- 投稿日:2020-01-10T23:12:20+09:00
javaでAtCoder Beginner Contest 150を解く
AtCoder Beginner Contest 150お疲れ様でした!
公式ページ残念ながらまたUnratedですね・・・
GitHub.comのアカウントを作った記念に、ちょっと前にはじめたAtCoderのコードもコンテストが終わった後にコミットしてみました。こちら
さらに、解説記事も書いてみます。競技プログラミングは最近はじめて言語も基本的にjavaくらいしか書けないのでjava使ってやってます。
(競プロでPythonとかC使ってる人多いのはなぜなのでしょうか・・・)問題A
掛け算して比較する問題。
特に解説は不要かと思います。問題B
ABCが順序通りに並んでいる数を調べる問題。
特に性能も気にしなくてもよさそうだったので、シンプルに3つとってきて一致するかどうかを調べました。問題C
もう少しいい方法はあると思いますが・・・
自分は2つの数列を「何番目に大きい数字を使っているか」で変換し、2つの数列を比較し、桁ごとに対応する階乗の値をかけて算出しました。あまりうまく文字で説明できません。コード見た方が分かりやすいかと思います。
問題D
最小公倍数的な問題。なぜ不正解か分かりません!
基本方針としては
- 最小公倍数算出
- 与えられたm+最小公倍数/2を最小公倍数で割り算した値を出力で行いました。
ただ、数列が2/4/6などの場合に答えは0となります。なぜなら、「2の何乗か」というのがあっていないため。
2*(p+0.5)は2の倍数ではありませんが、4*(p+0.5)は2の倍数です。このように、数列の数全ての2の何乗かというのがそろっている必要があります。が、不正解。この問題に苦戦していて終わりました・・・
https://github.com/ko-flavor/atcoder-java/blob/master/atcoder/src/abc/abc150/MainD.java今日はいくら考えても分からなかったので、また後日見てみたいと思います!
(追記)
プログラムにバグを無事発見し、修正してACになりました。
- 投稿日:2020-01-10T22:05:51+09:00
JavaでJSON文字列をエスケープするコード
Javaで未だに公式サポートされないJSON
大きなデータの作成は、JacksonやGsonを使う選択肢が普通と思いますが、
小さなデータを作成は、リッチなライブラリに頼らず、簡単な関数で済ませたい。
このような時の悩みの種は文字列のエスケープ処理です。エスケープ対象は、
対象文字 Byteコード エスケープ表記 BS 0x08 \b HT 0x09 \t LF 0x0A \n FF 0x0C \f CR 0x0D \r " 0x22 \" / 0x2F \/ \ 0x5C \ \ [4 byte Unicode] 先頭バイトが
0xF0 〜 0xF7\u[4 byte Unicode] コード
文字列を1バイトずつ置換する方式です。
private static String escapeJsonString(CharSequence cs) { final byte BACKSLASH = 0x5C; final byte[] BS = new byte[]{BACKSLASH, 0x62}; /* \\b */ final byte[] HT = new byte[]{BACKSLASH, 0x74}; /* \\t */ final byte[] LF = new byte[]{BACKSLASH, 0x6E}; /* \\n */ final byte[] FF = new byte[]{BACKSLASH, 0x66}; /* \\f */ final byte[] CR = new byte[]{BACKSLASH, 0x72}; /* \\r */ final byte[] UC = new byte[]{BACKSLASH, 0x75}; /* \\u */ try ( ByteArrayOutputStream strm = new ByteArrayOutputStream(); ) { byte[] bb = cs.toString().getBytes(StandardCharsets.UTF_8); for (byte b : bb) { if (b == 0x08 /* BS */) { strm.write(BS); } else if (b == 0x09 /* HT */) { strm.write(HT); } else if (b == 0x0A /* LF */) { strm.write(LF); } else if (b == 0x0C /* FF */) { strm.write(FF); } else if (b == 0x0D /* CR */) { strm.write(CR); } else if ( b == 0x22 /* " */ || b == 0x2F /* / */ || b == BACKSLASH /* \\ */ ) { strm.write(BACKSLASH); strm.write(b); } else if ( b >= (byte)0xF0 && b <= (byte)0xF7 /* 4 byte Unicode */ ) { strm.write(UC); strm.write(b); } else { strm.write(b); } } return new String(strm.toByteArray(), StandardCharsets.UTF_8); } catch (IOException notHappen) { throw new RuntimeException(notHappen); } }テスト
public static void main(String[] args) { String before = "abc \b \t \n \f \r / \\ \" ?"; String escaped = escapeJsonString(before); System.out.println("{\"value\":\"" + escaped + "\"}"); /* {"value":"abc \b \t \n \f \r \/ \\ \" \u?"} */ }
- 投稿日:2020-01-10T18:17:43+09:00
「Java8からJava11」で何が起きたのか、どう環境構築すればいいのか
この記事の目的
- 「Javaの環境構築」で絶対にハマったり、錯綜する情報にいつも惑わされる人に向けた記事です。
- 2017年以降のJavaは、移り変わりが激しい世界になりました。このことを認識し、「軸となる考え方」や「重要な動向」を把握できるように、調べた情報をまとめました。
- 「5年ぶりに(Java|JVM言語)触るんだけど環境周りが全然わからん」とか、「correttoとかAdoptOpenJDKとか、みんな何を言っているんだ」という人(つまりちょっと前の筆者)が、「今後に渡って2度とハマらないための基礎知識を得られること」を目的にしています。以下の3本立てです:
- ざっくりとした歴史
- 2020年におけるローカル開発環境構築
- 情報源と参考URL
- APIや言語仕様の変更点には触れません(他の良い記事があります)。
I. ざっくりとした歴史
- 2017年9月、OracleはJavaのリリース・モデルの変更を発表し、同時に「Oracle JDKの有償機能をOpenJDKで公開」することを発表した。すなわちJavaはオープン化されることになった(有償化ではなく)。
- 以前から有償契約でサポートを受けていたクライアントは、引き続き有償サポートを受けられる。この場合に限り、JDKは"Open"ではない「Oracle JDK」として提供され、プロダクション環境での利用が有償となる(ここが誤解されがち)。
リリースサイクルについて
- 毎年3月と9月にフィーチャー・リリースが提供され、メジャーバージョンが上がっていく。Ex: Java9 => 2017年9月、Java10 => 2018年3月、Java11 => 2018年9月、...
全フィーチャー・リリースがOracle JDKのLTS(Long Term Support)というわけではない。Java9以降では、Java11, Java17がLTS対象。それ以外はnon-LTS。
詳しくは、Oracle Java SE サポート・ロードマップを参照。
「8とそれ以降」
- Java8は「リリース・モデル変更前の最後のバージョン」という位置にいる。Java8自体もオープン化され、かつOracle JDKのLTS対象になっている。
- Java8からJava9に上がる際、Project Jigsawと呼ばれるモジュール化が採用され、設計に比較的大きな変更が入った。
- つまり、「Java8以前とJava9以降」ではリリース・モデルの面でも、互換性の面でも大きな隔たりがある。移行に際しては両面を(混同することなく)意識したほうが良い。
ディストリビューションの分化
- オープンソース化したことで、複数ベンダーがJDKをビルド、発表できるようになった。OpenJDKのソースを取り巻き、Linuxのように各社のディストリビューションが複数存在する状況が生まれた。
(出典: 最適なOpenJDKディストリビューションの選び方)
2020年現在、主要なディストリビューションは以下:
- Oracle OpenJDK (by Oracle)
- Red Hat OpenJDK (by Red Hat)
- Azul Zulu (by Azul Systems)
- SapMachine (by SAP)
- BellSoft Liberica (by BellSoft)
- Amazon Corretto (by Amazon)
- AdoptOpenJDK (Community Based)
各社のOpenJDKディストリビューションは、「latestだけ」「OracleのLTS対象だけ」などバージョンを絞って公開・サポートすることがある。
- 例えば2020年1月現在、Oracle OpenJDKは最新の13をGA(General-Availability Release)として公開。他バージョンもダウンロードは可能だが、使用は非推奨。
- 同じく2020年1月現在、Amazon Correttoは8と11を公開。
ディストリビューションにお墨付きを与えるため、Technology Compatibility Kit(TCK)という一連のテストがコミュニティによって用意されている。TCKをパスしたディストリビューションは、“Java SE compatible”と名乗ることができる
AdoptOpenJDKのように、TCKをpassしていないが比較的普及しているディストリビューションもある
どう選べばいいの?
サポート状況や、各ディストリビューションを取り巻くエコシステムで判断するのが現実的。
- 例えば、Zuluのような有償ライセンス / サポートがあるか?
- 例えば、インストーラはきちんと準備されていて、使いやすいか?
- 例えば、公式Dockerイメージは用意されているか?
とはいえ、現状目立った差は少なく、選びづらい面もある。これから特徴が出てくるかもしれない。
II. 2020年におけるローカル開発環境構築
Iに書いたような状況なので、定まったベストはなく、しかもすぐに陳腐化する傾向にある。=> SDKMAN!が現状のベストプラクティス。(2020.1.10 追記)
ここでは、「コマンドラインのみでインストールが終わること」「複数バージョンを切り替え可能な状態にすること」を重視し、以下2パターンの構築手順を例示する:
- パターン1: SDKMAN!(推奨)
- パターン2: Homebrew & jEnv
パターン1: SDKMAN!によるインストール
SDKMAN!は、Groovyの複数バージョン管理ツールであるGVMを前身とする。JVM言語やそのビルドツールを中心に多種多様なツールの複数バージョンの管理を実現してくれる。
SDKMAN!自体のインストールは公式を参照。導入後、Javaのインストールは以下のコマンドで完結する:
sdk install javaこのときインストールされるディストリビューションは、2020年1月現在はAdoptOpenJDKの11。
その他のディストリビューションに関しても、
list,install,defaultの3つのサブコマンドで自由に確認・切替えできる。バージョンやディストリビューションの指定はリスト中のIdentifierを使用する。sdk list java ================================================================================ Available Java Versions ================================================================================ Vendor | Use | Version | Dist | Status | Identifier -------------------------------------------------------------------------------- AdoptOpenJDK | | 13.0.1.j9 | adpt | | 13.0.1.j9-adpt | | 13.0.1.hs | adpt | | 13.0.1.hs-adpt | | 12.0.2.j9 | adpt | | 12.0.2.j9-adpt | | 12.0.2.hs | adpt | | 12.0.2.hs-adpt | | 11.0.5.j9 | adpt | | 11.0.5.j9-adpt | >>> | 11.0.5.hs | adpt | installed | 11.0.5.hs-adpt | | 8.0.232.j9 | adpt | | 8.0.232.j9-adpt | | 8.0.232.hs | adpt | | 8.0.232.hs-adpt Amazon | | 11.0.5 | amzn | | 11.0.5-amzn | | 8.0.232 | amzn | | 8.0.232-amzn | | 8.0.202 | amzn | | 8.0.202-amzn Azul Zulu | | 13.0.1 | zulu | | 13.0.1-zulu | | 12.0.2 | zulu | | 12.0.2-zulu ...(中略)... SAP | | 12.0.2 | sapmchn | | 12.0.2-sapmchn | | 11.0.4 | sapmchn | | 11.0.4-sapmchn ================================================================================なお、2つ目以降のJDKインストール時に、そのディストリビューションをデフォルトにするかどうかプロンプトで尋ねられる。
sdk install java 13.0.1-open # Oracle OpenJDK 13 Downloading: java 13.0.1-open ...(中略)... Installing: java 13.0.1-open Done installing! Do you want java 13.0.1-open to be set as default? (Y/n): Y Setting java 13.0.1-open as default.デフォルトに設定すれば、その時点でJavaのバージョンは切り替わる。パスの設定等は一切不要。試しにjshellの起動確認をしてみる。
jshell | JShellへようこそ -- バージョン13.0.1 | 概要については、次を入力してください: /help intro jshell>jshellはJava9から追加されたJavaのREPLである。他の言語でお馴染みかもしれないが、標準APIのちょっとした動作確認などに重宝する。
/exitで終了できるので、バージョンを戻して再実行してみる。sdk default java 11.0.5.hs-adpt Default java version set to 11.0.5.hs-adptjshell | JShellへようこそ -- バージョン11.0.5 | 概要については、次を入力してください: /help intro jshell>バージョンが切り替ることを確認できた。
パターン2: Homebrew & jEnvによるインストール
パターン2: Homebrew & jEnvによるインストール
SDKMAN!に比べて煩雑で、お勧めできない。裏側でどのようにパスが通されているかなどの参考にはなるかも
HomebrewでのJDKインストール
- 比較的最近(恐らく2019年11月)、Formulaeに
openjdkが追加された。したがって、brew install openjdkでインストール可能。- この時インストールされるディストリビューションは、Oracle OpenJDK。
- Java8やそれ以前をインストールする必要がある場合、または他のディストリビューションを利用したい場合は、現状Homebrew Caskを使うことになる(この記事では割愛する)。
- サポートされているFormulaeはここで検索するのが早い => https://formulae.brew.sh/formula/
インストールに成功するとCaveats(警告)が出ていることに気づく。以下はCatalina+zshで試したときのメッセージ。
==> Pouring openjdk-13.0.1+9.catalina.bottle.tar.gz ==> Caveats For the system Java wrappers to find this JDK, symlink it with sudo ln -sfn /usr/local/opt/openjdk/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk.jdk openjdk is keg-only, which means it was not symlinked into /usr/local, because macOS already provides this software and installing another version in parallel can cause all kinds of trouble. If you need to have openjdk first in your PATH run: echo 'export PATH="/usr/local/opt/openjdk/bin:$PATH"' >> ~/.zshrcさらっと書いてあるが、どのパラグラフも重要。環境によってはメッセージの細部や取るべき対応が違うこともある。
For the system Java wrappers to find this JDK, symlink it with...
"system Java wrappers"が何を指すか明確でないが、後述する
java_homeコマンドなどを動作させるために、シンボリックリンクの作成が必要。openjdk is keg-only, which means it was not symlinked into /usr/local,...
/usr/local以下にsymlinkされていないということなので、つまりこの時点でターミナルでjavaと打ってもここでインストールしたOpenJDKが直ちに動作するわけではないと言っている。If you need to have openjdk first in your PATH run:...
ここでインストールしたOpenJDKがパスとして最初に検索されるようにするためには、シェルの起動時にパスを追加する必要がある。
ただ、今回は複数バージョンのJDKを別ツールで管理する方針なので、Javaのパスを直接
~/.zshrcに書くことは避ける。以上を踏まえて、最初のメッセージが推奨する、シンボリックリンクの作成だけを実行する:
sudo ln -sfn /usr/local/opt/openjdk/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk.jdkこうすれば、以下のコマンドが動作するようになってくれるはずだ:
java --version openjdk 13.0.1 2019-10-15 OpenJDK Runtime Environment (build 13.0.1+9) OpenJDK 64-Bit Server VM (build 13.0.1+9, mixed mode, sharing)/usr/libexec/java_home /Library/Java/JavaVirtualMachines/openjdk.jdk/Contents/HomejEnvへの登録
pyenvのように、複数バージョンのJDKの管理を楽にしてくれるツール。インストール手順は公式に譲る。
brew installの実行後、パスを通す必要がある。例えばpyEnvだと
pyenv install 3.5.0などのコマンドでPythonをインストールできる。だがここまでの操作からもわかるように、jEnv自体にJDKをダウンロードしてくる機能はない。jenv addコマンドが引数として要求するのは、「ダウンロード済みのJDKのJAVA_HOMEへのフルパス」だ。このパスは先述のjava_homeコマンドで参照できる。/usr/libexec/java_home /Library/Java/JavaVirtualMachines/openjdk.jdk/Contents/Homeあとはこれを利用してJDKをjEnvに追加してやれば良い:
jenv add `/usr/libexec/java_home` openjdk64-13.0.1 added 13.0.1 added 13.0 added複数バージョンのインストール
上記の状態から、例えば、Oracle OpenJDKの11を追加でインストールする場合は以下のような手順になる:
# 1. JDKをインストールする brew install openjdk@11 # 2. JavaVirtualMachines配下にsymlinkを作成する # (brew install時にプロンプトに出てくるコマンドをコピペする) sudo ln -sfn /usr/local/opt/openjdk@11/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk-11.jdk # 3. jEnvの管理対象に加える jenv add `/usr/libexec/java_home -v 11`jEnvが複数バージョンを管理できるようになったことの確認と、jshellの起動確認をしてみる。
jenv versions * system 11.0 11.0.5 13.0 13.0.1 openjdk64-11.0.5 openjdk64-13.0.1バージョンを13に設定する。
jenv global 13.0 jenv versions system 11.0 11.0.5 * 13.0 13.0.1 openjdk64-11.0.5 openjdk64-13.0.1jshell | JShellへようこそ -- バージョン13.0.1 | 概要については、次を入力してください: /help intro jshell>続いてバージョンを切り替えて同じことをしてみる。
jenv global 11.0 jenv versions system * 11.0 11.0.5 13.0 13.0.1 openjdk64-11.0.5 openjdk64-13.0.1jshell | JShellへようこそ -- バージョン11.0.5 | 概要については、次を入力してください: /help introバージョンが切り替ることを確認できた。
ここまでやっておけば、ある程度ディストリビューションやバージョンの追加にも対応できるローカル開発環境と言えるはず。
III. 情報源と参考URL
以上述べてきたような経緯があるので、選択したディストリビューションによって開発者が参照すべき情報は異なってくる。
横断的に現状を把握できるページが見つかれば望ましいが、現状は、まずOpenJDKの開発をリードするOracle公式のロードマップを参照するのが良いだろう。
Oracle Java SE サポート・ロードマップ
https://www.oracle.com/technetwork/jp/java/eol-135779-ja.htmlRedHatなど、ベンダーが自社ディストリビューションのライフサイクルやポリシーを公開している場合もある。
OpenJDK Life Cycle and Support Policy
https://access.redhat.com/articles/1299013その他 参考URL
(本記事はほとんど以下の記事からの抜粋と要約なので、より深く知りたい方はぜひ!)
JDKの新しいリリース・モデルおよび提供ライセンスについて
https://www.oracle.com/technetwork/jp/articles/java/ja-topics/jdk-release-model-4487660-ja.htmlProject Jigsaw
https://openjdk.java.net/projects/jigsaw/最適なOpenJDKディストリビューションの選び方
https://www.oracle.co.jp/campaign/code/2019/pdfs/oct2019_b-3-3.pdf「Java 有償化」で誤解する人になるべく分かりやすく説明するためのまとめ
https://togetter.com/li/1343743OpenJDK - Wikipedia
https://ja.wikipedia.org/wiki/OpenJDKOracle JDK vs. OpenJDK builds comparison
https://devexperts.com/blog/oracle-jdk-vs-openjdk-builds-comparison/


- 投稿日:2020-01-10T17:31:32+09:00
Javaのsynchronizedの解説と注意点(誤りがあれば教えてください)
synchronizedの基本
プログラムにてスレッドを分けて処理しているけれど、複数スレッドに同時に処理を行わせてはいけない箇所(クリティカルセクション)があり、そこでは処理実行可能なスレッドを制限したいときなどに使う。
synchronizedと書けばいつも内部がシングルスレッド処理になるというものではないので、何のインスタンスを使って領域を守っているかをしっかり意識すること。synchronizedメソッド
synchronizedメソッドは、そのインスタンスにおいてsynchronized記述されているメソッドを実行できるスレッドを1つだけに制限するためのもの。
以下のクラスにおいて、someMethod()およびanotherMethod()はsynchronizedメソッドであり、このsomeClassインスタンスに対して複数のスレッドがsomeMethod()やanotherMethod()を呼び出しても、一度に処理を行えるのは1スレッドだけである。class SomeClass { synchronized void someMethod() { doSomething(); // ここに来れるのは1スレッドだけ } synchronized void anotherMethod() { doAnotherthing(); // ここに来れるのは1スレッドだけ } ... }synchronizedブロック
synchronizedブロックは、特定のコードブロックだけ1スレッド実行に制限するためのもの。
synchronizedメソッドは、メソッド内部の処理全体をsynchronzedブロックで囲って、thisを使って同期しているのと等価と考えてよい1。
つまり、以下のメソッドは、synchronized void someMethod() { doSomething(); }以下のメソッドと等価である1。
void someMethod() { synchronized (this) { doSomething(); } }synchronizedブロックで使用する同期インスタンスと典型的誤り
synchronizedブロックでよく用いられる同期インスタンスと典型的誤りを記す。
this
以下のコードで、
doSomething()とdoAnotherthing()は、ともにthisを使ったsynchronizedブロックで囲まれているため、このSomeClassインスタンスに対してdoSomething()もしくはdoAnotherthing()を実行できるスレッドは一つだけになる。class SomeClass() { void someMethod() { synchronized (this) { doSomething(); // ある時点でdoSomething()もしくはdoAnotherthing()を実行できるスレッドは一つだけ } } void anotherMethod() { synchronized (this) { doAnotherthing(); // ある時点でdoSomething()もしくはdoAnotherthing()を実行できるスレッドは一つだけ } } private void doSomething() { ... } private void doAnotherthing() { ... } }典型的誤り:他のSomeClassインスタンスに対する同期
同期インスタンスはthisのため、
new SomeClass()が複数回行われるなどして複数のインスタンスが生成された場合、ぞれぞれのインスタンスにてthisは別物である。ゆえに、SomeClassインスタンス間でのスレッドの制限は行われない。
これ以降の内容はnew SomeClass()が一度だけしか行われていない前提で記載する。mLock等のプライベート変数
以下では、mLock1とmLock2の二つの同期インスタンスを生成している。
mLock1にて守られているので、doSomething()を実行できるスレッドは一つだけ。同様に、mLock2にて守られているので、doAnotherthing()を実行できるスレッドも一つだけ。doSomething()とdoAnotherthing()の間では排他は行われない。class SomeClass() { private Object mLock1 = new Object(); private Object mLock2 = new Object(); void someMethod() { synchronized (mLock1) { doSomething(); // ある時点でdoSomething()を実行できるスレッドは一つだけ } } void anotherMethod() { synchronized (mLock2) { doAnotherthing(); // ある時点でdoAnotherthing()を実行できるスレッドは一つだけ } } private void doSomething() { ... } private void doAnotherthing() { ... } }典型的誤り:無意味なロックインスタンス生成
以下では、mLockというインスタンスを生成して同期インスタンスに使用しているが、不要である。thisを使えばよい。
class SomeClass() { private Object mLock = new Object(); // 定義しなくてもthisで良い void someMethod() { synchronized (mLock) { doSomething(); } } void anotherMethod() { synchronized (mLock) { doAnotherthing(); } } ... }典型的誤り:デッドロック
以下において、
someMethod()およびanotherMethod()が異なるスレッドで呼ばれるとデッドロックする可能性がある。特にdoSomething()の処理時間が長い場合はすぐに発生する。class SomeClass() { private Object mLock1 = new Object(); private Object mLock2 = new Object(); void someMethod() { synchronized(mLock1) { // mLock1を取得する doSomething(); synchronized(mLock2) { // mLock2の取得をしようとする doAnotherthing(); } } } void anotherMethod() { synchronized(mLock2) { // mLock2を取得する doSomething(); synchronized(mLock1) { // mLock1を取得しようとする *デッドロック doAnotherthing(); } } } ... }典型的誤り:不十分な保護
以下において、
anotherMethod()呼び出しによりmLockインスタンスが書き換わると、doSomething()が複数スレッドから実行可能になる。class SomeClass() { private Object mLock = new Object(); void someMethod() { synchronized(mLock) { doSomething(); } } void anotherMethod() { mLock = new Object(); // mLockが他インスタンスになる } ... }典型的誤り:無意味な保護
以下において、最初のsynchronizedブロックでmLockをすでに取得しているので、二つ目のsynchronizedブロックには意味がない。たぶん開発者の意図した動作になっていないと思うので、このコードを見つけた時には真意を聞いたほうがいい。
class SomeClass() { private Object mLock = new Object(); void method() { synchronized(mLock) { // mLockを取得する someMethod(); synchronized(mLock) { // mLockを取得済みなので意味がない otherMethod(); } } } }CLASS_NAME.class
以下では、SomeClass.classというインスタンスを使って同期を行っている。VM上でSomeClassだけに作られた唯一のインスタンス(
Class<SomeClass>インスタンス)を参照するため、VM上で単一であることが保証される。
かなり強いロックになるので、ロック取得と放棄のコストを考えるとシングルスレッド実行のほうが処理速度早いなんてことにもなる。class SomeClass() { void someMethod() { synchronized (SomeClass.class) { doSomething(); } } void anotherMethod() { synchronized (SomeClass.class) { doAnotherthing(); } } ... }その他の典型的誤り
synchronizedではないが、同じ同期カテゴリということで以下のような部分にも誤りが多いので記載しておく。
誤り:プリミティブ型変数への代入はアトミック操作
longとdouble以外のプリミティブ型変数への値の代入はアトミックなので誤解しがちだが、longとdoubleへ値の代入はアトミックではない。
以下はスレッドセーフだが、
class SomeClass { private int mValue = 0; void assign(int value) { mValue = value; } }以下はスレッドセーフではない。
class SomeClass { private long mValue = 0; void assign(long value) { mValue = value; } }誤り:volatile修飾子をつけた変数への操作はアトミック操作
変数xに対してスレッドAで書き込みを行った後にスレッドBで読み込みを行った際、xの最新の値が返ってくるとは限らない。変数定義の際にvolatileを付けておくと、最新の値が返ってくることが保証される。
volatileを付けておくとindex++等の処理がアトミックになると記載しているサイトがあるが、これは誤りである。TECHSCOREの記載も、volatileを付けていても
a=0, b=1となることはあるので誤りである。代替案
synchronizedを使わなくても、もっと軽量にスレッドセーフにすることができる場合があるので紹介する。
値の加算や除算をスレッドセーフに行う
java.util.concurrent.atomicに定義されたクラスを使う。
例えば、AtomicIntegerにはincrementAndGet()やaddAndGet(int delta)などのメソッドがあり、スレッドセーフにインクリメントや加算・除算を行うことが出来る。書き込み中の読み書きはロックしたいが、そうでない場合は読み込みを許可したい
以下のような場合は、
- 値の書き込みを行っているスレッドがある場合、他スレッドの書き込みと読み込みをブロックしたい
- 書き込みが行われていないときは読みこみをブロックしたくない
以下のように、値の
get()もadd()もsynchronizedで囲ってしまうのではなく、class DataStorage() { private List<Integer> mStorage = new ArrayList<>(); synchronized Integer get(int index) { return mStorage.get(index); } synchronized boolean add(Integer value) { return mStorage.add(value); }以下のように
ReentrantReadWriteLocksを使うことで、get()同士はブロックしないがadd()を処理中にはadd()とget()をブロックするというようなことができる。class DataStorage() { private List<Integer> mStorage = new ArrayList<>(); private ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); private Lock r = rwl.readLock(); private Lock w = rwl.writeLock(); synchronized Integer get(int index) { r.lock(); // read lock try { return mStorage.get(index); } finally { r.unlock(); // read unlock } } synchronized boolean add(Integer value) { w.lock(); // write lock try { return mStorage.add(value); } finally { w.unlock(); // write unlock } }この例だとCopyOnWriteArrayListを使ったほうがいいような気もするが。
ConcurrentModificationExceptionを防ぎたい場合
CopyOnWriteArrayList等のjava.util.concurrentパッケージに定義されたクラスを使う。その他のロック
SemaphoreやCountDownLatch等あり、便利なので以下を参照のこと。
Javaの排他制御(ロック)に関係するクラスまとめ
VMの実装によって実行時間は異なる可能性がある。 ↩
- 投稿日:2020-01-10T17:31:32+09:00
Javaのsynchronizedの解説と典型的誤り集(記事の誤りや意見等あれば是非教えてください)
synchronizedの基本
プログラムにてスレッドを分けて処理しているけれど、複数スレッドに同時に処理を行わせてはいけない箇所(クリティカルセクション)があり、そこでは処理実行可能なスレッドを制限したいときなどに使う。
synchronizedと書けばいつも内部がシングルスレッド処理になるというものではないので、何のインスタンスを使って領域を守っているかをしっかり意識すること。synchronizedメソッド
synchronizedメソッドは、そのインスタンスにおいてsynchronized記述されているメソッドを実行できるスレッドを1つだけに制限するためのもの。
以下のクラスにおいて、someMethod()およびanotherMethod()はsynchronizedメソッドであり、このsomeClassインスタンスに対して複数のスレッドがsomeMethod()やanotherMethod()を呼び出しても、一度に処理を行えるのは1スレッドだけである。class SomeClass { synchronized void someMethod() { doSomething(); // ここに来れるのは1スレッドだけ } synchronized void anotherMethod() { doAnotherthing(); // ここに来れるのは1スレッドだけ } ... }synchronizedブロック
synchronizedブロックは、特定のコードブロックの実行を1スレッドに制限するためのもの。以下のような形式で記載する。
synchronized(instance) { ... // ここの処理が行えるのは、上記instanceをロックとして取得できた1スレッドのみ }複数の箇所で同じ同期インスタンスに対してsynchronizedブロックが記述されている場合は、複数のコードブロックにまたがって1スレッド制限がかかる。
void someMethod() { synchronized(instance) { ... // ここの処理を行っているスレッドがあると } } void anotherMethod() { synchronized(instance) { ... // ここの処理を他スレッドが行うことはできない(実行を待たされる)。 } }synchronizedメソッドは、メソッド内部の処理全体をsynchronzedブロックで囲って、thisを使って同期しているのと等価と考えてよい1。
つまり、以下のメソッドは、synchronized void someMethod() { doSomething(); }以下のメソッドと等価である1。
void someMethod() { synchronized (this) { doSomething(); } }synchronizedブロックで使用する同期インスタンスと典型的誤り
synchronizedブロックでよく用いられる同期インスタンスと典型的誤りを記す。
this
以下のコードで、
doSomething()とdoAnotherthing()は、ともにthisを使ったsynchronizedブロックで囲まれているため、このSomeClassインスタンスに対してdoSomething()もしくはdoAnotherthing()を実行できるスレッドは一つだけになる。class SomeClass() { void someMethod() { synchronized (this) { doSomething(); // ある時点でdoSomething()もしくはdoAnotherthing()を実行できるスレッドは一つだけ } } void anotherMethod() { synchronized (this) { doAnotherthing(); // ある時点でdoSomething()もしくはdoAnotherthing()を実行できるスレッドは一つだけ } } private void doSomething() { ... } private void doAnotherthing() { ... } }典型的誤り:他のSomeClassインスタンスに対する同期
同期インスタンスはthisのため、
new SomeClass()が複数回行われるなどして複数のインスタンスが生成された場合、ぞれぞれのインスタンスにてthisは別物である。ゆえに、SomeClassインスタンス間でのスレッドの制限は行われない。
これ以降の内容はnew SomeClass()が一度だけしか行われていない前提で記載する。mLock等のプライベート変数
以下では、mLock1とmLock2の二つの同期インスタンスを生成している。
mLock1にて守られているので、doSomething()を実行できるスレッドは一つだけ。同様に、mLock2にて守られているので、doAnotherthing()を実行できるスレッドも一つだけ。doSomething()とdoAnotherthing()の間では排他は行われない。class SomeClass() { private Object mLock1 = new Object(); private Object mLock2 = new Object(); void someMethod() { synchronized (mLock1) { doSomething(); // ある時点でdoSomething()を実行できるスレッドは一つだけ } } void anotherMethod() { synchronized (mLock2) { doAnotherthing(); // ある時点でdoAnotherthing()を実行できるスレッドは一つだけ } } private void doSomething() { ... } private void doAnotherthing() { ... } }典型的誤り:無意味なロックインスタンス生成
以下では、mLockというインスタンスを生成して同期インスタンスに使用している。
基本的には、mLockを定義せず、thisを使ってロックすれば良いという場面が多い。例外についてはサンプルコードの下の記述を参照のこと。class SomeClass() { private Object mLock = new Object(); // 定義しなくてもthisで良い void someMethod() { synchronized (mLock) { doSomething(); } } void anotherMethod() { synchronized (mLock) { doAnotherthing(); } } ... }コメント踏まえて加筆
@sdkeiさんに教えてもらったが、thisは他クラスからも参照可能なので、無作法な利用者にロックに利用される可能性がある。それを防ぐためにprivateなmLockを定義して使用する場合がある。synchronizedメソッドにも同様の危険性がある。
95%くらいはthisを使えば良いと気づいていないケースだと思うのでこの誤りパターンは消さないが、周辺のメソッドやクラスにfinal修飾子が記載されているようなしっかりプロジェクトでは、明確な意思のもとでmLockを定義していると場合が多いだろう。典型的誤り:デッドロック
以下において、
someMethod()およびanotherMethod()が異なるスレッドで呼ばれるとデッドロックする可能性がある。特にdoSomething()の処理時間が長い場合はすぐに発生する。class SomeClass() { private Object mLock1 = new Object(); private Object mLock2 = new Object(); void someMethod() { synchronized(mLock1) { // mLock1を取得する doSomething(); synchronized(mLock2) { // mLock2の取得をしようとする doAnotherthing(); } } } void anotherMethod() { synchronized(mLock2) { // mLock2を取得する doSomething(); synchronized(mLock1) { // mLock1を取得しようとする *デッドロック doAnotherthing(); } } } ... }典型的誤り:不十分な保護
以下において、
anotherMethod()呼び出しによりmLockインスタンスが書き換わると、doSomething()が複数スレッドから実行可能になる。class SomeClass() { private Object mLock = new Object(); void someMethod() { synchronized(mLock) { doSomething(); } } void anotherMethod() { mLock = new Object(); // mLockが他インスタンスになる } ... }典型的誤り:無意味な保護
以下において、最初のsynchronizedブロックでmLockをすでに取得しているので、二つ目のsynchronizedブロックには意味がない。たぶん開発者の意図した動作になっていないと思うので、このコードを見つけた時には真意を聞いたほうがいい。
class SomeClass() { private Object mLock = new Object(); void method() { synchronized(mLock) { // mLockを取得する someMethod(); synchronized(mLock) { // mLockを取得済みなので意味がない otherMethod(); } } } }CLASS_NAME.class
以下では、SomeClass.classというインスタンスを使って同期を行っている。VM上でSomeClassだけに作られた唯一のインスタンス(
Class<SomeClass>インスタンス)を参照するため、VM上で単一であることが保証される。
かなり強いロックになるので、ロック取得と放棄のコストを考えるとシングルスレッド実行のほうが処理速度早いなんてことにもなる。class SomeClass() { void someMethod() { synchronized (SomeClass.class) { doSomething(); } } void anotherMethod() { synchronized (SomeClass.class) { doAnotherthing(); } } ... }その他の典型的誤り
synchronizedではないが、同じ同期カテゴリということで以下のような部分にも誤りが多いので記載しておく。
誤り:プリミティブ型変数への代入はアトミック操作
longとdouble以外のプリミティブ型変数への値の代入はアトミックなので誤解しがちだが、longとdoubleへ値の代入はアトミックではない。
以下はスレッドセーフだが、
class SomeClass { private int mValue = 0; void assign(int value) { mValue = value; } }以下はスレッドセーフではない。
class SomeClass { private long mValue = 0; void assign(long value) { mValue = value; } }誤り:volatile修飾子をつけた変数への操作はアトミック操作
変数xに対してスレッドAで書き込みを行った後にスレッドBで読み込みを行った際、xの最新の値が返ってくるとは限らない。変数定義の際にvolatileを付けておくと、最新の値が返ってくることが保証される。
volatileを付けておくとindex++等の処理がアトミックになると記載しているサイトがあるが、これは誤りである。TECHSCOREの記載も、volatileを付けていても
a=0, b=1となることはあるので誤りである。代替案
synchronizedを使わなくても、もっと軽量にスレッドセーフにすることができる場合があるので紹介する。
値の加算や除算をスレッドセーフに行う
java.util.concurrent.atomicに定義されたクラスを使う。
例えば、AtomicIntegerにはincrementAndGet()やaddAndGet(int delta)などのメソッドがあり、スレッドセーフにインクリメントや加算・除算を行うことが出来る。書き込み中の読み書きはロックしたいが、そうでない場合は読み込みを許可したい
以下のような場合は、
- 値の書き込みを行っているスレッドがある場合、他スレッドの書き込みと読み込みをブロックしたい
- 書き込みが行われていないときは読みこみをブロックしたくない
以下のように、値の
get()もadd()もsynchronizedで囲ってしまうのではなく、class DataStorage() { private List<Integer> mStorage = new ArrayList<>(); synchronized Integer get(int index) { return mStorage.get(index); } synchronized boolean add(Integer value) { return mStorage.add(value); }以下のように
ReentrantReadWriteLocksを使うことで、get()同士はブロックしないがadd()を処理中にはadd()とget()をブロックするというようなことができる。class DataStorage() { private List<Integer> mStorage = new ArrayList<>(); private ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); private Lock r = rwl.readLock(); private Lock w = rwl.writeLock(); synchronized Integer get(int index) { r.lock(); // read lock try { return mStorage.get(index); } finally { r.unlock(); // read unlock } } synchronized boolean add(Integer value) { w.lock(); // write lock try { return mStorage.add(value); } finally { w.unlock(); // write unlock } }この例だとCopyOnWriteArrayListを使ったほうがいいような気もするが。
ConcurrentModificationExceptionを防ぎたい場合
CopyOnWriteArrayList等のjava.util.concurrentパッケージに定義されたクラスを使う。その他のロック
SemaphoreやCountDownLatch等あり、便利なので以下を参照のこと。
Javaの排他制御(ロック)に関係するクラスまとめ
VMの実装によって実行時間は異なる可能性がある。 ↩
- 投稿日:2020-01-10T17:12:55+09:00
Java SE 7/8 Bronzeに学生がノー勉でチャレンジした。
初めに
この記事では
- ノー勉でチャレンジしてみた結果
- 取る意義
- 難易度
などを載せたいと思います。
現在自分は、専門学校1年生です。
Javaの経験は,3年間ぐらい独学でSwingなどでGUI系のソフトを作って遊んでいた + 1年の専門学校生活で学んだこと。
Javaの入門書の知識はほぼ全て理解(Java Silverなどで出題される標準APIなどは覚えてない)しているぐらいの知識はあります。
bronzeは入門書を理解できれば対策本はいらないことを証明するためにノー勉で挑みました。結果
見事受かりました。(合格ライン60点、点数65点)
危なすぎますね。
僕はSilverの練習問題をやってみて「余裕じゃん!」
とか言って自信満々だったのにこの点数です。
自信がない人は絶対対策本かったほうがいいです。取る意義
就活で役に立つかといわれると微妙ですね。
役立つのはSilverからでしょう。じゃあとる意味ないのかといわれると、僕はそうは思いません。
Bronzeを受けてみてほとんどの問題の意図を理解できた
(ただし意地悪な問題が多いので回答があっていたかどうかは置いておきます)なら、
それはオブジェクト指向をほぼ理解していることになると思います。
Javaを覚えるうえで一番難しいのはオブジェクト指向を理解することですからね
企業からの評価は得られませんが、自分の自信につながります。
僕はそれが一番の収穫でした。難易度
bronzeの難易度自体はそこまで高くないと思います。
しかし、意地悪問題が多いです。
練習問題を見るとJava bronzeだけがそうなのではなくsilver, goldも同様意地悪問題が多いです。例えば
int a = 3;
int b = (a = 4) + 5;
System.out.println(b);このコードがコンパイルに成功するかどうか?という問題でした。
こんなコード今まで一度も見たことがなかったのでかなり悩みました。
「実際に開発するときこんな書き方しなくない?」というのが結構出ました。
もしかしたら実務をしていたら見る機会がもあるかもしれませんが、初心者さんは間違いなく見たことないはずです。
僕はこういう変な問題に点数を多く奪われたので注意しましょう。最後に
少ない記事ですがbronzeをとる際の参考になれば幸いです。
私は年内goldを目指そうと思います。
現在Java 8、11どちらのバージョンで取ろうか迷っているので詳しい方いたらコメントで教えてくださるとうれしいです。
見てくださってありがとうございました。
- 投稿日:2020-01-10T15:43:06+09:00
Ubuntu18.04 LTSでminecraft server java edition構築備忘録
驚くほど簡単だったのでメモ
javaの確認
おそらくデフォルトで入っていると思うんですが、一応確認。入っていない場合は
sudo apt search openjdk-11-jreとかで検索して新しめのを入れておきましょう。which java # /usr/bin/java jave --version # openjdk 11.0.5 2019-10-15 # OpenJDK Runtime Environment (build 11.0.5+10-post-Ubuntu-0ubuntu1.118.04) # OpenJDK 64-Bit Server VM (build 11.0.5+10-post-Ubuntu-0ubuntu1.118.04, mixed mode, sharing)minecraft-serverをダウンロードする
MINECRAFT: JAVA EDITIONのサーバーをダウンロードします
上から最新版のjarを貰ってくる。今後のバージョン管理のため、リネームしてversionを明記しておくと吉cd /tmp curl -LOS https://... chmod 700 server.jar mv server.jar minecraft_server_1_15_1.jarとりあえず1回実行したろ
java -Xmx1024M -Xms1024M -jar minecraft_server_1_15_1.jar noguiエラーで落ちるけど、
eura.txtとserver.propertiesが生成される。要はEURAに同意しないとダメだよっていうエラーなので、同意しましょう。eura.txt
eura.txt. .. ... eura=false # trueに変更server.properties
サーバーの設定ファイル。
ipとかportとか変更出来る。デフォルトのportはなんとなく怖いので変更してます。各々の環境に合わせて変更しましょう。server.properties#Minecraft server properties #Fri Jan 10 14:08:05 JST 2020 broadcast-rcon-to-ops=true view-distance=10 max-build-height=256 server-ip=192.168.1.254 # default= level-seed= rcon.port=55575 # default=22275 gamemode=survival server-port=55565 # default=22265 allow-nether=true enable-command-block=false enable-rcon=false enable-query=false op-permission-level=4 prevent-proxy-connections=false generator-settings= resource-pack= level-name=world rcon.password= player-idle-timeout=0 motd=A Minecraft Server query.port=55565 # default=22265 force-gamemode=false hardcore=false white-list=false broadcast-console-to-ops=true pvp=true spawn-npcs=true generate-structures=true spawn-animals=true snooper-enabled=true difficulty=normal # default=easy function-permission-level=2 network-compression-threshold=256 level-type=default spawn-monsters=true max-tick-time=60000 enforce-whitelist=false use-native-transport=true max-players=2 # default=20 resource-pack-sha1= spawn-protection=16 online-mode=true allow-flight=false max-world-size=29999984port開放
最後に、
portを開けます。Ubuntuはufwという超絶便利なツールがあるのでそれを使いましょう。sudo ufw allow from 192.168.1.0/24 to any port 55565 sudo ufw allow from 192.168.1.0/24 to any port 55575再度実行
なんか
warnが流れてきますが、とりあえず動きます(解消法求む)
実際に運用する場合はもっと詰めて色々セキュアにしましょうね。java -Xmx1024M -Xms1024M -jar minecraft_server_1_15_1.jar nogui # 以下log [15:15:42] [main/WARN]: Ambiguity between arguments [teleport, destination] and [teleport, targets] with inputs: [Player, 0123, @e, dd12be42-52a9-4a91-a8a1-11c01849e498] [15:15:42] [main/WARN]: Ambiguity between arguments [teleport, location] and [teleport, destination] with inputs: [0.1 -0.5 .9, 0 0 0] [15:15:42] [main/WARN]: Ambiguity between arguments [teleport, location] and [teleport, targets] with inputs: [0.1 -0.5 .9, 0 0 0] [15:15:42] [main/WARN]: Ambiguity between arguments [teleport, targets] and [teleport, destination] with inputs: [Player, 0123, dd12be42-52a9-4a91-a8a1-11c01849e498] [15:15:42] [main/WARN]: Ambiguity between arguments [teleport, targets, location] and [teleport, targets, destination] with inputs: [0.1 -0.5 .9, 0 0 0] [15:15:42] [Server thread/INFO]: Starting minecraft server version 1.15.1 [15:15:42] [Server thread/INFO]: Loading properties [15:15:42] [Server thread/INFO]: Default game type: SURVIVAL [15:15:42] [Server thread/INFO]: Generating keypair [15:15:43] [Server thread/INFO]: Starting Minecraft server on 192.168.1.254:55565 [15:15:43] [Server thread/INFO]: Using epoll channel type [15:15:43] [Server thread/INFO]: Preparing level "world" [15:15:43] [Server thread/INFO]: Reloading ResourceManager: Default [15:16:48] [Server thread/INFO]: Loaded 6 recipes [15:16:48] [Server thread/INFO]: Loaded 825 advancements [15:16:49] [Server thread/INFO]: Preparing start region for dimension minecraft:overworld [15:16:51] [Server thread/INFO]: Preparing spawn area: 0% ... [15:17:06] [Server thread/INFO]: Preparing spawn area: 97% [15:17:06] [Server thread/INFO]: Time elapsed: 16974 ms [15:17:06] [Server thread/INFO]: Done (82.928s)! For help, type "help"やったぜ。サーバー側の操作は終わり。
ただ、このやり方だとconsoleを閉じたりctrl-c押したりするとserverも落ちるので、バックグラウンドで動かしたり、systemctldで管理させたほうが良いですね。nohup java -Xmx1024M -Xms1024M -jar minecraft_server_1_15_1.jar nogui &とりあえず動かすだけなら、上記のように
nohup ... &で実行すると、バックグラウンドで動かせます。ゲームから接続
実際にサーバーが動いたのを確認したら、マルチプレイヤーをやってみましょう。
- マルチプレイヤーを押す
- サーバーを追加
- ipアドレス:ポートを入力
- 接続!
終わり
お疲れさまでした。ところで、どなたか
minecraftを一緒にプレイして頂けるフレンズはいらっしゃいませんでしょうか??
私にはバグで未実装なようですので、よろしくお願いいたします。参考・引用・出典





- 投稿日:2020-01-10T15:42:31+09:00
Javaの三項演算子で異なる型をもつ値を返す話
Java SE 8 Silver資格を取ろうと勉強中、こんなコードを持つ問題を見つけた。
public static void main(String[] args) { int a = 100; int b = ++a; int c = b++; int d = ++c; System.out.println((a < b) ? (b < c) : (c < d) ? b : c); }山本道子(2016) , Javaプログラマ Silver SE 8 , 株式会社翔泳社
このコードについて少し考えてみたいと思う。
何が問題なのか
演習問題としてはこれの実行結果がどうなるかという普通の問題なのだが、今回考えたいのはこの三項演算子が返す型が単一でないということだ。
改行して分解、コメントをつけるとこうなる。
System.out.println( (a < b) ? (b < c): // a < b であるなら (b < c)の結果を、 (c < d) ? //そうでないなら c < d の結果を見て、 b: // c < d なら b を、 c // c >= d なら c を返す。 );ここで問題を見返すと b と c はどちらも int 型で、(b < c) は関係演算子があるので boolean 型。
第一項を ( a < b ) にもつ三項演算子の返す値の型が異なっていることがわかる。いかにprintln( )メソッドが多くの型の引数に対応したオーバーロードを持っていて、この式が条件によらず処理はできる結果しかないとしても、そもそも三項演算子でこれが許可されていることに驚いた。
しかしこれはコンパイルエラーにはならず、もちろん実行しても想定通りに動作する。
これはいったいどういうことなのか、答えにたどり着くまでの過程も含めて残しておく。検証
検証1 それぞれの型を引数にもつメソッド
まず「どちらの型も拾えるからコンパイルエラーにならないのでは」と仮定を立て、以下のプログラムを書いてみた。
Sample.javapublic class Sample { public static void main(String[] args) { int a = 10; ch(new java.util.Random().nextBoolean() ? a : "A" ); } static void ch(String s) { System.out.println("String"); } static void ch(int i) { System.out.println("int"); } }ランダムでどちらかが選ばれてどちらのメソッドが実行されたかわかるようにした。
結果から言うと、これはコンパイルエラーになる。エラーメッセージを確認すると、型 Sample のメソッド ch(String) は引数 (((new java.util.Random().nextBoolean()) ? a : "A")) に適用できません 型の不一致: int から String には変換できませんと出る。
??????
普通、メソッドの仮引数の型と実引数の型が一致しない場合には「引数(実引数の型名)に適用できません」と型名で言われる。しかしこの場合はプログラム上の文字列がそのまま使われている。Eclipseで書いているとコンパイルエラーに対して解決方法が出るのだが、そちらはこうなった。
メソッド 'ch(Object)' を作成しますつまり Object 型であれば拾えると言っているらしい。
問題のprintln()も、Object 型を仮引数にもつメソッドがオーバーロードされている。検証2 Object型を引数に持つメソッド
メソッドを追加してみる。追加した後のプログラムが以下になる。
Sample.javapublic class Sample { public static void main(String[] args) { int a = 10; ch(new java.util.Random().nextBoolean() ? a : "A" ); } static void ch(String s) { System.out.println("String"); } static void ch(int i) { System.out.println("int"); } static void ch(Object o) { System.out.println("Object"); } }こちらはコンパイルエラーにならず実行もでき、その結果は以下になった。
Object何度実行してもObjectが出力されることから、コンパイラはこの時点で String でも int でもない、かつ何かしらのインスタンスを見ているようだ。
検証3 渡されているインスタンスの確認
では、実際に渡されているインスタンスは何型なのか見てみようと思う。以下のプログラムを書いた。
Sample.javapublic class Sample { public static void main(String[] args) { int a = 10; ch(new java.util.Random().nextBoolean() ? a : "A" ); } static void ch(String s) { System.out.println("String"); } static void ch(int i) { System.out.println("int"); } static void ch(Object o) { System.out.println(o.getClass()); } }実行結果は以下のようになった。
class java.lang.Integerclass java.lang.Stringgetclass().toString() の内容が表示されていることから、ch(Object) が実行されていることがわかる。また、Integer 型が出ているということは int 型が返されたとき Object 型に入れるためインスタンスが作られていることもわかる。
コンパイラ側は、異なる型を返す三項演算子を結果の型によらず Object 型のインスタンスとして拾うことにしたようだ。
検証4 プリミティブ型だけでの参照
ではここで、どちらもプリミティブ型である int と boolean でやってみよう。
Sample.javapublic class Sample { public static void main(String[] args) { int a = 10; ch(new java.util.Random().nextBoolean()? a : true ); } static void ch(boolean b) { System.out.println("boolean"); } static void ch(int i) { System.out.println("int"); } static void ch(Object o) { System.out.println(o.getClass()); } }実行結果はこう。
class java.lang.Integerclass java.lang.Booleanどちらもプリミティブ型だった場合でも、同じくオートボクシングして Object として拾っていることがわかる。
ところで、三項演算子の返り値がどちらもプリミティブ型になったことで、ch(Object o)を削除した場合のエラーメッセージに変化があった。
型 Sample のメソッド ch(boolean) は引数 (Object & Comparable<?> & Serializable) に適用できませんObject クラス・インスタンスとして扱えることはすべてのクラス・インスタンスに共通であるので、自身のクラスと自然順序付けができて直列化可能な謎のクラスが、三項演算子全体の返り値として指定されているらしい。
ところでこれらの共通点は、プリミティブ型のラッパークラス全体に共通している。では、仮引数がObjectではなくSerializableでも動くということだろうか。試しにやってみる。
Sample.javapublic class Sample { public static void main(String[] args) { int a = 10; ch(new java.util.Random().nextBoolean()? a : true ); } static void ch(boolean b) { System.out.println("boolean"); } static void ch(int i) { System.out.println("int"); } static void ch(Serializable s) { System.out.println(s.getClass()); } }これもきちんと動作することが確認できた。ここから、単に「Object」として見ているのではなく、コンパイラは実際に発生しうるインスタンス候補から共通するクラスやインターフェースをチェックしていることがわかった。
最後に、検証1で String 型と並べた際は Object 型としてオーバーロードすることを推奨されたが、String型もSerializableインターフェースを実装しているので検証してみる。
検証5 推奨された型以外で参照させてみる
Sample.javapublic class Sample { public static void main(String[] args) { int a = 10; ch(new java.util.Random().nextBoolean()? a : "TRUE" ); } static void ch(Serializable s) { System.out.println(s.getClass()); } }こちらも問題なくコンパイルでき、エラーや例外を出すことなく動いた。
結論
異なる型の値を返す三項演算子は、返す値の型(あるいはそのラッパークラス)をコンパイラが見て、全体をまとめる単一の参照型として処理できるかどうかでエラーを出すか決められる。
- 投稿日:2020-01-10T14:40:32+09:00
[備忘録]dockerでjava環境を一から作る
DockerHubにあるjava環境イメージをpullしたら早いのに、一から作らないと落ち着かない損な性格なので作ってみた備忘録です。
環境
- macOS Catalina
- Docker Desktop for Mac (インストール済)
手順
1. ubuntuイメージ取得
$ docker pull ubuntu2. ubuntuコンテナ起動
$ docker run -it ubuntu bash以降はubuntuでの作業
3. apt-getコマンドの更新
$ apt-get update4. 最低限必要なコマンドをインストール
curlコマンド
$ apt-get install curlunzipコマンド
$ apt-get install unzipzipコマンド
$ apt-get install zip5. sdkmanのインストール
$ curl -s "https://get.sdkman.io" | bash$ source "/root/.sdkman/bin/sdkman-init.sh"確認
$ sdk help ==== BROADCAST ================================================================= * 2020-01-08: Asciidoctorj 2.2.0 released on SDKMAN! #asciidoctorj * 2020-01-07: Gradle 6.1-rc-2 released on SDKMAN! #gradle * 2020-01-06: Jbang 0.4.0.1 released on SDKMAN! #jbang ================================================================================ Usage: sdk <command> [candidate] [version] sdk offline <enable|disable> commands: install or i <candidate> [version] [local-path] uninstall or rm <candidate> <version> list or ls [candidate] use or u <candidate> <version> default or d <candidate> [version] current or c [candidate] upgrade or ug [candidate] version or v broadcast or b help or h offline [enable|disable] selfupdate [force] update flush <broadcast|archives|temp> candidate : the SDK to install: groovy, scala, grails, gradle, kotlin, etc. use list command for comprehensive list of candidates eg: $ sdk list version : where optional, defaults to latest stable if not provided eg: $ sdk install groovy local-path : optional path to an existing local installation eg: $ sdk install groovy 2.4.13-local /opt/groovy-2.4.13SDKMANのインストールは終わり
6. javaのインストール
インストールできるjavaを確認
$ sdk list java ================================================================================ Available Java Versions ================================================================================ Vendor | Use | Version | Dist | Status | Identifier -------------------------------------------------------------------------------- AdoptOpenJDK | | 13.0.1.j9 | adpt | | 13.0.1.j9-adpt | | 13.0.1.hs | adpt | | 13.0.1.hs-adpt | | 12.0.2.j9 | adpt | | 12.0.2.j9-adpt | | 12.0.2.hs | adpt | | 12.0.2.hs-adpt | | 11.0.5.j9 | adpt | | 11.0.5.j9-adpt | >>> | 11.0.5.hs | adpt | installed | 11.0.5.hs-adpt | | 8.0.232.j9 | adpt | | 8.0.232.j9-adpt | | 8.0.232.hs | adpt | | 8.0.232.hs-adpt Amazon | | 11.0.5 | amzn | | 11.0.5-amzn | | 8.0.232 | amzn | | 8.0.232-amzn Azul Zulu | | 13.0.1 | zulu | | 13.0.1-zulu | | 12.0.2 | zulu | | 12.0.2-zulu | | 11.0.5 | zulu | | 11.0.5-zulu | | 10.0.2 | zulu | | 10.0.2-zulu | | 9.0.7 | zulu | | 9.0.7-zulu | | 8.0.232 | zulu | | 8.0.232-zulu | | 7.0.242 | zulu | | 7.0.242-zulu | | 6.0.119 | zulu | | 6.0.119-zulu Azul ZuluFX | | 11.0.2 | zulufx | | 11.0.2-zulufx | | 8.0.202 | zulufx | | 8.0.202-zulufx BellSoft | | 13.0.1 | librca | | 13.0.1-librca | | 12.0.2 | librca | | 12.0.2-librca | | 11.0.5 | librca | | 11.0.5-librca | | 8.0.232 | librca | | 8.0.232-librca GraalVM | | 19.3.0.r11 | grl | | 19.3.0.r11-grl | | 19.3.0.r8 | grl | | 19.3.0.r8-grl | | 19.3.0.2.r11 | grl | | 19.3.0.2.r11-grl | | 19.3.0.2.r8 | grl | | 19.3.0.2.r8-grl | | 19.2.1 | grl | | 19.2.1-grl | | 19.1.1 | grl | | 19.1.1-grl | | 19.0.2 | grl | | 19.0.2-grl | | 1.0.0 | grl | | 1.0.0-rc-16-grl Java.net | | 15.ea.4 | open | | 15.ea.4-open | | 14.ea.30 | open | | 14.ea.30-open | | 13.0.1 | open | | 13.0.1-open | | 12.0.2 | open | | 12.0.2-open | | 11.0.5 | open | | 11.0.5-open | | 10.0.2 | open | | 10.0.2-open | | 9.0.4 | open | | 9.0.4-open | | 8.0.232 | open | | 8.0.232-open SAP | | 12.0.2 | sapmchn | | 12.0.2-sapmchn | | 11.0.4 | sapmchn | | 11.0.4-sapmchn ================================================================================ Use the Identifier for installation: $ sdk install java 11.0.3.hs-adpt ================================================================================インストールしたいjavaを指定
$ sdk install java 8.0.232-open確認
root@d9b652b0db21:/# java -version openjdk version "1.8.0_232" OpenJDK Runtime Environment (build 1.8.0_232-b09) OpenJDK 64-Bit Server VM (build 25.232-b09, mixed mode)以上で、DockerにJava環境を作りました。
あとは煮るなり焼くなり。
- 投稿日:2020-01-10T14:05:35+09:00
Java で JSON の Create
Jackson を使って JSON ファイルを作成します。
json_create.java// ----------------------------------------------------------------------- /* json_create.java Jan/10/2020 */ // ----------------------------------------------------------------------- import java.util.HashMap; import java.io.File; import java.io.FileWriter; import java.io.BufferedWriter; import java.io.PrintWriter; // ----------------------------------------------------------------------- public class json_create { // ----------------------------------------------------------------------- public static void main (String [] args) { System.err.println ("*** 開始 ***"); String json_file = args[0]; HashMap <String, HashMap <String,String>> dict_aa = data_prepare_proc (); String json_str = json_manipulate.dict_to_json_proc (dict_aa); file_write_proc (json_file,json_str); System.err.println ("*** 終了 ***"); } // ----------------------------------------------------------------------- static HashMap <String, HashMap <String,String>> data_prepare_proc () { HashMap <String, HashMap<String,String>> dict_aa = new HashMap <String, HashMap<String,String>> (); dict_aa = dict_append_proc (dict_aa,"t0921","宇都宮",19825,"2008-2-12"); dict_aa = dict_append_proc (dict_aa,"t0922","小山",35749,"2008-10-14"); dict_aa = dict_append_proc (dict_aa,"t0923","佐野",49128,"2008-4-9"); dict_aa = dict_append_proc (dict_aa,"t0924","足利",85972,"2008-3-21"); dict_aa = dict_append_proc (dict_aa,"t0925","日光",64152,"2008-7-25"); dict_aa = dict_append_proc (dict_aa,"t0926","下野",85793,"2008-10-9"); dict_aa = dict_append_proc (dict_aa,"t0927","さくら",73164,"2008-2-11"); dict_aa = dict_append_proc (dict_aa,"t0928","矢板",65237,"2008-5-27"); dict_aa = dict_append_proc (dict_aa,"t0929","真岡",28754,"2008-1-5"); dict_aa = dict_append_proc (dict_aa,"t0930","栃木",79571,"2008-7-4"); dict_aa = dict_append_proc (dict_aa,"t0931","大田原",36952,"2008-9-27"); dict_aa = dict_append_proc (dict_aa,"t0932","鹿沼",42316,"2008-10-24"); dict_aa = dict_append_proc (dict_aa,"t0933","那須塩原",64753,"2008-12-17"); dict_aa = dict_append_proc (dict_aa,"t0934","那須烏山",71298,"2008-11-15"); return dict_aa; } // ----------------------------------------------------------------------- static HashMap <String, HashMap<String,String>> dict_append_proc (HashMap <String, HashMap <String,String>> dict_aa, String key_aa,String name,int population,String date_mod) { String str_population = Integer.toString (population); HashMap <String,String> dict_unit = new HashMap <String,String> (); dict_unit.put ("name",name); dict_unit.put ("population",str_population); dict_unit.put ("date_mod",date_mod); dict_aa.put (key_aa,dict_unit); return dict_aa; } // ---------------------------------------------------------------- static void file_write_proc (String file_out,String str_out) { try { File file = new File (file_out); FileWriter filewriter = new FileWriter (file); BufferedWriter bw = new BufferedWriter (filewriter); PrintWriter pw = new PrintWriter (bw); pw.println (str_out); pw.close (); } catch (Exception ee) { ee.printStackTrace (); } } // ----------------------------------------------------------------------- } // -----------------------------------------------------------------------json_maninpulate.java// ----------------------------------------------------------------------- /* json_manipulate.java Jan/10/2020 */ // ----------------------------------------------------------------------- import java.util.HashMap; import com.fasterxml.jackson.core.type.TypeReference; import com.fasterxml.jackson.databind.ObjectMapper; // ----------------------------------------------------------------------- public class json_manipulate { // ----------------------------------------------------------------------- static String dict_to_json_proc (HashMap <String, HashMap<String,String>> dict_aa) { String str_json = ""; ObjectMapper mapper = new ObjectMapper(); try { str_json = mapper.writeValueAsString(dict_aa); } catch (Exception ee) { ee.printStackTrace (); } return str_json; } // ----------------------------------------------------------------------- } // -----------------------------------------------------------------------Makefileexport JAR=../jar # export CLASSPATH=.:$(JAR)/jackson-annotations-2.9.9.jar:$(JAR)/jackson-core-2.9.9.jar:$(JAR)/jackson-databind-2.9.9.jar json_create.class: json_create.java javac json_create.java clean: rm -f *.class実行
export JAR=../jar # export CLASSPATH=.:$JAR/jackson-annotations-2.9.9.jar:$JAR/jackson-core-2.9.9.jar:$JAR/jackson-databind-2.9.9.jar # java json_create out01.json
- 投稿日:2020-01-10T12:44:06+09:00
【Java】DIを使用したAbstractクラスのメソッドを子クラスから呼び出す処理作成時の注意点
DIを使用したAbstractクラスのメソッドを子クラスから呼び出す処理を作成する際のの注意点です。
問題のあるコード
Abstractクラスpublic class AbstractFoo { // DI public Bar bar; protected void update() { bar.update(); } }子クラスpublic class ChildFoo extends AbstractFoo { // DI public Bar bar; public void updateChild() { // Abstractクラスのupdateメソッドを実行 update(); } }実行結果
子クラスのupdateChildメソッドを実行すると、呼び出し先の親クラスのupdateメソッドでNullPointerExceptionで落ちる
対処方法
子クラスのDI
public Bar bar;
を削除する(下記では分かりやすいようにコメントアウト)修正後
Abstractクラスpublic class AbstractFoo { // DI public Bar bar; protected void update() { bar.update(); } }子クラスpublic class ChildFoo extends AbstractFoo { // DI // public Bar bar; public void updateChild() { // Abstractクラスのupdateメソッドを実行 update(); } }所感など
DIの内容を子クラスでの宣言によって上書き → Abstractクラスに渡してあげていないので、結果Abstractクラスでbarがnullになります。
子クラスではAbstractクラスで宣言した内容が継承されるので、そもそも論再度宣言する必要はないのですが、、
処理内容(記述内容)が増加してくると、見落としてうっかりやりがちなので、注意しましょう。
- 投稿日:2020-01-10T12:19:14+09:00
アルゴリズム体操13
Nth from the Last Node (Easy)
説明
Singly Linked Listの headノードと、整数nが渡されるので、
最後からn番目のノードを返すアルゴリズムを実装してみましょう(nが範囲外の場合はnullを返します)。Solution
考え方は、nノード離れた2つのポインター使っていきます。
1つ目のポインタはheadを指し、二つ目はn番目のノードを指すように最初に設定します(初期設定)。
もし二つ目のノードが初期設定の際に、リストの最終地点であるnullに達した場合はnullを返します(out-of-bounds)。
次に、ループで2つ目のポインターが最終地点に到達するまで、両方のポインターを前方に移動させていきます。
ループ終了後は、最初のポインターは最後からn番目のノードを指すことになるので、そのポインタを返します。Runtime Complexity O(n)
Singley Linked List に対して線形走査するので実行時間はO(n)となります。
Space Complexity O(1)
二つのポインタを使うのでメモリ効率はO(1)の定数となります。
例
3番目の最後のノード(n = 3)を検索する以下のリストの例を見てみましょう。
初期設定として、片方のポインタをnノード分移動させます。
先に進めてあるポインタが最終地点のnullに到達するまで両方のポインタを前に進めていきます。
これで、最後から3番目のnodeを見つけることができました。実装
lastNthFromList.javaclass lastNthFromList{ public LinkedListNode FindNthFromLast(LinkedListNode head,int n) { if (head == null || n < 1) return null; // edge case LinkedListNode targetNode = head; LinkedListNode searchNode = head; while (searchNode != null && n != 0) { searchNode = searchNode.next; n--; } if (n != 0) return null; // check out-of-bounds while(searchNode != null) { targetNode = targetNode.next; searchNode = searchNode.next; } return targetNode; } }





- 投稿日:2020-01-10T10:47:29+09:00
Java で JSON の Read
Jackson を使って 次のJSONファイルを読みます。
tochigi.json{ "t2381": { "name": "名古屋", "population": "74125", "date_mod": "2009-1-7" }, "t0922": { "name": "小山", "population": "17982", "date_mod": "2009-5-19" }, "t0923": { "name": "佐野", "population": "46819", "date_mod": "2009-3-28" } }Jackson の jar ファイルのダウンロード
SRC="http://repo1.maven.org/maven2/com/fasterxml/jackson/core" # wget $SRC/jackson-annotations/2.9.9/jackson-annotations-2.9.9.jar wget $SRC/jackson-core/2.9.9/jackson-core-2.9.9.jar wget $SRC/jackson-databind/2.9.9/jackson-databind-2.9.9.jar #json_read.java// ----------------------------------------------------------------------- /* json_read.java Jan/10/2020 */ // ----------------------------------------------------------------------- import java.util.HashMap; import com.fasterxml.jackson.core.type.TypeReference; import com.fasterxml.jackson.databind.ObjectMapper; public class json_read { public static void main(String[] args) throws Exception { System.err.println ("*** 開始 ***"); TypeReference<HashMap <String, HashMap<String,String>>> reference = new TypeReference<HashMap <String, HashMap<String,String>>> (){}; String file_in = "tochigi.json"; String json = file_io.file_to_str_proc (file_in); ObjectMapper mapper = new ObjectMapper(); HashMap <String, HashMap<String,String>> dict_aa = mapper.readValue(json, reference); text_manipulate.dict_display_proc (dict_aa); System.err.println ("*** 開始 ***"); } } // ----------------------------------------------------------------------file_io.java// ----------------------------------------------------------------------- /* file_io.java Jan/10/2020 */ // ----------------------------------------------------------------------- import java.io.File; import java.io.FileReader; import java.io.BufferedReader; // ----------------------------------------------------------------------- public class file_io { // ----------------------------------------------------------------------- static String file_to_str_proc (String file_in) { String str_in = ""; try { FileReader in_file = new FileReader (file_in); BufferedReader buff = new BufferedReader (in_file); String line; while ((line = buff.readLine ()) != null) { str_in += line; } } catch (Exception ee) { ee.printStackTrace (); } return str_in; } // ----------------------------------------------------------------------- } // ----------------------------------------------------------------------text_manipulate.java// ----------------------------------------------------------------------- /* text_manipulate.java Jan/10/2020 */ // ----------------------------------------------------------------------- import java.util.HashMap; import java.util.Set; import java.util.TreeSet; // ----------------------------------------------------------------------- public class text_manipulate { // ----------------------------------------------------------------------- static void dict_display_proc (HashMap <String, HashMap <String,String>> dict_aa) { HashMap <String,String> dict_unit = new HashMap <String,String> (); System.out.println (dict_aa.size ()); Set <String> set_aaa = dict_aa.keySet (); Set <String> ss = new TreeSet <String> (set_aaa); for (Object key_aa: ss) { String key = (String)key_aa; dict_unit = dict_aa.get (key_aa); System.out.print (key_aa + "\t"); System.out.print (dict_unit.get ("name") + "\t"); Object ppx = dict_unit.get ("population"); System.out.print (ppx + "\t"); System.out.println (dict_unit.get ("date_mod")); } } // ----------------------------------------------------------------------- } // -----------------------------------------------------------------------Makefile# export JAR=../jar # export CLASSPATH=.:$(JAR)/jackson-annotations-2.9.9.jar:$(JAR)/jackson-core-2.9.9.jar:$(JAR)/jackson-databind-2.9.9.jar json_read.class: json_read.java javac json_read.java clean: rm -f *.classコンパイル
make実行
# export JAR=../jar # export CLASSPATH=.:$JAR/jackson-annotations-2.9.9.jar:$JAR/jackson-core-2.9.9.jar:$JAR/jackson-databind-2.9.9.jar # java json_read
- 投稿日:2020-01-10T10:21:14+09:00
【自分用】Java メモ (随時更新)
メソッド
add("追加したい要素");
Listに要素を追加する。
contains("検証したい要素")
Listの要素の中で重複するものがあるかどうかを判定するメソッド。
remove("削除したい要素のインデックス");
Listの要素を削除する。引数はインデックス。
indexOf("インデックスを取得したい要素");
引数の要素のインデックスを取得する。
removeメソッドと一緒に使用できる。
Array.remove(Array.indexOf(element));Collections.reverse("リスト名");
リストの要素をreverseさせる。破壊的メソッド。
Collections.shuffle("リスト名");
リストの要素をshuffleさせる。破壊的メソッド。
Collections.sort("リスト名");
リストの要素をsortさせる。破壊的メソッド。
Integer.perseInt("int型に変換したいString型のデータ");
String -> Integerに変換。
エイリアスメソッドは↓
Integer.ValueOf();Integer.toString("String型に変換したint型のデータ");
Integer -> Stringに変換。
メモ
Listについて
Javaでは配列だけでなく、リストというものがある。
配列 → 要素数が固定
リスト → 要素数が可変
ArrayList<String> list = new ArrayList<String>();
listをループ処理する際は以下
for (String s: list) {}
- 投稿日:2020-01-10T09:46:19+09:00
【2020年1月版】世のチュートリアルは実装先行でイラッとする。もしくは Concordion で BDDに入門する。
例えば Quarkus のテストのチュートリアル
Quarkus のテストフレームワークの解説が以下のページにありますが・・・
このチュートリアル、テストの仕方の説明なのに実装ありきなのでイラッときますね。ビヘイビア駆動開発にとって、"実装ありきのテスト"なんてありえないのです。
またBDDやTDDに当たってテストケースを記述する上での問題の一つである"Mock"する/しない(卵が先か鶏が先か)という悩みはどういったタイミングで解決していけば良いのでしょうか。ここではQuarkusのチュートリアルを題材に、"Concordion使ってBDDでやるとどうなるのか?"をシミュレートしてみたいと思います。
Concordion とは?
まず今回ご紹介するConcordionについてですが、Markdown, HTML, Excel などで "仕様" を記述し、その"仕様"の記述に従ってJunit4のテストを実施する、というちょっと
アレな変わったフレームワークです。
JavaとC#に対応している模様です。Getting Start の中身を一部、拝借しまして、例えば以下のような仕様を検討したとします。
フルネームが "John Smith" のとき、分割の処理が行われると、ファーストネームが "John" でラストネームが "Smith" となる。
これを Concordionのスタイルで"Markdown"で書くと以下のように書けます。
/src/test/resource/sample/SplitName.md# 機能1 フルネームを受け取り、ファーストネームとラストネームを返却する ### 例1 フルネームが "[John Smith](- "#fullname")" のとき、[分割の処理が行われる](- "#result=splitName(#fullname)")と、ファーストネームが "[John](- "?=#result.firstName")" でラストネームが "[Smith](- "?=result.lastName")" となる。このようなMarkdownを記述します。
これに対応するような以下のテストクラスを作成します。
/src/test/java/sample/SplitNameFixture.javapackage sample; import org.concordion.api.MultiValueResult; import org.concordion.integration.junit4.ConcordionRunner; import org.junit.runner.RunWith; @RunWith(ConcordionRunner.class) public class SplitNameFixture { public MultiValueResult splitName(String fullname) { String[] words = fullName.split(" "); return new MultiValueResult() .with("firstName", words[0]) .with("lastName", words[1]); } }そして
mvn testなどと実行すると、以下のようなテスト結果がHTMLドキュメントとして作成されます。
(画像は本家サイトそのままです。。。)
このように、仕様のMarkdownとそれが満たされているかというHTML形式の検証結果レポート、2つのドキュメントで、プロダクトの仕様の記述とチェックが行えてしまいます。
仕様をテストメソッドのアノテーションに書いたり、"spec"のような特殊な構文で記述しなくても、MarkdownとHTMLという平文の文書(に非常に近い形式)で記述できるのは非常に嬉しいですね。
(Markdownに対応するテストクラスを実装する必要があるので、2度手間にはなります。)対象環境
それでは、Quarkus プロジェクトで Concordion を導入してみましょう。対象のバージョンなどは以下となります。
Java : JDK 8
Quarkus: 1.1.1
Concordion: 2.2.0冒頭に挙げたとおり、Quarkus のテストのチュートリアルページを元にプロジェクトを構築していきます。
BDD スタイルでQuarkus REST APIの実装
それでは早速、QuarkusのREST API の実装を BDD スタイルで行っていきましょう。
1. プロジェクトの生成
以下のコマンドでサンプルプロジェクトを生成します。
$ mvn io.quarkus:quarkus-maven-plugin:1.1.1.Final:create \ -DprojectGroupId=org.acme \ -DprojectArtifactId=getting-started cd getting-started2. テスト用依存関係の追加
以下のモジュールを
pom.xmlに追加します。pom.xml... <dependency> <groupId>io.quarkus</groupId> <artifactId>quarkus-junit5</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>io.rest-assured</groupId> <artifactId>rest-assured</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> <version>5.5.2</version> <scope>test</scope> </dependency> <dependency> <groupId>org.concordion</groupId> <artifactId>concordion</artifactId> <version>2.2.0</version> <scope>test</scope> </dependency> <dependency> <groupId>org.parboiled</groupId> <artifactId>parboiled-java</artifactId> <version>1.3.1</version> <scope>test</scope> </dependency> ...まず、
quarkus-junit5はQuarkuJUnitプラグインで、"junit5"と拡張機能が含まれています。rest-assuredは結果のアサート機能付きREST Clientです。
junit-vintage-engineはQuarkus同梱のJUnit5 上で、Concordion のJUnit4のテストケースを走らせるために必要な、Junitの後方互換エンジンです。
concordionはConcordionの本体、parboiled-javaはconcordionの動作に必要なモジュールです。concordionの依存関係にあるparboiled-javaは古いようで java8 ではエラーが出てしまいました。ですのでここで最新版をインストールしております。3. マークダウンでの仕様の記述
本家サイトのドキュメントにある通り、ここでは仕様を議論しつつ、記述していきましょう。
数時間に渡る激論の末、以下のようなAPIの仕様が固まったとします。
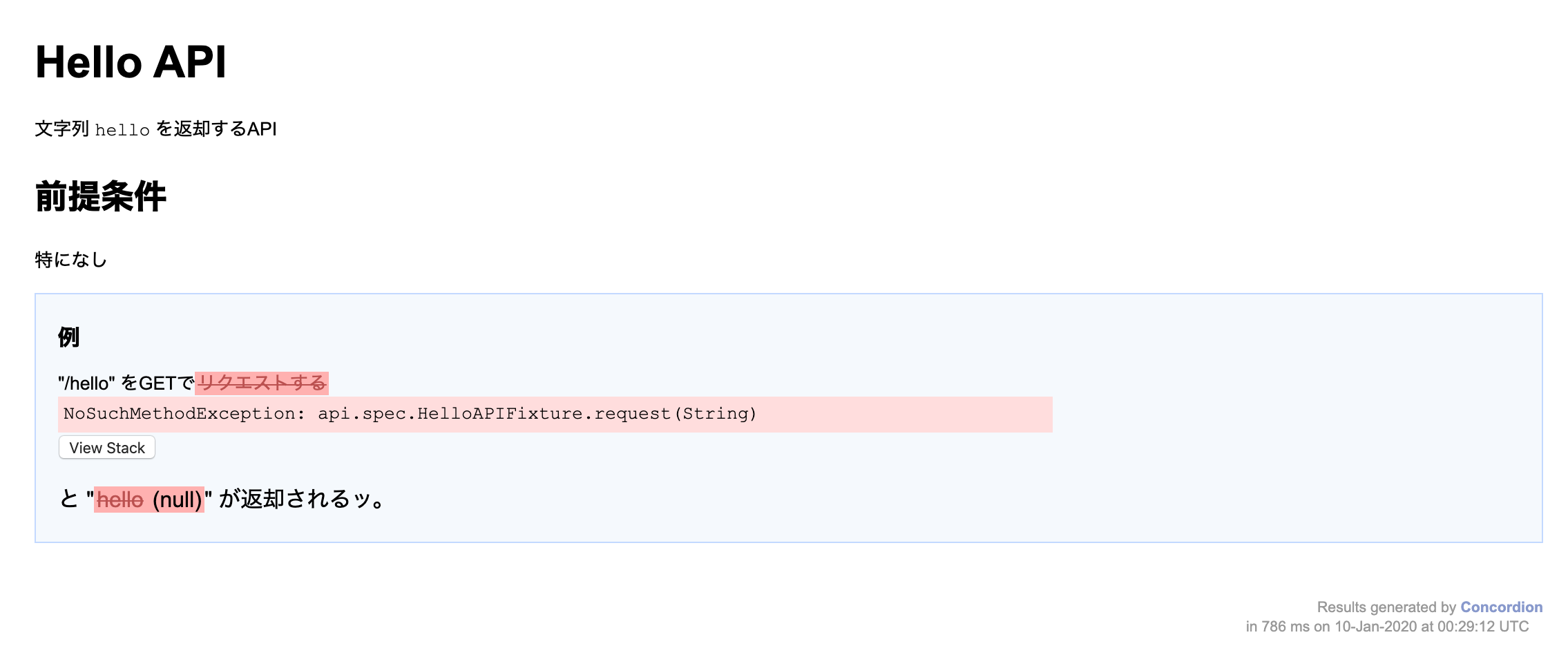
src/test/resources/com/xxxx/api/HelloAPI.md# Hello API 文字列 `hello` を返却するAPI ## 前提条件 特になし ### 例 "/hello" をGETでリクエストすると "hello" が返却されるッ。いや〜、熱い。このビジネスを支える根幹、渾身のAPIです。きっと。
そして以下のように "Concordion"スタイルでリンクを設定します。
src/test/resources/com/xxxx/api/HelloAPI.md# Hello API 文字列 `hello` を返却するAPI ## 前提条件 特になし ### [例](- "basic") "[/hello](- "#url")" をGETで[リクエストする](- "#result=request(#url)")と "[hello](- "?=#result")" が返却されるッ。Concordion では
### 〇〇の箇所がテストケースに相当し、文中の"#url"、"#result=request(#url)","?=#result"を評価してくれます。具体的には以下のような評価が行われます。
- (- "#url")では直前の角かっこで括った
/helloが変数#urlに代入されます。- (- "#result=request(#url)")では1.での変数
#urlを引数として、テストクラスのrequestメソッドを実行し、戻り値を#resultに代入します。- (- "?=#result")では直前の角かっこで括った
helloが?に代入され、2.での戻り値#resultと等しいかどうかのアサーションが行われます。これを複数記述することで複数のケースでテストが実施できます。
ここでは実施しませんが、マークダウンのテーブルを使ったり、Excelでテストケースを定義して実行する、ということも出来るそうです・・・?(というかExcelのサンプルの方がよかったか。。。)さて、このままでは流石にJUnitは動いてくれませんので、対応するテストクラスを作成いたしましょう。
4. テストクラスの作成
まずは空っぽのテストクラスを作成します。
上記で作成した".md"ファイルと同じパッケージになるようにsrc/test/java以下にクラスを作成します。
先ほどのパスはsrc/test/resources/com/xxxx/api/HelloAPI.mdでしたので、作成するクラスはsrc/test/java/com/xxxx/api/HelloAPIFixture.javaとします。
サフィックスにFixtureがConcordionの流儀の模様です。src/test/java/com/xxxx/api/HelloAPIFixture.javapackage com.xxxx.api; import org.concordion.integration.junit4.ConcordionRunner; import org.junit.runner.RunWith; @RunWith(ConcordionRunner.class) public class FruitsFixture { }一旦、これでテストを実行してみましょうか。
5. レポート出力先の変更
テストを実行する前に、レポートの出力先を調整します。
デフォルトではテスト結果のレポートがjava.io.tempdirに出力されます。
これを変更するためにconcordion.output.dirを設定する必要があります。
またシステムプロパティはどこからテストを実行するかで設定方法が異なりますので、以下にvscodeで実行した場合と mavenで指定する場合の2パターンについては設定方法を記載しておきます。5-1. VS Code プラグインの "Java Test Runner" から実行する場合
VS Code プラグインの "Java Test Runner" から実行する場合は、settings.jsonに以下の記述を追記しておきます。
settings.json{ ... "java.test.config": { "name": "concordion", "workingDirectory": "${workspaceFolder}", "vmargs" :["-Dconcordion.output.dir=${workspaceFolder}/target/concordion"], } ... }JavaVMの引数として
-Dを使っています。
今回はtarget/concordion以下にレポートが生成されるように設定いたしました。5-2.
mvn testから実行する場合
mvnコマンドを使用する場合は以下のようにpom.xmlに設定を追記します。pom.xml... <plugin> <artifactId>maven-surefire-plugin</artifactId> <version>${surefire-plugin.version}</version> <configuration> <systemProperties> <java.util.logging.manager>org.jboss.logmanager.LogManager</java.util.logging.manager> <concordion.output.dir>target/concordion</concordion.output.dir> </systemProperties> </configuration> </plugin> ..."maven-surefire-plugin"の設定で
systemPropertiesタグの中に使用したいシステムプロパティを設定すればOKです。6. "maven-surefire-plugin" の調整
maven-surefire-pluginはデフォルトで
**/*Test.javaなどのそれっぽいファイルをテストクラスとしてピックアップします。Concordionでは
TestではなくてFixtureなどを接尾辞として使うようですので、これらも含むように設定をpom.xmlに追加します。pom.xml... <plugin> <artifactId>maven-surefire-plugin</artifactId> <version>${surefire-plugin.version}</version> <configuration> <includes> <include>**/*.java</include> </includes> <systemProperties> <java.util.logging.manager>org.jboss.logmanager.LogManager</java.util.logging.manager> <concordion.output.dir>target/concordion</concordion.output.dir> </systemProperties> </configuration> </plugin> ...いろいろアレなので、
**/*.javaとして全ての.javaファイルを対象といたしました。。。7. 実行&レポートの確認
VSCodeで直接、テストクラスを
Run Testしても良いですし、ターミナルからmvn testを行ってもOKです。
target/concordion/com/xxxx/api/HelloAPI.htmlが生成されているはずです。
このHTMLをブラウザから表示してみましょう。尚、スッピンのHTMLなどを使用する際には個人的には VSCode の Live Serverプラグインがおすすめです。
さてブラウザからレポートを確認してみましょう。
一旦はこのように、"メソッドがない"というエラーが出ます。
それではテストメソッドを実装していきましょう。
8. テストクラスの実装
以下のようにテストクラスのメソッドを実装しましょう。
src/test/java/com/xxxx/api/HelloAPIFixture.javapackage com.xxxx.api; import org.concordion.integration.junit4.ConcordionRunner; import org.junit.runner.RunWith; import static io.restassured.RestAssured.given; @RunWith(ConcordionRunner.class) public class FruitsFixture { public String request(String path) { return given() .when().get(path) .body().asString(); } }Quarkusのテストフレームワークから
givenを拝借して使用致しました。
これでHelloAPI.mdで定義した"例"の箇所のFixtureがちゃんと動くはずです。今回はAPIという"外側からの仕様"をマークダウンで記述しました。
それではDBにアクセスしてビジネスロジックを記述するサービス層の仕様をMarkdownで記述したとすると、どうでしょう。そこではMockが必要になるはずです。ではDBにアクセスする永続化層の仕様をMarkdownで記述したとすると、どうでしょう。
Mockではなく実際のDBのアクセスが必要になるでしょう。このようにテストする層を絞ることでモックがいるかいらないか、が変わってきます。
今回は"外部の仕様をテスト"するのでquarkus:devでWEBサーバーの起動が必要になってきます。本来であればDBとの接続もできていなければならないはずです。このようにテストが何の層(レイヤー)をスコープとするか、で必要なコンポーネントが変わってくると思います。
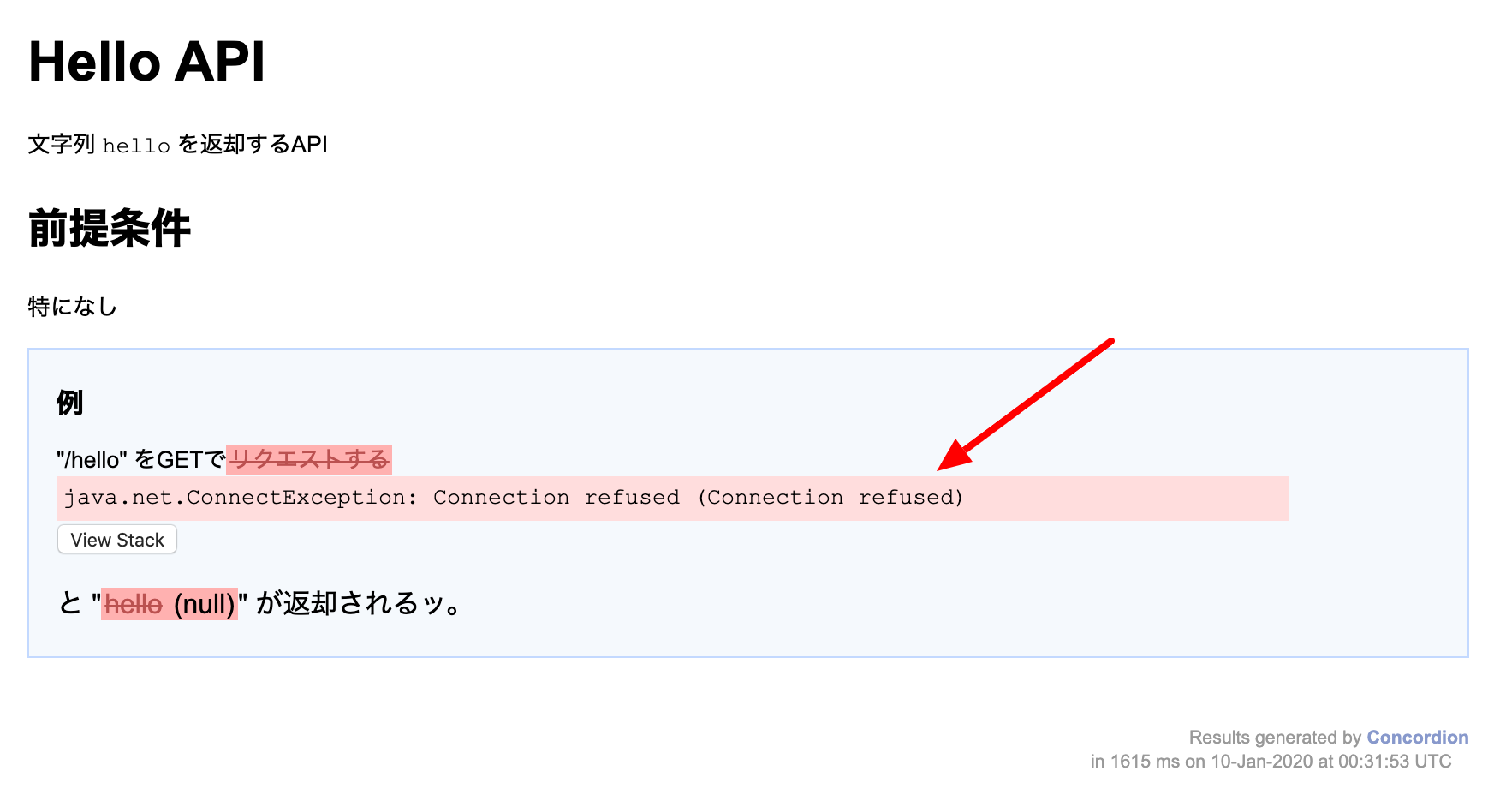
それでは再度、テストを実行してみましょう。
ちゃんと(!)失敗したはずです。いよいよ、機能の実装に移りたいと思います。
9. APIの実装とサーバーの起動
それでは失敗ケースを成功ケースに変えるべく、APIクラスを実装しましょうか。
テストケースでパスや戻り値が指定されているので迷うことなく実装できるはずです。src/main/java/com/xxxx/api/HelloResource.javapackage com.xxxx.api; import javax.ws.rs.GET; import javax.ws.rs.Path; @Path("/hello") public class HelloResoruce { @GET public String get() { return "hello"; } }実装が終わったら以下のコマンドで開発サーバーを立ち上げておきましょう。
$ mvn quarkus:dev10. テストの実施
それでは実装したAPIがちゃんと仕様を満たしているか確認をしましょう。
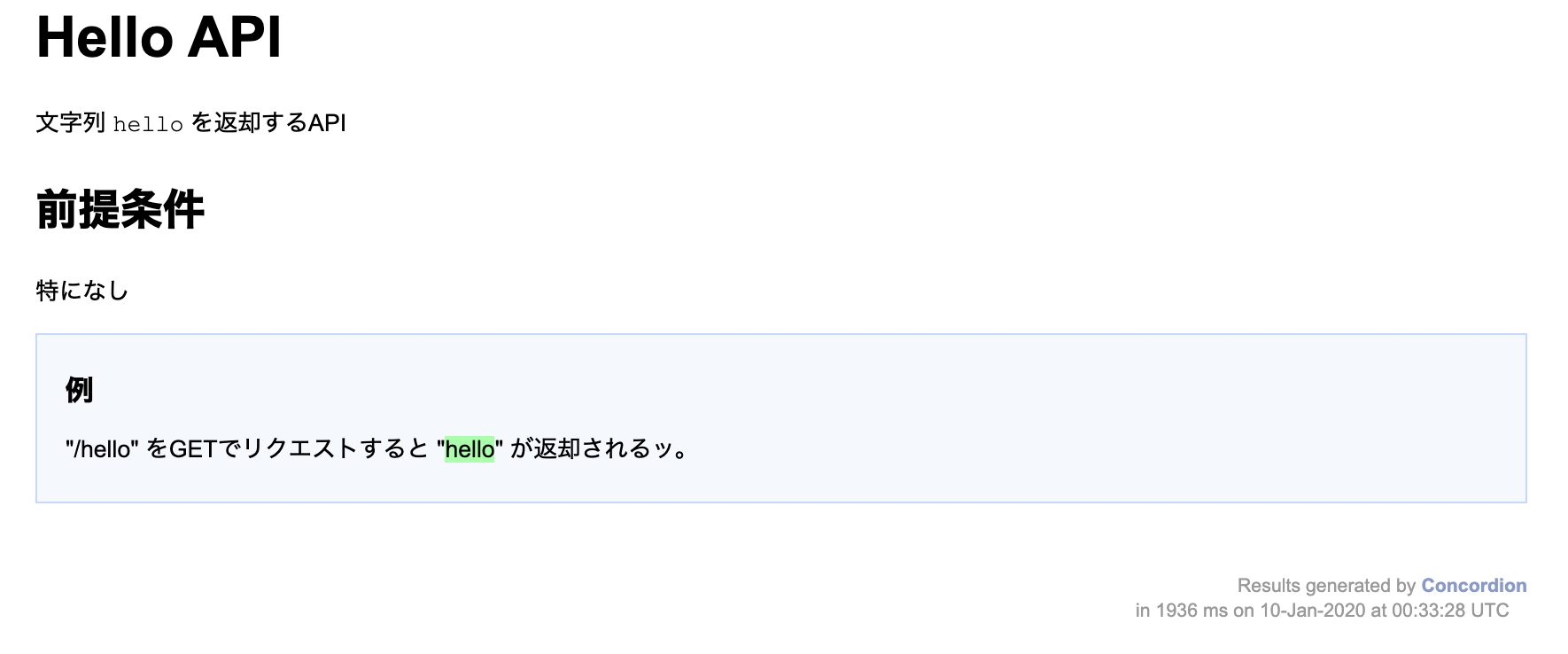
再度、テストを実施してみてください。実施後、レポートを確認すると・・・
無事にHTMLのレポートが"グリーン"に変わったかと思います!
これで仕様が満たされていることが確認できました。まとめ
Markdownのような文書で要求や仕様が記述できて、同時にテストケースのFixtureを定義して、そのままテストクラスに流し込めて結果レポートまで出してくれるなんて、なかなか素晴らしい仕組みだと思います。
Concordion初めて触ってみたけどなかなか興味深いですね!
今回は以上といたします。

- 投稿日:2020-01-10T07:39:19+09:00
Javaテクノロジー軽くまとめ
パブリックAPIの使用やサーブレットからの書き込みなどのメソッドがありますが、ここではjspにJavaコードを埋め込むためのテクノロジーについて説明します。
タグを列挙するためのクラス。
JavaでHTMLを操作する方法はいくつかあります。
。
Javaテクノロジーは3つのグループに編成されています。
オンラインプログラミングスクールであるTechAcademyは、Javaクラスを提供しています。
Javaおよびサーブレット技術を使用してWebアプリケーションを開発する方法を学びます。
呼び出し元の詳細なリファレンスとプロデューサー向けのドキュメントについては、JavaSEのドキュメントを参照してください。
アクティブなエンジニアが各学生にパーソナルメンターとして割り当てられ、アフターケアトレーニングと1対1のメンタリングが提供されるため、学生はわずか4週間で学習できます。名古屋骨董売りたい鑑定
タグの種類は数種類しかないため、拡張時に使用されるプロパティを追加する必要があります。
Java2Platform、EnterpriseEdition(J2EE)は、エンタープライズ情報システムに必要なテクノロジーを定義します。
- 投稿日:2020-01-10T01:15:05+09:00
Java 暦週の基準年にやられた
きっかけ
自分が開発した
javaのアプリがある。
その中にはアイテムを登録する機能があり、そこでは登録した日付もDBに登録している。
2019/12/29に登録したのだが、DBに登録したデータを見ると登録した日付が2020/12/29となっていた。
なんでやねんと思い調査し原因が判明したのでここに備忘としてまとめる。結果
いきなり結果であるが、登録した日付は
yyyy/MM/dd形式の文字列型で登録している。
そのためJavaで日付型をyyyy/MM/dd形式の文字列型に変換していた。
変換にはJavaのSimpleDateFormatを使用。年の部分をYYYYで定義したことにより年が暦週の基準年として扱われ2019/12/29は2020/12/29と変換されDBに登録された。暦週の基準年とは
暦週の基準年とはなんぞというと、「1/1が属する週は12月であっても翌年として扱われる。」という考え方です。
表現が下手でわかりづらいですね。すいません。カレンダーで表すとこんな感じ
黄色背景色の週に2020年の日が含まれているので12/29~31は2020年として扱われる。というものです。
※12/28は2019年扱いです。コード
ちなみにコードはこんな感じとなっていた。
henkan.java// ※ 実行日は2019/12/29 SimpleDateFormat sdf = new SimpleDAteFormat("YYYY/MM/dd"); Calender cal = Calender.getInstance(); String yyyymmdd = sdf.format(cal.getTime()); // このタイミングで2020/12/29となる。正常に扱うには
YYYYをyyyyに変更するのみです。以上、しょうもないミスでした。
さいごに
久々に
javaをやったのでこんなしょうもないミスをしてしまった。
それまではpythonを触っていて、pythonの日付の文字列変換では、年は%Yを使用するのでそれとごっちゃになって大文字のYを指定してしまったと思う。
気をつけんといかんですね。おまけ
ちなみに先ほどのコードですが、現在日時取得は
Dateのみでいけますね。
自分のコーディング能力の低さを露呈するという・・・。
