flask単体で簡単なAPIを作る。
まずなんでもいいから単純なAPIを作る。今回は、会員リスト(仮)から条件にあうデータだけをリストにして返すものを作ることに決めた。
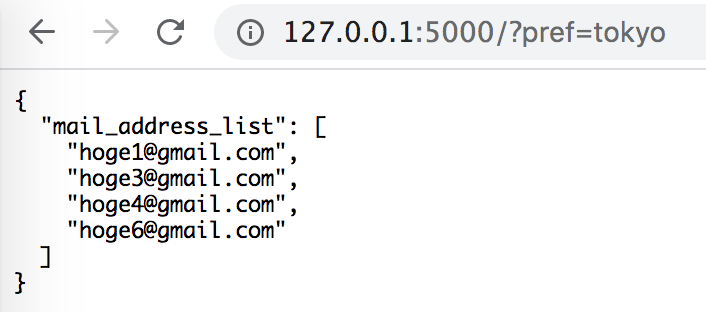
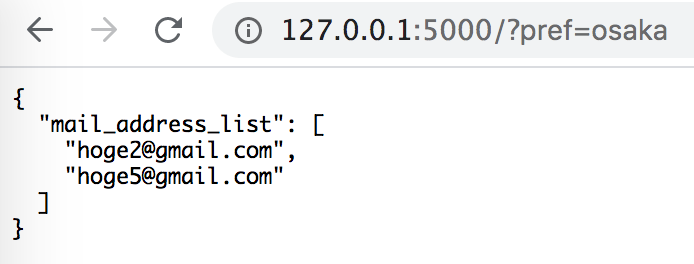
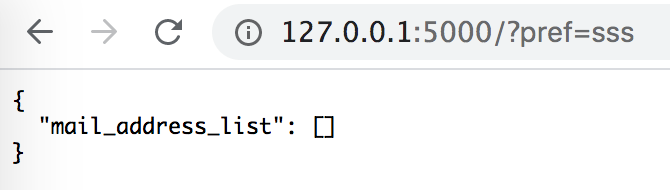
下のファイルから、prefectureがリクエストのパラメータと一致するmail_addressのリストを返却する機能を作る。
personal_info.csvmail_address,sex,age,name,prefecture hoge1@gmail.com,male,18,itirou,tokyo hoge2@gmail.com,male,23,zirou,osaka hoge3@gmail.com,male,31,saburou,tokyo hoge4@gmail.com,female,29,itiko,tokyo hoge5@gmail.com,mail,11,shirou,osaka hoge6@gmail.com,female,42,fumiko,tokyoFlaskを使ったコードはこちら。
超簡単で、app.pyを実行して、
http://127.0.0.1:5000/に?pref=xxxをつけると、pref=xxxに一致するmail_addressがリストで返却される。


次は、このAPIをDocker化する。
2. 1をDocker化する。
「Docker化する」とは、Dockerfileを作ってdocker buildしてDocker imageを作り、docker runでコンテナ内でapp.pyを実行してAPIリクエストが投げられる状態を作ることを目指す。
Dockerfileとは、作りたいコンテナに対し、"ベースとなるイメージを指定し、作成するコンテナの設定を記述して、コンテナ内でコマンドを実行する"動作を記述するもの。
2-1 ベースとなるイメージを指定
pythonでflaskを実行できれば良いので、pythonのイメージをベースにする。
2-2 コンテナの設定を記述
flaskのコードを動かすためには、以下が必要。
- ローカルのソースコードやデータをコンテナに配置する。
- 必要なライブラリをinstallする。
2-3 コンテナ内でコマンドを実行する。
作成したapp.pyを実行する。
これら2-1~2-3を意識して作ったDockerfileが以下。
# 2-1 ベースとなるイメージを指定 FROM python:3.6 # 2-2 コンテナの設定を記述 ARG work_dir=/work # Dockerfile内で扱う変数の作成 ADD pure_flask $work_dir/pure_flask # コードを/work/にコピー(ディレクトリをコピーする時は、右側にディレクトリ名を記述しないといけないので注意) WORKDIR $work_dir/pure_flask # cd work_directoryのイメージ RUN pip install -r requirements.txt # requirements.txtで必要なライブラリをインストール # 2-3 コンテナ内でコマンドを実行 CMD ["python", "/work/pure_flask/app.py"] # CMDは基本的にDockerfile内に1つだけ。requirements.txtは超簡単にflaskだけ記述。
requirements.txtflaskこの状態のDockerfileがあるディレクトリで
docker build -t flask:ver1 .を実行する。
上記コマンドの.はカレントディレクトリにあるDockerfileを使ってイメージをbuildすることを指す。次に、
docker run -it -d -p 5000:5000 flask:ver1を実行。
-dはバックグラウンド実行を、-p 5000:5000はローカルの5000番ポートと、コンテナの5000番ポートのポートフォワーディングを指定することを指してます。この状態でローカルマシンでlocalhost:5000でブラウザで確認すると、APIのreturnが確認できる。
ちなみにこの状態で
docker psとdocker imagesは以下のようになる。
もしdocker psで何も表示されない場合はエラーでこけてる可能性があるため、docker ps -aで表示したコンテナIDを使って、docker logs [コンテナID]をしてあげると理由がわかるかも。$ docker ps > CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES > dc371c597cef flask:ver1 "python /work/pure_f…" 9 minutes ago Up 9 minutes 0.0.0.0:5000->5000/tcp quizzical_margulis $ docker images > REPOSITORY TAG IMAGE ID CREATED SIZE > flask ver1 b4cda0e56563 9 minutes ago 923MB > python 3.6 138869855e44 5 days ago 913MB無事、1. Flask単体で簡単なAPIを作ると同じ動作がDocker上でも確認できた。
次は、MySQLを使うための準備をする。
3. MySQLを用意する。
MySQLもDockerで用意する。今回は、Docker-compose.yamlの利用も同時にする。
Docker-compose.yamlは、Dockerfileと似ているが、複数のコンテナの連携などを記述するためにある。
DBは接続されることが前提のため、Docker-composeで記述するのが自然だと思う。3-1 ベースとなるイメージを指定
MySQLが使いたいため、MySQLのイメージをベースにする。
3-2 コンテナの設定を記述
MySQLの設定ファイルやデータベースの初期化をする。
3-3 コンテナ内でコマンドを実行する。
MySQLのプロセスを起動する。
Dockerfileは以下。
# 3-1 ベースとなるイメージの指定 FROM mysql:5.7 # 3-2 コンテナの設定を記述 COPY conf.d/mysql.cnf /etc/mysql/conf.d/mysql.cnf # 文字コードの設定のセット COPY initdb.d/init.sql /docker-entrypoint-initdb.d/init.sql # 初期化用のSQLファイルのセットDockerfileの中でcopyしているconfigファイルとinit.sqlはそれぞれ以下。
mysql.cnf[mysqld] character-set-server=utf8 [mysql] default-character-set=utf8 [client] default-character-set=utf8init.sqlCREATE TABLE `personal_info` ( mail_address VARCHAR(100) NOT NULL, sex VARCHAR(6) NOT NULL, age INT NOT NULL, name VARCHAR(50) NOT NULL, prefecture VARCHAR(50) NOT NULL, createdAt DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, updatedAt DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (mail_address) ); INSERT INTO `personal_info` (mail_address, sex, age, name, prefecture, createdAt, updatedAt) VALUES ('hoge1_1@gmail.com', 'male', 18, 'ichirou1' , 'tokyo', current_timestamp(), current_timestamp()), ('hoge2@gmail.com', 'male', 23, 'zirou2', 'osaka', current_timestamp(), current_timestamp()), ('hoge3_3@gmail.com', 'male', 31, 'saburou', 'tokyo', current_timestamp(), current_timestamp()), ('hoge4@gmail.com', 'female', 29, 'itiko', 'tokyo', current_timestamp(), current_timestamp()), ('hoge5_5@gmail.com', 'mail', 11, 'shirou', 'osaka', current_timestamp(), current_timestamp()), ('hoge6@gmail.com', 'female', 42, 'fumiko', 'tokyo', current_timestamp(), current_timestamp());docker-compose.yamlは以下。
version: '3' # docker-compose.yamlの記述のバージョン services: db: build: mysql # mysqlディレクトリ配下のDockerfileを指定 container_name: db_server # Dockerコンテナの名前 ports: - '3306:3306' # ポートフォワーディング指定 environment: # 環境変数の設定 MYSQL_ROOT_PASSWORD: pass # MySQLのrootユーザーのパスワード MYSQL_DATABASE: testdb # MySQLのスキーマ TZ: Asia/Tokyo # タイムゾーンの指定 volumes: # MySQLのデータの永続化をするためのボリュームマウント - db-data/:/var/lib/mysql # 3-3 コンテナ内でコマンドを実行する command: mysqld # mysqldコマンドの実行 volumes: db-data:上記ができたら、
docker-compose up -dでdbコンテナを起動する。
その後、docker exec -it [コンテナID] /bin/bashでログインし、mysql -u root -pからパスワードを入力してテーブルを確認し、init.sqlの内容が入っていればOK。[備考]mysql周りのtips
MySQLのデータを永続化させるためのvolumeにデータが保存されない場合、Dockerホストでdocker volume lsでvolumeを確認して削除してからdocker-compose up -dすると良さげ。
init.sqlは/docker-entrypoint-initdb.d/に固定でコピーする。
次は、flaskとMySQLを接続させる。
4. FlaskとMySQLの連携をdocker-composeで実行できるようにする。
2と4で作成した二つのDockerコンテナを結合させる。
結合させるために必要なことは、以下。
- flaskもdocker-compose.yamlに入れる。
- flaskからMySQLへの接続が可能なようにする(ネットワークを)。
- flaskからMySQLへの接続が可能なようにする(コードを)。
4-1 flaskもdocker-compose.yamlに入れる
flaskのコンテナをMySQLのdocker-compose.yamlに追記したものは以下。
version: '3' services: api: build: python container_name: api_server ports: - "5000:5000" tty: yes environment: TZ: Asia/Tokyo FLASK_APP: app.py depends_on: # apiサーバーはdbサーバーが立ってから起動 - db networks: # apiとdbを接続するための共通ネットワーク指定 - app_net db: build: mysql container_name: db_server ports: - '3306:3306' environment: MYSQL_ROOT_PASSWORD: pass MYSQL_DATABASE: testdb TZ: Asia/Tokyo volumes: - ./db-data:/var/lib/mysql command: mysqld networks: - app_net volumes: db-data: networks: app_net: driver: bridgeservices直下の階層に、dbと同じ階層としてapiを記述。
4-2 flaskからMySQLへの接続が可能なようにする(ネットワークを)。
コンテナを二つ起動し、その間で接続をする場合、二つのコンテナを同一のネットワークで扱う必要がある。
4-1のdocker-compose.yaml内にそれぞれのserviceの中に以下を追記する。networks: - app_netこれにより、各コンテナがどのネットワークを利用するかを指定できる。二つを同じネットワークにしていることを意味する。
そして、docker-compose.yamlのトップレベルの階層に以下を記述する。networks: app_net: driver: bridgeこれは、dockerのネットワークの作成を意味していて、driverをbridge指定で作る指定。
これでapiとdbのコンテナが同一ネットワーク上となるため、apiからdbへの接続が可能となる。4-3 - flaskからMySQLへの接続が可能なようにする(コードを)。
flask側のコードとモジュールの修正。
pythonからMySQLに接続する方法は色々ありそうだが、今回はmysqlclientを使った。
pip install mysqlclientでmysqlclientをインストールし、以下のようなコードで接続して使う。import MySQLdb conn = MySQLdb.connect(user='root', passwd='pass', host='db_server', db='testdb') cur = conn.cursor() sql = "select * from personal_info;" cur.execute(sql) rows = cur.fetchall()このrowsには、タプルが返却され、レコード数の長さのタプルが取得できる。
rowsのイメージ.( (1レコード目の1カラム目の値, 1レコード目の2カラム目の値, ...), (2レコード目の1カラム目の値, 2レコード目の2カラム目の値, ...), (3レコード目の1カラム目の値, 3レコード目の2カラム目の値, ...) )これをpythonで受け取り、リストに格納してjsonで返却するようなイメージ。
修正後のソースはここ。
ディレクトリ構成とか、Dockerfileの位置などもこれを参照してもらえれば。あとは、pythonで扱いたいモジュールが増えたのでrequirements.txtにmysqlclientを追記する。
これで完了。
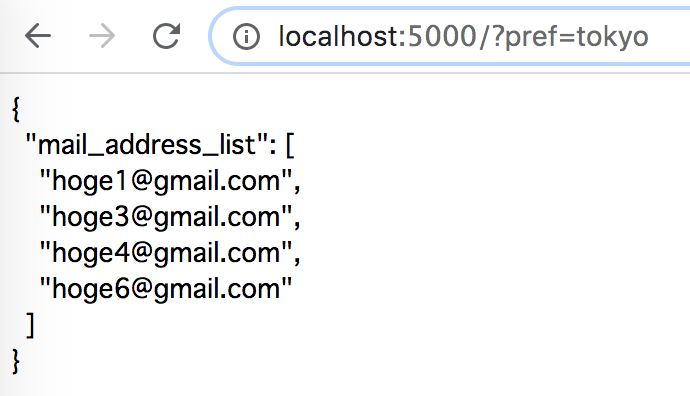
docker-compose up -dで全て起動したら、ローカルでhttp://0.0.0.0:5000/?pref=osakaなどを入れると、結果が確認できる。以上。
- 投稿日:2020-01-10T21:51:43+09:00
ながいPythonコードをシェル芸で実行させる
これは備忘録です.発想は単純だけど意外と面倒だった.
もちべ
長いコードを画像化して投げればいいのでは?
てじゅん
1. コードをbase64にする
まずはソースコードを文字にして画素値にさせる.
中間的な形式としてPPM画像で出力させる.
PPMで画像化するので3文字ごとに変換する.
AAABBCCCCならば0 0 0\n 1 1 2\n 2 2 2とさせるencode.pyimport sys import base64 argv = sys.argv f = open(argv[1], 'r').read() enc = base64.b64encode(bytes(f,"utf-8")) tri = [] for i in range(0,len(enc),3): e = enc[i:i+3] while len(e) != 3: e += b"=" tri.append(e) b2i = {c: i for i,c in enumerate('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=')} im = [] for t in tri: r = [] for c in t.decode('utf-8'): r.append(b2i[c]) im.append(r) ims = "\n".join([f"{c[0]} {c[1]} {c[2]}" for c in im]) print(ims)python encode.py src.py > image.ppm2 PPMをPNGにする
画像にするためには行数を縦横分割する必要がある.素因数分解して縦横比がちょうどよくなるような約数をえらぶ.
例えば行数が12486行の場合約数は$2,3,2081$だが2行増やした12488は$2,2,2,7,223$と正方形に近くなるように約数が選べるため上の出力結果に
64 64 64という行を追加してパディング.(64は=に相当するので)47 26 22 53 33 25 54 21 51 11 54 33 47 25 54 20 46 28 6 57 39 ... 8 34 36 64 64 64 <-ここに追加 64 64 64 <-ここに追加つぎに頭にメタ情報を付加する
P3 横の画素数 縦の画素数 画素の最大値 ...image.ppmP3 223 56 255 47 26 22 53 33 25 54 21 51 11 54 33 47 25 54 20 46 28 6 57 39 ... 8 34 36 64 64 64 64 64 64あとはconvertでpng化
convert image.ppm image.pngよくわかんない画像ができる.
3 Twitterに投げる
あとはこれをメディアに付加して
#シェル芸タグをつけて投稿python -c ' import numpy as n import matplotlib.pyplot as p f={i:c for i,c in enumerate("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=")} print("".join([f[int(255*i)] for i in p.imread("/media/0","png").flatten()]),end="") '|base64 -d|python #シェル芸文字制限ギリギリです.画像は
/media/0に格納される仕様なのでそれを利用する.実行例
https://t.co/xyBv6ejSGj pic.twitter.com/1FSVyLeNVF
— シェル芸bot (@minyoruminyon) January 10, 2020実際これは3万字近いヤツなので画像万歳といったところである.
なお,もととなる関数はWolflam Alphaより拝借している.
https://www.wolframalpha.com/input/?i=graph+yasuna+curve&lang=ja

- 投稿日:2020-01-10T21:22:13+09:00
一つのYoutubeチャンネルから再生回数TOP10を一括ダウンロード
Qiitaへの初投稿です。
基本的に私の備忘録も兼ねて使う予定です。
まだPython勉強中なのでコードに関して突っ込みなどあればご指摘お願いします。また、著作権などに関しては私的使用の範囲であれば可能という認識ですが、何か問題があった場合は指摘してください。
下準備
まずは、https://console.cloud.google.com/にアクセスしてプロジェクト作成、ライブラリからYoutube Data APIを有効化、認証情報(APIKey)の追加。
次に、Youtube Data APIを使うにあたって必要になるライブラリのインストール、動画の保存に当たって必要になるYoutube_DLのインストール。
pip install google-api-python-client pip install youtube-dlインストールできたら、まずライブラリのインポートと各変数への代入です。
from apiclient import discovery import youtube_dl DEVELOPER_KEY = "" # ここにAPIKey YOUTUBE_API_SERVICE_NAME = "youtube" YOUTUBE_API_VERSION = "v3" ydl_opts = { 'format': 'bestaudio/best', 'postprocessors': [ {'key': 'FFmpegExtractAudio', 'preferredcodec': 'mp3', 'preferredquality': '192'}, {'key': 'FFmpegMetadata'}, ], } # youtube-dlでダウンロードする動画を音楽に変換するもし音楽ではなく動画をダウンロードしたい場合はytdl_optsを空にすればOKです。
次に、チャンネルで最も多く再生されている動画のURLを0-10まで取得。
def youtube_search(channelId): videos = [] # URLを入れるリスト youtube = discovery.build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=DEVELOPER_KEY) search_response = youtube.search().list( part="snippet", channelId= channelId, maxResults=10, order="viewCount", ).execute() # APIでチャンネルを指定したうえで再生回数順に10件動画検索をかける for search_result in search_response.get("items", []): if search_result["id"]["kind"] == "youtube#video": print("https://www.youtube.com/watch?v=" + search_result['id']['videoId']) videos.append(search_result["id"]["videoId"]) # videosにURL追加 return videosちなみに検索数はmaxResults=0-50まで任意で指定できます。
最後にリストに入っているURLの動画すべてをダウンロード
def download_video(video_list): for i, videoId in enumerate(video_list): # インデックス番号と要素を同時に回す # ydl_opts['outtmpl'] = "music{}".format(str(i)) + '.%(ext)s' # もし再生回数順ををわかりやすくしたい場合はここの#を外せばmusic0-10.mp3(mp4)としてダウンロードできます ydl = youtube_dl.YoutubeDL(ydl_opts) ydl.extract_info("https://www.youtube.com/watch?v={}".format(videoId), download=True) # ytdl_opts=...の部分はファイル名の形式を表しています。 #を消せばmusic[0-10].mp3(mp4)の形式でダウンロードできます。最後
そのままコード実行して使える形
from apiclient import discovery import youtube_dl DEVELOPER_KEY = "YOUR_API_KEY" # ここにAPIKeyを入れてください YOUTUBE_API_SERVICE_NAME = "youtube" YOUTUBE_API_VERSION = "v3" ydl_opts = { 'format': 'bestaudio/best', 'postprocessors': [ {'key': 'FFmpegExtractAudio', 'preferredcodec': 'mp3', 'preferredquality': '192'}, {'key': 'FFmpegMetadata'}, ], } # youtube-dlでダウンロードする動画を音楽に変換する def youtube_search(channelId): videos = [] # URLを入れるリスト youtube = discovery.build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=DEVELOPER_KEY) search_response = youtube.search().list( part="snippet", channelId= channelId, maxResults=10, order="viewCount", ).execute() # APIでチャンネルを指定したうえで再生回数順に10件動画検索をかける for search_result in search_response.get("items", []): if search_result["id"]["kind"] == "youtube#video": print("https://www.youtube.com/watch?v=" + search_result['id']['videoId']) videos.append(search_result["id"]["videoId"]) # videosにURL追加 return videos def download_video(video_list): for i, videoId in enumerate(video_list): # インデックス番号と要素を同時に回す # ydl_opts['outtmpl'] = "music{}".format(str(i)) + '.%(ext)s' # もし各動画の再生回数順をわかりやすくしたい場合はここの#を外せばmusic0-10.mp3としてダウンロードできます ydl = youtube_dl.YoutubeDL(ydl_opts) ydl.extract_info("https://www.youtube.com/watch?v={}".format(videoId), download=True) if __name__ == '__main__': channel = input("チャンネルIDを入力してください:") videos = youtube_search(channel) download_video(videos) print('ダウンロードが完了しました。')この記事はここまでです。ありがとうございました。
- 投稿日:2020-01-10T21:08:23+09:00
Pythonで一度に、安全に、非破壊的に、複数辞書の結合と複数要素の追加を行う
やりたいこと
- 複数の辞書を結合して1つの辞書にしたい
- ついでに他にも要素を追加したい
dictA = {'A1': 1, 'A2': 1} dictB = {'B1': 1, 'B2': 1} # ---(辞書の結合 & 要素の追加)--- # => {'key1': 1, 'key2': 1, 'A1': 1, 'A2': 1, 'B1': 1, 'B2': 1}さらに、
- 非破壊的に (元の辞書に変更を加えずに) 処理したい
- valueの変更をしない (keyが重複していたらエラーになってほしい)
これらを実現するための効率の良い書き方を紹介したいと思います。
良くない書き方
これは、
.update()と辞書の追加記法を使えば一部実現可能です。dictA.update(dictB) dictA['key1'] = 1 dictA['key2'] = 1 new_dict = dictA print(new_dict) # => {'A1': 1, 'A2': 1, 'B1': 1, 'B2': 1, 'key1': 1, 'key2': 1}デメリット
元のdictAはなくなってしまいます。(dictAに要素の追加 (破壊的変更) をしているため)
print(dictA) # => {'A1': 1, 'A2': 1, 'B1': 1, 'B2': 1, 'key1': 1, 'key2': 1}また、keyが重複していると値が上書きされます。これは意図せぬ挙動(バグの原因)を引き起こす可能性があります。
dictA = {'key': 'dictA'} dictB = {'key': 'dictB'} dictA.update(dictB) print(dictA) # => {'key': 'dictB'}適切な書き方
結合や要素の追加ということを気にせず、dict関数のキーワード引数に値を渡して新たに辞書をつくります。何個でも可能です。
new_dict = dict( key1=1, key2=1, **dictA, **dictB, ) print(new_dict) # => {'key1': 1, 'key2': 1, 'A1': 1, 'A2': 1, 'B1': 1, 'B2': 1}非破壊的
非破壊的な処理なので元の辞書は変更を受けません。
new_dict['keyA1'] = 5 print(new_dict['keyA1']) # => 5 print(dictA['keyA1']) # => 1重複がある場合の挙動
重複がある場合はTypeErrorになるので、意図しない値の上書きを回避できます。
辞書内のkeyと明示的に書いたキーワード引数すべての重複に対してエラーになります。dictA = {'key': 'dictA'} dictB = {'key': 'dictB'} new_dict = dict( key='A', **dictA, **dictB, ) # => TypeError: type object got multiple values for keyword argument 'key'まとめ
dict関数で作り直せば辞書の結合、要素の追加は安全かつ簡潔に書けますよ、という話でした!
- 投稿日:2020-01-10T20:48:59+09:00
Raspberry Pi�+Flask+SQLite+Ajaxで温度計測シミュレート
はじめに
Raspberry Piで温度計測とGPIOでセンサー状態を取得するとき、ソフトウェア単体でデバッグできると便利です。
そこで温度計測とGPIOでセンサー状態の取得をシミュレートし、Webサイト(Flaskで作成)へ表示するデバッグ環境を作成しました。
シミュレートした温度とセンサー状態はSQLiteに保存し、Ajax経由でページを更新します。
温度とセンサー状態の数値では分かりにくいので、あたかもリビングの温度とセンサーが変化したように見せています。
この環境ではブレッドボードや配線は不要です。
リアルタイム性を必要とする温度計測やセンサー状態の取得には向いていません。30秒間隔で温度が分かれば良いという程度の環境を想定しています。動作イメージ
- 温度とセンサー状態の矢印が更新されます。
環境
- Raspberry Pi3 B
- Python 3.7.2
- Flask
- SQLite3
- Sqlalchemy
- jQuery 3.4.1
インストール
Python環境
- ここではSensorフォルダを作成し、pipenvで環境をインストールします。
- pipenv、Webサーバ(Nginx, uWSGIなど)のインストールは割愛します。
$ mkdir Sensor $ cd Sensor $ pipenv install --python 3.7.2 $ pipenv install flask $ pipenv install sqlalchemy $ pipenv shellフォルダとファイル構成
- 下記のフォルダとファイルを作成します。
- jQueryは、jQueryから適したバージョンをダウンロードします。
- 矢印アイコン(On/Off)は、【フリーアイコン】 矢印(上下左右)などからダウンロードします。
- 背景は、かわいいフリー素材集 いらすとやなどからダウンロードします。
└ Sensor/ ├ server.py ├ app/ │ ├ app.py │ └ static/ │ │ ├ css/ │ │ │ └ sample.css │ │ ├ img/ │ │ │ ├ arrow_on.png # Onのときの矢印 │ │ │ ├ arrow_off.png # Offのときの矢印 │ │ │ └ bg_house_living.jpg # 背景画像 │ │ ├ jquery/ │ │ │ └ jquery-3.4.1-min.js │ │ └ js/ │ │ └ sample.js │ └ templates/ │ └ index.html ├ models/ # SQLite3定義 │ ├ __init__.py │ ├ database.py │ └ models.py └ output_log/ # バックグラウンド実行のログフォルダソースコード
サーバメイン処理
- init_db()でDatabaseを初期化します。(*.dbファイルが存在しない場合のみ実行されます)
server.py# -*- coding: utf-8 -*- from flask import Flask from app.app import app from models.database import init_db if __name__ == "__main__": # Database初期化 init_db() # アプリ起動(host=0,0,0,0で全てのアクセス許可) app.run(host='0.0.0.0', debug=True)温度とセンサーのシミュレート処理
- 3秒間隔で温度とセンサーをシミュレートします。
- 温度は25度+αでシミュレートします。
- センサーは0 or 1でシミュレートします。
(参考)
Pythonで定周期で実行する方法と検証sensor.py# -*- coding: utf-8 -*- import time import threading import random from models.models import SensorCurrent from models.database import db_session from datetime import datetime # 定期実行処理 def schedule(): # 温度シミュレート(25度+α) now = time.time() temp = 25 + now % 5 + (now / 10) % 10 # 小数点第2位に切り捨て str = "{0:.2f}".format(temp) temp = float(str) # センサー状態シミュレート(0 or 1) sensor = random.randint(0, 1) # 現在データ更新 current = SensorCurrent.query.first() current.temp1 = temp current.sensor1 = sensor db_session.commit() db_session.close() # 定期実行設定処理 def scheduler(interval, f, wait = True): base_time = time.time() next_time = 0 while True: t = threading.Thread(target = f) t.start() if wait: t.join() next_time = ((base_time - time.time()) % interval) or interval time.sleep(next_time) if __name__ == "__main__": # 定期実行設定(3秒間隔) scheduler(3, schedule, True)アプリメイン処理
- Webサイト表示とAjax処理を記述します。
/app/app.py# -*- coding: utf-8 -*- from flask import Flask,render_template,request, json, jsonify from models.models import SensorCurrent app = Flask(__name__) # Webサイト表示処理 @app.route("/") def index(): # SQliteから温度とセンサーの現在データを取得 data = SensorCurrent.query.first() return render_template("index.html",sensor=data) # Ajax処理 @app.route("/currdata", methods=['POST']) def getCurrData(): # SQliteから温度とセンサーの現在データを取得 data = SensorCurrent.query.first() # JSONに変換して結果を返す json_data = { 'sensor1': data.sensor1, 'temp1': data.temp1 } return jsonify(Result=json.dumps(json_data)) if __name__ == "__main__": app.run(debug=True)データベース定義
- SQLite3データベース(sensor.db)を定義します。
models/database.py# -*- coding: utf-8 -*- from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session, sessionmaker from sqlalchemy.ext.declarative import declarative_base import os # データベースファイル設定 databese_file = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'sensor.db') engine = create_engine('sqlite:///' + databese_file, convert_unicode=True) db_session = scoped_session(sessionmaker(autocommit=False,autoflush=False,bind=engine)) Base = declarative_base() Base.query = db_session.query_property() # データベース初期化 def init_db(): import models.models Base.metadata.create_all(bind=engine)テーブル定義
- 温度とセンサーの現在データテーブル(currdata)を定義します。
models/models.py# -*- coding: utf-8 -*- from sqlalchemy import Column, Integer, Float, String, Text, DateTime from models.database import Base from datetime import datetime # 温度とセンサーの現在データテーブル定義 # ここでは温度データ1つ, センサーデータ1つを保存 # テーブル定義は適宜設定してください class SensorCurrent(Base): __tablename__ = 'currdata' id = Column(Integer, primary_key=True) name = Column(String(128)) temp1 = Column(Float) sensor1 = Column(Integer) date = Column(DateTime, default=datetime.now()) def __init__(self, name=None, temp1=None, sensor1=None, date=None): self.name = name self.temp1 = temp1 self.sensor1 = sensor1 self.date = date def __repr__(self): return '<Name %r>' % (self.name)Flaskを使用したメインページ
- 起動時に現在データを取得して表示します。(矢印のデフォルトはOffです)
- Ajaxを利用して2秒間隔で現在データを取得してページを書き換えます。
app/templates/index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>{{sensor.name}}</title> <meta name="viewport" content="width=device-width,initial-scale=1.0"> <link rel="stylesheet" type="text/css" href="../static/css/sample.css"> <script src="../static/jquery/jquery-3.4.1.min.js"></script> <script src="../static/js/sample.js"></script> </head> <body> <h1 id="h1_temp1">Temp : {{sensor.temp1}}</h1> <h1 id="h1_sensor1">Sensor : {{sensor.sensor1}}</h1> <div class="sample-box"> <img class="sample-box-bg" src="../static/img/bg_house_living.jpg" alt=""> <div class="sample-sensor"> <img class="sample-sensor-img" id="sensor1" src="../static/img/arrow_off.png" alt=""> </div> <div id="temp1" class="sample-tempareture"> </div> </div> </body> <script> setInterval(function () { getcurrdata(); }, 2000); </script> </html>現在データ取得処理
- Ajaxを利用して現在データを取得します。
app/static/js/sample.js// 現在データ取得 function getcurrdata() { $.ajax({ type: 'POST', url: '/currdata', data: '', contentType: 'application/json' }) .done( (data) => { // データ取得成功 console.log("success"); // JSONからデータ抽出 var json_data = JSON.parse(data.Result); const sensor1 = json_data.sensor1; const temp1 = json_data.temp1; // 背景画像内に温度設定 $("#temp1").html(temp1 + "℃"); // 温度設定(確認用) $("#h1_temp1").html("Temp : " + temp1); // センサー画像設定 if (sensor1 == 0) { $("#sensor1").attr("src", "../static/img/arrow_off.png"); } else { $("#sensor1").attr("src", "../static/img/arrow_on.png"); } // センサー設定(確認用) $("#h1_sensor1").html("Sensor : " + sensor1); }) .fail( (data) => { // データ取得失敗 console.log("error"); }); }メインページのCSS
- 簡易的にレスポンシブデザインに対応しています。
app/static/css/sample.css@charset "utf-8"; @media screen and (min-width: 481px) { .sample-box { position: relative; display:inline-block; } .sample-box-bg { } .sample-sensor { position: absolute; left: 60%; top: 5%; } .sample-sensor-img { } .sample-tempareture { position: absolute; top: 35%; left: 55%; color: RED; font-size: 36px; } } @media screen and (max-width: 480px) { .sample-box { position: relative; display:inline-block; } .sample-box-bg { width: 100%; } .sample-sensor { position: absolute; left: 60%; top: 5%; } .sample-sensor-img { width: 70%; height: 70%; } .sample-tempareture { position: absolute; top: 35%; left: 55%; color: RED; font-size: 22px; } }操作方法
温度とセンサーのシミュレートからWebサイトの表示までを説明します。
温度とセンサーの初期値を設定
- 温度とセンサーの初期値(1件のみ)currdataテーブルへ追加します。
- Sensorフォルダでpythonを起動し、下記のソースコードを実行します。
- 1回のみ実行でOKです。
$ python from models.database import db_session from models.models import SensorCurrent data = SensorCurrent("サンプル",25.3, 0) db_session.add(data) db_session.commit() exit()温度とセンサーのシミュレート開始
- Sensorフォルダから、バックグラウンドで温度とセンサーをシミュレートするアプリを起動します。
- バックグラウンドで実行するのは、サーバアプリと同時に実行したいためです。
# 下記のフォルダで実行 (Sensor) pi@raspberrypi:~/Sensor $ # 以下のコマンドを実行 nohup python sensor.py > ./output_log/out.log &
- 既にシミュレートを開始している場合は、プロセスをkillしてから開始します。
# pythonを実行しているプロセスを検索 $ ps aux | grep python pi 22965 0.7 2.0 32200 19176 pts/2 S 16:43 0:27 python sensor.py # sensor.pyプロセスをkill $ kill -9 (sensor.pyのプロセスID -> ここでは22965)Webサーバを起動
- サーバメイン処理を起動します。
# 下記のフォルダで実行 (Sensor) pi@raspberrypi:~/Sensor $ # 以下のコマンドを実行 python server.py表示確認
- ブラウザを起動し、http://127.0.0.1:5000へアクセスします。
- WebサーバのローカルIPアドレスへのアクセスでもOKです。
- スマートフォンからアクセスした場合、簡易的にレスポンシブデザインが適用されていると思います。
おわりに
Raspberry PiでIoTを試したいけど、ハードウェアも同時開発だったり、ブレッドボードや配線が用意できないとき、簡易的にシミュレートできます。温度やセンサー数はSQLiteの定義により自由に設計できるので、これから活用していこうと思います。
参考
下記のサイトを参考にさせていただきました。
Webアプリ開発未経験者がFlaskとSQLiteとHerokuを使って1週間でサービス公開までする
Raspberry pi + Nginx + uWSGIでWebサーバーを立ち上げDjangoアプリをデプロイしてみる その1
Pythonで定周期で実行する方法と検証
バックグラウンド実行で時間短縮しよう!!



- 投稿日:2020-01-10T19:06:49+09:00
関数に引数を入れて後で実行したい場合
def outer(a, b): def inner(): return a + b return inner# inner関数を呼び出すのではなくオブジェクトを返す f = outer(1,3) print(f) print(f())実行結果<function outer.<locals>.inner at 0x7**c3dfa*****> 4print(f)では
innerオブジェクトの情報が返ってきて、
a + bは実行されていない。f()とするとinnnerが実行される。
- 投稿日:2020-01-10T19:06:49+09:00
クロージャー 関数に引数を入れて後で実行したい場合
def outer(a, b): def inner(): return a + b return inner# inner関数を呼び出すのではなくオブジェクトを返す f = outer(1,3) print(f) print(f())実行結果<function outer.<locals>.inner at 0x7**c3dfa*****> 4print(f)では
innerオブジェクトの情報が返ってきて、
a + bは実行されていない。f()とするとinnnerが実行される。
- 投稿日:2020-01-10T18:11:44+09:00
Azure Cognitive ServicesのSpeaker RecognitionA PIによる話者識別をPythonで検証してみた。#2
前置き
という訳で「Speaker Recognition API」を使った話者識別の実際の検証について記載していきます。
(プログラミング経験が貧しいので、変なところがあったら教えてください!)処理の流れ
話者識別をするには、以下の3ステップが必要になります。
- ユーザのプロファイルを作成する
- ユーザのプロファイルに音声を登録する
- 登録した音声を元に、誰が発言したのか識別する
なので今回は自分が解りやすいように、それぞれのステップ毎で3つの処理を作成していきたいと思います。
ステップ1 ユーザのプロファイルを作成する
まずは話者識別させたいユーザを作成していきます。
API機能としては「Identification Profile」の「Create Profile」を使います。
これを使用するとユーザのプロファイルを作成して、ユーザのプロファイルIDを返してきます。
(名前は登録されないので、別でリスト管理する必要があります)検証スクリプトでは引数にユーザ名を指定する形にして「Profile_lIST.csv」というファイルにユーザ名とIDを紐づけて出力しています。
CreateProfile.py########### module ############# import sys # 引数を格納するためのライブラリ import requests # HTTPの通信を行うためのライブラリ import json # データをjson形式で使うためのライブラリ import base64 import csv ########### Args & variable ######################### args = sys.argv Profile_Name = args[1] Profile_lIST = 'Profile_lIST.csv' ########### Create Profile ######################### with open(Profile_lIST) as fp: lst = list(csv.reader(fp)) for i in lst: if Profile_Name in i: print('指定されたユーザは既に登録されています。') sys.exit() ApiPath = 'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/identificationProfiles' headers = { # Request headers 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } body = { 'locale':'en-us', } r = requests.post( ApiPath, # URL headers = headers, # ヘッダー json = body # ボディ ) try: ProfileId = r.json()['identificationProfileId'] except Exception: print('Error:{}'.format(r.status_code)) print(r.json()['error']) sys.exit() print(ProfileId) f = open(Profile_lIST, 'a') writer = csv.writer(f, lineterminator='\n') writer.writerow([Profile_Name, ProfileId]) ####################################ステップ2 ユーザのプロファイルに音声を登録する
上記で作成したユーザに音声を登録していきます。
(話者認証とは違ってフレーズが指定されていないので、内容はなんでもOKなようです)ここでは以下の機能を使用しています。
1.「Identification Profile」の「Create Enrollment」(音声登録)
2.「Speaker Recognition」の「Get Operation Status」(登録状況の確認)あと個人的にめちゃくちゃハマったのですが、利用できるオーディオファイルにかなり厳しめな制約があります。
プロパティ 必須値 コンテナー WAV エンコード PCM レート 16K サンプル形式 16 ビット チャネル モノラル なかなか条件を満たす音声が取れなかったのですが、「Audacity」という無料ソフトでなんとか録音することが出来ました。(これめっちゃ便利)
スクリプトの引数はユーザ名にしています。
(音声ファイルにユーザ名が付いている前提ですが、検証だしいいよね)########### module ############# import sys # 引数を格納するためのライブラリ import requests # HTTPの通信を行うためのライブラリ import json # データをjson形式で使うためのライブラリ import base64 import csv import time ########### Args & variable ######################### args = sys.argv Profile_Name = args[1] Profile_lIST = 'Profile_lIST.csv' WavFile = f'{Profile_Name}.wav' with open(Profile_lIST) as fp: lst = list(csv.reader(fp)) for i in lst: if Profile_Name in i: break j = lst.index(i) ProfileId = lst[j][1] ########### Create Enrollment ######################### ApiPath = f'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/identificationProfiles/{ProfileId}/enroll?shortAudio=true' headers = { # Request headers 'Content-Type': 'application/octet-stream', 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } with open(WavFile, 'rb') as f: body = f.read() r = requests.post( ApiPath, # URL headers = headers, # ヘッダー data = body # ボディ ) try: response = r print('response:', response.status_code) if response.status_code == 202: print(response.headers['Operation-Location']) operation_url = response.headers['Operation-Location'] else: print(response.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() #################################### ########### Get Operation Status ######################### url = operation_url headers = { # Request headers 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } status = '' while status != 'succeeded': r = requests.get( url, # URL headers = headers, # ヘッダー ) try: response = r print('response:', response.status_code) if response.status_code == 200: status = response.json()['status'] print(f'現在の状態;{status}') if status == 'failed': message = response.json()['message'] print(f'error:{message}') sys.exit() elif status != 'succeeded': time.sleep(3) else: print(r.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() enrollmentStatus = response.json()['processingResult']['enrollmentStatus'] remainingEnrollmentSpeechTime = response.json()['processingResult']['remainingEnrollmentSpeechTime'] speechTime = response.json()['processingResult']['speechTime'] if enrollmentStatus == 'enrolling': status = 'プロファイルは現在、登録中であり、識別の準備はできていません。' elif enrollmentStatus == 'training': status = 'プロファイルは現在、トレーニング中であり、識別の準備はできていません。' else: status = 'プロファイルは現在、登録中であり、識別の準備ができています。' print(f'\nステータス;{enrollmentStatus}') print(f'現在の状態;{status}') print(f'有効な音声の合計時間(秒):{speechTime}') print(f'登録を成功させるのに必要な残りの音声時間(秒):{remainingEnrollmentSpeechTime}')
- 投稿日:2020-01-10T18:11:44+09:00
Azure Cognitive ServicesのSpeaker Recognition APIによる話者識別をPythonで検証してみた。#2
前置き
という訳で「Speaker Recognition API」を使った話者識別の実際の検証について記載していきます。
(プログラミング経験が貧しいので、変なところがあったら教えてください!)処理の流れ
話者識別をするには、以下の3ステップが必要になります。
- ユーザのプロファイルを作成する
- ユーザのプロファイルに音声を登録する
- 登録した音声を元に、誰が発言したのか識別する
なので今回は自分が解りやすいように、それぞれのステップ毎で3つの処理を作成していきたいと思います。
ステップ1 ユーザのプロファイルを作成する
まずは話者識別させたいユーザを作成していきます。
API機能としては「Identification Profile」の「Create Profile」を使います。
これを使用するとユーザのプロファイルを作成して、ユーザのプロファイルIDを返してきます。
(名前は登録されないので、別でリスト管理する必要があります)検証スクリプトでは引数にユーザ名を指定する形にして「Profile_lIST.csv」というファイルにユーザ名とIDを紐づけて出力しています。
CreateProfile.py########### module ############# import sys # 引数を格納するためのライブラリ import requests # HTTPの通信を行うためのライブラリ import json # データをjson形式で使うためのライブラリ import base64 import csv ########### Args & variable ######################### args = sys.argv Profile_Name = args[1] Profile_lIST = 'Profile_lIST.csv' ########### Create Profile ######################### with open(Profile_lIST) as fp: lst = list(csv.reader(fp)) for i in lst: if Profile_Name in i: print('指定されたユーザは既に登録されています。') sys.exit() ApiPath = 'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/identificationProfiles' headers = { # Request headers 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } body = { 'locale':'en-us', } r = requests.post( ApiPath, # URL headers = headers, # ヘッダー json = body # ボディ ) try: ProfileId = r.json()['identificationProfileId'] except Exception: print('Error:{}'.format(r.status_code)) print(r.json()['error']) sys.exit() print(ProfileId) f = open(Profile_lIST, 'a') writer = csv.writer(f, lineterminator='\n') writer.writerow([Profile_Name, ProfileId]) ####################################ステップ2 ユーザのプロファイルに音声を登録する
上記で作成したユーザに音声を登録していきます。
(話者認証とは違ってフレーズが指定されていないので、内容はなんでもOKなようです)ここでは以下の機能を使用しています。
1.「Identification Profile」の「Create Enrollment」(音声登録)
2.「Speaker Recognition」の「Get Operation Status」(登録状況の確認)あと個人的にめちゃくちゃハマったのですが、利用できるオーディオファイルにかなり厳しめな制約があります。
プロパティ 必須値 コンテナー WAV エンコード PCM レート 16K サンプル形式 16 ビット チャネル モノラル なかなか条件を満たす音声が取れなかったのですが、「Audacity」という無料ソフトでなんとか録音することが出来ました。(これめっちゃ便利)
スクリプトの引数はユーザ名にしています。
(音声ファイルにユーザ名が付いている前提ですが、検証だしいいよね)
CreateEnrollment.py########### module ############# import sys # 引数を格納するためのライブラリ import requests # HTTPの通信を行うためのライブラリ import json # データをjson形式で使うためのライブラリ import base64 import csv import time ########### Args & variable ######################### args = sys.argv Profile_Name = args[1] Profile_lIST = 'Profile_lIST.csv' WavFile = f'{Profile_Name}.wav' with open(Profile_lIST) as fp: lst = list(csv.reader(fp)) for i in lst: if Profile_Name in i: break j = lst.index(i) ProfileId = lst[j][1] ########### Create Enrollment ######################### ApiPath = f'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/identificationProfiles/{ProfileId}/enroll?shortAudio=true' headers = { # Request headers 'Content-Type': 'application/octet-stream', 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } with open(WavFile, 'rb') as f: body = f.read() r = requests.post( ApiPath, # URL headers = headers, # ヘッダー data = body # ボディ ) try: response = r print('response:', response.status_code) if response.status_code == 202: print(response.headers['Operation-Location']) operation_url = response.headers['Operation-Location'] else: print(response.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() #################################### ########### Get Operation Status ######################### url = operation_url headers = { # Request headers 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } status = '' while status != 'succeeded': r = requests.get( url, # URL headers = headers, # ヘッダー ) try: response = r print('response:', response.status_code) if response.status_code == 200: status = response.json()['status'] print(f'現在の状態;{status}') if status == 'failed': message = response.json()['message'] print(f'error:{message}') sys.exit() elif status != 'succeeded': time.sleep(3) else: print(r.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() enrollmentStatus = response.json()['processingResult']['enrollmentStatus'] remainingEnrollmentSpeechTime = response.json()['processingResult']['remainingEnrollmentSpeechTime'] speechTime = response.json()['processingResult']['speechTime'] if enrollmentStatus == 'enrolling': status = 'プロファイルは現在、登録中であり、識別の準備はできていません。' elif enrollmentStatus == 'training': status = 'プロファイルは現在、トレーニング中であり、識別の準備はできていません。' else: status = 'プロファイルは現在、登録中であり、識別の準備ができています。' print(f'\nステータス;{enrollmentStatus}') print(f'現在の状態;{status}') print(f'有効な音声の合計時間(秒):{speechTime}') print(f'登録を成功させるのに必要な残りの音声時間(秒):{remainingEnrollmentSpeechTime}')ステップ3 登録した音声を元に、誰が発言したのか識別する
いよいよメインの処理です。
ここでは以下の機能を使用しています。1.「Speaker Recognition」の「Identification」(話者識別)
2.「Speaker Recognition」の「Get Operation Status」(識別結果の取得)今回の検証では引数を識別したい音声ファイルにしています。
ちなみに話者識別ですが、今のところ同時に検証できるのは10ユーザ(プロファイル)までのようです。
処理としては「Identification」で識別したい音声とプロファイルID(複数)をPOSTして、戻ってくるOperation-LocationというURLに対して、「Get Operation Status」を実行して、識別の状況と結果を取得するイメージです。{検証では識別完了まで最大9秒くらいかかってました)
また、識別結果として返ってくるのは「プロファイルID」なので、別途ユーザ名に置き換える必要があります。なお識別の信頼度も一緒に返ってくるのですが、こちらは低・中・高の3段階あるようですね。
Identification.py########### module ############# import sys # 引数を格納するためのライブラリ import requests # HTTPの通信を行うためのライブラリ import json # データをjson形式で使うためのライブラリ import base64 import csv import time ########### Args & variable ######################### args = sys.argv WavFile = args[1] Profile_lIST = 'Profile_lIST.csv' with open(Profile_lIST) as fp: lst = list(csv.reader(fp)) ########### Identification ######################### ProfileIds = '' for a, b in lst: ProfileIds += b + ',' ProfileIds = ProfileIds[:-1] url = 'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/identify' params = { 'identificationProfileIds': ProfileIds, 'shortAudio': True, } headers = { # Request headers 'Content-Type': 'application/octet-stream', 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } with open(WavFile, 'rb') as f: body = f.read() r = requests.post( url, # URL params = params, headers = headers, # ヘッダー data = body # ボディ ) try: response = r print('response:', response.status_code) if response.status_code == 202: print(response.headers['Operation-Location']) operation_url = response.headers['Operation-Location'] else: print(response.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() #################################### ########### Get Operation Status ######################### url = operation_url #url = 'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/operations/ea1edc22-32f4-4fb9-81d6-d597a0072c76' headers = { # Request headers 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } status = '' while status != 'succeeded': r = requests.get( url, # URL headers = headers, # ヘッダー ) try: response = r print('response:', response.status_code) if response.status_code == 200: status = response.json()['status'] print(f'現在の状態;{status}') if status == 'failed': message = response.json()['message'] print(f'error:{message}') sys.exit() elif status != 'succeeded': time.sleep(3) else: print(r.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() identifiedProfileId = response.json()['processingResult']['identifiedProfileId'] confidence = response.json()['processingResult']['confidence'] for i in lst: if identifiedProfileId in i: break j = lst.index(i) Profile_Name = lst[j][0] print(f'\n発言者;{Profile_Name}') print(f'信頼度;{confidence}') ####################################おわり
という事で今回は「Speaker Recognition API」を検証してみました。
日本語には未対応との事だったのですが、個人的に話者識別はなかなかの精度なんじゃないかと感じました。
上手く活用すれば色々な事ができそうですね!
- 投稿日:2020-01-10T18:11:44+09:00
Azure CognitiveServicesのSpeakerRecognition APIによる話者識別をPythonで検証してみた。#2
前置き
という訳で「Speaker Recognition API」を使った話者識別の実際の検証について記載していきます。
(変なところがあったら教えてください!)処理の流れ
話者識別をするには、以下の3ステップが必要になります。
- ユーザのプロファイルを作成する
- ユーザのプロファイルに音声を登録する
- 登録した音声を元に、誰が発言したのか識別する
なので今回は自分が解りやすいように、それぞれのステップ毎で3つの処理を作成していきたいと思います。
ステップ1 ユーザのプロファイルを作成する
まずは話者識別させたいユーザを作成していきます。
API機能としては「Identification Profile」の「Create Profile」を使います。
これを使用するとユーザのプロファイルを作成して、ユーザのプロファイルIDを返してきます。
(名前は登録されないので、別でリスト管理する必要があります)検証スクリプトでは引数にユーザ名を指定する形にして「Profile_List.csv」というファイルにユーザ名とIDを紐づけて出力しています。
CreateProfile.py########### module ############# import sys # 引数を格納するためのライブラリ import requests # HTTPの通信を行うためのライブラリ import json # データをjson形式で使うためのライブラリ import base64 import csv ########### Args & variable ######################### args = sys.argv Profile_Name = args[1] Profile_List = 'Profile_List.csv' ########### Create Profile ######################### with open(Profile_List) as fp: lst = list(csv.reader(fp)) for i in lst: if Profile_Name in i: print('指定されたユーザは既に登録されています。') sys.exit() ApiPath = 'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/identificationProfiles' headers = { # Request headers 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } body = { 'locale':'en-us', } r = requests.post( ApiPath, # URL headers = headers, # ヘッダー json = body # ボディ ) try: ProfileId = r.json()['identificationProfileId'] except Exception: print('Error:{}'.format(r.status_code)) print(r.json()['error']) sys.exit() print(ProfileId) f = open(Profile_List, 'a') writer = csv.writer(f, lineterminator='\n') writer.writerow([Profile_Name, ProfileId]) ####################################ステップ2 ユーザのプロファイルに音声を登録する
上記で作成したユーザに音声を登録していきます。
(話者認証とは違ってフレーズが指定されていないので、内容はなんでもOKなようです)ここでは以下の機能を使用しています。
1.「Identification Profile」の「Create Enrollment」(音声登録)
2.「Speaker Recognition」の「Get Operation Status」(登録状況の確認)あと個人的にめちゃくちゃハマったのですが、利用できるオーディオファイルにかなり厳しめな制約があります。
プロパティ 必須値 コンテナー WAV エンコード PCM レート 16K サンプル形式 16 ビット チャネル モノラル なかなか条件を満たす音声が取れなかったのですが、「Audacity」という無料ソフトでなんとか録音することが出来ました。(これめっちゃ便利)
スクリプトの引数はユーザ名にしています。
(音声ファイルにユーザ名が付いている前提ですが、検証だしいいよね)
CreateEnrollment.py########### module ############# import sys # 引数を格納するためのライブラリ import requests # HTTPの通信を行うためのライブラリ import json # データをjson形式で使うためのライブラリ import base64 import csv import time ########### Args & variable ######################### args = sys.argv Profile_Name = args[1] Profile_List = 'Profile_List.csv' WavFile = f'{Profile_Name}.wav' with open(Profile_List) as fp: lst = list(csv.reader(fp)) for i in lst: if Profile_Name in i: break j = lst.index(i) ProfileId = lst[j][1] ########### Create Enrollment ######################### ApiPath = f'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/identificationProfiles/{ProfileId}/enroll?shortAudio=true' headers = { # Request headers 'Content-Type': 'application/octet-stream', 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } with open(WavFile, 'rb') as f: body = f.read() r = requests.post( ApiPath, # URL headers = headers, # ヘッダー data = body # ボディ ) try: response = r print('response:', response.status_code) if response.status_code == 202: print(response.headers['Operation-Location']) operation_url = response.headers['Operation-Location'] else: print(response.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() #################################### ########### Get Operation Status ######################### url = operation_url headers = { # Request headers 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } status = '' while status != 'succeeded': r = requests.get( url, # URL headers = headers, # ヘッダー ) try: response = r print('response:', response.status_code) if response.status_code == 200: status = response.json()['status'] print(f'現在の状態;{status}') if status == 'failed': message = response.json()['message'] print(f'error:{message}') sys.exit() elif status != 'succeeded': time.sleep(3) else: print(r.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() enrollmentStatus = response.json()['processingResult']['enrollmentStatus'] remainingEnrollmentSpeechTime = response.json()['processingResult']['remainingEnrollmentSpeechTime'] speechTime = response.json()['processingResult']['speechTime'] if enrollmentStatus == 'enrolling': status = 'プロファイルは現在、登録中であり、識別の準備はできていません。' elif enrollmentStatus == 'training': status = 'プロファイルは現在、トレーニング中であり、識別の準備はできていません。' else: status = 'プロファイルは現在、登録中であり、識別の準備ができています。' print(f'\nステータス;{enrollmentStatus}') print(f'現在の状態;{status}') print(f'有効な音声の合計時間(秒):{speechTime}') print(f'登録を成功させるのに必要な残りの音声時間(秒):{remainingEnrollmentSpeechTime}')ステップ3 登録した音声を元に、誰が発言したのか識別する
いよいよメインの処理です。
ここでは以下の機能を使用しています。1.「Speaker Recognition」の「Identification」(話者識別)
2.「Speaker Recognition」の「Get Operation Status」(識別結果の取得)今回の検証では引数を識別したい音声ファイルにしています。
ちなみに話者識別ですが、今のところ同時に検証できるのは10ユーザ(プロファイル)までのようです。
処理としては「Identification」で識別したい音声とプロファイルID(複数)をPOSTして、戻ってくるOperation-LocationというURLに対して、「Get Operation Status」を実行し、識別の状況と結果を取得するイメージです。{検証では識別完了まで最大9秒くらいかかってました)
また、識別結果として返ってくるのは「プロファイルID」なので、別途ユーザ名に置き換える必要があります。なお識別の信頼度も一緒に返ってくるのですが、こちらは低・中・高の3段階あるようですね。
Identification.py########### module ############# import sys # 引数を格納するためのライブラリ import requests # HTTPの通信を行うためのライブラリ import json # データをjson形式で使うためのライブラリ import base64 import csv import time ########### Args & variable ######################### args = sys.argv WavFile = args[1] Profile_List = 'Profile_List.csv' with open(Profile_List) as fp: lst = list(csv.reader(fp)) ########### Identification ######################### ProfileIds = '' for a, b in lst: ProfileIds += b + ',' ProfileIds = ProfileIds[:-1] url = 'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/identify' params = { 'identificationProfileIds': ProfileIds, 'shortAudio': True, } headers = { # Request headers 'Content-Type': 'application/octet-stream', 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } with open(WavFile, 'rb') as f: body = f.read() r = requests.post( url, # URL params = params, headers = headers, # ヘッダー data = body # ボディ ) try: response = r print('response:', response.status_code) if response.status_code == 202: print(response.headers['Operation-Location']) operation_url = response.headers['Operation-Location'] else: print(response.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() #################################### ########### Get Operation Status ######################### url = operation_url #url = 'https://speaker-recognitionapi.cognitiveservices.azure.com/spid/v1.0/operations/ea1edc22-32f4-4fb9-81d6-d597a0072c76' headers = { # Request headers 'Ocp-Apim-Subscription-Key': '<サブスクリプションキー>', } status = '' while status != 'succeeded': r = requests.get( url, # URL headers = headers, # ヘッダー ) try: response = r print('response:', response.status_code) if response.status_code == 200: status = response.json()['status'] print(f'現在の状態;{status}') if status == 'failed': message = response.json()['message'] print(f'error:{message}') sys.exit() elif status != 'succeeded': time.sleep(3) else: print(r.json()['error']) sys.exit() except Exception: print(r.json()['error']) sys.exit() identifiedProfileId = response.json()['processingResult']['identifiedProfileId'] confidence = response.json()['processingResult']['confidence'] for i in lst: if identifiedProfileId in i: break j = lst.index(i) Profile_Name = lst[j][0] print(f'\n発言者;{Profile_Name}') print(f'信頼度;{confidence}') ####################################おわり
という事で今回は「Speaker Recognition API」を検証してみました。
日本語には未対応との事だったのですが、個人的に話者識別はなかなかの精度なんじゃないかと感じました。
上手く活用すれば色々な事ができそうですね!前の記事
Azure CognitiveServicesのSpeakerRecognition APIによる話者識別をPythonで検証してみた。#1
- 投稿日:2020-01-10T18:05:56+09:00
AtCoder のディレクトリ作成・サンプルケースのテスト・提出を自動化する。atcoder-cli と online-judge-tools
AtCoder を快適に解くための2つの CLI ツールを紹介します。
このエントリーで利用している環境は Windows 10, Python 3 です。もちろん他の OS 、言語にも対応しています。できること
コンテスト用ディレクトリを作成する
acc new {コンテストID}- コンテスト用ディレクトリが作成される。
- コンテスト用ディレクトリ配下には問題ごとにディレクトリが切られる。問題ディレクトリ配下には、解答を書く main.py ファイルと、サンプルケースの入力・出力を記述したテスト用ファイルが作成される。
- ディレクトリ構成は以下の通り。
Contest ID/
├ a/
│ └ main.py
│ └ test/
│ └ sample-1.in
│ └ sample-1.out
│ └ sample-2.in
│ └ ...
├ b/
│ └ main.py
│ └ test/
│ └ ...
└ ...サンプルケースのテストを実行する
- テストしたい問題のディレクトリで
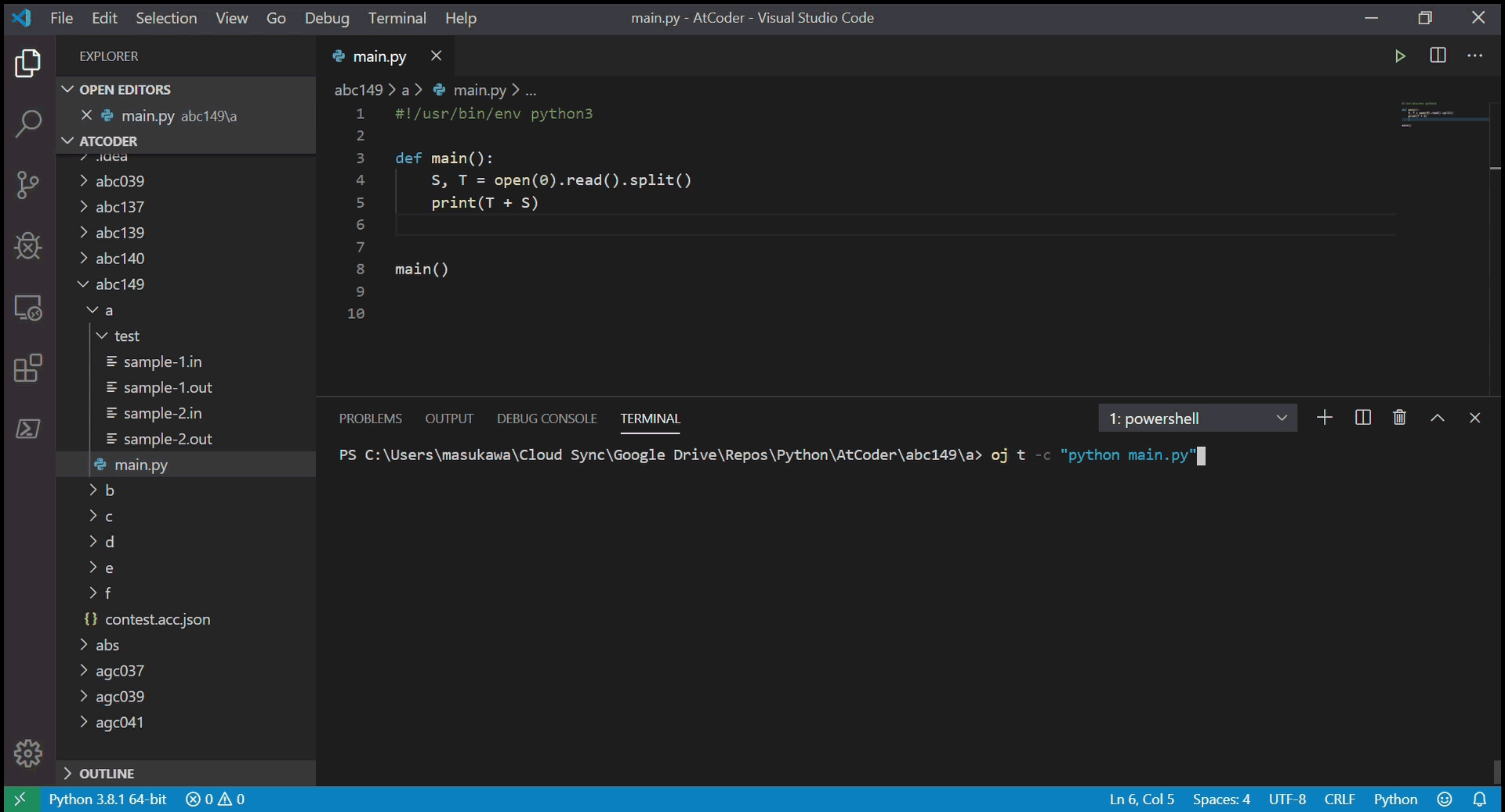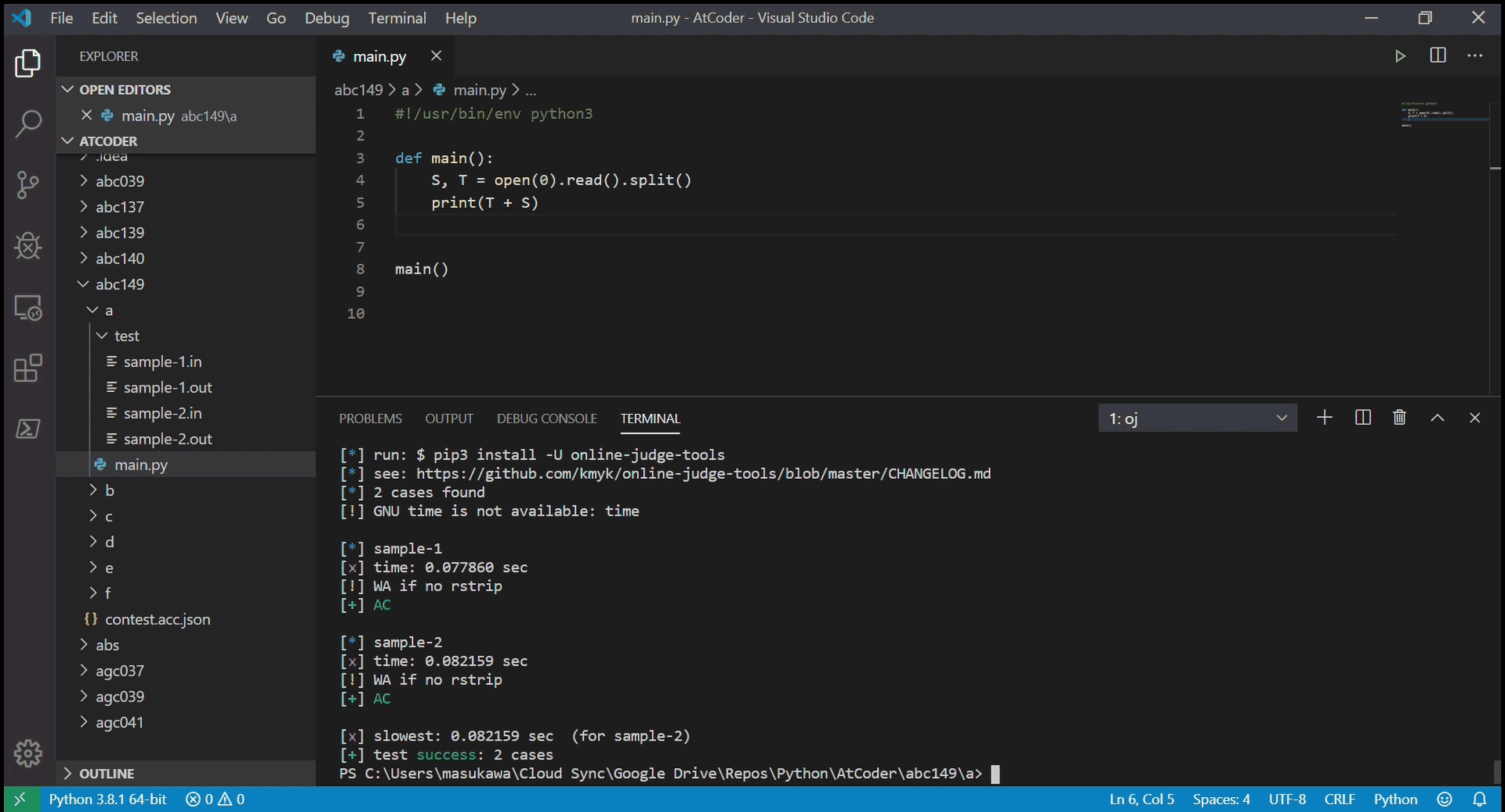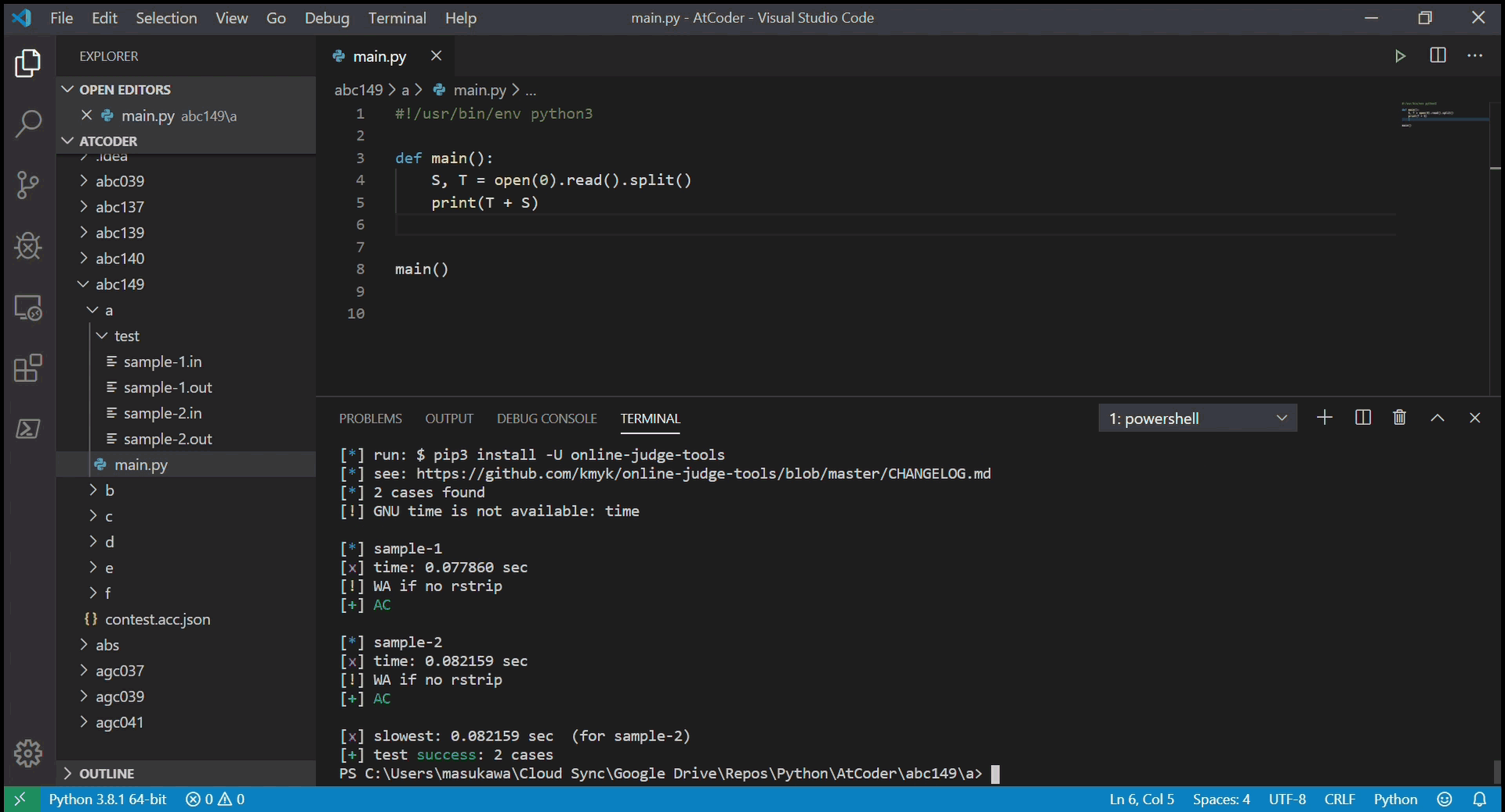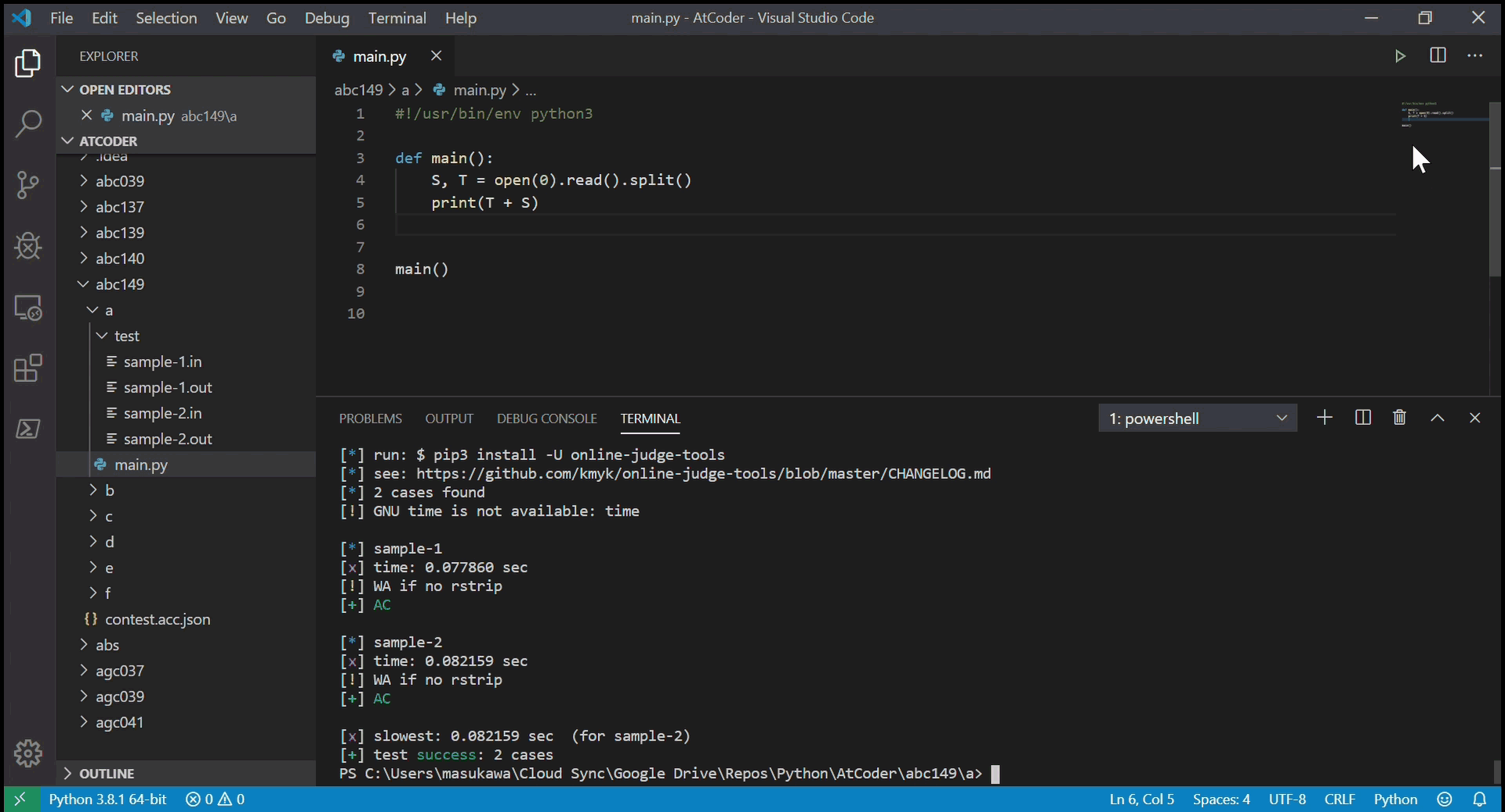
oj t -c "python main.py"- サンプルケースのテストを実行し、結果を返す。全ケースでACと出れば成功。
提出する
- 提出したい問題のディレクトリで
acc s- 完成したコードを AtCoder に提出する。ブラウザの新しいタブで提出画面が開き、結果が表示される。
導入方法
前提条件
- node.js がインストール済である
- Python >3.5がインストール済である
atcoder-cli は node.js で、 online-judge-tools は Python で動くため、これらのインストールが必要です。
インストールがまだの方は、 Chocolatey でのインストールをおすすめします (Windows の場合、Mac なら Homebrew )。
今後のアップデートが非常に楽になります。Chocolatey をインストールの上、下記のコマンドを実行すればOKです。
install.ps1cinst nodejs.install -y cinst python -yatcoder-cli と online-judge-tools の導入
以下のチュートリアルを参考に、
- インストール
- AtCoder へのログイン
を完了します。
atcoder-cli と online-judge-tools の両方で AtCoder にログインする必要があります。
設定
atcoder-cli を使いやすいように設定を変更しましょう。
なお、 online-judge-tools には設定がありません。Introduction to online-judge-tools (Japanese) # 存在しない機能 — online-judge-tools documentation
テンプレート設定
テンプレートを設定しておくと、以下が可能になります。
acc sでの解答の提出
- テンプレートがない場合はファイル名を指定する必要があります。
acc new {contestId}実行時に作成される解答用ファイルの雛形の設定
- コンソール入力の読み取り、Shebang (シバン)など、毎回使うコードを雛形として利用できます。
テンプレートファイルの設定はチュートリアルの「テンプレート設定」に従って行います。
私は以下のように設定しています。
- atcoder-cli の Config ディレクトリ
├ Config/
│ └ python/
│ └ main.py
│ └ template.json
│ └ config.json
│ └ session.jsontemplate.json{ "task": { "program": [ "main.py" ], "submit": "main.py" } }main.py#!/usr/bin/env python3 def main(): N = map(int, open(0).read().split()) main()
#!/usr/bin/env python3は Shebang です。AtCoder では Python の実行環境として Python2 と Python3 が選択できます。Shebang を利用して明示的に Python3 を利用することを指定しています。
これを忘れると、提出時に実行環境が1つに絞れないというエラーが出ます。
open(0).read().split()はコンソール入力の読み取りです。Config の変更
acc configで現在のグローバル設定を確認できます。デフォルトでは以下の通りです。config.sh$ acc config oj-path: C:/Python38/Scripts/oj.exe default-contest-dirname-format: {ContestID} default-task-dirname-format: {tasklabel} default-test-dirname-format: tests default-task-choice: inquire default-template:これを変更していきます。
$ acc config default-test-dirname-format testテストディレクトリ名を、online-judge-tools に合わせて変更します。これによって online-judge-tools がテストディレクトリを認識し、サンプルケースの自動テストが可能になります。
$ acc config default-task-choice all
acc new {Contest Id}を実行時、ディレクトリを作成する問題の選択方式を設定します。
デフォルトのinquireでは、毎回問題を手動で選択することになります。
私は一度に全てのディレクトリを作成したいので、allにしています。$ acc config default-template pythonデフォルトで利用したいテンプレートを指定します。
私は python にしていますが、「テンプレート設定」で作成した、最もよく使うテンプレートを各自指定しましょう。おわりに
以上で atcoder-cli と online-judge-tools の導入が完了し、冒頭の動画のように使用することが可能になります。
快適に AtCoder を楽しみましょう!
- 投稿日:2020-01-10T17:48:01+09:00
Azure Cognitive ServicesのSpeaker Recognition APIによる話者識別をPythonで検証してみた。#1
はじめに
Cognitive Servicesでは、様々なAPIが提供されていますが、今回はそのうちの「Speaker Recognition API」にて話者識別を試してみました。
(日本ではあまり流行ってないっぽいですが。。)ちなみに話者識別とは「いま誰が話しているのか」を識別してくれるもので、試した感じ、なかなかの精度かも。。と感じました。(まぁ自分の声でしか試してないんですけどね)
という訳で、早速検証していきたいと思います!
事前準備
まずはAzureにリソースを準備していきます。
Azureにログインして「リソースの作成」をクリックします。
画面左上の検索boxに
Speaker Recognitionと入力します。
以下の画面で「作成」をクリックします。
作成画面に移動するので、各項目を入力していきます!
ちなみにF0だと10,000 無料トランザクション / 月とのこと(検証には十分ですね)
入力が完了したら、画面下部の「Create!」をクリックします。
リソースのデプロイが完了したので、「リソースに移動」をクリックします。
サブスクリプションキーが表示されました。
これは後で使うので、コピーボタンを押して保管しておきます!
これでSpeaker Recognition APIを使用する準備が整いました。
見づらくなりそうなので、実際の処理は次の記事に記載します!






- 投稿日:2020-01-10T17:48:01+09:00
Azure CognitiveServicesのSpeakerRecognition APIによる話者識別をPythonで検証してみた。#1
はじめに
Cognitive Servicesでは、様々なAPIが提供されていますが、今回はそのうちの「Speaker Recognition API」にて話者識別を試してみました。
(日本ではあまり流行ってないっぽいですが。。)ちなみに話者識別とは「いま誰が話しているのか」を識別してくれるもので、試した感じ、なかなかの精度かも。。と感じました。(まぁ自分の声でしか試してないんですけどね)
という訳で、早速検証していきたいと思います!
事前準備
まずはAzureにリソースを準備していきます。
Azureにログインして「リソースの作成」をクリックします。
画面左上の検索boxに
Speaker Recognitionと入力します。
以下の画面で「作成」をクリックします。
作成画面に移動するので、各項目を入力していきます!
ちなみにF0だと10,000 無料トランザクション / 月とのこと(検証には十分ですね)
入力が完了したら、画面下部の「Create!」をクリックします。
リソースのデプロイが完了したので、「リソースに移動」をクリックします。
サブスクリプションキーが表示されました。
これは後で使うので、コピーボタンを押して保管しておきます!
これでSpeaker Recognition APIを使用する準備が整いました。
見づらくなりそうなので、実際の処理は次の記事に記載します!
次の記事(実際の検証)
Azure CognitiveServicesのSpeakerRecognition APIによる話者識別をPythonで検証してみた。#2
- 投稿日:2020-01-10T17:44:39+09:00
ニューラルネットとDoc2Vecを使った作者推定(青空文庫)
はじめに
青空文庫から引っ張ってきた作品を使って、作者を推定するというタスクをやったので記事にしました。コードはここで公開してます。
今回やった流れは以下です。
wgetを使って青空文庫から本文をダウンロード- MeCabを使って、本文を整形
- Doc2Vecを使って、本文をベクトル化(本文から作られたベクトルをx、作者IDをyとしたデータの作成)
- kerasを使ってニューラルネットを構成し、分類問題として教師あり学習
環境
- MacOS Catalina
- python3.7
ライブラリは主にBeautifulSoup, keras, Mecab, gensimを使っています。主旨からずれるので、これらのインストール方法は割愛します。基本的に
pipでなんとかなりました。下準備
まずは、作品をダウンロードする作者を決めます。今回はとりあえず「あ行の作者」かつ「公開作品数が20以上」を満たす人を対象としました。
青空文庫の作家リストから作品をダウンロードするために必要な作者IDを取得します。例えば芥川龍之介なら879です。
これらをまとめた
authors.txtを作成します。これも自動で作成するようにしてもよかったのですが、人数が少なかったので手作業で作っています。authors.txt芥川龍之介 879 有島武郎 25 アンデルセンハンス・クリスチャン 19 石川啄木 153 石原純 1429 泉鏡花 50 伊丹万作 231 伊藤左千夫 58 伊藤野枝 416 上田敏 235 上村松園 355 内田魯庵 165 海野十三 160 江戸川乱歩 1779 大久保ゆう 10 大隈重信 1879 大町桂月 237 丘浅次郎 1474 岡本かの子 76 岡本綺堂 82 小川未明 1475 小熊秀雄 124 小栗虫太郎 125 織田作之助 40 折口信夫 933全部で25人。名前と作者IDの間は半角スペースです。また、後述する問題の関係でこのリストから省いた人(大倉燁子)もいます。
あとは必要なライブラリのインポートです。これ以降のpythonスクリプトはauthor_prediction.ipynbで公開しているものと同じです。
from bs4 import BeautifulSoup import re import MeCab from gensim.models.doc2vec import Doc2Vec from gensim.models.doc2vec import TaggedDocument import numpy as np import matplotlib.pyplot as plt from keras import layers from keras import models from keras import optimizers from keras.utils import np_utilsこれで下準備は終わり。
1.
wgetを使って青空文庫から本文をダウンロード1.1 作品IDの取得
まずはauthors.txtを使って作者ごとの作品IDを取得する。これは
personID??.txtという名前で保存する(??は作者ID)。# authors.txtをもとに、wgetして作品IDが入ったpersonID??.txtを生成(??にはpersonIDが入る) # personID_listにはpersonIDを入れる personID_list = [] memo = open('./authors.txt') for line in memo: line = line.rstrip() line = line.split( ) #print(line) author = line[0] personID = line[1] personID_list.append(personID) # authors.txtのpersonIDをもとに、indexをwgetする(すでに作成済なのでやる必要なし) #!wget https://www.aozora.gr.jp/index_pages/person{personID}.html -O ./data/index{personID}.html #!sleep 1 # 保存したindex??.htmlを開く with open("./data/index{}.html".format(personID), encoding="utf-8") as f: soup = BeautifulSoup(f) ol = soup.find("ol").text bookID = re.findall('ID:[0-9]*', ol) # index??.htmlの中から、作品IDが書いてある部分を取得 #print(bookID) bookID_list = [] for b in bookID: b = b[3:] # 'ID:'の削除 bookID_list.append(b) # 作品IDの追加 #print(bookID_list) print('author {}\tpersonID {}\tnumber of cards {}'.format(author, personID, len(bookID_list))) # bookID_listをもとに、ある作者の作品IDが記述されているテキストファイルを作成(すでに作成済なのでやる必要なし) #with open('./data/personID{}.txt'.format(personID), mode='w') as f: # for b in bookID_list: # f.write(b + ' ')実行するとこんな感じの出力が得られます。これで
personID??.txtというファイルが25人分できます(??は作者ID)。author 芥川龍之介 personID 879 number of cards 376 author 有島武郎 personID 25 number of cards 44 author アンデルセンハンス・クリスチャン personID 19 number of cards 23 author 石川啄木 personID 153 number of cards 78 author 石原純 personID 1429 number of cards 24 author 泉鏡花 personID 50 number of cards 208 author 伊丹万作 personID 231 number of cards 23 author 伊藤左千夫 personID 58 number of cards 39 author 伊藤野枝 personID 416 number of cards 80 author 上田敏 personID 235 number of cards 53 author 上村松園 personID 355 number of cards 83 author 内田魯庵 personID 165 number of cards 26 author 海野十三 personID 160 number of cards 177 author 江戸川乱歩 personID 1779 number of cards 91 author 大久保ゆう personID 10 number of cards 68 author 大隈重信 personID 1879 number of cards 31 author 大町桂月 personID 237 number of cards 60 author 丘浅次郎 personID 1474 number of cards 25 author 岡本かの子 personID 76 number of cards 119 author 岡本綺堂 personID 82 number of cards 247 author 小川未明 personID 1475 number of cards 521 author 小熊秀雄 personID 124 number of cards 33 author 小栗虫太郎 personID 125 number of cards 22 author 織田作之助 personID 40 number of cards 70 author 折口信夫 personID 933 number of cards 197注意
上記のスクリプトにおいて、
#を外して自分でwgetしてpersonID??.txtを作ると、アップロードしてあるpersonID??.txtよりも作品IDが多いものが得られます。これは、次のスクリプトで本文を取り出す時にエラーが出る作品IDを手動で消してるからです。例えば、大久保ゆうさんの「あップルパイを」という作品では、通常の青空文庫のサイトの他に外部リンクが貼ってあって、そっちを取得してしまいます。この青空文庫のサイトが取れれば良いのに、外部サイトが取れてしまうということです。
また、小熊秀雄さんの短歌集のように、本文が存在しない(<div class="main_text">タグが存在しない)ものもあり、これもエラーの原因となります。このような例外的な作品IDは消した
personID??.txtをアップロードしているので、とりあえず動かしたい人はコメントを外すことは避けた方が無難です。動作を確認したい人だけコメントを外して保存先のディレクトリを変更する、といったことをすると良いと思います。1.2 作品を
wgetで保存次に、
personID??.txtに書かれている作品IDを用いて、作品をダウンロードする。作品ダウンロードにはpubserver2を使用させてもらっていますが、今考えるとpubserver2を経由しないで普通にwgetしてもよかったかも?# personID??.txtから作品IDを取得して、その作品をwgetで持ってくる(作者1人あたり50作品まで) # 作品が書かれているhtmlの名前はtext_x_y.html(xがpersonID、yがbookID) for personID in personID_list: print('personID', personID) with open("./data/personID{}.txt".format(personID), encoding="utf-8") as f: for bookID_str in f: bookID_list = bookID_str.split( ) print('number of cards', len(bookID_list)) # 作品数が多すぎると時間かかるので50作品までに限定 if len(bookID_list) >= 50: bookID_list = bookID_list[:50] for bookID in bookID_list: print('ID', bookID) # bookIDをもとにwgetして本文が記述されているhtmlを作成(すでに作成済なのでやる必要なし) #!wget http://pubserver2.herokuapp.com/api/v0.1/books/{bookID}/content?format=html -O ./data/text{personID}_{bookID}.html #!sleep 12. MeCabを使って、本文を整形
本文を整形して、タグづけする関数を作成。これはここを参考にしました。
タグは0から24の数字をauthors.txtの順に割り振っています(芥川龍之介が0、有島武郎が1、...、折口信夫が24)。タグの数字に作者IDをそのまま利用するとデータ生成の時に面倒なので、ここで新たに番号を振り直してます。# doc(作品の本文)を動詞・形容詞・名詞のみのwordsというリストにする # wordsとtagからなるTaggedDocumentを生成 def split_into_words(doc, name=''): mecab = MeCab.Tagger("-Ochasen") lines = mecab.parse(doc).splitlines() # 形態素解析 words = [] for line in lines: chunks = line.split('\t') # 名詞(数詞は除く)、動詞、形容詞のみ加える if len(chunks) > 3 and (chunks[3].startswith('動詞') or chunks[3].startswith('形容詞') or (chunks[3].startswith('名詞') and not chunks[3].startswith('名詞-数'))): words.append(chunks[0]) #print(words) return TaggedDocument(words=words, tags=[name])学習用データとのtrain_textと、評価用データのtest_textを生成する。
# 学習させるtrain_textを生成(著者1人あたり20作品で固定) # テスト用のtest_textも作る(学習で使わないデータの残り全てを使用) # 人によって作品数が違うので、test_textに含まれる作品数も人によって異なる train_text = [] test_text = [] for i, personID in enumerate(personID_list): print('personID', personID) with open("./data/personID{}.txt".format(personID), encoding="utf-8") as f: for bookID_str in f: #print(bookID) bookID_list = bookID_str.split( ) # 50作品以上はダウンロードしてないのでカット if len(bookID_list) >= 50: bookID_list = bookID_list[:50] print('number of cards', len(bookID_list)) for j, bookID in enumerate(bookID_list): # 先ほど保存した本文が含まれるhtmlを開く soup = BeautifulSoup(open("./data/text{}_{}.html".format(personID, bookID), encoding="shift_jis")) # 本文が書かれている<div>を取り出す main_text = soup.find("div", "main_text").text #print(main_text) # 最初の20作品はtrain_textに入れ、残りはtest_textに入れる if j < 20: train_text.append(split_into_words(main_text, str(i))) print('bookID\t{}\ttrain'.format(bookID)) else: test_text.append(split_into_words(main_text, str(i))) print('bookID\t{}\ttest'.format(bookID))3. Doc2Vecを使って、本文をベクトル化
Doc2Vecのモデルを作成する。alphaとかepochsとかのハイパーパラメータはかなり適当に決めています。
# Doc2Vecのモデルを作成し、学習させる model = Doc2Vec(vector_size=len(train_text), dm=0, alpha=0.05, min_count=5) model.build_vocab(train_text) model.train(train_text, total_examples=len(train_text), epochs=5) # 学習結果を保存 #model.save('./data/doc2vec.model')ニューラルネットで学習させるために、本文を数値ベクトルに変換させたデータを作成。
# 作成したmodelとTaggedDocumentのリストであるtextから、ニューラルネット用のデータを作る def text2xy(model, text): x = [] y = [] for i in range(len(text)): #print(i) vec = model.infer_vector(text[i].words) # 数値からなるベクトルに変換 x.append(vec.tolist()) y.append(int(text[i].tags[0])) x = np.array(x) y = np_utils.to_categorical(y) # tagの数字はonehotに変換 return x, y # 学習用データと評価用データの作成 x_train, y_train = text2xy(model, train_text) x_test, y_test = text2xy(model, test_text)4. kerasを使ってニューラルネットを構成し、分類問題として教師あり学習
モデルの作成から学習まで行う関数(dense_train)と、描画のための関数(draw_accとdraw_loss)を用意する。
作ったニューラルネットのモデルはかなり単純な全結合層3層からなるモデル。
損失関数には分類問題でよく使われるcategorical crossentropyを使用した。ユニットの数やlearning rateなどは適当です。
def dense_train(epochs): # モデルの定義 kmodel = models.Sequential() kmodel.add(layers.Dense(512, activation='relu', input_shape=(500,))) kmodel.add(layers.Dense(256, activation='relu')) kmodel.add(layers.Dense(25, activation='softmax')) kmodel.summary() # モデルのコンパイル kmodel.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc']) # モデルの学習 history = kmodel.fit(x=x_train, y=y_train, epochs=epochs, validation_data=(x_test, y_test)) # モデルの保存 #model.save('./data/dense.h5') return history, kmodel # 正解率のプロット def draw_acc(history): acc = history.history['acc'] val_acc = history.history['val_acc'] epochs = range(1, len(acc) + 1) fig = plt.figure() fig1 = fig.add_subplot(111) fig1.plot(epochs, acc, 'bo', label='Training acc') fig1.plot(epochs, val_acc, 'b', label='Validation acc') fig1.set_xlabel('epochs') fig1.set_ylabel('accuracy') fig.legend(bbox_to_anchor=(0., 0.19, 0.86, 0.102), loc=5) # anchor(凡例)の第2引数がy、第3引数がx # 画像の保存 fig.savefig('./acc.pdf') plt.show() # lossのプロット def draw_loss(history): loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(loss) + 1) fig = plt.figure() fig1 = fig.add_subplot(111) fig1.plot(epochs, loss, 'bo', label='Training loss') fig1.plot(epochs, val_loss, 'b', label='Validation loss') fig1.set_xlabel('epochs') fig1.set_ylabel('loss') fig.legend(bbox_to_anchor=(0., 0.73, 0.86, 0.102), loc=5) # anchor(凡例)の第2引数がy、第3引数がx # 画像の保存 #fig.savefig('./loss.pdf') plt.show()訓練させ、正解率のグラフを描画する。今回、エポック数は10とした。
history, kmodel = dense_train(10) draw_acc(history)得られた出力は以下。
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 512) 256512 _________________________________________________________________ dense_2 (Dense) (None, 256) 131328 _________________________________________________________________ dense_3 (Dense) (None, 25) 6425 ================================================================= Total params: 394,265 Trainable params: 394,265 Non-trainable params: 0 _________________________________________________________________ Train on 500 samples, validate on 523 samples Epoch 1/10 500/500 [==============================] - 0s 454us/step - loss: 3.0687 - acc: 0.1340 - val_loss: 2.9984 - val_acc: 0.3308 Epoch 2/10 500/500 [==============================] - 0s 318us/step - loss: 2.6924 - acc: 0.6300 - val_loss: 2.8255 - val_acc: 0.5698 Epoch 3/10 500/500 [==============================] - 0s 315us/step - loss: 2.3527 - acc: 0.8400 - val_loss: 2.6230 - val_acc: 0.6864 Epoch 4/10 500/500 [==============================] - 0s 283us/step - loss: 1.9961 - acc: 0.9320 - val_loss: 2.4101 - val_acc: 0.7610 Epoch 5/10 500/500 [==============================] - 0s 403us/step - loss: 1.6352 - acc: 0.9640 - val_loss: 2.1824 - val_acc: 0.8088 Epoch 6/10 500/500 [==============================] - 0s 237us/step - loss: 1.2921 - acc: 0.9780 - val_loss: 1.9504 - val_acc: 0.8337 Epoch 7/10 500/500 [==============================] - 0s 227us/step - loss: 0.9903 - acc: 0.9820 - val_loss: 1.7273 - val_acc: 0.8432 Epoch 8/10 500/500 [==============================] - 0s 220us/step - loss: 0.7424 - acc: 0.9840 - val_loss: 1.5105 - val_acc: 0.8642 Epoch 9/10 500/500 [==============================] - 0s 225us/step - loss: 0.5504 - acc: 0.9840 - val_loss: 1.3299 - val_acc: 0.8623 Epoch 10/10 500/500 [==============================] - 0s 217us/step - loss: 0.4104 - acc: 0.9840 - val_loss: 1.1754 - val_acc: 0.8719学習結果の図はこちら。
6エポック以降はサチっている気がするが、最終的に87.16%の正解率が得られた。ハイパーパラメータチューニングをほとんどやっていないのに、そこそこの正解率が得られたような気がする。
終わりに
ハイパーパラメータチューニングやモデルの選定(LSTMとか使う?)はもっとやっても良いかも。何かご指摘があればコメントください。ご覧いただきありがとうございました。

- 投稿日:2020-01-10T17:21:35+09:00
300万IDのループ処理に苦労していた話
昨日の記事の続き
■目的
300万個のIDそれぞれに対して、1ヶ月分のデータが用意されている
データの中身は、説明変数と目的変数が1つずつ。
つまりテーブルのカラムは、ID、説明変数、目的変数の3つ
レコード数は300万×30日 ≒ 9000万この時、300万のIDそれぞれに対し、30日分の説明変数と目的変数の単回帰を行い、
アウトプットとしてそれぞれのIDに対して相関係数、傾き、p値を格納したい。■方針
300万のIDに対し、forループの中で回帰を行い、結果をリストとして格納
最後にリストを結合してデータフレームとする■環境
EC2インスタンス (ubuntu: r5d.4xlarge)
JupyterLab 0.35.3■課題
IDをindexにしてdf.loc[]で抽出 + daskデータフレームを使用でも処理が遅い (2ヶ月かかる)
■解決策
下記のような形のテーブルを
ID x y 01 x.xx y.yy 01 x.xx y.yy ・・・ ・・・ ・・・ 01 x.xx y.yy 02 x.xx y.yy 02 x.xx y.yy ・・・ ・・・ ・・・ 02 x.xx y.yy 下記のような形に変換
ID monthly_x monthly_y 01 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 02 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 03 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 04 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 05 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 06 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 変換の流れは下記2段階
- pandas.pivot_tableを使用してpivot化 (内包表記を使える形にするため)
この処理は比較的高速。 (1IDあたり 約50μs、300万IDで 約2.5min)code1.pyimport pandas as pd # 元のデータフレームに日付を表す列を追加した状態(ここでは「date_」という列名とする) pivot_df = pd.pivot_table(df, index="ID",columns="date_")これでx,yそれぞれの値が日付ごとに横持された形になる。
- IDごとに月間(30日分)のxとyの値をリスト化して、別列に格納(内包表記で処理)
code2.pypivot_df["x"] = [list(pivot_df.x.loc[i,:]) for i in pivot_df.index] pivot_df["y"] = [list(pivot_df.y.loc[i,:]) for i in pivot_df.index]この処理は1IDあたり 約0.2ms、300万IDで 約10 ~ 15min (内包表記強し)
変換したテーブルに対して、回帰の処理を行ってみる
今回の回帰は、外れ値の事を考えロバスト回帰を使用
(ロバスト回帰についてはこちらがわかりやすい)
(ロバスト回帰の決定係数R^2の導出について、癖があるので時間があるときにまとめる、予定。あくまでも、予定)code3.pyimport statsmodels.api as sm pivot_df["model"] = [sm.RLM(i, sm.add_constant(j)) for i,j in zip(pivot_df.x ,pivot_df.y)] pivot_df["result"] = [i.fit() for i in pivot_df.model]上記コードで1IDあたり 約8.8ms
"model"の保存を行わず、ワンライナーでfitまで行うと1IDあたり 約7.9ms
ここまでで合計で、1IDあたり 約9ms前回記事では、1IDの抽出だけで1.7sかかっていたので、
回帰まで含めても1/200、回帰の前処理までの時間で比較すると1/10000に処理時間を短縮できた■結論
内包表記最強
300万IDのIDごとの処理時間が馬鹿正直にやると1年以上かかる計算だったのを、少しの工夫で8時間くらい回せば済むようにできた(他に良い方法等あればご教示いただけるとありがたいです)
■今後の予定
回帰に関して、今回の記事では単純にStatsModelsを使っただけだが、ロバスト回帰の決定係数はStatsModels等どのライブラリでも簡単に導出することができない(私の知る限り)ため、少し工夫が必要になる。こちらに関して調べながらまとめられたらいいな~、とフワッと思っている(
思っているだけ)
- 投稿日:2020-01-10T17:21:35+09:00
300万IDデータのループ処理に苦労していた話
昨日の記事の続き
■目的
300万個のIDそれぞれに対して、1ヶ月分のデータが用意されている
データの中身は、説明変数と目的変数が1つずつ。
つまりテーブルのカラムは、ID、説明変数、目的変数の3つ
レコード数は300万×30日 ≒ 9000万この時、300万のIDそれぞれに対し、30日分の説明変数と目的変数の単回帰を行い、
アウトプットとしてそれぞれのIDに対して相関係数、傾き、p値を格納したい。■方針
300万のIDに対し、forループの中で回帰を行い、結果をリストとして格納
最後にリストを結合してデータフレームとする■環境
EC2インスタンス (ubuntu: r5d.4xlarge)
JupyterLab 0.35.3■課題
IDをindexにしてdf.loc[]で抽出 + daskデータフレームを使用でも処理が遅い (2ヶ月かかる)
■解決策
下記のような形のテーブルを
ID x y 01 x.xx y.yy 01 x.xx y.yy ・・・ ・・・ ・・・ 01 x.xx y.yy 02 x.xx y.yy 02 x.xx y.yy ・・・ ・・・ ・・・ 02 x.xx y.yy 下記のような形に変換
ID monthly_x monthly_y 01 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 02 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 03 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 04 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 05 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 06 [x.xx, x.xx ,....] [y.yy, y.yy ,....] 変換の流れは下記2段階
- pandas.pivot_tableを使用してpivot化 (内包表記を使える形にするため)
この処理は比較的高速。 (1IDあたり 約50μs、300万IDで 約2.5min)code1.pyimport pandas as pd # 元のデータフレームに日付を表す列を追加した状態(ここでは「date_」という列名とする) pivot_df = pd.pivot_table(df, index="ID",columns="date_")これでx,yそれぞれの値が日付ごとに横持された形になる。
- IDごとに月間(30日分)のxとyの値をリスト化して、別列に格納(内包表記で処理)
code2.pypivot_df["x"] = [list(pivot_df.x.loc[i,:]) for i in pivot_df.index] pivot_df["y"] = [list(pivot_df.y.loc[i,:]) for i in pivot_df.index]この処理は1IDあたり 約0.2ms、300万IDで 約10 ~ 15min (内包表記強し)
変換したテーブルに対して、回帰の処理を行ってみる
今回の回帰は、外れ値の事を考えロバスト回帰を使用
(ロバスト回帰についてはこちらがわかりやすい)
(ロバスト回帰の決定係数R^2の導出について、癖があるので時間があるときにまとめる、予定。あくまでも、予定)code3.pyimport statsmodels.api as sm pivot_df["model"] = [sm.RLM(i, sm.add_constant(j)) for i,j in zip(pivot_df.x ,pivot_df.y)] pivot_df["result"] = [i.fit() for i in pivot_df.model]上記コードで1IDあたり 約8.8ms
"model"の保存を行わず、ワンライナーでfitまで行うと1IDあたり 約7.9ms
ここまでで合計で、1IDあたり 約9ms前回記事では、1IDの抽出だけで1.7sかかっていたので、
回帰まで含めても1/200、回帰の前処理までの時間で比較すると1/10000に処理時間を短縮できた■結論
内包表記最強
300万IDのIDごとの処理時間が馬鹿正直にやると1年以上かかる計算だったのを、少しの工夫で8時間くらい回せば済むようにできた(他に良い方法等あればご教示いただけるとありがたいです)
■今後の予定
回帰に関して、今回の記事では単純にStatsModelsを使っただけだが、ロバスト回帰の決定係数はStatsModels等どのライブラリでも簡単に導出することができない(私の知る限り)ため、少し工夫が必要になる。こちらに関して調べながらまとめられたらいいな~、とフワッと思っている(
思っているだけ)
- 投稿日:2020-01-10T16:22:48+09:00
pythonでPhotoshop形式のファイル(.psd)を作る
pytoshopというライブラリを使ってPSDファイルを作ります。
pytoshopで一旦psdファイルを読み込んで加工するのは結構他でも見つかりましたが、ゼロから作るのは見当たらなかったので公式ドキュメントみたりデバッグしなりしながら調べてみました。基本的にPythonで一般的なOpenCVの画像データ(numpy配列)でレイヤーを構成して書き出す感じです。
必要なパッケージのインストール
pip install numpy scipy opencv-python Pillow six psd-tools3 pytoshopスクリプト
main.py#! env python # -*- coding: utf-8 -*- import os import sys import cv2 import pytoshop from pytoshop import layers import numpy as np import cv2 def main(): # レイヤー用画像 test_img = cv2.imread("test1.tif") # # 白紙のPSDファイルを作る # psd = pytoshop.core.PsdFile(num_channels=3, height=test_img.shape[0], width=test_img.shape[1]) # 255埋めの画像を作る(透明度用) max_canvas = np.full(test_img.shape[:2], 255, dtype=np.uint8) # # レイヤーを作る # # 必要なレイヤーの枚数分行う # 透明度 np.ndarray([], dtype=np.uint8) # 255が不透明、0が透明になっており、グレースケールのマスク画像を設定することで、透明度を持ったレイヤーを作ることが出来る layer_1 = layers.ChannelImageData(image=max_canvas, compression=1) # RGB layer0 = layers.ChannelImageData(image=test_img[:, :, 2], compression=1) # R layer1 = layers.ChannelImageData(image=test_img[:, :, 1], compression=1) # G layer2 = layers.ChannelImageData(image=test_img[:, :, 0], compression=1) # B new_layer = layers.LayerRecord(channels={-1: layer_1, 0: layer0, 1: layer1, 2: layer2}, # RGB画像 top=0, bottom=test_img.shape[0], left=0, right=test_img.shape[1], # 位置 name="layer 1", # 名前 opacity=255, # レイヤーの不透明度 ) psd.layer_and_mask_info.layer_info.layer_records.append(new_layer) # # 書き出し # with open("output.psd", 'wb') as fd2: psd.write(fd2) return if __name__ == '__main__': main()
- 投稿日:2020-01-10T16:22:39+09:00
PythonとCythonのdtypeについて
pythonとcythonのdtypeがごちゃごちゃになったので、整理した。
背景
pythonのdtypeで例えば
float64などがあるが、cythonだとfloat64_tなどが使われる。これらの違いは何か。同じように使ってよいか。float64_tは何なのか
まず、
import numpy as np cimport numpy as npとすると、最初の行でnumpy moduleをimportし、次の行でnumpy.pxdを単にincludeする。
cythonのインストールフォルダーを見ると、たしかにnumpy.pxdがあり、float64_tはctypedef double npy_float64 ctypedef npy_float64 float64_tと定義されている。
結論
float64_t ≠ float64であり、float64_t = doubleだった。参考
- 投稿日:2020-01-10T16:12:33+09:00
Lambda@Edgeでとりあえずデバッグできる環境を作った時のメモ
やりたいこと
Lambda@Edgeを使って開発する時に最小構成で動くものを作る
それを使ってデバッグしながら開発したい
言語はPython3.7(3.8は現時点でサポート外)構成
リクエスト→CloudFront→S3
CloudWatchLogsにログを出力しつつ他は何もしないLamda@EdgeをはさむS3の用意
S3で適当なバケットを作る
適当なindex.htmlを置く(今回はこんな感じ)index.html<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"> <html lang="ja"> <head> <title>テストホームページ</title> </head> <body> <h1>テストホームページ</h1> <p>ただいま工事中です。 </body> </html>バケットにパブリックアクセス権限つける
バケットの「オブジェクトURL」からindex.htmlをブラウザに表示できるか確認する
表示できたらS3の設定は完了
S3の静的ホスティング設定をオンにしてindex.htmlを指定するCloudFrontとS3の連携
調べれば山ほど資料が出てくるので割愛
CloudFrontのドメイン経由でS3にアクセスしてブラウザに表示できるか確認する
表示できたら完了これでリクエスト→CloudFront→S3ができた
ここまでが下準備
ここにLambda@Edgeを挟むLambda@Edge
まずリージョン(ログインしているユーザ名の横にあるやつ)をバージニアにしてからLambda関数を作成する
Lambdaの中身をこれにする
lambda_function.pyimport json def lambda_handler(event, context): print('# lambda@edge start') print(event) # Viewer Response Origin Responseの場合はこっちをコメントアウトはずす # cfResponse = event['Records'][0]['cf']['response'] # return cfResponse # Viewer Request Origin Requestの場合はこっちをコメントアウトはずす # cfRequest = event['Records'][0]['cf']['request'] # return cfRequest・Lambda@Edgeはリクエストとレスポンスにそれぞれ必須のパラメータがあり、ない場合エラーとなってしまう
バージョンがLATESTになっている事を確認したらアクション→Lambda@Edgeへのデプロイを選択
ディストリビューションに作成したCloudFrontのIDを設定
CloudFrontイベントに設定したいLambda@Edgeのイベントを設定してデプロイをクリックするとデプロイできるCDNだからデプロイしてもしばらくはコンテンツの配信が完了してない地域がある
CloudFrontのコンソールでstatusがin Progressからdeployedになっていれば配信完了
完了自体は体感だと数分〜數十分くらいか、日本には1~3分で配信されていたように思うこれでCloudWatchLogsのLambda実行ログを見ればコードに書いたログが出力されるはずだ
あとはLambda@Edgeでやりたい事をデバッグしながらLambdaに実装するだけとなるLambda@Edgeのログについて(重要)
Lambda@EdgeのCloudWatchLogsは下記の分類で別々のグループに書き出されるので注意(一番ハマった)
コンソールから実行したテストのログ
リージョン:バージニア
出力対象:関数ごと
Lambda@Edgeで実行したLambdaのログ
リージョン;アクセスしたリージョン(日本ならほぼ東京)
出力対象:関数ごと
Lambda@Edgeで実行したLambda@Edgeのログ
リージョン;アクセスしたリージョン(日本ならほぼ東京)
出力対象:Lambda@Edgeが紐づけられている出力対象ごとこのメモが自分を含めて誰かの役に立てる事を祈る
- 投稿日:2020-01-10T16:07:22+09:00
xml形式のgenbankデータから分類情報などを取り出す
登録配列用スクリプト
Genbankの配列情報に関するxmlからは
以下のスクリプトでtaxon情報を取り出すことができるimport xml.etree.ElementTree as ET tree = ET.parse("./gene_file.xml") root = tree.getroot() for child in root.findall('GBSeq'): accession = child.find('GBSeq_accession-version').text taxon = child.find('GBSeq_taxonomy').text for child in child.findall('GBSeq_feature-table'): for child in child.findall('GBFeature'): for child in child.findall('GBFeature_quals'): for child in child.findall('GBQualifier'): if child.find('GBQualifier_value') is not None: taxon_id = child.find('GBQualifier_value').text if('taxon:' in taxon_id): taxon_id_out = taxon_id else: taxon_id_out = "" out +=(accession+"\t"+taxon_id_out+ "\t"+ taxon +"\n") with open("out10.taxon.txt", mode='w') as f: f.write(out)なんで書いたか
flat fileからのパースがめんどくさい+例外が置きまくるので、xmlからの読み込み、抽出に挑戦した。
- 投稿日:2020-01-10T16:01:42+09:00
Cythonでnumpyを扱う (memoryviewによる方法)
Pythonの計算を高速化するためにCythonに書き換えている。このとき、numpy配列の扱いにつまずいたのでメモした。
環境
ubuntu 18.04 LTS
jupyter lab 0.35.4
python 3.7.5CUIでCythonをやるよりも、jupyterの方が楽だと思っている。setupファイルを作らなくていいので。
Cythonでnumpyを使おうとする
まず、jupyter上では
%%cythonをつける。次に下準備。
import numpy as np cimport numpy as np cimport cythonnumpy配列を使うために、cのtypedef宣言と同じようなことをしてから、配列を作る。ここでは、次元3のaという配列を作る。
ctypedef np.float64_t DTYPE_t cdef np.ndarray[DTYPE_t, ndim=3] a問題点
ここまでが、色々なサイトを見ると書いてあることだが、このまま実行すると以下の様なエラーが出る。
Error compiling Cython file: ------------------------------------------------------------ ... cimport cython ctypedef np.float64_t DTYPE_t ctypedef np.int_t INT_t cdef np.ndarray[DTYPE_t, ndim=3] a ^ ------------------------------------------------------------ /home/qcmp/.cache/ipython/cython/_cython_magic_043176e78a21b81e31740451e1fe277a.pyx:9:33: Buffer types only allowed as function local variables Error compiling Cython file: ------------------------------------------------------------ ... import numpy as np ^ ------------------------------------------------------------ /home/qcmp/.cache/ipython/cython/_cython_magic_043176e78a21b81e31740451e1fe277a.pyx:2:0: Buffer vars not allowed in module scopeモジュールレベルの変数を使えず、ローカル変数だったら使えるという。
確かに、以下のようなローカル変数は、エラーが出ない。cdef int x解決法1
ローカル変数にすればよい。つまり、関数内で定義すればローカルになる。例えば、
def hoge(): ctypedef np.float64_t DTYPE_t cdef np.ndarray[DTYPE_t, ndim=3] a解決法2
解決法1のようにローカル変数にしたくないときもある。モジュールレベルの変数でどうしても扱いたいなと思っていたら、このstackoverflowの回答に手がかりが書いてあった。
Typically if I want to have an array as a module level variable (i.e not local to a method), I define a typed memoryview and then set it within a method
memoryviewを使うらしい。
メモリービューオブジェクトとは
変数をメモリとして参照するために使う。
公式ページの型付きメモリービューページを参照すると、こう書いてある。型付きメモリビューを使用すると、Pythonのオーバーヘッドを発生させることなく、基になるNumPy配列などのメモリバッファに効率的にアクセスできます。 メモリービューは、現在のNumPy配列バッファーのサポート(np.ndarray [np.float64_t、ndim = 2])に似ていますが、より多くの機能とより簡潔な構文があります。
基本的な構文としては
[:]を使うらしい。例えば一次元のintバッファを作るなら、cdef int[:] view1D = exporting_object三次元なら
cdef int[:,:,:] view3D = exporting_objectという具合である。
exporting_objectには、
1. numpy array
2. C array
3. Cython array
のメモリービューオブジェクトを指定する。
元々numpyだけ知ればいいのだが、折角なので簡単に全部紹介する。1. exporting_object が numpy arrrayの場合
np.arange(NUMBER , dtype) #NUMBERは任意の数で、detypeは
dtype=np.dtype("i")のように指定する。("i"はint)
次元を増やしたければ、reshapeすればよい。2. exporting_object が C arrayの場合
3次元なら
cdef int a[NUM1][NUM2][NUM3] #NUM1,2,3は任意の数。もちろんaも任意。3 exporting_object が Cython array の場合
まず、
from cython.view cimport array as cvarrayのように
cython.viewからarrayをcimportしなければならない。3次元なら
cvarray(shape=(NUM1,NUM2,NUM3), itemsize, format)itemsize, formatは
itemsize=sizeof(int),format="i"のように指定する。解決法2に戻る
memoryviewの紹介でnumpy以外も紹介したが、本来の問題に戻ると結局以下のように書けばよいだろう。
cimport numpy as np ctypedef np.float64_t DTYPE_t cdef DTYPE_t [:, :, :] aあとは
a = np.arange(27, dtype=np.double).reshape((3, 3, 3))などを代入すればいいだろう。
dtypeについてまたつまずいたので、別記事に書く。まとめ
Cythonでnumpy使うときは、1.関数内でローカル定義する か 2.memoryviewを使う のどちらかで解決。
参考
- Cythonで使える配列バッファオブジェクト
- Cython公式ページより Typed Memoryviews
- 投稿日:2020-01-10T13:48:50+09:00
いもす法
いもす法をABC035-Cを解いている際に実装したのでメモとして残しておきます。また、累積和を含めどのような時に使えば良さそうかについても最後に触れたいと思います。(今回初めていもす法を勉強したので間違っている箇所があるかもしれません。ご指摘していただくとありがたいです。)
いもす法とその実装
ABC035-Cの問題文は以下のようになります。
問題文通りに実装する場合、$l$から$r$までの駒を裏返す操作を繰り返せば良いので、N個の駒用の配列を用意して(最初はTrueかFalseで初期化)、Q回のそれぞれで$l_i$から$r_i$までのそれぞれの要素を反転させれば良く、以下のようなコードになります。
answerC1.pydef int2(k): return int(k)-1 n,q=map(int,input().split()) lr=[list(map(int2,input().split())) for i in range(q)] x=[False]*n for i in range(q): for j in range(lr[i][0],lr[i][1]+1): x[j]=not x[j] print("".join(list(map(str,map(int,x)))))しかし、n,qの制約が$2\times{10}^5$であり、最悪計算時間がO($nq$)になることから制限時間に間に合わないことがわかります。
ここで用いることができるのがいもす法になります(次元拡張や特殊な図形についても考えることができるので非常に有効な方法と考えられています。)。
いもす法では入口で加算、出口で減算をします(記録)。そして、記録の段階が終わったら前から順に足していきます(シミュレート)。したがって、この問題ではl番目からr番目からまでを裏返すとした時にl番目の要素に+1をしてr+1番目の要素に-1をして記録をしています。このようにすると、記録の後にシミュレートする際に前の要素の値を順に足していく(累積和を前の要素から順に求めていく)ことで、それぞれの要素が何回裏返されたかをより少ない計算量で求めることができます。(l番目の要素に+1をしてr+1番目の要素に-1をする際を考えると、i:0→nでループを回せばちょうどl番目からr番目だけ1で他の要素は0になっていることがわかります。)
以上をそのまま実装すると以下のようなコードになります(O($n+q$)になります。)。また、いもす法には関係ありませんが、inputをsys.stdin.readlineに変えたら実行時間が約半分になったのでPythonユーザーのかたは試してみると良いかと思います。
answerC2.py#いもす法 import sys #input→sys.stdin.readline半分の時間に input=sys.stdin.readline n,q=map(int,input().split()) x=[0]*n for i in range(q): l,r=map(int,input().split()) x[l-1]+=1 if r<n: x[r]-=1 for i in range(n-1): x[i+1]+=x[i] x[i]%=2 x[n-1]%=2 print("".join(list(map(str,x))))いもす法と累積和の使用法
前節でABC035におけるいもす法の実装については説明できたと思うので、実際にどんな時に使えば良いかを一般化して残しておきたいと思います。
まず、いもす法の場合は、それぞれの区間の値に対して更新が何回も行われ、最後にまとめて全体の値を求めたい場合に用いると考えられます。このような場合はその区間の入口と出口のみに対し、加算と減算をそれぞれ先に行い、最後に累積和を求めていくことで大幅に計算量を減らすことができます。
それに対し、累積和の場合は、区間の値の更新は起きず、最後にいくつもの区間の値を求めたい場合に用いられると考えられます。このような場合は、基準となる要素(多くの場合は一番初めや一番最後の要素)からの累積和を考え、求める際にはそれぞれの要素までの累積和の差分を考えることで大幅に計算量を減らすことができます。
おまけ(いもす法を使う問題)
answerC.ccimport sys #input→sys.stdin.readline3/4の時間に input=sys.stdin.readline n=int(input()) x=[0]*1000001 for i in range(n): a,b=map(int,input().split()) x[a]+=1 if b+1<1000001: x[b+1]-=1 ans=x[0] for i in range(1000000): x[i+1]+=x[i] ans=max(ans,x[i+1]) print(ans)

- 投稿日:2020-01-10T13:29:04+09:00
FlaskによるGET/POST通信(ついでにCORS対応についても)
概要
FlaskにおけるPOST通信の内容が曖昧だったので、GET/POST通信どちらもここにまとめる。
内容としては、「フォームによる通信」/「Json形式による通信」が存在する。「Flask POST」的に検索すると情報がごちゃごちゃで出てくる。ちなみにPython 3.7です。GET通信
from flask import Flask, request, jsonfy app = Flask(__name__) @app.route("/", methods=["POST"]) def test(): data = request.args.get('hoge', '') # ?hoge=valueの値を取得 return data # サンプルのためそのまま返すPOST通信
Json形式による通信
from flask import Flask, request, jsonfy import json app = Flask(__name__) @app.route("/", methods=["POST"]) def test(): data = json.loads(request.data.decode('utf-8')) # request.dataをutf-8にデコードしてjsonライブラリにてディクショナリ型とする return jsonfy(data) # サンプルのためそのまま返す以下でもできるらしいけど、まだ試していません。
from flask import Flask, request, jsonfy import json app = Flask(__name__) @app.route("/", methods=["POST"]) def test(): data = json.loads(request.get_data()) return jsonfy(data) # サンプルのためそのまま返すフォームによる通信
from flask import Flask, request, jsonfy app = Flask(__name__) @app.route("/", methods=["POST"]) def test(): data = request.form["hoge"] # フォームに存在する「"hoge"」キーの値を取得 return jsonfy(data) # サンプルのためそのまま返すCORS(Cross-Origin Resource Sharing)対応について
今回の内容では特に関係ないですが、次いでにCORS対応について説明します。
私はWeb系エンジニアではなので、詳しいことは分からないんですが、簡単に言うと別のサーバリソースを使用する際ためのルールとかって話らしいです(もう少し突っ込んで説明すると、URLのベースが同じか同じかどうかって感じですかね)。ひとまずpipにて「flask-cors」をインストールする。
pip install flask-corsあとは以下のような感じで。
from flask import Flask from flask_cors import CORS # これと app = Flask(__name__) CORS(app) #これ参考
- Flask クイックスタート:https://a2c.bitbucket.io/flask/quickstart.html
- 1AngularからFlask APIを呼んで、No 'Access-Control-Allow-Origin...で怒られた時の対処法:https://qiita.com/mitch0807/items/cd18e8fc15bb12416f3d
- JSONでPOSTしたものをpythonで使う方法:https://qiita.com/naoko_s/items/04d68998cfdbe9c1b5f2
- Flask-CORS:https://flask-cors.readthedocs.io/en/latest/
- CORS (Cross-Origin Resource Sharing) ってなに?:https://aloerina01.github.io/blog/2016-10-13-1